Мыши, содержащие мутации, вследствие которых экспрессируется укороченный на с-конце фибриллин-1 - RU2721125C1
Код документа: RU2721125C1
Чертежи
Описание
ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[1] Данная заявка заявляет приоритет по заявке США № 62/368924, поданной 29 июля 2016 года, которая полностью включена в данный документ посредством ссылки для всех целей.
ССЫЛКА НА ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ПОДАННЫЙ В ВИДЕ ТЕКСТОВОГО ФАЙЛА ЧЕРЕЗ EFS WEB
[2] Перечень последовательностей, записанный в файл 500041SEQLIST.txt, имеет размер 184 килобайта, был создан 28 июля 2017 года, и включен в данный документ посредством ссылки.
УРОВЕНЬ ТЕХНИКИ
[3] В гене fibrillin-1 (FBN1) людей было клинически идентифицировано более 3000 мутаций. Была выявлена связь между данными мутациями и различными патологиями, включающими в себя фибриллинопатии I типа, синдром Марфана, синдром MASS, синдром изолированной эктопии хрусталика, аневризмы грудной аорты, синдром Вайля-Марчезани, гелеофизическую и акромическую дисплазию, синдром жесткой кожи (врожденная фасциальная дистрофия) и неонатальный прогероидный синдром с врожденной липодистрофией (NPSCL - neonatal progeroid syndrome with congenital lipodystrophy). Доступные в данное время трансгенные, отличные от человека, сконструированные чтобы иметь мутации в FBN1, млекопитающие не моделируют адекватно симптомы NPSCL.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[4] Предложены способы и композиции для моделирования неонатального прогероидного синдрома с врожденной липодистрофией. В одном аспекте, согласно данному изобретению предложено отличное от человека млекопитающее, чей геном содержит ген fibrillin-1 (Fbn1), содержащий мутацию, вследствие чего результатом экспрессии гена является укороченный на С-конце белок Fbn1, что вызывает у отличающегося от человека млекопитающего развитие одного или большего количества симптомов, подобных симптомам врожденной липодистрофии неонатального прогероидного синдрома. Необязательно, отличное от человека млекопитающее является гетерозиготным по мутации. Необязательно, ген Fbn1 включает в себя промотор Fbn1, эндогенный для отличного от человека млекопитающего. Необязательно, мутация является мутацией сдвига рамки считывания.
[5] У некоторых отличных от человека млекопитающих мутация приводит к появлению преждевременного кодона терминации. Необязательно, преждевременный кодон терминации находится в предпоследнем или последнем экзоне гена Fbn1. Необязательно, преждевременный кодон терминации находится в последнем экзоне, или находится на меньше чем около 55 пар оснований выше последнего экзон-экзонного соединения в гене Fbn1. Необязательно, преждевременный кодон терминации находится на меньше чем около 55 пар оснований выше последнего экзон-экзонного соединения в гене Fbn1. Необязательно, преждевременный кодон терминации находится в последнем экзоне, или находится на меньше чем около 20 пар оснований выше последнего экзон-экзонного соединения в гене Fbn1. Необязательно, мутация является мутацией сайта сплайсинга, приводящей к пропуску предпоследнего экзона. Необязательно, мутация приводит к появлению преждевременного кодона терминации в последнем кодирующем экзоне.
[6] У некоторых млекопитающих, отличных от человека, мутация повреждает основную для распознавания пропротеин-конвертазами семейства фуринов последовательность аминокислот. У некоторых отличных от человека млекопитающих, мутация приводит к разрушению аспросина - С-концевого продукта отщепления от профибриллина-1. У некоторых отличных от человека млекопитающих, мутация приводит к повреждению аспросина - С-концевого продукта отщепления от профибриллина-1. У некоторых отличных от человека млекопитающих, преждевременный кодон терминации приводит к появлению кодируемого белка, имеющего положительно заряженный С-конец.
[7] У некоторых отличных от человека млекопитающих, кодируемый белок (то есть укороченный на C-конце белок Fbn1) укорачивают в позиции, соответствующей позиции между аминокислотами 2700 и 2790, между аминокислотами 2710 и 2780, между аминокислотами 2720 и 2770, между аминокислотами 2730 и 2760, или между аминокислотами 2737 и 2755 в мышином белке Fbn1 дикого типа, как указано в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30. Необязательно, кодируемый белок укорачивают так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2737, аминокислоте 2738 или аминокислоте 2755 в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30.
[8] У некоторых отличных от человека млекопитающих, кодируемый белок (то есть укороченный на С-конце белок Fbn1) имеет С-конец, состоящий из последовательности, представленной в SEQ ID NO: 8, 42 или 43. У некоторых отличных от человека млекопитающих, кодируемый белок имеет С-конец, состоящий из последовательности, представленной в SEQ ID NO: 8, 42, 43, 45, 46 или 47. Необязательно, кодируемый белок укорачивают так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2737 в мышином белке Fbn1 дикого типа, представленном в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 43. Необязательно, кодируемый белок укорачивают так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2737 в мышином белке Fbn1 дикого типа, представленном в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 43 или 46. Необязательно, кодируемый белок укорачивают так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2738 в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 8. Необязательно, кодируемый белок укорачивают так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2738 в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 8 или 45. Необязательно, кодируемый белок укорачивают так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2755 в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 42. Необязательно, кодируемый белок укорачивают так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2755 в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 42 или 47.
[9] У некоторых отличных от человека млекопитающих ген Fbn1 содержит мутацию в предпоследнем экзоне. Необязательно, предпоследний экзон гена Fbn1 содержит мутации, соответствующие мутациям в SEQ ID NO: 26, 27 или 28, относительно последовательности предпоследнего экзона Fbn1 мыши дикого типа, указанной в SEQ ID NO: 25, когда предпоследний экзон оптимально выровнен с SEQ ID NO: 26, 27 или 28.
[10] У некоторых отличных от человека млекопитающих весь ген или часть гена Fbn1 удалили и заменили последовательностю ортологичного гена FBN1 человека. Необязательно, мутация, приводящая к укорочению С-конца кодируемого белка, находится в последовательности ортологичного гена FBN1 человека. Необязательно, последовательность ортологичного гена FBN1 человека находится в эндогенном локусе Fbn1 не относящегося к человеку млекопитающего.
[11] У некоторых отличных от человека млекопитающих, белок, кодируемый мутированным геном Fbn1 состоит из последовательности, представленной в SEQ ID NO: 31, 32 или 33.
[12] В некоторых случаях, отличное от человека млекопитающее является грызуном. Необязательно, грызун представляет собой крысу или мышь.
[13] В некоторых случаях, отличное от человека млекопитающее является мышью. У некоторых отличных от человека млекопитающих или мышей, мутация содержит инсерцию или делецию в экзоне 64 эндогенного мышиного гена Fbn1, которая вызывает -1 сдвиг рамки считывания и приводит к появлению преждевременного кодона терминации на 3'-конце экзона 64 или 5'-конце экзона 65. Необязательно, мутация содержит инсерцию в экзоне 64, которая вызывает -1 сдвиг рамки считывания и приводит к появлению преждевременного кодона терминации на 5'-конце экзона 65. Необязательно, инсерция находится между позициями, соответствующими позициям 8179 и 8180 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1 содержащий мутацию, оптимально выровнен с SEQ ID NO: 20, и/или преждевременный кодон терминации находится в позиции, соответствующей позиции 8241 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1, содержащий мутацию, оптимально выровнен с SEQ ID NO: 20. Необязательно, мутация содержит инсерцию или делецию в экзоне 64, которая вызывает -1 сдвиг рамки считывания и приводит к появлению преждевременного кодона терминации на 3'-конце экзона 64. Необязательно, мутация содержит инсерцию между позициями, соответствующими позициям 8209 и 8210 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1 содержащий мутацию, оптимально выровнен с SEQ ID NO: 20, и/или преждевременный кодон терминации находится в позиции, соответствующей позиции 8214 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1 , содержащий мутацию, оптимально выровнен с SEQ ID NO: 20. Необязательно, мутация содержит делецию, начинающуюся в позиции, соответствующей позиция 8161 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1 содержащий мутацию, оптимально выровнен с SEQ ID NO: 20, и/или преждевременный кодон терминации находится в позиции, соответствующей позиции 8214 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1, содержащий мутацию, оптимально выровнен с SEQ ID NO: 20. Необязательно, укороченный на С-конце белок Fbn1 имеет положительно заряженный С-конец.
[14] У некоторых отличных от человека млекопитающих, симптомы включают в себя одно или большее количество из следующего: уменьшенная масса тела, уменьшенная масса без жира, уменьшенная жировая масса, уменьшенный процент жира в организме, увеличенное потребления пищи нормализованное по массе тела, и увеличенный кифоз. У некоторых отличных от человека млекопитающих, симптомы включают в себя одно или большее количество из следующего: уменьшенная масса тела, уменьшенная масса без жира, уменьшенная белая жировая ткань нормализованная по массе тела, уменьшенная белая жировая ткань в комбинации с сохранением бурой жировой ткани нормализованные по массе тела, сниженный процент жира в организме, увеличенное потребление пищи нормализованное по массе тела, и увеличенный кифоз. Необязательно, не относящееся к человеку млекопитающее, имеет одно или большее количество из следующего: нормальную толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Необязательно, не относящееся к человеку млекопитающее, имеет одно или большее количество из следующего: повышенную скорость метаболизма, улучшенную чувствительность к инсулину, нормальную толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Необязательно, симптомы включают в себя, по меньшей мере, одно из: уменьшенная жировая масса и уменьшенное процентное содержание жира в теле, и, по меньшей мере, одно из: нормальную толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Необязательно, симптомы включают в себя: уменьшенную жировую массу, уменьшенное процентное содержание жира в теле, нормальную толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Необязательно, симптомы включают в себя: уменьшенную массу белой жировой ткани нормализованной по массе тела, и по меньшей мере одно из: нормальную толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Необязательно, симптомы включают в себя уменьшенную массу белой жировой ткани нормализованную по массе тела, и улучшенную чувствительность к инсулину.
[15] В другом аспекте, согласно данному изобретению предложен способ получения любого отличного от человека млекопитающего, описанного в данном документе, включающий в себя: (a) приведение в контакт генома плюрипотентной клетки отличного от человека млекопитающего, не являющейся эмбрионом на одноклеточной стадии, с: (i) белком Cas9; и (ii) первой направляющей РНК, которая гибридизируется с последовательностью, которая распознается первой направляющей РНК, в геномном локусе-мишени в гене Fbn1, причем ген Fbn1 модифицирован так, что содержит мутацию, приводящую к укорочению С-конца кодируемого белка; (b) введение модифицированной плюрипотентной клетки отличного от человека млекопитающего в эмбрион-хозяин; и (c) имплантацию эмбриона-хозяина суррогатной матери для получения генетически модифицированного отличного от человека млекопитающего поколения F0, у которого ген Fbn1 модифицирован так, что содержит мутацию, приводящую к укорочению С-конца кодируемого белка, причем мутация вызывает симптомы, подобные симптомам врожденной липодистрофии у отличного от человека млекопитающего поколения F0. Необязательно, плюрипотентная клетка представляет собой эмбриональную стволовую (ЭС) клетку.
[16] В некоторых способах стадия (а) дополнительно включает в себя приведение в контакт генома плюрипотентной клетки отличного от человека млекопитающего с второй направляющей РНК, которая гибридизируется с последовательностью, которая распознается второй направляющей РНК, в геномном локусе-мишени в гене Fbn1. В некоторых способах, способ дополнительно включает в себя отбор модифицированной плюрипотентной клетки отличного от человека млекопитающего после стадии (а) и перед стадией (b), причем модифицированная плюрипотентная клетка отличного от человека млекопитающего является гетерозиготной по мутации, приводящей к укорочению С-конца кодируемого белка.
[17] В некоторых способах, стадия приведения в контакт (а) дополнительно включает в себя приведение в контакт генома с экзогенным шаблоном репарации, содержащим 5'-гомологичное плечо, которое гибридизируется с 5'-последовательностью-мишенью в локусе генома-мишени, и 3'-гомологичное плечо, которое гибридизируется с 3'-последовательностью-мишенью в целевом геномном локусе. Необязательно, экзогенный шаблон репарации дополнительно содержит нуклеотидную вставку, фланкированную 5'- и 3'-гомологичным плечом. Необязательно, нуклеотидная вставка является гомологичной или ортологичной по отношению к геномному локусу-мишени. Необязательно, экзогенный шаблон репарации имеет длину от около 50 нуклеотидов до около 1 т.п.н. Необязательно, экзогеннй шаблон репарации имеет длину от около 80 нуклеотидов до около 200 нуклеотидов. Необязательно, экзогенный шаблон репарации представляет собой одноцепочечный олигодезоксинуклеотид.
[18] В другом аспекте, согласно данному изобретению предложен способ получения любого отличного от человека млекопитающего, описанного в данном документе, включающий в себя: (a) приведение в контакт генома эмбриона на одноклеточной стадии отличного от человека млекопитающего с: (i) белком Cas9; и (ii) первой направляющей РНК, которая гибридизируется с последовательностью, которая распознается первой направляющей РНК, в геномном локусе-мишени в гене Fbn1, причем ген Fbn1 модифицирован так, что содержит мутацию, приводящую к укорочению С-конца кодируемого белка; и (b) имплантацию модифицированного эмбриона на одноклеточной стадии отличного от человека млекопитающего суррогатной матери для получения генетически модифицированного отличного от человека млекопитающего поколения F0, у которого ген Fbn1 модифицирован так, что содержит мутацию, приводящую к укорочению С-конца кодируемого белка, причем мутация вызывает симптомы, подобные симптомам врожденной липодистрофии у отличного от человека млекопитающего поколения F0.
[19] В некоторых способах, стадия (а) дополнительно включает в себя приведение в контакт генома эмбриона на одноклеточной стадии отличного от человека млекопитающего с второй направляющей РНК, которая гибридизируется с последовательностью, которая распознается второй направляющей РНК, в геномном локусе-мишени в гене Fbn1. В некоторых способах, способ дополнительно включает в себя отбор модифицированного эмбриона на одноклеточной стадии отличного от человека млекопитающего после стадии (а) и перед стадией (b), причем модифицированный эмбрион на стадии одной клетки отличного от человека млекопитающего является гетерозиготным по мутации, приводящей к укорочению С-конца кодируемого белка.
[20] В некоторых способах, стадия приведения в контакт (а) дополнительно включает в себя приведение в контакт генома с экзогенным шаблоном репарации, содержащим 5'-гомологичное плечо, которое гибридизируется с 5'-последовательностью-мишенью в локусе генома-мишени, и 3'-гомологичное плечо, которое гибридизируется с 3'-последовательностью-мишенью в целевом геномном локусе. Необязательно, экзогенный шаблон репарации дополнительно содержит нуклеотидную вставку, фланкированную 5'- и 3'-гомологичным плечом. Необязательно, нуклеотидная вставка является гомологичной или ортологичной по отношению к геномному локусу-мишени. Необязательно, экзогенный шаблон репарации имеет длину от около 50 нуклеотидов до около 1 т.п.н. Необязательно, экзогенный шаблон репарации имеет длину от около 80 нуклеотидов до около 200 нуклеотидов. Необязательно, экзогенный шаблон репарации представляет собой одноцепочечный олигодезоксинуклеотид.
[21] В другом аспекте, согласно данному изобретению предложен способ скрининга соединения на активность, уменьшающую симптомы, подобные симптомам врожденной липодистрофии, включающий в себя: (а) приведения в контакт любой особи отличного от человека млекопитающего, описанного выше, с соединением; и (b) определение наличия симптомов, подобных симптомам врожденной липодистрофии, у особи отличного от человека млекопитающего, в сравнении с контрольным отличным от человека млекопитающим, не приводившимся в контакт с соединением, причем контрольное отличное от человека млекопитающее содержит ту же мутацию Fbn1, что и особь отличного от человека млекопитающего; таким образом определяют активность относительно уменьшения симптомов, подобных симптомам врожденной липодистрофии, по уменьшенному проявления симптомов, подобных симптомам врожденной липодистрофии, у контрольной особи отличного от человека млекопитающего.
[22] В некоторых способах, симптомы включают в себя одно или большее количество из следующего: уменьшенная масса тела, уменьшенная масса без жира, уменьшенная жировая масса, уменьшенный процент жира в организме, увеличенное потребления пищи нормализованное по массе тела, и увеличенный кифоз. Необязательно, симптомы включают в себя, по меньшей мере, одно из: уменьшенная масса жира и уменьшенный процент жира в организме. Необязательно, симптомы включают в себя уменьшенную массу жира и уменьшенный процент жира в организме. В некоторых способах, симптомы включают в себя одно или большее количество из следующего: уменьшенная масса тела, уменьшенная масса без жира, уменьшенная белая жировая ткань нормализованная по массе тела, уменьшенная белая жировая ткань в комбинации с сохранением бурой жировой ткани нормализованные по массе тела, сниженный процент жира в организме, увеличенное потребление пищи нормализованное по массе тела, и увеличенный кифоз. Необязательно, симптомы включают в себя уменьшенную массу белой жировой ткани нормализованную по массе тела.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
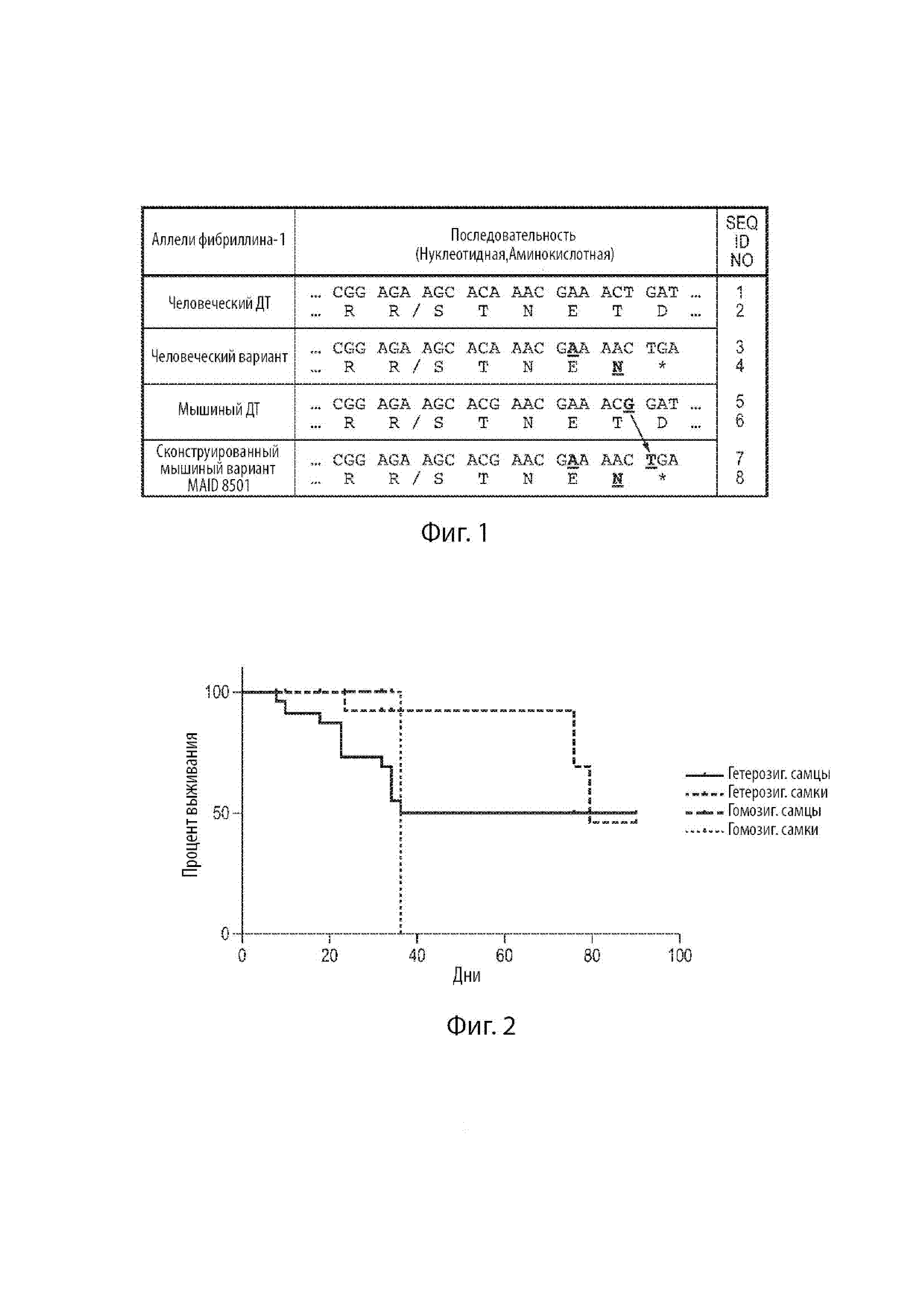
[23] Фиг. 1 демонстрирует нуклеотидную последовательность (и кодируемую аминокислотную последовательность) области в предпоследнем экзоне человеческого гена FBN1 дикого типа, и нуклеотидные и аминокислотные последовательности соответствующих областей в мутантном варианте человеческого гена FBN1, ассоциированного с неонатальным прогероидным синдромом с врожденной липодистрофией, мышином гене Fbn1 дикого типа, и сконструированном варианте мышиного гена Fbn1 MAID 8501. Косая черта в аминокислотных последовательностях между «R» и «S» указывает на сайт расщепления фурином.
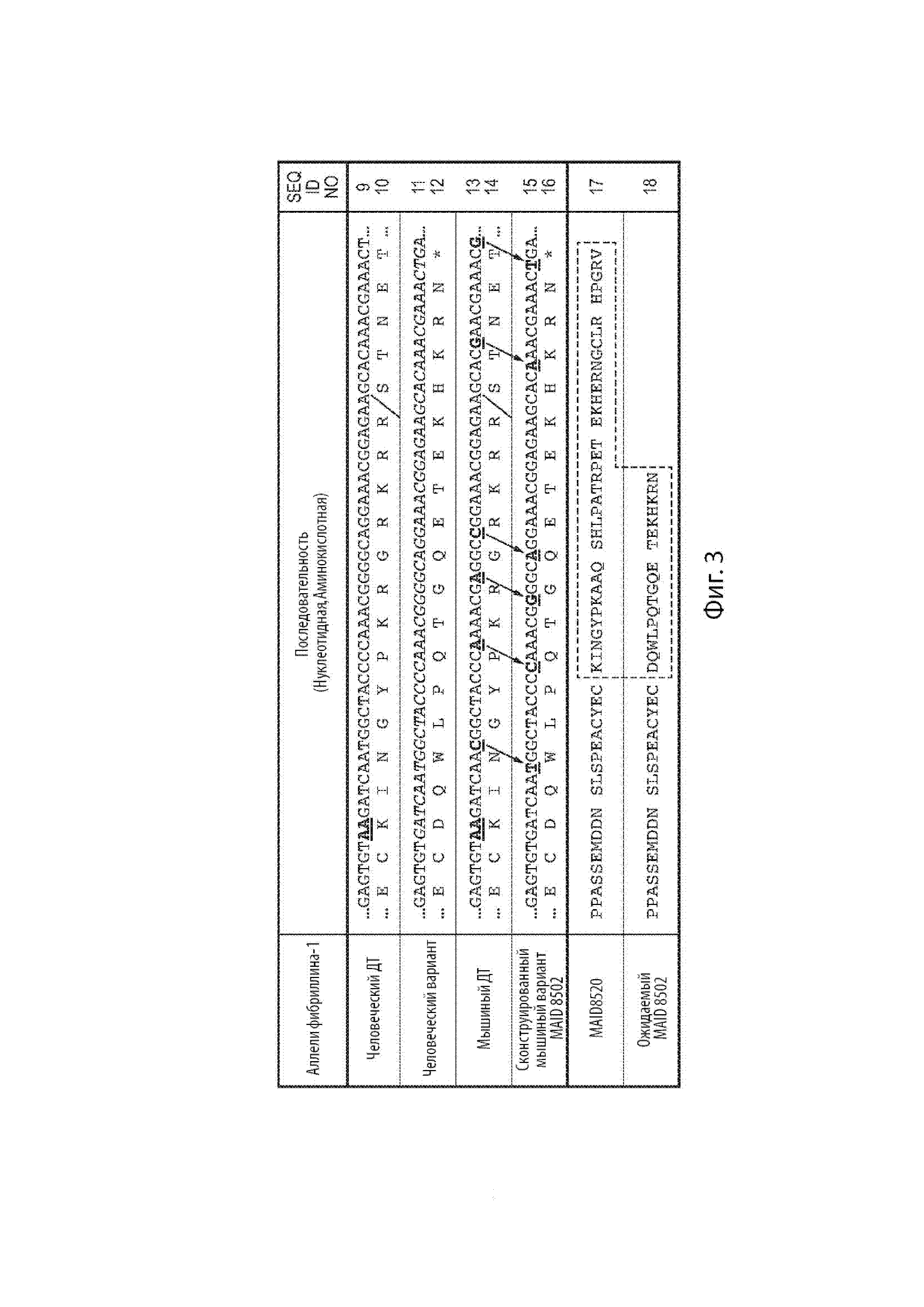
[24] Фиг. 2 показывает процент выживания самцов и самок мышей-родоначальников F0, гетерозиготных или гомозиготных по сконструированному варианту мышиного гена Fbn1 MAID 8501.
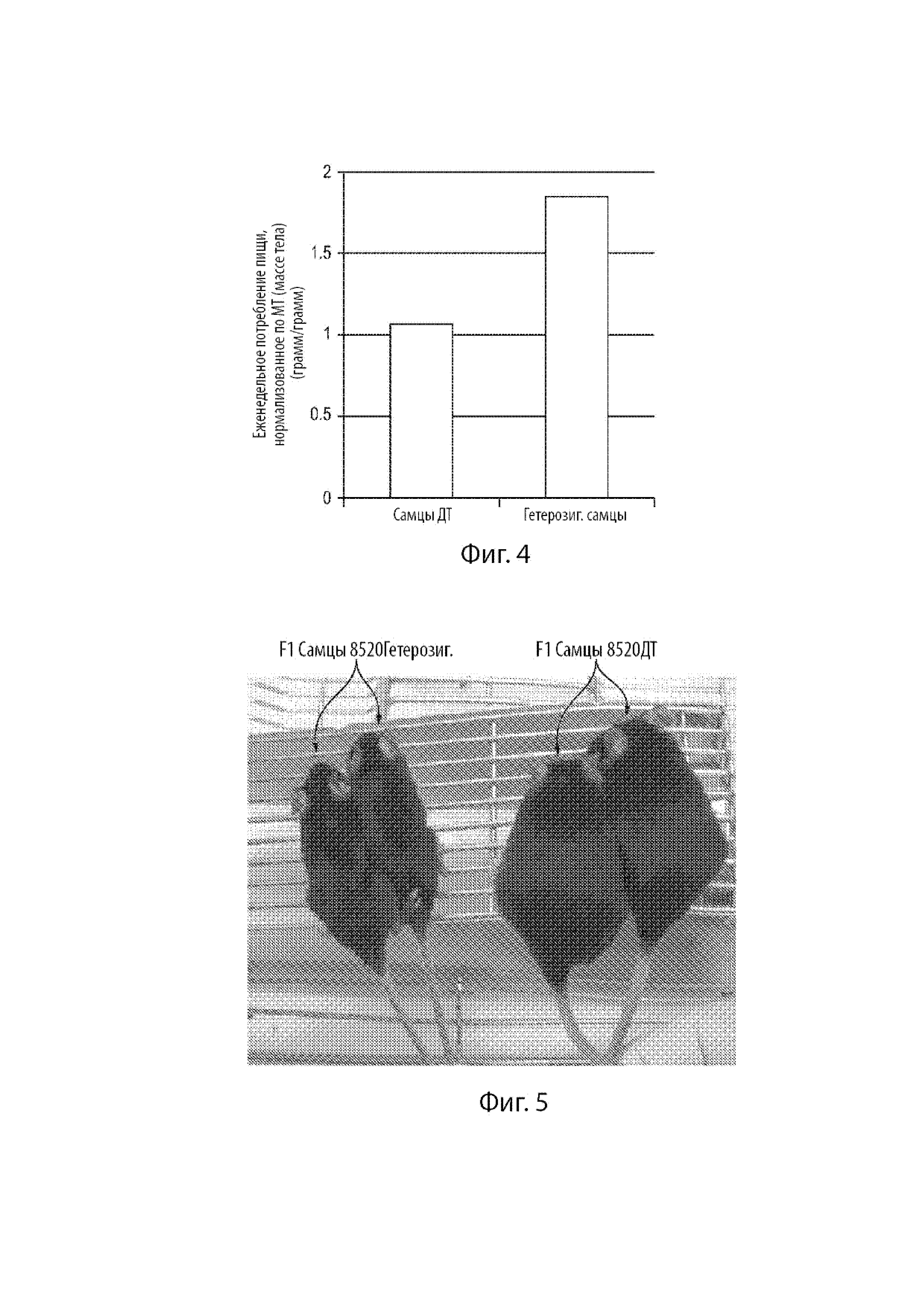
[25] Фиг. 3 демонстрирует нуклеотидную последовательность (и кодируемую аминокислотную последовательность) области в предпоследнем экзоне человеческого гена FBN1 дикого типа, и нуклеотидные и аминокислотные последовательности соответствующих областей в мутантном варианте человеческого гена FBN1, ассоциированного с неонатальным прогероидным синдромом с врожденной липодистрофией, мышином гене Fbn1 дикого типа, и сконструированном варианте мышиного гена Fbn1 MAID 8502. Фиг. 3 также демонстрирует кодируемую аминокислотную последовательность области в предпоследнем экзоне мышиного гена Fbn1 для ожидаемого варианта MAID 8502 и варианта MAID 8520, которые были созданы. Косая черта в аминокислотных последовательностях между «R» и «S» указывает на сайт расщепления фурином.
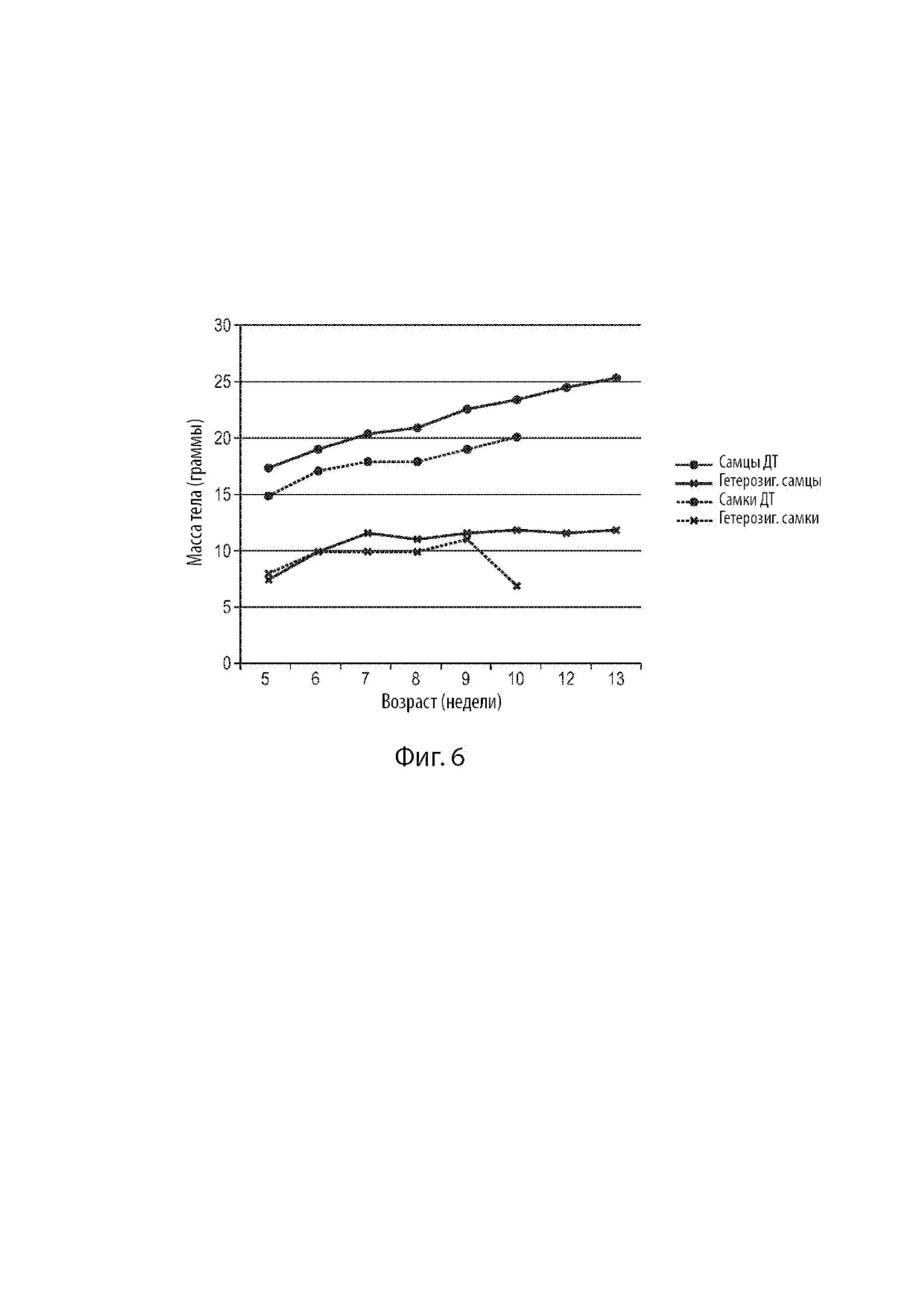
[26] Фиг. 4 демонстрирует еженедельное потребление пищи, нормализованное по массе тела, для мышиных самцов дикого типа и мышей поколения FI, гетерозиготных по сконструированному варианту мышиного гена Fbn1 MAID 8520.
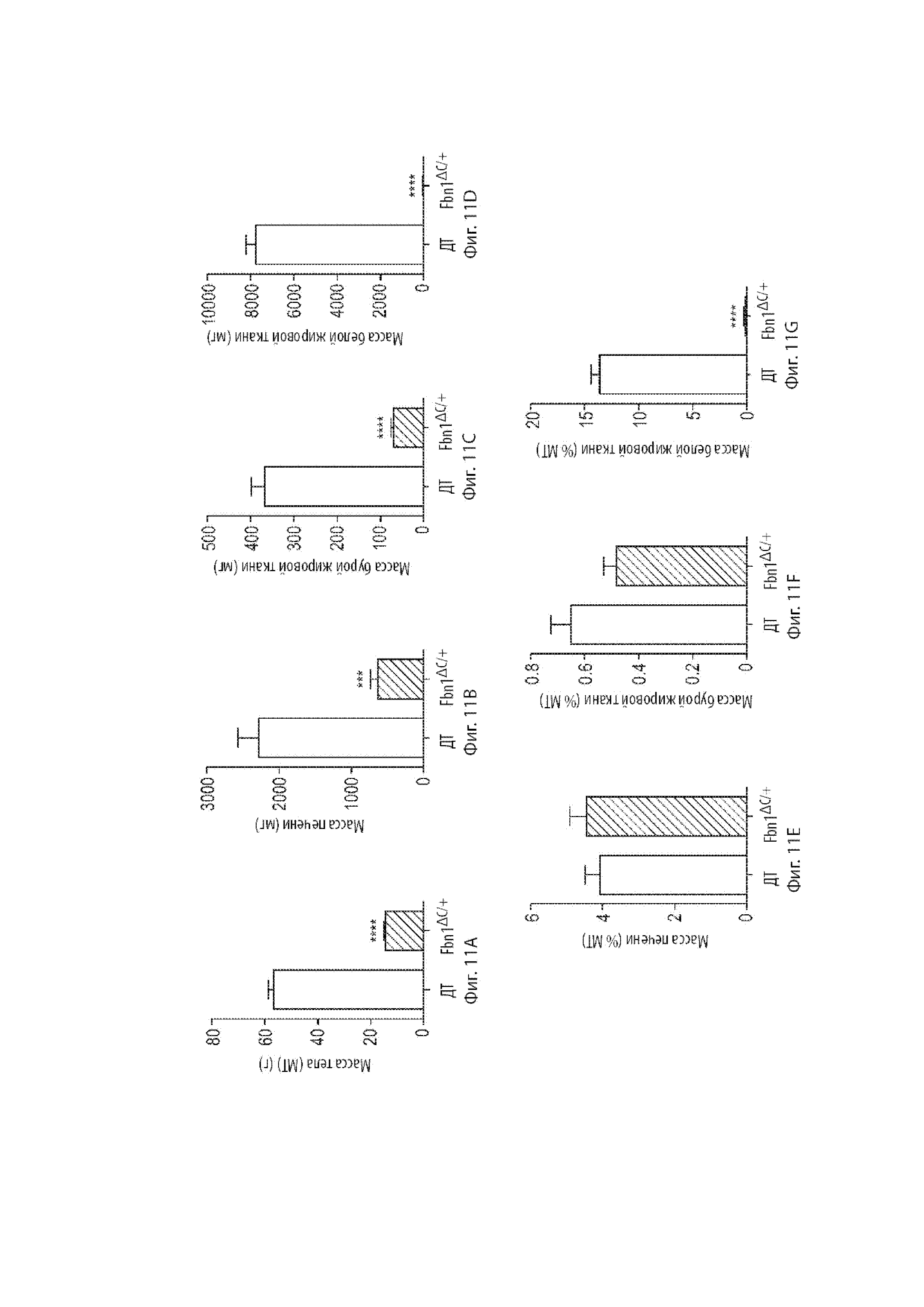
[27] Фиг. 5 демонстрирует 3-месячных мышиных самцов дикого типа и 3-месячных мышиных самцов поколения FI, гетерозиготных по сконструированному варианту мышиного гена Fbn1 MAID 8520.
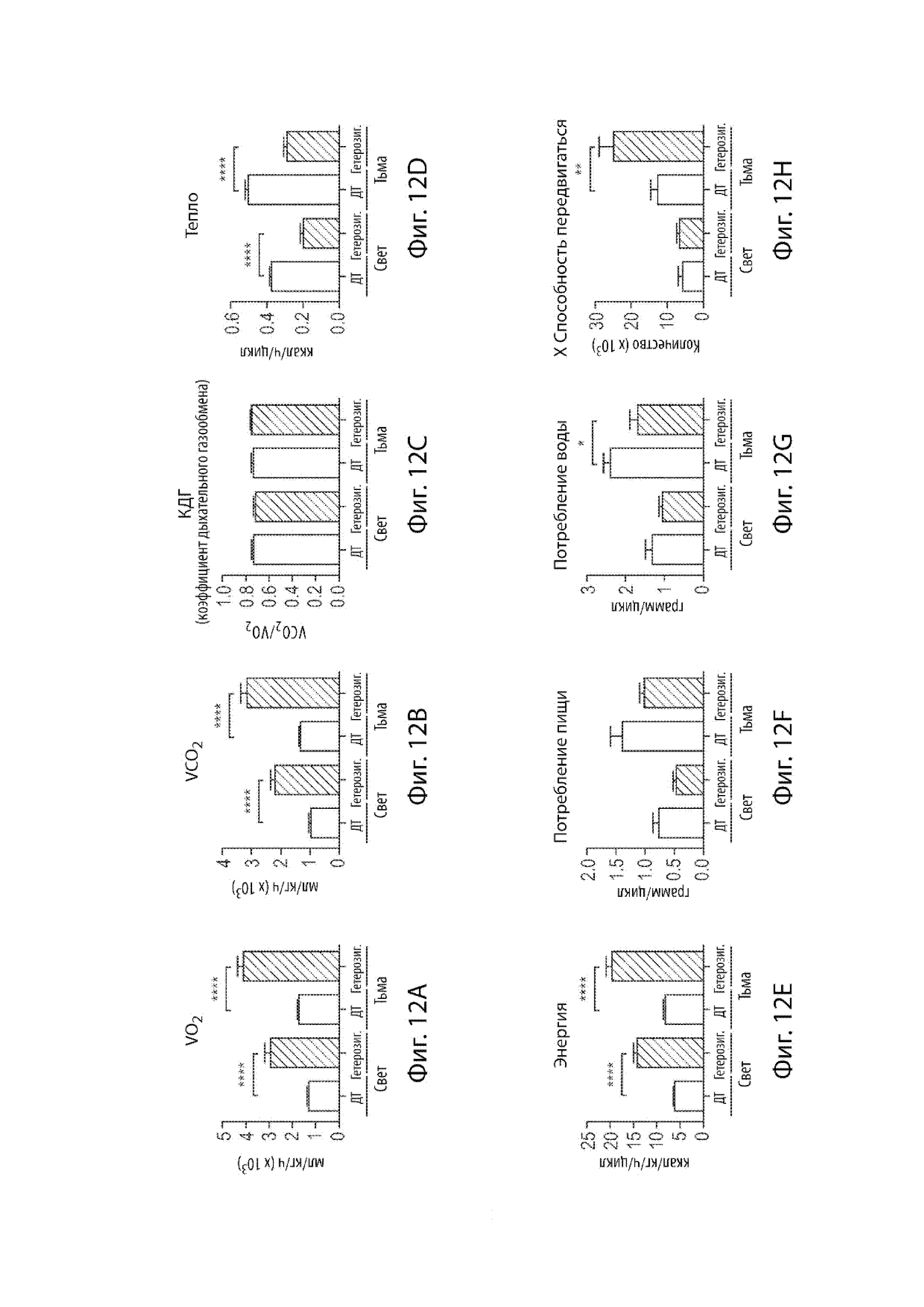
[28] Фиг. 6 демонстрирует массы тел мышей FI в зависимости от возраста, включая мышиных самцов дикого типа, мышиных самок дикого типа, и мышиных самок и самцов, гетерозиготных по сконструированному варианту мышиного гена Fbn1 MAID 8520.
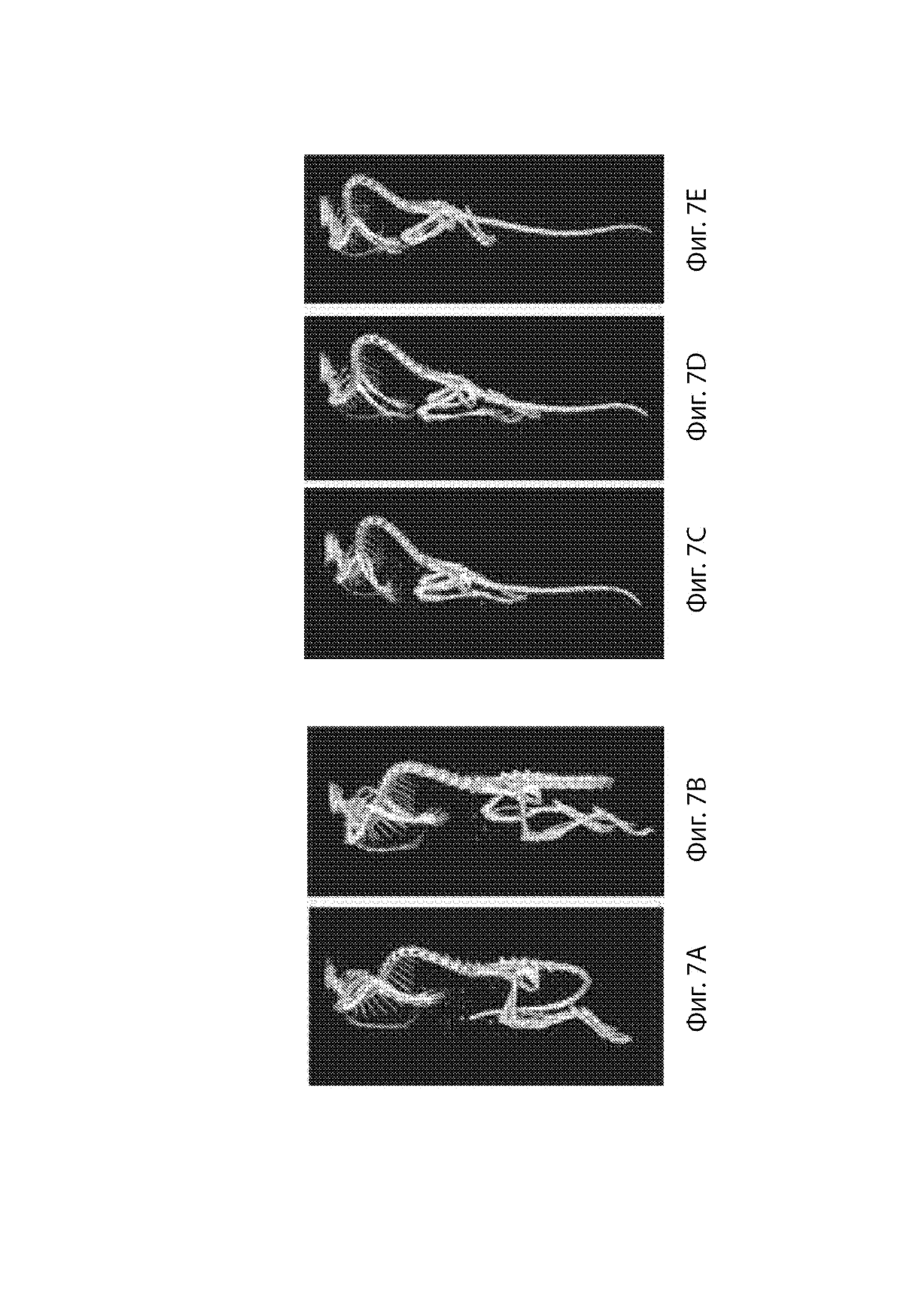
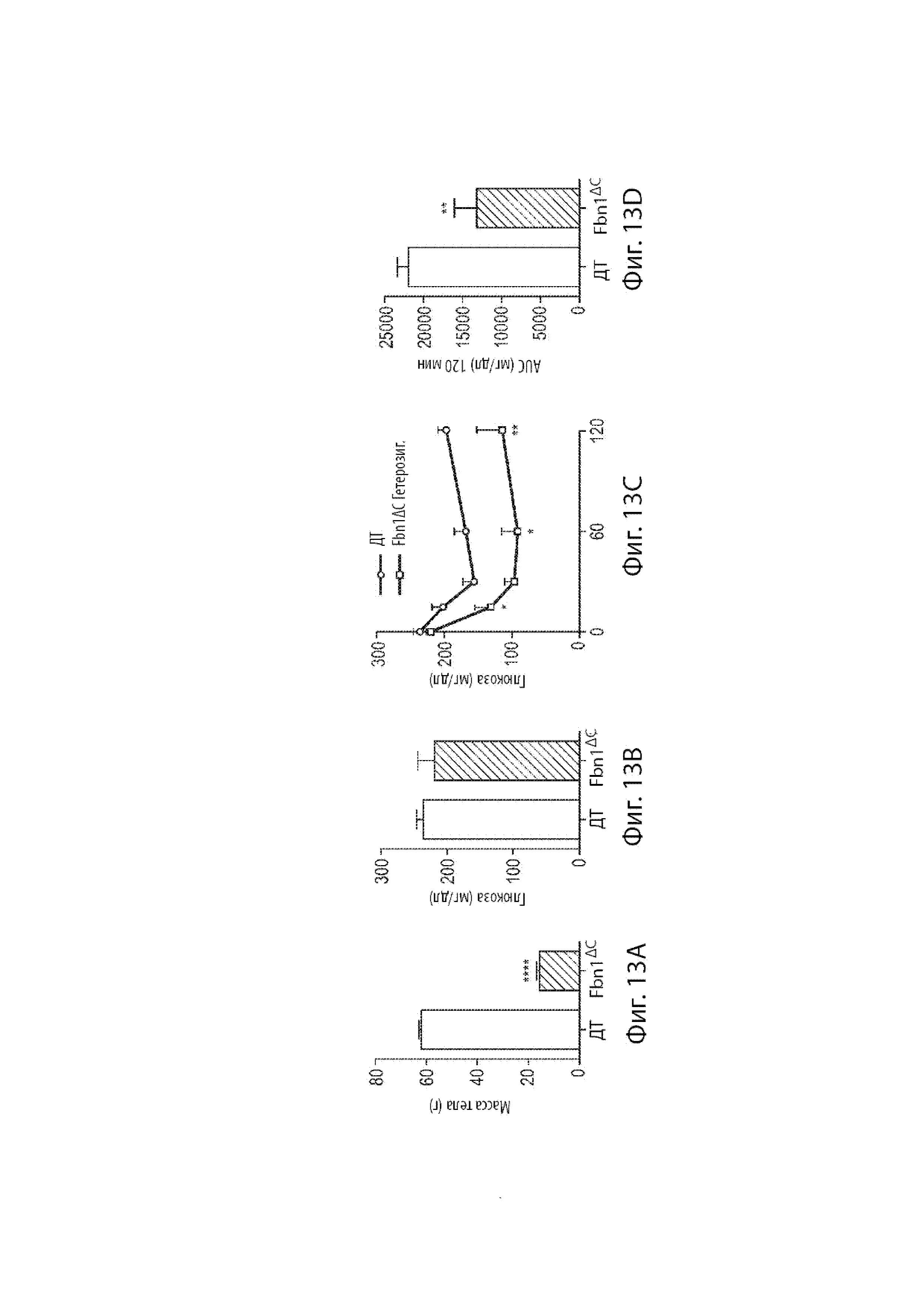
[29] Фиг. 7A-7E демонстрируют скелеты мышиных самок дикого типа (Фиг. 7A и 7B) и мышей, гетерозиготных по варианту MAID 8520 гена Fbn1 (Фиг. 7C-7E), показывающие uCT фотографии спинального кифоза.
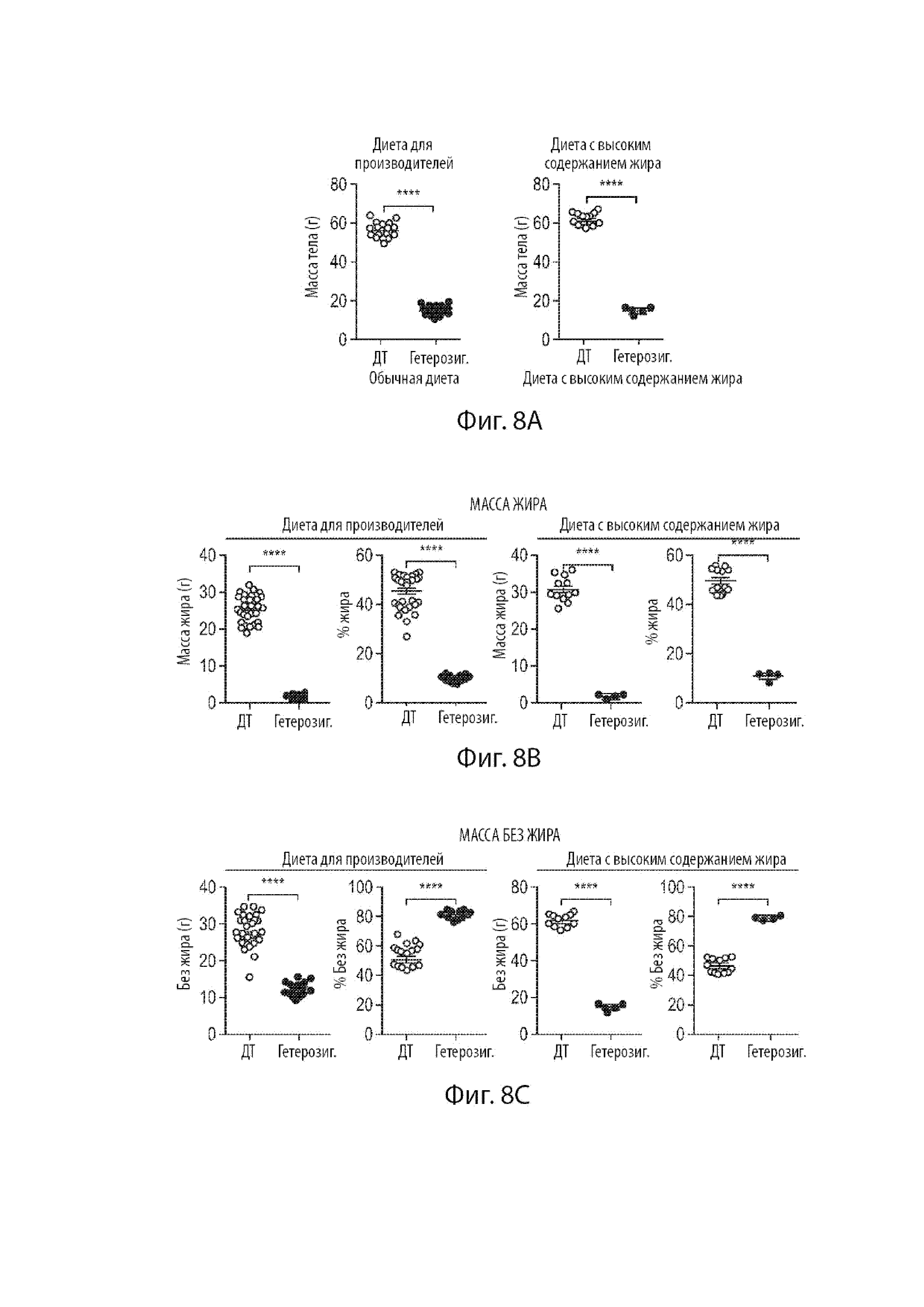
[30] Фиг. 8A-8C демонстрируют данные, связанные с массой тела и жировой массой. Фиг. 8A демонстрируют массу тела мышей дикого типа и мышей, гетерозиготных по варианту MAID 8520 гена Fbn1, которые были либо на диете с 21% жира для прозводителей, либо на диете с 60% жира. Фиг. 8B демонстрирует жировую массу (граммы жировой массы и процент жировой массы) мышей дикого типа и мышей, гетерозиготных по варианту MAID 8520 гена Fbn1, которые были либо на диете с 21% жира для производителей, либо на диете с 60% жира, как измерено с помощью ECHOMRI™. Фиг. 8C демонстрирует массу без жира (граммы массы без жира и процент массы без жира) мышей дикого типа и мышей, гетерозиготных по варианту MAID 8520 гена Fbn1, которые были либо на диете с 21% жира для производителей, либо на диете с 60% жира, как измерено с помощью ECHOMRI™. Все мыши были в возрасте 31 недели. Мыши удерживались на диете с высоким содержанием жира (60%) в течение 22 недель на время сканирования. Звездочки указывают p<0,0001 по непарному критерию Стьюдента.
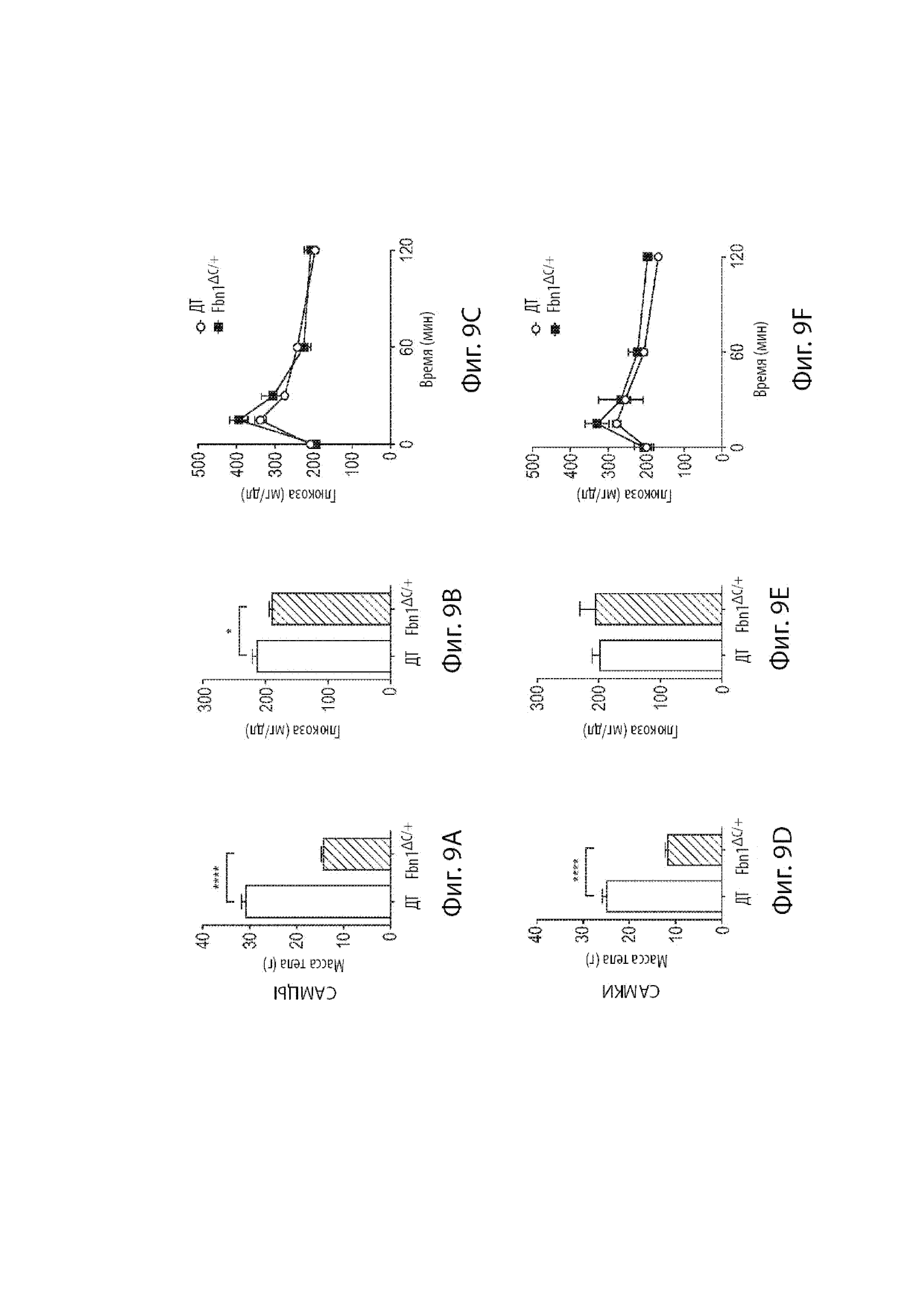
[31] Фиг. 9A-9C демонстрируют анализ, связанный с гомеостазом глюкозы у мышиных самцов. Фиг. 9A демонстрирует массу тела мышиных самцов дикого типа и мышей, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 9B демонстрирует глюкозу голодавших в течение ночи мышиных самцов дикого типа и мышиных самцов, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 9C демонстрирует толерантность к глюкозе, вводимой перорально, мышиных самцов дикого типа и мышиных самцов, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете.
[32] Фиг. 9D-9F демонстрируют анализы, связанные с гомеостазом глюкозы у мышиных самок. Фиг. 9D демонстрирует массу тела мышиных самок дикого типа и мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 9E демонстрирует глюкозу голодавших в течение ночи мышиных самок дикого типа и мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 9F демонстрирует толерантность к глюкозе, вводимой перорально, мышиных самом дикого типа и мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете.
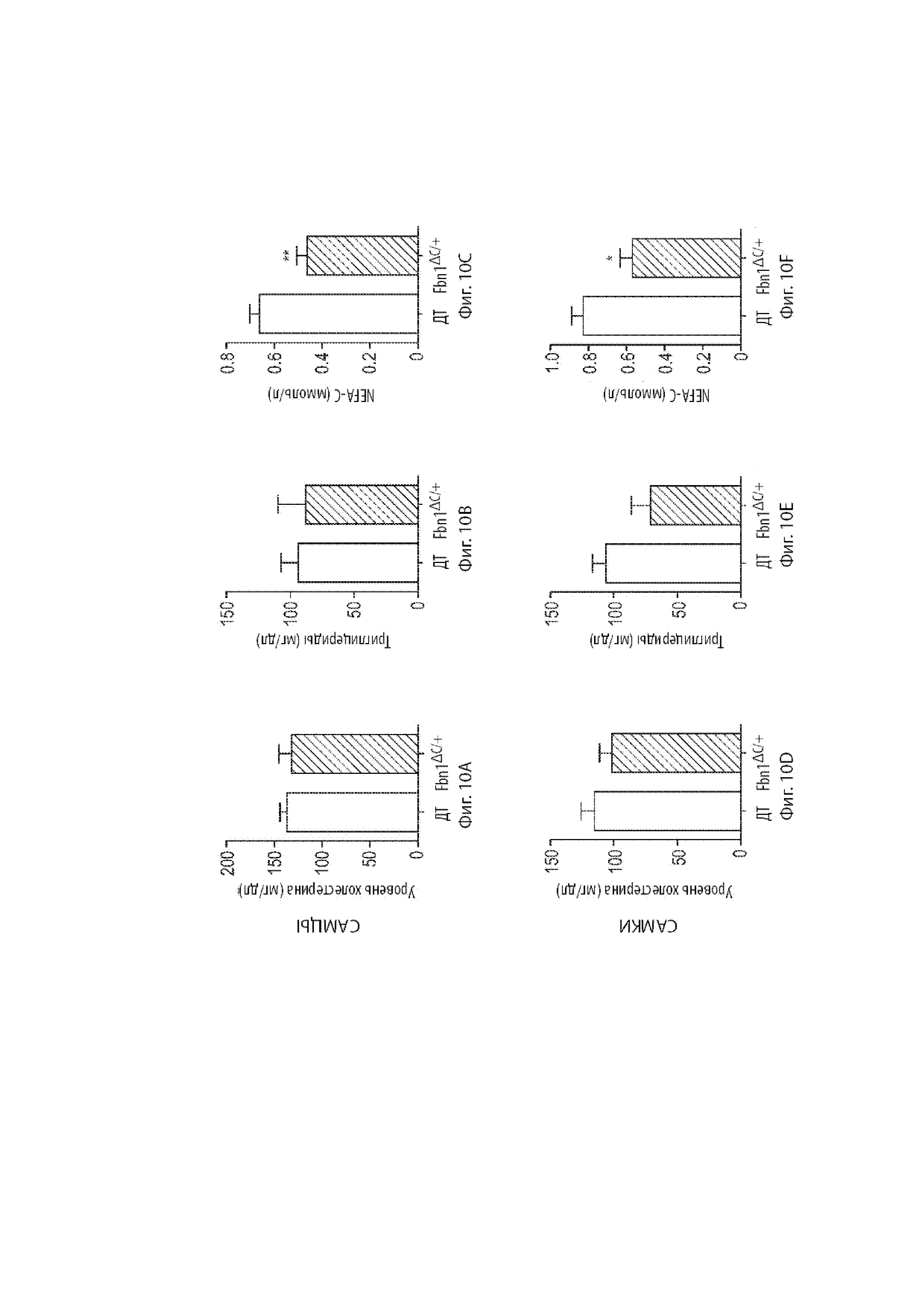
[33] Фиг. 10A-10C демонстрируют анализы, связанные с циркулирующими липидами у мышиных самцов. Фиг. 10A демонстрирует уровень холестерина в сыворотке мышиных самцов дикого типа и мышиных самцов, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 10B демонстрирует уровень триглицеридов у мышиных самцов дикого типа и мышиных самцов, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 10C демонстрирует уровень неэтерифицированные жирные кислоты (NEFA-C) у мышиных самцов дикого типа и мышиных самцов, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете.
[34] Фиг. 10D-10F демонстрируют анализы, связанные с циркулирующими липидами у мышиных самок. Фиг. 10D демонстрирует уровень холестерина в сыворотке мышиных самок дикого типа и мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 10E демонстрирует уровень триглицеридов у мышиных самок дикого типа и мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 10F демонстрирует уровень неэтерифицированные жирные кислоты (NEFA-C) у мышиных самок дикого типа и мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете.
[35] Фиг. 11A-11G демонстрируют конченые массы печени и жировых комочков относительно масс тел. Фиг. 11A демонстрирует массы тел мышиных самок в возрасте 34 недель, гетерозиготных по варианту MAID 8520 гена Fbn1, находящихся на обычной диете. Фиг. 11B-11D демонстрируют массы печени, бурой жировой ткани (BAT) и висцеральной белой жировой ткани (WAT) для каждой группы. Фиг. 11E-11G демонстрируют те же массы в виде процента от массы тела.
[36] Фиг. 12A-12H демонстрируют данные метаболической клетки системы Columbia Instruments Oxymax CLAMS мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, которых удерживали на диете с высоким содержанием жира (60%) в течение 12 недель.
[37] Фиг. 13A-13D демонстрируют результаты теста толерантности к глюкозе мышиных самок, гетерозиготных по варианту MAID 8520 гена Fbn1, которых удерживали на диете с высоким содержанием жира (60%) в течение 20 недель.
ОПРЕДЕЛЕНИЯ
[38] Термины «белок», «полипептид» и «пептид», используемые в данном документе взаимозаменяемо, включают в себя полимерные формы аминокислот любой длины, включая кодируемые и некодируемые аминокислоты, и химически или биохимически модифицированные, или дериватизированные аминокислоты. Термины также включают в себя полимеры, которые были модифицированы, такие как полипептиды, имеющие модифицированные пептидные каркасы.
[39] Говорят, что белки имеют «N-конец» и «С-конец». Термин «N-конец» относится к началу белка или полипептида, оканчивающемуся аминокислотой со свободной аминогруппой (-NH2). Термин «С-конец» относится к концу аминокислотной цепи (белка или полипептида), оканчивающемуся свободной карбоксильной группой (-СООН).
[40] Термины «нуклеиновая кислота» и «полинуклеотид», используемые в данном документе взаимозаменяемо, включают в себя полимерные формы нуклеотидов любой длины, включая рибонуклеотиды, дезоксирибонуклеотиды, или их аналоги или модифицированные варианты. Они включают в себя одно-, двух- и многоцепочечные ДНК или РНК, геномную ДНК, кДНК, гибриды ДНК-РНК и полимеры, содержащие пуриновые основания, пиримидиновые основания, или другие природные, химически модифицированные, биохимически модифицированные, неприродные или дериватизированные нуклеотидные основания.
[41] Считается, что нуклеиновые кислоты имеют «5'-концы» и «3'-концы», потому что мононуклеотиды вступают в реакцию с образованием олигонуклеотидов таким образом, что 5'-фосфат одного мононуклеотид-пентозного кольца присоединяется к 3'-кислороду его соседа в одном направление через фосфодиэфирную связь. Конец олигонуклеотида называют «5'-концом», если его 5'-фосфат не связан с 3'-кислородом мононуклеотид-пентозного кольца. Конец олигонуклеотида называют «3'-концом», если его 3'-кислород не связан с 5'-фосфатом другого мононуклеотид-пентозного кольца. Можно также сказать, что нуклеотидная последовательность, даже если она находится внутри более крупного олигонуклеотида, имеет 5' и 3' концы. В линейной или кольцевой молекуле ДНК дискретные элементы обозначаются как «расположенные выше» или 5' «расположенных ниже» или 3' элементов.
[42] Термин «дикий тип» включает в себя субъекты, имеющие структуру и/или активность, обнаруживаемую в нормальном (в отличие от мутантного, больного, измененного и т. д.) состоянии или обстановке. Ген и полипептиды дикого типа часто существуют в нескольких различных формах (например, аллелях).
[43] Термин «выделенный» в отношении белков и нуклеиновых кислот включает в себя белки и нуклеиновые кислоты, которые являются относительно очищенными по отношению к другим бактериальным, вирусным или клеточным компонентам, которые обычно могут присутствовать in situ, вплоть до, по существу, чистого препарата белка и полинуклеотида. Термин «выделенный» также включает в себя белки и нуклеиновые кислоты, которые не имеют встречающегося в природе аналога, были химически синтезированы и, таким образом, по существу не загрязнены другими белками или нуклеиновыми кислотами, или были отделены или очищены от большинства других клеточных компонентов, которыми они природно сопровождаются (например, другие клеточные белки, полинуклеотиды или клеточные компоненты).
[44] «Экзогенные» молекулы или последовательности включают в себя молекулы или последовательности, которые обычно не присутствуют в клетке в этой форме. Нормальное присутствие включает в себя присутствие относительно конкретной стадии развития и условий окружающей среды клетки. Например, экзогенная молекула или последовательность может включать в себя мутантную версию соответствующей эндогенной последовательности в клетке, такую как гуманизированная версия эндогенной последовательности, или может включать в себя последовательность, соответствующую эндогенной последовательности в клетке, но в другой форма (т. е. не в хромосоме). В противоположность этому, эндогенные молекулы или последовательности включают в себя молекулы или последовательности, которые обычно присутствуют в такой форме в конкретной клетке на конкретной стадии развития в определенных условиях окружающей среды.
[45] «Оптимизация кодона» в целом, как правило, включает в себя процесс модификации нуклеотидной последовательности для усиления экспрессии в конкретных клетках-хозяевах путем замены по меньшей мере одного кодона нативной последовательности на кодон, который чаще или чаще всего используется в генах клетки-хозяина, в то же время сохраняя нативную аминокислотную последовательность. Например, полинуклеотид, кодирующий белок Cas9, может быть модифицирован для замены кодонов, имеющих более высокую частоту использования в данной прокариотической или эукариотической клетке, включая бактериальную клетку, дрожжевую клетку, клетку человека, нечеловеческую клетку, клетку млекопитающего, клетку грызуна, клетку мыши, клетку крысы, клетку хомяка или любую другую клетку-хозяина, по сравнению с природной нуклеотидной последовательностью. Таблицы использования кодонов легко доступны, например, в «Базе данных использования кодонов». Эти таблицы могут быть адаптированы несколькими способами. Смотрите Nakamura el al. (2000) Nucleic Acids Research 28:292, который включен в данный документ посредством ссылки в полном объеме для всех целей. Также доступны компьютерные алгоритмы для оптимизации кодонов конкретной последовательности для экспрессии в конкретном хозяине (см., например, «Gene Forge»).
[46] Термин «локус» относится к конкретной позиции гена (или значимой последовательности), последовательности ДНК, последовательности, кодирующей полипептид, или позиции в хромосоме генома организма. Например, «локус Fbn1» может относиться к конкретной позиции гена Fbn1, последовательности ДНК Fbn1, последовательности, кодирующей Fbn1, или позиции Fbn1 в хромосоме генома организма, которая была идентифицирована как таковая, где находится такая последовательность. «Локус Fbn1» может содержать регуляторный элемент гена Fbn1, включая, например, энхансер, промотор, 5' и/или 3' UTR или их комбинацию.
[47] Термин «ген» относится к последовательности ДНК в хромосоме, которая кодирует продукт (например, РНК-продукт и/или полипептидный продукт) и включает в себя кодирующую область, прерываемую некодирующими интронами, и последовательность, расположенную рядом с кодирующей областью на обоих 5' и 3' концах, так что ген соответствует полноразмерной мРНК (включая 5'- и 3'-нетранслируемые последовательности). Термин «ген» также включает в себя другие некодирующие последовательности, включая регуляторные последовательности (например, промоторы, энхансеры и сайты связывания транскрипционных факторов), сигналы полиаденилирования, внутренние сайты посадки рибосомы, сайленсеры, изолирующую последовательность, и области прикрепления к матриксу. Эти последовательности могут быть близки к кодирующей области гена (например, в пределах 10 т.п.н.) или находиться на удаленных позициях, и они влияют на уровень или скорость транскрипции и трансляции гена.
[48] Термин «аллель» относится к вариантной форме гена. Некоторые гены имеют множество различных форм, которые размещены в одной и той же позиции или генетическом локусе в хромосоме. Диплоидный организм имеет два аллеля в каждом генетическом локусе. Каждая пара аллелей представляет генотип определенного генетического локуса. Генотипы описываются как гомозиготные, если в конкретном локусе находится два идентичных аллеля, и как гетерозиготные, если два аллеля различаются.
[49] «Промотор» представляет собой регуляторную область ДНК, обычно содержащую TATA-бокс, способный направлять РНК-полимеразу II для инициации синтеза РНК к соответствующему сайту инициации транскрипции для конкретной полинуклеотидной последовательности. Промотор может дополнительно содержать другие области, которые влияют на скорость инициации транскрипции. Раскрытые в данном документе промоторные последовательности модулируют транскрипцию функционально связанного полинуклеотида.
[50] «Функциональная связь» или «функционально связанный» включает в себя совмещение двух или большего количества компонентов (например, промотора и другого элемента последовательности) так, что оба компонента функционируют нормально и допускают возможность того, что по меньшей мере один из компонентов может выполнять функцию, которая может воздействовать по меньшей мере на один из других компонентов. Например, промотор может быть функционально связан с кодирующей последовательностью, если промотор контролирует уровень транскрипции кодирующей последовательности в ответ на присутствие или отсутствие одного или нескольких регуляторных факторов транскрипции. Функциональная связь может включать в себя такие последовательности, которые являются смежными друг с другом или действуют в транс-положении (например, регуляторная последовательность может действовать на расстоянии для управления транскрипцией кодирующей последовательности).
[51] «Комплементарность» нуклеиновых кислот означает, что нуклеотидная последовательность в одной нуклеотидной цепи, благодаря ориентации ее нуклеиновых оснований, образует водородные связи с другой последовательностью противоположной нуклеотидной цепи. Комплементарные основания в ДНК обычно представляют собой А с Т и С с G. В РНК они обычно представляют собой C с G и U с A. Комплементарность может быть полной или существенной/достаточной. Полная комплементарность между двумя нуклеиновыми кислотами означает, что две нуклеиновые кислоты могут образовывать дуплекс, в котором каждое основание в дуплексе связано с комплементарным основанием посредством спаривания Уотсона-Крика. «Существенная» или «достаточная» комплементарный означает, что последовательность в одной цепи не является полностью и/или совершенно комплементарной последовательности в противоположной цепи, но между основаниями двух цепей происходит достаточное связывание для образования стабильного гибридного комплекса при выполнении ряда условий гибридизации (например, концентрация соли и температура). Такие условия могут быть предсказаны с использованием последовательностей и стандартных математических расчетов для прогнозирования Tm (температуры плавления) гибридизированных цепей или путем эмпирического определения Tm с использованием рутинных способов. Tm включает в себя температуру, при которой популяция гибридизационных комплексов, сформированных между двумя нуклеотидными цепями, денатурируется на 50% (то есть популяция двухцепочечных молекул нуклеиновой кислоты становится наполовину диссоциированной на отдельные цепи). При температуре ниже Tm является предпочтительным формирование гибридизационного комплекса, тогда как при температуре выше Tm является предпочтительным плавление или разделение цепей в гибридизационном комплексе. Tm можно оценить для нуклеиновой кислоты, имеющей известное содержание G+C в водном 1 М растворе NaCl, используя, например, Tm = 81,5 + 0,41 (% G+C), хотя другие известные расчеты Tm учитывают структурные характеристики нуклеиновой кислоты.
[52] «Условие гибридизации» включает в себя совокупные условия среды, в которых одна нуклеотидная цепь связывается с второй нуклеотидной цепью посредством комплементарных взаимодействий цепей и формирования водородных связей с образованием гибридизационного комплекса. Такие условия включают в себя химические компоненты и их концентрации (например, соли, хелатирующие агенты, формамид) водного или органического раствора, содержащего нуклеиновые кислоты, и температуру смеси. Другие факторы, такие как продолжительность инкубации или размеры реакционной камеры, могут влиять на среду. Смотрите, например, Sambrook el al., Molecular Cloning, A Laboratory Manual, 2.sup.nd ed., pp. 1.90-1.91, 9.47-9.51, 1 1.47-11.57 (Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989), включен в данный документ посредством ссылки в полном объеме для всех целей.
[53] Гибридизация требует, чтобы две нуклеиновые кислоты содержали комплементарные последовательности, хотя возможны несоответствия между основаниями. Условия, подходящие для гибридизации между двумя нуклеиновыми кислотами, зависят от длины нуклеиновых кислот и степени комплементарности - переменных, которые хорошо известны в данной области техники. Чем выше степень комплементарности между двумя нуклеотидными последовательностями, тем большим является значение температуры плавления (Tm) для гибридов нуклеиновых кислот, имеющих эти последовательности. Для гибридизации между нуклеиновыми кислотами с короткими участками комплементарности (например, комплементарность больше 35 или меньше, 30 или меньше, 25 или меньше, 22 или меньше, 20 или меньше, или 18 или меньше нуклеотидов) важными становятся позиции неполной комплементарности (смотрите Sambrook el al., supra, 11.7-11.8). Как правило, длина гибридизуемой нуклеиновой кислоты составляет, по меньшей мере, около 10 нуклеотидов. Иллюстративные минимальные длины для гибридизируемой нуклеиновой кислоты включают в себя, по меньшей мере около 15 нуклеотидов, по меньшей мере около 20 нуклеотидов, по меньшей мере около 22 нуклеотидов, по меньшей мере около 25 нуклеотидов и, по меньшей мере, около 30 нуклеотидов. Кроме того, температура и концентрация соли в промывочном растворе могут регулироваться по мере необходимости в соответствии с такими факторами, как длина области комплементарности и степень комплементарности.
[54] Последовательность полинуклеотида не должна быть на 100% комплементарной последовательности нуклеиновой кислоты-мишени, чтобы быть специфически гибридизуемой. Кроме того, полинуклеотид может гибридизироваться с одним или большим количеством сегментов, так что промежуточные или смежные сегменты не участвуют в событии гибридизации (например, петлевая структура или шпильковая структура). Полинуклеотид (например, нРНК - направляющая РНК)) может иметь по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 99% или 100% комплементарности последовательности к области-мишени в пределах нуклеотидной последовательности-мишени, на которую он нацелен. Например, нРНК, в которой 18 из 20 нуклеотидов являются комплементарными области-мишени и, следовательно, будут специфически гибридизироваться, будет примером 90% комплементарности. В данном примере оставшиеся некомплементарные нуклеотиды могут быть кластеризованы или перемежены с комплементарными нуклеотидами и не должны быть смежными друг с другом или с комплементарными нуклеотидами.
[55] Процент комплементарности между конкретными участками нуклеотидных последовательностей в пределах нуклеиновых кислот может быть определен обычным способом с использованием программ BLAST (основные средства поиска локального выравнивания) и программ PowerBLAST, известных в данной области техники (Altschul el al. (1990) J. Mol. Biol. 215:403-410; Zhang and Madden (1997) Genome Res. 7:649-656) или с помощью программы Gap (Wisconsin Sequence Analysis Package, Version 8 for Unix, Genetics Computer Group, University Research Park, Madison Wis.), используя настройки по умолчанию, которая использует алгоритм Смита и Уотермана (Adv. Appl. Math., 1981, 2, 482-489).
[56] Способы и композиции, предложенные в данном документе, используют множество различных компонентов. Во всем описании признается, что некоторые компоненты могут иметь активные варианты и фрагменты. Такие компоненты включают в себя, например, белки Cas9, CRISPR РНК, транскрРНК и направляющие РНК. Биологическая активность каждого из этих компонентов описана в данном документе в другом месте.
[57] «Идентичность последовательности» или «идентичность» в контексте двух полинуклеотидных или полипептидных последовательностей относится к остаткам в двух последовательностях, которые являются одинаковыми при выравнивании для максимального соответствия в указанном окне сравнения. Когда процент идентичности последовательности используется в отношении белков, признается, что позиции остатков, которые не являются идентичными, часто отличаются консервативными аминокислотными заменами, где аминокислотные остатки заменены другими аминокислотными остатками со сходными химическими свойствами (например, заряд или гидрофобность) и поэтому не меняют функциональные свойства молекулы. Когда последовательности отличаются по консервативным заменам, процент идентичности последовательности может быть повышен, чтобы скорректировать консервативный характер замены. Говорят, что последовательности, которые отличаются такими консервативными заменами, имеют «сходство последовательностей» или «сходство». Средства для осуществления такой корректировки хорошо известны специалистам в данной области техники. Как правило, это включает в себя оценивания консервативной замены как частичное, а не полное несоответствие, что увеличивает процент идентичности последовательности. Таким образом, например, когда идентичная аминокислота получает оценку 1, а неконсервативная замена получает оценку 0, консервативная замена получает оценку от 0 до 1. Оценку консервативных замен рассчитывают, например, как реализовано в программе PC/GENE (Intelligenetics, Маунтин-Вью, Калифорния).
[58] «Процент идентичности последовательностей» включает в себя значение, определенное путем сравнения двух оптимально выровненных последовательностей в окне сравнения, причем часть полинуклеотидной последовательности в окне сравнения может содержать вставки или делеции (то есть пробелы) по сравнению с эталонной последовательностью (которая не содержит вставки или делеции) для оптимального выравнивания двух последовательностей. Процент рассчитывается путем определения количества позиций, в которых идентичное нуклеотидное основание или аминокислотный остаток встречается в обеих последовательностях, для получения числа совпадающих позиций, деля количество совпадающих позиций на общее количество позиций в окне сравнения и умножая результат на 100, чтобы получить процент идентичности последовательностей.
[59] Если не указано иное, значения идентичности/сходства последовательностей включают в себя значение, полученное с использованием GAP версии 10 с применением следующих параметров: % идентичности и % сходства для нуклеотидной последовательности с использованием GAP Weight 50 и Length Weight 3, и оценочной матрицы nwsgapdna.cmp; % идентичности и % сходства для аминокислотной последовательности с использованием GAP Weight 8 и Length Weight 2 и оценочной матрицы BLOSUM62; или любой эквивалентной для этого программы. «Эквивалентная программа» включает в себя любую программу сравнения последовательностей, которая для любых двух рассматриваемых последовательностей генерирует выравнивание, имеющее идентичные совпадения нуклеотидных или аминокислотных остатков, и идентичный процент идентичности последовательности по сравнению с соответствующим выравниванием, сгенерированным GAP версии 10.
[60] Термин «существенная идентичность», как применяется в данном документе, для обозначения общих эпитопов, включает в себя последовательности, которые содержат идентичные остатки в соответствующих позициях. Например, две последовательности можно считать практически идентичными, если, по меньшей мере 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% 98%, 99% или больше их соответствующих остатков идентичны на соответствующей протяженности остатков. Соответствующая протяженность может быть, например, полной последовательностью или может быть по меньшей мере 5, 10, 15 или большим количеством остатков.
[61] Термин «консервативная аминокислотная замена» относится к замене аминокислоты, которая обычно присутствует в последовательности, на другую аминокислоту аналогичного размера, заряда или полярности. Примеры консервативных замен включают в себя замену неполярного (гидрофобного) остатка, такого как изолейцин, валин или лейцин, на другой неполярный остаток. Аналогично, примеры консервативных замен включают в себя замену одного полярного (гидрофильного) остатка на другой, например пары аргинин и лизин, глутамин и аспарагин, или глицин и серин. Кроме того, замена основного остатка, такого как лизин, аргинин или гистидин, на другой, или замена одного кислотного остатка, такого как аспарагиновая кислота или глутаминовая кислота, на другой кислотный остаток, являются дополнительными примерами консервативных замен. Примеры неконсервативных замен включают в себя замену неполярного (гидрофобного) аминокислотного остатка, такого как изолейцин, валин, лейцин, аланин или метионин, на полярный (гидрофильный) остаток, такой как цистеин, глутамин, глутаминовая кислота или лизин, и/или полярного остатка на неполярный остаток. Типичное разделение аминокислот на группы приведено ниже.
[62] «Гомологичная» последовательность (например, нуклеотидная последовательность) включает в себя последовательность, которая является либо идентичной, либо по существу сходной с известной эталонной последовательностью, так что она, например, по меньшей мере на 50%, по меньшей мере на 55%, по меньшей мере на 60%, по меньшей мере на 65%, по меньшей мере на 70%, по меньшей мере на 75%, по меньшей мере на 80%, по меньшей мере на 85%, по меньшей мере на 90%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична известной эталонной последовательности. Гомологичные последовательности могут включать в себя, например, ортологичные последовательности и паралогичные последовательности. Например, гомологичные гены обычно происходят от общей предковой последовательности ДНК, создаваясь либо путем видообразования (ортологичные гены), либо путем генетической дупликации (паралогичные гены). «Ортологичные» гены включают в себя гены разных видов, которые произошли от общего предкового гена путем видообразования. Ортологи обычно сохраняют ту же функцию в ходе эволюции. «Паралогичные» гены включают в себя гены, сродство которых является результатом дупликации в геноме. Паралоги могут получать новые функции в ходе эволюции.
[63] Термин in vitro включает в себя искусственную среду, и процессы или реакции, которые происходят в искусственной среде (например, в пробирке). Термин in vivo включает естественную среду (например, клетку, организм или тело), и процессы или реакции, которые происходят в естественной среде. Термин ex vivo включает в себя клетки, которые были изъяты из организма человека, а также процессы или реакции, которые происходят в таких клетках.
[64] Композиции или способы, «содержащие» или «включающие в себя» один или большее количество перечисленных элементов, могут включать в себя другие элементы, которые конкретно не указаны. Например, композиция, которая «содержит» или «включает в себя» белок, может содержать белок отдельно или в комбинации с другими ингредиентами.
[65] Обозначение диапазона значений включает в себя все целые числа в пределах диапазона или определяющие диапазон, а также все поддиапазоны, определенные целыми числами в пределах диапазона.
[66] Если иное не очевидно из контекста, термин «около» охватывает значения в пределах стандартного диапазона погрешности измерения (например, СОС) заявленного значения.
[67] Единственное число существительного включает в себя отсылку к его множественному числу, если контекст явно не указывает иное. Например, термин «белок Cas9» или «по меньшей мере один белок Cas9» может включать в себя множество белков Cas9, включая их смеси.
[68] Статистически значимое означает р <0,05.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
I. Обзор
[69] Согласно данному изобретению предложены отличные от человека животные, содержащие мутацию в гене Fbn1 для моделирования неонатального прогероидного синдрома с врожденной липодистрофией (NPSCL). Также преложены способы получения таких отличных от человека животных моделей. Отличные от человека животные модели могут быть применены для скрининга соединений, проявляющих активность в виде ингибирования или снижения NPSCL или ослабления NPSCL-подобных симптомов, или скрининга соединений, проявляющих потенциально опасную активность в виде стимуляции или усугубления NPSCL, а также для получения представления о механизме NPSCL и потенциально новых терапевтических и диагностических целях.
II. Отличные от человека животные модели неонатального прогероидного синдрома с врожденной липодистрофией
[70] В данном документе предложены отличные от человека животные (например, отличные от человека млекопитающие, такие как крысы или мыши), содержащие мутацию в гене Fbn1. Такие отличные от человека животные моделируют неонатальный прогероидный синдром с врожденной липодистрофией (NPSCL) и проявляют NPSCL-подобные симптомы (например, симптомы, подобное симптомам врожденной липодистрофии).
A. Неонатальный прогероидный синдром с врожденной липодистрофией (NPSCL).
[71] Неонатальный прогероидный синдром (NPS) характеризуется врожденной, частичной липодистрофией, преимущественно поражающей лицо и конечности. O'Neill et al. (2007) Am. J. Med. Gen. A. 143A: 1421-1430, включен в данный документ посредством ссылки в полном объеме для всех целей. Его также называют неонатальным прогероидным синдромом с врожденной липодистрофией (NPSCL), марфаноид-прогероидным синдромом или марфаноид-прогероид-липодистрофическим синдромом (MPL). Для него характерна врожденная крайняя худоба из-за уменьшения количества подкожной жировой ткани, преимущественно поражающей лицо и конечности. Смотрите Hou et al. (2009) Pediatrics and Neonatology 50:102-109 и O'Neill et al. (2007) Am. J. Med. Gen. A. 143A:1421-1430, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Фенотип обычно проявляется при рождении, и даже до рождения как задержка внутриутробного развития, с тонкой кожей и выраженной сосудистой системой из-за недостатка подкожного жира. O'Neill et al. (2007). Пациенты имеют индекс массы тела (ИМТ) на несколько стандартных отклонений меньший нормы для всех возрастов. O'Neill et al. (2007). Хотя пациенты с NPS кажутся прогероидными из-за дисморфных черт лица и уменьшенного количества подкожного жира, у них нет обычных признаков настоящей прогерии, таких как катаракта, преждевременное поседение волос или резистентность к инсулину. O'Neill et al. (2007). Пациенты могут иметь нормальные уровни глюкозы и инсулина в плазме натощак, что свидетельствует о нормальной чувствительности к инсулину и нормальном метаболизме глюкозы. O'Neill et al. (2007).
[72] Главные особенности пациентов с NPSCL включают в себя: (1) врожденная липодистрофия; (2) преждевременные роды с ускоренным линейным ростом, непропорциональным увеличению веса; и (3) прогероидная внешность с отчетливыми чертами лица. Смотрите, например, Takenouchi et al. (2013) Am. J. Med. Genet. Part A 161A:3057-3062, включен в данный документ посредством ссылки в полном объеме для всех целей. Jacquinet et al. сообщают о марфаноидно-прогероидном фенотипе, как таковом, который включает в себя следующее: задержка внутриутробного развития и/или преждевременные роды, старческие черты лица и уменьшенное количество подкожного жира при рождении, и прогрессирующие черты марфаноидов. Со временем может появиться расширение основания аорты, эктопия хрусталика и дуральная эктазия. Основные этапы развития и интеллект кажутся нормальными. Jacquinet et al. (2014) Eur. J. Med. Genet. 57(5):203-234, включен в данный документ посредством ссылки в полном объеме для всех целей.
[73] Фенотип, наблюдаемый у человеческих пациентов с NPSCL, в отличие от многих липодистрофических синдромов, представляет собой нормальный метаболический профиль с точки зрения гомеостаза глюкозы и циркулирующих липидов, несмотря на отсутствие висцеральной жировой ткани. Человеческие пациенты с NPSCL имеют нормальный гомеостаз глюкозы, несмотря на потерю белой жировой ткани.
[74] Отличные от человека животные модели, раскрытые в данном документе, проявляют NPSCL-подобные симптомы (например, симптомы, подобные симптомам врожденной липодистрофии). Такие симптомы могут включать в себя, например, одно или большее количество из следующего: уменьшенная масса тела, уменьшенная масса без жира, уменьшенная жировая масса, уменьшенное количество белой жировой ткани (например, нормализованное по массе тела), уменьшенное количество белой жировой ткани в сочетании с сохранением количества бурой жировой ткани (например, нормализованное по массе тела), уменьшенное процентное содержание жира в организме, увеличенное потребление пищи, нормализованное по массе тела, и увеличенный кифоз. Такие симптомы могут включать в себя, например, одно или большее количество из следующего: уменьшенная масса тела, уменьшенная масса без жира, уменьшенная жировая масса, уменьшенный процент жира в организме, увеличенное потребления пищи нормализованное по массе тела, и увеличенный кифоз. Такие симптомы могут быть в комбинации с одним или большим количеством из следующего: повышенная скорость метаболизма, улучшенная чувствительность к инсулину, обычная толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. В альтернативном варианте, такие симптомы могут быть в комбинации с одним или большим количеством из следующего: обычная толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Например, симптомы могут включать в себя, по меньшей мере, одно из: уменьшенная жировая масса и уменьшенное процентное содержание жира в теле, и, по меньшей мере, одно из: обычная толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. В альтернативном варианте, симптомы могут включать в себя: уменьшенную жировую массу, уменьшенное процентное содержание жира в теле, нормальную толерантность к глюкозе, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Другие возможные фенотипы включают в себя одно или большее количество из следующего: уменьшенная масса печени, уменьшенная масса бурой жировой ткани (BAT), уменьшенная масса висцеральной белой жировой ткани (WAT), уменьшенная масса WAT, нормализованная по массе тела, повышенная скорость метаболизма, нормализованная по массе тела, увеличенный расход энергии, улучшенная толерантность к глюкозе, и улучшенная чувствительность к инсулину на диете с высоким содержанием жиров. Например, симптомы могут включать в себя: уменьшенную массу белой жировой ткани (например, в комбинации с сохранением количества бурой жировой ткани), нормализованную по массе тела, в комбинации с по меньшей мере одним из: повышенная скорость метаболизма, улучшенная чувствительность к инсулину, нормальные уровни холестерина в сыворотке, нормальные уровни триглицеридов в сыворотке, и нормальные уровни неэтерифицированных жирных кислот в сыворотке. Например, симптомы могут включать в себя: уменьшенную массу белой жировой ткани (например, в комбинации с сохранением количества бурой жировой ткани), нормализованную по массе тела, в комбинации с улучшенной чувствительностью к инсулину.
[75] Уменьшение или увеличение может быть статистически значимым. Например, уменьшение или увеличение может составлять, по меньшей мере около 1%, по меньшей мере около 2%, по меньшей мере около 3%, по меньшей мере около 4%, по меньшей мере около 5%, по меньшей мере около 10%, по меньшей мере около 15%, по меньшей мере около 20%, по меньшей мере около 30%, по меньшей мере около 40%, по меньшей мере около 50%, по меньшей мере около 60%, по меньшей мере около 70%, по меньшей мере около 80%, по меньшей мере около 90%, или 100% по сравнению с контрольным, отличным от человека животным.
B. Мутации Fbn1
[76] NPSCL связывают с мутациями в гене FBN1 людей. Смотрите, например Takenouchi et al. (2013) Am. J. Med. Genet. Part A 161A:3057-3062; Graul-Neumann et al. (2010) Am. J. Med. Genet. A. 152A(ll):2749-2755; Goldblatt et al. (2011) Am. J. Med. Genet. A 155A(4):717-720; Horn and Robinson (2011) Am. J. Med. Genet. A. 155A(4);721-724; Jacquinet et al. (2014) Eur. J. Med. Genet. 57(5):203-234; и Romere et al. (2016) Cell 165(3):566-579, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. FBN1 представляет собой ген размером 230 т.п.н. с 65 кодирующими экзонами (всего 66 экзонов), которые кодируют структурный гликопротеин фибриллин-1, основной компонент микрофибрилл в эластичном и неэластичном внеклеточном матриксе. Профибриллин-1 транслируется в виде пропротеина длиной 2871 аминокислота, который расщепляется на С-конце протеазой фурин. В результате образуется отщепленный C-концевой продукт длиной 140 аминокислот (то есть аспрозин) в дополнение к зрелому фибриллину-1 (компонент внеклеточного матрикса). Иллюстративной последовательности человеческого фибриллина-1 присвоен номер доступа UniProt P35555.
[77] Клинически было идентифицировано больше чем 3000 мутаций в гене FBN1. Смотрите, например, Wang et al. (2016) Forensic Science International 261:el-e4 и Ошибка! Недопустимый объект гиперссылки., каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Была выявлена связь между данными мутациями и различными патологиями, включающими в себя фибриллинопатии I типа, синдром Марфана, синдром MASS, синдром изолированной эктопии хрусталика, аневризмы грудной аорты, синдром Вайля-Марчезани, гелеофизическую и акромическую дисплазию, синдром жесткой кожи (врожденная фасциальная дистрофия) и неонатальный прогероидный синдром с врожденной липодистрофией (NPSCL). Смотрите, например, Davis and Summers (2012) Mol. Genet. Metab. 107(4):635-647, включен в данный документ посредством ссылки в полном объеме для всех целей. Наиболее распространенным из них является аутосомно-доминантный синдром Марфана, включающий в себя глазные, сердечно-сосудистые и скелетные проявления. Смотрите Loeys et al. (2010) J. Med. Genet. 47(7):476-485 и Jacquinet et al. (2014) Eur. J. Med. Genet. 57(5):203-234, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Мутации при классическом синдроме Марфана разбросаны по всему гену FBN1 с ограниченными взаимоотношениями генотип-фенотип. Смотрите, например, Faivre et al. (2007) Am. J. Hum. Genet. 81(3):454-466 и Jacquinet et al. (2014) Eur. J. Med. Genet. 57(5):203-234, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[78] Отличные от человека животные модели NPSCL, раскрытые в данном документе, содержат мутацию в гене Fbn1, которая вызывает NPSCL-подобные симптомы (например, симптомы, подобные симптомам врожденной липодистрофии) у отличного от человека животного. Мутации могут быть в эндогенном гене Fbn1 в отличном от человека животном. В альтернативном варианте, отличное от человека животное может содержать гуманизированный локус Fbn1 в котором удалили или заместили весь или часть эндогенного гена Fbn1 соответствующей ортологичной последовательностью из человеческого гена FBN1 или другими ортологичными последовательностями из других млекопитающих, таких как приматы, отличные от человека. Замена на ортологичную последовательность может быть выполнена в конкретном экзоне или интроне для внесения мутации из ортологичных последовательностей. Замена может также включать в себя все экзоны, или все экзоны и интроны, или все экзоны, интроны и фланкирующие последовательности, включая регуляторные последовательности. В зависимости от масштаба замены ортологичными последовательностями регуляторные последовательности, такие как промотор, могут быть эндогенными или поставляемыми замещающей ортологичной последовательностью.
[79] Предпочтительно, отличное от человека животное является гетерозиготным по мутации. Предпочтительно мутация приводит к укорочению С-конца кодируемого белка. Например, мутация может вызвать сдвиг рамки считывания. Мутация сдвига рамки считывания - это изменение последовательности между кодоном инициации трансляции (стартовым кодоном) и терминирующим кодоном (стоп-кодоном), при котором по сравнению с эталонной последовательностью трансляция начинается с другой рамки считывания. Например, рамка считывания может быть сдвинута на один нуклеотид в направлении 5' (сдвиг рамки считывания -1) или на один нуклеотид в направлении 3' (сдвиг рамки считывания +1). Белок, кодируемый геном с мутацией сдвига рамки считывания, будет идентичен белку, кодируемому геном дикого типа начиная с N-конца до мутации сдвига рамки считывания, но отличаться, начиная с данной точки. Такие сдвиги рамки считывания могут привести к появлению преждевременного кодона терминации. Такие преждевременные кодоны терминации могут находиться, например, в предпоследнем экзоне или последнем экзоне. Необязательно, преждевременный кодон терминации находится на меньше чем около 100 пар оснований выше или на меньше чем около 55 пар оснований выше последнего соединения экзон-экзон. Например, преждевременный кодон терминации может быть на меньше чем около 100 пар оснований, 90 пар оснований, 80 пар оснований, 70 пар оснований, 60 пар оснований, 55 пар оснований, 50 пар оснований, 40 пар оснований, 30 пар оснований, 25 оснований пары или 20 пар оснований выше последнего соединения экзон-экзон в предпоследнем кодирующем экзоне. В альтернативном варианте, преждевременный кодон терминации может находиться в последнем кодирующем экзоне (например, в результате мутации сайта сплайсинга, приводящей к пропуску предпоследнего кодирующего экзона). Необязательно, преждевременный кодон терминации находится в последнем кодирующем экзоне (например, экзоне 65 мышиного Fbn1) или находится в предпоследнем экзоне (например, экзоне 64 мышиного Fbn1), причем если преждевременный кодон терминации находится в предпоследнем экзоне, то он находится на меньше чем около 55 пар оснований (например, на меньше чем около 20 пар оснований, например, 19 пар оснований) выше последнего соединения экзон-экзон. Необязательно, если преждевременный кодон терминации находится в пределах последнего кодирующего экзона, то он находится меньше чем на около 100 пар оснований, 90 пар оснований, 80 пар оснований, 70 пар оснований, 60 пар оснований, 55 пар оснований, 50 пар оснований, 40 пар оснований, 30 пар оснований, 25 пар оснований, 20 пар оснований, 15 пар оснований, или 10 пар оснований (например, 9 пар оснований) ниже последнего соединения экзон-экзон. Необязательно, преждевременный кодон терминации находится между позициями, соответствующими позициям 8150 и 8300, 8160 и 8290, 8170 и 8280, 8180 и 8270, 8190 и 8260, 8200 и 8250, 8210 и 8300, 8210 и 8290, 8210 и 8280, 8210 и 8270, 8210 и 8260, 8210 и 8250, 8200 и 8300, 8200 и 8290, 8200 и 8280, 8200 и 8270, 8200 и 8260, 8200 и 8250, 8150 и 8245, 8160 и 8245, 8170 и 8245, 8180 и 8245, 8190 и 8245, 8200 и 8245, 8150 и 8250, 8160 и 8250, 8170 и 8250, 8180 и 8250, 8190 и 8250, 8200 и 8250, или 8210 и 8245 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1, содержащий мутацию оптимально выровнен с SEQ ID NO: 20.
[80] Преждевременный кодон терминации может стать причиной появления укороченного белка с положительно заряженным С-концом. Среди 20 обычных аминокислот пять имеют боковую цепь, которая может быть заряжена. При pH=7 две заряжены отрицательно (аспарагиновая кислота (Asp, D) и глутаминовая кислота (Glu, E)), а три заряжены положительно (лизин (Lys, K), аргинин (Arg, R) и гистидин (His, H)). В некоторых случаях, преждевременный кодон терминации может стать причиной появления укороченного белка с чрезвычайно положительно заряженным С-концом (например, ETEKHKRN (SEQ ID NO: 34)). В альтернативном варианте, преждевременный кодон терминации может стать причиной появления укороченного белка с менее положительно заряженным С-концом (например, ISLRQKPM (SEQ ID NO: 35)).
[0081] Необязательно, мутация повреждает основную распознаваемую аминокислотную последовательность пропротеин-конвертаз семейства фуринов. (RGRKRR (SEQ ID NO: 36)). Например, мутация может приводить к укорачиванию белка выше последовательности, распознаваемой фурином, может приводить к мутации последовательности, распознаваемой фурином, или может приводить к сдвигу рамки считывания перед последовательностью, распознаваемой фурином. Необязательно, мутация находится в пределах 100 пар оснований основной распознаваемой аминокислотной последовательности пропротеин-конвертаз семейства фуринов. Например, мутация может находиться в пределах около 90 пар оснований, 80 пар оснований, 70 пар оснований, 60 пар оснований, 50 пар оснований, 40 пар оснований или 30 пар оснований последовательности, распознаваемой фурином. В качестве примера, такие мутации могут включать в себя инсерции или делеции нуклеотидов, приводящие к сдвигу рамки считывания в предпоследнем экзоне или последнем экзоне. В качестве другого примера, такие мутации могут включать в себя мутации донорного сайта сплайсинга, которые приводят к пропуску предпоследнего экзона и последующему сдвигу рамки считывания, что приводит к появлению преждевременного кодона терминации в последнем экзоне.
[82] У некоторых отличных от человека животных, мутация приводит к повреждению или удалению (например, гетерозиготной абляции) С-концевого продукта отщепления (то есть аспрозина) профибриллина-1. Повреждение или удаление С-концевого продукта отщепления может приводить к, например, повреждению основной распознаваемой аминокислотной последовательности пропротеин-конвертаз семейства фуринов. В альтернативном варианте, повреждение или удаление С-концевого продукта отщепления может быть вызвано, например, мутацией, создающей преждевременный кодон терминации, так что С-концевой продукт отщепления становиться укороченным. Нарушение аспросина приводит либо к снижению продуцирования аспрозина, либо к продуцированию аспрозина с пониженной активностью. У некоторых отличных от человека животных, ген Fbn1 содержит мутацию в предпоследнем экзоне. Например, предпоследний экзон гена Fbn1 может содержать мутации, соответствующие мутациям в SEQ ID NO: 26, 27 или 28 (предпоследние экзоны из аллелей 8501, 8520 и 8502 MAID соответственно) относительно предпоследнего экзон Fbn1 мыши дикого типа (SEQ ID NO: 25), когда предпоследний экзон оптимально выровнен с SEQ ID NO: 26, 27 или 28.
[83] У некоторых отличных от человека животных, белок Fbn1, кодируемый мутированным геном Fbn1 является укороченным в позиции, соответствующей позиции между аминокислотами 2710 и 2780, между аминокислотами 2720 и 2770, между аминокислотами 2730 и 2760, или между аминокислотами 2737 и 2755, в мышином белке Fbn1 дикого типа, как указано в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30. Например, кодируемый белок может быть укорочен так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2737, аминокислоте 2738 или аминокислоте 2755 в мышином белке Fbn1 дикого типа, представленном в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30. Аналогично, кодируемый белок может быть укорочен так, что последняя аминокислота находится в позиции, соответствующей последней аминокислоте укороченных белков Fbn1, кодируемых вариантами 8501, 8502 и 8520 Fbn1 MAID, описанными в данном документе.
[84] В качестве другого примера, кодируемый белок может иметь С-конец, состоящий из последовательности, представленной в SEQ ID NO: 8, 42 или 43, или кодируемый белок может иметь С-конец, соответствующий С-концу белков, кодируемых вариантами 8501, 8502 и 8520 Fbn1 MAID, описанными в данном документе. Например, кодируемый белок может быть укорочен так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2737 в мышином белке Fbn1 дикого типа, представленном в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 43. В качестве другого примера, кодируемый белок может быть укорочен так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2738 в мышином белке Fbn1 дикого типа, представленном в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 8. В качестве другого примера, кодируемый белок может быть укорочен так, что последняя аминокислота находится в позиции, соответствующей аминокислоте 2755 в мышином белке Fbn1 дикого типа, представленном в SEQ ID NO: 30, когда кодируемый белок оптимально выровнен с SEQ ID NO: 30, и С-конец кодируемого белка состоит из последовательности, представленной в SEQ ID NO: 42. Иллюстративные укороченные белки Fbn1 включают в себя SEQ ID NO: 31, 32 и 33.
[85] Ген Fbn1 относится к любому известному гену, кодирующему белок Fbn1, такой как описано в базах данных Swiss-Prot и GenBank, и включает в себя варианты этих белков, как описано в таких базах данных, или в другом случае имеющие по меньшей мере 95, 96, 97, 98 или 99% идентичности с последовательностями дикого типа, включая гибриды таких генов, и включая любой такой ген или гибрид таких генов, модифицированных мутацией для получения NPSCL-подобных симптомов (например, симптомов, подобных симптомам врожденной липодистрофии), как дополнительно описано в данном документе. Если присутствуют какие-либо вариации, отличные от остатков, мутированных для получения NPSCL-подобных симптомов, эти вариации предпочтительно не влияют на кодирующие последовательности или, если они действительно влияют на кодирующие последовательности, предпочтительно делают это путем введения консервативных замен.
[86] У некоторых отличных от человека животных, раскрытых в данном документе, эндогенный ген Fbn1 мутируют, чтобы вызвать NPSCL-подобные симптомы. Иллюстративным последовательностям фибриллина-1 мыши присвоены номер доступа NM_007993.2 или номер доступа Q61554 UniProt. Иллюстративным последовательностям фибриллина-1 крысы присвоены номер доступа NM_031825.1 или номер доступа Q9WUH8 UniProt. Другие иллюстративные последовательности фибриллина-1 включают в себя номера доступа NM_001001771.1 (свинья), NM_001287085.1 (собака), и NM_174053.2 (корова). Мышиный ген Fbn1 находится на длинном плече хромосомы 15 в локусе 15q15-q21.1. Megenis et al. (1991) Genomics 11:346-351, включен в данный документ посредством ссылки в полном объеме для всех целей. Как и человеческий FBN1, это очень большой ген, который сильно фрагментирован на 65 экзонов. Pereira et al. (1993) Hum. Mol. Genet. 2:961-968, включен в данный документ посредством ссылки в полном объеме для всех целей.
[87] Такие мутации в эндогенном гене Fbn1 могут соответствовать мутациям, идентифицированным в человеческом человека Fbn1 у пациентов с диагнозом NPSCF, как описано в другом месте данного документа. Остаток (например, нуклеотид или аминокислота) в эндогенном гене Fbn1 (или белке) может быть определен как соответствующий остатку в человеческом гене FBN1 (или белке) путем оптимального выравнивания двух последовательностей для максимального соответствия в обозначенном окне сравнения (например, кодирующая последовательность Fbn1), причем часть полинуклеотидной (или аминокислотной) последовательности в окне сравнения может содержать инсерции или делеции (то есть пробелы) по сравнению с эталонной последовательностью (которая не содержит вставок или делеций) для оптимального выравнивания двух последовательностей (смотрите, например, обсуждение в другом месте в данном документе относительно идентичности и комплементарности последовательностей). Два остатка являются совпадающими, если они расположены в одной и той же позиции при оптимальном выравнивании.
[88] Конкретным примером мутации в гене Fbn1 мыши, которая вызывает NPSCL-подобные симптомы, является к.8207_8208ins1bp (эталонная последовательность NM_007993.2 или эталонная последовательность SEQ ID NO: 20). Некоторые отличные от человека животные, раскрытые в данном документе, содержат ген Fbn1 с мутацией, соответствующей к.8207_8208ins1bp в NM_007993.2 или SEQ ID NO: 20, когда ген Fbn1 оптимально выровнен с NM_007933.2 или SEQ ID NO: 20. Конкретным примером мутаций в последовательности гена Fbn1 мыши, которые могут вызывать NPSCL-подобные симптомы, являются мутации в SEQ ID NO: 21, 22 или 23 относительно SEQ ID NO: 20 (кДНК Fbn1 мыши WT), или мутации в SEQ ID NO: 26, 27 или 28 относительно SEQ ID NO: 25 (предпоследний экзон кДНК Fbn1 WT). Конкретные примеры мутированных белков Fbn1 мыши, которые могут воспроизводить NPSCL-подобные симптомы представляют собой SEQ ID NO: 31, 32, и 33.
У других отличных от человека животных, описанных в данном документе, весь или часть эндогенного гена Fbn1 удаляют и замещают соответствующей последовательностью из гена Fbn1 человека. Например, последовательность гена Fbn1 человека может размещаться в эндогенном локусе Fbn1 (то есть гуманизирован весь или часть эндогенного локуса Fbn1). У таких отличных от человека животных, соответствующая последовательность человеческого гена FBN1 может содержать мутацию, которая вызывает NPSCL-подобные симптомы. Иллюстративной последовательности кДНК FBN1 человека присвоен номер доступа NM_000138.3, а иллюстративной последовательности белка фибриллина-1 человека присвоен номер доступа P35555 UniProt. Когда конкретные позиции мутаций в человеческом гене FBN1 упоминаются в данном документе, они относятся к кДНК FBN1 NM_000138.3 (транскрипт FBN1-201 = ENST00000316623 Ensembl). Аналогично, когда в данном документе упоминаются интроны или экзоны гена FBN1 человека, они относятся к эталонной последовательности NM_000138.3 и ENST00000316623, причем нумерация экзонов начинается с экзона 2 в соответствии с локализацией стартового кодона ATG (то есть нумерация экзонов начинается с первого кодирующего экзона). Нумерация позиций мутаций основана на номенклатуре вариантов последовательностей Общества вариаций генома человека (HGVS) (varnomen.hgvs.org). Префикс «к» указывает на то, что эталонная последовательность представляет собой эталонную последовательность кодирующей ДНК (на основе транскрипта, кодирующего белок). Нумерация начинается с «к.1» с «A» кодона инициации трансляции «ATG» (старт) и заканчивается последним нуклеотидом кодона терминации (стоп) трансляции (то есть TAA, TAG или TGA). Нуклеотиды на 5'-конце интрона пронумерованы относительно последнего нуклеотида непосредственно расположенного выше экзона, за которым следует "+" (плюс) и их позиция в интроне (например, к.87+1). Нуклеотиды на 3'-конце интрона пронумерованы относительно первого нуклеотида непосредственно расположенного ниже экзона, за которым следует (минус) и их позиция вне интрона (например, к.88-3). Мутации замещения, при которых по сравнению с эталонной последовательностью один нуклеотид замещен другим нуклеотидом, имеют формат «префикс»«замещенная_позиция»«эталонный_нуклеотид»> «новый_нуклеотид» (например, к.123A> G указывает, что эталонная последовательность представляет собой кодирующую эталонную последовательность ДНК, и «A» в позиции 123 в эталонной последовательности заменяют на «G». Мутации в виде делеции, при которых по сравнению с эталонной последовательностью отсутствует один или большее количество нуклеотидов, имеют формат «префикс»«позиция_делеции»«del» (например, к.123_127del указывает, что нуклеотиды в позициях 123-127 в кодирующей эталонной последовательности ДНК удалены). Мутации в виде инсерции, при которых по сравнению с эталонной последовательностью вставляют один или большее количество нуклеотидов, и при это минсерция не копирует последовательность сразу же после 5' имеют формат «префикс»«позиции_инсерции»«ins»«вставленная_последовательность» (например, к.123_124insAGC указывает, что последовательность AGC вставлена между позициями 123 и 124 эталонной последовательности кодирующей ДНК). Мутации в виде инсерции/делеции (indel), при которых по сравнению с эталонной последовательностью один или большее количество нуклеотидов замещены одним или большим количеством других нуклеотидов (и при этом мутация не является заменой, инверсией или конверсией), имеют формат «префикс»«удаленная_позиция(ции)»«delins» «вставленная_последовательность» (например, к. 123_127delinsAG указывает на то,
что последовательность между позициями 123 и 127 была удалена и замещена последовательностью «AG» в кодирующей эталонной ДНК-последовательности).
[90] Предпочтительно, мутация находится между к.8100 и к.8300, или к.8150 и к.8250 в последовательности FBN1 человека или в соответствующих позициях в последовательности FBN1 не человека, когда оптимально выровнена с последовательностью FBN1 человека. Иллюстративные мутации в гене FBN1 человека включают в себя инсерции или делеции нуклеотидов, приводящие к сдвигу рамки считывания. Смотрите, например, Takenouchi et al. (2013) Am. J. Med. Genet. Part A 161A:3057-3062; Graul-Neumann et al. (2010) Am. J. Med. Genet. A. 152A(ll):2749-2755; и Goldblatt et al. (2011) Am. J. Med. Genet. A 155A(4):717-720, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Одним из примеров такой мутации в человеческом гене FBN1 является к.8155_8156del. Это делеция двух пар оснований в кодирующем экзоне 64 (предпоследний экзон), что вызывает сдвиг рамки считывания с последующим появлением преждевременного кодона терминации 17 кодонов после p.Lys2719. Смотрите, например, Graul-Neumann et al. (2010) Am. J. Med. Genet. A. 152A(ll):2749-2755. Другим примером такой мутации в человеческом гене FBN1, которая приводит к сдвигу рамки считывания, что приводит к появлению такого же преждевременного кодона терминации, является к.8156_8175del. Смотрите, например, Goldblatt et al. (2011) Am. J. Med. Genet. A 155A(4):717-720. Еще одним примером такой мутации в человеческом гене FBN1, которая приводит к сдвигу рамки считывания, что приводит к появлению такого же преждевременного кодона терминации, является к.8175_8182del. Смотрите, например, Takenouchi et al. (2013) Am. J. Med. Genet. Part A 161A:3057- 3062. Другим примером такой мутации в человеческом гене FBN1, приводящей к появлению преждевременного кодона терминации в кодирующем экзоне 64, является к.8206_8207insA. Смотрите, например, Romere et al. (2016) Cell 165(3):566-579. Описанные в данном документе отличные от человека животные, могут содержать ген Fbn1 с мутациями, соответствующими любой из даных мутаций, когда последовательность гена Fbn1 оптимально выровнена с геном Fbn1 человека, соответствующим последовательности кДНК, представленной под номером доступа NM_000138.3.
[91] Другие иллюстративные мутации в гене FBN1 человека включают в себя мутации донорного сайта сплайсинга, которые приводят к пропуску предпоследнего экзона (экзон 64) и последующему сдвигу рамки считывания, что приводит к появлению преждевременного кодона терминации в последнем экзоне (экзон 65). Смотрите, например, Horn and Robinson (2011) Am. J. Med. Genet. A. 155A(4):721-724 и Jacquinet et al. (2014) Eur. J. Med. Genet. 57(5):203-234, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Одним из примеров такой мутации в гене FBN1 человека является к.8226+1G>A. Смотрите, например, Jacquinet et al. (2014) Eur. J. Med. Genet. 57(5):203-234. Другим примером такой мутации в гене FBN1 человека является c.8226+1G>T. Смотрите, например, Horn and Robinson (2011) Am. J. Med. Genet. A. 155A(4):721-724 и Romere et al. (2016) Cell 165(3):566-579. Данные мутации влияют на донорный сайт сплайсинга интрона 64, изменяя высококонсервативный динуклеотид GT, и приводят к пропуску кодирующего экзона 64 и продуцированию стабильной мРНК, которая позволяет синтезировать укороченный профибриллин-1, в котором C-концевой сайт расщепления фурином изменен. Пропуск экзона 64 приводит к сдвигу рамки считывания в начале кодирующего экзона 65, и появлению преждевременного кодона терминации в девятом кодоне после сдвига.
[92] Описанные в данном документе отличные от человека животные, могут содержать ген Fbn1 с мутациями, соответствующими любой из даных мутаций, когда последовательность гена Fbn1 оптимально выровнена с последовательностью гена Fbn1 человека, соответствующей последовательности кДНК, представленной под номером доступа NM_000138.3. Аналогично, отличные от человека животные, описанные в данном документе, могут содержать ген Fbn1 с мутациями так, что мутантный ген Fbn1 кодирует белок Fbn1, соответствующий любому из человеческих белков FBN1, кодируемых любым из мутантных генов Fbn1 человека, описанных в данном документе. Точно так же кодируемый белок может быть укорочен так, что последняя аминокислота находится в позиции, соответствующей последней аминокислоте укороченных белков Fbn1, кодируемых любым из мутантных человеческих генов FBN1, описанных в данном документе, и/или может иметь С-конец, идентичный С-концу укороченных белков Fbn1, кодируемых любым из мутантных человеческих генов FBN1, описанных в данном документе.
[93] Некоторые иллюстративные мутантные аллели Fbn1 являются мутантными аллелями Fbn1 мыши. Например, мутация в мутантном аллеле Fbn1 мыши может включать в себя инсерцию или делецию в предпоследнем экзоне (экзон 64), который вызывает -1 сдвиг рамки считывания и приводит к появлению преждевременного кодона терминации на 3'-конце предпоследнего экзон (экзон 64) или 5'-конце последнего экзона (экзон 65) Fbn1.
[94] В качестве одного примера, мутация может включать в себя вставку или делецию в экзоне 64, которая вызывает -1 сдвиг рамки считывания и приводит к появлению преждевременного кодона терминации на 5'-конце экзона 65, как в аллеле MAID 8520, описанном в Примере 2, и представленном в SEQ ID NO: 22. Необязательно, инсерция или делеция находится выше позиции, соответствующей позиции 8241 (например, инсерция между позициями, соответствующими позициям 8179 и 8180) в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1, содержащий мутацию, оптимально выровнен с SEQ ID NO: 20, и/или преждевременный кодон терминации находится в позиции, соответствующей позиции 8241 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1, содержащий мутацию, оптимально выровнен с SEQ ID NO: 20.
[95] В качестве другого примера, мутация может включать в себя инсерцию или делецию в предпоследнем экзоне (экзон 64), которая вызывает -1 сдвиг рамки считывания и приводит к появлению преждевременного кодона терминации на 3'-конце предпоследнего экзона (экзон 64), как в аллеле MAID 8501, описанном в Примере 1, и представленном в SEQ ID NO: 21, или аллеле MAID 8502, описанном в Примере 2, и представленном в SEQ ID NO: 23. Необязательно, инсерция или делеция находится выше позиции, соответствующей позиции 8214 (например, инсерция между позициями, соответствующими позициям 8209 и 8210, или делеция, начинающаяся с позиции, соответствующей позиции 8161) в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1, содержащий мутацию, оптимально выровнен с SEQ ID NO: 20, и/или преждевременный кодон терминации находится в позиции, соответствующей позиции 8214 в кодирующей последовательности Fbn1 мыши дикого типа, представленной в SEQ ID NO: 20, когда ген Fbn1, содержащий мутацию, оптимально выровнен с SEQ ID NO: 20.
[96] Одним из примеров мутантного аллеля Fbn1 мыши является аллель MAID 8501, описанный в Примере 1 и представленный в SEQ ID NO: 21. Белок, кодируемый аллелем MAID 8501, представлен в SEQ ID NO: 31. Используя NM_007993.2 в качестве эталонной последовательности, мутация в этом мутантном аллеле Fbn1 представляет собой к.8213_8214delinsACT. Данная мутация, которая была создана путем инсерции A между к.8212 и 8213, и замены G>T в к.8214, приводит к появлению преждевременного кодона терминации в предпоследнем экзоне (экзон 64) Fbn1, 19 нуклеотидов выше границы между экзонами 64 и 65. Мутация находится в пределах последних 50 нуклеотидов (последние 24 нуклеотида) предпоследнего экзона и, как предполагается, избегает нонсенс-опосредованного распада (NMD) мРНК, что приводит к экспрессии мутантного укороченного белка профибриллина.
[97] Другим иллюстративным мышиным аллелем является аллель MAID 8502, описанный в Примере 2 и представленный в SEQ ID NO: 23. Белок, кодируемый аллелем MAID 8502, представлен в SEQ ID NO: 33. Это мутантный аллель Fbn1, соответствующий человеческому аллелю к.8155_8156del Fbn1, который имеет делецию двух пар оснований в кодирующем экзоне 64 (предпоследнем экзоне), которая вызывает сдвиг рамки считывания с последующим появлением преждевременного кодона терминации 17 кодонов после p.Lys2719. В аллеле MAID 8502 делеция двух пар оснований находится на 71 нуклеотид выше границы между экзонами 64 и 65. Мутация приводит к появлению преждевременного кодона терминации в предпоследнем экзоне (экзон 64) Fbn1 мыши, 19 нуклеотидов выше границы между экзонами 64 и 65.
[98] Другим иллюстративным мышиным аллелем является аллель MAID 8520, описанный в Примере 2 и представленный в SEQ ID NO: 22. Белок, кодируемый аллелем MAID 8520, представлен в SEQ ID NO: 32. Используя NM_007993.2 в качестве эталонной последовательности, мутация в этом мутантном аллеле Fbn1 представляет собой 8179_8180insAGGCGGCCCAGAGCCACCTGCCAGC. Данная мутация была создана путем инсерции 25 п.н. (вставленная последовательность представлена в SEQ ID NO: 44) в предпоследней экзон (экзон 64), 54 нуклеотида выше границы между экзонами 64 и 65. Это приводит к сдвигу рамки считывания в предпоследнем экзоне (экзоне 64) Fbn1 мыши. Мутация приводит к появлению преждевременного кодона терминации в последнем экзоне (экзон 65) мышиного Fbn1, 9 нуклеотидов ниже границы между экзонами 64 и 65.
[99] Каждый из приведенных выше иллюстративных аллелей Fbn1 мыши имеет мутацию сдвига рамки считывания в предпоследнем экзоне (экзоне 64) гена Fbn1 мыши. Каждая мутация сдвига рамки считывания приводит к появлению преждевременного кодона терминации либо на 3'-конце предпоследнего экзона (экзон 64), либо на 5'-конце последнего экзона (экзон 65) гена Fbn1 мыши. Поскольку каждая мутация приводит к появлению преждевременного кодона терминации, каждая мутация повреждает или аблирует С-концевой продукт отщепления (то есть аспрозин) профибриллина-1, потому что С-концевой продукт отщепления, если он продуцируется, обязательно также будет укорочен. Кроме того, каждый из приведенных иллюстративных аллелей Fbn1 мыши дает продукт с положительно заряженный С-концом из-за большего количества лизинов, аргининов и гистидинов по сравнению с аспарагиновой кислотой и глутаминовой кислотой. Последние 14 аминокислот белков Fbn1, кодируемых аллелями MAID 8501, MAID 8502 и MAID 8520, которые представлены в SEQ ID NO: 45, 46 и 47, соответственно.
C. Отличные от человека животные
[100] Любое подходящее животное, отличное от человека, может быть использовано в качестве модели NPSCL, как раскрыто в данном документе. Такими отличными от человека животными предпочтительно являются млекопитающие, такие как грызуны (например, крысы, мыши и хомяки). Другие отличные от человека млекопитающие включают в себя, например, отличных от человека приматов, обезьян, человекоподобных приматов, кошек, собак, кроликов, лошадей, быков, оленей, бизонов, домашний скот (например, виды крупного рогатого скота, такие как коровы, быки и т. д.; виды полорогих, такие как овцы, козы и так далее, и виды свиней, такие как домашние свиньи и кабаны). Термин «отличный от человека» исключает людей.
[101] Мыши, используемые в качестве отличных от человека животных моделей, описанных в данном документе, могут быть любой линии, включая, например, линию 129, линию C57BL/6, линию BALB/с, линию Swiss Webster, гибрид линий 129 и C57BL/6, гибрид линий BALB/c и C57BL/6, гибрид линий 129 и BALB/c, и гибрид линий BALB/c, C57BL/6 и 129. Например, мышь может быть, по меньшей мере, частично линии BALB/c (например, по меньшей мере на около 25%, по меньшей мере на около 50%, по меньшей мере на около 75% получена из линии BALB/c, или на около 25%, на около 50%, на около 75% или на около 100% получена из линии BALB/c). В одном примере, мыши происходят из линии, включающей в себя 50% BALB/c, 25% C57BL/6 и 25% 129. В альтернативном варианте, мыши могут быть линии или комбинации линий, которые исключают BALB/c.
[102] Примеры линий 129 включают в себя 129P1, 129P2, 129P3, 129X1, 129S1 (например, 129S1/SV, 129Sl/Svlm), 129S2, 129S4, 129S5, 129S9/SvEvH, 129S6 (129/SvEvTac), 129S7, 129S8, 129T1 и 129T2. Смотрите, например, Festing et al. (1999) Mammalian Genome 10(8):836, включен в данный документ посредством ссылки в полном объеме для всех целей. Примеры линий C57BL включают в себя C57BL/A, C57BL/An, C57BL/GrFa, C57BL/Kal_wN, C57BL/6, C57BL/6J, C57BL/6ByJ, C57BL/6NJ, C57BL/10, C57BL/10ScSn, C57BL/10Cr, и C57BL/O1a. Мыши, используемые в виде отличных от человека животных моделей, предложенных в данном документе, также могут быть гибридами вышеупомянутой линии 129 и вышеупомянутой линии C57BL/6 (например, 50% 129 и 50% C57BL/6). Аналогично, мыши, используемые в виде отличных от человека животных моделей, предложенных в данном документе, могут быть гибридами вышеупомянутых линий 129 или гибридами вышеупомянутых линий BL/6 (например, линия 129S6 (129/SvEvTac)).
[103] Крысы, используемые в виде отличных от человека животных моделей, предложенных в данном документе, могут быть любой крысиной линии, включая, например, линию крыс ACI, линию крыс Dark Agouti (DA), линию крыс Wistar, линию крыс LEA, линию крыс Sprague Dawley (SD) или линию крыс Фишера, такую как Fisher F344 или Fisher F6. Крысы также могут быть из линии, полученной в результате гибридизации двух или большего количества линий, указанных выше. Например, крыса может быть линии DA или линии ACI. Крысиная линия ACI характеризуется тем, что имеет цвет черного агути, белый живот и лапы, и гаплотип RT1av1. Такие линии можно получить в различных местах, включая Harlan Laboratories. Линия крыс Dark Agouti (DA) характеризуется тем, что имеет цвет черного агути гаплотип RT1av1. Таких крыс можно получить в различных местах, включая Charles River и Harlan Laboratories. В некоторых случаях, крысы представляют собой крыс из инбредной крысинной линии. Смотрите, например, US 2014/0235933 A1, включен в данный документ посредством ссылки в полном объеме для всех целей.
II. II. Получение животных моделей неонатального прогероидного синдрома с врожденной липодистрофией
A. Создание мутаций Fbn1 в клетках
[104] Предложены различные способы модификации гена Fbn1 в геноме клетки (например, плюрипотентной клетки или эмбрионе на одноклеточной стадии) с использованием нуклеазных агентов и/или экзогенных шаблонов репарации. Способ может быть выполнен in vitro, ex vivo, или in vivo. Нуклеазный агент может быть применен отдельно или в комбинации с экзогенным шаблоном репарации. В альтернативном варианте, экзогенный шаблон репарации может быть применен отдельно или в комбинации с нуклеазным агентом.
[105] Репарация в ответ на двухцепочечные разрывы (DSB) происходит главным образом через два консервативных пути репарации ДНК: негомологичное соединение концов (NHEJ) и гомологичная рекомбинация (HR). Смотрите Kasparek & Humphrey (2011) Seminars in Cell & Dev. Biol. 22:886- 897, включен в данный документ посредством ссылки в полном объеме для всех целей. NHEJ включает в себя репарацию двухцепочечных разрывов в нуклеиновой кислоте путем прямого лигирования концов разрывов друг с другом или с экзогенной последовательностью без необходимости наличия гомологичной матрицы. Лигирование несмежных последовательностей посредством NHEJ часто может приводить к делециям, инсерциям или транслокациям вблизи сайта двухцепочечного разрыва.
[106] Репарация нуклеиновой кислоты-мишени (например, гена Fbn1), опосредованная репарацией с помощью экзогенного шаблона, может включать в себя любой процесс обмена генетической информацией между двумя полинуклеотидами. Например, NHEJ может также привести к целевой интеграции экзогенного шаблона репарации посредством прямого лигирования концов разрыва с концами экзогенного шаблона репарации (то есть захвата на основе NHEJ). Такая NHEJ-опосредованная целевая интеграция может быть предпочтительной для инсерции экзогенного шаблона репарации, когда пути гомологичной прямой репарации (HDR) невозможно использовать (например, в неделящихся клетках, первичных клетках и клетках, в которых плохо работает гомологическая репарация ДНК). Кроме того, в отличие от гомологичной репарации, не требуется информация об идентичности относительно больших областей последовательностей, фланкирующих сайт расщепления (за пределами «липких» концов, созданных Cas-опосредованным расщеплением), что может быть полезным при попытке целенаправленной инсерции в организмы, которые имеют геномы, для которых мало что известно о геномной последовательности. Интеграция может происходить посредством лигирования тупых концов экзогенного шаблона репарации и расщепленной геномной последовательности, или посредством лигирования липких концов (то есть, имеющих 5' или 3' выступы) с использованием экзогенного шаблона репарации, который фланкирован липкими концами, которые совместимы с теми, которые создаются белком Cas в расщепленной геномной последовательности. Смотрите, например, US 2011/020722, WO 2014/033644, WO 2014/089290, и Maresca et al. (2013) Genome Res. 23(3):539-546, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Если лигируют тупые концы, то может потребоваться укорачивание мишени и/или донора для создания областей микрогомологии, необходимых для соединения фрагментов, что может привести к нежелательным изменениям в последовательности-мишени.
[107] Репарация также может происходить посредством гомологичной прямой репарации (HDR) или гомологичной рекомбинации (HR). HDR или HR включает в себя форму восстановления нуклеиновой кислоты, которая может требовать гомологии нуклеотидных последовательностей, использует «донорную» молекулу в качестве матрицы для восстановления молекулы «мишени» (то есть той, которая претерпела двухцепочечный разрыв) и приводит к переносу генетической информации от донора к мишени. Не желая быть связанными какой-либо конкретной теорией, такой перенос может включать в себя коррекцию неполной комплементарности гетеродуплекса ДНК, который формируется между поврежденной мишенью и донором, и/или отжиг синтез-зависимой цепи, при котором донор используется для повторного синтеза генетической информации, которая станет частью мишени, и/или связанные процессы. В некоторых случаях, донорный полинуклеотид, часть донорного полинуклеотида, копия донорного полинуклеотида, или часть копии донорного полинуклеотида, интегрируется в ДНК-мишень. Смотрите Wang et al. (2013) Cell 153:910-918; Mandalos et al. (2012) PLOS ONE 7:e45768:1-9; и Wang et al. (2013) Nat Biotechnol. 31:530-532, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[108] Целевые генетические модификации гена Fbn1 в геноме могут быть получены путем приведения в контакт клетки с экзогенным шаблоном репарации, содержащим 5'-гомологичное плече, которое гибридизируется с 5'-последовательностью-мишенью в геномном локусе-мишени в гене Fbn1 и 3'-гомологичное плечо, которое гибридизируется с 3'-последовательностью-мишенью в геномном локусе-мишени в гене Fbn1. Экзогенный шаблон репарации может рекомбинировать с геномным локусом-мишенью, чтобы внести целевую генетическую модификацию в ген Fbn1. Такие способы могут давать, например, ген Fbn1, модифицированный так, что содержит мутацию, приводящую к укорачиванию С-конца кодируемого белка. Примеры экзогенных шаблонов репарации описаны в данном документе в другом месте.
[109] Целевые генетические модификации гена Fbn1 в геноме также могут быть получены путем приведения в контакт клетки с нуклеазным агентом, который индуцирует один или большее количество одноцепочечных или двухцепочечных разрывов в распознаваемой последовательности в геномном локусе-мишени в пределах гена Fbn1. Такие способы могут давать, например, ген Fbn1, модифицированный так, что содержит мутацию, приводящую к укорачиванию С-конца кодируемого белка. Примеры и варианты нуклеазных агентов, которые могут быть применены в способах, описаны в другом месте данного документа.
[110] Например, целевые генетические модификации гена Fbn1 в геноме могут быть получены путем приведения в контакта клетки с белком Cas и одной или большим количеством направляющих РНК, которые гибридизуются с одной или большим количеством последовательностей, распознаваемых направляющей РНК, в пределах геномного локуса-мишени в гене Fbn1. Например, такие способы могут включать в себя приведение в контакт клетки с белком Cas и направляющей РНК, которая гибридизируется с последовательностью, распознаваемой направляющей РНК, в гене Fbn1. Белок Cas и направляющая РНК образуют комплекс, и белок Cas расщепляет последовательность, распознаваемую направляющей РНК. Расщепление белком Cas9 может создать двухцепочечный разрыв или одноцепочечный разрыв (например, если белок Cas9 является никазой). Такие способы могут давать, например, ген Fbn1, модифицированный так, что содержит мутацию, приводящую к укорачиванию С-конца кодируемого белка. Примеры и варианты белков Cas9 и направляющих РНК, которые могут быть применены в способах, описаны в другом месте данного документа.
[0111] Необязательно, клетка может дополнительно быть приведена в контакт с одной или большим количеством дополнительных направляющих РНК, которые гибридизируются с последовательностями, распознаваемыми дополнительными направляющими РНК, в пределах геномного локуса-мишени в гене Fbn1. Путем приведение в контакт зиготы с одной или большим количеством дополнительных направляющих РНК (например, с второй направляющей РНК, которая гибридизируется с последовательностью, распознаваемой второй направляющей РНК), расщепление белком Cas может создать два или большее количество двухцепочечных разрывов, или два или большее количество одноцепочечных разрывы (например, если белок Cas является никазой).
[112] Необязательно, клетка может быть дополнительно приведена в контакт с одним или большим количеством экзогенных шаблонов репарации, которые рекомбинируют с геномным локусом-мишенью в гене Fbn1, чтобы получить целевую генетическую модификацию. Примеры и варианты экзогенных шаблонов репарации, которые могут быть использованы в способах, раскрыты в другом месте данного документа.
[113] В клетку могут быть введены белок Cas, направляющая(щие) РНК, экзогенный(нные) шаблон(ы) репарации, в любой форме и любым способом, как описано в другом месте данного документа, и все или некоторые из белков Cas, направляющих РНК и экзогенных шаблонов репарации могут быть введены одновременно или последовательно в любой комбинации.
[114] В некоторых таких способах, репарация нуклеиновой кислоты-мишени (например, гена Fbn1) с помощью экзогенного шаблона репарации происходит посредством гомологической прямой репарации (HDR). Гомологическая прямая репарация может происходить, когда белок Cas расщепляет обе цепи ДНК в гене Fbn1, создавая двухцепочечный разрыв, когда белок Cas представляет собой никазу, которая расщепляет одну цепь ДНК в нуклеиновой кислоте-мишени, чтобы создать однонитевой разрыв, или когда никазы Cas используются для создания двухцепочечного разрыва, сформированного двумя разнесенными разрывами. В таких способах экзогенный шаблон репарации содержит 5' и 3' гомологичные плечи, соответствующие 5' и 3' последовательностям-мишеням. Последовательность(ти), распознаваемая(мые) направляющей РНК, или сайт(ы) расщепления может быть смежной(смежным) с 5'-последовательностью-мишенью, смежной(смежным) с 3'-последовательностью-мишенью, смежной(смежным) как с 5'-последовательностью-мишенью, так и с 3'-последовательностью-мишенью, или не быть смежной(смежным) ни с 5'-последовательностью-мишенью, ни с 3'-последовательностью-мишенью. Необязательно, экзогенный шаблон репарации может дополнительно содержать нуклеотидную вставку, фланкированную 5'- и 3'-гомологичными плечами, и нуклеотидную вставку вносят между 5'- и 3'-последовательностями-мишенями. Например, нуклеотидная вставка может содержать одну или большее количество модификаций по сравнению с последовательностью Fbn1 дикого типа отличного от человека животного, или она может содержать всю или часть кодирующей последовательности человеческого Fbn1, содержащую одну или большее количество модификаций по сравнению с человеческой последовательностью Fbn1 дикого типа. Если есть нуклеотидная вставка, то экзогенный шаблон репарации может функционировать так, чтобы удалять геномную последовательность между 5'- и 3'-последовательностями-мишенями. Примеры экзогенных шаблонов репарации описаны в данном документе в другом месте.
[115] В альтернативном варианте, репарация гена Fbn1, опосредованная экзогенным шаблоном репарации, может происходить через лигирование, опосредованное негомологичным соединением концов (NHEJ). В таких способах, по меньшей мере один конец экзогенного шаблона репарации содержит короткую одноцепочечную область, которая комплементарна, по меньшей мере одному липкому концу, созданному Cas-опосредованным расщеплением гена Fbn1. Комплементарный конец в экзогенном шаблоне репарации может фланкировать нуклеотидную вставку. Например, каждый конец экзогенного шаблона репарации может содержать короткую одноцепочечную область, которая комплементарна липкому концу, созданному Cas-опосредованным расщеплением гена Fbn1, и эти комплементарные области в экзогенном шаблоне репарации могут фланкировать нуклеотидную вставку. Например, нуклеотидная вставка может содержать одну или большее количество модификаций по сравнению с последовательностью Fbn1 дикого типа отличного от человека животного, или она может содержать всю или часть кодирующей последовательности FBN1 человека, содержащей одну или большее количество модификаций по сравнению с человеческой последовательностью FBN1 дикого типа.
[116] Липкие концы (то есть ступенчатые концы) могут быть созданы путем вырезания в тупых концах двухцепочечного разрыва, созданного Cas-опосредованным расщеплением. Такое вырезание может создавать области микрогомологии, необходимые для соединения фрагментов, но это может привести к нежелательным или неконтролируемым изменениям в гене Fbn1. В альтернативном варианте, такие липкие концы могут быть созданы с использованием парных никаз Cas. Например, клетка может быть приведена в контакт с первой и второй никазами, которые расщепляют противоположные цепи ДНК, в результате чего геном модифицируется посредством двойного разрезания. Это может быть достигнуто путем приведения в контакт клетки с первым белком-никазой Cas, первой направляющей РНК, которая гибридизируется с последовательностью, распознаваемой первой направляющей РНК в геномном локусе-мишени в гене Fbn1, вторым белком-никазой Cas и второй направляющей РНК, которая гибридизируется с последовательностью, распознаваемой второй направляющей РНК в геномном локусе-мишени в гене Fbn1. Первый белок Cas и первая направляющая РНК образуют первый комплекс, а второй белок Cas и вторая направляющая РНК образуют второй комплекс. Первый белок-никаза Cas расщепляет первую цепь геномной ДНК в последовательности, распознаваемой первой направляющей РНК, второй белок-никаза Cas расщепляет вторую цепь геномной ДНК в последовательности, распознаваемой второй направляющей РНК, и, необязательно, экзогенный шаблон репарации рекомбинирует с геномным локусом-мишенью в гене Fbn1 для создания целевой генетической модификации.
[117] Первая никаза может расщеплять первую цепь геномной ДНК (то есть комплементарную цепь), а вторая никаза может расщеплять вторую цепь геномной ДНК (то есть некомплементарную цепь). Первая и вторая никазы могут быть получены, например, путем мутирования каталитического остатка в домене RuvC (например, мутация D10A, описанная в другом месте данного документа) Cas9, или путем мутирования каталитического остатка в домене HNH (например, мутация H840A, описанная в другом месте данного документе) Cas9. В таких способах, двойное разрезание может быть использовано для создания двухцепочечного разрыва, имеющего ступенчатые концы (то есть липкие концы). Последовательности, распознаваемые первой и второй направляющей РНК, можно расположить так, чтобы создать сайт расщепления, так что одноцепочечные разрывы, созданные первой и второй никазами в первой и второй цепях ДНК, образовывали двухцепочечный разрив. Липкие концы получаются, когда одноцепочечные разрывы в пределах первой и второй последовательностей, распознаваемых РНК CRISPR, разнесены на определенное растояние. Окно разнесения может составлять, например, по меньшей мере около 5 п.н., 10 п.н., 20 п.н., 30 п.н., 40 п.н., 50 п.н., 60 п.н., 70 п.н., 80 п.н., 90 п.н., 100 п.н. или больше. Смотрите, например, Ran et al. (2013) Cell 154:1380-1389; Mali et al. (2013) Nat. Biotech.31:833-838; и Shen et al. (2014) Nat. Methods 11:399-404.
B. Нуклеазные агенты
[118] Любой нуклеазный агент, который вызывает одноцепочечный разрыв или двухцепочечный разрыв в желаемой распознаваемой последовательности, может быть использован в способах и композициях, раскрытых в данном документе. Природный или нативный нуклеазный агент может быть использован при условии, что нуклеазный агент вызывает одноцепочечный разрыв или двухцепочечный разрыв в желаемой распознаваемой последовательности. В альтернативном варианте, может быть использован модифицированный или сконструированный нуклеазный агент. «Сконструированный нуклеазный агент» включает в себя нуклеазу, которая сконструирована (модифицирована или получена) из ее нативной формы для специфического распознавания и индукции одноцепочечного разрыва или двухцепочечного разрыва в желаемой распознаваемой последовательности. Таким образом, сконструированный нуклеазный агент может быть получен из нативного, природного нуклеазного агента, или он может быть искусственно создан или синтезирован. Сконструированная нуклеаза может индуцировать одноцепочечный разрыв или двухцепочечный разрыв в распознаваемой последовательности, например, при этом распознаваемая последовательность не является последовательностью, которая распознавалась бы нативным (не сконструированным или немодифицированным) нуклеазным агентом. Модификация нуклеазного агента может представлять собой всего одну аминокислоту в белковом расщепляющем агенте или один нуклеотид в нуклеиновом расщепляющем агенте. Создание одноцепочечного разрыва или двухцепочечного разрыва в распознаваемой последовательности или другой ДНК может упоминаться в данном документе как «разрезание» или «расщепление» распознаваемой последовательности или другой ДНК.
[119] Также предлагаются активные варианты и фрагменты нуклеазных агентов (то есть сконструированного нуклеазного агента). Такие активные варианты могут иметь, по меньшей мере 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или больше идентичности последовательности с нативным нуклеазным агентом, причем активные варианты сохраняют способность разрезать желаемую распознаваемую последовательность и, следовательно, сохраняют активность, индуцирующую одноцепочечный разрыв или двухцепочечный разрыв. Например, любой из нуклеазных агентов, описанных в данном документе, может быть получен путем модифицирования последовательности нативной эндонуклеазы, и спроектирован для распознавания и индукции одноцепочечного разрыва или двухцепочечного разрыва в распознаваемой последовательности, которая не распознавалась нативным нуклеазным агентом. Таким образом, некоторые сконструированные нуклеазы обладают специфичностью вызывать одноцепочечный разрыв или двухцепочечный разыв в распознаваемой последовательности, которая отличается от соответствующей последовательности, распознаваемой нативным нуклеазным агентом. Анализы по активности внесения одноцепочечных или двухцепочечных разрывов являются известными, и как правило измеряют общую активность и специфичность эндонуклеазы на ДНК-субстратах, содержащих распознаваемую последовательность.
[120] Термин «распознаваемая нуклеазным агентом последовательность» включает в себя последовательность ДНК, в которой нуклеазный агент индуцирует одноцепочечный или двухцепочечный разрыв. Распознаваемая нуклеазным агентом последовательность может быть эндогенной (или нативной) для клетки, или распознаваемая последовательность может быть экзогенной для клетки. Распознаваемая последовательность, которая является экзогенной для клетки, не встречается в природе в геноме клетки. Распознаваемая последовательность также может быть экзогенной по отношению к полинуклеотидам интереса, которые кто-либо желает разместить в локусе-мишени. В некоторых случаях, распознаваемая последовательность присутствует только виде одной копии в геноме клетки-хозяина.
[121] Также предложены активные варианты и фрагменты приведенных в качестве примеров распознаваемых последовательностей. Такие активные варианты могут иметь, по меньшей мере 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99 % или большее идентичности последовательности с данной распознаваемой последовательностью, причем активные варианты сохраняют биологическую активность и, следовательно, способны распознаваться и расщепляться нуклеазным агентом, специфичным для последовательности образом. Анализы для измерения внесения нуклеазным агентом двухцепочечного разрыва в распознаваемую последовательность известны в данной области техники (например, кПЦР анализ TAQMAN®, Frendewey et al. (2010) Methods in Enzymology 476:295-307, включен в данный документ посредством ссылки в полном объеме для всех целей).
[122] Длина распознаваемой последовательности может варьировать, и включает в себя, например, распознаваемые последовательности, которые составляют около 30-36 п.н. для пары нуклеаз цинкового пальца (ZFN) (т.е. около 15-18 п.н. для каждой ZFN), около 36 п.н. для эффекторной нуклеазы, подобной активатору транскрипции (TALEN), или около 20 п.о. для направляющей РНК CRISPR/Cas9.
[123] Распознаваемая нуклеазным агентом последовательность может быть расположена где угодно в геномном локусе-мишени или около него. Распознаваемая последовательность может быть расположена в кодирующей области гена (например, гене Fbn1) или в регуляторных областях, которые влияют на экспрессию гена. Распознаваемая нуклеазным агентом последовательность может быть расположена в интроне, экзоне, промоторе, энхансере, регуляторной области или любой не кодирующей белок области.
[124] Один тип нуклеазного агента, который может быть использован в различных способах и композициях, раскрытых в данном документе, представляет собой эффекторную нуклеазу, подобную активатору транскрипции (TALEN). Эффекторные нуклеазы TAL представляют собой класс сиквенс-специфичных нуклеаз, которые могут быть использованы для создания двухцепочечных разрывов в определенных последовательностях-мишенях в геноме прокариотического или эукариотического организма. Эффекторные нуклеазы TAL создают путем слияния нативного или сконструированного эффектора, подобного активатору транскрипции (TAL), или его функциональной части, с каталитическим доменом эндонуклеазы, такой как Fokl. Уникальный, модульный ДНК-связывающий домен эффектора TAL позволяет создавать белки с потенциально любой специфичностью распознавания ДНК. Таким образом, ДНК-связывающие домены нуклеаз на основе эффектора TAL могут быть сконструированы для распознавания специфических сайтов-мишеней ДНК и, таким образом, использованы для создания двухцепочечных разрывов в желаемых последовательностях-мишенях. Смотрите WO 2010/079430; Morbitzer et al. (2010) Proc. Natl. Acad. Sci. U.S.A. 107(50:21617-21622; Scholze & Boch (2010) Virulence 1:428-432; Christian et al. (2010) Genetics 186:757-761; Li et al. (2011) Nucleic Acids Res. 39(l):359-372; и Miller et al. (2011) Nature Biotechnology 29:143-148, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[125] Примеры подходящих нуклеаз TAL, и способы получения подходящих нуклеаз TAL раскрыты, например, в US 2011/0239315 A1, US 2011/0269234 A1, US 2011/0145940 A1, US 2003/0232410 A1, US 2005/0208489 A1, US 2005/0026157 A1, US 2005/0064474 A1, US 2006/0188987 A1, и US 2006/0063231 A1, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. В различных вариантах осуществления, конструируют нуклеазы на основе эффектора TAL, которые делают разрыв в нуклеотидной последовательности-мишень или рядом с ней, например, в геномном локусе интереса, причем нуклеотидная последовательность-мишень находится в последовательности или около последовательности, подлежащей модификации с помощью экзогенного шаблона репарации. Нуклеазы TAL, подходящие для использования с различными способами и композициями, предложенными в данном документе, включают в себя те, которые специально предназначены для связывания с нуклеотидными последовательностями-мишенями или вблизи них, которые должны быть модифицированы с помощью экзогенных шаблонов репарации, как описано в другом месте данного документа.
[126] В некоторых TALEN каждый мономер TALEN содержит 33-35 повторов TAL, которые распознают одну пару оснований через два гипервариабельных остатка. В некоторых TALEN нуклеазный агент представляет собой химерный белок, содержащий ДНК-связывающий домен на основе TAL-повтора, функционально связанный с независимой нуклеазой, такой как эндонуклеаза FokI. Например, нуклеазный агент может содержать первый ДНК-связывающий домен на основе повтора TAL и второй ДНК-связывающий домен на основе повтора TAL, причем каждый первый и второй ДНК-связывающий домен на основе повтора TAL функционально связаны с нуклеазой FokI, при этом первый и второй ДНК-связывающий домен на основе повтора TAL распознают две непрерывные ДНК последовательности-мишени в каждой цепи ДНК последовательности-мишени, разделенные спейсерной последовательностью различной длины (12-20 п.о.), и при этом субъединицы нуклеазы FokI димеризуются, формируя активную нуклеазу, которая делает двухцепочечный разрыв в последовательности-мишени.
[127] Другим примером нуклеазного агента, который может быть использован в различных способах и композициях, раскрытых в данном документе, является нуклеаза цинкового пальца (ZFN). В некоторых ZFN каждый мономер ZFN содержит три или большее количество ДНК-связывающих доменов на основе цинкового пальца, причем каждый ДНК-связывающий домен на основе цинкового пальца связывается с субсайтом длинной в 3 п.н. В других ZFN, ZFN представляет собой химерный белок, содержащий ДНК-связывающий домен на основе цинкового пальца, функционально связанный с сторонней нуклеазой, такой как эндонуклеаза FokI. Например, нуклеазный агент может содержать первый ZFN и второй ZFN, причем каждый первый ZFN и второй ZFN функционально связан с субъединицей нуклеазы FokI, при этом первый и второй ZFN распознают две смежные ДНК последовательности-мишени в каждой цепи ДНК последовательности-мишени, разделенные спейсером около 5-7 п.н., причем субъединицы нуклеазы FokI димеризуются с образованием активной нуклеазы, которая делает разрыв двухцепочечной. Смотрите, например, US 2006/0246567; US 2008/0182332; US 2002/0081614; US 2003/0021776; WO 2002/057308 A2; US 2013/0123484; US 2010/0291048; WO 2011/017293 A2; и Gaj et al. (2013) Trends in Biotechnology 31(7):397-405, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[128] Другим типом нуклеазного агента, который может быть использован в различных способах и композициях, раскрытых в данном документе, является мегануклеаза. Мегануклеазы были классифицированы на четыре семейства на основе консервативных мотивов последовательности: «бокс» семейства LAGLIDADG, GIY-YIG, H-N-H, и His-Cys. Эти мотивы принимают участие в координации ионов металлов и гидролизе фосфодиэфирных связей. Мегануклеазы известны своими длинными последовательностями распознавания, и тем, что они устойчивы к некоторым полиморфизмам последовательностей своих ДНК-субстратов. Домены, структура и функции мегануклеаз являются известными. Смотрите, например, Guhan and Muniyappa (2003) CritRev Biochem Mol Biol. 38:199-248; Lucas et al. (2001) Nucleic Acids Res. 29:960-969; Jurica and Stoddard, (1999) Cell Mol Life Sci 55:1304-1326; Stoddard (2006) Q Rev Biophys 38:49-95; и Moure et al. (2002) Nat Struct Biol 9:764. В некоторых примерах, применяют природный вариант и/или сконструированное производное мегануклеазы. Известны способы модификации кинетики, взаимодействия с кофакторами, экспрессии, оптимальных условий и/или специфичности распознавания последовательности, а также способы скрининга активности. Смотрите, например, Epinat et al., (2003) Nucleic Acids Res. 31:2952-2962; Chevalier et al. (2002) Mol. Cell 10:895-905; Gimble et al. (2003) Mol. Biol. 334:993-1008; Seligman et al. (2002) Nucleic Acids Res. 30:3870-3879; Sussman et al. (2004) J. Mol. Biol. 342:31-41; Rosen et al. (2006) Nucleic Acids Res. 34:4791-4800; Chames et al. (2005) Nucleic Acids Res. 33:el78; Smith et al. (2006) Nucleic Acids Res. 34:el49; Gruen et al. (2002) Nucleic Acids Res. 30:e29; Chen and Zhao (2005) Nucleic Acids Res 33:el54; WO 2005/105989; WO 2003/078619; WO 2006/097854; WO 2006/097853; WO 2006/097784; и WO 2004/031346, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[129] Может быть применена любая мегануклеаза, в том числе, например, I-SceI, I-SceII, I-SceIII, I-SceIV, I-SceV, I-SceVI, I-SceVII, I-CeuI, I-CeuAIIP, I-CreI, I-CrepsbIP, I-CrepsbIIP, I-CrepsbIIIP, I-CrepsbIVP, I-TliI, I-PpoI, PI-PspI, F-SceI, F-SceII, F-SuvI, F-TevI, F-TevII, I-AmaI, I-AniI, I-ChuI, I-CmoeI, I-CpaI, I-CpaII, I-CsmI, I-CvuI, I-CvuAIP, I-DdiI, I-DdiII, I-DirI, I-DmoI, I-HmuI, I-HmuII, I-HsNIP, I-LlaI, I-MsoI, I-NaaI, I-NanI, I-NcIIP, I-NgrIP, I-NitI, I-NjaI, I-Nsp236IP, I-PakI, I-PboIP, I-PcuIP, I-PcuAI, I-PcuVI, I-PgrIP, I-PobIP, I-PorI, I-PorIIP, I-PbpIP, I-SpBetaIP, I-ScaI, I-SexIP, I-SneIP, I-SpomI, I-SpomCP, I-SpomIP, I-SpomIIP, I-SquIP, I-Ssp6803I, I-SthPhiJP, I-SthPhiST3P, I-SthPhiSTe3bP, I-TdeIP, I-TevI, I- TevII, I-TevIII, I-UarAP, I-UarHGPAIP, I-UarHGPA13P, I-VinIP, I-ZbiIP, PI-MtuI, PI-MtuHIP, PI-MtuHIIP, PI-PfuI, PI-PfuII, PI-PkoI, PI-PkoII, PI-Rma43812IP, PI-SpBetaIP, PI-SceI, PI-TfuI, PI-TfuII, PI-ThyI, PI-TliI, PI-TliII, или любые их активные варианты или фрагменты.
[130] Мегануклеазы могут распознавать, например, двухцепочечные последовательности ДНК из 12-40 пар оснований. В некоторых случаях, мегануклеаза распознает одну полностью комплементарную последовательность-мишень в геноме.
[131] Некоторые мегануклеазы являются «хоуминг» (homing) нуклеазами. Одним из типов хоминг-нуклеаз является семейство хоминг-нуклеаз LAGLIDADG, включающее в себя, например, I-Scel, I-Crel и I-Dmol.
[132] Подходящие нуклеазные агенты также включают в себя эндонуклеазы рестрикции, которые включают в себя эндонуклеазы типа I, типа II, типа III и типа IV. Эндонуклеазы рестрикции типа I и типа III распознают специфические распознаваемые последовательности, но обычно расщепляют цепь в вариабельной по отношению к сайту связывания нуклеазы позиции, который может находиться на расстоянии сотен пар оснований от сайта расщепления (распознаваемой последовательности). В системах типа II рестрикционная активность не зависит от активности метилазы, и расщепление обычно происходит в определенных сайтах в пределах или вблизи сайта связывания. Большинство ферментов типа II расщепляют палиндромные последовательности. Однако, ферменты типа IIа распознают непалиндромные распознаваемые последовательности и расщепляю цепь вне распознаваемой последовательности, ферменты типа IIb расщепляют последовательности дважды - оба сайта вне распознаваемой последовательности, а ферменты типа IIs распознают асимметричную распознаваемую последовательность и расщепляют с одной стороны и на определенном расстояние около 1-20 нуклеотидов от распознаваемой последовательности. Ферменты рестрикции типа IV нацелены на метилированную ДНК. Ферменты рестрикции дополнительно описаны и классифицированы, например, в базе данных REBASE (вебстраница rebase.neb.com; Roberts et al. (2003) Nucleic Acids Res. 31:418-420; Roberts et al. (2003) Nucleic Acids Res. 31:1805-1812; и Belfort et al. (2002) in Mobile DNA II, pp. 761-783, Eds. Craigie et al., (ASM Press, Washington, DC), каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[133] Другие подходящие нуклеазные агенты для использования в способах и композициях, описанных в данном документе, включают в себя системы CRISPR-Cas, которые описаны в другом месте данного документа.
[134] Нуклеазный агент может быть введен в клетку любым способом, известным в данной области техники. Полипептид, кодирующий нуклеазный агент, может быть прямо введен в клетку. В альтернативном варианте, в клетку может быть введен полинуклеотид, кодирующий нуклеазный агент. Когда полинуклеотид, кодирующий нуклеазный агент, вводят в клетку, нуклеазный агент может временно, при определенных условиях или конститутивно экспрессироваться в клетке. Например, полинуклеотид, кодирующий нуклеазный агент, может содержаться в экспресионной кассете и быть функционально связанным с зависящим промотором, индуцибельным промотором, конститутивным промотором или тканеспецифичным промотором. Такие промоторы обсуждаются более подробно в другом месте данного документа. В альтернативном варианте, нуклеазный агент может быть введен в клетку в виде мРНК, кодирующей нуклеазный агент.
[135] Полинуклеотид, кодирующий нуклеазный агент, может быть стабильно интегрирован в геном клетки и функционально связан с промотором, активным в клетке. В альтернативном варианте, полинуклеотид, кодирующий нуклеазный агент, может находиться в направленном на мишень векторе, или в векторе или плазмиде, которые отделены от направленного вектора, содержащие полинуклеотид-вставку.
[136] Когда нуклеазный агент вводят в клетку путем введения полинуклеотида, кодирующего нуклеазный агент, такой полинуклеотид, кодирующий нуклеазный агент, может быть модифицирован, чтобы заменить кодоны на кодоны, имеющие более высокую частоту использования в интересующей клетке, по сравнению с природной полинуклеотидной последовательностью, кодирующей нуклеазный агент. Например, полинуклеотид, кодирующий нуклеазный агент, может быть модифицирован для замены кодонов на кодоны, имеющие более высокую частоту использования в данной прокариотической или эукариотической клетке инетереса, включая бактериальную клетку, дрожжевую клетку, клетку человека, нечеловеческую клетку, клетку млекопитающего, клетку грызуна, клетку мыши, клетку крысы или любую другую клетку-хозяина интереса, по сравнению с природной полинуклеотидной последовательностью.
C. Системы CRISPR-Cas
[137] Способы, раскрытые в данном документе, могут использовать системы коротких палиндромных повторов, регулярно расположенных группами (CRISPR)/CRISPR (Cas)-ассоциированные системы, или компоненты таких систем для модификации генома в клетке. Системы CRISPR-Cas включают в себя транскрипты и другие элементы, участвующие в экспрессии или управлении активностью генов Cas. Система CRISPR-Cas может быть системой типа I, типа II или типа III. В альтернативном варианте, система CRISPR/Cas может представлять собой, например, систему типа V (например, подтип V-A или подтип V-B). Способы и композиции, раскрытые в данном документе, могут использовать системы CRISPR-Cas с применением комплексов CRISPR (содержащих направляющую РНК (нРНК) в комплексе с белком Cas) для сайт-направленного расщепления нуклеиновых кислот.
[138] Системы CRISPR-Cas, используемые в раскрытых в данном документе способах, являются неприродными. «Неприродная» система включает в себя все, что указывает на вмешательство человека, например, один или большее количество компонентов системы были изменены или мутированы из своего естественного состояния, будучи по меньшей мере по существу свободными по меньшей мере от одного другого компонента с которыми они естественным образом связаны в природе, или будучи связанными по меньшей мере с одним другим компонентом, с которым они не связаны в природе. Например, некоторые системы CRISPR-Cas используют неприродные комплексы CRISPR, содержащие нРНК и белок Cas, которые не встречаются в природе вместе.
(1) Белки Cas
[139] Белки Cas в целом, как правило, содержат по меньшей мере один домен распознавания или связывания РНК, который может взаимодействовать с направляющими РНК (нРНК, более подробно описанные ниже). Белки Cas также могут содержать нуклеазные домены (например, ДНКазные или РНКазные домены), ДНК-связывающие домены, геликазные домены, домены белок-белковых взаимодействий, домены димеризации и другие домены. Нуклеазный домен обладает каталитической активностью расщепления нуклеиновой кислоты, которая включает в себя разрыв ковалентных связей молекулы нуклеиновой кислоты. Расщепление может создавать тупые концы или в ступенчатые (липкие) концы, и оно может быть одноцепочечным или двухцепочечным. Например, белок Cas9 дикого типа обычно создает продукт расщепления с тупыми концами. В альтернативном варианте, белок Cpf1 дикого типа (например, FnCpf1) может создавать продукт расщепления с 5'-нуклеотидным липким концом из 5 нуклеотидов, причем расщепление происходит после 18-й пары оснований последовательности PAM на нецелевой цепи и после 23-го основания на целевой цепи. Белок Cas может обладать активностью полного расщепления, создавая двухцепочечный разрыв в гене Fbn1 (например, двухцепочечный разрыв с тупыми концами), или это может быть никаза, которая создает одноцепочечный разрыв в гене Fbn1.
[140] Примеры белков Cas включают в себя Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cas5e (CasD), Cas6, Cas6e, Cas6f, Cas7, Cas8al, Cas8a2, Cas8b, Cas8c, Cas9 (Csn1 или Csx12), Cas10, Cas10d, CasF, CasG, CasH, Csy1, Csy2, Csy3, Cse1 (CasA), Cse2 (CasB), Cse3 (CasE), Cse4 (CasC), Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4, и Cu1966, и их гомологичные или модифицированные версии.
[141] Предпочтительно белок Cas представляет собой белок Cas9 или получен из белка Cas9 из системы CRISPR-Cas типа II. Белки Cas9 происходят из системы CRISPR-Cas типа II и обычно имеют четыре ключевых мотива с консервативной архитектурой. Мотивы 1, 2 и 4 являются RuvC-подобными мотивами, а мотив 3 является мотивом HNH. Иллюстративные белки Cas9 получают из Streptococcus pyogenes, Streptococcus thermophilus, Streptococcus sp., Staphylococcus aureus, Nocardiopsis dassonvillei, Streptomyces pristinaespiralis, Streptomyces viridochromogenes, Streptomyces viridochromogenes, Streptosporangium roseum, Streptosporangium roseum, Alicyclobacillus acidocaldarius, Bacillus pseudomycoides, Bacillus selenitireducens, Exiguobacterium sibiricum, Lactobacillus delbrueckii, Lactobacillus salivarius, Microscilla marina, Burkholderiales bacterium, Polaromonas naphthalenivorans, Polaromonas sp., Crocosphaera watsonii, Cyanothece sp., Microcystis aeruginosa, Synechococcus sp., Acetohalobium arabaticum, Ammonifex degensii, Caldicelulosiruptor becscii, Candidatus Desulforudis, Clostridium botulinum, Clostridium difficile, Finegoldia magna, Natranaerobius thermophilus, Pelotomaculum thermopropionicum, Acidithiobacillus caldus, Acidithiobacillus ferrooxidans, Allochromatium vinosum, Marinobacter sp., Nitrosococcus halophilus, Nitrosococcus watsoni, Pseudoalteromonas haloplanktis, Ktedonobacter racemifer, Methanohalobium evestigatum, Anabaena variabilis, Nodularia spumigena, Nostoc sp., Arthrospira maxima, Arthrospira platensis, Arthrospira sp., Lyngbya sp., Microcoleus chthonoplastes, Oscillatoria sp., Petrotoga mobilis, Thermosipho africanus, или Acaryochloris marina. Дополнительные примеры членов семейства Cas9 описаны в WO 2014/131833, включен в данный документ посредством ссылки в полном объеме для всех целей. Cas9 из S. pyogenes (закрепленный номер доступа SwissProt Q99ZW2) является предпочтительным ферментом. Cas9 из S. aureus (закрепленный номер доступа UniProt J7RUA5) является другим предпочтительным ферментом.
[142] Другим примером белка Cas является белок Cpf1 (CRISPR из Prevotella и Francisella 1). Cpf1 представляет собой большой белок (около 1300 аминокислот), который содержит RuvC-подобный нуклеазный домен, гомологичный соответствующему домену Cas9 наряду с аналогом характерного богатого аргинином кластера Cas9. Однако в Cpf1 отсутствует нуклеазный домен HNH, присутствующий в белках Cas9, а RuvC-подобный домен является непрерывным в последовательности Cpf1, в отличие от Cas9, где он содержит длинные вставки, включая домен HNH. Смотрите, например, Zetsche el al. (2015) Cell 163(3):759-771, включен в данный документ посредством ссылки в полном объеме для всех целей. Иллюстративные белки Cpf1 получают из Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC20171, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011 _GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens, и Porphyromonas macacae. Cpf1 из Francisella novicida U112 (FnCpf1; закрепленный номер доступа UniProt A0Q7Q2) является предпочтительным ферментом.
[143] Белки Cas могут быть белками дикого типа (то есть природными), модифицированными белками Cas (то есть вариантами белков Cas) или фрагментами белков дикого типа или модифицированных белков Cas. Белки Cas также могут быть активными вариантами или фрагментами белков Cas дикого типа или модифицированных белков Cas. Активные варианты или фрагменты могут иметь, по меньшей мере 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или больше идентичности последовательности с белком Cas дикого типа или модифицированным белком Cas, или его частью, причем активные варианты сохраняют способность расщеплять желаемый сайт расщепления, следовательно, сохраняют активность, индуцирующую одноцепочечный разрыв или двухцепочечный разрыв. Анализы по активности внесения одноцепочечных или двухцепочечных разрывов являются известными, и как правило измеряют общую активность и специфичность белка Cas на ДНК-субстратах, содержащих сайт расщепления.
[144] Белки Cas могут быть модифицированы так, чтобы увеличить или уменьшить одну или большее количество аффинностей связывания нуклеиновых кислот, специфичностей связывания нуклеиновых кислот, и ферментативных активностей. Белки Cas также могут быть модифицированы для изменения любой другой активности или свойства белка, такого как стабильность. Например, один или большее количество нуклеазных доменов белка Cas могут быть модифицированы, удалены или инактивированы, или белок Cas может быть урезан для удаления доменов, которые не являются существенными для функционирования белка, или для оптимизации (например, для усиления или уменьшения активность белка Cas).
[145] Белки Cas могут содержать по меньшей мере один нуклеазный домен, такой как DN-азный домен. Например, белок Cpf1 дикого типа обычно содержит RuvC-подобный домен, который расщепляет обе цепи ДНК-мишени, возможно, в димерной конфигурации. Белки Cas могут содержать по меньшей мере два нуклеазных домена, таких как DN-азные домены. Например, белок Cas9 дикого типа в целом, как правило, содержит RuvC-подобный нуклеазный домен и HNH-подобный нуклеазный домен. Каждый из доменов RuvC и HNH может расщеплять разные цепи двухцепочечной ДНК, чтобы сделать двухцепочечный разрыв в ДНК. Смотрите, например, Jinek el al. (2012) Science 337:816-821, включен в данный документ посредством ссылки в полном объеме для всех целей.
[146] Один или оба нуклеазных домена могут быть удалены или мутированы, так что они больше не функционируют или имеют уменьшенную нуклеазную активность. Если один из нуклеазных доменов удален или мутирован, полученный белок Cas (например, Cas9) может быть назван никазой и может создавать одноцепочечный разрыв в распознаваемой направляющей РНК последовательности в пределах двухцепочечной ДНК, но не двухцепочечный разрыв (т.е. он может расщеплять комплементарную цепь или некомплементарную цепь, но не обе). Если оба нуклеазных домена удалены или мутированы, полученный белок Cas (например, Cas9) будет обладать уменьшенной способностью расщеплять обе цепи двухцепочечной ДНК (например, безнуклеазный белок Cas). Пример мутации, которая превращает Cas9 в никазу, представляет собой мутацию D10A (аспартат на аланин в позиции 10 в Cas9) в домене RuvC Cas9 из S. pyogenes. Аналогично, H939A (гистидин на аланин в аминокислотной позиции 839) или H840A (гистидин на аланин в аминокислотной позиции 840) в домене HNH Cas9 из S. pyogenes может превратить Cas9 в никазу. Другие примеры мутаций, которые превращают Cas9 в никазу, включают в себя соответствующие мутации в Cas9 из S. thermophilus. Смотрите, например, Sapranauskas et al. (2011) Nucleic Acids Research 39:9275-9282 и WO 2013/141680, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Такие мутации могут быть получены с использованием таких способов, как сайт-направленный мутагенез, ПЦР-опосредованный мутагенез или полный синтез гена. Примеры других мутаций, создающих никазы, можно найти, например, в WO 2013/176772 и WO 2013/142578, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[147] Белки Cas также могут быть функционально связаны с гетерологичными полипептидами в виде белков-гибридов. Например, белок Cas может быть слит с расщепляющим доменом, доменом эпигенетической модификации, доменом активации транскрипции или доменом-репрессором транскрипции. Смотрите WO 2014/089290, включен в данный документ посредством ссылки в полном объеме для всех целей. Белки Cas также могут быть слиты с гетерологичным полипептидом, обеспечивающим повышенную или пониженную стабильность. Гибридный домен или гетерологичный полипептид может быть расположен на N-конце, С-конце или внутри белка Cas.
[148] Примером гибридного белка Cas является белок Cas, слитый с гетерологичным полипептидом, который обеспечивает субклеточную локализацию. Такие гетерологичные полипептиды могут включать в себя, например, один или большее количество сигналов внутриядерной локализации (NLS), таких как NLS SV40 для нацеливания на ядро, сигнал локализации в митохондриях для нацеливания на митохондрии, сигнал удержания в ЭР (ретикулум) и тому подобное. Смотрите, например, Lange el al. (2007) J. Biol. Chem. 282:5101-5105, включен в данный документ посредством ссылки в полном объеме для всех целей. Такие субклеточные сигналы локализации могут быть размещены на N-конце, С-конце или в любом месте внутри белка Cas. NLS может содержать участок основных аминокислот и может представлять собой последовательность из одного компонента или последовательность из двух компонентов.
[149] Белки Cas также могут быть функционально связаны с доменом проникновения в клетку. Например, домен проникновения в клетку может быть получен из белка ТАТ ВИЧ-1, TLM-мотива проникновения в клетку вируса гепатита В человека, MPG, Pep-1, VP22, пептида проникновения в клетку вируса простого герпеса, или полиаргининовой пептидной последовательности. Смотрите, например, WO 2014/089290, включен в данный документ посредством ссылки в полном объеме для всех целей. Домен проникновения в клетку может быть расположен на N-конце, C-конце или в любом месте белка Cas.
[150] Белки Cas также могут быть функционально связаны с гетерологичным полипептидом для простоты отслеживания или очистки, с таким как флуоресцентный белок, тэг очистки или эпитопный тэг. Примеры флуоресцентных белков включают в себя зеленые флуоресцентные белки (например, GLP, GLP-2, tagGLP, turboGLP, eGLP, Emerald, Azami Green, Monomeric Azami Green, CopGLP, AceGLP, ZsGreenl), желтые флуоресцентные белки (например, YEP, eYFP, Citrine, Venus, YPet, PhiYFP, ZsYellowl), голубые флуоресцентные белки (например, eBFP, eBFP2, Azurite, mKalamal, GFPuv, Sapphire, T-sapphire), бирюзовые флуоресцентные белки (например, eCFP, Cerulean, CyPet, AmCyanl, Midoriishi-Cyan), красные флуоресцентные белки (mKate, mKate2, mPlum, DsRed monomer, mCherry, mRFPl, DsRed-Express, DsRed2, DsRed-Monomer, HcRed-Tandem, HcRedl, AsRed2, eqFP611, mRaspberry, mStrawberry, Jred), оранжевые флуоресцентные белки (mOrange, mKO, Kusabira-Orange, Monomeric Kusabira-Orange, mTangerine, tdTomato), и любой другой подходящий флуоресцентный белок. Примеры тэгов включают в себя глутатион-S-трансферазу (GST), хитин-связывающий белок (CBP), мальтоза-связывающий белок, тиоредоксин (TRX), поли(NANP), тэг тандемной аффинной очистки (TAP), myc, AcV5, AU1, AU5, E, ECS, E2, FLAG, гемагглютинин (HA), nus, Softag 1, Softag 3, Strep, SBP, Glu-Glu, HSV, KT3, S, S1, T7, V5, VSV-G, гистидин (His), белок-носитель карбоксибиотина (BCCP), и кальмодулин.
[151] Белки Cas9 также могут быть соединены с экзогенными шаблонами репарации или мечеными нуклеиновыми кислотами. Такое присоединение (то есть физическое связывание) может быть достигнуто посредством ковалентных взаимодействий или нековалентных взаимодействий, и соединение может быть прямым (например, посредством прямого слияния или химического конъюгирования, что может быть достигнуто путем модификации остатков цистеина или лизина в белке, или интеиновой модификацией), или может быть достигнуто с помощью одного или большего количества промежуточных линкеров или адаптерных молекул, таких как стрептавидин или аптамеры. Смотрите, например, Pierce et al. (2005) Mini Rev. Med. Chem. 5(1):41-55; Duckworth et al. (2007) Angew. Chem. Int. Ed. Engl. 46(46):8819-8822; Schaeffer and Dixon (2009) Australian J. Chem. 62(10):1328-1332; Goodman et al. (2009) Chembiochem. 10(9): 1551-1557; и Khatwani et al. (2012) Bioorg. Med. Chem. 20(14):4532-4539, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Нековалентные стратегии синтеза конъюгатов белок-нуклеиновая кислота включают в себя биотин-стрептавидин и никель-гистидиновые способы. Ковалентные конъюгаты белок-нуклеиновая кислота могут быть синтезированы путем соединения подходящим образом функционализированных нуклеиновых кислот и белков с использованием широкого спектра химикатов. Некоторые из этих химикатов вызывают прямое присоединение олигонуклеотида к аминокислотному остатку на поверхности белка (например, лизинамин или цистеинтиола), в то время как другие более сложные схемы требуют посттрансляционной модификации белка, или участия каталитического или реактивного белкового домена. Способы ковалентного присоединения белков к нуклеиновым кислотам могут включать в себя, например, химическое сшивание олигонуклеотидов с остатками лизина или цистеина белка, лигирование экспрессированного белка, хемоферментные способы и применение фотоаптамеров. Экзогенный шаблон репарации или меченая нуклеиновая кислота могут быть присоединены к С-концу, N-концу или к внутренней области в белке Cas9. Предпочтительно экзогенный шаблон репарации или меченую нуклеиновую кислоту присоединяют к С-концу или N-концу белка Cas9. Аналогично, белок Cas9 может быть присоединен к 5'-концу, 3'-концу или к внутренней области экзогенного шаблона репарации или меченой нуклеиновой кислоты. То есть экзогенный шаблон репарации или меченая нуклеиновая кислота могут быть присоединены в любой ориентации и полярности. Предпочтительно белок Cas9 соединен с 5'-концом или 3'-концом экзогенного шаблона репарации или меченой нуклеиновой кислоты.
[152] Белки Cas могут быть предложены в любой форме. Например, белок Cas может быть предложен в форме белка, такого как белок Cas, образующий комплекс с нРНК. В альтернативном варианте, белок Cas может быть предложен в форме нуклеиновой кислоты, кодирующей белок Cas, такой как РНК (например, матричная РНК (мРНК)) или ДНК. Необязательно, нуклеиновая кислота, кодирующая белок Cas, может быть кодон-оптимизированной для эффективной трансляции в белок в конкретной клетке или организме. Например, нуклеиновая кислота, кодирующая белок Cas, может быть модифицирована для замены кодонов на кодоны, имеющие более высокую частоту использования, в бактериальной клетке, дрожжевой клетке, клетке человека, нечеловеческой клетке, клетке млекопитающего, клетке грызуна, клетке мыши, клетке крысы или любой другой представляющей интерес клетке-хозяине по сравнению с природной полинуклеотидной последовательностью. Когда нуклеиновую кислоту, кодирующую белок Cas, вводят в клетку, белок Cas может временно, зависимо от условий или конститутивно экспрессироваться в клетке.
[153] Нуклеиновые кислоты, кодирующие белки Cas, могут быть стабильно интегрированы в геном клетки и функционально связаны с активным в клетке промотором. В альтернативном варианте, нуклеиновые кислоты, кодирующие белки Cas, могут быть функционально связаны с промотором в экспрессирующей конструкции. Экспрессирующие конструкции включают в себя любые конструкции нуклеиновых кислот, способные управлять экспрессией гена или другой нуклеотидной последовательностью интереса (например, гена Cas), и которые могут переносить такую нуклеотидную последовательность интереса в клетку-мишень. Например, нуклеиновая кислота, кодирующая белок Cas, может находиться в нацеливающем векторе, содержащем нуклеотидную вставку, и/или в векторе, содержащем ДНК, кодирующую нРНК. В альтернативном варианте, он может находиться в векторе или плазмиде, которые обособлены от нацеливающего вектора, содержащего нуклеотидную вставку, и/или обособлены от вектора, содержащего ДНК, кодирующую нРНК. Промоторы, которые могут быть использованы в экспрессионной конструкции, включают в себя промоторы, активные, например, в одной или большем количестве эукариотических клеток, клетке человека, нечеловеческой клетке, клетке млекопитающего, клетке отличного от человека млекопитающего, клетке грызуна, клетке мыши, клетке крысы, клетке хомяка, клетке кролика, плюрипотентной клетке, эмбриональной стволовой (ES) клетке или зиготе. Такими промоторами могут быть, например, зависимые от условий промоторы, индуцибельные промоторы, конститутивные промоторы или тканеспецифичные промоторы. Необязательно, промотор может быть двунаправленным промотором, управляющим экспрессией белка Cas в одном направлении, и направляющей РНК в другом направлении. Такие двунаправленные промоторы могут состоять из (1) полного, обычного, однонаправленного промотора Pol III, который содержит 3 внешних регулирующих элемента: дистальный элемент последовательности (DSE), проксимальный элемент последовательности (PSE) и TATA-бокс; и (2) второй основной промотор Pol III, который включает в себя PSE и TATA-бокс, слитый с 5' концом DSE в обратной ориентации. Например, в HI-промоторе DSE расположен вблизи с PSE и TATA-боксом, и промотор можно сделать двунаправленным, создав гибридный промотор, в котором транскрипция в обратном направлении контролируется путем добавления PSE и TATA-бокса, полученных из промотора U6. Смотрите, например, US 2016/0074535, включен в данный документ посредством ссылки в полном объеме для всех целей. Использование двунаправленного промотора для экспрессии генов, кодирующих белок Cas и направляющую РНК одновременно, позволяет создавать компактные экспрессионные кассеты для облегчения доставки.
(2) Направляющие РНК
[154] «Направляющая РНК» или «нРНК» представляет собой молекулу РНК, которая связывается с белком Cas (например, белком Cas9) и нацеливает белок Cas на определенное место в ДНК-мишени (например, гене Fbn1). Направляющие РНК могут содержать два сегмента: «ДНК-нацеливающий сегмент» и «белок-связывающий сегмент». «Сегмент» включает в себя участок или область молекулы, такую как непрерывную последовательность нуклеотидов в РНК. Некоторые нРНК содержат две отдельные молекулы РНК: «активаторную РНК» (например, транскрРНК) и «нацеливающую РНК» (например, CRISPR RNA или крРНК). Другие нРНК представляют собой единую молекулу РНК (единый полинуклеотид РНК), которая также может быть обозначена как «одномолекулярная нРНК», «единая направляющая РНК» или «енРНК». Смотрите, например, WO 2013/176772, WO 2014/065596, WO 2014/089290, WO 2014/093622, WO 2014/099750, WO 2013/142578, и WO 2014/131833, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Например, в случае Cas9 единая направляющая РНК может содержать крРНК, слитую с транскрРНК (например, через линкер). Например, в случае с Cpf1 для расщепления необходима только крРНК. Термины «направляющая РНК» и «нРНК» включают в себя как двухмолекулярные нРНК, так и одномолекулярные нРНК.
[155] Иллюстративная двухмолекулярная нРНК содержит крРНК-подобную («CRISPR РНК» или «нацеливающая РНК» или «крРНК» или «крРНК повтор») молекулу, и соответствующую транскрРНК-подобную («транс-активирующая CRISPR РНК» или «активирующая-РНК» или «транскрРНК» или «каракас») молекулу. крРНК содержит ДНК-нацеленный сегмент (одноцепочечный) нРНК, и последовательность нуклеотидов, которая формирует половину дцРНК дуплекса белок-связывающего сегмента нРНК.
[156] Соответствующая транскрРНК (активаторная-РНК) содержит последовательность нуклеотидов, которая формирует другую половину дцРНК дуплекса белок-связывающего сегмента нРНК. Последовательность нуклеотидов нРНК является комплементарной и гибридизируется с последовательностью нуклеотидов транскрРНК с образованием дцРНК-дуплекса белок-связывающего домена нРНК. Таким образом, можно сказать, что каждая крРНК имеет соответствующую транскрРНК.
[157] крРНК и соответствующая транскрРНК гибридизуются с образованием нРНК. В системах, в которых требуется только крРНК, крРНК может представлять собой нРНК. крРНК дополнительно предоставляет одноцепочечный ДНК-нацеленный сегмент, который гибридизируется с распознаваемой направляющей РНК последовательностью. Если используется для модификации внутри клетки, точная последовательность данной молекулы крРНК или транскрРНК может быть спроектирована так, чтобы она была специфичной для видов, в которых будут применяться молекулы РНК. Смотрите, например, Mali et al. (2013) Science 339:823-826; Jinek et al. (2012) Science 337:816-821; Hwang et al. (2013) Nat. Biotechnol. 31:227-229; Jiang et al. (2013) Nat. Biotechnol. 31:233-239; и Cong et al. (2013) Science 339:819-823, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[158] ДНК-нацеленный сегмент (крРНК) данной нРНК содержит нуклеотидную последовательность, которая комплементарна последовательности (то есть последовательности, распознаваемой направляющей РНК) в ДНК-мишени. ДНК-нацеленный сегмент нРНК взаимодействует с ДНК-мишенью (например, геном Fbn1) сиквенс-специфичным образом посредством гибридизации (то есть спаривания оснований). По существу, нуклеотидная последовательность ДНК-нацеленного сегмента, может варьироваться и определять местоположение в ДНК-мишени, с которым будут взаимодействовать нРНК и ДНК-мишень. ДНК-нацеленный сегмент нРНК согласно изобретению может быть модифицирован для гибридизации с любой желаемой последовательностью в ДНК-мишени. Природные крРНК различаются в зависимости от системы CRISPR-Cas и организма, но часто содержат нацеливающий сегмент длиной от 21 до 72 нуклеотидов, фланкированный двумя прямыми повторами (DR) длиной от 21 до 46 нуклеотидов (смотрите, например, WO 2014/131833, включен в данный документ посредством ссылки в полном объеме для всех целей). В случае S. pyogenes DR имеют длину 36 нуклеотидов, а нацеливающий сегмент имеет длину 30 нуклеотидов. 3'-расположенный DR является комплементарным и гибридизируется с соответствующей транскрРНК, которая, в свою очередь, связывается с белком Cas.
[159] ДНК-нацеленный сегмент может иметь длину по меньшей мере около 12 нуклеотидов, по меньшей мере около 15 нуклеотидов, по меньшей мере около 17 нуклеотидов, по меньшей мере около 18 нуклеотидов, по меньшей мере около 19 нуклеотидов, по меньшей мере около 20 нуклеотидов, по меньшей мере около 25 нуклеотиды, по меньшей мере, около 30 нуклеотидов, по меньшей мере, около 35 нуклеотидов или, по меньшей мере, около 40 нуклеотидов. Такие ДНК-нацеленные сегменты могут иметь длину от около 12 нуклеотидов до около 100 нуклеотидов, от около 12 нуклеотидов до около 80 нуклеотидов, от около 12 нуклеотидов до около 50 нуклеотидов, от около 12 нуклеотидов до около 40 нуклеотидов. от около 12 нуклеотидов до около 30 нуклеотидов, от около 12 нуклеотидов до около 25 нуклеотидов или от около 12 нуклеотидов до около 20 нуклеотидов. Например, ДНК-нацеленный сегмент может составлять от около 15 нуклеотидов до около 25 нуклеотидов (например, от около 17 нуклеотидов до около 20 нуклеотидов, или около 17 нуклеотидов, около 18 нуклеотидов, около 19 нуклеотидов или около 20 нуклеотидов). Смотрите, например US 2016/0024523, включен в данный документ посредством ссылки в полном объеме для всех целей. В случае Cas9 из S. pyogenes, типичный ДНК-нацеленный сегмент имеет длину от 16 до 20 нуклеотидов, или от 17 до 20 нуклеотидов. В случае Cas9 из S. aureus, типичный ДНК-нацеленный сегмент имеет длину от 21 до 23 нуклеотидов. В случае Cpf1 типичный ДНК-нацеленный сегмент имеет длину по меньшей мере 16 нуклеотидов, или длину по меньшей мере 18 нуклеотидов.
[160] ТракрРНК могут быть в любой форме (например, полноразмерные транскрРНК или активные частичные транскрРНК) и различной длины. Они могут включать в себя первичные транскрипты или обработанные формы. Например, транскрРНК (как часть одной направляющей РНК, или как отдельная молекула, часть двухмолекулярной нРНК) могут содержать или состоять из всей или части последовательности транскрРНК дикого типа (например, около или больше чем около 20, 26, 32, 45, 48, 54, 63, 67, 85 или больше нуклеотидов последовательности транскрРНК дикого типа). Примеры последовательности транскрРНК дикого типа из S. pyogenes включают в себя 171-нуклеотидную, 89-нуклеотидную, 75-нуклеотидную и 65-нуклеотидную версии. Смотрите, например, Deltcheva et al. (2011) Nature 471:602-607; WO 2014/093661, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Примеры транскрРНК в единых направляющих РНК (енРНК) включают в себя сегменты транскрРНК, обнаруженные в +48, +54, +67 и +85 версиях енРНК, где «+ n» указывает, что вплоть до +n нуклеотида транскрРНК дикого типа включена в енРНК. Смотрите US 8697359, включен в данный документ посредством ссылки в полном объеме для всех целей.
[161] Процент комплементарности между ДНК-нацеленной последовательностью, и распознаваемой направляющей РНК последовательностью в ДНК-мишени может составлять, по меньшей мере 60% (например, по меньшей мере 65%, по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99%, или 100%). Процент комплементарности между ДНК-нацеленной последовательностью и распознаваемой направляющей РНК последовательностью в ДНК-мишени может составлять, по меньшей мере 60% на протяжении около 20 смежных нуклеотидов. Например, процент комплементарности между ДНК-нацеленной последовательностью и распознаваемой направляющей РНК последовательностью в ДНК-мишени составляет 100% на протяжении 14 смежных нуклеотидов на 5'-конце распознаваемой направляющей РНК последовательностью в пределах комплементарной цепи ДНК-мишени, и составляет до 0% в остальной части. В таком случае, ДНК-нацеленная последовательность имеет длину 14 нуклеотидов. В качестве другого примера, процент комплементарности между ДНК-нацеленной последовательностью и распознаваемой направляющей РНК последовательностью в ДНК-мишени составляет 100% на протяжении семи смежных нуклеотидов на 5'-конце распознаваемой направляющей РНК последовательностью в пределах комплементарной цепи ДНК-мишени, и составляет до 0% в остальной части. В таком случае, ДНК-нацеленную последовательность можно рассматривать как таковою, что имеет длину 7 нуклеотидов. В некоторых направляющих РНК по меньшей мере 17 нуклеотидов в ДНК-нацеленной последовательности комплементарны ДНК-мишени. Например, ДНК-нацеленная последовательность может иметь длину 20 нуклеотидов и может содержать 1, 2 или 3 некомплементарных с ДНК-мишенью нуклеотида (распознаваемая направляющей РНК последовательность). Предпочтительно, некомплементарные нуклеотиды не являются смежными с прилегающим к протоспейсеру мотивом (PAM) (например, некомплементарные нуклеотиды находятся на 5'-конце ДНК-нацеленной последовательности, или они находятся по меньшей мере на растоянии 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 или 19 пар оснований от последовательности PAM).
[162] Белок-связывающий сегмент нРНК может содержать два участка нуклеотидов, которые комплементарны друг другу. Комплементарные нуклеотиды белок-связывающего сегмента гибридизуются с образованием двухцепочечного РНК-дуплекса (дцРНК). Белок-связывающий сегмент нРНК согласно изобретению взаимодействует с белком Cas, и нРНК направляет связанный белок Cas к специфической нуклеотидной последовательности в ДНК-мишени посредством ДНК-нацеленного сегмента.
[163] Направляющие РНК могут содержать модификации или последовательности, которые обеспечивают дополнительные желательные признаки (например, измененную или регулируемую стабильность; внутриклеточное нацеливание; отслеживание с помощью флуоресцентной метки; сайт связывания для белка или белкового комплекса; и тому подобное). Примеры таких модификаций включают в себя, например, 5'-кэп (например, 7-метилгуанилатный кэп (m7G)); 3'-полиаденилированный хвост (то есть 3'-поли(А) хвост); последовательность рибо-переключателя (например, для обеспечения регулируемой стабильности и/или регулируемой доступности для белков и/или белковых комплексов); последовательность контроля стабильности; последовательность, которая формирует дцРНК-дуплекс (то есть шпильку); модификацию или последовательность, которая направляет РНК к внутриклеточной целевой области (например, ядро, митохондрии, хлоропласты и тому подобное); модификацию или последовательность, которая обеспечивает обнаружение (например, прямое конъюгирование с флуоресцентной молекулой, конъюгирование с фрагментом, который облегчает флуоресцентное обнаружение, последовательность, которая делает возможным флуоресцентное обнаружение и т.д.); модификацию или последовательность, которая предоставляет сайт связывания для белков (например, белков, которые действуют на ДНК, включающих в себя активаторы транскрипции, репрессоры транскрипции, ДНК-метилтрансферазы, ДНК-деметилазы, гистонацетилтрансферазы, гистондеацетилазы и тому подобное); и их комбинации.
[164] Направляющие РНК могут быть предоставлены в любой форме. Например, нРНК может быть предложена в форме РНК, либо в виде двух молекул (отдельно крРНК и транскрРНК), либо в виде одной молекулы (енРНК) и, необязательно, в форме комплекса с белком Cas. Например, нРНК могут быть получены путем транскрипции in vitro с использованием, например, РНК-полимеразы Т7 (смотрите, например, WO 2014/089290 и WO 2014/065596, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей). Направляющие РНК также могут быть получены путем химического синтеза.
[165] нРНК также может быть предоставлена в форме ДНК, кодирующей нРНК. ДНК, кодирующая нРНК, может кодировать одну молекулу РНК (енРНК) или отдельные молекулы РНК (например, отдельные крРНК и транскрРНК). В последнем случае ДНК, кодирующая нРНК, может быть предложена в виде одной молекулы ДНК или в виде отдельных молекул ДНК, кодирующих крРНК и транскрРНК, соответственно.
[166] Когда нРНК предоставляется в форме ДНК, она может временно, зависимо от условий или конститутивно экспрессироваться в клетке. ДНК, кодирующие нРНК, могут быть стабильно интегрированы в геном клетки и функционально связаны с активным в клетке промотором. В альтернативном варианте, ДНК, кодирующие нРНК, могут быть функционально связаны с промотором в экспрессионной конструкции. Например, ДНК, кодирующая нРНК, может находиться в векторе, содержащем экзогенный шаблон репарации, и/или в векторе, содержащем нуклеиновую кислоту, кодирующую белок Cas. В альтернативном варианте, она может находиться в векторе или плазмиде, отдельном(ой) от вектора, содержащего экзогенный шаблон репарации, и/или в векторе, содержащего нуклеиновую кислоту, кодирующую белок Cas. Промоторы, которые могут быть использованы в экспрессионной конструкции, включают в себя промоторы, активные, например, в одной или большем количестве эукариотических клеток, клетке человека, нечеловеческой клетке, клетке млекопитающего, клетке отличного от человека млекопитающего, клетке грызуна, клетке мыши, клетке крысы, клетке хомяка, клетке кролика, плюрипотентной клетке, эмбриональной стволовой (ES) клетке или зиготе. Такими промоторами могут быть, например, зависимые от условий промоторы, индуцибельные промоторы, конститутивные промоторы или тканеспецифичные промоторы. Такими промоторами также могут быть, например, двунаправленные промоторы. Конкретные примеры подходящих промоторов включают в себя промотор РНК-полимеразы III, такой как промотор U6 человека, промотор U6 полимеразы III крысы, или промотор U6 полимеразы III мыши.
(3) Распознаваемые направляющей РНК последовательности
[167] Термин «распознаваемая направляющей РНК последовательность» включает в себя нуклеотидные последовательности, присутствующие в ДНК-мишени (например, гене Fbn1), с которыми будет связываться ДНК-нацеленный сегмент нРНК, при условии наличия соответствующих условий для связывания. Например, распознаваемые направляющей РНК последовательности включают в себя последовательности, которым комплементарна спроектированная направляющая РНК, причем гибридизация между распознаваемой направляющей РНК последовательностью и ДНК-нацеленной последовательностью, способствует образованию комплекса CRISPR. Полная комплементарность не обязательно требуется при условии, что существует достаточная комплементарность, вызывающая гибридизацию и способствующая образованию комплекса CRISPR. Распознаваемые направляющей РНК последовательности также включают в себя сайты расщепления белками Cas, более подробно описанные ниже. Распознаваемая направляющей РНК последовательность может содержать любой полинуклеотид, который может быть расположен, например, в ядре или цитоплазме клетки, или в органелле клетки, такой как митохондрия или хлоропласт.
[168] На распознаваемую направляющей РНК последовательность в ДНК-мишени может быть нацелен (то есть может связываться, или гибридизоваться, или быть комплементарной) белок Cas или нРНК. Подходящие условия связывания ДНК/РНК включают в себя физиологические условия, обычно присутствующие в клетке. Другие подходящие условия связывания ДНК/РНК (например, условия в бесклеточной системе) известны в данной области техники (смотрите, например, Molecular Cloning: A Laboratory Manual, 3rd Ed. (Sambrook el al., Harbor Laboratory Press 2001), полностью включен в данный документ посредством ссылки в полном объеме для всех целей.) Цепь ДНК-мишени, которая комплементарна и гибридизируется с белком Cas или нРНК, может называться «комплементарной цепью», а цепь ДНК-мишени, которая комплементарна «комплементарной цепи» (и, следовательно, не комплементарна белку Cas или нРНК) может называться «некомплементарной цепью» или «матричной цепью».
[169] Белок Cas может расщеплять нуклеиновую кислоту в сайте в пределах или вне последовательности нуклеиновой кислоты, присутствующей в ДНК-мишени, с которой будет связываться ДНК-нацеленный сегмент нРНК. «Сайт расщепления» включает в себя позицию нуклеиновой кислоты, в которой белок Cas создает одноцепочечный или двухцепочечный разрыв. Например, формирование комплекса CRISPR (содержащего нРНК, гибридизованную с распознаваемой направляющей РНК последовательностью и образовавшей комплекс с белком Cas), может привести к расщеплению одной или обеих цепей в или около (например, в пределах 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50 или большего количества пар оснований от) нуклеотидной последовательности, присутствующей в ДНК-мишени, с которой будет связываться ДНК-нацеленный сегмент нРНК. Если сайт расщепления находится за пределами нуклеотидной последовательности, с которой будет связываться ДНК-нацеленный сегмент нРНК, сайт расщепления по-прежнему считается находящимся в «распознаваемой направляющей РНК последовательности». Сайт расщепления может находиться только на одной цепи или на обеих цепях нуклеиновой кислоты. Сайты расщепления могут находиться в одной и той же позиции на обеих цепях нуклеиновой кислоты (создавая тупые концы) или могут быть в разных сайтах на каждой цепи (продуцируя ступенчатые концы (то есть липкие концы)). Cтупенчатые концы могут быть получены, например, с использованием двух белков Cas, которые создают одноцепочечный разрыв в различных сайтах на разных цепях, тем самым производя двухцепочечный разрыв. Например, первая никаза может создавать одноцепочечный разрыв в первой цепи двухцепочечной ДНК (дцДНК), а вторая никаза может создавать одноцепочный разрыв во второй цепи дцДНК, так что создаются перекрывающиеся последовательности (липкие концы). В некоторых случаях, распознаваемая направляющей РНК последовательность никазы в первой цепи отделена от распознаваемой направляющей РНК последовательности никазы во второй цепи по меньшей мере на 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 75, 100, 250, 500, или 1000 пар оснований.
[170] Сайт-специфическое расщепление ДНК-мишени белками Cas может происходить в местах, определяемых как (i) комплементарностью спаривания оснований между нРНК и ДНК-мишенью, так и (ii) коротким мотивом, называемым смежным с протоспейсером мотивом (PAM), в ДНК-мишени. PAM может фланкировать распознаваемую направляющей РНК последовательность. Необязательно, распознаваемая направляющей РНК последовательность может быть фланкирована PAM на 3'-конце. В альтернативном варианте, распознаваемая направляющей РНК последовательность может быть фланкирована PAM на 5'-конце. Например, сайт расщепления белков Cas может находиться на растоянии от около 1 до около 10, или от около 2 до около 5 пар оснований (например, 3 пары оснований) выше или ниже последовательности PAM. В некоторых случаях (например, когда используют Cas9 из S. pyogenes или близкородственный Cas9), последовательность PAM некомплементарной цепи может быть 5'-N1GG-3', где N1 является любым нуклеотидом ДНК и находиться непосредственно в позиции 3' по отношению к распознаваемой направляющей РНК последовательности некомплементарной цепи ДНК-мишени. Таким образом, последовательность PAM комплементарной цепи будет представлять собой 5'-CCN2-3', где N2 является любым нуклеотидом ДНК и находится непосредственно в позиции 5' по отношению к распознаваемой направляющей РНК последовательности комплементарной цепи ДНК-мишени. В некоторых таких случаях, N1 и N2 могут быть комплементарными и N1- N2 пара основ может быть любой парой основ (например, N1=C и N2=G; N1=G и N2=C; N1=A и N2=T; или N1=T, и N2=A). В случае с Cas9 из S. aureus, PAM может представлять собой NNGRRT (SEQ ID NO: 146) или NNGRR (SEQ ID NO: 147), где N можеть представлять собой A, G, C, или T, и R может представлять собой G или A. В некоторых случаях (например, для FnCpf1) последовательность PAM может быть перед 5'-концом и иметь последовательность 5'-TTN-3'.
[171] Примеры распознаваемых направляющей РНК последовательностей включают в себя последовательность ДНК, комплементарную ДНК-нацеленному сегменту нРНК, или такую последовательности ДНК вместе с последовательностью PAM. Например, мотив-мишень может представлять собой 20-нуклеотидную ДНК последовательность, непосредственно предшествующую мотиву NGG, распознаваемые белком Cas9, например GN19NGG (SEQ ID NO: 39) или N20NGG (SEQ ID NO: 40) (смотрите, например, WO 2014/165825, включен в данный документ посредством ссылки в полном объеме для всех целей). Гуанин на 5'-конце может способствовать транскрипции РНК-полимеразой в клетках. Другие примеры распознаваемых направляющими РНК последовательностей могут содержать два гуаниновых нуклеотида на 5'-конце (например, GGN20NGG; SEQ ID NO: 41) для содействия эффективной транскрипции с помощью полимеразы T7 in vitro. Смотрите, например, WO 2014/065596, включен в данный документ посредством ссылки в полном объеме для всех целей. Другие распознаваемые направляющими РНК последовательности могут иметь длину от 4 до 22 нуклеотидов SEQ ID NO: 39-41, включая 5' G или GG и 3' GG или NGG. Другие распознаваемые направляющими РНК последовательности могут иметь длину от 14 до 20 нуклеотидов последовательностей SEQ ID NO: 39-41.
[172] Распознаваемая направляющей РНК последовательность может быть любой нуклеотидной последовательностью, эндогенной или экзогенной для клетки. Распознаваемая направляющей РНК последовательность может быть последовательностью, кодирующей генный продукт (например, белок), или некодирующей последовательностью (например, регуляторная последовательность), или может содержать обе.
D. Экзогенные шаблоны репарации
[173] Способы и композиции, раскрытые в данном документе, могут использовать экзогенные шаблоны репарации для модификации гена Fbn1 после расщепления гена Fbn1 нуклеазным агентом. Например, клетка может представлять собой эмбрион на одноклеточной стадии, а длина экзогенного шаблона репарации может составлять меньше чем 5 т.п.н. В типах клеток, отличных от эмбрионов на одноклеточной стадии, экзогенный шаблон репарации (например, нацеленный вектор) может быть длиннее. Например, в типах клеток, отличных от эмбрионов на одноклеточной стадии, экзогенный шаблон репарации может представлять собой большой нацеленный вектор (LTVEC), как описано в другом месте данного документа (например, нацеленный вектор, имеющий длину по меньшей мере 10 т.п.н. или имеющий 5', и 3' гомологичные плечи, суммарно имеющие длину по меньшей мере 10 т.п.н.). Использование экзогенных шаблонов репарации в сочетании с нуклеазными агентами может обеспечивать более точные модификации в гене Fbn1 путем стимулирования гомологичной прямой репарации.
[174] В таких способах, нуклеазный агент расщепляет ген Fbn1, делая одноцепочечный разрыв (ник) или двухцепочечный разрыв, а экзогенный шаблон репарации рекомбинирует с геном Fbn1 посредством лигирования, опосредованного негомологичным соединением концов NHEJ, или посредством гомологической прямой репарации. Необязательно, репарация с использованием экзогенного шаблона репарации удаляет или повреждает сайт расщепления нуклеазой, так что нуклеазный агент не может быть повторно нацелен на аллели-мишени.
[175] Экзогенные шаблоны репарации могут содержать дезоксирибонуклеиновую кислоту (ДНК) или рибонуклеиновую кислоту (РНК), они могут быть одноцепочечными или двухцепочечными, и они могут быть в линейной или кольцевой форме. Например, экзогенный шаблон репарации может представлять собой одноцепочечный олигодезоксинуклеотид (оцОДН). Смотрите, например, Yoshimi el al. (2016) Nat. Commun. 7:10431, включен в данный документ посредством ссылки в полном объеме для всех целей. Иллюстративный экзогенный шаблон репарации имеет длину от около 50 нуклеотидов до около 5 т.п.н., длину от около 50 нуклеотидов до около 3 т.п.н. или длину от около 50 до около 1000 нуклеотидов. Другие иллюстративные экзогенные шаблоны репарации имеют длину от около 40 до около 200 нуклеотидов. Например, экзогенный шаблон репарации может иметь длину от около 50 до около 60, от около 60 до около 70, от около 70 до около 80, от около 80 до около 90, от около 90 до около 100, от около 100 до около 110, от около 110 до около 120, от около 120 до около 130, от около 130 до около 140, от около 140 до около 150, от около 150 до около 160, от около 160 до около 170, от около 170 до около 180, от около 180 до около 190, или от около 190 до около 200 нуклеотидов. В альтернативном варианте, экзогенный шаблон репарации может иметь длину от около 50 до около 100, от около 100 до около 200, от около 200 до около 300, от около 300 до около 400, от около 400 до около 500, от около 500 до около 600, от около 600 до около 700 длиной от около 700 до около 800, от около 800 до около 900, или от около 900 до около 1000 нуклеотидов. В альтернативном варианте, экзогенный шаблон репарации может иметь длину от около 1 т.п.н. до около 1,5 т.п.н., от около 1,5 т.п.н. до около 2 т.п.н., от около 2 т.п.н. до около 2,5 т.п.н., от около 2,5 т.п.н. до около 3 т.п.н., от около 3 т.п.н. до около 3,5 т.п.н., от около 3,5 до около 4 т.п.н., от около 4 т.п.н. до около 4,5 т.п.н., или от около 4,5 т.п.н. до около 5 т.п.н. В альтернативном варианте, экзогенный шаблон репарации может иметь длину, например, не больше чем 5 т.п.н., 4,5 т.п.н. 4 т.п.н., 3,5 т.п.н., 3 т.п.н., 2,5 т.п.н., 2 т.п.н., 1,5 т.п.н., 1 т.п.н., 900 нуклеотидов, 800 нуклеотидов, 700 нуклеотидов, 600 нуклеотидов, 500 нуклеотидов, 400 нуклеотидов, 300 нуклеотидов, 200 нуклеотидов, 100 нуклеотидов, или 50 нуклеотидов. В типах клеток, отличных от эмбрионов на одноклеточной стадии, экзогенный шаблон репарации (например, нацеленный вектор) может быть длиннее. Например, в типах клеток, отличных от эмбрионов на одноклеточной стадии, экзогенный шаблон репарации может представлять собой большой нацеленный вектор (FTVEC), как описано в другом месте данного документа.
[176] В одном примере, экзогенный шаблон репарации представляет собой оцОДН, длина которого составляет от около 80 нуклеотидов до около 200 нуклеотидов. В другом примере, экзогенный шаблон репарации представляют собой оцОДН, длина которого составляет от около 80 нуклеотидов до около 3 т.п.н.. Такой оцОДН может иметь гомологичные плечи, например, каждое из которых имеет длину от около 40 до около 60 нуклеотидов. Такой оцОДН может иметь гомологичные плечи, например, каждое из которых имеет длину от около 30 до около 100 нуклеотидов. Гомологичные плечи могут быть симметричными (например, каждое 40 нуклеотидов или каждое 60 нуклеотидов в длину), или они могут быть асимметричными (например, одно гомологичное плечо имеет длину 36 нуклеотидов и одно гомологичное плечо имеет длину 91 нуклеотид).
[177] Экзогенные шаблоны репарации могут содержать модификации или последовательности, которые обеспечивают дополнительные желательные признаки (например, измененную или регулируемую стабильность; отслеживание или обнаружение с помощью флуоресцентной метки; сайт связывания для белка или белкового комплекса и т. д.). Экзогенные шаблоны репарации могут содержать одну или большее количество флуоресцентных тэгов, тэгов для очистки, эпитопных тэгов, или их комбинации. Например, экзогенный шаблон репарации может содержать одну или большее количество флуоресцентных меток (например, флуоресцентных белков, или других флуорофоров или красителей), например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4 или, по меньшей мере 5 флуоресцентных меток. Иллюстративные флуоресцентные метки включают в себя флуорофоры, такие как флуоресцеин (например, 6-карбоксифлуоресцеин (6-FAM)), Texas Red, HEX, Cy3, Cy5, Cy5.5, Pacific Blue, 5-(и-6)-карбокситетраметилродамин (TAMRA), и Cy7. Для мечения олигонуклеотидов коммерчески доступен широкий спектр флуоресцентных красителей (например, от Integrated DNA Technologies). Такие флуоресцентные метки (например, внутренние флуоресцентные метки) могут быть использованы, например, для обнаружения экзогенного шаблона репарации, который был прямо интегрирован в расщепленный ген Fbn1, имеющий липкие концы, совместимые с концами экзогенного шаблона репарации. Метка или тэг могут находиться на 5'-конце, 3'-конце или внутри экзогенного шаблона репарации. Например, экзогенный шаблон репарации может быть конъюгирован на 5'-конце с флуорофором IR700 от Integrated DNA Technologies (5'IRDYE®700).
[178] Экзогенные шаблоны репарации могут также содержать нуклеотидные вставки, включая сегменты ДНК, которые должны быть интегрированы в ген Fbn1. Интеграция нуклеотидной вставки в ген Fbn1 может привести к добавлению нуклеотидной последовательности интереса в ген Fbn1, делеции нуклеотидной последовательности интереса в гене Fbn1 или замене нуклеотидной последовательности интереса в гене Fbn1 (т.е. делеции и инсерции). Некоторые экзогенные шаблоны репарации спроектированы для инсерции нуклеотидной вставки в ген Fbn1 без какой-либо соответствующей делеции в гене Fbn1. Другие экзогенные шаблоны репарации спроектированы для удаления нуклеотидной последовательности интереса в гене Fbn1 без какой-либо соответствующей инсерции нуклеотидной вставки. Еще другие экзогенные шаблоны репарации спроектированы для удаления нуклеотидной последовательности интереса в гене Fbn1 и ее замены на нуклеотидную вставку.
[179] Нуклеотидная вставка или соответствующая нуклеиновая кислота в гене Fbn1, которую удаляют или/и заменяют, может иметь различную длину. Иллюстративная нуклеотидная вставка или соответствующая нуклеиновая кислота в гене Fbn1, которую удаляют и/или заменяют, имеет длину от около 1 нуклеотида до около 5 т.п.н., или длину от около 1 нуклеотида до около 1000 нуклеотидов. Например, нуклеотидная вставка или соответствующая нуклеиновая кислота в гене Fbn1, которую удаляют и/или заменяют, может иметь длину от около 1 до около 10, от около 10 до около 20, от около 20 до около 30, от около 30 до около 40, от около 40 до около 50, от около 50 до около 60, от около 60 до около 70, от около 70 до около 80, от около 80 до около 90, от около 90 до около 100, от около 100 до около 110, от около 110 до около 120, от около 120 до около 130, от около 130 до около 140, от около 140 до около 150, от около 150 до около 160, от около 160 до около 170, от около 170 до около 180, от около 180 до около 190 или от около 190 до около 200 нуклеотидов. Аналогично, нуклеотидная вставка или соответствующая нуклеиновая кислота в гене Fbn1, которую удаляют и/или заменяют, может иметь длину от около 1 до около 100, от около 100 до около 200, от около 200 до около 300, от около 300 до около 400, от около 400 до около 500, от около 500 до около 600, от около 600 до около 700, от около 700 до около 800, от около 800 до около 900 или от около 900 до около 1000 нуклеотидов. Аналогично, нуклеотидная вставка или соответствующая нуклеиновая кислота в гене Fbn1, которую удаляют и/или заменяют, может иметь длину от около 1 т.п.н. до около 1,5 т.п.н., от около 1,5 т.п.н. до около 2 т.п.н., от около 2 т.п.н. до около 2,5 т.п.н., от около 2,5 т.п.н. до около 3 т.п.н., от около 3 т.п.н до около 3,5 т.п.н, от около 3,5 т.п.н до около 4 т.п.н, от около 4 т.п.н до около 4,5 т.п.н, или от около 4,5 т.п.н до около 5 т.п.н. Нуклеиновая кислота, которую удаляют из гена Fbn1, также может иметь длину от около 1 т.п.н. до около 5 т.п.н., от около 5 т.п.н. до около 10 т.п.н., от около 10 т.п.н. до около 20 т.п.н., от около 20 т.п.н. до около 30 т.п.н., от около 30 т.п.н. до около 40 т.п.н., от около 40 т.п.н. до около 50 т.п.н., от около 50 т.п.н. до около 60 т.п.н., от около 60 т.п.н. до около 70 т.п.н., от около 70 т.п.н. до около 80 т.п.н., от около 80 т.п.н. до около 90 т.п.н., от около 90 т.п.н. до около 100 т.п.н., от около 100 т.п.н. до около 200 т.п.н., от около 200 т.п.н. до около 300 т.п.н., от около 300 т.п.н. до около 400 т.п.н., от около 400 т.п.н. до около 500 т.п.н., от около 500 т.п.н. до около 600 т.п.н., от около 600 т.п.н. до около 700 т.п.н. от около 700 т.п.н. до около 800 т.п.н., от около 800 т.п.н. до около 900 т.п.н., от около 900 т.п.н. до около 1 млн.п.н. или больше. В альтернативном варианте, нуклеиновая кислота, которую удаляют из гена Fbn1, может иметь длину от около 1 млн.п.н. до около 1,5 млн.п.н., от около 1,5 млн.п.н. до около 2 млн.п.н., от около 2 млн.п.н. до около 2,5 млн.п.н., от около 2,5 млн.п.н. до около 3 млн.п.н., от около 3 млн.п.н. до около 4 млн.п.н., от около 4 млн.п.н. до около 5 млн.п.н., от около 5 млн.п.н. до около 10 млн.п.н., от около 10 млн.п.н. до около 20 млн.п.н., от около 20 млн.п.н. до около 30 млн.п.н., от около 30 млн.п.н. до около 40 млн.п.н., от около 40 млн.п.н. до около 50 млн.п.н., от около 50 млн.п.н. до около 60 млн.п.н., от около 60 млн.п.н. до около 70 млн.п.н., от около 70 млн.п.н. до около 80 млн.п.н., от около 80 млн.п.н. до около 90 млн.п.н. или около от 90 млн.п.н. до около 100 млн.п.н.
[180] Нуклеотидная вставка может содержать геномную ДНК или ДНК любого другого типа. Например, нуклеотидная вставка может происходить из прокариота, эукариота, дрожжей, птицы (например, курицы), отличного от человека млекопитающего, грызуна, человека, крысы, мыши, хомяка, кролика, свиньи, быка, оленя, овцы, козы, кошки, собаки, хорька, примата (например, мартышки, макака-резуса), одомашненного млекопитающего, сельскохозяйственного млекопитающего, черепахи или любого другого организм интереса.
[181] Нуклеотидная вставка может содержать последовательность, которая гомологична или ортологична всему или части гена Fbn1 (например, части гена, кодирующей конкретный мотив или область белка фибриллина-1). Гомологичная последовательность может быть из другого вида, или из одного и того же вида. Например, нуклеотидная вставка может содержать последовательность, которая содержит одну или большее количество точечных мутаций (например, 1, 2, 3, 4, 5 или большее количество) по сравнению с последовательностью, нацеленной для замены в гене Fbn1. В некоторых случаях, нуклеотидная вставка представляет собой последовательность Fbn1 человека. Это может привести к гуманизации всего или части локуса Fbn1 у отличного от человека животного, если инсерция нуклеотидной вставки приводит к замене всей или части нуклеотидной последовательности Fbn1 не человека, соответствующей ортологичной нуклеотидной последовательностью человека (т.е. нуклеотидная вставка вставлена вместо соответствующей ДНК-последовательности не человека в ее эндогенном геномном локусе). Вставленная человеческая последовательность может дополнительно содержать одну или большее количество мутаций в человеческом гене Fbn1.
[182] Нуклеотидная вставка или соответствующая нуклеиновая кислота в гене Fbn1, которую удаляют и/или заменяют, может представлять собой кодирующую область, такую как экзон; некодирующую область, такую как интрон, нетранслируемую область или регуляторную область (например, промотор, энхансер или элемент, связывающий транскрипционный репрессор); или любую их комбинацию.
[183] Нуклеотидная вставка также может содержать аллель, зависимый от условий. Зависимый от условий аллель может представлять собой многофункциональный аллель, как описано в US 2011/0104799, включен в данный документ посредством ссылки в полном объеме для всех целей. Например, зависимый от условий аллель может содержать: (а) запускающую последовательность, в смысловой ориентации, по отношению к транскрипции гена-мишени; (b) кассету для отбора с помощью лекарственного средства (DSC) в смысловой или антисмысловой ориентации; (c) нуклеотидную последовательность интереса (NSI) в антисмысловой ориентации; и (d) инверсионный модуль, с зависимой от условия инверсией (COIN, который использует экзон-разделяющий интрон и инвертируемый модуль, подобный генной ловушке), в обратной ориентации. Смотрите, например, US 2011/0104799. Зависимый от условий аллель может дополнительно содержать рекомбинируемые единицы, которые рекомбинируют при воздействии первой рекомбиназы с образованием зависимого от условий аллеля, который (i) не имеет запускающей последовательности и DSC; и (ii) содержит NSI в смысловой ориентации и COIN в антисмысловой ориентации. Смотрите, например, US 2011/0104799.
[184] Нуклеотидные вставки также могут содержать полинуклеотид, кодирующий маркер селекции. В альтернативном варианте, в нуклеотидных вставках может отсутствовать полинуклеотид, кодирующий маркер селекции. Маркер селекции может содержаться в кассете селекции. Необязательно, кассета селекции может быть само-удаляющейся кассетой. Смотрите, например, US 8697851 и US 2013/0312129, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. В качестве примера, само-удаляющаяся кассета может содержать ген Crei (содержит два экзона, кодирующих рекомбиназу Cre, которые разделены интроном), функционально связанный с промотором Prm1 мыши и геном устойчивости к неомицину, функционально связанным с промотором убиквитина человека. Применяя промотор Prm1, само-удаляющаяся кассета может быть удалена специфически в мужских гаметах животных F0. Иллюстративные маркеры селекции включают в себя неомицинфосфотрансферазу (neor), гигромицин B фосфотрансферазу (hygr), пуромицин-N-ацетилтрансферазу (puror), бластицидин S дезаминазу (bsrr), ксантин/гуанин фосфорибозил трансферазу (gpt), или тимидин киназу вируса простого герпеса (HSV-k), или их комбинации. Полинуклеотид, кодирующий маркер селекции, может быть функционально связан с промотором, активным в клетке-мишени. Примеры промоторов описаны в данном документе в другом месте.
[185] Нуклеотидная вставка также может содержать репортерный ген. Иллюстративные репортерные гены включают в себя гены, кодирующие люциферазу, P-галактозидазу, зеленый флуоресцентный белок (GFP), усиленный зеленый флуоресцентный белок (eGFP), бирюзовый флуоресцентный белок (CFP), желтый флуоресцентный белок (YFP), усиленный желтый флуоресцентный белок (eYFP), синий флуоресцентный белок (BFP), усиленный синий флуоресцентный белок (eBFP), DsRed, ZsGreen, MmGFP, mPlum, mCherry, tdTomato, mStrawberry, J-Red, mOrange, mKO, mCitrine, Venus, YPet, Emerald, CyPet, Cerulean, T-Sapphire, и щелочную фосфатазу. Такие репортерные гены могут быть функционально связаны с промотором, активным в клетке-мишени. Примеры промоторов описаны в данном документе в другом месте.
[186] Нуклеотидная вставка также может содержать одну или большее количество экспрессионных кассет или делеционных кассет. Данная кассета может содержать одну или большее количество нуклеотидных последовательностей интереса, полинуклеотид, кодирующий маркер селекции, и репортерный ген, вместе с различными регуляторными компонентами, которые влияют на экспрессию. Примеры маркеров селекции и репортерных генов, которые могут быть включены, подробно обсуждаются в другом месте данного документа.
[187] Нуклеотидная вставка может содержать нуклеиновую кислоту, фланкированную нацеленными последовательностями сайт-специфической рекомбинации. В альтернативном варианте, нуклеотидная вставка может содержать одну или большее количество нацеленных последовательностей сайт-специфической рекомбинации. Хотя вся нуклеотидная вставка может быть фланкирована такими нацеленными последовательностями сайт-специфической рекомбинации, любая область или отдельный полинуклеотид интереса внутри нуклеотидной вставки также могут быть фланкированы такими сайтами. Нацеленные последовательности сайт-специфической рекомбинации, которые могут фланкировать нуклеотидную вставку или любой полинуклеотид интереса в нуклеотидной вставке, могут включать в себя, например, loxP, lox511, lox2272, lox66, lox71, loxM2, lox5171, FRT, FRT11, FRT71, attp, att, FRT, rox или их комбинацию. В одном примере, сайты сайт-специфической рекомбинации фланкируют полинуклеотид, кодирующий маркер селекции и/или ген-репортер, содержащийся в нуклеотидной вставке. После интеграции нуклеотидной вставки в ген Fbn1, последовательности между сайтами сайт-специфической рекомбинации могут быть удалены. Необязательно, могут быть использованы два экзогенных шаблона репарации, каждый с нуклеотидной вставкой, содержащей сайт сайт-специфической рекомбинации. Экзогенные шаблоны репарации могут быть нацелены на 5'- и 3'-области, фланкирующие нуклеиновую кислоту интереса. После интеграции двух нуклеотидных вставок в локус-мишень генома, нуклеиновая кислота интереса между двумя вставленными сайтами сайт-специфической рекомбинации может быть удалена.
[188] Нуклеотидные вставки также могут содержать один или большее количество сайтов эндонуклеаз рестрикции (то есть ферментов рестрикции), которые включают в себя эндонуклеазы типа I, типа II, типа III и типа IV. Эндонуклеазы рестрикции типа I и типа III распознают специфические распознаваемые последовательности, но обычно расщепляют в вариабельной по отношению к сайту связывания нуклеазы позиции, которая может находиться на расстоянии сотен пар нуклеотидов от сайта расщепления (распознаваемой последовательности). В системах типа II рестрикционная активность не зависит от активности какой-либо метилазы, и расщепление обычно происходит в определенных сайтах внутри или вблизи сайта связывания. Большинство ферментов типа II разрезают палиндромные последовательности, однако ферменты типа IIa распознают непалиндромные распознаваемые последовательности и расщепляют вне распознаваемой последовательности, ферменты типа IIb расщепляют последовательности дважды с обоими сайтами вне распознаваемой последовательности, а ферменты типа IIs распознают асимметричную распознаваемую последовательность и расщепляют на одной стороне и на определенном расстоянии около 1-20 нуклеотидов от распознаваемой последовательности. Ферменты рестрикции типа IV нацелены на метилированную ДНК. Ферменты рестрикции дополнительно описаны и классифицированы, например, в базе данных REBASE (веб-страница rebase.neb.com; Roberts et al., (2003) Nucleic Acids Res. 31:418-420; Roberts et al., (2003) Nucleic Acids Res. 31:1805-1812; и Belfort et al. (2002) в Mobile DNA II, pp. 761-783, Eds. Craigie et al., (ASM Press, Washington, DC)).
(1) Шаблоны репарации для инсерции, опосредованной негомологическим соединением концов
[189] Некоторые экзогенные шаблоны репарации имеют короткие одноцепочечные области на 5'-конце и/или 3'-конце, которые комплементарны одному или большему количеству липких концов, создаваемых расщеплением, опосредованным Cas-белком, в геномном локусе-мишени (например, в гене Fbn1). Данные липкие концы также могут называться 5'- и 3'-гомологичными плечами. Например, некоторые экзогенные шаблоны репарации имеют короткие одноцепочечные области на 5'-конце и/или 3'-конце, которые комплементарны одному или большему количеству липких концов, создаваемых расщеплением, опосредованным Cas-белком, в 5'- и/или 3'-последовательностях мишенях в геномном локусе-мишени. Некоторые из таких экзогенных шаблонов репарации имеют комплементарную область только на 5'-конце или только на 3'-конце. Например, некоторые из таких экзогенных шаблонов репарации имеют комплементарную область только на 5'-конце, комплементарном липкому концу, созданному на 5'-конце последовательности-мишени в геномном локусе-мишени, или только на 3'-конце, комплементарном липкому концу, созданному на 3'-конце последовательности-мишень в геномном локусе-мишени. Другие такие экзогенные шаблоны репарации имеют комплементарные области как на 5', так и на 3' концах. Например, другие такие экзогенные шаблоны репарации имеют комплементарные области как на 5', так и на 3' концах, например, комплементарные первому и второму липким концам, соответственно, создаваемым Cas-опосредованным расщеплением в геномном локусе-мишени. Например, если экзогенный шаблон репарации является двухцепочечным, одноцепочечные комплементарные области могут продолжаться от 5'-конца верхней цепи шаблона репарации и 5'-конца нижней цепи шаблона репарации, создавая 5'-липкие концы на каждом конце. В альтернативном варианте, одноцепочечная комплементарная область может продолжаться от 3'-конца верхней цепи шаблона репарации и от 3'-конца нижней цепи шаблона репарации, создавая 3'-липкие концы.
[190] Комплементарные области могут быть любой длины, достаточной для того, чтобы способствовать лигированию между экзогенным шаблоном репарации и геном Fbn1. Иллюстративные комплементарные области имеют длину от около 1 до около 5 нуклеотидов, длину от около 1 до около 25 нуклеотидов, или длину от около 5 до около 150 нуклеотидов. Например, комплементарная область может иметь длину, по меньшей мере около 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24 или 25 нуклеотидов. В альтернативном варианте, комплементарная область может иметь длину от около 5 до около 10, от около 10 до около 20, от около 20 до около 30, от около 30 до около 40, от около 40 до около 50, от около 50 до около 60, от около 60 до около 70, от около 70 до около 80, от около 80 до около 90, от около 90 до около 100, от около 100 до около 110, от около 110 до около 120, от около 120 до около 130, от около 130 до около 140, от около 140 до около 150 нуклеотидов, или больше.
[191] Такие комплементарные области могут быть комплементарны липким концам, создаваемым двумя парами никаз. Два двухцепочечных разрыва с ступенчатыми концами могут быть созданы с помощью первой и второй никаз, которые расщепляют противоположные цепи ДНК, чтобы создать первый двухцепочечный разрыв, и третьей и четвертой никаз, которые расщепляют противоположные цепи ДНК, чтобы создать второй двухцепочечный разрыв. Например, белок Cas может быть использован для внесения одноцепочечного разрыва в первую, вторую, третью и четвертую последовательности, распознаваемые направляющей РНК, соответствующие первой, второй, третьей и четвертой направляющим РНК. Первая и вторая распознаваемые направляющими РНК последовательности могут быть расположены так, чтобы создать первый сайт расщепления таким образом, чтобы одноцепочечные разрывы, созданные первой и второй никазами на первой и второй цепях ДНК, создавали двухцепочечный разрыв (то есть первый сайт расщепления содержит одноцепочечные разрывы в первой и второй распознаваемых направляющими РНК последовательностях). Аналогичным образом, третья и четвертая распознаваемые направляющими РНК последовательности могут быть расположены так, чтобы создать второй сайт расщепления таким образом, чтобы одноцепочечные разрывы, созданные третьей и четвертой никазами в первой и второй цепях ДНК, создавали двухцепочечный разрыв (то есть второй сайт расщепления содержит одноцепочечные разрывы в третьей и четвертой распознаваемых направляющими РНК последовательностях). Предпочтительно, чтобы одноцепочечные разрывы в первой и второй распознаваемых направляющими РНК последовательностях и/или в третьей и четвертой распознаваемых направляющими РНК последовательностях могли быть смещенными одноцепочечными разрывами, которые создают липкие концы. Окно разнесения может составлять, например, по меньшей мере около 5 п.н., 10 п.н., 20 п.н., 30 п.н., 40 п.н., 50 п.н., 60 п.н., 70 п.н., 80 п.н., 90 п.н., 100 п.н. или больше. Смотрите Ran et al. (2013) Cell 154:1380-1389; Mali et al. (2013) Nat. Biotech.31:833-838; и Shen et al. (2014) Nat. Methods 11:399-404, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. В таких случаях, может быть спроектирован двухцепочечный экзогенный шаблон репарации с одноцепочечными комплементарными областями, которые комплементарны липким концам, создаваемым одноцепочечными разрывами в первой и второй распознаваемых направляющими РНК последовательностях и одноцепочечными разрывами в третьей и четвертой распознаваемых направляющими РНК последовательностях. Такой экзогенный шаблон репарации затем может быть вставлен путем лигирования, опосредованного негомологичным соединением концов.
(2) Шаблоны репарации для инсерции путем гомологичной прямой репарации
[192] Некоторые экзогенные шаблоны репарации содержат гомологичные плечи. Если экзогенный шаблон репарации также содержит нуклеотидную вставку, гомологичные плечи могут фланкировать нуклеотидную вставку. Для простоты упоминания, гомологичные плечи упоминаются в данном документе как 5' и 3' (то есть, выше и ниже) гомологичные плечи. Эта терминология относится к относительной позиции гомологичных плечей относительно нуклеотидной вставки в экзогенном шаблоне репарации. 5' и 3' гомологичные плечи соответствуют областям в гене Fbn1, которые обозначаются в данном документе как «5' последовательность-мишень» и «3' последовательность-мишень», соответственно.
[193] Гомологичное плечо и последовательность-мишень «соответствуют» или «подходят» друг другу, когда две области имеют достаточный уровень идентичности последовательности друг с другом, чтобы выступать в качестве субстратов для реакции гомологичной рекомбинации. Термин «гомология» включает в себя последовательности ДНК, которые либо идентичны, либо разделяют идентичность последовательности с соответствующей последовательностью. Идентичность последовательности между данной последовательностью-мишенью и соответствующим гомологичным плечом, обнаруженным в экзогенном шаблоне репарации, может быть любой степенью идентичности последовательностей, которая позволяет происходить гомологичной рекомбинации. Например, значение идентичности последовательностей, наблюдаемое для гомологичного плеча экзогенного шаблона репарации (или его фрагмента) и последовательности мишени (или ее фрагмента), может составлять, по меньшей мере 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94% 95%, 96%, 97%, 98%, 99% или 100% идентичности последовательностей, так что последовательности подвергаются гомологичной рекомбинации. Более того, соответствующая область гомологии между гомологичным плечом и соответствующей последовательностью-мишенью может иметь любую длину, достаточную для обеспечения гомологичной рекомбинации. Иллюстративные гомологичные плечи имеют длину от около 25 нуклеотидов до около 2,5 т.п.н., от около 25 нуклеотидов до около 1,5 т.п.н., или от около 25 до около 500 нуклеотидов. Например, данное гомологичное плечо (или каждое из гомологичных плеч) и/или соответствующая последовательность-мишень могут содержать соответствующие области гомологии, которые имеют длину от около 25 до около 30, от около 30 до около 40, от около 40 до около 50, от около 50 до около 60, от около 60 до около 70, от около 70 до около 80, от около 80 до около 90, от около 90 до около 100, от около 100 до около 150, от около 150 до около 200, от около 200 до около 250, от около 250 до около 300, от около 300 до около 350, от около 350 до около 400, от около 400 до около 450, или от около 450 до около 500 нуклеотидов, так что гомологичные плечи имеют достаточную гомологию для гомологичной рекомбинации с соответствующими последовательностями-мишенями в пределах гена Fbn1 . В альтернативном варианте, данное гомологичное плечо (или каждое из гомологичных плеч) и/или соответствующая последовательность-мишень могут содержать соответствующие области гомологии, которые имеют длину от около 0,5 т.п.н. до около 1 т.п.н., от около 1 т.п.н. до около 1,5 т.п.н., от около 1,5 т.п.н. до около 2 т.п.н., или от около 2 т.п.н. до около 2,5 т.п.н.. Например, каждое гомологичное плечо может иметь длину около 750 нуклеотидов. Гомологичные плечи могут быть симметричными (каждое примерно одинаковой длинны), или они могут быть асимметричными (одно длиннее другого).
[194] Гомологичные плечи могут соответствовать локусу, который является нативным для клетки (например, локус-мишень). В альтернативном варианте, например, они могут соответствовать области гетерологичного или экзогенного сегмента ДНК, который был интегрирован в геном клетки, включающей в себя, например, трансгены, экспрессионные кассеты, или гетерологичные или экзогенные области ДНК. В альтернативном варианте, гомологичные плечи нацеленного вектора могут соответствовать области искусственной дрожжевой хромосомы (YAC), искусственной бактериальной хромосомы (BAC), искусственной хромосомы человека или любой другой сконструированной области, содержащейся в соответствующей клетке-хозяине. Кроме того, гомологичные плечи нацеленного вектора могут соответствовать или быть получены из области библиотеки BAC, космидной библиотеки или библиотеки P1-фага, или могут быть получены из синтетической ДНК.
[195] Когда нуклеазный агент используется в комбинации с экзогенным шаблоном репарации, 5'- и 3'-последовательности-мишени предпочтительно расположены в достаточной близости от сайта расщепления нуклеазой, чтобы способствовать наступлению гомологичной рекомбинации между последовательностями-мишенями и гомологичными плечами при одноцепочечном разрыве («ник») или двухцепочечном разрыве в сайте расщепления нуклеазой. Термин «сайт расщепления нуклеазой» включает в себя последовательность ДНК, в которой нуклеазный агент делает одноцепочечный разрыв или двухцепочечный разрыв (например, белок Cas9, образовавший комплекс с направляющей РНК). Последовательности-мишени в гене Fbn1, которые соответствуют 5'- и 3'-гомологичным плечам экзогенного шаблона репарации «расположены в достаточной близости» к сайту расщепления нуклеазой, если расстояние такое, чтобы способствует наступлению гомологичной рекомбинации между 5'- и 3'-последовательностями-мишенями и гомологичными плечами при одноцепочечном разрыве или двухцепочечном разрыве в сайте расщепления нуклеазой. Таким образом, последовательности-мишени, соответствующие 5'- и/или 3'-гомологичным плечам экзогенного шаблона репарации, могут находиться, например, в пределах по меньшей мере 1 нуклеотида от данного сайта расщепления нуклеазой, или в пределах по меньшей мере от 10 нуклеотидов до около 1000 нуклеотидов от данного сайта расщепления нуклеазой. В качестве примера, сайт расщепления нуклеазой может быть размещен непосредственно возле по меньшей мере одной или обеих последовательностей-мишеней.
[196] Пространственное взаимное расположение последовательностей-мишеней, которые соответствуют гомологичным плечам экзогенного шаблона репарации, и сайта расщепления нуклеазой, может варьировать. Например, последовательности-мишени могут быть расположены 5' от сайта расщепления нуклеазой, последовательности-мишени могут быть расположены 3' от сайта расщепления нуклеазой, или последовательности-мишени могут фланкировать сайт расщепления нуклеазой.
[197] В клетках, отличных от эмбрионов на одноклеточной стадии, экзогенный шаблон репарации может представлять собой «большой нацеленный вектор» или «LTVEC», который включает в себя нацеленные векторы, которые содержат гомологичные плечи, которые соответствуют и получены из нуклеотидных последовательностей, больших, чем те, которые обычно используются в других подходах, предназначенных для осуществления гомологичной рекомбинации в клетках. LTVEC также включают в себя нацеленные векторы, содержащие нуклеотидные вставки, имеющие нуклеотидные последовательности, большие, чем те, которые обычно используются в других подходах, предназначенных для осуществления гомологичной рекомбинации в клетках. Например, LTVEC делают возможной модификацию больших локусов, которые не могут быть приведены в соответствие с традиционными нацеленными векторами на основе плазмид из-за их ограничений по размеру. Например, локус-мишень может быть (т. е. 5'- и 3'-гомологичные плечи могут соответствовать ему) локусом клетки, который не может быть сделан мишенью, используя обычный способ, или который может быть найден только неправильно или только с значительно низкой эффективностью при отсутствии одноцепочечного разрыва или двухцепочечного разрыва, вызванного нуклеазным агентом (например, белком Cas).
[198] Примеры LTVEC включают в себя векторы, полученные из искусственной бактериальной хромосомы (BAC), искусственной человеческой хромосомы или искусственной дрожжевой хромосомы (YAC). Неограничивающие примеры LTVEC и способы их получения описаны, например, в патентах США № 6586251; № 6596541; и № 7105348; и в WO 2002/036789, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. LTVEC могут быть в линейной или кольцевой форме.
[199] LTVEC могут быть любой длины и обычно имеют длину по меньшей мере 10 т.п.н.. Например, LTVEC могут быть от около 50 т.п.н. до около 300 т.п.н., от около 50 т.п.н. до около 75 т.п.н., от около 75 т.п.н. до около 100 т.п.н., от около 100 т.п.н. до 125 т.п.н., от около 125 т.п.н. до около 150 т.п.н. от около 150 т.п.н. до около 175 т.п.н., от около 175 т.п.н. до около 200 т.п.н., от около 200 т.п.н. до около 225 т.п.н., от около 225 т.п.н. до около 250 т.п.н., от около 250 т.п.н. до около 275 т.п.н., или от около 275 т.п.н. до около 300 т.п.н.. В альтернативном варианте, LTVEC может быть по меньшей мере 10 т.п.н., по меньшей мере 15 т.п.н., по меньшей мере 20 т.п.н., по меньшей мере 30 т.п.н., по меньшей мере 40 т.п.н., по меньшей мере 50 т.п.н., по меньшей мере 60 т.п.н., по меньшей мере 70 т.п.н., по меньшей мере 80 т.п.н., по меньшей мере 90 т.п.н., по меньшей мере 100 т.п.н., по меньшей мере 150 т.п.н., по меньшей мере 200 т.п.н., по меньшей мере 250 т.п.н., по меньшей мере 300 т.п.н., по меньшей мере 350 т.п.н., по меньшей мере 400 т.п.н., по меньшей мере 450 т.п.н. по меньшей мере 500 т.п.н. или больше. Размер LTVEC может быть слишком большим, чтобы сделать возможным скрининг событий достижения мишени с помощью традиционных анализов, например, с помощью саузерн-блоттинга и ПЦР для больших последовательностей (например, от 1 т.п.н. до 5 т.п.н.).
[200] Общая протяженность 5'-гомологичного плеча и 3'-гомологичного плеча в LTVEC обычно составляет по меньшей мере 10 т.п.н. В качестве примера, длинна 5'-гомологичного плеча может варьировать от около 5 т.п.н. до около 100 т.п.н., и/или длинна 3'-гомологичного плеча может варьировать от около 5 т.п.н. до около 100 т.п.н.. Каждое гомологичное плечо может быть, например, от около 5 т.п.н. до около 10 т.п.н., от около 10 т.п.н. до около 20 т.п.н., от около 20 т.п.н. до около 30 т.п.н., от около 30 т.п.н. до около 40 т.п.н., от около 40 т.п.н. до около 50 т.п.н., от около 50 т.п.н. до около 60 т.п.н., от около 60 т.п.н. до около 70 т.п.н., от около 70 т.п.н. до около 80 т.п.н., от около 80 т.п.н. до около 90 т.п.н., от около 90 т.п.н. до около 100 т.п.н., от около 100 до около 110 т.п.н., от около 110 до около 120 т.п.н., от около 120 до около 130 т.п.н., от около 130 до около 140 т.п.н., от около 140 до около 150 т.п.н., от около 150 т.п.н. до около 160 т.п.н., от около 160 т.п.н. до около 170 т.п.н., от около 170 т.п.н. до около 180 т.п.н., от около 180 т.п.н. до около 190 т.п.н., или от около 190 т.п.н. до около 200 т.п.н.. Общая протяженность 5'-гомологичного плеча и 3'-гомологичного плеча может составлять, например, от около 10 т.п.н. до около 20 т.п.н., от около 20 т.п.н. до около 30 т.п.н., от около 30 т.п.н. до около 40 т.п.н., от около 40 т.п.н. до около 50 т.п.н., от около 50 т.п.н. до около 60 т.п.н., от около 60 т.п.н. до около 70 т.п.н., от около 70 т.п.н. до около 80 т.п.н., от около 80 т.п.н. до около 90 т.п.н., от около 90 т.п.н. до около 100 т.п.н., от около 100 т.п.н. до около 110 т.п.н., от около 110 до около 120 т.п.н., от около 120 до около 130 т.п.н., от около 130 до около 140 т.п.н., от около 140 до около 150 т.п.н., от около 150 т.п.н. до около 160 т.п.н., от около 160 т.п.н. до около 170 т.п.н., от около 170 т.п.н. до около 180 т.п.н., от около 180 т.п.н. до около 190 т.п.н., или от около 190 т.п.н. до около 200 т.п.н.. В альтернативном варианте, каждое гомологичное плечо может быть по меньшей мере 5 т.п.н., по меньшей мере 10 т.п.н., по меньшей мере 15 т.п.н., по меньшей мере 20 т.п.н., по меньшей мере 30 т.п.н., по меньшей мере 40 т.п.н., по меньшей мере 50 т.п.н., по меньшей мере 60 т.п.н., по меньшей мере 70 т.п.н., по меньшей мере 80 т.п.н., по меньшей мере 90 т.п.н., по меньшей мере 100 т.п.н., по меньшей мере 110 т.п.н., по меньшей мере 120 т.п.н., по меньшей мере 130 т.п.н., по меньшей мере 140 т.п.н., по меньшей мере 150 т.п.н., по меньшей мере 160 т.п.н., по меньшей мере 170 т.п.н., по меньшей мере 180 т.п.н., по меньшей мере 190 т.п.н., или по меньшей мере 200 т.п.н.. Аналогичным образом, общая протяженность 5'- и 3'-гомологичных плечей может составлять по меньшей мере 10 т.п.н., по меньшей мере 15 т.п.н., по меньшей мере 20 т.п.н., по меньшей мере 30 т.п.н., по меньшей мере 40 т.п.н., по меньшей мере 50 т.п.н., по меньшей мере 60 т.п.н., по меньшей мере 70 т.п.н., по меньшей мере 80 т.п.н., по меньшей мере 90 т.п.н., по меньшей мере 100 т.п.н., по меньшей мере 110 т.п.н., по меньшей мере 120 т.п.н., по меньшей мере 130 т.п.н., по меньшей мере 140 т.п.н., по меньшей мере 150 т.п.н., по меньшей мере 160 т.п.н., по меньшей мере 170 т.п.н., по меньшей мере 180 т.п.н., по меньшей мере 190 т.п.н., или по меньшей мере 200 т.п.н..
[201] LTVEC могут содержать нуклеотидные вставки, имеющие нуклеотидные последовательности, большие, чем те, которые обычно используются в других подходах, предназначенных для осуществления гомологичной рекомбинации в клетках. Например, LTVEC может содержать нуклеотидную вставку с длинной в диапазоне от около 5 т.п.н. до около 10 т.п.н., от около 10 т.п.н. до около 20 т.п.н., от около 20 т.п.н. до около 40 т.п.н., от около 40 т.п.н. до около 60 т.п.н., от около 60 т.п.н. до около 80 т.п.н., от около 80 т.п.н. до около 100 т.п.н., от около 100 т.п.н. до около 150 т.п.н., от около 150 т.п.н. до около 200 т.п.н., от около 200 т.п.н. до около 250 т.п.н., от около 250 т.п.н. до около 300 т.п.н., от около 300 т.п.н. до около 350 т.п.н., от около 350 т.п.н. до около 400 т.п.н., или больше.
E. Приведение в контакт генома клетки и введение нуклеиновых кислот в клетки
[202] Приведение в контакт генома клетки может включать в себя введение одного или большего количества нуклеазных агентов или нуклеиновых кислот, кодирующих нуклеазные агенты (например, одного или большего количества белков Cas, или нуклеиновых кислот, кодирующих один или большее количество белков Cas, и одной или большего количество направляющих РНК или нуклеиновых кислот, кодирующих одну или большее количество направляющих РНК (то есть одну или большее количество CRISPR РНК, и одну или большее количество транскрРНК)) и/или одного или большего количества экзогенных шаблонов репарации в клетку, при условии, что если клетка является эмбрионом на одноклеточной стадии, то, например, экзогенный шаблон репарации может быть меньше чем 5 т.п.н.. Приведение в контакт генома клетки (то есть контактирование клетки) может включать в себя введение в клетку только одного из указанных выше компонентов, одного или большего количества компонентов, или всех компонентов. «Введение» включает в себя включение в клетку нуклеиновой кислоты или белка таким образом, что последовательность получает доступ к внутренней части клетки. Введение может быть выполнено любыми способами, и один или большее количество компонентов (например, два компонента или все компоненты) могут быть введены в клетку одновременно или последовательно в любой комбинации. Например, экзогенный шаблон репарации может быть введен до введения нуклеазного агента, или он может быть введен после введения нуклеазного агента (например, экзогенный шаблон репарации может быть введен примерно 1, 2, 3, 4, 8, 12, 24, 36, 48 или 72 часа до или после введения нуклеазного агента). Смотрите, например, US 2015/0240263 и US 2015/0110762, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[203] Нуклеазный агент может быть введен в клетку в форме белка или в форме нуклеиновой кислоты, кодирующей нуклеазный агент, такой как РНК (например, матричная РНК (мРНК)) или ДНК. ДНК может быть функционально связана с активным в клетке промотором при введении в форме ДНК. Такие ДНК могут находиться в одной или большем количестве экспрессионных конструкций.
[204] Например, белок Cas может быть введен в клетку в форме белка, такого как белок Cas, образовавший комплекс с нРНК, или в форме нуклеиновой кислоты, кодирующей белок Cas, такой как РНК (например, мессенджер РНК (мРНК)) или ДНК. Направляющая РНК может быть введена в клетку в форме РНК или в форме ДНК, кодирующей направляющую РНК. ДНК, кодирующая белок Cas и/или направляющую РНК, при введении в форме ДНК может быть функционально связана с активным в клетке промотором. Такие ДНК могут находиться в одной или большем количестве экспрессионных конструкций. Например, такие экспрессирующие конструкции могут быть компонентами одной молекулы нуклеиновой кислоты. В альтернативном варианте, они могут быть разделены в любой комбинации среди двух или большего количества молекул нуклеиновой кислоты (т.е. ДНК, кодирующие одну или больше количество CRISPR РНК, ДНК, кодирующие одну или больше количество транскрРНК, и ДНК, кодирующая белок Cas, могут быть компонентами отдельных молекул нуклеиновых кислот).
[205] В некоторых способах ДНК, кодирующая нуклеазный агент (например, белок Cas и направляющую РНК), и/или ДНК, кодирующая экзогенный шаблон репарации, может быть введена в клетку с помощью мини-кольцевой ДНК. Смотрите, например, WO 2014/182700, включен в данный документ посредством ссылки в полном объеме для всех целей. Мини-кольцевые ДНК представляют собой суперскрученные молекулы ДНК, которые можно использовать для невирусного переноса генов, которые не имеют ни точки начала репликации, ни маркера селекции на антибиотике. Таким образом, мини-кольцевые ДНК обычно меньше по размеру, чем плазмидный вектор. Эти ДНК лишены бактериальной ДНК и, следовательно, лишены неметилированных мотивов CpG, обнаруженных в бактериальной ДНК.
[206] Способы, предложенные в данном документе, не зависят от конкретного способа введения нуклеиновой кислоты или белка в клетку, важно только чтобы нуклеиновая кислота или белок попадали внутрь, по меньшей мере, одной клетки. Способы введения нуклеиновых кислот и белков в клетки различных типов известны в данной области техники и включают в себя, например, способы стабильной трансфекции, способы временной трансфекции и опосредованные вирусом способы.
[207] Протоколы трансфекции, а также протоколы введения в клетки нуклеиновых кислот или белков могут различаться. Неограничивающие способы трансфекции включают в себя химические способы трансфекции с использованием липосом; наночастиц; фосфата кальция (Graham et al. (1973) Virology 52 (2): 456-67, Bacchetti et al. (1977) Proc. Natl. Acad. Sci. USA 74 (4): 1590-4, и Kriegler, M (1991). Transfer and Expression: A Laboratory Manual. New York: W. H. Freeman and Company, pp. 96-97); дендримеров; или катионных полимеров, таких как DEAE-декстран или полиэтиленимин. Нехимические способы включают в себя электропорацию, сонопорация и оптическую трансфекцию. Трансфекция на основе частиц включает в себя использование генной пушки или магнитной трансфекции (Bertram (2006) Current Pharmaceutical Biotechnology 7, 277-28). Вирусные способы также могут быть использованы для трансфекции.
[208] Введение нуклеиновых кислот или белков в клетку также может быть опосредовано электропорацией, внутрицитоплазматической инъекцией, вирусной инфекцией, аденовирусом, аденоассоциированным вирусом, лентивирусом, ретровирусом, трансфекцией, липид-опосредованной трансфекцией или нуклеофекции. Нуклеофекция - это усовершенствованная технология электропорации, которая позволяет доставлять субстраты нуклеиновых кислот не только в цитоплазму, но также и через ядерную мембрану и в ядро. Кроме того, использование нуклеофекции в раскрытых в данном документе способах обычно требует гораздо меньше клеток, чем обычная электропорация (например, только около 2 миллионов по сравнению с 7 миллионами при обычной электропорации). В одном примере нуклеофекцию выполняют с использованием системы LONZA® NUCLEOFECTOR™.
[209] Введение нуклеиновых кислот или белков в клетку (например, эмбрион на одноклеточной стадии) также может быть осуществлено путем микроинъекции. Для эмбрионов на одноклеточной стадии микроинъекция может осуществляться в материнский и/или отцовский пронуклеус, или в цитоплазму. Если микроинъекцию выполняют только в один пронуклеус, отцовский пронуклеус является более предпочтительным из-за его большего размера. Микроинъекция мРНК предпочтительно осуществляется в цитоплазму (например, для доставки мРНК непосредственно к машинерии трансляции), тогда как микроинъекция белка или ДНК, кодирующей белок Cas, предпочтительно осуществляется в ядро/пронуклеус. В альтернативном варианте, микроинъекция может быть выполнена в виде инъекции как в ядро /пронуклеус, так и в цитоплазму: сперва игла может быть введена в ядро/пронуклеус, и может быть введено первое количество, и при удалении иглы из эмбриона на одноклеточной стадии второе количество может быть введено в цитоплазму. Если белок нуклеазного агента вводят в цитоплазму, белок предпочтительно содержит сигнал ядерной локализации для обеспечения доставки в ядро/пронуклеус. Методы проведения микроинъекции хорошо известны. Смотрите, например, Nagy el al. (Nagy A, Gertsenstein M, Vintersten K, Behringer R., 2003, Manipulating the Mouse Embryo. Cold Spring Harbor, New York: Cold Spring Harbor Laboratory Press); Meyer et al. (2010) Proc. Natl. Acad. Sci. USA 107:15022-15026 и Meyer et al. (2012) Proc. Natl. Acad. Sci. USA 109:9354-9359.
[210] Другие способы введения нуклеиновой кислоты или белков в клетку могут включать в себя, например, векторную доставку, опосредованную частицами доставку, экзосомо-опосредованную доставку, опосредованную липидными наночастицами доставку, опосредованную проникающим в клетку пептидом доставку, или опосредованную имплантируемым устройством доставку.
[211] Введение нуклеиновых кислот или белков в клетку может быть выполнено один раз или несколько раз за период времени. Например, введение может быть выполнено за по меньшей мере два раза за период времени, по меньшей мере три раза за период времени, по меньшей мере четыре раза за период времени, по меньшей мере пять раз за период времени, по меньшей мере шесть раз за период времени, по меньшей мере семь раз за период времени, по меньшей мере восемь раз за период времени, по меньшей мере девять раз за период времени, по меньшей мере десять раз за период времени, по меньшей мере одиннадцать раз, по меньшей мере двенадцать раз за период времени, по меньшей мере тринадцать раз за период времени, по меньшей мере четырнадцать раз за период времени, по меньшей мере пятнадцать раз за период времени, по меньшей мере шестнадцать раз за период времени, по меньшей мере семнадцать раз за период времени, по меньшей мере восемнадцать раз за период времени, по меньшей мере девятнадцать раз за период времени или, по меньшей мере двадцать раз за период времени.
[212] В некоторых случаях клетки, используемые в способах и композициях, имеют конструкцию ДНК, стабильно интегрированную в их геном. В таких случаях, приведение в контакт может включать в себя предоставление клетки с конструкцией, уже стабильно включенной в ее геном. Например, клетка, применяемая в способах, раскрытых в данном документе, может иметь уже стабильно интегрированный в ее геном ген, кодирующий Cas, (то есть Cas-подготовленная клетка). «Стабильно включенный» или «стабильно внедренный» или «стабильно интегрированный» включает в себя внедрение полинуклеотида в клетку таким образом, что нуклеотидная последовательность интегрируется в геном клетки и способна наследоваться ее потомством. Может применяться любой протокол для стабильного включения конструкций ДНК или различных компонентов нацеленной на геном системы интеграции.
F. Типы целевых генетических модификаций
[213] Различные типы целевых генетических модификаций могут быть внесены с использованием способов, описанных в данном документе. Такие целевые модификации могут включать в себя, например, добавления одного или большего количества нуклеотидов, делеции одного или большего количества нуклеотидов, замены одного или большего количества нуклеотидов, точечную мутацию, нокаут полинуклеотида интереса или его части, активацию полинуклеотида интереса или его части, замену эндогенной нуклеотидной последовательности гетерологичной, экзогенной, гомологичной или ортологичной нуклеотидной последовательностью, замену домена, замену экзона, замену интрона, замену регуляторной последовательности, замену гена или их комбинацию. Например, по меньшей мере 1, 2, 3, 4, 5, 7, 8, 9, 10 или большее количество нуклеотидов могут быть изменены (например, удалены, вставлены или заменены) для формирования целевой геномной модификации. Делеции, инсерции или замены могут быть любого размера, как раскрыто в данном документе в другом месте. Смотрите, например, Wang et al. (2013) Cell 153:910-918; Mandalos et al. (2012) PLOS ONE 7:e45768:l-9; и Wang et al. (2013) Nat Biotechnol. 31:530-532, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[214] Такие целевые генетические модификации могут приводить к повреждению геномного локуса-мишени, могут вносить вызывающие заболевание мутации или вызывающие заболевание аллели, могут приводить к гуманизации геномного локуса-мишени (то есть замены нечеловеческой нуклеотидной последовательности гомологичной или ортологичной человеческой нуклеотидной последовательностью), могут создавать зависящие от условий аллели и тому подобное. Нарушение может включать в себя изменение регуляторного элемента (например, промотора или энхансера), миссенс мутацию, нонсенс мутацию, мутацию сдвига рамки считывания, мутацию с укорачиванием, нуль-мутацию, или инсерцию или делецию небольшого количества нуклеотидов (например, вызывающую мутацию со сдвигом рамки считывания), и это может привести к инактивации (т.е. потере функции) или потере аллеля.
[215] Целевая генетическая модификация может представлять собой, например, двухаллельную модификацию или моноаллельную модификацию. Предпочтительно, целевая генетическая модификация представляет собой моноаллельную модификацию. Двухаллельные модификации включают в себя случаи, при которых одна и та же модификация вносится в один и тот же локус соответствующих гомологичных хромосом (например, в диплоидной клетке), или когда разные модификации вносят в один и том же локус соответствующих гомологичных хромосом. В некоторых способах, целевая генетическая модификация является моноаллельной модификацией. Моноаллельная модификация включает в себя события при которых модификацию вносят только в один аллель (то есть модификация гена Fbn1 только в одной из двух гомологичных хромосом). Гомологичные хромосомы включают в себя хромосомы, которые имеют одинаковые гены в одинаковых локусах, но, допускается наличие разных аллелей (например, хромосомы, которые спарены во время мейоза). Термин аллель включает в себя любую одну или большее количество альтернативных форм генетической последовательности. В диплоидной клетке или организме два аллеля данной последовательности обычно занимают соответствующие друг другу локусы в паре гомологичных хромосом.
[216] Моноаллельная мутация может приводить к получению гетерозиготной по целевой модификации Fbn1 клетке. Гетерозиготность включает в себя случай в котором только один аллель гена Fbn1 (т.е. соответствующие аллели на обеих гомологичных хромосомах) имеет целевую модификацию.
[217] Двухаллельная модификация может приводить к гомозиготности по целевой модификации. Гомозиготность включает в себя случаи при которых оба аллеля гена Fbn1 (т.е. соответствующие аллели на обеих гомологичных хромосомах) имеют целевую модификацию. Например, двухаллельная модификация может быть получена, когда белок Cas расщепляет пару первой и второй гомологичных хромосом в распознаваемой первой направляющей РНК последовательности (т.е. в первом сайте расщепления в распознаваемой первой направляющей РНК последовательности), тем самым создавая концевые последовательности в первой и второй гомологичных хромосомах. Концевые последовательности в каждой первой и второй гомологичных хромосомах могут затем подвергаться процессу репарации, опосредованной экзогенным шаблоном репарации, с образованием генома с двухаллельной модификацией, включающей в себя целевую генетическую модификацию. Например, если экзогенный шаблон репарации содержит нуклеотидную вставку, нуклеотидная вставка может быть вставлена в ген Fbn1 в паре первой и второй гомологичных хромосом, что приводит к образованию гомозиготного модифицированного генома.
[218] В альтернативном варианте, двухаллельная модификация может приводить к сложной гетерозиготности (например, гемизиготности) по целевой модификации. Сложная гетерозиготность включает в себя случаи в которых оба аллеля локуса-мишени (т.е. аллели обеих гомологичных хромосом) были модифицированы, но они были модифицированы различными способами (например, целевая модификация в одном аллеле, и инактивация или повреждение другого аллель). Например, в аллеле без целевой модификации двухцепочечный разрыв, созданный белком Cas, возможно, был восстановлен с помощью репарации ДНК, опосредованной негомологичным соединением концов (NHEJ), которая создает мутантный аллель, содержащий вставку или делецию нуклеотидной последовательности и, следовательно, является причиной повреждения этого геномного локуса. Например, двухаллельная модификация может являться причиной сложной гетерозиготности, если клетка имеет один аллель с целевой модификацией и другой аллель, который не способен к экспрессии. Сложная гетерозиготность включает в себя гемизиготность.
Гемизиготность включает в себя случаи в которых имеется только один аллель (то есть аллель на одной из двух гомологичных хромосом) локуса-мишени. Например, двухаллельная модификация может являться причиной гемизиготности по целевой модификации, если целевая модификация возникает в одном аллеле с соответствующей потерей или удалением другого аллеля.
G. Идентификация клеток с целевыми генетическими модификациями
[219] Раскрытые в данном документе способы могут дополнительно включать в себя идентификацию клетки, имеющей модифицированный ген Fbn1. Могут применяться различные способы для идентификации клеток, имеющих целевую генетическую модификацию, такую как делеция или инсерция. Такие способы могут включать в себя идентификацию одной клетки, имеющей целевую генетическую модификацию в гене Fbn1. Может быть проведен скрининг для выявления таких клеток с модифицированными геномными локусами.
[220] Стадия скрининга может включать в себя количественный анализ для оценки модификации аллеля (MOA) (например, анализы потери аллеля (LOA) и/или приобретения аллелем функции (GOA)) в родительской хромосомы. Например, количественный анализ может быть выполнен с помощью количественной ПЦР, такой как ПЦР в реальном времени (кПЦР). ПЦР в реальном времени может быть использована с первым набором праймеров, который распознает геномный локус-мишень, и вторым набором праймеров, который распознает эталонный локус, который не являться мишенью. Набор праймеров может содержать флуоресцентный зонд, который распознает амплифицируемую последовательность.
[221] Стадия скрининга может также включать в себя анализ удержания, который представляет собой анализ, используемый для различения правильных целевых инсерций нуклеотидных вставок в геномном локусе-мишени от случайных трансгенных инсерций нуклеотидной вставки в геномных позициях за пределами геномного локуса-мишени. Нормальные анализы для скрининга целевых модификаций, такие как ПЦР для больших последовательностей или Саузерн-блоттинг, идентифицируют вставленный нацеленный вектор в локусе-мишени. Однако из-за их больших размеров гомологичных плеч LTVEC не позволяют проводить скрининг с помощью таких обычных анализов. Для скрининга LTVEC могут быть применены анализы модификация аллеля (MOA), включая анализы потери аллеля (LOA) и приобретения аллелем функции (GOA) (смотрите, например, US 2014/0178879 и Frendewey et al. (2010) Methods Enzymol. 476:295-307, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Анализ потери аллеля (LOA) изменяет направление логики традиционного скрининга и определяет количество копий нативного локуса, в который была внесена мутация. В правильно модифицированном клеточном клоне анализ LOA обнаруживает один из двух нативных аллелей (для генов, не находящихся в хромосоме X или Y), причем другой аллель повреждается в результате целевой модификации. Тот же принцип может быть применен в обратном порядке в качестве анализа приобретения аллелем функции (GOA) для определения числа копий вставленного нацеленного вектора. Например, комбинированное применение анализов GOA и LOA выявит правильно модифицированный гетерозиготный клон, который потерял одну копию нативного гена-мишени и получил одну копию гена устойчивости к лекарству или другого вставленного маркера.
[222] В качестве примера, количественная полимеразная цепная реакция (кПЦР) может быть применена в качестве способа определения количества аллелей, но любой способ, который может надежно различать разницу между нулевой, одной и двумя копиями гена-мишени или между нулевой, одной и двумя копиями нуклеотидной вставки может быть использован для проведения анализа MOA. Например, TAQMAN® может быть использован для определения количества копий матрицы ДНК в образце геномной ДНК, особенно путем сравнения с эталонным геном (смотрите, например, US 6596541, включен в данный документ посредством ссылки в полном объеме для всех целей). Количество копий эталонного гена определяют в той же геномной ДНК, что содержит ген(ы)-мишень или локус(локусы)-мишень. Поэтому выполняются две амплификации TAQMAN® (каждая со своим соответствующим зондом). Один зонд TAQMAN® определяет «Ct» (пороговый цикл) эталонного гена, в то время как другой зонд определяет Ct области гена(ов)-мишени или локуса(локусов)-мишени, который заменяется в следствие успешного модифицирования (т.е. анализ LOA). Ct представляет собой количество, которое отражает количество исходной ДНК для каждого из зондов TAQMAN®, то есть менее численная последовательность требует большего количества циклов ПЦР для достижения порогового цикла. Уменьшение вдвое числа копий последовательности-матрицы в реакции TAQMAN® приведет к увеличению Ct примерно на одну единицу. Реакции TAQMAN® в клетках, где один аллель гена(ов)-мишени или локуса(локусов)-мишени был заменен в результате гомологичной рекомбинации, приведут к увеличению на единицу Ct для реакции TAQMAN®с мишенью без увеличения Ct для эталонного гена по сравнению с ДНК из клеток не мишеней. Для анализа GOA можно использовать другой зонд TAQMAN® для определения Ct нуклеотидной вставки, которая заменяет ген(ы)-мишень или локус(локусы)-мишень при успешном модифицировании.
[223] Поскольку парные нРНК могут создавать большие Cas-опосредованные делеции в геномном локусе-мишени, может быть полезно расширить стандартные анализы LOA и GOA для проверки правильного модифицирования с помощью LTVEC (т.е. в клетках, отличных от эмбрионов на одноклеточной стадии). Например, одни только анализы LOA и GOA могут не отличить правильно модифицированные клеточные клоны от клонов, в которых большая Cas-индуцированная делеция геномного локуса-мишени совпадает со случайной интеграцией LTVEC где-нибудь в другом месте в геноме, особенно если в анализе GOA используется зонд против селекционной кассеты в пределах вставки LTVEC. Поскольку давление отбора в модифицированной клетке основано на селекционной кассете, случайная трансгенная интеграция LTVEC где-нибудь в другом месте в геноме в целом, как правило, включает в себя селекционную кассету и смежные области LTVEC, но исключает более дистальные области LTVEC. Например, если часть LTVEC случайно интегрировалась в геном, и LTVEC содержит нуклеотидную вставку длиной около 5 т.п.н. или больше, с селекционной кассетой, соседствующей с 3'-гомологичным плечом, обычно с селекционной кассетой будет интегрировано 3'-гомологичное плечо, но не 5'-гомологичное плечо. В альтернативном варианте, если селекционная кассета расположена рядом с 5'-гомологичным плечом, обычно 5'-гомологичное плечо, но не 3'-гомологичное плечо, будет трансгенно интегрировано с селекционной кассетой. Например, если анализы LOA и GOA применяются для оценивания целевой интеграции LTVEC, и в анализе GOA применяют зонды против селекционной кассеты то, гетерозиготная делеция в геномном локусе-мишени в сочетании с случайной трансгенной интеграцией LTVEC даст то же самое считывание, что и гетерозиготная целевая интеграция LTVEC в геномном локусе-мишени. Чтобы проверить правильность нацеливания LTVEC, можно использовать анализы удержания, отдельно или в сочетании с анализами LOA и/или GOA.
[224] Анализы удержания определяют количество копий ДНК-матрицы в 5'-последовательности-мишени (соответствующей 5'-гомологичному плечу LTVEC) и/или 3'-последовательности-мишени (соответствующей 3'-гомологичному плечу LTVEC). В частности, полезно определить число копий ДНК-матрицы в последовательности-мишени, соответствующей гомологичному плечу, которое находится рядом с селекционной кассетой. В диплоидных клетках количества копий больше двух, как правило, указывают на трансгенную интеграцию LTVEC случайным образом вне геномного локуса-мишени, а не в геномном локусе-мишени, что является нежелательным. Правильно модифицированные клоны будут удерживать две копии. Кроме того, количества копий меньше двух в таких анализах удержания в целом, как правило указывают на большие Cas-опосредованные делеции, простирающиеся за пределы области, обозначенной мишенью делеции, что также является нежелательным. Смотрите, например, US 2016/0145646 и WO 2016/081923, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[225] Другие примеры подходящих количественных анализов включают в себя флуоресцентно-опосредованную гибридизацию in situ (FISH), сравнительную геномную гибридизацию, изотермическую амплификацию ДНК, количественную гибридизацию с иммобилизованным зондом(ами), зонды INVADER®, зонды TAQMAN® Molecular Beacon, или зондовую технологию ECLIPSE™ (смотрите, например, US 2005/0144655, включен в данный документ посредством ссылки в полном объеме для всех целей). Также могут быть использованы нормальные анализы для скрининга целевых модификаций, такие как ПЦР больших последовательностей, Саузерн-блоттинг или секвенирование Сэнгера. Такие анализы обычно используются для получения доказательств сцепления между встроенным нацеленным вектором и геномным локусом-мишенью. Например, для анализа ПЦР больших последовательностей один праймер может распознавать последовательность в встроенной ДНК, в то время как другой распознает последовательность геномного локуса-мишени за пределами концов гомологичных плеч нацеленного вектора.
[226] Секвенирование следующего поколения (NGS) также может быть применено для скрининга, особенно эмбрионов на одноклеточной стадии, которые были модифицированы. Секвенирование следующего поколения также может называться «NGS» или «крупномасштабное параллельное секвенирование» или «высокопроизводительное секвенирование». Такой NGS может использоваться в качестве инструмента скрининга в дополнение к анализам MOA и анализам удержания, чтобы определить точную природу целевой генетической модификации и обнаружить мозаицизм. Мозаицизм относится к наличию двух или большего количества популяций клеток с разными генотипами у одного индивида, который развился из одного оплодотворенного яйца (то есть зиготы). В способах, раскрытых в данном документе, нет необходимости проводить скрининг модифицированных клонов с использованием маркеров селекции. Например, анализам MOA и NGS, описанным в данном документе, можно доверять без использования селекционных кассет.
H. Способы получения генетически модифицированных отличных от человека животных
[227] Генетически модифицированные отличные от человека животные могут быть получены с использованием различных способов, раскрытых в данном документе. Любой удобный способ или протокол для получения генетически модифицированного организма, включая способы, описанные в данном документе, подходит для получения такого генетически модифицированного отличного от человека животного. Такие способы, начиная с генетической модификации плюрипотентной клетки, такой как эмбриональная стволовая (ES) клетка, в целом, как правило, включают в себя: (1) модифицирование генома плюрипотентной клетки, которая не является эмбрионом на одноклеточной стадии, с использованием способов, описанных в данном документе; (2) идентификацию или отбор генетически модифицированной плюрипотентной клетки; (3) введение генетически модифицированной плюрипотентной клетки в эмбрион-хозяин; и (4) имплантацию и вынашивание эмбриона-хозяина, содержащего генетически модифицированную плюрипотентную клетку, в суррогатной матери. Затем суррогатная мать может производить отличных от человека животных F0, содержащих целевую генетическую модификацию, и способных передавать целевую генетическую модификацию через зародышевую линию. Животных, несущих генетически модифицированный геномный локус, можно идентифицировать с помощью анализа модификации аллеля (MOA), как описано в данном документе. Клетка донора может быть введена в эмбрион-хозяин на любой стадии, такой как стадия бластоцисты или стадия пре-морулы (то есть стадия 4 клеток или стадия 8 клеток). Получают потомство, способное передавать генетическую модификацию через зародышевую линию. Плюрипотентная клетка может быть, например, ES клеткой (например, ES клеткой грызуна, ES клеткой мыши или ES клеткой крысы), как обсуждалось в другом месте данного документа. Смотрите, например, патент США № 7294754, включен в данный документ посредством ссылки в полном объеме для всех целей.
[228] В альтернативном варианте, такие способы, начиная с генетической модификации эмбриона на одноклеточной стадии, в целом, как правило, включают в себя: (1) модификацию генома эмбриона на одноклеточной стадии с использованием способов, описанных в данном документе; (2) идентификацию или отбор генетически модифицированных эмбрионов; и (3) имплантацию и вынашивание генетически модифицированного эмбриона в суррогатной матери. Затем суррогатная мать может производить отличных от человека животных F0, содержащих целевую генетическую модификацию, и способных передавать целевую генетическую модификацию через зародышевую линию. Животных, несущих генетически модифицированный геномный локус, можно идентифицировать с помощью анализа модификации аллеля (MOA), как описано в данном документе.
[229] Методы переноса ядра могут также применяться для получения отличных от человека животных-млекопитающих. Вкратце, способы переноса ядра могут включать в себя стадии: (1) изъятие ядра из ооцита или предоставление ооцита без ядра; (2) выделение или предоставление клетки донора или ядра для объединения с ооцитом без ядра; (3) введение клетки или ядра в ооцит без ядра с образованием преобразованной клетки; (4) имплантация преобразованной клетки в матку отличного от человека животного, с образованием зародыша; и (5) обеспечение развития эмбриона. В таких способах ооциты в целом, как правило, извлекают у умерших животных, хотя они могут быть выделены также из яйцеводов и/или яичников живых животных. Ооциты могут созревать в различных средах, известных специалистам в данной области техники, до изъятия ядра. Изъятие ядра из ооцита может быть выполнено рядом способов, хорошо известных специалистам в данной области техники. Введение клетки донора или ядра в ооцит без ядра с образованием преобразованной клетки может быть осуществлено путем микроинъекции клетки донора под zona pellucida перед слиянием. Слияние может быть вызвано применением электрического импульса постоянного тока через плоскость контакта/слияния (электрофузия), воздействием на клетки химических веществ, способствующих слиянию, таких как полиэтиленгликоль, или посредством инактивированного вируса, такого как вирус Сендай. Преобразованная клетка может быть активирована электрическими и/или неэлектрическими способами до, во время и/или после слияния ядра донора и ооцита-реципиента. Способы активации включают в себя электрические импульсы, химически индуцированный шок, проникновение сперматозоидов, повышение уровня двухвалентных катионов в ооците, и снижение фосфорилирования клеточных белков (как с помощью ингибиторов киназы) в ооците. Активированные преобразованные клетки или эмбрионы можно культивировать в среде, хорошо известной специалистам в данной области техники, и затем переносить в матку животного. Смотрите, например, US 2008/0092249, WO 1999/005266, US 2004/0177390, WO 2008/017234, и патент США № 7612250, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[230] Различные способы, предложенные в данном документе, делают возможным создание генетически модифицированного отличного от человека животного F0, при этом клетки генетически модифицированного животного F0 содержат целевую генетическую модификацию. Признано, что в зависимости от способа, использованного для получения животного F0, количество клеток в животном F0, которые имеют целевую генетическую модификацию, будет варьировать. Введение ES клеток донора в эмбрион на стадии пре-морулы из соответствующего организма (например, эмбрион мыши с 8 клетками), например, с помощью способа VEFOCIMOUSE® позволяет получать животное F0 с большим процентом клеточной популяции, содержащей клетки, имеющие целевую генетическую модификацию. Например, по меньшей мере 50%, 60%, 65%, 70%, 75%, 85%, 86%, 87%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% клеточного состава отличного от человека животного F0 может содержать клеточную популяцию, имеющую целевую генетическую модификацию. Кроме того, по меньшей мере одна или большее количество половых клеток животного F0 могут иметь целевую генетическую модификацию.
I. Типы отличных от человека животных и нечеловеческих клеток
[231] Способы, предложенные в данном документе, используют отличных от человека животных, и клетки и эмбрионы из отличных от человека животных. Такими отличными от человека животными предпочтительно являются млекопитающие, такие как грызуны (например, крысы, мыши и хомяки). Другие отличные от человека млекопитающие включают в себя, например, отличных от человека приматов, обезьян, человекоподобных приматов, кошек, собак, кроликов, лошадей, быков, оленей, бизонов, домашний скот (например, виды крупного рогатого скота, такие как коровы, быки и т. д.; виды полорогих, такие как овцы, козы и так далее, и виды свиней, такие как домашние свиньи и кабаны). Термин «отличный от человека» исключает людей.
[232] Клетка отличного от человека животного, используемая в способах, предложенных в данном документе, может представлять собой, например, тотипотентную клетку или плюрипотентную клетку (например, эмбриональную стволовую клетку (ES), такую как клетка ES грызуна, клетка ES мыши, или клетки ES крысы). Тотипотентные клетки включают в себя недифференцированные клетки, которые могут становиться клетками любого типа, а плюрипотентные клетки включают в себя недифференцированные клетки, которые обладают способностью развиваться в более чем один тип дифференцированных клеток. Такими плюрипотентными и/или тотипотентными клетками могут быть, например, клетки ES или клетки подобные ES, такие как индуцированные плюрипотентные стволовые клетки (iPS). Клетки ES включают в себя тотипотентные или плюрипотентные клетки, полученные из эмбрионов, которые способны становиться частью любой ткани развивающегося эмбриона при введении в эмбрион. Клетки ES могут быть получены из внутренней клеточной массы бластоцисты и способны дифференцироваться в клетки любого из трех слоев зародышей позвоночных (энтодерма, эктодерма и мезодерма).
[233] Клетки отличного от человека животного, используемые в способах, предложенных в данном документе, также могут включать в себя эмбрионы на одноклеточной стадии (то есть оплодотворенные ооциты или зиготы). Такие эмбрионы на одноклеточной стадии могут быть любой генетической линии (например, BALB/c, C57BL/6, 129 или их комбинации), могут быть свежими или замороженными, и могут быть получены в результате естественного скрещивания или оплодотворения in vitro.
[234] Мыши и клетки мыши, используемые в способах, предложенных в данном документе, могут быть из любой линии, включая, например, линию 129, линию C57BL/6, линию BALB/c, линию Swiss Webster, гибрид линий 129 и C57BL/6, гибрид линий BALB/c и C57BL/6, гибрид линий 129 и BALB/c, и гибрид линий BALB/c, C57BL/6 и 129. Например, мышь или клетка мыши, используемые в способах, предложенных в данном документе, могут быть, по меньшей мере, частично из линии BALB/c (например, по меньшей мере около 25%, по меньшей мере около 50%, по меньшей мере около 75% получено из линии BALB/с, или около 25%, около 50%, около 75% или около 100% получено из линии BALB/c). В одном примере, мыши или клетки мыши могут быть линии, включающей в себя 50% BALB/c, 25% C57BL/6 и 25% 129. В альтернативном варианте, мыши или клетки мыши могут быть линии или комбинации линий, что исключает BALB/c.
[235] Примеры линий 129 и линий C57BL раскрыты в данном документе в другом месте. Мыши и мышиные клетки, используемые в способах, предложенных в данном документе, также могут быть из гибрида вышеупомянутой линии 129 и вышеупомянутой линии C57BL/6 (например, 50% 129 и 50% C57BL/6). Аналогично, мыши и мышиные клетки, используемые в способах, предложенных в данном документе, могут быть из гибрида вышеупомянутых линий 129 или гибрида вышеупомянутых линий BL/6 (например, линии 129S6 (129/SvEvTac)). Конкретным примером мышиной ES клетки является клетка ES VGF1 мыши. Клетки ES VGF1 мыши (также известные как F1H4) были получены из гибридных эмбрионов, полученных путем скрещивания мышиной самки C57BL/6NTac с мышиным самцом 129S6/SvEvTac. Смотрите, например, Auerbach et al. (2000) Biotechniques 29, 1024-1028, включен в данный документ посредством ссылки в полном объеме для всех целей.
[236] Крысы или клетки крысы, используемые в способах, предложенных в данном документе, могут быть любой крысиной линии, включая, например, линию крыс ACI, линию крыс Dark Agouti (DA), линию крыс Wistar, линию крыс LEA, линию крыс Sprague Dawley (SD) или линию крыс Fischer, такую как Fisher F344 или Fisher F6. Крысы или клетки крысы также могут быть получены из линии, полученной из гибрида двух или большего количества линий, указанных выше. Например, крыса или клетка крысы может быть из линии DA или линии ACI. Крысиная линия ACI характеризуется тем, что имеет цвет черного агути, белый живот и лапы, и гаплотип RT1av1. Такие линии можно получить в различных местах, включая Harlan Laboratories. Примером линии крысиных клеток ES из крысы ACI является клетка ES ACI.G1. крысы. Линия крыс Dark Agouti (DA) характеризуется тем, что имеет цвет черного агути гаплотип RT1av1. Таких крыс можно получить в различных местах, включая Charles River и Harlan Laboratories. Примерами линий клеток ES крысы из крысы DA являются линия клеток ES DA.2B крысы и линия клеток ES DA.2C крысы. В некоторых случаях, крысы или клетки крысы представляют собой крыс из инбредной крысиной линии. Смотрите, например, US 2014/0235933 A1, включен в данный документ посредством ссылки в полном объеме для всех целей.
[237] Клетки, которые были имплантированы в эмбрион-хозяин, могут называться «клетками донора». Клетка донора может быть той же линии, что и эмбрион-хозяин, или другой линии. Аналогично, суррогатная мать может быть той же линии, что и клетка донора и/или эмбрион-хозяин, или суррогатная мать может быть другой линии, отличной от линии клетки донора и/или эмбриона-хозяина.
[238] В раскрытых в данном документе способах и композициях могут быть использованы различные эмбрионы-хозяева. Например, клетка донора (например, ES клетка донора) может быть введена в эмбрион на стадии пре-морулы (например, эмбрион на стадии 8 клеток) из соответствующего организма. Смотрите, например, US 7576259; US 7659442; US 7294754; и US 2008/0078000, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. В других способах, клетки донора могут быть имплантированы в эмбрион-хозяин на стадии 2 клеток, стадии 4 клеток, стадии 8 клеток, стадии 16 клеток, стадии 32 клеток или стадии 64 клеток. Эмбрион-хозяин также может быть бластоцистой или может представлять собой эмбрион пре-бластоцисты, эмбрион на стадии пре-морулы, эмбрион на стадии морулы (например, эмбрион на стадии агрегированной морулы), эмбрион на стадии неуплотненной морулы или эмбрион на стадии уплотненной морулы. При использовании мышиного эмбриона, стадия эмбриона-хозяина может представлять собой стадию 1 Тейлера (TS1), TS2, TS3, TS4, TS5 и TS6 со ссылкой на стадии Тейлера, описанные в Theiler (1989) «The House Mouse: Atlas of Mouse Developmen», Springer-Verlag, New York, включен в данный документ посредством ссылки в полном объеме для всех целей. Например, стадия Тейлера может быть выбрана из TS1, TS2, TS3 и TS4. В некоторых способах, эмбрион-хозяин содержит zona pellucida, а клетка донора представляет собой ES клетку, которая вводится в эмбрион-хозяин через отверстие в zona pellucida. В других способах, эмбрион-хозяин является эмбрионом без zona pellucida.
III. Способы скрининга соединений
[239] Отличные от человека животные, имеющие мутации в Fbn1, описанные в данном документе, могут быть использованы для скрининга соединений на активность, потенциально полезную для ингибирования или уменьшения неонатального прогероидного синдрома с врожденной липодистрофией (NPSCL) или для облегчения NPSCL-подобных симптомов (например, симптомов подобных симптомам врожденной липодистрофии) или скрининга соединений на потенциально вредную активность в виде способствования развитию или усугубления NPSCL. Соединения, обладающие активностью, ингибирующей или уменьшающие NPSCL, или уменьшающей NPSCL-подобные симптомы, потенциально могут быть использованы в качестве терапевтических или профилактических средств против NPSCL. Соединения, обладающие активностью, способствующей развитию или усугубляющей NPSCL, идентифицируют как токсичные, и их следует избегать в качестве терапевтических средств или при других обстоятельствах, в которых они могут вступать в контакт с людьми (например, в пищевых продуктах, сельском хозяйстве, строительстве или водоснабжении).
[240] Примеры соединений, которые могут быть подвергнуты скринингу, включают в себя антитела, антиген-связывающие белки, сайт-специфические ДНК-связывающие белки (например, комплексы CRISPR-Cas), полипептиды, бета-поворотные миметики, полисахариды, фосфолипиды, гормоны, простагландины, стероиды, ароматические соединения, гетероциклические соединения, бензодиазепины, олигомерные N-замещенные глицины и олигокарбаматы. Большие комбинаторные библиотеки соединений могут быть созданы способом кодированных синтетических библиотек (ESL), описанным в WO 1995/012608, WO 1993/006121, WO 1994/008051, WO 1995/035503, и WO 1995/030642, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей. Пептидные библиотеки также могут быть получены способами фагового дисплея. Смотрите, например, US 5432018, включен в данный документ посредством ссылки в полном объеме для всех целей. Применение библиотек направляющих РНК для нацеливания систем CRISPR-Cas на разные гены раскрыто, например, в WO 2014/204727, WO 2014/093701, WO 2015/065964 и WO 2016/011080, каждый из которых включен в данный документ посредством ссылки в полном объеме для всех целей.
[241] Анализы с применением животных, как правило, включают в себя введение соединения мутантному по Fbn1 отличному от человека животному, и оценивание изменения симптомов, напоминающих симптомы NPSCL у людей, в качестве ответа. Изменение может быть оценено по уровням симптома до и после приведения в контакт отличного от человека животного с соединением, или путем проведения контрольного эксперимента, проведенного с контрольным животным, имеющим такую же мутацию Fbn1 (например, когортным сиблингом дикого типа) без соединения.
[242] Подходящие NPSCL-подобные признаки или симптомы, которые можно отслеживать, включают в себя массу тела, массу без жира, жировую массу, массу белой жировой ткани (например, нормализованную по массе тела), процентное содержание жира в организме, потребление пищи нормализованное по массе тела, и кифоз, как описано в другом месте данного документа. Например, можно наблюдать за массой белой жировой ткани (например, нормализованной по массе тела). Данные симптомы могут оценивать в сочетании с одним или большим количеством из следующего: толерантность к глюкозе, уровни холестерина в сыворотке, уровни триглицеридов в сыворотке, и уровни неэтерифицированных жирных кислот в сыворотке. Аналогично, данные симптомы могут оцениваться в сочетании с одним или большим количеством из следующего: толерантность к глюкозе, уровни холестерина в сыворотке, уровни триглицеридов в сыворотке, уровни неэтерифицированных жирных кислот в сыворотке, масса печени, масса бурой жировой ткани (BAT), масса висцеральной белой жировой ткани (WAT), нормализованная по массе тела масса WAT, нормализованная по массе тела скорость метаболизма, расход энергии, и чувствительность к инсулину при диете с высоким содержанием жиров. Например, усугубление таких NPSCL-подобных симптомов может привести к одному или большему количеству из следующего: сниженная масса тела, уменьшенная масса без жира, уменьшенная масса жира, уменьшенная белая жировая ткань (например, нормализованная по массе тела), сниженный процент жира в организме, увеличенное потребление пищи, нормализованное по массе тела, и увеличенный кифоз по сравнению с степенью проявления симптомов до приведения в контакт с соединением, или по сравнению с степенью проявления симптомов у контрольного отличного от человека животного. Такие уменьшения и увеличения могут встречаться вместе с одним или большим количеством из: уменьшенная масса печени, уменьшенная масса бурой жировой ткани (BAT), уменьшенная масса висцеральной белой жировой ткани (WAT), уменьшенная масса WAT, нормализованная по массе тела, повышенная скорость метаболизма, нормализованная по массе тела, увеличенный расход энергии, улучшенная толерантность к глюкозе, и улучшенная чувствительность к инсулину при диете с высоким содержанием жиров. Такие снижения или увеличения могут встречаться вместе с одним или большим количеством из следующего, остающегося нормальным: толерантность к глюкозе, уровни холестерина в сыворотке, уровни триглицеридов в сыворотке, и уровни неэтерифицированных жирных кислот в сыворотке. В альтернативном варианте, облегчение таких NPSCL-подобных симптомов может привести к одному или большему количеству из: увеличенной массе тела, увеличенной массе без жира, увеличенной массе жира, увеличенному проценту жира в теле, уменьшенному потреблению пищи, нормализованному по массе тела, и уменьшенному кифозу по сравнению с степенью проявления симптомов до приведения в контакт с соединением, или по сравнению с степенью проявления симптомов у контрольного отличного от человека животного. Такие уменьшения и увеличения могут встречаться вместе с одним или большим количеством из: увеличенная масса печени, сохраненная или измененная масса бурой жировой ткани (BAT) (например, нормализованная по массе тела), увеличенная масса висцеральной белой жировой ткани (WAT), увеличенная масса WAT, нормализованная по массе тела, уменьшенная скорость метаболизма, нормализованная по массе тела, уменьшенный расход энергии, уменьшенная толерантность к глюкозе, и уменьшенная чувствительность к инсулину при диете с высоким содержанием жиров. Такие симптомы могут быть проанализированы, как описано в приведенных в данном документе примерах. Уменьшение или увеличение может быть статистически значимым. Например, уменьшение или увеличение может составлять, по меньшей мере около 1%, по меньшей мере около 2%, по меньшей мере около 3%, по меньшей мере около 4%, по меньшей мере около 5%, по меньшей мере около 10%, по меньшей мере около 15%, по меньшей мере около 20%, по меньшей мере около 30%, по меньшей мере около 40%, по меньшей мере около 50%, по меньшей мере около 60%, по меньшей мере около 70%, по меньшей мере около 80%, по меньшей мере около 90%, или 100%.
[243] Все патентные заявки, веб-сайты, другие публикации, номера доступа и тому подобное, указанные выше или ниже, включены посредством ссылки в полном объеме для всех целей в той же степени, как если бы каждый отдельный элемент был специально и отдельно указан для включения посредством ссылки. Если разные версии последовательности связаны с номером доступа в разное время, подразумевается версия, связанная с номером доступа на действительную дату подачи данной заявки. Действительная дата подачи означает более раннюю из фактической даты подачи или даты подачи приоритетной заявки со ссылкой на регистрационный номер, если применимо. Аналогичным образом, если разные версии публикации, веб-сайта и т. п. публикуются в разное время, подразумевается последняя версия, опубликованная на действительную дату подачи заявки, если не указано иное. Любой признак, этап, элемент, вариант осуществления или аспект изобретения может быть использован в сочетании с любым другим, если специально не указано иное. Хотя данное изобретение было описано более подробно с помощью иллюстрации и примера для ясности и понимания, будет очевидно, что определенные изменения и модификации могут быть осуществлены в рамках объема прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
[244] Нуклеотидные и аминокислотные последовательности, перечисленные в прилагаемом перечне последовательностей, показаны с использованием стандартных буквенных сокращений для нуклеотидных оснований, и трехбуквенного кода для аминокислот. Нуклеотидные последовательности соответствуют стандартному соглашению, начинаясь с 5'-конца последовательности и продолжаясь от него (то есть слева направо в каждой строке) до 3'-конца. Показана только одна цепь каждой нуклеотидной последовательности, но считается, что комплементарная цепь включена посредством любой ссылки на показанную цепь. Аминокислотные последовательности соответствуют стандартному соглашению, начинаясь с амино-конца последовательности и продолжаясь от него (то есть слева направо в каждой строке) к карбокси-концу.
[245] Таблица 1. Описание последовательностей.
ПРИМЕРЫ
Пример 1. Получение мутантной мыши с MAID 8501 Fbn1 с укороченным C-концом
[0246] Был получен мутантный аллель Fbn1 мыши для воспроизведения мутантного аллеля FBN1 человека. Используя NM_007993.2 в качестве эталонной последовательности мутация представляла собой к.8213_8214delinsACT. Данная мутация, которая была создана путем инсерции A между к.8212 и 8213, и замены G>T в к.8214, приводит к появлению преждевременного кодона терминации в предпоследнем экзоне Fbn1. Мутантный аллель обозначен как MAID 8501. Смотрите Фиг. 1. Мутация находится в пределах последних 50 нуклеотидов предпоследнего экзона и, как предполагается, позволяет избегать нонсенс-опосредованного распада мРНК (NMD), что приводит к экспрессии мутантного укороченного белка профибриллина.
[247] Для создания мутантного аллеля компоненты CRISPR/Cas9 вводили в эмбрион C57BL/6 на одноклеточной стадии посредством пронуклеарной инъекции или цитоплазматических пьезоинъекции мРНК вместе с донорной матрицей. Последовательность ДНК-нацеленной последовательности направляющей РНК представлена в SEQ ID NO: 37, а последовательность донора представлена в SEQ ID NO: 38. NGS использовали для скрининга прильно модифицированных клонов. Результаты модифицирования приведены в Таблице 2.
[248] Таблица 2. Результаты нацеливания для MAID 8501.
[249] Мыши-родоначальники F0 были получены после микроинъекции эмбрионов псевдобеременным мышиным самкам. Как показано на Фиг. 2, ни один из мышей мужского или женского пола, гомозиготных по мутации MAID 8501 Fbn1, не выжила после 40 дней, в то время как гетерозиготные мыши мужского и женского пола выживали значительно дольше.
Пример 2. Получение мутантной мыши с MAID 8520 Fbn1 с укороченным C-концом
[250] В другом эксперименте, были спроектированы последовательность направляющей РНК и донорная последовательность, чтобы получить мутантный аллель Fbn1, соответствующий человеческому аллелю к.8155_8156del Fbn1, который имеет делецию двух пар оснований в кодирующем экзоне 64 (предпоследнем экзоне), которая вызывает сдвиг рамки считывания с последующим появлением преждевременного кодона терминации 17 кодонов после p.Lys2719. Предсказанный мутантный аллель обозначен как MAID 8502. Смотрите Фиг. 3.
[251] Для создания мутантного аллеля компоненты CRISPR/Cas9 вводили в эмбрион C57BL/6 на одноклеточной стадии посредством пронуклеарной инъекции или цитоплазматических пьезоинъекции мРНК вместе с донорной матрицей. Один клон, который был получен, имел мутантный аллель MAID 8520, показанный на Фиг.3, а не ожидаемый аллель MAID 8502. Мутантный аллель MAID 8520 также приводит к образованию преждевременного кодона терминации в кодируемом белке Fbn1, как показано на Фиг. 3.
[252] Мыши-родоначальники F0 были получены после микроинъекции эмбрионов псевдобеременным мышиным самкам, и затем было получено поколение мышей F1. По сравнению с мышами дикого типа мыши, гетерозиготные по мутации Fbn1, ели намного больше при нормализации по массе тела. Смотрите, например, Фиг. 4, показывающую еженедельное потребление пищи, нормализованное по массе тела (грамм на грамм), причем гетерозиготные самцы ели примерно в 1,7 раза больше пищи, чем их сородичи дикого типа, при нормализации по массе тела. Несмотря на увеличение потребления пищи, масса тела мышиных самцов и самок, гетерозиготных по мутации Fbn1, была стабильно ниже, чем у соответствующих мышей дикого типа на промежутке времени. Смотрите, например, Фиг. 5, показывающую двух 3-месячных самцов гетерозиготных мышей F1, слева, и двух 3-месячных самцов F1 мышей дикого типа, справа. Смотрите также Фиг. 6, показывающую массу тела потомства F1 в возрасте от 5 недель до 13 недель. Например, в то время как масса тела гетерозиготных мутантных самцов составляла примерно 7 грамм через 5 недель и 12 грамм через 13 недель, масса тела соответствующих самцов дикого типа составляли примерно 18 грамм через 5 недель и 25 грамм через 13 недель. Эти тенденции также наблюдались у мышиных самок.
[253] Дополнительный анализ гетерозиготных самок в сравнении с самками дикого типа показал кифоз (то есть излишние округление спины) у гетерозиготных мутантных самок по сравнению с самками дикого типа. Смотрите Фиг. 7A-7E. Аналогично, у гетерозиготных самок было очень мало жира по сравнению с их сородичами дикого типа. Как показано на Фиг. 8А-8С, гетерозиготные мутантные самки имели статистически значимые более низкие уровни массы тела, массы без жира и массы жира, измеренные с помощью ECHOMRI™, который используется для измерения жира и массы без жира у грызунов. Эти различия сохранялись, даже если мышей удерживали на диете с высоким содержанием жиров (60%) в течение 21 недели. Несмотря на отсутствие жира в организме, гетерозиготные мутантные самки и соответствующие самки дикого типа демонстрировали сходную толерантность к глюкозе (пероральную толерантность к глюкозе, которою давали к количестве 2 мг/кг после ночного голодания) при обычном рационе, и не наблюдали повышенного уровня холестерина, триглицеридов и неэтерифицированных жирных кислот в сыворотке (измерено ADVIA). Смотрите, например, Фиг. 9A-9F и 10A-10F, соответственно.
[254] Дополнительный анализ гетерозиготных мутантных самок показал сохранение депо бурой жировой ткани (BAT), несмотря на почти полную потерю висцеральной белой жировой ткани. Смотрите Фиг. 11A-11H. Сохранение BAT побудило нас исследовать расход энергии гетерозиготных мутантных самок после 12 недель на диете с высоким содержанием жиров (60%). Смотрите Фиг. 12A- 12H. Анализ с помощью метаболической клетки с использованием системы Columbia Instruments Oxymax CLAMS показал, что у мышей была повышенна скорость метаболизма, нормализованная по массе тела, на что указывают их VO2, VCO2 и расход энергии (энергия). После 20 недель на диете с высоким содержанием жиров эти мыши также показали улучшенную толерантность к глюкозе. Смотрите Фиг. 13A-13D.
[255] Мыши, гетерозиготные по C-концевой делеции в фибрилине-1, являются худыми с большим уменьшением депо белой жировой ткани, но у них сохраняется депо бурой жировой ткани, повышенные энергетические затраты, аналогичная толерантность к глюкозе, улучшенная чувствительность к инсулину на диете с высоким содержанием жиров, и отсутствует повышение уровней сывороточных липидов по сравнению с мышами дикого типа. Это воспроизводит фенотип FBN1, наблюдаемый у человеческих пациентов с NPSCL, в том, что, подобно многим липодистрофическим синдромам, эти конкретные мыши имеют нормальный метаболический профиль с точки зрения гомеостаза глюкозы и циркулирующих липидов, несмотря на отсутствие висцеральной жировой ткани. Многие другие модели мутантных мышей FBN1 имеют в целом нормальные гетерозиготы, тогда как для гомозигот характерна ранняя постнатальная или эмбриональная гибель. Смотрите, например, Pereira el al. (1999) Proc. Natl. Acad. Sci. U.S.A. 96(7):3819-3823, включен в данный документ посредством ссылки в полном объеме для всех целей. Наша модель демонстрирует доминантный гетерозиготный фенотип, который повторяет многие особенности человеческих пациентов, что позволяет нам изучать терапевтические варианты. В частности, наша модель показывает потерю белой жировой ткани, в то время как бурая жировая ткань сохраняется в сочетании с улучшением чувствительности к инсулину, несмотря на потерю белой жировой ткани. Человеческие пациенты с NPSCL имеют нормальный гомеостаз глюкозы, несмотря на потерю белой жировой ткани, что отражает наша модель. Сохранение бурой жировой ткани, вероятно, является механизмом, лежащим в основе поддерживаемой/улучшенной чувствительности к инсулину, поскольку это может позволить мышам сжигать лишний жир, который они не могут накапливать.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Regeneron Pharmaceuticals, Inc.
<120> МЫШИ, СОДЕРЖАЩИЕ МУТАЦИИ, ВСЛЕДСТВИЕ КОТОРЫХ ЭКСПРЕССИРУЕТСЯ УКОРОЧЕННЫЙ НА С-КОНЦЕ ФИБРИЛЛИН-1
<130> 057766/500041
<150> US 62/368,924
<151> 2016-07-29
<160> 47
<170> версия PatentIn 3.5
<210> 1
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 1
cggagaagca caaacgaaac tgat 24
<210> 2
<211> 8
<212> PRT
<213> Homo sapiens
<400> 2
Arg Arg Ser Thr Asn Glu Thr Asp
1 5
<210> 3
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 3
cggagaagca caaacgaaaa ctga 24
<210> 4
<211> 7
<212> PRT
<213> Homo sapiens
<400> 4
Arg Arg Ser Thr Asn Glu Asn
1 5
<210> 5
<211> 24
<212> ДНК
<213> Mus musculus
<400> 5
cggagaagca cgaacgaaac ggat 24
<210> 6
<211> 8
<212> PRT
<213> Mus musculus
<400> 6
Arg Arg Ser Thr Asn Glu Thr Asp
1 5
<210> 7
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 7
cggagaagca cgaacgaaaa ctga 24
<210> 8
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 8
Arg Arg Ser Thr Asn Glu Asn
1 5
<210> 9
<211> 60
<212> ДНК
<213> Homo sapiens
<400> 9
gagtgtaaga tcaatggcta ccccaaacgg ggcaggaaac ggagaagcac aaacgaaact 60
<210> 10
<211> 20
<212> PRT
<213> Homo sapiens
<400> 10
Glu Cys Lys Ile Asn Gly Tyr Pro Lys Arg Gly Arg Lys Arg Arg Ser
1 5 10 15
Thr Asn Glu Thr
20
<210> 11
<211> 60
<212> ДНК
<213> Homo sapiens
<400> 11
gagtgtgatc aatggctacc ccaaacgggg caggaaacgg agaagcacaa acgaaactga 60
<210> 12
<211> 19
<212> PRT
<213> Homo sapiens
<400> 12
Glu Cys Asp Gln Trp Leu Pro Gln Thr Gly Gln Glu Thr Glu Lys His
1 5 10 15
Lys Arg Asn
<210> 13
<211> 60
<212> ДНК
<213> Mus musculus
<400> 13
gagtgtaaga tcaacggcta cccaaaacga ggccggaaac ggagaagcac gaacgaaacg 60
<210> 14
<211> 20
<212> PRT
<213> Mus musculus
<400> 14
Glu Cys Lys Ile Asn Gly Tyr Pro Lys Arg Gly Arg Lys Arg Arg Ser
1 5 10 15
Thr Asn Glu Thr
20
<210> 15
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 15
gagtgtgatc aatggctacc ccaaacgggg caggaaacgg agaagcacaa acgaaactga 60
<210> 16
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 16
Glu Cys Asp Gln Trp Leu Pro Gln Thr Gly Gln Glu Thr Glu Lys His
1 5 10 15
Lys Arg Asn
<210> 17
<211> 55
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 17
Pro Pro Ala Ser Ser Glu Met Asp Asp Asn Ser Leu Ser Pro Glu Ala
1 5 10 15
Cys Tyr Glu Cys Lys Ile Asn Gly Tyr Pro Lys Ala Ala Gln Ser His
20 25 30
Leu Pro Ala Thr Arg Pro Glu Thr Glu Lys His Glu Arg Asn Gly Cys
35 40 45
Leu Arg His Pro Gly Arg Val
50 55
<210> 18
<211> 37
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 18
Pro Pro Ala Ser Ser Glu Met Asp Asp Asn Ser Leu Ser Pro Glu Ala
1 5 10 15
Cys Tyr Glu Cys Asp Gln Trp Leu Pro Gln Thr Gly Gln Glu Thr Glu
20 25 30
Lys His Lys Arg Asn
35
<210> 19
<211> 8616
<212> ДНК
<213> Homo sapiens
<400> 19
atgcgtcgag ggcgtctgct ggagatcgcc ctgggattta ccgtgctttt agcgtcctac 60
acgagccatg gggcggacgc caatttggag gctgggaacg tgaaggaaac cagagccagt 120
cgggccaaga gaagaggcgg tggaggacac gacgcgctta aaggacccaa tgtctgtgga 180
tcacgttata atgcttactg ttgccctgga tggaaaacct tacctggcgg aaatcagtgt 240
attgtcccca tttgccggca ttcctgtggg gatggatttt gttcgaggcc aaatatgtgc 300
acttgcccat ctggtcagat agctccttcc tgtggctcca gatccataca acactgcaat 360
attcgctgta tgaatggagg tagctgcagt gacgatcact gtctatgcca gaaaggatac 420
atagggactc actgtggaca acctgtttgt gaaagtggct gtctcaatgg aggaaggtgt 480
gtggccccaa atcgatgtgc atgcacttac ggatttactg gaccccagtg tgaaagagat 540
tacaggacag gcccatgttt tactgtgatc agcaaccaga tgtgccaggg acaactcagc 600
gggattgtct gcacaaaaac gctctgctgt gccacagtcg gccgagcctg gggccacccc 660
tgtgagatgt gtcctgccca gcctcacccc tgccgccgtg gcttcattcc aaatatccgc 720
acgggagctt gtcaagatgt ggatgaatgc caggccatcc ccgggctctg tcagggagga 780
aattgcatta atactgttgg gtcttttgag tgcaaatgcc ctgctggaca caaacttaat 840
gaagtgtcac aaaaatgtga agatattgat gaatgcagca ccattcctgg aatctgtgaa 900
gggggtgaat gtacaaacac agtcagcagt tacttttgca aatgtccccc tggtttttac 960
acctctccag atggtaccag atgcatagat gttcgcccag gatactgtta cacagctctg 1020
acaaacgggc gctgctctaa ccagctgcca cagtccataa ccaaaatgca gtgctgctgt 1080
gatgccggcc gatgctggtc tccaggggtc actgtcgccc ctgagatgtg tcccatcaga 1140
gcaaccgagg atttcaacaa gctgtgctct gttcctatgg taattcctgg gagaccagaa 1200
tatcctcccc caccccttgg ccccattcct ccagttctcc ctgttcctcc tggctttcct 1260
cctggacctc aaattccggt ccctcgacca ccagtggaat atctgtatcc atctcgggag 1320
ccaccaaggg tgctgccagt aaacgttact gattactgcc agttggtccg ctatctctgt 1380
caaaatggac gctgcattcc aactcctggg agttaccggt gtgagtgcaa caaagggttc 1440
cagctggacc tccgtgggga gtgtattgat gttgatgaat gtgagaaaaa cccctgtgct 1500
ggtggtgagt gtattaacaa ccagggttcg tacacctgtc agtgccgagc tggatatcag 1560
agcacactca cgcggacaga atgccgagac attgatgagt gtttacagaa tggccggatc 1620
tgcaataatg gacgctgcat caacacagat ggcagttttc attgcgtgtg taatgcgggc 1680
tttcatgtta cacgagatgg gaagaactgt gaagatatgg atgaatgcag cataaggaac 1740
atgtgcctta atggaatgtg tatcaatgaa gatggcagtt ttaaatgtat ttgcaaacct 1800
ggattccagc tggcatcaga tggacgttat tgcaaagaca ttaacgagtg tgaaacccct 1860
gggatctgca tgaatgggcg ttgcgtcaac actgatggct cctacagatg tgaatgcttc 1920
cctggactgg ctgtgggtct ggatggccgt gtgtgtgttg acacacacat gcggagcaca 1980
tgctatggtg gatacaagag aggccagtgt atcaaacctt tgtttggtgc tgtcactaaa 2040
tctgaatgct gttgcgccag cactgagtat gcatttgggg aaccttgcca gccgtgtcct 2100
gcacagaatt cagcggaata tcaggcactc tgcagcagtg ggccaggaat gacgtcagca 2160
ggcagtgata taaatgaatg tgcactagat cctgatattt gcccaaatgg aatctgtgaa 2220
aaccttcgtg ggacctataa atgtatatgc aattcaggat atgaagtgga ttcaactggg 2280
aaaaactgcg ttgatattaa tgaatgtgta ctgaacagtc tcctttgtga caatggacaa 2340
tgtagaaata ctcctggaag ttttgtctgt acctgcccca agggatttat ctacaaacct 2400
gatctaaaaa catgtgaaga cattgatgaa tgcgaatcaa gtccttgcat taatggagtc 2460
tgcaagaaca gcccaggctc ttttatttgt gaatgttctt ctgaaagtac tttggatcca 2520
acaaaaacca tctgcataga aaccatcaag ggcacttgct ggcagactgt cattgatggg 2580
cgatgtgaga tcaacatcaa tggagccacc ttaaagtccc agtgctgctc ctccctcggt 2640
gctgcgtggg gaagcccgtg caccctatgc caagttgatc ccatatgtgg taaagggtac 2700
tcaagaatta aaggaacaca atgtgaagat atagatgaat gtgaagtgtt cccaggagtg 2760
tgtaaaaatg gcctgtgtgt taacactagg gggtcattca agtgtcagtg tcccagtgga 2820
atgactttgg atgccacagg aaggatctgt cttgatatcc gcctggaaac ctgcttcctg 2880
aggtacgagg acgaggagtg caccctgcct attgctggcc gccaccgcat ggacgcctgc 2940
tgctgctccg tcggggcagc ctggggtact gaggaatgcg aggagtgtcc catgagaaat 3000
actcctgagt acgaggagct gtgtccgaga ggacccggat ttgccacaaa agaaattaca 3060
aatggaaagc ctttcttcaa agatatcaat gagtgcaaga tgatacccag cctctgcacc 3120
cacggcaagt gcagaaacac cattggcagc tttaagtgca ggtgtgacag cggctttgct 3180
cttgattctg aagaaaggaa ctgcacagac attgacgaat gccgcatatc tcctgacctc 3240
tgtggcagag gccagtgtgt gaacacccct ggggactttg aatgcaagtg tgacgaaggc 3300
tatgaaagtg gattcatgat gatgaagaac tgcatggata ttgatgagtg tcagagagat 3360
cctctcctat gccgaggtgg tgtttgccat aacacagagg gaagttaccg ctgtgaatgc 3420
ccgcctggcc atcagctgtc ccccaacatc tccgcgtgta tcgacatcaa tgaatgtgag 3480
ctgagtgcac acctgtgccc caatggccgt tgcgtgaacc tcatagggaa gtatcagtgt 3540
gcctgcaacc ctggctacca ttcaactccc gataggctat tttgtgttga cattgatgaa 3600
tgcagcataa tgaatggtgg ttgtgaaacc ttctgcacaa actctgaagg cagctatgaa 3660
tgtagctgtc agccgggatt tgcactaatg cctgaccaga gatcatgcac cgacatcgat 3720
gagtgtgaag ataatcccaa tatctgtgat ggtggtcagt gcacaaatat ccctggagag 3780
tacaggtgct tgtgttatga tggattcatg gcatctgaag acatgaagac ttgtgtagat 3840
gtcaatgagt gtgacctgaa tccaaatatc tgcctaagtg ggacctgtga aaacacgaaa 3900
ggctcattta tctgccactg tgatatgggc tactccggca aaaaaggaaa aactggctgt 3960
acagacatca atgaatgtga aattggagca cacaactgtg gcaaacatgc tgtatgtacc 4020
aatacagcag gaagcttcaa atgtagctgc agtcccgggt ggattggaga tggcattaag 4080
tgcactgatc tggacgaatg ttccaatgga acccatatgt gcagccagca tgcagactgc 4140
aagaatacca tgggatctta ccgctgtctg tgcaaggaag gatacacagg tgatggcttc 4200
acttgtacag accttgatga gtgctctgag aacctgaatc tctgtggcaa tggccagtgc 4260
ctcaatgcac caggaggata ccgctgtgaa tgcgacatgg gcttcgtgcc cagtgctgac 4320
gggaaagcct gtgaagatat tgatgagtgc tcccttccga acatctgtgt ctttggaact 4380
tgccacaacc tccctggcct gttccgctgt gagtgtgaga taggctacga actggacaga 4440
agcggcggga actgcacaga tgtgaatgaa tgcctggatc caaccacgtg catcagtggg 4500
aactgtgtca acactccagg cagctatatc tgtgactgcc cacctgattt tgaactgaac 4560
ccaactcgag ttggctgtgt tgatacccgc tctggaaatt gctatttgga tattcgacct 4620
cgaggagaca atggagatac agcctgcagc aatgaaattg gagttggtgt ttccaaagct 4680
tcctgctgct gttctctggg taaagcctgg ggtactcctt gtgagatgtg tcctgctgtg 4740
aacacatccg agtacaaaat tctttgtcct ggaggggaag gtttccgacc aaatcctatc 4800
accgttatat tggaagatat tgatgagtgc caggagctac cagggctgtg ccaaggagga 4860
aaatgtatca acacctttgg gagtttccag tgccgctgtc caaccggcta ctacctgaat 4920
gaagatacac gagtgtgtga tgatgtgaat gaatgtgaga ctcctggaat ctgtggtcca 4980
gggacatgtt acaacaccgt tggcaactac acctgtatct gtcctccaga ctacatgcaa 5040
gtgaatgggg gaaataattg catggatatg agaagaagtt tgtgctacag aaactactat 5100
gctgacaacc agacctgtga tggagaattg ttattcaaca tgaccaagaa gatgtgctgc 5160
tgttcctaca acattggccg ggcgtggaac aagccctgtg aacagtgtcc catcccaagt 5220
acagatgagt ttgctacact ctgtggaagt caaaggccag gctttgtcat cgacatttat 5280
accggtttac ccgttgatat tgatgagtgc cgggagatcc caggggtctg tgaaaatgga 5340
gtgtgtatca acatggttgg cagcttccga tgtgaatgtc cagtgggatt cttctataat 5400
gacaagttgt tggtttgtga agatattgac gagtgtcaga acggcccagt gtgccagcgc 5460
aacgccgaat gcatcaacac tgcaggcagc taccgctgtg actgtaagcc cggctaccgc 5520
ttcacctcca caggacagtg caatgatcgt aatgaatgtc aagaaatccc caatatatgc 5580
agtcatgggc agtgcattga cacagttgga agcttttatt gcctttgcca cactggtttt 5640
aaaacaaatg atgaccaaac catgtgcttg gacataaatg aatgtgaaag agatgcctgt 5700
gggaatggaa cttgccggaa cacaattggt tccttcaact gccgctgcaa tcatggtttc 5760
atcctttctc acaacaatga ctgtatagat gttgatgaat gtgcaagtgg aaatgggaat 5820
ctttgcagaa atggccaatg cattaataca gtggggtctt tccagtgcca gtgcaatgaa 5880
ggctatgagg tggctccaga tgggaggacc tgtgtggata tcaatgaatg tcttctagaa 5940
cccagaaaat gtgcaccagg tacctgtcaa aacttggatg ggtcctacag atgcatttgc 6000
ccacctggat acagtcttca aaatgagaag tgtgaagata ttgatgagtg tgtcgaagag 6060
ccagaaattt gtgccctggg cacatgcagt aacactgaag gcagcttcaa atgtctgtgt 6120
ccagaagggt tttccttgtc ctccagtgga agaaggtgcc aagatttgcg aatgagctac 6180
tgttatgcga agtttgaagg aggaaagtgt tcatcaccca aatccagaaa tcactccaag 6240
caggaatgct gctgtgcctt gaagggagaa ggctggggag acccctgcga gctctgcccc 6300
acggaacctg atgaggcctt ccgccagata tgtccttatg gaagtgggat catcgtggga 6360
cctgatgatt cagcagttga tatggacgaa tgcaaagaac ccgatgtctg taaacatgga 6420
cagtgcatca atacagatgg ttcctatcgc tgcgagtgtc cctttggtta tattctagca 6480
gggaatgaat gtgtagatac tgatgaatgt tctgttggca atccttgtgg aaatggaacc 6540
tgcaagaatg tgattggagg ttttgaatgc acctgcgagg agggatttga gcccggtcca 6600
atgatgacat gtgaagatat aaatgaatgt gcccagaatc ctctgctctg tgccttccga 6660
tgtgtgaaca cttatgggtc atatgaatgc aaatgtcccg tgggatatgt gctcagagaa 6720
gaccgtagga tgtgcaaaga tgaggatgag tgtgaagagg gaaaacatga ctgtactgaa 6780
aaacaaatgg aatgcaagaa cctcattggc acatatatgt gcatctgtgg acccgggtat 6840
cagcggagac ctgatggaga aggctgtgta gatgagaatg aatgtcagac gaagccaggg 6900
atctgtgaga atgggcgctg cctcaacacc cgtgggagct acacctgtga gtgtaatgat 6960
gggtttaccg ccagccccaa ccaggacgag tgccttgaca atcgggaagg gtactgcttc 7020
acagaggtgc tacaaaacat gtgtcagatc ggctccagca acaggaaccc cgtcaccaaa 7080
tcggaatgct gctgtgacgg agggagaggc tggggtcccc actgtgagat ctgccctttc 7140
caggggactg tggctttcaa gaaactctgt ccccatggcc gaggattcat gaccaatgga 7200
gcagatatcg atgaatgcaa ggttattcac gatgtttgcc gaaatgggga atgtgtcaat 7260
gacagaggat catatcattg catttgtaaa actgggtaca ctccagatat aactgggact 7320
tcctgtgtag atctgaacga gtgcaaccag gctcccaaac cctgcaattt tatctgcaaa 7380
aacacagaag ggagttacca gtgttcatgc ccgaaaggct acattctgca agaggatgga 7440
aggagctgca aagatcttga tgagtgtgca accaagcaac acaactgcca gttcctatgt 7500
gttaacacca ttggcggctt cacatgcaaa tgtcctcccg gatttaccca acaccatacg 7560
tcctgcattg ataacaatga atgcacctct gacatcaatc tgtgcgggtc taagggcatt 7620
tgccagaaca ctcctggaag cttcacctgt gaatgccagc ggggattctc acttgatcag 7680
accggctcca gctgtgaaga cgtggacgag tgtgagggta accaccgctg ccagcatggc 7740
tgccagaaca tcattggggg ctacaggtgc agctgccccc agggctacct ccagcactac 7800
cagtggaacc agtgtgttga tgaaaacgaa tgcctcagcg ctcacatctg cggaggagcc 7860
tcctgtcaca acaccctggg gagctacaag tgcatgtgtc ccgccggctt ccagtatgaa 7920
cagttcagtg gaggatgcca agacatcaat gaatgtggct ctgcgcaggc cccctgcagc 7980
tatggctgtt ccaataccga gggcggttac ctgtgtggct gtccacctgg ttacttccgc 8040
ataggccaag ggcactgtgt ttctggaatg ggcatgggcc gaggaaaccc agagccacct 8100
gtcagtggtg aaatggatga caattcactc tccccagagg cttgttacga gtgtaagatc 8160
aatggctacc ccaaacgggg caggaaacgg agaagcacaa acgaaactga tgcctccaat 8220
atcgaggatc agtctgagac agaagccaat gtgagtcttg caagttggga tgttgagaag 8280
acagccatct ttgctttcaa tatttcccac gtcagtaaca aggttcgaat cctagaactc 8340
cttccagctc ttacaactct gacgaatcac aacagatact tgatcgaatc tggaaatgaa 8400
gatggcttct ttaaaatcaa ccaaaaggaa gggatcagct acctccactt cacaaagaag 8460
aagccagtgg ctggaaccta ttcattacaa atcagtagta ctccacttta taaaaagaaa 8520
gaacttaacc aactagaaga caaatatgac aaagactacc tcagtggtga actgggtgat 8580
aatctgaaga tgaaaatcca ggttttgctt cattaa 8616
<210> 20
<211> 8622
<212> ДНК
<213> Mus musculus
<400> 20
atgcggcgag gagggctgct ggaggtcgcg ctggcgttcg ccctgctcct cgagtcctac 60
acgagccatg gggcggacgc caatttggag gctgggagcc tgaaggagac cagagccaat 120
cgggccaaga gaagaggcgg cggaggacac gatgcgctga aaggacccaa tgtctgtgga 180
tcacgttata atgcatactg ttgtcctgga tggaaaacct tacctggtgg aaatcagtgt 240
attgttccca tttgccggca ttcctgtggg gatggattct gctcgaggcc aaatatgtgc 300
acttgcccgt ctggtcagat atctccttcc tgtggctcca gatccatcca acactgcagc 360
atccgctgta tgaatggggg cagctgcagc gatgaccact gtctgtgcca gaaagggtac 420
atcggcactc actgtggaca gcctgtctgt gaaagtggct gtctcaacgg agggaggtgt 480
gtggccccaa atcggtgtgc ttgcacgtac ggctttactg gaccccagtg tgaaagagat 540
tacagaacag gcccatgttt tactgtggta agcaaccaga tgtgccaggg acagctcagc 600
gggattgtct gcaccaaaac actttgctgt gccaccgtgg gccgagcctg gggccacccc 660
tgtgagatgt gtcctgccca gcctcacccc tgccgccgcg gcttcattcc caacatccgc 720
actggagctt gtcaagatgt ggatgaatgt caggccatcc cagggatgtg tcaaggagga 780
aattgcatta ataccgttgg atcttttgag tgcaaatgcc ctgctggaca caaatttaat 840
gaagtgtcac aaaaatgtga agatattgac gagtgcagca ccattcctgg agtctgcgat 900
ggcggggaat gtacaaacac tgtcagcagc tacttctgca aatgtccccc tggtttttac 960
acctctcctg atggcaccag atgcgtagat gttcgccctg gttactgcta cacagctctg 1020
gcaaacgggc gctgctctaa ccagctgcca cagtccataa ccaaaatgca gtgctgttgc 1080
gatcttggcc ggtgctggtc tccaggggtt actgttgctc ccgagatgtg tcccatcagg 1140
tcaactgagg atttcaacaa gctgtgctct gtccctctgg taattcccgg gagaccagaa 1200
tatcctcccc cacccattgg cccccttcct ccagttcagc ccgttcctcc tggctatcct 1260
cctgggcctg tgattccagc ccctcggcca ccgccagaat atccatatcc atctccgtct 1320
cgggaaccac caagggtgct gcctttcaac gttactgact actgtcaact ggtccgctat 1380
ctctgtcaaa atgggcgctg cattccaact cccggtagct accgctgcga gtgcaacaag 1440
ggcttccagc tggatatccg tggcgaatgc atcgacgtgg atgagtgtga gaagaaccca 1500
tgcactggtg gcgagtgcat caacaaccag ggctcctaca cctgtcactg cagagctggc 1560
taccagagca cactcaccag aactgagtgc agagacatag atgagtgtct tcagaatggc 1620
cggatctgca acaatggtcg ctgtatcaac acagacggca gcttccactg cgtatgcaat 1680
gcgggctttc atgtcacgcg ggacggaaag aactgtgaag atatggatga gtgcagcatc 1740
cgaaacatgt gcctaaacgg aatgtgtatt aatgaagatg gcagtttcaa gtgtatttgc 1800
aaacctgggt tccaactggc atcagatggc cgctactgca aagatatcaa tgagtgtgag 1860
acacctggga tctgcatgaa cggacgctgt gtgaacacgg atggctccta cagatgcgaa 1920
tgcttccccg gattggctgt gggtctagac ggacgtgtgt gtgttgacac acacatgcgg 1980
agcacatgct atggaggata caggagaggc cagtgcgtga agccgttgtt tggtgctgtt 2040
accaaatcgg aatgctgttg tgccagcact gagtatgcct ttggggaacc ctgccagccg 2100
tgtcctgcac agaattcagc ggaatatcag gcactctgca gcagtggacc gggaatgaca 2160
tcagcaggca ctgatataaa cgaatgtgca ttagatcctg atatttgccc aaatggaatt 2220
tgtgaaaatc tccgtgggac ctacaaatgt atatgcaact cgggatatga agtagacata 2280
actgggaaaa actgtgtcga tattaatgag tgtgtgctga acagtctact ttgtgacaat 2340
ggacaatgtc gaaacacacc tggaagtttt gtctgcacct gccccaaagg atttgtgtac 2400
aaacctgacc taaaaacctg tgaagacatt gatgaatgtg aatcgagtcc ttgcattaat 2460
ggagtctgca agaacagccc tggctccttc atttgtgaat gttctcctga aagtactctg 2520
gacccaacaa aaaccatctg catagaaacc atcaagggca cttgctggca gactgtcatc 2580
gacgggcgct gtgagatcaa catcaacgga gccaccttga agtccgagtg ctgctcctcc 2640
cttggtgctg cgtgggggag cccgtgcacc atctgtcaac ttgatcccat ttgtggtaaa 2700
gggttctcaa gaattaaagg cacgcaatgt gaagatatca atgagtgtga agtgttcccg 2760
ggagtatgca agaacggcct gtgtgtcaac tccaggggtt cattcaagtg cgagtgtccc 2820
aatggaatga ctttggatgc tacaggaaga atctgtcttg acatccgcct ggagacctgc 2880
ttcctcaagt atgacgatga agagtgcacc ttgcccatcg ctggccgcca ccgaatggat 2940
gcctgctgct gctctgttgg ggcagcctgg ggaacggaag agtgtgagga gtgtccattg 3000
agaaacagcc gggagtatga ggaactctgt ccccgaggac ctgggtttgc cacaaaagac 3060
attacaaatg ggaaaccttt cttcaaagat atcaatgagt gcaagatgat acccagcctc 3120
tgtacccacg gcaagtgcag gaacaccatt ggcagcttca agtgtaggtg tgacagtggc 3180
tttgctctgg attctgaaga gaggaactgt acagacattg atgagtgccg catatctcct 3240
gacctctgtg gccgaggcca gtgtgtgaac accccggggg actttgaatg caagtgtgat 3300
gaaggctatg aaagtggctt catgatgatg aagaactgca tggatattga tgaatgtcag 3360
agagatcctc tcctgtgtcg aggaggcatt tgccacaaca cagagggaag ctatcgctgc 3420
gaatgtcctc ctggtcacca attgtcccca aacatctctg catgcattga catcaacgag 3480
tgtgagctga gtgcgaatct ctgtccccat gggcgttgtg tgaacctcat agggaagtac 3540
cagtgtgcct gcaaccctgg ctaccacccc actcatgaca ggctcttctg tgtcgatatt 3600
gatgaatgca gcataatgaa cggtggttgt gagaccttct gcacaaactc tgacgggagc 3660
tatgaatgta gctgtcagcc aggcttcgcg ctaatgccag accagcgatc gtgcacagac 3720
attgatgagt gtgaagacaa ccccaatatc tgtgatggtg gccagtgcac aaacatacct 3780
ggggagtaca ggtgcctgtg ctatgatggg ttcatggcat ctgaagacat gaagacttgt 3840
gtggatgtca atgagtgtga cctgaatcca aacatctgcc ttagtgggac ctgtgaaaat 3900
actaaaggct cgttcatctg ccactgtgat atgggatatt cagggaagaa aggaaaaacg 3960
ggctgtacag atatcaatga atgtgagatc ggagcacaca actgtggcag acatgctgta 4020
tgcacaaata cagccgggag cttcaagtgc agctgcagtc ccggctggat tggagacggc 4080
attaagtgca cagatctgga tgaatgctct aatggaaccc acatgtgcag ccaacacgcg 4140
gactgcaaga acaccatggg gtcatatcgc tgtctctgta aggatggcta tacaggggat 4200
ggcttcacct gtacagacct cgacgagtgc tccgagaacc tgaacctctg tggcaatggc 4260
cagtgcctca acgcccctgg cgggtaccgc tgtgaatgcg acatgggctt cgtgcccagt 4320
gctgacggga aggcctgtga agatatcgat gagtgctccc ttccaaacat ctgtgtcttt 4380
ggaacttgcc acaacctccc gggcctcttc cgttgcgagt gtgagattgg ctatgaactg 4440
gaccgaagtg gtggaaactg cacagatgtt aatgagtgtc tggatcccac cacctgcatc 4500
agtggaaact gtgtcaacac tcccggtagt tacacatgcg attgtcctcc ggattttgag 4560
ctgaatccaa ctcgtgtcgg ctgtgtcgat actcgctctg gaaactgcta tctggatatc 4620
cgaccccggg gagacaatgg agatacagcc tgcagcaatg aaattggagt tggtgtctct 4680
aaggcttcct gctgttgttc actgggtaaa gcttggggaa ccccatgtga gctgtgtcct 4740
tctgtgaaca catctgagta taaaattctt tgccctggag gagaaggttt tcgtccaaat 4800
cccatcaccg ttatattgga agacatcgat gagtgccagg agcttccagg gctgtgccaa 4860
ggggggaagt gcatcaatac ctttggcagc ttccagtgtc gctgtccaac tggttactac 4920
ctgaatgaag acactcgagt gtgtgatgat gtgaacgaat gtgagactcc tggaatctgt 4980
ggtccgggga cctgttacaa caccgttggc aactatacct gcatttgtcc tccagactac 5040
atgcaagtga acgggggaaa taattgcatg gacatgagaa gaagtctatg ctacagaaac 5100
tattacgctg acaaccagac ctgcgatgga gaactcctgt tcaacatgac caagaagatg 5160
tgctgttgct cctacaacat cggcagagcc tggaacaaac cctgtgaaca gtgccccatc 5220
ccaagcacag atgagtttgc taccctctgt gggagccaga ggcccggctt cgtgattgac 5280
atttatacgg gtttacccgt ggatattgat gaatgccggg agatccctgg ggtctgtgaa 5340
aatggagtgt gcatcaacat ggttggcagc ttccggtgtg agtgtcccgt gggattcttc 5400
tataacgaca agttactggt ttgtgaagat atcgacgagt gtcagaatgg ccctgtgtgc 5460
cagcgaaatg cggaatgcat caacactgca ggcagctacc gctgtgactg taagcccggc 5520
taccgcctta cctccacagg tcaatgcaac gatcgaaacg agtgccaaga aatcccgaac 5580
atatgcagtc atggccagtg catcgacacc gtgggaagct tctactgcct ttgtcacact 5640
ggcttcaaaa caaatgtgga tcagaccatg tgcttagaca taaatgagtg tgagagagac 5700
gcctgtggga acgggacttg cagaaacacg attggctcct tcaactgtcg ctgtaaccat 5760
ggcttcatac tgtctcacaa caatgactgc atagatgttg atgagtgtgc aactggaaac 5820
gggaaccttt gcagaaatgg ccagtgtgtc aataccgtgg gctcctttca gtgcaggtgc 5880
aatgaaggct atgaggtggc tccggacggc aggacctgtg tggatatcaa cgagtgtgtt 5940
ctggatcctg ggaaatgtgc acctggaacc tgtcagaacc tggatggctc ctacagatgc 6000
atttgcccgc ctgggtatag tctacagaat gacaagtgtg aagatattga tgagtgtgtt 6060
gaagagccag aaatctgtgc cttggggacc tgcagcaaca ctgagggtag cttcaaatgt 6120
ctgtgtccag aggggttctc cctgtcctcc actggaagaa ggtgccaaga tttgcgaatg 6180
agctactgct atgcgaagtt tgaaggtggg aagtgttcat cacccaaatc cagaaaccat 6240
tccaagcagg agtgctgctg tgctttgaag ggagaaggct ggggagatcc ttgtgagttg 6300
tgccccactg agccagatga ggctttccgc cagatctgcc cctttggaag tgggatcatt 6360
gtgggccctg atgactcagc agttgatatg gacgaatgca aagaacctga tgtctgtaga 6420
catgggcagt gcattaacac agacggctcc tatcgatgcg agtgtccttt tggttatatt 6480
ctggaaggga atgagtgtgt ggataccgat gaatgctctg tgggcaatcc ttgtggaaat 6540
gggacctgca agaatgtgat tggaggtttt gaatgtacct gtgaggaggg gttcgagcct 6600
ggcccaatga tgacttgtga agatataaat gaatgtgccc agaatcctct gctctgcgcc 6660
ttccgctgtg taaataccta cgggtcctat gaatgcaaat gccctgttgg atacgttctc 6720
cgagaagaca ggaggatgtg taaagatgag gatgagtgtg cagagggaaa acacgactgt 6780
actgagaagc aaatggagtg taagaacctc attggtacct acatgtgcat ctgcggccct 6840
gggtaccagc gcagacccga tggagagggc tgcatagatg agaatgagtg tcagaccaag 6900
cccgggatct gtgagaatgg gcgttgcctc aacaccctgg gtagctacac ttgtgagtgt 6960
aacgatggct tcacagccag ccccactcag gatgagtgct tggacaaccg ggaagggtac 7020
tgcttttcgg aggtcttgca aaacatgtgc cagattggct caagcaacag gaaccccgtc 7080
accaagtccg agtgctgctg tgatggaggg agaggctggg gaccccactg tgagatctgc 7140
cctttcgagg gcacagtggc ttacaagaag ctctgtcccc acggccgagg attcatgacc 7200
aacggagcag atattgatga gtgcaaggtt attcatgatg tttgccgaaa tggggagtgt 7260
gtcaacgaca gagggtccta tcactgcatc tgtaaaactg gctacactcc ggatataaca 7320
gggaccgcct gtgtagatct gaatgaatgc aaccaggctc ccaaaccctg caattttata 7380
tgcaaaaaca cagaagggag ttaccagtgt tcctgcccga agggctacat tctgcaagag 7440
gatggaagga gctgcaaaga tcttgacgag tgtgcaacca agcagcataa ctgtcagttc 7500
ctgtgtgtta acaccatcgg tggcttcaca tgcaaatgcc ctcctgggtt tacccagcat 7560
cacactgcct gcattgataa caatgagtgc acgtctgata tcaacctgtg tgggtccaag 7620
ggtgtttgcc agaacactcc aggaagcttc acctgtgaat gccaacgggg gttctcactc 7680
gatcagagtg gtgccagctg tgaagatgtg gacgagtgtg agggtaacca ccgctgtcaa 7740
catggctgcc agaacatcat cggaggctat aggtgtagct gcccccaggg ctacctccag 7800
cactaccaat ggaaccagtg tgtagatgaa aacgagtgcc tgagtgcaca tgtctgtgga 7860
ggagcctcct gccacaacac cctggggagt tacaagtgca tgtgtcccac cggcttccag 7920
tacgaacagt tcagtggagg ctgccaagac atcaatgagt gtggctcatc ccaggccccc 7980
tgcagttacg gttgctctaa tactgagggt ggctacctgt gtggctgtcc accaggatac 8040
ttccggatag gccaagggca ttgtgtttct ggaatgggca tgggccgagg cggcccagag 8100
ccacctgcca gcagcgagat ggacgacaac tcactgtccc cagaggcctg ctatgagtgt 8160
aagatcaacg gctacccaaa acgaggccgg aaacggagaa gcacgaacga aacggatgcc 8220
tccgacatcc aggacgggtc tgagatggaa gccaacgtga gcctcgccag ctgggatgtg 8280
gagaagccgg ctagctttgc tttcaatatt tcccatgtca ataacaaggt ccgaatccta 8340
gagctcctgc cggccctcac aactctgatg aaccacaaca gatacttgat tgaatctgga 8400
aatgaagatg gcttctttaa aatcaaccag aaagaagggg tcagctacct ccacttcacg 8460
aagaagaagc cggtggctgg gacctactcc ttacaaatca gcagcacccc actttataaa 8520
aagaaagaac ttaaccagtt agaagacaga tatgacaaag actacctcag tggtgaactg 8580
ggcgataacc tgaagatgaa aattcagatc ttgctgcatt aa 8622
<210> 21
<211> 8623
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 21
atgcggcgag gagggctgct ggaggtcgcg ctggcgttcg ccctgctcct cgagtcctac 60
acgagccatg gggcggacgc caatttggag gctgggagcc tgaaggagac cagagccaat 120
cgggccaaga gaagaggcgg cggaggacac gatgcgctga aaggacccaa tgtctgtgga 180
tcacgttata atgcatactg ttgtcctgga tggaaaacct tacctggtgg aaatcagtgt 240
attgttccca tttgccggca ttcctgtggg gatggattct gctcgaggcc aaatatgtgc 300
acttgcccgt ctggtcagat atctccttcc tgtggctcca gatccatcca acactgcagc 360
atccgctgta tgaatggggg cagctgcagc gatgaccact gtctgtgcca gaaagggtac 420
atcggcactc actgtggaca gcctgtctgt gaaagtggct gtctcaacgg agggaggtgt 480
gtggccccaa atcggtgtgc ttgcacgtac ggctttactg gaccccagtg tgaaagagat 540
tacagaacag gcccatgttt tactgtggta agcaaccaga tgtgccaggg acagctcagc 600
gggattgtct gcaccaaaac actttgctgt gccaccgtgg gccgagcctg gggccacccc 660
tgtgagatgt gtcctgccca gcctcacccc tgccgccgcg gcttcattcc caacatccgc 720
actggagctt gtcaagatgt ggatgaatgt caggccatcc cagggatgtg tcaaggagga 780
aattgcatta ataccgttgg atcttttgag tgcaaatgcc ctgctggaca caaatttaat 840
gaagtgtcac aaaaatgtga agatattgac gagtgcagca ccattcctgg agtctgcgat 900
ggcggggaat gtacaaacac tgtcagcagc tacttctgca aatgtccccc tggtttttac 960
acctctcctg atggcaccag atgcgtagat gttcgccctg gttactgcta cacagctctg 1020
gcaaacgggc gctgctctaa ccagctgcca cagtccataa ccaaaatgca gtgctgttgc 1080
gatcttggcc ggtgctggtc tccaggggtt actgttgctc ccgagatgtg tcccatcagg 1140
tcaactgagg atttcaacaa gctgtgctct gtccctctgg taattcccgg gagaccagaa 1200
tatcctcccc cacccattgg cccccttcct ccagttcagc ccgttcctcc tggctatcct 1260
cctgggcctg tgattccagc ccctcggcca ccgccagaat atccatatcc atctccgtct 1320
cgggaaccac caagggtgct gcctttcaac gttactgact actgtcaact ggtccgctat 1380
ctctgtcaaa atgggcgctg cattccaact cccggtagct accgctgcga gtgcaacaag 1440
ggcttccagc tggatatccg tggcgaatgc atcgacgtgg atgagtgtga gaagaaccca 1500
tgcactggtg gcgagtgcat caacaaccag ggctcctaca cctgtcactg cagagctggc 1560
taccagagca cactcaccag aactgagtgc agagacatag atgagtgtct tcagaatggc 1620
cggatctgca acaatggtcg ctgtatcaac acagacggca gcttccactg cgtatgcaat 1680
gcgggctttc atgtcacgcg ggacggaaag aactgtgaag atatggatga gtgcagcatc 1740
cgaaacatgt gcctaaacgg aatgtgtatt aatgaagatg gcagtttcaa gtgtatttgc 1800
aaacctgggt tccaactggc atcagatggc cgctactgca aagatatcaa tgagtgtgag 1860
acacctggga tctgcatgaa cggacgctgt gtgaacacgg atggctccta cagatgcgaa 1920
tgcttccccg gattggctgt gggtctagac ggacgtgtgt gtgttgacac acacatgcgg 1980
agcacatgct atggaggata caggagaggc cagtgcgtga agccgttgtt tggtgctgtt 2040
accaaatcgg aatgctgttg tgccagcact gagtatgcct ttggggaacc ctgccagccg 2100
tgtcctgcac agaattcagc ggaatatcag gcactctgca gcagtggacc gggaatgaca 2160
tcagcaggca ctgatataaa cgaatgtgca ttagatcctg atatttgccc aaatggaatt 2220
tgtgaaaatc tccgtgggac ctacaaatgt atatgcaact cgggatatga agtagacata 2280
actgggaaaa actgtgtcga tattaatgag tgtgtgctga acagtctact ttgtgacaat 2340
ggacaatgtc gaaacacacc tggaagtttt gtctgcacct gccccaaagg atttgtgtac 2400
aaacctgacc taaaaacctg tgaagacatt gatgaatgtg aatcgagtcc ttgcattaat 2460
ggagtctgca agaacagccc tggctccttc atttgtgaat gttctcctga aagtactctg 2520
gacccaacaa aaaccatctg catagaaacc atcaagggca cttgctggca gactgtcatc 2580
gacgggcgct gtgagatcaa catcaacgga gccaccttga agtccgagtg ctgctcctcc 2640
cttggtgctg cgtgggggag cccgtgcacc atctgtcaac ttgatcccat ttgtggtaaa 2700
gggttctcaa gaattaaagg cacgcaatgt gaagatatca atgagtgtga agtgttcccg 2760
ggagtatgca agaacggcct gtgtgtcaac tccaggggtt cattcaagtg cgagtgtccc 2820
aatggaatga ctttggatgc tacaggaaga atctgtcttg acatccgcct ggagacctgc 2880
ttcctcaagt atgacgatga agagtgcacc ttgcccatcg ctggccgcca ccgaatggat 2940
gcctgctgct gctctgttgg ggcagcctgg ggaacggaag agtgtgagga gtgtccattg 3000
agaaacagcc gggagtatga ggaactctgt ccccgaggac ctgggtttgc cacaaaagac 3060
attacaaatg ggaaaccttt cttcaaagat atcaatgagt gcaagatgat acccagcctc 3120
tgtacccacg gcaagtgcag gaacaccatt ggcagcttca agtgtaggtg tgacagtggc 3180
tttgctctgg attctgaaga gaggaactgt acagacattg atgagtgccg catatctcct 3240
gacctctgtg gccgaggcca gtgtgtgaac accccggggg actttgaatg caagtgtgat 3300
gaaggctatg aaagtggctt catgatgatg aagaactgca tggatattga tgaatgtcag 3360
agagatcctc tcctgtgtcg aggaggcatt tgccacaaca cagagggaag ctatcgctgc 3420
gaatgtcctc ctggtcacca attgtcccca aacatctctg catgcattga catcaacgag 3480
tgtgagctga gtgcgaatct ctgtccccat gggcgttgtg tgaacctcat agggaagtac 3540
cagtgtgcct gcaaccctgg ctaccacccc actcatgaca ggctcttctg tgtcgatatt 3600
gatgaatgca gcataatgaa cggtggttgt gagaccttct gcacaaactc tgacgggagc 3660
tatgaatgta gctgtcagcc aggcttcgcg ctaatgccag accagcgatc gtgcacagac 3720
attgatgagt gtgaagacaa ccccaatatc tgtgatggtg gccagtgcac aaacatacct 3780
ggggagtaca ggtgcctgtg ctatgatggg ttcatggcat ctgaagacat gaagacttgt 3840
gtggatgtca atgagtgtga cctgaatcca aacatctgcc ttagtgggac ctgtgaaaat 3900
actaaaggct cgttcatctg ccactgtgat atgggatatt cagggaagaa aggaaaaacg 3960
ggctgtacag atatcaatga atgtgagatc ggagcacaca actgtggcag acatgctgta 4020
tgcacaaata cagccgggag cttcaagtgc agctgcagtc ccggctggat tggagacggc 4080
attaagtgca cagatctgga tgaatgctct aatggaaccc acatgtgcag ccaacacgcg 4140
gactgcaaga acaccatggg gtcatatcgc tgtctctgta aggatggcta tacaggggat 4200
ggcttcacct gtacagacct cgacgagtgc tccgagaacc tgaacctctg tggcaatggc 4260
cagtgcctca acgcccctgg cgggtaccgc tgtgaatgcg acatgggctt cgtgcccagt 4320
gctgacggga aggcctgtga agatatcgat gagtgctccc ttccaaacat ctgtgtcttt 4380
ggaacttgcc acaacctccc gggcctcttc cgttgcgagt gtgagattgg ctatgaactg 4440
gaccgaagtg gtggaaactg cacagatgtt aatgagtgtc tggatcccac cacctgcatc 4500
agtggaaact gtgtcaacac tcccggtagt tacacatgcg attgtcctcc ggattttgag 4560
ctgaatccaa ctcgtgtcgg ctgtgtcgat actcgctctg gaaactgcta tctggatatc 4620
cgaccccggg gagacaatgg agatacagcc tgcagcaatg aaattggagt tggtgtctct 4680
aaggcttcct gctgttgttc actgggtaaa gcttggggaa ccccatgtga gctgtgtcct 4740
tctgtgaaca catctgagta taaaattctt tgccctggag gagaaggttt tcgtccaaat 4800
cccatcaccg ttatattgga agacatcgat gagtgccagg agcttccagg gctgtgccaa 4860
ggggggaagt gcatcaatac ctttggcagc ttccagtgtc gctgtccaac tggttactac 4920
ctgaatgaag acactcgagt gtgtgatgat gtgaacgaat gtgagactcc tggaatctgt 4980
ggtccgggga cctgttacaa caccgttggc aactatacct gcatttgtcc tccagactac 5040
atgcaagtga acgggggaaa taattgcatg gacatgagaa gaagtctatg ctacagaaac 5100
tattacgctg acaaccagac ctgcgatgga gaactcctgt tcaacatgac caagaagatg 5160
tgctgttgct cctacaacat cggcagagcc tggaacaaac cctgtgaaca gtgccccatc 5220
ccaagcacag atgagtttgc taccctctgt gggagccaga ggcccggctt cgtgattgac 5280
atttatacgg gtttacccgt ggatattgat gaatgccggg agatccctgg ggtctgtgaa 5340
aatggagtgt gcatcaacat ggttggcagc ttccggtgtg agtgtcccgt gggattcttc 5400
tataacgaca agttactggt ttgtgaagat atcgacgagt gtcagaatgg ccctgtgtgc 5460
cagcgaaatg cggaatgcat caacactgca ggcagctacc gctgtgactg taagcccggc 5520
taccgcctta cctccacagg tcaatgcaac gatcgaaacg agtgccaaga aatcccgaac 5580
atatgcagtc atggccagtg catcgacacc gtgggaagct tctactgcct ttgtcacact 5640
ggcttcaaaa caaatgtgga tcagaccatg tgcttagaca taaatgagtg tgagagagac 5700
gcctgtggga acgggacttg cagaaacacg attggctcct tcaactgtcg ctgtaaccat 5760
ggcttcatac tgtctcacaa caatgactgc atagatgttg atgagtgtgc aactggaaac 5820
gggaaccttt gcagaaatgg ccagtgtgtc aataccgtgg gctcctttca gtgcaggtgc 5880
aatgaaggct atgaggtggc tccggacggc aggacctgtg tggatatcaa cgagtgtgtt 5940
ctggatcctg ggaaatgtgc acctggaacc tgtcagaacc tggatggctc ctacagatgc 6000
atttgcccgc ctgggtatag tctacagaat gacaagtgtg aagatattga tgagtgtgtt 6060
gaagagccag aaatctgtgc cttggggacc tgcagcaaca ctgagggtag cttcaaatgt 6120
ctgtgtccag aggggttctc cctgtcctcc actggaagaa ggtgccaaga tttgcgaatg 6180
agctactgct atgcgaagtt tgaaggtggg aagtgttcat cacccaaatc cagaaaccat 6240
tccaagcagg agtgctgctg tgctttgaag ggagaaggct ggggagatcc ttgtgagttg 6300
tgccccactg agccagatga ggctttccgc cagatctgcc cctttggaag tgggatcatt 6360
gtgggccctg atgactcagc agttgatatg gacgaatgca aagaacctga tgtctgtaga 6420
catgggcagt gcattaacac agacggctcc tatcgatgcg agtgtccttt tggttatatt 6480
ctggaaggga atgagtgtgt ggataccgat gaatgctctg tgggcaatcc ttgtggaaat 6540
gggacctgca agaatgtgat tggaggtttt gaatgtacct gtgaggaggg gttcgagcct 6600
ggcccaatga tgacttgtga agatataaat gaatgtgccc agaatcctct gctctgcgcc 6660
ttccgctgtg taaataccta cgggtcctat gaatgcaaat gccctgttgg atacgttctc 6720
cgagaagaca ggaggatgtg taaagatgag gatgagtgtg cagagggaaa acacgactgt 6780
actgagaagc aaatggagtg taagaacctc attggtacct acatgtgcat ctgcggccct 6840
gggtaccagc gcagacccga tggagagggc tgcatagatg agaatgagtg tcagaccaag 6900
cccgggatct gtgagaatgg gcgttgcctc aacaccctgg gtagctacac ttgtgagtgt 6960
aacgatggct tcacagccag ccccactcag gatgagtgct tggacaaccg ggaagggtac 7020
tgcttttcgg aggtcttgca aaacatgtgc cagattggct caagcaacag gaaccccgtc 7080
accaagtccg agtgctgctg tgatggaggg agaggctggg gaccccactg tgagatctgc 7140
cctttcgagg gcacagtggc ttacaagaag ctctgtcccc acggccgagg attcatgacc 7200
aacggagcag atattgatga gtgcaaggtt attcatgatg tttgccgaaa tggggagtgt 7260
gtcaacgaca gagggtccta tcactgcatc tgtaaaactg gctacactcc ggatataaca 7320
gggaccgcct gtgtagatct gaatgaatgc aaccaggctc ccaaaccctg caattttata 7380
tgcaaaaaca cagaagggag ttaccagtgt tcctgcccga agggctacat tctgcaagag 7440
gatggaagga gctgcaaaga tcttgacgag tgtgcaacca agcagcataa ctgtcagttc 7500
ctgtgtgtta acaccatcgg tggcttcaca tgcaaatgcc ctcctgggtt tacccagcat 7560
cacactgcct gcattgataa caatgagtgc acgtctgata tcaacctgtg tgggtccaag 7620
ggtgtttgcc agaacactcc aggaagcttc acctgtgaat gccaacgggg gttctcactc 7680
gatcagagtg gtgccagctg tgaagatgtg gacgagtgtg agggtaacca ccgctgtcaa 7740
catggctgcc agaacatcat cggaggctat aggtgtagct gcccccaggg ctacctccag 7800
cactaccaat ggaaccagtg tgtagatgaa aacgagtgcc tgagtgcaca tgtctgtgga 7860
ggagcctcct gccacaacac cctggggagt tacaagtgca tgtgtcccac cggcttccag 7920
tacgaacagt tcagtggagg ctgccaagac atcaatgagt gtggctcatc ccaggccccc 7980
tgcagttacg gttgctctaa tactgagggt ggctacctgt gtggctgtcc accaggatac 8040
ttccggatag gccaagggca ttgtgtttct ggaatgggca tgggccgagg cggcccagag 8100
ccacctgcca gcagcgagat ggacgacaac tcactgtccc cagaggcctg ctatgagtgt 8160
aagatcaacg gctacccaaa acgaggccgg aaacggagaa gcacgaacga aaactgatgc 8220
ctccgacatc caggacgggt ctgagatgga agccaacgtg agcctcgcca gctgggatgt 8280
ggagaagccg gctagctttg ctttcaatat ttcccatgtc aataacaagg tccgaatcct 8340
agagctcctg ccggccctca caactctgat gaaccacaac agatacttga ttgaatctgg 8400
aaatgaagat ggcttcttta aaatcaacca gaaagaaggg gtcagctacc tccacttcac 8460
gaagaagaag ccggtggctg ggacctactc cttacaaatc agcagcaccc cactttataa 8520
aaagaaagaa cttaaccagt tagaagacag atatgacaaa gactacctca gtggtgaact 8580
gggcgataac ctgaagatga aaattcagat cttgctgcat taa 8623
<210> 22
<211> 8647
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 22
atgcggcgag gagggctgct ggaggtcgcg ctggcgttcg ccctgctcct cgagtcctac 60
acgagccatg gggcggacgc caatttggag gctgggagcc tgaaggagac cagagccaat 120
cgggccaaga gaagaggcgg cggaggacac gatgcgctga aaggacccaa tgtctgtgga 180
tcacgttata atgcatactg ttgtcctgga tggaaaacct tacctggtgg aaatcagtgt 240
attgttccca tttgccggca ttcctgtggg gatggattct gctcgaggcc aaatatgtgc 300
acttgcccgt ctggtcagat atctccttcc tgtggctcca gatccatcca acactgcagc 360
atccgctgta tgaatggggg cagctgcagc gatgaccact gtctgtgcca gaaagggtac 420
atcggcactc actgtggaca gcctgtctgt gaaagtggct gtctcaacgg agggaggtgt 480
gtggccccaa atcggtgtgc ttgcacgtac ggctttactg gaccccagtg tgaaagagat 540
tacagaacag gcccatgttt tactgtggta agcaaccaga tgtgccaggg acagctcagc 600
gggattgtct gcaccaaaac actttgctgt gccaccgtgg gccgagcctg gggccacccc 660
tgtgagatgt gtcctgccca gcctcacccc tgccgccgcg gcttcattcc caacatccgc 720
actggagctt gtcaagatgt ggatgaatgt caggccatcc cagggatgtg tcaaggagga 780
aattgcatta ataccgttgg atcttttgag tgcaaatgcc ctgctggaca caaatttaat 840
gaagtgtcac aaaaatgtga agatattgac gagtgcagca ccattcctgg agtctgcgat 900
ggcggggaat gtacaaacac tgtcagcagc tacttctgca aatgtccccc tggtttttac 960
acctctcctg atggcaccag atgcgtagat gttcgccctg gttactgcta cacagctctg 1020
gcaaacgggc gctgctctaa ccagctgcca cagtccataa ccaaaatgca gtgctgttgc 1080
gatcttggcc ggtgctggtc tccaggggtt actgttgctc ccgagatgtg tcccatcagg 1140
tcaactgagg atttcaacaa gctgtgctct gtccctctgg taattcccgg gagaccagaa 1200
tatcctcccc cacccattgg cccccttcct ccagttcagc ccgttcctcc tggctatcct 1260
cctgggcctg tgattccagc ccctcggcca ccgccagaat atccatatcc atctccgtct 1320
cgggaaccac caagggtgct gcctttcaac gttactgact actgtcaact ggtccgctat 1380
ctctgtcaaa atgggcgctg cattccaact cccggtagct accgctgcga gtgcaacaag 1440
ggcttccagc tggatatccg tggcgaatgc atcgacgtgg atgagtgtga gaagaaccca 1500
tgcactggtg gcgagtgcat caacaaccag ggctcctaca cctgtcactg cagagctggc 1560
taccagagca cactcaccag aactgagtgc agagacatag atgagtgtct tcagaatggc 1620
cggatctgca acaatggtcg ctgtatcaac acagacggca gcttccactg cgtatgcaat 1680
gcgggctttc atgtcacgcg ggacggaaag aactgtgaag atatggatga gtgcagcatc 1740
cgaaacatgt gcctaaacgg aatgtgtatt aatgaagatg gcagtttcaa gtgtatttgc 1800
aaacctgggt tccaactggc atcagatggc cgctactgca aagatatcaa tgagtgtgag 1860
acacctggga tctgcatgaa cggacgctgt gtgaacacgg atggctccta cagatgcgaa 1920
tgcttccccg gattggctgt gggtctagac ggacgtgtgt gtgttgacac acacatgcgg 1980
agcacatgct atggaggata caggagaggc cagtgcgtga agccgttgtt tggtgctgtt 2040
accaaatcgg aatgctgttg tgccagcact gagtatgcct ttggggaacc ctgccagccg 2100
tgtcctgcac agaattcagc ggaatatcag gcactctgca gcagtggacc gggaatgaca 2160
tcagcaggca ctgatataaa cgaatgtgca ttagatcctg atatttgccc aaatggaatt 2220
tgtgaaaatc tccgtgggac ctacaaatgt atatgcaact cgggatatga agtagacata 2280
actgggaaaa actgtgtcga tattaatgag tgtgtgctga acagtctact ttgtgacaat 2340
ggacaatgtc gaaacacacc tggaagtttt gtctgcacct gccccaaagg atttgtgtac 2400
aaacctgacc taaaaacctg tgaagacatt gatgaatgtg aatcgagtcc ttgcattaat 2460
ggagtctgca agaacagccc tggctccttc atttgtgaat gttctcctga aagtactctg 2520
gacccaacaa aaaccatctg catagaaacc atcaagggca cttgctggca gactgtcatc 2580
gacgggcgct gtgagatcaa catcaacgga gccaccttga agtccgagtg ctgctcctcc 2640
cttggtgctg cgtgggggag cccgtgcacc atctgtcaac ttgatcccat ttgtggtaaa 2700
gggttctcaa gaattaaagg cacgcaatgt gaagatatca atgagtgtga agtgttcccg 2760
ggagtatgca agaacggcct gtgtgtcaac tccaggggtt cattcaagtg cgagtgtccc 2820
aatggaatga ctttggatgc tacaggaaga atctgtcttg acatccgcct ggagacctgc 2880
ttcctcaagt atgacgatga agagtgcacc ttgcccatcg ctggccgcca ccgaatggat 2940
gcctgctgct gctctgttgg ggcagcctgg ggaacggaag agtgtgagga gtgtccattg 3000
agaaacagcc gggagtatga ggaactctgt ccccgaggac ctgggtttgc cacaaaagac 3060
attacaaatg ggaaaccttt cttcaaagat atcaatgagt gcaagatgat acccagcctc 3120
tgtacccacg gcaagtgcag gaacaccatt ggcagcttca agtgtaggtg tgacagtggc 3180
tttgctctgg attctgaaga gaggaactgt acagacattg atgagtgccg catatctcct 3240
gacctctgtg gccgaggcca gtgtgtgaac accccggggg actttgaatg caagtgtgat 3300
gaaggctatg aaagtggctt catgatgatg aagaactgca tggatattga tgaatgtcag 3360
agagatcctc tcctgtgtcg aggaggcatt tgccacaaca cagagggaag ctatcgctgc 3420
gaatgtcctc ctggtcacca attgtcccca aacatctctg catgcattga catcaacgag 3480
tgtgagctga gtgcgaatct ctgtccccat gggcgttgtg tgaacctcat agggaagtac 3540
cagtgtgcct gcaaccctgg ctaccacccc actcatgaca ggctcttctg tgtcgatatt 3600
gatgaatgca gcataatgaa cggtggttgt gagaccttct gcacaaactc tgacgggagc 3660
tatgaatgta gctgtcagcc aggcttcgcg ctaatgccag accagcgatc gtgcacagac 3720
attgatgagt gtgaagacaa ccccaatatc tgtgatggtg gccagtgcac aaacatacct 3780
ggggagtaca ggtgcctgtg ctatgatggg ttcatggcat ctgaagacat gaagacttgt 3840
gtggatgtca atgagtgtga cctgaatcca aacatctgcc ttagtgggac ctgtgaaaat 3900
actaaaggct cgttcatctg ccactgtgat atgggatatt cagggaagaa aggaaaaacg 3960
ggctgtacag atatcaatga atgtgagatc ggagcacaca actgtggcag acatgctgta 4020
tgcacaaata cagccgggag cttcaagtgc agctgcagtc ccggctggat tggagacggc 4080
attaagtgca cagatctgga tgaatgctct aatggaaccc acatgtgcag ccaacacgcg 4140
gactgcaaga acaccatggg gtcatatcgc tgtctctgta aggatggcta tacaggggat 4200
ggcttcacct gtacagacct cgacgagtgc tccgagaacc tgaacctctg tggcaatggc 4260
cagtgcctca acgcccctgg cgggtaccgc tgtgaatgcg acatgggctt cgtgcccagt 4320
gctgacggga aggcctgtga agatatcgat gagtgctccc ttccaaacat ctgtgtcttt 4380
ggaacttgcc acaacctccc gggcctcttc cgttgcgagt gtgagattgg ctatgaactg 4440
gaccgaagtg gtggaaactg cacagatgtt aatgagtgtc tggatcccac cacctgcatc 4500
agtggaaact gtgtcaacac tcccggtagt tacacatgcg attgtcctcc ggattttgag 4560
ctgaatccaa ctcgtgtcgg ctgtgtcgat actcgctctg gaaactgcta tctggatatc 4620
cgaccccggg gagacaatgg agatacagcc tgcagcaatg aaattggagt tggtgtctct 4680
aaggcttcct gctgttgttc actgggtaaa gcttggggaa ccccatgtga gctgtgtcct 4740
tctgtgaaca catctgagta taaaattctt tgccctggag gagaaggttt tcgtccaaat 4800
cccatcaccg ttatattgga agacatcgat gagtgccagg agcttccagg gctgtgccaa 4860
ggggggaagt gcatcaatac ctttggcagc ttccagtgtc gctgtccaac tggttactac 4920
ctgaatgaag acactcgagt gtgtgatgat gtgaacgaat gtgagactcc tggaatctgt 4980
ggtccgggga cctgttacaa caccgttggc aactatacct gcatttgtcc tccagactac 5040
atgcaagtga acgggggaaa taattgcatg gacatgagaa gaagtctatg ctacagaaac 5100
tattacgctg acaaccagac ctgcgatgga gaactcctgt tcaacatgac caagaagatg 5160
tgctgttgct cctacaacat cggcagagcc tggaacaaac cctgtgaaca gtgccccatc 5220
ccaagcacag atgagtttgc taccctctgt gggagccaga ggcccggctt cgtgattgac 5280
atttatacgg gtttacccgt ggatattgat gaatgccggg agatccctgg ggtctgtgaa 5340
aatggagtgt gcatcaacat ggttggcagc ttccggtgtg agtgtcccgt gggattcttc 5400
tataacgaca agttactggt ttgtgaagat atcgacgagt gtcagaatgg ccctgtgtgc 5460
cagcgaaatg cggaatgcat caacactgca ggcagctacc gctgtgactg taagcccggc 5520
taccgcctta cctccacagg tcaatgcaac gatcgaaacg agtgccaaga aatcccgaac 5580
atatgcagtc atggccagtg catcgacacc gtgggaagct tctactgcct ttgtcacact 5640
ggcttcaaaa caaatgtgga tcagaccatg tgcttagaca taaatgagtg tgagagagac 5700
gcctgtggga acgggacttg cagaaacacg attggctcct tcaactgtcg ctgtaaccat 5760
ggcttcatac tgtctcacaa caatgactgc atagatgttg atgagtgtgc aactggaaac 5820
gggaaccttt gcagaaatgg ccagtgtgtc aataccgtgg gctcctttca gtgcaggtgc 5880
aatgaaggct atgaggtggc tccggacggc aggacctgtg tggatatcaa cgagtgtgtt 5940
ctggatcctg ggaaatgtgc acctggaacc tgtcagaacc tggatggctc ctacagatgc 6000
atttgcccgc ctgggtatag tctacagaat gacaagtgtg aagatattga tgagtgtgtt 6060
gaagagccag aaatctgtgc cttggggacc tgcagcaaca ctgagggtag cttcaaatgt 6120
ctgtgtccag aggggttctc cctgtcctcc actggaagaa ggtgccaaga tttgcgaatg 6180
agctactgct atgcgaagtt tgaaggtggg aagtgttcat cacccaaatc cagaaaccat 6240
tccaagcagg agtgctgctg tgctttgaag ggagaaggct ggggagatcc ttgtgagttg 6300
tgccccactg agccagatga ggctttccgc cagatctgcc cctttggaag tgggatcatt 6360
gtgggccctg atgactcagc agttgatatg gacgaatgca aagaacctga tgtctgtaga 6420
catgggcagt gcattaacac agacggctcc tatcgatgcg agtgtccttt tggttatatt 6480
ctggaaggga atgagtgtgt ggataccgat gaatgctctg tgggcaatcc ttgtggaaat 6540
gggacctgca agaatgtgat tggaggtttt gaatgtacct gtgaggaggg gttcgagcct 6600
ggcccaatga tgacttgtga agatataaat gaatgtgccc agaatcctct gctctgcgcc 6660
ttccgctgtg taaataccta cgggtcctat gaatgcaaat gccctgttgg atacgttctc 6720
cgagaagaca ggaggatgtg taaagatgag gatgagtgtg cagagggaaa acacgactgt 6780
actgagaagc aaatggagtg taagaacctc attggtacct acatgtgcat ctgcggccct 6840
gggtaccagc gcagacccga tggagagggc tgcatagatg agaatgagtg tcagaccaag 6900
cccgggatct gtgagaatgg gcgttgcctc aacaccctgg gtagctacac ttgtgagtgt 6960
aacgatggct tcacagccag ccccactcag gatgagtgct tggacaaccg ggaagggtac 7020
tgcttttcgg aggtcttgca aaacatgtgc cagattggct caagcaacag gaaccccgtc 7080
accaagtccg agtgctgctg tgatggaggg agaggctggg gaccccactg tgagatctgc 7140
cctttcgagg gcacagtggc ttacaagaag ctctgtcccc acggccgagg attcatgacc 7200
aacggagcag atattgatga gtgcaaggtt attcatgatg tttgccgaaa tggggagtgt 7260
gtcaacgaca gagggtccta tcactgcatc tgtaaaactg gctacactcc ggatataaca 7320
gggaccgcct gtgtagatct gaatgaatgc aaccaggctc ccaaaccctg caattttata 7380
tgcaaaaaca cagaagggag ttaccagtgt tcctgcccga agggctacat tctgcaagag 7440
gatggaagga gctgcaaaga tcttgacgag tgtgcaacca agcagcataa ctgtcagttc 7500
ctgtgtgtta acaccatcgg tggcttcaca tgcaaatgcc ctcctgggtt tacccagcat 7560
cacactgcct gcattgataa caatgagtgc acgtctgata tcaacctgtg tgggtccaag 7620
ggtgtttgcc agaacactcc aggaagcttc acctgtgaat gccaacgggg gttctcactc 7680
gatcagagtg gtgccagctg tgaagatgtg gacgagtgtg agggtaacca ccgctgtcaa 7740
catggctgcc agaacatcat cggaggctat aggtgtagct gcccccaggg ctacctccag 7800
cactaccaat ggaaccagtg tgtagatgaa aacgagtgcc tgagtgcaca tgtctgtgga 7860
ggagcctcct gccacaacac cctggggagt tacaagtgca tgtgtcccac cggcttccag 7920
tacgaacagt tcagtggagg ctgccaagac atcaatgagt gtggctcatc ccaggccccc 7980
tgcagttacg gttgctctaa tactgagggt ggctacctgt gtggctgtcc accaggatac 8040
ttccggatag gccaagggca ttgtgtttct ggaatgggca tgggccgagg cggcccagag 8100
ccacctgcca gcagcgagat ggacgacaac tcactgtccc cagaggcctg ctatgagtgt 8160
aagatcaacg gctacccaaa ggcggcccag agccacctgc cagcaacgag gccggaaacg 8220
gagaagcacg aacgaaacgg atgcctccga catccaggac gggtctgaga tggaagccaa 8280
cgtgagcctc gccagctggg atgtggagaa gccggctagc tttgctttca atatttccca 8340
tgtcaataac aaggtccgaa tcctagagct cctgccggcc ctcacaactc tgatgaacca 8400
caacagatac ttgattgaat ctggaaatga agatggcttc tttaaaatca accagaaaga 8460
aggggtcagc tacctccact tcacgaagaa gaagccggtg gctgggacct actccttaca 8520
aatcagcagc accccacttt ataaaaagaa agaacttaac cagttagaag acagatatga 8580
caaagactac ctcagtggtg aactgggcga taacctgaag atgaaaattc agatcttgct 8640
gcattaa 8647
<210> 23
<211> 8620
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 23
atgcggcgag gagggctgct ggaggtcgcg ctggcgttcg ccctgctcct cgagtcctac 60
acgagccatg gggcggacgc caatttggag gctgggagcc tgaaggagac cagagccaat 120
cgggccaaga gaagaggcgg cggaggacac gatgcgctga aaggacccaa tgtctgtgga 180
tcacgttata atgcatactg ttgtcctgga tggaaaacct tacctggtgg aaatcagtgt 240
attgttccca tttgccggca ttcctgtggg gatggattct gctcgaggcc aaatatgtgc 300
acttgcccgt ctggtcagat atctccttcc tgtggctcca gatccatcca acactgcagc 360
atccgctgta tgaatggggg cagctgcagc gatgaccact gtctgtgcca gaaagggtac 420
atcggcactc actgtggaca gcctgtctgt gaaagtggct gtctcaacgg agggaggtgt 480
gtggccccaa atcggtgtgc ttgcacgtac ggctttactg gaccccagtg tgaaagagat 540
tacagaacag gcccatgttt tactgtggta agcaaccaga tgtgccaggg acagctcagc 600
gggattgtct gcaccaaaac actttgctgt gccaccgtgg gccgagcctg gggccacccc 660
tgtgagatgt gtcctgccca gcctcacccc tgccgccgcg gcttcattcc caacatccgc 720
actggagctt gtcaagatgt ggatgaatgt caggccatcc cagggatgtg tcaaggagga 780
aattgcatta ataccgttgg atcttttgag tgcaaatgcc ctgctggaca caaatttaat 840
gaagtgtcac aaaaatgtga agatattgac gagtgcagca ccattcctgg agtctgcgat 900
ggcggggaat gtacaaacac tgtcagcagc tacttctgca aatgtccccc tggtttttac 960
acctctcctg atggcaccag atgcgtagat gttcgccctg gttactgcta cacagctctg 1020
gcaaacgggc gctgctctaa ccagctgcca cagtccataa ccaaaatgca gtgctgttgc 1080
gatcttggcc ggtgctggtc tccaggggtt actgttgctc ccgagatgtg tcccatcagg 1140
tcaactgagg atttcaacaa gctgtgctct gtccctctgg taattcccgg gagaccagaa 1200
tatcctcccc cacccattgg cccccttcct ccagttcagc ccgttcctcc tggctatcct 1260
cctgggcctg tgattccagc ccctcggcca ccgccagaat atccatatcc atctccgtct 1320
cgggaaccac caagggtgct gcctttcaac gttactgact actgtcaact ggtccgctat 1380
ctctgtcaaa atgggcgctg cattccaact cccggtagct accgctgcga gtgcaacaag 1440
ggcttccagc tggatatccg tggcgaatgc atcgacgtgg atgagtgtga gaagaaccca 1500
tgcactggtg gcgagtgcat caacaaccag ggctcctaca cctgtcactg cagagctggc 1560
taccagagca cactcaccag aactgagtgc agagacatag atgagtgtct tcagaatggc 1620
cggatctgca acaatggtcg ctgtatcaac acagacggca gcttccactg cgtatgcaat 1680
gcgggctttc atgtcacgcg ggacggaaag aactgtgaag atatggatga gtgcagcatc 1740
cgaaacatgt gcctaaacgg aatgtgtatt aatgaagatg gcagtttcaa gtgtatttgc 1800
aaacctgggt tccaactggc atcagatggc cgctactgca aagatatcaa tgagtgtgag 1860
acacctggga tctgcatgaa cggacgctgt gtgaacacgg atggctccta cagatgcgaa 1920
tgcttccccg gattggctgt gggtctagac ggacgtgtgt gtgttgacac acacatgcgg 1980
agcacatgct atggaggata caggagaggc cagtgcgtga agccgttgtt tggtgctgtt 2040
accaaatcgg aatgctgttg tgccagcact gagtatgcct ttggggaacc ctgccagccg 2100
tgtcctgcac agaattcagc ggaatatcag gcactctgca gcagtggacc gggaatgaca 2160
tcagcaggca ctgatataaa cgaatgtgca ttagatcctg atatttgccc aaatggaatt 2220
tgtgaaaatc tccgtgggac ctacaaatgt atatgcaact cgggatatga agtagacata 2280
actgggaaaa actgtgtcga tattaatgag tgtgtgctga acagtctact ttgtgacaat 2340
ggacaatgtc gaaacacacc tggaagtttt gtctgcacct gccccaaagg atttgtgtac 2400
aaacctgacc taaaaacctg tgaagacatt gatgaatgtg aatcgagtcc ttgcattaat 2460
ggagtctgca agaacagccc tggctccttc atttgtgaat gttctcctga aagtactctg 2520
gacccaacaa aaaccatctg catagaaacc atcaagggca cttgctggca gactgtcatc 2580
gacgggcgct gtgagatcaa catcaacgga gccaccttga agtccgagtg ctgctcctcc 2640
cttggtgctg cgtgggggag cccgtgcacc atctgtcaac ttgatcccat ttgtggtaaa 2700
gggttctcaa gaattaaagg cacgcaatgt gaagatatca atgagtgtga agtgttcccg 2760
ggagtatgca agaacggcct gtgtgtcaac tccaggggtt cattcaagtg cgagtgtccc 2820
aatggaatga ctttggatgc tacaggaaga atctgtcttg acatccgcct ggagacctgc 2880
ttcctcaagt atgacgatga agagtgcacc ttgcccatcg ctggccgcca ccgaatggat 2940
gcctgctgct gctctgttgg ggcagcctgg ggaacggaag agtgtgagga gtgtccattg 3000
agaaacagcc gggagtatga ggaactctgt ccccgaggac ctgggtttgc cacaaaagac 3060
attacaaatg ggaaaccttt cttcaaagat atcaatgagt gcaagatgat acccagcctc 3120
tgtacccacg gcaagtgcag gaacaccatt ggcagcttca agtgtaggtg tgacagtggc 3180
tttgctctgg attctgaaga gaggaactgt acagacattg atgagtgccg catatctcct 3240
gacctctgtg gccgaggcca gtgtgtgaac accccggggg actttgaatg caagtgtgat 3300
gaaggctatg aaagtggctt catgatgatg aagaactgca tggatattga tgaatgtcag 3360
agagatcctc tcctgtgtcg aggaggcatt tgccacaaca cagagggaag ctatcgctgc 3420
gaatgtcctc ctggtcacca attgtcccca aacatctctg catgcattga catcaacgag 3480
tgtgagctga gtgcgaatct ctgtccccat gggcgttgtg tgaacctcat agggaagtac 3540
cagtgtgcct gcaaccctgg ctaccacccc actcatgaca ggctcttctg tgtcgatatt 3600
gatgaatgca gcataatgaa cggtggttgt gagaccttct gcacaaactc tgacgggagc 3660
tatgaatgta gctgtcagcc aggcttcgcg ctaatgccag accagcgatc gtgcacagac 3720
attgatgagt gtgaagacaa ccccaatatc tgtgatggtg gccagtgcac aaacatacct 3780
ggggagtaca ggtgcctgtg ctatgatggg ttcatggcat ctgaagacat gaagacttgt 3840
gtggatgtca atgagtgtga cctgaatcca aacatctgcc ttagtgggac ctgtgaaaat 3900
actaaaggct cgttcatctg ccactgtgat atgggatatt cagggaagaa aggaaaaacg 3960
ggctgtacag atatcaatga atgtgagatc ggagcacaca actgtggcag acatgctgta 4020
tgcacaaata cagccgggag cttcaagtgc agctgcagtc ccggctggat tggagacggc 4080
attaagtgca cagatctgga tgaatgctct aatggaaccc acatgtgcag ccaacacgcg 4140
gactgcaaga acaccatggg gtcatatcgc tgtctctgta aggatggcta tacaggggat 4200
ggcttcacct gtacagacct cgacgagtgc tccgagaacc tgaacctctg tggcaatggc 4260
cagtgcctca acgcccctgg cgggtaccgc tgtgaatgcg acatgggctt cgtgcccagt 4320
gctgacggga aggcctgtga agatatcgat gagtgctccc ttccaaacat ctgtgtcttt 4380
ggaacttgcc acaacctccc gggcctcttc cgttgcgagt gtgagattgg ctatgaactg 4440
gaccgaagtg gtggaaactg cacagatgtt aatgagtgtc tggatcccac cacctgcatc 4500
agtggaaact gtgtcaacac tcccggtagt tacacatgcg attgtcctcc ggattttgag 4560
ctgaatccaa ctcgtgtcgg ctgtgtcgat actcgctctg gaaactgcta tctggatatc 4620
cgaccccggg gagacaatgg agatacagcc tgcagcaatg aaattggagt tggtgtctct 4680
aaggcttcct gctgttgttc actgggtaaa gcttggggaa ccccatgtga gctgtgtcct 4740
tctgtgaaca catctgagta taaaattctt tgccctggag gagaaggttt tcgtccaaat 4800
cccatcaccg ttatattgga agacatcgat gagtgccagg agcttccagg gctgtgccaa 4860
ggggggaagt gcatcaatac ctttggcagc ttccagtgtc gctgtccaac tggttactac 4920
ctgaatgaag acactcgagt gtgtgatgat gtgaacgaat gtgagactcc tggaatctgt 4980
ggtccgggga cctgttacaa caccgttggc aactatacct gcatttgtcc tccagactac 5040
atgcaagtga acgggggaaa taattgcatg gacatgagaa gaagtctatg ctacagaaac 5100
tattacgctg acaaccagac ctgcgatgga gaactcctgt tcaacatgac caagaagatg 5160
tgctgttgct cctacaacat cggcagagcc tggaacaaac cctgtgaaca gtgccccatc 5220
ccaagcacag atgagtttgc taccctctgt gggagccaga ggcccggctt cgtgattgac 5280
atttatacgg gtttacccgt ggatattgat gaatgccggg agatccctgg ggtctgtgaa 5340
aatggagtgt gcatcaacat ggttggcagc ttccggtgtg agtgtcccgt gggattcttc 5400
tataacgaca agttactggt ttgtgaagat atcgacgagt gtcagaatgg ccctgtgtgc 5460
cagcgaaatg cggaatgcat caacactgca ggcagctacc gctgtgactg taagcccggc 5520
taccgcctta cctccacagg tcaatgcaac gatcgaaacg agtgccaaga aatcccgaac 5580
atatgcagtc atggccagtg catcgacacc gtgggaagct tctactgcct ttgtcacact 5640
ggcttcaaaa caaatgtgga tcagaccatg tgcttagaca taaatgagtg tgagagagac 5700
gcctgtggga acgggacttg cagaaacacg attggctcct tcaactgtcg ctgtaaccat 5760
ggcttcatac tgtctcacaa caatgactgc atagatgttg atgagtgtgc aactggaaac 5820
gggaaccttt gcagaaatgg ccagtgtgtc aataccgtgg gctcctttca gtgcaggtgc 5880
aatgaaggct atgaggtggc tccggacggc aggacctgtg tggatatcaa cgagtgtgtt 5940
ctggatcctg ggaaatgtgc acctggaacc tgtcagaacc tggatggctc ctacagatgc 6000
atttgcccgc ctgggtatag tctacagaat gacaagtgtg aagatattga tgagtgtgtt 6060
gaagagccag aaatctgtgc cttggggacc tgcagcaaca ctgagggtag cttcaaatgt 6120
ctgtgtccag aggggttctc cctgtcctcc actggaagaa ggtgccaaga tttgcgaatg 6180
agctactgct atgcgaagtt tgaaggtggg aagtgttcat cacccaaatc cagaaaccat 6240
tccaagcagg agtgctgctg tgctttgaag ggagaaggct ggggagatcc ttgtgagttg 6300
tgccccactg agccagatga ggctttccgc cagatctgcc cctttggaag tgggatcatt 6360
gtgggccctg atgactcagc agttgatatg gacgaatgca aagaacctga tgtctgtaga 6420
catgggcagt gcattaacac agacggctcc tatcgatgcg agtgtccttt tggttatatt 6480
ctggaaggga atgagtgtgt ggataccgat gaatgctctg tgggcaatcc ttgtggaaat 6540
gggacctgca agaatgtgat tggaggtttt gaatgtacct gtgaggaggg gttcgagcct 6600
ggcccaatga tgacttgtga agatataaat gaatgtgccc agaatcctct gctctgcgcc 6660
ttccgctgtg taaataccta cgggtcctat gaatgcaaat gccctgttgg atacgttctc 6720
cgagaagaca ggaggatgtg taaagatgag gatgagtgtg cagagggaaa acacgactgt 6780
actgagaagc aaatggagtg taagaacctc attggtacct acatgtgcat ctgcggccct 6840
gggtaccagc gcagacccga tggagagggc tgcatagatg agaatgagtg tcagaccaag 6900
cccgggatct gtgagaatgg gcgttgcctc aacaccctgg gtagctacac ttgtgagtgt 6960
aacgatggct tcacagccag ccccactcag gatgagtgct tggacaaccg ggaagggtac 7020
tgcttttcgg aggtcttgca aaacatgtgc cagattggct caagcaacag gaaccccgtc 7080
accaagtccg agtgctgctg tgatggaggg agaggctggg gaccccactg tgagatctgc 7140
cctttcgagg gcacagtggc ttacaagaag ctctgtcccc acggccgagg attcatgacc 7200
aacggagcag atattgatga gtgcaaggtt attcatgatg tttgccgaaa tggggagtgt 7260
gtcaacgaca gagggtccta tcactgcatc tgtaaaactg gctacactcc ggatataaca 7320
gggaccgcct gtgtagatct gaatgaatgc aaccaggctc ccaaaccctg caattttata 7380
tgcaaaaaca cagaagggag ttaccagtgt tcctgcccga agggctacat tctgcaagag 7440
gatggaagga gctgcaaaga tcttgacgag tgtgcaacca agcagcataa ctgtcagttc 7500
ctgtgtgtta acaccatcgg tggcttcaca tgcaaatgcc ctcctgggtt tacccagcat 7560
cacactgcct gcattgataa caatgagtgc acgtctgata tcaacctgtg tgggtccaag 7620
ggtgtttgcc agaacactcc aggaagcttc acctgtgaat gccaacgggg gttctcactc 7680
gatcagagtg gtgccagctg tgaagatgtg gacgagtgtg agggtaacca ccgctgtcaa 7740
catggctgcc agaacatcat cggaggctat aggtgtagct gcccccaggg ctacctccag 7800
cactaccaat ggaaccagtg tgtagatgaa aacgagtgcc tgagtgcaca tgtctgtgga 7860
ggagcctcct gccacaacac cctggggagt tacaagtgca tgtgtcccac cggcttccag 7920
tacgaacagt tcagtggagg ctgccaagac atcaatgagt gtggctcatc ccaggccccc 7980
tgcagttacg gttgctctaa tactgagggt ggctacctgt gtggctgtcc accaggatac 8040
ttccggatag gccaagggca ttgtgtttct ggaatgggca tgggccgagg cggcccagag 8100
ccacctgcca gcagcgagat ggacgacaac tcactgtccc cagaggcctg ctatgagtgt 8160
gatcaatggc taccccaaac ggggcaggaa acggagaagc acaaacgaaa ctgatgcctc 8220
cgacatccag gacgggtctg agatggaagc caacgtgagc ctcgccagct gggatgtgga 8280
gaagccggct agctttgctt tcaatatttc ccatgtcaat aacaaggtcc gaatcctaga 8340
gctcctgccg gccctcacaa ctctgatgaa ccacaacaga tacttgattg aatctggaaa 8400
tgaagatggc ttctttaaaa tcaaccagaa agaaggggtc agctacctcc acttcacgaa 8460
gaagaagccg gtggctggga cctactcctt acaaatcagc agcaccccac tttataaaaa 8520
gaaagaactt aaccagttag aagacagata tgacaaagac tacctcagtg gtgaactggg 8580
cgataacctg aagatgaaaa ttcagatctt gctgcattaa 8620
<210> 24
<211> 175
<212> ДНК
<213> Homo sapiens
<400> 24
gcactgtgtt tctggaatgg gcatgggccg aggaaaccca gagccacctg tcagtggtga 60
aatggatgac aattcactct ccccagaggc ttgttacgag tgtaagatca atggctaccc 120
caaacggggc aggaaacgga gaagcacaaa cgaaactgat gcctccaata tcgag 175
<210> 25
<211> 175
<212> ДНК
<213> Mus musculus
<400> 25
gcattgtgtt tctggaatgg gcatgggccg aggcggccca gagccacctg ccagcagcga 60
gatggacgac aactcactgt ccccagaggc ctgctatgag tgtaagatca acggctaccc 120
aaaacgaggc cggaaacgga gaagcacgaa cgaaacggat gcctccgaca tccag 175
<210> 26
<211> 176
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 26
gcattgtgtt tctggaatgg gcatgggccg aggcggccca gagccacctg ccagcagcga 60
gatggacgac aactcactgt ccccagaggc ctgctatgag tgtaagatca acggctaccc 120
aaaacgaggc cggaaacgga gaagcacgaa cgaaaactga tgcctccgac atccag 176
<210> 27
<211> 200
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 27
gcattgtgtt tctggaatgg gcatgggccg aggcggccca gagccacctg ccagcagcga 60
gatggacgac aactcactgt ccccagaggc ctgctatgag tgtaagatca acggctaccc 120
aaaggcggcc cagagccacc tgccagcaac gaggccggaa acggagaagc acgaacgaaa 180
cggatgcctc cgacatccag 200
<210> 28
<211> 173
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 28
gcattgtgtt tctggaatgg gcatgggccg aggcggccca gagccacctg ccagcagcga 60
gatggacgac aactcactgt ccccagaggc ctgctatgag tgtgatcaat ggctacccca 120
aacggggcag gaaacggaga agcacaaacg aaactgatgc ctccgacatc cag 173
<210> 29
<211> 2871
<212> PRT
<213> Homo sapiens
<400> 29
Met Arg Arg Gly Arg Leu Leu Glu Ile Ala Leu Gly Phe Thr Val Leu
1 5 10 15
Leu Ala Ser Tyr Thr Ser His Gly Ala Asp Ala Asn Leu Glu Ala Gly
20 25 30
Asn Val Lys Glu Thr Arg Ala Ser Arg Ala Lys Arg Arg Gly Gly Gly
35 40 45
Gly His Asp Ala Leu Lys Gly Pro Asn Val Cys Gly Ser Arg Tyr Asn
50 55 60
Ala Tyr Cys Cys Pro Gly Trp Lys Thr Leu Pro Gly Gly Asn Gln Cys
65 70 75 80
Ile Val Pro Ile Cys Arg His Ser Cys Gly Asp Gly Phe Cys Ser Arg
85 90 95
Pro Asn Met Cys Thr Cys Pro Ser Gly Gln Ile Ala Pro Ser Cys Gly
100 105 110
Ser Arg Ser Ile Gln His Cys Asn Ile Arg Cys Met Asn Gly Gly Ser
115 120 125
Cys Ser Asp Asp His Cys Leu Cys Gln Lys Gly Tyr Ile Gly Thr His
130 135 140
Cys Gly Gln Pro Val Cys Glu Ser Gly Cys Leu Asn Gly Gly Arg Cys
145 150 155 160
Val Ala Pro Asn Arg Cys Ala Cys Thr Tyr Gly Phe Thr Gly Pro Gln
165 170 175
Cys Glu Arg Asp Tyr Arg Thr Gly Pro Cys Phe Thr Val Ile Ser Asn
180 185 190
Gln Met Cys Gln Gly Gln Leu Ser Gly Ile Val Cys Thr Lys Thr Leu
195 200 205
Cys Cys Ala Thr Val Gly Arg Ala Trp Gly His Pro Cys Glu Met Cys
210 215 220
Pro Ala Gln Pro His Pro Cys Arg Arg Gly Phe Ile Pro Asn Ile Arg
225 230 235 240
Thr Gly Ala Cys Gln Asp Val Asp Glu Cys Gln Ala Ile Pro Gly Leu
245 250 255
Cys Gln Gly Gly Asn Cys Ile Asn Thr Val Gly Ser Phe Glu Cys Lys
260 265 270
Cys Pro Ala Gly His Lys Leu Asn Glu Val Ser Gln Lys Cys Glu Asp
275 280 285
Ile Asp Glu Cys Ser Thr Ile Pro Gly Ile Cys Glu Gly Gly Glu Cys
290 295 300
Thr Asn Thr Val Ser Ser Tyr Phe Cys Lys Cys Pro Pro Gly Phe Tyr
305 310 315 320
Thr Ser Pro Asp Gly Thr Arg Cys Ile Asp Val Arg Pro Gly Tyr Cys
325 330 335
Tyr Thr Ala Leu Thr Asn Gly Arg Cys Ser Asn Gln Leu Pro Gln Ser
340 345 350
Ile Thr Lys Met Gln Cys Cys Cys Asp Ala Gly Arg Cys Trp Ser Pro
355 360 365
Gly Val Thr Val Ala Pro Glu Met Cys Pro Ile Arg Ala Thr Glu Asp
370 375 380
Phe Asn Lys Leu Cys Ser Val Pro Met Val Ile Pro Gly Arg Pro Glu
385 390 395 400
Tyr Pro Pro Pro Pro Leu Gly Pro Ile Pro Pro Val Leu Pro Val Pro
405 410 415
Pro Gly Phe Pro Pro Gly Pro Gln Ile Pro Val Pro Arg Pro Pro Val
420 425 430
Glu Tyr Leu Tyr Pro Ser Arg Glu Pro Pro Arg Val Leu Pro Val Asn
435 440 445
Val Thr Asp Tyr Cys Gln Leu Val Arg Tyr Leu Cys Gln Asn Gly Arg
450 455 460
Cys Ile Pro Thr Pro Gly Ser Tyr Arg Cys Glu Cys Asn Lys Gly Phe
465 470 475 480
Gln Leu Asp Leu Arg Gly Glu Cys Ile Asp Val Asp Glu Cys Glu Lys
485 490 495
Asn Pro Cys Ala Gly Gly Glu Cys Ile Asn Asn Gln Gly Ser Tyr Thr
500 505 510
Cys Gln Cys Arg Ala Gly Tyr Gln Ser Thr Leu Thr Arg Thr Glu Cys
515 520 525
Arg Asp Ile Asp Glu Cys Leu Gln Asn Gly Arg Ile Cys Asn Asn Gly
530 535 540
Arg Cys Ile Asn Thr Asp Gly Ser Phe His Cys Val Cys Asn Ala Gly
545 550 555 560
Phe His Val Thr Arg Asp Gly Lys Asn Cys Glu Asp Met Asp Glu Cys
565 570 575
Ser Ile Arg Asn Met Cys Leu Asn Gly Met Cys Ile Asn Glu Asp Gly
580 585 590
Ser Phe Lys Cys Ile Cys Lys Pro Gly Phe Gln Leu Ala Ser Asp Gly
595 600 605
Arg Tyr Cys Lys Asp Ile Asn Glu Cys Glu Thr Pro Gly Ile Cys Met
610 615 620
Asn Gly Arg Cys Val Asn Thr Asp Gly Ser Tyr Arg Cys Glu Cys Phe
625 630 635 640
Pro Gly Leu Ala Val Gly Leu Asp Gly Arg Val Cys Val Asp Thr His
645 650 655
Met Arg Ser Thr Cys Tyr Gly Gly Tyr Lys Arg Gly Gln Cys Ile Lys
660 665 670
Pro Leu Phe Gly Ala Val Thr Lys Ser Glu Cys Cys Cys Ala Ser Thr
675 680 685
Glu Tyr Ala Phe Gly Glu Pro Cys Gln Pro Cys Pro Ala Gln Asn Ser
690 695 700
Ala Glu Tyr Gln Ala Leu Cys Ser Ser Gly Pro Gly Met Thr Ser Ala
705 710 715 720
Gly Ser Asp Ile Asn Glu Cys Ala Leu Asp Pro Asp Ile Cys Pro Asn
725 730 735
Gly Ile Cys Glu Asn Leu Arg Gly Thr Tyr Lys Cys Ile Cys Asn Ser
740 745 750
Gly Tyr Glu Val Asp Ser Thr Gly Lys Asn Cys Val Asp Ile Asn Glu
755 760 765
Cys Val Leu Asn Ser Leu Leu Cys Asp Asn Gly Gln Cys Arg Asn Thr
770 775 780
Pro Gly Ser Phe Val Cys Thr Cys Pro Lys Gly Phe Ile Tyr Lys Pro
785 790 795 800
Asp Leu Lys Thr Cys Glu Asp Ile Asp Glu Cys Glu Ser Ser Pro Cys
805 810 815
Ile Asn Gly Val Cys Lys Asn Ser Pro Gly Ser Phe Ile Cys Glu Cys
820 825 830
Ser Ser Glu Ser Thr Leu Asp Pro Thr Lys Thr Ile Cys Ile Glu Thr
835 840 845
Ile Lys Gly Thr Cys Trp Gln Thr Val Ile Asp Gly Arg Cys Glu Ile
850 855 860
Asn Ile Asn Gly Ala Thr Leu Lys Ser Gln Cys Cys Ser Ser Leu Gly
865 870 875 880
Ala Ala Trp Gly Ser Pro Cys Thr Leu Cys Gln Val Asp Pro Ile Cys
885 890 895
Gly Lys Gly Tyr Ser Arg Ile Lys Gly Thr Gln Cys Glu Asp Ile Asp
900 905 910
Glu Cys Glu Val Phe Pro Gly Val Cys Lys Asn Gly Leu Cys Val Asn
915 920 925
Thr Arg Gly Ser Phe Lys Cys Gln Cys Pro Ser Gly Met Thr Leu Asp
930 935 940
Ala Thr Gly Arg Ile Cys Leu Asp Ile Arg Leu Glu Thr Cys Phe Leu
945 950 955 960
Arg Tyr Glu Asp Glu Glu Cys Thr Leu Pro Ile Ala Gly Arg His Arg
965 970 975
Met Asp Ala Cys Cys Cys Ser Val Gly Ala Ala Trp Gly Thr Glu Glu
980 985 990
Cys Glu Glu Cys Pro Met Arg Asn Thr Pro Glu Tyr Glu Glu Leu Cys
995 1000 1005
Pro Arg Gly Pro Gly Phe Ala Thr Lys Glu Ile Thr Asn Gly Lys
1010 1015 1020
Pro Phe Phe Lys Asp Ile Asn Glu Cys Lys Met Ile Pro Ser Leu
1025 1030 1035
Cys Thr His Gly Lys Cys Arg Asn Thr Ile Gly Ser Phe Lys Cys
1040 1045 1050
Arg Cys Asp Ser Gly Phe Ala Leu Asp Ser Glu Glu Arg Asn Cys
1055 1060 1065
Thr Asp Ile Asp Glu Cys Arg Ile Ser Pro Asp Leu Cys Gly Arg
1070 1075 1080
Gly Gln Cys Val Asn Thr Pro Gly Asp Phe Glu Cys Lys Cys Asp
1085 1090 1095
Glu Gly Tyr Glu Ser Gly Phe Met Met Met Lys Asn Cys Met Asp
1100 1105 1110
Ile Asp Glu Cys Gln Arg Asp Pro Leu Leu Cys Arg Gly Gly Val
1115 1120 1125
Cys His Asn Thr Glu Gly Ser Tyr Arg Cys Glu Cys Pro Pro Gly
1130 1135 1140
His Gln Leu Ser Pro Asn Ile Ser Ala Cys Ile Asp Ile Asn Glu
1145 1150 1155
Cys Glu Leu Ser Ala His Leu Cys Pro Asn Gly Arg Cys Val Asn
1160 1165 1170
Leu Ile Gly Lys Tyr Gln Cys Ala Cys Asn Pro Gly Tyr His Ser
1175 1180 1185
Thr Pro Asp Arg Leu Phe Cys Val Asp Ile Asp Glu Cys Ser Ile
1190 1195 1200
Met Asn Gly Gly Cys Glu Thr Phe Cys Thr Asn Ser Glu Gly Ser
1205 1210 1215
Tyr Glu Cys Ser Cys Gln Pro Gly Phe Ala Leu Met Pro Asp Gln
1220 1225 1230
Arg Ser Cys Thr Asp Ile Asp Glu Cys Glu Asp Asn Pro Asn Ile
1235 1240 1245
Cys Asp Gly Gly Gln Cys Thr Asn Ile Pro Gly Glu Tyr Arg Cys
1250 1255 1260
Leu Cys Tyr Asp Gly Phe Met Ala Ser Glu Asp Met Lys Thr Cys
1265 1270 1275
Val Asp Val Asn Glu Cys Asp Leu Asn Pro Asn Ile Cys Leu Ser
1280 1285 1290
Gly Thr Cys Glu Asn Thr Lys Gly Ser Phe Ile Cys His Cys Asp
1295 1300 1305
Met Gly Tyr Ser Gly Lys Lys Gly Lys Thr Gly Cys Thr Asp Ile
1310 1315 1320
Asn Glu Cys Glu Ile Gly Ala His Asn Cys Gly Lys His Ala Val
1325 1330 1335
Cys Thr Asn Thr Ala Gly Ser Phe Lys Cys Ser Cys Ser Pro Gly
1340 1345 1350
Trp Ile Gly Asp Gly Ile Lys Cys Thr Asp Leu Asp Glu Cys Ser
1355 1360 1365
Asn Gly Thr His Met Cys Ser Gln His Ala Asp Cys Lys Asn Thr
1370 1375 1380
Met Gly Ser Tyr Arg Cys Leu Cys Lys Glu Gly Tyr Thr Gly Asp
1385 1390 1395
Gly Phe Thr Cys Thr Asp Leu Asp Glu Cys Ser Glu Asn Leu Asn
1400 1405 1410
Leu Cys Gly Asn Gly Gln Cys Leu Asn Ala Pro Gly Gly Tyr Arg
1415 1420 1425
Cys Glu Cys Asp Met Gly Phe Val Pro Ser Ala Asp Gly Lys Ala
1430 1435 1440
Cys Glu Asp Ile Asp Glu Cys Ser Leu Pro Asn Ile Cys Val Phe
1445 1450 1455
Gly Thr Cys His Asn Leu Pro Gly Leu Phe Arg Cys Glu Cys Glu
1460 1465 1470
Ile Gly Tyr Glu Leu Asp Arg Ser Gly Gly Asn Cys Thr Asp Val
1475 1480 1485
Asn Glu Cys Leu Asp Pro Thr Thr Cys Ile Ser Gly Asn Cys Val
1490 1495 1500
Asn Thr Pro Gly Ser Tyr Ile Cys Asp Cys Pro Pro Asp Phe Glu
1505 1510 1515
Leu Asn Pro Thr Arg Val Gly Cys Val Asp Thr Arg Ser Gly Asn
1520 1525 1530
Cys Tyr Leu Asp Ile Arg Pro Arg Gly Asp Asn Gly Asp Thr Ala
1535 1540 1545
Cys Ser Asn Glu Ile Gly Val Gly Val Ser Lys Ala Ser Cys Cys
1550 1555 1560
Cys Ser Leu Gly Lys Ala Trp Gly Thr Pro Cys Glu Met Cys Pro
1565 1570 1575
Ala Val Asn Thr Ser Glu Tyr Lys Ile Leu Cys Pro Gly Gly Glu
1580 1585 1590
Gly Phe Arg Pro Asn Pro Ile Thr Val Ile Leu Glu Asp Ile Asp
1595 1600 1605
Glu Cys Gln Glu Leu Pro Gly Leu Cys Gln Gly Gly Lys Cys Ile
1610 1615 1620
Asn Thr Phe Gly Ser Phe Gln Cys Arg Cys Pro Thr Gly Tyr Tyr
1625 1630 1635
Leu Asn Glu Asp Thr Arg Val Cys Asp Asp Val Asn Glu Cys Glu
1640 1645 1650
Thr Pro Gly Ile Cys Gly Pro Gly Thr Cys Tyr Asn Thr Val Gly
1655 1660 1665
Asn Tyr Thr Cys Ile Cys Pro Pro Asp Tyr Met Gln Val Asn Gly
1670 1675 1680
Gly Asn Asn Cys Met Asp Met Arg Arg Ser Leu Cys Tyr Arg Asn
1685 1690 1695
Tyr Tyr Ala Asp Asn Gln Thr Cys Asp Gly Glu Leu Leu Phe Asn
1700 1705 1710
Met Thr Lys Lys Met Cys Cys Cys Ser Tyr Asn Ile Gly Arg Ala
1715 1720 1725
Trp Asn Lys Pro Cys Glu Gln Cys Pro Ile Pro Ser Thr Asp Glu
1730 1735 1740
Phe Ala Thr Leu Cys Gly Ser Gln Arg Pro Gly Phe Val Ile Asp
1745 1750 1755
Ile Tyr Thr Gly Leu Pro Val Asp Ile Asp Glu Cys Arg Glu Ile
1760 1765 1770
Pro Gly Val Cys Glu Asn Gly Val Cys Ile Asn Met Val Gly Ser
1775 1780 1785
Phe Arg Cys Glu Cys Pro Val Gly Phe Phe Tyr Asn Asp Lys Leu
1790 1795 1800
Leu Val Cys Glu Asp Ile Asp Glu Cys Gln Asn Gly Pro Val Cys
1805 1810 1815
Gln Arg Asn Ala Glu Cys Ile Asn Thr Ala Gly Ser Tyr Arg Cys
1820 1825 1830
Asp Cys Lys Pro Gly Tyr Arg Phe Thr Ser Thr Gly Gln Cys Asn
1835 1840 1845
Asp Arg Asn Glu Cys Gln Glu Ile Pro Asn Ile Cys Ser His Gly
1850 1855 1860
Gln Cys Ile Asp Thr Val Gly Ser Phe Tyr Cys Leu Cys His Thr
1865 1870 1875
Gly Phe Lys Thr Asn Asp Asp Gln Thr Met Cys Leu Asp Ile Asn
1880 1885 1890
Glu Cys Glu Arg Asp Ala Cys Gly Asn Gly Thr Cys Arg Asn Thr
1895 1900 1905
Ile Gly Ser Phe Asn Cys Arg Cys Asn His Gly Phe Ile Leu Ser
1910 1915 1920
His Asn Asn Asp Cys Ile Asp Val Asp Glu Cys Ala Ser Gly Asn
1925 1930 1935
Gly Asn Leu Cys Arg Asn Gly Gln Cys Ile Asn Thr Val Gly Ser
1940 1945 1950
Phe Gln Cys Gln Cys Asn Glu Gly Tyr Glu Val Ala Pro Asp Gly
1955 1960 1965
Arg Thr Cys Val Asp Ile Asn Glu Cys Leu Leu Glu Pro Arg Lys
1970 1975 1980
Cys Ala Pro Gly Thr Cys Gln Asn Leu Asp Gly Ser Tyr Arg Cys
1985 1990 1995
Ile Cys Pro Pro Gly Tyr Ser Leu Gln Asn Glu Lys Cys Glu Asp
2000 2005 2010
Ile Asp Glu Cys Val Glu Glu Pro Glu Ile Cys Ala Leu Gly Thr
2015 2020 2025
Cys Ser Asn Thr Glu Gly Ser Phe Lys Cys Leu Cys Pro Glu Gly
2030 2035 2040
Phe Ser Leu Ser Ser Ser Gly Arg Arg Cys Gln Asp Leu Arg Met
2045 2050 2055
Ser Tyr Cys Tyr Ala Lys Phe Glu Gly Gly Lys Cys Ser Ser Pro
2060 2065 2070
Lys Ser Arg Asn His Ser Lys Gln Glu Cys Cys Cys Ala Leu Lys
2075 2080 2085
Gly Glu Gly Trp Gly Asp Pro Cys Glu Leu Cys Pro Thr Glu Pro
2090 2095 2100
Asp Glu Ala Phe Arg Gln Ile Cys Pro Tyr Gly Ser Gly Ile Ile
2105 2110 2115
Val Gly Pro Asp Asp Ser Ala Val Asp Met Asp Glu Cys Lys Glu
2120 2125 2130
Pro Asp Val Cys Lys His Gly Gln Cys Ile Asn Thr Asp Gly Ser
2135 2140 2145
Tyr Arg Cys Glu Cys Pro Phe Gly Tyr Ile Leu Ala Gly Asn Glu
2150 2155 2160
Cys Val Asp Thr Asp Glu Cys Ser Val Gly Asn Pro Cys Gly Asn
2165 2170 2175
Gly Thr Cys Lys Asn Val Ile Gly Gly Phe Glu Cys Thr Cys Glu
2180 2185 2190
Glu Gly Phe Glu Pro Gly Pro Met Met Thr Cys Glu Asp Ile Asn
2195 2200 2205
Glu Cys Ala Gln Asn Pro Leu Leu Cys Ala Phe Arg Cys Val Asn
2210 2215 2220
Thr Tyr Gly Ser Tyr Glu Cys Lys Cys Pro Val Gly Tyr Val Leu
2225 2230 2235
Arg Glu Asp Arg Arg Met Cys Lys Asp Glu Asp Glu Cys Glu Glu
2240 2245 2250
Gly Lys His Asp Cys Thr Glu Lys Gln Met Glu Cys Lys Asn Leu
2255 2260 2265
Ile Gly Thr Tyr Met Cys Ile Cys Gly Pro Gly Tyr Gln Arg Arg
2270 2275 2280
Pro Asp Gly Glu Gly Cys Val Asp Glu Asn Glu Cys Gln Thr Lys
2285 2290 2295
Pro Gly Ile Cys Glu Asn Gly Arg Cys Leu Asn Thr Arg Gly Ser
2300 2305 2310
Tyr Thr Cys Glu Cys Asn Asp Gly Phe Thr Ala Ser Pro Asn Gln
2315 2320 2325
Asp Glu Cys Leu Asp Asn Arg Glu Gly Tyr Cys Phe Thr Glu Val
2330 2335 2340
Leu Gln Asn Met Cys Gln Ile Gly Ser Ser Asn Arg Asn Pro Val
2345 2350 2355
Thr Lys Ser Glu Cys Cys Cys Asp Gly Gly Arg Gly Trp Gly Pro
2360 2365 2370
His Cys Glu Ile Cys Pro Phe Gln Gly Thr Val Ala Phe Lys Lys
2375 2380 2385
Leu Cys Pro His Gly Arg Gly Phe Met Thr Asn Gly Ala Asp Ile
2390 2395 2400
Asp Glu Cys Lys Val Ile His Asp Val Cys Arg Asn Gly Glu Cys
2405 2410 2415
Val Asn Asp Arg Gly Ser Tyr His Cys Ile Cys Lys Thr Gly Tyr
2420 2425 2430
Thr Pro Asp Ile Thr Gly Thr Ser Cys Val Asp Leu Asn Glu Cys
2435 2440 2445
Asn Gln Ala Pro Lys Pro Cys Asn Phe Ile Cys Lys Asn Thr Glu
2450 2455 2460
Gly Ser Tyr Gln Cys Ser Cys Pro Lys Gly Tyr Ile Leu Gln Glu
2465 2470 2475
Asp Gly Arg Ser Cys Lys Asp Leu Asp Glu Cys Ala Thr Lys Gln
2480 2485 2490
His Asn Cys Gln Phe Leu Cys Val Asn Thr Ile Gly Gly Phe Thr
2495 2500 2505
Cys Lys Cys Pro Pro Gly Phe Thr Gln His His Thr Ser Cys Ile
2510 2515 2520
Asp Asn Asn Glu Cys Thr Ser Asp Ile Asn Leu Cys Gly Ser Lys
2525 2530 2535
Gly Ile Cys Gln Asn Thr Pro Gly Ser Phe Thr Cys Glu Cys Gln
2540 2545 2550
Arg Gly Phe Ser Leu Asp Gln Thr Gly Ser Ser Cys Glu Asp Val
2555 2560 2565
Asp Glu Cys Glu Gly Asn His Arg Cys Gln His Gly Cys Gln Asn
2570 2575 2580
Ile Ile Gly Gly Tyr Arg Cys Ser Cys Pro Gln Gly Tyr Leu Gln
2585 2590 2595
His Tyr Gln Trp Asn Gln Cys Val Asp Glu Asn Glu Cys Leu Ser
2600 2605 2610
Ala His Ile Cys Gly Gly Ala Ser Cys His Asn Thr Leu Gly Ser
2615 2620 2625
Tyr Lys Cys Met Cys Pro Ala Gly Phe Gln Tyr Glu Gln Phe Ser
2630 2635 2640
Gly Gly Cys Gln Asp Ile Asn Glu Cys Gly Ser Ala Gln Ala Pro
2645 2650 2655
Cys Ser Tyr Gly Cys Ser Asn Thr Glu Gly Gly Tyr Leu Cys Gly
2660 2665 2670
Cys Pro Pro Gly Tyr Phe Arg Ile Gly Gln Gly His Cys Val Ser
2675 2680 2685
Gly Met Gly Met Gly Arg Gly Asn Pro Glu Pro Pro Val Ser Gly
2690 2695 2700
Glu Met Asp Asp Asn Ser Leu Ser Pro Glu Ala Cys Tyr Glu Cys
2705 2710 2715
Lys Ile Asn Gly Tyr Pro Lys Arg Gly Arg Lys Arg Arg Ser Thr
2720 2725 2730
Asn Glu Thr Asp Ala Ser Asn Ile Glu Asp Gln Ser Glu Thr Glu
2735 2740 2745
Ala Asn Val Ser Leu Ala Ser Trp Asp Val Glu Lys Thr Ala Ile
2750 2755 2760
Phe Ala Phe Asn Ile Ser His Val Ser Asn Lys Val Arg Ile Leu
2765 2770 2775
Glu Leu Leu Pro Ala Leu Thr Thr Leu Thr Asn His Asn Arg Tyr
2780 2785 2790
Leu Ile Glu Ser Gly Asn Glu Asp Gly Phe Phe Lys Ile Asn Gln
2795 2800 2805
Lys Glu Gly Ile Ser Tyr Leu His Phe Thr Lys Lys Lys Pro Val
2810 2815 2820
Ala Gly Thr Tyr Ser Leu Gln Ile Ser Ser Thr Pro Leu Tyr Lys
2825 2830 2835
Lys Lys Glu Leu Asn Gln Leu Glu Asp Lys Tyr Asp Lys Asp Tyr
2840 2845 2850
Leu Ser Gly Glu Leu Gly Asp Asn Leu Lys Met Lys Ile Gln Val
2855 2860 2865
Leu Leu His
2870
<210> 30
<211> 2873
<212> PRT
<213> Mus musculus
<400> 30
Met Arg Arg Gly Gly Leu Leu Glu Val Ala Leu Ala Phe Ala Leu Leu
1 5 10 15
Leu Glu Ser Tyr Thr Ser His Gly Ala Asp Ala Asn Leu Glu Ala Gly
20 25 30
Ser Leu Lys Glu Thr Arg Ala Asn Arg Ala Lys Arg Arg Gly Gly Gly
35 40 45
Gly His Asp Ala Leu Lys Gly Pro Asn Val Cys Gly Ser Arg Tyr Asn
50 55 60
Ala Tyr Cys Cys Pro Gly Trp Lys Thr Leu Pro Gly Gly Asn Gln Cys
65 70 75 80
Ile Val Pro Ile Cys Arg His Ser Cys Gly Asp Gly Phe Cys Ser Arg
85 90 95
Pro Asn Met Cys Thr Cys Pro Ser Gly Gln Ile Ser Pro Ser Cys Gly
100 105 110
Ser Arg Ser Ile Gln His Cys Ser Ile Arg Cys Met Asn Gly Gly Ser
115 120 125
Cys Ser Asp Asp His Cys Leu Cys Gln Lys Gly Tyr Ile Gly Thr His
130 135 140
Cys Gly Gln Pro Val Cys Glu Ser Gly Cys Leu Asn Gly Gly Arg Cys
145 150 155 160
Val Ala Pro Asn Arg Cys Ala Cys Thr Tyr Gly Phe Thr Gly Pro Gln
165 170 175
Cys Glu Arg Asp Tyr Arg Thr Gly Pro Cys Phe Thr Val Val Ser Asn
180 185 190
Gln Met Cys Gln Gly Gln Leu Ser Gly Ile Val Cys Thr Lys Thr Leu
195 200 205
Cys Cys Ala Thr Val Gly Arg Ala Trp Gly His Pro Cys Glu Met Cys
210 215 220
Pro Ala Gln Pro His Pro Cys Arg Arg Gly Phe Ile Pro Asn Ile Arg
225 230 235 240
Thr Gly Ala Cys Gln Asp Val Asp Glu Cys Gln Ala Ile Pro Gly Met
245 250 255
Cys Gln Gly Gly Asn Cys Ile Asn Thr Val Gly Ser Phe Glu Cys Lys
260 265 270
Cys Pro Ala Gly His Lys Phe Asn Glu Val Ser Gln Lys Cys Glu Asp
275 280 285
Ile Asp Glu Cys Ser Thr Ile Pro Gly Val Cys Asp Gly Gly Glu Cys
290 295 300
Thr Asn Thr Val Ser Ser Tyr Phe Cys Lys Cys Pro Pro Gly Phe Tyr
305 310 315 320
Thr Ser Pro Asp Gly Thr Arg Cys Val Asp Val Arg Pro Gly Tyr Cys
325 330 335
Tyr Thr Ala Leu Ala Asn Gly Arg Cys Ser Asn Gln Leu Pro Gln Ser
340 345 350
Ile Thr Lys Met Gln Cys Cys Cys Asp Leu Gly Arg Cys Trp Ser Pro
355 360 365
Gly Val Thr Val Ala Pro Glu Met Cys Pro Ile Arg Ser Thr Glu Asp
370 375 380
Phe Asn Lys Leu Cys Ser Val Pro Leu Val Ile Pro Gly Arg Pro Glu
385 390 395 400
Tyr Pro Pro Pro Pro Ile Gly Pro Leu Pro Pro Val Gln Pro Val Pro
405 410 415
Pro Gly Tyr Pro Pro Gly Pro Val Ile Pro Ala Pro Arg Pro Pro Pro
420 425 430
Glu Tyr Pro Tyr Pro Ser Pro Ser Arg Glu Pro Pro Arg Val Leu Pro
435 440 445
Phe Asn Val Thr Asp Tyr Cys Gln Leu Val Arg Tyr Leu Cys Gln Asn
450 455 460
Gly Arg Cys Ile Pro Thr Pro Gly Ser Tyr Arg Cys Glu Cys Asn Lys
465 470 475 480
Gly Phe Gln Leu Asp Ile Arg Gly Glu Cys Ile Asp Val Asp Glu Cys
485 490 495
Glu Lys Asn Pro Cys Thr Gly Gly Glu Cys Ile Asn Asn Gln Gly Ser
500 505 510
Tyr Thr Cys His Cys Arg Ala Gly Tyr Gln Ser Thr Leu Thr Arg Thr
515 520 525
Glu Cys Arg Asp Ile Asp Glu Cys Leu Gln Asn Gly Arg Ile Cys Asn
530 535 540
Asn Gly Arg Cys Ile Asn Thr Asp Gly Ser Phe His Cys Val Cys Asn
545 550 555 560
Ala Gly Phe His Val Thr Arg Asp Gly Lys Asn Cys Glu Asp Met Asp
565 570 575
Glu Cys Ser Ile Arg Asn Met Cys Leu Asn Gly Met Cys Ile Asn Glu
580 585 590
Asp Gly Ser Phe Lys Cys Ile Cys Lys Pro Gly Phe Gln Leu Ala Ser
595 600 605
Asp Gly Arg Tyr Cys Lys Asp Ile Asn Glu Cys Glu Thr Pro Gly Ile
610 615 620
Cys Met Asn Gly Arg Cys Val Asn Thr Asp Gly Ser Tyr Arg Cys Glu
625 630 635 640
Cys Phe Pro Gly Leu Ala Val Gly Leu Asp Gly Arg Val Cys Val Asp
645 650 655
Thr His Met Arg Ser Thr Cys Tyr Gly Gly Tyr Arg Arg Gly Gln Cys
660 665 670
Val Lys Pro Leu Phe Gly Ala Val Thr Lys Ser Glu Cys Cys Cys Ala
675 680 685
Ser Thr Glu Tyr Ala Phe Gly Glu Pro Cys Gln Pro Cys Pro Ala Gln
690 695 700
Asn Ser Ala Glu Tyr Gln Ala Leu Cys Ser Ser Gly Pro Gly Met Thr
705 710 715 720
Ser Ala Gly Thr Asp Ile Asn Glu Cys Ala Leu Asp Pro Asp Ile Cys
725 730 735
Pro Asn Gly Ile Cys Glu Asn Leu Arg Gly Thr Tyr Lys Cys Ile Cys
740 745 750
Asn Ser Gly Tyr Glu Val Asp Ile Thr Gly Lys Asn Cys Val Asp Ile
755 760 765
Asn Glu Cys Val Leu Asn Ser Leu Leu Cys Asp Asn Gly Gln Cys Arg
770 775 780
Asn Thr Pro Gly Ser Phe Val Cys Thr Cys Pro Lys Gly Phe Val Tyr
785 790 795 800
Lys Pro Asp Leu Lys Thr Cys Glu Asp Ile Asp Glu Cys Glu Ser Ser
805 810 815
Pro Cys Ile Asn Gly Val Cys Lys Asn Ser Pro Gly Ser Phe Ile Cys
820 825 830
Glu Cys Ser Pro Glu Ser Thr Leu Asp Pro Thr Lys Thr Ile Cys Ile
835 840 845
Glu Thr Ile Lys Gly Thr Cys Trp Gln Thr Val Ile Asp Gly Arg Cys
850 855 860
Glu Ile Asn Ile Asn Gly Ala Thr Leu Lys Ser Glu Cys Cys Ser Ser
865 870 875 880
Leu Gly Ala Ala Trp Gly Ser Pro Cys Thr Ile Cys Gln Leu Asp Pro
885 890 895
Ile Cys Gly Lys Gly Phe Ser Arg Ile Lys Gly Thr Gln Cys Glu Asp
900 905 910
Ile Asn Glu Cys Glu Val Phe Pro Gly Val Cys Lys Asn Gly Leu Cys
915 920 925
Val Asn Ser Arg Gly Ser Phe Lys Cys Glu Cys Pro Asn Gly Met Thr
930 935 940
Leu Asp Ala Thr Gly Arg Ile Cys Leu Asp Ile Arg Leu Glu Thr Cys
945 950 955 960
Phe Leu Lys Tyr Asp Asp Glu Glu Cys Thr Leu Pro Ile Ala Gly Arg
965 970 975
His Arg Met Asp Ala Cys Cys Cys Ser Val Gly Ala Ala Trp Gly Thr
980 985 990
Glu Glu Cys Glu Glu Cys Pro Leu Arg Asn Ser Arg Glu Tyr Glu Glu
995 1000 1005
Leu Cys Pro Arg Gly Pro Gly Phe Ala Thr Lys Asp Ile Thr Asn
1010 1015 1020
Gly Lys Pro Phe Phe Lys Asp Ile Asn Glu Cys Lys Met Ile Pro
1025 1030 1035
Ser Leu Cys Thr His Gly Lys Cys Arg Asn Thr Ile Gly Ser Phe
1040 1045 1050
Lys Cys Arg Cys Asp Ser Gly Phe Ala Leu Asp Ser Glu Glu Arg
1055 1060 1065
Asn Cys Thr Asp Ile Asp Glu Cys Arg Ile Ser Pro Asp Leu Cys
1070 1075 1080
Gly Arg Gly Gln Cys Val Asn Thr Pro Gly Asp Phe Glu Cys Lys
1085 1090 1095
Cys Asp Glu Gly Tyr Glu Ser Gly Phe Met Met Met Lys Asn Cys
1100 1105 1110
Met Asp Ile Asp Glu Cys Gln Arg Asp Pro Leu Leu Cys Arg Gly
1115 1120 1125
Gly Ile Cys His Asn Thr Glu Gly Ser Tyr Arg Cys Glu Cys Pro
1130 1135 1140
Pro Gly His Gln Leu Ser Pro Asn Ile Ser Ala Cys Ile Asp Ile
1145 1150 1155
Asn Glu Cys Glu Leu Ser Ala Asn Leu Cys Pro His Gly Arg Cys
1160 1165 1170
Val Asn Leu Ile Gly Lys Tyr Gln Cys Ala Cys Asn Pro Gly Tyr
1175 1180 1185
His Pro Thr His Asp Arg Leu Phe Cys Val Asp Ile Asp Glu Cys
1190 1195 1200
Ser Ile Met Asn Gly Gly Cys Glu Thr Phe Cys Thr Asn Ser Asp
1205 1210 1215
Gly Ser Tyr Glu Cys Ser Cys Gln Pro Gly Phe Ala Leu Met Pro
1220 1225 1230
Asp Gln Arg Ser Cys Thr Asp Ile Asp Glu Cys Glu Asp Asn Pro
1235 1240 1245
Asn Ile Cys Asp Gly Gly Gln Cys Thr Asn Ile Pro Gly Glu Tyr
1250 1255 1260
Arg Cys Leu Cys Tyr Asp Gly Phe Met Ala Ser Glu Asp Met Lys
1265 1270 1275
Thr Cys Val Asp Val Asn Glu Cys Asp Leu Asn Pro Asn Ile Cys
1280 1285 1290
Leu Ser Gly Thr Cys Glu Asn Thr Lys Gly Ser Phe Ile Cys His
1295 1300 1305
Cys Asp Met Gly Tyr Ser Gly Lys Lys Gly Lys Thr Gly Cys Thr
1310 1315 1320
Asp Ile Asn Glu Cys Glu Ile Gly Ala His Asn Cys Gly Arg His
1325 1330 1335
Ala Val Cys Thr Asn Thr Ala Gly Ser Phe Lys Cys Ser Cys Ser
1340 1345 1350
Pro Gly Trp Ile Gly Asp Gly Ile Lys Cys Thr Asp Leu Asp Glu
1355 1360 1365
Cys Ser Asn Gly Thr His Met Cys Ser Gln His Ala Asp Cys Lys
1370 1375 1380
Asn Thr Met Gly Ser Tyr Arg Cys Leu Cys Lys Asp Gly Tyr Thr
1385 1390 1395
Gly Asp Gly Phe Thr Cys Thr Asp Leu Asp Glu Cys Ser Glu Asn
1400 1405 1410
Leu Asn Leu Cys Gly Asn Gly Gln Cys Leu Asn Ala Pro Gly Gly
1415 1420 1425
Tyr Arg Cys Glu Cys Asp Met Gly Phe Val Pro Ser Ala Asp Gly
1430 1435 1440
Lys Ala Cys Glu Asp Ile Asp Glu Cys Ser Leu Pro Asn Ile Cys
1445 1450 1455
Val Phe Gly Thr Cys His Asn Leu Pro Gly Leu Phe Arg Cys Glu
1460 1465 1470
Cys Glu Ile Gly Tyr Glu Leu Asp Arg Ser Gly Gly Asn Cys Thr
1475 1480 1485
Asp Val Asn Glu Cys Leu Asp Pro Thr Thr Cys Ile Ser Gly Asn
1490 1495 1500
Cys Val Asn Thr Pro Gly Ser Tyr Thr Cys Asp Cys Pro Pro Asp
1505 1510 1515
Phe Glu Leu Asn Pro Thr Arg Val Gly Cys Val Asp Thr Arg Ser
1520 1525 1530
Gly Asn Cys Tyr Leu Asp Ile Arg Pro Arg Gly Asp Asn Gly Asp
1535 1540 1545
Thr Ala Cys Ser Asn Glu Ile Gly Val Gly Val Ser Lys Ala Ser
1550 1555 1560
Cys Cys Cys Ser Leu Gly Lys Ala Trp Gly Thr Pro Cys Glu Leu
1565 1570 1575
Cys Pro Ser Val Asn Thr Ser Glu Tyr Lys Ile Leu Cys Pro Gly
1580 1585 1590
Gly Glu Gly Phe Arg Pro Asn Pro Ile Thr Val Ile Leu Glu Asp
1595 1600 1605
Ile Asp Glu Cys Gln Glu Leu Pro Gly Leu Cys Gln Gly Gly Lys
1610 1615 1620
Cys Ile Asn Thr Phe Gly Ser Phe Gln Cys Arg Cys Pro Thr Gly
1625 1630 1635
Tyr Tyr Leu Asn Glu Asp Thr Arg Val Cys Asp Asp Val Asn Glu
1640 1645 1650
Cys Glu Thr Pro Gly Ile Cys Gly Pro Gly Thr Cys Tyr Asn Thr
1655 1660 1665
Val Gly Asn Tyr Thr Cys Ile Cys Pro Pro Asp Tyr Met Gln Val
1670 1675 1680
Asn Gly Gly Asn Asn Cys Met Asp Met Arg Arg Ser Leu Cys Tyr
1685 1690 1695
Arg Asn Tyr Tyr Ala Asp Asn Gln Thr Cys Asp Gly Glu Leu Leu
1700 1705 1710
Phe Asn Met Thr Lys Lys Met Cys Cys Cys Ser Tyr Asn Ile Gly
1715 1720 1725
Arg Ala Trp Asn Lys Pro Cys Glu Gln Cys Pro Ile Pro Ser Thr
1730 1735 1740
Asp Glu Phe Ala Thr Leu Cys Gly Ser Gln Arg Pro Gly Phe Val
1745 1750 1755
Ile Asp Ile Tyr Thr Gly Leu Pro Val Asp Ile Asp Glu Cys Arg
1760 1765 1770
Glu Ile Pro Gly Val Cys Glu Asn Gly Val Cys Ile Asn Met Val
1775 1780 1785
Gly Ser Phe Arg Cys Glu Cys Pro Val Gly Phe Phe Tyr Asn Asp
1790 1795 1800
Lys Leu Leu Val Cys Glu Asp Ile Asp Glu Cys Gln Asn Gly Pro
1805 1810 1815
Val Cys Gln Arg Asn Ala Glu Cys Ile Asn Thr Ala Gly Ser Tyr
1820 1825 1830
Arg Cys Asp Cys Lys Pro Gly Tyr Arg Leu Thr Ser Thr Gly Gln
1835 1840 1845
Cys Asn Asp Arg Asn Glu Cys Gln Glu Ile Pro Asn Ile Cys Ser
1850 1855 1860
His Gly Gln Cys Ile Asp Thr Val Gly Ser Phe Tyr Cys Leu Cys
1865 1870 1875
His Thr Gly Phe Lys Thr Asn Val Asp Gln Thr Met Cys Leu Asp
1880 1885 1890
Ile Asn Glu Cys Glu Arg Asp Ala Cys Gly Asn Gly Thr Cys Arg
1895 1900 1905
Asn Thr Ile Gly Ser Phe Asn Cys Arg Cys Asn His Gly Phe Ile
1910 1915 1920
Leu Ser His Asn Asn Asp Cys Ile Asp Val Asp Glu Cys Ala Thr
1925 1930 1935
Gly Asn Gly Asn Leu Cys Arg Asn Gly Gln Cys Val Asn Thr Val
1940 1945 1950
Gly Ser Phe Gln Cys Arg Cys Asn Glu Gly Tyr Glu Val Ala Pro
1955 1960 1965
Asp Gly Arg Thr Cys Val Asp Ile Asn Glu Cys Val Leu Asp Pro
1970 1975 1980
Gly Lys Cys Ala Pro Gly Thr Cys Gln Asn Leu Asp Gly Ser Tyr
1985 1990 1995
Arg Cys Ile Cys Pro Pro Gly Tyr Ser Leu Gln Asn Asp Lys Cys
2000 2005 2010
Glu Asp Ile Asp Glu Cys Val Glu Glu Pro Glu Ile Cys Ala Leu
2015 2020 2025
Gly Thr Cys Ser Asn Thr Glu Gly Ser Phe Lys Cys Leu Cys Pro
2030 2035 2040
Glu Gly Phe Ser Leu Ser Ser Thr Gly Arg Arg Cys Gln Asp Leu
2045 2050 2055
Arg Met Ser Tyr Cys Tyr Ala Lys Phe Glu Gly Gly Lys Cys Ser
2060 2065 2070
Ser Pro Lys Ser Arg Asn His Ser Lys Gln Glu Cys Cys Cys Ala
2075 2080 2085
Leu Lys Gly Glu Gly Trp Gly Asp Pro Cys Glu Leu Cys Pro Thr
2090 2095 2100
Glu Pro Asp Glu Ala Phe Arg Gln Ile Cys Pro Phe Gly Ser Gly
2105 2110 2115
Ile Ile Val Gly Pro Asp Asp Ser Ala Val Asp Met Asp Glu Cys
2120 2125 2130
Lys Glu Pro Asp Val Cys Arg His Gly Gln Cys Ile Asn Thr Asp
2135 2140 2145
Gly Ser Tyr Arg Cys Glu Cys Pro Phe Gly Tyr Ile Leu Glu Gly
2150 2155 2160
Asn Glu Cys Val Asp Thr Asp Glu Cys Ser Val Gly Asn Pro Cys
2165 2170 2175
Gly Asn Gly Thr Cys Lys Asn Val Ile Gly Gly Phe Glu Cys Thr
2180 2185 2190
Cys Glu Glu Gly Phe Glu Pro Gly Pro Met Met Thr Cys Glu Asp
2195 2200 2205
Ile Asn Glu Cys Ala Gln Asn Pro Leu Leu Cys Ala Phe Arg Cys
2210 2215 2220
Val Asn Thr Tyr Gly Ser Tyr Glu Cys Lys Cys Pro Val Gly Tyr
2225 2230 2235
Val Leu Arg Glu Asp Arg Arg Met Cys Lys Asp Glu Asp Glu Cys
2240 2245 2250
Ala Glu Gly Lys His Asp Cys Thr Glu Lys Gln Met Glu Cys Lys
2255 2260 2265
Asn Leu Ile Gly Thr Tyr Met Cys Ile Cys Gly Pro Gly Tyr Gln
2270 2275 2280
Arg Arg Pro Asp Gly Glu Gly Cys Ile Asp Glu Asn Glu Cys Gln
2285 2290 2295
Thr Lys Pro Gly Ile Cys Glu Asn Gly Arg Cys Leu Asn Thr Leu
2300 2305 2310
Gly Ser Tyr Thr Cys Glu Cys Asn Asp Gly Phe Thr Ala Ser Pro
2315 2320 2325
Thr Gln Asp Glu Cys Leu Asp Asn Arg Glu Gly Tyr Cys Phe Ser
2330 2335 2340
Glu Val Leu Gln Asn Met Cys Gln Ile Gly Ser Ser Asn Arg Asn
2345 2350 2355
Pro Val Thr Lys Ser Glu Cys Cys Cys Asp Gly Gly Arg Gly Trp
2360 2365 2370
Gly Pro His Cys Glu Ile Cys Pro Phe Glu Gly Thr Val Ala Tyr
2375 2380 2385
Lys Lys Leu Cys Pro His Gly Arg Gly Phe Met Thr Asn Gly Ala
2390 2395 2400
Asp Ile Asp Glu Cys Lys Val Ile His Asp Val Cys Arg Asn Gly
2405 2410 2415
Glu Cys Val Asn Asp Arg Gly Ser Tyr His Cys Ile Cys Lys Thr
2420 2425 2430
Gly Tyr Thr Pro Asp Ile Thr Gly Thr Ala Cys Val Asp Leu Asn
2435 2440 2445
Glu Cys Asn Gln Ala Pro Lys Pro Cys Asn Phe Ile Cys Lys Asn
2450 2455 2460
Thr Glu Gly Ser Tyr Gln Cys Ser Cys Pro Lys Gly Tyr Ile Leu
2465 2470 2475
Gln Glu Asp Gly Arg Ser Cys Lys Asp Leu Asp Glu Cys Ala Thr
2480 2485 2490
Lys Gln His Asn Cys Gln Phe Leu Cys Val Asn Thr Ile Gly Gly
2495 2500 2505
Phe Thr Cys Lys Cys Pro Pro Gly Phe Thr Gln His His Thr Ala
2510 2515 2520
Cys Ile Asp Asn Asn Glu Cys Thr Ser Asp Ile Asn Leu Cys Gly
2525 2530 2535
Ser Lys Gly Val Cys Gln Asn Thr Pro Gly Ser Phe Thr Cys Glu
2540 2545 2550
Cys Gln Arg Gly Phe Ser Leu Asp Gln Ser Gly Ala Ser Cys Glu
2555 2560 2565
Asp Val Asp Glu Cys Glu Gly Asn His Arg Cys Gln His Gly Cys
2570 2575 2580
Gln Asn Ile Ile Gly Gly Tyr Arg Cys Ser Cys Pro Gln Gly Tyr
2585 2590 2595
Leu Gln His Tyr Gln Trp Asn Gln Cys Val Asp Glu Asn Glu Cys
2600 2605 2610
Leu Ser Ala His Val Cys Gly Gly Ala Ser Cys His Asn Thr Leu
2615 2620 2625
Gly Ser Tyr Lys Cys Met Cys Pro Thr Gly Phe Gln Tyr Glu Gln
2630 2635 2640
Phe Ser Gly Gly Cys Gln Asp Ile Asn Glu Cys Gly Ser Ser Gln
2645 2650 2655
Ala Pro Cys Ser Tyr Gly Cys Ser Asn Thr Glu Gly Gly Tyr Leu
2660 2665 2670
Cys Gly Cys Pro Pro Gly Tyr Phe Arg Ile Gly Gln Gly His Cys
2675 2680 2685
Val Ser Gly Met Gly Met Gly Arg Gly Gly Pro Glu Pro Pro Ala
2690 2695 2700
Ser Ser Glu Met Asp Asp Asn Ser Leu Ser Pro Glu Ala Cys Tyr
2705 2710 2715
Glu Cys Lys Ile Asn Gly Tyr Pro Lys Arg Gly Arg Lys Arg Arg
2720 2725 2730
Ser Thr Asn Glu Thr Asp Ala Ser Asp Ile Gln Asp Gly Ser Glu
2735 2740 2745
Met Glu Ala Asn Val Ser Leu Ala Ser Trp Asp Val Glu Lys Pro
2750 2755 2760
Ala Ser Phe Ala Phe Asn Ile Ser His Val Asn Asn Lys Val Arg
2765 2770 2775
Ile Leu Glu Leu Leu Pro Ala Leu Thr Thr Leu Met Asn His Asn
2780 2785 2790
Arg Tyr Leu Ile Glu Ser Gly Asn Glu Asp Gly Phe Phe Lys Ile
2795 2800 2805
Asn Gln Lys Glu Gly Val Ser Tyr Leu His Phe Thr Lys Lys Lys
2810 2815 2820
Pro Val Ala Gly Thr Tyr Ser Leu Gln Ile Ser Ser Thr Pro Leu
2825 2830 2835
Tyr Lys Lys Lys Glu Leu Asn Gln Leu Glu Asp Arg Tyr Asp Lys
2840 2845 2850
Asp Tyr Leu Ser Gly Glu Leu Gly Asp Asn Leu Lys Met Lys Ile
2855 2860 2865
Gln Ile Leu Leu His
2870
<210> 31
<211> 2738
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 31
Met Arg Arg Gly Gly Leu Leu Glu Val Ala Leu Ala Phe Ala Leu Leu
1 5 10 15
Leu Glu Ser Tyr Thr Ser His Gly Ala Asp Ala Asn Leu Glu Ala Gly
20 25 30
Ser Leu Lys Glu Thr Arg Ala Asn Arg Ala Lys Arg Arg Gly Gly Gly
35 40 45
Gly His Asp Ala Leu Lys Gly Pro Asn Val Cys Gly Ser Arg Tyr Asn
50 55 60
Ala Tyr Cys Cys Pro Gly Trp Lys Thr Leu Pro Gly Gly Asn Gln Cys
65 70 75 80
Ile Val Pro Ile Cys Arg His Ser Cys Gly Asp Gly Phe Cys Ser Arg
85 90 95
Pro Asn Met Cys Thr Cys Pro Ser Gly Gln Ile Ser Pro Ser Cys Gly
100 105 110
Ser Arg Ser Ile Gln His Cys Ser Ile Arg Cys Met Asn Gly Gly Ser
115 120 125
Cys Ser Asp Asp His Cys Leu Cys Gln Lys Gly Tyr Ile Gly Thr His
130 135 140
Cys Gly Gln Pro Val Cys Glu Ser Gly Cys Leu Asn Gly Gly Arg Cys
145 150 155 160
Val Ala Pro Asn Arg Cys Ala Cys Thr Tyr Gly Phe Thr Gly Pro Gln
165 170 175
Cys Glu Arg Asp Tyr Arg Thr Gly Pro Cys Phe Thr Val Val Ser Asn
180 185 190
Gln Met Cys Gln Gly Gln Leu Ser Gly Ile Val Cys Thr Lys Thr Leu
195 200 205
Cys Cys Ala Thr Val Gly Arg Ala Trp Gly His Pro Cys Glu Met Cys
210 215 220
Pro Ala Gln Pro His Pro Cys Arg Arg Gly Phe Ile Pro Asn Ile Arg
225 230 235 240
Thr Gly Ala Cys Gln Asp Val Asp Glu Cys Gln Ala Ile Pro Gly Met
245 250 255
Cys Gln Gly Gly Asn Cys Ile Asn Thr Val Gly Ser Phe Glu Cys Lys
260 265 270
Cys Pro Ala Gly His Lys Phe Asn Glu Val Ser Gln Lys Cys Glu Asp
275 280 285
Ile Asp Glu Cys Ser Thr Ile Pro Gly Val Cys Asp Gly Gly Glu Cys
290 295 300
Thr Asn Thr Val Ser Ser Tyr Phe Cys Lys Cys Pro Pro Gly Phe Tyr
305 310 315 320
Thr Ser Pro Asp Gly Thr Arg Cys Val Asp Val Arg Pro Gly Tyr Cys
325 330 335
Tyr Thr Ala Leu Ala Asn Gly Arg Cys Ser Asn Gln Leu Pro Gln Ser
340 345 350
Ile Thr Lys Met Gln Cys Cys Cys Asp Leu Gly Arg Cys Trp Ser Pro
355 360 365
Gly Val Thr Val Ala Pro Glu Met Cys Pro Ile Arg Ser Thr Glu Asp
370 375 380
Phe Asn Lys Leu Cys Ser Val Pro Leu Val Ile Pro Gly Arg Pro Glu
385 390 395 400
Tyr Pro Pro Pro Pro Ile Gly Pro Leu Pro Pro Val Gln Pro Val Pro
405 410 415
Pro Gly Tyr Pro Pro Gly Pro Val Ile Pro Ala Pro Arg Pro Pro Pro
420 425 430
Glu Tyr Pro Tyr Pro Ser Pro Ser Arg Glu Pro Pro Arg Val Leu Pro
435 440 445
Phe Asn Val Thr Asp Tyr Cys Gln Leu Val Arg Tyr Leu Cys Gln Asn
450 455 460
Gly Arg Cys Ile Pro Thr Pro Gly Ser Tyr Arg Cys Glu Cys Asn Lys
465 470 475 480
Gly Phe Gln Leu Asp Ile Arg Gly Glu Cys Ile Asp Val Asp Glu Cys
485 490 495
Glu Lys Asn Pro Cys Thr Gly Gly Glu Cys Ile Asn Asn Gln Gly Ser
500 505 510
Tyr Thr Cys His Cys Arg Ala Gly Tyr Gln Ser Thr Leu Thr Arg Thr
515 520 525
Glu Cys Arg Asp Ile Asp Glu Cys Leu Gln Asn Gly Arg Ile Cys Asn
530 535 540
Asn Gly Arg Cys Ile Asn Thr Asp Gly Ser Phe His Cys Val Cys Asn
545 550 555 560
Ala Gly Phe His Val Thr Arg Asp Gly Lys Asn Cys Glu Asp Met Asp
565 570 575
Glu Cys Ser Ile Arg Asn Met Cys Leu Asn Gly Met Cys Ile Asn Glu
580 585 590
Asp Gly Ser Phe Lys Cys Ile Cys Lys Pro Gly Phe Gln Leu Ala Ser
595 600 605
Asp Gly Arg Tyr Cys Lys Asp Ile Asn Glu Cys Glu Thr Pro Gly Ile
610 615 620
Cys Met Asn Gly Arg Cys Val Asn Thr Asp Gly Ser Tyr Arg Cys Glu
625 630 635 640
Cys Phe Pro Gly Leu Ala Val Gly Leu Asp Gly Arg Val Cys Val Asp
645 650 655
Thr His Met Arg Ser Thr Cys Tyr Gly Gly Tyr Arg Arg Gly Gln Cys
660 665 670
Val Lys Pro Leu Phe Gly Ala Val Thr Lys Ser Glu Cys Cys Cys Ala
675 680 685
Ser Thr Glu Tyr Ala Phe Gly Glu Pro Cys Gln Pro Cys Pro Ala Gln
690 695 700
Asn Ser Ala Glu Tyr Gln Ala Leu Cys Ser Ser Gly Pro Gly Met Thr
705 710 715 720
Ser Ala Gly Thr Asp Ile Asn Glu Cys Ala Leu Asp Pro Asp Ile Cys
725 730 735
Pro Asn Gly Ile Cys Glu Asn Leu Arg Gly Thr Tyr Lys Cys Ile Cys
740 745 750
Asn Ser Gly Tyr Glu Val Asp Ile Thr Gly Lys Asn Cys Val Asp Ile
755 760 765
Asn Glu Cys Val Leu Asn Ser Leu Leu Cys Asp Asn Gly Gln Cys Arg
770 775 780
Asn Thr Pro Gly Ser Phe Val Cys Thr Cys Pro Lys Gly Phe Val Tyr
785 790 795 800
Lys Pro Asp Leu Lys Thr Cys Glu Asp Ile Asp Glu Cys Glu Ser Ser
805 810 815
Pro Cys Ile Asn Gly Val Cys Lys Asn Ser Pro Gly Ser Phe Ile Cys
820 825 830
Glu Cys Ser Pro Glu Ser Thr Leu Asp Pro Thr Lys Thr Ile Cys Ile
835 840 845
Glu Thr Ile Lys Gly Thr Cys Trp Gln Thr Val Ile Asp Gly Arg Cys
850 855 860
Glu Ile Asn Ile Asn Gly Ala Thr Leu Lys Ser Glu Cys Cys Ser Ser
865 870 875 880
Leu Gly Ala Ala Trp Gly Ser Pro Cys Thr Ile Cys Gln Leu Asp Pro
885 890 895
Ile Cys Gly Lys Gly Phe Ser Arg Ile Lys Gly Thr Gln Cys Glu Asp
900 905 910
Ile Asn Glu Cys Glu Val Phe Pro Gly Val Cys Lys Asn Gly Leu Cys
915 920 925
Val Asn Ser Arg Gly Ser Phe Lys Cys Glu Cys Pro Asn Gly Met Thr
930 935 940
Leu Asp Ala Thr Gly Arg Ile Cys Leu Asp Ile Arg Leu Glu Thr Cys
945 950 955 960
Phe Leu Lys Tyr Asp Asp Glu Glu Cys Thr Leu Pro Ile Ala Gly Arg
965 970 975
His Arg Met Asp Ala Cys Cys Cys Ser Val Gly Ala Ala Trp Gly Thr
980 985 990
Glu Glu Cys Glu Glu Cys Pro Leu Arg Asn Ser Arg Glu Tyr Glu Glu
995 1000 1005
Leu Cys Pro Arg Gly Pro Gly Phe Ala Thr Lys Asp Ile Thr Asn
1010 1015 1020
Gly Lys Pro Phe Phe Lys Asp Ile Asn Glu Cys Lys Met Ile Pro
1025 1030 1035
Ser Leu Cys Thr His Gly Lys Cys Arg Asn Thr Ile Gly Ser Phe
1040 1045 1050
Lys Cys Arg Cys Asp Ser Gly Phe Ala Leu Asp Ser Glu Glu Arg
1055 1060 1065
Asn Cys Thr Asp Ile Asp Glu Cys Arg Ile Ser Pro Asp Leu Cys
1070 1075 1080
Gly Arg Gly Gln Cys Val Asn Thr Pro Gly Asp Phe Glu Cys Lys
1085 1090 1095
Cys Asp Glu Gly Tyr Glu Ser Gly Phe Met Met Met Lys Asn Cys
1100 1105 1110
Met Asp Ile Asp Glu Cys Gln Arg Asp Pro Leu Leu Cys Arg Gly
1115 1120 1125
Gly Ile Cys His Asn Thr Glu Gly Ser Tyr Arg Cys Glu Cys Pro
1130 1135 1140
Pro Gly His Gln Leu Ser Pro Asn Ile Ser Ala Cys Ile Asp Ile
1145 1150 1155
Asn Glu Cys Glu Leu Ser Ala Asn Leu Cys Pro His Gly Arg Cys
1160 1165 1170
Val Asn Leu Ile Gly Lys Tyr Gln Cys Ala Cys Asn Pro Gly Tyr
1175 1180 1185
His Pro Thr His Asp Arg Leu Phe Cys Val Asp Ile Asp Glu Cys
1190 1195 1200
Ser Ile Met Asn Gly Gly Cys Glu Thr Phe Cys Thr Asn Ser Asp
1205 1210 1215
Gly Ser Tyr Glu Cys Ser Cys Gln Pro Gly Phe Ala Leu Met Pro
1220 1225 1230
Asp Gln Arg Ser Cys Thr Asp Ile Asp Glu Cys Glu Asp Asn Pro
1235 1240 1245
Asn Ile Cys Asp Gly Gly Gln Cys Thr Asn Ile Pro Gly Glu Tyr
1250 1255 1260
Arg Cys Leu Cys Tyr Asp Gly Phe Met Ala Ser Glu Asp Met Lys
1265 1270 1275
Thr Cys Val Asp Val Asn Glu Cys Asp Leu Asn Pro Asn Ile Cys
1280 1285 1290
Leu Ser Gly Thr Cys Glu Asn Thr Lys Gly Ser Phe Ile Cys His
1295 1300 1305
Cys Asp Met Gly Tyr Ser Gly Lys Lys Gly Lys Thr Gly Cys Thr
1310 1315 1320
Asp Ile Asn Glu Cys Glu Ile Gly Ala His Asn Cys Gly Arg His
1325 1330 1335
Ala Val Cys Thr Asn Thr Ala Gly Ser Phe Lys Cys Ser Cys Ser
1340 1345 1350
Pro Gly Trp Ile Gly Asp Gly Ile Lys Cys Thr Asp Leu Asp Glu
1355 1360 1365
Cys Ser Asn Gly Thr His Met Cys Ser Gln His Ala Asp Cys Lys
1370 1375 1380
Asn Thr Met Gly Ser Tyr Arg Cys Leu Cys Lys Asp Gly Tyr Thr
1385 1390 1395
Gly Asp Gly Phe Thr Cys Thr Asp Leu Asp Glu Cys Ser Glu Asn
1400 1405 1410
Leu Asn Leu Cys Gly Asn Gly Gln Cys Leu Asn Ala Pro Gly Gly
1415 1420 1425
Tyr Arg Cys Glu Cys Asp Met Gly Phe Val Pro Ser Ala Asp Gly
1430 1435 1440
Lys Ala Cys Glu Asp Ile Asp Glu Cys Ser Leu Pro Asn Ile Cys
1445 1450 1455
Val Phe Gly Thr Cys His Asn Leu Pro Gly Leu Phe Arg Cys Glu
1460 1465 1470
Cys Glu Ile Gly Tyr Glu Leu Asp Arg Ser Gly Gly Asn Cys Thr
1475 1480 1485
Asp Val Asn Glu Cys Leu Asp Pro Thr Thr Cys Ile Ser Gly Asn
1490 1495 1500
Cys Val Asn Thr Pro Gly Ser Tyr Thr Cys Asp Cys Pro Pro Asp
1505 1510 1515
Phe Glu Leu Asn Pro Thr Arg Val Gly Cys Val Asp Thr Arg Ser
1520 1525 1530
Gly Asn Cys Tyr Leu Asp Ile Arg Pro Arg Gly Asp Asn Gly Asp
1535 1540 1545
Thr Ala Cys Ser Asn Glu Ile Gly Val Gly Val Ser Lys Ala Ser
1550 1555 1560
Cys Cys Cys Ser Leu Gly Lys Ala Trp Gly Thr Pro Cys Glu Leu
1565 1570 1575
Cys Pro Ser Val Asn Thr Ser Glu Tyr Lys Ile Leu Cys Pro Gly
1580 1585 1590
Gly Glu Gly Phe Arg Pro Asn Pro Ile Thr Val Ile Leu Glu Asp
1595 1600 1605
Ile Asp Glu Cys Gln Glu Leu Pro Gly Leu Cys Gln Gly Gly Lys
1610 1615 1620
Cys Ile Asn Thr Phe Gly Ser Phe Gln Cys Arg Cys Pro Thr Gly
1625 1630 1635
Tyr Tyr Leu Asn Glu Asp Thr Arg Val Cys Asp Asp Val Asn Glu
1640 1645 1650
Cys Glu Thr Pro Gly Ile Cys Gly Pro Gly Thr Cys Tyr Asn Thr
1655 1660 1665
Val Gly Asn Tyr Thr Cys Ile Cys Pro Pro Asp Tyr Met Gln Val
1670 1675 1680
Asn Gly Gly Asn Asn Cys Met Asp Met Arg Arg Ser Leu Cys Tyr
1685 1690 1695
Arg Asn Tyr Tyr Ala Asp Asn Gln Thr Cys Asp Gly Glu Leu Leu
1700 1705 1710
Phe Asn Met Thr Lys Lys Met Cys Cys Cys Ser Tyr Asn Ile Gly
1715 1720 1725
Arg Ala Trp Asn Lys Pro Cys Glu Gln Cys Pro Ile Pro Ser Thr
1730 1735 1740
Asp Glu Phe Ala Thr Leu Cys Gly Ser Gln Arg Pro Gly Phe Val
1745 1750 1755
Ile Asp Ile Tyr Thr Gly Leu Pro Val Asp Ile Asp Glu Cys Arg
1760 1765 1770
Glu Ile Pro Gly Val Cys Glu Asn Gly Val Cys Ile Asn Met Val
1775 1780 1785
Gly Ser Phe Arg Cys Glu Cys Pro Val Gly Phe Phe Tyr Asn Asp
1790 1795 1800
Lys Leu Leu Val Cys Glu Asp Ile Asp Glu Cys Gln Asn Gly Pro
1805 1810 1815
Val Cys Gln Arg Asn Ala Glu Cys Ile Asn Thr Ala Gly Ser Tyr
1820 1825 1830
Arg Cys Asp Cys Lys Pro Gly Tyr Arg Leu Thr Ser Thr Gly Gln
1835 1840 1845
Cys Asn Asp Arg Asn Glu Cys Gln Glu Ile Pro Asn Ile Cys Ser
1850 1855 1860
His Gly Gln Cys Ile Asp Thr Val Gly Ser Phe Tyr Cys Leu Cys
1865 1870 1875
His Thr Gly Phe Lys Thr Asn Val Asp Gln Thr Met Cys Leu Asp
1880 1885 1890
Ile Asn Glu Cys Glu Arg Asp Ala Cys Gly Asn Gly Thr Cys Arg
1895 1900 1905
Asn Thr Ile Gly Ser Phe Asn Cys Arg Cys Asn His Gly Phe Ile
1910 1915 1920
Leu Ser His Asn Asn Asp Cys Ile Asp Val Asp Glu Cys Ala Thr
1925 1930 1935
Gly Asn Gly Asn Leu Cys Arg Asn Gly Gln Cys Val Asn Thr Val
1940 1945 1950
Gly Ser Phe Gln Cys Arg Cys Asn Glu Gly Tyr Glu Val Ala Pro
1955 1960 1965
Asp Gly Arg Thr Cys Val Asp Ile Asn Glu Cys Val Leu Asp Pro
1970 1975 1980
Gly Lys Cys Ala Pro Gly Thr Cys Gln Asn Leu Asp Gly Ser Tyr
1985 1990 1995
Arg Cys Ile Cys Pro Pro Gly Tyr Ser Leu Gln Asn Asp Lys Cys
2000 2005 2010
Glu Asp Ile Asp Glu Cys Val Glu Glu Pro Glu Ile Cys Ala Leu
2015 2020 2025
Gly Thr Cys Ser Asn Thr Glu Gly Ser Phe Lys Cys Leu Cys Pro
2030 2035 2040
Glu Gly Phe Ser Leu Ser Ser Thr Gly Arg Arg Cys Gln Asp Leu
2045 2050 2055
Arg Met Ser Tyr Cys Tyr Ala Lys Phe Glu Gly Gly Lys Cys Ser
2060 2065 2070
Ser Pro Lys Ser Arg Asn His Ser Lys Gln Glu Cys Cys Cys Ala
2075 2080 2085
Leu Lys Gly Glu Gly Trp Gly Asp Pro Cys Glu Leu Cys Pro Thr
2090 2095 2100
Glu Pro Asp Glu Ala Phe Arg Gln Ile Cys Pro Phe Gly Ser Gly
2105 2110 2115
Ile Ile Val Gly Pro Asp Asp Ser Ala Val Asp Met Asp Glu Cys
2120 2125 2130
Lys Glu Pro Asp Val Cys Arg His Gly Gln Cys Ile Asn Thr Asp
2135 2140 2145
Gly Ser Tyr Arg Cys Glu Cys Pro Phe Gly Tyr Ile Leu Glu Gly
2150 2155 2160
Asn Glu Cys Val Asp Thr Asp Glu Cys Ser Val Gly Asn Pro Cys
2165 2170 2175
Gly Asn Gly Thr Cys Lys Asn Val Ile Gly Gly Phe Glu Cys Thr
2180 2185 2190
Cys Glu Glu Gly Phe Glu Pro Gly Pro Met Met Thr Cys Glu Asp
2195 2200 2205
Ile Asn Glu Cys Ala Gln Asn Pro Leu Leu Cys Ala Phe Arg Cys
2210 2215 2220
Val Asn Thr Tyr Gly Ser Tyr Glu Cys Lys Cys Pro Val Gly Tyr
2225 2230 2235
Val Leu Arg Glu Asp Arg Arg Met Cys Lys Asp Glu Asp Glu Cys
2240 2245 2250
Ala Glu Gly Lys His Asp Cys Thr Glu Lys Gln Met Glu Cys Lys
2255 2260 2265
Asn Leu Ile Gly Thr Tyr Met Cys Ile Cys Gly Pro Gly Tyr Gln
2270 2275 2280
Arg Arg Pro Asp Gly Glu Gly Cys Ile Asp Glu Asn Glu Cys Gln
2285 2290 2295
Thr Lys Pro Gly Ile Cys Glu Asn Gly Arg Cys Leu Asn Thr Leu
2300 2305 2310
Gly Ser Tyr Thr Cys Glu Cys Asn Asp Gly Phe Thr Ala Ser Pro
2315 2320 2325
Thr Gln Asp Glu Cys Leu Asp Asn Arg Glu Gly Tyr Cys Phe Ser
2330 2335 2340
Glu Val Leu Gln Asn Met Cys Gln Ile Gly Ser Ser Asn Arg Asn
2345 2350 2355
Pro Val Thr Lys Ser Glu Cys Cys Cys Asp Gly Gly Arg Gly Trp
2360 2365 2370
Gly Pro His Cys Glu Ile Cys Pro Phe Glu Gly Thr Val Ala Tyr
2375 2380 2385
Lys Lys Leu Cys Pro His Gly Arg Gly Phe Met Thr Asn Gly Ala
2390 2395 2400
Asp Ile Asp Glu Cys Lys Val Ile His Asp Val Cys Arg Asn Gly
2405 2410 2415
Glu Cys Val Asn Asp Arg Gly Ser Tyr His Cys Ile Cys Lys Thr
2420 2425 2430
Gly Tyr Thr Pro Asp Ile Thr Gly Thr Ala Cys Val Asp Leu Asn
2435 2440 2445
Glu Cys Asn Gln Ala Pro Lys Pro Cys Asn Phe Ile Cys Lys Asn
2450 2455 2460
Thr Glu Gly Ser Tyr Gln Cys Ser Cys Pro Lys Gly Tyr Ile Leu
2465 2470 2475
Gln Glu Asp Gly Arg Ser Cys Lys Asp Leu Asp Glu Cys Ala Thr
2480 2485 2490
Lys Gln His Asn Cys Gln Phe Leu Cys Val Asn Thr Ile Gly Gly
2495 2500 2505
Phe Thr Cys Lys Cys Pro Pro Gly Phe Thr Gln His His Thr Ala
2510 2515 2520
Cys Ile Asp Asn Asn Glu Cys Thr Ser Asp Ile Asn Leu Cys Gly
2525 2530 2535
Ser Lys Gly Val Cys Gln Asn Thr Pro Gly Ser Phe Thr Cys Glu
2540 2545 2550
Cys Gln Arg Gly Phe Ser Leu Asp Gln Ser Gly Ala Ser Cys Glu
2555 2560 2565
Asp Val Asp Glu Cys Glu Gly Asn His Arg Cys Gln His Gly Cys
2570 2575 2580
Gln Asn Ile Ile Gly Gly Tyr Arg Cys Ser Cys Pro Gln Gly Tyr
2585 2590 2595
Leu Gln His Tyr Gln Trp Asn Gln Cys Val Asp Glu Asn Glu Cys
2600 2605 2610
Leu Ser Ala His Val Cys Gly Gly Ala Ser Cys His Asn Thr Leu
2615 2620 2625
Gly Ser Tyr Lys Cys Met Cys Pro Thr Gly Phe Gln Tyr Glu Gln
2630 2635 2640
Phe Ser Gly Gly Cys Gln Asp Ile Asn Glu Cys Gly Ser Ser Gln
2645 2650 2655
Ala Pro Cys Ser Tyr Gly Cys Ser Asn Thr Glu Gly Gly Tyr Leu
2660 2665 2670
Cys Gly Cys Pro Pro Gly Tyr Phe Arg Ile Gly Gln Gly His Cys
2675 2680 2685
Val Ser Gly Met Gly Met Gly Arg Gly Gly Pro Glu Pro Pro Ala
2690 2695 2700
Ser Ser Glu Met Asp Asp Asn Ser Leu Ser Pro Glu Ala Cys Tyr
2705 2710 2715
Glu Cys Lys Ile Asn Gly Tyr Pro Lys Arg Gly Arg Lys Arg Arg
2720 2725 2730
Ser Thr Asn Glu Asn
2735
<210> 32
<211> 2755
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 32
Met Arg Arg Gly Gly Leu Leu Glu Val Ala Leu Ala Phe Ala Leu Leu
1 5 10 15
Leu Glu Ser Tyr Thr Ser His Gly Ala Asp Ala Asn Leu Glu Ala Gly
20 25 30
Ser Leu Lys Glu Thr Arg Ala Asn Arg Ala Lys Arg Arg Gly Gly Gly
35 40 45
Gly His Asp Ala Leu Lys Gly Pro Asn Val Cys Gly Ser Arg Tyr Asn
50 55 60
Ala Tyr Cys Cys Pro Gly Trp Lys Thr Leu Pro Gly Gly Asn Gln Cys
65 70 75 80
Ile Val Pro Ile Cys Arg His Ser Cys Gly Asp Gly Phe Cys Ser Arg
85 90 95
Pro Asn Met Cys Thr Cys Pro Ser Gly Gln Ile Ser Pro Ser Cys Gly
100 105 110
Ser Arg Ser Ile Gln His Cys Ser Ile Arg Cys Met Asn Gly Gly Ser
115 120 125
Cys Ser Asp Asp His Cys Leu Cys Gln Lys Gly Tyr Ile Gly Thr His
130 135 140
Cys Gly Gln Pro Val Cys Glu Ser Gly Cys Leu Asn Gly Gly Arg Cys
145 150 155 160
Val Ala Pro Asn Arg Cys Ala Cys Thr Tyr Gly Phe Thr Gly Pro Gln
165 170 175
Cys Glu Arg Asp Tyr Arg Thr Gly Pro Cys Phe Thr Val Val Ser Asn
180 185 190
Gln Met Cys Gln Gly Gln Leu Ser Gly Ile Val Cys Thr Lys Thr Leu
195 200 205
Cys Cys Ala Thr Val Gly Arg Ala Trp Gly His Pro Cys Glu Met Cys
210 215 220
Pro Ala Gln Pro His Pro Cys Arg Arg Gly Phe Ile Pro Asn Ile Arg
225 230 235 240
Thr Gly Ala Cys Gln Asp Val Asp Glu Cys Gln Ala Ile Pro Gly Met
245 250 255
Cys Gln Gly Gly Asn Cys Ile Asn Thr Val Gly Ser Phe Glu Cys Lys
260 265 270
Cys Pro Ala Gly His Lys Phe Asn Glu Val Ser Gln Lys Cys Glu Asp
275 280 285
Ile Asp Glu Cys Ser Thr Ile Pro Gly Val Cys Asp Gly Gly Glu Cys
290 295 300
Thr Asn Thr Val Ser Ser Tyr Phe Cys Lys Cys Pro Pro Gly Phe Tyr
305 310 315 320
Thr Ser Pro Asp Gly Thr Arg Cys Val Asp Val Arg Pro Gly Tyr Cys
325 330 335
Tyr Thr Ala Leu Ala Asn Gly Arg Cys Ser Asn Gln Leu Pro Gln Ser
340 345 350
Ile Thr Lys Met Gln Cys Cys Cys Asp Leu Gly Arg Cys Trp Ser Pro
355 360 365
Gly Val Thr Val Ala Pro Glu Met Cys Pro Ile Arg Ser Thr Glu Asp
370 375 380
Phe Asn Lys Leu Cys Ser Val Pro Leu Val Ile Pro Gly Arg Pro Glu
385 390 395 400
Tyr Pro Pro Pro Pro Ile Gly Pro Leu Pro Pro Val Gln Pro Val Pro
405 410 415
Pro Gly Tyr Pro Pro Gly Pro Val Ile Pro Ala Pro Arg Pro Pro Pro
420 425 430
Glu Tyr Pro Tyr Pro Ser Pro Ser Arg Glu Pro Pro Arg Val Leu Pro
435 440 445
Phe Asn Val Thr Asp Tyr Cys Gln Leu Val Arg Tyr Leu Cys Gln Asn
450 455 460
Gly Arg Cys Ile Pro Thr Pro Gly Ser Tyr Arg Cys Glu Cys Asn Lys
465 470 475 480
Gly Phe Gln Leu Asp Ile Arg Gly Glu Cys Ile Asp Val Asp Glu Cys
485 490 495
Glu Lys Asn Pro Cys Thr Gly Gly Glu Cys Ile Asn Asn Gln Gly Ser
500 505 510
Tyr Thr Cys His Cys Arg Ala Gly Tyr Gln Ser Thr Leu Thr Arg Thr
515 520 525
Glu Cys Arg Asp Ile Asp Glu Cys Leu Gln Asn Gly Arg Ile Cys Asn
530 535 540
Asn Gly Arg Cys Ile Asn Thr Asp Gly Ser Phe His Cys Val Cys Asn
545 550 555 560
Ala Gly Phe His Val Thr Arg Asp Gly Lys Asn Cys Glu Asp Met Asp
565 570 575
Glu Cys Ser Ile Arg Asn Met Cys Leu Asn Gly Met Cys Ile Asn Glu
580 585 590
Asp Gly Ser Phe Lys Cys Ile Cys Lys Pro Gly Phe Gln Leu Ala Ser
595 600 605
Asp Gly Arg Tyr Cys Lys Asp Ile Asn Glu Cys Glu Thr Pro Gly Ile
610 615 620
Cys Met Asn Gly Arg Cys Val Asn Thr Asp Gly Ser Tyr Arg Cys Glu
625 630 635 640
Cys Phe Pro Gly Leu Ala Val Gly Leu Asp Gly Arg Val Cys Val Asp
645 650 655
Thr His Met Arg Ser Thr Cys Tyr Gly Gly Tyr Arg Arg Gly Gln Cys
660 665 670
Val Lys Pro Leu Phe Gly Ala Val Thr Lys Ser Glu Cys Cys Cys Ala
675 680 685
Ser Thr Glu Tyr Ala Phe Gly Glu Pro Cys Gln Pro Cys Pro Ala Gln
690 695 700
Asn Ser Ala Glu Tyr Gln Ala Leu Cys Ser Ser Gly Pro Gly Met Thr
705 710 715 720
Ser Ala Gly Thr Asp Ile Asn Glu Cys Ala Leu Asp Pro Asp Ile Cys
725 730 735
Pro Asn Gly Ile Cys Glu Asn Leu Arg Gly Thr Tyr Lys Cys Ile Cys
740 745 750
Asn Ser Gly Tyr Glu Val Asp Ile Thr Gly Lys Asn Cys Val Asp Ile
755 760 765
Asn Glu Cys Val Leu Asn Ser Leu Leu Cys Asp Asn Gly Gln Cys Arg
770 775 780
Asn Thr Pro Gly Ser Phe Val Cys Thr Cys Pro Lys Gly Phe Val Tyr
785 790 795 800
Lys Pro Asp Leu Lys Thr Cys Glu Asp Ile Asp Glu Cys Glu Ser Ser
805 810 815
Pro Cys Ile Asn Gly Val Cys Lys Asn Ser Pro Gly Ser Phe Ile Cys
820 825 830
Glu Cys Ser Pro Glu Ser Thr Leu Asp Pro Thr Lys Thr Ile Cys Ile
835 840 845
Glu Thr Ile Lys Gly Thr Cys Trp Gln Thr Val Ile Asp Gly Arg Cys
850 855 860
Glu Ile Asn Ile Asn Gly Ala Thr Leu Lys Ser Glu Cys Cys Ser Ser
865 870 875 880
Leu Gly Ala Ala Trp Gly Ser Pro Cys Thr Ile Cys Gln Leu Asp Pro
885 890 895
Ile Cys Gly Lys Gly Phe Ser Arg Ile Lys Gly Thr Gln Cys Glu Asp
900 905 910
Ile Asn Glu Cys Glu Val Phe Pro Gly Val Cys Lys Asn Gly Leu Cys
915 920 925
Val Asn Ser Arg Gly Ser Phe Lys Cys Glu Cys Pro Asn Gly Met Thr
930 935 940
Leu Asp Ala Thr Gly Arg Ile Cys Leu Asp Ile Arg Leu Glu Thr Cys
945 950 955 960
Phe Leu Lys Tyr Asp Asp Glu Glu Cys Thr Leu Pro Ile Ala Gly Arg
965 970 975
His Arg Met Asp Ala Cys Cys Cys Ser Val Gly Ala Ala Trp Gly Thr
980 985 990
Glu Glu Cys Glu Glu Cys Pro Leu Arg Asn Ser Arg Glu Tyr Glu Glu
995 1000 1005
Leu Cys Pro Arg Gly Pro Gly Phe Ala Thr Lys Asp Ile Thr Asn
1010 1015 1020
Gly Lys Pro Phe Phe Lys Asp Ile Asn Glu Cys Lys Met Ile Pro
1025 1030 1035
Ser Leu Cys Thr His Gly Lys Cys Arg Asn Thr Ile Gly Ser Phe
1040 1045 1050
Lys Cys Arg Cys Asp Ser Gly Phe Ala Leu Asp Ser Glu Glu Arg
1055 1060 1065
Asn Cys Thr Asp Ile Asp Glu Cys Arg Ile Ser Pro Asp Leu Cys
1070 1075 1080
Gly Arg Gly Gln Cys Val Asn Thr Pro Gly Asp Phe Glu Cys Lys
1085 1090 1095
Cys Asp Glu Gly Tyr Glu Ser Gly Phe Met Met Met Lys Asn Cys
1100 1105 1110
Met Asp Ile Asp Glu Cys Gln Arg Asp Pro Leu Leu Cys Arg Gly
1115 1120 1125
Gly Ile Cys His Asn Thr Glu Gly Ser Tyr Arg Cys Glu Cys Pro
1130 1135 1140
Pro Gly His Gln Leu Ser Pro Asn Ile Ser Ala Cys Ile Asp Ile
1145 1150 1155
Asn Glu Cys Glu Leu Ser Ala Asn Leu Cys Pro His Gly Arg Cys
1160 1165 1170
Val Asn Leu Ile Gly Lys Tyr Gln Cys Ala Cys Asn Pro Gly Tyr
1175 1180 1185
His Pro Thr His Asp Arg Leu Phe Cys Val Asp Ile Asp Glu Cys
1190 1195 1200
Ser Ile Met Asn Gly Gly Cys Glu Thr Phe Cys Thr Asn Ser Asp
1205 1210 1215
Gly Ser Tyr Glu Cys Ser Cys Gln Pro Gly Phe Ala Leu Met Pro
1220 1225 1230
Asp Gln Arg Ser Cys Thr Asp Ile Asp Glu Cys Glu Asp Asn Pro
1235 1240 1245
Asn Ile Cys Asp Gly Gly Gln Cys Thr Asn Ile Pro Gly Glu Tyr
1250 1255 1260
Arg Cys Leu Cys Tyr Asp Gly Phe Met Ala Ser Glu Asp Met Lys
1265 1270 1275
Thr Cys Val Asp Val Asn Glu Cys Asp Leu Asn Pro Asn Ile Cys
1280 1285 1290
Leu Ser Gly Thr Cys Glu Asn Thr Lys Gly Ser Phe Ile Cys His
1295 1300 1305
Cys Asp Met Gly Tyr Ser Gly Lys Lys Gly Lys Thr Gly Cys Thr
1310 1315 1320
Asp Ile Asn Glu Cys Glu Ile Gly Ala His Asn Cys Gly Arg His
1325 1330 1335
Ala Val Cys Thr Asn Thr Ala Gly Ser Phe Lys Cys Ser Cys Ser
1340 1345 1350
Pro Gly Trp Ile Gly Asp Gly Ile Lys Cys Thr Asp Leu Asp Glu
1355 1360 1365
Cys Ser Asn Gly Thr His Met Cys Ser Gln His Ala Asp Cys Lys
1370 1375 1380
Asn Thr Met Gly Ser Tyr Arg Cys Leu Cys Lys Asp Gly Tyr Thr
1385 1390 1395
Gly Asp Gly Phe Thr Cys Thr Asp Leu Asp Glu Cys Ser Glu Asn
1400 1405 1410
Leu Asn Leu Cys Gly Asn Gly Gln Cys Leu Asn Ala Pro Gly Gly
1415 1420 1425
Tyr Arg Cys Glu Cys Asp Met Gly Phe Val Pro Ser Ala Asp Gly
1430 1435 1440
Lys Ala Cys Glu Asp Ile Asp Glu Cys Ser Leu Pro Asn Ile Cys
1445 1450 1455
Val Phe Gly Thr Cys His Asn Leu Pro Gly Leu Phe Arg Cys Glu
1460 1465 1470
Cys Glu Ile Gly Tyr Glu Leu Asp Arg Ser Gly Gly Asn Cys Thr
1475 1480 1485
Asp Val Asn Glu Cys Leu Asp Pro Thr Thr Cys Ile Ser Gly Asn
1490 1495 1500
Cys Val Asn Thr Pro Gly Ser Tyr Thr Cys Asp Cys Pro Pro Asp
1505 1510 1515
Phe Glu Leu Asn Pro Thr Arg Val Gly Cys Val Asp Thr Arg Ser
1520 1525 1530
Gly Asn Cys Tyr Leu Asp Ile Arg Pro Arg Gly Asp Asn Gly Asp
1535 1540 1545
Thr Ala Cys Ser Asn Glu Ile Gly Val Gly Val Ser Lys Ala Ser
1550 1555 1560
Cys Cys Cys Ser Leu Gly Lys Ala Trp Gly Thr Pro Cys Glu Leu
1565 1570 1575
Cys Pro Ser Val Asn Thr Ser Glu Tyr Lys Ile Leu Cys Pro Gly
1580 1585 1590
Gly Glu Gly Phe Arg Pro Asn Pro Ile Thr Val Ile Leu Glu Asp
1595 1600 1605
Ile Asp Glu Cys Gln Glu Leu Pro Gly Leu Cys Gln Gly Gly Lys
1610 1615 1620
Cys Ile Asn Thr Phe Gly Ser Phe Gln Cys Arg Cys Pro Thr Gly
1625 1630 1635
Tyr Tyr Leu Asn Glu Asp Thr Arg Val Cys Asp Asp Val Asn Glu
1640 1645 1650
Cys Glu Thr Pro Gly Ile Cys Gly Pro Gly Thr Cys Tyr Asn Thr
1655 1660 1665
Val Gly Asn Tyr Thr Cys Ile Cys Pro Pro Asp Tyr Met Gln Val
1670 1675 1680
Asn Gly Gly Asn Asn Cys Met Asp Met Arg Arg Ser Leu Cys Tyr
1685 1690 1695
Arg Asn Tyr Tyr Ala Asp Asn Gln Thr Cys Asp Gly Glu Leu Leu
1700 1705 1710
Phe Asn Met Thr Lys Lys Met Cys Cys Cys Ser Tyr Asn Ile Gly
1715 1720 1725
Arg Ala Trp Asn Lys Pro Cys Glu Gln Cys Pro Ile Pro Ser Thr
1730 1735 1740
Asp Glu Phe Ala Thr Leu Cys Gly Ser Gln Arg Pro Gly Phe Val
1745 1750 1755
Ile Asp Ile Tyr Thr Gly Leu Pro Val Asp Ile Asp Glu Cys Arg
1760 1765 1770
Glu Ile Pro Gly Val Cys Glu Asn Gly Val Cys Ile Asn Met Val
1775 1780 1785
Gly Ser Phe Arg Cys Glu Cys Pro Val Gly Phe Phe Tyr Asn Asp
1790 1795 1800
Lys Leu Leu Val Cys Glu Asp Ile Asp Glu Cys Gln Asn Gly Pro
1805 1810 1815
Val Cys Gln Arg Asn Ala Glu Cys Ile Asn Thr Ala Gly Ser Tyr
1820 1825 1830
Arg Cys Asp Cys Lys Pro Gly Tyr Arg Leu Thr Ser Thr Gly Gln
1835 1840 1845
Cys Asn Asp Arg Asn Glu Cys Gln Glu Ile Pro Asn Ile Cys Ser
1850 1855 1860
His Gly Gln Cys Ile Asp Thr Val Gly Ser Phe Tyr Cys Leu Cys
1865 1870 1875
His Thr Gly Phe Lys Thr Asn Val Asp Gln Thr Met Cys Leu Asp
1880 1885 1890
Ile Asn Glu Cys Glu Arg Asp Ala Cys Gly Asn Gly Thr Cys Arg
1895 1900 1905
Asn Thr Ile Gly Ser Phe Asn Cys Arg Cys Asn His Gly Phe Ile
1910 1915 1920
Leu Ser His Asn Asn Asp Cys Ile Asp Val Asp Glu Cys Ala Thr
1925 1930 1935
Gly Asn Gly Asn Leu Cys Arg Asn Gly Gln Cys Val Asn Thr Val
1940 1945 1950
Gly Ser Phe Gln Cys Arg Cys Asn Glu Gly Tyr Glu Val Ala Pro
1955 1960 1965
Asp Gly Arg Thr Cys Val Asp Ile Asn Glu Cys Val Leu Asp Pro
1970 1975 1980
Gly Lys Cys Ala Pro Gly Thr Cys Gln Asn Leu Asp Gly Ser Tyr
1985 1990 1995
Arg Cys Ile Cys Pro Pro Gly Tyr Ser Leu Gln Asn Asp Lys Cys
2000 2005 2010
Glu Asp Ile Asp Glu Cys Val Glu Glu Pro Glu Ile Cys Ala Leu
2015 2020 2025
Gly Thr Cys Ser Asn Thr Glu Gly Ser Phe Lys Cys Leu Cys Pro
2030 2035 2040
Glu Gly Phe Ser Leu Ser Ser Thr Gly Arg Arg Cys Gln Asp Leu
2045 2050 2055
Arg Met Ser Tyr Cys Tyr Ala Lys Phe Glu Gly Gly Lys Cys Ser
2060 2065 2070
Ser Pro Lys Ser Arg Asn His Ser Lys Gln Glu Cys Cys Cys Ala
2075 2080 2085
Leu Lys Gly Glu Gly Trp Gly Asp Pro Cys Glu Leu Cys Pro Thr
2090 2095 2100
Glu Pro Asp Glu Ala Phe Arg Gln Ile Cys Pro Phe Gly Ser Gly
2105 2110 2115
Ile Ile Val Gly Pro Asp Asp Ser Ala Val Asp Met Asp Glu Cys
2120 2125 2130
Lys Glu Pro Asp Val Cys Arg His Gly Gln Cys Ile Asn Thr Asp
2135 2140 2145
Gly Ser Tyr Arg Cys Glu Cys Pro Phe Gly Tyr Ile Leu Glu Gly
2150 2155 2160
Asn Glu Cys Val Asp Thr Asp Glu Cys Ser Val Gly Asn Pro Cys
2165 2170 2175
Gly Asn Gly Thr Cys Lys Asn Val Ile Gly Gly Phe Glu Cys Thr
2180 2185 2190
Cys Glu Glu Gly Phe Glu Pro Gly Pro Met Met Thr Cys Glu Asp
2195 2200 2205
Ile Asn Glu Cys Ala Gln Asn Pro Leu Leu Cys Ala Phe Arg Cys
2210 2215 2220
Val Asn Thr Tyr Gly Ser Tyr Glu Cys Lys Cys Pro Val Gly Tyr
2225 2230 2235
Val Leu Arg Glu Asp Arg Arg Met Cys Lys Asp Glu Asp Glu Cys
2240 2245 2250
Ala Glu Gly Lys His Asp Cys Thr Glu Lys Gln Met Glu Cys Lys
2255 2260 2265
Asn Leu Ile Gly Thr Tyr Met Cys Ile Cys Gly Pro Gly Tyr Gln
2270 2275 2280
Arg Arg Pro Asp Gly Glu Gly Cys Ile Asp Glu Asn Glu Cys Gln
2285 2290 2295
Thr Lys Pro Gly Ile Cys Glu Asn Gly Arg Cys Leu Asn Thr Leu
2300 2305 2310
Gly Ser Tyr Thr Cys Glu Cys Asn Asp Gly Phe Thr Ala Ser Pro
2315 2320 2325
Thr Gln Asp Glu Cys Leu Asp Asn Arg Glu Gly Tyr Cys Phe Ser
2330 2335 2340
Glu Val Leu Gln Asn Met Cys Gln Ile Gly Ser Ser Asn Arg Asn
2345 2350 2355
Pro Val Thr Lys Ser Glu Cys Cys Cys Asp Gly Gly Arg Gly Trp
2360 2365 2370
Gly Pro His Cys Glu Ile Cys Pro Phe Glu Gly Thr Val Ala Tyr
2375 2380 2385
Lys Lys Leu Cys Pro His Gly Arg Gly Phe Met Thr Asn Gly Ala
2390 2395 2400
Asp Ile Asp Glu Cys Lys Val Ile His Asp Val Cys Arg Asn Gly
2405 2410 2415
Glu Cys Val Asn Asp Arg Gly Ser Tyr His Cys Ile Cys Lys Thr
2420 2425 2430
Gly Tyr Thr Pro Asp Ile Thr Gly Thr Ala Cys Val Asp Leu Asn
2435 2440 2445
Glu Cys Asn Gln Ala Pro Lys Pro Cys Asn Phe Ile Cys Lys Asn
2450 2455 2460
Thr Glu Gly Ser Tyr Gln Cys Ser Cys Pro Lys Gly Tyr Ile Leu
2465 2470 2475
Gln Glu Asp Gly Arg Ser Cys Lys Asp Leu Asp Glu Cys Ala Thr
2480 2485 2490
Lys Gln His Asn Cys Gln Phe Leu Cys Val Asn Thr Ile Gly Gly
2495 2500 2505
Phe Thr Cys Lys Cys Pro Pro Gly Phe Thr Gln His His Thr Ala
2510 2515 2520
Cys Ile Asp Asn Asn Glu Cys Thr Ser Asp Ile Asn Leu Cys Gly
2525 2530 2535
Ser Lys Gly Val Cys Gln Asn Thr Pro Gly Ser Phe Thr Cys Glu
2540 2545 2550
Cys Gln Arg Gly Phe Ser Leu Asp Gln Ser Gly Ala Ser Cys Glu
2555 2560 2565
Asp Val Asp Glu Cys Glu Gly Asn His Arg Cys Gln His Gly Cys
2570 2575 2580
Gln Asn Ile Ile Gly Gly Tyr Arg Cys Ser Cys Pro Gln Gly Tyr
2585 2590 2595
Leu Gln His Tyr Gln Trp Asn Gln Cys Val Asp Glu Asn Glu Cys
2600 2605 2610
Leu Ser Ala His Val Cys Gly Gly Ala Ser Cys His Asn Thr Leu
2615 2620 2625
Gly Ser Tyr Lys Cys Met Cys Pro Thr Gly Phe Gln Tyr Glu Gln
2630 2635 2640
Phe Ser Gly Gly Cys Gln Asp Ile Asn Glu Cys Gly Ser Ser Gln
2645 2650 2655
Ala Pro Cys Ser Tyr Gly Cys Ser Asn Thr Glu Gly Gly Tyr Leu
2660 2665 2670
Cys Gly Cys Pro Pro Gly Tyr Phe Arg Ile Gly Gln Gly His Cys
2675 2680 2685
Val Ser Gly Met Gly Met Gly Arg Gly Gly Pro Glu Pro Pro Ala
2690 2695 2700
Ser Ser Glu Met Asp Asp Asn Ser Leu Ser Pro Glu Ala Cys Tyr
2705 2710 2715
Glu Cys Lys Ile Asn Gly Tyr Pro Lys Ala Ala Gln Ser His Leu
2720 2725 2730
Pro Ala Thr Arg Pro Glu Thr Glu Lys His Glu Arg Asn Gly Cys
2735 2740 2745
Leu Arg His Pro Gly Arg Val
2750 2755
<210> 33
<211> 2737
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 33
Met Arg Arg Gly Gly Leu Leu Glu Val Ala Leu Ala Phe Ala Leu Leu
1 5 10 15
Leu Glu Ser Tyr Thr Ser His Gly Ala Asp Ala Asn Leu Glu Ala Gly
20 25 30
Ser Leu Lys Glu Thr Arg Ala Asn Arg Ala Lys Arg Arg Gly Gly Gly
35 40 45
Gly His Asp Ala Leu Lys Gly Pro Asn Val Cys Gly Ser Arg Tyr Asn
50 55 60
Ala Tyr Cys Cys Pro Gly Trp Lys Thr Leu Pro Gly Gly Asn Gln Cys
65 70 75 80
Ile Val Pro Ile Cys Arg His Ser Cys Gly Asp Gly Phe Cys Ser Arg
85 90 95
Pro Asn Met Cys Thr Cys Pro Ser Gly Gln Ile Ser Pro Ser Cys Gly
100 105 110
Ser Arg Ser Ile Gln His Cys Ser Ile Arg Cys Met Asn Gly Gly Ser
115 120 125
Cys Ser Asp Asp His Cys Leu Cys Gln Lys Gly Tyr Ile Gly Thr His
130 135 140
Cys Gly Gln Pro Val Cys Glu Ser Gly Cys Leu Asn Gly Gly Arg Cys
145 150 155 160
Val Ala Pro Asn Arg Cys Ala Cys Thr Tyr Gly Phe Thr Gly Pro Gln
165 170 175
Cys Glu Arg Asp Tyr Arg Thr Gly Pro Cys Phe Thr Val Val Ser Asn
180 185 190
Gln Met Cys Gln Gly Gln Leu Ser Gly Ile Val Cys Thr Lys Thr Leu
195 200 205
Cys Cys Ala Thr Val Gly Arg Ala Trp Gly His Pro Cys Glu Met Cys
210 215 220
Pro Ala Gln Pro His Pro Cys Arg Arg Gly Phe Ile Pro Asn Ile Arg
225 230 235 240
Thr Gly Ala Cys Gln Asp Val Asp Glu Cys Gln Ala Ile Pro Gly Met
245 250 255
Cys Gln Gly Gly Asn Cys Ile Asn Thr Val Gly Ser Phe Glu Cys Lys
260 265 270
Cys Pro Ala Gly His Lys Phe Asn Glu Val Ser Gln Lys Cys Glu Asp
275 280 285
Ile Asp Glu Cys Ser Thr Ile Pro Gly Val Cys Asp Gly Gly Glu Cys
290 295 300
Thr Asn Thr Val Ser Ser Tyr Phe Cys Lys Cys Pro Pro Gly Phe Tyr
305 310 315 320
Thr Ser Pro Asp Gly Thr Arg Cys Val Asp Val Arg Pro Gly Tyr Cys
325 330 335
Tyr Thr Ala Leu Ala Asn Gly Arg Cys Ser Asn Gln Leu Pro Gln Ser
340 345 350
Ile Thr Lys Met Gln Cys Cys Cys Asp Leu Gly Arg Cys Trp Ser Pro
355 360 365
Gly Val Thr Val Ala Pro Glu Met Cys Pro Ile Arg Ser Thr Glu Asp
370 375 380
Phe Asn Lys Leu Cys Ser Val Pro Leu Val Ile Pro Gly Arg Pro Glu
385 390 395 400
Tyr Pro Pro Pro Pro Ile Gly Pro Leu Pro Pro Val Gln Pro Val Pro
405 410 415
Pro Gly Tyr Pro Pro Gly Pro Val Ile Pro Ala Pro Arg Pro Pro Pro
420 425 430
Glu Tyr Pro Tyr Pro Ser Pro Ser Arg Glu Pro Pro Arg Val Leu Pro
435 440 445
Phe Asn Val Thr Asp Tyr Cys Gln Leu Val Arg Tyr Leu Cys Gln Asn
450 455 460
Gly Arg Cys Ile Pro Thr Pro Gly Ser Tyr Arg Cys Glu Cys Asn Lys
465 470 475 480
Gly Phe Gln Leu Asp Ile Arg Gly Glu Cys Ile Asp Val Asp Glu Cys
485 490 495
Glu Lys Asn Pro Cys Thr Gly Gly Glu Cys Ile Asn Asn Gln Gly Ser
500 505 510
Tyr Thr Cys His Cys Arg Ala Gly Tyr Gln Ser Thr Leu Thr Arg Thr
515 520 525
Glu Cys Arg Asp Ile Asp Glu Cys Leu Gln Asn Gly Arg Ile Cys Asn
530 535 540
Asn Gly Arg Cys Ile Asn Thr Asp Gly Ser Phe His Cys Val Cys Asn
545 550 555 560
Ala Gly Phe His Val Thr Arg Asp Gly Lys Asn Cys Glu Asp Met Asp
565 570 575
Glu Cys Ser Ile Arg Asn Met Cys Leu Asn Gly Met Cys Ile Asn Glu
580 585 590
Asp Gly Ser Phe Lys Cys Ile Cys Lys Pro Gly Phe Gln Leu Ala Ser
595 600 605
Asp Gly Arg Tyr Cys Lys Asp Ile Asn Glu Cys Glu Thr Pro Gly Ile
610 615 620
Cys Met Asn Gly Arg Cys Val Asn Thr Asp Gly Ser Tyr Arg Cys Glu
625 630 635 640
Cys Phe Pro Gly Leu Ala Val Gly Leu Asp Gly Arg Val Cys Val Asp
645 650 655
Thr His Met Arg Ser Thr Cys Tyr Gly Gly Tyr Arg Arg Gly Gln Cys
660 665 670
Val Lys Pro Leu Phe Gly Ala Val Thr Lys Ser Glu Cys Cys Cys Ala
675 680 685
Ser Thr Glu Tyr Ala Phe Gly Glu Pro Cys Gln Pro Cys Pro Ala Gln
690 695 700
Asn Ser Ala Glu Tyr Gln Ala Leu Cys Ser Ser Gly Pro Gly Met Thr
705 710 715 720
Ser Ala Gly Thr Asp Ile Asn Glu Cys Ala Leu Asp Pro Asp Ile Cys
725 730 735
Pro Asn Gly Ile Cys Glu Asn Leu Arg Gly Thr Tyr Lys Cys Ile Cys
740 745 750
Asn Ser Gly Tyr Glu Val Asp Ile Thr Gly Lys Asn Cys Val Asp Ile
755 760 765
Asn Glu Cys Val Leu Asn Ser Leu Leu Cys Asp Asn Gly Gln Cys Arg
770 775 780
Asn Thr Pro Gly Ser Phe Val Cys Thr Cys Pro Lys Gly Phe Val Tyr
785 790 795 800
Lys Pro Asp Leu Lys Thr Cys Glu Asp Ile Asp Glu Cys Glu Ser Ser
805 810 815
Pro Cys Ile Asn Gly Val Cys Lys Asn Ser Pro Gly Ser Phe Ile Cys
820 825 830
Glu Cys Ser Pro Glu Ser Thr Leu Asp Pro Thr Lys Thr Ile Cys Ile
835 840 845
Glu Thr Ile Lys Gly Thr Cys Trp Gln Thr Val Ile Asp Gly Arg Cys
850 855 860
Glu Ile Asn Ile Asn Gly Ala Thr Leu Lys Ser Glu Cys Cys Ser Ser
865 870 875 880
Leu Gly Ala Ala Trp Gly Ser Pro Cys Thr Ile Cys Gln Leu Asp Pro
885 890 895
Ile Cys Gly Lys Gly Phe Ser Arg Ile Lys Gly Thr Gln Cys Glu Asp
900 905 910
Ile Asn Glu Cys Glu Val Phe Pro Gly Val Cys Lys Asn Gly Leu Cys
915 920 925
Val Asn Ser Arg Gly Ser Phe Lys Cys Glu Cys Pro Asn Gly Met Thr
930 935 940
Leu Asp Ala Thr Gly Arg Ile Cys Leu Asp Ile Arg Leu Glu Thr Cys
945 950 955 960
Phe Leu Lys Tyr Asp Asp Glu Glu Cys Thr Leu Pro Ile Ala Gly Arg
965 970 975
His Arg Met Asp Ala Cys Cys Cys Ser Val Gly Ala Ala Trp Gly Thr
980 985 990
Glu Glu Cys Glu Glu Cys Pro Leu Arg Asn Ser Arg Glu Tyr Glu Glu
995 1000 1005
Leu Cys Pro Arg Gly Pro Gly Phe Ala Thr Lys Asp Ile Thr Asn
1010 1015 1020
Gly Lys Pro Phe Phe Lys Asp Ile Asn Glu Cys Lys Met Ile Pro
1025 1030 1035
Ser Leu Cys Thr His Gly Lys Cys Arg Asn Thr Ile Gly Ser Phe
1040 1045 1050
Lys Cys Arg Cys Asp Ser Gly Phe Ala Leu Asp Ser Glu Glu Arg
1055 1060 1065
Asn Cys Thr Asp Ile Asp Glu Cys Arg Ile Ser Pro Asp Leu Cys
1070 1075 1080
Gly Arg Gly Gln Cys Val Asn Thr Pro Gly Asp Phe Glu Cys Lys
1085 1090 1095
Cys Asp Glu Gly Tyr Glu Ser Gly Phe Met Met Met Lys Asn Cys
1100 1105 1110
Met Asp Ile Asp Glu Cys Gln Arg Asp Pro Leu Leu Cys Arg Gly
1115 1120 1125
Gly Ile Cys His Asn Thr Glu Gly Ser Tyr Arg Cys Glu Cys Pro
1130 1135 1140
Pro Gly His Gln Leu Ser Pro Asn Ile Ser Ala Cys Ile Asp Ile
1145 1150 1155
Asn Glu Cys Glu Leu Ser Ala Asn Leu Cys Pro His Gly Arg Cys
1160 1165 1170
Val Asn Leu Ile Gly Lys Tyr Gln Cys Ala Cys Asn Pro Gly Tyr
1175 1180 1185
His Pro Thr His Asp Arg Leu Phe Cys Val Asp Ile Asp Glu Cys
1190 1195 1200
Ser Ile Met Asn Gly Gly Cys Glu Thr Phe Cys Thr Asn Ser Asp
1205 1210 1215
Gly Ser Tyr Glu Cys Ser Cys Gln Pro Gly Phe Ala Leu Met Pro
1220 1225 1230
Asp Gln Arg Ser Cys Thr Asp Ile Asp Glu Cys Glu Asp Asn Pro
1235 1240 1245
Asn Ile Cys Asp Gly Gly Gln Cys Thr Asn Ile Pro Gly Glu Tyr
1250 1255 1260
Arg Cys Leu Cys Tyr Asp Gly Phe Met Ala Ser Glu Asp Met Lys
1265 1270 1275
Thr Cys Val Asp Val Asn Glu Cys Asp Leu Asn Pro Asn Ile Cys
1280 1285 1290
Leu Ser Gly Thr Cys Glu Asn Thr Lys Gly Ser Phe Ile Cys His
1295 1300 1305
Cys Asp Met Gly Tyr Ser Gly Lys Lys Gly Lys Thr Gly Cys Thr
1310 1315 1320
Asp Ile Asn Glu Cys Glu Ile Gly Ala His Asn Cys Gly Arg His
1325 1330 1335
Ala Val Cys Thr Asn Thr Ala Gly Ser Phe Lys Cys Ser Cys Ser
1340 1345 1350
Pro Gly Trp Ile Gly Asp Gly Ile Lys Cys Thr Asp Leu Asp Glu
1355 1360 1365
Cys Ser Asn Gly Thr His Met Cys Ser Gln His Ala Asp Cys Lys
1370 1375 1380
Asn Thr Met Gly Ser Tyr Arg Cys Leu Cys Lys Asp Gly Tyr Thr
1385 1390 1395
Gly Asp Gly Phe Thr Cys Thr Asp Leu Asp Glu Cys Ser Glu Asn
1400 1405 1410
Leu Asn Leu Cys Gly Asn Gly Gln Cys Leu Asn Ala Pro Gly Gly
1415 1420 1425
Tyr Arg Cys Glu Cys Asp Met Gly Phe Val Pro Ser Ala Asp Gly
1430 1435 1440
Lys Ala Cys Glu Asp Ile Asp Glu Cys Ser Leu Pro Asn Ile Cys
1445 1450 1455
Val Phe Gly Thr Cys His Asn Leu Pro Gly Leu Phe Arg Cys Glu
1460 1465 1470
Cys Glu Ile Gly Tyr Glu Leu Asp Arg Ser Gly Gly Asn Cys Thr
1475 1480 1485
Asp Val Asn Glu Cys Leu Asp Pro Thr Thr Cys Ile Ser Gly Asn
1490 1495 1500
Cys Val Asn Thr Pro Gly Ser Tyr Thr Cys Asp Cys Pro Pro Asp
1505 1510 1515
Phe Glu Leu Asn Pro Thr Arg Val Gly Cys Val Asp Thr Arg Ser
1520 1525 1530
Gly Asn Cys Tyr Leu Asp Ile Arg Pro Arg Gly Asp Asn Gly Asp
1535 1540 1545
Thr Ala Cys Ser Asn Glu Ile Gly Val Gly Val Ser Lys Ala Ser
1550 1555 1560
Cys Cys Cys Ser Leu Gly Lys Ala Trp Gly Thr Pro Cys Glu Leu
1565 1570 1575
Cys Pro Ser Val Asn Thr Ser Glu Tyr Lys Ile Leu Cys Pro Gly
1580 1585 1590
Gly Glu Gly Phe Arg Pro Asn Pro Ile Thr Val Ile Leu Glu Asp
1595 1600 1605
Ile Asp Glu Cys Gln Glu Leu Pro Gly Leu Cys Gln Gly Gly Lys
1610 1615 1620
Cys Ile Asn Thr Phe Gly Ser Phe Gln Cys Arg Cys Pro Thr Gly
1625 1630 1635
Tyr Tyr Leu Asn Glu Asp Thr Arg Val Cys Asp Asp Val Asn Glu
1640 1645 1650
Cys Glu Thr Pro Gly Ile Cys Gly Pro Gly Thr Cys Tyr Asn Thr
1655 1660 1665
Val Gly Asn Tyr Thr Cys Ile Cys Pro Pro Asp Tyr Met Gln Val
1670 1675 1680
Asn Gly Gly Asn Asn Cys Met Asp Met Arg Arg Ser Leu Cys Tyr
1685 1690 1695
Arg Asn Tyr Tyr Ala Asp Asn Gln Thr Cys Asp Gly Glu Leu Leu
1700 1705 1710
Phe Asn Met Thr Lys Lys Met Cys Cys Cys Ser Tyr Asn Ile Gly
1715 1720 1725
Arg Ala Trp Asn Lys Pro Cys Glu Gln Cys Pro Ile Pro Ser Thr
1730 1735 1740
Asp Glu Phe Ala Thr Leu Cys Gly Ser Gln Arg Pro Gly Phe Val
1745 1750 1755
Ile Asp Ile Tyr Thr Gly Leu Pro Val Asp Ile Asp Glu Cys Arg
1760 1765 1770
Glu Ile Pro Gly Val Cys Glu Asn Gly Val Cys Ile Asn Met Val
1775 1780 1785
Gly Ser Phe Arg Cys Glu Cys Pro Val Gly Phe Phe Tyr Asn Asp
1790 1795 1800
Lys Leu Leu Val Cys Glu Asp Ile Asp Glu Cys Gln Asn Gly Pro
1805 1810 1815
Val Cys Gln Arg Asn Ala Glu Cys Ile Asn Thr Ala Gly Ser Tyr
1820 1825 1830
Arg Cys Asp Cys Lys Pro Gly Tyr Arg Leu Thr Ser Thr Gly Gln
1835 1840 1845
Cys Asn Asp Arg Asn Glu Cys Gln Glu Ile Pro Asn Ile Cys Ser
1850 1855 1860
His Gly Gln Cys Ile Asp Thr Val Gly Ser Phe Tyr Cys Leu Cys
1865 1870 1875
His Thr Gly Phe Lys Thr Asn Val Asp Gln Thr Met Cys Leu Asp
1880 1885 1890
Ile Asn Glu Cys Glu Arg Asp Ala Cys Gly Asn Gly Thr Cys Arg
1895 1900 1905
Asn Thr Ile Gly Ser Phe Asn Cys Arg Cys Asn His Gly Phe Ile
1910 1915 1920
Leu Ser His Asn Asn Asp Cys Ile Asp Val Asp Glu Cys Ala Thr
1925 1930 1935
Gly Asn Gly Asn Leu Cys Arg Asn Gly Gln Cys Val Asn Thr Val
1940 1945 1950
Gly Ser Phe Gln Cys Arg Cys Asn Glu Gly Tyr Glu Val Ala Pro
1955 1960 1965
Asp Gly Arg Thr Cys Val Asp Ile Asn Glu Cys Val Leu Asp Pro
1970 1975 1980
Gly Lys Cys Ala Pro Gly Thr Cys Gln Asn Leu Asp Gly Ser Tyr
1985 1990 1995
Arg Cys Ile Cys Pro Pro Gly Tyr Ser Leu Gln Asn Asp Lys Cys
2000 2005 2010
Glu Asp Ile Asp Glu Cys Val Glu Glu Pro Glu Ile Cys Ala Leu
2015 2020 2025
Gly Thr Cys Ser Asn Thr Glu Gly Ser Phe Lys Cys Leu Cys Pro
2030 2035 2040
Glu Gly Phe Ser Leu Ser Ser Thr Gly Arg Arg Cys Gln Asp Leu
2045 2050 2055
Arg Met Ser Tyr Cys Tyr Ala Lys Phe Glu Gly Gly Lys Cys Ser
2060 2065 2070
Ser Pro Lys Ser Arg Asn His Ser Lys Gln Glu Cys Cys Cys Ala
2075 2080 2085
Leu Lys Gly Glu Gly Trp Gly Asp Pro Cys Glu Leu Cys Pro Thr
2090 2095 2100
Glu Pro Asp Glu Ala Phe Arg Gln Ile Cys Pro Phe Gly Ser Gly
2105 2110 2115
Ile Ile Val Gly Pro Asp Asp Ser Ala Val Asp Met Asp Glu Cys
2120 2125 2130
Lys Glu Pro Asp Val Cys Arg His Gly Gln Cys Ile Asn Thr Asp
2135 2140 2145
Gly Ser Tyr Arg Cys Glu Cys Pro Phe Gly Tyr Ile Leu Glu Gly
2150 2155 2160
Asn Glu Cys Val Asp Thr Asp Glu Cys Ser Val Gly Asn Pro Cys
2165 2170 2175
Gly Asn Gly Thr Cys Lys Asn Val Ile Gly Gly Phe Glu Cys Thr
2180 2185 2190
Cys Glu Glu Gly Phe Glu Pro Gly Pro Met Met Thr Cys Glu Asp
2195 2200 2205
Ile Asn Glu Cys Ala Gln Asn Pro Leu Leu Cys Ala Phe Arg Cys
2210 2215 2220
Val Asn Thr Tyr Gly Ser Tyr Glu Cys Lys Cys Pro Val Gly Tyr
2225 2230 2235
Val Leu Arg Glu Asp Arg Arg Met Cys Lys Asp Glu Asp Glu Cys
2240 2245 2250
Ala Glu Gly Lys His Asp Cys Thr Glu Lys Gln Met Glu Cys Lys
2255 2260 2265
Asn Leu Ile Gly Thr Tyr Met Cys Ile Cys Gly Pro Gly Tyr Gln
2270 2275 2280
Arg Arg Pro Asp Gly Glu Gly Cys Ile Asp Glu Asn Glu Cys Gln
2285 2290 2295
Thr Lys Pro Gly Ile Cys Glu Asn Gly Arg Cys Leu Asn Thr Leu
2300 2305 2310
Gly Ser Tyr Thr Cys Glu Cys Asn Asp Gly Phe Thr Ala Ser Pro
2315 2320 2325
Thr Gln Asp Glu Cys Leu Asp Asn Arg Glu Gly Tyr Cys Phe Ser
2330 2335 2340
Glu Val Leu Gln Asn Met Cys Gln Ile Gly Ser Ser Asn Arg Asn
2345 2350 2355
Pro Val Thr Lys Ser Glu Cys Cys Cys Asp Gly Gly Arg Gly Trp
2360 2365 2370
Gly Pro His Cys Glu Ile Cys Pro Phe Glu Gly Thr Val Ala Tyr
2375 2380 2385
Lys Lys Leu Cys Pro His Gly Arg Gly Phe Met Thr Asn Gly Ala
2390 2395 2400
Asp Ile Asp Glu Cys Lys Val Ile His Asp Val Cys Arg Asn Gly
2405 2410 2415
Glu Cys Val Asn Asp Arg Gly Ser Tyr His Cys Ile Cys Lys Thr
2420 2425 2430
Gly Tyr Thr Pro Asp Ile Thr Gly Thr Ala Cys Val Asp Leu Asn
2435 2440 2445
Glu Cys Asn Gln Ala Pro Lys Pro Cys Asn Phe Ile Cys Lys Asn
2450 2455 2460
Thr Glu Gly Ser Tyr Gln Cys Ser Cys Pro Lys Gly Tyr Ile Leu
2465 2470 2475
Gln Glu Asp Gly Arg Ser Cys Lys Asp Leu Asp Glu Cys Ala Thr
2480 2485 2490
Lys Gln His Asn Cys Gln Phe Leu Cys Val Asn Thr Ile Gly Gly
2495 2500 2505
Phe Thr Cys Lys Cys Pro Pro Gly Phe Thr Gln His His Thr Ala
2510 2515 2520
Cys Ile Asp Asn Asn Glu Cys Thr Ser Asp Ile Asn Leu Cys Gly
2525 2530 2535
Ser Lys Gly Val Cys Gln Asn Thr Pro Gly Ser Phe Thr Cys Glu
2540 2545 2550
Cys Gln Arg Gly Phe Ser Leu Asp Gln Ser Gly Ala Ser Cys Glu
2555 2560 2565
Asp Val Asp Glu Cys Glu Gly Asn His Arg Cys Gln His Gly Cys
2570 2575 2580
Gln Asn Ile Ile Gly Gly Tyr Arg Cys Ser Cys Pro Gln Gly Tyr
2585 2590 2595
Leu Gln His Tyr Gln Trp Asn Gln Cys Val Asp Glu Asn Glu Cys
2600 2605 2610
Leu Ser Ala His Val Cys Gly Gly Ala Ser Cys His Asn Thr Leu
2615 2620 2625
Gly Ser Tyr Lys Cys Met Cys Pro Thr Gly Phe Gln Tyr Glu Gln
2630 2635 2640
Phe Ser Gly Gly Cys Gln Asp Ile Asn Glu Cys Gly Ser Ser Gln
2645 2650 2655
Ala Pro Cys Ser Tyr Gly Cys Ser Asn Thr Glu Gly Gly Tyr Leu
2660 2665 2670
Cys Gly Cys Pro Pro Gly Tyr Phe Arg Ile Gly Gln Gly His Cys
2675 2680 2685
Val Ser Gly Met Gly Met Gly Arg Gly Gly Pro Glu Pro Pro Ala
2690 2695 2700
Ser Ser Glu Met Asp Asp Asn Ser Leu Ser Pro Glu Ala Cys Tyr
2705 2710 2715
Glu Cys Asp Gln Trp Leu Pro Gln Thr Gly Gln Glu Thr Glu Lys
2720 2725 2730
His Lys Arg Asn
2735
<210> 34
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 34
Glu Thr Glu Lys His Lys Arg Asn
1 5
<210> 35
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 35
Ile Ser Leu Arg Gln Lys Pro Met
1 5
<210> 36
<211> 6
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 36
Arg Gly Arg Lys Arg Arg
1 5
<210> 37
<211> 23
<212> РНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 37
acggagaagc acgaacgaaa cgg 23
<210> 38
<211> 123
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 38
cagggccctt aggtatctgc agacaaggag accctgatat acctggatgt cggaggcatc 60
agttttcgtt cgtgcttctc cgtttccggc ctcgttttgg gtagccgttg atcttacact 120
cat 123
<210> 39
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<220>
<221> misc_feature
<222> (2)..(21)
<223> n = A, T, C, или G
<400> 39
gnnnnnnnnn nnnnnnnnnn ngg 23
<210> 40
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<220>
<221> misc_feature
<222> (1)..(21)
<223> n = A, T, C, или G
<400> 40
nnnnnnnnnn nnnnnnnnnn ngg 23
<210> 41
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<220>
<221> misc_feature
<222> (3)..(23)
<223> n = A, T, C, или G
<400> 41
ggnnnnnnnn nnnnnnnnnn nnngg 25
<210> 42
<211> 28
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 42
Ala Ala Gln Ser His Leu Pro Ala Thr Arg Pro Glu Thr Glu Lys His
1 5 10 15
Glu Arg Asn Gly Cys Leu Arg His Pro Gly Arg Val
20 25
<210> 43
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 43
Asp Gln Trp Leu Pro Gln Thr Gly Gln Glu Thr Glu Lys His Lys Arg
1 5 10 15
Asn
<210> 44
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 44
aggcggccca gagccacctg ccagc 25
<210> 45
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 45
Tyr Pro Lys Arg Gly Arg Lys Arg Arg Ser Thr Asn Glu Asn
1 5 10
<210> 46
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 46
Leu Pro Gln Thr Gly Gln Glu Thr Glu Lys His Lys Arg Asn
1 5 10
<210> 47
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> Синтетический
<400> 47
Lys His Glu Arg Asn Gly Cys Leu Arg His Pro Gly Arg Val
1 5 10
<---
Реферат
Изобретение относится к области биохимии, в частности к мыши, чей геном содержит мутацию в предпоследнем экзоне гена, к ее эмбриональной стволовой (ES) клетке, а также к способу получения вышеуказанной мыши. Также раскрыт способ скрининга соединения на активность, уменьшающую симптомы, подобные симптомам врожденной липодистрофии, предусматривающий использование вышеуказанной мыши. Изобретение позволяет эффективно моделировать неонатальный прогероидный синдром с врожденной липодистрофией. 5 н. и 57 з.п. ф-лы, 13 ил., 2 табл., 2 пр.
Комментарии