Способ и устройство для кодирования коэффициентов трансформации с алфавитным разделением для сжатия облака точек - RU2769460C1
Код документа: RU2769460C1
Чертежи







Описание
ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННУЮ ЗАЯВКУ
[0001] Для настоящей заявки испрашивается приоритет в соответствии с предварительными заявками на патент США №№62/958 839 и 62/958 846, поданными 9 января 2020 г., и заявкой на патент США №17/110 691, поданной 3 декабря 2020 г. в Бюро патентов и товарных знаков США, которые полностью включены в настоящий документ посредством ссылки.
УРОВЕНЬ ТЕХНИКИ
1. Область техники
[0002] Способы и устройства, согласующиеся с вариантами осуществления, относятся к сжатию облака точек на основе графа (graph-based point cloud compression, G-PCC) и, в частности, к способу и устройству для кодирования коэффициентов облака точек.
2. Описание предшествующего уровня техники
[0003] Усовершенствованные трехмерные (3D) представления мира обеспечивают более иммерсивные формы взаимодействия и коммуникации, а также позволяют машинам понимать, интерпретировать и ориентироваться в нашем мире. Трехмерные облака точек появились как возможность представления такой информации. Определен ряд вариантов использования, связанных с данными облака точек, и разработаны соответствующие требования для представления и сжатия облака точек. Например, облака точек можно использовать при автономном вождении для обнаружения и локализации объектов. Облака точек также могут использоваться в географических информационных системах (geographic information systems, GIS, ГИС) для картографии и в культурном наследии для визуализации и архивирования объектов и коллекций культурного наследия.
[0004] Облако точек - это набор точек в трехмерном пространстве, каждая из которых имеет связанные с ней атрибуты, например цвет, свойства материала и т.д. Облака точек могут использоваться для восстановления объекта или сцены как композиции таких точек. Они могут быть захвачены с помощью более камер, датчиков глубины или датчиков-лидаров в различных окружениях и могут состоять из тысяч и миллиардов точек для реалистичного представления реконструированных сцен.
[0005] Технологии сжатия необходимы для уменьшения объема данных для представления облака точек. Таким образом, необходимы технологии для сжатия облаков точек с потерями для использования в коммуникациях в реальном времени и в виртуальной реальности с шестью степенями свободы (6DoF, 6 degrees of freedom). Кроме того, требуется технология сжатия облаков точек без потерь в контексте динамического отображения для автономного вождения и приложений культурного наследия и т.д. Группа экспертов по движущимся изображениям (Moving Picture Experts Group, MPEG) начала работу над стандартом для сжатия геометрии и атрибутов, таких как цвета и коэффициент отражения, масштабируемое/прогрессивное кодирование, кодирование последовательностей облаков точек, захваченных в течение времени, и произвольный доступ к подмножествам облака точек.
[0006] Фиг. 1А - схема, иллюстрирующая способ генерации уровней детализации (levels of detail, LoD) в G-PCC.
[0007] Обращаясь к фиг. 1А, в текущем кодировании атрибутов G-PCC, LoD (т.е. группа) каждой трехмерной точки (например, Р0-Р9) генерируется на основе расстояния до каждой трехмерной точки, а затем значения атрибутов трехмерных точек в каждом LoD кодируют путем применения предсказания в порядке 110 на основе LoD вместо исходного порядка 105 трехмерных точек. Например, значение атрибутов трехмерной точки Р2 предсказывается путем вычисления среднего значения, взвешенного на основе расстояния, для трехмерных точек Р0, Р5 и Р4, которые были кодированы или декодированы до трехмерной точки Р2.
[0008] Текущий способ привязки в G-PCC работает следующим образом.
[0009] Сначала вычисляется изменчивость окрестности трехмерной точки, чтобы проверить, насколько разными являются значения соседей, и если изменчивость ниже порогового значения, вычисление предсказания взвешенного на основе расстояния среднего выполняется путем предсказания значений атрибутов (ai)i∈0…k-1, с использованием процесса линейной интерполяции на основе расстояний до ближайших соседей текущей точки i. Пусть




[0010]

[0011] Обратим внимание, что геометрические положения всех облаков точек уже доступны при кодировании атрибутов. Кроме того, соседние точки вместе с их реконструированными значениями атрибутов доступны как в кодере, так и в декодере в виде k-мерной древовидной структуры, которая используется для облегчения поиска ближайшего соседа для каждой точки идентичным образом.
[0012] Во-вторых, если изменчивость выше порогового значения, выполняется выбор предиктора (предсказателя), оптимизированного по критерию скорость-искажение (rate-distortion optimized, RDO). Множественные кандидаты-предикторы или предсказываемые значения кандидатов создаются на основе результата поиска соседней точки при генерировании LoD. Например, когда значение атрибутов трехмерной точки Р2 кодируется с использованием предсказания, средневзвешенное значение расстояний от трехмерной точки Р2 до трехмерных точек Р0, Р5 и Р4, соответственно, устанавливается равным индексу предиктора, равному 0. Затем расстояние от трехмерной точки Р2 до ближайшей соседней точки Р4 устанавливается равным индексу предиктора, равному 1. Кроме того, расстояния от трехмерной точки Р2 до следующих ближайших соседних точек Р5 и Р0, соответственно, устанавливаются на индексы предиктора, равные 2 и 3, как показано в Таблице 1 ниже.

[0013] После создания кандидатов-предикторов лучший предиктор выбирается путем применения процедуры оптимизации "скорость-искажение", а затем выбранный индекс предиктора отображается в усеченный унарный (truncated unary, TU) код, бины которого будут арифметически кодированы. Обратим внимание, что более короткий код TU будет назначен меньшему индексу предиктора в таблице 1.
[0014] Максимальное количество кандидатов-предикторов MaxNumCand определено и кодировано в заголовке атрибутов. В текущей реализации максимальное количество кандидатов-предикторов MaxNumCand установлено равным numberOfNearestNeighborsInPrediction + 1 и используется при кодировании и декодировании индексов предиктора с усеченной унарной бинаризацией.
[0015] Преобразование лифтинга для кодирования атрибутов в G-PCC строится на основе преобразования предсказания, описанного выше. Основное различие между схемой предсказания и схемой лифтинга заключается во введении оператора обновления.
[0016] Фиг. 1В - схема архитектуры для P/U (предсказания/обновления)-лифтинга в G-PCC. Чтобы облегчить этапы предсказания и обновления при лифтинге, нужно разделить сигнал на два набора с высокой корреляцией на каждом этапе разделения. В схеме лифтинга в G-PCC разделение выполняется путем использования структуры LoD, в которой ожидается такая высокая корреляция между уровнями, и каждый уровень создается путем поиска ближайшего соседа для организации неоднородных облаков точек в структурированные данные. Этап разложения P/U на уровне N приводит к сигналу детализации D (N-1) и сигналу аппроксимации A (N-1), который далее разлагается на D (N-2) и A (N-2). Этот шаг повторяется до тех пор, пока не будет получен сигнал аппроксимации базового уровня А (1).
[0017] Следовательно, вместо кодирования самого входного сигнала атрибута, который состоит из LOD (N), …, LOD (1), в конечном итоге в схеме лифтинга кодируется D (N-1), D (N-2), …, D (1), А (1). Отметим, что применение эффективных шагов P/U часто приводит к разреженным «коэффициентам» поддиапазонов в D (N-1), D (1), тем самым обеспечивая преимущество выигрыша кодирования с преобразованием.
[0018] В настоящее время предсказание взвешенного на основе расстояния среднего, описанное выше для преобразования предсказания, используется для этапа предсказания в лифтинге в качестве способа привязки в G-PCC.
[0019] При предсказании и лифтинге для кодирования атрибутов в G-PCC доступность соседних отсчетов атрибутов важна для эффективности сжатия, поскольку большее количество соседних отсчетов атрибутов может обеспечить лучшее предсказание. В случае, когда недостаточно соседей для предсказания, эффективность сжатия может быть снижена.
[0020] Другим типом преобразования для кодирования атрибутов в G-PCC может быть региональное адаптивное иерархическое преобразование (Region Adaptive Hierarchical Transform, RAHT). RAHT и обратное ему преобразование могут быть выполнены в отношении иерархии, определенной кодами Мортона местоположений вокселей. Код Мортона d-битовых неотрицательных целочисленных координат х, у и z может быть трехмерным неотрицательным целым числом, которое может быть получено перемежением битов х, у и z. Код Мортона М=morton (х, у, z) неотрицательных d-битовых целочисленных координат

где




где

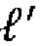

[0021]




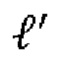



[0022] Региональное адаптивное преобразование Хаара для последовательности An, n=1, …, N, и обратное преобразование Хаара может включать в себя базовый случай и рекурсивную функцию. В базовом случае An может быть атрибутом точки, а Tn может быть ее преобразованием, где Tn=А. Для рекурсивной функции может быть два блока потомков и их родительский блок.


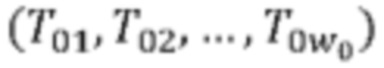


Далее



и

где

[0023] Преобразование родительского блока может быть конкатенацией двух блоков потомков, за исключением того, что первые компоненты преобразований (DC) двух блоков потомков могут быть заменены их взвешенной суммой и разностью, и наоборот, преобразования из двух блоков потомков могут быть скопированы из первой и последней частей преобразования родительского блока, за исключением того, что компоненты DC преобразований двух блоков потомков могут быть заменены их взвешенной разностью и суммой

и

[0024] Чтобы эффективно кодировать преобразованные коэффициенты атрибутов, может использоваться адаптивная поисковая таблица (adaptive look up table, A-LUT), которая может отслеживать N (например, 32) наиболее часто встречающихся символов коэффициентов, и кэш, который может отслеживать последние разные наблюдаемые М (например, 16) символов коэффициентов. A-LUT может быть инициализирован с помощью N символов, предоставленных пользователем, или вычислен в автономном режиме на основе статистики аналогичного класса облаков точек. Кэш может быть инициализирован с помощью М символов, предоставленных пользователем, или вычислен в автономном режиме на основе статистики аналогичного класса облаков точек. Когда кодируется символ S, может быть кодирована двоичная информация, указывающая, может ли S быть кодирован в A-LUT. Если S находится в A-LUT, индекс S в A-LUT может быть кодирован с использованием двоичного арифметического кодера. Количество появлений символа S в A-LUT может быть увеличено на единицу. Если S не в A-LUT, может быть кодирована двоичная информация, указывающая, находится ли S в кэше или нет. Если S находится в кэше, то двоичное представление его индекса может быть кодировано с использованием двоичного арифметического кодера. Если S отсутствует в кэше, то двоичное представление S может быть кодировано с использованием двоичного арифметического кодера. Символ S может быть добавлен в кэш, а самый старый символ в кэше удаляется.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0025] Согласно вариантам осуществления, способ кодирования коэффициентов облака точек выполняется по меньшей мере одним процессором и включает в себя разложение коэффициентов преобразования, связанных с данными облака точек, на значения индексов наборов и значения индексов символов, причем значение индекса символа указывает местоположение коэффициента преобразования в наборе. Разложенные коэффициенты преобразования могут быть разделены на один или более наборов на основе значений индексов наборов и значений индексов символов. Значения индексов наборов разделенных коэффициентов преобразования могут быть кодированы энтропийным кодированием, а значения индексов символов разделенных коэффициентов преобразования могут быть кодированы обходным (bypass) кодированием. Данные облака точек могут быть сжаты на основе энтропийно-кодированных значений индексов наборов и кодированных обходным кодированием значений индексов символов.
[0026] Согласно вариантам осуществления, устройство для кодирования коэффициентов облака точек включает в себя по меньшей мере одну память, выполненную с возможностью хранить код компьютерной программы, и по меньшей мере один процессор, выполненный с возможностью осуществлять доступ по меньшей мере к одной памяти и работать в соответствии с кодом компьютерной программы. Код компьютерной программы включает в себя код, сконфигурированный для того, чтобы заставлять по меньшей мере один процессор выполнять способ, который может включать в себя разложение коэффициентов преобразования, связанных с данными облака точек, на значения индексов наборов и значения индексов символов, причем значение индекса символа указывает местоположение коэффициента преобразования в наборе. Разложенные коэффициенты преобразования могут быть разделены на один или более наборов на основе значений индексов наборов и значений индексов символов. Значения индексов наборов разделенных коэффициентов преобразования могут быть кодированы энтропийным кодированием, а значения индексов символов разделенных коэффициентов преобразования могут быть кодированы обходным кодированием. Данные облака точек могут быть сжаты на основе энтропийно-кодированных значений индексов наборов и кодированных обходным кодированием значений индексов символов.
[0027] Согласно вариантам осуществления, машиночитаемый носитель данных хранит команды, которые заставляют по меньшей мере один процессор разлагать коэффициенты преобразования, связанные с данными облака точек, на значения индексов наборов и значения индексов символов, при этом значение индекса символа определяет расположение коэффициента преобразования в наборе. Разложенные коэффициенты преобразования могут быть разделены на один или более наборов на основе значений индексов наборов и значений индексов символов. Значения индексов наборов разделенных коэффициентов преобразования могут быть кодированы энтропийным кодированием, а значения индексов символов разделенных коэффициентов преобразования могут быть кодированы обходным кодированием. Данные облака точек могут быть сжаты на основе энтропийно-кодированных значений индексов наборов и кодированных обходным кодированием значений индексов символов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
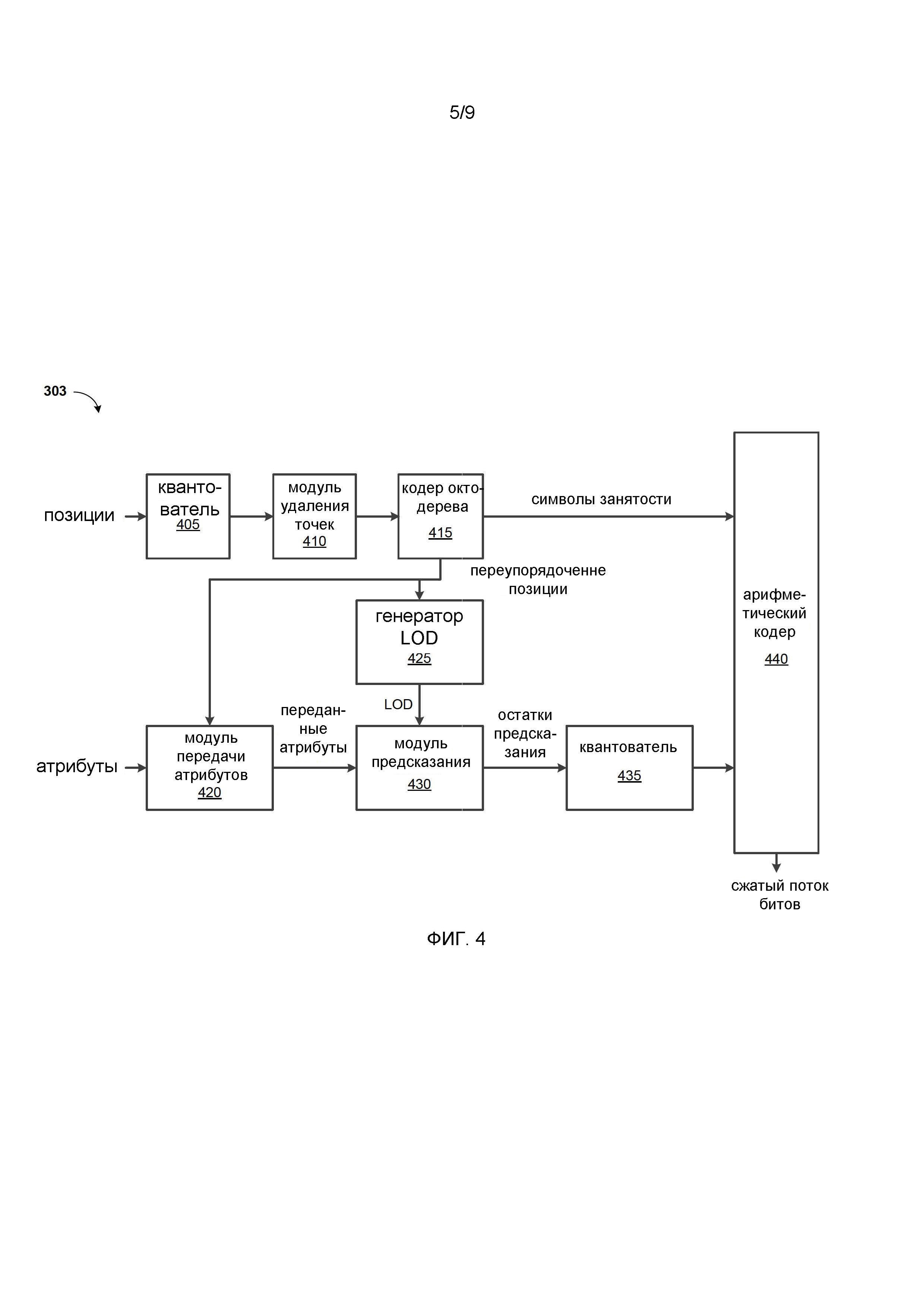
[0028] Фиг. 1А - схема, иллюстрирующая способ создания LoD в G-PCC.
[0029] Фиг. 1В - схема архитектуры для P/U-лифтинга в G-PCC.
[0030] Фиг. 2 структурная схема системы связи согласно вариантам осуществления.
[0031] Фиг. 3 - схема размещения компрессора G-PCC и декомпрессора G-PCC в окружающей среде согласно вариантам осуществления.
[0032] Фиг. 4 - функциональная схема компрессора G-PCC согласно вариантам осуществления.
[0033] Фиг. 5 - функциональная схема декомпрессора G-PCC согласно вариантам осуществления.
[0034] Фиг. 6 - блок-схема, иллюстрирующая способ кодирования коэффициентов облака точек согласно вариантам осуществления.
[0035] Фиг. 7 блок-схема устройства для кодирования коэффициентов облака точек согласно вариантам осуществления.
[0036] Фиг. 8 - схема компьютерной системы, подходящей для реализации вариантов осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
[0037] Описанные здесь варианты осуществления предлагают способ и устройство для кодирования коэффициентов облака точек. Более подробно, кодирование коэффициентов преобразования из лифтинга, предсказания-преобразования и RAHT может выполняться с помощью кодирования индекса таблицы поиска с сортировкой по частоте, кодирования индекса кэша и прямого кодирования значения символа. На практике может потребоваться несколько таблиц поиска и кэшей с множеством (обычно от 32 до, возможно, 256) записей для охвата однобайтовых кодовых слов. Эти справочные таблицы и кэши могут дополнительно нуждаться в регулярных обновлениях, частота которых может предполагать различные компромиссы с точки зрения вычислительных требований и эффективности кодирования. Следовательно, может быть выгодно улучшить кодирование коэффициентов преобразования для атрибутов в G-PCC с точки зрения компромиссов сложности/памяти и эффективности сжатия посредством алфавитного разделения и кодирования информации алфавитного разделения.
[0038] Фиг. 2 является структурной схемой системы 200 связи согласно вариантам осуществления. Система 200 связи может включать в себя по меньшей мере два терминала 210 и 220, соединенных между собой через сеть 250. Для однонаправленной передачи данных первый терминал 210 может кодировать данные облака точек в локальном местоположении для передачи на второй терминал 220 через сеть 250. Второй терминал 220 может принимать кодированные данные облака точек первого терминала 210 из сети 250, декодировать данные кодированного облака точек и отображать декодированные данные облака точек. Однонаправленная передача данных может быть обычным явлением в приложениях обслуживания мультимедиа и т.п.
[0039] Фиг. 2 дополнительно иллюстрирует вторую пару терминалов 230 и 240, предусмотренных для поддержки двунаправленной передачи данных кодированного облака точек, которая может происходить, например, во время видеоконференцсвязи. Для двунаправленной передачи данных каждый терминал 230 или 240 может кодировать данные облака точек, захваченные в локальном местоположении, для передачи на другой терминал через сеть 250. Каждый терминал 230 или 240 также может принимать кодированные данные облака точек, переданные другим терминалом, может декодировать данные кодированного облака точек и может отображать декодированные данные облака точек на локальном устройстве отображения.
[0040] На фиг. 2 терминалы 210-240 могут быть проиллюстрированы как серверы, персональные компьютеры и смартфоны, но принципы вариантов осуществления этим не ограничиваются. Варианты осуществления находят применение в портативных компьютерах, планшетных компьютерах, медиаплеерах и/или специализированном оборудовании для видеоконференцсвязи. Сеть 250 представляет любое количество сетей, которые передают кодированные данные облака точек между терминалами 210-240, включая, например, сети проводной и/или беспроводной связи. Сеть 250 связи может обмениваться данными по каналам с коммутацией каналов и/или с коммутацией пакетов. Репрезентативные сети включают в себя телекоммуникационные сети, локальные сети, глобальные сети и/или Интернет. Для целей настоящего обсуждения архитектура и топология сети 250 могут быть несущественными для работы вариантов осуществления, если это не объясняется в данном документе ниже.
[0041] Фиг. 3 является схемой размещения компрессора 303 G-PCC и декомпрессора 310 G-PCC в окружающей среде согласно вариантам осуществления. Раскрытый предмет изобретения может быть в равной степени применим к другим приложениям с поддержкой облака точек, включая, например, видеоконференцсвязь, цифровое телевидение, хранение сжатых данных облака точек на цифровых носителях, в том числе CD, DVD, карту памяти и т.п., и так далее.
[0042] Система 300 потоковой передачи может включать в себя подсистему 313 захвата, которая может включать в себя источник 301 облака точек, например цифровую камеру, создающую, например, несжатые данные 302 облака точек. Данные 302 облака точек, имеющие больший объем данных, могут обрабатываться компрессором 303 G-РСС, связанным с источником 301 облака точек. Компрессор 303 G-PCC может включать в себя аппаратное обеспечение, программное обеспечение или их комбинацию, чтобы активировать или реализовать аспекты раскрытого предмета, как более подробно описано ниже. Кодированные данные 304 облака точек, имеющие меньший объем данных, могут быть сохранены на сервере 305 потоковой передачи для будущего использования. Один или более клиентов 306 и 308 потоковой передачи могут получить доступ к серверу 305 потоковой передачи для извлечения копий 307 и 309 кодированных данных 304 облака точек. Клиент 306 может включать в себя декомпрессор 310 G-PCC, который декодирует входящую копию 307 кодированных данных облака точек и создает исходящие данные 311 облака точек, которые могут отображаться на дисплее 312 или других устройствах визуализации (не показаны). В некоторых потоковых системах кодированные данные 304, 307 и 309 облака точек могут быть кодированы в соответствии со стандартами кодирования/сжатия видео. Примеры этих стандартов включают стандарты, разработанные MPEG для G-PCC.
[0043] Фиг. 4 представляет собой функциональную схему компрессора 303 G-РСС согласно вариантам осуществления.
[0044] Как показано на фиг. 4, компрессор 303 G-PCC включает в себя квантователь 405, модуль 410 удаления точек, кодер 415 октодерева, модуль 420 передачи атрибутов, генератор 425 LoD (уровней детализации), модуль 430 предсказания, квантователь 435 и арифметический кодер 440.
[0045] Квантователь 405 принимает позиции точек во входном облаке точек. Позиции могут быть (х, у, z) - координатами. Квантователь 405 дополнительно квантует принятые позиции, используя, например, алгоритм масштабирования и/или алгоритм сдвига.
[0046] Модуль 410 удаления точек принимает квантованные позиции от квантователя 405 и удаляет или фильтрует повторяющиеся позиции из принятых квантованных позиций.
[0047] Кодер 415 октодерева принимает отфильтрованные позиции от модуля 410 удаления точек и кодирует принятые отфильтрованные позиции в символы занятости октодерева, представляющего входное облако точек, с использованием алгоритма кодирования октодерева. Ограничивающий бокс входного облака точек, соответствующего октодереву, может быть любой трехмерной формой, например кубом.
[0048] Кодер 415 октодерева дополнительно переупорядочивает принятые отфильтрованные позиции на основе кодирования отфильтрованных позиций.
[0049] Модуль 420 передачи атрибутов принимает атрибуты точек во входном облаке точек. Атрибуты могут включать в себя, например, цвет или значение RGB и/или отражательную способность каждой точки. Модуль 420 передачи атрибутов дополнительно принимает переупорядоченные позиции от кодера 415 октодерева.
[0050] Модуль 420 передачи атрибутов дополнительно обновляет принятые атрибуты на основе принятых переупорядоченных позиций. Например, модуль 420 передачи атрибутов может выполнять один или более из алгоритмов предварительной обработки принятых атрибутов, причем алгоритмы предварительной обработки включают в себя, например, взвешивание и усреднение полученных атрибутов и интерполяцию дополнительных атрибутов из принятых атрибутов. Модуль 420 передачи атрибутов далее передает обновленные атрибуты в модуль 430 предсказания.
[0051] Генератор 425 LoD принимает переупорядоченные позиции от кодера 415 октодерева и получает LoD каждой из точек, соответствующих принятым переупорядоченным позициям. Каждый LoD может рассматриваться как группа точек и может быть получен на основе расстояния до каждой из точек. Например, как показано на фиг. 1А, точки Р0, Р5, Р4 и Р2 могут находиться в LoD как LOD0, точки Р0, Р5, Р4, Р2, P1, Р6 и Р3 могут находиться в LoD как LOD1, а точки Р0, Р5, Р4, Р2, P1, Р6, Р3, Р9, Р8 и Р7 могут быть в LoD как LOD2.
[0052] Модуль 430 предсказания принимает переданные атрибуты от модуля 420 передачи атрибутов и принимает полученный LoD каждой из точек от генератора 425 LoD. Модуль 430 предсказания получает остатки (значения) предсказания соответственно принятых атрибутов посредством применения алгоритма предсказания к полученным атрибутам в порядке, основанном на полученном LoD каждой из точек. Алгоритм предсказания может включать в себя любой из различных алгоритмов предсказания, таких как, например, интерполяция, вычисление средневзвешенного значения, алгоритм ближайшего соседа и RDO.
[0053] Например, как показано на фиг. 1А, остатки предсказания соответственно принятых атрибутов точек Р0, Р5, Р4 и Р2, включенных в LoD как LOD0, могут быть получены раньше, чем остатки полученных атрибутов точек P1, Р6, Р3, Р9, Р8 и Р7, включенных соответственно в LoD как LOD1 и LOD2. Остатки предсказания принятых атрибутов точки Р2 могут быть получены путем вычисления расстояния на основе средневзвешенного значения точек Р0, Р5 и Р4.
[0054] Квантователь 435 принимает полученные остатки предсказания от модуля 430 предсказания и квантует полученные остатки предсказания, используя, например, алгоритм масштабирования и/или алгоритм сдвига.
[0055] Арифметический кодер 440 принимает символы занятости от кодера 415 октодерева и принимает квантованные остатки предсказания от квантователя 435. Арифметический кодер 440 выполняет арифметическое кодирование принятых символов занятости и квантованных остатков предсказаний для получения сжатого потока битов. Арифметическое кодирование может включать в себя любой из различных алгоритмов энтропийного кодирования, таких как, например, контекстно-адаптивное двоичное арифметическое кодирование.
[0056] Фиг. 5 является функциональной схемой декомпрессора 310 G-PCC согласно вариантам осуществления.
[0057] Как показано на фиг. 5, декомпрессор 310 G-PCC включает в себя арифметический декодер 505, декодер 510 октодерева, обратный квантователь 515, генератор 520 LoD, обратный квантователь 525 и модуль 530 обратного предсказания.
[0058] Арифметический декодер 505 принимает сжатый поток битов от компрессора 303 G-PCC и выполняет арифметическое декодирование принятого сжатого потока битов, чтобы получить символы занятости и квантованные остатки предсказания. Арифметическое декодирование может включать в себя любой из различных алгоритмов энтропийного декодирования, таких как, например, контекстно-адаптивное двоичное арифметическое декодирование.
[0059] Декодер 510 октодерева принимает полученные символы занятости от арифметического декодера 505 и декодирует принятые символы занятости в квантованные позиции, используя алгоритм декодирования октодерева.
[0060] Обратный квантователь 515 принимает квантованные позиции от декодера 510 октодерева и выполняет обратное квантование принятых квантованных позиций, используя, например, алгоритм масштабирования и/или алгоритм сдвига, чтобы получить реконструированные позиции точек во входном облаке точек.
[0061] Генератор 520 LoD принимает квантованные позиции от декодера 510 октодерева и получает LoD каждой из точек, соответствующих принятым квантованным позициям.
[0062] Обратный квантователь 525 принимает полученные квантованные остатки предсказания и выполняет обратное квантование принятых квантованных остатков предсказания, используя, например, алгоритм масштабирования и/или алгоритм сдвига, чтобы получить реконструированные остатки предсказания.
[0063] Модуль 530 обратного предсказания принимает полученные реконструированные остатки предсказания от обратного квантователя 525 и принимает полученный LoD каждой из точек от генератора 520 LoD. Модуль 530 обратного предсказания получает реконструированные атрибуты соответственно принятых реконструированных остатков предсказания путем применения алгоритма предсказания к принятым реконструированным остаткам предсказания в порядке, основанном на принятом LoD каждой из точек. Алгоритм предсказания может включать в себя любой из различных алгоритмов предсказания, таких как, например, интерполяция, вычисление средневзвешенного значения, алгоритм ближайшего соседа и RDO. Реконструированные атрибуты - это точки во входном облаке точек.
[0064] Теперь будут подробно описаны способ и устройство для кодирования коэффициентов облака точек. Такой способ и устройство могут быть реализованы в компрессоре 303 G-PCC, описанном выше, а именно в модуле 430 предсказания. Способ и устройство также могут быть реализованы в декомпрессоре 310 G-PCC, а именно в модуле 530 обратного предсказания.
[0065] Алфавитное разделение для коэффициентов преобразования
[0066] Преобразованные коэффициенты или их 8-битовые части могут быть кодированы либо с использованием справочных таблиц (например, A-LUT, описанных выше), либо путем обходного кодирования (bypass-coding) с 256 символами. 8-битовое значение коэффициента может быть разложено на индекс набора и индекс символа внутри набора, который может указывать точное местоположение значения коэффициента в наборе. Например, значения индексов могут соответствовать местоположениям в таблицах поиска или в кэше. 256 возможных значений коэффициентов могут быть сгруппированы в N наборов, как показано в Таблице 2 ниже.
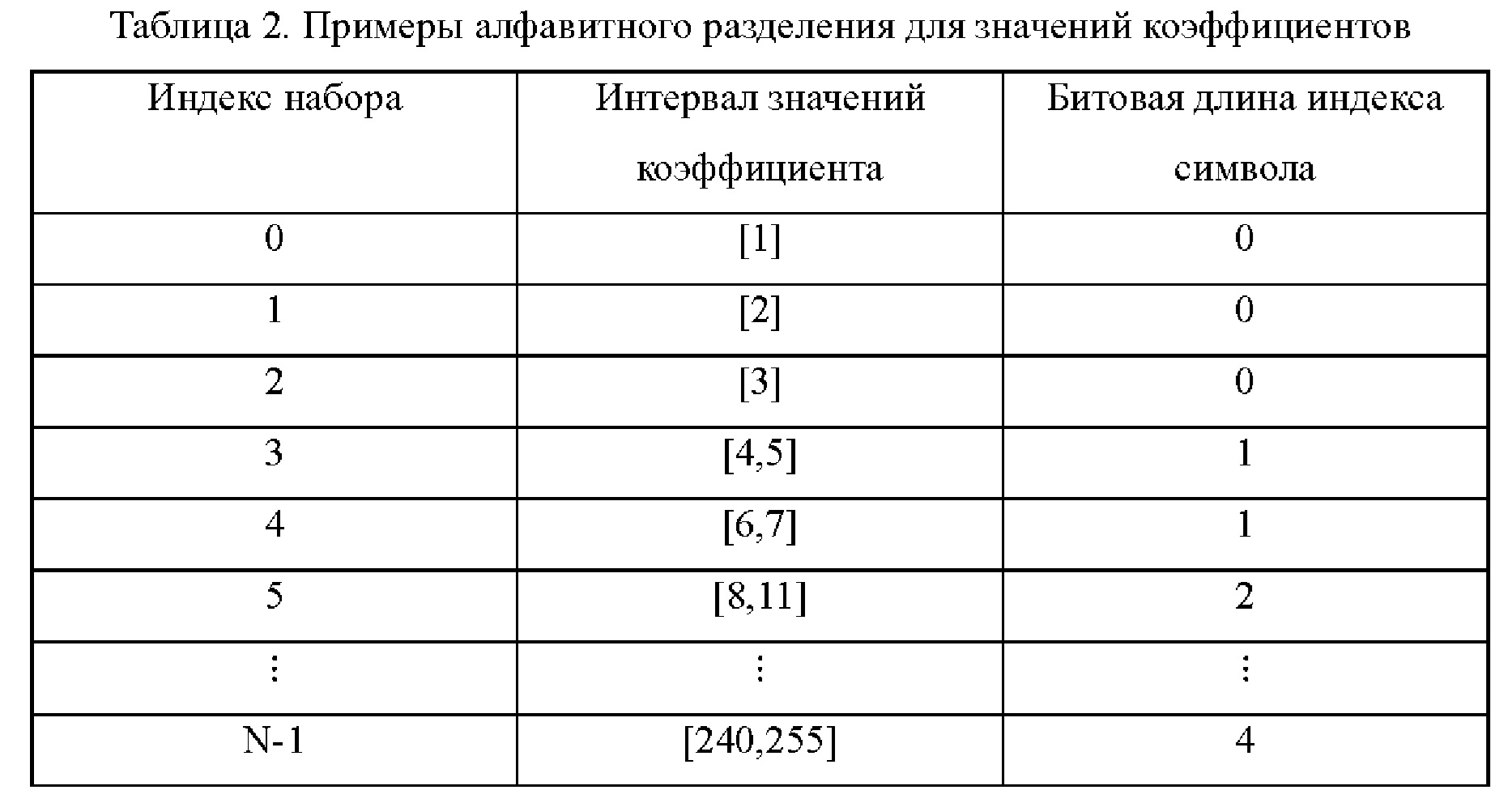
[0067] В одном или более вариантах осуществления может проводиться автономное обучение для разработки разделения значений коэффициентов при данном количестве разделений (N). Граничные значения алфавитного разделения можно сигнализировать явно. В качестве альтернативы, можно сигнализировать индекс для указания конкретного алфавитного разделения с соответствующими граничными значениями, заданными несколькими типами алфавитного разделения, совместно используемыми кодером и декодером. Понятно, что разделение может быть разработано так, чтобы более частые символы принадлежали наборам с более низкими индексами и меньшими размерами, и наоборот, для повышения эффективности кодирования.
[0068] В одном или более вариантах осуществления, LUT на основе кэша или частотной сортировки может использоваться для отслеживания частот значений коэффициентов в порядке убывания. При формировании алфавитного разделения более низкие индексы набора могут быть назначены более частым значениям коэффициентов посредством использования индексов в упомянутом кэше или LUT вместо самих значений коэффициентов, и наоборот. Этот процесс может выполняться "на лету" как в кодере, так и в декодере.
[0069] Кодирование информации алфавитного разделения
[0070] Полученные индексы набора могут быть энтропийно кодированы различными способами, в то время как сопутствующие индексы символов могут быть просто кодированы обходным кодированием, когда можно ожидать, что распределение символов внутри набора будет достаточно равномерным.
[0071] В одном или более вариантах осуществления, производные индексы набора кодируют посредством многосимвольного арифметического кодирования или других типов основанного на контексте двоичного арифметического кодирования. Различное алфавитное разделение может использоваться для лучшего использования различных характеристик коэффициентов.
[0072] В одном или более вариантах осуществления может использоваться различное алфавитное разделение для разных уровней детализации (LOD) коэффициентов лифтинга/предсказания, поскольку более высокие уровни LOD могут иметь меньшие коэффициенты в результате разложения лифтинга/предсказания.
[0073] В одном или более вариантах осуществления может использоваться различное алфавитное разделение для разных параметров квантования (QP), поскольку более высокие QP имеют тенденцию приводить к меньшим квантованным коэффициентам, и наоборот.
[0074] В одном или более вариантах осуществления может использоваться различное алфавитное разделение для разных уровней гранулярной масштабируемости для кодирования с масштабированием SNR (сигнал/шум), поскольку уровни улучшения (т.е. уровни, добавленные для уточнения реконструированного сигнала до меньшего уровня QP) могут быть более шумного или случайного характера с точки зрения корреляции между коэффициентами.
[0075] В одном или более вариантах осуществления может использоваться различное алфавитное разделение в зависимости от значений или функции значений реконструированных отсчетов из соответствующих местоположений на нижних уровнях уровня квантования в случае кодирования с масштабированием SNR. Например, вполне вероятно, что области с нулевыми или очень маленькими реконструированными значениями на нижних уровнях могут иметь характеристики коэффициентов, отличные от областей с противоположной тенденцией.
[0076] В одном или более вариантах осуществления может использоваться различное алфавитное разделение в зависимости от значений или функции значений реконструированных отсчетов из соответствующих местоположений в нижних LOD на том же уровне квантования. Эти отсчеты из соответствующих местоположений могут быть доступны в результате поиска ближайшего окружения при построении LOD в GPCC. Понятно, что эти отсчеты могут быть доступны в декодере, а также в результате реконструкции LOD-за-LOD (LOD-by-LOD) в схемах преобразования в G-PCC.
[0077] Фиг. 6 является блок-схемой, иллюстрирующей способ 600 кодирования коэффициентов облака точек согласно вариантам осуществления. В некоторых реализациях один или более блоков процесса на фиг. 6 может выполняться декомпрессором 310 G-PCC. В некоторых реализациях один или более блоков процесса фиг. 6 может выполняться другим устройством или группой устройств, отдельными от декомпрессора 310 G-PCC или включающими в себя декомпрессор 310 G-PCC, например, компрессором 303 G-PCC.
[0078] Ссылаясь на фиг. 6, в первом блоке 610 способ 600 включает в себя разложение коэффициентов преобразования, связанных с данными облака точек, на значения индексов наборов и значения индексов символов, причем значение индекса символа определяет местоположения коэффициентов преобразования в наборе.
[0079] Во втором блоке 620 способ 600 включает в себя разделение разложенных коэффициентов преобразования на один или более наборов на основе значений индексов наборов и значений индексов символов.
[0080] В третьем блоке 630 способ 600 включает в себя энтропийное кодирование значений индексов наборов разделенных коэффициентов преобразования.
[0081] В четвертом блоке 640 способ 600 включает в себя обходное кодирование значений индексов символов разделенных коэффициентов преобразования.
[0082] В пятом блоке 650 способ 600 включает в себя сжатие данных облака точек на основе энтропийно-кодированных значений индексов наборов и кодированных обходным кодированием значений индексов символов.
[0083] Хотя фиг. 6 показывает иллюстративные блоки способа 600, в некоторых реализациях способ 600 может включать в себя дополнительные блоки, меньшее количество блоков, разные блоки или блоки, расположенные иначе, чем те, которые изображены на фиг. 6. Дополнительно или альтернативно, два или более блока способа 600 могут выполняться параллельно.
[0084] Кроме того, предложенные способы могут быть реализованы схемами обработки (например, одним или несколькими процессорами или одной или несколькими интегральными схемами). В одном примере один или более процессоров выполняют программу, которая хранится на машиночитаемом носителе, для выполнения одного или более из предложенных способов.
[0085] Фиг. 7 является блок-схемой устройства 700 для кодирования коэффициентов облака точек согласно вариантам осуществления.
[0086] Ссылаясь на фиг. 7, устройство 700 включает в себя код 710 декомпозиции, код 720 разделения, код 730 энтропийного кодирования и код 740 обходного кодирования.
[0087] Код 710 декомпозиции сконфигурирован так, чтобы заставлять по меньшей мере один процессор разлагать коэффициенты преобразования, связанные с данными облака точек, на значения индексов наборов и значения индексов символов, причем значение индекса символа определяет местоположения коэффициентов преобразования в наборе.
[0088] Код 720 разделения сконфигурирован для побуждения по меньшей мере одного процессора разделять разложенные коэффициенты преобразования на один или более наборов на основе значений индексов наборов и значений индексов символов.
[0089] Код 730 энтропийного кодирования сконфигурирован для побуждения по меньшей мере одного процессора выполнять энтропийное кодирование значений индексов наборов разделенных коэффициентов преобразования.
[0090] Код 740 обходного кодирования сконфигурирован для побуждения по меньшей мере одного процессора выполнять обходное кодирование значений индексов символов разделенных коэффициентов преобразования.
[0091] Код 750 сжатия сконфигурирован для побуждения по меньшей мере одного процессора сжимать данные облака точек на основе энтропийно-кодированных значений индексов наборов и кодированных обходным кодированием значений индексов символов.
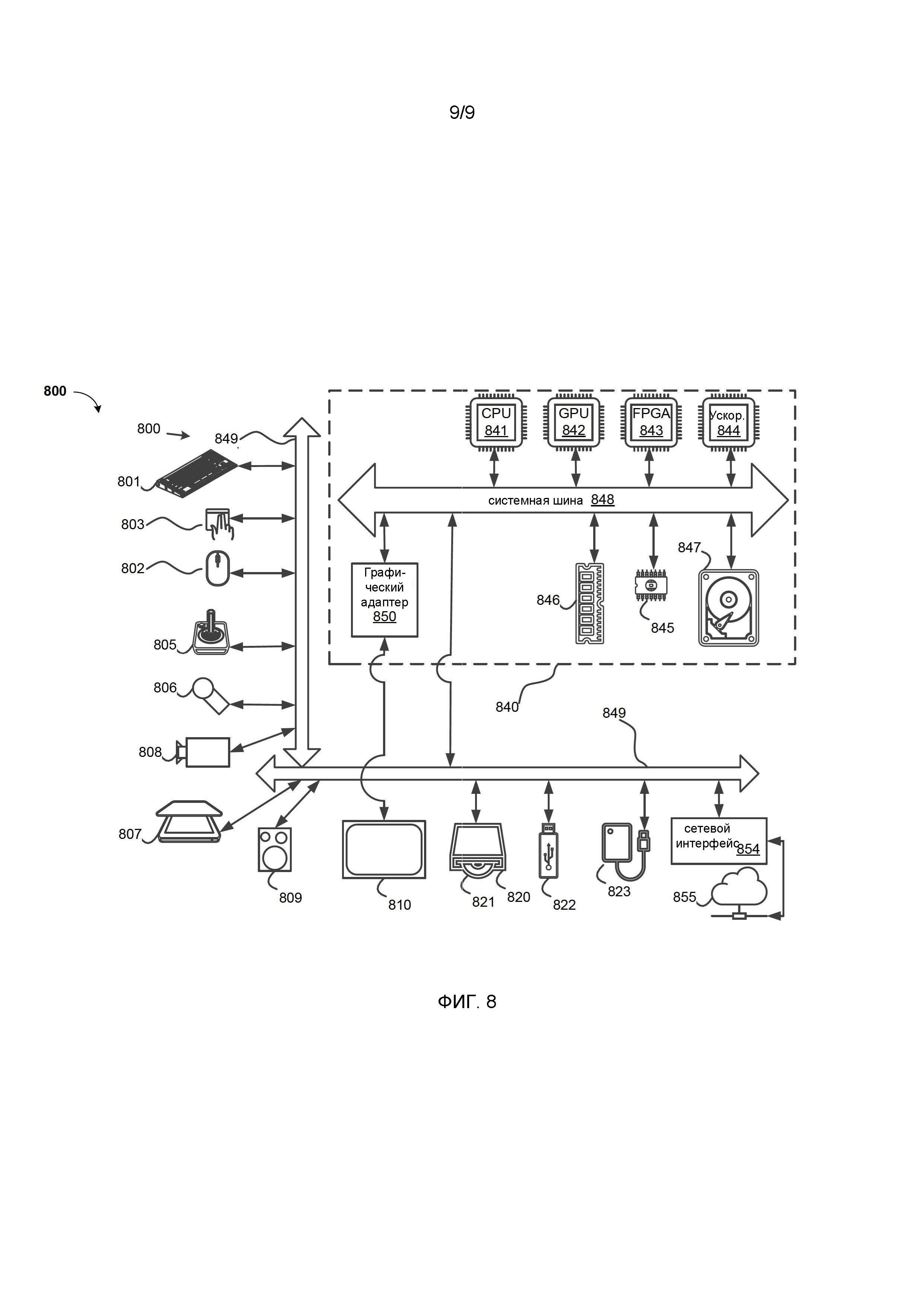
[0092] Фиг. 8 - схема компьютерной системы 800, подходящей для реализации вариантов осуществления.
[0093] Компьютерное программное обеспечение может быть кодировано с использованием любого подходящего машинного кода или компьютерного языка, который может быть предметом сборки, компиляции, связывания или подобных механизмов для создания кода, включающего в себя инструкции, которые могут выполняться напрямую или посредством интерпретации, выполнения микрокода и т.п. центральными процессорами (ЦП, CPU) компьютера, графическими процессорами (ГП, GPU) и т.п.
[0094] Инструкции могут выполняться на компьютерах различных типов или их компонентах, включая, например, персональные компьютеры, планшетные компьютеры, серверы, смартфоны, игровые устройства, устройства Интернета вещей и т.п.
[0095] Компоненты, показанные на фиг. 8 для компьютерной системы 800 являются примерами по своей природе и не предназначены для каких-либо ограничений в отношении объема использования или функциональных возможностей компьютерного программного обеспечения, реализующего варианты осуществления. Конфигурация компонентов также не должна интерпретироваться как имеющая какую-либо зависимость или требование относительно любого одного или комбинации компонентов, проиллюстрированных в вариантах осуществления компьютерной системы 800.
[0096] Компьютерная система 800 может включать в себя определенные человеко-машинные интерфейсы ввода. Такой человеко-машинный интерфейс ввода может реагировать на ввод одним или несколькими пользователями-людьми посредством, например, тактильного ввода (например, нажатия клавиш, смахивания, движения управляющей перчатки), звукового ввода (например, голоса, хлопков в ладоши), визуального ввода (например, жесты), обонятельного ввода (не показан). Человеко-машинные интерфейсы также могут использоваться для захвата определенных медиа, не обязательно напрямую связанных с сознательным вводом человеком, таких как аудио (например, речь, музыка, окружающий звук), изображения (например, сканированные изображения, фотографические изображения, полученные из камеры для неподвижных изображений), видео (например, двухмерное видео, трехмерное видео, включая стереоскопическое видео).
[0097] Человеко-машинные интерфейсы ввода могут включать в себя одно или более из (показано только по одному из каждого): клавиатура 801, мышь 802, трекпад 803, сенсорный экран 810, джойстик 805, микрофон 806, сканер 807 и камера 808.
[0098] Компьютерная система 800 может также включать в себя определенные человека-машинные интерфейсы вывода. Такие человеко-машинные интерфейсы вывода могут стимулировать чувства одного или более пользователей-людей посредством, например, тактильного вывода, звука, света и запаха/вкуса. Такие человеко-машинные интерфейсы вывода могут включать в себя тактильные устройства вывода (например, тактильную обратную связь от сенсорного экрана 810 или джойстика 805, но также могут быть устройства тактильной обратной связи, которые не служат в качестве устройств ввода), устройства вывода звука (например, динамики 809, наушники (не изображены)), устройства визуального вывода (такие как экраны 810, включая экраны с электроннолучевой трубкой (ЭЛТ), экраны жидкокристаллических дисплеев (ЖКД), плазменные экраны, экраны на органических светодиодах (OLED), каждое с возможностью или без возможности ввода с сенсорного экрана, каждый с возможностью тактильной обратной связи или без нее - некоторые из них могут осуществлять двухмерный визуальный вывод или более чем трехмерный вывод с помощью таких средств, как стереографический вывод; очки виртуальной реальности (не показаны), голографические дисплеи и дымовые баки (не показаны), и принтеры (не показаны). Графический адаптер 850 генерирует и выводит изображения на сенсорный экран 810.
[0099] Компьютерная система 800 также может включать в себя доступные человеку запоминающие устройства и связанные с ними носители, такие как оптические носители, включая привод 820 CD / DVD ROM / RW с CD/DVD или тому подобное, носитель 821, флэш-накопитель 822, съемный жесткий диск или твердотельный накопитель 823, традиционные магнитные носители, такие как лента и гибкий диск (не показаны), специализированные устройства на основе ROM (ПЗУ) / ASIC / PLD, такие как защитные аппаратные ключи (не показаны) и т.п.
[0100] Специалисты в данной области должны также понимать, что термин «машиночитаемый носитель», используемый в связи с раскрытым в настоящее время предметом изобретения, не охватывает среды передачи, несущие волны или другие кратковременные сигналы.
[0101] Компьютерная система 800 также может включать в себя интерфейс (-ы) к одной или нескольким коммуникационным сетям 855. Коммуникационные сети 855 могут, например, быть беспроводными, проводными, оптическими. Сети 855 дополнительно могут быть локальными, глобальными, городскими, автомобильными и промышленными, работающими в реальном времени, устойчивыми к задержкам и так далее. Примеры сетей 855 включают в себя локальные сети, такие как Ethernet, беспроводные локальные сети, сотовые сети, включая глобальные системы мобильной связи (GSM), третьего поколения (3G), четвертого поколения (4G), пятого поколения (5G), стандарт «Долгосрочное развитие» (LTE) и т.п., проводные телевизионные или беспроводные глобальные цифровые сети, включая кабельное телевидение, спутниковое телевидение и наземное широковещательное телевидение, автомобильные и промышленные, включая CANBus и так далее. Сети 855 обычно требуют адаптеров внешнего сетевого интерфейса, которые подключены к определенным портам данных общего назначения или периферийным шинам 849 (например, к портам универсальной последовательной шины (USB) компьютерной системы 800; другие обычно интегрируются в ядро компьютерной системы 800 путем присоединения к системной шине, как описано ниже, например, сетевой интерфейс 854, включающий в себя интерфейс Ethernet, в компьютерную систему ПК и/или интерфейс сотовой сети в компьютерную систему смартфона. Используя любую из этих сетей 855, компьютерная система 800 может связываться с другими объектами. Такая связь может быть однонаправленной, только для приема (например, широковещательное телевидение), однонаправленной только для отправки (например, CANbus на определенные устройства CANbus) или двунаправленной, например, с другими компьютерными системами, использующими локальные или глобальные цифровые сети. Некоторые протоколы и стеки протоколов могут использоваться в каждой из этих сетей 855 и сетевых интерфейсов 854, как описано выше.
[0102] Вышеупомянутые человеко-машинные интерфейсы, доступные человеку запоминающие устройства и сетевые интерфейсы 854 могут быть присоединены к ядру 840 компьютерной системы 800.
[0103] Ядро 840 может включать в себя один или более центральных процессоров (ЦП, CPU) 841, графических процессоров (ГП, GPU) 842, специализированных программируемых процессоров в виде программируемых логических интегральных схем (ПЛИС, FPGA) 843, аппаратных ускорителей 844 для определенных задач и так далее. Эти устройства, наряду с постоянным запоминающим устройством (ПЗУ, ROM) 845, оперативным запоминающим устройством (ОЗУ, RAM) 846, внутренним запоминающим устройством 847 большой емкости, таким как внутренние жесткие диски, не доступные пользователю, твердотельные накопители (SSD) и т.п., могут быть подключенными через системную шину 848. В некоторых компьютерных системах системная шина 848 может быть доступна в виде одного или более физических разъемов для обеспечения возможности расширения с помощью дополнительных процессоров, графических процессоров и т.п. Периферийные устройства могут быть подключены либо непосредственно к системной шине 848 ядра, либо через периферийные шины 849. Архитектура периферийной шины включает в себя соединение периферийных компонентов (PCI), USB и т.п.
[0104] CPUs 841, GPU 842, FPGA 843 и аппаратные ускорители 844 могут выполнять определенные инструкции, которые в комбинации могут составлять вышеупомянутый компьютерный код. Этот компьютерный код может храниться в ROM 845 или RAM 846. Переходные данные также могут храниться в RAM 846, тогда как постоянные данные могут храниться, например, во внутреннем запоминающем устройстве 847. Быстрое сохранение и извлечение в любое из устройств памяти может быть активировано посредством использования кэш-памяти, которая может быть тесно связана с CPU 841, GPU 842, внутренним запоминающим устройством 847, ROM 845, RAM 846 и т.п.
[0105] Машиночитаемый носитель может содержать компьютерный код для выполнения различных операций, реализуемых компьютером. Носители и компьютерный код могут быть специально спроектированными и сконструированными для целей вариантов осуществления, или они могут быть хорошо известными и доступными для специалистов в области компьютерного программного обеспечения.
[0106] В качестве примера, а не в качестве ограничения, компьютерная система 800, имеющая архитектуру, и, в частности, ядро 840, может обеспечивать функциональность в результате выполнения процессором (-ами) (включая CPU, GPU, FPGA, ускорители и т.п.) программного обеспечения, воплощенного на одном или более материальных, машиночитаемых носителях. Такие машиночитаемые носители могут быть носителями, ассоциированными с доступным для пользователя запоминающим устройством большой емкости, как описано выше, а также определенными запоминающими устройствами ядра 840, которые имеют долговременную природу, такими как внутреннее запоминающее устройство 847 большой емкости или ROM 845. Программное обеспечение, реализующее различные варианты осуществления, может храниться в таких устройствах и выполняться ядром 840. Машиночитаемый носитель может включать в себя одно или более запоминающих устройств или микросхем в соответствии с конкретными потребностями. Программное обеспечение может заставлять ядро 840 и, в частности, процессоры в нем (включая CPU, GPU, FPGA и т.п.) выполнять определенные процессы или определенные части конкретных процессов, описанных в данном документе, в том числе определение структур данных, хранящихся в RAM 846, и изменение таких структур данных в соответствии с процессами, определенными программным обеспечением. В дополнение или в качестве альтернативы, компьютерная система может обеспечивать функциональные возможности в результате логики, встроенной аппаратным образом или иным образом воплощенной в схеме (например, аппаратный ускоритель 844), которая может работать вместо или вместе с программным обеспечением для выполнения определенных процессов или отдельных частей конкретных процессов, описанных в данном документе. Ссылка на программное обеспечение может включать в себя логику и наоборот, где это уместно. Ссылка на машиночитаемый носитель может охватывать схему (например, интегральную схему (ИС)), хранящую программное обеспечение для выполнения, схему, воплощающую логику для выполнения, или и то, и другое, где это необходимо. Варианты осуществления охватывают любую подходящую комбинацию аппаратного и программного обеспечения.
[0107] Хотя это раскрытие описывает несколько вариантов осуществления, существуют изменения, перестановки и различные заменяющие эквиваленты, которые попадают в объем раскрытия. Таким образом, должно быть понятно, что специалисты в данной области техники смогут разработать многочисленные системы и способы, которые, хотя явно не показаны или не описаны здесь, воплощают принципы изобретения и, таким образом, находятся в пределах его сущности и объема.
Реферат
Изобретение относится к области кодирования данных. Технический результат заключается в обеспечении возможности сжатия облаков точек без потерь в контексте динамического отображения. Коэффициенты преобразования, связанные с данными облака точек, разлагают на значения индексов наборов и значения индексов символов, где значение индекса символа определяет местоположение коэффициента преобразования в наборе. Разложенные коэффициенты преобразования разделяют на один или более наборов на основе значений индексов наборов и значений индексов символов. Значения индексов наборов разделенных коэффициентов преобразования кодируют энтропийным кодированием, а значения индексов символов разделенных коэффициентов преобразования кодируют обходным кодированием. Данные облака точек сжимают на основе энтропийно-кодированных значений индексов наборов и кодированных обходным кодированием значений индексов символов. 3 н. и 17 з.п. ф-лы, 9 ил., 2 табл.
Формула
Документы, цитированные в отчёте о поиске
Способ и устройство для кодирования и декодирования исходных данных с использованием сжатия символов
Комментарии