Система и способ исключения шинглов от незначимых частей из сообщения при фильтрации спама - RU2583713C2
Код документа: RU2583713C2
Чертежи



Описание
Область техники
Изобретение относится к системам и способам исключения шинглов от незначимых частей из сообщения при фильтрации спама.
Уровень техники
Реклама в Интернете является одним из самых дешевых видов рекламы. Спам-сообщения, как основной и наиболее массовый вид рекламы в современном мире, занимает от 70-90% от общего объема почтового графика.
Спам - массовая рассылка рекламы или иного вида информации лицам, не выражавшим желания их получать. К спаму относятся сообщения, передаваемые по электронной почте, протоколам мгновенных сообщений, в социальных сетях, блогах, сайтах знакомств, форумах, а также SMS-, и MMS-сообщения.
Ввиду постоянного роста объемов рассылки спама возникают проблемы технического, экономического и криминального характера. Нагрузка на аппаратуру и каналы передачи данных, затраты времени пользователей на обработку сообщений, изменение направленности сообщений в сторону мошенничества и воровства - эти и другие аспекты показывают острую необходимость непрерывной борьбы со спамом.
Существует много способов противодействия спам-рассылкам. Одним из самых эффективных является использование антиспам-приложений - программ, предназначенных для обнаружения и удаления нежелательных спам-сообщений.
Антиспам-приложения используют методы, с помощью которых происходит фильтрация и удаление спама. При фильтрации спама одним их ключевых условий является отсутствие ложных срабатываний, которые заключаются в блокировании легитимных писем. Например, метод использования черных списков, суть которого заключается в удалении сообщений, приходящих с адресов из черного списка, обеспечивает стопроцентный отсев писем, полученных с адреса, который внесен в список. При ошибочном попадании в этот список адресов обычных пользователей происходит ложное срабатывание и удаление нужных сообщений, которые не являются спамом.
Еще одним методом противодействия спаму является метод контентной фильтрации, который заключается в использовании специальных спам-фильтров, анализирующих составные части сообщений, включая графические. По результатам анализа может быть сформирован лексический вектор либо вычислен спам-вес сообщения. На основании указанных величин выносится решение о том, что сообщение содержит либо не содержит спам.
Другой метод борьбы со спамом использует технологию кластеризации сообщений, которая предполагает выявление в потоке почты массовых сообщений, абсолютно идентичных или различающихся незначительно. Недостатком данного способа является то, что большинство легитимных сервисов, таких как, например, сервисы подписки на новости или обновления, также используют массовую рассылку и, следовательно, могут быть признаны при использовании данного способа источниками спам-рассылки.
Антиспам-лаборатории занимаются созданием и совершенствованием правил фильтрации, используемых спам-фильтрами. В то же время люди, которые занимаются рассылкой спама, непрерывно предпринимают попытки обойти защиту спам-фильтров. Очевидно, что существующие методы противодействия спаму имеют ряд недостатков и не могут решить проблему полностью.
В настоящее время существуют различные решения для снижения уровня ложных срабатываний почтового антиспам приложения за счет дополнительной фильтрации текста сообщения при использовании метода кластеризации сообщения. Патент US 7899866 B1 описывает технологию фильтрации писем на основании нескольких характеристик. Одной из характеристик может выступать структура (наличие той или иной части, даты, словосочетания и т.д.) текстового письма. В заявке US 20120078719 A1 описан алгоритм обработки текстов, выявления статистики появления важных ключевых слов, определения тематики и построения связывающих графов. На основе нескольких текстов (страниц, статей) строятся шинглы тематической направленности. Наборы похожих и часто встречающихся шинглов входят в кластер.
В целях уменьшения уровня ложных срабатываний при использовании метода кластеризации сообщений для фильтрации спама важную роль играет объем анализируемого сообщения. Очевидно, что спам-составляющая занимает не весь объем сообщения, поэтому необходимо анализировать сообщения с целью выделения незначимых для фильтрации частей.
Изобретения, перечисленные в указанных выше патентных публикациях, направлены на решение определенных задач при фильтрации спама, но они имеют один общий недостаток - отсутствие инструмента сокращения сообщения за счет исключения шинглов от незначимых частей из сообщения при фильтрации спама. Настоящее изобретение позволяет эффективно и результативно решить задачу сокращения объема сообщения за счет исключения шинглов от незначимых частей из сообщения при фильтрации спама.
Раскрытие изобретения
Настоящее изобретение предназначено для исключения шинглов от частей сообщения, которые встречались только в сообщениях, не содержащих спам, при фильтрации спама.
Технический результат настоящего изобретения заключается в сокращении размера сообщения при фильтрации спама. Указанный технический результат достигается за счет поиска и исключения шинглов, которые встречались только в сообщениях, не содержащих спам.
Система исключения шинглов, которые встречались только в сообщениях, не содержащих спам, при фильтрации спама, которая содержит: средство обработки текста, предназначенное для поиска частей текста, которые встречались только в сообщениях, не содержащих спам, которые следует исключить, путем анализа текста сообщения на наличие известных образцов текста, хранимых в базе данных образцов текста, исключения из текста сообщения найденных частей текста, которые встречались только в сообщениях, не содержащих спам, передачи сокращенного текста сообщения средству обработки шинглов; база данных образцов текста, предназначенная для хранения известных образцов текста, характерных для частей сообщения, которые встречались только в сообщениях, не содержащих спам; средство обработки шинглов, предназначенное для вычисления набора шинглов на основе сокращенного текста сообщения, поиска шинглов, которые следует исключить, путем сравнения шинглов из вычисленного набора шинглов с известными шинглами, которые хранятся в базе данных шинглов, исключения совпадающих шинглов, база данных шинглов, предназначенная для хранения известных шинглов, характерных для частей сообщения, которые встречались только в сообщениях, не содержащих спам.
В частном случае реализации системы средство обработки шинглов после исключения совпадающих шинглов передает сокращенный набор шинглов средству фильтрации.
В другом частном случае реализации системы дополнительно используют средство фильтрации, предназначенное для анализа сокращенного набора шинглов по крайней мере по одному из методов фильтрации.
Еще в одном частном случае реализации системы средство фильтрации производит анализ сокращенного набора шинглов по методу кластеризации.
В другом частном случае реализации системы средство фильтрации производит анализ сокращенного набора шинглов по методу Байеса.
Еще в одном частном случае реализации системы средство обработки текста производит канонизацию текста.
В другом частном случае реализации системы в базе данных образцов текста хранятся образцы текста, которые встречались только в сообщениях, не содержащих спам.
Еще в одном частном случае реализации системы базе данных шинглов хранятся шинглы, которые встречались только в сообщениях, не содержащих спам.
В другом частном случае реализации системы база данных образцов текста и база данных шинглов заполняются образцами текста и шинглами из сообщений, не содержащих спам, получаемых от пользователей персональных компьютеров посредством антивирусного сервера.
Способ исключения шинглов, которые встречались только в сообщениях, не содержащих спам, при фильтрации спама, в котором: при помощи средства обработки текста производят поиск частей сообщения, которые встречались только в сообщениях, не содержащих спам; при помощи средства обработки текста исключают части сообщения, которые встречались только в сообщениях, не содержащих спам; при помощи средства обработки шинглов вычисляют набор шинглов на основе сокращенного сообщения; при помощи средства обработки шинглов производят поиск шинглов, которые встречались только в сообщениях, не содержащих спам; при помощи средства обработки шинглов исключают из набора шинглов, вычисленного на основе сокращенного сообщения, найденные шинглы для последующей фильтрации.
В частном случае реализации способа производят поиск частей сообщения, которые встречались только в сообщениях, не содержащих спам, которые следует исключить, путем анализа текста сообщения на наличие известных образцов текста.
В другом частном случае реализации способа хранят известные образцы текста, которые встречались только в сообщениях, не содержащих спам.
Еще в одном частном случае реализации способа при исключении частей сообщения, которые встречались только в сообщениях, не содержащих спам, производят канонизацию текста.
В другом частном случае реализации способа производят поиск шинглов, которые следует исключить, путем сравнения шинглов из вычисленного набора шинглов с известными шинглами.
Еще в одном частном случае реализации способа хранят известные шинглы, которые встречались только в сообщениях, не содержащих спам.
В другом частном случае реализации способа после исключения из набора шинглов, вычисленного на основе сокращенного сообщения, найденных при поиске шинглов, получают сокращенный набор шинглов.
Еще в одном частном случае реализации способа анализ сокращенного набора шинглов производится по методу Байеса.
В другом частном случае реализации способа анализ сокращенного набора шинглов производится по методу кластеризации.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи.
Заявленное изобретение поясняется следующими чертежами, на которых:
Фиг.1 представляет примеры незначимого текста в виде подписей и автоподписей.
Фиг.2 показывает структурную схему системы исключения шинглов от незначимых частей из сообщения при фильтрации спама.
Фиг.3 отображает способ работы системы исключения шинглов от незначимых частей из сообщения при фильтрации спама.
Фиг.4 представляет пример компьютерной системы общего назначения.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
При обработке почтовых сообщений методом кластеризации сообщений по тексту письма проводится построение наборов объектов. Далее происходит сравнение с уже известными наборами объектов, содержащих спам, и наборами объектов, не содержащих спам. Исходя из репутации объектов из базы данных определяется, является ли анализируемое письмо спамом.
Объектами для сравнения могут быть слова, словосочетания, шинглы, свертки и т.д. Далее по тексту под шинглом подразумевается объект для сравнения при фильтрации почтовых писем.
Для того чтобы вычислить набор шинглов, текст письма разбивается на последовательности слов. Алгоритм сравнения шинглов может зависеть от способа подсчета шинглов и длины шингла. В ходе проработки текста встречаются части текста, которые не имеют значения при определении спама, но не исключаются при вычислении шинглов. Одной из таких незначимых частей текста, например, является подпись, в том числе и автоподпись. Автоподпись - часть текстового электронного письма, которая содержит информацию об отправителе либо любую служебную информацию о сервере или сообщении. Автоподпись генерируется и вставляется в сообщение автоматически. На Фиг.1 показаны примеры незначимого текста в виде подписей и автоподписей. Другими примерами незначимого текста являются части письма, содержащие почтовый адрес и телефон, постскриптум и т.д., которые встречаются в деловой переписке и несут формальный характер. Сокращения вышеописанных примеров незначимого текста сообщений позволяют избавляться от частей письма, которые не имеют значения при фильтрации спама, что увеличивает результативность и точность дальнейшей обработки сообщений.
В Фиг.2 изображена структурная схема системы исключения шинглов от незначимых частей из сообщения при фильтрации спама. В общем случае система исключения шинглов от незначимых частей из сообщения при фильтрации спама состоит из средства обработки текста 220, средства обработки шинглов 230, средства фильтрации 260, базы данных образцов текста 240 и базы данных шинглов 250. Средство обработки текста 220 предназначено для поиска незначимых частей текста, которые следует исключить, путем анализа текста сообщения на наличие известных образцов текста, хранимых в базе данных образцов текста 240, исключения найденных незначимых частей текста из сообщения, канонизации сокращенного текста сообщения и передачи сокращенного текста сообщения средству обработки шинглов 230. Средство обработки шинглов 230 предназначено для вычисления набора шинглов на основе сокращенного текста сообщения, поиска шинглов, которые следует исключить, путем сравнения шинглов из вычисленного набора шинглов с шинглами, которые хранятся в базе данных шинглов 250, исключения совпадающих шинглов, передачи сокращенного набора шинглов средству фильтрации 260. Средство фильтрации 260 производит фильтрацию сокращенного набора шинглов по одному из методов фильтрации, например по методу кластеризации, Байеса и т.д. База данных образцов текста 240 предназначена для хранения образцов текста, которые встречались только в сообщениях, не содержащих спам, и характерны для незначимых частей сообщения. База данных шинглов 250 предназначена для хранения информации о шинглах, которые встречались только в сообщениях, не содержащих спам, и характерны для незначимых частей сообщения.
Незначимыми образцами текста могут быть слова, словосочетания, символы или совокупности слов, словосочетаний и символов, которые встречались только в сообщениях, не содержащих спам. Характерность и значимость образцов текста выясняется экспертным путем и на основе статистических вычислений.
В некоторых случаях по ряду причин текст сообщения может быть недоступен для обработки, например по причине сохранения конфиденциальности, что не позволяет выполнять поиск образцов текста. В этом случае осуществляют обработку текста при помощи шинглов. Под шинглом понимают контрольную сумму от выделенной последовательности слов, идущих другу за другом. Длина шингла - количество слов в последовательности, обычно от 3 до 10. Разбивая текст, выборка слов для последовательности происходит внахлест. Количество последовательностей слов равно количеству слов в тексте минус длина шингла плюс один. После разбиения от каждой последовательности вычисляют контрольную сумму, в результате чего получают набор шинглов. Например, в случае, если предложение состоит из 7 слов (слово 1, слово 2… слово 7), а длина шингла - 4, количество последовательностей - 7-4+1=4, последовательности слов могут быть следующие: {слово 1, слово 2, слово 3, слово 4},…, {слово 4, слово 5, слово 6, слово 7}. После подсчета контрольной суммы от каждой последовательности, например по алгоритму MD5, получают набор шинглов: 1bc29b36f623ba82aaf6724fd3bl6718,…, 026f8e459c8f89ef75fa7a78265a0025.
Контрольная сумма - некоторое значение, рассчитанное по набору данных путем применения вычислительного алгоритма и используемое для проверки целостности данных при их передаче или хранении.
Предварительная обработка текста или канонизация приводит оригинальный текст к единой нормальной форме. Текст очищается от предлогов, союзов, знаков препинания, HTML-тегов, и прочего «мусора», который не должен участвовать в сравнении. Также при канонизации существительные приводят к именительному падежу в единственном числе либо оставляют от них только корни слов.
В качестве базы данных образцов текста 240 и базы данных шинглов 250 могут использоваться базы данных различных типов, например: иерархические (IMS, TDMS, System 2000), сетевые (Cerebrum, Cronospro, DBVist), реляционные (DB2, Informix, Microsoft SQL Server), объектно-ориентированные (Jasmine, Versant, POET), объектно-реляционные (Oracle Database, PostgreSQL, FirstSQL/J), функциональные и т.д.
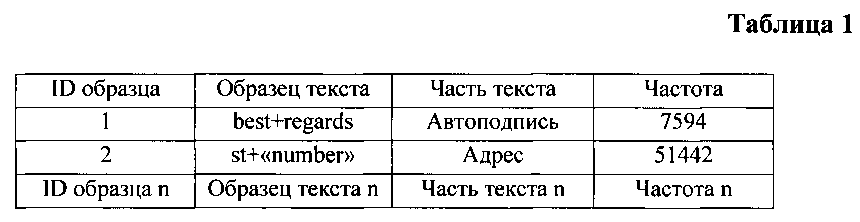
База данных образцов текста 240, например, может иметь вид, показанный в Таблице 1.
База данных шинглов 250, например, может иметь вид, показанный в Таблице 2.

Заполнение базы данных образцов текста и базы данных шинглов образцами текста и шинглами из сообщений, не содержащих спам, присылаемых от пользователей персональных компьютеров, возможно из антивирусного сервера 270.
Фиг 3 отображает способ работы системы исключения шинглов от незначимых частей из сообщения при фильтрации спама. На этапе 310 осуществляется получение входящего сообщения, затем сообщение передается для обработки средству обработки текста 220. На этапе 320 средство обработки текста 220 производит поиск незначимых частей текста, которые следует исключить, путем анализа текста сообщения на наличие образцов текста, хранимых в базе данных образцов текста 240. На этапе 330 средство обработки текста 220 исключает части сообщения, в которых были найдены известные образцы текста из базы данных образцов текста 240, и пересылает сокращенный текст сообщения средству обработки шинглов 230. Также на этапе 330 средство обработки текста 220 перед пересылкой производит канонизацию текста при необходимости. На этапе 340 средство обработки шинглов 230 вычисляет набор шинглов на основе сокращенного текста сообщения. На этапе 350 средство обработки шинглов 230 производит поиск шинглов, которые следует исключить, путем сравнения шинглов из вычисленного набора шинглов с известными шинглами, которые хранятся в базе данных шинглов 250. На этапе 360 средство обработки шинглов исключает совпадающие шинглы и передает сокращенный набор шинглов средству фильтрации 260. На этапе 370 средство фильтрации 260 производит фильтрацию сокращенного набора шинглов по одному из методов фильтрации, например по методу кластеризации, Байеса и т.д.
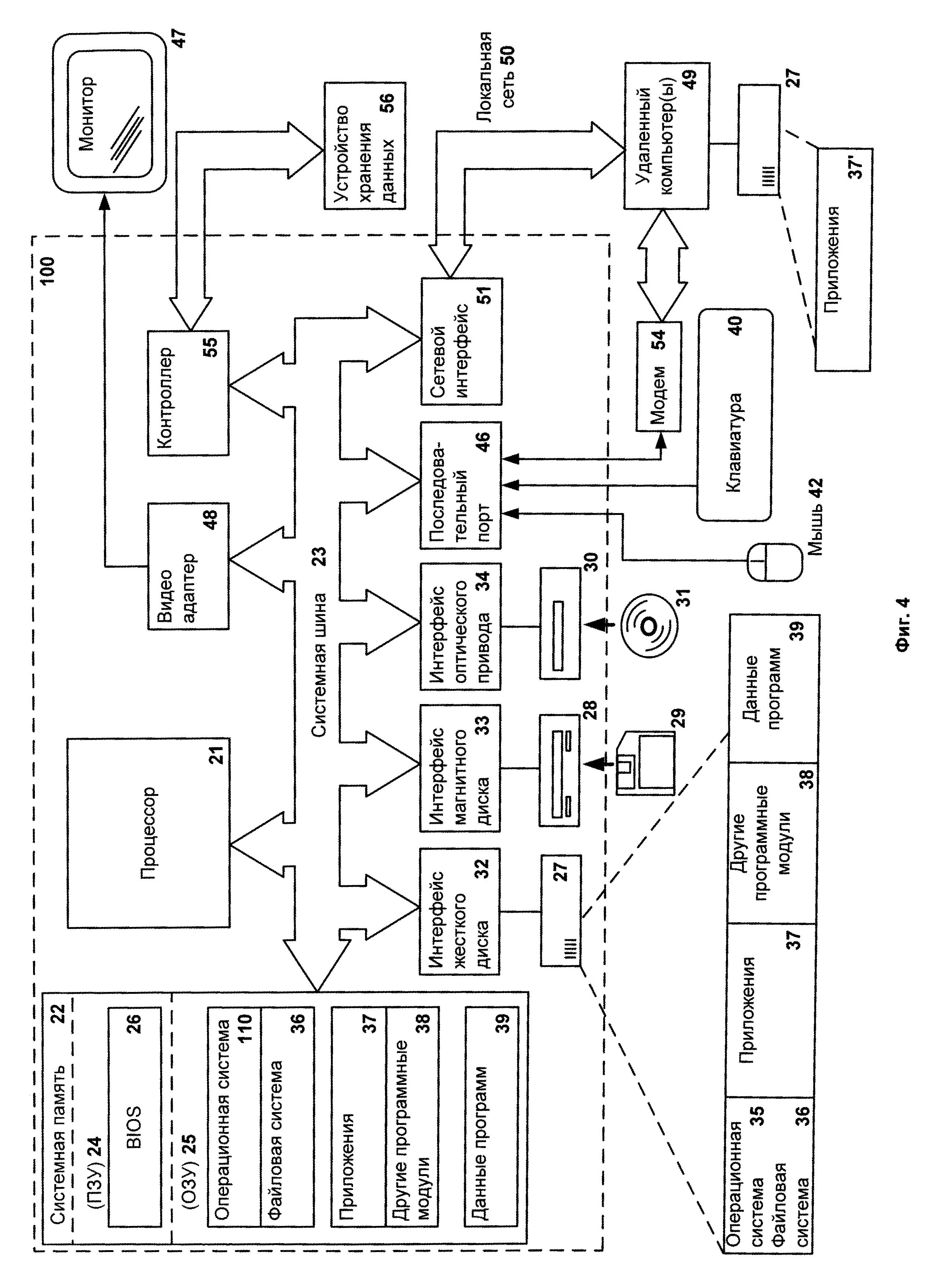
Фиг. 4 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 111, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая, в свою очередь, память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26 содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 111, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 111, в свою очередь, содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 111.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 111 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 111 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 111 через последовательный порт 46, который, в свою очередь, подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 111 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 111, представленного на Фиг. 6. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 111 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 111 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются только примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
Реферат
Изобретение относится к системам и способам исключения шинглов от частей сообщения, которые встречались только в сообщениях, не содержащих спам, при фильтрации спама. Технический результат настоящего изобретения заключается в сокращении размера сообщения при фильтрации спама. Система исключения шинглов, которые встречались только в сообщениях, не содержащих спам, содержит: а) средство обработки текста, предназначенное для: получения сообщения, по крайней мере одна часть текста которого является незначимой, при этом незначимой является часть текста сообщения, которая не имеет значения при определении спама и содержит слова, символы, по которым выделяют по меньшей мере почтовый адрес, телефон, постскриптум, автоподпись, и которая встречается в сообщениях, не содержащих спам, поиска в упомянутом сообщении тех частей текста, которые совпадают с известными частями текста из базы данных образцов текста, сокращения текста упомянутого сообщения путем исключения из текста упомянутого сообщения найденных частей текста, которые совпадают с известными частями текста из базы данных образцов текста, передачи сокращенного текста упомянутого сообщения средству обработки шинглов; б) базу данных образцов текста, предназначенную для хранения известных частей текста сообщения, которые встречались только в сообщениях, не содержащих спам, и характерны для незначимых частей сообщения; в) средство обработки шинглов, предназначенное для: вычисления набора шинглов на основе сокращенного текста упомянутого сообщения, сравнения вычисленного набора шинглов с известными шинглами из базы данных шинглов, сокращения вычисленного набора шингло
Формула
а) средство обработки текста, предназначенное для:
- получения сообщения, по крайней мере одна часть текста которого является незначимой, при этом незначимой является часть текста сообщения, которая не имеет значения при определении спама и содержит слова, символы, по которым выделяют по меньшей мере почтовый адрес, телефон, постскриптум, автоподпись, и которая встречается в сообщениях, не содержащих спам,
- поиска в упомянутом сообщении тех частей текста, которые совпадают с известными частями текста из базы данных образцов текста,
- сокращения текста упомянутого сообщения путем исключения из текста упомянутого сообщения найденных частей текста, которые совпадают с известными частями текста из базы данных образцов текста,
- передачи сокращенного текста упомянутого сообщения средству обработки шинглов;
б) базу данных образцов текста, предназначенную для хранения известных частей текста сообщения, которые встречались только в сообщениях, не содержащих спам, и характерны для незначимых частей сообщения;
в) средство обработки шинглов, предназначенное для:
- вычисления набора шинглов на основе сокращенного текста упомянутого сообщения,
- сравнения вычисленного набора шинглов с известными шинглами из базы данных шинглов,
- сокращения вычисленного набора шинглов путем исключения шинглов, которые совпадают с известными шинглами из базы данных шинглов;
г) базу данных шинглов, предназначенную для хранения известных шинглов, которые встречались только в сообщениях, не содержащих спам.
а) получают средством обработки текста сообщение, по крайней мере одна часть текста которого является незначимой, при этом незначимой является часть текста сообщения, которая не имеет значения при определении спама и содержит слова, символы, по которым выделяют по меньшей мере почтовый адрес, телефон, постскриптум, автоподпись, которые встречаются в сообщениях, не содержащих спам;
б) хранят известные части текста сообщения, которые встречались только в сообщениях, не содержащих спам, и характерны для незначимых частей сообщения, в базе данных образцов текста;
в) выполняют средством обработки текста поиск в упомянутом сообщении тех частей текста, которые совпадают с известными частями текста из базы данных образцов текста;
г) сокращают текст упомянутого сообщения средством обработки текста путем исключения из текста упомянутого сообщения найденных частей текста, которые совпадают с известными частями текст из базы данных образцов текста;
д) вычисляют средством обработки шинглов набор шинглов на основе сокращенного текста упомянутого сообщения;
е) хранят в базе данных шинглов известные шинглы, которые встречались только в сообщениях, не содержащих спам;
ж) сравнивают вычисленный набор шинглов с известными шинглами, из базы данных шинглов;
з) сокращают средством обработки шинглов вычисленный набор шинглов путем исключения шинглов, которые совпадают с известными шинглами из базы данных шинглов.
Документы, цитированные в отчёте о поиске
Способ автоматизированного анализа текстовых документов
Инфраструктура для обеспечения интеграции антиспамовых технологий
Комментарии