Генетическая конструкция - RU2734678C2
Код документа: RU2734678C2
Чертежи













Описание
Данное изобретение относится к генетическим конструкциям и рекомбинантным векторам, содержащим такие конструкции, а также к применению указанных конструкций и векторов в способах генной терапии для лечения ряда патологий, включая глаукому и глухоту, или для стимулирования регенерации и/или выживания нервов.
Глаукома - это термин, применяемый для определения группы патологий органа зрения, характеризующихся прогрессирующей дегенерацией зрительного нерва, гибелью ганглиозных клеток сетчатки (ГКС) и потерей аксонов, что приводит к "изрытому" внешнему виду диска зрительного нерва и потере зрения. Глаукома является ведущей причиной слепоты во всем мире [1], а заболеваемость глаукомой резко возрастает с возрастом. Около полумиллиона человек в США и более 2,2 миллиона человек в Северной Америке в возрасте 40 лет и старше имеют глаукому. Более того, каждый час в США один человек слепнет от этого заболевания, угрожающего потерей зрения [2]. Поскольку численность пожилого населения продолжает быстро расти, глаукома стала неминуемой социальной и медицинской проблемой. Повышенное внутриглазное давление (ВГД) наряду с возрастом является наиболее важным фактором риска развития глаукомы [3], и все одобренные в настоящее время способы лечения направлены на снижения ВГД [4-5].
Глаукому можно диагностировать до потери зрения путем определения поля зрения и офтальмоскопического осмотра зрительного нерва с целью обнаружения "экскавации". Существующая в настоящее время лечебная тактика при глаукоме основана на снижении ВГД до нормального уровня, который составляет от 10 до 21 мм рт. ст., тем самым предотвращая дальнейшее поражение зрительного нерва с помощью препаратов для местного применения [6]. Среднее значение ВГД у здоровых взрослых составляет от 15 до 16 мм рт.ст. В настоящее время существует пять основных классов лекарственных средств, которые применяются для снижения ВГД: β-адренергические антагонисты, адренергические агонисты, парасимпатомиметики, простагландиноподобные аналоги и ингибиторы карбоангидразы [7]. Несмотря на то, что эти препараты являются относительно эффективными для снижения ВГД при правильном применении, у некоторых пациентов они могут вызывать серьезные побочные эффекты и тем самым отрицательно влиять на качество жизни пациента. Кроме того, следование рекомендациям к лечению препаратами, снижающими ВГД, часто является слабым, особенно у пожилых пациентов, которым необходимо принимать несколько лекарственных средств. Согласно оценкам, менее 50% пациентов, которым назначены препараты, снижающие ВГД, в действительности регулярно их применяют в соответствии с предписаниями врача, фактически способствуя при этом контролю основного заболевания. Если показано дополнительное снижение ВГД или если лекарственное средство не может в достаточной степени снизить ВГД, можно применять лазерную трабекулопластику, но и это вмешательство не позволяет достичь адекватного снижения ВГД у многих пациентов. Если ВГД не удается контролировать в динамике надлежащим образом, может быть показано хирургическое лечение глаукомы. Тем не менее, снижение уровня ВГД не позволяет предотвратить ухудшение состояния многих пациентов, и глаукома остается основной причиной необратимой слепоты во всем мире. Таким образом, нейропротекция глаукоматозных ГКС и их аксональных выростов, которые образуют зрительный нерв, является ценной терапевтической парадигмой для применения в качестве дополнения к традиционным методам снижения ВГД и особенно важна у пациентов с прогрессированием заболеванием, несмотря на применение традиционного лечения [8].
Глаукоматозная оптическая невропатия, по-видимому, обусловлена определенными патофизиологическими изменениями и последующей смертью ГКС и их аксонов. Считается, что процесс гибели ГКС является двухфазным, т.е. вначале возникает первичное поражение, ответственное за начальные патологические изменения, за которыми следует более медленная вторичная дегенерация, связанная с неблагоприятной средой, окружающей дегенерирующие клетки [9].
Показано, что механизмы гибели ГКС в экспериментальных моделях глаукомы животных и глаукомы человека включают апоптоз [10]. Несмотря на то, что молекулярные процессы, инициирующие апоптоз, не были идентифицированы, предполагается, что возможными механизмами являются недостаточность нейротрофических факторов, ишемия, длительное повышение уровня глутамата и нарушенный метаболизм оксида азота [11].
Нейротрофический фактор головного мозга (НФГМ) наряду с фактором роста нервов (ФРН), нейротрофином-3 (NT-3) и нейротрофином-4/5 (NT-4/5) являются представителями нейротрофинового семейства трофических факторов [12-13]. Нейротрофины играют важную роль в развитии, выживании и функционировании широкого спектра нейронов как в периферической, так и в центральной нервной системах, включая ГКС. Нейротрофины взаимодействуют с двумя рецепторами клеточной поверхности: рецепторами p75NTR с низкой аффинностью и семейством тирозинкиназных рецепторов с высокой аффинностью (Trk) [12-13]. Фактор роста нервов (ФРН) предпочтительно связывается с TrkA, нейротрофический фактор головного мозга (НФГМ) и нейротрофин-4/5 (NT4/5), связываются с рецептором тропмиозин киназы-B (TrkB), а нейротрофин-3 (NT-3) связывается с TrkC (и с TrkA в меньшей степени) [12-13].
Среди нейротрофинов, НФГМ является наиболее сильным фактором выживания для пораженных ГКС [14-21]. НФГМ представляет собой молекулу белка, которая продуцируется в головном мозге и переносится в сетчатку путем ретроградного переноса аксонов через зрительный нерв, где она поддерживает РГК и обеспечивает их выживание [15-21]. В определенных условиях, например, при эксайтотоксических поражениях с агонистами глутаматного рецептора, такими как N-метил-D-аспартат, НФГМ также может быть получен в ГКС, хотя и на относительно низких уровнях [22-23]. НФГМ обычно продуцируется в виде препрополипептида (т.е. препроНФГМ), содержащего короткую сигнальную пептидную последовательность, которая облегчает передачу всего полипептида к везикулам для высвобождения во внеклеточное пространство. Расщепление и удаление сигнального пептида преобразует препроНФГМ в проНФГМ. N-концевая последовательность проНФГМ затем расщепляется либо внутриклеточно, либо внеклеточно для создания зрелого НФГМ (зрНФГМ) [24]. Как про-НФГМ, так и зрНФГМ обладают биологической активностью, при этом про-НФГМ предпочтительно активирует рецепторы p75NTR, а более короткие зрНФГМ активируют рецепторы TrkB [25-27]. Активация рецепторов p75NTR и TrkB в сетчатке демонстрирует противоположные эффекты на выживаемость ГКС, первый из которых ответственный за апоптоз посредством прямой ГКС-клеточной-p75NTR-активации [25-28] или косвенно посредством активации p75NTR на клетках MüМюллера, тем самым стимулируя высвобождение фактора фактора некроза опухоли (TNF-α), что еще больше способствует гибели ГКС [29].
На модели глаукомы у животных было продемонстрировано, что после размозжения нерва или в результате повышенного ВГД отмечался переход от нейротрофической передачи сигналов зрНФГМ/TrkB к пути про-НФГМ/p75NTR . Также было продемонстрировано снижение уровня зрНФГМ и рецепторов TrkB в сетчатке [27, 30-31] параллельно с повышением относительных уровней про-НФГМ [28] и рецепторов p75NTR [32]. Введение зрНФГМ крысам с экспериментально повышенным ВГД посредством инъекций в глаз рекомбинантного белка обуславливало повышение выживаемости ГКС по сравнению с глазами, не получавшими воздействия, тем самым подтверждая ключевую нейропротекторную роль этого нейротрофина [19-21].
С целью поддержания уровней зрНФГМ в глазах с глаукомой, необходимы регулярные инъекции зрНФГМ, поскольку внутри глаза зрНФГМ быстро разлагается. Во избежание необходимости в осуществлении регулярных внутриглазных инъекций зрНФГМ, при попытках обеспечить постоянный повышенный уровень НФГМ прибегли к применению доставки трансгенного кодирования НФГМ в сетчатку с помощью вектора рекомбинантного аденовируса или адено-ассоциированного вируса (rAAV) с целью приостановки или предотвращения гибели ГКС в моделях глаукомы животных [18, 33-34]. rAAV-векторы состоят из одноцепочечного генома ДНК. Они успешно применялись в качестве вирусного вектора для генной терапии во многих клинических исследованиях, демонстрируя ограниченную токсичность. Хотя было доказано, что интравитреальные инъекции рекомбинантного зрНФГМ или увеличение продукции локального НФГМ посредством генной терапии являются эффективными в предотвращении гибели ГКС в течение короткого периода после повышения ВГД или других поражений зрительного нерва, продемонстрировано, что благоприятный эффект НФГМ быть является преходящим [18]. Однако генная терапия, которая включает эндогенную последовательность гена НФГМ, также способна продуцировать и высвобождать про-НФГМ, а также предполагаемый зрНФГМ.
Генная терапия, направленная на ослабление или предотвращение потери сигнала TrkB посредством повышенной экспрессии рецептора в ГКС или путем постоянной стимуляции оставшихся внеклеточных рецепторов TrkB с применением антитела с агонистическими свойствами, также продемонстрировала успех в предотвращении гибели ГКС [35-36]. Однако снижение трофической передачи сигналов посредством пути зрНФГМ/TrkB еще больше осложняется интернализацией зрНФГМ-активированных рецепторов TrkB и замещением этих рецепторов на поверхности клетки изоформами TrkB, не способными к внутриклеточной передаче сигналов [37-38]. Кроме того, биохимическая система, ответственная за дезактивацию рецепторов TrkB после аутофосфорилирования димеров рецептора TrkB в присутствии зрНФГМ, повышающе регулируется в сетчатке, подвергнутой повышенному ВГД [39].
Кроме того, в дополнение к глаукоме, механизм НФГМ/TrkB также участвует в нейропротекции компонентов внутреннего уха, в частности, кохлеарной структуры, поражения которой могут привести к гибели волосковых клеток, что может стать причиной глухоты [40-42]; также механизм НФГМ/TrkB вовлекается в процесс регенерации нервов [43-44].
Следовательно, существует потребность в оптимизированной генной терапии для лечения глаукомы и глухоты, а также для стимулирования регенерации или выживания нервов.
Авторы изобрели новую генетическую конструкцию, которая кодирует тирозинкиназный рецептор B (TrkB) и агонист рецептора TrkB под контролем одного промотора. Промотор конструкции можно применять для обеспечения экспрессии агониста и рецептора только в ганглиозных клетках сетчатки (ГКС), кохлеарных или нервных клетках и для стимуляции выживания этих клеток.
Таким образом, согласно первому аспекту данного изобретения предлагается генетическая конструкция, содержащая промотор, функционально присоединённый к первой кодирующей последовательности, которая кодирует рецептор тирозинкиназы B (TrkB), и второй кодирующей последовательности, которая кодирует агонист рецептора TrkB.
Авторы продемонстрировали в Примерах, что можно комбинировать гены, которые кодируют как рецептор TrkB, так и его агонист в одной генетической конструкции. Это было особенно сложно, учитывая их большие размеры, и нельзя было спрогнозировать возможность их совместной экспрессии в физиологически пригодных концентрациях. Выгодным является то, что с указанной конструкцией по данному изобретению нет необходимости вводить рекомбинантный белок, как описано в предшествующем уровне техники. Кроме того, в предшествующем уровне техники было необходимо выполнять регулярные инъекции белка, тогда как в конструкции по данному изобретению требуется только одна инъекция препарата генной терапии.
Предпочтительно, при применении, рецептор TrkB активируется агонистом, чтобы таким образом стимулировать выживание ганглиозных клеток сетчатки (ГКС), нервных клеток или кохлеарных клеток. Выгодным является то, что указанная конструкция по данному изобретению может таким образом применяться для целенаправленного воздействия на РГК, нервные клетки или кохлеарные клетки, чтобы поддерживать или усиливать транскрипцию сигналов TrkB в этих клетках. Таким образом, указанную конструкцию можно применять для максимальной защиты от патофизиологических стрессоров при глаукоме и глухоте, а также для стимуляции регенерации и/или выживания нервов. Кроме того, указанную конструкцию можно применять для обеспечения длительного лечения глаукомы или глухоты в результате экспрессии рецептора TrkB и агониста рецептора под контролем одного или большего количества промоторов. Следовательно, благодаря указанной конструкции устранена необходимость применения множества альтернативных методов лечения, которые, даже в комбинации, обеспечивают только временный терапевтический эффект. Кроме того, указанная конструкция по данному изобретению является предпочтительной, поскольку она может применяться для значительного усиления чувствительности ГКС или кохлеарных клеток к агонистам рецептора TrkB из-за локализованного повышения уровня как рецептора TrkB, так и агониста рецептора.
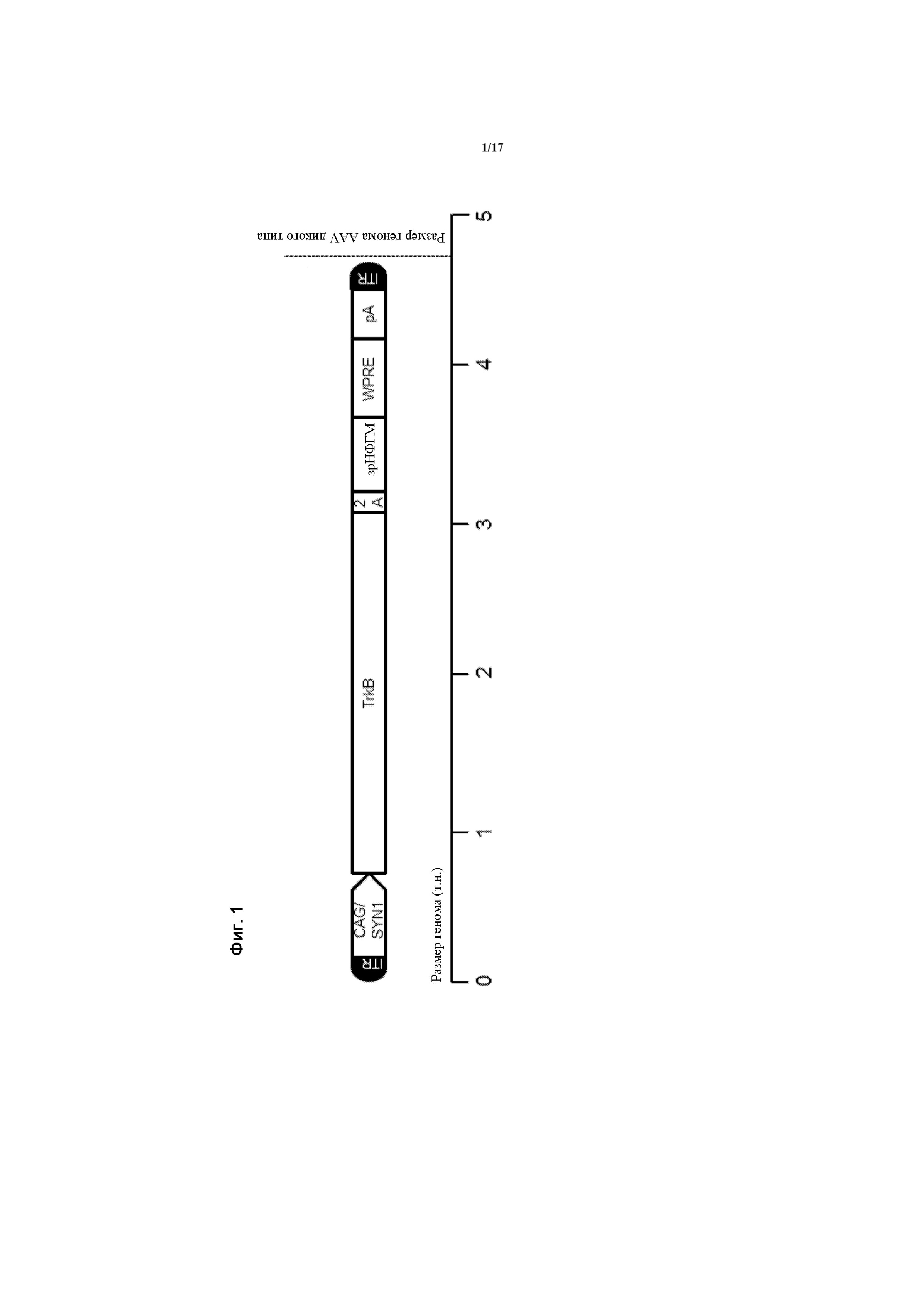
Предпочтительно, генетическая конструкция по данному изобретению содержит кассету экспрессии, один из вариантов которой проиллюстрирован на Фигуре 1. Как можно видеть на Фигуре 1, указанная конструкция содержит промотор, первую нуклеотидную последовательность, кодирующую рецептор TrkB, и вторую нуклеотидную последовательность, кодирующую зрелый нейротрофический фактор головного мозга (зрНФГМ), который функционирует как предпочтительный агонист рецептора TrkB. Следует понимать, что, однако, что можно применять другой агонист, как обсуждалось в данном документе. Также, как проиллюстрировано на Фигуре 1, кассета экспрессии также включает в себя 2А-спейсерную последовательность, последовательность, кодирующую пост-транскрипционный регуляторный элемент вируса гепатита (WHPE), последовательность, кодирующую хвост полиA, и последовательность лево- и правоинвертированного концевого повтора (ITR).
Следовательно, является предпочтительным, чтобы генетическая конструкция содержала спейсерную последовательность, расположенную между первой и второй кодирующими последовательностями, причем эта спейсерная последовательность кодирует пептидный спейсер, который сконфигурирован для расщепления или разрезания, чтобы таким образом продуцировать рецептор и агонист TrkB в виде отдельных молекул. В варианте осуществления данного изобретения, проиллюстрированном на Фигуре 1, кодирующая последовательность для рецептора TrkB расположена в положении 5' кодирующей последовательности для агониста рецептора (НФГМ) со спейсерной последовательностью между ними. Однако в другом варианте осуществления данного изобретения кодирующая последовательность для агониста рецептора может быть расположена в положении 5' кодирующей последовательности для рецептора со спейсерной последовательностью между ними.
Предпочтительно, генетическая конструкция содержит нуклеотидную последовательность, кодирующую пост-транскрипционный регуляторный элемент вируса гепатита сурков (WHPE), который усиливает экспрессию двух трансгенов, то есть рецептора TrkB и его агониста, который предпочтительно представляет собой НФГМ. Предпочтительно, кодирующая последовательность WHPE расположена в положении 3' последовательности, кодирующей трансген.
Один из вариантов осуществления транскрипционного регуляторного элемента вируса гепатита сурков (WHPE) длиной 592 п.о., включая элементы гамма-альфа-бета, упоминается в данном документе как SEQ ID No: 57 и выглядит следующим образом:
AATCAACCTCTGGATTACAAAATTTGTGAAAGATTGACTGGTATTCTTAACTATGTTGCTCCTTTTACGCTATGTGGATACGCTGCTTTAATGCCTTTGTATCATGCTATTGCTTCCCGTATGGCTTTCATTTTCTCCTCCTTGTATAAATCCTGGTTGCTGTCTCTTTATGAGGAGTTGTGGCCCGTTGTCAGGCAACGTGGCGTGGTGTGCACTGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCATTGCCACCACCTGTCAGCTCCTTTCCGGGACTTTCGCTTTCCCCCTCCCTATTGCCACGGCGGAACTCATCGCCGCCTGCCTTGCCCGCTGCTGGACAGGGGCTCGGCTGTTGGGCACTGACAATTCCGTGGTGTTGTCGGGGAAGCTGACGTCCTTTCCATGGCTGCTCGCCTGTGTTGCCACCTGGATTCTGCGCGGGACGTCCTTCTGCTACGTCCCTTCGGCCCTCAATCCAGCGGACCTTCCTTCCCGCGGCCTGCTGCCGGCTCTGCGGCCTCTTCCGCGTCTTCGCCTTCGCCCTCAGACGAGTCGGATCTCCCTTTGGGCCGCCTCCCCGCCTG
[SEQ ID NO. 57]
Предпочтительно, WHPE содержит последовательность нуклеиновой кислоты, по существу, как указано в SEQ ID No: 57, или ее фрагмент или вариант.
Однако в предпочтительном варианте осуществления данного изобретения применяется усеченный WHPE, который имеет длину 247 п.о. из-за делеции бета-элемента и который упоминается в данном документе как SEQ ID No: 58 и выглядит следующим образом:
AATCAACCTCTGGATTACAAAATTTGTGAAAGATTGACTGGTATTCTTAACTATGTTGCTCCTTTTACGCTATGTGGATACGCTGCTTTAATGCCTTTGTATCATGCTATTGCTTCCCGTATGGCTTTCATTTTCTCCTCCTTGTATAAATCCTGGTTAGTTCTTGCCACGGCGGAACTCATCGCCGCCTGCCTTGCCCGCTGCTGGACAGGGGCTCGGCTGTTGGGCACTGACAATTCCGTGGTGT [SEQ ID NO. 58]
Выгодным является то, что усеченная последовательность WHPE, применяемая в конструкции, сохраняет в общем около 300 п.о., не влияя отрицательно на экспрессию трансгена. Предпочтительно, WHPE содержит последовательность нуклеиновой кислоты, по существу, как указано в SEQ ID No: 58, или ее фрагмент или вариант.
Предпочтительно, генетическая конструкция содержит нуклеотидную последовательность, кодирующую хвост полиA. Предпочтительно, последовательность, кодирующую хвост полиA расположена в положении 3' последовательности, кодирующей трансген, и, предпочтительно, в положении 3' последовательности, кодирующей WHPE.
Предпочтительно, хвост полиA содержит последовательность поли-А вируса обезьян 40 длиной 224 п.о. Один из вариантов осуществления хвоста полиA упоминается в данном документе как SEQ ID No: 59 и выглядит следующим образом:
AGCAGACATGATAAGATACATTGATGAGTTTGGACAAACCACAACTAGAATGCAGTGAAAAAAATGCTTTATTTGTGAAATTTGTGATGCTATTGCTTTATTTGTAACCATTATAAGCTGCAATAAACAAGTTAACAACAACAATTGCATTCATTTTATGTTTCAGGTTCAGGGGGAGGTGTGGGAGGTTTTTTAAAGCAAGTAAAACCTCTACAAATGTGGTA [SEQ ID NO. 59]
Предпочтительно, хвост полиA содержит последовательность нуклеиновой кислоты, по существу, как указано в SEQ ID No: 59, или ее фрагмент или вариант.
Предпочтительно, генетическая конструкция содержит последовательности лево- и/или правоинвертированного концевого повтора (ITR). Предпочтительно, каждый ITR расположен на 5' и/или на 3' конце указанной конструкции.
Промотором в генетической конструкции по первому аспекту может быть любая нуклеотидная последовательность, которая способна индуцировать РНК-полимеразу к связыванию с и транскрибированию первой и второй кодирующих последовательностей. В одном предпочтительном варианте осуществления данного изобретения промотором является промотор синапсина I (SYN I) человека. Один из вариантов осуществления нуклеотидной последовательности 469, кодирующей промотор синапсина I (SYN I) человека упоминается в данном документе как SEQ ID NO.1 и выглядит следующим образом:
CTGCAGAGGGCCCTGCGTATGAGTGCAAGTGGGTTTTAGGACCAGGATGAGGCGGGGTGGGGGTGCCTACCTGACGACCGACCCCGACCCACTGGACAAGCACCCAACCCCCATTCCCCAAATTGCGCATCCCCTATCAGAGAGGGGGAGGGGAAACAGGATGCGGCGAGGCGCGTGCGCACTGCCAGCTTCAGCACCGCGGACAGTGCCTTCGCCCCCGCCTGGCGGCGCGCGCCACCGCCGCCTCAGCACTGAAGGCGCGCTGACGTCACTCGCCGGTCCCCCGCAAACTCCCCTTCCCGGCCACCTTGGTCGCGTCCGCGCCGCCGCCGGCCCAGCCGGACCGCACCACGCGAGGCGCGAGATAGGGGGGCACGGGCGCGACCATCTGCGCTGCGGCGCCGGCGACTCAGCGCTGCCTCAGTCTGCGGTGGGCAGCGGAGGAGTCGTGTCGTGCCTGAGAGCGCAG [SEQ ID NO. 1]
Поэтому, предпочтительно, промотор может содержать последовательность нуклеиновой кислоты, по существу, как указано в SEQ ID No: 1, или ее фрагмент или вариант.
В другом предпочтительном варианте осуществления данного изобретения промотор представляет собой промотор CAG. Промотор CAG предпочтительно содержит элемент раннего енхансера цитомегаловируса, первый экзон и первый интрон гена бета-актина цыплят и акцептор сплайсинга гена бета-глобина кроликов, тем самым облегчая специфическую тканевую экспрессию только в ГКС и кохлеарных клетках. Один из вариантов осуществления нуклеотидной последовательности 1733, кодирующей промотор CAG, упоминается в данном документе как SEQ ID NO: 2 и выглядит следующим образом:
CTCGACATTGATTATTGACTAGTTATTAATAGTAATCAATTACGGGGTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGCCCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTACGCCCCCTATTGACGTCAATGACGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTATGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTCGAGGTGAGCCCCACGTTCTGCTTCACTCTCCCCATCTCCCCCCCCTCCCCACCCCCAATTTTGTATTTATTTATTTTTTAATTATTTTGTGCAGCGATGGGGGCGGGGGGGGGGGGGGGGCGCGCGCCAGGCGGGGCGGGGCGGGGCGAGGGGCGGGGCGGGGCGAGGCGGAGAGGTGCGGCGGCAGCCAATCAGAGCGGCGCGCTCCGAAAGTTTCCTTTTATGGCGAGGCGGCGGCGGCGGCGGCCCTATAAAAAGCGAAGCGCGCGGCGGGCGGGAGTCGCTGCGCGCTGCCTTCGCCCCGTGCCCCGCTCCGCCGCCGCCTCGCGCCGCCCGCCCCGGCTCTGACTGACCGCGTTACTCCCACAGGTGAGCGGGCGGGACGGCCCTTCTCCTCCGGGCTGTAATTAGCGCTTGGTTTAATGACGGCTTGTTTCTTTTCTGTGGCTGCGTGAAAGCCTTGAGGGGCTCCGGGAGGGCCCTTTGTGCGGGGGGAGCGGCTCGGGGGGTGCGTGCGTGTGTGTGTGCGTGGGGAGCGCCGCGTGCGGCTCCGCGCTGCCCGGCGGCTGTGAGCGCTGCGGGCGCGGCGCGGGGCTTTGTGCGCTCCGCAGTGTGCGCGAGGGGAGCGCGGCCGGGGGCGGTGCCCCGCGGTGCGGGGGGGGCTGCGAGGGGAACAAAGGCTGCGTGCGGGGTGTGTGCGTGGGGGGGTGAGCAGGGGGTGTGGGCGCGTCGGTCGGGCTGCAACCCCCCCTGCACCCCCCTCCCCGAGTTGCTGAGCACGGCCCGGCTTCGGGTGCGGGGCTCCGTACGGGGCGTGGCGCGGGGCTCGCCGTGCCGGGCGGGGGGTGGCGGCAGGTGGGGGTGCCGGGCGGGGCGGGGCCGCCTCGGGCCGGGGAGGGCTCGGGGGAGGGGCGCGGCGGCCCCCGGAGCGCCGGCGGCTGTCGAGGCGCGGCGAGCCGCAGCCATTGCCTTTTATGGTAATCGTGCGAGAGGGCGCAGGGACTTCCTTTGTCCCAAATCTGTGCGGAGCCGAAATCTGGGAGGCGCCGCCGCACCCCCTCTAGCGGGCGCGGGGCGAAGCGGTGCGGCGCCGGCAGGAAGGAAATGGGCGGGGAGGGCCTTCGTGCGTCGCCGCGCCGCCGTCCCCTTCTCCCTCTCCAGCCTCGGGGCTGTCCGCGGGGGGACGGCTGCCTTCGGGGGGGACGGGGCAGGGCGGGGTTCGGCTTCTGGCGTGTGACCGGCGGCTCTAGAGCCTCTGCTAACCATGTTCATGCCTTCTTCTTTTTCCTACAGCTCCTGGGCAACGTGCTGGTTATTGTGCTGTCTCATCATTTTGGCAAAGAATTG [SEQ ID NO. 2]
В другом предпочтительном варианте осуществления данного изобретения промотор представляет собой усеченную форму промотора CAG, такую как нуклеотидная форма 664 промотора, которая упоминается в данном документе как SEQ ID NO: 3 и выглядит следующим образом:
CTAGATCTGAATTCGGTACCCTAGTTATTAATAGTAATCAATTACGGGGTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGACTATTTACGGTAAACTGCCCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTACGCCCCCTATTGACGTCAATGACGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTATGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTCGAGGTGAGCCCCACGTTCTGCTTCACTCTCCCCATCTCCCCCCCCTCCCCACCCCCAATTTTGTATTTATTTATTTTTTAATTATTTTGTGCAGCGATGGGGGCGGGGGGGGGGGGGGGGCGCGCGCCAGGCGGGGCGGGGCGGGGCGAGGGGCGGGGCGGGGCGAGGCGGAGAGGTGCGGCGGCAGCCAATCAGAGCGGCGCGCTCCGAAAGTTTCCTTTTATGGCGAGGCGGCGGCGGCGGCGGCCCTATAAAAAGCGAAGCGCGCGGCGGGCG [SEQ ID No:3]
В еще одном предпочтительном варианте осуществления данного изобретения промотор представляет собой усеченную форму промотора CAG, такую как нуклеотидная форма 584 промотора, которая упоминается в данном документе как SEQ ID NO: 48 и выглядит следующим образом:
GCGTTACATAACTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGACTATTTACGGTAAACTGCCCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTACGCCCCCTATTGACGTCAATGACGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTATGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTCGAGGTGAGCCCCACGTTCTGCTTCACTCTCCCCATCTCCCCCCCCTCCCCACCCCCAATTTTGTATTTATTTATTTTTTAATTATTTTGTGCAGCGATGGGGGCGGGGGGGGGGGGGGGGCGCGCGCCAGGCGGGGCGGGGCGGGGCGAGGGGCGGGGCGGGGCGAGGCGGAGAGGTGCGGCGGCAGCCAATCAGAGCGGCGCGCTCCGAAAGTTTCCTTTTATGGCGAGGCGGCGGCGGCGGCGGCCCTATAAAAAGCGAAGCGCGCGGCGGGCG [SEQ ID No: 48]
Поэтому, предпочтительно, промотор содержит последовательность нуклеиновой кислоты, по существу, как указано в SEQ ID No: 2, 3 или 48, или ее фрагмент или вариант.
Многие бицистронные генные конструкции, представленные в научной литературе, либо (i) включают двойные промоторы, чтобы отдельно управлять экспрессией двух генов, либо (ii) используют участок внутренней посадки рибосомы (IRES) вируса энцефаломиокардита (EMCV) для связывания двух генов, транскрибированных из одного промотора в рекомбинантных вирусных векторах [45-46]. Однако эффективность IRES-зависимой трансляции может варьироваться в разных клетках и тканях, а уровень IRES-зависимой экспрессии второго гена может быть значительно ниже, чем кэп-зависимая экспрессия первого гена в бицистронных векторах [47]. Более того, ограничение по размеру векторов rAAV (обычно < 5 т.н.) будет предотвращать включение крупных генных конструкций, таких как рецептор TrkB, вместе с НФГМ с применением двойных промоторов или линкеров IRES.
Соответственно, в предпочтительном варианте осуществления данного изобретения генетическая конструкция содержит спейсерную последовательность, расположенную между первой и второй кодирующими последовательностями, причем эта спейсерная последовательность кодирует пептидный спейсер, который сконфигурирован для расщепления, чтобы таким образом продуцировать рецептор и агонист TrkB в виде отдельных молекул. Предпочтительно, спейсерная последовательность содержит и кодирует вирусную пептидную спейсерную последовательность, более предпочтительно, вирусную 2А-пептидную спейсерную последовательность [47]. Предпочтительно, 2А-пептидная последовательность соединяет первую кодирующую последовательность со второй кодирующей последовательностью. Это позволяет конструкции преодолевать ограничения по размеру, которые встречаются при экспрессии в разных векторах, и позволяет экспрессировать все пептиды, кодируемые конструкцией по первому аспекту, под контролем одного промотора в виде одного белка.
Таким образом, после трансляции одного белка, содержащего последовательности TrkB, пептид 2A и агонист (предпочтительно, НФГМ), происходит расщепление в вирусной 2A-пептидной последовательности на концевом глицин-пролиновом мостике, в результате чего высвобождается два белка, т.е. TrkB и агонист (т.е. зрНФГМ). Генетическая конструкция разработана таким образом, что оставшаяся короткая N-концевая аминокислотная последовательность вирусного 2А-пептида остается присоединенной к внутриклеточной части рецептора TrkB, тем самым устраняя риски иммуногенности и не препятствуя внутриклеточной сигнальной способности зрелого рецептора. Остаточная аминокислота пролин из C-концевой вирусной 2A-последовательности остается присоединенной к N-концевому сигнальному пептиду НФГМ и в конечном счете удаляется из белка зрНФГМ после расщепления сигнальной последовательности от зрелого белка.
Авторы создали два варианта осуществления сенсорной последовательности. Одним важным участком пептидной спейсерной последовательности, которая является общей для обоих вариантов осуществления, описанных в данном документе, является С-конец. Соответственно, предпочтительно, когда пептидная спейсерная последовательность содержит аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 4, или ее фрагмент или вариант, и выглядит следующим образом:
QAGDVEENPGP
[SEQ ID No: 4]
Предпочтительно, место расщепления или разреза пептидной спейсерной последовательности расположено между терминальным глицином и концевым пролином в SEQ ID No: 4.
В первом предпочтительном варианте осуществления данного изобретения спейсерная последовательность содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 5, или ее фрагмент или вариант, и выглядит следующим образом:
GGAAGCGGAGCTACTAACTTCAGCCTGCTGAAGGCTGGAGACGTGGAGGAGAACCCTGGACCT [SEQ ID No: 5]
В этом первом варианте осуществления данного изобретения пептидная спейсерная последовательность содержит аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 6, или ее фрагмент или вариант, и выглядит следующим образом:
GSGATNFSLLQAGDVEENPGP [SEQ ID No: 6]
Во втором предпочтительном варианте осуществления данного изобретения спейсерная последовательность содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 7, или ее фрагмент или вариант, и выглядит следующим образом:
AGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCT [SEQ ID No: 7]
В этом втором варианте осуществления данного изобретения пептидная спейсерная последовательность содержит аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 8, или ее фрагмент или вариант, и выглядит следующим образом:
SGATNFSLLKQAGDVEENPGP [SEQ ID No: 8]
Авторы тщательно изучили последовательности рецептора TrkB и создали несколько предпочтительных вариантов осуществления рецептора, который кодируется первой кодирующей последовательностью в генетической конструкции по первому аспекту.
В одном предпочтительном варианте осуществления данного изобретения первая кодирующая последовательность содержит нуклеотидную последовательность, кодирующую каноническую изоформу TrkB человека. Предпочтительно, каноническая изоформа TrkB включает аминокислотную последовательность (822 остатка), которая упоминается в данном документе как SEQ ID NO. 9, или ее фрагмент или вариант, и выглядит следующим образом:
MSSWIRWHGPAMARLWGFCWLVVGFWRAAFACPTSCKCSASRIWCSDPSPGIVAFPRLEPNSVDPENITEIFIANQKRLEIINEDDVEAYVGLRNLTIVDSGLKFVAHKAFLKNSNLQHINFTRNKLTSLSRKHFRHLDLSELILVGNPFTCSCDIMWIKTLQEAKSSPDTQDLYCLNESSKNIPLANLQIPNCGLPSANLAAPNLTVEEGKSITLSCSVAGDPVPNMYWDVGNLVSKHMNETSHTQGSLRITNISSDDSGKQISCVAENLVGEDQDSVNLTVHFAPTITFLESPTSDHHWCIPFTVKGNPKPALQWFYNGAILNESKYICTKIHVTNHTEYHGCLQLDNPTHMNNGDYTLIAKNEYGKDEKQISAHFMGWPGIDDGANPNYPDVIYEDYGTAANDIGDTTNRSNEIPSTDVTDKTGREHLSVYAVVVIASVVGFCLLVMLFLLKLARHSKFGMKGPASVISNDDDSASPLHHISNGSNTPSSSEGGPDAVIIGMTKIPVIENPQYFGITNSQLKPDTFVQHIKRHNIVLKRELGEGAFGKVFLAECYNLCPEQDKILVAVKTLKDASDNARKDFHREAELLTNLQHEHIVKFYGVCVEGDPLIMVFEYMKHGDLNKFLRAHGPDAVLMAEGNPPTELTQSQMLHIAQQIAAGMVYLASQHFVHRDLATRNCLVGENLLVKIGDFGMSRDVYSTDYYRVGGHTMLPIRWMPPESIMYRKFTTESDVWSLGVVLWEIFTYGKQPWYQLSNNEVIECITQGRVLQRPRTCPQEVYELMLGCWQREPHMRKNIKGIHTLLQNLAKASPVYLDILG [SEQ ID No: 9]
Предпочтительно, в этом варианте осуществления данного изобретения первая кодирующая последовательность содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 10, или ее фрагмент или вариант, и выглядит следующим образом:
ATGTCGTCCTGGATAAGGTGGCATGGACCCGCCATGGCGCGGCTCTGGGGCTTCTGCTGGCTGGTTGTGGGCTTCTGGAGGGCCGCTTTCGCCTGTCCCACGTCCTGCAAATGCAGTGCCTCTCGGATCTGGTGCAGCGACCCTTCTCCTGGCATCGTGGCATTTCCGAGATTGGAGCCTAACAGTGTAGATCCTGAGAACATCACCGAAATTTTCATCGCAAACCAGAAAAGGTTAGAAATCATCAACGAAGATGATGTTGAAGCTTATGTGGGACTGAGAAATCTGACAATTGTGGATTCTGGATTAAAATTTGTGGCTCATAAAGCATTTCTGAAAAACAGCAACCTGCAGCACATCAATTTTACCCGAAACAAACTGACGAGTTTGTCTAGGAAACATTTCCGTCACCTTGACTTGTCTGAACTGATCCTGGTGGGCAATCCATTTACATGCTCCTGTGACATTATGTGGATCAAGACTCTCCAAGAGGCTAAATCCAGTCCAGACACTCAGGATTTGTACTGCCTGAATGAAAGCAGCAAGAATATTCCCCTGGCAAACCTGCAGATACCCAATTGTGGTTTGCCATCTGCAAATCTGGCCGCACCTAACCTCACTGTGGAGGAAGGAAAGTCTATCACATTATCCTGTAGTGTGGCAGGTGATCCGGTTCCTAATATGTATTGGGATGTTGGTAACCTGGTTTCCAAACATATGAATGAAACAAGCCACACACAGGGCTCCTTAAGGATAACTAACATTTCATCCGATGACAGTGGGAAGCAGATCTCTTGTGTGGCGGAAAATCTTGTAGGAGAAGATCAAGATTCTGTCAACCTCACTGTGCATTTTGCACCAACTATCACATTTCTCGAATCTCCAACCTCAGACCACCACTGGTGCATTCCATTCACTGTGAAAGGCAACCCCAAACCAGCGCTTCAGTGGTTCTATAACGGGGCAATATTGAATGAGTCCAAATACATCTGTACTAAAATACATGTTACCAATCACACGGAGTACCACGGCTGCCTCCAGCTGGATAATCCCACTCACATGAACAATGGGGACTACACTCTAATAGCCAAGAATGAGTATGGGAAGGATGAGAAACAGATTTCTGCTCACTTCATGGGCTGGCCTGGAATTGACGATGGTGCAAACCCAAATTATCCTGATGTAATTTATGAAGATTATGGAACTGCAGCGAATGACATCGGGGACACCACGAACAGAAGTAATGAAATCCCTTCCACAGACGTCACTGATAAAACCGGTCGGGAACATCTCTCGGTCTATGCTGTGGTGGTGATTGCGTCTGTGGTGGGATTTTGCCTTTTGGTAATGCTGTTTCTGCTTAAGTTGGCAAGACACTCCAAGTTTGGCATGAAAGGCCCAGCCTCCGTTATCAGCAATGATGATGACTCTGCCAGCCCACTCCATCACATCTCCAATGGGAGTAACACTCCATCTTCTTCGGAAGGTGGCCCAGATGCTGTCATTATTGGAATGACCAAGATCCCTGTCATTGAAAATCCCCAGTACTTTGGCATCACCAACAGTCAGCTCAAGCCAGACACATTTGTTCAGCACATCAAGCGACATAACATTGTTCTGAAAAGGGAGCTAGGCGAAGGAGCCTTTGGAAAAGTGTTCCTAGCTGAATGCTATAACCTCTGTCCTGAGCAGGACAAGATCTTGGTGGCAGTGAAGACCCTGAAGGATGCCAGTGACAATGCACGCAAGGACTTCCACCGTGAGGCCGAGCTCCTGACCAACCTCCAGCATGAGCACATCGTCAAGTTCTATGGCGTCTGCGTGGAGGGCGACCCCCTCATCATGGTCTTTGAGTACATGAAGCATGGGGACCTCAACAAGTTCCTCAGGGCACACGGCCCTGATGCCGTGCTGATGGCTGAGGGCAACCCGCCCACGGAACTGACGCAGTCGCAGATGCTGCATATAGCCCAGCAGATCGCCGCGGGCATGGTCTACCTGGCGTCCCAGCACTTCGTGCACCGCGATTTGGCCACCAGGAACTGCCTGGTCGGGGAGAACTTGCTGGTGAAAATCGGGGACTTTGGGATGTCCCGGGACGTGTACAGCACTGACTACTACAGGGTCGGTGGCCACACAATGCTGCCCATTCGCTGGATGCCTCCAGAGAGCATCATGTACAGGAAATTCACGACGGAAAGCGACGTCTGGAGCCTGGGGGTCGTGTTGTGGGAGATTTTCACCTATGGCAAACAGCCCTGGTACCAGCTGTCAAACAATGAGGTGATAGAGTGTATCACTCAGGGCCGAGTCCTGCAGCGACCCCGCACGTGCCCCCAGGAGGTGTATGAGCTGATGCTGGGGTGCTGGCAGCGAGAGCCCCACATGAGGAAGAACATCAAGGGCATCCATACCCTCCTTCAGAACTTGGCCAAGGCATCTCCGGTCTACCTGGACATTCTAGGC [SEQ ID No: 10]
В другом предпочтительном варианте осуществления данного изобретения первая кодирующая последовательность содержит нуклеотидную последовательность, которая кодирует изоформу 4 TrkB. Предпочтительно, изоформа 4 TrkB включает аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 11, или ее фрагмент или вариант, и выглядит следующим образом:
MSSWIRWHGPAMARLWGFCWLVVGFWRAAFACPTSCKCSASRIWCSDPSPGIVAFPRLEPNSVDPENITEIFIANQKRLEIINEDDVEAYVGLRNLTIVDSGLKFVAHKAFLKNSNLQHINFTRNKLTSLSRKHFRHLDLSELILVGNPFTCSCDIMWIKTLQEAKSSPDTQDLYCLNESSKNIPLANLQIPNCGLPSANLAAPNLTVEEGKSITLSCSVAGDPVPNMYWDVGNLVSKHMNETSHTQGSLRITNISSDDSGKQISCVAENLVGEDQDSVNLTVHFAPTITFLESPTSDHHWCIPFTVKGNPKPALQWFYNGAILNESKYICTKIHVTNHTEYHGCLQLDNPTHMNNGDYTLIAKNEYGKDEKQISAHFMGWPGIDDGANPNYPDVIYEDYGTAANDIGDTTNRSNEIPSTDVTDKTGREHLSVYAVVVIASVVGFCLLVMLFLLKLARHSKFGMKDFSWFGFGKVKSRQGVGPASVISNDDDSASPLHHISNGSNTPSSSEGGPDAVIIGMTKIPVIENPQYFGITNSQLKPDTFVQHIKRHNIVLKRELGEGAFGKVFLAECYNLCPEQDKILVAVKTLKDASDNARKDFHREAELLTNLQHEHIVKFYGVCVEGDPLIMVFEYMKHGDLNKFLRAHGPDAVLMAEGNPPTELTQSQMLHIAQQIAAGMVYLASQHFVHRDLATRNCLVGENLLVKIGDFGMSRDVYSTDYYRVGGHTMLPIRWMPPESIMYRKFTTESDVWSLGVVLWEIFTYGKQPWYQLSNNEVIECITQGRVLQRPRTCPQEVYELMLGCWQREPHMRKNIKGIHTLLQNLAKASPVYLDILG [SEQ ID No: 11]
Предпочтительно, этот вариант осуществления первой кодирующей последовательности содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 12, или ее фрагмент или вариант, и выглядит следующим образом:
ATGTCGTCCTGGATAAGGTGGCATGGACCCGCCATGGCGCGGCTCTGGGGCTTCTGCTGGCTGGTTGTGGGCTTCTGGAGGGCCGCTTTCGCCTGTCCCACGTCCTGCAAATGCAGTGCCTCTCGGATCTGGTGCAGCGACCCTTCTCCTGGCATCGTGGCATTTCCGAGATTGGAGCCTAACAGTGTAGATCCTGAGAACATCACCGAAATTTTCATCGCAAACCAGAAAAGGTTAGAAATCATCAACGAAGATGATGTTGAAGCTTATGTGGGACTGAGAAATCTGACAATTGTGGATTCTGGATTAAAATTTGTGGCTCATAAAGCATTTCTGAAAAACAGCAACCTGCAGCACATCAATTTTACCCGAAACAAACTGACGAGTTTGTCTAGGAAACATTTCCGTCACCTTGACTTGTCTGAACTGATCCTGGTGGGCAATCCATTTACATGCTCCTGTGACATTATGTGGATCAAGACTCTCCAAGAGGCTAAATCCAGTCCAGACACTCAGGATTTGTACTGCCTGAATGAAAGCAGCAAGAATATTCCCCTGGCAAACCTGCAGATACCCAATTGTGGTTTGCCATCTGCAAATCTGGCCGCACCTAACCTCACTGTGGAGGAAGGAAAGTCTATCACATTATCCTGTAGTGTGGCAGGTGATCCGGTTCCTAATATGTATTGGGATGTTGGTAACCTGGTTTCCAAACATATGAATGAAACAAGCCACACACAGGGCTCCTTAAGGATAACTAACATTTCATCCGATGACAGTGGGAAGCAGATCTCTTGTGTGGCGGAAAATCTTGTAGGAGAAGATCAAGATTCTGTCAACCTCACTGTGCATTTTGCACCAACTATCACATTTCTCGAATCTCCAACCTCAGACCACCACTGGTGCATTCCATTCACTGTGAAAGGCAACCCCAAACCAGCGCTTCAGTGGTTCTATAACGGGGCAATATTGAATGAGTCCAAATACATCTGTACTAAAATACATGTTACCAATCACACGGAGTACCACGGCTGCCTCCAGCTGGATAATCCCACTCACATGAACAATGGGGACTACACTCTAATAGCCAAGAATGAGTATGGGAAGGATGAGAAACAGATTTCTGCTCACTTCATGGGCTGGCCTGGAATTGACGATGGTGCAAACCCAAATTATCCTGATGTAATTTATGAAGATTATGGAACTGCAGCGAATGACATCGGGGACACCACGAACAGAAGTAATGAAATCCCTTCCACAGACGTCACTGATAAAACCGGTCGGGAACATCTCTCGGTCTATGCTGTGGTGGTGATTGCGTCTGTGGTGGGATTTTGCCTTTTGGTAATGCTGTTTCTGCTTAAGTTGGCAAGACACTCCAAGTTTGGCATGAAAGATTTCTCATGGTTTGGATTTGGGAAAGTAAAATCAAGACAAGGTGTTGGCCCAGCCTCCGTTATCAGCAATGATGATGACTCTGCCAGCCCACTCCATCACATCTCCAATGGGAGTAACACTCCATCTTCTTCGGAAGGTGGCCCAGATGCTGTCATTATTGGAATGACCAAGATCCCTGTCATTGAAAATCCCCAGTACTTTGGCATCACCAACAGTCAGCTCAAGCCAGACACATTTGTTCAGCACATCAAGCGACATAACATTGTTCTGAAAAGGGAGCTAGGCGAAGGAGCCTTTGGAAAAGTGTTCCTAGCTGAATGCTATAACCTCTGTCCTGAGCAGGACAAGATCTTGGTGGCAGTGAAGACCCTGAAGGATGCCAGTGACAATGCACGCAAGGACTTCCACCGTGAGGCCGAGCTCCTGACCAACCTCCAGCATGAGCACATCGTCAAGTTCTATGGCGTCTGCGTGGAGGGCGACCCCCTCATCATGGTCTTTGAGTACATGAAGCATGGGGACCTCAACAAGTTCCTCAGGGCACACGGCCCTGATGCCGTGCTGATGGCTGAGGGCAACCCGCCCACGGAACTGACGCAGTCGCAGATGCTGCATATAGCCCAGCAGATCGCCGCGGGCATGGTCTACCTGGCGTCCCAGCACTTCGTGCACCGCGATTTGGCCACCAGGAACTGCCTGGTCGGGGAGAACTTGCTGGTGAAAATCGGGGACTTTGGGATGTCCCGGGACGTGTACAGCACTGACTACTACAGGGTCGGTGGCCACACAATGCTGCCCATTCGCTGGATGCCTCCAGAGAGCATCATGTACAGGAAATTCACGACGGAAAGCGACGTCTGGAGCCTGGGGGTCGTGTTGTGGGAGATTTTCACCTATGGCAAACAGCCCTGGTACCAGCTGTCAAACAATGAGGTGATAGAGTGTATCACTCAGGGCCGAGTCCTGCAGCGACCCCGCACGTGCCCCCAGGAGGTGTATGAGCTGATGCTGGGGTGCTGGCAGCGAGAGCCCCACATGAGGAAGAACATCAAGGGCATCCATACCCTCCTTCAGAACTTGGCCAAGGCATCTCCGGTCTACCTGGACATTCTAGGC [SEQ ID No: 12]
Авторы приложили значительные изобретательские усилия на изучение последовательности рецептора TrkB и поняли, что TrkB включает пять остатков тирозина (в положениях 516, 701, 705, 706 и 816 SEQ ID No: 9), которые обычно фосфорилируются после димеризации и аутофосфорилирования в присутствии димера НФГМ. Проблема фосфорилирования этих пяти тирозиновых остатков заключается в том, что рецептор может быть легко дезактивирован фосфатазой, такой как фосфатаза Shp-2. Соответственно, для предотвращения фосфорилирования и, как следствие, дезактивации рецептора in vivo, предпочтительным является мутирование одного или большего количества из этих ключевых тирозинов (более предпочтительно, до глутаминовой кислоты), с целью имитации получаемого в результате фосфотирозина и продукции рецептора, который остается активным в присутствии НФГМ и не может быть дезактивирован фосфатазой, такой как фосфатаза Shp-2. Такие мутантные формы TrkB направлены на генерацию активности рецептора TrkB, который остается активным в течение более длительных периодов времени или до тех пор, пока рецептор не будет интернализирован.
Последовательности ДНК и аминокислот, представленные ниже, иллюстрируют положения этих пяти остатков тирозина (Y), которые были мутированы в пять остатков глутаминовой кислоты (E). Следует понимать, что 1, 2, 3, 4 или 5 этих остатков могут быть мутированы до глутаминовой кислоты в вариантах осуществления данного изобретения. Также предусматриваются различные комбинации этих мутаций, например, только в положениях 516 и 701, или только в положениях 705, 706 и 816 и т. д.
Соответственно, в другом предпочтительном варианте осуществления данного изобретения первая кодирующая последовательность содержит нуклеотидную последовательность, кодирующую мутантную форму рецептора TrkB, при этом один или большее количество остатков тирозина в положениях 516, 701, 705, 706 и/или 816 последовательности SEQ ID No: 9 являются модифицированными или мутированными. Предпочтительно, по меньшей мере два, три или четыре остатка тирозина в положениях 516, 701, 705, 706 и/или 816 последовательности SEQ ID No: 9 являются модифицированными. Наиболее предпочтительно, все пять тирозиновых остатков в положениях 516, 701, 705, 706 и/или 816 последовательности SEQ ID No: 9 являются модифицированными.
Предпочтительно, каждый остаток тирозина модифицируют до другого аминокислотного остатка, более предпочтительно, до глутаминовой кислоты. Таким образом, предпочтительно, мутантная форма рецептора TrkB включает Y516E, Y701E, Y705E, Y706E и/или Y816E.
Предпочтительно, модифицированная форма рецептора 4 TrkB включает аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 13, или ее фрагмент или вариант, и выглядит следующим образом:
MSSWIRWHGPAMARLWGFCWLVVGFWRAAFACPTSCKCSASRIWCSDPSPGIVAFPRLEPNSVDPENITEIFIANQKRLEIINEDDVEAYVGLRNLTIVDSGLKFVAHKAFLKNSNLQHINFTRNKLTSLSRKHFRHLDLSELILVGNPFTCSCDIMWIKTLQEAKSSPDTQDLYCLNESSKNIPLANLQIPNCGLPSANLAAPNLTVEEGKSITLSCSVAGDPVPNMYWDVGNLVSKHMNETSHTQGSLRITNISSDDSGKQISCVAENLVGEDQDSVNLTVHFAPTITFLESPTSDHHWCIPFTVKGNPKPALQWFYNGAILNESKYICTKIHVTNHTEYHGCLQLDNPTHMNNGDYTLIAKNEYGKDEKQISAHFMGWPGIDDGANPNYPDVIYEDYGTAANDIGDTTNRSNEIPSTDVTDKTGREHLSVYAVVVIASVVGFCLLVMLFLLKLARHSKFGMKGPASVISNDDDSASPLHHISNGSNTPSSSEGGPDAVIIGMTKIPVIENPQEFGITNSQLKPDTFVQHIKRHNIVLKRELGEGAFGKVFLAECYNLCPEQDKILVAVKTLKDASDNARKDFHREAELLTNLQHEHIVKFYGVCVEGDPLIMVFEYMKHGDLNKFLRAHGPDAVLMAEGNPPTELTQSQMLHIAQQIAAGMVYLASQHFVHRDLATRNCLVGENLLVKIGDFGMSRDVESTDEERVGGHTMLPIRWMPPESIMYRKFTTESDVWSLGVVLWEIFTYGKQPWYQLSNNEVIECITQGRVLQRPRTCPQEVYELMLGCWQREPHMRKNIKGIHTLLQNLAKASPVELDILG [SEQ ID No: 13]
Предпочтительно, в этом варианте осуществления данного изобретения первая кодирующая последовательность содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 14, или ее фрагмент или вариант, и выглядит следующим образом:
ATGTCGTCCTGGATAAGGTGGCATGGACCCGCCATGGCGCGGCTCTGGGGCTTCTGCTGGCTGGTTGTGGGCTTCTGGAGGGCCGCTTTCGCCTGTCCCACGTCCTGCAAATGCAGTGCCTCTCGGATCTGGTGCAGCGACCCTTCTCCTGGCATCGTGGCATTTCCGAGATTGGAGCCTAACAGTGTAGATCCTGAGAACATCACCGAAATTTTCATCGCAAACCAGAAAAGGTTAGAAATCATCAACGAAGATGATGTTGAAGCTTATGTGGGACTGAGAAATCTGACAATTGTGGATTCTGGATTAAAATTTGTGGCTCATAAAGCATTTCTGAAAAACAGCAACCTGCAGCACATCAATTTTACCCGAAACAAACTGACGAGTTTGTCTAGGAAACATTTCCGTCACCTTGACTTGTCTGAACTGATCCTGGTGGGCAATCCATTTACATGCTCCTGTGACATTATGTGGATCAAGACTCTCCAAGAGGCTAAATCCAGTCCAGACACTCAGGATTTGTACTGCCTGAATGAAAGCAGCAAGAATATTCCCCTGGCAAACCTGCAGATACCCAATTGTGGTTTGCCATCTGCAAATCTGGCCGCACCTAACCTCACTGTGGAGGAAGGAAAGTCTATCACATTATCCTGTAGTGTGGCAGGTGATCCGGTTCCTAATATGTATTGGGATGTTGGTAACCTGGTTTCCAAACATATGAATGAAACAAGCCACACACAGGGCTCCTTAAGGATAACTAACATTTCATCCGATGACAGTGGGAAGCAGATCTCTTGTGTGGCGGAAAATCTTGTAGGAGAAGATCAAGATTCTGTCAACCTCACTGTGCATTTTGCACCAACTATCACATTTCTCGAATCTCCAACCTCAGACCACCACTGGTGCATTCCATTCACTGTGAAAGGCAACCCCAAACCAGCGCTTCAGTGGTTCTATAACGGGGCAATATTGAATGAGTCCAAATACATCTGTACTAAAATACATGTTACCAATCACACGGAGTACCACGGCTGCCTCCAGCTGGATAATCCCACTCACATGAACAATGGGGACTACACTCTAATAGCCAAGAATGAGTATGGGAAGGATGAGAAACAGATTTCTGCTCACTTCATGGGCTGGCCTGGAATTGACGATGGTGCAAACCCAAATTATCCTGATGTAATTTATGAAGATTATGGAACTGCAGCGAATGACATCGGGGACACCACGAACAGAAGTAATGAAATCCCTTCCACAGACGTCACTGATAAAACCGGTCGGGAACATCTCTCGGTCTATGCTGTGGTGGTGATTGCGTCTGTGGTGGGATTTTGCCTTTTGGTAATGCTGTTTCTGCTTAAGTTGGCAAGACACTCCAAGTTTGGCATGAAAGGCCCAGCCTCCGTTATCAGCAATGATGATGACTCTGCCAGCCCACTCCATCACATCTCCAATGGGAGTAACACTCCATCTTCTTCGGAAGGTGGCCCAGATGCTGTCATTATTGGAATGACCAAGATCCCTGTCATTGAAAATCCCCAGGAATTTGGCATCACCAACAGTCAGCTCAAGCCAGACACATTTGTTCAGCACATCAAGCGACATAACATTGTTCTGAAAAGGGAGCTAGGCGAAGGAGCCTTTGGAAAAGTGTTCCTAGCTGAATGCTATAACCTCTGTCCTGAGCAGGACAAGATCTTGGTGGCAGTGAAGACCCTGAAGGATGCCAGTGACAATGCACGCAAGGACTTCCACCGTGAGGCCGAGCTCCTGACCAACCTCCAGCATGAGCACATCGTCAAGTTCTATGGCGTCTGCGTGGAGGGCGACCCCCTCATCATGGTCTTTGAGTACATGAAGCATGGGGACCTCAACAAGTTCCTCAGGGCACACGGCCCTGATGCCGTGCTGATGGCTGAGGGCAACCCGCCCACGGAACTGACGCAGTCGCAGATGCTGCATATAGCCCAGCAGATCGCCGCGGGCATGGTCTACCTGGCGTCCCAGCACTTCGTGCACCGCGATTTGGCCACCAGGAACTGCCTGGTCGGGGAGAACTTGCTGGTGAAAATCGGGGACTTTGGGATGTCCCGGGACGTGGAAAGCACTGACGAAGAAAGGGTCGGTGGCCACACAATGCTGCCCATTCGCTGGATGCCTCCAGAGAGCATCATGTACAGGAAATTCACGACGGAAAGCGACGTCTGGAGCCTGGGGGTCGTGTTGTGGGAGATTTTCACCTATGGCAAACAGCCCTGGTACCAGCTGTCAAACAATGAGGTGATAGAGTGTATCACTCAGGGCCGAGTCCTGCAGCGACCCCGCACGTGCCCCCAGGAGGTGTATGAGCTGATGCTGGGGTGCTGGCAGCGAGAGCCCCACATGAGGAAGAACATCAAGGGCATCCATACCCTCCTTCAGAACTTGGCCAAGGCATCTCCGGTCGAACTGGACATTCTAGGC [SEQ ID No: 14]
Следует понимать, что вторая кодирующая последовательность кодирует агонист рецептора TrkB, который предпочтительно является представителем нейротрофинового семейства трофических факторов. Поэтому предпочтительные агонисты рецептора TrkB можно выбрать из группы агонистов, состоящей из: нейротрофического фактора головного мозга (НФГМ); фактор роста нервов (ФРН); нейротрофина-3 (NT-3); нейротрофина-4 (NT-4); и нейротрофина-5 (NT-5); или их фрагментов.
Нуклеотидная и аминокислотная последовательности каждого из этих агонистов будут известны специалисту в данной области техники. Однако в качестве примера аминокислотная последовательность одного варианта осуществления нейротрофина-4 (NT-4) представляет собой по существу такую, как указано в SEQ ID NO. 49, и выглядит следующим образом:
MLPLPSCSLPILLLFLLPSVPIESQPPPSTLPPFLAPEWDLLSPRVVLSRGAPAGPPLLFLLEAGAFRESAGAPANRSRRGVSETAPASRRGELAVCDAVSGWVTDRRTAVDLRGREVEVLGEVPAAGGSPLRQYFFETRCKADNAEEGGPGAGGGGCRGVDRRHWVSECKAKQSYVRALTADAQGRVGWRWIRIDTACVCTLLSRTGRA [SEQ ID No: 49]
Кодирующая последовательность нуклеиновой кислоты этого варианта осуществления нейротрофина-4 (NT-4), является по существу такой, как указано в SEQ ID NO. 50, и выглядит следующим образом:
ATGCTCCCTCTCCCCTCATGCTCCCTCCCCATCCTCCTCCTTTTCCTCCTCCCCAGTGTGCCAATTGAGTCCCAACCCCCACCCTCAACATTGCCCCCTTTTCTGGCCCCTGAGTGGGACCTTCTCTCCCCCCGAGTAGTCCTGTCTAGGGGTGCCCCTGCTGGGCCCCCTCTGCTCTTCCTGCTGGAGGCTGGGGCCTTTCGGGAGTCAGCAGGTGCCCCGGCCAACCGCAGCCGGCGTGGGGTGAGCGAAACTGCACCAGCGAGTCGTCGGGGTGAGCTGGCTGTGTGCGATGCAGTCAGTGGCTGGGTGACAGACCGCCGGACCGCTGTGGACTTGCGTGGGCGCGAGGTGGAGGTGTTGGGCGAGGTGCCTGCAGCTGGCGGCAGTCCCCTCCGCCAGTACTTCTTTGAAACCCGCTGCAAGGCTGATAACGCTGAGGAAGGTGGCCCGGGGGCAGGTGGAGGGGGCTGCCGGGGAGTGGACAGGAGGCACTGGGTATCTGAGTGCAAGGCCAAGCAGTCCTATGTGCGGGCATTGACCGCTGATGCCCAGGGCCGTGTGGGCTGGCGATGGATTCGAATTGACACTGCCTGCGTCTGCACACTCCTCAGCCGGACTGGCCGGGCC [SEQ ID No: 50]
Аминокислотная последовательность сигнального пептида для последовательности NT-4 представляет собой по существу такую, как указано в SEQ ID NO. 51, и выглядит следующим образом:
MLPLPSCSLPILLLFLLPSVPIES [SEQ ID No: 51]
Последовательность нуклеиновой кислоты этого сигнального пептида представляет собой по существу такую, как указано в SEQ ID NO. 52, и выглядит следующим образом:
ATGCTCCCTCTCCCCTCATGCTCCCTCCCCATCCTCCTCCTTTTCCTCCTCCCCAGTGTGCCAATTGAGTCC [SEQ ID No: 52]
Аминокислотная последовательность пропептида для этой последовательности NT-4 представляет собой по существу такую, как указано в SEQ ID NO. 53, и выглядит следующим образом:
QPPPSTLPPFLAPEWDLLSPRVVLSRGAPAGPPLLFLLEAGAFRESAGAPANRSRR [SEQ ID No: 53]
Последовательность нуклеиновой кислоты этого пропептида представляет собой по существу такую, как указано в SEQ ID NO. 54, и выглядит следующим образом:
CAACCCCCACCCTCAACATTGCCCCCTTTTCTGGCCCCTGAGTGGGACCTTCTCTCCCCCCGAGTAGTCCTGTCTAGGGGTGCCCCTGCTGGGCCCCCTCTGCTCTTCCTGCTGGAGGCTGGGGCCTTTCGGGAGTCAGCAGGTGCCCCGGCCAACCGCAGCCGGCGT [SEQ ID No: 54]
Аминокислотная последовательность зрелой белковой последовательности для этой последовательности NT-4 представляет собой по существу такую, как указано в SEQ ID NO. 55, и выглядит следующим образом:
GVSETAPASRRGELAVCDAVSGWVTDRRTAVDLRGREVEVLGEVPAAGGSPLRQYFFETRCKADNAEEGGPGAGGGGCRGVDRRHWVSECKAKQSYVRALTADAQGRVGWRWIRIDTACVCTLLSRTGRA [SEQ ID No: 55]
Кодирующая последовательность нуклеиновой кислоты этого зрелого белка NT-4 представляет собой по существу такую, как указано в SEQ ID NO. 56, и выглядит следующим образом:
GGGGTGAGCGAAACTGCACCAGCGAGTCGTCGGGGTGAGCTGGCTGTGTGCGATGCAGTCAGTGGCTGGGTGACAGACCGCCGGACCGCTGTGGACTTGCGTGGGCGCGAGGTGGAGGTGTTGGGCGAGGTGCCTGCAGCTGGCGGCAGTCCCCTCCGCCAGTACTTCTTTGAAACCCGCTGCAAGGCTGATAACGCTGAGGAAGGTGGCCCGGGGGCAGGTGGAGGGGGCTGCCGGGGAGTGGACAGGAGGCACTGGGTATCTGAGTGCAAGGCCAAGCAGTCCTATGTGCGGGCATTGACCGCTGATGCCCAGGGCCGTGTGGGCTGGCGATGGATTCGAATTGACACTGCCTGCGTCTGCACACTCCTCAGCCGGACTGGCCGGGCC [SEQ ID No: 56]
Соответственно, в одном предпочтительном варианте осуществления данного изобретения, вторая кодирующая последовательность кодирует нейротрофин-4 (NT-4), который может содержать аминокислотную последовательность, по существу такую, как указано в SEQ ID NO: 49 или 55, или ее фрагмент или вариант. Таким образом, вторая кодирующая последовательность может содержать нуклеотидную последовательность, по существу такую, как указано в SEQ ID No: 50 или 56, или ее фрагмент или вариант.
Однако наиболее предпочтительные агонисты рецептора TrkB включают препро-нейротрофический фактор головного мозга (пре-про-НФГМ), про-НФГМF или зрелый НФГМ (зрНФГМ). НФГМ изначально синтезируется как белок-предшественник, препроНФГМ, посредством рибосом, обнаруженных на эндоплазматическом ретикулуме. Существует по меньшей мере 17 известных вариантов сплайсинга, кодируемых геном препроНФГМ человека (ENSG00000176697). Когда препроНФГМ входит в гранулярный эндоплазматический ретикулум, препроНФГМ преобразуется в проНФГМ путем расщепления сигнального пептида (т.е. последовательность "пре"). проНФГМ превращается в зрНФГМпутем расщепления дополнительной N-концевой пептидной последовательности, которая присутствует в проНФГМ. Как проНФГМ, так и зрНФГМ затем секретируются во внеклеточное пространство, где они связываются и активируют рецепторы на различных клетках, включая ГКС и кохлеарные клетки.
проНФГМ предпочтительно связывается и активирует рецептор, p75NTR, который при активации индуцирует апоптоз в ГКС и кохлеарных клетках. Таким образом, в одном предпочтительном варианте осуществления данного изобретения проНФГМ является агонистом рецептора p75NTR. В одном варианте осуществления данного изобретения проНФГМ является каноническим проНФГМ. Предпочтительно, канонический проНФГМ содержит аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 15, или ее фрагмент или вариант, и выглядит следующим образом:
APMKEANIRGQGGLAYPGVRTHGTLESVNGPKAGSRGLTSLADTFEHVIEELLDEDQKVRPNEENNKDADLYTSRVMLSSQVPLEPPLLFLLEEYKNYLDAANMSMRVRRHSDPARRGELSVCDSISEWVTAADKKTAVDMSGGTVTVLEKVPVSKGQLKQYFYETKCNPMGYTKEGCRGIDKRHWNSQCRTTQSYVRALTMDSKKRIGWRFIRIDTSCVCTLTIKRGR [SEQ ID No: 15]
Предпочтительно, в этом варианте осуществления данного изобретения вторая кодирующая последовательность содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 16, или ее фрагмент или вариант, и выглядит следующим образом:
GCCCCCATGAAAGAAGCAAACATCCGAGGACAAGGTGGCTTGGCCTACCCAGGTGTGCGGACCCATGGGACTCTGGAGAGCGTGAATGGGCCCAAGGCAGGTTCAAGAGGCTTGACATCATTGGCTGACACTTTCGAACACGTGATAGAAGAGCTGTTGGATGAGGACCAGAAAGTTCGGCCCAATGAAGAAAACAATAAGGACGCAGACTTGTACACGTCCAGGGTGATGCTCAGTAGTCAAGTGCCTTTGGAGCCTCCTCTTCTCTTTCTGCTGGAGGAATACAAAAATTACCTAGATGCTGCAAACATGTCCATGAGGGTCCGGCGCCACTCTGACCCTGCCCGCCGAGGGGAGCTGAGCGTGTGTGACAGTATTAGTGAGTGGGTAACGGCGGCAGACAAAAAGACTGCAGTGGACATGTCGGGCGGGACGGTCACAGTCCTTGAAAAGGTCCCTGTATCAAAAGGCCAACTGAAGCAATACTTCTACGAGACCAAGTGCAATCCCATGGGTTACACAAAAGAAGGCTGCAGGGGCATAGACAAAAGGCATTGGAACTCCCAGTGCCGAACTACCCAGTCGTACGTGCGGGCCCTTACCATGGATAGCAAAAAGAGAATTGGCTGGCGATTCATAAGGATAGACACTTCTTGTGTATGTACATTGACCATTAAAAGGGGAAGATAG [SEQ ID No: 16]
В другом варианте осуществления данного изобретения проНФГМ представляет собой изоформу 2 проНФГМ, которая предпочтительно содержит мутацию валина на метионион (подчеркнутая аминокислота). Предпочтительно, изоформа 2 проНФГМ включает аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 17, или ее фрагмент или вариант, и выглядит следующим образом:
APMKEANIRGQGGLAYPGVRTHGTLESVNGPKAGSRGLTSLADTFEHMIEELLDEDQKVRPNEENNKDADLYTSRVMLSSQVPLEPPLLFLLEEYKNYLDAANMSMRVRRHSDPARRGELSVCDSISEWVTAADKKTAVDMSGGTVTVLEKVPVSKGQLKQYFYETKCNPMGYTKEGCRGIDKRHWNSQCRTTQSYVRALTMDSKKRIGWRFIRIDTSCVCTLTIKRGR [SEQ ID No: 17]
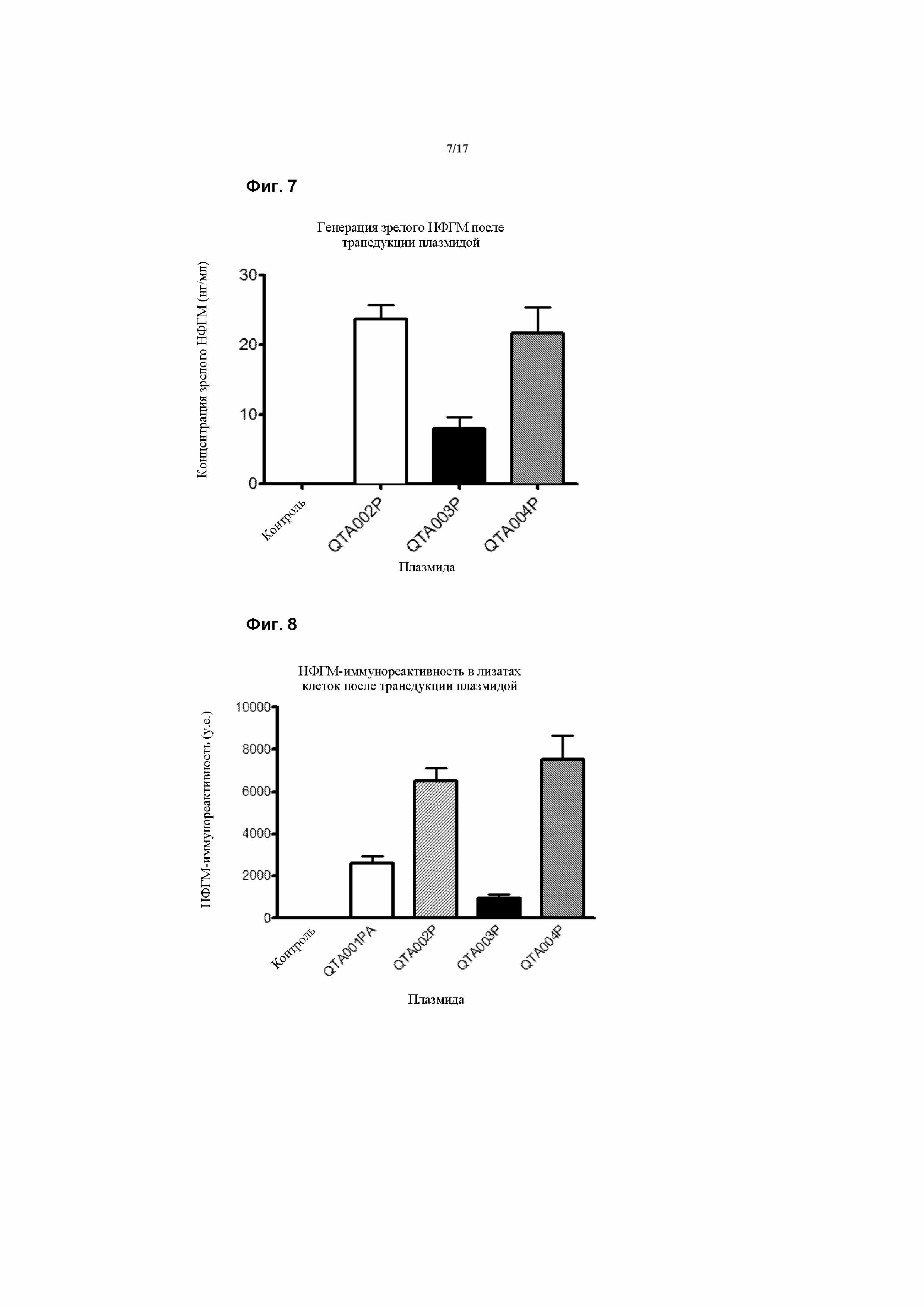
Однако в одном варианте осуществления данного изобретения агонист не является проНФГМ или его фрагментом или вариантом, но вместо этого вторая кодирующая последовательность предпочтительно содержит нуклеотидную последовательность, которая кодирует зрелый НФГМ. Зрелый НФГМ (зрНФГМ) предпочтительно связывается и активирует TrkB, который при активации индуцирует выживание ГКС и/или кохлеарных клеток. Таким образом, зрелый НФГМ является наиболее предпочтительным агонистом TrkB. Конструкция согласно первому аспекту является предпочтительной, поскольку, в отличие от других известных генетических конструкций, указанная конструкция способна продуцировать зрелый белок НФГМ, который не характеризовался неправильным сворачиванием.
Таким образом, в одном предпочтительном варианте осуществления данного изобретения вторая кодирующая последовательность содержит нуклеотидную последовательность, которая кодирует зрелый НФГМ. зрНФГМ является общим для всех 17 изоформ, кодируемых указанным геном. В этом месте существует 7 белковых различных последовательностей, пять из которых имеют удлиненные сигнальные последовательности в канонической форме, а одна имеет каноническую сигнальную последовательность, но в тоже время - мутацию валина на метионин (которая является общей для изоформ 2, 4, 7, 8, 9, 10, 11, 12, 13, 14 и 16). Считается, что мутация валина на метионин снижает высвобождение НФГМ из клетки.
Предпочтительно, зрелый НФГМ содержит аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 18, или ее фрагмент или вариант, и выглядит следующим образом:
HSDPARRGELSVCDSISEWVTAADKKTAVDMSGGTVTVLEKVPVSKGQLKQYFYETKCNPMGYTKEGCRGIDKRHWNSQCRTTQSYVRALTMDSKKRIGWRFIRIDTSCVCTLTIKRGR [SEQ ID No: 18]
Предпочтительно, этот вариант осуществления второй кодирующей последовательности содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 19, или ее фрагмент или вариант, и выглядит следующим образом:
ATGACCATCCTTTTCCTTACTATGGTTATTTCATACTTTGGTTGCATGAAGGCTGCCCCCATGAAAGAAGCAAACATCCGAGGACAAGGTGGCTTGGCCTACCCAGGTGTGCGGACCCATGGGACTCTGGAGAGCGTGAATGGGCCCAAGGCAGGTTCAAGAGGCTTGACATCATTGGCTGACACTTTCGAACACGTGATAGAAGAGCTGTTGGATGAGGACCAGAAAGTTCGGCCCAATGAAGAAAACAATAAGGACGCAGACTTGTACACGTCCAGGGTGATGCTCAGTAGTCAAGTGCCTTTGGAGCCTCCTCTTCTCTTTCTGCTGGAGGAATACAAAAATTACCTAGATGCTGCAAACATGTCCATGAGGGTCCGGCGCCACTCTGACCCTGCCCGCCGAGGGGAGCTGAGCGTGTGTGACAGTATTAGTGAGTGGGTAACGGCGGCAGACAAAAAGACTGCAGTGGACATGTCGGGCGGGACGGTCACAGTCCTTGAAAAGGTCCCTGTATCAAAAGGCCAACTGAAGCAATACTTCTACGAGACCAAGTGCAATCCCATGGGTTACACAAAAGAAGGCTGCAGGGGCATAGACAAAAGGCATTGGAACTCCCAGTGCCGAACTACCCAGTCGTACGTGCGGGCCCTTACCATGGATAGCAAAAAGAGAATTGGCTGGCGATTCATAAGGATAGACACTTCTTGTGTATGTACATTGACCATTAAAAGGGGAAGATAG [SEQ ID No: 19]
В еще одном предпочтительном варианте осуществления данного изобретения агонистом является зрНФГМ с сигнальным пептидом, конъюгированным с его N-концом. Как обсуждается ниже, сигнальный пептид может представлять собой канонический сигнальный пептид препроНФГМ или сигнальный пептид ИЛ-2 или новую сигнальную последовательность de novo, созданную авторами.
Предпочтительно, вторая кодирующая последовательность содержит нуклеотидную последовательность, кодирующую сигнальный пептид для агониста рецептора TrkB, наиболее предпочтительно, сигнальный пептид для НФГМ. В одном предпочтительном варианте осуществления данного изобретения нуклеотидная последовательность кодирует канонический сигнальный пептид для НФГМ. Предпочтительно, этот вариант осуществления второй кодирующей последовательности содержит нуклеотидную последовательность, которая кодирует сигнальный пептид, содержащий аминокислотную последовательность, которая упоминается в данном документе как SEQ ID NO. 20, или ее фрагмент или вариант, и выглядит следующим образом:
MTILFLTMVISYFGCMKA [SEQ ID No: 20]
Предпочтительно, этот вариант осуществления второй кодирующей последовательности содержит нуклеотидную последовательность, которая упоминается в данном документе как SEQ ID NO. 21, или ее фрагмент или вариант, и выглядит следующим образом:
ATGACCATCCTTTTCCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 21]
Авторы создали серию удлиненных сигнальных пептидов. В предпочтительных вариантах осуществления данного изобретения нуклеотидная последовательность, кодирующая сигнальный пептид изоформы для НФГМ, выбирают из группы, состоящей из: изоформы 2, 3, 6, 5 и 4. Последовательности нуклеиновой кислоты и аминокислот для каждого из этих удлиненных сигнальных пептидов приведены ниже.
Изоформа 2
MFHQVRRVMTILFLTMVISYFGCMKA [SEQ ID No: 22]
ATGTTCCACCAGGTGAGAAGAGTGATGACCATCCTTTTCCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 23]
Изоформа 3 и 6
MQSREEEWFHQVRRVMTILFLTMVISYFGCMKA [SEQ ID No: 24]
ATGCAGAGCCGGGAAGAGGAATGGTTCCACCAGGTGAGAAGAGTGATGACCATCCTTTTCCTT ACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 25]
Изоформа 5
MLCAISLCARVRKLRSAGRCGKFHQVRRVMTILFLTMVISYFGCMKA [SEQ ID No: 26]
ATGCTCTGTGCGATTTCATTGTGTGCTCGCGTTCGCAAGCTCCGTAGTGCAGGAAGGTGCGGGAAGTTCCACCAGGTGAGAAGAGTGATGACCATCCTTTTCCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 27]
Изоформа 4
MCGATSFLHECTRLILVTTQNAEFLQKGLQVHTCFGVYPHASVWHDCASQKKGCAVYLHVSVEFNKLIPENGFIKFHQVRRVMTILFLTMVISYFGCMKA [SEQ ID No: 28]
ATGTGTGGAGCCACCAGTTTTCTCCATGAGTGCACAAGGTTAATCCTTGTTACTACTCAGAATGCTGAGTTTCTACAGAAAGGGTTGCAGGTCCACACATGTTTTGGCGTCTACCCACACGCTTCTGTATGGCATGACTGTGCATCCCAGAAGAAGGGCTGTGCTGTGTACCTCCACGTTTCAGTGGAATTTAACAAACTGATCCCTGAAAATGGTTTCATAAAGTTCCACCAGGTGAGAAGAGTGATGACCATCCTTTTCCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 29]
Соответственно, в предпочтительных вариантах осуществления данного изобретения вторая кодирующая последовательность содержит нуклеотидную последовательность, кодирующую последовательность сигнального пептида, которая упоминается в данном документе как любая из SEQ ID NO. 23, 25, 27 или 29. Предпочтительно, сигнальный пептид содержит аминокислотную последовательность, которая упоминается в данном документе как любая из SEQ ID NO. 22, 24, 26 или 28.
Авторы также создали различные варианты осуществления новых сигнальных пептидов для агониста, предпочтительно, НФГМ. Эти сигнальные пептиды повышают уровень основности N-концевого участка (с добавлением остатков лизина (K) и аргинина (R)) и действующей гидрофобной области (с добавлением остатков лейцина (L)), которые увеличивают секрецию НФГМ по сравнению с уровнями, наблюдаемыми с канонической сигнальной последовательностью дикого типа.
a) QTA003P (сигнал ИЛ-2)
MYRMQLLSCIALSLALVTNS [SEQ ID No: 30]
ATGTACAGGATGCAACTCCTGTCTTGCATTGCACTAAGTCTTGCACTTGTCACAAACAGT [SEQ ID No: 31]
b) QTA004P
MKRRVMIILFLTMVISYFGCMK [SEQ ID No: 32]
ATGAAAAGAAGAGTGATGATCATCCTTTTCCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGAGCG [SEQ ID No: 33]
c) QTA009P (модифицированный ИЛ-2)
MRRMQLLLLIALSLALVTNS [SEQ ID No: 34]
ATGAGGAGGATGCAACTCCTGCTCCTGATTGCACTAAGTCTTGCACTTGTCACAAACAGT [SEQ ID No: 35]
d) QTA010P
MRRMQLLLLTMVISYFGCMKA [SEQ ID No: 36]
ATGAGGAGGATGCAACTCCTGCTCCTGACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 37]
e) QTA0012P
MRILLLTMVISYFGCMKA [SEQ ID No: 38]
ATGAGAATCCTTCTTCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 39]
f) QTA0013P
MRRILFLTMVISYFGCMKA [SEQ ID No: 40]
ATGAGAAGAATCCTTTTCCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 41]
g) QTA0014P
MRRFLFLLVISYFGCMKA [SEQ ID No: 42]
ATGAGGAGGTTCCTTTTCCTTCTTGTTATTTCATACTTCGGTTGCATGAAGGCG [SEQ ID No: 43]
i) QTA0015P
MRRFLFLLYFGCMKA [SEQ ID No: 44]
ATGAGGAGGTTCCTTTTCCTTCTTTACTTCGGTTGCATGAAGGCG [SEQ ID No: 45]
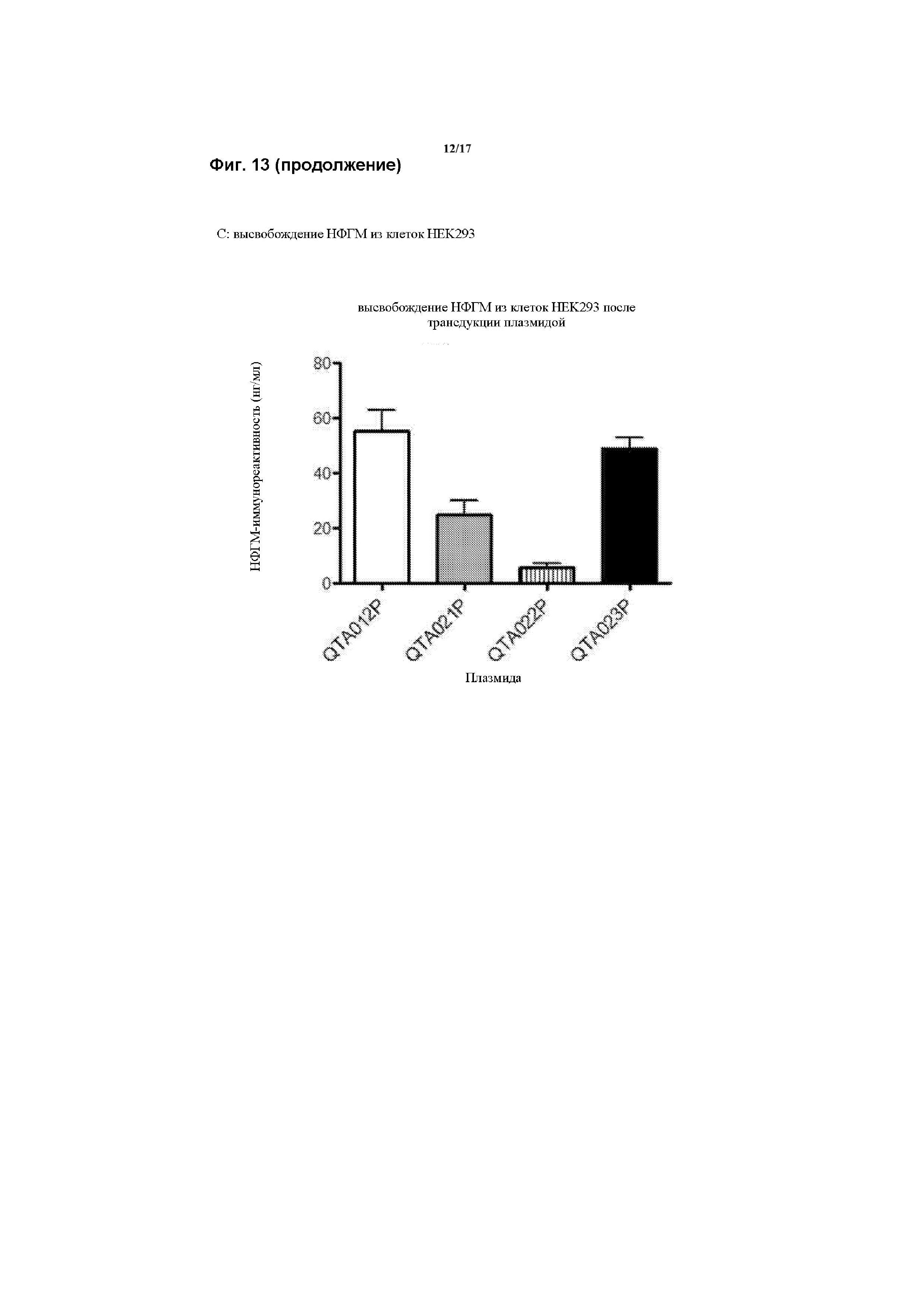
На Фигуре 6 проиллюстрированы нуклеотидные и аминокислотные последовательности для дополнительных предпочтительных осуществлений сигнального пептида, применяемого в конструкции данного изобретения, для усиления секреции агониста, предпочтительно, НФГМ. Второй остаток в сигнальном пептиде представляет собой треонин (Т), который предпочтительно заменяется одним или большим количеством основных остатков, таких как лизин (К) или аргинин (R). Следующий участок остатков в сигнальном пептиде, включающий изолейцин (I), лейцин (L), фенилаланин (F) и лейцин (L), предпочтительно заменяется одним или большим количеством гидрофобных остатков.
Соответственно, в предпочтительных вариантах осуществления данного изобретения вторая кодирующая последовательность содержит нуклеотидную последовательность, кодирующую последовательность сигнального пептида, которая упоминается в данном документе как любая из SEQ ID NO. 31, 33, 35, 37, 39, 41, 43, 45, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101 или 103. Предпочтительно, сигнальный пептид содержит аминокислотную последовательность, которая упоминается в данном документе как любая из SEQ ID NO. 30, 32, 34, 36, 38, 40, 42, 44, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100 или 102.
Соответственно, следует понимать, что авторы модифицировали последовательность гена НФГМ путем удаления про-последовательности, чего раньше также не удавалось достичь, в результате чего получали правильно сложенный зрелый НФГМ в комбинации с введением совершенно новых сигнальных пептидов, что значительно повышало уровни продукции и высвобождения НФГМ по сравнению с когда-либо достигнутыми при применении эндогенной последовательности.
Предпочтительно, генетическая конструкция содержит последовательности лево- и/или правоинвертированного концевого повтора (ITR). Предпочтительно, каждый ITR расположен на 5' и/или на 3' конце указанной конструкции. ITR может быть специфичной для серотипа вируса (например, AAV или лентивируса) и может быть любой последовательностью, при условии, что она образует петлю "шпильку" во вторичной структуре.
Последовательность ДНК по одному варианту осуществления ITR (левая ITR из коммерчески доступной плазмиды AAV) представлена в данном документе как SEQ ID No: 46 и выглядит следующим образом:
CCTGCAGGCAGCTGCGCGCTCGCTCGCTCACTGAGGCCGCCCGGGCGTCGGGCGACCTTTGGTCGCCCGGCCTCAGTGAGCGAGCGAGCGCGCAGAGAGGGAGTGGCCAACTCCATCACTAGGGGTTCCT [SEQ ID NO:46]
Последовательность ДНК по другому варианту осуществления ITR (правая ITR из коммерчески доступной плазмиды AAV) представлена в данном документе как SEQ ID No: 47 и выглядит следующим образом:
AGGAACCCCTAGTGATGGAGTTGGCCACTCCCTCTCTGCGCGCTCGCTCGCTCACTGAGGCCGGGCGACCAAAGGTCGCCCGACGCCCGGGCTTTGCCCGGGCGGCCTCAGTGAGCGAGCGAGCGCGCAGCTGCCTGCAGG [SEQ ID NO:47]
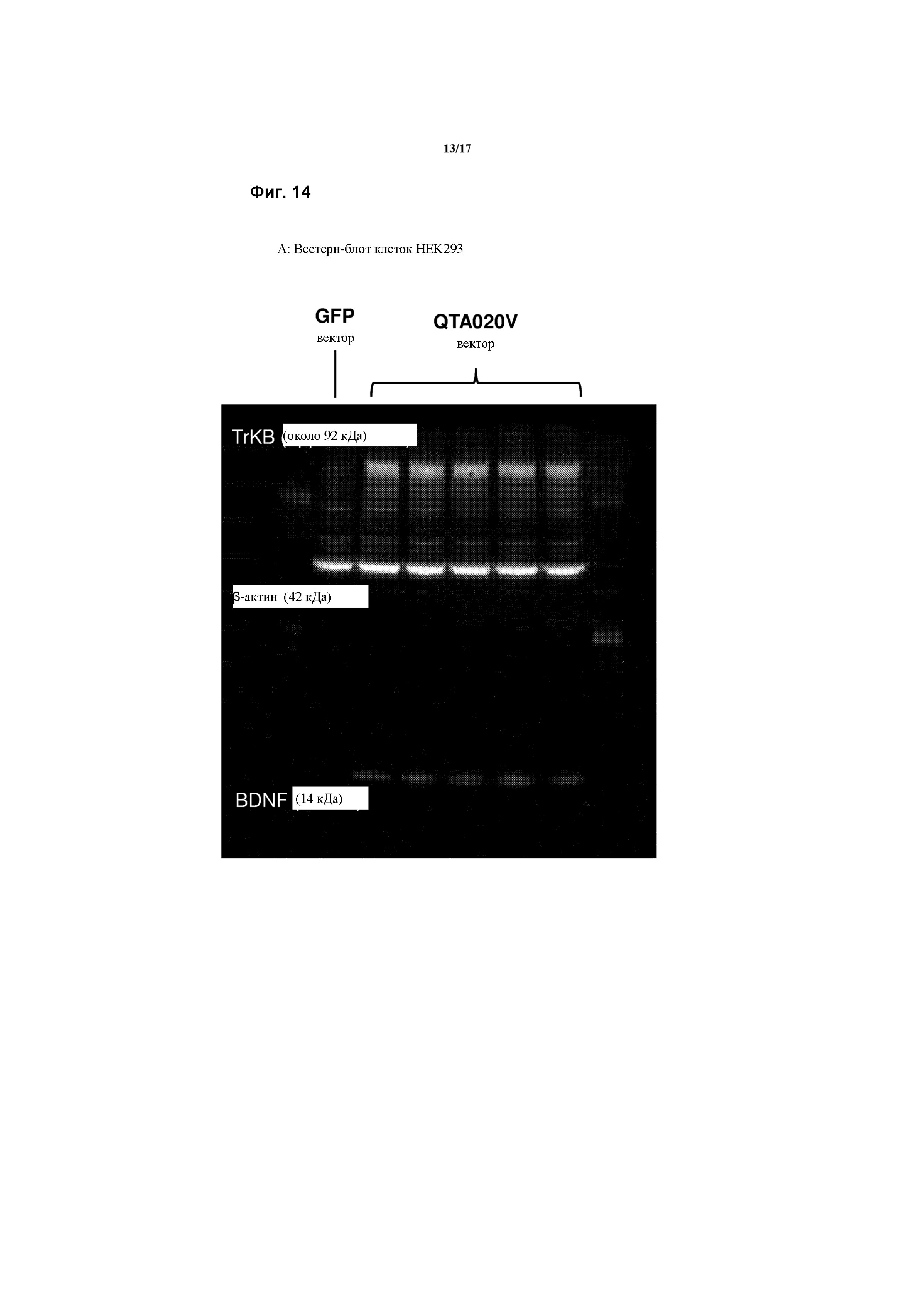
На основании вышеизложенного специалист в данной области техники будет иметь возможность оценить нуклеотидную последовательность согласно варианту осуществления конструкции по первому аспекту, а также аминокислотную последовательность кодированного трансгена. Однако, во избежание неоднозначности толкования, кодирующая последовательность кодон-оптимизированной последовательности 2940 п.о. для мышиного TrkB-рецептор-вирусного-2A-пептидного-зрНФГМ, содержащегося в плазмиде QTA020P (и векторе QTA020V), упоминается в данном документе как SEQ ID No: 107, и выглядит следующим образом:
ATGAGCCCATGGCTGAAGTGGCACGGACCAGCAATGGCAAGACTGTGGGGCCTGTGCCTGCTGGTGCTGGGCTTCTGGAGAGCCAGCCTGGCCTGTCCAACCTCCTGCAAGTGTAGCTCCGCCAGGATCTGGTGCACAGAGCCTTCTCCAGGCATCGTGGCCTTTCCCCGCCTGGAGCCTAACAGCGTGGATCCCGAGAATATCACCGAGATCCTGATCGCCAACCAGAAGCGGCTGGAGATCATCAATGAGGACGATGTGGAGGCCTACGTGGGCCTGAGAAACCTGACAATCGTGGACTCCGGCCTGAAGTTCGTGGCCTATAAGGCCTTTCTGAAGAACTCTAATCTGAGGCACATCAACTTCACCCGCAATAAGCTGACATCTCTGAGCCGGAGACACTTTCGGCACCTGGATCTGTCCGACCTGATCCTGACCGGCAATCCATTCACATGCTCTTGTGACATCATGTGGCTGAAGACCCTGCAGGAGACAAAGTCTAGCCCCGATACCCAGGACCTGTACTGTCTGAACGAGTCCTCTAAGAATATGCCTCTGGCCAACCTGCAGATCCCTAATTGTGGACTGCCAAGCGCCCGGCTGGCCGCACCTAACCTGACAGTGGAGGAGGGCAAGTCCGTGACACTGTCCTGTTCTGTGGGCGGCGATCCCCTGCCTACCCTGTATTGGGACGTGGGCAACCTGGTGTCTAAGCACATGAATGAGACCTCCCACACACAGGGCTCTCTGAGAATCACAAATATCAGCTCCGACGATAGCGGCAAGCAGATCTCTTGCGTGGCAGAGAACCTGGTGGGAGAGGATCAGGACAGCGTGAATCTGACCGTGCACTTCGCCCCCACCATCACATTTCTGGAGTCTCCTACCAGCGATCACCACTGGTGCATCCCCTTCACAGTGCGGGGAAACCCAAAGCCCGCCCTGCAGTGGTTTTACAACGGCGCCATCCTGAATGAGTCCAAGTATATCTGTACCAAGATCCACGTGACCAACCACACAGAGTACCACGGCTGCCTGCAGCTGGATAATCCCACCCACATGAACAATGGCGACTACACACTGATGGCCAAGAACGAGTATGGCAAGGACGAGAGGCAGATCAGCGCCCACTTCATGGGCCGCCCTGGAGTGGATTATGAGACCAACCCTAATTACCCAGAGGTGCTGTATGAGGACTGGACCACACCTACCGATATCGGCGACACCACAAACAAGTCTAATGAGATCCCAAGCACAGATGTGGCCGACCAGTCTAACAGGGAGCACCTGAGCGTGTACGCAGTGGTGGTCATCGCCTCCGTGGTGGGCTTCTGCCTGCTGGTCATGCTGCTGCTGCTGAAGCTGGCCCGCCACTCTAAGTTTGGCATGAAGGGCCCAGCCTCCGTGATCTCTAATGACGATGACAGCGCCAGCCCCCTGCACCACATCAGCAACGGCTCCAATACCCCTTCTAGCTCCGAGGGCGGCCCAGATGCCGTGATCATCGGCATGACAAAGATCCCCGTGATCGAGAACCCTCAGTACTTCGGCATCACCAATTCCCAGCTGAAGCCTGACACATTTGTGCAGCACATCAAGCGGCACAACATCGTGCTGAAGAGGGAACTGGGAGAGGGAGCCTTCGGCAAGGTGTTTCTGGCCGAGTGCTATAACCTGTGCCCAGAGCAGGATAAGATCCTGGTGGCCGTGAAGACCCTGAAGGATGCCAGCGACAACGCCCGGAAGGACTTCCACAGAGAGGCCGAGCTGCTGACAAATCTGCAGCACGAGCACATCGTGAAGTTTTACGGCGTGTGCGTGGAGGGCGACCCTCTGATCATGGTGTTCGAGTATATGAAGCACGGCGATCTGAACAAGTTTCTGAGAGCACACGGACCAGATGCCGTGCTGATGGCAGAGGGAAATCCCCCTACCGAGCTGACACAGTCTCAGATGCTGCACATTGCACAGCAGATTGCAGCAGGAATGGTGTACCTGGCCAGCCAGCACTTCGTGCACAGGGATCTGGCAACCAGAAACTGCCTGGTGGGAGAGAATCTGCTGGTGAAGATCGGCGACTTTGGCATGTCCCGGGACGTGTACTCTACCGACTACTATAGAGTGGGCGGCCACACAATGCTGCCCATCAGGTGGATGCCACCCGAGAGCATCATGTATCGCAAGTTCACCACAGAGTCTGACGTGTGGAGCCTGGGCGTGGTGCTGTGGGAGATCTTTACCTACGGCAAGCAGCCTTGGTATCAGCTGTCCAACAATGAAGTGATCGAGTGTATTACACAGGGACGCGTGCTGCAGAGGCCACGCACATGCCCCCAGGAGGTGTACGAGCTGATGCTGGGCTGTTGGCAGCGGGAGCCACACACCAGAAAGAACATCAAGAGCATCCACACACTGCTGCAGAATCTGGCCAAGGCCTCCCCCGTGTATCTGGACATCCTGGGCAGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCTATGAGAATCCTTCTTCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCGCACTCCGACCCTGCCCGCCGTGGGGAGCTGAGCGTGTGTGACAGTATTAGCGAGTGGGTCACAGCGGCAGATAAAAAGACTGCAGTGGACATGTCTGGCGGGACGGTCACAGTCCTAGAGAAAGTCCCGGTATCCAAAGGCCAACTGAAGCAGTATTTCTACGAGACCAAGTGTAATCCCATGGGTTACACCAAGGAAGGCTGCAGGGGCATAGACAAAAGGCACTGGAACTCGCAATGCCGAACTACCCAATCGTATGTTCGGGCCCTTACTATGGATAGCAAAAAGAGAATTGGCTGGCGATTCATAAGGATAGACACTTCCTGTGTATGTACACTGACCATTAAAAGGGGAAGATAG [SEQ ID No: 107]
Кодирующая последовательность кодон-оптимизированной последовательности 2943 п.о. для человеческого TrkB-рецептор-вирусного-2A-пептидного-зрНФГМ, содержащегося в плазмиде QTA029P (и векторе QTA029V), упоминается в данном документе как SEQ ID No: 108, и выглядит следующим образом:
ATGTCATCTTGGATCCGCTGGCACGGGCCAGCGATGGCCCGATTGTGGGGCTTCTGCTGGCTTGTTGTAGGCTTCTGGCGCGCGGCGTTCGCGTGTCCGACCTCTTGCAAATGCTCAGCAAGCCGAATTTGGTGCTCAGACCCTAGTCCAGGAATTGTTGCATTCCCCCGACTGGAACCAAACTCCGTCGACCCGGAGAATATAACTGAGATATTTATTGCAAATCAAAAACGCCTTGAAATCATTAACGAGGATGACGTGGAGGCCTACGTTGGTTTGAGAAATCTTACTATTGTCGACTCCGGACTTAAATTTGTAGCTCATAAAGCCTTCCTGAAGAACTCTAATCTGCAGCACATTAATTTCACGAGAAATAAGCTGACCAGCTTGTCCCGGAAGCATTTCCGCCATCTCGACCTGAGCGAGCTCATACTGGTCGGAAACCCATTTACGTGCTCCTGTGACATCATGTGGATCAAAACTCTGCAAGAGGCGAAAAGTAGTCCGGATACCCAAGACCTTTACTGTCTTAATGAAAGCTCAAAAAATATCCCGCTGGCCAACCTGCAGATACCGAACTGCGGACTTCCTAGTGCGAATTTGGCTGCCCCAAATCTTACCGTCGAAGAAGGCAAATCAATCACGCTTTCTTGTTCTGTAGCTGGAGATCCAGTGCCTAATATGTATTGGGACGTGGGTAACCTCGTCTCAAAACATATGAACGAAACGAGCCACACCCAGGGCTCTTTGCGGATAACAAACATCTCCTCTGATGATTCTGGAAAGCAAATCAGTTGCGTAGCTGAAAATCTGGTTGGCGAAGATCAAGATTCAGTCAATCTGACAGTCCATTTCGCCCCAACGATCACCTTTCTGGAGAGCCCAACTAGCGATCACCACTGGTGTATTCCGTTTACGGTAAAAGGAAATCCAAAACCTGCACTCCAATGGTTTTATAATGGAGCCATCTTGAATGAAAGCAAATATATCTGTACTAAAATCCATGTGACGAATCACACCGAGTATCACGGGTGTCTTCAATTGGATAATCCAACCCATATGAATAATGGTGATTATACTTTGATAGCGAAGAACGAATACGGCAAAGACGAAAAGCAAATATCCGCACATTTCATGGGTTGGCCTGGCATCGACGACGGTGCGAACCCGAACTACCCAGATGTTATTTACGAGGATTATGGGACTGCGGCAAACGACATTGGCGACACCACAAACCGAAGCAACGAGATACCAAGTACTGACGTCACTGACAAAACGGGTCGAGAGCATTTGTCTGTTTACGCCGTTGTTGTTATCGCCTCAGTTGTCGGATTTTGCCTGTTGGTCATGCTTTTCCTCCTGAAGCTCGCGCGACATTCCAAGTTTGGCATGAAGGGG CCAGCAAGTGTTATATCCAATGATGATGATAGCGCTTCTCCATTGCACCACATAAGTAACGGCTCAAACACGCCGTCATCTAGTGAAGGTGGACCAGACGCGGTCATTATAGGGATGACTAAAATTCCCGTAATCGAAAACCCTCAGTACTTCGGCATAACCAACAGTCAGCTTAAACCCGATACTTTCGTGCAGCACATCAAAAGGCACAACATAGTCCTCAAGCGCGAACTCGGGGAGGGAGCCTTCGGAAAGGTCTTTCTTGCTGAGTGCTATAATTTGTGTCCTGAGCAGGATAAAATTCTTGTGGCTGTAAAAACTCTCAAAGATGCTTCCGACAACGCACGGAAGGATTTTCATCGGGAGGCCGAACTGTTGACGAATTTGCAGCACGAGCATATAGTAAAGTTCTACGGGGTATGTGTTGAGGGGGACCCGTTGATTATGGTCTTCGAGTATATGAAGCACGGGGACCTGAACAAATTTTTGCGCGCCCATGGGCCTGATGCCGTCCTTATGGCAGAAGGGAACCCTCCAACAGAACTCACCCAGAGTCAGATGTTGCACATAGCGCAACAGATCGCGGCCGGCATGGTTTACCTGGCCAGTCAACACTTCGTGCATAGAGATCTTGCCACTCGCAACTGTTTGGTCGGGGAGAACCTTCTGGTTAAGATTGGTGACTTTGGTATGTCACGAGATGTGTATTCCACTGACTATTACAGAGTTGGGGGTCATACAATGCTTCCTATTCGGTGGATGCCCCCCGAATCCATCATGTACAGAAAGTTCACGACAGAGAGTGATGTT TGG AGT CTCGGCGTGGTGCTCTGGGAAATTTTCACATACGGAAAGCAGCCGTGGTATCAACTTAGCAACAATGAGGTGATAGAGTGTATTACACAGGGTCGGGTGTTGCAGCGCCCTCGAACGTGCCCACAAGAAGTATATGAACTTATGCTCGGGTGCTGGCAAAGAGAACCACATATGAGAAAAAATATCAAGGGGATACATACATTGCTTCAGAACTTGGCCAAGGCATCACCCGTCTACCTCGATATACTGGGCAGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCTATGAGAATCCTTCTTCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCGCACTCCGACCCTGCCCGCCGTGGGGAGCTGAGCGTGTGTGACAGTATTAGCGAGTGGGTCACAGCGGCAGATAAAAAGACTGCAGTGGACATGTCTGGCGGGACGGTCACAGTCCTAGAGAAAGTCCCGGTATCCAAAGGCCAACTGAAGCAGTATTTCTACGAGACCAAGTGTAATCCCATGGGTTACACCAAGGAAGGCTGCAGGGGCATAGACAAAAGGCACTGGAACTCGCAATGCCGAACTACCCAATCGTATGTTCGGGCCCTTACTATGGATAGCAAAAAGAGAATTGGCTGGCGATTCATAAGGATAGACACTTCCTGTGTATGTACACTGACCATTAAAAGGGGAAGATAG [SEQ ID No: 108]
Следовательно, в наиболее предпочтительном варианте осуществления данного изобретения указанная конструкция содержит нуклеотидную последовательность, по существу, как указано в SEQ ID No: 107 или 108, или ее фрагмент или вариант.
Авторы создали серию рекомбинантных экспрессионных векторов, содержащих конструкцию по данному изобретению.
Таким образом, согласно второму аспекту предлагается рекомбинантный вектор, содержащий генетическую конструкцию согласно первому аспекту.
Рекомбинантный вектор может представлять собой рекомбинантный вектор AAV (rAAV). rAAV может представлять собой вектор, встречающийся в природе, или вектор с гибридным серотипом AAV. rAAV может представлять собой AAV-1, AAV-2, AAV-3A, AAV-3B, AAV-4, AAV-5, AAV-6, AAV-7, AAV-8, AAV-9, AAV-10 и AAV-11. Предпочтительно, rAAV представляет собой серотип-2 rAAV.
Выгодным является то, что рекомбинантный AAV2 вызывает минимальный иммунный ответ в организмах-хозяевах и опосредует долгосрочную экспрессию трансгена, которая может сохраняться в сетчатке в течение по меньшей мере одного года после введения вектора.
В данном контексте термин "рекомбинантный вектор AAV (rAAV)" означает нуклеиновую кислоту, производную от рекомбинантного AAV, и содержащую по меньшей мере одну последовательность концевого повтора.
Предпочтительные варианты осуществления указанного вектора проиллюстрированы на Фигурах 2-5.
Конструкции и экспрессионные векторы, описанные в данном документе, можно применять для лечения патологий зрительного нерва и кохлеарных патологий и, в более общем смысле, для стимулирования регенерации и выживания нервов.
Следовательно, согласно третьему аспекту, предлагается генетическая конструкция согласно первому аспекту или рекомбинантный вектор согласно второму аспекту для применения в качестве лекарственного средства или в лечении.
Согласно четвертому аспекту предлагается генетическая конструкция согласно первому аспекту или рекомбинантный вектор согласно второму аспекту для применения в лечении, предотвращении или облегчении патологии зрительного нерва или кохлеарной патологии, или для стимулирования регенерации и/или выживаемости нервов.
Согласно пятому аспекту, предлагается способ лечения, предотвращения или облегчения патологии зрительного нерва или кохлеарной патологии у субъекта или стимулирования регенерации и/или выживания нервов у субъекта, при этом способ включает в себя введение субъекту, нуждающемуся в таком лечении, терапевтически эффективного количества генетической конструкции согласно первому аспекту, или рекомбинантного вектора согласно второму аспекту.
Предпочтительно, генетическая конструкция или рекомбинантный вектор согласно данному изобретению применяются в методах генной терапии. Агонист, кодируемый конструкцией или вектором, активирует TrkB, также кодируемый конструкцией/вектором, тем самым способствуя выживанию ганглиозных клеток сетчатки (ГКС) или кохлеарных клеток.
В одном варианте осуществления данного изобретения патология зрительного нерва, которая подлежит лечению, может представлять собой глаукому или любое другое патофизиологическое состояние, которое может привести к гибели ГКС, такое как травма головы или лица или сосудистые нарушения, например частичное или полное нарушение кровоснабжения глазных структур или областей мозга, которые получают иннервацию от зрительного нерва. Кроме того, указанную конструкцию можно также применять для обеспечения замещения ГКС посредством введения нетрансформированной или трансформированной стволовой клетки в глаз или области, ассоциированные с функцией зрения у пациентов.
В одном варианте осуществления данного изобретения кохлеарная патология, которая подлежит лечению, может представлять собой потерю слуха или глухоту. Конструкции и векторы по данному изобретению существенно усиливают чувствительность кохлеарной клетки к агонистам рецептора TrkB, обуславливая локализованное увеличение количества как рецептора TrkB, так и агониста рецептора. Кохлеарными клетками могут быть волосковые клетки или нейронные спиральные ганглиозные клетки, которые посылают слуховые сигналы через свои аксоны от уха до ствола головного мозга. Волосковыми клетками могут быть внутренние волосковые клетки или внешние волосковые клетки [42, 43, 44].
В другом варианте осуществления данного изобретения указанные конструкции и векторы можно применять для стимулирования регенерации и/или выживания нервов.
Следует понимать, что генетическую конструкцию согласно первому аспекту или рекомбинантный вектор согласно второму аспекту можно применять в составе лекарственного средства, которое в свою очередь можно применять в качестве монотерапии (т.е. применение генетической конструкции согласно первому аспекту или вектора согласно второму аспекту данного изобретения) для лечения, снижения интенсивности или предотвращения патологии зрительного нерва или кохлеарной патологии, или для стимулирования регенерации и/или выживания нервов. Кроме того, генетическую конструкцию или рекомбинантный вектор согласно данному изобретению можно применять в качестве дополнения или в комбинации с известными препаратами для лечения, облегчения или предотвращения патологии зрительного нерва или кохлеарной патологии или для стимулирования регенерации и/или выживания нервов.
Генетическую конструкцию или рекомбинантный вектор согласно данному изобретению можно комбинировать в композициях, имеющих несколько различных форм, в зависимости, в частности, от способа, с помощью которого необходимо применять указанную композицию. Так, например, композиция может быть в виде порошка, таблетки, капсулы, жидкости, мази, крема, геля, гидрогеля, аэрозоля, спрея, мицеллярного раствора, трансдермального пластыря, липосомной суспензии или в любой другой пригодной форме, которая может вводиться человеку или животному, нуждающемуся в лечении. Следует понимать, что носителем для лекарственных средств согласно данному изобретению должен быть такой носитель, который хорошо переносится субъектом, которому он вводится.
Генетическую конструкцию или рекомбинантный вектор согласно данному изобретению также можно вводить с помощью устройства с медленным или отсроченным высвобождением. Такие устройства можно, например, установить на кожу или под кожу, и лекарственное средство может выделяться в течение недель или даже месяцев. Указанное устройство может быть расположено по меньшей мере рядом с участком лечения. Такие устройства могут быть особенно полезными при длительном лечении генетической конструкцией или рекомбинантным вектором и которое обычно требует частого введения (например, по меньшей мере ежедневной инъекции).
В предпочтительном варианте осуществления данного изобретения лекарственные средства согласно данному изобретению можно вводить субъекту посредством инъекции в кровоток, нерв или непосредственно в участок, требующий лечения. Например, лекарственное средство можно вводить по меньшей мере рядом с сетчаткой или ухом. Инъекции могут быть внутривенными (болюсное или инфузионное введение) или подкожными (болюсное или инфузионное введение), или внутрикожными (болюсное или инфузионное введение).
Следует понимать, что необходимое для ввдения количество генетической конструкции или рекомбинантного вектора определяется их биологической активностью и биодоступностью, которая, в свою очередь, зависит от способа введения, физико-химических свойств генетической конструкции или рекомбинантного вектора и применения их в качестве монотерапии или комбинированной терапии. На частоту введения будет также влиять период полувыведения циклического полипептида в организме субъекта, подлежащего лечению. Оптимальные дозы, подлежащие введению, могут быть определены специалистами в данной области техники и будут варьироваться в зависимости от применения конкретной генетической конструкции или рекомбинантного вектора, активности фармацевтической композиции, способа введения и степени выраженности патологии зрительного нерва или кохлеарной патологии. Дополнительные факторы, зависящие от конкретного субъекта, подлежащего лечению, включая возраст, вес, пол, диету и время введения, будут обуславливать необходимость коррекции дозы.
Как правило, суточная доза, составляющая от 0,001 мкг/кг веса тела до 10 мг/кг веса тела или от 0,01 мкг/кг веса тела до 1 мг/кг веса тела циклического полипептида согласно данному изобретению, может применяться для лечения, облегчения или предотвращения патологии зрительного нерва или кохлеарной патологии, в зависимости от применяемой генетической конструкции или рекомбинантного вектора.
Генетическую конструкцию или рекомбинантный вектор можно вводить до, во время или после возникновения начальных проявлений патологии зрительного нерва или кохлеарной патологии. Суточную дозу можно вводить за одно введение (например, однократная ежедневная инъекция или ингаляция назального спрея). Кроме того, генетическая конструкция или рекомбинантный вектор может потребовать введения два или большее количество раз в течение суток. В качестве примера генетическую конструкцию или рекомбинантный вектор можно вводить в виде двух (или большего количества, в зависимости от тяжести патологии зрительного нерва или кохлеарной патологии, подлежащих лечению) суточных доз от 0,07 мкг и 700 мг (т.е. при весе тела 70 кг). Пациент, получающий лечение, может принимать первую дозу после пробуждения, после чего - вторую дозу вечером (при назначении схемы двух доз) или с 3- или 4-часовыми интервалами в дальнейшем. В альтернативном варианте можно применять устройство медленного высвобождения с целью получения пациентом оптимальных доз генетической конструкции или рекомбинантного вектора согласно данному изобретению без необходимости введения повторных доз.
Известные процедуры, обычно применяемые в фармацевтической промышленности (например, эксперименты, клинические исследования и т.д. in vivo), можно применять для составления конкретных составов генетической конструкции или рекомбинантного вектора согласно данному изобретению и разработки точных терапевтических схем (таких как суточные дозы агентов и частота введения). Авторы считают, что они первыми предлагают промотор, кодирующий генетическую конструкцию, функционально присоединённую к кодирующим последовательностям рецептора TrkB и агониста рецептора TrkB.
Согласно шестому аспекту, предлагается фармацевтическая композиция, содержащая генетическую конструкцию согласно первому аспекту или рекомбинантный вектор согласно второму аспекту и фармацевтически приемлемый носитель.
Согласно седьмому аспекту предлагается способ получения фармацевтической композиции согласно шестому аспекту, включающий в себя приведение в контакт генетической конструкции согласно первому аспекту или рекомбинантного вектора согласно второму аспекту с фармацевтически приемлемым носителем.
"Субъект" может быть позвоночным, млекопитающим или домашним животным. Следовательно, композиции и лекарственные средства согласно данному изобретению можно применять для лечения любого млекопитающего, например, сельскохозяйственных животных (например, лошадей), домашних животных, или можно применять в других ветеринарных целях. Наиболее предпочтительно, однако, субъект представляет собой человека.
"Терапевтически эффективное количество" генетической конструкции, рекомбинантного вектора или фармацевтической композиции представляет собой любое количество, которое при введении субъекту является количеством вышеупомянутого элемента, которое необходимо для лечения глаукомы, глухоты или получения желаемого эффекта, такого как как стимулирование регенерации и/или выживания нервов.
Например, терапевтически эффективное количество применяемой генетической конструкции, рекомбинантного вектора или фармацевтической композиции может составлять от около 0,01 мг до около 800 мг и, предпочтительно, от около 0,01 мг до около 500 мг. Предпочтительно, чтобы количество генетической конструкции, рекомбинантного вектора или фармацевтической композиции составляло от около 0,1 до около 250 мг и, наиболее предпочтительно, от около 0,1 мг до около 20 мг.
В данном контексте "фармацевтически приемлемый носитель" представляет собой любое известное соединение или комбинацию известных соединений, которые, как известно специалистам в данной области техники, могут быть пригодны при составлении фармацевтических композиций.
В одном варианте осуществления данного изобретения фармацевтически приемлемый носитель может быть твердым, а композиция может быть в виде порошка или таблетки. Твердый фармацевтически приемлемый носитель может включать одно или большее количество веществ, которые также могут функционировать как ароматизаторы, смазывающие агенты, солюбилизаторы, суспендирующие агенты, красители, наполнители, скользящие агенты, вспомогательные агенты для прессования, инертные связующие агенты, подсластители, консерванты, красители, агенты для покрытия или агенты для улучшения распадаемости таблеток. Носитель также может быть инкапсулирующим материалом. В порошках, носитель представляет собой тонкоизмельченное твердое вещество, которое находится в смеси с тонко измельченными активными агентами согласно данному изобретению. В таблетках, активный агент (например, генетическую конструкцию или рекомбинантного вектора согласно данному изобретению) можно смешивать с носителем, имеющим необходимые свойства прессования, в пригодных пропорциях, и уплотнять с приданием желаемой формы и размера. Порошки и таблетки предпочтительно содержат до 99% активных агентов. Пригодные твердые носители включают, например, фосфат кальция, стеарат магния, тальк, сахара, лактозу, декстрин, крахмал, желатин, целлюлозу, поливинилпирролидин, низкоплавкие воски и ионообменные смолы. В другом варианте осуществления данного изобретения фармацевтический носитель может представлять собой гель, а композиция может быть в виде крема или тому подобного.
Однако фармацевтический носитель может быть жидкостью, и фармацевтическая композиция будет находиться в форме раствора. Жидкие носители применяются для приготовления растворов, суспензий, эмульсий, сиропов, эликсиров и композиций под давлением. Генетическую конструкцию или рекомбинантный вектор согласно данному изобретению можно растворить или суспендировать в фармацевтически приемлемом жидком носителе, таком как вода, органический растворитель, смесь их обоих, или фармацевтически приемлемых маслах или жирах. Жидкий носитель может содержать другие пригодные фармацевтические добавки, такие как солюбилизаторы, эмульгаторы, буферы, консерванты, подсластители, ароматизаторы, суспендирующие агенты, загустители, красители, регуляторы вязкости, стабилизаторы или осмо-регуляторы. Пригодные примеры жидких носителей для перорального и парентерального введения включают воду (частично содержащую добавки, как указано выше, например, производные целлюлозы, предпочтительно, раствор карбоксиметилцеллюлозы натрия), спирты (включая одноатомные спирты и многоатомные спирты, например, гликоли) и их производные, а также масла (например, фракционированное кокосовое масло и арахисовое масло). Для парентерального введения носителем может быть также масляный эфир, такой как этилолеат и изопропилмиристат. Стерильные жидкие носители являются пригодными для стерильных композиций в жидкой форме для парентерального введения. Жидкий носитель для композиций под давлением может представлять собой галогенированный углеводород или другой фармацевтически приемлемый пропеллент.
Жидкие фармацевтические композиции, которые представляют собой стерильные растворы или суспензии, могут вводиться, например, посредством внутримышечной, интратекальной, эпидуральной, внутрибрюшинной, внутривенной и особенно подкожной инъекции. Генетическую конструкцию или рекомбинантный вектор можно приготовить в виде стерильной твердой композиции, которую можно растворить или суспендировать во время введения с применением стерильной воды, солевого раствора или другой пригодной стерильной инъекционной среды.
Генетическую конструкцию, рекомбинантный вектор и фармацевтическую композицию по данному изобретению можно вводить перорально в виде стерильного раствора или суспензии, содержащей другие растворенные вещества или суспендирующие агенты (например, достаточное количество солевого раствора или глюкозы для приготовления изотонического раствора), желчные соли, камедь, желатин, моноолеат сорбитана, полисорбат 80 (олеатные эфиры сорбита и его ангидриды, сополимеризованные с этиленоксидом) и тому подобное. Генетическую конструкцию, рекомбинантный вектор или фармацевтическую композицию согласно данному изобретению можно также вводить перорально либо в жидкой, либо в твердой форме композиции. Композиции, пригодные для перорального введения, включают твердые формы, такие как пилюли, капсулы, гранулы, таблетки и порошки и жидкие формы, такие как растворы, сиропы, эликсиры и суспензии. Формы, пригодные для парентерального введения, включают стерильные растворы, эмульсии и суспензии.
Следует понимать, что данное изобретение распространяется на любую нуклеиновую кислоту или пептид или его вариант, производное или аналог, который содержит по существу последовательности аминокислот или нуклеиновых кислот любой из последовательностей, упомянутых в данном документе, включая их варианты или фрагменты. Термины "по существу аминокислотная/нуклеотидная/пептидная последовательность", "вариант" и "фрагмент" могут означать последовательность, которая имеет по меньшей мере 40% идентичность последовательности с аминокислотными/нуклеотидными/пептидными последовательностями любой из последовательностей, упомянутых в данном документе, например 40% идентичность с последовательностью, обозначенной как SEQ ID No: 1-108, и так далее.
Также рассматриваются аминокислотые/полинуклеотидные/полипептидные последовательности с идентичностью последовательности, которая составляет более 65%, более предпочтительно более 70%, еще более предпочтительно более 75% и еще более предпочтительно более 80% идентичности последовательности с любой из последовательностей, упомянутых в данном документе. Предпочтительно, аминокислотная/полинуклеотидная/полипептидная последовательность имеет по меньшей мере 85% идентичность с любой из последовательностей, упомянутых в данном документе, более предпочтительно по меньшей мере 90% идентичность, еще более предпочтительно по меньшей мере 92% идентичность, еще более предпочтительно по меньшей мере 95% идентичность, еще более предпочтительно по меньшей мере 97% идентичность, еще более предпочтительно по меньшей мере 98% идентичность и, наиболее предпочтительно по меньшей мере 99% идентичность с любой из последовательностей, упомянутых в данном документе.
Квалифицированному специалисту будет понятно, как рассчитать процент идентичности между двумя аминокислотными/полинуклеотидными/полипептидными последовательностями. Чтобы рассчитать процент идентичности между двумя аминокислотными/полинуклеотидными/полипептидными последовательностями, сначала необходимо подготовить выравнивание двух последовательностей с последующим вычислением значения идентичности последовательности. Процент идентичности для двух последовательностей может принимать разные значения в зависимости от: (i) способа, применяемого для выравнивания последовательностей, например, ClustalW, BLAST, FASTA, Смита-Уотермана (реализованы в разных программах), или структурного выравнивания из 3D-сравнения; и (ii) параметров, применяемых в способе выравнивания, например, локального или глобального выравнивания, применяемой матрицы подсчета пар (например, BLOSUM62, PAM250, Gonnet и т. д.) и штрафа за гэпы, например, функциональной формы и константы.
После осуществления выравнивания, существует множество различных способов вычисления процента идентичности между двумя последовательностями. Например, можно разделить количество идентичностей на: (i) длину кратчайшей последовательности; (ii) длину выравнивания; (iii) среднюю длину последовательности; (iv) количество положений без гэпов; или (iv) количество эквивалентных положений, исключая выступы. Кроме того, будет понятно, что процент идентичность также сильно зависит от длины. Следовательно, чем короче пара последовательностей, тем выше идентичность последовательности, выявление которой можно ожидать случайно.
Исходя из этого, будет понятно, что точное выравнивание белковых или ДНК-последовательностей является сложным процессом. Популярная программа множественного выравнивания ClustalW (Thompson et al., 1994, Nucleic Acids Research, 22, 4673-4680; Thompson et al., 1997, Nucleic Acids Research, 24, 4876-4882) является предпочтительным способом для генерирования множественных выравниваний белков или ДНК согласно данному изобретению. Пригодными параметрами для ClustalW могут быть следующие: для выравниваний ДНК: штраф за открытие гэпа = 15,0, штраф за продление гэпа = 6,66 и матрица = идентичность. Для выравниваний белков: штраф за открытие гэпа = 10,0, штраф за продление гэпа = 0,2 и матрица = Gonnet. Для выравниваний ДНК и белка: ENDGAP = -1 и GAPDIST = 4. Специалисты в данной области техники должны знать, что для оптимального выравнивания последовательности могут потребоваться изменения этих и других параметров.
Предпочтительно, вычисление процента идентичностей между двумя аминокислотными/полинуклеотидными /полипептидными последовательностями можно затем рассчитать из такого выравнивания, как (N/T)* 100, где N представляет собой число положений, в которых последовательности имеют одинаковый остаток, а T общее количество положений, включая гэпы, но исключая выступы. Исходя из этого, наиболее предпочтительный способ вычисления процента идентичности между двумя последовательностями включает (i) подготовку выравнивания последовательности с применением программы ClustalW с пригодным набором параметров, например, как указано выше; и (ii) ввод значений N и T в следующую формулу: - Идентификация последовательности = (N/T)*100.
Специалистам в данной области техники будут известны альтернативные способы идентификации подобных последовательностей. Например, по существу подобная нуклеотидная последовательность кодируется последовательностью, которая гибридизуется с последовательностями ДНК или их комплементами в жестких условиях. Под жесткими условиями мы подразумеваем, что нуклеотид гибридизуется со связанной на фильтре ДНК или РНК в 3х хлориде натрия/цитрате натрия (SSC) при температуре около 45°С, за которой следует по меньшей мере одно промывание в 0,2х SSC/0,1% SDS при температуре около 20-65°С. В альтернативном варианте, по существу подобный полипептид может отличаться по меньшей мере на 1, но менее чем на 5, 10, 20, 50 или 100 аминокислот из последовательностей, показанных, например, в SEQ ID NO: 3 и 5.
Учитывая вырождение генетического кода будет ясно, что любая последовательность нуклеиновой кислоты, описанная в данном документе, может быть модифицирована или изменена без существенного влияния на последовательность белка, кодируемого таким образом, для обеспечения ее функционального варианта. Пригодными вариантами нуклеотидов являются те, которые имеют последовательность, измененную путем замещения различных кодонов, кодирующих одну и ту же аминокислоту в последовательности, тем самым получая "молчащее" изменение. Другими пригодными вариантами являются те, которые имеют гомологичные нуклеотидные последовательности, но содержат все или части последовательности, которые изменяются путем замещения различных кодонов, кодирующих аминокислоту с боковой цепью подобных биофизических свойств с аминокислотой, которую она замещает, для получения консервативного изменения. Например, малые неполярные, гидрофобные аминокислоты включают глицин, аланин, лейцин, изолейцин, валин, пролин и метионин. Большие неполярные, гидрофобные аминокислоты включают фенилаланин, триптофан и тирозин. Полярно-нейтральные аминокислоты включают серин, треонин, цистеин, аспарагин и глутамин. Положительно заряженные (основные) аминокислоты включают лизин, аргинин и гистидин. Отрицательно заряженные (кислые) аминокислоты включают аспарагиновую кислоту и глутаминовую кислоту. Поэтому следует понимать, какие аминокислоты могут быть заменены аминокислотой, имеющей сходные биофизические свойства, при этом квалифицированный специалист будет знать нуклеотидные последовательности, кодирующие эти аминокислоты.
Согласно другому аспекту предлагается генетическая конструкция, содержащая промотор, функционально присоединённый к первой кодирующей последовательности, которая кодирует
рецептор тирозинкиназы B (TrkB), и второй кодирующей последовательности, которая кодирует агонист рецептора Trk для активации TrkB, чтобы таким образом стимулировать выживание ганглиозных клеток сетчатки (ГКС), нервных клеток или кохлеарных клеток.
Все описанные в данном документе характеристики (включая любые сопроводительные формулы, реферат и графические материалы) и/или все этапы любого описанного способа или процесса могут быть объединены с любым из вышеперечисленных аспектов в любой комбинации, за исключением комбинаций, в которых по меньшей мере некоторые из таких характеристик и/или этапов являются взаимоисключающими.
Для лучшего понимания данного изобретения и с целью демонстрации разных способов реализации вариантов осуществления данного изобретения, далее будет сделана ссылка, в качестве примера, на сопроводительные Фигуры, при этом:
На Фигуре 1 схематично изображен один вариант осуществления генетической конструкции согласно данному изобретению;
На Фигуре 2 проиллюстрировано схематическое изображение первого варианта осуществления рекомбинантного вектора согласно данному изобретению, известного как "плазмида QTA001PA", содержащего каноническую сигнальную последовательность (синий) плюс проНФГМ (красный) и зрНФГМ (черный). Указанный вектор также включает в себя -IRES-GFP- последовательность (голубой и фиолетовый);
На Фигуре 3 проиллюстрировано схематическое изображение второго варианта осуществления рекомбинантного вектора согласно данному изобретению, известного как "плазмида QTA002P" без проНФГМ (но продуцирует только зрНФГМ), и такой же сигнальной последовательности (синий), что и QTA001PA. Указанный вектор также включает в себя -IRES-GFP- последовательность (голубой и фиолетовый);
На Фигуре 4 проиллюстрировано схематическое изображение третьего варианта осуществления рекомбинантного вектора согласно данному изобретению, известного как "плазмида QTA003P" без проНФГМ (но продуцирует только зрНФГМ), и сигнальной последовательности ИЛ-2 (синий). Указанный вектор также включает в себя -IRES-GFP- последовательность (голубой и фиолетовый);
На Фигуре 5 проиллюстрировано схематическое изображение четвертого варианта осуществления рекомбинантного вектора согласно данному изобретению, известного как "плазмида QTA004P" без проНФГМ (но продуцирует только зрНФГМ), и новой сигнальной последовательности (синий). Указанный вектор также включает в себя -IRES-GFP- последовательность (голубой и фиолетовый);
На Фигуре 6 проиллюстрированы нуклеотидные и аминокислотные последовательности для разных вариантов осуществления сигнального пептида, применяемого в конструкции данного изобретения. Второй остаток представляет собой треонин (t), который может быть заменен одним или большим количеством основных остатков, таких как лизин (К) или аргинин (R). Следующий участок остатков, включающий изолейцин (I), лейцин (L), фенилаланин (F) и лейцин (L), может быть заменен одним или большим количеством гидрофобных остатков;
На Фигуре 7 проиллюстрировано высвобождение НФГМ из клеток HEK293 с применением специфического анализа ELISA через 24 часа после трансдукции плазмидой (4 мкг ДНК/лунка), содержащей гены, кодирующие зрНФГМ с различными сигнальными пептидными последовательностями, и без кодирующей последовательности для удлиненного компонента проНФГМ (данные приведены как среднее ± СОС для n = 4);
На Фигуре 8 проиллюстрированы результаты вестерн-блоттинга клеточных концентраций НФГМ-иммунореактивного материала (условные единицы) в лизатах клеток HEK293 через 24 часа после трансдукции плазмидой (данные приведены как среднее ± СОС для n = 4);
На Фигуре 9 проиллюстрирована НФГМ-иммунореактивность в вестерн-блотах клеточных лизатов, демонстрирующих две полосы молекулярного веса (32 кДа и 14 кДа) при трансдукции клеток с применением плазмиды QTA001PA, по сравнению с только одной полосой 14 кДа при трансдукции с применением плазмид QTA002P, QTA003P и QTA004P;
На Фигуре 10 проиллюстрированы концентрации проНФГМ в инкубационной среде HEK293, измеренные с помощью специфического анализа ELISA через 24 часа после плазмидной трансдукции с применением селективного проНФГМ ELISA (данные приведены как среднее ± СОС для n = 4);
На Фигуре 11 проиллюстрирована экспрессия НФГМ в клеточном лизате HEK293 плазмидами QTA002P (эндогенная последовательность канонического сигнального пептида) и QTA009P до QTA013P. Данные приведены как среднее значение + СОС. ** р < 0,01 по сравнению с QTA002P;
На Фигуре 12 проиллюстрирована экспрессия НФГМ в среде инкубации клеток HEK293 плазмидами QTA002P (эндогенная последовательность канонического сигнального пептида) и QTA009P до QTA013P. Данные приведены как среднее значение + СОС. ** р < 0,01 по сравнению с QTA002P;
На Фигуре 13 проиллюстрированы результаты вестерн-блоттинга клеток HEK293 через 24 часа после их трансдукции плазмидами: QTA015P (экспрессирующей НФГМ и eGFP, разделенные спейсером IRES), QTA021P (экспрессирующей НФГМ с последующим eGFP, разделенные функциональной вирусной 2A- пептидной последовательностью), QTA022P (экспрессирующей НФГМ с последующим eGFP, разделенные нефункциональной вирусной 2A- пептидной последовательностью) и QTA023P (экспрессирующей eGFP с последующим кодированием НФГМ, разделенные функциональной вирусной 2A- пептидной последовательностью). Данные иллюстрируют НФГМ-иммунореактивность (A), eGFP-иммунореактивность (B) и количество НФГМ, высвобождаемое из клеток HEK293, в инкубационную среду (C). Данные приведены как среднее значение + СОС плотности в полосах;
На Фигуре 14A проиллюстрированы результаты вестерн-блоттинга гомогенатов клеток HEK293 через 48 часов после трансфекции вектором QTA020V, которые демонстрируют эффективный процессинг области кодирования большого предшественника, который включает рецептор TrkB и НФГМ, разделенные вирусной 2A-пептидной последовательностью. На Фигуре 14B и 14C проиллюстрировано, что трансгенные белки, полученные в результате расщепления вирусной 2A-пептидной последовательностью, транспортировались в надлежащие внутриклеточные отделы в клетках HEK293 после процессинга (рецепторы TrkB - на поверхности клеток, а НФГМ - к накопительным везикулам перед высвобождением);
На Фигуре 15A проиллюстрирована экспрессия рецептора TrkB, а на Фигуре 15B проиллюстрирована экспрессия НФГМ в гомогенате сетчатки мыши при применении вектора rAAV2, QTA020V. Данные приведены как среднее значение + СОС плотности в анализе вестерн-блоттинга гомогенатов сетчатки мыши. ** р < 0,01 по сравнению с неполучавшими лечения (животные, не получавшие инъекций);
На Фигуре 16 проиллюстрирована экспрессия трансгенов TrkB (A) и НФГМ (B) в слое ганглиозных клеток сетчатки мыши, как продемонстрировано при иммуноцитохимическом анализе после инъекции QTA020V, вектора rAAV2, содержащего кодирование рецептора TrkB и НФГМ, разделенных вирусной 2A-пептидной последовательностью; а также
На Фигуре 17 проиллюстрирована выживаемость ганглиозных клеток сетчатки (ГКС) после размозжения зрительного нерва (РЗН) у мышей по сравнению с контрольными животными, получавшими вектор rAAV2-CAG-eGFP. Данные приведенные как средние + СОС для среднего числа ганглиозных клеток сетчатки по всей сетчатке на животное, что подсчитывали с помощью количества Brn3A-положительных клеток в препаратах сетчатки на плоских предметных стеклах. *** р < 0,001, * р < 0,05 по сравнению с контролями.
Примеры
Методы и материалы
Молекулярные клонирующие и плазмидные конструкции
Оптимизацию кодонов последовательностей ДНК проводили с помощью он-лайн инструмента (http://www.idtdna.com/CodonOpt), а блоки ДНК были синтезированы компанией Integrated DNA technologies, Inc. (IDT; 9180 N. McCormick Boulevard, Скоки, штат Иллинойс 60076-2920, США) или GenScript (860 Centennial Ave, Пискатавей, штат Нью-Джерси 08854, США). Клонирование для получения возможности влиять на основную плазмиду QTA001PA и последующие плазмиды проводили с помощью стандартных методов молекулярной биологии и клонирования.
Наработка и очиска плазмид
ДНК-плазмиды нарабатывали в количестве в SURE компетентных клетках (Agilent Technologies, № по каталогу 200238) в течение ночи с целью получения плазмиды 2,29 мкг/мкл после максимальной подготовительной очистки. Остальные плазмиды были наработаны до 500 мкг с качеством трансдукции, характеризующимся минимальным присутствием эндотоксина.
Культура HEK293 и клеточная трансдукция с плазмидной ДНК
Клетки HEK293 (400000 клеток) культивировали в покрытых поли-L-лизином (10 мкг/мл, Sigma-Aldrich, № по каталогу P1274) 6-луночных планшетах в 1,5 мл минимально обогащённой среды Дульбекко (DMEM), содержащей 10% фетальной бычьей сыворотки (ФБС), 1% пенициллина и 1% стрептомицина (1% пен/стреп) до достижения 80% слияния. Затем среду меняли на 2 мл DMEM (без добавок). Через два-три часа в каждую лунку добавляли еще 0,5 мл трансфекционной среды, содержащей 4 мкг плазмидной ДНК плюс 10 мкл липофектамина (4 мкл/мл; Thermo Fisher Scientific; № по каталогу 12566014), в результате чего получали общий объем 2,5 мл в течение всего периода трансфекции и сбора супернатантов.
Измерение НФГМ с помощью ELISA
Количество НФГМ, секретирумое из клеток HEK293, измеряли в клеточной культуральной среде через 24 часа после трансфекции. Среду центрифугировали, удаляли дебри и измеряли Количество НФГМ с помощью коммерческого набора Human BDNF ELISA (Sigma-Aldrich, продукт № RAB0026). Концентрацию НФГМ определяли путем сравнения образцов с свежеприготовленными стандартами НФГМ.
Вестерн-блоттинг для НФГМ и рецепторов TrkB
Количество НФГМ и TrkB-иммунореактивность в клетках HEK293 измеряли путем удаления среды инкубации DMEM, промывания клеток в холодном забуференном фосфатом солевом растворе и добавления 350 мкл свежеприготовленного буфера для лизиса в лунки (10 мл реагента Лизис-M + 1 таблетка мини смеси ингибиторов протеаз, Roche, № по каталогу 04719964001, + 100 мкл смеси ингибиторов фосфатаз Halt (100X), Thermo Scientific; № по каталогу 78428). После гомогенизации клеток суспензию белка определяли количественно с помощью анализа BCA (набор для анализа белка Pierce BCA, Thermo Scientific; № по каталогу 23227). Белок/дорожку лизата клеток HEK293 от 6 мкг до 15 мкг пропускали через гель Бис-Трис (12% NuPAGE Novex; # NP0342BOX, Thermo Scientific) и исследовали с помощью вестерн-блоттинга с применением первичных кроличьих поликлональных антител анти-НФГМ (Santa Cruz Biotechnology Inc, продукт № sc-546, в разведении 1:500), кроличьих поликлональных антител анти-TrkB (Abcam; № по каталогу ab33655, применяемых в разведении 1:2000) или антител к eGFP (Abcam; продукт № ab-290, применяемых в разведении 1:500), которые инкубировали в течение ночи. Первичные антитела визуализировали с помощью HRP-конъюгированных антикроличьих антител (Vector Laboratories, № по каталогу # PI-1000, 1:8000), а обнаружение сигнала осуществляли с применением ECL Prime (Amersham, GE Healthcare, Великобритания) и системы визуализации Alliance Western blot (UVItec Ltd, Кембридж, Великобритания). Для вестерн-блоттов сетчатки мышы, глаза животных, получавших вектор, гомогенизировали в 500 мкл свежеприготовленного буфера для лизиса (10 мл реагента Лизис-M + 1 таблетка полной мини смеси ингибиторов протеаз, Roche, № по каталогу 0471996400, + 100 мкл смеси ингибиторов фосфатаз Halt (100X), Thermo Scientific, продукт № 78428). Ткань разрушали в течение 1 минуты (Qiagen, TissueRuptor, продукт № 9001273), а затем оставляли на льду еще на 15 минут. Затем белок анализировали с помощью вестерн-блоттинга, как описано выше.
Иммуноцитохимия
Клетки HEK293 (70 000) высевали на покрытые поли-L-лизином покровные стекла 13 мм в 4-луночных планшетах и инкубировали в DMEM, содержащей 10% ФБС и 1% пен/стреп в среде 0,5 мл. После достижения 80% слияния в результате роста клеток, среду заменяли на 0,4 мл DMEM (без добавок) в течение 2-3 часов, затем добавляли дополнительные 0,1 мкл трансфекционной среды (0,8 мкг плазмидной ДНК + 2 мкл липофектамина), в результате чего получали конечный объем 0,5 мл. Покровные стекла дважды промывали в ФСБ и фиксировали в течение 30 мин в 4% параформальдегиде в 1М забуференном фосфатом солевом растворе (ФСБ) при комнатной температуре. После еще трех промываний в ФСБ клетки блокировали и пермеабилизировали путем инкубации в 5% нормальной сыворотке козла (НСК), 3% бычьем сывороточном альбумине (БСА) и 0,3% Тритоне X-100 в ФСБ в течение 60 минут при комнатной температуре. Затем клетки инкубировали в течение ночи при 4°C с коммерческими кроличьими поликлональными антителами для НФГМ (Santa Cruz Biotechnology Inc, № продукта sc-546, в разведении 1:300) или TrkB (Abcam; продукт № ab33655, в разведении 1:500), разбавленными в блокирующем растворе. Окрашивание обнаруживали с применением вторичных антикроличьих антител, конъюгированных с флуоресцирующим агентом alexa 647 (Invitrogen, продукт № A21248, в разведении 1:1000) в течение 2 часов при комнатной температуре. Ядра клеток также контрастно окрашивали с применением 1 мкг/мл DAPI (Thermo Scientific, продукт № D1306, в разведении 1:8000). Клетки дополнительно промывали три раза, перед покрытием реагентом fluorSave ™ (Calbiochem/EMD Chemicals Inc., Гиббстаун, штат Нью-Джерси, США) перед визуализацией. Визуализацию выполняли с применением объектива 20X и эпифлуоресцентного микроскопа Leica DM6000 (Leica Microsystems, Ветцлар, Германия) или конфокального микроскопа Leica SP5 (Leica Microsystems, Ветцлар, Германия), оснащенного масляно-иммерсионным объективом 63X, с применением цифрового увеличения 3X и интервалом z-шага последовательного сканирования, составляющим 0,5-0,8.
Для проведения ммуноцитохимического анализа структуры сетчатки тщательно иссеченных глаз от контрольных или получавших вектор животных фиксировали в 4% параформальдегиде/0,1% ФСБ (рН 7,4) в течение ночи и дегидратировали в 30% сахарозе/0,1% ФСБ при 4°C (24 часа). Затем глаза заливали в силиконовые формы, содержащие соединение с оптимальной температурой для резания (OCT) (Sakura Finetek, Зутервауде, Нидерланды) и замороживали на сухом льду. Срезы толщиной 13 мкм через дорзально-вентральную/верхне-нижнюю ось сетчатки собирали на superfrost и предметные стекла (VWR продукт № 631-0108), используя криостат Bright OTF 5000 (Bright Instruments, Хантингтон, Великобритания). Предметные стекла промывали три раза в ФСБ и пермеабилизировали в 5% нормальной сыворотке козла (НСК), 3% бычьем сывороточном альбумине (БСА) и 0,3% Тритоне X-100 в ФСБ в течение 60 минут при комнатной температуре. Предметные стекла затем инкубировали в течение ночи при 4°C с коммерческими кроличьими поликлональными антителами для НФГМ (Santa Cruz Biotechnology, продукт Inc № sc-546 1:300) или TrkB (Abcam, продукт № ab33655 1: 500), разбавленными в блокирующем растворе. Окрашивание обнаруживали с применением вторичных антикроличьих антител, конъюгированных с флуоресцирующим агентом alexa 647 (Invitrogen, продукт № A21248, в разведении 1:1000) в течение 2 часов при комнатной температуре. Ядра клеток сетчатки также контрастно окрашивали с применением 1 мкг/мл DAPI (Thermo Scientific, продукт № D1306, в разведении 1:8000) Предметные стекла дополнительно промывали три раза, прежде чем соединять с реагентом fluorSave™ (Calbiochem/EMD Chemicals Inc., Гиббстаун, штат Нью-Джерси, США) перед визуализацией. Визуализацию выполняли с применением объектива 20X и эпифлуоресцентного микроскопа Leica DM6000 (Leica Microsystems, Ветцлар, Германия) или конфокального микроскопа Leica SP5 (Leica Microsystems, Ветцлар, Германия), оснащенного масляно-иммерсионным объективом 63X, с применением цифрового увеличения 3X и интервалом z-шага последовательного сканирования, составляющим 0,5-0,8.
Интравитреальные инъекции
После 7-10-дневного периода акклиматизации мышей рандомизировали в различные группы исследования. Затем их анестезировали с помощью внутрибрюшинной инъекции кетамина (50 мг/кг) и ксилазина (5 г/кг). Глазные капли с 1% тетракаином для местного применения вводили в День 1 исследования. Расширение зрачка достигали с помощью глазных капель с 1% тропикамидом. Под контролем операционного микроскопа, с помощью иглы 30 калибра и тонкой металлической микропипетки с диаметром наконечника 30 мкм и длиной наконечника 2,5 мм, для облегчения проникновения подлежащей склеры, сосудистой оболочки и сетчатки выполняли направляющее отверстие в склере, затрагивающее не все слои. Микропипетку затем соединяли со стеклянным шприцем емкостью 10 мкл (Hamilton Co., Рино, штат Невада), предварительно внося в пипетку 2 мкл векторных суспензий в зависимости от группы. Процедуру проводили с осторожностью во избежание пенетрации хрусталика или повреждения вортикозных вен при интравитреальной инъекции. Участок инъекции определялся примерно на 3 мм кзади к суперо-темпоральному лимбу. Инъекции проводили медленно в течение 1 минуты с целью обеспечения диффузии суспензии вектора. Правый глаз оставляли интактным и служил внутренним контралатеральным контролем.
Размозжение зрительного нерва (РЗН)
Через три недели (21 день) после введения вектора, мышей подвергали процедуре РЗН, оставляли без лечения или осуществляли имитацию размозжения. Под бинокулярным операционным микроскопом с помощью глазных пружинных ножниц делали небольшой разрез в конъюнктиве, начиная с передней поверхности глазного яблока и вокруг глаза темпорально. Посредством этого обнажалась задняя поверхность глазного яблока, что позволяло визуализировать зрительный нерв. Обнаженный зрительный нерв зажимали на расстоянии около 1-3 мм от глазного яблока с помощью крестообразных щипцов (Dumont # N7 № по каталогу RS-5027; Roboz) в течение 10 с, надавливая на нерв с воздействием лишь давления, получаемого от самозажимного действия. Через 10 с зрительный нерв высвобождали, щипцы извлекали, а глаз возвращали на место. Через 7 дней после РЗН животных отбраковывали. Оба глаза из каждой группы фиксировали, помещая орган в 4% параформальдегид/0,1% ФСБ (pH 7,4) на ночь. Затем, после рассечения задней структуры глаза от роговицы, готовили препараты сетчатки на плоских предметных стеклах, и удаляли хрусталик. Препараты сетчатки на плоских предметных стеклах постфиксировали в течение 30 минут в 4% параформальдегиде/0,1% ФСБ и промывали 0,5% Тритоном X-100 в ФСБ. Препараты сетчатки замораживали при -80°C в течение 10 минут, чтобы антитела просочились и лучше проникали через ядерную мембрану перед блокированием в 10% нормальной ослиной сыворотке (НОС), 2% бычьем сывороточном альбумине (БСА) и 2% Тритоне X-100 в ФСБ в течение 60 минут при комнатной температуре. RGCs контрастно окрашивали антителами против Brn3A (1: 200 Santa Cruz, № sc-31984) и визуализировали с помощью флуоресцентной микроскопиий с использованием объектива 20X и эпифлуоресцентного микроскопа Leica DM6000 (Leica Microsystems, Ветцлар, Германия). Изображения с более высоким разрешением были получены с помощью конфокального микроскопа Leica SP5 (Leica Microsystems), оснащенного масляно-иммерсионным объективом 40X, с применением цифрового увеличения 1,5X и интервалом z-шага последовательного сканирования, составляющим 0,5-0,8. Количество клеток ГКС измеряли с помощью плагина ImageJ, являющегося инструментом, основанным на анализе изображений, для подсчета количества ядер (ITCN) и выражали как плотность ГКС/мм2.
Конструкции и векторы
Авторы создали генетическую конструкцию, как проиллюстрировано на Фигуре 1, которую можно применять для лечения субъекта, имеющего патологию зрительного нерва, такую как глаукома, или кохлеарную патологию, или для стимулирования регенерации и/или выживания нервов. Конструкция была разработана для поддержания или увеличения плотности рецепторов TrkB на поверхности клеток ГКС и поддержания или увеличения передачи сигналов по TrkB-рецепторному пути посредством совместной продукции и локального высвобождения зрНФГМ.
Конструкция содержит трансгены, кодирующие рецептор TrkB и его агонист, зрелый нейротрофический фактор головного мозга. Эти трансгены функционально присоединённы к одному промотору, который является либо промотором синапсина I (SYN I) человека, либо промотором CAG. Выгодным является то, что конструкцию по Фигуре 1 можно поместить в вектор rAAV2 без затруднений из-за размера трансгенов, которые он кодирует. Это связано с тем, что конструкция ориентирована так, что первый трансген, TrkB, связан с вирусной 2A-пептидной последовательностью, за которой следует сигнальный пептид НФГМ, а затем зрелый белок. Эта ориентация также минимизирует риски иммуногенности, поскольку короткая N-концевая аминокислотная последовательность вирусного 2A-пептида остается присоединенной к внутриклеточной части рецептора TrkB, а остаточная аминокислота пролин из C-концевой вирусной 2A-последовательности остается присоединенной к N-концевому сигнальному пептиду НФГМ и в конечном счете удаляется из белка зрНФГМ после расщепления. Вектор может быть помещен в фармакологически приемлемый буферный раствор, который можно вводить субъекту.
На Фигурах 2-5 проиллюстрированы различные варианты осуществления экспрессионных векторов. На Фигуре 2 проиллюстрирован вектор, известный как "плазмида QTA001PA", содержащий каноническую сигнальную последовательность (синий) (т.е. MTILFLTMVISYFGCMKA [SEQ ID NO:20]) плюс проНФГМ (красный) и зрНФГМ (черный). На Фигуре 3 проиллюстрирован вектор, известный как "плазмида QTA002P". Он не кодирует проНФГМ, а продуцирует только зрНФГМ и кодирует одну и ту же сигнальную последовательность (синий), что и QTA001PA. На Фигуре 4 проиллюстрирован вектор, известный как "плазмида QTA003P", который также не кодирует проНФГМ, а продуцирует только зрНФГМ. Вместо канонической сигнальной последовательности для зрНФГМ он содержит сигнальную последовательность ИЛ-2 (синий). Наконец, на Фигуре 5 проиллюстрирован вектор, известный как "плазмида QTA004P". Он не кодирует проНФГМ, но вместо этого продуцирует только зрНФГМ. Он также кодирует новую сигнальную последовательность (синий), [SEQ ID NO: 32],
Авторы изобрели и исследовали конструкцию и вектор, относящиеся к концепции генной терапии глаукомы, начиная со зрелого элемента НФГМ (зрНФГМ). Они ясно продемонстрировали продукцию и высвобождение зрНФГМ из клеток HEK293 после липофектаминовой трансдукции плазмидой, которая содержит последовательность НФГМ без кодирующей области проНФГМ (QTA002P, см. Фигуру 3) (см. Фигуру 7). зрНФГМ, высвобождаемый из клеток, представляет собой моделированный мономер 14 кДа (что измерено с помощью Вестерн-блоттинга и коммерчески доступного антитела для НФГМ), не характеризующийся какими-либо признаками образования белковых агрегатов, о чем сообщалось несколькими группами, пытающимися генерировать коммерческие количества зрНФГМ с применением дрожжей и используя другие производственные подходы на основе клеток . Поэтому зрНФГМ высвобождается в форме, которая позволяет молекулам белка образовывать нековалентные димеры для активации рецепторов TrkB.
С помощью анализа ELISA для НФГМ (который не проводит диференциации между зрНФГМ и большим удлиненным белком проНФГМ), авторы также продемонстрировали, что можно заменить ДНК-последовательность, кодирующую каноническую последовательность эндогенного сигнального пептида из 18 аминокислот (MTILFLTMVISYFGCMKA) с помощью новой последовательности пептидов (QTA004P - см. Фигуру 5), и высвободить эквивалентные уровни НФГМ в инкубационную среду HEK293 после липофектаминовой трансдукции клеток плазмидами, содержащими ген НФГМ (см. Фигуру 7).
Замена эндогенного сигнального пептида последовательностью, кодирующей сигнальный пептид интерлейкина-2 (QTA003P - см. Фигуру 4), была менее эффективной для высвобождения НФГМ из среды. Уровни НФГМ, высвобождаемого в среду, в настоящее время составляют около 1-2 нМ, при этом концентрации этого агониста являются достаточными, чтобы максимально активировать специфические рецепторы TrkB (IC50 около 0,9 нМ). Уровни высвобождения НФГМ приблизительно в 35 раз выше (876 ± 87 нг/мл НФГМ) при применении плазмиды QTA001PA (см. Фигуру 2), которая содержит комбинированные последовательности проНФГМ и зрНФГМ, и которая также включает канонический сигнальный пептид с 18 аминокислотами по сравнению с применением плазмиды QTA002P (см. Фигуру 3) и QTA004P (см. Фигуру 5).
Измерения оставшегося в клетке НФГМ путем количественного вестерн-блоттинга через 24 часа после липофектаминовой трансдукции плазмидой, показали более низкие концентрации НФГМ при применении QTA001PA, по сравнению с применением QTA002P и QTA004P (см. Фигуру 8).
Кроме того, около половины иммунореактивности НФГМ в лизатах клеток, трансдуцированных QTA001PA, определяли в форме проНФГМ (полоса молекулярной массы при 32 кДа), тогда как полоса проНФГМ отсутствовала в лизатах клеток, трансдуцированных QTA002P, QTA003P и QTA004P (см. Фигуру 9), вероятно, потому, что эти плазмиды не содержат удлиненную кодирующую последовательность проНФГМ.
С помощью анализа ELISA, специфичного для проНФГМ, авторы смогли продемонстрировать, что около 70 нг/мл (2,2 нМ или 3,5%) иммунореактивности высвобожденного НФГМ из клеток, трансдуцированных QTA001PA, определяется в форме проНФГМ, тогда как большая часть (96,5% или 876 нг/мл / 63 нМ) высвобождается в форме зрНФГМ (см. Фигуру 10). Не обнаруживалась проНФГМ-иммунореактивность от клеток, трансдуцированных QTA002P, QTA003P или QTA004P, которые не содержат кодирующую последовательность для удлиненного проНФГМ.
Соответственно, является очевидным, что все плазмиды способны продуцировать белок зрНФГМ 14 кДа, но количество зрНФГМ, высвобождаемого из клеток HEK293, в значительной степени зависит от эффективности хранения и упаковки белка в секреторных везикулах. Поэтому удлиненная форма белка, содержащая комбинированные последовательности проНФГМ и зрНФГМ, продуцируемые плазмидой QTA001PA (Фигура 2), упаковывается в секреторные везикулы и высвобождается в среду инкубации гораздо эффективнее, чем форма белка с меньшими последовательностями зрНФГМ, которые, по-видимому, накапливаются внутри клетки.
Как проиллюстрировано на Фигуре 11, замещение кодирования последовательности эндогенного канонического сигнального пептида, представленной в плазмиде QTA002P, новыми последовательностями, включенными в плазмиды QTA009P-QTA013P, увеличивает концентрацию НФГМ в клетках HEK293 через 24 часа после трансдукции плазмидами. На Фигуре 12 продемонстрировано, что замещение последовательности, кодирующей эндогенный канонический сигнальный пептид и включенной в плазмиду QTA002P, новыми последовательностями (плазмиды QTA009P-QTA013P), увеличивает высвобождение НФГМ (измеряемого с помощью ELISA) из клеток HEK293, которое измеряли через 24 часа после трансдукции плазмидами.
Как проиллюстрировано на Фигуре 13, добавление вирусной 2А-пептидной последовательности приводит к эффективного процессинга кодирующей последовательности для большого белка-предшественника в два трансгена, eGFP и НФГМ. Результаты вестерн-блоттинга демонстрируют клетки HEK293 через 24 часа после их трансдукции плазмидами: (i) QTA015P (экспрессирующей НФГМ и eGFP, разделенные спейсером IRES), (ii) QTA021P (экспрессирующей НФГМ с последующим eGFP, разделенные функциональной вирусной 2A-пептидной последовательностью), (iii) QTA022P (экспрессирующей НФГМ с последующим eGFP, разделенные нефункциональной вирусной 2A- пептидной последовательностью) и (iv) QTA023P (экспрессирующей eGFP с последующим кодированием НФГМ, разделенные функциональной вирусной 2A- пептидной последовательностью).
Кодирующая последовательность плазмиды QTA021P (плазмида, содержащая кодон-оптимизированную последовательность для зрНФГМ-вирусного-2A- пептидного-eGFP) упоминается в данном документе как SEQ ID No: 104 и выглядит следующим образом:
ATGACTATCCTGTTTCTGACAATGGTTATTAGCTATTTCGGTTGCATGAAGGCTCACAGTGATCCCGCACGCCGCGGAGAACTTAGCGTGTGCGACAGCATCAGCGAGTGGGTCACCGCCGCCGATAAGAAGACCGCTGTGGATATGTCCGGCGGGACCGTCACTGTACTCGAAAAAGTTCCAGTGAGCAAAGGCCAACTGAAACAATATTTCTATGAAACTAAGTGCAACCCCATGGGGTACACCAAGGAGGGCTGCCGGGGAATCGACAAGAGACACTGGAATTCCCAGTGCCGGACCACTCAGAGCTACGTCCGCGCCTTGACGATGGATTCAAAGAAGCGCATCGGATGGCGGTTCATAAGAATCGACACCAGTTGTGTGTGCACGCTGACGATAAAACGGGGGCGGGCCCCCGTGAAGCAGACCCTGAACTTTGATTTGCTCAAGTTGGCGGGGGATGTGGAAAGCAATCCCGGGCCAATGGTGAGCAAGGGCGAGGAGCTGTTCACCGGCGTTGTGCCAATACTGGTTGAGTTGGATGGCGATGTCAACGGACACAAATTTAGCGTAAGCGGGGAGGGAGAGGGCGACGCCACATATGGCAAGCTGACCCTGAAGTTCATTTGCACGACCGGCAAATTGCCCGTCCCTTGGCCCACACTTGTGACGACCCTGACTTATGGCGTACAGTGCTTCAGCAGGTACCCTGATCATATGAAGCAACACGACTTCTTTAAGAGTGCCATGCCAGAGGGATACGTCCAGGAAAGAACCATATTCTTCAAAGATGATGGAAATTACAAAACCCGGGCAGAGGTCAAGTTTGAAGGCGACACCCTGGTGAACAGGATCGAACTCAAAGGCATCGATTTCAAAGAGGACGGAAACATCCTCGGACACAAACTGGAATACAATTACAACAGCCACAACGTCTACATCATGGCAGATAAACAAAAGAACGGTATTAAAGTGAACTTCAAGATCCGGCACAACATCGAAGACGGCTCCGTCCAGCTTGCCGACCACTACCAGCAAAATACCCCGATCGGCGACGGCCCCGTTCTCCTCCCCGATAATCACTACCTGAGTACACAGTCAGCCTTGAGCAAAGACCCTAATGAAAAGCGGGACCACATGGTTTTGCTGGAGTTCGTTACCGCAGCGGGTATTACGCTGGGTATGGACGAGCTTTACAAGTAA [SEQ ID No: 104]
Кодирующая последовательность плазмиды QTA022P (плазмида, содержащая кодон-оптимизированную последовательность для зрНФГМ-не функционального вирусного-2A-пептидного-eGFP) упоминается в данном документе как SEQ ID No: 105 и выглядит следующим образом:
ATGACTATCCTGTTTCTGACAATGGTTATTAGCTATTTCGGTTGCATGAAGGCTCACAGTGATCCCGCACGCCGCGGAGAACTTAGCGTGTGCGACAGCATCAGCGAGTGGGTCACCGCCGCCGATAAGAAGACCGCTGTGGATATGTCCGGCGGGACCGTCACTGTACTCGAAAAAGTTCCAGTGAGCAAAGGCCAACTGAAACAATATTTCTATGAAACTAAGTGCAACCCCATGGGGTACACCAAGGAGGGCTGCCGGGGAATCGACAAGAGACACTGGAATTCCCAGTGCCGGACCACTCAGAGCTACGTCCGCGCCTTGACGATGGATTCAAAGAAGCGCATCGGATGGCGGTTCATAAGAATCGACACCAGTTGTGTGTGCACGCTGACGATAAAACGGGGGCGGGCCCCTGTCAAACAAACCCTCAATTTTGACTTGCTGAAGCTTGCTGGGGATGTCGAGTCCGCTGCCGCGGCTATGGTGAGCAAGGGCGAGGAGCTGTTCACCGGCGTTGTGCCAATACTGGTTGAGTTGGATGGCGATGTCAACGGACACAAATTTAGCGTAAGCGGGGAGGGAGAGGGCGACGCCACATATGGCAAGCTGACCCTGAAGTTCATTTGCACGACCGGCAAATTGCCCGTCCCTTGGCCCACACTTGTGACGACCCTGACTTATGGCGTACAGTGCTTCAGCAGGTACCCTGATCATATGAAGCAACACGACTTCTTTAAGAGTGCCATGCCAGAGGGATACGTCCAGGAAAGAACCATATTCTTCAAAGATGATGGAAATTACAAAACCCGGGCAGAGGTCAAGTTTGAAGGCGACACCCTGGTGAACAGGATCGAACTCAAAGGCATCGATTTCAAAGAGGACGGAAACATCCTCGGACACAAACTGGAATACAATTACAACAGCCACAACGTCTACATCATGGCAGATAAACAAAAGAACGGTATTAAAGTGAACTTCAAGATCCGGCACAACATCGAAGACGGCTCCGTCCAGCTTGCCGACCACTACCAGCAAAATACCCCGATCGGCGACGGCCCCGTTCTCCTCCCCGATAATCACTACCTGAGTACACAGTCAGCCTTGAGCAAAGACCCTAATGAAAAGCGGGACCACATGGTTTTGCTGGAGTTCGTTACCGCAGCGGGTATTACGCTGGGTATGGACGAGCTTTACAAGTAA [SEQ ID No: 105]
Кодирующая последовательность плазмиды QTA023P (плазмида, содержащая кодон-оптимизированную последовательность для eGFP-вирусного-2A- пептидного-зрНФГМ) упоминается в данном документе как SEQ ID No: 106 и выглядит следующим образом:
ATGGTGAGCAAGGGCGAGGAGCTGTTCACCGGGGTGGTGCCCATCCTGGTCGAGCTGGACGGCGACGTAAACGGCCACAAGTTCAGCGTGTCCGGCGAGGGCGAGGGCGATGCCACCTACGGCAAGCTGACCCTGAAGTTCATCTGCACCACCGGCAAGCTGCCCGTGCCCTGGCCCACCCTCGTGACCACCCTGACCTACGGCGTGCAGTGCTTCAGCCGCTACCCCGACCACATGAAGCAGCACGACTTCTTCAAGTCCGCCATGCCCGAAGGCTACGTCCAGGAGCGCACCATCTTCTTCAAGGACGACGGCAACTACAAGACCCGCGCCGAGGTGAAGTTCGAGGGCGACACCCTGGTGAACCGCATCGAGCTGAAGGGCATCGACTTCAAGGAGGACGGCAACATCCTGGGGCACAAGCTGGAGTACAACTACAACAGCCACAACGTCTATATCATGGCCGACAAGCAGAAGAACGGCATCAAGGTGAACTTCAAGATCCGCCACAACATCGAGGACGGCAGCGTGCAGCTCGCCGACCACTACCAGCAGAACACCCCCATCGGCGACGGCCCCGTGCTGCTGCCCGACAACCACTACCTGAGCACCCAGTCCGCCCTGAGCAAGGACCCCAACGAGAAGCGCGATCACATGGTCCTGCTGGAGTTCGTGACCGCCGCCGGGATCACTCTCGGCATGGACGAGCTGTACAAGGCTCCCGTTAAACAAACTCTGAACTTCGACCTGCTGAAGCTGGCTGGAGACGTGGAGTCCAACCCTGGACCTATGACCATCCTTTTCCTTACTATGGTTATTTCATACTTCGGTTGCATGAAGGCGCACTCCGACCCTGCCCGCCGTGGGGAGCTGAGCGTGTGTGACAGTATTAGCGAGTGGGTCACAGCGGCAGATAAAAAGACTGCAGTGGACATGTCTGGCGGGACGGTCACAGTCCTAGAGAAAGTCCCGGTATCCAAAGGCCAACTGAAGCAGTATTTCTACGAGACCAAGTGTAATCCCATGGGTTACACCAAGGAAGGCTGCAGGGGCATAGACAAAAGGCACTGGAACTCGCAATGCCGAACTACCCAATCGTATGTTCGGGCCCTTACTATGGATAGCAAAAAGAGAATTGGCTGGCGATTCATAAGGATAGACACTTCCTGTGTATGTACACTGACCATTAAAAGGGGAAGATAG [SEQ ID No: 106]
На Фигуре 14А продемонстрирован вестерн-блоттинг гомогенатов клеток HEK293 через 48 часов после трансфекции вектором QTA020V. Результаты анализа показывают эффективный процессинг области кодирования большого предшественника, который включает рецептор TrkB и НФГМ, разделенные вирусной 2A-пептидной последовательностью. Два TrkB и зрНФГМ-иммунореактивные трансгены находятся в пределах моделируемых надлежащих значений молекулярных масс. Следует отметить отсутствие окрашивания большого белка-предшественника над полосой рецептора TrkB, что указывает на почти полный или полный процессинг белка-предшественника в пяти повторах. На Фигуре 14B и 14C проиллюстрировано, что трансгенные белки, полученные в результате расщепления вирусной 2A-пептидной последовательностью, транспортировались в надлежащие внутриклеточные отделы в клетках HEK293 после процессинга (рецепторы TrkB - на поверхности клеток, а НФГМ - к накопительным везикулам перед высвобождением).
На Фигуре 15 проиллюстрировано, что добавление вирусной 2А-пептидной последовательности, разделяющей две кодирующие области для рецептора TrkB и НФГМ, приводит к эффективному процессингу в двух трансгенах сетчатки мыши после интравитреальной инъекции вектора rAAV2, QTA020V.
На Фигуре 16 проиллюстрирована экспрессия трансгенов TrkB (A) и НФГМ (B) в слое ганглиозных клеток сетчатки мыши, как продемонстрировано при иммуноцитохимическом анализе после инъекции QTA020V, вектора rAAV2, содержащего кодирование рецептора TrkB и НФГМ, разделенных вирусной 2A-пептидной последовательностью. Тела целевых ганглиозных клеток сетчатки окрашивали красным с применением антител анти-rn3A, а ядра клеток контрастно окрашивали синим с применением DAPI, чтобы отличить слои сетчатки.
На Фигуре 17 продемонстрировано, что предварительное воздействие QTA020V (содержащей кодирование TrkB-рецептора и НФГМ, разделенных вирусной 2A-пептидной последовательностью) посредством интравитреальной инъекции (2 мкл 9x1012 векторных частиц/мл) обладает значительной нейропротекторной эффективностью относительно выживаемости ганглиозных леток сетчатки после размозжения зрительного нерва у мышей по сравнению с контрольными животными, получающими вектор rAAV2-CAG-eGFP. Уровень нейропротекции, наблюдаемый при применении вектора QTA020V также был выше уровня, обеспечиваемого вектором, экспрессирующим только НФГМ. Все три группы животных подвергались процедуре размозжения зрительного нерва, а количество ганглиозных клеток сетчатки измеряли через 7 дней после повреждения. Количество ганглиозных клеток сетчатки уменьшалось на 71% в контроле (черные полосы) по сравнению с животными, которым проводили имитацию размозжения (данные не приведены).
Литература
1. Quigley HA, Number of people with glaucoma worldwide. Brit. J. Ophthalmol. 1996, vol. 80, PP: 389-393.
2. www.preventblindness.org
3. Goldberg I, Relationship between intraocular pressure and preservation of visual field in glaucoma. Surv. Ophthalmol. 2003 vol. 48 Suppl. 1, PP: S3-S7.
4. Glaucoma, Merck Manual of Diagnosis and Therapy, 1999, Merck Research Laboratories; Whitehouse Station, NJ, PP: 733-738.
5. Alward WL, Medical Management of Glaucoma. New Eng. J. Med., 1998; vol. 339, PP: 1298-1307
6. Coleman AL, Glaucoma. Lancet, 1999; vol. 354, PP: 1803-1810.
7. Medeiros FA, and Weinreb RN, Medical Backgrounders: glaucoma. Drugs of Today 2002, vol. 38, PP: 563-570.
8. Bakalash S, Kipnis J, Yoles E, and Schwartz M, Resistance of retinal ganglion cells to an increase in intraocular pressure is immune-dependent. Invest. Ophthalmol. Vis. Sci., 2002, vol. 43, PP: 2648-2653.
9. Kipnis J, Yoles E, Porat Z, Cohen A, Mor F, Sela M, Cohen IR, and Schwartz M, T cell immunity to copolymer 1 confers neuroprotection on the damaged optic nerve: Possible therapy for optic neuropathies. Proc. Natl. Acad. Sci. 2000, vol. 97, PP: 7446-7451.
10. Quigley HA, Nickells RW, Kerrigan LA, Pease ME, Thibault DJ, and Zack DJ, Retinal ganglion cell death in experimental glaucoma and after axotomy occurs by apoptosis. Invest. Ophthalmol. Vis. Sci. 1995 vol. 36, PP: 774-786.
11. Weinreb RN, and Levin LA, Is neuroprotection a viable therapy for glaucoma? Arch. Ophthalmol. 1999, vol. 117, PP: 1540-1544.
12. Chao MV. Neurotrophins and their receptors: A convergence point for many signalling pathways. Nature Rev. Neurosci. 2003, vol. 4, PP: 299-309.
13. Dawbarn D, and Allen SJ, Neurotrophins and neurodegeneration. Neuropathol. Appl. Neurobiol. 2003, vol.29, PP: 211-230.
14. Barde Y-A, Leibrock J, Lottspeich F, Edgar D, Yancopoulos G, and Thoenen H, Brain-derived neurotrophic factor 1993, US patent 05229500.
15. Mey J, and Thanos S, Intravitreal injections of neurotrophic factors support the survival of axotomized retinal ganglion cells in adult rats in vivo. Brain Res. 1993, 602: 304-317.
16. Mansour-Rabaey S, Clarke DB, Wang Y-C, Bray GM, and Aguayo AJ, Effects of ocular injury and administration of brain-derived neurotrophic factor on survival and regrowth of axotomized retinal ganglion cells. Proc. Natl. Acad. Sci. USA. 1994, vol. 91, PP: 1632-1636.
17. Peinado-Ramon P, Salvador M, Viϋegas-Perez MP, and Vidal-Sanz M, Effects of axotomy and intraocular administration of NT-4, NT-3 and brain-derived neurotrophic factor on the survival of adult rat retinal ganglion cells. A quantitative in vivo study. Invest Ophthalmol. Vis. Sci. 1996, vol. 37, PP: 489-500.
18. Di Polo A, Aigner LJ, Dunn RJ, Bray GM, and Aguayo AJ, Prolonged delivery of brain-derived neurotrophic factor by adenovirus- infected Mϋller cells temporarily rescues injured retinal ganglion cells. Proc. Natl. Acad. Sci. USA. 1998, vol. 95, PP: 3978-3983.
19. Klocker N, Kermer P, Weishaupt JH, Labes M, Ankerhold R, and Bähr M, Brain-derived neurotrophic factor-mediated neuroprotection of adult rat retinal ganglion cells in vivo does not exclusively depend on phosphatidyl-inositol-3'-kinase/protein kinase B signaling. J. Neurosci. 2000, vol. 20, PP: 6962-6967.
20. Ko ML, Hu DN, Ritch R, Sharma SC, and Chen CF, Patterns of retinal ganglion cell survival after brain-derived neurotrophic factor administration in hypertensive eyes of rats. Neurosci. Lett. 2001, vol. 305, PP: 139-142.
21. Chen H, and Weber AJ, BDNF enhances retinal ganglion cell survival in cats with optic nerve damage. Invest Opthamol. Vis. Sci. 2001, vol. 42, PP: 966-974.
22. Pόrez MTR, and Caminos E, Expression of brain-derived neurotrophic factor and its functional receptor in neonatal and adult rat retina. Neυrosci. Lett. 1995, vol. 183, PP: 96-99.
23. Vecino E, Ugarte M, Nash MS, and Osborne NN. NMDA induces BDNF expression in the albino rat retina in vivo. Neuroreport. 1999 vol.10, PP: 1103-1106.
24. Mowla SJ, Farhadi HF, Pareek S, Atwal JK, Morris SJ, Seidah NG, and Murphy RA. Biosynthesis and post-translational processing of the precursor to brain-derived neurotrophic factor. J. Biol. Chem. 2001 vol 276, PP: 12660-12666.
25. Gupta VK, You Y, Gupta VB, Klistorner A, and Graham SL. TrkB receptor signalling: Implications in neurodegenerative, psychiatric and proliferative disorders. Int. J. Mol. Sci. 2013, vol.14, PP: 10122-10142
26. Teng,H.K., Teng,K.K., Lee,R., Wright,S., Tevar,S., Almeida,R.D., Kermani,P., Torkin,R., Chen,Z.Y., Lee,F.S., Kraemer,R.T., Nykjaer,A. and Hempstead,B.L. ProBDNF induces neuronal apoptosis via activation of a receptor complex of p75NTR and sortilin. J. Neurosci. 2005, vol. 25, PP: 5455-5463.
27. Wei Y, Zhang F, Zao J, Jiang X, Lu Q, Gao E and Wand N. Enhanced protein expression of proBDNF and proNGF in elevated intraocular pressure-induced rat retinal ischemia. Chin. Med. J. 2012, vol. 125, PP: 3875-3879.
28. Woo NH, Teng HK, Siao C-J, Chiaruttini C, Pang PT, Milner TA, Hempstead BL and Lu B. Activation of p75NTR by proBDNF facilitates hippocampal long-term depression. Nature Neurosci. 2005, vol 8, PP: 1069-1077.
29. Lebrun-Julien F, Bertrand MJ, De Backer O, Stellwagen D, Morales CR, Di Polo A, and Barker PA. ProNGF induces TNFalpha-dependent death of retinal ganglion cells through a p75NTR non-cell-autonomous signaling pathway. Proc. Natl. Acad. Sci. U S A. 2010 vol. 107, PP: 3817-3822.
30. Quigley HA, McKinnon SJ, Zack DJ, Pease ME, Kerrigan-Baumrind LA, Kerrigan DF, and Mitchell RS, Retrograde axonal transport of BDNF in retinal ganglion cells is blocked by acute IOP elevation in rats. Invest. Ophthalmol. Vis. Sci., 2000 vol. 41, PP: 3460–3466.
31. Pease ME McKinnon SJ, Quigley HA, Kerrigan-Baumrind LA, and Zack DJ, Obstructed axonal transport of BDNF and its receptor TRKB in experimental glaucoma. Invest. Ophthalmol. Vis. Sci. 2000, vol. 41, PP: 764-774.
32. Wei Y, Wang N, Lu Q, Zhang N, Zheng D, and Li J. Enhanced protein expressions of sortilin and p75NTR in retina of rat following elevated intraocular pressure-induced retinal ischemia. Neurosci. Lett. 2007, vol. 429, PP: 169-174.
33. Martin KRG, Quigley HA, Zack DJ, Levkovitch-Verbin H, Kielczewski J, Valenta D, Baumrind L, Pease ME, Klein RL, and Hauswirth WW, Gene therapy with brain-derived neurotrophic factor as a protection: Retinal ganglion cells in a rat glaucoma model. Invest. Ophthalmol. Vis. Sci., 2003, vol. 44, PP: 4357-4365.
34. Ren R, Li Y, Liu Z, Liu K, and He S, Long-term rescue of rat retinal ganglion cells and visual function by AAV-mediated BDNF expression after acute elevation of intraocular pressure. Invest. Ophthamol. Vis. Sci., 2012, vol. 53, PP: 1003-1011.
35. Cheng L, Sapieha P, Kittlerova P, Hauswirth WW, Di Polo A, TrkB gene transfer protects retinal ganglion cells from axotomy-induced death in vivo. J. Neurosci., 2002, vol. 22, PP: 3977-3986.
36. Bai Y, Xu J, Brahimi F, Zhuo Y, Sarunic MV, and Saragovi HU, An agonistic TrkB mAb causes sustained TrkB activation, delays RGC death, and protects the retinal structure in optic nerve axotomy and in glaucoma. Invest. Ophthalmol. Vis. Sci. 2012, vol. 51, PP: 4722-4731.
37. Jelsma TN, Hyman Friedman H, Berkelaar M, Bra. GM, and Aguayo AJ, Different forms of the neurotrophin receptor trkB mRNA predominate in rat retina and optic nerve. J. Neurobiol. 1993, vol. 24, PP: 1207-1214.
38. Gomes JR, Costa JT, Melo CV, Felizzi F, Monteiro P, Pinto MJ, Inácio AR, Wieloch T, Almeida RD, Grãos M, and Duarte CB, Excitotoxicity down regulates TrkB.Fl signaling and up regulates the neuroprotective truncated TrkB receptors in cultured hippocampal and striatal neurons J. Neurosci. 2012, vol. 32, PP: 4610-4622.
39. Gupta VK, You Y, Klistorner A, and Graham SL. Shp-2 regulates the TrkB receptor activity in the retinal ganglion cells under glaucomatous stress. Biochimica et Biophysica Acta 2012, vol. 1822, PP: 1643–1649.
40. Khalin I, Alyautdin R, Kocherga G, Bakar MA, Targeted delivery of brain-derived neurotrophic factor for the treatment of blindness and deafness. Int. J. Nanomedicine. 2015, vol. 10, PP: 3245–3267.
41. Budenz CL, Wong HT, Swiderski DL, Shibata SB, Pfingst BE, Raphael Y, Differential effects of AAV.BDNF and AAV.Ntf3 in the deafened adult guinea pig ear. Sci. Rep. 2015, vol. 5 PP: 8619.
42. Havenith S, Versnel H, Klis SF, Grolman W, Local delivery of brain-derived neurotrophic factor on the perforated round window membrane in Guinea pigs: a possible clinical application. Otol Neurotol. 2015, vol.36, PP:705-711.
43. Jian-Yi Zhang J-Y, Luo X-G, Xian CJ, Liu Z-H, Zhou X-F (2008) Endogenous BDNF is required for myelination and regeneration of injured sciatic nerve in rodents. Eur. J. Neurosci. Vol. 12, PP: 4171-4180.
44. Lindsey RM (1988) Nerve growth factors (NGF, BDNF) enhance axonal regeneration but are not required for survival of adult sensory neurons. J. Neurosci. vol. 8, PP: 2394-2405.
45. Martinez-Salas E. Internal ribosome entry site biology and its use in expression vectors. Curr. Opin. Biotechnol. 1999, vol. 10, PP: 458–464.
46. Harries M et al. Comparison of bicistronic retroviral vectors containing internal ribosome entry sites (IRES) using expression of human interleukin-12 (IL-12) as a readout. J. Gene Med. 200 vol. 2, PP: 243–249.
47. Furler S, Paterna J-C, Weibel M and Bueler H Recombinant AAV vectors containing the foot and mouth disease virus 2A sequence confer efficient bicistronic gene expression in cultured cells and rat substantia nigra neurons Gene Ther. 2001, vol. 8, PP: 864–873.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Quethera Limited
<120> ГЕНЕТИЧЕСКАЯ КОНСТРУКЦИЯ
<130> 77097PCT1
<160> 108
<170> PatentIn версия 3.5
<210> 1
<211> 469
<212> ДНК
<213> Homo sapiens
<220>
<221> Промотор
<223> Промотор синапсина I (SYN I) человека
<400> 1
ctgcagaggg ccctgcgtat gagtgcaagt gggttttagg accaggatga ggcggggtgg 60
gggtgcctac ctgacgaccg accccgaccc actggacaag cacccaaccc ccattcccca 120
aattgcgcat cccctatcag agagggggag gggaaacagg atgcggcgag gcgcgtgcgc 180
actgccagct tcagcaccgc ggacagtgcc ttcgcccccg cctggcggcg cgcgccaccg 240
ccgcctcagc actgaaggcg cgctgacgtc actcgccggt cccccgcaaa ctccccttcc 300
cggccacctt ggtcgcgtcc gcgccgccgc cggcccagcc ggaccgcacc acgcgaggcg 360
cgagataggg gggcacgggc gcgaccatct gcgctgcggc gccggcgact cagcgctgcc 420
tcagtctgcg gtgggcagcg gaggagtcgt gtcgtgcctg agagcgcag 469
<210> 2
<211> 1733
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Промотор
<223> Это промотор CAG, который включает следующие элементы:
(C) элемент раннего енхансера цитомегаловируса (CMV),
(A) промотор, первый экзон и первый интрон гена бета-актина цыплят,
<400> 2
ctcgacattg attattgact agttattaat agtaatcaat tacggggtca ttagttcata 60
gcccatatat ggagttccgc gttacataac ttacggtaaa tggcccgcct ggctgaccgc 120
ccaacgaccc ccgcccattg acgtcaataa tgacgtatgt tcccatagta acgccaatag 180
ggactttcca ttgacgtcaa tgggtggagt atttacggta aactgcccac ttggcagtac 240
atcaagtgta tcatatgcca agtacgcccc ctattgacgt caatgacggt aaatggcccg 300
cctggcatta tgcccagtac atgaccttat gggactttcc tacttggcag tacatctacg 360
tattagtcat cgctattacc atggtcgagg tgagccccac gttctgcttc actctcccca 420
tctccccccc ctccccaccc ccaattttgt atttatttat tttttaatta ttttgtgcag 480
cgatgggggc gggggggggg ggggggcgcg cgccaggcgg ggcggggcgg ggcgaggggc 540
ggggcggggc gaggcggaga ggtgcggcgg cagccaatca gagcggcgcg ctccgaaagt 600
ttccttttat ggcgaggcgg cggcggcggc ggccctataa aaagcgaagc gcgcggcggg 660
cgggagtcgc tgcgcgctgc cttcgccccg tgccccgctc cgccgccgcc tcgcgccgcc 720
cgccccggct ctgactgacc gcgttactcc cacaggtgag cgggcgggac ggcccttctc 780
ctccgggctg taattagcgc ttggtttaat gacggcttgt ttcttttctg tggctgcgtg 840
aaagccttga ggggctccgg gagggccctt tgtgcggggg gagcggctcg gggggtgcgt 900
gcgtgtgtgt gtgcgtgggg agcgccgcgt gcggctccgc gctgcccggc ggctgtgagc 960
gctgcgggcg cggcgcgggg ctttgtgcgc tccgcagtgt gcgcgagggg agcgcggccg 1020
ggggcggtgc cccgcggtgc ggggggggct gcgaggggaa caaaggctgc gtgcggggtg 1080
tgtgcgtggg ggggtgagca gggggtgtgg gcgcgtcggt cgggctgcaa ccccccctgc 1140
acccccctcc ccgagttgct gagcacggcc cggcttcggg tgcggggctc cgtacggggc 1200
gtggcgcggg gctcgccgtg ccgggcgggg ggtggcggca ggtgggggtg ccgggcgggg 1260
cggggccgcc tcgggccggg gagggctcgg gggaggggcg cggcggcccc cggagcgccg 1320
gcggctgtcg aggcgcggcg agccgcagcc attgcctttt atggtaatcg tgcgagaggg 1380
cgcagggact tcctttgtcc caaatctgtg cggagccgaa atctgggagg cgccgccgca 1440
ccccctctag cgggcgcggg gcgaagcggt gcggcgccgg caggaaggaa atgggcgggg 1500
agggccttcg tgcgtcgccg cgccgccgtc cccttctccc tctccagcct cggggctgtc 1560
cgcgggggga cggctgcctt cgggggggac ggggcagggc ggggttcggc ttctggcgtg 1620
tgaccggcgg ctctagagcc tctgctaacc atgttcatgc cttcttcttt ttcctacagc 1680
tcctgggcaa cgtgctggtt attgtgctgt ctcatcattt tggcaaagaa ttg 1733
<210> 3
<211> 664
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Промотор
<223> Последовательность усеченного нуклеотидного промотора CAG.
<400> 3
ctagatctga attcggtacc ctagttatta atagtaatca attacggggt cattagttca 60
tagcccatat atggagttcc gcgttacata acttacggta aatggcccgc ctggctgacc 120
gcccaacgac ccccgcccat tgacgtcaat aatgacgtat gttcccatag taacgccaat 180
agggactttc cattgacgtc aatgggtgga ctatttacgg taaactgccc acttggcagt 240
acatcaagtg tatcatatgc caagtacgcc ccctattgac gtcaatgacg gtaaatggcc 300
cgcctggcat tatgcccagt acatgacctt atgggacttt cctacttggc agtacatcta 360
cgtattagtc atcgctatta ccatggtcga ggtgagcccc acgttctgct tcactctccc 420
catctccccc ccctccccac ccccaatttt gtatttattt attttttaat tattttgtgc 480
agcgatgggg gcgggggggg ggggggggcg cgcgccaggc ggggcggggc ggggcgaggg 540
gcggggcggg gcgaggcgga gaggtgcggc ggcagccaat cagagcggcg cgctccgaaa 600
gtttcctttt atggcgaggc ggcggcggcg gcggccctat aaaaagcgaa gcgcgcggcg 660
ggcg 664
<210> 4
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> Пептидная последовательность спейсерного С-конца
<400> 4
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro
1 5 10
<210> 5
<211> 63
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Первый вариант осуществления спейсерной нуклеотидной последовательности
<400> 5
ggaagcggag ctactaactt cagcctgctg aaggctggag acgtggagga gaaccctgga 60
cct 63
<210> 6
<211> 21
<212> PRT
<213> Искусственная последовательность
<220>
<223> Первый вариант осуществления спейсерной пептидной последовательности
<400> 6
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Gln Ala Gly Asp Val Glu
1 5 10 15
Glu Asn Pro Gly Pro
20
<210> 7
<211> 63
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Второй вариант осуществления спейсерной нуклеотидной последовательности
<400> 7
agcggagcta ctaacttcag cctgctgaag caggctggag acgtggagga gaaccctgga 60
cct 63
<210> 8
<211> 21
<212> PRT
<213> Искусственная последовательность
<220>
<223> Второй вариант осуществления спейсерной пептидной последовательности
<400> 8
Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu
1 5 10 15
Glu Asn Pro Gly Pro
20
<210> 9
<211> 822
<212> PRT
<213> Homo sapiens
<400> 9
Met Ser Ser Trp Ile Arg Trp His Gly Pro Ala Met Ala Arg Leu Trp
1 5 10 15
Gly Phe Cys Trp Leu Val Val Gly Phe Trp Arg Ala Ala Phe Ala Cys
20 25 30
Pro Thr Ser Cys Lys Cys Ser Ala Ser Arg Ile Trp Cys Ser Asp Pro
35 40 45
Ser Pro Gly Ile Val Ala Phe Pro Arg Leu Glu Pro Asn Ser Val Asp
50 55 60
Pro Glu Asn Ile Thr Glu Ile Phe Ile Ala Asn Gln Lys Arg Leu Glu
65 70 75 80
Ile Ile Asn Glu Asp Asp Val Glu Ala Tyr Val Gly Leu Arg Asn Leu
85 90 95
Thr Ile Val Asp Ser Gly Leu Lys Phe Val Ala His Lys Ala Phe Leu
100 105 110
Lys Asn Ser Asn Leu Gln His Ile Asn Phe Thr Arg Asn Lys Leu Thr
115 120 125
Ser Leu Ser Arg Lys His Phe Arg His Leu Asp Leu Ser Glu Leu Ile
130 135 140
Leu Val Gly Asn Pro Phe Thr Cys Ser Cys Asp Ile Met Trp Ile Lys
145 150 155 160
Thr Leu Gln Glu Ala Lys Ser Ser Pro Asp Thr Gln Asp Leu Tyr Cys
165 170 175
Leu Asn Glu Ser Ser Lys Asn Ile Pro Leu Ala Asn Leu Gln Ile Pro
180 185 190
Asn Cys Gly Leu Pro Ser Ala Asn Leu Ala Ala Pro Asn Leu Thr Val
195 200 205
Glu Glu Gly Lys Ser Ile Thr Leu Ser Cys Ser Val Ala Gly Asp Pro
210 215 220
Val Pro Asn Met Tyr Trp Asp Val Gly Asn Leu Val Ser Lys His Met
225 230 235 240
Asn Glu Thr Ser His Thr Gln Gly Ser Leu Arg Ile Thr Asn Ile Ser
245 250 255
Ser Asp Asp Ser Gly Lys Gln Ile Ser Cys Val Ala Glu Asn Leu Val
260 265 270
Gly Glu Asp Gln Asp Ser Val Asn Leu Thr Val His Phe Ala Pro Thr
275 280 285
Ile Thr Phe Leu Glu Ser Pro Thr Ser Asp His His Trp Cys Ile Pro
290 295 300
Phe Thr Val Lys Gly Asn Pro Lys Pro Ala Leu Gln Trp Phe Tyr Asn
305 310 315 320
Gly Ala Ile Leu Asn Glu Ser Lys Tyr Ile Cys Thr Lys Ile His Val
325 330 335
Thr Asn His Thr Glu Tyr His Gly Cys Leu Gln Leu Asp Asn Pro Thr
340 345 350
His Met Asn Asn Gly Asp Tyr Thr Leu Ile Ala Lys Asn Glu Tyr Gly
355 360 365
Lys Asp Glu Lys Gln Ile Ser Ala His Phe Met Gly Trp Pro Gly Ile
370 375 380
Asp Asp Gly Ala Asn Pro Asn Tyr Pro Asp Val Ile Tyr Glu Asp Tyr
385 390 395 400
Gly Thr Ala Ala Asn Asp Ile Gly Asp Thr Thr Asn Arg Ser Asn Glu
405 410 415
Ile Pro Ser Thr Asp Val Thr Asp Lys Thr Gly Arg Glu His Leu Ser
420 425 430
Val Tyr Ala Val Val Val Ile Ala Ser Val Val Gly Phe Cys Leu Leu
435 440 445
Val Met Leu Phe Leu Leu Lys Leu Ala Arg His Ser Lys Phe Gly Met
450 455 460
Lys Gly Pro Ala Ser Val Ile Ser Asn Asp Asp Asp Ser Ala Ser Pro
465 470 475 480
Leu His His Ile Ser Asn Gly Ser Asn Thr Pro Ser Ser Ser Glu Gly
485 490 495
Gly Pro Asp Ala Val Ile Ile Gly Met Thr Lys Ile Pro Val Ile Glu
500 505 510
Asn Pro Gln Tyr Phe Gly Ile Thr Asn Ser Gln Leu Lys Pro Asp Thr
515 520 525
Phe Val Gln His Ile Lys Arg His Asn Ile Val Leu Lys Arg Glu Leu
530 535 540
Gly Glu Gly Ala Phe Gly Lys Val Phe Leu Ala Glu Cys Tyr Asn Leu
545 550 555 560
Cys Pro Glu Gln Asp Lys Ile Leu Val Ala Val Lys Thr Leu Lys Asp
565 570 575
Ala Ser Asp Asn Ala Arg Lys Asp Phe His Arg Glu Ala Glu Leu Leu
580 585 590
Thr Asn Leu Gln His Glu His Ile Val Lys Phe Tyr Gly Val Cys Val
595 600 605
Glu Gly Asp Pro Leu Ile Met Val Phe Glu Tyr Met Lys His Gly Asp
610 615 620
Leu Asn Lys Phe Leu Arg Ala His Gly Pro Asp Ala Val Leu Met Ala
625 630 635 640
Glu Gly Asn Pro Pro Thr Glu Leu Thr Gln Ser Gln Met Leu His Ile
645 650 655
Ala Gln Gln Ile Ala Ala Gly Met Val Tyr Leu Ala Ser Gln His Phe
660 665 670
Val His Arg Asp Leu Ala Thr Arg Asn Cys Leu Val Gly Glu Asn Leu
675 680 685
Leu Val Lys Ile Gly Asp Phe Gly Met Ser Arg Asp Val Tyr Ser Thr
690 695 700
Asp Tyr Tyr Arg Val Gly Gly His Thr Met Leu Pro Ile Arg Trp Met
705 710 715 720
Pro Pro Glu Ser Ile Met Tyr Arg Lys Phe Thr Thr Glu Ser Asp Val
725 730 735
Trp Ser Leu Gly Val Val Leu Trp Glu Ile Phe Thr Tyr Gly Lys Gln
740 745 750
Pro Trp Tyr Gln Leu Ser Asn Asn Glu Val Ile Glu Cys Ile Thr Gln
755 760 765
Gly Arg Val Leu Gln Arg Pro Arg Thr Cys Pro Gln Glu Val Tyr Glu
770 775 780
Leu Met Leu Gly Cys Trp Gln Arg Glu Pro His Met Arg Lys Asn Ile
785 790 795 800
Lys Gly Ile His Thr Leu Leu Gln Asn Leu Ala Lys Ala Ser Pro Val
805 810 815
Tyr Leu Asp Ile Leu Gly
820
<210> 10
<211> 2466
<212> ДНК
<213> Homo sapiens
<400> 10
atgtcgtcct ggataaggtg gcatggaccc gccatggcgc ggctctgggg cttctgctgg 60
ctggttgtgg gcttctggag ggccgctttc gcctgtccca cgtcctgcaa atgcagtgcc 120
tctcggatct ggtgcagcga cccttctcct ggcatcgtgg catttccgag attggagcct 180
aacagtgtag atcctgagaa catcaccgaa attttcatcg caaaccagaa aaggttagaa 240
atcatcaacg aagatgatgt tgaagcttat gtgggactga gaaatctgac aattgtggat 300
tctggattaa aatttgtggc tcataaagca tttctgaaaa acagcaacct gcagcacatc 360
aattttaccc gaaacaaact gacgagtttg tctaggaaac atttccgtca ccttgacttg 420
tctgaactga tcctggtggg caatccattt acatgctcct gtgacattat gtggatcaag 480
actctccaag aggctaaatc cagtccagac actcaggatt tgtactgcct gaatgaaagc 540
agcaagaata ttcccctggc aaacctgcag atacccaatt gtggtttgcc atctgcaaat 600
ctggccgcac ctaacctcac tgtggaggaa ggaaagtcta tcacattatc ctgtagtgtg 660
gcaggtgatc cggttcctaa tatgtattgg gatgttggta acctggtttc caaacatatg 720
aatgaaacaa gccacacaca gggctcctta aggataacta acatttcatc cgatgacagt 780
gggaagcaga tctcttgtgt ggcggaaaat cttgtaggag aagatcaaga ttctgtcaac 840
ctcactgtgc attttgcacc aactatcaca tttctcgaat ctccaacctc agaccaccac 900
tggtgcattc cattcactgt gaaaggcaac cccaaaccag cgcttcagtg gttctataac 960
ggggcaatat tgaatgagtc caaatacatc tgtactaaaa tacatgttac caatcacacg 1020
gagtaccacg gctgcctcca gctggataat cccactcaca tgaacaatgg ggactacact 1080
ctaatagcca agaatgagta tgggaaggat gagaaacaga tttctgctca cttcatgggc 1140
tggcctggaa ttgacgatgg tgcaaaccca aattatcctg atgtaattta tgaagattat 1200
ggaactgcag cgaatgacat cggggacacc acgaacagaa gtaatgaaat cccttccaca 1260
gacgtcactg ataaaaccgg tcgggaacat ctctcggtct atgctgtggt ggtgattgcg 1320
tctgtggtgg gattttgcct tttggtaatg ctgtttctgc ttaagttggc aagacactcc 1380
aagtttggca tgaaaggccc agcctccgtt atcagcaatg atgatgactc tgccagccca 1440
ctccatcaca tctccaatgg gagtaacact ccatcttctt cggaaggtgg cccagatgct 1500
gtcattattg gaatgaccaa gatccctgtc attgaaaatc cccagtactt tggcatcacc 1560
aacagtcagc tcaagccaga cacatttgtt cagcacatca agcgacataa cattgttctg 1620
aaaagggagc taggcgaagg agcctttgga aaagtgttcc tagctgaatg ctataacctc 1680
tgtcctgagc aggacaagat cttggtggca gtgaagaccc tgaaggatgc cagtgacaat 1740
gcacgcaagg acttccaccg tgaggccgag ctcctgacca acctccagca tgagcacatc 1800
gtcaagttct atggcgtctg cgtggagggc gaccccctca tcatggtctt tgagtacatg 1860
aagcatgggg acctcaacaa gttcctcagg gcacacggcc ctgatgccgt gctgatggct 1920
gagggcaacc cgcccacgga actgacgcag tcgcagatgc tgcatatagc ccagcagatc 1980
gccgcgggca tggtctacct ggcgtcccag cacttcgtgc accgcgattt ggccaccagg 2040
aactgcctgg tcggggagaa cttgctggtg aaaatcgggg actttgggat gtcccgggac 2100
gtgtacagca ctgactacta cagggtcggt ggccacacaa tgctgcccat tcgctggatg 2160
cctccagaga gcatcatgta caggaaattc acgacggaaa gcgacgtctg gagcctgggg 2220
gtcgtgttgt gggagatttt cacctatggc aaacagccct ggtaccagct gtcaaacaat 2280
gaggtgatag agtgtatcac tcagggccga gtcctgcagc gaccccgcac gtgcccccag 2340
gaggtgtatg agctgatgct ggggtgctgg cagcgagagc cccacatgag gaagaacatc 2400
aagggcatcc ataccctcct tcagaacttg gccaaggcat ctccggtcta cctggacatt 2460
ctaggc 2466
<210> 11
<211> 838
<212> PRT
<213> Homo sapiens
<400> 11
Met Ser Ser Trp Ile Arg Trp His Gly Pro Ala Met Ala Arg Leu Trp
1 5 10 15
Gly Phe Cys Trp Leu Val Val Gly Phe Trp Arg Ala Ala Phe Ala Cys
20 25 30
Pro Thr Ser Cys Lys Cys Ser Ala Ser Arg Ile Trp Cys Ser Asp Pro
35 40 45
Ser Pro Gly Ile Val Ala Phe Pro Arg Leu Glu Pro Asn Ser Val Asp
50 55 60
Pro Glu Asn Ile Thr Glu Ile Phe Ile Ala Asn Gln Lys Arg Leu Glu
65 70 75 80
Ile Ile Asn Glu Asp Asp Val Glu Ala Tyr Val Gly Leu Arg Asn Leu
85 90 95
Thr Ile Val Asp Ser Gly Leu Lys Phe Val Ala His Lys Ala Phe Leu
100 105 110
Lys Asn Ser Asn Leu Gln His Ile Asn Phe Thr Arg Asn Lys Leu Thr
115 120 125
Ser Leu Ser Arg Lys His Phe Arg His Leu Asp Leu Ser Glu Leu Ile
130 135 140
Leu Val Gly Asn Pro Phe Thr Cys Ser Cys Asp Ile Met Trp Ile Lys
145 150 155 160
Thr Leu Gln Glu Ala Lys Ser Ser Pro Asp Thr Gln Asp Leu Tyr Cys
165 170 175
Leu Asn Glu Ser Ser Lys Asn Ile Pro Leu Ala Asn Leu Gln Ile Pro
180 185 190
Asn Cys Gly Leu Pro Ser Ala Asn Leu Ala Ala Pro Asn Leu Thr Val
195 200 205
Glu Glu Gly Lys Ser Ile Thr Leu Ser Cys Ser Val Ala Gly Asp Pro
210 215 220
Val Pro Asn Met Tyr Trp Asp Val Gly Asn Leu Val Ser Lys His Met
225 230 235 240
Asn Glu Thr Ser His Thr Gln Gly Ser Leu Arg Ile Thr Asn Ile Ser
245 250 255
Ser Asp Asp Ser Gly Lys Gln Ile Ser Cys Val Ala Glu Asn Leu Val
260 265 270
Gly Glu Asp Gln Asp Ser Val Asn Leu Thr Val His Phe Ala Pro Thr
275 280 285
Ile Thr Phe Leu Glu Ser Pro Thr Ser Asp His His Trp Cys Ile Pro
290 295 300
Phe Thr Val Lys Gly Asn Pro Lys Pro Ala Leu Gln Trp Phe Tyr Asn
305 310 315 320
Gly Ala Ile Leu Asn Glu Ser Lys Tyr Ile Cys Thr Lys Ile His Val
325 330 335
Thr Asn His Thr Glu Tyr His Gly Cys Leu Gln Leu Asp Asn Pro Thr
340 345 350
His Met Asn Asn Gly Asp Tyr Thr Leu Ile Ala Lys Asn Glu Tyr Gly
355 360 365
Lys Asp Glu Lys Gln Ile Ser Ala His Phe Met Gly Trp Pro Gly Ile
370 375 380
Asp Asp Gly Ala Asn Pro Asn Tyr Pro Asp Val Ile Tyr Glu Asp Tyr
385 390 395 400
Gly Thr Ala Ala Asn Asp Ile Gly Asp Thr Thr Asn Arg Ser Asn Glu
405 410 415
Ile Pro Ser Thr Asp Val Thr Asp Lys Thr Gly Arg Glu His Leu Ser
420 425 430
Val Tyr Ala Val Val Val Ile Ala Ser Val Val Gly Phe Cys Leu Leu
435 440 445
Val Met Leu Phe Leu Leu Lys Leu Ala Arg His Ser Lys Phe Gly Met
450 455 460
Lys Asp Phe Ser Trp Phe Gly Phe Gly Lys Val Lys Ser Arg Gln Gly
465 470 475 480
Val Gly Pro Ala Ser Val Ile Ser Asn Asp Asp Asp Ser Ala Ser Pro
485 490 495
Leu His His Ile Ser Asn Gly Ser Asn Thr Pro Ser Ser Ser Glu Gly
500 505 510
Gly Pro Asp Ala Val Ile Ile Gly Met Thr Lys Ile Pro Val Ile Glu
515 520 525
Asn Pro Gln Tyr Phe Gly Ile Thr Asn Ser Gln Leu Lys Pro Asp Thr
530 535 540
Phe Val Gln His Ile Lys Arg His Asn Ile Val Leu Lys Arg Glu Leu
545 550 555 560
Gly Glu Gly Ala Phe Gly Lys Val Phe Leu Ala Glu Cys Tyr Asn Leu
565 570 575
Cys Pro Glu Gln Asp Lys Ile Leu Val Ala Val Lys Thr Leu Lys Asp
580 585 590
Ala Ser Asp Asn Ala Arg Lys Asp Phe His Arg Glu Ala Glu Leu Leu
595 600 605
Thr Asn Leu Gln His Glu His Ile Val Lys Phe Tyr Gly Val Cys Val
610 615 620
Glu Gly Asp Pro Leu Ile Met Val Phe Glu Tyr Met Lys His Gly Asp
625 630 635 640
Leu Asn Lys Phe Leu Arg Ala His Gly Pro Asp Ala Val Leu Met Ala
645 650 655
Glu Gly Asn Pro Pro Thr Glu Leu Thr Gln Ser Gln Met Leu His Ile
660 665 670
Ala Gln Gln Ile Ala Ala Gly Met Val Tyr Leu Ala Ser Gln His Phe
675 680 685
Val His Arg Asp Leu Ala Thr Arg Asn Cys Leu Val Gly Glu Asn Leu
690 695 700
Leu Val Lys Ile Gly Asp Phe Gly Met Ser Arg Asp Val Tyr Ser Thr
705 710 715 720
Asp Tyr Tyr Arg Val Gly Gly His Thr Met Leu Pro Ile Arg Trp Met
725 730 735
Pro Pro Glu Ser Ile Met Tyr Arg Lys Phe Thr Thr Glu Ser Asp Val
740 745 750
Trp Ser Leu Gly Val Val Leu Trp Glu Ile Phe Thr Tyr Gly Lys Gln
755 760 765
Pro Trp Tyr Gln Leu Ser Asn Asn Glu Val Ile Glu Cys Ile Thr Gln
770 775 780
Gly Arg Val Leu Gln Arg Pro Arg Thr Cys Pro Gln Glu Val Tyr Glu
785 790 795 800
Leu Met Leu Gly Cys Trp Gln Arg Glu Pro His Met Arg Lys Asn Ile
805 810 815
Lys Gly Ile His Thr Leu Leu Gln Asn Leu Ala Lys Ala Ser Pro Val
820 825 830
Tyr Leu Asp Ile Leu Gly
835
<210> 12
<211> 2514
<212> ДНК
<213> Homo sapiens
<400> 12
atgtcgtcct ggataaggtg gcatggaccc gccatggcgc ggctctgggg cttctgctgg 60
ctggttgtgg gcttctggag ggccgctttc gcctgtccca cgtcctgcaa atgcagtgcc 120
tctcggatct ggtgcagcga cccttctcct ggcatcgtgg catttccgag attggagcct 180
aacagtgtag atcctgagaa catcaccgaa attttcatcg caaaccagaa aaggttagaa 240
atcatcaacg aagatgatgt tgaagcttat gtgggactga gaaatctgac aattgtggat 300
tctggattaa aatttgtggc tcataaagca tttctgaaaa acagcaacct gcagcacatc 360
aattttaccc gaaacaaact gacgagtttg tctaggaaac atttccgtca ccttgacttg 420
tctgaactga tcctggtggg caatccattt acatgctcct gtgacattat gtggatcaag 480
actctccaag aggctaaatc cagtccagac actcaggatt tgtactgcct gaatgaaagc 540
agcaagaata ttcccctggc aaacctgcag atacccaatt gtggtttgcc atctgcaaat 600
ctggccgcac ctaacctcac tgtggaggaa ggaaagtcta tcacattatc ctgtagtgtg 660
gcaggtgatc cggttcctaa tatgtattgg gatgttggta acctggtttc caaacatatg 720
aatgaaacaa gccacacaca gggctcctta aggataacta acatttcatc cgatgacagt 780
gggaagcaga tctcttgtgt ggcggaaaat cttgtaggag aagatcaaga ttctgtcaac 840
ctcactgtgc attttgcacc aactatcaca tttctcgaat ctccaacctc agaccaccac 900
tggtgcattc cattcactgt gaaaggcaac cccaaaccag cgcttcagtg gttctataac 960
ggggcaatat tgaatgagtc caaatacatc tgtactaaaa tacatgttac caatcacacg 1020
gagtaccacg gctgcctcca gctggataat cccactcaca tgaacaatgg ggactacact 1080
ctaatagcca agaatgagta tgggaaggat gagaaacaga tttctgctca cttcatgggc 1140
tggcctggaa ttgacgatgg tgcaaaccca aattatcctg atgtaattta tgaagattat 1200
ggaactgcag cgaatgacat cggggacacc acgaacagaa gtaatgaaat cccttccaca 1260
gacgtcactg ataaaaccgg tcgggaacat ctctcggtct atgctgtggt ggtgattgcg 1320
tctgtggtgg gattttgcct tttggtaatg ctgtttctgc ttaagttggc aagacactcc 1380
aagtttggca tgaaagattt ctcatggttt ggatttggga aagtaaaatc aagacaaggt 1440
gttggcccag cctccgttat cagcaatgat gatgactctg ccagcccact ccatcacatc 1500
tccaatggga gtaacactcc atcttcttcg gaaggtggcc cagatgctgt cattattgga 1560
atgaccaaga tccctgtcat tgaaaatccc cagtactttg gcatcaccaa cagtcagctc 1620
aagccagaca catttgttca gcacatcaag cgacataaca ttgttctgaa aagggagcta 1680
ggcgaaggag cctttggaaa agtgttccta gctgaatgct ataacctctg tcctgagcag 1740
gacaagatct tggtggcagt gaagaccctg aaggatgcca gtgacaatgc acgcaaggac 1800
ttccaccgtg aggccgagct cctgaccaac ctccagcatg agcacatcgt caagttctat 1860
ggcgtctgcg tggagggcga ccccctcatc atggtctttg agtacatgaa gcatggggac 1920
ctcaacaagt tcctcagggc acacggccct gatgccgtgc tgatggctga gggcaacccg 1980
cccacggaac tgacgcagtc gcagatgctg catatagccc agcagatcgc cgcgggcatg 2040
gtctacctgg cgtcccagca cttcgtgcac cgcgatttgg ccaccaggaa ctgcctggtc 2100
ggggagaact tgctggtgaa aatcggggac tttgggatgt cccgggacgt gtacagcact 2160
gactactaca gggtcggtgg ccacacaatg ctgcccattc gctggatgcc tccagagagc 2220
atcatgtaca ggaaattcac gacggaaagc gacgtctgga gcctgggggt cgtgttgtgg 2280
gagattttca cctatggcaa acagccctgg taccagctgt caaacaatga ggtgatagag 2340
tgtatcactc agggccgagt cctgcagcga ccccgcacgt gcccccagga ggtgtatgag 2400
ctgatgctgg ggtgctggca gcgagagccc cacatgagga agaacatcaa gggcatccat 2460
accctccttc agaacttggc caaggcatct ccggtctacc tggacattct aggc 2514
<210> 13
<211> 822
<212> PRT
<213> Homo sapiens
<400> 13
Met Ser Ser Trp Ile Arg Trp His Gly Pro Ala Met Ala Arg Leu Trp
1 5 10 15
Gly Phe Cys Trp Leu Val Val Gly Phe Trp Arg Ala Ala Phe Ala Cys
20 25 30
Pro Thr Ser Cys Lys Cys Ser Ala Ser Arg Ile Trp Cys Ser Asp Pro
35 40 45
Ser Pro Gly Ile Val Ala Phe Pro Arg Leu Glu Pro Asn Ser Val Asp
50 55 60
Pro Glu Asn Ile Thr Glu Ile Phe Ile Ala Asn Gln Lys Arg Leu Glu
65 70 75 80
Ile Ile Asn Glu Asp Asp Val Glu Ala Tyr Val Gly Leu Arg Asn Leu
85 90 95
Thr Ile Val Asp Ser Gly Leu Lys Phe Val Ala His Lys Ala Phe Leu
100 105 110
Lys Asn Ser Asn Leu Gln His Ile Asn Phe Thr Arg Asn Lys Leu Thr
115 120 125
Ser Leu Ser Arg Lys His Phe Arg His Leu Asp Leu Ser Glu Leu Ile
130 135 140
Leu Val Gly Asn Pro Phe Thr Cys Ser Cys Asp Ile Met Trp Ile Lys
145 150 155 160
Thr Leu Gln Glu Ala Lys Ser Ser Pro Asp Thr Gln Asp Leu Tyr Cys
165 170 175
Leu Asn Glu Ser Ser Lys Asn Ile Pro Leu Ala Asn Leu Gln Ile Pro
180 185 190
Asn Cys Gly Leu Pro Ser Ala Asn Leu Ala Ala Pro Asn Leu Thr Val
195 200 205
Glu Glu Gly Lys Ser Ile Thr Leu Ser Cys Ser Val Ala Gly Asp Pro
210 215 220
Val Pro Asn Met Tyr Trp Asp Val Gly Asn Leu Val Ser Lys His Met
225 230 235 240
Asn Glu Thr Ser His Thr Gln Gly Ser Leu Arg Ile Thr Asn Ile Ser
245 250 255
Ser Asp Asp Ser Gly Lys Gln Ile Ser Cys Val Ala Glu Asn Leu Val
260 265 270
Gly Glu Asp Gln Asp Ser Val Asn Leu Thr Val His Phe Ala Pro Thr
275 280 285
Ile Thr Phe Leu Glu Ser Pro Thr Ser Asp His His Trp Cys Ile Pro
290 295 300
Phe Thr Val Lys Gly Asn Pro Lys Pro Ala Leu Gln Trp Phe Tyr Asn
305 310 315 320
Gly Ala Ile Leu Asn Glu Ser Lys Tyr Ile Cys Thr Lys Ile His Val
325 330 335
Thr Asn His Thr Glu Tyr His Gly Cys Leu Gln Leu Asp Asn Pro Thr
340 345 350
His Met Asn Asn Gly Asp Tyr Thr Leu Ile Ala Lys Asn Glu Tyr Gly
355 360 365
Lys Asp Glu Lys Gln Ile Ser Ala His Phe Met Gly Trp Pro Gly Ile
370 375 380
Asp Asp Gly Ala Asn Pro Asn Tyr Pro Asp Val Ile Tyr Glu Asp Tyr
385 390 395 400
Gly Thr Ala Ala Asn Asp Ile Gly Asp Thr Thr Asn Arg Ser Asn Glu
405 410 415
Ile Pro Ser Thr Asp Val Thr Asp Lys Thr Gly Arg Glu His Leu Ser
420 425 430
Val Tyr Ala Val Val Val Ile Ala Ser Val Val Gly Phe Cys Leu Leu
435 440 445
Val Met Leu Phe Leu Leu Lys Leu Ala Arg His Ser Lys Phe Gly Met
450 455 460
Lys Gly Pro Ala Ser Val Ile Ser Asn Asp Asp Asp Ser Ala Ser Pro
465 470 475 480
Leu His His Ile Ser Asn Gly Ser Asn Thr Pro Ser Ser Ser Glu Gly
485 490 495
Gly Pro Asp Ala Val Ile Ile Gly Met Thr Lys Ile Pro Val Ile Glu
500 505 510
Asn Pro Gln Glu Phe Gly Ile Thr Asn Ser Gln Leu Lys Pro Asp Thr
515 520 525
Phe Val Gln His Ile Lys Arg His Asn Ile Val Leu Lys Arg Glu Leu
530 535 540
Gly Glu Gly Ala Phe Gly Lys Val Phe Leu Ala Glu Cys Tyr Asn Leu
545 550 555 560
Cys Pro Glu Gln Asp Lys Ile Leu Val Ala Val Lys Thr Leu Lys Asp
565 570 575
Ala Ser Asp Asn Ala Arg Lys Asp Phe His Arg Glu Ala Glu Leu Leu
580 585 590
Thr Asn Leu Gln His Glu His Ile Val Lys Phe Tyr Gly Val Cys Val
595 600 605
Glu Gly Asp Pro Leu Ile Met Val Phe Glu Tyr Met Lys His Gly Asp
610 615 620
Leu Asn Lys Phe Leu Arg Ala His Gly Pro Asp Ala Val Leu Met Ala
625 630 635 640
Glu Gly Asn Pro Pro Thr Glu Leu Thr Gln Ser Gln Met Leu His Ile
645 650 655
Ala Gln Gln Ile Ala Ala Gly Met Val Tyr Leu Ala Ser Gln His Phe
660 665 670
Val His Arg Asp Leu Ala Thr Arg Asn Cys Leu Val Gly Glu Asn Leu
675 680 685
Leu Val Lys Ile Gly Asp Phe Gly Met Ser Arg Asp Val Glu Ser Thr
690 695 700
Asp Glu Glu Arg Val Gly Gly His Thr Met Leu Pro Ile Arg Trp Met
705 710 715 720
Pro Pro Glu Ser Ile Met Tyr Arg Lys Phe Thr Thr Glu Ser Asp Val
725 730 735
Trp Ser Leu Gly Val Val Leu Trp Glu Ile Phe Thr Tyr Gly Lys Gln
740 745 750
Pro Trp Tyr Gln Leu Ser Asn Asn Glu Val Ile Glu Cys Ile Thr Gln
755 760 765
Gly Arg Val Leu Gln Arg Pro Arg Thr Cys Pro Gln Glu Val Tyr Glu
770 775 780
Leu Met Leu Gly Cys Trp Gln Arg Glu Pro His Met Arg Lys Asn Ile
785 790 795 800
Lys Gly Ile His Thr Leu Leu Gln Asn Leu Ala Lys Ala Ser Pro Val
805 810 815
Glu Leu Asp Ile Leu Gly
820
<210> 14
<211> 2466
<212> ДНК
<213> Homo sapiens
<400> 14
atgtcgtcct ggataaggtg gcatggaccc gccatggcgc ggctctgggg cttctgctgg 60
ctggttgtgg gcttctggag ggccgctttc gcctgtccca cgtcctgcaa atgcagtgcc 120
tctcggatct ggtgcagcga cccttctcct ggcatcgtgg catttccgag attggagcct 180
aacagtgtag atcctgagaa catcaccgaa attttcatcg caaaccagaa aaggttagaa 240
atcatcaacg aagatgatgt tgaagcttat gtgggactga gaaatctgac aattgtggat 300
tctggattaa aatttgtggc tcataaagca tttctgaaaa acagcaacct gcagcacatc 360
aattttaccc gaaacaaact gacgagtttg tctaggaaac atttccgtca ccttgacttg 420
tctgaactga tcctggtggg caatccattt acatgctcct gtgacattat gtggatcaag 480
actctccaag aggctaaatc cagtccagac actcaggatt tgtactgcct gaatgaaagc 540
agcaagaata ttcccctggc aaacctgcag atacccaatt gtggtttgcc atctgcaaat 600
ctggccgcac ctaacctcac tgtggaggaa ggaaagtcta tcacattatc ctgtagtgtg 660
gcaggtgatc cggttcctaa tatgtattgg gatgttggta acctggtttc caaacatatg 720
aatgaaacaa gccacacaca gggctcctta aggataacta acatttcatc cgatgacagt 780
gggaagcaga tctcttgtgt ggcggaaaat cttgtaggag aagatcaaga ttctgtcaac 840
ctcactgtgc attttgcacc aactatcaca tttctcgaat ctccaacctc agaccaccac 900
tggtgcattc cattcactgt gaaaggcaac cccaaaccag cgcttcagtg gttctataac 960
ggggcaatat tgaatgagtc caaatacatc tgtactaaaa tacatgttac caatcacacg 1020
gagtaccacg gctgcctcca gctggataat cccactcaca tgaacaatgg ggactacact 1080
ctaatagcca agaatgagta tgggaaggat gagaaacaga tttctgctca cttcatgggc 1140
tggcctggaa ttgacgatgg tgcaaaccca aattatcctg atgtaattta tgaagattat 1200
ggaactgcag cgaatgacat cggggacacc acgaacagaa gtaatgaaat cccttccaca 1260
gacgtcactg ataaaaccgg tcgggaacat ctctcggtct atgctgtggt ggtgattgcg 1320
tctgtggtgg gattttgcct tttggtaatg ctgtttctgc ttaagttggc aagacactcc 1380
aagtttggca tgaaaggccc agcctccgtt atcagcaatg atgatgactc tgccagccca 1440
ctccatcaca tctccaatgg gagtaacact ccatcttctt cggaaggtgg cccagatgct 1500
gtcattattg gaatgaccaa gatccctgtc attgaaaatc cccaggaatt tggcatcacc 1560
aacagtcagc tcaagccaga cacatttgtt cagcacatca agcgacataa cattgttctg 1620
aaaagggagc taggcgaagg agcctttgga aaagtgttcc tagctgaatg ctataacctc 1680
tgtcctgagc aggacaagat cttggtggca gtgaagaccc tgaaggatgc cagtgacaat 1740
gcacgcaagg acttccaccg tgaggccgag ctcctgacca acctccagca tgagcacatc 1800
gtcaagttct atggcgtctg cgtggagggc gaccccctca tcatggtctt tgagtacatg 1860
aagcatgggg acctcaacaa gttcctcagg gcacacggcc ctgatgccgt gctgatggct 1920
gagggcaacc cgcccacgga actgacgcag tcgcagatgc tgcatatagc ccagcagatc 1980
gccgcgggca tggtctacct ggcgtcccag cacttcgtgc accgcgattt ggccaccagg 2040
aactgcctgg tcggggagaa cttgctggtg aaaatcgggg actttgggat gtcccgggac 2100
gtggaaagca ctgacgaaga aagggtcggt ggccacacaa tgctgcccat tcgctggatg 2160
cctccagaga gcatcatgta caggaaattc acgacggaaa gcgacgtctg gagcctgggg 2220
gtcgtgttgt gggagatttt cacctatggc aaacagccct ggtaccagct gtcaaacaat 2280
gaggtgatag agtgtatcac tcagggccga gtcctgcagc gaccccgcac gtgcccccag 2340
gaggtgtatg agctgatgct ggggtgctgg cagcgagagc cccacatgag gaagaacatc 2400
aagggcatcc ataccctcct tcagaacttg gccaaggcat ctccggtcga actggacatt 2460
ctaggc 2466
<210> 15
<211> 229
<212> PRT
<213> Homo sapiens
<400> 15
Ala Pro Met Lys Glu Ala Asn Ile Arg Gly Gln Gly Gly Leu Ala Tyr
1 5 10 15
Pro Gly Val Arg Thr His Gly Thr Leu Glu Ser Val Asn Gly Pro Lys
20 25 30
Ala Gly Ser Arg Gly Leu Thr Ser Leu Ala Asp Thr Phe Glu His Val
35 40 45
Ile Glu Glu Leu Leu Asp Glu Asp Gln Lys Val Arg Pro Asn Glu Glu
50 55 60
Asn Asn Lys Asp Ala Asp Leu Tyr Thr Ser Arg Val Met Leu Ser Ser
65 70 75 80
Gln Val Pro Leu Glu Pro Pro Leu Leu Phe Leu Leu Glu Glu Tyr Lys
85 90 95
Asn Tyr Leu Asp Ala Ala Asn Met Ser Met Arg Val Arg Arg His Ser
100 105 110
Asp Pro Ala Arg Arg Gly Glu Leu Ser Val Cys Asp Ser Ile Ser Glu
115 120 125
Trp Val Thr Ala Ala Asp Lys Lys Thr Ala Val Asp Met Ser Gly Gly
130 135 140
Thr Val Thr Val Leu Glu Lys Val Pro Val Ser Lys Gly Gln Leu Lys
145 150 155 160
Gln Tyr Phe Tyr Glu Thr Lys Cys Asn Pro Met Gly Tyr Thr Lys Glu
165 170 175
Gly Cys Arg Gly Ile Asp Lys Arg His Trp Asn Ser Gln Cys Arg Thr
180 185 190
Thr Gln Ser Tyr Val Arg Ala Leu Thr Met Asp Ser Lys Lys Arg Ile
195 200 205
Gly Trp Arg Phe Ile Arg Ile Asp Thr Ser Cys Val Cys Thr Leu Thr
210 215 220
Ile Lys Arg Gly Arg
225
<210> 16
<211> 690
<212> ДНК
<213> Homo sapiens
<400> 16
gcccccatga aagaagcaaa catccgagga caaggtggct tggcctaccc aggtgtgcgg 60
acccatggga ctctggagag cgtgaatggg cccaaggcag gttcaagagg cttgacatca 120
ttggctgaca ctttcgaaca cgtgatagaa gagctgttgg atgaggacca gaaagttcgg 180
cccaatgaag aaaacaataa ggacgcagac ttgtacacgt ccagggtgat gctcagtagt 240
caagtgcctt tggagcctcc tcttctcttt ctgctggagg aatacaaaaa ttacctagat 300
gctgcaaaca tgtccatgag ggtccggcgc cactctgacc ctgcccgccg aggggagctg 360
agcgtgtgtg acagtattag tgagtgggta acggcggcag acaaaaagac tgcagtggac 420
atgtcgggcg ggacggtcac agtccttgaa aaggtccctg tatcaaaagg ccaactgaag 480
caatacttct acgagaccaa gtgcaatccc atgggttaca caaaagaagg ctgcaggggc 540
atagacaaaa ggcattggaa ctcccagtgc cgaactaccc agtcgtacgt gcgggccctt 600
accatggata gcaaaaagag aattggctgg cgattcataa ggatagacac ttcttgtgta 660
tgtacattga ccattaaaag gggaagatag 690
<210> 17
<211> 229
<212> PRT
<213> Homo sapiens
<400> 17
Ala Pro Met Lys Glu Ala Asn Ile Arg Gly Gln Gly Gly Leu Ala Tyr
1 5 10 15
Pro Gly Val Arg Thr His Gly Thr Leu Glu Ser Val Asn Gly Pro Lys
20 25 30
Ala Gly Ser Arg Gly Leu Thr Ser Leu Ala Asp Thr Phe Glu His Met
35 40 45
Ile Glu Glu Leu Leu Asp Glu Asp Gln Lys Val Arg Pro Asn Glu Glu
50 55 60
Asn Asn Lys Asp Ala Asp Leu Tyr Thr Ser Arg Val Met Leu Ser Ser
65 70 75 80
Gln Val Pro Leu Glu Pro Pro Leu Leu Phe Leu Leu Glu Glu Tyr Lys
85 90 95
Asn Tyr Leu Asp Ala Ala Asn Met Ser Met Arg Val Arg Arg His Ser
100 105 110
Asp Pro Ala Arg Arg Gly Glu Leu Ser Val Cys Asp Ser Ile Ser Glu
115 120 125
Trp Val Thr Ala Ala Asp Lys Lys Thr Ala Val Asp Met Ser Gly Gly
130 135 140
Thr Val Thr Val Leu Glu Lys Val Pro Val Ser Lys Gly Gln Leu Lys
145 150 155 160
Gln Tyr Phe Tyr Glu Thr Lys Cys Asn Pro Met Gly Tyr Thr Lys Glu
165 170 175
Gly Cys Arg Gly Ile Asp Lys Arg His Trp Asn Ser Gln Cys Arg Thr
180 185 190
Thr Gln Ser Tyr Val Arg Ala Leu Thr Met Asp Ser Lys Lys Arg Ile
195 200 205
Gly Trp Arg Phe Ile Arg Ile Asp Thr Ser Cys Val Cys Thr Leu Thr
210 215 220
Ile Lys Arg Gly Arg
225
<210> 18
<211> 119
<212> PRT
<213> Homo sapiens
<400> 18
His Ser Asp Pro Ala Arg Arg Gly Glu Leu Ser Val Cys Asp Ser Ile
1 5 10 15
Ser Glu Trp Val Thr Ala Ala Asp Lys Lys Thr Ala Val Asp Met Ser
20 25 30
Gly Gly Thr Val Thr Val Leu Glu Lys Val Pro Val Ser Lys Gly Gln
35 40 45
Leu Lys Gln Tyr Phe Tyr Glu Thr Lys Cys Asn Pro Met Gly Tyr Thr
50 55 60
Lys Glu Gly Cys Arg Gly Ile Asp Lys Arg His Trp Asn Ser Gln Cys
65 70 75 80
Arg Thr Thr Gln Ser Tyr Val Arg Ala Leu Thr Met Asp Ser Lys Lys
85 90 95
Arg Ile Gly Trp Arg Phe Ile Arg Ile Asp Thr Ser Cys Val Cys Thr
100 105 110
Leu Thr Ile Lys Arg Gly Arg
115
<210> 19
<211> 744
<212> ДНК
<213> Homo sapiens
<400> 19
atgaccatcc ttttccttac tatggttatt tcatactttg gttgcatgaa ggctgccccc 60
atgaaagaag caaacatccg aggacaaggt ggcttggcct acccaggtgt gcggacccat 120
gggactctgg agagcgtgaa tgggcccaag gcaggttcaa gaggcttgac atcattggct 180
gacactttcg aacacgtgat agaagagctg ttggatgagg accagaaagt tcggcccaat 240
gaagaaaaca ataaggacgc agacttgtac acgtccaggg tgatgctcag tagtcaagtg 300
cctttggagc ctcctcttct ctttctgctg gaggaataca aaaattacct agatgctgca 360
aacatgtcca tgagggtccg gcgccactct gaccctgccc gccgagggga gctgagcgtg 420
tgtgacagta ttagtgagtg ggtaacggcg gcagacaaaa agactgcagt ggacatgtcg 480
ggcgggacgg tcacagtcct tgaaaaggtc cctgtatcaa aaggccaact gaagcaatac 540
ttctacgaga ccaagtgcaa tcccatgggt tacacaaaag aaggctgcag gggcatagac 600
aaaaggcatt ggaactccca gtgccgaact acccagtcgt acgtgcgggc ccttaccatg 660
gatagcaaaa agagaattgg ctggcgattc ataaggatag acacttcttg tgtatgtaca 720
ttgaccatta aaaggggaag atag 744
<210> 20
<211> 18
<212> PRT
<213> Homo sapiens
<400> 20
Met Thr Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 21
<211> 54
<212> PRT
<213> Homo sapiens
<400> 21
Ala Thr Gly Ala Cys Cys Ala Thr Cys Cys Thr Thr Thr Thr Cys Cys
1 5 10 15
Thr Thr Ala Cys Thr Ala Thr Gly Gly Thr Thr Ala Thr Thr Thr Cys
20 25 30
Ala Thr Ala Cys Thr Thr Cys Gly Gly Thr Thr Gly Cys Ala Thr Gly
35 40 45
Ala Ala Gly Gly Cys Gly
50
<210> 22
<211> 26
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность для изоформы 2 удлиненного сигнального пептида
<400> 22
Met Phe His Gln Val Arg Arg Val Met Thr Ile Leu Phe Leu Thr Met
1 5 10 15
Val Ile Ser Tyr Phe Gly Cys Met Lys Ala
20 25
<210> 23
<211> 78
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты для изоформы 2 удлиненного сигнального пептида
<400> 23
atgttccacc aggtgagaag agtgatgacc atccttttcc ttactatggt tatttcatac 60
ttcggttgca tgaaggcg 78
<210> 24
<211> 33
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность для изоформ 3 и 6 удлиненного сигнального пептида
<400> 24
Met Gln Ser Arg Glu Glu Glu Trp Phe His Gln Val Arg Arg Val Met
1 5 10 15
Thr Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met Lys
20 25 30
Ala
<210> 25
<211> 99
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты для изоформ 3 и 6 удлиненного сигнального пептида
<400> 25
atgcagagcc gggaagagga atggttccac caggtgagaa gagtgatgac catccttttc 60
cttactatgg ttatttcata cttcggttgc atgaaggcg 99
<210> 26
<211> 47
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность для изоформы 5 удлиненного сигнального пептида
<400> 26
Met Leu Cys Ala Ile Ser Leu Cys Ala Arg Val Arg Lys Leu Arg Ser
1 5 10 15
Ala Gly Arg Cys Gly Lys Phe His Gln Val Arg Arg Val Met Thr Ile
20 25 30
Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met Lys Ala
35 40 45
<210> 27
<211> 141
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты для изоформы 5 удлиненного сигнального пептида
<400> 27
atgctctgtg cgatttcatt gtgtgctcgc gttcgcaagc tccgtagtgc aggaaggtgc 60
gggaagttcc accaggtgag aagagtgatg accatccttt tccttactat ggttatttca 120
tacttcggtt gcatgaaggc g 141
<210> 28
<211> 100
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность для изоформы 4 удлиненного сигнального пептида
<400> 28
Met Cys Gly Ala Thr Ser Phe Leu His Glu Cys Thr Arg Leu Ile Leu
1 5 10 15
Val Thr Thr Gln Asn Ala Glu Phe Leu Gln Lys Gly Leu Gln Val His
20 25 30
Thr Cys Phe Gly Val Tyr Pro His Ala Ser Val Trp His Asp Cys Ala
35 40 45
Ser Gln Lys Lys Gly Cys Ala Val Tyr Leu His Val Ser Val Glu Phe
50 55 60
Asn Lys Leu Ile Pro Glu Asn Gly Phe Ile Lys Phe His Gln Val Arg
65 70 75 80
Arg Val Met Thr Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly
85 90 95
Cys Met Lys Ala
100
<210> 29
<211> 300
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты для изоформы 4 удлиненного сигнального пептида
<400> 29
atgtgtggag ccaccagttt tctccatgag tgcacaaggt taatccttgt tactactcag 60
aatgctgagt ttctacagaa agggttgcag gtccacacat gttttggcgt ctacccacac 120
gcttctgtat ggcatgactg tgcatcccag aagaagggct gtgctgtgta cctccacgtt 180
tcagtggaat ttaacaaact gatccctgaa aatggtttca taaagttcca ccaggtgaga 240
agagtgatga ccatcctttt ccttactatg gttatttcat acttcggttg catgaaggcg 300
<210> 30
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA003P (сигнал ИЛ-2)
<400> 30
Met Tyr Arg Met Gln Leu Leu Ser Cys Ile Ala Leu Ser Leu Ala Leu
1 5 10 15
Val Thr Asn Ser
20
<210> 31
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA003P (сигнал ИЛ-2)
<400> 31
atgtacagga tgcaactcct gtcttgcatt gcactaagtc ttgcacttgt cacaaacagt 60
<210> 32
<211> 22
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA004P
<400> 32
Met Lys Arg Arg Val Met Ile Ile Leu Phe Leu Thr Met Val Ile Ser
1 5 10 15
Tyr Phe Gly Cys Met Lys
20
<210> 33
<211> 70
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA004P
<400> 33
atgaaaagaa gagtgatgat catccttttc cttactatgg ttatttcata cttcggttgc 60
atgaagagcg 70
<210> 34
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA009P (модифицированный ИЛ-2)
<400> 34
Met Arg Arg Met Gln Leu Leu Leu Leu Ile Ala Leu Ser Leu Ala Leu
1 5 10 15
Val Thr Asn Ser
20
<210> 35
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA009P (модифицированный ИЛ-2)
<400> 35
atgaggagga tgcaactcct gctcctgatt gcactaagtc ttgcacttgt cacaaacagt 60
<210> 36
<211> 21
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA010P
<400> 36
Met Arg Arg Met Gln Leu Leu Leu Leu Thr Met Val Ile Ser Tyr Phe
1 5 10 15
Gly Cys Met Lys Ala
20
<210> 37
<211> 63
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA010P
<400> 37
atgaggagga tgcaactcct gctcctgact atggttattt catacttcgg ttgcatgaag 60
gcg 63
<210> 38
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA0012P
<400> 38
Met Arg Ile Leu Leu Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 39
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA0012P
<400> 39
atgagaatcc ttcttcttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 40
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA0013P
<400> 40
Met Arg Arg Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys
1 5 10 15
Met Lys Ala
<210> 41
<211> 57
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA0013P
<400> 41
atgagaagaa tccttttcct tactatggtt atttcatact tcggttgcat gaaggcg 57
<210> 42
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA0014P
<400> 42
Met Arg Arg Phe Leu Phe Leu Leu Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 43
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA0014P
<400> 43
atgaggaggt tccttttcct tcttgttatt tcatacttcg gttgcatgaa ggcg 54
<210> 44
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Аминокислотная последовательность сигнального пептида для агониста:
QTA0015P
<400> 44
Met Arg Arg Phe Leu Phe Leu Leu Tyr Phe Gly Cys Met Lys Ala
1 5 10 15
<210> 45
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Sig_пептид
<223> Последовательность нуклеиновой кислоты сигнального пептида для агониста:
QTA0015P
<400> 45
atgaggaggt tccttttcct tctttacttc ggttgcatga aggcg 45
<210> 46
<211> 130
<212> ДНК
<213> Неизвестно
<220>
<223> ДНК последовательность левого ITR
<400> 46
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcgtcg ggcgaccttt 60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact 120
aggggttcct 130
<210> 47
<211> 141
<212> ДНК
<213> Unknown
<220>
<223> ДНК последовательность правого ITR
<400> 47
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgg gctttgcccg ggcggcctca gtgagcgagc 120
gagcgcgcag ctgcctgcag g 141
<210> 48
<211> 584
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Промотор
<223> Последовательность усеченного нуклеотидного промотора CAG.
<400> 48
gcgttacata acttacggta aatggcccgc ctggctgacc gcccaacgac ccccgcccat 60
tgacgtcaat aatgacgtat gttcccatag taacgccaat agggactttc cattgacgtc 120
aatgggtgga ctatttacgg taaactgccc acttggcagt acatcaagtg tatcatatgc 180
caagtacgcc ccctattgac gtcaatgacg gtaaatggcc cgcctggcat tatgcccagt 240
acatgacctt atgggacttt cctacttggc agtacatcta cgtattagtc atcgctatta 300
ccatggtcga ggtgagcccc acgttctgct tcactctccc catctccccc ccctccccac 360
ccccaatttt gtatttattt attttttaat tattttgtgc agcgatgggg gcgggggggg 420
ggggggggcg cgcgccaggc ggggcggggc ggggcgaggg gcggggcggg gcgaggcgga 480
gaggtgcggc ggcagccaat cagagcggcg cgctccgaaa gtttcctttt atggcgaggc 540
ggcggcggcg gcggccctat aaaaagcgaa gcgcgcggcg ggcg 584
<210> 49
<211> 210
<212> PRT
<213> Homo sapiens
<400> 49
Met Leu Pro Leu Pro Ser Cys Ser Leu Pro Ile Leu Leu Leu Phe Leu
1 5 10 15
Leu Pro Ser Val Pro Ile Glu Ser Gln Pro Pro Pro Ser Thr Leu Pro
20 25 30
Pro Phe Leu Ala Pro Glu Trp Asp Leu Leu Ser Pro Arg Val Val Leu
35 40 45
Ser Arg Gly Ala Pro Ala Gly Pro Pro Leu Leu Phe Leu Leu Glu Ala
50 55 60
Gly Ala Phe Arg Glu Ser Ala Gly Ala Pro Ala Asn Arg Ser Arg Arg
65 70 75 80
Gly Val Ser Glu Thr Ala Pro Ala Ser Arg Arg Gly Glu Leu Ala Val
85 90 95
Cys Asp Ala Val Ser Gly Trp Val Thr Asp Arg Arg Thr Ala Val Asp
100 105 110
Leu Arg Gly Arg Glu Val Glu Val Leu Gly Glu Val Pro Ala Ala Gly
115 120 125
Gly Ser Pro Leu Arg Gln Tyr Phe Phe Glu Thr Arg Cys Lys Ala Asp
130 135 140
Asn Ala Glu Glu Gly Gly Pro Gly Ala Gly Gly Gly Gly Cys Arg Gly
145 150 155 160
Val Asp Arg Arg His Trp Val Ser Glu Cys Lys Ala Lys Gln Ser Tyr
165 170 175
Val Arg Ala Leu Thr Ala Asp Ala Gln Gly Arg Val Gly Trp Arg Trp
180 185 190
Ile Arg Ile Asp Thr Ala Cys Val Cys Thr Leu Leu Ser Arg Thr Gly
195 200 205
Arg Ala
210
<210> 50
<211> 630
<212> ДНК
<213> Homo sapiens
<400> 50
atgctccctc tcccctcatg ctccctcccc atcctcctcc ttttcctcct ccccagtgtg 60
ccaattgagt cccaaccccc accctcaaca ttgccccctt ttctggcccc tgagtgggac 120
cttctctccc cccgagtagt cctgtctagg ggtgcccctg ctgggccccc tctgctcttc 180
ctgctggagg ctggggcctt tcgggagtca gcaggtgccc cggccaaccg cagccggcgt 240
ggggtgagcg aaactgcacc agcgagtcgt cggggtgagc tggctgtgtg cgatgcagtc 300
agtggctggg tgacagaccg ccggaccgct gtggacttgc gtgggcgcga ggtggaggtg 360
ttgggcgagg tgcctgcagc tggcggcagt cccctccgcc agtacttctt tgaaacccgc 420
tgcaaggctg ataacgctga ggaaggtggc ccgggggcag gtggaggggg ctgccgggga 480
gtggacagga ggcactgggt atctgagtgc aaggccaagc agtcctatgt gcgggcattg 540
accgctgatg cccagggccg tgtgggctgg cgatggattc gaattgacac tgcctgcgtc 600
tgcacactcc tcagccggac tggccgggcc 630
<210> 51
<211> 24
<212> PRT
<213> Homo sapiens
<400> 51
Met Leu Pro Leu Pro Ser Cys Ser Leu Pro Ile Leu Leu Leu Phe Leu
1 5 10 15
Leu Pro Ser Val Pro Ile Glu Ser
20
<210> 52
<211> 72
<212> ДНК
<213> Homo sapiens
<400> 52
atgctccctc tcccctcatg ctccctcccc atcctcctcc ttttcctcct ccccagtgtg 60
ccaattgagt cc 72
<210> 53
<211> 56
<212> PRT
<213> Homo sapiens
<400> 53
Gln Pro Pro Pro Ser Thr Leu Pro Pro Phe Leu Ala Pro Glu Trp Asp
1 5 10 15
Leu Leu Ser Pro Arg Val Val Leu Ser Arg Gly Ala Pro Ala Gly Pro
20 25 30
Pro Leu Leu Phe Leu Leu Glu Ala Gly Ala Phe Arg Glu Ser Ala Gly
35 40 45
Ala Pro Ala Asn Arg Ser Arg Arg
50 55
<210> 54
<211> 168
<212> ДНК
<213> Homo sapiens
<400> 54
caacccccac cctcaacatt gccccctttt ctggcccctg agtgggacct tctctccccc 60
cgagtagtcc tgtctagggg tgcccctgct gggccccctc tgctcttcct gctggaggct 120
ggggcctttc gggagtcagc aggtgccccg gccaaccgca gccggcgt 168
<210> 55
<211> 130
<212> PRT
<213> Homo sapiens
<400> 55
Gly Val Ser Glu Thr Ala Pro Ala Ser Arg Arg Gly Glu Leu Ala Val
1 5 10 15
Cys Asp Ala Val Ser Gly Trp Val Thr Asp Arg Arg Thr Ala Val Asp
20 25 30
Leu Arg Gly Arg Glu Val Glu Val Leu Gly Glu Val Pro Ala Ala Gly
35 40 45
Gly Ser Pro Leu Arg Gln Tyr Phe Phe Glu Thr Arg Cys Lys Ala Asp
50 55 60
Asn Ala Glu Glu Gly Gly Pro Gly Ala Gly Gly Gly Gly Cys Arg Gly
65 70 75 80
Val Asp Arg Arg His Trp Val Ser Glu Cys Lys Ala Lys Gln Ser Tyr
85 90 95
Val Arg Ala Leu Thr Ala Asp Ala Gln Gly Arg Val Gly Trp Arg Trp
100 105 110
Ile Arg Ile Asp Thr Ala Cys Val Cys Thr Leu Leu Ser Arg Thr Gly
115 120 125
Arg Ala
130
<210> 56
<211> 390
<212> ДНК
<213> Homo sapiens
<400> 56
ggggtgagcg aaactgcacc agcgagtcgt cggggtgagc tggctgtgtg cgatgcagtc 60
agtggctggg tgacagaccg ccggaccgct gtggacttgc gtgggcgcga ggtggaggtg 120
ttgggcgagg tgcctgcagc tggcggcagt cccctccgcc agtacttctt tgaaacccgc 180
tgcaaggctg ataacgctga ggaaggtggc ccgggggcag gtggaggggg ctgccgggga 240
gtggacagga ggcactgggt atctgagtgc aaggccaagc agtcctatgt gcgggcattg 300
accgctgatg cccagggccg tgtgggctgg cgatggattc gaattgacac tgcctgcgtc 360
tgcacactcc tcagccggac tggccgggcc 390
<210> 57
<211> 592
<212> ДНК
<213> Marmota monax
<400> 57
aatcaacctc tggattacaa aatttgtgaa agattgactg gtattcttaa ctatgttgct 60
ccttttacgc tatgtggata cgctgcttta atgcctttgt atcatgctat tgcttcccgt 120
atggctttca ttttctcctc cttgtataaa tcctggttgc tgtctcttta tgaggagttg 180
tggcccgttg tcaggcaacg tggcgtggtg tgcactgtgt ttgctgacgc aacccccact 240
ggttggggca ttgccaccac ctgtcagctc ctttccggga ctttcgcttt ccccctccct 300
attgccacgg cggaactcat cgccgcctgc cttgcccgct gctggacagg ggctcggctg 360
ttgggcactg acaattccgt ggtgttgtcg gggaagctga cgtcctttcc atggctgctc 420
gcctgtgttg ccacctggat tctgcgcggg acgtccttct gctacgtccc ttcggccctc 480
aatccagcgg accttccttc ccgcggcctg ctgccggctc tgcggcctct tccgcgtctt 540
cgccttcgcc ctcagacgag tcggatctcc ctttgggccg cctccccgcc tg 592
<210> 58
<211> 247
<212> ДНК
<213> Искусственная последовательность
<220>
<221> Энхансер
<223> Нуклеотидная последовательность усеченного WHPE. Бета-элемент был
удален.
<400> 58
aatcaacctc tggattacaa aatttgtgaa agattgactg gtattcttaa ctatgttgct 60
ccttttacgc tatgtggata cgctgcttta atgcctttgt atcatgctat tgcttcccgt 120
atggctttca ttttctcctc cttgtataaa tcctggttag ttcttgccac ggcggaactc 180
atcgccgcct gccttgcccg ctgctggaca ggggctcggc tgttgggcac tgacaattcc 240
gtggtgt 247
<210> 59
<211> 224
<212> ДНК
<213> Вирус обезьян 40
<400> 59
agcagacatg ataagataca ttgatgagtt tggacaaacc acaactagaa tgcagtgaaa 60
aaaatgcttt atttgtgaaa tttgtgatgc tattgcttta tttgtaacca ttataagctg 120
caataaacaa gttaacaaca acaattgcat tcattttatg tttcaggttc agggggaggt 180
gtgggaggtt ttttaaagca agtaaaacct ctacaaatgt ggta 224
<210> 60
<211> 18
<212> PRT
<213> Homo sapiens
<400> 60
Met Thr Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 61
<211> 54
<212> ДНК
<213> Homo sapiens
<400> 61
atgaccatcc ttttccttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 62
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID NO: 60, но первая «Т» SEQ ID No. 60 заменена на «R».
<400> 62
Met Arg Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 63
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID NO: 61, но «acc» SEQ ID NO: 61 заменена на «aga».
<400> 63
atgagaatcc ttttccttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 64
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID NO: 60, но первая «Т» SEQ ID No. 60 заменена на «RR».
<400> 64
Met Arg Arg Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys
1 5 10 15
Met Lys Ala
<210> 65
<211> 57
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID NO: 61, но «acc» SEQ ID No. 61 заменена на «aganaga».
<400> 65
atgagaagaa tccttttcct tactatggtt atttcatact tcggttgcat gaaggcg 57
<210> 66
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID NO: 60, но первая «Т» SEQ ID No. 60 заменена на «RRR».
<400> 66
Met Arg Arg Arg Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly
1 5 10 15
Cys Met Lys Ala
20
<210> 67
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID NO: 61, но «acc» SEQ ID NO: 61 заменена на "agaagaaga".
<400> 67
atgagaagaa gaatcctttt ccttactatg gttatttcat acttcggttg catgaaggcg 60
<210> 68
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но первая
«Т» SEQ ID No. 60 заменена на "K".
<400> 68
Met Lys Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 69
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID No. 61, но «acc»
SEQ ID No. 61 заменена на "aaa".
<400> 69
atgaaaatcc ttttccttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 70
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но первая
«Т» SEQ ID No. 60 заменена на "KK".
<400> 70
Met Lys Lys Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys
1 5 10 15
Met Lys Ala
<210> 71
<211> 57
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID No. 61, но «acc»
SEQ ID No. 61 заменена на "aaaaka".
<400> 71
atgaaaakaa tccttttcct tactatggtt atttcatact tcggttgcat gaaggcg 57
<210> 72
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но первая
«Т» SEQ ID No. 60 заменена на "KKK".
<400> 72
Met Lys Lys Lys Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly
1 5 10 15
Cys Met Lys Ala
20
<210> 73
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID No. 61, но «acc»
SEQ ID No. 61 заменена на "aaaaaaaaa".
<400> 73
atgaaaaaaa aaatcctttt ccttactatg gttatttcat acttcggttg catgaaggcg 60
<210> 74
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но первая
«Т» SEQ ID No. 60 заменена на "KRR".
<400> 74
Met Lys Arg Arg Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly
1 5 10 15
Cys Met Lys Ala
20
<210> 75
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID No. 61, но «acc»
SEQ ID No. 61 заменена на "aaaagaaga".
<400> 75
atgaaaagaa gaatcctttt ccttactatg gttatttcat acttcggttg catgaaggcg 60
<210> 76
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но первая
«Т» SEQ ID No. 60 заменена на "RKR".
<400> 76
Met Arg Lys Arg Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly
1 5 10 15
Cys Met Lys Ala
20
<210> 77
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID No. 61, но «acc»
SEQ ID No. 61 заменена на "agaaaaaga".
<400> 77
atgagaaaaa gaatcctttt ccttactatg gttatttcat acttcggttg catgaaggcg 60
<210> 78
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но первая
«Т» SEQ ID No. 60 заменена на"RRK".
<400> 78
Met Arg Arg Lys Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly
1 5 10 15
Cys Met Lys Ala
20
<210> 79
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID No. 61, но «acc»
SEQ ID No. 61 заменена на "agaagaaaa".
<400> 79
atgagaagaa aaatcctttt ccttactatg gttatttcat acttcggttg catgaaggcg 60
<210> 80
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но первая
«Т» SEQ ID No. 60 заменена на "KKR".
<400> 80
Met Lys Lys Arg Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly
1 5 10 15
Cys Met Lys Ala
20
<210> 81
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты: Та же последовательность, что и SEQ ID No. 61, но «acc»
SEQ ID No. 61 заменена на "aaaaaaaga".
<400> 81
atgaaaaaaa gaatcctttt ccttactatg gttatttcat acttcggttg catgaaggcg 60
<210> 82
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60, но
последовательность "ILFL" SEQ ID No. 60 заменена на "FLFL".
<400> 82
Met Thr Phe Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 83
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 6`, но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttccttttcctt".
<400> 83
atgaccttcc ttttccttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 84
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FFFL".
<400> 84
Met Thr Phe Phe Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 85
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcttcttcctt".
<400> 85
atgaccttct tcttccttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 86
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FIFL".
<400> 86
Met Thr Phe Ile Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 87
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcatcttcctt".
<400> 87
atgaccttca tcttccttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 88
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FIFI".
<400> 88
Met Thr Phe Ile Phe Ile Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 89
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcatcttcatc".
<400> 89
atgaccttca tcttcatcac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 90
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FVFI".
<400> 90
Met Thr Phe Val Phe Ile Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 91
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcgttttcatc".
<400> 91
atgaccttcg ttttcatcac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 92
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FVFV".
<400> 92
Met Thr Phe Val Phe Val Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 93
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcgttttcgtt".
<400> 93
atgaccttcg ttttcgttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 94
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FLFV".
<400> 94
Met Thr Phe Leu Phe Val Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 95
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttccttttcgtt".
<400> 95
atgaccttcc ttttcgttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 96
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FIFV".
<400> 96
Met Thr Phe Ile Phe Val Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 97
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcatcttcgtt".
<400> 97
atgaccttca tcttcgttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 98
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FFFI".
<400> 98
Met Thr Phe Phe Phe Ile Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 99
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcttcttcatc".
<400> 99
atgaccttct tcttcatcac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 100
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FFFV".
<400> 100
Met Thr Phe Phe Phe Val Thr Met Val Ile Ser Tyr Phe Gly Cys Met
1 5 10 15
Lys Ala
<210> 101
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcatccttttcctt".
<400> 101
atgaccttct tcttcgttac tatggttatt tcatacttcg gttgcatgaa ggcg 54
<210> 102
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 60 , но
"ILFL" последовательность SEQ ID No. 60 заменена на "FILFL".
<400> 102
Met Thr Phe Ile Leu Phe Leu Thr Met Val Ile Ser Tyr Phe Gly Cys
1 5 10 15
Met Lys Ala
<210> 103
<211> 57
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность: Та же последовательность, что и SEQ ID No. 61 , но
"atccttttcctt" последовательность SEQ ID No. 61 заменена на
"ttcttcttcgtt".
<400> 103
atgaccttca tccttttcct tactatggtt atttcatact tcggttgcat gaaggcg 57
<210> 104
<211> 1203
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты для QTA021P, которая представляет собой плазмиду, содержащую кодон-оптимизированную последовательность для зрНФГМ-вирусного-2A-пептида-eGFP.
<400> 104
atgactatcc tgtttctgac aatggttatt agctatttcg gttgcatgaa ggctcacagt 60
gatcccgcac gccgcggaga acttagcgtg tgcgacagca tcagcgagtg ggtcaccgcc 120
gccgataaga agaccgctgt ggatatgtcc ggcgggaccg tcactgtact cgaaaaagtt 180
ccagtgagca aaggccaact gaaacaatat ttctatgaaa ctaagtgcaa ccccatgggg 240
tacaccaagg agggctgccg gggaatcgac aagagacact ggaattccca gtgccggacc 300
actcagagct acgtccgcgc cttgacgatg gattcaaaga agcgcatcgg atggcggttc 360
ataagaatcg acaccagttg tgtgtgcacg ctgacgataa aacgggggcg ggcccccgtg 420
aagcagaccc tgaactttga tttgctcaag ttggcggggg atgtggaaag caatcccggg 480
ccaatggtga gcaagggcga ggagctgttc accggcgttg tgccaatact ggttgagttg 540
gatggcgatg tcaacggaca caaatttagc gtaagcgggg agggagaggg cgacgccaca 600
tatggcaagc tgaccctgaa gttcatttgc acgaccggca aattgcccgt cccttggccc 660
acacttgtga cgaccctgac ttatggcgta cagtgcttca gcaggtaccc tgatcatatg 720
aagcaacacg acttctttaa gagtgccatg ccagagggat acgtccagga aagaaccata 780
ttcttcaaag atgatggaaa ttacaaaacc cgggcagagg tcaagtttga aggcgacacc 840
ctggtgaaca ggatcgaact caaaggcatc gatttcaaag aggacggaaa catcctcgga 900
cacaaactgg aatacaatta caacagccac aacgtctaca tcatggcaga taaacaaaag 960
aacggtatta aagtgaactt caagatccgg cacaacatcg aagacggctc cgtccagctt 1020
gccgaccact accagcaaaa taccccgatc ggcgacggcc ccgttctcct ccccgataat 1080
cactacctga gtacacagtc agccttgagc aaagacccta atgaaaagcg ggaccacatg 1140
gttttgctgg agttcgttac cgcagcgggt attacgctgg gtatggacga gctttacaag 1200
taa 1203
<210> 105
<211> 1203
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты QTA022P, которая представляет собой плазмиду, содержащую кодон-оптимизированную последовательность для зрНФГМ-нефункционального вирусного-2A-пептида-eGFP.
.
<400> 105
atgactatcc tgtttctgac aatggttatt agctatttcg gttgcatgaa ggctcacagt 60
gatcccgcac gccgcggaga acttagcgtg tgcgacagca tcagcgagtg ggtcaccgcc 120
gccgataaga agaccgctgt ggatatgtcc ggcgggaccg tcactgtact cgaaaaagtt 180
ccagtgagca aaggccaact gaaacaatat ttctatgaaa ctaagtgcaa ccccatgggg 240
tacaccaagg agggctgccg gggaatcgac aagagacact ggaattccca gtgccggacc 300
actcagagct acgtccgcgc cttgacgatg gattcaaaga agcgcatcgg atggcggttc 360
ataagaatcg acaccagttg tgtgtgcacg ctgacgataa aacgggggcg ggcccctgtc 420
aaacaaaccc tcaattttga cttgctgaag cttgctgggg atgtcgagtc cgctgccgcg 480
gctatggtga gcaagggcga ggagctgttc accggcgttg tgccaatact ggttgagttg 540
gatggcgatg tcaacggaca caaatttagc gtaagcgggg agggagaggg cgacgccaca 600
tatggcaagc tgaccctgaa gttcatttgc acgaccggca aattgcccgt cccttggccc 660
acacttgtga cgaccctgac ttatggcgta cagtgcttca gcaggtaccc tgatcatatg 720
aagcaacacg acttctttaa gagtgccatg ccagagggat acgtccagga aagaaccata 780
ttcttcaaag atgatggaaa ttacaaaacc cgggcagagg tcaagtttga aggcgacacc 840
ctggtgaaca ggatcgaact caaaggcatc gatttcaaag aggacggaaa catcctcgga 900
cacaaactgg aatacaatta caacagccac aacgtctaca tcatggcaga taaacaaaag 960
aacggtatta aagtgaactt caagatccgg cacaacatcg aagacggctc cgtccagctt 1020
gccgaccact accagcaaaa taccccgatc ggcgacggcc ccgttctcct ccccgataat 1080
cactacctga gtacacagtc agccttgagc aaagacccta atgaaaagcg ggaccacatg 1140
gttttgctgg agttcgttac cgcagcgggt attacgctgg gtatggacga gctttacaag 1200
taa 1203
<210> 106
<211> 1203
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нуклеиновой кислоты для QTA023P, которая представляет собой плазмиду, содержащую кодон-оптимизированную последовательность для eGFP-вирусного-2A-пептида-зрНФГМ.
<400> 106
atggtgagca agggcgagga gctgttcacc ggggtggtgc ccatcctggt cgagctggac 60
ggcgacgtaa acggccacaa gttcagcgtg tccggcgagg gcgagggcga tgccacctac 120
ggcaagctga ccctgaagtt catctgcacc accggcaagc tgcccgtgcc ctggcccacc 180
ctcgtgacca ccctgaccta cggcgtgcag tgcttcagcc gctaccccga ccacatgaag 240
cagcacgact tcttcaagtc cgccatgccc gaaggctacg tccaggagcg caccatcttc 300
ttcaaggacg acggcaacta caagacccgc gccgaggtga agttcgaggg cgacaccctg 360
gtgaaccgca tcgagctgaa gggcatcgac ttcaaggagg acggcaacat cctggggcac 420
aagctggagt acaactacaa cagccacaac gtctatatca tggccgacaa gcagaagaac 480
ggcatcaagg tgaacttcaa gatccgccac aacatcgagg acggcagcgt gcagctcgcc 540
gaccactacc agcagaacac ccccatcggc gacggccccg tgctgctgcc cgacaaccac 600
tacctgagca cccagtccgc cctgagcaag gaccccaacg agaagcgcga tcacatggtc 660
ctgctggagt tcgtgaccgc cgccgggatc actctcggca tggacgagct gtacaaggct 720
cccgttaaac aaactctgaa cttcgacctg ctgaagctgg ctggagacgt ggagtccaac 780
cctggaccta tgaccatcct tttccttact atggttattt catacttcgg ttgcatgaag 840
gcgcactccg accctgcccg ccgtggggag ctgagcgtgt gtgacagtat tagcgagtgg 900
gtcacagcgg cagataaaaa gactgcagtg gacatgtctg gcgggacggt cacagtccta 960
gagaaagtcc cggtatccaa aggccaactg aagcagtatt tctacgagac caagtgtaat 1020
cccatgggtt acaccaagga aggctgcagg ggcatagaca aaaggcactg gaactcgcaa 1080
tgccgaacta cccaatcgta tgttcgggcc cttactatgg atagcaaaaa gagaattggc 1140
tggcgattca taaggataga cacttcctgt gtatgtacac tgaccattaa aaggggaaga 1200
tag 1203
<210> 107
<211> 2940
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Кодирующая последовательность нуклеиновой кислоты кодон-оптимизированной последовательности 2940 п.о. для мышиного TrkB-рецептор-вирусного-2A-пептидного-зрНФГМ, содержащегося в плазмиде QTA020P (и векторе QTA020V)
<400> 107
atgagcccat ggctgaagtg gcacggacca gcaatggcaa gactgtgggg cctgtgcctg 60
ctggtgctgg gcttctggag agccagcctg gcctgtccaa cctcctgcaa gtgtagctcc 120
gccaggatct ggtgcacaga gccttctcca ggcatcgtgg cctttccccg cctggagcct 180
aacagcgtgg atcccgagaa tatcaccgag atcctgatcg ccaaccagaa gcggctggag 240
atcatcaatg aggacgatgt ggaggcctac gtgggcctga gaaacctgac aatcgtggac 300
tccggcctga agttcgtggc ctataaggcc tttctgaaga actctaatct gaggcacatc 360
aacttcaccc gcaataagct gacatctctg agccggagac actttcggca cctggatctg 420
tccgacctga tcctgaccgg caatccattc acatgctctt gtgacatcat gtggctgaag 480
accctgcagg agacaaagtc tagccccgat acccaggacc tgtactgtct gaacgagtcc 540
tctaagaata tgcctctggc caacctgcag atccctaatt gtggactgcc aagcgcccgg 600
ctggccgcac ctaacctgac agtggaggag ggcaagtccg tgacactgtc ctgttctgtg 660
ggcggcgatc ccctgcctac cctgtattgg gacgtgggca acctggtgtc taagcacatg 720
aatgagacct cccacacaca gggctctctg agaatcacaa atatcagctc cgacgatagc 780
ggcaagcaga tctcttgcgt ggcagagaac ctggtgggag aggatcagga cagcgtgaat 840
ctgaccgtgc acttcgcccc caccatcaca tttctggagt ctcctaccag cgatcaccac 900
tggtgcatcc ccttcacagt gcggggaaac ccaaagcccg ccctgcagtg gttttacaac 960
ggcgccatcc tgaatgagtc caagtatatc tgtaccaaga tccacgtgac caaccacaca 1020
gagtaccacg gctgcctgca gctggataat cccacccaca tgaacaatgg cgactacaca 1080
ctgatggcca agaacgagta tggcaaggac gagaggcaga tcagcgccca cttcatgggc 1140
cgccctggag tggattatga gaccaaccct aattacccag aggtgctgta tgaggactgg 1200
accacaccta ccgatatcgg cgacaccaca aacaagtcta atgagatccc aagcacagat 1260
gtggccgacc agtctaacag ggagcacctg agcgtgtacg cagtggtggt catcgcctcc 1320
gtggtgggct tctgcctgct ggtcatgctg ctgctgctga agctggcccg ccactctaag 1380
tttggcatga agggcccagc ctccgtgatc tctaatgacg atgacagcgc cagccccctg 1440
caccacatca gcaacggctc caatacccct tctagctccg agggcggccc agatgccgtg 1500
atcatcggca tgacaaagat ccccgtgatc gagaaccctc agtacttcgg catcaccaat 1560
tcccagctga agcctgacac atttgtgcag cacatcaagc ggcacaacat cgtgctgaag 1620
agggaactgg gagagggagc cttcggcaag gtgtttctgg ccgagtgcta taacctgtgc 1680
ccagagcagg ataagatcct ggtggccgtg aagaccctga aggatgccag cgacaacgcc 1740
cggaaggact tccacagaga ggccgagctg ctgacaaatc tgcagcacga gcacatcgtg 1800
aagttttacg gcgtgtgcgt ggagggcgac cctctgatca tggtgttcga gtatatgaag 1860
cacggcgatc tgaacaagtt tctgagagca cacggaccag atgccgtgct gatggcagag 1920
ggaaatcccc ctaccgagct gacacagtct cagatgctgc acattgcaca gcagattgca 1980
gcaggaatgg tgtacctggc cagccagcac ttcgtgcaca gggatctggc aaccagaaac 2040
tgcctggtgg gagagaatct gctggtgaag atcggcgact ttggcatgtc ccgggacgtg 2100
tactctaccg actactatag agtgggcggc cacacaatgc tgcccatcag gtggatgcca 2160
cccgagagca tcatgtatcg caagttcacc acagagtctg acgtgtggag cctgggcgtg 2220
gtgctgtggg agatctttac ctacggcaag cagccttggt atcagctgtc caacaatgaa 2280
gtgatcgagt gtattacaca gggacgcgtg ctgcagaggc cacgcacatg cccccaggag 2340
gtgtacgagc tgatgctggg ctgttggcag cgggagccac acaccagaaa gaacatcaag 2400
agcatccaca cactgctgca gaatctggcc aaggcctccc ccgtgtatct ggacatcctg 2460
ggcagcggag ctactaactt cagcctgctg aagcaggctg gagacgtgga ggagaaccct 2520
ggacctatga gaatccttct tcttactatg gttatttcat acttcggttg catgaaggcg 2580
cactccgacc ctgcccgccg tggggagctg agcgtgtgtg acagtattag cgagtgggtc 2640
acagcggcag ataaaaagac tgcagtggac atgtctggcg ggacggtcac agtcctagag 2700
aaagtcccgg tatccaaagg ccaactgaag cagtatttct acgagaccaa gtgtaatccc 2760
atgggttaca ccaaggaagg ctgcaggggc atagacaaaa ggcactggaa ctcgcaatgc 2820
cgaactaccc aatcgtatgt tcgggccctt actatggata gcaaaaagag aattggctgg 2880
cgattcataa ggatagacac ttcctgtgta tgtacactga ccattaaaag gggaagatag 2940
<210> 108
<211> 2943
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Кодирующая последовательность нуклеиновой кислоты кодон-оптимизированной последовательности 2943 п.о. для человеческого TrkB-рецептор-вирусного-2A-пептидного-зрНФГМ, содержащегося в плазмиде QTA029P (и векторе QTA029V)
<400> 108
atgtcatctt ggatccgctg gcacgggcca gcgatggccc gattgtgggg cttctgctgg 60
cttgttgtag gcttctggcg cgcggcgttc gcgtgtccga cctcttgcaa atgctcagca 120
agccgaattt ggtgctcaga ccctagtcca ggaattgttg cattcccccg actggaacca 180
aactccgtcg acccggagaa tataactgag atatttattg caaatcaaaa acgccttgaa 240
atcattaacg aggatgacgt ggaggcctac gttggtttga gaaatcttac tattgtcgac 300
tccggactta aatttgtagc tcataaagcc ttcctgaaga actctaatct gcagcacatt 360
aatttcacga gaaataagct gaccagcttg tcccggaagc atttccgcca tctcgacctg 420
agcgagctca tactggtcgg aaacccattt acgtgctcct gtgacatcat gtggatcaaa 480
actctgcaag aggcgaaaag tagtccggat acccaagacc tttactgtct taatgaaagc 540
tcaaaaaata tcccgctggc caacctgcag ataccgaact gcggacttcc tagtgcgaat 600
ttggctgccc caaatcttac cgtcgaagaa ggcaaatcaa tcacgctttc ttgttctgta 660
gctggagatc cagtgcctaa tatgtattgg gacgtgggta acctcgtctc aaaacatatg 720
aacgaaacga gccacaccca gggctctttg cggataacaa acatctcctc tgatgattct 780
ggaaagcaaa tcagttgcgt agctgaaaat ctggttggcg aagatcaaga ttcagtcaat 840
ctgacagtcc atttcgcccc aacgatcacc tttctggaga gcccaactag cgatcaccac 900
tggtgtattc cgtttacggt aaaaggaaat ccaaaacctg cactccaatg gttttataat 960
ggagccatct tgaatgaaag caaatatatc tgtactaaaa tccatgtgac gaatcacacc 1020
gagtatcacg ggtgtcttca attggataat ccaacccata tgaataatgg tgattatact 1080
ttgatagcga agaacgaata cggcaaagac gaaaagcaaa tatccgcaca tttcatgggt 1140
tggcctggca tcgacgacgg tgcgaacccg aactacccag atgttattta cgaggattat 1200
gggactgcgg caaacgacat tggcgacacc acaaaccgaa gcaacgagat accaagtact 1260
gacgtcactg acaaaacggg tcgagagcat ttgtctgttt acgccgttgt tgttatcgcc 1320
tcagttgtcg gattttgcct gttggtcatg cttttcctcc tgaagctcgc gcgacattcc 1380
aagtttggca tgaaggggcc agcaagtgtt atatccaatg atgatgatag cgcttctcca 1440
ttgcaccaca taagtaacgg ctcaaacacg ccgtcatcta gtgaaggtgg accagacgcg 1500
gtcattatag ggatgactaa aattcccgta atcgaaaacc ctcagtactt cggcataacc 1560
aacagtcagc ttaaacccga tactttcgtg cagcacatca aaaggcacaa catagtcctc 1620
aagcgcgaac tcggggaggg agccttcgga aaggtctttc ttgctgagtg ctataatttg 1680
tgtcctgagc aggataaaat tcttgtggct gtaaaaactc tcaaagatgc ttccgacaac 1740
gcacggaagg attttcatcg ggaggccgaa ctgttgacga atttgcagca cgagcatata 1800
gtaaagttct acggggtatg tgttgagggg gacccgttga ttatggtctt cgagtatatg 1860
aagcacgggg acctgaacaa atttttgcgc gcccatgggc ctgatgccgt ccttatggca 1920
gaagggaacc ctccaacaga actcacccag agtcagatgt tgcacatagc gcaacagatc 1980
gcggccggca tggtttacct ggccagtcaa cacttcgtgc atagagatct tgccactcgc 2040
aactgtttgg tcggggagaa ccttctggtt aagattggtg actttggtat gtcacgagat 2100
gtgtattcca ctgactatta cagagttggg ggtcatacaa tgcttcctat tcggtggatg 2160
ccccccgaat ccatcatgta cagaaagttc acgacagaga gtgatgtttg gagtctcggc 2220
gtggtgctct gggaaatttt cacatacgga aagcagccgt ggtatcaact tagcaacaat 2280
gaggtgatag agtgtattac acagggtcgg gtgttgcagc gccctcgaac gtgcccacaa 2340
gaagtatatg aacttatgct cgggtgctgg caaagagaac cacatatgag aaaaaatatc 2400
aaggggatac atacattgct tcagaacttg gccaaggcat cacccgtcta cctcgatata 2460
ctgggcagcg gagctactaa cttcagcctg ctgaagcagg ctggagacgt ggaggagaac 2520
cctggaccta tgagaatcct tcttcttact atggttattt catacttcgg ttgcatgaag 2580
gcgcactccg accctgcccg ccgtggggag ctgagcgtgt gtgacagtat tagcgagtgg 2640
gtcacagcgg cagataaaaa gactgcagtg gacatgtctg gcgggacggt cacagtccta 2700
gagaaagtcc cggtatccaa aggccaactg aagcagtatt tctacgagac caagtgtaat 2760
cccatgggtt acaccaagga aggctgcagg ggcatagaca aaaggcactg gaactcgcaa 2820
tgccgaacta cccaatcgta tgttcgggcc cttactatgg atagcaaaaa gagaattggc 2880
tggcgattca taaggataga cacttcctgt gtatgtacac tgaccattaa aaggggaaga 2940
tag 2943
<---
Реферат
Изобретение относится к биотехнологии. Описан рекомбинантный аденоассоциированный экспрессионный вектор (rAAV), содержащий генетическую конструкцию, которая содержит промотор, функционально присоединённый к первой кодирующей последовательности, которая кодирует рецептор тирозинкиназы B (TrkB), и ко второй кодирующей последовательности, которая кодирует агонист рецептора TrkB, при этом агонистом является зрелый НФГМ или зрелый NT-4, при этом вторая кодирующая последовательность содержит нуклеотидную последовательность, кодирующую сигнальный пептид для агониста рецептора TrkB, так что при экспрессии сигнальный пептид конъюгирован с N-концом зрелого НФГМ, и причем генетическая конструкция содержит спейсерную последовательность, расположенную между первой и второй кодирующими последовательностями, причем эта спейсерная последовательность кодирует пептидный спейсер, который сконфигурирован для расщепления, чтобы таким образом продуцировать рецептор и агонист TrkB в виде отдельных молекул. Изобретение может быть использовано для лечения, предотвращения или облегчения патологии зрительного нерва или кохлеарной патологии или для стимулирования регенерации и/или выживания нервов. 4 н. и 37 з.п. ф-лы, 1 пр., 17 ил.
Комментарии