Способ и устройство кодирования аудиосигнала с использованием извлечения гармоник - RU2289858C2
Код документа: RU2289858C2
Чертежи


Описание
Область техники
Настоящее изобретение относится к способу сжатия аудиосигнала, и более конкретно к способу и устройству для эффективного сжатия аудиосигнала в звуковой сигнал уровня 3 стандарта MPEG-1 с низкой скоростью передачи информации в битах.
Предшествующий уровень техники
Стандарт MPEG-1 (группа экспертов по движущимся изображениям-1) устанавливает требование относительно сжатия цифрового видеосигнала и сжатия цифрового аудиосигнала и поддерживается Международной организацией по стандартизации (ISO). Стандарт MPEG-1 аудиосигнала используется для сжатия 16-рзрядного аудиосигнала, дискретизируемого частотой дискретизации 44,1 кГц и записываемого на 60-минутном или 72-мнутном компакт-диске (CD), и классифицируется по 3 уровням в соответствии со способом сжатия и сложностью кодека (кодера-декодера).
Уровень III является наиболее сложным, использует значительно больше фильтров, чем уровень II, и применяет кодирование Хаффмана. При кодировании со скоростью 112 кбит/с может прослушиваться звучание превосходного качества. При кодировании со скоростью 128 кбит/с звучание весьма близко к исходному звучанию. При кодировании со скоростью 160 кбит/с или 192 кбит/с качество звучания таково, что человеческое ухо не может отличить его от исходного звука. Обычно аудиосигнал уровня 3 стандарта MPEG-1 обозначают как аудиосигнал MP3.
Аудиосигнал MP3 формируется посредством дискретного косинусного преобразования (ДКП) распределения битов на основе психоакустической модели 2, квантования и т.п. Более конкретно, хотя количество битов, используемых для сжатия аудиоданных, поддерживается минимальным, модифицированное ДКП (МДКП) выполняется с использованием результата психоакустической модели 2.
В методах сжатия аудиосигнала ухо человека является наиболее важным. Человеческое ухо не может слышать, если интенсивность звука находится на определенном уровне или ниже. Если кто-то громко говорит в офисном помещении, легко можно распознать, кто говорит. Однако, если в этот момент пролетает самолет, разговор услышать невозможно. Даже после того как самолет пролетел, разговор все еще невозможно расслышать из-за задерживающегося звука. Соответственно, в психоакустической модели 2 выбираются данные, имеющие громкость, равную или превышающую пороговый уровень маскирования, среди данных, имеющих громкость, равную или превышающую минимальный предел слышимости, соответствующий спокойной обстановке. Выборка выполняется в каждом поддиапазоне.
Однако, когда аудиосигнал сжимается на низкой скорости передачи информации в битах, которая не превышает 64 кбит/с, психоакустическая модель 2 не подходит, потому что количество битов, используемых для квантования сигнала, типа сигнала опережающего эха, ограничено. Следовательно, чтобы преодолеть эту проблему, вызванную медленным аудиосигналом MP3 низкой скорости, настоящее изобретение обеспечивает способ эффективной обработки аудиосигнала на низкой скорости посредством удаления гармонической составляющей из исходного сигнала с использованием быстрого преобразования Фурье (БПФ), принятого в психоакустической модели 2, и сжатия только изменяющейся составляющей с использованием МДКП.
В процессе БПФ, принятом в обычной психоакустической модели, выполняется только анализ сигнала, а результат БПФ не используется. Поскольку для сжатия сигнала результат БПФ не используется, его можно рассматривать как ненужную трату ресурсов.
В публикации Корейского патента № 1995-022322 описан способ распределения битов с использованием психоакустической модели. Однако известный способ отличается от способа согласно настоящему изобретению повышенной эффективностью сжатия благодаря удалению гармонической составляющей из исходного сигнала с использованием результата БПФ, принятого в психоакустической модели.
В публикации Корейского патента № 1998-072457 описан способ и устройство обработки сигналов в психоакустической модели 2, в которых объем вычислений значительно сокращается за счет сокращения перегрузки вычислений при сжатии аудиосигнала. То есть известный способ обработки сигналов включает в себя этап получения индивидуального маскирующего граничного значения с использованием результата БПФ, этап выбора общего маскирующего граничного значения и этап смещения к следующей частотной позиции. Этот способ сходен с настоящим изобретением в отношении использования значения результата БПФ, но отличается тем, что в нем используется другой способ квантования.
В патенте США № 5930373 описан способ повышения качества аудиосигнала с использованием остаточных гармоник низкочастотного сигнала. Однако известный способ и способ квантования согласно настоящему изобретению различаются использованием разных методов использования остаточных гармоник.
Сущность изобретения
Для решения вышеупомянутых и других проблем аспектом настоящего изобретения является обеспечение способа эффективной обработки аудиосигнала с низкой скоростью посредством удаления гармонической составляющей из исходного аудиосигнала, использования результата быстрого преобразования Фурье (БПФ), используемого в психоакустической модели 2, и сжатия только остаточных изменяющихся составляющих с использованием модифицированного дискретного косинусного преобразования (МДКП).
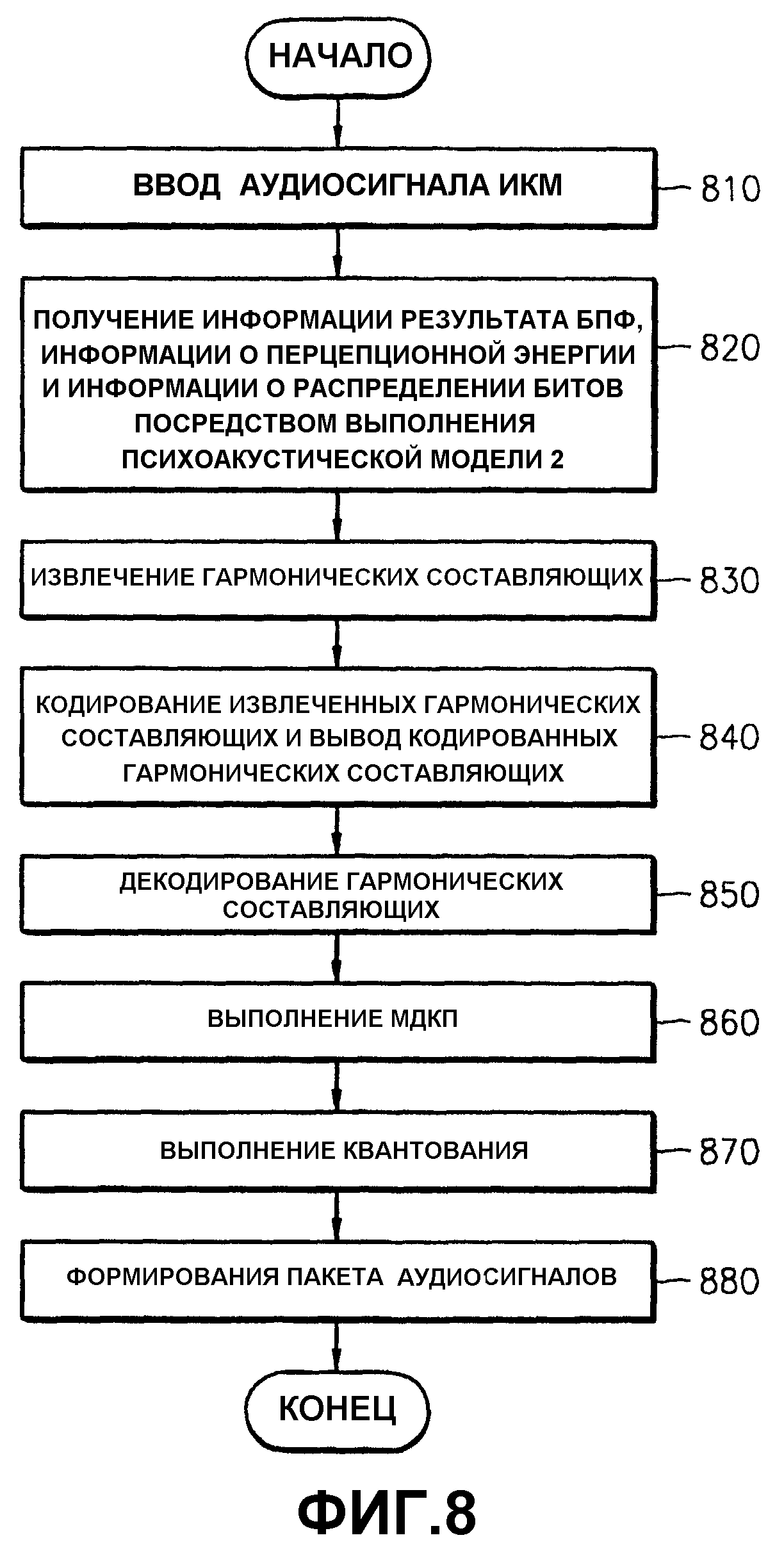
Вышеупомянутые и другие аспекты настоящего изобретения реализуются в способе кодирования аудиосигнала, использующего гармонические составляющие. В этом способе сначала принимаются аудиоданные импульсно-кодовой модуляции (ИКМ), и из принятых аудиоданных ИКМ извлекаются гармонические составляющие с применением психоакустической модели 2. Затем выполняется модифицированное дискретное косинусное преобразование (МДКП) на принятых аудиоданных ИКМ, из которых удалены извлеченные гармонические составляющие. После этого подвергнутые МДКП аудиоданные квантуются, и из квантованных аудиоданных и извлеченных гармонических составляющих формируется пакет аудиосигналов.
Вышеупомянутые и другие аспекты настоящего изобретения также реализуются в способе кодирования аудиосигнала с использованием гармонических составляющих, в котором аудиоданные ИКМ сначала принимаются и сохраняются. Затем к сохраненным данным применяется психоакустическая модель 2, основанная на характеристиках пределов слышимости человека, чтобы получить результат быстрого преобразования Фурье (БПФ), информацию о перцепционной энергии относительно принятых данных и информацию о распределении битов, используемую для квантования. После этого из принятых аудиоданных ИКМ извлекаются гармонические составляющие с использованием информации результата БПФ. Затем извлеченные гармонические составляющие кодируются, и кодированные гармонические составляющие декодируются. Затем выполняется МДКП на некотором количестве выборок принятых аудиоданных ИКМ, из которых удалены извлеченные гармонические составляющие, которое зависит от значения информации о перцепционной энергии. После этого подвергнутые МДКП аудиоданные квантуются путем распределения битов в соответствии с информацией о распределении битов. Наконец, из квантованных, подвергнутых МДКП аудиоданных и кодированных гармонических составляющих формируется пакет аудиосигналов.
Вышеупомянутые и другие аспекты настоящего изобретения, кроме того, реализуются в устройстве кодирования аудиосигнала с использованием гармонических составляющих. В этом устройстве модуль хранения аудиоданных ИКМ принимает и сохраняет аудиоданные ИКМ. Модуль выполнения психоакустической модели 2 принимает аудиоданные ИКМ от модуля хранения аудиоданных ИКМ и выполняет психоакустическую модель 2 для получения информации результата БПФ, информации о перцепционной энергии относительно принятых данных и информации о распределении битов, используемой для квантования. Модуль извлечения гармоник извлекает гармонические составляющие из принятых аудиоданных ИКМ с использованием информации результата БПФ. Модуль кодирования гармоник кодирует извлеченные гармонические составляющие, давая кодированные гармонические составляющие. Модуль декодирования гармоник декодирует кодированные гармонические составляющие. Модуль МДКП выполняет МДКП на сохраненных аудиоданных ИКМ, из которых удалены декодированные гармонические составляющие, в соответствии с информацией о перцепционной энергии. Модуль квантования квантует подвергнутые МДКП аудиоданные в соответствии с информацией о распределении битов. Модуль формирования битового потока уровня III MPEG преобразует квантованные, подвергнутые МДКП аудиоданные и кодированные гармонические составляющие, полученные от модуля кодирования гармоник, в пакет аудиосигналов уровня III MPEG.
Для реализации вышеупомянутых и других аспектов настоящее изобретение обеспечивает машиночитаемый носитель записи, на котором сохранена компьютерная программа для выполнения вышеупомянутых способов.
Краткое описание чертежей
Фиг.1 - формат аудиопотока уровня III MPEG-1;
фиг.2 - блок-схема устройства для формирования аудиопотока уровня III MPEG-1;
фиг.3 - блок-схема алгоритма, иллюстрирующая процесс вычисления в психоакустической модели;
фиг.4 - блок-схема устройства согласно настоящему изобретению для формирования низкоскоростного аудиопотока уровня III MPEG-1;
фиг.5 - блок-схема алгоритма, иллюстрирующая извлечение гармоник, кодирование гармоник и декодирование гармоник на основе психоакустической модели 2;
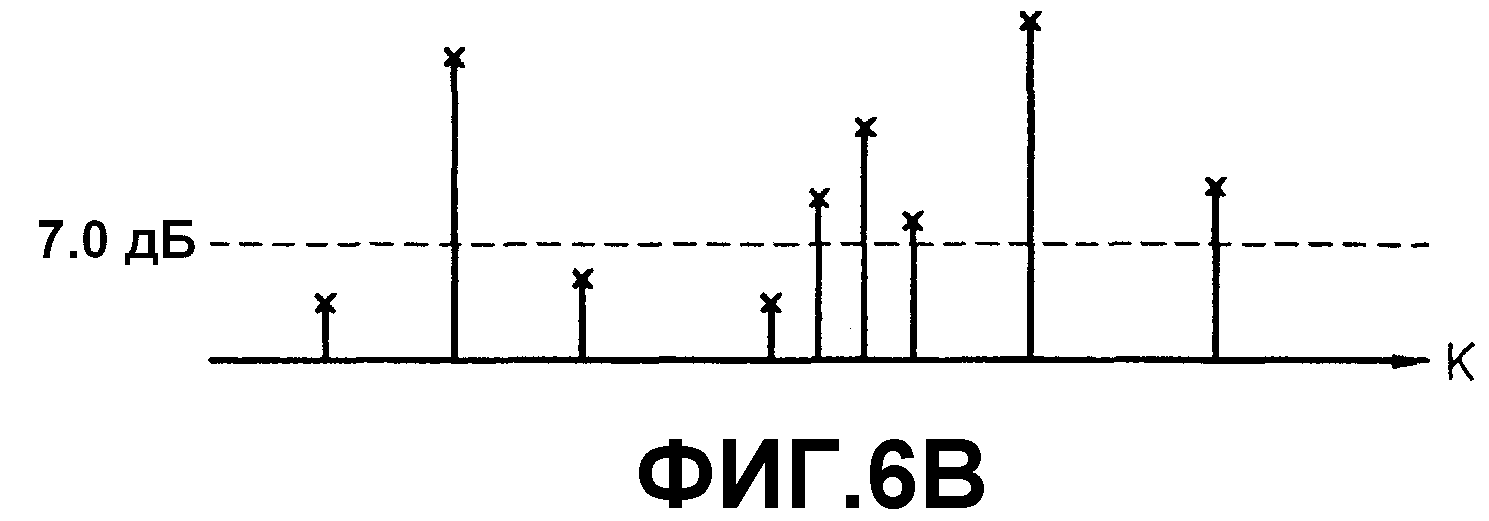
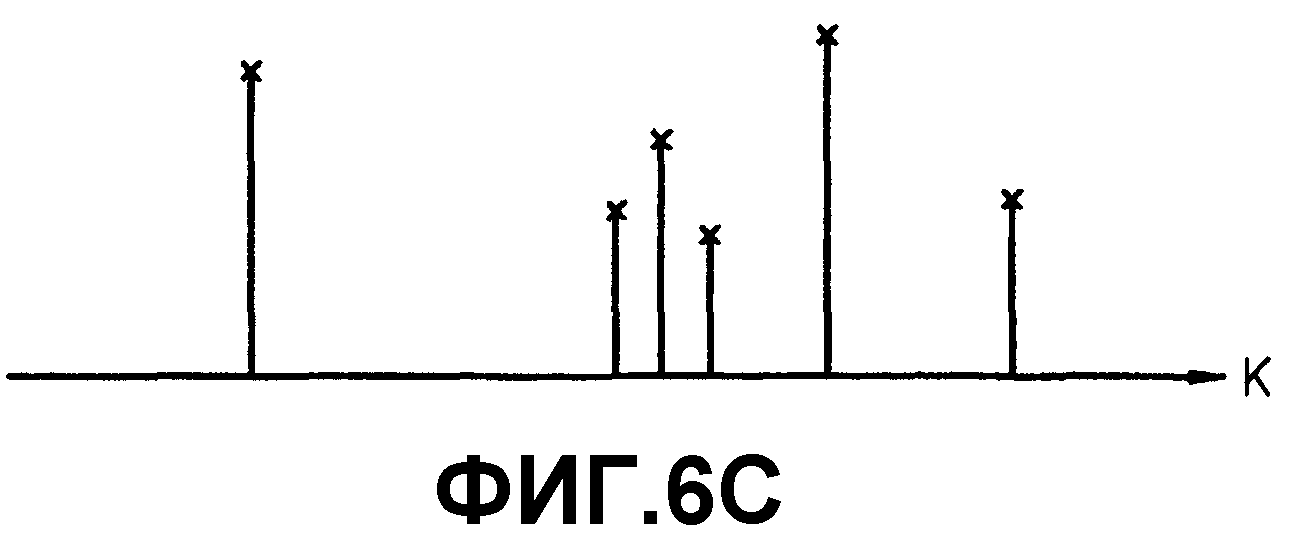
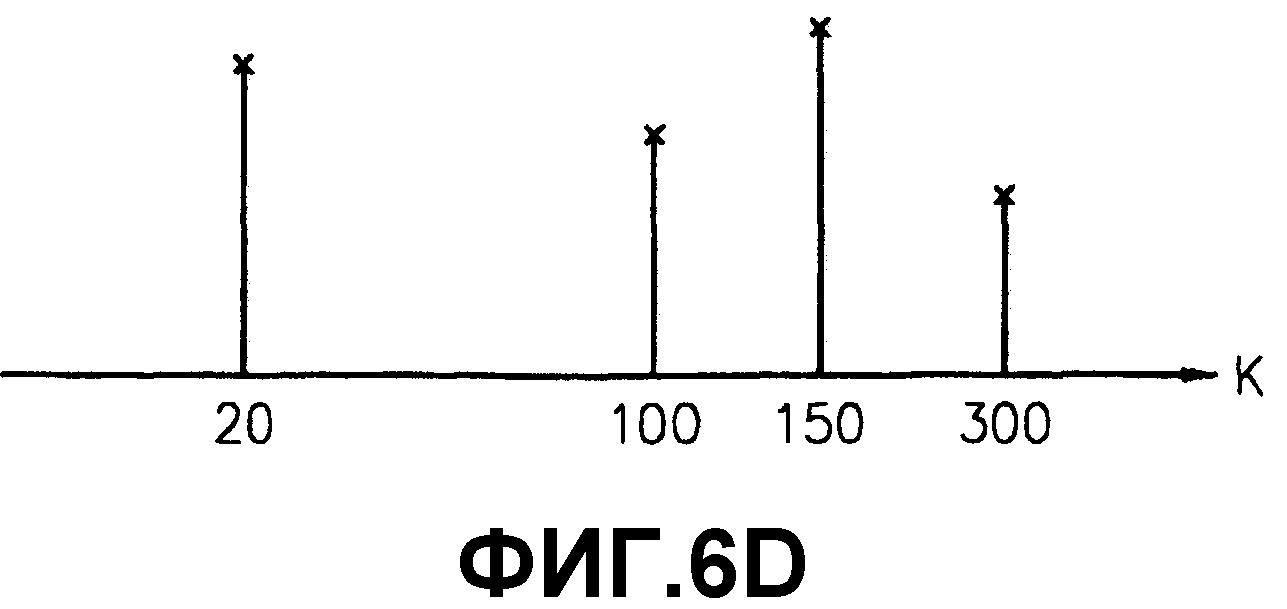
фиг.6A, 6B, 6C и 6D - выборки гармонических составляющих, извлекаемые поэтапно для извлечения гармонических составляющих с использованием результата БПФ в психоакустической модели 2;
фиг.7 - таблица, показывающая ограниченные частотные диапазоны, изменяющиеся в соответствии со значениями K; и
фиг.8 - блок-схема алгоритма, иллюстрирующая процесс согласно настоящему изобретению для формирования аудиопотока посредством удаления гармонической составляющей.
Предпочтительный вариант осуществления изобретения
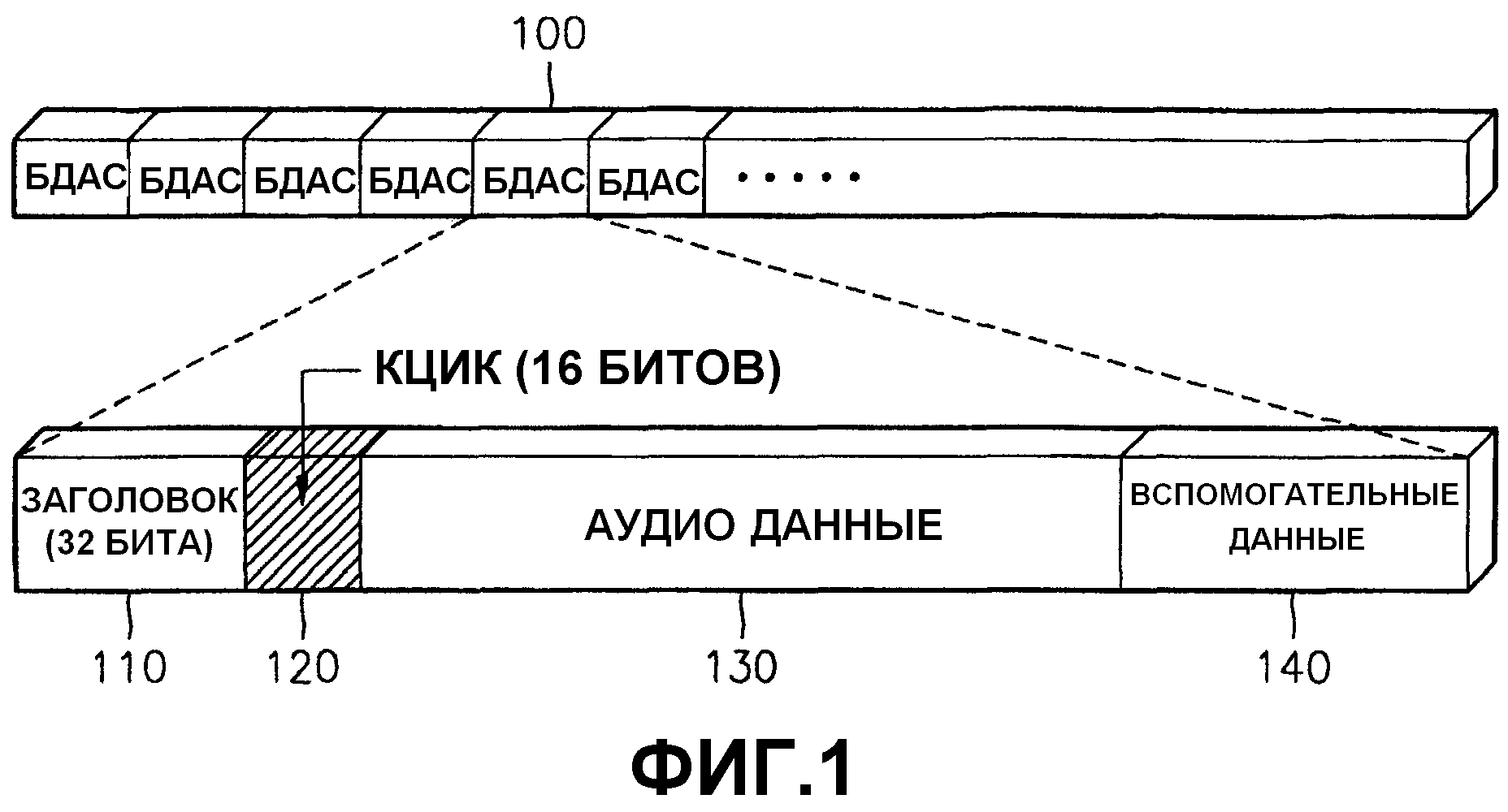
Согласно фиг.1, аудиопоток уровня III стандарта (MPEG)-1 состоит из блоков доступа аудиосигнала (БДАС) 100. БДАС 100 представляет собой минимальный блок, к которому может быть независимо получен доступ, и который сжимает и сохраняет данные с установленным количеством выборок. БДАС 100 включает в себя заголовок 110, биты контроля циклическим избыточным кодом (КЦИК) 120, аудиоданные 130 и вспомогательные данные 140.
Заголовок 110 хранит синхрослово, информацию ИД, информацию уровня, информацию относительно того, существует ли бит защиты, информацию показателя скорости передачи в битах, информацию частоты выборок, информацию относительно того, существует ли бит заполнения, бит конфиденциальности, информацию режима, информацию расширении режима, информацию об авторском праве, информацию относительно того, является ли аудиопоток исходным или копией, и информацию характеристик предыскажения.
КЦИК 120 является необязательным. Присутствие или отсутствие КЦИК 120 определено в заголовке 110, а длина КЦИК 120 составляет 16 битов.
Аудиоданные 130 представляют собой участок, содержащий сжатые аудиоданные.
Вспомогательные данные 140 представляют собой данные, которыми заполнено остающееся пространство, или конец аудиоданных 130 не достигает конца БДАС. Во вспомогательные данные 140 могут быть введены произвольные данные, отличающиеся от аудиосигнала MPEG.
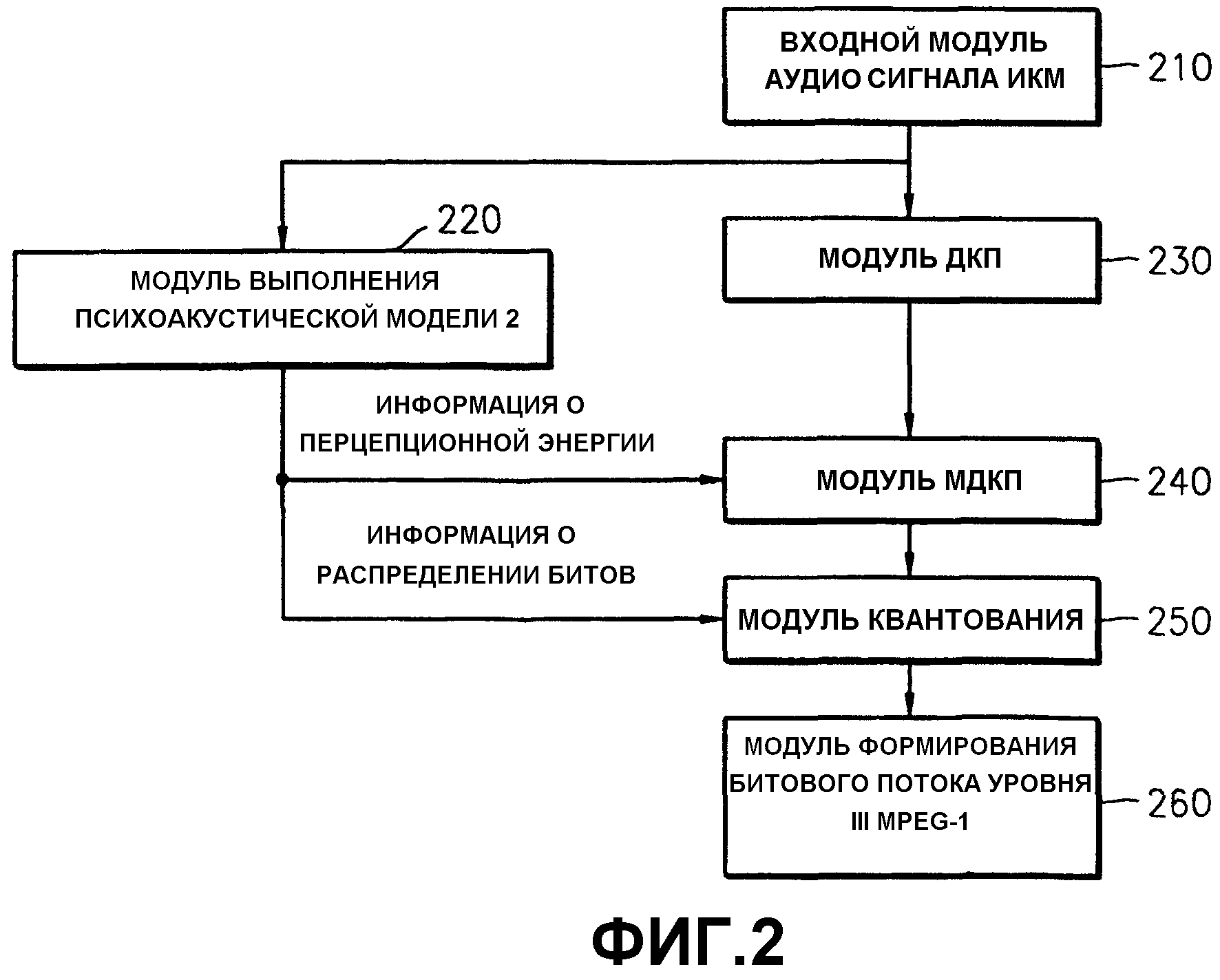
Фиг.2 представляет блок-схему устройства для формирования аудиопотока уровня III MPEG-1. Входной модуль 210 аудиосигнала импульсно-кодовой модуляции (ИКМ) имеет буфер для сохранения аудиоданных ИКМ. Входной модуль 210 аудиосигнала ИКМ принимает, в качестве аудиоданных ИКМ, блоки, каждый из которых состоит из 576 выборок.
Модуль 220 выполнения психоакустической модели 2 принимает аудиоданные ИКМ из буфера входного модуля 210 аудиосигнала ИКМ и выполняет психоакустическую модель 2. Модуль 230 дискретного косинусного преобразования (ДКП) принимает аудиоданные ИКМ в блоках с выборками и выполняет операцию ДКП одновременно с выполнением психоакустической модели 2.
Модуль 240 модифицированного ДКП (МДКП) выполняет МДКП с использованием результата применения психоакустической модели 2 и результата ДКП, выполненного модулем 230 ДКП. Если перцепционная энергия больше, чем предварительно определенное пороговое значение, МДКП выполняется с использованием короткого окна. Если перцепционная энергия меньше, чем предварительно определенное пороговое значение, МДКП выполняется с использованием длинного окна.
В перцепционном кодировании, которое представляет собой метод сжатия аудиосигнала, воспроизводимый сигнал отличается от исходного сигнала. То есть детализированная информация, которую люди не могут воспринимать, используя характеристики человеческого уха, может быть опущена. Перцепционная энергия обозначает энергию, которую человек может воспринимать.
Модуль 250 квантования выполняет квантование с использованием информации о распределении битов, полученной в результате применения психоакустической модели 2, и с использованием результата операции МДКП. Модуль 260 формирования битового потока уровня III MPEG-1 преобразует квантованные данные в данные, подлежащие введению в область аудиоданных битового потока MPEG-1, с использованием кодирования Хаффмана.
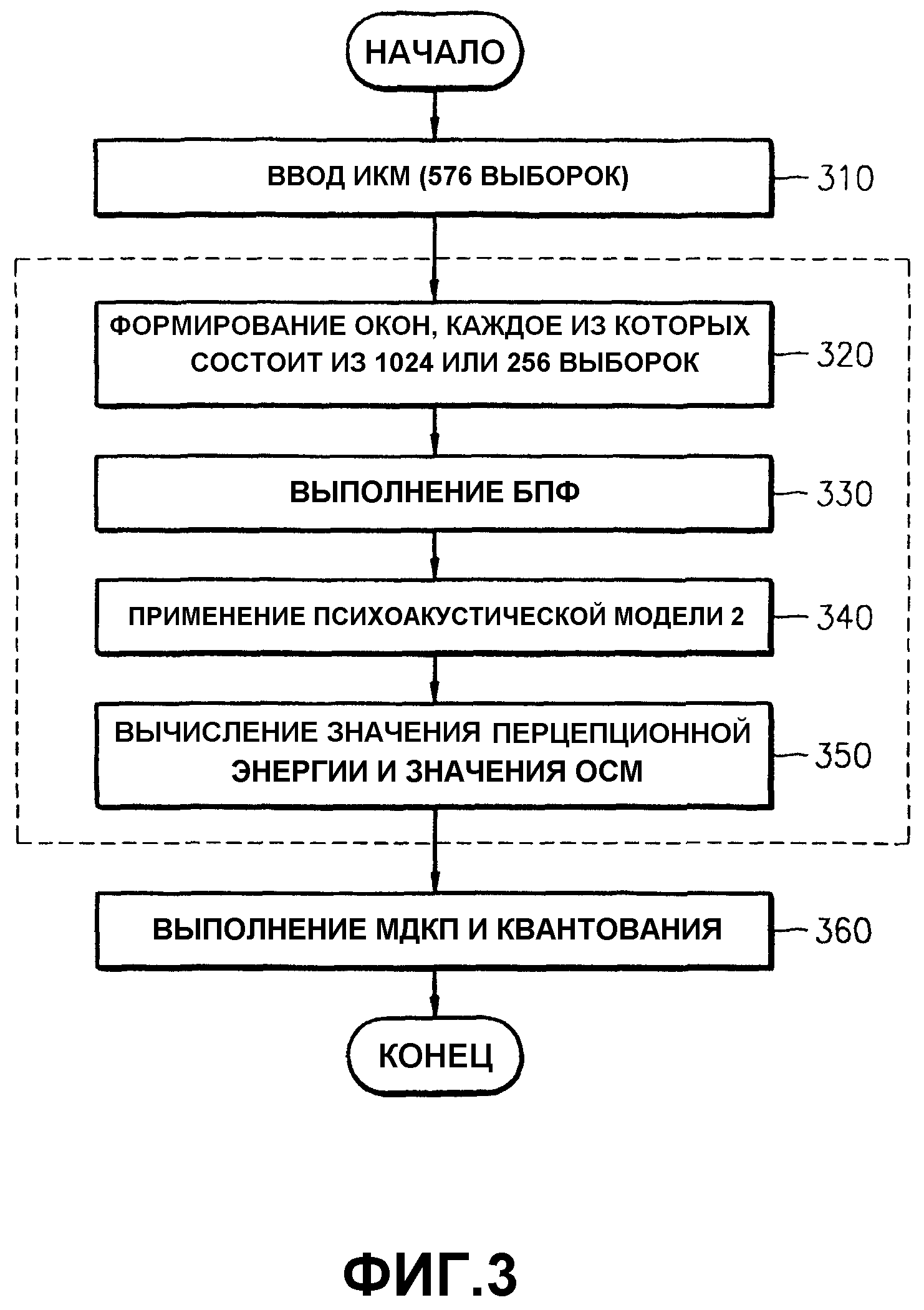
Фиг.3 представляет блок-схему алгоритма, иллюстрирующую процесс вычисления в психоакустической модели. Сначала, на этапе 310 аудиоданные ИКМ принимаются в блоках, каждый из которых состоит из 576 выборок. Затем, на этапе 320 с использованием принятых аудиоданных ИКМ формируются длинные окна, каждое из которых состоит из 1024 выборок, или короткие окна, каждое из которых состоит из 256 выборок. То есть один пакет состоит из множества выборок.
После этого, на этапе 330, выполняется быстрое преобразование Фурье (БПФ) на окнах, сформированных на этапе 320, на одном окне одновременно.
Затем, на этапе 340 применяется психоакустическая модель 2.
На этапе 350 получают значение перцепционной энергии с применением психоакустической модели 2, применимое к модулю МДКП, а модуль МДКП выбирает окно, подлежащее применению. Рассчитывается значение отношения сигнала к маскированию (ОСМ) для каждой пороговой ширины полосы, применяемое к модулю квантования, для определения количества битов, подлежащих распределению.
Наконец, на этапе 360 выполняются МДКП и квантование с использованием значения перцепционной энергии и значения ОСМ.
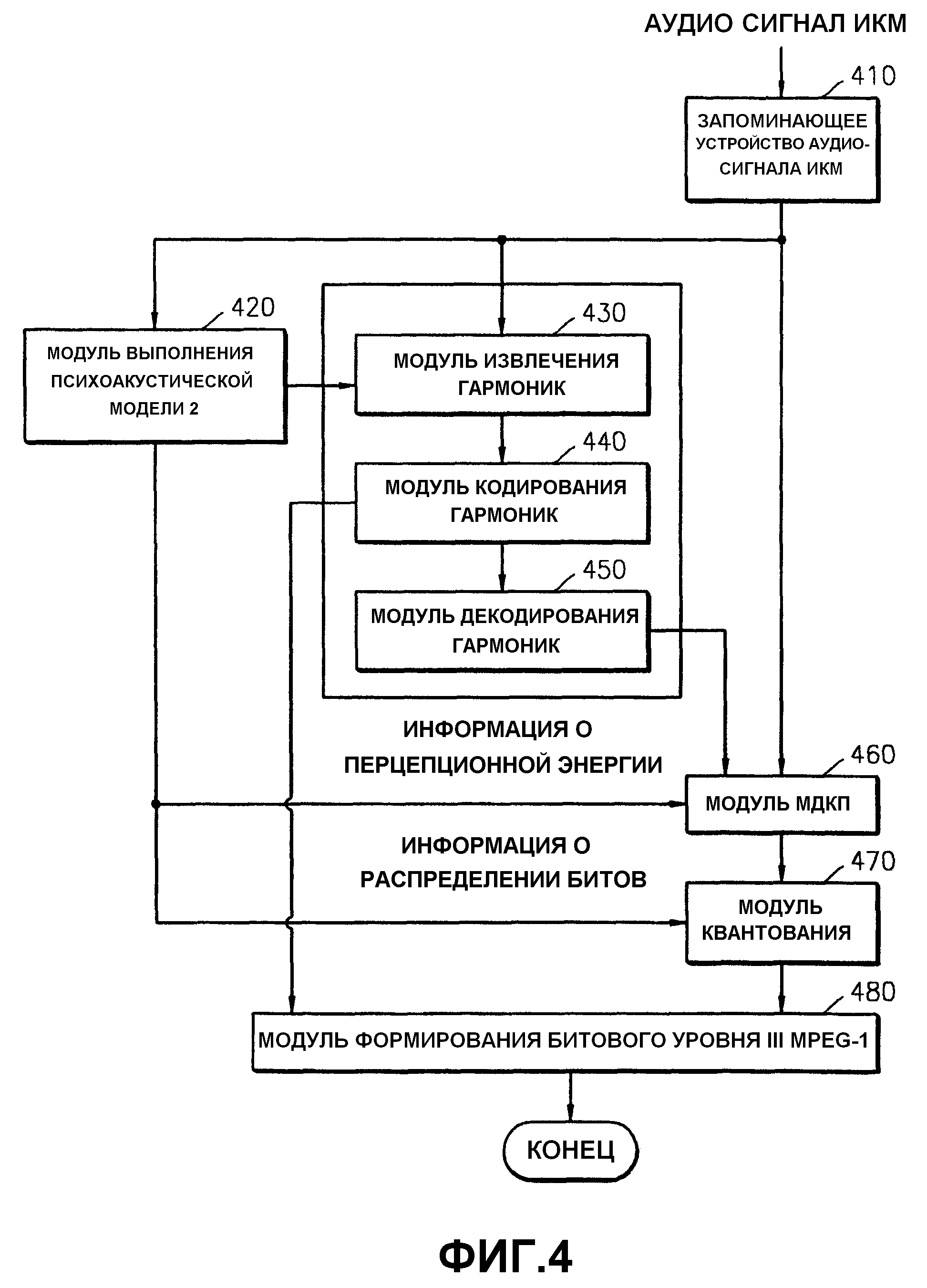
Фиг.4 представляет блок-схему устройства для формирования низкоскоростного аудиопотока уровня III стандарта MPEG-1 согласно настоящему изобретению. Запоминающее устройство 410 аудиосигнала ИКМ имеет буфер для сохранения аудиоданных ИКМ. Модуль 420 выполнения психоакустической модели 2 выполняет БПФ на 1024 выборках или 256 выборках одновременно и выводит информацию о перцепционной энергии и информацию о распределении битов.
Как описано выше со ссылкой на фиг.3, когда применяется психоакустическая модель 2, выводится информация о перцепционной энергии и информация о распределении битов, которая зависит от ОСМ. Поскольку модуль 420 выполнения психоакустической модели 2 выполняет БПФ, модуль 430 извлечения гармоник извлекает гармоническую составляющую из результата БПФ, как описано ниже со ссылкой на фиг.6.
Модуль 440 кодирования гармоник кодирует извлеченную гармоническую составляющую и передает кодированную гармоническую составляющую в модуль 480 формирования битового потока уровня III стандарта MPEG-1. Кодированная гармоническая составляющая формирует аудиосигнал стандарта MPEG-1, вместе с квантованными аудиоданными. Процесс кодирования гармонической составляющей подробно описан ниже.
Модуль 450 декодирования гармоник декодирует кодированную гармоническую составляющую, чтобы получить данные ИКМ во временной области. Модуль 460 МДКП вычитает декодированную гармоническую составляющую из исходного входного сигнала ИКМ и выполняет МДКП на результате вычитания. Если значение информации о перцепционной энергии, принятое от модуля 420 психоакустической модели 2, больше предварительно определенного порогового значения, МДКП выполняется одновременно на 18 выборках. Если значение информации о перцепционной энергии, принятое от модуля 420 выполнения психоакустической модели 2, является равным или меньше, чем предварительно определенное пороговое значение, МДКП одновременно выполняется на 36 выборках.
Извлечение гармонической составляющей выполняется на данных частотной области с использованием условия тонального/нетонального решения и характеристик пределов слышимости, которые определены в психоакустической модели 2, подробно описано ниже.
Модуль 470 квантования выполняет квантование с использованием информации о распределении битов, полученную модулем 420 выполнения психоакустической модели 2. Модуль 480 формирования битового потока уровня III стандарта MPEG-1 пакетирует данные гармонических составляющих, сформированные модулем 440 кодирования гармоник, и квантованные аудиоданные, полученные модулем 470 квантования, для получения сжатых аудиоданных.
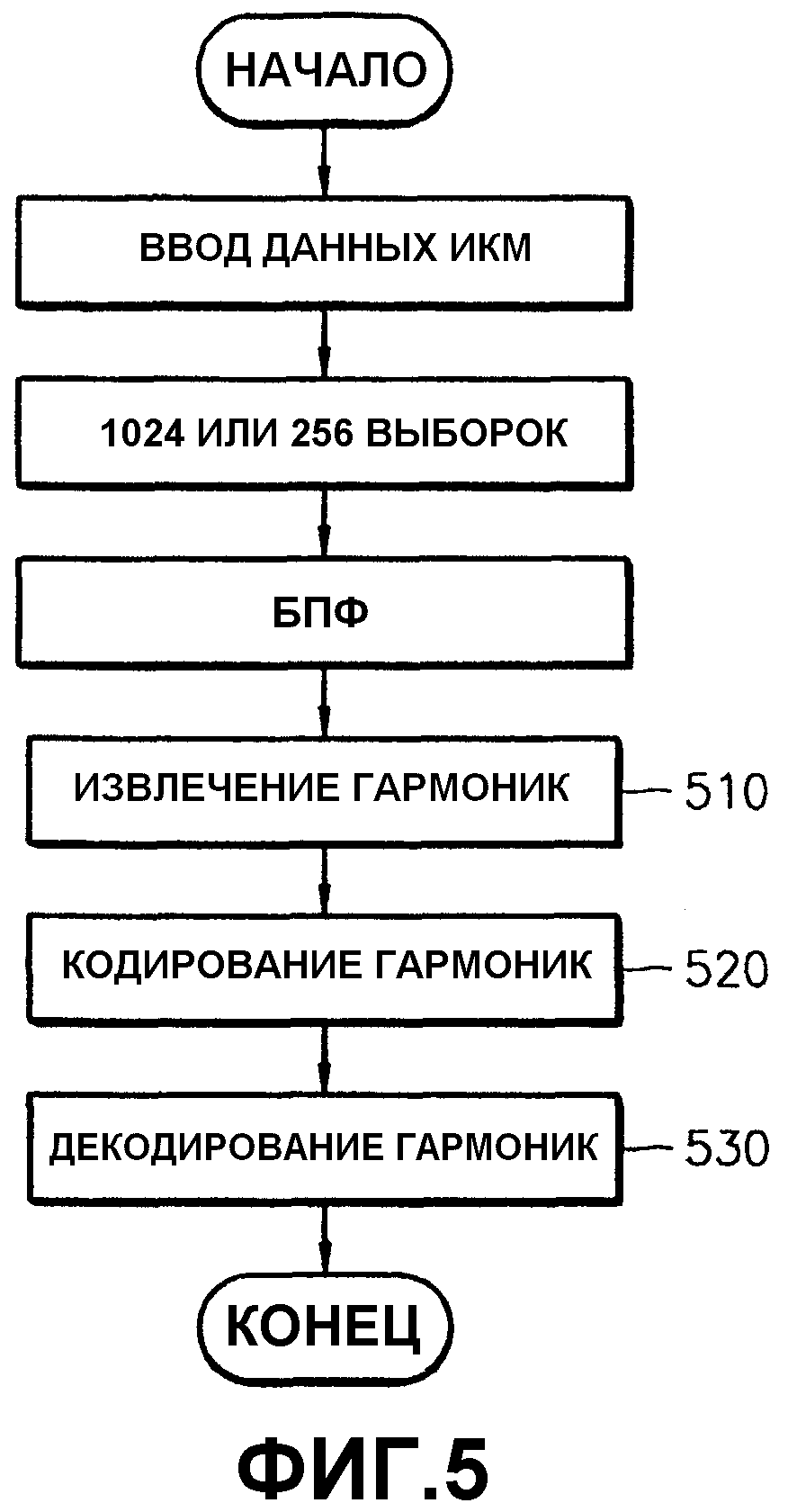
Фиг.5 представляет блок-схему алгоритма, иллюстрирующую этап 510 извлечения гармоник, этап 520 кодирования гармоник и этап 530 декодирования гармоник на основании психоакустической модели 2. Этапы, выполняемые в психоакустической модели 2 на фиг.5, такие же, как этапы, выполняемые в психоакустической модели 2 на фиг.3. На этапе 510 извлечения гармонической составляющей используется результат БПФ, выполняемого на основе модуля выполнения психоакустической модели 2. На этапе 520 извлеченная гармоническая составляющая кодируется в битовый поток MPEG-1. Этап 510 извлечения гармоник описан более подробно ниже со ссылкой на фиг.6A-6D.
Фиг.6A, 6B, 6C и 6D иллюстрируют выборки, извлекаемые поэтапно, когда гармонические составляющие извлекаются с использованием результата БПФ, выполненного в психоакустической модели 2. Если вводятся аудиоданные ИКМ, как показано на фиг.6A, БПФ сначала выполняется на принятых данных, чтобы определить звуковое давление для каждого элемента данных. Выбирается одно из множества принятых аудиоданных ИКМ, звуковое давление которого было получено. Если значения аудиоданных ИКМ с левой и правой сторон от выбранных данных меньше, чем выбранное значение аудиоданных ИКМ, извлекаются только выбранные аудиоданные ИКМ. Этот процесс применяется для всех принятых аудиоданных ИКМ.
Звуковое давление представляет собой значение энергии выборки в частотной области. В настоящем изобретении только выборки, имеющие звуковые давления, превышающие предварительно определенный уровень, определяются как гармонические составляющие. Соответственно, извлекаются выборки, показанные на фиг.6B. После этого извлекаются только выборки, имеющие звуковые давления, превышающие предварительно определенный уровень. Например, если предварительно определенный уровень установлен равным 7,0 дБ, выборки, имеющие звуковые давления меньшее 7,0 дБ, не выбираются, и остаются только выборки, показанные на фиг.6C. Не все остающиеся выборки рассматриваются как гармонические составляющие, и из остающихся выборок извлекаются некоторые выборки согласно таблице фиг.7. Следовательно, окончательно остаются выборки, показанные на фиг.6D.
Фиг.7 представляет таблицу, показывающую ограниченный частотный диапазон, который изменяется в соответствии со значением K. При условии, что K - значение, представляющее расположение выборки в частотной области, если значение K меньше 3 или больше 500, значения выборок, представленных в пределах ограниченного частотного диапазона 0, составляют 0 и, соответственно, не выбираются. Аналогично этому, как показано на фиг.7, если значение K равно или больше 3 и меньше 63, соответствующее значение диапазона устанавливается равным 2. Если значение K равно или больше 63 и меньше 127, соответствующее значение диапазона устанавливается равным 3. Если значение K равно или больше 127 и меньше 255, соответствующее значение диапазона устанавливается равным 6. Если значение K равно или больше 255 и меньше 500, соответствующее значение диапазона устанавливается равным 12.
Выбор 500 в качестве предела определяется с учетом предела слышимой частоты человека и основан на предположении, что отсутствует различие в качестве воспроизводимого звучания между тем, когда учитывается значения выборок, соответствующие частоте, равной или превышающей 500, и когда они не учитываются.
Следовательно, только значения выборок, представленные на фиг.6D, извлекаются и определяются как гармонические составляющие.
Кодирование 520 гармоник включает в себя кодирование амплитуд, кодирование частот и кодирование фаз. Эти три способа кодирования используют уравнения 1 и 2:
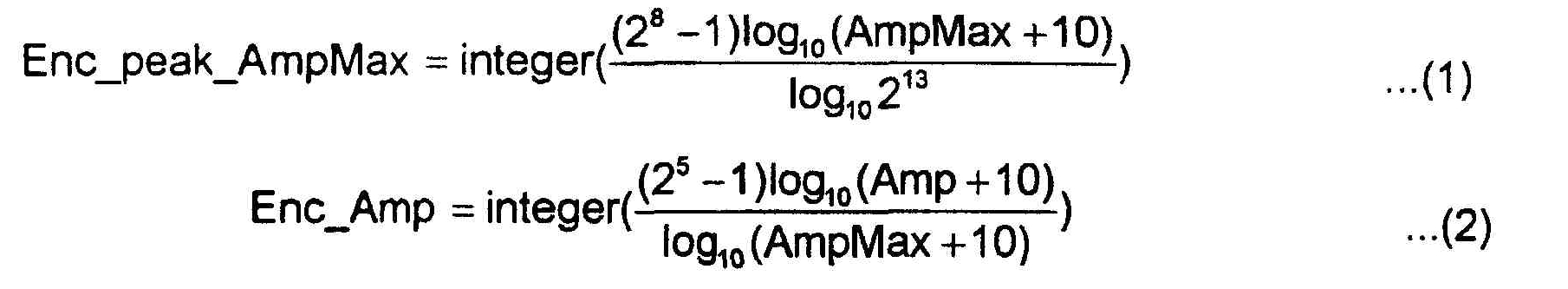
где AmpMax обозначает максимальную амплитуду, Enc_peak-AmpMax обозначает значение результата, полученного при кодировании значения AmpMax, а Amp обозначает амплитуды, отличающиеся от максимальной амплитуды.
При кодировании амплитуды, когда максимальная амплитуда установлена как значение AmpMax, максимальная амплитуда сначала кодируется в 8-битовом логарифмическом масштабе, чтобы получить Enc_peak_AmpMax, как показано в Уравнении (1), а другие амплитуды Amp кодируются в 5-битовом логарифмическом масштабе, чтобы получить Enc-Amp, как показано в Уравнении (2).
При кодировании частот кодируются только выборки, соответствующие значениям K в пределах от 58 (от 2498 Гц) до 372 (16 кГц), с учетом слуховых характеристик человека. Поскольку 314 получено вычитанием 58 из 372, выборки кодируются с использованием 9 битов.
Кодирование фаз осуществляется с использованием 3 битов.
После такого извлечения гармоник и кодирования гармоник кодированные гармонические составляющие декодируются, а затем подвергаются МДКП.
Фиг.8 представляет блок-схему алгоритма, иллюстрирующую процесс формирования аудиопотока посредством удаления гармонических составляющих согласно настоящему изобретению. Сначала на этапе 810 аудиоданные ИКМ принимаются и запоминаются. Затем на этапе 820 к сохраненным данным применяется психоакустическая модель 2 с использованием характеристик пределов слышимости человека, чтобы получить информацию результата БПФ, информацию о перцепционной энергии относительно принятых данных и информацию о распределении битов, используемую для квантования. После этого на этапе 830 из принятых аудиоданных ИКМ извлекаются гармонические составляющие с использованием информации результата БПФ.
Гармонические составляющие извлекаются в следующем процессе. Сначала получают звуковое давление для каждого из множества принятых аудиоданных ИКМ, используя информацию результата БПФ. Затем выбираются одни из множества принятых аудиоданных ИКМ, звуковые давления которых получены. Если значения аудиоданных ИКМ с левой и с правой сторон от выбранных данных меньше, чем значение выбранных аудиоданных ИКМ, извлекаются только выбранные аудиоданные ИКМ. Этот процесс применяется ко всем принятым аудиоданным ИКМ. После этого из аудиоданных ИКМ, извлеченных на предыдущем этапе, извлекаются только аудиоданные ИКМ, каждые из которых имеют звуковое давление больше, чем предварительно определенное значение 7,0 дБ. Наконец, гармонические составляющие извлекаются без учета выбора аудиоданных PCM в предварительно определенном частотном диапазоне из аудиоданных, извлеченных на предыдущем этапе.
После извлечения гармоник на этапе 830 на этапе 840 извлеченные гармонические составляющие кодируются и выводятся. Затем, на этапе 850 кодированные гармонические составляющие декодируются.
Затем, на этапе 860, принятые аудиоданные ИКМ, из которых удалены декодированные гармонические составляющие, подвергаются МДКП согласно информации о перцепционной энергии. При этом, если значение перцепционной энергии больше, чем предварительно определенное пороговое значение, выполняется МДКП с использованием короткого окна, например, одновременно на 18 выборках. Если значение перцепционной энергии меньше, чем предварительно определенное пороговое значение, МДКП выполняется с использованием длинного окна, например, одновременно на 36 выборках.
После этого, на этапе 870, значения результата МДКП квантуются посредством распределения битов в соответствии с информацией о распределении битов.
Наконец, на этапе 880, квантованные аудиоданные и кодированные гармонические составляющие подвергаются кодированию Хаффмана для получения пакета аудиосигналов.
Варианты осуществления настоящего изобретения могут быть записаны в виде компьютерных программ и могут быть реализованы на универсальных цифровых ЭВМ, которые выполняют программы с использованием машиночитаемого носителя записи. Примеры машиночитаемых носителей записи включают в себя магнитные устройства памяти (например, ПЗУ (постоянные запоминающие устройства), гибкие диски, жесткие диски, и т.д.), оптические носители записи (например, CD-ROM (неперезаписываемые компакт-диски) или DVD (многоцелевые цифровые диски)) и носитель данных в виде несущего колебания (например, передача через Интернет).
Хотя настоящее изобретение главным образом было показано и описано со ссылкой на предпочтительные варианты его осуществления, специалистам в данной области техники должно быть понятно, что в них могут осуществляться различные видоизменения по форме и в деталях без отклонения от объема и сущности настоящего изобретения, как определено прилагаемой формулой изобретения. Следовательно, раскрытые варианты осуществления следует рассматривать не как ограничительные, а как иллюстративные. Объем настоящего изобретения определяется не приведенным выше описанием, а формулой изобретения, и все различия в объеме, эквивалентном объему формулы изобретения, следует интерпретировать как включенные в настоящее изобретение.
Промышленная применимость
Как описано выше, в настоящем изобретении количество битов квантования, генерируемых при формировании низкоскоростного аудиопотока уровня III стандарта MPEG-1, снижено до минимума. При использовании результатов БПФ, применяемых в психоакустической модели 2, гармонические составляющие просто удаляются из входного аудиосигнала, и сжимается только изменяющаяся часть с использованием МДКП. Поэтому входной аудиосигнал может быть эффективно сжат при низкой скорости передачи в битах.
Реферат
Изобретение относится к способу и устройству для эффективного сжатия аудиосигнала в звуковой сигнал уровня III стандарта MPEG-1 с низкой скоростью передачи информации. Сущность изобретения заключается в том, что в способе кодирования аудиосигнала гармонические составляющие извлекают с использованием информации результата быстрого преобразования Фурье (БПФ), которую получают с использованием психоакустической модели 2 к принятым аудиоданным импульсно-кодовой модуляции (ИКМ). Затем извлеченные гармонические составляющие удаляют из принятых аудиоданных ИКМ. После этого аудиоданные, из которых удалены извлеченные гармонические составляющие, подвергают модифицированному дискретному косинусному преобразованию (МДКП) и квантованию. Технический результат - обеспечить эффективное сжатие сигнала при низкой скорости путем сжатия только изменяющейся части сигнала посредством модифицированного дискретного косинусного преобразования. 5 н. и 7 з.п. ф-лы, 11 ил.
Формула
Документы, цитированные в отчёте о поиске
Сжатие и расширение данных звукового сигнала
Комментарии