Восстановление текстовых аннотаций, связанных с информационными объектами - RU2665261C1
Код документа: RU2665261C1
Чертежи






















Описание
ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к вычислительным системам, а точнее - к системам и способам обработки естественного языка.
УРОВЕНЬ ТЕХНИКИ
[0002] Интерпретация неструктурированной или слабо структурированной информации, представленной в виде текста на естественном языке, может быть затруднена из-за неоднозначности, присущей конструкциям естественного языка. Эта неоднозначность может быть вызвана, например, многозначностью слов и фраз естественного языка и (или) некоторыми особенностями механизмов естественного языка, которые используются для установления связей между словами и (или) группами слов в предложениях на естественном языке (таких как падежи существительных, порядок слов и т.д.).
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа восстановления текстовой аннотации, связанной с информационным объектом, может включать: получение текста на естественном языке, извлечение из текста на естественном языке множества информационных объектов, где каждый информационный объект связан с одним или более атрибутами; верификацию значений атрибутов множества информационных объектов, определение информационного объекта в множестве информационных объектов, такого, чтобы как минимум один атрибут определенного информационного объекта не был связан как минимум с одной текстовой аннотацией; и восстановление текстовой аннотации, связанной с атрибутом определенного информационного объекта, где текстовая аннотация представлена фрагментом текста на естественном языке, соответствующим значению атрибута.
[0004] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа восстановления текстовой аннотации, связанной с информационным объектом, может включать: получение текста на естественном языке, связанного с множеством информационных объектов, где каждый информационный объект связан с одним или более атрибутами; определение информационного объекта из множества информационных объектов, такого, чтобы как минимум один атрибут определенного информационного объекта не был связан как минимум с одной текстовой аннотацией;определение одной или более текстовых аннотаций-кандидатов, связанных с этим атрибутом, таких, чтобы каждая текстовая аннотация-кандидат была представлена фрагментом текста на естественном языке, соответствующим значению атрибута; определение рейтинговых оценок определенных текстовых аннотаций-кандидатов и выбор одной или более текстовых аннотаций-кандидатов с оптимальной рейтинговой оценкой.
[0005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при выполнении их вычислительной системой приводят к следующим действиям вычислительной системы: получение текста на естественном языке; извлечение из текста на естественном языке множества информационных объектов, где каждый информационный объект связан с одним или более атрибутами; верификацию значений атрибутов множества информационных объектов; определение информационного объекта в множестве информационных объектов, такого, чтобы как минимум один атрибут определенного информационного объекта не был связан как минимум с одной текстовой аннотацией; и восстановление текстовой аннотации, связанной с атрибутом определенного информационного объекта, где текстовая аннотация представлена фрагментом текста на естественном языке, соответствующим значению атрибута. Технический результат от внедрения изобретения состоит в увеличении эффективности системы извлечения информации, заключающееся в повышении точности связывания извлеченных информационных объектов с исходным текстом.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
[0007] На Фиг. 1 изображена блок-схема одного иллюстративного примера способа настройки параметров функции классификатора, используемой для оценки атрибутов, связанных с информационными объектами, в соответствии с одним или более вариантами реализации настоящего изобретения;
[0008] На Фиг. 2 схематически показан пример линейного классификатора, создающего разделительную гиперплоскость в гиперпространстве, которая определяется значениями F1 и F2, соответствующими признакам, используемым для извлечения атрибутов в соответствии с одним или более вариантами реализации настоящего изобретения;
[0009] На Фиг. 3А-3В схематически показаны примеры документов 300А и 300В на естественном языке с извлеченными признаками, связанными с некоторыми информационными объектами, в соответствии с одним или более вариантами реализации настоящего изобретения;
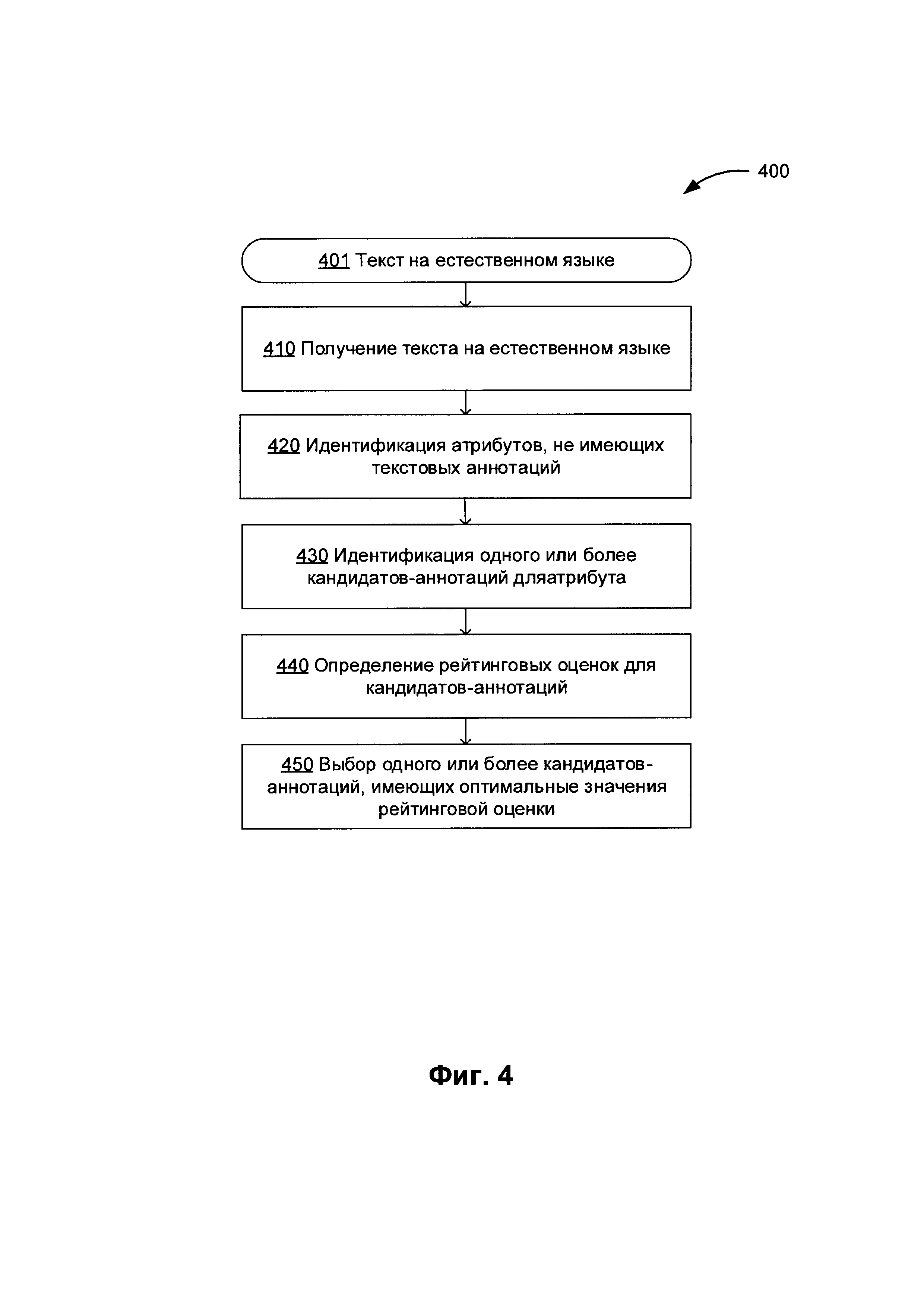
[00010] На Фиг. 4 изображена блок-схема одного иллюстративного примера способа восстановления текстовой аннотации, связанной с информационными объектами, в соответствии с одним или более вариантами реализации настоящего изобретения;
[00011] На Фиг. 5 схематически показана семантическая структура, полученная в результате анализа примера предложения в соответствии с одним или более вариантами реализации настоящего изобретения;
[00012] На Фиг. 6 схематически показаны информационные объекты и факты, извлеченные из примера предложения, приведенного на Фиг. 5, с помощью систем и способов, работающих в соответствии с одним или более вариантами реализации настоящего изобретения;
[00013] На Фиг. 7А-7С схематически показаны фрагменты семантической структуры, соответствующей этому примеру предложения;
[00014] На Фиг. 8А-8С схематически показаны продукционные правила, применяемые на подмножестве семантической структуры, представляющей пример предложения для извлечения информационных объектов и фактов в соответствии с одним или более вариантами реализации настоящего изобретения;
[00015] На Фиг. 9 приведена блок-схема одного иллюстративного примера способа 400 для выполнения семантико-синтаксического анализа предложения на естественном языке в соответствии с одним или более вариантами реализации настоящего изобретения;
[00016] На Фиг. 10 схематически показан пример лексико-морфологической структуры предложения в соответствии с одним или более вариантами реализации настоящего изобретения;
[00017] На Фиг. 11 схематически показаны языковые описания, представляющие модель естественного языка, в соответствии с одним или более вариантами реализации настоящего изобретения;
[00018] На Фиг. 12 схематически показаны примеры морфологических описаний в соответствии с одним или более вариантами реализации настоящего изобретения;
[00019] На Фиг. 13 схематически показаны примеры синтаксических описаний в соответствии с одним или более вариантами реализации настоящего изобретения;
[00020] На Фиг. 14 схематически показаны примеры семантических описаний в соответствии с одним или более вариантами реализации настоящего изобретения;
[00021] На Фиг. 15 схематически показаны примеры лексических описаний в соответствии с одним или более вариантами реализации настоящего изобретения;
[00022] На Фиг. 16 схематически показаны примеры структур данных, которые могут быть использованы в рамках одного или более способов, реализованных в соответствии с одним или более вариантами реализации настоящего изобретения;
[00023] На Фиг. 17 схематически показан пример графа обобщенных составляющих в соответствии с одним или более вариантами реализации настоящего изобретения;
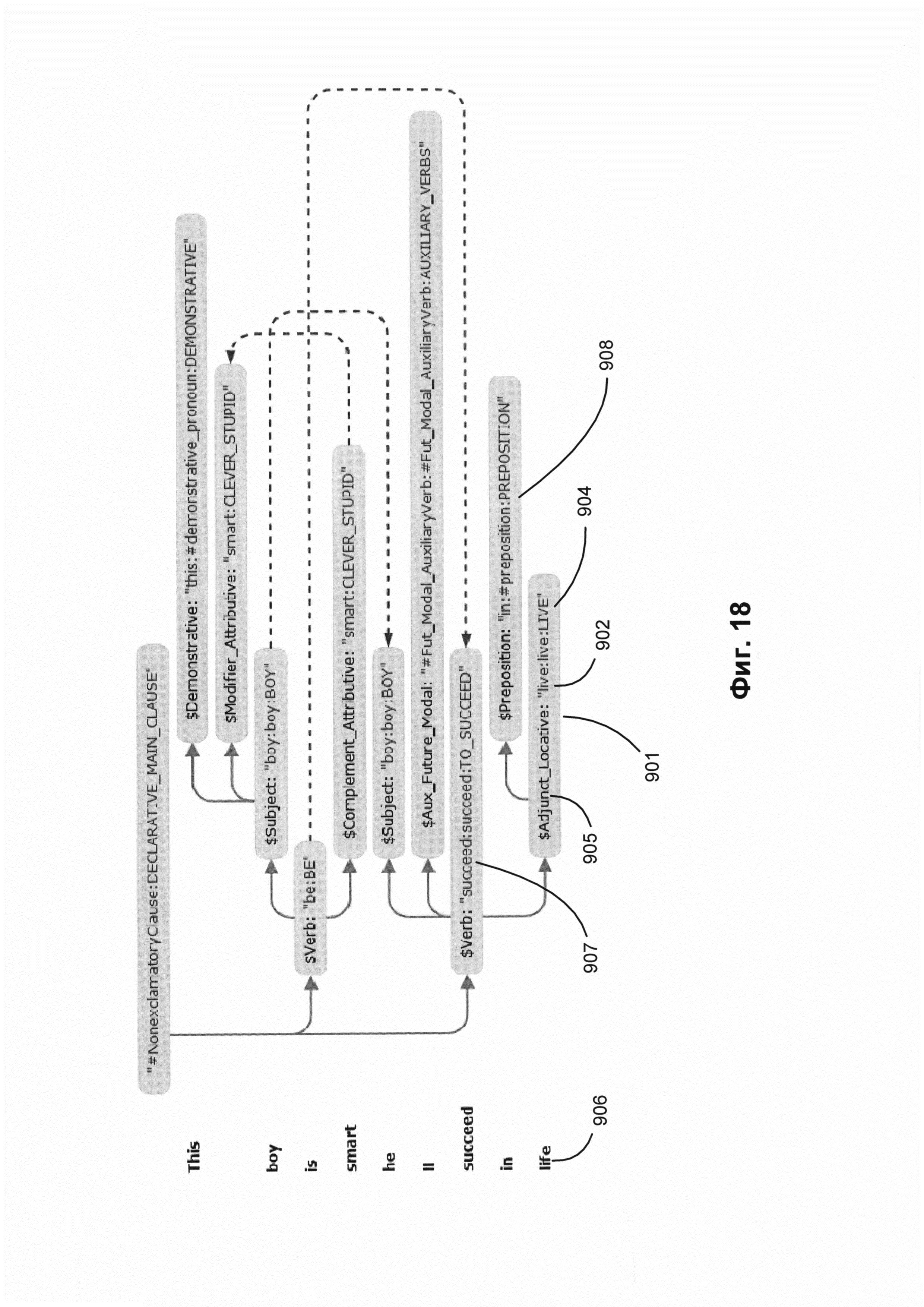
[00024] На Фиг. 18 показан пример синтаксической структуры, соответствующей предложению, приведенному на Фиг. 17;
[00025] На Фиг. 19 показана семантическая структура, соответствующая синтаксической структуре, приведенной на Фиг. 18;
[00026] На Фиг. 20 показана схема примера вычислительной системы, реализующей методы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00027] В настоящем документе описываются способы и системы восстановления текстовых аннотаций, связанных с информационными объектами. Описанные в настоящем документе системы и способы могут быть использованы для обучения моделей классификаторов, которые используются для выполнения различных задач по извлечению информации (включая распознавание именованных сущностей, извлечение фактов и т.д.) в контексте различных приложений для обработки естественных языков, таких как машинный перевод, построение семантического индекса, семантический поиск (включая многоязычный семантический поиск), классификация документов, электронные исследования и др.
[00028] В настоящем документе термин «вычислительная система» означает устройство обработки данных, оснащенное универсальным процессором, памятью и по меньшей мере одним интерфейсом связи. Примерами вычислительных систем, которые могут использовать описанные в этом документе способы, являются, в частности, настольные компьютеры, ноутбуки, планшетные компьютеры и смартфоны.
[00029] Извлечение информации может включать анализ текста на естественном языке для распознавания информационных объектов (например, именованных сущностей), их атрибутов и их связей. Распознавание именованных сущностей (NER) представляет собой задачу по извлечению информации, в ходе выполнения которой производится определение токенов в тексте на естественном языке и классификация их по заранее определенным категориям, таким как имена людей, названия организаций, географические названия, представление времени, количества, денежные суммы, проценты и т.д. Эти категории могут быть представлены концептами заранее определенной или динамически выстраиваемой онтологии.
[00030] «Онтология» в настоящем документе означает модель, которая представляет объекты, относящиеся к определенной области знаний (предметной области), и отношения между данными объектами. Информационный объект может представлять собой материальный объект реального мира (например, человек или вещь) либо некое понятие, соотнесенное с одним или более объектами реального мира (например, число или слово). Онтология может включать определения некого множества классов, где каждый класс соответствует отдельному понятию, относящемуся к определенной области знаний. Каждое определение класса может включать определения одного или более отнесенных к данному классу объектов. Согласно общепринятой терминологии класс онтологии может также называться «концепт», а принадлежащий классу объект может означать экземпляр данного концепта. Объект может характеризоваться одним или более атрибутами. Атрибут может определять свойство информационного объекта или связь между данным информационным объектом и другим информационным объектом. Таким образом, определение класса онтологии может содержать одно или более определений атрибутов, описывающих типы атрибутов, которые могут быть связаны с объектами данного класса (например, тип связи между объектом данного класса и другими информационными объектами). В качестве иллюстративного примера класс «Person» (человек) может быть связан с одним или более информационными объектами, соответствующими определенным лицам. В другом иллюстративном примере информационный объект «John Smith» (Джон Смит) может иметь атрибут «Smith» (Смит) типа «surname» (фамилия).
[00031] Некоторые атрибуты могут быть необязательными, а другие атрибуты - необходимыми для всех информационных объектов данного класса. Информационный объект может иметь один или более атрибутов данного типа. Определенные атрибуты могут принимать только значения, выбранные из набора из одного или более предварительно определенных значений для всех информационных объектов данного класса.
[00032] После распознавания именованных сущностей может быть выполнено извлечение информации для установления кореференций и анафорических связей между токенами естественного текста. «Кореференция» в настоящем документе означает конструкцию естественного языка, содержащую два или более токенов естественного языка, которые относятся к одной сущности (например, одному и тому же лицу, вещи, месту или организации). Например, в предложении «После того как Джон получил диплом MIT, ему предложили работу в Microsoft» собственное имя «Джон» и местоимение «ему» относится к одному человеку. Из двух токенов кореференций тот токен, на который дается ссылка, может обобщенно именоваться антецедентом, а тот, который ссылается на него, - проформой или анафорой. Различные способы установления кореференций могут включать выполнение синтаксического и (или) семантического анализа как минимум части текста на естественном языке.
[00033] После извлечения информационных объектов и установления кореференций может производиться извлечение информации с целью определения отношений между извлеченными информационными объектами. Одно или более отношений между информационным объектом и другими информационными объектами могут задаваться одним или более свойствами информационного объекта, которые отражают один или более атрибутов. Отношение может быть установлено между двумя информационными объектами, между данным информационным объектом и группой информационных объектов или между одной группой информационных объектов и другой группой информационных объектов. Подобные отношения могут быть выражены фрагментами на естественном языке (текстовыми аннотациями), которые могут содержать множество слов из одного или более предложений.
[00034] Например, информационный объект класса «Person» (человек) может иметь, среди прочих, следующие атрибуты: имя, дата рождения, адрес проживания и информация о предшествующей трудовой деятельности. Каждый атрибут может быть представлен одной или более текстовыми строками, одним или более числовыми значениями и (или) одним или более значениями определенного типа данных (например, дата). Атрибут может быть представлен сложным атрибутом, ссылающимся на два или более информационных объектов. В иллюстративном примере атрибут «address» (адрес) может ссылаться на информационные объекты, соответствующие нумерованному дому, улице, городу и штату. В иллюстративном примере атрибут «employment history» (информация о предшествующей трудовой деятельности) может ссылаться на один или более информационных объектов, соответствующих одному или более работодателям и соответствующим должностям и времени работы.
[00035] Определенные отношения между информационными объектами могут также обобщенно называться «фактами». Примерами таких отношений могут быть работа персоны X в организации Y, расположение физического объекта X в географическом положении Y, приобретение организации X организацией Y и т.д.; факт может быть связан с одной или более категориями фактов, таких, что категория фактов указывает на тип связи между информационными объектами определенного класса. Например, факт, связанный с персоной, может относиться к рождению, его образованию, занятости, трудовой деятельности и т.д. В другом примере факт, ассоциативно связанный с коммерческой сделкой, может иметь отношение к типу сделки и к сторонам этой сделки, к обязательствам сторон, дате подписания договора, дате совершения сделки, расчетам по договору и т.д. Извлечение фактов предполагает идентификацию различных отношений между извлеченными информационными объектами.
[00036] На информационный объект может ссылаться один или более фрагментов текста на естественном языке, обобщенно называемых «токенами естественного языка», так что каждый токен естественного языка может содержать одно или более слов естественного языка из одного или более предложений. Фрагменты текста, или токены, ссылающиеся на информационный объект, в этом документе обобщенно называются «аннотациями объекта». Фрагменты текста, или токены, ссылающиеся на атрибут информационного объекта, в этом документе обобщенно называются «аннотациями атрибута». Аннотация может быть определена ее положением в тексте, включая позицию начала и позицию конца.
[00037] Аннотированные тексты на естественном языке (например, один или более текстов на естественном языке с аннотациями, определяющими типы информационных объектов) могут использоваться для определения значений параметров моделей машинного обучения (например, функций классификатора, отражающих степень ассоциации исходной семантико-синтаксической структуры с определенным классом информационных объектов, типом отношений или категорией фактов). Обученные модели машинного обучения могут использоваться для выполнения различных операций обработки естественного языка, таких как распознавание именованных сущностей, извлечение информационных объектов, извлечение фактов, машинный перевод, семантический поиск и др.
[00038] Однако некоторые аннотированные тексты на естественном языке могут сопровождаться только спецификациями типов и отношений различных информационных объектов, представленных в текстах, при этом нет возможности определить хотя бы некоторые из координат текстовых аннотаций фрагментов на естественном языке, соответствующих извлеченным информационным объектам. В иллюстративном примере по меньшей мере некоторые текстовые аннотации, связанные с текстом на естественном языке, могут быть утрачены в процессе верификации пользователем извлеченной информации, который может включать подтверждение или корректировку класса онтологии, связанного с информационным объектом, типом отношений, типом или значением атрибута. Коррекция пользователем любой части извлеченной информации может привести к несостоятельности или утрате текстовых аннотаций, которые ранее были связаны с неправильно определенным классом онтологии, типом отношений, типом или значением атрибута.
[00039] Системы и способы по настоящему изобретению позволяют восстанавливать текстовые аннотации, связанные с информационными объектами и (или) атрибутами информационных объектов. В иллюстративном примере вычислительная система, в которой реализованы способы восстановления текстовых аннотаций, может получать текст на естественном языке и соответствующий набор информационных объектов с соответствующими значениями атрибутов. Вычислительная система может перебирать атрибуты с отсутствующими аннотациями и для каждого атрибута определять одну или более аннотаций-кандидатов, таких, что каждая аннотация-кандидат может быть представлена фрагментом текста на естественном языке. В некоторых вариантах осуществления аннотация-кандидат может определяться путем выполнения нечеткого поиска значения атрибута в тексте на естественном языке. Вычислительная система может затем вычислять один или более критериев ранжирования определенных аннотаций-кандидатов и выбирать одну или более аннотаций-кандидатов, имеющих оптимальное (например, максимальное или минимальное) значение рейтинговой оценки. Для каждой выбранной аннотации значение атрибута может быть связано с позицией начала и позицией конца соответствующего фрагмента текста на естественном языке, как более подробно описано ниже в этом документе.
[00040] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, не с целью ограничения.
[00041] На Фиг. 1 изображена блок-схема одного иллюстративного примера способа регулировки параметров функции классификатора, используемой для оценки атрибутов, связанных с информационными объектами, в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 100 и (или) каждая из его отдельных функций, стандартных программ, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы (например, вычислительная система 1000 на Фиг. 20), реализующими этот способ. В некоторых вариантах реализации способ 100 может осуществляться в одном потоке обработки. При альтернативном подходе способ 100 может осуществляться с использованием двух или более потоков обработки, при этом в каждом потоке реализована одна или более отдельных функций, процедур, подпрограмм или действий этого способа. В одном из иллюстративных примеров потоки обработки, в которых реализован способ 100, могут быть синхронизированы {например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, в которых реализован способ 100, могут выполняться асинхронно по отношению друг к другу.
[00042] На шаге 110 блок-схемы вычислительное устройство, в котором реализован этот способ, может получить текст на естественном языке 101 (например, документ или совокупность документов). В иллюстративном примере вычислительное устройство может получить текст на естественном языке в виде электронного документа, который может быть получен путем сканирования или за счет применения иного способа изображения с бумажного документа с последующим выполнением оптического распознавания символов (OCR) для получения текста документа. В другом иллюстративном примере вычислительная система может получить текст на естественном языке в виде одного или более форматированных файлов, например, файлов системы электронной обработки текста, сообщений электронной почты, файлов цифровых данных и т.д.
[00043] На шаге 120 блок-схемы вычислительная система может выполнить одну или более операций извлечения информации из текста на естественном языке. Операции извлечения информации могут включать определение информационных объектов, представленных текстом на естественном языке, и отнесение их к одному или более определенным классам, определение связей одного или более типов между определенными информационными объектами, извлечение фактов одной или более категорий из определенных информационных объектов и (или) определение атрибутов, относящихся к определенным информационным объектам.
[00044] В некоторых вариантах осуществления операции извлечения информации могут выполняться путем анализа множества семантико-синтаксических структур, соответствующих тексту на естественном языке, которые можно получить путем семантико-синтаксического анализа текста на естественном языке. Семантико-синтаксический анализ может получать множество семантических структур, в котором каждая из семантических структур представляет соответствующее предложение на естественном языке, как более подробно описано выше в этом документе со ссылкой на Фиг. 5-15. Семантическая структура может быть представлена ациклическим графом, который включает множество узлов, соответствующих семантическим классам, и множество дуг, соответствующих семантическим отношениям, как более подробно описано ниже со ссылкой на Фиг. 9. Для упрощения любое подмножество семантической структуры в этом документе мы будем называть «структурой» (а не «подструктурой»), если только не рассматривается отношение типа родитель-потомок между двумя семантическими структурами.
[00045] В некоторых вариантах реализации вычислительная система реализует способ, который позволяет интерпретировать множество семантических структур, используя набор продукционных правил для извлечения множества объектов, представляющих идентифицированные информационные объекты. Извлеченные объекты могут быть представлены в виде RDF-графа (Resource Description Framework) 130. RDF (Resource Description Framework - среда описания ресурса) присваивает каждому информационному объекту уникальный идентификатор и сохраняет информацию о таком объекте в виде наборов из трех элементов (триплетов) SPO, где S означает «субъект» и содержит идентификатор объекта, Р означает «предикат» и определяет некоторое свойство этого объекта, а О означает «объект» и хранит в себе значение рассматриваемого свойства данного объекта. Это значение может быть либо примитивным типом данных (примеры: строка, число, булево (логическое) значение), либо идентификатором другого объекта. В одном из иллюстративных примеров триплет SPO может связывать информационный объект со значением атрибута.
[00046] Продукционные правила, используемые для интерпретации семантических структур, могут включать правила интерпретации и правила идентификации. Правило интерпретации может содержать левую часть, представленную набором логических выражений, определенных на одном или более шаблонах семантической структуры, и правую часть, представленную одним или более утверждениями относительно информационных объектов, представляющих сущности, на которые имеется ссылка в тексте на естественном языке.
[00047] Шаблон семантической структуры может содержать некоторые элементы семантической структуры (например, принадлежность к определенному лексическому или семантическому классу, связь с некоторой поверхностной или глубинной позицией, наличие определенной граммемы или семантемы и т.д.). Отношения между элементами семантических структур могут задаваться с помощью одного или более логических выражений (конъюнкция, дизъюнкция и отрицание) и (или) операций, характеризующих взаимное расположение узлов в семантико-синтаксическом дереве. В одном из иллюстративных примеров такая операция может проверять один из узлов на принадлежность к поддереву другого узла.
[00048] Идентификация соответствия шаблона семантической структуры, определенного левой частью продукционного правила, семантической структуре, представляющей по крайней мере часть предложения текста на естественном языке, может запускать правую часть продукционного правила. Правая часть продукционного правила может устанавливать ассоциативную связь между одним или более атрибутами (отражающими лексические, синтаксические и (или) семантические свойства слов из первоначального предложения) и информационными объектами, представленными узлами, и (или) определять значения одного или более атрибутов. В одном из иллюстративных примеров такая правая часть продукционного правила может содержать выражение, связывающее информационный объект с определенным значением атрибута.
[00049] Правило идентификации может использоваться для установления ассоциативной связи для пары информационных объектов, которые представляют одну и ту же сущность реального мира. Правило идентификации - это продукционное правило, левая часть которого содержит одно или более логических выражений, указывающих на узлы семантического дерева, соответствующие информационным объектам. Если указанная пара информационных объектов удовлетворяет условиям, заданным логическими выражениями, то происходит слияние информационных объектов в один информационный объект.
[00050] В некоторых вариантах реализации вычислительная система может дополнительно выполнять одну или более функций классификатора. Функция классификатора может генерировать значение, отражающее степень ассоциации исходной семантико-синтаксической структуры с определенным классом информационных объектов, типом отношений или значением атрибута. В одном из иллюстративных примеров функция классификатора может быть реализована на основе метода адаптивного улучшения (AdaBoost) с классификатором деревьев решений. Алгоритм дерева решений использует дерево решений в качестве прогнозирующей модели для установления соответствия наблюдаемых параметров элемента (например, лексических или грамматических признаков подмножества семантико-синтаксической структуры) с выводами об искомом значении элемента (например, значения атрибута, связанного с семантико-синтаксической структурой). Этот способ может использоваться с деревом классификации, в котором каждый внутренний узел помечен входящим признаком (например, лексическими или грамматическими признаками подмножества семантико-синтаксической структуры). Дуги, связанные с узлом, который помечен признаком, помечены возможными значениями входящего признака. Каждый лист дерева помечен идентификатором класса (например, значением или диапазоном значений определенного атрибута, связанного с информационным объектом, связанным с семантико-синтаксической структурой) или степенью ассоциации с классом.
[00051] Ввиду существенной неоднозначности конструкций различных естественных языков связывание значения атрибута с информационным объектом не всегда может быть точным; в этом случае оно может описываться степенью уверенности, которая может быть выражена в виде числового значения на заданной шкале (например, действительным числом в диапазоне от 0 до 1). В соответствии с одним или более вариантами реализации настоящего изобретения на шаге 140 вычислительная система, реализующая способ, может определять значение степени уверенности, связанное с определенными атрибутами. В одном из иллюстративных примеров вычислительная система может вычислять функцию уверенности, связанную с функцией классификатора и (или) продукционными правилами, которые были использованы для получения атрибута. Область определения функции для вычисления степени уверенности данного атрибута может быть представлена одним или более аргументами, отражающими различные аспекты процесса извлечения информации, представленного на шаге 120. Эти аргументы могут включать, например, идентификаторы функций классификатора и (или) продукционных правил, которые использовались для получения рассматриваемого атрибута и (или) родственных атрибутов, оценки надежности функций классификатора и (или) продукционных правил, которые использовались для получения рассматриваемого атрибута и (или) родственных атрибутов, расчетных значений одной или более независимых от языка семантических структур, полученных при семантико-синтаксическом анализе текста на естественном языке, некоторые признаки семантических классов, полученных при синтаксическом и семантическом анализе информационного объекта, который характеризуется рассматриваемым атрибутом, и (или) другие характеристики процесса извлечения информации. В некоторых вариантах реализации изобретения вычислительная система может дополнять объекты данных, соответствующие тексту на естественном языке (например, RDF-граф 130), соответствующими значениями степени уверенности с атрибутами объектов, в результате чего будет получен дополненный RDF-граф 150.
[00052] В отдельных вариантах реализации изобретения функция уверенности может быть представлена линейным классификатором, оценивающим расстояние от информационного объекта до разделительной гиперплоскости в гиперпространстве признаков, которое можно использовать для извлечения атрибутов. Фиг. 2 схематически иллюстрирует пример линейного классификатора, создающего разделяющую гиперплоскость, представленную плоскостью 220 в гиперпространстве, представленном двухмерным пространством 207, которое может быть определено значениями F1 и F2, которые используются для извлечения атрибутов. Таким образом, каждый объект может быть представлен точкой в двухмерном пространстве 207, такой, что координаты точки соответствуют значениям F1 и F2 соответственно. Например, объект, имеющий значения признаков F1=f1 и F2=f2, может быть представлен точкой 231 с координатами (f1, f2). В соответствии с одним или более вариантами реализации настоящего изобретения расстояние между определенным объектом и разделительной гиперплоскостью 220 в гиперпространстве 207, как показано на Фиг. 2, может отражать степень уверенности, связанную с атрибутом объекта, который был идентифицирован в ходе процесса извлечения информации, описанного на шаге 140.
[00053] Значения параметров линейного классификатора могут быть определены с помощью методов машинного обучения. В некоторых вариантах реализации изобретения набор данных для обучения, используемый в методах машинного обучения, может содержать один или более текстов на естественном языке, в которых для некоторых объектов указаны соответствующие значения атрибутов (например, в тексте размечены классы или концепты онтологии для отдельных слов). Вычислительная система может итеративно идентифицировать значения параметров линейного классификатора, которые оптимизируют выбранную целевую функцию (например, позволяют выбрать максимальное значение целевой функции, соответствующее числу текстов на естественном языке, которые можно правильно классифицировать, используя указанные значения параметров линейного классификатора).
[00054] На Фиг. 1 на шаге 160 блок-схемы определенные значения атрибутов могут быть верифицированы с помощью графического интерфейса пользователя (GUI), используемого для вывода информационных объектов с одним или более связанными с ними атрибутами и получения от пользователя подтверждения или изменений связи выбранного атрибута с указанным информационным объектом и (или) получения от пользователя подтверждения или изменения значения атрибута. В одном из иллюстративных примеров GUI может содержать один или более флажков для подтверждения связи выбранного атрибута с информационным объектом или для подтверждения выводимого значения атрибута. В другом иллюстративном примере GUI может содержать один или более кнопок выбора для подтверждения связи выбранного атрибута с информационным объектом или выбора одного из выводимых значений атрибута. В другом иллюстративном примере GUI может содержать раскрывающийся список для выбора одного из выводимых значений атрибута.
[00055] В некоторых вариантах реализации атрибуты, степень уверенности которых находится ниже определенного порогового значения, могут быть подсвечены, заключены в описывающие прямоугольники, визуально связаны с заранее определенными символами или значками («?») или визуально выделены иным образом. В некоторых реализациях изобретения необходимое пороговое значение уверенности может выбираться пользователем с помощью ползунка GUI. Кроме того, пороговое значение уверенности может автоматически устанавливаться вычислительной системой, реализующей способ, и может, например, последовательно увеличиваться один или более раз после получения указания пользователя о завершении процесса верификации для текущей степени уверенности. Поскольку основное количество ошибок предположительно обнаруживается при низких степенях уверенности, то по мере повышения порогового значения уверенности количество ошибок будет уменьшаться, и процесс верификации может быть завершен, когда отношение количества ошибок к количеству правильно определенных атрибутов будет ниже заранее или динамически установленного порогового значения.
[00056] В ответ на получение сообщений пользователя о завершении процесса верификации вычислительная система может создать верифицированный RDF-граф 170, соответствующий исходному тексту 101 на естественном языке.
[00057] Таким образом, процесс верификации может изменить классы онтологии, типы отношений, типы атрибутов или значения атрибутов, связанные с одним или более информационными объектами, что может привести к несостоятельности ассоциированных текстовых аннотаций, которые ранее были связаны с неправильно определенным классом онтологии, типом отношений, типом или значением атрибута. Кроме того, значение атрибута может иметь написание, отличающееся от написания ассоциированного фрагмента текста на естественном языке, что может быть вызвано, например, ошибками оптического распознавания символов (OCR), которые привели к отсутствию знаков пунктуации или различию в расположении заглавных букв в одном или более словах.
[00058] На Фиг. 3А-3В схематически показаны примеры документов 300А и 300В на естественном языке с извлеченными признаками, связанными с определенными информационными объектами. Каждый из этих документов является источником определенного факта, например, операции купли-продажи. Стороны операции, их адреса и другие идентификаторы, сумма сделки интерпретируются как атрибуты, связанные с информационным объектом, представляющим операцию покупки. Документы 300А и 300В могут пройти пользовательскую верификацию атрибутов и могут содержать различные неточности, вызванные ошибками OCR и (или) разницей в написании некоторых атрибутов, каждый из которых как минимум дважды упоминается в тексте на естественном языке.
[00059] В иллюстративном примере на Фиг. 3А дата заключения соглашения ссылается на два текстовых фрагмента 310А и 310В, которые отличаются порядком слов, наименование первой стороны ссылается на два текстовых фрагмента 320А и 320В, которые отличаются капитализацией использованных букв, и наименование второй стороны ссылается на два текстовых фрагмента 330А и 330В, которые также отличаются капитализацией. В иллюстративном примере на Фиг. 3В наименование первой стороны ссылается на два текстовых фрагмента 340А и 340В, которые отличаются словами и используемой капитализацией, и наименование второй стороны ссылается на два текстовых фрагмента 350А и 350В, которые отличаются словами и капитализацией. Таким образом, способ восстановления аннотаций должен учитывать указанные и другие неточности и вариативность исходного текста на естественном языке.
[00060] На шаге 180 блок-схемы реализующая способ вычислительная система может восстановить одну или более текстовых аннотаций, связанных с информационными объектами и (или) атрибутами информационных объектов, как подробнее описано ниже в этом документе со ссылкой на Фиг. 4. Восстановление аннотаций может привести к созданию верифицированного RDF-графа с восстановленными аннотациями 185. В некоторых вариантах осуществления RDF-граф 185 может также включать рейтинговые оценки, связанные с восстановленными текстовыми аннотациями.
[00061] На шаге 190 RDF-граф 185 может быть добавлен к обучающему набору данных, который на шаге 195 блок-схемы может быть использован для коррекции параметров одной или более моделей классификаторов, используемых для вычисления атрибутов, связанных с информационными объектами.
[00062] На Фиг. 4 изображена блок-схема одного иллюстративного примера способа восстановления текстовой аннотации, связанной с информационными объектами, в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 400 и (или) каждая из его отдельных функций, программ, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы (например, вычислительной системы 1000 на Фиг. 20), реализующими этот способ. В некоторых вариантах реализации способ 400 может выполняться в одном потоке обработки. При альтернативном подходе способ 400 может быть реализован с помощью двух или более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций данного способа. В иллюстративном примере потоки обработки, реализующие способ 400, могут быть синхронизированы (например, с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 400, могут выполняться асинхронно друг относительно друга.
[00063] На шаге 410 вычислительная система, реализующая способ, получает текст на естественном языке и соответствующий набор информационных объектов с соответствующими значениями атрибутов (например, представленный дополненным RDF-графом), как более подробно описано выше в этом документе.
[00064] На шагах 420-450 блок-схемы вычислительная система может перебирать множество атрибутов, связанных с информационными объектами, извлеченными из текста на естественном языке. После определения на шаге 420 отсутствия текстовой аннотации, связанной с атрибутом, на шаге 430 вычислительная система может определять одну или более аннотаций-кандидатов, которые будут связаны с атрибутом, таких, что каждая аннотация-кандидат может быть представлена фрагментом текста на естественном языке. В некоторых вариантах осуществления аннотация-кандидат может определяться путем выполнения нечеткого поиска значения атрибута в тексте на естественном языке. В одном из иллюстративных примеров нечеткий поиск может базироваться на корневой морфеме значения атрибута (например, на значении атрибута, которое было извлечено из одного или более окончаний и (или) суффиксов). В одном из иллюстративных примеров нечеткий поиск может базироваться на одном или более синонимических выражений, связанных со значением атрибута.
[00065] Следует заметить, что идентификация текстовых аннотаций на основе нечеткого поиска может быть затруднена тем фактом, что два или более информационных объектов, извлеченных из текста на естественном языке, могут иметь идентичные или схожие значения атрибутов, и (или) несколько атрибутов одного информационного объекта могут иметь идентичные или схожие значения атрибутов. Поэтому на шаге 440 блок-схемы вычислительная система может оценивать один или более критериев ранжирования найденных аннотаций-кандидатов. В одном из иллюстративных примеров рейтинговая оценка, полученная при вычислении критерия ранжирования, может отражать расстояние в тексте на естественном языке между аннотацией-кандидатом и токеном текста, соответствующим аннотируемому информационному объекту. В другом иллюстративном примере рейтинговая оценка может отражать наличие других атрибутов на заранее определенном расстоянии от токена текста, соответствующего аннотируемому информационному объекту. В другом иллюстративном примере рейтинговая оценка может создаваться моделью классификатора, которая была обучена на обучающей выборке данных, включающей один или более текстов на естественном языке из той же категории, что и анализируемый текст на естественном языке. Параметры такой модели классификатора могут быть дополнительно отрегулированы с использованием одного или более верифицированных текстов на естественном языке с восстановленными атрибутами.
[00066] На шаге 450 блок-схемы для каждого атрибута информационного объекта могут выбираться одна или более аннотаций-кандидатов, имеющих оптимальное (например, максимальное или минимальное) значение рейтинговой оценки. Для каждой выбранной аннотации значение атрибута может быть связано с позицией начала и позицией конца соответствующего фрагмента текста на естественном языке.
[00067] На Фиг. 5 схематически изображена семантическая структура 501, отображающая пример английского предложения: «Serving in the House of Representatives since 1990, Republican John Boehner was elected Speaker of the House of Representatives in November 2010».
[00068] На Фиг. 6 схематически показаны информационный объект (представленный именованными сущностями) и факты, извлеченные из примера предложения с помощью систем и способов, действующих в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 6, факт из категории «Employment» (трудовая деятельность) связан с именованными сущностями из категорий «Person» (человек) и «Employer» (работодатель).
[00069] На Фиг. 7А-7С схематично показаны фрагменты 701, 702 и 703 семантической структуры 501, отображающей пример предложения, к которому применены продукционные правила с целью извлечения именованных сущностей и фактов.
[00070] На Фиг. 8А-8С схематично показаны продукционные правила, применяемые к подмножеству семантической структуры, соответствующей примеру предложения на Фиг. 5, для извлечения информационных объектов и фактов. Правила 801-803 применяются к семантической структуре 701. Правило 801 извлекает именованную сущность категории «Person» (персона). Правило 802 как минимум частично устанавливает кореференцию, связанную с извлеченной именованной сущностью. Правило 803 связывает извлеченные именованные сущности («Person» (персона) и «Employer» (работодатель)) отношением, указывающим на то, что человек (некоторая персона) работает у работодателя. Правила 804-805 применяются к семантической структуре 701. Правило 804 создает факт категории «Занятость», связывающий извлеченные именованные сущности. Правило 805 связывает атрибут «Employer» (работодатель) созданного факта с извлеченной именованной сущностью категории «Organization» (организация). Правила 806 и 805 применяются к семантической структуре 703. Правило 806 создает факт категории «Occupation» (занятость), связывающий извлеченные именованные сущности.
[00071] На Фиг. 9 приведена блок-схема одного иллюстративного примера способа 400 для выполнения семантико-синтаксического анализа предложения на естественном языке 212 в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 400 может быть применен к одной или более синтаксическим единицам (например, предложениям), включенным в определенный текстовый корпус, для формирования множества семантико-синтаксических деревьев, соответствующих синтаксическим единицам. В различных иллюстративных примерах предложения на естественном языке, подлежащие обработке способом 400, могут извлекаться из одного или более электронных документов, которые могут создаваться путем сканирования (или другим способом получения изображений бумажных документов) и оптического распознавания символов (OCR), для формирования текстов, связанных с данными документами. Предложения на естественном языке также могут извлекаться из других различных источников, включая сообщения, отправляемые по электронной почте, тексты из социальных сетей, файлы с цифровым содержимым, обработанные с использованием способов распознавания речи и т.д.
[00072] На шаге 214 вычислительная система, реализующая данный способ, может проводить лексико-морфологический анализ предложения 212 для установления морфологических значений слов, входящих в состав предложения. В настоящем документе «морфологическое значение» слова означает одну или более лемм (то есть канонических или словарных форм), соответствующих слову, и соответствующий набор значений грамматических атрибутов, которые определяют грамматическое значение слова. В число таких грамматических признаков могут входить лексическая категория слова и один или более морфологических признаков (например, падеж, род, число, спряжение и т.д.). Ввиду омонимии и (или) совпадающих грамматических форм, соответствующих разным лексико-морфологическим значениям определенного слова, для данного слова может быть установлено два или более морфологических значений. Более подробное описание иллюстративного примера проведения лексико-морфологического анализа предложения приведено ниже в настоящем документе со ссылкой на Фиг. 10.
[00073] На шаге 215 блок-схемы вычислительная система может проводить грубый синтаксический анализ предложения 212. Грубый синтаксический анализ может включать определение одной или более синтаксических моделей, которые могут быть соотнесены с предложением 212, с последующим установлением поверхностных (то есть синтаксических) связей в рамках предложения 212 для получения графа обобщенных составляющих. В настоящем документе «составляющая» означает группу соседних слов исходного предложения, функционирующую как одна грамматическая сущность. Составляющая включает в себя ядро в виде одного или более слов и может также включать одну или более дочерних составляющих на более низких уровнях. Дочерняя составляющая является зависимой составляющей, которая может быть соотнесена с одной или более родительскими составляющими.
[00074] На шаге 216 блок-схемы вычислительная система может проводить точный синтаксический анализ предложения 212 для формирования одного или более синтаксических деревьев предложения. Причиной многообразия возможных синтаксических деревьев, соответствующих какому-либо данному исходному предложению, может быть омонимия и (или) совпадающие грамматические формы, соответствующие разным лексико-морфологическим значениям одного или более слов в составе исходного предложения. Среди различных синтаксических деревьев на основе определенной функции оценки с учетом совместимости лексических значений слов исходного предложения, поверхностных отношений, глубинных отношений и т.д. может быть отобрано одно или более лучших синтаксических деревьев, соответствующих предложению 212.
[00075] На шаге 217 вычислительная система может обрабатывать синтаксические деревья для формирования семантической структуры 218, соответствующей предложению 212. Семантическая структура 218 может включать множество узлов, соответствующих семантическим классам, и также может включать множество дуг, соответствующих семантическим отношениям, как более подробно описано ниже в настоящем документе.
[00076] На Фиг. 10 схематически иллюстрируется пример лексико-морфологической структуры предложения в соответствии с одним или более вариантами реализации настоящего изобретения. Пример лексико-морфологической структуры 500 может предполагать наличие множества пар «лексическое значение-грамматическое значение» для примера предложения. В качестве иллюстративного примера, «II» может быть соотнесено с лексическим значением «shall» 512 и «will» 514. Грамматическим значением, соотнесенным с лексическим значением 512, является
[00077] На Фиг. 11 схематически иллюстрируются языковые описания 610, в том числе морфологические описания 201, лексические описания 203, синтаксические описания 202 и семантические описания 204, а также отношения между ними. Среди них морфологические описания 201, лексические описания 203 и синтаксические описания 202 зависят от языка. Набор языковых описаний 610 представляет собой модель определенного естественного языка.
[00078] В качестве иллюстративного примера определенное лексическое значение в лексических описаниях 203 может быть соотнесено с одной или более поверхностными моделями синтаксических описаний 202, соответствующих данному лексическому значению. Определенная поверхностная модель синтаксических описаний 202 может быть соотнесена с глубинной моделью семантических описаний 204.
[00079] На Фиг. 12 схематически иллюстрируются несколько примеров морфологических описаний. В число компонентов морфологических описаний 201 могут входить описания словоизменения 310, грамматическая система 320, описание словообразования 330 и другие. Грамматическая система 320 включает набор грамматических категорий, таких как часть речи, падеж, род, число, лицо, возвратность, время, вид и их значения (так называемые «граммемы»), в том числе, например, прилагательное, существительное или глагол; именительный, винительный или родительный падеж; женский, мужской или средний род и т.д. Соответствующие граммемы могут использоваться для составления описания словоизменения 310 и описания словообразования 330.
[00080] Описание словоизменения 310 определяет формы данного слова в зависимости от его грамматических категорий (например, падеж, род, число, время и т.д.) и в широком смысле включает в себя или описывает различные возможные формы слова. Описание словообразования 330 определяет, какие новые слова могут быть образованы от данного слова (например, сложные слова).
[00081] В соответствии с одним из вариантов реализации настоящего изобретения при установлении синтаксических отношений между элементами исходного предложения могут использоваться модели составляющих. Составляющая представляет собой группу соседних слов в предложении, ведущих себя как единое целое. Ядром составляющей является слово, она также может содержать дочерние составляющие на более низких уровнях. Дочерняя составляющая является зависимой составляющей и может быть прикреплена к другим составляющим (родительским) для построения синтаксических описаний 202 исходного предложения.
[00082] На Фиг. 13 приведены примеры синтаксических описаний. В число компонентов синтаксических описаний 202 могут входить, среди прочего, поверхностные модели 410, описания поверхностных позиций 420, описание референциального и структурного контроля 456, описание управления и согласования 440, описание недревесного синтаксиса 450 и правила анализа 460. Синтаксические описания 202 могут использоваться для построения возможных синтаксических структур исходного предложения на заданном естественном языке с учетом свободного линейного порядка слов, недревесных синтаксических явлений (например, согласование, эллипсис и т.д.), референциальных отношений и других факторов.
[00083] Поверхностные модели 410 могут быть представлены в виде совокупностей одной или более синтаксических форм («синтформ» 412) для описания возможных синтаксических структур предложений, входящих в состав синтаксического описания 102. В целом лексическое значение слова на естественном языке может быть связано с поверхностными (синтаксическими) моделями 410. Поверхностная модель может представлять собой составляющие, которые возможны, если лексическое значение выступает в роли «ядра». Поверхностная модель может включать набор поверхностных позиций дочерних элементов, описание линейного порядка и (или) диатезу. В настоящем документе «диатеза» означает определенное отношение между деятелем (субъектом) и одним или более объектами, синтаксические роли которых определяются морфологическими и (или) синтаксическими средствами. В качестве иллюстративного примера диатеза может быть представлена залогом глагола: когда субъект является агентом действия, то глагол находится в активном залоге, а когда субъект является целью, на которую направлено действие, глагол находится в пассивном залоге.
[00084] В модели составляющих может использоваться множество поверхностных позиций 415 дочерних составляющих и описаний их линейного порядка 416 для описания грамматических значений 414 возможных заполнителей этих поверхностных позиций. Диатезы 417 могут представлять соответствия между поверхностными позициями 415 и глубинными позициями 514 (как показано на Фиг. 14). Коммуникативные описания 480 описывают коммуникативный порядок в предложении.
[00085] Описание линейного порядка 416 может быть представлено в виде выражений линейного порядка, отражающих последовательность, в которой различные поверхностные позиции 415 могут встречаться в предложении. Выражения линейного порядка могут включать имена переменных, имена поверхностных позиций, круглые скобки, граммемы, оценки, оператор «or» (или) и т.д. В одном из иллюстративных примеров описание линейного порядка простого предложения «Boys play footbalb можно представить в виде «Subject Core Object Direct» (подлежащее - ядро - прямое дополнение), где Subject (подлежащее), Core (ядро) и Object Direct (прямое дополнение) представляют собой имена поверхностных позиций 415, соответствующих порядку слов.
[00086] Коммуникативные описания 480 могут описывать порядок слов в синтаксической форме 412 с точки зрения коммуникативных актов, представленных в виде коммуникативных выражений порядка, которые похожи на выражения линейного порядка. Описание управления и согласования 440 может включать правила и ограничения на грамматические значения прикрепленных составляющих, которые используются во время синтаксического анализа.
[00087] Описания недревесного синтаксиса 450 могут создаваться для отражения различных языковых явлений, таких как эллипсис и согласование; они используются при трансформациях синтаксических структур, которые создаются на различных этапах анализа в различных вариантах реализации изобретения. Описания недревесного синтаксиса 450 могут, среди прочего, включать описание эллипсиса 452, описание согласования 454, а также описание референциального и структурного контроля 430.
[00088] Правила анализа 460 могут давать общее описание свойств конкретного языка и использоваться в рамках семантического анализа. Правила анализа 460 могут включать правила вычисления семантем 462 и правила нормализации 464. Правила нормализации 464 могут использоваться для описания трансформаций семантических структур, которые могут отличаться в разных языках.
[00089] На Фиг. 14 приведен пример семантических описаний. Компоненты семантических описаний 204 не зависят от языка и могут, среди прочего, включать семантическую иерархию 510, описания глубинных позиций 520, систему семантем 530 и прагматические описания 540.
[00090] Ядро семантических описаний может быть представлено семантической иерархией 510, в которую могут входить семантические понятия (семантические сущности), также называемые семантическими классами. Последние могут быть упорядочены в иерархическую структуру, отражающую отношения «родитель-потомок». В целом дочерний семантический класс может унаследовать одно или более свойств своего прямого родителя и других семантических классов-предков. В одном из иллюстративных примеров семантический класс SUBSTANCE (вещество) является дочерним семантическим классом класса ENTITY (сущность) и материнским семантическим классом для классов GAS, (газ), LIQUID (жидкость), METAL (металл), WOOD_MATERIAL (древесина) и т.д.
[00091] Каждый семантический класс в семантической иерархии 510 может сопровождаться глубинной моделью 512. Глубинная модель 512 семантического класса может включать множество глубинных позиций 514, которые могут отражать семантические роли дочерних составляющих в различных предложениях с объектами данного семантического класса в качестве ядра родительской составляющей. Глубинная модель 512 также может включать возможные семантические классы, выступающие в роли заполнителей глубинных моделей. Глубинные позиции 514 могут выражать семантические отношения, в том числе, например, «agent» (агент), «addressee» (адресат), «instrument» (инструмент), «quantity» (количество) и т.д. Дочерний семантический класс может наследовать и уточнять глубинную модель своего непосредственного родительского семантического класса.
[00092] Описания глубинных позиций 520 отражают семантические роли дочерних составляющих в глубинных моделях 512 и могут использоваться для описания общих свойств глубинных позиций 514. Описания глубинных позиций 520 также могут содержать грамматические и семантические ограничения в отношении заполнителей глубинных позиций 514. Свойства и ограничения, связанные с глубинными позициями 514 и их возможными заполнителями в различных языках, могут быть в значительной степени подобными и зачастую идентичными. Таким образом, глубинные позиции 514 не зависят от языка.
[00093] Система семантем 530 может представлять собой множество семантических категорий и семантем, которые представляют значения семантических категорий. В качестве иллюстративного примера семантическая категория «DegreeOfComparison» (степень сравнения) может использоваться для описания степени сравнения и включать следующие семантемы: «Positive» (положительная), «ComparativeHigherDegree» (сравнительная степень сравнения), «SuperlativeHighestDegree» (превосходная степень сравнения) и другие. В качестве еще одного иллюстративного примера семантическая категория «RelationToReferencePoint» (отношение к реперной точке) может использоваться для описания порядка (пространственного или временного в широком смысле анализируемых слов) как, например, до или после реперной точки, и включать семантемы «Previous» (предыдущий) и «Subsequent» (последующий). В еще одном иллюстративном примере семантическая категория «EvaluationObjective» (оценка) может использоваться для описания объективной оценки, например, «Bad» (плохой), «Good» (хороший) и т.д.
[00094] Система семантем 530 может включать независимые от языка семантические атрибуты, которые могут выражать не только семантические характеристики, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы могут использоваться для выражения атомарного значения, которое находит регулярное грамматическое и (или) лексическое выражение в естественном языке. По своему целевому назначению и использованию системы семантем могут разделяться на категории, например грамматические семантемы 532, лексические семантемы 534 и классифицирующие грамматические (дифференцирующие) семантемы 536.
[00095] Грамматические семантемы 532 могут использоваться для описания грамматических свойств составляющих при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы 534 могут описывать конкретные свойства объектов (например, «being flat» (быть плоским) или «being liquid» (являться жидкостью)) и использоваться в описаниях глубинных позиций 520 как ограничение заполнителей глубинных позиций (например, для глаголов «face (with)» (облицовывать) и «flood» (заливать) соответственно). Классифицирующие грамматические (дифференцирующие) семантемы 536 могут выражать дифференциальные свойства объектов внутри одного семантического класса. В одном из иллюстративных примеров в семантическом классе HAIRDRESSER (парикмахер) семантема <
[00096] Прагматические описания 540 позволяют назначать определенную тему, стиль или жанр текстам и объектам семантической иерархии 510 (например, «Экономическая политика», «Внешняя политика», «Юриспруденция», «Законодательство», «Торговля», «Финансы» и т.д.). Прагматические свойства также могут выражаться семантемами. В качестве иллюстративного примера прагматический контекст может приниматься во внимание при семантическом анализе.
[00097] На Фиг. 15 приведен пример лексических описаний. Лексические описания 203 представляют собой множество лексических значений 612 конкретного естественного языка для каждого компонента предложения. Для каждого лексического значения 612 можно установить связь 602 с его независимым от языка семантическим родителем для того, чтобы указать положение какого-либо заданного лексического значения в семантической иерархии 510.
[00098] Лексическое значение 612 лексико-семантической иерархии 510 может быть соотнесено с поверхностной моделью 410, которая в свою очередь через одну или более диатез 417 может быть соотнесена с соответствующей глубинной моделью 512. Лексическое значение 612 может наследовать семантический класс своего родителя и уточнять свою глубинную модель 512.
[00099] Поверхностная модель 410 лексического значения может включать одну или более синтаксических форм 412. Синтаксическая форма 412 поверхностной модели 410 может включать одну или более поверхностных позиций 415, в том числе их соответствующие описания линейного порядка 416, одно или более грамматических значений 414, выраженных в виде набора грамматических категорий (граммем), одно или более семантических ограничений, соотнесенных с заполнителями поверхностных позиций, и одну или более диатез 417. Семантические ограничения, соотнесенные с определенным заполнителем поверхностной позиции, могут быть представлены в виде одного или более семантических классов, объекты которых могут заполнить эту поверхностную позицию.
[000100] На Фиг. 16 схематически иллюстрируются примеры структур данных, которые могут быть использованы в рамках одного или более методов настоящего изобретения. На Фиг. 9 в блоке 214 блок-схемы вычислительное устройство, реализующее данный способ, может проводить лексико-морфологический анализ предложения 212 для построения лексико-морфологической структуры 722 согласно Фиг. 16. Лексико-морфологическая структура 722 может включать множество соответствий лексического и грамматического значений для каждого лексического элемента (например, слова) исходного предложения. На Фиг. 10 схематически иллюстрируется пример лексико-морфологической структуры.
[000101] На шаге 215 блок-схемы вычислительное устройство может проводить грубый синтаксический анализ исходного предложения 212 для построения графа обобщенных составляющих 732 согласно Фиг. 16. Грубый синтаксический анализ предполагает применение одной или более возможных синтаксических моделей возможных лексических значений к каждому элементу множества элементов лексико-морфологической структуры 722 с тем, чтобы установить множество потенциальных синтаксических отношений в составе исходного предложения 212, представленных графом обобщенных составляющих 732.
[000102] Граф обобщенных составляющих 732 может быть представлен ациклическим графом, включающим множество узлов, соответствующих обобщенным составляющим исходного предложения 212 и включающим множество дуг, соответствующих поверхностным (синтаксическим) позициям, которые могут выражать различные типы отношений между обобщенными лексическими значениями. В рамках данного способа может применяться множество потенциально жизнеспособных синтаксических моделей для каждого элемента множества элементов лексико-морфологических структур исходного предложения 212 для формирования набора составляющих ядра исходного предложения 212. Затем в рамках способа может рассматриваться множество возможных синтаксических моделей и синтаксических структур исходного предложения 212 для построения графа обобщенных составляющих 732 на основе набора составляющих. Граф обобщенных составляющих 732 на уровне поверхностной модели может отражать множество потенциальных связей между словами исходного предложения 212. Поскольку количество возможных синтаксических структур может быть относительно большим, то граф обобщенных составляющих 732 может в общем включать избыточную информацию, в том числе относительно большие числа лексического значения по определенным узлам и (или) поверхностные позиции по определенным дугам графа.
[000103] Граф обобщенных составляющих 732 может изначально строиться в виде дерева, начиная с концевых узлов (листьев) и двигаясь далее к корню, путем добавления дочерних компонентов, заполняющих поверхностные позиции 415 множества родительских составляющих с тем, чтобы все лексические единицы исходного предложения 212 были отражены.
[000104] В определенных вариантах осуществления корень графа обобщенных составляющих 732 представляет собой предикат. В ходе описанного выше процесса дерево может стать графом, так как определенные составляющие более низкого уровня могут быть включены в одну или более составляющих более верхнего уровня. Множество составляющих, которые представляют определенные элементы лексико-морфологической структуры, затем может быть обобщено для получения обобщенных составляющих. Составляющие могут быть обобщены на основе их лексических или грамматических значений 414, например на основе обозначений частей речи и отношений между ними. На Фиг. 17 схематически иллюстрируется пример графа обобщенных составляющих.
[000105] На шаге 216 вычислительная система может проводить точный синтаксический анализ предложения 212 для формирования одного или более синтаксических деревьев 742 согласно Фиг. 16 на основе графа обобщенных составляющих 732. Для каждого из одного или более синтаксических деревьев вычислительное устройство может определить общую оценку на основе определенных расчетов и априорных оценочных показателей. Дерево с наилучшей оценкой может быть выбрано для построения наилучшей синтаксической структуры 746 исходного предложения 212.
[000106] В ходе построения синтаксической структуры 746 на основе выбранного синтаксического дерева вычислительная система может установить одну или более недревесных связей (например, путем создания избыточного пути среди как минимум двух узлов графа). Если этот процесс заканчивается неудачей, то вычислительная система может выбрать синтаксическое дерево с условно оптимальной оценкой, наиболее близкой к оптимальной, и производится попытка установить одну или более недревесных связей в дереве. Наконец, в результате точного синтаксического анализа создается синтаксическая структура 746, которая представляет собой лучшую синтаксическую структуру, соответствующую исходному предложению 212. Фактически в результате отбора лучшей синтаксической структуры 746 создаются лучшие лексические значения 240 исходного предложения 212.
[000107] На шаге 217 вычислительная система может обрабатывать синтаксические деревья для формирования семантической структуры 218, соответствующей предложению 212. Семантическая структура 218 может отражать передаваемую исходным предложением семантику в независимых от языка понятиях. Семантическая структура 218 может быть представлена в виде ациклического графа (например, дерево, дополненное по меньшей мере одной недревесной связью, такой как дуга, формирующая избыточный путь среди как минимум двух узлов графа). Исходные слова естественного языка представлены в виде узлов, соответствующих независимыми от языка семантическими классами семантической иерархии 510. Дуги графа представляют глубинные (семантические) отношения между узлами. Семантическая структура 218 может строиться на основе правил анализа 460 и предполагать соотнесение одного или более атрибутов (отражающих лексические, синтаксические и (или) семантические свойства слов исходного предложения 212) с каждым семантическим классом.
[000108] На Фиг. 18 показан пример синтаксической структуры предложения, порожденной из графа обобщенных составляющих, приведенного на Фиг. 17. Узел 901 соответствует лексическому элементу «life» (жизнь) 906 в исходном предложении 212. Применяя способ описанного в настоящем документе семантико-синтаксического анализа, вычислительная система может установить, что лексический элемент «life» (жизнь) 906 представляет одну из лексем производной формы «live» (жить) 902, соотнесенной с семантическим классом «LIVE» (ЖИТЬ) 904, и заполняет поверхностную позицию $Adjunctr_Locative 905 в родительской составляющей, представленной управляющим узлом Verb:succeed:succeed:TO_SUCCEED 907.
[000109] На Фиг. 19 показана семантическая структура, соответствующая синтаксической структуре, приведенной на Фиг. 18. В отношении вышеупомянутого лексического элемента «life» (жизнь) 906 на Фиг. 18 семантическая структура включает лексический класс 1010 и семантический класс 1030, подобные представленным на Фиг. 18, однако вместо поверхностной позиции 905 семантическая структура включает глубинную позицию «Sphere» (сфера) 1020.
[000110] Как отмечено выше в настоящем документе, в качестве «онтологии» может выступать модель, которая представляет собой объекты, относящиеся к определенной области знаний (предметной области), и отношения между данными объектами. Таким образом, онтология отличается от семантической иерархии, несмотря на то что она может быть соотнесена с элементами семантической иерархии через определенные отношения (также называемые «якоря»). Онтология может включать определения некого множества классов, где каждый класс соответствует концепту предметной области. Каждое определение класса может включать определения одного или более отнесенных к данному классу объектов. Согласно общепринятой терминологии класс онтологии может также называться «концепт», а принадлежащий классу объект может означать экземпляр данного концепта.
[000111] В соответствии с одним или более вариантами реализации настоящего изобретения вычислительная система, реализующая способы, описанные в настоящем документе, может индексировать один или более параметров, полученных в результате семантико-синтаксического анализа. Таким образом, способы настоящего изобретения позволяют рассматривать не только несколько слов в составе исходного текстового корпуса, но и несколько лексических значений этих слов, сохраняя и индексируя всю синтаксическую и семантическую информацию, полученную в ходе синтаксического и семантического анализа каждого предложения исходного корпуса текста. Такая информация может дополнительно включать данные, полученные в ходе промежуточных этапов анализа, а также результаты лексического выбора, в том числе результаты, полученные в ходе устранения неоднозначностей, вызванных омонимией и (или) совпадающими грамматическими формами, соответствующими различным лексико-морфологическим значениям определенных слов исходного языка.
[000112] Для каждой семантической структуры можно создать один или более индексов. Индекс можно представить в виде структуры данных в памяти, например в виде таблицы, состоящей из множества записей. Каждая запись может представлять собой установление соответствия между определенным элементом семантической структуры (например, одно или более слов, синтаксическое отношение, морфологическое, синтаксическое или семантическое свойство или синтаксическая или семантическая структура) и одним или более идентификаторами (или адресами) случаев употребления данного элемента семантической структуры в исходном тексте.
[000113] В определенных вариантах реализации изобретения индекс может быть представлен одним или более значениями морфологических, синтаксических, лексических и (или) семантических параметров. Эти значения могут создаваться в процессе двухэтапного семантического анализа (более подробное описание см. в настоящем документе). Индекс можно использовать для выполнения различных задач обработки естественного языка, в том числе для выполнения семантического поиска.
[000114] Вычислительная система, реализующая данный способ, может извлекать широкий спектр лексических, грамматических, синтаксических, прагматических и (или) семантических характеристик в ходе проведения семантико-синтаксического анализа и создания семантических структур. В иллюстративном примере система может извлекать и сохранять определенную лексическую информацию, данные о принадлежности определенных лексических единиц семантическим классам, информацию о грамматических формах и линейном порядке, информацию об использовании синтаксических отношений и поверхностных позиций, информацию об использовании определенных форм, аспектов, тональности (например, положительной или отрицательной), глубинных позиций, недревесных связей, семантем и т.д.
[000115] Вычислительная система, в которой реализованы описанные здесь способы, может производить анализ, используя один или более описанных в этом документе способов анализа текста, и индексировать любой один или множество параметров описаний языка, включая лексические значения, семантические классы, граммемы, семантемы и т.д. Индексацию семантического класса можно использовать в различных задачах обработки естественного языка, включая семантический поиск, классификацию, кластеризацию, фильтрацию текста и т.д. Индексация лексических значений (вместо индексации слов) позволяет искать не только слова и формы слов, но и лексические значения, то есть слова, имеющие определенные лексические значения. Вычислительная система, реализующая способы, описанные в настоящем документе, также может хранить и индексировать синтаксические и семантические структуры, созданные одним или более описанными в настоящем документе методами текстового анализа, для использования данных структур и (или) индексов при проведении семантического поиска, классификации, кластеризации и фильтрации документов.
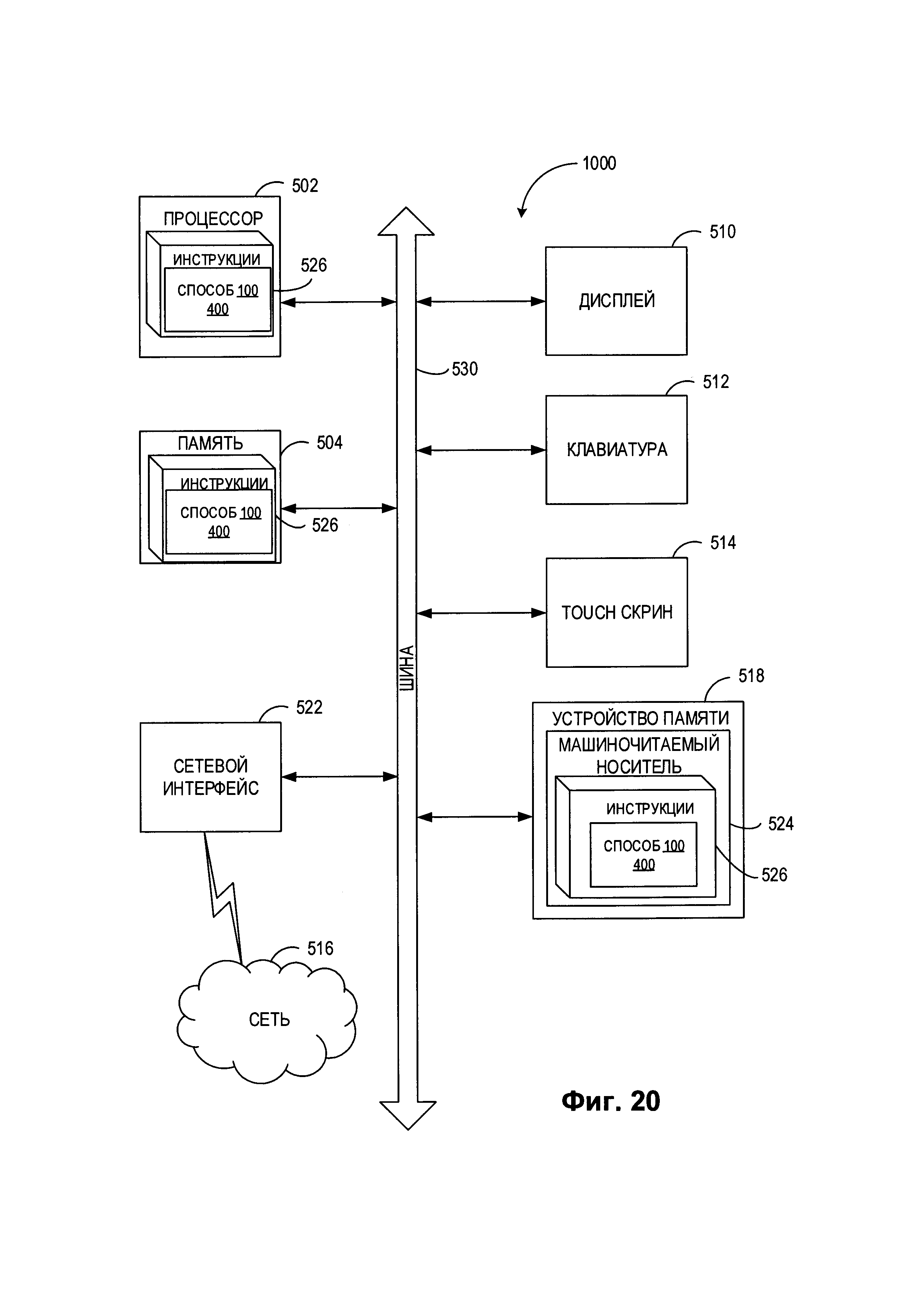
[000116] На Фиг. 20 показан иллюстративный пример вычислительной системы 1000, которая может исполнять набор команд, которые вызывают выполнение вычислительной системой любого отдельно взятого или нескольких способов настоящего изобретения. Вычислительная система может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система может работать в качестве сервера или клиента в сетевой среде «клиент / сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или более наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[000117] Пример вычислительной системы 1000 включает процессор 502, основную память 504 (например, постоянное запоминающее устройство (ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных 518, которые взаимодействуют друг с другом по шине 530.
[000118] Процессор 502 может быть представлен одной или более универсальными вычислительными системами, например микропроцессором, центральным процессором и т.д. В частности, процессор 502 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд или процессоры, реализующие комбинацию наборов команд. Процессор 502 также может представлять собой одну или более вычислительных систем специального назначения, например заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 502 настроен на выполнение команд 526 для осуществления рассмотренных в настоящем документе операций и функций.
[000119] Вычислительная система 1000 может дополнительно включать устройство сетевого интерфейса 522, устройство визуального отображения 510, устройство ввода символов 512 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 514.
[000120] Устройство хранения данных 518 может содержать машиночитаемый носитель данных 524, в котором хранится один или более наборов команд 526 и в котором реализованы одна или более методик или функций, рассмотренных в настоящем документе. Команды 526 также могут находиться полностью или по меньшей мере частично в основной памяти 504 и (или) в процессоре 502 во время выполнения их в вычислительной системе 1000, при этом оперативная память 504 и процессор 502 также представляют собой машиночитаемый носитель данных. Команды 526 также могут передаваться или приниматься по сети 516 через устройство сетевого интерфейса 522.
[000121] В некоторых вариантах реализации изобретения набор команд 526 может содержать команды способов 100, 400 восстановления текстовых аннотаций, связанных с информационными объектами, в соответствии с одним или более вариантами реализации настоящего изобретения. Несмотря на то что машиночитаемый носитель данных 524 показан в примере на Фиг. 20 в виде одного носителя, термин «машиночитаемый носитель» следует понимать в широком смысле, подразумевающем один носитель или более носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как включающий любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельной памяти, а также к оптическим и магнитным носителям.
[000122] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор), или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[000123] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[000124] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций над битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[000125] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если явно не указано обратное, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «определение», «изменение» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и устройствах памяти вычислительной системы, в другие данные, также представленные в виде физических величин в устройствах памяти или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[000126] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально выполнено для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[000127] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.
Реферат
Изобретение относится к способам восстановления текстовых аннотаций в системах извлечения информации из текстов на естественном языке и постоянному машиночитаемому носителю данных. Технический результат заключается в восстановлении текстовых аннотаций, связанных с информационными объектами и атрибутами информационных объектов. Способ включает в себя получение текста на естественном языке, извлечение из текста на естественном языке одного или более информационного объекта, где каждый информационный объект связан с одним или более атрибутами, при этом указанное извлечение включает определение значения степени уверенности, ассоциированного с атрибутом каждого информационного объекта, верификацию значений атрибутов множества информационных объектов, идентификацию во множестве информационных объектов такого информационного объекта, для которого по меньшей мере один атрибут определенного информационного объекта не был связан с по меньшей мере одной текстовой аннотацией, и восстановление текстовой аннотации, связанной с атрибутом определенного информационного объекта, где текстовая аннотация представлена фрагментом текста на естественном языке, соответствующим значению атрибута. 3 н. и 13 з.п. ф-лы, 25 ил.
Комментарии