Усовершенствование звукового сигнала возможностью повторного микширования - RU2414095C2
Код документа: RU2414095C2
Чертежи


















Описание
Родственные заявки
Эта заявка испрашивает преимущество приоритета по европейской патентной заявке № EP06113521 на «Enhancing Stereo Audio With Remix Capability» («Усовершенствование стереофонического звукового сигнала возможностью повторного микширования»), поданной 4 мая 2006 года, каковая заявка включена в материалы настоящей заявки посредством ссылки во всей своей полноте.
Эта заявка испрашивает приоритет по предварительной заявке на выдачу патента США под № 60/829,350, на «Enhancing Stereo Audio With Remix Capability», поданной 13 октября 2006 года, каковая заявка включена в материалы настоящей заявки посредством ссылки во всей своей полноте.
Эта заявка испрашивает приоритет по предварительной заявке на выдачу патента США под № 60/884,594 на «Separate Dialogue Volume» («Раздельный уровень громкости диалога»), поданной 11 января 2007 года, каковая заявка включена в материалы настоящей заявки посредством ссылки во всей своей полноте.
Эта заявка испрашивает приоритет по предварительной заявке на выдачу патента США под № 60/885,742 на «Enhancing Stereo Audio With Remix Capability», поданной 19 января 2007 года, каковая заявка включена в материалы настоящей заявки посредством ссылки во всей своей полноте.
Эта заявка испрашивает приоритет по предварительной заявке на выдачу патента США под № 60/888,413 на «Object-Based Signal Reproduction» («Воспроизведение объектно-ориентированного сигнала»), поданной 6 февраля 2007 года, каковая заявка включена в материалы настоящей заявки посредством ссылки во всей своей полноте.
Эта заявка испрашивает приоритет по предварительной заявке на выдачу патента США под № 60/894,162 на «Bitstream and Side Information For SAOC/Remix» («Битовый поток и дополнительная информация для SAOC/повторного микширования»), поданной 9 марта 2007 года, каковая заявка включена в материалы настоящей заявки посредством ссылки во всей своей полноте.
Область техники
Объект изобретения этой заявки в целом имеет отношение к обработке звуковых сигналов.
Уровень техники
Многие потребительские звуковые устройства (например, стереосистемы, медиаплееры, мобильные телефоны, игровые консоли и т.п.) предоставляют пользователям возможность модифицировать стереофонические звуковые сигналы с использованием средств управления для коррекции (например, нижних звуковых частот, верхних звуковых частот), уровня громкости, акустических эффектов помещений и т.п. Эти модификации, однако, применяются ко взятому в целом звуковому сигналу, а не к отдельным звуковым объектам (например, инструментам), которые составляют звуковой сигнал. Например, пользователь не может модифицировать по отдельности стереофоническое панорамирование или коэффициент усиления гитар, барабанов или вокальных партий в песне, не воздействуя на песню, взятую в целом.
Были предложены технологии, которые обеспечивают гибкость микширования в декодере. Эти технологии полагаются на кодирование бинауральными контрольными сигналами (BCC), параметрический или пространственный звуковой декодер для формирования микшированного выходного сигнала декодера. Ни одна из этих технологий, однако, не кодирует непосредственно стереофонические микшированные сигналы (например, профессионально микшированную музыку) для предоставления возможности обратной совместимости без дискредитации качества звучания.
Технологии пространственного звукового кодирования были предложены для представления стереофонических или многоканальных звуковых каналов с использованием межканальных контрольных сигналов (например, перепада уровней, разновременности, разности фаз, когерентности). Межканальные контрольные сигналы передаются в качестве «дополнительной информации» в декодер для использования при формировании многоканального выходного сигнала. Эти традиционные технологии пространственного звукового кодирования, однако, имеют несколько недостатков. Например, по меньшей мере, некоторые из этих технологий требуют, чтобы отдельный сигнал для каждого звукового объекта передавался в декодер, даже если звуковой объект не будет модифицироваться в декодере. Такое требование имеет следствием излишнюю обработку в кодировщике и декодере. Еще одним недостатком является ограничение выходного сигнала декодера либо стереофоническим (или многоканальным) звуковым сигналом либо звуковым сигналом источника, имея следствием пониженную гибкость для повторного микширования в декодере. В заключение, по меньшей мере, некоторые из этих традиционных технологий требуют сложной декорреляционной обработки в декодере, делающей такие технологии непригодными для некоторых применений или устройств.
Сущность изобретения
Один или более атрибутов (например, панорамирование, усиление, и т.п.), ассоциативно связанных с одним или более объектов (например, инструментов) стереофонического или многоканального звукового сигнала, могут модифицироваться для предоставления возможности повторного микширования.
В некоторых реализациях способ включает в себя получение первого многоканального звукового сигнала, содержащего набор объектов; получение дополнительной информации, по меньшей мере, некоторая часть которой представляет зависимость между первым многоканальный звуковым сигналом и одним или более сигналами источников, представляющими объекты, которые должны повторно микшироваться; получение набора параметров микширования; и формирование второго многоканального звукового сигнала с использованием дополнительной информации и набора параметров микширования.
В некоторых реализациях, способ включает в себя получение звукового сигнала, содержащего набор объектов; получение подмножества сигналов источников, представляющих подмножество объектов; и формирование дополнительной информации из подмножества сигналов источников, по меньшей мере, некоторая часть дополнительной информации представляет взаимосвязь между звуковым сигналом и подмножеством сигналов источников.
В некоторых реализациях, способ включает в себя получение многоканального звукового сигнала; определение коэффициентов усиления для набора сигналов источников с использованием требуемых перепадов уровней источников, представляющих требуемые направления звучания набора сигналов источников в павильоне звукозаписи; оценивание мощности поддиапазона для направления прямого звучания набора сигналов источников с использованием многоканального звукового сигнала; и оценивание мощности поддиапазонов для по меньшей мере некоторых из сигналов источников в наборе сигналов источников посредством модифицирования мощности поддиапазона для направления прямого звучания в качестве функции направления прямого звучания и требуемого направления звучания.
В некоторых реализациях, способ включает в себя получение микшированного звукового сигнала; получение набора параметров микширования для повторного микширования микшированного звукового сигнала; если дополнительная информация доступна, повторное микширование микшированного звукового сигнала с использованием дополнительной информации и набора параметров микширования; если дополнительная информация не доступна, формирование набора слепых параметров из микшированного звукового сигнала; и формирование повторно микшированного звукового сигнала с использованием слепых параметров и набора параметров микширования.
В некоторых реализациях, способ включает в себя получение микшированного звукового сигнала, включающего в себя сигналы речевого источника; получение параметров микширования, задающих требуемое усовершенствование одному или более речевых сигналов источников; формирование набора слепых параметров из микшированного звукового сигнала; формирование параметров повторного микширования из слепых параметров и параметров микширования; и применение параметров к микшированному сигналу, чтобы усовершенствовать один или более речевых сигналов источников в соответствии с параметрами микширования.
В некоторых реализациях, способ включает в себя формирование пользовательского интерфейса для приема входных данных, задающих параметры микширования; получение параметра микширования через пользовательский интерфейс; получение первого звукового сигнала, включающего в себя сигналы источников; получение дополнительной информации, по меньшей мере, некоторая часть которой представляет зависимость между первым звуковым сигналом и одним или более сигналами источников; и повторное микширование одного или более сигналов источников с использованием дополнительной информации и параметра микширования, чтобы сформировать второй звуковой сигнал.
В некоторых реализациях, способ включает в себя получение первого многоканального звукового сигнала, содержащего набор объектов; получение дополнительной информации, по меньшей мере, некоторая часть которой представляет зависимость между первым многоканальный звуковым сигналом и одним или более сигналами источников, представляющими подмножество объектов, которые должны повторно микшироваться; получение набора параметров микширования; и формирование второго многоканального звукового сигнала с использованием дополнительной информации и набора параметров микширования.
В некоторых реализациях, способ включает в себя получение микшированного звукового сигнала; получение набора параметров микширования для повторного микширования микшированного звукового сигнала; формирование параметров повторного микширования с использованием микшированного звукового сигнала и набора параметров микширования; и формируют повторно микшированный звуковой сигнал, применяя параметры повторного микширования к микшированному звуковому сигналу с использованием матрицы n на n.
Раскрыты другие реализации для усовершенствования звукового сигнала возможностью повторного микширования, в том числе реализации, направленные на системы, способы, устройства, машиночитаемые носители и пользовательские интерфейсы.
Описание чертежей
Фиг.1A - структурная схема реализации системы кодирования для кодирования стереофонического сигнала плюс M сигналов источников, соответствующих объектам, которые должны повторно микшироваться в декодере.
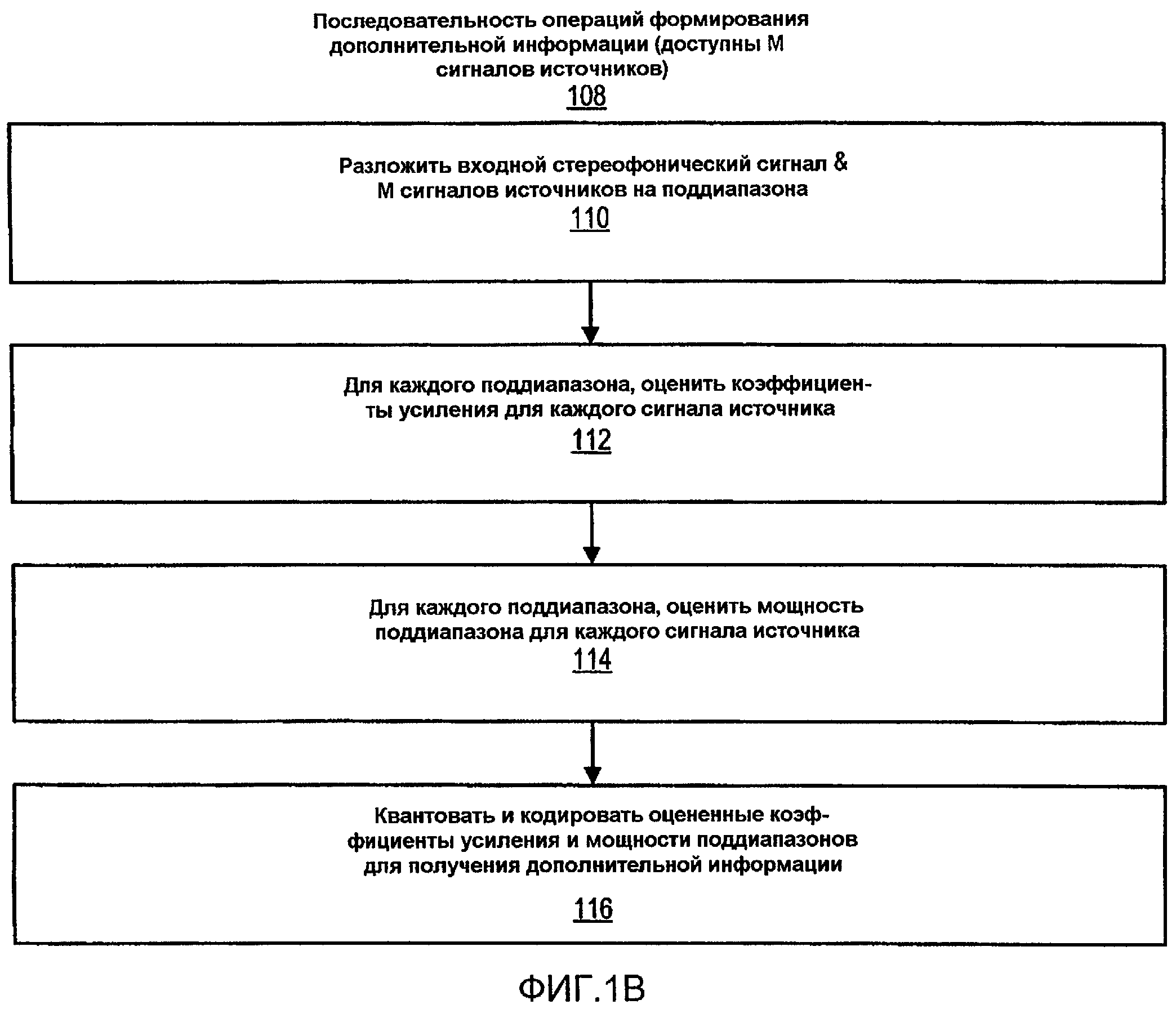
Фиг.1B - блок-схема последовательности операций способа реализации последовательности операций для кодирования стереофонического сигнала плюс M сигналов источников, соответствующих объектам, которые должны повторно микшироваться в декодере.
Фиг.2 иллюстрирует времячастотное графическое представление для анализа и обработки стереофонического сигнала и M сигналов источников.
Фиг.3A - структурная схема реализации системы повторного микширования для оценки повторно микшированного стереофонического сигнала с использованием исходного стереофонического сигнала плюс дополнительной информации.
Фиг.3B - блок-схема последовательности операций способа реализации последовательности операций для оценки повторно микшированного стереофонического сигнала с использованием системы повторного микширования по фиг.3A.
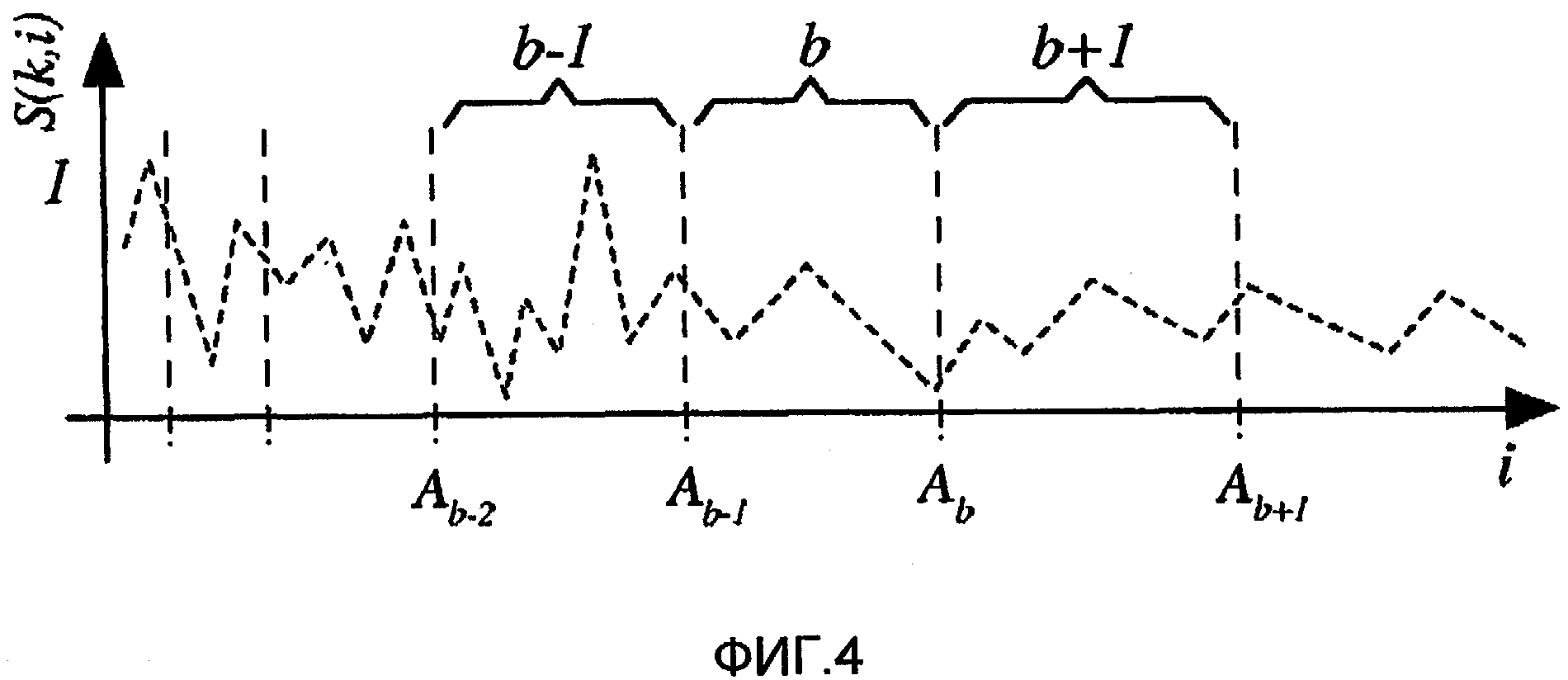
Фиг.4 иллюстрирует индексы i коэффициентов краткосрочного преобразования Фурье (STFT), принадлежащих сегменту с индексом b.
Фиг.5 иллюстрирует группирование спектральных коэффициентов равномерного спектра STFT в имитационное неравномерное частотное разрешение слухового аппарата человека.
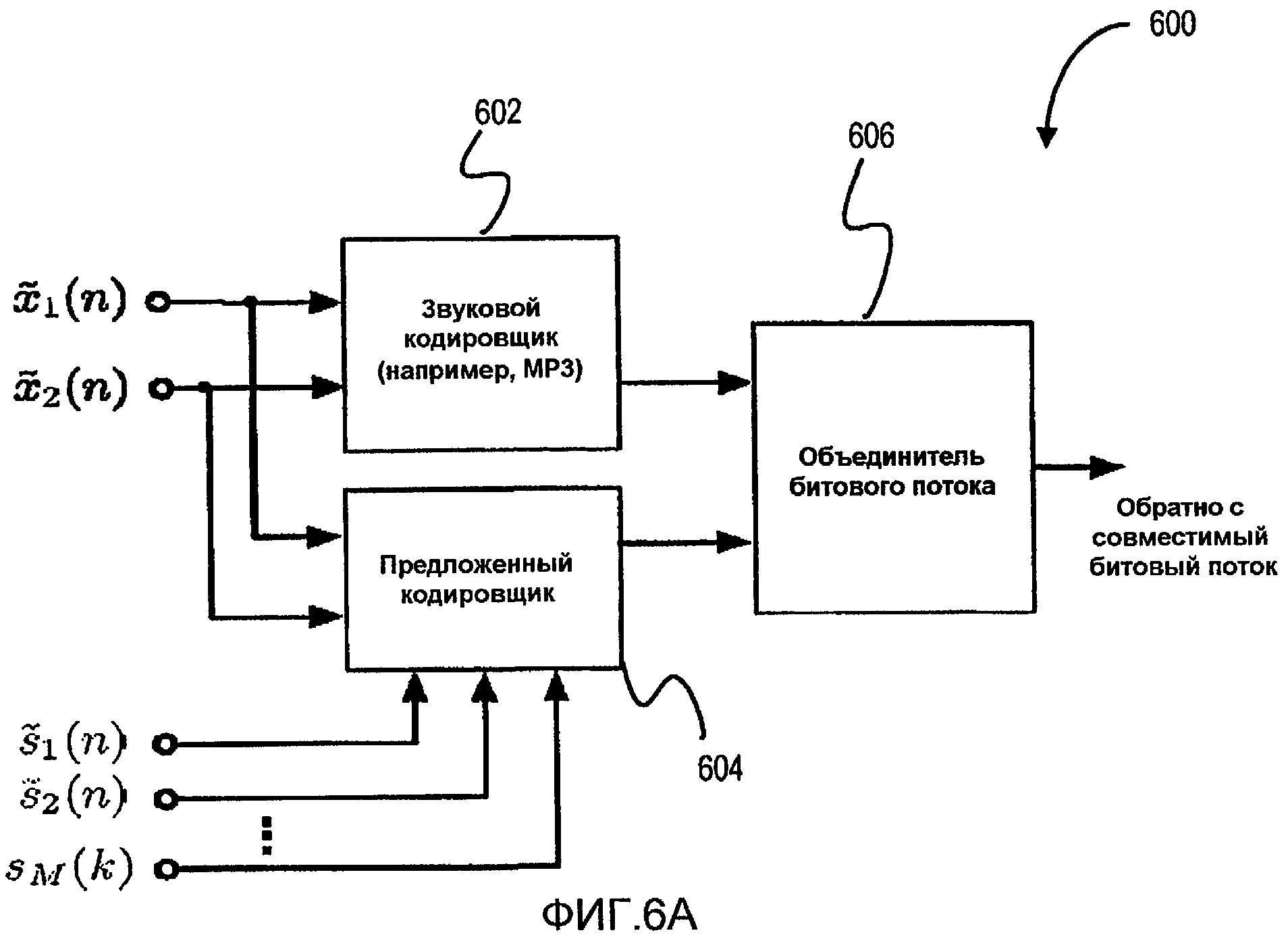
Фиг.6A - структурная схема реализации системы кодирования по фиг.1, объединенной с традиционным стереофоническим звуковым кодировщиком.
Фиг.6B - блок-схема последовательности операций способа реализации последовательности операций кодирования с использованием системы кодирования по фиг.1, объединенной с традиционным стереофоническим звуковым кодировщиком.
Фиг.7A - структурная схема реализации системы повторного микширования по фиг.3A, объединенной с традиционным стереофоническим звуковым декодером.
Фиг.7B - блок-схема последовательности операций способа реализации последовательности операций повторного микширования с использованием системы повторного микширования по фиг.7A, объединенной со стереофоническим звуковым кодировщиком.
Фиг.8A - структурная схема реализации системы кодирования, реализующей полностью слепое формирование дополнительной информации.
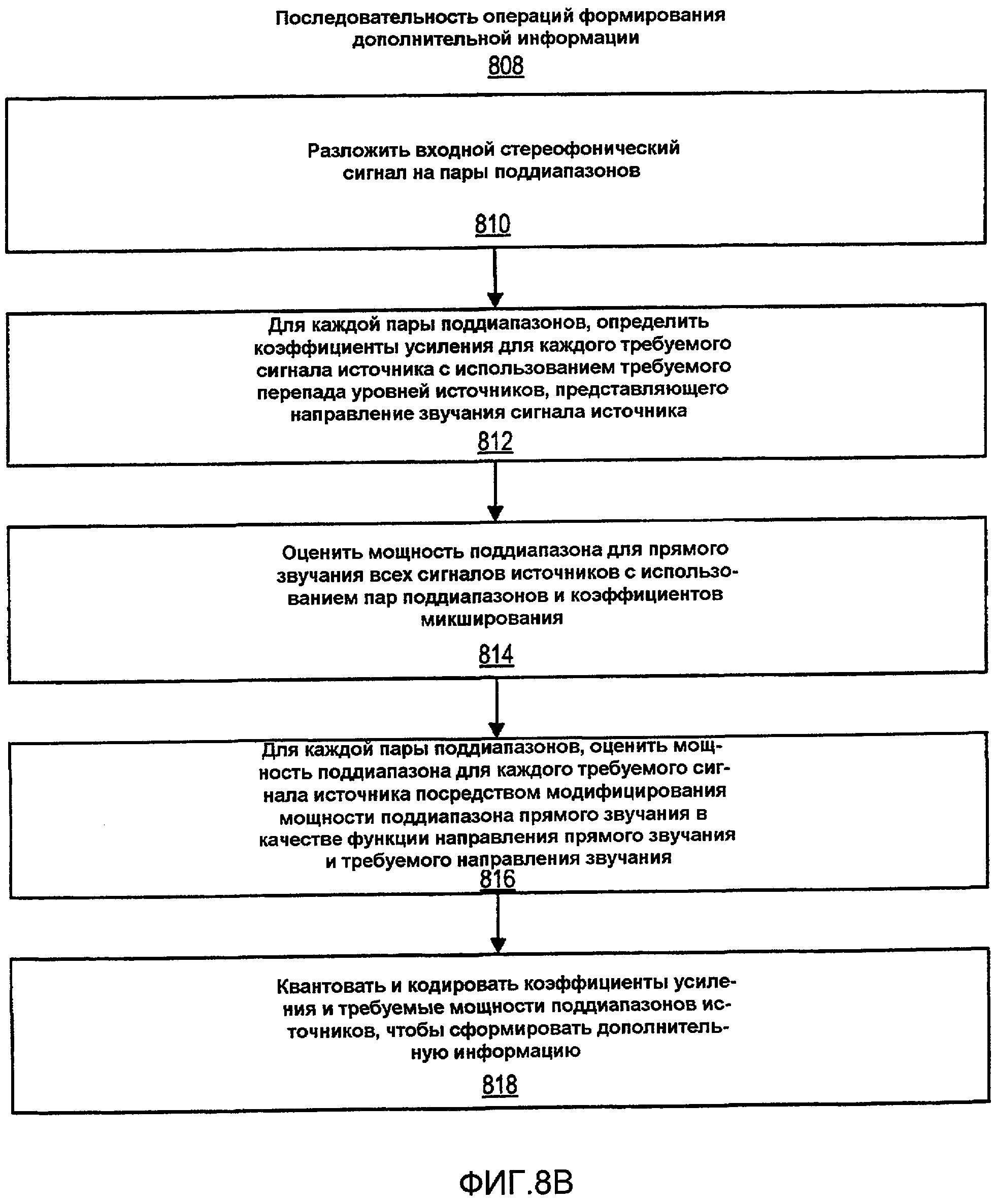
Фиг.8B - блок-схема последовательности операций способа реализаций последовательности операций кодирования с использованием системы кодирования по фиг.8A.
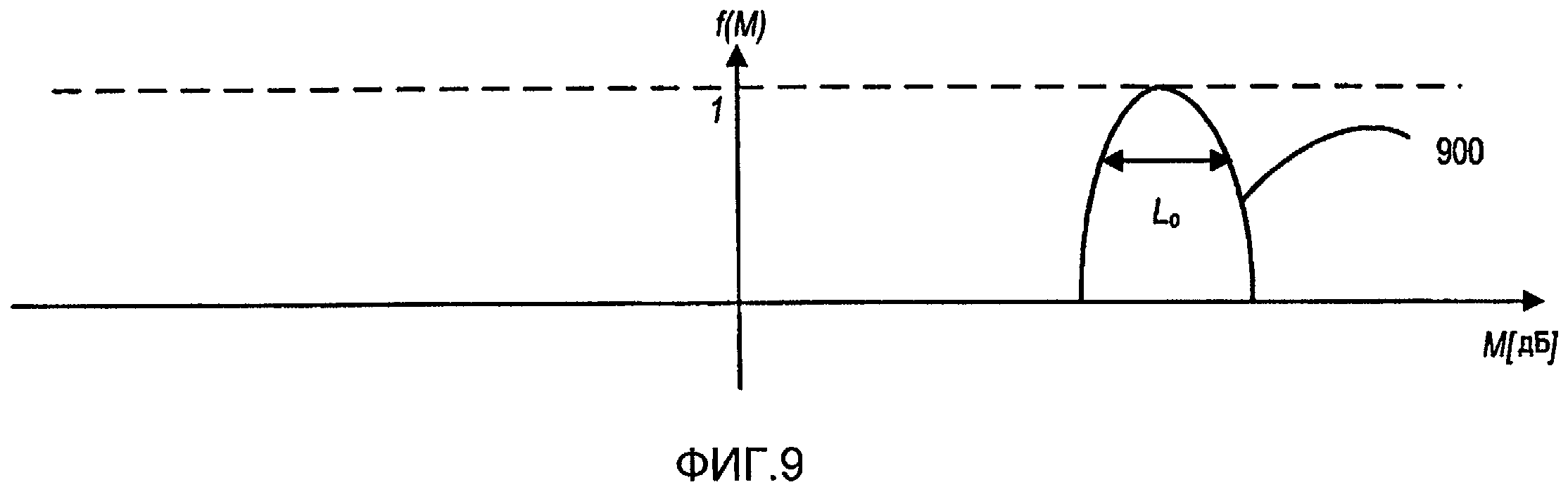
Фиг.9 иллюстрирует примерную функцию усиления, f(M), для требуемого перепада уровней источников, Li=L dB.
Фиг.10 - схема реализации последовательности операций формирования дополнительной информации с использованием технологии частично слепого формирования.
Фиг.11 - структурная схема реализации клиент-серверной архитектуры для поставки стереофонических сигналов и M сигналов источников и/или дополнительной информации в звуковые устройства с возможность повторного микширования.
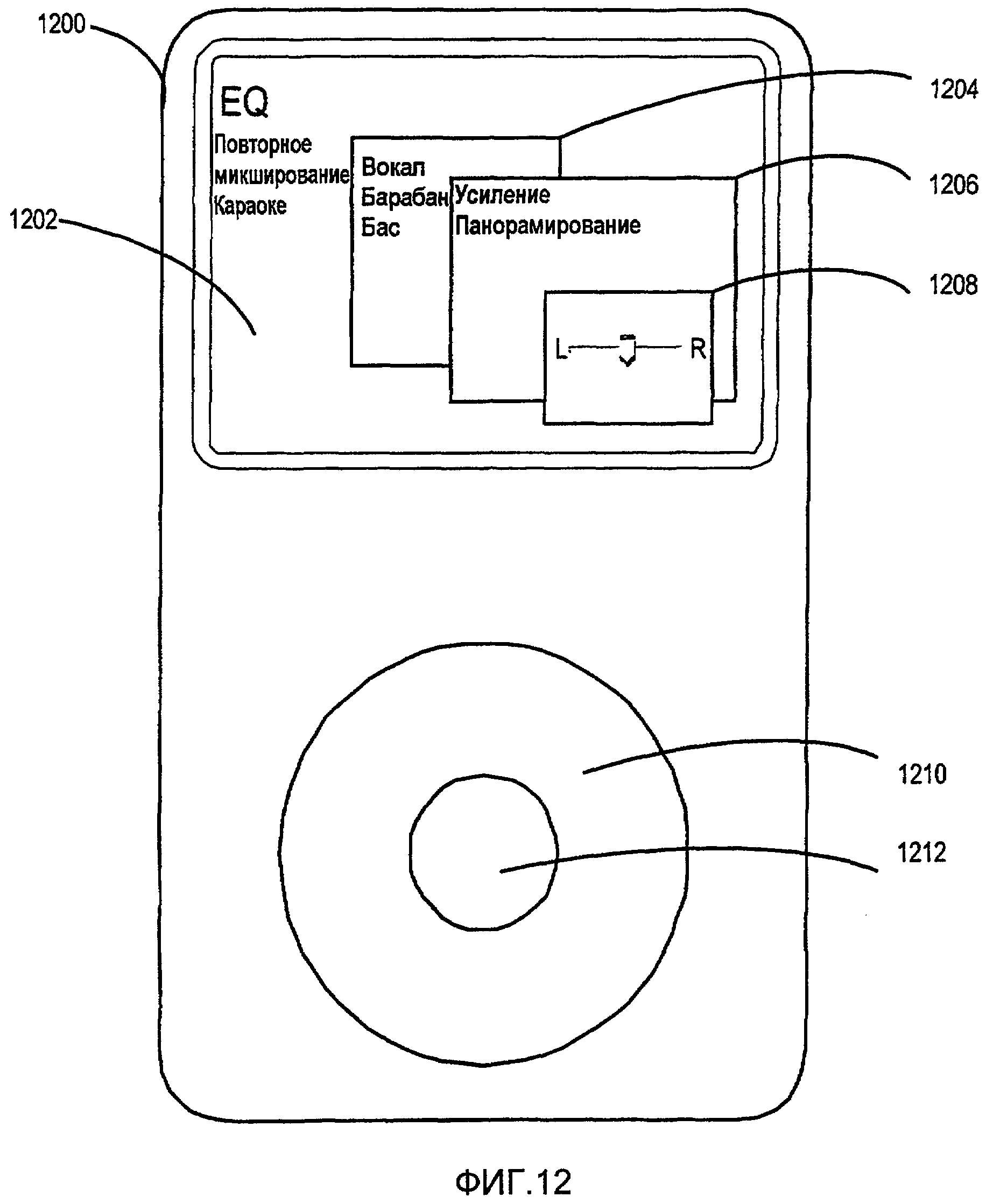
Фиг.12 иллюстрирует реализацию пользовательского интерфейса для медиаплеера с возможностью повторного микширования.
Фиг.13 иллюстрирует реализацию системы декодирования, объединяющей декодирование пространственно кодированных звуковых объектов (SAOC) и декодирование повторного микширования.
Фиг.14A иллюстрирует обычную модель микширования для раздельного уровня громкости диалога (SDV).
Фиг.14B иллюстрирует реализацию системы, объединяющей SDV и технологию повторного микширования.
Фиг.15 иллюстрирует реализацию рендерера эквивалентного микширования, показанного на фиг.14В.
Фиг.16 иллюстрирует реализацию системы распространения для технологии повторного микширования, описанной со ссылкой на фиг.1-15.
Фиг.17А иллюстрирует элементы различных реализации битового потока для предоставления информации повторного микширования.
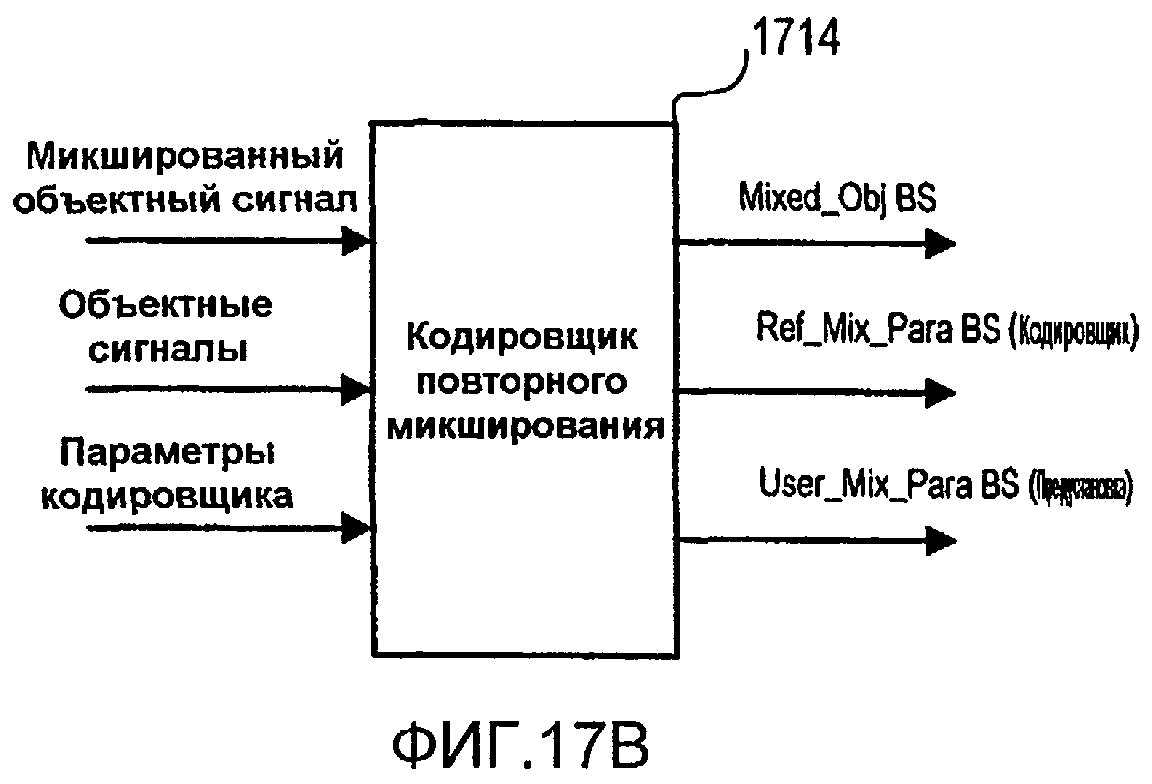
Фиг.17В иллюстрирует реализацию интерфейса кодировщика повторного микширования для формирования битовых потоков, проиллюстрированных на фиг.17А.
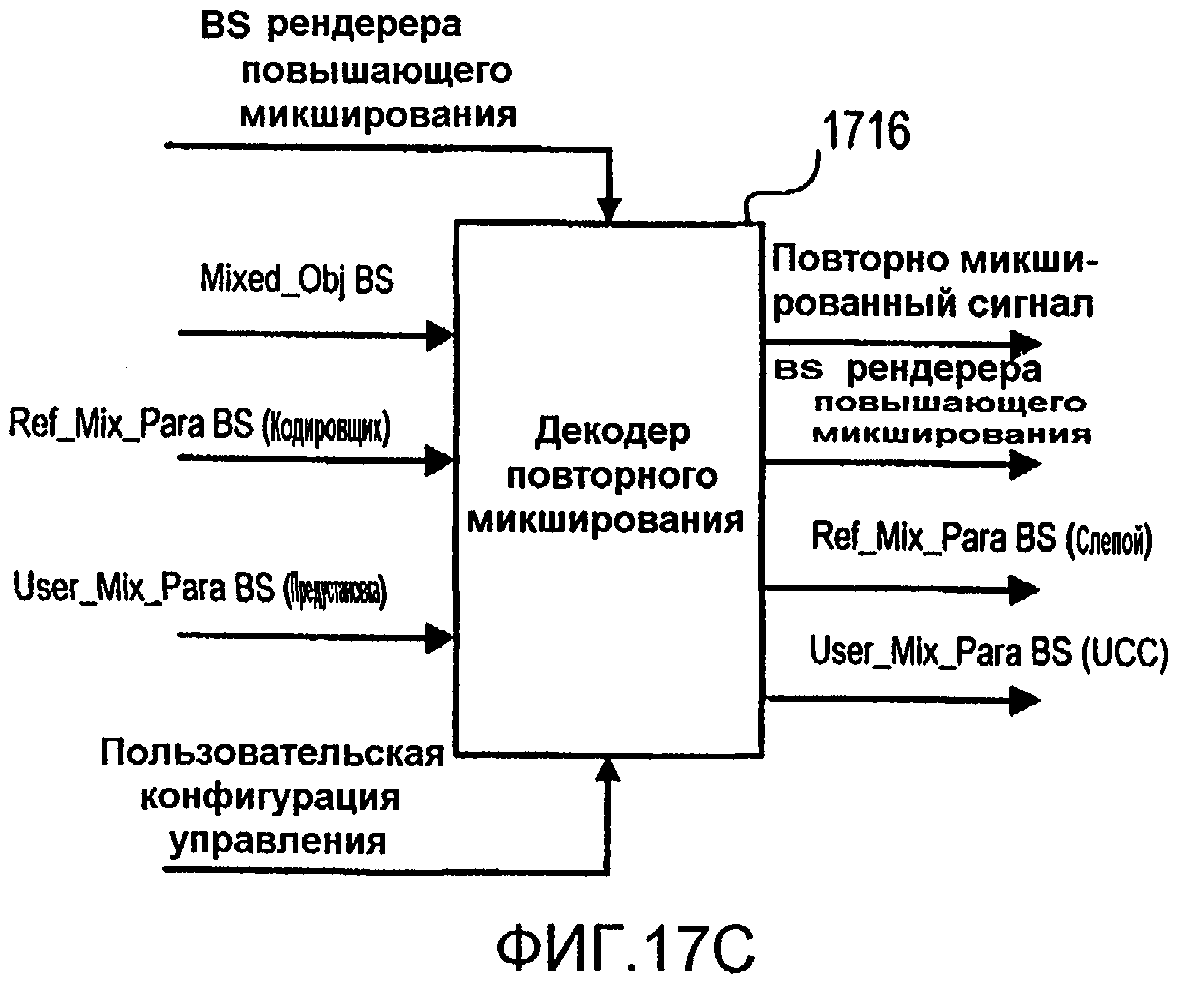
Фиг.17С иллюстрирует реализацию интерфейса декодера повторного микширования для приема битовых потоков, сформированных кодировщиком, проиллюстрированным на фиг.17В.
Фиг.18 - структурная схема реализации системы, включающей в себя расширения для формирования добавочной дополнительной информации для определенных объектных сигналов, чтобы обеспечивать улучшенные эксплуатационные качества повторного микширования.
Фиг.19 - структурная схема реализации формирователя (рендерера) повторно микшированного сигнала, показанного на фиг.18.
Подробное описание
I. Повторное микширование стереофонических сигналов
Фиг.1А - структурная схема реализации системы 100 кодирования для кодирования стереофонических сигналов плюс М сигналов источников, соответствующих объектам, которые должны повторно микшироваться в декодере. В некоторых реализациях, система 100 кодирования обычно включает в себя матрицу 102 гребенки фильтров, формирователь 104 дополнительной информации и кодировщик 106.
A. Исходный и требуемый повторно микшированный сигнал
Два канала стереофонического звукового сигнала с временной дискретизацией обозначены
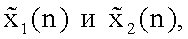

где I - количество сигналов источников (например, инструментов), которые содержатся в стереофоническом сигнале (например, MP3), а


В некоторых реализациях, система 100 кодирования выдает или формирует информацию (в дальнейшем также указываемую ссылкой как «дополнительная информация») для модифицирования исходного стереофонического звукового сигнала (в дальнейшем также указываемого ссылкой как «стереофонический сигнал»), из условия, чтобы M сигналов источников «повторно микшировались» в стереофонический сигнал с разными коэффициентами усиления. Требуемый модифицированный стереофонический сигнал может быть представлен в виде:

где ci и di - новые коэффициенты усиления (в дальнейшем также указываемые ссылкой как «коэффициенты усиления микширования» или «параметры микширования») для M сигналов источников, которые должны микшироваться (то есть сигналов источников с индексами 1, 2,..., M).
Цель системы 100 кодирования состоит в том, чтобы выдавать или формировать информацию для повторного микширования стереофонического сигнала, при заданном только исходном стереофоническом сигнале и небольшом количестве дополнительной информации (например, небольшой по сравнению с информацией, содержащейся в форме колебаний стереофонического сигнала). Дополнительная информация, поставляемая или формируемая системой 100 кодирования, может использоваться в декодере для относящейся к восприятию имитации требуемого модифицированного стереофонического сигнала [2] при заданном исходном стереофоническом сигнале [1]. С системой 100 кодирования формирователь 104 дополнительной информации формирует дополнительную информацию для повторного микширования исходного стереофонического сигнала, а система 300 декодирования (фиг.3A) формирует требуемый повторно микшированный стереофонический звуковой сигнал с использованием дополнительной информации и исходного стереофонического сигнала.
B. Обработка кодировщика
Вновь со ссылкой на фиг.1A исходный стереофонический сигнал и M сигналов источников подаются в качестве входного сигнала в матрицу 102 гребенки фильтров. Исходный стереофонический сигнал также непосредственно выводится из кодировщика 102. В некоторых реализациях, стереофонический сигнал, непосредственно выведенный из кодировщика 102, может задерживаться для синхронизации с битовым потоком дополнительной информации. В других реализациях, вывод стереофонического сигнала может синхронизироваться с дополнительной информацией в декодере. В некоторых реализациях, система 100 кодирования адаптируется к статистическим данным сигнала в качестве функции времени и частоты. Таким образом, для анализа и синтеза стереофонический сигнал и M сигналов источников обрабатываются во времячастотном представлении, как описано со ссылкой на фиг.4 и 5.
Фиг.1B - блок-схема последовательности операций способа реализации последовательности 108 операций для кодирования стереофонического сигнала плюс M сигналов источников, соответствующих объектам, которые должны повторно микшироваться в декодере. Входной стереофонический сигнал и M сигналов источников раскладываются на поддиапазоны (110). В некоторых реализациях, разложение реализуется с помощью матрицы гребенки фильтров. Для каждого поддиапазона коэффициенты усиления оцениваются для M сигналов источников (112), как более полно описано ниже. Для каждого поддиапазона краткосрочные оценки мощности вычисляются для M сигналов источников (114), как описано ниже. Оцененные коэффициенты усиления и мощности подиапазонов могут квантоваться и кодироваться для формирования дополнительной информации (116).
Фиг.2 иллюстрирует времячастотное графическое представление для анализа и обработки стереофонического сигнала и M сигналов источников. Ось ординат графика представляет частоту и делится на множество неравномерных поддиапазонов 202. Ось абсцисс представляет время и делится на временные интервалы 204. Каждый из штрихпунктирных прямоугольников на фиг.2 представляет соответственную пару поддиапазона и временного интервала. Таким образом, для заданного временного интервала 204 один или более поддиапазонов 202 соответствующих временному интервалу 204, могут обрабатываться в качестве группы 206. В некоторых реализациях, ширины подиапазонов 202 выбираются на основании пределов восприятия, ассоциативно связанных со слуховым аппаратом человека, как описано со ссылкой на фиг.4 и 5.
В некоторых реализациях, входной стереофонический сигнал и M входных сигналов источников раскладываются матрицей 102 гребенки фильтров на некоторое количество поддиапазонов 202. Поддиапазоны 202 на каждой центральной частоте могут обрабатываться подобным образом. Пара поддиапазонов стереофонических звуковых входных сигналов, на отдельной частоте, обозначена x1(k) и x2(k), где k подвергнутый понижающей дискретизации индекс времени сигналов поддиапазонов. Подобным образом соответствующие сигналы поддиапазонов M входных сигналов источников обозначены s1(k), s2(k),..., sM(k). Отметим, что для простоты обозначения, индексы для поддиапазонов были опущены в этом примере. Что касается понижающей дискретизации, для эффективности могут использоваться сигналы поддиапазонов с меньшей частотой дискретизации. Обычно гребенки фильтров и STFT фактически получают подвергнутые подвыборке сигналы (или спектральные коэффициенты).
В некоторых реализациях, дополнительная информация, необходимая для повторного микширования сигнала источника с индексом i, включает в себя коэффициенты ai и bi усиления и в каждом поддиапазоне, оценку мощности сигнала поддиапазона в качестве функции времени, E{si2(k)}. Коэффициенты ai и bi усиления могут задаваться (если эти сведения о стереофоническом сигнале известны) или оцениваться. Для многих стереофонических сигналов, ai и bi являются статическими. Если ai и bi являются меняющимися в качестве функции времени k, эти коэффициенты усиления могут оцениваться в качестве функции времени. Она не обязательно должна использовать среднее значение или оценку мощности поддиапазона для формирования дополнительной информации. Предпочтительнее в некоторых реализациях реальная мощность Si2 поддиапазона может использоваться в качестве оценки мощности.
В некоторых реализациях, краткосрочная мощность поддиапазона может оцениваться с использованием однополюсного усреднения, где E{si2(k)} может вычисляться как:

где α∈[0,1] определяет постоянную времени экспоненциально затухающего окна оценки,

а fs обозначает частоту дискретизации поддиапазона. Подходящим значением для T, например, может быть 40 миллисекунд. В последующих уравнениях E{.} обычно обозначает краткосрочное усреднение.
В некоторых реализациях, некоторая или вся из дополнительной информации ai, bi и E{si2(k)} может поставляться на тех же носителях, что и стереофонический сигнал. Например, издатель музыкальных произведений, студия звукозаписи, ретушер звукозаписи или тому подобные, могут поставлять дополнительную информацию с соответствующим стереофоническим сигналом на компакт-диске (CD), цифровом видеодиске (DVD), флэш-памяти и тому подобном. В некоторых реализациях, некоторая или вся из дополнительной информации может поставляться по сети (например, сети Интернет, сети Ethernet, беспроводной сети) встраиванием дополнительной информации в битовый поток стереофонического сигнала или передачей дополнительной информации в отдельном битовом потоке.
Если ai и bi не заданы, то эти коэффициенты могут оцениваться. Поскольку,



Подобным образом bi может вычисляться в качестве

Если ai и bi являются самонастраивающимися со временем, оператор E{.} представляет операцию краткосрочного усреднения. С другой стороны, если коэффициенты ai и bi усиления являются статическими, коэффициенты усиления могут вычисляться, учитывая стереофонические сигналы во всей их полноте. В некоторых вариантах осуществления коэффициенты ai и bi усиления могут оцениваться независимо для каждого поддиапазона. Отметим, что в [5] и [6] сигналы si источников являются независимыми, но, вообще, не сигнал si источника и стереофонические каналы x1 и x2, поскольку si содержится в стереофонических каналах x1 и x2.
В некоторых реализациях краткосрочные оценки мощности и коэффициенты усиления для каждого поддиапазона квантуются и кодируются кодировщиком 106, чтобы сформировать дополнительную информацию (например, битовый поток с низкой скоростью передачи битов). Отметим, что эти значения могут не квантоваться и кодироваться непосредственно, но сначала могут преобразовываться в другие величины, более подходящие для квантования и кодирования, как описано со ссылкой на фиг.4 и 5. В некоторых реализациях, E{si2(k)} может быть нормализована относительно мощности поддиапазона входного стереофонического звукового сигнала, делая систему 100 кодирования устойчивой касательно изменений, когда традиционный звуковой кодировщик используется для эффективного кодирования стереофонического звукового сигнала, как описано со ссылкой на фиг.6-7.
C. Обработка декодера
Фиг.3A - структурная схема реализации системы 300 повторного микширования для оценки повторно микшированного стереофонического сигнала с использованием исходного стереофонического сигнала плюс дополнительной информации. В некоторых реализациях, система 300 повторного микширования обычно включает в себя матрицу 302 гребенки фильтров, декодер 304, модуль 306 повторного микширования и обратную матрицу 308 гребенки фильтров.
Оценка повторно микшированного звукового сигнала может выполняться независимо в некотором количестве поддиапазонов. Дополнительная информация включает в себя мощность поддиапазона, E{s2i (k)} и коэффициенты усиления, ai и bi, с которыми M сигналов источников содержатся в стереофоническом сигнале. Новые коэффициенты усиления или коэффициенты усиления микширования требуемого повторно микшированного стереофонического сигнала представлены посредством ci и di. Коэффициенты усиления ci и di микширования могут задаваться пользователем через пользовательский интерфейс звукового устройства, такого как описанное со ссылкой на фиг.12.
В некоторых реализациях входной стереофонический сигнал раскладывается на поддиапазоны матрицей 302 гребенки фильтров, где пара поддиапазонов на отдельной частоте обозначена x1(k) и x2(k). Как проиллюстрировано на фиг.3A, дополнительная информация декодируется декодером 304, давая для каждого из M сигналов источников, которые должны повторно микшироваться, коэффициенты ai и bi усиления, которые содержаться во входном стереофоническом сигнале, и для каждого поддиапазона оценку мощности, E{si2(k)}. Декодирование дополнительной информации описано более подробно со ссылкой на фиг.4 и 5.
При заданной дополнительной информации, соответствующая пара поддиапазонов повторно микшированного стереофонического звукового сигнала может оцениваться модулем 306 повторного микширования в качестве функции коэффициентов ci и di усиления микширования повторно микшированного стереофонического сигнала. Обратная матрица 308 гребенки фильтров применяется к оцененным парам поддиапазонов для предоставления повторно микшированного стереофонического сигнала временной области.
Фиг.3B - блок-схема последовательности операций способа реализации последовательности 310 операций для оценивания повторно микшированного стереофонического сигнала с использованием системы повторного микширования по фиг.3A. Входной стереофонический сигнал раскладывается на пары поддиапазонов (312). Дополнительная информация декодируется для пар поддиапазонов (314). Пары поддиапазонов повторно микшируются с использованием дополнительной информации и коэффициентов усиления микширования (318). В некоторых реализациях, коэффициенты усиления микширования предоставляются пользователем, как описано со ссылкой на фиг.12. В качестве альтернативы коэффициенты усиления микширования могут предоставляться программно, приложением, операционной системой или тому подобным. Коэффициенты усиления микширования также могут поставляться по сети (например, сети Интернет, сети Ethernet, беспроводной сети), как описано со ссылкой на фиг.11.
D. Последовательность операций повторного микширования
В некоторых реализациях, повторно микшированный стереофонический сигнал может аппроксимироваться в математическом смысле с использованием оценки методом наименьших квадратов. По выбору относящиеся к восприятию соображения могут использоваться для модификации оценки.
Уравнения [1] и [2] к тому же рассматривают пары x1(k) и x2(k), а также y1(k) и y2(k) поддиапазонов соответственно. В этом случае сигналы источников замещаются сигналами поддиапазонов источников, si(k).
Пара поддиапазонов стереофонического сигнала задается согласно

а парой поддиапазонов повторно микшированного стереофонического звукового сигнала являются

При заданной паре поддиапазона исходного стереофонического сигнала, x1(k) и x2(k), пара поддиапазона стереофонического сигнала с разными коэффициентами усиления оценивается в качестве линейной комбинации исходной пары левого и правого стереофонических поддиапазонов:

где w11(k), w12(k), w21(k) и w22(k) - заданные действительными значениями весовые коэффициенты.
Ошибка оценки определяется в качестве

Веса w11(k), w12(k), w21(k) и w22(k) могут вычисляться в каждый момент k времени для поддиапазонов на каждой частоте, из условия чтобы минимизировались среднеквадратические ошибки E{e12(k)} и E{e22(k)}. Для вычисления w11(k) и w12(k), отметим, что E{e12(k)} минимизируется, когда ошибка e1(k) ортогональна x1(k) и x2(k), то есть

Отметим, что для удобства обозначения индекс k времени был опущен.
Переписывание этих уравнений дает:

Коэффициенты усиления являются решением этой системы линейных уравнений:
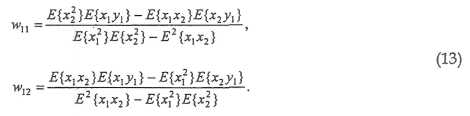
Несмотря на то, что E{x12}, E{x22} и E{x1x2} могут непосредственно оцениваться при заданной паре поддиапазонов входного стереофонического сигнала декодера, E{x1y1} и E{x2y2} могут оцениваться с использованием дополнительной информации (E{s12}, ai, bi) и коэффициентов усиления микширования, ci и di, требуемого повторно микшированного стереофонического сигнала:

Подобным образом вычисляются w21и w22, давая в результате
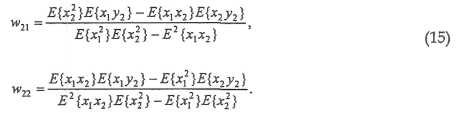
Причем
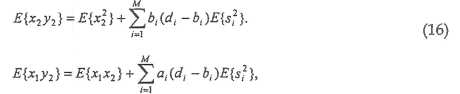
Когда левый и правый сигналы поддиапазонов когерентны или почти когерентны, то есть когда

близко к единице, то решение для весов неуникально или плохо обусловлено. Таким образом, если ϕ является большим, чем определенное пороговое значение (например, 0,95), то веса, например, вычисляются согласно

При условии ϕ=1 уравнение [18] является одним из неуникальных решений, удовлетворяющих [12] и подобной системе уравнений ортогональности для двух других весов. Отметим, что когерентность в [17] используется для вынесения суждения, насколько x1 и x2 подобны друг другу. Если когерентность равна нулю, то x1 и x2 независимы. Если когерентность равна единице, то x1 и x2 подобны (но могут иметь разные уровни). Если x1 и x2 сильно подобны (когерентность близка к единице), то двухканальное вычисление Винера (вычисление четырех весов) является плохо обусловленным. Примерным диапазоном для порогового значения является от приблизительно 0,4 до приблизительно 1,0.
Результирующий повторно микшированный стереофонический сигнал, полученный преобразованием вычисленных сигналов поддиапазонов во временную область, звучание, подобное стереофоническому сигналу, который действительно микшировался бы с разными коэффициентами усиления микширования, ci и di, (в последующем этот сигнал обозначен «требуемым сигналом»). С одной стороны, математически это требует, чтобы вычисленные сигналы поддиапазонов были подобны действительно по-разному микшированным сигналам поддиапазонов. Это верно до определенной степени. Поскольку оценка выполняется в области мотивированных восприятием поддиапазонов, требование к подобию является менее строгим. До тех пор, пока контрольные сигналы значимого для восприятия определения местоположения (например, контрольные сигналы перепада уровней и когерентности) достаточно подобны, вычисленный повторно микшированный стереофонический сигнал будет звучать подобно требуемому сигналу.
E.Необязательная возможность: настройка контрольных сигналов перепадов уровней
В некоторых реализациях, если используется обработка, описанная в материалах настоящей заявки, могут быть получены хорошие результаты. Тем не менее, чтобы быть уверенным, что важные контрольные сигналы определения местоположения перепада уровней весьма близки к контрольным сигналам перепадов уровней требуемого сигнала, домасштабирование поддиапазонов может применяться для «настройки» контрольных сигналов перепадов уровней, чтобы удостовериться, что они соответствуют контрольным сигналам перепадов уровней требуемого сигнала.
Для модификации оценок сигналов поддиапазонов методом наименьших квадратов в [9] учитывается мощность поддиапазона. Если мощность поддиапазона является надлежащей, то перепад уровней важного пространственного контрольного сигнала также может быть надлежащим. Требуемой мощностью левого поддиапазона сигнала [8] является

а мощностью поддиапазона оценки по [9] является

Таким образом, чтобы
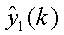

Подобным образом


чтобы иметь такую же мощность, как требуемый сигнал y2(k) поддиапазона.
II. Квантование и кодирование дополнительной информации
A. Кодирование
Как описано в предыдущем разделе, дополнительной информацией, необходимой для повторного микширования сигнала источника с индексом i, являются коэффициенты ai и bi, и в каждом поддиапазоне мощность как функция времени, E{s12(k)}. В некоторых реализациях, соответствующие значения перепадов усиления и уровней для коэффициентов ai и bi усиления могут вычисляться в дБ, как изложено ниже:

В некоторых реализациях, значения усиления и перепада уровней квантуются и кодируются кодом Хаффмана. Например, равномерный квантователь с размером шага квантователя в 2 дБ и одномерный кодировщик Хаффмана могут использоваться для квантования и кодирования соответственно. Другие известные квантователи и кодировщики также могут использоваться (например, векторный квантователь).
Если ai и bi являются независящими от времени, и предполагается, что дополнительная информация достоверно поступает в декодер, соответствующим кодированным значениям необходимо передаваться только один раз. Иначе ai и bi могут передаваться через равные промежутки времени или в ответ на запускающее событие (например, всякий раз, когда меняются кодированные значения).
Чтобы быть устойчивым к масштабированию стереофонического сигнала и потере/приросту мощности, обусловленным кодированием стереофонического сигнала, в некоторых реализациях мощность E{si2(k)} поддиапазона не кодируется непосредственно в качестве дополнительной информации. Предпочтительнее может использоваться показатель, определенный относительно стереофонического сигнала:

Может быть полезным использовать одинаковые окна/постоянные времени оценки для вычисления E{.} по разным сигналам. Преимущество определения дополнительной информации в качестве относительного значения мощности [24] содержит этапы, на которых в декодере, если требуется, могут использоваться окно/постоянная времени оценки иные, чем в кодировщике. К тому же влияние временной рассогласованности между дополнительной информацией и стереофоническим сигналом снижается по сравнению со случаем, когда мощность источника передавалась бы в качестве абсолютного значения. Для квантования и кодирования Ai(k) в некоторых реализациях используется равномерный квантователь, например, с размером шага 2 дБ, и одномерный кодировщик Хаффмана. Результирующая скорость передачи битов может быть такой же небольшой, как 3 килобита/с (килобитов в секунду) на звуковой объект, который должен повторно микшироваться.
В некоторых реализациях, скорость передачи битов может снижаться, когда входной сигнал источника, соответствующий объекту, который должен повторно микшироваться в декодере, является неозвученным. Режим кодирования кодировщика может обнаруживать неозвученный объект, а затем передавать в декодер информацию (например, единственный бит на кадр) для указания, что объект является неозвученным.
B. Декодирование
При заданных декодированных из кода Хаффмана (квантованных) значениях [23] и [24] значения, необходимые для повторного микширования, могут вычисляться, как изложено ниже:

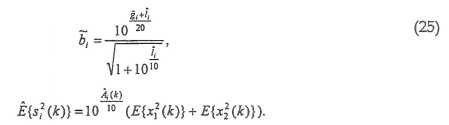
III. Подробности реализации
A. Времячастотная обработка
В некоторых реализациях, основанная на STFT (краткосрочном преобразовании Фурье) обработка используется для систем кодирования/декодирования, описанных со ссылкой на фиг.1-3. Могут использоваться другие времячастотные преобразования для достижения требуемого результата, в том числе, но не в качестве ограничения, гребенка фильтров с квадратурными зеркальными фильтрами (QMF), модифицированное дискретное косинусное преобразование (MDCT), гребенка вейвлетных фильтров и т.п.
Для обработки анализа (например, прямой операции гребенки фильтров) в некоторых реализациях кадр из N отсчетов может перемножаться с окном до того, как применяется N-точечное дискретное преобразование Фурье (ДПФ, DFT) или быстрое преобразование Фурье (БПФ, FFT). В некоторых реализациях, может использоваться следующее синусоидальное окно:
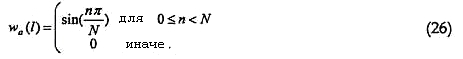
Если размер блока обработки является иным, чем размер ДПФ/БПФ, то в некоторых реализациях заполнение нулями может использоваться для эффективного получения меньшего окна, чем N. Описанная обработка анализа, например, может повторяться каждые N/2 отсчетов (размер скачка окна с равными количествами), давая в результате 50-процентное перекрытие окон. Другие вырезающие (оконные) функции и процентные перекрытия могут использоваться для достижения требуемого результата.
Для преобразования из спектральной области STFT во временную область к спектрам могут применяться обратные ДПФ или БПФ. Результирующий сигнал вновь перемножается с окном, описанным в [26], и смежные блоки сигналов, являющиеся следствием перемножения с окном, объединяются с перекрытием, добавленным для получения непрерывного сигнала во временной области.
В некоторых случаях равномерное спектральное разрешение STFT может не быть хорошо адаптированным к человеческому восприятию. В таких случаях в противоположность обработке каждого частотного коэффициента STFT по отдельности коэффициенты STFT могут «группироваться» из условия, чтобы одна группа имела ширину полосы пропускания, приблизительно в два раза большую эквивалентной прямоугольной полосы пропускания (ERB), каковое является пригодным частотным разрешением для пространственной звуковой обработки.
Фиг.4 иллюстрирует индексы i коэффициентов STFT, принадлежащих сегменту с индексом b. В некоторых реализациях, учитываются только первые N/2+1 спектральных коэффициентов спектра, так как спектр является симметричным. Индексами коэффициентов STFT, которые принадлежат сегменту с индексом b (1≤b≤ B), являются i ∈ {Ab-1, Ab-1 +1,..., Ab}, причем A0=0, как проиллюстрировано на фиг.4. Сигналы, представленные спектральными коэффициентами сегментов, соответствуют мотивированному восприятием разложению поддиапазонов, используемому системой кодирования. Таким образом, в пределах каждого такого сегмента описанная обработка применяется совместно к коэффициентам STFT в пределах сегмента.
Фиг.5 примерно иллюстрирует группирование спектральных коэффициентов равномерного спектра STFT в имитационное неравномерное частотное разрешение слухового аппарата человека. На фиг.5 N=1024 для частоты дискретизации в 44,1 кГц и количества сегментов, B = 20, причем каждый сегмент имеет ширину полосы пропускания приблизительно в 2 ERB. Отметим, что последний сегмент является меньшим, чем ERB, вследствие среза на частоте Найквиста.
B.Оценка статистических данных
При заданных двух коэффициентах STFT, xi(k) и xj(k), значения E{xi(k)xj(k)}, необходимые для вычисления повторно микшированного стереофонического звукового сигнала, могут оцениваться итерационно. В этом случае частота fs дискретизации поддиапазона является частотой во времени, с которой вычисляются спектры STFT. Чтобы получать оценки для каждого относящегося к восприятию сегмента (а не для каждого коэффициента STFT), оцененные значения могут усредняться в пределах сегментов перед дальнейшим использованием.
Обработка, описанная в предыдущих разделах, может применяться к каждому сегменту, как будто он был одним диапазоном. Сглаживание между сегментами, например, может достигаться с использованием перекрывающихся спектральных окон, чтобы избегать внезапных изменений обработки по частоте, таким образом уменьшая артефакты.
C. Сочетание с традиционными звуковыми кодировщиками
Фиг.6A - структурная схема реализации системы 100 кодирования по фиг.1A, объединенной с традиционным стереофоническим звуковым кодировщиком. В некоторых реализациях комбинированная система 600 кодирования включает в себя традиционный звуковой кодировщик 602, предложенный кодировщик 604 (например, систему 100 кодирования) и объединитель 606 битовых потоков. В показанном примере стереофонические звуковые входные сигналы кодируются традиционным звуковым кодировщиком 602 (например, MP3, AAC, объемного звучания MPEG, и т.д.) и анализируются предложенным кодировщиком 604 для предоставления дополнительной информации, как описано ранее со ссылкой на фиг.1-5. Два результирующих битовых потока объединяются объединителем 606 потоков для предоставления обратно совместимого битового потока. В некоторых реализациях объединение результирующих битовых потоков включает в себя встраивание дополнительной информации с низкой скоростью передачи битов (например, коэффициентов ai, bi усиления, и мощности E{si2(k)} поддиапазона) в обратно совместимый битовый поток.
Фиг.6B - блок-схема последовательности операций способа реализации последовательности 608 операций кодирования с использованием системы 100 кодирования по фиг.1, объединенной с традиционным стереофоническим звуковым кодировщиком. Входной стереофонический сигнал кодируется с использованием традиционного стереофонического звукового кодировщика (610). Дополнительная информация формируется из стереофонического сигнала и M сигналов источников с использованием системы 100 кодирования по фиг.1A (612). Формируются (614) один или более обратно совместимых битовых потоков, включающих в себя кодированный стереофонический сигнал и дополнительную информацию.
Фиг.7A - структурная схема реализации системы 300 повторного микширования по фиг.3A, объединенной с традиционным стереофоническим звуковым декодером для предоставления комбинированной системы 700. В некоторых реализациях комбинированная система 700 обычно включает в себя анализатор 702 битового потока, традиционный звуковой декодер 704 (например, MP3, AAC) и предложенный декодер 706. В некоторых реализациях предложенным декодером 706 является система 300 повторного микширования по фиг.3A.
В показанном примере битовый поток разделяется на стереофонический звуковой битовый поток и битовый поток, содержащий дополнительную информацию, необходимую предложенному декодеру 706 для обеспечения возможности повторного микширования. Стереофонический сигнал декодируется традиционным звуковым декодером 704 и подается в предложенный декодер 706, который модифицирует стереофонический сигнал в качестве функции дополнительной информации, полученной из битового потока и пользовательского ввода (например, коэффициентов ci и di усиления микширования).
Фиг.7B - блок-схема последовательности операций способа реализации последовательности 708 операций повторного микширования с использованием комбинированной системы 700 по фиг.7A. Битовый поток, принятый из кодировщика, анализируется для выдачи битового потока кодированного стереоскопического сигнала и битового потока дополнительной информации (710). Кодированный стереофонический сигнал декодируется с использованием традиционного звукового декодера (712). Примерные декодеры включают в себя MP3, AAC (в том числе различные стандартизованные профили AAC), параметрический стереофонический сигнал, спектральную репликацию полос (SBR), объемное звучание MPEG или любую их комбинацию. Декодированный стереофонический сигнал повторно микшируется с использованием дополнительной информации и пользовательского ввода (например, ci и di).
IV. Повторное микширование многоканальных звуковых сигналов
В некоторых реализациях системы 100, 300 кодирования и повторного микширования, описанные в предыдущих разделах, могут быть расширены для повторного микширования многоканальных звуковых сигналов (например, сигналов объемного звучания 5,1). В дальнейшем стереофонический сигнал и многоканальный сигнал также указываются ссылкой как «многоканальные» сигналы. Специалисты в данной области техники поняли бы, каким образом следует переписать с [7] по [22] для схемы многоканального кодирования/декодирования, то есть для более чем двух сигналов x1(k), x2(k), x3(k),..., xC(k), где C - количество звуковых каналов микшированного сигнала.
Уравнение [9] для многоканального случая становится:

Уравнение, подобное [11] с C уравнениями, может выводиться и решаться для определения весов, как описано ранее.
В некоторых реализациях определенные каналы могут быть оставлены необработанными. Например, для объемного звучания 5,1 два задних канала могут быть оставлены необработанными, а повторное микширование применяться только к передним левому, правому и центральному каналам. В этом случае алгоритм повторного микширования трех каналов может применяться к передним каналам.
Качество звукозаписи, вытекающее из раскрытой схемы повторного микширования, зависит от сущности модификации, которая выполняется. Для относительно слабых модификаций, например изменения панорамирования с 0 дБ до 15 дБ или модификации усиления в 10 дБ, результирующее качество звукозаписи может быть более высоким, чем достигаемое традиционными технологиями. К тому же качество предложенной раскрытой схемы повторного микширования может быть выше, чем традиционные схемы повторного микширования, так как стереофонический сигнал модифицируется только по необходимости, чтобы достигать требуемого повторного микширования.
Схема повторного микширования, раскрытая в материалах настоящей заявки, предоставляет несколько преимуществ над традиционными технологиями. Прежде всего она предоставляет возможность повторного микширования меньшего, чем суммарное количества объектов в данном стереофоническом или многоканальном звуковом сигнале. Это достигается посредством оценивания дополнительной информации в качестве функции данного стереофонического звукового сигнала, плюс M сигналов источников, представляющих M объектов в стереофоническом звуковом сигнале, которые должны быть задействованы для повторного микширования в декодере. Раскрытая система повторного микширования обрабатывает заданный стереофонический сигнал в качестве функции дополнительной информации и в качестве функции пользовательского ввода (требуемого повторного микширования), чтобы формировать стереофонический сигнал, который подобен по восприятию стереофоническому сигналу, микшированному действительно по-иному.
V. Усовершенствования к основной схеме повторного микширования
A. Предварительная обработка дополнительной информации
Когда поддиапазон ослабляется слишком сильно относительно соседних поддиапазонов, могут возникать звуковые артефакты. Таким образом, требуется ограничивать максимальное затухание. Более того, поскольку статистические данные стереофонического сигнала и объектного сигнала источника измеряются независимо в кодировщике и декодере соответственно, отношение между измеренной мощностью поддиапазона стереофонического сигнала и мощностью поддиапазона объектного сигнала (которое представлено дополнительной информацией) может отклоняться от реальности. Вследствие этого дополнительная информация может быть такой, что она физически невозможна, например мощность сигнала у повторно микшированного сигнала [19] может становиться отрицательной. Обе из этих проблем могут быть преодолены, как описано ниже.
Мощностью поддиапазона левого и правого повторно смешанного сигнала является:

где PSi равна квантованной и кодированной оценке мощности поддиапазона, заданной в [25], которая вычисляется в качестве функции дополнительной информации. Мощность поддиапазона повторно микшированного сигнала может быть ограничена так, что она никогда не бывает меньшей, чем на L дБ ниже мощности поддиапазона исходного стереофонического сигнала, E{x12}. Подобным образом E{y22} ограничена, чтобы не быть меньшей, чем на L дБ ниже E{x22}. Этот результат может достигаться с помощью следующих операций:
1. Вычислить мощность поддиапазона левого и правого повторно микшированного сигнала согласно [28].
2. Если E{y12}

3. Если E{y22}

4. Значение
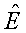
B.Выбор между использованием четырех или двух весов
Для многих случаев, два веса [18] достаточны для вычисления левого и правого поддиапазонов повторно микшированного сигнала [9]. В некоторых случаях лучшие результаты могут достигаться использованием четырех весов [13] и [15]. Использование двух весов означает, что, для формирования левого выходного сигнала используется только левый исходный сигнал и то же самое для правого выходного сигнала. Таким образом, сценарий, где желательны четыре веса, имеет место тогда, когда объект по одну сторону повторно микшируется, чтобы быть по другую сторону. В этом случае ожидалось бы, что использование четырех весов является благоприятным, так как сигнал, который изначально был только по одну сторону (например, в левом канале), по большей части будет по другую сторону (например, в правом канале) после повторного микширования. Таким образом, четыре веса могут использоваться для предоставления сигналу возможности перетекать из исходного левого канала в повторно микшированный правый канал, и наоборот.
Когда задача метода наименьших квадратов по вычислению четырех весов является плохо обусловленной, амплитуда весов может быть большой. Подобным образом, когда используется описанное выше повторное микширование с одной стороны на другую сторону, может быть большой амплитуда весов, когда используются только два веса. Оправданный этим наблюдением в некоторых реализациях может использоваться следующий критерий, чтобы решать, следует ли использовать четыре или два веса.
Если A

C.Улучшение степени затухания, когда требуется
Когда источник должен быть полностью удален, например с удалением дорожки ведущей вокальной партии для применения Караоке, его коэффициентами усиления микширования являются ci=0 и di=0. Однако когда пользователь выбирает нулевые коэффициенты усиления микширования, степень достижимого затухания может быть ограниченной. Таким образом, для улучшенного затухания значения мощностей поддиапазонов источника соответствующих сигналов источника, полученные из дополнительной информации,
D. Улучшение качества звукозаписи сглаживанием весов
Было обнаружено, что раскрытая схема повторного микширования может привносить артефакты в требуемый сигнал, особенно когда звуковой сигнал является тональным или стационарным. Чтобы улучшить качество звукозаписи, в каждом поддиапазоне может вычисляться показатель стационарности/тональности. Если показатель стационарности/тональности превышает определенное пороговое значение, TON0, то веса оценки сглаживаются по времени. Операция сглаживания описана, как изложено ниже: для каждого поддиапазона, на каждом индексе k времени, получаются веса, которые применяются для вычисления выходных поддиапазонов, как изложено ниже:
Если TON(k)>TON0, то

где




Иначе

E. Регулирование окружения/реверберации
Технология повторного микширования, описанная в материалах настоящей заявки, предусматривает пользовательское управление в показателях коэффициентов ci и di усиления микширования. Это соответствует определению для каждого объекта, коэффициента усиления, Gi, и амплитудного панорамирования, Li (направления), где усиление и панорамирование полностью определяются посредством ci и di:

В некоторых реализациях может быть желательным регулировать другие признаки стереофонического микшированного сигнала, иные, чем усиление и амплитудное панорамирование сигналов источников. В последующем описании описана технология для модификации степени окружения стереофонического звукового сигнала. Никакая дополнительная информация не используется для этой задачи декодера.
В некоторых реализациях модель прохождения сигналов, заданная в [44], может использоваться для модифицирования степени окружения стереофонического сигнала, где мощности поддиапазона у n1 и n2 предполагаются равными, то есть

Вновь может быть допущено, что s, n1 и n2 являются взаимно независимыми. При условии этих допущений, когерентность [17] может быть записана в виде:

Это соответствует квадратному уравнению с переменной PN(k):
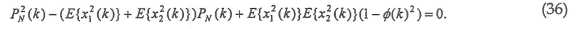
Решениями этого квадратного уравнения являются:

Физически возможным решением является таковое с отрицательным знаком перед квадратным корнем:

так как PN(k) должна быть меньшей, чем или равной E{x12(k)}+E{x22(k)}.
В некоторых реализациях для регулирования левого и правого окружения технология повторного микширования может применяться касательно двух объектов: Одним объектом является источник с индексом i1, с мощностью E{si12(k)}=PN(k) поддиапазона по левую сторону, то есть, ai1=1 и bi1=0; другим объектом является источник с индексом i2, с мощностью E{si22(k)}=PN(k) поддиапазона по правую сторону, то есть ai2=0 и bi2=1. Для изменения величины окружения пользователь может выбирать ci1=di1=10ga/20 и ci2=di1=0, где ga - прирост окружения в дБ.
F. Иная дополнительная информация
В некоторых реализациях модифицированная или иная дополнительная информация может использоваться в раскрытой схеме повторного микширования, которая более эффективна в показателях скорости передачи битов. Например, в [24], Ai(k) может иметь произвольные значения. Также есть зависимость от уровня исходного сигнала si(n) источника. Таким образом, для получения дополнительной информации в требуемом диапазоне уровню входного сигнала источника понадобилось бы настраиваться. Чтобы избежать этой настройки и чтобы устранить зависимость дополнительной информации от уровня исходного сигнала источника, в некоторых реализациях мощность поддиапазона источника может не только нормализоваться относительно мощности поддиапазона стереофонического сигнала, как в [24], но также могут учитываться коэффициенты усиления микширования:

Это соответствует использованию, в качестве дополнительной информации мощности источника, содержащейся в стереофоническом сигнале (а не непосредственно мощности источника), нормализованной стереофоническим сигналом. В качестве альтернативы можно использовать нормализацию, подобную этой:

Эта дополнительная информация также более эффективна, поскольку Ai(k) может принимать только значения, меньшие или равные 0 дБ. Отметим, что [39] и [40] могут быть решены для мощности E{si2(k)} поддиапазона.
G. Стереофонические сигналы/объекты источника
Схема повторного микширования, описанная в материалах настоящей заявки, может быть легко расширена для манипулирования стереофоническими сигналами источников. С ракурса дополнительной информации стереофонические сигналы источника обрабатываются подобно двум монофоническим сигналам источника: один микшируется в левый, а другой микшируется в правый. То есть левый канал i источника имеет ненулевой левый коэффициент ai усиления и нулевой правый коэффициент bi+1 усиления. Коэффициенты усиления, ai и bi+1, могут оцениваться с помощью [6]. Дополнительная информация может передаваться, как если бы стереофонический источник был двумя монофоническими источниками. Некоторой информации необходимо передаваться в декодер, чтобы указывать декодеру, какие источники являются монофоническими источниками, а какие являются стереофоническими источниками.
Касательно обработки декодера и графического интерфейса пользователя (GUI) можно представлять в декодере стереофонический сигнал источника так же, как монофонический сигнал источника. То есть стереофонический сигнал источника имеет регулировку усиления и панорамирования, подобную монофоническому сигналу источника. В некоторых реализациях зависимость между регулировкой усиления и панорамирования GUI немикшированного повторно стереофонического сигнала и коэффициентами усиления может выбираться, чтобы быть:

То есть GUI может устанавливаться в эти значения изначально. Зависимость между GAIN и PAN, выбранная пользователем, и новые коэффициенты усиления могут быть выбраны, чтобы быть:

Уравнения [42] могут быть решены для ci и di+1, которые могут использоваться в качестве коэффициентов усиления микширования (причем ci+1=0 и di=0). Описанные функциональные возможности подобны регулировке «баланса» на стереофоническом усилителе. Усиления левого и правого каналов сигнала источника модифицируются без привнесения взаимного влияния.
VI. Слепое формирование дополнительной информации
A. Полностью слепое формирование дополнительной информации
В раскрытой схеме повторного микширования кодировщик принимает стереофонический сигнал и некоторое количество сигналов источников, представляющих объекты, которые должны повторно микшироваться в декодере. Дополнительная информация, необходимая для повторного микширования сигнала источника с индексом i в декодере, определяется по коэффициентам ai и bi усиления и мощности E{si2(k)} поддиапазона. Определение дополнительной информации описывалось в предыдущих разделах в случае, когда заданы сигналы источников.
Несмотря на то, что стереофонический сигнал легко получается (поскольку это соответствует изделию, существующему сегодня), может быть трудным получать сигналы источника, соответствующие объектам, которые должны повторно микшироваться в декодере. Таким образом, желательно формировать дополнительную информацию для повторного микширования, даже если сигналы источников объектов не доступны. В последующем описании описана технология полностью слепого формирования для формирования дополнительной информации только из стереофонического сигнала.
Фиг.8A - структурная схема реализации системы 800 кодирования, реализующей полностью слепое формирование дополнительной информации. Система 800 кодирования обычно включает в себя матрицу 802 гребенки фильтров, формирователь 804 дополнительной информации и кодировщик 806. Стереофонический сигнал принимается матрицей 802 гребенки фильтров, которая раскладывает стереофонический сигнал (например, левый и правый каналы) на пары поддиапазонов. Пары поддиапазонов принимаются процессором 804 дополнительной информации, который формирует дополнительную информацию из пар поддиапазонов с использованием требуемых перепада Li уровней источника и функции f(M) усиления. Отметим, что ни матрица 802 гребенки фильтров, ни процессор 804 дополнительной информации не оперируют сигналами источников. Дополнительная информация выводится полностью из входного стереофонического сигнала, требуемого перепада уровней источника, Li, и функции усиления, f(M).
Фиг.8B - блок-схема последовательности операций способа реализации последовательности 808 операций кодирования с использованием системы 800 кодирования по фиг.8A. Входной стереофонический сигнал раскладывается на пары поддиапазонов (810). Для каждого поддиапазона коэффициенты усиления, ai и bi, определяются для каждого требуемого сигнала источника с использованием требуемого значения перепада уровней источника, Li (812). Для сигнала источника прямого звучания (например, сигнала источника, панорамированного по центру в павильоне звукозаписи), требуемым перепадом уровней источника является Li=0 дБ. При заданном Li вычисляются коэффициенты усиления:

где A=10Li/10. Отметим, что ai и bi были рассчитаны из условия, чтобы ai2+bi2=1. Это условие не является необходимостью, скорее оно является произвольным выбором для предохранения ai или bi от становления большими, когда велика амплитуда Li.
Затем оценивается мощность поддиапазона прямого звучания с использованием пары поддиапазонов и коэффициентов усиления микширования (814). Для вычисления мощности поддиапазона прямого звучания можно допустить, что левый и правый поддиапазон каждого входного сигнала в каждый момент времени может быть выражен:

где a и b - коэффициенты усиления микширования, s представляет прямое звучание всех сигналов источников, а n1 и n2 представляют независимое звуковое сопровождение. Может быть допущено, что a и b являются:

где B=E{x22(k)}/E{x12(k)}. Отметим, что a и b могут вычисляться из условия, чтобы перепад уровней, с которым s содержится в x2 и x1, являлся таким же, как перепад уровней между x2 и x1. Перепадом уровней в дБ у прямого звучания является M=log10B.
Можем вычислять мощность поддиапазона прямого звучания, E{s2(k)}, согласно модели прохождения сигналов, приведенной в [44]. В некоторых реализациях используется следующая система Уравнений:

Было допущено в [46], что s, n1 и n2 в [34] взаимно независимы, левосторонние параметры в [46] могут измеряться, и доступны a и b. Таким образом, тремя неизвестными в [46] являются E{s2(k)}, E{n12(k)} и E{n22(k)}. Мощность поддиапазона прямого звучания, E{s2(k)}, может быть задана посредством

Мощность поддиапазона прямого звучания также может быть записана в качестве функции когерентности [17]

В некоторых реализациях вычисление требуемой мощности поддиапазона источника, E{si2(k)}, может выполняться в два этапа: сначала вычисляется мощность поддиапазона прямого звучания, E{s2(k)}, где s представляет прямое звучание всех источников (например, панорамированное по центру) в [44]; затем, вычисляются (816) требуемые мощности поддиапазонов источников, E{si2(k)}, посредством модифицирования мощности поддиапазона прямого звучания, E{s2(k)}, в качестве функции направления прямого звучания (представленного M) и требуемого направления звучания (представленного требуемым перепадом L уровней источников):

где f(.) - функция усиления, которая является функцией направления, возвращает коэффициент усиления, который близок к единице только для направления требуемого источника. В качестве заключительного этапа коэффициенты усиления и мощности E{si2(k)} подиапазонов могут квантоваться и кодироваться для формирования дополнительной информации (818).
Фиг.9 иллюстрирует примерную функцию f(M) усиления для требуемого перепада уровней источника, Li=L dB. Отметим, что степень направленности может регулироваться в показателях выбора f(M), чтобы имела более или менее узкий пик вокруг требуемого направления Lo. Для требуемого источника в центре может использоваться ширина пика Lo=6 дБ.
Отметим, что с полностью слепой технологией, описанной выше, может быть определена дополнительная информация (ai, bi, E{si2(k)}) для заданного сигнала si источника.
B. Сочетание между слепым и неслепым формированием дополнительной информации
Технология полностью слепого формирования, описанная выше, может быть ограничена при определенных условиях. Например, если два объекта имеют одинаковое местоположение (направление) в павильоне стереофонической звукозаписи, то может не быть возможным вслепую формировать дополнительную информацию, относящуюся к одному или обоим объектам.
Альтернативой полностью слепому формированию дополнительной информации является частично слепое формирование дополнительной информации. Частично слепая технология формирует колебательный сигнал объекта, который грубо соответствует исходному колебательному сигналу объекта. Это, например, может делаться вынуждением певцов или музыкантов проигрывать/воспроизводить отдельный объектный сигнал. Либо можно применять данные MIDI (цифрового интерфейса музыкальных инструментов) для этой цели, или позволить синтезатору формировать объектный сигнал. В некоторых реализациях «необработанный» колебательный сигнал объекта является выравненным по времени со стереофоническим сигналом, относительно которого должна формироваться дополнительная информация. В таком случае дополнительная информация может формироваться с использованием последовательности операций, которая является комбинацией слепого и неслепого формирования дополнительной информации.
Фиг.10 - схема реализации последовательности 1000 операций формирования дополнительной информации с использованием технологии частично слепого формирования. Последовательность 1000 операций начинается получением входного стереофонического сигнала и M «необработанных» сигналов источников (1002). Затем коэффициенты ai и bi усиления определяются для М «необработанных» сигналов источников (1004). В каждом временном интервале, в каждом поддиапазоне, определяется первая краткосрочная оценка мощности поддиапазона, E{si2(k)}, для каждого «необработанного» сигнала источника (1006). Вторая краткосрочная оценка мощности поддиапазона, Ehat{si2(k)}, определяется для каждого «необработанного» сигнала источника с использованием технологии полностью слепого формирования, примененной к входному стереофоническому сигналу (1008).
В заключение к оцененным мощностям поддиапазонов применяется функция, которая объединяет первую и вторую оценки мощности поддиапазона и возвращает заключительную оценку, которая может эффективно использоваться для вычисления дополнительной информации (1010). В некоторых реализациях функция F() задана согласно

VI. Архитектуры, пользовательские интерфейсы, синтаксис битового потока
A. Клиент/серверная архитектура
Фиг.11 - структурная схема реализации клиент-серверной архитектуры 1100 для поставки стереофонических сигналов и M сигналов источников и/или дополнительной информации в звуковые устройства 1110 с возможностью повторного микширования. Архитектура 1100 является только примером. Возможны другие архитектуры, в том числе архитектуры с большим или меньшим количеством компонентов.
Архитектура 1100, как правило, включает в себя службу 1102 загрузки, имеющую хранилище 1104 (например, MySQL™) и сервер 1106 (например, сервер Windows™ NT, Linux). Хранилище 1104 может хранить различные типы контента, включая профессионально микшированные стереофонические сигналы и ассоциативно связанные сигналы источников, соответствующие объектам в стереофонических сигналах и различным эффектам (например, реверберации). Стереофонические сигналы могут храниться в многообразии стандартизованных форматов, в том числе MP3, PCM, AAC и т.п.
В некоторых реализациях сигналы источников хранятся в хранилище 1104 и сделаны доступными для загрузки в звуковые устройства 1110. В некоторых реализациях предварительно обработанная дополнительная информация хранится в хранилище 1104 и сделана доступной для загрузки в звуковые устройства 1110. Предварительно обработанная дополнительная информация может формироваться сервером 1106 с использованием одной или более схем кодирования, описанных со ссылкой на фиг.1A, 6A и 8A.
В некоторых реализациях служба 1102 загрузки (например, веб-сайт, музыкальный магазин) поддерживает связь с звуковыми устройствами 1110 через сеть 1108 (например, сеть Интернет, сеть интранет, сеть Ethernet, беспроводную сеть, одноранговую сеть). Звуковые устройства 1110 могут быть любым устройством, допускающим реализацию раскрытых схем повторного микширования (например, медиаплеерами/устройствами записи, мобильными телефонами, персональными цифровыми секретарями (PDA), игровыми консолями, телевизионными абонентскими приставками, телевизионными приемниками, медиацентрами и т.п.).
B. Архитектура звукового устройства
В некоторых реализациях звуковое устройство 1110 включает в себя один или более процессоров или процессорных ядер 1112, устройства 1114 ввода (например, координатное колесо, мышь, джойстик, сенсорный экран), устройства 1120 вывода (например, ЖКД (жидкокристаллический дисплей LCD)), сетевые интерфейсы 1118 (например, USB, FireWire, Ethernet, плату сетевого интерфейса, беспроводный приемопередатчик) и машиночитаемый носитель 1116 (например, память, жесткий диск, флэш-память). Некоторые или все из этих компонентов могут отправлять и/или принимать информацию через каналы 1122 связи (например, шину, мост).
В некоторых реализациях машиночитаемый носитель 1116 включает в себя операционную систему, музыкальный диспетчер, звуковой процессор, модуль повторного микширования и музыкальную библиотеку. Операционная система ответственна за управление основными административными и коммуникационными задачами звукового устройства 1110, в том числе управление файлами, доступ к памяти, конфликты на шине, управление периферией, управление пользовательским интерфейсом, управление питанием и т.п. Музыкальный диспетчер может быть приложением, которое управляет музыкальной библиотекой. Звуковой процессор может быть традиционным звуковым процессором для воспроизведения музыкальных файлов (например, MP3, звукозаписи CD, и т.п.). Модуль повторного микширования может быть одним или более компонентов программного обеспечения, которые реализуют функциональные возможности схем повторного микширования, описанных со ссылкой на фиг.1-10.
В некоторых реализациях сервер 1106 кодирует стереофонический сигнал и формирует дополнительную информацию, как описано в ссылках на фиг.1A, 6A и 8A. Стереофонический сигнал и дополнительная информация загружаются в звуковое устройство 1110 через сеть 1108. Модуль повторного микширования декодирует сигналы и дополнительную информацию и предоставляет возможность повторного микширования на основании пользовательского ввода, принятого через устройство 1114 ввода (например, клавиатуру, координатное колесо, сенсорный экран).
C. Пользовательский интерфейс для приема пользовательского ввода
Фиг.12 иллюстрирует реализацию пользовательского интерфейса 1202 для медиаплеера 1200 с возможностью повторного микширования. Пользовательский интерфейс 1202 также может быть адаптирован к другим устройствам (например, мобильным телефонам, компьютерам и т. п.). Пользовательский интерфейс не ограничен показанными конфигурацией и форматом и может включать в себя разные типы элементов пользовательского интерфейса (например, элементы управления навигацией, сенсорные интерфейсы).
Пользователь может вводить режим «повторного микширования» для устройства 1200, выделяя надлежащий элемент на пользовательском интерфейсе 1202. В этом примере предполагается, что пользователь выбрал песню из музыкальной библиотеки, и пожелал бы изменить настройку панорамирования дорожки ведущей вокальной партии. Например, пользователь может пожелать слышать больше ведущей вокальной партии в левом звуковом канале.
Чтобы получить доступ к требуемому элементу управления панорамированием, пользователь может осуществлять навигацию по последовательности подменю 1204, 1206 и 1208. Например, пользователь может осуществлять прокрутку для просмотра по пунктам в подменю 1204, 1206 и 1208 с использованием колеса 1210. Пользователь может выбирать выделенный пункт меню щелчком по кнопке 1212. Подменю 1208 предоставляет доступ к требуемому элементу управления панорамированием для дорожки ведущей вокальной партии. Затем пользователь может манипулировать ползунком (например, с использованием колеса 1210) для настройки панорамирования ведущей вокальной партии, как требуется, в то время как проигрывается песня.
D. Синтаксис битового потока
В некоторых реализациях схемы повторного микширования, описанные со ссылкой на фиг.1-10, могут быть включены в существующие или будущие стандарты звукового кодирования (например, MPEG-4). Синтаксис битового потока для существующих и будущих стандартов кодирования может включать в себя информацию, которая может использоваться декодером с возможностью повторного микширования для определения, каким образом обрабатывать битовый поток, чтобы предусмотреть повторное микширование пользователем. Такой синтаксис может быть разработан для обеспечения обратной совместимости с традиционными схемами кодирования. Например, структура данных (например, заголовок пакета), включенный в битовый поток, может включать в себя информацию (например, один или более битов или флажковых признаков), указывающую наличие дополнительной информации (например, коэффициентов усиления, мощности поддиапазонов) для повторного микширования.
Раскрытые и другие варианты осуществления и функциональные операции, описанные в этом описании изобретения, могут быть реализованы в цифровой электронной схеме, или в компьютерном программном обеспечении, аппаратно реализованном программном обеспечении, включающих в себя структуры, раскрытие в этом описании изобретения и их структурные эквиваленты, или в комбинациях одного или более из них. Раскрытые и другие варианты осуществления могут быть реализованы в качестве одного или более компьютерных программных изделий, то есть одного или более модулей команд компьютерной программы, закодированных на машиночитаемом носителе для выполнения посредством или для управления работой устройства обработки данных. Машиночитаемый носитель может быть машиночитаемым устройством хранения данных, машиночитаемой запоминающей подложкой, устройством памяти, композицией, воздействующей на машиночитаемый распространяемый сигнал, или комбинацией одного или более из них. Термин «устройство обработки данных» охватывает все устройства, приспособления и машины для обработки данных, в том числе в качестве примера программируемый процессор, компьютер, либо многочисленные процессоры или компьютеры. Устройство может включать в себя в дополнение к аппаратным средствам машинную программу, которая создает среду выполнения для данной компьютерной программы, например машинную программу, которая составляет аппаратно реализованное программное обеспечение процессора, стек протоколов, систему управления базой данных, операционную систему или комбинацию одного или более из них. Распространяемый сигнал является искусственно сформированным сигналом, например сформированным машиной электрическим, оптическим или электромагнитным сигналом, который формируется, чтобы кодировать информацию для передачи на пригодное устройство приемника.
Компьютерная программа (также известная как программа, программное обеспечение, программно реализованное приложение, сценарий или код) может быть написана на любой разновидности языка программирования, в том числе компилируемых или интерпретируемых языках, и она может применяться в любой форме, в том числе в качестве автономной программы или в качестве модуля, компонента, процедуры или другого блока, пригодного для использования в вычислительной среде. Компьютерная программа не обязательно соответствует файлу или файловой системе. Программа может храниться в части файла, который удерживает другие программы или данные (например, один или более сценариев, хранимых в документе на языке разметки), в одиночном файле, выделенном для данной программы, или многочисленных скоординированных файлах (например, файлах, которые хранят один или более модулей, подпрограмм, или порций кода). Компьютерная программа может быть развернута, чтобы выполняться на одном компьютере или на многочисленных компьютерах, которые расположены на одной площадке или распределены по многочисленным площадкам и взаимосвязаны сетью связи.
Последовательности операций и логические потоки, описанные в этом описании изобретения, могут выполняться одним или более программируемых процессоров, приводящих в исполнение одну или более компьютерных программ для выполнения функций посредством оперирования с входными данными и формирования выходных сигналов. Последовательности операций и логические потоки также могут выполняться посредством, и устройство также может быть реализовано в качестве логической схемы специального назначения, например FPGA (программируемой пользователем вентильной матрицы) или ASIC (специализированной интегральной схемы).
Процессоры, пригодные для выполнения компьютерной программы, включают в себя в качестве примера микропроцессоры как общего применения, так и специального назначения, и любые один или более процессоров любой разновидности цифрового компьютера. Обычно процессор будет принимать команды и данные из постоянного запоминающего устройства или оперативного запоминающего устройств, либо обоих. Существенными элементами компьютера являются процессор для выполнения команд и одно или более устройств памяти для хранения команд и данных. Как правило, компьютер также будет включать в себя или будет оперативно присоединен для приема данных из или передачи данных в, либо того и другого к одному или более устройствам хранения большой емкости для хранения данных, например магнитным, магнитооптическим дискам или оптическим дискам. Однако компьютеру не обязательно содержать такие устройства. Машиночитаемые носители для хранения команд и данных компьютерной программы включают в себя все разновидности энергозависимой памяти, носителей и устройств памяти, в том числе в качестве примера полупроводниковые устройства памяти, например СППЗУ (стираемое программируемое постоянное запоминающее устройство, EPROM), ЭСППЗУ (электрически стираемое программируемое постоянное запоминающее устройство, EEPROM), и устройства флэш-памяти; магнитные диски, например внутренние жесткие диски или съемные диски; магнитооптические диски; и диски CD-ROM (ПЗУ на компакт диске) и DVD-ROM (ПЗУ на многофункциональном цифровом диске). Процессор и память могут быть дополнены или включены в состав логической схемой специального назначения.
Чтобы предусмотреть взаимодействие с пользователем, раскрытые варианты осуществления могут быть реализованы на компьютере, имеющем в распоряжении устройство отображения, например монитор с ЭЛТ (электронно-лучевой трубкой, CRT), либо ЖКД (жидкокристаллическим дисплеем), для отображения информации пользователю, а также клавиатуру и координатно-указательное устройство, например мышь или шаровой манипулятор, посредством которых пользователь может выдавать входные данные в компьютер. Другие виды устройств могут использоваться, чтобы также предусматривать взаимодействие с пользователем; например, обратная связь, предоставляемая пользователю, может быть любой формой сенсорной обратной связи, например визуальной обратной связью, слуховой обратной связью, тактильной обратной связью; и входные данные от пользователя могут приниматься в любой форме, включая акустический, речевой или тактильный ввод.
Раскрытые варианты осуществления могут быть реализованы в вычислительной системе, которая включает в себя компонент прикладного программного обеспечения, например как сервер данных, или которая включает в себя компонент межплатформенного программного обеспечения, например сервер приложений, или которая включает в себя компонент интерфейсного программного обеспечения, например клиентский компьютер, имеющий графический интерфейс пользователя или веб-браузер, с помощью которого пользователь может взаимодействовать с реализацией того, что здесь описано, или любое сочетание одного или более компонентов прикладного программного обеспечения, межплатформенного программного обеспечения или интерфейсного программного обеспечения. Компоненты системы могут быть взаимосвязаны любой формой или носителем цифровой передачи данных, например сетью связи. Примеры сетей связи включают в себя локальную сеть («LAN») и глобальную сеть («WAN»), например сеть Интернет.
Вычислительная система может включать в себя клиентов и серверы. Клиент и сервер обычно являются удаленными друг от друга и типично взаимодействуют через сеть связи. Взаимосвязь клиента и сервера возникает в силу компьютерных программ, работающих на соответственных компьютерах и имеющих клиент-серверное взаимоотношение друг с другом.
Vii. Примеры систем, использующих технологию повторного микширования
Фиг.13 иллюстрирует реализацию системы 1300 декодера, объединяющей декодирование пространственно кодированных звуковых объектов (SAOC) и декодирование повторного микширования. SAOC является технологией звукозаписи для обработки многоканального аудио, которая предоставляет возможность интерактивного управления кодированными объектами звучания.
В некоторых реализациях система 1300 включает в себя декодер 1301 сигнала микширования, формирователь 1302 параметров и рендерер 1304 повторного микширования. Формирователь 1302 параметров включает в себя блок 1308 слепой оценки, формирователь 1310 пользовательских параметров микширования и формирователь 1306 параметров повторного микширования. Формирователь 1306 параметров повторного микширования включает в себя формирователь 1312 параметров эквивалентного микширования и формирователь 1314 параметров повышающего микширования.
В некоторых реализациях система 1300 предусматривает две последовательности операций звуковой обработки. В первой последовательности операций дополнительная информация, поставляемая системой кодирования, используется формирователем 1306 параметров повторного микширования для формирования параметров повторного микширования. Во второй последовательности операций слепые параметры формируются блоком 1308 слепой оценки и используются формирователем 1306 параметров повторного микширования для формирования параметров повторного микширования. Слепые параметры и последовательности операций полностью или частично слепого формирования могут выполняться блоком 1308 слепой оценки, как описано со ссылкой на фиг.8A и 8B.
В некоторых реализациях формирователь 1306 параметров повторного микширования принимает дополнительную информацию или слепые параметры и набор пользовательских параметров микширования из формирователя 1310 пользовательских параметров микширования. Формирователь 1310 пользовательских параметров микширования принимает параметры микширования, заданные конечными пользователями (например, усиление, панорамирование), и преобразует параметры микширования в формат, пригодный для обработки повторного микширования формирователем 1306 параметров повторного микширования (например, преобразует в коэффициенты ci, di+1 усиления). В некоторых реализациях формирователь 1310 пользовательских параметров микширования дает пользователю интерфейс для предоставления пользователю возможности задавать требуемые параметры микширования, например, такой как пользовательский интерфейс 1200 медиаплеера, как описано со ссылкой на фиг.12.
В некоторых реализациях формирователь 1306 параметров микширования может обрабатывать как стереофонические, так и многоканальные звуковые сигналы. Например, формирователь 1312 параметров эквивалентного микширования может формировать параметры повторного микширования для целевого сигнала стереофонических каналов, а формирователь 1314 параметров повышающего микширования может формировать параметры повторного микширования для многоканального целевого сигнала. Формирователь параметров повторного микширования, основанный на многоканальных звуковых сигналах, описывался со ссылкой на раздел IV.
В некоторых реализациях рендерер 1304 повторного микширования принимает параметры повторного микширования для стереофонического целевого сигнала или многоканального целевого сигнала. Рендерер 1316 эквивалентного микширования применяет параметры стереофонического повторного микширования к исходному стереофоническому сигналу, принятому непосредственно из декодера 1301 сигнала микширования, чтобы выдавать требуемый повторно микшированный стереофонический сигнал на основании форматированных заданных пользователем параметров стереофонического микширования, поставляемых формирователем 1310 пользовательских параметров микширования. В некоторых реализациях параметры стереофонического микширования могут применяться к исходному стереофоническому сигналу с использованием матрицы n×n (например, матрицы 2×2) параметров стереофонического микширования. Рендерер 1318 повышающего микширования применяет параметры многоканального повторного микширования к исходному многоканальному сигналу, принятому непосредственно из декодера 1301 сигнала микширования, чтобы выдавать требуемый повторно микшированный многоканальный сигнал на основании форматированных заданных пользователем параметров многоканального микширования, поставляемых формирователем 1310 пользовательских параметров микширования. В некоторых реализациях формирователь 1320 эффектов формирует сигналы эффектов (например, реверберацию), которые должны применяться к исходным стереофоническим или многоканальным сигналам рендерером 1316 эквивалентного микширования или рендерером повышающего микширования соответственно. В некоторых реализациях рендерер 1318 повышающего микширования принимает исходный стереофонический сигнал и преобразует (или осуществляет повышающее микширование) стереофонический сигнал в многоканальный сигнал в дополнение к применению параметров повторного микширования, чтобы сформировать повторно микшированный многоканальный сигнал.
Система 1300 может обрабатывать звуковые сигналы, имеющие многообразие конфигураций каналов, предоставляющих системе 1300 возможность интегрироваться в существующие схемы звукового кодирования (например, SAOC, MPEG AAC, параметрический стереофонический сигнал), наряду с сохранением обратной совместимости с такими схемами звукового кодирования.
Фиг.14A иллюстрирует обычную модель микширования для раздельного уровня громкости диалога (SDV). SDV является улучшенной технологией расширения диалога, описанной в предварительной заявке на выдачу патента США, под № 60/884,594 на «Separate Dialogue Volume». В одной из реализаций SDV стереофонические сигналы записываются и микшируются из условия, чтобы для каждого источника сигнал когерентно входил в левый и правый каналы сигнала с отдельными контрольными сигналами направления (например, перепадом уровней, разновременностью), а отраженные/реверберированные независимые сигналы входили в каналы, определяющие ширину слухового явления и контрольные сигналы охвата слушателя. Со ссылкой на фиг.14A коэффициент a определяет направление, в котором имеет место слуховое явление, где s - прямой звук, а n1 и n2 - боковые отражения. Сигнал s имитирует локализованное звучание с направления, определенного коэффициентом a. Независимые сигналы, n1 и n2, соответствуют отраженному/реверберированному звуку, часто указываемому звуковым сопровождением или окружением. Описанный сценарий является мотивированным восприятием разложением для стереофонических сигналов с одним звуковым источником:

фиксирующим местоположение звукового источника и окружения.
Фиг.14B иллюстрирует реализацию системы 1400, объединяющей SDV с технологией повторного микширования. В некоторых реализациях система 1400 включает в себя гребенку 1402 фильтров (например, STFT), блок 1404 слепой оценки, рендерер 1406 эквивалентного микширования, формирователь 1408 параметров и обратную гребенку 1410 фильтров (например, обратное STFT).
В некоторых реализациях сигнал понижающего микширования SDV принимается и раскладывается гребенкой 1402 фильтров на сигналы поддиапазонов. Сигнал понижающего микширования может быть стереофоническим сигналом, x1, x2, заданным согласно [51]. Сигналы X1 (i, k), X2(i, k) поддиапазонов вводятся либо непосредственно в рендерер 1406 эквивалентного микширования либо в блок 1404 слепой оценки, который выводит слепые параметры, A, PS, PN. Вычисление этих параметров описано в предварительной заявке на выдачу патента США под № 60/884,594 на «Separate Dialogue Volume». Слепые параметры вводятся в формирователь 1408 параметров, который формирует параметры эквивалентного микширования, w11- w22, из слепых параметров и заданных пользователем параметров g(i, k) микширования (например, центрального усиления, ширины центра, частоты среза, сухости). Вычисление параметров эквивалентного микширования описано в разделе I. Параметры эквивалентного микширования применяются к сигналам поддиапазонов рендерером 1406 эквивалентного микширования, чтобы выдавать подвергшиеся рендерингу выходные сигналы, y1, y2. Подвергшиеся рендерингу выходные сигналы рендерера 1406 эквивалентного микширования вводятся в обратную гребенку 1410 фильтров, которая преобразует подвергшиеся рендерингу выходные сигналы в требуемый стереофонический сигнал SDV на основании заданных пользователем параметров микширования.
В некоторых реализациях система 1400 также может обрабатывать звуковые сигналы с использованием технологии повторного микширования, как описано со ссылкой на фиг.1-12. В режиме повторного микширования гребенка 1402 фильтров принимает стереофонические или многоканальные сигналы, такие как сигналы, описанные в [1] и [27]. Сигналы раскладываются на сигналы X1 (i, k), X2(i, k) поддиапазонов гребенкой 1402 фильтров и вводятся непосредственно в эквивалентный рендерер 1406 и блок 1404 слепой оценки для оценки слепых параметров. Слепые параметры вводятся в формирователь 1408 вместе с дополнительной информацией ai, bi, Psi, принятой в битовом потоке. Формирователь 1408 параметров применяет слепые параметры и дополнительную информацию к сигналам поддиапазонов, чтобы сформировать подвергшиеся рендерингу выходные сигналы. Подвергшиеся рендерингу выходные сигналы вводятся в обратную гребенку 1410 фильтров, которая формирует требуемый сигнал повторного микширования.
Фиг.15 иллюстрирует реализацию рендерера 1406 эквивалентного микширования, показанного на фиг.14B. В некоторых реализациях сигнал X1 понижающего микширования масштабируется модулями 1502 и 1504 масштабирования, а сигнал X2 понижающего микширования масштабируется модулями 1506 и 1508 масштабирования. Модуль 1502 масштабирования масштабирует сигнал X1 понижающего микширования параметром w11 эквивалентного микширования, модуль 1504 масштабирования масштабирует сигнал X1 понижающего микширования параметром w21 эквивалентного микширования, модуль 1506 масштабирования масштабирует сигнал X2 понижающего микширования параметром w12 эквивалентного микширования, и модуль 1508 масштабирования масштабирует сигнал X2 понижающего микширования параметром w22 эквивалентного микширования. Выходные сигналы модулей 1502 и 1506 масштабирования суммируются, чтобы выдавать первый подвергшийся рендерингу выходной сигнал y1, а модулей 1504 и 1508 масштабирования суммируются, чтобы выдавать второй подвергшийся рендерингу выходной сигнал y2.
Фиг.16 иллюстрирует систему 1600 распространения для технологии повторного микширования, описанной относительно фиг.1-15. В некоторых реализациях поставщик 1602 контента использует авторское инструментальное средство 1606, которое включает в себя кодировщик 1606 повторного микширования, для формирования дополнительной информации, как описано ранее относительно фиг.1A. Дополнительная информация может быть частью одного или более файлов и/или включаться в битовый поток для услуги потоковой передачи битов. Файлы повторного микширования могут иметь уникальное расширение имени файла (например, filename.rmx). Одиночный файл может включать в себя исходный микшированный звуковой сигнал и дополнительную информацию. В качестве альтернативы исходный микшированный звуковой сигнал и дополнительная информация могут распространяться в качестве отдельных файлов в пакете, комплекте, упаковке или другом подходящем контейнере. В некоторых реализациях файлы повторного микширования могут распространяться с предустановленными параметрами микширования, чтобы помогать пользователю изучать технологию и/или для маркетинговых целей.
В некоторых реализациях исходный контент (например, исходный файл микшированного аудио), дополнительная информация и необязательные предустановленные параметры микширования («информация повторного микширования») могут поставляться поставщику 1608 услуг (например, в музыкальный портал) или размещаться на физическом носителе (например, CD-ROM, DVD, медиаплеере, флэш-памяти). Поставщик 1608 услуг может управлять одним или более серверами 1610 для обслуживания всей или части информации повторного микширования и/или битовых потоков, содержащих всю или часть информации повторного микширования. Информация повторного микширования может храниться в хранилище 1612. Поставщик 1608 услуг также может предоставлять виртуальную среду (например, социальную общность, портал, доску объявлений) для совместного использования сформированных пользователем параметров микширования. Например, параметры микширования, сформированные пользователем в подготовленном для повторного микширования устройстве 1616 (например, медиаплеере, мобильном телефоне), могут сохраняться в файле параметров микширования, который может выгружаться поставщику 1608 услуг для совместного использования с другими пользователями. Файлы параметров микширования могут иметь уникальное расширение имени (например, filename.rms). В показанном примере пользователь формировал файл параметров микширования с использованием устройства A воспроизведения повторного микширования и выгружал файл параметров микширования к поставщику 1608 услуг, где файл впоследствии загружался пользователем, эксплуатирующим устройство B воспроизведения повторного микширования.
Система 1600 может быть реализована с использованием любой известной схемы управления цифровыми правами и/или другими известными способами защиты для защиты исходного контента и информации повторного микширования. Например, пользователю, эксплуатирующему устройство B воспроизведения повторного микширования, может понадобиться загрузить исходный контент отдельно и защитить право использования до того, как пользователь может осуществлять доступ или пользоваться признаками повторного микширования, предоставленными устройством B воспроизведения повторного микширования.
Фиг.17A иллюстрирует основные элементы битового потока для предоставления информации повторного микширования. В некоторых реализациях на задействованное повторным микшированием устройство может доставляться единый интегрированный битовый поток 1702, который включает в себя микшированный звуковой сигнал (Mixed_Obj BS), коэффициенты усиления и мощности поддиапазонов (Ref_Mix_Para BS), а также заданные пользователем параметры микширования (User_Mix_Para BS). В некоторых реализациях многочисленные битовые потоки для информации повторного микширования могут независимо доставляться на задействованные повторным микшированием устройства. Например, микшированный звуковой сигнал может доставляться в первом битовом потоке 1704, а коэффициенты усиления, мощности поддиапазонов и заданные пользователем параметры микширования могут доставляться во втором битовом потоке 1706. В некоторых реализациях микшированный звуковой сигнал, коэффициенты усиления и мощности поддиапазонов, и заданные пользователем параметры микширования могут доставляться в трех отдельных битовых потоках, 1708, 1710 и 1712. Эти отдельные битовые потоки могут доставляться на одной и той же или разных скоростях передачи битов. Битовые потоки могут обрабатываться по необходимости с использованием многообразия известных технологий для сбережения полосы пропускания и обеспечения надежности, в том числе побитовое перемежение, энтропийное кодирование (например, кодирование кодом Хаффмана), исправление ошибок и т.п.
Фиг.17B иллюстрирует интерфейс битового потока для кодировщика 1714 повторного микширования. В некоторых реализациях входные сигналы в интерфейс 1714 кодировщика повторного кодирования могут включать в себя микшированный объектный сигнал, индивидуальные сигналы объекта или источника и варианты выбора кодировщика. Выходные сигналы интерфейса 1714 кодировщика могут включать в себя битовый поток микшированного звукового сигнала, битовый поток, включающий в себя коэффициенты усиления и мощности поддиапазонов, и битовый поток, включающий в себя предустановленные параметры микширования.
Фиг.17C иллюстрирует интерфейс битового потока для декодера 1716 повторного микширования. В некоторых реализациях входные сигналы в интерфейс 1716 декодера могут включать в себя битовый поток микшированного звукового сигнала, битовый поток, включающий в себя коэффициенты усиления и мощности поддиапазонов, и битовый поток, включающий в себя предустановленные параметры микширования. Выходные сигналы интерфейса 1716 декодера могут включать в себя повторно микшированный звуковой сигнал, битовый поток рендерера повышающего микширования (например, многоканальный сигнал), слепые параметры повторного микширования и пользовательские параметры повторного микширования.
Возможны другие конфигурации для интерфейсов кодировщика и декодера. Конфигурации интерфейсов, проиллюстрированные на фиг.17B и 17C, могут использоваться, чтобы определять интерфейс прикладного программирования (API) для предоставления задействованным повторным микшированием устройствам возможности обрабатывать информацию повторного микширования. Показанные интерфейсы, проиллюстрированные на фиг.17B и 17C, являются примерами, и возможны другие конфигурации, в том числе конфигурации с разными количествами и типами входных и выходных сигналов, которые могут быть частично основаны на устройстве.
Фиг.18 - структурная схема, показывающая примерную систему 1800, включающую в себя расширения для формирования добавочной дополнительной информации для определенных объектных сигналов, чтобы обеспечивать улучшенное воспринимаемое качество повторно микшированного сигнала. В некоторых реализациях система 1800 включает в себя (на стороне кодирования) кодировщик 1808 сигнала микширования и усовершенствованный кодировщик 1802 повторного микширования, который включает в себя кодировщик 1804 повторного микширования и кодировщик 1806 сигналов. В некоторых реализациях система 1800 включает в себя (на стороне декодирования) декодер 1810 сигнала микширования, рендерер 1814 повторного микширования и формирователь 1816 параметров.
На стороне кодировщика микшированный звуковой сигнал кодируется кодировщиком 1808 сигнала микширования (например, кодировщиком mp3) и отправляется на сторону декодирования. Объектные сигналы (например, ведущая вокальная партия, гитара, барабаны или другие инструменты) вводятся в кодировщик 1804 повторного микширования, который формирует дополнительную информацию (например, коэффициенты усиления и мощности поддиапазонов), например, как описано ранее со ссылкой на фиг.1A и 3A. Дополнительно один или более интересующих объектных сигналов вводятся в кодировщик 1806 сигналов (например, кодировщик mp3), чтобы вырабатывать добавочную дополнительную информацию. В некоторых реализациях информация выравнивания вводится в кодировщик 1806 сигналов для выравнивания выходных сигналов кодировщика 1808 сигнала микширования и кодировщика 1806 сигналов соответственно. Информация выравнивания может включать в себя информацию временного выравнивания, тип используемого кодека, целевую скорость передачи битов, информацию или стратегию распределения битов и т.п.
На стороне декодера выходной сигнал кодировщика сигнала микширования вводится в декодер 1810 сигнала микширования (например, декодер mp3). Выходной сигнал декодера 1810 сигнала микширования и дополнительная информация кодировщика (например, сформированные кодировщиком коэффициенты усиления, мощности поддиапазонов, добавочная дополнительная информация) вводятся в формирователь 1816 параметров, который использует эти параметры, вместе с параметрами управления (например, заданными пользователем параметрами микширования), для формирования параметров повторного микширования и дополнительных данных повторного микширования. Параметры повторного микширования и дополнительные данные повторного микширования могут использоваться формирователем (рендерером) 1814 повторно микшированного сигнала для формирования повторно микшированного звукового сигнала.
Дополнительные данные повторного микширования (например, объектный сигнал) используются формирователем 1814 повторно микшированного сигнала для повторного микширования конкретного объекта в исходном звуковом сигнале микширования. Например, в приложении караоке объектный сигнал, представляющий ведущую вокальную партию, может использоваться усовершенствованным кодировщиком 1802 повторного микширования для формирования добавочной дополнительной информации (например, кодированного объектного сигнала). Этот сигнал может использоваться формирователем 1816 параметров для формирования дополнительных данных повторного микширования, которые могут использоваться формирователем 1814 повторно микшированного сигнала для повторного микширования ведущей вокальной партии в исходном звуковом сигнале микширования (например, с подавлением или ослаблением ведущей вокальной партии).
Фиг.19 - структурная схема, показывающая пример формирователя 1814 повторно микшированного сигнала, показанного на фиг.18. В некоторых реализациях сигналы X1, Х2 повторного микширования вводятся в объединители 1904, 1906 соответственно. Сигналы X1, Х2 понижающего микширования, например, могут быть левым и правым каналами исходного звукового сигнала микширования. Объединители 1904, 1906 объединяют сигналы X1, Х2 понижающего микширования с дополнительными данными повторного микширования, поставляемыми формирователем 1816 параметров. В примере караоке объединение может включать в себя вычитание объектного сигнала ведущей вокальной партии из сигналов X1, Х2 понижающего микширования перед повторным микшированием для ослабления или подавления ведущей вокальной партии в повторно микшированном звуковом сигнале.
В некоторых реализациях сигнал X1 понижающего микширования (например, левый канал исходного звукового сигнала микширования) объединяется с дополнительными данными повторного микширования (например, левым каналом объектного сигнала ведущей вокальной партии) и масштабируется модулями 1906а и 1906b масштабирования, а сигнал Х2 понижающего микширования (например, правый канал исходного звукового сигнала микширования) объединяется с дополнительными данными повторного микширования (например, правым каналом объектного сигнала ведущей вокальной партии) и масштабируется модулями 1906c и 1906d масштабирования. Модуль 1906a масштабирования масштабирует сигнал X1 понижающего микширования параметром w11 эквивалентного микширования, модуль 1906b масштабирования масштабирует сигнал X1 понижающего микширования параметром w21 эквивалентного микширования, модуль 1906c масштабирования масштабирует сигнал X2 понижающего микширования параметром w12 эквивалентного микширования, и модуль 1906d масштабирования масштабирует сигнал X2 понижающего микширования параметром w22 эквивалентного микширования, Масштабирование может быть реализовано с использованием линейной алгебры, к примеру с использованием матрицы n на n (например, 2×2). Выходные сигналы модулей 1906a и 1906c масштабирования суммируются, чтобы выдавать первый подвергшийся рендерингу выходной сигнал Y1, а модулей 1906b и 1906d масштабирования суммируются, чтобы выдавать второй подвергшийся рендерингу выходной сигнал Y2.
В некоторых реализациях можно реализовать элемент управления (например, переключатель, ползунок, кнопку) в пользовательском интерфейсе, чтобы переходить между исходным стереофоническим микшированием, режимом «караоке» и/или режимом «без инструментального сопровождения». В качестве функции положения этого управляющего элемента объединитель 1902 управляет линейной комбинацией между исходным стереофоническим сигналом и сигналом(ами), полученным посредством добавочной дополнительной информации. Например, для режима караоке сигнал, полученный из добавочной дополнительной информации, может вычитаться из стереофонического сигнала. Обработка повторным микшированием может применяться впоследствии для удаления шума квантования (если стереофонический и/или другой сигнал кодировался с потерями). Для частичного удаления вокальных партий необходимо вычитаться только части сигнала, полученного посредством добавочной дополнительной информации. Для воспроизведения только вокальных партий, объединитель 1902 выбирает сигнал, полученный посредством добавочной дополнительной информации. Для воспроизведения вокальных партий с некоторой фоновой музыкой объединитель 1902 добавляет масштабированный вариант стереофонического сигнала к сигналу, полученному посредством добавочной дополнительной информации.
Несмотря на то, что это описание изобретения содержит много особенностей, таковые должны интерпретироваться не в качестве ограничений на объем того, что является формулой изобретения, или того, что может быть заявлено формулой изобретения, а скорее в качестве описаний признаков, специфичных конкретным вариантам осуществления. Определенные признаки, которые описаны в этом описании изобретения в контексте отдельных вариантов осуществления, также могут быть реализованы в комбинации в едином варианте осуществления. Наоборот, различные признаки, которые описаны в контексте одиночного варианта осуществления, также могут быть реализованы в многочисленных вариантах осуществления, раздельно или в любой подкомбинации. Более того, хотя признаки могут быть описаны выше как действующие в определенных комбинациях, и даже изначально заявлены как таковые, один или более признаков из заявленной комбинации, в некоторых случаях, могут исключаться из комбинации, и заявленная комбинация может быть направлена на подкомбинацию или вариант подкомбинации.
Подобным образом, несмотря на то, что операции описаны на чертежах в конкретной очередности, это не должно пониматься в качестве требования, чтобы такие операции выполнялись в конкретной показанной очередности или в последовательном порядке, или чтобы выполнялись все проиллюстрированные операции для достижения требуемых результатов. В определенных случаях могут быть полезны многозадачность и параллельная обработка. Более того, разделение различных компонентов системы в вариантах осуществления, описанных выше, не должно пониматься в качестве требования такого разделения во всех вариантах осуществления, и должно быть понятно, что описанные программные компоненты и системы, в общем смысле, могут быть объединены вместе в едином программном обеспечении или упакованы в многочисленные программные изделия.
В этом описании изобретения были описаны конкретные варианты осуществления объекта изобретения. Другие варианты осуществления находятся в объеме последующей формулы изобретения. Например, действия, перечисленные в формуле изобретения, могут выполняться в разной очередности и по-прежнему достигать требуемых результатов. В качестве одного из примеров последовательность операций, изображенная на прилагаемых фигурах, не обязательно требует конкретной показанной очередности, или последовательного порядка, для достижения требуемых результатов.
В качестве еще одного примера предварительная обработка дополнительной информации, описанная в разделе 5A, предусматривает нижнюю границу в мощности поддиапазона повторно микшированного сигнала для предотвращения отрицательных значений, которые вступают в противоречие с моделью прохождения сигналов, приведенной в [2]. Однако эта модель прохождения сигналов подразумевает не только положительную мощность повторно микшированного сигнала, но также положительные векторные произведения между исходными стереофоническими сигналами и повторно микшированными стереофоническими сигналами, а именно E{x1y1}, E{x1y2}, E{x2y1} и E{x2y2}.
Начиная со случая с двумя весами, чтобы не допустить, чтобы векторные произведения E{x1y1} и E{x2y2} становились отрицательными, веса, определенные в [18], ограничиваются определенным пороговым значением, из условия, чтобы они никогда не были меньшими, чем A дБ.
В таком случае векторные произведения ограничиваются, учитывая следующие условия, где sqrt обозначает квадратный корень, а Q определено в качестве Q=10Λ-A/10:
Если E{x1y1}<Q*E{x12}, то векторное произведение ограничено до E{x1y1}=Q*E{x12}.
Если E{y1,y2}<Q*sqrt(E{x12}E{x22}), то векторное произведение ограничено до E{x1y2}=Q*sqrt(E{x12}E{x22}).
Если E{x2,y1}
Если E{x2y2}<Q*E{x22}, то векторное произведение ограничено до E{x2y2}=Q*E{x22}.
Реферат
Изобретение относится к обработке звуковых сигналов, Один или более атрибутов (например, панорамирование, усиление и т.п.), ассоциативно связанных с одним или более объектов (например, инструментов) стереофонического или многоканального звукового сигнала, могут модифицироваться для предоставления возможности повторного микширования. Технический результат - обеспечение эффективного кодирования звукового сигнала. 17 н. и 33 з.п. ф-лы, 19 ил.
Формула
получают исходный многоканальный звуковой сигнал, содержащий набор сигналов источников, который включает в себя один или более сигналов источников, предназначенных для повторного микширования;
получают дополнительную информацию, представляющую, по меньшей мере, одно из зависимости между исходным многоканальным звуковым сигналом и каждым из набора сигналов источников и энергетического уровня каждого из набора сигналов источников;
получают набор параметров микширования для повторного микширования исходного многоканального звукового сигнала и
формируют повторно микшированный многоканальный звуковой сигнал с использованием исходного многоканального звукового сигнала, дополнительной информации и набора параметров микширования.
раскладывают исходный многоканальный звуковой сигнал на первый набор сигналов поддиапазонов;
оценивают второй набор сигналов поддиапазонов, соответствующий повторно микшированному многоканальному звуковому сигналу, с использованием дополнительной информации и набора параметров микширования и
преобразуют второй набор сигналов поддиапазонов в повторно микшированный многоканальный звуковой сигнал.
декодируют дополнительную информацию, чтобы предоставить коэффициенты усиления и оценки мощностей поддиапазонов, ассоциативно связанные с одним или более сигналами источников, предназначенных для повторного микширования;
определяют один или более наборов весов на основании коэффициентов усиления, оценок мощностей поддиапазонов и набора параметров микширования и
оценивают второй набор сигналов поддиапазонов с использованием, по меньшей мере, одного набора весов.
определяют набор весов, который минимизирует разность между исходным многоканальным звуковым сигналом и повторно микшированным многоканальным звуковым сигналом.
формируют систему линейных уравнений, в которой каждое уравнение в системе является суммой произведений, а каждое произведение сформировано перемножением сигнала поддиапазона с весом; и
определяют вес, решая систему линейных уравнений.
настраивают один или более контрольных сигналов перепадов уровней, ассоциативно связанных со вторым набором сигналов поддиапазонов, чтобы соответствовать одному или более контрольных сигналов перепадов уровней, ассоциативно связанных с первым набором сигналов поддиапазонов.
ограничивают оценку мощности поддиапазона повторно микшированного многоканального звукового сигнала, чтобы была большей или равной пороговому значению ниже оценки мощности поддиапазона исходного многоканального звукового сигнала.
масштабируют оценки мощностей поддиапазонов значением, большим, чем таковое до использования оценок мощностей поддиапазонов, чтобы определять один или более наборов весов.
модифицируют степень окружения исходного многоканального звукового сигнала с использованием оценок мощностей поддиапазонов и набора параметров микширования.
получают заданные пользователем значения усиления и панорамирования и определяют набор параметров микширования по значениям усиления и панорамирования, а также дополнительной информации.
принимают пользовательский ввод, задающий набор параметров микширования.
определяют амплитуду первого набора весов и
определяют амплитуду второго набора весов, при этом второй набор весов включает в себя иное количество весов, чем первый набор весов.
сравнивают амплитуды первого и второго наборов весов и
выбирают один из первого и второго наборов весов для использования при оценивании второго набора сигналов поддиапазонов на основании результатов сравнения.
сглаживают один или более наборов весов по времени.
регулируют сглаживание одного или более наборов весов по времени, чтобы уменьшать звуковые искажения.
определяют, превышает ли тональный или стационарный показатель исходного многоканального звукового сигнала пороговое значение; и
сглаживают один или более наборов весов по времени, если показатель превышает пороговое значение
получают звуковой сигнал, содержащий набор объектов;
получают сигналы источников, включающие в себя один или более сигналов источников, предназначенных для повторного микширования; и
формируют дополнительную информацию из сигналов источников и звукового сигнала, представляющую, по меньшей мере, одно из зависимости между звуковым сигналом и каждым из сигналов источников и энергетического уровня каждого из сигналов источников.
раскладывают звуковой сигнал и подмножество сигналов источников на первый набор сигналов поддиапазонов и второй набор сигналов поддиапазонов, соответственно;
причем для каждого сигнала поддиапазона во втором наборе сигналов поддиапазонов:
оценивают мощность поддиапазона для сигнала поддиапазона;
получают один или более коэффициентов усиления и
формируют дополнительную информацию из одного или более коэффициентов усиления и мощности поддиапазона.
получают многоканальный звуковой сигнал;
определяют коэффициенты усиления для набора сигналов источников с использованием требуемых перепадов уровней источников, представляющих требуемые направления звучания набора сигналов источников в павильоне звукозаписи;
оценивают мощность поддиапазона для направления прямого звучания набора сигналов источников с использованием многоканального звукового сигнала и
оценивают мощности поддиапазонов для, по меньшей мере, некоторых из сигналов источников в наборе сигналов источников, модифицируя мощность поддиапазона для направления прямого звучания в качестве функции направления прямого звучания и требуемого направления звучания.
получают микшированный звуковой сигнал;
получают набор параметров микширования для повторного микширования микшированного звукового сигнала;
если дополнительная информация доступна,
повторно микшируют микшированный звуковой сигнал с использованием дополнительной информации и набора параметров микширования;
если дополнительная информация недоступна,
формируют набор слепых параметров из микшированного звукового сигнала и
формируют повторно микшированный звуковой сигнал с использованием слепых параметров и набора параметров микширования.
формируют параметры повторного микширования либо из слепых параметров, либо из дополнительной информации и, если параметры повторного микширования формируются из дополнительной информации,
формируют повторно микшированный звуковой сигнал из параметров повторного микширования и микшированного сигнала.
добавляют один или более эффектов в повторно микшированный звуковой сигнал.
получают микшированный звуковой сигнал, включающий в себя сигналы речевого источника;
получают параметры микширования, задающие улучшенное усовершенствование одному или более речевым сигналам источников;
формируют набор слепых параметров из микшированного звукового сигнала;
формируют параметры повторного микширования из слепых параметров и параметров микширования и
применяют параметры повторного микширования к микшированному сигналу, чтобы усовершенствовать один или более речевых сигналов источников в соответствии с параметрами микширования.
формируют пользовательский интерфейс для приема входных данных, задающих параметры микширования;
получают параметр микширования через пользовательский интерфейс;
получают исходный звуковой сигнал, включающий в себя сигналы источников;
получают дополнительную информацию, представляющую зависимость между исходным звуковым сигналом и одним или более сигналами источников; и
повторно микшируют один или более сигналов источников с использованием дополнительной информации и параметра микширования, чтобы сформировать повторно микшированный звуковой сигнал.
принимают исходный звуковой сигнал или дополнительную информацию из сетевого ресурса.
получают микшированный звуковой сигнал;
получают набор параметров микширования для повторного микширования микшированного звукового сигнала;
формируют параметры повторного микширования с использованием микшированного звукового сигнала и набора параметров микширования и
формируют повторно микшированный звуковой сигнал, применяя параметры повторного микширования к микшированному звуковому сигналу с использованием матрицы n×n.
декодер, сконфигурированный для приема исходного многоканального звукового сигнала, содержащего набор сигналов источников, который включает в себя один или более сигналов источников, предназначенных для повторного микширования, и для приема дополнительной информации, представляющей, по меньшей мере, одно из зависимости между исходным многоканальным звуковым сигналом и каждым из набора сигналов источников, и энергетического уровня каждого из набора сигналов источников;
интерфейс, сконфигурированный для получения набора параметров микширования для повторного микширования исходного многоканального звукового сигнала; и
модуль повторного микширования, соединенный с декодером и интерфейсом, причем модуль повторного микширования является конфигурируемым для повторного микширования сигналов источников с использованием дополнительной информации и набора параметров микширования, чтобы формировать повторно микшированный многоканальный звуковой сигнал.
интерфейс, конфигурируемый для получения звукового сигнала, содержащего набор объектов и сигналы источников, представляющие объекты;
и
формирователь дополнительной информации, соединенный с интерфейсом и конфигурируемый для формирования дополнительной информации из сигналов источников, причем дополнительная информация представляет взаимосвязь между звуковым сигналом и сигналами источников.
интерфейс, конфигурируемый для получения многоканального звукового сигнала; и
формирователь дополнительной информации, конфигурируемый для определения коэффициентов усиления для набора сигналов источников с использованием требуемых перепадов уровней источников, представляющих требуемые направления звучания набора сигналов источников в павильоне звукозаписи, оценивания мощности поддиапазона для направления прямого звучания набора сигналов источников с использованием многоканального звукового сигнала и оценивания мощностей поддиапазонов для, по меньшей мере, некоторых из сигналов источников в наборе сигналов источников посредством модифицирования мощности поддиапазона для направления прямого звучания в качестве функции направления прямого звучания и требуемого направления звучания.
формирователь параметров, конфигурируемый для получения микшированного звукового сигнала и набора параметров микширования для повторного микширования звукового сигнала и для определения того, доступна ли дополнительная информация; и
формирователь повторно микшированного сигнала, соединенный с формирователем параметров и конфигурируемый для повторного микширования микшированного звукового сигнала с использованием дополнительной информации и набора параметров микширования, если дополнительная информация доступна, а если дополнительная информация недоступна, приема набора слепых параметров и формирования повторно микшированного звукового сигнала с использованием слепых параметров и набора параметров микширования.
интерфейс, конфигурируемый для получения микшированного звукового сигнала, включающего в себя сигналы речевых источников и параметры микширования, задающие улучшенное усовершенствование для одного или более речевых сигналов источников;
формирователь параметров микширования, соединенный с интерфейсом и конфигурируемый для формирования набора слепых параметров из микшированного звукового сигнала и для формирования параметров из слепых параметров и параметров микширования; и
формирователь повторно микшированного сигнала, конфигурируемый для применения параметров к микшированному сигналу, чтобы усовершенствовать один или более речевых сигналов источников в соответствии с параметрами микширования.
интерфейс, конфигурируемый для получения набора параметров микширования для повторного микширования микшированного звукового сигнала; и
модуль повторного микширования, соединенный с интерфейсом и конфигурируемый для формирования параметров повторного микширования с использованием микшированного звукового сигнала и набора параметров микширования и для формирования повторно микшированного звукового сигнала посредством применения параметров повторного микширования к микшированному звуковому сигналу с использованием матрицы n×n.
получение исходного многоканального звукового сигнала, содержащего набор сигналов источников, который включает в себя один или более сигналов источников, предназначенных для повторного микширования;
получение дополнительной информации, представляющей, по меньшей мере, одно из зависимости между исходным многоканальным звуковым сигналом и каждым из набора сигналов источников, и энергетического уровня каждого из набора сигналов источников;
получение набора параметров микширования для повторного микширования исходного многоканального звукового сигнала и
формирование повторно микшированного многоканального звукового сигнала с использованием исходного многоканального звукового сигнала, дополнительной информации и набора параметров микширования.
получение звукового сигнала, содержащего набор объектов;
получение сигналов источников, включающих в себя один или более сигналов источников, предназначенных для повторного микширования; и
формирование дополнительной информации из сигналов источников и звукового сигнала, представляющей по меньшей мере одно из зависимости между звуковым сигналом и каждым из сигналов источников, и энергетического уровня каждого из набора сигналов источников.
процессор и
машиночитаемый носитель, соединенный с процессором и включающий в себя команды, которые, когда выполняются процессором, предписывают процессору выполнять операции, содержащие:
получение исходного многоканального звукового сигнала, содержащего набор сигналов источников, который включает в себя один или более сигналов источников, предназначенных для повторного микширования;
получение дополнительной информации, представляющей, по меньшей мере, одно из зависимости между исходным многоканальным звуковым сигналом и каждым из набора сигналов источников, и энергетического уровня каждого из набора сигналов источников;
получение набора параметров микширования для повторного микширования исходного многоканального звукового сигнала и
формирование повторно микшированного многоканального звукового сигнала с использованием исходного многоканального звукового сигнала, дополнительной информации и набора параметров микширования.
процессор и
машиночитаемый носитель, присоединенный к процессору и включающий в себя команды, которые, когда выполняются процессором, предписывают процессору выполнять операции, содержащие:
получение звукового сигнала, содержащего набор объектов;
получение сигналов источников, включающих в себя один или более сигналов источников, предназначенных для повторного микширования;
и
формирование дополнительной информации из сигналов источников и звукового сигнала, представляющей, по меньшей мере, одно из зависимости между звуковым сигналом и каждым из сигналов источников, и энергетического уровня каждого из набора сигналов источников.
Документы, цитированные в отчёте о поиске
Способ и устройство масштабированного кодирования и декодирования звука
Способ передачи и/или запоминания цифровых сигналов нескольких каналов
Комментарии