Предложение родственных терминов для многосмыслового запроса - RU2005111000A
Код документа: RU2005111000A
Реферат
1. Способ предложения родственных терминов, заключающийся в том, что создают кластеры терминов в зависимости от вычисленного подобия векторов терминов, причем каждый вектор термина создают из результатов поиска, связанных с группой предыдущих запросов с высокой частотой появления (ЧП), поданных ранее в поисковую машину, и в ответ на получение термина/фразы от объекта оценивают этот термин/фразу, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов.
2. Способ по п.1, по которому данный термин/фраза содержится в многосмысловом запросе.
3. Способ по п.1, по которому объектом является компьютерное программное приложение и/или конечный пользователь.
4. Способ по п.1, по которому также определяют вычисленное подобие как

где весовой коэффициент
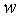

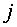
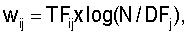
где

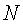


5. Способ по п.1, по которому также собирают термины предыдущих запросов из журнала запросов и определяют термины предыдущих запросов, имеющие высокую ЧП.
6. Способ по п.1, по которому перед созданием кластеров терминов также уменьшают размерность векторов терминов и нормируют векторы терминов.
7. Способ по п.1, по которому при оценивании также определяют совпадение между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров терминов, и в ответ на определение формируют предложение (предложения) родственных терминов, содержащее данный термин (термины)/фразу (фразы).
8. Способ по п.7, по которому предложение (предложения) родственных терминов также содержит для каждого термина/фразы из термина (терминов)/фразы (фраз) значение частоты появления, указывающее, сколько раз данный термин/фраза появлялся в группе извлеченных предыдущих запросов.
9. Способ по п.1, по которому при создании кластеров терминов также посылают соответствующие из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска и извлекают векторы терминов из, по меньшей мере, подгруппы признаков, соответствующих соответствующим запросам, и создают векторы терминов из признаков как функции частоты термина и обратной частоты термина.
10. Способ по п.9, по которому признаки содержат заголовок, описание и/или контекст для соответствующих предыдущих терминов запроса с высокой ЧП.
11. Способ по п.9, по которому соответствующие результаты содержат результаты поиска высшего ранга.
12. Способ по п.1, по которому кластеры терминов являются первой группой кластеров терминов, при этом также определяют, что отсутствует совпадение между термином/фразой и терминами/фразами, и в ответ на это определение создают вторую группу кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор термина создают из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и оценивают термин/фразу, принимая во внимание термины/фразы второй группы кластеров терминов, для определения одного или более предложений родственных терминов.
13. Способ по п.12, по которому при создании также идентифицируют предыдущие запросы с низкой ЧП из предыдущих запросов, извлеченных из журнала запросов, посылают соответствующие запросы из, по меньшей мере, подгруппы предыдущих запросов с низкой ЧП в поисковую машину для получения результатов поиска, извлекают признаки из, по меньшей мере, подгруппы результатов поиска и создают векторы терминов из признаков как функции частоты термина и обратной частоты термина.
14. Способ по п.13, по которому после кластеризации также определяют, что отсутствует совпадение между термином/фразой и термином (терминами)/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и в ответ на определение идентифицируют совпадение между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, причем вторая группа основана на предыдущих запросах с низкой ЧП, и в ответ для идентификации формируют предложение (предложения) родственных терминов, содержащее данный термин (термины)/фразу (фразы).
15. Машиночитаемый носитель, содержащий исполняемые машиной команды для создания кластеров терминов в зависимости от вычисленного подобия векторов терминов, причем каждый вектор термина сформирован из результатов поиска, связанных с группой предыдущих запросов с высокой частотой появления (ЧП), поданных ранее в поисковую машину, и в ответ на получение термина/фразы от объекта оценки термина/фразы, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов.
16. Машиночитаемый носитель по п.15, в котором данный термин/фраза содержится в многосмысловом запросе.
17. Машиночитаемый носитель по п.15, в котором объектом является компьютерное программное приложение и/или конечный пользователь.
18. Машиночитаемый носитель по п.15, который также содержит исполняемые машиной команды для определения вычисленного подобия как
где весовой коэффициент

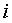

и где
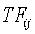
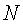
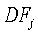

19. Машиночитаемый носитель по п.15, который также содержит исполняемые машиной команды для сбора терминов предыдущих запросов из журнала запросов и определения предыдущих терминов запроса, имеющих высокую ЧП.
20. Машиночитаемый носитель по п.15, который также содержит перед созданием кластеров терминов, исполняемые машиной команды для уменьшения размерности векторов термина и нормирования векторов терминов.
21. Машиночитаемый носитель по п.15, который также содержит при оценивании исполняемые машиной команды для определения совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров терминов, и в ответ на идентификацию формирования предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
22. Машиночитаемый носитель по п.21, в котором предложение (предложения) родственных терминов также содержит для каждого термина/фразы из терминов/фраз значение частоты появления, показывающее, сколько раз данный термин/фраза появлялся в группе извлеченных предыдущих запросов.
23. Машиночитаемый носитель по п.15, который также содержит при создании кластеров терминов исполняемые машиной команды для посылки соответствующих запросов из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска, извлечения признаков, по меньшей мере, из подгруппы результатов поиска, соответствующих упомянутым соответствующим запросам, и создания векторов терминов из признаков как функции частоты терминов и обратной частоты терминов.
24. Машиночитаемый носитель по п.23, в котором признаки включают в себя заголовок, описание и/или контекст для терминов соответствующих запросов из предыдущих запросов с высокой ЧП.
25. Машиночитаемый носитель по п.23, в котором соответствующие запросы содержат результаты поиска высшего ранга.
26. Машиночитаемый носитель по п.15, в котором кластеры терминов являются первой группой кластеров терминов, при этом исполняемые машиной команды также содержат команды для определения, что отсутствует совпадение между термином/фразой и терминами/фразами, и в ответ на это определение создания второй группы кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и оценки термина/фразы, принимая во внимание термины/фразы второй группы кластеров терминов, для идентификации одного или более предложений родственных терминов.
27. Машиночитаемый носитель по п.26, который также содержит при создании исполняемые машиной команды для идентификации предыдущих запросов с низкой ЧП из предыдущих запросов, извлеченных из журнала запросов, посылки соответствующих запросов, по меньшей мере, из подгруппы предыдущих запросов с низкой ЧП в поисковую машину для получения результатов поиска, извлечения признаков, по меньшей мере, из подгруппы результатов поиска и создания векторов терминов из признаков как функции частоты термина и обратной частоты термина.
28. Машиночитаемый носитель по п.27, который также содержит исполняемые машиной команды после кластеризации для определения, что отсутствует совпадение между термином/фразой и термином (терминами)/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и в ответ на данное определение идентификации совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, основанной на предыдущих запросах с низкой ЧП, и в ответ для идентификации формирования предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
29. Вычислительное устройство, содержащее процессор и память, подсоединенную к процессору, содержащую машинные команды, исполняемые процессором, для создания кластеров терминов в зависимости от вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с высокой частотой появления (ЧП), поданных ранее в поисковую машину, и в ответ на получение термина/фразы от объекта оценки термина/фразы, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов.
30. Вычислительное устройство по п.29, в котором данный термин/фраза содержится в многосмысловом запросе.
31. Вычислительное устройство по п.29, в котором объектом является машинное программное приложение и/или конечный пользователь.
32. Вычислительное устройство по п.29, которое также содержит исполняемые машиной команды для определения вычисленного подобия как
где весовой коэффициент


и где

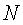

33. Вычислительное устройство по п.29, которое также содержит исполняемые машиной команды для сбора терминов предыдущих запросов из журнала запросов и определения терминов предыдущих запросов, имеющих высокую ЧП.
34. Вычислительное устройство по п.29, которое также содержит перед созданием кластеров терминов исполняемые машиной команды для уменьшения размерности векторов терминов и нормирования векторов терминов.
35. Вычислительное устройство по п.29, которое также содержит при оценивании исполняемые машиной команды для идентификации совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров терминов, и в ответ на идентификацию создания предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
36. Вычислительное устройство по п.35, в котором предложение (предложения) родственных терминов также содержит для каждого термина/фразы из термина (терминов)/фразы (фраз) значение частоты появления, показывающее, сколько раз данный термин/фраза появлялся в группе извлеченных предыдущих запросов.
37. Вычислительное устройство по п.29, которое также содержит при создании кластеров терминов исполняемые машиной команды для посылки соответствующих из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска, извлечения признаков, по меньшей мере, из подгруппы результатов поиска, соответствующих упомянутым соответствующим запросам, и создания векторов терминов из признаков как функции частоты термина и обратной частоты термина.
38. Вычислительное устройство по п.37, в котором признаки включают в себя заголовок, описание и/или контекст для соответствующих терминов из предыдущих запросов с высокой ЧП.
39. Вычислительное устройство по п.37, в котором соответствующие запросы содержат результаты поиска высшего ранга.
40. Вычислительное устройство по п.29, в котором кластеры терминов являются первой группой кластеров терминов, при этом исполняемые машиной команды также содержат команды для определения, что отсутствует совпадение между термином/фразой и терминами/фразами, и в ответ на это определение создания второй группы кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и оценки термина/фразы, принимая во внимание термины/фразы второй группы кластеров терминов, для идентификации одного или более предложений родственных терминов.
41. Вычислительное устройство по п.40, которое также содержит при создании исполняемые машиной команды для идентификации предыдущих запросов с низкой ЧП из предыдущих запросов, извлеченных их журнала запросов, посылки соответствующих запросов, по меньшей мере, из подгруппы предыдущих запросов с низкой ЧП в поисковую машину для получения результатов поиска, извлечения признаков, по меньшей мере, из подгруппы результатов поиска и создания векторов терминов из признаков как функции частоты термина и обратной частоты термина.
42. Вычислительное устройство по п.41, которое также содержит после кластеризации исполняемые машиной команды для определения, что отсутствует совпадение между термином/фразой и термином (терминами)/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и в ответ на упомянутое определение идентификации совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, основанной на предыдущих запросах с низкой ЧП, и в ответ на идентификацию формирования предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
43. Вычислительное устройство, содержащее средство для создания кластеров терминов как функции вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с высокой частотой появления (ЧП), поданных ранее в поисковую машину, и средство для оценки, в ответ на получение термина/фразы от объекта, термина/фразы, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов.
44. Вычислительное устройство по п.43, в котором данный термин/фраза содержится в многосмысловом запросе.
45. Вычислительное устройство по п.43, в котором объектом является машинное программное приложение и/или конечный пользователь.
46. Вычислительное устройство по п.43, которое также содержит средство для сбора терминов предыдущих запросов из журнала запросов и средство для определения терминов предыдущих запросов с высокой ЧП.
47. Вычислительное устройство по п.43, в котором средство для оценки также содержит средство для определения совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров терминов, и средство для создания в ответ на определение предложения (предложений) родственных терминов, содержащего термин (термины)/фразу (фразы).
48. Вычислительное устройство по п.43, в котором средство для создания кластеров терминов также содержит средство для посылки соответствующих запросов из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска, средство для извлечения признаков, по меньшей мере, из подгруппы результатов поиска, соответствующих упомянутым соответствующим запросам, и средство для создания векторов терминов из признаков.
49. Вычислительное устройство по п.43, в котором кластеры терминов являются первой группой кластеров терминов, при этом вычислительное устройство также содержит средство для определения, что отсутствует совпадение между термином/фразой и терминами/фразами, и в ответ на это определение средство для создания второй группы кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и средство для оценки термина/фразы, принимая во внимание термины/фразы второй группы кластеров терминов, для идентификации одного или более предложений родственных терминов.
50. Вычислительное устройство по п.49, которое также содержит средство для вычисления, что отсутствует совпадение между данным термином/фразой и термином (терминами)/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и средство для идентификации в ответ на упомянутое вычисление совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, основанной на предыдущих запросах с низкой ЧП, и средство для формирования в ответ на упомянутую идентификацию предложения (предложений) родственных терминов, содержащего термин (термины)/фразу (фразы).
Комментарии