Системы и способы поддержки клинических решений - RU2543563C2
Код документа: RU2543563C2
Чертежи
Описание
Нижеследующее описание относится к медицине, медицинской диагностике, администрированию историй болезни, экспертным системам и родственным областям.
Системы поддержки клинических решений (CDS) представляют собой экспертные системы, предназначенные для предоставления автоматической помощи врачам и другому медицинскому персоналу при принятии медицинских решений, например диагностировании заболеваний, выборе лечения, реализации аспектов схемы лечения и т.д. Некоторые иллюстративные системы CDS описаны, например, в опубликованной патентной заявке № 2007/0175980 A1, принадлежащей Alsafadi.
При традиционной или "ручной" клинической диагностике результаты наблюдения, основанные на личном опыте врача, ложатся в основу решений, принимаемых врачом в отношении новых клинических ситуаций. Система CDS на основе историй болезни пытается эмулировать этот подход за счет облегчения автоматического доступа к обширному массиву предыдущих случаев, который превышает исторический опыт любого отдельно взятого врача. Например, система CDS на основе историй болезни может обеспечивать поддержку решений для диагностирования патологии, найденной в исследованиях рака груди пациента, путем извлечения результатов тестов и другой релевантной информации из историй болезни предыдущих пациентов (при этом данным пациента подходящим образом придается анонимность в соответствии с требованиями или стандартами охраны частной жизни пациента). Такие системы CDS на основе историй болезни эмулируют принятие клинических решений в процессах, которые, в целом, признаются в медицинском сообществе правильными. Таким образом, система CDS действует как система извлечения информации, которая извлекает сходные медицинские случаи, имевшие место в прошлом, и может также извлекать и, в частности, идентифицировать соответствующие результаты медицинских тестов или другую информацию о данном случае, которая с высокой степенью вероятности, будет доказательной для настоящего диагноза или другого настоящего медицинского решения.
Известные системы CDS на основе историй болезни для автоматического принятия решений используют различные методы для идентификации аналогичных случаев. Например, при извлечении изображений, для идентификации сходных изображений иногда используется парное сравнение признаков, связанных с изображением. Однако такие подходы не позволяют легко различать "веса" или значимость, присвоенные различным признакам, связанным с изображением, при количественном определении сходства или несходства изображений. Кроме того, если такие парные сравнения производятся вручную, могут вкрадываться экспериментальные или индивидуальные погрешности в силу малого или ограниченного "объема выборки" двух сравниваемых предметов.
Различные подходы к обучению машины также использовались в системах извлечения информации для автоматического группирования сходных объектов на основании автоматического анализа признаков объекта. Однако, опять же, обучение машины не позволяет легко обеспечивать информацию в качестве основы для оценивания сходства или несходства. Машинно-обученный алгоритм - это "черный ящик", который может быть пригоден применительно, например, к извлечению изображений, но маловероятно, что врач или другой медицинский работник будет чувствовать себя комфортно, ставя медицинский диагноз или принимая другое медицинское решение на эмпирической основе, не понимая логики принятия решений.
Известны также методы обратной связи по релевантности. Согласно этим методам осуществляемый человеком или другой компетентный анализ применяется к результатам извлечения информации для оценивания фактической релевантности извлеченной информации. Эти компетентные оценки используются для уточнения алгоритма извлечения информации с целью улучшить последующие операции извлечения. Недостаток обратной связи по релевантности применительно к CDS состоит в том, что обратная связь в течение времени, скорее всего, приходит от разных врачей, что может приводить к различиям или противоречиям в обратной связи по релевантности. Кроме того, обратная связь по релевантности требует времени для оценки извлеченных результатов и обеспечения обратной связи, и занятой врач может отказаться делать это. Кроме того, обратная связь по релевантности обеспечивает уточнение только для существующей системы извлечения информации и не обеспечивает основу для построения системы CDSс самого начала.
Ниже представлены новые и усовершенствованные устройства и способы, позволяющие преодолеть вышеупомянутые и другие проблемы.
Согласно одному раскрытому аспекту система поддержки клинических решений (CDS) содержит: подсистему группирования историй болезни, включающую в себя графический пользовательский интерфейс, способный одновременно отображать данные, представляющие совокупность историй болезни пациентов, и дополнительно выполненный с возможностью позволять пользователю группировать выбранные истории болезни пациентов, представленные одновременно отображаемыми данными, в клинически связанные группы по выбору пользователя; подсистему определения доказательных признаков, способную определять доказательные признаки, которые коррелируют с клинически связанными группами; и пользовательский интерфейс CDS, способный принимать данные текущего пациента, относящиеся к истории болезни текущего пациента, и выводить информацию поддержки клинических решений на основании значений доказательных признаков, определенных из принятых данных текущего пациента.
Согласно другому раскрытому аспекту предусмотрен способ поддержки клинических решений (CDS), осуществляемый системой CDS, способ CDS содержит этапы, на которых: обеспечивают графический пользовательский интерфейс, с помощью которого пользователь группирует истории болезни пациентов в клинически связанные группы, причем графический пользовательский интерфейс графически представляет истории болезни пациентов посредством пиктограмм историй болезни пациентов, содержащих изображения пациентов или пиктографические изображения, генерируемые из изображений пациентов; определяют доказательные признаки историй болезни пациентов, имеющие значения, которые коррелируют с клинически связанными группами; и автоматически обеспечивают информацию поддержки клинических решений на основании принятых данных текущего пациента, относящихся к истории болезни текущего пациента, на основании значений доказательных признаков, определенных из принятых данных текущего пациента.
Согласно еще одному раскрытому аспекту предусмотрен носитель информации, причем на носителе информации хранятся инструкции, выполняемые цифровым процессором для осуществления способа поддержки клинических решений (CDS), описанного в предыдущем абзаце.
Одно преимущество состоит в обеспечении групп историй болезни пациентов, целостно определенных врачом или другим опытным медицинским работником для установления информации экспериментальных данных сходства для операции CDS.
Другое преимущество состоит в обеспечении пользовательского интерфейса для ручного группирования сходных историй болезни пациентов, в котором истории болезни пациентов представлены пиктограммами пациентов, содержащими изображения пациентов или пиктографические изображения, генерируемые из изображений пациентов.
Еще одно преимущество состоит в автоматическом определении признаков, связанных с изображением и, в необязательном порядке, не связанных с изображением, которые коррелируют с информацией экспериментальных данных сходства.
Другие преимущества станут ясны специалисту в данной области техники по ознакомлении с нижеследующим подробным описанием.
Фиг. 1 - схема системы поддержки клинических решений (CDS).
Фиг. 2-4 - скриншоты графического пользовательского интерфейса (GUI) подсистемы группирования историй болезни системы CDS, показанной на фиг. 1.
Фиг. 5 - схема подходящего способа, осуществляемого подсистемой определения доказательных признаков системы CDS, показанной на фиг. 1.
Фиг. 6 - схема подходящего способа, осуществляемого подсистемой пользовательского интерфейса CDS системы CDS, показанной на фиг. 1.
Настоящее раскрытие предусматривает, что работу системы CDS можно разделить на две части: (i) кластеризация сходных историй болезни пациентов для идентификации "экспериментальных данных" сходства (определенных ниже в конце следующего параграфа); и (ii) идентификация доказательных признаков для поддержки клинических решений. Настоящее раскрытие предусматривает, что часть (i), кластеризацию сходных историй болезни пациентов, нелегко автоматизировать таким образом, чтобы она была приемлема для врачей. Методы автоматического обучения машины являются, в общем случае, слишком эмпирическими, чрезмерно склонны к формированию ошибочных кластеров и не обеспечивают принципиальной основы для принятия решений. Подходы к обучению машины также могут оказаться бесполезными для выявления субъективных факторов или факторов с трудом поддающихся количественной оценке, традиционно используемых врачами при оценивании случаев и постановке сложных медицинских диагнозов.
Соответственно, в данной заявке раскрыт графический пользовательский интерфейс (GUI), поддерживающий ручное группирование историй болезни пациентов с использованием целостного GUI на визуальной основе, который одновременно отображает более двух историй болезни пациентов и, предпочтительно, существенное количество историй болезни пациентов, во избежание ошибок, которые могут порождаться ограниченными парными сравнениями. В результате ручной кластеризации получается информация экспериментальных данных сходства. Информация является "экспериментальными данными", поскольку известно или предполагается, что кластеры правильно сгруппированы, поскольку решения относительно группирования приняты опытными врачами на основании существенного количества совместно рассмотренных историй болезни пациентов.
С другой стороны, настоящее раскрытие предусматривает, что часть (ii), идентификацию доказательных признаков, можно успешно автоматизировать с использованием обучения машины. Автоматическую идентификацию доказательных признаков можно успешно использовать для ввода точной информации экспериментальных данных сходства. Автоматизированная часть (ii) системы CDS повышает эффективность, а также обеспечивает получение информации, поскольку корреляции между историями болезни пациентов в различных группах идентифицируются автоматически. Такие корреляции, вероятно, остались бы незамеченными врачом, одновременно рассматривающим лишь несколько случаев. Преимущество состоит в том, что доказательные признаки, являющиеся предметом обучения машины, могут включать в себя признаки, не связанные с изображением, например возраст пациента, пол пациента, этническую принадлежность пациента, семейную медицинскую карту, генетические предрасположенности и т.д.
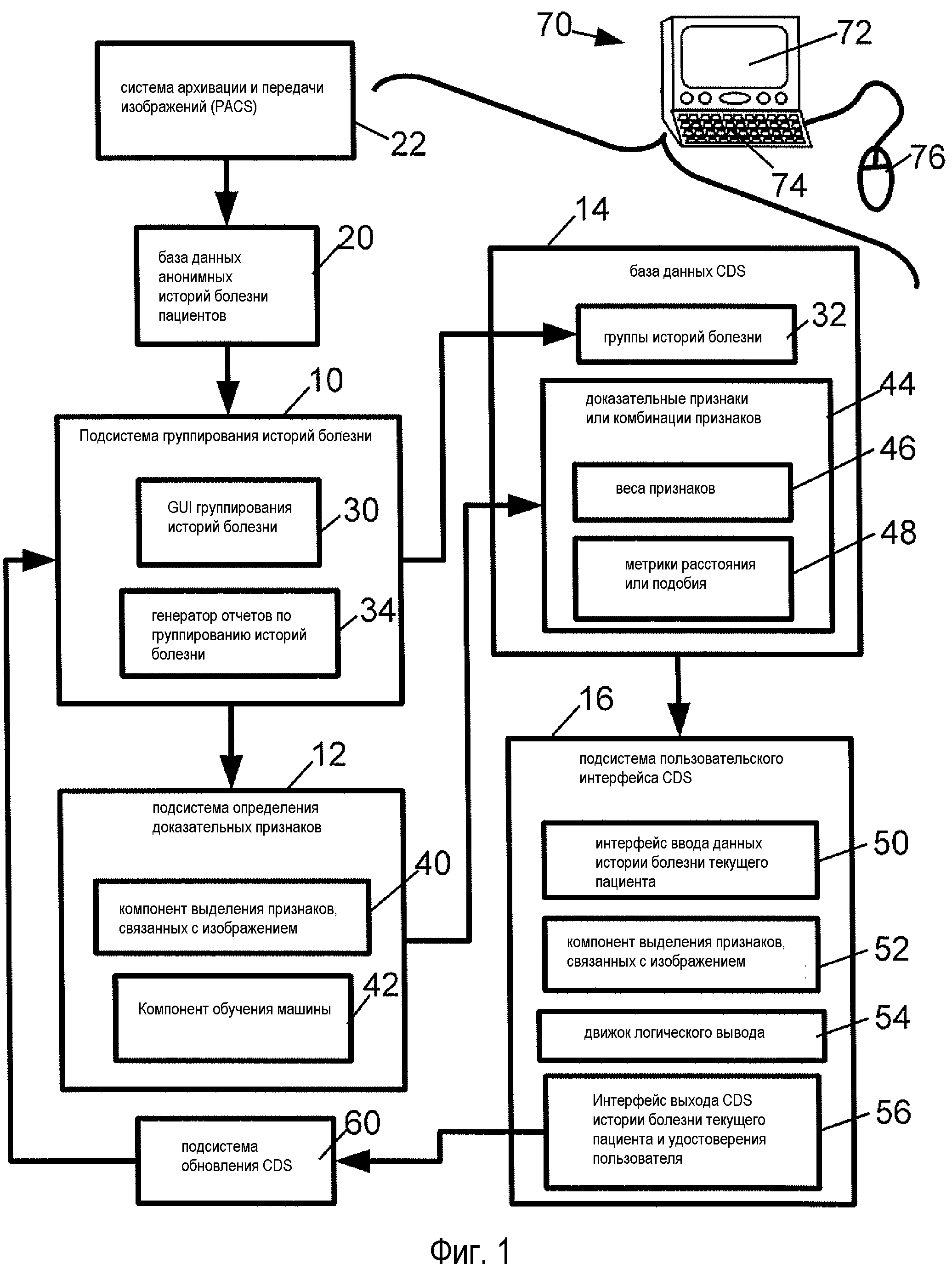
Согласно фиг. 1, система поддержки клинических решений (CDS) включает в себя подсистему 10 группирования историй болезни пациентов и подсистему 12 определения доказательных признаков, которые способны генерировать базу данных 14 CDS, к которой обращается подсистема 16 пользовательского интерфейса CDS для обеспечения информации поддержки клинических решений. Подсистема 10 группирования историй болезни пациентов оперирует с содержимым базы данных 20 историй болезни пациентов. Историям болезни пациентов предпочтительно придавать анонимность, удаляя идентификационную информацию, например истинные имена, адреса и т.д., в соответствии с действующими законами и стандартами относительно охраны личной жизни. Базу данных 20 историй болезни пациентов можно формировать на основе больничной информационной сети (не показана), и данные историй болезни пациентов включают в себя изображения пациентов, полученные в одном или нескольких режимах формирования медицинских изображений, например компьютерной томографии (КТ); магнитно-резонансной томографии (МРТ); позитрон-эмиссионной томографии (ПЭТ); гамма-томографии (SPECT); флюорографии, ультразвукового исследования, рентгенографии; и т.д. В порядке примера, изображения пациентов, в необязательном порядке, хранятся в специализированной системе 22 архивации и передачи изображений (PACS), где хранятся медицинские изображения пациентов совместно с метаданными, например, информацией, относящейся к режиму формирования медицинских изображений, разрешению или другим параметрам получения изображения, временным меткам получения и т.д.
Истории болезни пациентов первоначально обрабатываются графическим пользовательским интерфейсом 30 группирования историй болезни (GUI) подсистемы 10 группирования историй болезни, способным одновременно отображать данные, относящиеся к более чем двум разным историям болезни пациентов, представленным, например, в виде пиктограмм пациентов, содержащих изображения пациентов или пиктографические изображения, генерируемые из изображений пациентов. Термин "пиктографическое изображение" означает изображение пониженного разрешения, генерируемые путем снижения дискретизации изображения более высокого разрешения. В порядке примера, пиктографические изображения, в необязательном порядке, имеют стандартный размер и/или стандартное аспектное отношение (например, являясь изображениями размером 128x256 пикселей). Пиктографические изображения также, в необязательном порядке, "упрощаются" другими средствами по сравнению с исходным изображением, например путем преобразования цветного изображения в серое пиктографическое изображение. В качестве другого иллюстративного варианта, пиктографические изображения можно заменять или дополнять информацией, не связанной с изображением, например блоком сводки в виде текстового или графического представления клинических данных (например, графиков, например, линейного графика зависимости кровяного давления от времени или кинетических кривых, используемых при анализе МРТ, или разного рода диаграмм, например, столбчатой диаграммы ряда различных измерений для каждого пациента, например, возраста, роста, веса и т.д.).
Благодаря одновременному отображению информации для существенного количества историй болезни пациентов GUI 30 позволяет пользователю не сравнивать истории болезни пациентов попарно, что может приводить к ошибочному формированию групп. Однако предполагается, что GUI 30 позволяет пользователю выбирать истории болезни отдельных пациентов для более пристального изучения, например, отображая информацию истории болезни пациента, не связанную с изображением, при соответствующем выборе через GUI 30 истории болезни конкретного пациента. Кроме того, GUI 30 выполнен с возможностью позволять пользователю группировать разные истории болезни пациентов, представленные одновременно отображаемыми данными, в клинически связанные группы, определенные пользователем. Пользователь предпочтительно является врачом или другим опытным специалистом по медицинской диагностике или совокупностью врачей или других опытных специалистов по медицинской диагностике, который(ая) генерирует клинически связанные группы. Например, группирование историй болезни пациентов в клинически связанные группы может осуществляться единичным пользователем (например, единичным компетентным врачом) или может устанавливаться в порядке консенсуса в консилиуме или другой группе компетентных врачей или другого компетентного медицинского персонала. Истории болезни пациентов клинически связанной группы рассматриваются врачом, который генерирует группу, чтобы иметь медицинское соотношение, позволяющее предполагать, что одна и та же или сходная схема лекарственного лечения применима к случаям пациентов в группе. Например, клинически связанная группа может содержать группу историй болезни пациентов, в которой все пациенты страдают раком одного типа или другим заболеванием одного типа. Полученные группы 32 историй болезни подходящим образом сохраняются в базе данных 14 CDS. В необязательном порядке, подсистема 10 группирования историй болезни дополнительно включает в себя генератор 34 отчетов по группированию историй болезни, который генерирует отчет, предназначенный для прочтения человеком, о группах историй болезни для обеспечения письменного протокола по клинически связанным группам, или для необязательного обозрения другими врачами или другими опытными специалистами по медицинской диагностике, или в других целях.
Клинически связанные группы 32 предполагаются верными, т.е. предполагается, что истории болезни пациентов сгруппированы верно, демонстрируя медицински значимое соотношение, предусматривающее одинаковую или сходную схему лекарственного лечения. Это предположение, скорее всего, справедливо, поскольку клинически связанные группы 32 генерируются врачом или другим опытным специалистом по медицинской диагностике или совокупностью врачей или других опытных специалистов по медицинской диагностике на основании существенного количества историй болезни пациентов, представленного GUI 30 целостным образом. Из этого предположения следует, что клинически связанные группы 32 представляют экспериментальные данные сходства историй болезни в базе данных 20. Поскольку группирование осуществляется вручную, подсистема 10 группирования историй болезни не предоставляет быструю информацию в качестве основы или логического обоснования группы историй болезни пациентов. Действительно, врач или другой опытный специалист по медицинской диагностике или совокупность врачей или других опытных специалистов по медицинской диагностике может использовать различные объективные и субъективные соображения при генерации групп историй болезни пациентов.
Хотя основы, используемые людьми-диагностами при формировании различных клинически связанных групп 32, могут не быть легко доступны, разумно предположить, что клинически связанные группы 32 имеют некие объективно определяемые сходства или корреляции и что эти объективные сходства или корреляции являются латентной информацией, содержащейся в клинически связанных группах 32.
Соответственно, подсистема 12 определения доказательных признаков анализирует клинически связанные группы 32 для идентификации доказательных признаков, которые коррелируют с различными группами. С этой целью компонент 40 выделения признаков, связанных с изображением, выделяет количественные признаки, связанные с изображением, которые с достаточной степенью вероятности коррелируют с клинически значимыми аспектами историй болезни пациентов. Некоторые иллюстративные примеры подходящих количественных признаков, связанных с изображением, включают в себя размер опухоли, аспектное отношение опухоли, плотность ткани опухоли, выражаемые интенсивностью изображения в области опухоли, и т.д. В необязательном порядке, компонент 40 выделения признаков, связанных с изображением, может взаимодействовать с пользователем, например, компонент 40 выделения признаков, связанных с изображением, может отображать медицинское изображение пациента и предлагать пользователю идентифицировать или очертить опухоль в изображении с использованием мыши или другого механизма пользовательского ввода. Дополнительно или альтернативно, компонент 40 выделения признаков, связанных с изображением может использовать автоматическую идентификацию опухоли или другой автоматический или полуавтоматический анализ медицинского изображения. Помимо признаков, связанных с изображением, подсистема 12 определения доказательных признаков может рассматривать признаки, не связанные с изображением, например, возраст пациента, пол пациента, этническую принадлежность пациента, семейную медицинскую карту, генетические предрасположенности и т.д., каковая информация обеспечивается в базе данных 20 историй болезни пациентов или выводится из нее.
Доступный признак может быть или не быть доказательным. Иными словами, доступный признак может коррелировать с одной или несколькими из групп 32 историй болезни пациентов, в каковом случае признак является доказательным признаком, или же признак может иметь слабую или нулевую корреляцию с любой из групп 32 историй болезни пациентов, в каковом случае он не является доказательным. Признаки также могут быть доказательными в комбинации, например признаки размера опухоли и аспектного отношения опухоли, взятые по отдельности, могут иметь слабую корреляцию с любой из групп 32 историй болезни пациентов, в то же время, комбинация размера опухоли и аспектного отношения опухоли может коррелировать с одной или несколькими из групп 32 историй болезни пациентов.
Компонент 42 обучения машины обрабатывает доступные признаки для идентификации доказательных признаков или комбинаций 44 признаков, которые коррелируют с одной или несколькими из групп 32 историй болезни пациентов, и эти доказательные признаки или комбинации 44 признаков также сохраняются в базе данных 14 CDS. Компонент 42 обучения машины может применять любой метод обучения машины для идентификации таких корреляций. В некоторых приведенных здесь иллюстративных примерах компонент 42 обучения машины использует генетический алгоритм. В необязательном порядке, компонент 42 обучения машины также идентифицирует силу корреляции доказательного признака с группами 32 историй болезни пациентов и присваивает веса 46 признаков, отражающие силу корреляции. В необязательном порядке, компонент 42 обучения машины также идентифицирует комбинации или взвешенные комбинации доказательных признаков, которые коррелируют с группами 32 историй болезни пациентов, и сохраняет эти комбинации или взвешенные комбинации в качестве метрик 48 расстояния или подобия. В необязательном порядке, информация 44, 46, 48 идентифицированных доказательных признаков предоставляется пользователю для обозрения, например, генератором 34 отчетов по группированию историй болезни или другим инструментом составления отчетов. В необязательном порядке, пользователь может изменять, удалять или иначе регулировать информацию 44, 46, 48 доказательных признаков на основании пользовательской экспертизы медицинской диагностики.
Пользователь, генерирующий группы 32 историй болезни пациентов с помощью подсистемы 10 группирования историй болезни и, в необязательном порядке, просматривающий информацию 44, 46, 48 доказательных признаков, предпочтительно является врачом или другим опытным специалистом по медицинской диагностике, или совокупностью врачей или других опытных специалистов по медицинской диагностике, который/е имеют особенно большой опыт в медицинской диагностике. Например, этот пользователь или пользователи может/гут включать в себя один или несколько старших врачей или специалистов-медиков, обладающих обширными знаниями и опытом в соответствующей области или областях медицины. Эти пользователи могут быть специалистами, благодаря чему, например, истории болезни кардиологических пациентов группируются одним или несколькими старшими специалистами-кардиологами, тогда как истории болезни онкологических пациентов группируются одним или несколькими специалистами-онкологами и т.д. Наполнение базы данных 14 CDS, в общем случае, осуществляется до использования системы CDS для операции поддержки клинических решений, хотя согласно данному раскрытию возможны также единовременные обновления базы данных 14 CDS.
Когда база данных 14 CDS наполнена, содержимое базы данных 14 CDS используется подсистемой 16 пользовательского интерфейса CDS для генерации информации поддержки клинических решений, представляемой пользователю. Таким образом, подсистема 16 пользовательского интерфейса CDS осуществляет операции поддержки клинических решений, опираясь на базу данных 14 CDS. Пользователь-человек или совокупность пользователей-людей взаимодействует(ют) с подсистемой 16 пользовательского интерфейса CDS, запрашивая информацию поддержки клинических решений для историй болезни текущих пациентов. Пользователем подсистемы 16 пользовательского интерфейса CDS обычно является врач или другой медицинский работник или совокупность медицинских работников. Однако пользователь подсистемы 16 пользовательского интерфейса CDS не обязательно является старшим врачом, специалистом или другим многоопытным медицинским диагностом. Напротив, пользователем подсистемы 16 пользовательского интерфейса CDS может быть обычный врач со стандартными навыками, который использует подсистему 16 пользовательского интерфейса CDS для получения помощи в принятии клинических решений. В общем случае, пользователем подсистемы 16 пользовательского интерфейса CDS может быть врач или другой медицинский работник с, по существу, любым уровнем опытности.
Подсистема 16 пользовательского интерфейса CDS включает в себя интерфейс 50 ввода данных истории болезни текущего пациента, через который пользователь вводит релевантную информацию из истории болезни текущего пациента, для которого пользователь ищет поддержки клинических решений. Предоставленная информация истории болезни текущего пациента может включать в себя данные изображения, например изображения пациентов, и, в необязательном порядке, также может включать в себя информацию, не связанную с изображением, например возраст пациента, пол пациента, этническую принадлежность пациента, семейную медицинскую карту, генетические предрасположенности и т.д. Изображения пациентов обрабатываются компонентом 52 выделения признаков, связанных с изображением (который, в необязательном порядке, может быть реализован воедино с компонентом 40 выделения признаков, связанных с изображением, подсистемы 12 определения доказательных признаков), для выделения доказательных признаков, связанных с изображением. Доказательные признаки, связанные с изображением, совместно с любыми доказательными признаками, не связанными с изображением, обеспеченными через интерфейс 50 ввода данных истории болезни текущего пациента, подлежат вводу в движок логического вывода 54 поддержки клинических решений, который рассматривает корреляции между значениями доказательных признаков истории болезни текущего пациента и значениями доказательных признаков историй болезни из различных групп 32 историй болезни пациентов. Идентифицируя общие корреляции, движок логического вывода 54 связывает историю болезни текущего пациента с одной из групп 32 историй болезни пациентов. Интерфейс 56 выхода CDS истории болезни текущего пациента и удостоверения пользователя предоставляет пользователю информацию поддержки клинических решений на основании результатов движка 54 логического вывода. Например, информация поддержки клинических решений может включать в себя: идентификацию группы историй болезни пациентов, наиболее сильно связанной с историей болезни текущего пациента; идентификацию медицинского состояния этой группы с предположением о том, что текущий пациент может иметь такое же медицинское состояние; представление одной или нескольких сходных историй болезни, извлеченных из группы историй болезни пациентов, наиболее сильно связанной с историей болезни текущего пациента; представление предложенной схемы лекарственного лечения, соответствующей схеме лекарственного лечения, применяемой в случаях пациентов из группы историй болезни пациентов, наиболее сильно связанной с историей болезни текущего пациента; и т.д.
В необязательном порядке, интерфейс 56 выхода CDS истории болезни текущего пациента и удостоверения пользователя также обеспечивает функцию удостоверения пользователя, в которой пользователь принимает, отвергает или, в необязательном порядке, изменяет представленную информацию поддержки клинических решений. В этом случае информация удостоверения пользователя, в необязательном порядке, используется подсистемой 60 обновления CDS для оценивания и, в необязательном порядке, обновления базы данных 14 CDS. Например, согласно одному подходу история болезни текущего пациента совместно с медицинским диагнозом пользователя (который может соглашаться или не соглашаться с информацией поддержки клинических решений, предоставленной подсистемой 16 пользовательского интерфейса CDS), сохраняется совестно с аналогичными результатами для других историй болезни "текущих" пациентов, для обеспечения обновления или пополнения первоначальной базы данных 20 историй болезни пациентов. Время от времени, обновленная или пополненная коллекция или база данных историй болезни пациентов вновь обрабатывается компонентами 10, 12 генерации содержимого базы данных CDS для обновления или пополнения базы данных 14 CDS. Согласно альтернативному подходу, требующему меньший объем вычислений, история болезни текущего пациента добавляется в группу историй болезни пациентов из групп 32 историй болезни, если пользователь согласен, что история болезни текущего пациента действительно связана с этой группой историй болезни пациентов. Для этого можно, например, предоставлять пользователю диалоговое окно GUI с вопросом "Добавить историю болезни текущего пациента в группу <<<>>>?", где "<<<>>>" является идентификацией группы историй болезни пациентов указанной системой CDS как соответствующей истории болезни текущего пациента.
Систему CDS, показанную фиг. 1, можно реализовать по-разному. В иллюстрируемом варианте осуществления компьютер 70 включает в себя дисплей 72 для отображения визуального или графического выхода компонентов 30, 56, для отображения диалоговых и других окон и пр. компонента 50 пользовательского ввода и т.д. Компьютер 70 также включает в себя проиллюстрированные клавиатуру 74, мышь 76 и/или другое(ие) устройство(а) пользовательского ввода для приема пользовательских вводов и дополнительно включает в себя цифровой процессор (не показан) и один или несколько носителей информации (не показаны, но подходящим образом реализованы, например, в виде жесткого диска, оптического дисковода, оперативной памяти (ОЗУ), постоянной памяти (ПЗУ) и т.д.). Цифровой процессор выполняет инструкции компьютерной программы или компьютерный код, хранящийся на одном или нескольких носителях информации, для реализации компонентов обработки 10, 12, 16 системы CDS, и база данных CDS 14 подходящим образом хранится на одном или нескольких носителях информации компьютера 70 или на удаленном носителе информации, доступ к которому осуществляется через больничную цифровую сеть. В других возможных вариантах осуществления процессор, реализующий компоненты обработки 10, 12, 16, может располагаться на удаленном сервере или в его части, каковой сервер логически располагается в больничной цифровой сети, и проиллюстрированный компьютер 70 обеспечивает интерфейсное оборудование 72, 74, 76. В других возможных вариантах осуществления интерфейсное оборудование может быть реализовано в виде карманного персонального компьютера (КПК), сотового телефона или другого портативного электронного устройства, снабженного цифровым процессором, принадлежащего врачу.
Рассмотрев в целом иллюстративную систему CDS, показанную на фиг. 1, которая выступает в качестве иллюстративного примера, обратимся к некоторым дополнительным или альтернативным аспектам и другому раскрытию.
В некоторых приведенных здесь иллюстративных вариантах осуществления система CDS и соответствующие способы CDS описаны применительно к диагностике рака груди на основании динамической магнитно-резонансной томографии (МРТ) и дополнительной клинической информации, не связанной с изображением. Следует понимать, что это всего лишь иллюстративное применение и иллюстративный режим построения изображений и что раскрытые системы CDS и способы CDS, в общем случае, применимы, по существу, к любой области медицинской диагностики, с использованием, по существу, любого режима построения изображений, который является доказательным для медицинского приложения, для которого предназначены система и способ CDS.
История болезни каждого пациента в базе данных может включать в себя несколько разных исследований путем построения изображений, проведенных в одном режиме или в разных режимах. Кроме того, для каждой истории болезни разные виды этих исследований могут храниться или выводиться путем обработки изображений. Кроме того, данная история болезни пациента в ряде случаев может быть сочетанием или комбинацией изображений или других данных, полученных от двух или более пациентов с аналогичными заболеваниями. Исследования путем построения изображений, хранящиеся в истории болезни каждого пациента в базе данных, можно, в общем случае, получать в одном или нескольких режимах построения единичных изображений, например рентгеновском, ультразвуковом, МРТ, КТ и т.д., или в режиме построения множественных изображений для одного пациента, например рентгеновской маммографии, ультразвукового исследования, МРТ груди. Исследования путем построения изображений, в необязательном порядке, включают в себя временную последовательность. Например, для случая рака груди можно получить разные последовательности изображений динамической МРТ с контрастным усилением. Таким образом, для каждого пациента в базе данных могут храниться преконтрастировочные (до ввода пациенту контрастного вещества), и множественные постконтрастировочные исследования, полученные в разные моменты времени после ввода контрастного вещества. База данных также может включать в себя производные последовательности, например множественные разностные последовательности, полученные вычитанием преконтрастировочного исследования из разных постконтрастировочных исследований. База данных, в необязательном порядке, также включает в себя производные последовательности изображений, представляющие аномалии и окружающие области, например интересующий объем (VOI) для таких вариаций. База данных 20, в необязательном порядке, дополнительно включает в себя клиническую информацию, не связанную с изображением, помимо исследований путем построения изображений. Данные, не связанные с изображением, могут включать в себя, например, демографическую информацию, например пол, возраст, этническую принадлежность, личную медицинскую карту пациента, семейную медицинскую карту, основные жалобы, генетические предрасположенности (например, при положительных BRCA1 и/или BRCA2 рака груди) и другие факторы риска. База данных 20 подходящим образом использует иерархическую модель базы данных, реляционную модель с применением техники SQL или другую подходящую конфигурацию базы данных.
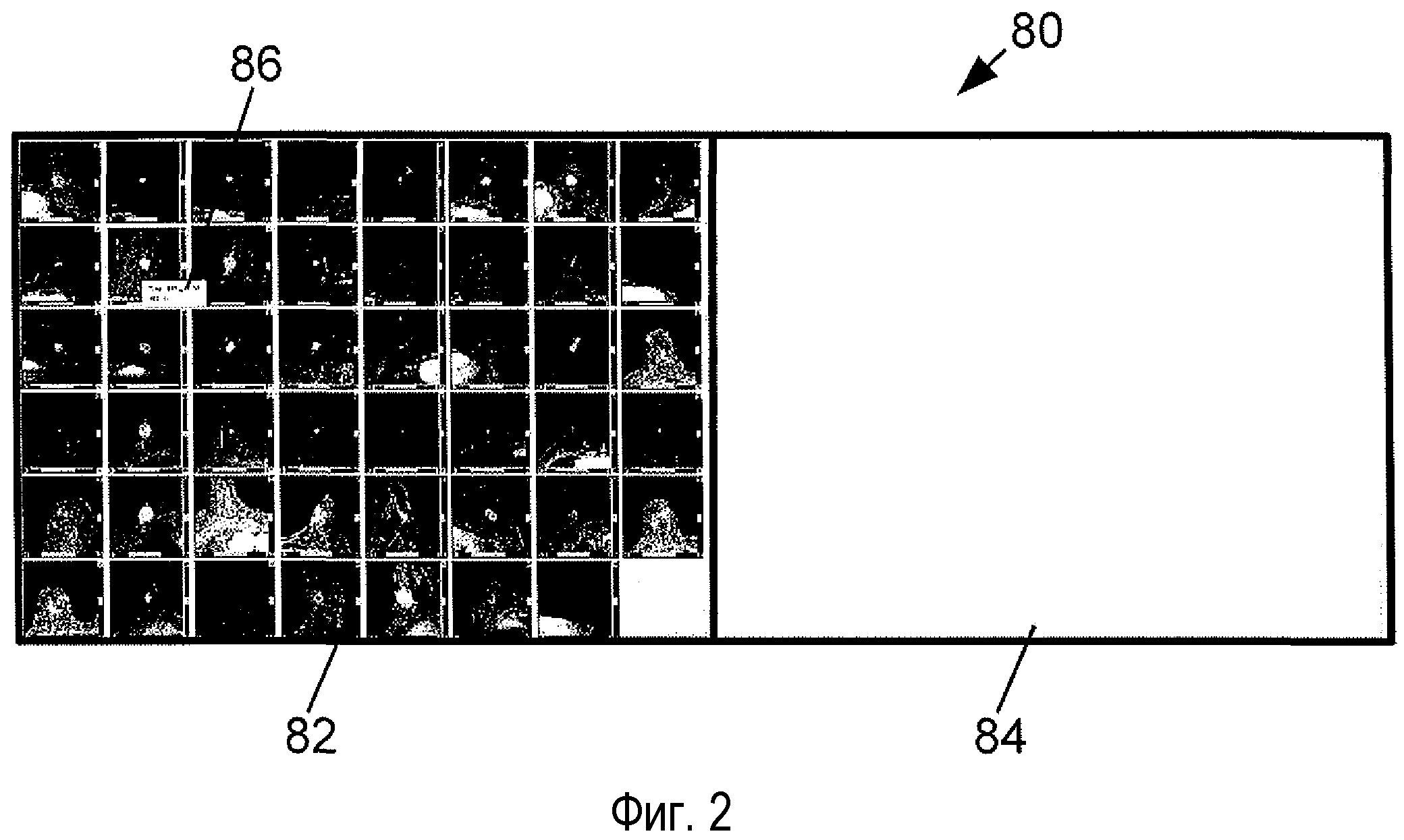
Согласно фиг. 2, интерактивный графический пользовательский интерфейс (GUI) 30 группирования историй болезни отображает данные, представляющие множественные истории болезни пациентов на дисплее 80. В левом окне 82 отображены данные, представляющие несгруппированные истории болезни пациентов, а в правом окне 84 отображены данные, представляющие сгруппированные истории болезни пациентов. На фиг. 2 правое окно 84 пусто, что указывает на тот факт, что истории болезни пациентов еще не рассортированы по группам. Следует понимать, что дисплей 80 может включать в себя два или более устройств отображения, например два или более компьютерных монитора, и указание "левое" или "правое" является произвольным. Например, в некоторых вариантах осуществления применяется два компьютерных монитора - на одном мониторе отображается окно 82, демонстрирующее несгруппированные истории болезни пациентов, а на другом отображается окно 84, демонстрирующее сгруппированные истории болезни пациентов. В иллюстративных вариантах осуществления отображаемые репрезентативные данные содержат изображение пациента или пиктографическое изображение, генерируемые из изображение пациента, для представления истории болезни каждого пациента. Другими словами, изображение пациента или соответствующее пиктографическое изображение выступает в качестве пиктограммы пациента для графического процесса сортировки. Предпочтительно, отображаемое изображение представляет интересующий объем (VOI), содержащий интересующую клиническую аномалию. В иллюстративном примере, показанном на фиг. 2, репрезентативные изображения представляют собой VOI, полученные вычитанием последовательностей (т.е. 2-е постконтрастировочное исследование МРТ - преконтрастировочное исследование МРТ взвешенное по T1), и демонстрируют патологические изменения груди.
В необязательном порядке, данные, не связанные с изображением, также могут отображаться. Например, на фиг. 2 показано "всплывающее окно" 86, где отображены данные, не связанные с изображением, например "Возраст: 47" для истории болезни пациента, возникающее при наведении курсора или иного указателя на репрезентативную пиктограмму пациента. Всплывающее окно может быть временным окном, которое исчезает при отводе курсора, или может быть постоянным окном, которое остается открытым, пока его не закроют. В некоторых вариантах осуществления при наведении курсора возникает временное окно с ограниченной информацией, не связанной с изображением, тогда как в результате положительного действия пользователя, например кликанья по пиктограмме пациента с использованием мыши 76, возникает постоянное окно, содержащее больше информации. Помимо показа данных, не связанных с изображением, эти подходы можно дополнительно или альтернативно использовать для демонстрации метаданных изображения, например временной метки получения, разрешения, и т.д.
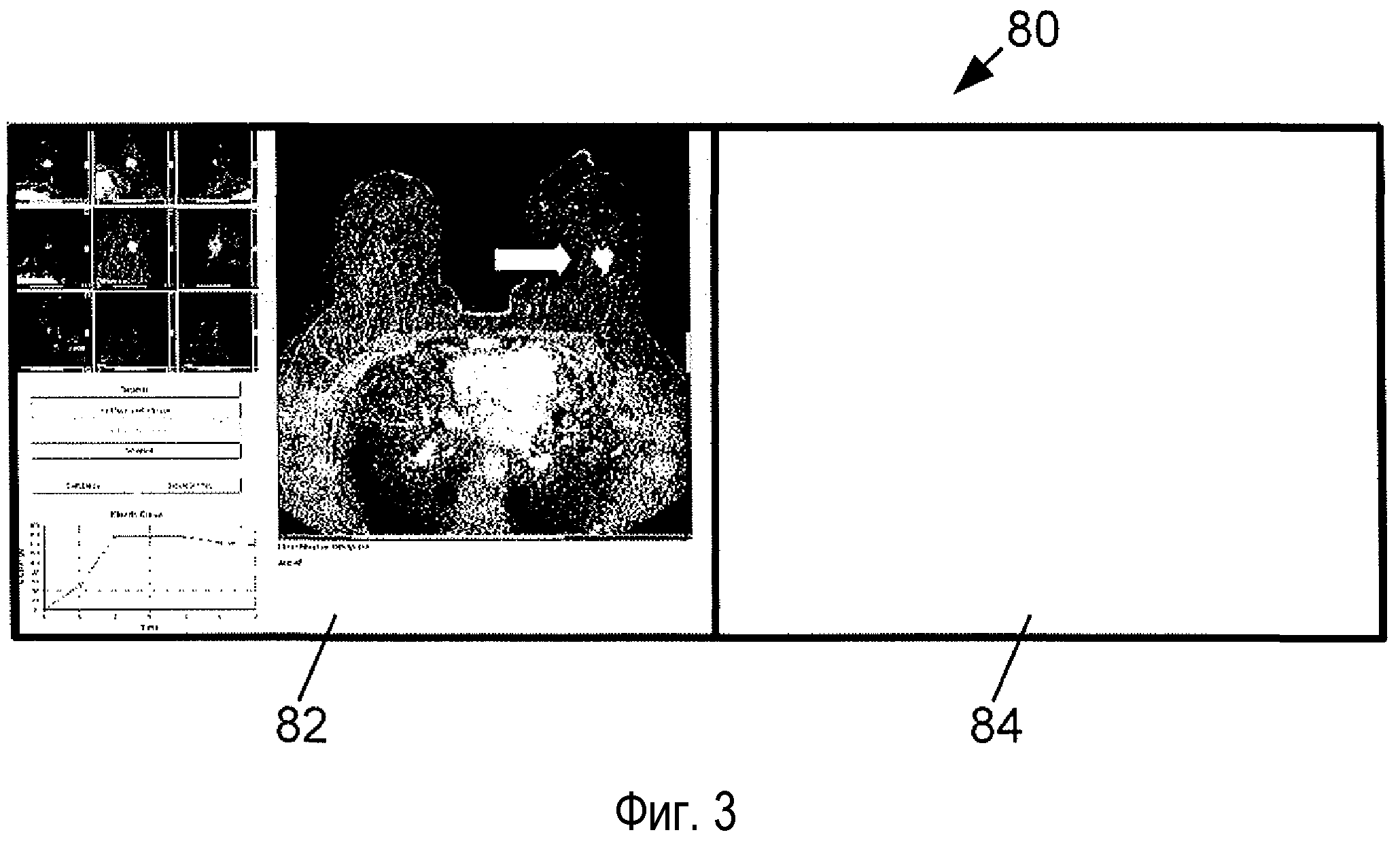
Согласно фиг. 3, в результате положительного действия пользователя, например кликанья по пиктограмме пациента с использованием мыши 76, также, в необязательном порядке, обеспечиваться более полная информация. Согласно фиг. 3, такое действие приводит к отображению более полной информации о выбранной истории болезни пациента, которая может полностью занимать левое окно 82. В необязательном порядке, с этой целью можно использовать оба окна 82, 84 или можно отображать отдельное (третье) окно, содержащее эту информацию. Этот необязательный режим отображения позволяет пользователю более пристально изучать выбранную историю болезни пациента. В примере, показанном на фиг. 3, этот режим отображает, для случая рака груди, соответствующее исследование на основе построения изображений методом динамической МРТ с контрастным усилением. В этом примере, в левом окне 82 отображается двусторонний вид груди и стрелка, указывающая аномалию, для упрощения идентификации. Стрелка подходящим образом генерируется на основании метаданных, идентифицирующих аномалию, хранящихся в PACS 22. В необязательном порядке, GUI 30 позволяет пользователю избирательно переключаться между разными исследованиями путем построения изображений клинического случая. Например, для исследований на основе построения изображений груди методом МР пользователь может, в необязательном порядке, переключаться между преконтрастировочными, разными постконтастировочными исследованиями, разными последовательностями получения, например последовательностями, взвешенными по T2, или производными последовательностями, например разностной последовательностью. Для каждой последовательности пользователь может, в необязательном порядке, изменять окно или настройку уровня, чтобы иметь оптимальный вид для конкретной последовательности и для разных пользователей. Могут отображаться кинетические кривые, представляющие усваивание контрастного вещества в аномалиях с течением времени, показанные, например, в левом нижнем углу окна 82 на фиг. 3. В левом верхнем углу этого вида также показаны восемь соседних историй болезни, подлежащие сортировке, и они представлены посредством VOI. VOI в середине соответствует случаю, когда вид груди в целом показан в правой стороне. Под двусторонним видом груди отображается клиническая информация. В необязательном порядке, дополнительные окна, части монитора или дополнительные мониторы могут иметь одни и те же функции, чтобы показывать другие клинические случаи. Например, в некоторых вариантах осуществления пользователь может выбирать два окна 82, 84 для более детального отображения двух историй болезни пациентов для традиционного визуального сравнения.
На фиг. 4 показан скриншот GUI 30 группирования историй болезни, используемого для создания клинически связанных групп по выбору пользователя. Пользователь использует механизм перетаскивания, в котором пиктограммы историй болезни пациентов перетаскиваются из левого окна 82 в область правого окна 84, представляющую группу. Для создания группы пиктограмма истории болезни пациента перетаскиваются из левого окна 82 в необозначенную область правого окна 84, которая задает область создания новой группы. При перетаскивании пиктограммы истории болезни пациента в область создания новой группы создается группа сходства, включающая в себя эту историю болезни пациента. В необязательном порядке, пользователь может помечать или иначе аннотировать группы для указания основания клинической связи историй болезни пациентов в группе или для обеспечения другой полезной информации. В необязательном порядке, подокно для группы может включать в себя линейки прокрутки, чтобы вмещать в себя больше историй болезни пациентов, чем может одновременно отображаться, и/или может включать в себя такие признаки, как зуммирование или панорамирование с использованием клавиатуры, мыши или других устройств взаимодействия. В необязательном порядке, историю болезни пациента можно перемещать из одной группы в другую в соответствии с решением пользователя на перемещение истории болезни пациента. В необязательном порядке, историю болезни пациента можно удалить из любой существующей группы и заменить любой из множества историй болезни, которые еще не сгруппированы, т.е. из левого окна 82. Операции перетаскивания можно реализовать с использованием мыши 76 или с использованием клавиатуры 74 (например, переключаясь между различными окнами и подокнами), или в виде других операций взаимодействия с пользователем. Кроме того, для осуществления операций группирования можно использовать манипуляции, предусмотренные GUI, например функцию «лассо» и пр.
В конфигурации, показанной на фиг. 4, история болезни каждого пациента назначается исключительно одной группе клинически связанных случаев. В связи с этим пиктограмма истории болезни пациента удаляется из левого окна 82 при ее перетаскивании в одну из групп в правом окне 84, в результате чего сетка пиктограмм историй болезни пациентов, показанная в левом окне 82 на фиг. 4, имеет многочисленные пробелы. В альтернативном варианте осуществления история болезни каждого пациента может, в необязательном порядке, назначаться двум или более группам клинически связанных случаев. Например, единичная история болезни пациента может быть назначена группе, имеющей в качестве своего клинического соотношения конкретную характеристику опухоли, и также может быть назначена группе, имеющей в качестве своего клинического соотношения изображение, свидетельствующее об определенном уровне метастазирования. В этом альтернативном варианте осуществления пиктограмма истории болезни пациента может оставаться в левом окне 82 после перемещения в группу, отображаемую в правом окне 84, чтобы по-прежнему быть доступной для включения в другие группы клинически связанных случаев.
После того как пользователь закончит размещение историй болезни пациентов в клинически связанные группы, например описанное со ссылкой на фиг. 2-4, генератор 34 отчетов по группированию историй болезни, в необязательном порядке, вызывается для генерации отчета, предназначенного для прочтения человеком, где описаны группы сходства. Отчет может представлять собой, например, отчет в произвольной текстовой форме или структурированный отчет на основе электронной таблицы. Описание в отчете по клинически связанной группе может включать в себя, например: название группы; идентификацию историй болезни, содержащихся в группе по ID субъекта (предпочтительно, анонимному), ID исследования и т.д.; текстовое описание группы, введенное пользователем; и т.д. Идентификатор группы сходства назначается каждой истории болезни во внутреннем представлении данных.
В некоторых вариантах осуществления, после перетаскивания пиктограммы истории болезни пациента в группу сходства, задается групповой идентификатор истории болезни пациента для идентификации этой группы. Таким образом, после генерации отчета необходимо определить количество групп сходства. После установления полного количества групп, генератор 34 отчетов просматривает каждую группу, находя истории болезни пациентов в этой группе и записывая релевантную информацию в отчет. В необязательном порядке, генератор 34 отчетов также может генерировать промежуточный отчет, не сортируя все истории болезни пациентов по группам сходства.
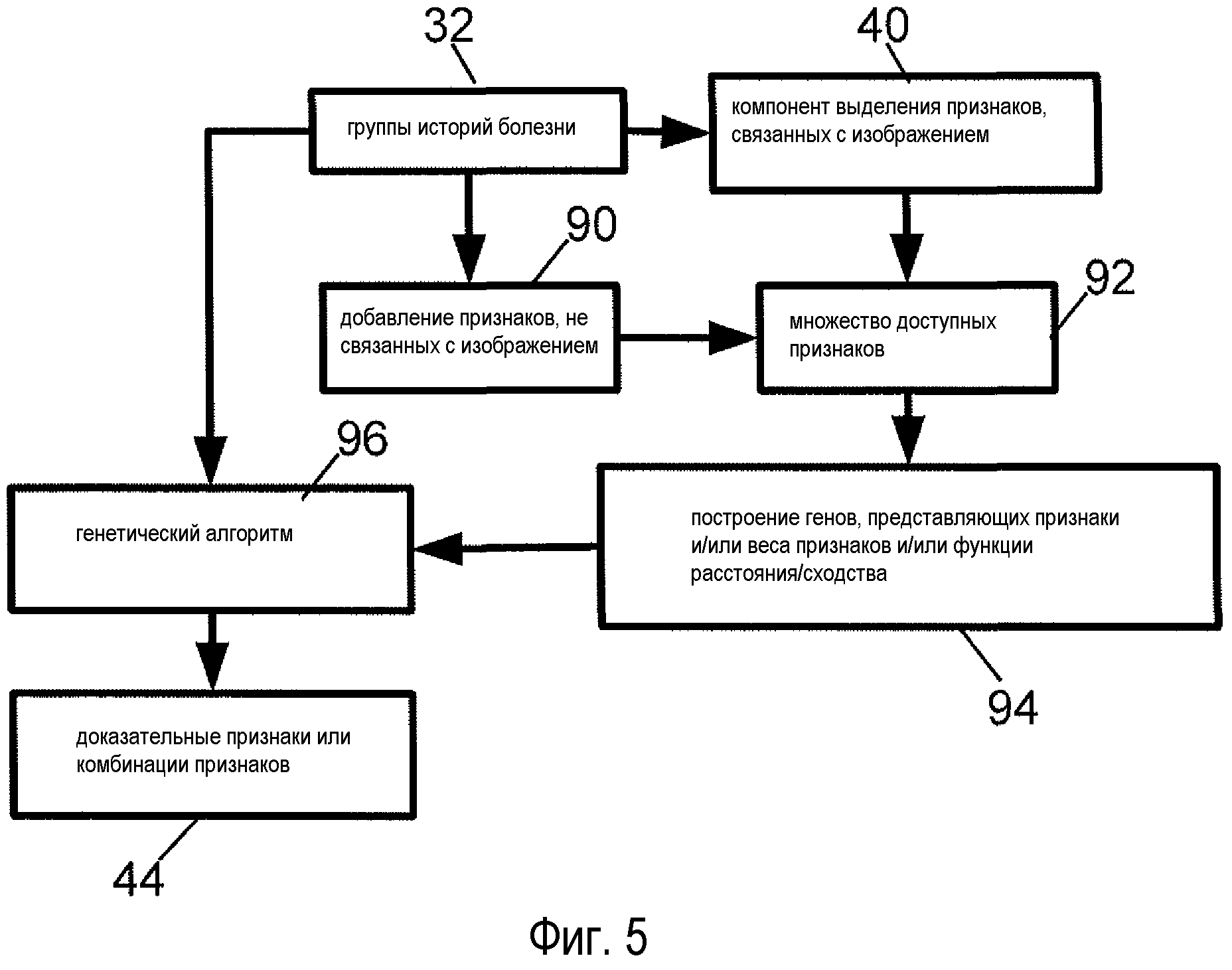
Согласно фиг. 5, осуществляется получение экспериментальных данных сходства, количественно определенных клинически связанными группами 32, обрабатываются для идентификации релевантных (т.е. доказательных) перцептивных и клинических признаков, позволяющих отличить группы друг от друга. В иллюстративном варианте осуществления, для получения доказательных признаков путем оптимизации отбора доказательных признаков, соответствующих группам 32 историй болезни, можно применять методы обработки изображений и обучения машины. Это переводит ощущение сходства у врача, отраженное в группах 32, задающих экспериментальные данные сходства, в оптимальные компьютерно-идентифицируемые доказательные признаки. Эти доказательные признаки можно использовать для представления историй болезни пациентов в системе CDS. В необязательном порядке, оптимальная метрика расстояния или сходства определяется методами обучения машины с использованием экспериментальных данных сходства в качестве обучающих данных. Согласно фиг. 5, изображения групп 32 историй болезни обрабатываются компонентом 40 выделения признаков, связанных с изображением, для идентификации признаков, связанных с изображением. В необязательном порядке, признаки, не связанные с изображением, добавляются 90 для генерации множества 92 доступных признаков. Данный доступный признак может быть или не быть доказательным, в том смысле, что он может быть полезен или бесполезен для установления различий между историями болезни пациентов из групп 32. Затем, с использованием методов обучения машины, применяется отбор признаков для отыскания множества доказательных признаков и, в необязательном порядке, для дополнительного отыскания метрики расстояния или сходства, использующей доказательные признаки.
В иллюстративном варианте осуществления, показанном на фиг. 5, для обучения машины используется генетический алгоритм вкупе с кластеризацией по k-среднему, и установленные кластеры сходства используются в качестве экспериментальных данных. Генетические алгоритмы (ГА) полезны для оптимизации задач в многомерных пространствах, а также обнаружили свою полезность в комбинаторных проблемах, например отборе признаков. При отборе признаков на основе ГА разные подмножества признаков кодируются в совокупности "хромосом". Популяция различных хромосом эволюционирует в процессе скрещивания (обмена признаками), репродукции и мутации. Давление отбора задействуется таким образом, чтобы наиболее приспособленные хромосомы, выявленные согласно подходящему критерию приспособленности, имели наибольшую вероятность передать свою генетическую информацию. Таким образом, популяция эволюционирует к подмножеству признаков, оптимальных в отношении целевой функции, именуемой функцией приспособленности или критерием приспособленности.
В некоторых вариантах осуществления для нахождения подмножества оптимальных признаков и метрики расстояния генетические алгоритмы объединяют с классификацией k ближайших соседей и установленные кластеры сходства используют в качестве экспериментальных данных. Генетический алгоритм итерационно идентифицирует подмножество признаков-кандидатов, которые оцениваются посредством функции приспособленности. Клиническая информация, не связанная с изображением, в необязательном порядке, добавляется к массиву признаков, например с использованием метода масштабирования «1 из C» для масштабирования признаками, связанными с изображением.
Строятся 94 хромосомы, представляющие доступные признаки. Например, каждый доступный признак можно представить двоичным геном хромосомы, в котором двоичное значение "1" указывает, что признак является доказательным признаком, и двоичное значение "0" указывает, что признак не является доказательным. В типичном генетическом алгоритме генерируется существенное множество (т.е. "популяция") хромосом, в которых различные гены случайно или псевдослучайно активируются (т.е. получают значение "1", указывающее, что признак является доказательным) или деактивируются (т.е. получают значение "0", указывающее, что признак не является доказательным). Затем генетический алгоритм 96 итерационно применяется, при этом в качестве алгоритма отбора используется корреляция с группами 32 историй болезни, и для оптимизации или "эволюции" популяции хромосом в отношении корреляции с группами 32 историй болезни пациентов применяются алгоритмы случайной или псевдослучайной мутации генов. Активные гены или комбинации активных генов хромосом эволюционировавшей популяции определяют доказательные признаки или комбинации признаков 44.
В необязательном порядке, гены могут иметь непрерывные значения, указывающие силу корреляции соответствующих признаков с группами 32 историй болезни, а не двоичные генные значения. В этих вариантах осуществления эволюция генетического алгоритма выражается в весах генов из популяции хромосом, в результате чего гены эволюционировавшей популяции обеспечивают веса корреляции для доказательных признаков. В ряде таких вариантов осуществления комбинацию весов, имеющих наибольшую корреляцию с группами 96 историй болезни пациентов, представленную комбинацией генов в выживших эволюционировавших хромосомах, также можно использовать для задания метрики расстояния или сходства.
Например, на первом этапе итерации генетического алгоритма 96, одна история болезни пациента может быть пропущена, и вычисляются расстояния между этой историей болезни пациента и всеми остальными историями болезни с использованием признаков, представленных в хромосоме. Функцию приспособленности генетического алгоритма 96 можно определять в зависимости от этих расстояний и групп сходства, которым принадлежат истории болезни пациентов (например, упорядочивая расстояния от наименьшего к наибольшему, в зависимости от того, сколько расстояний не принадлежит собственной группе сходства пропущенной истории болезни пациента). Это делается для каждой истории болезни пациента в группах 32, и выводится накопленное значение приспособленности. Затем хромосомы подвергаются изменению или "мутации" случайным или псевдослучайным образом согласно принципу выбранного генетического алгоритма 96.
В другом варианте осуществления генетический алгоритм ограничивается тем, что всегда активирует или деактивирует определенную группу признаков совместно, например, по указанию врача или другого специалиста по медицинской диагностике, который знает, как связаны эти признаки. В этих вариантах осуществления построение хромосом в операции 94 можно осуществлять следующим иллюстративным способом: ген представляет доступный признак, и гены, пытающиеся измерить одну и ту же концептуальную категорию признаков, группируются друг с другом. Таким образом, генетический алгоритм 96 имеет ограничение, состоящее в том, что генетический алгоритм никогда не позволяет отбрасывать все гены, представляющие вычисленные меры для аспекта, например, сочленение спикул. Иными словами, генетический алгоритм имеет ограничение, состоящее в том, что, по меньшей мере, один признак или ген сочленения спикул всегда присутствует в хромосоме, поскольку врачам-людям известно, что сочленение спикул является доказательным признаком для диагнозов рака груди.
В других вариантах осуществления генетический алгоритм 96 может выбирать тип метрики расстояния (например, евклидово расстояние, расстояние Махалонобиса или манхэттенское расстояние и т.д.) путем включения генов, представляющих разные функции расстояния.
Хотя в иллюстративном примере, приведенном на фиг. 5, используется генетический алгоритм для компонента 42 обучения машины, это всего лишь иллюстративный пример. В общем случае, компонент 42 обучения машины может применять, по существу, любой способ или комбинацию способов обучения машины, включающие в себя в качестве некоторых иллюстративных примеров: метод имитации отжига; исчерпывающие поиски; плавающие поиски; анализ главных компонентов (PCA) или другие методы редукции признаков; и т.д. Кроме того, возможно исключение компонента 42 обучения машины и настройка подсистемы 12 определения доказательных признаков для обеспечения графического пользовательского интерфейса, позволяющего врачу или другому специалисту по медицинской диагностике, или совокупности таких врачей или других специалистов по медицинской диагностике, вручную выбирать доказательные признаки на основании рассмотрения доступных признаков групп 32 историй болезни пациентов. Например, список доказательных перцептивных и клинических признаков можно, в необязательном порядке, получать вручную от врача с использованием когнитивных методов. В порядке конкретного примера, применительно к раку груди на основе построения изображений методом динамической МРТ с контрастным усилением, врач может вычислять морфологические признаки аномалий и окружающих областей, например форму, границы, текстуру, кинетические кривые, и т.д., с использованием различных методов обработки изображений и проверять их доказательность. Врачу известно, например, что сочленение спикул является доказательным признаком для диагнозов рака груди, поэтому врач, скорее всего, будет рассматривать различные меры сочленения спикул в качестве возможных доказательных признаков. Проверяя значения различных мер сочленения спикул в историях болезни пациентов из групп 32 историй болезни пациентов, врач может вручную выбирать те меры сочленения спикул, которые лучше всего коррелируют с группами 32, в качестве доказательных признаков. Методы ручного когнитивного анализа также можно успешно сочетать с подходами к обучению машины. Например, когнитивный анализ можно использовать для генерации множества возможных доказательных признаков с последующим применением PCA или другого метода редукции признаков для уменьшения количества доказательных признаков.
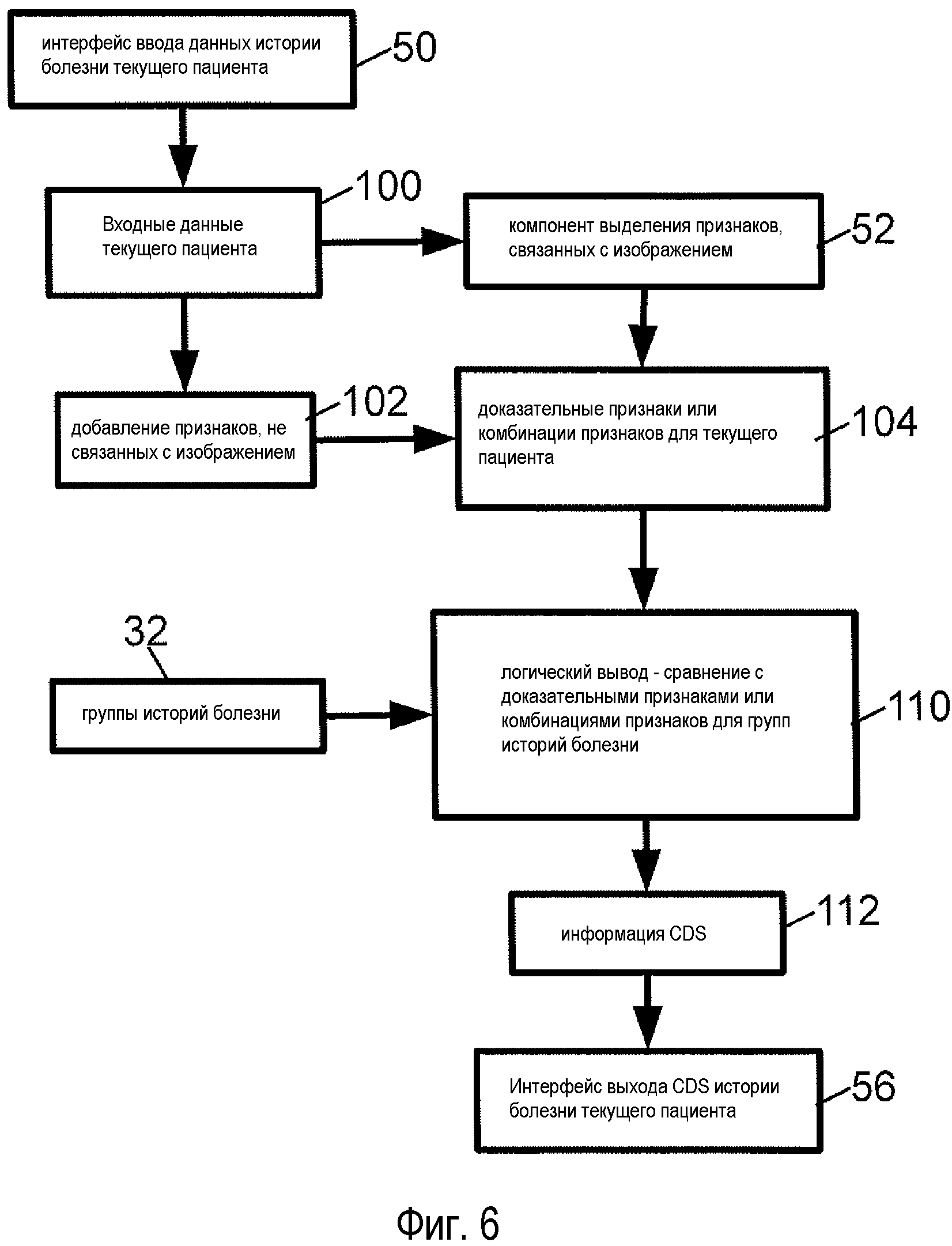
На фиг. 6 проиллюстрирована работа подсистемы 16 пользовательского интерфейса CDS. Пользователь применяет интерфейс 50 ввода данных истории болезни текущего пациента для ввода данных 100 текущего пациента. Входные данные 100 текущего пациента в общем случае включают в себя одно или несколько изображений пациентов, например изображения пациента, полученные одним или несколькими из методов: КТ, МР, ПЭТ, SPECT, флюорографии, ультразвукового исследования и рентгенографии. Компонент 52 выделения признаков, связанных с изображением, обрабатывает эти изображения текущих пациентов для выделения доказательных признаков, связанных с изображением, и, в необязательном порядке, доказательные признаки, не связанные с изображением, объединяются 102 с доказательными признаками, связанными с изображением, для задания множества доказательных признаков или комбинаций признаков 104 для истории болезни текущего пациента. Как отмечено выше, компонент 52 выделения признаков, связанных с изображением, может, в необязательном порядке, быть реализован тем же компонентом, который реализует компонент 40 выделения признаков, связанных с изображением, в подсистеме 12 определения доказательных признаков.
Движок логического вывода 54 CDS осуществляет операцию логического вывода 110 для генерации информации 112 поддержки клинических решений, которая представляется пользователю через интерфейс 56 выхода CDS истории болезни текущего пациента. Движок логического вывода 54 CDS можно реализовать по-разному. В некоторых вариантах осуществления метрика/и 48 расстояния или сходства используется/используются для количественного определения расстояния (или, аналогично, для количественного определения сходства) истории болезни текущего пациента относительно каждой истории болезни в каждой группе клинически связанных случаев из групп 32. Для метрики расстояния движок логического вывода использует следующее соотношение:

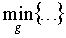
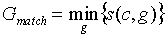
Ниже описаны дополнительные аспекты предложенного варианта осуществления, относящиеся к диагностике рака груди. В настоящее время, рак груди является наиболее распространенной формой рака и занимает втрое место по смертности по причине рака среди женщин в США. Раскрытые здесь системы и способы CDS на основе контентного метода извлечения изображений (CBIR) имитируют мышление реального врача, извлекая сходные случаи, которые напоминают ранее рассмотренные и диагностированные случаи у пациентов. Эти способы опираются на накопленный опыт и предоставляют дополнительную информацию, например автоматическую идентификацию коррелирующих доказательных признаков, помогая врачу принимать решения. Таким образом, раскрытая система CDS на контентной основе для диагностики рака груди помогает врачам решать, с какой степенью вероятности рассматриваемый случай является злокачественным или доброкачественным, что позволяет избегать неверной интерпретации и предотвращать ненужные биопсии. Хотя динамическая МРТ с контрастным усилением (DCE-MRI) стала основным инструментом диагностики для характеристики повреждения груди благодаря своей высокой чувствительности, она часто приводит к высокой частотности отрицательных биопсий. Раскрытая здесь подсистема 12 определения доказательных признаков, включающая в себя компонент 42 обучения машины, переводит субъективное восприятие врачом (или врачами) сходства историй болезни пациента, отраженного в группах 32 историй болезни, в доказательные признаки 44, в необязательном порядке, включающие в себя автоматически вычисляемые метрики 46, 48.
Предполагается, что раскрытая здесь система CDS на основе CBIR, оптимизированная по клиническому сходству для исследований рака груди с помощью DCE-MRI, существенно повысит точность диагнозов, поставленных врачами, и сократит количество ненужных биопсий и задержки в лечении. Контентное извлечение на основании морфологических и кинетических признаков, выделенных из исследований груди DCE-MRI, позволяет извлекать предыдущие случаи с тем же диагнозом и аналогичными характеристиками построения изображений, что и в данном случае. Раскрытые системы и способы CDS позволяют создавать группы на основании клинического сходства случаев рака груди с использованием экспертизы опытных врачей. Доказательные признаки, связанные с изображением, и признаки, не связанные с изображением, идентифицируются на основании когнитивного анализа или других методов корреляции признаков с группами историй болезни. Интеграция передовых методов компьютерного наблюдения, обработки изображений и обучения машины позволила разработать и оптимизировать систему CDS на основе CBIR для применения к диагностике рака груди, благодаря чему, она, по существу, полностью имитирует принятие решений по сходству, производимое врачами-людьми. Хотя здесь, в качестве иллюстративного применения, рассмотрена диагностика рака груди, очевидно, что подходы, лежащие в ее основе, можно обобщить и адаптировать к другим твердым опухолям, например раку толстой кишки, легких, печени, мозга, и для диагностики других типов медицинских заболеваний, относящихся или не относящихся к онкологии.
В данной заявке описаны один или несколько предпочтительных вариантов осуществления. Изучение вышеприведенного подробного описания позволяет предложить различные модификации и альтернативы. Предполагается, что заявка охватывает все подобные модификации и альтернативы при условии, что они не выходят за рамки объема формулы изобретения и ее эквивалентов.
Реферат
Изобретение относится к администрированию историй болезни и экспертным системам. Техническим результатом является повышение достоверности данных текущего пациента для поддержки клинических решений на основании определенных значений доказательных признаков. Система содержит: подсистему (10) группирования историй болезни, включающую в себя графический пользовательский интерфейс (30), способный одновременно отображать данные, представляющие совокупность историй болезни пациентов, и дополнительно выполненный с возможностью позволять пользователю группировать выбранные истории болезни пациентов, представленные одновременно отображаемыми данными в клинически-связанные группы (32) по выбору пользователя; подсистему (12) определения доказательных признаков, способную определять доказательные признаки (44), которые коррелируют с клинически связанными группами; и пользовательский интерфейс CDS (16), способный принимать данные текущего пациента, относящиеся к истории болезни текущего пациента, и выводить информацию поддержки клинических решений на основании значений доказательных признаков, определенных из принятых данных текущего пациента. 2 н. и 13 з.п. ф-лы, 6 ил.
Формула
подсистему (10) группирования историй болезни, включающую в себя графический пользовательский интерфейс (30), способный одновременно отображать данные, представляющие совокупность историй болезни пациентов, и дополнительно выполненный с возможностью позволять пользователю группировать выбранные истории болезни пациентов, представленные одновременно отображаемыми данными в клинически-связанные группы (32) по выбору пользователя,
подсистему (12) определения доказательных признаков, способную определять доказательные признаки (44), которые коррелируют с клинически-связанными группами, и
пользовательский интерфейс CDS (16), способный принимать данные текущего пациента, относящиеся к истории болезни текущего пациента, и выводить информацию поддержки клинических решений на основании значений доказательных признаков, определенных из принятых данных текущего пациента.
компонент (40) выделения признаков, связанных с изображением, способный выделять признаки, связанные с изображением, из изображения пациента, компонент (42) обучения машины, оперирующий с, по меньшей мере, признаками, связанными с изображением.
движок (54) логического вывода, способный генерировать информацию поддержки клинических решений на основании значений доказательных признаков, определенных из принятых данных текущего пациента.
обеспечивают графический пользовательский интерфейс (30), с помощью которого пользователь группирует истории болезни пациентов в клинически-связанные группы (32), причем графический пользовательский интерфейс графически представляет истории болезни пациентов посредством пиктограмм историй болезни пациентов, содержащих изображения пациентов или пиктографические изображения, генерируемые из изображений пациентов,
определяют доказательные признаки (44) историй болезни пациентов, имеющие значения, которые коррелируют с клинически-связанными группами, и
автоматически обеспечивают информацию поддержки клинических решений на основании принятых данных текущего пациента, относящихся к истории болезни текущего пациента, на основании значений доказательных признаков, определенных из принятых данных текущего пациента.
автоматически определяют доказательные признаки (42) историй болезни пациентов, имеющие значения, которые коррелируют с клинически-связанными группами (32), с использованием компонента (42) обучения машины.
выделяют признаки, связанные с изображением, из изображений пациентов, причем признаки, связанные с изображением, обрабатываются компонентом (42) обучения машины.
Комментарии