Система детектирования речи - RU2363994C2
Код документа: RU2363994C2
Чертежи
Описание
Настоящее изобретение относится к системе ввода аудиоинформации. Более конкретно, настоящее изобретение относится к обработке речи при использовании системы ввода с многосенсорным преобразователем.
В различных приложениях с распознаванием речи очень важный и, может быть, критический момент состоит в обеспечении чистого и постоянного ввода аудиоинформации - речи для распознавания, передаваемой в систему автоматического распознавания речи. Ввод аудиоинформации в систему распознавания речи может быть нарушен шумами двух категорий, которые представляют собой окружающие шумы и шумы, образованные фоновой речью. Была проведена большая работа по разработке технологии подавления шумов, направленной на отсечение шумов окружающей среды от вводимой аудиоинформации. Некоторые такие коммерчески доступные технологии уже применяют в программном обеспечении для обработки звука или они интегрированы в цифровые микрофоны, такие как микрофоны, работающие с универсальной последовательной шиной (УПШ, USB).
Устранение шума, связанного с фоновой речью, является более проблематичным. Такой шум может возникнуть во многих различных зашумленных средах. Например, когда человек, речь которого представляет интерес, разговаривает в толпе или среди других людей, обычный микрофон часто воспринимает речь других говорящих людей, помимо речи человека, представляющего интерес. В принципе, в любом окружении, когда говорят другие люди, звуковой сигнал, генерируемый говорящим человеком, представляющим интерес, может быть нарушен.
Одно из решений известного уровня техники, направленных на подавление фоновой речи, состоит в установке переключателя "включения/выключения" на проводе головной гарнитуры или на телефонной трубке. Такой переключатель "включения/выключения" называется нажимной кнопкой "разговор", и пользователь должен нажимать на кнопку перед тем, как он начнет говорить. Когда пользователь нажимает на кнопку, вырабатывается сигнал кнопки. Сигнал кнопки указывает системе распознавания речи, что представляющий интерес говорящий человек в данный момент говорит или собирается говорить. Однако некоторые исследования показали, что система такого типа является неудовлетворительной или нежелательной для пользователей.
Кроме того, была проведена работа, направленная на отделение фоновых разговоров, улавливаемых микрофонами, от голоса говорящего человека, представляющего интерес (или человека, говорящего на переднем плане). Были получены результаты, хорошо работающие в чистом окружении офиса, но они оказались недостаточны для работы в сильно зашумленном окружении.
В еще одной технологии известного уровня техники сигнал стандартного микрофона комбинируют с сигналом ларингофона. Ларингофон опосредованно регистрирует движения гортани путем измерения изменений электрического полного внутреннего сопротивления в горле при разговоре. Сигнал, генерируемый ларингофоном, комбинируют с обычным микрофоном, на основе чего были построены модели спектрального содержания комбинированных сигналов.
Для составления структуры зашумленного комбинированного сигнала стандартного микрофона и ларингофона использовали алгоритм очистки сигнала стандартного микрофона. Его оценка была проведена с использованием вероятностной оптимальной фильтрации. Однако, хотя ларингофон является весьма устойчивым к фоновым шумам, спектральное содержание сигнала ларингофона остается весьма ограниченным. Поэтому его применение для построения структуры, используемой для очистки оценки вектора сигнала, оказалось не очень точным. Эта технология более подробно описана в публикации Frankco и др., COMBINING HETEROHENEOUS SENSORS WITH STANDARD MICROPHONES FOR NOISY ROBUST RECOGNITION, Presentation at the DARPA ROAR Workshop, Orlando, Fl (2001). Кроме того, необходимость надевать ларингофон увеличивает неудобство для пользователя.
В настоящем изобретении обычный аудиомикрофон скомбинирован с дополнительным датчиком речи, который формирует сигнал датчика речи на основе дополнительно вводимой информации. Сигнал датчика речи генерируется на основе действия, производимого говорящим человеком во время разговора, например, движения лица, вибрации кости, вибрации горла, изменений полного внутреннего сопротивления горла и т.д. Компонент датчика речи принимает входной сигнал от датчика речи и подает на выход сигнал детектирования речи, указывающий на то, что пользователь говорит. Датчик речи генерирует сигнал детектирования речи на основе сигнала микрофона и сигнала датчика речи.
В одном варианте выполнения сигнал детектирования речи поступает в процессор распознавания речи. Процессор распознавания речи на основе сигнала микрофона и сигнала детектирования речи, поступающего с выхода дополнительного датчика речи, формирует выходной сигнал распознавания, указывающий на наличие речи, представленной сигналом аудиомикрофона.
Настоящее изобретение также направлено на способ детектирования речи. Способ включает генерирование первого сигнала, представляющего собой аудиоинформацию, поступающую с выхода аудиомикрофона, генерирование второго сигнала, указывающего на движение лица пользователя, определяемое датчиком движения лица, и определение на основе первого и второго сигналов, говорит ли пользователь.
В одном варианте выполнения второй сигнал содержит вибрацию или изменение полного внутреннего сопротивления шеи пользователя, или вибрацию черепа или челюсти пользователя. В другом варианте выполнения, второй сигнал содержит изображение, указывающее на движения рта пользователя. В еще одном варианте выполнения датчик температуры, такой как термистор, установлен в потоке дыхания, например на держателе, рядом с микрофоном, который определяет наличие речи по изменению температуры.
На Фиг.1 показана блок-схема одной из конфигураций, в которой можно использовать настоящее изобретение.
На Фиг.2 показана блок-схема системы распознавания речи, с которой можно использовать настоящее изобретение.
На Фиг.3 показана блок-схема системы детектирования речи в соответствии с одним вариантом выполнения настоящего изобретения.
На Фиг.4 и 5 иллюстрируются два различных варианта выполнения части системы, представленной на фигуре 3.
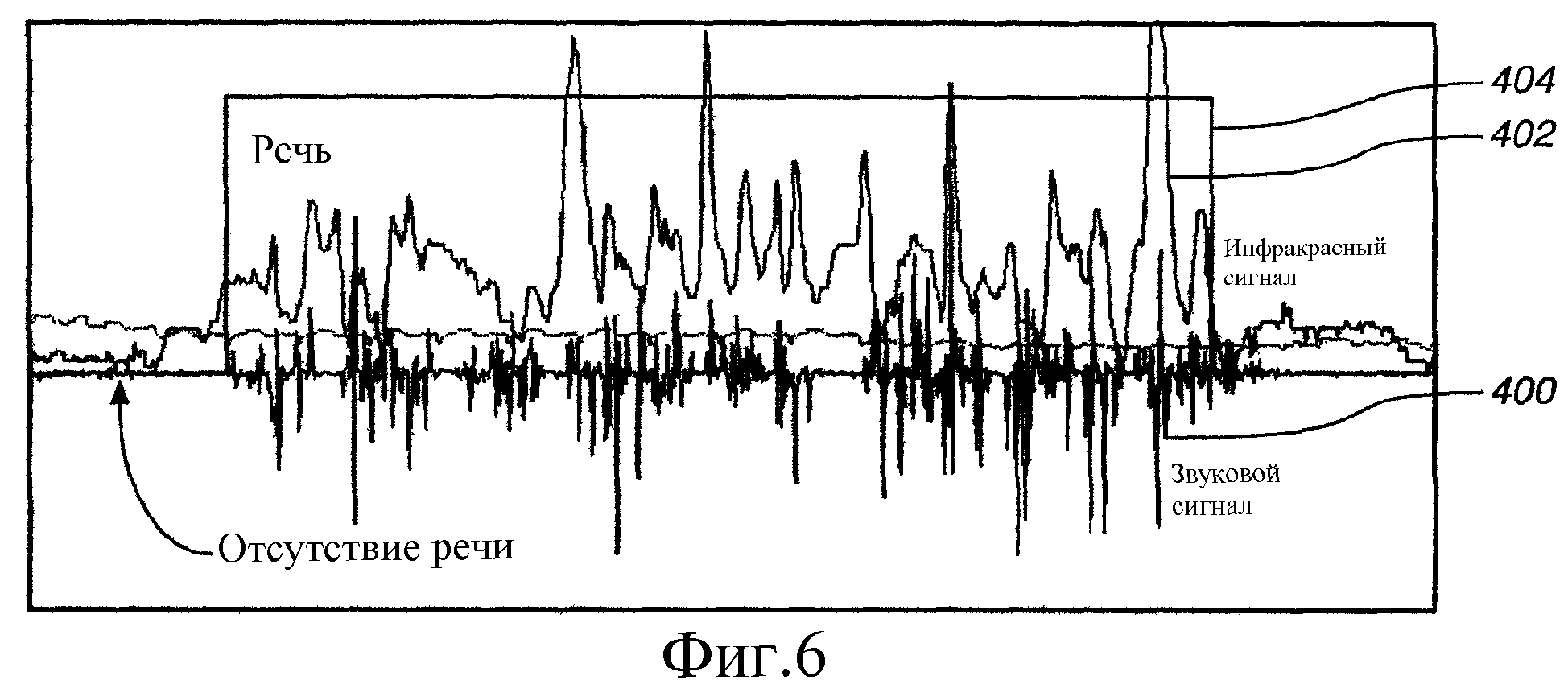
На Фиг.6 показан график зависимости уровня сигнала от времени для сигнала микрофона и сигнала инфракрасного датчика.
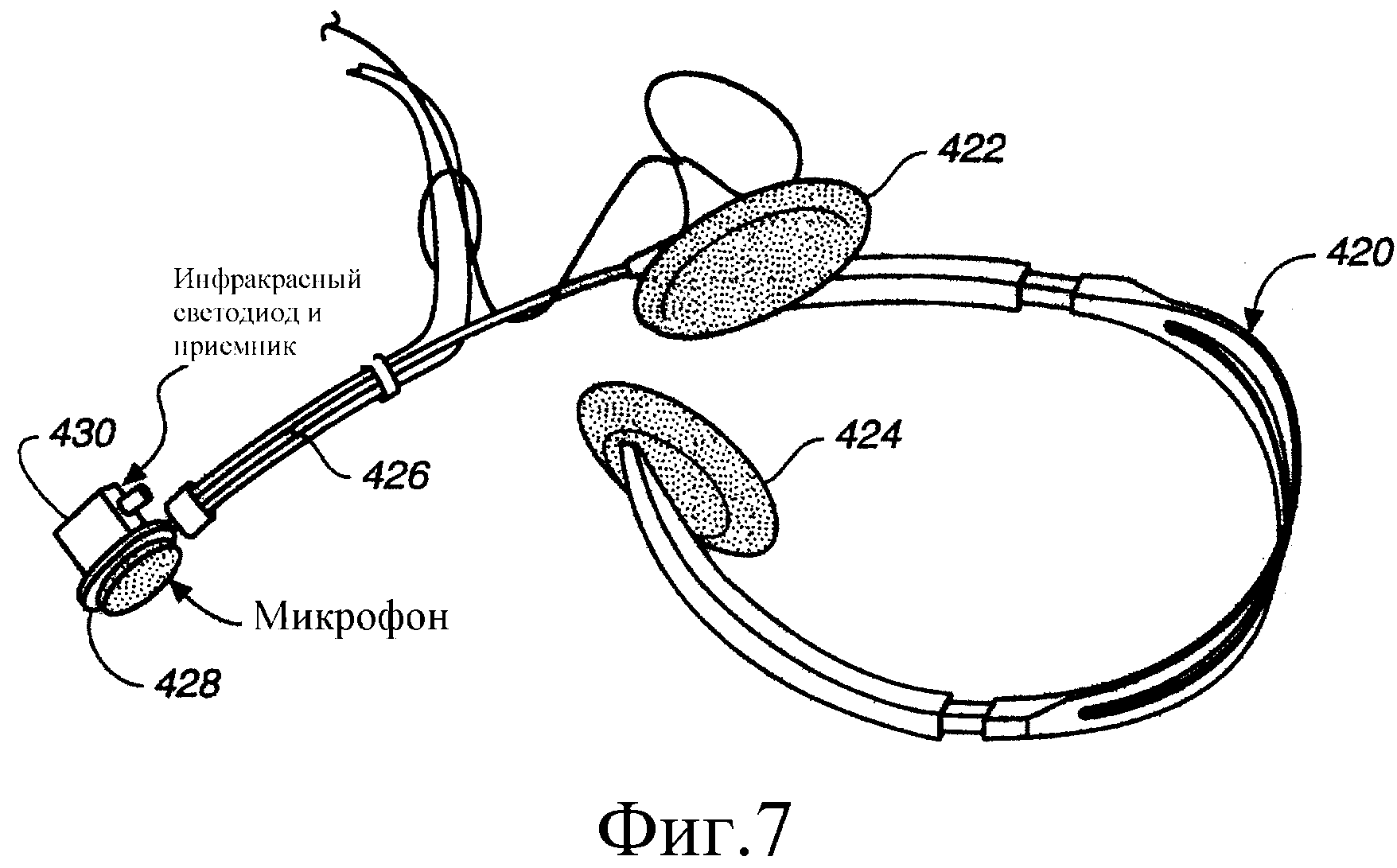
На Фиг.7 представлена иллюстрация одного из вариантов выполнения обычного микрофона и датчика речи.
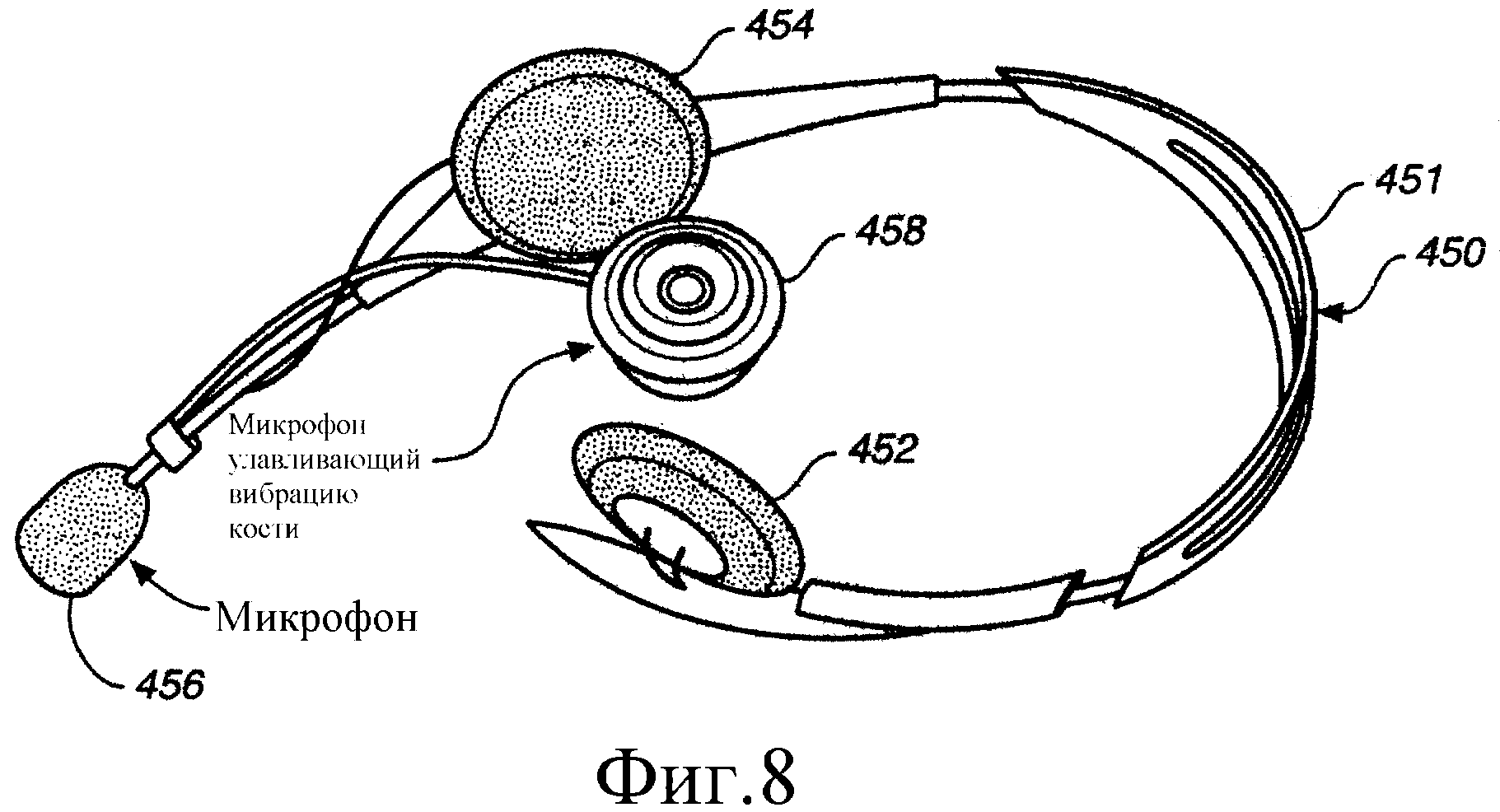
На Фиг.8 представлено изображение микрофона, устанавливаемого на кости, используемого вместе с обычным аудиомикрофоном.
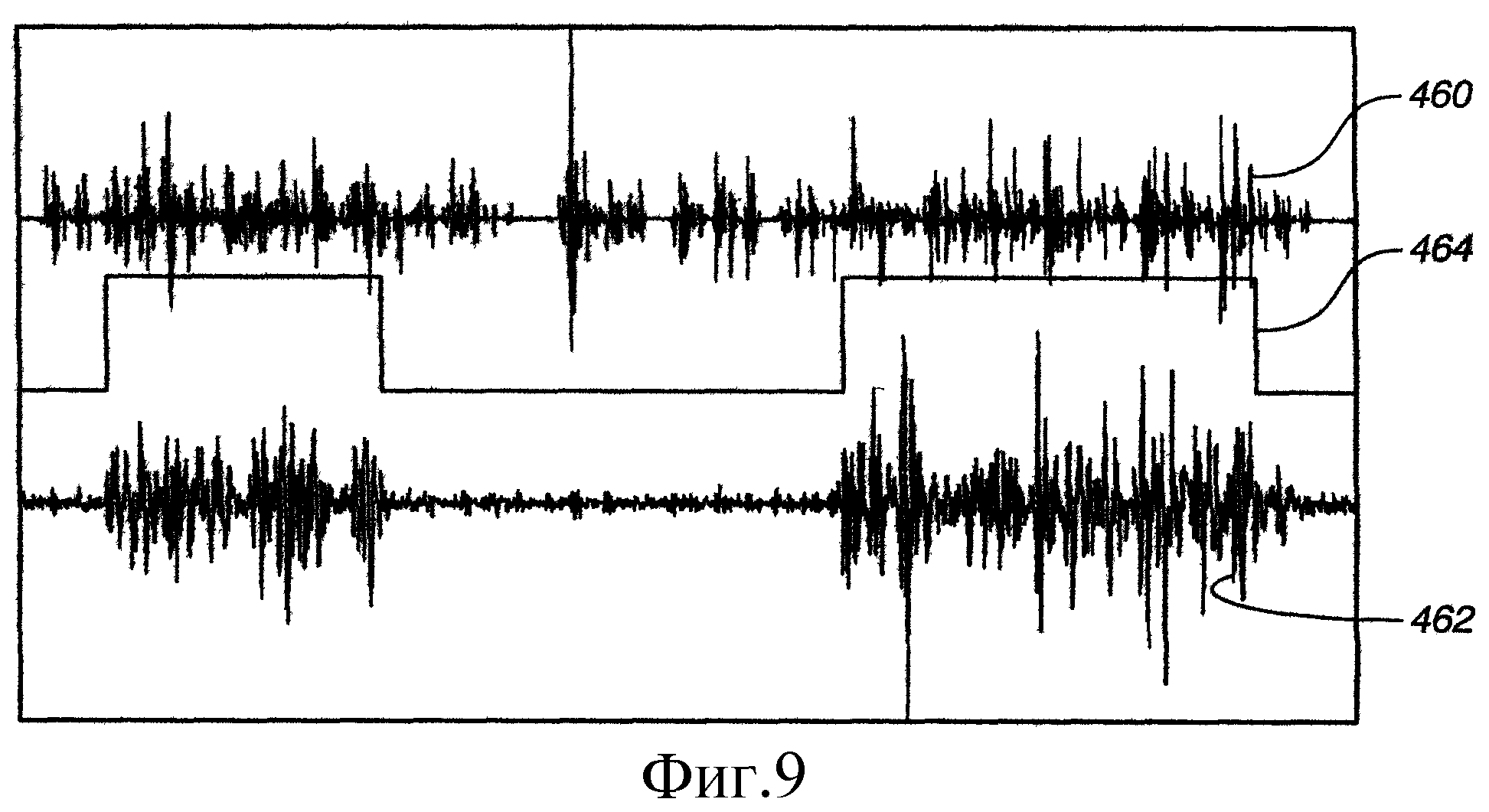
На Фиг.9 показан график зависимости уровня сигнала от времени для сигнала микрофона и сигнала аудиомикрофона, соответственно.
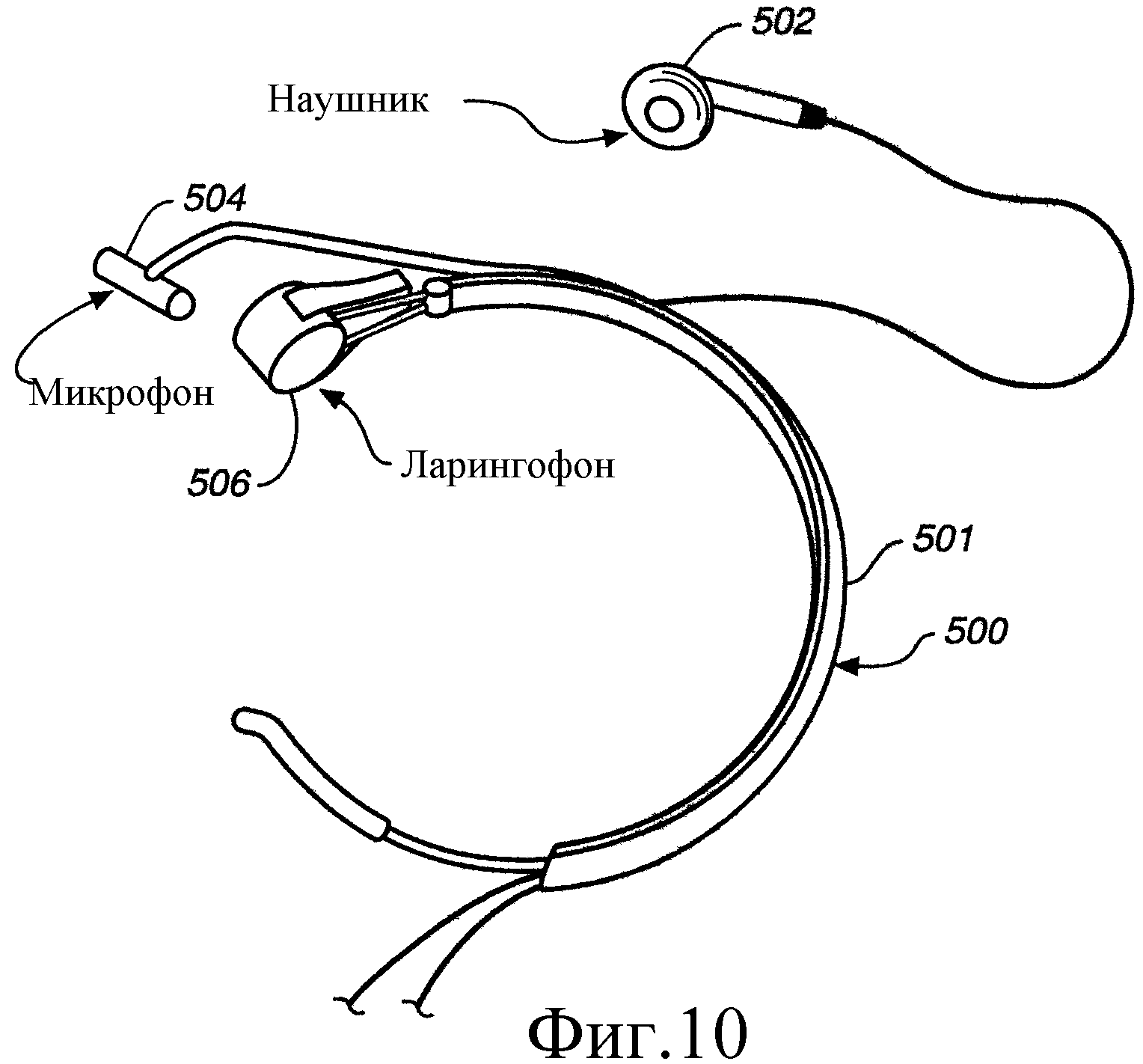
На Фиг.10 представлено изображение ларингофона, используемого вместе с обычным аудиомикрофоном.
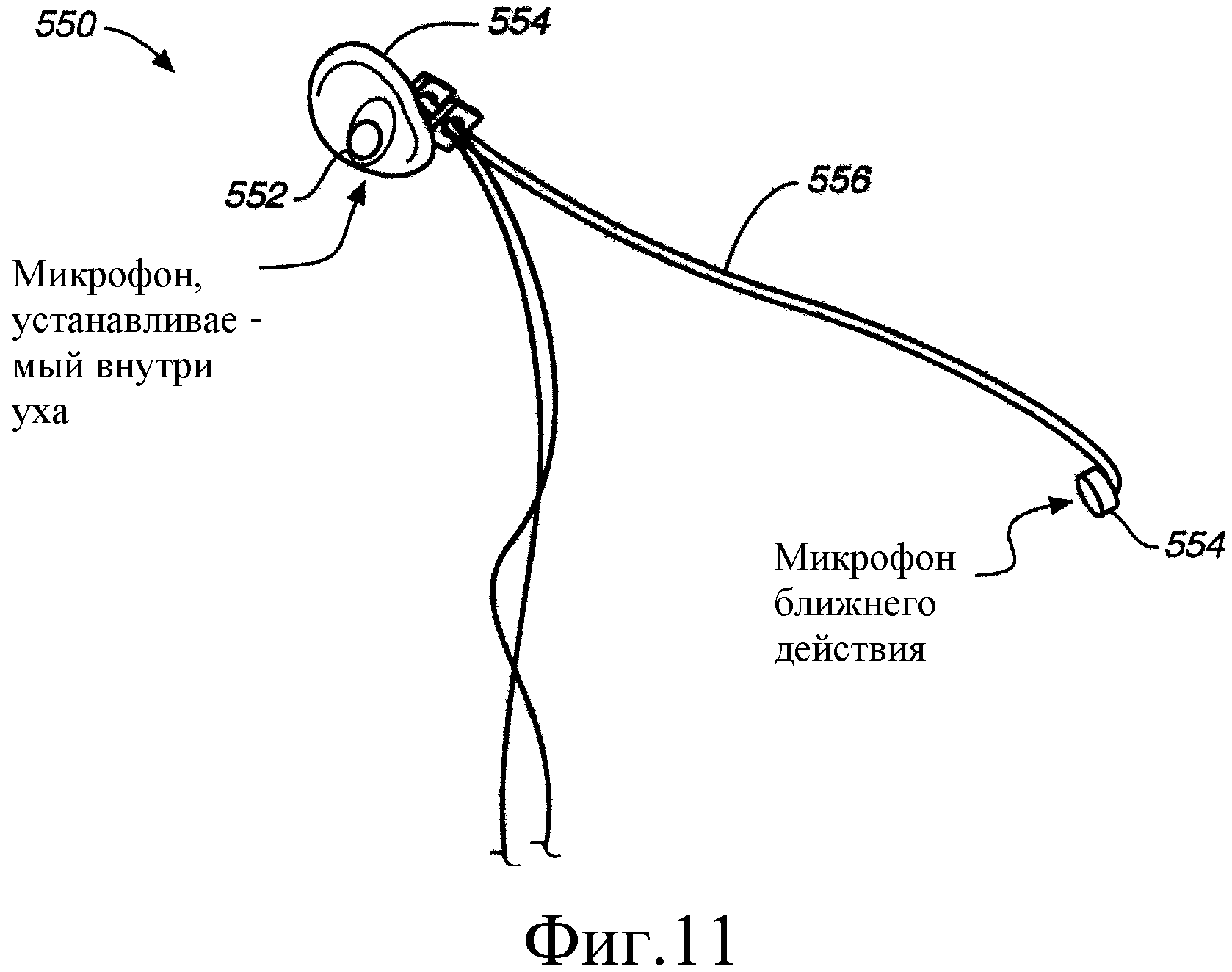
На Фиг.11 представлено изображение микрофона, устанавливаемого в ухо, используемого вместе с микрофоном ближнего действия.
Настоящее изобретение относится к детектированию речи. Более конкретно, настоящее изобретение относится к улавливанию входного сигнала многосенсорного преобразователя и генерированию выходного сигнала, указывающего на то, что пользователь разговаривает, на основе входного сигнала, поступающего от множества датчиков. Однако перед более подробным описанием настоящего изобретения описан иллюстративный вариант выполнения конфигурации, в которой можно использовать настоящее изобретение.
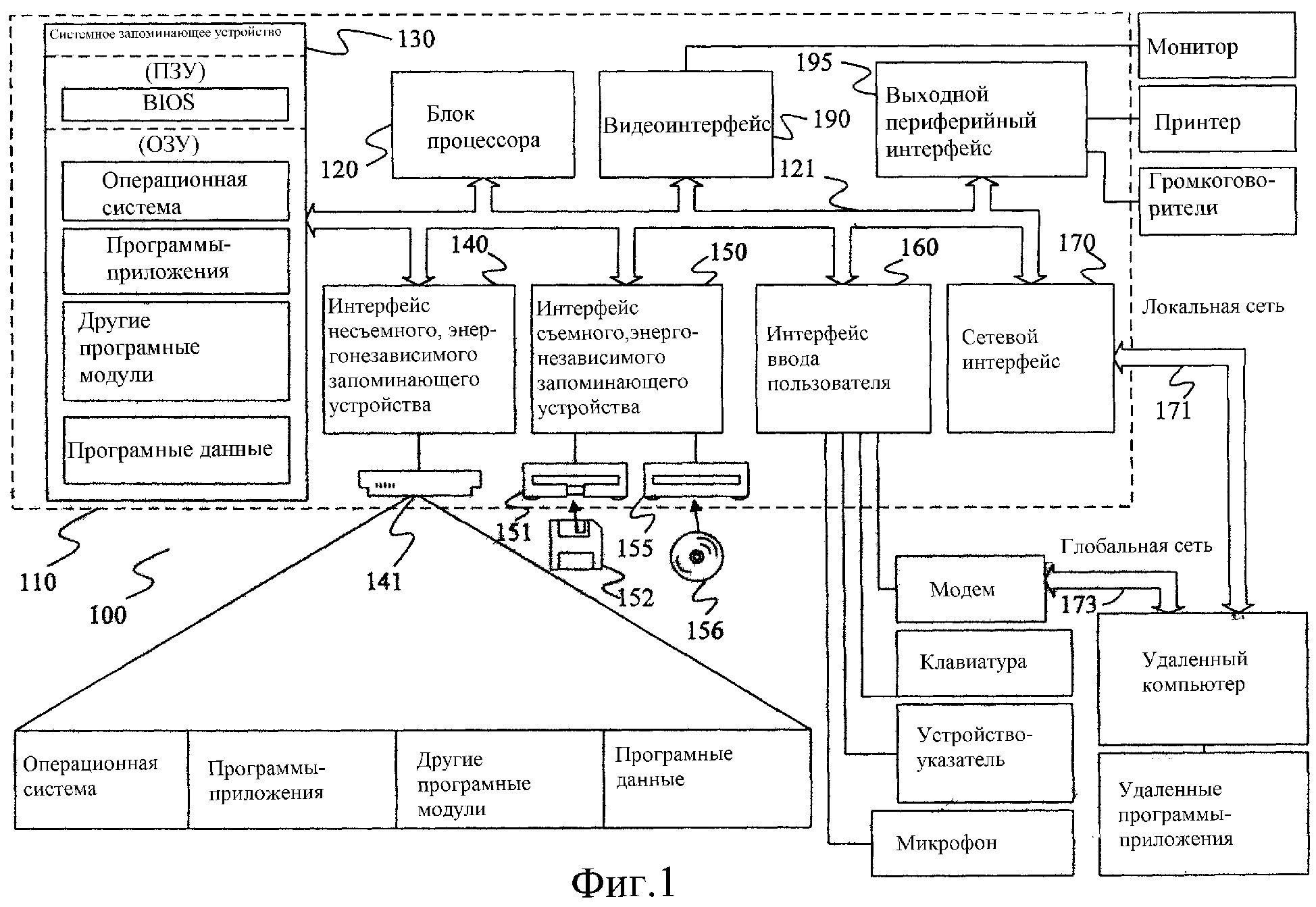
На Фиг.1 представлен пример соответствующей конфигурации 100 компьютерной системы, с которой можно использовать настоящее изобретение. Конфигурация 100 компьютерной системы представляет собой только один из примеров соответствующей конфигурации вычислительной системы и не предназначена для использования в качестве какого-либо ограничения объема использования или функций настоящего изобретения. Компьютерную конфигурацию 100 также не следует интерпретировать, как в какой-либо степени зависящую от комбинации компонентов, представленных в примере рабочей конфигурации 100.
Настоящее изобретение может работать с множеством других компьютерных систем или конфигураций общего или специального назначения. Примеры хорошо известных компьютерных систем и/или конфигураций, которые можно использовать с настоящим изобретением, включают, без ограничений, персональные компьютеры, компьютеры-серверы, карманные или переносные компьютеры, многопроцессорные системы, системы на основе микропроцессора, компьютерные приставки, программируемые электронные устройства потребителей, сетевые ПК, миникомпьютеры, универсальные компьютеры, распределенные компьютерные среды, которые включают любую из вышеуказанных систем или устройств, и т.п.
Настоящее изобретение может быть описано в общем контексте выполняемых на компьютере инструкций, таких как программные модули, выполняемые на компьютере. В общем случае, программные модули включают процедуры, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или представляют собой воплощение определенных абстрактных типов данных. Настоящее изобретение также можно использовать на практике в распределенных вычислительных средах, в которых задачи выполняются с использованием устройств удаленной обработки, соединенных по сети передачи данных. В распределенной компьютерной среде программные модули могут быть расположены как в локальных, так и в удаленных компьютерных средах хранения информации, включая запоминающие устройства.
Как показано на Фиг.1, пример системы, используемой для выполнения настоящего изобретения, включает компьютерное устройство общего назначения, представленное в форме компьютера 110. Компоненты компьютера 110 могут включать, без ограничений, блок 120 процессора, системное запоминающее устройство 130 и системную шину 121, которая соединяет различные системные компоненты, включая соединение системного запоминающего устройства с блоком процессора 120. Системная шина 121 может быть любой из нескольких типов шин, включая шину запоминающего устройства или контроллер запоминающего устройства, периферийную шину и локальную шину с использованием любой из множества архитектур шины. Например, и без ограничений, такие архитектуры включают шину Архитектуры промышленного стандарта (АПС, ISA), шину Многоканальной архитектуры (МКА, MCA), шину Расширенной стандартной архитектуры для промышленного применения (РСАП, EISA), локальную шину, соответствующую Стандарту ассоциации по стандартам в области видеоэлектроники (АСОВ, VESA), и шину взаимного соединения периферийных компонентов (ВПК, PCI), также известную как шина расширения второго уровня.
Компьютер 110 обычно включает множество носителей, считываемых компьютером. Носители, считываемые компьютером, могут представлять собой любые известные носители, доступ к которым может осуществляться с компьютера 110, и включают как энергозависимые, так и энергонезависимые носители, съемные и несъемные носители. В качестве примера и без ограничений, носители, считываемые компьютером, могут содержать компьютерные среды хранения информации и среды передачи данных. Компьютерные среды хранения информации включают как энергозависимые, так и энергонезависимые, съемные и несъемные носители, выполненные с использованием любого способа или технологии хранения информации, такой как считываемые компьютерные инструкции, структуры данных, программные модули или другие данные. Компьютерные среды хранения информации включают, без ограничений, ОЗУ (RAM), ПЗУ (ROM), электронно-перепрограммируемые ПЗУ (EEPROM), запоминающие устройства типа флэш или запоминающие устройства, построенные с использованием других технологий, CD-ROM (запоминающее устройство на компакт-дисках), запоминающие устройства на цифровых универсальных дисках (DVD) или другие оптические дисковые носители записи, запоминающие устройства на магнитных кассетах, магнитной ленте, накопители на магнитных дисках или другие устройства магнитной записи, или любая другая среда хранения информации, которую можно использовать для записи требуемой информации и доступ к которой может осуществляться с помощью компьютера 100. Среды передачи данных обычно реализуют машиносчитываемые инструкции, структуры данных, программные модули или другие данные в модулированном сигнале передачи данных, таком как носитель ФЗК, (WAV) (в форме звуковых колебаний) или с использованием другого механизма передачи данных, и включают любой носитель для передачи информации. Термин "модулированный сигнал данных" означает сигнал, который имеет один или больше характеристик, устанавливаемых или изменяемых таким образом, что информация кодируется в сигнале. В качестве примера и без ограничений, среда передачи данных включают проводную среду, такую как кабельная сеть или прямое кабельное соединение, и беспроводные среды, такие как акустические, радиочастотные (РЧ, RF), инфракрасные и другие беспроводные среды. Комбинации любых из вышеприведенных примеров также должны быть включены в объем носителей, считываемых компьютером.
Системное запоминающее устройство 130 включает компьютерные запоминающие устройства в форме энергозависимых и/или энергонезависимых запоминающих устройств, таких как постоянное запоминающее устройство (ПЗУ) 131 и оперативное запоминающее устройство (ОЗУ) 132. Базовая система 133 ввода-вывода (БСВВ, BIOS), содержащая основные процедуры, которые обеспечивают передачу информации между элементами компьютера 110, например, при загрузке, обычно записана в ПЗУ 131. ОЗУ 132 обычно содержит данные и/или программные модули, к которым может осуществляться непосредственный доступ, и/или которые работают в данный момент времени с блоком 120 процессора. В качестве примера и без ограничений, на Фиг.1 представлена операционная система 134, программы 135 приложения, другие программные модули 136 и программные данные 137.
Компьютер 110 также может включать другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные запоминающие устройства. Только в качестве примера, на Фиг.1 представлен привод 141 жесткого диска, который обеспечивает считывание информации с несъемного, энергонезависимого магнитного носителя и/или запись на него, привод 151 магнитного диска, который обеспечивает считывание со съемного, энергонезависимого магнитного диска 152 или запись на него, и привод 155 оптического диска, который обеспечивает считывание со съемного, энергонезависимого оптического диска 156 такого, как CD ROM или другой оптический носитель, или запись на него. Другие съемные/несъемные, энергозависимые/энергонезависимые носители компьютерной записи, которые можно использовать в примере рабочей конфигурации, включают, без ограничений, магнитные кассеты, карты памяти типа флэш, цифровые универсальные диски, цифровую видеоленту, твердотельное ОЗУ, твердотельное ПЗУ и т.п. Привод 141 на жестком диске обычно соединен с системной шиной 121 через интерфейс несъемного запоминающего устройства, такой как интерфейс 140, и привод 151 магнитного диска, и привод 155 оптического диска обычно подключены к системной шине 121 через интерфейс съемного запоминающего устройства, такой как интерфейс 150.
Приводы и установленные на них носители компьютерной записи, описанные выше и представленные на Фиг.1, предоставляют пространство для хранения считываемых компьютером инструкций, структур данных, программных модулей и других данных компьютера 110. На Фиг.1, например, представлен жесткий диск 141, как устройство хранения операционной системы 144, программ 145 приложений, других программных модулей 146 и программных данных 147. Следует отметить, что эти компоненты могут представлять собой те же операционную систему 134, программы 135 приложений, другие программные модули 136 и программные данные 137 или могут быть другими компонентами. Операционная система 144, программы 145 приложения, другие программные модули 146 и программные данные 147 обозначены здесь различными номерами для иллюстрации того, что, как минимум, они представляют собой разные копии.
Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода данных, такие как клавиатура 162, микрофон 163 и устройство 161 указатель, такое как указатель типа мышь, шаровой манипулятор или сенсорная панель. Другие устройства ввода (не показаны) могут включать джойстик, игровую клавиатуру, спутниковую антенну, сканер или тому подобное. Эти и другие устройства ввода данных часто подключены к блоку 120 процессора через интерфейс 160 ввода пользователя, который соединен с системной шиной, но они также могут быть подключены через другой интерфейс и структуры шины, такие как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или устройство дисплея другого типа также подключено к системной шине 121 через интерфейс, такой как видеоинтерфейс 190. В дополнение к монитору компьютеры также могут включать другие периферийные устройства вывода информации, такие как громкоговорители 197 и принтер 196, которые могут быть подключены через выходной периферийный интерфейс 190.
Компьютер 110 может работать в сетевой среде с использованием логических соединений с одним или несколькими удаленными компьютерами, такими как удаленный компьютер 180. Удаленный компьютер 180 может представлять собой персональный компьютер, карманное устройство, сервер, маршрутизатор, сетевой персональный компьютер - ПК, равноправное устройство или другой обычный сетевой узел и обычно включает множество или все элементы, описанные выше в отношении компьютера 110. Логические соединения, представленные на Фиг.1, включают локальную сеть (ЛС, LAN) 171 и глобальную сеть (ГС, WAN) 173, но также могут включать другие сети. Такие сетевые среды являются общеиспользуемыми в офисах, компьютерных сетях предприятий, Интранет (корпоративная локальная сеть) и Интернет.
При использовании в сетевой среде локальной сети компьютер 110 подключают к LAN 171 через сетевой интерфейс или адаптер 170. При использовании в сетевой конфигурации WAN компьютер 110 обычно включает модем 172 или другие средства установления связи с WAN, такой как Интернет. Модем 172, который может быть внутренним или внешним, может быть подключен к системной шине 121 через интерфейс 160 ввода пользователя или другой соответствующий механизм. В сетевой конфигурации программные модули, описанные по отношению к компьютеру 110 или его компонентам, могут быть записаны на удаленных запоминающих устройствах. В качестве примера, без ограничений, на Фиг.1 представлены удаленные программы 185 приложения, установленные на удаленном компьютере 180. Следует понимать, что показанные сетевые соединения представляют собой примеры и можно использовать другие средства установления канала связи между компьютерами.
Следует отметить, что настоящее изобретение может быть выполнено на основе компьютерной системы, такой как описана со ссылкой на Фиг.1. Однако настоящее изобретение также может быть выполнено на сервере, компьютере, выделенном для обработки сообщений, или на распределенной системе, в которой различные части настоящего изобретения выполнены на различных частях распределенной компьютерной системы.
На Фиг.2 представлена блок-схема примера системы распознавания речи, в которой можно использовать настоящее изобретение. На Фиг.2 говорящий человек 400 говорит в микрофон 404. Звуковые сигналы, детектируемые микрофоном 404, преобразуются в электрические сигналы, которые поступают в аналогово-цифровой (А-Ц, A-D) преобразователь 406.
A-D преобразователь 406 преобразует аналоговый сигнал микрофона 404 в последовательность цифровых значений. В нескольких вариантах выполнения A-D преобразователь 406 производит выборку аналогового сигнала с частотой 16 кГц и размером 16 бит на выборку, создавая, таким образом, речевые данные с потоком 32 килобайта в секунду. Эти цифровые значения передают в конструктор 407 кадра, который, в одном варианте выполнения, группирует значения в кадры по 25 миллисекунд, начало которых следует с разносом 10 миллисекунд.
Кадры данных, создаваемые конструктором 407 кадра, поступают в модуль 408 выделения признака, который выделяет определенный признак из каждого кадра. Примеры модулей выделения признака включают модули, выполняющие линейное предиктивное кодирование (ЛПК, LPC), кепстр (косинус-преобразование Фурье логарифма спектра мощности), получаемый с использованием LPC, линейное предиктивное восприятие (ЛПВ, PLP), выделение признака слуховой модели и коэффициенты кепстра Mel-частоты (ККМЧ, MFCC) выделения признака (Mel - внесистемная единица измерения высоты звука). Следует отметить, что настоящее изобретение не ограничено этими модулями выделения признака и что в контексте настоящего изобретения можно использовать другие модули.
Модуль 408 выделения признака производит поток векторов признака так, что каждый из них связан с кадром речевого сигнала. Этот поток векторов признака поступает на декодер 412, который идентифицирует наиболее вероятную последовательность слов на основе потока векторов признака, словаря 414, модели 416 языка (например, на основе N-грамматики, бесконтекстной грамматики или их гибрида) и акустической модели 418. Конкретный способ, используемый для декодирования, не важен для целей настоящего изобретения. Однако аспекты настоящего изобретения включают модификации акустической модели 418 и ее использования.
Наиболее вероятная последовательность гипотетически полученных слов может быть передана в используемый в случае необходимости модуль 420 измерения достоверности. Модуль 420 измерения достоверности идентифицирует, какие слова, наиболее вероятно, были неправильно идентифицированы устройством распознавания речи. Такая идентификация частично может быть основана на вторичной акустической модели (не показана). Модуль 420 измерения достоверности затем передает последовательность гипотетических слов в выходной модуль 422 вместе с идентификаторами, указывающими, какие слова, возможно, были идентифицированы неправильно. Для специалистов в данной области техники будет понятно, что модуль 420 измерения достоверности не является необходимым для выполнения на практике настоящего изобретения.
В ходе речевой сигнал, соответствующий тексту 426 обучения, поступает в декодер 412 вместе с лексической транскрипцией текста 426 обучения. Блок 424 обучения производит обучение акустической модели 418 на основе входных сигналов обучения.
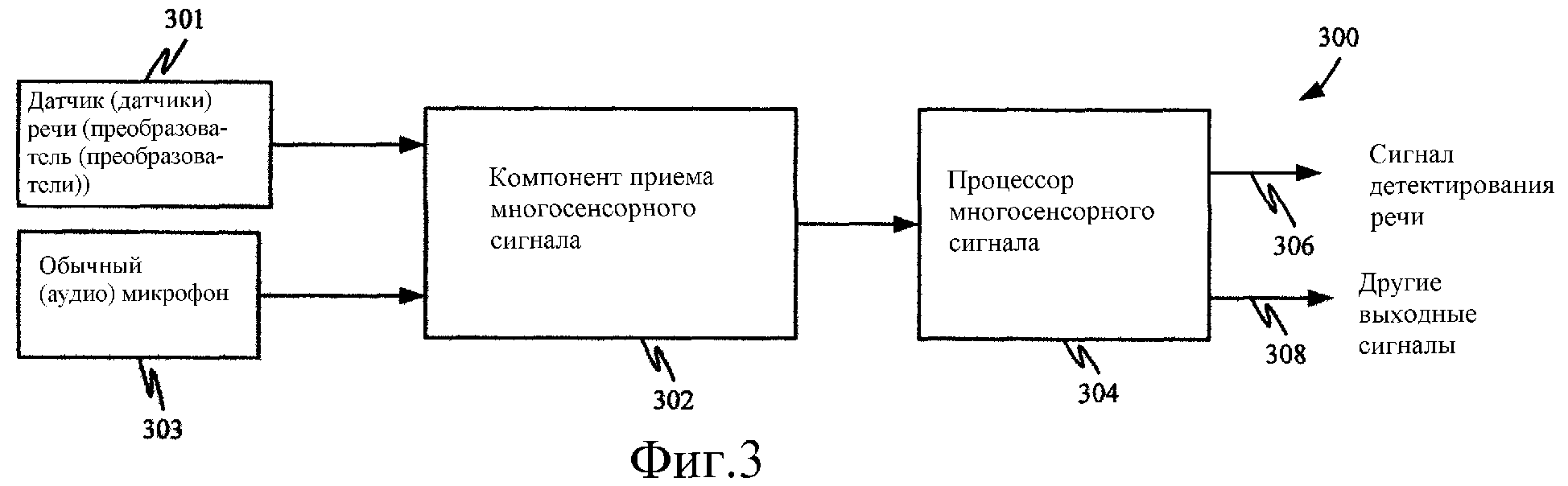
На Фиг.3 представлена система 300 детектирования речи в соответствии с одним вариантом выполнения настоящего изобретения. Система 300 детектирования речи включает датчик речи или преобразователь 301, обычный аудиомикрофон 303, компонент 302 приема многосенсорного сигнала и процессор 304 многосенсорного сигнала.
Компонент 302 приема получает сигналы от обычного микрофона 303 в форме звукового сигнала. Компонент 302 также принимает входной сигнал от преобразователя 301 речи, который указывает на то, что пользователь говорит. Сигнал, генерируемый этим преобразователем, может быть сгенерирован с использованием широкого разнообразия других преобразователей. Например, в одном варианте выполнения преобразователь представляет собой инфракрасный датчик, который обычно направлен на лицо пользователя, в частности, на область рта, и который генерирует сигнал, указывающий на изменение движений лица пользователя, которые соответствуют речи. В другом варианте выполнения датчик включает множество инфракрасных излучателей и датчиков, направленных на различные участки лица пользователя. В других вариантах выполнения датчик или датчики 301 речи могут включать ларингофон, который измеряет полное внутренне сопротивление горла пользователя или вибрации горла. В других вариантах выполнения датчик представляет собой микрофон, чувствительный к вибрации кости, который установлен рядом с лицевой костью или костью черепа пользователя (такой как кость челюсти) и улавливает вибрации, которые соответствуют речи, генерируемой пользователем. Датчик такого типа также может быть установлен в контакте с горлом, или рядом с ним, или внутри уха пользователя. В другом варианте выполнения используют датчик температуры, такой как термистор, который установлен в потоке дыхания, например, на том же держателе, на котором установлен обычный микрофон. Когда пользователь говорит, выдыхаемый поток воздуха приводит к изменению температуры датчика, который, таким образом, детектирует речь. Такой датчик может быть улучшен путем пропускания небольшого постоянного тока через термистор, незначительно нагревающего его до температуры, превышающей температуру окружающей среды. Тогда поток дыхания будет охлаждать термистор, что может быть определено по изменению напряжения на термисторе. В любом случае, представленный преобразователь 301 в высокой степени не чувствителен к фоновой речи, но строго указывает на то, что пользователь разговаривает.
В одном варианте выполнения компонент 302 получает сигналы преобразователей 301 и микрофона 303 и преобразует их в цифровую форму в виде синхронизированной по времени последовательности выборок сигнала. Компонент 302 затем формирует сигнал на одном или нескольких выводах, поступающий в процессор 304 многосенсорного сигнала. Процессор 304 обрабатывает входные сигналы, полученные компонентом 302, и подает на выход сигнал 306 детектирования речи, который указывает на то, что пользователь разговаривает. Процессор 304, в случае необходимости, также подает на выход дополнительные сигналы 308, такие как выходной звуковой сигнал, или такие как сигналы детектирования речи, которые указывают на вероятность или возможность того, что пользователь разговаривает, получаемые на основе сигналов от множества различных преобразователей. Другие выходы 308 в данной иллюстрации могут быть использованы по-разному, исходя из выполняемой задачи. Однако в одном варианте выполнения выходы 308 включают выход улучшенного звукового сигнала, который используется в системе распознавания речи.
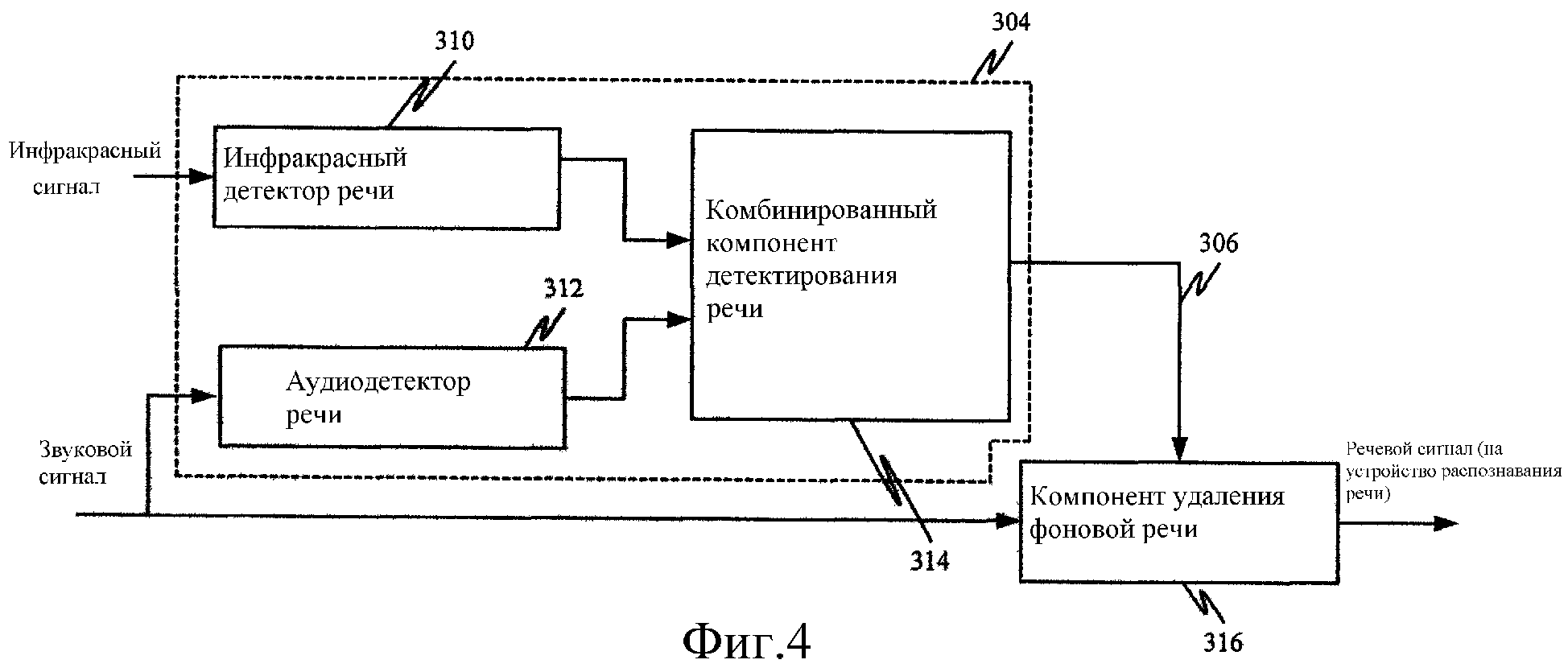
На Фиг.4 более подробно представлен один вариант выполнения процессора 304 многосенсорного сигнала. В варианте выполнения, показанном на Фиг.4, процессор 304 будет описан со ссылкой на входной сигнал преобразователя 301, который представляет собой инфракрасный сигнал, генерируемый инфракрасным датчиком, установленным рядом с лицом пользователя. Следует, конечно, понимать, что также можно легко привести описание Фиг.4 в отношении преобразователя сигнала, который является датчиком горла, датчиком вибрации и т.д.
В любом случае, на Фиг.4 показано, что процессор 304 содержит инфракрасный (ИК, IR) детектор 310 речи, аудиодетектор 312 речи и комбинированный компонент 314 детектирования речи. Инфракрасный детектор 310 речи принимает инфракрасный сигнал, излучаемый инфракрасным излучателем и отраженный от лица говорящего человека, и определяет, говорит ли пользователь, на основе ИК сигнала. Аудиодетектор 312 речи принимает звуковой сигнал и определяет, говорит ли пользователь, на основе звукового сигнала. Выходной сигнал с детекторов 310 и 312 поступает в комбинированный компонент 314 детектирования речи. Компонент 314 принимает сигналы и выполняет общую оценку в отношении того, говорит ли пользователь, на основе двух входных сигналов. Выход компонента 314 содержит сигнал 306 детектирования речи. В одном варианте выполнения сигнал 306 детектирования речи поступает в компонент 316 удаления фоновой речи. Сигнал 306 детектирования речи используется для указания в звуковом сигнале, когда пользователь в действительности разговаривает.
В частности, используют два независимых детектора 310 и 312, в одном варианте выполнения, каждый из которых генерирует вероятностное описание того, что пользователь разговаривает. В одном варианте выполнения выход инфракрасного детектора 310 речи представляет собой вероятность того, что пользователь разговаривает, получаемую на основе инфракрасного входного сигнала. Аналогично, выходной сигнал аудиодетектора 312 речи представляет собой вероятность того, что пользователь говорит, получаемую на основе входного звукового сигнала. Эти два сигнала затем анализируют в компоненте 314 для того, чтобы принять, например, двоичное решение в отношении того, говорит ли пользователь.
Сигнал 306 можно использовать для дополнительной обработки звукового сигнала в компоненте 316 удаления фоновой речи. В одном варианте выполнения сигнал 306 просто используют для подачи сигнала речи в процессор распознавания речи через компонент 316, когда сигнал 306 детектирования речи указывает, что пользователь говорит. Если сигнал 306 детектирования речи указывает, что пользователь не говорит, тогда сигнал речи не поступает через компонент 316 в процессор распознавания речи.
В другом варианте выполнения компонент 314 формирует сигнал 306 детектирования речи, как меру вероятности, указывающую на вероятность того, что пользователь говорит. В этом варианте выполнения звуковой сигнал перемножают в компоненте 316 на вероятность, содержащуюся в сигнале 306 детектирования речи. Поэтому, когда вероятность того, что пользователь говорит, высока, сигнал речи, поступающий в процессор распознавания речи через компонент 316, также имеет большую величину. Однако, когда вероятность того, что пользователь говорит, низка, сигнал речи, поступающий в процессор распознавания речи через компонент 316, имеет очень малую величину. Конечно, в другом варианте выполнения, сигнал 306 детектирования речи может быть просто передан непосредственно в процессор распознавания речи, который позволяет непосредственно определять, говорит ли пользователь, и производит обработку речевого сигнала на основе этого определения.
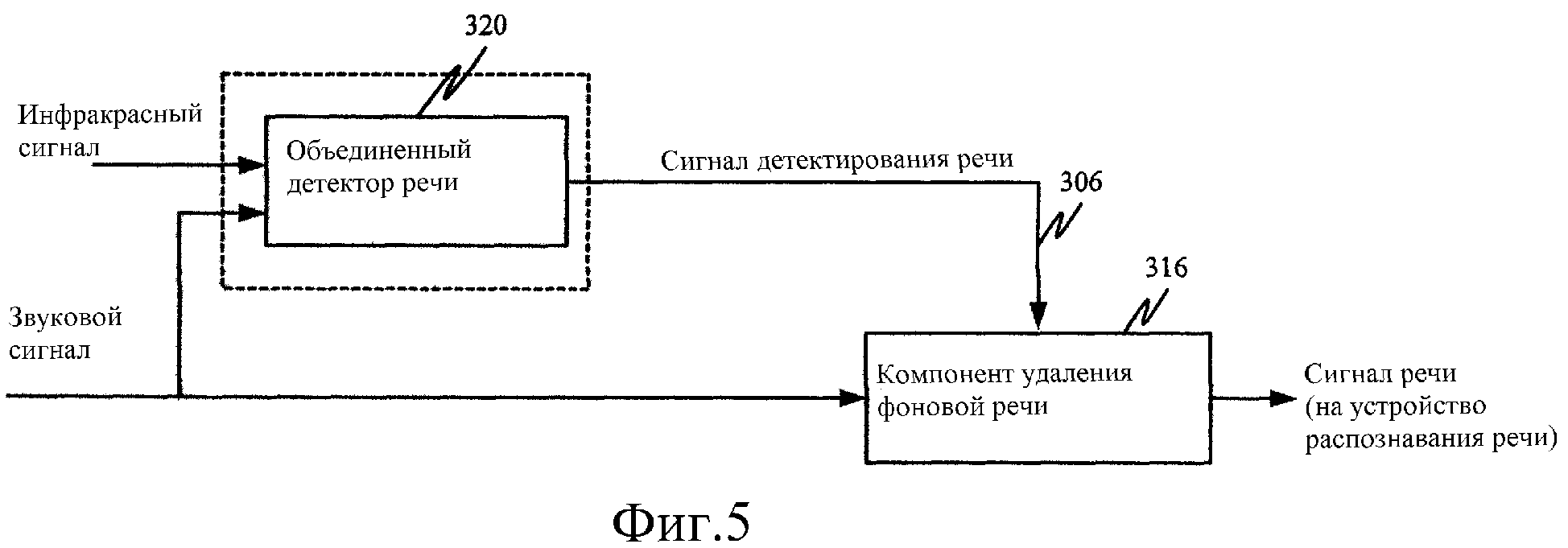
На Фиг.5 более подробно изображен другой вариант выполнения процессора 304 многосенсорного сигнала. Вместо использования множества детекторов для определения, говорит ли пользователь, в варианте выполнения, показанном на Фиг.5, представлено, что процессор 304 сформирован из одиночного объединенного детектора 320 речи. Детектор 320 принимает как инфракрасный сигнал, так и звуковой сигнал, и выполняет определение на основе обоих этих сигналов, говорит ли пользователь. В этом варианте выполнения вначале выделяют признаки, независимо от инфракрасных и звуковых сигналов, и эти признаки подают в детектор 320. На основе принятых признаков детектор 320 определяет, говорит ли пользователь, и, соответственно, подает на выход сигнал 306 детектирования речи.
Независимо от типа используемой системы (система, показанная на Фиг.4 или представленная на Фиг.5) могут быть построены детекторы речи и может быть проведено их обучение с использованием данных обучения, в которые зашумленный звуковой сигнал поступает вместе с инфракрасным сигналом, а также с указанием, включаемым вручную (таким как сигнал нажимной кнопки разговора), которое, в частности, указывает, что пользователь говорит.
Для лучшего описания работы такой системы на Фиг.6 показан график звукового сигнала 400 и инфракрасного сигнала 402 в виде зависимости величины сигналов от времени. На Фиг.6 также показан сигнал 404 детектирования речи, который указывает, когда пользователь говорит. Когда сигнал 404 имеет логически высокое значение, это указывает на решение детектора речи о том, что человек говорит. Когда сигнал 404 имеет низкое логическое значение, это указывает на то, что пользователь не говорит. Для определения, говорит ли пользователь и для генерирования сигнала 404 на основе сигналов 400 и 402, периодически вычисляют среднее значение и величину дисперсии сигналов 400 и 402, например, через каждые 100 миллисекунд. Вычисленные средние значения и величину дисперсии используют в качестве базовой линии средних значений и дисперсии, по которым принимают решения о детектировании речи. Можно видеть, что, как звуковой сигнал 400, так и инфракрасный сигнал 402 имеют большую дисперсию, когда пользователь говорит, чем тогда, когда пользователь не говорит. Поэтому, при обработке наблюдений, например, каждые 5-10 миллисекунд среднее значение и величину и дисперсии (или только величину дисперсии) сигнала за период наблюдения сравнивают с базовой линией средних значений и дисперсии (или только с базовой линией дисперсии). Если наблюдаемые значения больше, чем значения базовой линии, тогда определяют, что пользователь говорит. Если нет, тогда определяют, что пользователь не говорит. В одном иллюстративном варианте выполнения детектирование речи производят на основе превышения наблюдаемыми значениями значений базовой линии на заранее определенную пороговую величину. Например, за период каждого наблюдения, если инфракрасный сигнал не находится в пределах трех значений среднеквадратического отклонения от базовой линии среднего значения, тогда считают, что пользователь говорит. Такой же подход можно использовать для звукового сигнала.
В соответствии с другим вариантом выполнения настоящего изобретения детекторы 310, 312, 314 или 320 также можно адаптировать при использовании, например, приспосабливать их к изменениям условий окружающего освещения, или, например, к изменениям положения головы пользователя, которые могут вызвать незначительные изменения освещения, влияющие на инфракрасный сигнал. Повторная оценка среднего значения и величины дисперсии базовой линии может быть проведена, например, каждые 5-10 секунд или на основе другого периодически повторяющегося временного окна. Это позволяет обновлять эти значения для отражения изменений в течение времени. Также, перед обновлением среднего значения и дисперсии базовой линии, с использованием подвижного окна, вначале можно определять, соответствуют ли входные сигналы тому, что пользователь говорит или не говорит. Среднее значение и дисперсия могут быть повторно рассчитаны с использованием только частей сигнала, которые соответствуют моменту, когда пользователь не говорит.
Кроме того, на Фиг.6 можно видеть, что инфракрасный сигнал обычно может предшествовать звуковому сигналу. Это происходит потому, что пользователь может, в общем, изменять положение рта или лица перед тем, как он произнесет какой-либо звук. Это позволяет системе детектировать речь даже до того, как поступит речевой сигнал.
На Фиг.7 представлена иллюстрация одного варианта выполнения инфракрасного датчика и аудиомикрофона в соответствии с настоящим изобретением. На Фиг.7 головная гарнитура 420 содержит пару наушников 422 и 424, а также держатель 426. На дальнем конце держателя 426 установлен обычный аудиомикрофон 428, а также инфракрасный приемопередатчик 430. Приемопередатчик 430, в качестве иллюстрации, может быть представлен инфракрасным светоизлучающим диодом (СИД, LED) и инфракрасным приемником. Когда лицо пользователя, в частности, его рот, движется при разговоре, свет, отраженный от лица пользователя, в частности, ото рта, представленный в виде сигнала инфракрасного датчика, может изменяться, как показано на Фиг.6. Таким образом, на основе сигнала инфракрасного датчика можно определять, говорит ли пользователь.
Следует также отметить, что, хотя в варианте выполнения, показанном на Фиг.7, представлен один инфракрасный приемопередатчик, в настоящем изобретении также предусматривается использование множества инфракрасных приемопередатчиков. В этом варианте выполнения вероятности, получаемые на основе инфракрасных сигналов, генерируемых каждым инфракрасным приемопередатчиком, могут обрабатываться отдельно или одновременно. Если их обрабатывают отдельно, можно использовать простую логику голосования для определения, указывают ли инфракрасные сигналы на то, что человек говорит. В качестве альтернативы, можно использовать вероятностную модель для определения, говорит ли пользователь, работающую на основе множества инфракрасных сигналов.
Как описано выше, дополнительный преобразователь 301 может быть выполнен в других формах, помимо инфракрасного преобразователя. На Фиг.8 представлено изображение головной гарнитуры 450, которая включает крепление 451 для размещения на голове с наушниками 452 и 454, а также обычный аудиомикрофон 456 и, кроме того, микрофон 458, чувствительный к вибрации кости. Оба микрофона 456 и 458 могут быть механически и даже жестко соединены с креплением 451 на голове. Микрофон 458, чувствительный к вибрации кости, преобразует вибрации лицевых костей, когда звуковые волны проходят через череп говорящего человека, в электронные голосовые сигналы. Микрофоны такого типа известны и являются коммерчески доступными, и имеют различные форму и размер. Микрофон 458, чувствительный к вибрации кости, обычно сформирован как контактный микрофон, который устанавливают в верхней части черепа или позади уха (для контакта с сосцевидным отростком). Такой микрофон чувствителен к вибрациям кости и в гораздо в меньшей степени чувствителен к внешним голосовым источникам.
На Фиг.9 представлено множество сигналов, включая сигнал 460 от обычного микрофона 456, сигнал 462 от микрофона 458, чувствительного к вибрациям кости, и двоичный сигнал 464 детектирования речи, который соответствует выходному сигналу детектора речи. Когда сигнал 464 имеет логически высокое значение, это указывает на то, что детектор определил, что человек говорит. Когда он имеет логически низкое значение, это соответствует определению того, что человек не говорит. Сигналы на Фиг.9 могут улавливаться из окружающей среды, из которой были собраны данные, в то время как на голову пользователя надета система микрофонов, показанная на Фиг.8, одновременно с воспроизведением фонового звука. Таким образом, звуковой сигнал 460 представляет существенную активность, даже когда пользователь не говорит. Однако сигнал 462 микрофона, чувствительного к вибрациям кости, показывает незначительную активность сигналов, за исключением, когда пользователь в действительности говорит. Таким образом, можно видеть, что, если рассматривать только звуковой сигнал 460, очень трудно определить, говорит ли пользователь в действительности. Однако при использовании сигнала микрофона, чувствительного к вибрации кости, как отдельно, так и совместно со звуковым сигналом, можно гораздо проще определять, когда пользователь говорит.
На Фиг.10 показан другой вариант выполнения настоящего изобретения, в котором головная гарнитура 500 включают крепление 501 для установки на голове, наушник 502, а также обычный аудиомикрофон 504 и ларингофон 506. Оба микрофона 504 и 506 механически закреплены на креплении 501 на голове и могут быть жестко соединены с ним. Существует множество различных, пригодных для использования ларингофонов. Например, в данном случае представлены конструкции из одиночного элемента и двойного элемента. Обе они функционируют путем определения вибраций горла и преобразования этих вибраций в сигналы микрофона. Представленные ларингофоны надевают вокруг шеи и удерживают на месте с помощью эластичной полоски или ленты на шее. Они хорошо работают, когда чувствительные элементы установлены с каждой стороны "Адамова яблока" пользователя в гортани пользователя.
На Фиг.11 показан другой вариант выполнения настоящего изобретения, в котором головная гарнитура 550 включают микрофон 552, устанавливаемый внутри уха, вместе с обычным аудиомикрофоном 554. В варианте выполнения, представленном на Фиг.11, микрофон 552, устанавливаемый внутри уха, интегрирован с наушником 554. Однако следует отметить, что наушник может быть сформирован в виде компонента, установленного отдельно от микрофона 552, устанавливаемого внутри уха. На Фиг.11 также показано, что обычный аудиомикрофон 554 выполнен как микрофон ближнего действия и соединен с микрофоном 552, устанавливаемым внутри уха, с помощью держателя 556. Держатель 556 может быть жестким или гибким. В головной гарнитуре 550 часть крепления на голове головной гарнитуры содержит микрофон 552, устанавливаемый внутри уха, и дополнительный наушник 554, который позволяет установить головную гарнитуру 550 на голове человека, благодаря соединению с трением с внутренней областью уха говорящего человека.
Микрофон 552, устанавливаемый внутри уха, улавливает голосовые вибрации, которые передаются через ушной канал говорящего человека, или через кости, окружающие ушной канал говорящего человека, или по обоим этим путям. Система работает аналогично головной гарнитуре с микрофоном 458, чувствительным к вибрации кости, показанной на Фиг.8. Голосовые вибрации, улавливаемые микрофоном 552, установленным внутри уха, преобразуются в сигналы микрофона, которые используют при дальнейшей обработке.
Хотя выше был описан ряд вариантов выполнения датчиков или преобразователей 301 речи, следует понимать, что также можно использовать другие датчики или преобразователи речи. Например, вместо инфракрасного датчика можно использовать устройство с зарядовой связью (или цифровой камерой). Кроме того, также можно использовать гортанные датчики. Приведенные выше варианты выполнения описаны только в качестве примера.
Другой пример определения речи с использованием сигналов аудиодатчиков и/или датчиков речи описан ниже. В представленном варианте выполнения строят гистограмму всех дисперсий последних кадров в течение определяемой пользователем продолжительности времени (например, в течение одной минуты и т.д.). Для каждого наблюдаемого кадра, поступающего после этого, вычисляют дисперсию входных сигналов и сравнивают ее величину со значениями гистограммы для определения, представляет ли текущий кадр то, что человек говорит или не говорит. Гистограмму затем обновляют. Следует отметить, что, если текущий кадр просто вводить в гистограмму и при этом удалять самый старый кадр, тогда гистограмма может представлять только кадры речи или ситуации, когда пользователь говорит в течение длительного периода времени. Для решения проблемы в этой ситуации отслеживают множество кадров с наличием речи и отсутствием речи в гистограмме и гистограмму избирательно обновляют. Если текущий кадр классифицируется как кадр речи, в то время как количество кадров речи в гистограмме больше, чем половина общего количества кадров, тогда текущий кадр просто не вводят в гистограмму. Конечно, также можно использовать другие технологии обновления, и эта приведена только в качестве примера.
Настоящую систему можно использовать в самых разных вариантах применения. Например, во многих современных системах, в которых требуется нажатие кнопки при разговоре, требуется, чтобы пользователь нажимал и удерживал элемент включения входа (например, кнопку), для взаимодействия с речевыми режимами. Исследования возможности использования показали, что пользователю трудно обеспечить удовлетворительную манипуляцию кнопкой. Кроме того, пользователь начинает говорить одновременно с нажатием на аппаратную кнопку, что приводит к потере начала произносимого слова. Таким образом, настоящую систему проще использовать для распознавания речи вместо систем, требующих нажатия кнопки для разговора.
Аналогично, настоящее изобретение можно использовать для удаления фоновой речи. Фоновая речь была идентифицирована как чрезвычайно часто появляющийся источник шума, совместно с телефонными звонками и шумом кондиционеров воздуха. Благодаря использованию настоящего описанного выше сигнала детектирования речи большая часть такого фонового шума может быть устранена.
Аналогично, могут быть улучшены системы кодирования речи, работающие с переменной скоростью кодирования. Поскольку настоящее изобретение позволяет сформировать выходной сигнал, указывающий на то, говорит ли пользователь, можно использовать гораздо более эффективную систему кодирования речи. Для такой системы могут быть снижены требования к полосе пропускания при организации аудиоконференции, поскольку кодирование речи выполняют только, когда пользователь в действительности говорит.
При передаче данных в режиме реального времени также может быть улучшено управление предоставлением слова в ходе аудиоконференции. Важный аспект, который теряется при проведении обычных аудиоконференций, состоит в отсутствии механизма, который можно использовать для информирования других о том, что участник аудио-конференции желает говорить. Это может привести к ситуациям, в которых один участник монополизирует встречу, просто потому что он или она не знает, что другие также желают высказаться. В настоящем изобретении пользователю просто требуется включить датчики для указания того, что пользователь желает говорить. Например, когда используют инфракрасный датчик, пользователю просто необходимо выполнить движение лицевыми мускулами, подражая речи. Это приведет к формированию сигнала детектирования речи, который указывает, что пользователь говорит или желает говорить. Используя ларингофон или микрофон, чувствительный к вибрации кости, пользователь может просто произнести любой очень мягкий звук, который также включит ларингофон или микрофон, чувствительный к вибрации кости, для указания того, что пользователь говорит или желает говорить.
В еще одном варианте применения может быть улучшено управление питанием карманных компьютеров или небольших вычислительных устройств, таких как карманные компьютеры, ноутбуки или компьютеры других аналогичных типов. Длительность работы от батареи представляет собой основную проблему в таких портативных устройствах. Когда известно, говорит ли пользователь, ресурсы, выделяемые для обработки цифрового сигнала, требуемые для выполнения обычных вычислительных функций, и ресурсы, требуемые для распознавания речи, могут быть выделены гораздо более эффективно.
В еще одном варианте применения звуковой сигнал от обычного аудиомикрофона и сигнал от датчика речи могут быть соответствующим образом скомбинированы так, что фоновая речь может быть удалена из звукового сигнала, даже когда человек, говорящий на фоне, говорит одновременно с человеком, представляющим интерес. Возможность выполнения такого улучшения речи может быть чрезвычайно предпочтительной в определенных условиях.
Хотя настоящее изобретение было описано со ссылкой на конкретные варианты выполнения, для специалистов в данной области техники будет понятно, что могут быть проведены изменения в его форме и деталях, без отхода от объема и сущности настоящего изобретения.
Реферат
Изобретение предназначено для ввода аудиоинформации. Система содержит аудиомикрофон, объединенный с датчиком речи, формирующим сигнал, основанный на входном незвуковом сигнале, генерируемом на основе действия, производимого говорящим человеком во время разговора, такого как движение лица, вибрация кости, вибрация горла, изменение полного внутреннего сопротивления горла и так далее. Компонент детектора речи генерирует сигнал детектирования речи, указывающий на вероятность того, что пользователь говорит, и дополнительно вычисляет комбинированный сигнал путем умножения сигнала детектирования речи на сигнал микрофона, а процессор распознавания речи распознает речь для обеспечения выходного сигнала распознавания, указывающего на речь в сигнале микрофона на основании комбинированного сигнала. Технический результат - устранение шума, связанного с фоновой речью и повышение удобства для пользователя. 3 н. и 10 з.п. ф-лы, 11 ил.
Формула
аудиомикрофон, на выходе которого вырабатывается сигнал микрофона, основанный на улавливаемом входном звуковом сигнале;
датчик речи, на выходе которого вырабатывается сигнал датчика, основанный на входном незвуковом сигнале, генерируемом под действием речи; и
компонент детектора речи, на выходе которого вырабатывается сигнал детектирования речи, указывающий на вероятность того, что пользователь говорит, основанный на сигнале микрофона и основанный на уровне дисперсии первой характеристики сигнала датчика,
при этом первая характеристика сигнала датчика имеет первый уровень дисперсии, когда пользователь говорит, и второй уровень дисперсии, когда пользователь не говорит; и
при этом компонент детектора речи вырабатывает сигнал детектирования речи на основании отношения уровня дисперсии первой характеристики сигнала датчика к уровню базовой линии дисперсии первой характеристики, который содержит заданный один из первого и второго уровней упомянутой характеристики в течение данного периода времени; причем компонент детектора речи дополнительно вычисляет комбинированный сигнал путем умножения сигнала детектирования речи на сигнал микрофона; и
процессор распознавания речи, распознающий речь для обеспечения выходного сигнала распознавания, указывающего на речь в сигнале микрофона на основании комбинированного сигнала, причем распознавание речи содержит повышение вероятности того, что речь будет распознана, на значение, основанное на вероятности того, что сигнал детектирования речи указывает на то, что пользователь говорит; и снижение вероятности того, что речь будет распознана, на значение, основанное на вероятности того, что сигнал детектирования речи указывает на то, что пользователь не говорит.
датчик речи, вырабатывающий сигнал датчика, основанный на входном незвуковом сигнале, генерируемом в результате действия речи; и
компонент детектора речи, вырабатывающий сигнал детектирования речи, указывающий на вероятность того, что пользователь говорит, основанный на сигнале микрофона и сигнале датчика, причем компонент детектора речи вычисляет комбинированный сигнал путем умножения сигнала детектирования речи на сигнал микрофона; и
процессор распознавания речи, распознающий речь для обеспечения выходного сигнала распознавания, указывающего на речь в улавливаемом входном звуковом сигнале;
повышающий вероятность того, что речь будет распознана, на значение, основанное на вероятности того, что сигнал детектирования речи указывает на то, что пользователь говорит; и
понижающий вероятность того, что речь будет распознана, на значение, основанное на вероятности того, что сигнал детектирования речи указывает на то, что пользователь не говорит.
генерирование первого сигнала, указывающего на поступление на вход звукового сигнала, получаемого с помощью аудиомикрофона;
генерирование второго сигнала, указывающего на движения лица пользователя, улавливаемое датчиком движения лица;
генерирование третьего сигнала, указывающего на вероятность того, что пользователь говорит, на основании первого и второго сигналов;
генерирование четвертого сигнала путем умножения значения вероятности того, что пользователь говорит, на первый сигнал; и
распознавание речи на основании четвертого сигнала и сигнала детектирования речи,
причем распознавание речи содержит
повышение вероятности того, что речь будет распознана, на значение, основанное на вероятности того, что сигнал детектирования речи указывает на то, что пользователь говорит; и
снижение вероятности того, что речь будет распознана, на значение, основанное на вероятности того, что сигнал детектирования речи указывает на то, что пользователь не говорит.
Комментарии