Обработка пространственного аудио - RU2735652C2
Код документа: RU2735652C2
Чертежи
Описание
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Данное изобретение относится к обработке пространственного аудио и в частности, но не исключительно, к обработке пространственного аудио для применений виртуальной реальности.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Применения пространственного аудио стали многочисленными и широко распространенными и все чаще образуют по меньшей мере часть многих аудиовизуальных восприятий. В самом деле, новые и улучшенные пространственные восприятия и применения непрерывно развиваются, что приводит к увеличенному спросу на обработку и воспроизведение аудио.
Например, в последние годы, виртуальная реальность (VR) и дополненная реальность (AR) получили повышенный интерес, и некоторое число реализаций и применений достигли потребительского рынка. В самом деле, оборудование разрабатывается как для воспроизведения восприятия, так и для захвата или записи подходящих данных для таких применений. Например, было разработано относительно низкое по стоимости оборудование для обеспечения игровым консолям возможности предоставления полного восприятия VR. Ожидается, что эта тенденция будет продолжаться и на самом деле будет набирать темп на рынке для VR и AR, достигнув существенного размера за короткий период времени.
Идея виртуальной реальности или дополненной реальности охватывает очень широкое поле идей. Она может включать в себя сценарии с полным погружением, где пользователь осуществляет навигацию в виртуальном 3D мире, как если бы он был в реальном (например, осматривается физически двигая головой, или даже физически ходя вокруг), или может, например, включать в себя более простые сценарии, где навигация в виртуальном мире совершается посредством явных элементов управления.
Однако, большинство усилий до сих пор было сконцентрировано на визуальной стороне обеспечиваемого восприятия, т.е. оно было сконцентрировано на разработке подходов для захвата и воспроизведения трехмерных адаптивных визуальных восприятий.
Например, недавно были разработаны различные системы для 360-градусного (2D и 3D) захвата видео. Особенно интересной технологией захвата VR-видео является так называемая "камера светового поля" (также известная как "пленоптическая" камера). Такие камеры не просто захватывают интенсивность света сцены на изображении, но также захватывают направление, из которого свет достигает камеры. Это обеспечивает возможность различных типов постобработки записанного изображения. В частности, это обеспечивает возможность изменения фокальной плоскости изображения после того, как изображение было записано. На практике это означает, что возможно изменить расстояние, находящееся "в фокусе" (относительно точки местоположения камеры) во время воспроизведения изображения.
Было предложено предоставить систему сферических камер для приложений VR, состоящую из многочисленных камер светового поля в сферической компоновке. Такая система камер обеспечивает возможность захвата 360-градусных панорамных 3D записей, при этом делая возможным изменение фокусного расстояния и/или изменения масштаба при постобработке.
Такие разработки на стороне видео открывают ряд возможностей для генерирования интерактивного визуального контента и восприятий с эффектом присутствия. Однако, в основном, меньший интерес был сфокусирован на обеспечении улучшенных и более подходящих восприятий пространственного аудио. В самом деле, обычно аудиорешения являются наименее адаптивными и имеют тенденцию к использованию в основном обыкновенного восприятия пространственного аудио, где единственной способностью к адаптации может быть то, что можно изменять положение некоторых аудиоисточников.
Поэтому будет предпочтительна улучшенная система пространственного аудио и, в частности, предпочтительным будет подход к обработке аудио, обеспечивающий возможность повышенной гибкости, улучшенной способности к адаптации, улучшенного восприятия виртуальной реальности, улучшенных эксплуатационных характеристик, повышенного пользовательского контроля или адаптации, манипуляции со стороны пользователя, и/или улучшенного восприятия пространственного аудио.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Соответственно, данное изобретение стремится к предпочтительному ослаблению, смягчению или устранению одного или более из вышеупомянутых недостатков по одиночке или в любой комбинации.
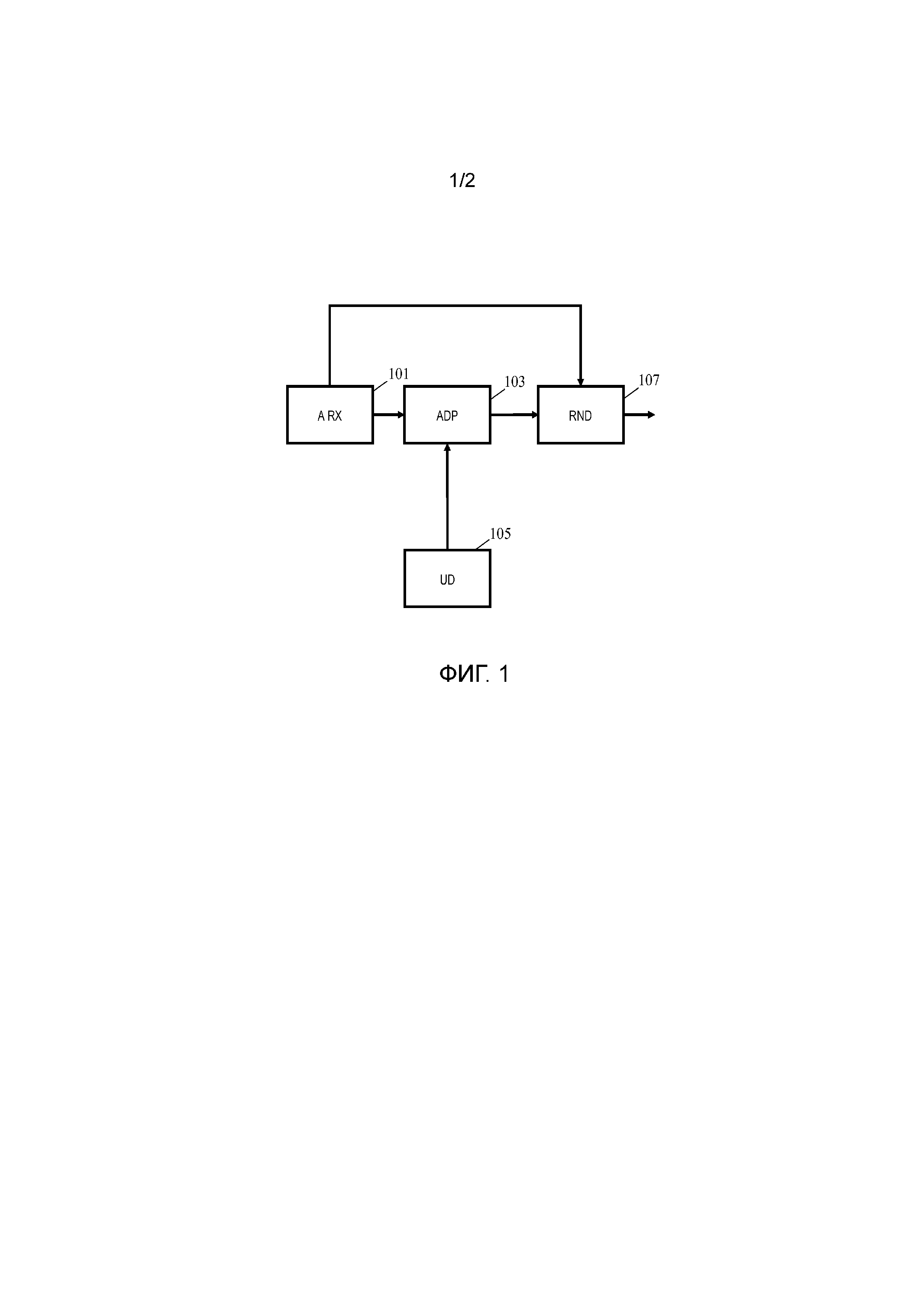
Согласно аспекту изобретения предусматривается устройство обработки пространственного аудио, содержащее: приемник (101) для приема данных аудиосцены, описывающих аудиосцену, причем данные аудиосцены, содержащие аудиоданные, описывающие компоненты пространственного аудио, и данные положения, описывающие положения в аудиосцене по меньшей мере для некоторых компонентов пространственного аудио; блок (105) расстояния для предоставления переменного фокусного расстояния, указывающего расстояние от опорного положения в аудиосцене; адаптер (103) для адаптации свойства ощущаемой выразительности по меньшей мере первого компонента пространственного аудио из компонентов пространственного аудио относительно по меньшей мере одного другого компонента пространственного аудио аудиосцены в ответ на показатель разности, отражающий разность между переменным фокусным расстоянием и расстоянием в аудиосцене от опорного положения до положения первого компонента пространственного аудио; устройство воспроизведения аудио для воспроизведения компонентов пространственного аудио, причем воспроизведение осуществляется в ответ на данные положения, и воспроизведение первого компонента пространственного аудио осуществляется вслед за адаптацией адаптером свойства ощущаемой выразительности.
Данный подход может обеспечить улученное восприятие пространственного аудио во многих вариантах осуществления. В частности, данный подход может, например, обеспечить улучшенное восприятие виртуальной реальности, и может, например, обеспечить возможность более близкой корреляции между визуальным ощущением и ощущением аудио. Во многих вариантах осуществления, данный подход может обеспечить улучшенный фокус пользователя, при этом обеспечивая целостное пространственное восприятие. Например, в окружении виртуальной реальности, данный подход может обеспечить улучшенную пользовательскую фокусировку, которая адаптируется к изменениям в пользовательских характеристиках (например, перемещение головы или глаз), при этом обеспечивая постоянное и целостное окружение виртуальной реальности, т.е. без перемещения аудиоисточников относительно друг друга, как функцию измененного фокуса.
Данный подход может обеспечить улучшенную адаптацию времени воспроизведения на стороне пользователя для воспроизводимой аудиосцены. Он может обеспечить повышенный пользовательский контроль за обеспечиваемым восприятием аудио. В частности, он может обеспечить выразительность на стороне воспроизведения конкретных аудиоисточников относительно других аудиоисточников.
Данный подход может обеспечить аудиосигнал/ аудиоданные, подходящие для пространственного воспроизведения с улучшенной пространственной целостностью, адаптированной также к текущим характеристикам и предпочтениям прослушивания. В частности, он может во многих вариантах осуществления обеспечить возможность выразительности аудиоисточников, соответствующих текущему фокусу пользователя.
Данное улучшение может обычно достигаться при относительно низкой сложности, и данный подход может во многих сценариях обеспечить возможность реализации с относительно низкой стоимостью.
Опорным положением может конкретно быть положение слушателя или прослушивания в аудиосцене (конкретно может быть виртуальное положение, представляющее положение слушателя в виртуальной аудиосцене).
Фокусное расстояние варьируется относительно опорной точки. Адаптер может быть выполнен с возможностью варьирования свойства ощущаемой выразительности для первого компонента пространственного аудио в ответ на вариации переменного фокусного расстояния.
Опорное положение может быть переменным положением в аудиосцене. Переменное фокусное расстояние может не зависеть от опорного положения. Во многих вариантах осуществления, элемент управления переменным фокусным расстоянием может не зависеть от элемента управления опорным положением. Конкретно переменное фокусное расстояние может варьироваться для фиксированного/неизменного опорного положения. Адаптер может быть выполнен с возможностью варьирования адаптации в ответ на вариации в фокусном расстоянии для постоянного опорного положения.
В дополнение к аудиоданным, описывающим конкретные аудиоисточники, аудиоданные могут содержать данные, представляющие неточечные источники или на самом деле нелокализованные (или непространственные) аудиоисточники. Например, могут быть включены аудиоданные, которые описывают распределенный окружающий фоновый звук или шум. В некоторых вариантах осуществления, по меньшей мере некоторые из компонентов аудио могут быть точечными источниками.
В некоторых вариантах осуществления, для каждого или по меньшей мере некоторых из компонентов пространственного аудио могут быть предоставлены отдельные аудиоданные, т.е. компонент аудио может быть описан аудиоданными, предоставляющими информацию, относящуюся только к компоненту аудио. В некоторых вариантах осуществления, каждый компонент пространственного аудио может быть представлен отдельным, полным и индивидуальным набором аудиоданных. Каждый компонент аудио может, например, быть представлен как отдельный аудиообъект и может соответствовать одиночному аудиоисточнику.
В некоторых вариантах осуществления, аудиоданные могут описывать один или более аудиосигналов, из которых может быть излечен отдельный источник пространственного аудио. Например, аудиоданные могут представлять/описывать множество каналов пространственного аудио, например, соответствующих предварительно определенным положениям, и отдельные компоненты аудио могут быть извлечены из данных аудиоканала (например, с использованием метода главных компонент). В качестве другого примера, аудио может быть представлено в соответствии с форматом аудио, известным как "Spatial Audio Object Coding", стандартизированным группой MPEG.
Данные положения могут представлять пространственные положения компонентов пространственного аудио. Данные положения для компонента пространственного аудио могут указывать положение в аудиосцене для аудиоисточника, представленного компонентом пространственного аудио. Положение может быть рекомендуемым положением, которое возможно может быть изменено (например, в ответ на пользовательский ввод) устройством воспроизведения.
Во многих вариантах осуществления, устройство воспроизведения может определить положение устройства воспроизведения для первого компонента пространственного аудио независимо от переменного фокусного расстояния. Устройство воспроизведения может воспроизвести первый компонент аудио в положении, которое зависит от переменного фокусного расстояния. Во многих сценариях, устройство воспроизведения может воспроизвести первый компонент аудио в положении, соответствующим положению в аудиосцене, указанному в данных положения для первого компонента пространственного аудио.
Аудиосцена может быть представлена компонентами пространственного и непространственного аудио. Компоненты пространственного аудио могут представлять источники пространственного аудио, которые конкретно могут быть точечными источниками.
Переменное фокусное расстояние может, например, быть получено из ручного пользовательского ввода или может, например, быть автоматически определено на основе анализа поведения пользователя. Переменное фокусное расстояние может указывать расстояние от опорного положения в аудиосцене до (целевого) фокуса, такое как конкретно до точки, плоскости или расстояние в аудиосцене, на котором (как предполагается/ожидается) пользователь фокусируется. Однако, будет понятно, что данный подход не требует, чтобы слушатель фактически непрерывно фокусировался на этом расстоянии. Скорее, термин "переменное фокусное расстояние" относится к расстоянию, которое устройство обработки пространственного аудио использует как образец для адаптации (термин "фокус" может рассматриваться лишь как метка). Устройство обработки пространственного аудио может адаптировать компоненты аудио так, что выразительность компонентов аудио, которые ближе к переменному фокусному расстоянию, увеличивается, тем самым обычно обеспечивая увеличенный фокус пользователя.
Свойством ощущаемой выразительности может быть любое свойство компонента аудио, и конкретно может отражать ощущаемую выразительность компонента аудио в аудиосцене. Свойством ощущаемой выразительности может быть конкретно по меньшей мере одно из свойства уровня аудио, свойства частотного распределения и свойства диффузности.
В некоторых вариантах осуществления, свойством ощущаемой выразительности является уровень аудио для первого компонента пространственного аудио.
Это может обеспечить особенно предпочтительное пользовательское восприятие во многих вариантах осуществления. В частности это может обеспечить улучшенное пользовательское восприятие аудио, которое может, например, сильно совпадать с визуальным восприятием, например, обеспечивая как визуальному воспроизведению, так и воспроизведению аудио возможность адаптирования выразительности в отношении одинаковых аспектов, например, сцены виртуальной реальности, и дополнительно обеспечивая им возможность варьироваться динамически. Данный подход может обеспечить возможность улучшенного и/или выраженного ощущения конкретных аудиоисточников, таких как аудиоисточники, которые в настоящее время наиболее интересны пользователю.
Вариация уровня аудио в зависимости от показателя разности может обычно быть вариацией амплитуды не более, чем 10 дБ, и часто не более, чем 6 дБ.
Адаптер может генерировать адаптированное свойство ощущаемой выразительности для первого компонента пространственного аудио посредством адаптирования свойства ощущаемой выразительности. Устройство воспроизведения аудио может быть размещено для воспроизведения первого компонента пространственного аудио в ответ на адаптированное свойство ощущаемой выразительности.
В соответствии с опциональным признаком данного изобретения, адаптер выполнен с возможностью определения значения свойства ощущаемой выразительности как непрерывной функции разности между переменным фокусным расстоянием и расстоянием в аудиосцене от опорного положения до положения первого компонента пространственного аудио.
Функция может быть градиентной функцией, и таким образом значение свойства ощущаемой выразительности, например, усиление или уровень аудио, может постепенно изменяться для постепенных изменений в разности между фокусным расстоянием и расстоянием до заданного компонента аудио. Это может обеспечить полезный эффект, который ощущается как более естественное восприятие аудио, особенно когда фокус динамически варьируется для заданного неизменного опорного положения/положения прослушивания. В соответствии с опциональным признаком данного изобретения, адаптер выполнен с возможностью увеличения усиления для первого компонента пространственного аудио относительно по меньшей мере одного другого компонента пространственного аудио для показателя разности, указывающего убывающую разность.
Это может обеспечить особенно предпочтительное функционирование во многих вариантах осуществления. Это может обеспечить возможность относительно низкой сложности и также обеспечить высокие эксплуатационные характеристики. Вариация усиления может во многих вариантах осуществления составлять не более, чем 10 дБ, и часто не более, чем 6 дБ.
Усиление для компонентов аудио может быть монотонно убывающей функцией показателя разности.
В соответствии с опциональным признаком данного изобретения, усиление определяется как функция показателя разности, причем функция является асимметричной относительно расстояний от опорного положения до положения первого компонента аудио, меньших, чем переменное фокусное расстояние, и расстояний от опорного положения до положения первого компонента пространственного аудио, больших, чем переменное фокусное расстояние.
Это может обеспечить улучшенное пользовательское восприятие во многих вариантах осуществления.
В соответствии с опциональным признаком данного изобретения, свойством ощущаемой выразительности является частотное распределение сигнала для первого компонента пространственного аудио.
Это может обеспечить особенно предпочтительное пользовательское восприятие во многих вариантах осуществления. В частности, это может обеспечить улучшенное пользовательское восприятие аудио, которое может, например, сильно совпадать с визуальным восприятием, например, обеспечивая как визуальному воспроизведению, так и воспроизведению аудио возможность адаптирования выразительности в отношении одинаковых аспектов, например, сцены виртуальной реальности, и дополнительно обеспечивая им возможность варьироваться динамически. Данный подход может обеспечить возможность улучшенного и/или выраженного ощущения конкретных аудиоисточников, таких как аудиоисточники, которые в настоящее время наиболее интересны пользователю.
Во многих вариантах осуществления, адаптер может быть выполнен с возможностью все большего отклонения распределения сигнала от низких частот к высоким частотам для уменьшения показателя разности. Адаптер может быть выполнен с возможностью увеличения энергии высокочастотного сигнала относительно энергии низкочастотного сигнала для уменьшения показателя разности.
В соответствии с опциональным признаком данного изобретения, адаптер выполнен с возможностью варьирования частотно-зависимой фильтрации по меньшей мере одного другого компонента пространственного аудио в ответ на показатель разности.
Это может обеспечить эффективную реализацию и/или может обеспечить улучшенные эксплуатационные характеристики. Адаптер может обеспечить частотную коррекцию или фильтрацию, которая зависит от показателя разности.
В соответствии с опциональным признаком данного изобретения, свойством ощущаемой выразительности является свойство диффузности для первого компонента пространственного аудио.
Это может обеспечить особенно предпочтительное пользовательское восприятие во многих вариантах осуществления. В частности, это может обеспечить улучшенное пользовательское восприятие аудио, которое может, например, сильно совпадать с визуальным восприятием, например, обеспечивая как визуальному воспроизведению, так и воспроизведению аудио возможность адаптирования выразительности в отношении одинаковых аспектов, например, сцены виртуальной реальности, и дополнительно обеспечивая им возможность варьироваться динамически. Данный подход может обеспечить возможность улучшенного и/или выраженного ощущения конкретных аудиоисточников, таких как аудиоисточники, которые в настоящее время наиболее интересны пользователю.
В соответствии с опциональным признаком данного изобретения, адаптер выполнен с возможностью уменьшения степени диффузности для первого компонента пространственного аудио относительно по меньшей мере одного другого компонента пространственного аудио аудиосцены для показателя разности, указывающего убывающую разность.
Это может во многих приложениях обеспечить улучшенное пользовательское восприятие. В частности, это может во многих случаях обеспечить возможность ощущения аудио, которое представляет в настоящее время для пользователя особый интерес, как более конкретных и хорошо определенных аудиоисточников, и может, например, обеспечить им возможность сильнее выделяться в ощущаемой звуковой сцене.
В соответствии с опциональным признаком данного изобретения, показатель разности дополнительно зависит от направления от опорного положения к положению первого компонента пространственного аудио.
Это может обеспечить улучшенное пользовательское восприятие во многих вариантах осуществления.
В соответствии с опциональным признаком данного изобретения, данные аудиосцены содержат аудиообъекты, представляющие собой по меньшей мере некоторые из компонентов пространственного аудио.
Данный подход может обеспечить возможность особенно эффективного функционирования для аудиообъектов, что дает в результате улучшенный эффект и, таким образом, улучшенное пользовательского восприятие.
Данные аудиосцены могут дополнительно содержать данные положения, например, как метаданные, указывающие положения аудиообъектов в аудиосцене.
В соответствии с опциональным признаком данного изобретения, блок расстояния выполнен с возможностью определения переменного фокусного расстояния в ответ по меньшей мере на одно из отслеживания головы и глаз слушателя.
Данный подход может, например, обеспечить возможность автоматизированной адаптации к движениям пользователя, тем самым, например, обеспечивая возможность целостного пользовательского восприятия виртуальной реальности с эффектом погружения. Это может обеспечить возможность сильной когерентности между визуальным восприятием и восприятием аудио, обеспечиваемыми пользователю.
В соответствии с опциональным признаком данного изобретения, адаптер выполнен с возможностью адаптации свойства ощущаемой выразительности без изменения интераурального интервала для первого компонента пространственного аудио.
Это может существенно улучшить пользовательское восприятие во многих вариантах осуществления и может, например, обеспечить возможность динамической адаптации относительной выразительности источников звука в аудиосцене к текущим предпочтениям пользователя, при этом обеспечивая ощущаемые положения источников звука.
В соответствии с опциональным признаком данного изобретения, адаптер выполнен с возможностью адаптации свойства ощущаемой выразительности, чтобы снизить выразительность первого компонента аудио для возрастающего показателя разности, где переменное фокусное расстояние больше, чем расстояние от опорного положения до положения первого компонента пространственного аудио.
Это может обеспечить полезный эффект и на самом деле может обеспечить увеличенный фокус в разных зонах в аудиосцене, включая в частности более отдаленные компоненты аудио.
Во многих вариантах осуществления, устройство воспроизведения размещено для воспроизведения по меньшей мере первых компонентов пространственного аудио в положении, указанном данными положения для первого компонента пространственного аудио.
Это может предоставить привлекательный сценарий использования во многих вариантах осуществления и может в частности обеспечить возможность динамической адаптации выразительности в отношении разных объектов в сцене без изменения пространственных свойств сгенерированной аудиосцены.
Может быть предоставлена система виртуальной реальности, содержащая устройство обработки аудио, как описано.
Данный подход может обеспечить улучшенное восприятие виртуальной реальности.
Система виртуальной реальности может дополнительно содержать устройство воспроизведения видео для воспроизведения виртуальной (например, трехмерной) визуальной сцены, совпадающей с аудиосценой.
Согласно аспекту данного изобретения, предоставляется способ обработки пространственного аудио, содержащий: прием данных аудиосцены, описывающих аудиосцену, причем данные аудиосцены, содержащие аудиоданные, описывающие компоненты пространственного аудио, и данные положения, описывающие положения в аудиосцене по меньшей мере для некоторых компонентов пространственного аудио; предоставление переменного фокусного расстояния, указывающего расстояние от опорного положения в аудиосцене; адаптацию свойства ощущаемой выразительности по меньшей мере первого компонента пространственного аудио из компонентов пространственного аудио относительно по меньшей мере одного другого компонента пространственного аудио аудиосцены в ответ на показатель разности, отражающий разность между переменным фокусным расстоянием и расстоянием в аудиосцене от опорного положения до положения первого компонента пространственного аудио; и вслед за адаптацией свойства ощущаемой выразительности, воспроизведение компонентов пространственного аудио, включающих в себя первый компонент пространственного аудио, причем воспроизведение осуществляется в ответ на данные положения.
Эти и другие аспекты, признаки и преимущества данного изобретения будут понятны исходя из варианта(ов) осуществления, описанных в дальнейшем в этом документе, и объяснены со ссылкой на них.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления данного изобретения будут описаны, только в качестве примера, со ссылкой на чертежи, в которых
Фиг. 1 иллюстрирует некоторые элементы устройства обработки пространственного аудио в соответствии с некоторыми вариантами осуществления данного изобретения; и
Фиг. 2 иллюстрирует некоторые элементы системы виртуальной реальности в соответствии с некоторыми вариантами осуществления данного изобретения.
ПОДРОБНОЕ ОПИСАНИЕ НЕКОТОРЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Нижеследующее описание фокусируется на вариантах осуществления данного изобретения, применимых к системе адаптивного аудиовизуального воспроизведения и в частности к системе виртуальной реальности для обеспечения пользователю восприятия виртуальной реальности. Однако, будет понятно, что данное изобретение не ограничивается этим применением, но может быть применено ко многим другим аудиопроцессам и приложениям
Фиг. 1 иллюстрирует некоторые элементы устройства обработки пространственного аудио в соответствии с некоторыми вариантами осуществления данного изобретения.
Устройство обработки пространственного аудио содержит аудиоприемник 101, который выполнен с возможностью приема данных аудиосцены, которые описывают аудиосцену, содержащую компоненты пространственного аудио, ассоциированные с пространственными положениями. Данные аудиосцены содержат аудиоданные, которые описывают некоторое количество компонентов аудио. Каждый компонент аудио может соответствовать источнику звука (которое может быть точечным источником звука, распределенным источником, или на самом деле непространственно размещенным диффузным (например, окружающим) источником. В дополнение, данные аудиосцены включают в себя данные положения, которые предоставляют информацию положения для одного, более или всех компонентов аудио.
В конкретном примере, аудиосцена представлена некоторым количеством аудиообъектов, где каждый аудиообъект является независимым и отдельным аудиоисточником. Таким образом, каждый аудиообъект может быть обработан и визуализирован отдельно от других аудиообъектов. Конкретно, во многих вариантах осуществления, данные аудиосцены содержат индивидуальные наборы аудиоданных, причем каждый набор, предоставляющий полное аудиоописание аудиообъекта. К тому же, индивидуальные данные положения могут быть предоставлены для каждого (или по меньшей мере некоторых) из аудиообъектов.
В некоторых вариантах осуществления, каждый компонент аудио может таким образом быть отдельным аудиообъектом, который может быть обработан независимо и отдельно от других компонентов аудио.
В конкретном примере, данные аудиосцены могут таким образом дополнительно содержать информацию положения для каждого аудиообъекта. Конкретно, данные аудиосцены могут содержать метаданные, которые предоставляют информацию положения для всех или некоторых из аудиообъектов. Таким образом, данные аудиосцены описывают аудиосцену, содержащую некоторое количество аудиоисточников, представленных компонентами аудио (и конкретно аудиообъектами). Конкретно, данные аудиосцены содержат как информацию в отношении аудио, производимом аудиоисточниками, также и их положение в аудиосцене.
Во многих вариантах осуществления, по меньшей мере некоторые из компонентов аудио/аудиообъектов будут соответствовать точечным аудиоисточникам, имеющим единственное ассоциированное положение. В некоторых вариантах осуществления, данные аудиосцены могут включать в себя компоненты аудио, которые не соответствуют точечным аудиоисточникам. Например, один или более из аудиоисточников могут соответствовать более разнесенным или распределенным аудиоисточникам. На самом деле, в некоторых сценариях, один или более компонентов аудио могут соответствовать полностью распределенным аудиоисточникам, таким, как например, аудиоисточники, которые представляют диффузные окружающие звуки.
Аудиоприемник 101 соединен с адаптером 103, который выполнен с возможностью адаптации по меньшей мере одного из компонентов аудио. Адаптация основана на переменном фокусном расстоянии, которое принимается из блока 105 расстояния.
Блок 105 расстояния таким образом выполнен с возможностью предоставления переменного фокусного расстояния адаптеру 103. Переменное фокусное расстояние может предоставить указание расстояния или даже положения в аудиосцене, в котором слушатель/пользователь в настоящее время, как считается/предполагается/оценивается, фокусирует свое внимание. Переменное фокусное расстояние указывает расстояние от опорного положения в аудиосцене. Переменное фокусное расстояние таким образом предоставляет расстояние от текущего опорного положения в аудиосцене. Опорным положением может конкретно быть положение прослушивания, где как считается находится слушатель/пользователь/наблюдатель, и таким образом предполагается, что расстояние, указанное переменным фокусным расстоянием, является расстоянием, на котором пользователь фокусируется в настоящее время (или хочет сфокусироваться), и адаптер 103 выполнен с возможностью адаптации по меньшей мере одного из компонентов аудио, такого что может быть увеличенная ощущаемая выразительность в отношении аудиоисточников на этом расстоянии от опорного положения.
В некоторых вариантах осуществления, переменное фокусное расстояние может быть предоставлено от конкретного пользовательского ввода. Например, блок 105 расстояния может содержать пользовательский ввод, например, в виде слайдера. Пользователь может затем вручную отрегулировать такой слайдер, чтобы непосредственно изменить фокусное расстояние. Таким образом, в некоторых вариантах осуществления, переменное фокусное расстояние может быть непосредственно задано пользователем. В других вариантах осуществления, переменное фокусное расстояние может быть определено автоматически или полуавтоматически, например, посредством отслеживания перемещений глаз. Фокусное расстояние может варьироваться заданной опорной точки/точки прослушивания в сцене. В частности, для фиксированной/неизменной опорной точки, фокусное расстояние может варьироваться и таким образом может быть задано в разные значения.
Для краткости, переменное фокусное расстояние в нижеследующем также будет называться просто фокусным расстоянием.
В некоторых вариантах осуществления, фокусное расстояние может предоставить трехмерное положение в аудиосцене, из которого может быть определено расстояние, например, посредством геометрического вычисления или посредством извлечения релевантных данных. Таким образом, в некоторых случаях, фокусное расстояние может быть предоставлено посредством трехмерного положения, из которого может быть вычислено расстояние до опорного положения. В других вариантах осуществления, фокусное расстояние может содержать только одномерное указание. Например, оно может непосредственно предоставить единственное значение расстояния, которое может быть непосредственно использовано как фокусное расстояние.
Фокусное расстояние может в некоторых вариантах осуществления быть трехмерным расстоянием, относящимся к трехмерной аудиосцене, но может в других вариантах осуществления быть двухмерным или одномерным расстоянием, т.е. фокусное расстояние может относиться только, например, к двум или одному измерению из трех мерного пространства.
Адаптер 103 выполнен с возможностью адаптации свойства ощущаемой выразительности одного или более компонентов аудио в ответ на положение компонентов аудио и фокусное расстояние. Свойством ощущаемой выразительности может быть любое свойство, которое может воздействовать на ощущаемую выразительность компонента аудио в аудиосцене. Таким образом, посредством модификации свойства ощущаемой выразительности можно изменять относительную ощущаемую выразительность или отчетливость аудиоисточника. Таким образом, заданный компонент аудио может быть модифицирован, чтобы сильнее выделяться в аудиосцене (или выделяться меньше).
Конкретно, для заданного компонента пространственного аудио, называемого первым компонентом пространственного аудио, свойство ощущаемой выразительности модифицируется относительно по меньшей мере одного другого компонента аудио в ответ на показатель разности, отражающий разность между фокусным расстоянием и расстоянием от опорного положения до положения первого компонента пространственного аудио.
Расстояние может быть трехмерным расстоянием (конкретно трехмерным евклидовым расстоянием) или может, например, быть двухмерным или одномерным восприятием. Например, расстояние может быть определено как проекция трехмерного расстояния на двухмерную плоскость или на одномерное направление, такое как ось трехмерной системы координат. Например, аудиосцена может быть представлена положениями в евклидовой трехмерной системе координат (координаты x, y и z). Расстояние может относится к трехмерному расстоянию в такой системе координат (например, определяемому как квадратный корень разности для каждой координаты). Однако, расстояние может также быть определено как расстояние в двух из координат (т.е. одна из координат может быть проигнорирована). В некоторых вариантах осуществления, расстояние может определяться, учитывая только одну координату (например, учитывая только координату z).
Например, расстояние может быть использовано для указания трехмерного расстояния от опорного положения до желаемой точки фокуса в аудиосцене. В качестве другого примера, расстояние может быть одномерным расстоянием, задающим двухмерную плоскость фокуса.
Таким образом, адаптер 103 может определить расстояние между опорным положением в аудиосцене и положением первого компонента пространственного аудио. В некоторых вариантах осуществления, опорное положение может быть фиксированным, и на самом деле аудиосцена может быть описана относительно этого опорного положения. Например, положения всех аудиоисточников/компонентов аудио/аудиообъектов могут быть заданы относительно номинального опорного положения. Расстояние от компонента аудио до опорного положения может быть вычислено непосредственно исходя из значений координат положения компонента аудио. На самом деле, если положения задаются полярными координатами, координата длины может быть использована непосредственно как расстояние между первым компонентом пространственного аудио и опорным положением (в аудиосцене). Если, например, используются прямоугольные координаты, расстояние может быть вычислено посредством простых геометрических вычислений.
Опорным положением является опорное положение в аудиосцене. Адаптер 103 соответственно выполнен с возможностью адаптации свойства первого компонента пространственного аудио в зависимости от того, как положение первого компонента пространственного аудио относится к виртуальному опорному положению в виртуальной аудиосцене.
Адаптер 103 сравнивает это расстояние, т.е. расстояние от положения первого компонента пространственного аудио до опорного положения, с этого момента называемое расстоянием аудиоисточника, с фокусным расстоянием и генерирует показатель разности, который указывает, как сильно они отличаются друг от друга. Показатель разности может иметь возрастающее значение/разность (или абсолютное значение/разность) для возрастающей разности между расстоянием компонента аудио и фокусным расстоянием. Показатель разности может быть монотонной и непрерывной функцией разности между расстоянием компонента аудио и фокусным расстоянием.
Будет понятно, что в разных вариантах осуществления могут быть использованы разные показатели разности в зависимости от индивидуальных требований и предпочтений конкретного приложения. Во многих вариантах осуществления и сценариях, может быть использован простой показатель разности, просто вычитающий два расстояния друг из друга.
Адаптер 103 может затем адаптировать свойство ощущаемой выразительности первого компонента пространственного аудио относительно одного или более из других компонентов пространственного аудио на основе этого показателя разности. Обычно, свойство ощущаемой выразительности первого компонента аудио адаптируется (таким образом адаптация будет относительно всех остальных компонентов аудио). Однако, будет понятно, что в некоторых вариантах осуществления, свойство ощущаемой выразительности одного, более или обычно всех остальных компонентов пространственного аудио может быть модифицировано, тем самым приводя к изменению взаимосвязи между свойством ощущаемой выразительности первого компонента пространственного аудио и свойством ощущаемой выразительности остальных компонентов аудио несмотря на то, что свойство ощущаемой выразительности первого компонента пространственного аудио не изменяется.
Свойством ощущаемой выразительности может конкретно быть уровень (аудио) первого компонента пространственного аудио относительно одного или более из других компонентов пространственного аудио. Конкретно, адаптер 103 может быть выполнен с возможностью адаптации уровня первого компонента аудио в ответ на показатель разности, и может конкретно быть выполнен с возможностью увеличения уровня аудио по мере уменьшения показателя разности, т.е. чем ближе расстояние компонента аудио к фокусному расстоянию.
Соответственно, если первый компонент аудио находится близко к фокусному расстоянию, уровень аудиоисточника, соответствующего первому компоненту аудио, будет увеличен относительно того, когда первый компонент аудио отдаляется от фокусного расстояния. Таким образом, если аудиоисточник находится близко к текущему (предполагаемому/указанному) фокусу слушателя, громкость аудиоисточника будет увеличена, тем самым сильнее выделяя аудиоисточник в аудиосцене. Таким образом, выразительность аудиоисточника относительно других аудиоисточников будет зависеть от того, как близко он находится к положению текущего фокуса слушателя.
Будет понятно, что вместо увеличения уровня для первого компонента аудио, адаптер 103 может уменьшить уровень для одного или более других компонентов аудио в аудиосцене, или на самом деле может сделать и то и другое. Например, для уменьшения показателя разности, уровень аудио может быть увеличен для первого компонента аудио и может быть уменьшен для всех остальных компонентов аудио, так чтобы общий объединенный уровень аудио для сцены оставался постоянным.
Будет понятно, что адаптер 103 может перейти к применению аналогичной обработки всех компонентов аудио, или например, к подходящему поднабору компонентов аудио, такому как, например, все компоненты аудио, соответствующие точечным аудиоисточникам. Таким образом, адаптер 103 может эффективно применять переменное усиление или весовую функцию среди аудиосцен с весами в разных положениях в зависимости от расстояния до опорного положения, и конкретно от разности между этим расстоянием и фокусным расстоянием. Чем ближе компонент аудио находится к фокусному расстоянию, тем сильнее может быть усиление. Таким образом, адаптер 103 может применять адаптацию или модификацию к аудиосцене (образованной компонентами аудио), так что аудиоисточники, которые находятся ближе к конкретному текущему фокусу слушателя, делаются выразительными, чтобы сильнее выделяться в ощущаемой аудиосцене.
Адаптер 103 соединен с устройством 107 воспроизведения аудио, которое размещено для воспроизведения аудиосцены посредством воспроизведения компонентов пространственного аудио. Устройство 107 воспроизведения аудио является устройством пространственного воспроизведения, которое может воспроизвести компоненты аудио, так что они ощущаются как исходящие из заданного положения (например, с использованием оборудования объемного звука или наушников с сигналами, генерируемыми посредством бинауральной обработки, которая позднее будет описана более подробно). Таким образом, устройство 107 воспроизведения аудио может эффективно репродуцировать аудиосцену.
Устройство 107 воспроизведения аудио принимает данные положения, извлеченные из данных аудиосцены и переходит к воспроизведению компонентов аудио в положениях, которые по меньшей мере для одного компонента аудио определены на основе принятых данных положения. Конкретно, устройство воспроизведения аудио может быть размещено для воспроизведения одного или более компонентов аудио в положениях, соответствующих положениям, указанным данными положения. Таким образом, аудиосцена воспроизводится с помощью обеспечиваемой информации положения, и ощущаемая пространственная структура аудиосцены обеспечивается также как задано входными данными. Однако, аудиоисточники могут быть модифицированы так, что аудиоисточники, близкие к желаемой, например, фокальной плоскости, будут более выразительны относительно компонента аудио, более отдаленного от фокальной плоскости. Таким образом, аудиоисточники, представляющие конкретный интерес, могут выделяться сильнее, тогда как в то же время пространственная целостность и размещение обеспечивается также, так что аудиосцена не ощущается пространственно измененной.
Будет понятно, что в некоторых вариантах осуществления, устройство воспроизведения может изменить или модифицировать положение одного или более компонентов аудио. Например, пользователь может располагаться с возможностью сдвига положения конкретного компонента аудио в сцене посредством предоставления пользовательского ввода устройству воспроизведения.
Данный подход системы по Фиг. 1 может обеспечить улучшенное пользовательское восприятие во многих вариантах осуществления и может в частности обеспечить более гибкое пользовательское восприятие, где представление аудио для пользователя адаптировано для текущих характеристик пользователя, тем самым обеспечивая пользователю возможность динамического и гибкого изменения фокуса на другие части аудиосцены. Таким образом, вместо воспроизведения фиксированной и негибкой аудиосцены на основе принятых данных аудиосцены, данный подход обеспечивает возможность адаптации на стороне пользователя, что обеспечивает пользователю возможность выделать или сделать выразительными разные аудиоисточники, которые выбираются динамически (вручную или автоматически).
Переменное фокусное расстояние может быть динамически изменено пользователем во многих вариантах осуществления. На самом деле, во многих вариантах осуществления, таких как, например, в приложениях виртуальной реальности, пользователь может располагаться с возможностью управления опорной точкой в пределах аудиосцены, где опорная точка соответствует положению прослушивания в аудиосцене. Элементом управления опорной точки во многих вариантах осуществления пользователь может управлять вручную, например, посредством использования джойстика, геймпада, клавиатуры, детектора движения и т.д. Однако, в дополнение к этому управлению, пользователь может также управлять фокусом в аудиосцене. Это может достигаться посредством переменного фокусного расстояния, которое предоставляется относительно опорного положения. В частности, для заданной опорной точки, фокусное расстояние может варьироваться для предоставления разности зон/точек фокуса относительно этой опорной точки. На самом деле, элемент управления фокусным расстоянием и элемент управления опорной точкой могут не зависеть друг от друга.
Таким образом, фокусное расстояние является переменным по отношению к опорной точке и не является фиксированным, или предварительно определенной зоне, заданной опорной точкой. Переменное фокусное расстояние может, например, быть определено в ответ на пользовательский ввод, например, обеспечивая пользователю, для фиксированного положения прослушивания/опорного положения в аудиосцене, возможность динамического изменения фокуса аудио в аудиосцене. В некоторых вариантах осуществления, фокусное расстояние может, например, быть определено динамически в ответ на автоматическое обнаружение поведения пользователя, такое как обнаружение движение головы или движение глаз. Это может, например, обеспечить слушателю возможность оставаться в фиксированном положении прослушивания в пределах аудиосцены, но динамически изменять фокус аудио в пределах сцены. Таким образом, слушатель может динамически изменять фокус в аудиосцене, например, выбирая источники звука в разных частях сцены.
Устройство обработки пространственного аудио может в частности обеспечить эффект, который аналогичен визуальному подходу, где, например, плоскость фокуса может изменяться динамически на стороне пользователя, так что объекты в сцене, которые находятся в фокусе, могут быть выбраны в момент воспроизведения.
Например, сцена может захватываться камерой светового поля с кодированием и распространением данных результирующего изображения. В дополнение, аудио сцены может быть захвачено набором микрофонов, обеспечивающих возможность определения пространственных характеристик для разных компонентов аудио. Могут быть сгенерированы соответствующие данные аудиосцены, описывающие компоненты аудио и ассоциированную информацию положения, и может быть сгенерирован аудиосигнал, содержащий данные изображения и данные аудиосцены.
Аудиовизуальный сигнал может быть распределенным, и конечное пользовательское устройство может затем обработать соответствующие визуальные и аудиоданные, приводя в результате к воспроизведению трехмерного аудиовизуального восприятия.
Конкретно, данные изображения могут быть обработаны на конце пользователя, так что изображение генерируется при выборе плоскости фокуса во время воспроизведения. Например, пользователю может быть предоставлен слайдер, обеспечивающий пользователю возможность перемещения плоскости фокуса вперед и назад в сцене лишь посредством перемещения слайдера. Это приведет к входу и выходу разных объектов изображения из фокуса в зависимости от задания слайдера и из расстояния до положения просмотра.
В то же время, слайдер может управлять устройством обработки пространственного аудио, так что аудиоисточники, близкие к фокальной плоскости, становятся выразительными относительно аудиоисточников, которые находятся дальше от фокальной плоскости. На самом деле, опорное положение может соответствовать положению наблюдателя для изображения (т.е. оно может соответствовать положению камеры светового поля, когда захватывается изображение сцены), и фокусное расстояние может быть задано, чтобы соответствовать расстоянию от этого положения до фокальной плоскости. В результате, аудиообъекты, близкие к фокальной плоскости будут, например, иметь увеличенный уровень аудио по сравнению с уровнем, когда фокальная плоскость находится на другом расстоянии.
В качестве примера, данный подход может предоставить слайдер, где пользователь может перемещать фокальную плоскость назад и вперед на изображении, при этом в то же время воспринимая, что аудио адаптируется, чтобы соответствовать изменениям фокальной плоскости. Таким образом, как только объект изображения, соответствующий источнику звука (например, динамику или радио) попадает в фокус, источник звука также становится громче и более заметным в аудиосцене.
Данный подход может таким образом обрабатывать аудиовизуальные данные, представляющие виртуальную сцену (например, полученную посредством захвата реальной сцены с использованием камеры светового поля и оборудование с пространственно чувствительными микрофонами) для того, чтобы обеспечить гибкий выбор/управление на стороне пользователя тем, на чем будет фокусироваться пользователь в сцене. Стороны аудио и видео могут размещаться для поддержки друг друга и обеспечивать соответствующие восприятия, тем самым обеспечивая существенно более интересное и желаемое пользовательское восприятие. В частности, может быть обеспечен эффект виртуальной реальности, где действия пользователя могут привести к представлению и ощущению пользователем сцены, динамически изменяющейся, так что пользователь может управлять ощущением сцены.
Во многих вариантах осуществления, адаптер 103 может определить значение свойства ощущаемой выразительности, такое как уровень аудио или усиление, как непрерывную функцию разности между переменным фокусным расстоянием и расстоянием в аудиосцене от опорного положения до положения первого компонента пространственного аудио. Может быть обеспечена постепенная зависимость, такая что выразительность компонентов аудио постепенно уменьшается по мере их отдаления от фокуса. Это может обеспечить полезный эффект, который является особенно важным, когда фокусное расстояние варьируется динамически.
В частности, данный подход может быть особенно предпочтительным в варианте осуществления, где пользователь по отношению к фиксированному положению прослушивания может динамически перемещать фокус в аудиосцене, при этом компоненты аудио входят и выходят из фокуса. Постепенный эффект, достигаемый непрерывной функцией, приведет к гораздо более естественному и менее заметному эффекту.
Адаптер 103 также во многих вариантах осуществления выполнен с возможностью адаптации свойства ощущаемой выразительности, чтобы снизить выразительность первого компонента аудио для возрастающего показателя разности, где переменное фокусное расстояние больше, чем расстояние от опорного положения до положения первого компонента пространственного аудио. Таким образом, выразительность придается не только лишь аудиоисточникам, близким к слушателю, но скорее адаптер может уменьшить выразительность, например, посредством уменьшения уровня аудио или усиления для компонентов аудио, чем ближе они находятся к положению прослушивания, и таким образом, чем дальше они находятся от зоны фокуса, указанной фокусным расстоянием.
Такой эффект может обеспечить улучшенное восприятие, где выразительность может быть расположена в зонах, которые более отдалены от положения прослушивания. Например, для аудиовизуального восприятия виртуальной реальности, предоставляя и аудио, и визуальное воспроизведение, пользователь может изменить фокус, скажем, с динамика, близкого к опорному положению, скажем, на телевизор на заднем плане сцены. Это может привести к визуальному сдвигу фокуса с динамика на телевизор, приводя к тому, что динамик становится менее заметным, и телевизор становится более заметным. Такой же эффект обеспечивается в области аудио, где не только телевизор делается громче, но и динамик также делается тише. Например, воспроизведение может измениться с динамика, являющегося четким и громким, на телевизор, являющийся четким и громким. Таким образом, эффект на слушателя может состоять в том, что аудио адаптируется автоматически с того, что он "слышит" динамик, на то, что он "слышит" телевизор.
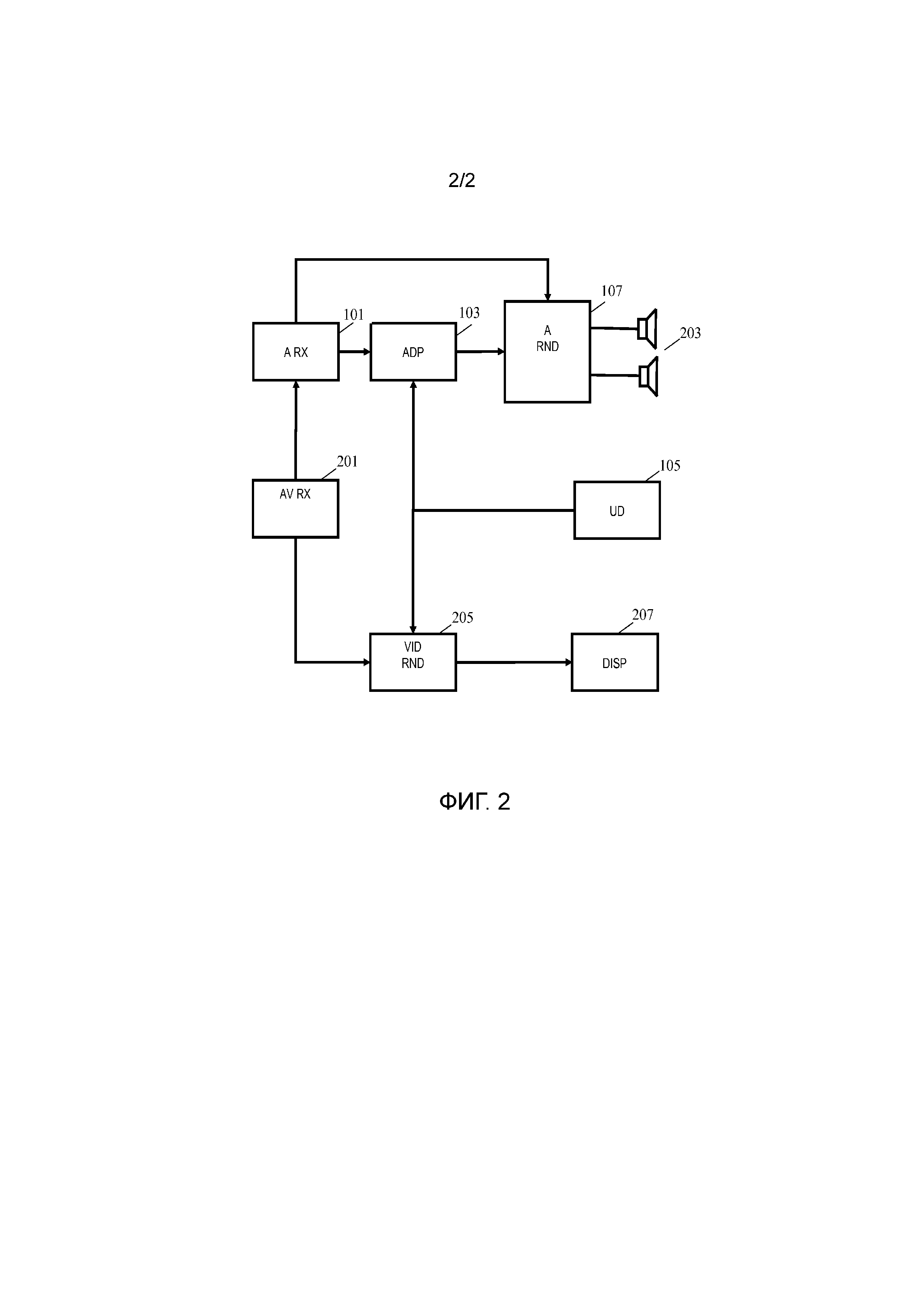
Фиг. 2 раскрывает систему виртуальной реальности, которая размещена для воспроизведения трехмерной аудиовизуальной сцены для пользователя, при этом обеспечивая пользователю возможность динамической адаптации представления аудиосцены, и конкретно обеспечивает пользователю возможность динамического изменения представления сцены. На самом деле, пользователь может изменить фокус в сцене, и может во многих вариантах осуществления также динамически изменить направление или положение прослушивания и просмотра.
Система виртуальной реальности содержит аудиовизуальный приемник 201, который принимает аудиовизуальные данные, описывающие сцену. Аудиовизуальные данные содержат данные аудиосцены, как описано ранее, и в дополнение содержит трехмерные данные изображения (или видео).
Система виртуальной реальности содержит устройство обработки пространственного аудио по Фиг. 1, и аудиовизуальный приемник 201 выполнен с возможностью извлечения данных аудиосцены и подачи их в аудиоприемник 101, где они могут быть обработаны адаптером 103, как описано ранее.
Адаптер 103 соединен с устройством 107 воспроизведения аудио, которое дополнительно соединено с набором аудиопреобразователей 203. Устройство 107 воспроизведения аудио размещено для воспроизведения компонентов аудио адаптации адаптером 103, так что модифицированная аудиосцена воспроизводится посредством аудиопреобразователей 203. Воспроизведение, однако, основывается на первоначальных данных положения, и во многих случаях при этом компоненты аудио воспроизводятся, чтобы соответствовать положениям, указанным данными положения.
Аудиопреобразователями 203 могут, например, быть накладные наушники или вставные наушники, и устройство 107 воспроизведения аудио может включать в себя функциональность для приведения в действие таких накладных наушников или вставных наушников для обеспечения трехмерного пространственного восприятия. Например, устройство 107 воспроизведения аудио может включать в себя функциональность для бинауральной обработки и воспроизведения, включая в себя обработку компонентов аудио с использованием передаточных функций слухового аппарата человека (HRTF) и т.д., как будет известно специалисту в данной области техники.
В некоторых вариантах осуществления, аудиопреобразователями 203 может быть множество динамиков, расположенных так, чтобы обеспечить слушателю пространственное восприятие. Например, аудиопреобразователями может быть набор динамиков объемного звука, например, образующих установку из динамиков объемного звука 5.1 или 7.1.
Устройство 107 воспроизведения аудио может быть размещено для использования любого подходящего подхода для воспроизведения аудиосцены, и будет понятно, что многие разные подходы для воспроизведения пространственного аудио будут известны специалисту в данной области техники, который может реализовать подход, подходящий для конкретных предпочтений и требований отдельного варианта осуществления.
Также будет понятно, что распределение функциональности для аудиотракта может варьироваться между разными вариантами осуществления. Например, в некоторых вариантах осуществления, аудиоприемник 101 может выполнить декодирование аудио, применяемое, например, к отдельным аудиообъектам, чтобы сгенерировать отдельный аудиосигнал для каждого компонента аудио. Адаптер 103 может реализовать переменные усиления для разных компонентов аудио, где усиление для заданного компонента аудио зависит от показателя разности для компонента аудио. Результирующие аудиосигналы могут быть затем обработаны устройством 107 воспроизведения аудио посредством HRTF-функций и объединены в бинауральный сигнал для наушников.
В качестве другого примера, аудиоданные для аудиообъектов могут быть поданы непосредственно в устройство 107 воспроизведения аудио вместе с данными от адаптера 103, указывающими относительную регулировку уровня/усиление для отдельного аудиообъекта (определенное на основе показателя разности). Устройство 107 воспроизведения аудио может затем декодировать аудиообъекты, применить регулировку уровня и объединить результирующие аудиосигналы в сигналы аудиоканала для динамиков объемного звука (с весами для каждого канала, зависящими от положения отдельного аудиообъекта).
Таким образом, будет понятно, что тогда как Фиг. 1 и 2 показывают конкретное распределение, последовательность и разделение функциональности в аудиотракте, другие варианты осуществления могут реализовывать другие распределения, последовательности или разделения функциональности. Например, регулировка усиления может, например, быть частью воспроизведения или может, например, быть выполнена до декодирования аудиоданных.
Система виртуальной реальности кроме того содержит устройство 205 воспроизведения видео, которое соединено с аудиовизуальным приемником 201 и со средством 207 отображения.
Средство 207 отображения размещено для предоставления визуального вывода пользователю, обеспечивая пользователю возможность просмотра сцены, представленной принятыми аудиовизуальными данными. Средством 207 отображения может быть двухмерный дисплей или может быть трехмерный дисплей, или например, пара очков для стереоизображений. Средством 207 отображения во многих вариантах осуществления конкретно может быть набор стереодисплеев для шлема виртуальной реальности или может, например, быть автостереоскопический дисплей.
Устройство 205 воспроизведения видео размещено для приема визуальных данных сцены от аудиовизуального приемника 201 и для приведения в действие средства 207 отображения для представления визуального представления сцены. Будет понятно, что специалистам в данной области техники будут известны многие разные подходы и способы приведения в действие дисплеев (либо 2D, либо 3D) исходя из данных трехмерного изображения или видео, и что может быть использован любой подходящий подход.
В конкретном примере, принятые данные трехмерного изображения принимаются от камеры светового поля. Соответственно, устройство 205 воспроизведения видео может сгенерировать, например, двухмерное выходное изображение посредством обработки данных, чтобы сгенерировать изображение с фокусом на конкретном расстоянии, т.е. устройство 205 воспроизведения видео может быть размещено для обработки принятых визуальных данных для обеспечения варьируемой фокальной плоскости.
Устройство 205 воспроизведения видео соединено с блоком 105 расстояния и размещено также для приема фокусного расстояния. Устройство 205 воспроизведения видео может затем отрегулировать фокальную плоскость в зависимости от указания фокусного расстояния.
Таким образом, в системе, пользователь может вручную регулировать ручной ввод, такой как слайдер, чтобы перемещать фокальную плоскость назад и вперед на представленном изображении. Наряду с этой визуальной адаптацией, аудио адаптируется так, что аудиообъекты, размещенные близко к текущей фокальной плоскости, делаются выразительными относительно других аудиообъектов. Таким образом, может быть обеспечено желаемое пользовательское восприятие, которое предоставляет пользователю гибкую систему, где аудиовизуальное представление может динамически модифицироваться на конце пользователя. Например, пользователь может вручную адаптировать представление. Кроме того, может быть предоставлена тесно связанная адаптация аудио и визуального представления, тем самым обеспечивая очень целостное пользовательское восприятие.
Будет понятно, что в некоторых вариантах осуществления, это не только фокусное расстояние в виде расстояния от фиксированной точки, которое может быть изменено пользователем, но на самом деле в некоторых вариантах осуществления пользователь может также адаптировать положение (или например, направление просмотра) пользователя в виртуальной сцене. Например, в некоторых вариантах осуществления, визуальные данные могут быть предоставлены в виде трехмерной модели виртуального окружения, и данные аудиосцены могут быть предоставлены как аудиообъекты, связанные с этой моделью (конкретно с положениями аудиообъектов, заданными как положения внутри модели). Пользователь может управлять перемещением виртуального положения пользователя в виртуальном окружении, и устройство 205 воспроизведения видео может динамически изменять представленное(ые) изображение(я) для отражения этого перемещения. В дополнение, адаптер 103 может динамически вычислять расстояния от текущего опорного положения до аудиообъектов и динамически адаптировать уровень/усиление аудио для аудиообъектов, чтобы отражать эти вариации.
Адаптер 103 может быть конкретно выполнен с возможностью адаптации свойства ощущаемой выразительности, такого как уровень аудио, фактически не приводя к изменению положения соответствующего аудиоисточника/компонента аудио в сцене. Конкретно, относительные положения аудиоисточников/компонентов аудио могут оставаться такими же несмотря на гибкое изменение. На самом деле, адаптация не влияет на принятые данные положения, но скорее они подаются в устройство 107 воспроизведения аудио, которое может использовать их для воспроизведения сцены пространственного аудио. Во многих сценариях можно расположить компоненты аудио в положениях, указанных данными положения, таким образом давая в результате положения компонентов аудио, которые воспроизводились в первоначальных положениях. Таким образом, ощущаемая выразительность/отчетливость отдельных компонентов аудио может быть изменена относительно друг друга, тогда как положения сохраняются такими же.
Таким образом, несмотря на изменение в свойстве ощущаемой выразительности, адаптер 103 может выполнить адаптацию без существенного изменения ощущаемого положения. Таким образом, пространственные характеристики, предоставленные посредством воспроизведения компонента аудио, могут быть по существу независимыми от адаптации, которая выполняется в ответ на показатель разности.
На самом деле, в большинстве вариантов осуществления, адаптер 103 может быть выполнен с возможностью модификации свойства ощущаемой выразительности без каких-либо изменений привязки по времени компонента аудио относительно других компонентов аудио, т.е. адаптер 103 выполнен с возможностью адаптации свойства ощущаемой выразительности без изменения временной взаимосвязи между компонентами пространственного аудио. Конкретно, относительное время поступления в уши слушателя не варьируется в ответ на фокусное расстояние, и таким образом относительные интерауральные интервалы (ITD) для разных аудиоисточников поддерживаются постоянным. Так как ITD является самой значительной ощущаемой пространственной характеристикой, положения аудиоисточников будут ощущаться находящимися в тех же положениях в аудиосцене. Соответственно, пользователь будет ощущать, что аудиоисточники, близкие к фокусному расстоянию пользователя, являются выразительными в аудиосцене, но эти аудиоисточники остаются в тех же положениях.
Как описано ранее, адаптер 103 может быть выполнен с возможностью адаптации уровня аудио по меньшей мере первого компонента пространственного аудио из компонентов пространственного аудио относительно по меньшей мере одного другого компонента аудио аудиосцены в ответ на показатель разности, отражающий разность между расстоянием в аудиосцене от опорного положения до положения первого компонента пространственного аудио и фокусным расстоянием. Обычно, уровень аудио может быть адаптирован для множества аудиообъектов, и в некоторых сценариях уровень аудио всех компонентов аудио может быть модифицирован.
Адаптер 103 может конкретно быть выполнен с возможностью применения усиления к компонентам пространственного аудио, где усиление для компонента пространственного аудио зависит от разности между фокусным расстоянием и расстоянием от опорного положения до компонента пространственного аудио. Конкретно, адаптер 103 может увеличить усиление для компонента пространственного аудио относительно других компонентов аудио для показателя разности, указывающего убывающий показатель. Таким образом, усиление может быть применено к компонентам аудио, где усиление является монотонно убывающей функцией показателя разности.
Усиление может в некоторых вариантах осуществления быть сгенерировано посредством умножения отдельных компонентов аудио на заданный коэффициент усиления, определенный как функция показателя разности. Усиление может, например, в некоторых вариантах осуществления быть применено после декодирования компонента аудио. Конкретно, значения декодированного сигнала могут быть умножены на коэффициент усиления. В качестве другого примера, усиление может в некоторых вариантах осуществления быть выполнено посредством прямого изменения кодированных аудиоданных. Например, если отдельные компоненты аудио предоставляются как номинальные данные сигнала уровня аудио и ассоциированный параметр, указывающий уровень аудио соответствующего аудиоисточника, адаптер 103 может просто модифицировать параметр уровня аудио.
Адаптер 103 может соответственно быть выполнен с возможностью модификации уровней отдельных компонентов аудио относительно друг друга, в зависимости от их расстояния до выбранного расстояния "в фокусе" относительно точки просмотра пользователя.
Уровни отдельных компонентов аудио могут быть модифицированы с использованием весовой кривой уровня, которая имеет свой максимум в выбранном расстоянии в фокусе и убывает постепенно для увеличения радиального расстояния от этого расстояние в фокусе (как видно с точки просмотра пользователя). В качестве примера, может быть использована кривая Гаусса.
В некоторых вариантах осуществления, усиление определяется как функция показателя разности, который является асимметричным относительно расстояний от опорного положения до положения первого компонента аудио относительно фокусного расстояния. Таким образом, функция может варьироваться асимметрично по отношению к расстоянию до компонента аудио, которое больше, чем фокусное расстояние, или которое меньше, чем фокусное расстояние.
Конкретно, во многих вариантах осуществления усиление для заданной разности расстояния может быть ниже для расстояний, которые больше, чем фокусное расстояние, чем для расстояний, которые меньше, чем фокусное расстояние. В частности, в некоторых вариантах осуществления, минимальный уровень аудио для компонентов аудио может быть применен к компонентам аудио, более близким к пользователю, чем фокусное расстояние, чем для компонентов аудио, более дальних, чем фокусное расстояние (или возможно наоборот).
Такой подход может во многих сценариях обеспечить улучшенное пользовательское восприятие. Он может конкретно обеспечить адаптивную аудиосцену, которая может казаться более реалистичной для многих пользователей. Данный подход может отражать, что аудиоисточники, близкие к пользователю, обычно ощущаются значимыми и имеют относительно высокие (или не немаловажные) уровни, тогда как более отдаленные аудиоисточники могут иметь очень низкие уровни. Соответственно, данный подход может предотвратить, что ощущается нереалистичная аудиосцена из-за слишком чрезмерного ослабления, при этом все еще обеспечивая более высокое ослабление аудиоисточников, которые не оказывают такого эффекта. Данный подход может таким образом помочь в сохранении естественного свойства, что объекты, которые ближе к слушателю, имеют более высокий уровень звука, чем объекты, которые находятся дальше (" закон 1/r").
Описанный подход может особенно подходить для представления изображений из камер светового поля, где пользователь может отрегулировать плоскость фокуса во время использования. На самом деле, данный подход может обеспечить возможность механизма интерактивной обработки аудио, который обеспечивает возможность изменения расстояния "в фокусе" воспроизводимой аудиосцены во время воспроизведения. Механизм управления фокусировкой аудио может быть соединен с соответствующим механизмом управления фокусировкой для визуальной части системы, и для управления и совмещения механизмов фокусировки обеих модальностей может быть использован единый параметр управления. Таким образом, один и тот же элемент управления может воздействовать как на визуальный фокус, так и фокус аудио, ощущаемый пользователем.
В отличие, например, от масштабирования аудио с использованием способов формирования луча на основе микрофонных решеток, описанный подход может стремиться к балансированию уровней звука источников, которые размещены на уровнях с разными расстояниями относительно пользователя, но оставляя их пространственную взаимосвязь по отношению друг к другу и к пользователю ненарушенной. На самом деле, способы формирования луча стремятся как можно больше изолировать звук, поступающий из некоторого направления или от источника звука в некоторой точке в пространстве, подавляя все остальные источники/направления звука, насколько возможно. Текущий подход может динамически придавать выразительность источникам звука, близким к заданному фокусному расстоянию, в соответствии с идеей постфокусировки для камер светового поля. Для таких камер, визуальные объекты на других расстояниях все равно видны на воспроизведенном изображении и их пространственная взаимосвязь остается такой же, но относительная четкость разных объектов может варьироваться по мере изменения фокальной плоскости. Текущий подход может обеспечить соответствующий эффект для аудио, где все аудиоисточники остаются, но некоторые аудиоисточники становятся по ощущению более значимыми, когда находятся близко к выбранной фокальной плоскости.
В некоторых вариантах осуществления, может быть предоставлен сценарий 360-градусного (или даже 3D сферического) воспроизведения VR. Описанный подход обработки аудио может обеспечить пользователю возможность, например, посмотреть вокруг, и управлять расстоянием относительно его точки просмотра, на котором объекты в виртуальной сцене как видны, так и слышны с максимальной "четкостью". Другими словами: это альтернативный механизм взаимодействия, близкий к известному подходу "масштабирования", где объекты при масштабировании расстояния эффективно придвигаются ближе к пользователю (или, эквивалентно: точка просмотра пользователя перемещается к точке масштабирования).
Предыдущее описание фокусировалось на вариантах осуществления, где свойством ощущаемой выразительности, которое модифицируется, является уровень (или усиление) аудио для отдельных компонентов аудио. Однако, в других вариантах осуществления, другие свойства могут дополнительно или в качестве альтернативы быть адаптированы для изменения выразительности или, например, ощущаемой "четкости" компонентов аудио, близких к фокусному расстоянию.
В некоторых вариантах осуществления, свойством ощущаемой выразительности может быть свойство диффузности для первого компонента пространственного аудио. Диффузность воспроизведенного аудиосигнала может влиять на то, насколько локализованным должен ощущаться аудиоисточник. Обычно, по мере увеличения показателя свойств диффузности аудиосигнала, ощущаемое разнесение или нелокальность увеличивается. И наоборот, посредством уменьшения свойства диффузности, аудиоисточник может ощущаться как более локализованный и конкретный аудиоисточник (ближе к точечному источнику). Соответственно, аудиоисточник может ощущаться как "более четкий", когда степень диффузности уменьшается.
Во многих вариантах осуществления, адаптер 103 может быть выполнен с возможностью уменьшения степени диффузности для первого компонента пространственного аудио относительно одного или более других пространственных компонентов для показателя разности, указывающего убывающий показатель. Адаптер 103 может соответственно определить параметр диффузности как функцию показателя разности с параметром диффузности, модифицируемым для уменьшения степени диффузности, чем меньше показатель разности.
В некоторых вариантах осуществления, параметр диффузности может быть непосредственно изменен посредством изменения параметра, указывающего диффузность, которая должна быть применена, когда воспроизводится компонент аудио. Например, некоторые аудиостандарты, которые поддерживают объектное аудио, такие как ADM, MDA и MPEG-H 3D Audio, уже содержат метаданные объекта, которые могут быть использованы для управления диффузностью воспроизведенных объектов. Весовая функция, аналогичная весовой функции, описанной для модификации уровня, может быть применена к свойствам диффузности аудиообъектов, при этом минимальное взвешивание диффузности применяется к объектам на выбранном расстоянии в фокусе (так они воспроизводятся как максимально "четкие"), и возрастающее взвешивание диффузности для объектов при возрастающем радиальном расстоянии от расстояния в фокусе (так что объекты, размещенные далеко от расстояния в фокусе, воспроизводятся как более диффузные и возможно с высокой степенью диффузности).
В качестве другого примера, адаптер 103 может быть выполнен с возможностью модификации разнесения временной области аудиосигнала в зависимости от показателя разности. Например, аудиосигнал для компонента аудио может быть свернут с импульсной характеристикой. Для очень локализованного источника, импульсная характеристика может иметь энергию, сконцентрированную в очень короткий временной интервал и конкретно может быть одиночным импульсом Дирака. Однако, для источника с большей диффузностью, энергия может быть разнесена на более длительную продолжительность, соответствующую возрастающему числу отражений, и например, может включать в себя остатки реверберации, соответствующие разрозненным откликам вместо отдельных отражений. Таким образом, импульсная характеристика может включать в себя эффекты реверберации и т.д. В некоторых вариантах осуществления, адаптер 103 может, например, выбирать между множеством предварительно определенных импульсных характеристик, соответствующих разным степеням диффузности. Выбор может быть основан на показателе разности, и выбранная импульсная характеристика может быть применена к аудиосигналу, давая в результате диффузность, которая зависит от того, как близко компонент аудио находится к фокусному расстоянию.
В таких примерах, временное воспроизведение компонента аудио может быть изменено, тем самым внося диффузность. Однако, в качестве альтернативы или дополнительно, пространственное воспроизведение может быть модифицировано для увеличения диффузности компонента аудио. В таких подходах, корреляция между двумя ушами слушателя может быть уменьшена для увеличения диффузности компонента аудио.
Конкретно, ощущаемая диффузность может зависеть от временного разнесения сигналов, также как и корреляции между ушами слушателя. Больше информации о диффузности для применений аудио может, например, быть найдено в "Acoustics and Audio Technology (Acoustics: Information and Communication)", написанном Mendel Kleiner, J Ross Publishing, 2011, ISBN 1604270527 или "Communication Acoustics" написанном Pulkki, John Wiley & Sons, 2015, ISBN 1118866541.
В частности, ощущаемая диффузность обычно зависит от разности уровней между прямым звуком и реверберирующим звуком. Указание этой разности может быть непосредственно определено как:
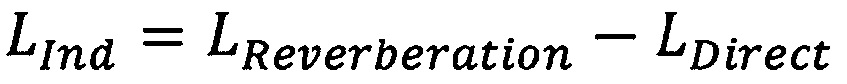
или, например, как соотношение между уровнями:

или пропорция уровня сигнала реверберации относительно общего уровня:
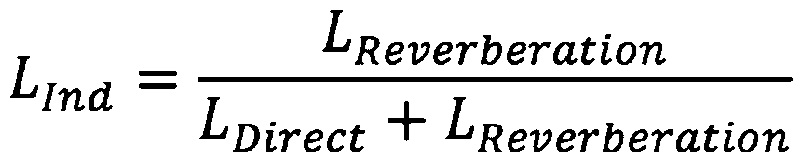
где LDirect является уровнем компонентов прямого звука, LReverberation является уровнем компонентов реверберирующего звука, и LInd является указанием взаимосвязи между ними (причем указание, возрастающее для возрастающей диффузности).
Таким образом, в некоторых вариантах осуществления, адаптер 103 может быть выполнен с возможностью адаптации взаимосвязи между уровнем прямого звука относительно уровня реверберирующего звука в ответ на показатель разности, и конкретно может увеличить уровень реверберирующего звука относительно прямого звука для возрастающего показателя разности.
Будет понятно, что прямой звук и реверберирующий звук можно задать, определить и управлять разными способами в разных вариантах осуществления в зависимости от индивидуальных предпочтений и требований. Например, в некоторых вариантах осуществления, компонент прямого звука может соответствовать всем пикам, соответствующим трактам прямого звука (например, всем импульсам Дирака в импульсной характеристике) с остающимся сигналом, соответствующим компоненту реверберирующего звука.
В других вариантах осуществления, компоненты звука могут быть дифференцированы лишь на основании времени, при этом компоненты прямого звука определяются как компоненты прямого звука, соответствующие компонентам, поступающим на слушателя со временем передачи, меньшим, чем первый временной порог, и реверберирующий звук определяется как реверберирующий звук, соответствующий компонентам, поступающим на слушателя со временем передачи, большим, чем второй временной порог (обычно больший, чем первый временной порог). Например, аудиосигнал для заданного компонента пространственного аудио может быть обработан фильтром (диффузности), имеющим импульсную характеристику. Уровень прямого звука может быть определен как энергия с импульсной характеристикой до первого временного порога, например, 20-100 мс. Это соответствует прямому звуку и первичным отражениям в обычной комнате. Уровень реверберирующего звука может быть определен как энергия с импульсной характеристикой после второго временного порога, например 70-150 мс. Это может соответствовать (обычно нечетко) реверберации в обычной комнате.
Адаптер 103 может, например, переключаться между разными фильтрами (диффузности), имеющими разные импульсные характеристики, для того, чтобы предоставить импульсную характеристику, которая дает в результате желаемую взаимосвязь между прямым и реверберирующим звуком, и тем самым желаемую вариацию в диффузности. Например, может быть предоставлена таблица соответствий с некоторое количеством импульсных характеристик, и адаптер 103 может выбрать между ними на основе показателя разности.
В качестве альтернативы или дополнительно, адаптер 103 может, как упомянуто, быть выполнен с возможностью варьирования корреляции между сигналами между двумя ушами слушателя в зависимости от показателя разности. Конкретно, адаптер 103 может быть выполнен с возможностью варьирования интерауральной корреляции в зависимости от показателя разности, и конкретно может быть выполнен с возможностью уменьшения интерауральной корреляции возрастающего показателя разности.
Конкретно, интерауральный коэффициент взаимной корреляции (ICCC) может быть задан как:

где x(t) и y(t) являются сигналами двух ушей, τ является смещением между каналами (в зависимости от направления источника звука к слушателю), и t1 и t2 являются подходящими временными пределами для интеграции (которые может обычно составлять, например, 50-100 мс).
Адаптер 103 может быть выполнен с возможностью обработки сигнала для адаптации ICCC в зависимости от показателя разности. Например, импульсные характеристики могут храниться для банка фильтров, причем импульсные характеристики являются разными для правого и левого уха. Степень разности, и таким образом корреляция между левым и правым ухом, может быть разной для разных пар фильтров, и таким образом, адаптер 103 может, в зависимости от показателя разности, выбрать пару импульсных характеристик, дающих в результате желаемый ICCC. В качестве конкретного примера, импульсные характеристики могут иметь немного разные задержки для разных частотных диапазонов, причем задержки, варьирующиеся (как функция частоты) по-разному для правого и левого уха соответственно.
Управление диффузностью посредством управления интерауральной взаимной корреляцией может часто особенно подходить для приложений воспроизведения для наушников, тогда как управление диффузностью посредством управления прямым вместо реверберирующего звука может часто подходить больше для воспроизведения с использованием установки пространственных громкоговорителей.
Таким образом, аудиоисточники, которые находятся ближе к фокусному расстоянию, могут ощущаться как более конкретные и пространственно определенные, чем аудиоисточники, которые находятся дальше от фокусного расстояния.
В некоторых вариантах осуществления, адаптер 103 может дополнительно или в качестве альтернативы быть выполнен с возможностью изменения частотного распределения сигнала для первого компонента пространственного аудио в зависимости от показателя разности для первого устройства обработки пространственного аудио.
Таким образом, распределение энергии в частотной области компонента аудио может варьироваться в зависимости от показателя разности. Адаптер 103 может конкретно фильтровать сигнал компонента аудио посредством применения фильтра, который имеет частотную характеристику, которая зависит от показателя разности. Например, адаптер 103 может фильтровать сигнал посредством фильтра низких частот и фильтр высоких частот и затем сгенерировать объединенный сигнал посредством взвешенной комбинации отфильтрованных сигналов. Веса могут быть определены как функция показателя разности.
Адаптер 103 может специально повысить компоненты высокочастотного сигнала относительно компонентов низкочастотного сигнала, чем меньше показатель разности, т.е. чем ближе компонент аудио находится к фокусному расстоянию.
Аудиоисточник может часто ощущаться более заметным и выделяться больше (и, например, становиться все более "четким"), когда он имеет возрастающий высокочастотный контент. Соответственно, система может усилить высокочастотный контент относительно низкочастотного контента, чем ближе аудиообъект находится к фокусному расстоянию, тем самым делая аудиообъекты, которые ближе к фокусному расстоянию, более отчетливыми и заметными.
В качестве другого примера, система может сделать выразительным частотный контент в конкретном частотном диапазоне/области. Например, диапазон средних-высоких частот может быть усилен/ослаблен, чтобы модифицировать ощущаемую выразительность разных аудиоисточников.
Таким образом, в некоторых вариантах осуществления, компонент пространственного аудио может (при воспроизведении) быть отфильтрован фильтром, который имеет частотную характеристику, которая зависит от показателя разности. Например, модифицированный аудиосигнал может быть сгенерирован как:

где

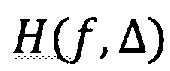
В частности, система может сначала декодировать аудиоданные для компонента пространственного аудио, чтобы сгенерировать аудиосигнал временной области и затем он может быть преобразован в частотную область с использованием FFT. В каждом элементе, сигнал частотной области может быть умножен на коэффициент фильтра, где коэффициент фильтра по меньшей мере для некоторых элементов, определяется как функция показателя разности.
В некоторых вариантах осуществления, относительно сложные функции могут быть использованы для определения каждого отдельного коэффициента фильтра как функции показателя разности. Однако, во многих вариантах осуществления, может быть использован относительно простой подход.
Например, во многих вариантах осуществления, коэффициент для среднего диапазона частот может составлять 1, т.е. значение аудиосигнала в этом элементе не модифицируется. Для высоких частот, коэффициент может быть увеличен для возрастающего показателя разности, тогда как для низких частот, коэффициент может быть уменьшен для убывающего показателя разности. Таким образом, выразительность высоких частот увеличивается относительно выразительности низких частот для убывающего показателя разности, т.е. высокочастотный контент делается выразительным для аудиообъектов, близких к фокусному расстоянию, и невыразительным для более дальних источников.
Во многих вариантах осуществления, адаптер 103 может быть выполнен с возможностью выбора между диапазоном разных фильтров с разными частотными характеристиками в зависимости от показателя разности. Таким образом, таблицей соответствий может содержать банк фильтров, и адаптер 103 может выбирать между ними на основе показателя разности.
Будет понятно, что такие фильтры могут во многих вариантах осуществления варьировать как частотное распределение сигнала компонента аудио, так и его диффузность. Таким образом, хранящаяся частотная характеристика может варьировать как частотную характеристику, так и интерауральную взаимную корреляцию и/или взаимосвязь между компонентами прямого и реверберирующего звука.
Во многих вариантах осуществления, частотно-избирательная фильтрация сигнала компонента пространственного аудио может включать в себя нормализацию, такую что общая энергия/уровень сигнала не модифицируется.
В системе, ощущаемая выразительность/невыразительность разных аудиоисточников может соответственно быть достигнута полностью или частично посредством модификации того, как энергия сигнала распределяется в частотной области. Конкретно, фильтрация фильтром, имеющим частотную характеристику, которая зависит от показателя разности, может применяться к сигналу компонента пространственного аудио, тем самым делая в результате частотное распределение сигнала (особенно, как энергия сигнала распределяется в частотной области) варьируемым как функция показателя разности.
Частотное распределение сигнала может быть определено как распределение энергии сигнала в частотной области. Например, сегмент аудиосигнала для компонента пространственного аудио может быть выбран и преобразован в частотную область с использованием FFT. До адаптации, это может обеспечить заданный набор значений частот, соответствующих заданному распределению сигнала в частотной области (каждое значение, указывающее энергию в этом конкретном элементе разрешения по частоте). Такой же подход может быть применен к модифицированному аудиосигналу, т.е. после выполнения адаптации в зависимости от показателя разности. Значения частот разных элементов разрешения по частоте могут теперь изменяться в соответствии с разным распределением энергии аудиосигнала в частотной области. Так как адаптация зависит от показателя разности, значения по меньшей мере в некоторых элементах разрешения по частоте будут также зависеть от показателя разности, и таким образом достигается разное частотное распределение сигнала, которое является функцией показателя разности.
Простым показателем/указанием частотного распределения сигнала может просто быть энергия в низкочастотном интервале по сравнению с энергией в высокочастотном интервале. Эта взаимосвязь может во многих вариантах осуществления быть модифицирована в зависимости от показателя разности.
Будет понятно, что тогда как частотное распределение сигнала может быть измерено непосредственно в отношении сигналов, модификация частотного распределения сигнала на основе показателя разности обычно выполняется без каких-либо явных измерений, но просто возникает в результате применения фильтров переменной частоты, где фильтры зависят от показателя разности.
В некоторых вариантах осуществления, обработка компонентов аудио может зависеть не только от расстояния от положения аудиоисточника до опорного положения, но может также зависеть от направления от положения аудиоисточника к опорному положению, т.е. показатель разности может зависеть от направления от опорного положения к положению первого компонента пространственного аудио. Конкретно, показатель разности может зависеть по меньшей мере от одного из азимута и оценки разности между положением, указанным фокусным расстоянием, и положением первого компонента пространственного аудио, при просмотре с опорного положения. Таким образом, в таких вариантах осуществления фокусное расстояние, предоставленное, например, пользователем, может быть предоставлено как положение, из которого может быть определено расстояние, и из которого может быть определен азимут и/или оценка по отношению к опорному положению. В других вариантах осуществления, фокусное расстояние может непосредственно предоставить значение расстояния и может в дополнение включать в себя указание положения, задающее конкретное положение.
В некоторых вариантах осуществления, показатель разности может быть составным значением, содержащим множество значений, таких как например значение, зависящее от расстояния от аудиоисточника до опорного положения, и значение, зависящее от направления от аудиоисточника к опорному положению.
Во многих вариантах осуществления, система может таким образом обеспечить более дифференцированную выразительность в отношении компонентов аудио, и конкретно может увеличить выразительность в отношении аудиообъектов, которые находятся в направлении, в котором фокусируется пользователь. Например, пользователь может указать направление просмотра и расстояние, и показатель разности может отражать то, как близко компоненты аудио находятся к указанному положению. Описанные подходы для изменения свойства ощущаемой выразительности (например, уровня аудио, степени диффузности и/или частотного распределения) могут применяться на основе определенного показателя разности.
Данный подход может предоставить улучшенное пользовательское восприятие во многих ситуациях. На самом деле, во многих случаях использования, где аудио объединено с соответствующим видео, может быть нежелательно помещать все аудиообъекты "в фокус", которые расположены на выбранном расстоянии в фокусе где-либо в пространстве. Скорее может быть предпочтительным, чтобы выразительность придавалась только тем, которые находятся в пределах ограниченного пространственного диапазона около направления просмотра, или которые находятся в пределах фактической области просмотра пользователя. Ограничение "фокусировки" аудио таким образом может быть предпочтительнее, чем применение взвешивания максимального уровня для всех аудиообъектов, которые находятся на выбранном расстоянии в фокусе, включая объекты, которые, например, размещаются за пользователем (относительно его точки просмотра и направления просмотра).
Как описано, это может быть реализовано посредством применения показателя разности как описано ранее, но с минимумом в направлении просмотра и с возрастающими значениями для возрастающего угла (азимута и/или оценки) относительно направления просмотра, также как и для возрастающей разности в расстоянии между фокусным расстоянием и аудиообъектом относительно расстояния опорного положения. В динамическом сценарии VR, где пользователь двигает своей головой (или в более общем смысле: изменяет свое направление просмотра), эта функция взвешивания может быть модифицирована соответственно.
В качестве примера, показатель расстояния может быть вычислен посредством определения расстояния между трехмерным положением компонента аудио и трехмерным положением, указанным данными фокусного расстояния. Это расстояние, отражающее расстояние в трех измерениях, может в некоторых вариантах осуществления быть использовано непосредственно как показатель разности. Будет понятно, что в некоторых вариантах осуществления, разные измерения могут быть взвешены по-разному.
В качестве другого примера, показатель разности может быть получен как умножение двух взвешивающих кривых, причем одна зависит от расстояния от аудиообъекта до опорного положения относительно фокусного расстояния, и другая может зависеть от разности между направлением фокуса и направлением от аудиообъекта к опорному положению.
В предыдущих примерах, пользователь может вручную управлять указанием фокуса и конкретно фокусным расстоянием. Однако, во многих вариантах осуществления устройство обработки пространственного аудио может содержать трекер, который отслеживает голову и конкретно глаза пользователя. Фокусное расстояние, может быть затем определено посредством отслеживания его головы или глаз. Трекер может конкретно выполнить обнаружение взгляда или просмотра, чтобы определить положение фокуса для пользователя. Были разработаны различные подходы для такой функциональности, включающие в себя конкретно подходы, называемые адаптивным отслеживанием глубины резкости.
Показатель разности может быть затем определен на основе этого автоматического обнаружения и аудиосцена может быть обработана для увеличения выразительности в отношении аудиообъектов, близких к точке фокуса пользователя. Данный подход может таким образом обеспечить систему, которая автоматически адаптирует аудиосцену для обеспечения увеличенного фокуса в отношении аудиоисточников, близких к тому, куда пользователь смотрит в визуальной сцене. Таким образом, система может автоматически определить, например, расстояние, на котором пользователь фокусирует свои глаза, и эта информация может быть использована для управления как фокусировки видео, так и аудио.
Описанные варианты осуществления фокусировались на реализациях, где данные аудиосцены содержат отдельные аудиообъекты, представляющие по меньшей мере некоторые, и обычно все, из компонентов пространственного аудио. К тому же, для аудиообъектов было предположено представление явной информации положения, например, таких как метаданные.
Таким образом, во многих вариантах осуществления, аудиосцена может быть описана некоторым количеством аудиообъектов, которые индивидуально представлены аудиоданными и ассоциированными метаданными, которые конкретно могут включать в себя информацию положения и информацию воспроизведения, такую как, например, информацию о предлагаемом уровне, параметры реверберации и т.д.
В последние годы, значительные усилия были вложены в разработку некоторого количества аудиоформатов, которые представляют отдельные аудиоисточники, как отдельные аудиообъекты. Таким образом, вместо представления аудиосцены посредством аудиоканалов, соответствующих конкретным (номинальным или опорным) положениям, было предложено предоставить отдельные аудиообъекты, каждый из которых представляет конкретный аудиоисточник (включающий в себя, например, источники фонового, диффузного и окружающего звука). Обычно, аудиообъектам может быть предоставлена (опционально) информация положения, которая указывает целевое положение аудиообъекта в звуковой сцене. Таким образом, в таких подходах, аудиоисточник может быть представлен как отдельный и одиночный аудиообъект, вместо вклада, который он вносит в аудиоканалы, ассоциированные с конкретными предварительно определенными положениями (громкоговорителей).
Например, для того, чтобы поддерживать аудиообъекты, MPEG стандартизировала формат, известный как "Spatial Audio Object Coding" (ISO/IEC MPEG-D SAOC). В отличие от систем кодирования многоканального аудио, таких как DTS, Dolby Digital и MPEG Surround, SAOC обеспечивает эффективное кодирование отдельных аудиообъектов, а не аудиоканалов. Тогда как в MPEG Surround, каждый канал громкоговорителя может рассматриваться как возникающий из разной комбинации звуковых объектов, SAOC обеспечивает возможность для интерактивной манипуляции размещением отдельных звуковых объектов при многоканальной комбинации.
Аналогично MPEG Surround, SAOC также создает понижающее моно или стереомикширование. В дополнение, вычисляются и включаются параметры объектов. На стороне декодера, пользователь может манипулировать этими параметрами для управления различными признаками отдельных объектов, таких как положение, уровень, компенсация, или даже применять эффекты, такие как реверберация.
SAOC обеспечивает возможность более гибкого подхода и в частности обеспечивает большую возможность адаптации на основе воспроизведения посредством передачи аудиообъектов в дополнение к только репродукции каналов. Это обеспечивает стороне декодера возможность помещения аудиообъектов в произвольных положениях в пространстве, в том случае, если пространство достаточно покрыто громкоговорителями. Таким образом между передаваемым аудио и установкой репродукции или воспроизведения нет взаимосвязи, поэтому могут быть использованы произвольные установки громкоговорителей. Это предпочтительно, например, для установок домашнего кинотеатра в обычной гостиной, где громкоговорители почти никогда не находятся в предназначенных положениях. В SAOC, на стороне декодера принимается решение, где объекты помещаются в звуковой сцене. Однако, поскольку поддерживается манипуляция аудиообъектами на стороне воспроизведения, обычно желательно, чтобы могло быть воспроизведено не требуя пользовательских вводов, при этом все равно обеспечивая подходящую звуковую сцену. В частности, когда аудио предоставляется вместе с привязанным видеосигналом, желательно, чтобы аудиоисточники воспроизводились в положениях, соответствующих положениям на изображении. Соответственно, аудиообъекты могут быть часто обеспечены целевыми данными положения, которые указывают предложенное положение воспроизведения для отдельного аудиообъекта.
Другие примеры форматов на основе аудиообъектов включают в себя MPEG-H 3D Audio [ISO/IEC 23008-3 (DIS): Information technology - High efficiency coding and media delivery in heterogeneous environments - Part 3: 3D audio, 2014.], ADM [EBU Tech 3364 "Audio Definition Model Ver. 1.0", 2014] и проприетарные стандарты, такие как Dolby Atmos [SMPTE TC-25CSS10 WG в "Interoperable Immersive Sound Systems for Digital Cinema", 2014] и DTS-MDA [ETSI документ TS 103 223, "The Multi-Dimensional Audio (MDA) Content Creation Format Specification with Extensions for Consumer Environments", 2014].
Данные аудиосцены могут включать в себя аудиоданные, точно определяющие число разных аудиообъектов для различных аудиоисточников в сцене. Некоторые из этих аудиообъектов могут быть диффузными или основными звуками, которые не ассоциированы с какими-либо конкретными положениями. Например, один или более аудиообъектов могут быть окружающими или фоновыми аудиообъектами, которые представляют фоновые или окружающие звуки. Однако, другие аудиообъекты могут быть ассоциированы с конкретными источниками звука, соответствующими конкретным положениям в звуковой сцене. Соответственно, аудиовизуальный сигнал может также содержать данные положения, которые предоставляют указания желаемых положений для конкретных аудиообъектов, т.е. он может включать в себя целевые данные положения для аудиообъектов.
В некоторых сценариях, один или более аудиообъектов могут быть ассоциированы с конкретными объектами изображения. Например, аудиообъект может соответствовать речи от человека на изображении. Этот аудиообъект может таким образом быть ассоциирован с объектом изображения, соответствующим человеку, или более конкретно (например, для крупных планов) рту человека. Аудиовизуальный сигнал может в таком примере содержать аудиоданные, которые описывают речь, и данные положения, которые указывают положение соответствующего объекта изображения на 3D изображении (т.е. говорящего (или рта говорящего)).
Для аудиообъектов, ассоциация с трехмерным изображением может не быть ассоциацией с конкретным объектом изображения, но может относиться более косвенно к сцене, представленной 3D изображением. Например, может происходить из источника, который невидим на воспроизведенном изображении (например, из-за загораживания, расстояния или размера).
Аудиообъекты таким образом обычно не являются компонентами канала, предоставленными для конкретного предварительно определенного или опорного положения, а скорее обычно соответствуют отдельным источникам звука в сцене. В частности, один или более из аудиообъектов могут непосредственно относиться к одному объекту изображения на 3D изображении (например, аудиообъект речи может быть ассоциирован с объектом изображения, представляющим говорящего). Данные положения для заданного аудиообъекта могут указывать положение в сцене источника звука, представленного аудиообъектом.
Будет понятно, что данные положения не должны включаться для всех аудиообъектов. В частности, некоторые аудиообъекты могут не соответствовать источникам звука, которые имеют конкретные положения, а скорее могут иметь рассеянные или разрозненные положения источников. Например, некоторые аудиообъекты могут соответствовать окружающему или фоновому звуку, который не предназначен для воспроизведения из конкретных положений.
Хотя описанный подход может быть особенно предпочтительным при использовании с данными аудиосцены, содержащими аудиообъекты, будет понятно, что аудиоданные могут быть предоставлены другими способами в других вариантах осуществления. Например, данные аудиосцены могут предоставить данные для множества каналов пространственного аудио, таких как, например, может быть предоставлен обыкновенный аудиосигнал объемного звука. Аудиоприемник 101 может в таких вариантах осуществления быть выполнен с возможностью извлечения компонентов аудио, например, с использованием метода главных компонент (PCA) или другого подходящего подхода извлечения аудио. Такие способы могут также предоставить расчетное положение для извлеченных компонентов аудио. Результирующие компоненты аудио и информация положения могут быть затем обработаны как описано для аудиообъектов.
Будет понятно, что вышеуказанное описание для ясности описывает варианты осуществления данного изобретения со ссылкой на разные функциональные схемы, блоки и процессоры. Однако, будет понятно, что любое подходящее распределение функциональности между разными функциональными схемами, блоками или процессорами может быть использовано без ущерба изобретению. Например, функциональность, проиллюстрированная для выполнения отдельными процессорами или контроллерами, может быть выполнена одним процессором или контроллерами. Поэтому, ссылки на конкретные функциональные блоки или схемы следует рассматривать как ссылки на подходящие средства для обеспечения описанной функциональности, а не указывающими строгую логическую или физическую структуру или организацию.
Данное изобретение может быть реализовано в любой подходящей форме, включающей в себя аппаратные средства, программное обеспечение, программно-аппаратные средства или любую их комбинацию. Данное изобретение может быть опционально реализовано по меньшей мере частично как компьютерное программное обеспечение, выполняющееся на одном или более процессорах обработки данных и/или процессорах цифровой обработки сигналов. Элементы и компоненты варианта осуществления данного изобретения могут быть физически, функционально и логически реализованы любым подходящим образом. Фактически, функциональность может быть реализована в одиночном блоке, во множестве блоков или как часть других функциональных блоков. В связи с этим, данное изобретение может быть реализовано в одиночном блоке или может быть физически и функционально распределено между разными блоками, схемами и процессорами.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами осуществления, оно не предназначено для ограничения конкретными формами изложенными, в настоящем документе. Скорее, объем настоящего изобретения ограничен только прилагающейся формулой изобретения. Дополнительно, хотя признак может оказаться описанным в связи с конкретными вариантами осуществления, специалисты в данной области техники поймут, что различные признаки описанных вариантов осуществления могут быть скомбинированы в соответствии с данным изобретением. В формуле изобретения, термин "содержащий" не исключает присутствия других элементов или этапов.
К тому же, хотя перечислены отдельно, множество средств, элементов, схем или этапов способа могут быть реализованы, например, посредством одиночной схемы, блока или процессора. Дополнительно, хотя отдельные признаки могут быть включены в разные пункты формулы изобретения, они возможно могут быть предпочтительным образом скомбинированы, и включение в разные пункты формулы изобретения не предполагает, что комбинация этих признаков не выполнима и/или предпочтительна. Также данное включение признака в одну категорию формулы изобретения не предполагает ограничение этой категорией, а скорее указывает, что признак в равной степени применим к другим категориям формулы изобретения в соответствующих случаях. К тому же, порядок признаков в формуле изобретения не предполагает какого-либо конкретного порядка, в котором признаки должны работать, и в частности, порядок отдельных этапов в формуле изобретения на способ не предполагает, что этапы должны быть выполнены в этом порядке. Скорее, данные этапы могут быть выполнены в любом подходящем порядке. В добавление, ссылки на единственное число не исключают множественности. Таким образом, указание единственности, "первый", "второй" и т.д., не устраняют множественности. Ссылки в формуле изобретения предоставлены лишь в качестве разъясняющего примера, и не должны быть истолкованы в качестве ограничения объема формулы изобретения каким-либо образом.
Реферат
Изобретение относится к средствам для обработки пространственного аудио. Технический результат заключается в повышении эффективности обработки аудио. Принимают данные аудиосцены, описывающие аудиосцену, причем данные аудиосцены содержат аудиоданные, описывающие компоненты пространственного аудио, и данные положения, описывающие положения в аудиосцене по меньшей мере для некоторых компонентов пространственного аудио. Предоставляют переменное фокусное расстояние, указывающее расстояние от опорного положения в аудиосцене. Адаптируют свойство ощущаемой выразительности по меньшей мере первого компонента пространственного аудио из компонентов пространственного аудио относительно по меньшей мере одного другого компонента пространственного аудио аудиосцены в ответ на показатель разности, отражающий разность между переменным фокусным расстоянием и расстоянием в аудиосцене от опорного положения до положения первого компонента пространственного аудио. 2 н. и 12 з.п. ф-лы, 2 ил.
Комментарии