Звуковое кодирующее устройство и звуковое декодирующее устройство - RU2487427C2
Код документа: RU2487427C2
Чертежи
Описание
Настоящее изобретение относится к области звукового кодирования, в частности к кодированию на основе кодирования энтропии.
Традиционные представления об аудиокодировании включают схему кодирования энтропии для уменьшения избыточной информации в передаваемом сигнале. Как правило, кодирование энтропии использует дискретные спектральные коэффициенты для частотной области и выполняется на основе схем кодирования или дискретных выборок во временной области с использованием схем кодирования. Эти схемы кодирования энтропии обычно используют передачу комбинации кодовых слов в соответствии с индексом кодовой таблицы, который позволяет декодеру найти определенную страницу кодовой таблицы для декодирования закодированного информационного слова, соответствующего переданному кодовому слову на указанной странице. В некоторых принципах кодирования передача индекса кодовой таблицы, тем не менее, не является обязательной, например, для случаев, когда индекс кодовой таблицы может быть определен по символу, который, например, является кодировкой энтропии, как описано в Meine, Edier, "Improved Quantization and Lossless Coding for Subband Audio Coding" and Meine, "Vektorquantisierung und kontextabhängige arithmetische Codierung für MPEG-4 AAC", Dissertation, Gottfried Wilhelm Leibnitz Universitat Hannover, Hanover 2007.
Поскольку звуковое кодирование основывается на частотной или спектральной области, контекст [история появления символа, то есть, информация о символах, предшествующих текущему в сжимаемом потоке] может содержать символы, или статистические свойства, например дискретные спектральные коэффициенты, предшествующие по времени и/или частоте. В некоторых из обычно используемых принципов кодирования эти символы могут быть доступны и в кодирующем устройстве и в декодере, и созданная из этих символов кодовая таблица или контекст могут быть определены одновременно и в кодирующем устройстве и в декодере.
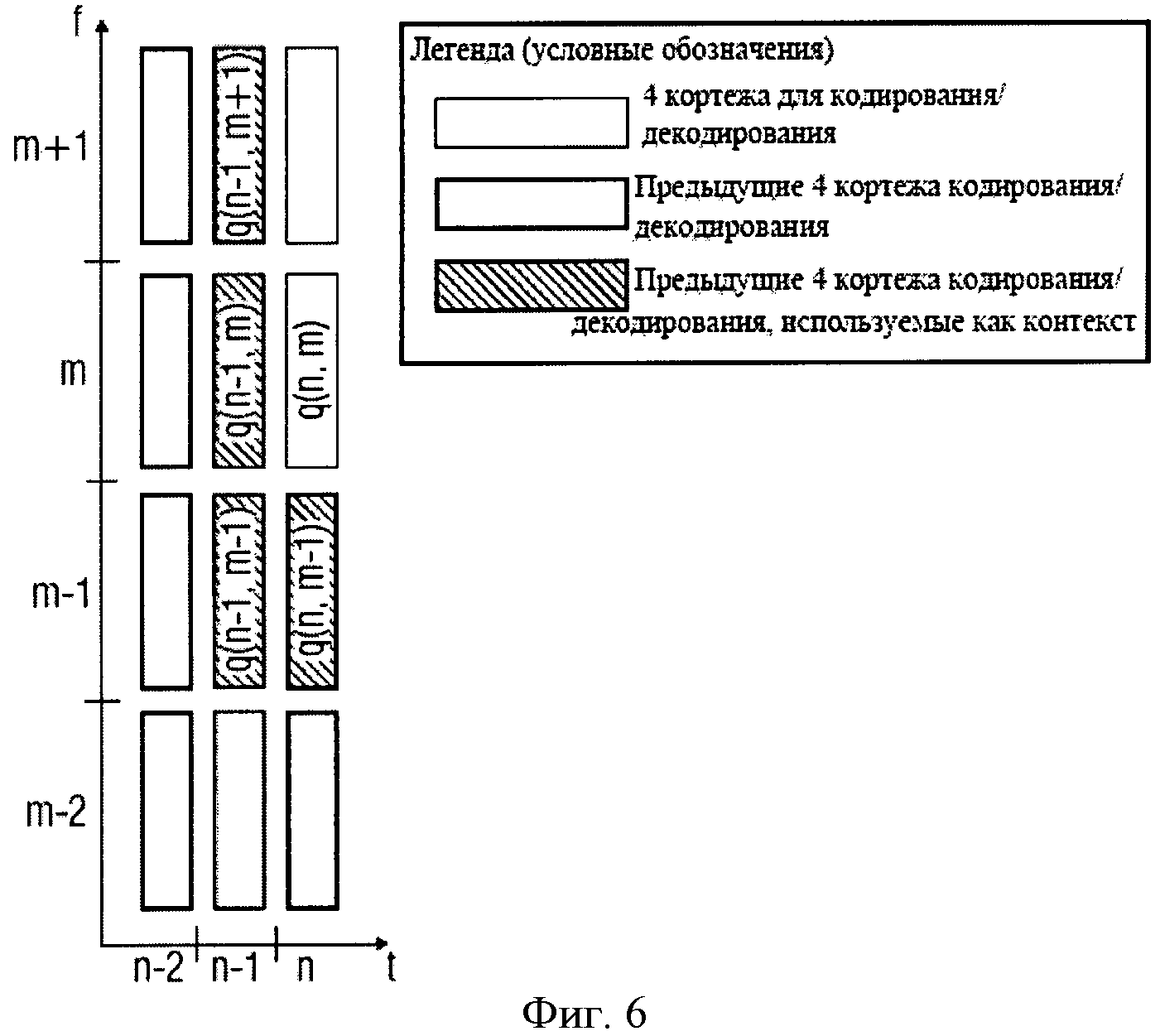
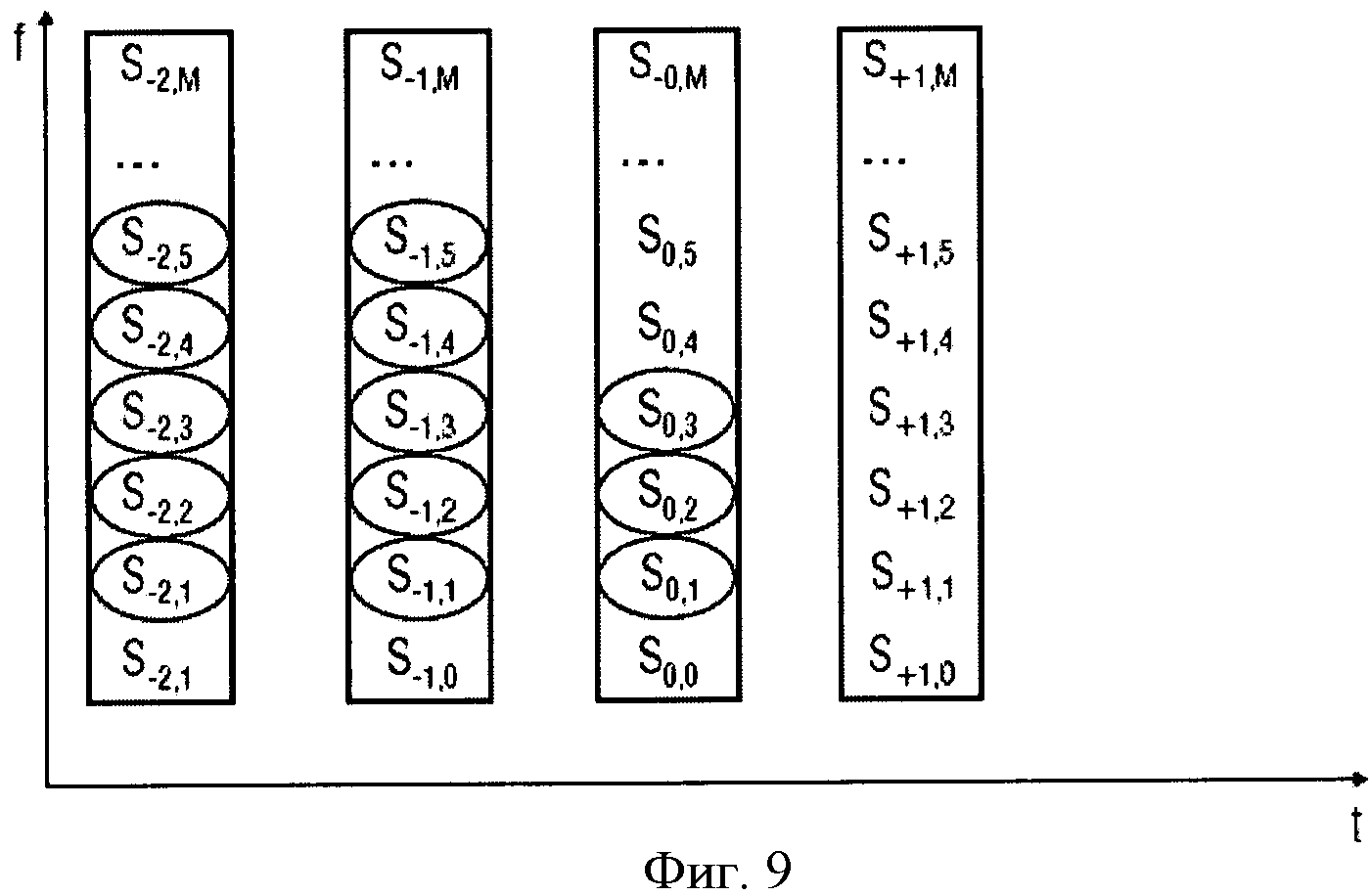
Фиг.9 иллюстрирует пример контекста и его зависимостей. Фиг.9 показывает плоскость частота-время, в которой указано много символов. Символ Sn, м. обозначает символ во времени n и частоту m. Фиг.9 показывает, что для кодирования определенного символа, используется его контекст и определяется соответствующая кодовая таблица. Например, для символа Sn0,m0 то это будут все символы с
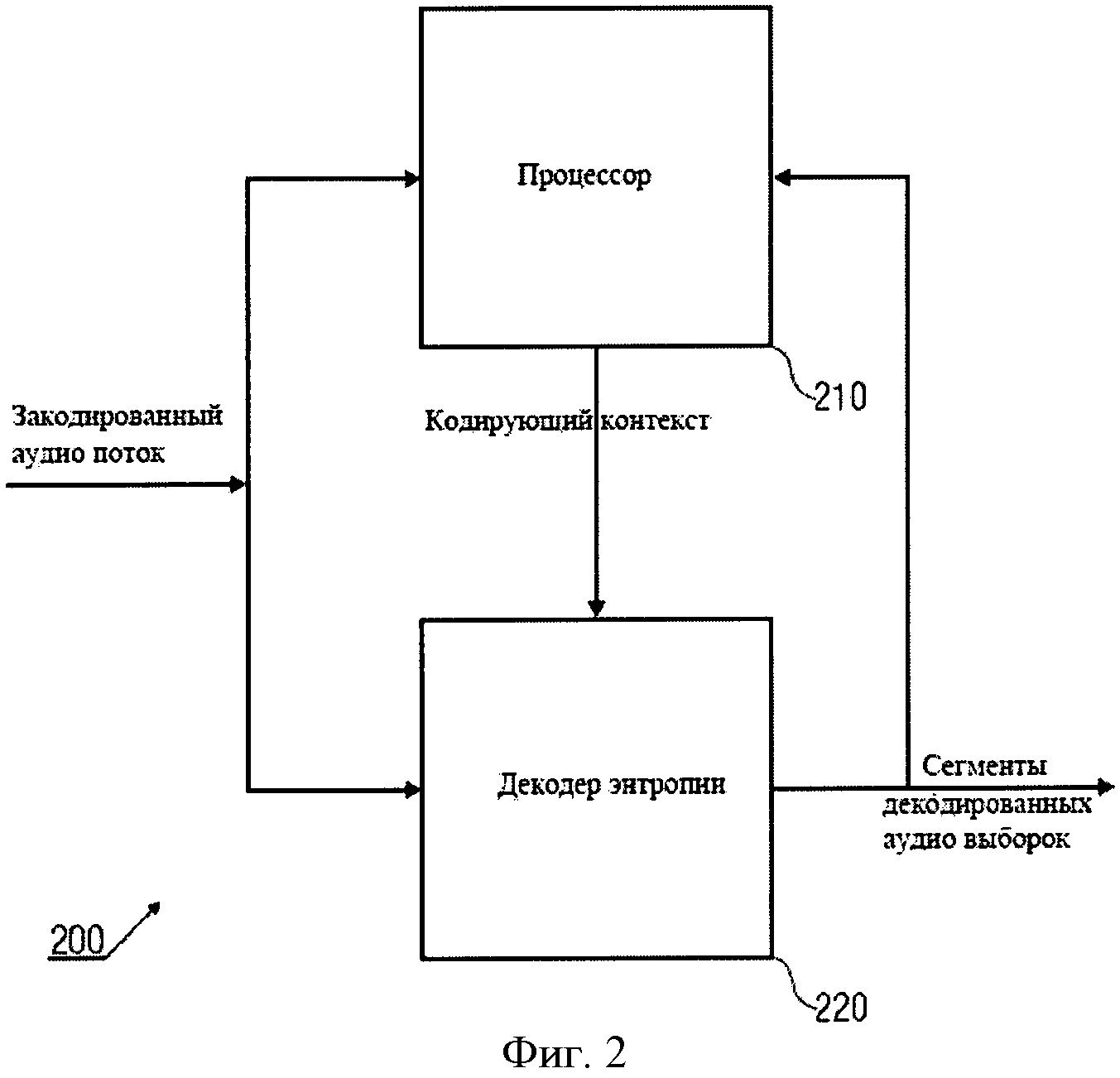
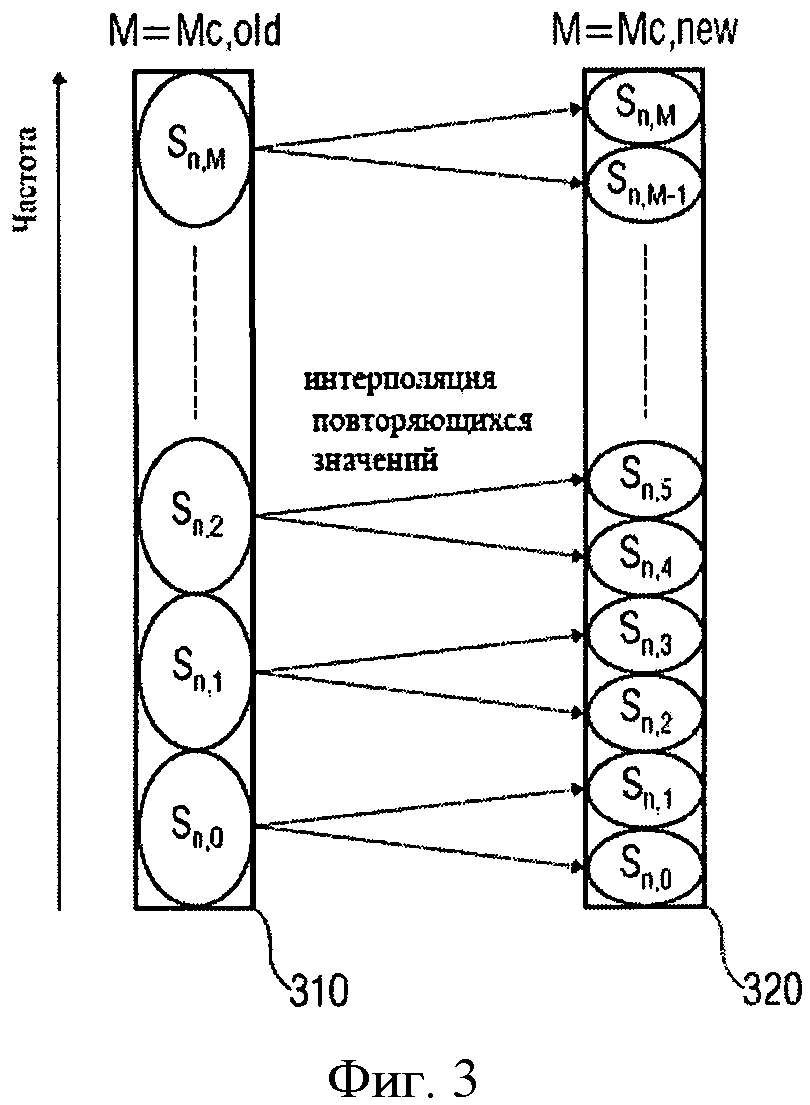
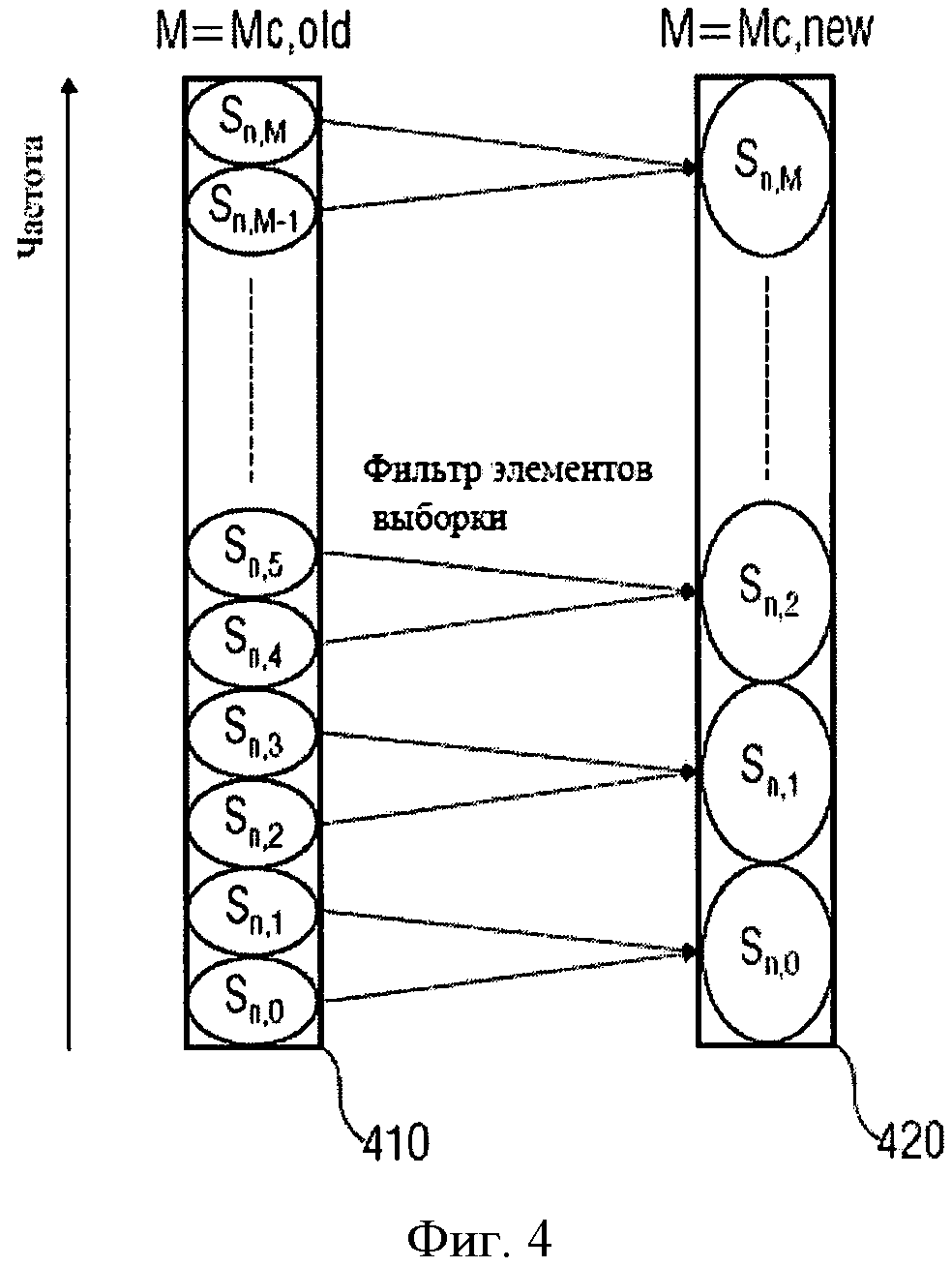
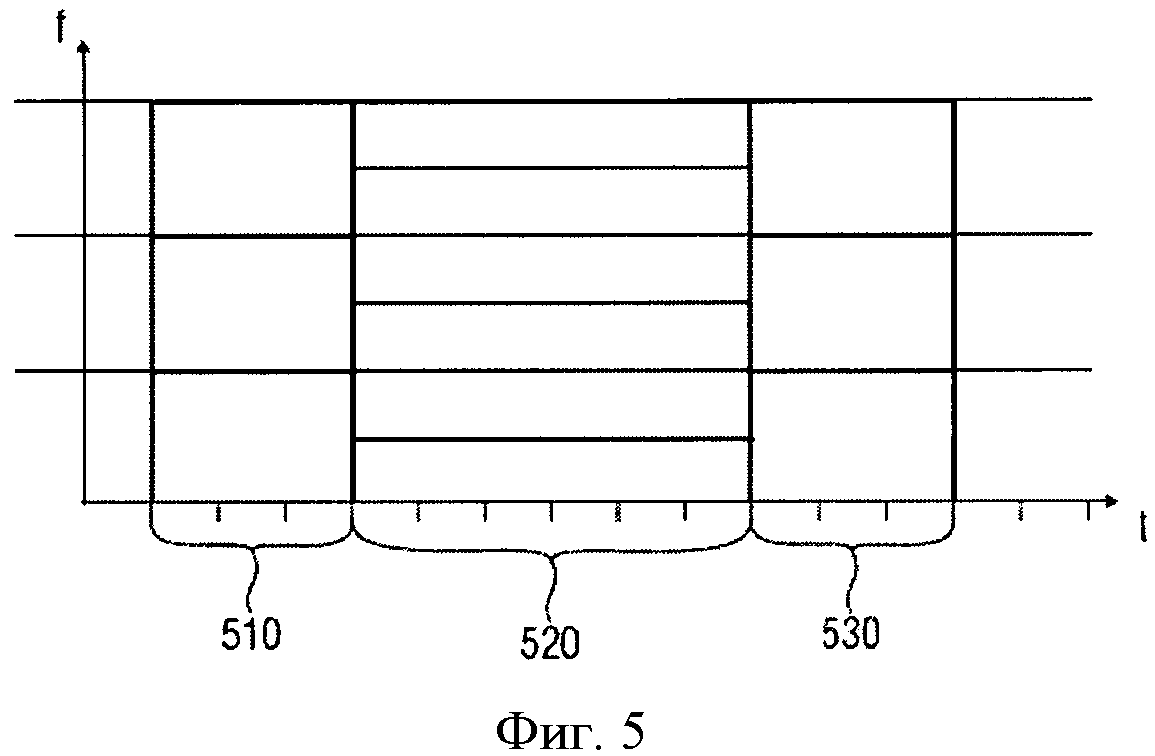
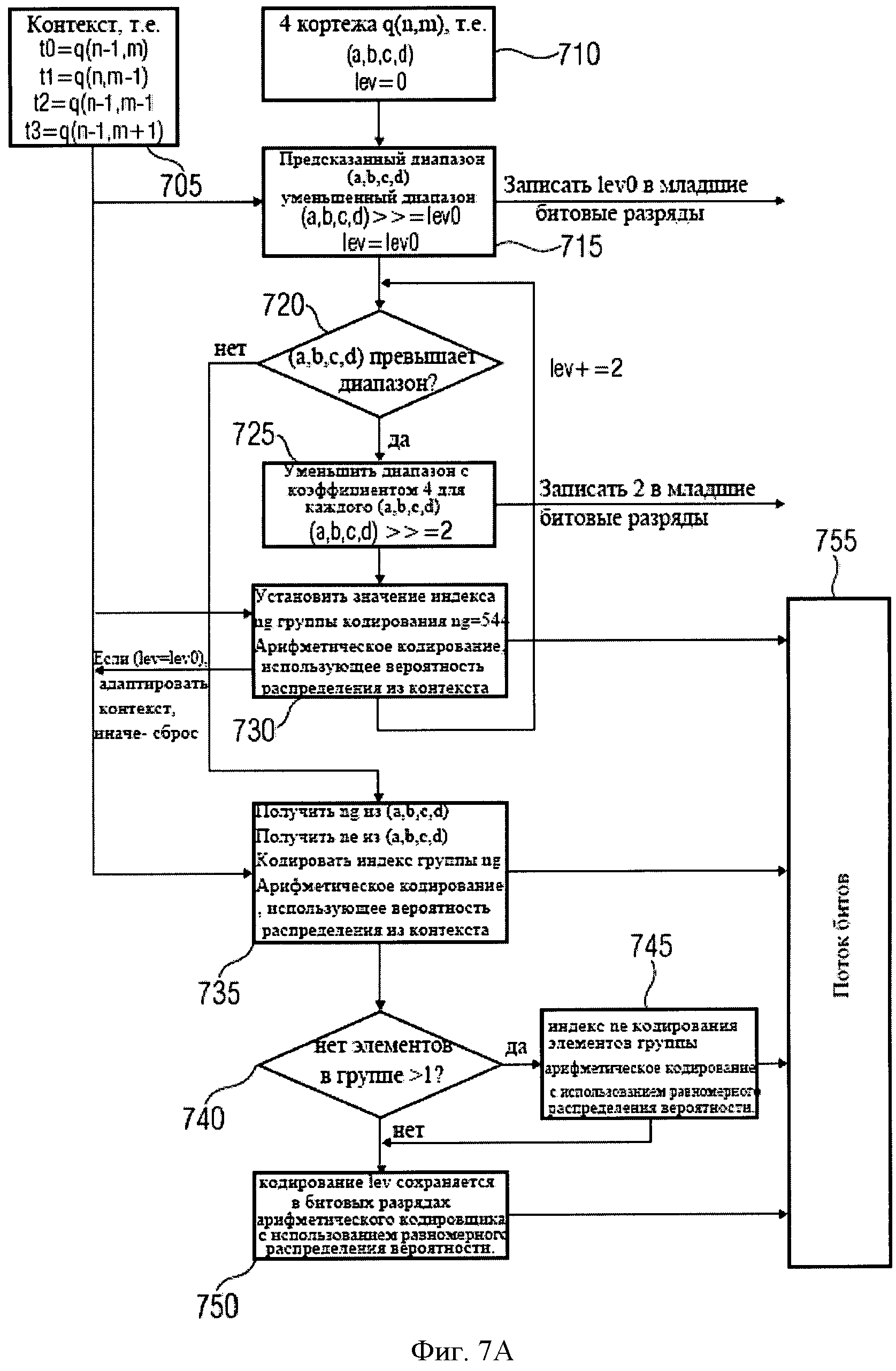
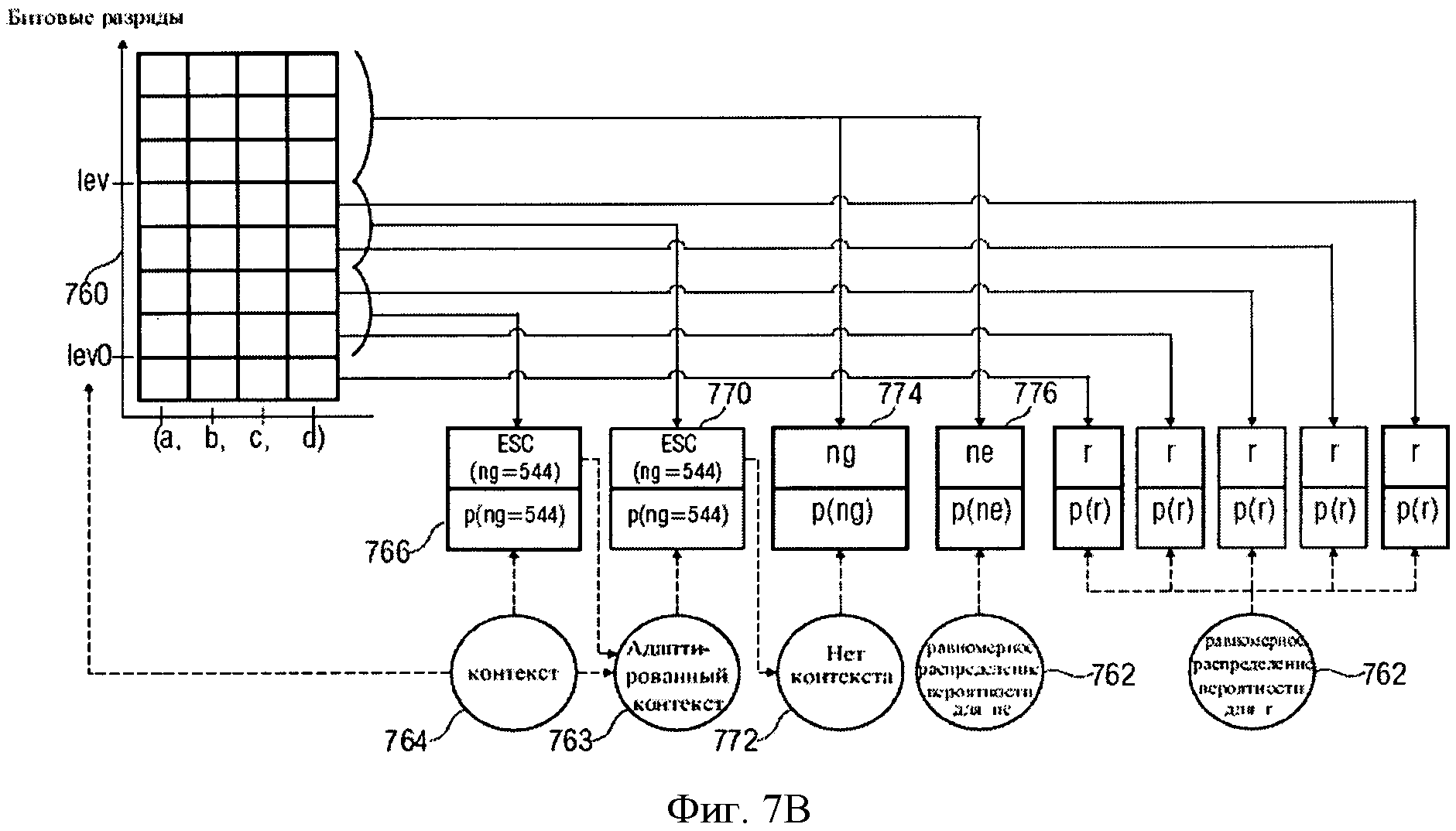
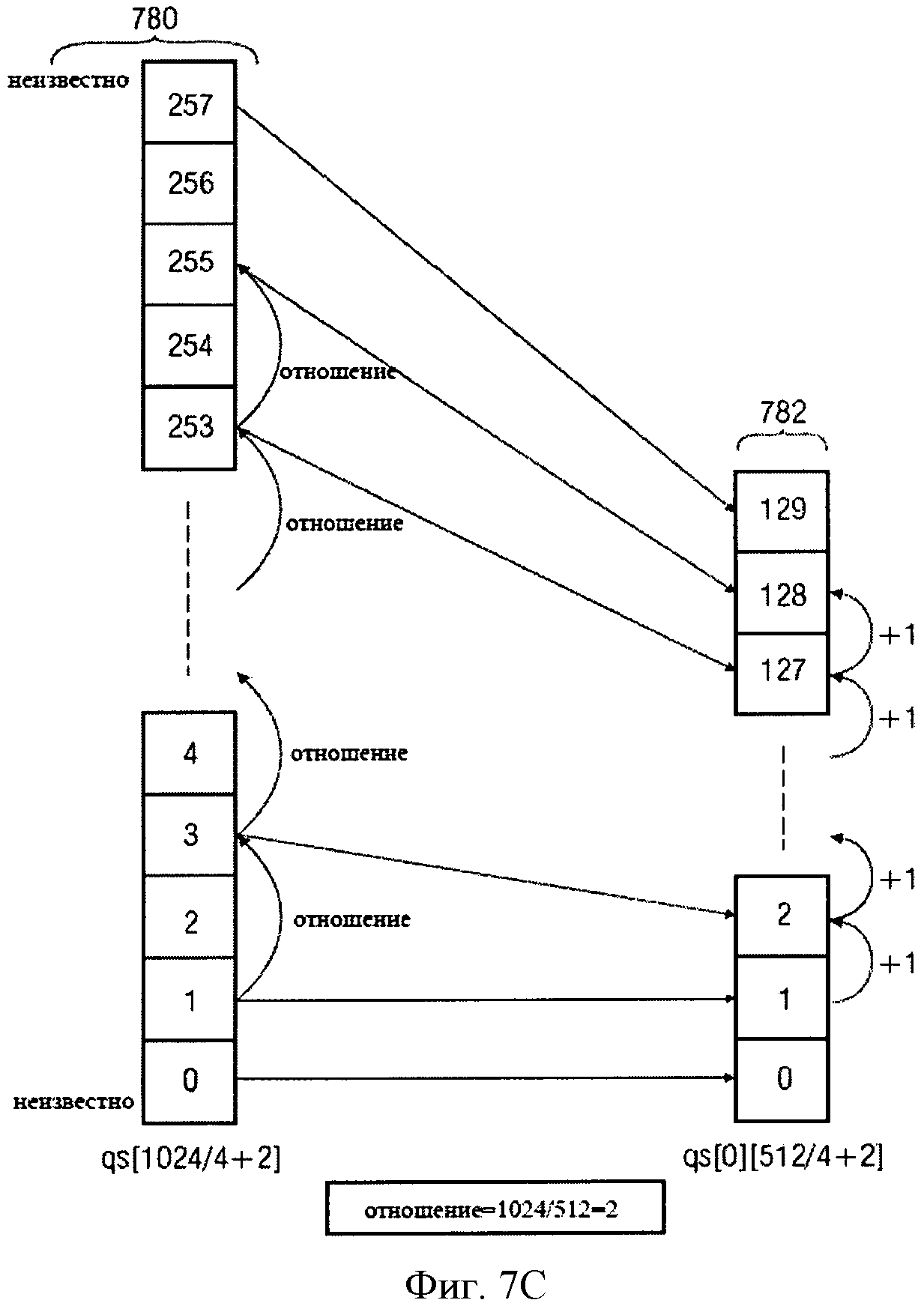
n В практических применениях контекст будет не бесконечным, а ограниченным. В примере, изображенном в Фиг.9, контекст для символа, S0,3, например, может быть S0,2, S0,l, S-1,5, S-1,4, S-1,3, S-1,2, S-1,1, S-2,5, S-2,4, S-2,3, S-2,2, S-2,1. Для звукового кодирования, использующего частоту, могут использоваться изменение времени, сигнал адаптивной группы фильтров или так называемые блоки преобразования, что, в качестве примера, описано в Edler, В., "Codierung von Audiosignalen mit überlappender Transformation und adaptiven Fensterfunktionen", Frequenz, Ausgabe 43, September 1989. Другими словами, в рамках этих принципов аудиокодирования, в течение длительного времени могут происходить изменения разрешения частоты/времени. Популярный принцип аудиокодирования - так называемый ААС (ААС - широкополосный алгоритм аудиокодирования), в котором используются блоки двух размеров, в которых закодированы, например, 128 или 1024 коэффициентов преобразования, представляющих, соответственно, частотные компоненты 256 или 2048 оконных выборок во временном интервале. Такой принцип кодирования позволяет выполнять переключение между различными разрешениями, в зависимости от определенных характеристик сигнала, например, относящихся к изменению уровня сигнала, тональности, или имеет ли сигнал сходство с музыкой или речью, и т.д. Что касается примера для случая переключения между различными разрешениями время/частота, в различных типах блоков ААС контекст не будет последовательным. Использование обычных принципов или современных реализаций может привести к потере контекста, то есть к переходу в состояние, в котором никакой контекст не доступен и обнуляется. Этот подход может работать достаточно хорошо, например, в ААС, так как он гарантирует по крайней мере два длинных блока или восемь коротких блоков в строке, если предположить, что переключение происходит очень редко. Однако обычные способы, перезагружающие контекст, вообще не оптимальны с точки зрения эффективности кодирования, так как каждый раз, когда контекст перезагружается, последующий выбор кодовой таблицы основан на значениях, которые рассматриваются в качестве запасного решения для неизвестного контекста. В общем случае, тогда выбираются неоптимальные кодовые таблицы. Недостаток в эффективности кодирования может быть незначительным в случаях, если переключение происходит очень редко. Однако для сценария с более частым переключением это приводит к существенной потере эффективности кодирования. С одной стороны, более частое переключение весьма желательно для более низких скоростей передачи данных/частоты дискретизации, так как здесь особенно желательна оптимальная адаптация длины преобразования к характеристикам сигнала. С другой стороны, эффективность кодирования значительно уменьшается при частых переключениях. Задача настоящего изобретения в предложении способа переключения между различными длинами преобразования в аудиокодировании, обеспечивающее лучшую эффективность кодирования. Это достигается использованием звукового кодирующего устройства согласно положению 1, метода аудиокодирования согласно положению 8, звукового декодера согласно положению 9 и метода аудиодекодирования согласно положению 16. Настоящее изобретение основано на открытии, что контекст, использующий такое кодирование, как, например, кодирование энтропии, которое может быть применено к различным разрешениям по времени/частоте, и метод отображения контекста, который может использоваться в случае разрешения по времени/частоте, изменяющимся в течение длительного времени, позволяет достичь повышенной эффективности кодировки. Одно из открытий настоящего изобретения состоит в том, что переключение между различными разрешениями по времени или частоте, или контекстами коэффициентов, имеющими новые разрешения, могут быть получены из коэффициентов, имеющих старые разрешения. Одно из открытий настоящего изобретения состоит в том, что, например, интерполяция, экстраполяция, использование низкочастотных или высокочастотных выборок и т.д., могут использоваться для согласования и/или вывода контекста, при котором происходит переключение разрешения по времени/частоте в звуковом кодировании. Воплощения настоящего изобретения обеспечивают метод отображения, который устанавливает соответствие между частотными или спектральными коэффициентами, сохраняющимися в контексте, на который ссылается старое разрешение, с разрешением по частоте в текущем контексте или текущем фрейме. Другими словами, информация предыдущего контекста может использоваться для определения кодовой таблицы, то есть получения информации нового контекста. Воплощения изобретения позволяют выполнять более частое переключение размера блока и способствуют лучшей адаптации характеристик сигнала без потерь эффективности кодирования. Воплощения настоящего изобретения будут детализированы с использованием сопровождающих рисунков, на которых: Фиг.1 показывает воплощение звукового кодирующего устройства; Фиг.2 показывает воплощение звукового декодера; Фиг.3 показывает воплощение для контекста с высокочастотными выборками; Фиг.4 показывает воплощение для контекста с низкочастотными выборками; Фиг.5 иллюстрирует время переключения аудио и разрешение по частоте; Фиг.6 иллюстрирует пример выполнения воплощения; Фиг.7а показывает блок-схему воплощения метода кодирования; Фиг.7b иллюстрирует общую процедуру обновления контекста воплощения; Фиг.7с иллюстрирует процедуру обновления контекста воплощения для изменений разрешения; Фиг.8 показывает блок-схему воплощения метода декодирования; и Фиг.9 показывает современную схему кодировки в координатах частота - время. Фиг.1 показывает воплощение звукового кодирующего устройства 100 для кодирования сегментов коэффициентов, имеющих различное разрешение по времени или частоте, выбранного звукового сигнала. Звуковое кодирующее устройство 100 содержит процессор 110 для получения контекста кодирования кодируемого текущего коэффициента текущего сегмента, основанного на ранее закодированном коэффициенте предыдущего сегмента, имеющим разрешение по времени или частоте, отличающееся от кодируемого в настоящий момент коэффициента. Кроме того, воплощение звукового кодирующего устройства включает также кодирующее устройство энтропии 120 для значения энтропии, кодирующего текущий коэффициент, основанный на кодирующем контексте для получения закодированного звукового потока. В воплощениях коэффициенты могут соответствовать звуковым образцам, дискретным звуковым образцам, спектральным или частотным коэффициентам, масштабным коэффициентам, коэффициентам преобразования или фильтрации и т.д. или любой комбинации из перечисленных. В других вариантах исполнения звуковое кодирующее устройство 100 может содержать средства для выделения сегментов коэффициентов из звукового потока, коэффициентов, формирующих спектральное представление звукового сигнала при спектральном разрешении, изменяющимся для различных коэффициентов. Средства для выделения сегментов могут быть адаптированы для определения сегментов, имеющих различные размеры длины окна временного интервала или различные звуковые фреймы, то есть звуковые фреймы, имеющие различные длины или различные значения коэффициентов в диапазоне частот, и, следовательно, различное спектральное или частотное разрешение. Такие средства могут быть приспособлены для определения сегментов 1024 и 128 временных, частотных или спектральных коэффициентов. Процессор 110 в воплощениях может быть приспособлен для получения кодирующего контекста, основанного на представлениях текущих и предшествующих коэффициентов или сегментов в частотной или спектральной областях. Другими словами, в воплощениях последовательные сегменты могут быть представлены в различных временных и/или частотных или спектральных областях. Процессор 110 может быть адаптирован для получения кодирующего контекста в частотном или спектральном диапазоне, например, основанного на соседних спектральных коэффициентах предыдущих сегментов и/или текущих сегментов. В воплощениях сегменты могут быть первоначально определены во временной области, например, входной поток аудиоокна. Основанные на этих сегментах во временной области или коэффициентах сегменты частотной или спектральной областей или коэффициенты могут быть определены посредством преобразования. Сегменты могут быть представлены в частотной или спектральной области в терминах энергии, амплитуды и фазы, амплитуды и знака, и т.д. в частотном или спектральном диапазоне, то есть сегменты распределяются по различным частотам или диапазонам. Таким образом, в ряде применений процессор 110 может получить кодирующие контексты в частотном или спектральном диапазоне. Процессор 110 и кодирующее устройство энтропии 120 могут быть приспособлены для работы на основе низкочастотных выборок или спектральных коэффициентов предыдущего сегмента, когда предыдущий сегмент имеет контекст, включающий лучшее спектральное или частотное разрешение, чем текущий сегмент. В воплощениях процессор 110 и кодирующее устройство энтропии 120 могут быть приспособлены для работы на основе высокочастотных выборок или спектральных коэффициентов, когда предыдущий сегмент контекста включает более грубое спектральное или частотное разрешение, чем текущий сегмент. Воплощения могут обеспечить метод для кодирования коэффициентов сегментов, соответствующих различным временным или частотным разрешениям выбранного звукового сигнала. Метод может содержать этап получения кодирующего контекста для кодируемого в настоящее время или текущего коэффициента в текущем сегменте, основанного на закодированном ранее или предыдущем коэффициенте от предыдущего сегмента, а также, возможно, на кодируемом в настоящее время или текущем коэффициенте, причем ранее закодированный или предыдущий коэффициент имеет отличающееся разрешение по времени или частоте от кодируемого в настоящее время или текущего коэффициента. Метод может включить последующий этап энтропии, на котором кодируется текущий коэффициент, основанный на закодированном контексте, для получения закодированного звукового потока. Соответственно, воплощения могут содержать звуковое декодирующее устройство 200, показанное на фиг.2. Звуковое декодирующее устройство 200 приспособлено для декодирования закодированного звукового потока и получения сегментов коэффициентов, имеющих различное разрешение по времени или частоте, выбранного звукового сигнала, звуковое декодирующее устройство 200 содержит процессор 210 для получения кодирующего контекста для декодируемого в настоящее время или текущего коэффициента, основанного на ранее декодированном или предыдущем коэффициенте, коэффициенте, имеющем отличающееся разрешение по времени или частоте от декодируемого в настоящее время коэффициента. Кроме того, звуковое декодирующее устройство 200 содержит декодирующее устройство энтропии 220 для декодирования энтропии текущего коэффициента, декодирующее устройство, использующее кодирующий контекст и закодированный звуковой поток. В воплощениях звуковое декодирующее устройство 200 может содержать декодирующее устройство энтропии 220, которое приспособлено для определения сегментов коэффициентов декодирования, основанных на различных длинах окна временного интервала или различных длинах звуковых фреймов. Декодирующее устройство энтропии 220 может использоваться для определения, например, 1024 и 128 сегментов для выборок во временном или частотном интервале или спектральных коэффициентов. Соответственно, процессор 210 может быть использован для получения кодирующего контекста, основанного на представлении коэффициентов предыдущих сегментов и/или текущего сегмента в частотной или спектральной области. В воплощениях процессор 210 может использоваться для получения кодирующего контекста вне частотного или спектрального диапазона текущего сегмента, например, основанного на соседних спектральных коэффициентах предыдущего сегмента или сегментов, выбранных произвольно из текущего сегмента. Другими словами, сегменты могут быть обработаны в частотной или спектральной области, которая может быть вынесена за пределы частотного или спектрального диапазона. Соответственно, процессор 210 может быть использован для получения определенного контекста в частотном или спектральном диапазоне. Декодирующее устройство энтропии 200 может быть использовано для декодирования энтропии текущего коэффициента, основанного на энтропии или на способе кодирования с изменением длины. Процессор 210 может быть использован для получения кодирующего контекста, основанного на уменьшении выборок по частоте или спектральным коэффициентам предыдущего сегмента в случаях, когда предыдущий сегмент включает больше коэффициентов в диапазоне частот (то есть имеет лучшее спектральное или частотное разрешение), чем текущий сегмент. В последующих воплощениях процессор 210 и кодирующее устройство энтропии 220 могут применяться для работы, основанной на высокочастотных выборках спектральных коэффициентов предыдущего сегмента, когда предыдущий сегмент имеет меньше коэффициентов в диапазоне частот (то есть имеет худшее спектральное или частотное разрешение), чем текущий сегмент. Следовательно, воплощения могут обеспечить метод декодирования закодированного звукового потока для получения сегментов коэффициентов, представляющих декодированные звуковые выборки. Метод декодирования может содержать этап получения кодирующего контекста для декодируемого в настоящее время или текущего коэффициента текущего сегмента, основанного на ранее декодированном или предыдущем коэффициенте предыдущего сегмента, т.е. коэффициенте, имеющем отличающееся временное или частотное разрешение от декодируемого в настоящее время коэффициента. Кроме того, метод может включать этап декодирования энтропии текущего коэффициента, основанный на кодирующем контексте и закодированном звуковом потоке. В любом воплощении, метод может включать этап определения сегментов закодированных звуковых коэффициентов из закодированного звукового потока, сегментов, имеющих разное количество звуковых коэффициентов. Фиг.3 показывает каким образом процессор 110; 210 может получить кодирующий контекст для коэффициентов текущего сегмента Mc,new, основанный на коэффициентах предыдущего сегмента Mc,old, причем предыдущий сегмент включает количество звуковых коэффициентов, отличающееся от числа коэффициентов текущего сегмента. В воплощении, показанном на фиг.3, количество коэффициентов сегмента М определяет частотное или спектральное разрешение сегмента. Воплощение может включать метод отображения, который отображает коэффициенты Mc,old предыдущего сегмента на коэффициенты Mc,new, имеющие такое же частотное или спектральное разрешение, как и контекст текущего сегмента. Фиг.3 показывает два набора коэффициентов в пределах двух сегментов, то есть оригинальный предыдущий сегмент 310, представляемый коэффициентами Mc,old, Sn,0, Sn,1, Sn,2, и т.д., и соответственно, отображение предыдущего сегмента 320, которое имеет более высокое разрешение, то есть разрешение Mc,new лучше, чем Mc,old, которое представлено Mc,new с коэффициентами Sn,0, Sn,1, Sn,2, Sn,3, и т.д. Вообще, два воплощения можно отличить, в зависимости от того, лучше или хуже разрешение контекста текущего сегмента, чем разрешение контекста предыдущего сегмента. Фиг.3 показывает воплощение, в котором разрешение коэффициентов Mc,old предыдущего сегмента хуже, чем разрешение коэффициентов Mc,new текущего сегмента. Фиг.3 показывает коэффициенты предыдущего сегмента 310 и символы, отражающие предыдущий сегмент 320. Из Фиг.3 можно заметить, что разрешение коэффициентов Mc,new текущего сегмента лучше, чем разрешение предыдущего сегмента 310, имеющего только коэффициенты Mc,old. В одном из вариантов исполнения предыдущий сегмент 310 имеет большее число выборок по сравнению с сегментом 320 коэффициентов Mc,new для согласования частотного или спектрального разрешения текущего сегмента. Это может быть проведено обычным увеличением числа выборок с дублированием символа и механизмами исключения каждого десятого символа, например, повторением каждого значения Mc,new, взятого до исключения каждого десятого символа, и в результате получается сегмент с увеличением числа выборок, с использованием только 1 коэффициента из каждого Mc,old. Также могут использоваться и другие виды интерполяции или экстраполяции. В воплощениях отображение может быть выполнено для всех предыдущих сегментов 310, которые необходимы для определения контекстов текущего сегмента, например, в момент времени n, другими словами, может быть учтено большое число предыдущих сегментов, то есть предыдущие сегменты в моменты времени n-1, n-2 и т.д. Вообще, воплощения могут учитывать большое число выборок по времени или предыдущих сегментов, количество выборок по времени, необходимых для определения полного контекста, может быть различным для различных вариантов исполнения или воплощений. Фиг.4 представляет другое воплощение, в котором коэффициенты предыдущего сегмента 410 имеют меньшее количество выборок по сравнению с сегментом 420, используемым для вычисления контекстов текущего сегмента, то есть в котором число коэффициентов Mc,old предыдущего сегмента 410 больше чем количество коэффициентов Mc,new текущего сегмента. Иллюстрация на фиг.4 аналогична фиг.3, и, соответственно, большое количество коэффициентов показано в каждом сегменте 410 и 420. Как показано на фиг.4, количество коэффициентов Mc,old, больше чем в Mc,new. Поэтому коэффициенты Mc,old подбираются таким образом, чтобы соответствовать частотному или спектральному разрешению коэффициентов Mc,new текущего сегмента, то есть в вариантах использования предыдущие сегменты, имеющие более высокое разрешение, могут быть подобраны таким образом, чтобы соответствовать разрешению текущего сегмента, имеющего более низкое разрешение. В воплощениях это может быть реализовано обычным уменьшением числа выборок с соответствующим коэффициентом дублирования и исключением каждого десятого символа, и в результате получается сегмент с увеличением числа выборок, с использованием только 1 коэффициента из каждого Mc,old; например, путем повторения каждого значения Mc,new, взятого до исключения каждого десятого символа из выбранного сегмента, с использованием только 1 коэффициента из каждого Mc,old. В других воплощениях могут использоваться операции фильтрации, например усреднение двух или более смежных значений. Фиг.5 иллюстрирует другое воплощение, в котором выполнено переключение между различными разрешениями. Фиг.5 показывает плоскость времени/частоты, в которой представлены три последовательных сегмента звуковых коэффициентов, а именно 510, 520 и 530. Каждый из сегментов 510, 520 и 530 соответствует единственному набору коэффициентов. В воплощении, показанном на Фиг.5, предполагается, что второй сегмент 520 в два раза длиннее первого и третьего сегментов 510 и 530. Это может быть достигнуто при использовании различных окон при делении на сегменты во временной области, например, сделанном в ААС. В воплощении, иллюстрированном на фиг.5, предполагается, что норма осуществления выборки остается постоянной, другими словами, более длинный второй сегмент 520 включает в два раза больше звуковых коэффициентов в диапазоне частот, чем первый или третий сегмент 510 или 530. Фиг.5 показывает, что в этом случае разрешение в частотной или спектральной области определяется размером сегмента во временной области. Другими словами, чем короче окно во временной области, тем ниже разрешение в частотной или спектральной области. Фиг.5 показывает, что при оценке контекстов для кодирования выборки в частотной или спектральной области, необходимо иметь более высокую степень разрешения сегмента 510, в рассматриваемом примере, при кодировании второго сегмента 520 должно быть получено двойное разрешение сегмента 510. В следующих воплощениях, особенно с использованием других видов преобразования частота-время или набора фильтров, могут быть получены другие соотношения между разрешениями во временной и частотной области. Согласно воплощению коэффициенты, закодированные при обработке первого сегмента 510, дают возможность определить контекст для второго сегмента 520, например, посредством дополнительных промежуточных выборок. Другими словами, содержание контекста, полученное из первого сегмента 510, может быть обеспечено дополнительными выборками из первого сегмента 510, например, путем интерполяции или экстраполяции для получения контекста второго сегмента 520 с более высоким разрешением. Как показано на фиг.5, при переключении от второго сегмента 520 к третьему сегменту 530 элемент контекста также должен измениться, поскольку разрешение теперь уменьшилось. Согласно воплощению коэффициенты, закодированные при обработке второго сегмента 520, могут использоваться для получения контекста для третьего сегмента, посредством уменьшения количества промежуточных выборок. Это может быть выполнено, например, путем усреднения или, проще, с использованием только каждого второго значения или других способов уменьшения выборок. Воплощения имеют преимущества в увеличении эффективности кодирования на основе использования предыдущего контекста, полученного из предыдущих сегментов, даже когда существуют различия в разрешении или длине окна. Элементы контекста могут быть адаптированы к новым разрешениям, с увеличением или уменьшением выборок, например, с помощью интерполяции или экстраполяции, фильтрации или усреднения, и т.д. Следующее, более конкретное воплощение будет представлено с точки зрения спектрального кодирования с исключением шумов. Спектральное кодирование с исключением шумов может использовать дополнительное сокращение избыточности дискретного спектра в звуковом кодировании. Спектральное кодирование с исключением шумов может быть основано на арифметическом кодировании с использованием динамической адаптации контекста. Кодирование с исключением шумов может быть основано на дискретных спектральных значениях и может использовать взаимосвязанный контекст совокупных таблиц частот, полученный, например, из четырех ранее декодированных соседних кортежей [в базах данных, кортежем называется группа взаимосвязанных элементов данных]. Фиг.6 иллюстрирует другое воплощение. Фиг.6 показывает плоскость частота-время, причем на оси времени показаны три значения времени n, n-1 и n-2. Кроме того, Фиг.6 иллюстрирует четыре частотных или спектральных диапазона, которые обозначены m-2, m-1, m и m+1. Фиг.6 показывает пределы выбранных интервалов частота-время, в которых представлены кортежи выборок, которые будут закодированы или декодированы. на Фиг.6 показаны три различных типа кортежей, в которых соединительные порты блоков, имеющие сплошную или пунктирную границу, указывают остающиеся кортежи, которые будут закодированы или декодированы, блоки белого цвета, имеющие сплошную границу, соответствуют ранее закодированным или декодированным сегментам кортежа, и блоки серого цвета со сплошной границей соответствуют ранее закодированным/декодированным кортежам, которые используются для определения контекста для текущего кортежа, который будет закодирован или декодирован. Заметим, что предыдущие и текущие кортежи, упомянутые в описанных выше воплощениях, могут соответствовать кортежу в существующем воплощении, другими словами, кортежи могут быть обработаны в соответствующих участках диапазона в частотной или спектральной области. Как иллюстрировано в Фиг.6, кортежи или сегменты в окрестности текущего кортежа (то есть во временной и частотной или спектральной области) могут использоваться для получения контекста. Затем совокупные таблицы частот могут использоваться арифметическим кодировщиком для формирования двоичного кода переменной длины. Арифметический кодировщик может выработать двоичный код для данного набора символов и их соответствующих вероятностей. Двоичный код может быть произведен отображением интервала вероятности, в котором находится набор символов, на ключевое слово. В описанных выше воплощениях арифметический кодировщик может соответствовать кодирующему устройству энтропии 120 и, соответственно, декодирующему устройству энтропии 220. В настоящем воплощении контекст получен на основе арифметического кодирования, которое может быть выполнено на основе 4 кортежей (то есть на четырех индексах спектральных коэффициентов), обозначенных q(n, m), представляющих спектральные коэффициенты после дискретизации, коэффициенты, которые граничат в частотной или спектральной области и которые являются энтропией, закодированной в один этап. Как было описано выше, кодирование может быть выполнено на основе кодирующего контекста. В дополнение к 4 закодированным кортежам (то есть к текущему сегменту) на Фиг.6 показаны четыре ранее закодированных 4 кортежа, которые должны учитываться при получении контекста. Эти четыре 4 кортежа определяют контекст и являются предыдущими в частотной и/или во временной области. Фиг.7а показывает блок-схему USAC (USAC = Универсальный Речевой и Звуковой Кодировщик) арифметического кодировщика взаимосвязанного контекста для схемы кодирования спектральных коэффициентов. Процесс кодирования зависит от текущих 4 кортежей и контекста, где контекст используется для выбора распределения вероятности арифметического кодировщика и предсказания амплитуды спектральных коэффициентов. На фиг.7а блок 705 выполняет определение контекста, основанное на t0, t1, t2 и t3, соответствующих q (n-1, m), q(n, m-1), q(n-1, m-1) и q(n-1, m+1), которые изображены на Фиг.6 блоками серого цвета со сплошными границами. Вообще, в воплощениях кодирующее устройство энтропии может быть использовано для кодирования текущего сегмента в блоках с 4 кортежами спектральных коэффициентов и предсказания диапазона амплитуд 4 кортежей, основанного на кодирующем контексте. В настоящем воплощении схема кодирования включает несколько этапов. Во-первых, буквенное слово кодируется с использованием арифметического устройства кодирования и конкретного распределения вероятности. Закодированное слово представляет четыре близкорасположенных спектральных коэффициента (а, b, с, d), причем каждый из коэффициентов а, b, с, d ограничен по диапазону: -5 В общем случае, в воплощениях изобретения кодирующее устройство энтропии 120 может быть использовано для разделения на 4 кортежа при помощи коэффициента, определяемого ранее по мере необходимости как результат разделения предсказанного или предварительно определенного диапазона, (кодирующее устройство энтропии 120 может быть использовано) для кодирования необходимого количества поддиапазонов, определения остатка деления и результата деления для случая, когда 4 кортежа не лежат в предсказанном диапазоне. Далее, если в этом воплощении изобретения набор коэффициентов (а, b, с, d), то есть какой-нибудь из коэффициентов а, b, с, d, выходит за пределы данного диапазона, в общем случае можно использовать, по мере необходимости, деление (а, b, с, d) на коэффициент (например, 2 или 4) несколько раз, для того, чтобы получающееся закодированное слово находилось в пределах данного диапазона. Деление на коэффициент 2 соответствует двоичному сдвигу в правую сторону, то есть (а, b, с, d)>>1. Это изменение вносится в полное представление, т.е. информация может быть утрачена. Младшие биты, которые могут быть потеряны при сдвиге вправо, сохраняются и позже кодируются с использованием арифметического кодировщика и однородного распределения вероятности. Процесс сдвига вправо выполняется для всех четырех спектральных коэффициентов (а, b, с, d). В общих воплощениях кодирующее устройство энтропии 120 может быть приспособлено для кодирования результата деления или 4 кортежей с использованием индекса группы ng, индекса группы ng, ссылающегося на группу из одного или нескольких кодовых слов, для которых распределение вероятности основано на кодирующем контексте, и индексе элемента ne в случае, если группа включает более чем одно кодовое слово, индекс элемента ne, ссылающийся на кодовое слово в пределах группы. Индекс элемента можно считать равномерно распределенным, а для кодирования число делений определяется по числу исключенных символов. Исключенный символ, указанный индексом группы ng, используется только для обозначения деления и для кодирования остатков деления на основе равномерного распределения с использованием правила арифметического кодирования. Кодирующее устройство энтропии 120 может быть приспособлено для кодирования последовательности символов в закодированный аудиопоток на основе символов алфавита, содержащих исключенный символ, группу символов, соответствующих набору доступных индексов группы, символ алфавита, соответствующий индексам элемента, и символ алфавита, соответствующий различным значениям остатков от деления. В воплощении Фиг.7а распределение вероятности для кодирования буквенного кодового слова, а также оценка количества шагов по уменьшению диапазона могут быть получены из контекста. Например, все кодовые слова в количестве 84=4096, полностью представлены в 544 группах, которые состоят из одного или более элементов. Кодовое слово может быть представлено в потоке битов как индекс группы ng и элемент группы ne. Оба значения могут быть закодированы арифметическим кодировщиком с использованием определенного распределения вероятности. В одном из воплощений распределение вероятности для ng может быть получено из контекста, а распределение вероятности для ne может предполагаться однородным. Комбинация ng и ne может однозначно идентифицировать кодовое слово. Остаток от деления, то есть сдвинутые [перемещенные] разрядные матрицы, также может предполагаться однородно распределенным. На Фиг.7а, на шаге 710, показаны 4 кортежа q (n, m), то есть (а, b, с, d) или текущий сегмент определены, и параметр lev инициализируется с установкой его значения в 0. На шаге 715 на основе контекста оценен диапазон (а, b, с, d). Согласно этой оценке (а, b, с, d) может быть уменьшен в соответствии со значением lev0, то есть разделен на множитель 21ev0. Младшие разряды матрицы lev0 сохранены для последующего использования на шаге 750. На шаге 720 происходит проверка, не превышает ли (а, b, с, d) данный диапазон, и, если это так, диапазон (а, b, с, d) уменьшается с параметром 4 на шаге 725. Другими словами, на шаге 725 (а, b, с, d) перемещены с параметром 2 вправо, и исключенные разряды матрицы сохраняются для последующего использования на шаге 750. Для того чтобы зафиксировать этот этап сокращения, для ng установлено значение 544 на шаге 730, то есть ng=544 служит признаком исключения кодового слова. Затем это кодовое слово записывается в поток битов на шаге 755, где для получения кодового слова на шаге 730 используется арифметический кодировщик с распределением вероятности, полученным из контекста. В случае если этот этап сокращения был использован в первый раз, то есть когда lev=lev0, контекст немного адаптирован. В случае если этап сокращения применен более одного раза, контекст не используется, и далее применяется распределение по умолчанию. Затем процесс продолжается с шага 720. Если на шаге 720 достигается согласование диапазона, то есть если (а, b, с, d) соответствует условию диапазона, (а, b, с, d) отображается на группу ng, индекс элемента группы ne, если он применяется. Это отображение однозначно, то есть (а, b, с, d) может быть получено из ng и ne. Индекс группы ng затем кодируется арифметическим кодировщиком с использованием распределения вероятности, полученного для адаптированного/отбрасываемого контекста на шаге 735. Индекс группы ng затем включается в поток битов на шаге 755. На следующем шаге 740 проверяется является ли число элементов в группе больше чем 1. В случае необходимости, то есть когда группа, индексированная с помощью ng, состоит более чем из одного элемента, индекс элемента группы ne кодируется арифметическим кодировщиком на шаге 745, в предположении однородного распределения вероятности в представленном воплощении. На следующем шаге 745, индекс группы элемента ne включается в поток битов на шаге 755. Наконец, на шаге 750, все сохраненные разряды матрицы, кодируются с использованием арифметического кодировщика в предположении однородного распределения вероятности. Затем закодированные сохраненные разряды матрицы также включаются в поток битов на шаге 755. В различных воплощениях декодер энтропии 220 может быть приспособлен для декодирования индекса группы ng путем использования закодированного звукового потока, основанного на распределении вероятности, полученном из кодирующего контекста, причем индекс группы ng представляет группу из одного или более кодовых слов. При использовании однородного распределения вероятности декодер энтропии 220 может быть приспособлен для декодирования индекса элемента ne из закодированного звукового потока, если индекс группы ng указывает группу, включающую более чем одно кодовое слово, и для получения 4 кортежей из спектральных коэффициентов текущего сегмента, основанного на индексе группы ng и индексе элемента ne, таким образом формируя спектральное представление области в кортежах спектральных коэффициентов. В других вариантах воплощений декодер энтропии 220 может быть приспособлен к декодированию последовательности символов из закодированного звукового потока, основанного на распределении вероятности, полученном из кодирующего контекста с использованием символа алфавита, включающего исключенный символ и символы группы, соответствующие ряду доступных индексов группы ng, для получения предварительных 4 кортежей из спектральных коэффициентов, основанных на доступном индексе группы ng, для которого символ группы последовательности символов соответствует и основывается на индексе элемента ne, и [декодер энтропии 220 может быть приспособлен] для умножения предварительных 4 кортежей с коэффициентом, зависящим от количества исключенных символов из последовательности символов, для получения кортежа спектральных коэффициентов. Кроме того, декодер энтропии 220 может быть приспособлен для декодирования остатка от закодированного звукового потока, основанного на однородном распределении вероятности, с использованием правила арифметического кодирования и для добавления остатка к умноженным предварительным 4 кортежам для получения 4 кортежей спектральных коэффициентов. Декодер энтропии 220 может быть адаптирован для умножения 4 кортежей на предварительно определенный коэффициент так часто, как происходит декодирование исключенного символа из закодированного звукового потока, исключенный символ, являющийся специальным индексом группы ng, используемым только для указания умножения и для декодирования остатка от закодированного звукового потока, основанного на однородном распределении вероятности, с использованием правила арифметического кодирования, затем декодер энтропии 220 может быть использован для добавления остатка к умноженным 4 кортежам и получения текущего сегмента. В следующем воплощении контекста USAC будет описана схема декодирования арифметического кодировщика. В соответствии с вышеупомянутым воплощением схемы кодирования, рассматриваются 4 кортежа, соответствующие дискретным спектральным коэффициентам, которые закодированы с исключением шумов. Кроме того, предполагается, что 4 кортежа передаются начиная с самой низкой частоты или спектрального коэффициента и заканчивая самой высокой частотой или спектральным коэффициентом. Коэффициенты могут, например, соответствовать коэффициентам ААС, которые сохраняются в массиве, и порядок передачи закодированных кодовых слов с исключением шумов предполагается таким, что они затем декодируются в соответствии с порядком, полученным и сохраненным в массиве, bin является наиболее быстро увеличивающимся индексом, a g - наиболее медленно увеличивающимся индексом. В пределах ключевого слова порядок декодирования - а, b, с, d. Фиг.7b иллюстрирует общую процедуру обновления контекста в данном воплощении. Подробности, относящиеся к адаптации контекста в соответствии с механизмом предсказания глубины битов, будут рассмотрены в этом воплощении. Фиг.7b показывает плоскость 760, отражающую возможный диапазон 4 кортежей (а, b, с, d) в терминах разрядов матрицы. Глубина битов, то есть число разрядов матриц, необходимых для представления 4 кортежей, может быть предсказана контекстом текущих 4 кортежей путем вычисления переменной, названной lev0, которая также показана на фиг.7b. Затем 4 кортежа делятся на 2lev0, то есть lev=lev0 разряды матрицы исключаются и сохраняются для последующего использования согласно вышеописанному шагу 715. Если 4 кортежа находятся в диапазоне -5<а,b,с,d<4, предсказанная битовая глубина lev0 была правильно предсказана или завышена. Затем 4 кортежа могут быть закодированы индексом группы ng, индексом элемента ne и lev остающимися разрядами матрицы в соответствии с описанным выше. Кодирование текущих 4 кортежей на этом заканчивается. Кодирование индекса элемента ne обозначено на Фиг.7b однородным распределением вероятности 762, которое далее будет всегда использоваться для кодирования индексов элемента, где на Фиг.7b параметр r представляет остаток от 4 кортежей после деления, а р(r) представляет соответствующую однородную функцию плотности вероятности. Если 4 кортежа не находятся в диапазоне -5<а,b,с,d<4, предсказание, основанное на кодирующем контексте 764, слишком мало, исключенный символ (ng=544) закодируется значением 766, 4 кортежа делятся на 4 и lev увеличивается на 2 согласно шагу 730 на Фиг.7а. Контекст адаптируется следующим образом. Если lev=lev0+2, контекст немного адаптирован в соответствии с 768 на Фиг.7b. Флаг может быть установлен в представлении контекста, t, и тогда будет использоваться новая модель распределения вероятности для кодирования последующих символов ng. Если lev>lev0+2, кодируется другой исключенный символ согласно шагу 770 на Фиг.7b, контекст полностью перезагружается, сравнивается с 772 и, соответственно, отбрасывается как в шаге 730 на Фиг.7а. Далее не используется никакая адаптация контекста, потому что это будет неважно для текущего кодирования 4 кортежей. По умолчанию выбирается та модель вероятности, когда никакой контекст недоступен, и затем она используется для следующих символов ng, которые обозначены шагами 774 и 776 на Фиг.7b. Процесс затем повторяется для других кортежей. Чтобы подвести итог, адаптация контекста - механизм для уменьшения значения контекста в адаптивном контекстном кодировании. Адаптация контекста может быть вызвана, когда предсказанный lev0 и фактический lev рассогласованы. Это легко обнаруживается количеством закодированных исключенных символов (ng=544), сравнением с 766 и 770 на Фиг.7b, и поэтому может быть успешно выполнено в декодере подобным способом. Адаптация контекста может быть сделана по срабатыванию флага в представлении состояния контекста t. Значение t вычисляется функцией get_state(), как и lev0, при использовании контекста, полученного из предыдущей и/или текущего фрейма или сегмента текущих 4 кортежей, которые сохраняются в таблице q[][]. Состояние контекста может, например, быть представлено 24 битами. Существует 1905800 состояний, возможных в этом воплощении. Эти состояния могут быть представлены только 21 битом. 23-й и 24-й биты t сохраняются для адаптирования состояния контекста. В соответствии со значениями 23-го и 24-х битов, get_pk() создаст различные модели распределения вероятности. В одном воплощении 23-й бит t может быть установлен в единицу, когда 4 кортежа делятся на 4, будучи ранее разделенными на lev0, то есть lev=lev0+2. Впоследствии отображение между состоянием контекста t и моделью распределения вероятности pki, будет отличаться для lev=lev0+2 по сравнению с lev=lev0. Отображение между контекстом t и моделью pki предварительно определяется во время фазы обучения путем выполнения оптимизации по полной статистике обучающей последовательности. Когда lev>lev0+2, контекст и t могут быть установлены в ноль. Затем на выходе функции Get_pk() используется модель распределения вероятности по умолчанию pki, которая соответствует t=0. Далее будут описаны детали отображения контекста в одном из воплощений. Отображение контекста - первая операция, сделанная в адаптивном контекстном кодировании после возможного сброса контекста в настоящем воплощении. Это сделано двумя этапами. Во-первых, перед кодированием, таблица контекста qs [] имеет размерность previous_lg/4, сохраненную в предыдущем фрейме, отображается в таблице контекста q [0] [] с размерностью lg/4, соответствующей размерности текущего фрейма. Отображение сделано функцией arith_map_context, которая представляется следующим псевдокодом:
Как можно заметить из псевдокода, отображение не может быть точно таким же для всех кодирующих стратегий. В настоящем воплощении отображения для коэффициента различаются, когда используется ААС (Расширенное Аудио Кодирование) (core_mode==0), и когда используется ТСХ (Кодирование, Основанное на Преобразовании) (core_mode==1). Одно из отличий происходит из того, как обработаны границы таблиц. В ААС отображение может начаться с индекса 0 (первое значение в таблице), в то время как для ТСХ оно может начаться с индекса 1 (второе значение в таблице)), полагая, что первое значение всегда устанавливается в "неопределенное" состояние (особое состояние используется для сброса контекста). Отношение previous_lg к lg определяет порядок высокочастотных выборок (ratio<1) или низкочастотных выборок (ratio>1), который будет выполнен в настоящем воплощении. Фиг.7с иллюстрирует случай ТСХ, когда преобразование выполняется из сохраненной таблицы контекста размера 1024/4, происходит сравнение левой стороны 780 рисунка Фиг.7с с размером 512/4 с правой стороной 782 рисунка Фиг.7с. Можно заметить, что, в то время как для текущей таблицы контекста 782 используются пошаговые приращения 1, для сохраненной таблицы контекста 780 используются пошаговые приращения описанного выше отношения. Фиг.7с иллюстрирует процедуру обновления контекста воплощения для изменений решения. Как только отображение сделано, выполняется адаптивное кодирование контекста. В конце кодирования текущие элементы фрейма сохраняются в таблице qs [] для следующего фрейма. Это может быть сделано с помощью процедуры arith_update_context (), которая представляется следующим псевдокодом:



В существующем воплощении сохранения проводится дифференцирование согласно основному кодировщику (ААС или ТСХ). В ТСХ контекст всегда сохраняется в таблице qs[] размерностью 1024/4. Это дополнительное отображение может быть сделано по замкнутому алгоритму AMR-WB + (Адаптивный Многоскоростной Широкополосный Кодировщик), В замкнутом алгоритме несколько процедур копирования состояний кодировщика необходимы для проверки каждой возможной комбинации TCXs и ACELP (Кодирование Линейного Предсказания с Алгебраическим Возбуждением). Копирование состояния легче осуществить, когда все виды ТСХ имеют один и тот же размер таблицы qs []. Затем используется отображение для систематического преобразования из размерности lg/4 на 1024/4. С другой стороны, ААС сохраняет только контекст и не выполняет отображение во время этого этапа.
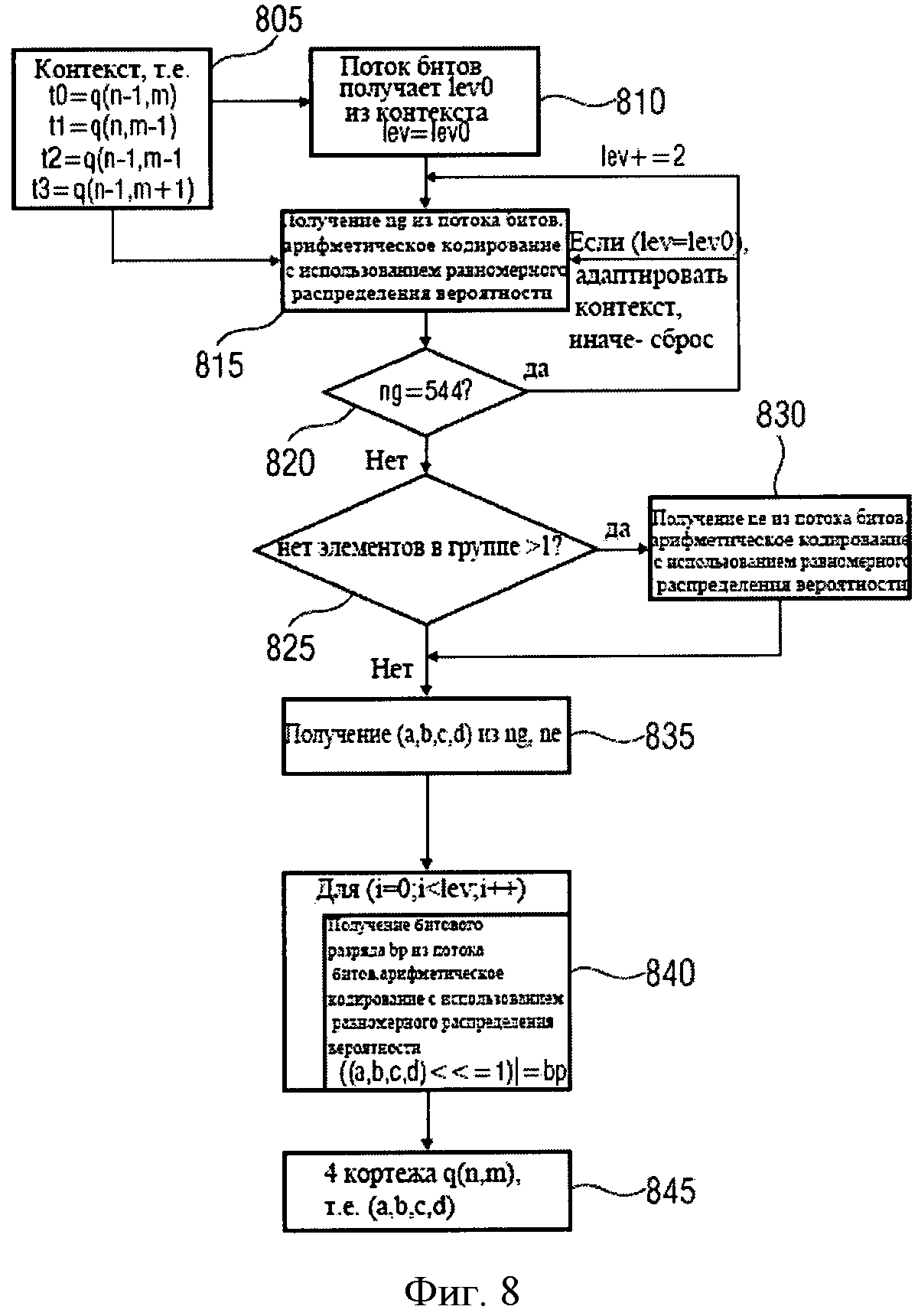
Фиг.8 иллюстрирует блок-схему воплощения схемы декодирования. На шаге 805, соответствующем шагу 705, контекст получен на основе t0, t1, t2 и t3. На шаге 810, первый уровень сокращения lev0 оценивается по контексту, и переменная lev устанавливается равной lev0. На следующем шаге 815, группа ng считывается из потока битов, а распределение вероятности для декодирования ng получено из контекста. Затем на шаге 815 группа ng может быть декодирована из потока битов.
На шаге 820 определяется, равняется ли значение ng 544, которое соответствует исключению. Если это так, то переменная lev может быть увеличена на 2 прежде, чем происходит возврат на шаг 815. В случае первого использования этой ветви, то есть, если lev=lev0, распределение вероятности, подходящее для контекста, соответственно может быть использовано либо отменено, если ветвь используется не впервые, в соответствии с описанным выше механизмом адаптации контекста, сравни с Фиг.7b и 7с. В случае если индекс группы ng не равен 544 на шаге 820, на следующем шаге 825 определяется, больше ли число элементов в группе чем 1, и если это так, на шаге 830, элемент группы ne прочитан и декодирован в потоке битов в предположении однородного распределения вероятности. Индекс элемента ne получен из потока битов с использованием арифметического кодирования и однородного распределения вероятности.
В шаге 835 буквенное кодовое слово (а, b, с, d) может быть получено из ng и ne процессом поиска в таблицах, например, при помощи обращения к dgroups[ng] и acod_ne[ne].
На шаге 840 для всех lev отсутствуют разрядные матрицы, массивы считываются из потока битов с использованием арифметического кодирования в предположении однородного распределения вероятности. Затем разрядные матрицы могут быть применены к (а, b, с, d) со сдвигом (а, b, с, d) влево и добавлением процедуры bitplane bp: ((а, b, с, d)<<=1)|=bp. Этот процесс может быть многократным повторением lev.
Наконец, на шаге 845 формируются 4 кортежа q (n, m), то есть создается (а, b, с, d). В следующих псевдокодах детали исполнения обеспечиваются согласно воплощению. Будут использоваться следующие определения. (а, b, с, d) 4 кортежа для декодирования
ng индекс группы 2 битных разрядных матриц старших битов с 4 кортежами, где 0<=ng<=544. Последнее значение 544 соответствует исключенному символу, ARITH_ESCAPE.
ne индекс элемента в пределах группы. Значение ne находится между 0 и главным элементом каждой группы mm. Максимальное число элементов в пределах группы 73. lev - уровень остающихся разрядных матриц. Он [уровень] соответствует разности числа разрядных матриц младших битов и числа 2 битных разрядных матриц старших битов. egroups[b] [с] [d] таблица индекса группы. Она разрешает отображать разрядные матрицы старших битов с 4 кортежами (а, b, с, d) в эти 544 группы.
mm главный элемент группы
og Смещение группы
dgroups[] Отображает индекс группы ng на главный элемент каждой группы mm (первые 8 битов) и смещение группы og в dgvectors[] (последние 8 битов).
dgvectors[] Отображает смещение группы og и индекса элемента ne на разрядные матрицы старших битов с 4 кортежами (а, b, с, d).
arith_cf_ng_hash[] Добавочная таблица, отображающая состояние контекста на совокупный индекс таблицы частот pki.
arith_cf_ng[pki] [545] Модели совокупных частот для символа индекса группы ng.
arith_cf_ne[] Совокупные частоты для символа индекса элемента ne.
r Разрядная матрица разности числа разрядных матриц младших битов и числа 2 битных разрядных матриц старших битов.
arith_cf_r[] Совокупные частоты для символа разрядных матриц младших битов r
Далее процесс декодирования считается первым. Четыре кортежа дискретных спектральных коэффициентов кодируются с исключением шума и передаются, начиная с самой низкой частоты или спектрального коэффициента и заканчивая самой высокой частотой или спектральным коэффициентом. Коэффициенты от ААС сохраняются во множестве x_ac_quant[r] [win] [sfb] [bin], и порядок передачи закодированных кодовых слов с исключением шума таков, что, когда они декодируются в порядке получения и сохраняются в массиве, причем bin является наиболее быстро увеличивающимся индексом, a g - наиболее медленно увеличивающимся индексом. В пределах кодового слова порядок декодирования - а, b, с, d. Коэффициент от ТСХ сохраняется непосредственно в массиве x_tcx_invquant [win] [bin], и порядок передачи закодированных кодовых слов с исключением шума таков, что, когда они декодируются в порядке получения и сохраняются в массиве, bin - наиболее быстро увеличивающий индекс, a win -наиболее медленно увеличивающий индекс. В пределах кодового слова порядок расшифровки - а, b, с, d. Прежде всего, флаг arith_reset_flag определяет, должен ли контекст быть перезагружен. Если флаг имеет значение TRUE, вызывается следующая функция:


Если arith_reset_flag имеет значение FALSE, отображение проводится между прошлым контекстом и текущим контекстом:

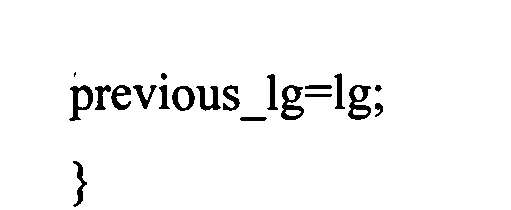
4 кортежа на выходе декодера с исключением шума представляют дискретные спектральные коэффициенты. Первоначальное состояние контекста вычисляется на основе четырех ранее декодированных групп, включающих 4 декодируемых кортежа. Состояние контекста задается функцией arith_get_context():


Как только состояние известно, группа, к которой принадлежит 2-битная разрядная матрица старших битов с 4 кортежами, декодируется функцией arith_decode(), использующей подходящую совокупную таблицу частот, соответствующую состоянию контекста. Соответствие выполнено функцией arith_get_pk():

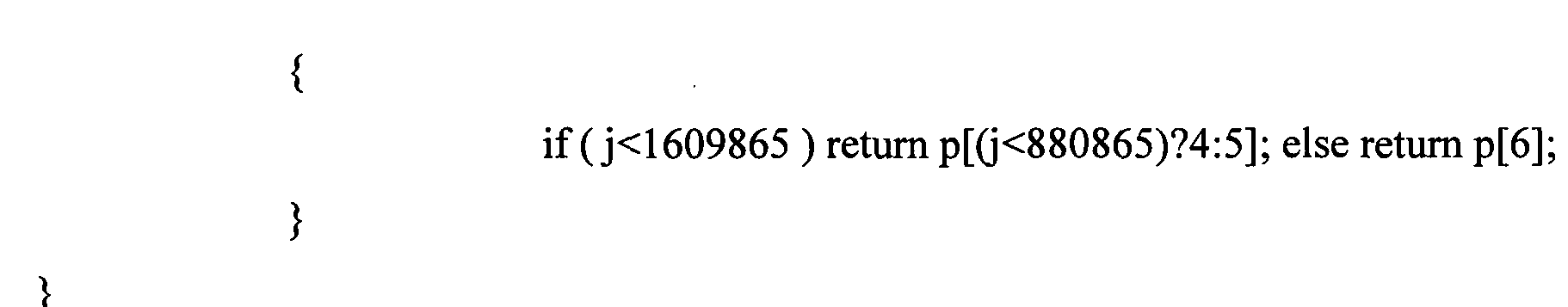
Затем вызывается функция arith_decode() с совокупной таблицей частот, соответствующей индексу возврата arith_get_pk(). Арифметический кодировщик генерирует тег [или дескриптор, элемент языка разметки гипертекста] целого типа с вычислением. Следующий псевдокод на языке С описывает используемый алгоритм.



Если декодированный индекс группы ng является исключенным символом, ARITH_ESCAPE, декодируется дополнительный индекс группы ng и переменная lev увеличивается на два. Если декодированный индекс группы не является исключенным символом, ARITH_ESCAPE, количество элементов, mm, в пределах группы и группа смещения, og, выводятся в таблицу dgroups[]:
mm=dgroups [nq]&255
og=dgroups[nq]>>8
Затем декодируется индекс элемента ne с помощью вызова arith_decode() с совокупной таблицей частот (arith_cf_ne+((mm*(mm-l))>>l)[]. Как только индекс элемента декодирован, 2 битная разрядная матрица старших битов с 4 кортежами может быть получена в таблице dgvector[]:
a=dgvectors[4*(og+ne)]
b=dgvectors[4*(og+ne)+1]
c=dgvectors[4*(og+ne)+2]
d=dgvectors[4*(og+ne)+3]
Остающиеся разрядные матрицы декодированы от самого старшего до самого младшего разряда с помощью вызова lev раз функции arith_decode() с совокупной таблицей частот arith_cf_r []. Декодированная разрядная матрица r позволяет улучшить декодирование 4 кортежей следующим путем:
a=(а<<1)|(r&1)
b=(b<<1)|((r>>1)&1)
c=(с<<1)|((r>>2)&1)
d=(d<
Как только 4 кортежа (а, b, с, d) полностью декодированы, таблицы контекста q и qs обновляются с помощью вызова функции arith_update_context().

В зависимости от определенных требований выполнения методов изобретения, методы изобретения могут быть реализованы аппаратными средствами либо программным обеспечением. Выполнение может быть осуществлено с использованием цифрового носителя данных, в частности DVD-диск или CD-диск, путем сохранения на них управляющего сигнала, считываемого электронным способом, [управляющего сигнала] который взаимодействует с программируемым компьютером, на котором реализованы методы изобретения. В целом, настоящее изобретение является результатом компьютерной программы с кодом программы для машиночитаемого носителя, кодом программы, являющимся средством для выполнения методов изобретения, когда компьютерная программа запускается на компьютере. Другими словами, методы изобретения реализованы в компьютерной программе, имеющей программный код для выполнения по крайней мере одного из методов изобретения, когда компьютерная программа запускается на компьютере.
Реферат
Изобретение относится к области звукового кодирования, в частности к кодированию на основе энтропии. Звуковое кодирующее устройство (100) для кодирования сегментов коэффициентов, сегментов коэффициентов, имеющих различные временные или частотные разрешения выбранного звукового сигнала, включает процессор (ПО), для получения кодирующего контекста для текущего закодированного коэффициента текущего сегмента на основе ранее закодированного коэффициента предыдущего сегмента, ранее закодированного коэффициента, имеющего отличающееся временное или частотное разрешение от текущего закодированного коэффициента. Также звуковое кодирующее устройство (100) содержит кодирующее устройство энтропии (120) для энтропии, кодирующей текущий коэффициент на основе кодирующего контекста, для получения закодированного звукового потока. Технический результат - улучшение эффективности кодирования. 9 н. и 9 з.п ф-лы, 11 ил.
Формула
Документы, цитированные в отчёте о поиске
Способ и устройство кодирования аудиосигнала с использованием извлечения гармоник
Комментарии