Молекулы новых искусственных нуклеиновых кислот - RU2757675C2
Код документа: RU2757675C2
Чертежи




























Описание
Настоящее изобретение разработано при поддержке правительства по Договору №HR0011-11-3-0001, заключенному с Управлением перспективных исследовательских проектов Министерства обороны США (Defense Advanced Research Projects Agency - DARPA). В настоящей заявке испрашивают приоритет международной патентной заявки РСТ/ЕР 2014/003479, поданной 30 декабря 2014 года, которая включена в настоящее описание в виде ссылки.
Настоящее изобретение относится к молекулам искусственных нуклеиновых кислот, содержащим открытую рамку считывания, элемент 3'-нетранслируемой области (элемент 3'-UTR) и или элемент 5'-нетранслируемой области (элемент 5'-UTR) и необязательно последовательность поли(А) и/или сигнал полиаденилирования. Настоящее изобретение также относится к вектору, содержащему элемент 3'-UTR и/или элемент 5'-UTR, к клетке, содержащей молекулу искусственной нуклеиновой кислоты или вектор, к фармацевтической композиции, содержащей молекулу искусственной нуклеиновой кислоты или вектор, и к набору, содержащему молекулу искусственной нуклеиновой кислоты, вектор и/или фармацевтическую композицию, предпочтительно для использования в области генной терапии и/или генетической вакцинации. Генная терапия и генетическая вакцинация относятся к наиболее перспективным и быстро развивающимся методам современной медицины. Они могут предоставить высокоспецифичные и индивидуальные варианты терапии большого числа различных заболеваний. Такие методы могут применяться для лечения наследственных генетических заболеваний, аутоиммунных заболеваний, раковых или связанных с опухолями заболеваний, а также воспалительных заболеваний. Кроме того, предусматривают предотвращение раннего начала перечисленных заболеваний с помощью указанных подходов.
В основе генной терапии лежит изменение экспрессии нарушенных генов, связанных с патологическими состояниями определенных заболеваний. Патологически измененная экспрессия гена может приводить к отсутствию или избыточной экспрессии важных генных продуктов, например, сигнальных факторов, например, гормонов, факторов «домашнего хозяйства» (housekeeping factors), ферментов метаболизма, структурных белков и других. Измененная экспрессия гена может быть связана не только с неправильной регуляцией транскрипции и/или трансляции, но также с мутациями в открытой рамке считывания (ORF), кодирующей определенный белок. Патологические мутации могут быть вызваны, например, хромосомной аберрацией или более конкретными мутациями, например, точечными мутациями или мутациями типа сдвига рамки, в результате чего происходит ограничение функции и, возможно, полная потеря функции генного продукта. Однако может также произойти нарушение регуляции транскрипции или трансляции, если мутации влияют на гены, кодирующие белки, которые участвуют в аппарате транскрипции или трансляции в клетке. Такие мутации могут приводить к патологическому повышению или понижению регуляции генов, что также влияет на функциональность. Гены, кодирующие генные продукты, которые оказывают такие регуляторные функции, могут быть, например, факторами транскрипции, сигнальными рецепторами, белками-посредниками или генами других продуктов. Однако потеря функции таких генов, кодирующих регуляторные белки, при определенных обстоятельствах может быть отменена искусственным введением других факторов, действующих дальше по цепи от продукта измененного гена. Такие генные дефекты также могут быть компенсированы генной терапией путем замены самого измененного гена.
Генетическая вакцинация позволяет индуцировать требуемый иммунный ответ на выбранные антигены, например, специфические компоненты на поверхности бактериальных клеток, вирусные частицы, опухолевые антигены или другие. В целом, вакцинация является одним из основных достижений современной медицины. Однако эффективные вакцины в настоящее время доступны только для ограниченного числа заболеваний. Соответственно, инфекции, которые не поддаются профилактике при вакцинации, по-прежнему воздействуют на миллионы людей каждый год.
Обычно вакцины могут быть подразделены на вакцины первого, второго и третьего поколения. Вакцины первого поколения обычно являются вакцинами, представляющими целые организмы. Они основаны либо на живых, либо на аттенуированных или убитых патогенах, например, вирусах, бактериях или других организмах. Основным недостатком живых и аттенуированных вакцин является риск возврата к вариантам, опасным для жизни. Таким образом, хотя и аттенуированные, такие патогены могут по-прежнему представлять непредсказуемый риск. Убитые патогены могут быть не столь эффективными для обеспечения специфического иммунного ответа. Чтобы свести к минимуму такой риск, были разработаны вакцины второго поколения. Обычно это вакцины состоят из частей, а именно из определенных антигенов или рекомбинантных белковых компонентов, которые получены из патогенов.
Генетические вакцины, то есть вакцины, предназначенные для генетической вакцинации, обычно рассматривают в качестве вакцин третьего поколения. Обычно они состоят из молекул сконструированных нуклеиновых кислот, которые допускают экспрессию фрагментов пептида или белка (антигенов), характерных для патогена или опухолевого антигена in vivo. Генетические вакцины экспрессируются при введении пациенту после их поглощения клетками-мишенями. Экспрессия вводимых нуклеиновых кислот приводит к получению кодируемых ими белков. Если эти белки распознаются иммунной системе пациента в качестве чужеродных, активируется иммунный ответ.
Из вышесказанного следует, что оба метода, генная терапия и генетическая вакцинация, основаны главным образом на введении молекул нуклеиновой кислоты пациенту с последующей транскрипцией и/или трансляцией закодированной генетической информации. В другом варианте генетическая вакцинация или генная терапия могут также подразумевать способы, которые включают выделение из организма подвергаемого лечению пациента определенных клеток, последующую трансфекцию ex vivo этих клеток и повторное введение обработанных клеток пациенту.
ДНК, а также РНК, могут быть использованы в качестве молекул нуклеиновых кислот для введения в контексте генной терапии или генетической вакцинации. Известно, что ДНК относительно стабильна и проста в обращении. Однако использование ДНК несет риск нежелательной инсерции введенных ДНК-фрагментов в геном пациента, что может привести к мутациям, например, к потере функции ослабленных генов. Также дополнительный риск представляет опасная ситуация, связанная с выработкой анти-ДНК-антител. Другим недостатком является ограниченный уровень экспрессии закодированного пептида или белка, который достигается при введении ДНК, потому что ДНК должна войти в ядро для транскрипции раньше, чем может произойти трансляция мРНК. Среди других причин находится уровень экспрессии вводимой ДНК, который может зависеть от наличия специфических факторов транскрипции, которые регулируют транскрипцию ДНК. При отсутствии таких факторов транскрипция ДНК не даст достаточных количеств РНК. В результате уровень полученного в результате трансляции пептида или белка ограничен.
Используя РНК вместо ДНК для генной терапии или генетической вакцинации, риск нежелательной геномной интеграции и выработки анти-ДНК-антител минимизируется или исключается. Однако РНК рассматривают в качестве довольно нестабильных молекул, которые могут быть легко разрушены повсеместно присутствующими РНКазами.
Обычно разрушение РНК способствует регуляции времени полураспада РНК. Этот эффект был рассмотрен и одобрен для точной настройки регуляции экспрессии генов эукариот (Friedel с соавт., 2009). Соответственно, каждая встречающаяся в природе мРНК имеет свой индивидуальный период полураспада в зависимости от гена, от которого получена мРНК, и от типа клеток, в которых она экспрессируется. Это влияет на регулирование уровня экспрессии этого гена. Нестабильные РНК важны для реализации временной генной экспрессии в разные моменты времени. Однако долгоживущие РНК могут быть связаны с накоплением отдельных белков или с непрерывной экспрессией генов. In vivo период полураспада мРНК также может зависеть от факторов окружающей среды, таких как гормональная терапия, что было показано, например, для мРНК инсулиноподобного фактора роста I, актина и альбумина (Johnson с соавт., 1991).
Для генной терапии и генетической вакцинации обычно требуется стабильная РНК. Это, с одной стороны, связано с тем, что обычно желательно, чтобы продукт, кодируемый последовательностью РНК, накапливался in vivo. С другой стороны, РНК должна сохранять свою структурную и функциональную целостность при приготовлении соответствующей лекарственной формы, в процессе ее хранения и при введении. Таким образом, были предприняты усилия по созданию стабильных молекул РНК для генной терапии или генетической вакцинации, чтобы предотвратить их раннее разрушение.
Установлено, что содержание G/C в молекулах нуклеиновых кислот может влиять на их стабильность. Поэтому нуклеиновые кислоты, содержащие повышенное количество остатков гуанина (G) и/или цитозина (С), могут быть функционально более стабильными, чем нуклеиновые кислоты, содержащие большое количество адениновых (А) и тиминовых (Т) или урацильных (U) нуклеотидов. В этом контексте предусматривают фармацевтическую композицию, содержащую мРНК, которая стабилизируется с помощью модификаций последовательности в кодируемой области (WO 02/098443). Преимущество такой модификации последовательностей использует в качестве преимущества вырождение генетического кода. Соответственно, кодоны, которые содержат менее благоприятную комбинацию нуклеотидов (менее благоприятных с точки зрения стабильности РНК), могут быть заменены другими кодонами без изменения закодированной аминокислотной последовательности. Такой метод стабилизации РНК ограничен положениями специфической нуклеотидной последовательности в случае каждой отдельной молекулы РНК, которая не позволяет выйти за рамки требуемой аминокислотной последовательности. Кроме того, этот подход ограничивается кодирующими областями РНК.
В качестве альтернативного варианта стабилизации мРНК было установлено, что природные молекулы эукариотической мРНК содержат специфические стабилизирующие элементы. Например, они могут содержать так называемые нетранслируемые области (untranslated regions - UTR) с 5'-конца (5'-UTR) и/или с 3'-конца (3'-UTR), а также другие структурные характеристики, например, структуру 5'-кэп или 3'-поли(А) хвост. И 5'-UTR, и 3'-UTR, обычно транскрибируются с геномной ДНК и, таким образом, являются элементом незрелой мРНК. Характерные структурные особенности зрелой мРНК, например, 5'-кэп и 3'-поли(А) хвост (также называемый поли(А) хвостом или последовательностью поли(А)), обычно добавляют к транскрибированной (незрелой) мРНК при процессинге мРНК.
3'-поли(А) хвост обычно представляет монотонный отрезок последовательности из аденозиновых нуклеотидов, добавленных к 3'-концу транскрибируемой мРНК. Он может содержать до 400 аденозиновых нуклеотидов. Установлено, что длина такого 3'-поли(А) хвоста потенциально является принципиально важным элементом стабильности индивидуальной мРНК.
Также было показано, что 3'-UTR α-глобина может быть важным фактором для известной стабильности мРНК α-глобина (Rodgers с соавт., 2002).
Установлено, что 3'-UTR мРНК α-глобина участвует в формировании специфического рибонуклеопротеинового комплекса, α-комплекса, чье присутствие коррелирует со стабильностью мРНК in vitro (Wang с соавт., 1999).
Интересная регуляторная функция была также показана для UTR в мРНК рибосомных белков: хотя 5'-UTR мРНК рибосомных белков контролирует связанную с ростом трансляцию мРНК, строгость такой регуляции обусловливается соответствующим 3'-UTR в мРНК рибосомных белков (Ledda с соавт., 2005). Этот механизм способствует модели специфической экспрессии рибосомных белков, которые обычно транскрибируются постоянно, поэтому некоторые мРНК рибосомных белков, например, рибосомного белка S9 или рибосомного белка L32, называются генами «домашнего хозяйства» (Janovick-Guretzky с соавт., 2007). Таким образом, связанная с ростом картина экспрессии рибосомных белков обусловлена главным образом регулированием уровня трансляции.
Независимо от факторов, влияющих на стабильность мРНК, эффективная трансляция введенных молекул нуклеиновых кислот клетками-мишенями или тканью имеет решающее значение для какого-либо подхода с использованием молекул нуклеиновых кислот для генной терапии или генетической вакцинации. Как видно из приведенных выше примеров, наряду с регуляцией стабильности, также трансляция большинства мРНК регулируется такими структурными характеристиками, как UTR, 5'-кэп и 3'-поли(А) хвост. В этом контексте показано, что длина поли(А) хвоста может также играть важную роль в эффективности трансляции. Однако стабилизирующие 3'-элементы также могут оказывать ослабляющее воздействие на трансляцию.
Задача настоящего изобретения заключается в получении молекул нуклеиновых кислот, которые могут быть применимы в генной терапии и/или генетической вакцинации. В частности, задача настоящего изобретения заключается в получении типов мРНК, стабилизированных против преждевременного разрушения без проявления существенного ухудшения эффективности трансляции. Кроме того, задача настоящего изобретения заключается в получении искусственных молекул нуклеиновых кислот, предпочтительно мРНК, которые характеризуется повышенной экспрессией соответствующего белка, кодируемого указанной молекулой нуклеиновой кислоты. Одной из конкретных задач настоящего изобретения является получение мРНК, причем эффективность трансляции соответствующего кодированного белка повышается. Другой задачей настоящего изобретения является получение молекул нуклеиновой кислоты, кодирующих такие улучшенные виды мРНК, которые могут быть пригодны для применения в генной терапии и/или генетической вакцинации. Еще одной задачей, решаемой в настоящем изобретении, является предоставление фармацевтической композиции для использования в генной терапии и/или генетической вакцинации. Таким образом, целью настоящего изобретения является предоставление улучшенных видов нуклеиновых кислот, которые преодолевают вышеупомянутые недостатки предшествующего уровня техники с помощью экономичного и прямого подхода.
Сущность, лежащая в основе настоящего изобретения, представлена в формуле изобретения.
Для ясности и четкости понимания настоящего изобретения ниже приведено определение применяемых в настоящем изобретении понятий. Какая-либо техническая характеристика, приведенная в определениях, может быть прочитана в каждом варианте осуществления настоящего изобретения. Дополнительные определения и пояснения могут быть специально приведены в контексте вариантов осуществления настоящего изобретения.
Адаптивный иммунный ответ. Адаптивный иммунный ответ обычно понимают в виде антигенспецифического ответа иммунной системы. Специфичность антигена позволяет получать ответы, адаптированные к конкретным патогенам или инфицированным патогенами клеткам. Способность повышать такие ответные реакции обычно поддерживается в организме с помощью «клеток памяти». Если патоген инфецирует организм более одного раза, указанные клетки памяти обеспечивают быструю элиминацию патогена. В этом контексте первой стадией адаптивного иммунного ответа является активация наивных антигенспецифических Т-клеток или различных иммунных клеток, способных индуцировать антигенспецифический иммунный ответ с помощью антигенпрезентирующих клеток. Это происходит в лимфоидных тканях и органах, через которые постоянно проходят наивные Т-клетки. Тремя типами клеток, которые могут выступать в роли антигенпрезентирующих клеток, являются дендритные клетки, макрофаги и В-клетки. Каждая из этих клеток имеет определенную функцию в индукции иммунного ответа.
Дендритные клетки могут поглощать антигены фагоцитозом и макропиноцитозом и могут стимулироваться за счет контакта, например, с чужим антигеном, для миграции в локальную лимфоидную ткань, где происходит дифференциация этих клеток в зрелые дендритные клетки. Макрофаги поглощают антигены-частицы, например, бактерии, и индуцируются инфекционными агентами или другими соответствующими стимулами для экспрессии молекул МНС. Уникальная способность В-клеток связывать и интернализировать растворимые белковые антигены через их рецепторы также может иметь важное значение для индукции Т-клеток. Молекулы МНС обычно отвечают за презентацию антигена Т-клеткам. При этом путем презентации антигена на молекулах МНС происходит активация Т-клеток, которая индуцирует их пролиферацию и дифференцировку в усиленные эффекторные Т-клетки. Важнейшей функцией эффекторных Т-клеток является уничтожение инфицированных клеток CD8+ цитотоксическими Т-клетками и активация макрофагов клетками Th1, которые вместе составляют опосредованный клетками иммунитет, а также активация В-клеток как клетками Th2, так и клетками Th1, для получения различных классов антител, что в результате вызывает гуморальный иммунный ответ. Т-клетки распознают антиген своими рецепторами, которые не распознают и не связывают антиген непосредственно, а вместо этого распознают короткие пептидные фрагменты, например, производные от патогенов белковые антигены, т.е. так называемые эпитопы, которые связываются с молекулами МНС на поверхностях других клеток.
Адаптивная иммунная система. Адаптивная иммунная система по существу предназначена для устранения или предотвращения патогенного роста. Она обычно регулирует адаптивный иммунный ответ, обеспечивая иммунную систему позвоночных способностью распознавать и запоминать специфические патогены (для выработки иммунитета) и усиливать силу атаки каждый раз при столкновении с патогеном. Система способна выработать высокую степень адаптации из-за соматической гипермутации (процесса повышенного возникновения соматических мутаций) и рекомбинации V(D)J (необратимая генетическая рекомбинация сегментов гена антигенного рецептора). Этот механизм позволяет небольшому числу генов вырабатывать огромное количество различных антигенных рецепторов, которые затем однозначно экспрессируются на каждом отдельном лимфоците. Поскольку перегруппировка генов приводит к необратимому изменению ДНК в каждой клетке, все потомство такой клетки наследует гены, кодирующие ту же специфичность рецептора, включая В-клетки памяти и Т-клетки памяти, которые являются ключевыми для долговременного специфического иммунитета.
Адъювант/адъювантный компонент. Адъювант или адъювантный компонент в самом широком смысле обычно является фармакологическим и/или иммунологическим агентом, который может модифицировать, например, повышать действие других агентов, например, лекарств или вакцин. Понятие «адъювант» следует толковать в широком смысле и применять в отношении широкого спектра веществ. Обычно адъюванты могут повышать иммуногенность антигенов. Например, адъюванты могут быть распознаны врожденными иммунными системами и, например, могут вызывать врожденный иммунный ответ. «Адъюванты» обычно не вызывают адаптивного иммунного ответа. Поскольку «адъюванты» не квалифицируются в качестве антигенов, их механизм действия отличается от эффектов, вызванных антигенами и приводящих к адаптивному иммунному ответу.
Антиген. В контексте настоящего изобретения понятие «антиген» обычно относят к веществу, которое может быть распознано иммунной системой, предпочтительно адаптивной иммунной системой, и которое способно инициировать антигенспецифический иммунный ответ, например, путем образования антител и/или антигенспецифических Т-клеток в качестве части адаптивного иммунного ответа. Как правило, антиген может быть белком или пептидом или может содержать белок или пептид, который может быть презентирован МНС Т-клеткам. В настоящем изобретении антиген может быть продуктом трансляции предоставленной молекулы нуклеиновой кислоты, предпочтительно мРНК по настоящему изобретению. Также в этом контексте фрагменты, варианты и производные пептидов и белков, включающие по меньшей мере один эпитоп, рассматривают в качестве антигенов. В настоящем изобретении особенно предпочтительными являются опухолевые антигены и антигены патогенов согласно описанию настоящего изобретения.
Молекула искусственной нуклеиновой кислоты. Под молекулой искусственной нуклеиновой кислоты обычно подразумевают молекулу нуклеиновой кислоты, например, ДНК или РНК, которая не возникает естественным образом. Иначе говоря, под молекулой искусственной нуклеиновой кислоты можно понимать неприродную молекулу нуклеиновой кислоты. Такая молекула нуклеиновой кислоты может быть неприродной, исходя из присущей ей специфической последовательности (которая не возникает естественным образом), и/или из-за других модификаций, например, структурных модификаций нуклеотидов, которые не встречаются в природе. Молекула искусственной нуклеиновой кислоты может быть молекулой ДНК, молекулой РНК или гибридной молекулой, содержащей части и ДНК, и РНК. Обычно молекулы искусственных нуклеиновых кислот могут быть разработаны и/или получены методами генной инженерии, чтобы соответствовать требуемой искусственной последовательности нуклеотидов (гетерологичной последовательности). В этом контексте искусственная последовательность обычно является последовательностью, которая может естественным образом не возникать, то есть она отличается от исходной последовательности, по меньшей мере, одним нуклеотидом. Понятие «исходная последовательность» означает природную последовательность, также называемую последовательностью дикого типа. Кроме того, понятие «молекула искусственной нуклеиновой кислоты» не ограничивается понятием «одна молекула», но обычно оно означает совокупность идентичных молекул. Соответственно, это понятие может относиться к множеству идентичных молекул, содержащихся в аликвоте.
Бицистронная РНК, мультицистронная РНК. Бицистронная или мультицистронная РНК обычно означает РНК, предпочтительно мРНК, которая может иметь иметь две (бицистронные) или более (мультицистронные) открытые рамки считывания (open reading frames - ORF). Открытая рамка считывания в этом контексте представляет последовательность кодонов, которая может транслироваться в пептид или белок.
Носитель/полимерный носитель. Носителем в контексте изобретения обычно может быть соединение, которое способствует транспорту другого соединения (груза) и/или образованию с ним комплекса. Полимерный носитель это обычно носитель, образованный из полимера. Носитель может быть связан со своим грузом за счет ковалентной или нековалентной связи. Носитель может транспортировать нуклеиновые кислоты, например, РНК или ДНК, к клеткам-мишеням. В некоторых вариантах осуществления настоящего изобретения носитель может быть катионным компонентом.
Катионный компонент. Понятие «катионный компонент» обычно относят к заряженной молекуле, которая заряжена положительно (катион) при значении рН обычно от 1 до 9, предпочтительно при значении рН ниже 9 (например, от 5 до 9), или ниже 8 (например, от 5 до 8), или ниже 7 (например, от 5 до 7), наиболее предпочтительно при физиологическом рН, например от 7,3 до 7,4. Соответственно, катионным компонентом может быть какое-либо положительно заряженное соединение или полимер, предпочтительно катионный пептид или белок, который положительно заряжен в физиологических условиях, особенно в физиологических условиях in vivo. «Катионный пептид или белок» может содержать, по меньшей мере, одну положительно заряженную аминокислоту или более одной положительно заряженной аминокислоты, например, выбранных из Arg, His, Lys или Orn. Соответственно, «поликатионные» компоненты в данных условиях имеют более одного положительного заряда и также входят в рамки охвата настоящего изобретения.
5'-кэп. 5'-кэп представляет объект, обычно модифицированный нуклеотидный объект, который обычно «закрывает» 5'-конец зрелой мРНК. 5'-кэп обычно может быть образован модифицированным нуклеотидом, в частности, производным гуанинового нуклеотида. Предпочтительно 5'-кэп связан с 5'-концом через 5'-5'-трифосфатную связь. 5'-кэп может быть метилирован, например, m7GpppN, где N представляет концевой 5'-нуклеотид нуклеиновой кислоты, несущей 5'-кэп, обычно 5'-конец РНК. Другие примеры 5'-кэп-структур включают глицерил, инвертированный остаток дезоксиазотистого основания (часть молекулы), 4'-,5'-метиленовый нуклеотид, 1-(бета-D-эритрофуранозил)нуклеотид, 4'-тионуклеотид, карбоциклический нуклеотид, 1,5-ангидроксигекситольный нуклеотид, L-нуклеотиды, альфа-нуклеотид, модифицированное основание нуклеотида, трео-пентофуранозильный нуклеотид, ациклический 3', 4'-секонуклеотид, ациклический 3,4-дигидроксибутилнуклеотид, ациклический 3,5-дигидроксипентильный нуклеотид, 3'-3'-инвертированную нуклеотидную часть молекулы, 3'-3'-инвертированную часть молекулы без азотистого основания, 3'-2'-инвертированную нуклеотидную часть молекулы, 3'-2'-инвертированную часть молекулы без азотистого основания, 1,4-бутандиолфосфат, 3'-фосфорамидат, гексилфосфат, аминогексилфосфат, 3'-фосфат, 3'-фосфоротиоат, фосфородитиоат, и связующую или несвязующую часть молекулы.
Клеточный иммунитет/клеточный иммунный ответ. Клеточный иммунитет обычно связан с активацией макрофагов, природных клеток киллеров (natural killer - NK), антигенспецифических цитотоксических Т-лимфоцитов и высвобождением различных цитокинов в ответ на антиген. В общих выражениях, клеточный иммунитет основан не на антителах, а на активации клеток иммунной системы. Как правило, клеточный иммунный ответ может быть охарактеризован, например, путем активации антигенспецифических цитотоксических Т-лимфоцитов, которые способны индуцировать апоптоз в клетках, например, в специфических иммунных клетках, например, в дендритных клетках или других клетках с эпитопами чужеродных антигенов на поверхности. Такие клетки могут быть инфицированы вирусом или инфицированы внутриклеточными бактериями, или могут быть раковыми клетками, несущими на поверхности опухолевые антигены. Другими свойствами могут быть активация макрофагов и природных клеток киллеров, что позволяет им разрушать патогены и стимулировать клетки к секреции разнообразных цитокинов, которые влияют на функцию других клеток, участвующих в адаптивных иммунных реакциях и врожденных иммунных реакциях.
Понятие «производный от», используемое в настоящем описании, относится к нуклеиновой кислоты, то есть к нуклеиновой кислоты, «производный от» (другой) нуклеиновой кислоты, что означает, что нуклеиновая кислота, которая получена из (другой) нуклеиновой кислоты, последовательность которой по меньшей мере на 50%, предпочтительно по меньшей мере на 60%, предпочтительно по меньшей мере на 70%, более предпочтительно по меньшей мере на 75%, более предпочтительно по меньшей мере на 80%, более предпочтительно по меньшей мере на 85%, еще более предпочтительно по меньшей мере на 90%, еще больше предпочтительно по меньшей мере на 95%, и особенно предпочтительно по меньшей мере на 98%, идентична последовательности нуклеиновой кислоты, производной которой она является. Специалисту известно, что идентичность последовательности обычно вычисляют для одних и тех же типов нуклеиновых кислот, то есть для последовательностей ДНК или для последовательностей РНК. Таким образом, очевидно, что если ДНК «производная от» РНК или если РНК «производна от» ДНК, на первой стадии последовательность РНК конвертируют в соответствующую последовательность ДНК (в частности, путем замены урацилов (U) тимидинами (Т) во всей последовательности) или, наоборот, последовательность ДНК конвертируют в соответствующую последовательность РНК (в частности, заменяя тимидины (Т) урацилами (U) во всей последовательности). После этого определяют идентичность последовательностей ДНК или идентичность последовательностей РНК. Предпочтительно, понятие нуклеиновой кислоты, «производной от» другой нуклеиновой кислоты, также относится к нуклеиновой кислоте, которую модифицируют по сравнению с нуклеиновой кислотой, от которой она производна, например, чтобы еще больше повысить стабильность РНК, и/или продлить, и/или увеличить выработку белка. Безусловно, что предпочтительными являются те модификации, которые не ухудшают стабильности РНК, например, по сравнению с нуклеиновой кислотой, из которой она получена.
ДНК. ДНК - это аббревиатура дезоксирибонуклеиновой кислоты. ДНК -молекула нуклеиновой кислоты, то есть полимер, состоящий из нуклеотидов. Этими нуклеотидами обычно являются мономеры дезоксиаденозинмонофосфат, дезокситимидинмонофосфат, дезоксигуанозинмонофосфат и дезоксицитидинмонофосфат, которые состоят из фрагмента сахара (дезоксирибозы), фрагмента основания и фрагмента фосфата и полимеризуются в специфическую каркасную структуру. Структура каркаса обычно образована фосфодиэфирными связями между фрагментом сахара в нуклеотиде, то есть между дезоксирибозой, первого мономера и фосфатной частью второго соседнего мономера. Определенный порядок мономеров, т.е. порядок оснований, связанных с каркасом молекулы из сахаров/фосфатов, называется последовательностью ДНК. ДНК может быть одноцепочечной или двухцепочечной. В двухцепочечной форме нуклеотиды первой цепи обычно гибридизуются с нуклеотидами второй цепи, например, путем спаривания оснований А/Т и G/C.
Эпитоп. Эпитопы (также называемые «антигенными детерминантами») можно подразделить на эпитопы Т-клеток и эпитопы В-клеток. Эпитопы Т-клеток или части белков в контексте настоящего изобретения могут содержать фрагменты, предпочтительно длиной примерно от 6 до примерно 20 или даже более аминокислот, например, фрагменты, процессированные и презентированные молекулами МНС класса I, предпочтительно длиной примерно от 8 до примерно 10 аминокислот, например, 8, 9 или 10 (или даже 11 или 12 аминокислот), или фрагменты, процессированные и презентированные молекулами МНС класса II, предпочтительно длиной примерно 13 или более аминокислот, например. 13, 14, 15, 16, 17, 18, 19, 20 или даже боле аминокислот, причем эти фрагменты могут быть получены из какой-либо части аминокислотной последовательности. Эти фрагменты обычно распознаются Т-клетками в виде комплекса, состоящего из фрагмента пептида и молекулы МНС, то есть фрагменты обычно не распознаются в своей нативной форме. Эпитопы В-клеток обычно представляют фрагменты, расположенные на внешней поверхности (нативного) белка или пептидных антигенов, согласно описанию настоящего изобретения, состоящие предпочтительно из 5-15 аминокислот, более предпочтительно из 5-12 аминокислот, еще более предпочтительно из 6-9 аминокислот, которые могут быть распознаны антителами, то есть в их нативной форме.
Такие эпитопы белков или пептидов могут также быть выбраны из каких-либо указанных в настоящем изобретении вариантов таких белков или пептидов. В этом контексте антигенными детерминантами могут быть конформационные или прерывистые эпитопы, которые состоят из сегментов белков или пептидов, согласно описанию настоящего изобретения, которые являются прерывистыми по аминокислотной последовательности белками или пептидами, согласно описанию настоящего изобретения, но которые объединены в трехмерную структуру, или непрерывные или линейные эпитопы, которые состоят из одной полипептидной цепи.
Фрагмент последовательности. Фрагмент последовательности обычно бывает более короткой частью последовательности полной длины, например, молекулы нуклеиновой кислоты или аминокислотной последовательности. Соответственно, фрагмент бычно состоит из последовательности, которая идентична соответствующему отрезку в последовательности полной длины. Предпочтительный фрагмент последовательности в контексте настоящего изобретения состоит из непрерывного отрезка мономеров, а именно нуклеотидов или аминокислот, соответствующих непрерывному отрезку из мономеров в молекуле, из которой получен этот фрагмент, иднтичный по меньшей мере на 5%, 10%, 20%, предпочтительно по меньшей мере на 30%, более предпочтительно по меньшей мере на 40%, более предпочтительно по меньшей мере на 50%, еще более предпочтительно по меньшей мере на 60%, еще более предпочтительно по меньшей мере на 70% и наиболее предпочтительно по меньшей мере на 80% целой (то есть полной по размеру) молекуле, из которой получен фрагмент.
Модификация G/C. Модифицированная G/C нуклеиновая кислота обычно бывает нуклеиновой кислотой, предпочтительно молекулой искусственной нуклеиновой кислоты, согласно описанию настоящего изобретения, на основе модифицированной исходной последовательности, содержащей предпочтительно повышенное количество нуклеотидов гуанозина и/или цитозина по сравнению с исходной последовательностью. Такое повышенное количество может быть получено путем замещения кодонов, содержащих нуклеотиды аденозин или тимидин, кодонами, содержащими нуклеотиды гуанозин или цитозин. Если повышенное содержание G/C осуществляют в кодирующей области ДНК или РНК, то оно построено на вырожденности генетического кода. Соответственно, замещения кодонов предпочтительно не изменяют закодированные аминокислотные остатки, а исключительно увеличивают содержание G/C в молекуле нуклеиновой кислоты.
Генная терапия. Обычно под генной терапией понимают лечение организма пациента или отдельных элементов организма пациента, например, отдельных тканей/клеток, нуклеиновыми кислотами, кодирующими пептид или белок. Обычно генная терапия включает, по меньшей мере, одну из стадий а) введения нуклеиновой кислоты, предпочтительно молекулы искусственной нуклеиновой кислоты по настоящему изобретению, непосредственно пациенту каким-либо способом введения, или in vitro - к выделенным клеткам/тканям пациента, что приводит к трансфекции клеток пациента, или in vivo/ex vivo, или in vitro; б) транскрипции и/или трансляции интродуцированной молекулы нуклеиновой кислоты; и необязательно в) повторного введения выделенных трансфицированных клеток пациенту, если нуклеиновая кислота не вводилась непосредственно пациенту.
Генетическая вакцинация. Обычно под генетической вакцинацией понимают вакцинацию путем введения молекулы нуклеиновой кислоты, кодирующей антиген, или иммуноген, или их фрагменты. Молекулу нуклеиновой кислоты можно вводить в организм субъекта или в выделенные клетки субъекта. При трансфекции определенных клеток организма или при трансфекции выделенных клеток антиген или иммуноген могут быть экспрессированы этими клетками и впоследствии презентированы иммунной системе, вызывая адаптивный, то есть антигенспецифический иммунный ответ. Соответственно, генетическая вакцинация обычно включает, по меньшей мере, одну из стадий: а) введения нуклеиновой кислоты, предпочтительно молекулы искусственной нуклеиновой кислоты по настоящему изобретению, субъекту, предпочтительно пациенту, или в выделенные клетки субъекта, предпочтительно пациента, что обычно приводит к трансфекции клеток субъекта in vivo или in vitro; б) транскрипции и/или трансляции интродуцированной молекулы нуклеиновой кислоты; и необязательно в) повторное введение выделенных, трансфицированных клеток субъекту, предпочтительно пациенту, если нуклеиновую кислоту не вводили непосредственно пациенту.
Гетерологичная последовательность. Обычно две последовательности рассматривают в качестве «гетерологичных», если они не происходят от одного и того же гена. Таким образом, хотя гетерологичные последовательности могут быть получены из одного и того же организма, они естественным образом (по своей природе) не содержатся в одной и той же молекуле нуклеиновой кислоты, например, в одной и той же мРНК.
Гуморальный иммунитет/гуморальный иммунный ответ. Обычно под гуморальным иммунитетом понимают выработку антител и, необязательно, вспомогательные процессы, сопровождающие выработку антител. Гуморальный иммунный ответ обычно можно описать, например, путем активации Th2 и выработкой цитокинов, образованием зародышевого центра и переключением изотипов, созреванием аффинности и генерацией клеток памяти. Гуморальный иммунитет также обычно может относить к эффекторным функциям антител, которые включают нейтрализацию патогенов и токсинов, активацию классического комплемента и стимуляцию опсонина, способствующую фагоцитозу и элиминации патогенов.
Иммуноген. В контексте настоящего изобретения под иммуногеном обычно понимают соединение, способное стимулировать иммунный ответ. Предпочтительно иммуноген представляет пептид, полипептид или белок. В одном из предпочтительных вариантов осуществления настоящего изобретения иммуногеном является продукт трансляции полученной молекулы нуклеиновой кислоты, предпочтительно молекулы искусственной нуклеиновой кислоты по настоящему изобретению. Обычно иммуноген вызывает, по меньшей мере, адаптивный иммунный ответ.
Иммуностимулирующая композиция. В контексте настоящего изобретения иммуностимулирующая композиция обычно означает композицию, содержащую, по меньшей мере, один компонент, который способен индуцировать иммунный ответ или из которой можно получить компонент, который способен индуцировать иммунный ответ. Такой иммунный ответ может быть предпочтительно врожденным иммунным ответом или комбинацией адаптивного и врожденного иммунного ответа. Предпочтительно иммуностимулирующая композиция в контексте настоящего изобретения содержит, по меньшей мере, одну молекулу искусственной нуклеиновой кислоты, более предпочтительно РНК, например молекулу мРНК. Иммуностимулирующий компонент, например, мРНК, может быть соединен с подходящим носителем. Таким образом, иммуностимулирующая композиция может содержать комплекс мРНК/носитель. Кроме того, иммуностимулирующая композиция может содержать адъювант и/или соответствующий носитель для иммуностимулирующего компонента, например, для мРНК.
Иммунный ответ. Обычно иммунный ответ может быть специфической реакцией адаптивной иммунной системы на определенный антиген (так называемый специфический или адаптивный иммунный ответ), или неспецифической реакцией врожденной иммунной системы (так называемый неспецифический или врожденный иммунный ответ), или их комбинацией.
Иммунная система. Иммунная система может защитить организмы от инфекции. Если патогену удается пройти физический барьер организма и внедриться, врожденная иммунная система обеспечивает немедленный, но неспецифический ответ. Если патогены уклоняются от такого врожденного ответа, позвоночные обладают вторым уровнем защиты - адаптивной иммунной системой. По настоящему изобретению иммунная система адаптирует свой ответ во время инфекции, чтобы улучшить распознавание патогена. Такой улучшенный ответ сохраняется после элиминации патогена в виде иммунологической памяти и позволяет адаптивной иммунной системе быстрее и эффективнее атаковать каждый раз при появлении патогена. Таким образом, иммунная система включает врожденную и адаптивную иммунную систему.
Каждая из этих двух частей обычно содержит так называемые гуморальные и клеточные компоненты.
Иммуностимулирующая РНК. Иммуностимулирующая РНК (исРНК) в контексте настоящего изобретения обычно представляет РНК, способную индуцировать врожденный иммунный ответ. Такая РНК обычно не содержит открытой рамки считывания и, таким образом, не предоставляет пептид-антиген или иммуноген, но вызывает иммунный ответ, например, путем связывания специфического типа Toll-подобного рецептора (Toll-like-receptor - TLR) или других соответствующих рецепторов. Однако мРНК, которые также безусловно содержат открытую рамку считывания и кодируют пептид/белок, могут индуцировать врожденный иммунный ответ и, таким образом, могут быть иммуностимулирующими РНК.
Врожденная иммунная система. Врожденная иммунная система, также называемая неспецифической иммунной системой, обычно включает клетки и механизмы, которые неспецифическим образом защищают хозяина от инфекции другими организмами. Это означает, что клетки врожденной системы могут распознавать и реагировать на патогены генерическим образом, но в отличие от адаптивной иммунной системы это не приводит к долговременному защитному иммунитету хозяину. Врожденная иммунная система может быть, например, активирована лигандами Toll-подобных рецепторов (TLR) или другими вспомогательными веществами, такими как липополисахариды, TNF-альфа, лиганд CD40 или цитокины, монокины, лимфокины, интерлейкины или хемокины, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, IL- 14, IL-15, IL-16, IL-17, IL-18, IL-19, IL-20, IL-21, IL-22, IL-23, IL-24, IL-25, IL-26, IL-27, IL-28, IL-29, IL-30, IL-31, IL-32, IL-33, IFN-альфа, IFN-бета, IFN-гамма, GM-CSF, G-CSF, CSF, LT-бета, TNF-альфа, факторы роста и hGH, лиганд Toll-подобного рецептора человека TLR1, TLR2, TLR3, TLR4, TLR5, TLR6, TLR7, TLR8, TLR9, TLR10, лиганд мышиного Toll-подобного рецептора TLR1, TLR2, TLR3, TLR4, TLR5, TLR6, TLR7, TLR8, TLR9, TLR10, TLR11, TLR12 или TLR13, лиганд NOD-подобного рецептора, лиганд RIG-I-подобного рецептора, иммуностимулирующая нуклеиновая кислота, иммуностимулирующая РНК (исРНК), CpG-ДНК, антибактериальный агент или противовирусный агент.
Сайт клонирования. Обычно сайтом клонирования является сегмент молекулы нуклеиновой кислоты, который подходит для инсерции последовательности нуклеиновой кислоты, например, последовательности нуклеиновой кислоты, содержащей открытую рамку считывания. Инсерция может выполняться каким-либо методом молекулярной биологии, известным специалисту в данной области техники, например, путем рестрикции и лигирования. Один или несколько сайтов рестрикции может быть распознано ферментами рестрикции, которые расщепляют ДНК по этим сайтам. Сайт клонирования, который содержит более одного сайта рестрикции, также может быть назван сайтом множественного клонирования (multiple cloning site - MCS) или полилинкером.
Молекула нуклеиновой кислоты. Молекула нуклеиновой кислоты является молекулой, предпочтительно состоящей из компонентов нуклеиновой кислоты. Понятие «молекула нуклеиновой кислоты» предпочтительно относится к молекулам ДНК или РНК. Его предпочтительно используют в качестве синонима понятия «полинуклеотид». Предпочтительно, молекула нуклеиновой кислоты является полимером, содержащим или состоящим из нуклеотидных мономеров, которые ковалентно связаны друг с другом фосфодиэфирными связями каркаса молекулы из сахара/фосфата. Понятие «молекула нуклеиновой кислоты» также относится к модифицированным молекулам нуклеиновой кислоты, например, к молекулам ДНК или РНК с модифицированными основаниями, модифицированными сахарами или модифицированным каркасом молекулы.
Открытая рамка считывания. Открытая рамка считывания (open reading frame -ORF) в контексте настоящего изобретения может представлять последовательность из некоторого количества нуклеотидных триплетов, которые могут быть транслированы в пептид или белок. Открытая рамка считывания предпочтительно содержит стартовый кодон, то есть комбинацию из трех последовательно расположенных нуклеотидов, кодирующих обычно аминокислоту метионин (ATG), на 5'-конце и последующую область, которая обычно имеет длину, кратную 3 нуклеотидам. ORF предпочтительно заканчивается стоп-кодоном (например, ТАА, TAG, TGA). Обычно это единственный стоп-кодон открытой рамки считывания. Таким образом, открытая рамка считывания в контексте настоящего изобретения предпочтительно представляет собой нуклеотидную последовательность, состоящую из ряда нуклеотидов, количество которых может быть разделено на три и которые начинаются с исходного кодона (например, ATG), причем указанная последовательность предпочтительно заканчивается стоп-кодоном (например, ТАА, TGA или TAG). Открытая рамка считывания может быть выделена или может быть инкорпорирована в более длинную последовательность нуклеиновой кислоты, например, в векторе или мРНК. Открытую рамку считывания также можно назвать «областью кодирования белка».
Пептид. Пептид или полипептид обычно представляет полимер из аминокислотных мономеров, связанных пептидными связями. Обычно он содержит менее 50 мономерных единиц. Тем не менее, понятие «пептид» также относится к молекулам, содержащим более 50 мономерных единиц. Длинные пептиды также называют полипептидами, обычно имеющими от 50 до 600 мономерных единиц.
Фармацевтически эффективное количество. Фармацевтически эффективное количество в контексте настоящего изобретения обычно означает количество, которое является достаточным для индукции фармацевтического эффекта, например, иммунного ответа, изменяющего патологический уровень экспрессированного пептида или белка, или заменяющим отсутствующий генный продукт, например, в случае патологической ситуации.
Белок А. Белок А обычно содержит один или несколько пептидов или полипептидов. Белок обычно складывается в трехмерную форму, которая может потребоваться для того, чтобы белок мог выполнять свою биологическую функцию.
Последовательность поли(А). Последовательность поли(А), также называемая поли(А) хвостом или 3'-поли(А) хвостом, обычно означает последовательность аденозиновых нуклеотидов, например, включающую примерно 400 аденозиновых нуклеотидов, например примерно от 20 до примерно 400, предпочтительно примерно от 50 до примерно 400, более предпочтительно примерно от 50 до примерно 300, еще более предпочтительно примерно от 50 до примерно 250, наиболее предпочтительно примерно от 60 до примерно 250 аденозиновых нуклеотидов. Поли (А) последовательность обычно расположена в 3'-конце мРНК. В контексте настоящего изобретения поли(А) последовательность может быть расположена внутри мРНК или какой-либо другой молекулы нуклеиновой кислоты, например, в векторе, например, в векторе, служащем в качестве матрицы для выработки РНК, предпочтительно мРНК, например, путем транскрипции вектора.
Полиаденилирование. Обычно понятие «полиаденилирование» означает добавление поли(А) последовательности к молекуле нуклеиновой кислоты, например, к молекуле РНК, например, к незрелой мРНК. Полиаденилирование может быть вызвано так называемым сигналом полиаденилирования. Этот сигнал предпочтительно расположен в пределах отрезка нуклеотидов с 3'-конца молекулы нуклеиновой кислоты, например, молекулы РНК, подвергаемой полиаденилированию. Сигнал полиаденилирования обычно включает гексамер, состоящий из адениновых и урациловых/тиминовых нуклеотидов, предпочтительно гексамерную последовательность AAUAAA. Возможны также другие последовательности, предпочтительно гексамерные. Полиаденилирование обычно происходит во время процессирования пре-мРНК (также называемой незрелой мРНК). Обычно созревание РНК (от пре-мРНК до зрелой мРНК) включает стадию полиаденилирования.
Сайт рестрикции. Сайт рестрикции, также называемый сайтом распознавания ферментов рестрикции, представляет собой нуклеотидную последовательность, распознаваемую ферментом рестрикции. Сайт рестрикции обычно представляет короткую предпочтительно палиндромную нуклеотидную последовательность, например, последовательность, содержащую от 4 до 8 нуклеотидов. Сайт рестрикции предпочтительно специфически распознается ферментом рестрикции. Фермент рестрикции обычно расщепляет нуклеотидную последовательность, содержащую сайт рестрикции в этом месте. В двухцепочечной нуклеотидной последовательности, например, двухцепочечной последовательности ДНК, фермент рестрикции обычно разрезает обе нити нуклеотидной последовательности.
РНК, мРНК. РНК является аббревиатурой рибонуклеиновой кислоты. Это молекула нуклеиновой кислоты, то есть полимер, состоящий из нуклеотидов. Эти нуклеотиды обычно представляют мономеры аденозинмонофосфат, уридинмонофосфат, гуанозинмонофосфат и цитидинмонофосфат, которые связаны друг с другом вдоль так называемого каркаса молекулы. Каркас молекулы образован фосфодиэфирными связями между сахаром, то есть рибозой, первого мономера и фосфатной частью второго соседнего мономера. Определенная последовательность мономеров называется последовательностью РНК. Обычно РНК может быть получена путем транскрипции последовательности ДНК, например, внутри клетки. В эукариотических клетках транскрипция обычно происходит внутри ядра или в митохондриях. Обычно транскрипция ДНК обычно приводит к так называемой незрелой РНК, которая должна быть процессирована в так называемую матричную РНК, обычно сокращенно обозначаемую «мРНК». Процессирование незрелой РНК, например, в эукариотических организмах, включает множество различных посттранскрипционных модификаций, например, сплайсинг, 5'-кэпирование, полиаденилирование, экспорт из ядра или митохондрий и другие. Сумма этих процессов также называется созреванием РНК. Зрелая мРНК обычно представляет нуклеотидную последовательность, которая может быть транслирована в аминокислотную последовательность определенного пептида или белка. Обычно зрелая мРНК содержит 5'-кэп, 5'-UTR, открытую рамку считывания, 3'-UTR и поли(А) последовательность. Помимо матричной РНК существует несколько некодирующих типов РНК, которые могут участвовать в регуляции транскрипции и/или трансляции.
Последовательность молекулы нуклеиновой кислоты. Последовательность молекулы нуклеиновой кислоты обычно представляет определенный индивидуальный порядок, т.е. последовательность нуклеотидов. Последовательность белка или пептида обычно подразумевает порядок, то есть последовательность аминокислот.
Идентичность последовательностей. Две или более последовательностей идентичны, если они имеют одинаковую длину и порядок нуклеотидов или аминокислот. Процент идентичности обычно описывает степень идентичности двух последовательностей, то есть он обычно описывает процент нуклеотидов, которые соответствуют по положению в последовательности идентичным нуклеотидам в сравниваемой последовательности. Для определения степени идентичности сравниваемые последовательности предположительно должны иметь равную длину, то есть длину самой длинной из последовательностей. Это означает, что первая последовательность, состоящая из 8 нуклеотидов, на 80% идентична второй последовательности, состоящей из 10 нуклеотидов и содержащей первую последовательность. Иначе говоря, в контексте настоящего изобретения идентичность последовательностей предпочтительно относится к проценту нуклеотидов последовательности, которые имеют одинаковое положение в двух или более последовательностях, имеющих одинаковую длину.
Гэпы обычно рассматривают в качестве неидентичных положений, независимо от их фактического положения при выравнивании.
Стабилизированная молекула нуклеиновой кислоты. Стабилизированная молекула нуклеиновой кислоты представляет молекулу нуклеиновой кислоты, предпочтительно молекулу ДНК или РНК, которая модифицирована таким образом, что она более устойчива к распаду, например, к факторам окружающей среды или к ферментативному расщеплению, например, экзо- или эндонуклеазами, чем молекула нуклеиновой кислоты без модификации. Предпочтительно, стабилизированная молекула нуклеиновой кислоты в контексте настоящего изобретения стабилизируется в клетке, например, прокариотической или эукариотической клетке, предпочтительно в клетке млекопитающего, например, клетке человека. Эффект стабилизации также может проявляться вне клеток, например, в буферном растворе и т.д., например, в процессе получения фармацевтической композиции, содержащей стабилизированную молекулу нуклеиновой кислоты.
Трансфекция. Понятие «трансфекция» относится к интродукции молекул нуклеиновой кислоты, например, молекул ДНК или РНК (например, мРНК), в клетки, предпочтительно в эукариотические клетки. В контексте настоящего изобретения понятие «трансфекция» охватывает какой-либо метод, известный специалисту в данной области для интродукции молекул нуклеиновой кислоты в клетки, предпочтительно в эукариотические клетки, например, в клетки млекопитающих. Такие методы включают, например, электропорацию, липофекцию, например, на основе катионных липидов и/или липосом, осаждение фосфатом кальция, трансфекцию на основе наночастиц, трансфекцию на основе вирусов или трансфекцию на основе катионных полимеров, например, DEAE-декстрана или полиэтилененимина и т.д. Предпочтительно интродукция не является основанной на вирусах.
Вакцина. Обычно вакциной называют профилактический или терапевтический материал, обеспечивающий по меньшей мере один антиген, предпочтительно иммуноген. Антиген или иммуноген могут быть получены из какого-либо материала, который пригоден для вакцинации. Например, антиген или иммуноген могут быть получены из патогена, например, из бактерий или вирусных частиц и т.д., или из опухоли или раковой ткани. Антиген или иммуноген стимулирует адаптивную иммунную систему организма для обеспечения адаптивного иммунного ответа.
Вектор. Понятие «вектор» относится к молекуле нуклеиновой кислоты, предпочтительно к молекуле искусственной нуклеиновой кислоты. Вектор в контексте настоящего изобретения пригоден для инкорпорации или сохранения нужной последовательности нуклеиновой кислоты, например, последовательности нуклеиновой кислоты, содержащей открытую рамку считывания. Такие векторы могут быть векторами хранения, векторами экспрессии, векторами клонирования, векторами переноса и т.д. Вектор хранения представляет вектор, который позволяет удобно хранить молекулы нуклеиновой кислоты, например, молекулы мРНК. Таким образом, вектор может содержать последовательность, соответствующую, например, желаемой последовательности мРНК или ее части, например, последовательности, соответствующей открытой рамке считывания и 3'-UTR и/или 5'-UTR мРНК. Вектор экспрессии может быть использован для получения продуктов экспрессии, например, РНК, например, мРНК или пептидов, полипептидов или белков. Например, вектор экспрессии может содержать последовательности, необходимые для транскрипции отрезка последовательности вектора, например, промоторной последовательности, например, последовательности промотора РНК-полимеразы. Вектор клонирования обычно представляет вектор, который содержит сайт клонирования, который может быть использован для инкорпорации последовательностей нуклеиновых кислот в вектор. Вектор клонирования может представлять, например, плазмидный вектор или вектор бактериофага. Вектор трансфекции может быть вектором, который подходит для переноса молекул нуклеиновой кислоты в клетки или организмы, например, вирусным вектором. Вектор в контексте настоящего изобретения может представлять, например, РНК-вектор или ДНК-вектор. Предпочтительно, вектор является молекулой ДНК. Предпочтительно вектор в контексте настоящего изобретения содержит сайт клонирования, селективный маркер, например, фактор устойчивости к антибиотику, и последовательность, пригодную для мультипликации вектора, например, начало репликации. Предпочтительно, вектор в контексте настоящей заявки представляет плазмидный вектор.
Носитель. Обычно носителем является материал, который пригоден для хранения, транспортировки и/или введения соединения, например, фармацевтически активного соединения. Например, это может быть физиологически приемлемая жидкость, пригодная для хранения, транспортировки и/или введения фармацевтически активного соединения.
3'-нетранслируемая область (3'-UTR). Обычно понятие «3'-UTR» относят к части молекулы искусственной нуклеиновой кислоты, которая расположена с 3'-конца (т.е. «вниз по цепи») открытой рамки считывания и которая не транслируется в белок. Обычно 3'-UTR является частью мРНК, которая расположена между областью кодирования белка (открытой рамкой считывания (ORF) или кодирующей последовательностью (coding sequence - CDS)) и поли(А) последовательностью мРНК. В контексте настоящего изобретения понятие «3'-UTR» также может содержать элементы, которые не кодируются в матрице, с которой транскрибируется РНК, но которые добавляются после транскрипции во время созревания, например, последовательность поли(А). 3'-UTR мРНК не транслируется в аминокислотную последовательность. Последовательность 3'-UTR обычно кодируется геном, который транскрибируется в соответствующую мРНК во время процесса экспрессии гена. Геномную последовательность сначала транскрибируется в незрелую мРНК, которая содержит необязательные интроны. Незрелую мРНК затем дополнительно процессируют в зрелую мРНК в процессе созревания. Такой процесс созревания включает стадии 5'-кэпирования, сплайсирования незрелой мРНК, чтобы вырезать необязательные интроны, и модификации 3'-конца, например, полиаденилированием 3'-конца незрелой мРНК и необязательное расщепление эндо- и/или экзонуклеазой и т.д. В контексте настоящего изобретения 3'-UTR соответствует последовательности зрелой мРНК, которая локализована между стоп-кодоном кодирующей белок области, предпочтительно сразу 3' по отношению к стоп-кодону области кодирования белка и поли(А) последовательности мРНК. Понятие «соответствует» означает, что последовательность 3'-UTR может быть последовательностью РНК, например, последовательностью мРНК, используемой для определения последовательности 3'-UTR, или последовательность ДНК, которая соответствует такой последовательности РНК. В контексте настоящего изобретения понятие «3'-UTR гена» означает последовательность, которая соответствует 3'-UTR зрелой мРНК, полученной из этого гена, то есть мРНК, полученной в результате транскрипции гена и созревания незрелой мРНК. Понятие «3'-UTR гена» охватывает последовательность ДНК и последовательность РНК (как смысловую, так и антисмысловую нить, и как зрелую, так и незрелую) 3'-UTR. Предпочтительно, 3'UTR имеют в длину более 20, 30, 40 или 50 нуклеотидов.
5'-нетранслируемая область (5'-UTR). Обычно понятие «5'-UTR» относят к части молекулы искусственной нуклеиновой кислоты, которая расположена с 5'-конца (т.е. «вверх по цепи») открытой рамки считывания и которая не транслируется в белок. Обычно 5'-UTR является частью матричной РНК (мРНК), которая расположена с 5'-конца открытой рамки считывания мРНК. Обычно 5'-UTR начинается с сайта начала транскрипции и заканчивается одним нуклеотидом перед стартовым кодоном открытой рамки считывания. Предпочтительно области 5'UTR имеют длину более 20, 30, 40 или 50 нуклеотидов. 5'-UTR может содержать элементы контроля экспрессии генов, также называемые регулирующими элементами. Такими регулирующими элементами могут быть, например, сайты рибосомного связывания. Область 5'-UTR может быть посттрансляционно модифицированной, например, путем добавления 5'-САР. Область 5'-UTR мРНК не транслируется в аминокислотную последовательность. Последовательность 5'-UTR обычно кодируется геном, который транскрибируется в соответствующую мРНК во время процесса экспрессии гена. Геномную последовательность сначала транскрибируют в незрелую мРНК, которая содержит необязательные интроны. Незрелую мРНК затем дополнительно процессируют в зрелую мРНК в процессе созревания. Этот процесс созревания включает стадии 5'-кэппирования, сплайсирования незрелой мРНК для вырезания необязательных интронов и модификаций 3'-конца, полиаденилирования 3'-конца незрелой мРНК и необязательные расщепления эндо- и/или экзонуклеазой и т.д. В контексте настоящего изобретения 5'-UTR соответствует последовательности зрелой мРНК, которая расположена между стартовым кодоном и, например, 5'-САР. Предпочтительно 5'-UTR соответствует последовательности, которая простирается от нуклеотида, расположенного от 3' до 5'-САР, более предпочтительно от нуклеотида, расположенного сразу от 3' до 5'-САР, до нуклеотида, расположенного с 5', до стартового кодона области кодирования белка, предпочтительно к нуклеотиду, расположенному сразу от 5' до стартового кодона области кодирования белка. Нуклеотид, расположенный сразу от 3'до 5'-САР зрелой мРНК, обычно соответствует сайту начала транскрипции. Понятие «соответствует» означает, что последовательность 5'-UTR может представлять собой последовательность РНК, например, последовательность мРНК, используемую для определения последовательности 5'-UTR, или последовательность ДНК, которая соответствует такой последовательности РНК. В контексте настоящего изобретения понятие «5'-UTR гена» представляет последовательность, которая соответствует 5'-UTR зрелой мРНК, полученной из этого гена, то есть мРНК, полученной транскрипцией гена и созреванием зрелой мРНК. Понятие «5'-UTR гена» охватывает последовательность ДНК и последовательность РНК (как смысловую, так и антисмысловую нить и как зрелые, так и незрелые) 5'-UTR.
5'-концевой олигопиримидиновый тракт (Terminal Oligopyrimidine Tract - TOP). 5'-концевой олигопиримидиновый тракт (ТОР) обычно представляет участок пиримидиновых нуклеотидов, расположенный в 5'-концевой области молекулы нуклеиновой кислоты, например, 5'-концевой области некоторых молекул мРНК или 5'-концевой области функционального объекта, например транскрибируемой области, определенных генов. Последовательность начинается с цитидина, который обычно соответствует сайту начала транскрипции, и за ним следует отрезок, обычно состоящий примерно из 3-30 пиримидиновых нуклеотидов. Например, ТОР может содержать 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 или даже больше нуклеотидов. Пиримидиновый отрезок и, соответственно, 5'-ТОР, заканчивается одним нуклеотидом 5' по отношению к первому пуриновому нуклеотиду, расположенному ниже по цепи от ТОР. Матричную РНК, которая содержит 5'-концевой олигопиримидиновый тракт, часто обозначают «ТОР-мРНК». Соответственно, гены, которые предоставляют такие матричные РНК, называют генами ТОР. Последовательности ТОР, например, обнаружены в генах и мРНК, кодирующих факторы элонгации пептидов и рибосомные белки.
ТОР-мотив. В контексте настоящего изобретения ТОР-мотив представляет собой последовательность нуклеиновой кислоты, которая соответствует 5'ТОР, согласно описанному выше. Таким образом, ТОР-мотив в контексте настоящего изобретения предпочтительно представляет фрагмент пиримидиновых нуклеотидов длиной 3-30 нуклеотидов. Предпочтительно ТОР-мотив состоит, по меньшей мере, из 3 пиримидиновых нуклеотидов, предпочтительно по меньшей мере из 4 пиримидиновых нуклеотидов, предпочтительно по меньшей мере из 5 пиримидиновых нуклеотидов, более предпочтительно по меньшей мере из 6 нуклеотидов, более предпочтительно по меньшей мере из 7 нуклеотидов, наиболее предпочтительно по меньшей мере из 8 пиримидиновых нуклеотидов, причем участок пиримидиновых нуклеотидов предпочтительно начинается с 5'-конца с цитозинового нуклеотида. В ТОР-генах и ТОР-мРНК ТОР-мотив предпочтительно начинается с 5'-конца с сайта начала транскрипции и заканчивается одним нуклеотидом 5' к первому пуриновому остатку в указанном гене или мРНК. Мотив ТОР в контексте настоящего изобретения предпочтительно расположен в 5'-конце последовательности, которая представляет 5'-UTR, или в 5'-конце последовательности, которая кодирует 5'-UTR. Таким образом, предпочтительно, участок из 3 или более пиримидиновых нуклеотидов называют «ТОР-мотивом» в контексте настоящего изобретения, если этот участок локализован в 5'-конце соответствующей последовательности, например, молекулы искусственной нуклеиновой кислоты, 5'-UTR элемента молекулы искусственной нуклеиновой кислоты или последовательности нуклеиновой кислоты, которая производна от 5'-UTR гена ТОР, согласно описанию настоящего изобретения. Иначе говоря, участок из 3 или более пиримидиновых нуклеотидов, который не расположен на 5'-конце 5'-UTR или 5'-UTR-элемента, но где-либо в пределах 5'-UTR или 5'-UTR элемента, предпочтительно не называют «ТОР-мотивом».
ТОР-ген. ТОР-гены обычно характеризуются наличием 5'-концевого олигопиримидинового тракта. Кроме того, большинство генов ТОР характеризуются связанной с ростом регуляцией трансляции. Однако известны также гены ТОР с тканеспецифичной регуляцией трансляции. Согласно описанному выше, 5'-UTR гена ТОР соответствует последовательности 5'-UTR зрелой мРНК, производной от гена ТОР, которая предпочтительно расположена от нуклеотида, локализованного с 3' к 5'-CAP нуклеотида, локализованного с 5' к стартовому кодону. 5'-UTR гена ТОР обычно не содержит каких-либо стартовых кодонов, предпочтительно нет расположенных вверх по цепи AUG (upstream AUG - uAUG) или расположенных вверх по цепи открытых рамок считывания (upstream - uORF). В этом случае AUG и расположенные выше по цепи открытые рамки считывания обычно рассматривают в качестве AUG и открытых рамок считывания, которые находятся с 5' стартового кодона (AUG) открытой рамки считывания, с которой должно быть транслирование. 5'-UTR генов ТОР обычно довольно короткие. Длины 5'-UTR генов ТОР могут варьировать в диапазоне от 20 до 500 нуклеотидов и обычно составляют менее примерно 200 нуклеотидов, предпочтительно менее чем около 150 нуклеотидов, более предпочтительно менее примерно 100 нуклеотидов. Типичными 5'-UTR генов ТОР в контексте настоящего изобретения являются последовательности нуклеиновых кислот, простирающиеся от нуклеотида в положении 5 до нуклеотида, расположенного непосредственно 5' по отношению к стартовому кодону (например, ATG) в последовательностях, соответствующих SEQ ID NO: 1-1363 в патентной заявки WO 02013/143700, сущность которой включена в настоящее изобретение в виде ссылки. В этом контексте особенно предпочтительным фрагментом 5'-UTR гена ТОР является область 5'-UTR гена ТОР, утратившая 5'-ТОР-мотив. Понятия «5'-UTR гена ТОР» или «5'-TOP UTR» предпочтительно относятся к 5'-UTR встречающегося в природе гена ТОР.
Первый объект, предусмотренный в настоящем изобретении, относится к молекуле искусственной нуклеиновой кислоты, включающей:
а. по меньшей мере, одну открытую рамку считывания (ORF); и
б. по меньшей мере, один элемент 3'-нетранслируемой области (элемент 3'-UTR) и/или, по меньшей мере, один элемент 5'-нетранслируемой области (элемент 5'-UTR), причем, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR продлевает и/или увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты и, по меньшей мере, один элемент 3'-UTR и/или, по меньшей мере, один элемент 5'-UTR является производным от стабильной мРНК.
Предпочтительно, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не содержит 3'-UTR (элемент) и/или 5'-UTR (элемент) рибосомального белка S6, RPL36AL, rps16 или рибосомального белка L9. Более предпочтительно, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не содержит 3'-UTR (элемент) и/или 5'-UTR (элемент) рибосомального белка S6, RPL36AL, rps16 или рибосомального белка L9, и открытая рамка считывания молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не кодирует белок GFP. Еще более предпочтительно, если молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не содержит 3'-UTR (элемент) и/или 5'-UTR (элемент) рибосомального белка S6, RPL36AL, rps16 или рибосомального белка L9, и открытая рамка считывания молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не кодируют репортерный белок, например, выбранный из группы, состоящей из глобиновых белков (особенно бета-глобина), белка люциферазы, белков GFP, белков глюкуринодазы (в частности, бета-глюкуринодазы) или их вариантов, например, вариантов, демонстрирующих идентичность последовательности с глобиновым белком, белком люциферазы, белком GFP или белком глюкуринодазы, по меньшей мере, на 70%.
Понятие «элемент 3'-UTR» относится к последовательности нуклеиновой кислоты, которая содержит или состоит из последовательности нуклеиновой кислоты, производной от 3'-UTR или от варианта или фрагмента 3'-UTR. Элемент «3'-UTR» предпочтительно относится к последовательности нуклеиновой кислоты, которая состоит из 3'-UTR последовательности искусственной нуклеиновой кислоты, например, искусственной мРНК. Соответственно, в контексте настоящего изобретения предпочтительно элемент 3'-UTR может быть включен в 3'-UTR мРНК, предпочтительно искусственной мРНК, или элемент 3'-UTR может быть включен в 3'-UTR соответствующей матрицы транскрипции. Предпочтительно, элемент 3'-UTR представляет последовательность нуклеиновой кислоты, которая соответствует мРНК 3'-UTR, предпочтительно искусственной мРНК 3'-UTR, например, мРНК, полученной транскрипцией генноинженерной векторной конструкции. Предпочтительно элемент 3'-UTR в контексте настоящего изобретения функционирует в качестве 3'-UTR или кодирует нуклеотидную последовательность, которая выполняет функцию 3'-UTR.
Соответствующим образом, понятие «элемент 5'-UTR» относится к последовательности нуклеиновой кислоты, которая содержит или состоит из последовательности нуклеиновой кислоты, которая является производной от 5'-UTR или от варианта или фрагмента 5'-UTR. «Элемент 5'-UTR» предпочтительно относится к последовательности нуклеиновой кислоты, которая состоит из 5'-UTR последовательности искусственной нуклеиновой кислоты, например, искусственной мРНК. Соответственно, в контексте настоящего изобретения предпочтительно элемент 5'-UTR может состоять из 5'-UTR мРНК, предпочтительно из искусственной мРНК, или элемент 5'-UTR может состоять из 5'-UTR соответствующей матрицы транскрипции. Предпочтительно, 5'-UTR-элемент представляет последовательность нуклеиновой кислоты, которая соответствует 5'-UTR мРНК, предпочтительно 5'-UTR искусственной мРНК, например, мРНК, полученной транскрипцией генноинженерной векторной конструкции. Предпочтительно, 5'-UTR-элемент в контексте настоящего изобретения функционирует в качестве 5'-UTR или кодирует нуклеотидную последовательность, которая выполняет функцию 5'-UTR.
Элемент 3'-UTR и/или элемент 5'-UTR в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением продлевает и/или увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты. Таким образом, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может, в частности, содержать:
- элемент 3'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 5'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 5'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 5'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который увеличивает выработку белка из указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который продлевает производство белка из указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты,
- элемент 3'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и элемент 5'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, или
- элемент 3'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты и элемент 5'-UTR, который увеличивает и продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты.
Предпочтительно, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит элемент 3'-UTR, который продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и/или элемент 5'-UTR, который увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты.
Предпочтительно молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит, по меньшей мере, один элемент 3'-UTR и, по меньшей мере, один элемент 5'-UTR, то есть, по меньшей мере, один элемент 3'-UTR, который продлевает и/или увеличивает выработку белка с указанной искусственной молекулы нуклеиновой кислоты и который является производным стабильной мРНК, а также, по меньшей мере, один элемент 5'-UTR, который продлевает и/или увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты и который получен из стабильной мРНК.
Понятие «продление и/или увеличение выработки белка с указанной молекулы искусственной нуклеиновой кислоты» в общем случае относится к количеству белка, выработанного с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, с соответствующим элементом 3'-UTR и/или элементом 5'-UTR по сравнению с количеством белка, выработанного с соответствующей молекулы контрольной нуклеиновой кислоты, не содержащей 3'-UTR и/или 5'-UTR, или содержащей контрольную 3'-UTR и/или контрольную 5'-UTR, например, 3'-UTR и/или 5'-UTR, встречающиеся в природе в комбинации с ORF.
В частности, по меньшей мере, один элемент 3'-UTR и/или 5'-UTR-элемент молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением продлевают выработку белка с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, с мРНК в соответствии с настоящим изобретением, по сравнению с соответствующей нуклеиновой кислотой, не содержащей 3'-UTR и/или 5'-UTR, или содержащей контрольную 3'-UTR и/или 5'-UTR, например, 3'- и/или 5'-UTR, встречающиеся в природе в комбинации с ORF.
В частности, по меньшей мере, один элемент 3'-UTR и/или элемент 5'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением увеличивает выработку белка, в частности экспрессию белка и/или общую выработку белка, с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, с мРНК в соответствии с настоящим изобретением, по сравнению с соответствующей нуклеиновой кислотой, не содержащей 3'- и/или 5'-UTR, или содержащей контрольные 3'-и/или 5'-UTR, например, 3'- и/или 5'-UTR, встречающиеся в природе в комбинации с ORF.
Предпочтительно, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не оказывают отрицательного воздействия на эффективность трансляции нуклеиновой кислоты по сравнению с эффективностью трансляции соответствующей нуклеиновой кислоты, не содержащей 3'-UTR и/или 5'-UTR, или содержащей контрольный 3'-UTR и/или контрольный 5'-UTR, например, 3'-UTR и/или 5'- UTR, естественным образом встречающийся в комбинации с ORF. Еще более предпочтительно эффективность трансляции усиливается за счет 3'-UTR и/или 5'-UTR по сравнению с эффективностью трансляции белка, кодируемого соответствующей ORF в ее естественном виде.
В контексте настоящего изобретения понятие «соответствующая молекула нуклеиновой кислоты» или «контрольная молекула нуклеиновой кислоты» означает, что, кроме различных 3'-UTR и/или 5'-UTR, контрольная молекула нуклеиновой кислоты является сравнимой, предпочтительно идентичной, с разработанной в настоящем изобретении молекулой искусственной нуклеиновой кислоты, содержащей элемент 3'-UTR и/или элемент 5'-UTR.
Для оценки выработки белка in vivo или in vitro по настоящему изобретению (т.е. понятие «in vitro» относится к «живым» клеткам и/или тканям, включая ткань живого субъекта; клетки включают, в частности, клеточные линии, первичные клетки, клетки в тканях или субъектах, предпочтительными являются клетки млекопитающих, например клетки человека и мыши, и особенно предпочтительными являются линии клеток человека HeLa и U-937, и линии клеток мыши NIH3T3, JAWSII и L929, кроме того, наиболее предпочтительными являются первичные клетки, в частности предпочтительными вариантами осуществления настоящего изобретения являются дермальные фибробласты человека (human dermal fibroblasts - HDF)) с помощью молекулы искусственной нуклеиновой кислоты по настоящему изобретению, экспрессию закодированного белка определяют после инъекции/трансфекции молекулы искусственной нуклеиновой кислоты по настоящему изобретению в клетки-мишени/ткани и сравнивают с экспрессией белка, индуцированной контрольной нуклеиновой кислотой. Количественные методы определения экспрессии белка известны в данной области (например, вестерн-блоттинг, FACS, ELISA, масс-спектрометрия). Особенно полезным в этом контексте является определение экспрессии репортерных белков, таких как люцифераза, зеленый флуоресцентный белок (Green fluorescent protein - GFP) или секретируемая щелочная фосфатаза (SEAP). Таким образом, искусственная нуклеиновая кислота по настоящему изобретению или контрольная нуклеиновая кислота вводится в ткань или клетку-мишень, например, через трансфекцию или инъекцию, предпочтительно в систему экспрессии млекопитающих, например, в клетки млекопитающих, например, в клетки HeLa или HDF. Через несколько часов или несколько дней (например, 6, 12, 24, 48 или 72 ч) после инициации экспрессии или после введения молекулы нуклеиновой кислоты образец клетки-мишени отбирают и измеряют с помощью FACS и/или лизируют. Затем лизаты могут быть использованы для обнаружения экспрессированного белка (и, таким образом, определения эффективности экспрессии белка) с использованием нескольких способов, например, вестерн-блоттинг, FACS, ELISA, масс-спектрометрия или измерение флуоресценции или люминесценции.
Таким образом, если экспрессию белка с молекулы искусственной нуклеиновой кислоты согласно настоящему изобретению сравнивают с экспрессией белка с контрольной молекулы нуклеиновой кислоты в определенный момент времени (например, через 6, 12, 24, 48 или 72 ч после начала экспрессии или после интродукции молекулы нуклеиновой кислоты), обе молекулы нуклеиновой кислоты вводятся отдельно в целевую ткань/клетки, образец ткани/клеток берут по прошествии определенного времени, белковые лизаты получают в соответствии с определенным протоколом, заданным для определенного метода обнаружения (например, вестерн-блоттинга, ELISA, измерения флуоресценции или люминесценции и т.д., известных в данной области), и белок определяют выбранным методом. В качестве альтернативы измерению количества экспрессированного белка в клеточных лизатах - или в дополнение к измерению количества белка в клеточных лизатах до лизиса собранных клеток или с использованием аликвоты в параллельных исследованиях - количество белка также может быть определено методом FACS.
Понятие «продление выработки белка», получаемого с молекулы искусственной нуклеиновой кислоты, например, искусственной мРНК, предпочтительно означает, что выработка белка с молекулы искусственной нуклеиновой кислоты, например, искусственной мРНК, пролонгируется по сравнению с выработкой белка с контрольной молекулы нуклеиновой кислоты, например, с контрольной мРНК, например включающей контрольную область 3'-и/или 5'-UTR или отсутствие 3'- и/или 5'-UTR, предпочтительно в системе экспрессии млекопитающих, например, в клетках HeLa или HDF. Таким образом, выработку белка с молекулы искусственной нуклеиновой кислоты, например, с искусственной мРНК, наблюдают в течение более длительного периода времени, чем можно наблюдать для белка, вырабатываемого с контрольной молекулы нуклеиновой кислоты. Иначе говоря, количество белка, вырабатываемого с молекулы искусственной нуклеиновой кислоты, например, с искусственной мРНК, измеренное в более поздний момент времени, например, через 48 ч или 72 ч после трансфекции, больше, чем количество белка, выработанного с контрольной молекулы нуклеиновой кислоты, например, с контрольной мРНК в соответствующий более поздний момент времени. Такой «более поздний момент времени» может быть, например, в любое время после 24 ч после начала экспрессии, например, посттрансфекции молекулы нуклеиновой кислоты, например, через 36, 48, 60, 72, 96 ч после начала экспрессии, то есть после трансфекции. Кроме того, для той же нуклеиновой кислоты количество белка, продуцируемого в более поздний момент времени, может быть нормализовано по количеству, выработанному в более ранний (контрольный) момент времени, например, количество белка в более поздний момент времени может быть выражено в процентах от количества белка через 24 ч после трансфекции.
Предпочтительно такой эффект продления выработки белка определяют (i) измерением количества белка, например, полученного путем экспрессии закодированного репортерного белка, например, люциферазы, предпочтительно в системе экспрессии млекопитающих, например, в клетках HeLa или HDF, на протяжении времени, (ii) определением количества белка, наблюдаемого в «контрольной» точке за время t1, например t1=24 ч после трансфекции, и определением этого количества белка равным 100%, (iii) определением количества белка, наблюдаемого в один или несколько более поздних временных точек t2, t3 и т.д., например t2=48 ч и t3=72 ч после трансфекции, и вычисление относительного количества белка, наблюдаемого в более поздний момент времени в виде процента от количества белка в момент времени t1. Например, белок, который экспрессирован в момент времени t1 в количестве «80», в момент времени t2 экспрессирован в количестве «20», а при t3 экспрессирован в количестве «10», относительное количество белка в момент времени t2 может составлять 25%, и в момент времени t3 - 12,5%. Такие относительные количества в более поздний момент времени затем можно сравнить на стадии (iv) с относительными количествами белка в соответствующие моменты времени для молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'-и/или 5'-UTR, соответственно. Путем сравнения относительного количество белка, выработанного с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, с относительным количеством белка, выработанного с контрольной молекулы нуклеиновой кислоты, то есть молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей эталонный 3'- и/или 5'-UTR, соответственно, может быть определен фактор, посредством которого выработка белка с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением продлевается по сравнению с выработкой белка с контрольной молекулы нуклеинового кислотной молекулы.
Предпочтительно, по меньшей мере, один 3'- и/или 5'-UTR элемент в молекуле искусственной нуклеиновой кислоты по настоящему изобретению продлевает выработку белка с указанной молекулы искусственной нуклеиновой кислоты по меньшей мере в 1,2 раза, предпочтительно по меньшей мере в 1,5 раза, более предпочтительно на по меньшей мере, в 2 раза, еще более предпочтительно, по меньшей мере, в 2,5 раза по сравнению с выработкой белка с контрольной молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'- и/или 5'- UTR, соответственно. Иначе говоря, (относительное) количество белка, выработанного с молекулы искусственной нуклеиновой кислоты по настоящему изобретению, в некоторый более поздний момент времени, согласно описанию выше, увеличивается в по меньшей мере в 1,2 раза, предпочтительно по меньшей мере в 1,5 раза, более предпочтительно по меньшей мере, в 2 раза, еще более предпочтительно по меньшей мере в 2,5 раза по сравнению с (относительным) количеством белка, выработанного с контрольной молекулы нуклеиновой кислоты, которая, например, не имеют 3'- и/или 5'-UTR соответственно или содержат контрольные 3'- и/или 5'-UTR, соответственно, для одного и того же более более позднего момента времени.
В другом варианте эффект продления выработки белка также может быть определен посредством (i) измерения количества белка, например, образованного в результате экспрессии закодированного репортерного белка, например, люциферазы, предпочтительно в системе экспрессии млекопитающих, например, в клетках HeLa или HDF, на протяжении времени, (ii) определения времени, когда количество белка отличается от количества белка, наблюдаемого, например, через 1, 2, 3, 4, 5 или 6 ч после начала экспрессии, например 1, 2, 3, 4, 5 или 6 ч после трансфекции молекулы искусственной нуклеиновой кислоты, и (iii) сравнения момента времени, при котором количество белка отличается от количества белка, наблюдаемого на 1, 2, 3, 4, 5 или 6 ч после начала экспрессии до указанного момента времени, определенного для молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'- и/или 5'-UTR, соответственно.
Например, выработка белка с молекулы искусственной нуклеиновой кислоты, например, с искусственной мРНК, в количестве, которое представляет, по меньшей мере, количество, наблюдаемое в начальной фазе экспрессии, например, через 1, 2, 3, 4, 5 или 6 ч после инициация экспрессии, например, после трансфекции молекулы нуклеиновой кислоты, продлевается, по меньшей мере, примерно на 5 ч, предпочтительно, по меньшей мере, примерно на 10 ч, более предпочтительно, по меньшей мере, примерно на 24 ч по сравнению с выработкой белка с контрольной молекулы нуклеиновой кислоты, например, контрольной мРНК, в системе экспрессии млекопитающих, например, в клетках млекопитающих, например, в клетках HeLa или HDF. Таким образом, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением предпочтительно обеспечивает длительную выработку белка в количестве, которое составляет, по меньшей мере, количество, наблюдаемое в начальной фазе экспрессии, например, через 1, 2, 3, 4, 5 или 6 часов после начала экспрессии, например, после трансфекции, по меньшей мере, примерно на 5 ч, предпочтительно, по меньшей мере, примерно на 10 ч, более предпочтительно, по меньшей мере, примерно на 24 ч по сравнению с контрольной молекулой нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'- и/или 5'-UTR, соответственно.
В предпочтительных вариантах осуществления настоящего изобретения период выработки белка с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением продлевается по меньшей мере в 1,2 раза, предпочтительно по меньшей мере в 1,5 раза, более предпочтительно по меньшей мере в 2 раза, еще более предпочтительно по меньшей мере в 2,5 раза по сравнению с выработкой белка с исходной молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'- и/или 5'-UTR, соответственно.
Предпочтительно достигается такой пролонгированный эффект выработки белка, хотя общее количество выработанного белка с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, в течение 48 или 72 ч, соответствует, по меньшей мере, количеству белка, выработанного с контрольной молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'- и/или 5'-UTR, соответственно, например, 3'-UTR и/или 5'-UTR, встречающиеся естественным образом в ORF молекулы искусственной нуклеиновой кислоты. Таким образом, настоящее изобретение предусматривает молекулу искусственной нуклеиновой кислоты, которая обеспечивает длительную выработку белка в экспрессирующей системе млекопитающих, например, в клетках млекопитающих, например, в клетках HeLa или HDF согласно указанному выше, причем общее количество белка, вырабатываемого с указанной молекулы искусственной нуклеиновой кислоты, например, в течение 48 или 72 ч, представляет, по меньшей мере, общее количество вырабатываемого белка, например, в пределах установленного промежутка времени, с контрольной молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'-и/или 5'-UTR, соответственно, например, 3'- и/или 5'-UTR, встречающиеся естественным образом в ORF молекулы искусственной нуклеиновой кислоты.
Кроме того, понятие «продленная экспрессия белка» также включает понятие «стабилизированная экспрессия белка», причем понятие «стабилизированная экспрессия белка» предпочтительно означает, что существует более однородная выработка белка с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением в течение заранее определенного периода времени, например, более 24 ч, более предпочтительно более 48 ч, еще более предпочтительно в течение 72 ч, по сравнению с контрольной молекулой нуклеиновой кислоты, например, мРНК, содержащей контрольные 3'- и/или 5'-UTR, соответственно, или не сдержащие 3'- и/или 5'-UTR, соответственно.
Соответственно, уровень выработки белка, например, в системе млекопитающих, с молекулы искусственной нуклеиновой кислоты, содержащей элемент 3'- и/или 5'-UTR в соответствии с настоящим изобретением, например, с мРНК в соответствии с настоящим изобретением, предпочтительно не падает до степени, наблюдаемой для контрольной молекулы нуклеиновой кислоты, наример, контрольной мРНК согласно описанному выше. Для оценки того, в какой степени выработка белка с определенной молекулы нуклеиновой кислоты падает, например, количество белка (кодируемое соответствующей ORF), наблюдаемое через 24 ч после начала экспрессии, например, через 24 ч после трансфекции молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением в клетку, например, клетку млекопитающего, можно сравнить с количеством белка, наблюдаемом через 48 ч после начала экспрессии, например, через 48 ч после трансфекции. Таким образом, соотношение количества белка, кодируемого ORF молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, количества репортерного белка, например люциферазы, наблюдаемого в более поздний момент времени, например, через 48 ч после начала экспрессии, например, после трансфекции, до количества белка, наблюдаемого в более ранний момент времени, например, через 24 ч после начала экспрессии, например, после трансфекции, предпочтительно выше соответствующего соотношения (в одни и те же моменты времени) для контрольной молекулы нуклеиновой кислоты, содержащей контрольные 3'- и/или 5'-UTR, соответственно, или не имеющей 3'-и/или 5'-UTR, соответственно.
Предпочтительно, соотношение количества белка, кодируемого ORF молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, количество репортерного белка, например люциферазы, наблюдаемое в более поздний момент времени, например, через 48 ч после начала экспрессии, например, после трансфекции, до количества белка, наблюдаемого в более ранний момент времени, например, 24 ч после начала экспрессии, например, после трансфекции, предпочтительно составляет по меньшей мере 0,2, более предпочтительно, по меньшей мере, около 0,3, еще более предпочтительно, по меньшей мере, примерно 0,4, еще более предпочтительно, по меньшей мере, примерно 0,5 и особенно предпочтительно по меньшей мере примерно 0,7. Для соответствующей контрольной молекулы нуклеиновой кислоты, например, мРНК, содержащую контрольные 3'- и/или 5'-UTR, соответственно или не имеющие 3'- и/или 5'-UTR, соответственно, указанное соотношение может составлять, например, примерно от 0,05 до примерно 0,35.
Таким образом, настоящее изобретение относится к молекуле искусственной нуклеиновой кислоты, содержащей ORF и 3'- и/или 5'-UTR элемент согласно описанному выше, причем соотношение количества белка, например, количества люциферазы, наблюдаемое через 48 ч после начала экспрессии, к количеству белка, наблюдаемому через 24 ч после начала экспрессии, предпочтительно в экспрессирующей системе млекопитающих, например, в клетках млекопитающих, например, в клетках HDF или в клетках HeLa, предпочтительно составляет по меньшей мере 0,2, более предпочтительно, по меньшей мере, около 0,3, более предпочтительно, по меньшей мере, около 0,4, еще более предпочтительно по меньшей мере около 0,5, еще более предпочтительно, по меньшей мере, около 0,6 и особенно предпочтительно, по меньшей мере, около 0,7. Таким образом, предпочтительно общее количество белка, полученного с указанной молекулы искусственной нуклеиновой кислоты, например, в течение 48 ч, соответствует, по меньшей мере, полному количеству продуцируемого белка, например, в пределах указанного промежутка времени, с эталонной молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'- и/или 5'-UTR, соответственно, например, 3'-UTR и/или 5'-UTR, встречающиеся в природе с ORF молекулы искусственной нуклеиновой кислоты.
Предпочтительно, настоящее изобретение предусматривает молекулу искусственной нуклеиновой кислоты, содержащую ORF и элемент 3'-UTR и/или элемент 5'-UTR согласно описанному выше, причем соотношение количества белка, например, количества люциферазы, наблюдаемое через 72 ч после начала экспрессии, к количеству белка, наблюдаемому через 24 ч после начала экспрессии, предпочтительно в экспрессирующей системе млекопитающих, например, в клетках млекопитающих, например, в клетках HeLa или клетках HDF, предпочтительно выше примерно 0,05, более предпочтительно выше примерно 0,1, более предпочтительно выше примерно 0,2, еще более предпочтительно выше примерно 0,3, причем предпочтительно общее количество белка, полученного с указанной молекулы искусственной нуклеиновой кислоты, например, в течение периода времени в 72 ч, составляет, по меньшей мере, общее количество белка, вырабатываемого, например, в пределах указанного отрезка времени, с контрольной молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно, или содержащей контрольные 3'- и/или 5'-UTR, соответственно, например, 3'- и/или 5'-UTR, встречающиеся естественным образом в ORF молекулы искусственной нуклеиновой кислоты.
Предпочтительно понятие «повышенная экспрессия белка» или «увеличенная экспрессия белка» в контексте настоящего изобретения предпочтительно означает увеличенную/повышенную экспрессию белка в определенный момент времени после инициации экспрессии или увеличенное/повышенное общее количество экспрессированного белка по сравнению с экспрессией, индуцированной контролой молекулой нуклеиновой кислоты. Таким образом, уровень белка, наблюдаемый в определенный момент времени после начала экспрессии, например, после трансфекции молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, после трансфекции мРНК в соответствии с настоящим изобретением, например, через 6, 12, 24, 48 или 72 ч после трансфекции, предпочтительно выше, чем уровень белка, наблюдаемый в тот же момент времени после начала экспрессии, например, после трансфекции контрольной молекулы нуклеиновой кислоты, наример, контрольной мРНК, содержащей контрольные 3'- и/или 5'-UTR, соответственно, или не содержащей 3'- и/или 5'-UTR, соответственно. В предпочтительном варианте осуществления настоящего изобретения максимальное количество белка (определенное, например, по белковой активности или массы), экспрессированное с молекулы искусственной нуклеиновой кислоты, увеличивается в отношении количества белка, экспрессированного с контрольной нуклеиновой кислоты, содержащей контрольную 3'- и/или 5'-UTR соответственно или не имеющей 3'- и/или 5'-UTR, соответственно. Пиковые уровни экспрессии предпочтительно достигают в течение 48 ч, более предпочтительно в течение 24 ч и еще более предпочтительно в течение 12 ч, например, после трансфекции.
Предпочтительно понятие «повышенная выработка общего белка» или «увеличенная выработка общего белка» с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением относится к увеличенной/повышенной выработке белка на потяжении определенного периода времени, когда белок получают с молекулы искусственной нуклеиновой кислоты, например 48 ч или 72 ч, предпочтительно в системе экспрессии млекопитающих, например, в клетках млекопитающих, например, в клетках HeLa или HDF, по сравнению с контрольной молекулой нуклеиновой кислоты, не содержащей 3'-и/или 5'-UTR, соответственно, или содержащей контрольный элемент 3'- и/или 5'-UTR, соответственно. В соответствии с предпочтительным вариантом осуществления настоящего изобретения суммарное количество белка, экспрессируемое в течение определенного времени, увеличивается при использовании молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением.
Общее количество белка в течение определенного периода времени может быть определено путем (i) сбора ткани или клеток в нескольких временных точках после введения молекулы искусственной нуклеиновой кислоты (например, через 6, 12, 24, 48 и 72 ч после начала экспрессии или после интродукции молекулы нуклеиновой кислоты), и количество белка в определенной временной точке может быть определено согласно описанию настоящего изобретения. Чтобы вычислить суммарное количество белка, можно использовать математический метод определения общего количества белка, например, площадь под кривой (area under the curve - AUC) может быть определена по следующей формуле:

Для расчета площади под кривой для общего количества белка рассчитывают интеграл уравнения кривой экспрессии по каждой конечной точке (а и b).
Таким образом, «общая выработка белка» предпочтительно относится к площади под кривой (area under the curve - AUC), представляющей выработку белка на протяжении времени.
Предпочтительно, по меньшей мере, один 3'- или 5'-UTR элемент в соответствии с настоящим изобретением увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, по меньшей мере в 1,5 раза, предпочтительно по меньшей мере в 2 раза, более предпочтительно, по меньшей мере в 2,5 раза по сравнению с выработкой белка с контрольной молекулы нуклеиновой кислоты, не содержащей 3'- и/или 5'-UTR, соответственно. Иначе говоря, общее количество белка, полученного с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением в определенный момент времени, например, 48 ч или 72 ч после начала экспрессии, например, после трансфекции, увеличивается, по меньшей мере в 1,5 раза, предпочтительно по меньшей мере в 2 раза, более предпочтительно по меньшей мере в 2,5 раза по сравнению с (относительным) количеством белка, полученным с контрольной молекулы нуклеиновой кислоты, которая, например, не имеет 3'- и/или 5'-UTR, соответственно, или содержат контрольный 3'- и/или 5'-UTR соответственно для определенной более поздней временной точки.
Эффект и эффективность продления выработки мРНК и/или белка и/или эффект и эффективность роста выработки белка вариантов, фрагментов и/или фрагментов вариантов 3'-UTR и/или 5'-UTR, а также эффект и эффективность продления выработки мРНК и/или белка, и/или эффект и эффективность повышения выработки белка по меньшей мере одного 3'-UTR-элемента и/или по меньшей мере одного 5'-UTR-элемента молекулы искусственной нуклеиновой кислоты в соответствии с настоящее изобретением может быть определено каким-либо методом, пригодным для этой цели и известным специалистам.
Например, могут быть получены молекулы искусственной мРНК, содержащие кодирующую последовательность/открытую рамку считывания (open reading frame - ORF) для репортерного белка, например, для люциферазы, и элемент 3'-UTR в соответствии с настоящим изобретением, то есть который продлевает и/или увеличивает выработку белка с указанной молекулы искусственной мРНК. Кроме того, молекула мРНК по настоящему изобретению может дополнительно содержать элемент 5'-UTR в соответствии с настоящим изобретением, то есть элемент, который продлевает и/или увеличивает выработку белка с указанной молекулы искусственной мРНК, но не содержит элемент 5'-UTR или элемент 5'-UTR, который не соответствует настоящему изобретению, например контрольный 5'-UTR. Соответственно, могут быть получены молекулы искусственной мРНК, содержащие кодирующую последовательность/открытую рамку считывания (ORF) для репортерного белка, например, для люциферазы, и элемент 5'-UTR в соответствии с настоящим изобретением, то есть который продлевает иили увеличивает выработку белка с указанной молекулы искусственной мРНК. Кроме того, подобная молекула мРНК по настоящему изобретению может дополнительно содержать элемент 3'-UTR в соответствии с настоящим изобретением, то есть элемент, который продлевает и/или увеличивает выработку белка с указанной молекулы искусственной мРНК, не содержит элемент 3'-UTR или элемент 3'-UTR, который не соответствует настоящему изобретению, например, контрольный элемент 3'-UTR.
В соответствии с настоящим изобретением мРНК могут быть получены, например, путем транскрипции in vitro соответствующих векторов, например, векторов плазмид, например, включающих промотор Т7 и последовательность, кодирующую соответствующие последовательности мРНК. Полученные молекулы мРНК могут быть трансфицированы в клетки каким-либо методом трансфекции, пригодным для трансфекции мРНК, например, они могут быть трансфицированы методом липофекции в клетки млекопитающих, например, в клетки HeLa или HDF, и образцы могут анализироваться через определенные моменты времени после трансфекции, например, через 6 ч, 24 ч, 48 ч и 72 ч после трансфекции. В указанных образцах могут быть исследованы количество мРНК и/или белка известными специалистами методами. Например, количество репортерной мРНК, присутствующей в клетках в определенные моменты времени, может быть определено методами количественной ПЦР. Количество репортерного белка, кодируемого соответствующими мРНК, может быть определено, например, методами вестерн-блоттинга, ELISA, анализа репортеров FACS, например, анализом люциферазы, в зависимости от используемого репортерного белка. Эффект стабилизации экспрессии белка и/или удлинения экспрессии белка может быть проанализирован, например, путем определения соотношения уровня белка, наблюдаемого через 48 ч после трансфекции, и уровня белка, наблюдаемого через 24 ч после трансфекции. Чем ближе указанное значение к 1, тем более стабильной является экспрессия белка в течение соответствующего периода времени. Безусловно, такие измерения также могут выполняться в течение 72 ч или более, и соотношение уровня белка, наблюдаемого через 72 ч после трансфекции, и уровня белка, наблюдаемого через 24 ч после трансфекции, можно определить для определения стабильности экспрессии белка.
Кроме того, по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением является производным стабильной мРНК. Таким образом, понятие молекула, «производная» стабильной мРНК, означает, что по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR идентичен по меньшей мере на 50%, предпочтительно по меньшей мере на 60%, предпочтительно по меньшей мере на 70%, более предпочтительно по меньшей мере на 75%, более предпочтительно по меньшей мере на 80%, более предпочтительно по меньшей мере на 85%, еще более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95% и особенно предпочтительно по меньшей мере на 98% последовательности элемента 3'-UTR и/или элемента 5'-UTR стабильной мРНК. Предпочтительно стабильная мРНК представляет природную мРНК и, таким образом, элемент 3'-UTR и/или элемент 5'-UTR стабильной мРНК относится к 3'-UTR и/или 5'-UTR, или к их фрагментам или их вариантам, встречающимся в природной мРНК. Кроме того, элемент 3'-UTR и/или элемент 5'-UTR, полученный из стабильной мРНК, предпочтительно также относится к элементу 3'-UTR и/или к элементу 5'-UTR, который модифицирован по сравнению с природным элементом 3'-UTR и/или элементом 5'-UTR, например, чтобы еще больше повысить стабильность РНК и или продлить и/или увеличить выработку белка. Безусловно, что такие модификации являются предпочтительными, которые не ухудшают стабильности РНК, например, по сравнению с естественным (немодифицированным) элементом 3'-UTR и/или элементом 5'-UTR. В частности, понятие мРНК в контексте настоящего изобретения относится к молекуле мРНК, однако оно также может относиться к виду мРНК согласно описанию настоящего изобретения.
Предпочтительно стабильность мРНК, т.е. распад и/или период полувыведения мРНК, оценивают в стандартных условиях, например, в стандартных условиях (стандартные среда, условия инкубиования и т.д.) для определенной клеточной линии.
В контексте настоящего изобретения понятие «стабильная мРНК» в общем относится к мРНК, распад которой происходит медленно. Таким образом, «стабильная мРНК» обычно имеет длительный период полураспада. Период полураспада мРНК - это время, необходимое для разрушения 50% молекул мРНК в условиях in vivo или in vitro. Соответственно, стабильность мРНК обычно оценивают in vivo или in vitro. Таким образом, понятие «in vitro» относится, в частности, к («живым») клеткам и или тканям, включая ткань живого субъекта. К клеткам отнсятся, в частности, клеточные линии, первичные клетки, клетки в тканях или субъектах. В некоторых вариантах осуществления настоящего изобретения клеточные типы, допускающие культивирование клеток, могут быть применимы в настоящем изобретении. Особенно предпочтительными являются клетки млекопитающих, например, клетки человека и клетки мыши. В особенно предпочтительных вариантах осуществления настоящего изобретения используют линии клеток человека HeLa и U-937 и линии клеток мыши NIH3T3, JAWSII и L929. Кроме того, первичные клетки являются особенно предпочтительными, в частности в предпочтительных вариантах осуществления настоящего изобретения могут быть использованы дермальные фибробласты человечека (human dermal fibroblasts - HDF). В другом варианте также может быть применена ткань субъекта.
Предпочтительно период полураспада «стабильной мРНК» составляет по меньшей мере 5 ч, по меньшей мере 6 ч, по меньшей мере 7 ч, по меньшей мере 8 ч, по меньшей мере ч, по меньшей мере 10 ч, по меньшей мере 11 ч, по меньшей мере 12 ч, по меньшей мере 13 ч, по меньшей мере 14 ч и/или по меньшей мере 15 ч. Период полураспада представляющей интерес мРНК может быть определен различными методами, известными специалисту в данной области. Обычно период полураспада представляющей интерес мРНК определяют путем определения константы распада, в соответствии с чем обычно предполагают использовать идеальную ситуацию in vivo (или in vitro согласно описанному выше), при которой транскрипция представляющей интерес мРНК может быть полностью выключена (или, по крайней мере, находится на уровне ниже определяемого). В такой идеальной ситуации обычно предполагают, что распад мРНК следует кинетике первого порядка. Соответственно, распад мРНК обычно может быть описан следующим уравнением:

где А0 означает количество (или концентрацию) представляющей интерес мРНК в момент времени 0, то есть до начала распада, A(t) означает количество (или концентрацию) представляющей интерес мРНК за время t во время распада, и λ означает константу распада. Таким образом, если количество (или концентрация) представляющей интерес мРНК в момент времени 0 (А0) и количество (или концентрация) представляющей интерес мРНК в момент времени t во время процесса распада (A(t) и t) известны, можно рассчитать константу распада λ. На основании константы распада λ можно рассчитать период полураспада t1/2 по следующему уравнению:

поскольку согласно определению A(t)/A0=1/2 при t1/2. Таким образом, для оценки периода полураспада исследуемой мРНК обычно определяют количество или концентрацию мРНК во время процесса распада РНК in vivo (или in vitro согласно описанному выше).
Чтобы определить количество или концентрацию мРНК во время процесса распада РНК in vivo (или in vitro, согласно описанному выше), могут быть использованы различные методы, которые известны специалистам в данной области. К примерам, не ограничивающим области охвата настоящего изобретения, относят общее ингибирование транскрипции, например, таким ингибитором транскрипции, как актиномицин D, использование индуцируемых промоторов для специфической индукции временной транскрипции, например, c-fos индуцируемой сывороткой промоторной системы и регуляторной промоторной системы Tet-off, а также методы кинетической маркировки, например, импульсной маркировки, например, 4-тиоуридином (4sU), 5-этиниллуридином (ЕС) или 5'-бром-уридином (BrU). Дополнительные подробности и предпочтительные варианты осуществления настоящего изобретения касаются определения количества или концентрации мРНК во время распада РНК, описанных ниже, в контексте способа идентификации элемента 3'-UTR и/или по меньшей мере одного элемента 5'-UTR, который являеся прозводным стабильной мРНК по настоящему изобретению. Соответствующее описание и предпочтительные варианты его осуществления также касаются применяемых в настоящем изоберетении способов определения количества или концентрации мРНК во время распада РНК.
Предпочтительно, «стабильная мРНК» в контексте настоящего изобретения распадается медленнее, чем средняя мРНК, что предпочтительно оценивают in vivo (или in vitro, согласно описанному выше). Например, «распад средней мРНК» можно оценить, исследуя распад мРНК множества видов мРНК, предпочтительно 100, по меньшей мере 300, по меньшей мере 500, по меньшей мере 1000, по меньшей мере 2000, по меньшей мере 3000, по меньшей мере 4000, при по меньшей мере 5000, по меньшей мере 6000, по меньшей мере 7000, по меньшей мере 8000, по меньшей мере 9000, по меньшей мере 10000, по меньшей мере 11000, по меньшей мере 12000, по меньшей мере 13000, не менее 14000, не менее 15000, не менее 16000, по меньшей мере 17000, по меньшей мере 18000, по меньшей мере 19000, по меньшей мере 20000, по меньшей мере 21000, по меньшей мере 22000, по меньшей мере 23000, по меньшей мере 24000, по меньшей мере 25000, по меньшей мере 26000, по меньшей мере 27000, по меньшей мере 28000, по меньшей мере 29000, по меньшей мере 30000 мРНК. Особенно предпочтительно, когда оценивают весь транскриптом, или так много видов мРНК транскриптома, насколько это взможно. Это может быть достигнуто, например, с использованием микроматрицы, обеспечивающей охват всего транскрипта.
Понятие «виды мРНК» в контексте настоящего изобретения означает единицу транскрипции генома, т.е. обычно ген. Таким образом, в пределах одного «вида мРНК» могут встречаться различные транскрипты, например, из-за процессинга мРНК. Например, вид мРНК может быть представлен пятном на микрочипе. Соответственно, микрочип представляет собой полезный инструмент для определения количества видов мРНК в множестве, например, в определенный момент времени во время распада мРНК. Однако специалистам известны также другие методы, которые могут быть применены, например, сиквенс РНК, количественная ПЦР и др.
В настоящем изобретении особенно предпочтительно, чтобы стабильная мРНК отличалась расщеплением мРНК, причем отношение количества указанной мРНК во второй временной точке к количеству указанной мРНК в первой временной точке составляет по меньшей мере 0,5 (50%), по меньшей мере 0,6 (60%), по меньшей мере 0,7 (70%), по меньшей мере 0,75 (75%), по меньшей мере 0,8 (80%), по меньшей мере 0,85 (85%) или по меньшей мере 0,95 (95%). Таким образом, вторая временная точка наступает позже в процессе распада, чем первая временная точка.
Предпочтительно, первую временную точку выбирают таким образом, что рассматривают только мРНК, подвергающуюся процессу распада, т.е. возникающую мРНК - т.е. в ходе транскрипции - исключают. Например, если применяют методы кинетической маркировки, например, импульсной маркировка, первую временную точку предпочтительно выбираются таким образом, что включение метки в мРНК завершается, то есть не происходит постоянного включения метки в мРНК. Таким образом, если используют кинетическую маркировку, первая временная точка может составлять по меньшей мере 10 мин, по меньшей мере 20 мин, по меньшей мере 30 мин, по меньшей мере 40 мин, по меньшей мере 50 мин, по меньшей мере 60 мин, по меньшей мере 70 мин по меньшей мере 80 мин или по меньшей мере 90 мин после окончания экспериментальной процедуры нанесения метки, например после окончания инкубации клеток с меткой.
Например, первая временная точка может составлять предпочтительно от 0 до 6 ч после остановки транскрипции (например, ингибитором транскрипции), остановки индукции промотора в случае индуцибельных промоторов или после прекращения подачи импульса или метки, например, после окончания нанесения метки. Более предпочтительно, первая временная точка может составлять от 30 мин до 5 ч, еще более предпочтительно от 1 ч до 4 ч и особенно предпочтительно примерно через 3 ч после прекращения транскрипции (например, ингибитором транскрипции), прекращение индукции промотора в случае индуцируемых промоторов или после остановки подачи импульсов или меток, например после окончания нанесения метки.
Предпочтительно вторую временную точку выбирают как можно позже во время процесса распада мРНК. Однако если рассматривать множество видов мРНК, второй момент времени предпочтительно выбирают таким образом, что все еще существенное количество множества видов мРНК, предпочтительно по меньшей мере 10% видов мРНК, присутствует в обнаружимом количестве, то есть в количестве больше 0. Предпочтительно, второй момент времени составляет по меньшей мере 5 ч, по меньшей мере 6 ч, по меньшей мере 7 ч, по меньшей мере 8 ч, по меньшей мере 9 ч, по меньшей мере 10 ч, по меньшей мере 11 ч, по меньшей мере 12 ч, по меньшей мере 13 ч, по меньшей мере 14 ч или по меньшей мере 15 ч после окончания транскрипции или в конце экспериментальной процедуры несения метки.
Таким образом, временной интервал между первой временной точкой и второй временной точкой предпочтительно имеет наибольший размер, насколько это возможно, в указанным выше пределах. Таким образом, временной интервал между первой временной точкой и второй временной точкой предпочтительно составляет по меньшей мере 4 ч, по меньшей мере 5 ч, по меньшей мере 6 ч, по меньшей мере 7 ч, по меньшей мере 8 ч, по меньшей мере 9 ч, по меньшей мере 10 ч, по меньшей мере 11 ч или по меньшей мере 12 ч.
Кроме того, предпочтительно, что по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, который является производным от стабильной мРНК, идентифицируют методом идентификации элемента 3'-UTR и/или элемента 5'-UTR, который является производным от стабильной мРНК в соответствии с настоящим изобретением. Особенно предпочтительно, чтобы по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением идентифицируют методом идентификации элемента 3'-UTR и/или элемента 5'-UTR, который продлевает и/или увеличивает выработку белка с молекулы искусственной нуклеиновой кислоты и который является производным от стабильной мРНК согласно описанию настоящего изобретения.
Предпочтительно, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR в молекуле искусственной нуклеиновой кислоты согласно настоящему изобретению содержит или состоит из последовательности нуклеиновой кислоты, которая получена из 3'-UTR и/или 5'-UTR эукариотического гена, кодирующего белок, предпочтительно из 3'-UTR и/или 5'-UTR гена, кодирующего белок позвоночного, более предпочтительно из 3'-UTR и/или 5'-UTR гена, кодирующего белок млекопитающего, например из генов, кодирующих белок мыши и человека, еще более предпочтительно из 3'-UTR и/или 5'-UTR гена, кодирующего белок примата или грызуна, в частности 3'-UTR и/или 5'-UTR гена, кодирующего белок человека или мыши.
В целом, очевидно что по меньшей мере один элемент 3'-UTR в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит или состоит из последовательности нуклеиновой кислоты, которая предпочтительно получена от природной 3'-UTR, тогда как по меньшей мере один элемент 5'-UTR в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит или состоит из последовательности нуклеиновой кислоты, которая предпочтительно получена от природной 5'-UTR.
Предпочтительно, по меньшей мере, одна открытая рамка считывания является гетерологичной по меньшей мере одному элементу 3'-UTR и/или по меньшей мере одному элементу 5'-UTR. Понятие «гетерологичные» в контексте настоящего изобретения означает, что два элемента последовательности, состоящие из молекулы искусственной нуклеиновой кислоты, например, открытая рамка считывания и элемент 3'-UTR, и/или открытая рамка считывания и элемент 5'-UTR, действительно не встречаются естественным образом (в природе) в такой комбинации. Они обычно являются рекомбинантными. Предпочтительно, элемент 3'-UTR и/или элемент 5'-UTR производны от другого гена, чем открытая рамка считывания. Например, ORF может быть производным от другого гена, чем элемент 3'-UTR, и/или по меньшей мере один элемент 3'-UTR, например, кодирование другого белка или того же белка, но другого вида и т.д. То есть, открытая рамка считывания производна от гена, который отличен от гена, производным которого является элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR. В предпочтительном варианте осуществления настоящего изобретения ORF не кодирует рибосомальный белок человека или растения (например, Arabidopsis), предпочтительно не кодирует человеческий рибосомный белок S6 (RPS6), L36a-подобный рибосомальный белок человека (RPL36AL) или рибосомальный белок S16 (RPS16) Arabidopsis. В еще одном предпочтительном варианте осуществления настоящего изобретения открытая рамка считывания (ORF) не кодирует рибосомный белок S6 (RPS6), L36a-подобный рибосомальный белок человека (RPL36AL) или рибосомальный белок S16 (RPS16).
В некоторых вариантах осуществления настоящего изобретения предпочтительно, чтобы открытая рамка считывания не кодировала репортерный белок, например, выбранный из группы, состоящей из белков глобина (в частности, бета-глобина), белка люциферазы, белков GFP или их вариантов, например, вариантов, которые по меньшей мере на 70% идентичны глобиновым белкам, белку люциферазы или белку GFP. Таким образом, особенно предпочтительно, чтобы открытая рамка считывания не кодировала белок GFP. Также особенно предпочтительно, чтобы открытая рамка считывания (ORF) не кодировала репортерный ген или не была получена из репортерного гена, где репортерный ген предпочтительно не выбран из группы, состоящей из глобиновых белков (в частности, бета-глобина), белка люциферазы, бета-глюкуронидазы (GUS) и белков GFP или их вариантов, предпочтительно не выбранных из EGFP, или вариантов каких-либо из вышеуказанных генов, обычно по меньшей мере на 70% идентичных последовательности какого-либо репортерного гена, предпочтительно глобинового белка, белка люциферазы или белка GFP.
Еще более предпочтительно элемент 3'-UTR и/или 5'-UTR-элемент являются гетерологичными какому-либо другому элементу, содержащемуся в искусственной нуклеиновой кислоте согласно описанию настоящего изобретения. Например, если искусственная нуклеиновая кислота согласно настоящему изобретению содержит элемент 3'-UTR из данного гена, то он предпочтительно не содержит какой-либо другой последовательности нуклеиновой кислоты, в частности, какой-либо функциональной последовательности нуклеиновой кислоты (например, кодирующей или регуляторной последовательности) из того же самого гена, включая его регуляторные последовательности на 5'- и 3'-концах ORF гена. Соответственно, например, если искусственная нуклеиновая кислота согласно настоящему изобретению содержит элемент 5'-UTR данного гена, она предпочтительно не содержит какой-либо другой последовательности нуклеиновой кислоты, в частности, никакой функциональной последовательности нуклеиновой кислоты (например, элемента кодирующей или регуляторной последовательности) из того же самого гена, включая его регуляторные последовательности на 5'- и 3'-конце ORF гена.
Кроме того, предпочтительно, если искусственная нуклеиновая кислота в соответствии с настоящим изобретением содержит по меньшей мере одну открытую рамку считывания, по меньшей мере один 3'-UTR (элемент) и по меньшей мере один 5'-UTR (элемент), в соответствии с чем, либо по меньшей мере один 3'-UTR (элемент) представляет элемент 3'-UTR согласно настоящему изобретению и/или по меньшей мере один 5'-UTR (элемент) представляет элемент 5'-UTR в соответствии с настоящим изобретением. В такой предпочтительной искусственной нуклеиновой кислоте в соответствии с настоящим изобретением, которая содержит по меньшей мере одну открытую рамку считывания, по меньшей мере один 3'-UTR (элемент) и по меньшей мере один 5'-UTR (элемент), особенно предпочтительно, чтобы каждый компонент из перечисленных, а именно по меньшей мере одна открытая рамка считывания, по меньшей мере один 3'-UTR (элемент) и по меньшей мере один 5'-UTR (элемент), были гетерологичными, то есть чтобы по меньшей мере ни один 3'-UTR (элемент) и по меньшей мере один 5'-UTR (элемент), и ни одна открытая рамка считывания и 3'-UTR (элемент) или 5'-UTR (элемент), соответственно, не встречаются естественным образом в такой комбинации. Это означает, что молекула искусственной нуклеиновой кислоты содержит ORF, 3'-UTR (элемент) и 5'-UTR (элемент), которые все являются гетерологичными друг другу, например, они являются рекомбинантными, поскольку каждый из них получен из разных генов (и их 5'- и 3'-UTR). В другом предпочтительном варианте осуществления 3'-UTR (элемент) не является производным 3'-UTR (элемента) вирусного гена или не имеет вирусного происхождения.
Предпочтительно, молекула искусственной нуклеиновой кислоты согласно настоящему изобретению:
(i) содержит, по меньшей мере, один элемент 3'-UTR и по меньшей мере один элемент 5'-UTR, причем предпочтительно (каждый) из по меньшей мере одного элемента 5'-UTR и по меньшей мере одного элемента 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, производной от 3'-UTR или 5'-UTR, соответственно, гена, кодирующего белок человека или мыши;
(ii) по меньшей мере один элемент 3'-UTR, по меньшей мере один элемент 5'-UTR и по меньшей мере одна открытая рамка считывания молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением гетерологичны друг другу;
(iii) по меньшей мере один 3'-UTR-элемент является производным гена, выбранного из группы, состоящей из: генов «домашнего хозяйства», генов, кодирующих мембранные белки, генов, участвующих в клеточном метаболизме, генов, участвующих в процессах транскрипции, трансляции и репликации, генов, участвующих в модификации белка и генов, участвующих в делении клеток; а также
(iv) 3'UTR не является производным гена, кодирующего рибосомный белок, или гена на фиг. 4.
Гены «домашнего хозяйства» обычно являются конститутивными генами, которые необходимы для поддержания основной клеточной функции и которые обычно экспрессируются во всех клетках организма в нормальных и патофизиологических условиях. Хотя некоторые гены «домашнего хозяйства» экспрессируются на относительно постоянных уровнях при максимально непатологических ситуациях, другие гены «домашнего хозяйства» могут варьироваться в зависимости от условий эксперимента. Обычно гены «домашнего хозяйства» экспрессируются по меньшей мере в количестве не менее 25 копий на клетку, а иногда их количество выражается в тысячах копий. Предпочтительные примеры генов «домашнего хозяйства» в контексте настоящего изобретения показаны ниже в табл. 10.



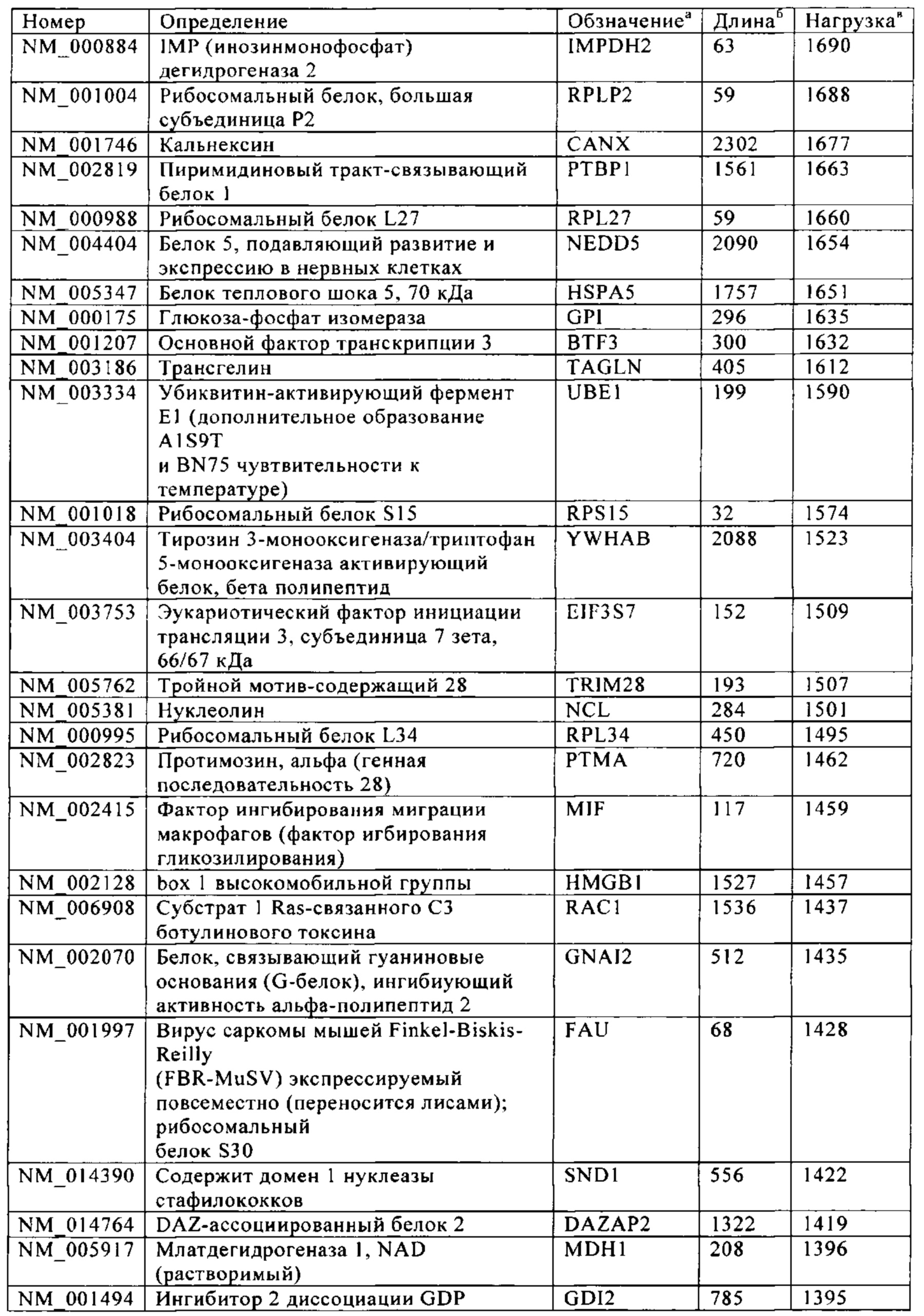



Приведенная выше таблица взята из WO 2007/068265 А1, табл. 1; она основана на перечне номеров, которые были даны Е. Eisenberg и Е.Y. Levanon (Trends Genet. 19(7), 2003, 362-365). Эти номера используют в качестве входных данных для компьютерной программы PERL (Programmed Extraction Report Language), которая извлекает данные EST из базы данных Unigene. База данных Unigene была загружена в виде текстового файла с сайта NCBI. Длину 3'UTR извлекают путем компьютерного извлечения 3'UTR (Bakheet с соавт., Nucleic Acids Research. 29, 2001, 246-254). Обозначения: <а> - обычно используемая аббревиатура продукта гена; <б> - длина 3'UTR; <в> - количество EST.
К предочтительны генам домашнего хозяйства относятся LDHA, NONO, PGK1 и PPIH.
Геном, кодирующим мембранный белок, обычно называют такой ген, который кодирует белок, взаимодействующий с биологическими мембранами. В большинстве геномов около 20-30% всех генов кодируют мембранные белки. Обычные типы белков включают - помимо мембранных белков - растворимые глобулярные белки, фибриллярные белки и неупорядоченные белки. Таким образом, гены, кодирующие мембранные белки, обычно отличаются от генов, кодирующих растворимые глобулярные белки, фибриллярные белки или неупорядоченные белки. Мембранные белки включают мембранные рецепторы, транспортные белки, мембранные ферменты и молекулы клеточной адгезии.
Геном, участвующим в клеточном метаболизме, обычно называют ген, который кодирует белок, участвующий в клеточном метаболизме, то есть в наборе жизнеобеспечивающих химических превращений в клетках живых организмов. Обычно это реакции, катализируемые ферментами, позволяют организму расти и воспроизводить, поддерживать свои структуры и реагировать на окружающую среду. Соответственно, предпочтительными генами, участвующими в клеточном метаболизме, являются такие гены, которые кодируют ферменты, катализирующие реакцию, позволяющую организму расти и воспроизводить, поддерживать свои структуры и реагировать на окружающую среду. К другим примерам генов, участвующих в клеточном метаболизме, относят гены, кодирующие белки, несущие структурную или механическую функцию, например, формирование цитоскелета. Другие белки, участвующие в клеточном метаболизме, включают белки, участвующие в клеточной передаче сигналов, иммунных реакциях, клеточной адгезии, активном переносе через мембраны и клеточном цикле. Метаболизм обычно подразделяют на две категории: катаболизм - разрушение органического вещества посредством клеточного дыхания, и анаболизм - строительство компонентов клеток, например, белков и нуклеиновых кислот.
К генам, участвующим в процессах транскрипции, трансляции и репликации, обычно относят гены, которые кодируют белки, вовлеченные в процессы транскрипции, трансляции и репликации. В частности, понятие «репликация» в контексте настоящего изобретения предпочтительно относят к репликации нуклеиновых кислот, например, к репликации ДНК. Предпочтительными генами, участвующими в процессах транскрипции, трансляции и репликации, являются гены, кодирующие ферменты, участвующие в процессах транскрипции, трансляции и/или репликации (ДНК). Другие предпочтительные примеры включают гены, кодирующие фактор транскрипции или фактор трансляции. Рибосомные гены являются другими предпочтительными примерами генов, участвующих в процессах транскрипции, трансляции и репликации.
Ген, участвующий в модификации белка, обычно означает ген, который кодирует белок, участвующий в модификации белка. Предпочтительными примерами таких генов являются гены, кодирующие ферменты, участвующие в модификации белка, в частности в процессах пост-трансляционной модификации. Предпочтительные примеры ферментов, участвующих в посттрансляционной модификации, включают (i) ферменты, участвующие в добавлении гидрофобных групп, в частности, для локализации мембран, например, ферменты, индуцированные в миристоилировании, пальмитоилировании, изопренилировании или пренилировании, фарнезилировании, геранилировании или в глипиалировании; (ii) ферменты, участвующие в добавлении кофакторов для повышения ферментативной активности, например, ферменты, участвующие в липоилировании, в присоединении фрагмента флавина, в присоединении гема С, к фосфопантэтеинилированию или в образовании ретинилидена основания шиффа; (iii) ферменты, участвующие в модификации трансляционных факторов, например, в образовании дифтамида, в присоединении фосфоглицерина этаноламина или в образовании гипузина; и (vi) ферменты, участвующие в добавлении небольших химических групп, например, в ацилировании, например, ацетилировании и формилирование, алкилировании, например в метилировании, образовании амидной связи, например, в амидировании на С-конце, и в добавлении аминокислоты (например, в аргинилировании, полиглутамилировании и полиглицилировании), бутирилировании, гамма-карбоксилировании, гликозилировании, малонилировании, гидроксилировании, йодировании, добавлении нуклеотидов, окислении, формировании фосфатного эфира или фосфорамидатов, например, в фосфорилировании и аденилировании, пропионилировании, образовании пироглутамата, S-глутатионилировании, S-нитрозилировании, сукцинилировании и сульфатировании.
Геном, участвующим в процессах деления клеток, обычно является ген, который кодирует белок, участвующий в делении клеток. Деление клеток - это процесс, с помощью которого родительская клетка делится на две или более дочерних клеток. Деление клеток обычно являеся составляющей более крупного клеточного цикла. У эукариот существуют два различных типа деления клеток: вегетативное деление, при котором каждая дочерняя клетка генетически идентична родительской клетке (митоз) и редуктивное клеточное деление, при котором количество хромосом в дочерних клетках уменьшается на половину, для получения гаплоидных гамет (мейоз). Соответственно, предпочтительный ген, участвующий в процессе деления клеток, кодирует белок, вовлеченный в митоз и/или мейоз.
Фиг. 4 представляет аббревиатуру для фактор-индуцированного гена. Ген на фиг.4 кодирует полифосфоинозитидфосфатазу, также называемую фосфатидилинозитол 3,5-бисфосфат-5-фосфатазой или SAC домен-содержащим белком 3 (Sac3).
Предпочтительно, молекула искусственной нуклеиновой кислоты согласно настоящему изобретению:
(i) содержит, по меньшей мере, один элемент 3'-UTR и по меньшей мере один элемент 5'-UTR, причем предпочтительно (каждый из) по меньшей мере одного элемента 3'-UTR и по меньшей мере одного элемента 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR или 5'-UTR, соответственно, гена, кодирующего белок человека или мыши;
(ii) по меньшей мере один элемент 3'-UTR, по меньшей мере один элемент 5'-UTR и по меньшей мере одна открытая рамка считывания все являются гетерологичными по отношению друг к другу;
(iii) по меньшей мере один элемент 5'-UTR является производным гена, выбранного из группы, состоящей из генов домашнего хозяйства, генов, кодирующих мембранные белки, генов, участвующих в клеточном метаболизме, генов, участвующих в процессах транскрипции, трансляции и репликации, генов, участвующих в модификации белков, и гены, участвующие в делении клеток;
(iv) 5'-UTR предпочтительно не является 5 'TOP UTR; а также
(v) 3'-UTR предпочтительно не являются производными гена, кодирующего рибосомальный белок или альбумин, или гена, педставленного на фиг. 4.
Более предпочтительно такая молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением:
(i) содержит, по меньшей мере, один элемент 3'-UTR и по меньшей мере один элемент 5'-UTR, где предпочтительно (каждый из) по меньшей мере одного элемента 3'-UTR и по меньшей мере одного элемента 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая получена из 3'-UTR или 5'-UTR, соответственно, гена, кодирующего белок человека или мыши;
(ii) по меньшей мере один элемент 3'-UTR, по меньшей мере один элемент 5'-UTR и по меньшей мере одна открытая рамка считывания являются все гетерологичными по отношению друг к другу;
(ii) по меньшей мере один элемент 3'-UTR, по меньшей мере один элемент 5'-UTR и по меньшей мере одна открытая рамка считывания являются все гетерологичными отношению друг к другу;
(iii) по меньшей мере один элемент 3'-UTR получен из гена человека или мыши, выбранного из группы, состоящей из генов домашнего хзяйства, генов, кодирующих мембранные белки, генов, участвующих в клеточном метаболизме, генов, участвующих в процессах транскрипции, трансляции и репликации, генов, участвующих в модификации белка, и генов, участвующие в делении клеток;
(iv) 3'UTR не является производной гена, кодирующего рибосомальный белок, или альбумин, или из ген, представленный на фиг. 4;
(v) по меньшей мере один элемент 5'-UTR, который является производным гена человека или мыши, выбранного из группы, состоящей из генов домашнего хозяйства, генов, кодирующих мембранные белки, генов, участвующих в клеточном метаболизме, генов, участвующих в процессах транскрипции, трансляции и репликации, генов, участвующих в модификации белка, и генов, участвующих в делении клеток; а также
(vi) 5'-UTR не является 5 'TOP UTR.
Таким образом, в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением предпочтительно, чтобы 3'-UTR и 5'-UTR являлись производными генов домашнего хозяйства человека или мыши. Также предпочтительно, чтобы 3'-UTR и 5'-UTR являлись производными гена человека или мыши, кодирующего мембранный белок. Также предпочтительно, чтобы 3'-UTR и 5'-UTR являлись производными гена человека или мыши, участвующего в клеточном метаболизме. Также предпочтительно, чтобы 3'-UTR и 5'-UTR являлись производными гена человека или мыши, кодирующего в процессах транскрипции, трансляции и репликации. Также предпочтительно, чтобы 3'-UTR и 5'-UTR являлись производными гена человека или мыши участвующего в модификации белка. Также предпочтительно, чтобы 3'-UTR и 5'-UTR являлись производными гена человека или мыши участвующего в делении клеток. В этом контексте специалисту в данной области очевидно, что если (i) 3'-UTR и 5'-UTR являются производными генов, принадлежащих к одному и тому же классу генов, и (ii) по меньшей мере один 3'-UTR и по меньшей мере один 5'-UTR гетерологичны друг другу, то 3'-UTR и 5'-UTR получены не из одного и того же гена, а из разных генов, принадлежащих к одному и тому же классу генов. Соответственно, предпочтительно, чтобы по меньшей мере один 3'-UTR и по меньшей мере один 5'-UTR являются производными разных генов, принадлежащих к одному и тому же классу генов.
В контексте настоящего изобретения понятие «класс генов» относится к классификации генов. Примеры генных классов включают (i) гены домашнего хозяйства, (ii) гены, кодирующие мембранный белок, (iii) гены, участвующие в клеточном метаболизме, (iv) гены, участвующие в процессах транскрипции, трансляции и репликации, (v) гены, участвующие в модификации белка, и (vi) гены, участвующие в делении клеток. Иначе говоря, «гены домашнего хозяйства» - это один класс генов, а «гены, участвующие в транскрипции», представляют другой класс генов, «гены, участвующие в клеточном метаболизме», представляют еще один класс генов, и т.д.
Также предпочтительно, если в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением 3'-UTR и 5'-UTR, являющиеся производными гена человека или мыши, выбраны из группы, состоящей из генов, кодирующих мембранный белок, генов, участвующих в клеточном метаболизме, генов, участвующих в процессах транскрипции, трансляции и репликации, генов, участвующих в модификации белка, и генов, участвующих в делении клеток, где 3'-UTR и 5'-UTR выбраны из генов разных классов.
Предпочтительно, по меньшей мере, один элемент 3'-UTR и/или, по меньшей мере, один элемент 5'-UTR функционально связан с ORF. Это означает, что предпочтительно, чтобы элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR был ассоциирован с ORF таким образом, чтобы он мог выполнять функцию, например, усиления или стабилизации экспрессии закодированного пептида или белка или стабилизирующую функцию на молекуле искусственной нуклеиновой кислоты. Предпочтительно, ORF и элемент 3'-UTR ассоциированы в 5'→3' направлении и/или элемент 5'-UTR и ORF ассоциированы в 5'→3' направлении. Таким образом, предпочтительно, чтобы молекула искусственной нуклеиновой кислоты содержала в основном структуру 5'-[элемент 5'-UTR]-(необязательно)-линкер-ORF-(необязательно)-линкер-[элемент 3'-UTR]-3', причем молекула искусственной нуклеиновой кислоты может содержать только элемент 5'-UTR, но не элемент 3'-UTR, только элемент 3'-UTR, но не элемент 5'-UTR, или оба элемента - 3'-UTR и 5'-UTR. Кроме того, линкер может присутствовать или отсутствовать. Например, линкером может быть один или несколько нуклеотидов, например, фрагмент из 1-50 или 1-20 нуклеотидов, например, содержащий или не состоящий один или несколько сайтов распознавания ферментом рестрикции (сайты рестрикции).
Предпочтительно, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR и/или 5'-UTR транскрипта гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), Ybx1 (Y-Box-связывающий белок 1), Ndufb8 (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8), CNTN1 (контактин 1), LTA4H, SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, GRAMD1C, C11orf80, C9orf46, ANXA4, ТВСК, IFI6, C2orf34, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, NT5DC1, RAB7A, AGA, TPK1, MBNL3, HADHB, MCCC2, CAT, ANAPC4, PCCB, PHKB, ABCB7, PGCP, GPD2, TMEM38B, NFU1, OMA1, LOC128322/NUTF2, NUBPL, LANCL1, HHLA3, PIR, ACAA2, CTBS, GSTM4, ALG8, Atp5e, Gstm5, Uqcr11, Ifi27I2a, Anapc13, Atp5I, Tmsb10, Nenf, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Snrpd2, Mgst3, Aldh2, Ssr4, Myl6, Prdx4, Ubl5, 1110001J03Rik, Ndufa13, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufs5, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Hexa, Ndufb11, Map1lc3a, Gpx4, Mif, Cox6b1, RIKEN кДНК 2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrpl23, Uba52, Tomm6, Mtch1, Pcbd2, Ecm1, Hrsp12, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappc6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Rps4x, Rps13, Sepp1, Gaa, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, D HRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, COX11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1.
В особенно предпочтительном варианте осуществления настоящего изобретения по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR и/или 5'-UTR транскрипта гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), Ybx1 (Y-Box-связывающий белок 1), Ndufb8 (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8), CNTN1 (контактин 1), LTA4H, SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, GRAMD1C, C11orf80, C9orf46, ANXA4, ТВСК, IFI6, C2orf34, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, NT5DC1, RAB7A, AGA, TPK1, MBNL3, HADHB, MCCC2, CAT, ANAPC4, PCCB, PHKB, ABCB7, PGCP, GPD2, TMEM38B, NFU1, OMA1, LOC128322/NUTF2, NUBPL, LANCL1, HHLA3, PIR, ACAA2, CTBS, GSTM4, ALG8, Atp5e, Gstm5, Uqcr11, Ifi27I2a, Anapc13, Atp5I, Tmsb10, Nenf, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Snrpd2, Mgst3, Aldh2, Ssr4, Myl6, Prdx4, Ubl5, 1110001J03Rik, Ndufa13, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufs5, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Hexa, Ndufb11, Map1lc3a, Gpx4, Mif, Cox6b1, RIKEN cDNA2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrpl23, Uba52, Tomm6, Mtch1, Pcbd2, Ecm1, Hrspl2, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappca6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Rps4x, Rps13, Sepp1, Gaa, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, DHRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, COX11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1.
Более предпочтительно, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая является производной от 3'-UTR и/или 5'-UTR транскрипта гена, выбранного из группы, состоящей из GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (ген кДНК 2010107Е04 RIKEN), Ybx1 (Y-Box-связывающий белок 1), NODFb8 (NADH дегидрогеназа (убихинон) 1 бета-подкомплекс 8), CNTN1 (контактин 1) и NDUFA4 (НАДГ дегидрогеназа (убихинон) 1 альфа-подкомплекс 4).
Предпочтительно, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит или состоит из «функционального фрагмента», «функционального варианта» или «функциональный фрагмент варианта» 3'-UTR и/или 5'-UTR транскрипта гена.
Предпочтительно, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR и/или 5'-UTR транскрипта гена человека, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), LTA4H, SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, GRAMD1C, C11orf80, C9orf46, ANXA4, ТВСК, IFI6, C2orf34, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, NT5DC1, RAB7A, AGA, TPK1, MBNL3, HADHB, MCCC2, CAT, ANAPC4, PCCB, PHKB, ABCB7, PGCP, GPD2, TMEM38B, NFU1, OMA1, LOC128322/NUTF2, NUBPL, LANCL1, HHLA3, PIR, ACAA2, CTBS, GSTM4, ALG8, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, DHRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, COX11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, CNTN1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1.
В другом варианте или дополнительно также предпочтительно, если по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR и/или 5'-UTR транскрипта гена мыши, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), Atp5e, Gstm5, Uqcr11, Ifi27I2a, Anapc13, Atp5I, Tmsb10, Nenf, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Snrpd2, Mgst3, Aldh2, Ssr4, Myl6, Prdx4, Ubl5, 1110001 J03Rik, Ndufa13, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufs5, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Hexa, Ndufb11, Map1lc3a, Gpx4, Mif, Cox6b1, RIKEN cDNA2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Ndufb8, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrpl23, Uba52, Tomm6, Mtch1, Pcbd2, Ecm1, Hrsp12, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappc6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Rps4x, Rps13, Ybx1, Sepp1 и Gaa.
Предпочтительно, по меньшей мере, один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, ТМЕМ14А, GRAMD1C, C11orf80, ANXA4, ТВСК, IFI6, C2orf34, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, HADHB, ANAPC4, РССВ, АВСВ7, PGCP, NFU1, ОМА1, HHLA3, АСАА2, GSTM4, ALG8, Atp5e, Gstm5, Uqcr11, Ifi27I2a, Cbr2, Atp5I, Tmsb10, Nenf, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Gnas, Snrpd2, Mgst3, Aldh2, Ss4, Myl6, Prdx4, Ubl5, 1110001J03Rik, Ndufa13, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufa4, Ndufs5, Gstm1, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Ndufb11, Map1lc3a, Morn2, Gpx4, Mif, Cox6b1, RIKEN cDNA2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Ndufb8, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrpl23, Uba52, Tomm6, Mtch1, Pcbd2, Ecm1, Hrsp12, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappc6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Rps4x, Rps13, Ybx1, Sepp1, Gaa, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, DHRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, COX11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, CNTN1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1. Более предпочтительно, по меньшей мере, один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), Ybx1 (Y-Box связывающий белок 1), Ndufb8 (NADH-дегидрогеназа (убихинон) 1 бета-субкомплекс 8) и CNTN1 (контактин 1).
В особенно предпочтительном варианте осуществления настоящего изобретения по меньшей мере один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, ТМЕМ14А, GRAMD1C, C11orf80, ANXA4, TBCK, IFI6, C2orf34, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, HADHB, ANAPC4, PCCB, ABCB7, PGCP, NFU1, OMA1, HHLA3, ACAA2, GSTM4, ALG8, Atp5e, Gstm5, Uqcr11, Ifi27I2a, Cbr2, Atp5I, Tmsb10, Nenf, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Gnas, Snrpd2, Mgst3, Aldh2, Ss4, Myl6, Prdx4, Ubl5, 1110001J03Rik, Ndufa13, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufa4, Ndufs5, Gstm1, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Ndufb11, Map1lc3a, Morn2, Gpx4, Mif, Cox6b1, RIKEN cDNA2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Ndufb8, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrp123, Tomm6, Mtch1, Pcbd2, Ecm1, Hrsp12, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappc6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Ybx1, Sepp1, Gaa, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, DHRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, COX11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, CNTN1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1. Более предпочтительно, по меньшей мере один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), Ybx1 (Y-Box связывающий белок 1), Ndufb8 (NADH-дегидрогеназа (убихинон) 1 бета-субкомплекс 8) и CNTN1 (контактин 1).
Более предпочтительно, по меньшей мере, один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, TMEM14A, GRAMD1C, C11orf80, ANXA4, TBCK, IFI6, C2orD4, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, HADHB, ANAPC4, PCCB, ABCB7, PGCP, NFU1, OMA1, HHLA3, ACAA2, GSTM4, ALG8, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, DHRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, COX11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, CNTN1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1; предпочтительно, по меньшей мере, один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена человека, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), Ybx1 (Y-Box связывающий белок 1), Ndufb8 (NADH дегидрогеназае (убихинон) 1 бета субкомплекс 8) и CNTN1 (контактин 1).
Соответственно, предпочтительно, если по меньшей мере один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена мыши, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), Ybx1 (Y-Box связывающий белок 1), Ndufb8 (NADH дегидрогеназае (убихинон) 1 бета субкомплекс 8) и CNTN1 (контактин 1), Ndufa1, Atp5e, Gstm5, Uqcr11, Ifi27I2a, Cbr2, Atp5I, Tmsb10, Nenf, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Gnas, Snrpd2, Mgst3, Aldh2, Ssr4, Myl6, Prdx4, Ubl5, 1110001 J03Rik, Ndufal3, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufa4, Ndufs5, Gstm1, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Ndufb11, Map1lc3a, Morn2, Gpx4, Mif, Cox6b1, RIKEN cDNA2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Ndufb8, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrpl23, Uba52, Tomm6, Mtch1, Pcbd2, Ecm1, Hrsp12, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappc6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Rps4x, Rps13, Ybx1, Sepp и Gaa; предпочтительно, по меньшей мере, один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR транскрипта гена мыши, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), Ybx1 (Y-Box связывающий белок 1), Ndufb8 (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8) и CNTN1 (контактин 1).
Предпочтительно, по меньшей мере, один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта гена, выбранного из группы, включающей МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), LTA4H, DECR1, PIGK, TBC1D19, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, C9orf46, ANXA4, IFI6, C2orD4, ALDH6A1, CCDC53, CCDC104, CASP1, NDUFB6, BCKDHB, BBS2, HERC5, FAMI75A, NT5DC1, RAB7A, AGA, TPK1, MBNL3, МССС2, CAT, ANAPC4, PHKB, АВСВ7, GPD2, ТМЕМ38 В, NFU1, LOC128322/NUTF2, NUBPL, LANCL1, PIR, CTBS, GSTM4, Ndufa1, Atp5e, Gstm5, Cbr2, Anapcl3, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Ndufs6, Sec61b, Snrpd2, Mgst3, Prdx4; Pgcp; Myeov2; Ndufa4; Ndufs5; Gstml; Atp5o; Tspo; Taldo1; Bloc1s1; и Hexa. Более предпочтительно по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта МР68 (RIKEN кДНК 2010107Е04 ген) или NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4).
В одном из предпочтительных вариантов осуществления настоящего изобретения по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта гена, выбранного из группы, включающей МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), LTA4H, DECR1, PIGK, TBC1D19, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, C9orf46, ANXA4, IFI6, C2orf34, ALDH6A1, CCDC53, CCDC104, CASP1, NDUFB6, BCKDHB, BBS2, HERC5, FAM175A, NT5DC1, RAB7A, AGA, TPK1, MBNL3, MCCC2, CAT, ANAPC4, PHKB, ABCB7, GPD2, TMEM38B, NFU1, LOC128322/NUTF2, NUBPL, LANCL1, PIR, CTBS, GSTM4, Ndufa1, Atp5e, Gstm5, Cbr2, Anapc13, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Ndufs6, Sec61b, Snrpd2, Mgst3, Prdx4; Pgcp; Myeov2; Ndufa4; Ndufs5; Gstm1; Atp5o; Tspo; Taldo1; Bloc1s1; и Hexa. Более предпочтительно по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта МР68 (RIKEN кДНК 2010107Е04 ген) или NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4).
Более предпочтительно по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта гена человека, выбранного из группы, включающей МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), LTA4H, DECR1, PIGK, TBC1D19, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, C9orf46, ANXA4, IFI6, C2orf34, ALDH6A1, CCDC53, CCDC104, CASP1, NDUFB6, BCKDHB, BBS2, HERC5, FAM175A, NT5DC1, RAB7A, AGA, TPK1, MBNL3, MCCC2, CAT, ANAPC4, PHKB, ABCB7, GPD2, TMEM38B, NFU1, LOC128322/NUTF2, NUBPL, LANCL1, PIR, CTBS и GSTM4; предпочтительно по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта гена человека МР68 (RIKEN кДНК 2010107Е04 ген) или NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4).
Соответственно, более предпочтительно, если по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта гена мыши, выбранного из группы, включающей МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), Ndufa1, Atp5e, Gstm5, Cbr2, Anapc13, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Ndufs6, Sec61b, Snrpd2, Mgst3, Prdx4; Pgcp; Myeov2; Ndufa4; Ndufs5; Gstm1; Atp5o; Tspo; Taldo1; Bloc1s1 и Неха; предпочтительно по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR транскрипта гена мыши МР68 (RIKEN кДНК 2010107Е04 ген) или NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4).
Понятие «последовательность нуклеиновой кислоты, которая производна от 3'-UTR и/или 5'-UTR транскрипта гена», предпочтительно относится к последовательности нуклеиновой кислоты, которая основана на последовательности 3'-UTR и/или последовательности 5'-UTR транскрипта гена, или его фрагмента, или части его фрагмента, предпочтительно природного гена или его фрагмента или части его фрагмента. Это понятие включает последовательности, соответствующие всей последовательности 3'-UTR и/или всей последовательности 5'-UTR, то есть последовательности полной длины 3'-UTR и/или 5'-UTR транскрипта гена, и последовательности, соответствующие к фрагменту последовательности 3'-UTR и/или последовательности 5'-UTR транскрипта гена. Предпочтительно фрагмент транскрипта гена 3'-UTR и/или 5'-UTR состоит из непрерывного участка нуклеотидов, соответствующего непрерывному участку нуклеотидов в транскрипте гена 3'-UTR и/или 5'-UTR полной длины, который представляет по меньшей мере 5%, 10%, 20%, предпочтительно по меньшей мере 30%, более предпочтительно по меньшей мере 40%, более предпочтительно по меньшей мере 50%, еще более предпочтительно по меньшей мере 60%, еще более предпочтительно по меньшей мере 70%, еще более предпочтительно по меньшей мере 80% и наиболее предпочтительно по меньшей мере 90% транскрипта гена 3'-UTR и/или 5'-UTR полной длины. Такой фрагмент, в контексте настоящего изобретения предпочтительно является функциональным фрагментом согласно описанному в настоящем изобретении. Предпочтительно фрагмент сохраняет регуляторную функцию для трансляции ORF, связанной с 3'-UTR и/или 5'-UTR или ее фрагментом.
Понятия «вариант 3'-UTR и/или вариант 5'-UTR транскрипта гена» и «его вариант» в контексте 3'-UTR и/или 5'-UTR транскрипта гена относится к варианту 3'-UTR и/или 5'-UTR транскрипта природного гена, предпочтительно к варианту 3'-UTR и/или 5'-UTR транскрипта гена позвоночного, более предпочтительно к варианту 3'-UTR и/или 5'-UTR транскрипта гена млекопитающего, еще более предпочтительно к варианту 3'-UTR и/или 5'-UTR транскрипта гена примата, особенно гена человека согласно описанному выше. Такой вариант может быть модифицированным транскриптом гена 3'-UTR и/или 5'-UTR. Например, вариант 3'-UTR и/или вариант 5'-UTR могут проявлять одну или несколько нуклеотидных делеций, инсерций, добавок и/или замещений по сравнению с встречающимися в природе 3'-UTR и/или 5'-UTR, производными которых является эти варианты. Предпочтительно вариант 3'-UTR и/или вариант 5'-UTR транскрипта гена идентичен по меньшей мере на 40%, предпочтительно по меньшей мере на 50%, более предпочтительно по меньшей мере на 60%, более предпочтительно на менее на 70%, еще более предпочтительно по меньшей мере на 80%, еще более предпочтительно по меньшей мере на 90%, наиболее предпочтительно по меньшей мере на 95% природному варианту 3'-UTR и/или 5'-UTR, от которого он происходит. Предпочтительно вариант является функциональным вариантом по настоящему изобретению.
Понятие «последовательность нуклеиновой кислоты, которая является производной варианта транскрипта гена 3'-UTR и/или варианта 5'-UTR», предпочтительно относится к последовательности нуклеиновой кислоты, которая основана на варианте последовательности транскрипта гена 3'-UTR и/или 5'-UTR или его фрагмента или части фрагмента согласно описанному выше. К этому понятию относятся последовательности, соответствующие всей последовательности варианта 3'-UTR и/или 5'-UTR транскрипта гена, то есть полной длины последовательности варианта 3'-UTR и/или полной длины варианта 5'-UTR последовательности транскрипта гена и последовательностей, соответствующих фрагменту варианта 3'-UTR последовательности и/или фрагмента варианта 5'-UTR последовательности транскрипта гена. Предпочтительно фрагмент варианта 3'-UTR и/или 5'-UTR транскрипта гена состоит из непрерывного участка нуклеотидов, соответствующего непрерывному участку нуклеотидов в варианте полной длины 3-UTR и/или 5'-UTR транскрипта гена, который представляет по меньшей мере 20%, предпочтительно по меньшей мере 30%, более предпочтительно по меньшей мере 40%, более предпочтительно по меньшей мере 50%, еще более предпочтительно, по меньшей мере 60%, еще более предпочтительно по меньшей мере 70%, еще более предпочтительно по меньшей мере 80% и наиболее предпочтительно по меньшей мере 90% варианта 3'-UTR и/или 5'-UTR транскрипта ген полной длины. Такой фрагмент варианта в контексте настоящего изобретения предпочтительно является функциональным фрагментом варианта, описанного в настоящем изобретении.
Понятия «функциональный вариант», «функциональный фрагмент» и «функциональный фрагмент варианта» (также называемый «фрагмент функционального варианта») в контексте настоящего изобретения означают, что фрагмент 3'-UTR и/или 5'-UTR, вариант 3'-UTR и/или 5'-UTR или фрагмент варианта 3'-UTR и/или 5'-UTR транскрипта гена выполняют по меньшей мере одну, предпочтительно более чем одну функцию встречающегося в природе 3'-UTR и/или 5'-UTR транскрипта гена, из которого получен вариант, фрагмент или фрагмент варианта. Такой функцией может быть, например, стабилизация мРНК и/или повышение, стабилизация и/или продление выработки белка с мРНК, и/или увеличение экспрессии белка или общей продуктивности белка из мРНК, предпочтительно в клетках млекопитающего, например, в клетках человека. Предпочтительно, функция 3'-UTR и/или 5'-UTR относится к трансляции белка, кодируемого ORF. Более предпочтительно, эта функция заключается в повышении эффективности трансляции ORF, связанной с 3'-UTR и/или 5'-UTR, или с его фрагментом или вариантом. Особенно предпочтительно, если вариант, фрагмент и фрагмент варианта в контексте настоящего изобретения выполняют функцию стабилизации мРНК, предпочтительно в клетках млекопитающего, например, в клетках человека, по сравнению с мРНК, содержащей контрольную 3'-UTR и/или контрольную 5'-UTR, или без 3'-UTR и/или 5'-UTR, и/или функцию усиления, стабилизации и/или продления выработки белка с мРНК, предпочтительно в клетках млекопитающего, например, в клетках человека, по сравнению с мРНК, содержащей контрольный 3'-UTR и/или контрольный 5'-UTR или без 3'-UTR и/или 5'-UTR, и/или функцию увеличения выработки белка с мРНК, предпочтительно в клетках млекопитающего, например, в клетках человека, по сравнению с мРНК, содержащей эталонную 3'-UTR и/или контрольную 5'-UTR или без 3'-UTR и/или 5'-UTR. Контрольной 3'-UTR и/или контрольной 5'-UTR может быть, например, 3'-UTR и/или 5'-UTR, встречающаяся в природе в комбинации с ORF. Кроме того, функциональный вариант, функциональный фрагмент или фрагмент функционального варианта 3'-UTR и/или 5'-UTR транскрипта гена предпочтительно не оказывают существенного снижения эффективности трансляции мРНК, которая содержит такой вариант, фрагмент или фрагмент варианта 3'-UTR и/или 5'-UTR по сравнению с 3'-UTR дикого типа и/или 5'-UTR дикого типа, от которых производны вариант, фрагмент или фрагмент варианта. Особенно предпочтительная функция «функционального фрагмента», «функционального варианта» или «фрагмента функционального варианта» 3'-UTR и/или 5'-UTR транскрипта гена в контексте настоящего изобретения представляет усиление, стабилизацию и/или продление выработки белка путем экспрессии мРНК, несущей функциональный фрагмент, функциональный вариант или функциональный фрагмент варианта согласно описанному выше.
Предпочтительно, эффективность одной или нескольких функций, оказываемых функциональным вариантом, функциональным фрагментом или функциональным вариантом фрагмента, например, эффективность стабилизации мРНК и/или белка, и/или эффективность увеличения выработки белка, увеличиваются, по меньшей мере, на 5%, более предпочтительно по меньшей мере на 10%, более предпочтительно по меньшей мере на 20%, более предпочтительно по меньшей мере на 30%, более предпочтительно по меньшей мере на 40%, более предпочтительно по меньшей мере на 50%, более предпочтительно по меньшей мере на 60%, еще более предпочтительно, по меньшей мере, на 70%, еще более предпочтительно по меньшей мере на 80%, наиболее предпочтительно по меньшей мере на 90% по отношению к эффективности стабилизации мРНК и/или белка и/или повышению эффективности производства белка, проявляемому природным 3'-UTR и/или 5'-UTR транскриптом гена, производным которого является вариант, фрагмент или фрагмент варианта.
В контексте настоящего изобретения фрагмент 3'-UTR и/или 5'-UTR транскрипта гена или варианта 3'-UTR и/или 5'-UTR транскрипта гена предпочтительно имеет длину, по меньшей мере, примерно из 3 нуклеотидов, предпочтительно по меньшей мере примерно из 5 нуклеотидов, более предпочтительно по меньшей мере примерно из 10, 15, 20, 25 или 30 нуклеотидов, еще более предпочтительно по меньшей мере примерно из 50 нуклеотидов, наиболее предпочтительно по меньшей мере примерно из 70 нуклеотидов. Предпочтительно такой фрагмент 3'-UTR и/или 5'-UTR транскрипта гена или варианта 3'-UTR и/или 5'-UTR транскрипта гена является функциональным фрагментом согласно описанному выше. В предпочтительном варианте осуществления настоящего изобретения 3'-UTR и/или 5'-UTR транскрипта гена, или его фрагмента, или его варианта имеет длину от 3 до 500 нуклеотидов, предпочтительно от 5 до 150 нуклеотидов, более предпочтительно от 10 до 100 нуклеотидов, еще более предпочтительно от 15 до 90, наиболее предпочтительно от 20 до 70. Обычно элемент 5'-UTR и/или элемент 3'-UTR характеризуются менее чем 500, 400, 300, 200, 150 или менее чем 100 нуклеотидами.
Предпочтительно, по меньшей мере, один 3'-UTR-элемент содержит или состоит из последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 1,2, 3, 4, 5, 10, 15, 20, 30 или 40%, предпочтительно по меньшей мере, примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99% идентична последовательности нуклеиновой кислоты, выбранной из группы, состоящей из последовательностей SEQ ID NO: 1-24 и SEQ ID NO: 49-318 или соответствующей последовательности РНК соответственно, или где по меньшей мере один 3'-UTR содержит или состоит из фрагмента последовательности нуклеиновой кислоты, которая имеет идентичность по меньшей мере около 40%, предпочтительно по меньшей мере около 50%, предпочтительно по меньшей мере примерно 60%, предпочтительно по меньшей мере около 70% более предпочтительно по меньшей мере около 80%, более предпочтительно по меньшей мере около 90%, еще более предпочтительно по меньшей мере около 95%, еще более предпочтительно по меньшей мере, приблизительно 99% к последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: от 1 до 24 и SEQ ID NO: 49-318 или соответствующей последовательности РНК, соответственно:
Homo sapiens SLC38A6 3'-UTR
SLC38A6-001 ENST00000267488

Homo sapiens DECR1 3'-UTR
NM_001359.1

Homo sapiens PIGK 3'-UTR

Homo sapiens FAM175A 3'-UTR
FAM175A-009 ENST00000506553

Homo sapiens PHYH 3'-UTR
PHYH-002 ENST00000396913

Homo sapiens TBC1D19 3'-UTR
TBC1D19-001 ENST00000264866

Homo sapiens TBC1D19 NM_018317.2 3'-UTR
Homo sapiens PIGB 3'-UTR
PIGB-201 ENST00000539642

Homo sapiens ALG6 3'-UTR
ALG6-006 ENST00000263440

Homo sapiens CRYZ 3'-UTR
CRYZ-005 ENST00000370871


Homo sapiens BRP44L 3'-UTR
BRP44L-001 ENST00000360961

Homo sapiens ACADSB 3'-UTR
ACADSB-004

Homo sapiens TMEM14A 3'-UTR
NM_014051.3


Homo sapiens GRAMD1C 3'-UTR
GRAMD1C-005 ENST00000472026

Homo sapiens C11orf80 3'-UTR
C11orf80-201 ENST00000360962

Homo sapiens ANXA4 3'-UTR
ANXA4-002 ENST00000409920

Homo sapiens TBCK 3'-UTR
TBCK-002 ENST00000361687

Homo sapiens IFI6 3'-UTR
IFI6-001 ENST00000361157

Homo sapiens CAMKMT 3'-UTR
(synonym C2orf34) ENST00000378494

Homo sapiens ALDH6A1 3'-UTR
NM_005589.2
Homo sapiens AGTPBP1 3'-UTR
AGTPBP1-004 ENST00000357081


Homo sapiens CCDC53 3'-UTR
CCDC53-001 ENST00000240079

Homo sapiens LRRC28 3'-UTR
LRRC28-002 ENST00000331450

Homo sapiens CCDC109B 3'-UTR
NM_017918.4

Homo sapiens PUS10 3'-UTR
PUS10-001 ENST00000316752


Homo sapiens CCDC104 3'-UTR
CCDC104-002 ENST00000339012

Homo sapiens CASP1 3'-UTR
CASP1-007 ENST00000527979

Homo sapiens SNX14 3'-UTR
SNX14-007 ENST00000513865

Homo sapiens SKAP2 3'-UTR
SKAP2-201 (part of SKAP2.001 ENST00000345317)

Homo sapiens NDUFB6 3'-UTR
NM_182739.2
Homo sapiens EFHA1 3'-UTR
EFHA1-001 ENST00000382374

Homo sapiens BCKDHB 3'-UTR
BCKDHB-005 ENST00000356489

Homo sapiens BCKDHB 3'-UTR
NM_001164783.1

Homo sapiens BBS2 3'-UTR
NM_031885.3


Homo sapiens LMBRD1 3'UTR
NM_018368.3

Homo sapiens ITGA6 3'-UTR
ITGA6-003 ENST00000409532
Homo sapiens HERC5 3'-UTR
HERC5-001 ENST00000264350


Homo sapiens HADHB 3'-UTR
HADHB-001 ENST00000317799

Homo sapiens ANAPC4 3'-UTR
ANAPC4-001 ENST00000315368

Homo sapiens PCCB 3'-UTR
NM_000532.4

Homo sapiens ABCB7 3'-UTR
ABCB7-001 ENST00000253577

Homo sapiens PGCP 3'-UTR
CPQ-001 ENST00000220763


Homo sapiens NFU1 3'-UTR
NM_001002755.2

Homo sapiens OMA1 3'-UTR
OMA1-001 ENST00000371226
Homo sapiens HHLA3 3'-UTR
NM_001036646.1

Homo sapiens HHLA3 3'-UTR
NM_001031693.2

Homo sapiens ACAA2 3'-UTR
NM_006111.2

Homo sapiens GSTM4 3'-UTR
GSTM4-001 ENST00000369836

Homo sapiens GSTM4 3'-UTR
GSTM4-003 ENST00000326729

Homo sapiens ALG8 3'-UTR
NM_001007027.2


Homo sapiens C11orf74 3'UTR

Mus musculus Ndufa1 3'-UTR
Ndufa1-001 ENSMUST00000016571

Mus musculus Atp5e 3'-UTR
NM_025983
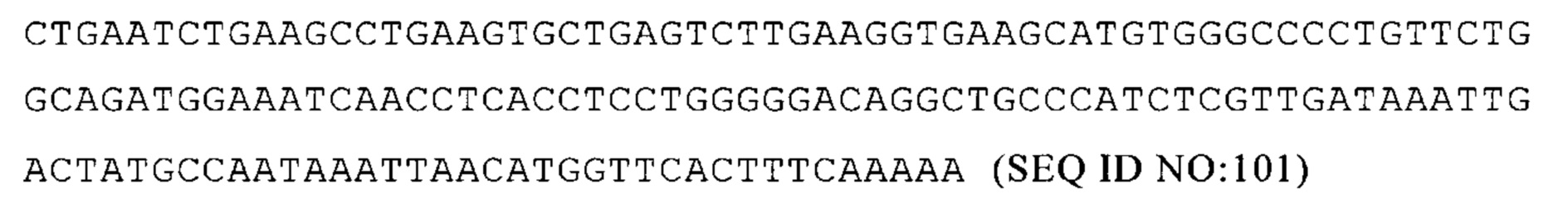
Mus musculus Gstm5 3'-UTR
NM_010360

Mus musculus Uqcr11 3'-UTR
NM_025650

Mus musculus IFi27I2a 3'-UTR
IFi27I2a-001 ENSMUST00000055071; NM_029803

Mus musculus Cbr2 3'-UTR
NM_007621

Mus musculus Atp5l 3'-UTR
Atp5l-201 ENSMUST00000043675

Mus musculus Tmsb10 3'-UTR
NM_025284
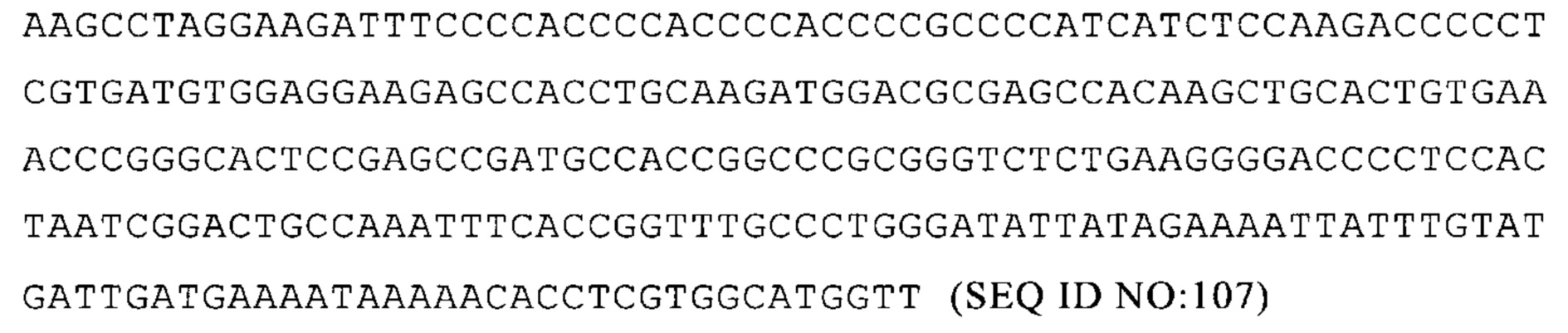
Mus musculus Nenf 3'-UTR
NM_025424

Mus musculus Atp5k 3'-UTR
NM_007507

Mus musculus 1110008P14Rik 3'-UTR
1110008P14Rik-001 ENSMUST00000048792


Mus musculus Cox4i1 3'-UTR
NM_009941

Mus musculus Cox6a1 3'-UTR
NM_007748

Mus musculus Ndufs6 3'-UTR
NM_010888

Mus musculus Sec61b 3'-UTR
NM_024171

Mus musculus Romo1 3'-UTR
NM_025946

Mus musculus Gnas 3'-UTR
NM_010309


Mus musculus Snrpd2 3'-UTR
NM_026943

Mus musculus Mgst3 3'-UTR
NM_025569

Mus musculus Aldh2 3'-UTR
NM_009656

Mus musculus Mp68 (2010107E04Rik) 3'-UTR
NM_027360

Mus musculus Ssr4 3'-UTR
NM_001166480

Mus musculus Myl6 3'-UTR
NM_010860


Mus musculus Prdx4 3'-UTR
Prdx4-001, NM_016764

Mus musculus Ubl5 3'-UTR
NM_025401

Mus musculus 1110001J03Rik 3'-UTR
NM_025363

Mus musculus Ndufa13 3'-UTR
Ndufa13-201 ENSMUST00000110167

Mus musculus Ndufa3 3'-UTR
NM_025348

Mus musculus Gstp2 3'-UTR
NM_181796

Mus musculus Tmem160 3'-UTR
NM_026938

Mus musculus Ergic3 3'-UTR
NM_025516

Mus musculus Pgcp 3'-UTR
NM_018755

Mus musculus Slpi 3'-UTR
NM_011414

Mus musculus Myeov2 3'-UTR
NM_001163425

Mus musculus Ndufa4 3'-UTR
NM_010886

Mus musculus Ndufs5 3'-UTR
NM_001030274

Mus musculus Gstm1 3'-UTR
NM_010358

Mus musculus 1810027O10Rik 3'-UTR
1810027O10Rik-001 ENSMUST00000094065

Mus musculus 1810027O10Rik 3'-UTR
BC117077

Mus musculus Atp5o 3'-UTR
NM_138597
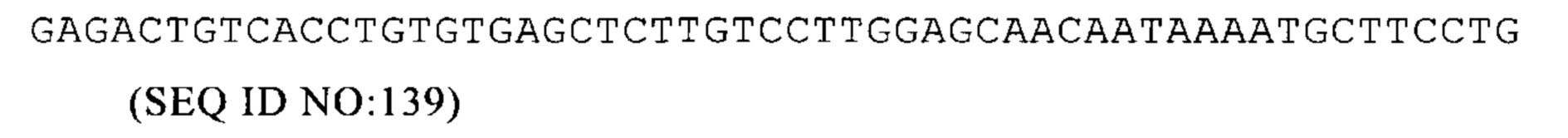
Mus musculus Shfm1 3'-UTR
NM_009169

Mus musculus Tspo 3'-UTR
NM_009775

Mus musculus S100a6 3'-UTR
NM_011313

Mus musculus Taldo1 3'-UTR
NM_011528

Mus musculus Bloc1s1 3'-UTR
NM_015740

Mus musculus Ndufb11 3'-UTR
NM_019435

Mus musculus Map1lc3a 3'-UTR
NM_025735
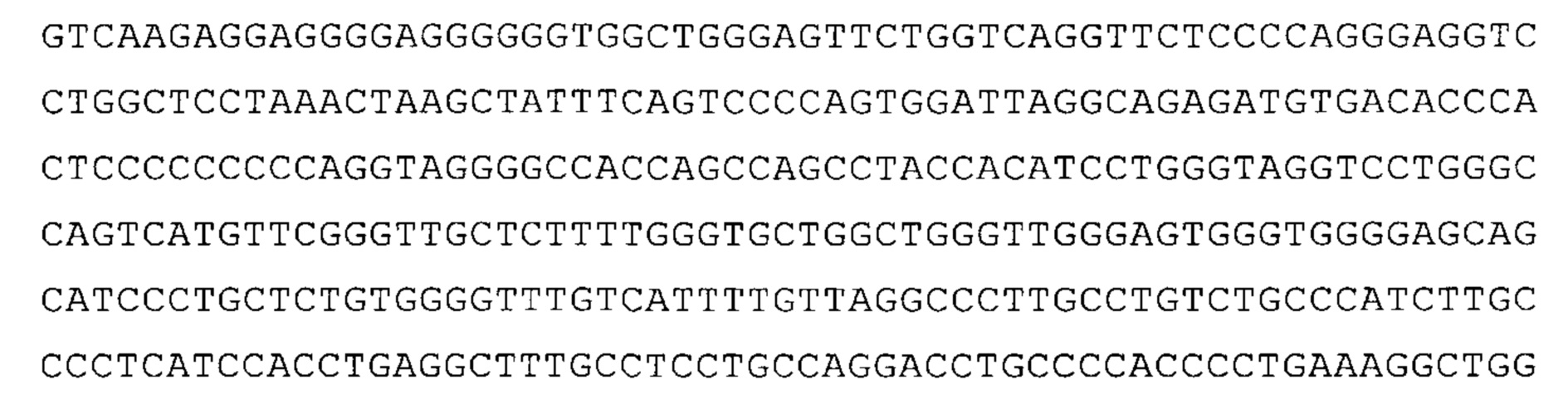

Mus musculus Morn2 3'-UTR
NM_194269

Mus musculus Gpx4 3'-UTR
NM_008162.2

Mus musculus Mif 3'-UTR
NM_010798.2

Mus musculus Cox6b1 3'-UTR
NM_025628

Mus musculus RIKEN cDNA2900010J23 (Swi5) 3'-UTR
NM_175190

Mus musculus Sec61g 3'-UTR
NM_011343.3

Mus musculus 2900010M23Rik 3'-UTR
BC_030629
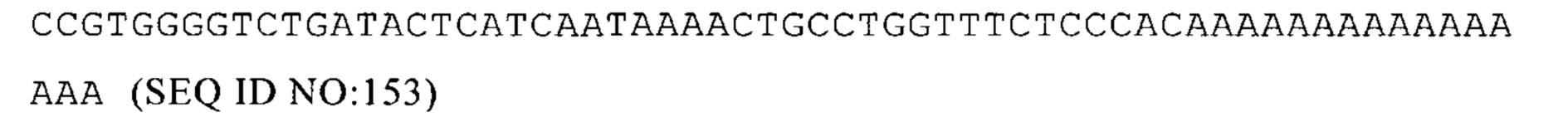
Mus musculus Anapc5 3'-UTR
Anapc5-201 ENSMUST00000086216

Mus musculus Mars2 3'-UTR
BC132343.1

Mus musculus Phpt1 3'-UTR
NM_029293

Mus musculus Ndufb8 3'-UTR
NM_026061

Mus musculus Pfdn5 3'-UTR
NM_027044


Mus musculus Arpc3 3'-UTR
NM_019824

Mus musculus Ndufb7 3'-UTR
NM_025843

Mus musculus Atp5h 3'-UTR
NM_027862

Mus musculus Mrpl23 3'-UTR
NM_011288

Mus musculus Tomm6 3'-UTR
NM_025365.3

Mus musculus Tomm6 3'-UTR
Tomm6-002 ENSMUST00000113301

Mus musculus Tomm6 3'-UTR

Mus musculus Mtch1 3'-UTR
NM_019880

Mus musculus Pcbd2 3'-UTR
NM_028281
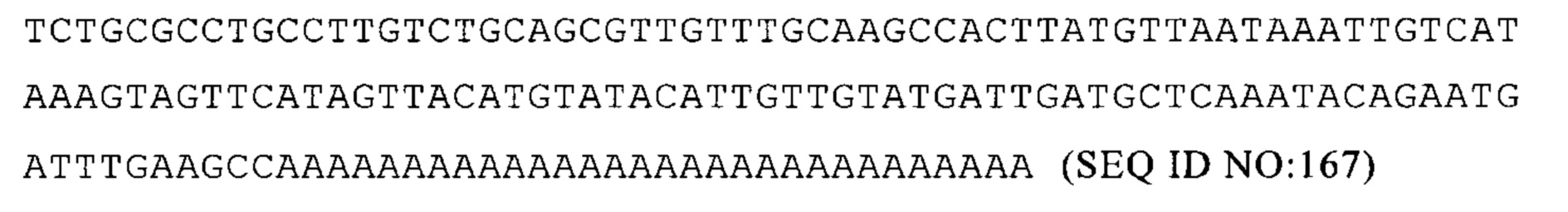
Mus musculus Ecm1 3'-UTR
NM_007899

Mus musculus Hrsp12 3'-UTR
Hrsp12-001 ENSMUST00000022946

Mus musculus Mecr 3'-UTR
NM_025297
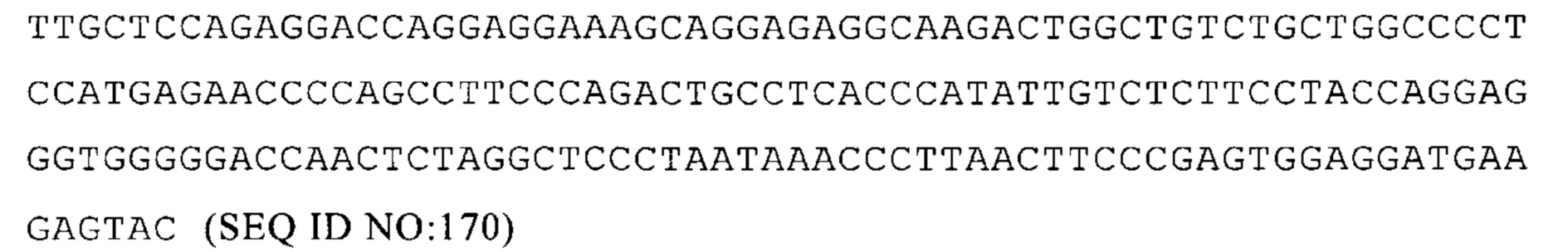
Mus musculus Uqcrq 3'-UTR
NM_025352

Mus musculus Gstm3 3'-UTR
NM_010359

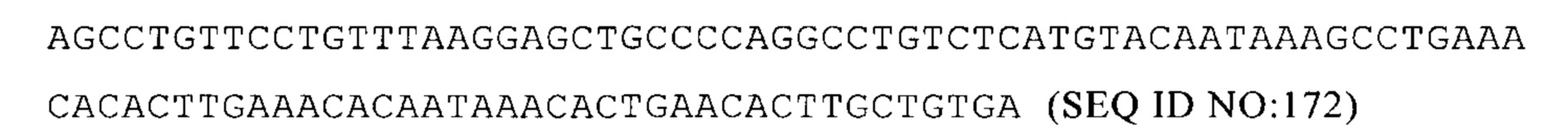
Mus musculus Lsm4 3'-UTR
NM_015816

Mus musculus Park7 3'-UTR
NM_020569
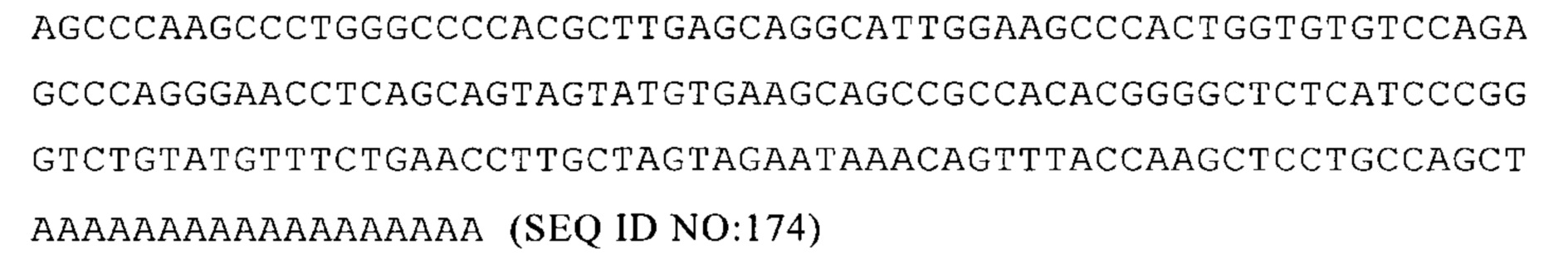
Mus musculus Usmg5 3'-UTR
NM_023211

Mus musculus Cox8a 3'-UTR
NM_007750

Mus musculus Ly6c1 3'-UTR
NM_010741

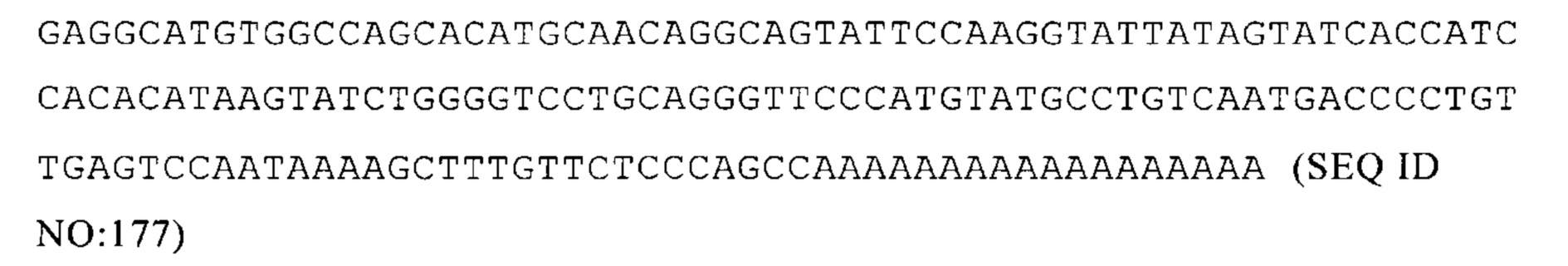
Mus musculus Ly6c1 3'-UTR
NM_001252058.1

Mus musculus Cox7b 3'-UTR
NM_025379

Mus musculus Ppib 3'-UTR
NM_011149

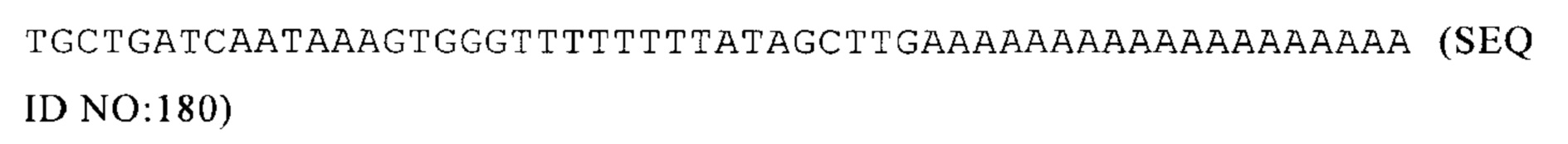
Mus musculus Bag1 3'-UTR
NM_009736

Mus musculus S100a4 3'-UTR
S100a4-201 ENSMUST00000001046

Mus musculus Bcap31 3'-UTR
NM_012060

Mus musculus Tecr 3'-UTR
NM_134118

Mus musculus Rabac1 3'-UTR
NM_010261

Mus musculus Robld3 3'-UTR
NM_031248 (Lamtor2)

Mus musculus Sod1 3'-UTR
NM_011434

Mus musculus Nedd8 3'-UTR
NM_008683

Mus musculus Higd2a 3'-UTR
NM_025933

Mus musculus Trappc6a 3'-UTR
Trappc6a-001 ENSMUST00000002112

Mus musculus Ldhb 3'-UTR
Ldhb-001 ENSMUST00000032373


Mus musculus Nme2 3'-UTR
Nme2-001 ENSMUST00000021217

Mus musculus Snrpg 3'-UTR
NM_026506

Mus musculus Ndufa2 3'-UTR
NM_010885
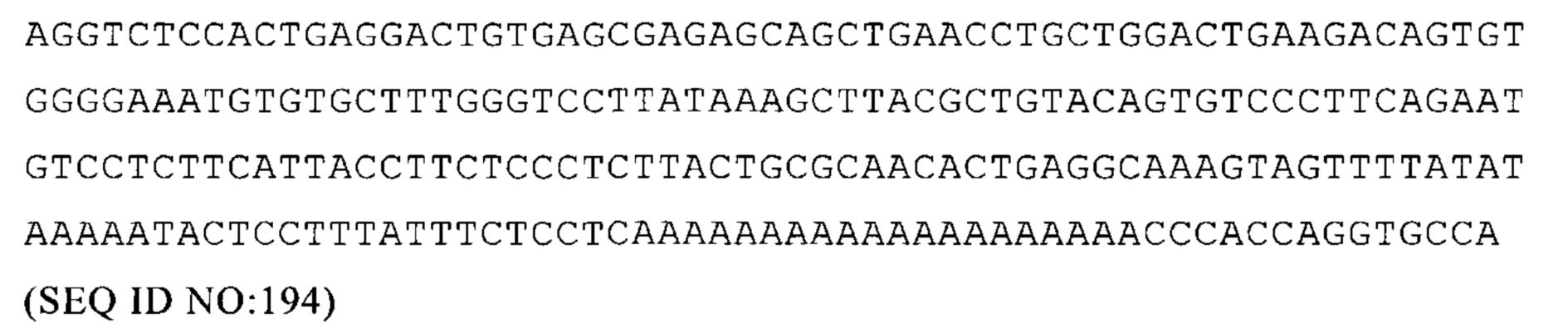
Mus musculus Serf1 3'-UTR
Serf1-003 ENSMUST00000142155

Mus musculus Oaz1 3'-UTR
Oaz1-001 ENSMUST00000180036
Mus musculus Ybx1 3'-UTR
Ybx1-001 ENSMUST00000079644

Mus musculus Ybx1(v2) 3'-UTR
с мутацией T128bpG и делецией del236-237bp

Mus musculus Sepp1 3'-UTR
NM_009155


Mus musculus Gaa 3'-UTR
Gaa-001 ENSMUST00000106259

Homo sapiens ACTR10 3'-UTR
ACTR10-002 ENST00000254286

Homo sapiens PIGF 3'-UTR
NM_173074


Homo sapiens PIGF 3'-UTR
NM_002643.3
Homo sapiens MGST3 3'-UTR
MGST3-001 ENST00000367889

Homo sapiens SCP2 3'-UTR
NM_001193599

Homo sapiens SCP2 3'-UTR
SCP2-015 ENST00000435345

Homo sapiens HPRT1 3'-UTR
HPRT1-001 ENST00000298556

ACSF2
Homo sapiens

Homo sapiens VPS13A 3'-UTR
NM_033305

Homo sapiens CTH 3'-UTR
NM_001190463.1

Homo sapiens CTH 3'-UTR
CTH-001 ENST00000370938


Homo sapiens CTH 3'-UTR
CTH-002 ENST00000346806

Homo sapiens NXT2 3'-UTR
NXT2-004 ENST00000372107

Homo sapiens MGST2 3'-UTR
NM_002413

Homo sapiens MGST2 3'-UTR
NM_001204366.1

Homo sapiens C11orf67 3'-UTR
AAMDC-005 ENST00000526415

Homo sapiens PCCA 3'-UTR
NM_000282

Homo sapiens GLMN 3'-UTR
NM_053274

Homo sapiens DHRS1 3'-UTR
NM_001136050
Homo sapiens PON2 3'-UTR
PON2-001 ENST00000433091

Homo sapiens NME7 3'-UTR
NM_013330

Homo sapiens ETFDH 3'-UTR
NM_004453

Homo sapiens ALG13 3'-UTR
BC117377
Homo sapiens ALG13 3'-UTR
NM_001099922.2

Homo sapiens DDX60 3'-UTR
DDX60-001 ENST00000393743

Homo sapiens DYNC2LI1 3'-UTR
NM_015522.3

Homo sapiens VPS8 3'-UTR
NM_001009921, NM_015303


Homo sapiens ITFG1 3'-UTR
NM_030790

Homo sapiens CDK5 3'-UTR
NM_004935

Homo sapiens C1orf112 3'-UTR
BC091516

Homo sapiens IFT52 3'-UTR
NM_016004

Homo sapiens CLYBL 3'-UTR
CLYBL-003 ENST00000339105

Homo sapiens FAM114A2 3'-UTR
FAM114A2-006 ENST00000520667

Homo sapiens NUDT7 3'-UTR
NM_001243661

Homo sapiens AKD1 3'-UTR
NM_001145128


Homo sapiens MAGED2 3'-UTR
NM_014599

Homo sapiens HRSP12 3'-UTR
HRSP12-001 ENST00000254878

Homo sapiens STX8 NM_004853 3'-UTR

Homo sapiens ACAT1 3'-UTR
ACAT1-001 ENST00000265838

Homo sapiens IFT74 3'-UTR
IFT74-201 ENST00000433700
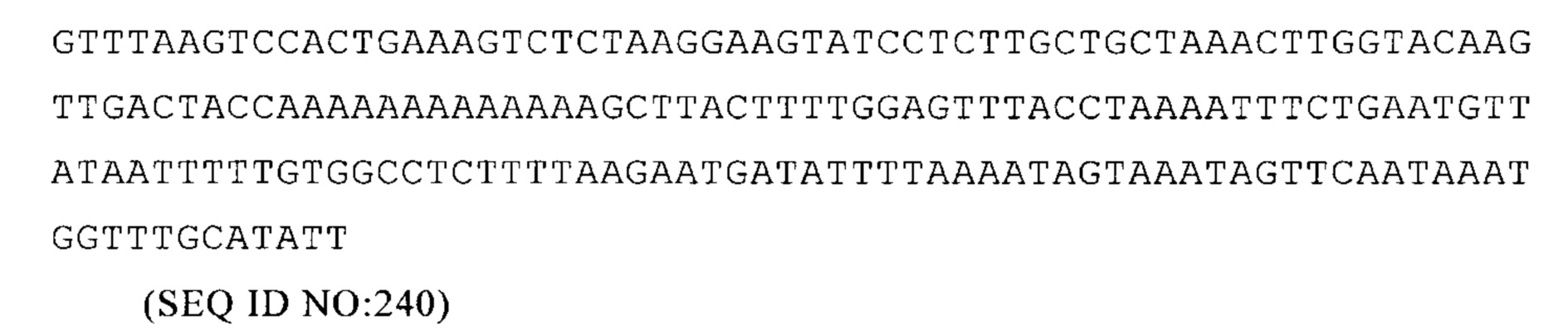
Homo sapiens KIFAP3 3'-UTR
NM_014970
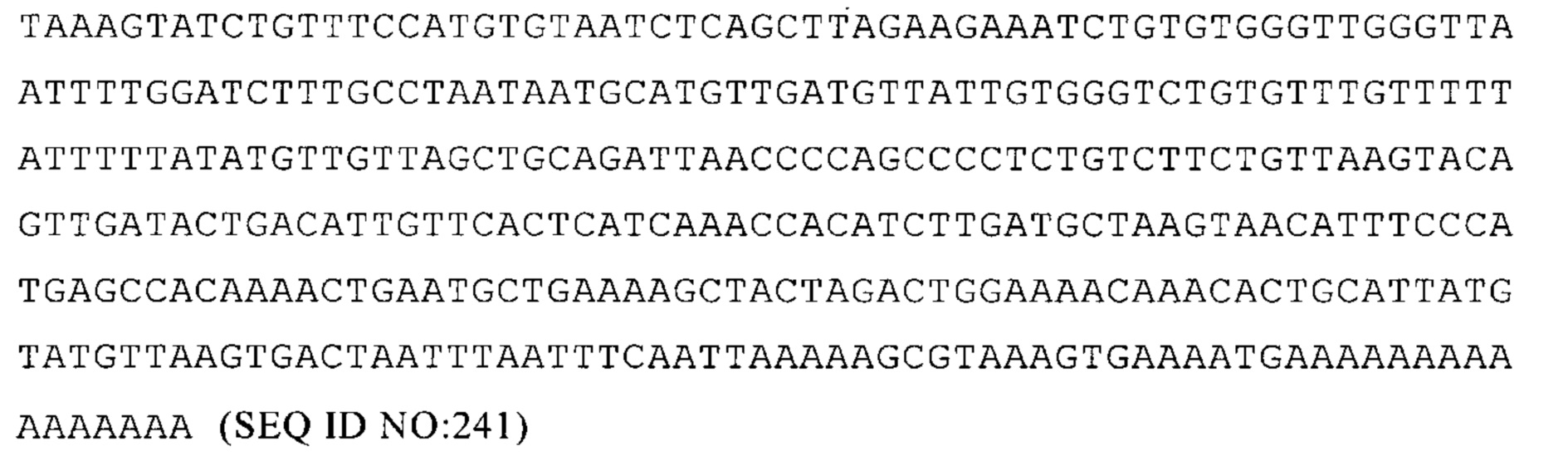
Homo sapiens CAPN1 3'-UTR
NM_005186

Homo sapiens COX11 3'-UTR
NM_001162861

Homo sapiens GLT8D4 3'-UTR
BC127733

Homo sapiens GLT8D4 3'-UTR
NM_001080393

Homo sapiens HACL1 3'-UTR
NM_012260

Homo sapiens IFT88 3'-UTR
NM_175605

Homo sapiens IFT88 3'-UTR
IFT88-001 ENST00000351808

Homo sapiens NDUFB3 3'-UTR
NM_002491

Homo sapiens ANO10 3'-UTR
NM_018075

Homo sapiens ANO10 3'-UTR
ANO10-005 ENST00000451430

Homo sapiens ARL6 3'-UTR
NM_032146

Homo sapiens LPCAT3 3'-UTR
NM_005768

Homo sapiens ABCD3 3'-UTR
NM_001122674

Homo sapiens COPG2 3'-UTR
NM_012133

Homo sapiens MIPEP 3'-UTR
NM_005932

Homo sapiens LEPR 3'-UTR
NM_002303

Homo sapiens LEPR 3'-UTR
NM_001198688

Homo sapiens C2orf76 3'-UTR
NM_001017927

Homo sapiens C2orf76 3'-UTR
C2orf76-001 ENST00000409466

Homo sapiens ABCA6 3'-UTR
NM_080284.2

Homo sapiens LY96 3'-UTR
NM_015364.4

Homo sapiens CROT 3'-UTR
NM_001243745.1

Homo sapiens ENPP5 3'-UTR
ENPP5-002 ENST00000230565


Homo sapiens SERPINB7 3'-UTR
SERPINB7-203 ENST00000546027

Homo sapiens TCP11L2 3'-UTR
NM_152772

Homo sapiens IRAK1BP1 3'-UTR
NM_001010844

Homo sapiens CDKL2 3'-UTR
CDKL2-002 ENST00000307465

Homo sapiens GHR 3'-UTR
GHR-202 ENST00000537449
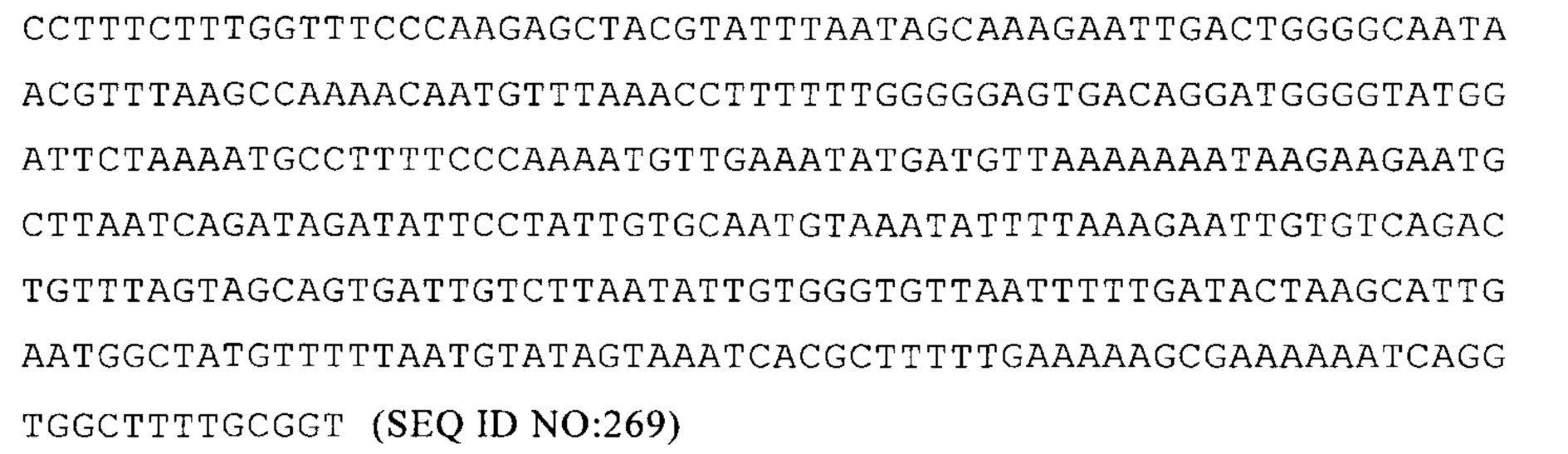
Homo sapiens KIAA1107 3'-UTR
NM_015237

Homo sapiens RPS6KA6 3'-UTR
RPS6KA6-001 ENST00000262752


Homo sapiens CLGN 3'-UTR
NM_004362, NM_001130675

Homo sapiens CLGN-202 3'-UTR
NM_004362, NM_001130675
ENST00000325617

Homo sapiens TMEM45A 3'-UTR
NM_018004
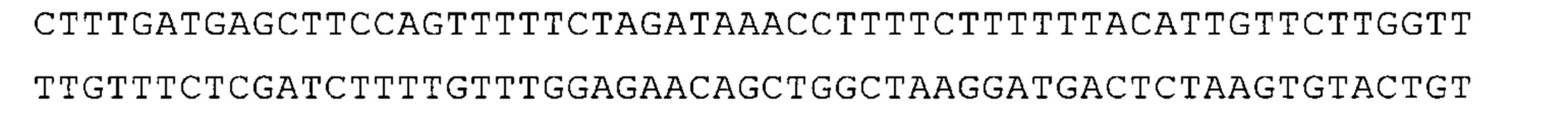

Homo sapiens TBC1D8B 3'-UTR
TBC1D8B-007 ENST00000276175

Homo sapiens ACP6 3'-UTR
NM_016361

Homo sapiens RP6-213H19.1 3'-UTR
MST4-003 (RBM4B-003 ENST00000496850)

Homo sapiens SNRPN 3'-UTR
NM_022807

Homo sapiens GLRB 3'-UTR
GLRB-005 ENST00000512619

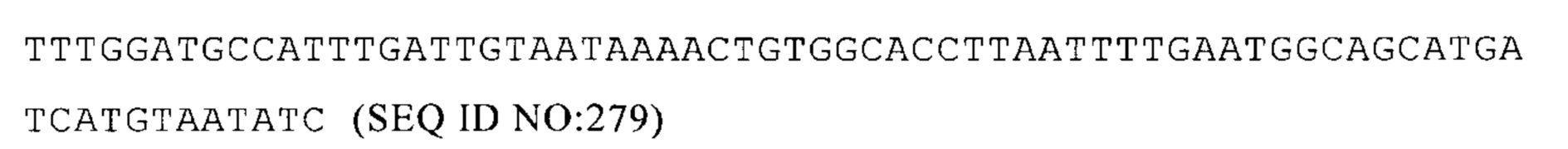
Homo sapiens HERC6 3'-UTR
NM_017912

Homo sapiens CFH 3'-UTR
NM_000186

Homo sapiens GALC 3'-UTR
GALC-002 ENST00000393569

Homo sapiens GALC 3'-UTR
GALC-005 ENST00000393568

Homo sapiens PDE1A 3'-UTR
NM_001003683.2
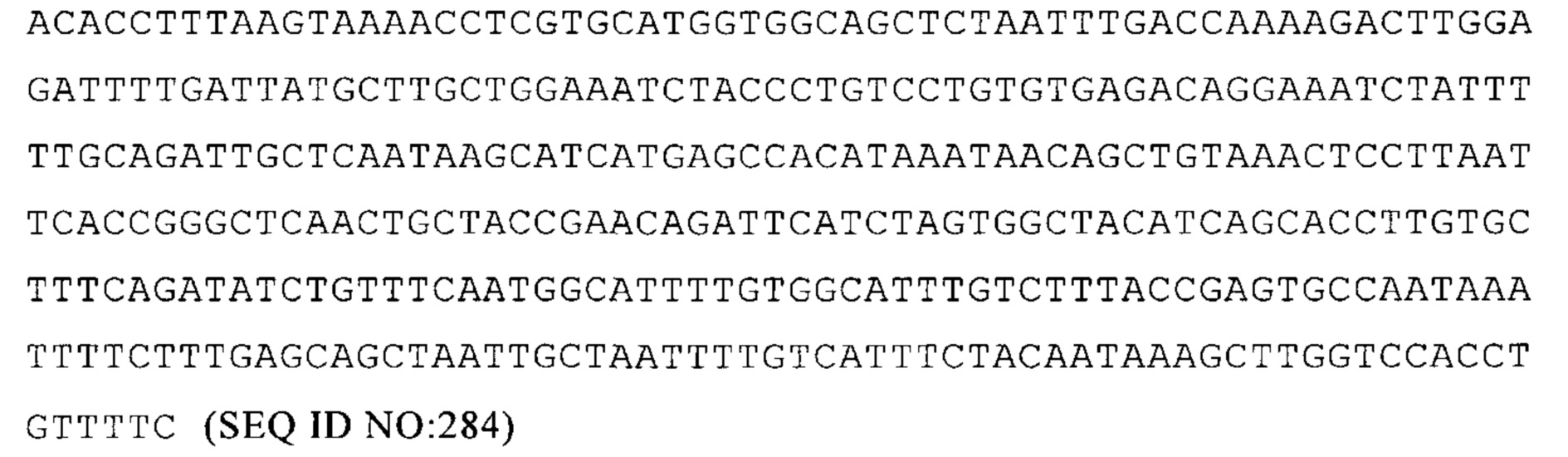
Homo sapiens PDE1A 3'-UTR
PDE1A-003 ENST00000410103

Homo sapiens GSTM5 3'-UTR
NM_000851


Homo sapiens CADPS2 3'-UTR
CADPS2-002 ENST00000412584
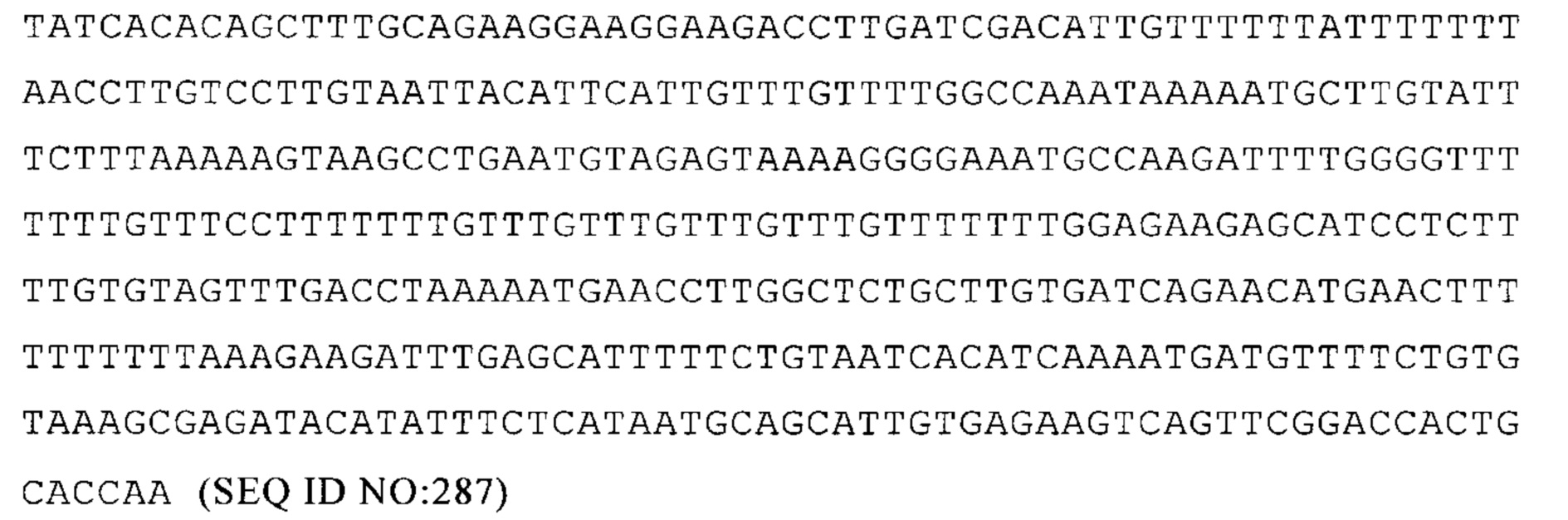
Homo sapiens CADPS2 3'-UTR
CADPS2-001 ENST00000449022

Homo sapiens AASS 3'-UTR
AASS-001 ENST00000417368
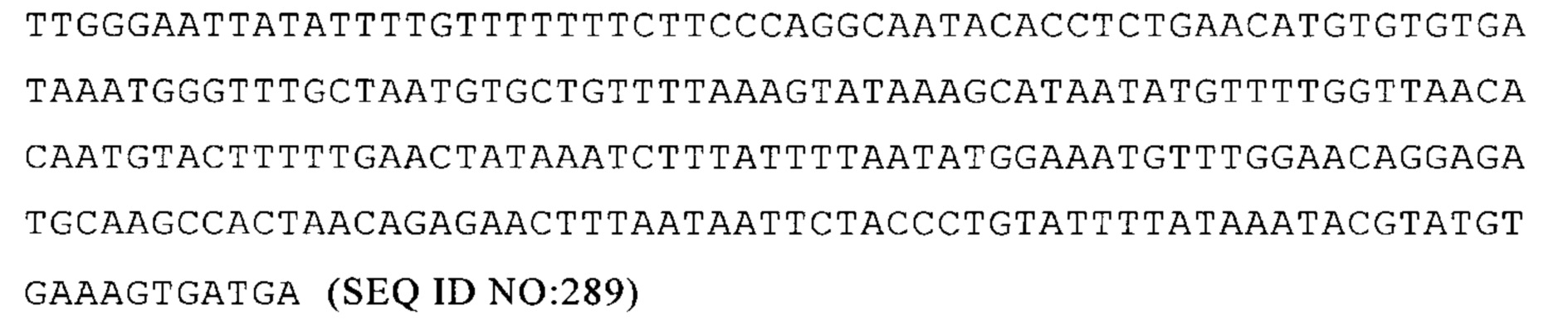
Homo sapiens TRIM6-TRIM34 3'-UTR
NM_001003819


Homo sapiens SEPP1 3'-UTR
NM_005410

Homo sapiens SEPP1 3'-UTR
SEPP1-004 ENST00000506577

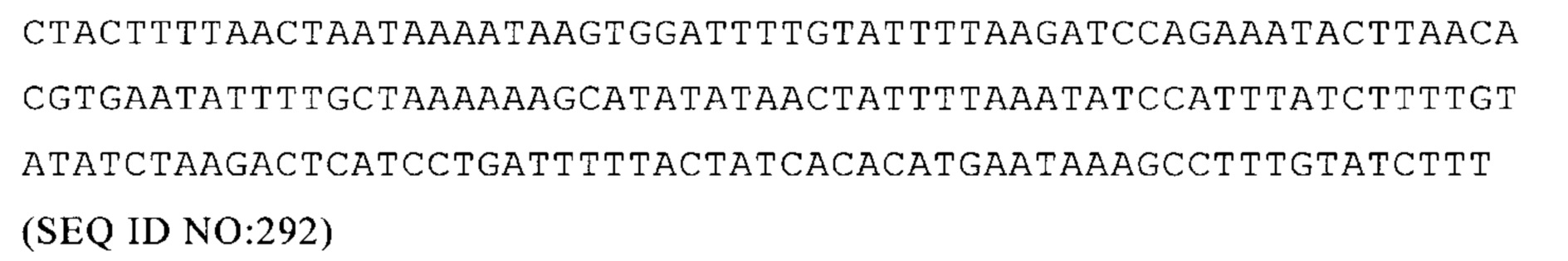
Homo sapiens PDE5A 3'-UTR
PDE5A-002 ENST00000264805

Homo sapiens SATB1 3'-UTR
SATB1-004 ENST00000417717

Homo sapiens CCPG1 3'-UTR
CCPG1-002 ENST00000442196


Homo sapiens CCPG1 3'-UTR
CCPG1-004 ENST00000425574

Homo sapiens CNTN1 3'-UTR
CNTN1-002 ENST00000348761

Homo sapiens CNTN1 3'-UTR
CNTN1-004 ENST00000547849


Homo sapiens CNTN1 3'-UTR
CNTN1-004 ENST00000547849
+T в позиции 30 п.о., мутации G727bpT, A840bpG


Homo sapiens LMBRD2 3'-UTR

Homo sapiens TLR3 3'-UTR
NM_003265

Homo sapiens BCAT1 3'-UTR
BCAT1-002 ENST00000342945


Homo sapiens BCAT1 3'-UTR

Homo sapiens TOM1L1 3'-UTR
TOM1L1-001 ENST00000575882

Homo sapiens SLC35A1 3'-UTR
SLC35A1-201 ENST00000369556


Homo sapiens GLYATL2 3'-UTR
GLYATL2-003 ENST00000532258

Homo sapiens STAT4 3'-UTR
STAT4-002 ENST00000392320

Homo sapiens GULP1 3'-UTR
GULP1-002 ENST00000409609

Homo sapiens GULP1 3'-UTR
GULP1-010 ENST00000409805

Homo sapiens EHHADH 3'-UTR
EHHADH-002 ENST00000456310

Homo sapiens NBEAL1 3'-UTR
NM_001114132.1

Homo sapiens KIAA1598 3'-UTR
NM_001258299.1

Homo sapiens HFE 3'-UTR
HFE-006 ENST00000317896


Homo sapiens HFE 3'-UTR
HFE-004 ENST00000349999

Homo sapiens HFE 3'-UTR
HFE-005 ENST00000397022

Homo sapiens HFE 3'-UTR
HFE-012 ENST00000336625

Homo sapiens KIAA1324L 3'-UTR
KIAA1324L-005 ENST00000416314

Homo sapiens MANSC1 NM_018050 3'-UTR

Предпочтительно, по меньшей мере один элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 1, 2, 3, 4, 5, 10, 15, 20, 30 или 40%, предпочтительно по меньшей мере, примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95% еще более предпочтительно по меньшей мере примерно на 99% идентична последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 25 или SEQ ID NO: 30 и SEQ ID NO: 319-338, или соответствующей последовательности ДНК или РНК, соответственно, или в которой по меньшей мере один элемент 5'-UTR содержит или состоит из фрагмента последовательности нуклеиновой кислоты, который по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, и еще более предпочтительно по меньшей мере примерно на 99% идентичен последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 25 или SEQ ID NO: 30 и SEQ ID NO: 319-338 или соответствующей последовательности ДНК или РНК, соответственно:
Homo sapiens LTA4H 5'-UTR
LTA4H-001 ENST00000228740

Homo sapiens DECR1 5'-UTR
DECR1-001 ENST00000220764

Homo sapiens PIGK 5'-UTR
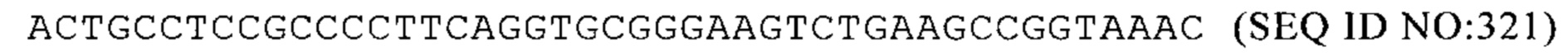
Homo sapiens BRP44L 5'-UTR
BRP44L-001

Homo sapiens ACADSB 5'-UTR
ACADSB-004 NM_001609.3 ENST00000368869

Homo sapiens SUPT3H 5'-UTR
SUPT3H-006 ENST00000371459
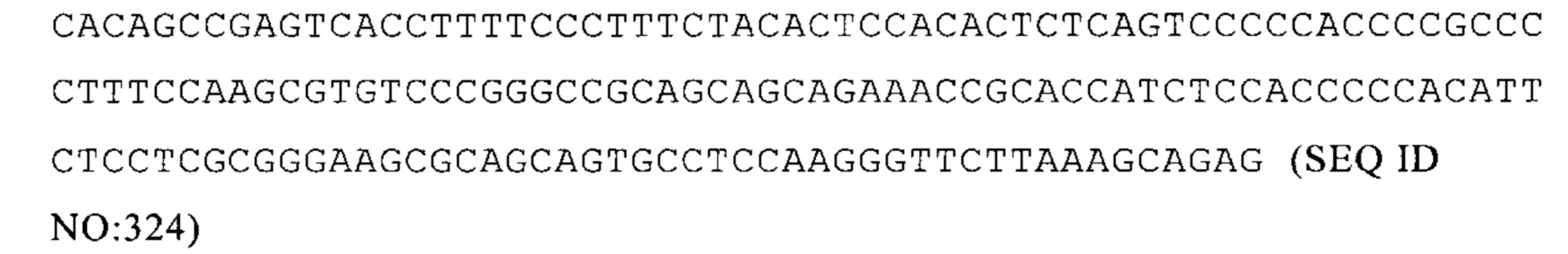
Homo sapiens TMEM14A 5'-UTR
NM_014051.3

Homo sapiens C9orf46 5'-UTR
AF225420.1
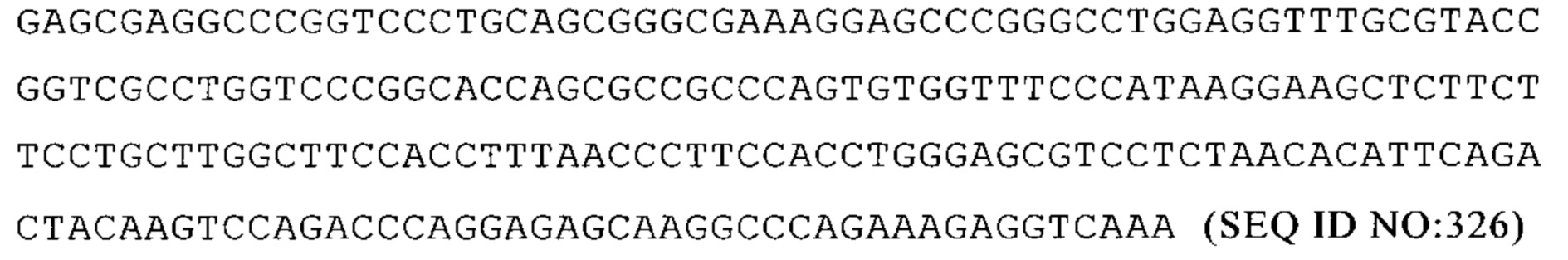
Homo sapiens ANXA4 5'-UTR
NM_001153.3

Homo sapiens IFI6 5'-UTR
NM_022873.2

Homo sapiens C2orf34 5'-UTR
CAMKMT-008 ENST00000402247

Homo sapiens C2or04 5'-UTR
NM_024766.3

Homo sapiens ALDH6A1 5'-UTR
ALDH6A1-002 ENST00000350259

Homo sapiens CCDC53 5'-UTR
CCDC53-002 ENST00000545679

Homo sapiens CASP1 5'-UTR
NM_001257119.1

Homo sapiens NDUFB6 5'-UTR
NM_182739.2

Homo sapiens BCKDHB 5'-UTR
BCKDHB-002 ENST00000369760

Homo sapiens BCKDHB 5'-UTR
NM_001164783.1

Homo sapiens BBS2 5'-UTR
NM_031885.3
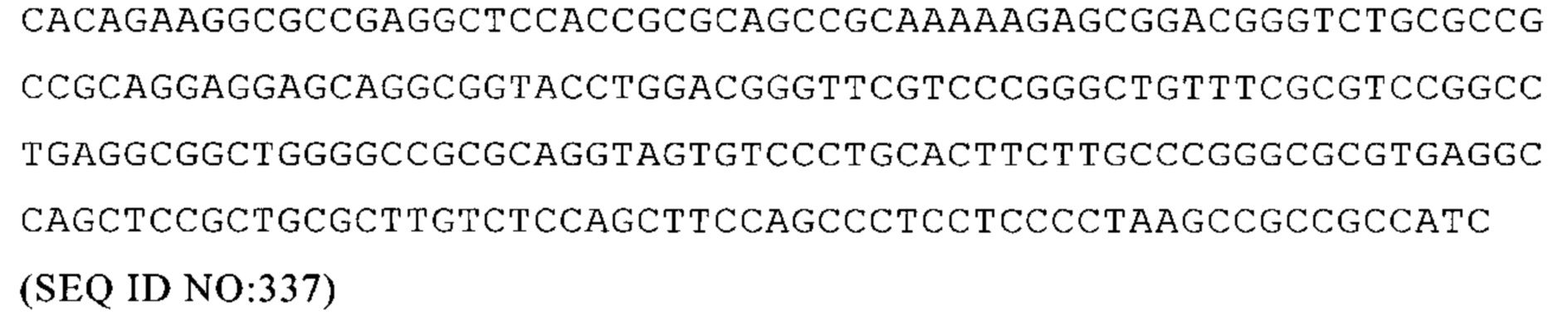
Homo sapiens HERC5 5'-UTR
HERC5-001 ENST00000264350

Homo sapiens FAM175A 5'-UTR
NM_139076.2

Homo sapiens NT5DC1 5'-UTR
NT5DC1-002 ENST00000319550

Homo sapiens RAB7A 5'-UTR
RAB7A-001 ENST00000265062
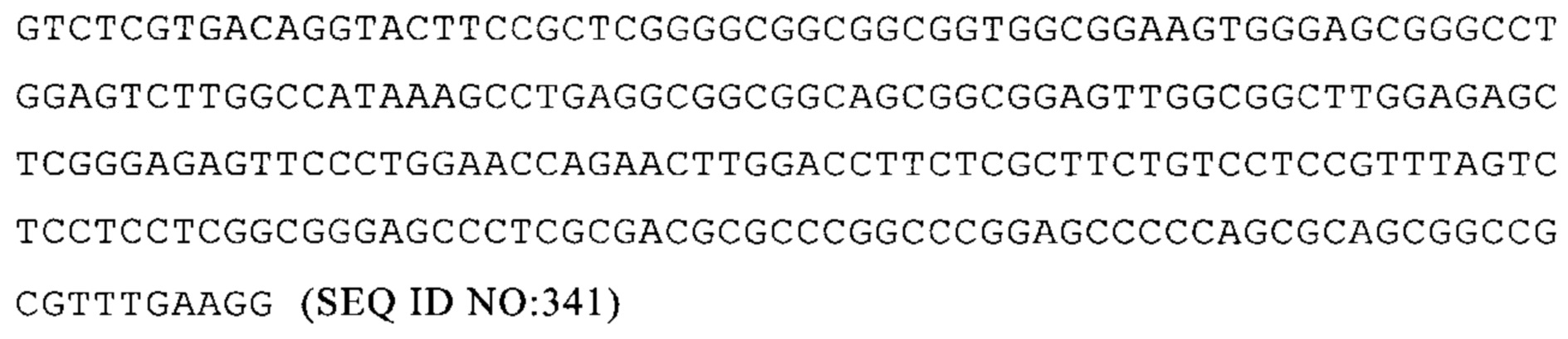
Homo sapiens AGA 5'-UTR
AGA-001 ENST00000264595

Homo sapiens TPK1 5'-UTR
TPK1-001 ENST00000360057

Homo sapiens MBNL3 5'-UTR
MBNL3-001 ENST00000370839

Homo sapiens MCCC2 5'-UTR
MCCC2-001 ENST00000340941

Homo sapiens CAT 5'-UTR
CAT-001 ENST00000241052
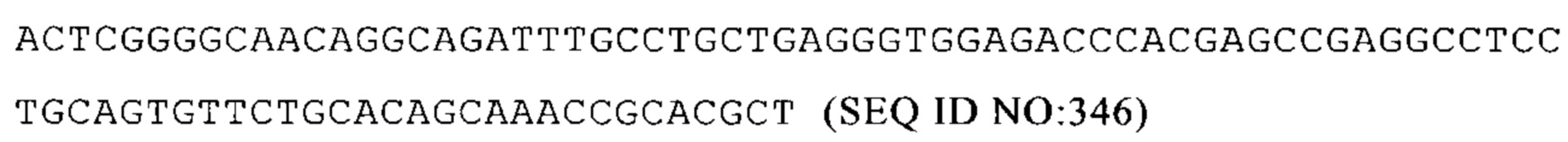
Homo sapiens ANAPC4 5'-UTR
ANAPC4-001 ENST00000315368

Homo sapiens RNAB 5'-UTR
PHKB-002 ENST00000323584

Homo sapiens ABCB7 5'-UTR
ABCB7-001 ENST00000253577

Homo sapiens GPD2 5'-UTR
GPD2-002 ENST00000438166

Homo sapiens TMEM38B 5'-UTR
TMEM38B-001 ENST00000374692

Homo sapiens NFU1 5'-UTR
NM_001002755.2

Homo sapiens LOC128322/NUTF2 5'-UTR
NM_005796.1
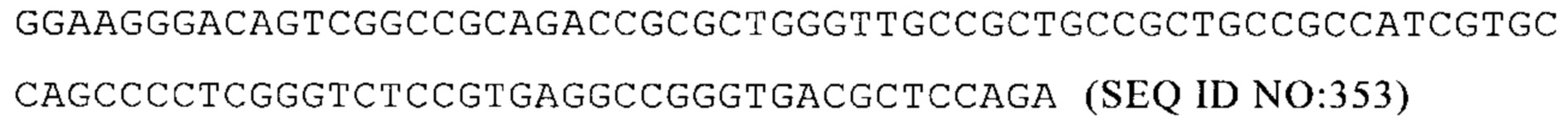
Homo sapiens NUBPL 5'-UTR
NM_025152.2

Homo sapiens LANCL1 5'-UTR
LANCL1-004 ENST00000233714

Homo sapiens PIR 5'-UTR
PIR-002 ENST00000380420

Homo sapiens CTBS 5'-UTR
NM_004388.2

Homo sapiens GSTM4 5'-UTR
NM_000850.4

Mus musculus Ndufal 5'-UTR
Ndufa1-001 ENSMUST00000016571

Mus musculus Atp5e 5'-UTR
NM_025983

Mus musculus Gstm5 5'-UTR
NM_010360
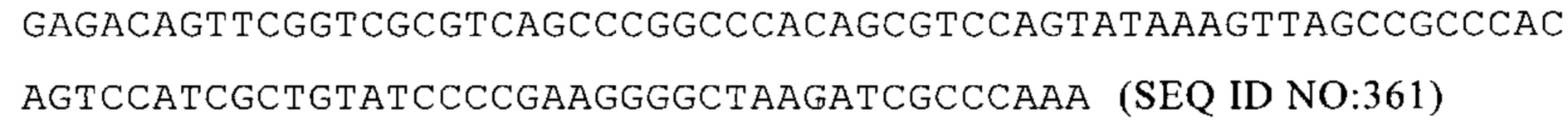
Mus musculus Cbr2 5'-UTR
NM_007621

Mus musculus Anapc13 5'-UTR
NM_181394

Mus musculus Ndufa7 5'-UTR
NM_023202

Mus musculus Atp5k 5'-UTR
NM_007507

Mus musculus Cox4i1 5'-UTR
NM_009941

Mus musculus Ndufs6 5'-UTR
NM_010888

Mus musculus Sec61b 5'-UTR
NM_024171

Mus musculus Snrpd2 5'-UTR
NM_026943

Mus musculus Mgst3 5'-UTR
NM_025569

Mus musculus Mp68 (2010107E04Rik) 5'-UTR
NM_027360

Mus musculus Prdx4-001, 5'-UTR
NM_016764

Mus musculus Pgcp 5'-UTR
NM_176073
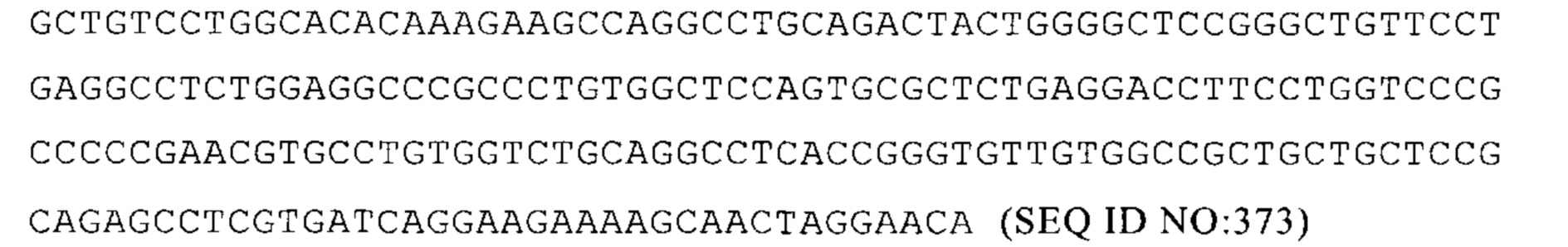
Mus musculus Myeov2 5'-UTR
NM_001163425

Mus musculus Ndufa4 5'-UTR
NM_010886

Mus musculus Ndufs5 5'-UTR
NM_001030274

Mus musculus Gstm1 5'-UTR
NM_010358

Mus musculus Atp5o 5'-UTR
NM_138597

Mus musculus Tspo 5'-UTR
NM_009775

Mus musculus Taldo1 5'-UTR
NM_011528

Mus musculus Bloc1s1 5'-UTR
NM_015740

Mus musculus Hexa 5'-UTR
NM_010421

Предпочтительно, по меньшей мере, один элемент 3'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит или состоит из последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности 3'-UTR транскрипта гена, выбранного из группы, состоящей из GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), Ybx1 (Y-Box-связывающий белок 1), Ndufb8 (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8), CNTN1 (контактин 1); где CNTN1-004 является особенно предпочтительным). Наиболее предпочтительно, по меньшей мере, один элемент 3'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит или состоит из последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50% предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности, выбранной из группы, состоящей из SEQ ID NO: 1 - SEQ ID NO: 24, или соответствующих последовательностей РНК:
SEQ ID NO: 1

SEQ ID NO: 2

SEQ ID NO: 3

SEQ ID NO: 4


SEQ ID NO: 5

SEQ ID NO: 6

SEQ ID NO: 7

SEQ ID NO: 8

SEQ ID NO: 9

SEQ ID NO: 10

SEQ ID NO: 11

SEQ ID NO: 12

SEQ ID NO: 13

SEQ ID NO: 14

SEQ ID NO: 15

SEQ ID NO: 16


SEQ ID NO: 17

SEQ ID NO: 18

SEQ ID NO: 19

SEQ ID NO: 20


SEQ ID NO: 21

SEQ ID NO: 22


SEQ ID NO: 23


SEQ ID NO: 24

Предпочтительно, по меньшей мере, один элемент 5'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит или состоит из последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности 5'-UTR транскрипта МР68 (RIKEN кДНК 2010107Е04 ген) или NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа-подкомплекс 4). Наиболее предпочтительно, по меньшей мере, один элемент 5'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит или состоит из последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50% предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности SEQ ID NO: 25 или SEQ ID NO: 30 или соответствующей последовательности РНК:
SEQ ID NO: 25

SEQ ID NO: 26

SEQ ID NO: 27


SEQ ID NO: 28

SEQ ID NO: 29

SEQ ID NO: 30

По меньшей мере один элемент 3'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может также содержать или состоять из фрагмента последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности нуклеиновой кислоты 3'-UTR транскрипта гена, например, 3'-UTR последовательности SEQ ID NO: 1-24 и SEQ ID NO: 49-318, причем фрагмент предпочтительно представляет функциональный фрагмент или фрагмент функционального, варианта описанный выше. Такой фрагмент предпочтительно имеет длину, составляющую по меньшей мере примерно 3 нуклеотида, предпочтительно по меньшей мере примерно 5 нуклеотидов, более предпочтительно по меньшей мере примерно 10, 15, 20, 25 или 30 нуклеотидов, еще более предпочтительно по меньшей мере примерно 50 нуклеотидов, наиболее предпочтительно по меньшей мере примерно 70 нуклеотидов. В предпочтительном варианте осуществления настоящего изобретения его фрагмент или его вариант имеет длину от 3 до 500 нуклеотидов, предпочтительно от 5 до 150 нуклеотидов, более предпочтительно от 10 до 100 нуклеотидов, еще более предпочтительно от 15 до 90 нуклеотидов, наиболее предпочтительно от 20 до 70 нуклеотидов. Предпочтительно указанные варианты, фрагменты или фрагменты вариантов являются функциональными вариантами, функциональными фрагментами или функциональными фрагментами вариантов 3'-UTR, продлевающими выработку белка с молекулы искусственной нуклеиновой кислоты по настоящему изобретению с эффективностью продления выработки белка по меньшей мере 30%, предпочтительно с эффективностью по меньшей мере 40%, более предпочтительно по меньшей мере 50%, более предпочтительно по меньшей мере 60%, еще более предпочтительно по меньшей мере 70%, еще более предпочтительно по меньшей мере 80%, наиболее предпочтительно по меньшей мере 90%, проявляемой молекулой искусственной нуклеиновой кислоты, содержащей последовательность нуклеиновой кислоты, выбранную из группы, состоящей из SEQ ID NO: 1 - SEQ ID NO: 24.
По меньшей мере один 5'-UTR-элемент молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может также содержать или состоять из фрагмента последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности нуклеиновой кислоты 5'-UTR транскрипта гена, например, 5'-UTR последовательности в соответствии с SEQ ID NO: 25 или SEQ ID NO: 30 и SEQ ID NO: 319-338, причем фрагмент предпочтительно представляет функциональный фрагмент или фрагмент функционального варианта согласно описанному выше. Такой фрагмент предпочтительно имеет длину, составляющую по меньшей мере примерно 3 нуклеотида, предпочтительно по меньшей мере примерно 5 нуклеотидов, более предпочтительно по меньшей мере примерно 10, 15, 20, 25 или 30 нуклеотидов, еще более предпочтительно по меньшей мере примерно 50 нуклеотидов, наиболее предпочтительно по меньшей мере примерно 70 нуклеотидов. В предпочтительном варианте осуществления настоящего изобретения фрагмент или вариант имеет длину от 3 до 500 нуклеотидов, предпочтительно от 5 до 150 нуклеотидов, более предпочтительно от 10 до 100 нуклеотидов, еще более предпочтительно от 15 до 90 нуклеотидов, наиболее предпочтительно от 20 до 70 нуклеотидов. Предпочтительно указанные варианты, фрагменты или фрагменты вариантов являются функциональными вариантами, функциональными фрагментами или функциональными фрагментами вариантов 5'-UTR, которые увеличивают выработку белка с молекулы искусственной нуклеиновой кислоты согласно настоящему изобретению с эффективностью, превышающей по меньшей мере на 30%, предпочтительно с эффективностью по меньшей мере на 40%, более предпочтительно по меньшей мере на 50%, более предпочтительно по меньшей мере на 60%, еще более предпочтительно по меньшей мере на 70%, еще более предпочтительно по меньшей мере на 80%, предпочтительно по меньшей мере на 90% относительно эффективности выработки белка, проявляемой с молекулы искусственной нуклеиновой кислоты, содержащей последовательность нуклеиновой кислоты, выбранную из группы, состоящей из SEQ ID NO: 25 - SEQ ID NO: 30.
Предпочтительно, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением имеет длину, по меньшей мере, около 3 нуклеотидов, предпочтительно по меньшей мере около 5 нуклеотиды, более предпочтительно по меньшей мере около 10, 15, 20, 25 или 30 нуклеотидов, еще более предпочтительно по меньшей мере около 50 нуклеотидов, наиболее предпочтительно по меньшей мере около 70 нуклеотидов. Верхний предел длины по меньшей мере одного элемента 3'-UTR и/или по меньшей мере одного элемента 5'-UTR может составлять 500 нуклеотидов или менее, например, 400, 300, 200, 150 или 100 нуклеотидов. Для других вариантов осуществления настоящего изобретения верхний предел может быть выбран в пределах от 50 до 100 нуклеотидов. Например, фрагмент или его вариант может иметь длину от 3 до 500 нуклеотидов, предпочтительно от 5 до 150 нуклеотидов, более предпочтительно от 10 до 100 нуклеотидов, еще более предпочтительно от 15 до 90 нуклеотидов, наиболее предпочтительно от 20 до 70 нуклеотидов.
Кроме того, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может содержать более одного 3'-UTR-элемента и/или более одного элемента 5'-UTR согласно описанному выше. Например, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может содержать один, два, три, четыре или более элементов 3'-UTR и/или один, два, три, четыре или более элементов 5'-UTR, отдельные элементы 3'-UTR могут быть одинаковыми или могут быть разными, и аналогичным образом отдельные элементы 5'-UTR могут быть одинаковыми или могут быть разными. Например, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может содержать два по существу идентичных элемента 3'-UTR согласно описанному выше, например, два элемента 3'-UTR, содержащие или состоящие из последовательности нуклеиновой кислоты, которая получена из 3'-UTR транскрипта гена, например, последовательность в соответствии с SEQ ID NO: 1-24 и SEQ ID NO: 49-318 или из фрагмента или варианта 3'-UTR транскрипта гена, его функциональных вариантов, его функциональных фрагментов или их функциональных фрагментов согласно описанному выше. Соответственно, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, может содержать два по существу идентичных элемента 5'-UTR согласно описанному выше, например, два элемента 5'-UTR, содержащие или состоящие из последовательности нуклеиновой кислоты, которая получена из 5'-UTR транскрипта гена, например, последовательность в соответствии с SEQ ID NO: 25-30 и SEQ ID NO: 319-338 или из фрагмента или варианта 5'-UTR транскрипта гена, его функциональных вариантов, функциональных фрагментов или их функциональных фрагментов согласно описанному выше.
Неожиданно в настоящем изобретении было установлено, что молекула искусственной нуклеиновой кислоты, содержащая элемент 3'-UTR согласно описанному выше, и/или элемент 5'-UTR согласно описанному выше, может представлять или может предусматривать молекулу мРНК, которая позволяет увеличить, продлить и/или стабилизировать выработку белка. Таким образом, элемент 3'-UTR по настоящему изобретению и/или элемент 5'-UTR по настоящему изобретению может улучшить стабильность экспрессии белка с молекулы мРНК и/или улучшить эффективность трансляции.
В частности, молекула искусственной нуклеиновой кислоты по настоящему изобретению может содержать (i) по меньшей мере один элемент 3'-UTR и по меньшей мере один элемент 5'-UTR, который продлевает и/или увеличивает выработку белка; (ii) по меньшей мере один элемент 3'-UTR, который продлевает и/или увеличивает выработку белка, но не содержит элемент 5'-UTR, который продлевает и/или увеличивает выработку белка; или (iii) по меньшей мере один элемент 5'-UTR, который продлевает и/или увеличивает выработку белка, но не содержит 3'-UTR-элемент, который продлевает и/или увеличивает выработку белка.
Однако, в частности, в случае (ii) и (iii), но, возможно, также в случае (i), молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может дополнительно содержать один или несколько «дополнительных элементов 3'-UTR и/или элементов 5'-UTR», т.е. элементы 3'-UTR и/или элементы 5'-UTR, которые в полной мере не отвечают описанным выше требованиям. Например, молекула искусственной нуклеиновой кислоты по настоящему изобретению, которая содержит элемент 3'-UTR в соответствии с настоящим изобретением, то есть элемент 3'-UTR, который продлевает и/или увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, может дополнительно содержат какие-либо дополнительные 3'-UTR и/или какие-либо дополнительные 5'-UTR, в частности дополнительный 5'-UTR, например 5'-ТОР UTR или какую-либо другую 5'-UTR или какой-либо другой элемент 5'-UTR. Сходным образом, например, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, которая содержит 5'-UTR-элемент в соответствии с настоящим изобретением, то есть элемент 5'-UTR, который продлевает и/или увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, может дополнительно содержать какие-либо дополнительные 3'-UTR и/или какие-либо дополнительные 5'-UTR, в частности дополнительные 3'-UTR, например 3'-UTR, производные от 3'-UTR гена альбумина, особенно предпочтительно 3'-UTR, содержащую последовательность SEQ ID NO: 31 или 32, в частности, SEQ ID NO: 32, или какую-либо другую 3'-UTR или какой-либо другой элемент 3'-UTR.
Кроме того, в настоящем изобретении по меньшей мере один элемент 5'-UTR и/или по меньшей мере один элемент 3'-UTR, который продлевает и/или увеличивает выработку белка, а также дополнительно 3'-UTR (элемент) и/или дополнительно 5'-UTR (элемент) присутствуют в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, дополнительный 5'-UTR (элемент) и/или дополнительный 3'-UTR (элемент) могут взаимодействовать с элементом 3'-UTR по настоящему изобретению и/или с элемент 5'-UTR по настоящему изобретению и, таким образом, поддерживать увеличение и/или продление эффекта элемента 3'-UTR по настоящему изобретению и/или элемента 5'-UTR по настоящему изобретению, соответственно. Такие дополнительные 3'-UTR и/или 5'-UTR (элементы) могут дополнительно поддерживать стабильность и эффективность трансляции. Боле того, если в молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением присутствуют оба элемента, а именно 3'-UTR по настоящему изобретению и 5'-UTR по настоящему изобретению, то эффект элемента 5'-UTR по настоящему изобретению и элемента 3'-UTR по настоящем изобретению в виде продления и/или увеличения предпочтительно приводит к синергетическому эффекту в виде увеличенной и продленной выработки белка.
Предпочтительно, дополнительная 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая получена из 3'-UTR гена, выбранного из группы, состоящей из гена альбумина, гена α-глобина, гена β-глобина, гена тирозингидроксилазы, гена липоксигеназы и гена коллагена альфа, например, гена коллагена альфа 1(I), или из варианта 3'-UTR гена, выбранного из группы, состоящей из гена альбумина, гена α-глобина, гена β-глобина, гена тирозингидроксилазы, гена липоксигеназы и гена коллагена альфа, например, гена коллагена альфа 1(I) в соответствии с SEQ ID NO: 1369-1390 в патентной заявке WO 2013/143700, сущность которой включена в настоящее изобретение в виде ссылки. В особенно предпочтительном варианте осуществления настоящего изобретения дополнительный 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR гена альбумина, предпочтительно гена альбумина позвоночных, более предпочтительно гена альбумина млекопитающих, наиболее предпочтительно ген альбумина человека в соответствии с SEQ ID NO: 31:
SEQ ID NO: 31:

(3'-UTR альбумина человека; соответствует SEQ ID NO: 1369 патентной заявки WO 2013/143700)
В этом контексте особенно предпочтительно, чтобы молекула нуклеиновой кислоты по настоящему изобретению содержала дополнительно элемент 3'-UTR, производный от нуклеиновых кислот, соответствующих последовательностям SEQ ID N 1369-1390 из патентной заявки WO 2013/143700, или их фрагментам, гомологам или его вариантам.
Наиболее предпочтительно дополнительный 3'-UTR содержит последовательность нуклеиновой кислоты, производную от фрагмента гена альбумина человека, соответствующего SEQ ID NO: 32:
SEQ ID NO: 32:

В этом контексте особенно предпочтительно, чтобы дополнительная 3'-UTR молекулы искусственной нуклеиновой кислоты по настоящему изобретению содержал или состоял из последовательности нуклеиновой кислоты в соответствии с SEQ ID NO: 32, или соответствующей последовательности РНК.
Дополнительная область 3'-UTR может также содержать или состоять из последовательности нуклеиновой кислоты, производной от гена, кодирующего рибосомальный белок, причем гены, кодирующие рибосомный белок, от которых может быть получена дополнительная 3'-UTR, включают, но ими не ограничиваются, рибосомальный белок L9 (RPL9), рибосомальный белок L3 (RPL3), рибосомальный белок L4 (RPL4), рибосомальный белок L5 (RPL5), рибосомальный белок L6 (RPL6), рибосомальный белок L7 (RPL7), рибосомальный белок L7a (RPL7A), рибосомальный белок L11 (RPL11), рибосомальный белок L12 (RPL12), рибосомальный белок L13 (RPL13), рибосомальный белок L23 (RPL23), рибосомальный белок L18 (RPL18), рибосомальный белок L18a (RPL18A), рибосомальный белок L19 (RPL19), рибосомальный белок L21 (RPL21), рибосомальный белок L22 (RPL22), рибосомальный белок L23a (RPL23A), рибосомальный белок L17 (RPL17), рибосомальный белок L24 (RPL24), рибосомальный белок L26 (RPL26), рибосомальный белок L27 (RPL27), рибосомальный белок L30 (RPL30), рибосомальный белок L27a (RPL27A), рибосомальный белок L28 (RPL28), рибосомальный белок L29 (RPL29), рибосомальный белок L31 (RPL31), рибосомальный белок L32 (RPL32), рибосомальный белок L35a (RPL35A), рибосомальный белок L37 (RPL37), рибосомальный белок L37a (RPL37A), рибосомальный белок L38 (RPL38), рибосомальный белок L39 (RPL39), рибосомный белок, большой, Р0 (RPLP0), рибосомальный белок, большой, Р1 (RPLP1), рибосомальный белок, большой, Р2 (RPLP2), рибосомальный белок S3 (RPS3), рибосомальный белок S3A (RPS3A), рибосомальный белок S4, X-связанный (RPS4X), рибосомальный белок S4, Y-linked 1 (RPS4Y1), ribosomal protein S5 (RPS5), ribosomal protein S6 (RPS6), рибосомальный белок S7 (RPS7), рибосомальный белок S8 (RPS8), рибосомальный белок S9 (RPS9), рибосомальный белок S10 (RPS10), рибосомальный белок S11 (RPS11), рибосомальный белок S12 (RPS12), рибосомальный белок S13 (RPS13), рибосомальный белок S15 (RPS15), рибосомальный белок S15a (RPS15A), рибосомальный белок S16 (RPS16), рибосомальный белок S19 (RPS19), рибосомальный белок S20 (RPS20), рибосомальный белок S21 (RPS21), рибосомальный белок S23 (RPS23), рибосомальный белок S25 (RPS25), рибосомальный белок S26 (RPS26), рибосомальный белок S27 (RPS27), рибосомальный белок S27a (RPS27a), рибосомальный белок S28 (RPS28), рибосомальный белок S29 (RPS29), рибосомальный белок L15 (RPL15), рибосомальный белок S2 (RPS2), рибосомальный белок L14 (RPL14), рибосомальный белок S14 (RPS14), рибосомальный белок L10 (RPL10), рибосомальный белок L10a (RPL10A), рибосомальный белок L35 (RPL35), рибосомальный белок L13a (RPL13A), рибосомальный белок L36 (RPL36), рибосомальный белок L36a (RPL36A), рибосомальный белок L41 (RPL41), рибосомальный белок S18 (RPS18), рибосомальный белок S24 (RPS24), рибосомальный белок L8 (RPL8), рибосомальный белок L34 (RPL34), рибосомальный белок S17 (RPS17), рибосомальный белок SA (RPSA), убиквитин А-52 остаточный рибосомальный белок гибридный продукт 1 (ген UBA52), Вирус саркомы мышей Finkel-Biskis-Reilly (FBR-MuSV) повсеместно экспрессируемый (FAU), рибосомальный белок L22-like 1 (RPL22L1), рибосомальный белок S17 (RPS17), рибосомальный белок L39-like (RPL39L), рибосомальный белок L10-like (RPL10L), рибосомальный белок L36a-like (RPL36AL), рибосомальный белок L3-like (RPL3L), рибосомальный белок S27-like (RPS27L), рибосомальный белок L26-like 1 (RPL26L1), рибосомальный белок L7-like 1 (RPL7L1), рибосомальный белок L13a псевдогена (RPL13AP), рибосомальный белок L37a псевдогена 8 (RPL37AP8), рибосомальный белок S10 псевдогена 5 (RPS10P5), рибосомальный белок S26 псевдогена 11 (RPS26P11), рибосомальный белок L39 псевдогена 5 (RPL39P5), рибосомальный белок, крупный, РО псевдогена 6 (RPLP0P6) и рибосомальный белок L36 псевдогена 14 (RPL36P14).
Предпочтительно, дополнительная 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR гена ТОР или которая получена из фрагмента, гомолога или варианта 5'-UTR гена ТОР.
Особенно предпочтительно, чтобы элемент 5'-UTR не содержал ТОР-мотив или 5'ТОР согласно описанному выше. В частности, предпочтительно, чтобы 5'-UTR гена ТОР представлял 5'-UTR гена ТОР, не обладающего ТОР-мотивом.
Последовательность нуклеиновой кислоты, которая является производной 5'-UTR гена ТОР эукариот, предпочтительно гена ТОР животного или животного, более предпочтительно гена ТОР хордовых, еще более предпочтительно гена ТОР позвоночных, наиболее предпочтительно ген ТОР млекопитающих, например, ген ТОР человека.
Например, дополнительный 5'-UTR предпочтительно выбирают из элементов 5'-UTR, содержащих или состоящих из последовательности нуклеиновой кислоты, которая получена из последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 из патентной заявки WO 2013/143700, сущность которой включена в настоящее изобретение в виде ссылки, из гомологов SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 из патентной заявки WO 2013/143700, из ее варианта или предпочтительно из соответствующей последовательности РНК. Понятие «гомологи SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 из патентной заявки WO 2013/143700» относится к последовательностям других видов, помимо Homo sapiens, которые гомологичны последовательностям SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 из патентной заявки WO 2013/143700.
В предпочтительном варианте осуществления настоящего изобретения дополнительная 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая является производной от последовательности нуклеиновой кислоты, расположенной от нуклеотида в положении 5 (т.е. нуклеотида, который находится в положении 5 в последовательности) до положения нуклеотида сразу после 5' к стартовому кодону (расположенному на 3'-конце последовательностей), например, положение нуклеотида сразу после 5' к последовательности ATG, последовательности нуклеиновой кислоты, выбранной из SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 из патентной заявки WO 2013/143700, из гомологов SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 из патентной заявки WO 2013/143700, из ее варианта или соответствующей последовательности РНК. Особенно предпочтительно, что дополнительная 5'-UTR является производной от последовательности нуклеиновой кислоты, расположенной от нуклеотида в положении сразу от 3' к 5'ТОР до положения нуклеотида сразу от 5' до стартового кодона (расположенного на 3'-конце последовательности), например, в положении нуклеотида сразу 5' к последовательности ATG, последовательности нуклеиновой кислоты, выбранной из SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 из патентной заявки WO 2013/143700, от гомологов SEQ ID NO: 1-1363, SEQ ID NO: 1395, SEQ ID NO: 1421 и SEQ ID NO: 1422 патентной заявки WO 2013/143700, от ее варианта или соответствующей последовательности РНК.
В особенно предпочтительном варианте осуществления настоящего изобретения дополнительный 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR гена ТОР, кодирующего рибосомальный белок, или от варианта 5'-UTR гена ТОР, кодирующего рибосомальный белок. Например, 5'-UTR-элемент содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR последовательности нуклеиновой кислоты в соответствии с какой-либо из последовательностей SEQ ID NO: 170, 232, 244, 259, 1284, 1285, 1286, 1287, 1288, 1289, 1290, 1291, 1292, 1293, 1294, 1295, 1296, 1297, 1298, 1299, 1300, 1301, 1302, 1303, 1304, 1305, 1306, 1307, 1308, 1309, 1310, 1311, 1312, 1313, 1314, 1315, 1316, 1317, 1318, 1319, 1320, 1321, 1322, 1323, 1324, 1325, 1326, 1327, 1328, 1329, 1330, 1331, 1332, 1333, 1334, 1335, 1336, 1337, 1338, 1339, 1340, 1341, 1342, 1343, 1344, 1346, 1347, 1348, 1349, 1350, 1351, 1352, 1353, 1354, 1355, 1356, 1357, 1358, 1359 или 1360 из патентной заявки WO 2013/143700, от соответствующей последовательности РНК, ее гомолога или варианта согласно описанию настоящего изобретения предпочтительно без 5'-ТОР-мотива. Согласно описанному выше последовательность, простирающаяся от положения 5 до нуклеотида, непосредственно после 5' к ATG (который расположен в 3'-конце последовательностей), соответствует 5'-UTR указанных последовательностей.
Предпочтительно дополнительная 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR гена ТОР, кодирующего рибосомальный большой белок (RPL) или от гомолога или варианта 5'-UTR гена ТОР, кодирующего рибосомальный большой белок (RPL). Например, S'-UTR-элемент содержит или состоит из последовательности нуклеиновой кислоты, которая получена из 5'-UTR последовательности нуклеиновой кислоты в соответствии с какой-либо из SEQ ID NO: SEQ ID NO: 67, 259, 1284-1318, 1344, 1346, 1348-1354, 1357, 1358, 1421 и 1422 из патентной заявки WO 2013/143700, соответствующей последовательности РНК, ее гомолога или варианта согласно описанию настоящего изобретения, предпочтительно без 5'ТОР-мотива.
В особенно предпочтительном варианте осуществления настоящего изобретения элемент 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая производна от 5'-UTR гена рибосомного белка большого 32, предпочтительно от гена рибосомального белка большого 32 (L32) позвоночных, более предпочтительно от гена большого 32 (L32) белка рибосомного млекопитающих, наиболее предпочтительно от гена большого 32 (L32) белка рибосомы человека, или от варианта 5'-UTR гена рибосомального белка большого 32, предпочтительно от гена рибосомального белка большого 32 (L32) позвоночного, более предпочтительно от гена рибосомного белка большого 32 (L32) млекопитающего, наиболее предпочтительно от гена рибосомального белка большого 32 (L32) человека, причем также предпочтительно, что 5'-UTR не содержит 5'ТОР указанного гена.
Соответственно, в особенно предпочтительном варианте осуществления настоящего изобретения дополнительный 5'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая идентична по меньшей мере приблизительно на 40%, предпочтительно по меньшей мере приблизительно на 50%, предпочтительно по меньшей мере приблизительно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно, по меньшей мере примерно на 99% последовательности нуклеиновой кислоты в соответствии с SEQ ID NO: 33 (5'-UTR рибосомального белка большого 32 человека, не имеющего 5'-концевого олигопиримидинового тракта:

соответствующего SEQ ID NO: 1368 в патентной заявке WO 2013/143700) или предпочтительно соответствующего последовательности РНК, или где дополнительно 5'-UTR содержит или состоит из фрагмента последовательности нуклеиновой кислоты, которая по меньшей мере примерно на 40%, предпочтительно от по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно, по меньшей мере, примерно на 95% более предпочтительно по меньшей мере примерно на 99% к последовательности нуклеиновой кислоты в соответствии с SEQ ID NO: 33 или более предпочтительно к соответствующей последовательности РНК, причем предпочтительно фрагмент является описанным выше, то есть является непрерывным отрезком нуклеотидов, представляющим по меньшей мере 20% и т.д. 5'-UTR полной длины. Предпочтительно длина фрагмента составляет по меньшей мере примерно 20 нуклеотидов или более, предпочтительно по меньшей мере около 30 нуклеотидов или более, более предпочтительно по меньшей мере примерно 40 нуклеотидов или более. Предпочтительно, фрагмент является функциональным фрагментом, описанным в настоящем изобретении.
В некоторых вариантах осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты включает дополнительную область 5'-UTR, которая включает или состоит из последовательности нуклеиновой кислоты, полученной из 5'-UTR гена ТОР позвоночных, например, гена млекопитающего, например, гена ТОР человека, выбранного из RPSA, RPS2, RPS3, RPS3A, RPS4, RPS5, RPS6, RPS7, RPS8, RPS9, RPS10, RPS11, RPS12, RPS13, RPS14, RPS15, RPS15A, RPS16, RPS17, RPS18, RPS19, RPS20, RPS21, RPS23, RPS24, RPS25, RPS26, RPS27, RPS27A, RPS28, RPS29, RPS30, RPL3, RPL4, RPL5, RPL6, RPL7, RPL7A, RPL8, RPL9, RPL10, RPL10A, RPL11, RPL12, RPL13, RPL13A, RPL14, RPL15, RPL17, RPL18, RPL18A, RPL19, RPL21, RPL22, RPL23, RPL23A, RPL24, RPL26, RPL27, RPL27A, RPL28, RPL29, RPL30, RPL31, RPL32, RPL34, RPL35, RPL35A, RPL36, RPL36A, RPL37, RPL37A, RPL38, RPL39, RPL40, RPL41, RPLP0, RPLP1, RPLP2, RPLP3, RPLP0, RPLP1, RPLP2, EEF1A1, EEF1B2, EEF1D, EEF1G, EEF2, EIF3E, EIF3F, EIF3H, EIF2S3, EIF3C, EIF3K, EIF3EIP, EIF4A2, PABPC1, HNRNPA1, TPT1, TUBB1, UBA52, NPM1, ATP5G2, GNB2L1, NME2, UQCRB или из их гомологов или вариантов, причем предпочтительная 5'-UTR не содержит ТОР-мотива или 5'ТОР указанных генов, и необязательно дополнительная 5'-UTR начинается с 5'-конца с нуклеотида, расположенного в положении 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 вниз по цепи 5'-концевого олигопиримидинового тракта (ТОР), а также необязательно дополнительно область 5'-UTR, производная от 5'-UTR гена ТОР, заканчивается на 3'-конце нуклеотидом, расположенным в положениях 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 вверх по цепи от стартового кодона (A(U/T)G) гена, производным которого он является.
Искусственная молекула нуклеиновой кислоты в соответствии с настоящим изобретением может представлять РНК, например, мРНК или вирусную РНК или репликон, ДНК, например, плазмидную ДНК или вирусную ДНК, или может быть модифицированную молекулу РНК или ДНК. Она может быть предусмотрена в виде двухцепочечной молекулы, имеющей смысловую цепь и антисмысловую цепь, например, в виде молекулы ДНК, имеющей смысловую цепь и антисмысловую цепь.
Молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может дополнительно содержать необязательно 5'-кэп. Необязательный 5'-кэп предпочтительно локализован в положении 5' к ORF, более предпочтительно 5' по меньшей мере к одной 5'-UTR или к какой-либо дополнительной 5'-UTR внутри молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением.
Предпочтительно, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением дополнительно содержит поли(А) последовательность и/или сигнал полиаденилирования. Предпочтительно, чтобы необязательная поли(А) последовательность локализована с 3'-конца по меньшей мере одного элемента 3'-UTR или какой-либо дополнительной 3'-UTR, более предпочтительно необязательная полу(А) последовательность соединена с 3'-концом элемента 3'-UTR. Соединение может быть прямым или опосредованным, например, через отрезок из 2, 4, 6, 8, 10, 20 и т.д. нуклеотидов, например, с помощью линкера из 1-50, предпочтительно из 1-20 нуклеотидов, например, содержащих или состоящих из одного или нескольких сайтов рестрикции. Однако даже если молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не содержит 3'-UTR, например, если она содержит только по меньшей мере один элемент 5'-UTR, то она предпочтительно все еще содержит поли(А) последовательность и/или сигнал полиаденилирования.
В одном варианте осуществления необязательный сигнал полиаденилирования расположен ниже по цепи от 3'-конца элемента 3'-UTR. Предпочтительно, сигнал полиаденилирования содержит консенсусную последовательность NN(U/T)ANA, с N=А или U, предпочтительно AA(U/T)AAA или A(U/T)(U/T)AAA. Такая консенсусная последовательность может быть распознана большинством животных и бактериальных клеточных систем, например, факторами полиаденилирования, например, специфическим фактором расщепления/полиаденилирования (CPSF), взаимодействующего с CstF, PAP, РАВ2, CFI и/или CFII. Предпочтительно, сигнал полиаденилирования, предпочтительно консенсусная последовательность NNUANA, расположен менее чем примерно в 50 нуклеотидах, более предпочтительно менее чем примерно в 30 основаниях, наиболее предпочтительно менее чем примерно в 25 основаниях, например, на 21 основании ниже по цепи от 3'-конца 3'-UTR или ORF, если нет элемента 3'-UTR.
Транскрипция молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, молекула искусственной ДНК, содержащая сигнал полиаденилирования ниже по цепи от элемента 3'-UTR (или от ORF), приводит к незрелой РНК, содержащей сигнал полиаденилирования ниже по цепи от элемента 3'-UTR (или ORF).
Использование соответствующей системы транскрипции приводит к присоединению последовательности поли(А) к незрелой РНК. Например, молекула искусственной нуклеиновой кислоты по настоящему изобретению может быть молекулой ДНК, содержащей элемент 3'-UTR согласно описанному выше и сигнал полиаденилирования, что может приводить к полиаденилированию РНК после транскрипции соответствующей молекулы ДНК. Соответственно, получаемая РНК может содержать комбинацию элемента 3'-UTR по настоящему изобретению, за которым следует последовательность поли(А).
Потенциальными системами транскрипции являются системы транскрипции in vitro или клеточные системы транскрипции и др. Соответственно, транскрипция молекулы искусственной нуклеиновой кислоты по настоящему изобретению, например, транскрипция молекулы искусственной нуклеиновой кислоты, содержащей открытую рамку считывания, элемент 3'-UTR и/или элемент 5'-UTR и, необязательно, сигнал полиаденилирования, может приводить к тому, что молекула мРНК содержит открытую рамку считывания, элемент 3'-UTR и, необязательно, последовательность поли(А).
Соответственно, настоящее изобретение также предусматривает молекулу искусственной нуклеиновой кислоты, которая представляет молекулу мРНК, содержащую открытую рамку считывания, элемент 3'-UTR по настоящему изобретению, и/или элемент 5'-UTR согласно описанному выше и необязательно последовательность поли(А).
В другом варианте осуществления 3'-UTR молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением не содержит сигнала полиаденилирования или последовательности поли(А). Кроме того, предпочтительно, чтобы молекула искусственной нуклеиновой кислоты по настоящему изобретению не содержала сигнала полиаденилирования или последовательности поли(А). Более предпочтительно, 3'-UTR молекулы искусственной нуклеиновой кислоты или сама молекула искусственной нуклеиновой кислоты по настоящему изобретению не содержит сигнала полиаденилирования, в частности, не содержит сигнала полиаденилирования AAU/TAAA.
В предпочтительном варианте осуществления настоящего изобретения предусматривают молекулу искусственной нуклеиновой кислоты, которая представляет молекулу искусственной РНК, содержащую открытую рамку считывания и последовательность РНК, соответствующую последовательности ДНК, выбранной из группы, состоящей из последовательностей SEQ ID NO: 1-30, предпочтительно из группы, состоящей из последовательностей SEQ ID NO: 1, SEQ ID NO: 5, SEQ ID NO: 8, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 17, SEQ ID NO: 20, SEQ ID NO: 25 и SEQ ID NO: 28, или последовательностей, которые по меньшей мере примерно на 40% или более идентичны последовательностям SEQ ID NO: 1-30, предпочтительно SEQ ID NO: 1, SEQ ID NO: 5, SEQ ID NO: 8, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 17, SEQ ID NO: 20, SEQ ID NO: 25 и SEQ ID NO: 28 или их фрагментам согласно описанному выше. Кроме того, также предусматривают соответствующие искусственные молекулы ДНК.
В другом предпочтительном варианте осуществления настоящее изобретение относится к молекуле искусственной нуклеиновой кислоты, которая представляет молекулу искусственной ДНК, содержащую открытую рамку считывания и последовательность, выбранную из группы, состоящей из последовательностей SEQ ID NO: 1-30, предпочтительно из группы, состоящей из последовательностей SEQ ID NO: 1, SEQ ID NO: 5, SEQ ID NO: 8, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 17, SEQ ID NO: 20, SEQ ID NO: 25 и SEQ ID NO: 28, или последовательностей, которые идентичны по меньшей мере примерно на 40% или более последовательностям SEQ ID NO: 1-30, предпочтительно последовательностям SEQ ID NO: 1, SEQ ID NO: 5, SEQ ID NO: 8, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 17, SEQ ID NO: 20, SEQ ID NO: 25 и SEQ ID NO: 28.
Настоящее изобретение также предусматривает молекулу искусственной нуклеиновой кислоты, которая может служить матрицей для молекулы РНК, предпочтительно для молекулы мРНК, которая стабилизируется и оптимизируется для эффективности трансляции. Иначе говоря, молекула искусственной нуклеиновой кислоты может быть ДНК, которую можно использовать в качестве матрицы для выработки мРНК. С получаемой мРНК, в свою очередь, можно транслировать требуемый пептид или белок, кодируемый открытой рамкой считывания. Если молекула искусственной нуклеиновой кислоты является ДНК, ее можно, например, применять в качестве двухцепочечной формы хранения для продолжения и повторения получения мРНК in vitro или in vivo. Таким образом, понятие «in vitro» относится, в частности, к («живым») клеткам и/или тканям, включая ткань живого субъекта. Клетки включают, в частности, линии клеток, первичные клетки, клетки в ткани или в субъектах. В некоторых вариантах осуществления настоящего изобретения типы клеток могут быть применимы в рамках настоящего изобретения. Особенно предпочтительными являются клетки млекопитающих, например, клетки человека и клетки мыши. В особенно предпочтительных вариантах осуществления настоящего изобретения используют линии клеток человека HeLa и U-937 и линии клеток мыши NIH3T3, JAWSII и L929. Кроме того, первичные клетки являются особенно предпочтительными, в частности предпочтительными вариантами осуществления могут быть использованы дермальные фибробласты человека человеческие дермальные фибробласты (human dermal fibroblasts - HDF). В другом варианте также можно использоваться ткань субъекта.
В одном из вариантов осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением дополнительно содержит последовательность поли(А). Например, молекула ДНК, содержащая ORF, необязательно сопровождаемую 3'-UTR, может содержать участок тимидиновых нуклеотидов, который может быть транскрибирован в последовательность поли(А) в формируемой мРНК. Длина последовательности poly(A) может изменяться. Например, последовательность поли(А) может состоять в длину примерно от 20 адениновых нуклеотидов до примерно 300 адениновых нуклеотидов, предпочтительно примерно от 40 до примерно 200 адениновых нуклеотидов, более предпочтительно примерно от 50 до примерно 100 адениновых нуклеотидов, например, примерно из 60, 70, 80, 90 или 100 адениновых нуклеотидов. Наиболее предпочтительно нуклеиновая кислота по настоящему изобретению содержит последовательность поли(А), состоящую примерно из 60-70 нуклеотидов, наиболее предпочтительно из 64 адениновых нуклеотидов.
Искусственные молекулы РНК также могут быть получены in vitro обычными методами химического синтеза, не требующими транскрипции с родительской ДНК.
В особенно предпочтительном варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением представляет молекулу РНК, предпочтительно молекулу мРНК, содержащую в направлении от 5' к 3' открытую рамку считывания, элемент 3'-UTR согласно описанному выше и последовательность поли(А), или содержащую в направлении от 5' к 3' элемент 5'-UTR согласно описанному выше открытую рамку считывания и последовательность поли(А).
В предпочтительном варианте осуществления настоящего изобретения открытая рамка считывания является производной гена, который отличен от гена, от которого является производным элемент 3'-UTR и/или элемент 5'-UTR искусственной нуклеиновой кислоты по настоящему изобретению. В некоторых других предпочтительных вариантах осуществления настоящего изобретения открытая рамка считывания не кодирует гена, выбранного из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глутатион-S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), Ybx1 (Y-Box-связывающий белок 1), Ndufb8 (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8), CNTN1 (контактин 1), предпочтительно CNTN1-004 или его варианты, при условии, что элемент 3'-UTR и/или элемент 5'-UTR является последовательность, выбранной из группы, состоящей из последовательностей от SEQ ID NO: 1 до SEQ ID NO: 30.
В предпочтительном варианте осуществления ORF не кодирует рибосомальные белки человека или растения, в частности Arabidopsis, в частности не кодирует рибосомальный белок человека S6 (RPS6), рибосомальный белок человека L36a-подобный (RPL36AL) или рибосомальный белок S16 (RPS16) Arabidopsis. В другом предпочтительном варианте осуществления настоящего изобретения открытая рамка считывания (ORF) не кодирует рибосомальный белок S6 (RPS6), рибосомальный белок L36a-подобный (RPL36AL) или рибосомальный белок S16 (RPS16) независимо от его происхождения.
В одном из вариантов осуществления настоящего изобретения предусматривают искусственную молекулу ДНК, содержащую открытую рамку считывания, предпочтительно открытую рамку считывания, производную от гена, который отличается от гена, от которого получен элемент 3'-UTR и/или элемент 5'-UTR выводится; элемент 3'-UTR, содержащий или состоящий из последовательности, которая по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере на 99%, еще более предпочтительно на 100% идентична последовательности ДНК, выбранной из группы, состоящей из последовательностей SEQ ID NO: 1-24, и/или элемент 5'-UTR, содержащий или состоящий из последовательности, которая по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере на 99%, еще более предпочтительно на 100% идентична последовательности ДНК, выбранной из группы, состоящей из последовательностей SEQ ID NO: 25-30; и сигнал полиаденилирования и/или последовательность поли(А).
В другом варианте осуществления настоящего изобретения предусматривают композицию, содержащую множество молекул РНК по настоящему изобретению в фармацевтически приемлемом носителе, причем по меньшей мере примерно 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или более РНК в композиции содержит последовательность поли(А), которая отличается по длине не более чем на 10 нуклеотидов. В предпочтительном варианте осуществления настоящего изобретения по меньшей мере примерно 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или более РНК в композиции содержат последовательность поли(А) одинаковой длины. В некоторых вариантах осуществления настоящего изобретения последовательность поли(А) расположена на 3'-конце РНК, причем никакие другие нуклеотиды не располагаются с 3'-конца относительно последовательности поли(А). В еще одном варианте осуществления настоящего изобретения предусматривают композицию, содержащую множество молекул РНК согласно описанию настоящего изобретения в фармацевтически приемлемом носителе, где указанное множество молекул РНК содержит как кэпированные, так и некэпированные РНК. Например, в некоторых аспектах композиция содержит множество молекул РНК, в которых не более 95%, 90%, 80%, 70% или 60% молекул РНК содержат кэп, а оставшиеся молекулы РНК являются некэпированными.
В настоящем изобретении также предусматривают молекулу искусственной РНК, предпочтительно молекулу искусственной молекулы мРНК или молекулу искусственной вирусной РНК, содержащую открытую рамку считывания, предпочтительно открытую рамку считывания, производную гена, который отличается от гена, от которого происходит элемент 3'-UTR и/или элемент 5'-UTR, элемент 3'-UTR, содержащий или состоящий из последовательности, которая по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере на 99%, еще более предпочтительно на 100% идентична последовательности РНК, соответствующей последовательности ДНК, выбранной из группы, состоящей из последовательностей SEQ ID NO: 1-24, и/или элемент 5'-UTR, содержащий или состоящий из последовательности, которая по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере на 99%, еще более предпочтительно на 100% идентична последовательности РНК, соответствующей последовательности ДНК, выбранной из группы, состоящей из последовательностей SEQ ID NO: 25-30; и сигнал полиаденилирования и/или последовательность поли(А).
Настоящее изобретение также предусматривает молекулу искусственной нуклеиновой кислоты, предпочтительно искусственную мРНК, которая может отличаться повышенной и/или более длительной экспрессией закодированного пептида или белка. Предположительно, повышенная стабильность экспрессии белка и, следовательно, более длительная экспрессия белка могут быть результатом уменьшения разрушения молекулы искусственной нуклеиновой кислоты, например, молекулы искусственной мРНК в соответствии с настоящим изобретением. Соответственно, элемент 3'-UTR по настоящему изобретению и/или элемент 5'-UTR по настоящему изобретению могут препятствовать разрушению искусственной нуклеиновой кислоты.
Предпочтительно, молекула искусственной нуклеиновой кислоты может дополнительно содержать гистонную структуру стебель-петля. Таким образом, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может, например, содержать в направлении от 5'-к-3' ORF, элемент 3'-UTR, необязательно последовательность гистонной структуры стебель-петля, необязательно последовательность поли(А) или сигнал полиаденилирования и необязательно последовательность поли(С), или в направлении от 5' к 3' элемент 5'-UTR, ORF, необязательно последовательность гистонной структуры стебель-петля, необязательно последовательность поли(А) или сигнал полиаденилирования и необязательно последовательность поли(С), или в направлении 5'-к-3' элемент 5'-UTR, ORF, элемент 3'-UTR, необязательно последовательность гистонной структуры стебель-петля, необязательно последовательность поли(А) или сигнал полиаденилирования и необязательно последовательность поли(С). Она также может содержать в направлении 5'-к-3' ORF, элемент 3'-UTR, необязательно последовательность поли(А), необязательно последовательность поли(С) и необязательно последовательность гистонной структуры стебель-петля или в направлении 5'-к-3' элемент 5'-UTR, ORF, необязательно последовательность поли(А), необязательно последовательность поли(С) и необязательно последовательность гистонной структуры стебель-петля, или в направлении от 5'-к-3' элемент 5'-UTR, ORF, элемент 3'-UTR, необязательно последовательность поли(А), необязательно последовательность поли(С) и необязательно последовательность гистонной структуры стебель-петля.
В предпочтительном варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты по настоящему изобретению включает по меньшей мере одну последовательность гистонной структуры стебель-петля.
Такие последовательности гистонной структуры стебель-петля предпочтительно выбраны из последовательностей гистонной структуры стебель-петля, описанных в WO 2012/019780, сущность которой включена в настоящее изобретение в виде ссылки.
Последовательность гистонной структуры стебель-петля, пригодную для применения в рамках настоящего изобретения, предпочтительно выбирают по меньшей мере по одной из следующих формул (I) или (II):
формула (I) (последовательность структуры стебель-петля без ограничительных элементов в части стебля):

формула (II) (последовательность структуры стебель-петля с ограничительными элементами в части стебля):

где:
ограничительные элементы в части стебля 1 или стебля 2 N1-6 представляют последовательность, включающую от 1 до 6, предпочтительно от 2 до 6, более предпочтительно от 2 до 5, еще более предпочтительно от 3 до 5, наиболее предпочтительно от 4 до 5 или 5 N, где каждый N независимо от другого представляет нуклеотид, выбранный из нуклеотидов A, U, Т, G и С или их нуклеотидных аналогов;



где
стебель 1 и стебель 2 способны к спариванию оснований друг с другом, образуя обратно-комплементарную последовательность, в которой спаривание оснований может происходить между стеблем 1 и стеблем 2, например, путем спаривания оснований по Уотсону и Крику А и U/T или G и С или не путем спаривания оснований по Уотсону и Крику, например, путем спаривания оснований по Хугстину, путем обратного спаривания оснований по Хугстину, или путем спаривания оснований друг с другом, образуя частично обратную комплементарную последовательность, где может происходить неполное спаривание оснований между стеблем 1 и стеблем 2, на основе, заключающейся в том, что одно или несколько оснований в одном стебле не имеют комплементарного основания или оснований в обратной комплементарной последовательности другого стебля.
В соответствии с еще одним предпочтительным вариантом осуществления настоящего изобретения последовательность гистонной структуры стебель-петля может быть выбрана в соответствии, по меньшей мере, с одной из следующих формул (Ia) или (IIa):
формула (Ia) (последовательность структуры стебель-петля без ограничительных элементов в части стебля):
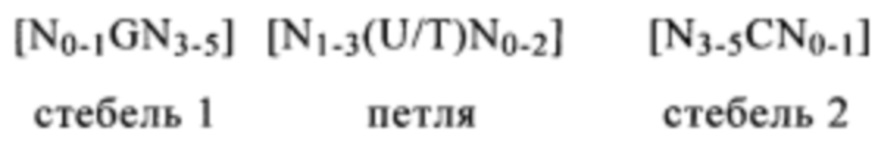
формула (IIa) (последовательность структуры стебель-петля с ограничительными элементами в части стебля):

где
значения N, С, G, Т и U те же, что и описанные выше.
В соответствии с еще более предпочтительным вариантом осуществления настоящего изобретения, касающегося первого объекта, молекула искусственной нуклеиновой кислоты может содержать, по меньшей мере, одну последовательность гистонной структуры стебель-петля в соответствии с одной из следующих формул (Iб) или (IIб):
формула (Iб) (последовательность структуры стебель-петля без ограничительных элементов в части стебля):

формула (IIб) (последовательность структуры стебель-петля с ограничительными элементами в части стебля):

где
значения N, С, G, Т и U такие же, как и описанные выше.
Определенная предпочтительная последовательность гистонной структуры стебель-петля является последовательностью SEQ ID NO: 34: CAAAGGCTCTTTTCAGAGCCACCA или, более предпочтительно, соответствующая последовательность РНК последовательности нуклеиновой кислоты в соответствии с SEQ ID NO: 34.
В качестве примера, отдельные элементы могут присутствовать в молекуле искусственной нуклеиновой кислоты в следующем порядке:
5'-кэп - 5'-UTR (элемент) - ORF - 3'-UTR (элемент) - гистонная структура стебель-петля - последовательность поли(А)/(С);
5'-кэп - 5'-UTR (элемент) - ORF - 3'-UTR (элемент) - последовательность поли(А)/(С) - гистонная структура стебель-петля;
5'-кэп - 5'-UTR (элемент) - ORF - IRES - ORF - 3'-UTR (элемент) - гистонная структура стебель-петля - последовательность поли(А)/(С);
5'-кэп - 5'-UTR (элемент) - ORF - IRES - ORF - 3'-UTR (элемент) - гистонная структура стебель-петля - последовательность поли(А)/(С) -последовательность поли(А)/(С);
5'-кэп - 5'-UTR (элемент) - ORF - IRES - ORF - 3'-UTR (элемент) - последовательность поли(А)/(С) - гистонная структура стебель-петля;
5'-кэп - 5'-UTR (элемент) - ORF - IRES - ORF - 3'-UTR (элемент) - последовательность поли(А)/(С) - последовательность поли(А)/(С) - гистонная структура стебель-петля;
5'-кэп - 5'-UTR (элемент) - ORF - 3'-UTR (элемент) - последовательность поли(А)/(С) - последовательность поли(А)/(С);
5'-кэп - 5'-UTR (элемент) - ORF - 3'-UTR (элемент) - последовательность поли(А)/(С) - последовательность поли(А)/(С) - гистонная структура стебель-петля; и др.
В некоторых вариантах осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты содержит дополнительные элементы, например, 5'-кэп, последовательность поли (С) и/или IRES-мотив. 5'-кэп может быть добавлен во время транскрипции или после транскрипции к 5'-концу РНК. Кроме того, молекула искусственной нуклеиновой кислоты по настоящему изобретению, в частности, если нуклеиновая кислота находится в форме мРНК или кодирует мРНК, может быть модифицирована последовательностью по меньшей мере из 10 цитидинов, предпочтительно по меньшей мере из 20 цитидинов, более предпочтительно по меньшей мере из 30 цитидинов (так называемая «последовательность поли (С)»). В частности, молекула искусственной нуклеиновой кислоты по изобретению может содержать, особенно если нуклеиновая кислота находится в форме (м)РНК или кодирует мРНК, последовательность поли (С) обычно составляет примерно от 10 до 200 цитидиновых нуклеотидов, предпочтительно примерно от 10 до 100 цитидиновых нуклеотидов, более предпочтительно примерно от 10 до 70 цитидиновых нуклеотидов или еще более предпочтительно от 20 до 50 или даже от 20 до 30 цитидиновых нуклеотидов. Наиболее предпочтительно нуклеиновая кислота по настоящему изобретению содержит последовательность поли(С) из 30 остатков цитидина. Таким образом, предпочтительно, если молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением содержит, предпочтительно, в направлении 5'-3' по меньшей мере один элемент 5'-UTR согласно описанному выше, ORF, по меньшей мере один элемент 3'-UTR согласно описанному выше, последовательность поли(А) или сигнал полиаденилирования, а также последовательность поли(С) или, в направлении 5'-3', необязательно дополнительно 5'-UTR, ORF, по меньшей мере один элемент 3'-UTR согласно описанному выше, последовательность поли(А) или сигнал полиаденилирования, а также последовательность поли(С) или, в направлении 5'-3' по меньшей мере один элемент 5'-UTR согласно описанному выше, ORF, необязательно дополнительно 3'-UTR, последовательность поли(А) или сигнал полиаденилирования и последовательность поли(С).
Участок внутренней посадки рибосомы (internal ribosome entry site - IRES) или IRES-мотив может отделять несколько открытых рамок считывания, например, если молекула искусственной нуклеиновой кислоты кодирует два или более пептидов или белков. IRES-последовательность может быть особенно полезна, если молекула искусственной нуклеиновой кислоты представляет собой молекулу двух- или полицистронной нуклеиновой кислоты.
Кроме того, молекула искусственной нуклеиновой кислоты может содержать дополнительные 5'-элементы, предпочтительно промотор или промотор-содержащую последовательность. Промотор может направлять и регулировать транскрипцию молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, молекулы искусственной ДНК согласно настоящему изобретению.
Предпочтительно молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, предпочтительно открытая рамка считывания, по меньшей мере частично была модифицирована по G/C. Таким образом, молекула искусственной нуклеиновой кислоты по настоящему изобретению может быть термодинамически стабилизирована путем модификации содержания G (гуанозина)/С (цитидина) в молекуле. Содержание G/C в открытой рамке считывания молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может быть увеличено по сравнению с содержанием G/C в открытой рамке считывания соответствующей последовательности дикого типа, предпочтительно путем использования вырожденности генетического кода. Таким образом, закодированную аминокислотную последовательность молекулы искусственной нуклеиновой кислоты предпочтительно не модифицируют путем изменения содержания G/C по сравнению с закодированной аминокислотной последовательностью определенной последовательности дикого типа. Кодоны кодирующей последовательности или целой молекулы искусственной нуклеиновой кислоты, например, мРНК, поэтому может варьироваться по сравнению с кодирующей последовательностью дикого типа, таким образом, что включают повышенное количество нуклеотидов G/C, хотя транслируемая аминокислотная последовательность остается неизменной. Из-за того, что несколько кодонов кодируют одну и ту же аминокислоту (так называемое вырождение генетического кода), возможно изменение кодонов без изменения кодируемой последовательности пептида/белка (так называемое использование альтернативных кодонов). Следовательно, можно специфически интродуцировать определенные кодоны (в обмен на соответствующие кодоны дикого типа, кодирующие одну и ту же аминокислоту), которые являются более благоприятными в плане стабильности РНК и/или в плане использования кодонов у субъекта (так называемая оптимизация кодонов).
В зависимости от аминокислоты, кодируемой кодирующей областью молекулы искусственной нуклеиновой кислоты по настоящему изобретению, существуют различные возможности для модификации последовательности нуклеиновой кислоты, например, открытой рамки считывания, по сравнению с областью кодирования дикого типа. В случае аминокислот, которые кодируются кодонами, содержащими исключительно нуклеотиды G или С, модификации кодона не требуется. Таким образом, кодоны для Pro (ССС или CCG), Arg (CGC или CGG), Ala (GCC или GCG) и Gly (GGC или GGG) не требуют модификации, поскольку они не содержат А или U/T.
Напротив, кодоны, которые содержат нуклеотиды А и/или U/T могут быть модифицированы путем замены других кодонов, которые кодируют одни и те же аминокислоты, но не содержат А и/или U/T. Например:
кодоны Pro СС(UT) или ССА могут быть заменены на ССС или CCG;
кодоны Arg CG(U/T), или CGA, или AGA, или AGG могут быть заменены на CGC или CGG;
кодоны Ala GC(U/T) или GCA могут быть заменены на GCC или GCG;
кодоны Gly GG(U/T) или GGA могут быть заменены на GGC или GGG.
В других случаях, хотя нуклеотиды А или (U/T) не могут быть элиминированы из кодонов, однако можно уменьшить содержание А и (U/T) с использованием кодонов, которые содержат меньше нуклеотидов А и/или (U/T). Примерами являются:
кодоны Phe (U/T)(U/T)(U/T) могут быть заменены на (U/T) (U/T)C;
кодоны Leu (U/T) (U/T)A, (U/T) (U/T)G, C(U/T) (U/T) или C(U/T)A могут быть заменены на C(U/T)C или C(U/T)G;
кодоны Ser (U/T)C(U/T), или (U/T)CA, или AG(U/T) могут быть заменены на (U/T)CC, (U/T)CG или AGC;
кодон Tyr (U/T)A(U/T) может быть заменен на (U/T)AC;
кодон Cys (U/T)G(U/T) может быть заменен на (U/T)GC;
кодон His CA(U/T) может быть заменен на САС;
кодон Gln САА может быть заменен на CAG;
кодоны Ile A(U/T)(U/T) или А(U/Т)А могут быть заменены на A(U/T)C;
кодоны Thr AC(U/T) или АСА могут быть заменены на АСС или ACG;
кодон Asn AA(U/T) может быть заменен на ААС;
кодон Lys AAA может быть заменен на AAG;
кодоны Val G(U/T)(U/T) или G(U/T)A могут быть заменены на G(U/T)C или G(U/T)G;
кодон Asp GA(U/T) может быть заменен на GAC;
кодон Glu GAA может быть заменен на GAG;
стоп-кодон (U/T)AA может быть заменен на (U/T)AG или (U/T)GA.
Для кодонов Met (A(U/T)G) и Trp ((U/T)GG) не существует возможности изменения последовательности нуклеотидов без изменения закодированной аминокислоты.
Замещения, перечисленные выше, можно использовать отдельно или во всех возможных комбинациях для увеличения содержания G/C в открытой рамке считывания молекулы искусственной нуклеиновой кислоты согласно описанному выше, по сравнению с соответствующей открытой рамкой считывания дикого типа (то есть исходной последовательностью). Так, например, все кодоны Thr, встречающиеся в последовательности дикого типа, могут быть модифицированы в АСС (или ACG).
Предпочтительно содержание G/C в открытой рамке считывания молекулы искусственной нуклеиновой кислоты по настоящему изобретению согласно описанному выше, увеличивается по меньшей мере на 7%, более предпочтительно по меньшей мере на 15%, особенно предпочтительно по меньшей мере на 20% по сравнению с G/C в кодирующей области дикого типа без изменения закодированной аминокислотной последовательности, то есть за счет использования вырожденности генетического кода В одном из вариантов осуществления настоящего изобретения, по меньшей мере, 5%, 10%, 20%, 30%, 40%, 50%, 60%, более предпочтительно по меньшей мере 70%, еще более предпочтительно по меньшей мере 80% и наиболее предпочтительно по меньшей мере 90%, 95% или даже 100% замещаемых кодонов в открытой рамке считывания молекулы искусственной нуклеиновой кислоты по настоящему изобретению или ее фрагмента, варианта или производного замещены, в результате чего содержание G/C в открытой рамке считывания увеличивается.
В этом контексте особенно предпочтительно увеличить содержание G/C в открытой рамке считывания молекулы искусственной нуклеиновой кислоты по настоящему изобретению до максимума (т.е. до 100% замещаемых кодонов) по сравнению с открытой рамкой считывания дикого типа без изменения закодированной аминокислотной последовательности.
Кроме того, открытая рамка считывания предпочтительно, по меньшей мере, частично оптимизирована по кодонам. Оптимизация по кодонам основана на том, что эффективность трансляции может быть определена путем другой частоты присутствия транспортной РНК (тРНК) в клетках. Таким образом, если так называемые «редкие кодоны» присутствуют в кодирующей области молекулы искусственной нуклеиновой кислоты по настоящему изобретению в большей степени, трансляция с соответствующей модифицированной последовательности нуклеиновой кислоты менее эффективна, чем в том случае, когда присутствуют кодоны, кодирующие относительно «частые» тРНК.
Таким образом, открытая рамка считывания молекулы искусственной нуклеиновой кислоты по настоящему изобретению предпочтительно модифицирована по сравнению с соответствующей кодирующей областью дикого типа таким образом, что по меньшей мере один кодон последовательности дикого типа, который соответствует тРНК, которая относительно редко встречается в клетке, обменивают на кодон, который соответствует тРНК, которая сравнительно часто встречается в клетке и несет ту же самую аминокислоту, что и относительно редкая тРНК. Благодаря такой модификации открытую рамку считывания молекулы искусственной нуклеиновой кислоты по настоящему изобретению модифицируют таким образом, что кодоны, для которых имеются часто встречающиеся тРНК, могут быть заменены кодонами, которые соответствуют редким тРНК. Другими словами, в соответствии с настоящим изобретением посредством такой модификации все кодоны открытой рамки считывания дикого типа, которые кодируют редкую тРНК, могут быть заменены на кодоны, которые соответствуют тРНК, которая чаще встречается в клетке и которая несет ту же аминокислоту, что и редко встречающаяся тРНК. Какие тРНК встречаются относительно часто в клетке и какие, напротив, встречаются относительно редко, известно специалистам в данной области (см., например, Akashi, Curr. Opin. Genet. Dev. 11(6), 2001, 660-666). Соответственно предпочтительно, чтобы открытая рамка считывания была оптимизирована по кодонам, предпочтительно в отношении системы, в которой молекула искусственной нуклеиновой кислоты согласно настоящему изобретению должна экспрессироваться, предпочтительно по отношению к системе, в которой молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением должна транслироваться. Предпочтительно использование кодонов в открытой рамке считывания оптимизируют по кодонам в соответствии с использованием кодонами млекопитающих, более предпочтительно в соответствии с кодонами человека. Предпочтительно, если открытая рамка считывания оптимизирована по кодонам и модифицирована по содержанию G/C.
Для дальнейшего повышения устойчивости к разрушению, например, устойчивости к разрушению in vivo (или in vitro, в соответствии с описанным выше) экзо- или эндонуклеазой, и/или для дальнейшего улучшения стабильности экспрессии белка с молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, молекула искусственной нуклеиновой кислоты может дополнительно содержать модификации, например, модификации сахара и/или модификации основания, например, модификации липидов или другие. Предпочтительно, транскрипция и/или трансляция молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением существенно не ухудшаются при осуществлении указанных модификаций.
Обычно, молекула искусственной нуклеиновой кислоты по настоящему изобретению может включать какой-либо нативный (природный) нуклеотид, например, гуанозин, урацил, аденозин и/или цитозин или их аналог. В этом отношении нуклеотидные аналоги рассматривают в качестве нативных и неприродных вариантов встречающихся в природе нуклеотидов аденозина, цитозина, тимидина, гуанозина и уридина. Соответственно, аналоги представляют собой, например, химически дериватизированные нуклеотиды с неприродными функциональными группами, которые предпочтительно добавляют или удаляют из природного нуклеотида, или которыми заменяют природные функциональные группы нуклеотида. Соответственно, каждый компонент природного нуклеотида может быть модифицирован, а именно компонент основания, компонент сахара (рибозы) и/или компонент фосфата, которые формируют каркас последовательности РНК (см. выше). Аналоги гуанозина, уридина, аденозина, тимидина и цитозина включают, без каких-либо ограничений, какие-либо изначально встречающиеся или не встречающиеся в природе гуанозин, уридин, аденозин, тимидин или цитозин, которые были изменены, например, химически, например, путем ацетилирования, метилирования, гидроксилирования и т.д.; к таким аналогам относятся 1-метиладенозин, 1-метилгуанозин, 1-метилинозин, 2,2-диметилгуанозин, 2,6-диаминопурин, 2'-амино-2'-дезоксиаденозин, 2'-амино-2'-дезоксицитидин, 2'-амино-2'-дезоксигуанозин, 2'-амино-2'-дезоксиуридин, 2-амино-6-хлорпуринрибозид, 2-аминопуринрибозид, 2'-арааденозин, 2'-арацитидин, 2'-арауридин, 2'-азидо-2'дезоксиаденозин, 2'-азидо-2'-дезоксицитидин, 2'-азидо-2'-дезоксигуанозин, 2'-азидо-2'-дезоксиуридин, 2-хлораденозин, 2'-фтор-2'-дезоксиаденозин, 2'-фтор-2'-дезоксицитидин, 2'-фтор-2'-дезоксигуанозин, 2'-фтор-2'-дезоксиуридин, 2'-фтортимидин, 2-метиладенозин, 2-метилгуанозин, 2-метилтио-N6-изопенениладенозин, 2'-O-метил-2-аминоаденозин, 2'-O-метил-2'-дезоксиаденозин, 2'-O-метил-2'-дезоксицитидин, 2'-O-метил-2'-дезоксигуанозин, 2'-O-метил-2'-дезоксиуридин, 2'-O-метил-5-метилуридин, 2'-О-метилинозин, 2'-О-метилпсевдоуридин, 2-тиоцитидин, 2-тиоцитозин, 3-мметилцитозин, 4-ацетилцитозин, 4-тиоуридин, 5-(карбоксигидроксиметил)урацил, 5,6-дигидроуридин, 5-аминоаллилцидин, 5-аминоаллилдезоксиуридин, 5-бромуридин, 5-карбоксиметиламинометил-2-тио-урацил, 5-карбоксиметиламинометилурацил, 5-хлор-ара-цитозин, 5-фтор-уридин, 5-иодуридин, 5-метоксикарбонилметил-уридин, 5-метокси-уридин, 5-метил-2-тиоуридин, 6-азацитидин, 6-азауридин, 6-Хлор-7-дезазагуанозин, 6-хлорпуринрибозид, 6-меркапто-гуанозин, 6-метилмеркаптопуринрибозид, 7-деаза-2'-дезоксигуанозин, 7-деазааденозин, 7-метилгуанозин, 8-азааденозин, 8-бромаденозин, 8-бромгуанозин, 8-меркаптогуанозин, 8-оксогуанозин, бензимидазолрибозид, бета-D-маннозил- квеозин, дигидроурацил, инозин, N1-метиладенозин, N6-([6-аминогексил] карбамоилметил)аденозин, N6-изопентенил-аденозин, N6-метил-аденозин, N7-метил-ксантозин, метиловый эфир N-урацил-5-оксиуксусной кислоты, пуромицин, квеозин, урацил-5-оксиуксусная кислота, метиловый эфир Урацил-5-оксиуксусной кислоты сложный эфир, вибутоксозин, ксантозин и ксилоаденозин. Получение таких аналогов известно специалисту в данной области, например, из патентов US 4373771, US 4401796, US 4415732, US 4458066, US 4500707, US 4668777, US 4976779, US 5047524, US 5131418, US 533319, US 5262530 и US 5700642. В случае описанных выше аналогов определенное предпочтение может быть отдано в соответствии с некоторыми вариантами осуществления настоящего изобретения тем аналогам, которые увеличивают экспрессию кодируемого белка или пептида, или которые увеличивают иммуногенность молекулы искусственной нуклеиновой кислоты по настоящему изобретению и/или не мешают дополнительной модификации молекулы искусственной нуклеиновой кислоты, которая была интродуцирована.
В соответствии с определенным вариантом осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты по настоящему изобретению может содержать липидную модификацию.
В предпочтительном варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты содержит, предпочтительно, в направлении от 5' к 3' следующие элементы:
элемент 5'-UTR, который продлевает и/или увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, предпочтительно с последовательности нуклеиновой кислоты какой-либо из последовательностей SEQ ID NO: 25-30 и SEQ ID NO: 319-338, более предпочтительно 5'-UTR МР68 или NDUFA4; или дополнительно 5'-UTR, предпочтительно 5'-ТОР UTR;
по меньшей мере одну открытую рамку считывания (ORF), причем ORF предпочтительно включает, по меньшей мере, одну модификацию относительно последовательности дикого типа;
элемент 3'-UTR, который продлевает и/или повышает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, предпочтительно с последовательности нуклеиновой кислоты какой-либо из SEQ ID NO: 1-24 и SEQ ID NO: 49-318, более предпочтительно 3'-UTR из GNAS, MORN2, GSTM1, NDUFA1, CBR2, YBX1, NDUFB8, или CNTN1; или дополнительно 3'-UTR, предпочтительно 3'-UTR albumin7;
последовательность поли(А), предпочтительно включающая 64 аденилата;
последовательность поли(С), предпочтительно включающая 30 цитидилатов;
последовательность гистонной структуры стебель-петля.
В другом предпочтительном варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты включает или состоит из нуклеотидной последовательности, выбранной из группы, состоящей из последовательностей нуклеиновой кислоты SEQ ID NO: 36-40, SEQ ID NO: 42 и 43, SEQ ID NO: 45-48 и SEQ ID NO: 384-388 (см. фиг. 2-6, фиг. 8, 9, 11, фиг. 19-21 и фиг. 26-30), или комплементарной последовательности ДНК.
В особенно предпочтительном варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты по настоящему изобретению может дополнительно включать одну или несколько модификаций, описанных ниже:
Химические модификации:
В контексте настоящего изобретения понятие «модификация», используемое в настоящем изобретении в отношении молекулы искусственной нуклеиновой кислоты, может относиться к химическим модификациям, включающим модификации каркаса молекулы, а также модификации сахара или модификации основания.
В этом контексте молекула искусственной нуклеиновой кислоты, предпочтительно молекула РНК по настоящему изобретению, может содержать нуклеотидные аналоги/модификации, например, модификации каркаса молекулы, модификации сахара или модификации основания. Модификация каркаса молекулы в связи с настоящим изобретением представляет модификацию, в которой фосфаты каркаса молекулы из нуклеотидов, содержащихся в молекуле нуклеиновой кислоты согласно описанному выше, являются химически модифицированными. Модификация сахара в связи с настоящим изобретением представляет собой химическую модификацию сахара нуклеотидов молекулы нуклеиновой кислоты согласно описанию настоящего изобретения. Кроме того, модификация оснований в связи с настоящим изобретением представляет химическую модификацию основной части из нуклеотидов молекулы нуклеиновой кислоты. В этом контексте нуклеотидные аналоги или модификации предпочтительно выбирают из нуклеотидных аналогов, которые применимы для транскрипции и/или трансляции.
Модификации сахаров
Модифицированные нуклеозиды и нуклеотиды, которые могут быть инкорорированы в молекулу искусственной нуклеиновой кислоты, предпочтительно РНК, согласно описанному в настоящем изобретении, могут быть модифицированы в части молекулы, представленной сахаром. Например, 2'-гидроксильная группа (ОН) молекулы РНК может быть модифицирована или замещена несколькими различными «окси» или «дезокси» заместителями. Примеры модификаций «окси»-2' гидроксильной группы включают, но ими перечень не ограничивается, алкокси или арилокси (-OR, например, R=Н, алкил, циклоалкил, арил, аралкил, гетероарил или сахар); полиэтиленгликоли (ПЭГ), -O(CH2CH2O)nCH2CH2OR; «закрытые» нуклеиновые кислоты («locked» nucleic acids - LNA), в которых 2'-гидроксил соединен, например, метиленовым мостиком с 4'-углеродом того же рибозного сахара; и аминогруппы (-О-амино, где аминогруппа, например, NRR, может представлять собой алкиламино, диалкиламино, гетероциклил, ариламино, диариламино, гетероариламино или дигетероарил амино, этилендиамин, полиамино) или аминоалкокси.
Модификации «дезокси» включают водород, амино (например, NH2, алкиламино, диалкиламино, гетероциклил, ариламино, диариламино, гетероариламино, дигетероарил амино или аминокислоту); или аминогруппа может быть присоединена к сахару через линкер, где линкер содержит один или несколько атомов С, N и О.
Группа сахара также может содержать один или несколько атомов углерода, которые имеют противоположную стереохимическую конфигурацию, чем конфигурация соответствующего углерода в рибозе. Таким образом, модифицированная молекула нуклеиновой кислоты может включать нуклеотиды, содержащие в качестве сахара, например, арабинозу.
Модификации каркаса молекул
Фосфатный каркас молекулы может быть дополнительно модифициран в модифицированных нуклеозидах и нуклеотидах, которые могут быть включены в молекулу искусственной нуклеиновой кислоты, предпочтительно в РНК согласно описанию настоящего изобретения. Фосфатные группы каркаса молекулы могут быть модифицированы путем замены одного или нескольких атомов кислорода на другой заместитель. Кроме того, модифицированные нуклеозиды и нуклеотиды могут включать полную замену немодифицированных фосфатных частей молекулы на модифицированные фосфаты согласно описанию настоящего изобретения. Примеры модифицированных фосфатных групп включают, но ими перечень не ограничивается, фосфоротиоат, фосфороселенаты, боранофосфаты, сложные эфиры боранофосфата, гидрогенфосфанаты, фосфороамидаты, алкил- или арилфосфонаты и фосфотриэфиры. Фосфородитиоаты имеют два несвязывающих кислорода, замещенных серой. Фосфатный линкер также может быть модифицирован заменой связующего кислорода азотом (связующие фосфороамидаты), серой (связующие фосфоротиоаты) и углеродом (связующие метиленфосфонаты).
Модификации оснований
Модифицированные нуклеозиды и нуклеотиды, которые могут быть инкорпорированы в молекулу искусственной нуклеиновой кислоты, предпочтительно молекулу РНК по описанию настоящего изобретения, могут быть дополнительно модифицированы в части нуклеиновых оснований. Примеры нуклеиновых оснований, обнаруженных в РНК, включают, но ими перечень не ограничивается, аденин, гуанин, цитозин и урацил. Например, нуклеозиды и нуклеотиды, описанные в настоящем изобретении, могут быть химически модифицированы на поверхности большой канавки. В некоторых вариантах осуществления настоящего изобретения химические модификации большой канавки могут включать аминогруппу, тиольную группу, алкильную группу или галогеновую группу.
В особенно предпочтительных вариантах осуществления настоящего изобретения нуклеотидные аналоги/модификации выбирают из модификаций оснований, которые предпочтительно выбирают из 2-амино-6-хлорпуринерибозид-5'-трифосфата, 2-аминопуринрибозид-5'-трифосфата, 2-аминоаденозин-5'-трифосфата, 2'-амино-2'-дезоксицитидинтрифосфата, 2-тиоцитидин-5'-трифосфата, 2-тиоуридин-5'-трифосфата, 2'-фтортимидин-5'-трифосфата, 2'-O-метилинозин-5'-трифосфата, 4-тиоуридин-5'-трифосфата, 5-аминоаллилцидин-5'-трифосфата, 5-аминоаллилуридин-5'трифосфата, 5-бромцитидин-5'-трифосфата, 5-бромуридин-5'-трифосфата, 5-бром-2'-дезоксицитидин-5'-трифосфата, 5-бром-2'-дезоксиуридин-5'-трифосфата, 5-иодцитидин-5'-трифосфата, 5-иод-2'-дезоксицитидин-5'-трифосфата, 5-йодоридин-5'-трифосфата, 5-йод-2'-дезоксиуридин-5'-трифосфата, 5-метилцитидин-5'-трифосфата, 5-метилуридин-5'-трифосфата, 5-пропинил-2'-дезоксицитидин-5'-трифосфата, 5-пропинил-2'-дезоксиуридин-5'-трифосфата, 6-азацитидин-5'-трифосфата, 6-азауридин-5'-трифосфата, 6-хлорпуринергибозид-5'-трифосфата, 7-деазаэденозин-5'-трифосфата, 7-дезагагуанозин-5'-трифосфата, 8-азааденозин-5'-трифосфата, 8-азидоаденозин-5'-трифосфата, бензимидазол-рибозид-5'-трифосфата, N1-метиладенозин-5'-трифосфата, N1-метилгуанозин-5'-трифосфата, N6-метиладенозин-5'-трифосфата, O6-метилгуанозин-5'-трифосфата, псевдоуридин-5'-трифосфат или пуромицин-5'-трифосфат, ксантозин-5'-трифосфат. Особое предпочтение отдают нуклеотидам с модифицированными основаниями, выбранными из группы нуклеотидов с модифицированными основаниями, состоящими из 5-метилцитидин-5'-трифосфата, 7-дезазагуанозин-5'-трифосфата, 5-бромцитидин-5'-трифосфата и псевдоуридин-5'-трифосфата.
В некоторых вариантах осуществления настоящего изобретения модифицированные нуклеозиды включают пиридин-4-он рибонуклеозид, 5-аза-уридин, 2-тио-5-аза-уридин, 2-тиоуридин, 4-тио-псевдоуридин, 2-тио-псевдоуридин, 5-гидроксиуридин, 3-метилуридин, 5-карбоксиметил-уридин, 1-карбоксиметил-псевдоуридин, 5-пропинил-уридин, 1-пропинил-псевдоуридин, 5-тауринометилуридин, 1-тауринометил-псевдоуридин, 5-тауринометил-2-тиоуридин, 1-тауринометил-4-тиоуридин, 5-метил-уридин, 1-метил-псевдоуридин, 4-тио-1-метил-псевдоуридин, 2-тио-1-метил-псевдуридин, 1-метил-1-деаза-псевдоуридин, 2-тио-1-метил-1-деаза-псевдоуридин, дигидроуридин, дигидропсевдоуридин, 2-тиодигидроуридин, 2-тиодигидропсудуридин, 2-метоксиуридин, 2-метокси-4-тиоуридин, 4-метокси-псевдуридин и 4-метокси-2-тио-псевдоуридин.
В некоторых вариантах осуществления настоящего изобретения модифицированные нуклеозиды включают 5-азацитидин, псевдоизоцитидин, 3-метилцитидин, N4-ацетилцитидин, 5-формилцитидин, N4-метилцитидин, 5-гидроксиметилцитидин, 1-метилпсевдоизоцитидин, пирролоцитидин, пирролопсевдоизоцитидин, 2-тиоцитидин, 2-тио-5-метилцитидин, 4-тио-псевдоизоцитидин, 4-тио-1-метил-псевдоизоцитидин, 4-тио-1-метил-1-деаза-псевдоизоцитидин, 1-метил-1-дезазапсевдоизоцитидин, зебуларин, 5-азазебуларин, 5-метил-зебуларин, 5-аза-2-тио-зебуларин, 2-тиозебуларин, 2-метоксицитидин, 2-метокси-5-метилцитидин, 4-метоксипсевдоизоцитидин и 4-метокси-1-метил-псевдоизоцитидин.
В других вариантах осуществления настоящего изобретения модифицированные нуклеозиды включают 2-аминопурин, 2,6-диаминопурин, 7-деазааденин, 7-дезаза-8-азааденин, 7-дезаза-2-аминопурин, 7-дезаза-8-аза-2-аминопурин, 7-дезаза-2,6-диаминопурин, 7-дезаза-8-аза-2,6-диаминопурин, 1-метиладенозин, N6-метиладенозин, N6-изопентениладенозин, N6-(цис-гидроксиизопентенил)аденозин, 2-метилтио-N6-(цисгидроксиизопентенил)аденозин, N6-глицинилкарбамоиладенозин, N6-треонилкарбамоиладенозин, 2-метилтио-N6-треонилкарбамоиладенозин, N6, N6-диметиладенозин, 7-метиладенин, 2-метилтиоаденин и 2-метоксиаденин.
В других вариантах осуществления настоящего изобретения модифицированные нуклеозиды включают инозин, 1-метилинозин, виозин, вибутозин, 7-дезазагуанозин, 7-дезаза-8-азагуанозин, 6-тиогуанозин, 6-тио-7-дезазагуанозин, 6-тио-7-дезаза-8-азагуанозин, 7-метилгуанозин, 6-тио-7-метилгуанозин, 7-метилинозин, 6-метоксигуанозин, 1-метилгуанозин, N2-метилгуанозин, N2,N2-диметилгуанозин, 8-оксогуанозин, 7-метил-8-оксогуанозин, 1-метил-6-тиогуанозин, N2-метил-6-тиогуанозин и N2,N2-диметил-6-тиогуанозин.
В некоторых вариантах осуществления настоящего изобретения нуклеотид может быть модифицирован на поверхности большой канавки и может включать замену водорода по С-5 урацила метильной группой или галогеновой группой.
В некоторых вариантах осуществления настоящего изобретения модифицированный нуклеозид представляет 5'-O-(1-тиофосфат)аденозин, 5'-O-(1-тифосфат)цитидин, 5'-O-(1-тифосфат)гуанозин, 5'-O-(1-тифосфат)уридин или 5'-O-(1-тиофосфат)псевдоуридин.
В других вариантах осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты, предпочтительно молекула РНК, может содержать модификации нуклеозидов, выбранные из 6-аза-цитидина, 2-тиоцитидина, альфа-тиоцитидина, псевдоизотицитидина, 5-аминоаллилуридина, 5-йодуриди, N1-метилпсевдоуридина, 5,6-дигидроуридина, альфа-тиоуридина, 4-тиоуридина, 6-азауридина, 5-гидроксиуридина, дезокситимидина, 5-метилуридина, пирролоцитидина, инозина, альфа-тиогуанозина, 6-метилгуанозин, 5-метилцитидина, 8-оксогуанозина, 7-дезазагуанозина, N1-метиладенозина, 2-амино-6-хлор-пурина, N6-метил-2-аминопурина, псевдоизоцитидина, 6-хлорпурина, N6-метиладенозина, альфа-тиоаденозина, 8-азидоаденозина, 7-дезазааденозина.
Модификации липидов
В еще одном из вариантов осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты, предпочтительно РНК согласно описанному выше может содержать липидную модифицированные липиды. Такая липид-модифицированная РНК обычно представляет РНК по настоящему изобретению. Такая модифицированная липидом молекула РНК по настоящему изобретению обычно дополнительно содержит, по меньшей мере, один линкер, ковалентно связанный с такой молекулой РНК, и по меньшей мере один липид, ковалентно связанный с соответствующим линкером. В другом варианте осуществления настоящего изобретения модифицированная липидом РНК представляет по меньшей мере одну молекулу РНК по настоящему изобретению и по меньшей мере один (бифункциональный) липид, ковалентно связанный (без линкера) с такой молекулой РНК. Согласно третьему варианту молекула РНК, модифицированная липидом, представляет молекулу искусственной нуклеиновой кислоты, предпочтительно молекулу РНК по настоящему изобретению, по меньшей мере один линкер, ковалентно связанный с молекулой РНК и по меньшей мере один липид, ковалентно связанный с соответствующим линкером, а также, по меньшей мере, один (бифункциональный) липид, ковалентно связанный (без линкера) с такой молекулой РНК. В этом контексте особенно предпочтительно, чтобы липидная модификация присутствовала на концах линейной последовательности РНК.
Модификация 5'-конца модифицированной РНК
В другом предпочтительном варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты, предочтительно молекула РНК по настоящему изобретению может быть модифицирована путем добавления так называемой структуры «5' САР (5'-кэп)».
Структура 5'-кэп обычно представляет модифицированную нуклеотидную структуру, которая обычно «накрывает» 5'-конец зрелой мРНК. Структура 5'-кэп обычно может быть образована модифицированным нуклеотидом, в частности, производным гуанинового нуклеотида. Предпочтительно структура 5'-кэп связана с 5'-концом через 5'-5'-трифосфатную связь. Структура 5'-кэп может быть метилирована, например, m7GpppN, где N представляет собой концевой 5'-нуклеотид нуклеиновой кислоты, несущий 5'-кэп, обычно 5'-конец РНК. m7GpppN представляет структуру 5'-кэп, которая естественным образом встречается в мРНК, транскрибируемой полимеразой II, и поэтому не рассматривается в качестве модификации, содержащейся в модифицированной РНК по настоящему изобретению. Это означает, что молекула искусственной нуклеиновой кислоты, предпочтительно молекула РНК, в соответствии с настоящим изобретением может содержать m7GpppN в виде структуры 5'-кэп, но дополнительно молекула искусственной нуклеиновой кислоты, предпочтительно молекула РНК, содержит по меньшей мере одну дополнительную модификацию по настоящему изобретению.
К другим примерам стпуктур 5'-кэп относятся глицерил, инвертированный дезоксиабазиновый остаток (часть молекулы), 4',5'-метиленовый нуклеотид, 1-(бета-D-эритрофуранозил)нуклеотид, 4'-тионуклеотид, карбоциклический нуклеотид, 1,5-ангидрогекситный нуклеотид, L-нуклеотиды, альфа-нуклеотид, модифицированное основание нуклеотида, трео-пентофуранозильный нуклеотид, ациклический 3',4'-секонуклеотид, ациклический 3,4-дигидроксибутильный нуклеотид, ациклический 3,5-дигидроксипентильный нуклеотид, 3'-3'-инвертированный нуклеотидный фрагмент, 3'-3'-инвертированный фрагмент без азотистого основания, 3'-2'-инвертированный нуклеотидный фрагмент, 3'-2'-инвертированный фрагмент без азотистого основания, 1,4-бутандиолфосфат, 3'-фосфорамидат, гексилфосфат, аминогексилфосфат, 3'-фосфат, 3'-фосфоротиоат, фосфородитиоат или связующий или несвязующий метилфосфонатный фрагмент. Эти модифицированные структуры 5'-кэп рассматривают в качестве по меньшей мере одной модификации, представляющей молекулу искусственной нуклеиновой кислоты, предпочтительно молекулу РНК в соответствии с настоящим изобретением.
Особенно предпочтительными модифицированными структурами 5'-CAP являются САР1 (метилирование рибозы соседнего нуклеотида от m7G), САР2 (метилирование рибозы второго нуклеотида ниже по цепи от m7G), САР3 (метилирование рибозы 3-го нуклеотида ниже по цепи от m7G), САР4 (метилирование рибоза 4-го нуклеотида ниже по цепи от m7G), ARCA (антиреверсный аналог САР), модифицированный ARCA (например, модифицированный фосфотиоатом ARCA), инозин, N1-метилгуанозин, 2'-фторгуанозин, 7-дезаза-гуанозин, 8-оксо-гуанозин, 2-аминогуанозин, LNA-гуанозин и 2-азидогуанозин.
В предпочтительном варианте осуществления настоящего изобретения по меньшей мере одна открытая рамка считывания кодирует терапевтический белок или пептид. В другом варианте осуществления настоящего изобретения антиген кодируется по меньшей мере одной открытой рамкой считывания, например, патогенный антиген, опухолевый антиген, аллергенный антиген или аутоиммунный антиген. В этом случае введение молекулы искусственной нуклеиновой кислоты, кодирующей антиген, используют в методе генетической вакцинации против заболевания, включающего указанный антиген.
В другом варианте осуществления настоящего изобретения антитело или антигенспецифичный Т-клеточный рецептор или его фрагмент кодируются по меньшей мере одной открытой рамкой считывания молекулы искусственной нуклеиновой кислоты согласно настоящему изобретению.
Антигены
Патогенные антигены
Молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением может кодировать белок или пептид, который включает патогенный антиген или его фрагмент, вариант или их производное. Такие патогенные антигены производны от патогенных организмов, в частности бактериальных, вирусных или протозойных (многоклеточных) патогенных организмов, которые вызывают иммунологическую реакцию у субъекта, в частности субъекта млекопитающих, в частности человека. Точнее, патогенные антигены предпочтительно представляют собой поверхностные антигены, например, белки (или фрагменты белков, например внешнюю часть поверхностного антигена), расположенные на поверхности вируса, или бактерии, или простейшего.
Патогенными антигенами являются пептидные или белковые антигены, предпочтительно полученные от патогена, связанного с инфекционным заболеванием, которые предпочтительно выбирают из антигенов, полученных от патогенов Acinetobacter baumannii, Anaplasma genus, Anaplasma phagocytophilum, Ancylostoma braziliense, Anapylostoma duodenale, Arcanobacterium haemolyticum, Ascaris lumbricoides, из рода Aspergillus, Astroviridae, из рода Babesia, Bacillus anthracis, Bacillus cereus, Bartillella henselae, вируса BK, Blastocystis hominis, Blastomyces dermatitidis, Bordetella pertussis, Borrelia burgdorferi, Borrelia, Borrelia spp., из рода Brucella, Brugia malayi, Bunyaviridae, Burkholderia cepacia и других видов Burkholderia, Burkholderia mallei, Burkholderia pseudomallei, из семейства Caliciviridae, из рода Campylobacter, Candida albicans, Candida spp., Chlamydia trachomatis, Chlamydophila pneumoniae, Chlamydophila psittaci, прионов CJD, Clonorchis sinensis, Clostridium botulinum, Clostridium difficile, Clostridium perfringens, Clostridium perfringens, Clostridium spp., Clostridium tetani, Coccidioides spp., коронавирусов, Corynebacterium diphtheriae, Coxiella burnetii, вируса крымско-конгской геморрагической лихорадки, Cryptococcus neoformans, Cryptosporidium, цитомегаловируса (CMV), вирусов денге (DEN-1, DEN-2, DEN-3 и DEN-4), Dientamoeba fragilis, вируса эболы (EBOV), из рода Echinococcus, Ehrlichia chaffeensis, Ehrlichia ewingii, из рода Ehrlichia, Entamoeba histolytica, из рода Enterococcus, из рода энтеровирусов, преимущественно вируса Коксаки А и энтеровируса 71 (EV71), Epidermophyton spp., вируса Эпштейна-Барра (EBV), Escherichia coli O157: Н7, О111 и О104: Н4, Fasciola hepatica и Fasciola gigantica, приона FFI, из суперсемейства Filarioidea, от флавивирусов, Francisella tularensis, из рода Fusobacterium, Geotrichum candidum, Giardia intestinalis, Gnathostoma spp., от приона GSS, вируса Guanarito, Haemophilus ducreyi, Haemophilus influenzae, Helicobacter pylori, Henipavirus (вируса Hendra, вируса Nipah), вируса гепатита А, вируса гепатита (HBV), вируса гепатита (HCV), вируса гепатита D, вируса гепатита Е, вируса простого герпеса 1 и 2 (HSV-1 и HSV-2), Histoplasma capsulatum, ВИЧ (вирус иммунодефицита человека), Hortaea werneckii, Human bocavirus (HBoV), вируса герпеса человека 6 (HHV-6) и вируса герпеса человека 7 (HHV-7), Human metapneumovirus (hMPV), Human papillomavirus (HPV), вируса Human parainfluenza (HPIV), вируса Japanese encephalitis, вируса JC, вируса Junin, Kingella kingae, Kelbsiella granulomatis, приона куру, вируса Ласса, Legionella pneumophila, из рода Leishmania, из рода Leptospira, Listeria monocytogenes, вируса Lymphocytic choriomeningitis virus (LCMV), вируса Machupo, вируса Malassezia spp., вируса марбург, вируса кори, Metagonimus yokagawai, Microsporidia phylum, Molluscum contagiosum virus (вируса контагиозного вируса - MCV), вируса свинки (Mumps virus), Mycobacterium leprae и Mycobacterium lepromatosis, Mycobacterium tuberculosis, Mycobacterium ulcerans, Mycoplasma pneumoniae, Naegleria fowleri, Necator americanus, Neisseria gonorrhoeae, Neisseria meningitidis, Nocardia asteroides, Nocardia spp., Onchocerca volvulus, Orientia tsutsugamushi, Orthomyxoviridae {Influenza), Paracoccidioides brasiliensis, Paragonimus spp., Paragonimus westermani, парвовируса В19, из рода Pasteurella, из рода Plasmodium, Pneumocystis jirovecii, полиовируса, вируса бешенства, респираторного синцитиального вируса (Respiratory syncytial virus - RSV), Rhinovirus, риновирусов, риноцирусы, Rickettsia akari, Rickettsia genus, Rickettsia prowazekii, Rickettsia rickettsii, Rickettsia typhi, вируса лихорадки долины Рифт, ротавируса, вируса краснухи, вируса Сабии, из рода Salmonella, Sarcoptes scabiei, коронавируса SARS, из рода Schistosoma, из рода Shigella, вируса Sin Nombre, хантавируса, Sporothrix schenckii, из рода Staphylococcus, из рода Staphylococcus, Streptococcus agalactiae, Streptococcus pneumoniae, Streptococcus pyogenes, Strongyloides stercoralis, из рода Taenia, Taenia solium, вируса клещевого энцефалита (Tick-borne encephalitis virus - TBEV), Toxocara canis или Toxocara cati, Toxoplasma gondii, Treponema pallidum, Trichinella spiralis, Trichomonas vaginalis, Trichophyton spp., Trichuris trichiura, Trypanosoma brucei, Trypanosoma cruzi, Ureaplasma urealyticum, вируса ветряной оспы (Varicella zoster virus - VZV), Variola major или Variola minor (вирусы черной оспы), приона vCJD, вируса венесуэльского энцефалита лошадей, Vibrio cholerae, вируса Западного Нила, вируса западного энцефалита лошадей, Wuchereria bancrofti, вируса желтой лихорадки, Yersinia enterocolitica, Yersinia pestis и Yerinia pseudotuberculosis.
Опухолевые антигены
В другом варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты по настоящему изобретению может кодировать белок или пептид, который представляет белок или пептид, включающий опухолевый антиген, фрагмент, вариант или производное указанного опухолевого антигена, предпочтительно, где опухолевый антиген является специфичным для меланоцитов антигеном, антигеном рака семенников или опухолеспецифичным антигеном, предпочтительно антигеном СТ-Х, не-ХСТ-антигеном, связующим партнером для антигена СТ-Х или связующим партнером для не-Х-СТ-антигена или опухолеспецифичным антигеном, более предпочтительно антигеном СТ-Х, связующий партнером для не-Х-СТ-антигена или опухолеспецифичного антигена или фрагмента, варианта или производного указанного опухолевого антигена; причем каждая из последовательностей нуклеиновой кислоты кодирует другой пептид или белок; по меньшей мере одна из последовательностей нуклеиновой кислоты кодирует 5Т4, 707-АР, 9D7, AFP, AlbZIP HPG1, альфа-5-бета-1-интегрин, альфа-5-бета-6-интегрин, альфа-актинин-4/м, альфа-метилацил-кофермент А рацемаза, ART-4, ARTC1/m, В7Н4, BAGE-1, BCL-2, bcr/abl, бета-катенин/m, BING-4, BRCA1/m, BRCA2/m, CA 15-3/CA 27-29, CA 19-9, CA72-4, CA125, карлетикулин, CAMEL, CASP-8/m, катепсин В, катепсин L, CD19, CD20, CD22, CD25, CDE30, CD33, CD4, CD52, CD55, CD56, CD80, CDC27/m, CDK4/m, CDKN2A/m, CEA, CLCA2, CML28, CML66, COA-1/m, coactosin-подобный белок, коллаген XXIII, COX-2, CT-9/BRD6, Cten, циклин B1, циклин D1, cyp-B, CYPB1, DAM-10, DAM-6, DEK-CAN, EFTUD2/m, EGFR, ELF2/m, EMMPRIN, EpCam, EphA2, EphA3, ErbB3, ETV6-AML1, EZH2, FGF-5, FN, Frau-1, G250, GAGE-1, GAGE-2, GAGE-3, GAGE-4, GAGE-5, GAGE-6, GAGE7b, GAGE-8, GDEP, GnT-V, gp100, GPC3, GPNMB/m, HAGE, HAST-2, гепсин, Her2/neu, HERV-K-MEL, HLA-A*0201-R17I, HLA-A11/m, HLA-A2/m, HNE, гомеобокс NKX3.1, HOM-TES-14/SCP-1, HOM-TES-85, HPV-E6, HPV-E7, HSP70-2M, HST-2, hTERT, iCE, IGF-1R, IL-13Ra2, IL-2R, IL-5, незрелый рецептор ламинина, калликреин-2, калликреин-4, Ki67, KIAA0205, KIAA0205/m, KK-LC-1, K-Ras/m, LAGE-A1, LDLR-FUT, MAGE-A1, MAGE-A2, MAGE-A3, MAGE-A4, MAGE-A6, MAGE-A9, MAGE-A10, MAGE-A12, MAGE-B1, MAGE-B2, MAGE-B3, MAGE-B4, MAGE-B5, MAGE-B6, MAGE-B10, MAGE-B16, MAGE-B17, MAGE-C1, MAGE-C2, MAGE-C3, MAGE-D1, MAGE-D2, MAGE-D4, MAGE-E1, MAGE-E2, MAGE-F1, MAGE-H1, MAGEL2, маммаглобин A, MART-1/melan-A, MART-2, MART-2/m, белок матрикса 22, MC1R, M-CSF, ME1/m, мезотелин, MG50/PXDN, MMP11, MN/CA IX-антиген, MRP-3, MUC-1, MUC-2, MUM-1/m, MUM-2/m, MUM-3/m, класс I/m миозина, NA88-A, N-ацетилглюкозаминилтрансфераза-V, Neo-PAP, Neo-PAP/m, NFYC/m, NGEP, NMP22, NPM/ALK, N-Ras/m, NSE, NY-ESO-1, NY-ESO-B, OA1, OFA-iLRP, OGT, OGT/m, OS-9, OS-9/m, остеокальцин, остеопонтин, p15, p190 minor bcr-abl, p53, p53/m, PAGE-4, PAI-1, PAI-2, PAP, PART-1, PATE, PDEF, Pim-1-Kinase, Pin-1, Pml/PARalpha, POTE, PRAME, PRDX5/m, простеин, протеиназа-3, PSA, PSCA, PSGR, PSM, PSMA, PTPRK/m, RAGE-1, RBAF600/m, RHAMM/CD168, RU1, RU2, S-100, SAGE, SART-1, SART-2, SART-3, SCC, SIRT2/m, Sp17, SSX-1, SSX-2/HOM-MEL-40, SSX-4, STAMP-1, STEAP-1, сурвивин, сурвивин-2В, SYT-SSX-1, SYT-SSX-2, TA-90, TAG-72, TARP, TEL-AML1, TGFbeta, TGFbetaRII, TGM-4, TPI/m, TRAG-3, TRG, TRP-1, TRP-2/6b, TRP/INT2, TRP-p8, тирозиназа, UPA, VEGFR1, VEGFR-2/FLK-1, WT1 и идиотин иммуноглобулина лимфоидных клеток крови или идиотии рецептора Т-клеток лимфоидных клеток крови, или фрагмент, или вариант, или производное указанного опухолевого антигена; предпочтительно сурвивин или его гомолог, антиген из семейства MAGE, или его связующий партнер, или фрагмент, вариант или производное указанного опухолевого антигена. Особенно предпочтительными в этом контексте являются опухолевые антигены NY-ESO-1, 5Т4, MAGE-C1, MAGE-C2, Сурвивин, Muc-1, PSA, PSMA, PSCA, STEAP и РАР.
В предпочтительном варианте осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты кодирует белок или пептид, который представляет терапевтический белок или его фрагмен, вариант или производное.
В настоящем изобретении терапевтические белки являются пептидами или белками, которые полезны для лечения какого-либо наследственного или приобретенного заболевания или которые улучшают состояние индивидуума. В частности, терапевтические белки играют важную роль при разработке терапевтических агентов, которые могут модифицировать и репарировать генетические ошибки, разрушать раковые клетки или инфицированные патогеном клетки, лечить расстройства иммунной системы, лечить метаболические или эндокринные расстройства, наряду с другими функциями. Например, эритропоэтин (Erythropoietin - ЕРО), гормон белковой природы, может быть использован для лечения пациентов с дефицитом эритроцитов, что является распространенной причиной осложнений на почках. Кроме того, к терапевтическим антителам относят адъювантные белки, терапевтические антитела, а также с ними связывают гормонально-заместительную терапию, которую, например, используют для лечения женщин в период менопаузы. В недавно разработанных подходах соматические клетки пациента используют для их перепрограммирования в плюрипотентные стволовые клетки, которые заменяют спорную терапию стволовыми клетками. Также эти белки, используемые для перепрограммирования соматических клеток или используемые для дифференциации стволовых клеток, определены в настоящем изобретении в качестве терапевтических белков. Кроме того, терапевтические белки могут быть применимы для других целей, например, для заживления ран, регенерации тканей, ангиогенеза и т.д. Кроме того, антигенспецифичные рецепторы В-клеток и их фрагменты и варианты определены в настоящем изобретении в качестве терапевтических белков.
Таким образом, терапевтические белки могут быть применены для различных целей, включая лечение различных заболеваний, например, инфекционных заболеваний, новообразований (например, раковых или опухолевых заболеваний), заболеваний крови и кроветворных органов, эндокринных, пищевых и метаболических заболеваний, заболеваний нервной системы, заболеваний системы кровообращения, заболеваний органов дыхания, заболеваний пищеварительной системы, заболеваний кожи и подкожной клетчатки, заболеваний опорно-двигательного аппарата и соединительной ткани, а также заболеваний мочеполовой системы, независимо друг от друга, если они наследственные или приобретенные.
В этом контексте особенно предпочтительны следующие терапевтические белки, которые могут быть использованы наряду с другими средствами для лечения метаболических или эндокринных расстройств (в скобках - конкретное заболевание, для лечения которого применяют терапевтический белок): кислая сфингомиелиназа (болезнь Ниманна-Пика), адипотид (ожирение), агалзидаза-бета (галактозидаза А человека) (болезнь Фабри, предотвращает накопление липидов, которые могут приводить к почечным и сердечно-сосудистым осложнениям), альглюкозидаза (болезнь Помпе (гликогеноз II типа)), альфа галактозидаза А (альфа-GAL А, агализидаза альфа) (болезнь Фабри), альфа-глюкозидаза (гликогеноз (GSD), Morbus Pompe), альфа-L-идуронидаза (мукополисахаридоз (MPS), синдром Херлера, синдром Шеи), альфа-N-ацетилглюкозаминидаза (синдром Санфилиппо), амфирегулин (рак, нарушение обмена веществ), ангиопоэтин ((Ang1, Ang2, Ang3, Ang4, ANGPTL2, ANGPTL3, ANGPTL4, ANGPTL5, ANGPTL6, ANGPTL7) (ангиогенез, созревание сосудов), бетацеллюлин (метаболическое расстройство), бетаглюкоронидаза (синдром Слая), белок морфогенеза костей BMP (ВМР1, ВМР2, ВМР3, ВМР4, ВМР5, ВМР6, ВМР7, ВМР8а, BMP8b, ВМР10, ВМР15) (регенеративный эффект, связанные с костью состояния, хроническая почечная недостаточность (chronic kidney disease - CKD)), белок CLN6 (болезнь CLN6 - атипичный поздний инфантильный, вариант с поздним началом, ранняя ювенильная, нейрональный цероидный липофусциноз (Neuronal Ceroid Lipofuscinoses - NCL)), эпидермальный фактор роста (Epidermal growth factor - EGF) (заживление ран, регуляция роста клеток, пролиферация и дифференцировка), эпиген (метаболическое расстройство), эпирегулин (метаболическое расстройство), фактор роста фибробластов (Fibroblast Growth Factor - FGF; FGF, FGF-1, FGF-2, FGF-3, FGF-4, FGF-5, FGF-6, FGF-7, FGF- 8, FGF-9, FGF-10, FGF-11, FGF-12, FGF-13, FGF-14, FGF-16, FGF-17, FGF-17, FGF-18, FGF-19, FGF-20, FGF-21, FGF-22, FGF-23) (заживление ран, ангиогенез, эндокринные расстройства, регенерация тканей), галсульфаза (мукополисахаридоз VI), грелин (синдром раздраженной толстой кишки (irritable bowel syndrome - IBS), ожирение, синдром Прадера-Вилли, диабет II типа), глюкоцереброзидаза (болезнь Гоше), GM-CSF (регенеративный эффект, производство белых кровяных клеток, рак), связывающий гепарин EGF-подобный фактор роста (HB-EGF) (заживление ран, сердечная гипертрофия и развитие и функция сердца), фактор роста гепатоцитов (Hepatocyte growth factor - HGF, регенеративный эффект, заживление ран), гепсидин (расстройства метаболизма железа, бета-талассемия), альбумин человека (снижение производства альбумина (гипопротеинемия), увеличение потери альбумина (нефротический синдром), гиповолемия, гипербилирубинемия), идурсульфаза (идурон-2-сульфатаза) (мукополисахаридоз II (Синдром Хантера)), интегрины αVβ3, αVβ5 и α5β1 (макромолекулы связывания матрикса и протеиназы, ангиогенез), индуронатсульфотаза (синдром Хантера), ларонидаза (формы синдрома Гурлер и Гурлер-Шейе мукополисахаридоза I), N-ацетилгалактозамин-4-сульфатаза (rhASB; галсульфаза, арилсульфатаза A (ARSA), арилсульфатаза В (ARSB)) (дефицит арилсульфатазы В, синдром Марото-Лами, мукополисахаридоз VI), N-ацетилглюкозамин-6-сульфатаза (синдром Санфилиппо), фактор роста нервов (Nerve growth factor - NGF, производный от мозга нейротрофический Фактор (Brain-Derived Neurotrophic Factor - BDNF), нейротрофин-3 (NT-3) и нейротрофин 4/5 (NT-4/5) (регенеративный эффект, сердечно-сосудистые заболевания, коронарный атеросклероз, ожирение, диабет 2 типа, метаболический синдром, острые коронарные синдромы, слабоумие, депрессия, шизофрения, аутизм, синдром Ретта, нервная анорексия, нервная булимия, заживление ран, язвы кожи, язвы роговицы, болезнь Альцгеймера), нейрегулин (NRG1, NRG2, NRG3, NRG4) (метаболическое расстройство, шизофрения), нейропилин (NRP-1, NRP-2) (ангиогенез, наведение аксонов, выживаемость клеток, миграция), обестатин (синдром раздраженной толстой кишки (IBS), ожирение, синдром Прадера-Вилли, сахарный диабет II типа), производный от тромбоцитов фактор роста (Platelet Derived Growth factor - PDGF; PDFF-A, PDGF-B, PDGF-C, PDGF-D) (регенеративный эффект, заживление ран, нарушение в ангиогенезе, артериосклерозе, фиброзе, раке), бета-рецепторы TGF (эндоглин, рецептор TGF-бета 1, рецептор TGF-бета 2, рецептор TGF-бета 3) (почечный фиброз, заболевание почек, диабет, в итоге конечная стадия болезни почек (end-stage renal disease - ESRD), ангиогенез), тромбопоэтин (ТНРО) (фактор роста и развития мегакариоцитов (Megakaryocyte growth and development factor - MGDF)) (расстройства тромбоцитов, тромбоциты для донорства, восстановление количества тромбоцитов после миелосупрессивной химиотерапии), трансформирующий фактор роста (Transforming Growth factor -TGF; (TGF-альфа, TGF-бета (TGFbeta1, TGFbeta2 и TGFbeta3))) (регенеративный эффект, заживление ран, иммунитет, рак, сердечные заболевания, диабет, синдром Марфана, синдром Лойеса-Дитца), VEGF (VEGF-A, VEGF-B, VEGF-C, VEGF-D, VEGF-E, VEGF-F и PIGF) (регенеративный эффект, ангиогенез, заживление ран, рак, проницаемость), несиритид (острая декомпенсированная застойная сердечная недостаточность), трипсин (пролежни, варикозная язва, очищение язв, дегенерирующая рана, солнечный ожог, мекониевая непроходимость кишечника), адренокортикотрофный гормон (АКТГ) (болезнь Аддисона, мелкоклеточная карцинома, адренолейкодистрофия, врожденная гиперплазия надпочечников, синдром Кушинга, синдром Нельсона, инфантильные спазмы), предсердный натрийуретический пептид (Atrial-natriuretic peptide - ANP) (эндокринные расстройства), холецистокинин (разнообразный), гастрин (гипогастринемия), лептин (диабет, гипертриглицеридемия, ожирение), окситоцин (стимулируют грудное вскармливание, не прогрессирует родов), соматостатин (симптоматическое лечение карциноидного синдрома, острое варикозное кровотечение и акромегалия, поликистозные заболевания печени и почек, акромегалия и симптомы, вызванные нейроэндокринными опухолями), вазопрессин (антидиуретический гормон) (несахарный диабет), кальцитонин (постменопаузальный остеопороз, гиперкальциемия, болезнь Педжета, метастазы в костях, фантомная боль конечностей, спинальный стеноз), экзенатид (устойчивый к лечению метформином и сульфонилмочевиной диабет второго типа), гормон роста (Growth hormone - GH), соматотропин (сбой роста из-за дефицита GH или хронической почечной недостаточности, синдром Прадера-Вилли, синдром Тернера, упадок сил или кахексия при СПИД при противовирусной терапии), инсулин (сахарный диабет, диабетический кетоацидоз, гиперкалиемия), инсулиноподобный фактор роста 1 IGF-1 (нарушение роста у детей с делецией гена GH или первичной тяжелой недостаточностью IGF1, нейродегенеративное заболевание, сердечнососудистые заболевания, сердечная недостаточность), мекасермин ринфабат, аналог IGF-1 (нарушение роста у детей с делецией гена GH или первичной тяжелой недостаточностью IGF1, нейродегенеративное заболевание, сердечно-сосудистые заболевания, сердечная недостаточность), мекасермин, IGF-1 аналог (нарушение роста у детей с делецией гена GH или первичной тяжелой недостаточностью IGF1, нейродегенеративное заболевание, сердечно-сосудистые заболевания, сердечная недостаточность), пегвизомант (акромегалия), прамлинтид (при сахарном диабете, в сочетании с инсулином), терипаратид (1-34 гормона паращитовидной железы человека) (тяжелый остеопороз), бекаплермин (очистка диабетических язв), диботермин-альфа (костный морфогенетический белок 2) (операция спинального слияния, восстановление повреждений костей), гистрелин ацетат (гонадотропин-высвобождающий гормон; gonadotropin releasing hormone - GnRH) (досрочное половое созревание), октреотид (акромегалия, симптоматическое облегчение ацетил-секреции VIP-секретирующей аденомы и метастазирующих карциноидных опухолей) и палифермин (фактор роста кератиноцитов, keratinocyte growth factor - KGF) (тяжелый оральный мукозит у пациентов, проходящих химиотерапию, заживление ран).
Эти и другие белки оценивают в качестве терапевтических, поскольку они предназначены для лечения субъекта путем замены его дефектной эндогенной выработки функционального белка в достаточных количествах. Соответственно, такими терапевтическими белками обычно являются белки млекопитающие, в частности белки человека.
Для лечения заболеваний крови, заболеваний сердечно-сосудистой системы, заболеваний органов дыхания, рака или опухолевых заболеваний, инфекционных заболеваний или иммунодефицитов после терапевтических белков могут быть применены(в скобках указаны конкретные заболевания, для которых в лечении используют терапевтический белок): альтеплаза (активатор тканевого плазминогена, tPA) (легочная эмболия, инфаркт миокарда, острый ишемический инсульт, окклюзия устройств центрального венозного доступа), анистреплаза (тромболизис), антитромбин III (АТ-III) (наследственный дефицит АТ-III, тромбоэмболия), бивалирудин (снижение риска свертывания крови при коронарной ангиопластике и индуцированной гепарином тромбоцитопении), дарбепоэтин альфа (лечение анемии у пациентов с хронической почечной недостаточностью (+/- диализ)), дротрекогин альфа (активированный белок С) (тяжелый сепсис с высоким риском смерти), эритропоэтин, эпоэтин альфа, эритропоэтин, эртропоэтин (анемия при хронических заболеваниях, милеодисплазия, анемия из-за почечной недостаточности или химиотерапии, предоперационная подготовка), фактор IX (гемофилия В), фактор VIIa (кровоизлияние у пациентов с гемофилией А или В и ингибиторы фактора VIII или фактора IX), фактор VIII (гемофилия А), лепирудин (индуцированная гепарином тромбоцитопения), концентрат белка С (венозный тромбоз, молниеносная пурпура), ретеплаза (деелция мутеина tPA) (лечение острого инфаркта миокарда, улучшение функции желудочков), стрептокиназа (острый эвалюирующий трансмуральный инфаркт миокарда, эмболия легочной артерии, тромбоз глубоких вен, артериальный тромбоз или эмболия, окклюзия артериовенозной канюли), тенектеплаза (острый инфаркт миокарда), урокиназа (легочная эмболия), ангиостатин (рак), анти-CD22-иммунотоксин (рецидивирующий CD33+ острый миелоидный лейкоз), денилейкин-дифтитокс (кожная Т-клеточная лимфома (Cutaneous T-cell lymphoma - CTCL)), иммуноцианин (рак мочевого пузыря и простаты), металлопанстимулин (Metallopanstimulin - MPS) (рак), афлиберцепт (немелкоклеточный рак легкого (Non-small cell lung cancer - NSCLC), метастатический колоректальный рак (mCRC), гормон-рефрактерный метастатический рак предстательной железы, мокрая дегенерация желтого пятна), эндостатин (рак, воспалительные заболевания, например, ревматоидный артрит, болезнь Крона, диабетическая ретинопатия, псориаз и эндометриоз), коллагеназа (удаление хронических кожных язв и сильно обожженных областей, контрактура Дюпюитрена, болезнь Пейрони), дезокси-рибонуклеаза I человека, дорназа (кистозный фиброз; уменьшает инфекции дыхательных путей у отдельных пациентов с FVC более чем на 40% от прогнозируемого), гиалуронидаза (используется в качестве адъюванта для увеличения абсорбции и дисперсии инъецированных лекарств, особенно анестетиков в офтальмохирургии, а также некоторых средств визуализации), папаин (удаление некротической ткани или сжижение шелушения при острых и хронических поражениях, например, пролежней, варикозных и диабетических язв, ожогов, послеоперационных ран, пилонидальных кист, карбункулов и других ран), L-аспарагиназа (острый лимфоцитарный лейкоз, который требует экзогенного аспарагина для пролиферации), ПЭГ-аспарагиназа (острый лимфоцитарный лейкоз, который требует экзогенного аспарагина для пролиферации), расбуриказа (педиатрические пациенты с лейкозой, лимфомой и солидными опухолями, проходящие противоопухолевую терапию, которая может вызвать синдром лизиса опухоли), хорионический гонадотропин человека (HCG) (вспомогательное воспроизведение), фолликулостимулирующий гормон человека (FSH) (вспомогательное воспроизведение), лютропин альфа (бесплодие с дефицитом лютеинизирующего гормона), пролактин (гипопролактинемия, дефицит пролактина сыворотки, дисфункция яичников у женщин, тревожность, артериогенная эректильная дисфункция, преждевременная эякуляция, олигозооспермия, астеноспермия, гипофункция семенных пузырьков, гипоандрогенизм у мужчин), альфа-1 ингибитор протеиназы (дефицит врожденного антитрипсина), лактаза (газ, вздутие живота, судороги и диарея из-за невозможности переваривать лактозу), ферменты поджелудочной железы (липаза, амилаза, протеаза) (кистозный фиброз, хронический панкреатит, недостаточность поджелудочной железы, после операции по шунтированию желудка по Бильрот II, обструкция поджелудочной железы, стеаторея, плохое пищеварение, газы, вздутие живота), аденозиндезаминаза (пэгадемаза быка, PEG-ADA) (тяжелое комбинированное иммунодефицитное заболевание из-за дефицита аденозиндезаминазы), абатасепт (ревматоидный артрит (особенно при трудно поддающемуся лечению ингибирования TNFalpha)), алефасепт (пятнистый псориаз), анакинра (ревматоидный артрит), этанерцепт (ревматоидный артрит, многосуставный ювенильный ревматоидный артрит, псориатический артрит, анкилозирующий спондилоартрит, псориаз бляшек, анкилозирующий спондилоартрит), антагонист рецептора интерлейкина-1 (IL-1), анакинра (дегенерация воспаления и хряща, связанная с ревматоидным артритом), тимулин (нейродегенеративные заболевания, ревматизм, нервная анорексия), антагонист TNF-альфа (аутоиммунные нарушения, например, ревматоидный артрит, анкилозирующий спондилоартрит, болезнь Крона, псориаз, гнойный гидраденит, рефрактерная астма), энфувиртид (инфекция ВИЧ-1) и тимозин α1 (гепатит В и С).
В другом варианте осуществления настоящего изобретения предусматривают вектор, включающий:
а. открытую рамку считывания (ORF) и/или сайт клонирования, например, для инсерции открытой рамки считывания или последовательности, содержащей открытую рамку считывания; а также
б. по меньшей мере, один элемент 3'-нетранслируемой области (элемент 3'-UTR) и/или по меньшей мере один элемент 5'-нетранслируемой области (5'-UTR-элемент), причем по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR продлевает и/или увеличивает выработку белка с указанной молекулы искусственной нуклеиновой кислоты, и по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR является производным стабильной мРНК.
В общем, вектор в соответствии с настоящим изобретением может содержать молекулу искусственной нуклеиновой кислоты в соответствии с настоящим изобретением согласно описанному выше. В частности, предпочтительные варианты осуществления настоящего изобретения, описанные выше для молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, также применимы для молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, которая состоит из вектора в соответствии с настоящим изобретением. Например, в векторе по настоящему изобретению по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR и ORF являются описанными выше для молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, включая предпочтительный варианты. Например, в векторе в соответствии с настоящим изобретением стабильная мРНК, производным которой является по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR, предпочтительно может отличаться распадом мРНК, причем соотношение количества указанной мРНК во второй временной точке к количеству указанной мРНК в первой временной точке составляет по меньшей мере 0,5 (50%), по меньшей мере 0,6 (60%), по меньшей мере 0,7 (70%), по меньшей мере 0,75 (75%), по меньшей мере 0,8 (80%), по меньшей мере 0,85 (85%), по меньшей мере 0,9 (90%) или по меньшей мере 0,95 (95%).
Клонируемым сайтом может быть какая-либо последовательность, которая применима для интродукции открытой рамки считывания или последовательности, содержащей открытую рамку считывания, например, один или несколько сайтов рестрикции. Таким образом, вектор, содержащий клонируемый сайт, предпочтительно применим для инсерции открытой рамки считывания в вектор, предпочтительно для инсерции открытой рамки считывания с 3'-конца к элементу 5'-UTR и/или с 5'-конца к элементу 3'-UTR. Предпочтительно клонируемый сайт или ORF расположены с 3'-конца элемента 5'-UTR и/или с 5'-конца элемента 3'-UTR, предпочтительно в непосредственной близости от 3'-конца 5'-UTR-элемента и/или от 5'-конца элемента 3'-UTR. Например, клонируемый сайт или ORF могут быть непосредственно подключены к 3'-концу 5'-UTR-элемента и/или к 5'-концу элемента 3'-UTR или они могут быть соединены отрезком нуклеотидов, например, из 2, 4, 6, 8, 10, 20 и т.д. нуклеотидов, согласно описанному выше для молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением.
Предпочтительно вектор согласно настоящему изобретению подходит для получения молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, предпочтительно для получения искусственной мРНК в соответствии с настоящим изобретением, например, путем необязательной инсерции открытой рамки считывания или последовательности, включающей открытую рамку считывания, в вектор, и транскрибирования вектора. Таким образом, предпочтительно вектор содержит элементы, необходимые для транскрипции, например, промотора, например, промотора РНК-полимеразы. Предпочтительно, такой вектор применим для транскрипции с использованием эукариотических, прокариотических, вирусных или фаговых транскрипционных систем, например, эукариотических клеток, прокариотических клеток или эукариотических, прокариотических, вирусных или фаговых систем транскрипции in vitro. Так, например, вектор может содержать промоторную последовательность, которая распознается полимеразой, такой как РНК-полимераза, например, эукариотической, прокариотической, вирусной или фаговой РНК-полимеразой. В предпочтительном варианте осуществления настоящего изобретения вектор содержит промотор фаговой РНК-полимеразы, например, SP6, Т3 или Т7, предпочтительно промотор Т7. Предпочтительно, этот вектор применим для транскрипции in vitro с использованием системы транскрипции in vitro, основанной на фаге, например, Т7-РНК-полимеразы, основанной на системе транскрипции in vitro.
В другом варианте осуществления настоящего изобретения вектор может быть применен непосредственно для экспрессии закодированного пептида или белка в клетках или ткани. Для этой цели вектор содержит определенные элементы, которые необходимы для экспрессии в этих клетках/тканях, например, определенные промоторные последовательности, например, промотор CMV.
Вектор может дополнительно содержать последовательность поли(А) и/или сигнал полиаденилирования согласно описанному выше для молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением.
Вектор может быть РНК-вектором или ДНК-вектором. Предпочтительно вектор является ДНК-вектором. Вектор может быть каким-либо вектором, известным специалистам в данной области, например, вирусным вектором или плазмидным вектором. Предпочтительно, вектор является плазмидным вектором, предпочтительно плазмидным ДНК-вектором.
В предпочтительном варианте осуществления настоящего изобретения вектор по настоящему изобретению содержит молекулу искусственной нуклеиновой кислоты по настоящему изобретению.
Предпочтительно, ДНК-вектор по настоящему изобретению содержит последовательность нуклеиновой кислоты, которая по меньшей мере примерно на 1, 2, 3, 4, 5, 10, 15, 20, 30 или 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности нуклеиновой кислоты 3'-UTR транскрипта гена, например, последовательности нуклеиновой кислоты в соответствии с SEQ ID NO: 1-24 и SEQ ID NO: 49-318.
Предпочтительно, ДНК-вектор по настоящему изобретению содержит последовательность нуклеиновой кислоты, которая по меньшей мере примерно на 1, 2, 3, 4, 5, 10, 15, 20, 30 или 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99%, наиболее предпочтительно на 100% идентична последовательности нуклеиновой кислоты 5'-UTR транскрипта гена, например, последовательности нуклеиновой кислоты в соответствии с SEQ ID NO: 25-30 и SEQ ID NO: 319-382.
Предпочтительно, ДНК-вектор по настоящему изобретению содержит последовательность, выбранную из группы, состоящей из последовательностей ДНК в соответствии с SEQ ID NO: 1-30, или последовательность, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99% идентична последовательностям ДНК согласно SEQ ID NO: 1-30 или их фрагментам согласно описанному выше, предпочтительно функциональным фрагментам.
Предпочтительно, РНК-вектор по настоящему изобретению содержит последовательность, выбранную из группы, состоящей из последовательностей РНК в соответствии с последовательностями ДНК в соответствии с SEQ ID NO: 1-30, или последовательность, которая по меньшей мере примерно на 40%, предпочтительно по меньшей мере примерно на 50%, предпочтительно по меньшей мере примерно на 60%, предпочтительно по меньшей мере примерно на 70%, более предпочтительно по меньшей мере примерно на 80%, более предпочтительно по меньшей мере примерно на 90%, еще более предпочтительно по меньшей мере примерно на 95%, еще более предпочтительно по меньшей мере примерно на 99% идентична последовательностям ДНК в соответствии с SEQ ID NO: 1-30 или их фрагментам согласно описанному выше, предпочтительно функциональным фрагментам.
Предпочтительно, вектор представляет кольцевую молекулу. Предпочтительно, вектор представляет двухцепочечную молекулу, например, двухцепочечную молекулу ДНК. Такую кольцевую, предпочтительно двухцепочечную молекулу ДНК удобно использовать в качестве формы хранения для молекулы искусственной нуклеиновой кислоты по настоящему изобретению. Кроме того, вектор может быть использован для трансфекции клеток, например культивируемых клеток. Также вектор может быть использован для транскрипции in vitro для получения молекулы искусственной РНК в соответствии с настоящим изобретением.
Предпочтительно вектор, предпочтительно кольцевой вектор, линеаризуют, например, путем расщепления ферментом рестрикции. В предпочтительном варианте осуществления настоящего изобретения вектор содержит сайт расщепления, например, сайт рестрикции, предпочтительно уникальный сайт расщепления, расположенный сразу с 3'-конца в ORF, или, если присутствует, расположенный сразу с 3'-конца элемента 3'-UTR, или, если присутствует, находится с 3'-конца поли(А) последовательности или сигнала полиаденилирования, или, если присутствует, находится с 3'-конца поли(С) последовательности, или, если присутствует, находится с 3'-конца гистонной структуры стебель-петля. Таким образом, предпочтительно продукт, полученный линеаризацией вектора, заканчивается на 3'-конце 3'-концом ORF или, если присутствует, на 3'-конце 3'-концом элемента 3'-UTR, или, если присутствует, 3'-концом поли(А) последовательности или сигналом полиаденилирования, или, если присутствует, 3'-концом поли(С) последовательности. В одном из вариантов осуществления настоящего изобретения, в котором вектор в соответствии с настоящим изобретением содержит молекулу искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, сайт рестрикции, предпочтительно уникальный сайт рестрикции, предпочтительно расположен сразу с 3'-конца до 3'-конца молекулы искусственной нуклеиновой кислоты.
В другом варианте осуществления настоящее изобретение относится к клетке, содержащей молекулу искусственной нуклеиновой кислоты в соответствии с настоящим изобретением или вектор в соответствии с настоящим изобретением. Клеткой может быть любая клетка, например, бактериальная клетка, клетка насекомого, растительная клетка, клетка позвоночных, например, клетка млекопитающего. Такие клетки могут быть, например, использованы для репликации вектора по настоящему изобретению, например, бактериальные клетки. Кроме того, клетка может быть применена для транскрипции молекулы искусственной нуклеиновой кислоты или вектора в соответствии с настоящим изобретением и/или трансляции открытой рамки считывания молекулы искусственной нуклеиновой кислоты или вектора в соответствии с настоящим изобретением. Например, клетка может быть применена для выработки рекомбинантного белка.
Клетки в соответствии с настоящим изобретением, например, могут быть получены стандартными методами передачи нуклеиновой кислоты, например, стандартными методами трансфекции, трансдукции или трансформации. Например, молекула искусственной нуклеиновой кислоты или вектор в соответствии с настоящим изобретением могут быть перенесены в клетку путем электропорации, липофекции, например, на основе катионных липидов и/или липосом, осаждения фосфатом кальция, трансфекцией на основе наночастиц, трансфекцией на основе вируса или на основе катионных полимеров, например, DEAE-декстрана или полиэтилененимина, и т.д.
Предпочтительно клетки являются клетками млекопитающего, например, клетками человека, домашнего животного, лабораторного животного, например, мыши или крысы. Предпочтительно клетками являются клетки человека. Клетки могут быть клетками определенной клеточной линии, например, СНО, BHK, 293Т, COS-7, HELA, HEK и т.д., или клетки могут быть первичными клетками, например, клетками дермальных фибробластов человека (human dermal fibroblast - HDF) и т.д., предпочтительно клетками, выделенными из организма. В предпочтительном варианте осуществления настоящего изобретения клетками являются изолированные клетки субъекта млекопитающего, предпочтительно человека. Например, клетки могут быть иммунными клетками, например, дендритными клетками, раковыми клетками или опухолевыми клетками, или какими-либо соматическими клетками и т.д., предпочтительно субъекта млекопитающего, предпочтительно субъекта человека.
В другом варианте осуществления настоящее изобретение относится к фармацевтической композиции, содержащей молекулу искусственной нуклеиновой кислоты по настоящему изобретению, вектор по настоящему изобретению или клетку по настоящему изобретению. Фармацевтическую композицию согласно изобретению можно применять, например, в качестве вакцины, например, для генетической вакцинации. Таким образом, ORF может, например, кодировать антиген для введения пациенту для вакцинации. Таким образом, в предпочтительном варианте осуществления фармацевтическая композиция в соответствии с настоящим изобретением представляет собой вакцину. Кроме того, фармацевтическая композиция в соответствии с настоящим изобретением может быть использована, например, для генной терапии.
Предпочтительно фармацевтическая композиция дополнительно содержит один или несколько фармацевтически приемлемых носителей, разбавителей и/или эксципиентов и/или один или нескольких адъювантов. В контексте настоящего изобретения фармацевтически приемлемый носитель обычно представляет жидкую или нежидкую основу для фармацевтической композиции по настоящему изобретению. В одном из вариантов осуществления настоящего изобретения фармацевтическую композицию получают в жидкой форме. В этом контексте предпочтительно, чтобы чтобы растворитель был на водной основе, например, на пирогенной воде, изотоническом солевом растворе или буферных (водных) растворах, например, фосфатных, цитратных и т.п.буферных растворах. Буфер может быть гипертоническим, изотоническим или гипотоническим по отношению к определенной сравниваемой среде, то есть буфер может иметь более высокое, равное или более низкое содержание соли по отношению к определенной сравниваемой среде, причем предпочтительно могут быть использованы такие концентрации вышеупомянутых солей, которые не приводят к повреждению клеток млекопитающих из-за осмоса или других эффектов, связанных с концентрациями. Контрольными средами являются, например, жидкости, используемые в методах «in vivo», например, кровь, лимфатические, цитозольные жидкости или другие жидкости организма или, например, жидкости, которые можно использовать в качестве эталонных сред в методах «in vitro», например, обычные буферы или жидкости. Такие обычные буферы или жидкости известны специалистам. Раствор Рингера-лактата особенно предпочтителен в качестве жидкой основы.
Один или несколько совместимых твердых или жидких наполнителей, или разбавителей, или инкапсулирующих соединений, пригодных для введения пациенту, также могут использоваться в фармацевтической композиции по настоящему изобретению. Используемое в настоящем изобретении понятие «совместимые» означает, что компоненты фармацевтической композиции по настоящему изобретению могут смешиваться с искусственной нуклеиновой кислотой, вектором или клетками по настоящему изобретению таким образом, чтобы не происходило никакого взаимодействия, которое могло бы существенно уменьшить фармацевтическую эффективность фармацевтической композиции по настоящему изобретению в типичных условиях применения.
Фармацевтическая композиция в соответствии с настоящим изобретением может необязательно дополнительно содержать один или несколько дополнительных фармацевтически активных компонентов. Фармацевтически активный компонент в этом контексте является соединением, которое проявляет терапевтический эффект, направленный на лечение, облегчение состояния или предотвращения определенного симптома или заболевания. Такие соединения включают, но ими не ограничиваются, пептиды или белки, нуклеиновые кислоты (терапевтически активные), низкомолекулярные органические или неорганические соединения (с молекулярной массой менее 5000, предпочтительно менее 1000), сахара, антигены или антитела, уже известные в предшествующем уровне техники терапевтические агенты, антигенные клетки, антигенные клеточные фрагменты, клеточные фракции, компоненты клеточных стенок (например, полисахариды), модифицированные, ослабленные или деактивированные (например, химически или облучением) патогены (вирусы, бактерии и т.д.).
Кроме того, фармацевтическая композиция по настоящему изобретению может содержать носитель для молекулы искусственной нуклеиновой кислоты или вектора. Такой носитель может быть пригодным в качестве средства для растворения в физиологически приемлемых жидкостях, для переноса и поглощении клетками молекул фармацевтической активной искусственной нуклеиновой кислоты или вектора. Соответственно, такой носитель может быть компонентом, который может быть пригодным в качестве депо и доставки молекулы искусственной нуклеиновой кислоты или вектора в соответствии с настоящим изобретением. Такими компонентами могут быть, например, катионные или поликатионные носители или соединения, которые могут служить в качестве агентов трансфекции или комплексообразования.
Особенно предпочтительными агентами трансфекции или комплексообразования в этом контексте являются катионные или поликатионные соединения, включая протамин, нуклеолин, спермин или спермидин, или другие катионные пептиды или белки, например, поли-L-лизин (poly-L-lysine - PLL), полиаргинин, основные полипептиды, проникающие в клетки пептиды (cell penetrating peptides -СРР), включая ВИЧ-связывающие пептиды, ВИЧ-1 Tat (ВИЧ), Tat-производные пептиды, пенетратин, VP22-производные или аналоговые пептиды, HSV VP22 (Herpes simplex), MAP, KALA или домены трансдукции белка (protein transduction domains - PTD), PpT620, пептиды с высоким содержанием пролина, пептиды с высоким содержанием аргинина, пептиды с высоким содержанием лизина, MPG-пептиды, Рер-1, L-олигомеры, пептид (пептиды) кальцитонина, пептиды, полученные из Antennapedia (особенно от Drosophila antennapedia), pAntp, pIsl, FGF, лактоферрин, транспортан, буфорин-2, Вас715-24, SynB, SynB (1), pVEC, hCT-производные пептиды, SAP или гистоны.
Кроме того, такие катионные или поликатионные соединения или носители могут быть катионными или поликатионными пептидами или белками, которые предпочтительно содержат или дополнительно модифицированы таким образом, чтобы включать по меньшей мере одну группу -SH. Предпочтительно катионный или поликатионный носитель выбирают из катионных пептидов, имеющих следующую общую формулу (I):

где l+m+n+о+х=3-100 и 1, m, n или о независимо друг от друга представляют число, выбранное из 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21-30, 31-40, 41-50, 51-60, 61-70, 71-80, 81-90 и 91-100, при условии, что среднее содержание Arg (аргинина), Lys (лизина), His (гистидина) и Orn (орнитина) составляет по меньшей мере 10% от всех аминокислот в олигопептиде; Хаа означает какую-либо аминокислоту, выбранную из нативных (= природных) или ненативных аминокислот, за исключением Arg, Lys, His или Orn; х означает какое-либо число, выбранное из 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21-30, 31-40, 41-50, 51-60, 61-70, 71-80, 81-90, при условии, что среднее содержание Хаа не превышает 90% от всех аминокислот в олигопептиде. Какая-либо из аминокислот Arg, Lys, His, Orn и Хаа может быть расположена в каком-либо месте пептида. В этом контексте катионные пептиды или белки в диапазоне 7-30 аминокислот особенно предпочтительны.
Кроме того, катионный или поликатионный пептид или белок, если его определенный по указанной выше формуле {(Arg)l;(Lys)m;(His)n;(Orn)o;(Xaa)x} (формула (I)), включает или является дополнительно модифицированным таким образом, чтобы содержать по меньшей мере одну группу -SH, возможно ею не ограничиваясь, выбранный по субформуле (Ia):

где (Arg)l;(Lys)m;(His)n;(Orn)o; и х являются такими же, что и описанные выше, Хаа' означает какую-либо аминокислоту, выбранную из нативных (= природных) или ненативных аминокислот, за исключением Arg, Lys, His, Orn или Cys, и у означает какое-либо число, выбранное из 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21-30, 31-40, 41-50, 51-60, 61-70, 71-80, 81-90, при условии, что среднее содержание Arg (аргинина), Lys (лизина), His (гистидина) и Orn (орнитина) составляет по меньшей мере 10% от всех аминокислот олигопептида. Кроме того, катионный или поликатионный пептид может быть выбран по субформуле (Iб):

причем эмпирическая формула {(Arg)l;(Lys)m;(His)n;(Orn)o;(Xaa)x} (формула (III)) является описанной в настоящем изобретении и образует ядро аминокислотной последовательности согласно (полуэмпирической) формуле (III) и где Cys1 и Cys2 являются цистеинами, проксимальными или концевыми в отношении (Arg)l;(Lys)m;(His)n;(Orn)o;(Xaa)x.
Другие предпочтительные катионные или поликатионные соединения, которые могут быть использованы в качестве агентов трансфекции или комплексообразования, могут включать катионные полисахариды, например хитозан, полибрен, катионные полимеры, например, полиэтиленимин (polyethyleneimine - PEI), катионные липиды, например, DOTMA: [1-(2,3-сиолейлокси)пропил)-N,N,N-триметиламмоний хлорид, DMRIE, ди-С14-амидин, DOTIM, SAINT, DC-Chol, BGTC, СТАР, DOPC, DODAP, DOPE: диолеилфосфатидилэтаноламин, DOSPA, DODAB, DOIC, DMEPC, DOGS: диоктадециламидоглицилспермин, DIMRI:
димиристооксипропилдиметилгидроксиэтиламмоний бромид, DOTAP: диолеилокси-3-(триметиламмонио)пропан, DC-6-14: O,O-дитетрадеканоил-N-(α-триметиламмониоацетил)диэтаноламин хлорид, CLIP1: rac-[(2,3-диоктадецилоксипропил)(2-гидроксиэтил)]-диметиламмоний хлорид, CLIP6: rac-[2(2,3-дигексадецилоксипропилоксиметилокси)этил]-триметиламмоний, CLIP9: rac-[2(2,3-дигексадецилоксипропилоксисукцинилокси)этил]триметиламмоний, олигофектамин или катионные или поликатионные полимеры, например модифицированные полиаминокислоты, например, β-аминокислотные полимеры или реверсированные полиамиды и т.д., модифицированные полиэтилены, например, PVP (поли(N-этил-4-винилпиридиний бромид)) и т.д., модифицированные акрилаты, например, pDMAEMA (поли(диметиламиноэтилметилакрилат) и т.д., модифицированные амидоамины, например, рАМАМ (поли(амидоамин)) и т.д., модифицированный полибетааминоэфир (РВАЕ), например, модифицированные по диаминовому концу 1,4-бутандиолдиакрилат-со-5-амино-1-пентанольные полимеры, дендримеры, например, полипропиламинные дендримеры или дендримеры на основе рАМАМ и т.д., полиимин (полиимины), например, PEI: поли(этиленимин), поли(пропиленимин) и т.д., полиаллиламин, полимеры на основе сахаров, например, полимеры на основе циклодекстрина, полимеры на основе декстрана, хитозана и т.д., полимеры с каркасом из силана, например, сополимеры PMOXA-PDMS и т.д., блокполимеры, состоящие из комбинации одного или нескольких катионных блоков (например, выбранных из катионного полимера, указанного выше), и один или несколько гидрофильных или гидрофобных блоков (например, полиэтиленгликолевых); и т.п.
В другом варианте осуществления настоящего изобретения фармацевтическая композиция по настоящему изобретению может содержать адъювант для усиления иммуностимулирующих свойств фармацевтической композиции. В этом контексте адъювантом может быть какое-либо соединение, которое пригодно в качестве вспомогательного средства для введения и доставки компонентов, например, молекулы искусственной нуклеиновой кислоты или вектора, содержащихся в фармацевтической композиции по настоящему изобретению. Кроме того, такой адъювант может, не будучи связанным с ними, инициировать или увеличивать иммунный ответ врожденной иммунной системы, то есть неспецифический иммунный ответ. Иначе говоря, при введении фармацевтическая композиция в соответствии с настоящим изобретением обычно инициирует адаптивный иммунный ответ в отношении антигена, кодируемого молекулой искусственной нуклеиновой кислоты. Кроме того, фармацевтическая композиция по настоящему изобретению может вырабатывать (поддерживающий) врожденный иммунный ответ за счет добавления адъюванта, согласно описанию настоящего изобретения, к фармацевтической композиции в соответствии с настоящим изобретением.
Такой адъювант может быть выбран из каких-либо адъювантов, известных специалисту в данной области и пригодных для настоящего изобретения, то есть способствующих индукции иммунного ответа у млекопитающего. Предпочтительно, адъювант может быть выбран из группы, включающей, но ими перечень не ограничивается, TDM, MDP, мурамилдипептид, плюроники, раствора квасцов, гидроксида алюминия, ADJUMERTM (полифосфазен); алюминиевый фосфатный гель; глюканы из водорослей; алгаммулин; гель гидроксида алюминия (квасцы); высокоадсорбирующий белки гель гидроксида алюминия; гель с низкой вязкостью гидроксида алюминия; AF или SPT (эмульсия сквалана (5%), Твин 80 (0,2%), плюроник L121 (1,25%), забуференный фосфатом физиологический раствор, рН 7,4); AVRIDINETM (пропандиамин); BAY R1005TM (N-(2-дезокси-2-L-лейциламино-b-D-глюкопиранозил)-N-октадецилдодеканоиламида гидроацетат), CALCITRIOLTM (1-альфа, 25-дигидрокси-витамин D3), гель кальций фосфатный; САРТМ (наночастицы фосфата кальция), голотоксин холеры, фрагмент гибридного белка холерного токсина-А1-белка-AD, субъединица В холерного токсина, CRL 1005 (блок-сополимер Р1205), цитокинсодержащие липосомы, DDA (диметилдиоктадециламмоний бромид), DHEA (дегидроэпиандростерон), DMPC (димиристоилфосфатидилхолин), DMPG (димиристоилфосфатидилглицерин), DOC/комплекс квасцов (натриевая соль дезоксихолевой кислоты), полный адъювант Фрейнда, неполный адъювант Фрейнда, гамма-инулин, адъювант Гербу (смесь: i) N-ацетилглюкозаминил-(Р1-4)-N-ацетилмурамил-L-аланил-D-глутамина (GMDP), ii) диметилдиоктадециламмоний хлорида (DDA), iii) комплекса соли цинка-L-пролина (ZnPro-8); GM-CSF); GMDP (N-ацетилглюкозаминил-(b1-4)-N-ацетилмурамил-L-аланил-D-изоглутамин); имиквимод (1-(2-метилпропил)-1Н-имидазо[4,5-с]хинолин-4-амин); ImmTherTM (N-ацетилглюкозаминил-N-ацетилмурамил-L-Ала-D-изоGlu-L-Ala-глицерин дипальмитат); DRV (иммунолипосомы, полученные из везикул дегидратации-регидратации); интерферон-гамма; интерлейкин-1-бета; интерлейкин-2; интерлейкин-7; интерлейкин-12; ISCOMSTM; ISCOPREP 7.0.3. ТМ; липосомы; LOXORIBINETM (7-аллил-8-оксогуанозин); LT оральный адъювант (лабильный энтеротоксин-протоксин Е. coli); микросферы и микрочастицы какой-либо композиции; MF59TM; (сквален-водная эмульсия); MONTANIDE ISA 51ТМ (очищенный неполный адъювант Фрейнда); MONTANIDE ISA 720ТМ (метаболизируемый масленый адъювант); MPLTM (3-Q-дезацил-4'-монофосфорильный липид А); липосомы МТР-РЕ и МТР-РЕ ((N-ацетил-L-аланил-D-изоглутаминил-L-аланин-2-(1,2-дипальмитоил-sn-глицеро-3-(гидроксифосфорилокси))-этиламид, мононатриевая соль), MURAMETIDETM (Nac-Mur-L-Ala-D-Gln-ОСН3), MURAPALMITINETM и D-MURAPALMITINETM (Nac-Mur-L-Thr-D-isoGIn-sn-глицеролдипальмитоил), NAGO (нейраминидаза-галактозоксидаза); наносферы или наночастицы какого-либо состава, NISV (неионные верикулы поверхностно-активных веществ), PLEURANTM (-глюкан), PLGA, PGA и PLA (гомо- и сополимеры молочной кислоты и гликолевой кислоты, микросферы/наносферы), PLURONIC L121TM; ПММА (полиметилметакрилат), PODDSTM (протеиноидные микросферы), производные полиэтиленкарбамата, поли-rA: поли-rU (комплекс полиадениловой кислоты и полиуридиловой кислоты), полисорбат 80 (Tween 80), белковые кохлеаты (фирма Avanti Polar Lipids, Inc., Alabaster, Алабама), STIMULONTM (QS-21), Quil-A (Quil-a-сапонин), S-28463 (4-амино-otec-диметил-2-этоксиметил-1Н-имидазо [4,5c] хинолин-1-этанол), SAF-1TM («синтекс-адъювантная композиция»), протеолипосомы вируса сендай и сендай-содержащие липидные матрицы; Span-85 (сорбитан-триолеат); Specol (эмульсия Marcol 52, Span 85 и Tween 85); сквален или продукт Robane® (2,6,10,15,19,23-гексаметилтетракозан и 2,6,10,15,19,23-гексаметил-2,6,10,14,18,22-тетракозагексан); стеарилтирозин (октадецилтирозин гидрохлорид); продукт Theramid® (N-ацетилглюкозаминил-N-ацетилмурамил-L-Ala-D-изоGlu-L-Ala-дипальмитоксипропиламид); Теронил-MDP (TermurtideTM или [thr 1]-MDP; N-ацетилмурамил-L-треонил-D-изоглутамин); Ту-частицы (Ty-VLP или вирусоподобные частицы); kипосомы Уолтера-Рида (липосомы, содержащие липид А, адсорбированные на гидроксиде алюминия) и липопептиды, включая Pam3Cys, в частности соли алюминия, например, продукты Adju-phos, Alhydrogel и Rehydragel; эмульсии, включая CFA, SAF, IFA, MF59, продукты Provax, TiterMax, Montanide, Vaxfectin; сополимеры, включая Optivax (CRL1005), L121, Poloaxmer4010) и т.д.; липосомы, включая Stealth, cochleates, включая BIORAL; растительные адъюванты, включая QS21, Quil A, Iscomatrix, ISCOM; адъюванты, применимые для костимуляции, включая томатин, биополимеры, включая PLG, РММ, инулин; адъюванты на основе микроорганизмов, включая ромуртид, DETOX, MPL, CWS, Mannose, CpG последовательности нуклеиновых кислот, CpG7909, лиганды TLR 1-10 человека, лиганды TLR 1-13 мыши, ISS-1018, IC31, имидазохинолины, Ampligen, Ribi529, IMOxine, IRIV, VLP, токсин холеры, термолабильный токсин, Pam3Cys, флагеллин, GPI anchor, LNFPIII/Lewis X, антимикробные пептиды, UC-1V150, гибридный белок RSV, cdiGMP; адъюванты, применимые для антагонистов, включая нейропептид CGRP.
Пригодные адъюванты также могут быть выбраны из катионных или поликатионных соединений, причем адъювант предпочтительно получают при комплексообразовании молекулы искусственной нуклеиновой кислоты или вектора фармацевтической композиции с катионным или поликатионным соединением. Ассоциация или комплексообразование молекулы искусственной нуклеиновой кислоты или вектора фармацевтической композиции с катионными или поликатионными соединениями по настоящему соединению, предпочтительно обеспечивает адъювантные свойства и придает стабилизирующий эффект молекуле искусственной нуклеиновой кислоты или вектору фармацевтической композиции. В частности, такие предпочтительные, катионные или поликатионные соединения выбраны из катионных или поликатионных пептидов или белков, включая протамин, нуклеолин, спермин или спермидин, или другие катионные пептиды или белки, например, поли-L-лизин (PLL), полиаргинин, основные полипептиды, проникающие в клетку пептиды (СРР), включая ВИЧ-связывающие пептиды, Tat, HIV-1 Tat (ВИЧ), Tat-производные пептиды, пенетратин, VP22 или аналоговые пептиды, HSV VP22 (Herpes simplex), MAP, KALA или (ПТД, РрТ620, обогащенные пролином пептиды, обогащенные аргинином пептиды, обогащенные лизином пептиды, MPG-пептид (-пептиды), Рер-1, L-олигомеры, пептид (пептиды) кальцитонина, пептиды, полученные из Antennapedia (в частности, от Drosophila antennapedia), pAntp, pIsl, FGF, лактоферрин, транспортан, буфорин-2, Вас715-24, SynB, SynB (1), pVEC, hCT-производные пептиды, SAP, протамин, спермин, спермидин или гистоны. К другим катионным или поликатионным соединениям могут относиться катионные полисахариды, например, хитозан, полибрен, катионные полимеры, т.е. полиэтиленимин (PEI), катионные липиды, например, DOTMA: -N,N,N-триметиламмоний]1-(2,3-сиолейлокси)пропил)[хлорид, DMRIE, ди-С14-амидин, DOTIM, SAINT, DC-Chol, BGTC, СТАР, DOPC, DODAP, DOPE: диолеилфосфатидилэтаноламин, DOSPA, DODAB, DOIC, DMEPC, DOGS: диоктадециламидоглицилспермин, DIMRI:
димиристооксипропилдиметилгидроксиэтиламмоний бромид, DOTAP: диолеоилокси-3-(триметиламмонио)пропан, DC-6-14: O,O-дитретрадеканоил-N-(-триметиламмоний ацетил)диэтаноламин α хлорид, CLIP1: rac-[(2,3-диоктадецилоксипропил)(2-гидроксиэтил)]диметиламмоний хлорид, CLIP6: rac-[2(2,3-дигексадецилоксипропилоксиметилокси)этил]триметиламмоний, CLIP9: rac-[2(2,3-дигексадецилоксипропилоксисукцинилокси)этил]триметиламмоний, олигофектамин, или катионные или поликатионные полимеры, например, модифицированные аминокислотные полимеры или ревертированные β-полиаминокислоты, например, полиамиды и т.д., модифицированные полиэтилены, например, PVP (поли(N-этил-4-винилпиридиний бромид)) и т.д., модифицированные акрилаты, такие как pDMAEMA (поли(диметиламиноэтилметилакрилат)) и т.д., модифицированные амидоамины, например, рАМАМ (поли(амидоамин)) и т.д., модифицированный полибетааминоэфир (РВАЕ), например, модифицированные по диаминовому концу 1,4-бутандиол-диакрилат-со-5-амино-1-пентанольные полимеры и т.д., дендримеры, например, полипропиламиновые дендримеры или дендримеры на основе рАМАМ и т.д., полиимин (полиимины), например, PEI: поли(этиленимин), поли(пропиленимин) и т.д., полиаллиламин, полимеры на основе сахаров, например, основанные на циклодекстрине полимеры, полимеры на основе декстрана, хитозан и т.д., полимеры на основе силана, например, сополимеры PMOXA-PDMS и т.д., блокполимеры, состоящие из комбинации одного или нескольких катионных блоков (например, выбранных из катионного полимера, согласно описанному выше), и один или несколько гидрофильных или гидрофобных блоков (например, полиэтиленгликоль); и т.п.
Кроме того, предпочтительные катионные или поликатионные белки или пептиды, которые могут быть использованы в качестве адъюванта путем комплексообразования молекулы искусственной нуклеиновой кислоты или вектора (предпочтительно РНК) в композиции, могут быть выбраны из следующих белков или пептидов, имеющих следующую общую формулу (I): (Arg)l;(Lys)m;(His)n;(Orn)o;(Xaa)x, где l+m+n+о+х=8-15, и l, m, n или о независимо друг от друга могут быть каким-либо числом, выбранным из 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 или 15, при условии, что общее содержание Arg, Lys, His и Orn представляют по меньшей мере 50% всех аминокислот олигопептида; и Хаа может представлять какую-либо аминокислоту, выбранную из нативных (= природных) или неприродных аминокислот, за исключением Arg, Lys, His или Orn; и х может быть каким-либо числом, выбранным из 0, 1, 2, 3 или 4, при условии, что общее содержание Хаа не превышает 50% всех аминокислот олигопептида. Особенно предпочтительными олигоаргининами в этом контексте являются, например, Arg7, Arg8, Arg9, Arg7, H3R9, R9H3, H3R9H3, YSSR9SSY, (RKH) 4, Y (RKH) 2R и т.д.
Соотношение искусственной нуклеиновой кислоты или вектора к катионному или поликатионному соединению может быть рассчитано на основе соотношения азот/фосфат (отношение N/P) всего комплекса нуклеиновых кислот. Например, 1 мкг РНК обычно содержит около 3 нмоль фосфатных остатков, при условии, что РНК имеет статистическое распределение оснований. Кроме того, 1 мкг пептида обычно содержит примерно х нмолей остатков азота, в зависимости от молекулярной массы и количества основных аминокислот. По примерной оценке для (Arg)9 (молекулярная масса 1424 г/моль, 9 атомов азота) 1 мкг (Arg)9 содержит примерно 700 пмоль (Arg)9 и, таким образом, 700×9=6300 пмоль основных аминокислот = 6,3 нмоль атомов азота. Для соотношения масс, примерно равного 1:1 PHK/(Arg) 9, можно рассчитать соотношение N/P, примерно равное 2. При примерном вычислении для протамина (молекулярная масса примерно 4250 г/моль, 21 атом азота, когда используется протамин лосося) с массовым соотношением примерно 2:1 с 2 мкг РНК, 6 нмоль фосфата рассчитывают для РНК; 1 мкг протамина содержит примерно 235 пмоль молекул протамина и, таким образом, 235×21=4935 пмоль основных атомов азота = 4,9 нмоль атомов азота. Для соотношения масс примерно 2:1 РНК/протамина можно рассчитать соотношение N/P примерно 0,81. Для соотношения масс примерно 8:1 РНК/протамина можно рассчитать соотношение N/P примерно 0,2. В контексте настоящего изобретения соотношение N/P предпочтительно находится в интервале приблизительно от 0,1 до 10, предпочтительно в диапазоне приблизительно 0,3-4 и наиболее предпочтительно в диапазоне приблизительно 0,5-2 или 0,7-2 относительно соотношения нуклеиновой кислоты : пептид в комплексе и наиболее предпочтительно в пределах около 0,7-1,5.
Патентная заявка WO 2010/037539, описание которой включено в настоящее изобретение в виде ссылки, описывает иммуностимулирующую композицию и способы получения иммуностимулирующей композиции. Соответственно, в предпочтительном варианте осуществления настоящего изобретения композицию получают за две отдельные стадии, чтобы получить как эффективный иммуностимулирующий эффект, так и эффективную трансляцию молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением. При этом так называемый «адъювантный компонент» получают на первой стадии путем комплексообразования молекулы искусственной нуклеиновой кислоты или вектора, предпочтительно РНК, адъювантного компонента с катионным или поликатионным соединением в определенном соотношении для формирования стабильного комплекса. В этом контексте важно, что после образования комплекса с нуклеиновой кислотой в адъювантном компоненте не остается свободного катионного или поликатионного соединения, а только возможно пренебрежительно малое его количество. Соответственно, соотношение нуклеиновой кислоты и катионного или поликатионного соединения в адъювантном компоненте обычно выбирают в таком диапазоне, в котором нуклеиновая кислота полностью входит в комплекс, и в композиции не остается свободного катионного или поликатионного соединения или только их пренебрежительно малое количество. Предпочтительно соотношение адъювантного компонента, т.е. соотношение нуклеиновой кислоты к катионному или поликатионному соединению, выбирают из диапазона примерно от 6:1 (мас./мас.) до примерно 0,25:1 (мас./мас.), более предпочтительно примерно от 5:1 (мас./мас.) до примерно 0,5:1 (мас./мас.), еще более предпочтительно примерно от 4:1 (мас./мас.) до примерно 1:1 (мас./мас.) или примерно от 3:1 (мас./мас.) до примерно 1:1 (мас./мас.), наиболее предпочтительно примерно от 3:1 (мас./мас.) до примерно 2:1 (мас./мас.).
В предпочтительном варианте осуществления настоящего изобретения молекулу искусственной нуклеиновой кислоты или вектор, предпочтительно молекулу РНК по настоящему изобретению, добавляют на второй стадии к комплексной молекуле нуклеиновой кислотой, предпочтительно РНК, адъювантного компонента, для образования (иммуностимулирующей) композиции по настоящему изобретению. В этом случае молекулу искусственной нуклеиновой кислоты или вектор, предпочтительно РНК по настоящему изобретению, добавляют в виде свободной нуклеиновой кислоты, то есть нуклеиновой кислоты, которая не образуется в комплексе с другими соединениями. Перед добавлением молекула свободной искусственной нуклеиновой кислоты или вектор не образуют комплекса и предпочтительно не будут подвергаться какой-либо обнаруживаемой или значительной реакции комплексообразования при добавлении адъювантного компонента.
К другим применимым адъювантам относят нуклеиновые кислоты, имеющие формулу (II): GlXmGn, где G означает гуанозин, урацил или аналог гуанозина или урацила; X означает гуанозин, урацил, аденозин, тимидин, цитозин или аналог вышеупомянутых нуклеотидов; 1 означает целое число от 1 до 40, причем если 1=1, G означает гуанозин или его аналог, когда 1>1, то по меньшей мере 50% нуклеотидов представляют гуанозин или его аналог; m означает целое число, которое не менее 3; если m=3, то X означает урацил или его аналог, если m>3 - по меньшей мере 3 последовательно расположенных урацила или аналога урацила; n означает целое число от 1 до 40, причем если n=1, то G означает гуанозин или его аналог, если n>1 по меньшей мере 50% нуклеотидов являются гуанозином или его аналогами.
К другим применимым адъювантам относят нуклеиновые кислоты, имеющие формулу (III): ClXmCn, где С означает цитозин, урацил или аналог цитозина или урацила; X означает гуанозин, урацил, аденозин, тимидин, цитозин или аналог вышеупомянутых нуклеотидов; 1 означает целое число от 1 до 40, причем если 1=1, то С означает цитозин или его аналог, если 1>1, то по меньшей мере 50% нуклеотидов являются цитозином или его аналогами; m означает целое число, которое не менее 3; если m=3, то X означает урацил или его аналог, если m>3, то по меньшей мере 3 последовательнно расположенных урацила или аналога урацила; n означает целое число от 1 до 40, причем если n=1, то С означает цитозин или его аналог, если n>1, то по меньшей мере 50% нуклеотидов являются цитозином или его аналогами.
Фармацевтическая композиция в соответствии с настоящим изобретением предпочтительно включает «безопасное и эффективное количество» компонентов фармацевтической композиции, в частности, молекулы искусственной нуклеиновой кислоты по настоящему изобретению, вектора и/или клеток, согласно описанному. В контексте настоящего изобретения понятие «безопасное и эффективное количество» означает количество, достаточное для существенной индукции положительной модификации заболевания или расстройства согласно описанному. В то же время понятие «безопасное и эффективное количество» предпочтительно означает отсутствие тяжелых побочных эффектов и обеспечение разумного баланса между преимуществом и риском. Определение этих пределов обычно входит в сферу обоснованного медицинского заключения.
В другом варианте осуществления настоящее изобретение относится к молекуле искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, к вектору в соответствии с настоящим изобретением, к клеткам в соответствии с настоящим изобретением или к фармацевтической композиции в соответствии с настоящим изобретением для применения в качестве лекарственного средства, например, в качестве вакцины (при генетической вакцинации) или генной терапии.
Искусственная молекула нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическая композиция в соответствии с настоящим изобретением особенно пригодны для какого-либо медицинского применения, в котором важно терапевтическое действие или свойство пептидов, полипептидов или белков, или в котором требуется дополнительное введение определенного пептида или белка. Таким образом, настоящее изобретение предлагает молекулу искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическую композицию в соответствии с настоящим изобретением для использования при лечении или профилактике болезни или расстройства, поддающихся лечению терапевтическим действием или действием пептидов, полипептидов или белков, или поддающихся лечению путем добавления определенного пептида, полипептида или белка. Например, молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическая композиция в соответствии с настоящим изобретением могут быть применены для лечения или профилактики генетических заболеваний, аутоиммунных заболеваний, раковых или опухолевых заболеваний, инфекционных заболеваний, хронических заболеваний и т.п., например, путем генетической вакцинации или генной терапии.
В частности, такое терапевтическое лечение, польза от которого связана с повышенным и продленным присутствием терапевтических пептидов, полипептидов или белков у подлежащего лечению субъекта, особенно пригодно для медицинского применения в контексте настоящего изобретения, поскольку элемент 3'-UTR по настоящему изобретению обеспечивает стабильность и продолжительность экспрессии пептида или белка, закодированного в молекуле искусственной нуклеиновой кислоты или в векторе по настоящему изобретению, и/или элемент 5'-UTR по настоящему изобретению обеспечивает повышенную экспрессию пептида или белка, закодированного в молекуле искусственной нуклеиновой кислоты или в векторе по настоящему изобретению.
Таким образом, особенно применимым медицинским назначением для молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектора в соответствии с настоящим изобретением, клеток в соответствии с настоящим изобретением или фармацевтической композиции в соответствии с настоящим изобретением является вакцинация. Таким образом, настоящее изобретение предусматривает молекулу искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическую композицию в соответствии с настоящим изобретением для вакцинации субъекта, предпочтительно субъект млекопитающего, более предпочтительно человека. Предпочтительная вакцинация представляет вакцинацию против инфекционных заболеваний, например, бактериальных, протозойных или вирусных инфекций, и противоопухолевую вакцинацию. Такие процедуры вакцинации могут быть профилактическими или терапевтическими.
В зависимости от заболевания, подлежащего лечению, или заболевания, которое нужно предотвратить, может быть выбрана ORF. Например, открытая рамка считывания может кодировать белок, который должен быть доставлен пациенту, страдающему от полного отсутствия или, по меньшей мере, частичной потери функции белка, например, пациенту с генетическим заболеванием. Кроме того, открытая рамка считывания может быть выбрана из ORF, кодирующих пептид или белок, который благотворно влияет на состояние больного субъекта. Кроме того, открытая рамка считывания может кодировать пептид или белок, который приводит к снижению регуляции патологически избыточной выработки природного пептида или белка или к элиминации клеток, экспрессирующих патологический белок или пептид. Такой недостаток, потеря функции или патологически избыточная выработка, могут, например, возникать в случае опухоли и неоплазии, аутоиммунных заболеваний, аллергии, инфекций, хронических заболеваний или других заболеваний. Кроме того, открытая рамка считывания может кодировать антиген или иммуноген, например, эпитоп патогена или опухолевого антигена. Таким образом, в предпочтительных вариантах осуществления настоящего изобретения молекула искусственной нуклеиновой кислоты или вектор в соответствии с настоящим изобретением содержит ORF, кодирующую аминокислотную последовательность, содержащую или состоящую из антигена или иммуногена, например, эпитоп патогена или связанный с опухолью антиген, 3'-UTR-элемент согласно описанному выше и/или 5'-UTR-элемент согласно описанному выше и необязательные дополнительные компоненты, например, поли(А) последовательность и другие.
В контексте медицинского применения, в частности, в контексте вакцинации, предпочтительно, чтобы молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением представляла собой РНК, предпочтительно мРНК, поскольку ДНК несет риск вызова иммунного ответа против ДНК и имеет тенденцию встраиваться в геномную ДНК. Однако в некоторых вариантах осуществления настоящего изобретения, например, если применяют в качестве носителя вирус, например аденовирус для доставки молекулы искусственной нуклеиновой кислоты или вектора в соответствии с настоящим изобретением, например, в контексте лечения методами генной терапии, может быть желательно, чтобы молекула искусственной нуклеиновой кислоты или вектор были молекулой ДНК.
Молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическая композиция в соответствии с настоящим изобретением могут вводиться перорально, парентерально, путем ингаляционного спрея, местно, ректально, назально, буккально, вагинально, через имплантированный резервуар или путем инъекции струей. Понятие «парентерально» в настоящем изобретении означает метод введения подкожный, внутривенный, внутримышечный, внутрисуставной, внутрисинусовый, внутригрудинный, интратекальный, внутрипеченочный, внутриочаговый, внутричерепной, трансдермальный, внутрикожный, внутрилегочный, внутрибрюшинный, внутрисердечный, внутриартериальный и сублингвальный путем инъекции или инфузии. В предпочтительном варианте осуществления настоящего изобретения молекулу искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическую композицию в соответствии с настоящим изобретением вводят посредством инъекции без иглы (например, безыгольным впрыскиванием).
Предпочтительно молекулу искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическую композицию в соответствии с настоящим изобретением вводят парентерально, например, путем парентеральной инъекции, более предпочтительно подкожно, внутривенно, внутримышечно, внутрисуставно, внутрисиновиально, интрастернально, интратекально, внутрипеченочно, внутричерепной инъекцией, чрезкожно, внутрикожно, внутрилегочно, внутрибрюшинно, внутрисердечно, внутриартериально, подъязычной инъекцией или с помощью инфузионных методов. Особенно предпочтительными являются внутрикожная и внутримышечная инъекции. Стерильные инъекционные формы фармацевтической композиции по настоящему изобретению могут быть водной или масляной суспензией. Эти суспензии могут быть переработаны в соответствии со способами, известными специалистам в данной области, с использованием подходящих диспергирующих или смачивающих агентов и суспендирующих агентов. Предпочтительно растворы или суспензии вводят посредством инъекции без иглы (например, безыгольным впрыскиванием).
Молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическую композицию в соответствии с настоящим изобретением также могут вводить орально в орально приемлемых дозовых формах, включая, но ими не ограничиваясь, капсулы, таблетки, водные суспензии или растворы.
Молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическую композицию в соответствии с настоящим изобретением также могут вводить местно, особенно когда мишень для лечения представляет часть органа, легко доступную для местного введения, например, при заболеваниях кожи или каких-либо других доступных эпителиальных тканей. Соответствующие местные составы легко приготовить для каждого из таких мест тела или органов. Для местного применения молекула искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектор в соответствии с настоящим изобретением, клетки в соответствии с настоящим изобретением или фармацевтическая композиция в соответствии с настоящим изобретением могут быть переработаны в подходящей мази, суспендированной или растворенной в одном или нескольких носителях.
В одном варианте осуществления настоящего изобретения применение в качестве лекарственного средства включает стадию трансфекции клеток млекопитающих, предпочтительно трансфекцию клеток млекопитающих in vitro или ex vivo, более предпочтительно трансфекцию in vitro выделенных клеток субъекта, подлежащего лечению лекарственным средством. Если применение включает трансфекцию in vitro выделенных клеток, применение в качестве лекарственного средства может дополнительно включать повторное введение трансфицированных клеток пациенту. Использование разработанных молекул искусственной нуклеиновой кислоты или вектора в качестве лекарственного средства может дополнительно включать стадию отбора успешно трансфицированных выделенных клеток. Таким образом, может оказаться полезным, если вектор дополнительно содержит селективный маркер. Кроме того, применение в качестве лекарственного средства может включать трансфекцию in vitro выделенных клеток и очистку продукта экспрессии, то есть закодированного пептида или белка из этих клеток. Этот очищенный пептид или белок затем может вводиться субъекту, нуждающемуся в этом.
Настоящее изобретение также относится к способу лечения или предупреждения заболевания или расстройства согласно описанному выше, включающему введение молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, вектора в соответствии с настоящим изобретением, клеток в соответствии с настоящим изобретением или фармацевтической композиции в соответствии с настоящим изобретением, субъекту, который в этом нуждается.
Кроме того, настоящее изобретение относится к способу лечения или предупреждения заболевания или расстройства, включающего трансфекцию клетки молекулой искусственной нуклеиновой кислоты в соответствии с настоящим изобретением или вектором в соответствии с настоящим изобретением. Указанная трансфекция может быть выполнена in vitro, ex vivo или in vivo. В предпочтительном варианте осуществления настоящего изобретения трансфекцию клетки осуществляют in vitro и трансфицированные клетки вводят субъекту, нуждающемуся в этом, предпочтительно субъекту человеку. Предпочтительно клетка, которая должна быть трансфицирована in vitro, является выделенной клеткой субъекта, предпочтительно пациента человека. Таким образом, настоящее изобретение относится к способу лечения, включающему стадии выделения клеток из субъекта, предпочтительно из человека, трансфицирования выделенных клеток искусственной нуклеиновой кислотой согласно настоящему изобретению или вектором согласно настоящему изобретению, и введения трансфицированных клеток субъекту, предпочтительно пациенту человека.
Способ лечения или профилактики расстройства по настоящему изобретению предпочтительно представляет способ вакцинации или способ генной терапии, описанные выше.
Выше было описано, что представленный в настоящем изобретении элемент 3'-UTR и/или представленный в настоящем изобретении элемент 5'-UTR способны продлевать и/или увеличивать выработку белка с мРНК. Таким образом, другой объект настоящего изобретения относится к способу увеличения и/или продления выработки белка с молекулы искусственной нуклеиновой кислоты, предпочтительно с молекулы мРНК или вектора, который включает стадию ассоциации открытой рамки считывания с элементом 3'-UTR и/или элементом 5'-UTR, причем элемент 3'-UTR и/или элемент 5'-UTR продлевает и/или увеличивает выработку белка с получаемой молекулы искусственной нуклеиновой кислоты, и по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR является производным от стабильной мРНК, для получения молекулы искусственной нуклеиновой кислоты, предпочтительно молекулы мРНК по настоящему изобретению согласно описанному выше, или вектора по настоящему изобретению согласно описанному выше.
Предпочтительно способ повышения и/или продления выработки белка с молекулы искусственной нуклеиновой кислоты, предпочтительно с молекулы мРНК или вектора, причем в соответствии с настоящим изобретением элемент 3'-UTR и/или элемент 5'-UTR включает или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR и/или 5'-UTR транскрипта гена, выбранного из группы, состоящей из GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глютатион S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), LTA4H, SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, GRAMD1C, C11orf80, C9orf46, ANXA4, TBCK, IFI6, C2orf34, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, NT5DC1, RAB7A, AGA, TPK1, MBNL3, HADHB, MCCC2, CAT, ANAPC4, РССВ, PHKB, АВСВ7, PGCP, GPD2, ТМЕМ38В, NFU1, ОМА1, LOC128322/NUTF2, NUBPL, LANCL1, HHLA3, PIR, АСАА2, CTBS, GSTM4, ALG8, Atp5e, Gstm5, Uqcr11, Ifi27I2a, Anapc13, Atp5I, Tmsb10, Nenf, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Snrpd2, Mgst3, Aldh2, Ssr4, Myl6, Prdx4, Ubl5, 1110001J03Rik, Ndufa13, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufs5, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Hexa, Ndufb11, Map1lc3a, Gpx4, Mif, Cox6b1, RIKEN CDNA2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Ndufb8, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrpl23, Uba52, Tomm6, Mtch1, Pcbd2, Ecm1, Hrsp12, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappc6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Rps4x, Rps13, Ybx1, Sepp1, Gaa, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, DHRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, COX11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, CNTN1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1; предпочтительно из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глютатион S-трансфераза, mu 1), NDUFA1 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), Ybx1 (Y-Box связывающий белок 1), Ndufb8 (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8) и CNTN1 (контактин 1).
Понятие «ассоциация молекулы искусственной нуклеиновой кислоты или вектора с элементом 3'-UTR и/или элементом 5'-UTR» в контексте настоящего изобретения предпочтительно означает функциональное связывание или функциональное объединение молекулы искусственной нуклеиновой кислоты или вектора с элементом 3'-UTR и/или с элементом 5'-UTR. Это означает, что молекула искусственной нуклеиновой кислоты или вектор и элемент 3'-UTR и/или элемент 5'-UTR, предпочтительно элемент 3'-UTR и/или 5'-UTR-элемент, описанные выше, ассоциированы или связаны таким образом, что действует функция элемента 3'-UTR и/или элемента 5'-UTR, например продления и/или увеличения количества РНК и/или белка. Обычно это означает, что элемент 3'-UTR и/или элемент 5'-UTR интегрируют в молекулу искусственной нуклеиновой кислоты или в вектор, предпочтительно в молекулу мРНК, 3' и/или 5', соответственно, к открытой рамке считывания, предпочтительно сразу с 3' в открытую рамку считывания и/или сразу с 5' в открытую рамку считывания, элемент 3'-UTR предпочтительно между открытой рамкой считывания и поли(А) последовательностью или сигналом полиаденилирования. Предпочтительно элемент 3'-UTR и/или элемент 5'-UTR интегрируют в молекулу искусственной нуклеиновой кислоты или вектор, предпочтительно мРНК, в виде 3'-UTR и/или как 5'-UTR соответственно, таким образом, что элемент 3'-UTR и/или элемент 5'-UTR представляет 3'-UTR и/или 5'-UTR, соответственно, молекулы искусственной нуклеиновой кислоты или вектора, предпочтительно мРНК, то есть таким образом, что 5'-UTR заканчивается непосредственно перед 5'-концом ORF, а 3'-UTR простирается от 3'-стороны открытой рамки считывания до 5'-стороны поли(А) последовательности или полиаденилирующего сигнала, необязательно связанный посредством короткого линкера, например такой последовательностью, содержащей из одного или нескольких сайтов рестрикции. Таким образом, предпочтительно, понятие «ассоциация молекулы искусственной нуклеиновой кислоты или вектора с элементом 3'-UTR и/или элементом 5'-UTR» означает функциональную ассоциацию элемента 3'-UTR и/или элемента 5'-UTR с открытой рамкой считывания, расположенной внутри молекулы искусственной нуклеиновой кислоты или вектора, предпочтительно в молекуле мРНК. 3'-UTR и/или 5'-UTR и ORF являются такими, как описано выше для молекулы искусственной нуклеиновой кислоты в соответствии с настоящим изобретением, например, предпочтительно ORF и 3'-UTR являются гетерологичными и/или ORF и 5'-UTR являются гетерологичными соответственно, например, полученными от разных генов, что описано выше.
В другом объекте настоящего изобретения предусматривают применение элемента 3'-UTR и/или элемента 5'-UTR, преимущественно элемента 3'-UTR согласно описанному выше и/или элемента 5'-UTR согласно описанному выше, для увеличения и/или продления выработки белка с молекулы искусственной нуклеиновой кислоты, предпочтительно с молекулы мРНК или вектора, причем элемент 3'-UTR и/или элемент 5'-UTR включает или состоит из последовательности нуклеиновой кислоты, которая производна от 3'-UTR и/или 5'-UTR транскрипта гена, выбранного из группы, состоящей из GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глютатион S-трансфераза, mu 1), NDUFA1 (NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), LTA4H, SLC38A6, DECR1, PIGK, FAM175A, PHYH, TBC1D19, PIGB, ALG6, CRYZ, BRP44L, ACADSB, SUPT3H, ТМЕМ14А, GRAMD1C, C11orf80, C9orf46, ANXA4, ТВСК, IFI6, C2orD4, ALDH6A1, AGTPBP1, CCDC53, LRRC28, CCDC109B, PUS10, CCDC104, CASP1, SNX14, SKAP2, NDUFB6, EFHA1, BCKDHB, BBS2, LMBRD1, ITGA6, HERC5, NT5DC1, RAB7A, AGA, TPK1, MBNL3, HADHB, MCCC2, CAT, ANAPC4, PCCB, PHKB, ABCB7, PGCP, GPD2, TMEM38B, NFU1, OMA1, LOC128322/NUTF2, NUBPL, LANCL1, HHLA3, PIR, ACAA2, CTBS, GSTM4, ALG8, Atp5e, Gstm5, Uqcr11, Ifi27I2a, Anapc13, Atp5I, Tmsb10, Nenf, Ndufa7, Atp5k, 1110008P14Rik, Cox4i1, Cox6a1, Ndufs6, Sec61b, Romo1, Snrpd2, Mgst3, Aldh2, Ssr4, Myl6, Prdx4, Ubl5, 1110001J03Rik, Ndufa13, Ndufa3, Gstp2, Tmem160, Ergic3, Pgcp, Slpi, Myeov2, Ndufs5, 1810027O10Rik, Atp5o, Shfm1, Tspo, S100a6, Taldo1, Bloc1s1, Hexa, Ndufb11, Map1lc3a, Gpx4, Mif, Cox6b1, RIKEN cDNA2900010J23 (Swi5), Sec61g, 2900010M23Rik, Anapc5, Mars2, Phpt1, Ndufb8, Pfdn5, Arpc3, Ndufb7, Atp5h, Mrpl23, Uba52, Tomm6, Mtch1, Pcbd2, Ecm1, Hrsp12, Mecr, Uqcrq, Gstm3, Lsm4, Park7, Usmg5, Cox8a, Ly6c1, Cox7b, Ppib, Bag1, S100a4, Bcap31, Tecr, Rabac1, Robld3, Sod1, Nedd8, Higd2a, Trappc6a, Ldhb, Nme2, Snrpg, Ndufa2, Serf1, Oaz1, Rps4x, Rps13, Ybx1, Sepp1, Gaa, ACTR10, PIGF, MGST3, SCP2, HPRT1, ACSF2, VPS13A, CTH, NXT2, MGST2, C11orf67, PCCA, GLMN, DHRS1, PON2, NME7, ETFDH, ALG13, DDX60, DYNC2LI1, VPS8, ITFG1, CDK5, C1orf112, IFT52, CLYBL, FAM114A2, NUDT7, AKD1, MAGED2, HRSP12, STX8, ACAT1, IFT74, KIFAP3, CAPN1, СОХ11, GLT8D4, HACL1, IFT88, NDUFB3, ANO10, ARL6, LPCAT3, ABCD3, COPG2, MIPEP, LEPR, C2orf76, ABCA6, LY96, CROT, ENPP5, SERPINB7, TCP11L2, IRAK1BP1, CDKL2, GHR, KIAA1107, RPS6KA6, CLGN, TMEM45A, TBC1D8B, ACP6, RP6-213H19.1, SNRPN, GLRB, HERC6, CFH, GALC, PDE1A, GSTM5, CADPS2, AASS, TRIM6-TRIM34 (сквозной транскрипт), SEPP1, PDE5A, SATB1, CCPG1, CNTN1, LMBRD2, TLR3, BCAT1, TOM1L1, SLC35A1, GLYATL2, STAT4, GULP1, EHHADH, NBEAL1, KIAA1598, HFE, KIAA1324L и MANSC1; предпочтительно из группы, включающей GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий комплексный локус), MORN2 (MORN-повтор содержащий 2), GSTM1 (глютатион S-трансфераза, mu 1), NDUFA1 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс), CBR2 (карбонилредуктаза 2), МР68 (RIKEN кДНК 2010107Е04 ген), NDUFA4 (NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4), Ybx1 (Y-Box связывающий белок 1), Ndufb8 (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8) и CNTN1 (контактин 1).
Применение в соответствии с настоящим изобретением предпочтительно включает связывание молекулы искусственной нуклеиновой кислоты, вектора или РНК с элементом 3'-UTR согласно описанному выше и/или с элементом 5'-UTR согласно описанному выше.
Соединения и ингредиенты фармацевтической композиции по настоящему изобретению могут также изготавливаться и продаваться отдельно друг от друга. Таким образом, изобретение относится также к набору или набору частей, содержащих молекулу искусственной нуклеиновой кислоты по настоящему изобретению, вектор по настоящему изобретению, клетки по настоящему изобретению и/или фармацевтическую композицию по настоящему изобретению. Предпочтительно такой набор или наборы частей может дополнительно содержать инструкции по применению, клетки для трансфекции, адъювант, средства для введения фармацевтической композиции, фармацевтически приемлемый носитель и/или фармацевтически приемлемый раствор для растворения или разбавления молекулы искусственной нуклеиновой кислоты, вектора, клеток или фармацевтической композиции.
В другом объекте настоящего изобретения предусматривают способ идентификации элемента 3'-нетранслируемой области (элемента 3'-UTR) и/или элемента 5'-нетранслируемой области (элемента 5'-UTR), который является производным стабильной мРНК, включающий следующие стадии:
а. анализа стабильности мРНК, включающего подстадии:
i. определения количества мРНК в первой временной точке во время процесса распада указанной мРНК,
ii. определения количества мРНК во второй временной точке во время процесса распада указанной мРНК, и
iii. рассчета соотношения количества указанной мРНК, определенной на стадии (i), к количеству указанной мРНК, определенной на стадии (ii);
б. отбора стабильных мРНК, у которых соотношение, рассчитанное на подстадии (iii), составляет по меньшей мере 0,5 (50%), по меньшей мере 0,6 (60%), по меньшей мере 0,7 (70%), по меньшей мере 0,75 (75%), по меньшей мере 0,8 (80%), по меньшей мере 0,85 (85%), по меньшей мере 0,9 (90%) или по меньшей мере 0,95 (95%); а также
в. определения нуклеотидной последовательности элемента 3'-UTR и/или элемента 5'-UTR указанной стабильной мРНК.
Таким образом, стабильность мРНК предпочтительно оценивают в стандартных условиях, например стандартных условиях (стандартная среда, инкубация и т.д.) для определенной линии клеток или используемого типа клеток.
Для анализа стабильности мРНК процесс распада мРНК оценивают путем определения количества или концентрации указанной мРНК в первой и во второй временных точках во время процесса распада указанной мРНК (см. стадии a) i. и а) ii).
Для определения количества или концентрации мРНК во время процесса распада РНК in vivo или in vitro согласно описанному выше (т.е. in vitro, относящиеся, в частности, к («живым») клеткам и/или тканям, включая ткань живого субъекта; применяют определенные клеточные линии, первичные клетки, клетки в ткани или в субъектах, предпочтительными являются клетки млекопитающих, например клетки человека и клетки мыши, особенно предпочтительными являются линии клеток человека HeLa и U-937, а также линии клеток мыши NIH3T3, JAWSII и L929; кроме того, особенно предпочтительными являются первичные клетки, в особенно предпочтительных вариантах осуществления настоящего изобретения дермальные фибробласты человека (HDF)), могут быть применены различные методы, известные специалистам в данной области. К примерам, не ограничивающим области охвата настоящего изобретения, относят методы общего подавления транскрипции, например, ингибитором транскрипции, таким как актиномицин D, использование индуцируемых промоторов для специфической индукции временной транскрипции, например, c-fos-индуцибельную промоторную систему и регуляторную промоторную систему Tet-off, а также методы кинетической маркировки, например, импульсной маркировки.
Например, если на стадии а) применяют арест транскрипции, опосредованный ингибитором транскрипции, для определения количества или концентрации мРНК во время процесса распада РНК in vivo или in vitro согласно описанному выше, могут быть применены ингибиторы транскрипции, например, актиномицин D (ActD), 5, 6-дихлор-1-D-рибофуранозил-бензимидазол (DRB) или α-аманитин (α-Am). Таким образом, для оценки распада мРНК ингибиторы транскрипции обычно добавляют к клеткам и обычно в результате ингибируется транскрипция, и расщепление РНК можно наблюдать без помехи в виде непрерывной транскрипции.
В другом варианте индуцируемые промоторы для специфической индукции временной транскрипции могут быть применены на стадии а), при этом задача заключается в том, чтобы обеспечить стимул, который активирует транскрипцию и приводит к всплеску синтеза мРНК, затем удаляют стимул, чтобы отключить транскрипцию и контролировать распад мРНК. Таким образом, индуцибельный промотор обеспечивает строгий контроль, поэтому индукция и глушение транскрипции осуществляются в узком временном диапазоне. Известно, что в клетках млекопитающих промотор cfos полезен для этой цели, поскольку он может быть индуцирован в ответ на быстрое и временное добавление сыворотки, тем самым обеспечивая надежный и простой способ достижения временного всплеска транскрипции. Система промотора Tet-off обеспечивает еще одну возможность, еще больше расширяя применение импульсного подхода к транскрипции для изучения оборота мРНК в клетках млекопитающих.
Однако в настоящем изобретении методы кинетической маркировки предпочтительны на стадии а) для определения количества мРНК во время процесса распада РНК in vivo или in vitro согласно описанному выше. В кинетической маркировке обычно маркируют РНК, причем метку включают в определенные меченые нуклеотиды и меченые нуклеозиды, и особенно предпочтительными являются меченый уридин и меченый урацил. Примеры предпочтительных меток включают 4-тиоуридин (4sU), 2-тиоуридин, 6-тиогуанозин, 5-этинилуридин (ЕС), 5-бром-уридин (BrU), биотин-16-аминоаниллилуридин, 5-аминоаллилуридин, 5-аминоаллилцитидин, и т.д., где более предпочтительными являются 4-тиоуридин (4sU), 5-этинилуридин (ЕС) или 5'-бром-уридин (BrU). Особенно предпочтительным является 4-тиоуридин (4sU). 4-Тиоуридин (4sU) предпочтительно используют в концентрации 100-500 мкМ. Кроме того, могут быть использованы также радиоактивно меченые нуклеотиды, например, уридин-3Н. Также могут быть использованы комбинации вышеуказанных меченых нуклеотидов, в связи с чем особенно предпочтительна комбинация 4-тиоуридина и 6-тиогуанозина.
При кинетической маркировке обычно образующуюся РНК метят, например, путем включения маркированного уридина или урацила во время транскрипции. Через некоторое время поступление метки прекращают, и затем распад РНК можно наблюдать путем оценки специфически меченной РНК, не ингибируя транскрипцию в целом.
Для определения количества мРНК во время процесса распада РНК на стадии а) предпочтительна импульсная маркировка, и особенно предпочтительна методика вытеснения метки. Используемое в настоящем изобретении понятие «импульсная маркировка» относится к методу, в котором метка, например, описанная выше метка, используется для измерения скоростей синтеза и/или распада соединений в живых клетках. Обычно клетки подвергаются воздействию небольшого количества метки на протяжении короткого периода, поэтому применяют понятие «импульс». В методе импульсного вытеснения после импульсной маркировки обычно требуется значительно большее количество немеченого соединения, соответствующего «импульсу» (например, немеченный уридин, если уридин с меткой используют в качестве импульса) добавляют в течение требуемого периода обработки меткой. Эффект конкуренции между меченым и немеченым соединением заключается в том, чтобы уменьшить до незначительного уровня дальнейшее поглощение меченого соединения, отсюда понятие «вытеснение».
Для определения количества или концентрации мРНК обычно необходимо выделить мРНК. Специалистам в данной области техники известны различные методы выделения РНК, например, экстракция гуанидинием тиоцианат-фенол-хлороформом или выделение на основе капиллярной кварцевой колонки. Также можно применять доступные наборы, например, набор RNeasy фирмы Qiagen.
Кроме того, может потребоваться стадия выделения, в частности, если используют кинетическую маркировку (в отличие от ингибитора транскрипции, где полная РНК представляет собой «разрушающуюся» РНК, поскольку транскрипция обычно ингибируется). На стадии экстракции меченую РНК (то есть представляющую «разрушающуюся» РНК) экстрагируют из общей выделенной РНК. Таким образом, средства извлечения могут быть выбраны в зависимости от используемой метки. Например, можно применять иммуноочистку антителами к метке.
Кроме того, например, для извлечения тио-меченых молекул РНК, например, меченых 4-тиоуридином (4sU), HPDP-биотин (активированный пиридилдитиолом, сульфгидрил-реактивный реагент биотинилирования, который конъюгирует через расщепляемую (обратимую) дисульфидную связь), может быть инкубирован с выделенной «полной РНК». Этот реагент специфически реагирует с восстановленными тиолами (-SH) в РНК, меченой 4-тиоуридином (4SU), с образованием обратимых дисульфидных связей. Биотинилирование позволяет связывать тио-меченые, например. 4-тиоуридином (4SU), РНК со стрептавидином, и поэтому РНК может быть выделена из общей РНК путем восстановления дисульфидной связи с дитиотреитолом или бета-меркаптоэтанолом (или каким-либо другим восстанавливающим агентом).
В случае меченых биотином нуклеотидов, например, биотин-16-аминоаллилуридина, стрептавидин можно непосредственно применять для извлечения меченой РНК из общей РНК.
Например, для извлечения вновь транскрибированных меченных 5-этинилуридином (ЕС) РНК из общей РНК может быть использовано биотинилирование ЕС в катализируемой медью реакции циклоприсоединения (часто называемой клик-химией), за которой следует аффинная очистка с применением стрептавидина. Этот метод коммерчески доступен в виде набора для захвата РНК (Click-iT Nascent RNA Capture Kit (номнр в каталоге С10365, фирма Invitrogen). В инструкции изготовителя этого набора рекомендуют, чтобы время импульсной маркировки составляло от 30 до 60 минут для дозы 0,5 мМ ЕС или от 1 до 24 часов для дозы 0,1 или 0,2 мМ ЕС.
Например, BrU-меченые молекулы РНК могут быть экстрагированы путем иммуноочистки антителом против бромдезоксиуридина (например, клон 2 В1, номер в каталоге MI-11-3, фирма MBL) и белком G-сефарозой.
Количество или концентрация мРНК, то есть уровень транскрипта, затем могут быть измерены различными методами, известными специалистам в данной области. Примерами таких методов, не ограничивающих рамок охвата настоящего изобретения, являются микроматричный анализ, нозерн-блоттинг, количественная ПЦР или секвенирование нового поколения (высокопроизводительное секвенирование). Особенно предпочтительными являются микроматричный анализ и секвенирование нового поколения. Кроме того, особенно предпочтительны цельногеномные подходы к геному в целом/анализ целых транскриптом, например, микроматричный анализ всего генома, например, Affymetrix Human Gene 1.0 ST, или 2.0 ST, или Affymetrix Mouse Gene 1.0 ST, или 2.0 ST, или микроматричный анализ всего транскриптома с последующим секвенированием.
На субстадиях i. и ii. стадии а) количество мРНК определяют в первой и во второй временных точках во время процесса распада мРНК. Обычно это означает, что выделяют мРНК в первой и во второй временных точках во время процесса распада мРНК для определения соответствующих количеств мРНК. Таким образом, понятия «в первый момент времени» и «во второй момент времени» относятся, в частности, к таким моментам в ходе распада РНК, когда РНК выделяют для определения ее количества. Соответственно, «второй момент времени» наступает позже по ходу распада РНК, чем «первый момент времени».
Предпочтительно, первый момент времени выбирают таким образом, чтобы рассматривать только мРНК, подвергающуюся процессу распада, то есть возникающая мРНК, например, в результате продолжающейся транскрипции, исключается. Например, если применяют методы кинетической маркировки, например, импульсной маркировки, первую временную точку предпочтительно выбирают таким образом, чтобы включение метки в мРНК завершалось, то есть не происходило постоянного включения метки в мРНК. Таким образом, если используют кинетическую маркировку, первый момент времени может составлять по меньшей мере 10 мин, по меньшей мере 20 мин, по меньшей мере 30 мин, по меньшей мере 40 мин, по меньшей мере 50 мин, по меньшей мере 60 мин, по меньшей мере 70 мин, по меньшей мере, 80 мин или по меньшей мере 90 мин после окончания процедуры маркировки, например после окончания инкубации клеток с меткой.
Например, первая временная точка может быть предпочтительно через от 0 до 6 ч после остановки транскрипции (например, вызванной ингибитором транскрипции), остановки индукции промотора в случае индуцибельных промоторов или после прекращения подачи импульса или метки, например, после окончания маркировки. Более предпочтительно, первая временная точка может быть в интервале от 30 мин до 5 ч, еще более предпочтительно от 1 ч до 4 ч и особенно предпочтительно примерно через 3 ч после прекращения транскрипции (например, вызванного ингибитором транскрипции), прекращения индукции промотора в случае индуцируемых промоторов или после прекращения подачи импульсов или меток, например после окончания маркировки.
Предпочтительно вторую временную точку выбирают как можно позже во время процесса распада мРНК. Однако, если рассматривают множество видов мРНК, вторую временную точку предпочтительно выбирают таким образом, что все еще значительное количество видов мРНК из имеющегося множества мРНК, предпочтительно по меньшей мере 10% видов мРНК, содержится в фиксируемом количестве, то есть более 0. Предпочтительно вторая временная точка наступает через по меньшей мере 5 ч, по меньшей мере 6 ч, по меньшей мере 7 ч, по меньшей мере 8 ч, по меньшей мере 9 ч, по меньшей мере 10 ч, по меньшей мере 11 ч, по меньшей мере 12 ч, по меньшей мере 13 ч, по меньшей мере 14 ч или по меньшей мере 15 ч после остановки транскрипции (например, ингибитором транскрипции), после индукции промотора в случае индуцируемых промоторов или после прекращения подачи импульса или метки, например после окончания маркировки.
Например, вторая временная точка может быть предпочтительно от 3 до 48 ч после прекращения транскрипции (например, ингибитором транскрипции), остановки индукции промотора в случае индуцибельных промоторов или после прекращения подачи импульса или метки, например, после окончания маркировки. Более предпочтительно, вторая временная точка может быть через от 6 мин до 36 ч, еще более предпочтительно от 10 ч до 24 ч и особенно предпочтительно примерно через 15 ч после прекращения транскрипции (например, ингибитором транскрипции), прекращения индукции промотора в случай индуцируемых промоторов или после прекращения подачи импульсов или меток, например после окончания маркировки.
Таким образом, временной интервал между первой временной точкой и второй временной точкой предпочтительно является максимально возможным в указанных выше интервалах. Следовательно, временной интервал между первой временной точкой и второй временной точкой составляет предпочтительно не менее 4 ч, по меньшей мере 5 ч, по меньшей мере 6 ч, по меньшей мере 7 ч, по меньшей мере 8 ч, по меньшей мере 9 ч, по меньшей мере 10 ч, по меньшей мере 11 ч или по меньшей мере 12 ч, причем особенно предпочтительным является временной интервал примерно в 12 ч. В общем, второй временной интервал по меньшей мере на 10 мин позже первого временного интервала.
На субстадии iii. стадии а) рассчитывают отношение количества мРНК, определенного на стадии (i), к количеству мРНК, определенного на стадии (ii). С этой целью количество мРНК (уровень транскрипта), определенное согласно описанному выше во второй временной точке, делят на количество мРНК (уровень транскрипта), определенное согласно описанному выше в первой временной точке. Это соотношение показывает, что стабильные мРНК, которые уже в первый момент времени присутствуют только в очень малых количествах, не учитываются в отношении мРНК, которые присутствуют в больших количествах.
На стадии б) выбирают такую мРНК, которая имеет соотношение, вычисленное на субстадии (iii) стадии а) и составляющее по меньшей мере 0,5 (50%), по меньшей мере 0,6 (60%), по меньшей мере 0,7 (70%), по меньшей мере 0,75 (75%), по меньшей мере 0,8 (80%), по меньшей мере 0,85 (85%), по меньшей мере 0,9 (90%) или по меньшей мере 0,95 (95%). Такую мРНК в настоящем изобретении рассматривают в качестве особенно стабильной мРНК.
На стадии в) определяют нуклеотидную последовательность элемента 3'-UTR и/или элемента 5'-UTR указанной мРНК, то есть мРНК, выбранной на стадии б). С этой целью могут быть применены различные способы, известные специалистам в данной области, например, секвенирования или выбора из общедоступной базы данных, например, из NCBI (National Center for Biotechnology Information - Национальный центр биотехнологической информации). Например, по последовательности мРНК, выбранной на стадии б), может быть проведен поиск в базе данных, и 3'-UTR и/или элемента 5'-UTR могут быть получены из последовательности мРНК, присутствующей в базе данных.
В частности, в описанном выше способе идентификации элемент 3'-нетранслируемой области (3'-UTR-элемент) и/или элемент 5'-нетранслируемой области (5'-UTR-элемент), который является производным от стабильной мРНК, понятия «мРНК» и/или «стабильная мРНК» соответственно могут также относиться к виду мРНК, описанному в настоящем изобретении, и/или к виду стабильной мРНК, соответственно.
Кроме того, в предпочтительном варианте осуществления настоящего изобретения «стабильная мРНК» может иметь более медленный распад мРНК по сравнению со средним распадом мРНК, предпочтительно оцениваемым in vivo или in vitro согласно описанному выше. Таким образом, «средний распад мРНК» может быть оценен путем исследования распада множества видов мРНК.
Соответственно, настоящее изобретение предусматривает еще один вариант способа идентификации элемента 3'-нетранслируемой области (элемент 3'-UTR) и/или элемента 5'-нетранслируемой области (элемент 5'-UTR), который является производным стабильной мРНК, включающего следующие стадии:
а. анализа стабильности множества видов мРНК, включающего следующие подстадии:
i. определения количества мРНК каждого вида из указанного множества видов мРНК в первой временной точке во время процесса распада указанных видов мРНК,
ii. определения количества мРНК каждого вида из указанного множества видов мРНК во второй временной точке во время процесса распада указанных видов мРНК, и
iii. рассчета соотношения количества мРНК каждого вида из указанного множества видов мРНК, определенного на стадии (i), к количеству мРНК каждого вида из указанного множества, определенного на стадии (ii);
б. ранжирования видов мРНК из множества видов мРНК в соответствии с соотношением, рассчитанным на подстадии (iii) для каждого вида мРНК;
в. отбора одного или нескольких видов мРНК, имеющих наивысшее соотношение или наивысшие соотношения, рассчитанные на подстадии (iii); и
г. Определения нуклеотидной последовательности элемента 3'-UTR и/или элемента 5'-UTR указанной стабильной мРНК.
В контексте настоящего изобретения понятие «вид мРНК» означает единицу геномного транскрипта, т.е. обычно ген. В рамках «одного вида мРНК» могут быть разные транскрипты, например, из-за процессинга мРНК. Например, вид мРНК может быть представлен пятном на микрочипе. Соответственно микрочип представляет перспективный инструмент для определения количества видов мРНК в множесте молекул, например, в определенной точке времени в ходе распада мРНК. Однако специалистам также известны другие методы, которые могут быть применены, например, RNA-seq (также метод называется методом дробовика для секвенирования целого транскриптома), количественной ПЦР и другие.
Предпочтительно понятие «множество видов мРНК» относится по меньшей мере к 100, по меньшей мере к 300, по меньшей мере к 500, по меньшей мере к 1000, по меньшей мере к 2000, по меньшей мере к 3000, по меньшей мере к 4000, по меньшей мере к 5000, по меньшей мере к 6000, по меньшей мере к 7000, по меньшей мере к 8000, по меньшей мере к 9000, по меньшей мере к 10000, по меньшей мере к 11000, по меньшей мере к 12000, по меньшей мере к 13000, по меньшей мере к 14000, по меньшей мере к 15000, по меньшей мере к 16000, по меньшей мере к 17000, по меньшей мере к 18000, по меньшей мере к 19000, по меньшей мере к 20000, по меньшей мере к 21000, по меньшей мере к 22000, по меньшей мере к 23000, по меньшей мере к 24000, по меньшей мере к 25000, по меньшей мере к 26000, по меньшей мере к 27000, по меньшей мере к 28000, по меньшей мере к 29000 или по меньшей мере к 30000 видам мРНК. Особенно предпочтительно, если оценивают весь транскриптом, или так много видов мРНК транскриптома, кнасколько это возможно. Это может быть достигнуту, например, за счет применения микрочипа, обеспечивающего покрытие всего транскрипта.
Стадия а) этого способа с субстадиями i.-iii. по существу соответствует стадии а) с субстадиями i.-iii. ранее описанного способа, но отличается только тем, что количество каждого вида мРНК из множества видов мРНК определяют в первую и во вторую временные точки, и тем, что соотношение рассчитывают для каждого вида мРНК. Соответственно, в настоящем изобретении подробно описанные способы и предпочтительные варианты осуществления настоящего изобретения, описанные выше, применяют в настоящем изобретении, а также соотношение для отдельных видов мРНК (и для каждого отдельного вида мРНК, соответственно) может быть определено так же, как описано выше для «мРНК».
Однако, в отличие от указанного выше способа, стабильность мРНК оценивают не по абсолютной величине соотношения, а по ранжированию видов мРНК из множества видов мРНК в соответствии с соотношением, вычисленным на субстадии (iii) стадии а) для каждого вида мРНК. Затем на субстадии в) выбирают один или несколько видов мРНК, имеющих наивысшее соотношение или наивысшие соотношения, вычисленные на субстадии (iii) стадии а).
В этом контексте особенно предпочтительно выбрать 0,1%, 0,2%, 0,3%, 0,4%, 0,5%, 0,6%, 0,7%, 0,8%, 0,9%, 1%, 2%, 3%, 4%, 5%, 10%, 15%, 20% наиболее стабильных видов мРНК на стадии в). В другом варианте или дополнительно на стадии в) могут быть выбраны такие виды мРНК, у которых соотношение, вычисленное на субстадии iii. стадии а), соответствуют по меньшей мере 100% среднего соотношения, рассчитанного по всем исследованным видам мРНК. Более предпочтительно выбирают такие виды мРНК, которые показывают соотношение, составляющее по меньшей мере 150%, еще более предпочтительно по меньшей мере 200% и наиболее предпочтительно по меньшей мере 300% от среднего соотношения, рассчитанного по всем проанализированным видам мРНК.
На стадии г) нуклеотидную последовательность элемента 3'-UTR и/или элемента 5'-UTR мРНК, выбранной на стадии в), определяют согласно описанному выше для стадии в) ранее описанного способа по настоящему изобретению.
Предпочтительно в обоих описанных выше способах идентификации элемента 3'-UTR и/или элемента 5'-UTR мРНК в соответствии с настоящим изобретением период времени между первой временной точкой и второй временной точкой составляет по меньшей мере 5 ч, предпочтительно по меньшей мере 6 ч, предпочтительно по меньшей мере 7 ч, более предпочтительно по меньшей мере 8 ч, более предпочтительно по меньшей мере 9 ч, еще более предпочтительно по меньшей мере 10 ч, еще более предпочтительно по меньшей мере 11 ч и особенно предпочтительно по меньшей мере 12 ч.
Предпочтительно в обоих описанных выше способах идентификации элемента 3'-UTR и/или элемента 5'-UTR мРНК в соответствии с настоящим изобретением стабильность мРНК анализируют путем импульсной маркировки, предпочтительно с использованием метода вытеснения метки.
В другом варианте осуществления настоящего изобретения также предусматривают способ идентификации элемента 3'-нетранслируемой области (элемент 3'-UTR) и/или элемента 5'-нетранслируемой области (элемент 5'-UTR), который продлевает и/или увеличивает выработку белка с молекулы искусственной нуклеиновой кислоты и которая является производной стабильной мРНК, включающий следующие стадии:
а) идентификации элемента 3'-UTR и/или элемента 5'-UTR, который происходит от стабильной мРНК, методом идентификации элемента 3'-UTR и/или элемента 5'-UTR по какому-либо способу, описанному выше:
б) синтеза молекулы искусственной нуклеиновой кислоты, содержащей, по меньшей мере, одну открытую рамку считывания и, по меньшей мере, один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR, который соответствует или состоит из элемента 3'-UTR и/или 5'-UTR, идентифицированных на стадии а);
в) анализа экспрессии белка, кодируемого по меньшей мере одной открытой рамкой считывания (ORF) молекулы искусственной нуклеиновой кислоты, синтезированной на стадии б);
г) анализа экспрессии белка, кодируемого, по меньшей мере, одной открытой рамкой считывания контрольной молекулы искусственной нуклеиновой кислоты без элемента 3'-UTR и/или элемента 5'-UTR;
д) сравнения экспрессии белка с молекулы искусственной нуклеиновой кислоты, проанализированной на стадии в), с экспрессией белка с контрольной молекулы искусственной нуклеиновой кислоты, проанализированной на стадии г); а также
е) отбора элемента 3'-UTR и/или элемент 5'-UTR, если экспрессия белка с молекулы искусственной нуклеиновой кислоты, проанализированная на стадии в), продлевается и/или увеличивается по сравнению с экспрессией белка с контрольной молекулы искусственной нуклеиновой кислоты, проанализированной на стадии г).
В этом способе сначала идентифицируют элемент 3'-UTR и/или элемент 5'-UTR способом по настоящему изобретению, описанным выше. Это позволяет синтезировать элемент 3'- и/или элемент 5'-UTR способами, известными специалистам в данной области техники, например, с помощью ПЦР-амплификации. Праймеры, используемые для такой ПЦР, предпочтительно могут содержать сайты рестрикции для клонирования. В другом варианте элемент 3'-UTR и/или элемент 5'-UTR может быть синтезирован, например, химическим синтезом или отжигом. Соответственно, на стадии б) синтезируют молекулу искусственной нуклеиновой кислоты, содержащую по меньшей мере одну открытую рамку считывания и по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR, который соответствует или состоит из элемента 3'-UTR и/или элемента 5'-UTR, идентифицированных на стадии а). В частности, по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR обычно объединяют с открытой рамкой считывания, что приводит к образованию искусственной нуклеиновой кислоты, содержащей элемент 3'-UTR и/или элемент 5'-UTR в соответствии с настоящим изобретением, если элемент 3'-UTR и/или элемент 5'-UTR соответствует в полной мере требованиям, то есть, если они продлевают и/или увеличивают экспрессию белка. Чтобы проверить это, элемент 3'-UTR и/или элемент 5'-UTR, идентифицированный на стадии а), или фрагмент ПЦР или его синтезированная последовательность, соответственно, могут быть клонированы в определенный вектор, предпочтительно в вектор экспрессии, чтобы оценить экспрессию белка с соответствующей ORF.
Экспрессия белка с молекулы искусственной нуклеиновой кислоты, содержащей по меньшей мере один элемент 3'-UTR и/или по меньшей мере один элемент 5'-UTR, затем оценивают на стадии в) согласно описанию настоящего изобретения и сравнивают с экспрессией белка, оценку которой получают на стадии г), с соответствующей контрольной молекулы искусственной нуклеиновой кислоты, не содержащей элемента 3'-UTR и/или элемента 5'-UTR согласно описанию настоящего изобретения на стадии д).
Затем на стадии е) выбирают такой элемент 3'-UTR и/или элемент 5'-UTR, который продлевает и/или увеличивает экспрессию белка с молекулы искусственной нуклеиновой кислоты, проанализированной на стадии в), по сравнению с экспрессией белка с контрольной молекулы искусственной нуклеиновой кислоты, исследованной на стадии г). Сравнение экспрессии белка с молекулы нуклеиновой кислоты по настоящему изобретению с экспрессией белка с исходной молекулы нуклеиновой кислоты осуществляют согласно описанию настоящего изобретения, в частности в контексте разработанной молекулы искусственной нуклеиновой кислоты по настоящему изобретению.
Кроме того, настоящее изобретение предусматривает особенно предпочтительный способ идентификации 3'-нетранслируемого элемента области (элемент 3'-UTR) и/или 5'-нетранслируемый элемент области (элемент 5'-UTR), который продлевает и/или увеличивает выработку белка с молекулы искусственной нуклеиновой кислоты, являющейся производной от стабильной мРНК; способ включает следующие стадии:
а. питания/инкубирования клеток с меченым нуклеотидом для инкорпорирования во вновь транскрибируемые молекулы РНК (пульс-вытеснение метки);
б. выделения общей РНК клеток в первой временной точке и, по меньшей мере, в одной более поздней второй временной точке;
в. выделения меченых молекул РНК из общей РНК, выделенной на стадии б);
г. измерения количества/уровня транскриптов разных видов мРНК в составе меченой РНК;
д. вычисления соотношения количества/уровня транскрипта видов мРНК, присутствующих по меньшей мере на одну секунду позже по времени, к количеству/уровню транскрипта видов мРНК, присутствующих в первой временной точке;
е. ранжирования видов мРНК в соответствии с соотношением, определенным на этапе д);
ж. отбора наиболее стабильных видов мРНК;
з. определения нуклеотидной последовательности 3'-UTR и/или 5'-UTR наиболее стабильных видов мРНК, выбранных на стадии ж);
и. синтеза элемента 3'-UTR и/или элемента 5'-UTR, включенного в 3'-UTR и/или 5'-UTR, определенных на стадии з);
к. комбинирования элемента 3'-UTR и/или элемента 5'-UTR, синтезированных на стадии i), с открытой рамкой считывания для получения нуклеиновой кислоты, описанной в настоящем изобретении; и
л. необязательно сравнения экспрессии открытой рамки считывания, присутствующей в нуклеиновой кислоте по настоящему изобретению, по сравнению с экспрессией открытой рамки считывания в исходной нуклеиновой кислоте без элемента 3'- и/или элемента 5'-UTR согласно описанию настоящего изобретения.
Таким образом, подробности и предпочтительные варианты осуществления, описанные выше для способов по настоящему изобретению, также применимы в настоящем изобретении в пределах, указанных на стадиях от а) до л).
В частности, следующие меченые нуклеотиды являются предпочтительными для питания клеток на стадии а) предлагаемого способа: 4-тиуоридин (4sU), 2-тиоуридин, 6-тиогуанозин, 5-этинилуридин (ЕС), 5-бром-уридин (BrU), биотин-16-аминоаллилуридин, 5-аминоаллилулридин, 5-аминоаллилцитидин и т.д. Особенно предпочтительным является 4-тиоуридин (4sU). 4-тиоуридин предпочтительно используют в концентрации 100-500 мкМ. В другом варианте могут быть использованы радиоактивно меченые нуклеотиды, например, уридин-3Н. Могут быть использованы комбинации указанных выше нуклеотидов. Особенно предпочтительной является комбинация 4-тиоуридина и 6-тиогуанозина.
Инкубирование клеток с меченым нуклеотидом на стадии а) можно варьировать. Особенно предпочтительным является инкубирование (время питания клеток) от 10 минут до 24 ч. Особенно предпочтительными являются от 2 до 6 ч, более предпочтительно от 2 до 3 ч.
Клетки, которые могут быть применены в способах настоящего изобретения, в частности, линии клеток, первичные клетки, клетки в ткани или клетки субъектов. В некоторых вариантах осуществления настоящего изобретения в способе по настоящему изобретению могут быть применимы типы клеток, которые можно культивировать. Особенно предпочтительными являются клетки млекопитающих, например, клетки человека и клетки мыши. В особенно предпочтительных вариантах осуществления настоящего изобретения используют линии клеток человека HeLa и U-937 и линии клеток мыши NIH3T3, JAWSII и L929. Кроме того, первичные клетки особенно предпочтительны; в частности могут быть применимы дермальные фибробласты человека (HDF). В других вариантах меченый нуклеотид также можно наносить на ткань субъекта, и после окончания времени инкубирования РНК выделяют из ткани в соответствии со стадией в).
Для определения наиболее стабильных мРНК клеток (типов) общую РНК экстрагируют в первой временной точке, согласно описанному выше, например, через 0-6 ч после маркировки, предпочтительно через 3 ч после маркировки, и во второй временной точке в соответствии с описанным выше, например, через 3-48 ч после маркировки, предпочтительно через 10-24 ч, наиболее предпочтительно через 15 ч после маркировки. Вторая временная точка по времени по меньшей мере на 10 мин позже первой.
На стадии е) виды мРНК ранжируют в соответствии с соотношением, рассчитанным на этапе д). В этом контексте особенно предпочтительно выбирать 0,1%, 0,2%, 0,3%, 0,4%, 0,5%, 0,6%, 0,7%, 0,8%, 0,9%, 1%, 2%, 3%, 4%, 5%, 10%), 15%, 20% наиболее стабильных видов мРНК.
В этом контексте также предпочтительно выбирать виды мРНК, показывающие уровень транскрипта/количество мРНК, которое меньше по меньшей мере на 50% (меньше в 0,5 раза), по меньшей мере на 60% (меньше в 0,6 раза), по меньшей мере на 70% (меньше в 0,7 раза), по меньшей мере на 90% в (меньше в 0,9 раза) или по меньшей мере на 95% (меньше в 0,95 раза) во второй, более поздней временной точке по сравнению с первой. Этот вариант осуществления настоящего изобретения особенно предпочтителен, если РНК выделяют через 3 часа (первая временная точка) и через 15 ч (вторая временная точка) после маркировки.
В другом варианте или дополнительно отбирают такие виды мРНК, которые показывают соотношение, вычисленное на стадии д), соответствующее, по меньшей мере, 100% среднего соотношения, рассчитанного по всем проанализированным видам мРНК. Более предпочтительно такие выбранные виды мРНК, показывают соотношение по меньшей мере 150%, более предпочтительно по меньшей мере 200% и наиболее предпочтительно по меньшей мере 300% от среднего соотношения, рассчитанного по всем проанализированным видам мРНК.
На следующей стадии способа по настоящему изобретению определяют нуклеотидную последовательность 3'-UTR и/или 5'-UTR наиболее стабильных видов мРНК, выбранных на стадии ж), и на стадии и) 3'-UTR и/или 5'-UTR синтезируют, например, с помощью ПЦР-амплификации. Праймеры, используемые для ПЦР, предпочтительно могут содержать сайты рестрикции для клонирования. В другом варианте элемент 3'-UTR и/или элемент 5'-UTR предпочтительно может быть синтезирован (например, путем химического синтеза или отжигом).
На стадии к) способа по настоящему изобретению полученный фрагмент ПЦР или синтезированная последовательность объединяют с открытой рамкой считывания, в результате чего получают искусственную нуклеиновую кислоту, содержащую элемент 3'-UTR и/или элемент 5'-UTR по настоящему изобретению. Предпочтительно фрагмент или последовательность ПЦР могут быть клонированы в вектор.
В особенно предпочтительном варианте осуществления настоящего изобретения предусматривают способ, включающий стадии от а) до л) для идентификации элементов 3'-нетранслируемой области (элементов 3'-UTR) и/или элементов 5'-нетранслируемой области (элементов 5'-UTR), причем элементы 3'-UTR и/или элементы 5'-UTR продлевают выработку белка с молекулы искусственной нуклеиновой кислоты, включающей по меньшей мере один из элементов 3'-UTR и/или по меньшей мере один из элементов 5'-UTR.
В другом варианте осуществления настоящее изобретение также предусматривает способ выработки молекулы искусственной нуклеиновой кислоты, причем молекула искусственной нуклеиновой кислоты включает по меньшей мере одну открытую рамку считывания и по меньшей мере один из элементов 3'-UTR и/или по меньшей мере один из элементов 5'-UTR, идентифицированных методом идентификации элемента 3'-UTR и/или элемента 5'-UTR по настоящему изобретению согласно описанному выше. Синтез такой молекулы искусственной нуклеиновой кислоты обычно осуществляют способами, известными специалистам, например, методами клонирования, например, общеизвестными или описанными в настоящем изобретении.
Предпочтительно, вектор по настоящему изобретению, описанный в настоящем изобретении, применяют в таком способе по настоящему изобретению, для получения молекулы искусственной нуклеиновой кислоты.
Предпочтительно, молекула искусственной нуклеиновой кислоты, полученная таким способом получения молекулы искусственной нуклеиновой кислоты, представляет собой молекулу нуклеиновой кислоты в соответствии с настоящим изобретением.
Кроме того, настоящее изобретение также предусматривает молекулу искусственной нуклеиновой кислоты, получаемую способом получения молекулы искусственной нуклеиновой кислоты в соответствии с описанным настоящим изобретением.
Приводимые ниже фигуры, последовательности и примеры являются иллюстрациями настоящего изобретения. Они никоим образом не ограничивают рамок охвата настоящего изобретения.
Фиг. 1-11, 19-21 и 25-30 представляют последовательности, кодирующие мРНК, которые могут быть получены в результате транскрипции in vitro. Используют следующие аббревиатуры:
• PpLuc (GC): GC-обогащенная последовательность мРНК, кодирующая люциферазу Photinus pyralis;
• А64: поли(А)-последовательность, аденилированная 64 раза;
• С30: poly(С)-последовательность, цитидинилированная 30 раз;
• hSL: последовательность гистонной структуры стебель-петля, взятая из работы Cakmakci с соавтю, Mol. Cell. Biol. 28(3), 2008, 1182-1194;
• 32L4: 5'-UTR рибосомального белка человека, большой субъединицы 32, без 5'-концевого олигопиримидинового тракта;
• albumin7: 3'-UTR альбумина человека, три отдельные точечные мутации, интродуцированные для удаления сигнала терминации Т7, а также сайты рестрикции HindIII и XbaI;
• gnas: элемент 3'-UTR, производный от 3'-UTR gnas мыши; Mus musculus GNAS (белок, связывающий гуаниновые нуклеотиды, альфа-стимулирующий) комплексный локус (Gnas), мРНК;
• morn2: элемент 3'-UTR, производный от 3'-UTR morn2мыши; Mus musculus MORN-повтор содержащий 2 (Morn2), мРНК;
• gstml: элемент 3'-UTR, производный от gstm1 мыши; Mus musculus глутатион-S-трансфераза, mu 1mu 1 (Gstm1), мРНК;
• ndufa1: элемент 3'-UTR, производный от 3'-UTR ndufa1 мыши; Mus musculus NADH-дегидрогеназа (убихинон) 1 альфа-субкомплекс, (Ndufa1), мРНК;
• cbr2: элемент 3'-UTR, производный от 3'-UTR cbr2 мыши; Mus musculus карбонилредуктаза 2 (Cbr2), мРНК;
• mp68: элемент 5'-UTR, производный от 5'-UTR mp68 мыши; Mus musculus RIKEN кДНК 2010107E04 ген (2010107E04Rik), мРНК;
• ndufa4: элемент 5'-UTR, производный от 5'-UTR nudfa4 мыши; Mus musculus NADH дегидрогеназа (убихинон) 1 альфа субкомплекс 4 (Ndufa4), мРНК;
• Ybx1: элемент 3'-UTR, производный от 3'-UTR Ybx1 мыши (Y-Box связывающий белок 1);
• Ndufb8: элемент 3'-UTR, производный от 3'-UTR Ndufb8 мыши (NADH дегидрогеназа (убихинон) 1 бета субкомплекс 8);
• CNTN1: элемент 3'-UTR, производный от 3'-UTR CNTN1 человека (контактин 1).
Фиг. 1. Последовательность SEQ ID NO: 35, т.е. последовательность мРНК 32L4 - PpLuc(GC) - А64 - С30 - hSL. (R2464). 5'-UTR является производным мРНК рибосомального белка человека большой субъединицы 32 без 5' концевого олигопиримидинового тракта. ORF PpLuc (GC) выделена курсивом.
Фиг. 2. Последовательность SEQ ID NO: 36, т.е. последовательность мРНК 32L4 - PpLuc(GC) - gnas-A64-C30-hSL. (R3089). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от транскрипта Gnas мыши, подчеркнут.
Фиг. 3. Последовательность SEQ ID NO: 37, т.е. последовательность мРНК 32L4 - PpLuc(GC) - morn2- А64 - С30 - hSL. (R3106). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от morn2 мыши, подчеркнут.
Фиг. 4. Последовательность SEQ ID NO: 38, т.е. последовательность мРНК 32L4 - PpLuc(GC) - gstm1- А64 - С30 - hSL. (R3107). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от gstm1 мыши, подчеркнут.
Фиг. 5. Последовательность SEQ ID NO: 39, т.е. последовательность мРНК 32L4 - PpLuc(GC) - ndufal - А64 - С30 - hSL. (R3108). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от ndufa1 мыши, подчеркнут.
Фиг. 6. Последовательность SEQ ID NO: 40, т.е. последовательность мРНК 32L4 - PpLuc(GC) - cbr2 - А64 - С30 - hSL. (R3109). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от cbr2 мыши, подчеркнут.
Фиг. 7. Последовательность SEQ ID NO: 41, т.е. последовательность мРНК PpLuc(GC)-albumin7-A64-C30-hSL. (R2463). Элемент 3'-UTR, производный от альбумина человека с тремя точечными мутациями, интродуцированными для удаления сигнала терминации Т7, а также сайтами рестрикции HindIII и XbaI (albumin7). ORF PpLuc(GC) выделена курсивом.
Фиг. 8. Последовательность SEQ ID NO: 42, т.е. последовательность мРНК Мр68 - PpLuc(GC) - albumin7-A64-C30-hSL. (R3111). ORF PpLuc(GC) выделена курсивом. Элемент 5'-UTR, производный от mp68 мыши, подчеркнут.
Фиг. 9. Последовательность SEQ ID NO: 43, т.е. последовательность мРНК Ndufa4 - PpLuc(GC)-albumin7-A64-C30-hSL. (R3112). ORF PpLuc(GC) выделена курсивом. Элемент 5'-UTR, производный от Ndufa4 мыши, подчеркнут.
Фиг. 10. Последовательность SEQ ID NO: 44, т.е. последовательность мРНК PpLuc(GC)-A64-C30-hSL (R2462) The PpLuc(GC) ORF is highlighted in italics.
Фиг. 11. Последовательность SEQ ID NO: 45, т.е. последовательность мРНК PpLuc(GC)-gnas-A64-C30-hSL (R3116). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от Gnas мыши, подчеркнут.
Фиг. 12. Различные элементы 3'-UTR, а именно элементы 3'-UTR, которые являются производными gnas, morn2, gstm1, ndufa1 и cbr2 и очевино продлевают экспрессию белка с мРНК.
Исследуют влияние элементов 3'-UTR по настоящему изобретению, производных от gnas, morn2, gstm1, ndufa1 и cbr2 3'-UTR, на экспрессию люциферазы с мРНК, и сравнивают с экспрессией люциферазы с мРНК, не содержащей 3'-UTR. С этой целью HeLa человека трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряли в разное время после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc в течение 24 ч принимают за 100% и рассчитывают относительную экспрессию за 24 ч. 3'-UTR продлевают экспрессию люциферазы. Показаны средние значения трех независимых экспериментов. Значения суммированы в примере 7.а.
Фиг. 13. Различные элементы 3'-UTR, а именно элементы 3'-UTR, производные от gnas, morn2, gstm1, ndufa1 и cbr2, очевидно продлевают экспрессию белка с мРНК.
Исследуют влияние элементов 3'-UTR по настоящему изобретению, производных от gnas, morn2, gstm1, ndufa1 и cbr2 3'-UTR, на экспрессию люциферазы с мРНК, и сравнивают с экспрессией люциферазы с мРНК, не содержащей 3'-UTR. С этой целью дермальные фибробласты человека (human dermal fibroblasts - HDF) трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют в разное время после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc в течение 24 ч принимают за 100% и рассчитывают относительную экспрессию за 24 ч. 3'-UTR продлевают экспрессию люциферазы. Показаны средние значения трех независимых экспериментов. Значения суммированы в примере 7.а.
Фиг. 14. Различные элементы 5'-UTR, а именно элементы 5'-UTR, производные от Мр68 и ndufa4, очевидно повышают экспрессию белка с мРНК.
Исследуют влияние элементов 5'-UTR по настоящему изобретению, производных от Мр68 и ndufa4, на экспрессию люциферазы с мРНК. С этой целью клетки человека HeLa (human dermal fibroblasts - HDF) трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют через 6, 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Вычисляют общую экспрессию белка (площадь под кривой). Для сравнения уровней экспрессии с мРНК, содержащих элементы 5'-UTR по настоящему изобретению, с мРНК, не содержащей 5'-UTR, уровни экспрессии контрольной конструкции без 5 'UTR устанавливают равными 1. Показаны средние значения трех независимых экспериментов. Значения суммированы в примере 7.б.
Фиг. 15. Различные элементы 5'-UTR, а именно элементы 5'-UTR, производные от Мр68 и ndufa4, очевидно повышают экспрессию белка с мРНК.
Исследуют влияние элементов 5'-UTR по настоящему изобретению, производных от Мр68 и ndufa4, на экспрессию люциферазы с мРНК. С этой целью клетки HDF трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют через 6, 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Вычисляют общую экспрессию белка (площадь под кривой). Для сравнения уровней экспрессии с мРНК, содержащих элементы 5'-UTR по настоящему изобретению, с мРНК, не содержащей 5'-UTR, уровни экспрессии контрольной конструкции без 5 'UTR устанавливают равными 1. Показаны средние значения трех независимых экспериментов. Значения суммированы в примере 7.б.
Фиг. 16. элемент 3'-UTR, производный от gnas, очевидно продлевает экспрессию белка с мРНК.
Исследуют влияние элементов 3'-UTR по настоящему изобретению, производных от gnas 3'-UTR, на экспрессию люциферазы с мРНК, и сравнивают с экспрессией люциферазы с мРНК, не содержащей 3'-UTR. С этой целью клетки человека HDF трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют через 24, 48 и 72 после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc в течение 24 ч принимают за 100% и рассчитывают относительную экспрессию за 24 ч. Установлено, что gnas 3'-UTR продлевает экспрессию люциферазы. Результаты суммированы в примере 7.в.
Фиг. 17. Различные элементы 3'-UTR, производные от gnas, очевидно продлевают экспрессию белка с мРНК.
Исследуют влияние элемента 3'-UTR по настоящему изобретению, производному от gnas 3'-UTR, на экспрессию люциферазы с мРНК, и сравнивают с экспрессией люциферазы с мРНК, не содержащей 3'-UTR. С этой целью клетки HeLa трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют на 2 и 3 сутки (соответственно, d2 и d3) после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc в течение 24 ч принимают за 100% и рассчитывают относительную экспрессию за 24 ч. Установлено, что gnas 3'-UTR продлевает экспрессию люциферазы. Результаты суммированы в примере 7.в.
Фиг. 18. Различные элементы 3'-UTR, производные от ybx1(V2), ndufb8 и cntn1-004(V2), очевидно продлевают экспрессию белка с мРНК.
Исследуют влияние элемента 2'-UTR по настоящему изобретению, производному от ybx1(V2), ndufb8 и cntn1-004(V2) 3'-UTR, на экспрессию люциферазы с мРНК, и сравнивают с экспрессией люциферазы с мРНК, не содержащей 3'-UTR. С этой целью клетки HDF трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют в разные сроки после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc к 24 ч принимают за 100% и рассчитывают относительную экспрессию за 24 ч. Установлено, что 3'-UTR продлевает экспрессию люциферазы. Результаты суммированы в примере 7.г.
Фиг. 19. Элемент SEQ ID NO: 46, т.е. последовательность мРНК 32L4-PpLuc(GC)-Ybx1-001(V2)-A64-C30-hSL (R3623) mus musculus 3'UTR с мутацией T128bpG и делецией del236-237bp. ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от транскрипта Ybx1 мыши, подчеркнут.
Фиг. 20. Элемент SEQ ID NO: 47, т.е. последовательность 32L4-PpLuc(GC)-Ndufb8-A64-C30-hSL (R3624).
Фиг. 21. Элемент SEQ ID NO: 48, т.е. последовательность мРНК 32L4-PpLuc(GC)-Cntn1-004(V2)-A64-C30-hSL (R3625) +Т в положении 30 п.о., мутации G727bpT, A840bpG. ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от транскрипта Cntn1 человека, подчеркнут.
Фиг. 22. Различные элементы 3'-UTR, а именно элементы 3'-UTR, производные от gnas, morn2, ndufal (Mm; mus musculus) и NDUFA1 (Hs; homo sapiens), явно продлевают экспрессию с мРНК. Исследуют влияние элементов 3'-UTR по настоящему изобретению, производные от gnas, morn2, ndufa1 (Mm; mus musculus) и NDUFA1 (Hs; homo sapiens), на экспрессию люциферазы с мРНК и сравнивают с экспрессией люциферазы с мРНК без 3'-UTR. С этой целью клетки Hela человека трансфицируют соответствующими мРНК путем липофекции. Уровни люциферазы измеряют в разное время после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc к 24 ч принимают за 100% и рассчитывают относительную экспрессию за 24 ч. Установлено, что 3'-UTR продлевает экспрессию люциферазы. Показаны средние значения трех независимых экспериментов. Результаты суммированы в табл. 8.
Фиг. 23. Различные элементы 5'-UTR, а именно элементы 5'-UTR, производные от Мр68 и ndufa4, очевидно повышают экспрессию суммарного белка с мРНК. Исследуют влияние элементов 5'-UTR по настоящему изобретению, производных от Мр68 и ndufa4, на экспрессию люциферазы с мРНК. С этой целью клетки Hela человека трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют через 6, 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Рассчитывают общую экспрессию белка (площадь под кривой). Для сравнения уровней экспрессии мРНК, содержащей элементы 5'-UTR по настоящему изобретению, с мРНК без 5'-UTR, уровни контрольной конструкции без 5'-UTR устанавливают на 1. Показаны средние значения. Результаты суммированы в табл. 9.
Фиг. 24. Различные элементы 5'-UTR, а именно элементы 5'-UTR, производные от Мр68 и ndufa4, очевидно повышают экспрессию суммарного белка с мРНК. Исследуют влияние элементов 5'-UTR по настоящему изобретению, производных от Мр68 и ndufa4, на экспрессию люциферазы с мРНК. С этой целью клетки Hela человека трансфицируют различными мРНК путем липофекции. Уровни люциферазы измеряют через 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Рассчитывают общую экспрессию белка (площадь под кривой). Для сравнения уровней экспрессии мРНК, содержащих элементы 5'-UTR по настоящему изобретению, с мРНК без 5'-UTR, уровни экспрессии контрольной конструкции без 5'-UTR устанавливают на 1. Показаны средние значения. Результаты суммированы в табл. 9.
Фиг. 25. SEQ ID NO: 383, т.е. последовательность мРНК 32L4-PpLuc(GC)-A64-C30-hSL (R2462). ORF PpLuc(GC) выделена курсивом.
Фиг. 26. SEQ ID NO: 384, т.е. последовательность мРНК PpLuc(GC)-morn2-А64-С30-hSL. (R3948). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от morn2 мыши, подчеркнут.
Фиг. 27. SEQ ID NO: 385, т.е. последовательность мРНК PpLuc(GC)-ndufa1-A64-C30-hSL. (R4043). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от ndufa1 мыши, подчеркнут.
Фиг. 28. SEQ ID NO: 386, т.е. последовательность мРНК PpLuc(GC)-NDFUA1-A64-C30-hSL. (R3948). ORF PpLuc(GC) выделена курсивом. Элемент 3'-UTR, производный от NDUFA1 человека, подчеркнут.
Фиг. 29. SEQ ID NO: 387, т.е. последовательность мРНК Mp68-PpLuc(GC)-A64-C30-hSL. (R3954). ORF PpLuc(GC) выделена курсивом. Элемент 5'-UTR, производный от mp68 мыши, подчеркнут.
Фиг. 30. SEQ ID NO: 388, т.е. последовательность мРНК Ndufa4-PpLuc(GC)-A64-С30-hSL. (R3951). ORF PpLuc(GC) выделена курсивом. Элемент 5'-UTR, производный от ndufa4 мыши, подчеркнут.
Примеры
1. Идентификация элементов 3'-нетранслируемой области (элементов 3'-UTR) и/или элементов 5'-нетранслируемой области (элементов 5'-UTR), продлевающих и/или увеличивающих выработку белка
Распад мРНК в разных типах клеток человека и мыши оценивают методом вытеснения метки. С этой целью три разных типа клеток человека (HeLa, HDF и U-937) и три разных типа клеток мыши (NIH3T3, JAWSII и L929) высевают на ночь в соответствующую для них среду: HeLa, U-937, L929 в среду RPMI, JAWSII и NIH3T3 в среду DMEM и HDF в среду для роста фибробластов 2 (Fibroblast Growth Medium 2). Клетки инкубируют в течение 3 ч в соответствующей среде, содержащей 200 мкМ 4-тиоуридина (4sU), чтобы пометить вновь синтезированную РНК («импульс»). После инкубирования (нанесения метки) клетки промывают один раз и среду заменяют свежей средой, обогащенной 2 мМ уридином («вытеснение»). Клетки инкубируют дополнительно в течение 3 ч (1-я временная точка) или 15 ч (2-я временная точка) до завершения эксперимента.
Соответственно, клетки собирают через 3 ч (1-я временная точка) или 15 ч (2-я временная точка) после окончания нанесения метки. Суммарную РНК выделяют из этих клеток с использованием набора RNeasy Mini Kit (фирма Qiagen).
Затем HPDP-биотин (EZ-Link Biotin-HPDP, фирма Thermo Scientific; пиридилдитиол-активированный, сульфгидрил-реагирующий реагент для биотинилирования, который конъюгирует через расщепляемую (обратимую) дисульфидную связь) инкубируют с суммарной РНК с целью экстракции 4-тиоуридин(4sU)-меченой РНК. HPDP-биотин специфически реагирует с восстановленными тиолами (-SH) в 4-тиоуридиновый (4sU)-меченой РНК с образованием обратимых дисульфидных связей. Биотинилированную РНК подвергают ультрафильтрованию с использованием устройства Amicon-30, инкубируют со стрептавидин-связанными парамагнитными микрочастицами dynabeads (фирма Life Technologies) и извлекают из стрептавидина с помощью DTT. Затем РНК очищают с использованием набора RNeasy Mini Kit. Для каждой клеточной линии проводят три независимых эксперимента.
Выделенную 4sU-меченую РНК используют для в анализа на микрочипе для определения уровней транскрипции большого количества разнообразных видов мРНК (то есть количества видов мРНК), присутствующих в первой временной точке (через 3 часа после нанесения метки), и уровней транскрипции большого разнообразия видов мРНК (т.е. количества видов мРНК), присутствующих во второй временной точке (через 15 ч после нанесения метки). Используют микрочипы Affymetrix Human Gene 1.0 ST и Affymetrix Mouse Gene 1.0 ST. Микрочип Affymetrix Human Gene 1.0 ST содержит 36079 видов мРНК. Микрочип Affymetrix Mouse Gene 1.0 ST содержит 26166 видов мРНК.
Поскольку такие микрочипы обеспечивают полный охват транскриптов, то есть они обеспечивают полный профиль экспрессии мРНК, соотношение уровня транскриптов определенных видов мРНК во второй временной точке к уровню транскриптов тех же видов мРНК в первой временной точке, соответственно, определяют для большого числа видов мРНК. Эти соотношения, таким образом, отражают х-кратность уровней транскриптов видов мРНК (показанных в виде генных символов) во второй временной точке по сравнению с первой временной точкой.
Результаты этих экспериментов показаны ниже в табл. 1-3. Каждая из табл. 1-3 показывает ранжирование наиболее стабильных видов мРНК, то есть в соответствии с соотношением уровня транскрипта определенного вида мРНК во второй временной точке к уровню транскрипта определенного вида мРНК в первой временной точке (табл. 1: комбинированный анализ типов клеток человека (HeLa, HDF и U-937); табл. 2: комбинированный анализ линий клеток мыши (NIH3T3, JAWSII и L929); табл. 3: линия клеток человека HDF (дермальные фибробласты человека). Такие виды мРНК рассматривают в качестве «наиболее устойчивых видов мРНК», которые показывают величину соотношения уровня транскриптов в первой временной точке к уровню транскриптов во второй временной точке равной, по меньшей мере, 0,549943138 (приблизительно 55%, табл. 1), 0,676314425 (приблизительно 68%, табл. 2) или 0,8033973 (приблизительно 80%, табл. 3).
Также рассчитывают связь соотношения определенного вида мРНК со средним соотношением (т.е. средним соотношением всех определенных видов мРНК, показанном в таблицах в графе «Среднее соотношение») и приводят в качестве процента средней величины.
Таблица 1. Стабильные мРНК, образованные в результате комбинированного анализа типов клеток человека (HeLa, HDF и U-937) с микрочипом Affymetrix Human Gene 1.0 ST. 113 видов мРНК от 36079 образцов мРНК выбирают в качестве «наиболее стабильных» видов мРНК. Это соответствует 0,31% видов мРНК, находящихся на микрочипе.



Таблица 2. Стабильные мРНК, образованные в результате комбинированного анализа линий клеток мыши (NIH3T3, JAWSII и L929) с микрочипом Mouse Gene 1.0 ST: 99 видов мРНК от 26166 образцов мРНК на микрочипе выбирают в качестве «наиболее стабильных» видов мРНК. Это соответствует 0,38% видов мРНК, находящихся на микрочипе.



Таблица 3. Стабильные мРНК, образованные в результате анализа линии клеток человека HDF (дермальные фибробласты человека) с микрочипом Affymetrix Human Gene 1.0 ST: 46 видов мРНК из 36079 видов мРНК на микрочипе выбирают в качестве «наиболее стабильных» видов мРНК. Это соответствует 0,13% видов мРНК, находящихся на микрочипе.

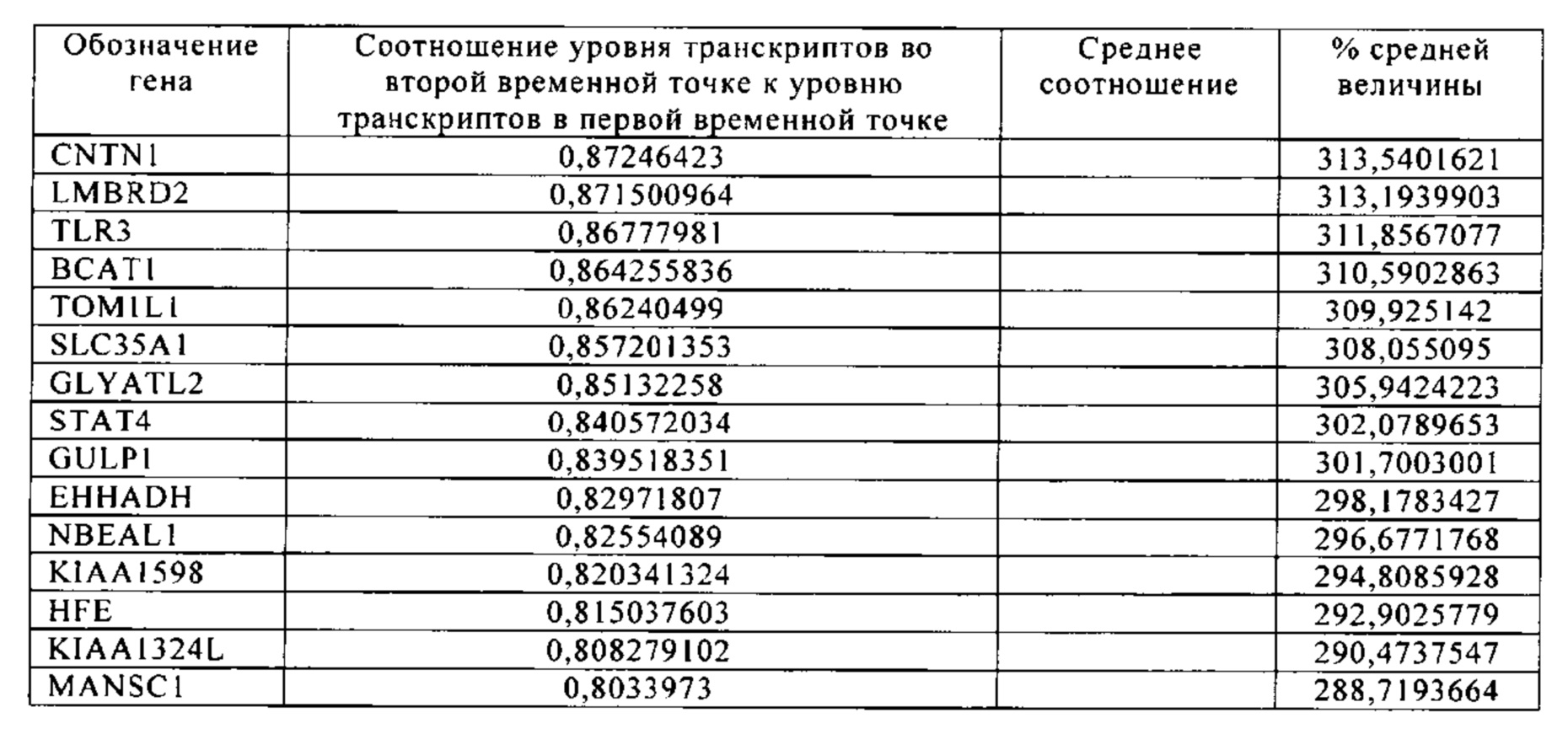
2. Клонирование элементов 5'-UTR и 3'-UTR стабильно экспрессируемых мРНК
Нуклеотидную последовательность 5'- и/или 3'-UTR видов мРНК, показанных в табл. 1-3, определяют путем анализа базы данных и амплифицируют с помощью ПЦР или синтезировали путем олиго-отжига. Получаемые фрагменты ПЦР клонируют в векторе, что подробно описано в примере 3 ниже. Элементы 5'-UTR клонируют в векторе PpLuc (GC)-albumin7-A64-C30-hSL (SEQ ID NO: 41, фиг. 7); элементы 3'-UTR клонируют в векторе 32L4-PpLuc (GC)-A64-C30-hSL (SEQ ID NO: 35, фиг. 1) или в векторе PpLuc (GC)-A64-C30-hSL (SEQ ID NO: 44, фиг. 10).
3. Получение матриц ДНК
Конструируют вектор для транскрипции in vitro, содержащий промотор Т7 и последовательность, обогащенную GC, которая кодирует люциферазу Photinus pyralis (PpLuc (GC)). Последовательность A64 поли(А), за которой следует С30 и гистонная структура стебель-петля, инсертируют с 3'-конца PpLuc(GC). За последовательностью гистонной структуры стебель-петля следует сайт рестрикции, используемый для линеаризации вектора перед транскрипцией in vitro.
Для исследования влияния различных 3'-UTR элементов на экспрессию белка используют описанный выше вектор, который модифицируют, чтобы включить целевой элемент 3'-UTR. В другом варианте вектор конструируют согласно выше описанному, в результате чего 5'-нетранслируемую область (5'-UTR) 32L4 (рибосомальный белок большой субъединицы 32) инсертируют с 5'-конца PpLuc (GC). Затем этот вектор модифицируют, чтобы включить различные 3'-UTR-элементы, или не включать 3'-UTR (контроль).
В частности, следующие мРНК получают с этих векторов путем транскрипции in vitro (последовательности мРНК показаны на фиг. 1-6, фиг. 10, 11 и фиг. 19-21):
32L4-PpLuc(GC)-А64-С30-hSL (SEQ ID NO: 35, фиг. 1);
32L4-PpLuc(GC)-gnas-A64-C30-hSL (SEQ ID NO: 36, фиг. 2);
32L4-PpLuc(GC)-morn2-A64-C30-hSL (SEQ ID NO: 37, фиг. 3);
32L4-PpLuc(GC)-gstm1-A64-C30-hSL (SEQ ID NO: 38, фиг. 4);
32L4-PpLuc(GC)-ndufa1-A64-C30-hSL (SEQ ID NO: 39, фиг.5);
32L4-PpLuc(GC)-cbr2-A64-C30-hSL (SEQ ID NO: 40, фиг. 6);
PpLuc(GC)-A64-C30-hSL (SEQ ID NO: 44, фиг. 10);
PpLuc(GC)-gnas-A64-C30-hSL (SEQ ID NO: 45, фиг. 11);
32L4-PpLuc(GC)-Ybx1(V2)-A64-C30-hSL (SEQ ID NO: 46, фиг. 19);
32L4-PpLuc(GC)-Ndufb8-A64-C30-hSL (SEQ ID NO: 47, фиг. 20); и
32L4-PpLuc(GC)-Cntn1-004(V2)-A64-C30-hSL (SEQ ID NO: 48, фиг. 21).
Другой вариант последовательности конструкции 32L4-PpLuc(GC)-A64-С30-hSL показан на фиг. 25 (SEQ ID NO: 383). Однако, SEQ ID NO: 35, фиг. 1, применяют в описанных в настоящем изобретении примерах, и таким образом, она предпочтительнее для конструкции 32L4-PpLuc(GC)-A64-C30-hSL.
Для исследования влияния различных элементов 5'-UTR на экспрессию белка, конструируют вектор согласно описанному выше, в результате чего 3'-нетранслируемую область (3'-UTR) albumin7 (3'-UTR гена альбумина человека с тремя точечными мутациями, интродуцированными для удаления сигнала терминации Т7, а также сайта рестрикции HindIII и XbaI) инсертируют с 3'-конца PpLuc (GC). Этот вектор модифицируют таким образом, чтобы либо включить различные элементы 5'UTR, либо не включать 5'-UTR (контроль).
В частности, следующие мРНК получают с таких векторов путем транскрипции in vitro (последовательности мРНК представлены на фиг. 7-9): PpLuc(GC) albumin7-A64-C30-hSL (SEQ ID NO: 41, фиг. 7);
Mp68-PpLuc(GC)-albumin7-A64-C30-hSL (SEQ ID NO: 42, фиг. 8); и
Ndufa4-PpLuc(GC)-albumin7-A64-C30-hSL (SEQ ID NO: 43, фиг. 9);
4. Транскрипция in vitro
Матрицы ДНК в примерах 2 и 3 линеаризуруют и транскрибируют in vitro, используя полимеразу T7-RNA. Матрицы ДНК затем расщепляют обработкой ДНКазой. Транскрипты мРНК, содержащие структуру 5'-САР, получают добавлением избытка М7-метил-гуанозин-5'-трифосфат-5'-гуанозин в реакцию транскрипции. Полученную таким образом мРНК очищают и ресуспендируют в воде.
5. Экспрессия люциферазы путем липофекции мРНК
Дермальные фибробласты человека (Human dermal fibroblasts - HDF) и клетки HeLa высевают в 96-луночный планшет в количестве 1×104 клеток на лунку. На следующий день клетки промывают в Opti-MEM и трансфицируют с помощью 12,5 нг на лунку объединенной с Lipofectamine2000 PpLuc-кодирующей мРНК в Opti-MEM. Нетрансфицированные клетки служат контролем. Трансфицируют мРНК, кодирующую люциферазу Renilla reniformis (RrLuc), вместе с мРНК PpLuc для контроля эффективности трансфекции (1 нг RrLuc мРНК на лунку). Через 90 мин после начала трансфекции Opti-MEM заменяют средой. Через 6, 24, 48, 72 ч после трансфекции среду отсасывают и клетки лизируют в 100 мкл буфера Passive Lysis buffer (фирма Promega). Лизаты хранят при -80°С до измерения активности люциферазы.
6. Измерение люциферазы
Активность люциферазы измеряют в относительных световых единицах (relative light units - RLU) в планшетном ридере Hidex Chameleon. Активность Ppluc и Rrluc измеряют последовательно из одного образца путем двойного анализа люциферазы. Сначала измеряют активность PpLuc, время измерения 2 сек, используя 20 мкл лизата и 50 мкл лизирующего реактива Beetle juice (фирма pjk GmbH). После 1500 мсек задержки измеряют активность RrLuc с 50 мкл лизирующего реактива Beetle juice (фирма pjk GmbH).
7. Результаты
7а. Экспрессию белка с мРНК, содержащей элементы 3'-UTR по настоящему изобретению, повышают и продлевают.
Чтобы исследовать влияние различных элементов 3'-UTR на экспрессию белка с мРНК, мРНК, содержащие различные элементы 3'-UTR, сравнивают с мРНК без 3'-UTR.
Клетки человека HeLa и HDF трансфицируют мРНК, кодирующими люциферазу, и измеряют уровни люциферазы (в RLU) через 6, 24, 48 и 72 ч после трансфекции.
Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc к 24 ч принимают за 100% и рассчитывают относительную экспрессию за 24 ч (см. ниже табл. 4, а также фиг. 12 (клетки HeLa) и фиг. 13 (клетки HDF)).
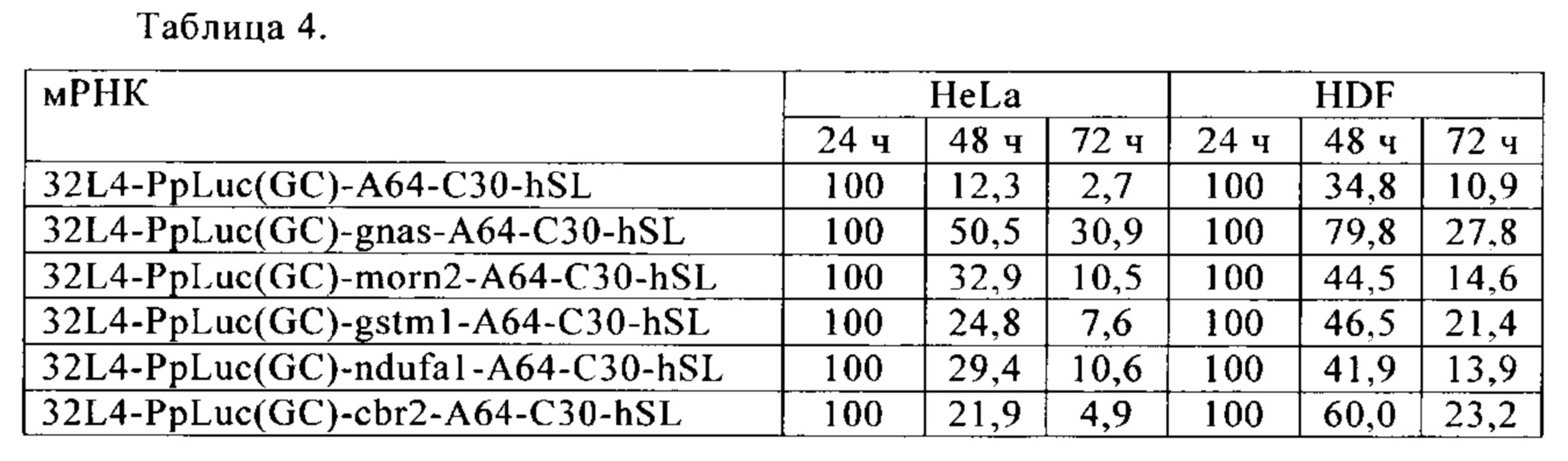
Табл. 4 показывает относительную экспрессию PpLuc, нормализованную по RrLuc (приведены средние значения трех независимых экспериментов).
Люцифераза экспрессируется с мРНК, не содержащей 3'-UTR. Тем не менее, 3'-UTR-элементы по настоящему изобретению, gnas, morn2, gstml, ndufa и cbr2, существенно продлевают экспрессию люциферазы.
7б. Экспрессия белка с мРНК, содержащей элементы 5'-UTR по настоящему изобретению, повышена и/или продлена.
Чтобы исследовать влияние различных элементов 5'-UTR на экспрессию белка с мРНК, мРНК, содержащие различные 5'-UTR, сравнивают с мРНК, не содержащей 5'-UTR.
Клетки HeLa и HDF человека трансфицируют мРНК, кодирующими люциферазу, и уровни люциферазы измеряют через 6, 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Общую экспрессию белка от 0 до 72 часов рассчитывают в виде площади под кривой (AUC). Уровни контрольной конструкции без 5 'UTR устанавливают равными 1 (см. ниже табл. 5 и фиг. 14 (клетки HeLa) и фиг. 15 (клетки HDF)).

В табл. 5 показана общая экспрессия PpLuc, нормализованная по RrLuc (приведены средние значения трех независимых экспериментов).
Люцифераза экспрессируется с мРНК без 5'-UTR. Однако, элементы 5'-UTR по настоящему изобретению mp68 и ndufa4 значительно увеличивают экспрессию люциферазы.
7в. Экспрессия белка с мРНК, содержащей элементы 3'-UTR по настоящему изобретению, продлевается.
Чтобы исследовать влияние различных 3'UTR на экспрессию белка с мРНК, мРНК, содержащие разные 3'UTR, сравнивают с мРНК без 3'UTR.
Клетки HeLa и HDF человека трансфицируют мРНК, кодирующими люциферазу, и уровни люциферазы (в RLU) измеряют через 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc.
Общую экспрессию белка от 0 до 72 ч рассчитывают в виде площади под кривой (AUC). Уровни контрольной конструкции без 5 'UTR устанавливают равными 1 (см. ниже табл. 5 и фиг. 14 (клетки HeLa) и фиг. 15 (клетки HDF)). Нормализованные уровни PpLuc к 24 ч устанавливают на 100% и рассчитывают относительную экспрессию к 24 ч (см. табл. 6 и 16 (клетки HeLa) и табл. 17 (клетки HDF)).

В табл. 6 показана относительная экспрессия PpLuc, нормализованная по RrLuc (приведены средние значения трех независимых экспериментов).
7г. Продленная экспрессия белка с мРНК, содержащей элементы 3'-UTR по настоящему изобретению.
Чтобы исследовать влияние различных 3'UTR на экспрессию белка с мРНК, мРНК, содержащие различные 3'UTR, сравнивают с мРНК без 3'UTR.
Клетки HeLa и HDF человека трансфицируют мРНК, кодирующими люциферазу, и уровни люциферазы измеряют через 6, 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Общую экспрессию белка от 0 до 72 ч рассчитывают в качестве площади под кривой (AUC). Уровни контрольной конструкции без 5 'UTR устанавливают равными 1 (см. ниже табл. 7 и фиг. 18 (клетки HDF) и фиг. 17 (клетки HeLa)).
Клетки HeLa и HDF человека трансфицируют мРНК, кодирующей люциферазу, и уровни люциферазы (в RLU) измеряют через 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Нормализованные уровни PpLuc в течение 24 ч устанавливают на 100% и рассчитывают относительную экспрессию к 24 ч (см. табл. 7 и фиг. 18 (клетки HDF)).

В табл. 7 показывают относительную экспрессию PpLuc, нормализованную по RrLuc (приводят средние значения трех независимых экспериментов).
8. Влияние дополнительных 3'UTR на экспрессию белка
Чтобы дополнительно исследовать влияние различных 3'UTR на экспрессию белка с мРНК, получают новые конструкции мРНК, и эти мРНК, содержащие разные 3'UTR, сравнивают с мРНК без 3'UTR.
С этой целью, выбранные элементы 3'-UTR (gnas, morn2, ndufa1 и NDUFA1) клонируют в векторе PpLuc(GC)-A64-C30-hSL (SEQ ID NO: 44, фиг. 10), который конструируют таким образом, что он включает промотор Т7 и GC-обогащенную последовательность, кодирующую люциферазу Photinus pyralis (PpLuc(GC)). Последовательность A64 поли(А), за которой следует С30 и гистонная структура стебель-петля, инсертируют с 3'-конца PpLuc(GC). За последовательностью гистонной структуры стебель-петля следует сайт рестрикции, используемый для линеаризации вектора перед транскрипцией in vitro.
В частности, с таких векторов были получены следующие мРНК путем транскрипции in vitro (последовательности мРНК показаны на фиг. 11, 26-28):
PpLuc(GC)-gnas-A64-C30-hSL (SEQ ID NO: 45, фиг. 11);
PpLuc(GC)-morn2-A64-C30-hSL (SEQ ID NO: 384, фиг. 26);
PpLuc(GC)-ndufa1-A64-C30-hSL (SEQ ID NO: 385, фиг. 27); и
PpLuc(GC)-NDUFA1-A64-C30-hSL (SEQ ID NO: 386, фиг. 28).
Клетки HeLa человека трансфицируют мРНК, кодирующими люциферазу, и измеряют уровни люциферазы через 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc (см. ниже табл. 8 и фиг. 22).

Эти данные и данные, представленные на фиг. 22, показывают, что экспрессия белка с мРНК, содержащей элементы 3'-UTR, продлена.
9. Воздействие дополнительных 5'UTR на экспрессию белка.
Для дальнейшего исследования воздействия различных 5'UTR на экспрессию белка с мРНК получают новые конструкции мРНК, и те мРНК, которые содержат разные 5'UTR, сравнивают с мРНК без 5'UTR.
Для этой цели, отобранные элементы 5'-UTR (mp68 и ndufa4) клонируют в векторе PpLuc(GC)-A64-C30-hSL (SEQ ID NO: 44, фиг. 10), который конструируют, включая промотор Т7 и GC-обогащенную последовательность, кодирующую люциферазу Photinus pyralis (PpLuc(GC)).
Последовательность А64 поли(А), за которой следует С30 и гистонная структура стебель-петля, инсертируют с 3'-конца PpLuc(GC). За последовательностью гистонной структуры стебель-петля следует сайт рестрикции, используемый для линеаризации вектора перед транскрипцией in vitro.
В частности, следующие мРНК получают с таких векторов путем транскрипции in vitro (последовательности мРНК показаны на фиг. 29 и 30):
Mp68-PpLuc(GC)-A64-C30-hSL (SEQ ID NO: 387, фиг. 29); и
Ndufa4-PpLuc(GC)-A64-C30-hSL (SEQ ID NO: 388, фиг. 30).
Клетки HDF и HeLa человека трансфицируют мРНК, кодирующими люциферазу, и уровни люциферазы измеряют через 24, 48 и 72 ч после трансфекции. Сигнал PpLuc корректируют по эффективности трансфекции сигналом котрансфицированного RrLuc. Расчитывают общую экспрессию белка (область под кривой). Уровни контрольной конструкции без 5'-UTR устанавливают на 1 (см. приведенные ниже табл. 9, а также фиг. 23 и 24).

Эти данные и данные, представленные на фиг. 23 и 24, показывают, что экспрессия белка с мРНК, содержащей элементы 5'-UTR в соответствии с настоящим изобретением, увеличивается.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> CUREVAC AG
<120> Novel artificial nucleic acid molecules
<130> CU01P167WO1
<150> PCT/EP2014/003479
<151> 2014-12-30
<160> 388
<170> PatentIn version 3.5
<210> 1
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus GNAS 3'-UTR
<400> 1
gaagggaaca cccaaattta attcagcctt aagcacaatt aattaagagt gaaacgtaat 60
gtacaagcag ttggtcaccc accatagggc atgatcaaca ccgcaacctt tcctttttcc 120
cccagtgatt ctgaaaaacc cctcttccct tcagcttgct tagatgttcc aaatttagta 180
agcttaaggc ggcctacaga agaaaaagaa aaaaaaggcc acaaaagttc cctctcactt 240
tcagtaaata aaataaaagc agcaacagaa ataaagaaat aaatgaaatt caaaatgaaa 300
taaatattgt ttgtgcagca ttaaaaaatc aataaaaatt aaaaatgagc a 351
<210> 2
<211> 353
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus GNAS 3'-UTR
<400> 2
gaagggaaca cccaaattta attcagcctt aagcacaatt aattaagagt gaaacgtaat 60
tgtacaagca gttggtcacc caccataggg catgatcaac accgcaacct ttcctttttc 120
ccccagtgat tctgaaaaac ccctcttccc ttcagcttgc ttagatgttc caaatttagt 180
aagcttaagg cggcctacag aagaaaaaga aaaaaaaggc cacaaaagtt ccctctcact 240
ttcagtaaat aaaataaaag cagcaacaga aataaagaaa taaatgaaat tcaaaatgaa 300
ataaatattg tgttgtgcag cattaaaaaa tcaataaaaa ttaaaaatga gca 353
<210> 3
<211> 385
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GNAS 3'-UTR
<400> 3
gaagggaacc cccaaattta attaaagcct taagcacaat taattaaaag tgaaacgtaa 60
ttgtacaagc agttaatcac ccaccatagg gcatgattaa caaagcaacc tttcccttcc 120
cccgagtgat tttgcgaaac ccccttttcc cttcagcttg cttagatgtt ccaaatttag 180
aaagcttaag gcggcctaca gaaaaaggaa aaaaggccac aaaagttccc tctcactttc 240
agtaaaaata aataaaacag cagcagcaaa caaataaaat gaaataaaag aaacaaatga 300
aataaatatt gtgttgtgca gcattaaaaa aaatcaaaat aaaaattaaa tgtgagcaaa 360
gaatgaaaaa aaaaaaaaaa aaaaa 385
<210> 4
<211> 1476
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GNAS 3'-UTR
<400> 4
tggaggacgc cgtccagatt ctccttgttt tcatggattc aggtgctgga gaatctggta 60
aaagcaccat tgtgaagcag atgaggatcc tgcatgttaa tgggtttaat ggagagggcg 120
gcgaagagga cccgcaggct gcaaggagca acagcgatgg cagtgagaag gcaaccaaag 180
tgcaggacat caaaaacaac ctgaaagagg cgattgaaac cattgtggcc gccatgagca 240
acctggtgcc ccccgtggag ctggccaacc ccgagaacca gttcagagtg gactacatcc 300
tgagtgtgat gaacgtgcct gactttgact tccctcccga attctatgag catgccaagg 360
ctctgtggga ggatgaagga gtgcgtgcct gctacgaacg ctccaacgag taccagctga 420
ttgactgtgc ccagtacttc ctggacaaga tcgacgtgat caagcaggct gactatgtgc 480
cgagcgatca ggacctgctt cgctgccgtg tcctgacttc tggaatcttt gagaccaagt 540
tccaggtgga caaagtcaac ttccacatgt ttgacgtggg tggccagcgc gatgaacgcc 600
gcaagtggat ccagtgcttc aacgatgtga ctgccatcat cttcgtggtg gccagcagca 660
gctacaacat ggtcatccgg gaggacaacc agaccaaccg cctgcaggag gctctgaacc 720
tcttcaagag catctggaac aacagatggc tgcgcaccat ctctgtgatc ctgttcctca 780
acaagcaaga tctgctcgct gagaaagtcc ttgctgggaa atcgaagatt gaggactact 840
ttccagaatt tgctcgctac actactcctg aggatgctac tcccgagccc ggagaggacc 900
cacgcgtgac ccgggccaag tacttcattc gagatgagtt tctgaggatc agcactgcca 960
gtggagatgg gcgtcactac tgctaccctc atttcacctg cgctgtggac actgagaaca 1020
tccgccgtgt gttcaacgac tgccgtgaca tcattcagcg catgcacctt cgtcagtacg 1080
agctgctcta agaagggaac ccccaaattt aattaaagcc ttaagcacaa ttaattaaaa 1140
gtgaaacgta attgtacaag cagttaatca cccaccatag ggcatgatta acaaagcaac 1200
ctttcccttc ccccgagtga ttttgcgaaa cccccttttc ccttcagctt gcttagatgt 1260
tccaaattta gaaagcttaa ggcggcctac agaaaaagga aaaaaggcca caaaagttcc 1320
ctctcacttt cagtaaaaat aaataaaaca gcagcagcaa acaaataaaa tgaaataaaa 1380
gaaacaaatg aaataaatat tgtgttgtgc agcattaaaa aaaatcaaaa taaaaattaa 1440
atgtgagcaa agaatgaaaa aaaaaaaaaa aaaaaa 1476
<210> 5
<211> 117
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus MORN2 3'-UTR
<400> 5
acctgctgcc ttaacgctga gatgtggcct ctgcaacccc ccttaggcaa agcaactgaa 60
ccttctgcta aagtgacctg ccctcttccg taagtccaat aaagttgtca tgcaccc 117
<210> 6
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus MORN2 3'-UTR
<400> 6
acctgctgcc ttaacgctga gatgtggcct ctgcaacccc ccttaggcaa agcaactgaa 60
ccttctgcta aagtgacctg ccctcttccg taagtccaat aaagttgtca tgcacccaca 120
aaaaaaaaaa aaaaa 135
<210> 7
<211> 210
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MORN2 3'-UTR
<400> 7
catgtagatg tgatgttaaa ttaaagttga aatgtagtaa ttgaagcttt tagttgtaag 60
gaaagcaact taatctgtta tttgaaatga cttcatacac tacccctata agtttgccaa 120
taaaaccatc acctgcttac acctttttga actttatatt cattgtctta caattagttt 180
aaaataaatg acatgattca aaaaaaaaaa 210
<210> 8
<211> 438
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus GSTM1 3'-UTR
<400> 8
gcccttgcta cacgggcact cactaggagg acctgtccac actggggatc ctgcaggccc 60
tgggtgggga cagcaccctg gccttctgca ctgtggctcc tggttctctc tccttcccgc 120
tcccttctgc agcttggtca gccccatctc ctcaccctct tcccagtcaa gtccacacag 180
ccttcattct ccccagtttc tttcacatgg ccccttcttc attggctccc tgacccaacc 240
tcacagcccg tttctgcgaa ctgaggtctg tcctgaactc acgcttccta gaattacccc 300
gatggtcaac actatcttag tgctagccct ccctagagtt accccgaagg tcaatacttg 360
agtgccagcc tgttcctggt ggagtagcct ccccaggtct gtctcgtcta caataaagtc 420
tgaaacacac ttgccatg 438
<210> 9
<211> 455
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus GSTM1 3'-UTR
<400> 9
gcccttgcta cacgggcact cactaggagg acctgtccac actggggatc ctgcaggccc 60
tgggtgggga cagcaccctg gccttctgca ctgtggctcc tggttctctc tccttcccgc 120
tcccttctgc agcttggtca gccccatctc ctcaccctct tcccagtcaa gtccacacag 180
ccttcattct ccccagtttc tttcacatgg ccccttcttc attggctccc tgacccaacc 240
tcacagcccg tttctgcgaa ctgaggtctg tcctgaactc acgcttccta gaattacccc 300
gatggtcaac actatcttag tgctagccct ccctagagtt accccgaagg tcaatacttg 360
agtgccagcc tgttcctggt ggagtagcct ccccaggtct gtctcgtcta caataaagtc 420
tgaaacacac ttgccatgaa aaaaaaaaaa aaaaa 455
<210> 10
<211> 531
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GSTM1 3'-UTR
<400> 10
ggccttgaag gccaggaggt gggagtgagg agcccatact cagcctgctg cccaggctgt 60
gcagcgcagc tggactctgc atcccagcac ctgcctcctc gttcctttct cctgtttatt 120
cccatcttta ctcccaagac ttcattgtcc ctcttcactc cccctaaacc cctgtcccat 180
gcaggccctt tgaagcctca gctacccact atccttcgtg aacatcccct cccatcatta 240
cccttccctg cactaaagcc agcctgacct tccttcctgt tagtggttgt gtctgcttta 300
aagggcctgc ctggcccctc gcctgtggag ctcagccccg agctgtcccc gtgttgcatg 360
aaggagcagc attgactggt ttacaggccc tgctcctgca gcatggtccc tgccttaggc 420
ctacctgatg gaagtaaagc ctcaaccaca aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 480
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa a 531
<210> 11
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus NDUFA1 3'-UTR
<400> 11
ggaagcattt tcctggctga ttaaaagaaa ttactcagct atggtcatct gttcctgtta 60
gaaggctatg cagcatatta tatactatgc gcatgttatg aaatgcataa taaaaaattt 120
taaaaaatct aaa 133
<210> 12
<211> 148
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NDUFA1 3'-UTR
<400> 12
ggaagcattt tcctgattga tgaaaaaaat aactcagtta tggccatcta cccctgctag 60
aaggttacag tgtattatgt agcatgcaat gtgttatgta gtgcttaata aaaataaaat 120
gaaaaaaatg caaaaaaaaa aaaaaaaa 148
<210> 13
<211> 237
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus CBR2 3'-UTR
<400> 13
tctgctcagt tgccgcggac atctgagtgg ccttcttagc cccaccctca gccaaagcat 60
ttactgatct cgtgactccg ccctcatgct acagccacgc ccaccacgca gctcacagtt 120
ccacccccat gttactgtcg atcccacaac cactccaggc gcagaccttg ttctctttgt 180
ccactttgtt gggctcattt gcctaaataa acgggccacc gcgttacctt taactat 237
<210> 14
<211> 416
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus YBX1 3'-UTR
<400> 14
atgccggctt accatctcta ccatcatccg gtttggtcat ccaacaagaa gaaatgaata 60
tgaaattcca gcaataagaa atgaacaaag attggagctg aagaccttaa gtgcttgctt 120
tttgcccgct gaccagataa cattagaact atctgcatta tctatgcagc atggggtttt 180
tattattttt acctaaagat gtctcttttt ggtaatgaca aacgtgtttt ttaagaaaaa 240
aaaaaaaggc ctggtttttc tcaatacacc tttaacggtt tttaaattgt ttcatatctg 300
gtcaagttga gatttttaag aacttcattt ttaatttgta ataaagttta caacttgatt 360
ttttcaaaaa agtcaacaaa ctgcaagcac ctgttaataa aggtcttaaa taataa 416
<210> 15
<211> 418
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus YBX1 3'-UTR
<400> 15
atgccggctt accatctcta ccatcatccg gtttggtcat ccaacaagaa gaaatgaata 60
tgaaattcca gcaataagaa atgaacaaag attggagctg aagaccttaa gtgcttgctt 120
tttgccctct gaccagataa cattagaact atctgcatta tctatgcagc atggggtttt 180
tattattttt acctaaagat gtctcttttt ggtaatgaca aacgtgtttt ttaagaaaaa 240
aaaaaaaaag gcctggtttt tctcaataca cctttaacgg tttttaaatt gtttcatatc 300
tggtcaagtt gagattttta agaacttcat ttttaatttg taataaagtt tacaacttga 360
ttttttcaaa aaagtcaaca aactgcaagc acctgttaat aaaggtctta aataataa 418
<210> 16
<211> 415
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens YBX1 3'-UTR
<400> 16
atgccggctt accatctcta ccatcatccg gtttagtcat ccaacaagaa gaaatatgaa 60
attccagcaa taagaaatga acaaaagatt ggagctgaag acctaaagtg cttgcttttt 120
gcccgttgac cagataaata gaactatctg cattatctat gcagcatggg gtttttatta 180
tttttaccta aagacgtctc tttttggtaa taacaaacgt gttttttaaa aaagcctggt 240
ttttctcaat acgcctttaa aggtttttaa attgtttcat atctggtcaa gttgagattt 300
ttaagaactt catttttaat ttgtaataaa agtttacaac ttgatttttt caaaaaagtc 360
aacaaactgc aagcacctgt taataaaggt cttaaataat aaaaaaaaaa aaaaa 415
<210> 17
<211> 66
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufb8 3'-UTR
<400> 17
ggaggcttga tgggcttttt gccctcgttc ctagaggctt aaccataata aaatccctaa 60
taaagc 66
<210> 18
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens Ndufb8 3'-UTR
<400> 18
ggaggcttcg tgggcttttg ggtcctctaa ctaggactcc ctcattccta gaaatttaac 60
cttaatgaaa tccctaataa aactcagtgc tgtgttattt gtgcctcaaa aaaaaaaaaa 120
aaaaa 125
<210> 19
<211> 377
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens Ndufb8 3'-UTR
<400> 19
gtgaggaaga ggagtgctgt tcctgccttc ctagcccagc tgggtctgac cagaggctac 60
tgtgtaccca tttaccatgc gtgattgtta actcagagtg gggtgtagcc aggtattgac 120
tgaatgtatg ttcttgctga cctgtgtttt tttctgtagg gaccaaagca gtatccttac 180
aataatctgt acctggaacg aggcggtgat ccctccaaag aaccagagcg ggtggttcac 240
tatgagatct gaggaggctt cgtgggcttt tgggtcctct aactaggact ccctcattcc 300
tagaaattta accttaatga aatccctaat aaaactcagt gctgtgttat ttgtgcctca 360
aaaaaaaaaa aaaaaaa 377
<210> 20
<211> 922
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1-004 3'-UTR
<400> 20
tcgttgacac tcaccatttc tgtgaaagac tttttttttt tttaacatat tatactagat 60
ttgactaact caatcttgta gcttctgcag ttctccccac ccccaaccta gttcttagag 120
tatgtttccc cttttgaaac atgtaaacat actttgggca taaatatttt ttaaaatata 180
actataatgc ttcactaata ccttaaaaat gcctagtgaa ctaactcagt acattatata 240
atggccaagt gaaagttttg tgttttcatg tcctgttttt ctttgaaatt atatagccca 300
gaaattagct cattatctga aaaacgtata agaactgatg aattgtataa tacaggagta 360
ttgccattga atgtactgtt tgatttattc aagcaggtaa tgaacaatgt tgtcaaactc 420
tctaatgaga catcataatt aggacataag ctaaaagggg cattactccg gcagtctttt 480
tttcttaatc ctagtaccat acatattctt tggcatgaaa gaatgaaaag cattagtaaa 540
caactgaagt cctaccatgg ctctgtaggg tttttggaac aattcctgga attggaaagt 600
gaaaatggat agcatgtggg ggaaaccctc atctgagtag caagatttta gtaaagatga 660
ctaagccatt aacagcatgc attcatattt aattttattg actcctgcca tcagcttttg 720
tagatctttt gggtggaagg ttgtgatttt tactgggagg acttgagtag aagtggatga 780
ttaaaattga ggagtatata attctttctg ggactgctta aatgttattg tttgaaaatg 840
ccttcacttt ccccctttgg tcaaagagat gtgcttaaaa ttcttattcc ttcacaataa 900
ataattttga ttttcttaga ca 922
<210> 21
<211> 922
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1-004 3'-UTR
<400> 21
tcgttgacac tcaccatttc tgtgaaagac tttttttttt ttaacatatt atactagatt 60
tgactaactc aatcttgtag cttctgcagt tctccccacc cccaacctag ttcttagagt 120
atgtttcccc ttttgaaaca tgtaaacata ctttgggcat aaatattttt taaaatataa 180
ctataatgct tcactaatac cttaaaaatg cctagtgaac taactcagta cattatataa 240
tggccaagtg aaagttttgt gttttcatgt cctgtttttc tttgaaatta tatagcccag 300
aaattagctc attatctgaa aaacgtatga agaactgatg aattgtataa tacaggagta 360
ttgccattga atgtactgtt tgatttattc aagcaggtaa tgaacaatgt tgtcaaactc 420
tctaatgaga catcataatt aggacataag ctaaaagggg cattactccg gcagtctttt 480
tttcttaatc ctagtaccat acatattctt tggcatgaaa gaatgaaaag cattagtaaa 540
caactgaagt cctaccatgg ctctgtaggg tttttggaac aattcctgga attggaaagt 600
gaaaatggat agcatgtggg ggaaaccctc atctgagtag caagatttta gtaaagatga 660
ctaagccatt aacagcatgc attcatattt aattttattg actcctgcca tcagcttttg 720
tagatcgttt gggtggaagg ttgtgatttt tactgggagg acttgagtag aagtggatga 780
ttaaaattga ggagtatata attctttctg ggactgctta aatgttattg tttgaaaata 840
ccttcacttt ccccctttgg tcaaagagat gtgcttaaaa ttcttattcc ttcacaataa 900
ataattttga ttttcttaga ca 922
<210> 22
<211> 928
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1-004 3'-UTR
<400> 22
ttttttcgtt gacactcacc atttctgtga aagacttttt ttttttttaa catattatac 60
tagatttgac taactcaatc ttgtagcttc tgcagttctc cccaccccca acctagttct 120
tagagtatgt ttcccctttt gaaacatgta aacatacttt gggcataaat attttttaaa 180
atataactat aatgcttcac taatacctta aaaatgccta gtgaactaac tcagtacatt 240
atataatggc caagtgaaag ttttgtgttt tcatgtcctg tttttctttg aaattatata 300
gcccagaaat tagctcatta tctgaaaaac gtatgaagaa ctgatgaatt gtataataca 360
ggagtattgc cattgaatgt actgtttgat ttattcaagc aggtaatgaa caatgttgtc 420
aaactctcta atgagacatc ataattagga cataagctaa aaggggcatt actccggcag 480
tctttttttc ttaatcctag taccatacat attctttggc atgaaagaat gaaaagcatt 540
agtaaacaac tgaagtccta ccatggctct gtagggtttt tggaacaatt cctggaattg 600
gaaagtgaaa atggatagca tgtgggggaa accctcatct gagtagcaag attttagtaa 660
agatgactaa gccattaaca gcatgcattc atatttaatt ttattgactc ctgccatcag 720
cttttgtaga tcttttgggt ggaaggttgt gatttttact gggaggactt gagtagaagt 780
ggatgattaa aattgaggag tatataattc tttctgggac tgcttaaatg ttattgtttg 840
aaaatgcctt cactttcccc ctttggtcaa agagatgtgc ttaaaattct tattccttca 900
caataaataa ttttgatttt cttagaca 928
<210> 23
<211> 2380
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1-004 3'-UTR
<400> 23
atgtgttgtg acagctgctg ttcccatccc agctcagaag acacccttca accctgggat 60
gaccacaatt ccttccaatt tctgcggctc catcctaagc caaataaatt atactttaac 120
aaactattca actgatttac aacacacatg atgactgagg cattcgggaa ccccttcatc 180
caaaagaata aacttttaaa tggatataaa tgatttttaa ctcgttccaa tatgccttat 240
aaaccactta acctgattct gtgacagttg catgatttaa cccaatggga caagttacag 300
tgttcaattc aatactatag gctgtagagt gaaagtcaaa tcaccatata caggtgcttt 360
aaatttaata acaagttgtg aaatataata gagattgaaa tgttggttgt atgtggtaaa 420
tgtaagagta atacagtctc ttgtactttc ctcactgttt tgggtactgc atattattga 480
atggccccta tcattcatga catcttgagt tttcttgaaa agacaataga gtgtaacaaa 540
tattttgtca gaaatcccat tatcaaatca tgagttgaaa gattttgact attgaaaacc 600
aaattctaga acttactatc agtattctta ttttcaaagg aaataatttt ctaaatattt 660
gattttcaga atcagttttt taatagtaaa gttaacatac catatagatt tttttttact 720
tttatattct actctgaagt tattttatgc ttttcttatc aatttcaaat ctcaaaaatc 780
acagctctta tctagagtat cataatattg ctatatttgt tcatatgtgg agtgacaaat 840
tttgaaaagt agagtgcttc cttttttatt gagatgtgac agtctttaca tggttaggaa 900
taagtgacag ttaagtgaat atcacaatta ctagtatgtt ggtttttctg cttcattcct 960
aagtattacg tttctttatt gcagatgtca gatcaaaaag tcacctgtag gttgaaaaag 1020
ctaccgtatt ccattttgta aaaataacaa taataataat aataataatt agttttaagc 1080
tcatttccca cttcaatgca atactgaaaa ctggctaaaa ataccaaatc aatatactgc 1140
taatggtact ttgaagagta tgcaaaactg gaaggccagg aggaggcaaa taatatgtct 1200
ttccgatggt gtctcccaag tgttggtgct ttgggttttt ataagttgtg aaaaggaaga 1260
tgcacatttc ttcattctcc atggtgtgca tggaaatgtg tttgagtgtg gatgtaaaag 1320
aaatcgagta ataaagaatt agctggcttg tgaaatagtg cagtgttgga tgcttcaaga 1380
ggtataatcc tattttatta gcacaaactt gctagctaat tagagtttat ctttttagaa 1440
aggacaccgt ataggttcgt aaaaaatatt tacaggaagc aaaatagatc tattactact 1500
ttaccgactt tacccccttt ctttaatttg tataattttt gtactatata tcgatgtgta 1560
aatgtttaga gtcttcatta tgaaaatatc aataaatatt tcattagttt acatttaact 1620
ctggtataaa atgaaacttt taaaaataag tgaaatggat gatttcccag tggaagtatg 1680
tcaacagtct taagatcatt gccagatttc ataaaatatt taagtatttg aaaaagaaac 1740
aaaatgtctt catactttag ggaaacgaat accctgtata ccttctgtac aaatgtttgt 1800
gttttcattg ttacactttg gggttttact tttgcaatgt gacccatgtt gggcattttt 1860
atataatcaa caactaaatc ttttgccaaa tgcatgcttg ccttttattt tctaatatat 1920
gataataacg agcaaaactg gttagatttt gcatgaaatg gttctgaaag gtaagaggaa 1980
aacagacttt ggaggttgtt tagttttgaa tttctgacag agataaagta gtttaaaatc 2040
tctcgtacac tgataactca agcttttcat tttctcatac agttgtacag atttaactgg 2100
gaccatcagt tttaaactgt tgtcaagcta actaataatc atctgcttta agacgcaaga 2160
ttctgaatta aactttatat aggtatagat acatctgttg tttctttgta tttcaggaaa 2220
ggtgatagta gttttatttg atactgataa atattgaatt gattttttag ttatttttta 2280
tcattttttc aatggagtag tataggactg tgctttgtcc tttttatgaa tgaaaaaatt 2340
agtataaagt aataaatgtc ttatgttacc caagaaaaaa 2380
<210> 24
<211> 1204
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1-004 3'-UTR
<400> 24
tcgttgacac tcaccatttc tgtgaaagac tttttttttt ttaacatatt atactagatt 60
tgactaactc aatcttgtag cttctgcagt tctccccacc cccaacctag ttcttagagt 120
atgtttcccc ttttgaaaca tgtaaacata ctttgggcat aaatattttt taaaatataa 180
ctataatgct tcactaatac cttaaaaatg cctagtgaac taactcagta cattatataa 240
tggccaagtg aaagttttgt gttttcatgt cctgtttttc tttgaaatta tatagcccag 300
aaattagctc attatctgaa aaacgtatga agaactgatg aattgtataa tacaggagta 360
ttgccattga atgtactgtt tgatttattc aagcaggtaa tgaacaatgt tgtcaaactc 420
tctaatgaga catcataatt aggacataag ctaaaagggg cattactccg gcagtctttt 480
tttcttaatc ctagtaccat acatattctt tggcatgaaa gaatgaaaag cattagtaaa 540
caactgaagt cctaccatgg ctctgtaggg tttttggaac aattcctgga attggaaagt 600
gaaaatggat agcatgtggg ggaaaccctc atctgagtag caagatttta gtaaagatga 660
ctaagccatt aacagcatgc attcatattt aattttattg actcctgcca tcagcttttg 720
tagatcgttt gggtggaagg ttgtgatttt tactgggagg acttgagtag aagtggatga 780
ttaaaattga ggagtatata attctttctg ggactgctta aatgttattg tttgaaaata 840
ccttcacttt ccccctttgg tcaaagagat gtgcttaaaa ttcttattcc ttcacaataa 900
ataattttga ttttcttaga caggtttgtg tttaggtatg agtttctctt ttacttcatc 960
tagcaattct ctctgtggtc agaagaactc tgaagaaagc tttgagggaa atgaatataa 1020
ctcttaaatt attatatgtg tgtgtatata tatagtttaa ctttaaaaat aatttattag 1080
tcatcataaa gaaataaatg tctctggctc aagatgttac ttatttcctt cttttatatt 1140
ttctagtctc aattactgtt ccaaaaggag ctatcttaga acttagacta gagatccaga 1200
ttaa 1204
<210> 25
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus MP68 5'-UTR
<400> 25
ctttcccatt ctgtagcaga atttggtgtt gcctgtggtc ttggtcccgc ggag 54
<210> 26
<211> 97
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MP68 5'-UTR
<400> 26
cttcccggca tcccctgcgc gcgcctgcgc gctcggtgac ctttccgagt tggctgcaga 60
tttgtggtgc gttctgagcc gtctgtcctg cgccaag 97
<210> 27
<211> 315
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MP68 5'-UTR
<400> 27
cttcccggca tcccctgcgc gcgcctgcgc gctcggtgac ctttccgagt tggctgcaga 60
tttgtggtgc gttctgagcc gtctgtcctg cgccaaggga gcgtaccttg gccttgagag 120
gttcagctgc ctaacccaga ggctacgcag agttagagaa gccagagtcc aagccaagaa 180
ctctgactcc acatccagtc ccttctctcc tttataactc aagtttcctt gcgccacact 240
gccctccacg ttatgctgta catgacaact tgggtgaggc aacagggaag ctgaaaagag 300
atcatacggt gctga 315
<210> 28
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus NDUFA4 5'-UTR
<400> 28
gtccgctcag ccaggttgca gaagcggctt agcgtgtgtc ctaatcttct ctctgcgtgt 60
aggtaggcct gtgccgcaaa c 81
<210> 29
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NDUFA4 5'-UTR
<400> 29
guccgcucag ccagguugca gaagcggcuu agcguguguc cuaaucuucu cucugcgugu 60
agguaggccu gugccgcaaa c 81
<210> 30
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NDUFA4 5'-UTR
<400> 30
gggtccttca ggtaggaggt cctgggtgac tttggaagtc cgtagtgtct cattgcagat 60
aatttttagc ttagggcctg gtggctaggt cggttctctc ctttccagtc ggagacctct 120
gccgcaaac 129
<210> 31
<211> 186
<212> DNA
<213> Artificial Sequence
<220>
<223> Human albumin 3'-UTR
<400> 31
catcacattt aaaagcatct cagcctacca tgagaataag agaaagaaaa tgaagatcaa 60
aagcttattc atctgttttt ctttttcgtt ggtgtaaagc caacaccctg tctaaaaaac 120
ataaatttct ttaatcattt tgcctctttt ctctgtgctt caattaataa aaaatggaaa 180
gaatct 186
<210> 32
<211> 186
<212> DNA
<213> Artificial Sequence
<220>
<223> albumin7 3'-UTR
<400> 32
catcacattt aaaagcatct cagcctacca tgagaataag agaaagaaaa tgaagatcaa 60
tagcttattc atctcttttt ctttttcgtt ggtgtaaagc caacaccctg tctaaaaaac 120
ataaatttct ttaatcattt tgcctctttt ctctgtgctt caattaataa aaaatggaaa 180
gaacct 186
<210> 33
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> 5'-UTR of human ribosomal protein Large 32 lacking the 5'
terminal oligopyrimidine tract
<400> 33
ggcgctgcct acggaggtgg cagccatctc cttctcggca tc 42
<210> 34
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> histone stem-loop
<400> 34
caaaggctct tttcagagcc acca 24
<210> 35
<211> 1848
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - A64 - C30 - hSL
<400> 35
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uaguagaucu aaaaaaaaaa aaaaaaaaaa 1740
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaugcauc cccccccccc 1800
cccccccccc cccccccccc aaaggcucuu uucagagcca ccagaauu 1848
<210> 36
<211> 2201
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - gnas-A64-C30-hSL
<400> 36
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uagugaaggg aacacccaaa uuuaauucag 1740
ccuuaagcac aauuaauuaa gagugaaacg uaauuguaca agcaguuggu cacccaccau 1800
agggcaugau caacaccgca accuuuccuu uuucccccag ugauucugaa aaaccccucu 1860
ucccuucagc uugcuuagau guuccaaauu uaguaagcuu aaggcggccu acagaagaaa 1920
aagaaaaaaa aggccacaaa aguucccucu cacuuucagu aaauaaaaua aaagcagcaa 1980
cagaaauaaa gaaauaaaug aaauucaaaa ugaaauaaau auuguguugu gcagcauuaa 2040
aaaaucaaua aaaauuaaaa augagcaaga ucuaaaaaaa aaaaaaaaaa aaaaaaaaaa 2100
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaugc aucccccccc cccccccccc 2160
cccccccccc cccaaaggcu cuuuucagag ccaccagaau u 2201
<210> 37
<211> 1965
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - morn2- A64 - C30 - hSL
<400> 37
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uaguaccugc ugccuuaacg cugagaugug 1740
gccucugcaa ccccccuuag gcaaagcaac ugaaccuucu gcuaaaguga ccugcccucu 1800
uccguaaguc caauaaaguu gucaugcacc cagaucuaaa aaaaaaaaaa aaaaaaaaaa 1860
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa augcaucccc cccccccccc 1920
cccccccccc cccccccaaa ggcucuuuuc agagccacca gaauu 1965
<210> 38
<211> 2286
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - gstm1- A64 - C30 - hSL
<400> 38
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uagugcccuu gcuacacggg cacucacuag 1740
gaggaccugu ccacacuggg gauccugcag gcccugggug gggacagcac ccuggccuuc 1800
ugcacugugg cuccugguuc ucucuccuuc ccgcucccuu cugcagcuug gucagcccca 1860
ucuccucacc cucuucccag ucaaguccac acagccuuca uucuccccag uuucuuucac 1920
auggccccuu cuucauuggc ucccugaccc aaccucacag cccguuucug cgaacugagg 1980
ucuguccuga acucacgcuu ccuagaauua ccccgauggu caacacuauc uuagugcuag 2040
cccucccuag aguuaccccg aaggucaaua cuugagugcc agccuguucc ugguggagua 2100
gccuccccag gucugucucg ucuacaauaa agucugaaac acacuugcca ugagaucuaa 2160
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 2220
aaugcauccc cccccccccc cccccccccc ccccccccaa aggcucuuuu cagagccacc 2280
agaauu 2286
<210> 39
<211> 1981
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - ndufa1 - A64 - C30 - hSL
<400> 39
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uaguggaagc auuuuccugg cugauuaaaa 1740
gaaauuacuc agcuaugguc aucuguuccu guuagaaggc uaugcagcau auuauauacu 1800
augcgcaugu uaugaaaugc auaauaaaaa auuuuaaaaa aucuaaaaga ucuaaaaaaa 1860
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaugc 1920
aucccccccc cccccccccc cccccccccc cccaaaggcu cuuuucagag ccaccagaau 1980
u 1981
<210> 40
<211> 2085
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - cbr2 - A64 - C30 - hSL
<400> 40
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uaguucugcu caguugccgc ggacaucuga 1740
guggccuucu uagccccacc cucagccaaa gcauuuacug aucucgugac uccgcccuca 1800
ugcuacagcc acgcccacca cgcagcucac aguuccaccc ccauguuacu gucgauccca 1860
caaccacucc aggcgcagac cuuguucucu uuguccacuu uguugggcuc auuugccuaa 1920
auaaacgggc caccgcguua ccuuuaacua uagaucuaaa aaaaaaaaaa aaaaaaaaaa 1980
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa augcaucccc cccccccccc 2040
cccccccccc cccccccaaa ggcucuuuuc agagccacca gaauu 2085
<210> 41
<211> 1997
<212> RNA
<213> Artificial Sequence
<220>
<223> PpLuc(GC) - albumin7- A64 - C30 - hSL
<400> 41
gggagaaagc uugaggaugg aggacgccaa gaacaucaag aagggcccgg cgcccuucua 60
cccgcuggag gacgggaccg ccggcgagca gcuccacaag gccaugaagc gguacgcccu 120
ggugccgggc acgaucgccu ucaccgacgc ccacaucgag gucgacauca ccuacgcgga 180
guacuucgag augagcgugc gccuggccga ggccaugaag cgguacggcc ugaacaccaa 240
ccaccggauc guggugugcu cggagaacag ccugcaguuc uucaugccgg ugcugggcgc 300
ccucuucauc ggcguggccg ucgccccggc gaacgacauc uacaacgagc gggagcugcu 360
gaacagcaug gggaucagcc agccgaccgu gguguucgug agcaagaagg gccugcagaa 420
gauccugaac gugcagaaga agcugcccau cauccagaag aucaucauca uggacagcaa 480
gaccgacuac cagggcuucc agucgaugua cacguucgug accagccacc ucccgccggg 540
cuucaacgag uacgacuucg ucccggagag cuucgaccgg gacaagacca ucgcccugau 600
caugaacagc agcggcagca ccggccugcc gaagggggug gcccugccgc accggaccgc 660
cugcgugcgc uucucgcacg cccgggaccc caucuucggc aaccagauca ucccggacac 720
cgccauccug agcguggugc cguuccacca cggcuucggc auguucacga cccugggcua 780
ccucaucugc ggcuuccggg ugguccugau guaccgguuc gaggaggagc uguuccugcg 840
gagccugcag gacuacaaga uccagagcgc gcugcucgug ccgacccugu ucagcuucuu 900
cgccaagagc acccugaucg acaaguacga ccugucgaac cugcacgaga ucgccagcgg 960
gggcgccccg cugagcaagg aggugggcga ggccguggcc aagcgguucc accucccggg 1020
cauccgccag ggcuacggcc ugaccgagac cacgagcgcg auccugauca cccccgaggg 1080
ggacgacaag ccgggcgccg ugggcaaggu ggucccguuc uucgaggcca agguggugga 1140
ccuggacacc ggcaagaccc ugggcgugaa ccagcggggc gagcugugcg ugcgggggcc 1200
gaugaucaug agcggcuacg ugaacaaccc ggaggccacc aacgcccuca ucgacaagga 1260
cggcuggcug cacagcggcg acaucgccua cugggacgag gacgagcacu ucuucaucgu 1320
cgaccggcug aagucgcuga ucaaguacaa gggcuaccag guggcgccgg ccgagcugga 1380
gagcauccug cuccagcacc ccaacaucuu cgacgccggc guggccgggc ugccggacga 1440
cgacgccggc gagcugccgg ccgcgguggu ggugcuggag cacggcaaga ccaugacgga 1500
gaaggagauc gucgacuacg uggccagcca ggugaccacc gccaagaagc ugcggggcgg 1560
cgugguguuc guggacgagg ucccgaaggg ccugaccggg aagcucgacg cccggaagau 1620
ccgcgagauc cugaucaagg ccaagaaggg cggcaagauc gccguguaag acuagugcau 1680
cacauuuaaa agcaucucag ccuaccauga gaauaagaga aagaaaauga agaucaauag 1740
cuuauucauc ucuuuuucuu uuucguuggu guaaagccaa cacccugucu aaaaaacaua 1800
aauuucuuua aucauuuugc cucuuuucuc ugugcuucaa uuaauaaaaa auggaaagaa 1860
ccuagaucua aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1920
aaaaaaaaaa aaaugcaucc cccccccccc cccccccccc ccccccccca aaggcucuuu 1980
ucagagccac cagaauu 1997
<210> 42
<211> 2048
<212> RNA
<213> Artificial Sequence
<220>
<223> Mp68 - PpLuc(GC) - albumin7- A64 - C30 - hSL
<400> 42
gggcuuuccc auucuguagc agaauuuggu guugccugug gucuuggucc cgcggagaag 60
cuugaggaug gaggacgcca agaacaucaa gaagggcccg gcgcccuucu acccgcugga 120
ggacgggacc gccggcgagc agcuccacaa ggccaugaag cgguacgccc uggugccggg 180
cacgaucgcc uucaccgacg cccacaucga ggucgacauc accuacgcgg aguacuucga 240
gaugagcgug cgccuggccg aggccaugaa gcgguacggc cugaacacca accaccggau 300
cguggugugc ucggagaaca gccugcaguu cuucaugccg gugcugggcg cccucuucau 360
cggcguggcc gucgccccgg cgaacgacau cuacaacgag cgggagcugc ugaacagcau 420
ggggaucagc cagccgaccg ugguguucgu gagcaagaag ggccugcaga agauccugaa 480
cgugcagaag aagcugccca ucauccagaa gaucaucauc auggacagca agaccgacua 540
ccagggcuuc cagucgaugu acacguucgu gaccagccac cucccgccgg gcuucaacga 600
guacgacuuc gucccggaga gcuucgaccg ggacaagacc aucgcccuga ucaugaacag 660
cagcggcagc accggccugc cgaagggggu ggcccugccg caccggaccg ccugcgugcg 720
cuucucgcac gcccgggacc ccaucuucgg caaccagauc aucccggaca ccgccauccu 780
gagcguggug ccguuccacc acggcuucgg cauguucacg acccugggcu accucaucug 840
cggcuuccgg gugguccuga uguaccgguu cgaggaggag cuguuccugc ggagccugca 900
ggacuacaag auccagagcg cgcugcucgu gccgacccug uucagcuucu ucgccaagag 960
cacccugauc gacaaguacg accugucgaa ccugcacgag aucgccagcg ggggcgcccc 1020
gcugagcaag gaggugggcg aggccguggc caagcgguuc caccucccgg gcauccgcca 1080
gggcuacggc cugaccgaga ccacgagcgc gauccugauc acccccgagg gggacgacaa 1140
gccgggcgcc gugggcaagg uggucccguu cuucgaggcc aagguggugg accuggacac 1200
cggcaagacc cugggcguga accagcgggg cgagcugugc gugcgggggc cgaugaucau 1260
gagcggcuac gugaacaacc cggaggccac caacgcccuc aucgacaagg acggcuggcu 1320
gcacagcggc gacaucgccu acugggacga ggacgagcac uucuucaucg ucgaccggcu 1380
gaagucgcug aucaaguaca agggcuacca gguggcgccg gccgagcugg agagcauccu 1440
gcuccagcac cccaacaucu ucgacgccgg cguggccggg cugccggacg acgacgccgg 1500
cgagcugccg gccgcggugg uggugcugga gcacggcaag accaugacgg agaaggagau 1560
cgucgacuac guggccagcc aggugaccac cgccaagaag cugcggggcg gcgugguguu 1620
cguggacgag gucccgaagg gccugaccgg gaagcucgac gcccggaaga uccgcgagau 1680
ccugaucaag gccaagaagg gcggcaagau cgccguguaa gacuagugca ucacauuuaa 1740
aagcaucuca gccuaccaug agaauaagag aaagaaaaug aagaucaaua gcuuauucau 1800
cucuuuuucu uuuucguugg uguaaagcca acacccuguc uaaaaaacau aaauuucuuu 1860
aaucauuuug ccucuuuucu cugugcuuca auuaauaaaa aauggaaaga accuagaucu 1920
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1980
aaaaugcauc cccccccccc cccccccccc cccccccccc aaaggcucuu uucagagcca 2040
ccagaauu 2048
<210> 43
<211> 2075
<212> RNA
<213> Artificial Sequence
<220>
<223> Ndufa4 - PpLuc(GC) - albumin7- A64 - C30 - hSL
<400> 43
gggguccgcu cagccagguu gcagaagcgg cuuagcgugu guccuaaucu ucucucugcg 60
uguagguagg ccugugccgc aaacaagcuu gaggauggag gacgccaaga acaucaagaa 120
gggcccggcg cccuucuacc cgcuggagga cgggaccgcc ggcgagcagc uccacaaggc 180
caugaagcgg uacgcccugg ugccgggcac gaucgccuuc accgacgccc acaucgaggu 240
cgacaucacc uacgcggagu acuucgagau gagcgugcgc cuggccgagg ccaugaagcg 300
guacggccug aacaccaacc accggaucgu ggugugcucg gagaacagcc ugcaguucuu 360
caugccggug cugggcgccc ucuucaucgg cguggccguc gccccggcga acgacaucua 420
caacgagcgg gagcugcuga acagcauggg gaucagccag ccgaccgugg uguucgugag 480
caagaagggc cugcagaaga uccugaacgu gcagaagaag cugcccauca uccagaagau 540
caucaucaug gacagcaaga ccgacuacca gggcuuccag ucgauguaca cguucgugac 600
cagccaccuc ccgccgggcu ucaacgagua cgacuucguc ccggagagcu ucgaccggga 660
caagaccauc gcccugauca ugaacagcag cggcagcacc ggccugccga aggggguggc 720
ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc cgggacccca ucuucggcaa 780
ccagaucauc ccggacaccg ccauccugag cguggugccg uuccaccacg gcuucggcau 840
guucacgacc cugggcuacc ucaucugcgg cuuccgggug guccugaugu accgguucga 900
ggaggagcug uuccugcgga gccugcagga cuacaagauc cagagcgcgc ugcucgugcc 960
gacccuguuc agcuucuucg ccaagagcac ccugaucgac aaguacgacc ugucgaaccu 1020
gcacgagauc gccagcgggg gcgccccgcu gagcaaggag gugggcgagg ccguggccaa 1080
gcgguuccac cucccgggca uccgccaggg cuacggccug accgagacca cgagcgcgau 1140
ccugaucacc cccgaggggg acgacaagcc gggcgccgug ggcaaggugg ucccguucuu 1200
cgaggccaag gugguggacc uggacaccgg caagacccug ggcgugaacc agcggggcga 1260
gcugugcgug cgggggccga ugaucaugag cggcuacgug aacaacccgg aggccaccaa 1320
cgcccucauc gacaaggacg gcuggcugca cagcggcgac aucgccuacu gggacgagga 1380
cgagcacuuc uucaucgucg accggcugaa gucgcugauc aaguacaagg gcuaccaggu 1440
ggcgccggcc gagcuggaga gcauccugcu ccagcacccc aacaucuucg acgccggcgu 1500
ggccgggcug ccggacgacg acgccggcga gcugccggcc gcgguggugg ugcuggagca 1560
cggcaagacc augacggaga aggagaucgu cgacuacgug gccagccagg ugaccaccgc 1620
caagaagcug cggggcggcg ugguguucgu ggacgagguc ccgaagggcc ugaccgggaa 1680
gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc aagaagggcg gcaagaucgc 1740
cguguaagac uagugcauca cauuuaaaag caucucagcc uaccaugaga auaagagaaa 1800
gaaaaugaag aucaauagcu uauucaucuc uuuuucuuuu ucguuggugu aaagccaaca 1860
cccugucuaa aaaacauaaa uuucuuuaau cauuuugccu cuuuucucug ugcuucaauu 1920
aauaaaaaau ggaaagaacc uagaucuaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1980
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa augcaucccc cccccccccc cccccccccc 2040
cccccccaaa ggcucuuuuc agagccacca gaauu 2075
<210> 44
<211> 1810
<212> DNA
<213> Artificial Sequence
<220>
<223> PpLuc(GC) - A64 - C30 - hSL
<400> 44
gggagaaagc ttgaggatgg aggacgccaa gaacatcaag aagggcccgg cgcccttcta 60
cccgctggag gacgggaccg ccggcgagca gctccacaag gccatgaagc ggtacgccct 120
ggtgccgggc acgatcgcct tcaccgacgc ccacatcgag gtcgacatca cctacgcgga 180
gtacttcgag atgagcgtgc gcctggccga ggccatgaag cggtacggcc tgaacaccaa 240
ccaccggatc gtggtgtgct cggagaacag cctgcagttc ttcatgccgg tgctgggcgc 300
cctcttcatc ggcgtggccg tcgccccggc gaacgacatc tacaacgagc gggagctgct 360
gaacagcatg gggatcagcc agccgaccgt ggtgttcgtg agcaagaagg gcctgcagaa 420
gatcctgaac gtgcagaaga agctgcccat catccagaag atcatcatca tggacagcaa 480
gaccgactac cagggcttcc agtcgatgta cacgttcgtg accagccacc tcccgccggg 540
cttcaacgag tacgacttcg tcccggagag cttcgaccgg gacaagacca tcgccctgat 600
catgaacagc agcggcagca ccggcctgcc gaagggggtg gccctgccgc accggaccgc 660
ctgcgtgcgc ttctcgcacg cccgggaccc catcttcggc aaccagatca tcccggacac 720
cgccatcctg agcgtggtgc cgttccacca cggcttcggc atgttcacga ccctgggcta 780
cctcatctgc ggcttccggg tggtcctgat gtaccggttc gaggaggagc tgttcctgcg 840
gagcctgcag gactacaaga tccagagcgc gctgctcgtg ccgaccctgt tcagcttctt 900
cgccaagagc accctgatcg acaagtacga cctgtcgaac ctgcacgaga tcgccagcgg 960
gggcgccccg ctgagcaagg aggtgggcga ggccgtggcc aagcggttcc acctcccggg 1020
catccgccag ggctacggcc tgaccgagac cacgagcgcg atcctgatca cccccgaggg 1080
ggacgacaag ccgggcgccg tgggcaaggt ggtcccgttc ttcgaggcca aggtggtgga 1140
cctggacacc ggcaagaccc tgggcgtgaa ccagcggggc gagctgtgcg tgcgggggcc 1200
gatgatcatg agcggctacg tgaacaaccc ggaggccacc aacgccctca tcgacaagga 1260
cggctggctg cacagcggcg acatcgccta ctgggacgag gacgagcact tcttcatcgt 1320
cgaccggctg aagtcgctga tcaagtacaa gggctaccag gtggcgccgg ccgagctgga 1380
gagcatcctg ctccagcacc ccaacatctt cgacgccggc gtggccgggc tgccggacga 1440
cgacgccggc gagctgccgg ccgcggtggt ggtgctggag cacggcaaga ccatgacgga 1500
gaaggagatc gtcgactacg tggccagcca ggtgaccacc gccaagaagc tgcggggcgg 1560
cgtggtgttc gtggacgagg tcccgaaggg cctgaccggg aagctcgacg cccggaagat 1620
ccgcgagatc ctgatcaagg ccaagaaggg cggcaagatc gccgtgtaag actagtagat 1680
ctaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1740
aaaaaatgca tccccccccc cccccccccc cccccccccc ccaaaggctc ttttcagagc 1800
caccagaatt 1810
<210> 45
<211> 2163
<212> RNA
<213> Artificial Sequence
<220>
<223> PpLuc(GC) - gnas- A64 - C30 - hSL
<400> 45
gggagaaagc uugaggaugg aggacgccaa gaacaucaag aagggcccgg cgcccuucua 60
cccgcuggag gacgggaccg ccggcgagca gcuccacaag gccaugaagc gguacgcccu 120
ggugccgggc acgaucgccu ucaccgacgc ccacaucgag gucgacauca ccuacgcgga 180
guacuucgag augagcgugc gccuggccga ggccaugaag cgguacggcc ugaacaccaa 240
ccaccggauc guggugugcu cggagaacag ccugcaguuc uucaugccgg ugcugggcgc 300
ccucuucauc ggcguggccg ucgccccggc gaacgacauc uacaacgagc gggagcugcu 360
gaacagcaug gggaucagcc agccgaccgu gguguucgug agcaagaagg gccugcagaa 420
gauccugaac gugcagaaga agcugcccau cauccagaag aucaucauca uggacagcaa 480
gaccgacuac cagggcuucc agucgaugua cacguucgug accagccacc ucccgccggg 540
cuucaacgag uacgacuucg ucccggagag cuucgaccgg gacaagacca ucgcccugau 600
caugaacagc agcggcagca ccggccugcc gaagggggug gcccugccgc accggaccgc 660
cugcgugcgc uucucgcacg cccgggaccc caucuucggc aaccagauca ucccggacac 720
cgccauccug agcguggugc cguuccacca cggcuucggc auguucacga cccugggcua 780
ccucaucugc ggcuuccggg ugguccugau guaccgguuc gaggaggagc uguuccugcg 840
gagccugcag gacuacaaga uccagagcgc gcugcucgug ccgacccugu ucagcuucuu 900
cgccaagagc acccugaucg acaaguacga ccugucgaac cugcacgaga ucgccagcgg 960
gggcgccccg cugagcaagg aggugggcga ggccguggcc aagcgguucc accucccggg 1020
cauccgccag ggcuacggcc ugaccgagac cacgagcgcg auccugauca cccccgaggg 1080
ggacgacaag ccgggcgccg ugggcaaggu ggucccguuc uucgaggcca agguggugga 1140
ccuggacacc ggcaagaccc ugggcgugaa ccagcggggc gagcugugcg ugcgggggcc 1200
gaugaucaug agcggcuacg ugaacaaccc ggaggccacc aacgcccuca ucgacaagga 1260
cggcuggcug cacagcggcg acaucgccua cugggacgag gacgagcacu ucuucaucgu 1320
cgaccggcug aagucgcuga ucaaguacaa gggcuaccag guggcgccgg ccgagcugga 1380
gagcauccug cuccagcacc ccaacaucuu cgacgccggc guggccgggc ugccggacga 1440
cgacgccggc gagcugccgg ccgcgguggu ggugcuggag cacggcaaga ccaugacgga 1500
gaaggagauc gucgacuacg uggccagcca ggugaccacc gccaagaagc ugcggggcgg 1560
cgugguguuc guggacgagg ucccgaaggg ccugaccggg aagcucgacg cccggaagau 1620
ccgcgagauc cugaucaagg ccaagaaggg cggcaagauc gccguguaag acuagugaag 1680
ggaacaccca aauuuaauuc agccuuaagc acaauuaauu aagagugaaa cguaauugua 1740
caagcaguug gucacccacc auagggcaug aucaacaccg caaccuuucc uuuuuccccc 1800
agugauucug aaaaaccccu cuucccuuca gcuugcuuag auguuccaaa uuuaguaagc 1860
uuaaggcggc cuacagaaga aaaagaaaaa aaaggccaca aaaguucccu cucacuuuca 1920
guaaauaaaa uaaaagcagc aacagaaaua aagaaauaaa ugaaauucaa aaugaaauaa 1980
auauuguguu gugcagcauu aaaaaaucaa uaaaaauuaa aaaugagcaa gaucuaaaaa 2040
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaau 2100
gcaucccccc cccccccccc cccccccccc cccccaaagg cucuuuucag agccaccaga 2160
auu 2163
<210> 46
<211> 2264
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - Ybx1(V2)-A64-C30-hSL
<400> 46
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uaguaugccg gcuuaccauc ucuaccauca 1740
uccgguuugg ucauccaaca agaagaaaug aauaugaaau uccagcaaua agaaaugaac 1800
aaagauugga gcugaagacc uuaagugcuu gcuuuuugcc cgcugaccag auaacauuag 1860
aacuaucugc auuaucuaug cagcaugggg uuuuuauuau uuuuaccuaa agaugucucu 1920
uuuugguaau gacaaacgug uuuuuuaaga aaaaaaaaaa aggccugguu uuucucaaua 1980
caccuuuaac gguuuuuaaa uuguuucaua ucuggucaag uugagauuuu uaagaacuuc 2040
auuuuuaauu uguaauaaag uuuacaacuu gauuuuuuca aaaaagucaa caaacugcaa 2100
gcaccuguua auaaaggucu uaaauaauaa agaucuaaaa aaaaaaaaaa aaaaaaaaaa 2160
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa ugcauccccc cccccccccc 2220
cccccccccc ccccccaaag gcucuuuuca gagccaccag aauu 2264
<210> 47
<211> 1914
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - Ndufb8-A64-C30-hSL
<400> 47
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uaguggaggc uugaugggcu uuuugcccuc 1740
guuccuagag gcuuaaccau aauaaaaucc cuaauaaagc agaucuaaaa aaaaaaaaaa 1800
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa ugcauccccc 1860
cccccccccc cccccccccc ccccccaaag gcucuuuuca gagccaccag aauu 1914
<210> 48
<211> 2771
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - Cntn1-004(V2)-A64-C30-hSL
<400> 48
ggggcgcugc cuacggaggu ggcagccauc uccuucucgg caucaagcuu gaggauggag 60
gacgccaaga acaucaagaa gggcccggcg cccuucuacc cgcuggagga cgggaccgcc 120
ggcgagcagc uccacaaggc caugaagcgg uacgcccugg ugccgggcac gaucgccuuc 180
accgacgccc acaucgaggu cgacaucacc uacgcggagu acuucgagau gagcgugcgc 240
cuggccgagg ccaugaagcg guacggccug aacaccaacc accggaucgu ggugugcucg 300
gagaacagcc ugcaguucuu caugccggug cugggcgccc ucuucaucgg cguggccguc 360
gccccggcga acgacaucua caacgagcgg gagcugcuga acagcauggg gaucagccag 420
ccgaccgugg uguucgugag caagaagggc cugcagaaga uccugaacgu gcagaagaag 480
cugcccauca uccagaagau caucaucaug gacagcaaga ccgacuacca gggcuuccag 540
ucgauguaca cguucgugac cagccaccuc ccgccgggcu ucaacgagua cgacuucguc 600
ccggagagcu ucgaccggga caagaccauc gcccugauca ugaacagcag cggcagcacc 660
ggccugccga aggggguggc ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc 720
cgggacccca ucuucggcaa ccagaucauc ccggacaccg ccauccugag cguggugccg 780
uuccaccacg gcuucggcau guucacgacc cugggcuacc ucaucugcgg cuuccgggug 840
guccugaugu accgguucga ggaggagcug uuccugcgga gccugcagga cuacaagauc 900
cagagcgcgc ugcucgugcc gacccuguuc agcuucuucg ccaagagcac ccugaucgac 960
aaguacgacc ugucgaaccu gcacgagauc gccagcgggg gcgccccgcu gagcaaggag 1020
gugggcgagg ccguggccaa gcgguuccac cucccgggca uccgccaggg cuacggccug 1080
accgagacca cgagcgcgau ccugaucacc cccgaggggg acgacaagcc gggcgccgug 1140
ggcaaggugg ucccguucuu cgaggccaag gugguggacc uggacaccgg caagacccug 1200
ggcgugaacc agcggggcga gcugugcgug cgggggccga ugaucaugag cggcuacgug 1260
aacaacccgg aggccaccaa cgcccucauc gacaaggacg gcuggcugca cagcggcgac 1320
aucgccuacu gggacgagga cgagcacuuc uucaucgucg accggcugaa gucgcugauc 1380
aaguacaagg gcuaccaggu ggcgccggcc gagcuggaga gcauccugcu ccagcacccc 1440
aacaucuucg acgccggcgu ggccgggcug ccggacgacg acgccggcga gcugccggcc 1500
gcgguggugg ugcuggagca cggcaagacc augacggaga aggagaucgu cgacuacgug 1560
gccagccagg ugaccaccgc caagaagcug cggggcggcg ugguguucgu ggacgagguc 1620
ccgaagggcc ugaccgggaa gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc 1680
aagaagggcg gcaagaucgc cguguaagac uaguucguug acacucacca uuucugugaa 1740
agacuuuuuu uuuuuuuaac auauuauacu agauuugacu aacucaaucu uguagcuucu 1800
gcaguucucc ccacccccaa ccuaguucuu agaguauguu uccccuuuug aaacauguaa 1860
acauacuuug ggcauaaaua uuuuuuaaaa uauaacuaua augcuucacu aauaccuuaa 1920
aaaugccuag ugaacuaacu caguacauua uauaauggcc aagugaaagu uuuguguuuu 1980
cauguccugu uuuucuuuga aauuauauag cccagaaauu agcucauuau cugaaaaacg 2040
uaugaagaac ugaugaauug uauaauacag gaguauugcc auugaaugua cuguuugauu 2100
uauucaagca gguaaugaac aauguuguca aacucucuaa ugagacauca uaauuaggac 2160
auaagcuaaa aggggcauua cuccggcagu cuuuuuuucu uaauccuagu accauacaua 2220
uucuuuggca ugaaagaaug aaaagcauua guaaacaacu gaaguccuac cauggcucug 2280
uaggguuuuu ggaacaauuc cuggaauugg aaagugaaaa uggauagcau gugggggaaa 2340
cccucaucug aguagcaaga uuuuaguaaa gaugacuaag ccauuaacag caugcauuca 2400
uauuuaauuu uauugacucc ugccaucagc uuuuguagau cuuuugggug gaagguugug 2460
auuuuuacug ggaggacuug aguagaagug gaugauuaaa auugaggagu auauaauucu 2520
uucugggacu gcuuaaaugu uauuguuuga aaaugccuuc acuuuccccc uuuggucaaa 2580
gagaugugcu uaaaauucuu auuccuucac aauaaauaau uuugauuuuc uuagacaaga 2640
ucuaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 2700
aaaaaaaugc aucccccccc cccccccccc cccccccccc cccaaaggcu cuuuucagag 2760
ccaccagaau u 2771
<210> 49
<211> 201
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SLC38A6 3'-UTR
SLC38A6-001 ENST00000267488
<400> 49
aagaaatatt ttcctacttc ttacaagaat aatatacccc tagttgcaag aatgaattat 60
tccggaagac accctggatg aaaaataaca ttttaataaa aattattaac agaaaagcag 120
aacaaaatgg cagtgggtat ggggaagtaa gagtgtggca gttttaatca aaaaaagaaa 180
caaactcgaa atgctcttaa a 201
<210> 50
<211> 102
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens DECR1 3'-UTR
NM_001359.1
<400> 50
gaccactttg gccttcatct tggttacaga aaagggaata gaaatgaaac aaattatctc 60
tcatcttttg actatttcaa gtctaataaa ttcttaatta ac 102
<210> 51
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PIGK 3'-UTR
<400> 51
acttgatgat gaatgaagaa tgcatggagg actgcaaact tggataataa tttatgtcat 60
tatatatttt taaaaatgtg tttctcttgt atgaattgga aataagtata aggaaactaa 120
atttgaatca actattaatt ttataactta aagaaaaata attgttaatg caactgctta 180
atggcactaa atatattcca gttttgtatt ttgtgtatta taaaagcgaa tgagacagag 240
atcagaatac attgactgtt tttgaaaata gtaatttccc cttatcccct tttcatttgg 300
aaaagaaaca attgtgaaga cattaaattc tcactaacag aagtaacttt ggttaattat 360
tttttgtat 369
<210> 52
<211> 460
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens FAM175A 3'-UTR
FAM175A-009 ENST00000506553
<400> 52
tccttttaac cttacaagga gattttttta tttggctgat gggtaaagcc aaacatttct 60
attgttttta ctatgttgag ctacttgcag taagttcatt tgtttttact atgttcacct 120
gtttgcagta atacacagat aactcttagt gcatttactt cacaaagtac tttttcaaac 180
atcagatgct tttatttcca aacctttttt tcacctttca ctaagttgtt gaggggaagg 240
cttacacaga cacattcttt agaattggaa aagtgagacc aggcacagtg gctcacacct 300
gtaatcccag cacttaggga agacaagtca ggaggattga ttgaagttag gagttagaga 360
ccagcctggg caacgtattg agaccatgtc tattaaaaaa taaaatggaa aagcaagaat 420
agccttattt tcaaaatatg gaaagaaatt tatatgaaaa 460
<210> 53
<211> 505
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PHYH 3'-UTR
PHYH-002 ENST00000396913
<400> 53
aatagccatc tgctataact ctttcaacag aaaaccaaaa ccaaacgaaa tgtctaagga 60
aaatgttttc ttaatgagat gatgtaacct tttctatcac ttgttaaaag cagaaaacat 120
gtatcaggta cttaattgca tagagttagt tttgcagcac aatggtgttg ctttaatgga 180
aaaaaaaaac agtaaaagtg aaatattact gttttaagga aaactaattt agggtggcag 240
ccaataaagg tggttggtgt ctaatttaag tgttaaatca atttctttca ttcagttagc 300
tctttaccca agaagaagtg aatgatttgg agcttagggt atgttttgta tcccctttct 360
gataaaccca ttccctacca attttatgtc ataagagatt tttttccccc aaatctagaa 420
caatgtataa tacattcaca tctagtcaag ggcataggaa cggtgtcatg gagtccaaat 480
aaagtggata ttcctgctcg gacaa 505
<210> 54
<211> 404
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TBC1D19 3'-UTR
TBC1D19-001 ENST00000264866
<400> 54
tcttcttcac agtcactggc aacacatcta gtttttcatt agaaacaaat catgaactat 60
gcaaactctg cataaaacca aaatgaaact ttgcatataa gccaataaag atcatgttcc 120
ctcttcagtt aaacctaagt agtttctcac tttttgaaac aataactctg caccaaatat 180
tgcatcgcat gctgctgatt ttcaagagag aagcaataaa cacaacttct gctaaattga 240
gcattatata tataatatta taatatatat ataatcctga cttgtcaatg gcatgtaata 300
atatatgcaa taagaactaa agatactgta ataaacttca agaggtaatg tagcttcttg 360
gataattctt ttatgtcagt ttataaattt atctctagat aatg 404
<210> 55
<211> 353
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TBC1D19 NM_018317.2 3'-UTR
<400> 55
tcttcttcac agtcactggc aacacatcta gtttttcatt agaaacaaat catgaactat 60
gcaaactctg cataaaacca aaatgaaact ttgcatataa gccaataaag atcatgttcc 120
ctcttcagtt aaacctaagt agtttctcac tttttgaaac aataactctg caccaaatat 180
tgcatcgcat gctgctgatt ttcaagagag aagcaataaa cacaacttct gctaaattga 240
gcattatata tataatatta taatatatat ataatcctga cttgtcaatg gcatgtaata 300
atatatgcaa taagaactaa agatactgta ataaacttca agaggtaaaa aaa 353
<210> 56
<211> 242
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PIGB 3'-UTR
PIGB-201 ENST00000539642
<400> 56
aaattcaaca tgaagatgaa attctgaact ttcctagata aattaacatt gctgggtgga 60
aatattcaga tgctgcttaa atacttcggt aaacactggg taagattcat ggaacttaga 120
aaaaagctgt atgaactgct ttaccaaata tcactactga ggaaatgtat aaaataccac 180
atagtataaa attacatgtt aatacaatgc cagattttaa ataaagacct ttagttttcc 240
tc 242
<210> 57
<211> 157
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ALG6 3'-UTR
ALG6-006 ENST00000263440
<400> 57
ctgtattcct aaacaaattg tttcctaaac aaatgtgaaa atgtgaacag tgctgaaagg 60
ttttgtgaac tttttgctat gtataaatga aattaccatt ttgagaacca tggaaccaca 120
ggaaaggaaa tggtgaaaag tcattgttgt ctacaca 157
<210> 58
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CRYZ 3'-UTR
CRYZ-005 ENST00000370871
<400> 58
tgattaattc tttcatggat ttcctatgta attagaggta ctgtctttcc cccagttgta 60
cttaccctat cttttcttta attaacattc gattccatga gcttcttatg tgaaaaaata 120
agatttttct ttagagagca gaagcagaag agtaaaattt attgtatagc tagcaatatt 180
tttttatgcc atctgtctca aatcaaagag tcatcatagt aggaaataac atgttagttg 240
tcatttggca tgagtgtgca ttccagtaat tcttaattga tatttgatta attccatacc 300
tttgattaaa acatgctagt tcaa 324
<210> 59
<211> 510
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BRP44L 3'-UTR
BRP44L-001 ENST00000360961
<400> 59
caatggaaaa ggaagaacaa ggtcttgaag ggacagcatt gccagctgct gctgagtcac 60
agatttcatt ataaatagcc tccctaagga aaatacactg aatgctattt ttactaacca 120
ttctattttt atagaaatag ctgagagttt ctaaaccaac tctctgctgc cttacaagta 180
ttaaatattt tacttctttc cataaagagt agctcaaaat atgcaattaa tttaataatt 240
tctgatgatg gttttatctg cagtaatatg tatatcatct attagaattt acttaatgaa 300
aaactgaaga gaacaaaatt tgtaaccact agcacttaag tactcctgat tcttaacatt 360
gtctttaatg accacaagac aaccaacagc tggccacgta cttaaaattt tgtccccact 420
gtttaaaaat gttacctgtg tatttccatg cagtgtatat attgagatgc tgtaacttaa 480
tggcaataaa tgatttaaat atttgttaaa 510
<210> 60
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ACADSB 3'-UTR
ACADSB-004
<400> 60
cgtctatagg agtgggaccc ctccctggtg tcactgctgt aaaattttaa acggttgtgt 60
cttgttggga gtaagtgcct tgcgtgggaa taaacttcca cagcattcga atattttaat 120
gaagccctta gtcagggtcc tggtgttggc ctttttggtt ttctcttttc aggctgttta 180
acttaggcac aggagatcca cttttaaact tgggaaataa gcacctgtat ttttttccaa 240
aactgttttt aaagctgtat acgcatacat atatatattt ttactctgtc ttactctgtc 300
acccaggcta gagtgcagtg gcgcgatctc agctcactgc agccttgacc tcct 354
<210> 61
<211> 539
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TMEM14A 3'-UTR
NM_014051.3
<400> 61
gcatctggag gaacagaaaa ctaagttcat gtcatcctgc tgtaatgggc agagcatatt 60
ttttttgtat ttaaaagata aacttcaata tggaatgcta gaaacacaaa tagcactgtc 120
acctctaata tgaacattag tttgaggtag tttttttcta aagcaaaaat tttaactgtt 180
ttctaattgt caagcactat tttcattaaa agtgtctaat gaatcatgat atactcttcc 240
atttgttgtg tctatttttt atatatttgg tattttttga aaattccaaa tactcatgtc 300
tcaagtaagc ttaaactaca acttgtcaca taaaggaagt cttaagtgga gttcacagaa 360
tgataatgta tctatttgtc atttgtgtta tatttgaaat tattagaaat tatgcttttt 420
ccattttaat tgtattgctg ccagtgctat ttttttcttt aaaaaatttt attcttagca 480
cactgttatg tcctaactga atgtattcag tattcaaata aaagacattt tggttcaaa 539
<210> 62
<211> 292
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GRAMD1C 3'-UTR
GRAMD1C-005 ENST00000472026
<400> 62
tgatctgaag gactaaaacc gcagagatac ttggaactta aagaaaatac ctggaagaaa 60
accagacgaa tgaaggattt tggcatagaa catttctatg ttttttcatt attgagattt 120
ctaatatgaa catttctttc agtaacattt atttgataat tagtttctgc tggccttaat 180
aatccatcct ttcacttctt atagatattt ttaagctgtg aatttcttca gtgaaccatg 240
aaatatatta tagaactgaa tttctctgat acaaaaagaa aatgacacac cc 292
<210> 63
<211> 94
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C11orf80 3'-UTR
<400> 63
gccgggtccc cttccgcaag cgcccaccga tccggaggct gcgggcagcc gttatcccgt 60
ggtttaataa agctgccgcg cgctcaccaa gtcc 94
<210> 64
<211> 266
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ANXA4 3'-UTR
ANXA4-002 ENST00000409920
<400> 64
aataaaaatc ccagaaggac aggaggattc tcaacacttt gaattttttt aacttcattt 60
ttctacactg ctattatcat tatctcagaa tgcttatttc caattaaaac gcctacagct 120
gcctcctaga atatagactg tctgtattat tattcaccta taattagtca ttatgatgct 180
ttaaagctgt acttgcattt caaagcttat aagatataaa tggagatttt aaagtagaaa 240
taaatatgta ttccatgttt ttaaaa 266
<210> 65
<211> 490
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TBCK 3'-UTR
TBCK-002 ENST00000361687
<400> 65
agaaccaaga gtgtgactgc caaaacttag tgtggcatca gcaccaacag cacagttctt 60
catatccacg ccactctcag acaaaactag atgtccagat tgttgcattt ccgtaaagtt 120
tgtcacgaga cattttttaa aatctcataa cccacatgtt cagttatcca tgcaagaaac 180
ttgactctac atgtattgct gaaagaattt tcttaacagt gaaatctgat catatatttt 240
taccacactg ccacataaag cccaagaaat tcagctgaca agacagattt agcattatca 300
agaaatccca tttgccctga aaaagctgtc ctccattgta ctgaacagac agtcctgtcg 360
attgtgttat ttagaaacat acactgaatg tgggctgaaa tcatcatctt tccataatga 420
aaactgagaa actattcaca atgcattcct tataaataaa tgctacattt agtaactcat 480
ttcacccaaa 490
<210> 66
<211> 320
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens IFI6 3'-UTR
IFI6-001 ENST00000361157
<400> 66
ccagcagctc ccagaacctc ttcttccttc ttggcctaac tcttccagtt aggatctaga 60
actttgcctt tttttttttt tttttttttt tgagatgggt tctcactata ttgtccaggc 120
tagagtgcag tggctattca cagatgcgaa catagtacac tgcagcctcc aactcctagc 180
ctcaagtgat cctcctgtct caacctccca agtaggatta caagcatgcg ccgacgatgc 240
ccagaatcca gaactttgtc tatcactctc cccaacaacc tagatgtgaa aacagaataa 300
acttcaccca gaaaacactt 320
<210> 67
<211> 479
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CAMKMT 3'-UTR
(synonym C2orf34) ENST00000378494
<400> 67
aagattaagc ttctcaaaga cgaagaaacg tatcaagtgc atagggaata tttttacaaa 60
aacggaaatc tgtaaggggt ataatcgcct gcctgcgccc tttgcagcat ttcacgtgtg 120
ggctatggac tccacctgtc ctcacccacg ttattcccca gctgccctct ccagctccct 180
ccccgcctct ttttacactc tgcttgttgc tcgtcctgcc ctaaaccttt gtttgtcttt 240
aaatgtgtat aagctgcctg tctgtgactt gaatttgact ggtgaacaaa ctaaatattt 300
ttccctgtaa ttgagacaga atttcttttg atgataccca tccctccttc attttttttt 360
tttttttggt ctttgttctg ttttggtggt ggtagttttt aatcagtaaa cccagcaaat 420
atcatgattc tttcctggtt agaaaaataa ataaagtgta tctttttatc tccctccaa 479
<210> 68
<211> 476
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ALDH6A1 3'-UTR
NM_005589.2
<400> 68
aaacaagttt gtttaagact gactccatcc tgagtaatct ccctttattt ttgaccagct 60
tcatttgtca gctttgctca gatcagatcg atgggattgg aatacattgt aactaaaatc 120
ttcctcagga ctattaaccc ccgcaaagtt tctataggga actgcctagt gtaacaatga 180
aaccagattt ctcacttgct cttcatactt ctattttgag gtaactgttg taactatgaa 240
atgcttatct gaaagtagtg cttaaacctg atttctaaaa attatcccat tttctgatga 300
tttgaagggg agaaaagcca gtgtatgtaa agaaaatgtt ccagccaggc gcggtggctc 360
acgcctgtaa ttccatcatt ttgggaggcc acagtgggca gattgcttga gcccaggagt 420
tgaagaacgt ggcgaaaccc cgtatctatt atttaaaaaa attgaaaaag taaaaa 476
<210> 69
<211> 567
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens AGTPBP1 3'-UTR
AGTPBP1-004 ENST00000357081
<400> 69
gcccgctgcc atctcttgtt aactgcaaag aataaatgaa atatcttggt ttttatttcc 60
caggaagctt gagagaaatg agtttataca gagctgactc aaaaagacaa aaagtaactt 120
gggccagttt ggtttcaaga taataaatgt gttattaatt aatgataaaa ttggcgcttg 180
ttttattttc gatattcaat gcactttatg tagcattgaa tgatcaaata ttggatttac 240
ctttaaaaaa aaaacctgag tatcattgca tgaattttta tctccctatg gttatatcct 300
gcatcaagtg gataattttg aagtgtgttc agaatataaa attgaaattt tagagttgtt 360
gaaaatcctg acttgttgaa aactaatata tatgtacatg gatttctata gatgtgtttg 420
tttagaagtg ggtagatatt gcagataaga ctgttcttca gaatcatgtt aactattggg 480
ttgtgactga agtagtccag ggtttgcctt gaaaccatta cattctacat ttaccaaatt 540
aaacaaataa aaactgtatt aaatgtt 567
<210> 70
<211> 169
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CCDC53 3'-UTR
CCDC53-001 ENST00000240079
<400> 70
gcttaatttt gataagaatt acatatgcat gcataggggt acatttacat tctgtaagag 60
attgagcctg aactctctta gtcataaaaa catcaaatgg ccacatgtcc actaccaagc 120
ttcttctatg ttaaaaaaat aataataaag cagttttaac ctgccagta 169
<210> 71
<211> 194
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LRRC28 3'-UTR
LRRC28-002 ENST00000331450
<400> 71
taaacactca agaacctcag gagcgctgcc agcttgacac tggggaatcc agccagtcca 60
gcacactctt ccatcctgtc ctgtccaatg cgggggcact gcagaactct ctagaaatgt 120
catgattgag cttcagagct aaaatgcctt cacccttccc ccaagttgga atatatcctc 180
ccccaaatta agga 194
<210> 72
<211> 120
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CCDC109B 3'-UTR
NM_017918.4
<400> 72
tcttacagtt ttaaatgtcg tcagattttc cattatgtat tgattttgca acttaggatg 60
tttttgagtc ccatggttca ttttgattgt ttaatctttg ttattaaatt cttgtaaaac 120
<210> 73
<211> 426
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PUS10 3'-UTR
PUS10-001 ENST00000316752
<400> 73
ctttcaaatt tggagacaaa gagtatggtt ttcctggcat gatgtggaca tccatggagc 60
acatgccgta aaatggctgt ttacccacca taacggtgtc ttgaaaacta tttggatcat 120
gttgatctat ataattgtta atttgttgta acatctcagg atctatatat gtgtatattt 180
tgtgttaaat tgttccaagg atgtcttagg atttttctca ttccctcttt cacccccaca 240
aaccaaacta tgaataatga aataattctc cttaattctt tcatttagag aggtgcacaa 300
acaggacaca ttctctgtta acctaagaag ctgtaatttc agcaagattt ccctccacaa 360
gagatatacc acctttaaaa tcatgttcta atttttgtaa attatctgaa taaaagttat 420
atctag 426
<210> 74
<211> 71
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CCDC104 3'-UTR
CCDC104-002 ENST00000339012
<400> 74
taattaagaa caatttaaca aaatggaagt tcaaattgtc ttaaaaataa attatttagt 60
ccttacactg a 71
<210> 75
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CASP1 3'-UTR
CASP1-007 ENST00000527979
<400> 75
aataaggaaa ctgtatgaat gtctgtgggc aggaagtgaa gagatccttc tgtaaaggtt 60
tttggaatta tgtctgctga ataataaact tttttgaaat aataaatctg gtagaaaaat 120
gaaaa 125
<210> 76
<211> 174
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SNX14 3'-UTR
SNX14-007 ENST00000513865
<400> 76
acacttggat ttggtataga ataacccatt gaaatttctg ctgtgcgagg gtggtagaaa 60
tttacttttt tgggtatatt cttatatata ttatgtacat cgctgtctga aattttagtt 120
attttttgtt tttaataaag actaacacaa acttaatgat taaaagtgat tgag 174
<210> 77
<211> 237
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SKAP2 3'-UTR
SKAP2-201 (part of SKAP2.001 ENST00000345317)
<400> 77
gagtcctgga aaaggaaaat tcttctgctt gtctgcaaat gctttggatt tagaagcgtc 60
atgaaagcac gagtgacagc tcctaacctc tccttgtttt attaaacatt acttatcttt 120
gactgttatt ttatgcagtc gctcattaaa atattcctct gatgtgaaat taaatgaagg 180
atattaatgt aaattagatg caaccagtta agttatacct gttgctattt tgcaaag 237
<210> 78
<211> 362
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NDUFB6 3'-UTR
NM_182739.2
<400> 78
agattatgta aaaagttaaa aggcttatga gcctaagttt gttcctatat taccatattt 60
actgaatttt ctggaaaagt aactttaata aagtttaatc tcagaaattg tcatatctgt 120
tttcaagcat tgtacaattt gagactgagt aatttaacaa taagtaaaaa gtggacatgc 180
taaacaaata tgagagacta cctacttttt ctggtcattc ttgacttgga aaacggtatg 240
gaaaagtatt tagttacatg tttgtttgtt tttttcttac acagtactta cactaatttg 300
gtatcagggt atgcaacagt gaaatatcac aataaacaaa tgtaagaaca aaaaaaaaaa 360
aa 362
<210> 79
<211> 549
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens EFHA1 3'-UTR
EFHA1-001 ENST00000382374
<400> 79
taaaagatat aatagtatgg caattatatt gttccaaatg tcaaaatttg tgatttttta 60
gaagtacttg ctatttatct tcttaagtct tcattgatat tctgtgtgaa ataagcatgt 120
cttgtacttg ctttctgatt cataatttta ttaaagaact tagtagaaag aaaagtaagt 180
ataaaaatag atattggatt ctgtcagaag gcctagattt gaaataatgt tttgtacttc 240
ggtaagatgg aaaacttagt gattcactga tttcttagac actctaatat gatatgcttt 300
ctggaaggat aaaacaaata catatgggaa aaagtacttg agaccaaggc cagcatcaat 360
tccagacatc ttcatgttcc taataggcta aatgaagtta aaaacttatt tcagattttt 420
ctcatctgta ccttatatct cataaattta ttgcatattt tatgtcagta gcttagctgt 480
ttattgtctt taaaataaca tgtaaacttc aatgttctat ctggaagcag aataaaatat 540
ttacataga 549
<210> 80
<211> 288
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BCKDHB 3'-UTR
BCKDHB-005 ENST00000356489
<400> 80
ccatatagaa aagctggaag attatgacta gatatggaaa tattttttct gaattttttt 60
ttatatttcc tccgacttac ctctttttga aaagagagtt tttattaagt gaaccatcac 120
gatattggct gaaaagttct acattctatt attgtattgt aacacacatg tattgatgat 180
tttcattaag agtttcagat taactttgaa aaatattcca catggtaatc ttataaattc 240
tgtttaatta catctgtaaa tattatgtgt gtgatagtat tcaataaa 288
<210> 81
<211> 414
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BCKDHB 3'-UTR
NM_001164783.1
<400> 81
gacctgctca gcccaccccc acccatcctc agctaccccg agaggtagcc ccactctaag 60
gggagcaggg ggacctgaca gcacaccact gtcttcccca gtcagctccc tctaaaatac 120
tcagcggcca gggcggctgc cactcttcac ccctgctcct cccggctgtt acattgtcag 180
gggacagcat ctgcagcagt tgctgaggct ccgtcagccc cctcttcacc tgttgttaca 240
gtgccttctc ccaggggctg ggtgagggca cattcaggac tagaagcccc tctgggcatg 300
gggtggacat ggcaggtcag cctgtggaac ttgcgcaggt gcgagtggcc agcagaggtc 360
acgaataaac tgcatctctg cgcctggctc tctaccaaaa aaaaaaaaaa aaaa 414
<210> 82
<211> 414
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BBS2 3'-UTR
NM_031885.3
<400> 82
gtgaggaaaa tacaggtcat gaagttcctg gcaaagattt tctgttaaaa acctatgctg 60
gtttgctttg gatcacaccc tggtgaaccc cgggtgctaa gaatgaaaat aaccttggtg 120
agttgtacaa attaaagaca aagaactaca tgtgaagata gacttgcttt ctatttttaa 180
atcagtagta gtactgttgc tgaataatac taggttttta tggaatagga tgaatgcttt 240
tgaagtatta gggcttcaga gtccaatttt gcttatttat ggtatataaa tacatatttt 300
tttcttgaaa ttgcaattga gtttgtactt ttcaaataga ttatctactt tttcattaaa 360
atgtaaagat gttaaacttt gtgttgattg attataaaat caccaccaaa tcag 414
<210> 83
<211> 409
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LMBRD1 3'UTR
NM_018368.3
<400> 83
cagccttctg tcttaaaggt tttataatgc tgactgaata tctgttatgc atttttaaag 60
tattaaacta acattaggat ttgctaacta gctttcatca aaaatgggag catggctata 120
agacaactat attttattat atgttttctg aagtaacatt gtatcataga ttaacatttt 180
aaattaccat aatcatgcta tgtaaatata agactactgg ctttgtgagg gaatgtttgt 240
gcaaaatttt ttcctctaat gtataatagt gttaaattga ttaaaaatct tccagaatta 300
atattccctt ttgtcacttt ttgaaaacat aataaatcat ctgtatctgt gccttaggtt 360
ctccagagtg atgtggaatt ttaaagtgtc tctctctgat tgcctccaa 409
<210> 84
<211> 466
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ITGA6 3'-UTR
ITGA6-003 ENST00000409532
<400> 84
tattgatcta cttctgtaat tgtgtggatt ctttaaacgc tctaggtacg atgacagtgt 60
tccccgatac catgctgtaa ggatccggaa agaagagcga gagatcaaag atgaaaagta 120
tattgataac cttgaaaaaa aacagtggat cacaaagtgg aacgaaaatg aaagctactc 180
atagcggggg cctaaaaaaa aaaagcttca cagtacccaa actgcttttt ccaactcaga 240
aattcaattt ggatttaaaa gcctgctcaa tccctgagga ctgatttcag agtgactaca 300
cacagtacga acctacagtt ttaactgtgg atattgttac gtagcctaag gctcctgttt 360
tgcacagcca aatttaaaac tgttggaatg gatttttctt taactgccgt aatttaactt 420
tctgggttgc ctttattttt ggcgtggctg acttacatca tgtgtt 466
<210> 85
<211> 285
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HERC5 3'-UTR
HERC5-001 ENST00000264350
<400> 85
ccagcttgct tgtccaacag ccttattttg ttgttgttat cgttgttgtt gttgttgttg 60
ttgttgtttc tctactttgt tttgttttag gcttttagca gcctgaagcc atggtttttc 120
atttctgtct ctagtgataa gcaggaaaga gggatgaaga agagggttta ctggccggtt 180
agaacccgtg actgtattct ctcccttgga tacccctatg cctacatcat attccttacc 240
tcttttggga aatatttttc aaaaataaaa taaccgaaaa attaa 285
<210> 86
<211> 515
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HADHB 3'-UTR
HADHB-001 ENST00000317799
<400> 86
tagatccaga agaagtgacc tgaagtttct gtgcaacact cacactaggc aatgccattt 60
caatgcatta ctaaatgaca tttgtagttc ctagctcctc ttaggaaaac agttcttgtg 120
gccttctatt aaatagtttg cacttaagcc ttgccagtgt tctgagcttt tcaataatca 180
gtttactgct ctttcaggga tttctaagcc accagaatct cacatgagat gtgtgggtgg 240
ttgtttttgg tctctgttgt cactaaagac taaatgaggg tttgcagttg ggaaagaggt 300
caactgagat ttggaaatca tctttgtaat atttgcaaat tatacttgtt cttatctgtg 360
tcctaaagat gtgttctcta taaaatacaa accaacgtgc ctaattaatt atggaaaaat 420
aattcagaat ctaaacacca ctgaaaactt ataaaaaatg tttagataca taaatatggt 480
ggtcagcgtt aataaagtgg agaaatattg gagaa 515
<210> 87
<211> 116
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ANAPC4 3'-UTR
ANAPC4-001 ENST00000315368
<400> 87
tctagcttgc cattattgtg tgtgtaatta tggccaaaag gacataggag atggactaag 60
atgtcttgga ccacctttgt gtaacaaaga aataaacagt aaattttatt ttttca 116
<210> 88
<211> 154
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PCCB 3'-UTR
NM_000532.4
<400> 88
acaaatcaaa ggaaaagaaa ccaagaactg aattactgtc tgcccattca catcccattc 60
ctgccttttg caatcatgaa acctgggaat ccaaatagtt ggataactta gaataactaa 120
gtttattaaa ttctagaaag atctcaaaaa aaaa 154
<210> 89
<211> 90
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ABCB7 3'-UTR
ABCB7-001 ENST00000253577
<400> 89
gtcacataag acattttctt tttttgttgt tttggactac atatttgcac tgaagcagaa 60
ttgttttatt aaaaaaatca tacattccca 90
<210> 90
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PGCP 3'-UTR
CPQ-001 ENST00000220763
<400> 90
aaacagtaag aaagaaacgt tttcatgctt ctggccagga atcctgggtc tgcaactttg 60
gaaaactcct cttcacataa caatttcatc caattcatct tcaaagcaca actctatttc 120
atgctttctg ttattatctt tcttgatact ttccaaattc tctgattcta gaaaaaggaa 180
tcattctccc ctccctccca ccacatagaa tcaacatatg gtagggatta cagtgggggc 240
atttctttat atcacctctt aaaaacattg tttccacttt aaaagtaaac acttaataaa 300
tttttggaag atctctga 318
<210> 91
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NFU1 3'-UTR
NM_001002755.2
<400> 91
aataatctgg attttctttg ggcataacag tcagacttgt tgataatata tatcaagttt 60
ttattattaa tatgctgagg aacttgaaga ttaataaaat atgctcttca gagaatgata 120
tataaatatt gca 133
<210> 92
<211> 246
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens OMA1 3'-UTR
OMA1-001 ENST00000371226
<400> 92
attaaaattt atgagacaca agatatatga agaatgttgc agtccttatc attttatgtt 60
actttttaaa aaatgatgtt tgaagtgaaa aaaaaaagga tattcagggt caaatcatgt 120
acattacaga tattatctaa attcttctag aatttatttt tcatgaaata ttgatgtatt 180
ttaatctatg ttaaaatatc ttcaatgagg aaaatgtcac agaataaatt tatattacac 240
atttta 246
<210> 93
<211> 423
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HHLA3 3'-UTR
NM_001036646.1
<400> 93
ggcgaatcca tagagtaagc ttagtgatgt gtgtcagacc tctgagccca agcaaagcca 60
tcatatcccc tgtgacctgc atgtatacat ccagatggcc tgaagcaagt gaagaatcac 120
aaaagaagtg aaaagggccg gttcctgcct taactgatga cattccacca ttgtgatttg 180
ttcctgcccc accttaactg agcgattaac ctgtgaactt ccttctcctg gctcagaagc 240
ttccccactg agcaccttgt gacccccgcc cctgcctgcc atagaacaac cccctttgat 300
tgtaattttc ctttacctac ccaaatccta taaaacggcc ccacccctat ctcccttcgc 360
tgacactctc tttggactca gcctgcctgc acctaggtga ttaaaaagct ttattgctca 420
cgc 423
<210> 94
<211> 292
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HHLA3 3'-UTR
NM_001031693.2
<400> 94
aaagggccgg ttcctgcctt aactgatgac attccaccat tgtgatttgt tcctgcccca 60
ccttaactga gcgattaacc tgtgaacttc cttctcctgg ctcagaagct tccccactga 120
gcaccttgtg acccccgccc ctgcctgcca tagaacaacc ccctttgatt gtaattttcc 180
tttacctacc caaatcctat aaaacggccc cacccctatc tcccttcgct gacactctct 240
ttggactcag cctgcctgca cctaggtgat taaaaagctt tattgctcac gc 292
<210> 95
<211> 342
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ACAA2 3'-UTR
NM_006111.2
<400> 95
agagaccagt gagctcactg tgacccatcc ttactctact tggccaggcc acagtaaaac 60
aagtgacctt cagagcagct gccacaactg gccatgccct gccattgaaa cagtgattaa 120
gtttgatcaa gccatggtga cacaaaaatg cattgatcat gaataggagc ccatgctaga 180
agtacattct ctcagatttg aaccagtgaa atatgatgta tttctgagct aaaactcaac 240
tatagaagac attaaaagaa atcgtattct tgccaagtaa ccaccacttc tgccttagat 300
aatatgatta taaggaaatc aaataaatgt tgccttaact tc 342
<210> 96
<211> 446
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GSTM4 3'-UTR
GSTM4-001 ENST00000369836
<400> 96
tgccttgaag gccaggaggt gggagtgagg agcccatact cagcctgctg cccaggctgt 60
gcagcgcagc tggactctgc atcccagcac ctgcctcctc gttcctttct cctgtttatt 120
cccatcttta cccccaagac tttattgggc ctcttcactt cccctaaacc cctgtcccat 180
gcaggccctt tgaagcctca gctacccact ttccttcatg aacatccccc tcccaacact 240
acccttccct gcactaaagc cagcctgacc ttccttcctg ttagtggttg tatctgcttt 300
gaagggccta cctggcccct cgcctgtgga gctcagccct gagctgtccc cgtgttgcat 360
gacagcattg actggtttac aggccctgct cctgcagcat ggcccctgcc ttaggcctac 420
ctgatcaaaa taaagcctca gccaca 446
<210> 97
<211> 465
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GSTM4 3'-UTR
GSTM4-003 ENST00000326729
<400> 97
tggtcaattt tctgcatcaa cttgactggg ctaagggatg ctcagatggc aggtaaaatc 60
attgtgcttg tgagggtgtt tccagaagag atttgccttt gaatcagaag acagcaaaga 120
tttccttcag caatgaagga ggcatccacc aaactgtcag ggcccagaga gaagaaaaag 180
acaggaaggg tgaatttgac ctctctgact gggacatcca tctctgccta tcctgggacc 240
tccacactcc tggttctctg gccttcagac ttgatcaggg actaacacca tcgcctccca 300
cccccacctt tgttctgagg cctttagcct ctgaatgata ccactggctt tcctgcttct 360
ctatcctgca gtcggcagat catgggactt cttcactcca aaattgtgtg agccaattcc 420
cataacagat agataaattt ataaataaac acacaaattt cctac 465
<210> 98
<211> 274
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ALG8 3'-UTR
NM_001007027.2
<400> 98
ctgaaacctc cgcctcccag aaaagaaaaa cctcttttta attggatgga aactttctac 60
ctgcttggcc tggggcctct ggaagtctgc tgtgaatttg tattcccttt cacctcctgg 120
aaggtgaagt accccttcat ccctttgtta ctaacctcag tgtattgtgc agtaggcatc 180
acatatgctt ggttcaaact gtatgtttca gtattgattg actctgctat tggcaagaca 240
aagaaacaat gaataaagga actgcttaga tatg 274
<210> 99
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C11orf74 3'UTR
<400> 99
ttcacagagg cattttgtgt gtgtgtgctt attttaattt tgttcttatt ctagcaacat 60
tagaataaaa gataaaccta ctataattcc ctttgtggaa atttaaaaaa aaaaaaaaaa 120
aa 122
<210> 100
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa1 3'-UTR
Ndufa1-001 ENSMUST00000016571
<400> 100
ggaagcattt tcctggctga ttaaaagaaa ttactcagct atggtcatct gttcctgtta 60
gaaggctatg cagcatatta tatactatgc gcatgttatg aaatgcataa taaaaaattt 120
taaaaaatct aaa 133
<210> 101
<211> 155
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5e 3'-UTR
NM_025983
<400> 101
ctgaatctga agcctgaagt gctgagtctt gaaggtgaag catgtgggcc cctgttctgg 60
cagatggaaa tcaacctcac ctcctggggg acaggctgcc catctcgttg ataaattgac 120
tatgccaata aattaacatg gttcactttc aaaaa 155
<210> 102
<211> 136
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gstm5 3'-UTR
NM_010360
<400> 102
gccagagctc gctgctgctg agccatcttg ccctgagggg cccacactct tagctcactg 60
tcagtcttgt tccatcctgt cctgagggcc cccactctgt ctcctctgct ctttctaata 120
aacagcagtt gcatta 136
<210> 103
<211> 189
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Uqcr11 3'-UTR
NM_025650
<400> 103
gcagcccctc ccccaccaca ggcctcgatg gtaccatgtg ccgaggcctc agacacagcg 60
tagtcctgtg gaagacactg aggaagctgg acactggaga ggtctgcacc gctcagggag 120
cttccatgtt gacagacact agggctgcct tgatgggtgc agcattaaac cttattctta 180
tgccttgga 189
<210> 104
<211> 143
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus IFi27I2a 3'-UTR
IFi27I2a-001 ENSMUST00000055071; NM_029803
<400> 104
gcttaggaga tgacacttct atcagctcaa ctcaaagcct gtacagacta cgcaggagat 60
gaagttccaa aaggcacctt cagaaccctc actgatgtca aagaatgatg aaaacaacaa 120
agtatatggg ctggtgttcc taa 143
<210> 105
<211> 237
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cbr2 3'-UTR
NM_007621
<400> 105
tctgctcagt tgccgcggac atctgagtgg ccttcttagc cccaccctca gccaaagcat 60
ttactgatct cgtgactccg ccctcatgct acagccacgc ccaccacgca gctcacagtt 120
ccacccccat gttactgtcg atcccacaac cactccaggc gcagaccttg ttctctttgt 180
ccactttgtt gggctcattt gcctaaataa acgggccacc gcgttacctt taactat 237
<210> 106
<211> 118
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5l 3'-UTR
Atp5l-201 ENSMUST00000043675
<400> 106
agaccaatct ttaacttctg atttgagttc ttatttgaat gttcttggac catgtgtaac 60
aggactgcta tctgaataaa atactaggtg ttgaaaacac tgctgtgttt tctctgtc 118
<210> 107
<211> 271
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tmsb10 3'-UTR
NM_025284
<400> 107
aagcctagga agatttcccc accccacccc accccgcccc atcatctcca agaccccctc 60
gtgatgtgga ggaagagcca cctgcaagat ggacgcgagc cacaagctgc actgtgaaac 120
ccgggcactc cgagccgatg ccaccggccc gcgggtctct gaaggggacc cctccactaa 180
tcggactgcc aaatttcacc ggtttgccct gggatattat agaaaattat ttgtatgatt 240
gatgaaaata aaaacacctc gtggcatggt t 271
<210> 108
<211> 116
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Nenf 3'-UTR
NM_025424
<400> 108
tgtctagctg agaagcagcc ggttctaggg agaagtgagg ggacaggagt taagtgtccc 60
tcggaacaag cggaggaagc ctccgagtgc cctgcagctg aataaagcga atgttt 116
<210> 109
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5k 3'-UTR
NM_007507
<400> 109
ggcgtcagcg agcttgcttt tctctagtcg ttgagaacga ataaagcttc attgtgtgaa 60
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 120
aaa 123
<210> 110
<211> 260
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus 1110008P14Rik 3'-UTR
1110008P14Rik-001 ENSMUST00000048792
<400> 110
gtgccgggag cccccatcca ggccctaccc tcacctctct aggccatgtt ctggcctggg 60
tagatactac ttggcttaga caccatctcg ggtactggcc tccagatcct agtgggtcta 120
ccagcctgga ccagtcccca ttcactgccc atcacccttc ctggagtcag gtgcaatcct 180
acagttctcc cacttgtctg tcttctttcc cctccatcca gactgagagt ccgaattaaa 240
gatgtctccc acaccactgc 260
<210> 111
<211> 102
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cox4i1 3'-UTR
NM_009941
<400> 111
gagcccgctg cctgccggct ccctgcctcc ctcactccct cggcatgctg gaagctgccg 60
tatccaatgg tccatgctaa taaaagacca gtttacgtgg tg 102
<210> 112
<211> 189
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cox6a1 3'-UTR
NM_007748
<400> 112
agagaacctg gcctccccca ggcaacaaag ggaccacagc actggttttg gacccttact 60
ctgtgtggac cacgaaaacc ctttggatgc taagctcgtg tctcctttcc tcagatggcg 120
accattactc tgatcttcca tcccttctgc ttgtaagagg agatgcctta aataaataac 180
ttaaactca 189
<210> 113
<211> 139
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufs6 3'-UTR
NM_010888
<400> 113
tgtgggctgt gtcctggtcc tctgactcct atggaacatc tccacgctgg gtgttctgtg 60
tgaggccact gctctgtgaa tggtgtccct tgttttgaat aaaggatgct cccaccatga 120
aaaaaaaaaa aaaaaaaaa 139
<210> 114
<211> 171
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Sec61b 3'-UTR
NM_024171
<400> 114
attgggctac atccatctgt catctgaaga agaagaagaa ggaaaaaaac ccaacatatc 60
ttggaccaaa agtgtagtga ttttctgttc acgtgtatta ttttacagag aataagaatt 120
gactttgaga aatcagtttt ttctatggct aataaacttt ggaattgctt t 171
<210> 115
<211> 101
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Romo1 3'-UTR
NM_025946
<400> 115
ttagggctag gatgccctgc aatacctaaa cttccccatc catttcgacc cttgtacaat 60
aataaagttg ttttcttctc gttaaaaaaa aaaaaaaaaa a 101
<210> 116
<211> 370
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gnas 3'-UTR
NM_010309
<400> 116
gaagggaaca cccaaattta attcagcctt aagcacaatt aattaagagt gaaacgtaat 60
tgtacaagca gttggtcacc caccataggg catgatcaac accgcaacct ttcctttttc 120
ccccagtgat tctgaaaaac ccctcttccc ttcagcttgc ttagatgttc caaatttagt 180
aagcttaagg cggcctacag aagaaaaaga aaaaaaaggc cacaaaagtt ccctctcact 240
ttcagtaaat aaaataaaag cagcaacaga aataaagaaa taaatgaaat tcaaaatgaa 300
ataaatattg tgttgtgcag cattaaaaaa tcaataaaaa ttaaaaatga gcaaaaaaaa 360
aaaaaaaaaa 370
<210> 117
<211> 96
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Snrpd2 3'-UTR
NM_026943
<400> 117
agcctgctcc ctgccctgcg aaggcctgca gaaccctgcc cagtgggcga gaaataaaac 60
cctgtgcttt ttggttaaaa aaaaaaaaaa aaaaaa 96
<210> 118
<211> 119
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mgst3 3'-UTR
NM_025569
<400> 118
ggtgtggagg gccttccgac tctcactcac ctccagcgac tcaccctgat ttccagttgc 60
actggttttt tttttttttt taatataata aaaacttatc tggcatcagc ctcatacct 119
<210> 119
<211> 304
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Aldh2 3'-UTR
NM_009656
<400> 119
agcggcatgc ctgcttcctc agcccgcacc cgaaaaccca acaagatata ctgagaaaaa 60
ccgccacaca cactgcgcct ccaaagagaa accccttcac caaagtgtct tgggtcaaga 120
aagaatttta taaacagggc ggggctggtg ggggggaaag ctcctgataa actgggtagg 180
ggatgaagct caatgcagac cgatcacgcg tccagatgtg caggatgctg ccttcaacct 240
gcagtcccta agcagcaaat gagcaataaa aatcagcaga tcaaagccac ggggtcagtt 300
ctct 304
<210> 120
<211> 134
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mp68 (2010107E04Rik) 3'-UTR
NM_027360
<400> 120
ctgctccgaa tccacaagat gaagacgtcg gctaaacttg agcaagcttt gttagatggg 60
aacatggaac atcactgtac acttatctaa gtaccattta taatgtggca ttaataaatg 120
tatctgtgaa tacc 134
<210> 121
<211> 87
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ssr4 3'-UTR
NM_001166480
<400> 121
gggcagcaac ttcagccgtc cattgcttct ttcaataaac agtcactatt tgacatgagt 60
acattcaaga aaaaaaaaaa aaaaaaa 87
<210> 122
<211> 186
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Myl6 3'-UTR
NM_010860
<400> 122
ggacattctg tatcccgagt ctgttccttg cccagtgtga tttctgtgtg gctccagagg 60
ctcccctgtc acagcacctt gcccatttgg tttcttttgg atgatgtttg ccttccccaa 120
ataaaatttg ctctctttgc cctccaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 180
aaaaaa 186
<210> 123
<211> 58
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Prdx4 3'-UTR
Prdx4-001, NM_016764
<400> 123
aaagtacttc agttatgatg tttggacctt ctcaataaag gtcattgtgt tattacca 58
<210> 124
<211> 130
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ubl5 3'-UTR
NM_025401
<400> 124
agggggattc cttctcctcc tcgccctgct ctgccctgcc ctcctctccc atcctcatct 60
gacactggtg tagatggtca tttttaacag ttcacatgaa taaaaacttg gctgctgctt 120
tgctgctgtc 130
<210> 125
<211> 87
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus 1110001J03Rik 3'-UTR
NM_025363
<400> 125
tgcagagagt cctcagatgt tccttcattc aagagtttaa ccatttctaa caatatgtag 60
ttatcattaa atctttttta aagtgtg 87
<210> 126
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa13 3'-UTR
Ndufa13-201 ENSMUST00000110167
<400> 126
ggcctgagcc aacgcacata ataaagagtg gtc 33
<210> 127
<211> 69
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa3 3'-UTR
NM_025348
<400> 127
atgcctctgc tgatggaaga ggccccttcc ctgttgctct ccaataaaaa tgtgaaaact 60
aataacccc 69
<210> 128
<211> 96
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gstp2 3'-UTR
NM_181796
<400> 128
tggactgaag agacaagagc ttcttgtccc cgttttccca gcactaataa agtttgtaag 60
acaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaa 96
<210> 129
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tmem160 3'-UTR
NM_026938
<400> 129
acaacagggc tgtggggact ggctgggcct gacgactggg acattaaaac ctgacccttc 60
cgcaaaaaaa aaaaaaaaaa aaaaaaaaa 89
<210> 130
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ergic3 3'-UTR
NM_025516
<400> 130
ctctctccct tccccacagc ttgtcctgcc ctctcttccc ctgtgggttt accctccagc 60
ctgtcaacta cccatatcct ctcctcagcc agcccagccc agggcaataa atatgaattg 120
tgataggaa 129
<210> 131
<211> 295
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Pgcp 3'-UTR
NM_018755
<400> 131
ggagaacaag aagagaggac cttgttctct gtagttggga atcccaactc tgaatcttta 60
caacatccat cgtcacaaaa gagtgttata catttaatcc acagggcata gttttcttta 120
taccttctgt taatcatctt tccttaatac tttcttatct gtttctagaa taaatcatga 180
tccctactgc accaccttga aaatgttgtt tccagtttta aaataagcaa taaatatttg 240
aaatgcttct gatttttcat tttcatttaa aaacattaaa ttaaatgtaa tgaga 295
<210> 132
<211> 263
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Slpi 3'-UTR
NM_011414
<400> 132
gcctgatccc tgacattggc gccggctctg gactcgtgct cggtgtgctc tggaaactac 60
ttccctgctc ccaggcgtcc ctgctccggg ttccatggct cccggctccc tgtatcccag 120
gcttggatcc tgtggaccag ggttactgtt ttaccactaa catctccttt tggctcagca 180
ttcaccgatc tttagggaaa tgctgttgga gagcaaataa ataaacgcat tcatttctct 240
atgcaaaaaa aaaaaaaaaa aaa 263
<210> 133
<211> 241
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Myeov2 3'-UTR
NM_001163425
<400> 133
ggccgcccgg tcctatgtgc tccatgtctg tgatgtgtct ggagtctctc gggacacgac 60
cagctgattg tagacaccgt gttgatatca ctagaaatga agaccttgtc aaccaataga 120
ggaactgtct gaaccaactg ggtactgatg tctctgggaa tgccagcccg tgtccttgtt 180
taagttaata aagaacactg taacacgcag ggtgatttta aaaaaaaaaa aaaaaaaaaa 240
a 241
<210> 134
<211> 162
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa4 3'-UTR
NM_010886
<400> 134
actatgaagt tcactgtaaa gctgctgata atgaaggtct ttcagaagcc atccgcacaa 60
ttttccactt aagcaggaaa tatgtctctg aatgcatgaa atcatgttga tttttttttt 120
ttttggagtt tattacactg atgaataaat ctctgaaact tg 162
<210> 135
<211> 143
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufs5 3'-UTR
NM_001030274
<400> 135
gcggggcagc tggaggccgc tgtcatgctc tgttttcccc tggagagaat atttaaggaa 60
agctccttca ttaagtatta agtatgtgga aataaagaat tactcagtct taaaaaaaaa 120
aaaaaaaaaa aaaaaaaaaa aaa 143
<210> 136
<211> 455
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gstm1 3'-UTR
NM_010358
<400> 136
gcccttgcta cacgggcact cactaggagg acctgtccac actggggatc ctgcaggccc 60
tgggtgggga cagcaccctg gccttctgca ctgtggctcc tggttctctc tccttcccgc 120
tcccttctgc agcttggtca gccccatctc ctcaccctct tcccagtcaa gtccacacag 180
ccttcattct ccccagtttc tttcacatgg ccccttcttc attggctccc tgacccaacc 240
tcacagcccg tttctgcgaa ctgaggtctg tcctgaactc acgcttccta gaattacccc 300
gatggtcaac actatcttag tgctagccct ccctagagtt accccgaagg tcaatacttg 360
agtgccagcc tgttcctggt ggagtagcct ccccaggtct gtctcgtcta caataaagtc 420
tgaaacacac ttgccatgaa aaaaaaaaaa aaaaa 455
<210> 137
<211> 109
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus 1810027O10Rik 3'-UTR
1810027O10Rik-001 ENSMUST00000094065
<400> 137
agtctcttgt ttaagcgccc agtcctggcc tttctgggta attgggcgca gagggaagga 60
gccaatgttg aagcagaaaa gaaattaaaa gaaaaaggca tataaagaa 109
<210> 138
<211> 49
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus 1810027O10Rik 3'-UTR
BC117077
<400> 138
agtctcttgt ttaagcgccc agtcctggcc tttctgggta attgggcgc 49
<210> 139
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5o 3'-UTR
NM_138597
<400> 139
gagactgtca cctgtgtgag ctcttgtcct tggagcaaca ataaaatgct tcctg 55
<210> 140
<211> 174
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Shfm1 3'-UTR
NM_009169
<400> 140
catctgggaa tgtcccagga acctcaatca tggactctac cacagtctag gacagagaaa 60
gcaggacggg atactttaaa gaacatgttt atttcattat ctgcttcaat ttatttttgt 120
tttataacaa aaaaaataag taaataaatg ttttgattta atctttttgg ttca 174
<210> 141
<211> 260
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tspo 3'-UTR
NM_009775
<400> 141
aggcacccag ccatcaggaa tgcagccctg ccagccaggc accatgggtg gcagccatca 60
tgcttttatg accattgggc ctgctggtct acctggtctt agcccaggaa gccaccaggt 120
aggttagggt ggtcagtgcc gagtctcctg cagacacagt tatacctgcc tttctgcact 180
gctccaggca tgcccttaga gcatggtgtt ttaaagctaa ataaagtctc taacttcatg 240
tgtaaaaaaa aaaaaaaaaa 260
<210> 142
<211> 92
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus S100a6 3'-UTR
NM_011313
<400> 142
aatgggaccg ttgagatgac ttccgggggc ctctctcggt caaatccagt ggtgggtagt 60
tatacaataa atatttcgtt tttgttatgc ct 92
<210> 143
<211> 200
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Taldo1 3'-UTR
NM_011528
<400> 143
tgcaacaccc gaggccccag tcctgcaccg aggctgaccc cagacctgca ctgcctttga 60
gctgggtcct aattgcacat ggcttgtgac gaatgaatct tgcatttttt agtgatcgga 120
gaagggatgg atcataggat tctgatttta tgtgaaattt tgtctaattc attaaagcag 180
ttgcttttcc tatgctgttt 200
<210> 144
<211> 83
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Bloc1s1 3'-UTR
NM_015740
<400> 144
actaaaaccc acccctctta cttcaccctc ctggacagga gggaaactgg tgagccacga 60
ataaaaacac aagcttccat tct 83
<210> 145
<211> 93
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufb11 3'-UTR
NM_019435
<400> 145
tggcttaccg agcagggcct aagaagcatt actcatccgc tgcttgttat ttacctggtt 60
cctcagaaca ccttattaaa ggaattgaaa gta 93
<210> 146
<211> 454
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Map1lc3a 3'-UTR
NM_025735
<400> 146
gtcaagagga ggggaggggg gtggctggga gttctggtca ggttctcccc agggaggtcc 60
tggctcctaa actaagctat ttcagtcccc agtggattag gcagagatgt gacacccact 120
ccccccccca ggtaggggcc accagccagc ctaccacatc ctgggtaggt cctgggccag 180
tcatgttcgg gttgctcttt tgggtgctgg ctgggttggg agtgggtggg gagcagcatc 240
cctgctctgt ggggtttgtc attttgttag gcccttgcct gtctgcccat cttgcccctc 300
atccacctga ggctttgcct cctgccagga cctgccccac ccctgaaagg ctggctcccc 360
ttgtcctgac tcggtgtatg gatctgtggt catttcctct gcagaaagaa taaagactgc 420
tcaggcctgc ctggccaaaa aaaaaaaaaa aaaa 454
<210> 147
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Morn2 3'-UTR
NM_194269
<400> 147
acctgctgcc ttaacgctga gatgtggcct ctgcaacccc ccttaggcaa agcaactgaa 60
ccttctgcta aagtgacctg ccctcttccg taagtccaat aaagttgtca tgcacccaca 120
aaaaaaaaaa aaaaa 135
<210> 148
<211> 238
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gpx4 3'-UTR
NM_008162.2
<400> 148
ctagccctac aagtgtgtgc ccctacaccg agcccccctg ccctgtgacc cctggagcct 60
tccaccccgg cactcatgaa ggtctgcctg aaaaccagcc tgctggtggg gcagtcctga 120
ggacctggcg tgcatccctg ccggaggaag gtccagaggc ctgtggccct gggctcgagc 180
ttcaccctgg ctgccttgtg ggaataaaat gtagaaatgt gaaaaaaaaa aaaaaaaa 238
<210> 149
<211> 124
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mif 3'-UTR
NM_010798.2
<400> 149
gtcctggccc cacttacctg caccgctgtt ctttgagcct cgctccacgt agtgttctgt 60
gtttatccac cggtagcgat gcccaccttc cagccgggag aaataaatgg tttataagag 120
acca 124
<210> 150
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cox6b1 3'-UTR
NM_025628
<400> 150
cctggctccg cccacctctc ctctgttctt tgtctttctc cccggataga aaagggggac 60
ctcagcatat gatggtcctt accctgggac cctgaatcat gatgcaacta ctaataaaaa 120
ctcactggaa aagtt 135
<210> 151
<211> 267
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus RIKEN cDNA2900010J23 (Swi5) 3'-UTR
NM_175190
<400> 151
gcagcttctt ggagattttc atctacagcc cacagggaca ggaggatggg ggcataaaag 60
gcagagtcta gacagtatgt tcatatggtt ttcagatttt aaaagatgct agaagccctc 120
caaagtttgg ggtgggttct agagaagagg agtattggga ggggtgggta ttgtcaatgt 180
taaggttcct aaacatactt gtgagtaggt gtgtgtggtt gtcccttttg ttaataaaca 240
tatgagcagt caaaaaaaaa aaaaaaa 267
<210> 152
<211> 160
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Sec61g 3'-UTR
NM_011343.3
<400> 152
gtccttctca tcatgggacg agtgagccag agcgggggaa agggcatgaa gtaaagcgtt 60
gcctgaatgc tgtgtggtgt tttgtttctt cctccttcct atgaggtttt ctacttctca 120
attaaaataa tttcaaaata aacacttttt ccataacaga 160
<210> 153
<211> 62
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus 2900010M23Rik 3'-UTR
BC_030629
<400> 153
ccgtggggtc tgatactcat caataaaact gcctggtttc tcccacaaaa aaaaaaaaaa 60
aa 62
<210> 154
<211> 338
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Anapc5 3'-UTR
Anapc5-201 ENSMUST00000086216
<400> 154
ccaggactcc ctgcttgatg gtgtgcattt aggggtgggt cattacatgc tatcttgtca 60
ataaactgtt ctgatcagtt tgtctgaagt gggttttttt ttatttttct gggttgaatt 120
gtcagtatct ttgttaagaa ctgtgtatct aggggctgga gagatggctt agcagttaag 180
agcactaact gttcttctaa aggacctggg ttcaattcct agcaccctca tgacagctca 240
cagctgtctg taactcctgt tccagggact ctgacaccct caggcagaca taaaagcagt 300
caaaacaccg atgtacataa aattaaaata aattattt 338
<210> 155
<211> 71
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mars2 3'-UTR
BC132343.1
<400> 155
gaactcagct cttactgact ggtagtaaaa gatcaaatgt attctttttg cgtttttaag 60
taaagtcatg c 71
<210> 156
<211> 176
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Phpt1 3'-UTR
NM_029293
<400> 156
agctctgccc caccccccac cccccggact aagtcaggtc tctgctcttg ctgtgttctg 60
ttttgagggg ctggccctgt gctttccttt tgtaccttag gcagcatagc acctgccagg 120
ccttagaggc cagaccaatc tggtccatag gaattaaaag cattgatatg cctact 176
<210> 157
<211> 66
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufb8 3'-UTR
NM_026061
<400> 157
ggaggcttga tgggcttttt gccctcgttc ctagaggctt aaccataata aaatccctaa 60
taaagc 66
<210> 158
<211> 170
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Pfdn5 3'-UTR
NM_027044
<400> 158
gagtgcactg cagaaatgaa gcagagtgag ggacccttct tcaaggggcc tgggactttt 60
tccggcaatg gcctcctggg aaagtggcct gggaagagag tgttttgtgt ttaatgttaa 120
taaatgtgac cgctgcgcaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 170
<210> 159
<211> 278
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Arpc3 3'-UTR
NM_019824
<400> 159
gaggagcctg ggcagcacca tcacgtggag acacatcata ggacacacag gccaatgtgt 60
ctgttcatac ctaccgtatc aaggagagaa gagagcctgt ctttgctgga aaagctcttg 120
gtcaagaatt gggagggtgg gtgttgggcg atttcgattt ttggcagttt taagctggta 180
cttaatatat aataaatgtc actgcttatg ttagacattg aattaaaaca tttttgagaa 240
aaagctttaa aaaaaaaaaa aaaaaaaaaa aaaaaaaa 278
<210> 160
<211> 58
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufb7 3'-UTR
NM_025843
<400> 160
ggattacccg ccagcctgtg gacctatcag tgaaataaaa gctttgggtc acctgcct 58
<210> 161
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5h 3'-UTR
NM_027862
<400> 161
agcagcctgg gacggagccc cggccgacat gaaataaaac atttaaatag t 51
<210> 162
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mrpl23 3'-UTR
NM_011288
<400> 162
cctatgacag caggatttgg accacagacc ctagtgagca cagtggttct gacaagccca 60
aataaaaatt ctttgtggag 80
<210> 163
<211> 387
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tomm6 3'-UTR
NM_025365.3
<400> 163
ccagagaatg gaactcctgt gtattcagac tttccaaaga cagcctactg tctgtgacca 60
caagatccta cctgagtggc agctgaagtt gactccctct ccttgcctga accccccccc 120
actgcccccc catcccccag tgtcggctga gatgttgcct ctgcacggtt ctgtgtgcag 180
ttcccaactt tctgcagaag atggtccttg cccttgtcct gaagagtagt aatggttctt 240
gaaaaagatt tcaaataaag cctgcacata aaagacaggt attttattct tttaataaga 300
aacttattac aaaaacaagg tgtaaaaagt ccgcttacaa aaatcaaata aacatgactt 360
gtatttcaaa aaaaaaaaaa aaaaaaa 387
<210> 164
<211> 327
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tomm6 3'-UTR
Tomm6-002 ENSMUST00000113301
<400> 164
ccaggtgaga gcagttctcc tgtgtttccc cgtttctgat gctgttatct gcttacagag 60
aatggaactc ctgtgtattc agactttcca aagacagcct actgtctgtg accacaagat 120
cctacctgag tggcagctga agttgactcc ctctccttgc ctgaaccccc ccccactgcc 180
cccccatccc ccagtgtcgg ctgagatgtt gcctctgcac ggttctgtgt gcagttccca 240
actttctgca gaagatggtc cttgcccttg tcctgaagag tagtaatggt tcttgaaaaa 300
gatttcaaat aaagcctgca cataaaa 327
<210> 165
<211> 273
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tomm6 3'-UTR
<400> 165
ccagagaatg gaactcctgt gtattcagac tttccaaaga cagcctactg tctgtgacca 60
caagatccta cctgagtggc agctgaagtt gactccctct ccttgcctga accccccccc 120
actgcccccc catcccccag tgtcggctga gatgttgcct ctgcacggtt ctgtgtgcag 180
ttcccaactt tctgcagaag atggtccttg cccttgtcct gaagagtagt aatggttctt 240
gaaaaagatt tcaaataaag cctgcacata aaa 273
<210> 166
<211> 631
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mtch1 3'-UTR
NM_019880
<400> 166
cctaagctgc ccgaccaaac atttatgggg tcttagccta cccctggtga ggacccatca 60
tctcagatgc ccaagggtga ctccagccca gcctggcttc atgtccatat ttgccatgtg 120
tctgtccaga tgtgggctgg tggaggtggg tcacctggga cctggggaag cctgggggag 180
cagtgttggg gtggcatccc cttcctgcct agaggtactg gagtccatct tgtactcagg 240
cagaggcagg ctgcagaggc aaacgtcact cagtggcaag gcttccctgc acctctagcc 300
cagctcatcc tgccagtcag ccagaagcac ccccgccccc cacttcctgc tttgtaaatt 360
gggcgccatc acacctgggc catgggaggc tggagctatg ttcccaacac taattttctt 420
atacaagggt ggtgccttct cctgaatagg aaatcatgtt ctcctcagac catcccctca 480
tctgcttgtc tgtgctggtg acgccaggtg tgagggttca gtcactgtgc tgggtgcgaa 540
tacgcacagg ttacataggc cgacatctag tcctcccctc gtggtaagat agacccatct 600
cctcgaataa atgtattggt ggtgatttgg a 631
<210> 167
<211> 158
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Pcbd2 3'-UTR
NM_028281
<400> 167
tctgcgcctg ccttgtctgc agcgttgttt gcaagccact tatgttaata aattgtcata 60
aagtagttca tagttacatg tatacattgt tgtatgattg atgctcaaat acagaatgat 120
ttgaagccaa aaaaaaaaaa aaaaaaaaaa aaaaaaaa 158
<210> 168
<211> 93
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ecm1 3'-UTR
NM_007899
<400> 168
gtcaccctga gcctcagagg attagatggg ggaactccgc cctactccac cctcctcgaa 60
cactcattac aataaatgcc tcttggattt ggc 93
<210> 169
<211> 458
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Hrsp12 3'-UTR
Hrsp12-001 ENSMUST00000022946
<400> 169
ctataagtag ccatgctgat gttgactccg gaggttttag aatgtctttc acactttaat 60
ttttacaaat gatgctggga agtataaaaa tgaccagagt ggttgaagtt attgtggaag 120
tgatcaaata tgtggagatt tgacattaat tggagattat tcagtatagt gactgatgtt 180
ctaatttcac ttatgttgct gggtgtgaga gaagaggtgc acagctactg agatgggaag 240
cagaaggaaa gatgggctgt tgtacatgag aaatagtaag gagcacatct acttaaatca 300
tattaatttg ctcatgtgaa atacttagtt cttatgttag atataagaaa ctaaattgaa 360
atattcaaac ttgaatagta ccaggagaac aagtggacca aaatcttata cagataatat 420
tactttaatt gaaataaaaa atagatgtgt aactttcc 458
<210> 170
<211> 183
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mecr 3'-UTR
NM_025297
<400> 170
ttgctccaga ggaccaggag gaaagcagga gaggcaagac tggctgtctg ctggcccctc 60
catgagaacc ccagccttcc cagactgcct cacccatatt gtctcttcct accaggaggg 120
tgggggacca actctaggct ccctaataaa cccttaactt cccgagtgga ggatgaagag 180
tac 183
<210> 171
<211> 120
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Uqcrq 3'-UTR
NM_025352
<400> 171
acggcctgca cctgggtgac agtcccctgc ctctgaaaga cccttctctg ggagaggaat 60
ccacactgta gtcttgaaga caataaacta cttatggact tccctttgaa aaaaaaaaaa 120
<210> 172
<211> 511
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gstm3 3'-UTR
NM_010359
<400> 172
gcccctgcca tgctgtcact cagagtgggg gacctgtcca tactgcggat cctgcaggct 60
ctgggtgggg acagcaccct ggccttctgc actgtggctc ccggttctct ctccttcccg 120
ctcccttctg cagcttggtc agccccatct cctcatcctc accccagtca agcccatgca 180
gcctttattc tccccatttt tttttcacat ggccccttct tcattggtgc ccagacccaa 240
cctcacagcc cttttctgca atctgaggtc tgtcctgaac tcaggctccc tagagttacc 300
ccaatggtca acactatctt agtgccagcc ctccctagag ataccctgat ggtcaatact 360
atcttagtga cggccctccc tagagttacc ctgaaggtca atactcgagt gccagcctgt 420
tcctgtttaa ggagctgccc caggcctgtc tcatgtacaa taaagcctga aacacacttg 480
aaacacaata aacactgaac acttgctgtg a 511
<210> 173
<211> 312
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Lsm4 3'-UTR
NM_015816
<400> 173
tcactccctg cctgagccga gcccagaacg gtgggtgagg cctcagggca cctttgtgtg 60
aagccccact tggcgtctgg tccagtgaag tccctcgctg gccactgact cagtttctgg 120
aaggttccga gtctgaggtg cctgtggagc cttagatgcc ctttgaaggg ctgacttctt 180
ccaggcatgt ttgagtttca gttggagctg caggctcagc ccatggcggc tcacctgtcc 240
tttaccagcc ataccctgta catcttctgt ttgaaaaata aaagcaaaca ccatagaaag 300
aaaaaaaaaa aa 312
<210> 174
<211> 195
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Park7 3'-UTR
NM_020569
<400> 174
agcccaagcc ctgggcccca cgcttgagca ggcattggaa gcccactggt gtgtccagag 60
cccagggaac ctcagcagta gtatgtgaag cagccgccac acggggctct catcccgggt 120
ctgtatgttt ctgaaccttg ctagtagaat aaacagttta ccaagctcct gccagctaaa 180
aaaaaaaaaa aaaaa 195
<210> 175
<211> 131
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Usmg5 3'-UTR
NM_023211
<400> 175
atggattttg aaatgtctga cctcacctgt taagtcccat gcctgaagaa gctgatgtga 60
actcatcatg taatactcaa tttgtacaat aaattatgaa cccaaaaaaa aaaaaaaaaa 120
aaaaaaaaaa a 131
<210> 176
<211> 231
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cox8a 3'-UTR
NM_007750
<400> 176
agggagcagt cttccctcat cctttgacta gaccactttt gccagcccac cttgatcatg 60
ttgcctgcat tcctggctgg ccttccccgg gatcatgtta ttcaattcca gtcacctctt 120
ctgcaatcat gacctctcga tgtctccatg gtgacaactg ggaccacatg tattggctct 180
gcttggtggg gtcccccttt gtaacaataa agtctattta aaccttgctc c 231
<210> 177
<211> 403
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ly6c1 3'-UTR
NM_010741
<400> 177
tggtccttcc aatgaccccc acccttttcc ttttatcttc atgtgcaacc actctttcct 60
ggagtcctct agtgacaaat tatatgttat agaaggtcca atgtggggat agtgtgtgga 120
acaccctgtt tcacctttat agcccctgct gggtaagtgc ccgactcctc tctagggctt 180
tcaaatctgt acttcttgca atgccattta gttgtggatt tctattcttg gccctggagg 240
catgtggcca gcacatgcaa caggcagtat tccaaggtat tatagtatca ccatccacac 300
ataagtatct ggggtcctgc agggttccca tgtatgcctg tcaatgaccc ctgttgagtc 360
caataaaagc tttgttctcc cagccaaaaa aaaaaaaaaa aaa 403
<210> 178
<211> 309
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ly6c1 3'-UTR
NM_001252058.1
<400> 178
actcataaaa atgctcctgc ctcggtcttc caagttctag gattgcaagt ctgacttcaa 60
catgccttac agacaactct gggacatcca ggcctagtgg catgttgccc agatatgggg 120
atgctctgtg gcccctgcat aagaagtgag tcactccctg atttcttgca gactctcaaa 180
gaaggaaact aaagacccgt cagtgccttt ctttctgccc tgctggtgtg ccaatcaggg 240
atcctaacat cagggagagg acttcctgtt gcagcgaaga cctctgcaat gcagcagttc 300
ccactgcag 309
<210> 179
<211> 802
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cox7b 3'-UTR
NM_025379
<400> 179
tcgtgccagc tggtacaata atcaaggaat tgtttaaaac caacttataa gtgaatgcca 60
agtcaaagaa tcatgtactc attatactat ggcagattga agaacaaata aagaaataaa 120
gtaccttaac cttcattcta ggctttgttt ttttcctttg taaatgaagc ccaagcatgg 180
tgacttctca tttatttaag ctgtattgtc tcttaaaatg gctttttacc ctatgaggtg 240
gtatgaggga aatctatgat caggagggca cctttatagt aagctgaaat tacagagaat 300
gaagaaataa gcacagagct gttttaggag cccactgggt cattggccat ataggttatg 360
cttactgccc tctacctcgt ggttatattt ggaattgcca ttagctccct tctgcttaga 420
gactggactg tcaccaaacc caaggggata gtgatcctgt aatgatcctg tgtgaactag 480
gtttgctaaa gactaccacc tccttacact gtatggcata ttcatctgaa ataggtgcta 540
atttttcagc ataatcctta atctttagga tctgtcatac ttcctagtaa tttaactgtt 600
gctgaagaaa taaaggctat ctgttaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 660
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 720
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 780
aaaaaaaaaa aaaaaaaaaa aa 802
<210> 180
<211> 231
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ppib 3'-UTR
NM_011149
<400> 180
agagcctggg ggacctcatc cctctaagca gctgtctgtg tgggtcctgt caatccccac 60
acagacgaag gtagccagtc acaaggttct gtgccaccct ggccctagtg cttccatctg 120
atggggtgac cacacccctc acattccaca ggcctgattt ttataaaaaa ctaccaatgc 180
tgatcaataa agtgggtttt ttttatagct tgaaaaaaaa aaaaaaaaaa a 231
<210> 181
<211> 205
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Bag1 3'-UTR
NM_009736
<400> 181
agtgcagtgg agagtggctg tactggcctg aagagcagct ttacagccct gccctctctg 60
gaacagaagt cgcctgtttc tccatggctg ccaggggcaa ctagccaaat gtcaatttcc 120
ctgctcctcc gtcggttctc aatgaaaaag tcctgtcttt gcaacctgaa ttagacttgt 180
gttttctcaa aaaaaaaaaa aaaaa 205
<210> 182
<211> 140
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus S100a4 3'-UTR
S100a4-201 ENSMUST00000001046
<400> 182
agactcctca gatgaagtgt tggggtgtag tttgccagtg ggggatcttc cctgttggct 60
gtgagcatag tgccttactc tggcttcttc gcacatgtgc acagtgctga gcaaattcaa 120
taaaaggttt tgaaactatt 140
<210> 183
<211> 374
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Bcap31 3'-UTR
NM_012060
<400> 183
aggcttggtg tttccctgcc tgccgctggc ttctacctga cccatgctta ctgcttcctt 60
ggagcccaga ctatccctct ggtacttggg tttattccct acttccccaa ttttcttcca 120
tggcttatag atcattattt tggcaccatt acacatactg ctcttatacc aaaagggacc 180
tgattgttgt ttattcagag tacttttgcc actgttctgc ctggctaggg cactttccac 240
tcctggaagt gtagaaaagc actggtgacc tggcctgcag tttgaacccc tttttatttt 300
gcaatgtacc ctaaaggagg ctgctgtgaa gcaggtcaac tgttttatcc tgaggggaat 360
aaatgttgtt atgt 374
<210> 184
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tecr 3'-UTR
NM_134118
<400> 184
gcagctcctc acggctctgc ccagtaatac tctccacccc tcactgcccc tgtcctgatg 60
tgtggctggc catggctctc cagcagcaac aataaaacct gcttacccaa aaaaaaaaaa 120
aaaaaa 126
<210> 185
<211> 171
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Rabac1 3'-UTR
NM_010261
<400> 185
agtgtcctcc aggacctgcc ggcctctcct gccggccggc tgtcccatct ctgtctgttc 60
tcgtcctacc tggccttgct gctcagctcc gagccttcca cctgaggcct caaacccagg 120
gaggggcttt tgtctttgga aataaagctg ttacaattgc tatttggcca a 171
<210> 186
<211> 144
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Robld3 3'-UTR
NM_031248 (Lamtor2)
<400> 186
cagcgtgatg gaggctggag tagaaaaggg atgatgatct ggagggaggg gcggggccct 60
agaaacgcca tatcgggcga ggtacaggaa gggggggttg cttttttctg aataaatttt 120
caactcttaa aaaaaaaaaa aaaa 144
<210> 187
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Sod1 3'-UTR
NM_011434
<400> 187
acattccctg tgtggtctga gtctcagact catctgctac cctcaaacca ttaaactgta 60
atctgaaaaa aaaaaaaaaa 80
<210> 188
<211> 262
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Nedd8 3'-UTR
NM_008683
<400> 188
agaaacttgg ttccgtttac ctccttgccc tgccaatcat aatgtggcat cacatatcct 60
ctcactctct gggacaccag agccactgcc ccctctcttg gatgcccaat cttgtgtgtc 120
tactggtggg agaatgtgag gaccccaggg tgcagtgttc ctggcccaga tggcccctgc 180
tggctattgg gttttagttt gcagtcatgt gtgcttccct gtcttatggc tgtatccttg 240
gttatcaata aaatatttcc tg 262
<210> 189
<211> 257
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Higd2a 3'-UTR
NM_025933
<400> 189
gtatagccgg gtcttaaagc gccatggaaa ccattacaaa acccaggaac aacagacatc 60
cctgtcagac ttgctccctc cgtttcagac cggaccttat tgtcatttgg gtgaggaagt 120
ggccgatttt gtaactgatt tgcgcttcca ccgctgcccc ctcccgctcc caaaatccca 180
ggttcatttc agttgggttg catgcttcta tttgtgatgc gtccccttaa ttacttaata 240
aaagcttatt acacttg 257
<210> 190
<211> 268
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Trappc6a 3'-UTR
Trappc6a-001 ENSMUST00000002112
<400> 190
ggaccccaga ccccaggctt gcccttccct aagcttagcc tcggaatgtg gcacctgacc 60
ctgcctcact gctcaccttt gcaggtcgcc ttgaagctgg agctcacagg ctctggggag 120
gtcacatgtg cttcagacaa gggaatgaaa gggccgggag ggtcccggga ggtgggacca 180
tcccctgagt tccaagtcag catggaggga cattagggca tcacccagat gacagatgtt 240
cagtaaaggt tctttatgtg caaacaga 268
<210> 191
<211> 188
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ldhb 3'-UTR
Ldhb-001 ENSMUST00000032373
<400> 191
ctgccagtct ctaggctgta gaacacaaac ctccaatgtg accatgaacc tttagtcttc 60
agccatgtat gtaggtcaca gtttgcttct tccctgacat gtgatatgag ctcacagatc 120
aaagcccagg cttgtttgat gtttgcacta ggagctcctg atcaaataaa gttagcaatt 180
gcagcata 188
<210> 192
<211> 112
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Nme2 3'-UTR
Nme2-001 ENSMUST00000021217
<400> 192
acatgaagaa accagaatcc ttttcagcac tactgatggg tttctggaca gagctcttca 60
tcccactgac aggatggatc atcttttcta aaacaataaa gactttggaa ct 112
<210> 193
<211> 119
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Snrpg 3'-UTR
NM_026506
<400> 193
cctgtgctca gcaagcagtg tccacatccc tccccaaagg cctgtttgat tgtgatgtag 60
aattaggtca tgtacatttt catatggaac tttttactaa ataaactttt gtgatactc 119
<210> 194
<211> 235
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa2 3'-UTR
NM_010885
<400> 194
aggtctccac tgaggactgt gagcgagagc agctgaacct gctggactga agacagtgtg 60
gggaaatgtg tgctttgggt ccttataaag cttacgctgt acagtgtccc ttcagaatgt 120
cctcttcatt accttctccc tcttactgcg caacactgag gcaaagtagt tttatataaa 180
aatactcctt tatttctcct caaaaaaaaa aaaaaaaaaa acccaccagg tgcca 235
<210> 195
<211> 196
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Serf1 3'-UTR
Serf1-003 ENSMUST00000142155
<400> 195
tgactggctt tttggaaaac ctgggtgcta ttgccagtgg gtgcatcata cgctctaaga 60
ttaaaatttc acagtgacta atcattatat gtgttataac ttgtccttat aaaactattt 120
taaactttac tcttcagcct atcttaatgt gatgttttaa gaccatcaaa aaataaagta 180
ctgaccttgc atgtaa 196
<210> 196
<211> 286
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Oaz1 3'-UTR
Oaz1-001 ENSMUST00000180036
<400> 196
gtgccagccc tgcccagtgt ccctgtgccc tctcctgggt tagtccacat gtcgtgattg 60
tgcagaataa acgctcactc cattagcggg gtgcttcttc gagctgaatg ctgtgtttgt 120
cacactcaag tgttggcttt aattctaaat aaaggtttct attttacttt tttattgctg 180
tttaagatgg tcaggtgacc tatgctatag cagtctcctt tgaagtctgg aaaaatagtg 240
tcacctcccc tggctcaaat ccaataaagt gatctcgttc attggc 286
<210> 197
<211> 418
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ybx1 3'-UTR
Ybx1-001 ENSMUST00000079644
<400> 197
atgccggctt accatctcta ccatcatccg gtttggtcat ccaacaagaa gaaatgaata 60
tgaaattcca gcaataagaa atgaacaaag attggagctg aagaccttaa gtgcttgctt 120
tttgccctct gaccagataa cattagaact atctgcatta tctatgcagc atggggtttt 180
tattattttt acctaaagat gtctcttttt ggtaatgaca aacgtgtttt ttaagaaaaa 240
aaaaaaaaag gcctggtttt tctcaataca cctttaacgg tttttaaatt gtttcatatc 300
tggtcaagtt gagattttta agaacttcat ttttaatttg taataaagtt tacaacttga 360
ttttttcaaa aaagtcaaca aactgcaagc acctgttaat aaaggtctta aataataa 418
<210> 198
<211> 421
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ybx1(v2) 3'-UTR
with mutation T128bpG and deletion del236-237bp
<400> 198
tttttatgcc ggcttaccat ctctaccatc atccggtttg gtcatccaac aagaagaaat 60
gaatatgaaa ttccagcaat aagaaatgaa caaagattgg agctgaagac cttaagtgct 120
tgctttttgc ccgctgacca gataacatta gaactatctg cattatctat gcagcatggg 180
gtttttatta tttttaccta aagatgtctc tttttggtaa tgacaaacgt gttttttaag 240
aaaaaaaaaa aaggcctggt ttttctcaat acacctttaa cggtttttaa attgtttcat 300
atctggtcaa gttgagattt ttaagaactt catttttaat ttgtaataaa gtttacaact 360
tgattttttc aaaaaagtca acaaactgca agcacctgtt aataaaggtc ttaaataata 420
a 421
<210> 199
<211> 798
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Sepp1 3'-UTR
NM_009155
<400> 199
attatttaaa acaaggcata cctctcccca actcagtcta aagacacaat ttcattttga 60
gaatgtttac agcccattta attaatcagt gaactaaaag tcatagaaat tggatttgtg 120
caaatgtaga gaaatctacc atattggctt ccaaaattta aaaattttat gccacagaac 180
atttcatcca aatcagattt gtacaatagg gcacctgaaa agtgactgca gcctttggtt 240
aatatgtctt tctttttcct ttttccagtg ttctagttac attaatgaga acagaaacat 300
aaactatgac ctaggggttt ctgttggata gcttgtaatt aagaacggag aaagaacaac 360
aaagacatat tttccagttt tttttttctt tacttaaact ctgaaaacaa cagaaacttt 420
gtcttcctac tcttacattc taaaccgatg aaatctttaa cagattacac tttaaatatc 480
tactcatcat tttctctctc agagtcctag cttgagttgc actgcatgta tctgtgcatc 540
ttgttctctt catttaatgc tgtactgttc tgctgagctc tgagggacta tcttgagaga 600
tgtaatggaa ggaaagcgtg gtgttaatct gcgtactgct taagacagta tttccataat 660
caatgatggt ttcatagaga aactaagtcc tatgaacctg acctctttta tggctaatac 720
gactaagcaa gaatggagta cagaattaag tggctacagt acacacttat caaaataaat 780
gcaattttaa aacctttc 798
<210> 200
<211> 390
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gaa 3'-UTR
Gaa-001 ENSMUST00000106259
<400> 200
gagagtccgt cgtttacaga ggcctccagg gaggcagagg gagcttgagc tggctctggc 60
tggtggctcc tgtaaggacc tgcgtcctgc tctcctgaca catctttgag cttttcccac 120
cgtgttactg catgcgcccc tgaagctctg tgttcttagg agagtgaggc tcgcctcacc 180
tgccccaccc cagctgtctg tccctcacct ggcactagag aatgtggagc tcggcgtggg 240
gacatcgtgt ctgcaccaac atcaggctgt gcagccactg cagccgcaac cctgcagaga 300
cagagctggt gccttcacca ggttcccaag actcgagaaa cttactgtga agtgtactta 360
cttttaataa aaaggatatt gtttggaagc 390
<210> 201
<211> 481
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ACTR10 3'-UTR
ACTR10-002 ENST00000254286
<400> 201
aagtttgatt aaaaatcaac cttgcttcat atcaaatatt taaccaatta taagcaaatt 60
gtacaaagta tgtaggatgt tttgttatag aggactatag tggaagtgaa agcattctgt 120
gtttactctt tgcattaata tataattctt ttgactttgt ttctcttgtg tagtggtaaa 180
atggtagctg gtgcttattg agatttgctg tatttatatc aataaagtat agtaaagcag 240
tttgattttg gaagtttgtt atgtggcttt tttttttttt ttttttttga gacggagtct 300
cgctctgtca cttaggctgg agtgcagtgg cacaatctct actcattgca agctccgcct 360
cccgggttta cgccattctg tctcagcctc ctgagtagct gggactatag gcatacgcca 420
ccccgcccgg ctaatttttt gtatatttag tagagacggg gtttcaccat gttagccagg 480
a 481
<210> 202
<211> 347
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PIGF 3'-UTR
NM_173074
<400> 202
gtaacttaat cctgacaacc gtagtgcaag gtatggccca tctcctgtac gcttggagcg 60
acctttggct acgtggctgg ccttgttatt tcaccactct ggatatactg gaatagaaag 120
caacttacat acaagaacaa ttaactggag caaagggaga tatttctttg tgcagattct 180
gtaagggctg ggcagaaatg tgtatggtca aagccaagca gttccattta cagctctgtt 240
ttttacgtag ttacaacatg atgtgattgt agctttttaa actatgaaac ccctgagaga 300
ttgtaccttc tagttgaaat aaagtattta taatagattg tggcttc 347
<210> 203
<211> 233
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PIGF 3'-UTR
NM_002643.3
<400> 203
ctggagcaaa gggagatatt tctttgtgca gattctgtaa gggctgggca gaaatgtgta 60
tggtcaaagc caagcagttc catttacagc tctgtttttt acgtagttac aacatgatgt 120
gattgtagct ttttaaacta tgaaacccct gagagattgt accttctagt tgaaataaag 180
tatttataat agattgtggc ttcaaaaaaa aaaaaaaaaa aaaaaaaaaa aaa 233
<210> 204
<211> 116
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MGST3 3'-UTR
MGST3-001 ENST00000367889
<400> 204
agaattatag gggtttaaaa actctcattc attttaaatg acttaccttt atttccagtt 60
acattttttt tctaaatata ataaaaactt acctggcatc agcctcatac ctaaaa 116
<210> 205
<211> 913
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SCP2 3'-UTR
NM_001193599
<400> 205
agaactccct ttggctactt ttgaaaatca agatgagata tatagatata tatccataca 60
ttttattgtc agaatttaga ctgaaactac acattggcaa atagcgtggg atagatttgt 120
ttcttaatgg gtgtgaccaa tcctgttttt cctatgctct gggtgaatag agcctgatgg 180
tatactactg ctttgcggaa ttgcatacaa ctgtgcatta caaagttaat atggtaatta 240
tggtctgggg taaaattgag tttcagaata aaattaggaa cagtaaaatc caaagaacta 300
tgtaaacaaa aaagcttttg ttttgcttac aaagtatatt taaggattat tctgctgaag 360
attcagttta agagttttcc ttgggagaac taagtaagaa acacaatgcc aacagctggc 420
cagtaattag tgttgtgcac ttcatgtcat taatcaattt ctcaatagtt cttaaaatta 480
gtgagattaa aaatctaaaa attttgcatt tcatgctatc agaaacagta ttttcttccc 540
aaatcaaaat aaaagaaata tgatcagagc ttgaacacag gcttattttt aaaataaaaa 600
tatttttaac atgggtttcc ttattgaaaa atcagtgtat tagtcataaa acaccatcat 660
taagaataat tgaacaataa agtttgcttt cagatgcagt tttcaaatta taatctcatt 720
tcaatttata acgttctcag tcctttgtta taattttcct ttttcatgta agtttaatta 780
tctgcattta tcttttttcc tagtttttct aatactaatg ttatttctta aaattcagtg 840
agatatagga taaaataatg ctttgagaag aatgtttaat agaaaattaa aataactttt 900
tctggcctct ctt 913
<210> 206
<211> 409
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SCP2 3'-UTR
SCP2-015 ENST00000435345
<400> 206
agaactccct ttggctactt ttgaaaatca agatgagata tatagatata tatccataca 60
ttttattgtc agaatttaga ctgaaactac acattggcaa atagcgtggg atagatttgt 120
ttcttaatgg gtgtgaccaa tcctgttttt cctatgctct gggtgaatag agcctgatgg 180
tatactactg ctttgcggaa ttgcatacaa ctgtgcatta caaagttaat atggtaatta 240
tggtctgggg taaaattgag tttcagaata aaattaggaa cagtaaaatc caaagaacta 300
tgtaaacaaa aaagcttttg ttttgcttac aaagtatatt taaggattat tctgctgaag 360
attcagttta agagttttcc ttgggagaac taagtaagaa acacaatgc 409
<210> 207
<211> 591
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HPRT1 3'-UTR
HPRT1-001 ENST00000298556
<400> 207
gatgagagtt caagttgagt ttggaaacat ctggagtcct attgacatcg ccagtaaaat 60
tatcaatgtt ctagttctgt ggccatctgc ttagtagagc tttttgcatg tatcttctaa 120
gaattttatc tgttttgtac tttagaaatg tcagttgctg cattcctaaa ctgtttattt 180
gcactatgag cctatagact atcagttccc tttgggcgga ttgttgttta acttgtaaat 240
gaaaaaattc tcttaaacca cagcactatt gagtgaaaca ttgaactcat atctgtaaga 300
aataaagaga agatatatta gttttttaat tggtatttta atttttatat atgcaggaaa 360
gaatagaagt gattgaatat tgttaattat accaccgtgt gttagaaaag taagaagcag 420
tcaattttca catcaaagac agcatctaag aagttttgtt ctgtcctgga attattttag 480
tagtgtttca gtaatgttga ctgtattttc caacttgttc aaattattac cagtgaatct 540
ttgtcagcag ttccctttta aatgcaaatc aataaattcc caaaaattta a 591
<210> 208
<211> 283
<212> DNA
<213> Artificial Sequence
<220>
<223> ACSF2
Homo sapiens
<400> 208
ataaagcagc aggcctgtcc tggccggttg gcttgactct ctcctgtcag aatgcaacct 60
ggctttatgc acctagatgt ccccagcacc cagttctgag ccaggcacat caaatgtcaa 120
ggaattgact gaacgaacta agagctcctg gatgggtccg ggaactcgcc tgggcacaag 180
gtgccaaaag gcaggcagcc tgcccaggcc ctccctcctg tccatccccc acattcccct 240
gtctgtcctt gtgatttggc ataaagagct tctgttttct ttg 283
<210> 209
<211> 555
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens VPS13A 3'-UTR
NM_033305
<400> 209
aattcatatg ttctttattt tacttggaat gtttcattaa catgttttgt atgacttata 60
ccataatgcc catatgtcca tttataggga ggtaaaacac attttctttt aaaatgtttt 120
cctacacatt ttcataaagc aaaataattg tattatttaa gcacagaaaa aaatgtatct 180
tacatccaaa gtagggaggg catccaacat attatagatt tgcttttata tattttatag 240
ctttgtattg catagtttgt ctttaagagt tcaagttaga cttaaatata attttgatgt 300
tcactggttt tattttaaat tgccttctta tttgttagca aaatgccttt ttttaatggt 360
ctctgtaaat tttctgggct ttaatgtaat gccactgtgt aaaaaaaaag gaagaaaata 420
gtaatagcca tttaatgttt tatatttatc attttaaaga tatttttgtc aaatttcttt 480
taataataat aaacatatgt aatctaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 540
aaaaaaaaaa aaaaa 555
<210> 210
<211> 724
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CTH 3'-UTR
NM_001190463.1
<400> 210
tattccagag ctgctattag aagctgcttc ctgtgaagat caaatcttcc tgagtaatta 60
aatggaccaa caatgagcct ttgcaaaatt ttcaagcgga aattttaagg cacctcatta 120
tctttcataa ctgtaatttt cttagggatc atctctgtta aaaagttttc tgtatgtcat 180
gttataatta caggtcaatt ctgttaatat ctttttgtta attttgctct atgtttgcct 240
ctgaaggagg tgagatttgt gctactttgg gagattatgt tcttttttca tgtctaagat 300
ttattttgat catgtttata atataatggt aattcatttt tgatgttttg tgaagaattt 360
aaatttaaac gaatgttctt aaatcaagtg tgattttttt gcatatcatt gaaaagaaca 420
ttaaaagcaa tggtttacac ttagttacca taagccgaaa atcaaatact tgaaaagttt 480
actgtgaaat tctactgatt taagactata cttaatattt ttaaaaaaat aaatcagctg 540
ggcgcggtgg ctcacgcatg taatgccagc acttttggag gataaggcgg gcggatcacg 600
aggtcaggag attgagacca tcctggctag cgcagtgaaa cccccatctc tactaaaaat 660
gcaaaaaaaa ttagacggac gtggtggcgg gtgcctgtag tcccagctac ttgggaggct 720
gagg 724
<210> 211
<211> 443
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CTH 3'-UTR
CTH-001 ENST00000370938
<400> 211
tattccagag ctgctattag aagctgcttc ctgtgaagat caaatcttcc tgagtaatta 60
aatggaccaa caatgagcct ttgcaaaatt ttcaagcgga aattttaagg cacctcatta 120
tctttcataa ctgtaatttt cttagggatc atctctgtta aaaagttttc tgtatgtcat 180
gttataatta caggtcaatt ctgttaatat ctttttgtta attttgctct atgtttgcct 240
ctgaaggagg tgagatttgt gctactttgg gagattatgt tcttttttca tgtctaagat 300
ttattttgat catgtttata atataatggt aattcatttt tgatgttttg tgaagaattt 360
aaatttaaac gaatgttctt aaatcaagtg tgattttttt gcatatcatt gaaaagaaca 420
ttaaaagcaa tggtttacac tta 443
<210> 212
<211> 77
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CTH 3'-UTR
CTH-002 ENST00000346806
<400> 212
tattccagag ctgctattag aagctgcttc ctgtgaagat caaatcttcc tgagtaatta 60
aatggaccaa caatgag 77
<210> 213
<211> 286
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NXT2 3'-UTR
NXT2-004 ENST00000372107
<400> 213
aggggcaaaa gtccattctc atttggtcca ttagttccag caattgaaat ttatgtgaat 60
tattttgatt gtagaagcac tataatatgt gctgaaacta aatttcttta atattttcta 120
ttcctgtcag caccttttct agcagctgcc agtttggagc attgccctct aagagcttta 180
aaactatttt tttacatgcc ttatatacat tccactaatg acattcttat aataatatta 240
aacacatgat cttggtacta acatactcac tgtgaaccca gcctat 286
<210> 214
<211> 121
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MGST2 3'-UTR
NM_002413
<400> 214
ctttttctct tccctttaat gcttgcagaa gctgttccca ccatgaaggt aatatggtat 60
catttgttaa ataaaaataa agtctttatt ctgtttttct tgaaaaaaaa aaaaaaaaaa 120
a 121
<210> 215
<211> 582
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MGST2 3'-UTR
NM_001204366.1
<400> 215
ctttttctct tccctttaat gcttgcagaa gctgttccca ccatgaaggc ttgaagccac 60
agtgcatggc cagaaccagc cagacctttg gagttcaaga actcgagagg tgggtgaaaa 120
ctgccattgc ctccacagac tgtcttctcc gtggaaagaa gacctgagtc accagggctg 180
ggaaacctgc accactgaga cgagcacagc ctctgccggc atgcaagtgg ccgctgtcag 240
gacacatgga ctgaaagtgg tttgtcagct gctccattag gtttttttta cccatatgtt 300
tgctaccttt ctttccttga tttaaaaata gggaggggga gcagtctcag ctgtcttcag 360
ctgctaggga gatttttttc cccctcctga gctactgttt cccccaaccc gagcctttct 420
ctcttattgt acccaccctt tctgatgaag tcatcaaagc aaagattgca taactgatgc 480
ataggcctat cttgtgttat actgggagac aggccaatgt ttccattaat agacaagagc 540
accaccacgc tgccaaatgg agctctctgc tgcaaccact ac 582
<210> 216
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C11orf67 3'-UTR
AAMDC-005 ENST00000526415
<400> 216
tggagcctta agaggagaat aaatcactaa gtgccta 37
<210> 217
<211> 266
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PCCA 3'-UTR
NM_000282
<400> 217
aggatttata acctttcagt catcacccaa tttaattagc catttgcatg atgctttcac 60
acacaattga ttcaagcatt atacaggaac acccctgtgc agctacgttt acgtcgtcat 120
ttattccaca gagtcaagac caatattctg ccaaaaaatc accaatggaa attttcattg 180
atataaatac ttgtacatat gatttgtact tctgctgtga gattccctag tgtcaaaatt 240
aaatcaataa aactgagcat ttgtct 266
<210> 218
<211> 142
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GLMN 3'-UTR
NM_053274
<400> 218
aagttccatt tcctaaataa aaactaataa aatatagtac tttccattat gattcattta 60
atacctttat aaaaaatttt tctgtaaaaa tttactgctt gaaaaataaa tgtagctttt 120
ctcatttatc aaaaaaaaaa aa 142
<210> 219
<211> 276
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens DHRS1 3'-UTR
NM_001136050
<400> 219
ccctcctggt ctgacactac gtctctgctt gtcttctcat ttggacttgg tggttcgtcc 60
tgtctcagtg aaacagcagc ctttcttgtt tacccatacc cttgatatga agagaagccc 120
tctgctgtgt gtccgtggtg agttctgggg tgcgcctagg tcccttcttt gtgccttggt 180
tttccttgtc cttcttttta ctttttgcct tagtattgaa aaatgctctt ggagctaata 240
aaagtctcat ttctctttca aaaaaaaaaa aaaaaa 276
<210> 220
<211> 450
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PON2 3'-UTR
PON2-001 ENST00000433091
<400> 220
attgtacttt tggcatgaaa gtgcgataac ttaacaatta attttctatg aattgctaat 60
tctgagggaa tttaaccagc aacattgacc cagaaatgta tggcatgtgt agttaatttt 120
attccagtaa ggaacggccc ttttagttct tagagcactt ttaacaaaaa aggaaaatga 180
acaggttctt taaaatgcca agcaagggac agaaaagaaa gctgctttcg aataaagtga 240
atacattttg cacaaagtaa gcctcacctt tgccttccaa ctgccagaac atggattcca 300
ctgaaataga gtgaattata tttccttaaa atgtgagtga cctcacttct ggcactgtga 360
ctactatggc tgtttagaac tactgataac gtattttgat gttttgtact tacatctttg 420
tttaccatta aaaagttgga gttatattaa 450
<210> 221
<211> 277
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NME7 3'-UTR
NM_013330
<400> 221
tggtgtggaa agtaaagaag tcacaggttg ggacatttag acaagagtga atcacacacg 60
aggaatgtgt tcattctttt attgtccgtt gttttaacct gactgaatac aagatcaaca 120
agagcactgt actcctggca attattacat atgttagaac atggattttg cactgtagac 180
aacatttaac accagtctat ggggtactgc attgcttttt ataaagttca aaataaagat 240
ttattttcaa acaaaaaaaa aaaaaaaaaa aaaaaaa 277
<210> 222
<211> 163
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ETFDH 3'-UTR
NM_004453
<400> 222
actgcagcta gccagtttct ttcaagtatg gcaagctaac gttaaaatgt ttagagatta 60
acagatttca gaatgtcttt ctgcatatta ctgaacagaa tagtcacaaa atgattatca 120
aataaaaatt ttatactata tgtaagattg tcccataaag aaa 163
<210> 223
<211> 275
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ALG13 3'-UTR
BC117377
<400> 223
gatccagcag tatgaagtat tcttgcactg ccattttctt gctgtttttg tttttaaaaa 60
gtattttatg ttagtggtta aatgatttag gtgattagtg tttactattg tatttgtctt 120
taaaattatt ttatcttttg atttaaaata gtactttaaa attaaggggt attattttgg 180
gctgtgacta aggaaattga gatggatgta caactagccc catattgagc atacttcatt 240
gtattcagct gttttcctgt cagccatttg tcagc 275
<210> 224
<211> 664
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ALG13 3'-UTR
NM_001099922.2
<400> 224
gatccagcag tatgaagtat tcttgcactg ccattttctt gctgtttttg tttttaaaaa 60
gtattttatg ttagtggtta aatgatttag gtgattagtg tttactattg tatttgtctt 120
taaaattatt ttatcttttg atttaaaata gtactttaaa attaaggggt attattttgg 180
gctgtgacta aggaaattga gatggatgta caactagccc catattgagc atacttcatt 240
gtattcagct gttttcctgt cagccatttg tcagctttat attagctgat ggtaccaatt 300
gataaaatga atataaagta tttcattggt tcaaaaatca cacatcatat taaaccatgc 360
agaattggag taacttccac ttttttctag aaagtaaaac caagagcctt tgcttctgga 420
taactcactt aatattaaat taaagagctc ttcacgtttc ttgagaatta tctgaagcca 480
gttgcattct gtgatatcag ttttgaaggc acatggttct ctgctttaga tttatcccat 540
atgctattgt ttaatactgg atgtatgtaa gtgttttact gcactgtatt gaattggtgt 600
cttttgcaca gttagcagta aataaaaatt agcatttaaa attgccaaaa aaaaaaaaaa 660
aaaa 664
<210> 225
<211> 640
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens DDX60 3'-UTR
DDX60-001 ENST00000393743
<400> 225
aaacaaagtc tatgcaaacc acttaaaaat aattccatag tagtttttca ggtcacgttt 60
ttgattctta tgcttcttgc cagaaataca ttatgataaa gtggaaatac attacgatga 120
agtggaaaga gcaaacactt tggaatcaaa cagagttgca atcaaacctg ccatgttctg 180
tcatgaatac tcacaaatta tttagtatac ctgaatcttg gtttcttttt ataactgagt 240
aataatggtt acatctcagg tagtttgagg attgactaaa aaaatgcgag aatgttgtat 300
gtgactgaat aacaattttt actctgcgaa gccaaagtaa atataatatt atcagtaact 360
ttatccccag tgtcagtatt tataaaatgt ttattaaggc tagaaaaaat gaatacaata 420
tcctgaaggt gaaatatatt ctcttcaatt agcataaata tgatttacat aagttagcta 480
tacagctatt gagatagtac tttctagtaa acttaaacta ctttttaaac atacattttg 540
tgatgattta acaaaaatat agagaatgat ttgctttatt gtaattgtat ataagtgact 600
ggaaaagcac aaagaaataa agtgggttcg atctgtttac 640
<210> 226
<211> 451
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens DYNC2LI1 3'-UTR
NM_015522.3
<400> 226
aattcatttg atgtagatga acctgttcac tggaaaatta cagcaattta ttaaaacctc 60
agtaagagca aaacaaggaa gaagattcct tatatcttct tgttagacat cttctgtgat 120
tgttatggca tattacacca atcagagaaa tagagtttta aagtagtggt ttgatattga 180
ttttataatc tctgtaaaaa tgaagataaa aagccagatt gtacaaaagt cacctgacaa 240
agactagatg aagctacaac tttaagcaag gggtagagtt gtaatagcct tcaccatcac 300
tctgtatttt acattcattt cgtttctgtc acttattcag tatcttttta tcatctgaca 360
gctaattaaa ttataaagtt gctatgatgg taacacaagt tcttcaaata caataataaa 420
tatcatcatc tggaaaaaaa aaaaaaaaaa a 451
<210> 227
<211> 606
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens VPS8 3'-UTR
NM_001009921, NM_015303
<400> 227
tgactccatg gagcctggcc caggagaacc agagatgatc ccgaggcagc tggggagagg 60
ccccgcctct ggtgggcttg gcctccacca cctcccacgc ttctgagaag aggttccaaa 120
ttgggcttct gtgcccagag cgtccacagc accattccca gtgtagactc ccagtcttct 180
ccacattgct gtcatggcgt cagttcacca gactcattga ttttgttttg cttgttaagc 240
aaaggaatgt cacatacctc tgtccagctt tttaggaaat acatttcgcc tattgcgact 300
ttttccattt accctgaagc ctagaaagta ggtggaactc acacaaatgg cattccagag 360
tctgccatac tccgtctcct ccagctgctg gataatacag aggaacttca acttctacag 420
ggaacagtgg ttggccaggc tgcagtataa ctgaagcatg ccttggagag agcagacact 480
gtgggggcca gggccatctc cctttaatgt gttcatgtta aaacctattt gagtgtaaga 540
cttgcccttt ctaacaataa atgctccgtg tttaagttct gcaggtctca aaaaaaaaaa 600
aaaaaa 606
<210> 228
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ITFG1 3'-UTR
NM_030790
<400> 228
cttgccttta atattacata atggaatggc tgttcacttg attagttgaa acacaaattc 60
tggcttgaaa aaatagggga gattaaatat tatttataaa tgatgtatcc catggtaatt 120
attggaaagt attcaaataa atatggtttg aatatgtcac aaggtctttt tttttaaagc 180
actttgtata taaaaatttg ggttctctat tctgtagtgc tgtacatttt tgttcctttg 240
tggaatgtgt tgcatgtact ccagtgtttg tgtatttata atcttatttg catcatgatg 300
atggaaaaag ttgtgtaaat aaaaataatt aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 360
<210> 229
<211> 215
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CDK5 3'-UTR
NM_004935
<400> 229
gccccgggac ccccggcctc caggctgggg cctggcctat ttaagccccc tcttgagagg 60
ggtgagacag tgggggtgcc tggtgcgctg tgctccagca gtgctgggcc cagccggggt 120
ggggtgcctg agcccgaatt tctcactccc tttgtggact ttatttaatt tcataaattg 180
gctcctttcc cacagtcaaa aaaaaaaaaa aaaaa 215
<210> 230
<211> 146
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C1orf112 3'-UTR
BC091516
<400> 230
aacttatcac taggcagaac tgggtttgat gctttgtcaa ctgaaaatac ttatgtctgt 60
acattttcta acagatataa aacaaatttt gtaaagttga aaaaaaaaaa aaaaaaaaaa 120
aaaaaaaaaa aaaaaaaaaa aaaaaa 146
<210> 231
<211> 239
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens IFT52 3'-UTR
NM_016004
<400> 231
agaccatgcc tcttgaagct ttttctgcct cctgattctc tctttgtaaa ctattttcaa 60
attgtttttc aactccttat caaaattgtt tatacactct ttcctccatg agctctggaa 120
ggtatatgca tcttctgtaa tactcagata ggtataagat ttttcacaaa atccttatgt 180
aagatacatt ccatttttaa aaattaaatg tatggttgca tctgtctttt tatacccta 239
<210> 232
<211> 146
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CLYBL 3'-UTR
CLYBL-003 ENST00000339105
<400> 232
tctgttaaat gaagctgtca tcaggctaaa gggtattgaa gctgcagagg gatcaacttg 60
tgcttgccag aggacgccaa tgaagtttga aacaccaaca atcagagatt ttgtttctgt 120
tcctcattaa atcatgagct tttgtg 146
<210> 233
<211> 477
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens FAM114A2 3'-UTR
FAM114A2-006 ENST00000520667
<400> 233
agaatggaga cgttttgacc tgggacttgt gacggccaag gaatgccacc ttattctggc 60
tactcctgca gaaatgaagg agtggggtta ttttagtata taaaaattca ggcaggagag 120
atggtttaaa gaggaagatt gttgccttca gtgtttgatt gaagtattca ggttctcaca 180
gtattctttc cagttgttgt aattcataaa ttatttgaaa agaaactttt gtagaaagtc 240
caagaataat aactctagat aaagattagt gggacactca ggcaaaaatg ttggtctttc 300
tttgacatgt tgcaaaatgt tatcaatttt gtcatggata taatttgcag cccatggata 360
taactggttg ataagccaga gaaaaataat ttagtgttct aaaattcatg gcatgtgtgg 420
tttattaatg ccatgtactt tctcctttct ggaataaaat ctatggcttt aagaaaa 477
<210> 234
<211> 310
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NUDT7 3'-UTR
NM_001243661
<400> 234
tttactagag caagagacaa agaactattc acgaggattc tgtgtgtgct tattcgtaga 60
acaacaacaa tgccagctgt tggaatttga caggtgtgaa tattttttct gcagtatgta 120
gttagaatcc ttgcctcttt tccagttgcc ttctattgtc tgaaaaagta aaagccattc 180
aaaaatgaaa actatgttca tagtgttgca tattttcacc cacaatatgt taataatatt 240
tttcttacac atataataaa gaatatctgg cacatactag gcccttaata aagatttttt 300
gaatatataa 310
<210> 235
<211> 513
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens AKD1 3'-UTR
NM_001145128
<400> 235
tttacttagg tgatagcagc ctgaatctca agagttatct gaaagtgata gagggaaact 60
gagagaagta gattgaaaat ctgggcctct tggaagtact tttgcctcct gagcaaggta 120
ccatggctgc cagacttcag gtgaactcaa aggtctgcca gccaggaagg agcactctta 180
tggaaacaag ttttaataca attttaaaat gtattgctct ttgcctgaac tttgatgctt 240
taacaaaata aacattctat ttataattcc atatagaaaa gttaagtgac ttatttaata 300
aatgtattat tttccttttt aacattttca gtagaaaagt cagtctctgt taaaattact 360
cattaaatgt tagaaagctt taagacattt aacattgtta taaatgaaac caaaatatgg 420
gttatacatt ttacatacaa aactgtttgt gaactttgtg aacataagat actatcattt 480
tcccaataaa ataaatggat tttgcaacaa ctt 513
<210> 236
<211> 160
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MAGED2 3'-UTR
NM_014599
<400> 236
gattttagat attgttaatc ctgccagtct ttctcttcaa gccagggtgc atcctcagaa 60
acctactcaa cacagcactc taggcagcca ctatcaatca attgaagttg acactctgca 120
ttaaatctat ttgccatttc aaaaaaaaaa aaaaaaaaaa 160
<210> 237
<211> 498
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HRSP12 3'-UTR
HRSP12-001 ENST00000254878
<400> 237
gtgggcccag tgctgtgtag tctggaattg ttaacatttt aatttttaca attgatgtaa 60
catcttaatt aaccttttaa ttttcacaat tgatgacagt gtgagtttga tgaaaatatc 120
tgaagctatt atggaaatac catgtaatag ggagagttga acatgaatat tagagaagga 180
atccagttac ttttttaaat tacacctgtg tgcacctgta ttactgaata taggaaagag 240
atacccatta catagttact cagtaaacaa aagagaaata ccaggtagga aagaagagtt 300
actattcctg agaaataatc aagaacatat ttaatttaaa ctaatgatgt gaactattta 360
gttttgatgt ccgttatgtg attctgcttt tacttgagta aaattaaagt gtttaaattt 420
gagatcaagg agaagatagt ggaacaaaat gttatataga taatattttt ctaatggaaa 480
taaaataggc agatttcc 498
<210> 238
<211> 127
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens STX8 NM_004853 3'-UTR
<400> 238
tggcagtaaa gagaccacca gcagtgacac ctgccaatga cagatgcaag cccaacaccc 60
ttttggtacg caaaacctgc tctcaataaa ttcccccaaa gctctgaaaa aaaaaaaaaa 120
aaaaaaa 127
<210> 239
<211> 386
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ACAT1 3'-UTR
ACAT1-001 ENST00000265838
<400> 239
acaacctctg ctatttaagg agacaaccct atgtgaccag aaggcctgct gtaatcagtg 60
tgactactgt gggtcagctt atattcagat aagctgtttc attttttatt attttctatg 120
ttaactttta aaaatcaaaa tgatgaaatc ccaaaacatt ttgaaattaa aaataaattt 180
cttcttctgc ttttttcttg gtaaccttga aaagtttgat acatttttgc attctgagtc 240
tatacttatc gaaatatggt agaaatacca atgtgtaata ttagtgactt acataagtag 300
ctagaagttt ccatttgtga gaacacattt atatttttga ggattgttaa aggtcaagtg 360
aatgctcttt ataggtaatt tacatt 386
<210> 240
<211> 189
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens IFT74 3'-UTR
IFT74-201 ENST00000433700
<400> 240
gtttaagtcc actgaaagtc tctaaggaag tatcctcttg ctgctaaact tggtacaagt 60
tgactaccaa aaaaaaaaaa agcttacttt tggagtttac ctaaaatttc tgaatgttat 120
aatttttgtg gcctctttta agaatgatat tttaaaatag taaatagttc aataaatggt 180
ttgcatatt 189
<210> 241
<211> 361
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens KIFAP3 3'-UTR
NM_014970
<400> 241
taaagtatct gtttccatgt gtaatctcag cttagaagaa atctgtgtgg gttgggttaa 60
ttttggatct ttgcctaata atgcatgttg atgttattgt gggtctgtgt ttgtttttat 120
ttttatatgt tgttagctgc agattaaccc cagcccctct gtcttctgtt aagtacagtt 180
gatactgaca ttgttcactc atcaaaccac atcttgatgc taagtaacat ttcccatgag 240
ccacaaaact gaatgctgaa aagctactag actggaaaac aaacactgca ttatgtatgt 300
taagtgacta atttaatttc aattaaaaag cgtaaagtga aaatgaaaaa aaaaaaaaaa 360
a 361
<210> 242
<211> 783
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CAPN1 3'-UTR
NM_005186
<400> 242
ggcagggact cggtccccct tgccgtgctc ccctccctcc tcgtctgcca agcctcgcct 60
cctaccacac cacaccaggc caccccagct gcaagtgcct tccttggagc agagaggcag 120
cctcgtcctc ctgtcccctc tcctcccagc caccatcgtt catctgctcc gggcagaact 180
gtgtggcccc tgcctgtgcc agccatgggc tcgggatgga ctccctgggc cccacccatt 240
gccaagccag gaaggcagct ttcgcttgtt cctgcctcgg gacagccccg ggtttcccca 300
gcatcctgat gtgtcccctc tccccacttc agaggccacc cactcagcac caccggcctg 360
gccttgcctg cagactataa actataacca ctagctcgac acagtctgca gtccaggcgt 420
gtggagccgc ctcccggctc ggggaggccc cggggctggg aacgcctgtg ccttcctgcg 480
ccgaagccaa cgccccctct gtccttccct ggccctgctg ccgaccagga gctgcccagc 540
ctgtgggcgg tcggccttcc ctccttcgct ccttttttat attagtgatt ttaaagggga 600
ctcttcaggg acttgtgtac tggttatggg ggtgccagag gcactaggct tggggtgggg 660
aggtcccgtg ttccatatag aggaacccca aataataaaa ggccccacat ctgtctgtga 720
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 780
aaa 783
<210> 243
<211> 88
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens COX11 3'-UTR
NM_001162861
<400> 243
agagttggca cctttgatgt ggtagtgagc tgatcatcca ctttcttcta aaataaagag 60
aagaaaatgg ccagtaaaaa aaaaaaaa 88
<210> 244
<211> 77
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GLT8D4 3'-UTR
BC127733
<400> 244
atattttgtc ttgttgcaag tcaattaggt gtcttgtgaa caaggaaata ctaatctcta 60
agctgcctgg gtctttt 77
<210> 245
<211> 215
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GLT8D4 3'-UTR
NM_001080393
<400> 245
atattttgtc ttgttgcaag tcaattaggt gtcttgtgac caaggaaata ctaatctcta 60
agctgcctgg gtctttttgt gtgaatattt aatggtgctc catgactgtt gagttttaaa 120
aacctcgtta aattttgcca aatcagttgc ccccaaaagg gaatatgctt ttccttattt 180
ttttttctaa aatgctattt atctctaagg aaaaa 215
<210> 246
<211> 140
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HACL1 3'-UTR
NM_012260
<400> 246
ataaagacgc cagttggtgg tcttgagttt tctctttctt gcaagatgaa attttatttt 60
ccacagcaaa attactctac tgttaaaatt gtgcaaaata aaataaacat ttaaaatgac 120
attttacagt aaaaaaaaaa 140
<210> 247
<211> 273
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens IFT88 3'-UTR
NM_175605
<400> 247
tattcacttt aatatttatt aaaggaaaga aattgcctta tgagatcatc ctcatgttaa 60
accttggatt aaatatctaa cctgtaatta ttttttttca ctgtcaaaac ttaagtaagt 120
gtattctatt ctgtatgtat gcatttaagt tgtttttttc ttttaaggaa taaaaacagg 180
taaaactaat actttaggcc agtgacttcc ttagcttttt gaaaacattg acacacagga 240
agaaataaat ttcataacac aaaaaaaaaa aaa 273
<210> 248
<211> 187
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens IFT88 3'-UTR
IFT88-001 ENST00000351808
<400> 248
tattcacttt aatatttatt aaaggaaaga aattgcctta tgagatcatc ctcatgttaa 60
accttggatt aaatatctaa cctgtaatta ttttttttca ctgtcaaaac ttaagtaagt 120
gtattctatt ctgtatgtat gcatttaagt tgtttttttc ttttaaggaa taaaaacagg 180
taaaact 187
<210> 249
<211> 150
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NDUFB3 3'-UTR
NM_002491
<400> 249
agataatacc tggaagcatc atagtggttt cttaactctc caaaataaga tttcttctct 60
gtagcctact tgtctggttt atcccttaca gaatattagt aagatttaat caattaaaat 120
atatatatat gccaaaaaaa aaaaaaaaaa 150
<210> 250
<211> 589
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ANO10 3'-UTR
NM_018075
<400> 250
gtgcccagcg tgcccagctg ccctgttggc agaggcctgt gtctgtgcca cacctgccac 60
ggtggcaggg ggggtacccg gggcagcatc gtggctcctg aacccagacc caatgcttag 120
ccaaacgaag tggctcccat gtggcaagca cccttctcag tttcgcagtg gcttggctcg 180
ggatccttgg cagttccccc agccccaccc tgtctgctcc ttcccagttc cttcccgggc 240
cccacacgct gctccagctg ccaactttgc tgcagagcca ctgccgccct tgagcctctc 300
accatgagtg agccaccagc tctccacgtt cccctcatag cagtgtcact cccaacccca 360
ccatggccca gggacccgtg gacaggttgg ggatggggtg tgtgcccact gtgctcatca 420
caggagcctc agttgagagt gagcggggta cagtaaggca gtgcttccca cactggacct 480
ctttcctggt tctcttttgc aatacattaa cagacccttt atcaacataa acaatagtaa 540
ctgagctatt aaaggcaacc tctctgactc cttctgccta aaaaaaaaa 589
<210> 251
<211> 263
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ANO10 3'-UTR
ANO10-005 ENST00000451430
<400> 251
gtgcccagcg tgcccagctg ccctgttggc agaggcctgt gtctgtgcca cacctgccac 60
ggtggcaggg ggggtacccg gggcagcatc gtggctcctg aacccagacc caatgcttag 120
ccaaacgaag tggctcccat gtggcaagca cccttctcag tttcgcagtg gcttggctcg 180
ggatccttgg cagttccccc agccccaccc tgtctgctcc ttcccagttc cttcccgggc 240
cccacacgct gctccagctg cca 263
<210> 252
<211> 486
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ARL6 3'-UTR
NM_032146
<400> 252
aaagataata gttggaaacc tcagcaattt tcaattcaag gaatctatct aagacaaata 60
gaatacattt tgtaaaagat gtttatgcat caaaaaatat aattttctgc ttgcatttat 120
ggactctgac ctttttaaga acataggact tcaggtatgc taatttggcc attaattatt 180
taaaaactaa atattccctc aaaagggctc cctagaatta tcaagttctt agtgaaggtc 240
tacatttgat tgtacgtaga atgtttaaaa gtcagttata agccatctca tcccatcata 300
atttatgata tgtttaatat attttatttt ttaattgtct ttttaaaaaa tttagtttat 360
gactttgcag tatgaattgt gcttgtgaaa aagaacttta aatatttata agggaccatg 420
ggtaattaat atatattcaa tttttactat gtgtcactgt caataaaatg taaaatataa 480
tgtgcc 486
<210> 253
<211> 719
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LPCAT3 3'-UTR
NM_005768
<400> 253
tccatttccc tggtggcctg tgcgggactg gtgcagaaac tactcgtctc ccttttcaca 60
gcactccttt gccccagagc agagaatgga aaagccaggg aggtggaaga tcgatgcttc 120
cagctgtgcc tctgctgcca gccaagtctt catttggggc caaaggggaa actttttttt 180
ggagaaggcg tcttgctttg tcacccacgc tggaatgcag tggcgggatc tcagctcacc 240
gcaacctcca cctcctgggt tcaagtgatt ttcctgcctc agcctcccaa gtagctggga 300
atacaggcac gccaccatgc ccagctaatt tttgtatttt cagtagaaac gggatttcac 360
cacgttggcc aggctggtct cgaactcctg accgcaagtg atccacccgc ctccgcctcc 420
caaagtgctg ggattacagg cgtgagccac cgtgcccggc ccaaagggga aactcttgtg 480
ggaggagcag aggggctcac atctcccctc tgattccccc atgcacattg ccttatctct 540
ccccatctag ccaggaatct attgtgtttt tcttctgcca atttactatg attgtgtatg 600
tgccgctacc accacccccc ccatgggggg gtggagaggg gtgcaaggcc ctgcctgctc 660
cactttttct accttggaac tgtattagat aaaatcactt ctgtttgttc agtttttca 719
<210> 254
<211> 154
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ABCD3 3'-UTR
NM_001122674
<400> 254
aaaccagaca aatgtattgg ccaggcgtgg tggctcatgc ctgtaatccc agcactttgg 60
gaggctgaga tgggaggatc gcttgaatcc aggagttcga gacaagcctg gacaaaaagc 120
gagacccgct tctttaaaaa ataataataa aaca 154
<210> 255
<211> 448
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens COPG2 3'-UTR
NM_012133
<400> 255
atgcttactg gacaagagga aactgatgca cactacatgg tcagtgggct tttaggctag 60
tggcatcagt ttcccagaat cagacttttg aagatgaatg actttggaga agcaaattaa 120
acatttggcc ctgagccagc agatcaagca aatgtctatc tttgcgcatg ggttgttttt 180
tttttttttc tttttattct acttggtcag ctttgggacg atagtgcagc tttgggtgat 240
cttgaaaatc aaatactatc ctatactcca gctgcttaac ttcattttat tctttaatgt 300
gtacctgaaa gctcctggca atgctggaaa atttttatcc cagaggggtg ggggggaggg 360
gggaggggaa gccagagtcc acttttgtca caattcattt ttattaatag aaaataaaca 420
cttattccag tttcaaaaaa aaaaaaaa 448
<210> 256
<211> 176
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MIPEP 3'-UTR
NM_005932
<400> 256
aagaaacact ctacacctct taaatcaagg tcatgtagat aatgactttg ttataaatgc 60
tacagctgtg agagcttgtt tctgatttca ttgttcgctt ctgtaattct gaaaaacttt 120
aaactggtag aacttggaat aaataatttg ttttaattaa aaaaaaaaaa aaaaaa 176
<210> 257
<211> 478
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LEPR 3'-UTR
NM_002303
<400> 257
tttcactgaa gaaaccttca gatttgtgtt ataatgggta atataaagtg taatagatta 60
tagttgtggg tgggagagag aaaagaaacc agagtcaaat ttgaaaataa ttgttccaaa 120
tgaatgttgt ctgtttgttc tctcttagta acatagacaa aaaatttgag aaagccttca 180
taagcctacc aatgtagaca cgctcttcta ttttattccc aagctctagt gggaaggtcc 240
cttgtttcca gctagaaata agcccaacag acaccatctt ttgtgagatg taattgtttt 300
ttcagagggc gtgttgtttt acctcaagtt tttgttttgt accaacacac acacacacac 360
acattcttaa cacatgtcct tgtgtgtttt gagagtatat tatgtattta tattttgtgc 420
tatcagactg taggatttga agtaggactt tcctaaatgt ttaagataaa cagaattc 478
<210> 258
<211> 64
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LEPR 3'-UTR
NM_001198688
<400> 258
gaaatgcttg tagactacgt cctacctcgc tgccgcacct gctctccctg aggtgtgcac 60
aatg 64
<210> 259
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C2orf76 3'-UTR
NM_001017927
<400> 259
aaacatctcg agggcttcct ttttgcat 28
<210> 260
<211> 244
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C2orf76 3'-UTR
C2orf76-001 ENST00000409466
<400> 260
aaacatctcg agggcttcct ttttgcatac ctgtattaag ctctttattc cactgctgaa 60
tttttgaaat tgacaaacaa atcttaaaaa attaatccca ggctatactc tttgagctaa 120
aatctggtta tttctttctc ttcaggtctt tccttctctc tttctttttc tttgttgttg 180
taaaataata tattatgaga aaaacatttg atctttttaa agggaaataa attgttatta 240
aaaa 244
<210> 261
<211> 267
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ABCA6 3'-UTR
NM_080284.2
<400> 261
aacctcaaac ctagtaattt tttgttgatc tcctataaac tcatgtttta tgtaataatt 60
aatagtatgt ttaattttaa agatcattta aaattaacat caggtatatt ttgtaaattt 120
agttaacaaa tacataaatt ttaaaattat tcttcctctc aaacataggg gtgatagcaa 180
acctgtgata aaggcaatac aaaatattag taaagtcacc caaagagtca ggcactgggt 240
attgtggaaa taaaactata taaactt 267
<210> 262
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LY96 3'-UTR
NM_015364.4
<400> 262
aataaattga gtatttaaaa aaaaaaaaaa aaaaaaaaaa aaaaa 45
<210> 263
<211> 755
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CROT 3'-UTR
NM_ 001243745.1
<400> 263
tgatgatgtt taaagaatga taaataaaaa gtgcatagtt tttattttta aattattgct 60
gtaaaaattt ttacagttat tattgttatt ttcataatcc aaaagaagga atgaatcact 120
taactttggg agttttcagt gggtggattc gggaacttgt taaaatgcag atttgctggg 180
ataagtgatt ctgattcaca tggctggaat gaggcccaga gattcttatt ttaacaatca 240
cttcatgtgg tttggctgca ggtaatctgt agaccatgct gaaggaaaac attttgtcca 300
ggtgactagc ttgaaaaatc agaaacacta aaatagacat gtcacatagg tggcatagaa 360
atattttcgt agtacaatgg agaaagggaa tcattaaaaa tcagagtgga gaatggttat 420
gtatattgta tatttcagtt agataaattg aggaagctag tataataatt attgaaggtc 480
tcaataattt tccacaaaat tctttaactt cttcagctca accatttctg tacttctcta 540
ctatgaatca gaggatgagg ttgtataatt caaaagcatt gccttagtct agaaataatt 600
attgtaccta tcatttagtt ttagaaataa aaagcaagct gatttttttt gatgaaccat 660
ttatatctgt gatggaataa taaaatttca cacttccgga ttcctttgtt ctcaattttg 720
agccttgagt tgttttaatt aaagaggggt aaagg 755
<210> 264
<211> 911
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ENPP5 3'-UTR
ENPP5-002 ENST00000230565
<400> 264
tgttactttg aagtggattt gcatattgaa gtggagattc cataattatg tcagtgttta 60
aaggtttcaa attctgggaa accagttcca aacatttgca gaaaccatta agcagttaca 120
tatttaggta tacacacaca cacacacaca catacacaca cacggaccaa aatacttaca 180
cctgcaaagg aataaagatg tgagagtatg tctccattgt tcactgtagc atagggatag 240
ataagatcct gctttatttg gacttggcgc agataatgta tatatttagc aactttgcac 300
tatgtaaagt accttatgta ttgcacttta aatttctctc ctgatgggta ctttaatttg 360
aaatgcactt tatgcacagt tatgtcttat aacttgattg aaaatgacaa ctttttgcac 420
ccatgtcaca gaatacttgt tacgcattgt tcaaactgaa ggaaatttct aataatcccg 480
aataatgaac gtagaaatct atctccataa attgagagaa gaagaaggtg ataagtgttg 540
aaaattaaat gtgataacct ttgaaccttg aattttggag atgtattccc aacagcagaa 600
tgcaactgtg ggcatttctt gtcttatttc tttccagaga acgtggtttt catttatttt 660
tccctcaaaa gagagtcaaa tactgacaga ttcgttctaa atatattgtt tctgtcataa 720
aattattgtg atttcctgat gagtcatatt actgtgattt tcataataat gaagacacca 780
tgaatatact ttttttctat atagttcagc aatggcctga atagaagcaa ccaggcacca 840
tctcagcaat gttttctctt gtttgtaatt atttgctcct ttgaaaatta aatcactatt 900
aattacatta a 911
<210> 265
<211> 300
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SERPINB7 3'-UTR
SERPINB7-203 ENST00000546027
<400> 265
aaatccaatt ggtttctgtt atagcagtcc ccacaacatc aaagaaccac cacaagtcaa 60
tagatttgag tttaattgga aaaatgtggt gtttcctttg agtttatttc ttcctaacat 120
tggtcagcag atgacactgg tgacttgacc cttcctagac acctggttga ttgtcctgat 180
ccctgctctt agcattctac caccatgtgt ctcacccatt tctaatttca ttgtctttct 240
tcccacgctc atttctatca ttctccccca tgacccgtct ggaaattatg gagagtgctc 300
<210> 266
<211> 509
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TCP11L2 3'-UTR
NM_152772
<400> 266
agaagaactg acattggacg agagattgga aatccagtac tttggtatcc agtccacttc 60
cattgatggc attagagatc cagcacattc tcagtactgt ggtgcagtat tagcccaaat 120
ctgtgtaatg ggtaatatta gcattacaga agacacacac atcacataga ccctcagaag 180
acgtaaacat cacatagacc ctatttgtgc atcattttca agtttaaaac agatatttgt 240
aatgaacaga aaacaatttg taattaatta tattacctat ataatacttg taaatgtttt 300
cttaaccatt tatatttggc ttatgacatt taacccctaa ggagttgttt ttctcacttg 360
ttattatcaa acctaatggt ttttaatttt ggtacaactc cttaaagggt tgaaggttgt 420
gacaataact gagggaactg atgttctgaa taaatgatgt gaagtaaaca caattgtatt 480
tgaaaaaaaa aaaaaaaaaa aaaaaaaaa 509
<210> 267
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens IRAK1BP1 3'-UTR
NM_001010844
<400> 267
aattccaaac aaattatatt gtacttgtat ctttttacct atttttatac tttttataat 60
gtttacgttt gtcctgaata tata 84
<210> 268
<211> 338
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CDKL2 3'-UTR
CDKL2-002 ENST00000307465
<400> 268
gaaccatttt ggttctgaac tggatgatgc tcttgcactt gagatgacat cttcttgcag 60
caagagtgct gatatcccaa gaggagagat tcatggtttt gatcatttcc ttctgaactg 120
cctgcatttt ctgaggaagg ccttctagaa gaaggaaaga caaagacttc caaatgtttc 180
aaaggaagat tgaacaaatg gccctcccca actgttatcc cattaccttt cacgtccacc 240
gatgctattt caagacatat ccagtggaat aacagtgata tggttcttgt tacatgaatg 300
tgtatttact gttaggagat tgtatatttt aagttacc 338
<210> 269
<211> 367
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GHR 3'-UTR
GHR-202 ENST00000537449
<400> 269
cctttctttg gtttcccaag agctacgtat ttaatagcaa agaattgact ggggcaataa 60
cgtttaagcc aaaacaatgt ttaaaccttt tttgggggag tgacaggatg gggtatggat 120
tctaaaatgc cttttcccaa aatgttgaaa tatgatgtta aaaaaataag aagaatgctt 180
aatcagatag atattcctat tgtgcaatgt aaatatttta aagaattgtg tcagactgtt 240
tagtagcagt gattgtctta atattgtggg tgttaatttt tgatactaag cattgaatgg 300
ctatgttttt aatgtatagt aaatcacgct ttttgaaaaa gcgaaaaaat caggtggctt 360
ttgcggt 367
<210> 270
<211> 406
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens KIAA1107 3'-UTR
NM_015237
<400> 270
gtgttaacat tttggaaaaa tttatgccac tcctttattt tttgatgcct atattatatc 60
caaatgataa ttgcattagc cggatataaa ctttctttaa tattgagtct ttccaattta 120
atgaggtaaa catagtttat ttattaatat atcacatata gaaaaatgtt tttctaaagt 180
ttttgagcat gttttctcta attattagag aaattagaag acttataagg aaaccctagc 240
ttcagttttc ctttcctagc tgatgatttg ttcacttaat cattattcaa gaatttaaaa 300
tgtgaatgca gaagtagatc agtcccttta ctttttgctc tgcatagggt aacatagtaa 360
tttaacaata aaaacttacc gtgcttgtgt ccaaaaaaaa aaaaaa 406
<210> 271
<211> 301
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens RPS6KA6 3'-UTR
RPS6KA6-001 ENST00000262752
<400> 271
gatttgtggt gttcctaggc caaactggat gaagatgaaa ttaaatgtgt ggcttttttc 60
ctattcttat caaaggcatc gttgtctgct aaattacttg aatattaagt aatattaaat 120
ccccattttt aggggaagtg agatttaaaa aaccattcac aggtccacaa tattcatact 180
atgtgtttgc agtagtgttc aagtgtttat ttaagcatat aattggtgtc caccaggtcc 240
tcacaacttc tctgcacaca agcttctaaa attcctttca aataaagtta ctttaatatt 300
t 301
<210> 272
<211> 777
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CLGN 3'-UTR
NM_004362, NM_001130675
<400> 272
actagattga aatattttta attcccgaga gggatgtttg gcattgtaaa aatcagcatg 60
ccagacctga actttaatca gtctgcacat cctgtttcta atatctagca acattatatt 120
ctttcagaca tttattttag tccttcattt cagaggaaaa agaagcaact ttgaagttac 180
ctcatctttg aatttagaat aaaagtggca cattacatat cggatctaag agattaatac 240
cattagaagt tacacagttt tagttgtttg gagatagttt tggtttgtac agaacaaaat 300
aatatgtagc agcttcattg ctattggaaa aatcagttat tggaatttcc acttaaatgg 360
ctatacaaca atataactgg tagttctata ataaaaatga gcatatgttc tgttgtgaag 420
agctaaatgc aataaagttt ctgtatggtt gtttgattct atcaacaatt gaaagtgttg 480
tatatgaccc acatttacct agtttgtgtc aaattatagt tacagtgagt tgtttgctta 540
aattatagat tcctttaagg acatgccttg ttcataaaat cactggatta tattgcagca 600
tattttacat ttgaatacaa ggataatggg ttttatcaaa acaaaatgat gtacagattt 660
tttttcaagt ttttatagtt gctttatgcc agagtggttt accccattca caaaatttct 720
tatgcataca ttgctattga aaataaaatt taaatatttt ttcatcctga aaaaaaa 777
<210> 273
<211> 466
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CLGN-202 3'-UTR
NM_004362, NM_001130675
ENST00000325617
<400> 273
actagattga aatattttta attcccgaga gggatgtttg gcattgtaaa aatcagcatg 60
ccagacctga actttaatca gtctgcacat cctgtttcta atatctagca acattatatt 120
ctttcagaca tttattttag tccttcattt cagaggaaaa agaagcaact ttgaagttac 180
ctcatctttg aatttagaat aaaagtggca cattacatat cggatctaag agattaatac 240
cattagaagt tacacagttt tagttgtttg gagatagttt tggtttgtac agaacaaaat 300
aatatgtagc agcttcattg ctattggaaa aatcagttat tggaatttcc acttaaatgg 360
ctatacaaca atataactgg tagttctata ataaaaatga gcatatgttc tgttgtgaag 420
agctaaatgc aataaagttt ctgtatggtt gtttgattct atcaac 466
<210> 274
<211> 423
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TMEM45A 3'-UTR
NM_018004
<400> 274
ctttgatgag cttccagttt ttctagataa accttttctt ttttacattg ttcttggttt 60
tgtttctcga tcttttgttt ggagaacagc tggctaagga tgactctaag tgtactgttt 120
gcatttccaa tttggttaaa gtatttgaat ttaaatattt tctttttagc tttgaaaata 180
ttttgggtga tactttcatt ttgcacatca tgcacatcat ggtattcagg ggctagagtg 240
atttttttcc agattatcta aagttggatg cccacactat gaaagaaata tttgttttat 300
ttgccttata gatatgctca aggttactgg gcttgctact atttgtaact ccttgaccat 360
ggaattatac ttgtttatct tgttgctgca atgagaaata aatgaatgta tgtattttgg 420
tgc 423
<210> 275
<211> 152
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TBC1D8B 3'-UTR
TBC1D8B-007 ENST00000276175
<400> 275
atccctagga attgcctatc atagacaagt ttactaacat tcctgtagct gtcagtttga 60
ttcctgtgag tagggctcag ggatttatct tgttaccaat gtgtctgaag gccaaaatat 120
atatccagaa gcacaatgca tcattccttt gt 152
<210> 276
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ACP6 3'-UTR
NM_016361
<400> 276
ctgatttata aaagcaggat gtgttgattt taaaataaag tgcctttata caatgccaaa 60
aaaaaaaaaa aaaaaaaaaa a 81
<210> 277
<211> 111
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens RP6-213H19.1 3'-UTR
MST4-003 (RBM4B-003 ENST00000496850)
<400> 277
gaaacttatt attggcttct gtttcatatg gacccagaga gccccaccaa acctacgtca 60
agattaacaa tgcttaaccc atgagctcca tgtgcctttt ggatctttgc a 111
<210> 278
<211> 138
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SNRPN 3'-UTR
NM_022807
<400> 278
catactgttg atccatctca gtcacttttt cccctgcaat gcgtcttgtg aaattgtgta 60
gagtgtttgt gagctttttg ttccctcatt ctgcattaat aatagctaat aataaatgca 120
tagagcaatt aaactgtg 138
<210> 279
<211> 425
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GLRB 3'-UTR
GLRB-005 ENST00000512619
<400> 279
gatctaatga cttcagcatt gttggaagct taccaagaga ttttgaacta tccaattatg 60
actgctatgg aaaacccatt gaagttaaca acggacttgg gaaatctcag gctaagaaca 120
acaagaagcc tccccctgcg aaacctgtta ttccaacagc agcaaagcga attgatcttt 180
atgcaagagc attgtttcct ttctgcttct tgttcttcaa tgttatatat tggtctatat 240
atttatgata aatcttttcc atttgtacaa aataaaattc catttcattg tgacctactc 300
ctttcataaa tgccaatctg tgagaacttt tgaattttca tagcaacatt gcattttgga 360
tgccatttga ttgtaataaa actgtggcac cttaattttg aatggcagca tgatcatgta 420
atatc 425
<210> 280
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HERC6 3'-UTR
NM_017912
<400> 280
tcacctctga gagactcagg gtgggctttc tcacacttgg atccttctgt tcttccttac 60
acctaaataa tacaagagat taatgaatag tggttagaag tagttgaggg agagattggg 120
ggaatgggga gatgatgatg atggtcaaag ggtgcaaaat ctcacacaag actgaggcag 180
gagaataggg tacagagata gggatctaag gatgacttgg acacactccc tggcactgaa 240
gagtctgaac actggcctgt gattggtcca ttccaggacc ttcatttgca taaggtatca 300
aaccacatca gcctctgatt ggccatgggc cagacctgca ctctggccaa tgattggttc 360
attccaggac attcatttgc ataaggagtc aaaccacacc agtcttggat tggctgtgag 420
ccaattcacc tcagtctcta attggctgtg agtcagtctt tcatttacat agggtgtaac 480
catcaagaaa cctctacagg gtacttaagc cccagaagat tttgctacca gggctcttga 540
gccacttgct ctagcccact cccaccctgt ggaatgtact ttcacttttg ctgcttcact 600
gccttgtgct ccaataaatc cactccttca ccacccaaaa aaaaaaaaaa a 651
<210> 281
<211> 264
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CFH 3'-UTR
NM_000186
<400> 281
aatcaatcat aaagtgcaca cctttattca gaactttagt attaaatcag ttctcaattt 60
cattttttat gtattgtttt actccttttt attcatacgt aaaattttgg attaatttgt 120
gaaaatgtaa ttataagctg agaccggtgg ctctcttctt aaaagcacca tattaaatcc 180
tggaaaacta aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 240
aaaaaaaaaa aaaaaaaaaa aaaa 264
<210> 282
<211> 401
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GALC 3'-UTR
GALC-002 ENST00000393569
<400> 282
tacttaacag ggcatcatag aatactctgg attttcttcc cttctttttg gttttggttc 60
agagccaatt cttgtttcat tggaacagta tatgaggctt ttgagactaa aaataatgaa 120
gagtaaaagg ggagagaaat ttatttttaa tttaccctgt ggaagatttt attagaatta 180
attccaaggg gaaaactggt gaatctttaa cattacctgg tgtgttccct aacattcaaa 240
ctgtgcattg gccataccct taggagtggt ttgagtagta cagacctcga agccttgctg 300
ctaacactga ggtagctctc ttcatcttat ttgcaagcgg tcctgtagat ggcagtaact 360
tgatcatcac tgagatgtat ttatgcatgc tgaccgtgtg t 401
<210> 283
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GALC 3'-UTR
GALC-005 ENST00000393568
<400> 283
tacttaacag ggcatcatag aatactctgg attttcttcc cttctttttg g 51
<210> 284
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PDE1A 3'-UTR
NM_001003683.2
<400> 284
acacctttaa gtaaaacctc gtgcatggtg gcagctctaa tttgaccaaa agacttggag 60
attttgatta tgcttgctgg aaatctaccc tgtcctgtgt gagacaggaa atctattttt 120
gcagattgct caataagcat catgagccac ataaataaca gctgtaaact ccttaattca 180
ccgggctcaa ctgctaccga acagattcat ctagtggcta catcagcacc ttgtgctttc 240
agatatctgt ttcaatggca ttttgtggca tttgtcttta ccgagtgcca ataaattttc 300
tttgagcagc taattgctaa ttttgtcatt tctacaataa agcttggtcc acctgttttc 360
<210> 285
<211> 308
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PDE1A 3'-UTR
PDE1A-003 ENST00000410103
<400> 285
acacctttaa gtaaaacctc gtgcatggtg gcagctctaa tttgaccaaa agacttggag 60
attttgatta tgcttgctgg aaatctaccc tgtcctgtgt gagacaggaa atctattttt 120
gcagattgct caataagcat catgagccac ataaataaca gctgtaaact ccttaattca 180
ccgggctcaa ctgctaccga acagattcat ctagtggcta catcagcacc ttgtgctttc 240
agatatctgt ttcaatggca ttttgtggca tttgtcttta ccgagtgcca ataaattttc 300
tttgagca 308
<210> 286
<211> 855
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GSTM5 3'-UTR
NM_000851
<400> 286
ggcccagtga tgccagaaga tgggagggag gagccaacct tgctgcctgc gaccctggag 60
gacagcctga ctccctggac ctgccttctt cctttttcct tctttctact ctcttctctt 120
ccccaaggcc tcattggctt cctttcttct aacatcatcc ctccccgcat cgaggctctt 180
taaagcttca gctccccact gtcctccatc aaagtccccc tcctaacgtc ttcctttccc 240
tgcactaacg ccaacctgac tgcttttcct gtcagtgctt ttctcttctt tgagaagcca 300
gactgatctc tgagctccct agcactgtcc tcaaagacca tctgtatgcc ctgctccctt 360
tgctgggtcc ctaccccagc tccgtgtgat gcccagtaaa gcctgaacca tgcctgccat 420
gtcttgtctt attccctgag gctcccttga ctcaggactg tgctcgaatt gtgggtggtt 480
ttttgtcttc tgttgtccac agccagagct tagtggatgg gtgtgtgtgt gtgtgtgttg 540
ggggtggtga tcaggcaggt tcataaattt ccttggtcat ttctgccctc tagccacatc 600
cctctgttcc tcactgtggg gattactaca gaaaggtgct ctgtgccaag ttcctcactc 660
attcgcgctc ctgtaggccg tctagaactg gcatggttca aagaggggct aggctgatgg 720
ggaagggggc tgagcagctc ccaggcagac tgccttcttt caccctgtcc tgatagactt 780
ccctgatcta gatatccttc gtcatgacac ttctcaataa aacgtatccc accgtattgt 840
aaaaaaaaaa aaaaa 855
<210> 287
<211> 419
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CADPS2 3'-UTR
CADPS2-002 ENST00000412584
<400> 287
tatcacacag ctttgcagaa ggaaggaaga ccttgatcga cattgttttt tattttttta 60
accttgtcct tgtaattaca ttcattgttt gttttggcca aataaaaatg cttgtatttc 120
tttaaaaagt aagcctgaat gtagagtaaa aggggaaatg ccaagatttt ggggtttttt 180
tgtttccttt ttttgtttgt ttgtttgttt gtttttttgg agaagagcat cctcttttgt 240
gtagtttgac ctaaaaatga accttggctc tgcttgtgat cagaacatga actttttttt 300
ttaaagaaga tttgagcatt tttctgtaat cacatcaaaa tgatgttttc tgtgtaaagc 360
gagatacata tttctcataa tgcagcattg tgagaagtca gttcggacca ctgcaccaa 419
<210> 288
<211> 162
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CADPS2 3'-UTR
CADPS2-001 ENST00000449022
<400> 288
tatcacacag ctttgcagaa ggaaggaaga ccttgatcga cattgttttt tattttttta 60
accttgtcct tgtaattaca ttcattgttt gttttggcca aataaaaatg cttgtatttc 120
tttaaaaagt aagcctgaat gtagagtaaa aggggaaatg cc 162
<210> 289
<211> 247
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens AASS 3'-UTR
AASS-001 ENST00000417368
<400> 289
ttgggaatta tattttgttt ttttcttccc aggcaataca cctctgaaca tgtgtgtgat 60
aaatgggttt gctaatgtgc tgttttaaag tataaagcat aatatgtttt ggttaacaca 120
atgtactttt tgaactataa atctttattt taatatggaa atgtttggaa caggagatgc 180
aagccactaa cagagaactt taataattct accctgtatt ttataaatac gtatgtgaaa 240
gtgatga 247
<210> 290
<211> 695
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TRIM6-TRIM34 3'-UTR
NM_001003819
<400> 290
attttctcat ttcttcacct acaacccttt gtcttgactt atctcctgca actgactcat 60
ctgcaacatt cacaccattg cttccttgtg gtttcccttc tttagaactt ttactcatcc 120
ttgagatgta tggtgtattt ggcttgagtt atgagagatg cttatttatt catttactct 180
ttttcatatt ttcagagaaa gttacctaat ccctcctaaa gacacagcag tatgggtata 240
acatccttgc cttcccattt atccatgttt cactttatca ctgatatgaa gaggcccaaa 300
gcctgttagc caccatccat gctacctagg tagtccatag gaaccacccc catgaccacc 360
accaacatca actaaaggtt cttggagggt atgtcagtgt gttgctcagg ataccccagg 420
tacatcaagg aatcaaggag aggaaaatat gagcaatatg tgtattcaga gtgaagattt 480
tatgtccaga gtatttgagc tcaaaccttg cctgttgttt tctaatcatg atgaatactt 540
tctcagtttc tttttcctga aatataaatt gggatttaag actgtaccta actattaaga 600
tcactgtgta aaactaagtg tctctaaatg taatgcatcg atttagtgtc tggaacataa 660
taaatatttg ctctcatgat tgctaaaaaa aaaaa 695
<210> 291
<211> 918
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SEPP1 3'-UTR
NM_005410
<400> 291
atatttaaaa taggacatac tccccaattt agtctagaca caatttcatt tccagcattt 60
ttataaacta ccaaattagt gaaccaaaaa tagaaattag atttgtgcaa acatggagaa 120
atctactgaa ttggcttcca gattttaaat tttatgtcat agaaatattg actcaaacca 180
tattttttat gatggagcaa ctgaaaggtg attgcagctt ttggttaata tgtctttttt 240
tttctttttc cagtgttcta tttgctttaa tgagaataga aacgtaaact atgacctagg 300
ggtttctgtt ggataattag cagtttagaa tggaggaaga acaacaaaga catgctttcc 360
atttttttct ttacttatct ctcaaaacaa tattactttg tcttttcaat cttctacttt 420
taactaataa aataagtgga ttttgtattt taagatccag aaatacttaa cacgtgaata 480
ttttgctaaa aaagcatata taactatttt aaatatccat ttatcttttg tatatctaag 540
actcatcctg atttttacta tcacacatga ataaagcctt tgtatctttc tttctctaat 600
gttgtatcat actcttctaa aacttgagtg gctgtcttaa aagatataag gggaaagata 660
atattgtctg tctctatatt gcttagtaag tatttccata gtcaatgatg gtttaatagg 720
taaaccaaac cctataaacc tgacctcctt tatggttaat actattaagc aagaatgcag 780
tacagaattg gatacagtac ggatttgtcc aaataaattc aataaaaacc ttaaagctga 840
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 900
aaaaaaaaaa aaaaaaaa 918
<210> 292
<211> 589
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SEPP1 3'-UTR
SEPP1-004 ENST00000506577
<400> 292
atatttaaaa taggacatac tccccaattt agtctagaca caatttcatt tccagcattt 60
ttataaacta ccaaattagt gaaccaaaaa tagaaattag atttgtgcaa acatggagaa 120
atctactgaa ttggcttcca gattttaaat tttatgtcat agaaatattg actcaaacca 180
tattttttat gatggagcaa ctgaaaggtg attgcagctt ttggttaata tgtctttttt 240
tttctttttc cagtgttcta tttgctttaa tgagaataga aacgtaaact atgacctagg 300
ggtttctgtt ggataattag cagtttagaa tggaggaaga acaacaaaga catgctttcc 360
atttttttct ttacttatct ctcaaaacaa tattactttg tcttttcaat cttctacttt 420
taactaataa aataagtgga ttttgtattt taagatccag aaatacttaa cacgtgaata 480
ttttgctaaa aaagcatata taactatttt aaatatccat ttatcttttg tatatctaag 540
actcatcctg atttttacta tcacacatga ataaagcctt tgtatcttt 589
<210> 293
<211> 60
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PDE5A 3'-UTR
PDE5A-002 ENST00000264805
<400> 293
gtggcctatt tcatgcagag ttgaagttta cagagatggt gtgttctgca atatgcctag 60
<210> 294
<211> 422
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SATB1 3'-UTR
SATB1-004 ENST00000417717
<400> 294
gataaaagta tttgtttcgt tcaacagtgc cactggtatt tactaacaaa atgaaaagtc 60
caccttgtct tctctcagaa aacctttgtt gttcattgtt tggccaatga atcttcaaaa 120
acttgcacaa acagaaaagt tggaaaagga taatacagac tgcactaaat gttttcctct 180
gttttacaaa ctgcttggca gccccaggtg aagcatcaag gattgtttgg tattaaaatt 240
tgtgttcacg ggatgcacca aagtgtgtac cccgtaagca tgaaaccagt gttttttgtt 300
ttttttttag ttcttattcc ggagcctcaa acaagcatta taccttctgt gattatgatt 360
tcctctccta taattatttc tgtagcactc cacactgatc tttggaaact tgccccttat 420
tt 422
<210> 295
<211> 981
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CCPG1 3'-UTR
CCPG1-002 ENST00000442196
<400> 295
ttcacaattg agttaaatta gacaactgta agagaaaaat ttatgctttg tataatgttt 60
ggtattgaaa ctaatgaaat taccaagatg acaatgtctt ttcttttgtt tctaagtatc 120
agtttgataa ctttatatta ttcctcagaa gcattagtta aaagtctact aacctgcatt 180
ttcctgtagt ttagcttcgt tgaatttttt ttgacactgg aaatgttcaa ctgtagtttt 240
attaaggaag ccaggcatgc aacagatttt gtgcatgaaa tgagacttcc tttcagtgta 300
agagcttaaa gcaagctcag tcatacatga caaagtgtaa ttaacactga tgtttgtgtt 360
aaatttgcag cagagcttga gaaaagtaca ttgttctgga atttcatcat taacatttta 420
taatcttaca ctcacttctt gtctttttgt gggttcaaga gccctctgac ttgtgaagaa 480
tttgctgccc tcttaagagc ttgctgactt gttttcttgt gaaatttttt gcacatctga 540
atatcgtgga agaaacaata aaactacacc atgaggaaaa ctaaaggtct ttatttaaaa 600
tctggcattg tattaacatg taattttata ctatgtggta ttttatacat ttcctcagta 660
gtgatatttg gtaaagcagt tcatacagct tttttctaag ttccatgaat cttacccagt 720
gtttaccgaa gtatttaagc agcatctgaa tatttccacc cagcaatgtt aatttatcta 780
ggaaagttca gaatttcatc ttcatgttga atttcccttt taacttccgt tcatagacat 840
atatgtgact tccaattcga ccctctggca agtgagtgtg gaagaaaaca gcagttcttt 900
tataattgct tgaaattagg aaagcgctta tttcctagaa gcaaataaat gtttaagtaa 960
ataaaggcta cattttgctg a 981
<210> 296
<211> 575
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CCPG1 3'-UTR
CCPG1-004 ENST00000425574
<400> 296
ttcacaattg agttaaatta gacaactgta agagaaaaat ttatgctttg tataatgttt 60
ggtattgaaa ctaatgaaat taccaagatg acaatgtctt ttcttttgtt tctaagtatc 120
agtttgataa ctttatatta ttcctcagaa gcattagtta aaagtctact aacctgcatt 180
ttcctgtagt ttagcttcgt tgaatttttt ttgacactgg aaatgttcaa ctgtagtttt 240
attaaggaag ccaggcatgc aacagatttt gtgcatgaaa tgagacttcc tttcagtgta 300
agagcttaaa gcaagctcag tcatacatga caaagtgtaa ttaacactga tgtttgtgtt 360
aaatttgcag cagagcttga gaaaagtaca ttgttctgga atttcatcat taacatttta 420
taatcttaca ctcacttctt gtctttttgt gggttcaaga gccctctgac ttgtgaagaa 480
tttgctgccc tcttaagagc ttgctgactt gttttcttgt gaaatttttt gcacatctga 540
atatcgtgga agaaacaata aaactacacc atgag 575
<210> 297
<211> 230
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1 3'-UTR
CNTN1-002 ENST00000348761
<400> 297
atgtgttgtg acagctgctg ttcccatccc agctcagaag acacccttca accctgggat 60
gaccacaatt ccttccaatt tctgcggctc catcctaagc caaataaatt atactttaac 120
aaactattca actgatttac aacacacatg atgactgagg cattcgggaa ccccttcatc 180
caaaagaata aacttttaaa tggatataaa tgatttttaa ctcgttccaa 230
<210> 298
<211> 922
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1 3'-UTR
CNTN1-004 ENST00000547849
<400> 298
tcgttgacac tcaccatttc tgtgaaagac tttttttttt ttaacatatt atactagatt 60
tgactaactc aatcttgtag cttctgcagt tctccccacc cccaacctag ttcttagagt 120
atgtttcccc ttttgaaaca tgtaaacata ctttgggcat aaatattttt taaaatataa 180
ctataatgct tcactaatac cttaaaaatg cctagtgaac taactcagta cattatataa 240
tggccaagtg aaagttttgt gttttcatgt cctgtttttc tttgaaatta tatagcccag 300
aaattagctc attatctgaa aaacgtatga agaactgatg aattgtataa tacaggagta 360
ttgccattga atgtactgtt tgatttattc aagcaggtaa tgaacaatgt tgtcaaactc 420
tctaatgaga catcataatt aggacataag ctaaaagggg cattactccg gcagtctttt 480
tttcttaatc ctagtaccat acatattctt tggcatgaaa gaatgaaaag cattagtaaa 540
caactgaagt cctaccatgg ctctgtaggg tttttggaac aattcctgga attggaaagt 600
gaaaatggat agcatgtggg ggaaaccctc atctgagtag caagatttta gtaaagatga 660
ctaagccatt aacagcatgc attcatattt aattttattg actcctgcca tcagcttttg 720
tagatcgttt gggtggaagg ttgtgatttt tactgggagg acttgagtag aagtggatga 780
ttaaaattga ggagtatata attctttctg ggactgctta aatgttattg tttgaaaata 840
ccttcacttt ccccctttgg tcaaagagat gtgcttaaaa ttcttattcc ttcacaataa 900
ataattttga ttttcttaga ca 922
<210> 299
<211> 928
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CNTN1 3'-UTR
CNTN1-004 ENST00000547849
+T at pos. 30bp, mutations G727bpT, A840bpG
<400> 299
ttttttcgtt gacactcacc atttctgtga aagacttttt ttttttttaa catattatac 60
tagatttgac taactcaatc ttgtagcttc tgcagttctc cccaccccca acctagttct 120
tagagtatgt ttcccctttt gaaacatgta aacatacttt gggcataaat attttttaaa 180
atataactat aatgcttcac taatacctta aaaatgccta gtgaactaac tcagtacatt 240
atataatggc caagtgaaag ttttgtgttt tcatgtcctg tttttctttg aaattatata 300
gcccagaaat tagctcatta tctgaaaaac gtatgaagaa ctgatgaatt gtataataca 360
ggagtattgc cattgaatgt actgtttgat ttattcaagc aggtaatgaa caatgttgtc 420
aaactctcta atgagacatc ataattagga cataagctaa aaggggcatt actccggcag 480
tctttttttc ttaatcctag taccatacat attctttggc atgaaagaat gaaaagcatt 540
agtaaacaac tgaagtccta ccatggctct gtagggtttt tggaacaatt cctggaattg 600
gaaagtgaaa atggatagca tgtgggggaa accctcatct gagtagcaag attttagtaa 660
agatgactaa gccattaaca gcatgcattc atatttaatt ttattgactc ctgccatcag 720
cttttgtaga tcttttgggt ggaaggttgt gatttttact gggaggactt gagtagaagt 780
ggatgattaa aattgaggag tatataattc tttctgggac tgcttaaatg ttattgtttg 840
aaaatgcctt cactttcccc ctttggtcaa agagatgtgc ttaaaattct tattccttca 900
caataaataa ttttgatttt cttagaca 928
<210> 300
<211> 734
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LMBRD2 3'-UTR
<400> 300
agtctgaaaa agtttgtggg accactaacc aaggtcaaca catcagttca gtcttgatga 60
acatctgtgt accctagaat ttcctctata cacagtgaaa agtgtcaaga taacaaaaaa 120
ggcactgaga attaattata tcttaggaat aatagtttaa tgtgcattga atagagtatc 180
acctttttca acaagattta ttacatatca tttcctaagc atctgcctta gaaatacagt 240
tacagtggaa ggactttaag aaagatcaac atatgttaag aacatgcagt tcagtttgtt 300
tcagattaat tttttttcaa gagagttatt ttaaagattc aaggaagcca taagtcatac 360
taaataatat tatatacagt tttgttattg tgacttacat ttttgttact tctaaaaagt 420
atattcaacc tgtatttccc aaagaaatgt aagtgaatgg agacctcaaa taataactgt 480
attcataaaa ctcgtgtctt aaaacaaggc ttacttacta gacataactg aatgtaaaaa 540
gtgctttttc aaatctgttt gcaaactcgt gggggatttt tgcatgtata agattaagat 600
tatacttcaa gtgatgcgtg tctgtgtatt tagcatgtgt actataatca ggtgatatag 660
tattccttca gtctttgtag taactggatt tttttatgct tctggtattg ctttataaaa 720
gattttcatt tcag 734
<210> 301
<211> 241
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TLR3 3'-UTR
NM_003265
<400> 301
atttatttaa atattcaatt agcaaaggag aaactttctc aatttaaaaa gttctatggc 60
aaatttaagt tttccataaa ggtgttataa tttgtttatt catatttgta aatgattata 120
ttctatcaca attacatctc ttctaggaaa atgtgtctcc ttatttcagg cctatttttg 180
acaattgact taattttacc caaaataaaa catataagca cgtaaaaaaa aaaaaaaaaa 240
a 241
<210> 302
<211> 527
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BCAT1 3'-UTR
BCAT1-002 ENST00000342945
<400> 302
atggaaaata gaggatacaa tggaaaatag aggataccaa ctgtatgcta ctgggacaga 60
ctgttgcatt tgaattgtga tagatttctt tggctacctg tgcataatgt agtttgtagt 120
atcaatgtgt tacaagagtg attgtttctt catgccagag aaaatgaatt gcaatcatca 180
aatggtgttt cataacttgg tagtagtaac ttaccttacc ttacctagaa aaacattaat 240
gtaagccata taacatggga ttttcctcaa tgattttagt gcctcctttt gtacttcact 300
cagatactaa atagtagttt attctttaat ataagttaca ttctgctcct caaacaaatg 360
caattttttg tgtgtgtttg aaagctaatt tgagaaaatt tcataggtta catttcctgc 420
agcctatctt tatccacaga aagtgttttc ttttttttaa atcaagactt ttaaaactgg 480
atttcctccc atcactgttt tttgaaggtc ctccaagtcc gtgttaa 527
<210> 303
<211> 199
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BCAT1 3'-UTR
<400> 303
atggaaaata gaggatacaa tggaaaatag aggataccaa ctgtatgcta ctgggacaga 60
ctgttgcatt tgaattgtga tagatttctt tggctacctg tgcataatgt agtttgtagt 120
atcaatgtgt tacaagagtg attgtttctt catgccagag aaaatgaatt gcaatcatca 180
aatggtgttt cataacttg 199
<210> 304
<211> 716
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TOM1L1 3'-UTR
TOM1L1-001 ENST00000575882
<400> 304
gaagaaagtg gatgatcagc tcactaccac atcaaaggtg ccaactctct aaaacgtaga 60
ctctgtgcag ctttgaagcc tggaagacaa tacctaccaa catgtcaaag ccatggtggc 120
acatttctgc tataatgaag attaaataga ataacagttc caggataaca ctgattcctg 180
acaacagcgt gagatttcaa cagaacttgt ttggaacaaa tactcactta aaacttcagc 240
agaagaaaaa ttacttagtc cttaggccaa ccaatttaac tgcagtgtca tgtttcacag 300
gccttcctac atttagaaat cgtcacacag ctgtgataag agtagattat tttactatga 360
aataattctg aatagatgaa agcataaaat gtgagaaact gaatgtatta ttcaggaaga 420
atactgagtg ccttcattta actaaagttg aatgtaaaag tcaatttgca cttctttata 480
atcctctggt ttagaattat aaattgttaa aaccttgata attgtcattt aattatattt 540
caggtgtcct gaacaggtca ctagactcta cattgggcag cctttaaata tgattctttg 600
taatgctaaa tagccttttt ttctcttttt actgcaactt aatatttcta tttagaacac 660
agaaaatgaa aatatttaga ataagttgta catttgatga caaataaatc actatt 716
<210> 305
<211> 804
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SLC35A1 3'-UTR
SLC35A1-201 ENST00000369556
<400> 305
ttttagcctc acgtgagact ccttttaaga ctaaaccatt tgcattaaac tagagcctta 60
agtcaatctc agaaggtagc ataaacaaat aaaaattaac tgtatggcat gatcagtgcg 120
gttatgtgga aacaacaaca aacaaacgaa gctatctgag tgaactgcta atacagaaac 180
ttaatgtaga cctgtttggg gtctactatt gttttagaat gaaggaattg tattattgtg 240
tgtatatata atttgtaaat aaaaagtatg gagatgatac ggtgttaaaa aaaatcatgg 300
taaggctaca atactcaagt aacaaggttt gggacaatgt ctaagggtta aagtgccaaa 360
gccatttctg tactaactgt tctcttgttc cggtaccggg gagaaggatg acccctcctt 420
attctccaat tcatgtacag tattttgtcc tagcagcata aagacctagc tcttttctta 480
caagaggcag aaacaagaca ggctagttca taaacaaact gtgtaacttc tcaaaatgaa 540
tctatttcat aactcggaca atttctgggt ggtgactgag taccccttta gtgagtaccc 600
ctttagtgct atatttgtgc cattcattat ctggttcata tttcttttct gttagatgat 660
acacatttct tcaaaaaaat ttctaatgtc acttttgtac ttttttaaat aaagtatgtt 720
taactgttgg gctctcaata atttgtgaaa tttcagtgtt ttctataatg ttaatgggga 780
aattcagcaa taaactttat ttgt 804
<210> 306
<211> 332
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GLYATL2 3'-UTR
GLYATL2-003 ENST00000532258
<400> 306
ttgattccac tgtccatttc aaatctttct tatcagtaaa aaaacattaa ttcaaacaca 60
agcattgtga tctacattag cacaaaatgc aactgattat ctaggatctg tgtattactt 120
aagctcaccc ttaacagttt taccttcctt ctcctctgta ttcttacaga aaattagaag 180
ctcaatttta tggtctcata atttccttta tgacagacat ctcagaatta aaatcaccca 240
aagccaatca ttagtgccaa gataaccctt taacggcaac actttcttaa atgaagacta 300
tttctttcat gaaaaaattc acttttatga ct 332
<210> 307
<211> 260
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens STAT4 3'-UTR
STAT4-002 ENST00000392320
<400> 307
caggataaac tctgacgcac caagaaagga agcaaatgaa aaagtttaaa gactgttctt 60
tgcccaataa ccacatttta tttcttcagc tttgtaaata ccaggttcta ggaaatgttt 120
gacatctgaa gctctcttca cactcccgtg gcactcctca attgggagtg ttgtgactga 180
aatgcttgaa accaaagctt cagataaact tgcaagataa gacaacttta agaaaccagt 240
gttaataaca atattaacag 260
<210> 308
<211> 270
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GULP1 3'-UTR
GULP1-002 ENST00000409609
<400> 308
catcaagaac aagaaatcct gattcatgtt aaatgtgttt gtatacacat gtcatttatt 60
attattactt taagataggt attattcatg tgtcaatgtt tttgaatatt ttaatatttt 120
gaaaattttc tcagttaaat ttcctcacct tcactattga tctgtaattt ttattttaaa 180
aacagcttac tgtaaagtag atcatacttt tatgttcctt tctgtttcta ctgtagatga 240
atttgtaatt gaaagacata ttatacaaat 270
<210> 309
<211> 79
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GULP1 3'-UTR
GULP1-010 ENST00000409805
<400> 309
catcaagaac aagaaatcct gattcatgtt aaatgtgttt gtatacacat gtcatttatt 60
attattactt taagatagg 79
<210> 310
<211> 256
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens EHHADH 3'-UTR
EHHADH-002 ENST00000456310
<400> 310
ttcagtcttc cagattatgc ctcacatgct agcatcaggt aatgctgact gaatttcagt 60
gaaattaaat caaaaatcca aagtaagatt gttctgaaat acaaagcaaa ataaataatc 120
attagaatct tctgtgtaac gactctaatg gtcaaatctt taggaatgtg cttcctatgc 180
ctctgaatct gtccttatca gataaattca atgcatgaac ttgtgtgaat ataataccat 240
aatagctaat gaaaga 256
<210> 311
<211> 640
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NBEAL1 3'-UTR
NM_001114132.1
<400> 311
ttgttatttc cattttctgt tatgattact gaaacctgat ttattgcttt gtcactttaa 60
ccacatctct caactctctg caatgttgca aggcttttat ccctgaaaat catttacaga 120
taaccacaat ttgctgtggt atataaacta attcttggtc tatactaaga tgtatttgag 180
aaaatacatt tgatttgatt ttgtggccca ttcctaaagg tcattgtatc catttttaaa 240
acaaactaaa atgagaacat taggttcaat tttcttatta ttccaaatga taaaatttaa 300
gatttttcta ataaaagagt acagataatg ggacagttga gagagatggc tttaaataca 360
ttcttaagta atcattttcc tatttactga ccactgtaat gaaaatatat caatttattt 420
atggaactcc tgattgggga taatatttta aaggtatctg ttgcacactt ggattttcaa 480
aactcggtga aagttacaag tttgcatggt aagaataaaa taagaatatt gaaactggta 540
cattagctaa ttctattact acttagcgtg tttctaatga gaagttactg aaatctatta 600
ctgtccttaa taaaaattga gtagaaaaaa gtggaactag 640
<210> 312
<211> 225
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens KIAA1598 3'-UTR
NM_001258299.1
<400> 312
tctgaatcag aaaatactgc aactccttcc tccttttgtc tgccttttgt tctccaaaag 60
taagtggaaa ttacatttcc aagaaaggaa atgaaataat tgcaggccca aggtctgcaa 120
aatatgtgtt gaattgacag tgaaaaggat ccatgtgttg acagacacag ttgttagatg 180
ccataaaggc agatgtgaag ctcaatttat ttctcatctt gcttg 225
<210> 313
<211> 991
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HFE 3'-UTR
HFE-006 ENST00000317896
<400> 313
cacgcagcct gcagactcac tgtgggaagg agacaaaact agagactcaa agagggagtg 60
catttatgag ctcttcatgt ttcaggagag agttgaacct aaacatagaa attgcctgac 120
gaactccttg attttagcct tctctgttca tttcctcaaa aagatttccc catttaggtt 180
tctgagttcc tgcatgccgg tgatccctag ctgtgacctc tcccctggaa ctgtctctca 240
tgaacctcaa gctgcatcta gaggcttcct tcatttcctc cgtcacctca gagacataca 300
cctatgtcat ttcatttcct atttttggaa gaggactcct taaatttggg ggacttacat 360
gattcatttt aacatctgag aaaagctttg aaccctggga cgtggctagt cataacctta 420
ccagattttt acacatgtat ctatgcattt tctggacccg ttcaactttt cctttgaatc 480
ctctctctgt gttacccagt aactcatctg tcaccaagcc ttggggattc ttccatctga 540
ttgtgatgtg agttgcacag ctatgaaggc tgtacactgc acgaatggaa gaggcacctg 600
tcccagaaaa agcatcatgg ctatctgtgg gtagtatgat gggtgttttt agcaggtagg 660
aggcaaatat cttgaaaggg gttgtgaaga ggtgtttttt ctaattggca tgaaggtgtc 720
atacagattt gcaaagttta atggtgcctt catttgggat gctactctag tattccagac 780
ctgaagaatc acaataattt tctacctggt ctctccttgt tctgataatg aaaattatga 840
taaggatgat aaaagcactt acttcgtgtc cgactcttct gagcacctac ttacatgcat 900
tactgcatgc acttcttaca ataattctat gagataggta ctattatccc catttctttt 960
ttaaatgaag aaagtgaagt aggccgggca c 991
<210> 314
<211> 761
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HFE 3'-UTR
HFE-004 ENST00000349999
<400> 314
cacgcagcct gcagactcac tgtgggaagg agacaaaact agagactcaa agagggagtg 60
catttatgag ctcttcatgt ttcaggagag agttgaacct aaacatagaa attgcctgac 120
gaactccttg attttagcct tctctgttca tttcctcaaa aagatttccc catttaggtt 180
tctgagttcc tgcatgccgg tgatccctag ctgtgacctc tcccctggaa ctgtctctca 240
tgaacctcaa gctgcatcta gaggcttcct tcatttcctc cgtcacctca gagacataca 300
cctatgtcat ttcatttcct atttttggaa gaggactcct taaatttggg ggacttacat 360
gattcatttt aacatctgag aaaagctttg aaccctggga cgtggctagt cataacctta 420
ccagattttt acacatgtat ctatgcattt tctggacccg ttcaactttt cctttgaatc 480
ctctctctgt gttacccagt aactcatctg tcaccaagcc ttggggattc ttccatctga 540
ttgtgatgtg agttgcacag ctatgaaggc tgtacactgc acgaatggaa gaggcacctg 600
tcccagaaaa agcatcatgg ctatctgtgg gtagtatgat gggtgttttt agcaggtagg 660
aggcaaatat cttgaaaggg gttgtgaaga ggtgtttttt ctaattggca tgaaggtgtc 720
atacagattt gcaaagttta atggtgcctt catttgggat g 761
<210> 315
<211> 142
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HFE 3'-UTR
HFE-005 ENST00000397022
<400> 315
cacgcagcct gcagactcac tgtgggaagg agacaaaact agagactcaa agagggagtg 60
catttatgag ctcttcatgt ttcaggagag agttgaacct aaacatagaa attgcctgac 120
gaactccttg attttagcct tc 142
<210> 316
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HFE 3'-UTR
HFE-012 ENST00000336625
<400> 316
cacgcagcct gcagactcac tgtgggaagg a 31
<210> 317
<211> 394
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens KIAA1324L 3'-UTR
KIAA1324L-005 ENST00000416314
<400> 317
agagacagtg ctgtagcctt gagactaatg aacaaagaaa cctgctctag ttttacagga 60
ccatatttta gggtctgtcc tcatacctgt cacattggtg atctcacaga ggagggccat 120
gccgctgaaa agggaaggag attgaaacat ttgattgcct tatcacatgg tcaagtacct 180
tgccaaataa aggaaagcaa atgatttggg tctcaactga agatgaagct caactcagga 240
agagatttat ctgtatatac acataactga aaaccaagtt taagcccacc aatgcactgc 300
tgatgcatgc catataatta atgggtaact tttattcttt atgatgtcta cataacaagt 360
gtgatttgga aggcacatgt gagcatatgc atta 394
<210> 318
<211> 743
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MANSC1 NM_018050 3'-UTR
<400> 318
ggatggaact cggtgtctct taattcattt agtaaccaga agcccaaatg caatgagttt 60
ctgctgactt gctagtctta gcaggaggtt gtattttgaa gacaggaaaa tgcccccttc 120
tgctttcctt tttttttttt ggagacagag tcttgctttg ttgcccaggc tggagtgcag 180
tagcacgatc tcggctctca ccgcaacctc cgtctcctgg gttcaagcga ttctcctgcc 240
tcagcctcct aagtatctgg gattacaggc atgtgccacc acacctgggt gatttttgta 300
tttttagtag agacggggtt tcaccatgtt ggtcaggctg gtctcaaact cctgacctag 360
tgatccaccc tcctcggcct cccaaagtgc tgggattaca ggcatgagcc accacagctg 420
gcccccttct gttttatgtt tggtttttga gaaggaatga agtgggaacc aaattaggta 480
attttgggta atctgtctct aaaatattag ctaaaaacaa agctctatgt aaagtaataa 540
agtataattg ccatataaat ttcaaaattc aactggcttt tatgcaaaga aacaggttag 600
gacatctagg ttccaattca ttcacattct tggttccaga taaaatcaac tgtttatatc 660
aatttctaat ggatttgctt ttctttttat atggattcct ttaaaactta ttccagatgt 720
agttccttcc aattaaatat ttg 743
<210> 319
<211> 142
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LTA4H 5'-UTR
LTA4H-001 ENST00000228740
<400> 319
aagaaacttc ctttcccggc gtgcaccgcg aatccctcct cctcttcttt acctctctcc 60
ctcctcctca ggttctctat cgacgagtct ggtagctgag cgttgggctg taggtcgctg 120
tgctgtgtga tcccccagag cc 142
<210> 320
<211> 88
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens DECR1 5'-UTR
DECR1-001 ENST00000220764
<400> 320
tccagccccg agaactttgt tctttttgtc ccgccccctg cgcccaaccg cctgcgccgc 60
cttccggccc gagttctgga gactcaac 88
<210> 321
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PIGK 5'-UTR
<400> 321
actgcctccg ccccttcagg tgcgggaagt ctgaagccgg taaac 45
<210> 322
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BRP44L 5'-UTR
BRP44L-001
<400> 322
gtcgtgaggc gggccttcgg gctggctcgc cgtcggctgc cggggggttg gccggggtgt 60
cattggctct gggaagcggc agcagaggca gggaccactc ggggtctggt gtcggcacag 120
cc 122
<210> 323
<211> 117
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ACADSB 5'-UTR
ACADSB-004 NM_001609.3 ENST00000368869
<400> 323
agggattaag ggggggtgtg tgcggggcgg gtactgagtg ggcggggcct tgctcgggta 60
actcccaggg gctggctaga gacccagagg cgcagagcgg agaggcctgc ggcgagg 117
<210> 324
<211> 166
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens SUPT3H 5'-UTR
SUPT3H-006 ENST00000371459
<400> 324
cacagccgag tcaccttttc cctttctaca ctccacactc tcagtccccc accccgcccc 60
tttccaagcg tgtcccgggc cgcagcagca gaaaccgcac catctccacc cccacattct 120
cctcgcggga agcgcagcag tgcctccaag ggttcttaaa gcagag 166
<210> 325
<211> 176
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TMEM14A 5'-UTR
NM_014051.3
<400> 325
gtttccagga gggagcggcc tttgctcagc gcgagacggc tgggcgccga gtgggacagc 60
gctggtgcgg agactgcttc cggactccag gtaccgcgct tggcggcagc tggccccaga 120
cttctgtctt ttcagctgca gtgaaggctc ggggctgcag aattgcaacc ttgcca 176
<210> 326
<211> 222
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C9orf46 5'-UTR
AF225420.1
<400> 326
gagcgaggcc cggtccctgc agcgggcgaa aggagcccgg gcctggaggt ttgcgtaccg 60
gtcgcctggt cccggcacca gcgccgccca gtgtggtttc ccataaggaa gctcttcttc 120
ctgcttggct tccaccttta acccttccac ctgggagcgt cctctaacac attcagacta 180
caagtccaga cccaggagag caaggcccag aaagaggtca aa 222
<210> 327
<211> 227
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ANXA4 5'-UTR
NM_001153.3
<400> 327
gccccaggtg cgcttcccct agagagggat tttccggtct cgtgggcaga ggaacaacca 60
ggaacttggg ctcagtctcc accccacagt ggggcggatc cgtcccggat aagacccgct 120
gtctggccct gagtagggtg tgacctccgc agccgcagag gaggagcgca gcccggcctc 180
gaagaacttc tgcttgggtg gctgaactct gatcttgacc tagagtc 227
<210> 328
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens IFI6 5'-UTR
NM_022873.2
<400> 328
ccagccttca gccggagaac cgtttactcg ctgctgtgcc catctatcag caggctccgg 60
gctgaagatt gcttctcttc tctcctccaa ggtctagtga cggagcccgc gcgcggcgcc 120
acc 123
<210> 329
<211> 58
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C2orf34 5'-UTR
CAMKMT -008 ENST00000402247
<400> 329
tcctggcagg ggacgagctg cggcggtggc acctccgggt gtggaaggct ccagtgag 58
<210> 330
<211> 104
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens C2orf34 5'-UTR
NM_024766.3
<400> 330
gagggtgccg ggcgtcacag gtcctgacag ggaagaagtt ggcaggtcct ggcaggggac 60
gagctgcggc ggtggcacct ccgggtgtgg aaggctccag tgag 104
<210> 331
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ALDH6A1 5'-UTR
ALDH6A1-002 ENST00000350259
<400> 331
agtgcttctg ggcagtagag gcgcggggtg cggagctagg gcggccgaga gcc 53
<210> 332
<211> 117
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CCDC53 5'-UTR
CCDC53-002 ENST00000545679
<400> 332
ggaagggccc cggaggcggg cacttggggg gaaagttgag acgtgattac cgggttgggc 60
gggccccatc tgggaggggt ttgtgggtga actcggggtc caccgcccgc tgaggag 117
<210> 333
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CASP1 5'-UTR
NM_001257119.1
<400> 333
atactttcag tttcagtcac acaagaaggg aggagagaaa agcc 44
<210> 334
<211> 124
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NDUFB6 5'-UTR
NM_182739.2
<400> 334
gtaataaccg cgcgcggcgc tcggcgttcc cgcaaggtcg ctttgcagag cgggagcgcg 60
cttaagtaac tagtccgtag ttcgagggtg cgccgtgtcc ttttgcgttg gtaccagcgg 120
cgac 124
<210> 335
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BCKDHB 5'-UTR
BCKDHB-002 ENST00000369760
<400> 335
aggcggcgtg cggctgcata gcctgagaat cccggtggtg agcgggg 47
<210> 336
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BCKDHB 5'-UTR
NM_001164783.1
<400> 336
ctacgtgagt gccggaccgc tgagtggttg ttagccaag 39
<210> 337
<211> 234
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens BBS2 5'-UTR
NM_031885.3
<400> 337
cacagaaggc gccgaggctc caccgcgcag ccgcaaaaag agcggacggg tctgcgccgc 60
cgcaggagga gcaggcggta cctggacggg ttcgtcccgg gctgtttcgc gtccggcctg 120
aggcggctgg ggccgcgcag gtagtgtccc tgcacttctt gcccgggcgc gtgaggccag 180
ctccgctgcg cttgtctcca gcttccagcc ctcctcccct aagccgccgc catc 234
<210> 338
<211> 153
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens HERC5 5'-UTR
HERC5-001 ENST00000264350
<400> 338
tcagtagctg aggctgcggt tccccgacgc cacgcagctg cgcgcagctg gttcccgctc 60
tgcagcgcaa cgcctgaggc agtgggcgcg ctcagtcccg ggaccaggcg ttctctcctc 120
tcgcctctgg gcctgggacc ccgcaaagcg gcg 153
<210> 339
<211> 65
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens FAM175A 5'-UTR
NM_139076.2
<400> 339
accacagggt cttgcctccg cgcgccccgc cctcgtcctc ttgtgtagcc tgaggcggcg 60
gtagc 65
<210> 340
<211> 82
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NT5DC1 5'-UTR
NT5DC1-002 ENST00000319550
<400> 340
cggtcctgtc ccgcagcgtc ccgccagcca gctccttgca cccttcgcgg ccgaggcgct 60
ccctggtgct ccccgcgcag cc 82
<210> 341
<211> 246
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens RAB7A 5'-UTR
RAB7A-001 ENST00000265062
<400> 341
gtctcgtgac aggtacttcc gctcggggcg gcggcggtgg cggaagtggg agcgggcctg 60
gagtcttggc cataaagcct gaggcggcgg cagcggcgga gttggcggct tggagagctc 120
gggagagttc cctggaacca gaacttggac cttctcgctt ctgtcctccg tttagtctcc 180
tcctcggcgg gagccctcgc gacgcgcccg gcccggagcc cccagcgcag cggccgcgtt 240
tgaagg 246
<210> 342
<211> 128
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens AGA 5'-UTR
AGA-001 ENST00000264595
<400> 342
agggacgcct gagcgaaccc ccgagagagc gggcgtgggc gccaggcggg cggggcactg 60
gggattaatt gttcggcgat cgctggctgc cgggactttt ctcgcgctgg tctcttcggt 120
ggtcaggg 128
<210> 343
<211> 103
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TPK1 5'-UTR
TPK1-001 ENST00000360057
<400> 343
aaggctcctc agccgagcgc cgagcggtcg atcgccgtag ctcccgcagc ctgcgatctc 60
cagtctgtgg ctcctaccag ccattgtagg ccaataatcc gtt 103
<210> 344
<211> 79
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MBNL3 5'-UTR
MBNL3-001 ENST00000370839
<400> 344
aattcatttt taatccttta atagtccaca gtaatattgt cctaaagagg gtacattgga 60
ttttaatttt gctttcaat 79
<210> 345
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens MCCC2 5'-UTR
MCCC2-001 ENST00000340941
<400> 345
agaatcagag aaaccttctc tggggctgca aggacctgag ctcagcttcc gccccagcca 60
gggaagcggc aggggaaagc accggctcca ggccagcgtg ggccgctctc tcgctcggtg 120
cccgccgcc 129
<210> 346
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CAT 5'-UTR
CAT-001 ENST00000241052
<400> 346
actcggggca acaggcagat ttgcctgctg agggtggaga cccacgagcc gaggcctcct 60
gcagtgttct gcacagcaaa ccgcacgct 89
<210> 347
<211> 142
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ANAPC4 5'-UTR
ANAPC4-001 ENST00000315368
<400> 347
cccgacgccg gaagtgcctg gagcgcgcga cagcggcggg gcggggcggc ctggaggctg 60
tggcgcgcgg ccggcagagg gaggggagag gccactgggg ccgtgttagt ctgccggtgg 120
ggactcttgc agggccgtcc cc 142
<210> 348
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PHKB 5'-UTR
PHKB-002 ENST00000323584
<400> 348
ggccaaggcg gcgaccggag cgcg 24
<210> 349
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens ABCB7 5'-UTR
ABCB7-001 ENST00000253577
<400> 349
ctcggttcct ctttcctcgc tcaag 25
<210> 350
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GPD2 5'-UTR
GPD2-002 ENST00000438166
<400> 350
cccgcgcgcc tcgctgggag cacccgggcc gaggctctga ttctgggggg aggccgactc 60
caccctggct ggaggaactg ggtgctcctg cccgctggcc cctcgcgcgt gaggatctat 120
ctcaggctaa gaa 133
<210> 351
<211> 117
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens TMEM38B 5'-UTR
TMEM38B-001 ENST00000374692
<400> 351
gctggagccg gcgcggagga gcgggcggcc gcggctgtgc cctctcctac tcctcaccgc 60
gcgagcgcgg ggaaccagta gccgcggctg cttcggttgc cgcggtcggt ggtcgtt 117
<210> 352
<211> 206
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NFU1 5'-UTR
NM_001002755.2
<400> 352
gggaaaggtt ccccggcctc tcttggtcag ggtgacgcag tagcctgcaa acctcggcgc 60
gtaggccacc gcacttatcc gcagcaggac cgcccgcagc cggtagggtg ggctcttccc 120
agtgcccgcc cagctaccgg ccagcctgcg gctgcgcaga tctttcgtgg ttctgtcagg 180
gagaccctta ggcactccgg actaag 206
<210> 353
<211> 99
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LOC128322/NUTF2 5'-UTR
NM_005796.1
<400> 353
ggaagggaca gtcggccgca gaccgcgctg ggttgccgct gccgctgccg ccatcgtgcc 60
agcccctcgg gtctccgtga ggccgggtga cgctccaga 99
<210> 354
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens NUBPL 5'-UTR
NM_025152.2
<400> 354
actccgcgcc acccgcgaca gtttcccagc agggctcaca gcagcgttcc gcgtc 55
<210> 355
<211> 75
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens LANCL1 5'-UTR
LANCL1-004 ENST00000233714
<400> 355
gagaagggct tcaggacgcg ggaggcgcac ttgcttcaag tcgcgggcgt gggaacgggg 60
cttgcttccg gcgtc 75
<210> 356
<211> 204
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens PIR 5'-UTR
PIR-002 ENST00000380420
<400> 356
cctcccgcct cctctaggcc gccggccgcg aagcgctgag tcacggtgag gctactggac 60
ccacactctc ttaacctgcc ctccctgcac tcgctcccgg cggctcttcg cgtcaccccc 120
gccgctaagg ctccaggtgc cgctaccgca gcccctccat cctctacagc tcagcatcag 180
aacactctct ttttagactc cgat 204
<210> 357
<211> 65
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens CTBS 5'-UTR
NM_004388.2
<400> 357
gacgcgcagc aggccccgcc cacccaggcg gtaggaaccc actccggccc gctagacctg 60
ctgct 65
<210> 358
<211> 314
<212> DNA
<213> Artificial Sequence
<220>
<223> Homo sapiens GSTM4 5'-UTR
NM_000850.4
<400> 358
aagctggcga ggccgagccc ctcctagtgc ttccggacct tgctccctga acactcggag 60
gtggcggtgg atcttactcc ttccagccag tgaggatcca gcaacctgct ccgtgcctcc 120
cgcgcctgtt ggttggaagt gacgaccttg aagatcggcc ggttggaagt gacgaccttg 180
aagatcggcg ggcgcagcgg ggccgagggg gcgggtctgg cgctaggtcc agcccctgcg 240
tgccgggaac cccagaggag gtcgcagttc agcccagctg aggcctgtct gcagaatcga 300
caccaaccag catc 314
<210> 359
<211> 73
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa1 5'-UTR
Ndufa1-001 ENSMUST00000016571
<400> 359
gccggaagag aggtaaagcc gggtcacctc tgaggagccg gtgacgggtt ggcgtgcgag 60
taacggtgcg gag 73
<210> 360
<211> 105
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5e 5'-UTR
NM_025983
<400> 360
cccacccctt ccgctactca ggcctgacct tcctgctgcc gggccggttt gaggctactc 60
tgaagcgacc cagcggttct gcccgacgcg cccgctcgag acacc 105
<210> 361
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gstm5 5'-UTR
NM_010360
<400> 361
gagacagttc ggtcgcgtca gcccggccca cagcgtccag tataaagtta gccgcccaca 60
gtccatcgct gtatccccga aggggctaag atcgcccaaa 100
<210> 362
<211> 49
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cbr2 5'-UTR
NM_007621
<400> 362
ataaaagctg agcccatctc ttgcttcgga agaagctggt gtcagcagc 49
<210> 363
<211> 78
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Anapc13 5'-UTR
NM_181394
<400> 363
gtgacccaga agaagggcgg ggccgggagg aagccgacgc gcgcgcagtg ggcctgacaa 60
gatcaaagct gcaggagg 78
<210> 364
<211> 16
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa7 5'-UTR
NM_023202
<400> 364
tcggagcgga aggaat 16
<210> 365
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5k 5'-UTR
NM_007507
<400> 365
cgaaggtcac ggacaaa 17
<210> 366
<211> 67
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Cox4i1 5'-UTR
NM_009941
<400> 366
cttccggtcg cgagcacccc agggtgtaga gggcggtcgc ggcggtcgcc tgggcagcgg 60
tggcaga 67
<210> 367
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufs6 5'-UTR
NM_010888
<400> 367
ttggtacgac gcgtggggtc aagggtcacc ggcaag 36
<210> 368
<211> 90
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Sec61b 5'-UTR
NM_024171
<400> 368
agagcctgta tctacgagag ttctgagtgc tcggcaactt cacgacttcc ctcttcctgc 60
ctcctgtgcc caccgttctt aggcatcagc 90
<210> 369
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Snrpd2 5'-UTR
NM_026943
<400> 369
aaggctggag caacgcgctt ggaggcggga gtgatctgcg agcgaaacct acacc 55
<210> 370
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mgst3 5'-UTR
NM_025569
<400> 370
actgctgtgc ttctcaggtc tgtaccaggc gcacgaaggt gagccagagc caag 54
<210> 371
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Mp68 (2010107E04Rik) 5'-UTR
NM_027360
<400> 371
ctttcccatt ctgtagcaga atttggtgtt gcctgtggtc ttggtcccgc ggag 54
<210> 372
<211> 92
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Prdx4-001, 5'-UTR
NM_016764
<400> 372
gcgcggtctc cagcgcgccg ttttagctgg ctgcctggcg gcaggggact ctgtgcttta 60
gcagagggac gtgttttcgc gcttgcttgg tc 92
<210> 373
<211> 215
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Pgcp 5'-UTR
NM_176073
<400> 373
gctgtcctgg cacacaaaga agccaggcct gcagactact ggggctccgg gctgttcctg 60
aggcctctgg aggcccgccc tgtggctcca gtgcgctctg aggaccttcc tggtcccgcc 120
cccgaacgtg cctgtggtct gcaggcctca ccgggtgttg tggccgctgc tgctccgcag 180
agcctcgtga tcaggaagaa aagcaactag gaaca 215
<210> 374
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Myeov2 5'-UTR
NM_001163425
<400> 374
agaaggggct ggccggaagt gagcgcaacg ccgccttgtc gag 43
<210> 375
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufa4 5'-UTR
NM_010886
<400> 375
gtccgctcag ccaggttgca gaagcggctt agcgtgtgtc ctaatcttct ctctgcgtgt 60
aggtaggcct gtgccgcaaa c 81
<210> 376
<211> 76
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Ndufs5 5'-UTR
NM_001030274
<400> 376
acggcaggcg tctgcgtcct cccgcagccg gcggtcggga attgcaccag ggacctgaca 60
agggcactgc agagcc 76
<210> 377
<211> 198
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Gstm1 5'-UTR
NM_010358
<400> 377
ctgccttccg ctttagggtc tgctgctctg gttacagacc taggaagggg agtgcctaat 60
tgggattggt gcagggttgg gagggacccg ctgttttgtc ctgcccacgt ttctctagta 120
gtctgtataa agtcacaact ccaaacacac aggtcagtcc tgctgaagcc agtttgagaa 180
gaccacagca ccagcacc 198
<210> 378
<211> 75
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Atp5o 5'-UTR
NM_138597
<400> 378
ctggcgcgcg cgcgtgcgct ctggcgccag tagtctcttt tcatttgggt ttgacctaca 60
gccgcccggg aaaag 75
<210> 379
<211> 101
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Tspo 5'-UTR
NM_009775
<400> 379
gtcagcggct accaacctct gtgcgcagtg tccttcacgg aacaaccagc gactgcgtga 60
gcggggctgt ggatctttcc agaacatcag ttgcaatcac c 101
<210> 380
<211> 62
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Taldo1 5'-UTR
NM_011528
<400> 380
gacgcgcggg gcattgtggg ttagcacgca ccggctaccg cctcagctgt tcgcgtttcg 60
cc 62
<210> 381
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Bloc1s1 5'-UTR
NM_015740
<400> 381
gtgacgcctt ccgggtgagc caaggcatag tccagttcct gcagccttag ggaggggtcc 60
gccgtgccca cacccagcca gactcgacc 89
<210> 382
<211> 57
<212> DNA
<213> Artificial Sequence
<220>
<223> Mus musculus Hexa 5'-UTR
NM_010421
<400> 382
agctgaccgg ggctcacgtg ggctcagcct gctggaaggg gagctggccg gtgggcc 57
<210> 383
<211> 1810
<212> RNA
<213> Artificial Sequence
<220>
<223> 32L4 - PpLuc(GC) - A64-C30-hSL
<400> 383
gggagaaagc uugaggaugg aggacgccaa gaacaucaag aagggcccgg cgcccuucua 60
cccgcuggag gacgggaccg ccggcgagca gcuccacaag gccaugaagc gguacgcccu 120
ggugccgggc acgaucgccu ucaccgacgc ccacaucgag gucgacauca ccuacgcgga 180
guacuucgag augagcgugc gccuggccga ggccaugaag cgguacggcc ugaacaccaa 240
ccaccggauc guggugugcu cggagaacag ccugcaguuc uucaugccgg ugcugggcgc 300
ccucuucauc ggcguggccg ucgccccggc gaacgacauc uacaacgagc gggagcugcu 360
gaacagcaug gggaucagcc agccgaccgu gguguucgug agcaagaagg gccugcagaa 420
gauccugaac gugcagaaga agcugcccau cauccagaag aucaucauca uggacagcaa 480
gaccgacuac cagggcuucc agucgaugua cacguucgug accagccacc ucccgccggg 540
cuucaacgag uacgacuucg ucccggagag cuucgaccgg gacaagacca ucgcccugau 600
caugaacagc agcggcagca ccggccugcc gaagggggug gcccugccgc accggaccgc 660
cugcgugcgc uucucgcacg cccgggaccc caucuucggc aaccagauca ucccggacac 720
cgccauccug agcguggugc cguuccacca cggcuucggc auguucacga cccugggcua 780
ccucaucugc ggcuuccggg ugguccugau guaccgguuc gaggaggagc uguuccugcg 840
gagccugcag gacuacaaga uccagagcgc gcugcucgug ccgacccugu ucagcuucuu 900
cgccaagagc acccugaucg acaaguacga ccugucgaac cugcacgaga ucgccagcgg 960
gggcgccccg cugagcaagg aggugggcga ggccguggcc aagcgguucc accucccggg 1020
cauccgccag ggcuacggcc ugaccgagac cacgagcgcg auccugauca cccccgaggg 1080
ggacgacaag ccgggcgccg ugggcaaggu ggucccguuc uucgaggcca agguggugga 1140
ccuggacacc ggcaagaccc ugggcgugaa ccagcggggc gagcugugcg ugcgggggcc 1200
gaugaucaug agcggcuacg ugaacaaccc ggaggccacc aacgcccuca ucgacaagga 1260
cggcuggcug cacagcggcg acaucgccua cugggacgag gacgagcacu ucuucaucgu 1320
cgaccggcug aagucgcuga ucaaguacaa gggcuaccag guggcgccgg ccgagcugga 1380
gagcauccug cuccagcacc ccaacaucuu cgacgccggc guggccgggc ugccggacga 1440
cgacgccggc gagcugccgg ccgcgguggu ggugcuggag cacggcaaga ccaugacgga 1500
gaaggagauc gucgacuacg uggccagcca ggugaccacc gccaagaagc ugcggggcgg 1560
cgugguguuc guggacgagg ucccgaaggg ccugaccggg aagcucgacg cccggaagau 1620
ccgcgagauc cugaucaagg ccaagaaggg cggcaagauc gccguguaag acuaguagau 1680
cuaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1740
aaaaaaugca uccccccccc cccccccccc cccccccccc ccaaaggcuc uuuucagagc 1800
caccagaauu 1810
<210> 384
<211> 1927
<212> RNA
<213> Artificial Sequence
<220>
<223> PpLuc(GC) - morn2- A64 - C30 - hSL
<400> 384
gggagaaagc uugaggaugg aggacgccaa gaacaucaag aagggcccgg cgcccuucua 60
cccgcuggag gacgggaccg ccggcgagca gcuccacaag gccaugaagc gguacgcccu 120
ggugccgggc acgaucgccu ucaccgacgc ccacaucgag gucgacauca ccuacgcgga 180
guacuucgag augagcgugc gccuggccga ggccaugaag cgguacggcc ugaacaccaa 240
ccaccggauc guggugugcu cggagaacag ccugcaguuc uucaugccgg ugcugggcgc 300
ccucuucauc ggcguggccg ucgccccggc gaacgacauc uacaacgagc gggagcugcu 360
gaacagcaug gggaucagcc agccgaccgu gguguucgug agcaagaagg gccugcagaa 420
gauccugaac gugcagaaga agcugcccau cauccagaag aucaucauca uggacagcaa 480
gaccgacuac cagggcuucc agucgaugua cacguucgug accagccacc ucccgccggg 540
cuucaacgag uacgacuucg ucccggagag cuucgaccgg gacaagacca ucgcccugau 600
caugaacagc agcggcagca ccggccugcc gaagggggug gcccugccgc accggaccgc 660
cugcgugcgc uucucgcacg cccgggaccc caucuucggc aaccagauca ucccggacac 720
cgccauccug agcguggugc cguuccacca cggcuucggc auguucacga cccugggcua 780
ccucaucugc ggcuuccggg ugguccugau guaccgguuc gaggaggagc uguuccugcg 840
gagccugcag gacuacaaga uccagagcgc gcugcucgug ccgacccugu ucagcuucuu 900
cgccaagagc acccugaucg acaaguacga ccugucgaac cugcacgaga ucgccagcgg 960
gggcgccccg cugagcaagg aggugggcga ggccguggcc aagcgguucc accucccggg 1020
cauccgccag ggcuacggcc ugaccgagac cacgagcgcg auccugauca cccccgaggg 1080
ggacgacaag ccgggcgccg ugggcaaggu ggucccguuc uucgaggcca agguggugga 1140
ccuggacacc ggcaagaccc ugggcgugaa ccagcggggc gagcugugcg ugcgggggcc 1200
gaugaucaug agcggcuacg ugaacaaccc ggaggccacc aacgcccuca ucgacaagga 1260
cggcuggcug cacagcggcg acaucgccua cugggacgag gacgagcacu ucuucaucgu 1320
cgaccggcug aagucgcuga ucaaguacaa gggcuaccag guggcgccgg ccgagcugga 1380
gagcauccug cuccagcacc ccaacaucuu cgacgccggc guggccgggc ugccggacga 1440
cgacgccggc gagcugccgg ccgcgguggu ggugcuggag cacggcaaga ccaugacgga 1500
gaaggagauc gucgacuacg uggccagcca ggugaccacc gccaagaagc ugcggggcgg 1560
cgugguguuc guggacgagg ucccgaaggg ccugaccggg aagcucgacg cccggaagau 1620
ccgcgagauc cugaucaagg ccaagaaggg cggcaagauc gccguguaag acuaguaccu 1680
gcugccuuaa cgcugagaug uggccucugc aaccccccuu aggcaaagca acugaaccuu 1740
cugcuaaagu gaccugcccu cuuccguaag uccaauaaag uugucaugca cccagaucua 1800
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1860
aaaugcaucc cccccccccc cccccccccc ccccccccca aaggcucuuu ucagagccac 1920
cagaauu 1927
<210> 385
<211> 1943
<212> RNA
<213> Artificial Sequence
<220>
<223> PpLuc(GC) - ndufa1- A64 - C30 - hSL
<400> 385
gggagaaagc uugaggaugg aggacgccaa gaacaucaag aagggcccgg cgcccuucua 60
cccgcuggag gacgggaccg ccggcgagca gcuccacaag gccaugaagc gguacgcccu 120
ggugccgggc acgaucgccu ucaccgacgc ccacaucgag gucgacauca ccuacgcgga 180
guacuucgag augagcgugc gccuggccga ggccaugaag cgguacggcc ugaacaccaa 240
ccaccggauc guggugugcu cggagaacag ccugcaguuc uucaugccgg ugcugggcgc 300
ccucuucauc ggcguggccg ucgccccggc gaacgacauc uacaacgagc gggagcugcu 360
gaacagcaug gggaucagcc agccgaccgu gguguucgug agcaagaagg gccugcagaa 420
gauccugaac gugcagaaga agcugcccau cauccagaag aucaucauca uggacagcaa 480
gaccgacuac cagggcuucc agucgaugua cacguucgug accagccacc ucccgccggg 540
cuucaacgag uacgacuucg ucccggagag cuucgaccgg gacaagacca ucgcccugau 600
caugaacagc agcggcagca ccggccugcc gaagggggug gcccugccgc accggaccgc 660
cugcgugcgc uucucgcacg cccgggaccc caucuucggc aaccagauca ucccggacac 720
cgccauccug agcguggugc cguuccacca cggcuucggc auguucacga cccugggcua 780
ccucaucugc ggcuuccggg ugguccugau guaccgguuc gaggaggagc uguuccugcg 840
gagccugcag gacuacaaga uccagagcgc gcugcucgug ccgacccugu ucagcuucuu 900
cgccaagagc acccugaucg acaaguacga ccugucgaac cugcacgaga ucgccagcgg 960
gggcgccccg cugagcaagg aggugggcga ggccguggcc aagcgguucc accucccggg 1020
cauccgccag ggcuacggcc ugaccgagac cacgagcgcg auccugauca cccccgaggg 1080
ggacgacaag ccgggcgccg ugggcaaggu ggucccguuc uucgaggcca agguggugga 1140
ccuggacacc ggcaagaccc ugggcgugaa ccagcggggc gagcugugcg ugcgggggcc 1200
gaugaucaug agcggcuacg ugaacaaccc ggaggccacc aacgcccuca ucgacaagga 1260
cggcuggcug cacagcggcg acaucgccua cugggacgag gacgagcacu ucuucaucgu 1320
cgaccggcug aagucgcuga ucaaguacaa gggcuaccag guggcgccgg ccgagcugga 1380
gagcauccug cuccagcacc ccaacaucuu cgacgccggc guggccgggc ugccggacga 1440
cgacgccggc gagcugccgg ccgcgguggu ggugcuggag cacggcaaga ccaugacgga 1500
gaaggagauc gucgacuacg uggccagcca ggugaccacc gccaagaagc ugcggggcgg 1560
cgugguguuc guggacgagg ucccgaaggg ccugaccggg aagcucgacg cccggaagau 1620
ccgcgagauc cugaucaagg ccaagaaggg cggcaagauc gccguguaag acuaguggaa 1680
gcauuuuccu ggcugauuaa aagaaauuac ucagcuaugg ucaucuguuc cuguuagaag 1740
gcuaugcagc auauuauaua cuaugcgcau guuaugaaau gcauaauaaa aaauuuuaaa 1800
aaaucuaaaa gaucuaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1860
aaaaaaaaaa aaaaaaaaau gcaucccccc cccccccccc cccccccccc cccccaaagg 1920
cucuuuucag agccaccaga auu 1943
<210> 386
<211> 1941
<212> RNA
<213> Artificial Sequence
<220>
<223> PpLuc(GC) - NDUFA1- A64 - C30 - hSL
<400> 386
gggagaaagc uugaggaugg aggacgccaa gaacaucaag aagggcccgg cgcccuucua 60
cccgcuggag gacgggaccg ccggcgagca gcuccacaag gccaugaagc gguacgcccu 120
ggugccgggc acgaucgccu ucaccgacgc ccacaucgag gucgacauca ccuacgcgga 180
guacuucgag augagcgugc gccuggccga ggccaugaag cgguacggcc ugaacaccaa 240
ccaccggauc guggugugcu cggagaacag ccugcaguuc uucaugccgg ugcugggcgc 300
ccucuucauc ggcguggccg ucgccccggc gaacgacauc uacaacgagc gggagcugcu 360
gaacagcaug gggaucagcc agccgaccgu gguguucgug agcaagaagg gccugcagaa 420
gauccugaac gugcagaaga agcugcccau cauccagaag aucaucauca uggacagcaa 480
gaccgacuac cagggcuucc agucgaugua cacguucgug accagccacc ucccgccggg 540
cuucaacgag uacgacuucg ucccggagag cuucgaccgg gacaagacca ucgcccugau 600
caugaacagc agcggcagca ccggccugcc gaagggggug gcccugccgc accggaccgc 660
cugcgugcgc uucucgcacg cccgggaccc caucuucggc aaccagauca ucccggacac 720
cgccauccug agcguggugc cguuccacca cggcuucggc auguucacga cccugggcua 780
ccucaucugc ggcuuccggg ugguccugau guaccgguuc gaggaggagc uguuccugcg 840
gagccugcag gacuacaaga uccagagcgc gcugcucgug ccgacccugu ucagcuucuu 900
cgccaagagc acccugaucg acaaguacga ccugucgaac cugcacgaga ucgccagcgg 960
gggcgccccg cugagcaagg aggugggcga ggccguggcc aagcgguucc accucccggg 1020
cauccgccag ggcuacggcc ugaccgagac cacgagcgcg auccugauca cccccgaggg 1080
ggacgacaag ccgggcgccg ugggcaaggu ggucccguuc uucgaggcca agguggugga 1140
ccuggacacc ggcaagaccc ugggcgugaa ccagcggggc gagcugugcg ugcgggggcc 1200
gaugaucaug agcggcuacg ugaacaaccc ggaggccacc aacgcccuca ucgacaagga 1260
cggcuggcug cacagcggcg acaucgccua cugggacgag gacgagcacu ucuucaucgu 1320
cgaccggcug aagucgcuga ucaaguacaa gggcuaccag guggcgccgg ccgagcugga 1380
gagcauccug cuccagcacc ccaacaucuu cgacgccggc guggccgggc ugccggacga 1440
cgacgccggc gagcugccgg ccgcgguggu ggugcuggag cacggcaaga ccaugacgga 1500
gaaggagauc gucgacuacg uggccagcca ggugaccacc gccaagaagc ugcggggcgg 1560
cgugguguuc guggacgagg ucccgaaggg ccugaccggg aagcucgacg cccggaagau 1620
ccgcgagauc cugaucaagg ccaagaaggg cggcaagauc gccguguaag acuaguggaa 1680
gcauuuuccu gauugaugaa aaaaauaacu caguuauggc caucuacccc ugcuagaagg 1740
uuacagugua uuauguagca ugcaaugugu uauguagugc uuaauaaaaa uaaaaugaaa 1800
aaaaugcaga ucuaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1860
aaaaaaaaaa aaaaaaaugc aucccccccc cccccccccc cccccccccc cccaaaggcu 1920
cuuuucagag ccaccagaau u 1941
<210> 387
<211> 1861
<212> RNA
<213> Artificial Sequence
<220>
<223> Mp68 - PpLuc(GC) - A64 - C30 - hSL
<400> 387
gggcuuuccc auucuguagc agaauuuggu guugccugug gucuuggucc cgcggagaag 60
cuugaggaug gaggacgcca agaacaucaa gaagggcccg gcgcccuucu acccgcugga 120
ggacgggacc gccggcgagc agcuccacaa ggccaugaag cgguacgccc uggugccggg 180
cacgaucgcc uucaccgacg cccacaucga ggucgacauc accuacgcgg aguacuucga 240
gaugagcgug cgccuggccg aggccaugaa gcgguacggc cugaacacca accaccggau 300
cguggugugc ucggagaaca gccugcaguu cuucaugccg gugcugggcg cccucuucau 360
cggcguggcc gucgccccgg cgaacgacau cuacaacgag cgggagcugc ugaacagcau 420
ggggaucagc cagccgaccg ugguguucgu gagcaagaag ggccugcaga agauccugaa 480
cgugcagaag aagcugccca ucauccagaa gaucaucauc auggacagca agaccgacua 540
ccagggcuuc cagucgaugu acacguucgu gaccagccac cucccgccgg gcuucaacga 600
guacgacuuc gucccggaga gcuucgaccg ggacaagacc aucgcccuga ucaugaacag 660
cagcggcagc accggccugc cgaagggggu ggcccugccg caccggaccg ccugcgugcg 720
cuucucgcac gcccgggacc ccaucuucgg caaccagauc aucccggaca ccgccauccu 780
gagcguggug ccguuccacc acggcuucgg cauguucacg acccugggcu accucaucug 840
cggcuuccgg gugguccuga uguaccgguu cgaggaggag cuguuccugc ggagccugca 900
ggacuacaag auccagagcg cgcugcucgu gccgacccug uucagcuucu ucgccaagag 960
cacccugauc gacaaguacg accugucgaa ccugcacgag aucgccagcg ggggcgcccc 1020
gcugagcaag gaggugggcg aggccguggc caagcgguuc caccucccgg gcauccgcca 1080
gggcuacggc cugaccgaga ccacgagcgc gauccugauc acccccgagg gggacgacaa 1140
gccgggcgcc gugggcaagg uggucccguu cuucgaggcc aagguggugg accuggacac 1200
cggcaagacc cugggcguga accagcgggg cgagcugugc gugcgggggc cgaugaucau 1260
gagcggcuac gugaacaacc cggaggccac caacgcccuc aucgacaagg acggcuggcu 1320
gcacagcggc gacaucgccu acugggacga ggacgagcac uucuucaucg ucgaccggcu 1380
gaagucgcug aucaaguaca agggcuacca gguggcgccg gccgagcugg agagcauccu 1440
gcuccagcac cccaacaucu ucgacgccgg cguggccggg cugccggacg acgacgccgg 1500
cgagcugccg gccgcggugg uggugcugga gcacggcaag accaugacgg agaaggagau 1560
cgucgacuac guggccagcc aggugaccac cgccaagaag cugcggggcg gcgugguguu 1620
cguggacgag gucccgaagg gccugaccgg gaagcucgac gcccggaaga uccgcgagau 1680
ccugaucaag gccaagaagg gcggcaagau cgccguguaa gacuaguaga ucuaaaaaaa 1740
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaugc 1800
aucccccccc cccccccccc cccccccccc cccaaaggcu cuuuucagag ccaccagaau 1860
u 1861
<210> 388
<211> 1888
<212> RNA
<213> Artificial Sequence
<220>
<223> Ndufa4 - PpLuc(GC) - A64 - C30 - hSL
<400> 388
gggguccgcu cagccagguu gcagaagcgg cuuagcgugu guccuaaucu ucucucugcg 60
uguagguagg ccugugccgc aaacaagcuu gaggauggag gacgccaaga acaucaagaa 120
gggcccggcg cccuucuacc cgcuggagga cgggaccgcc ggcgagcagc uccacaaggc 180
caugaagcgg uacgcccugg ugccgggcac gaucgccuuc accgacgccc acaucgaggu 240
cgacaucacc uacgcggagu acuucgagau gagcgugcgc cuggccgagg ccaugaagcg 300
guacggccug aacaccaacc accggaucgu ggugugcucg gagaacagcc ugcaguucuu 360
caugccggug cugggcgccc ucuucaucgg cguggccguc gccccggcga acgacaucua 420
caacgagcgg gagcugcuga acagcauggg gaucagccag ccgaccgugg uguucgugag 480
caagaagggc cugcagaaga uccugaacgu gcagaagaag cugcccauca uccagaagau 540
caucaucaug gacagcaaga ccgacuacca gggcuuccag ucgauguaca cguucgugac 600
cagccaccuc ccgccgggcu ucaacgagua cgacuucguc ccggagagcu ucgaccggga 660
caagaccauc gcccugauca ugaacagcag cggcagcacc ggccugccga aggggguggc 720
ccugccgcac cggaccgccu gcgugcgcuu cucgcacgcc cgggacccca ucuucggcaa 780
ccagaucauc ccggacaccg ccauccugag cguggugccg uuccaccacg gcuucggcau 840
guucacgacc cugggcuacc ucaucugcgg cuuccgggug guccugaugu accgguucga 900
ggaggagcug uuccugcgga gccugcagga cuacaagauc cagagcgcgc ugcucgugcc 960
gacccuguuc agcuucuucg ccaagagcac ccugaucgac aaguacgacc ugucgaaccu 1020
gcacgagauc gccagcgggg gcgccccgcu gagcaaggag gugggcgagg ccguggccaa 1080
gcgguuccac cucccgggca uccgccaggg cuacggccug accgagacca cgagcgcgau 1140
ccugaucacc cccgaggggg acgacaagcc gggcgccgug ggcaaggugg ucccguucuu 1200
cgaggccaag gugguggacc uggacaccgg caagacccug ggcgugaacc agcggggcga 1260
gcugugcgug cgggggccga ugaucaugag cggcuacgug aacaacccgg aggccaccaa 1320
cgcccucauc gacaaggacg gcuggcugca cagcggcgac aucgccuacu gggacgagga 1380
cgagcacuuc uucaucgucg accggcugaa gucgcugauc aaguacaagg gcuaccaggu 1440
ggcgccggcc gagcuggaga gcauccugcu ccagcacccc aacaucuucg acgccggcgu 1500
ggccgggcug ccggacgacg acgccggcga gcugccggcc gcgguggugg ugcuggagca 1560
cggcaagacc augacggaga aggagaucgu cgacuacgug gccagccagg ugaccaccgc 1620
caagaagcug cggggcggcg ugguguucgu ggacgagguc ccgaagggcc ugaccgggaa 1680
gcucgacgcc cggaagaucc gcgagauccu gaucaaggcc aagaagggcg gcaagaucgc 1740
cguguaagac uaguagaucu aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1800
aaaaaaaaaa aaaaaaaaaa aaaaugcauc cccccccccc cccccccccc cccccccccc 1860
aaaggcucuu uucagagcca ccagaauu 1888
<---
Реферат
Изобретение относится к молекуле искусственной нуклеиновой кислоты, для экспрессии белка или пептида in vitro, включающей по меньшей мере одну открытую рамку считывания и по меньшей мере один элемент 3'-нетранслируемой области, причем по меньшей мере один элемент 3'-UTR продлевает и/или увеличивает выработку белка указанной молекулы искусственной нуклеиновой кислоты и происходит от стабильной мРНК, в которой по меньшей мере один элемент 3'-UTR содержит или состоит из последовательности нуклеиновой кислоты, которая происходит от 3'-UTR транскрипта – GNAS. Изобретение также относится к вектору и клетке для обеспечения транскрипции молекулы нуклеиновой кислоты, способу получения белка или пептида, синтезируемого искусственной молекулой нуклеиновой кислоты и применению элемента 3'-UTR и/или элемента 5'-UTR для получения белка или пептида in vitro за счет увеличения и/или продления его выработки молекулой искусственной нуклеиновой кислоты или вектором. 5 н. и 14 з.п. ф-лы, 9 пр., 30 ил., 10 табл.
Комментарии