Способ и система для хранения и поиска информации, извлекаемой из текстовых документов - RU2605077C2
Код документа: RU2605077C2
Чертежи





Описание
Область техники, к которой относится изобретение
[0001] Данное изобретение относится к области автоматической обработки естественного языка, в частности к способу и устройству для хранения и поиска информации, извлекаемой из текстовых документов.
Описание предшествующего уровня техники
[0002] Распространение интернета привело к доступности в режиме реального времени больших объемов документов в электронной форме, таких как электронные книги, статьи, электронная почта, чаты и т.д. Автоматическая обработка таких текстовых документов требует применения технологий автоматической обработки текстов (АОТ). Ключевыми элементами таких технологий, включая методы и создаваемые на их основе приложения, являются системы анализа текстов на естественном языке, лингвистические описания, системы извлечения информации и онтологии как модели предметных областей.
[0003] Электронные текстовые документы, как правило, не структурированы, и потому задача автоматического извлечения и структурирования содержащейся в них информации является довольно сложной. Эти процессы включают идентификацию различных информационных объектов в текстовых документах и идентификацию отношений между ними и отношений между ними и сущностями реального мира для последующего использования при построении формальных моделей предметных областей в различных приложениях.
[0004] В большинстве случаев, извлеченная информация может храниться в виде графов Среды описания ресурсов (Resource Description Framework - RDF), которая совместима с различными онтологиями. Эти информационные RDF-графы могут быть очень сложными из-за огромного числа концептов онтологии, экземпляров и отношений между ними. Кроме того, компьютерной системой должен быть легко осуществляем поиск на этих RDF-графах в процессе автоматической обработки текстов. Поэтому существует потребность в эффективных методах извлечения, хранения и поиска информации, извлеченной из текстовых документов.
Раскрытие изобретения
[0005] Описываются примеры реализации системы и способа для хранения, поиска и обновления данных, извлекаемых из текстовых документов.
[0006] В одной из реализаций способа производят извлечение по крайней мере одного первого информационного объекта из текстового документа; формируют по крайней мере один триплет вида <субъект, предикат, объект>; обеспечивают организацию доступа к хранилищу извлеченной информации, содержащему RDF- граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов; осуществляют поиск в хранилище извлеченной информации второго информационного объекта, представляющего тот же объект реального мира, что и первый информационный объект, где любые два информационных объекта отождествляются, если указанные объекты имеют по крайней мере общий объектный параметр, и где поиск включает выбор и поиск в по меньшей мере одной из трех типов таблиц идентификаторов, содержащих дуплетный, триплетный или квадовый поисковый индекс, где каждый поисковый индекс основан на по крайней мере двух параметрах, выбираемых из множества: субъект, предикат, объект, документ, и если найден по меньшей мере один второй информационный объект, который соотносится с тем же самым объектом реального мира, что и первый информационный объект, обновляют состояние хранилища извлеченной информации посредством добавления по крайней мере одного триплета <субъект, предикат, объект> о первом информационном объекте к RDF-графу и обновляют, по крайней мере, один из трех типов индексов.
[0007] В одной из реализаций выбор поискового индекса зависит от типа объекта поиска и его свойств.
[0008] В одной из реализаций строки таблиц идентификаторов поискового индекса упорядочены в лексикографическом порядке.
[0009] В одной из реализаций дуплетный индекс включает таблицу с двумя столбцами, которые хранят идентификаторы субъекта (s) и документа (d) соответственно.
[0010] В одной из реализаций триплетный индекс включает одну или более таблиц с тремя столбцами, которые хранят одну или более комбинаций идентификаторов субъекта (s), предиката (р) и объекта (о) соответственно.
[0011] В одной из реализаций квадовый индекс включает таблицу с четырьмя столбцами, которые хранят идентификаторы документа (d), субъекта (s), предиката (р) и объекта (о) соответственно.
[0012] В одной из реализаций в случае, если в хранилище извлеченной информации найден по меньшей мере один второй информационный объект, соотнесенный с тем же самым объектом реального мира, что и первый информационный объект, обновление хранилища дополнительно включает определение идентификатора субъекта второго информационного объекта в хранилище; и добавление одного или более свойств первого информационного объекта к свойствам идентификатора субъекта второго информационного объекта в хранилище. В одной из реализаций в случае, если в хранилище извлеченной информации не найден хотя бы один второй информационный объект, соотнесенный с тем же самым объектом реального мира, что и первый информационный объект, обновление хранилища дополнительно включает присвоение нового идентификатора объекта первому информационному объекту; и добавление одного или более новых свойств первого информационного объекта в таблицы идентификаторов трех типов.
[0013] В одной из реализаций способ дополнительно включает генерацию аннотации для первого информационного объекта, которая показывает отношение аннотируемого информационного объекта к текстовому документу; разметку в текстовом документе аннотируемого первого информационного объекта; и сохранение в хранилище извлеченной информации аннотации и по крайней мере порции текстового документа, содержащей аннотируемый первый информационный объект.
[0014] В одной из представлена реализаций система для хранения, поиска и обновления данных, извлекаемых из текстовых документов включает хранилище извлеченной информации, содержащее RDF-граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов; аппаратный процессор, соединенный с хранилищем, процессор сконфигурированный для: извлечения по крайней мере одного первого информационного объекта из текстового документа; формирования по крайней мере один триплет вида <субъект, предикат, объект>; организации доступа к хранилищу извлеченной информации, содержащему RDF-граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов; поиска в хранилище извлеченной информации второго информационного объекта, представляющего тот же объект реального мира, что и первый информационный объект, где любые два информационных объекта отождествляются, если указанные объемы имеют по крайней мере общий объектный параметр, и где поиск включает выбор и поиск в по меньшей мере одной из трех типов таблиц идентификаторов, содержащих дуплетный, триплетный или квадовый поисковый индекс, где каждый поисковый индекс основан на по крайней мере двух параметрах, выбираемых из множества: субъект, предикат, объект, документ; и если найден по меньшей мере один второй информационный объект, который соотносится с тем же самым объектом реального мира, что и первый информационный объект, обновляют состояние хранилища извлеченной информации посредством добавления по крайней мере одного триплета <субъект, предикат, объект> о первом информационном объекте к RDF-графу и обновляют, по крайней мере, один из трех типов индексов.
[0015] В одной из реализаций представлена программа для компьютера или компьютерной системы, записанная на машиночитаемый носитель информации, программа для хранения, поиска и обновления данных, извлекаемых из текстовых документов, система, включающая инструкции для: извлечения по крайней мере одного первого информационного объекта из текстового документа; формирования по крайней мере один триплет вида <субъект, предикат, объект>; организации доступа к хранилищу извлеченной информации, содержащему RDF- граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов; поиска в хранилище извлеченной информации второго информационного объекта, представляющего тот же объект реального мира, что и первый информационный объект, где любые два информационных объекта отождествляются, если указанные объекты имеют по крайней мере общий объектный параметр, и где поиск включает выбор и поиск в по меньшей мере одной из трех типов таблиц идентификаторов, содержащих дуплетный, триплетный или квадовый поисковый индекс, где каждый поисковый индекс основан на по крайней мере двух параметрах, выбираемых из множества: субъект, предикат, объект, документ; и если найден по меньшей мере один второй информационный объект, который соотносится с тем же самым объектом реального мира, что и первый информационный объект, обновляют состояние хранилища извлеченной информации посредством добавления по крайней мере одного триплета <субъект, предикат, объект> о первом информационном объекте к RDF-графу и обновляют, по крайней мере, один из трех типов индексов.
[0016] Данное краткое введение не является исчерпывающим и не ограничивает сферу данного описания. Различные аспекты изобретения и его возможных реализаций детально представлены в нижеследующем описании. Предполагается, что черты и свойства одной из реализаций, данной в описании, могут быть распространены и на другие возможные реализации. Все объекты, свойства и преимущества данного изобретения станут понятны из нижеследующего детального описания и сопровождающих его чертежей. Новизна изобретения отражена в формуле изобретения.
Краткое описание чертежей
[0017] Сопровождающие чертежи, включенные в данное описание и являющиеся его частью, иллюстрируют одну или более реализаций настоящего изобретения, и вместе с детальным описанием изобретения предназначены для разъяснения его принципов и реализации.
[0018] Фиг. 1 иллюстрирует общую схему пополнения хранилища в соответствии с одним или несколькими вариантами реализации изобретения.
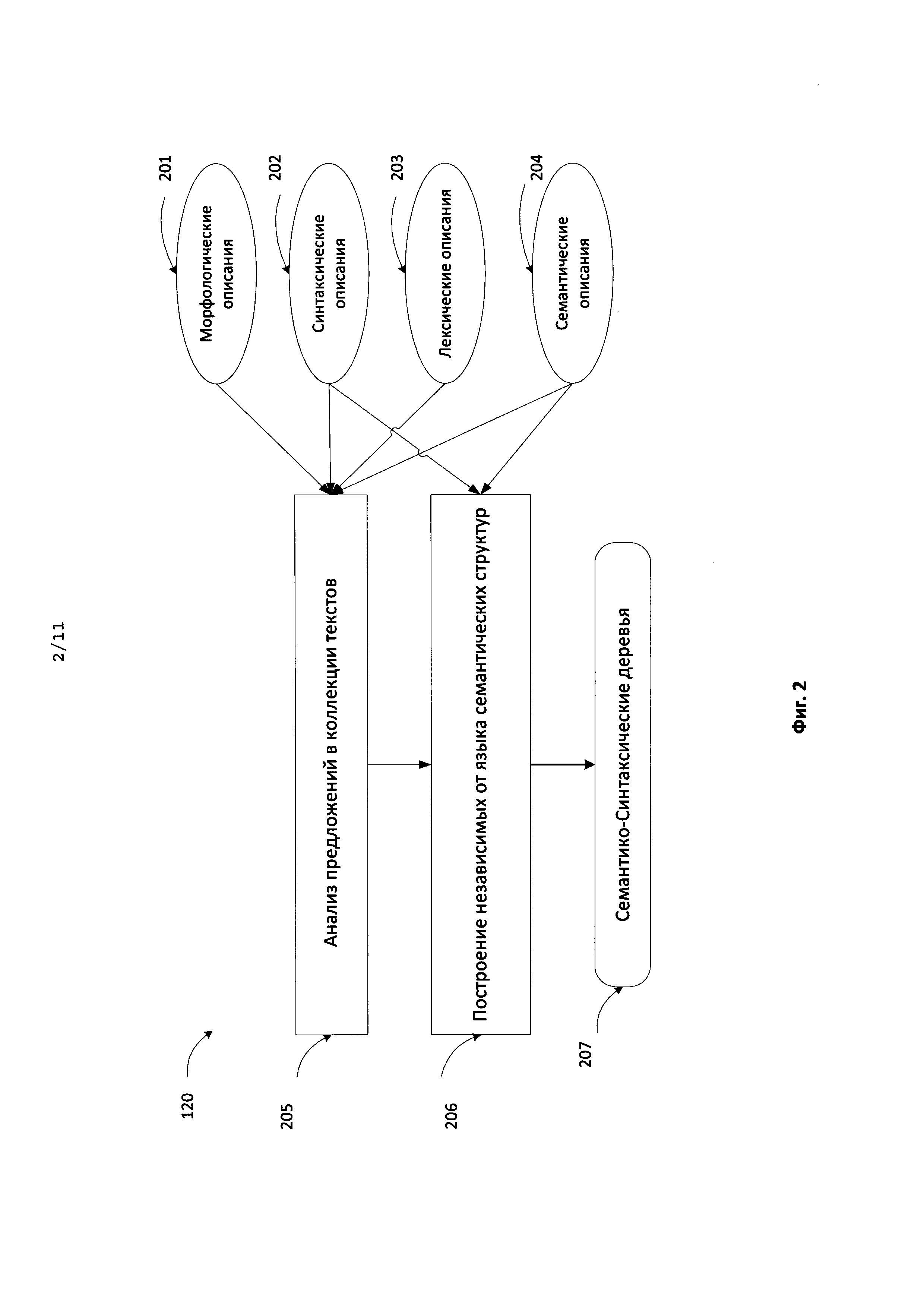
[0019] Фиг. 2 иллюстрирует последовательность шагов семантико-синтаксического анализа в соответствие с одним или несколькими вариантами реализации изобретения.
[0020] Фиг. 3 иллюстрирует общую схему процесса извлечения информации.
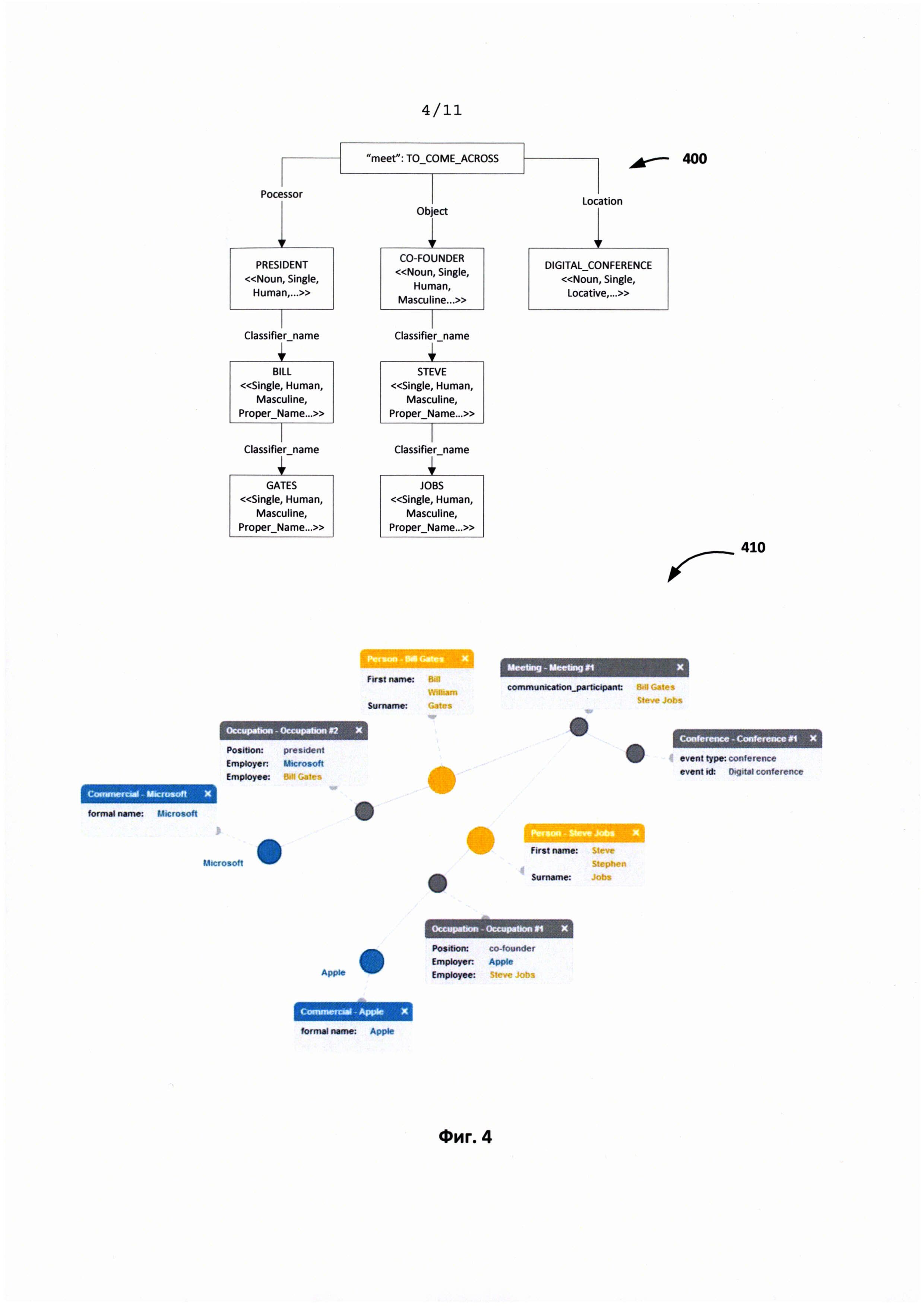
[0021] Фиг. 4 иллюстрируют пример работы правил извлечения информации для предложения «The president of Microsoft Bill Gates met Apple co-founder Steve Jobs at Digital conference.»
[0022] Фиг. 5 иллюстрирует RDF-граф предложения «The president of Microsoft Bill Gates met Apple co-founder Steve Jobs at Digital conference».
[0023] Фиг. 6 иллюстрирует общую схему процесса глобальной идентификации.
[0024] Фиг. 7 иллюстрирует пример визуализации аннотаций.
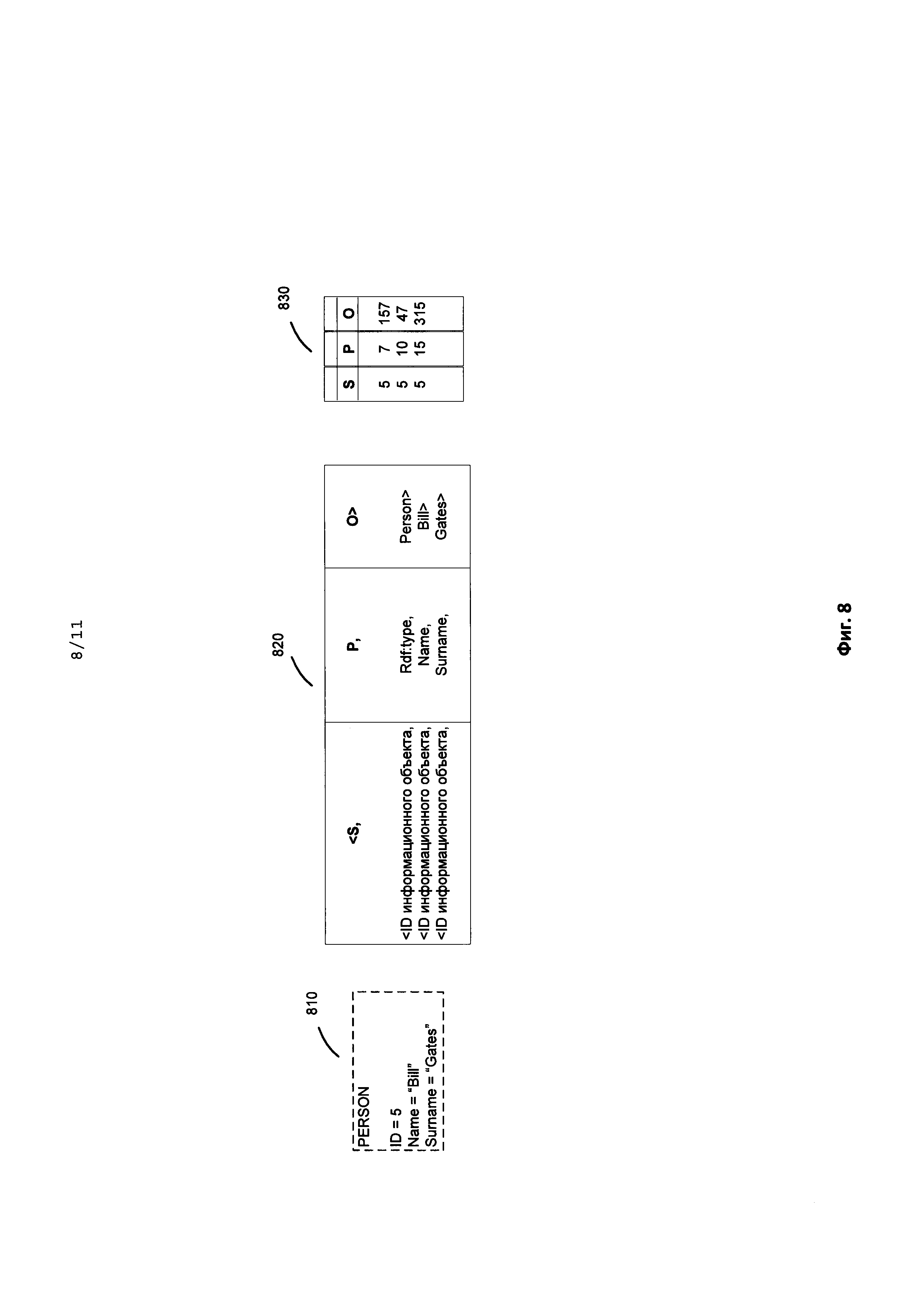
[0025] Фиг. 8 иллюстрирует пример построения триплетного индекса.
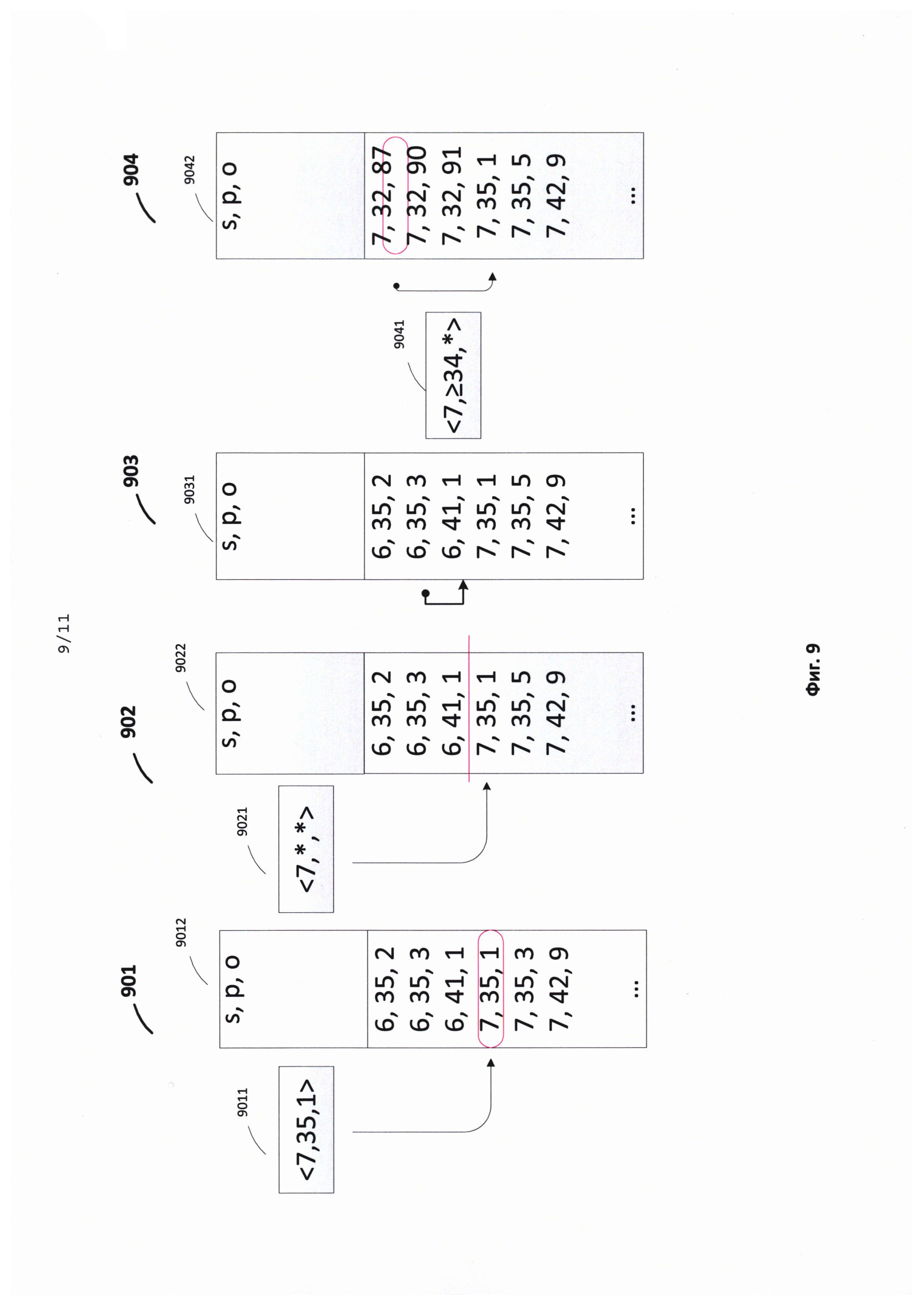
[0026] Фиг. 9 иллюстрирует примеры поисковых операций в триплетном индексе.
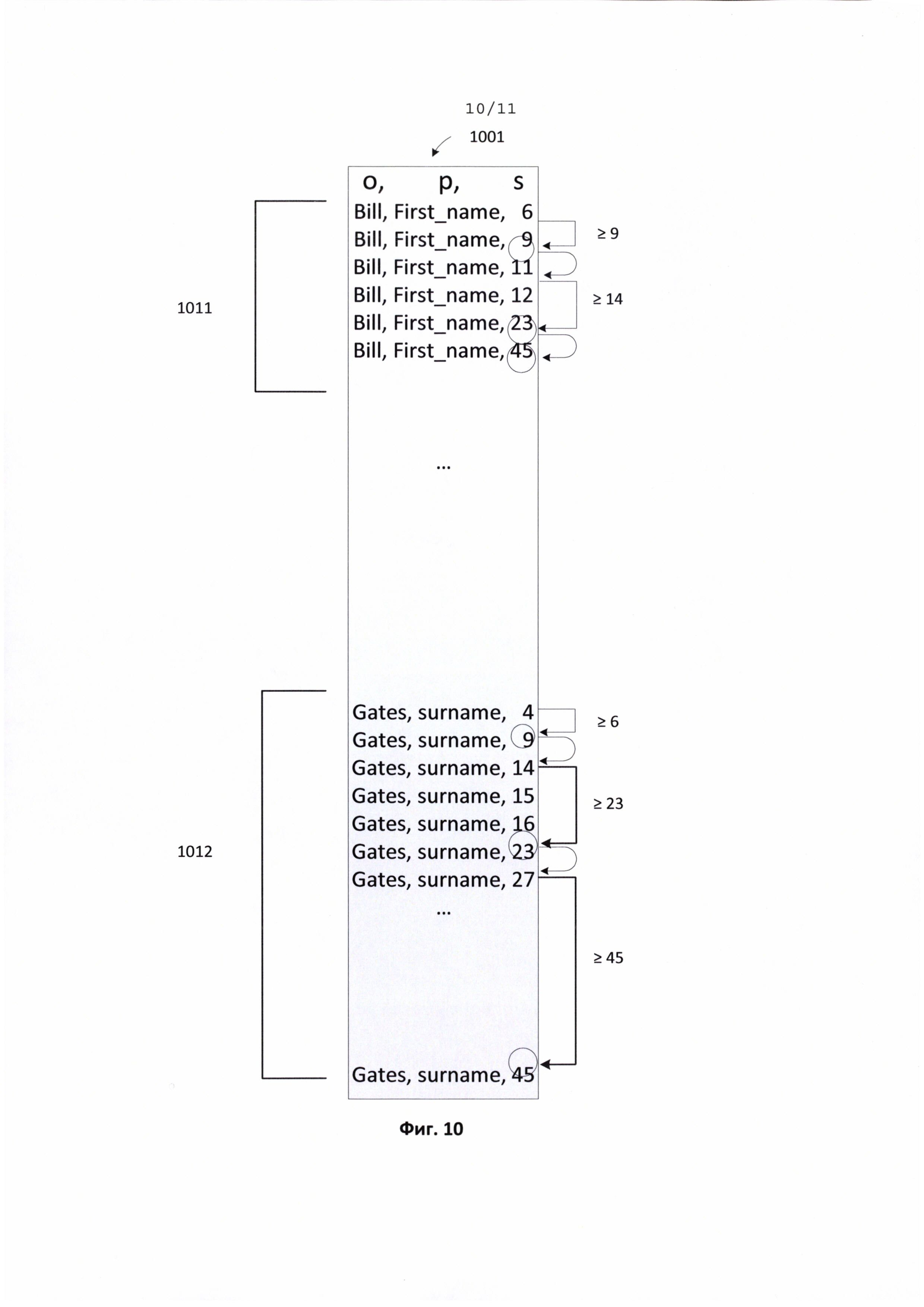
[0027] Фиг. 10 иллюстрирует пример сложной поисковой операции в триплетном индексе.
[0028] Фиг. 11 иллюстрирует пример схемы аппаратного обеспечения, необходимого для реализации изобретения.
[0029] На протяжении всего приведенного ниже подробного описания делаются ссылки на эти прилагаемые чертежи. На этих чертежах одинаковые символы обычно означают аналогичные компоненты, если контекст не требует иного. Иллюстрирующие варианты осуществления, приведенные в подробном описании, на чертежах и пунктах формулы изобретения, не являются единственно возможными. Возможны другие варианты осуществления изобретения, возможны и другие изменения, не затрагивающие его объект и сущность. Различные аспекты настоящего изобретения, приведенные в настоящем описании изобретения и проиллюстрированные чертежами, можно комбинировать, заменять, группировать и конструировать для получения широкого спектра различных вариантов применения, все они явно подразумеваются в настоящем описании изобретения и считаются его частью.
Детальное описание предпочтительных вариантов осуществления изобретения
[0030] Описываются примеры реализации изобретения в контексте системы и способа хранения и поиска информации, извлеченной из текстов для использования в приложениях автоматической обработки текстов. Специалисты, сведущие в данной области, могут рассматривать последующее описание только как иллюстрацию, которое не следует рассматривать как ограничение. Другие варианты реализации с использованием преимуществ данного описания могут быть предложены специалистами в данной области. Детали реализации раскрываются с помощью ссылок на сопровождающие чертежи. Одни и те же номера на чертежах обозначают одни и те же или аналогичные элементы.
Общее описание процесса извлечения информации
[0031] Описывается способ организации хранилища информации, извлеченной из текста (корпуса текстов), написанного на естественном языке. Прежде чем попасть в хранилище, информация должна быть извлечена из текста и представлена с помощью специальной структуры данных, которая позволяет осуществлять быстрый поиск информации, а также обеспечивает ее компактное хранение. Кроме того, сам процесс извлечения информации представляет сложную техническую задачу, которая в рамках настоящего изобретения осуществляется с помощью системы продукционных правил, которые в свою очередь применяются к структурам, полученным в результате полного семантико-синтаксического анализа.
[0032] Основные шаги описываемого метода схематично изображены на Фиг. 1. На вход системе на этапе 110 подаются текстовые данные (размеченные или не размеченные), которые подвергаются семантико-синтаксическому анализу 120. В Патенте США US Patent 8078450 описан способ, включающий глубинный синтаксический и семантический анализ текстов на естественном языке, основанный на исчерпывающих лингвистических описаниях. Метод использует широкий спектр лингвистических описаний, как универсальных семантических механизмов, относящихся к конкретному языку, что позволяет отразить все реальные сложности языка без упрощения и искусственных ограничений, не опасаясь при этом неуправляемого роста сложности. Сверх того, указанные способы анализа основаны на принципах целостного и целенаправленного распознавания, т.е. гипотезы о структуре части предложения верифицируются в рамках проверки гипотезы о структуре всего предложения. Это позволяет избежать анализа большого множества аномалий и вариантов. Подробнее семантико-синтаксический анализ будет описан ниже.
[0033] Результаты полного семантико-синтаксического анализа затем используются в процессе извлечения информации 130, на выходе которого формируется RDF (Resource Description Framework) - граф. Модуль извлечения информации обрабатывает лес семантико-синтаксических деревьев, по одному дереву на каждое предложение исходного текста. Согласно концепции RDF извлеченные данные представляются в виде множества триплетов <субъект, предикат, объект> (
[0034] Для добавления извлеченной из документов информации в хранилище необходима глобальная идентификация 140, целью которой является объединение RDF-графов отдельных документов в один общий граф, со слиянием информационных объектов, описывающих один и тот же объект реального мира.
[0035] Процесс глобальной идентификации завершается импортом данных, полученных из нового документа, в хранилище онтологической информации 150.
[0036] Остановимся подробнее на каждом из шагов описываемого метода.
Семантико-синтаксический анализ
[0037] Фиг. 2 иллюстрирует общую схему метода глубинного синтаксического и семантического анализа 120 текстов на естественных языках 110, основанного на лингвистических описаниях. Метод подробно представлен в патенте США 8,078,450. Метод использует широкий спектр лингвистических описаний, как универсальных семантических механизмов. Данные способы анализа основаны на принципах целостного и целенаправленного распознавания, т.е. гипотезы о структуре части предложения верифицируются в рамках проверки гипотезы о структуре всего предложения. Это позволяет избежать анализа большого количества вариантов.
[0038] В одной из реализаций изобретения глубинный анализ включает лексико-морфологический, синтаксический и семантический анализ каждого предложения корпуса текстов, в результате которого строятся семантические структуры, независимые от языка (language-independent semantic structures), в которых каждому слову текста сопоставляется соответствующий семантический класс (СК) из универсальной Семантической Иерархии (СИ).
[0039] В одном из возможных подходов Семантическая иерархия (СИ) представляет собой лексико-семантический словарь, в котором содержится вся лексика языка, необходимая для анализа и синтеза текста. Семантическая Иерархия организована в виде дерева родо-видовых отношений, в узлах которого находятся Семантические Классы (СК) - универсальные (единые для всех языков), отражающие некоторое понятийное содержание; и лексические классы (ЛК) - конкретноязыковые, являющиеся потомками некоторого семантического класса. Совокупность лексических классов одного Семантического Класса определяет семантическое поле - лексическое выражение понятийного содержания Семантического Класса. Наиболее распространенные понятия находятся на верхних уровнях иерархии.
[0040] В одном из возможных подходов дочерний семантический класс в Семантической Иерархии наследует большинство свойств своего прямого родителя и всех семантических классов - предков. Например, семантический класс SUBSTANCE (Вещество) является дочерним семантическим классом класса ENTITY (Сущность) и материнским семантическим классом для классов GAS (Газ), LIQUID (Жидкость), METAL (Металл), WOOD_MATERIAL (Древесина) и т.д.
[0041] Исходные предложения в тексте/коллекции текстов 110 подвергаются семантико-синтаксическому анализу 205 с использованием лингвистических описаний, как исходного языка, так и универсальных семантических описаний, что позволяет анализировать не только поверхностную синтаксическую структуру, но и распознавать глубинную, семантическую структуру, выражающую смысл высказывания, содержащегося в каждом предложении, а также связи между предложениями или фрагментами текста. Лингвистические описания могут включать лексические описания 203, морфологические описания 201, синтаксические описания 202 и семантические описания 204. Анализ 205 включает синтаксический анализ, реализованный в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа), использующий лингвистические модели и информацию различных уровней для вычисления вероятностей и генерации множества синтаксических структур. В результате чего на этапе 206 строится семантико-синтаксическая структура (207), или другими словами семантико-синтаксическое дерево.
[0042] В одном из возможных подходов морфологическая модель семантико-синтаксического анализатора существует вне семантической иерархии. Для каждого языка существует список лексем и их парадигмы. Внутри семантической иерархии каждая лексема может прикрепляться к одному или нескольким лексическим классам. Лексический класс обычно связывает вместе несколько лексем.
[0043] В одном из возможных подходов каждый узел полученного семантико-синтаксического дерева прикрепляется к какому-то лексическому классу семантической иерархии, что подразумевает устранение двузначности слов в процессе анализа. Каждый узел также хранит в себе грамматическую и семантическую информацию, которая определяет его роль в тексте, а именно набор граммем и семантем.
[0044] В одном из возможных подходов каждая дуга семантико-синтаксического дерева хранит поверхностную позицию (т.е. синтаксическую функцию зависимого узла, например $Subject или $Object_Direct) и глубинную позицию (т.е. семантическую роль зависимого узла, например Agent или Experiencer). Набор глубинных позиций универсален и не зависит от языка, в отличие от набора поверхностных позиций, который отличается от языка к языку.
[0045] Семантико-синтаксическое дерево является независимым от конкретного языка, что позволяет использовать его в различных приложениях, например, в системе машинного перевода. К полученному лесу деревьев разбора применяется набор правил извлечения информации. Для извлечения информации из текстов используются онтологические правила. Онтологические правила - это правила, которые описывают, как факты выражаются в текстах. Предварительный семантико-синтаксический анализ текстов с использованием описанной технологии позволяет описывать и использовать онтологические правила на структурированных данных, а именно, в глубинных (семантических) структурах с учетом лексических, синтаксических и семантических атрибутов, извлеченных во время предварительного разбора.
[0046] Система извлечения информации также работает преимущественно с глубинной структурой. Это делает правила более обобщенными и универсальными. Однако, синтаксис правил позволяет обращаться и к поверхностным свойствам синтаксического дерева, т.к. именно они хранят всю поверхностно-синтаксическую информацию. В ряде случаев система извлечения информации может обращаться к исходному тексту анализируемого документа напрямую, «не глядя» на семантико-синтаксические деревья. В частности, если исходный документ оказывается заранее размечен в соответствии с некоторой системой тэгов, есть возможность учитывать эту разметку в процессе извлечения информации (в правилах извлечения есть специальная конструкция для работы с тэгированными областями).
Онтология
[0047] Онтология представляет собой формальное явное описание некой предметной области. Основными компонентами онтологии являются концепты (или другими словами, классы), экземпляры и отношения. Концепты онтологии представляют собой формально описанное именованное множество экземпляров, обобщенных по какому-либо признаку. Примером концепта может быть множество всех людей, объединенных в концепт «Person» («Персона»). Концепты в онтологии объединены в таксономию, т.е. в иерархическую структуру. Экземпляр представляет собой конкретный объект или явление предметной области, которое входит в концепт. Например, экземпляр Yury_Gagarin («Юрий Гагарин») входит в концепт «Person» («Персона»). Отношения - это формальные описания между концептами, которые фиксируют, какие связи могут быть установлены между экземплярами данных концептов. Онтология представляет собой модель предметной области, описываемую с помощью фрагмента языка OWL DL. Онтология - не то же самое, что семантическая иерархия, несмотря на то, что она может быть связана с элементами семантической иерархии референциальными связями. Онтологии могут наследоваться из других онтологий. Считается, что все концепты, экземпляры и отношения, принадлежащие родительской онтологии, также принадлежат и онтологии-потомку.
[0048] Отношение в онтологии имеет так называемую кардинальность, которая определяет границы количества значений, которые может иметь свойство. Например, у отношения <фамилия> может быть только одно значение, поскольку у персоны не может быть несколько фамилий одновременно.
[0049] Для представления информации о ситуациях и событиях используется подход, близкий к изложенному в рекомендации консорциума W3C о моделировании N-арных отношений.
[0050] Согласованность данных, порождаемых модулем извлечения информации, с моделью предметной области обеспечивается автоматически. С одной стороны, этому способствует синтаксис языка правил извлечения информации. С другой стороны, в систему встроены специальные механизмы валидации, не допускающие появления онтологически некорректных данных.
Механизм извлечения информации
[0051]. Процесс извлечения информации управляется системой продукционных правил. Существует два типа правил: правила интерпретации фрагментов семантико-синтаксических деревьев и правила идентификации информационных объектов.
[0052] Правила интерпретации позволяют описывать фрагменты семантико-синтаксических деревьев, при обнаружении которых вступают в силу определенные наборы логических утверждений. Одно правило представляет собой продукцию, левой частью которой является шаблон фрагмента семантико-синтаксического дерева, а правой - набор выражений, описывающих логические утверждения.
[0053] Левая часть правил интерпретации - это шаблон семантико-синтаксического дерева (древесный шаблон), который представляет из себя формулу. Ее атомарными элементами являются проверки различных свойств узлов семантико-синтаксического дерева (наличия той или иной граммемы/семантемы, принадлежности к лексическому/семантическому классу, нахождения в некоторой поверхностной/глубинной позиции и многое другое).
[0054] Правая часть правил содержит утверждения следующих типов:
[0055] 1. Утверждения о существовании объекта, которые постулируют существование информационных объектов (резервируют для них уникальные идентификаторы).
[0056] 2. Утверждения о принадлежности к классу (концепту), которые уточняют или как-то модифицируют принадлежность объекта к концепту из онтологии. Например, можно уточнить уже существующий объект типа "Организация" до типа "Коммерческая организация".
[0057] 3. Утверждения о свойствах, которые задают свойства информационных объектов. Можно утверждать, что множество значений определенного свойства некоторого объекта включает некоторое конкретное значение. В соответствии с концепцией RDF оно может либо являться идентификатором другого информационного объекта, либо относится к простому типу данных (числовому, строковому, булевому).
[0058] 4. Утверждения об аннотациях, которые позволяют связывать с информационным объектом некоторый отрезок исходного текста. Координаты этого отрезка вычисляются по границам узлов семантико-синтаксических деревьев. Для задания аннотации можно использовать начальные и конечные координаты узла непосредственно (конкретного слова) или целого поддерева, корнем которого он является.
[0059] 5. Утверждения о якорях, которые позволяют привязывать информационные объекты к узлам семантико-синтаксических деревьев. Один информационный объект может быть в общем случае зацеплен якорями за некоторый набор узлов семантико-синтаксических деревьев (с помощью нескольких утверждений о якорях).
[0060] 6. Утверждения об идентичности, которые позволяют определить, что два информационных объекта являются одним и тем же объектом реального мира.
[0061] 7. Функциональные ограничения, которые можно наложить на группу информационных объектов. В мешок утверждений можно добавить функцию, возвращающую значение булева типа и принимающую в качестве аргументов набор идентификаторов информационных объектов и каких-то констант (например, идентификаторов узлов семантико-синтаксических деревьев).
[0062] Логические утверждения образуют, так называемый, «мешок утверждений», который обладает рядом свойств:
[0063] 1. Кумулятивность. Можно лишь добавлять в мешок новые утверждения, но не удалять.
[0064] 2. Непротиворечивость. Утверждения в мешке не противоречат друг другу, то есть, например, не нарушают согласованность с онтологией (не меняют кардинальности отношения).
[0065] 3. Онтологичность. По мешку утверждений в любой момент можно построить аннотированный RDF-граф (RDF-граф с информацией об аннотациях), согласованный с онтологией.
[0066] 4. Транзакционность. Утверждения в мешок добавляются группами. Если хотя бы одно утверждение в группе входит в противоречие с другими утверждениями мешка (или самой группы), то отменяется добавление всех утверждений группы.
[0067] В древесных шаблонах могут встречаться условия, описывающие информационные объекты, которые, для того, чтобы правило сработало, должны быть привязаны якорями к соответствующим узлам семантико-синтаксического дерева. Это так называемые положительные объектные условия. Существуют так же отрицательные объектные условия, позволяющие, наоборот, формулировать, какие объекты не должны быть привязаны к узлу. Объектные условия уже упоминались выше в связи с утверждениями о якорях.
[0068] При записи логических утверждений в правой части правил часто требуется ссылаться на узлы означенного в левой части фрагмента семантико-синтаксического дерева и информационные объекты, сопоставленные с положительными объектными условиями. Для этого предусмотрена возможность именования отдельных частей древесных шаблонов. В случае успешного сопоставления шаблона с некоторым фрагментом семантико-синтаксического дерева, конкретные узлы становятся доступны по именам частей шаблона. Такие имена, вводимые в левых частях, называются переменными. Переменные используются в правых частях правил для формулировки утверждений и в ряде случаев в левых частях (для формулировки сложных условий, выражающих некоторую зависимость между несколькими узлами дерева). Переменные могут быть множественными или уникальными. С множественными переменными может сопоставиться более одного узла, а с уникальными - максимум один.
[0069] Метод извлечения информации схематично изображен на Фиг. 3. На шаге 302 детектируются все сопоставления для правил интерпретации без объектных условий. Далее найденные сопоставления добавляются 304 в сортированную очередь сопоставлений. Если очередь сопоставлений пуста 306, то работа завершается. Если очередь непустая, то из очереди выбирается 308 наиболее приоритетное сопоставление. Далее 310 формируется набор логических утверждений по правой части соответствующего правила. Далее сформированный набор добавляется в мешок утверждений 312. В случае неудачи, сопоставление объявляется неверным 314, после чего снова проверяется очередь сопоставления на пустоту. Иначе в случае успеха, производится поиск новых сопоставлений 316. Новые сопоставления, если они найдены, добавляются в очередь. Далее снова переходим к шагу 306.
[0070] На Фиг. 4 проиллюстрирован пример работы правил интерпретации, в результате которого узлы семантико-синтаксического дерева 400 предложения «The president of Microsoft Bill Gates met Apple co-founder Steve Jobs at Digital conference» переходят в связанные между собой информационные объекты, образующие информационный граф 410. Вершинами его являются информационные объекты: например, факты или персоны, как в рассматриваемом примере, а дугами - связи между этими объектами, которые соответствуют отношениям из онтологии.
[0071] Как было сказано выше, в процессе извлечения информации создается информационный граф. На Фиг. 5 приведен пример RDF - графа 500 предложения «The president of Microsoft Bill Gates met Apple co-founder Steve Jobs at Digital conference)) («Президент Microsoft Билл Гейтс встретился с сооснователем Apple Стивом Джобсом на конференции по Вычислительной технике»), который является вариантом представления информационного графа 410. В соответствии с концепцией RDF, информационный граф 410 описывается в виде триплетов <субъект, предикат, объект>. Субъекту соответствует вершина графа с исходящей стрелкой, предикатом является сама именованная стрелка, а объекту соответствует вершина, в которую данная именованная стрелка входит. Триплет может задавать необъектные свойства информационного объекта, то есть его атрибуты, либо объектные свойства информационного объекта, то есть его отношения с другими информационными объектами. Рассмотрим информационный объект "Bill Gates", он принадлежит типу «Person». Тогда триплет, описывающий свойство информационного объекта иметь тип «Person», задает необъектное свойство. Субъектом в данном примере будет идентификатор информационного объекта (ID=1), предикатом - отношение rdf:type, объектом - тип «Person». И триплет будет выглядеть как
Правила идентификации информационных объектов (Глобальная идентификация)
[0072] Завершающим этапом процесса извлечения информации является добавление извлеченных из текста данных в хранилище онтологической информации. Для его реализации используется процесс глобальной идентификации, основные шаги которого проиллюстрированы на Фиг. 6. Задача глобальной идентификации состоит в том, чтобы сопоставить объекты из документа с теми, которые уже содержать в хранилище, и произвести слияние одинаковых объектов. Поскольку информация об объектах представлена в виде дерева, то задача глобальной идентификации иначе формулируется как поиск одинаковых подграфов в RDF-графах документа и хранилища.
[0073] Глобальная идентификация осуществляется с помощью упомянутых ранее правил идентификации. Существенным отличием правил идентификации от правил интерпретации является то, что правила идентификации работают только с информационными объектами, то есть нет возможности обращаться к узлам семантико-синтаксических деревьев. Правила идентификации содержат объектные условия, с которыми соотносятся информационные объекты, и по результатам сопоставления делается вывод об идентичности этих информационных объектов.
[0074] Правила идентификации иначе называются шаблонами. Для описания шаблонов используется язык SPAPQL. Один шаблон отвечает лишь за один признак информационного объекта, и потому, как правило, для достоверной идентификации используются не отдельные шаблоны, а их комбинации. Например, для идентификации информационного объекта типа «Person», используют комбинацию шаблонов <«First name», «Surname»>. Комбинация может состоять из произвольного числа шаблонов. Значением комбинации является массив значений шаблонов, в нее входящих. Все шаблоны глобальной идентификации содержаться в специальной библиотеке. Она устроена таким образом, что шаблоны, предназначенные для идентификации различных объектов реального мира, размещены отдельно друг от друга.
[0075] На Фиг. 6 изображена схема процесса глобальной идентификации. В описываемом методе механизм глобальной идентификации ступенчатый. То есть идентификация запускается последовательно для каждого нового документа, добавляемого в хранилище, которое содержит уже идентифицированную коллекцию документов.
[0076] На вход процессу глобальной идентификации поступает RDF-граф документа 320 (При этом мы считаем, что проведена идентификация объектов внутри одного документа, и все информационные объекты в графе различные). На первом этапе идентификации запускается поиск известных шаблонов и их комбинаций 610 в RDF-графе документа 320. Затем поиск соответствующих шаблонов и комбинаций проводится и в хранилище 620. Если шаблоны и комбинации найдены, то составляется список объектов-кандидатов на слияние 630, которые проходят проверку на непротиворечивость 640. Непротиворечивость означает, что слияние информационных объектов не нарушает кардинальности их отношений (не нарушается согласованность с онтологией). Если пара не проходит проверку, то процесс идентификации возвращается к этапу 620. Если же проверка на непротиворечивость 640 пройдена, это означает, что объект из документа уже содержится в хранилище, и все новые свойства данного объекта, извлеченные из документа, помещаются в список добавления 660. Если на этапе 620 для комбинаций, найденных в RDF-графе документа, не нашлись соответствующие комбинации в хранилище, это означает, что в документе содержатся новые объекты, и совершается пополнение списка добавления 650 этими новыми объектами. На последнем этапе список добавления 670, который содержит новые объекты из документа, а также новые свойства уже существующих в хранилище объектов целиком импортируется в хранилище онтологической информации 150.
Хранилище онтологической информации
[0077] В хранилище онтологической информации содержится один или более RDF-граф, который описывает всю извлеченную информацию об объектах реального мира, коллекция текстов документов с аннотациями. Для хранения RDF-графа используются следующие типы структур: N-граммные таблицы идентификаторов (N-граммные здесь означает, что таблицы имеют N столбцов), а также бор для хранения значений простых свойств.
Хранение аннотаций
[0078] В одной из реализаций изобретения, помимо самого RDF-графа, согласованного с OWL-онтологией, хранилище может содержать коллекцию текстов документов и информацию о связи выделенных информационных объектов с исходным текстом (аннотации, или "подсветка" объектов).
[0079] На Фиг. 7 приведен пример подсветки информационных объектов 700, а также пример описания аннотаций 710. Каждая аннотация 711 содержит три параметра: идентификатор объекта 712, начало отрезка (номер символа) 713, конец отрезка (номер символа) 714. Аннотации объектов сохраняются в следующем формате:
- Все аннотации сортируются в порядке возрастания начал отрезков.
- Записывается количество аннотаций.
- Последовательно для каждой аннотации записывается:
a. Идентификатор объекта;
b. Расстояние между началом отрезка текущей аннотации и началом отрезка предыдущей аннотации. Для первой аннотации записывается начало отрезка;
c. Длина аннотации.
[0080] По этим данным восстанавливаются начала и концы отрезков всех аннотаций, а также идентификаторы объектов, привязанных к этим аннотациям. Используются аннотации для подсветки всех информационных объектов в тексте, при этом цвет выделения соответствует типу информационного объекта (персона, локация, организация и др.). Также с помощью аннотаций можно выделить все вхождения одного конкретного информационного объекта в тексте. Например, в тексте встретился информационный объект «Bill Gates» и мы хотим увидеть, где еще в тексте он встречается, тогда кликнув на данный информационный объект, система выделит все его вхождения в текст документа, одним цветом для удобства просмотра.
Организация таблиц идентификаторов
[0081] В хранилище используется 3 типа N-граммных таблиц идентификаторов: N-граммные таблицы могут содержать N=2, 3, 4 столбца. Таблицы с 2 столбцами хранят дуплеты идентификаторов <х, у>, с 3 столбцами - триплеты идентификаторов <х, у, z> и с 4 столбцами - квады идентификаторов <х, у, z, о>. Элементы-идентификаторы х, у, z, о дуплетов <х, у>, триплетов <х, у, z> и квадов <х, у, z, о> являются беззнаковыми целыми числами.
[0082] Каждая таблица задает целочисленный индекс идентификаторов, по которому осуществляется доступ к данным. Строки каждой таблицы упорядочены лексикографически. А именно, триплет [0083] В хранилище содержится дуплетный индекс, который дает возможность итерации по парам <объект (s), документ (d)> . Для каждого объекта s этот индекс позволяет просмотреть список документов, в которых он содержится. Такой поиск всех документов, в которых содержится запрашиваемый информационный объект, можно выполнить эффективно благодаря тому, что все пары [0084] В другой реализации в хранилище содержатся триплетные индексы, количество которых соответствует всем вариантам перестановки столбцов в таблице для триплетов <субъект (s), предикат (р), объект (о)>: [0085] В еще одной реализации в хранилище содержится индекс квадов <документ (d), субъект (s), предикат (р), объект (о)>, то есть для каждого документа хранится список триплетов, извлеченных из этого документа. [0086] В таблицах могут присутствовать идентификаторы концептов, предикатов, информационных объектов, документов и значений простых свойств. [0087] Идентификаторы концептов и предикатов (атрибутов и отношений) задаются при описании конкретной предметной области. [0088] Идентификатор информационного объекта присваивается в момент добавления новой вершины в RDF-граф хранилища (то есть является порядковым номером информационного объекта в хранилище). [0089] Идентификатор документа - также присваивается при добавлении документа в хранилище. [0090] Идентификаторы простых свойств - это идентификаторы строк и чисел. Идентификаторы строк вычисляются с помощью специальной структуры данных - бор. С помощью бора можно по строке быстро получить ее идентификатор и искать триплеты, где она является значением объекта. Идентификаторы чисел также вычисляются с помощью бора и хранятся в нем. [0091] В зависимости от типа предиката р, элемент о принимает различные значения. Так, если значениям отношения является информационный объект определенного типа (относящийся к определенному концепту из онтологии), то о имеет значение идентификатора информационного объекта. Если отношение является rdf:type (отнесение объекта к некоторому концепту), то о имеет значение идентификатора концепта. Если типом значений является простой тип bool, то значением о триплета будет 0 или 1. Если типом значений отношения является простой тип строка, то значением о будет идентификатор строки в хранилище строк. Если типом значений отношения является простой тип число, то значением будет идентификатор строки, содержащей строковое представление этого числа. [0092] Диапазон значений элементов триплета s, р, о, разделен на следующие непересекающиеся поддиапазоны: - Идентификаторы концептов; - Идентификаторы предикатов, представляющих необъектные свойства; - Идентификаторы предикатов, представляющих объектные свойства; - Идентификаторы информационных объектов. [0093] По диапазону значений элементов триплета можно определить его тип. Это помогает, например, при поиске всех связей конкретного информационного объекта с другими информационными объектами реального мира. Поиск в данном случае будет осуществляться по индексу [0094] Вернемся к Фиг. 5 и рассмотрим пример информационного объекта "Bill Gates", имеющего тип «Person». Пусть при добавлении информационного объекта 510 в хранилище, ему был присвоен идентификатор, равный 5 (ID=5). Тип информационного объекта в RDF задается отношением rdf:type, пусть он в хранилище имеет идентификатор ID=7. При описании предметной области концепт «Person» получил, например, идентификатор 570, то есть его ID=570. При этом у концепта «Person» есть атрибуты [0095] Поисковые операции с N-граммной таблицей, используемые в хранилище, включают: поиск строки в индексе, поиск строки с неизвестными параметрами, переход к следующей строке после текущей, переход к следующей строке с уточнением, сложный поиск. [0096] В различных реализациях выбор поискового индекса может быть обусловлен типом объекта поиска и его свойствами. Например, если в хранилище ищутся объекты реального мира, соотносимые с объектами, извлеченными из документа, может выполняться поиск по триплетам в индексе, где на первом месте стоит параметр - отношение между объектами, т.е. предикат р. Поиск может выполняться в индексе триплетов <р, s, о> или <р, о, s>. В другой реализации, если поисковый запрос содержит строку, например, "Иван", поиск может выполняться в индексе, где на первом месте стоит параметр "о". Такой поиск может выполняться в индексе триплетов <о, р, s> или <о, s, р>. Аналогичным образом, если в ответ на поисковый запрос надо получить всю информацию о субъекте s в документе d, то может быть использован двойной индекс [0097] На Фиг. 9 и Фиг. 10 схематично изображены перечисленные поисковые операции. Поиск строки 901 в индексе 9012 - это операция, которая удовлетворяет запросу 9011, содержащему все три параметра [0098] Также возможен поиск по одному или двум параметрам из трех, называемый поиском с неизвестными параметрами 902. Например, необходимо найти все свойства информационного объекта "Digital conference" (ID=7), поиск будет проходить по параметрам s. Запрос 9021 в данном случае будет иметь вид <7, *, *>. Поиск будет осуществляться в той части индекса 9022, в которой содержатся триплеты с идентификатором ID=7. Результатом такой поисковой операции будут все триплеты, для которых s=7. [0099] Другой вид поисковой операции в индексе - это переход от строки к следующей по лексикографическому порядку строке 903 индекса 9031. Например, поиск следующей строки после <6, 35, 3> вернет строку <6, 41, 1>. [00100] Еще один вид поисковой операции по индексу - это переход от строки к одной из последующих с уточнением 904. Пусть мы производим поиск в индексе 9042, и текущее положение поискового итератора - <7, 32, 87>. Пусть в этот момент мы хотим найти последующую строку с идентификатором s, равным 7, и идентификатором р, не меньшим 34. Такой уточняющий запрос <7,≥34, *>9041 позволяет сразу "перескочить" с текущего положения на первую строку, содержащую необходимые параметры. Поиск с уточнением находит применение при обработке сложных запросов, позволяет сократить количество итераций и ускорить тем самым процедуру поиска. [00101] Один из примеров сложного поиска проиллюстрирован на Фиг. 10. [00102] Этот вид поиска может использоваться, например, для поиска одинаковых информационных объектов (т.е., например, для поиска двух информационных объектов, относящихся к одному и тому же объекту реального мира) в отсортированных списках. В нашем примере списками 1011 и 1012 являются разные части одного индекса 1001. Пусть, например, необходимо найти информационные объекты типа "Person", обладающие одновременно свойствами: носящие фамилию "Gates" и имя "Bill. В индексе 1001 содержатся триплеты, упорядоченные по параметрам <о, р, s>, в которых о - идентификаторы строк имени "Bill" и фамилии "Gates", р - идентификаторы атрибутов "First_name" и "surname", s - идентификаторы информационных объектов. Поскольку строки упорядочены лексикографически, сравниваем их по параметру s. Для начала выполним два поисковых запроса с неизвестным о для определения начальных позиций двух итераторов. Первый итератор будет двигаться по информационным объектам, имеющим имя Bill. Его первоначальная позиция задается поисковым запросом <47, 10, *>. Второй итератор будет двигаться по информационным объектам, имеющим фамилию Gates. Его первоначальная позиция задается поисковым запросом <315, 15, *>. Сравниваем значения идентификаторов первых информационных объектов, удовлетворяющих запросам. В нашем случае это 6 и 4. Двигаем меньший итератор (списка 1012) уточняющим поиском до значения, не меньшего 6, он остановится на значении 9. Новые значения 6 и 9 соответственно. Далее снова двигаем меньший итератор (списка 1011) уточняющим поиском до значения, не меньшего 9, он остановится на значении 9. Значения совпали. Следовательно, информационный объект со значением идентификатора 9 удовлетворяет поисковому запросу. Далее повторяем перемещения итераторов уточняющим поиском до следующего совпадения идентификаторов. А именно: двигаем итераторы списков 1011 и 1012 на следующее за 9 значение - это 11 и 14. Тогда меньший из итераторов двигаем уточняющим поиском до значения большего или равного 14, итератор останавливается на 23. Итератор списка 1012 двигаем уточняющим поиском до значения, большего или равного 23, он остановится на 23. Получаем второе совпадение. Аналогично находим пересечение информационных объектов с идентификатором 45. Такие «прыжки» по спискам позволяют избежать чтения всех значений идентификатора s в каждом из списков. Время на выполнение такого «прыжка» сравнимо со временем перемещения к следующей строке списка, за счет этого существенно сокращается время указанного сложного поиска. Такой поиск называется ZigZag Join (Зигзагообразное соединение сортированных списков). [00103] Операции, изменяющие N-граммную таблицу, включают: вставку строки, удаление строки. [00104] В одной из реализаций изобретения операция вставки строки выполняется при добавлении очередного документа в хранилище информации. Процесс глобальной идентификации решает, содержатся ли в хранилище информационные объекты, которые встретились в документах. Возможно два случая: в хранилище не содержится информационный объект, встретившийся в добавляемом документе, в хранилище уже содержится информационный объект, встретившийся в добавляемом документе. В первом случае, информационному объекту будет присвоен свой идентификатор s, и все свойства нового объекта будут добавлены в индексы SPO, SOP, POS, PSO, OPS, OSP, также в индекс DSPO добавятся свойства нового информационного объекта, в индекс SD добавится новая строка. Во втором случае, идентификатор информационного объекта s уже известен, и в хранилище будут добавлены только новые свойства данного информационного объекта, которых в хранилище ранее не было. Соответственно, эти новые свойства будут добавлены во все триплетные, квадовый индекс, а в дуплетный добавится новая строка. Например, в хранилище содержалась информация о персонах Билл Гейтс ("Bill Gates") и Стив Джобс ("Steve Jobs"), но не было информации о таком событии как Конференция по вычислительной технике ("Digital conference"). В добавляемом документе встретился факт встречи Билла Гейтса и Стива Джобса на конференции по вычислительной технике, и в хранилище добавится новый информационный объект - факт встречи с его атрибутами и отношениями. Примером добавления новых свойств к содержащимся в хранилище информационным объектам может быть, например, добавление отчества объекту типа «Персона». [00105] Операция удаления строки используется при удалении документа из хранилища, когда происходит стирание информации об объектах из удаляемого документа. [00106] Для хранения индекса используются В-деревья. Для каждого индекса строятся свои В-деревья, вершинами которого являются строки таблицы, упорядоченные лексикографически. Использование такой структуры данных позволяет хранить индекс на жестком диске и эффективно выполнять поисковые операции и операции, модифицирующие индекс. Хранение информации об одном документе [00107] Для каждого документа отдельно хранится следующая информация: - Имя документа. - URL документа. - Хеш документа для быстрой проверки наличия документа по содержимому. - Аннотации объектов, упомянутых в документе. [00108] В одной из реализаций сами упомянутые объекты и их свойства хранятся в индексах [00109] На Фиг. 11 приведен возможный пример вычислительного средства 1100, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 1100 включает в себя, по крайней мере, один процессор 1102, соединенный с памятью 1104. Процессор 1102 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер или представлять собой чип или другое устройство, способное производить вычисления. Память 1104 может представлять собой оперативное запоминающее устройство (ОЗУ), а также содержать любые другие типы и виды памяти, в частности, устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например, жесткие диски и т.д. Кроме того, может считаться, что память 1104 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 1100, например, кэш-память в процессоре 1102, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 1110. [00110] Вычислительное средство 1100 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 1100 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 1108 (например, жидкокристаллический дисплей или сигнальные индикаторы). Вычислительное средство 1100 также может иметь одно или более постоянных запоминающих устройств 1110, например, привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 1100 может иметь интерфейс с одной или более сетями 1112, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные с всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 1100 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 1102 и каждым из компонентов 1104, 1106, 1108, 1110 и 1112. [00111] Вычислительное средство 1100 работает под управлением операционной системы 1114 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 1116. [00112] У описываемой системы, методов и программных продуктов для хранения и поиска извлекаемой из документов информации есть ряд преимуществ. Например, использование целочисленных индексов, обеспечивающих эффективное хранение и быстрый поиск в хранилище извлеченных данных. Триплетные индексы всех перестановок могут использоваться для быстрого поиска с использованием любой формы запроса <*, р, *>. Дуплетный индекс [00113] Программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт, либо их комбинацию. [00114] Все управление подпрограммами в использовании реализаций может быть выполнено операционной системой или отдельными приложениями, компонентами, программами, объектами, модулями или последовательностями инструкций, обобщенно называемыми "компьютерными программами". Компьютерные программы обычно представляют собой серию инструкций, записанных в различные запоминающие устройства компьютера. После того, как инструкции записаны, процессоры выполняют операции, требуемые для инициализации элементов описанной реализации. Несколько вариантов реализаций были описаны в контексте существующих компьютеров и компьютерных систем. Специалисты в данной области смогут оценить возможности определенных модификаций изобретения в виде различных программных продуктов на любых типах носителей информации. Примеры таких носителей - энергозависимые и энергонезависимые запоминающие устройства, такие как дискеты и другие съемные диски, жесткие диски, оптические диски (такие как CD-ROM, DVD, флэш-диски) и многие другие. Такой пакет программ может быть загружен через Интернет. [00115] В описании, представленном выше, многие специфические детали представлены исключительно для объяснения. Для специалистов в данной области эти детали являются не более, чем примерами. В других случаях структуры и устройства показаны в виде блок-схем, чтобы избежать неоднозначности в истолковании. [00116] В различных реализациях описанные системы и методы могут быть реализованы с использованием аппаратного обеспечения, программного обеспечения, микропрограмм и любых их комбинаций. В случае реализации в программном обеспечении, эти методы могут быть записаны как инструкции или код в постоянную память компьютера. Машиночитаемый носитель информации также включает хранилище данных. Для примера, но не ограничения, такой машиночитаемый носитель информации может включать RAM, ROM, EEPROM, CD-ROM, флеш-память или другие типы электронных, магнитных или оптических запоминающих носителей или других носителей информации, которые могут быть использованы для переноса и хранения программного кода в форме инструкций или структур данных, доступ к которым может осуществляться процессором компьютера общего назначения. [00117] В интересах ясности не все рутинные черты реализаций здесь раскрыты. Будет понято, что при разработке любой фактической реализации настоящего изобретения на основе данного раскрытия должны быть приняты многочисленные конкретные решения для достижения конкретных целей разработчика и эти конкретные цели могут различаться для разных реализаций и разных разработчиков. Понято, что такие попытки разработки могут оказаться сложным и потребовать много времени, но, тем не менее, использование преимуществ настоящего раскрытия было бы обычной инженерной задачей для специалистов в данной области. [00118] Кроме того, понятно, что выражения или термины, употребляемые здесь, для цели описания, не являются ограничениями, так что терминология или фразеология настоящей спецификации должны быть интерпретированы квалифицированными специалистами в свете указаний, приведенных здесь. Более того, ни для какого термина в спецификации или формуле изобретения не предусмотрено приписывание ему необычного или специального значения, если они не изложены явно.
Реферат
Изобретение относится к области автоматической обработки естественного языка, в частности к способу и устройству для хранения и поиска информации, извлекаемой из текстовых документов. Техническим результатом является повышение скорости навигации и поиска данных в хранилище извлеченных данных. В способе для хранения, поиска и обновления данных, извлекаемых из текстовых документов, извлекают информационный объект из текстового документа и формируют триплет вида <субъект, предикат, объект>. Организуют доступ к хранилищу извлеченной информации, содержащему RDF- граф, включающий множество триплетов вида <субъект, предикат, объект> для множества объектов. Осуществляют поиск в хранилище извлеченной информации второго информационного объекта, представляющего тот же объект реального мира, что и первый объект, где любые два объекта отождествляются, если они имеют общий объектный параметр, и где поиск включает выбор и поиск в таблице идентификаторов. Если второй информационный объект найден, обновляют состояние хранилища извлеченной информации посредством добавления триплета <субъект, предикат, объект> о первом информационном объекте к основному RDF-графу хранилища и обновляют индекс в таблице. 3 н. и 23 з.п. ф-лы, 11 ил.
Формула
- производят извлечение по крайней мере одного первого информационного объекта из текстового документа;
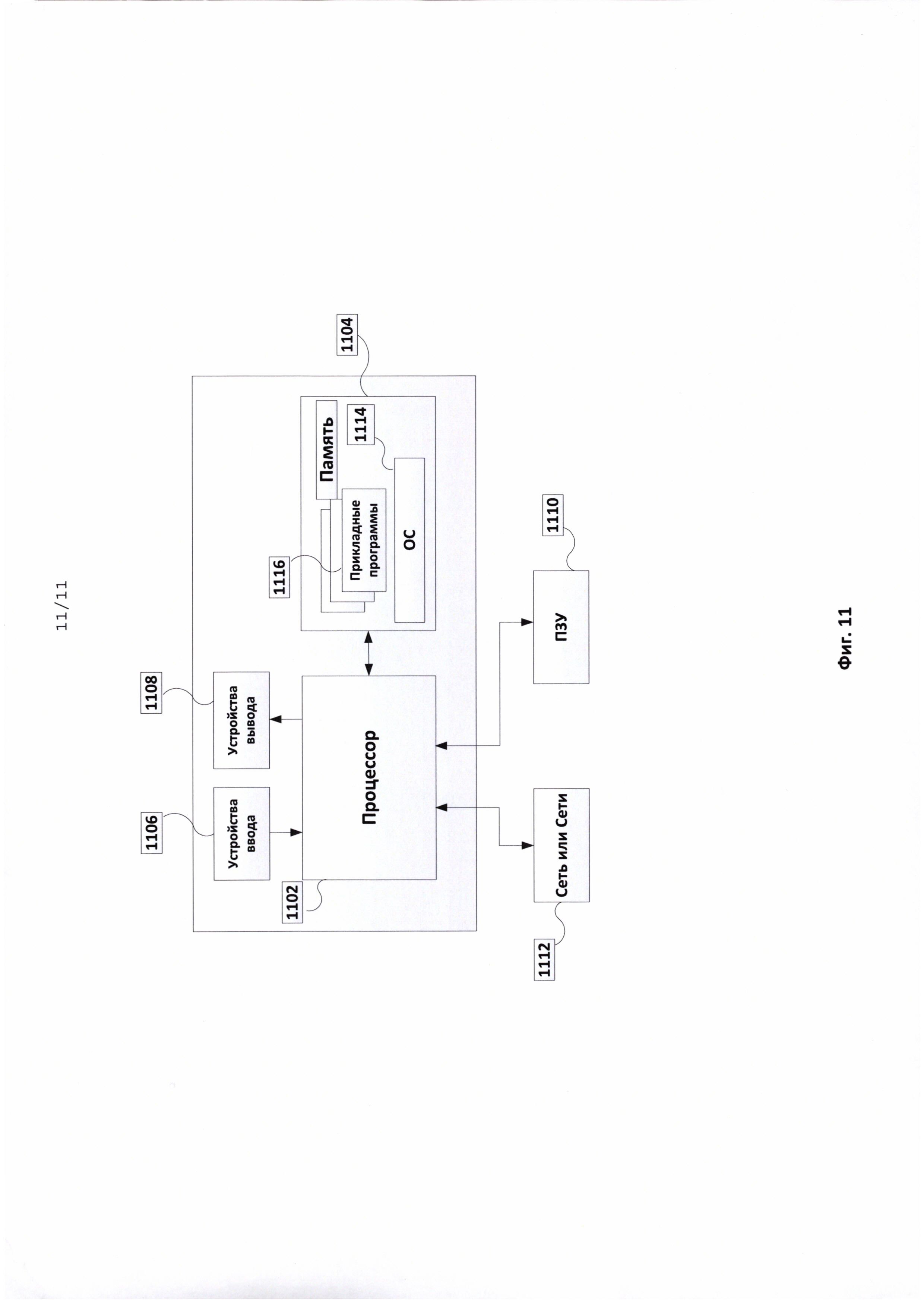
- формируют по крайней мере один триплет вида <субъект, предикат, объект>;
- обеспечивают организацию доступа к хранилищу извлеченной информации, содержащему RDF-граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов;
- осуществляют поиск в хранилище извлеченной информации второго информационного объекта, представляющего тот же объект реального мира, что и первый информационный объект, где любые два информационных объекта отождествляются, если указанные объекты имеют по крайней мере общий объектный параметр, и где поиск включает выбор и поиск в по меньшей мере одной из трех типов таблиц идентификаторов, содержащих дуплетный, триплетный или квадовый поисковый индекс, где каждый поисковый индекс основан на по крайней мере двух параметрах, выбираемых из множества: субъект, предикат, объект, документ,
- и если найден по меньшей мере один второй информационный объект, который соотносится с тем же самым объектом реального мира, что и первый информационный объект, обновляют состояние хранилища извлеченной информации посредством добавления по крайней мере одного триплета <субъект, предикат, объект> о первом информационном объекте к RDF-графу и обновляют по крайней мере один из 3-х типов индексов.
- определение идентификатора субъекта второго информационного объекта в хранилище и
- добавление одного или более свойств первого информационного объекта к свойствам идентификатора субъекта второго информационного объекта в хранилище.
- присвоение нового идентификатора объекта первому информационному объекту и
- добавление одного или более новых свойств первого информационного объекта в таблицы идентификаторов трех типов.
- генерацию аннотации для первого информационного объекта, которая показывает отношение аннотируемого информационного объекта к текстовому документу;
- разметку в текстовом документе аннотируемого первого информационного объекта; и
- сохранение в хранилище извлеченной информации аннотации и по крайней мере порции текстового документа, содержащей аннотируемый первый информационный объект.
- хранилище извлеченной информации, содержащее RDF-граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов;
- аппаратный процессор, соединенный с хранилищем, процессор, сконфигурированный для:
- извлечения по крайней мере одного первого информационного объекта из текстового документа;
- формирования по крайней мере один триплет вида <субъект, предикат, объект>;
- организации доступа к хранилищу извлеченной информации, содержащему RDF-граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов;
- поиска в хранилище извлеченной информации второго информационного объекта, представляющего тот же объект реального мира, что и первый информационный объект, где любые два информационных объекта отождествляются, если указанные объекты имеют по крайней мере общий объектный параметр, и где поиск включает выбор и поиск в по меньшей мере одной из трех типов таблиц идентификаторов, содержащих дуплетный, триплетный или квадовый поисковый индекс, где каждый поисковый индекс основан на по крайней мере двух параметрах, выбираемых из множества: субъект, предикат, объект, документ;
и если найден по меньшей мере один второй информационный объект, который соотносится с тем же самым объектом реального мира, что и первый информационный объект, обновляют состояние хранилища извлеченной информации посредством добавления по крайней мере одного триплета <субъект, предикат, объект> о первом информационном объекте к RDF-графу и обновляют по крайней мере один из трех типов индексов.
- определение идентификатора субъекта второго информационного объекта в хранилище и
- добавление одного или более свойств первого информационного объекта к свойствам идентификатора субъекта второго информационного объекта в хранилище.
- присвоение нового идентификатора объекта первому информационному объекту и
- добавление одного или более новых свойств первого информационного объекта в таблицы идентификаторов трех типов.
- генерацию аннотации для первого информационного объекта, которая показывает отношение аннотируемого информационного объекта к текстовому документу,
- разметку в текстовом документе аннотируемого первого информационного объекта и
- сохранение в хранилище извлеченной информации аннотации и по крайней мере порции текстового документа, содержащей аннотируемый первый информационный объект.
- извлечения по крайней мере одного первого информационного объекта из текстового документа;
- формирования по крайней мере один триплет вида <субъект, предикат, объект>;
- организации доступа к хранилищу извлеченной информации, содержащему RDF-граф, включающий множество триплетов вида <субъект, предикат, объект> для множества различных информационных объектов, извлеченных из множества разных текстовых документов;
- поиска в хранилище извлеченной информации второго информационного объекта, представляющего тот же объект реального мира, что и первый информационный объект, где любые два информационных объекта отождествляются, если указанные объекты имеют по крайней мере общий объектный параметр, и где поиск включает выбор и поиск в по меньшей мере одной из трех типов таблиц идентификаторов, содержащих дуплетный, триплетный или квадовый поисковый индекс, где каждый поисковый индекс основан на по крайней мере двух параметрах, выбираемых из множества: субъект, предикат, объект, документ;
и если найден по меньшей мере один второй информационный объект, который соотносится с тем же самым объектом реального мира, что и первый информационный объект, обновляют состояние хранилища извлеченной информации посредством добавления по крайней мере одного триплета <субъект, предикат, объект> о первом информационном объекте к RDF-графу и обновляют по крайней мере один из трех типов индексов.
- генерацию аннотации для первого информационного объекта, которая показывает отношение аннотируемого информационного объекта к текстовому документу;
- разметку в текстовом документе аннотируемого первого информационного объекта; и
- сохранение в хранилище извлеченной информации аннотации и по крайней мере порции текстового документа, содержащей аннотируемый первый информационный объект.
Комментарии