Усовершенствование интерфейса pci express - RU2645288C2
Код документа: RU2645288C2
Чертежи


















Описание
Область техники, к которой относится изобретение
Настоящее изобретение относится к компьютерным системам, в частности (но не исключительно) к соединениям точка-точка.
Уровень техники
Достижения в области технологии полупроводниковых приборов и в проектировании логических устройств позволили увеличить объем логических устройств, которые могут быть размещены в одной интегральной схеме. Как следствие, произошло развитие конфигураций компьютерных систем от одной или более интегральных схем до систем с множеством ядер, множеством аппаратных потоков и множеством логических процессоров в одной индивидуальной интегральной схеме, равно как и других интерфейсов, интегрированных в таких процессорах. Процессор или интегральная схема обычно содержит один физический процессорный кристалл, где этот процессорный кристалл может содержать произвольное число ядер, аппаратных потоков, логических процессоров, интерфейсов, запоминающих устройств, контроллеров-концентраторов и т.п.
В результате возросших возможностей вместить больше процессорных мощностей в корпуса меньшего размера выросла популярность малогабаритных компьютерных устройств. Численность и сфера применения смартфонов, планшетов, ультратонких ноутбуков и других пользовательских устройств росли экспоненциально. Однако эти малогабаритные устройства зависят от серверов как для хранения данных, так и для осуществления сложной обработки данных, для которой не хватает возможностей, ограниченных форм-фактором малогабаритных устройств. Следовательно, потребности в создании рынка высокопроизводительных вычислений (т.е. в серверном пространстве) тоже выросли. Например, современный сервер обычно содержит не только один многоядерный процессор, но и несколько физических процессоров (также называемых несколькими сокетами) для увеличения вычислительной мощности. Но по мере роста процессорных мощностей вместе с числом устройств в компьютерной системе связь между сокетами и другими устройствами становится все более критичной.
На деле технология соединений между устройствами прошла путь развития от более традиционных многоотводных шин, осуществлявших преимущественно электрическую связь, до полностью развитой полнофункциональной архитектуры соединений, способствующей осуществлению высокоскоростной связи. К сожалению, по мере роста требований к процессорам будущего работать на все более высоких скоростях, соответствующие требования предъявляются и к возможностям существующих архитектур соединений.
Краткое описание чертежей
Фиг. 1 иллюстрирует вариант компьютерной системы, содержащей архитектуру соединений.
Фиг. 2 иллюстрирует вариант архитектуры соединений, содержащей многоуровневый стек.
Фиг. 3 иллюстрирует вариант запроса или пакета, какие следует генерировать или принимать в архитектуре соединений.
Фиг. 4 иллюстрирует варианты пары из передатчика и приемника для архитектуры соединений.
Фиг. 5 иллюстрирует вариант примера канала для соединения между двумя разъемами.
Фиг. 6 представляет упрощенную блок-схему соединительной структуры, имеющей сквозные соединения, в разрезе.
Фиг. 7 представляет соединение в разрезе с использованием «высверливания» столбиков сквозных соединений сзади.
Фиг. 8 представляет блок-схему структуры возможностей, включая регистр состояния ошибки линии.
Фиг. 9 представляет упрощенную схему, иллюстрирующую потоки данных в много линейном соединении.
Фиг. 10 показывает представление примера символов кадрирующего маркера.
Фиг. 11 представляет упрощенную схему, иллюстрирующую потоки данных, включая пример упорядоченного множества пропуска (SKP).
Фиг. 12 представляет упрощенную схему, иллюстрирующую ошибки линии, сообщение о которых может быть передано в регистр ошибок.
Фиг. 13A-13D представляют логические схемы, иллюстрирующие примеры передачи сообщений об ошибках линий канала связи.
Фиг. 14 иллюстрирует вариант блок-схемы компьютерной системы, содержащей многоядерный процессор.
Фиг. 15 иллюстрирует другой вариант блок-схемы компьютерной системы, содержащей многоядерный процессор.
Фиг. 16 иллюстрирует вариант блок-схемы процессора.
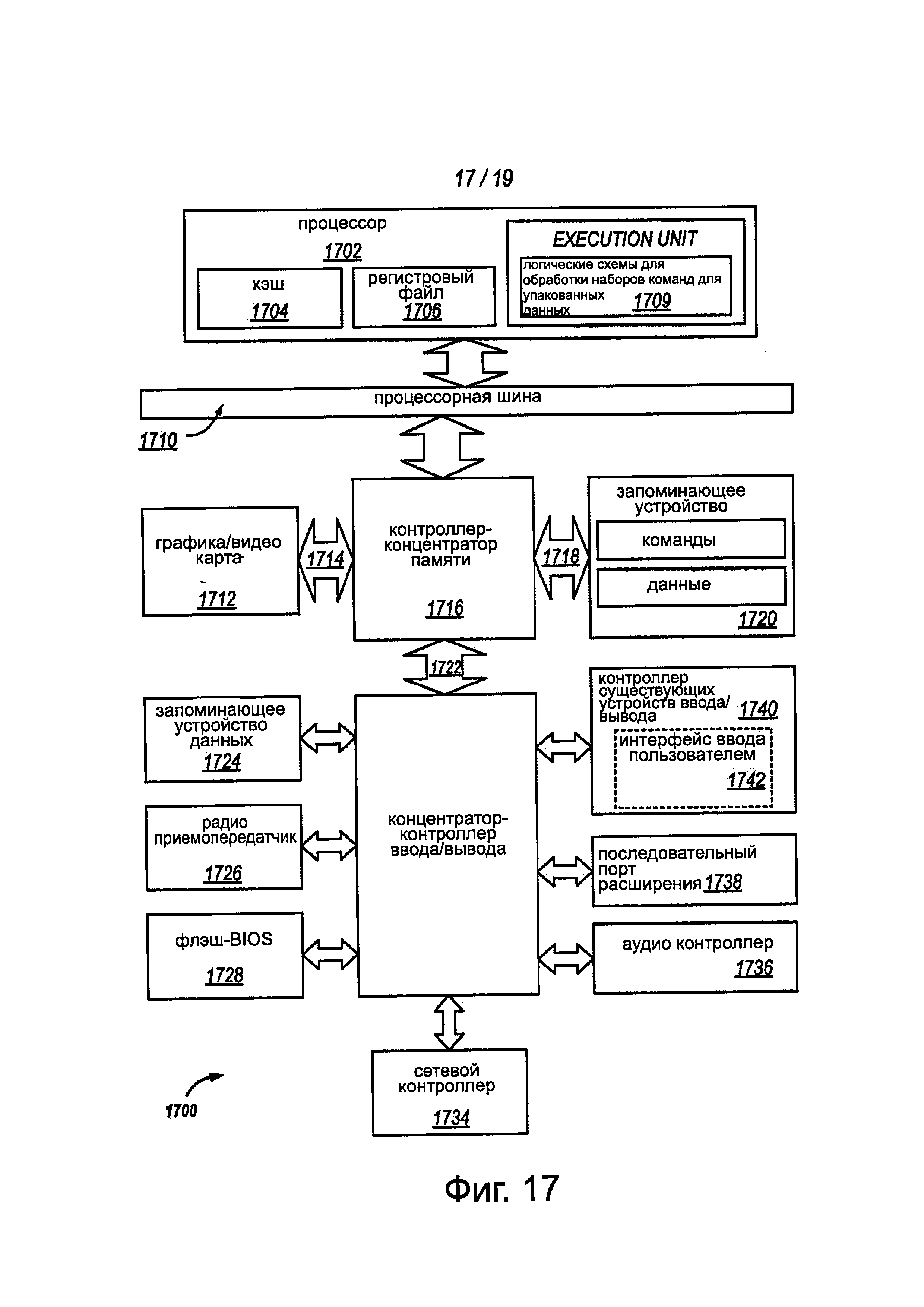
Фиг. 17 иллюстрирует другой вариант блок-схемы компьютерной системы, содержащей процессор.
Фиг. 18 иллюстрирует вариант блок-схемы компьютерной системы, содержащей несколько процессоров.
Фиг. 19 иллюстрирует пример системы, реализованной в виде системы на кристалле (SoC).
Подобные цифровые и иные позиционные обозначения на разных чертежах указывают подобные элементы.
Осуществление изобретения
В последующем описании приведены многочисленные конкретные детали, такие как примеры конкретных типов процессоров и конфигурации систем, конкретные структуры аппаратуры, конкретные архитектурные и микроархитектурные подробности, конкретные конфигурации регистров, конкретные типы команд, конкретные компоненты систем, конкретные размеры/высоты, конкретные ступени процессорных конвейеров и операций и т.п., с целью предоставления возможности полного понимания настоящего изобретения. Однако специалисту в рассматриваемой области должно быть понятно, что эти конкретные детали не обязательно использовать при практической реализации настоящего изобретения. В других случаях хорошо известные компоненты или способы, такие как конкретные и альтернативные процессорные архитектуры, конкретные логические схемы/коды для описываемых алгоритмов, конкретные коды встроенного программного обеспечения, конкретные соединительные операции, конкретные логические конфигурации, конкретные способы изготовления и материалы, конкретные варианты реализации компилятора, конкретные выражения алгоритмов в виде кода, конкретные способы/логические устройства для выключения питания/стробирования и другие конкретные подробности работы компьютерных систем здесь не были описаны подробно, чтобы избежать нежелательного загромождения и «затемнения» описания настоящего изобретения.
Хотя последующие варианты могут быть описаны с точки зрения энергосбережения и энергетической эффективности конкретных интегральных схем, таких как компьютерные платформы или микропроцессоры, другие варианты применимы к другим типам интегральных схем и логических устройств. Способы и принципы, аналогичные описываемым здесь вариантам, могут быть применены к другим типам схем или полупроводниковых приборов, которые также могут выиграть от лучшей энергетической эффективности и сбережения энергии. Например, описываемые варианты не ограничиваются настольными компьютерными системами или компьютерами типа Ultrabooks™. Они могут быть также использованы в других устройствах, таких как ручные устройства, планшеты, другие тонкие ноутбуки, системы на кристалле (system on а chip (SOC)) и встроенные приложения. В качестве некоторых примеров ручных устройств можно указать сотовые телефоны, устройства Интернет-протокола, цифровые фото и видеокамеры, персональные цифровые помощники (personal digital assistants (PDA)) и ручные персональные компьютеры. Встроенные приложения обычно содержат микроконтроллер, цифровой процессор сигнала (digital signal processor (DSP)), систему на кристалле, сетевые компьютеры (network computers (NetPC)), приставки, сетевые концентраторы, коммутаторы глобальной сети связи (wide area network (WAN)) или какие-либо другие системы, которые могут осуществлять функции и операции, рассматриваемые ниже. Более того, аппаратура, способы и системы, рассматриваемые здесь, не ограничиваются физическими компьютерными устройствами, а могут также относиться к программным оптимизациям с целью сбережения энергии и энергетической эффективности. Как станет легко понятно из приведенного ниже описания, варианты способов, аппаратуры и систем, описываемые здесь (будь то со ссылками на аппаратуру, встроенное программное обеспечение, загружаемое программное обеспечение или сочетания этих компонентов) являются жизненно важными для так называемой «зеленой технологии» будущего, сбалансированной с учетом соображений производительности.
По мере совершенствования компьютерных систем компоненты таких систем становятся все более сложными. В результате сложность архитектуры соединений для связи между компонентами также возрастает, чтобы удовлетворить требованиям к широкополосности связи для оптимальной работы компонентов. Более того, разные сегменты рынка требуют различных аспектов архитектуры соединений для удовлетворения разных потребностей рынка. Например, от серверов требуется высокая производительность, тогда мобильная экосистема иногда может пожертвовать общей производительностью в пользу энергосбережения. До сих пор единственным требованием к большинству систем соединений являлось достижение наивысшей возможной производительности при максимальном энергосбережении. Ниже обсуждаются некоторые системы соединений, которые потенциально должны были бы выиграть от некоторых аспектов настоящего изобретения, рассматриваемых здесь.
Одна из архитектур соединений содержит архитектуру соединений периферийных устройств Peripheral Component Interconnect (PCI) Express (PCIe). Основной целью архитектуры PCIe является обеспечение возможности для компонентов и устройств от разных поставщиков взаимодействовать в открытой архитектуре, охватывая несколько сегментов рынка: а именно Клиентов (Client) (настольных (Desktop) и мобильных (Mobile)), Серверов (Server) (обычных (Standard) и серверов предприятий (Enterprise)), а также встроенных (Embedded) устройств и устройств связи (Communication). Стандарт интерфейса PCI Express представляет собой стандарт высокопроизводительной системы соединений ввода/вывода общего назначения, созданный для самого широкого спектра компьютерных платформ и платформ связи будущего. Некоторые атрибуты интерфейса PCI, такие как модель использования, архитектура загрузки-хранения и программные интерфейсы, были сохранены во всех редакциях этого интерфейса, тогда как прежняя параллельная реализация шины была заменена в высокой степени масштабируемым полностью последовательным интерфейсом. Более новые версии интерфейса PCI Express используют достижения в области двухпунктовых соединений, технологии на основе коммутации и протокола передачи пакетов данных для достижения новых, более высоких уровней производительности и характеристик. Среди усовершенствованных характеристик интерфейса PCI Express можно указать управление питанием (Power Management), управление качеством обслуживания (Quality Of Service (QoS)), поддержку «горячего» подключения в рабочем состоянии (Hot-Plug) и «горячей» замены в рабочем состоянии (Hot-Swap) устройств, обеспечение целостности данных (Data Integrity) и обработку ошибок (Error Handling).
На Фиг. 1 представлен вариант архитектуры соединений, составленной из каналов связи точка-точка, соединяющих множество компонентов. Система 100 содержит процессор 105 и системное запоминающее устройство ПО, соединенные с контроллером-концентратором 115. Процессор 105 содержит какой-либо процессорный элемент, такой как микропроцессор, главный процессор, встроенный процессор, сопроцессор или какой-либо другой процессор. Процессор 105 соединен с контроллером-концентратором 115 посредством внешней шины (front-side bus (FSB)) 106. В одном из вариантов шина FSB 106 представляет собой последовательное двухпунктовое соединение, как описано ниже. В другом варианте канал 106 связи содержит последовательную дифференциальную архитектуру соединений, совместимую с другим стандартом соединений.
Системное запоминающее устройство 110 представляет собой запоминающее устройство какого-либо типа, такое как запоминающее устройство с произвольной выборкой (RAM), энергонезависимое запоминающее устройство (non-volatile (NV) memory) или какое-нибудь другое запоминающее устройство, доступное для других устройств в системе 100. Системное запоминающее устройство 110 связано с контроллером-концентратором 115 через интерфейс 116 памяти. Среди примеров таких интерфейсов памяти можно указать интерфейс памяти с удвоенной скоростью передачи данных (double-data rate (DDR)) двухканальный DDR-интерфейс памяти и интерфейс памяти для динамического (DRAM).
В одном из вариантов контроллер-концентратор 115 представляет собой корневой концентратор, корневой комплекс или корневой контроллер в иерархии соединений Peripheral Component Interconnect Express (PCIe или PCIE). К примерам таких контроллеров-концентраторов 115 относятся чипсет, контроллер-концентратор памяти (МСН), схема «Северный мост» (northbridge), контроллер-концентратор соединений (ICH), схема «Южный мост» (southbridge) и корневой контроллер/концентратор. Часто термин «чипсет» относится к двум физически раздельным контроллерам-концентраторам, т.е. к контроллеру-концентратору памяти (МСН), связанному с контроллером-концентратором соединений (ICH). Отметим, что современные системы часто содержат блок МСН, интегрированный с процессором 105, тогда как контроллер 115 предназначен для связи с устройствами ввода/вывода аналогично тому, как описано ниже. В некоторых вариантах корневым комплексом 115 в качестве опции поддерживается одноранговая маршрутизация.
Здесь контроллер-концентратор 115 соединен с коммутатором/мостом 120 посредством последовательного канала 119 связи. Модули 117 и 121 ввода/вывода, которые могут также называться интерфейсами/портами 117 и 121, содержат/реализуют многоуровневый стек протоколов для осуществления связи между контроллером-концентратором 115 и коммутатором 120. В одном из вариантов с коммутатором 120 могут быть соединены несколько устройств.
Коммутатор/мост 120 осуществляет маршрутизацию пакетов/сообщений от устройства 125 «вверх», т.е. вверх по иерархии по направлению к корневому комплексу, к контроллеру-концентратору 115 и «вниз», т.е. вниз по иерархии прочь от корневого контроллера, от процессора 105 или системного запоминающего устройства 110 к устройству 125. Коммутатор 120 в одном из вариантов называется логической сборкой из нескольких виртуальных мостовых устройств PCI-k-PCI/. Устройство 125 содержит какое-либо внутреннее устройство или компонент для соединения с электронной системой. Это устройство или компонент может представлять собой устройство ввода/вывода, контроллер сетевого интерфейса (Network Interface Controller (NIC)), расширительную плату, аудио процессор, сетевой процессор, накопитель на жестком диске, запоминающее устройство, накопитель CD/DVD ROM, монитор, принтер, мышь, клавиатуру, маршрутизатор, портативное запоминающее устройство, устройство с шиной сверхбыстрой передачи данных (Firewire), устройство с универсальной последовательной шиной (Universal Serial Bus (USB)), сканер или другое устройство ввода/вывода. Часто на жаргоне PCIe такое устройство называется конечной или крайней точкой. Хотя это не показано специально, устройство 125 может содержать мост для соединения PCIe с PCI/PCI-X с целью поддержки PCI-устройств, соответствующих прежним устаревшим или другим версиям. Устройства конечных точек в системах PCIe часто классифицируют как прежние, устаревшие конечные точки, конечные точки PCIe или интегральные конечные точки корневого комплекса.
С контроллером-концентратором 115 по последовательному каналу 132 связи соединен также графический ускоритель 130. В одном из вариантов графический ускоритель 130 соединен с блоком МСН, который связан с блоком ICH. Коммутатор 120 и соответственно устройство 125 ввода/вывода затем соединены с блоком ICH. Модули 131 и 118 ввода/вывода также реализуют многоуровневый стек протоколов для осуществления связи между графическим ускорителем 130 и контроллером-концентратором 115. Аналогично обсуждавшемуся выше блоку МСН графический контроллер или графический ускоритель 130 сам может быть интегрирован в процессор 105.
На Фиг. 2 показан вариант многоуровневого стека протоколов. Этот многоуровневый стек 200 протоколов может содержать какую-либо форму многоуровневого стека связи, такую как стек шины быстрого соединения (Quick Path Interconnect (QPI)), стек PCIe, стек высокопроизводительных компьютерных соединений следующего поколения или другой многоуровневый стек. Хотя приведенное непосредственно ниже со ссылками на Фиг. 1-4 обсуждение относится к стеку PCIe, те же самые принципы могут быть применены и к другим стекам соединений. В одном из вариантов стек 200 протоколов является PCIe-стеком протоколов, содержащим уровень 205 транзакций, канальный уровень 210 и физический уровень 220. Интерфейс, такой как интерфейсы 117, 118, 121, 122, 126 и 131, может быть представлен в виде стека 200 протоколов связи. Представление в виде стека протоколов связи может также называться модулем или интерфейсом, реализующим/содержащим стек протоколов.
Интерфейс PCI Express использует пакеты для передачи информации между компонентами. Пакеты формируются на уровне 205 транзакций (Transaction Layer) и на уровне 210 канала передачи данных или канальном уровне (Data Link Layer) для переноса информации от передающего компонента к приемному компоненту. Когда передаваемые пакеты проходят через другие уровни, происходит расширение этих пакетов за счет добавления дополнительной информации, необходимой для обработки пакетов на этих уровнях. На приемной стороне осуществляется обратный процесс и происходит преобразование пакетов от представления, которое они имели на физическом уровне 220 (Physical Layer) к представлению на канальном уровне 210 и, в конце концов (для пакетов уровня транзакций) к форме, в которой эти пакеты могут быть обработаны на уровне 205 транзакций в приемном устройстве.
Уровень транзакций
В одном из вариантов уровень 205 транзакций служит интерфейсом между процессорным ядром устройства и архитектурой соединений, такой как канальный уровень 210 и физический уровень 220. С этой точки зрения главной сферой ответственности уровня 205 транзакций является сборка и разборка пакетов (т.е. пакетов уровня транзакций (transaction layer packet) или TLP). Уровень 205 транзакций обычно осуществляет управление потоком на кредитной основе для пакетов TLP. Интерфейс PCIe осуществляет расщепленные транзакции, т.е. транзакции, для которых запрос и ответ разделены во времени, что позволяет каналу связи передавать другой трафик, пока целевое устройство собирает данные для ответа.
Кроме того, интерфейс PCIe использует управление потоком на кредитной основе. При использовании такой схемы устройство объявляет первоначальный объем кредита для каждого из приемных буферов на уровне 205 транзакций. Внешнее устройство на противоположном конце канала связи, такое как контроллер-концентратор 115, показанный на Фиг. 1, подсчитывает число кредитов, израсходованных каждым пакетом TLP. Любая транзакция может быть передана, только если она не превышает кредитный лимит. После приема ответа объем кредита восстанавливается. Преимущество такой кредитной схемы состоит в том, что задержка возврата кредита не влияет на производительность при условии, что кредитный лимит не достигнут.
В одном из вариантов совокупность четырех адресных пространств транзакций содержит адресное пространство конфигурации, адресное пространство памяти, адресное пространство ввода/вывода и адресное пространство сообщений. К транзакциям в пространстве памяти относятся один или несколько запросов считывания и запросов записи для передачи данных в/из позиций памяти. В одном из вариантов транзакции в пространстве памяти могут использовать два разных формата адресов, например, короткий адресный формат, такой как 32-битовые адреса, или длинный адресный формат, такой как 64-битовые адреса. Транзакции в пространстве конфигурации используются для доступа в пространство конфигурации PCIe-устройств. Транзакции в пространстве конфигурации содержат запросы считывания и запросы записи. Транзакции в пространстве сообщений (или просто сообщения) определены для поддержки передачи данных через сеть между PCIe-агентами.
Поэтому в одном из вариантов уровень 205 транзакций собирает заголовок/полезную нагрузку пакета 206. Формат для заголовков/полезной нагрузки пакетов, действующий на сегодня, можно найти в спецификациях интерфейса PCIe на веб-сайте спецификаций PCIe.
Фиг. 3 иллюстрирует один из вариантов дескриптора транзакции для интерфейса PCIe. В одном из вариантов дескриптор 300 транзакции представляет собой механизм для передачи информации о транзакции. В этом смысле дескриптор 300 транзакции поддерживает идентификацию транзакций в системе. Среди других потенциальных областей использования дескриптора можно указать отслеживание модификаций порядка транзакций по умолчанию и ассоциирование транзакций с каналами.
Дескриптор 300 транзакции содержит поле глобального идентификатора 302, поле 304 атрибутов и поле идентификатора 306 канала. В иллюстрируемом примере показано, что поле глобального идентификатора 302 содержит поле локального идентификатора 308 транзакции и поле идентификатора 310 источника. В одном из вариантов глобальный идентификатор 302 транзакции является уникальным для всех ожидающих выполнения запросов.
Согласно одному из вариантов поле локального идентификатора 308 транзакции представляет собой поле идентификатора, генерируемого запросившим агентом и являющегося уникальным для всех невыполненных запросов, которые нуждаются в выполнении, от этого запросившего агента. Более того, в этом примере идентификатор 310 источника однозначно идентифицирует запросившего агента в иерархии PCIe. Соответственно, вместе с идентификатором 310 источника поле локального идентификатора 308 транзакции обеспечивает глобальную идентификацию транзакции в иерархической области.
Поле 304 атрибутов определяет характеристики и взаимосвязи транзакции. С этой точки зрения поле 304 атрибутов потенциально используется для предоставления дополнительной информации, которая позволяет модифицировать обработку транзакций по умолчанию. В одном из вариантов поле 304 атрибутов содержит поле 312 приоритета, зарезервированное поле 314, поле 316 упорядочения и поле 318 запрета снупинга (несанкционированного вмешательства). Здесь субполе 312 приоритета может быть модифицировано инициатором, чтобы назначить приоритет транзакции. Зарезервированное поле 314 атрибута остается в резерве на будущее или для использования в целях, заданных поставщиком. С применением этого зарезервированного поля атрибутов могут быть реализованы возможные модели использования, применяющие атрибуты приоритета или безопасности.
В этом примере поле 316 атрибута упорядочения используется для передачи информации об опциях, которая несет тип упорядочения и которая может модифицировать правила упорядочения по умолчанию. Согласно одному из примеров реализации атрибут упорядочения, равный "0", обозначает, что следует применять правила упорядочения по умолчанию, тогда как атрибут упорядочения, равный "1", обозначает ослабленные правила упорядочения, где операции записи могут проходить по записям в одном и том же направлении, и завершения считывания могут проходить по записям в одном и том же направлении. Поле 318 атрибута снупинга используется для определения, производится ли снупинг транзакций. Как показано, поле идентификатора 306 канала обозначает канал, с которым ассоциирована транзакция.
Канальный уровень
Канальный уровень 210, также именуемый уровнем 210 канала передачи данных, служит промежуточным уровнем между уровнем 205 транзакций и физическим уровнем 220. В одном из вариантов ответственность уровня 210 канала передачи данных состоит в создании надежного механизма обмена пакетами уровня транзакций (Transaction Layer Packet (TLP)) между двумя компонентами канала связи. Одна сторона уровня 210 канала передачи данных принимает пакеты TLP, собранные уровнем 205 транзакций, присваивает идентификатор 211 последовательности пакетов, т.е. идентификационный номер или номер пакета, вычисляет и применяет код контроля ошибок, т.е. циклически избыточный контрольный код CRC 212, и передает модифицированные пакеты TLP на физический уровень 220 для передачи по физическим линиям связи внешнему устройству.
Физический уровень
В одном из вариантов физический уровень 220 содержит логический субблок 221 и электрический субблок 222 для физической передачи пакета внешнему устройству. Здесь логический субблок 221 отвечает за «цифровые» функции физического уровня 220. Для этого логический субблок содержит передающую секцию для подготовки исходящей информации к передаче посредством физического субблока 222 и приемную секцию для идентификации и подготовки принятой информации перед тем, как передать ее на канальный уровень 210.
Физический блок 222 содержит передатчик и приемник. Передатчик получает символы от логического субблока 221, преобразует эти символы в последовательную форму и передает внешнему устройству. Приемник получает преобразованные в последовательную форму символы от внешнего устройства и преобразует принятые сигналы в поток битов данных. Этот поток битов данных преобразуют из последовательной формы и передают логическому субблоку 221. В одном из вариантов используется код передачи 8b/10b, где передают/принимают 10-битовые символы. Здесь специальные символы используются для разбиения пакета на кадры 223. Кроме того, в одном из примеров приемник генерирует также тактовый сигнал символов, выделенный из входящего последовательного потока данных.
Как указано выше, хотя уровень 205 транзакций, канальный уровень 210 и физический уровень 220 обсуждаются здесь применительно к конкретному варианту стека протоколов PCIe, многоуровневый стек протоков этим не ограничивается. На деле, здесь может быть включен/реализован любой многоуровневый протокол. В качестве примера, порт/интерфейс, представленный в виде многоуровневого протокола, содержит: (1) первый уровень для сборки пакетов, т.е. уровень транзакций; второй уровень для выстраивания последовательности пакетов, т.е. канальный уровень; и третий уровень, для передачи пакетов, т.е. физический уровень. В качестве конкретного примера используется многоуровневый протокол общего стандартного интерфейса (common standard interface (CSI)).
Далее, на Фиг. 4 показаны последовательные двухпунктовые соединения согласно стандарту PCIe. Хотя здесь показан вариант последовательного двухпунктового канала согласно стандарту PCIe, само условие последовательного двухпунктового канала не является столь уж ограничивающим, поскольку оно охватывает любой передающий тракт, позволяющий передавать последовательные данные. В показанном варианте базовый канал связи интерфейса PCIe содержит две пары устройств для работы с низковольтными дифференциальными сигналами: пару передатчиков 406/411 и пару приемников 412/407. Соответственно, устройство 405 содержит передающую логическую схему 406 для передачи данных устройству 410 и приемную логическую схему 407 для приема данных от устройства 410. Другими словами, в канал связи интерфейса PCIe входят два передающих тракта, т.е. тракты 416и417, и два приемных тракта, т.е. тракты 418 и 419.
Передающим трактом называется любой тракт для передачи данных, такой как линия передачи, медный провод, оптическая линия передачи, канал радиосвязи, инфракрасная линия связи или другой тракт связи. Соединение между двумя устройствами, такими как устройство 405 и устройство 410, называется каналом связи, таким как канал 415 связи. Канал связи может поддерживать одну линию - где каждая линия представляет набор пар дифференциальных сигналов (одна пара для передачи и одна пара для приема). Для масштабирования полосы канал связи может агрегировать несколько линий, обозначенных xN, где N - какая-либо поддерживаемая ширина канала, такая как 1, 2, 4, 8, 12, 16, 32, 64 или шире.
Дифференциальная пара обозначает два передающих тракта, таких как проводники 416 и 417, для передачи дифференциальных сигналов. В качестве примера, когда проводник 416 переключается с низкого уровня напряжения на высокий уровень, т.е. происходит восходящий перепад уровней, проводник 417 переходит с высокого логического уровня на низкий логический уровень, т.е. имеет место нисходящий перепад уровней. Дифференциальные сигналы потенциально демонстрируют лучшие электрические характеристики, такие как лучшая целостность сигнала, т.е. меньше перекрестные связи, меньше положительные/отрицательные выбросы напряжения, меньше «звон» и т.д. Это позволяет лучше определить временное окно синхронизации и, тем самым, дает возможность использовать более высокие частоты передачи.
Высокоскоростной канал
Новой редакцией спецификаций ввода/вывода для интерфейса PCIe является стандарт PCIe редакция 4.0 (или PCIe 4.0). При скорости 16 ГТ/с (Гигатранзакций/с) (GT/s) интерфейс PCIe 4.0 имеет целью удвоить полосу соединения по сравнению со стандартом PCIe 3.0, сохраняя при этом совместимость с программными и механическими интерфейсами. Расширение рабочей полосы по сравнению с интерфейсами PCIe предшествующих поколений может обеспечить масштабирование производительности, согласованное с потребностями расширения полосы со стороны разнообразных вновь разрабатываемых приложений, и при этом нацелено на достижение небольшой стоимости, небольшой потребляемой мощности и минимальных возмущений на уровне платформы. Одним из основных факторов широкого применения архитектуры PCIe является ее чувствительность к возможностям массового производства и соответствующим материалам, таким как недорогие печатные платы, дешевые разъемы и т.д.
Скорость передачи данных 16 ГТ/с направлена на достижение оптимального компромисса между производительностью, технологичностью, стоимостью, мощностью и совместимостью. Для выработки рекомендаций о характеристиках для устройств и каналов связи, поддерживающих скорость передачи данных 16 ГТ/с для интерфейса PCIe 4.0, был проведен анализ реализуемости. Анализ PCI-SIG охватывал множество топологий. Например, анализ определил, что достижение скорости 16 ГТ/с при использовании медных проводников, что должно удвоить ширину полосы по сравнению с возможностями интерфейса PCIe 3.0, технически реализуемо при приблизительно таких же уровнях мощности, какие используют интерфейсы PCIe 3.0. Здесь соединения со скоростью передачи данных 16 ГТ/с потенциально могут быть изготовлены с применением типовой кремниевой технологии и развернуты с использованием существующих недорогих материалов и инфраструктуры при сохранении совместимости с архитектурами PCIe предшествующих поколений.
Системы с последовательным вводом/выводом и высокой скоростью передачи данных (например, 16 ГТ/с согласно стандарту PCIe 4.0) должны рассеивать значительную мощность и обладать повышенной сложностью схем, что потенциально ведет к увеличению используемой площади кремния (Si). Эти соображения в перспективе имеют потенциал ограничить интеграцию интерфейсов стандарта PCIe 4.0 (и других подобных высокоскоростных архитектур соединений) в центральные процессоры CPU и системы, использующие увеличенное число линий. В некоторых примерах реализаций, например, ограничения накладываются на длину соединений и число соединителей, используемых в высокоскоростной архитектуре, такой как PCIe 4.0. Например, такое ограничение определено на уровне спецификаций. В одном из примеров, длина соединительного канала связи ограничена одним (1) соединителем и двенадцатью (12) или меньшим числом дюймов.
Наложение ограничений на соединительные каналы связи может ограничить их применимость в некоторых системах. Например, в серверных соединительных приложениях соединения платформы могут достигать в длину двадцать (20) дюймов и более и иметь два соединителя. Если архитектура ограничивает соединительные каналы связи максимальной длиной 12 дюймов и наличием только одного соединителя, придется вводить отдельный кристалл ретранслятора или другое дополнительное устройство для соединения двух каналов по 12 дюймов и адаптации к расстояниям между устройствами, присущим серверной системе, это среди потенциально других примерах.
В некоторых вариантах реализации может быть организован соединительный канал связи, конфигурированный в соответствии со стандартом интерфейса PCIe 4.0 и другими соединениями, допускающий создание имеющего два соединителя канала длиной не меньше двадцати дюймов и при этом все еще поддерживающего скорости передачи данных 16 ГТ/с. Например, схема и соединение могут быть совместно оптимизированы таким образом, чтобы можно было исключить ретрансляторы и другие устройства из более длинных «пролетов» соединительных каналов. Это может помочь снизить производственные затраты, уменьшить задержку ввода/вывода и расширить область применения более широкополосных архитектур с повышенной скоростью на новые, дополнительные приложения. Например, кристалл ретранслятора может содержать передатчик, приемник, тактовый генератор (например, контур фазовой автоподстройки частоты (phase lock loop (PLL))), схему выделения тактового сигнала и ассоциированные функции. Такие компоненты могут использовать ценную площадь на плате. Кроме того, в соединении х16 PCIe 4.0 каждый ретранслятор может рассеивать дополнительную мощность и вносить дополнительные затраты при изготовлении системы, среди прочих потенциальных недостатков. Например, ретрансляторы могут также вносить дополнительную задержку ввода/вывода.
На Фиг. 5 показан пример конфигурации канала связи с двумя соединителями. Например, канал 500 может содержать несколько секций, таких как секции сокета (например, центрального процессора CPU), материнскую плату, расширительную плату, надстроечную плату среди других элементов, через которые может проходить канал связи для соединения двух устройств (например, 505, 510) в системе. Каждая секция канала может иметь свою длину, в этом примере длины секций равны L1=1ʺ, L2=10.5ʺ, L3=0.5ʺ, L4=4ʺ, L5=3ʺ и L6=lʺ, всего 20ʺ для полной длины канала 500. Этот канал связи может быть соединен с каждым из устройств 505, 510 с использованием соответствующего соединителя 515, 520 (в каждом корпусе).
При использовании традиционных способов конфигурация, такая как показана на Фиг. 5, может дать отрицательный запас по всему каналу связи. В одном из примеров может быть создан имеющий два соединителя канал связи длинной 20ʺ, поддерживающий скорость 16 ГТ/с передачи данных (например, 500), минимизирующий эффект столбиков сквозных соединений, минимизирующий эффект сокетов серверных процессоров (SPU), использующий усовершенствованные и обладающие небольшими потерями платы персональных компьютеров (personal computer board (РСВ)) и обеспечивающий увеличение усиления входного блока выполненного на кристалле приемника среди потенциально других признаков, для реализации положительного коэффициента усиления по длине канала связи.
Соединитель может содержать одно или более сквозных соединений, используемых для создания электрических соединений между слоями. Сквозные соединения могут быть использованы, например, для передачи сигналов или питания между слоями печатной платы или компонента. В высокоскоростных системах часть такого сквозного соединения остается поверх соединителя, кристалла или платы, так что эта часть не используется в двухпунктовом канале электрической связи, проходящем через это сквозное соединение. На Фиг. 6 показано упрощенное представление 600 одного или нескольких столбиковых сквозных соединений 605, 610. Сквозное соединение может создать электрические соединения между слоями печатной платы, например, с использованием технологии металлизированных сквозных отверстий (plated through hole (РТН)). Например, сквозные соединения могут электрически соединять штырьки соединителей с внутренними сигнальными слоями (например, дорожками). В примере, показанном на Фиг. 6, часть канала связи может быть реализована с использованием участка (например, 615, 620) металлизированного сквозного отверстия (РТН) для соединения одного отрезка канала связи с другим (например, дорожки (например, 625), проходящей в слое 630 рассматриваемого компонента к другому компоненту, другому сквозному соединению и т.п. по каналу связи). Остальная часть (например, 635) сквозного соединения может считаться столбиком. В высокоскоростных соединениях с использованием сквозных соединений столбик 635 в составе сквозного соединения может создавать резонансные эффекты (например, нули на резонансных частотах), что ведет к деградации сигнала в канале связи (например, в линии). Соответственно, в некоторых вариантах столбики в составе сквозных соединений могут быть «высверлены», как показано поз. 650, чтобы ослабить указанные эффекты. «Высверливание» столбиков в сквозных соединений может удалить столбиковую часть сквозного соединения, являющуюся источником указанных отрицательных электромагнитных эффектов. В некоторых случаях высверливание может быть реализовано уже после изготовления структуры, так что высверленное отверстие имеет больший диаметр по сравнению с первоначальным металлизированным сквозным отверстием (plated through hole (РТН)).
Столбики в сквозных соединениях в двух соединителях, используемых в канале связи длиной 20" со скоростью передачи данных 16 ГТ/с, могут быть удалены или минимизированы, например, посредством высверливания, создания U-образных сквозных соединений и применения других решений. В случае высверливания выбирают тип соединителя на основе того, какой из соединителей является хорошим кандидатом для высверливания. Например, некоторые соединители могут быть механически скомпрометированы и выйти из строя в случае высверливания этих соединителей. Другие типы соединителей, такие как соединители для поверхностного монтажа, могут быть более подходящими.
В дополнение к улучшению электрического качества соединителей посредством высверливания можно улучшить также электрическое качество процессорных (CPU) сокетов, что позволит реализовать каналы связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с. Например, каждый штырек процессорного (CPU) сокета или другого устройства, соответствующий линии канала связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с, соединенный и проходящий сквозь плату с использованием сквозного соединения, может быть высверлен. Длина столбика сокета в таких более длинных имеющих по два соединителя высокоскоростных каналах связи также может быть уменьшена посредством резервирования слоев, расположенных ближе к штырькам, для дорожек, используемых каналом связи. Это может позволить ограничить длину столбика сокета (в сквозном соединении) путем маршрутизации этих линий сквозь такие слои платы.
Процедура минимизации эффектов процессорного сокета CPU может содержать проектирование компоновки выходных штырьков и разрывов платы таким образом, чтобы линии каналов связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с, имели заданный уровень приоритета в этой компоновке. Например, каналы связи могут быть маршрутизированы в слоях таким образом, чтобы сделать высверливание возможным для каждого штырька процессора CPU, соединенного с этим каналом связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с. В качестве альтернативы (или в дополнение) маршрутизация может быть спроектирована таким образом, чтобы каналы связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с использовали слои, позволяющие ограничить длину столбиков сокета.
На Фиг. 7 показано упрощенное представление разреза платы, через которую два устройства 705, 710 соединены с использованием пример канала связи, имеющего два соединителя (такого как канал связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с). В этом примере раскладка штырьков устройств 705, 710 может быть спроектирована таким образом, чтобы можно было применить высверливание без блокирования других выходных каналов связи. Например, внутренние штырьки (например, 715) могут быть рассчитаны на выход в слоях поверх выходов выходных штырьков (например, 720), проложенных в нижних слоях платы. Далее, штырьки могут быть размещены таким образом, чтобы любой штырек, для которого столбик в сквозном соединении должен быть высверлен, (например, штырек для канала связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с) не располагался рядом со сквозным соединением для цепей питания, поскольку высверливание (например, 725a-f) может вызвать риск перфорации плоскостей и профилей питания, что потенциально ведет к образованию, неэффективной сети распределения питания. Кроме того, среди других правил и примеров, штырьки заземления могут быть размещены на основе расположения отверстий, которые могут остаться в плоскостях заземления после высверливания.
В канал длиной 20ʺ с двумя соединителями могут быть введены дополнительные свойства, чтобы скорости передачи данных в канале соответствовали уровню 16 ГТ/с или превосходили его, но при этом коэффициент усиления по всему каналу связи оставался положительным. Например, может быть реализована печатная плата с небольшими потерями, например, такая плата, где дифференциальные вносимые потери дорожки не превышают 0.48 дБ/дюйм на частоте 4 ГГц.
В дополнение к ослаблению эффектов столбиков в соединителях и сокетах обладающего двумя соединителями канала длиной 12ʺ и создания такого канала с использованием печатной платы с небольшими потерями, скорости порядка 16 ГТ/с в канале длиной по меньшей мере 20ʺ могут быть, в некоторых случаях, реализованы путем дополнительного увеличения коэффициента усиления во входном блоке приемника и/или дополнительного «обострения» характеристики в работающем в непрерывном времени линейном корректоре (continuous time linear equalizer (CTLE)). В некоторых примерах входной блок приемника может содержать сочетание аналоговых схем в тракте сигнала данных, включая, например, корректор CTLE, схему автоматической регулировки усиления (AGC (automatic gain control)), корректор с решающей обратной связью (DFE (decision-feedback equalizer)) и/или схему выборки данных (именуемая также схемой выделения срезов данных), среди прочих потенциальных примеров. Например, в одном из вариантов реализации добавление всего приблизительно 6 дБ усиления (например, сверх базового уровня для стандарта PCIe 4.0) во входном блоке приемника и/или в корректоре CTLE может позволить реализовать канал связи длиной 20ʺ со скоростью передачи данных 16 ГТ/с. Реализация вполне скромного коэффициента усиления (например, приблизительно 6 дБ) может быть достигнута ценой лишь вполне умеренного увеличения мощности и сложности схемы, например, путем добавления только одного каскада усиления, среди других примеров. Кроме того, в некоторых системах коэффициент усиления в канале связи может быть настраиваемым или конфигурируемым другим способом. Например, канал связи может быть программируемо настроен для приложений, где используются скорости порядка 16 ГТ/с, и это дополнительное усиление может быть отключено для приложений, использующих меньшие скорости передачи данных, среди других примеров.
Надежность, работоспособность и удобство эксплуатации (Reliability, Availability, and Serviceability (RAS))
В некоторых вариантах архитектура соединений, такая как PCIe, может содержать средства для улучшения показателей надежности, работоспособности и удобства эксплуатации (Reliability, Availability, and Serviceability (RAS)) системы. Хотя этот принцип может быть применен для всех скоростей передачи данных, некоторые архитектуры могут применять специальные схемы кодирования при работе с повышенными скоростями передачи данных. Например, интерфейс PCIe 4.0 (равно как и интерфейс PCIe редакция 3.0) использует схему кодирования 128b/130b, например, для скоростей передачи данных, превосходящих 8 ГТ/с. В схеме 128b/130b информацию о четности для каждой линии передают посредство упорядоченного множества пропусков (SKP (или "skip") Ordered Set (SKP OS)) с целью идентификации, какие именно линии в канале связи могут оказаться не справившимися с выполнением упреждающего анализа и потому должны будут работать с уменьшенной шириной канала связи, если применимо, среди других примеров. Четность линий может быть эффективным инструментом для идентификации ошибок в конкретных линиях в канале связи, однако, в некоторых случаях, когда канал связи преимущественно находится в состоянии простоя (например, в канале связи передают только логические кадрирующие маркеры простоя (IDL)), возможна ситуация, когда способность обнаружения ошибок с использованием бита четности окажется подорванной, поскольку ошибки в кадрирующем маркере (например, IDL) могут привести к восстановлению канала связи, которое устраняет информацию о четности вплоть до этого момента. В механизмах обнаружения ошибок в традиционных архитектурах могут существовать «слепые пятна», которые могут вызвать недооценку ошибок. Например, архитектура соединений может не определить или вообще оказаться неспособной определить неисправные линии, связанные с обнаруженными ошибками кадрирующих маркеров, среди других недостатков.
В некоторых архитектурах может быть создан регистр для идентификации ошибок, обнаруженных или предполагаемых в канале связи, равно как, в некоторых случаях, конкретных линий, где произошли ошибки. Например, как показано на Фиг. 8, интерфейс PCIe может создать регистр 805 состояния ошибок линий (Lane Error Status (LES)) в связи со структурой возможностей, такой как структура вторичных расширенных возможностей интерфейса PCIe (Secondary PCIe Extended Capability). Такая структура 800 возможностей может содержать заголовок 810 вторичных расширенных возможностей интерфейса PCIe (Secondary PCIe Extended Capability Header), Регистр 815 управления каналом связи 3 (Link Control 3 Register) и регистр 820 управления коррекцией (Equalization Control Register) в дополнение к регистру 805 LES. В некоторых вариантах этот регистр LES может содержать 32-битовый вектор, где каждый бит соответствует, например, линии в канале связи (идентифицированной номером линии) и указывает, обнаружена ли в соответствующей линии ошибка. В стандарте PCIe определен ряд ошибок, которые могут привести к появлению сообщения о событии ошибки в регистре LES. Например, как описывается выше, четность данных может быть реализована посредством бита четности, входящего в множество SKP OS и указывающего, обнаружена ли положительная четность в полезной нагрузке всех блоков данных, переданных после скремблирования после последней последовательности SKP OS (или упорядоченной последовательности начала потока данных (Start of Data Stream (SDS) Ordered Set)), среди других примеров. Четность данных может быть вычислена для каждой линии независимо. Приемные и передающие устройства вычисляют четность данных одинаковым способом, и приемник сравнивает вычисленную им четность для каждой линии с четностью, вычисленной в передатчике (как это обозначено битом четности) с целью идентификации потенциальных ошибок. Например, если вычисленная и принятая величины не совпадают, может быть задан бит в регистре LES (например, соответствующий номеру линии, где обнаружено несовпадение).
Как обсуждается выше и иллюстрируется упрощенным представлением 900, показанным на Фиг. 9, данные можно передавать по двум или более линиям в составе канала передачи данных. Например, как показано в примере интерфейса PCIe, базовым объектом передачи данных может быть символ, такой как символ, реализованный в виде 8-битового знака данных. Полезная нагрузка блока данных представляет собой поток символов, определенный как поток данных, который может содержать кадрирующие маркеры, пакеты уровня транзакций (TLP), пакеты канального уровня передачи данных (DLLP) и т.п. Каждый символ потока данных может быть помещен в одну линию канала связи для передачи, так что этот поток символов оказывается распределен «полосками» по всем линиям канала передачи данных и занимает промежуток между границами блока. Далее, в некоторых случаях физических уровень может использовать блочный код по линиям. Каждый блок может содержать двухбитовый синхронизационный заголовок и полезную нагрузку. В стандарте PCIe определены два действующих вида кодирования синхронизационного заголовка: 10b и 01b, что определяет тип полезной нагрузки, которую содержит блок. Например, синхронизационный заголовок 10b может указывать на блок данных, а синхронизационный заголовок 01b может указывать на блок упорядоченного множества. В качестве примера, на Фиг. 9 показана передача потока данных по четырем линиям (Lane) 0, 1, 2 и 3. Все линии многолинейного канала связи передают блоки с одинаковым синхронизационным заголовком одновременно. Порядок передачи битов может начинаться с синхронизационного заголовка (представленного как "Н1Н0", помещенного в линию как "Н0-Н1"), за которым следует первый символ, представленный как "S7-S6-S5-S4-S3-S2-S1-S0", помещенный в линию, начиная с "S0" и заканчивая "S7".
Интерфейс PCIe предоставляет приемнику опцию сообщать регистрам LES об ошибках, соответствующих рассогласованным или недействительным синхронизационным заголовкам в потоке данных. Например, определение, что одна или несколько линий (например, во время первых двух элементов UI в потоке данных) содержит синхронизационный заголовок, имеющий недействительную величину, (например, 00b, 11b) может быть идентифицировано как ошибка в линии, о которой может быть сообщено в регистр LES, среди других примеров.
На Фиг. 10 показаны представления примеров кадрирующих маркеров 1005, 1010, 1015, 1020, 1025. Кадрирующий маркер (или «маркер» ("token")) может представлять собой объект инкапсуляции данных на физическом уровне, который задает или подразумевает число символов, ассоциированных с этим маркером, и тем самым идентифицирует положение следующего кадрирующего маркера. Кадрирующий маркер в потоке данных может располагаться в первом символе (символ 0) первой линии (например, Линии 0) первого блока данных в потоке данных. В одном из примеров интерфейс PCIe определяет пять кадрирующих маркеров и в том числе маркер 1005 начала пакета TLP (STP), маркер 1010 конца потока данных (EDS), маркер 1015 конечного дефекта (EDB), маркер 1020 начала пакета DLLP (SDP) и логический маркер 1025 простоя (IDL). Маркер 1005 STP может иметь длину четыре (4) символа, и за ним может следовать информация канального уровня передачи данных. Пример маркера 1010 EDS может иметь длину четыре (4) символа и может указывать, что следующий блок будет блоком упорядоченного множества. Маркер 1015 EDB также может иметь длину четыре (4) символа и может подтверждать, что пакет TLP был «плохим» (дефектным) и потому был исключен. Маркер EDB может всегда следовать за данными пакета TLP. Далее, маркер 1020 SDP может быть короче, два (2) символа в длину, и за ним может следовать информация пакета DLLP. Наконец, в этом примере маркер 1025 может представлять собой один символ и может быть передан, когда по каналу связи не передают пакеты TLP, DLLP или другие кадрирующие маркеры.
Фиг. 11 иллюстрирует представление 1100, показывающее пример данных, передаваемых по каналу связи х8, иллюстрируя признаки потока данных, определяемые в соответствии с конкретной архитектурой соединений, такой как архитектура PCIe. В этом примере данные могут содержать передачу упорядоченного множества SKP. Поток в этом примере может начаться с передачи синхронизационных заголовков HI НО=10b, указывающих на блок данных. Соответственно кадрирующий маркер STP может быть передан в качестве первого символа 0 в Линиях 0-3 для указания начала потока пакетов TLP. За данными пакетов TLP может следовать циклически избыточный контрольный код канала передачи данных (link cyclic redundancy check (LCRC)), а за ним может следовать заголовок SDP, указывающий, что далее должны быть переданы данные пакета DLLP (например, в Символах 3-4). В связи с этими данными пакета DLLP могут быть также переданы данные циклически избыточного контрольного кода (CRC).
В примере, показанном на Фиг. 11, логические маркеры простоя (IDL) передают, когда не происходит передача данных по каналу передачи данных в течение ряда элементов UI. Затем может быть передан маркер EDS для указания перехода к упорядоченному множеству данных в линиях. Например, другой синхронизационный заголовок (например, 1105) может быть передан в виде кода "01b" для указания, что следующие блоки данных будут блоками данных упорядоченного множества. В этом конкретном примере передаваемое упорядоченное множество представляет собой упорядоченное множество (OS) SKP. Как отмечено выше, в некоторых вариантах множество SKP OS может содержать бит четности, являющийся указанием состояния четности для каждой линии (например, Линии 0-7) канала передачи данных. Множество SKP OS может далее иметь заданную компоновку, идентифицируемую приемником. Например, в случае применения кодирования 128b/130b в интерфейсе PCIe, множество SKP OS может в базовом варианте содержать шестнадцать символов. Какой-либо порт может добавить или удалить группу из четырех символов SKP, так что множество SKP OS может иметь размер 8, 12, 16, 20 или 24 символа и т.п. Далее, в линии может быть передан символ SKPEND, как показано на Фиг. 11, для указания местонахождения конца множества SKP OS и положения синхронизационного заголовка следующего блока, который нужно передать по линиям, среди других примеров.
В некоторых примерах вариантов может быть создана логическая схема для обнаружения дополнительных ошибок линий в архитектуре соединений. Программное обеспечение в системе может контролировать регистр, такой как регистр LES, для отслеживания ошибок по принципу линия за линией в течение некоторого периода времени. Одна ошибка лини может еще не означать, что есть проблемы с ошибками. Однако если ошибки появляются со статистически значимой частотой в одной или нескольких конкретных линиях канала передачи данных, системное программное обеспечение может определить факт наличия потенциальной проблемы применительно к этим конкретным линиям. Далее в некоторых вариантах могут быть приняты корректирующие меры, чтобы избежать передачи по меньшей мере некоторых системных данных по линии, склонной к ошибкам, например, путем реконфигурирования канала передачи данных, генерации уведомления для более внимательной проверки канала передачи данных, среди других примеров. Некоторые ошибки может быть трудно обнаружить при проверке линия за линией. Хотя уже разработаны некоторые механизмы для обнаружения части ошибок в канале передачи данных и передачи сообщений об этих ошибках (например, на основе четности или неправильных синхронизационных заголовков), другие признаки архитектуры и правила могут быть привлечены для идентификации таких дополнительных правил, специфичных для каких-то линий. Об этих ошибках также может быть извещен регистр с целью учета вместе с отчетами о традиционных ошибках линий и построения более полной картины исправности индивидуальных линий в канале передачи данных, среди других примеров и соображений.
В первом примере, как и в примере интерфейса PCIe, описанном выше, если линия принимает блок упорядоченного множества с недействительным (несогласованным, неправильным или по другой причине неожиданным) маркером EDS, непосредственно предшествующим этому блоку, можно предполагать наличие ошибки в линии, где был обнаружен недействительный маркер EDS. Далее, об ошибке, относящейся к недействительному маркеру EDS в линии, может быть сообщено регистру ошибок, например, посредством установления соответствующего бита в регистре LES интерфейса PCIe.
В другом примере заданный формат для конкретного упорядоченного множества может быть использован для идентификации дополнительных ошибок линий. Например, множество SKP OS может содержать хорошо определенные символы SKP, пока не будут переданы символы SKPEND для идентификации конца упорядоченного множества. Если в конкретной линии будет обнаружен недействительный или неправильный символ SKP в пределах совокупности ожидаемых символов SKP из состава этого упорядоченного множества (и прежде символов SKPEND), идентификация этого ошибочного символа SKP может быть использована для запуска передачи сообщения об ошибке в указанной конкретной линии регистру ошибок, такому как регистр LES. Кроме того, заданные моменты времени поступления символов конкретного множества OS также могут быть использованы для идентификации того, что в какой-то линии был принят неожиданный символ. Например, продолжая пример упорядоченных множеств SKP, поскольку число символов в упорядоченном множестве SKP OS должно быть кратно четырем, отсутствие приема символа SKP_END на месте символа 8, 12, 16, 20 или 24 в одной или нескольких конкретных линиях канала передачи данных может привести к установлению соответствующего бита для этих конкретных линий в регистре ошибок, среди других потенциальных примеров.
В некоторых вариантах реализации могут возникать и могут быть обнаружены разнообразные ошибки кадрирования. Например, при обработке символов, которые, как ожидается, должны представлять собой кадрирующий маркер, прием символа или последовательности символов, которые не соответствуют определению кадрирующего маркера, может быть ошибкой кадрирования. Кроме того, некоторые кадрирующие маркеры могут быть заданы для следования после данных других типов, тогда неожиданный приход (или задержка прихода) конкретного кадрирующего маркера может быть ошибкой кадрирования. В качестве всего лишь одного из примеров, может быть задано, что маркер EDB должен быть принят сразу же после пакета TLP, а прием маркера EDB в любое другое время (отличное от момента сразу же после пакета TLP) может инициировать ошибку кадрирования, среди многих других примеров, такой как ошибки кадрирования, которые определены в спецификациях стандарта PCIe. Хотя ошибки кадрирования могут быть определены внутри системы, в некоторых вариантах ошибки кадрирования не определяют по принципу линия за линией или не отображают на конкретную линию канала передачи данных. Действительно, в некоторых случаях ошибка кадрирования может вызвать инициирование восстановления канала передачи данных, еще более затрудняя обнаружение ошибок линии, когда при восстановлении канала передачи данных происходит удаление результатов вычисления четности и отчетов (например, через бит четности, передаваемый во множестве SKP OS), среди других примеров.
В некоторых вариантах реализации логические схемы в составе логического физического уровня PHY (например, в приемнике) могут дополнительно идентифицировать неисправную линию на основе кадрирующего маркера. В первом примере могут быть заданы символы кадрирующего маркера (как это показано в примерах на Фиг. 10) и может быть идентифицирована ошибка в одном из символов, величина которого отличается от ожидаемой величины, равно как может быть определена линия, в которой идентифицирован ошибочный символ маркера. Например, может быть идентифицирован первый символ кадрирующего маркера, и если этот символ не совпадает с первым символом какого-либо одного из совокупности заданных кадрирующих маркеров для физического уровня (PHY), может быть передан сигнал ошибки. Эта ошибка может быть зарегистрирована, например, в регистре LES. В примере кадрирующих маркеров стандарта PCIe, если первый символ принятого кадрирующего маркера не совпадает с первым символом, заданным для какого-либо из маркеров IDL, SDP, STP, EDB или EDS в стандарте PCIe, может быть определено наличие ошибки в линии, где появился ошибочный первый символ кадрирующего маркера, и эта ошибка может быть зарегистрирована в регистре ошибок линии, соответствующего идентифицированной линии.
Второе, в другом примере, кадрирующие маркеры IDL, поскольку длина такого маркера составляет только один символ, могут быть заданы для передачи по всем линиям канала передачи данных, когда не происходит передача какого-либо пакета TLP, DLLP или другого кадрирующего маркера. Соответственно, когда первый маркер IDL появился в одной из линий канала передачи данных, имеющего четыре или более линий, можно ожидать, что такие маркеры IDL появятся также в Линиях с номерами n+1, n+2 и n+3 (здесь для первой Линии n (n modulo 4=0)). После передачи маркера IDL первый символ маркера STP или SDP может быть задан для передачи в Линию 0 во время следующего символа. Соответственно, с учетом этих ограничений на использование и ожидаемого применения маркеров IDL, если маркер IDL не повторяется, как ожидалось, или если первый маркер IDL появится в неправильной линии, может быть идентифицирована линия, где появился не повторяющийся маркер IDL или другой ошибочный символ, и также зарегистрирована в регистре ошибок, таком как регистр LES, как ошибка для конкретной линии.
Еще в одном примере может быть определена конкретная длина маркера EDB, такая как четыре символа в стандарте PCIe. Вследствие этого ошибка кадрирования может быть результатом идентификации первого символа EDB, а затем отсутствия идентификации дополнительных символов EDB в непосредственно следующих символах в пределах этой заданной длины. Например, в интерфейсе PCIe, если кадрирующий маркер EDB обнаружен в Линии n (n modulo 4=0), сразу же после пакета TLP, но не обнаружен в какой-либо из Линий n+1, n+2 или n+3, может быть передано сообщение об ошибке в регистр ошибок той линии (например, Линии n+1, n+2 или n+3), где не появился ожидаемый действительный символ EDB. Кроме того, может быть задано, что первый символ любого маркера EDB должен быть помещен сразу же после потока пакета TLP, а это означает, что предшествующий кадрирующий маркер, а именно маркер STP, был последним кадрирующим маркером, появившимся в канале передачи данных. Соответственно, ошибка в Линии n может быть идентифицирована и сообщена регистру ошибок, когда в этой Линии n появился первый символ маркера EDB, но самый последний предшествующий ему кадрирующий маркер отличался от маркера STP, среди других примеров.
Аналогично ошибке кадрирования маркера EDB ошибки кадрирования могут быть следствием отклонений длины, формата и позиции других кадрирующих маркеров. Например, в другом случае, где первый символ маркера SDP обнаружен в Линии n, в соответствии с правилами размещения действительных маркеров SDP (например, перед трафиком пакетов DLLP), но символ в Линии n+1 не совпадает с ожидаемым вторым символом маркера SDP, логическая схема физического уровня (PHY) может идентифицировать ошибку в Линии n+1 и зарегистрировать эту ошибку в регистре ошибок.
На Фиг. 12 представлена упрощенная блок-схема, иллюстрирующая расширенный способ обнаружения и регистрации ошибок линий (например, 1205, 1210, 1215, 1220, 1225, 1230, 1235, 1240) в примере регистра 1250 ошибок, таком как регистр LES интерфейса PCIe, соответствующий каналу передачи данных. Например, в дополнение к сообщениям об ошибках 1205 синхронизационных заголовках в линиях и ошибках 1210 битов четности, могут быть обнаружены и другие ошибки и в том числе ошибки упорядоченных множеств в линиях, таких как ошибка 1215 в виде появления блока OS без предшествующего маркера EDS и ошибка 1220 множества SKP OS (такая, как описано в примерах выше). Возможно также сообщения о других ошибках, включая, например, ошибки кадрирующих маркеров в линиях, такие как ошибки 1225 первого символа кадрирующего маркера, ошибки 1230 кадрирующего маркера IDL (например, относящиеся к правильному повторению маркера IDL после первоначального маркера IDL в Линии n), ошибки 1235 кадрирующего маркера EDB (например, включая ошибки размещения символов маркера EDB, как это описано, например, в предшествующем обсуждении) и ошибки 1240 кадрирующего маркера SDP (например, включая ошибку, обнаруженную во втором символе какого-либо маркера SDP), среди других потенциальных примеров использования правил, заданных для упорядоченных множеств, блоков данных и кадрирующих маркеров в архитектуре.
Как отмечено выше, в некоторых случаях ошибки или другие события, вызывающие принудительное восстановление канала передачи данных, могут отрицательно повлиять на работу механизмов обнаружения ошибок линий, таких как определение четности. Как отмечено выше, приемные и передающие устройства могут определять четность для потока данных или другого потока, а информация о четности, вычисленная передатчиком, может быть сообщена приемнику для сравнения этой принятой информации о четности с соответствующей информацией о четности (для линии), вычисленной приемником для того же самого потока данных. Информацию о четности можно передавать периодически. Например, может быть передано множество SKP OS, содержащее один или несколько битов четности в символах SKP OS, служащих индикацией четности, вычисленной передатчиком для каждой линии. В некоторых традиционных системах, однако, восстановления канала передачи данных или другие события могут привести к стиранию информации о четности и/или перезапуска процедуры определения четности прежде, чем ранее вычисленная информация о четности будет сообщена приемнику. Соответственно, в таких случаях информация об ошибках, обнаруженных для конкретной линии на основе информации о четности, также может быть утрачена, а сообщения об этих ошибках переданы не будут, что отрицательно влияет на точность передачи сообщений об ошибках для этой конкретной линии.
В одном из вариантов информация о четности может быть сохранена путем задания режима, в котором восстановлению канала передачи данных автоматически предшествует передача множества SKP OS или другого множества данных, содержащего данные сообщения информации о четности для каждой линии в канале передачи данных, подлежащем восстановлению. Например, протокол восстановления канала передачи данных может быть переопределен таким образом, чтобы передавать множество SKP OS (включая биты четности) в ответ на ошибку кадрирования или другое событие, запускающее процедуру восстановления канала передачи данных. Тем самым множество SKP OS может передавать информацию о четности, вычисленную передатчиком вплоть до момента, когда произошел запуск процедуры восстановления канала передачи данных, что позволяет приемнику идентифицировать потенциальные ошибки линии на основе информации о четности.
В одном из примеров, информация о четности может быть передана перед восстановлением путем передачи множества SKP OS перед тем, как канал передачи данных покинет активное (например, L0) состояние для входа в режим восстановления. Например, каждый передатчик может передать множество SKP OS (например, в соответствии с заданными интервалами, такими как максимальный интервал между передачами множеств SKP OS) и затем передать дополнительный блок данных с маркером EDS перед тем, как войти в режим восстановления. Это может обеспечить получение приемником информации о четности для предшествующих принятых им блоков данных, включая один или несколько блоков данных, которые могли вызвать ошибку кадрирования. После этого приемник может зарегистрировать ошибку в подходящем регистре LES, если сравнение битов четности укажет на присутствие ошибки.
В другом примере, вместо того, чтобы преждевременно «выгружать» информацию о четности перед восстановлением или другим событием (например, в попытке гарантировать, что информация о четности будет передана прежде, чем она окажется утраченной), информация о четности, такая как информация о четности для множества SKP OS, может быть расширена так, чтобы охватывать четность потоков данных, пока канал передачи данных остается активным (например, "LinkUp=1b" в интерфейсе PCIe). Далее, информация о четности может сохраняться постоянно для каждой линии канала передачи данных, таким образом, эта информация о четности сохраняется в течение всего события восстановления. Там, где традиционное восстановление канала передачи данных должно было бы вызвать утрату информации о четности для предшествующего блока данных (например, прерванного процедурой восстановления), постоянное сохранение информации о четности может позволить сохранить информацию о четности в течение всей процедуры восстановления и передать ее после завершения восстановления (например, в первом множестве SKP OS после восстановления). Кроме того, в некоторых случаях информация о четности для новых блоков данных, передаваемых после восстановления канала передачи данных, (и перед следующим множеством SKP OS) также может быть определена и в некоторых случаях добавлена к информации о четности, сохраненной перед восстановлением, после чего эта объединенная информация о четности может быть передана, например, в следующем множестве SKP OS, среди других примеров.
Следует понимать, что рассмотренные выше примеры не являются ограничивающими, а приведены только с целью иллюстрации некоторых принципов и признаков. Далее, некоторые системы могут содержать различные сочетания из двух или более рассмотренных выше признаков и компонентов. В качестве примера, система может содержать сочетания ряда функций обнаружения ошибок, описываемых выше, таких как рассмотренные выше функции обнаружения ошибок линий.
На Фиг. 13A-13D показаны примеры логических схем 1300a-d, иллюстрирующих примеры способов обнаружения ошибок в линиях канала передачи данных. Например, на Фиг. 13А, данные могут быть приняты 1305 по каналу передачи данных, содержащему несколько линий. Эти данные могут содержать символы, причем эти символы можно контролировать для определения 1310, являются ли один или несколько символов ошибочными символами. Ошибочный символ может быть символом кадрирующего маркера (например, EDB, EDS, STP, IDL, SDP и т.п.), упорядоченного множества (например, SKP OS и т.п.) или другой определенной последовательности, имеющим неправильную величину, следующим в неправильном или неожиданном порядке, передаваемым по неправильной или неожиданной линии, не принадлежащим конкретной заданной последовательности, среди других примеров. Может быть идентифицирована 1315 линия, по которой был передан ошибочный символ, и затем может быть передано 1320 сообщение об ошибке в идентифицированной линии, например, в регистр ошибок линии, на основе этого ошибочного символа, среди других примеров.
В схеме, показанной на Фиг. 13В, могут быть переданы 1325 данные по каналу передачи данных, содержащему несколько линий. Для каждой линии в составе этого канала передачи данных может сохраняться 1330 информация о четности. В ответ на идентификацию 1335, что канал передачи данных должен выйти из активного состояния, (например, в связи с восстановлением этого канала) может быть передана 1340 информация о четности перед выходом рассматриваемого канала передачи данных из активного состояния. В одном из примеров индикация информации о четности может быть включена в биты четности передаваемого получателю упорядоченного множества, такого как множество SKP согласно стандарту PCIe. Индикация информации о четности может быть использована (например, получателем конкретной информации) для сравнения этой информации о четности с информацией о четности, принятой этим получателем. Несовпадения в информации о четности могут быть идентифицированы как свидетельства ошибки в линии, соответствующей зафиксированному несовпадению информации о четности.
В примере, показанном на Фиг. 13С, данные могут быть переданы 1345 по линиям канала передачи данных, и может быть определена 1350 информация о четности для каждой из линий на основе данных, идентифицированных в этой линии. При этом возможны события восстановления канала передачи данных, а информация о четности может сохраняться 1355 во время такого восстановления. После восстановления может быть передано 1370 указание информации о четности, которая может быть основана на информации о четности, сохранявшейся во время восстановления канала передачи данных. В качестве опции по каналу передачи данных после восстановления могут быть переданы дополнительные данные, а информации о четности для каждой линии может быть определена на основе этих данных, переданных после восстановления. Информация о четности для каждой линии может быть обновлена 1365 на основе данных, переданных в этой линии до и после восстановления, а переданное 1370 сообщение с информацией о четности может служить индикатором такой объединенной информации о четности.
В соответствии с примером, показанным на Фиг. 13С, согласно схеме, показанном на Фиг. 13D, по каналу передачи данных могут быть приняты 1375 первые данные, и может быть определена 1380 первая информация о четности для каждой линии на основе данных, принимаемых по этим линиям. Эта информация о четности может быть сохранена 1385 в процессе восстановления канала передачи данных после приема первых данных. После восстановления канала передачи данных могут быть приняты 1398 вторые данные о четности, как это идентифицировано в битах четности принятого упорядоченного множества SKP. Эти вторые данные о четности можно сравнить с информацией о четности, сохраняемой в процессе (и за пределами) восстановления канала передачи данных. В некоторых случаях сохраненная информация о четности может быть обновлена 1394 для учета информации о четности, вычисленной для линий на основе вторых данных, принятых 1390 в этих линиях после восстановления канала передачи данных (например, согласно обновлению информации о четности в соответствующем передатчике на основе передач данных после восстановления), среди других примеров.
Следует отметить, что хотя значительная часть приведенных выше принципов и примеров описаны здесь в контексте стандарта интерфейса PCIe и конкретных редакций спецификаций этого интерфейса PCIe, принципы, технические решения и признаки, описываемые здесь, могут быть в равной степени применимы к другим протоколам и системам. Например, аналоговые ошибки линий могут быть обнаружены в других каналах передачи данных с использованием других протоколов на основе аналоговых символов, потоков данных и маркеров, равно как правил, заданных для использования, размещения и форматирования таких структур в составе данных, передаваемых по этим другим каналам. Кроме того, альтернативные механизмы и структуры (например, помимо регистра LES интерфейса PCIe или множества SKP OS) могут быть использованы для обнаружения ошибок и передачи сообщений функциональным устройствам в пределах системы. Более того, в системах могут быть применены сочетания приведенных выше решений, включая сочетания логических и физических усовершенствований в канале передачи данных и в соответствующих логических устройствах этого канала, как они описаны здесь, среди других примеров.
Отметим, что рассмотренные выше устройства, способы и системы могут быть реализованы в каком-либо электронном устройстве или системе, как отмечено ранее. В качестве конкретных иллюстраций рассмотренные ниже чертежи предлагают примеры систем, использующих настоящее изобретение. В ходе приведенного ниже более подробного описания указанных систем будут рассмотрены различные соединения, в том числе посредством повторных обращений к уже приведенному выше обсуждению. И, как легко понятно, описанные выше усовершенствования могут быть применены к любым из этих соединений, структур и архитектур.
На Фиг. 14 представлен вариант блок-схемы компьютерной системы, содержащей многоядерный процессор. Процессор 1400 представляет собой какой-либо процессор или процессорное устройство, такое как микропроцессор, встроенный процессор, цифровой процессор сигнала (digital signal processor (DSP)), сетевой процессор, ручной процессор, процессор приложений, сопроцессор, систему на кристалле (system on a chip (SOC)) или другое устройство для выполнения кода. Процессор 1400 в одном из вариантов содержит по меньшей мере два ядра - ядро 1401 и ядро 1402, которые могут быть асимметричными ядрами или симметричными ядрами (иллюстрируемый вариант). Однако процессор 1400 может содержать произвольное число процессорных элементов - симметричных или асимметричных.
В одном из вариантов термин «процессорный элемент» обозначает аппаратуру или логическое устройство для поддержки выполнения потоков программного обеспечения. К примерам аппаратных процессорных элементов относятся: потоковый модуль, потоковый слот, поток, процессорный модуль, контекст, контекстный модуль, логический процессор, аппаратный поток, ядро и/или какой-либо другой элемент, способный иметь и сохранять состояние процессора, такое как состояние выполнения или архитектурное состояние. Другими словами, процессорный элемент в одном из вариантов обозначает какую-либо аппаратуру, способную быть независимо ассоциированной с кодом, таким как программный поток, операционная система, приложение или другой код. Термин «физический процессор» (или процессорный сокет) обычно обозначает интегральную схему, которая потенциально содержит какое-либо число других процессорных элементов, таких как ядра или аппаратные потоки.
Термин «ядро» часто обозначает логическую схему, расположенную в составе интегральной схемы и способную сохранять независимое архитектурное состояние, где каждое независимо сохраняемое архитектурное состояние ассоциировано по меньшей мере с некоторыми выделенными исполнительными ресурсами. В отличие от ядер термин «аппаратный поток» обозначает какую-либо логическую схему, расположенную в составе интегральной схемы и способную сохранять независимое архитектурное состояние, где эти независимо сохраняемые архитектурные состояния совместно используют доступ к исполнительным ресурсам. Как можно видеть, когда какие-то ресурсы используются совместно, а другие ресурсы специально выделены для какого-то архитектурного состояния, происходит наложение линий между номенклатурой аппаратных потоков и ядер. Также часто операционная система видит ядро и аппаратный поток как индивидуальные логические процессоры, так что эта операционная система может индивидуально планировать операции для каждого логического процессора.
Физический процессор 1400, как показано на Фиг. 14, содержит два ядра - ядро 1401 и ядро 1402. Здесь ядра 1401 и 1402 считаются симметричными ядрами, т.е. ядрами с одинаковыми конфигурациями, функциональными модулями и/или логическими структурами. В другом варианте ядро 1401 представляет собой процессорное ядро для внеочередного (не по порядку) выполнения команд, а ядро 1402 представляет собой процессорное ядро с очередным (по порядку) выполнением команд. Однако для ядер 1401 и 1402 можно индивидуально выбирать какой-либо из типов ядер, таких как собственное, естественное ядро, программно управляемое ядро, ядро для выполнения собственной структуры системы команд (Instruction Set Architecture (ISA)), ядро для выполнения транслированной структуры системы команд (ISA), ядро совместного проектирования или другое известное ядро. В среде с гетерогенными ядрами (т.е. с асимметричными ядрами) некоторые формы трансляции, такие как двоичная трансляция, могут быть использованы для планирования или выполнения кода на одном или обоих ядрах. При этом функциональные модули, показанные в ядре 1401, более подробно описаны ниже, тогда как в представленном варианте модули, изображенные в ядре 1402, работают аналогичным образом.
Как показано на чертеже, ядро 1401 содержит два аппаратных потока 1401а и 1401b, которые могут быть также названы слотами 1401а и 1401b аппаратных потоков. Поэтому программные объекты, такие как операционная система, в одном из вариантов потенциально видят процессор 1400 как четыре раздельных процессора, т.е. как четыре логических процессора или процессорных элемента, способных выполнять четыре программных потока одновременно. Как указано выше, первый поток ассоциирован с регистрами 1401а состояния архитектуры, второй поток ассоциирован с регистрами 1401b состояния архитектуры, третий поток может быть ассоциирован с регистрами 1402а состояния архитектуры и четвертый может быть ассоциирован с регистрами 1402b состояния архитектуры. Здесь каждый из регистров состояния архитектуры (1401а, 1401b, 1402а и 1402b) может быть отнесен к процессорным элементам, потоковым слотам или потоковым модулям, как описано выше. Как показано, регистры 1401а состояния архитектуры дублированы в регистрах 1401b состояния архитектуры, так что индивидуальные состояния архитектуры/контексты могут быть сохранены для логического процессора 1401а и логического процессора 1401b. В ядре 1401 другие ресурсы меньшего объема, такие как указатели команд и логическая схема переименования в блоке 1430 распределения ресурсов и переименования, могут быть также дублированы для потоков 1401а и 1401b. Некоторые ресурсы, такие как буферы переупорядочения в модуле 1435 переупорядочения/завершения, буфер 1420 быстрого преобразования адресов команд (I-TLB), буферы загрузки/хранения и очереди могут использоваться совместно посредством секционирования. Другие ресурсы, такие как внутренние регистры общего назначения, базовые регистры страниц-таблиц, кэш данных низкого уровня и буфер 1415 быстрого преобразования адресов данных, исполнительные модули 1440 и части модуля 1435 для внеочередного (не по порядку) выполнения команд потенциально являются полностью совместно используемыми.
Процессор 1400 часто содержит другие ресурсы, которые могут быть полностью совместно используемыми, совместно используемыми посредством секционирования или выделенными посредством/для процессорных элементов. На Фиг. 14 показан только пример процессора с иллюстративными логическими модулями/ресурсами для процессора. Отметим, что процессор может содержать или исключить любые из этих функциональных модулей, равно как может иметь в составе и любые друге известные, но не показанные здесь, функциональные модули, логические схемы и встроенное программное обеспечение. Как показано на чертеже, ядро 1401 представляет собой упрощенное репрезентативное процессорное ядро с внеочередным (не по порядку) (ООО) выполнением команд. Однако в различных вариантах может быть также использован процессор с выполнением команд по порядку. Ядро ООО с внеочередным выполнением команд содержит буфер 1420 целевого ветвления для предсказания ветвей, которые нужно исполнять/взять и буфер 1420 быстрого преобразования адресов команд (instruction-translation buffer (I-TLB)) для сохранения преобразованных адресов команд.
Ядро 401 дополнительно содержит модуль 1425 декодирования, соединенный с модулем 1420 выборки для декодирования выбранных элементов. Логическая схема выборки в одном из вариантов содержит индивидуальные формирователи последовательности, ассоциированные с потоковыми слотами 1401а, 1401b, соответственно. Обычно ядро 1401 ассоциировано с первой структурой ISA, которая определяет/задает команды, выполняемые процессором 1400. Часто команда в машинном коде, являющаяся частью первой структуры ISA содержит часть команды (именуемую опкод), ссылающуюся/задающую команду или операцию, которая должна быть выполнена. Логическая схема 1425 декодирования содержит схему, распознающую эти команды на основе их опкодов и передающую декодированные команды в конвейер для обработки, как это определено первой системой ISA. Например, как обсуждается более подробно ниже, декодеры 1425 в одном из вариантов содержат логические схемы, распознающие команды конкретного вида, такие как команды транзакций. В результате распознавания команд декодерами 1425 архитектура или ядро 1401 осуществляет конкретные заданные действия для выполнения задач, ассоциированных с подходящей командой. Здесь важно отметить, что любые задачи, блоки, операции и способы, описываемые здесь, могут быть выполнены в ответ на одну или несколько команд; так что некоторые из этих команд могут быть новыми или старыми командами. Отметим, что декодеры 1426 в одном из вариантов распознают команды той же самой структуры ISA (или ее подмножества). В качестве альтернативы, в среде с гетерогенными ядрами декодеры 1425 распознают вторую структуру ISA (либо подмножество первой структуры ISA, либо отдельную структуру ISA).
В одном из примеров блок 1430 распределения ресурсов и переименования содержит распределитель для резервирования ресурсов, такой как регистровые файлы для сохранения результатов выполнения команд. Однако потоки 1401а и 1401b потенциально могут выполнять команды не по порядку, так что блок 1430 распределения ресурсов и переименования резервирует также другие ресурсы, такие как буферы переупорядочения для отслеживания результатов выполнения команд. Блок 1430 может также содержать схемы переименования регистров, которые осуществляют переименование опорных регистров программ/команд в другие регистры, внутренние для процессора 1400. Модуль 1435 переупорядочения/исключения содержит компоненты, такие как буферы переупорядочения, отмеченные выше, буферы загрузки и буферы хранения, для поддержки выполнения команд не по порядку и последующего исключения по порядку команд, выполненных не по порядку.
Блок 1440 модулей планирования и исполнительных модулей в одном из вариантов содержит модуль планирования, осуществляющий планирование команд/операций для исполнительных модулей. Например, команду для операций с плавающей запятой планируют для передачи в порт исполнительных модулей, где имеется доступный исполнительный модуль для операций с плавающей запятой. Регистровые файлы, ассоциированные с исполнительными модулями, также используются для хранения результатов выполнения команд обработки информации. К примерам исполнительных модулей относятся исполнительный модуль для операций с плавающей запятой, исполнительный модуль для целочисленных операций, исполнительный модуль для операций перехода (скачков), исполнительный модуль загрузки, исполнительный модуль хранения и другие известные исполнительные модули.
С исполнительными модулями 1440 соединены кэш данных низкого уровня и буфер 1450 быстрого преобразования адресов данных (data translation buffer (D-TLB)). Кэш данных служит для хранения самых последних использованных/подвергнутых операциям элементов, таких как операнды данных, потенциально удерживаемых в состояниях когерентности памяти. Буфер D-TLB служит для хранения результатов последних преобразований виртуальных/линейных адресов в физические адреса. В качестве конкретного примера процессор может содержать структуру таблицы страниц для разбиения физической памяти на несколько виртуальных страниц.
Здесь ядра 1401 и 1402 совместно используют доступ к кэшу более высокого уровня или к последующему кэшу, такому как кэш второго уровня, ассоциированный с выполненным на кристалле интерфейсом 1410. Отметим, что указания более высокого уровня или последующего уровня (еще более высокого уровня) относятся к уровня кэша, порядок (уровень) которых возрастает по мере «удаления» от исполнительных модулей. В одном из вариантов кэш более высокого уровня является кэшем данных самого последнего уровня - последним кэшем в иерархии памяти в кристалле процессора, таким как кэш данных второго или третьего уровня. Однако понятие кэша более высокого уровня этим не ограничивается, поскольку оно может быть ассоциировано с или содержать кэш команд. Вместо этого, после декодера 1425 может быть присоединен трассовый кэш, являющийся разновидностью кэша команд, для сохранения недавно декодированных трасс. Здесь термин «команда» потенциально означает макрокоманду (т.е. общую команду, распознаваемую декодерами), которая может быть декодирована и преобразована в несколько микрокоманд (микроопераций).
В описываемой конфигурации процессор 1400 также содержит модуль 1410 выполненного на кристалле интерфейса. Исторически, контроллер памяти, который будет более подробно описан ниже, был введен в компьютерную систему вне процессора 1400. В этом сценарии выполненный на кристалле интерфейс 1410 должен осуществлять связь с устройствами вне процессора 1400, такими как системное запоминающее устройство 1475, чипсет (часто содержащий контроллер-концентратор памяти для соединения с запоминающим устройством 1475 и контроллер-концентратор ввода/вывода для соединения с периферийными устройствами), контроллер-концентратор памяти, северный мост или другая интегральная схема. В таком сценарии шина 1405 может представлять собой какое-либо известное соединение, такое как многоотводная шина, двухпунктовое соединение, последовательное соединение, параллельная шина, когерентная (например, когерентная кэшу) шина, архитектура многоуровневого протокола, дифференциальная шина и шина логического приемопередатчика Ганнинга (GTL).
Запоминающее устройство 1475 может быть специально выделено для работы с процессором 1400 или может использоваться совместно с другими устройствами в системе. К общим примерам возможных типов запоминающего устройства 1475 относится динамическое RAM (DRAM), статическое RAM (SRAM), энергонезависимое запоминающее устройств (NV) и другие известные запоминающие устройства. Отметим, что устройство 1480 может представлять собой графический ускоритель, процессор или плату, соединенную с контроллером-концентратором памяти, запоминающее устройство данных, соединенное с контроллером-концентратором ввода/вывода, радио приемопередатчик, устройство флэш-памяти, аудио контроллер, сетевой контроллер или другое известное устройство.
В последнее время, однако, по мере того, как все больше логических схем и других стали интегрировать в одно кристалле интегральной схемы, таком как система на кристалле (SOC), появилась возможность встроить каждое из этих устройств в микросхему процессора 1400. Например, в одном из вариантов контроллер-концентратор памяти находится в одном корпусе и/или на одном кристалле с процессором 1400. Здесь часть ядра (часть «на ядре») 1410 содержит один или несколько контроллеров для сопряжения с другими устройствами, такими как запоминающее устройство 1475 или графическое устройство 1480. Конфигурация, содержащая соединение и контроллеры для сопряжения с такими устройствами, часто называется конфигурацией «на ядре» (on-core или un-core). В качестве примера, выполненный на кристалле интерфейс 1410 содержит кольцевое соединение для связи на кристалле и высокоскоростную последовательную двухпунктовую линию 1405 связи для осуществления связи с объектами вне кристалла. Также, в среде системы на кристалле (SOC) еще больше устройств, таких как сетевой интерфейс, сопроцессоры, запоминающее устройство 1475, графический процессор 1480 и какие-либо другие известные компьютерные устройства/интерфейсы могут быть интегрированы в одном кристалле или в одной интегральной схеме для реализации небольшого форм-фактора с широкими функциональными возможностями и небольшой потребляемой мощностью.
В одном из вариантов процессор 1400 способен выполнять код 1477 компиляции, оптимизации и/или трансляции с целью компиляции, трансляции и/или оптимизации кода 1476 приложения (прикладной программы) для поддержки устройств и способов, описываемых здесь или для сопряжения с ними. Компилятор часто содержит программу или набор программ для трансляции исходного текста/кода в целевой текст/код. Обычно компиляция программы/кода приложения посредством компилятора осуществляется в несколько этапов и проходов с целью преобразования кода на языке программирования высокого уровня в код на языке машинных команд низкого уровня или на языке ассемблер. В то же время, для простой компиляции могут быть по-прежнему использованы «однопроходные» компиляторы. Компилятор может использовать какой-либо известный способ компиляции и выполнять какие-либо известные операции компиляции, такие как лексический анализ, предварительная обработка, синтаксический анализ, семантический анализ, генерация кода, трансформация кода и оптимизация кода.
Работа компиляторов большего масштаба часто проходит в несколько фаз, но наиболее часто эти фазы входят в две обобщенные фазы: (1) входная часть, т.е. где, в общем, могут иметь место синтаксическая обработка, семантическая обработка и некоторая часть трансформации/оптимизации, и (2) выходная часть, т.е. где, в общем, имеют место анализ, трансформации, оптимизация и генерация кода. Некоторые компиляторы относятся к компиляторам среднего уровня (средним), что иллюстрирует «размывание» границы между входной частью и выходной частью компилятора. В результате, ссылки на вставку, ассоциирование, генерацию или другую операцию компилятора могут иметь место в любой из отмеченных выше фаз или проходов, равно как и в какой-либо другой известной фазе или проходе в работе компилятора. В качестве иллюстративного примера, компилятор потенциально вставляет операции, вызовы, функции и т.п.в одну или несколько фаз компиляции, например, вставляет вызовы/операции во входную часть компиляции и затем трансформирует вызовы/операции в код низкого уровня во время фазы трансформации. Отметим, что во время динамической компиляции код компиляции или код динамической оптимизации может вставлять такие операции/вызовы, равно как оптимизировать код для выполнения во время работы. В качестве конкретного иллюстративного примера, двоичный код (уже скомпилированный код) может быть динамически оптимизирован во время исполнения (работы). Здесь программный код может содержать код динамической оптимизации, двоичный код или их сочетание.
Аналогично компилятору транслятор, такой как двоичный транслятор, осуществляет статическую или динамическую трансляцию кода с целью оптимизации и/или трансляции кода. Поэтому ссылки на исполнение кода, код приложения, программный код или другую программную среду могут относиться к: (1) выполнению программ компилятора, оптимизатора кода или транслятора, динамически или статически, с целью компиляции программного кода, сохранения структур программного обеспечения, выполнения других операций или трансляции кода; (2) выполнению кода основной программы, включая операции/вызовы, такого как код приложения, который был оптимизирован/скомпилирован; (3) выполнению другого программного кода, например, библиотек, ассоциированных с кодом основной программы, для сохранения структур программного обеспечения, для осуществления других операций, относящихся к программному обеспечению, или для оптимизации кода; или (4) сочетанию этих моментов.
На Фиг. 15 показана блок-схема одного из вариантов многоядерного процессора. Как показано в варианте, представленном на Фиг. 15, процессор 1500 содержит несколько областей. В частности, область 1530 ядер содержит несколько ядер 1530A-1530N, область 1560 графики содержит один или более графических процессоров, и в том числе медийный процессор 1565, и область 1510 системного агента.
В различных вариантах область 1510 системного агента обрабатывает события контроля и управления питанием, так что индивидуальными модулями областей 1530 и 1560 (например, ядрами и/или графическими процессорами) можно управлять независимо для динамической работы в подходящем режиме/с подходящим уровнем питания (например, активный режим, турбо режим, «спящий» режим, режим гибернации («зимней спячки»), режим глубокого сна или другие подобные состояния усовершенствованного интерфейса конфигурирования питания) в свете активности (или неактивности), имеющей место в рассматриваемом модуле. Каждая из областей 1530 и 1560 может работать при различных напряжениях и/или мощностях, а также каждый из индивидуальных модулей в областях потенциально может работать с независимыми от других модулей частотой и напряжением. Отметим, что хотя показаны только три области, понимание объема настоящего изобретения в этом отношении не ограничено, так что в других вариантах могут быть представлены дополнительные области.
Как показано, каждое ядро 1530 далее содержит кэши низкого уровня в дополнение к различным исполнительным модулям и дополнительным процессорным элементам. Здесь различные ядра соединены одно с другим и с совместно используемым кэшем, образованным из нескольких модулей или срезов кэша последнего уровня (last level cache (LLC)) 1540A-1540N; эти кэши LLC часто содержат также функциональные схемы контроллеров памяти и кэша и совместно используются ядрами, а также потенциально графическими процессорами.
Как показано, кольцевое соединение 1550 связывает ядра одно с другим и обеспечивает соединение между областью 1530 ядер, графической областью и схемами 1510 системного агента через несколько кольцевых прерывателей 1552A-1552N, каждый из которых находится в точке соединения между ядром и срезом кэша LLC. Как показано на Фиг. 15, соединение 1550 используется для передачи разнообразной информации, включая адресную информацию, данные, информацию квитирования и информацию снупинга/недействительную информацию. Хотя показано кольцевое соединение, здесь может быть использовано любое известное соединение на кристалле или система таких соединений на кристалле. В качестве иллюстративного примера, некоторые из обсуждаемых здесь систем соединений (например, другие соединения на кристалле, система соединений на кристалле, (On-chip System Fabric (OSF)), соединения усовершенствованной архитектуры шин микроконтроллера (Advanced Microcontroller Bus Architecture (AMBA)), многомерная ячеистая система соединений или другая известная архитектура соединений) могут быть использованы аналогичным образом.
Как показано далее, область 1510 системного агента содержит дисплейный процессор, осуществляющий управление ассоциированным дисплеем и реализующий интерфейс к этому дисплею. Область 1510 системного агента может содержать другие модули, такие как: интегральный контроллер 1520 памяти, образующий интерфейс к системной памяти (например, к динамическому RAM (DRAM), реализованному в виде несколько модулей памяти с двухрядным расположением выводов (DIMM)); когерентное логическое устройство 1522 для осуществления когерентных операций с памятью. Могут быть представлены несколько интерфейсов для обеспечения соединения между процессором и другими схемами. Например, в одном из вариантов создан по меньшей мере один интерфейс 1516 средств личной связи (direct media interface (DMI)), равно как и один или несколько интерфейсов 1514 PCIe™. Дисплейный процессор и эти интерфейсы обычно связываются с памятью через мост PCIe™ 1518. Кроме того, здесь могут быть созданы один или несколько других интерфейсов для связи между другими агентами, такими как дополнительные процессоры и другие схемы.
На Фиг. 16 показана блок-схема репрезентативного ядра; конкретнее, логических блоков выходной части ядра, такого как ядро 1530, изображенное на Фиг. 15. В общем, структура, показанная на Фиг. 16, содержит процессор для внеочередного выполнения команд, имеющий модуль 1670 входной части, используемый для выборки входящих команд, выполнения разнообразной обработки (например, кэширования, декодирования, прогнозирования ветвления и т.п.) и передачи команд/операций собственно процессору 1680 для внеочередного (ООО) выполнения команд. Этот ООО-процессор 1680 осуществляет дальнейшую обработку декодированных команд.
В частности, в варианте, представленном на Фиг. 16, процессор 1680 для внеочередного (не по порядку) выполнения команд содержит модуль 1682 распределителя для приема декодированных команд, которые могут иметь форму одной или нескольких микрокоманд или микроопераций, от модуля 1670 входной части, и распределения их по подходящим ресурсам, таким как регистры и т.д. Затем команды поступают на станцию 1784 резервирования, которая резервирует ресурсы и планирует их для выполнения в одном из нескольких исполнительных модулей 1686A-1686N. Здесь могут быть исполнительные модули разных типов, например, арифметическо-логические устройства (АЛУ) (arithmetic logic unit (ALU)), модули загрузки и хранения, модули векторных процессоров (vector processing unit (VPU)), исполнительные модули для операций с плавающей запятой, среди прочего. Результаты работы этих различных исполнительных модулей поступают в буфер 1688 переупорядочения (reorder buffer (ROB)), который получает неупорядоченные результаты и возвращает их в правильном порядке программы.
Обратившись снова к Фиг. 16, отметим, что оба устройства - модуль 1670 входной части и процессор 1680 для внеочередного (не по порядку) выполнения команд, соединены с разными уровнями иерархии памяти. В частности, показан кэш 1672 уровня команд, который в свою очередь соединен с кэшем 1676 среднего уровня, который в свою очередь соединен с кэшем 1695 последнего уровня. В одном из вариантов кэш 1695 последнего уровня реализован в модуле 1690 на кристалле (иногда именуемом uncore). В качестве примера, модуль 1690 аналогичен системному агенту 1510, показанному на Фиг. 15. Как обсуждается выше, модуль uncore 1690 осуществляет связь с системным запоминающим устройством 1699, которое в иллюстрируемом варианте реализовано в виде ED RAM (встраиваемое динамическое RAM). Отметим также, что различные исполнительные модули 1686 в составе процессора 1680 с внеочередным выполнением команд осуществляют связь с кэшем 1674 первого уровня, который также связан с кэшем 1676 среднего уровня. Отметим также, что с кэшем 1695 последнего уровня (LLC) могут быть соединены дополнительные ядра 1630N-2 - 1630N. Хотя вариант, представленный на Фиг. 16, показывает все на этом высоком уровне, понятно, что возможны различные изменения и присутствие дополнительных компонентов.
На Фиг. 17 представлена блок-схема примера компьютерной системы, имеющей процессор, содержащий исполнительные модули для выполнения команд, где одно или несколько соединений реализуют один или несколько признаков согласно одному из вариантов настоящего изобретения. Система 1700 содержит компонент, такой как процессор 1702, для использования исполнительных модулей, включая логические устройства для выполнения алгоритмов обработки данных согласно настоящему изобретению, как в описываемом здесь варианте. Система 1700 является представителем процессорных систем на основе микропроцессоров PENTIUM III™, PENTIUM 4™, Xeon™ Itanium, XScale™ и/или StrongARM™, хотя могут быть также использованы другие системы (включая персональные компьютеры на основе других микропроцессоров, инженерные рабочие станции, приставки и другие подобные системы). В одном из вариантов представленная в качестве примера система 1700 использует версию операционной системы WINDOWS™, поставляемой корпорацией Microsoft из Редмонда, шт. Вашингтон, хотя также можно использовать другие операционные системы (UNIX и Linux, например), встроенное программное обеспечение и/или графические интерфейсы пользователя. Таким образом, возможные варианты настоящего изобретения не ограничиваются каким-либо конкретным сочетанием аппаратуры и программного обеспечения.
Варианты настоящего изобретения не ограничиваются компьютерными системами. Альтернативные варианты могут быть использованы в других устройствах, таких как ручные устройства и встроенные приложения. К некоторым примерам ручных устройств относятся сотовые телефоны устройства интернет-протокола (IP), цифровые видеокамеры, персональные цифровые помощники (PDA) и ручные персональные компьютеры. Встроенные приложения могут представлять собой микроконтроллер, цифровой процессор сигнала (DSP), систему на кристалле, сетевые компьютеры (NetPC), приставки, сетевые концентраторы, коммутаторы глобальной сети связи (wide area network (WAN)) или какую-либо другую систему, способную выполнять одну или несколько команд согласно по меньшей одному из вариантов.
В рассматриваемом варианте процессор 1702 содержит один или несколько исполнительных модулей 1708 для осуществления алгоритма, предназначенного для выполнения по меньшей мере одной команды. Один из вариантов может быть рассмотрен в контексте однопроцессорной настольной или серверной системы, но альтернативные варианты могут быть реализованы в многопроцессорной системе. Система 1700 является примером системной архитектуры «концентратора». Компьютерная система 1700 содержит процессор 1702 для обработки сигналов данных. Этот процессор 1702, в одном из иллюстративных вариантов, представляет собой микропроцессор компьютера с полным набором команд (complex instruction set computer (CISC)), микропроцессор компьютера с сокращенным набором команд (reduced instruction set computing (RISC)), микропроцессор с очень длинным командным словом (very long instruction word (VLIW)), процессор, реализующий сочетание наборов команд или какое-либо другое процессорное устройство, такое как цифровой процессор сигнала, например. Процессор 1702 соединен с процессорной шиной 1710, передающей сигналы данных между процессором 1702 и другими компонентами системы 1700. Элементы системы 1700 (например, графический ускоритель 1712, контроллер-концентратор 1716 памяти, запоминающее устройство 1720, контроллер-концентратор 1724 ввода/вывода, радио приемопередатчик 1726, флэш BIOS 1728, сетевой контроллер 1734, аудио контроллер 1736, последовательный порт 1738 расширения, контроллер 1740 ввода/вывода и т.д.) выполняют свои обычные функции, хорошо известные специалистам в рассматриваемой области.
В одном из вариантов процессор 1702 содержит внутреннюю кэш-память 1704 уровня 1 (Level 1 (L1)). В зависимости от архитектуры процессор 1702 может иметь один внутренний кэш или несколько уровней внутренних кэшей. Другие варианты содержат различные сочетания внутренних и внешних кэшей в зависимости от конкретной реализации и потребностей. Регистровый файл 1706 служит для сохранения данных различных типов в разнообразных регистрах и в том числе в целочисленных регистрах, регистрах с плавающей запятой, векторных регистрах, группах регистров, теневых регистрах, контрольных регистрах, регистрах состояния и регистрах указателей команд.
Исполнительный модуль 1708, содержащий логические схемы для выполнения целочисленных операций и операций с плавающей запятой, также располагается в процессоре 1702. Процессор 1702 в одном из вариантов содержит ROM микрокода (ucode) для сохранения микрокода, который при выполнении реализует алгоритмы для определенных команд или для обработки сложных сценариев. Здесь микрокод является потенциально обновляемым для обработки логических ошибок/сбоев в процессоре ROM 1702. В одном из вариантов исполнительный модуль 1708 содержит логические схемы для обработки наборов 1709 команд для упакованных данных. Благодаря введению набора 1709 команд для обработки упакованных данных в набор команд процессора 1702 общего назначения вместе с соответствующей схемой для выполнения этих команд, можно осуществлять операции, используемые многими мультимедийными приложениями, над упакованными данными в процессоре 1702 общего назначения. Таким образом, выполнение многих мультимедийных приложений ускоряется и становится более эффективным за счет использования полной ширины процессорной шины данных для осуществления одной или нескольких операций, по одному элементу данных за один раз.
Альтернативные варианты исполнительного модуля 1708 также могут быть использованы в микроконтроллерах, встроенных процессорах, графических устройствах, процессорах DSP и логических схемах других типов. Система 1700 содержит запоминающее устройство 1720. Это запоминающее устройство 1720 может представлять собой динамическое запоминающее устройство с произвольной выборкой (DRAM), статическое RAM (SRAM), устройство флэш-памяти или запоминающее устройство другого типа. Запоминающее устройство 1720 сохраняет команды и/или данные, представленные сигналами данных, для выполнения процессором 1702.
Отметим, что любые из перечисленных выше признаков или аспектов настоящего изобретения могут быть использованы в одном или нескольких соединениях, показанных на Фиг. 17. Например, соединение на кристалле (on-die interconnect (ODI)), которое здесь не показано, для соединения внутренних модулей процессора 1702 реализует один или несколько аспектов настоящего изобретения, описанных выше. Либо настоящее изобретение ассоциировано с процессорной шиной 1710 (например, другими известными высокопроизводительными компьютерными соединениями), широкополосным трактом 1718 памяти, ведущим к запоминающему устройству 1720, двухпунктовой линией связи к графическому ускорителю 1712, (например, соединение, соответствующее стандарту интерфейса PCIe), соединению 1722 для контроллера-концентратора, линям ввода/вывода или другим соединениям (например, USB, PCI, PCIe) для связи с другими показанными компонентами. К некоторым примерам таких компонентов относятся аудио контроллер 1736, концентратор встроенного программного обеспечения (флэш-BIOS) 1728, радио приемопередатчик 1726, запоминающее устройство (хранилище) 1724 данных, контроллер 1710 известных устройств ввода/вывода, содержащий интерфейсы 1742 для ввода пользователем и для клавиатуры, последовательный порт 1738 расширения, такой как порт универсальной последовательной шины (Universal Serial Bus (USB)) и сетевой контроллер 1734. Запоминающее устройство 1724 данных может содержать накопитель на жестком диске, дисковод для дискет, устройство CD-ROM, устройство флэш-памяти или другое запоминающее устройство большой емкости.
На Фиг. 18 показана блок-схема второй системы 1800 согласно одному из вариантов настоящего изобретения. Как показано на Фиг. 18, многопроцессорная система 1800 представляет собой систему двухпунктовых соединений и содержит первый процессор 1870 и второй процессор 1880, соединенные посредством двухпунктового соединения 1850. Каждый из этих процессоров 1870 и 1880 может представлять собой некую версию процессора. В одном из вариантов соединения 1852 и 1854 составляют часть последовательной двухпунктовой когерентной системы соединений, такой как высокопроизводительная архитектура. В результате настоящее изобретение может быть реализовано в рамках архитектуры быстрых соединений QPI.
Хотя на чертеже показаны только два процессора, 1870, 1880, следует понимать, что объем настоящего изобретения этим не ограничивается. В других вариантах в составе рассматриваемого конкретного процессора могут присутствовать один или несколько дополнительных процессоров.
Показано, что процессоры 1870 и 1880 содержат встроенные модули 1872 и 1882, соответственно, контроллеров памяти. Процессор 1870 содержит также, в качестве части своих модулей контроллеров шин, двухпунктовые (point-to-point (Р-Р)) интерфейсы 1876 и 1878; аналогично второй процессор 1880 содержит двухпунктовые (Р-Р) интерфейсы 1886 и 1888. Процессоры 1870, 1880 могут обмениваться информацией через двухпунктовый (Р-Р) интерфейс 1850 с использованием двухпунктовых (Р-Р) интерфейсных схем 1878, 1888. Как показано на Фиг. 18, контроллеры IMC 1872 и 1882 соединяют процессоры с соответствующими запоминающими устройствами, а именно с запоминающим устройством 1832 и запоминающим устройством 1834, которые могут быть частями главного запоминающего устройства, локально соединенными с соответствующими процессорами.
Каждый из процессоров 1870, 1880 обменивается информацией с чипсетом 1890 через индивидуальные точка-точка (Р-Р) интерфейсы 1852, 1854 с использованием двухпунктовых интерфейсных схем 1876, 1894, 1886, 1898. Чипсет 1890 также обменивается информацией с высокопроизводительной графической схемой 1838 через интерфейсную схему 1892 по высокопроизводительному графическому соединению 1839.
В составе каждого процессора или вне обоих процессоров может находиться совместно используемый кэш (не показан), соединенный с этими процессорами посредством точка-точка (Р-Р) соединений, так что локальная кэшируемая информация любого или обоих процессоров может быть сохранена в этом совместно используемом кэше, если соответствующий процессор переходит в режим пониженного потребления энергии.
Чипсет 1890 может быть соединен с первой шиной 1816 через интерфейс 1896. В одном из вариантов первая шина 1816 может представлять собой шину интерфейса периферийных устройств (PCI), либо такую шину, как шина PCI Express, либо какую-либо другую шину ввода/вывода третьего поколения, хотя объем настоящего изобретения этим не ограничивается.
Как показано на Фиг. 18, различные устройства 1814 ввода/вывода соединены с первой шиной 1816, вместе с мостом 1818 шин (шинным интерфейсом), который связывает первую шину 1816 со второй шиной 1820. В одном из вариантов вторая шина 1820 содержит шину с небольшим числом контактов (low pin count (LPC)). Co второй шиной 1820 соединены различные устройства, включая, например, клавиатуру и/или мышь 1822, устройства 1827 связи и запоминающее устройство 1828, такое как дисковод или другое запоминающее устройство большой емкости, которое часто содержит команды/код и данные 1830, в одном из вариантов. Далее, показано аудио устройство 1824 ввода/вывода, соединенное со второй шиной 1820. Отметим, что возможны и другие архитектуры, где варьируются входящие в систему компоненты и структуры соединений. Например, вместо двухпунктовой архитектуры, показанной на Фиг. 18, система может реализовать многоотводную шину или другую подобную архитектуру.
На Фиг. 19 показан вариант системы на кристалле (system on-chip (SOC)) согласно настоящему изобретению. В конкретном иллюстративном примере система SOC 1900 входит в состав абонентского терминала (user equipment (UE)). В одном из вариантов терминал UE обозначает любое устройство для использования конечным пользователем для связи, такое как ручной телефон, смартфон, планшет, ультратонкий компьютер-ноутбук, ноутбук с широкополосным адаптером или какое-либо другое аналогичное устройство связи. Часто терминал UE соединяется с базовой станцией или узлом, что потенциально соответствует по природе мобильной станции (mobile station (MS)) в сети сотовой связи стандарта GSM.
Здесь система SOC 1900 содержит два ядра - 1906 и 1907. Аналогично приведенному выше обсуждению ядра 1906 и 1907 могут соответствовать какой-либо структуре системы команд (Instruction Set Architecture), такой как процессор на основе Intel® Architecture Core™, процессор производства компании Advanced Micro Devices, Inc. (AMD), процессор на основе многоканальной процессорной системы MLPS, процессор на основе ARM или какой-либо клиент с таким процессором, равно как процессоры, выпускаемые по лицензии соответствующих фирм или после адаптации к требованиям других систем. Ядра 1906 и 1907 соединены с модулем 1908 управления кэшем, который ассоциирован с модулем 1909 шинного интерфейса и с кэшем L2 1911, для связи с другими частями системы 1900. Соединение 1910 содержит выполненные на кристалле соединения, такие как разработанная фирмой «Интел» система соединений на кристалле (IOSF), расширенная шинная архитектура для микроконтроллеров (АМВА) или другая система соединений, обсуждавшаяся выше и потенциально реализующая один или несколько описанных здесь аспектов.
Интерфейс 1910 предоставляет каналы связи для соединения с другими компонентами, такими как модуль 1930 идентификации абонента (Subscriber Identity Module (SIM)) для сопряжения с SIM-картой, ROM 1935 загрузки, где хранится код загрузчика для выполнения ядрами 1906 и 1907 с целью инициализации и загрузки системы SOC 1900, контроллер 1940 синхронного динамического RAM (SDRAM) для сопряжения с внешней памятью (например, DRAM 1960), контроллер 1945 флэш-памяти для сопряжения с энергонезависимой памятью (например, флэш-памятью 1965), контроллер 1950 периферийных устройств (например, последовательный интерфейс периферийных устройств) для сопряжения с периферийными устройствами, видео кодек 1920 и видео интерфейс 1925 для представления на дисплее и приема входных команд и данных (например, сенсорный ввод), графический процессор GPU 1915 для выполнения вычислений, относящихся к графике, и т.п. Любой из этих интерфейсов может содержать аспекты описываемого здесь изобретения.
Кроме того, система иллюстрирует периферийные устройства для связи, такие как модуль Bluetooth 1970, модем 1975 третьего поколения (3G) 1975, модуль GPS 1985 и модуль WiFi 1985. Отметим, что терминал UE содержит радио приемопередатчик для связи. В результате, в системе нужны не все эти периферийные модули связи. Однако в терминале UE должна быть некая форма радио приемопередатчика для связи с внешними устройствами.
Хотя настоящее изобретение было описано применительно к ограниченному числу вариантов, специалисты в рассматриваемой области смогут понять многочисленные модификации и вариации. Прилагаемая Формула изобретения должна охватывать все такие модификации и вариации, попадающие в рамки истинного смысла и объема настоящего изобретения.
Проектирование может проходить в несколько этапов, от разработки к моделированию и изготовлению. Данные, представляющие проект, могут представлять его несколькими способами. Во-первых, как это удобно для моделирования, аппаратура может быть представлена с использованием языка описания аппаратных средств или какого-либо другого языка функционального описания. Кроме того, на некоторых этапах процесса проектирования может быть создана модель на уровне с логическими элементами и/или транзисторными вентилями. Более того, большинство проектов на некоторых этапах достигают уровня данных, представляющих физическое размещение различных устройств в модели аппаратуры. В случае применения обычных технологий изготовления полупроводниковых приборов данные, представляющие модель аппаратуры, могут описывать присутствие или отсутствие различных элементов в фотошаблонах для различных слоев, используемых при изготовлении интегральных схем. В любом представлении проекта данные могут быть сохранены на машиночитаемом носителе любого подходящего типа. Таким машиночитаемым носителем для сохранения информации, передаваемой оптическими или электромагнитными волнами, модулируемыми или генерируемыми другим способом для передачи такой информации, могут быть какое-либо запоминающее устройство, либо магнитный или оптический носитель, такой как диск. Когда происходит передача электрических волн несущей, указывающих или передающих код или проект, в той степени, в какой осуществляется копирование, буферизация или ретрансляция электрического сигнала, создается новая копия. Таким образом, провайдер связи или сетевой провайдер может сохранять на материальном машиночитаемом носителе, по меньшей мере временно, объект, такой как информация, кодированная на волнах несущей, осуществляя способы согласно вариантам настоящего изобретения.
Термин «модуль» как он используется здесь, может относиться к какому-либо сочетанию аппаратуры, загружаемого программного обеспечения и/или встроенного программного обеспечения. В качестве примера, модуль содержит аппаратуру, такую как микроконтроллер, ассоциированный с энергонезависимым носителем для сохранения кода, который должен выполнять этот микроконтроллер. Поэтому ссылки на модуль в одном из вариантов относятся к аппаратуре, специально конфигурированной для распознавания и/или выполнения кода, который должен храниться на энергонезависимом носителе. Более того, в другом варианте, использование термина «модуль» ссылается на энергонезависимый носитель, содержащий код, специально разработанный для выполнения микроконтроллером с целью осуществления заданных операций. И как легко можно понять, еще в одном варианте термин «модуль» (в этом примере) может относиться к сочетанию микроконтроллера и энергонезависимого носителя. Часто границы модулей, которые показаны как раздельные, могут изменяться и потенциально накладываться одни на другие. Например, первый и второй модули могут совместно использовать аппаратуру, загружаемое или встроенное программное обеспечение или их сочетания, потенциально сохраняя некоторую независимость аппаратуры и загружаемого или встроенного программного обеспечения. В одном из вариантов использование термина «логическая схема» обозначает аппаратуру, такую как транзисторы, регистры или другая аппаратура, такая как программируемые логические устройства.
Использование фразы «конфигурирован для» в одном из вариантов относится к организации, размещению в одном месте, изготовлению, предложению на продажу, импорту и/или проектированию устройств, аппаратуры, логических схем или элементов для выполнения назначенной или определенной задачи. В этом примере, устройство или его элемент, который не работает или не используется в данный момент, все равно «конфигурирован для» выполнения назначенной задачи, если он был спроектирован, связан и/или соединен для выполнения этой назначенной задачи. В качестве чисто иллюстративного примера, логический вентиль может во время работы передавать на выход (генерировать) 1 или 0. Однако понятие логического вентиля «конфигурированного для» передачи сигнала включения часов не включает в себя каждый потенциальный логический вентиль, который может генерировать 1 или 0. Напротив, упомянутый логический вентиль представляет собой вентиль соединенный таким образом, чтобы во время работы передавать 1 или 0 для включения часов. Отметим еще раз, что использование термина «конфигурированный для» не требует работы, а сосредоточено на латентном состоянии устройства, аппаратуры и/или элемента, так что в латентном состоянии это устройство, аппаратура и/или элемент рассчитаны на выполнение конкретной задачи, когда рассматриваемые устройство, аппаратура и/или элемент работают.
Далее, использование фраз «для», «способный к/для» и/или «работающий для» в одном из вариантов относится к некоторому устройству, логической схеме, аппаратуре и/или элементу, спроектированным таким образом, чтобы можно было использовать эти устройство, логическую схему, аппаратуру и/или элемент заданным образом. Отметим, что, как указано выше, использование терминов «для», «способный к/для» и/или «работающий для» относится, в одном из вариантов, к латентному состоянию этих устройства, логической схемы, аппаратуры и/или элемента, в котором эти устройство, логическая схема, аппаратура и/или элемент не работают, но спроектированы так, чтобы можно было использовать какое-либо устройство заданным образом.
Слово «значение» или «величина», как оно используется здесь, охватывает любое известное представление числа, состояния, логического состояния или двоичного логического состояния. Часто использование логических уровней, логических величин и логических значений также относится к обозначениям «1» и «0», которые представляют просто двоичные логические состояния. Например, «1» обозначает высокий логический уровень, а «0» обозначает низкий логический уровень. В одном из вариантов ячейка памяти, такая как транзистор или ячейка флэш-памяти, может быть способна сохранять одну логическую величину или несколько логических величин. Однако в компьютерных системах до настоящего времени используются также другие представления величин. Например, десятичное число десять может быть представлено двоичной величиной 1010 и шестнадцатиричной величиной А. Поэтому понятие «величина», «значение» охватывает любое представление информации, которое может иметь место в компьютерной системе.
Более того, состояния могут быть представлены величинами или частями величин. В качестве примера, первая величина, такая как логическая единица, может представлять состояние по умолчанию или начальное состояние, тогда как вторая величина, такая как логический нуль, может представлять состояние не по умолчанию. Кроме того, термины «сбросить» и «задать» в одном из вариантов относятся к величине или состоянию по умолчанию и к обновленной величине или состоянию, соответственно. Например, величина по умолчанию потенциально имеет высокое логическое значение, т.е. сброс, тогда как обновленная величина потенциально имеет низкое логическое значение, т.е. задание. Отметим, что любое сочетание величин может быть использовано для представления любого числа состояний.
Варианты способов, аппаратуры, загружаемого программного обеспечения, встроенного программного обеспечения или кодов могут быть реализованы посредством команд или кода, который сохраняется на доступном для машины, машиночитаемом, доступном для компьютера или читаемом компьютером носителе и который может быть выполнен процессорным элементом. Энергонезависимый доступный/читаемый машиной носитель представляет собой какой-либо механизм, предоставляющий (т.е. сохраняющий и/или передающий) информацию в форме, читаемой машиной, такой как компьютер или электронная система. Например, энергонезависимый доступный для машины носитель может представлять собой RAM, такое как статическое RAM (SRAM) или динамическое RAM (DRAM); ROM; магнитный или оптический носитель для хранения информации; устройства флэш-памяти; электрические запоминающие устройства; оптические запоминающие устройства, акустические запоминающие устройства, а также другие виды запоминающих устройств для сохранения информации, принимаемой посредством энергозависимых (распространяющихся) сигналов (например, волн несущих, инфракрасных сигналов, цифровых сигналов); и т.п., которые следует отличать от энергонезависимых носителей, способных принимать информацию из энергозависимых источников.
Команды, используемые для программирования логических схем с целью осуществления вариантов настоящего изобретения, могут быть сохранены в запоминающем устройстве в системе, таком как динамическое RAM (DRAM), кэш, флэш-память или другое запоминающее устройство. Далее эти команды могут быть распределены через сеть связи или посредством другого компьютерного носителя информации. Таким образом, машиночитаемый носитель может содержать любой механизм для хранения или передачи информации в форме, читаемой машиной (например, компьютером), не ограничиваясь, дискеты, оптические диски, ROM на компакт-дисках (CD-ROM), магнитооптические диски, постоянные запоминающие устройства (ROM), RAM, стираемое программируемое ROM (Erasable Programmable Readonly Memory (EPROM)), электрически стираемое программируемое ROM (Electrically Erasable Programmable Read-Only Memory (EEPROM)), магнитные или оптические карточки, устройства флэш-памяти или материальное машиночитаемое запоминающее устройство, используемое для передачи информации через Интернет посредством электрических, оптических, акустических или других видов распространяющихся сигналов (например, волн несущих, инфракрасных сигналов, цифровых сигналов и т.п.). Соответственно компьютерный носитель представляет собой материальный машиночитаемый носитель любого типа, подходящий для хранения или передачи электронных команд или информации в форме, читаемой машиной (например, компьютером).
Последующие примеры относятся к вариантам согласно настоящему описанию. Один или несколько вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ создания канала на основе протокола Peripheral Component Interconnect (PCI) Express (PCIe) для поддержки скорости передачи данных по меньшей мере 16 Гигатранзакций в секунду (ГТ/с (GT/s)), где канал содержит два соединителя и имеет блину больше двенадцати дюймов.
По меньшей мере в одном примере канал содержит по меньшей мере одно сквозное соединение, а столбик в этом сквозном соединении по меньшей мере частично удален.
По меньшей мере в одном примере сквозное соединение «высверливают» сзади для удаления столбика.
По меньшей мере в одном примере сквозное соединение представляет собой сквозное соединение первого из соединителей.
По меньшей мере в одном примере «высверливают» с обратной стороны каждое сквозное соединение, используемое соединителем для соединения с первым устройством.
По меньшей мере в одном примере «высверливают» с обратной стороны сквозные соединения второго из соединителей, используемого для соединения со вторым устройством.
По меньшей мере в одном примере сквозное соединение представляет собой сквозное соединение процессорного сокета.
По меньшей мере в одном примере каждая линия канала передачи данных содержит соответствующий участок соответствующего процессорного сокета, и каждый из процессорных сокетов соответствует одной из линий канала передачи данных, столбик сквозного соединения которого «высверлен» с обратной стороны.
По меньшей мере в одном примере предложена печатная плата с малыми потерями, а указанный канал передачи данных реализован по меньшей мере частично в этой плате.
По меньшей мере в одном примере печатная плата с небольшими потерями имеет маленькие вносимые потери дорожки для передачи дифференциального сигнала
По меньшей мере в одном примере во входном блоке приемника в канале передачи данных применяют усиление сигнала.
По меньшей мере в одном примере указанный коэффициент усиления составляет приблизительно 6 дБ.
По меньшей мере в одном примере усиление применяют в работающем в непрерывном времени линейном корректоре канала передачи данных.
По меньшей мере в одном примере суммарный коэффициент усиления, применяемый во входном блоке приемника и в работающем в непрерывном времени линейном корректоре, составляет приблизительно 6 дБ.
По меньшей мере в одном примере канал передачи данных содержит по меньшей мере одно сквозное соединение с «высверленным» с обратной стороны столбиком, канал выполнен по меньшей мере частично на печатной плате с небольшими потерями, и суммарный коэффициент усиления приблизительно 6 дБ применяется в одном или нескольких устройствах из совокупности входного блока приемника канала передачи данных и работающего в непрерывном времени линейного корректора для этого канала.
По меньшей мере в одном примере длина канала передачи данных составляет по меньшей мере двадцать (20) дюймов.
Один или более вариантов могут обеспечивать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ передачи данных со скоростью по меньшей мере 16 ГТ/с по каналу передачи данных, представляющему собой имеющий два соединителя многолинейный канал, где длина этого канала передачи данных больше двенадцати дюймов.
По меньшей мере в одном примере длина канала передачи данных составляет по меньшей мере двадцать (20) дюймов.
По меньшей мере в одном примере канал передачи данных содержит одно или более сквозных соединений, а столбики в этих сквозных соединениях «высверлены» с обратной стороны.
По меньшей мере в одном примере указанные одно или более сквозных соединений входят в состав одного или обоих из двух соединителей.
По меньшей мере в одном примере канал передачи данных содержит процессорные сокеты, так что эти процессорные сокеты имеют сквозные соединений.
По меньшей мере в одном примере канал передачи данных содержит по меньшей мере одно сквозное соединение с «высверленным» с обратной стороны столбиком, канал выполнен по меньшей мере частично на печатной плате с небольшими потерями, и суммарный коэффициент усиления приблизительно 6 дБ применяется в одном или нескольких устройствах из совокупности входного блока приемника канала передачи данных и работающего в непрерывном времени линейного корректора для этого канала.
По меньшей мере в одном примере канал передачи данных представляет собой канал передачи данных на основе интерфейса PCIe.
Один или более вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ приема данных, переданных со скоростью по меньшей мере 16 ГТ/с по каналу передачи данных, представляющему собой имеющий два соединителя многолинейный канал, где длина этого канала передачи данных больше двенадцати дюймов.
По меньшей мере в одном примере длина канала передачи данных составляет по меньшей мере двадцать (20) дюймов.
По меньшей мере в одном примере канал передачи данных содержит одно или несколько сквозных соединений, а столбики в этих сквозных соединениях «высверлены» с обратной стороны.
По меньшей мере в одном примере указанные одно или несколько сквозных соединений входят в состав одного или обоих из двух соединителей.
По меньшей мере в одном примере канал передачи данных содержит процессорные сокеты, так что эти процессорные сокеты имеют сквозные соединений.
По меньшей мере в одном примере канал передачи данных содержит по меньшей мере одно сквозное соединение с «высверленным» с обратной стороны столбиком, канал выполнен по меньшей мере частично на печатной плате с небольшими потерями, и суммарный коэффициент усиления приблизительно 6 дБ применяется в одном или нескольких устройствах из совокупности входного блока приемника канала передачи данных и работающего в непрерывном времени линейного корректора для этого канала.
По меньшей мере в одном примере канал передачи данных представляет собой канал передачи данных на основе интерфейса PCIe.
По меньшей мере в одном примере предложена система, содержащая первое устройство и второе устройство, осуществляющее связь с первым устройством с использованием соединительного канала передачи данных, где этот соединительный канал представляет собой канал передачи данных согласно протоколу интерфейса Peripheral Component Interconnect (PCI) Express (PCIe) для поддержки скорости передачи данных по меньшей мере 16 ГТ/с, причем этот канал передачи данных содержит два соединителя, а длина этого канала передачи данных больше двенадцати дюймов.
По меньшей мере в одном примере система содержит серверный чипсет.
По меньшей мере в одном примере первое устройство представляет собой процессорное устройство.
Один или более вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ идентификации первой ошибки линии в одной конкретной линии из нескольких линий в составе канала передачи данных на основе обнаружения по меньшей мере одного ошибочного символа, переданного по этой конкретной линии и передачи сообщения об этой первой ошибке линии в регистр ошибок линий.
По меньшей мере в одном примере ошибки линии, о которых сообщено регистру ошибок линий, идентифицируют соответствующую линию в совокупности множества линий.
По меньшей мере в одном примере вторую ошибку линии идентифицируют в канале передачи данных на основе обнаружения ошибочного синхронизационного заголовка по меньшей мере в одной из множества линий и передают сообщение об этой второй ошибке линии в регистр ошибок линии.
По меньшей мере в одном примере идентифицируют третью ошибку линии на основе несовпадения информации о четности для потоков данных, передаваемых по каналу передачи данных, и передают сообщение об этой третьей ошибке линии в регистр ошибок линии.
По меньшей мере в одном примере информацию о четности, принимают в составе упорядоченного множества SKP (SKP OS).
По меньшей мере в одном примере логическое устройство ввода/вывода представляет собой логическое устройство физического уровня.
По меньшей мере в одном примере указанный ошибочный символ содержит ошибку в символе, входящем в состав множества SKP OS.
По меньшей мере в одном примере указанный ошибочный символ представляет собой символ, не принадлежащий к множеству SKP OS, обнаруженный между первым символом SLP OS в составе множества SKP OS и маркером S LP END в этом множестве SKP OS.
По меньшей мере в одном примере ошибочный символ представляет собой маркер SKPEND, помещенный в символ, отличный от символа 8, 12, 16, 20 или 24 в составе множества SKP OS.
По меньшей мере в одном примере ошибочный символ представляет собой первый символ кадрирующего маркера.
По меньшей мере в одном примере кадрирующий маркер представляет собой кадрирующий маркер стандарта PCIe.
По меньшей мере в одном примере кадрирующий маркер представляет собой по меньшей мере один из маркеров - логический кадрирующий маркер простоя (IDL), маркер (SDP) начала пакета (DLLP) данных уровня канала передачи данных, маркер (STP) начала пакета (TLP) данных уровня транзакций или маркер (EDB) конечного дефекта для пакета TLP.
По меньшей мере в одном примере ошибочный символ представляет собой ошибочный символ маркера IDL.
По меньшей мере в одном примере первый маркер IDL передают в конкретной Линии n из совокупности нескольких линий, а ошибочный символ представляет собой символ не из состава маркера IDL, обнаруженный в какой-либо из Линий с номерами n+1, n+2 и n+3 из совокупности множества линий.
По меньшей мере в одном примере ошибочный символ представляет собой символ маркера EDB.
По меньшей мере в одном примере первый маркер EDB следует за пакетом TLP в конкретной Линии n из совокупности нескольких линий, а ошибочный символ представляет собой символ не из состава маркера EDB, обнаруженный в какой-либо из Линий с номерами n+1, n+2 и n+3 из совокупности нескольких линий.
По меньшей мере в одном примере ошибочный символ представляет собой символ из состава маркера EDB и маркер EDB следует за кадрирующим маркером, отличным от маркера SDP.
По меньшей мере в одном примере ошибочный символ представляет собой символ маркера SDP.
По меньшей мере в одном примере первый символ маркера SDP передают в конкретной Линии n из совокупности нескольких линий, а ошибочный символ представляет собой символ не из состава маркера SDP, обнаруженный в Линии n+1 из совокупности нескольких линий.
По меньшей мере в одном примере регистр ошибок линий представляет собой регистр состояния ошибок линий (Lane Error Status (LES)) согласно стандарту PCIe.
По меньшей мере в одном примере канал передачи данных представляет собой канал передачи данных, соответствующий стандарту PCIe.
По меньшей мере в одном примере вторую ошибку линии идентифицируют в канале передачи данных на основе обнаружения блока упорядоченного множества, перед которым не было предшествующего маркера EDS.
По меньшей мере в одном примере идентифицируют ошибку в линии на основе обнаружения ошибки в каком-либо из символов упорядоченного множества, символе маркера IDL, символе маркера SDP, символе маркера STP или символе маркера EDB и передают сообщение об этой ошибке.
По меньшей мере в одном примере контролируют информацию в регистре ошибок линий с целью идентификации ошибок линий, касающихся конкретной линии, и могут определить, что эта конкретная линия неисправна, на основе совокупности нескольких ошибок, идентифицированных для этой конкретной линии, в регистре ошибок линий.
По меньшей мере в одном примере процедура определения, что конкретная линия неисправна, содержит статистический анализ совокупности нескольких ошибок.
Один или более вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ идентификации, что канал передачи данных должен выйти из активного состояния, где канал передачи данных содержит несколько линий, сохранения информации о четности для линий на основе информации, ранее переданной по каналу передачи данных, и передачи индикации информации о четности прежде, чем выйти из активного состояния.
По меньшей мере в одном примере указание информации о четности передают в ответ на выход из активного состояния.
По меньшей мере в одном примере указание информации о четности передают в составе упорядоченного множества.
По меньшей мере в одном примере указание информации о четности для каждой линии включают в соответствующий бит четности для каждой линии, входящей в упорядоченное множество.
По меньшей мере в одном примере упорядоченное множество представляет собой множество SKP OS согласно стандарту PCIe.
По меньшей мере в одном примере принимают решение о выходе канала передачи данных из активного состояния на основе восстановления канала передачи данных.
По меньшей мере в одном примере восстановление канала передачи данных осуществляется на основе ошибки, обнаруженной в канале передачи данных.
По меньшей мере в одном примере ошибка представляет собой ошибку кадрирующего маркера.
Один или несколько вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ передачи данных по каналу передачи данных, содержащему множество линий, сохранения информации о четности для каждой линии на основе переданных данных, идентификации, что канал передачи данных должен выйти из активного состояния, и передачи информации о четности прежде, чем выйти из активного состояния.
Один или более вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ сохранения первой информации о четности для каждой из множества линий в составе канала передачи данных на основе данных, ранее переданных по каналу передачи данных, приема второй информации о четности в ответ на событие, вызывающее выход канала передачи данных из активного состояния, где вторую информацию о четности передают перед выходом из активного состояния. Первую информацию о четности сравнивают со второй информации о четности для идентификации потенциальных ошибок линий в одной или более линий.
По меньшей мере в одном примере вторая информация о четности входит в состав упорядоченного множества.
По меньшей мере в одном примере вторая информация о четности включена в биты четности, входящие в состав упорядоченного множества.
По меньшей мере в одном примере упорядоченное множество представляет собой множество SKP OS.
По меньшей мере в одном примере канал передачи данных выходит из активного состояния на основе восстановления этого канала передачи данных.
По меньшей мере в одном примере процедура восстановления запускается в ответ на обнаружение ошибки в канале передачи данных.
По меньшей мере в одном примере ошибка представляет собой ошибку кадрирующего маркера.
По меньшей мере в одном примере о потенциальных ошибках линий сообщают регистру ошибок линии.
По меньшей мере в одном примере регистр ошибок линий представляет собой регистр LES.
По меньшей мере в одном примере событие представляет собой обнаружение ошибки в канале передачи данных.
По меньшей мере в одном примере восстановление канала передачи данных должно запускаться на основе ошибки, и при этом, восстановление вызывает выход канала передачи данных из активного состояния.
По меньшей мере в одном примере потенциальные ошибки линий идентифицируют на основе обнаружения, что первая информация о четности не совпадает со второй информацией о четности.
Один или более вариантов могут обеспечивать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ приема данных по каналу передачи данных, содержащему несколько линий, сохранения первой информации о четности для каждой из этих нескольких линий на основе принятых данных, приема второй информации о четности в ответ на событие, где это событие вызывает выход канала передачи данных из активного состояния, а вторую информацию о четности передают перед выходом из активного состояния, и сравнения первой информации о четности со второй информации о четности для идентификации потенциальных ошибок линий в одной или более линий.
Один или более вариантов могут обеспечивать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ сохранения первой информации о четности для каждой из множества линий в составе канала передачи данных на основе первой части данных, переданных по каналу передачи данных, где информацию о четности сохраняют в течение восстановления канала передачи данных, и возобновления вычислений информации о четности после завершения восстановления канала передачи данных, где эта информация о четности дополнительно основана на второй части данных, передаваемых по каналу передачи данных, и вторая часть данных постоянно учитывает восстановление канала передачи данных.
По меньшей мере в одном примере первая часть данных соответствует первому блоку данных, а вторая часть данных соответствует отличному от первого второму блоку данных.
По меньшей мере в одном примере первый блок данных прерывается процедурой восстановления, а второй блок данных начинается после восстановления.
По меньшей мере в одном примере восстановление происходит на основе ошибки, обнаруженной в канале передачи данных.
По меньшей мере в одном примере приемному устройству передают индикацию информации о четности, вычисленную на основе первой и второй частей данных.
По меньшей мере в одном примере информация о четности содержит первую информацию о четности, и логическая схема ввода/вывода дополнительно принимает от передающего устройства индикацию второй информации о четности, вычисленной передающим устройством на основе первой и второй частей данных, а логическая схема сравнивает индикацию второй информации о четности с первой информацией о четности.
По меньшей мере в одном примере определяют, что в одной или нескольких линий присутствуют потенциальные ошибки на основе сравнения индикации второй информации о четности с первой информацией о четности.
По меньшей мере в одном примере передают сообщения о потенциальных ошибках в регистр ошибок линий.
По меньшей мере в одном примере регистр ошибок линий представляет собой регистр LES согласно стандарту PCIe.
По меньшей мере в одном примере индикация второй информации о четности входит в состав множества SKP OS.
По меньшей мере в одном примере индикация второй информации о четности содержит биты четности из состава множества SKP OS.
По меньшей мере в одном примере канал передачи данных представляет собой канал передачи данных, соответствующий стандарту PCIe.
Один или более вариантов могут обеспечивать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ передачи первых данных по каналу передачи данных, содержащему множество линий, определения информации о четности для каждой из этих линий на основе переданных первых данных, участия в восстановлении канала передачи данных, где информацию о четности сохраняют во время восстановления канала передачи данных, передачи вторых данных по каналу передачи данных после восстановления канала и обновления информации о четности для генерации обновленной информации о четности, где обновленная информация о четности основана на первых данных и вторых данных.
Один или более вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ приема первых данных от какого-либо устройства, где первые данные принимают по каналу передачи данных, содержащему множество линий, определения информации о четности для каждой из этих множества линий на основе принятых первых данных, участия в восстановлении канала передачи данных, где информацию о четности сохраняют во время восстановления канала передачи данных, приема вторых данных по каналу передачи данных от указанного устройства после восстановления канала и обновления информации о четности для генерации обновленной информации о четности, где обновленная информация о четности основана на первых данных и вторых данных.
По меньшей мере в одном примере конкретную информацию о четности можно сравнивать с другой информацией о четности для определения одной или более потенциальных ошибок линий.
По меньшей мере в одном примере указанная другая информация о четности входит в состав множества SKP OS.
По меньшей мере в одном примере указанная другая информация о четности может быть идентифицирована из битов четности, входящих в состав множества SKP OS.
Один или более вариантов могут предлагать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логическую схему на аппаратной и/или программной основе и способ приема первых данных от какого-либо устройства, где первые данные принимают по каналу передачи данных, содержащему множество линий, определения информации о четности для каждой из этих множества линий на основе принятых первых данных, участия в восстановлении канала передачи данных, где информацию о четности сохраняют во время восстановления канала передачи данных, приема вторых данных по каналу передачи данных от указанного устройства после восстановления канала и обновления информации о четности для генерации обновленной информации о четности, где обновленная информация о четности основана на первых данных и вторых данных.
Ссылки в пределах настоящего описания на «один вариант» или «в одном из вариантов» означают, что конкретный признак, структура или характеристика, описываемые в связи с этим вариантом, входят в состав по меньшей мере одного из вариантов настоящего изобретения. Таким образом, случаи появления фраз «в одном из вариантов» или «в каком-либо варианте» в различных местах настоящего описания не обязательно все относятся к одному и тому же варианту. Более того, конкретные признаки, структуры или характеристики могут сочетаться каким-либо подходящим образом в одном или более вариантах.
В приведенном выше описании подробное рассмотрение было дано со ссылками на конкретные примеры вариантов. Должно быть, однако, очевидно, что могут быть сделаны разнообразные модификации и изменения в этих вариантах без отклонения от более широкого смысла и объема настоящего изобретения, как они указаны в прилагаемой Формуле изобретения. Настоящее описание и чертежи следует, соответственно, рассматривать только в качестве иллюстраций, а не ограничений. Более того, употребление выше ссылок на вариант или пример не обязательно относится к одному и тому же варианту или одному и тому же примеру, а может относиться к разным и различным вариантам, равно как потенциально к одному и тому же варианту.
Реферат
Изобретение относится к технологиям сетевой связи. Технический результат заключается в повышении скорости передачи данных. Устройство обработки данных содержит логическую схему ввода/вывода для: идентификации, что канал передачи данных должен выйти из активного состояния, причем канал передачи данных содержит множество линий; поддержки информации о четности для указанных линий на основе данных, ранее переданных по каналу передачи данных, и передачи указания информации о четности перед выходом из активного состояния. 4 н. 21 з.п. ф-лы, 19 ил.
Комментарии