Повышение разборчивости речи с помощью четкости голоса - RU2469423C2
Код документа: RU2469423C2
Чертежи



Описание
Область техники
Изобретение относится к обработке аудиосигнала. В частности, оно относится к процессору или способу обработки для повышения разборчивости речи и очистки зашумленного речевого аудиосигнала. Изобретение также относится к компьютерным программам для практического осуществления таких способов или управления таким устройством.
Ссылки на литературные источники
Следующие публикации, таким образом, включены посредством ссылки, каждая в полном объеме.



Сущность изобретения
Согласно первому аспекту изобретения, речевые компоненты аудиосигнала, состоящего из речевых и шумовых компонентов, улучшают. Аудиосигнал изменяют из временной области во множество поддиапазонов в частотной области. Затем обрабатывают поддиапазоны аудиосигнала. Обработка включает в себя управление усилением аудиосигнала в некоторых из упомянутых поддиапазонов, при этом усилением в поддиапазоне управляют, по меньшей мере, процессами, которые переносят либо аддитивные/субтрактивные разности в усилении, либо мультипликативные отношения усиления для того, чтобы (1) снижать усиление в поддиапазоне, когда уровень шумовых компонентов увеличивается по отношению к уровню речевых компонентов в поддиапазоне, и (2) увеличивать усиление в поддиапазоне при присутствии речевых компонентов в поддиапазонах аудиосигнала. Все процессы реагируют на поддиапазоны аудиосигнала и управляют усилением независимо друг от друга для обеспечения обработанного аудиосигнала поддиапазона. Обработанный аудиосигнал поддиапазона изменяют из частотной области во временную область для обеспечения аудиосигнала, в котором речевые компоненты улучшены.
Процессы могут включать в себя процесс повышения разборчивости речи, который реагирует на поддиапазоны аудиосигнала для снижения усиления в таких поддиапазонах, когда уровень шумовых компонентов увеличивается по отношению к уровню речевых компонентов в таких поддиапазонах.
Процессы могут включать в себя процесс четкости голоса, который реагирует на поддиапазоны аудиосигнала для увеличения усиления в некоторых из поддиапазонов при присутствии речевых компонентов в поддиапазонах аудиосигнала. Увеличение усиления может быть снижено в соответствии с временным сглаживанием при переходе от присутствия речевых компонентов к отсутствию речевых компонентов.
Процессы также могут включать в себя процесс детектирования голосовой активности, который реагирует на поддиапазоны аудиосигнала для определения присутствия речи в зашумленном речевом сигнале, причем процесс четкости голоса также реагирует на упомянутый процесс детектирования голосовой активности.
Когда процессы включают в себя процесс детектирования голосовой активности, который реагирует на поддиапазоны аудиосигнала для определения присутствия речи в зашумленном речевом сигнале, причем каждый из процессов повышения разборчивости речи и четкости голоса также может реагировать на процесс детектирования голосовой активности.
Согласно другому аспекту изобретения, речевые компоненты аудиосигнала, состоящего из речевых и шумовых компонентов, улучшают. Аудиосигнал изменяют из временной области во множество поддиапазонов в частотной области. Затем обрабатывают поддиапазоны аудиосигнала. Обработка включает в себя увеличение усиления в поддиапазоне при присутствии речевых компонентов в поддиапазонах аудиосигнала для обеспечения обработанного аудиосигнала поддиапазона. Поддиапазоны обработанного аудиосигнала поддиапазона обрабатывают, причем обработка включает в себя управление усилением обработанного аудиосигнала поддиапазона в некоторых из упомянутых поддиапазонов, при этом усиление в поддиапазоне снижают, когда уровень шумовых компонентов увеличивается по отношению к уровню речевых компонентов в поддиапазоне для обеспечения дополнительно обработанного аудиосигнала поддиапазона. Дополнительно обработанный аудиосигнал поддиапазона изменяют из частотной области во временную область для обеспечения аудиосигнала, в котором речевые компоненты улучшены.
Обработка может включать в себя процесс повышения разборчивости речи, который реагирует на обработанные поддиапазоны аудиосигнала для снижения усиления в таких поддиапазонах, когда уровень шумовых компонентов увеличивается по отношению к уровню речевых компонентов в таких поддиапазонах.
Дополнительно обработка может включать в себя процесс четкости голоса, который реагирует на поддиапазоны аудиосигнала для увеличения усиления в некоторых из поддиапазонов при присутствии речевых компонентов в поддиапазонах аудиосигнала. Увеличение усиления может быть снижено в соответствии с временным сглаживанием при переходе от присутствия речевых компонентов к отсутствию речевых компонентов.
Обработка и/или дополнительная обработка может включать в себя процесс детектирования голосовой активности, который реагирует на поддиапазоны аудиосигнала для определения присутствия речи в зашумленном речевом сигнале, причем процесс четкости голоса также реагирует на процесс детектирования голосовой активности.
Обработка и/или дополнительная обработка может включать в себя процесс детектирования голосовой активности, который реагирует на поддиапазоны аудиосигнала для определения присутствия речи в зашумленном речевом сигнале, причем каждый из упомянутых процессов повышения разборчивости речи и четкости голоса также реагирует на процесс детектирования голосовой активности.
Обработка может включать в себя процесс детектирования голосовой активности, который реагирует на поддиапазоны аудиосигнала для определения присутствия речи в зашумленном речевом сигнале, причем каждый из упомянутых процессов повышения разборчивости речи и четкости голоса также реагирует на процесс детектирования голосовой активности.
Краткое описание чертежей
Фиг.1 является функциональной блок-схемой, показывающей иллюстративный вариант осуществления изобретения.
Фиг.2 является функциональной блок-схемой, показывающей альтернативный иллюстративный вариант осуществления изобретения.
Фиг.3 является графиком, показывающим значение GVCk(m) как функцию Ek(m)/Emax(m).
Фиг.4 является блок-схемой последовательности операций способа, относящейся к иллюстративному варианту осуществления с фиг.1.
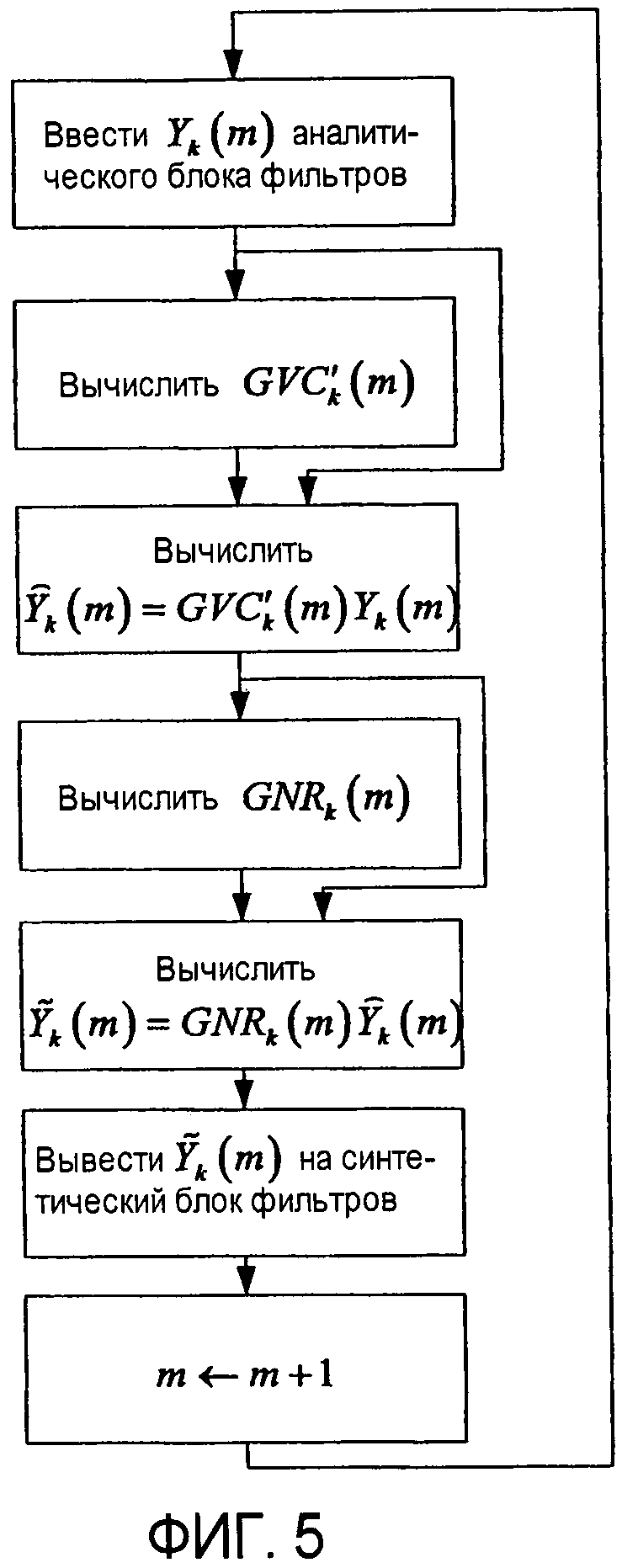
Фиг.5 является блок-схемой последовательности операций способа, относящейся к иллюстративному варианту осуществления с фиг.2.
Предпочтительные варианты осуществления изобретения
На фиг.1 показан иллюстративный вариант осуществления аспектов настоящего изобретения согласно первой топологической функциональной конфигурации. Входной сигнал генерируется путем оцифровки аналогового речевого сигнала, который поддерживает как чистую речь, так и шум. Затем этот неизменный аудиосигнал y(n) ("зашумленная речь"), где n=0, 1, ... - временной индекс, посылается на устройство или функцию аналитического блока фильтров ("Аналитический блок фильтров") 2, с созданием K множественных сигналов поддиапазона, Yk(m), k=1, …, K, m=0, 1, ..., ∞, где k является номером поддиапазона и m является временным индексом каждого сигнала поддиапазона. Аналитический блок фильтров 2 изменяет аудиосигнал из временной области во множество поддиапазонов в частотной области.
Сигналы поддиапазона поступают на устройство или функцию шумоподавления ("Повышение разборчивости речи") 4, детектор или функцию детектирования голосовой активности ("VAD") 6, и улучшитель или функцию улучшения четкости голоса ("Четкость голоса") 8.
В ответ на входные сигналы поддиапазона и, в необязательном порядке, в ответ на VAD 6 повышение 4 разборчивости речи управляет масштабным коэффициентом GNRk(m) усиления, который масштабирует амплитуду сигналов поддиапазона. Такое применение масштабного коэффициента усиления к сигналу поддиапазона символически показано символом 10 умножения. Для ясности представления на фигурах подробно показаны генерация и применение масштабного коэффициента усиления только к одному из множественных сигналов (k) поддиапазона.
Значение масштабного коэффициента GNRk(m) усиления управляется повышением 4 разборчивости речи, благодаря чему поддиапазоны, где преобладают шумовые компоненты (с низким отношением сигнал-шум ("SNR")), сильно подавляются, тогда как поддиапазоны, где преобладает речь (с высоким SNR), сохраняются. Значение GNRk(m) уменьшается (более сильное подавление) в частотных областях (поддиапазонах), в которых уменьшается отношение (SNR) сигнал-шум, и наоборот.
В ответ на входные сигналы поддиапазона VAD 6 определяет присутствие речи в зашумленном речевом сигнале y(n), обеспечивая, например, выход VAD=1 при присутствии речи и выход VAD=0 при отсутствии речи.
В ответ на входные сигналы поддиапазона и в ответ на VAD 6 четкость 8 голоса управляет масштабным коэффициентом GVC'k(n) усиления, который масштабирует амплитуду сигналов поддиапазона. Такое применение масштабного коэффициента усиления к сигналу поддиапазона символически показано символом 12 умножения. Значение масштабного коэффициента GVC'k (m) усиления управляется четкостью 8 голоса таким образом, чтобы поднимать поддиапазоны, важные для артикуляции речи. Четкость 8 голоса управляется VAD 6 таким образом, чтобы коэффициент GVC'k(m) усиления обеспечивал подъем в, по меньшей мере, части частотного спектра голоса при присутствии речи. Как дополнительно объяснено ниже, можно применять сглаживание для минимизации внесения слышимых артефактов при отключении подъема в отсутствие речи.
Таким образом, улучшенные речевые сигналы
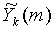

Символ точки ("·") указывает умножение. Масштабные коэффициенты GNRk(m) и GVC'k(m) усиления можно применять к неулучшенным входным сигналам Yk(m) поддиапазона в любом порядке - повышение 4 разборчивости речи и четкость 8 голоса не связаны друг с другом и действуют независимо от сигналов поддиапазона.
Затем обработанные сигналы
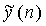
Аудиоустройства и процессы поддиапазона могут использовать или аналоговые, или цифровые технологии, или сочетание двух технологий. Блок фильтров поддиапазона можно реализовать посредством блока цифровых полосовых фильтров или блока аналоговых полосовых фильтров. Для цифровых полосовых фильтров входной сигнал дискретизируется до фильтрации. Выборки проходят через блок цифровых фильтров и затем подвергаются понижающей дискретизации для получения сигналов поддиапазона. Каждый сигнал поддиапазона содержит выборки, представляющие часть спектра входного сигнала. Для аналоговых полосовых фильтров входной сигнал делится на несколько аналоговых сигналов, каждый их которых имеет полосу, соответствующую полосе полосового фильтра блока фильтров. Аналоговые сигналы поддиапазона можно оставить в аналоговой форме или преобразовать в цифровую форму путем дискретизации и квантования.
Аудиосигналы поддиапазона также можно получать с использованием преобразующего кодера, который реализует любое одно из нескольких преобразований из временной области в частотную область и который функционирует как блок цифровых полосовых фильтров. Дискретизированный входной сигнал делится на "блоки выборок сигнала" до фильтрации. Один или более соседних коэффициентов преобразования или бинов можно группировать вместе для задания "поддиапазонов", эффективные полосы которых являются суммами полос отдельных коэффициентов преобразования.
Хотя изобретение можно реализовать с использованием аналоговых или цифровых технологий или даже смешанной конфигурации таких технологий, изобретение удобнее реализовать с использованием цифровых технологий, и раскрытые здесь предпочтительные варианты осуществления являются цифровыми реализациями. Таким образом, аналитический блок фильтров 2 и синтетический блок фильтров 14 можно реализовать в виде любого подходящего блока фильтров и блока обратных фильтров или преобразования и обратного преобразования соответственно.
На фиг.2 показан иллюстративный вариант осуществления настоящего изобретения согласно альтернативной топологической функциональной конфигурации. Устройства и функции, соответствующие показанным на фиг.2, обозначены теми же позициями.
Фиг.2 отличается от фиг.1 тем, что повышение 4 разборчивости речи и четкость 8 голоса не отделены друг от друга и не действуют независимо от сигналов поддиапазона. Сигналы поддиапазона поступают сначала на четкость 8 голоса и VAD 6. Масштабный коэффициент GVC'k(m) усиления четкости голоса поступает на умножитель 12. Как и в топологии на фиг.1, четкость 8 голоса управляется VAD 6 таким образом, чтобы коэффициент GVC'k(m) усиления избирательно обеспечивал подъем при присутствии речи. В отличие от топологии на фиг.1, повышение 4 разборчивости речи принимает и действует на сигналах


Символ точки ("·") указывает умножение.
Обе топологии на фиг.1 и фиг.2 позволяют использовать повышение разборчивости речи на основе подавления шума и подъема сигнала без подъема сигнала, аннулирующего подавление шума.
Хотя на фиг.1 и 2 показано, что масштабные коэффициенты усиления мультипликативно управляют амплитудами поддиапазонов, специалистам в данной области техники очевидно, что можно применять эквивалентные аддитивные/субстрактивные конфигурации.
Блок-схема последовательности операций способа, показанная на фиг.5, показывает процесс, лежащий в основе иллюстративного варианта осуществления, на фиг.2. Как и в блок-схеме последовательности операций способа с фиг.4, последний этап указывает, что временной индекс m затем продвигается на единицу ("m←m+1"), и процесс с фиг.5 повторяется.
Повышение 4 разборчивости речи
Различные устройства и функции улучшения спектра могут быть полезны при реализации повышения 4 разборчивости речи в практических вариантах осуществления настоящего изобретения. Среди таких устройств и функций улучшения спектра существуют те, которые используют блоки оценки уровня шума на основе VAD, и те, которые используют блоки статистической оценки уровня шума. Такие полезные устройства и функции улучшения спектра могут включать в себя описанные в литературных источниках 1, 2, 3, 6 и 7, перечисленных выше, и в следующих четырех предварительных патентных заявках США:
(1) "Noise Variance Estimator for Speech Enhancement" от Rongshan Yu, за №60/918,964, поданной 19 марта 2007 г.;
(2) "Speech Enhancement Employing a Perceptual Model" от Rongshan Yu, за №60/918,986, поданной 19 марта 2007 г.; и
(3) "Speech Enhancement with Noise Level Estimation Adjustment," от Rongshan Yu, за №60/993,548, поданной 12 сентября 2007 г.
(4) "Speech Enhancement," от C. Philip Brown, за №60/993,601, поданной 12 сентября 2007 г.
Коэффициент GNRk(m) усиления повышения разборчивости речи можно называть "подавительным усилением", поскольку его целью является подавление шума. Один способ управления подавительным усилением известен как "спектральное вычитание" (ссылки [1], [2] и [7]), в котором подавительное усиление GNRk(m), применяемое к сигналу Yk(m) поддиапазона, можно выразить в виде:

где Yk(m) является амплитудой сигнала Yk(m) поддиапазона, λk(m) является энергией шума в поддиапазоне k и a>1 является коэффициентом "перевычитания", который выбирается так, чтобы гарантировать применение достаточного подавительного усиления. "Перевычитание" дополнительно объясняется в источнике [7] на странице 2 и в источнике [6] на странице 127.
Для определения надлежащих величин подавительных усилений важно иметь точную оценку энергии шума для поддиапазонов во входящем сигнале. Однако это не является тривиальной задачей, когда шумовой сигнал смешан вместе с речевым сигналом во входящем сигнале. Один путь решения этой проблемы состоит в использовании блока оценки уровня шума на основе детектирования голосовой активности, который использует автономный детектор (VAD) голосовой активности для определения, присутствует ли речевой сигнал во входящем сигнале или нет. Энергия шума обновляется в течение периода отсутствия речи (VAD=0). См., например, источник [3]. В таком блоке оценки шума оценка λk(m) энергии шума для времени m может задаваться в виде:

Начальное значение оценки λk(-1) энергии шума может быть установлено на нуль или установлено на энергию шума, измеренную на стадии инициализации процесса. Параметр β является коэффициентом сглаживания, имеющим значение 0<<β<1. В отсутствие речи (VAD=0) оценку энергии шума можно получить с применением временного сглаживателя первого порядка (иногда именуемого "интегратором с утечкой") к мощности входного сигнала Yk(m). Коэффициент β сглаживания может иметь положительное значение, чуть меньшее единицы. Обычно для стационарного входного сигнала, чем ближе значение β к единице, тем точнее оценка. С другой стороны, значение β не должно быть слишком близко к единице во избежание утраты способности отслеживать изменения энергии шума, когда входной сигнал перестает быть стационарным. В практических вариантах осуществления настоящего изобретения было установлено, что для обеспечения удовлетворительных результатов приемлемо значение β=0,98. Однако это значение не является критическим. Можно также оценивать энергию шума с использованием более сложного временного сглаживателя, который может быть нелинейным или линейным (например, многополюсным низкочастотным фильтром).
Период времени каждого m, как и в любой цифровой системе, определяется частотой дискретизации поддиапазона. Поэтому он может изменяться в зависимости от частоты дискретизации входного сигнала и используемого блока фильтров. В практической реализации периодом времени для каждого m является 1(с)/8000×32=4 мс для речевого сигнала с частотой дискретизации 8 кГц и блока фильтров с коэффициентом понижения дискретизации 32.
Детектор 6 голосовой активности (VAD)
Известно много детекторов и функций детектирования голосовой активности. Подходящие устройства или функции описаны в главе 10 источника [17] и его библиографии. Использование любого конкретного детектора голосовой активности не критично для изобретения.
Четкость 8 голоса
Различные устройства и функции четкости голоса могут быть полезны при реализации четкости 8 голоса в практических вариантах осуществления настоящего изобретения.
Речь состоит из нескольких разных стимулов, которые используются в восприятии. При выбросе воздуха из легких голосовые связки вибрируют. При выходе воздуха гортань, рот и нос изменяют акустическую энергию, создавая различные звуки. "Гласные" имеют области высокой энергии гармоник и генерируются с беспрепятственным потоком воздуха. "Согласные", включающие в себя "аппроксиманты", "фрикативы" и "взрывные" согласные, генерируются путем нарастающего ограничения потока воздуха и имеют более высокочастотный контент (но с более низкой энергией), чем гласные звуки. Давно известно, что согласные звуки речи вносят значительный вклад в артикуляцию; и гласные, хотя они обычно имеют более высокие энергии, вносят сравнительно меньший вклад. По этой причине устройства и функции четкости голоса обычно используют эквалайзер, обрезной фильтр высоких частот или фильтр высоких частот, например, в источнике [4] для подъема частотных диапазонов, где присутствуют слабые согласные, обычно с более высокими частотами, речи для улучшения артикуляции. Аналогичные технологии также используются в приложениях улучшениях слышимости для слабослышащих людей, которым трудно воспринимать высокочастотные компоненты речевого сигнала, упомянутых в источнике [5]. Подход уплощения спектра, например, описанный ниже и в предварительной патентной заявке США "" от C. Phillip Brown, за №60/993,601, поданной 12 сентября 2007 г. Масштабные коэффициенты усиления четкости голоса увеличивают уровни относительно слабых компонентов речевого сигнала, чтобы они лучше воспринимались человеком. Выбор того или иного конкретного устройства или функции четкости голоса не критично для настоящего изобретения.
Усиление GVC'k(m) четкости голоса может быть создано посредством процесса или устройства четкости голоса следующим образом:
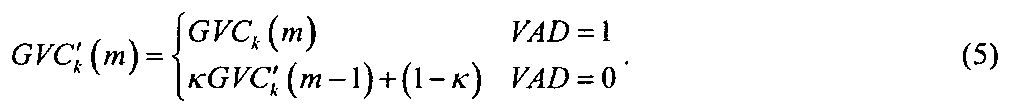
GVC'k(m) является усилением четкости голоса, когда входным сигналом является речь, и 0<κ<1 является коэффициентом сглаживания. Значение κ управляет скоростью усиления четкости голоса, снижая его до единицы (отсутствие подъема) во время паузы в речи. Его наилучшее значение можно устанавливать экспериментально. В практическом варианте осуществления настоящего изобретения было найдено, что для обеспечения хороших результатов значение должно быть κ=0,9. Однако это значение не является критическим. Таким образом, процесс четкости голоса увеличивает усиление при присутствии речевых компонентов, причем усиление снижается в соответствии с временным сглаживанием при переходе от присутствия речевых компонентов к отсутствию речевых компонентов.
Коэффициенты GVCk(m) усиления предназначены для подъема уровней выбранных частотных областей относительно других для улучшения артикуляции речевого сигнала. В одной полезной реализации этого изобретения GVCk(m) можно вычислять как меньшее из Gmax и масштабного отношения энергии в поддиапазоне, имеющем наивысшую энергию, к энергии в каждом из других поддиапазонов:
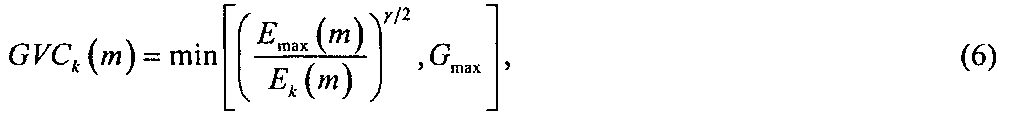
где
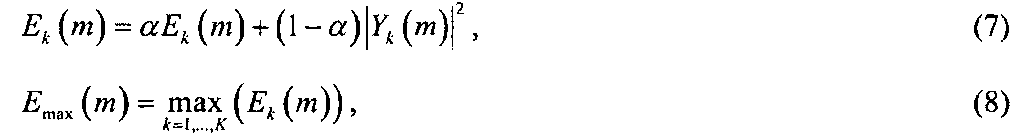
0<γ<1 является заранее выбранным масштабным коэффициентом, 0<<α<1 является коэффициентом сглаживания и Gmax является заранее выбранным максимальным усилением. Начальное значение Ek(-1) может быть установлено на нуль. Значение γ определяет отношение энергии слабых компонентов к энергии сильных компонентов речи после обработки. Например, если γ=0,5, насколько бы энергия Ek(m) поддиапазона ни была ниже Emax(m), она поднимается на половину их разности, что соответствует действию компрессора 2-1 для поддиапазона. Значение Gmax управляет максимальной допустимой величиной подъема для алгоритма четкости голоса. Значения γ и Gmax управляют агрессивностью процесса четкости голоса, совместно определяя величину подъема слабых компонентов речи. Их оптимальные значения изменяются согласно характеристикам обрабатываемого сигнала, акустической среде конечного приложения и предпочтениям пользователей. Подъем можно осуществлять не до фиксированной величины, но, альтернативно, до величины, зависящей от частоты, например, задаваемой характеристикой обрезного фильтра высоких частот.
В качестве примера, на фиг.3 показано значение GVCk(m) как функции Ek(m)/Emax(m). В этом примере γ=1 и Gmax=20 дБ. Что касается вышеупомянутых коэффициентов сглаживания, коэффициент α сглаживания можно реализовать с помощью временного сглаживателя первого порядка, например, однополюсного низкочастотного фильтра (иногда именуемого "интегратором с утечкой") или более сложного временного сглаживателя, который может быть нелинейным или линейным (например, многополюсным низкочастотным фильтром).
Реализация
Изобретение может быть реализовано в оборудовании, или программном обеспечении, или в их комбинации (например, в виде программируемых логических матриц). Если не указано обратное, процессы, включенные как часть изобретения, непосредственно не связаны с каким-либо конкретным компьютером или другим устройством. В частности, различные машины общего назначения можно использовать с программами, написанными в соответствии с изложенными здесь принципами, или может быть удобнее построить более специализированное устройство (например, интегральные схемы) для осуществления необходимых этапов способа. Таким образом, изобретение может быть реализовано в одной или более компьютерных программах, выполняющихся на одной или более программируемых компьютерных системах, каждая из которых содержит, по меньшей мере, один процессор, по меньшей мере, одну систему хранения данных (включающую в себя энергозависимую и энергонезависимую память и/или запоминающие элементы), по меньшей мере, одно устройство или порт ввода и, по меньшей мере, одно устройство или порт вывода. Программный код применяется к входным данным для выполнения описанных здесь функций и генерации выходной информации. Выходная информация поступает на одно или более устройств вывода известным образом.
Каждую такую программу можно реализовать на любом желаемом компьютерном языке (включая машинный код, ассемблер или высокоуровневые процедрурно-, логически- или объектно-ориентированные языки программирования) для связи с компьютерной системой. В любом случае язык может быть компилируемым или интерпретируемым.
Очевидно, что различные устройства, функции и процессы, показанные и описанные здесь в различных примерах, можно представлять совместно или по отдельности иным образом, чем показано на приведенных здесь фигурах. Например, в случае реализации в виде последовательности инструкций компьютерного программного обеспечения, функции можно реализовать в виде последовательности инструкций многопоточного программного обеспечения, выполняющегося на подходящем оборудовании цифровой обработки сигнала, в каковом случае различные устройства и функции в примерах, показанных на фигурах, могут соответствовать части программных инструкций.
Каждая такая компьютерная программа предпочтительно хранится или загружается на носитель информации или запоминающее устройство (например, память или носитель на полупроводниковой основе, или магнитный или оптический носитель), считываемое программируемым компьютером общего или специального назначения, для настройки и эксплуатации компьютера, когда носитель информации или запоминающее устройство считывается компьютерной системой для выполнения описанных здесь процедур. Систему, отвечающую изобретению, также можно рассматривать как реализуемую в виде считываемого компьютером носителя данных, на котором записана компьютерная программа, каковой носитель данных способен предписывать компьютерной системе работать в конкретном и заранее заданном режиме для выполнения описанных здесь функций.
Реферат
Изобретение относится к обработке аудиосигнала, в частности к процессору или способу обработки для повышения разборчивости речи и очистки зашумленного речевого аудиосигнала. Техническим результатом является повышение разборчивости речи и четкости голоса. Указанный результат достигается тем, что в способе улучшения речевых компонентов аудиосигнала, состоящего из речевых и шумовых компонентов, изменяют аудиосигнал из временной области во множество поддиапазонов в частотной области, с созданием множественных сигналов поддиапазона, обрабатывают поддиапазоны аудиосигнала, причем упомянутая обработка включает в себя управление усилением аудиосигнала в некоторых из упомянутых поддиапазонов, при этом усилением в поддиапазоне управляют путем аддитивной/субстрактивной или мультипликативной комбинации а) снижения усиления в поддиапазоне при увеличении оценки уровня шумовых компонентов в поддиапазоне, при этом оценку уровня шумовых компонентов в поддиапазоне определяют при отсутствии речи, и b) увеличения усиления в поддиапазоне при присутствии речевых компонентов в поддиапазоне аудиосигнала, причем увеличение усиления снижают в соответствии с временным сглаживанием при переходе от присутствия речевых компонентов к отсутствию речевых компонентов. Далее изменяют обработанный аудиосигнал поддиапазона из частотной области во временную область для обеспечения аудиосигнала, в котором речевые компоненты улучшены. 4 н.п. ф-лы, 5 ил.
Формула
изменяют аудиосигнал из временной области во множество поддиапазонов в частотной области, с созданием К множественных сигналов поддиапазона, Yk(m), k=1, …, К, m=0, 1, …, ∞, где k является номером поддиапазона и m является временным индексом каждого сигнала поддиапазона,
обрабатывают поддиапазоны аудиосигнала, причем упомянутая обработка включает в себя управление усилением аудиосигнала в некоторых из упомянутых поддиапазонов, при этом усилением в поддиапазоне управляют путем аддитивной/субстрактивной или мультипликативной комбинации
a) снижения усиления в поддиапазоне при увеличении оценки уровня шумовых компонентов в поддиапазоне, при этом оценку уровня шумовых компонентов в поддиапазоне определяют при отсутствии речи, и
b) увеличения усиления в поддиапазоне при присутствии речевых компонентов в поддиапазоне аудиосигнала, причем увеличение усиления снижают в соответствии с временным сглаживанием при переходе от присутствия речевых компонентов к отсутствию речевых компонентов,
причем каждый из процессов а) и b) выполняют согласно набору параметров, непрерывно обновляемых для каждого временного индекса m, причем упомянутые параметры являются зависящими только от своего соответствующего предшествующего значения при временном индексе (m-1), характеристик поддиапазона при временном индексе m и набора заранее определенных постоянных, и
изменяют обработанный аудиосигнал поддиапазона из частотной области во временную область для обеспечения аудиосигнала, в котором речевые компоненты улучшены.
изменяют аудиосигнал из временной области во множество поддиапазонов в частотной области, с созданием К множественных сигналов поддиапазона, Yk(m), k=1, …, К, m=0, 1, …, ∞, где k является номером поддиапазона и m является временным индексом каждого сигнала поддиапазона,
обрабатывают поддиапазоны аудиосигнала, причем упомянутая обработка включает в себя увеличение усиления в поддиапазоне при присутствии речевых компонентов в поддиапазоне аудиосигнала для обеспечения обработанного аудиосигнала поддиапазона, причем увеличение усиления снижают в соответствии с временным сглаживанием при переходе от присутствия речевых компонентов к отсутствию речевых компонентов,
обрабатывают поддиапазоны обработанного аудиосигнала поддиапазона, причем упомянутая обработка поддиапазонов обработанного аудиосигнала поддиапазона включает в себя управление усилением обработанного аудиосигнала поддиапазона в некоторых из упомянутых поддиапазонов, при этом усиление в поддиапазоне снижают, когда оценка уровня шумовых компонентов увеличивается по отношению к уровню речевых компонентов в поддиапазоне, для обеспечения дополнительно обработанного аудиосигнала поддиапазона, при этом оценку уровня шумовых компонентов в поддиапазоне определяют при отсутствии речи,
при этом как изложенную первую, так и изложенную вторую обработку выполняют согласно набору параметров, непрерывно обновляемых для каждого временного индекса m, причем упомянутые параметры являются зависящими только от своего соответствующего предшествующего значения при временном индексе (m-1), характеристик поддиапазона при временном индексе m и набора заранее определенных постоянных, и
изменяют дополнительно обработанный аудиосигнал из частотной области во временную область для обеспечения аудиосигнала, в котором речевые компоненты улучшены.
Документы, цитированные в отчёте о поиске
Система адаптивной фильтрации аудиосигналов для улучшения разборчивости речи при наличии шума
Комментарии