Параллельный каскадный сверточный код с конечной последовательностью битов и декодер для такого кода - RU2187196C2
Код документа: RU2187196C2
Чертежи




Описание
Изобретение относится к кодированию с исправлением ошибок, используемому при передаче коротких сообщений по каналам низкого качества, и, более конкретно, к способу параллельного каскадного сверточного кодирования и к соответствующему устройству декодирования.
Предшествующий уровень техники
Один из видов параллельного каскадного кодирования, определяемый как параллельное каскадное сверточное кодирование или
"турбо"-кодирование, явился предметом недавних исследований, связанных со способами кодирования, ввиду весьма существенного выигрыша, обеспечиваемого таким кодированием, при использовании с блоками из
10000 и более битов (см. C.Berrou, A.Glavieux, P. Thitimajshima, "Near Shannon Limit Error-Correcting Coding and Decoding: Turbo-Codes, "Proceedings of the IEEE International Conference on
Communications, 1993, pp. 1064-1070; J.D. Andersen, "The TURBO Coding Scheme, "Report IT-146 ISSN 0105-854, Institute of Telecommunication, Technical University of Denmark, December 1994; P. Robertson,
"Illuminating the Structure of Code and Decoder of Parallel Concatenated Recursive Systematic (Turbo) Codes", 1994 IEEE Globecom Conference, pp. 1298-1303).
Однако было показано, что эффективность турбо-кода существенно снижается по мере уменьшения длины кодированного блока данных. Этот эффект обусловлен сильной зависимостью структуры весов рекурсивных систематических кодов для их компонентов от длины блока. Еще одной проблемой является надлежащее завершение блоков сообщения, подаваемых на турбо-кодер. Как описано в работе O. Joersson, H.Meyer, "Terminating the Trellis of Turbo-Codes", IEE Electronics Letters, vol.30, 16, August 4, 1994, pp. 1285-1286, перемежение, используемое в турбо-кодерах, может привести к невозможности завершения входных последовательностей кодера как с перемежением, так и без перемежения единственным набором конечных битов. Хотя возможно использование второй конечной последовательности в составе структуры сообщения, так чтобы кодер, работающий с последовательностью данных с перемежением, имел возможность надлежащего завершения последовательности данных, однако такой подход приводит к удвоению непроизводительных расходов на обработку, связанных с завершением цикла обработки кодера, и к снижению эффективной скорости кода. Альтернативный подход состоит в том, чтобы не завершать одну из последовательностей кодера, однако это снижает эффективность системы кодирования/декодирования, в частности, при применении для коротких сообщений. В работе A.S. Barbulescu, S.S. Pietrobon, "Terminating the Trellis of Turbo-Codes in the Same State", IEE Electronics Letters, 1995, vol. 31, 1, January 5, pp. 22-23, описан способ, который предусматривает ограничения, накладываемые на схему перемежителя, для того, чтобы обеспечить завершение цикла обработки рекурсивных систематических сверточных кодеров двух компонентов одной последовательностью битов завершения. Полученные результаты показывают некоторое снижение эффективности по сравнению с эффективностью, обеспечиваемой завершением цикла обработки обоих кодеров при использовании оптимизированного перемежителя. Кроме того, опубликованные данные для частоты ошибок по битам (BER) в зависимости от отношения энергии, приходящейся на бит, к спектральной плотности мощности шума (Еb/N0) показывают выравнивание коэффициента BER в диапазоне значений отношения Еb/N0, когда в турбо-кодере используются устройства кодирования на основе рекурсивного систематического сверточного кода.
Таким образом, существует необходимость в создании усовершенствованного способа параллельного каскадного кодирования для коротких блоков данных.
Сущность изобретения
В соответствии с настоящим
изобретением схема параллельного каскадного сверточного кодирования использует нерекурсивные систематические сверточные коды (NSC-коды) с конечной последовательностью битов. Соответствующее устройство
декодирования итеративно использует циклическое декодирование по методу апостериорного максимума (МАР-декодирование) для формирования на выходе непрограммируемого и программируемого решения.
Использование кодов конечной последовательности битов решает проблему завершения входных последовательностей данных при турбо-кодировании, без связанного обычно с этим снижения эффективности
устройства декодирования. Хотя нерекурсивные систематические сверточные коды, т. е. NSC-коды, в общем случае асимптотически слабее, чем рекурсивные систематические сверточные коды (RSC-коды), имеющие
ту же память, по мере увеличения длины блока данных, свободное кодовое расстояние для NSC-кодов менее чувствительно к длине блока данных. Следовательно, параллельное каскадное кодирование с
использованием NSC-кодов будет давать лучший результат, чем при использовании RSC-кодов с той же самой памятью для сообщений, которые короче, чем некоторое пороговое значение размера блока данных.
Краткое описание чертежей
Признаки и преимущества настоящего изобретения поясняются в нижеследующем детальном описании изобретения, иллюстрируемом чертежами, на которых
представлено следующее:
фиг.1 - упрощенная блок-схема, иллюстрирующая параллельный каскадный кодер;
фиг. 2 - упрощенная блок-схема, иллюстрирующая декодер для использования с
параллельными каскадными кодами;
фиг. 3 - упрощенная блок-схема, иллюстрирующая нерекурсивный систематический сверточный кодер с конечной последовательностью битов, предназначенный для
использования в схеме кодирования согласно настоящему изобретению;
фиг. 4 - упрощенная блок-схема, иллюстрирующая циклический МАР-декодер, используемый в качестве декодера компонента, для
декодера, соответствующего схеме параллельного каскадного сверточного кодирования, согласно настоящему изобретению;
фиг.5 - упрощенная блок-схема, иллюстрирующая другой вариант циклического
MAP-декодера, используемого в качестве декодера компонента, для декодера, соответствующего схеме параллельного каскадного сверточного кодирования, согласно настоящему изобретению.
Детальное описание изобретения
На фиг. 1 представлена обобщенная блок-схема кодера 10, осуществляющего обработку по схемам параллельного каскадного кодирования. Он содержит множество N
кодеров компонентов 12, которые осуществляют обработку блоков битов данных, поступающих от источника. Блоки данных подвергаются перестановке согласно алгоритмам перемежения, реализуемым блоками
перемежения 14. Как показано на чертеже, множеству N кодеров 12 соответствуют N-1 блоков перемежения 14. Выходы кодеров компонентов объединены для формирования одного составного кодового слова с
помощью блока форматирования 16 кодового слова. Блок форматирования кодового слова соответствует характеристикам канала, и за ним может следовать блок форматирования кадра, соответствующий каналу и
методу доступа к каналу системы связи. Блок форматирования кадра может обеспечивать ввод необходимых дополнительных элементов, таких как контрольные биты и символы синхронизации.
Значительное преимущество, касающееся скорости кода, может быть получено при параллельном каскадном кодировании, если коды компонентов представляют собой систематические коды. Кодовые слова (полученные на выходе), генерируемые систематическим кодером, включают в себя биты исходных данных, являющихся входными для кодера, и дополнительные биты контроля четности. (Избыточность, обусловленная контрольными битами, обеспечивает возможность исправления ошибок кода.) Поэтому если в параллельном каскадном кодере, показанном на фиг. 1, используются систематические кодеры, то кодовые слова, формируемые всеми кодерами компонентов 12, содержат биты входных данных. Если блок форматирования 16 формирует пакет данных или составное кодовое слово, содержащее только биты контроля четности, генерируемые каждым кодером компонентов 12, и блок информационных битов, подлежащий кодированию, то достигается существенное улучшение в скорости составного параллельного каскадного кода за счет исключения повторения информационных битов в передаваемом составном кодовом слове. Например, если кодер компонента 1 и кодер компонента 2 параллельного каскадного сверточного кодера, содержащего только два кодера компонентов, оба имеют скорость кодов, определяемую как 1/2, то скорость составного параллельного каскадного кода увеличивается с 1/4 для несистематических кодов компонентов до 1/3 при использовании систематических кодов компонентов.
Схемы параллельного каскадного кодирования, которые используют рекурсивные систематические сверточные коды (RSC-коды), в последнее время стали предметом множества исследований. Такие параллельные каскадные сверточные коды в литературе известны как "турбо"-коды. Как отмечено выше, показано, что эти параллельные каскадные сверточные коды могут обеспечивать высокую эффективность в смысле коэффициента BER в зависимости от отношения Еb/N0 для случая относительно больших сообщений, например, состоящих из десяти тысяч или более битов. Однако также было показано, что выигрыш, получаемый за счет кодирования, обеспечиваемый "турбо"-кодами, существенно снижается, когда размер блока данных уменьшается, так как мощность кодов компонентов, представляющих собой рекурсивные систематические сверточные коды, весьма чувствительная к длине блока данных. С другой стороны, эффективность нерекурсивного систематического сверточного кода с конечной последовательностью битов не зависит от длины блока данных для большинства практических целей. Достигаемая эффективность снижается, только если блок кодируемых битов данных меньше, чем минимальный размер, который определяется свойствами глубины решения для NSC-кодов.
На фиг. 2 показана обобщенная блок-схема декодера 20,
используемого с параллельными каскадными кодами. Декодер 20 содержит следующие блоки: преобразователь 22 составного кодового слова в кодовые слова-компоненты, обеспечивающий преобразование составного
кодового слова, принятого из канала, в индивидуальные принятые кодовые слова для каждого декодера компонентов 24; N декодеров компонентов 24, соответствующих N кодерам компонентов, показанных на фиг.
1; блоки перемежения 14 того же типа, что и использованные в параллельном каскадном кодере по фиг.1; первый и второй блоки исключения перемежения 28 и 29 соответственно, каждый из которых имеет
характеристику переупорядочивания последовательности, которая эквивалентна последовательной цепочке из N-1 блоков исключения перемежения 30, соответственно N-1 блокам перемежения, использованных при
кодировании. Требуемый порядок этих блоков исключения перемежения показан на фиг.2 и является обратным порядку блоков перемежения по фиг. 1. На выходах декодеров компонентов 24 формируется информация
программируемого решения некоторого типа для оцениваемого значения каждого бита данных в принимаемом кодовом слове. Например, на выходах декодеров компонентов может быть сформирована первая функция
вероятностей, что декодированные биты представляют собой 0 или 1 при условии принятой последовательности символов из канала. Одним из примеров такой первой функции, которая устраняет влияние условной
вероятности P{djt=0/Yjt}, является вероятность того, что j-й информационный бит в момент t равен 0 при условии j-го (систематического) бита
принятого выходного символа Yt канала. Как вариант, информация программируемого решения, выдаваемого на выходе декодеров компонентов 24, может представлять собой функцию отношения
правдоподобия

или функцию логарифма отношения правдоподобия

Как показано N-ый декодер компонента имеет второй выход, например, второй функции условных вероятностей для декодируемых значений битов или указанных выше отношений правдоподобия. Примером такой второй функции является произведение P{djt=0/YL1} и априорной вероятности, что djt=0 принято от предыдущего декодера компонента.
Декодер для параллельных каскадных кодов работает итеративным методом следующим образом. Первый декодер компонента (декодер 1) вычисляет множество программируемых решений для последовательности информационных битов, кодированных первым кодером компонента, на основе принятого кодового слова и априорной информации о переданных информационных битах. В первой итерации, если отсутствует априорная информация о статистических характеристиках источника, предполагается, что биты могут с равной вероятностью принимать значения 0 и 1 ( т.е. Р{бит=0}=Р{бит=1}=1/2). Значения программируемых решений, вычисленные декодером 1, затем обрабатываются с перемежением с использованием блока перемежения того де типа (или того же самого блока), что был использован в кодере для обеспечения перестановки блока битов данных для второго кодера. Полученные значения программируемого решения с перестановкой и соответствующее принятое кодовое слово образуют входные данные для следующего декодера компонента (декодера 2). Значения программируемого решения с перестановкой, полученные от предыдущего декодера компонента и блока перемежения, затем используются следующим декодером компонента в качестве априорной информации о битах данных, которые должны быть декодированы. Декодеры компонентов осуществляют указанную обработку последовательно до тех пор, пока N-й декодер не вычислит множество выходных программируемых решений для блока битов данных, которые были закодированы кодером. На следующем этапе осуществляется исключение перемежения для значений программируемых решений с выхода N-го декодера, как описано выше. Затем первый декодер вновь осуществляет обработку принятого кодового слова, используя новые значения программируемого решения с N-го декодера в качестве априорной информации. Такая обработка в декодере осуществляется для желательного числа итераций. В заключение последней итерации последовательность значений, которые являются второй функцией выходных программируемых решений, вычисленных N-м декодером, обрабатывается для исключения перемежения и восстановления данных в порядке, в котором они были приняты параллельным каскадным сверточным кодером. Число итераций может быть задано предварительно, или может определяться динамически путем определения сходимости декодера.
Декодер обеспечивает информацию программируемого решения, которая является функцией вероятности P{djt=0/YL1}, т.е.
условной вероятности того, что j-й бит данных в k-битовом символьном входном сигнале кодера в момент t равен 0 при условии, что принимается множество канальных выходных сигналов YL1,={y1,..,yL}. Кроме того, декодер может обеспечить информацию непрограммируемого решения в функции своих выходных данных программируемого решения посредством
устройства принятия решения, которое реализует решающее правило, такое как

Это означает, что если P{djt=0/YL1}>1/2, то


Типовые турбо-декодеры используют либо MAP-декодеры, как описано в работе L.R.Bahl, J.Соске, F.Jelinek, J.Raviv,
"Optimal Decoding of Linear Codes for Minimizing Symbol error Rate", IEEE Transactions of Information Theory, March 1974, pp.284-287, или декодеры, использующие алгоритм Витерби для программируемых
выходных данных (SOVA-декодеры), как описано в работе J. Hagenauer. P.Hoeher, "A Viterbi Algorithm with Soft-Decision Outputs and its Applications, 1989 IEEE Globecom Conference, pp. 1680-1686.
MAP-декодер формирует вероятность того, что декодированное значение бита равно 0 или 1. С другой стороны, SOVA-декодер обычно вычисляет отношение правдоподобия

для каждого декодированного бита. Очевидно, что это отношение правдоподобия может быть получено из вероятности Р {декодированный бит имеет значение 0} и, наоборот, с использованием вероятности Р{декодированный бит имеет значение 0}=1-Р{декодированный бит имеет значение 1}. Некоторые преимущества в смысле вычислений могут быть получены, если MAP-декодеры или SOVA-декодеры определяют логарифм отношений правдоподобия, то есть

Показано, что выигрыш, получаемый за счет кодирования (возможность исправления ошибок), обеспечиваемый турбо-кодами, существенно снижается при уменьшении размера блока данных. Некоторые авторы объясняли данную закономерность в первую очередь свойствами RSC-кодов. Показано, что кодовое расстояние RSC-кода увеличивается с увеличением длины блока данных. И наоборот, минимальное кодовое расстояние RSC-кода уменьшается с уменьшением длины блока данных. Вторая проблема состоит в трудности завершения цикла обработки всех RSC-кодов, образующих схему турбо-кодирования, вследствие перемежения. К сожалению, отрицательные эффекты, обусловленные отсутствием завершения последовательности или наложением ограничений на схему блока перемежения, становятся тем более значительными при уменьшении длины блока данных.
В соответствии с настоящим изобретением коды компонентов в схеме параллельного каскадного кодирования содержат нерекурсивные систематические сверточные коды конечной последовательности битов. Использование таких кодов конечной последовательности битов решает проблему завершения цикла обработки входных последовательностей данных при турбо-кодировании и, тем самым, позволяет избежать ухудшения эффективности декодера для коротких сообщений. Хотя NSC-коды в общем случае более слабы, чем RSC-коды с той же самой памятью, свободное кодовое расстояние для NSC-кода менее чувствительно к длине блока данных. Следовательно, параллельное каскадное кодирование с использованием NSC-кодов будет более эффективно, чем с использованием RSC-кодов, при той же самой памяти для сообщений более коротких, чем предварительно определенное пороговое значение размера блока данных. Точка пересечения, определяющая эффективность, является функцией требуемой частоты ошибок в декодированных битах, скорости кода и памяти кода.
На фиг.3 представлен пример нерекурсивного систематического сверточного кодера с конечной последовательностью битов для скорости =1/2 и памяти = m, предназначенного для использования в схеме параллельного каскадного сверточного кодирования согласно настоящему изобретению. Для целей настоящего описания кодер, обозначенный как (n, k, m)-кодер, представляет собой кодер, для которого входные символы содержат k битов, выходные символы содержат n битов и m - память кодера в k-битовых символах. Для целей иллюстрации схема на фиг.3 показана для двоичных входных символов, т.е. k=1. Однако настоящее изобретение применимо для любых значений k, n, m.
Первоначально переключатель 50 находится в нижнем положении, и L входных битов записываются в регистр сдвига 52, по k за один раз (по одному входному символу за один раз для данного примера). После загрузки L-го бита в кодер переключатель устанавливается в верхнее положение, и кодирование начинается со сдвига пяти первых битов из второго регистра сдвига 54 в нерекурсивный систематический кодер; состояние кодера в этот момент соответствует {bL, bL-1,..., bL-(km-1)} В данном примере выходные данные кодера содержат текущий входной бит и бит контроля четности, сформированный в блоке 56 (показанном в данном примере как сумматор по модулю 2) в функции состояния кодера и текущего входного символа. Кодирование заканчивается, когда закодирован L-й бит.
Другой аспект настоящего изобретения связан с декодером, соответствующим вышеописанному параллельному каскадному кодеру, содержащим циклический MAP-декодер, как описано авторами настоящего изобретения в совместно поданной заявке на патент США (RD-24923). В частности, в указанной заявке описан циклический MAP-декодер, предназначенный для декодирования сверточных кодов с конечной последовательностью битов. Циклический MAP-декодер может вырабатывать как оценку блока кодированных данных, так и надежную информацию для приемника данных, например процессора синтеза речевого сигнала для использования при маскировании ошибок передачи или процессора протокола для пакетированных данных в качестве меры вероятности ошибок блока для использования при принятии решений о запросе повторения.
В частности, как описано в вышеуказанной заявке, циклический МАР-декодер для решетчатых кодов с исправлением ошибок, которые используют конечные последовательности битов, формирует выходные данные программируемого ("мягкого") решения. Циклический МАР-декодер обеспечивает оценку вероятностей состояний в первом каскаде решеточного кода, причем эти вероятности заменяют априорно известное начальное состояние в обычном МАР-декодере. Циклический МАР-декодер обеспечивает распределение вероятности начального состояния любым из двух способов. Первый из них связывает решение с задачей собственного значения, для которой результирующий собственный вектор представляет собой желательное распределение вероятности начального состояния. Зная начальное состояние, циклический МАР-декодер выполняет остальную часть декодирования в соответствии с обычным алгоритмом декодирования на основе максимума апостериорной вероятности. Второй способ основан на рекурсивной обработке для обеспечения сходимости итераций к распределению начального состояния. После достаточного количества итераций состояние циклической последовательности состояний известно с высокой вероятностью, и циклический МАР-декодер выполняет остальную часть обработки в соответствии с обычным алгоритмом декодирования по методу максимума апостериорной вероятности.
Задачей обычного алгоритма максимума апостериорной
вероятности является нахождение следующих условных вероятностей:
Р{состояние в момент времени t/выходные данные канала приема у1,...,уL}.
В этом выражении L представляет длину блока данных в единицах числа символов кодера. (Кодер для (n,k)-кода обрабатывает k-битовые входные символы для формирования n-битовых выходных символов.) Обозначение уt представляет собой выходные данные (символ) канала в момент t.
Алгоритм декодирования на основе максимума апостериорной вероятности прежде всего определяет
вероятности:
λt(m) = P{St= m; Y}; (1)
т. е.
совместную вероятность того, что состояние St кодера в момент t есть m и принято множество данных каналов YL1={y1,...,yL}. Это требуемые
вероятности, умноженные на постоянную (Р{YL1}, вероятность приема множества выходных данных каналов {y1,...,yL}).
Затем определяем
элементы матрицы Гt в следующем виде:
Гt(i,j)=Р{состояние j в момент t; уt состояние i в момент t-1}
Матрица Гt вычисляется как функция
вероятности перехода канала R(Yt, X), вероятности рt(m/m'), что кодер осуществляет переход из состояния m в состояние m' в момент времени t, и вероятности qt(X/m',m)
того, что выходной символ кодера есть Х, при условии, что предыдущее состояние кодера есть m', а текущее состояние кодера есть m. В частности, каждый элемент Гt вычисляется суммированием
всех возможных выходных данных Х кодера следующим образом:

МАР-декодер вычисляет L таких матриц, по одной для каждого решетчатого кода. Они формируются из принятых выходных символов канала с учетом свойства ветвей решетки для данного кода.
Затем определяется М элементов
совместной вероятности вектора-строки αt в виде

и М элементов условных вероятностей вектора-столбца βt в виде

для j= 0, 1,..., (М-1), где М - число состояний кодера, (матрицы и вектора обозначены жирным шрифтом. ) Этапы алгоритма МАР-декодирования можно представить следующим образом:
(i) Вычислить α1,...,αL посредством прямой рекурсии:
αt= αt-1Гt, t = 1,..,L. (5)
(ii) Вычислить β1,...,βL-1 посредством обратной рекурсии:
βt= Гt+1βt+1, t = L-1,...,1. (6)
(iii) Вычислить элементы λt согласно выражению
λt(i) = αt(i)βt(i), all i, t = 1,...,L. (7)
(iv) Найти связанные величины, если это необходимо. Например, пусть АJt -множество состояний St={S1t, S2t,..., Skmt) такое, что j-й элемент Sjt множества St равен нулю. Для обычного нерекурсивного решетчатого кода Sjt=djt, т.е. бит данных в момент t. Поэтому выходные данные программируемого решения декодера имеют вид

где

Выходные данные "жесткого" решения или
декодированные биты получают с использованием выражения P{djt=0/YL1} к следующему решающему правилу:

T.e. ecли P{djt=0/YL1}>1/2, то

если P{djt=0/YL1}<1/2, то

в других случаях djt принимает случайным образом значения 0 или 1.
В качестве другого
примера связанных значений для этапа (iv), упомянутого выше, можно привести матрицу вероятностей σt, содержащую элементы, как определено ниже:
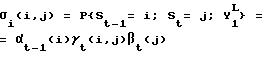
Эти вероятности можно использовать, когда желательно определить апостериорную вероятность выходных битов кодера.
В стандартном применении алгоритма МАР-декодирования прямая рекурсия инициализируется вектором α0= (1, 0,...,0), а обратная рекурсия инициализируется вектором βL= (1,0,..., 0)T. Эти начальные условия основываются на предположении, что начальное состояние кодера S0=0, а его конечное состояние SL=0.
В одном из вариантов циклического МАР-декодера определяется распределение вероятности начальных состояний путем решения задачи собственных значений следующим образом. Пусть αt, βt, Гt, λt будут теми же, что и ранее, а начальные α0 и βL определяются следующим образом: βL - вектор-столбец (111... 1 )T, а α0- неизвестная (векторная) переменная.
Тогда
(i) Вычислить Гt для t=1, 2,...L согласно уравнению
(2).
(ii) Найти максимальное собственное значение матричного произведения Г1 Г2. . .ГL Нормировать соответствующий собственный вектор так, чтобы его компоненты суммировались до единицы. Этот вектор представляет собой решение для α0. Собственное значение есть P(YL1).
(iii) Сформировать последующее значение αt путем прямой рекурсии согласно уравнению (5).
(iv) Начиная с βL, инициализированного, как указано выше, сформировать βt путем обратной рекурсии, как установлено в уравнении (6).
(v) Сформировать λt, как указано в уравнении (7), а также другие переменные, например выходные данные программируемого решения P{djt=0/YL1} или матрицу вероятностей σt, как описано выше.
Изобретателями показано, что неизвестная переменная α0 удовлетворяет матричному уравнению.
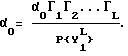
Из того факта, что эта формула выражает соотношение вероятностей, известно, что произведение Гt матриц в правой части имеет максимальное собственное значение, равное P{ YL1} , и что соответствующий собственный вектор должен быть вектором вероятности.
При первоначальном βL= (111...1)T уравнение (6) дает βL-1. Таким образом, повторное применение этой обратной рекурсии даст все значения βt. Если α0 известно, a βL установлено, все вычисления в циклическом МАР-декодере в соответствии с изобретением осуществляются согласно обычному алгоритму МАР-декодирования.
На фиг.4 представлена упрощенная блок-схема, иллюстрирующая циклический МАР-декодер 110 для декодирования решетчатого кода с конечной последовательностью битов с исправлением ошибок в соответствии со способом, использующим собственный вектор, как описано выше. Декодер 110 содержит вычислитель Гt, осуществляющий вычисление Гt в функции выходных данных канала уt. Вычислитель 112 получает на своих входах из памяти 130 следующие величины: вероятность перехода канала R(Yt/X), вероятность pt(m/m') того, что кодер осуществил переход из состояния m' в состояние m в момент t, и вероятность qt((X/m', m) того, что выходной символ кодера есть X при условии, что предыдущее состояние кодера есть m', а текущее состояние кодера - m. Вычислитель 112 вычисляет каждый элемент Гt путем суммирования по всем возможным выходным данным Х кодера в соответствии с уравнением (2).
Вычисленные
значения Гt подаются на вычислитель произведения матриц 114 для формирования матричного произведения Г1, Г2...ГL с использованием единичной матрицы 116,
например, из памяти переключателя 118 и схемы задержки 120. В момент t=l единичная матрица подается на вход вычислителя матричного произведения. Для каждого последующего момента времени с t=2 до t=L
матричное произведение

подается назад через схему задержки на вычислитель матричного произведения. Затем в момент времени t=L полученное матричное произведение подается через переключатель 121 на вычислитель нормированного собственного вектора 122, который вычисляет нормированный собственный вектор, соответствующий максимальному собственному значению матричного произведения, введенного в него. Если таким образом инициализировано α0, т.е. как этот нормированный собственный вектор, последующие вектора αt определяются рекурсивно в соответствии с уравнением (5) в вычислителе матричного произведения 124 с использованием задержки 126 и переключателя 128. Соответствующие значения Гt извлекаются из памяти 130, и полученные значения αt запоминаются в памяти 130.
Значения βt определяются в вычислителе матричного произведения 132 с использованием переключателя 134 и задержки 136 в соответствии с уравнением (6). Затем с использованием значений αt и βt вычисляются вероятности λt в вычислителе поэлементного произведения 140 согласно уравнению (7). Значения λt/ подаются на вычислитель вероятности значений декодированных битов 150, который определяет вероятность того, что j-й декодированный бит в момент времени t, т.е. dt, равен нулю. Эта вероятность подается на устройство пороговой обработки 152, которое реализует следующее решающее правило: если вероятность с вычислителя 150 превышает 1/2, то принимается решение, что декодированный бит равен нулю; если вероятность меньше 1/2, то принимается решение, что декодированный бит равен единице; если вероятность равна 1/2 то декодированному биту случайным образом присваивается значение 0 или 1. Выходное значение устройства пороговой обработки соответствует биту на выходе декодера в момент времени t.
Вероятность того, что декодированный бит равен нулю, т.е. P(djt=0/Yjt), также подается, как показано на фиг. 4, на блок 154 определения функции "мягкого" выходного результата для определения функции вероятности, т.е. f(P{djt=0/Yjt)), так, чтобы, например,

в качестве выходного результата "мягкого" решения декодера. Кроме того. может быть использована другая функция P(djt=0/Yjt),

Как вариант, полезной функцией для блока 154 может быть просто единичная функция, так что программируемое выходное решение соответствует просто P(djt=О/Yjt).
Альтернативный вариант осуществления МАР-декодера определяет
распределения вероятности состояния путем рекурсивного метода. В частности, в одном из вариантов осуществления (метод динамической сходимости) рекурсия продолжает осуществляться, пока не будет
обнаружена сходимость декодера. В этом рекурсивном методе (или методе динамической сходимости) этапы (ii) и (iii) метода собственного вектора, описанного выше, заменяются следующим образом:
(ii.a) Начиная с начального α0 равного (1/М,...,1/М), где М - число состояний в решетчатом коде, вычислить рекурсию вперед L раз. Нормировать результаты так, чтобы элементы каждого
нового αt суммировались до единицы. Сохранить все L векторов αt.
(ii.b) Принимая α0 равным αL из предыдущего этапа и
начиная с момента t= 1, вычислить первые Lwmin векторов αt. Т.е. вычислить

для m=0, 1,...,М-1 и t=1, 2,..., Lwmin,
где Lwmin соответствующее минимальное число каскадов решетчатого кода. Осуществить нормировку, как описано выше. Сохранить только самое последнее множество из L векторов α, найденных путем рекурсивного вычисления согласно этапам (ii.a) и (ii.b), и αLwmin найденное ранее на этапе (ii.a).
(ii. c) Сравнить αLwmin полученное на этапе (ii.b) с ранее полученным множеством, полученным на этапе (ii.a). Если М соответствующих элементов их нового и старого значения αLwmin находятся в пределах поля допуска, то перейти к этапу (iv), как описано выше. В противном случае продолжать обработку согласно этапу (ii.d).
(ii.d) При t=t+1 вычислить αt= αt-1Гt. Осуществить нормировку, как и ранее. Сохранить только самое последнее множество из L вычисленных векторов α и αt, полученные ранее на этапе (ii.a).
(ii. e) Сравнить новые значения αt с ранее найденным множеством. Если М новых и старые αt находятся в пределах поля допуска, то перейти к этапу (iv). В противном случае продолжить обработку с этапа (ii.d), если два самых последних вектора не совпадают в пределах поля допуска и если число рекурсий не превысило определенный максимум (в типовом случае 2L); в противном случае перейти к этапу (iv).
Данный способ затем продолжается обработкой на этапах (iv) и (v), описанных выше для способа с использованием собственных векторов, для получения выходных результатов "мягкого" (программируемого) решения и декодированных выходных битов циклического МАР-декодера.
В другом варианте осуществления циклического МАР-декодера, как описано в заявке на патент США (RD-24923), способ рекурсии, описанный выше, модифицирован таким образом, что декодеру необходимо только обрабатывать предварительно определенное фиксированное число каскадов решеточного кода для второго раза, т. е. на предварительно определенную глубину цикла. Это дает преимущества при реализации, так как количество вычислений. требуемых для декодирования, одно и то же для каждого кодированного блока сообщений. Соответственно, снижается сложность аппаратных средств и программного обеспечения.
Возможный способ оценки требуемой глубины цикла для МАР-декодирования сверточного кода с конечной последовательностью битов состоит в определении ее из экспериментов с аппаратными средствами или с программным обеспечением при условии, что необходимо осуществить циклический МАР-декодер с переменной глубиной цикла, причем эксперименты должны проводиться для измерения частоты ошибок в декодированных битах данных в зависимости от отношения Еb/N0 для последовательно возрастающих значений глубины цикла. Минимальная глубина цикла декодера, которая обеспечивает минимальную вероятность ошибки декодированных битов данных для конкретного значения отношения Еb/N0 находится при условии, когда дальнейшее увеличение глубины цикла не снижает вероятности ошибки.
Если частота ошибок в декодированных битах данных, которая превышает минимально достижимую при конкретном значении отношения Еb/N0, допустима, то возможно уменьшить требуемое число каскадов решетчатого кода, обрабатываемых МАР-декодером. В частности, поиск глубины цикла, как описано выше, может быть просто завершен, когда получена желаемая вероятность ошибки в битах данных.
Другим способом определения глубины цикла для данного кода является использование свойств кодового расстояния. С этой целью необходимо определить две различные глубины для принятия решения в декодере. Как использовано в настоящем описании, термин "корректный путь" относится к последовательности состояний или к пути через решетчатый код, который вытекает из кодирования блока битов данных. Термин "некорректное подмножество узла" относится к множеству некорректных (решетчатых) ответвлений из узла корректного пути и их "спускам". Обе глубины решений, определенные ниже, зависят от сверточного кодера.
Глубины решений определяются следующим образом.
(i) Определить глубину прямого решения для исправления е-ошибки, LF(e), в качестве первой глубины в решетчатом коде, при которой все пути в некорректном подмножестве исходного узла корректного пути, независимо от того, сливается ли этот узел с корректным путем или нет, лежат более чем на Хэмминговом расстоянии 2е от корректного пути. Важность параметра LF(e) состоит в том, что если е или менее ошибок имеется перед исходным узлом, и известно, что кодирование начато в той позиции, то декодер должен осуществлять корректное декодирование. Формальное табулирование глубин прямого решения для сверточных кодов было проведено в работе J.B.Anderson. K.Balachandran, "Decision Depth of Convolutional Codes", IEEE Transactions on Information Theory, vol. IT-35, pp.455-59, March 1989. Ряд свойств параметра LF(e) был описан в указанной работе, а также в работе J.B.Anderson, S.Mohan, "Source and Channel Coding An Algorithmic Approach, Kluwer Academic Publishers, Norwell, MA, 1991. Главным из этих свойств является то, что существует простое линейное соотношение между LF и е, например, для кодов скорости 1/2 параметр LF примерно равен 9,08е.
(ii) Затем определить глубину решения без слияния для исправления е-ошибок, т.е. LU(е), которая определяется как первая глубина в решетчатом коде, при которой все пути в решетчатом коде, которые нигде не касаются корректного пути, лежат более чем на Хэмминговом расстоянии 2е от корректного пути.
Важность параметра LU(e) для циклического МАР-декодирования с принятием программируемого решения состоит в том, что вероятность идентификации состояния на действительно переданном пути высока после того, как декодер обработает LU(e) каскадов решетчатого кода. Поэтому минимальная глубина цикла для циклического МАР-декодирования равна LU(е). Вычисления глубины LU(е) показывают, что она всегда больше, чем LF(e), но что она подчиняется тому же самому аппроксимирующему закону. Это означает, что минимальная глубина цикла может быть оценена как глубина прямого решения LF(e), если глубина решения без слияния для кода не известна.
Путем нахождения минимальной глубины решения без слияния для данного кодера тем самым находим наименьшее число каскадов решетчатого кода, которое должно
быть обработано конкретным циклическим декодером, который генерирует выходные результаты "мягкого" (программируемого) решения. Алгоритм нахождения LF(e), т.е. глубины прямого решения, был представлен
в работе J.B.Anderson, К. Balachandran, "Decision Depths of Convolutional Codes", упомянутой выше. Для определения LU(e) необходимо осуществить следующую обработку:
(i) Вытянуть "решетку"
кода слева направо, начиная со всех узлов решетчатого кода, за исключением нулевого состояния.
(ii) На каждом уровне исключить любые пути, которые сливаются с корректным (все нули) путем; не растягивать какие-либо пути за пределы узла корректного (нулевого) состояния.
(iii) На уровне k найти наименьшее Хэммингово расстояние, или вес, среди всех путей, завершающихся в узлах на этом уровне.
(iv) Если это наименьшее расстояние превышает 2е, то прекратить обработку. Тогда LU(e)=k.
Как описано в заявке на патент США
(RD-24923), эксперименты с использованием математического моделирования привели к двум неожиданным результатам: (1) циклическая обработка βe привела к повышению эффективности
декодера; (2) использование глубины цикла LU(е)+LF(e)≈2LF(e) существенно повысило эффективность. Следовательно, предпочтительный вариант алгоритма для циклического МАР-декодера, основанного на
рекурсивной обработке, включает следующие этапы:
(i) Вычислить Гt для t=1, 2,..., L в соответствии с уравнением (2).
(ii) Начиная с исходного α0, равного (1/М,....1/М), где М - число состояний в решетчатом коде, вычислить рекурсию вперед уравнения (5) (L+Lw) раз для u= 1, 2, ...(L+Lw), где Lw - глубина цикла декодера. Индекс уровня решетчатого кода t принимает значения ((u-1)modL)+1. Когда декодер осуществляет циклическую обработку принятой последовательности символов из канала, αL обрабатывается как α0. Осуществить нормировку результатов так, чтобы элементы каждого нового вектора αt суммировались до единицы. Сохранить L самых последних векторов α, найденных посредством этой рекурсивной обработки.
(iii) Начиная с исходного βL, равного (1,...,1)T, вычислить обратную рекурсию согласно уравнению (6) (L+Lw) раз для u=1, 2,...(L +Lw). Индекс уровня решетчатого кода t принимает значения L-(u modL). Когда декодер осуществляет циклическую обработку принятой последовательности, β1 используется как βL+1, а Г1 используется как Г1+1 при вычислении нового βL. Осуществить нормировку результатов так, чтобы элементы каждого нового вектора βt суммировались до единицы. Сохранить L самых последних векторов β, найденных посредством этой рекурсивной обработки.
Следующий этап этого предпочтительного способа рекурсивной обработки является тем же самым, что и этап (v), описанный выше относительно способа собственных векторов, для получения "мягких" решений и выходных декодированных битов с использованием циклического МАР-декодера.
На фиг.5 представлена упрощенная блок-схема, иллюстрирующая циклический МАР-декодер 180, выполненный в соответствии с данным предпочтительным вариантом осуществления изобретения. Декодер 180 содержит вычислитель Гt 182 для вычисления Гt как функции выходных данных канала yt. Выходные данные y1, ..., yL подаются на вычислитель Гt через переключатель 184. Когда переключатель установлен в нижнее положение, L выходных символов каналов загружаются в вычислитель Гt 182 и в регистр сдвига 186 по одному в каждый момент времени. Затем переключатель 184 перемещается в верхнее положение, обеспечивая перемещение первых Lw принятых символов в вычислитель Гt для обеспечения циклической обработки. Вычислитель Гt получает на своих входах из памяти 196 вероятность перехода канала R(Yt,X), вероятность pt(m/m') того, что кодер осуществил переход из состояния m' в состояние m в момент t, и вероятность qt(X/m', m) того, что выходной символ кодера есть X, при условии, что предыдущее состояние кодера есть m', а текущее состояние кодера m. Вычислитель 182 вычисляет каждый элемент Гt путем суммирования по всем возможным выходным данным Х кодера в соответствии с уравнением (2).
Вычисленные значения Гt подаются на вычислитель матричного произведения 190, который умножает матрицу Гt на матрицу αt-1, которая рекурсивно выдается с помощью элемента задержки 192 и схемы демультиплексора 194. Управляющий сигнал CNTRL1 обеспечивает в демультиплексоре 194 выбор α0 из памяти 196 в качестве входных данных для вычислителя матричного произведения 190 при t= 1. Когда 2≤t≤L, управляющий сигнал CNTRL1 обеспечивает в демультиплексоре 194 выбор αt-1 с элемента задержки 192 в качестве входных данных для вычислителя матричного произведения 190. Значения Гt и αt запоминаются в памяти 196, если это необходимо.
Вектора βt вычисляются рекурсивно в вычислителе матричного произведения 200 с помощью элемента задержки 202 и схемы демультиплексора 204. Управляющий сигнал CNTRL2 обеспечивает в демультиплексоре 204 выбор βL из памяти 196 в качестве входных данных для вычислителя матричного произведения 200 при t= L-1. Когда L-2≥t≥1, управляющий сигнал CNTRL2 обеспечивает в демультиплексоре 204 выбор βt+1 с элемента задержки 122 в качестве входных данных для вычислителя матричного произведения 200. Полученные в результате значения βt умножаются на значения αt, получаемые из памяти 196, в вычислителе поэлементных произведений 206 для получения вероятностей λt как описано выше. Тем же самым способом, как описано выше со ссылками на фиг.4, значения λt подаются на вычислитель 150 вероятности значения декодированных битов, выходной результат которого подается на устройство пороговой обработки 152, в результате чего формируются декодированные выходные биты декодера.
Условная
вероятность P(djt= 0/Yjt) того, что декодированный бит равен нулю, также показана на фиг.5, как подаваемая на функциональный блок 154
программируемого выходного результата, для получения функции вероятности, т. е. f(P(djt=0/Yjt)), например в виде

в качестве выходного результата программируемого решения. Другой полезной функцией вероятности является (P(djt=0/Yjt)) является

Как вариант, полезной функцией для блока 154 может быть просто единичная функция, так что программируемый выходной результат равен (P(djt=0/Yjt )).
В соответствии с настоящим изобретением также возможно увеличить частоту схемы параллельного каскадного кодирования, содержащую нерекурсивные систематические коды с конечными последовательностями битов путем исключения выделенных битов в составном кодовом слове, формируемом блоком форматирования составного кода в соответствии с предпочтительно выбранной комбинацией, перед передачей битов составного кодового слова в канале. Этот метод известен как "пробивание". Схема такого "пробивания" известна в декодере. Следующий простой дополнительный этап, выполняемый преобразователем принятого составного кодового слова в кодовые слова-компоненты, обеспечивает желательную операцию декодера: преобразователь принятого составного кодового слова в кодовые слова-компоненты просто вводит нейтральное значение для каждого известного "пробиваемого" бита в процессе формирования принятых кодовых слов-компонентов. Например, нейтральное значение используется для случая диаметрально противоположной ("антиподной") сигнализации в канале аддитивного белого гауссова шума. Остальная часть операций обработки в декодере такая, как описано выше.
До сих пор считалось, что нерекурсивные систематические сверточные коды (NSC-коды) не могут использоваться в качестве кодов компонентов в схеме параллельного каскадного кодирования ввиду того, что наилучшими свойствами кодового расстояния обладают рекурсивные систематические коды сверточные (RSC-коды), как показано, например, в работе S. Benedetto, G.Montorsi, "Design of Parallel Concatenated Convolutional Codes, "IEEE Transaction on Communications", подготовленной к публикации. Однако, как описано выше, изобретателями определено, что минимальное расстояние NSC-кода менее чувствительно к длине блока данных, и поэтому это свойство может быть использовано с выгодой в системах связи, которые передают короткие блоки битов данных в очень зашумленных каналах. Кроме того, изобретателями определено, что использование кодов с конечной последовательностью битов решает проблему завершения последовательностей входных данных в турбо-кодах. Использование сверточных кодов как кодов компонентов в схеме параллельного каскадного кодирования ранее не предлагалось. Следовательно, настоящее изобретение предусматривает схему параллельного каскадного нерекурсивного систематического сверточного кодирования с конечной последовательностью битов с использованием декодера, включающего в себя циклические МАР-декодеры для декодирования сверточных кодов компонентов с конечной последовательностью битов для обеспечения лучших характеристик для коротких длин блоков данных, по сравнению с обычными схемами сверточного турбо-кодирования, измеряемых через частоту ошибок в битах данных в зависимости от отношения сигнал/шум.
Реферат
Изобретение относится к кодированию с исправлением ошибок, используемому при передаче коротких сообщений по каналам низкого качества, и, более конкретно, к способу параллельного каскадного сверточного кодирования и к соответствующему устройству декодирования. Технический результат повышение точности кодирования и декодирования при применении коротких сообщений. Схема параллельного каскадного сверточного кодирования использует нерекурсивные систематические сверточные коды с конечной последовательностью битов. Соответствующий декодер осуществляет циклическое декодирование по методу максимума апостериорной вероятности для формирования выходных результатов непрограммируемого и программируемого решений. Данная схема кодирования/декодирования обеспечивает повышение эффективности исправления ошибок для коротких сообщений. 6 с. и 30 з.п.ф-лы, 5 ил.

Комментарии