Способ сжатия речевого сигнала путем кодирования с переменной скоростью и устройство для его осуществления, кодер и декодер - RU2107951C1
Код документа: RU2107951C1
Чертежи



















Описание
Изобретение относится к области обработки речевых сигналов, точнее к созданию новых усовершенствованных способов и устройств для сжатия речевых сигналов, в которых степень сжатия динамически меняется с целью минимизации влияния сжатия на качество воспроизводимой речи. Более того, поскольку сжатая речевая информация предназначена для передачи по каналу связи, который может вносить искажения, способ и устройство, предложенные в изобретении, позволяют минимизировать влияние канальных искажений на качество воспроизводимой речи.
Передача голоса цифровыми средствами получила широкое распространение, особенно применительно к дальней и радиотелефонной связи. Это в свою очередь вызвало повышенный интерес к определению минимального количества информация, передаваемой по каналу связи, которое обеспечивает приемлемое качество воспроизводимой речи. Если при передаче речи используются просто дискретизация и цифровое кодирование, то для достижения качества воспроизводимой речи обычного аналогового телефона потребуется скорость передачи данных около 64 кб/с. Однако применение анализа речи перед соответствующим кодированием и передачей и синтеза речи на приемной стороне позволяет достичь существенного снижения скорости передачи данных.
Устройства, которые используют методы сжатия речевых сигналов путем выделения параметров, связанных с моделью генерации человеческой речи, обычно называют вокодерами. Такие устройства содержат кодер, который анализирует входной речевой сигнал для выделения нужных параметров, и декодер, который синтезирует речевой сигнал, используя параметры, полученные по каналу связи. Чтобы быть точной, модель должна постоянно меняться. Поэтому речевой сигнал делится на временные блоки или анализируемые кадры, в течение которых рассчитываются параметры речевых сигналов. Эти параметры затем обновляются для каждого нового кадра.
Из речевых кодеров различных классов кодеры, использующие кодирование методом линейного предсказания с кодовым возбуждением (ЛПККВ) стохастическое кодирование или речевое кодирование с векторным возбуждением, относятся к одному классу. Пример кодирующего алгоритма этого класса описан в работе "А 4. 8 kbps Code Excited Linear Predictive Code", Thomas E Tremain et al., Proceedings of the Mobile Satellite Conference, 1988.
Задачей вокодера является сжатие оцифрованного речевого сигнала в сигнал с малой скоростью передачи битов с помощью устранения всех естественных избыточностей, присутствующих в речи. Типичный речевой сигнал имеет кратковременные избыточности, обусловленные прежде всего фильтрацией в голосовом тракте и долговременные избыточности обусловленные возбуждением голосового тракта голосовыми связками. В кодере ЛПККВ эти операции моделируются двумя фильтрами, формантным фильтром формирующим кратковременные избыточности, и тоновым фильтром долговременных избыточностей. Как только эти избыточности устранены, полученный остаточный сигнал может моделироваться как белый Гауссовый шум, который должен быть также закодирован. Данная процедура основана на расчете параметров фильтра, называемого фильтром кодирования с линейным предсказанием, который осуществляет краткосрочное предсказание формы речевого сигнала, используя модель человеческого голосового тракта. Кроме того, долговременные воздействия, относящиеся к речевому тону, моделируются путем расчета параметров тонового фильтра, который по существу моделирует человеческие голосовые связки. Наконец, эти фильтры должны быть возбуждены, и это осуществляется путем определения того, какое колебание из некоторого набора случайных возбуждающих колебаний, находящихся в кодовом словаре, будучи поданным для возбуждения упомянутых выше двух фильтров, обеспечивает ближайшую аппроксимацию исходного речевого сигнала. Таким образом передаваемые параметры относятся к фильтру кодирования с линейным предсказанием ЛПК тональному фильтру и возбуждению кодового словаря. Несмотря на то, что использование методов сжатия речевого сигнала решает задачу уменьшения количества информации, передаваемой по каналу, при обеспечении приемлемого качества воспроизводимой речи, требуется применение других методов, чтобы еще больше уменьшить количество передаваемой информации. Одним из методов, используемых для уменьшение передаваемого количества информации, является стробирование активности речевого сигнала. При применении этого метода отсутствует передача информации во время пауз речи. Хотя этот способ позволяет достичь желаемых результатов по сокращению передаваемых данных, он обладает рядом недостатков.
Во многих случаях качество речи ухудшается из-за отсечения начальных частей слов. Другим недостатком запирания канала во время пауз является то, что пользователи системы отсутствие окружающего шума, который обычно сопутствует речевому сигналу, оценивают как снижение качества канала ниже, чем обычного телефонного канала. Следующим недостатком метода стробирования является подверженность воздействию случайных, внезапных шумов, которые могут запустить передатчик при отсутствии речевого сигнала, что приводит к нежелательным трескам на приемной стороне.
Для того, чтобы улучшить качество синтезируемой речи в системах со стробированием речевого сигнала во время процесса декодирования к нему добавляется синтезированный привычный шум. Хотя добавление этого шума позволяет достичь некоторого улучшения качества, оно реально не улучшает общее качество, так как этот шум не моделирует реальный фоновый шум на входе кодера.
Более предпочтительным методом сжатия данных и как следствие - уменьшения количества передаваемой информации, является кодирование : речевых данных с переменной скоростью. Так как речь неотъемлемо содержит периоды молчания, т. е. паузы, количество данных, требуемых для представления этих периодов, может быть уменьшено. Кодирование данных с переменной скоростью наиболее эффективно использует это свойство, уменьшая скорость передачи данных во время этих периодов молчания. Уменьшение скорости передачи данных в противоположность полному запрещению передачи данных в периоды молчания позволяет устранить недостатки, присущие методу стробирования активности речевого сигнала, способствуя при этом уменьшению передаваемой информации.
Таким образом, целью предлагаемого изобретения является создание новых более совершенных способа и устройства для сжатия речевого сигнала, использующих методы кодирования с переменной скоростью.
Предлагаемое изобретение предусматривает создание алгоритма кодирования речевого сигнала для ранее упомянутого класса вокодеров, использующих кодирование методом линейного предсказания с кодовым возбуждением (ЛПККВ), стохастическое кодирование или речевое кодирование с векторным возбуждением. Метод ЛПККВ сам по себе обеспечивает существенное уменьшение объема данных, необходимых для представления речи таким образом, чтобы получить высокое качество восстановленной речи. Как отмечалось ранее, параметры вокодера корректируются для каждого кадра. Вокодер, предлагаемый в настоящем изобретении обеспечивает переменную скорость выходных данных путем изменения частоты и точности параметров модели.
Предлагаемое изобретение существенно отличается от классического метода ЛПККВ тем, что производит выходные данные с переменной скоростью, на основе активности речевого сигнала. Особенностью данного метода является то, что параметры корректируются менее часто или с меньшей точностью в течение пауз речи. Такая процедура позволяет достичь существенно большего уменьшения информации, предназначенной для передачи. Свойством, которое используется для уменьшения скорости передачи данных, является коэффициент активности голоса, под которым подразумевается среднее время в процентах фактически занимаемое словами, произносимыми говорящим во время разговора. Для типичной двусторонней телефонной связи средняя скорость передачи данных уменьшается в два и более раз. Во время речевых пауз в вокодере кодируется только окружающий шум. В эти моменты нет необходимости передавать часть параметров, относящихся к модели человеческого голосового тракта.
Упомянутый ранее известный метод ограничения информации, передаваемой в течение периодов молчания, называется стробированием активности речевого сигнала, при котором никакой информации не передается в течение периодов молчания. На приемной стороне такой период может быть заполнен синтезированным "комфортным шумом", т.е. шумом, обычно сопровождающим человеческую речь. В противоположность этому вокодер с переменной скоростью передачи постоянно передает данные, в предпочтительном варианте осуществления изобретения со скоростями, диапазон которых лежит примерно между 8 кб/с и 1 кб/с. Вокодер, который осуществляет непрерывную передачу данных, не нуждается в синтезированном "комфортном" шуме, а путем кодирования окружающего шума обеспечивает более естественное качество синтезированной речи. Поэтому предлагаемое изобретение обеспечивает существенное улучшение качества синтезированной речи по отношению к качеству, обеспечиваемому методом стробирования активности речевого сигнала благодаря сглаживанию перехода между периодами активной речи и паузами с окружающим шумом.
Настоящее изобретение использует в дальнейшем новую процедуру для маскировки ошибок. Так как данные, предназначенные для передачи по каналу связи, могут быть искажены шумом, например в случае радиосвязи, то этот метод должен быть приспособлен к ошибкам в данных. Известные методы, использующие канальное кодирование для уменьшения числа ошибок, являются довольно эффективными. Однако канальное кодирование само по себе" не дает в полной мере степени защиты от помех, необходимой для обеспечения высокого качества восстанавливаемой речи. В вокодере с переменной скоростью передачи, где процесс кодирования речевого сигнала осуществляется непрерывно, ошибка может исказить данные, относящиеся к некоторым важным частям речи, таким как начало, слова или слог. Типичным недостатком вокодеров, основанных на кодировании методом линейного предсказания (ЛПК), является то, что искажения параметров, относящихся к модели голосового тракта, приводят к появлению звуков, не похожих на человеческий голос и настолько искаженных, что они могут вызвать замешательство со стороны слушающего. В предлагаемом изобретении ошибки маскируются, чтобы они не ощущались слушающим. Таким образом, маскирование ошибок, применяемое в предлагаемом изобретении, обеспечивает существенное снижение степени воздействия ошибок на разборчивость речи.
Поскольку максимальное значение, которое может принимать любой параметр, ограничивается меньшим диапазоном на низких скоростях, ошибки, возникающие при передаче этих параметров, на этих скоростях будут влиять на качество речи в меньшей степени. Так как ошибки на различных скоростях передачи обладают различной степенью воздействия на качество речи, система передачи может быть оптимизирована, чтобы обеспечить лучшую защиту на более высоких скоростях передачи данных. Поэтому дополнительным преимуществом изобретения является устойчивость по отношению к канальным ошибкам.
Изобретение благодаря использованию варианта алгоритма ЛПККВ с переменной скоростью обеспечивает коэффициент сжатия речевого сигнала, который динамически меняется от 8:1 до 64:1 в зависимости от активности голосового сигнала. Указанные значения коэффициентов сжатия, 1 относятся к входным данным с законом компандирования с μ -характеристикой, для входных данных с линейным законом коэффициенты сжатия выше примерно в два раза. Определение скорости делается на уровне кадров, чтобы получить полное преимущество от использования коэффициента активности голоса. Несмотря на то, что во время речевых пауз передается меньшее число данных ощутимое увеличение синтезированного фонового шума сведено к минимуму. Использование методов, предложенных в настоящем изобретении, позволяет для обычного разговора получить почти наилучшее качество речи при максимальной скорости передачи данных около 8 кб/с и средней скорости передачи данных порядка 3,5 кб/с.
Так как предполагается обнаружение коротких пауз в речи, то эффективный коэффициент активности голоса уменьшается. Решение о величине скорости передачи может приниматься на уровне кадров, без "хвостов" (затягивания), так что для речевых пауз скорость передачи может быть снижена до длительности кадра, как правило, 20 мс в предпочтительном варианте осуществления изобретения. Поэтому могут быть обнаружены такие паузы, как паузы между слогами. Эта процедура снижает коэффициент активности голоса ниже традиционно принимаемого значения, так что не только длинные паузы между фразами, но также и короткие паузы могут кодироваться с более низкими скоростями.
Так как решения о скорости передачи принимаются на уровне кадров, отсутствует усечение начальной части слова, которое имеет место в системе со стробированием активности речевого сигнала. Усечения такого типа присутствуют в системах со стробированием активности речевого сигнала из-за задержки между обнаружением речевого сигнала и возобновлением передачи данных. Регулирование скорости передачи на каждом кадре позволяет получить речевой сигнал, где все переходы имеют естественное звучание.
Когда вокодер постоянно передает сигналы, шум от окружающей среды, где находится говорящий, постоянно слышен на приемной стороне, создавая более естественный фон во время речевых пауз. Предлагаемое изобретение, таким образом, обеспечивает плавный переход к фоновому шуму. То, что слушающий слышит параллельно с передаваемой речью, не будет неожиданно превращаться в синтезированный "комфортный" шум в периоды пауз, как это имеет место в системах со стробированием активности голоса.
Так как окружающий шум постоянно кодируется для передачи, представляющие интерес фоновые звуки могут быть переданы с полной ясностью. В определенных случаях такой представляющий интерес фоновый шум может быть даже закодирован с максимальной скоростью. Максимальная скорость кодирования может потребоваться, например, когда рядом с передающим абонентом находится громко разговаривающий субъект, или когда автомобиль скорой помощи проезжает мимо пользователя, стоящего на углу улицы. Однако постоянный или медленно меняющийся окружающий шум будет кодироваться с малой скоростью.
Использование кодирования с переменной скоростью позволяет увеличить емкость цифровых систем сотовой телефонной связи с параллельным доступом и кодовым разделением каналов (систем ПДКРК) более чем в два раза. Параллельный доступ с кодовым разделением каналов и кодирование речи с переменной скоростью уникально сочетаются друг с другом, поскольку межканальные помехи автоматически уменьшаются при уменьшении скорости передачи данных в любом канале. Этим системы с кодовым разделением каналов выгодно отличаются от систем, в которых для каналов выделяются частотные или временные области, т.е. от систем с параллельным доступом и временным разделением каналов и систем с параллельным доступом и частотным разделением каналов. Для того, чтобы в подобных системах получить выигрыш от уменьшения скорости передачи данных, требуется внешнее вмешательство для координации повторного назначения неиспользованных областей - частотных или временных - другим пользователям. Присущая таким системам задержка приводит к тому, что канал может быть переназначен только в периоды длительных разговорных пауз. Поэтому полностью реализовать преимущества, обеспечиваемые использованием коэффициента активности речевого сигнала, не удается. Однако при наличии внешней координации кодирование речевых сигналов с переменной скоростью целесообразно и в системах, отличных от систем с кодовым разделением каналов, по другим упомянутым причинам.
В системах с параллельным доступом и кодовым разделением каналов качество речевого сигнала может быть слегка ухудшено в тех случаях, когда желательна система с чрезмерно большой емкостью. Вокодер может рассматриваться в виде множества вокодеров, работающих с разными скоростями и разным качеством речи. Поэтому качество речи может быть усреднено, чтобы еще больше уменьшить среднюю скорость передачи данных. Предварительные эксперименты показывают, что при смешивании речевых сигналов, кодированных с полной скоростью и с половинной скоростью, например, когда максимально допустимая скорость изменяется на уровне кадров между 8 кб/с и 4 кб/с, результирующие речевые сигналы имеют лучшее качество, чем при кодировании с половинной скоростью, т.е. максимум 4 кб/с, но не такое хорошее, как при кодировании с полной скоростью, т.е. максимум 8 кб/с.
Хорошо известно, что в большинстве телефонных разговоров в данный момент времени говорит только один абонент. В качестве дополнительной функции полной дуплексной телефонной линии может быть предусмотрена взаимозависимость скоростей передачи. Если на одной стороне линии связи идет передача с максимальной скоростью, то другая сторона связи вынуждена передавать с наименьшей скоростью. Такая взаимосвязь скоростей в обоих направлениях может гарантировать, что среднее использование в каждом направлении канала связи составляет не более 50%. Однако, когда канал запирается, как это имеет место в случае взаимозависимости скоростей при стробировании активности голоса, слушающий не может прервать говорящего, чтобы взять на себя активную роль в разговоре. Предлагаемое изобретение легко обеспечивает изменение скоростей путем управления сигналами, которые устанавливают скорость кодирования речевых сигналов.
Следует отметить, что путем использования кодирования речевых сигналов с переменной скоростью одновременно с речевыми данными может передаваться вспомогательная информация при минимальном влиянии на качество передаваемого речевого сигнала. Например, высокоскоростной кадр может быть разбит на две части, одна из которых используется для передачи с более низкой скоростью речевых данных, а другая - для передачи вспомогательных сигнальных данных. В вокодере согласно предпочтительному варианту осуществления изобретения происходит лишь незначительное снижение качества воспроизводимой речи при передаче с половинной скоростью по сравнению с передачей с полной скоростью. Поэтому кодирование речевого сигнала на более низкой скорости с целью одновременной передачи других данных приводит к почти неразличимой для слушателя разнице в качестве воспроизводимой речи.
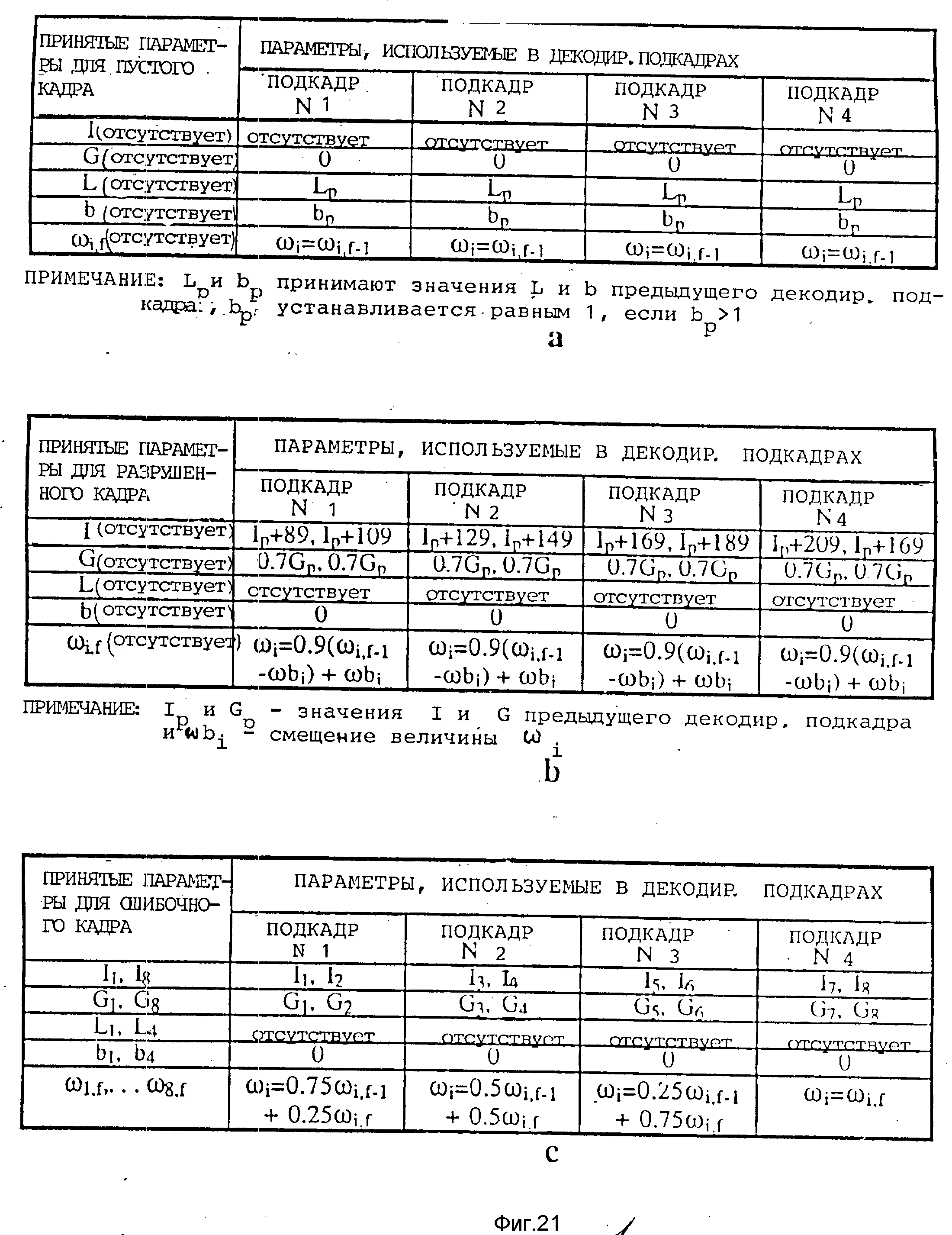
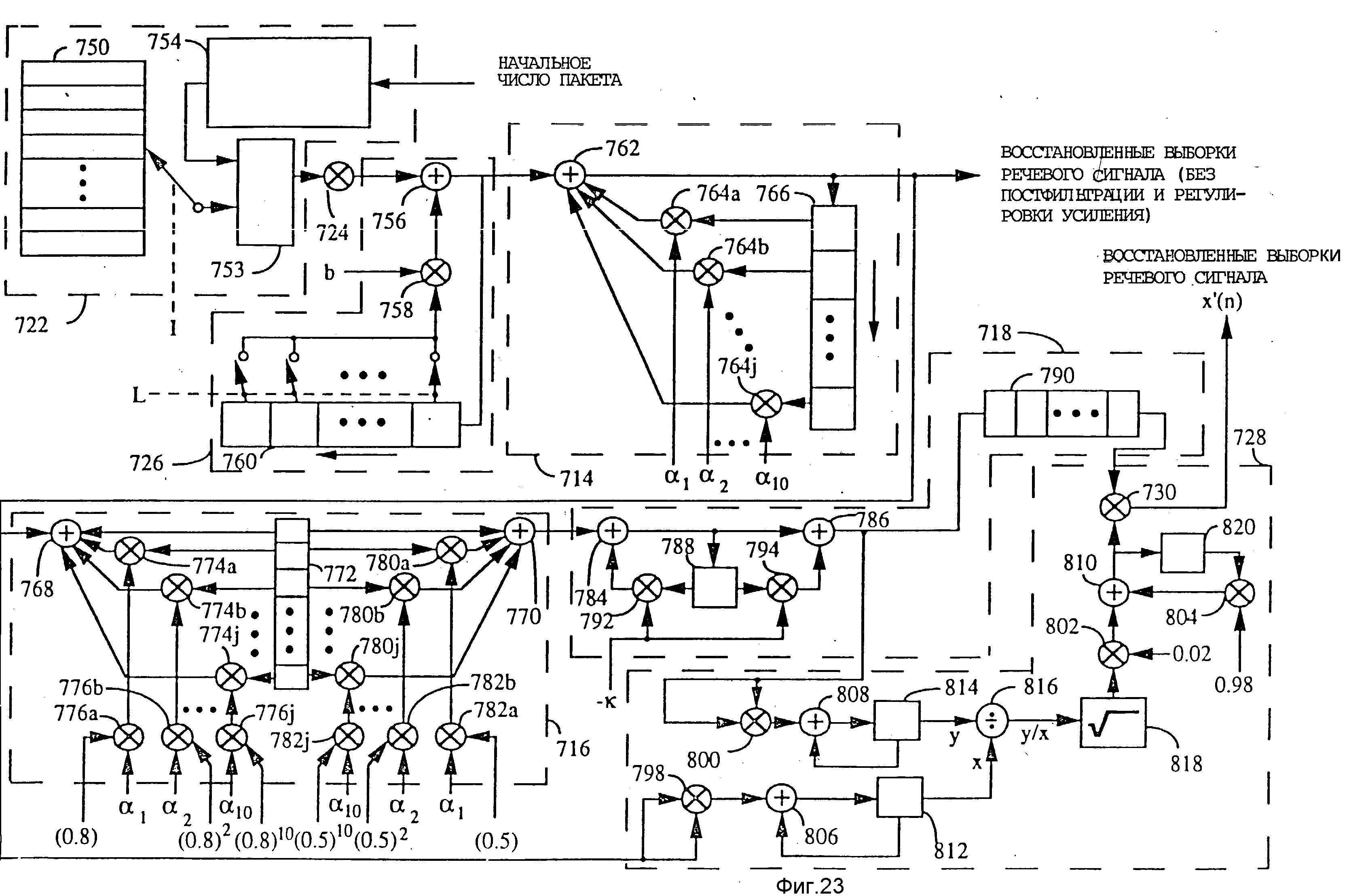
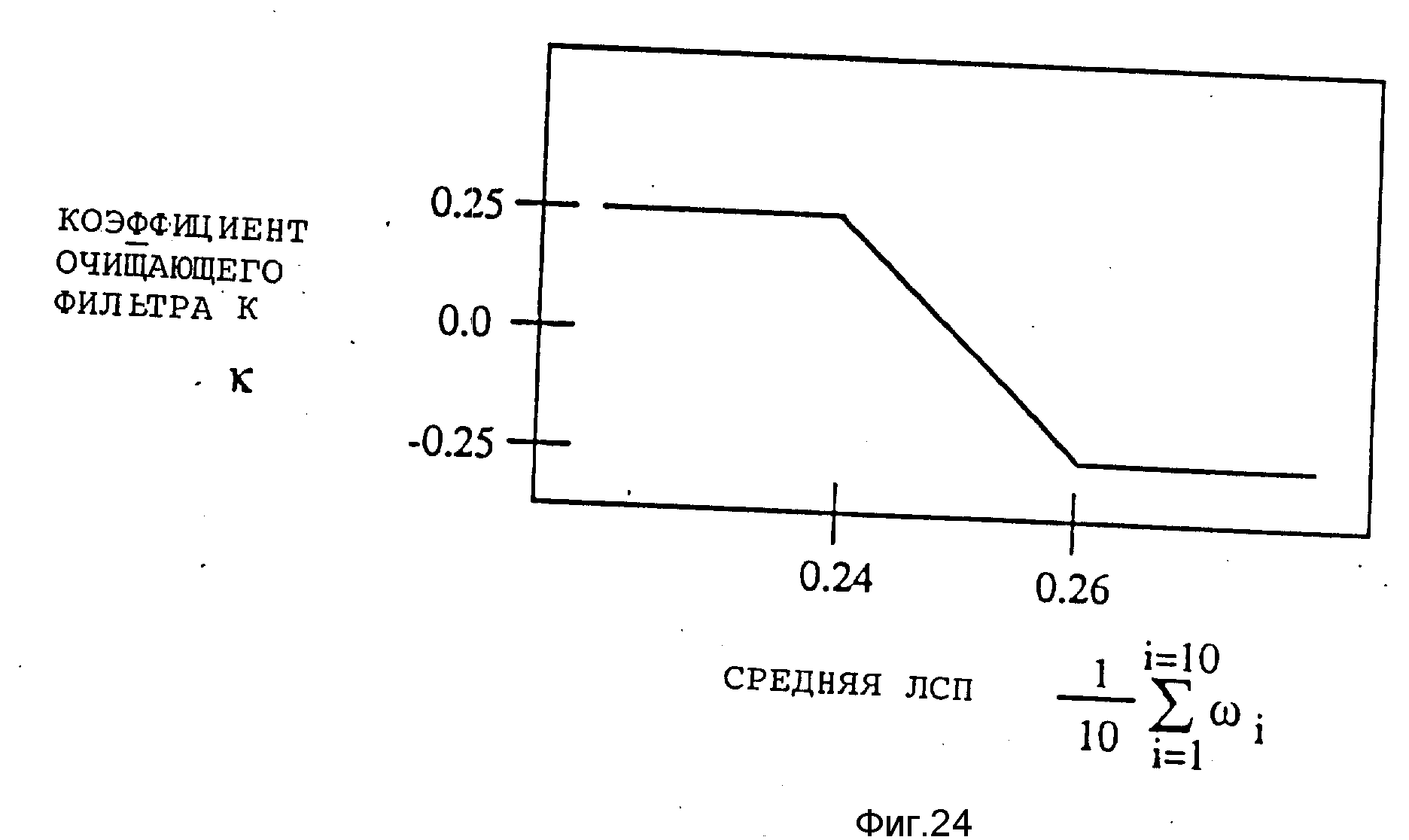
На фиг. 1(a-e) изображены кадры и подкадры, анализируемые вокодером при различных скоростях; на фиг. 2(a-d) - ряд карт, иллюстрирующих распределение битов в выходных сигналах вокодера при различных скоростях; на фиг.3 изображена обобщенная блок-схема варианта реализации кодера; на фиг.4 - алгоритм кодирования; на фиг.5 обобщенная блок-схема варианта выполнения декодера; на фиг. 6 - алгоритм декодирования; на фиг.7 - более подробная блок-схема кодера; на фиг.8 - блок-схема примера реализации подсистемы окна Хемминга и автокорреляции; на фиг. 9 - блок-схема примера реализации подсистемы определения скорости; на фиг.10 - блок-схема примера реализации подсистемы анализа коэффициентов ЛПК (кодирование методом линейного предсказания); на фиг.11 блок-схема примера реализации подсистемы преобразования коэффициентов ЛПК в ЛСП (линейные спектральные пары); на фиг.12 - блок-схема примера реализации подсистемы квантования ЛПК; на фиг.13 - блок-схема примера реализации подсистемы интерполяции ЛСП и преобразования ЛСП в ЛПК; на фиг.14 блок-схема примера реализации адаптивного кодового словаря для поиска тона; на фиг.15 - блок-схема кодера-декодера; на фиг.16 - блок-схема подсистемы поиска тона; на фиг.17 блок-схема подсистемы поиска кодового словаря; на фиг.18 - блок-схема подсистемы упаковки данных; на фиг. 19 приведена более подробную блок-схему декодера; на фиг. 20(a-2d) представлены карты, иллюстрирующие принятые декодером параметры и декодируемые данные подкадра для различных скоростей передачи; на фиг. 21(a-c) - карты, дополнительно иллюстрирующие принятые декодером параметры и декодируемые данные подкадра при некоторых особых условиях; на фиг. 22 - блок-схема подсистемы обратного квантования ЛСП; на фиг.23 более подробно изображен декодер с постфильтрацией и автоматической регулировкой усиления; на фиг.24 - график характеристики адаптивного очищающего фильтра.
Согласно предлагаемому изобретению, звуковые сигналы, такие как речь и/или окружающий шум, квантуют и преобразуют в цифровую форму, используя хорошо известные способы. Например, аналоговый сигнал может быть преобразован в цифровой формат с помощью стандартного формата "8 бит/закон компандирования, с μ -характеристикой, после чего выполняется преобразование закон компандирования с μ -характеристикой/равномерный (однородный) код. В качестве альтернативы аналоговый сигнал может быть сразу преобразован в цифровую форму с равномерным кодом в формате импульсно-кодовой модуляции. Каждая выборка в предпочтительном варианте осуществления изобретения представляется одним словом данных длиной в 16 бит. Выборки аналогового сигнала объединяются в кадры входных данных, причем каждый кадр содержит определенное число выборок. В примере реализации рассматриваются выборки с частотой дискретизации 8 кГц. Каждый кадр содержит из 160 выборок аналогового сигнала, что соответствует длительности сигнала речи 20 мс при частоте дискретизации 8 кГц. Могут быть использованы другие размеры кадра и частоты дискретизации.
Для кодирования сигналов речи используют различные способы, одним из которых является кодирование методом линейного предсказания с кодовым возбуждением (ЛПККВ). Краткие сведения об этом способе изложены в указанной работе "A 4,8 kbps Code Excited Linear Predictive Coder". Изобретение использует вид кодирования ЛПККВ, чтобы обеспечить переменную скорость кодирования речевых данных, причем ЛПК анализ осуществляется на постоянном числе выборок, а поиск, параметров тона и кодового словаря производится на переменном числе выборок, которое зависит от скорости передачи. Принцип кодирования ЛПККВ, используемого в предлагаемом изобретении, поясняется с помощью фиг.3 и 5.
В предпочтительном варианте изобретения длительность кадра, в течение которого осуществляется анализ речевого сигнала, составляет 20 мс и предполагается, что выделенные для передачи параметры речевого сигнала передаются посылками 50 раз в 1 с. Кроме того скорость передачи данных меняется дискретно и принимает значения примерно 8, 4, 2 и 1 кб/с. При полной скорости (в тексте описания обозначается как скорость 1) передача данных осуществляется со скоростью 8,55 кб/с при использовании 171 бита для кодирования параметров каждого кадра, включая 11 битов для контроля с использованием циклического избыточного кода (КЦИК). В случае отсутствия КЦИК битов скорость передачи была бы 8 кб/с. При половинной скорости (в тексте описания обозначается как скорость 1/2) скорость передачи данных составляет 4 кб/с при использовании 80 битов в каждом кадре для кодирования передаваемых параметров. На четвертичной скорости (в тексте описания обозначается как скорость 1/4) скорость передачи данных составляет 2 кб/с с использованием 40 бит в каждом кадре для кодирования передаваемых параметров. При одной восьмой полной скорости (в тексте описания обозначается как скорость 1/8) скорость передачи составляет чуть меньше 1 кб/с при использовании 16 битов в каждом кадре для кодирования передаваемых данных.
Фиг. 1 иллюстрирует пример анализируемого кадра речевых данных 10 и расположение окна Хемминга 12, используемого при анализе с кодированием методом линейного предсказания (ЛПК). Анализируемый ЛПК кадр, а также подкадры тона и кодового словаря для различных скоростей изображены на фиг.2, a-d. Должно быть понятно, что анализируемый ЛПК кадр имеет одинаковый размер для всех скоростей передачи.
Обратимся теперь к фиг.1,a. Анализ с ЛПК использует 160 выборок речевого сигнала в кадре 10, которые взвешиваются с использованием окна Хемминга 12. Как показано на фиг. 1,a, выборки сигнала s(n) пронумерованы 0-159 внутри каждого кадра. Окно Хемминга 12 смещено по отношению к кадру 10 на 60 выборок, т.е. окно Хемминга 12 начинается с 60-й выборки s(59) текущего кадра 10 данных и продолжается до 59-й выборки s(58) включительно следующего кадра 14 данных. Взвешенные данные, выработанные для текущего кадра 10, таким образом, содержат данные, полученные на основе данных следующего кадра 14.
В зависимости от скорости передачи данных производится поиск для вычисления параметров возбуждения тонового фильтра и кодового словаря несколько раз на различных подкадрах кадра 10 данных, как изображено на фиг. 1b-1е. Должно быть понятно, что в данном варианте изобретения только одна скорость передачи выбрана для кадра 10, так что поиски тона и кодового словаря делаются в подкадрах разных размеров в соответствии с выбранной скоростью передачи. Однако для наглядности структура подкадров поиска тона и кодового словаря для различных допустимых в данном варианте скоростей передачи изображена на фиг.1b-1e. На всех скоростях передачи по каждому кадру 10 осуществляется только одно вычисление коэффициентов ЛПК, как это изображено на фиг. 1, a. Как видно из фиг.1b, на полной скорости передачи существуют два подкадра 18 кодового словаря для каждого подкадра 16 тона. При полной скорости передачи существуют четыре корректировки тона, по одной на каждый из четырех тоновых подкадров 16 с длительностью равной 40 выборкам речевого сигнала (5 мс). Кроме того, при полной скорости имеется восемь корректировок кодового словаря, по одной на каждый из восьми подкадров 18 кодового словаря, с длительностью 20 выборок речевого сигнала (2, 5 мс).
При половинной скорости передачи данных, как это изображено на фиг.1c, существует два подкадра 22 кодового словаря для каждого тонового подкадра 20. Тон корректируется дважды, один раз для каждого из двух подкадров 20 тона, в то время как кодовый словарь корректируется четыре раза, один раз в каждом из четырех подкадров 22 кодового словаря. На четвертной скорости передачи данных, как показано на фиг.1d, существует два подкадра 26 кодового словаря для одного тонового подкадра 24. Тон корректируется один раз для тонового подкадра 24, в то время как кодовый словарь - дважды, один раз для каждого из двух подкадров 26 кодового словаря. В соответствии с фиг.1e, при одной восьмой полной скорости передачи данных тон не определяется, а кодовый словарь обновляются только один раз в кадре 28, который соответствует кадру 10.
Кроме того, хотя коэффициенты ЛПК вычисляются только один раз за кадр, они линейно интерполируются в виде линейных спектральных пар (ЛСП) до четырех раз, используя частоты ЛСП, полученные из предыдущего кадра, чтобы аппроксимировать результаты анализа коэффициентов ЛПК с взвешивающей функцией Хемминга, отцентрированной на каждом подкадре. Исключение составляет случай передачи с полной скоростью, когда коэффициенты ЛПК не интерполируются для подкадров кодового словаря. Более подробно о вычислении частот ЛСП будет сказано ниже.
Кроме того, поиски параметров тона и кодового словаря осуществляются менее часто на меньших скоростях, меньшее число битов выделяется для передачи коэффициентов ЛПК. Число битов, выделенных на различных скоростях передачи, показано на фиг. 2a-2d. Каждая из фиг.2a-2d представляет число битов закодированных вокодером данных, которые выделены каждому кадру речи, состоящему из 160 выборок. На фиг.2a-2d число в соответствующих блоках ЛПК 30a-30d является числом битов, используемых при соответствующих скоростях для кодирования кратковременных коэффициентов ЛПК. В предпочтительном варианте изобретения число битов, используемых для кодирования ЛПК коэффициентов на полной, половинной, четвертной и одной восьмой полной скоростях передачи, равно соответственно 40, 20, 10 и 10.
Для того, чтобы осуществить кодирование с переменной скоростью, коэффициенты ЛПК сначала преобразуются в линейные спектральные пары (ЛСП), и полученные в результате частоты ЛСП индивидуально кодируются с помощью кодеров дифференциальной импульсно-кодовой модуляции (ДИКМ). Порядок коэффициентов ЛПК равен 10, поэтому существует 10 частот ЛСП и 10 независимых кодеров. Распределение битов для кодеров ДИКМ дано в табл.1.
Как при кодировании, так и при декодировании частоты, ЛСП обратно преобразуются в коэффициенты фильтра ЛПК перед использованием при поиске тона и кодового словаря.
Что касается поиска тона, то при полной скорости, как показано на фиг. 2a, скорректированные параметры тона рассчитываются четыре раза, один раз для каждой четверти кадра речевого сигнала. Для каждой корректировки тона при полной скорости передачи используется 10 битов для кодирования новых параметров тона. Корректировка тона осуществляется различное число раз для других скоростей передачи данных, как показано на фиг.2b-2d. По мере того, как скорость передачи уменьшается, уменьшается и число корректировок тона.
На фиг. 2b показано, что корректированные данные тона половинной скорости вычисляются дважды, один раз для каждой половины кадра речевого сигнала. Аналогично, на фиг. 2c показано что при четвертной скорости передачи корректированные параметры тона вычисляются один раз в каждом полном кадре сигнала речи. Как и для случая полной скорости, 10 битов используются для кодирования новых параметров тона при половинной и четвертной скоростях. Однако для одной восьмой полной скорости передачи, как это иллюстрируется на фиг.2d, скорректированные тоновые параметры не вычисляются, так как эта скорость передачи используется для кодирования кадров, когда речевой сигнал слаб либо отсутствует вовсе и тоновой избыточности в речевом сигнале не существует.
Из каждых 10 битов скорректированного тона 7 битой представляют задержку тона и 3 бита - усиление тона. Диапазон задержки тона лежит между 17 и 143. Усиление тона линейно квантуется в диапазоне от 0 до 2 для представления 3 битами.
Что касается поиска кодового словаря, то при полной скорости передачи, как это показано на фиг.2a, скорректированные данные кодового словаря вычисляются восемь раз, один раз в каждой восьмой части кадра речевого сигнала. Для каждого корректированного значения кодового словаря при полной скорости передачи используется 10 битов для кодирования новых параметров кодового словаря. Корректировка данных кодового словаря осуществляется разное число раз на различных скоростях передачи данных, как это показано на фиг. 2b-2d. Однако по мере того, как уменьшается скорость передачи, уменьшается и количество корректировок кодового словаря. На фиг.2b показано, что корректированные параметры кодового словаря при половинной скорости передачи данных вычисляются четыре раза, один раз для каждой четверти кадра речевого сигнала. На фиг. 2c представлены скорректированные данные при четвертной скорости передачи данных, которые вычисляются дважды, один раз для каждой половины кадра речевого сигнала. Как и при полной скорости передачи данных, 10 битов используются для кодирования новых параметров кодового словаря для каждой корректировки тона при половинной и четвертной скоростях, На фиг.2d показаны скорректированные данные кодового словаря при одной восьмой полной скорости передачи, которые вычисляются один раз для каждого полного кадра речевого сигнала. Следует отметить что при скорости передачи данных, равной одной восьмой от полной скорости, передается 6 битов: 2 бита представляют усиление кодового словаря, а 4 бита - случайные. Более подробно относительно распределения битов для скорректированных данных кодового словаря будет сказано ниже.
Биты, выделенные для скорректированных данных кодового словаря, являются теми битами, которые требуются для векторного квантования остатка предсказания тона. Для полной, половинной и четвертной скоростей передачи каждое скорректированное значение содержит 7 битов для индекса кодового словаря и 3 бита для усиления кодового словаря, всего 10 битов. Усиление кодового словаря кодируется с помощью кодера дифференциальной импульсно-кодовой модуляцией (ДИКМ), работающего в логарифмической области. Хотя аналогичное кодирование может быть использовано и для одной восьмой полной скорости передачи, предпочтительна другая схема. При скорости передачи, равной одной восьмой полной скорости, усиление кодового словаря представлено двумя битами, в то время как 4 генерируемых по случайному закону бита используются в принимаемых данных как начальное число генератора псевдослучайных чисел, который заменяет кодовый словарь.
Из блок-схемы кодера (см. фиг.3) видно, что анализ ЛПК выполняют по разомкнутому контуру. Из каждого кадра выборок s(n) входного речевого сигнала вычисляют коэффициенты α1-α10 ЛПК с помощью анализатора-квантователя 50 ЛПК для подачи их на вход фильтра 60 синтеза форманты.
В то же время вычисление при поиске тона выполняется по замкнутому контуру методом, часто называемым методом анализа через синтез. Однако в данном варианте используется новая гибридная схема с замкнутым/разомкнутым контуром для поиска параметров тона. При поиске тона кодирование осуществляется путем выбора параметров, которые минимизируют среднеквадратичную ошибку в синтезированном речевом сигнале относительно входного речевого сигнала. Для простоты в этой части описания вопросы, связанные с выбором скорости передачи не обсуждаются. Однако в дальнейшем вопросы, связанные с влиянием выбранной скорости кодирования на поиск тона и кодового словаря будут обсуждены более подробно.
В варианте, изображенном на фиг.3,
персептуальный, т.е. имеющий отношение к восприятию взвешивающий фильтр 52 характеризуется следующим уравнением:

где

является фильтром предсказания форманты, а μ представляет собой персептуальный весовой параметр, который в данном примере равен μ = 0,8. Фильтр 58 синтеза тона характеризуется следующим уравнением:

Фильтр 60 синтеза форманты, "взвешенный" фильтр, как поясняется ниже, характеризуется следующим
уравнением:

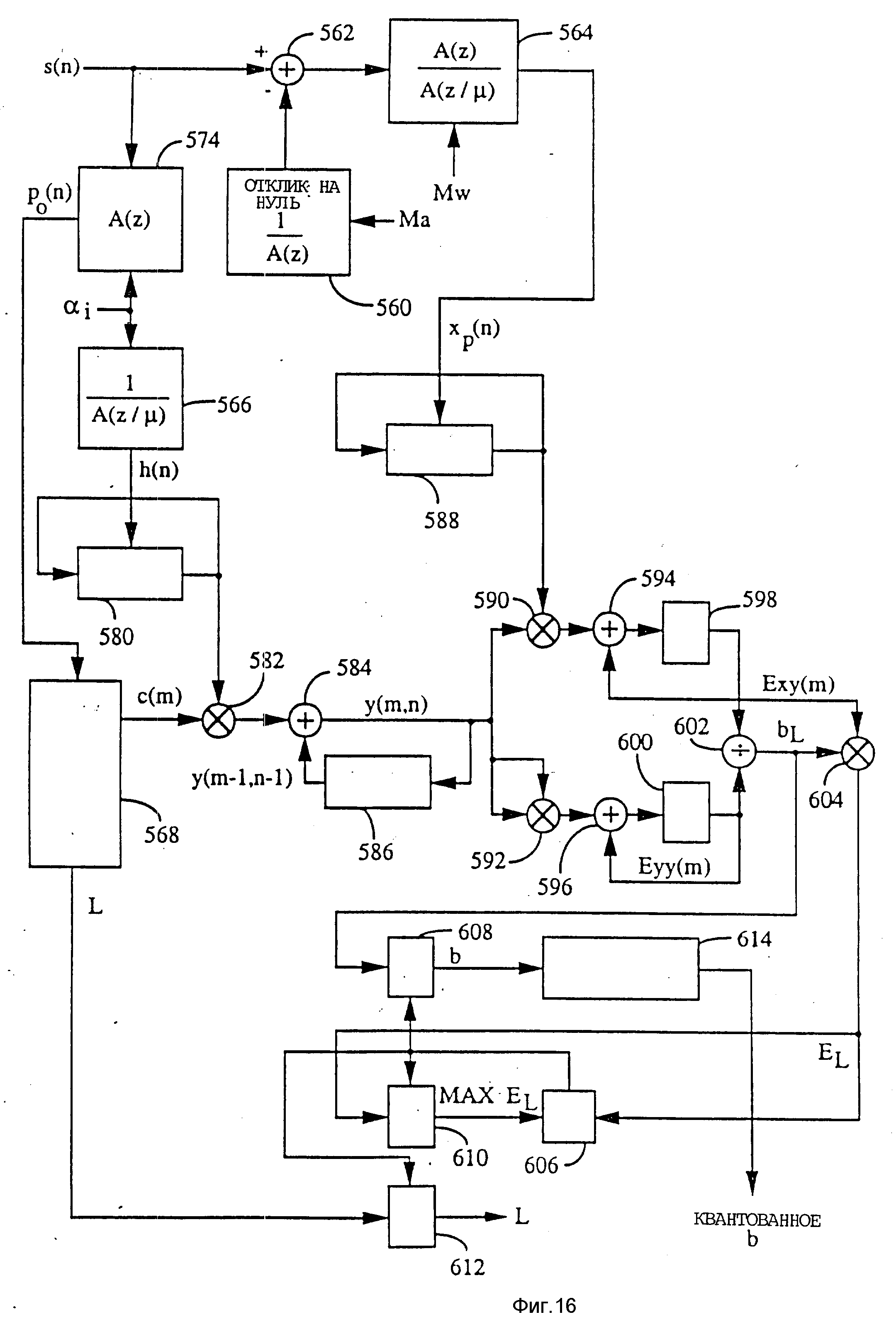
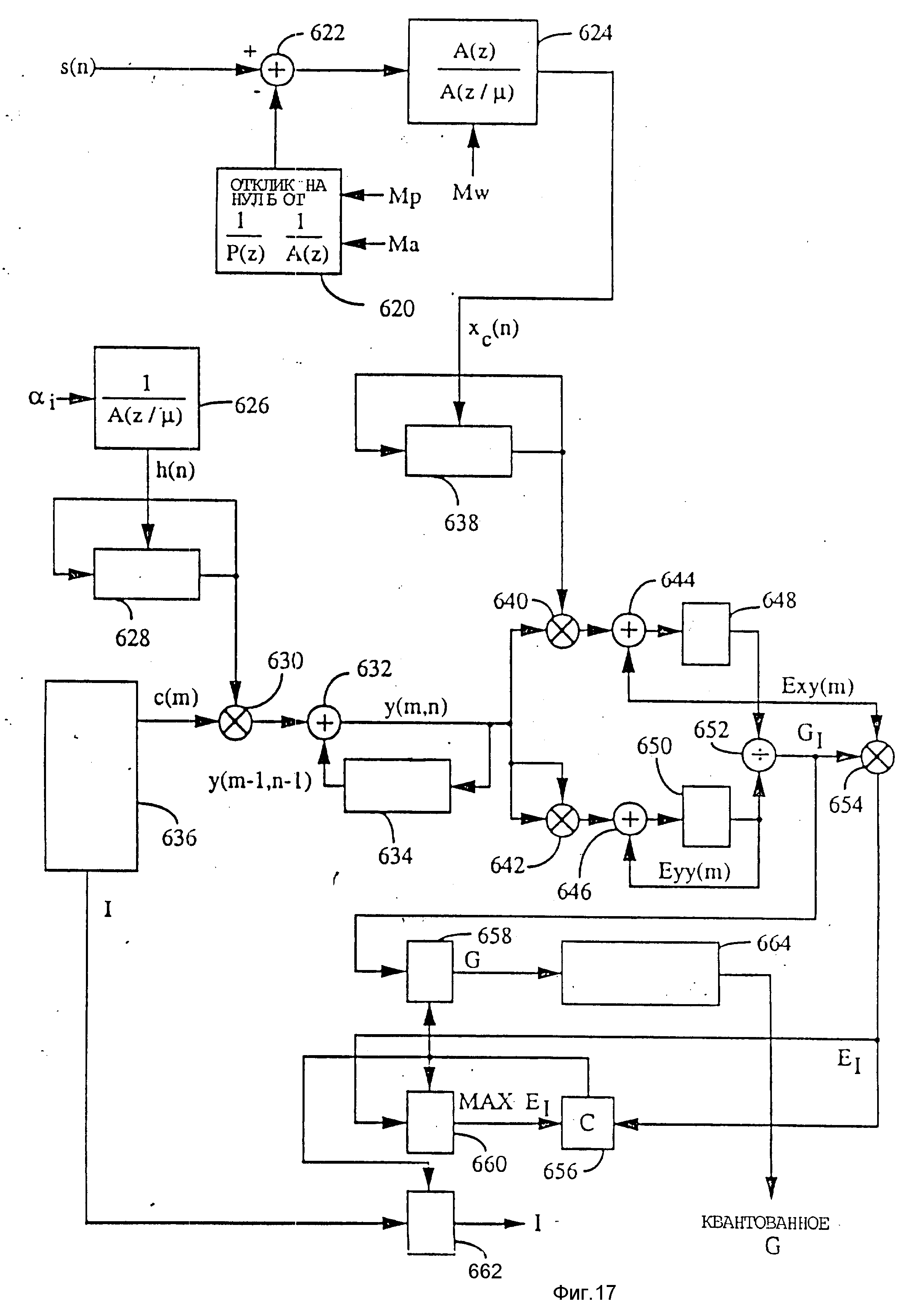
Выборки s(n) входного речевого сигнала взвешиваются персептуальным взвешивающим фильтром 52 и взвешенные выборки x(n) речевого сигнала поступают на суммирующий вход сумматора 62. Персептуальное взвешивание используется в отношении ошибок на частотах, где мощность сигнала мала. Это те частоты, на которых более ощутимым является шум. Выборки x'(n) синтезированного речевого сигнала формируются на выходе фильтра 60 синтеза форманты и подаются на вычитающий вход сумматора 62, где они вычитаются из выборок x(n). Разности выборок с выхода сумматора 62 поступают на вход элемента 64 вычисления среднеквадратичной ошибки (СКО), где эти разности возводятся в квадрат и суммируются. Выходной сигнал с элемента 64 СКО подается на вход минимизирующего элемента 66, который вырабатывает значения задержки L тона, усиления b тона, индекса I кодового словаря и усиления кодового словаря.
С выходов минимизирующего элемента 66 все возможные значения L параметра задержки тона в выражении P(z), наряду со значениями c(n) с выхода умножителя 56, поступают на вход фильтра 58 синтеза тона. Во время поиска параметров тона отсутствует вклад со стороны кодового словаря, т.е. c(n)=0. С помощью минимизирующего элемента 66 выбираются значения L и b, которые минимизируют взвешенную ошибку в синтезированном речевом сигнале относительно входного речевого сигнала. Фильтр 58 синтеза тона вырабатывает и выдает на выход значение p(n) для фильтра 60 синтеза форманты. Как только задержка L тона и усиление b тона найдены, осуществляется поиск параметров кодового словаря аналогичным образом.
Следует пояснить, что фиг.3 иллюстрирует принцип метода анализа через синтез принятого в предлагаемом изобретении. В примере реализации изобретения фильтры не используются в типичной цепи обратной связи с замкнутым контуром. В изобретении цепь обратной связи размыкается во время поиска и заменяется формантным остатком разомкнутого контура, что более подробно будет пояснено позже.
Минимизирующий элемент 66 затем формирует значения для индекса I кодового словаря и усиления G кодового словаря. Сигналы с выхода кодового словаря 54, выбранные из множества значений случайного Гауссова вектора в соответствии с индексом I кодового словаря, умножаются в умножителе 56 на значение усиления G кодового словаря для получения последовательности значений c(n), используемых в фильтре 58 синтеза тона. Те индексы I и усиление G кодового словаря, которые минимизируют среднеквадратичную погрешность, выбираются для передачи.
Следует отметить, что персептуальное взвешивание W(Z) применяется как для входного речевого сигнала с помощью взвешивающего фильтра 52, так и для синтезированного речевого сигнала с помощью весовой функции, объединенной с фильтром 60 синтеза форманты. Поэтому фильтр 60 синтеза форманты фактически является взвешенным фильтром синтеза форманты, который сочетает весовую функцию уравнения (1) с обычной характеристикой 1/A(z) фильтра предсказания форманты для получения взвешенной функции синтеза форманты в соответствии с уравнением (3).
Должно быть понятно, что в альтернативном случае персептуальный взвешивающий фильтр 52 может быть помещен между сумматором 62 и элементом 64 СКО. В этом случае фильтр 60 синтеза форманты имел бы характеристику обычного фильтра 1/A(z).
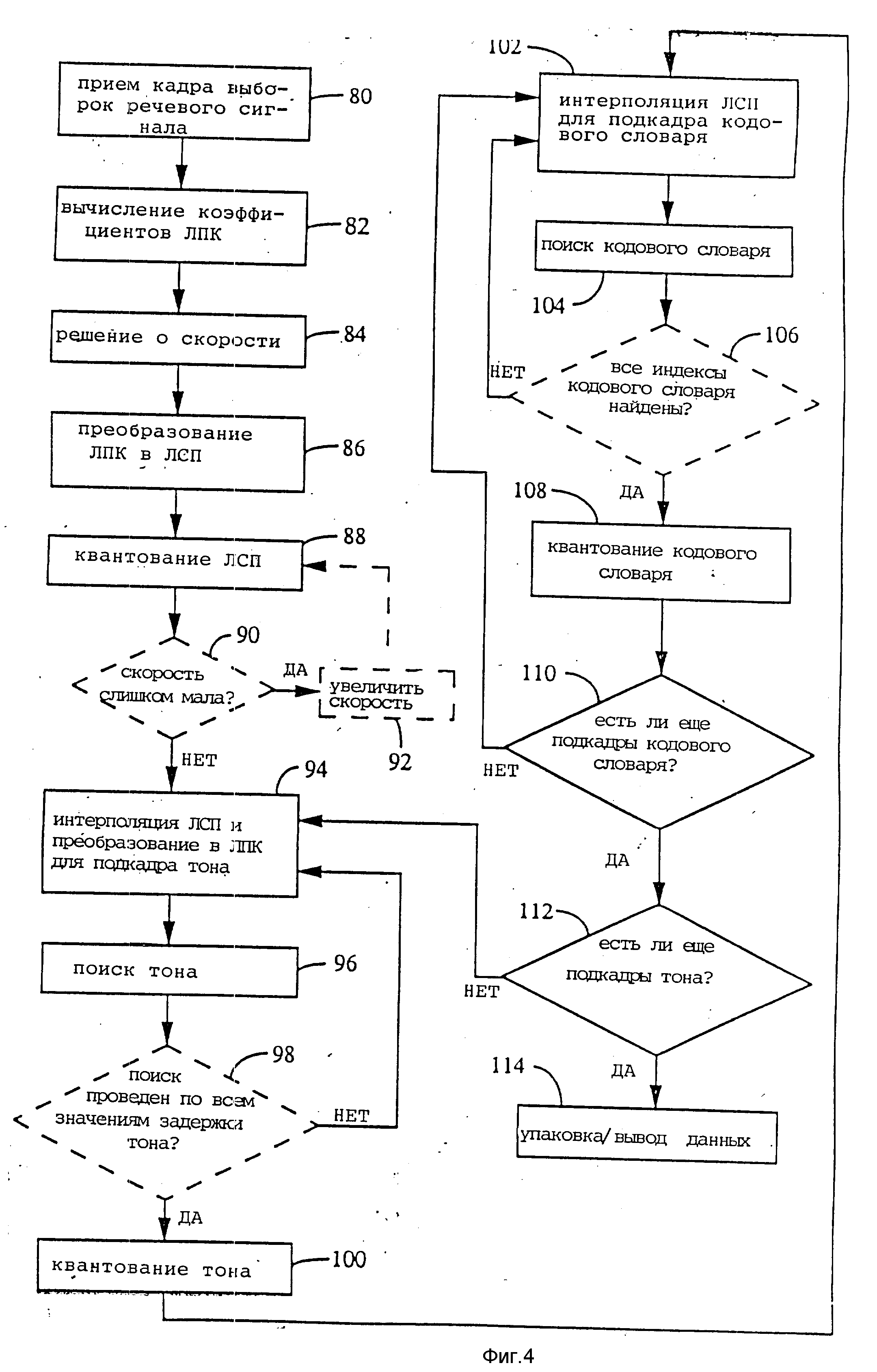
Фиг. 4 иллюстрирует последовательность процедур, применяемых для кодирования речевого сигнала кодером, изображенным на фиг.3. С целью пояснения на фиг. 4 показаны операции, обеспечивающие выбор скорости передачи. Оцифрованные выборки речевого сигнала поступают (80) из схемы дискретизации, затем из этих выборок вычисляют коэффициенты ЛПК (82). При вычислении коэффициентов ЛПК используют окно Хемминга и автокорреляционные методы. Начальное значение скорости передачи для анализируемого кадра в данном варианте выбирают исходя из энергии кадра (84).
Для того, чтобы эффективно закодировать коэффициенты ЛПК малым числом битов, коэффициенты ЛПК преобразуют (86) в частоты линейных спектральных пар (ЛСП) и затем квантуют (88) для передачи. В качестве необязательного варианта может дополнительно определяться скорость передачи (90) с соответствующим увеличением скорости, если квантование коэффициентов ЛСП при начальной скорости передачи считается недостаточным (92).
Для первого тонового подкадра анализируемого кадра речевого сигнала частоты ЛСП интерполируют и преобразуются в коэффициенты ЛПК (94) для использования при поиске тона. При поиске тона возбуждение кодового словаря устанавливается равным нулю. При поиске тона, в котором используется метод анализа через синтез (96, 98), для каждой возможной задержки L тона синтезированный речевой сигнал сравнивается с исходным речевым сигналом. Для каждого значения L, представляющего целое число, определяют оптимальное усиление b тона. Из множеств значений L и b оптимальные значения L и b обеспечивают минимальную взвешенную среднеквадратичную ошибку в синтезированной речи исходного речевого сигнала. Для определения оптимальных значений L и b в конкретном тоновом подкадре, значения b квантуются (100) для передачи вместе с соответствующим значением L. В альтернативном варианте поиска тона квантование значений b можно осуществлять в процессе поиска тона и уже квантованные значения b использовать в процессе поиска тона. Поэтому в этом случае надобность в квантовании выбранных значений b после поиска тона (100) отпадает.
Для первого подкадра кодового словаря анализируемого кадра речевого сигнала частоты ЛСП интерполируются и преобразуются в коэффициенты ЛПК (102), которые используют при поиске параметров кодового словаря. Однако в данном примере реализации при полной скорости передачи частоты ЛСП интерполируют только до уровня тонового подкадра. Эти интерполяцию и преобразование осуществляют для поиска параметров кодового словаря дополнительно к поиску тона благодаря разнице в размерах подкадров кодового словаря и тона на всех скоростях передачи за исключением одной восьмой полной скорости, когда результат неопределен, так как данные тона не вычисляются. При поиске кодового словаря (104 и 106) оптимальные значения задержки L и усиления b тона используют в фильтре синтеза тона таким образом, что для каждого возможного индекса I кодового словаря синтезированный речевой сигнал сравнивают с исходным речевым сигналом. Для каждого значения I (целое число) определяют величину оптимального значения усиления G кодового словаря. Из множеств значений I и G оптимальные значения I и G обеспечивают минимальную ошибку в синтезированной речи относительно исходной речи. Для определенных таким образом оптимальных значений I и G в конкретном подкадре кодового словаря значение G квантуют (108) для передачи одновременно с соответствующим значением I. В альтернативном варианте поиска кодового словаря квантование значений G может являться частью процесса поиска параметров кодового словаря и квантованные значения могут использоваться в поиске параметров кодового словаря. В этом альтернативном варианте необходимость в квантовании выбранных в результате поиска параметров кодового словаря значений G (108) отпадает.
После поиска параметров кодового словаря декодер в составе кодера использует оптимальные значения I, G, L и b. При этом этот декодер восстанавливает запомненные в памяти фильтра кодера параметры для использования их в последующих подкадрах.
Проверка, которая затем делается (110), необходима для того, чтобы определить являлся ли анализируемый подкадр кодового словаря, анализ которого только что закончен, последним подкадром из группы подкадров кодового словаря, соответствующих подкадру тона, для которого проводился поиск. Иными словами, определяют существуют ли еще подкадры кодового словаря, соответствующие тоновому подкадру. В рассматриваемом примере существуют только два подкадра кодового словаря на каждый тоновый подкадр. Если в результате определения обнаружено, что есть еще подкадр кодового словаря, который соответствует тоновому подкадру, операции (102-108) повторяются для этого подкадра кодового словаря.
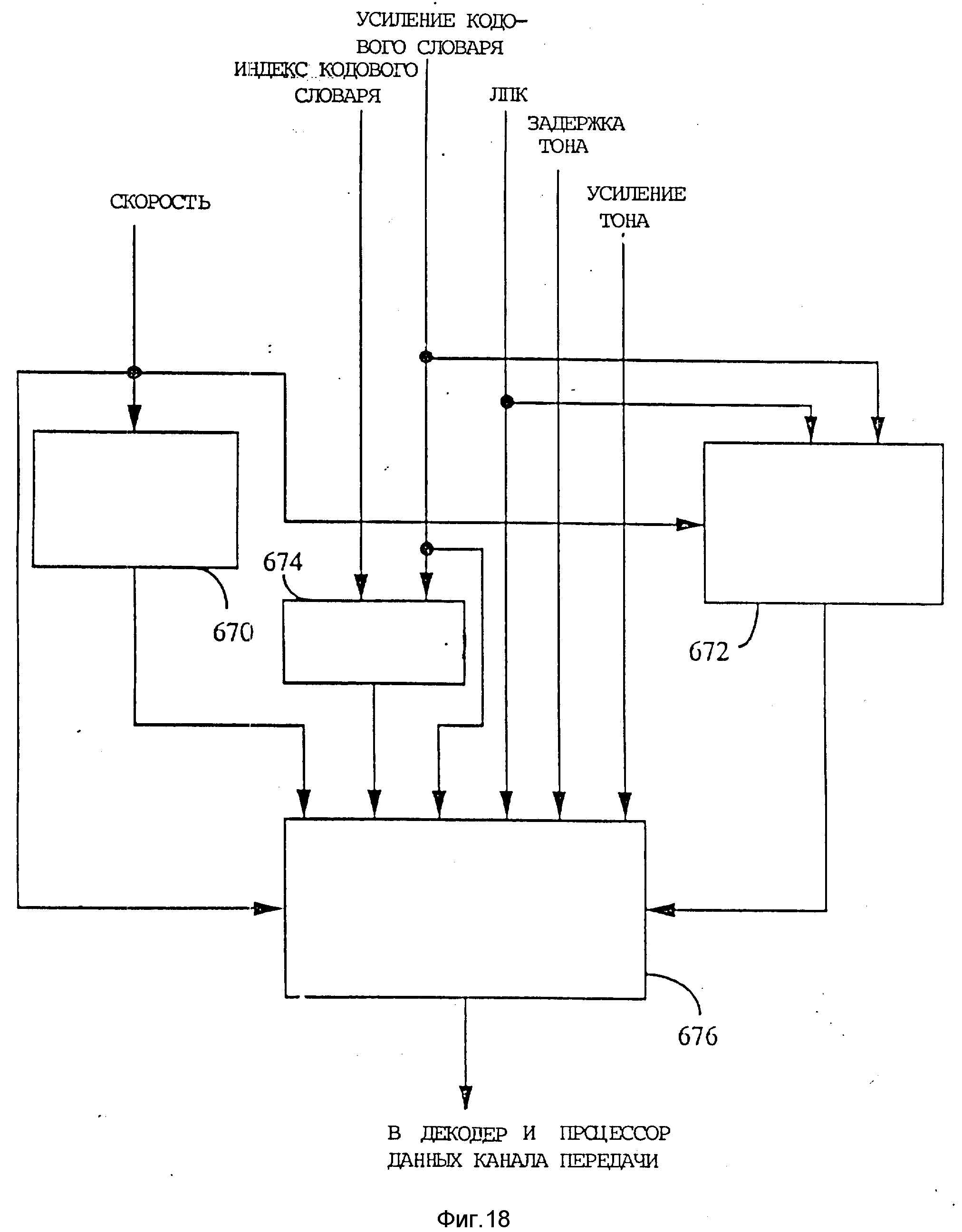
В противном случае, т.е. когда больше нет подкадров кодового словаря, соответствующих данному тоновому подкадру, производится проверка (102): существуют ли другие тоновые подкадры в анализируемом кадре речевого сигнала. Если есть другой тоновый подкадр в анализируемом кадре речевого сигнала, то повторяются операции (94- 110) для каждого тонового подкадра и соответствующих ему подкадров кодового словаря. Когда все вычисления для текущего анализируемого кадра речевого сигнала завершены, величины, представляющие коэффициенты ЛПК кадра речевого сигнала, задержки L и усиления b тона для каждого тонового подкадра и индекса I и усиления G кодового словаря для каждого подкадра кодового словаря упаковываются для передачи по каналу связи (114).
Фиг.5 представляет блок-схему декодера и иллюстрирует в каких его частях используются принятые значения коэффициентов (αj) ЛПК, задержки и усиления тона (L и b) и индекса и усиления кодового словаря (I и G) для синтеза речи. Так же, как и на фиг.3, на фиг.5 с целью упрощения информация, относящаяся к скорости передачи, не рассматривается. Данные о скорости передачи могут посылаться как побочная информация и в некоторых случаях могут быть получены на стадии демодуляции.
Декодер содержит кодовый словарь 130, в который поступают принятые индексы кодового словаря, или для одной восьмой полной скорости - случайное начальное слово. Выходной сигнал кодового словаря 130 подается на один из входов умножителя 132, на другой вход которого поступает усиление G кодового словаря. Сигнал с выхода умножителя 132 вместе с задержкой L и усилением b тона поступает на фильтр 134 синтеза тона. Сигнал с выхода фильтра 134 синтеза тона поступает вместе с коэффициентами αi ЛПК на фильтр 136 синтеза форманты. С выхода фильтра 136 синтеза форманты сигнал подается на вход адаптивного постфильтра 138, выходной сигнал которого является восстановленным речевым сигналом. Как будет показано ниже, декодер в одном из вариантов входит в состав кодера. В этом случае в декодере отсутствует адаптивный постфильтр 138, но зато имеется персептуальный взвешивающий фильтр.
Фиг. 6 представляет блок-схему алгоритма работы декодера, изображенного на фиг.5. В декодере речевой сигнал восстанавливается из принятых параметров (150). В частности, принятое значение индекса кодового словаря является входным сигналом кодового словаря, который генерирует кодовый вектор (152). Умножитель принимает кодовый вектор и принятое усиление G кодового словаря и перемножает эти параметры (154), выдавая выходной сигнал на вход фильтра синтеза тона. Следует отметить, что усиление G кодового словаря восстанавливается путем декодирования и обратного квантования принятых параметров ДИКМ. Фильтр синтеза тона получает значения принятых задержки L и усиления b тона, а также выходной сигнал умножителя и фильтрует выходной сигнал умножителя (156).
Значения, полученные путем фильтрации вектора кодового словаря фильтром синтеза тона, поступают на фильтр синтеза форманты, на который также подаются коэффициенты αi ЛПК, используемые при фильтрации выходного сигнала фильтра синтеза тона (158). Коэффициенты ЛПК восстанавливаются в декодере для интерполяции путем декодирования принятых параметров ДИКМ в квантовые частоты ЛСП, обратного квантования частот ЛСП и преобразования частот ЛСП в коэффициенты αi ЛПК. Выходной сигнал фильтра синтеза форманты подводится к входу адаптивного постфильтра, где происходит сглаживание шума от квантования и осуществляется регулировка усиления восстановленного речевого сигнала (160). Восстановленный речевой сигнал выводится (162) для преобразования в аналоговую форму.
Рассмотрим теперь блок-схему на фиг.7a и 7b, более подробно иллюстрирующую методы кодирования речи, предлагаемые в настоящем изобретении. На фиг.7a каждый кадр дискретизированных выборок речевого сигнала подводится к подсистеме 200, реализующей взвешивающую функцию Хемминга, где входной речевой сигнал взвешивается перед вычислением коэффициентов автокорреляции в подсистеме 202 автокорреляции.
Подсистема 200 взвешивающей функции Хемминга и подсистема 202 автокорреляции изображены в виде примера на фиг.8. Подсистема 200 взвешивающей функции Хемминга содержит просмотровую таблицу 250, обычно представляющую собой постоянное запоминающее устройство (ПЗУ) емкостью 80•16 бит, и умножитель 252. Для каждой скорости передачи функция взвешивания речевого сигнала центрируется между 139-й и 140-й выборками каждого анализируемого кадра, который содержит 160 выборок. Взвешивающая функция для вычисления коэффициентов автокорреляции таким образом смещена от анализируемого кадра на 60 выборок.
Взвешивание осуществляется с помощью ПЗУ таблицы, содержащей 80 из 160 значений
Wн(n), так как взвешивающая функция Хемминга симметрична относительно центра. Смещение взвешивающей функции Хемминга осуществляется путем сдвига указателя адреса ПЗУ на 60 позиций
относительно первой выборки анализируемого кадра. Эти значения перемножаются с одинарной точностью с соответствующими выборками входного речевого сигнала в умножителе 252. Пусть s(n)-входной речевой
сигнал, предназначенный для взвешивания. Тогда взвешенный сигнал sW(n) определится как
sW(n)=s(n+60)Wн(n) для 0≤n≤79, (5)
и
sW(n)=s(n+60)Wн(159-n) для 80≤n≤159 (6)
Примеры значений содержимого просмотровой таблицы 250 в шестнадцатиричной форме представлены в табл.2. Эти значения
интерпретируются как числа в дополнительном (до двух) коде, имеющие 14 дробных двоичных разрядов, при этом таблица читается слева направо и сверху вниз.
Подсистема 202 автокорреляции включает регистр 254, мультиплексор 256, сдвиговый регистр 258, умножитель 260, сумматор 262, закольцованный сдвиговый регистр 264 и буфер 266. Взвешенные выборки sW(n) речевого сигнала вычисляются каждые 20 мс и буферизуются в регистре 254. На выборке sW(0), т.е. на первой выборке анализируемого с помощью ЛПК кадра, сдвиговые регистры 258 и 264 устанавливаются в нулевое значение. На каждой новой выборке sW(n) мультиплексор 256 принимает селектирующий новую выборку сигнал, который разрешает чтение выборки из регистра 254. Новая выборка sW(n) подается также на умножитель 260, где перемножается с выборкой sW(n-10), которая содержится в последней позиции SR10 сдвигового регистра 258. Результат умножения суммируется в сумматоре 262 со значением последней позиции CSR11 закольцованного сдвигового регистра 264. Сдвиговые регистры 258 и 260 по каждому синхронизирующему сигналу заменяют sW(n-1) на sW(n) в первой позиции SR1 сдвигового регистра 258 и заменяют значение, хранившееся до этого в позиции CSR10. При синхронизации сдвигового регистра 258 сигнал селекции новой выборки снимается с входа мультиплексора 256, так что разрешается подача в него выборки s(n-9), находящейся в данный момент в позиции SR10 сдвигового регистра 264. В закольцованном сдвиговом регистре 264 значение, хранившееся перед этим в позиции CSR11, сдвигается в первую позицию CSR1. После снятия сигнала селекции новой выборки с входа мультиплексора в сдвиговом регистре 258 происходит циркуляция данных, как это имеет место в закольцованном сдвиговом регистре 264.
Сдвиговые регистры 258 и 264 синхронизируются 11 раз для каждой выборки, так что осуществляется 11 операций умножения/накапливания. После обработки 160 выборок результаты автокорреляционных вычислений, содержащиеся в закольцованном сдвиговом регистре 264 переписываются в буферный регистр 266 в виде значений R(0)-R(10). Все сдвиговые регистры сбрасываются в нулевое состояние, и процесс повторяется для следующего кадра взвешенных выборок речевого сигнала с выхода подсистемы 200 взвешивающей функции Хемминга.
Обратимся снова к фиг.7a. После расчета коэффициентов автокорреляции для кадра речевого сигнала подсистема 204 определения скорости передачи и подсистема 206 ЛПК используют эти данные для расчета скорости передачи данных кадра и коэффициентов ЛПК. Так как эти операции независимы друг от друга, они могут производиться в любой последовательности и даже одновременно. С целью более последовательного объяснения сначала описывается процесс определения скорости передачи данных.
Подсистема 204 определения скорости передачи имеет две функции: (1) определение скорости передачи текущего кадра и (2) вычисление новой оценки уровня окружающего шума. Скорость передачи текущего анализируемого кадра первоначально определяется на основе энергии текущего кадра, ранее оцененного уровня окружающего шума и команды скорости из управляющего микропроцессора. Новый уровень окружающего шума оценивается с помощью предыдущей оценки уровня окружающего шума и энергии текущего кадра.
Изобретение использует адаптивный пороговый метод для определения скорости передачи. По мере изменения уровня окружающего шума изменяются и пороги, которые используются для
выбора скорости передачи. В данном примере реализации рассчитываются три порога, чтобы сделать предварительный выбор скорости RTp передачи данных. Пороги являются квадратичными функциями
ранее полученной оценки окружающего шума и приводятся ниже:
T1(B)=-5.544613 (10-6)B2+4•047152 B+363•1293, (7)
T2
(B)=-1.529733 (10-5)B2+8•750045 B+1136•214 (8)
и
T3(B)=-3.957050 (10-5)B2+18•89962 B+3346•789,
(9)
где
B - ранее полученная оценка уровня окружающего шума.
Энергия кадра сравнивается с тремя порогами T1(B), T2(B) и T3(B). Если энергия кадра ниже всех трех порогов, выбирается наименьшая скорость передачи (1 кб/с), скорость 1/8, где RTp=4. Если энергия кадра ниже двух порогов, выбирается вторая скорость передачи (2 кб/с), скорость 1/4, где RTp= 3. Если энергия кадра ниже только одного порога, выбирается третья скорость передачи (4 кб/с), скорость 1/2, где RTp=2. Если энергия кадра выше трех порогов, выбирается наивысшая скорость передачи (8 кб/с), скорость 1, где RTp=1.
Предварительная скорость передачи RTp может затем модифицироваться на основе последней скорости RTr передачи предыдущего кадра. Если предварительная скорость RTp меньше чем последняя скорость предыдущего кадра за вычетом единицы (т.е. RTr-1), то устанавливается промежуточная скорость RTm= (RTr-1). Такого типа модификация вызывает медленное снижение скорости передачи по линейному закону, когда имеет место переход от сильного сигнала к слабому. Однако если первоначально выбранная скорость передачи равна или больше, чем предыдущая скорость минус один (т.е. RTn-1), то промежуточная скорость RTm устанавливается той же самой, что и предварительная скорость RTp т.е. RTm=RTp. В этом случае скорость передачи быстро увеличивается, когда имеет место переход от слабого сигнала к сильному сигналу.
Промежуточная скорость RTm кроме того, модифицируется командами предельных скоростей из микропроцессора. Если скорость RTm больше, чем наивысшая скорость, разрешенная микропроцессором, то начальная скорость RTi устанавливается равной наивысшему допустимому значению. Аналогично, если промежуточная скорость RTm меньше, чем наименьшая разрешенная микропроцессором скорость передачи, то начальная скорость RTi устанавливается равной наименьшему допустимому значению. В определенных случаях может быть желательно кодировать весь речевой сигнал при скорости передачи, определенной микропроцессором. Команды предельных скоростей могут быть использованы для установки скорости кадров на желательном уровне путем установки требуемой максимальной и минимальной допустимых скоростей передачи. Команды предельных скоростей могут быть использованы для управления скоростью передачи в специальных случаях, таких как обеспечение взаимозависимости скоростей и ослабление и увеличение сигнала, что будет описано ниже.
Фиг. 9 представляет пример реализации алгоритма принятия решения о величине скорости. Перед началом вычислений регистр 270 перезагружается значением 1, которое поступает на сумматор 272. Закольцованные сдвиговые регистры 274, 276 и 278 загружаются соответственно первым, вторым и третьим коэффициентами квадратичных пороговых уравнений (7)-(9). Например, последняя, средняя и первая позиции закольцованного сдвигового регистра 274 соответственно загружаются первыми коэффициентами уравнений, из которых вычисляются значения T1, T2 и T3. Аналогично, последняя, средняя и первая позиции закольцованного сдвигового регистра 276 соответственно загружаются вторыми коэффициентами уравнений, из которых вычисляются T1, T2 и T3. Наконец, последняя, средняя и первая позиции закольцованного сдвигового регистра 278 загружаются соответственно постоянными членами уравнений, из которых вычисляются T1, T2 и T3. В каждом из закольцованных сдвиговых регистров 274, 276 и 278 выходные сигналы снимаются с последней позиции.
При вычислении первого порога Т1 оценка В уровня шума в предшествующем кадре возводится в квадрат путем умножения самой на себя в умножителе 280. Полученное значение B2 умножается на первый коэффициент -5.544613(10-6), который снимается с последней позиции закольцованного сдвигового регистра 274. Полученное значение складывается в сумматоре 286 с результатом умножения уровня окружающего шума B2 на второй коэффициент 4.047152, выведенный из последней позиции закольцованного сдвигового регистра 276, в умножителе 284. Значение с выхода сумматора 286 затем суммируется в сумматоре 288 с постоянным числом 336. 1293, снимаемым с последней позиции закольцованного сдвигового регистра 278. Выход сумматора 288 дает вычисленное значение T1.
Вычисленное значение T1 с выхода сумматора 288 вычитается в сумматоре 290 из значения Ef энергии кадра, которым в данном примере реализации является величина R(0) в линейной области, поступающая из подсистемы автокорреляции.
В альтернативном
варианте энергия Ef кадра может представляться в логарифмической области в дБ, где она аппроксимируется десятичным логарифмом первого коэффициента R(0) автокорреляции, нормализованного
эффективной шириной окна
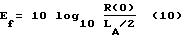
где
LA - ширина автокорреляционного окна.
Должно быть понятно, что значение активности речевого сигнала может быть получено из ряда других параметров, включая прогнозируемое усиление тона или прогнозируемое усиление Ga
форманты:
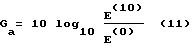
где
E(10) - прогнозируемая остаточная энергия после 10-й итерации, а E(0) - начальная прогнозируемая остаточная энергия ЛПК, как это будет пояснено позже в связи с анализом ЛПК, причем эта начальная остаточная энергия представляет собой то же, что и R(0).
С выхода сумматора 290 дополнение знакового бита разности в двоичном дополнительном коде выделяется компаратором или ограничителем 292 и подается на сумматор 272, где складывается с содержимым регистра 270. Таким образом, если разность между R(0) и T1 положительна, то содержимое регистра 270 увеличивается на единицу. Если эта разность отрицательна, содержимое регистра 270 не изменяется.
Закольцованные сдвиговые регистры 274, 276 и 278 затем зацикливаются так, что на их выходах появляются коэффициенты для T2, уравнение (8). Процесс вычисления величины порога T2 и сравнивание его с величиной энергии кадра повторяется таким же образом, как и для процесса вычисления величины порога T1. Закольцованные сдвиговые регистры 274, 276 и 278 затем снова зацикливаются, так что на их выходах появляются коэффициенты уравнения для T3, уравнение (9). Вычисление величины порога T3 и сравнение со значением энергии кадра происходит так же, как было описано выше. После окончания вычислений всех трех порогов и сравнений, регистр 270 содержит начальную оценку RTi скорости передачи. Предварительная оценка RTp подается в логическую схему 294 линейного снижения скорости передачи. На вход логической схемы 294 из подсистемы квантования частот ЛСП поступает также последняя скорость RTr предыдущего кадра, которая хранится в регистре 298. Логическая схема 296 вычисляет значение (RTr-1) и формирует на своем выходе большее из значений предварительной оценки RTp скорости передачи и величины (RTr-1). Значение RTm подается на логическую схему 296 ограничения скорости передачи.
Как упоминалось ранее, микропроцессор выдает в вокодер команды предельных скоростей, в частности на вход логической схемы 296. При цифровой реализации процессора эта команда принимается логической схемой 296 до окончания анализа ЛПК, являющегося частью процесса кодирования. Логическая схема 296 обеспечивает, чтобы скорость передачи не превышала установленные пределы и модифицирует значение RTm в случае, если она превысит эти пределы. В случае, если значение RTm находится внутри диапазона допустимых скоростей, то это значение появляется на выходе логической схемы 296 как начальное значение скорости RTi. Значение исходной скорости RTi с выхода логической схемы 296 подается в подсистему 210 квантования ЛСП, фиг.7a.
Оценка окружающего шума, как отмечалось ранее, используется при вычислении адаптивных порогов скорости. Для текущего кадра оценка B шума в предыдущем кадре используется при установлении порогов для текущего кадра. Однако для каждого кадра оценка шума корректируется для использования в определении порогов скорости для следующего кадра. Новая оценка B' окружающего шума определяется в текущем кадре, основываясь на оценке B окружающего шума предыдущего кадра и на энергии Ef текущего кадра.
При определении новой оценки B' фонового шума для использования в течение следующего кадра (в качестве оценки B фонового шума предыдущего кадра) вычисляются два значения. Первое значение V1 - есть просто энергия Ef текущего кадра. Второе значение V2 - это большее из B+1 и КВ, где К=1,00547. Чтобы предотвратить слишком большой рост второго значения, оно удерживается на уровне ниже постоянной величины М=160. 000. Меньшее из двух значений V1 или V2 выбирается как новая оценка B' фонового шума.
Формально
V1 + R(0), (12)
V2 = min(160000, max(KB,B+1)), (13)
и новая оценка B' окружающего шума будет
B' = min(V1, V2), (14)
где
min (x, y) - минимальная величина из x и y, а max(x, y) - максимальная
величина из x и y.
Фиг. 9 представляет реализацию алгоритма оценки окружающего шума. Первым значением V1 является просто величина энергии Ef текущего кадра, поступающая непосредственно на один вход мультиплексора 300.
Второе значение V2 вычисляется из величин KB и B+1, которые вычисляются первыми. При вычислении значений KB и B+1, оценка B окружающего шума предыдущего кадра, запомненная в регистре 302, поступает на входы сумматора 304 и умножителя 306. Следует заметить, что оценка B шума предыдущего кадра, запомненная в регистре 302 для использования в текущем кадре, такая же, как новая оценка B' окружающего шума, рассчитанная в предыдущем кадре. На сумматор 304 подается также значение 1 для сложения с величиной B, чтобы сформировать выражение B+1. Умножитель 304 также получает на вход величину K для умножения на значение B, чтобы получить выражение KB. Операнды B+1 и KB с выходов соответственно сумматора 304 и умножителя 306 поступают на отдельные входы мультиплексора 308 и сумматора 310.
Сумматор 310 и компаратор или ограничитель 312 используются для выбора большего из значений B+1 и KB. Сумматор 310 вычитает значение B+1 из KB и выдает результат на компаратор или ограничитель 312. Ограничитель 312 формирует управляющий сигнал для мультиплексора 308, так чтобы пропустить на выход последнего большее из значений B+1 и KB. Выбранное значение B+1 или KB с выхода мультиплексора 308 поступает на ограничитель 314, который является ограничителем с насыщением и выдает на выходе либо выбранное значение из значений B+1 и KB, если это значение ниже постоянной величины M, либо величину M, если выбранное значение из B+1 и KB превышает M. С выхода ограничителя 314 сигнал поступает на второй вход мультиплексора 300 и на вход сумматора 316.
На второй вход сумматора 316 поступает значение энергии Ef кадра. Сумматор 316 и компаратор или ограничитель 318 используются для выбора меньшего из значений Ef и значения с выхода ограничителя 314. Сумматор 316 вычитает величину энергии кадра из величины с выхода ограничителя 314 и выдает результирующий сигнал на компаратор или ограничитель 318. Ограничитель 318 формирует управляющий сигнал на мультиплексор 300, чтобы пропустить на его выход меньшую величину из Ef и сигнала на выходе ограничителя 314. Выбранное значение кода с выхода мультиплексора 300 поступает в качестве новой оценки B' окружающего шума в регистр 302, где запоминается для использования в течение следующего кадра уже в качестве оценки В окружающего шума предыдущего кадра по отношению к текущему кадру.
Возвращаясь к фиг. 7, можно видеть, что коэффициенты автокорреляции R(0)-R(10) поступают с выхода подсистемы 202 автокорреляции на подсистему 206 анализа ЛПК. Коэффициенты ЛПК вычисляются в подсистеме 206 анализа ЛПК с помощью как персептуального взвешивающего фильтра 52, так и фильтра 60 синтеза форманты.
Коэффициенты ЛПК могут быть получены автокорреляционным методом, используя рекурсивный алгоритм Дурбина, как это показано в Digital Processing of
Speech Signals, Rabiner & Schafer, Prentice-Hall, Inc. 1978. Этот метод является весьма эффективным методом получения коэффициентов ЛПК. Алгоритм может быть записан в виде следующих
выражений
Е0=R(0), i=1 (15)

если
i<10, то выполняется переход к выражению (16) с i=i+1 (20)
Десять коэффициентов ЛПК обозначаются α , при 1≤j≤10.
Прежде чем закодировать коэффициенты ЛПК, необходимо обеспечить устойчивость фильтра. Устойчивость фильтра достигается незначительным радиальным масштабированием полюсов передаточной функции фильтра, которое уменьшает величину пиков амплитудно-частотной характеристики с одновременным расширением их полосы. Этот метод известен как расширение полосы и более подробно описан в статье "Spectral Smoothing in PARCOR speech Analisis-Sinthesis", Tohkura et al., ASSP Transactions, December 1978. В данном случае расширение полосы может быть эффективно выполнено масштабированием каждого коэффициента ЛПК. Поэтому сформированные коэффициенты ЛПК, как показано в табл.3, умножаются каждый на соответствующее шестнадцатиричное число для окончательного формирования коэффициентов ЛПК α1-α10 на выходе подсистемы 206 анализа ЛПК. Следует заметить, что величины, представленные в табл.3, даются в шестнадцатиричной форме с 15 дробными битами в дополнительном (до двух) коде. В такой форме значение 0х8000 представляет -1,0, а значение 0х7333 (или 29491) представляет 0,899994=29491/32768.
Операции предпочтительно осуществляются с двойной точностью, т.е. 32-разрядными делителями, умножителями и сумматорами. Двойная точность предпочтительна для того, чтобы сохранить динамический диапазон автокорреляционных функций и коэффициентов фильтрации.
На фиг.10 показана блок-схема примера реализации подсистемы 206 ЛПК, которая осуществляет вычисления в соответствии с уравнениями (15)-(20). Подсистема 206 ЛПК содержит три схемные части: главная вычислительная схема 330 и две буферные схемы 332 и 334 обновления данных, которые используются для корректировки данных в регистрах главной вычислительной схемы 330. Вычисление начинается с загрузки значений R(1)-R(10) в буфер 340. Для того, чтобы начать вычисления регистр 348 предварительно загружается значением R(1) через мультиплексор 344. Регистр 348 инициализируется значением R(0) через мультиплексор 350, буфер 352 (который хранит 10 значений α) инициализируется в нулевое значение через мультиплексор 354, буфер 356 (который хранит 10 значений α )сбрасывается в нулевое значение через мультиплексор 358, а i устанавливается равным единице для вычислительного цикла. С целью упрощения, счетчики циклов i и j и другие системы, управляющие циклами вычислений, не показаны, но расчет и интеграция этого типа логических схем не представляет сложности для специалистов в области разработки цифровых логических устройств.
Значение α формируется на выходе буфера 356 для вычисления члена kiE(i-1) в качестве множества коэффициентов в уравнении (14). Каждое значение R(i-j) снимается с выходов буфера 340 для умножения на величину α в умножителе 360. Каждое значение результата умножения вычитается в сумматоре 362 из величины, хранимой в регистре 346. Результаты каждого вычитания запоминаются в регистре 346 для последующего вычитания из него следующего члена. Осуществляется i-1 умножений и накоплений в i-ом цикле. В конце цикла величина, хранимая в регистре 346, делится в делителе 364 на значение Ei-1, поступающее из регистра 348, для формирования величины ki.
Значение ki используется затем в буферной схеме 332 обновления данных для расчета значения E(i) в уравнении (19), которое, в свою очередь, используется как значение E(i-1) во время следующего цикла вычислений ki. Значение ki в текущем цикле умножается само на себя в умножителе 366 для получения величины k . Величина k затем вычитается из величины 1 в сумматоре 368. Результат этого сложения умножается в умножителе 370 на значение E(i), поступающее из регистра 348. Полученное значение E(i) поступает на вход регистра 348 через мультиплексор 350 для запоминания в качестве величины E(i-1) для следующего цикла.
Значение ki затем используется для вычисления значения α в соответствии с уравнением (15). В этом случае значение ki поступает на вход буфера 356 через мультиплексор 358. Значение ki также используется в буферной схеме 334 обновления данных для вычисления величин α из величин α в соответствии с уравнением (18). Величины, хранимые в данный момент в буфере 352, используются в вычислении величин α. . Как видно из уравнения (18), осуществляется (i-1) вычислений в i-м цикле. В первой итерации, i=1, таких вычислений не требуется. Для каждого значения j в i-м цикле вычисляется значение α . При вычислении каждого значения α каждое значение α умножается в умножителе 372 на значение ki для выдачи их на сумматор 374. В сумматоре 374 значение kiα вычитается из величины α , также поступающей на сумматор 374. Результат каждого умножения и сложения в качестве величины α поступает в буфер 356 через мультиплексор 358.
Как только величины α и α вычислены для текущего цикла, значения, только что вычисленные и запомненные в буфере 356, подаются на буфер 352 через мультиплексор 354. Значения, запомненные в буфере 356, запоминаются в соответствующих разрядах буфера 352. Буфер 352, таким образом, содержит обновленные данные для вычисления величины ki для (i+1)-го цикла.
Следует отметить, что данные α , полученные в конце предыдущего цикла, используются в текущем цикле для формирования обновленных данных α для следующего цикла. Эти данные, полученные в предыдущем цикле, должны быть сохранены, чтобы полностью сформировать обновленные данные для следующего цикла. Таким образом, два буфера 356 и 352 используются для сохранения этих данных предыдущего цикла до тех пор, пока не будут полностью сформированы обновленные данные.
Вышеприведенное описание предполагает параллельную передачу данных от буфера 356 к буферу 352 после завершения процесса вычисления значений обновленных данных. Такая реализация гарантирует сохранение старых данных на время всего процесса расчета новых данных без потери старых данных до тех пор, пока надобность в них отпадает, что могло бы иметь место при использовании единственного буфера. Описанная реализация является одной из нескольких уже существующих реализаций, созданных для тех же целей. Например, буферы 352 и 356 могут быть мультиплексованы таким образом, что после вычисления значений ki для текущего цикла из величин, запомненных в первом буфере, обновленные данные запоминаются во втором буфере для использования их в течение следующего вычислительного цикла. В этом следующем цикле величины ki вычисляются из значений, запомненных во втором буфере. Значения, хранящиеся во втором буфере, и значение ki используются для формирования обновленных данных для следующего цикла с запоминанием этих обновленных данных в первом буфере. Такое альтернативное использование этих буферов обеспечивает сохранение промежуточных значений продолжающегося вычислительного цикла, из которых формируются обновленные данные, при запоминании обновленных данных без переписывания промежуточных значений, необходимых для формирования обновленных данных. Использование такой схемы может минимизировать задержку, связанную с вычислением величины ki для следующего цикла. Поэтому обновленные данные для процессов умножения/накопления при вычислении ki могут быть получены одновременно с вычислением следующего значения α .
Десять коэффициентов ЛПК α, запомненных в буфере 356 по завершении последнего вычислительного цикла (1=10), масштабируются, чтобы преобразоваться в окончательные коэффициенты αj ЛПК. Масштабирование осуществляется подачей сигнала выбора масштаба на мультиплексоры 344, 376 и 378 так, что масштабирующие величины, запомненные в просмотровой таблице 342, т.е. шестнадцатиричные величины, приведенные в табл. 3, выбираются для прохождения через мультиплексор 344. Величины, запомненные в просмотровой таблице 342, под действием синхроимпульсов последовательно поступают на вход умножителя 360. Умножитель 360, кроме этого, принимает через мультиплексор 376 значения α , последовательно выводимые из регистра 356. Масштабированные величины с выхода умножителя 360 через мультиплексор 378 поступают на подсистему 208 преобразования ЛПК в ЛСП (фиг.7).
Для того, чтобы эффективно закодировать каждый из десяти масштабированных коэффициентов ЛПК малым числом битов, эти коэффициенты преобразуются в частоту линейных спектральных пар, как это подробно изложено в статье "Line Spectrum Pair (LSP) and Speech Data Compression", Soong and Juang, ICASSP'84. Вычисление параметров ЛСП поясняется ниже уравнениями (21) и (22), а также табл.4.
Частотами ЛСП являются десять корней, находящихся между 0 и π , следующих уравнений:
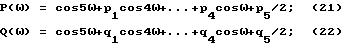
где значения, pn и qn определяются рекурсивно из табл.4, а n=1, 2, 3, 4.
В табл.4 величины α1,..., α10 - масштабированные коэффициенты, полученные при анализе ЛПК. Десять корней уравнений (21) и (22) масштабируются для простоты в диапазоне от G до 0, 5. Свойство частот ЛСП таково, что если фильтр ЛПК устойчив, то корни этих двух функций чередуются, т.е. наименьший корень ω1 является наименьшим корнем P(ω) , следующий наименьший корень ω2 является наименьшим корнем Q(ω) и т.д. Из десяти частот нечетные являются корнями P(ω) , а четные - корнями Q(ω). .
Поиск корней производится следующим образом. Сначала коэффициенты p и q вычисляются с двойной точностью суммированием коэффициентов ЛПК, как показано выше. Затем P(ω) вычисляется в точках через каждые π/256 радиан и эти значения затем оцениваются на предмет изменения знака, чтобы идентифицировать корень в этой подобласти. Если корень найден, то делается линейная интерполяция между двумя границами этой области, чтобы аппроксимировать расположение этого корня. Один корень Q гарантированно существует между каждой парой корней P (пятый корень Q находится между пятым корнем P и π благодаря свойству чередования частот. Для определения расположения корней Q производится двоичный поиск между каждой парой корней P. Для упрощения реализации каждый корень P аппроксимируется ближайшим значением π/256 и двоичный поиск осуществляется уже между этими аппроксимированными значениями. Если корень не найден, то используются прежние неквантованные значения частот ЛСП из последнего кадра, где используются найденные корни.
Обратимся теперь к фиг.11, где приведен пример реализации схемы, используемой для генерации частот ЛСП. Описанная выше операция требует 257 значений косинуса между 0
и π , которые запоминаются с двойной точностью в просмотровой таблице, просмотровой таблицы 400 косинусов, которая адресуется счетчиком 402 по модулю 256. Для каждого значения j на входе
таблицы 400 она выдает на своем выходе значения cosω, cos2ω, cos3ω, cos4ω, cos5ω,
где
ω = jπ/256 (23) ,
j - значение
отсчета.
Значения cosω, cos2ω, cos3ω и cos4ω с выхода просмотровой таблицы 400 поступают на соответствующие умножители 404, 406, 408 и 410, в то время как величина cos5ω подается прямо на вход сумматора 412. Эти значения умножаются в соответствующих умножителях 404, 406, 408 и 410 соответственно на одно из значений p4, p3, p2 и p1, поступающих через мультиплексоры 414, 416, 418 и 420. Результаты этих умножений подаются на сумматор 412. Кроме того, величина p5 поступает через мультиплексор 422 на умножитель 424, на который также подается постоянная величина 0,5, т.е. 1/2. Результат с выхода умножителя 424 подается на другой вход сумматора 412. Мультиплексоры 414-422 осуществляют выбор между величинами p1-p5 или q1-q5 в ответ на сигнал выбора коэффициента p/q, так что одна и та же схема используется для вычисления значений P(ω) и Q(ω) . Схемы для формирования значений p1-p5 или q1-q5 не показаны, но они легко реализуемы с помощью сумматоров для суммирования и вычитания коэффициентов ЛПК и величин p1-p5 и q1-q5 и регистров для запоминания величин p1-p5 и q1-q5.
Сумматор 412 суммируют входные величины для формирования на выходе значений P(ω) или Q(ω).. С целью упрощения дальнейшего описания будет рассмотрен случай формирования P(ω) , полагая, что значения Q(ω) рассчитываются аналогичным образом, используя значения q1-q5. Текущее значение P(ω)/ формируется на выходе сумматора 412 и запоминается в регистре 426. Промежуточное значение P(ω) , ранее запомненное в регистре 426, передается в регистр 428. Знаковые биты текущего и предыдущего значений P(ω) проходят через элемент 430 исключающее ИЛИ, чтобы обеспечить индикацию пересечения нулевого уровня или смены знака, в виде сигнала разрешения, который подается на нелинейный интерполятор 434. Текущее и предыдущее значения P(ω) с выходов регистров 426 и 428 также поступают на линейный интерполятор 434, который запускается сигналом разрешения для интерполирования точки между двумя значениями P(ω) , при которых происходит пересечение нулевого уровня. Этот дробный результат линейной интерполяции, представляющий собой расстояние от значения (j-1), подается в буфер 436 наряду со значением j с выхода счетчика 256. Элемент 430 формирует также разрешающий сигнал для буфера 436, который разрешает запоминание значения j и соответствующей дробной величины FVj.
Дробная величина вычитается из величины i в сумматоре 438 или в ином варианте это вычитание может осуществляться на входе буфера 436. В альтернативном варианте в цепи j на входе буфера 436 может быть использован регистр, так что значение i-1 вводится в буфер 436 вместе с подаваемой в него дробной величиной. Дробная величина может быть прибавлена к значению j-1 либо до запоминания в регистре 436, либо после выхода из регистра 436. В любом случае результирующая величина (i+FVj) или (j-1)+FVj подается на делитель 440, где делится на постоянную величину 512. Операция деления может быть осуществлена простым перемещением запятой в слове, представленном в двоичном коде. Эта операция деления обеспечивает необходимое масштабирование, чтобы привести частоты ЛСП в диапазон от 0 по 0,5.
Каждое вычисление значений функции P(ω) или Q(ω) требует 5 просмотров значений косинуса, 4 операции умножения с двойной точностью и 4 операции суммирования. Вычисленные корни обычно имеют точность лишь 13 битов и запоминаются с одинарной точностью. Частоты ЛСП поступают в подсистему 210 квантования ЛСП для квантования (фиг. 7).
Как только частоты ЛСП вычислены, они должны квантоваться для передачи. Каждая из десяти частот ЛСП центрируется грубо относительно значения смещения. Следует заметить, что частоты ЛСП аппроксимируют значения смещения, когда входной речевой сигнал обладает равномерным спектром и невозможно сделать даже близкого прогноза. Эти значения смещения вычитаются в кодере и применяется простое квантование с ДИКМ. В декодере величины смещения прибавляются вновь. Отрицательное значение смещения в шестнадцатиричной форме для каждой частоты ЛСП ω1-ω10, полученной в подсистеме преобразования ЛПК в ЛСП, приведены в табл.5. В табл.5 значения также даны в дополнительном двоичном коде с 15 дробными битами. Шестнадцатиричное значение 0х8000 (или -327680) представляет собой -1,0. Таким образом, первое значение в табл.5 0хfa2f (или -1489) представляет собой -0,045441=-1489/32768.
Прогнозирующий параметр, используемый в подсистеме, представляет собой 0,9 от квантованной частоты ЛСП предыдущего кадра, хранимой в буфере подсистемы. Благодаря введению постоянной затухания ошибки, возникающие в канале связи, в конечном счете подавляются.
Используемые квантователи являются линейными, но изменяются по динамическому диапазону и шагу квантования с изменением скорости. К тому же в кадрах, передаваемых с высокой скоростью, большее число битов используется для передачи каждой частоты ЛСП, поэтому число уровней квантования зависит от скорости передачи. В табл.6 приведены число передаваемых битов и динамический диапазон квантования для каждой скорости и для каждой частоты. Например, при скорости передачи 1, частота ω1 квантуется равномерно с использованием 4 битов (т.е. по 16 уровням) с наивысшим и наинизшим уровнями квантования равными соответственно 0,025 и -0,025.
Если диапазоны квантования для скорости передачи, выбранной на основе алгоритма выбора скорости, недостаточно велики или появляются переполнения, то скорость передачи увеличивается до следующей более высокой скорости. Скорость передачи продолжает повышаться до тех пор, пока не будет достигнут необходимый динамический диапазон или полная скорость передачи. Фиг. 12 представляет пример реализации необязательной схемы увеличения скорости.
На фиг.12 показана блок-схема примера реализации подсистемы 210 квантования ЛСП, которая включает схему увеличения скорости передачи. На фиг.12 частоты ЛСП текущего кадра поступают с выхода делителя 440 (фиг.11) на регистр 442, где они запоминаются для выдачи на выход в следующем кадре во время операции определения необходимости увеличения скорости. Частоты ЛСП предыдущего кадра и частоты ЛСП текущего кадра поступают соответственно из регистров 442 и делителя 440 на логическую схему 444 для определения необходимости увеличения скорости передачи в текущем кадре. Логическая схема 444, кроме того, получает сигналы исходной скорости передачи наряду с командами скорости и предельной скорости из подсистемы 204 определения скорости. При определении необходимости увеличения скорости логическая схема 444 сравнивает частоты ЛСП предыдущего кадра с частотами ЛСП текущего кадра, определяя сумму квадратов разностей между частотами ЛСП предыдущего и текущего кадров. Результат этого суммирования затем сравнивается со значением порога, превышение которого означает, что необходимо увеличение скорости для обеспечения высокого качества кодирования речевого сигнала. При превышении уровня порога логическая схема 442 обеспечивает приращение значения начальной скорости на одну градацию скорости таким образом, чтобы обеспечить на выходе конечное значение, используемое кодером.
На фиг.12 каждое значение частоты ЛСП ω1-ω10 поступает на вход сумматора 450 одновременно с соответствующим значением смещения. Значение смещения вычитается из входного значения ЛСП и результат вычитания поступает на сумматор 452. Сумматор 452 принимает на другой вход прогнозируемое значение, полученное в предыдущем кадре и соответствующее значению ЛСП, умноженному на постоянную затухания. Прогнозируемое значение вычитается из значения на выходе сумматора 450 с помощью сумматора 452. Результат вычитания с выхода сумматора 452 подается на вход квантователя 454.
Квантователь 454 содержит ограничитель 456, таблицу 458 просмотра минимального динамического диапазона, таблицу 460 просмотра величины обратного шага, сумматор 462, умножитель 464 и битовую маску 466. При квантовании в квантователе 454 сначала определяется, находится ли входная величина в пределах динамического диапазона квантователя 454. Входная величина подается на ограничитель 546, который ограничивает ее верхней и нижней границами динамического диапазона, если входной сигнал переходит границы, определяемые просмотровой таблицей 458. Просмотровая таблица 458 выдает запомненные значения границ динамического диапазона, соответствующие табл.6, для ограничителя 456 в ответ на входные сигналы скорости передачи и индекса i частоты ЛСП. Значение с выхода ограничителя 456 поступает на вход сумматора 462, где из него вычитается минимальное значение динамического диапазона, выданное просмотровой таблицей 458. Значение с выхода таблицы 458 снова определяется значениями скорости и индексом i частоты ЛСП в соответствии с минимальными значениями динамического диапазона, приведенными в табл.6, без учета знака. Например, значение на выходе просмотровой таблицы 458 для полной скорости ω1 равно 0,025.
Выход сумматора 462 затем умножается в умножителе 464 на величину, выбранную из просмотровой таблицы 460. Просмотровая таблица 460 содержит значения, соответствующие обратной величине шага для каждого значения ЛСП при каждой скорости в соответствии с данными табл.6. Выходная величина просмотровой таблицы 460 выбирается в зависимости от величины скорости и индекса i частоты ЛСП. Для каждой скорости и индекса i частоты ЛСП величина, запомненная в таблице 460, равна (2n-1)/динамический диапазон), где n - число битов, представляющих квантованную величину. Например, величина в просмотровой таблице 460 для скорости 1 ω1 равна (15/0,05) или 300.
С выхода умножителя 464 величина, лежащая в диапазоне от 0 до 2n-1, поступает на битовую маску 466. Битовая маска 466 в зависимости от величины скорости передачи и индекса частоты ЛСП выделяет из входного значения определенное число битов в соответствии с табл.6. Выделенные биты представляют целое число n битов входного значения, что позволяет получить выходные значения Δ ωi с ограниченным числом битов. Значения Δωi представляют собой квантованные не смещенные дифференциально кодированные частоты ЛСП, которые передаются по каналу связи, представляя коэффициенты ЛПК.
Значение Δωi также поступает на схему прогнозирования, включающую обратный квантователь 468, сумматор 470, буфер 472 и умножитель 474. Обратный квантователь 468 содержит просмотровую таблицу 476 величины шага, просмотровую таблицу 478 минимального динамического диапазона, умножитель 480 и сумматор 482.
Величина Δωi поступает на умножитель 480 вместе со значением, выбранным из просмотровой таблицы 476. Просмотровая таблица 476 содержит значения, соответствующие величине шага для каждого значения ЛСП при каждой скорости в соответствии с табл.6. Величина из просмотровой таблицы 476 выбирается в зависимости от скорости передачи и индекса i частоты ЛСП. Для каждых скорости передачи и индекса i значение, запомненное в просмотровой таблице 460, равно величине (динамический диапазон/2n-1), где n - число битов, представляющих квантованное значение. Умножитель 480 перемножает поданные на его входы значения, и сигнал с его выхода подается на вход сумматора 482.
Сумматор 482 принимает на второй вход величину из просмотровой таблицы 478. Эта величина из таблицы 478 определяется скоростью передачи и индексом i частоты ЛСП в соответствии со значениями минимального динамического диапазона, без учета знака, согласно табл.6. Сумматор 482 суммирует значение минимального динамического диапазона, полученное из просмотровой таблицы 478, с выходной величиной умножителя 480, при этом результирующее значение поступает на сумматор 470.
Сумматор 470 принимает на свой второй вход прогнозируемое значение с выхода умножителя 474. Эти величины складываются в сумматоре 470 и запоминаются в буфере 472 памяти емкостью десять слов. Каждое значение с выхода буфера 472, полученное в предыдущем кадре, в текущем кадре умножается в умножителе 474 на постоянную величину 0,9. Прогнозируемое значение с выхода умножителя 474 подается на оба сумматора 452 и 470, как указывалось ранее.
В текущем кадре величина, запомненная в буфере 472, представляет собой восстановленные величины ЛСП предыдущего кадра за вычетом величины смещения. Аналогично в текущем кадре выходным значением сумматора 470 являются восстановленные значения ЛСП текущего кадра с вычтенным значением смещения. В текущем кадре выходные величины буфера 472 и сумматора 470 подаются соответственно на сумматоры 484 и 486, где значение смещения суммируется с этими значениями. Выходные значения сумматоров 484 и 486 представляют собой восстановленные значения частот ЛСП предыдущего кадра и текущего кадра соответственно. Сглаживание ЛСП осуществляется на низких скоростях в соответствии с уравнением.
Сглаженная ЛСП=а(ЛСП текущего кадра)+(1-а)(ЛСП предыдущего кадра), (24)
где
а=0 для полной скорости
а=0,1 для половинной скорости
а=0,5
для четвертной скорости
а=0,85 для одной восьмой полной скорости.
Значение восстановленной частоты


Коэффициенты ЛПК, используемые во взвешивающем фильтре и в фильтре синтеза форманты, предназначены для кодируемого подкадра тона. Для тоновых подкадров интерполяция коэффициентов ЛПК осуществляется один раз для каждого подкадра тона в виде, показанном в табл.7.
Счетчик 224 подкадров тона используется для отслеживания подкадров тона, для которых вычисляются параметры тона, и с его выхода сигнал поступает на подсистему 216 интерполяции ЛСП подкадров тона для использования при интерполяции ЛСП подкадров тона. Выход счетчика 224 подкадров тона подается также на подсистему 236 упаковки данных для индикации завершения поиска подкадра тона для выбранной скорости передачи.
Фиг. 13 иллюстрирует пример реализации подсистемы 216 интерполяции ЛСП подкадра тона, предназначенной для интерпелляции частот ЛСП в анализируемом подкадре тона. На фиг.13 частоты

Подсистема 218 преобразования ЛСП в коэффициенты ЛПК преобразует интерполированные частоты ЛСП
обратно в коэффициенты ЛПК для использования при синтезировании речевого сигнала. Подробное изложение и вывод алгоритма, используемого в данном изобретении для этого процесса преобразования,
приводится в статье "Line Spectrum Pair (LSP) and Speech Data Compression", Soong u Juang. Вычислительные особенности таковы, что величины как P(z) и Q(z) могут быть выражены через частоты ЛСП
следующими уравнениями:
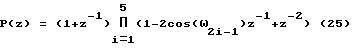
где
ωi - корни полинома P' (нечетные частоты), и

где
ωi - корни полинома Q' (четные частоты)

Прежде всего вычисляют значения 2cos( (ωi) ) для всех частот с нечетным индексом i. Вычисление выполняется с использованием разложения в косинусный ряд Тейлора в точке нуль (0) с одинарной точностью до пятого члена. Разложение в ряд Тейлора в ближайшей точке таблицы косинуса было бы более точным, но разложение в точке 0 позволяет достичь необходимой точности и избежать чрезмерного увеличения количества вычислений.
После этого вычисляются коэффициенты полинома P. Коэффициенты произведения полиномов определяются в виде свертки последовательностей коэффициентов отдельных полиномов. Таким образом затем вычисляется свертка шести последовательностей из z коэффициентов полинома в уравнении (25) {1,-2cos (ω1) ,1}, {1,-2 cos (ω3) ,1}, ... {1,-2cos (ω9) ,1} и {1,1}.
После того, как полином P вычислен, та же самая процедура повторяется для полинома Q, где шесть последовательностей из z коэффициентов полинома в уравнении (26) выражаются как {1,-2cos (ω2),1}, {1,-2cos (ω4)),1}, ...{1,-2cos (ω10), 1} и {1,-1}, соответствующие коэффициенты суммируются и делятся на 2, т.е. сдвигаются на один бит, для формирования коэффициентов ЛПК.
Фиг.13 представляет, кроме того, подробную блок-схему примера реализации подсистемы преобразования ЛСП в коэффициенты ЛПК. Часть 508 схемы вычисляет величину -2cos (ωi) из входной величины ωi. Часть 508 схемы содержит буфер 509, сумматоры 510 и 515, умножители 511, 512, 514. 516 и 518, а также регистры 513 и 515. При вычислении величин -2cos регистры 513 516 сбрасываются в нуль. Так как эта схема вычисляет sin (ωi) предварительно вычитается в сумматоре 510 из входной постоянной величины (ωi), ωi . Результат возводится в квадрат с помощью умножителя 511, и затем последовательно вычисляются величины π/2. с использованием умножителя 512 и регистра 513.
Коэффициенты c[1]-c[4] разложения в ряд Тейлора последовательно подаются на умножитель 514 наряду с величинами с выхода умножителя 512. Величины с выхода умножителя 514 поступают на вход сумматора 515, где суммируются с величинами с выхода регистра 516, чтобы получить c[1]
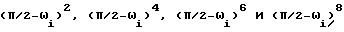
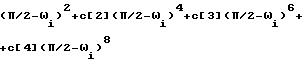
Часть 520 схемы используется для вычисления коэффициентов полинома P. Часть 520 схемы включает запоминающее устройство 521, умножитель 522 и сумматор 523. Запоминающие ячейки P(1). .. P(11) устанавливаются в 0, за исключением P(1), которая устанавливается в 1. Значения -2cos (ωi) со старыми индексами подаются на умножитель 524 для получения свертки из (1, -2cos (ωi) ,1), где: 1≤i≤ 5; 1≤i≤2i+1, P(j)=0 для j<1. Часть 520 схемы дублируется (не показано) для вычисления коэффициентов полинома Q. Окончательный результат, то есть новые значения P(1)- P(11) и Q(1)-Q(11) подаются на часть 524 схемы.
Часть 524 схемы предназначена для завершения вычисления десяти коэффициентов (ωi) (i= 1, 2,..., 10) ЛПК подкадра тона. Часть 524 схемы включает буферы 525 и 526, сумматоры 522, 528 и 529 и делитель или схему 530 сдвига битов. Окончательные значения P(i) и Q(i) запоминаются в буферах 525 и 526. Значения P(i) и P(i+1) суммируются в сумматоре 527, в то время как соответствующие значения Q(i) и Q(i+1) вычитаются в сумматоре 528, для 1≤i≤10. Значения с выходов сумматоров 527 и 528, соответственно P(z) и Q(z), подаются на вход сумматора 529, где суммируются для получения на выходе величины (P(x)+Q(z)). Эта величина делится на два путем сдвига битов на один разряд. Каждое сдвинутое на один разряд значение (P(z)+Q(z))/2 является выходным коэффициентом αi ЛПК. Коэффициенты ЛПК подкадра тона подаются в подсистему 220 поиска тона на фиг.7.
Частоты ЛСП интерполируются также для каждого подкадра кодового словаря в соответствии с выбранной скоростью передачи, за исключением полной скорости. Интерполяция осуществляется аналогично интерполяции ЛСП для подкадра тона. Интерполированные значения ЛСП подкадра кодового словаря вычисляются в подсистеме 226 интерполяции ЛСП подкадра кодового словаря и подаются в подсистему 228 преобразования ЛСП в коэффициенты ЛПК, где это преобразование вычисляется методом, подобным методу, использованному в подсистеме 218 преобразования ЛСП в коэффициенты ЛПК.
При обсуждении фиг. 3 отмечалось, что поиск тона производится методом анализа через синтез, согласно которому кодирование осуществляется путем выбора параметров, минимизирующих ошибку между входным речевым сигналом и сигналом речи, синтезированным с использованием этих параметров. При поиске тона речевой сигнал синтезируется с помощью фильтра синтеза тона передаточная характеристика которого выражается уравнением (2). Каждые 20 мс кадр речевого сигнала разбивается на ряд подкадров тона, число которых, как указывалось ранее, зависит от выбранной скорости передачи для данного кадра. При этом для каждого подкадра тона вычисляются параметры b и L, усиление и задержка тонового сигнала соответственно. В данном примере реализации задержка L тона лежит в диапазоне между 17 и 143. при этом для удобства передачи L=16 резервируется для случая, когда b=0.
Кодер речевого сигнала использует фильтр взвешивания персептуального (т. е. имеющего отношение к восприятию) шума, характеристика которого определена уравнением (1). Как отмечалось ранее, задачей этого взвешивающего фильтра является взвешивание ошибки на частотах с более низкой мощностью в спектре сигнала, чтобы уменьшить влияние ошибки, обусловленной шумом. Фильтр взвешивания персептуального шума получается из фильтра кратковременного предсказания, найденного ранее. Коэффициенты ЛПК, используемые во взвешивающем фильтре, и фильтр синтеза форманты, описанный ниже, являются интерполированными величинами, соответствующими кодируемому подкадру.
При осуществлении метода анализа через синтез в кодере используется копия декодера/синтезатора сигнала речи. Вид синтезирующего фильтра, используемого в кодере речи, определяется уравнениями (3) и (4). Уравнения (3) и (4) соответствуют синтезирующему речь фильтру декодера, за которым следует фильтр взвешивания персептуального шума, называемый поэтому фильтром взвешенного синтезированного сигнала.
Поиск тона осуществляется с предположения
нулевого вклада со стороны кодового словаря в текущем кадре, т.е. G=0. Для каждого возможного значения задержки L тона синтезируется речевой сигнал и сравнивается с исходным речевым сигналом. Ошибка,
соответствующая различию между входным речевым сигналом и синтезированным речевым сигналом, взвешивается фильтром взвешивания персептуального шума, перед тем как рассчитывается ее среднеквадратичное
значение (СКО). Цель заключается в том, чтобы подобрать такие значения L и b из всех возможных величин L и b, которые минимизируют ошибку, соответствующую рассогласованию между персептуально
взвешенным сигналам речи и персептуально взвешенным синтезированным сигналом речи. Процесс минимизации ошибки может быть выражен следующим уравнением:
αi ,
где
Lp - число выборок сигнала в тоновом подкадре, которое в данном примере реализации равно 40, для полной скорости передачи подкадра тона. Вычисляется усиление b тона, которое
минимизирует среднеквадратичную ошибку (СКО). Эти вычисления повторяются для всех разрешенных значений L, и величины L и b, которые обеспечивают минимальную среднеквадратичную ошибку, выбираются в
качестве параметров тонового фильтра.
При вычислении оптимальной задержки тона используется формантный остаток (p(n) на фиг. 3) для любых значений времени между n=-Lmax и n=(Lp-Lmin)-1, где Lmax - максимальная величина задержки тона, Lmin - минимальная величина задержки тона, а Lp - длительность подкадра тона для выбранной скорости передачи, и где n=0 является началом подкадра тона. В примере реализации Lmax= 143 и Lmin=17. Используя нумерацию в соответствии с фиг.14, имеем: для скорости передачи 1/4 n=-143 по n=442; для скорости передачи 1/2 n=-143 по n= 62; для скорости передачи 1, n=-143 по n=22. Для n<0 (формантным остатком является просто выход тонового фильтра от предыдущих подкадров тона, который содержится в памяти тонового фильтра и назван формантным остатком замкнутого контура. Для n≥0 формантный остаток представляет собой выход фильтра анализа форманты, который имеет передаточную характеристику A(z) и на вход которого поступают выборки речевого сигнала анализируемого текущего кадра. Для n≥0 формантный остаток назван формантным остатком разомкнутого контура и был бы равен точно p(n), если бы тоновый фильтр и кодовый словарь осуществляли точное предсказание в данном подкадре. Дальнейшее пояснение процедуры вычисления оптимальной задержки тона по связанным с ней значениям формантного остатка проводится со ссылкой на фиг.14-17.
Поиск тона производится по 143 восстановленным выборкам формантного остатка замкнутого контура, P(n) для n<0 и по (Lp-Lmin) неквантованным выборкам формантного остатка разомкнутого контура, p0(n) для n≥0. Поиск изменяется постепенно от поиска в основном по разомкнутому контуру, где L мало и поэтому большинство используемых выборок формантного остатка имеют n>0, до поиска главным образом по замкнутому контуру, когда L велико и поэтому все используемые выборки формантного остатка имеют n<0. Например, используя нумерацию фиг.14, при полной скорости передачи, когда тоновый подкадр содержит 40 выборок речевого сигнала, поиск тона начинается с использованием ряда выборок формантного остатка с номерами от n=-17 до n=22. В этой схеме при n от n=-17 до n=-1 выборки являются выборками (формантного остатка замкнутого контура, в то время как при n от n=0 до n=22 выборки являются выборками формантного остатка разомкнутого контура. Следующей группой выборок формантного остатка, используемых при определении оптимальной задержки тона, являются выборки с номерами от n=-18 до n=21. Аналогично, при n от n=-18 до n=-1 выборки являются выборками формантного остатка замкнутого контура, в то время как при n от n=0 до n=21 выборки являются выборками формантного остатка разомкнутого контура. Процесс продолжается с группами выборок до тех пор, пока не будет вычислена задержка тона для последней группы выборок формантного остатка, от n=-143 до n=-104.
Как отмечалось ранее, в связи с уравнением (28), целью является минимизация ошибки, соответствующей различиям между x(n),
персептуально взвешенным речевым сигналом за вычетом отклика фильтра взвешенной форманты на нулевой входной сигнал, и x'(n), персептуально взвешенным синтезированным речевым сигналом, формируемым
фильтрами без памяти, при всех возможных значениях L и b, выдаваемых стохастическим кодовым словарем при его нулевом состоянии (G=0). Уравнение (28) может быть переписано по отношению к b как:
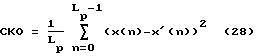
где

где
y(n) - взвешенный синтезированный речевой сигнал с тоновой задержкой L, когда b= 1, и h(n) - временная характеристика фильтра синтеза взвешенной форманты, имеющего передаточную характеристику в соответствии с уравнением (3).
Процесс минимизации эквивалентен процессу максимизации значения EL, где

оптимальное значение b для данного значения L равно
Поиск повторяется для всех возможных значений L. Оптимальная величина b ограничивается положительными значениями, поэтому значения L, при которых Exy отрицательно, не используются при поиске. В конце концов для передачи выбираются значения задержки L и усиления b тона, которые максимизируют величину EL.
Как было сказано выше, x(n) является по сути персептуально взвешенной разностью между входным речевым сигналом и откликом фильтра взвешенной форманты на нулевой сигнал, так как для рекурсивной свертки, приведенной ниже в уравнениях (35)-(38), предполагается, что фильтр A(z) всегда начинает работу с обнуленной памятью. Однако начальное обнуление памяти фильтра не является принципиальным. При синтезе фильтр будет иметь состояние, оставшееся от предыдущего подкадра. В примере реализации начальное состояние памяти фильтра вычитается из персептуально взвешенного речевого сигнала в начале анализа. Таким образом, достаточно вычислить только отклик фильтра A(z) в установившемся состоянии, с памятью, установленной сначала в нуль, на воздействие p(n) для каждого L, и рекурсивная свертка может быть использована. Это значение x(n) необходимо вычислить только один раз, но y(n), отклик формантного фильтра при нулевом состоянии на сигнал с выхода тонового фильтра, должен вычисляться для каждой задержки L. Вычисление каждого значения y(n) требует большого числа избыточных умножений, которые не нужно выполнять для каждой задержки. Для минимизации объема требуемых вычислений используется алгоритм рекурсивной свертки, описанный ниже.
В соответствии с алгоритмом рекурсивной свертки значение yL(n) определяется значением y(n) как:
yL
(n)=h(n)*p(n-L) 17≤L≤143, (35)
или
YL(n) = ∑ h(i)p(n-L-i) 17 ≤ L ≤ 143 (36) .
Из уравнений (32) и (33)
видно, что Таким
образом, по первой вычисленной свертке для y17(n) рекурсивно могут быть получены оставшиеся свертки, существенно снижая объем требуемых вычислений. Для данного выше примера со скоростью
передачи 1, величина y17(n) вычисляется с помощью уравнения (36), используя группы выборок формантного остатка с номерами от n=-17 до n=22. В соответствии с фиг.15, кодер
содержит схему, являющуюся точной копией декодера, приведенного на фиг. 5, декодирующей подсистемы 235, приведенной на фиг. 7, но не имеет адаптивного постфильтра. На фиг.15 входом фильтра 550 синтеза
тона является произведение значения c1(n) кодового словаря и усиления G кодового словаря. Выходные выборки формантного остатка p(n) поступают на вход фильтра 552 синтеза форманты, где
фильтруются и выдаются на выход в качестве выборок s'(n) синтезированного речевого сигнала. Выборки s'(n) синтезированного речевого сигнала вычитаются из соответствующих выборок s(n) входного сигнала
речи в сумматоре 554. Разность между выборками s(n) и s'(n) поступает на вход персептуального взвешивающего фильтра 556. Все фильтры, включая фильтр 550 синтеза тона, фильтр 552 синтеза форманты и
персептуальный взвешивающий фильтр 556, содержат каждый память для запоминания состояния фильтров, при этом на фиг.15: Mp-память фильтра 550, синтеза тона, Ma- память фильтра 552
синтеза форманты и Mw-память персептуального взвешивающего фильтра 556. Значение состояния фильтра Ma из фильтра 552 синтеза форманты декодирующей подсистемы
поступает в подсистему 220 поиска тона на фиг.7. На фиг.16 значение Ma состояния фильтра используется для вычисления отклика фильтра 560 на нулевой входной сигнал, вычисляющего отклик
фильтра 552 синтеза форманты на нулевой входной сигнал. Вычисленное значение отклика на нулевой сигнал вычитается из выборок s(n) входного сигнала речи в сумматоре 562, результирующая величина с
выхода которого взвешивается персептуальным взвешивающим фильтром 554. Величина xp(n) с выхода персептуального взвешивающего фильтра 564 используется в качестве взвешенного речевого сигнала
в уравнениях (28)-(34), где x(n)=xp(n). Возвращаясь снова к фиг.14 и 15, отметим, что фильтр 552 синтеза тона, как показано на фиг.14, формирует сигнал для адаптивного
кодового словаря 568. который по сути является блоком памяти для хранения выборок формантного остатка разомкнутого и замкнутого контуров, вычисленных как описано выше. Формантный остаток замкнутого
контура хранится в области 570 памяти, а формантный остаток разомкнутого контура хранится в области 572 памяти. Выборки запоминаются в соответствии с нумерацией, как было рассмотрено выше. Формантный
остаток замкнутого контура организуется так же, как описано выше применительно к использованию при поиске каждой задержки L тона. Формантный остаток разомкнутого контура вычисляется из выборок s(n)
входного сигнала речи для каждого тонового подкадра с использованием фильтра 574 анализа форманты, который использует память Ma фильтра 552 синтеза форманты декодирующей подсистемы пои
вычислении значений p0(n). Значения p0(n) для текущего тонового подкадра сдвигаются с помощью цепочки элементов 576 задержки перед подачей в область 572 памяти адаптивного
кодового словаря 568. Формантные остатки разомкнутого контура запоминаются с первой сформированной выборкой формантного остатка, имеющей номер 0, и с последней, имеющей номер 142. В
соответствии с фиг.16, временная импульсная характеристика h(n) формантного фильтра вычисляется в фильтре 556 и с него подается на сдвиговый регистр 580. Как указывалось выше в связи с временной
характеристикой формантного фильтра h(n), уравнения (29)-(30) и (35)- (38), эти значения вычисляются для каждого тонового подкадра в фильтре. Чтобы дополнительно уменьшить требуемый объем
вычислительных операций подсистемы тонового фильтра, временная импульсная характеристика формантного фильтра h(n) усекается до 20 выборок. Сдвиговый регистр 580 наряду с умножителем
582, сумматором 584 и сдвиговым регистром 586 служит для вычисления рекурсивной свертки между величинами h(n) с выхода сдвигового регистра 560 и величинами c(m) с выхода адаптивного кодового словаря
568. Операция свертки осуществляется для того, чтобы определить отклик формантного фильтра в нулевом состоянии на входной сигнал, поступающий из памяти тонового фильтра, в предположении, что усиление
тона установлено равным 1. При осуществлении циклов свертки n периодически повторяются от Lp до 1 для каждого m, в то время как m периодически повторяется от (Lp-17)-1 до -143. В
регистре 586 не происходит сдвиг данных вперед, когда n=1, и не происходит фиксация данных, когда n=Lp. Данные выдаются с выхода схемы свертки, когда m≤-17. За
схемой свертки следуют схемы корреляции и сравнения, которые осуществляют поиск оптимальных значений задержки L тона и усиления b тона. Схема корреляции, которая также называется схемой
среднеквадратичной ошибки (СКО), вычисляет автокорреляцию и кросскорреляцию отклика в нулевом состоянии с персептуально взвешенной разностью между откликом формантного фильтра на нулевой сигнал и
входным речевым сигналом, т.е. x(n). Используя эти величины, схема корреляции вычисляет значения оптимального усиления b тона для каждого значения задержки тона. Схема корреляции включает сдвиговый
регистр 588, умножители 590 и 592, сумматоры 594 и 596, регистры 598 и 600 и делитель 602. В схеме корреляции вычисления проводятся таким образом, что параметр n периодически последовательно принимает
значения от Lp до 1, в то время как параметр m периодически последовательно принимает значения от (Lp-17)-1 до -143. Выход схемы корреляции соединен с входом
схемы сравнения, которая осуществляет сравнение и запоминание данных с целью определения оптимальных величин задержки L тона и усиления b тона. Схема сравнения содержит умножитель 604, компаратор 606,
регистры 608, 610 и 612 и квантователь 614. Схема сравнения формирует на выходе для каждого тонового подкадра величины L и b, которые минимизируют ошибку между синтезированным и входным речевыми
сигналами. Величина b квантуется восемью уровнями в квантователе 614 и представляется трехбитовым значением, при этом предусмотрен дополнительный уровень b= 0 при L=16. Эти значения L и b поступают в
подсистему 230 поиска кодового словаря и буфер 222 данных. Кроме того, эти значения поступают через подсистему 238 упаковки данных или буфер 222 данных в декодер 234 для использования при поиске
тона. Подобно процессу поиска тона, поиск кодового словаря осуществляется методом анализа через синтез, когда кодирование производится путем выбора параметров, которые минимизируют
ошибку между входным сигналом речи и синтезированным с использованием этих параметров сигналом речи. Для скорости передачи 1/8 усиление тона b устанавливается равным нулю. Как
указывалось ранее, каждые 20 мс делятся на ряд подкадров кодового словаря, число которых зависит от величины скорости передачи данных, выбранной для кадра. Один раз в каждом подкадре кодового словаря
вычисляются параметры G и I, усиление и индекс кодового словаря соответственно. При расчете этих параметров частоты ЛСП интерполируются для подкадра, за исключением случая полной скорости передачи, в
подсистеме 226 интерполяции ЛСП подкадра кодового словаря методом, аналогичным методу, описанному применительно к подсистеме 216 интерполяции ЛСП подкадра тона. Интерполированные частоты ЛСП подкадра
кодового словаря также преобразуются в коэффициенты ЛПК с помощью подсистемы 228 преобразования ЛСП в ЛПК для каждого подкадра кодового словаря. Счетчик 232 подкадров кодового словаря используется для
отслеживания номеров подкадров кодового словаря, для которых вычисляются параметры кодового словаря. Выход счетчика 232 соединен с входом подсистемы 226 интерполяции ЛСП подкадров кодового словаря.
Счетчик 232 подкадров кодового словаря указывает также счетчику 224 подкадров тона на окончание подкадра кодового словаря при выбранной скорости передачи. Возбуждение кодового словаря
состоит из 2M кодовых векторов, которые получаются из одновариантной белой Гауссовой случайной последовательности. Существует 128 входных воздействий для кодового словаря при M=7. Кодовый
словарь организуется рекурсивным способом так, что каждый кодовый вектор отличается от смежного кодового вектора на одну выборку, т.е. выборки в кодовом векторе сдвинуты на одну позицию так, что новая
выборка вводится на одном конце и одна выборка выводится с другого. Поэтому рекурсивный кодовый словарь может быть запомнен в виде линейного массива длиной 2M+(Lc)-1), где Lc - длина подкадра кодового словаря. Однако, чтобы упростить схему и сократить объем требуемой памяти, используется кольцевой кодовый словарь длиной 2M выборок (128 выборок). Чтобы уменьшить объем вычислений, Гауссовы значения в кодовом словаре отсекаются с обеих сторон. Эти величины первоначально выбираются из белого Гауссова процесса с дисперсией равной 1.
Затем значения с величиной меньше 1,2 устанавливаются равными нулю. При этом в нуль устанавливается 75% значений и формируется кодовый словарь импульсов. Такое двустороннее ограничение кодового
словаря уменьшает число операций умножения, требуемых для формирования рекурсивной свертки при поиске кодового словаря, в 4 раза, так как умножение на нуль не производится. Кодовый словарь,
используемый в рассматриваемом примере реализации, приведен в табл.8. Так же, как и раньше, кодер речевого сигнала использует взвешивающий фильтр персептуального шума в соответствии с
уравнением (1), который включает фильтр взвешенного синтезированного сигнала, соответствующий уравнению (3). Для каждого индекса I кодового словаря синтезируется речевой сигнал и сравнивается с
исходным речевым сигналом. Сигнал ошибки взвешивается взвешивающим фильтром персептуального шума перед вычислениям его среднеквадратичной ошибки (СКО). Как было сказано выше, задача
сводится к минимизации ошибки между x(n) и x'(n) при всех возможных значениях I и G. Минимизация ошибки может быть выражена следующим уравнением
yL(0)=p(-L)h(0), (37)
yL(n)=yL-1(n-1)+p(-L)h(n) 1≤n≤Lp, 17

где
Lc - число выборок в подкадре кодового словаря.
Уравнение (38) может быть выражено через G как

где
y получается путем свертки импульсной временной характеристики формантного фильтра с I-м кодовым вектором, предполагая, что G=1. Минимизация СКО эквивалентна максимизации величины:

Оптимальная величина G для данного значения I находится в соответствии со следующим уравнением:

Этот поиск повторяется для всех возможных величин I. В отличие от поиска тона, оптимальное усиление G может быть как положительным, так и отрицательным. В итоге выбирается индекс I и усиление G кодового словаря, которые обеспечивают максимальное EI.
Еще раз следуют отметить, что x(n), персептуально взвешенная разность между входным речевым сигналом и откликом на нуль фильтров взвешенных тона и форманты должна вычисляться только один раз. Однако y(n), отклик состояния тонового и формантного фильтров в нулевом состоянии для каждого кодового вектора, должен рассчитываться для каждого индекса I. Поскольку используется кольцевой кодовый словарь, то для минимизации объема требуемых вычислений может быть использован метод рекурсивной свертки, приведенный при описании поиска тона.
Обратимся снова к фиг.15, где кодер включающий декодер, аналогичный декодеру, изображенному на фиг.5 в декодирующей подсистеме 235, изображенной на фиг.7, вычисляет состояния фильтров, при этом Mp- память фильтра 550 синтеза тона. Ma-память фильтра 552 синтеза форманты и Mw-память персептуального взвешивающего фильтра 556.
Состояния фильтров Mp и Ma, соответственно фильтра 550 синтеза тона и фильтра 552 синтеза форманты (фиг.15) декодирующей подсистемы поступают в подсистему 230 поиска кодового словаря на фиг.7. На фиг.17 состояния Mp и Ma фильтров поступают на фильтр 620 отклика на нулевой сигнал, вычисляющий такой отклик фильтров 550 и 552 синтеза тона и форманты. Вычисленные отклики фильтров синтеза тона и форманты на нулевой сигнал вычитаются из выборок s(n) входного речевого сигнала в сумматоре 662, результирующий сигнал с выхода которого взвешивается персептуальным взвешивающим фильтром 624. Выходной сигнал xc(n) персептуального взвешивающего фильтра 564 используется как взвешенный входной речевой сигнал для вычисления СКО в приведенных выше уравнениях (39)-(44), где x(n)=xc(n).
На фиг. 17 импульсная временная характеристика h(n) формантного фильтра вычисляется в фильтре 626 и подается на сдвигающий регистр 628. Импульсная характеристика формантного фильтра h(n) вычисляется для каждого подкадра кодового словаря. Чтобы уменьшишь объем вычислений, импульсная характеристика h(n) усекается до 20 выборок.
Сдвигающий регистр 628 вместе с умножителем 630, сумматором 632 и сдвигающим регистром 634 предназначен для получения рекурсивной свертки между величинами h(n) с выхода сдвигающего регистра 628 и величинами c(m) с выхода кодового словаря 636, который содержит векторы кодового словаря, как было сказано выше. Эта операция свертки выполняется, чтобы найти отклик формантного фильтра в нулевом состоянии на каждый кодовый вектор, в предположении, что усиление кодового словаря установлено равным 1. При работе схемы свертки n периодически принимает значения от Lc до 1 для каждого m, в то время как m периодически изменяется от 1 до 256. В регистре 586 данные не продвигаются, когда n= 1 и данные не фиксируются, когда n=Lc. Данные поступают из схемы свертки, когда m≤1. Следует заметить, что схема свертки должна быть инициирована, прежде чем проводить операцию свертки, путем циклического сдвига m раз (m-размер подкадра) перед запуском схемы корреляции и сравнения, которая следует за схемой свертки.
Схема корреляции и сравнения проводит фактический поиск индекса кодового словаря и усиления G кодового словаря. Схема корреляции, называемая еще схемой среднеквадратичной ошибки (СКО), вычисляет авто- и кросскорреляцию отклика в нулевом состоянии с персептуально взвешенными разностями между откликами на нуль тонового и формантного фильтров и значениями x'(n) входного речевого сигнала. Иными словами, схема корреляции вычисляет значение усиления G кодового словаря для каждого значения индекса I кодового словаря. Схема корреляции содержит сдвигающий регистр 638, умножители 640 и 642, сумматоры 644 и 646, регистры 648 и 650, а также делитель 652. В схеме корреляции вычисления выполняются при циклическом изменении n от Lc до 1 и циклическом изменении m от 1 до 256.
За схемой корреляции следует схема сравнения, которая осуществляет сравнение и запоминание данных для определения оптимальных значений индекса I и усиления G кодового словаря. Схема сравнения содержит умножитель 654, компаратор 656, регистры 658, 660 и 662, а также квантователь 664. Схема сравнения формирует для каждого подкадра кодового словаря значения I и G, которые минимизируют ошибку между синтезированным и входным речевыми сигналами. Усиление G кодового словаря квантуется в квантователе 664, который кодирует с помощью ДИКМ значения аналогично процедуре квантования и кодирования частот ЛСП с удаленным смещением, как это было показано со ссылкой на фиг.12. Полученные значения I и G затем подаются в буфер 222 данных.
При квантовании и кодировании с помощью ДИКМ усиление G кодового словаря
вычисляется в соответствии со следующим уравнением:
Квантованное Gi=20logGi-0,45(20logGi-1+20logGi-2), (45)
где
20logGi-1 и 20logGi-2 - соответственно величины, вычисленные для непосредственно предшествующего кадра (i-1) и кадра, предшествующего непосредственно предшествующему кадру (i-2).
Значения ЛСП, I, G, L и b наряду со значениями скорости передачи поступают в подсистему 236 упаковки данных, где данные готовятся для передачи. В одном из вариантов значения ЛСП, I, G, L и b вместе со значением скорости передачи могут подаваться на декодер 234 через подсистему 236 упаковки данных. В другом варианте эти значения могут подаваться через буфер 222 данных на декодер 234 для использования при поиске параметров тона. Однако в предпочтительном варианте осуществления изобретения используется защита знакового бита кодового словаря в подсистеме 236 упаковки данных, который может влиять на индекс кодового словаря. Поэтому эта защита должна приниматься во внимание, если I и G поступают непосредственно из буфера 222 данных.
В подсистеме 236 упаковки данных данные могут паковаться в соответствии с различными форматами для передачи. Фиг. 18 изображает пример реализации функциональных элементов подсистемы 236 упаковки данных. Подсистема 236 упаковки данных включает генератор 670 псевдослучайных чисел (ГПЧ), элемент 672 контроля при помощи циклического избыточного кода (КЦИК), логическую схему 674 защиты данных и объединитель 676 данных. Генератор 670 псевдослучайных чисел принимает значения скорости передачи и для скорости, равной одной восьмой полной скорости, вырабатывает четырехразрядное двоичное случайное число, которое подается на объединитель 676. Элемент 672 с КЦИК получает значения усиления G кодового словаря и ЛСП наряду со значением скорости передачи, и для полной скорости вырабатывает 11- разрядный внутренний код КЦИК, который поступает на объединитель 676 данных.
Объединитель 676 данных получает случайное число, код КЦИК, значение скорости передачи, а также значения ЛСП, I, G, L и b с выхода буфера 222 (фиг. 7b) и выдает сигнал на подсистему 234 процессора канала передачи данных. В реализациях, где данные подаются непосредственно из буфера 222 на декодер 234, в него из генератора 670 псевдослучайных чисел через объединитель 676 данных поступает как минимум четырехразрядное число. При полной скорости передачи биты КЦИК вместе с данными кадра имеются на выходе объединителя 674, в то время как при скорости, равной одной восьмой полной скорости передачи, индекс кодового словаря опускается и заменяется случайным четырехразрядным числом.
В данном примере реализации предпочтительно обеспечить защиту знакового разряда усиления кодового словаря. Защита этого разряда делает декодер вокодера менее чувствительным к ошибке в этом разряде. Если знаковый разряд изменится из-за необнаруженной ошибки, индекс кодового словаря укажет вектор, далекий от оптимального. В случае появления ошибки без организации защиты будет выбрано отрицательное значение оптимального вектора, что по существу является наихудшим возможным вектором для использования. Схема защиты в данном случае работает так, что появление ошибки в знаковом разряде усиления не приводит к выбору отрицательного значения оптимального вектора. Логика 674 защиты данных принимает значения индекса и усиления кодового словаря и проверяет знаковый разряд значения усиления. Если оказывается, что значение знакового разряда отрицательно, то прибавляется величина 89 по модулю 128 к соответствующему индексу кодового словаря. Немодифицированный или модифицированный таким образом индекс кодового словаря поступает с выхода логической схемы 674 защиты данных в объединитель 676 данных.
В данном примере реализации предпочтительно, чтобы на полной скорости передачи наиболее персептуально
чувствительные биты пакета данных сжатого речевого сигнала также защищались с помощью внутреннего контроля циклическим избыточным кодом (КЦИК). Для реализации функции обнаружения и исправления ошибок,
позволяющей, исправить любую единичную ошибку в защищенном блоке, используются одиннадцать дополнительных битов. Защищенный блок состоит из самого старшего бита десяти частот ЛСП и самого старшего
бита восьми значений усиления кодового словаря. Если в этом блоке возникает ошибка, не поддающаяся исправлению, то пакет отбрасывается и объявляется разрушение (стирание), описанное ниже. Иначе,
усиление тона устанавливается равным нулю, а остальные параметры используются в том виде, в каком они получены. В данном примере реализации выбран циклический код, чтобы получить производящий
полином
g(x)=1+x3+x5+x6+x8+x9+x10, (46)
формирующий (31, 21) циклический код. Однако следует понимать, что могут
быть использованы другие производящие полиномы. Чтобы получить (31, 21)код добавляется контрольный бит общей четности. Поскольку существует только 18 информационных битов, первые 3 цифры в кодовом
слове устанавливаются нулевыми и не передаются. Такая процедура обеспечивает дополнительную защиту, так что если синдром указывает на ошибку в этих позициях, то это означает наличие не поддающейся
исправлению ошибки. Кодирование циклическим кодом в систематической форме влечет за собой вычисление контрольного бита четности как x10 u(x) по модулю g(x), где u(x)-полином сообщения.
На декодирующем конце синдром вычисляется как остаток от деления принятого вектора на g(x). Если синдром показывает отсутствие ошибки, пакет принимается независимо от состояния контрольного бита четности. Если синдром указывает на наличие одной ошибки, то ошибка исправляется при несоответствующем состоянии контрольного бита четности. Если синдром обнаруживает более чем одну ошибку, пакет отбрасывается. Более подробно о такого рода защите изложено в разделе 4.5 "Error Control coding: Fundamentals and Applications", Lin and Costello для особенностей вычисления синдрома.
При использовании вокодера в телефонной системе с параллельным доступом и кодовым разделением каналов данные из объединителя 674 поступают в подсистему 238 процессора данных канала передачи для упаковки с целью передачи в виде кадров длительностью 20 мс. В кадре передачи, в котором вокодер установлен на полную скорость, передаются 192 бита с эффективной скоростью 9,6 кб/с. В этом случае кадр передачи содержит один бит для идентификации кадра смешанного типа (0-при передаче только голоса, 1-при передаче и голоса и данных/вспомогательных сигналов), 160 битов данных вокодера вместе с 11 битами внутреннего КЦИК, 12 битов внешнего или кадрового КЦИК и 8 остаточных или заключительных битов. При половинной скорости передачи передается 80 битов данных вокодера наряду с 8 битами КЦИК кадра, а также 8 остаточных битов при эффективной скорости передачи 4. 8 кб/с. При четвертной скорости передается 40 битов данных вокодера наряду с 8 остаточными битами при эффективной скорости передачи 2.4 кб/с. Наконец, при одной восьмой скорости передается 16 битов данных вокодера наряду с 8 остаточными битами при эффективной скорости передачи 1.2 кб/с.
Более подробную информацию о модуляции, используемой в системе с параллельным доступом и кодовым разделением каналов, в которой может быть использован предлагаемый вокодер, можно найти в заявке США N 07/543.496 от 25.05.1990г. на патент США поданной настоящим заявителем. В этой системе при скорости передачи, отличной от полной скорости, используется схема, в которой биты данных организуются в группы, расположение которых внутри 20 мс кадра передаваемых данных имеет псевдослучайный характер. Должно быть понятно, что могут быть использованы другие величины скоростей передачи и другое разделение битов, отличные от показанных выше в примере реализации вокодера и системы с параллельным доступом и кодовым разделением каналов (ПДКРК), поскольку существуют другого типа реализации вокодеров и применяются другие системы связи.
В системе с параллельным доступом и кодовым разделением каналов, как и в ряде других систем, процессорная подсистема 238 может на уровне кадров прерывать передачу данных вокодера для передачи других данных, таких как сигнальные данные или другого рода не речевые информационные данные. Этот особенный вид передачи называется "пробел и пачка". Процессорная подсистема 238 по существу заменяет данные вокодера желательными данными в кадре.
Другая ситуация может возникнуть, когда есть необходимость передать как данные вокодера, так и другие данные в течение одного и того же кадра передачи. Такого типа вариант передачи носит название "ослабление и пачка". При передаче "ослабление и пачка" на вокодер поступают команды предельных скоростей, которые устанавливают в качестве конечной скорости вокодера желательную скорость, например половинную скорость. Закодированные с половинной скоростью данные вокодера подаются в процессорную подсистему 238, которая вводит дополнительные данные вместе с данными вокодера для данного кадра передачи.
Дополнительной функцией, присущей полной дуплексной телефонной связи, является взаимосвязь скоростей передачи. Если одна строка осуществляет передачу с наивысшей скоростью, то другая сторона вынуждена передавать данные с наименьшей скоростью. Даже при наименьшей скорости передачи разборчивость для активной стороны является достаточной, чтобы понять, что она прерывается, и прекратить говорить, передавая активную роль другой стороне связи. Более того, если активная сторона продолжает говорить, несмотря на попытку прерывания, она возможно не почувствует ухудшения качества, потому что ее собственная речь "заглушает" способность чувствовать качество. Как и прежде, путем использования команд предельных скоростей передачи вокодер может быть переведен в режим кодирования речи с меньшей, чем нормальная, скоростью.
Следует понимать, что команды предельных скоростей могут быть использованы для установки максимальной скорости кодирования, меньшей чем полная скорость, когда требуется дополнительная емкость системы с параллельным доступом и кодовым разделением каналов. В этой системе, где для передачи используется общий спектр частот, сигнал одного пользователя является помехой для других пользователей в системе. Емкость системы (т.е. количество пользователей в системе), таким образом, ограничивается общими помехами, создаваемыми всеми пользователями. По мере того, как уровень помех увеличивается обычно из-за увеличения числа пользователей системы, пользователи ощущают снижение качества передачи.
Вклад каждого пользователя в создаваемые помехи в системе с параллельным доступом и кодовым разделением каналов зависит от скорости передаваемых этим пользователем данных. Путем установки вокодера в режим кодирования речи со скоростью меньшей, чем нормальная скорость, уменьшается скорость передачи кодирования данных, что, в свою очередь, уменьшает уровень помех в системе, создаваемых этим пользователем. Поэтому емкость системы может быть существенно увеличена путем кодирования сигнала речи с меньшей скоростью. Когда требуется расширение емкости системы, вокодеры пользователей под управлением команд от контроллера системы или базовой сотовой станции могут уменьшить скорость кодирования. Предложенный вокодер обладает тем качеством, что различие между речевыми сигналами, закодированными на полной и половинной скоростях, мало, хотя и ощутимо. Поэтому влияние на качество связи между пользователями системы, когда речевой сигнал кодируется на меньшей скорости, например на половинной скорости, существенно меньше по сравнению со случаем увеличения помех из-за увеличения числа пользователей в системе.
Поэтому могут быть использованы различные схемы для установки границ скорости отдельного вокодера для меньших, чем нормальная, скоростей кодирования. Например, всем пользователям в сотовой системе могут выдаваться команды кодировать речевые сигналы с половинной скоростью. Такая акция соответственно уменьшает уровень помех в системе при незначительном ухудшении качества связи между пользователями, в то время как емкость системы увеличивается. До тех пор, пока уровень помех, возрастающий из-за подключения дополнительных пользователей, не достигнет критического уровня, ухудшения качества связи между пользователями не происходит.
Как отмечалось ранее, кодер включает схему, являющуюся копией декодера, для осуществления метода анализа через синтез при кодировании кадров выборок речевого сигнала. Как показано на фиг.7, декодер 234 получает значения L, b и I либо через подсистему 238 упаковки данных, либо через буфер 222 данных для восстановления синтезированного речевого сигнала и сравнения его с входным речевым сигналом. Выходами декодера являются значения Mp, Ma и Mw, как было показано ранее. Более подробно работа декодера, используемого в кодере для восстановления синтезированного речевого сигнала на другом конце канала связи, может быть пояснена с помощью фиг.19-24.
Фиг.19 изображает блок-схему примера реализации декодера согласно настоящему изобретению. Благодаря одинаковой структуре декодеров, используемых в кодере и в приемнике, они рассматриваются вместе. Фиг. 19 прежде всего касается декодера на конце канала передачи, так как полученные данные должны быть предварительно обработаны в декодере, в то время как соответствующие данные в декодере, входящем в состав кодера (скорость, I, G, L и b), принимаются непосредственно от подсистемы 238 упаковки данных или от буфера 222. Однако основная функция декодера схемы одинакова для обоих декодеров.
Как было показано ранее со ссылкой на фиг.5, для каждого подкадра кодового словаря вектор кодового словаря, определяемый индексом I кодового словаря, получают в результате поиска из запомненного кодового словаря. Этот вектор умножается на усиление G кодового словаря и затем фильтруется тоновым фильтром в каждом тоновом подкадре для получения формантного остатка. Формантный остаток фильтруется формантным фильтром и затем проходит через адаптивный формантный постфильтр и очищающий постфильтр, а также через схему автоматической регулировки усиления для формирования выходного речевого сигнала.
Хотя длина подкадров тона и кодового словаря меняется, декодирование осуществляется по блокам в 40 выборок для упрощения реализации. Принятые сжатые данные сначала распаковываются в значения усиления кодового словаря, индекса кодового словаря, усиления тона, задержки тона и частот ЛСП. Частоты ЛСП должны быть пропущены через соответствующие обратные квантователи и декодеры ДИКМ, как это поясняется со ссылкой на фиг. 22. Аналогично, значения усиления кодового словаря должны быть обработаны так же, как частоты ЛСП, за исключением аспекта, касающегося смещения. Кроме того, значения усиления тона подвергаются обратному квантованию. Эти параметры затем формируются для каждого подкадра декодирования. В каждом подкадре декодирования требуются две группы параметров кодового словаря (G и I), одна группа параметров тона (b и L) и одна группа коэффициентов ЛПК, чтобы получить 40 выходных выборок. Фиг. 20 и 21 иллюстрируют декодируемые параметры подкадра для различных скоростей передачи и других условий.
Для кадров, передаваемых с полной скоростью, существует 8 групп принятых параметров кодового словаря и 4 группы принятых параметров тона. Частоты ЛСП интерполируются четыре раза для образования четырех групп частот ЛСП. Принятые параметры и соответствующая информация о подкадрах приводится на фиг. 20a.
Для кадров с половинной скоростью передачи каждая группа из четырех принятых параметров кодового словаря повторяется один раз и каждая группа из двух принятых параметров тона повторяется один раз. Частоты ЛСП интерполируются три раза, чтобы получить 4 группы частот ЛСП. Принятые параметры и соответствующая информация о подкадрах даны на фиг.20b.
Для кадров, передаваемых с четвертной скоростью, каждая группа из двух принятых параметров кодового словаря повторяется четыре раза, группа параметров тона также повторяется четыре раза. Частоты ЛСП интерполируются один раз для получения 2-х групп частот ЛСП. Принятые параметры и соответствующая информация о подкадрах даны на фиг.20c.
Для кадров, передаваемых со скоростью, равной одной восьмой полной скорости, группа принимаемых параметров кодового словаря используется для всего кадра. Параметры тона при передаче с одной восьмой полной скорости отсутствуют и усиление тона просто устанавливается равным нулю. Частоты ЛСП интерполируются один раз для получения одной группы частот ЛСП. Принятые параметры и соответствующая информация о подкадрах для этой скорости даны на фиг.20d.
Иногда пакеты речевых сигналов могут бланкироваться (т.е. иметь пробелы) для того, чтобы дать возможность сотовой станции или подвижному абоненту передать сигнальную информацию. Когда вокодер принимает пустой кадр, он продолжает работу со слегка модифицированными параметрами предыдущего кадра. Усиление кодового словаря устанавливается равным нулю. Задержка и усиление тона предыдущего кадра используются как задержка и усиление тона текущего кадра, за исключением случаев, когда величина усиления ограничивается единицей или меньшей величиной. Частоты ЛСП предыдущего кадра используются без интерполяции. Заметим, что кодирующая и декодирующая стороны синхронизированы и вокодер способен быстро выйти из пустого кадра. Принятые параметры и соответствующая информация о подкадрах для этого случая приведены на фиг. 21a.
В случае, если кадр потерян из-за ошибки в канале, вокодер пытается замаскировать эту ошибку путем поддержания части
энергии предыдущего кадра и плавного перехода к фоновому шуму. В этом случае усиление тона устанавливается равным нулю; случайный кодовый словарь выбирается с помощью индекса кодового словаря
предыдущего подкадра, увеличенного на 89; усиление кодового словаря равно 0,7 от значения усиления кодового словаря предыдущего подкадра. Следует заметить, что нет ничего странного в числе 89,
поскольку это удобный способ выбора вектора псевдослучайного кодового словаря. Происходит вынужденное уменьшение частот ЛСП предыдущего кадра к их значениям смещения:
ωi =0,
9(предыдущее ωi -значение смещения ωi +значение смещения ωi ) (47)
Значения смещения частот ЛСП даны в табл.5. Принятые параметры и
соответствующая информация о подкадрах указаны на фиг.21b.
Если скорость передачи не может быть определена на приемном конце, принятый пакет отбрасывается и объявляется стирание. Однако если приемник определяет достаточно большую вероятность того, что данный кадр был послан с полной скоростью передачи, хотя и с ошибками, то делается следующее. Как указывалось ранее, при полной скорости передачи наиболее персептуально чувствительные биты сжатого пакета речевых данных защищаются с помощью внутреннего контроля циклическим избыточным кодом (КЦИК). На декодирующем конце синдром вычисляется как остаток от деления принятого вектора на g(x), полученное из уравнения (46). Если синдром указывает на отсутствие ошибок, пакет принимается независимо от того, в каком состоянии находятся контрольный бит общей четности. Если синдром обнаруживает единичную ошибку, то эта ошибка исправляется в случае несоответствующего состояния контрольного бита общей четности. Если синдром указывает на наличие более чем одной ошибки, то принятый пакет отбрасывается. Если в этом блоке присутствуют ошибки, не поддающиеся исправлению, то пакет отбрасывается и объявляется разрушение. Иначе, усиление тона устанавливается равным нулю, а остальные параметры используются в том виде, в каком они приняты, с исправлениями, как это иллюстрируется на фиг.21c.
Постфильтр,
используемый в данной реализации, впервые был описан в "Real-Time Vector АРС Speech Codinq At 4800 BPS with Adaptive Postfilterinq", J. H. Chen et al., Proc. ICASSP, 1987. Так как форманты речи с
точки зрения восприятия более важны, чем спектральные провалы, постфильтр незначительно усиливает форманты, чтобы улучшить персептуальное, т. e. касающееся восприятия качество закодированного речевого
сигнала. Это делается путем масштабирования полюсов фильтра синтеза форманты радиально по направлению к началу отсчета. Однако полюсный постфильтр вносит спектральный наклон, который приводит к
глушению отфильтрованного сигнала речи. Спектральный наклон этого полюсного постфильтра уменьшается добавлением нулей, имеющих те же самые фазовые углы, что и полюса, но с меньшими радиусами, в
результате чего постфильтр имеет вид

где
A(z)-фильтр предсказания форманты, а величины ρ и σ - масштабирующие коэффициенты постфильтра, где ρ устанавливается равным 0,5, а σ устанавливается равным 0,8.
Адаптивный очищающий фильтр
вводится с целью дополнительной компенсации спектрального наклона, вносимого формантным постфильтром. Очищающий фильтр имеет вид

где
величина k (коэффициент этого фильтра с одним отводом) определяется средним значением частот ЛСП, которые аппроксимируют изменение в спектральном наклоне A(z).
Чтобы избежать существенных колебаний усиления, вызванных постфильтрацией, вводится автоматическая регулировка усиления (АРУ) для масштабирования выходного речевого
сигнал таким образом, чтобы он имел примерно ту же самую энергию, что и сигнал речи, не прошедший операцию постфильтрации. Сигнал регулировки усиления формируется с помощью деления суммы квадратов 40
выборок на входе фильтра на сумму квадратов 40 выходных выборок на выходе фильтра для получения инверсного значения усиления фильтра. Корень квадратный из этого коэффициента затем сглаживается:
Сглаженное β =0,2 текущее β +0,98 предыдущее β (50)
и выходной сигнал фильтра умножается на этот сглаженный инверсный коэффициент усиления для получения выходного
речевого сигнала.
На фиг.19 данные из канала вместе со значением скорости, либо передаваемым вместе с данными, либо полученным другими средствами, подаются в подсистему 700 распаковки данных. В примере реализации для использования в системе связи с параллельным доступом и кодовым разделением каналов решение о величине скорости передачи может быть получено исходя из коэффициента ошибки принятых данных, когда они декодируются на каждой из различных скоростей. При полной скорости в подсистеме 700 распаковки данных делается проверка на наличие ошибок с помощью КЦИК с выдачей результата этой проверки в подсистему 702 распаковки данных подкадра. Подсистема 700 обеспечивает индикацию ненормальных состояний принятых кадров, таких как пустой кадр, разрушенный кадр или ошибочный кадр с соответственными данными для подсистемы 702. Подсистема 700 выдает значение скорости наряду со значениями параметров I, G, L и b данного кадра для подсистемы 702. При формировании значений индекса I и усиления G кодового словаря знаковый бит значения усиления проверяется в подсистеме 702. Если знаковый бит отрицательный, из соответствующего индекса кодового словаря вычитается величина 89 по модулю 128. Кроме того, в подсистеме усиление кодового словаря подвергается инверсному квантованию и декодированию ДИКМ, а усиление тона подвергается только инверсному квантованию.
Подсистема 700 также формирует значения скорости передачи и частоты ЛСП для подсистемы 704 инверсного квантования/ интерполяции. Подсистема 700 также формирует сигналы индикации пустого кадра, разрушенного кадра или ошибочного кадра с полезными данными для подсистемы 704. Индикация значения i и j отсчета подкадров для обеих подсистем 702 и 704 обеспечивается счетчиком 706 декодируемых подкадров.
В подсистеме 704 частоты ЛСП подвергаются инверсному квантованию и интерполированию. На фиг. 22 показана часть подсистемы 704, выполняющая инверсное квантование, а часть этой подсистемы 704, выполняющая интерполяцию, идентична описанной при рассмотрении фиг. 12. На фиг. 22 часть подсистемы 704, реализующая инверсное квантование, содержит инверсный квантователь 750, который структурно идентичен инверсному квантователю 468 на фиг. 12 и работает аналогично ему. Выходной сигнал инверсного квантователя 750 подается на один из входов сумматора 752. На другой вход сумматора 752 поступает сигнал с выхода умножителя 754. Выходной сигнал сумматора 752 поступает на регистр 756, где запоминается для умножения на постоянный коэффициент 0,9 в умножителе 754. Кроме того, выходной сигнал сумматора 752 подается на сумматор 758, где к частоте ЛСП снова прибавляется величина смещения. Упорядочение частот ЛСП обеспечивается логической схемой 760, которая обеспечивает минимальное разделение частот ЛСП. В общем случае необходимости в принудительном разделении нет, если не появляется ошибок при передаче. Частоты ЛСП интерполируются, как было описано со ссылкой на фиг. 13, 20a-20d, а также на фиг. 21a-21c.
Вернемся к рассмотрению фиг. 19, где блок 708 памяти соединен с подсистемой 704 для запоминания частот ЛСП ωi, f-1 предыдущего кадра и может также использоваться для запоминания величин смещения bωi. . Эти значения предыдущего кадра используются при интерполяции для всех скоростей. В случае пустого, разрушенного или ошибочного кадра с полезной информацией предыдущие частоты ЛСП ωi,f-1 используются в соответствии с картами на фиг. 21a-21c. В ответ на индикацию пустого кадра из подсистемы 700 подсистема 704 производит поиск частот ЛСП предыдущего кадра, запомненных в блоке 708 памяти, для использования в текущем кадре. В ответ на индикацию разрушенного кадра подсистема 704 снова производит поиск частот ЛСП предыдущего кадра в блоке 708 памяти вместе с величинами смещения для того, чтобы вычислить частоты ЛСП для текущего кадра, как описано выше. При реализации этого вычисления запомненные величины смещения вычитаются из частот ЛСП предыдущего кадра в сумматоре с последующим умножением результата вычитания на постоянный коэффициент 0,9 в умножителе, после чего в сумматоре к результату умножения прибавляется запомненная величина смещения. В ответ на индикацию о появлении ошибочного кадра с полезными данными частоты ЛСП интерполируются в виде, как это было бы при полной скорости, если проходит контроль КЦИК.
Частоты ЛСП поступают в подсистему 710 преобразования ЛСП в коэффициенты ЛПК, где частоты ЛСП преобразуются обратно в величины ЛПК. Подсистема 710 в сущности идентична подсистемам 218 и 228 преобразования ЛСП в ЛПК на фиг. 7, как это было показано при рассмотрении фиг. 13. Затем коэффициенты ЛПК αi подаются как на формантный фильтр 714, так и на формантный постфильтр 716. Частоты ЛСП также усредняются для подкадра в подсистеме 712 усреднения ЛСП и подаются в адаптивный очищающий фильтр 718 в виде значения k.
Подсистема 702 получает параметры I, G, L и b для кадра из подсистемы 700 наряду с величиной скорости или индикацией ненормального состояния кадра. Подсистема 702 также получает от счетчика 706 подкадров отсчеты j для каждого отсчета i в каждом декодируемом подкадре 1-4. Подсистема 702, кроме того, соединена с блоком 720 памяти, который запоминает величины G, I, L и b предыдущего кадра для использования в случае ненормального состояния кадра. Когда имеет место ненормальное состояние кадра, подсистема 702 выдает, если скорость не равна одной восьмой полной скорости, значение индекса I кодовому словарю 722, значение G усиления кодового словаря - умножителю 724 и значение задержки L и усиление b тона - тоновому фильтру 726 в соответствии с фиг. 20а-20d. Что касается скорости, равной одной восьмой полной скорости, то поскольку значение индекса кодового словаря не передается, на кодовый словарь 722 вместе с индикацией величины скорости подается начальное число пакета, которое при этой скорости представляет собой шестнадцатиразрядное значение параметра (фиг. 2d). Значения, выдаваемые подсистемой 702 в случае ненормального состояния кадра, даны на фиг. 21a-21c. Кроме того, для скорости, равной одной восьмой полной скорости, выдается индикация кодовому словарю 722, как показано при рассмотрении фиг. 23.
В ответ на индикацию пустого кадра из подсистемы 700 подсистема 702 ищет значения задержки L и усиления b тона предыдущего кадра, запомненных в блоке 708 памяти, для использования в декодируемых подкадрах текущего кадра, причем значение усиления ограничено единицей или меньшей величиной. При этом индекс I кодового словаря не выдается, а усиление G кодового словаря устанавливается равным нулю. В ответ на индикацию разрушенного кадра подсистема 702 снова ищет индекс кодового словаря подкадров предыдущего кадра в блоке 720 памяти и складывает его в сумматоре с величиной 89. Усиление кодового словаря подкадров предыдущего кадра умножается в умножителе на постоянную величину 0,7, чтобы получить соответствующие значения G для подкадров. При этом величина задержки тона не выдается, а значение усиления тона устанавливается равным нулю. В ответ на индикацию ошибочного кадра с полезными данными индекс кодового словаря и величина усиления снова используется, как в случае полной скорости кадров, при условии, что происходит контроль КЦИК, в то время как значение задержки тона не выдается, а усиление тона устанавливается равным нулю.
Как показано при описании работы декодера, входящего в состав кодера, с использованием метода анализа через синтез, индекс I кодового словаря используется как начальный адрес значения кодового словаря, подаваемого на умножитель 724. Усиление кодового словаря умножается на значение с выхода кодового словаря 722 в умножителе 724, выход которого поступает на тоновый фильтр 726. Тоновый фильтр 726 использует значения задержки L тона и усиления b тона для формирования формантного остатка, который поступает на формантный фильтр 714. В формантном фильтре 714 при фильтрации формантного остатка используются коэффициенты ЛПК таким образом, что происходит восстановление речевого сигнала. В декодере приемника восстановленный речевой сигнал далее фильтруется в формантном постфильтре 716 и в адаптивном очищающем фильтре 718. Схема 728 АРУ соединена с выходом формантного фильтра 714 и выходом умножителя 730, второй вход которого соединен с выходом адаптивного очищающего фильтра 718. На выходе умножителя 730 формируется сигнал восстановленной речи, который затем преобразуется в аналоговую форму с помощью известных способов и подается к слушателю. На выходе декодера кодера имеется персептуальный взвешивающий фильтр для обновления данных его памяти.
Фиг. 23 изображает более подробно вариант выполнения самого декодера. На фиг. 23 кодовый словарь 722 включает блок 750 памяти, аналогичный блоку памяти, описанному при рассмотрении фиг. 17. Однако с целью получения большей ясности, на фиг. 23 показан несколько иной подход к блоку 750 памяти и адресации к нему. Кодовый словарь 722, кроме того, включает переключатель 752, мультиплексор 753 и генератор 754 псевдослучайных чисел (ПСЧ). Переключатель 752 реагирует на индекс кодового словаря и указывает на адрес индекса в блоке 750 памяти, как это пояснялось в отношении фиг. 17. Блок 750 памяти представляет собой динамическую память с переключателем 752, указывающим на начальную ячейку памяти, при этом хранимые в блоке памяти значения сдвигаются для вывода. Выходные величины кодового словаря с выхода блока 750 памяти через переключатель 752 поступают на один из входов мультиплексора 753. Мультиплексор 753 при полной, половинной и четвертной скоростях пропускает сигналы, прошедшие через переключатель 752, к усилителю значения усиления кодового словаря, умножителю 724. При скорости, равной одной восьмой полной скорости, мультиплексор 753 осуществляет выбор числа с выхода генератора 754 псевдослучайных чисел для подачи его в качестве выхода кодового словаря на умножитель 724.
Для поддержания высокого качества речи при кодировании методом линейного предсказания с кодовым возбуждением (ЛПККВ) кодер и декодер должны иметь одинаковые величины, запомненные во внутренних блоках памяти их фильтров. Это осуществляется путем передачи индекса кодового словаря, благодаря чему фильтры декодера и кодера возбуждаются одними и теми же последовательностями величин. Однако в случае речевого сигнала высшего качества эти последовательности состоят в основном из нулей с небольшим количеством пиков, распределенных между ними. Этот тип возбуждений не является оптимальным для кодирования фонового шума.
При кодировании фонового шума, осуществляемого на самой низкой скорости, псевдослучайная последовательность может использоваться для возбуждения фильтров. Для того, чтобы блоки памяти фильтров кодера и декодера были одинаковы, две псевдослучайные последовательности должны быть одинаковыми. Начальное число должно быть каким-то образом передано в декодер приемника. Так как не существует дополнительных битов, которые могли бы быть использованы для передачи этого начального числа, то в качестве начального числа могут быть использованы биты передаваемого пакета, как если бы они составляли число. Этот метод может быть осуществлен, потому что на низких скоростях для определения усиления и индекса кодового словаря используется один и тот же метод анализа через синтез при кодировании ЛПККВ. Различие заключается только в том, что индекс кодового словаря опускается и блоки памяти фильтров в этом случае обновляются с использованием псевдослучайной последовательности. Поэтому начальное число для возбуждения может быть определено по окончании анализа. Чтобы исключить циклическое повторение самих пакетов между группой комбинаций битов вместо значений индекса кодового словаря при скорости, равной одной восьмой полной скорости, вводятся четыре случайных бита. Поэтому начальное число пакета представляет собой шестнадцатиразрядное число, как показано на фиг. 2d.
Генератор 754 псевдослучайных чисел выполнен с применением широко известных методов с использованием различных алгоритмов. В рассматриваемом примере реализации используется алгоритм, сущность которого изложена в статье "DSP chips can produce random numbers using proven algorithm", Paul Mennen, EDN, January 21, 1991. Передаваемый пакет битов используется в качестве начального числа (из подсистемы 700 на фиг. 18) для генерации последовательности. В другом варианте начальное число умножается на величину 521 с добавлением величины 259. В результирующем значении в качестве указанного 16-разрядного числа используются младшие разряды. Это значение затем используется в качестве начального числа при генерировании следующего значения кодового словаря. Последовательность, вырабатываемая генератором псевдослучайных чисел нормализуется, чтобы иметь дисперсию, равную 1.
Каждое значение с выхода кодового словаря 722 умножается в умножителе 724 на величину усиления G кодового словаря в течение декодируемого подкадра. Это значение поступает на один из входов сумматора 756 тонового фильтра 726. Тоновый фильтр 726 содержит умножитель 758 и блок 760 памяти. Тоновая задержка L определяет отвод блока 760 памяти, который подается на умножитель 758. Значение с выхода блока 760 памяти перемножается с величиной b усиления тона в умножителе 758, сигнал с выхода которого поступает на сумматор 756. Выход сумматора 756 подается на вход блока 760 памяти, который представляет собой цепочку элементов задержки, например сдвиговый регистр. Запомненные значения сдвигаются в элементах блока 760 памяти (в направлении, указанном стрелкой) и выдаются на отвод, выбранный в соответствии с величиной L. Так как хранимые в блоке 760 памяти значения сдвигаются, то значения, поступившие после 143 сдвигов отбрасываются. Сигнал с выхода сумматора 756 также поступает на вход формантного фильтра 714.
Выход сумматора 756 соединен с одним из входов сумматора 762 формантного фильтра 714. Форматный фильтр, в свою очередь, включает группу умножителей 764a-764j и блок 766 памяти. Выход сумматора 762 соединен с входом блока 766 памяти, который также выполнен в виде цепочки элементов задержки с отводами, например, в виде сдвигового регистра. Запомненные значения сдвигаются в блоке 766 памяти (в направлении, указанном стрелкой) и выводятся на конце. Каждый элемент блока памяти имеет выход в виде отвода, соединенный соответственно с одним из умножителей 764a-764j. На каждый из умножителей 764a-764j также поступает один из соответствующих коэффициентов ЛПК α1-α10 для умножения их на величины с выходов блока 766 памяти. Выход сумматора 762 является выходом формантного фильтра 714.
Выход формантного фильтра 714 соединен с входами формантного постфильтра 716 и подсистемы 728 АРУ. Формантный постфильтр 716 содержит сумматоры 768 и 770, блок 722 памяти и умножители 774a-774j, 776a-776j, 780a-780j и 782a-782j. По мере сдвига запомненных величин в блоке 772 памяти они выводятся с соответствующих отводов для умножения на масштабированные коэффициенты ЛПК и дальнейшего суммирования результатов умножения в сумматорах 768 и 770. Выход формантного постфильтра 716 связан с входом адаптивного очищающего фильтра 718.
Адаптивный очищающий фильтр 718 содержит сумматоры 784 и 786, регистры 788 и 790, а также умножители 792 и 794. На фиг.24 представлен график, иллюстрирующий характеристики адаптивного очищающего фильтра. Выход формантного постфильтра 716 подсоединен к одному из входов сумматора 784, другой вход которого соединен с выходом умножителя 792. Выходной сигнал сумматора 784 поступает на регистр 788 и задержанный на один цикл выдается в течение следующего цикла на умножители 792 и 794 вместе с величиной - k, поступающей из усреднителя 712 ЛСП на фиг.19. Выходы умножителей 792 и 794 соединены с сумматорами 784 и 786. Выход сумматора 786 подсоединен к подсистеме 728 АРУ и к сдвиговому регистру 790. Регистр 790 используется в качестве линии задержки для надежного кодирования подачи данных с выхода формантного фильтра 714 на подсистему 728 АРУ и подачи данных в адаптивный очищающий фильтр 718 через формантный постфильтр 716.
Подсистема 728 АРУ принимает данные из формантного постфильтра 716 и адаптивного очищающего фильтра 718 с целью масштабирования энергии выходного речевого сигнала примерно до энергии речевого сигнала на входах формантного постфильтра 716 и адаптивного очищающего фильтра 718. Подсистема 728 АРУ включает умножители 798, 800. 802 и 804, сумматоры 806, 808 и 810, регистры 812, 814 и 816, делитель 818 и элемент 820 вычисления квадратного корня. 40 выборок с выхода формантного постфильтра 716 возводятся в квадрат в умножителе 798 и суммируются в накапливающем сумматоре, состоящем из сумматора 806 и регистра 812, для формирования величины "x". Аналогично 40 выборок с выхода адаптивного очищающего фильтра 718, взятые до их поступления в регистр 790, возводятся в квадрат в умножителе 800 и суммируются в накапливающем сумматоре, состоящем из сумматора 808 и регистра 814, для формирования величины "y". Величина "y" делится на величину "x" в делителе 816 для получения величины, обратной усилению фильтров. Корень квадратный из величины, обратной усилению, формируется в элементе 818, выходное значение которого сглаживается. Операция сглаживания осуществляется путем умножения текущей величины усиления G на постоянный коэффициент 0.02 в умножителе 802, при этом полученный результат прибавляется в сумматоре 810 к умноженной в умножителе 804 на 0, 98 величине предыдущего усиления, хранимой в регистре 820. Затем величина с выхода фильтра 718 умножается на сглаженную величину, обратную усилению, в умножителе 730 для получения восстановленного сигнала речи. Выходной речевой сигнал преобразуется в аналоговую форму с использованием различных хорошо известных методов для выдачи пользователю.
Очевидно, что рассматриваемый вариант осуществления настоящего изобретения приведен только в качестве примера и могут иметь место и другие, функционально эквивалентные варианты осуществления. Изобретение может быть реализовано в процессоре цифровых сигналов под управлением соответствующей программы, обеспечивающей проведение функциональных операций, описанных здесь, для кодирования выборок речевого сигнала и декодирования закодированной речи. В других вариантах выполнения изобретение может быть реализовано на специальных интегральных схемах, выполненных со сверхбольшой степенью интеграции.
Приведенное описание примера реализации дает возможность любому специалисту в данной области использовать данное изобретение. Для специалистов очевидно, что возможны различные модификации описанных вариантов осуществления изобретения и что могут быть разработаны другие варианты на изложенных здесь принципах. Таким образом, изобретение не ограничивается описанными примерами его осуществления, а имеет широкий объем в соответствии с принципами и новыми признаками, изложенными в формуле изобретения.
Реферат
Предложены устройство и способ для сжатия речевого сигнала путем кодирования с переменной скоростью кадров оцифрованных выборок (10) речевого сигнала. Определяют уровень активности речевого сигнала для каждого кадра оцифрованных выборок речевого сигнала и выбирают скорость кодирования пакета выходных данных из группы множества скоростей в соответствии с определенным уровнем активности речевого сигнала в кадре. Наиболее низкая скорость из группы скоростей соответствует обнаруженному минимальному уровню активности речевого сигнала, например, фоновому шуму или речевым паузам, в то время как наиболее высокая скорость соответствует обнаруженному максимальному уровню активности речевого сигнала, например активная вокализация. Затем каждый кадр кодируют в соответствии с заранее определенным форматом кодирования для выбранной скорости передачи, причем каждой скорости передачи соответствует определенное число битов, представляющих закодированный кадр. Для каждого закодированного кадра формируют пакет данных, причем скорость каждого пакета выходных данных соответствует выбранной скорости. 4 с. и 37 з.п.ф-лы, 8 табл., 24 ил.

Комментарии