Неинвазивная диагностика путем секвенирования 5-гидроксиметилированной бесклеточной днк - RU2742355C2
Код документа: RU2742355C2
Чертежи













Описание
Перекрестные ссылки
Настоящая заявка претендует на приоритет от предварительной заявки на патент США No. 62/319,702, поданной 7 апреля 2016 г., No. 62/444,122, поданной 9 января 2017 г., и No. 62/461,712, поданной 21 февраля 2017 г., которые включены сюда во всей полноте путем ссылки.
Уровень техники
Модификации ДНК в виде 5-метилцитозина (5mC) и недавно идентифицированного 5-гидроксиметилцитозина (5hmC) представляют две главные эпигенетические метки, обнаруженные в геноме млекопитающих, и они влияют на широкий круг биологических процессов от регуляции генов до нормального развития. Выявление аномальных изменений 5mC и 5hmC в бесклеточной ДНК (cfDNA, бкДНК) может составлять привлекательный неинвазивный подход к диагностике рака. БкДНК - это циркулирующая ДНК, которая встречается в нашей крови и происходит из разных тканей, которая уже используется для неинвазивных пренатальных анализов, диагностики трансплантатов органов и выявления рака. В сравнении с интенсивными исследованиями по бесклеточной 5mC-ДНК в качестве биомаркера для диагностики рака, бесклеточная 5hmC-ДНК остается неиспользованной, главным образом из-за низкого уровня 5hmC по сравнению с 5mC в геноме человека (в 10-100 раз меньше, чем 5mC), а также отсутствия чувствительного метода секвенирования небольших количеств 5hmC при работе с очень маленьким количеством бкДНК (как правило, всего несколько нанограмм на мл плазмы).
Сущность изобретения
Предусмотрен, среди прочего, способ секвенирования гидроксиметилированной ДНК в образцах циркулирующей бесклеточной ДНК. В некоторых воплощениях способ включает введение аффинной метки только в молекулы гидроксиметилированной ДНК в образце бкДНК, обогащение молекул ДНК, помеченных аффинной меткой, и секвенирование обогащенных молекул ДНК.
В некоторых воплощениях способ включает: добавление адаптерных последовательностей на концы бкДНК; инкубирование лигированной с адаптером бкДНК с ДНК-β-глюкозилтрансферазой и UDP-глюкозой, модифицированной хемоселективной группой, при этом происходит ковалентное мечение молекул гидроксиметилированной ДНК в бкДНК хемоселективной группой; присоединение биотинового компонента к хемоселективно модифицированной бкДНК по реакции циклоприсоединения; обогащение биотинилированных молекул ДНК путем связывания с носителем, связывающимся с биотином; амплификацию обогащенной ДНК с помощью праймеров, связывающихся с адаптерами; и секвенирование амплифицированной ДНК с получением множества прочтений последовательности.
Также предусмотрен способ, включающий: (а) получение образца, содержащего циркулирующую бесклеточную ДНК, (b) обогащение гидроксиметилированной ДНК в образце и (с) независимое определение количества таких нуклеиновых кислот в обогащенной гидроксиметилированной ДНК, которые картируются по одному или каждому из нескольких целевых локусов.
Среди прочего, последовательности, полученные данным способом, можно использовать, к примеру, в качестве средств диагностики, тераностики или прогнозирования для различных заболеваний или состояний.
Также предусмотрены различные композиции, включая композиции, содержащие циркулирующую бесклеточную ДНК, причем остатки гидроксиметилцитозина в ДНК модифицированы так, чтобы они содержали метку захвата.
Далее эти и другие особенности настоящего изобретения изложены подробно.
Краткое описание фигур
Специалистам должно быть понятно, что описанные ниже чертежи приводятся только для иллюстрации. Эти чертежи не должны никоим образом ограничивать объем настоящего изобретения.
Фиг. 1A-1C. Секвенирование 5hmC в бкДНК. Фиг. 1A. Общая процедура секвенирования бесклеточного 5hmC. БкДНК лигируется с адаптером Illumina и метится биотином по 5hmC для выделения с помощью стрептавидиновых шариков. Конечная библиотека составляется методом ПЦР прямо из стрептавидиновых гранул. Фиг. 1B. Процент прочтений, относящихся к добавленной контрольной ДНК в библиотеках для секвенирования. Планки погрешностей означают S.D. Фиг. 1C. Метагенные профили log2 изменения бесклеточного 5hmC относительно исходной бкДНК в генах, ранжированных по уровню их экспрессии при секвенировании бесклеточной РНК.
Фиг. 2A-2D. Рак легких ведет к прогрессирующей потере обогащения 5hmC в бкДНК. Фиг. 2A. Распределение бесклеточного 5hmC в районе 10 mb на хромосоме 6 в геномном браузере. Представлено совмещение записей от здоровых образцов, образцов неметастатического рака легких, метастатического рака легких и исходной бкДНК в виде линейных графиков. Фиг. 2B. Теплокарта 1159 дифференциальных генов метастатического рака легких в здоровых образцах, образцах рака легких и необогащенной исходной бкДНК. Проводилась иерархическая кластеризация по генам и образцам. Фиг. 2C. Ящичковая диаграмма количества hMRs, выявленных в каждой группе (нормировано на 1 миллион прочтений). Фиг. 2D. Ящичковые диаграммы FPKM 5hmC у CCNY и PDIA6 в образцах рака легких и других образцах бкДНК. * p<0,05, ** p<0,01, *** p<0,001, **** p<10-5, t-критерий Уэлча.
Фиг. 3A-3E. Бесклеточный 5hmC для мониторинга прогрессирования и лечения HCC. Фиг. 3A. График tSNE по FPKM 5hmC из здоровых образцов, образцов HBV и HCC. Фиг. 3B. Теплокарта 1006 дифференциальных генов HCC в здоровых образцах, образцах HBV и HCC. Проводилась иерархическая кластеризация по генам и образцам. Фиг. 3C-3D. Ящичковые диаграммы AHSG (фиг. 3C) и MTBP (фиг. 3D) 5hmC FPKM в образцах HBV, HCC (до операции), HCC после операции, рецидивов HCC и других образцах бкДНК. * p<0,05, ** p<10-4, *** p<10-5, t-критерий Уэлча. Фиг. 3E. График tSNE по FPKM 5hmC из здоровых образцов, образцов HCC до операции, HCC после операции и рецидивов HCC.
Фиг. 4A-4C. Предсказание типа и стадии рака по бесклеточному 5hmC. Фиг. 4A. График tSNE по FPKM 5hmC в бкДНК из здоровых образцов и различных раковых образцов. Фиг. 4B. Фактическая и прогнозируемая классификация при кросс-валидации с одним пропуском по алгоритмам Mclust (MC) и Random Forest (RF) на основе набора по двум признакам (тело гена и DhMR). Фиг. 4C. Каппа-коэффициент Коэна для измерения согласия между классификаторами (GB означает тело гена). Планки погрешностей означают стандартную ошибку оценки каппа-коэффициента Коэна.
Фиг. 5A-5F. Секвенирование бесклеточного 5hmC модифицированным методом hMe-Seal. Фиг. 5A. Реакции hMe-Seal. 5hmC в ДНК метится модифицированной азидом глюкозой при помощи βGT, а затем соединяется с группой биотина методами клик-химии. Фиг. 5B. Проверка на обогащение одного пула ампликонов, содержащих C, 5mC или 5hmC, добавленных к бкДНК. Анализ геля показывает, что после hMe-Seal только 5hmC-содержащие ампликоны подвергаются ПЦР на стрептавидиновых гранулах. Фиг. 5C. Ящичковая диаграмма глубины секвенирования по всем бесклеточным образцам. Фиг. 5D. Ящичковая диаграмма показателя уникального недвойственного картирования по всем бесклеточным образцам. Фиг. 5E. MA-график нормированного количества прочтений бесклеточного 5hmC (прочтений на 1 миллион) при разбиении по 10 kb по всему геному между техническими пробами. Горизонтальная синяя линия M=0 означает одинаковые значения в двух пробах. Кривая наименьшего соответствия (красная) означает возможный тренд смещения, связанного со средним значением. Фиг. 5F. Диаграмма Венна перекрывания hMR между техническими повторами секвенирования бесклеточного 5hmC и сборным образцом из обеих проб.
Фиг. 6A-6D. Геномное распределение 5hmC в бкДНК. Фиг. 6A. Распределение 5hmC в районе 10 mb на хромосоме 20 в геномном браузере. Представлены записи от обогащенной бкДНК и гДНК из цельной крови вместе с необогащенной исходной бкДНК. Фиг. 6B. Круговая диаграмма общего геномного распределения hMR в бкДНК. Фиг. 6C. Относительное обогащение hMRs по различным участкам генома в бкДНК и гДНК из цельной крови. Фиг. 6D. График tSNE по FPKM 5hmC в бкДНК и гДНК цельной крови из здоровых образцов.
Фиг. 7A-7E. Дифференциальные сигналы 5hmC между бкДНК и гДНК из цельной крови. Фиг. 7A. Теплокарта 2082 дифференциальных генов между бкДНК и гДНК крови. Проводилась иерархическая кластеризация по генам и образцам. Фиг. 7B. Ящичковая диаграмма уровня экспрессии обогащенных 5hmC генов в бкДНК и гДНК из цельной крови. Сверху приведены значения p. Фиг. 7C и 7D. GO-анализ обогащенных 5hmC генов, специфичных для цельной крови (фиг. 7C) и для бкДНК (фиг. 7D), при пороге отсечения значений p в 0,001. Фиг. 7E. Распределение 5hmC в локусах FPR1/FPR2 (сверху) и GLP1R (внизу) в геномном браузере. Представлено совмещение записей от бкДНК, гДНК цельной крови и исходной бкДНК в виде линейных графиков.
Фиг. 8A-8D. Бесклеточный гидроксиметилом при раке легких. Фиг. 8A. График tSNE по FPKM 5hmC из здоровых образцов, образцов неметастатического рака легких и метастатического рака легких, а также необогащенной исходной бкДНК. Фиг. 8B. Метагенные профили бесклеточного 5hmC в здоровой группе и различных раковых группах вместе с необогащенной исходной бкДНК. Заштрихованные участки означают S.E.M. Фиг. 8C. Процент прочтений, картированных относительно добавленной контрольной ДНК в библиотеках для секвенирования из различных групп. Планки погрешностей означают S.D. Фиг. 8D. Распределение бесклеточного 5hmC в локусах CREM/CCNY (слева) и ATP6V1C2/PDIA6 (справа) в здоровых образцах и образцах рака легких в геномном браузере. Представлено совмещение записей в виде линейных графиков.
Фиг. 9A-9E. Бесклеточный гидроксиметилом при HCC. Фиг. 9A. Ящичковая диаграмма уровня экспрессии специфичных для HCC обогащенных и обедненных 5hmC генов в ткани печени. Сверху приведены значения p. Фиг. 9B. Распределение бесклеточного 5hmC в локусе AHSG в здоровых образцах, образцах HBV и HCC в геномном браузере. Представлено совмещение записей в виде линейных графиков. Фиг. 9C. Экспрессия AHSG в печени и других тканях. Фиг. 9D. Распределение бесклеточного 5hmC в локусе MTBP в здоровых образцах, образцах HBV и HCC в геномном браузере. Представлено совмещение записей в виде линейных графиков. Фиг. 9E. Изменения показателя HCC в 4 случаях последующего наблюдения HCC. Внизу представлено состояние заболевания. Сверху представлено время в месяцах. Пунктирные линии представляют медианные значения показателей HCC в группах HCC, HBV и здоровой группе. Треугольники означают лечение. Показатель HCC представляет собой линейную комбинацию из 1006 дифференциальных генов HCC (фиг. 3B), которые наилучшим образом отделяют образцы HCC от HBV и здоровых образцов.
Фиг. 10A-10E. Бесклеточный гидроксиметилом при раке поджелудочной железы. Фиг. 10А. Теплокарта 713 дифференциальных генов рака поджелудочной железы в здоровых образцах и образцах рака поджелудочной железы. Проводилась иерархическая кластеризация по генам и образцам. Фиг. 10B и 10C. Ящичковые диаграммы по FPKM 5hmC в локусах ZFP36L1, DCXR (фиг. 10B) и GPR21, SLC19A3 (фиг.10C) в образцах рака поджелудочной железы и других образцах бкДНК. * p<0,001, ** p<10-5, t-критерий Уэлча. Фиг. 10D и 10E. Распределение бесклеточного 5hmC в локусах ZFP36L1, DCXR (фиг. 10D) и GPR21, SLC19A3 (фиг. 10E) в здоровых образцах и образцах рака поджелудочной железы в геномном браузере. Представлено совмещение записей в виде линейных графиков.
Фиг. 11A-11D. Бесклеточный гидроксиметилом в раковых образцах. Фиг. 11A. График tSNE по FPKM промоторов 5hmC (отстоящих на 5 kb выше от TSS) из здоровых образцов и различных раковых образцов. Фиг. 11B. График tSNE по FPKM 5hmC из здоровых образцов и различных раковых образцов бкДНК вместе с образцами гДНК из цельной крови. Фиг. 11C. Возрастное распределение здоровых лиц и различных больных раком. Фиг. 11D. График tSNE по FPKM 5hmC в бкДНК из здоровых образцов и различных раковых образцов (фиг. 4A), расцвеченных по партиям, пронумерованным в соответствии с продолжительностью процесса.
Фиг. 12A-12G. Предсказание типа и стадии рака по бесклеточному 5hmC. Фиг. 12A и 12B. График байесовского информационного критерия (BIC) по Mclust при обучении по набору из 90 значений признака тела гена (фиг. 12A) и 17 значений признака DhMR (фиг. 12B), указывающий на высокое значение BIC при разбиении на пять групп с использованием модели EEI для Mclust. Фиг. 12C. 4-Мерный график уменьшения размерности на основе Mclust с использованием признака DhMR. В нижней части представлен график разброса, а в верхней части - график плотности. Фиг. 12D и 12E. Важность переменных (среднее снижение Gini) для самых верхних 15 тел генов (фиг. 12D) и DhMRs (фиг. 12E) в обучающейся модели типа случайного леса. На фиг. 12F и 12G представлена важность переменных для тел генов и DhMRs, полученная другим методом.
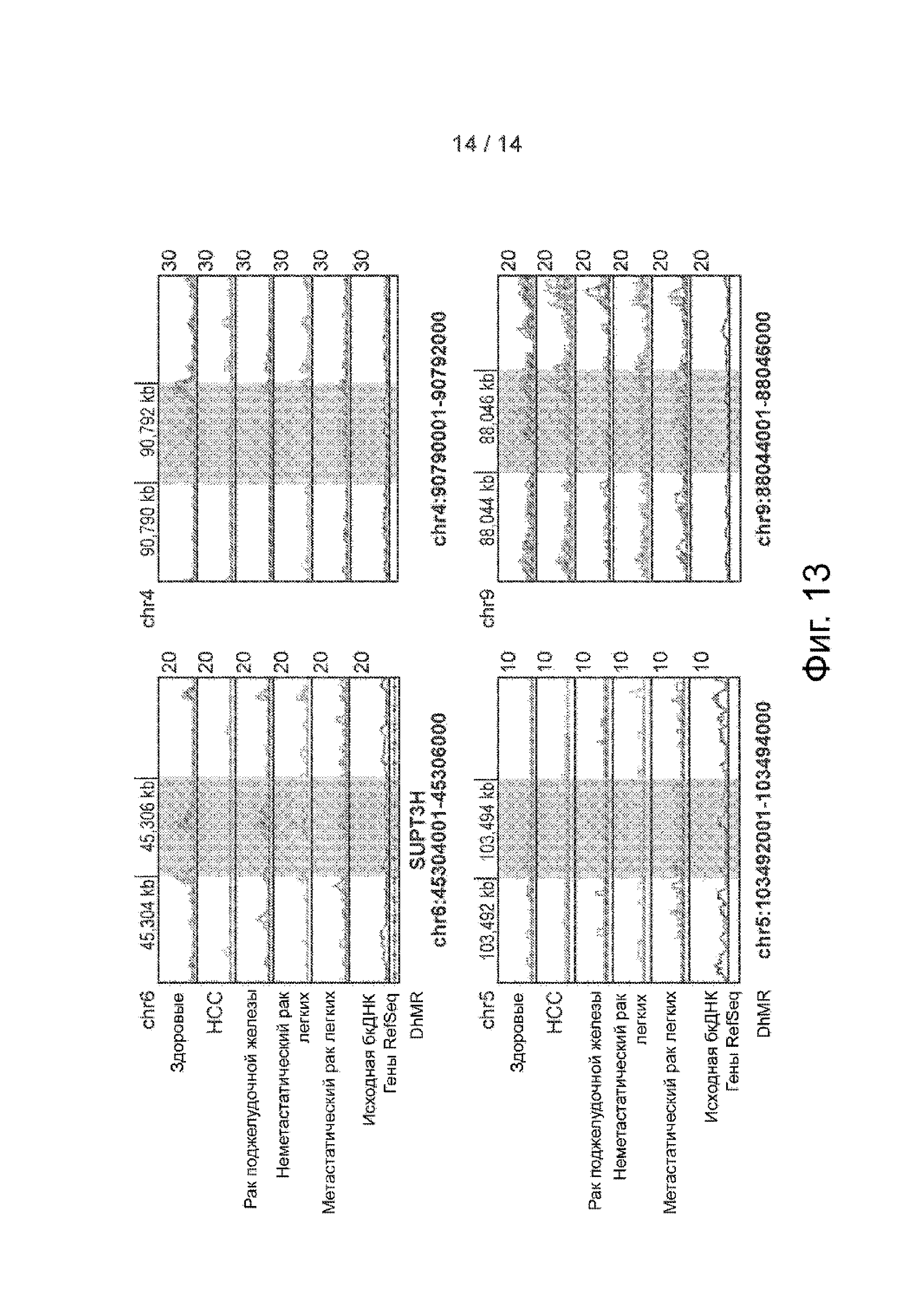
Фиг. 13. Примеры DhMRs в модели случайного леса. Распределение бесклеточного 5hmC в четырех DhMR с высокой значимостью переменной в модели случайного леса в различных группах в виде геномного браузера. Представлено совмещение записей в виде линейных графиков. Заштрихованные участки означают DhMRs.
Определения
Если не указано иначе, все технические и научные термины, используемые здесь, имеют такие же значения, которые обычно понимается рядовыми специалистами в той области техники, к которой относится настоящее изобретение. Хотя при практическом применении или тестировании настоящего изобретения могут применяться любые способы и материалы, аналогичные или эквивалентные описанным здесь, однако предпочтительны описанные способы и материалы.
Все патенты и публикации, упомянутые здесь, включая все последовательности, приведенные в таких патентах и публикациях, прямо включены сюда путем ссылки.
Числовые диапазоны включают числа, определяющие диапазон. Если не указано иначе, нуклеиновые кислоты записаны слева направо в ориентации от 5'- к 3'-концу; аминокислотные последовательности записаны слева направо в ориентации от N- к C-концу, соответственно.
Приведенные здесь заголовки не налагают ограничений на различные аспекты или воплощения изобретения. Соответственно, приведенные ниже термины более полно определяются со ссылкой на все описание в целом.
Если не указано иначе, все технические и научные термины, используемые здесь, имеют такие же значения, которые обычно понимаются рядовыми специалистами в той области техники, к которой относится настоящее изобретение. Общие значения многих терминов, используемых здесь, приведены в Singleton et al., Dictionary of Microbiology and Molecular Biology, 2nd Ed., John Wiley and Sons, New York (1994); и Hale & Markham, The Harper Collins Dictionary of Biology, Harper Perennial, N.Y. (1991). Тем не менее, для четкости и удобства ссылки некоторые термины определены ниже.
Термин “образец” в настоящем изобретении означает материал или смесь материалов, как правило, хотя и необязательно, в жидком виде, содержащих одно или несколько анализируемых веществ.
Термин “образец нуклеиновой кислоты” в настоящем изобретении означает образец, содержащий нуклеиновые кислоты. Используемые здесь образцы нуклеиновой кислоты могут быть сложными в том, что они содержат несколько различных молекул, содержащих последовательности. Примером сложных образцов является геномная ДНК млекопитающих (например, мыши или человека). Сложные образцы могут содержать более 104, 105, 106 или 107 различных молекул нуклеиновой кислоты. ДНК-мишень может происходить из любого источника типа геномной ДНК или искусственной конструкции из ДНК. При этом можно использовать любые образцы, содержащие нуклеиновую кислоту, например, геномную ДНК, полученную из клеток культуры ткани или образца ткани. Образец нуклеиновой кислоты может быть получен из любого подходящего источника, включая образцы зубов, костей, волос или костей и т.п.
Термин “нуклеотид” охватывает такие молекулы, которые содержат не только известные пуриновые и пиримидиновые основания, но и другие гетероциклические основания, подвергавшиеся модификации. Такие модификации включают метилированные пурины или пиримидины, ацилированные пурины или пиримидины, алкилированные рибозы или другие гетероциклы. Кроме того, термин “нуклеотид” охватывает и такие молекулы, которые содержат гаптены или флуоресцентные метки и могут содержать не только обычные сахара рибозы и дезоксирибозы, но и другие сахара. Модифицированные нуклеозиды или нуклеотиды включают и такие модификации сахаров, например, при которых одна или несколько гидроксильных групп заменены на атомы галогенов или алифатические группы либо функционализированы в виде простых эфиров, аминов и т.п.
Термины “нуклеиновая кислота” и “полинуклеотид” применяются здесь взаимозаменяемо для описания полимеров любой длины, например, более 2 оснований, более 10 оснований, более 100 оснований, более 500 оснований, более 1000 оснований и вплоть до 10000 или больше оснований, состоящих из нуклеотидов, например, дезоксирибонуклеотидов или рибонуклеотидов, и могут быть получены ферментативным или синтетическим путем (например, ПНК, как описано в U.S. Patent No. 5,948,902 и приведенных в нем ссылках), которые могут гибридизироваться с природными нуклеиновыми кислотами специфичным для последовательности образом аналогично гибридизации двух природных нуклеиновых кислот, например, могут участвовать во взаимодействиях типа парных оснований Ватсона-Крика. Природные нуклеотиды включают гуанин, цитозин, аденин и тимин (G, C, A и T, соответственно). ДНК и РНК имеют остов из сахара дезоксирибозы или рибозы, соответственно, тогда как остов ПНК состоит из повторяющихся звеньев N-(2-аминоэтил)глицина, соединенных пептидными связями. В ПНК различные пуриновые и пиримидиновые основания соединяются с остовом метиленкарбонильными связями. Закрытая нуклеиновая кислота (LNA), часто называемая недоступной РНК, состоит из модифицированных РНК-нуклеотидов. Рибозная часть нуклеотидов LNA модифицирована дополнительным мостиком, соединяющим 2'-кислород и 4'-углерод. Мостик “блокирует” рибозу в конформации 3'-эндо (North), которая часто встречается в дуплексах A-формы. При необходимости LNA-нуклеотиды могут быть смешаны с остатками ДНК или РНК в олигонуклеотидах. Термин “неструктурированная нуклеиновая кислота” или “UNA” означает нуклеиновую кислоту, содержащую неприродные нуклеотиды, которые связываются друг с другом с пониженной стабильностью. Например, неструктурированная нуклеиновая кислота может содержать остаток G' и остаток C', причем эти остатки соответствуют неприродным формам, т.е. аналогам G и C, которые образуют пары друг с другом с пониженной стабильностью, но сохраняют способность спариваться с природными остатками C и G, соответственно. Неструктурированная нуклеиновая кислота описана в US 2005/0233340, который включен сюда путем ссылки для раскрытия UNA. Также в это определение включены ZNAs, т.е. zip-нуклеиновые кислоты.
Термин “олигонуклеотид” в настоящем изобретении обозначает одноцепочечный мультимер нуклеотидов длиной от 2 до 200 нуклеотидов, вплоть до 500 нуклеотидов. Олигонуклеотиды могут быть синтетическими или могут быть получены ферментативным путем, в некоторых воплощениях они состоят из 30-150 нуклеотидов. Олигонуклеотиды могут содержать рибонуклеотидные мономеры (то есть это олигорибонуклеотиды) и/или дезоксирибонуклеотидные мономеры. К примеру, олигонуклеотид может содержать от 10 до 20, от 21 до 30, от 31 до 40, от 41 до 50, от 51 до 60, от 61 до 70, от 71 до 80, от 80 до 100, от 100 до 150 или от 150 до 200 нуклеотидов.
Термин “гибридизация” относится к способу, посредством которого одна цепь нуклеиновой кислоты соединяется с комплементарной цепью посредством спаривания оснований, как это известно в данной области. Считается, что нуклеиновая кислота “избирательно гибридизуется” с эталонной последовательностью нуклеиновой кислоты, если две последовательности специфически гибридизуются друг с другом в условиях средней или высокой жесткости гибридизации и отмывки. Условия средней или высокой жесткости гибридизации известны (например, см. Ausubel et al., Short Protocols in Molecular Biology, 3rd ed., Wiley & Sons, 1995; и Sambrook et al., Molecular Cloning: A Laboratory Manual, Third Edition, 2001, Cold Spring Harbor, N.Y.). Один из примеров условий высокой жесткости включает гибридизацию при 42°C в 50% формамиде, 5×SSC, 5×растворе Денхардта, 0,5% SDS и 100 мкг/мл денатурированной ДНК носителя с последующей промывкой два раза в 2×SSC и 0,5% SDS при комнатной температуре и еще два раза в 0,1×SSC и 0,5% SDS при 42°C.
Термин “праймер” означает олигонуклеотид, природный либо синтетический, который при образовании дуплекса с полинуклеотидной матрицей способен действовать в качестве точки запуска синтеза нуклеиновой кислоты и элонгироваться от своего 3'-конца вдоль матрицы с образованием элонгированного дуплекса. Последовательность нуклеотидов, добавленных в процессе элонгации, определяется последовательностью полинуклеотида-матрицы. Обычно праймеры элонгируются под действием ДНК-полимеразы. Праймеры обычно имеют длину, совместимую с их использованием при синтезе продуктов элонгации праймеров, которая обычно составляет от 8 до 100 нуклеотидов, как-то от 10 до 75, от 15 до 60, от 15 до 40, от 18 до 30, от 20 до 40, от 21 до 50, от 22 до 45, от 25 до 40 и т.д. Типичные праймеры могут иметь длину в пределах 10-50 нуклеотидов, как-то 15-45, 18-40, 20-30, 21-25 и т.д., а также любой длины между указанными пределами. В некоторых воплощениях длина праймеров обычно составляет не более 10, 12, 15, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 55, 60, 65 или 70 нуклеотидов.
Термин “дуплекс” или “дуплексный” в настоящем изобретении означает два комплементарных полинуклеотида со спаренными основаниями, т.е. они гибридизованы друг с другом.
Термины “определение”, “измерение”, “оценка”, “установление”, “опробование” и “анализ” применяются здесь взаимозаменяемо для обозначения любых измерений и включают определение наличия или отсутствия элемента. Эти термины включают и количественные, и качественные определения. Оценка может быть относительной или абсолютной. “Оценка присутствия” включает определение количества присутствующего, а также определение того, присутствует оно или отсутствует.
Термин “применение” имеет свое обычное значение и в таком качестве означает использование, например, запуск способа или композиции для достижения цели. Например, если применяется программа для создания файла, то программа исполняется с получением файла, а файл обычно является результатом программы. В другом примере, если применяется компьютерный файл, то его обычно вскрывают, считывают и используют информацию, хранящуюся в файле, для достижения цели. Аналогично, если применяется уникальный идентификатор, например, баркод, то уникальный идентификатор обычно считывают для идентификации, к примеру, объекта или файла, связанного с уникальным идентификатором.
Термин “лигирование” в настоящем изобретении означает катализируемое ферментом соединение концевого нуклеотида на 5'-конце первой молекулы ДНК с концевым нуклеотидом на 3'-конце второй молекулы ДНК.
“Множество” содержит не менее 2 членов. В некоторых случаях множество может содержать по меньшей мере 10, по меньшей мере 100, по меньшей мере 1000, по меньшей мере 10000, по меньшей мере 100000, по меньшей мере 106, по меньшей мере 107, по меньшей мере 108 или по меньшей мере 109 и более членов.
Если две нуклеиновые кислоты “комплементарны”, то каждое основание одной из нуклеиновых кислот образует пару с соответствующим нуклеотидом в другой нуклеиновой кислоте. Две нуклеиновые кислоты не обязательно должны быть совершенно комплементарными, чтобы гибридизироваться друг с другом.
Термин “разделение” в настоящем изобретении означает физическое разделение двух элементов (например, по размеру или по сродству и т.д.), а также разрушение одного элемента, оставляя другой неповрежденным.
Термин “секвенирование” в настоящем изобретении означает метод, при помощи которого устанавливают идентичность по меньшей мере 10 последовательных нуклеотидов (например, по меньшей мере 20, по меньшей мере 50, по меньшей мере 100 или по меньшей мере 200 и более последовательных нуклеотидов) в полинуклеотидах.
Термины “секвенирование следующего поколения” или “высокопроизводительное секвенирование” в настоящем изобретении относятся к так называемым платформам параллельного секвенирования путем синтеза или секвенирования путем лигирования, которые сейчас применяются фирмами Illumina, Life Technologies, Roche и др. Методы секвенирования следующего поколения также могут включать в себя нанопоровые методы секвенирования типа метода фирмы Oxford Nanopore Technologies, методы на основе электронного детектирования типа технологии Ion Torrent фирмы Life Technologies или одномолекулярные методы на основе флуоресценции типа метода фирмы Pacific Biosciences.
Термин “секвенирование следующего поколения” относится к так называемым платформам параллельного секвенирования путем синтеза или секвенирования путем лигирования, которые сейчас применяются фирмами Illumina, Life Technologies, Roche и др. Методы секвенирования следующего поколения также могут включать в себя нанопоровые методы секвенирования или методы на основе электронного детектирования типа технологии Ion Torrent фирмы Life Technologies.
Термин “адаптер” относится к такой нуклеиновой кислоте, которая лигируется с обеими цепями двухцепочечной молекулы ДНК. В одном воплощении адаптер может представлять собой шпилькообразный адаптер (т.е. это одна молекула, которая гибридизуется сама с собой, образуя структуру, которая содержит двухцепочечный стебелек и петлю, причем 3'- и 5'-концы молекулы лигируются с 5'- и 3'-концами двухцепочечной молекулы ДНК, соответственно). В другом воплощении адаптер может представлять собой Y-образный адаптер. В другом воплощении адаптер может сам состоять из двух отдельных молекул олигонуклеотидов, которые гибридизуются друг с другом. Как видно, лигируемый конец адаптера может быть спроектирован так, чтобы он был совместимым с выступами, образующимися при расщеплении рестрикционным ферментом, или же он может иметь тупые концы либо свисающий 5'-T. Термин “адаптер” относится как к двухцепочечным, так и к одноцепочечным молекулам. Адаптером может быть ДНК или РНК либо их смесь. Адаптер, содержащий РНК, может расщепляться при обработке РНКазой или при щелочном гидролизе. Адаптер может содержать от 15 до 100 оснований, например, от 50 до 70 оснований, хотя предусмотрены адаптеры и за пределами этого диапазона.
Термин “лигированная с адаптером” в настоящем изобретении относится к такой нуклеиновой кислоте, которая лигирована с адаптером. Адаптер может быть лигирован с 5'-концом и/или 3'-концом молекулы нуклеиновой кислоты.
Термин “асимметричный адаптер” в настоящем изобретении означает такой адаптер, который при лигировании с обоими концами двухцепочечного фрагмента нуклеиновой кислоты приводит к тому, что верхняя цепь, содержащая последовательность 5'-тега, не будет такой же или комплементарной последовательности метки на 3'-конце. Типичные асимметричные адаптеры описаны в U.S. Patents 5,712,126 и 6,372,434 и WO 2009/032167; которые все включены сюда путем ссылки во всей полноте. Фрагмент с асимметричными тегами может быть амплифицирован при помощи двух праймеров: одного, который гибридизуется с последовательностью первого тега, добавленного к 3'-концу цепи, и другого, который гибридизуется с комплементарной последовательностью второго тега, добавленного к 5'-концу цепи. Примерами асимметричных адаптеров являются Y-адаптеры и шпилькообразные адаптеры (которые могут расщепляться после лигирования с образованием “Y-адаптера”).
Термин “Y-адаптер” означает такой адаптер, который содержит: двухцепочечный участок и одноцепочечный участок, в котором противоположные последовательности не являются комплементарными. Конец двухцепочечного участка может присоединиться к молекулам мишени типа двухцепочечных фрагментов геномной ДНК, например, при помощи лигирования или реакции, катализируемой транспозазой. Каждая цепь двухцепочечной ДНК с тегами от адаптера, которая была лигирована с Y-адаптером, несет асимметричные теги, так как она содержит последовательность одной цепи Y-адаптера на одном конце и другой цепи Y-адаптера на другом конце. Амплификация молекул нуклеиновой кислоты, соединенных с Y-адаптерами на обоих концах, дает нуклеиновую кислоту с асимметричными тегами, то есть такую нуклеиновую кислоту, у которой 5'-конец содержит последовательность одного тега, а 3'-конец содержит последовательность другого тега (метки).
Термин “шпилькообразный адаптер” означает такой адаптер, который имеет вид шпильки. В одном воплощении петля шпильки после лигирования может расщепляться с образованием цепей, содержащих некомплементарные метки-теги на концах. В некоторых случаях петля адаптера типа шпильки может содержать остаток урацила, поэтому петля может расщепляться с помощью урациловой ДНК-гликозилазы и эндонуклеазы VIII, хотя известны и другие способы.
Термин “лигированный с адаптером образец” в настоящем изобретении относится к таким образцам, которые лигированы с адаптером. Как следует из приведенных выше определений, образцы, которые лигированы с асимметричным адаптером, содержат цепи, имеющие некомплементарные последовательности на 5'- и 3'-концах.
“Сайт связывания олигонуклеотида” означает сайт, с которым олигонуклеотид гибридизуется в целевом полинуклеотиде. Если олигонуклеотид “обеспечивает” сайт связывания для праймера, то праймер может гибридизоваться с этим олигонуклеотидом или комплементарным ему.
Термин “нить” в настоящем изобретении относится к нуклеиновой кислоте, состоящей из нуклеотидов, ковалентно связанных между собой ковалентными связями, например, фосфодиэфирными связями. В клетке ДНК обычно существует в двухцепочечной форме и поэтому имеет две комплементарные цепи нуклеиновой кислоты, которые обозначаются здесь как “верхняя” и “нижняя” цепь. В некоторых случаях комплементарные цепи хромосомной области могут обозначаться как “плюс-нить” и “минус-нить”, “первая” и “вторая” цепь, “кодирующая” и “некодирующая” цепь, “нить Уотсона” и “нить Крика” или “смысловая” и “антисмысловая” цепь. Определение цепи как верхней или нижней является произвольным и не подразумевает какой-либо конкретной ориентации, функции или структуры. Нуклеотидные последовательности первой цепи нескольких типичных хромосомных областей млекопитающих (например, BACs, сборных комплектов, хромосом и т.д.) известны и могут находиться, к примеру, в базе данных Genbank NCBI.
Термин “введение метки-тега” в настоящем изобретении означает присоединение тега последовательности (содержащего последовательность идентификатора) к молекуле нуклеиновой кислоты. Метка-тег последовательности может быть добавлена к 5'-концу, 3'-концу или к обоим концам молекулы нуклеиновой кислоты. Метка-тег последовательности может быть введена во фрагменты путем лигирования адаптера с фрагментами при помощи, например, ДНК-лигазы T4 или другой лигазы.
Термин “молекулярный баркод” охватывает последовательности идентификаторов образцов и последовательности идентификаторов молекул, как описано ниже. В некоторых воплощениях молекулярный баркод может иметь длину в пределах от 1 до 36 нуклеотидов, например, от 6 до 30 нуклеотидов или от 8 до 20 нуклеотидов. В некоторых случаях последовательности молекулярных идентификаторов могут быть с коррекцией ошибок, что означает, что даже если есть ошибка (например, если последовательность молекулярного баркода синтезирована неправильно, считывается неправильно или искажается в результате различных стадий обработки, ведущих к определению последовательности молекулярного баркода), то код все равно может быть правильно интерпретирован. Описания типичных последовательностей с коррекцией ошибок можно найти в литературе (например, US 2010/0323348 и US 2009/0105959, которые включены сюда путем ссылки). В некоторых воплощениях последовательность идентификаторов может быть относительно низкой сложности (например, она может состоять из смеси от 4 до 1024 различных последовательностей), хотя в некоторых случаях могут использоваться последовательности идентификаторов большей сложности.
Термин “последовательность идентификатора образца” и “индекс образца” означает последовательность нуклеотидов, которая добавляется к целевому полинуклеотиду, причем эта последовательность идентифицирует источник целевого полинуклеотида (то есть образца, из которого происходит целевой полинуклеотид). На практике каждый образец маркируется другой последовательностью идентификатора образца (например, к каждому образцу присоединяется одна последовательность, а к разным образцам присоединяются различные последовательности), и маркированные тегами образцы объединяются. После секвенирования сборного образца последовательность идентификатора образца может использоваться для идентификации источника последовательностей. Последовательность идентификатора образца может присоединяться к 5'-концу полинуклеотида или 3'-концу полинуклеотида. В некоторых случаях часть последовательности идентификатора образца может находиться на 5'-конце полинуклеотида, а остальная часть последовательности идентификатора образца может находиться на 3'-конце полинуклеотида. Когда элементы имеют последовательности идентификаторов образцов на каждом конце, то вместе эти 3'- и 5'-последовательности идентификаторов образцов идентифицируют всю выборку. Во многих примерах последовательность идентификатора образца составляет лишь часть тех оснований, которые добавляются к целевому олигонуклеотиду.
Термин “последовательность идентификатора молекулы” означает последовательность нуклеотидов, которая добавляется к фрагментам нуклеиновой кислоты в образце с тем, что присоединенная последовательность нуклеотидов, одна или в сочетании с другими признаками фрагментов, например, их точками фрагментации, может использоваться для различения различных молекул фрагментов в образце или его части. Сложность популяции последовательностей идентификаторов молекул, используемых в какой-либо реализации, может варьироваться в зависимости от различных параметров, например, количества фрагментов в образце и/или количества образца, которое используется на следующей стадии. Например, в некоторых случаях последовательность идентификаторов молекул может быть низкой сложности (например, она может состоять из смеси от 8 до 1024 последовательностей). В других случаях последовательность идентификаторов молекул может быть высокой сложности (например, она может состоять от 1025 до 1 млн. и более последовательностей). В некоторых воплощениях популяция последовательностей идентификаторов молекул может содержать участок вырожденных оснований (DBR), содержащий один или несколько (например, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5 или от 5 до 30 и более) нуклеотидов, выбранных из R, Y, S, W, K, M, B, D, H, V, N (по кодировке IUPAC) либо их вариантов. Как описано в US 8,741,606, последовательность идентификаторов молекул может состоять из последовательностей, которые не являются смежными. В некоторых воплощениях популяция последовательностей идентификаторов молекул может быть получена путем смешивания олигонуклеотидов с определенной последовательностью вместе. В этих воплощениях последовательность идентификаторов молекул у каждого из олигонуклеотидов может быть с коррекцией ошибок. В описанных здесь способах последовательность идентификаторов молекул может применяться для различения различных фрагментов в одной части исходного образца, которая была извлечена из исходного образца. Последовательности идентификаторов молекул могут применяться для различения фрагментов в сочетании с другими признаками фрагментов (например, концевыми последовательностями фрагментов, которые определяют точки фрагментации).
В настоящем изобретении термин “соответствует” в отношении прочтения последовательности, которое соответствует определенной (например, верхней или нижней) цепи фрагмента, относится к прочтению последовательности, полученному из этой цепи или ее продукта амплификации.
Термин “ковалентное связывание” относится к образованию ковалентной связи между двумя отдельными молекулами.
В настоящем изобретении термин “циркулирующая бесклеточная ДНК” относится к той ДНК, которая циркулирует в периферической крови пациента. Молекулы ДНК в бесклеточной ДНК могут иметь средний размер менее 1 тпо (например, в пределах от 50 до 500 п.о., от 80 до 400 п.о. или от 100 до 1000 п.о.), хотя могут присутствовать фрагменты со средним размером за пределами этого диапазона. Бесклеточная ДНК может содержать циркулирующую опухолевую ДНК (ctDNA), то есть опухолевую ДНК, свободно циркулирующую в крови больных раком, или циркулирующую фетальную ДНК (если субъектом является беременная женщина). БкДНК может быть сильно фрагментирована и в некоторых случаях может иметь средний размер фрагментов примерно 165-250 п.о. (Newman et al., Nat., 2014, 20: 548-54). БкДНК может быть получена путем центрифугирования цельной крови для удаления всех клеток, а затем выделения ДНК из оставшейся плазмы или сыворотки. Такие методы хорошо известны (например, см. Lo et al., Am J Hum Genet 1998, 62: 768-75). Циркулирующая бесклеточная ДНК является двухцепочечной, но ее можно сделать одноцепочечной путем денатурации.
В настоящем изобретении термин “добавление последовательностей адаптеров” относится к факту добавления последовательности адаптера к концам фрагментов в образце. Это можно сделать путем заполнения концов фрагментов с помощью полимеразы, добавления непарного A, а затем лигирования адаптера, содержащего выступающий T, с содержащими неспаренный A фрагментами.
В настоящем изобретении термин “UDP-глюкоза, модифицированная хемоселективной группой” относится к UDP-глюкозе, функционализированной, в особенности в положении 6-гидроксила, группой, способной участвовать в реакции 1,3-циклоприсоединения (или “клик-реакции”). К таким группам относятся азидогруппа и алкинил (например, циклооктин), хотя известны и другие (Kolb et al., 2001; Speers and Cravatt, 2004; Sletten and Bertozzi, 2009). Примером UDP-глюкозы, модифицированной хемоселективной группой, является UDP-6-N3-Glu, хотя известны и другие.
В настоящем изобретении термин “биотиновый компонент” означает такую аффинную метку-тег, которая включает биотин или аналог биотина типа детиобиотина, оксибиотина, 2-иминобиотина, диаминобиотина, биотинсульфоксида, биоцитина и т.п. Биотиновые компоненты связываются со стрептавидином со сродством не менее 10-8 М.
В настоящем изобретении термины “реакция циклоприсоединения” и “клик-реакция” применяются взаимозаменяемо в отношении реакции 1,3-циклоприсоединения между азидом и алкином с образованием пятичленного гетероцикла. В некоторых воплощениях алкин может быть деформирован (например, в кольце типа циклооктина), а реакция циклоприсоединения может проводиться в условиях отсутствия меди. Примерами алкинов, которые могут участвовать в реакции циклоприсоединения в отсутствие меди, являются дибензоциклооктин (DBCO) и дифтороктин (DIFO), хотя известны и другие группы. Например, см. Kolb et al. (Drug Discov Today 2003, 8: 1128-113); Baskin et al. (Proc. Natl. Acad. Sci., 2007, 104: 16793-16797); и Sletten et al. (Accounts of Chemical Research 2011, 44: 666-676) насчет обзора по такой химии.
В настоящем изобретении термин “носитель, который связывается с биотином” означает такой носитель (например, шарики, которые могут быть магнитными), который связан со стрептавидином или авидином, либо его функциональный эквивалент.
Термин “амплификация” в настоящем изобретении относится к получению одной или нескольких копий целевой нуклеиновой кислоты с использованием целевой нуклеиновой кислоты в качестве матрицы.
Термин “копии фрагментов” относится к продуктам амплификации, причем копия фрагмента может быть обратно комплементарна одной цепи фрагмента или иметь такую же последовательность, как и одна цепь фрагмента.
Термины “обогащать” и “обогащение” относятся к частичной очистке аналитов, обладающих определенным признаком (например, нуклеиновых кислот, содержащих гидроксиметилцитозин), от аналитов, не обладающих этим признаком (например, нуклеиновых кислот, не содержащих гидроксиметилцитозина). При обогащении концентрация аналитов, обладающих этим признаком (например, нуклеиновых кислот, содержащих гидроксиметилцитозин), обычно повышается по меньшей мере в 2 раза, по меньшей мере в 5 раз или по меньшей мере в 10 раз по сравнению с аналитами, не обладающими этим признаком. После обогащения по меньшей мере 10%, по меньшей мере 20%, по меньшей мере 50%, по меньшей мере 80% или по меньшей мере 90% аналитов в образце могут обладать признаком, используемым для обогащения. Например, по меньшей мере 10%, по меньшей мере 20%, по меньшей мере 50%, по меньшей мере 80% или по меньшей мере 90% молекул нуклеиновой кислоты в обогащенной композиции могут содержать цепь с одним или несколькими гидроксиметилцитозинами, которая подвергалась модификации с тем, чтобы она содержала метку захвата.
По всему описанию могут появляться и другие определения терминов.
Описание типичных воплощений
В настоящем изобретении предусмотрен способ секвенирования гидроксиметилированной бесклеточной ДНК. В некоторых воплощениях способ включает введение аффинной метки только в молекулы гидроксиметилированной ДНК в образце бкДНК; обогащение молекул ДНК, помеченных аффинной меткой; и секвенирование обогащенных молекул ДНК.
На фиг. 1A представлена одна реализация способа. Обращаясь к фиг. 1A, в некоторых воплощениях способ может включать: (а) добавление адаптерных последовательностей на концы бесклеточной ДНК (бкДНК), (b) инкубацию лигированной с адаптерами бкДНК с ДНК-β-глюкозилтрансферазой и UDP-глюкозой, модифицированной хемоселективной группой, при этом молекулы гидроксиметилированной ДНК в бкДНК метятся хемоселективной группой; (c) связывание биотинового компонента с хемоселективно модифицированной бкДНК по реакции циклоприсоединения; (d) обогащение биотинилированных молекул ДНК путем связывания продукта из стадии введения биотиновой метки (стадии c) с носителем, связывающимся с биотином; (e) амплификацию обогащенной ДНК с помощью праймеров, связывающихся с адаптерами; и (f) секвенирование амплифицированной ДНК с получением множества прочтений последовательности.
Как видно из фиг. 1A, в некоторых воплощениях способ не включает высвобождения биотинилированных молекул ДНК из носителя перед амплификацией (т.е. после стадии (d) перед стадией (е)), а в некоторых воплощениях стадия амплификации (d) может включать амплификацию обогащенной ДНК, связанной с носителем (с). Это может быть реализовано путем: i) промывки носителя (d) после того, как молекулы биотинилированной ДНК свяжутся с носителем; а затем ii) проведения реакции амплификации в присутствии носителя, без высвобождения биотинилированных молекул ДНК из носителя.
Также, как видно из фиг. 1A, стадия (a) может выполняться путем лигирования ДНК с универсальным адаптером, то есть таким адаптером, который лигируется с обоими концами фрагментов бкДНК. В некоторых случаях универсальный адаптер может быть получен путем лигирования Y-адаптера (или шпилькообразного адаптера) по концам бкДНК, получая при этом двухцепочечную молекулу ДНК, у которой верхняя цепь содержит последовательность 5'-тега, которая не такая же либо не комплементарна последовательности тега, введенного на 3'-конец этой цепи. Следует иметь в виду, что фрагменты ДНК, используемые на начальной стадии способа, не должны подвергаться амплификации и предварительной денатурации. Как видно из фиг. 1A, эта стадия может потребовать зачистки (то есть затупления) концов бкДНК с помощью полимеразы, введения непарного A во фрагменты, например, с помощью Taq-полимеразы, и лигирования Y-адаптера, содержащего неспаренный T, с содержащими непарный A фрагментами. Эта начальная стадия лигирования может выполняться на минимальном количестве бкДНК. Например, бкДНК, с которой лигируют адаптеры, может содержать менее 200 нг ДНК, например, от 10 пг до 200 нг, от 100 пг до 200 нг, от 1 нг до 200 нг или от 5 нг до 50 нг или менее 10000 (например, менее 5000, менее 1000, менее 500, менее 100 или менее 10) эквивалентов гаплоидного генома, в зависимости от генома. В некоторых воплощениях способ выполняется с использованием менее 50 нг бкДНК (что соответствует примерно 5 мл плазмы) или менее 10 нг бкДНК, что соответствует примерно 1 мл плазмы. Например, Newman et al. (Nat Med. 2014, 20: 548-54) получали библиотеки из 7-32 нг бкДНК, выделенной из 1-5 мл плазмы. Это эквивалентно 2121-9697 гаплоидным геномам (из расчета 3,3 пг на 1 гаплоидный геном). Адаптер, лигированный с бкДНК, может содержать молекулярный баркод для облегчения мультиплексирования и количественного анализа секвенируемых молекул. В частности, адаптер может быть “индексирован” в том смысле, что он содержит молекулярный баркод, который идентифицирует образец, с которым он был лигирован (что позволяет объединять образцы перед секвенированием). С другой стороны, адаптер может содержать случайный баркод или типа того. Такой адаптер можно лигировать с фрагментами, при этом практически каждый фрагмент, соответствующий определенной области, будет помечен другой последовательностью. Это позволит идентифицировать дубликаты при ПЦР и сосчитать молекулы.
На следующей стадии этой реализации способа молекулы гидроксиметилированной ДНК в бкДНК метятся хемоселективной группой, то есть такой группой, которая может участвовать в клик-реакции. Эта стадия может осуществляться путем инкубации лигированной с адаптером бкДНК с ДНК-β-глюкозилтрансферазой (например, с ДНК-β-глюкозилтрансферазой T4, которая коммерчески доступна от ряда поставщиков, хотя существуют и другие ДНК-β-глюкозилтрансферазы) и, например, UDP-6-N3-Glu (т.е. UDP-глюкозой, содержащей азид). Эта стадия может осуществляться по методике, адаптированной, к примеру, из US 2011/0301045 или Song et al. (Nat. Biotechnol., 2011, 29: 68-72).
Следующая стадия этой реализации способа включает присоединение биотинового компонента к хемоселективно модифицированной ДНК по реакции циклоприсоединения (клик-реакции). Эта стадия может осуществляться путем непосредственного добавления биотинилированного реагента, например, модифицированного дибензоциклооктином биотина в глюкозилтрансферазную реакцию по завершении этой реакции, то есть через подходящий промежуток времени (например, через 30 мин или более). В некоторых воплощениях биотинилированный реагент может иметь общую формулу B-L-X, где B означает биотиновый компонент, L - линкер, а X - группа, реагирующая с хемоселективной группой, введенной в бкДНК по реакции циклоприсоединения. В некоторых случаях линкер может сделать соединение более растворимым в водной среде и при этом может содержать полиэтиленгликолевый (ПЭГ) линкер или его эквивалент. В некоторых воплощениях добавляемое соединение может представлять собой дибензоциклооктин-PEGn-биотин, где n равно 2-10, например, 4. Дибензоциклооктин-ПЭГ4-биотин является относительно гидрофильным и растворяется в водном буфере до концентрации 0,35 мМ. Добавляемое на этой стадии соединение не обязательно должно содержать расщепляемую связь, например, может не содержать дисульфидную связь и т.д. На этой стадии реакция циклоприсоединения может быть между азидогруппой, введенной в гидроксиметилированную бкДНК, и алкинильной группой (например, группой дибензоциклооктина), связанной с биотиновым компонентом. Опять же, эта стадия может осуществляться по методике, адаптированной, к примеру, из US 2011/0301045 или Song et al. (Nat. Biotechnol., 2011, 29: 68-72).
Стадия обогащения в этом способе может осуществляться с использованием магнитных стрептавидиновых шариков, хотя можно использовать и другие носители. Как отмечено выше, обогащенные молекулы бкДНК (которые соответствуют молекулам гидроксиметилированной бкДНК) подвергают амплификации методом ПЦР, а затем секвенируют.
В этих воплощениях обогащенный образец ДНК можно амплифицировать с помощью одного или нескольких праймеров, гибридизующихся со введенными адаптерами (или их комплементами). В тех воплощениях, в которых применяются Y-адаптеры, лигированные с адаптерами нуклеиновые кислоты можно амплифицировать методом ПЦР с помощью двух праймеров: первого праймера, который гибридизуется с одноцепочечным участком верхней цепи адаптера, и второго праймера, который гибридизуется с комплементарной последовательностью одноцепочечного участка нижней цепи Y-адаптера (или адаптера типа шпильки после расщепления петли). Например, в некоторых воплощениях используемый Y-адаптер может иметь плечи P5 и P7 (их последовательности совместимы с платформой секвенирования фирмы Illumina), а продукты амплификации будут иметь последовательность P5 на одном конце и последовательности P7 на другом. Эти продукты амплификации можно подвергнуть гибридизации с секвенирующим субстратом фирмы Illumina и просеквенировать. В другом воплощении пара праймеров, используемых для амплификации, может иметь 3'-концы, которые гибридизуются с Y-адаптером, и 5'-концы, которые имеют последовательность P5 либо последовательность P7. В этом воплощении продукты амплификации также будут иметь последовательность Р5 на одном конце и последовательность P7 на другом. Эти продукты амплификации можно подвергнуть гибридизации с секвенирующим субстратом фирмы Illumina и просеквенировать. Эта стадия амплификации может осуществляться методом ПЦР с ограниченным количеством циклов (например, 5-20 циклов).
Стадия секвенирования может осуществляться любым удобным методом секвенирования следующего поколения и может давать по меньшей мере 10000, по меньшей мере 50000, по меньшей мере 100000, по меньшей мере 500000, по меньшей мере 1 млн., по меньшей мере 10 млн., по меньшей мере 100 млн. либо по меньшей мере 1 млрд. прочтений последовательности. В некоторых случаях прочтения являются прочтениями с парными концами. Следует иметь в виду, что праймеры, используемые для амплификации, могут быть совместимы с их применением в любой платформе секвенирования следующего поколения, в которой применяется элонгация праймеров, например, в методе обратимых терминаторов фирмы Illumina, методе пиросеквенирования фирмы Roche, секвенирования путем лигирования фирмы Life Technologies (платформа SOLiD), платформе Ion Torrent фирмы Life Technologies или методе отщепления флуоресцентных оснований фирмы Pacific Biosciences. Примеры таких методов описаны в следующих ссылках: Margulies et al. (Nature 2005, 437: 376-80); Ronaghi et al. (Analytical Biochemistry 1996, 242: 84-9); Shendure (Science 2005, 309: 1728); Imelfort et al. (Brief Bioinform. 2009, 10: 609-18); Fox et al. (Methods Mol Biol. 2009, 553: 79-108); Appleby et al. (Methods Mol Biol. 2009, 513: 19-39) English (PLoS One. 2012, 7:e47768) и Morozova (Genomics 2008, 92: 255-64), которые включены сюда путем ссылки для общего описания методов и конкретных стадий этих методов, включая все исходные материалы, реагенты и конечные продукты по каждой стадии.
В некоторых воплощениях секвенируемый образец может содержать пул молекул ДНК из нескольких образцов, причем нуклеиновые кислоты в образце имеют молекулярный баркод, указывающий на их источник. В некоторых воплощениях анализируемые нуклеиновые кислоты могут происходить из одного источника (например, одного организма, вируса, ткани, клетки, субъекта и т.п.), тогда как в других воплощениях образец нуклеиновой кислоты может представлять собой пул нуклеиновых кислот, выделенных из нескольких источников (например, пул нуклеиновых кислот из нескольких организмов, тканей, клеток, субъектов и т.п.), причем под “несколькими” подразумеваются два или больше. Так, в некоторых воплощениях образец нуклеиновой кислоты может содержать нуклеиновые кислоты из 2 и более источников, 3 и более источников, 5 и более источников, 10 и более источников, 50 и более источников, 100 и более источников, 500 и более источников, 1000 и более источников, 5000 и более источников, вплоть до 10000 и более источников. Молекулярные баркоды позволяют различать последовательности из разных источников после их анализа.
Прочтения последовательностей можно анализировать на компьютере, причем инструкции для выполнения изложенных ниже операций могут быть представлены в виде программного обеспечения, которое может быть записано на подходящем считываемом компьютером физическом носителе данных.
В некоторых воплощениях прочтения последовательностей можно анализировать для количественной оценки того, какие последовательности гидроксиметилированы в бкДНК. Это можно сделать, например, путем подсчета прочтений последовательностей или же подсчета количества исходных молекул до амплификации на основании их точек фрагментации и/или того, что они содержат одну и ту же последовательность индексатора. Для различения фрагментов известно применение молекулярных баркодов в сочетании с другими признаками фрагментов (например, концевыми последовательностями фрагментов, которые определяют точки разрыва). Молекулярные баркоды и типичные методы подсчета индивидуальных молекул описаны в Casbon (Nucl. Acids Res., 2011, 22 e81); Fu et al. (Proc Natl Acad Sci USA 2011, 108: 9026-31) и др. Молекулярные баркоды описаны в US 2015/0044687, US 2015/0024950, US 2014/0227705, US 8,835,358 и US 7,537,897, а также в ряде других публикаций.
В некоторых воплощениях вышеприведенными методами можно сравнивать два различных образца бкДНК. Различные образцы могут состоять из “экспериментального” образца, то есть представляющего интерес образца бкДНК, и “контрольного” образца бкДНК, с которым можно сравнить экспериментальный образец кДНК. Во многих воплощениях различные образцы получают от субъектов, причем один субъект является предметом интереса, например, пациент с заболеванием, а другой - контрольным субъектом, т.е. пациент без заболевания. Типичные пары образцов включают, к примеру, бкДНК от субъекта с заболеванием типа рака толстой кишки, молочной железы, простаты, легких, кожи либо инфицированного патогеном) и бкДНК от нормальных субъектов без заболевания, а также бкДНК из двух разных временных точек от одного и того же субъекта, например, до и после проведения терапии и пр.
Также предусмотрен способ идентификации профиля гидроксиметилирования, коррелирующего с фенотипом, например, заболеванием, состоянием или клиническим исходом и пр. В некоторых воплощениях этот способ может включать (a) выполнение вышеописанного способа на множестве образцов бкДНК, причем образцы бкДНК выделены от пациентов с известным фенотипом, например, заболеванием, состоянием или клиническим результатом, при этом определяется, какие последовательности гидроксиметилированы в бкДНК от каждого из пациентов; и (b) определение сигнатуры гидроксиметилирования, коррелирующей с фенотипом.
В некоторых воплощениях сигнатура гидроксиметилирования может быть диагностической (например, может давать диагноз заболевания или состояния либо типа или стадии заболевания или состояния и т.д.), прогностической (например, указывать на клинический результат, например, выживание или смерть во временных рамках) или тераностической (например, указывать, какое лечение будет наиболее эффективным).
Также предусмотрен способ анализа образцов от пациентов. В этом воплощении способ может включать: (a) идентификацию вышеописанным способом тех последовательностей, которые являются гидроксиметилированными в бкДНК пациента; (b) сравнение идентифицированных последовательностей с набором сигнатурных последовательностей, коррелирующих с фенотипом, например, заболеванием, состоянием или клиническим исходом и пр.; и (c) составление отчета, показывающего корреляцию с фенотипом. Это воплощение может дополнительно включать в себя постановку диагноза, прогноза или тераноза по результатам сравнения.
В некоторых воплощениях способ может включать составление отчета, как описано выше (электронная форма которого могла бы быть отправлена из другого места), и направление отчета врачу или другому медицинскому специалисту для определения того, что у пациента имеется фенотип (например, рак и т.п.), или для определения подходящей терапии для пациента. Отчет может использоваться в качестве диагностического средства для определения того, что у субъекта имеется заболевание, например, рак. В некоторых воплощениях способ может применяться, к примеру, для определения стадии или типа рака, для идентификации метастазирующих клеток или мониторинга реакции пациента на лечение.
В любых воплощениях отчет может быть отправлен в “удаленное место”, причем “удаленное место” означает другое место, чем то, в котором изучается изображение. К примеру, удаленное место может означать другое место (например, офис, лаборатория и т.д.) в том же городе, другое место в другом городе, другое место в другом штате, другое место в другой стране и т.д. При этом, когда один элемент обозначается как “удаленный” от другого, подразумевается, что два элемента могут находиться в одной и той же комнате, но раздельно, или же в разных комнатах или разных зданиях, и могут быть на расстоянии как минимум в одну милю, 10 миль или по меньшей мере 100 миль друг от друга. “Передача” информации означает передачу данных, представляющих эту информацию, в виде электрических сигналов через соответствующий канал связи (например, частную или общедоступную сеть). “Пересылка” элемента означает любой способ передачи этого элемента из одного места в другое, будь то физическая транспортировка этого элемента или иным образом (если это возможно), и включает, по крайней мере в случае данных, физическую транспортировку носителя, несущего данные, или передачу данных. Примеры коммуникационных носителей включают радио- или инфракрасные каналы передачи, а также сетевое подключение к другому компьютеру или сетевому устройству и интернет, в том числе по электронной почте, и передачу информации, записанной на веб-сайтах и т.п. В некоторых воплощениях отчет может проанализировать доктор или другой квалифицированный медицинский специалист, а составленное по результатам анализа изображения сообщение может быть отправлено пациенту, от которого был получен образец.
Также предусмотрен способ анализа образцов, включающий (a) определение вышеописанным способом, какие последовательности гидроксиметилированы в первом образце бкДНК и какие последовательности гидроксиметилированы во втором образце бкДНК, причем первый и второй образец бкДНК получены от одного и того же пациента в двух различных временных точках; и (b) сравнение профиля гидроксиметилирования у первого образца с профилем гидроксиметилирования у второго образца, чтобы установить, было ли изменение гидроксиметилирования с течением времени. Этот способ может быть количественным, а в некоторых воплощениях стадия сравнения (b) может включать сравнение уровня гидроксиметилирования одной или нескольких выбранных последовательностей. Стадия сравнения в этом способе может отражать изменения в гидроксиметилировании в ходе заболевания или при лечении заболевания.
Фенотипом пациента может быть любая наблюдаемая характеристика или признак субъекта, как-то заболевание, стадия заболевания, восприимчивость к заболеванию, прогноз заболевания, физиологическое состояние или реакция на терапию и т.п. Фенотип может быть результатом экспрессии гена у субъекта, а также влияния факторов окружающей среды и взаимодействий между ними, а также эпигенетических модификаций в последовательности нуклеиновых кислот.
Фенотип у субъекта можно охарактеризовать путем анализа бкДНК вышеописанным способом. Например, характеристика фенотипа у субъекта или индивида может включать выявление заболевания (включая предсимптоматическое выявление на ранней стадии), определение прогноза, диагноза или тераноза заболевания или определение стадии или течения заболевания. Характеристика фенотипа также может включать идентификацию подходящих методов лечения, эффективных для лечения определенных заболеваний и стадий заболеваний, прогнозирование и анализ вероятности прогрессирования заболевания, в частности повторности заболевания, распространения метастазов или рецидива заболевания. Фенотип также может означать клинически особый тип или подтип заболевания типа рака или опухоли. Определение фенотипа также может означать определение физиологического состояния или оценку расстройства органа или отторжения органа типа после трансплантации. Описанные здесь продукты и процессы позволяют оценивать субъекта на индивидуальной основе, что может обеспечить преимущества более эффективных и экономичных решений при лечении.
В некоторых воплощениях способ может применяться для идентификации сигнатуры, предсказывающей, будет ли субъект реагировать на лечение заболевания или расстройства.
Характеристика фенотипа может включать прогнозирование статуса восприимчивости/невосприимчивости у субъекта, причем восприимчивые поддаются лечению заболевания, а невосприимчивые - не поддаются лечению. Если сигнатура гидроксиметилирования у субъекта более точно совпадает с таковой у предыдущих субъектов, которые поддавались лечению, то субъекта можно характеризовать или прогнозировать как поддающегося лечению. Аналогично, если сигнатура гидроксиметилирования у субъекта более точно совпадает с таковой у предыдущих субъектов, которые не поддавались лечению, то субъекта можно характеризовать или прогнозировать как не поддающегося лечению. Лечение может быть для любого подходящего заболевания, расстройства или другого состояния. Способ может применяться при любых заболеваниях, при которых известна сигнатура гидроксиметилирования, коррелирующая со статусом восприимчивости/невосприимчивости.
В некоторых воплощениях фенотип включает заболевание типа тех, что перечислены ниже. Например, фенотип может включать наличие или вероятность возникновения опухоли, новообразования или рака. Выявление или определение рака с помощью описанных здесь продуктов или процессов включает, без ограничения, рак молочной железы, рак яичников, рак легких, рак толстой кишки, гиперпластические полипы, аденому, колоректальный рак, дисплазию в сильной степени, дисплазию в слабой степени, гиперплазию предстательной железы, рак простаты, меланому, рак поджелудочной железы, рак мозга (типа глиобластомы), гематологические неоплазии, гепатоцеллюлярную карциному, рак шейки матки, рак эндометрия, рак головы и шеи, рак пищевода, стромальные опухоли желудочно-кишечного тракта (GIST), почечно-клеточную карциному (RCC) или рак желудка. Колоректальный рак может представлять собой CRC Dukes B или Dukes C-D. Гематологическая неоплазия может представлять собой B-клеточную хроническую лимфоцитарную лейкемию, B-клеточную лимфому типа DLBCL, B-клеточную лимфому DLBCL типа зародышевых центров, B-клеточную лимфому DLBCL типа активированных B-клеток и лимфому Беркитта.
В некоторых воплощениях фенотип может означать предраковое состояние типа актинического кератоза, атрофического гастрита, лейкоплакии, эритроплазии, лимфоматоидного гранулематоза, прелейкемии, фиброза, цервикальной дисплазии, дисплазии шейки матки, пигментной ксеродермы, пищевода Барретта, колоректального полипа или другого аномального роста тканей или поражения, которое может превратиться в злокачественную опухоль. Трансформативные вирусные инфекции типа ВИЧ и ВПЧ также представляют фенотипы, которые можно оценивать данным способом.
Характеризуемый настоящим способом рак может представлять собой, без ограничения, карциному, саркому, лимфому или лейкемию, опухоль зародышевых клеток, бластому или другое раковое заболевание. Карциномы включают, без ограничения, эпителиальные неоплазии, плоскоклеточные неоплазии, плоскоклеточные карциномы, базально-клеточные неоплазии, базально-клеточные карциномы, переходно-клеточные папилломы и карциномы, аденомы и аденокарциномы (желез), аденомы, аденокарциномы, пластический линит, инсулиномы, глюкагономы, гастриномы, випомы, холангиокарциномы, гепатоцеллюлярные карциномы, аденоидные кистозные карциномы, карциноидные опухоли аппендикса, пролактиномы, онкоцитомы, аденомы из клеток Гюртле, почечно-клеточные карциномы, опухоли Гравитца, множественные эндокринные аденомы, эндометриоидные аденомы, неоплазии придатков кожи, мукоэпидермоидные неоплазии, кистозные, муцинозные и серозные неоплазии, цистаденомы, псевдомиксомы брюшной полости, протоковые, лобулярные и медуллярные неоплазии, неоплазии ацинарных клеток, комплексные эпителиальные неоплазии, опухоли Уортина, тимомы, специализированные гонадальные неоплазии, стромальные опухоли половых тяжей, текомы, гранулезоклеточные опухоли, арренобластомы, опухоли из клеток Сертоли-Лейдига, гломусные опухоли, параганглиомы, феохромоцитомы, невоидные опухоли и меланомы, меланоцитарный невус, злокачественные меланомы, меланомы, нодулярные меланомы, диспластический невус, лентигинозные меланомы, поверхностно-распространяющиеся меланомы и злокачественные акролентигинозные меланомы. Саркомы включают, без ограничения, опухоли Аскина, ботриоидные саркомы, хондросаркомы, саркомы Юинга, злокачественные гемангиоэндотелиомы, злокачественные шванномы, остеосаркомы, саркомы мягких тканей, в том числе альвеолярные мягкотканные саркомы, ангиосаркомы, филлоидные цистосаркомы, дерматофибросаркомы, десмоидные опухоли, десмопластические мелкокруглоклеточные опухоли, эпителиоидные саркомы, внескелетные хондросаркомы, внескелетные остеосаркомы, фибросаркомы, гемангиоперицитомы, гемангиосаркомы, саркомы Капоши, лейомиосаркомы, липосаркомы, лимфангиосаркомы, лимфосаркомы, злокачественные фиброзные гистиоцитомы, нейрофибросаркомы, рабдомиосаркомы и синовиальные саркомы. Лимфомы и лейкемии включают, без ограничения, хронические лимфоцитарные лейкемии/мелколимфоцитарные лимфомы, B-клеточные пролимфоцитарные лейкемии, лимфоплазмацитарные лимфомы (типа макроглобулинемии Вальденстрома), селезеночные лимфомы маргинальной зоны, плазмацитарные миеломы, плазмацитомы, болезни отложения моноклональных иммуноглобулинов, болезни тяжелой цепи, экстранодальные B-клеточные лимфомы маргинальной зоны, также известные как MALT-лимфомы, нодальные B-клеточные лимфомы маргинальной зоны (NMZL), фолликулярные лимфомы, лимфомы клеток мантии, диффузные крупно-В-клеточные лимфомы, медиастинальные (тимические) крупно-В-клеточные лимфомы, внутрисосудистые крупно-В-клеточные лимфомы, первичные эффузионные лимфомы, лимфомы/лейкемии Беркитта, T-клеточные пролимфоцитарные лейкемии, T-клеточные крупнозернистые лимфоцитарные лейкемии, агрессивные NK-клеточные лейкемии, Т-клеточные лейкемии/лимфомы взрослых, экстранодальные NK/Т-клеточные лимфомы назального типа, Т-клеточные лимфомы типа энтеропатии, гепатоспленические Т-клеточные лимфомы, бластные NK-клеточные лимфомы, грибовидный микоз/синдром Сезари, первичные кожные CD30-положительные Т-клеточные лимфопролиферативные заболевания, первичные кожные анапластические крупноклеточные лимфомы, лимфоматоидный папулез, ангиоиммунобластные Т-клеточные лимфомы, периферические Т-клеточные лимфомы, неустановленные, анапластические крупноклеточные лимфомы, классические лимфомы Ходжкина (с нодулярным склерозом, смешанноклеточный, со множеством лимфоцитов, с подавлением лимфоцитов или без подавления) и нодулярные лимфомы Ходжкина со множеством лимфоцитов. Опухоли зародышевых клеток включают, без ограничения, герминомы, дисгерминомы, семиномы, негерминоматозные опухоли зародышевых клеток, эмбриональные карциномы, эндодермальные синусовые опухоли, хориокарциномы, тератомы, полиэмбриомы и гонадобластомы. Бластомы включают, без ограничения, нефробластомы, медуллобластомы и ретинобластомы. Другие раковые заболевания, включают, без ограничения, губные карциномы, карциномы гортани, подглоточные карциномы, карциномы языка, карциномы слюнных желез, карциномы желудка, аденокарциномы, рак щитовидной железы (медуллярные и папиллярные карциномы щитовидной железы), почечные карциномы, карциномы почечной паренхимы, карциномы шейки матки, карциномы тела матки, карциномы эндометрия, карциномы хориона, карциномы яичек, карциномы мочевого пузыря, меланомы, опухоли головного мозга типа глиобластомы, астроцитомы, менингиомы, медуллобластомы и периферические нейроэктодермальные опухоли, карциномы желчного пузыря, бронхиальные карциномы, множественные миеломы, базалиомы, тератомы, ретинобластомы, хороидальные меланомы, семиномы, рабдомиосаркомы, краниофарингеомы, остеосаркомы, хондросаркомы, миосаркомы, липосаркомы, фибросаркомы, саркомы Юинга и плазмоцитомы.
В другом воплощении подлежащий анализу рак может представлять собой рак легких, включая немелкоклеточный рак легких и мелкоклеточный рак легких, в том числе мелкоклеточные карциномы (овсяноклеточный рак), смешанные мелкоклеточные/крупноклеточные карциномы и комбинированные мелкоклеточные карциномы, рак толстой кишки, рак молочной железы, рак простаты, рак печени, рак поджелудочной железы, рак мозга, рак почек, рак яичников, рак желудка, рак кожи, рак кости, рак желудка, рак молочной железы, рак поджелудочной железы, глиомы, глиобластомы, гепатоцеллюлярные карциномы, папиллярные почечные карциномы, плоскоклеточные карциномы головы и шеи, лейкемии, лимфомы, миеломы или солидные опухоли.
В других воплощениях рак может представлять собой острый лимфобластный лейкоз; острый миелоидный лейкоз; адренокортикальную карциному; связанное со СПИД раковое заболевание; связанную со СПИДом лимфому; анальный рак; рак аппендикса; астроцитому; атипичную тератоидную/рабдоидную опухоль; базально-клеточную карциному; рак мочевого пузыря; глиому ствола мозга; опухоль головного мозга (включая глиому ствола мозга, атипичные тератоидные/рабдоидные опухоли центральной нервной системы, эмбриональные опухоли центральной нервной системы, астроцитому, краниофарингиому, эпендимобластому, эпендимому, медуллобластому, медуллоэпителиому, паренхиматозные опухоли эпифиза промежуточной дифференцировки, супратенториальные примитивные нейроэктодермальные опухоли и пинеобластомы); рак молочной железы; бронхиальную опухоль; лимфому Беркитта; рак с неизвестным первичным очагом; карциноидную опухоль; карциному с неизвестным первичным очагом; атипичную тератоидную/рабдоидную опухоль центральной нервной системы; эмбриональную опухоль центральной нервной системы; рак шейки матки; детское раковое заболевание; хордому; хронический лимфоцитарный лейкоз; хроническую миелогенную лейкемию; хроническое миелопролиферативное заболевание; рак толстой кишки; колоректальный рак; краниофарингиому; кожную Т-клеточную лимфому; опухоль островковых клеток эндокринной поджелудочной железы; рак эндометрия; эпендимобластому; эпендимому; рак пищевода; эстезионейробластому; саркому Юинга; внечерепную опухоль зародышевых клеток; экстрагонадальную опухоль зародышевых клеток; внепеченочный рак желчных протоков; рак желчного пузыря; рак желудка; желудочно-кишечную карциноидную опухоль; опухоль стромальных клеток желудочно-кишечного тракта (GIST); гестационную трофобластную опухоль; глиому; трихоцитарную лейкемию; рак головы и шеи; рак сердца; лимфому Ходжкина; подглоточный рак; внутриглазную меланому; опухоль островковых клеток; саркому Капоши; рак почек; гистиоцитоз клеток Лангерганса; рак гортани; губной рак; рак печени; рак кости типа злокачественной фиброзной гистиоцитомы; медуллобластому; медуллоэпителиому; меланому; карциному клеток Меркеля; кожную карциному клеток Меркеля; мезотелиому; метастатический плоскоклеточный рак шеи с оккультным первичным очагом; рак ротовой полости; синдром множественной эндокринной неоплазии; множественную миелому; множественную миелому/плазмацитарную неоплазию; грибовидный микоз; миелодиспластический синдром; миелопролиферативную неоплазию; рак носовой полости; рак носоглотки; нейробластому; неходжкинскую лимфому; немеланомный рак кожи; немелкоклеточный рак легких; рак полости рта; рак ротовой полости; рак ротоглотки; остеосаркому; другую опухоль головного или спинного мозга; рак яичников; эпителиальный рак яичников; опухоль зародышевых клеток яичников; опухоль яичников с низким потенциалом злокачественности; рак поджелудочной железы; папилломатоз; рак околоносовых пазух; рак паращитовидной железы; рак таза; рак полового члена; рак глотки; паренхиматозную опухоль эпифиза промежуточной дифференцировки; пинеобластому; опухоль гипофиза; плазмацитарную неоплазию/множественную миелому; плевролегочную бластому; первичную лимфому центральной нервной системы (ЦНС); первичный гепатоцеллюлярный рак печени; рак простаты; рак прямой кишки; почечный рак; рак почек; почечно-клеточный рак; рак дыхательных путей; ретинобластому; рабдомиосаркому; рак слюнных желез; синдром Сезари; мелкоклеточный рак легких; рак тонкой кишки; саркому мягких тканей; плоскоклеточную карциному; плоскоклеточный рак шеи; рак желудка; супратенториальную примитивную нейроэктодермальную опухоль; Т-клеточную лимфому; рак яичек; рак горла; тимическую карциному; тимому; рак щитовидной железы; переходно-клеточный рак; переходно-клеточный рак почечной лоханки и мочеточников; трофобластную опухоль; рак мочеточников; рак уретры; рак матки; саркому матки; вагинальный рак; рак вульвы; макроглобулинемию Вальденстрома; или опухоль Вильма. Для характеристики этих и других видов рака могут применяться способы по изобретению. Таким образом, характеристика фенотипа может обеспечить диагностику, прогноз или тераноз одного из описанных здесь раковых заболеваний.
Фенотипом также может быть воспалительное заболевание, иммунное заболевание или аутоиммунное заболевание. Например, заболевание может представлять собой воспалительное заболевание кишечника (IBD), болезнь Крона (CD), язвенный колит (UC), воспаление тазовых органов, васкулит, псориаз, диабет, аутоиммунный гепатит, рассеянный склероз, миастению, диабет I типа, ревматоидный артрит, псориаз, системную красную волчанку (SLE), тиреоидит Хашимото, базедову болезнь, анкилозирующий спондилит, болезнь Шегрена, синдром CREST, склеродермию, ревматизм, отторжение органа, первичный склерозирующий холангит или сепсис.
Фенотип также может включать сердечно-сосудистые заболевания, как-то атеросклероз, застойная сердечная недостаточность, фиброатерома, инсульт или ишемия. Сердечно-сосудистое заболевание или состояние может означать высокое кровяное давление, стеноз, окклюзию сосудов или тромботическое явление.
Фенотип также может включать неврологические заболевания, как-то рассеянный склероз (MS), болезнь Паркинсона (PD), болезнь Альцгеймера (AD), шизофрения, биполярное расстройство, депрессия, аутизм, прионовые болезни, болезнь Пика, деменция, болезнь Хантингтона (HD), синдром Дауна, цереброваскулярные заболевания, энцефалит Расмуссена, вирусный менингит, нейропсихиатрическая системная красная волчанка (NPSLE), боковой амиотрофический склероз, болезнь Крейтцфельдта-Якоба, болезнь Герстмана-Штрауслера-Шейнкера, трансмиссивная спонгиозная энцефалопатия, ишемическо-реперфузионные повреждения (например, инсульт), травмы головного мозга, микробные инфекции или синдром хронической усталости. Фенотип также может означать состояние типа фибромиалгии, хронической невропатической боли или периферической невропатической боли.
Фенотип также может включать инфекционные заболевания, как-то бактериальные, вирусные или дрожжевые инфекции. Например, заболевание может представлять собой болезнь Уиппла, прионовое заболевание, цирроз, устойчивое к метициллину заражение золотистым стафилококком, ВИЧ, гепатит, сифилис, менингит, малярию, туберкулез или грипп. Для характеристики вирусных заболеваний можно определять вирусные белки типа частиц ВИЧ или HCV в пузырьках.
Фенотип также может включать перинатальные или связанные с беременностью заболевания (например, преэклампсию или преждевременные роды), метаболические заболевания типа метаболических заболеваний, связанных с метаболизмом железа. Например, характеристики дефицита железа можно анализировать гепцидин в пузырьках. Метаболическое заболевание также может быть представлено диабетом, воспалением или перинатальным заболеванием.
Коррелятивная “сигнатура” может представлять собой группу из 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 и более последовательностей, которые независимо друг от друга являются либо недогидроксиметилированными, либо гипергидроксиметилированными относительно контроля (например, “нормальной” бкДНК), причем в совокупности идентичность этих последовательностей и, необязательно, степень гидроксиметилирования в связи с этими последовательностями коррелирует с фенотипом.
Используемая в способе бкДНК может быть от млекопитающих, как-то быков, птиц, собак, лошадей, кошек, овец, свиней или приматов (включая людей и других приматов). В некоторых воплощениях у субъекта может быть уже существующее заболевание типа рака. С другой стороны, у субъекта может не быть никаких известных существующих заболеваний. Субъект также может быть не восприимчивым к существующему или прошлому лечению типа лечения рака. В некоторых воплощениях бкДНК может быть от беременной женщины. В некоторых воплощениях профиль гидроксиметилирования в фетальной фракции бкДНК может коррелировать с хромосомной аномалией у плода (например, анеуплоидией). В других воплощениях можно определить пол у плода по профилю гидроксиметилирования в фетальной фракции бкДНК и/или определить фетальную фракцию бкДНК.
Также предусмотрен способ, включающий: (a) получение образца, содержащего циркулирующую бесклеточную ДНК, (b) обогащение гидроксиметилированной ДНК в образце и (с) независимое определение содержания нуклеиновых кислот в обогащенной гидроксиметилированной ДНК, которые относятся к (то есть их последовательности соответствуют) каждому из одного или нескольких целевых локусов (например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5 или по меньшей мере 10 целевых локусов). Этот способ может дополнительно включать: (d) определение того, является ли одна или несколько последовательностей нуклеиновой кислоты в обогащенной гидроксиметилированной ДНК чрезмерно представленной или недостаточно представленной в обогащенной гидроксиметилированной ДНК относительно контроля. Идентичность тех нуклеиновых кислот, которые чрезмерно или недостаточно представлены в обогащенной гидроксиметилированной ДНК (а в некоторых случаях и степень, в которой эти нуклеиновые кислоты представлены чрезмерно или недостаточно в обогащенной гидроксиметилированной ДНК), может использоваться для получения диагноза, решения о лечении или прогноза. Например, в некоторых случаях анализ обогащенной гидроксиметилированной ДНК может идентифицировать сигнатуру, которая коррелирует с фенотипом, как изложено выше. В некоторых воплощениях содержание тех молекул нуклеиновой кислоты в обогащенной гидроксиметилированной ДНК, которые относятся к каждому из одного или нескольких целевых локусов (например, генов/интервалов, перечисленных ниже), можно определить методом qPCR, цифровой ПЦР, матриц, секвенирования или любым другим количественным методом.
В некоторых воплощениях диагностика, решение о лечении или прогноз может составлять диагностику рака. В этих воплощениях целевые локусы могут включать в себя один или несколько (например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5, по меньшей мере 10, по меньшей мере 15 или по меньшей мере 20) тел генов (т.е. транскрибируемых областей) из следующих: ABRACL, ADAMTS4, AGFG2, ALDH1A3, ALG10B, AMOTL1, APCDD1L-AS1, ARL6IP6, ASF1B, ATP6V0A2, AUNIP, BAGE, C2orf62, C8orf22, CALCB, CC2D1B, CCDC33, CCNL2, CLDN15, COMMD6, CPLX2, CRP, CTRC, DACH1, DAZL, DDX11L1, DHRS3, DUSP26, DUSP28, EPN3, EPPIN-WFDC6, ETAA1, FAM96A, FENDRR, FLJ16779, FLJ31813, GBX1, GLP2R, GMCL1P1, GNPDA2, GPR26, GSTP1, HMOX2, HOXC5, IGSF9B, INSC, INSL4, IRF7, KIF16B, KIF20B, LARS, LDHD, LHX5, LINC00158, LINC00304, LOC100128946, LOC100131234, LOC100132287, LOC100506963, LOC100507250, LOC100507410, LOC255411, LOC729737, MAFF, NPAS4, NRADDP, P2RX2, PAIP1, PAX1, PODXL2, POU4F3, PSMG1, PTPN2, RAG1, RBM14-RBM4, RDH11, RFPL3, RNF122, RNF223, RNF34, SAMD11, SHISA2, SIGLEC10, SLAMF7, SLC25A46, SLC25A47, SLC9A3R2, SORD, SOX18, SPATA31E1, SSR2, STXBP3, SYT11, SYT2, TCEA3, THAP7-AS1, TMEM168, TMEM65, TMX2, TPM4, TPO, TRAM1, TTC24, UBQLN4, WASH7P, ZNF284, ZNF423, ZNF444, ZNF800, ZNF850 и ZRANB2.
Например, в некоторых воплощениях можно независимо определить содержание нуклеиновых кислот, относящихся к каждому из одного или нескольких (например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5 или по меньшей мере 10) следующих тел генов: ZNF800, TMEM65, GNPDA2, ALG10B, CLDN15, TMEM168, ETAA1, AMOTL1, STXBP3, ZNF444, LINC00158, IRF7, SLC9A3R2, TRAM1 и SLC25A46, как показано на фиг. 12D.
В другом примере, в некоторых воплощениях можно независимо определить содержание нуклеиновых кислот, относящихся к каждому из одного или нескольких (например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5 или по меньшей мере 10) следующих тел генов: CLDN15, SLC25A47, ZRANB2, LOC10050693, STXBP3, GPR26, P2RX2, LOC100507410, LHX5, HOXC5, FAM96A, CALCB, RNF223, SHISA2 и SLAMF7, как показано на фиг. 12F.
В этих воплощениях целевые локусы могут включать в себя один или несколько (например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5, по меньшей мере 10 или по меньшей мере 15) следующих интервалов (представлена нумерация относительно эталонного генома hg19, который опубликован как GRCh37 в феврале 2009 г.): chr1:114670001-114672000, chr1:169422001-169424000, chr1:198222001-198224000, chr1:239846001-239848000, chr1:24806001-24808000, chr1:3234001-3236000, chr1:37824001-37826000, chr1:59248001-59250000, chr1:63972001-63974000, chr1:67584001-67586000, chr1:77664001-77666000, chr2:133888001-133890000, chr2:137676001-137678000, chr2:154460001-154462000, chr2:200922001-200924000, chr2:213134001-213136000, chr2:219148001-219150000, chr2:41780001-41782000, chr2:49900001-49902000, chr3:107894001-107896000, chr3:108506001-108508000, chr3:137070001-137072000, chr3:17352001-17354000, chr3:23318001-23320000, chr3:87312001-87314000, chr3:93728001-93730000, chr4:39342001-39344000, chr4:90790001-90792000, chr5:103492001-103494000, chr5:39530001-39532000, chr5:83076001-83078000, chr6:122406001-122408000, chr6:129198001-129200000, chr6:156800001-156802000, chr6:157286001-157288000, chr6:45304001-45306000, chr7:11020001-11022000, chr7:13364001-13366000, chr8:42934001-42936000, chr8:53686001-53688000, chr8:69672001-69674000, chr9:3496001-3498000 и chr9:88044001-88046000.
Например, в некоторых воплощениях можно независимо определить содержание нуклеиновых кислот, относящихся к каждому из одного или нескольких (например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5 или всех) следующих интервалов: chr4:90790001-90792000, chr6:45304001-45306000, chr5:103492001-103494000, chr7:11020001-11022000, chr2:49900001-49902000, chr2:137676001-137678000, chr3:87312001-87314000 и chr9:88044001-88046000, как показано на фиг. 12E.
В другом примере, в некоторых воплощениях можно независимо определить содержание нуклеиновых кислот, относящихся к каждому из одного или нескольких (например, по меньшей мере 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5 или всех) следующих интервалов: chr4:90790001-90792000, chr6:45304001-45306000, chr1:169422001-169424000, chr1:67584001-67586000, chr5:103492001-103494000, chr3:87312001-87314000, chr2:219148001-219150000, chr1:198222001-198224000, chr8:53686001-53688000, chr1:239846001-239848000, chr3:23318001-23320000, chr6:122406001-122408000, chr9:3496001-3498000, chr1:24806001-24808000 и chr8:69672001-69674000, как показано на фиг. 12G.
Если диагноз составляет диагноз рака, то диагностика может включать указание тканевого типа рака, то есть представлен ли он раком легких, раком печени, раком поджелудочной железы и т.п.
Следует отметить, что стадия количественной оценки (c) может выполняться с применением различных методов. Например, как описано выше и ниже, определение может проводиться путем присоединения последовательностей идентификаторов молекул к обогащенным фрагментам, их секвенирования, а затем подсчета количества последовательностей идентификаторов молекул, связанных с прочтениями последовательностей, приуроченных к одному или нескольким локусам (например, см. US 2011/0160078). С другой стороны, количественное определение может осуществляться, к примеру, методом цифровой ПЦР (например, см. Kalinina et al., Nucleic Acids Research, 1997, 25 (10): 1999-2004) или гибридизации с матрицей.
В некоторых воплощениях образец бкДНК может подвергаться дополнительному анализу методом визуализации, описанным в Song et al. (Proc. Natl. Acad. Sci. 2016 113: 4338-43), который включен сюда путем ссылки. В этих воплощениях способ может включать (a) маркировку образца, содержащего бкДНК, путем: (i) добавления метки захвата на концы молекул ДНК в образце; и (ii) маркировку молекул, содержащих гидроксиметилцитозин, первым флуорофором; (b) иммобилизацию молекул ДНК, помеченных на стадии (a), на носителе; и (c) визуализацию индивидуальных молекул гидроксиметилированной ДНК на носителе. В некоторых воплощениях этот способ может включать (d) подсчет количества индивидуальных молекул, помеченных первым флуорофором, тем самым определяя количество молекул гидроксиметилированной ДНК в образце. В этих воплощениях первый флуорофор на стадии (a)(ii) вводится путем инкубации молекул ДНК с ДНК-β-глюкозилтрансферазой и UDP-глюкозой, модифицированной хемоселективной группой, при этом молекулы гидроксиметилированной ДНК ковалентно метятся хемоселективной группой, и связывания первого флуорофора с хемоселективно модифицированной ДНК по реакции циклоприсоединения. В некоторых воплощениях стадия (a)(i) может дополнительно включать добавление второго флуорофора к концам молекул ДНК в образце. В некоторых воплощениях стадия (a) после стадии (ii) может дополнительно включать (iii) маркировку молекул, содержащих метилцитозин, вторым флуорофором; а стадия (c) дополнительно включает визуализацию индивидуальных молекул метилированной ДНК на носителе. В этих воплощениях способ может включать (d) подсчет (i) количества индивидуальных молекул, помеченных первым флуорофором, и (ii) количества индивидуальных молекул, помеченных вторым флуорофором. В этих воплощениях способ может дополнительно включать (e) вычисление относительных количеств гидроксиметилированной ДНК и метилированной ДНК в образце. В некоторых воплощениях молекулы, содержащие метилцитозин, метятся вторым флуорофором путем инкубации продукта стадии (а)(ii) с метилцитозиндиоксигеназой, при этом метилцитозин превращается в гидроксиметилцитозин; инкубации ДНК, обработанной метилцитозиндиоксигеназой, с ДНК-β-глюкозилтрансферазой и UDP-глюкозой, модифицированной хемоселективной группой, при этом молекулы гидроксиметилированной ДНК ковалентно метятся хемоселективной группой; и связывания второго флуорофора с хемоселективно модифицированной ДНК по реакции циклоприсоединения.
В этом способе стадия (a) может дополнительно включать (iii) мечение молекул, содержащих метилцитозин, вторым флуорофором; а стадия (c) может включать визуализацию индивидуальных молекул геномной ДНК путем детектирования сигналов FRET (флуоресцентного резонансного переноса энергии), исходящих из первого или второго флуорофора (a)(ii) или (a)(iii), причем сигнал FRET указывает, что молекула содержит гидроксиметилцитозин и метилцитозин, которые проксимальны (близки) друг к другу. В этих воплощениях способ может включать определение того, содержит ли молекула проксимальный гидроксиметилцитозин и метилцитозин в одной и той же цепи. С другой стороны, способ может включать определение того, содержит ли молекула проксимальный гидроксиметилцитозин и метилцитозин на разных цепях.
Статус гидроксиметилцитозина/метилцитозина у генов/интервалов, перечисленных в таблицах 10A, 10B, 11A и 11B, можно исследовать с помощью матрицы зондов. Например, в некоторых воплощениях способ может включать прикрепление меток к молекулам ДНК, содержащим один или несколько нуклеотидов гидроксиметилцитозина и метилцитозина в образце бкДНК, причем нуклеотиды гидроксиметилцитозина метятся первой оптически детектируемой меткой (например, первым флуорофором), а нуклеотиды метицитозина метятся второй оптически детектируемой меткой (например, вторым флуорофором), которая отличается от первой метки, получая помеченный образец, и гибридизацию образца с матрицей зондов, причем матрица зондов содержит зонды по меньшей мере для 1, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5, по меньшей мере 10 или по меньшей мере 20 генов или интервалов, перечисленных в таблицах 10A, 10B, 11A и 11B. В некоторых случаях матрица может содержать зонды для верхней цепи и зонды для нижней цепи, что позволяет детектировать помеченные верхние и нижние цепи независимо друг от друга.
В некоторых воплощениях способ может включать присоединение меток к молекулам ДНК, содержащим один или несколько нуклеотидов гидроксиметилцитозина и метилцитозина в образце бкДНК, причем нуклеотиды гидроксиметилцитозина метятся первой меткой захвата, а нуклеотиды метицитозина метятся второй меткой захвата, которая отличается от первой, получая помеченный образец; обогащение помеченных молекул ДНК; и секвенирование обогащенных молекул ДНК. Это воплощение способа может включать раздельное обогащение молекул ДНК, содержащих один или несколько гидроксиметилцитозинов, и молекул ДНК, содержащих один или несколько нуклеотидов метилцитозина. Мечение можно адаптировать из методов, описанных выше, либо из Song et al. (Proc. Natl. Acad. Sci. 2016, 113: 4338-43), используя метки захвата вместо флуоресцентных меток. Например, в некоторых воплощениях способ может включать инкубацию бкДНК (например, лигированной с адаптером бкДНК) с ДНК-β-глюкозилтрансферазой и UDP-глюкозой, модифицированной хемоселективной группой, при этом молекулы гидроксиметилированной ДНК в бкДНК ковалентно метятся хемоселективной группой; связывание первой метки захвата с хемоселективно модифицированной бкДНК через хемоселективную группу, например, по реакции циклоприсоединения; инкубацию продукта этой стадии с метилцитозиндиоксигеназой, ДНК-β-глюкозилтрансферазой и UDP-глюкозой, модифицированной хемоселективной группой; и связывание второй метки захвата с хемоселективно модифицированной ДНК через хемоселективную группу, например, по реакции циклоприсоединения.
В некоторых воплощениях стадия определения может проводиться относительно контроля. В частности, в некоторых воплощениях способ может включать определение того, является ли одна или несколько последовательностей нуклеиновых кислот в обогащенной гидроксиметилированной ДНК чрезмерно представленной относительно контроля и/или определение того, является ли одна или несколько последовательностей нуклеиновых кислот в обогащенной гидроксиметилированной ДНК недостаточно представленной относительно контроля. В некоторых воплощениях контрольные последовательности могут находиться в обогащенной гидроксиметилированной ДНК. В этих воплощениях контрольные последовательности могут находиться в том же образце, что и нуклеиновые кислоты, относящиеся к целевым локусам, но они не относятся к целевым локусам. В других воплощениях контрольные последовательности могут находиться в образце из (a), содержащем циркулирующую бесклеточную ДНК до обогащения по гидроксиметилированной ДНК. В других воплощениях контрольные последовательности могут находиться в образце из (a), содержащем циркулирующую бесклеточную ДНК после обогащения по гидроксиметилированной ДНК (то есть во фракции циркулирующей бесклеточной ДНК, не содержащей гидроксилиметилированной ДНК). В других воплощениях контрольные последовательности могут быть из другого образца. В других воплощениях определение может исходить из полученного эмпирически порога, полученного при анализе нескольких образцов.
Наборы
Настоящим изобретением также предусмотрены наборы, содержащие реагенты для практического применения способов, как описано выше. Данные наборы содержат один или несколько из компонентов, описанных выше. Например, в некоторых воплощениях набор может предназначаться для анализа бкДНК. В этих воплощениях набор может содержать ДНК-β-глюкозилтрансферазу, UDP-глюкозу, модифицированную хемоселективной группой; и адаптер, содержащий молекулярный баркод, как описано выше. В некоторых воплощениях адаптер может быть представлен Y-адаптером или шпилькообразным адаптером. В некоторых воплощениях набор также может содержать биотиновый компонент, причем биотиновый компонент реагирует с хемоселективной группой.
Различные компоненты набора могут находиться в отдельных контейнерах или же некоторые совместимые компоненты могут быть предварительно объединены в одном контейнере, если нужно.
В дополнение к вышеупомянутым компонентам данные наборы могут дополнительно включать инструкции по использованию компонентов набора для практического применения рассматриваемых способов, то есть инструкции по анализу образцов. Инструкции для практического применения рассматриваемых способов обычно записаны на подходящем носителе записи. Например, инструкции могут быть напечатаны на основе типа бумаги или пластика и пр. При этом инструкции могут находиться в наборах в виде вложенной листовки при маркировке контейнера из набора или его компонентов (т.е. связанной с упаковкой или субупаковкой) и т.д. В других воплощениях инструкции представлены в виде электронного файла для хранения данных, находящегося на подходящем считываемом компьютером носителе, например, CD-ROM, дискете и т.п. Еще в других воплощениях в наборе нет фактических инструкций, но представлены средства для получения инструкций из удаленного источника, например, через Интернет. Примером этого воплощения является набор, который включает в себя веб-адрес, где инструкции можно просматривать и/или из которого инструкции можно загрузить. Как и в случае с инструкциями, это средство для получения инструкций записано на подходящей основе.
Композиции
Настоящим изобретением также предусмотрены различные композиции, которые содержат продукты, полученные настоящим способом. В некоторых воплощениях композиции могут содержать циркулирующую бесклеточную ДНК, причем остатки гидроксиметилцитозина в ДНК модифицированы, содержа метку захвата. В этих воплощениях в композиции могут находиться обе цепи циркулирующей бесклеточной ДНК. В некоторых воплощениях ДНК может находиться в двухцепочечной форме. В других воплощениях ДНК может быть в одноцепочечной форме (например, если композиция была денатурирована, к примеру, при инкубации при повышенной температуре).
Как следует из описания в разделе методов настоящего изобретения, меткой захвата может служить биотиновый компонент (например, биотин) или хемоселективная группа (например, азидогруппа или алкинильная группа типа UDP-6-N3-Glu). В некоторых воплощениях композиция может дополнительно содержать: i) β-глюкозилтрансферазу и ii) UDP-глюкозу, модифицированную хемоселективной группой (например, UDP-6-N3-Glu). Эти молекулы не являются флуоресцентно мечеными или мечеными оптически детектируемой меткой.
В некоторых воплощениях бесклеточная гидроксиметилированная ДНК лигирована с адаптерами (то есть она была лигирована с адаптерами). В некоторых воплощениях ДНК может содержать адаптеры, например, двухцепочечные, Y- или шпилькообразные адаптеры, лигированные к обеим цепям на обоих концах.
В некоторых воплощениях композиция может быть обогащенной с тем, что по меньшей мере 10% (например, по меньшей мере 20%, по меньшей мере 50%, по меньшей мере 80% или по меньшей мере 90%) молекул нуклеиновой кислоты в композиции содержат один или несколько гидроксиметилцитозинов, модифицированных так, что они содержат метку захвата. В этих воплощениях композиция может дополнительно содержать в растворе копии бесклеточной гидроксиметилированной ДНК, которые были получены методом ПЦР. В этих воплощениях композиция может содержать популяцию продуктов ПЦР, в которой по меньшей мере 10% (например, по меньшей мере 20%, по меньшей мере 50%, по меньшей мере 80% или по меньшей мере 90%) продуктов ПЦР скопированы (прямо или косвенно) с гидроксиметилированной ДНК.
В некоторых воплощениях композиция может дополнительно содержать носитель (например, шарики типа магнитных шариков или другое твердое вещество), причем носитель и циркулирующая бесклеточная ДНК связаны друг с другом через метку захвата. Связывание может осуществляться через ковалентную связь или нековалентную связь. Отметим, что носитель может быть связан со стрептавидином, а метка захвата может быть связана с биотином.
Примеры
Далее аспекты настоящего изобретения станут более понятными в свете следующих примеров, которые никоим образом не следует воспринимать как ограничивающие объем настоящего изобретения.
Здесь приведен первый глобальный анализ гидроксиметилома в бкДНК. При раке легких наблюдалась характерная глобальная потеря бесклеточного 5hmC, тогда как при HCC и раке поджелудочной железы были идентифицированы значительные изменения бесклеточного 5hmC меньшего масштаба. При HCC проводилось поисковое исследование лонгитюдных образцов, которое показало, что бесклеточный 5hmC можно использовать для мониторинга лечения и рецидивов. Эти три типа рака проявляли разные профили бесклеточного гидроксиметилома, и мы смогли использовать алгоритмы машинного обучения с тренировкой по характеристикам бесклеточного 5hmC для прогнозирования трех типов рака с большой точностью. Предполагается, что профилирование бесклеточного 5hmC будет полезным инструментом для диагностики рака, а также других заболеваний, включая, без ограничения, нейродегенеративные заболевания, сердечно-сосудистые заболевания и диабет. Кроме того, общие рамки этого метода могут быть легко адаптированы для секвенирования других модификаций в бесклеточных нуклеиновых кислотах путем применения соответствующего химизма введения метки к модифицированным основаниям. Это позволит получить всесторонний и глобальный обзор генетических и эпигенетических изменений при различных заболеваниях и еще больше повысить возможности персонализированной диагностики.
Эти данные были получены с использованием low-input whole-genome cell-free 5hmC sequencing method (метода низкозатратного полногеномного секвенирования бесклеточного 5hmC), адаптированного из метода селективной химической маркировки, известного как “hMe-Seal” (например, см. Song et al., Nat. Biotechnol., 2011, 29, 68-72). hMe-Seal - надежный метод, в котором используется β-глюкозилтрансфераза (βGT) для избирательного мечения 5hmC биотином через модифицированную азидом глюкозу для извлечения содержащих 5hmC фрагментов ДНК для секвенирования (см. фиг. 5A). При стандартной процедуре hMe-Seal требуются микрограммы ДНК. В описанном здесь модифицированном подходе сначала лигировали бкДНК с секвенирующими адаптерами и избирательно метили 5hmC биотиновой группой. После захвата содержащей 5hmC бкДНК с помощью стрептавидиновых шариков создавали конечную библиотеку методом ПЦР прямо из гранул вместо элюирования захваченной ДНК. При этом сводится к минимуму потеря образца при очистке. Способ схематически представлен на фиг. 1A.
Материалы и методы
Сбор и обработка образцов
Образцы от здоровых субъектов получали из Гематологического центра Stanford. Пациентов с HCC и раком молочной железы набирали по протоколу, одобренному Наблюдательной комиссией Стэнфордского университета. Пациентов с раком легких, раком поджелудочной железы, GBM, раком желудка и колоректальным раком набирали по протоколу, одобренному Наблюдательной комиссией West China Hospital. Все привлеченные субъекты давали информированное согласие. Кровь собирали в покрытые ЭДТА флаконы Vacutainer. Из образцов крови получали плазму после центрифугирования при 1600×g в течение 10 мин при 4°C и 16000×g в течение 10 мин при 4°C. БкДНК экстрагировали с помощью набора Circulating Nucleic Acid Kit (Qiagen). Геномную ДНК из цельной крови экстрагировали с помощью набора DNA Mini Kit (Qiagen) и фрагментировали с помощью дцДНК-фрагментазы (NEB) в среднем до 300 пар оснований. ДНК определяли на флуориметре Qubit (Life Technologies). Бесклеточную РНК экстрагировали с помощью набора Plasma/Serum Circulating and Exosomal RNA Purification Kit (Norgen). Выделенную бесклеточную РНК дополнительно расщепляли с помощью ДНКаз Baseline-ZERO (Epicenter) и удаляли рРНК с помощью набора для удаления рРНК Ribo-Zero rRNA Removal Kit (Epicenter) по методике фирмы Clontech.
Получение добавляемого контрольного ампликона
Для получения добавляемого (внутреннего) контроля подвергали ПЦР-амплификации ДНК лямбда с помощью ДНК-полимеразы Taq (NEB) и очищали на шариках AMPure XP (Beckman Coulter) в виде неперекрывающихся ампликонов ~180 п.о. с помощью коктейля из dATP/dGTP/dTTP и одного из следующего: dCTP, dmCTP или 10% dhmCTP (Zymo)/90% dCTP. Последовательности праймеров: dCTP, прямой праймер: CGTTTCCGTTCTTCTTCGTC (SEQ ID NO: 1), обратный: TACTCGCACCGAAAATGTCA (SEQ ID NO: 2); dmCTP, прямой праймер: GTGGCGGGTTATGATGAACT (SEQ ID NO: 3), обратный: CATAAAATGCGGGGATTCAC (SEQ ID NO: 4); 10% dhmCTP/90% dCTP, прямой праймер: TGAAAACGAAAGGGGATACG (SEQ ID NO: 5), обратный: GTCCAGCTGGGAGTCGATAC (SEQ ID NO: 6).
Получение, мечение, захват и высокопроизводительное секвенирование 5hmC-библиотек
БкДНК (1-10 нг) или фрагментированную геномную ДНК из цельной крови (1 мкг) с добавленными контрольными ампликонами (0,001 пг каждого ампликона на 10 нг ДНК) подвергали репарации концов, 3'-аденилировали и лигировали с ДНК-баркодами (BioScientific) с помощью набора KAPA Hyper Prep Kit (Kapa Biosystems) в соответствии с инструкциями производителя. Лигированную ДНК инкубировали в 25 мкл раствора, содержащего 50 мМ буфера HEPES (рН 8), 25 мМ MgCl2, 100 мкМ UDP-6-N3-Glc (Active Motif) и 12,5 ед. βGT (Thermo) в течение 2 часов при 37°C. После этого прямо в реакционную смесь добавляли 2,5 мкл DBCO-PEG4-биотина (Click Chemistry Tools, 20 мМ в ДМСО) и инкубировали 2 часа при 37°C. Затем в реакционную смесь добавляли 10 мкг расщепленной ДНК спермы лосося (Life Technologies) и очищали ДНК на колонке Micro Bio-Spin 30 (Bio-Rad). Очищенную ДНК инкубировали с 0,5 мкл стрептавидиновых шариков M270 (Life Technologies), предварительно блокированных ДНК спермы лосося в буфере 1 (5 мМ трис pH 7,5, 0,5 мМ ЭДТА, 1М NaCl и 0,2% Tween 20) в течение 30 мин. После этого шарики отмывали 3 раза по 5 мин, каждый раз буфером 1, буфером 2 (буфер 1 без NaCl), буфером 3 (буфер 1 с рН 9) и буфером 4 (буфер 3 без NaCl). Все операции связывания и отмывки проводили при комнатной температуре с легким вращением. Затем шарики ресуспендировали в воде и подвергали ПЦР-амплификации с 14 (бкДНК) или 9 (геномная ДНК из цельной крови) циклами ПЦР с помощью ДНК-полимеразы Phusion (NEB). Продукты ПЦР очищали с помощью шариков AMPure XP. Отдельно получали вводные библиотеки методом ПЦР прямо из лигированной ДНК без мечения и захвата. Для технических повторов бкДНК от одного субъекта разделяли на две повторные пробы. Проводили секвенирование по спаренным концам в 75 п.о. на приборе NextSeq.
Обработка данных и анализ тел генов
Последовательности FASTQ совмещали с UCSC/hg19 с помощью Bowtie2 v2.2.5 и дополнительно фильтровали с помощью SAMtools 0.1.19 (view-f2-F1548-q30 и rmdup), получая уникальные недублированные соответствия в геноме. Прочтения по спаренным концам подвергали элонгации и преобразовывали в формат BedGraph, нормированный по общему количеству выровненных прочтений с помощью BedTools, а затем преобразовывали в формат BigWig с помощью BedGraphToBigWig из геномного браузера UCSC для визуализации в Integrated Genomics Viewer. Последовательности FASTQ также выравнивали с тремя добавленными контрольными последовательностями для оценки эффективности выделения. Добавленный контроль используется только для подтверждения успешного извлечения в каждом образце. hMRs идентифицировали с помощью MACS, используя необогащенную исходную ДНК в качестве фона и значения по умолчанию (порог отсечения значений p в 10-5). Геномные аннотации hMR проводили путем определения процента hMRs, перекрывающих каждую геномную область ≥1 bp. Метагенные профили получали с помощью NGS.plot. Количество FPKM 5hmC рассчитывали по числу фрагментов в каждом теле гена по RefSeq, полученных с помощью BedTools. При дифференциальном анализе исключали гены меньше 1 kb или относящиеся к хромосомам X и Y. Дифференциальный анализ геномного 5hmC проводили с помощью пакета Limma на языке R. Анализ GO проводили, используя DAVID Bioinformatics Resources с помощью GOTERM_BP_FAT. Тканеспецифическую экспрессию генов получали из BioGPS. Для графиков tSNE в качестве матрицы расстояний для tSNE использовали корреляцию Пирсона по FPKM 5hmC в теле генов для tSNE. MA-графики, иерархические кластеризации, tSNE, LDA и теплокарты выполняли на языке R.
Предсказание типа и стадии рака
Маркерные гены, специфичные к типам рака, выбирали по t-критерию Стьюдента между 1) одной раковой группой и здоровой группой, 2) одной раковой группой и другими раковыми образцами, 3) двумя различными раковыми группами. Затем проводили коррекцию Benjamini-Hochberg для необработанных значений p, а затем сортировали гены по значениям q. Отбирали верхние 5-20 генов с наименьшими значениями q в качестве набора признаков для обучения классификатора. Для более высокого разрешения идентифицировали DhMRs путем разбиения референтного генома (hg19) на окна по 2тпо in silico и вычисления значений FPKM 5hmC для каждого окна. Перед дальнейшим анализом отфильтровывали попадающие в черный список области генома, склонные давать артефактные сигналы по ENCODE. Для специфичных к типам рака DhMRs проводили коррекцию значений p по Benjamini-Hochberg при сравнении между каждым типом рака и здоровыми контролями по t-критерию Стьюдента. Для каждого типа рака отбирали верхние 2-10 DhMRs с наименьшими значениями q. На комплекте данных проводили анализ типа случайного леса и классификатора Mclust по гауссовской модели, используя ранее описанные признаки (тела генов и DhMRs). Классификаторы подвергали тренировке на образцах рака легких, рака поджелудочной железы, HCC и здоровых образцах. Параметры для метода случайного леса, включая случайное зерно и mtry (количество переменных, отбираемых случайным образом в качестве кандидатов при каждом разбиении), настраивали на наименьшую оценку ошибки out-of-bag, используя tuneRF в пакете randomForest R. Верхние 15 признаков с наибольшей важностью переменной наносили на графики. Проводили анализ на нормальной модели смеси, используя пакет Mclust R. Для обучения классификаторов Mclust на этой модели строили график байесовского информационного критерия (BIC) для визуализации эффективности классификации на различных мультипараметрических моделях смесей. По умолчанию для классификации Mclust была выбрана модель типа EEI (диагональ, одинаковый объем и форма) и модель типа EDDA (один компонент для каждого класса с одинаковой структурой ковариации между классами). Для усиления анализа проводили кросс-валидацию с одним пропуском (LOO) для метода случайного леса и классификатора Mclust с одинаковыми значениями параметров. Для кросс-валидации Mclust использоваи cvMclustDA в пакете Mclust R.
Конструирование библиотек бесклеточной РНК и высокопроизводительное секвенирование
Библиотеки бесклеточной РНК получали с помощью набора для приготовления библиотек ScriptSeq v2 RNA-Seq (Epicenter) по протоколу FFPE RNA с 19 циклами ПЦР-амплификации. Затем продукты ПЦР очищали с помощью шариков AMPure XP. Секвенирование по спаренным концам в 75 п.о. проводили на приборе NextSeq. Прочтения RNA-Seq сначала урезали с помощью Trimmomatic 0.33, а затем совмещали с помощью TopHat 2.0.14. Значения экспрессии RPKM получали с помощью CuffLinks 2.2.1, используя модели генов из RefSeq.
Результаты и обсуждение
Вышеописанным способом легко выявляется бесклеточный 5hmC в образцах, содержащих менее 10 нг бкДНК (например, 1-10 нг бкДНК). При добавлении пула ампликонов по 180 п.о., содержащих C, 5mC или 5hmC в бкДНК, было показано, что после извлечения при ПЦР на шариках обнаруживается только содержащая 5hmC ДНК (фиг. 5B). Этот результат подтвердился при секвенировании конечных библиотек, которые проявляли более чем 100-кратное обогащение прочтений, относительно добавленной контрольной 5hmC-ДНК (фиг. 1В). Кроме того, наш подход одинаково хорошо работал и с бкДНК, и с общей геномной ДНК (1 мкг геномной ДНК (гДНК) из цельной крови) (фиг. 1В). Конечные библиотеки бесклеточного 5hmC очень сложны, доля средних уникальных недублированных соответствий составляет 0,75 при легком секвенировании (в среднем 15 миллионов прочтений, ~0,5-кратный охват генома человека) (фиг. 5C-5D и таблица 1 ниже), однако технические повторные пробы хорошо воспроизводимы (фиг. 5E). В данных по последовательности идентифицировали обогащенные 5hmC участки (hMRs) пуассоновским методом. hMRs хорошо согласуются между техническими повторами и объединенным образцом: свыше 75% hMRs в объединенном образце являются общими для каждого из повторов (фиг. 5F), достигая стандарта ENCODE для ChIP-Seq. Эти результаты свидетельствуют, что профиль бесклеточного 5hmC легко и надежно определяется модифицированным методом hMe-Seal.
Таблица 1. Сводка по результатам секвенирования 5hmC
§ Технический повтор
† Необогащенная исходная ДНК
Секвенировали бесклеточный 5hmC от 8 здоровых лиц (таблицы 1 и 2). Также секвенировали 5hmC в гДНК из цельной крови от 2 лиц, так как лизированные клетки крови могут быть важным источником бесклеточной нуклеиновой кислоты. Полногеномные профили показали, что распределение бесклеточного 5hmC было почти идентичным у здоровых лиц и четко отличалось от распределения 5hmC и в цельной крови, и в исходной бкДНК (фиг. 6A). Предыдущие исследования 5hmC в тканях мыши и человека показали, что большая часть 5hmC в геноме находится в телах генов и проксимальных участках промоторов (Mellen et al., Cell 2012, 151: 1417-1430; Thomson, Genome Biol. 2012, 13, R93). Полногеномный анализ hMRs в наших данных по бкДНК показал, что большая часть (80%) является внутригенной с наибольшим обогащением в экзонах (соотношение наблюдаемые/ожидаемые, o/e = 7,29) и обеднением в межгенных участках (o/e = 0,46), что соответствует таковому в цельной крови (фиг. 6В-6С) и в других тканях. Известно, что обогащение 5hmC в телах генов коррелирует с транскрипционной активностью в таких тканях, как мозг и печень (например, см. Mellen et al., Cell, 2012, 151: 1417-1430; Thomson, Genome Biol., 2012, 13, R93). Чтобы определить, сохраняется ли это соотношение в бкДНК, мы проводили секвенирование бесклеточной РНК от одних и тех же лиц. При разбиении генов на 3 группы согласно их бесклеточной экспрессии и построении графиков усредненного профиля бесклеточного 5hmC вдоль тела генов (метагенный анализ) оказалось, что 5hmC концентрируется в телах генов и вокруг них у более сильно экспрессируемых генов (фиг. 1С). Эти результаты подтверждают, что бесклеточный 5hmC происходит из самых разных типов тканей и содержит информацию по другим тканям, чем кровь.
Таблица 2. Клиническая информация по здоровым образцам
Поскольку бесклеточный 5hmC в основном концентрируется во внутригенных участках, для сравнения бесклеточного гидроксиметилома с гидроксиметиломом цельной крови использовали количество генных фрагментов с 5hmC в 1 т.п.о. гена на 1 млн. картированных прочтений (FPKM). Так, беспристрастный анализ генного 5hmC методом t-распределенного стохастического вложения соседей (tSNE) показал четкое разделение между бесклеточными образцами и образцами цельной крови (фиг. 6D). С помощью пакета Limma (Ritchie et al., Nucleic Acids Res. 2015: 43, e47) было идентифицировано 2082 дифференцированно гидрометилированных гена между образцами цельной кровью и бесклеточными образцами (значения q, т.е. значения p с коррекцией по Benjamini-Hochberg <0,01, кратность отличий >2, фиг. 7A). А именно, проявлялась повышенная экспрессия 735 специфичных для крови обогащенных 5hmC генов в цельной крови по сравнению с 1347 обогащенными 5hmC генами, специфичными для бесклеточных образцов (p<2,2×10-16, t-критерий Уэлча) (фиг. 7В). В согласии с дифференциальной экспрессией, анализ по генной онтологии (GO) специфичных для крови обогащенных 5hmC генов идентифицировал главным образом процессы, связанные с клетками крови (фиг. 7C), тогда как анализ специфичных для бесклеточных образцов обогащенных 5hmC генов идентифицировал гораздо более разнообразные биологические процессы (фиг. 7D). Примеры обогащенных 5hmC генов, специфичных для цельной крови (FPR1, FPR2) и для бесклеточных образцов (GLP1R), представлены на фиг. 7E. В целом эти результаты подтверждают концепцию о том, что все ткани вносят свой 5hmC в бкДНК и что измерение этого является приближенным эквивалентом экспрессии генов.
Для изучения диагностического потенциала бесклеточного 5hmC этот метод применяли к секвенированию бкДНК у комплекта из 49 пациентов с первичным раком без лечения, включая 15 пациентов с раком легких, 10 с гепатоцеллюлярной карциномой (HCC), 7 с раком поджелудочной железы, 4 с глиобластомой (GBM), 5 с раком желудка, 4 с колоректальным раком, 4 с раком молочной железы (таблицы 3-9, ниже). Эти пациенты варьируются от ранней стадии рака до поздней стадии метастатического рака. При раке легких наблюдалась прогрессирующая глобальная потеря обогащения 5hmC с ранней стадии неметастатического рака легких до поздней стадии метастатического рака легких по сравнению со здоровой бкДНК, и постепенно она становилась похожей на необогащенную исходную бкДНК (фиг. 2A). Беспристрастный анализ тел генов методом tSNE также показал зависимый от стадии переход профиля при раке легких от здорового профиля к профилю, похожему на необогащенную исходную бкДНК (фиг. 8A). Примечательно, что даже образцы ранних стадий рака легких хорошо отделены от здоровых образцов (фиг. 8А). Явления глобального гипогидроксиметилирования также подтверждались по другим показателям. Во-первых, при метастатическом раке легких большинство дифференциальных генов (значения q<10-7, 1159 генов) проявляли зависимое от стадии истощение 5hmC по сравнению со здоровыми образцами (фиг. 2B). Во-вторых, метагенный профиль показал зависимое от стадии ослабление сигнала 5hmC из тел генов и сходство с необогащенной исходной бкДНК (фиг. 8B). В-третьих, отмечалось резкое снижение количества hMRs, идентифицированных при раке легких, особенно при метастатическом раке легких, по сравнению со здоровыми и другими раковыми образцами (фиг. 2C). Эти данные подтверждают зависимое от стадии глобальное падение уровня 5hmC в бкДНК при раке легких.
Таблица 3. Клиническая информация по образцам рака легких
Все образцы - немелкоклеточного рака легких, если не указано иначе
§ Мелкоклеточный рак легких
Таблица 4. Клиническая информация по образцам HCC
HCC - гепатоцеллюлярная карцинома;
HBV - вирус гепатита B
§ - по наибольшему размеру
Таблица 5. Клиническая информация по образцам рака поджелудочной железы
Таблица 6. Клиническая информация по образцам GBM
GBM - глиобластома
Таблица 7. Клиническая информация по образцам рака желудка
Таблица 8. Клиническая информация по образцам колоректального рака
Таблица 9. Клиническая информация по образцам рака молочной железы
Следует отметить, что глобальная потеря обогащения 5hmC в бкДНК, наблюдавшаяся при раке легких, не обусловлена несостоятельностью нашего метода обогащения, так как добавленный контроль во всех образцах, включая образцы рака легких, проявлял сильное обогащение содержащей 5hmC ДНК (фиг. 8C). Но это явление, уникальное для рака легких, которое не наблюдается при других исследованных раковых заболеваниях, о чем свидетельствует количество hMRs (фиг. 2C) и метагенные профили (фиг. 8B). Примеры обедненных 5hmC генов при раке легких представлены на фиг. 2D и фиг. 8D. В раковой ткани легких может быть низкий уровень 5hmC по сравнению с нормальной тканью легких, а легкие могут давать сравнительно большой вклад в бкДНК. Весьма вероятно, что рак легких, особенно метастатической рак легких, вызывает высвобождение больших количеств гипогидроксиметилированной гДНК в бкДНК, эффективно разбавляя бкДНК и приводя к истощению 5hmC в бесклеточном фонде 5hmC. С другой стороны, гипогидроксиметилирование бкДНК может возникать из-за гипогидроксиметилирования гДНК в крови, наблюдаемого у пациентов с метастатическим раком легким, как сообщалось недавно. В целом эти результаты показывают, что секвенирование бесклеточного 5hmC может использоваться для раннего выявления рака легких, а также для мониторинга прогрессирования и метастазирования рака легких.
Что касается HCC, то секвенировали бесклеточный 5hmC от 7 пациентов с инфекцией вирусом гепатита B (HBV), так как большинство случаев HCC являются следствием заражения вирусным гепатитом (таблица 4). Беспристрастный анализ уровня 5hmC в генах методом tSNE показал, что отмечается постепенное изменение бесклеточного 5hmC при переходе от здоровых к HBV, а затем к HCC, что отражает развитие заболевания (фиг. 3A). Специфичные для HCC дифференциальные гены (значения q<0,001, кратность отличий > 1,41, 1006 генов) способны отделить образцы HCC от здоровых и большей части образцов HBV (фиг. 3B). Можно идентифицировать и обогащенные, и обедненные HCC-специфичные гены при сравнении с другими образцами бкДНК (фиг. 3B), а обогащенные гены (379 генов) проявляли повышенную экспрессию в тканях печени по сравнению с обедненные генами (637 генов) (значения p<2,2×10-16, t-критерий Уэлча) (фиг. 9A), что согласуется с пермиссивным действием 5hmC на экспрессию генов. Примером HCC-специфичных генов, обогащенных 5hmC, является AHSG, секретируемый белок, который сильно экспрессируется в печени (фиг. 3C и фиг. 9B-9C), а примером HCC-специфичных генов, обедненных 5hmC, является MTBP, который, как сообщалось, ингибирует распространение и метастазирование HCC и подавляется в тканях HCC (фиг. 3D, а также данные из фиг. 5D). В целом эти результаты указывают на модель, в которой вирусная инфекция и развитие HCC ведут к постепенному повреждению ткани печени и повышению присутствия ДНК печени в крови.
Для дальнейшего изучения потенциала бесклеточного 5hmC для мониторинга лечения и прогрессирования заболевания продолжали обследовать 4 пациентов с HCC. Этим пациентам проводилась хирургическая резекция, после которой у 3 из них наблюдались рецидивы заболевания (таблица 4). Анализ серийных образцов плазмы у этих пациентов (до операции; после операции; и рецидивы) методом tSNE показал, что образцы «после операции» кластеризуются со здоровыми образцами, а образцы рецидивов кластеризуются с HCC (фиг. 3Е). Такая картина проявлялась и по изменениям FPKM 5hmC у AHSG и MTBP (фиг. 3C-3D). В качестве примера использования бесклеточного 5hmC для отслеживания лечения и прогрессирования HCC использовали линейный дискриминантный анализ (LDA) для сведения линейной комбинации HCC-специфичных дифференциальных генов (фиг. 3B) в одно значение (показатель HCC), которое наилучшим образом отделяет HCC до операции от здоровых и образцов HBV. Затем рассчитывали показатель HCC для образцов после операции и рецидивов HCC и оказалось, что показатель HCC может точно отслеживать состояния лечения и рецидивов (фиг. 5E). В целом эти результаты показывают, что секвенирование бесклеточного 5hmC является мощным инструментом для выявления HCC, а также мониторинга результатов лечения и рецидивов заболевания.
Также было обнаружено, что рак поджелудочной железы вызывает резкие изменения бесклеточного гидроксиметилома даже у некоторых пациентов с ранней стадией рака поджелудочной железы (таблица 5). Подобно HCC, рак поджелудочной железы ведет к появлению генов как с повышенным, так и с пониженным уровнем 5hmC по сравнению со здоровыми лицами (значение q<0,01, кратность отличий > 2, 713 генов) (фиг. 10A). Примеры специфичных для рака поджелудочной железы генов, обогащенных и обедненных 5hmC по сравнению с другими образцами бкДНК, представлены на фиг. 6B-6E. Результаты свидетельствуют, что секвенирование бесклеточного 5hmC может быть потенциально важным для раннего выявления рака поджелудочной железы.
Несмотря на большой интерес к использованию бкДНК в качестве “жидкой биопсии” для выявления рака, оказалось, что трудно идентифицировать происхождение раковой бкДНК, а тем самым и местоположение опухоли. Наши результаты показали, что анализ бесклеточного 5hmC может решить эту проблему, так как анализ методом tSNE всех 7 типов рака показал, что рак легких, HCC и рак поджелудочной железы проявляют четкие сигнатуры и их можно легко отделить друг от друга и от здоровых образцов (фиг. 4A). Другие 4 типа рака проявляли сравнительно небольшие изменения по сравнению со здоровыми образцами. При использовании других признаков типа участков промоторов (на 5 т.п.о. выше от сайта начала транскрипции (TSS)) проявлялась аналогичная картина (фиг. 11A). Отметим, что ни один конкретный тип рака, который был исследован, не был похожим на профиль цельной крови (фиг. 11В), свидетельствуя о том, что загрязнение клетками крови не является значительным источником вариаций. Все пациенты в этой группе примерно того же возраста, что и здоровые лица (фиг. 11C и таблица 2-9), поэтому возраст вряд ли является мешающим фактором. Не наблюдался и групповой эффект (фиг. 11D).
Для дальнейшего изучения способности 5hmC в бкДНК служить биомаркером для прогнозирования типа рака использовали два широко применяемых метода машинного обучения - модель нормальной смеси и метод случайного леса. Прогнозирование было сосредоточено на HCC, раке поджелудочной железы, неметастатическом и метастатическом раке легких. На основании трех правил (см. ниже) было идентифицировано 90 генов (таблица 10), у которых средний уровень 5hmC в телах генов может отличаться между раковыми и здоровыми группами или между самими раковыми группами.
Таблица 10A. Набор из 90 генов, который использовался для прогнозирования рака по признаку тела гена
При втором анализе с использованием другого метода были идентифицированы тела генов, перечисленных в таблице 10B, как прогностические для рака.
Таблица 10B. Набор из 40 верхних генов, который использовался для прогнозирования рака по признаку тела гена
Целевые локусы при анализе вышеописанным способом могут включать одно или несколько (например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше, например, 15 или больше либо 20 или больше) тел генов из приведенных в таблице 10A и/или 10B, как показано выше.
Наряду с телом гена, 5hmC в некодирующих участках вполне мог бы служить биомаркером при прогнозировании типа рака. Был разработан другой набор признаков путем исследования каждого из окон по 2 т.п.о. по всему геному и идентификации дифференциальных hMRs (DhMRs) для каждого типа рака. Было идентифицировано 17 маркерных DhMRs для четырех отдельных групп рака (таблица 11A).
Таблица 11A. Набор из 17 DhMRs, который использовался для прогнозирования рака по признаку DhMR
При втором анализе с использованием другого метода были идентифицированы DhMRs, перечисленные в таблице 11B, как прогностические для рака.
Таблица 11B. Набор из 36 верхних DhMRs, который использовался для прогнозирования рака по признаку DhMR
Целевые локусы при анализе вышеописанным способом могут включать один или несколько (например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше, например, 15 или больше либо 20 или больше) DhMRs из приведенных в таблице 11A и/или 11B, как показано выше.
Два алгоритма машинного обучения подвергали обучению, используя 90 генов либо 17 DhMRs в качестве признака, и оценивали точность прогноза при кросс-валидации с одним пропуском (LOO). Предиктор на основе модели нормальной смеси (Mclust) давал ошибку при кросс-валидации LOO в 10% и 5% при использовании тела гена и DhMR в качестве признака, соответственно (фиг. 4B и фиг. 12A-12B). При снижении размерности по Mclust проявлялись четкие границы между группами (фиг. 12C). Предиктор типа случайного леса давал ошибку при кросс-валидации LOO в 5% и 0% при использовании тела гена и DhMR в качестве признака, соответственно (фиг. 4B). При различных типах рака наблюдались разные профили 5hmC по нескольким DhMRs с высокой важностью переменных при прогнозировании на модели случайного леса (фиг. 12D-12E). Наконец, для оценки степени согласия между различными моделями прогнозирования использовали каппа-коэффициент Коэна. Все комбинации проявляли высокое согласие (каппа Коэна ~0,9) при сравнении между классификаторами и по сравнению с фактической классификацией (фиг. 4C). На фиг. 12F и 12G представлена важность переменной для тел генов и DhMRs, полученная другим методом. Эти результаты свидетельствуют, что бесклеточный 5hmC может применяться для диагностики и выявления стадии рака.
Специалистам в данной области должно быть понятно, что, хотя изобретение и было описано выше в виде предпочтительных воплощений, оно не ограничивается ими. Различные признаки и аспекты вышеописанного изобретения могут применяться индивидуально или совместно. Кроме того, хотя изобретение было описано в контексте его реализации в конкретной среде и для конкретных применений (например, анализа бкДНК), специалистам в данной области должно быть понятно, что его применимость не ограничивается этим, и оно может выгодно применяться в самых разных средах и реализациях, в которых нужно исследовать гидроксиметилирование. Соответственно, приведенная ниже формула изобретения должна восприниматься с учетом всей полноты и сущности изложенного здесь изобретения.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> THE BOARD OF TRUSTEES OF THE LELAND STANFORD JUNIOR UNIVERSITY
<120> NONINVASIVE DIAGNOSTICS BY SEQUENCING 5 HYDROXYMETHYLATED
CELL-FREE DNA
<130> STAN-1318WO
<150> 62/319,702
<151> 2016-04-07
<150> 62/444,122
<151> 2017-01-09
<150> 62/461,712
<151> 2017-02-21
<160> 6
<170> PatentIn version 3.5
<210> 1
<211> 20
<212> DNA
<213> artificial sequence
<220>
<223> synthetic oligonucleotide
<400> 1
cgtttccgtt cttcttcgtc 20
<210> 2
<211> 20
<212> DNA
<213> artificial sequence
<220>
<223> synthetic oligonucleotide
<400> 2
tactcgcacc gaaaatgtca 20
<210> 3
<211> 20
<212> DNA
<213> artificial sequence
<220>
<223> synthetic oligonucleotide
<400> 3
gtggcgggtt atgatgaact 20
<210> 4
<211> 20
<212> DNA
<213> artificial sequence
<220>
<223> synthetic oligonucleotide
<400> 4
cataaaatgc ggggattcac 20
<210> 5
<211> 20
<212> DNA
<213> artificial sequence
<220>
<223> synthetic oligonucleotide
<400> 5
tgaaaacgaa aggggatacg 20
<210> 6
<211> 20
<212> DNA
<213> artificial sequence
<220>
<223> synthetic oligonucleotide
<400> 6
gtccagctgg gagtcgatac 20
<---
Реферат
Изобретение относится к биотехнологии, в частности, представлен способ секвенирования гидроксиметилированной бесклеточной ДНК. В некоторых воплощениях способ включает введение аффинной метки только в молекулы гидроксиметилированной ДНК в образце бкДНК, обогащение молекул ДНК, помеченных аффинной меткой, и секвенирование обогащенных молекул ДНК. 4 н. и 21 з.п. ф-лы, 11 табл., 1 пр., 13 ил.
Комментарии