Способ и устройство для обработки аудиосигнала - RU2455709C2
Код документа: RU2455709C2
Чертежи
Описание
Уровень техники
Область техники
Настоящее изобретение относится к устройству обработки аудиосигнала для эффективного кодирования и декодирования различных типов аудиосигналов, а также к его способу.
Описание предшествующего уровня техники
Согласно существующим технологиям кодирования кодеры классифицируются на два типа - перцепционные аудиокодеры и кодеры на основе линейного предсказания. Например, в перцепционном аудиокодере, оптимизированном под музыку, применяется схема сокращения объема информации в процессе кодирования посредством принципа маскирования, который соответствует теории психоакустического слухового восприятия человека, по частотной оси. С другой стороны, в кодере на основе линейного предсказания, оптимизированном под речь, применяется схема для сокращения объема информации путем моделирования вокализации речи по временной оси.
Тем не менее, каждая из вышеупомянутых технологий обеспечивает хорошую производительность по отдельному оптимизированному аудиосигналу (например, сигналу речи, сигналу музыки), но эти технологии не могут обеспечить стабильный уровень производительности для аудиосигнала, который генерируется путем сложного смешения различных типов аудиосигналов или сигналов речи и музыки.
Сущность изобретения
Соответственно, настоящее изобретение направлено на предоставление устройства для обработки аудиосигнала и способа для этого, которые, по существу, устраняют одну или более из вышеупомянутых проблем, связанных с ограничениями и недостатками существующего уровня техники.
Задачей настоящего изобретения является предоставление способа и устройства для обработки аудиосигнала, посредством которых аудиосигналы разных типов могут сжиматься и/или восстанавливаться с более высокой эффективностью.
Еще одной задачей настоящего изобретения является предоставление схемы аудиокодирования, подходящей для характеристик аудиосигнала.
Следует понимать, что как вышеизложенное общее описание, так и следующее подробное описание настоящего изобретения являются примерными и толковательными, и они предназначены для предоставления дополнительного объяснения настоящего изобретения согласно формуле изобретения.
Краткое описание чертежей
Сопутствующие чертежи, которые включены в состав данного документа для предоставления дополнительного разъяснения изобретения и которые представляют часть этого описания, иллюстрируют варианты осуществления настоящего изобретения и вместе с описанием служат для разъяснения принципов настоящего изобретения.
На чертежах:
Фиг.1 - структурная схема устройства аудиокодирования согласно одному предпочтительному варианту осуществления настоящего изобретения;
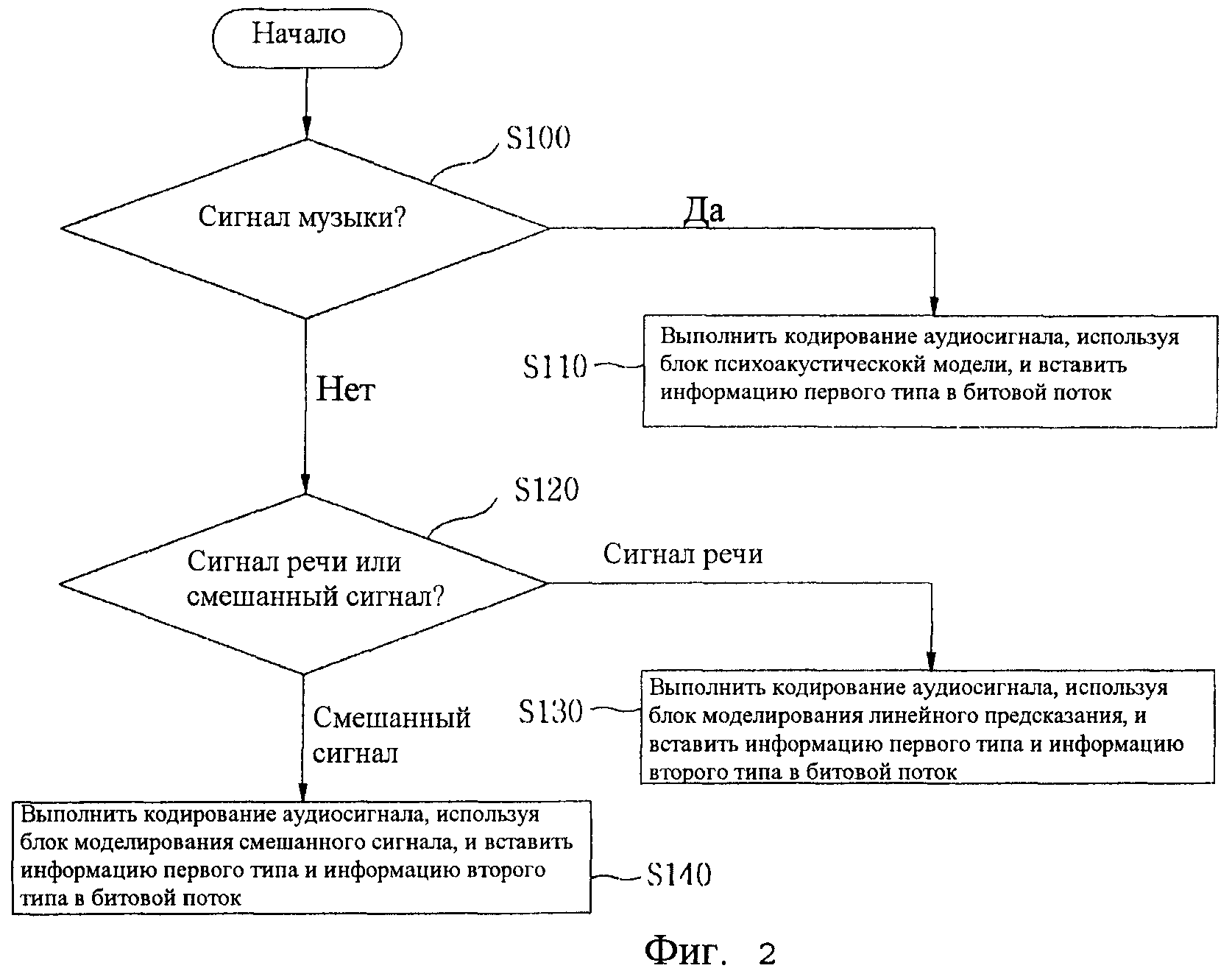
Фиг.2 - схема последовательности операций способа кодирования аудиосигнала, в котором используется информация типа аудиосигнала, согласно одному варианту осуществления настоящего изобретения;
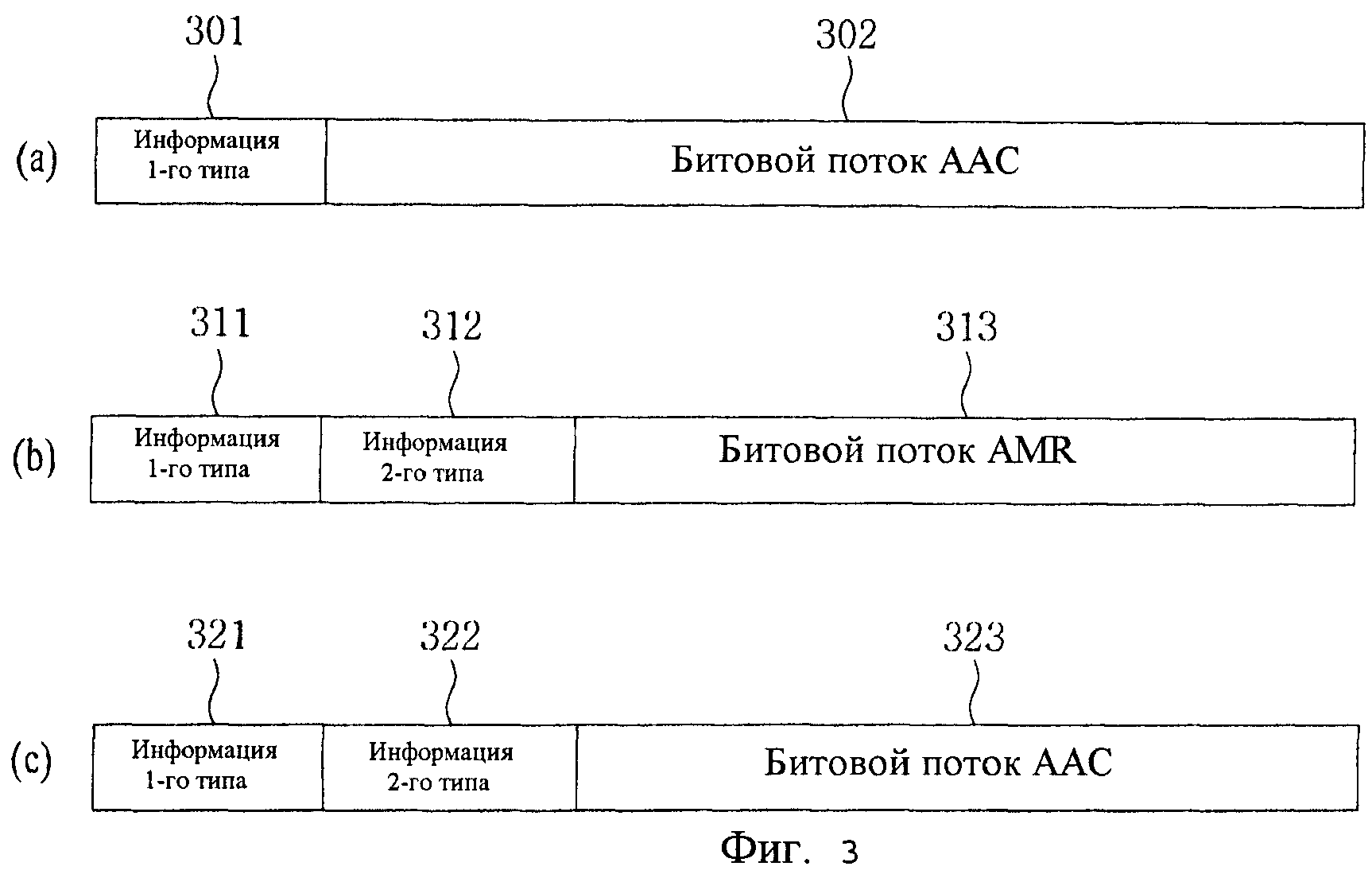
Фиг.3 - схема примера структуры битового потока аудио, закодированного согласно настоящему изобретению;
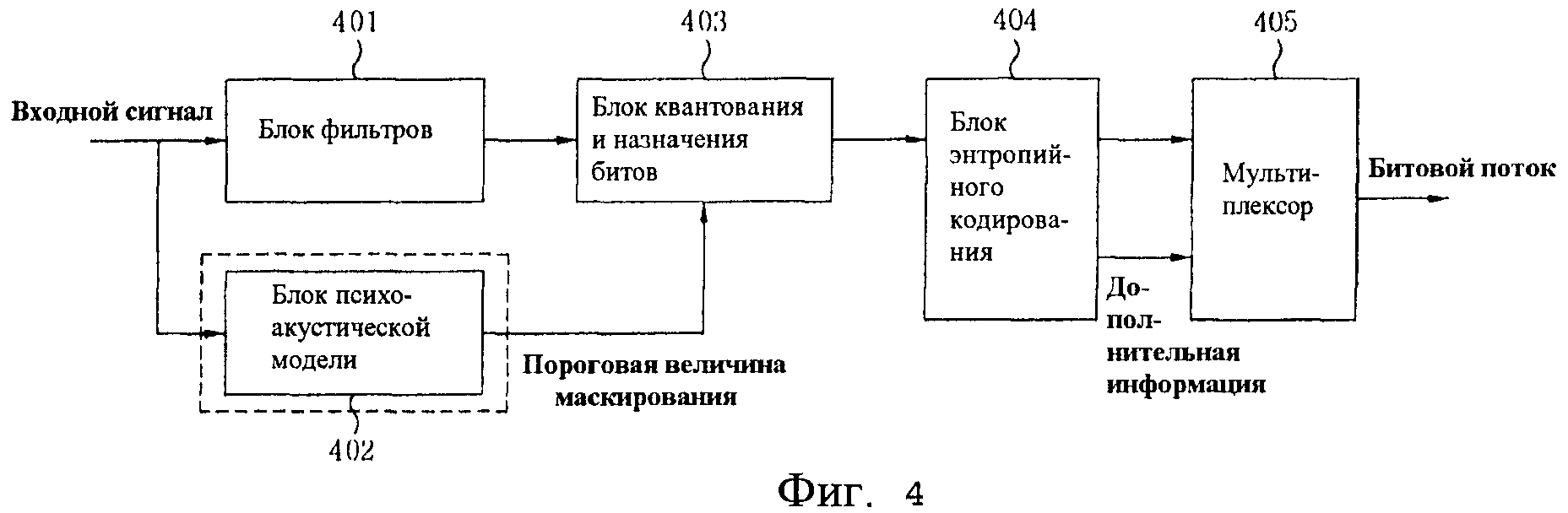
Фиг.4 - структурная схема устройства аудиокодирования, в котором используется психоакустическая модель, согласно одному варианту осуществления настоящего изобретения;
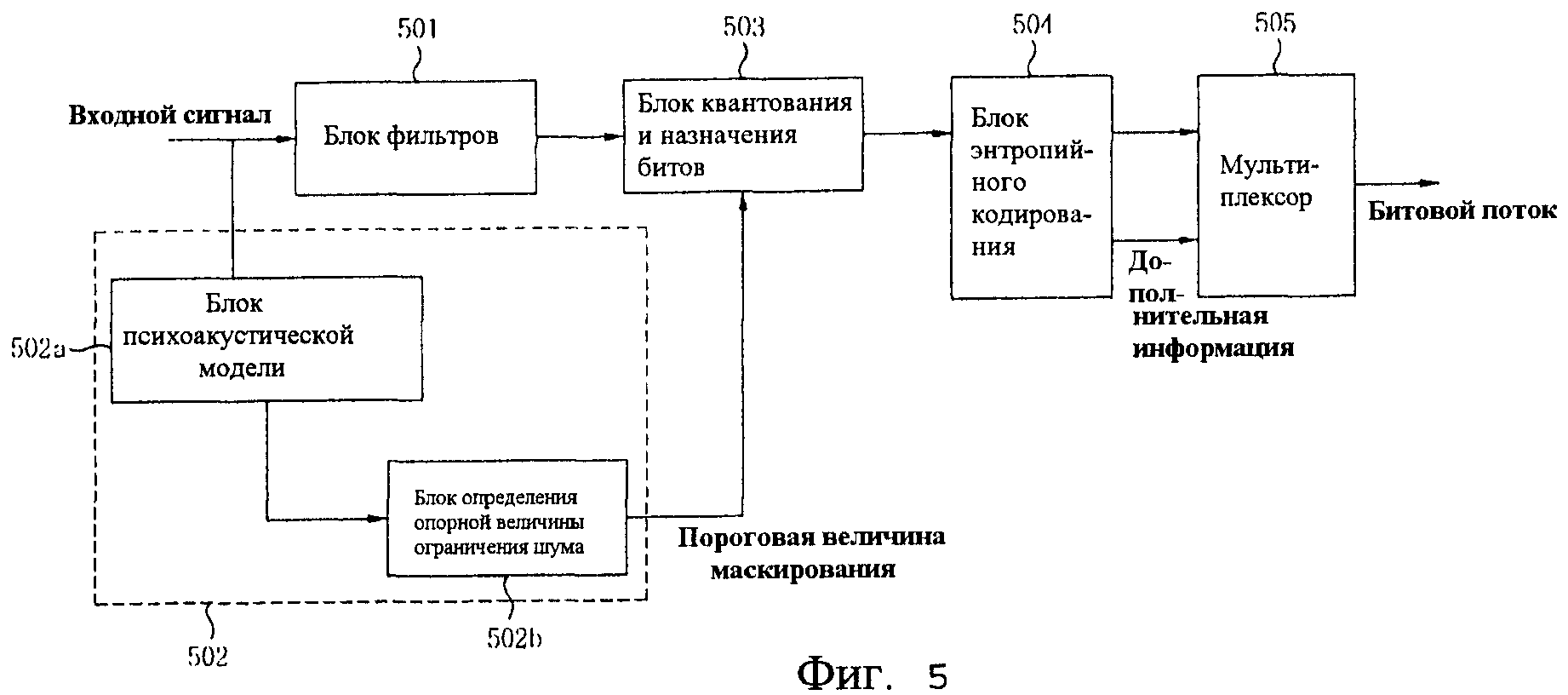
Фиг.5 - структурная схема устройства аудиокодирования, в котором используется психоакустическая модель, согласно еще одному варианту осуществления настоящего изобретения;
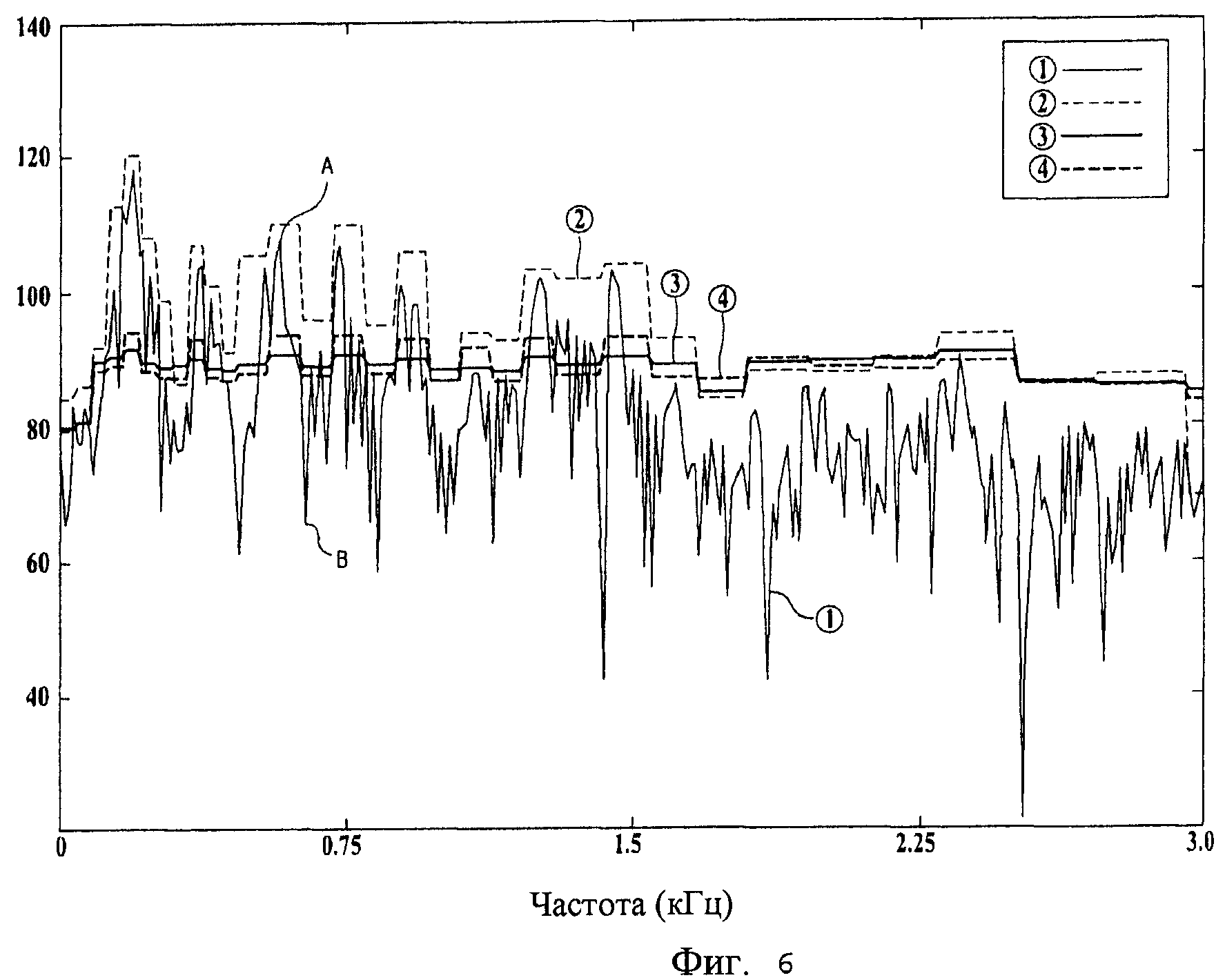
Фиг.6 - диаграмма вариаций модифицированной по шуму опорной величины посредством блока психоакустической модели согласно еще одному варианту осуществления настоящего изобретения;
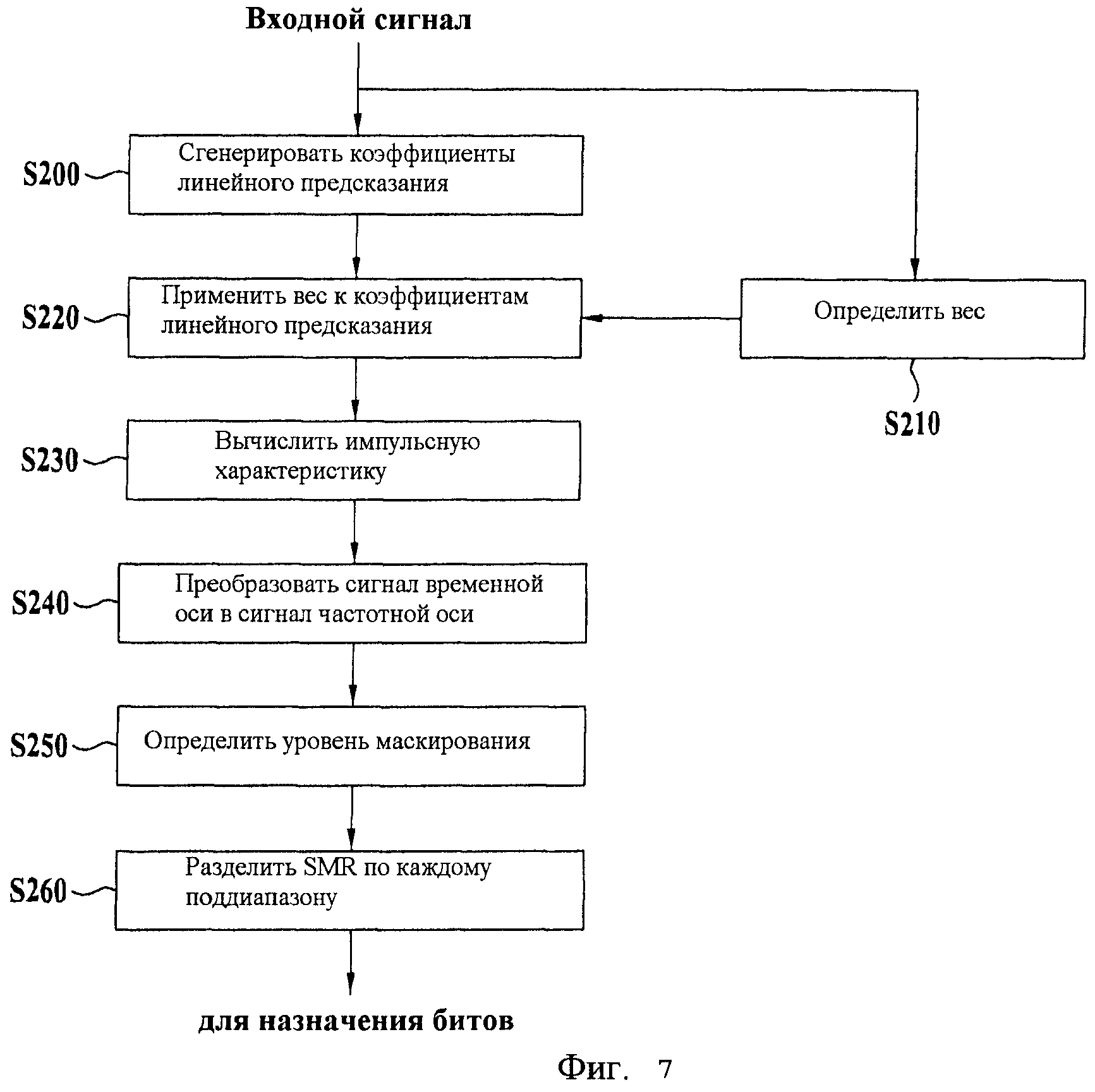
Фиг.7 - схема последовательности операций способа генерации модифицированной по шуму опорной величины посредством блока психоакустической модели согласно еще одному варианту осуществления настоящего изобретения;
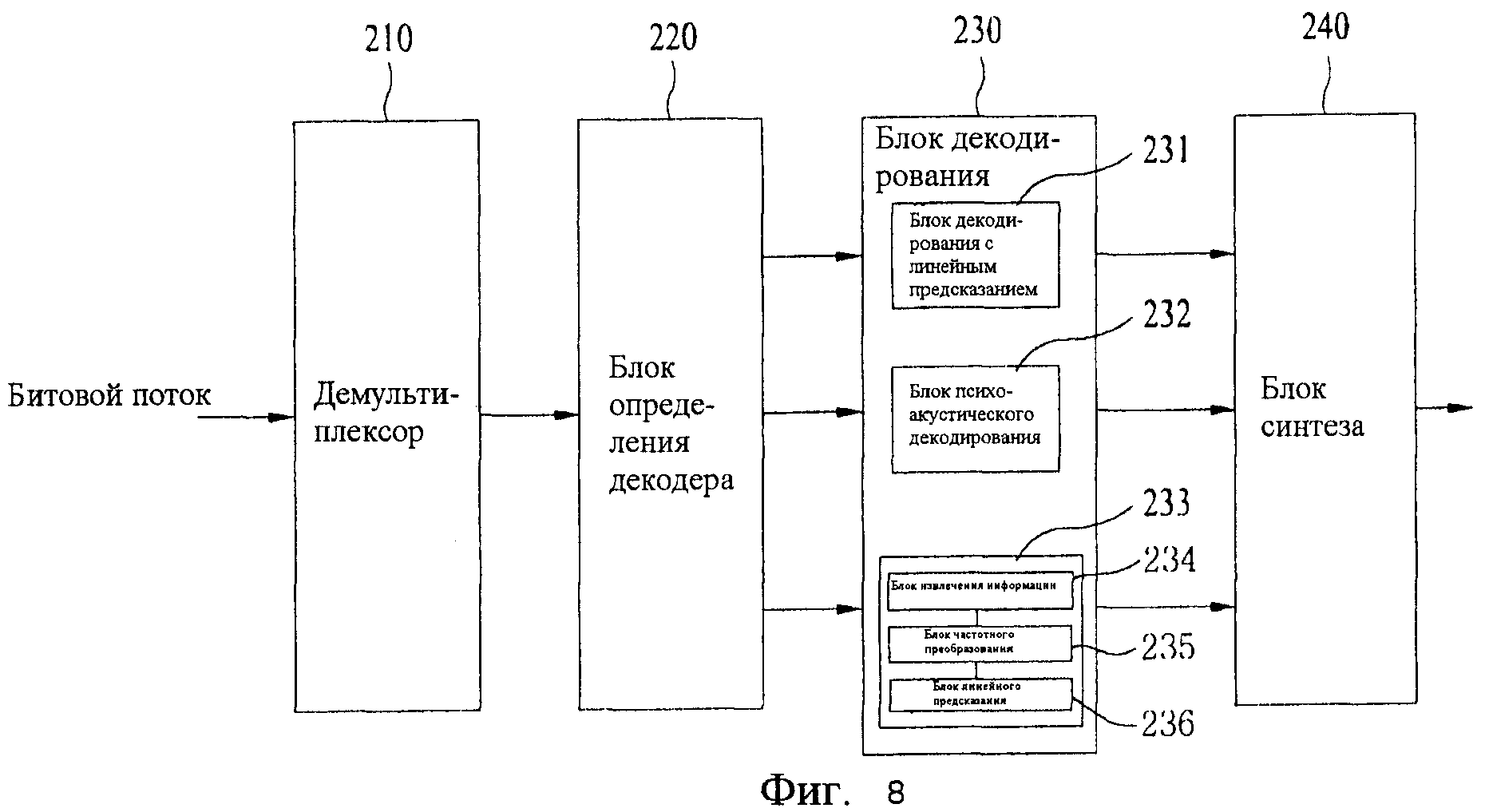
Фиг.8 - структурная схема устройства аудиодекодирования согласно одному предпочтительному варианту осуществления настоящего изобретения;
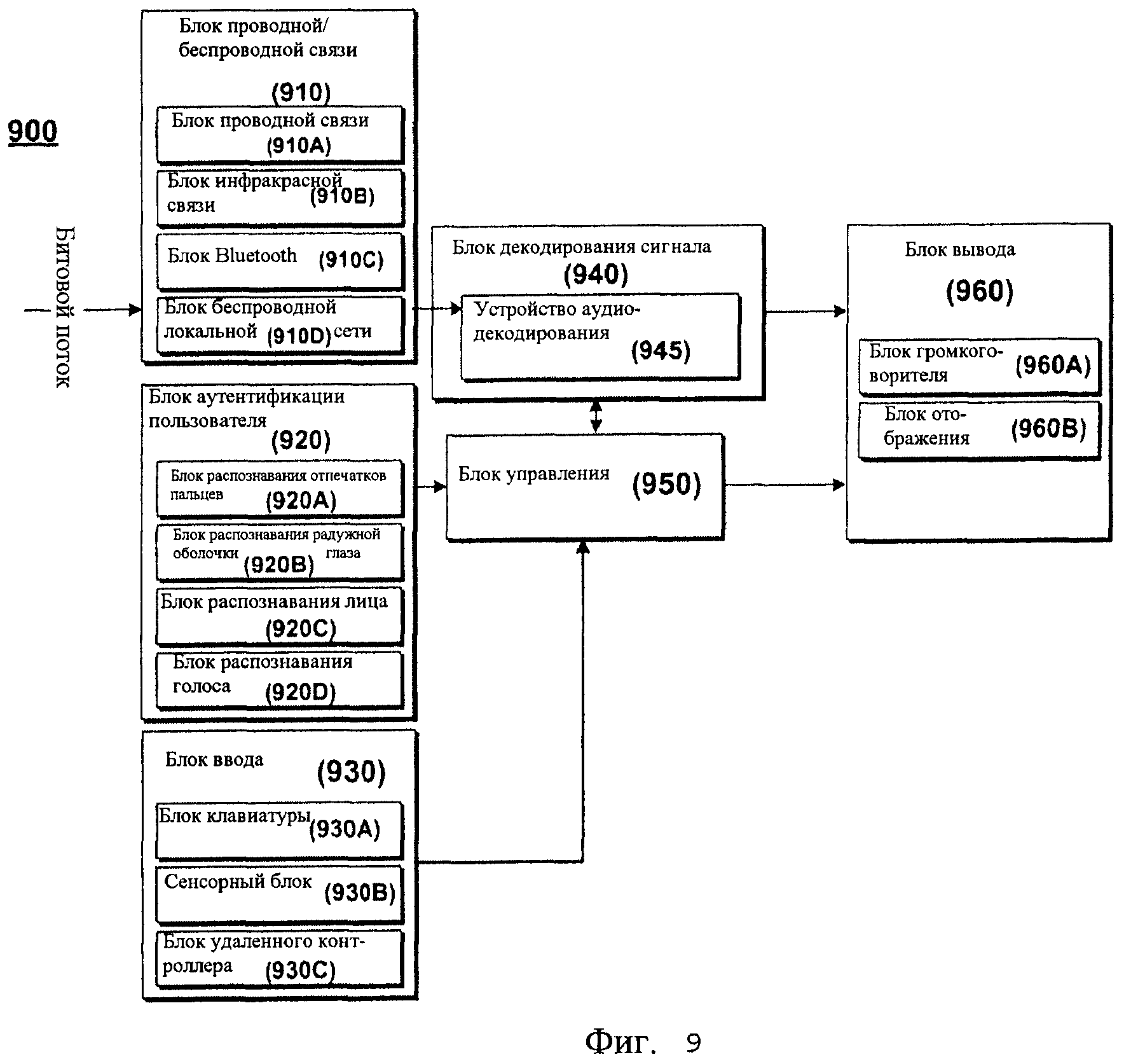
Фиг.9 - схема конфигурации изделия, реализованного посредством устройства аудиодекодирования, согласно одному варианту осуществления настоящего изобретения;
Фиг.10 - схема одного примера взаимосвязей между изделиями, реализованными посредством устройства аудиодекодирования, согласно одному варианту осуществления настоящего изобретения; и
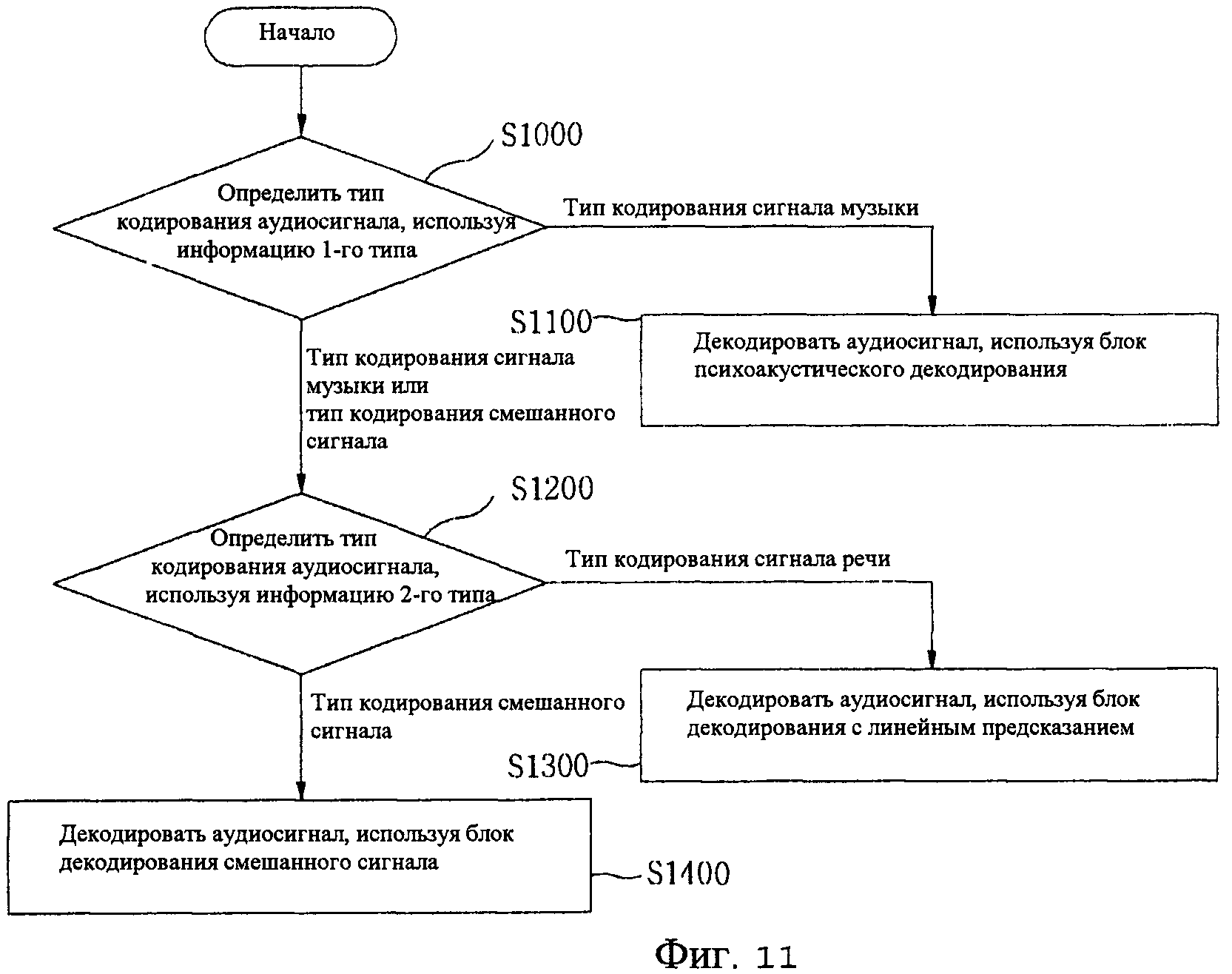
Фиг.11 - схема последовательности операций способа аудиодекодирования согласно одному варианту осуществления настоящего изобретения.
Подробное описание изобретения
Ниже следует подробное описание предпочтительных вариантов осуществления настоящего изобретения, примеры которых проиллюстрированы на прилагаемых чертежах.
В настоящем описании терминология, связанная с данным изобретением, может быть истолкована следующим образом. Во-первых, "кодирование" может означать кодирование или декодирование. Термин "информация" включает в себя величины, параметры, коэффициенты, элементы и т.п.
Согласно настоящему изобретению "аудиосигнал" концептуально отличается от видеосигнала. Так, аудиосигнал обозначает все сигналы, которые могут быть идентифицированы на слух при воспроизведении. Следовательно, аудиосигналы могут быть классифицированы на сигнал речи, который главным образом связан с вокализацией человеком, или сигнал, схожий с сигналом речи (далее "сигнал речи"), сигнал музыки, который главным образом связан с механическим шумом и звуком, или сигнал, схожий с сигналом музыки (далее "сигнал музыки), и "смешанный сигнал", генерируемый путем смешения сигнала речи и сигнала музыки. Целью настоящего изобретения является предоставление устройства для кодирования/декодирования вышеописанных трех типов аудиосигналов и способа, чтобы кодировать/декодировать аудиосигналы для обеспечения подходящих характеристик. Тем не менее, упомянутые аудиосигналы классифицируются подобным образом только для описания настоящего изобретения. Очевидно, что техническая идея настоящего изобретения также применима к случаю классификации аудиосигналов по другому способу.
Фиг.1 представляет собой структурную схему устройства аудиокодирования согласно одному предпочтительному варианту осуществления настоящего изобретения. В частности, на Фиг.1 проиллюстрирован процесс классификации введенного аудиосигнала согласно предустановленной опорной величине и последующего кодирования классифицированного аудиосигнала путем выбора схемы аудиокодирования, подходящей для соответствующего аудиосигнала.
Ссылаясь на Фиг.1, устройство аудиокодирования согласно одному предпочтительному варианту осуществления настоящего изобретения включает в себя блок 100 классификации сигнала (детектор звуковой активности), который классифицирует входной аудиосигнал как сигнал речи, сигнал музыки или смешанный сигнал речи и музыки путем анализа характеристик введенного аудиосигнала, блок 110 моделирования линейного предсказания, который кодирует сигнал речи, определенный блоком 100 классификации сигнала, блок 120 психоакустической модели, который кодирует сигнал музыки, и блок 130 моделирования смешанного сигнала, который кодирует смешанный сигнал речи и музыки. Устройство аудиокодирования, сверх того, включает в себя блок 101 переключения, сконфигурированный так, чтобы выбирать схему кодирования, подходящую для аудиосигнала, который был классифицирован блоком 100 классификации сигнала. Блок 101 переключения действует посредством информации типа кодирования аудиосигнала (например, информации первого типа и информации второго типа, которые подробно описаны ниже со ссылкой на Фиг.2 и 3), которая генерируется блоком 100 классификации сигнала в качестве управляющего сигнала. Более того, блок 130 моделирования смешанного сигнала может включать в себя блок 131 линейного предсказания, блок 132 извлечения остаточного сигнала и блок 133 частотного преобразования. В следующем разделе подробно описаны соответствующие элементы, показанные на Фиг.1.
Блок 100 классификации сигнала классифицирует введенный аудиосигнал и, далее, генерирует управляющий сигнал, чтобы выбрать схему аудиокодирования, подходящую для классифицированного типа. Например, блок 100 классификации сигнала классифицирует введенный аудиосигнал как сигнал музыки, сигнал речи или смешанный сигнал речи и музыки. Таким образом, тип введенного аудиосигнала классифицируется, чтобы для каждого типа аудиосигнала выбрать оптимальную схему кодирования из множества схем, которые описаны ниже. Следовательно, блок 100 классификации сигнала выполняет процесс анализа введенного аудиосигнала и процесс выбора схемы аудиокодирования, которая является оптимальной для этого входного аудиосигнала. Например, блок 100 классификации сигнала генерирует информацию типа аудиокодирования путем анализа введенного аудиосигнала. Сгенерированная информация типа аудиокодирования используется как опорное значение для выбора схемы кодирования. Сгенерированная информация типа аудиокодирования включается в состав окончательно закодированного аудиосигнала в виде битового потока и, далее, передается в устройство декодирования или приема. Способ и устройство декодирования, в которых применяется информация типа аудиокодирования, подробно описаны ниже со ссылкой на Фиг.8 и 11. Более того, информация типа аудиокодирования, сгенерированная блоком 100 классификации сигнала, может включать в себя информацию первого типа и информацию второго типа, например. Это описано ниже со ссылкой на Фиг.2 и 3.
Блок 100 классификации сигнала определяет тип аудиосигнала согласно характеристике введенного аудиосигнала. Например, если введенный сигнал лучше для моделирования посредством конкретного коэффициента и остаточного сигнала, то блок 100 классификации сигнала определяет этот введенный аудиосигнал как сигнал речи. Если введенный сигнал плохо подходит для моделирования посредством конкретного коэффициента и остаточного сигнала, то блок 100 классификации сигнала определяет этот введенный аудиосигнал как сигнал музыки. Если сложно классифицировать введенный аудиосигнал как сигнал речи или сигнал музыки, то блок 100 классификации сигнала определяет этот входной аудиосигнал как смешанный сигнал. Что касается деталей определения, например, когда сигнал моделируется посредством конкретного коэффициента и остаточного сигнала, если отношение уровня энергии остаточного сигнала к упомянутому сигналу меньше предустановленной опорной величины, то этот сигнал может быть определен как хорошо подходящий для моделирования. Следовательно, этот сигнал может быть определен как сигнал речи. Если этот сигнал имеет высокую избыточность по временной оси, то этот сигнал может быть определен как хорошо подходящий для моделирования путем линейного предсказания в целях предсказания текущего сигнала из старого сигнала. Следовательно, этот сигнал может быть определен как сигнал музыки.
Если сигнал, введенный согласно этой опорной величине, определяется как сигнал речи, то можно кодировать введенный сигнал посредством кодера речи, который оптимизирован для сигнала речи. Согласно настоящему варианту осуществления блок 100 моделирования линейного предсказания используется для схемы кодирования, подходящей для сигнала речи. Блок 100 моделирования линейного предсказания снабжен разными схемами. Например, в блоке 110 моделирования с линейным предсказанием применима схема кодирования Предсказания с Возбуждением по Алгебраической Кодовой Книге (Algebraic Code Excited Linear Prediction, ACELP), Адаптивная Многоскоростная (Adaptive Multi-Rate, AMR) схема кодирования или Широкополосная Адаптивная Многоскоростная (Adaptive Multi-Rate Wideband, AMR-WB) схема кодирования.
Блок 110 моделирования с линейным предсказанием способен выполнять кодирование с линейным предсказанием введенного аудиосигнала в единицах кадров. Блок 110 моделирования с линейным предсказанием извлекает коэффициент предсказания по каждому кадру и, далее, квантует извлеченный коэффициент предсказания. Например, обычно используется схема извлечения коэффициента предсказания с использованием "алгоритма Левинсона-Дурбина".
В частности, если введенный аудиосигнал состоит из множества кадров или если существует множество суперкадров, каждый из которых образует единицу из множества кадров, то можно определить, следует ли применять схему моделирования с линейным предсказанием по каждому кадру. Можно применять разные схемы моделирования с линейным предсказанием к каждой единице кадра, существующей в одном суперкадре, или к каждому подкадру в единице кадра. Это может повысить эффективность кодирования аудиосигнала.
Между тем, если введенный аудиосигнал классифицируется блоком классификации сигнала как сигнал музыки, то можно кодировать введенный сигнал посредством кодера музыки, который оптимизирован для сигнала музыки. Согласно настоящему варианту осуществления блок 120 психоакустической модели используется для схемы кодирования, подходящей для сигнала музыки. Пример блока 120 психоакустической модели, применимого к настоящему изобретению, подробно описан ниже со ссылкой на Фиг.4-7.
Если входной аудиосигнал классифицируется как смешанный сигнал, в котором речь и музыка смешены друг с другом, то можно кодировать входной сигнал посредством кодера, который оптимизирован для смешанного сигнала. Согласно настоящему варианту осуществления блок 130 моделирования смешанного сигнала используется для схемы кодирования, подходящей для смешанного сигнала.
Блок 130 моделирования смешанного сигнала может выполнять кодирование путем смешанной схемы, формируемой путем смешения вышеупомянутой схемы моделирования с линейным предсказанием и схемы психоакустического моделирования. В частности, блок 130 моделирования смешанного сигнала применяет кодирование с линейным предсказанием к входному сигналу, получает остаточный сигнал, равный разности между сигналом результата линейного предсказания и исходным сигналом, и, далее, кодирует остаточный сигнал посредством схемы кодирования с частотным преобразованием.
Например, на Фиг.1 показан пример, где блок 130 моделирования смешанного сигнала включает в себя блок 131 линейного предсказания, блок 132 извлечения остаточного сигнала и блок 123 частотного преобразования.
Блок 131 линейного предсказания применяет анализ линейного предсказания к введенному сигналу и, далее, извлекает коэффициент линейного предсказания, указывающий характеристику этого сигнала. Блок 132 извлечения остаточного сигнала извлекает из введенного сигнала остаточный сигнал, из которого удаляется избыточный компонент, посредством извлеченного коэффициента линейного предсказания. Поскольку избыточность удаляется из остаточного сигнала, соответствующий остаточный сигнал может иметь тип белого шума. Блок 131 линейного предсказания способен выполнять кодирование с линейным предсказанием введенного аудиосигнала в единицах кадров. Блок 131 линейного предсказания извлекает коэффициент предсказания по каждому кадру и, далее, квантует извлеченный коэффициент предсказания. В частности, если введенный аудиосигнал состоит из множества кадров или если существует множество суперкадров, каждый из которых образует единицу из множества кадров, то можно определить, следует ли применять схему моделирования с линейным предсказанием по каждому кадру. Можно применять разные схемы моделирования с линейным предсказанием к каждой единице кадра, существующей в одном суперкадре, или к каждому подкадру в единице кадра. Это может повысить эффективность кодирования аудиосигнала.
Блок 132 извлечения остаточного сигнала принимает ввод остающегося сигнала, кодированного посредством блока 131 линейного предсказания, и ввод исходного аудиосигнала, который прошел через блок 100 классификации сигнала, и, далее, извлекает остаточный сигнал, который представляет собой сигнал разности между упомянутыми двумя введенными сигналами.
Блок 133 частотного преобразования вычисляет пороговое значение маскирования или Отношение Сигнала к Маске (Signal-to-Mask Ratio, SMR) путем применения преобразования частотной области к введенному остаточному сигналу посредством Модифицированного Дискретного Косинусного Преобразования (Modified Discrete Cosine Transform, MDCT) или т.п. и впоследствии кодирует остаточный сигнал. Блок 133 частотного преобразования может кодировать остаточный сигнал, используя TCX, а также психоакустическое моделирование.
Поскольку блок 100 моделирования с линейным предсказанием и блок 131 линейного предсказания извлекают отражающий звуковую характеристику Коэффициент Линейного Предсказания (Linear Predictive Coefficient, LPC) путем выполнения линейного предсказания и анализа введенного аудиосигнала, можно рассматривать схему использования переменных битов для способа передачи данных LPC.
Например, мода данных LPC определяется путем рассмотрения схемы кодирования по каждому кадру. Далее, можно назначить коэффициент линейного предсказания с переменным количеством битов для каждой определенной моды данных LPC. Таким образом, сокращается общее количество битов. Следовательно, аудиокодирование и аудиодекодирование может быть выполнено более эффективно.
Между тем, как упомянуто выше, блок 100 классификации сигнала генерирует информацию типа кодирования аудиосигнала путем классификации аудиосигнала в один из двух типов информации кодирования, обеспечивает возможность включения в состав битового потока этой информации типа кодирования и, далее, передает упомянутый битовой поток в декодирующее устройство. Ниже со ссылкой на Фиг.2 и 3 подробно описана информация типа аудиокодирования согласно настоящему изобретению.
Фиг.2 представляет собой схему последовательности операций способа кодирования аудиосигнала, в котором используется информация типа аудиосигнала, согласно одному предпочтительному варианту осуществления настоящего изобретения.
Ссылаясь на Фиг.2, согласно настоящему изобретению предлагается способ представления типа аудиосигнала в форме использования информации первого типа и информации второго типа для классификации. Например, если введенный аудиосигнал определяется как сигнал музыки [S100], то блок 100 классификации сигнала управляет переключающим блоком 101 таким образом, чтобы выбрать схему кодирования (например, схему психоакустического моделирования, показанную на Фиг.2), которая подходит для сигнала музыки, и, далее, обеспечивает возможность выполнения кодирования согласно выбранной схеме кодирования [S110]. Далее, соответствующая управляющая информация конфигурируется как информация первого типа и передается путем ее включения в состав аудиобитового потока. Соответственно, информация первого типа выполняет роль информации идентификации кодирования, которая указывает, что тип кодирования аудиосигнала соответствует типу кодирования сигнала музыки. Информация первого типа используется при декодировании аудиосигнала согласно способу и устройству декодирования.
Более того, если введенный аудиосигнал определяется как сигнал речи [S120], то блок 100 классификации сигнала управляет переключающим блоком 101 таким образом, чтобы выбрать схему кодирования (например, схему моделирования с линейным предсказанием, показанную на Фиг.2), которая подходит для сигнала речи, и, далее, обеспечивает возможность выполнения кодирования согласно выбранной схеме кодирования [S130]. Если введенный аудиосигнал определяется как смешанный сигнал речи [S120], то блок 100 классификации сигнала управляет переключающим блоком 101 таким образом, чтобы выбрать схему кодирования (например, схему моделирования смешанного сигнала, показанную на Фиг.2), которая подходит для смешанного сигнала, и, далее, обеспечивает возможность выполнения кодирования согласно выбранной схеме кодирования [S140]. Далее, управляющая информация, указывающая либо тип кодирования сигнала речи, либо тип кодирования смешанного сигнала, конфигурируется в информацию второго типа. Информация второго типа, далее, передается путем ее включения в состав кодированного аудиобитового потока вместе с информацией первого типа. Соответственно, информация второго типа выполняет роль информации идентификации кодирования, которая указывает, что тип кодирования аудиосигнала соответствует типу кодирования сигнала речи или типу кодирования смешанного сигнала. Информация второго типа используется вместе с вышеупомянутой информацией первого типа при декодировании аудиосигнала согласно способу и устройству декодирования.
Относительно информации первого типа и информации второго типа существует два случая согласно характеристикам введенных аудиосигналов. То есть требуется передать либо только информацию первого типа, либо как информацию первого типа, так и информацию второго типа. Например, если тип введенного аудиосигнала соответствует типу кодирования сигнала музыки, то путем включения в состав битового потока передается только информация первого типа, а информация второго типа может не включаться в состав битового потока [см.Фиг.3(a)]. То есть информация второго типа включается в состав битового потока, только если тип кодирования введенного аудиосигнала соответствует типу кодирования сигнала речи или типу кодирования смешанного сигнала. Следовательно, обеспечивается возможность предотвращения использования ненужных битов для представления типа кодирования аудиосигнала.
Хотя согласно примеру настоящего изобретения информация первого типа указывает присутствие или отсутствие типа музыкального сигнала, это всего лишь пример. Очевидно, что информация первого типа также может быть использована для индикации типа кодирования сигнала речи или типа кодирования смешанного сигнала. Таким образом, путем использования типа аудиокодирования, вероятность которого высока согласно окружению кодирования, к которому применяется настоящее изобретение, обеспечивается возможность сокращения общего количества битов в битовом потоке.
Фиг.3 представляет собой схему примера структуры аудиобитового потока, закодированного согласно настоящему изобретению.
Ссылаясь на Фиг.3(a), введенный аудиосигнал соответствует сигналу музыки. В состав битового потока включается только информация 301 первого типа, а информация второго типа не включается в состав битового потока. В битовый поток включаются аудиоданные, закодированные по типу кодирования, соответствующему информации 301 первого типа (например, битовый поток 302 AAA).
Ссылаясь на Фиг.3(b), введенный аудиосигнал соответствует сигналу речи. В состав битового потока включается как информация 311 первого типа, так и информация 312 второго типа. В битовый поток включаются аудиоданные, закодированные по типу кодирования, соответствующему информации 312 второго типа (например, битовый поток 313 AMR).
Ссылаясь на Фиг.3(c), введенный аудиосигнал соответствует смешанному сигналу. В состав битового потока включается как информация 321 первого типа, так и информация 322 второго типа. В битовый поток включаются аудиоданные, закодированные по типу кодирования, соответствующему информации 322 второго типа (например, битовый поток 323 AAC, к которому применено TCX).
Информация, включенная в состав аудиобитового потока, закодированного посредством настоящего изобретения, является иллюстративной. Очевидно, что в рамках настоящего изобретения возможны различные приложения. Например, в настоящем изобретении в качестве примеров кодирования путем добавления информации для идентификации соответствующих схем кодирования приняты AMR и AAC. Сверх того, применимы разные схемы кодирования и доступна информация идентификации кодирования для идентификации различных схем кодирования. Кроме того, настоящее изобретение, проиллюстрированное на Фиг.3(a)-(c), применимо к одному суперкадру, одному кадру и одному подкадру. То есть настоящее изобретение способно предоставлять информацию типа кодирования аудиосигнала по каждой предварительно заданной единице кадра.
В качестве этапа предварительной обработки процесса кодирования входного сигнала посредством блока 110 моделирования линейного предсказания, блока 120 психоакустической модели и блока 130 моделирования смешанного сигнала может быть выполнен процесс расширения частотной полосы (который на данном чертеже не показан). В качестве примера процесса расширения частотной полосы можно использовать Репликацию Спектральной Полосы (Spectral Band Replication, SBR) и Расширение Полосы Высоких Частот (High Band Extension, HBE) для генерации высокочастотного компонента в блоке декодирования расширения полосы пропускания с использованием низкочастотного компонента.
В качестве этапа предварительной обработки процесса кодирования входного сигнала посредством блока 110 моделирования линейного предсказания, блока 120 психоакустической модели и блока 130 моделирования смешанного сигнала может быть выполнен процесс расширения канала (который на данном чертеже не проиллюстрирован). Процесс расширения канала может сократить размер назначения битов путем кодирования информации канала аудиосигнала в дополнительную информацию. Например, существует блок расширения канала, такой как Параметрическое Стерео (Parametric Stereo, PS). В этом случае, параметрическое стерео представляет собой схему кодирования стереосигнала путем понижающего микширования стереосигнала в моносигнал.
Согласно одному варианту осуществления, если стереосигнал 48 кГц передается с использованием SBR и PS, то посредством SBR/PS сохраняется моносигнал 24 кГц. Этот моносигнал может быть закодирован посредством кодера. Таким образом, входной сигнал кодера имеет частоту 24 кГц. Это обусловлено тем, что высокочастотный компонент кодируется посредством SBR и субдискретизируется в половину исходной частоты. Таким образом, входной сигнал превращается в моносигнал. Это обусловлено тем, что стереофонический аудиосигнал извлекается в качестве параметра путем PS, и он должен быть заменен на сумму моносигнала и дополнительного аудиосигнала.
Далее следует описание процесса кодирования сигнала музыки с использованием блока психоакустической модели.
Фиг.4 представляет собой структурную схему устройства аудиокодирования, в котором используется психоакустическая модель, согласно одному варианту осуществления настоящего изобретения.
Ссылаясь на Фиг.4, устройство аудиокодирования, в котором используется психоакустическая модель, согласно одному варианту осуществления настоящего изобретения включает в себя блок 401 фильтров (блок фильтров анализа), блок 402 психоакустической модели, блок 403 квантования и назначения битов, блок 404 энтропийного кодирования и мультиплексор 405.
Блок 401 фильтров преобразует аудиосигнал в сигнал частотной оси путем выполнения Модифицированного Дискретного Косинусного Преобразования (Modified Discrete Cosine Transform, MDCT), чтобы кодировать введенный аудиосигнал, который представляет собой сигнал временной оси.
Блок 402 психоакустической модели определяет размер допустимого максимального шума квантования по каждой частоте, необходимого для процесса назначения битов, путем выполнения анализа перцепционной характеристики введенного аудиосигнала. Максимально допустимый шум квантования по каждой частоте может быть схематически представлен как опорная величина ограничения шума. В частности, поскольку блок 402 психоакустической модели анализирует перцепционную характеристику входного сигнала на частотной оси, необходим процесс частотного преобразования для входного сигнала. Хотя частотное преобразование выполняется блоком 401 фильтров в процессе кодирования аудиосигнала, поскольку результаты испытаний психоакустической теории по большей части достигаются на оси Дискретного Преобразования Фурье (Discrete Fourier Transform, DFT), все же предпочтительней выполнение Быстрого Преобразования Фурье (Fast Fourier Transform, FFT). После завершения процесса преобразования сигнала по частотной оси в психоакустической модели может быть получена опорная величина ограничения шума путем свертывания между частотным спектром и функцией расширения, соответствующей каждому частотному компоненту. Спектр аудиосигнала квантуется путем вычисления разности между опорной величиной ограничения шума, полученной посредством психоакустической модели, и спектром входного сигнала, после чего выполняется назначение битов.
Блок 403 квантования квантует результирующий объект, сгенерированный путем "кодирования с потерями", для удаления размера шума квантования, лежащего ниже опорной величины ограничения шума, определенной блоком 402 психоакустической модели в аудиосигнале, преобразованном в сигнал частотной оси посредством блока 401 фильтров. Блок 403 квантования также назначает биты квантованному сигналу. Процесс назначения битов оптимизируется таким образом, что шум квантования, генерируемый из-за процесса квантования, становится меньше размера максимально допустимого шума, полученного из психоакустической модели в заданной битовой скорости.
Блок 404 энтропийного кодирования максимизирует коэффициент сжатия аудиосигнала путем назначения кода аудиосигналу, который был квантован и которому были назначены биты блоком 403 квантования согласно используемой частоте. В частности, эффективность сжатия максимизируется путем назначения кода таким образом, чтобы средняя длина кода была максимально близка к энтропии. Основной принцип заключается в том, что общий размер данных сокращается путем представления каждого символа или последовательных символов в качестве кода подходящей длины согласно статистической частоте появления символов данных. Средний размер информации, обозначаемый термином "энтропия", определяется согласно вероятности появления символа данных. Целью энтропийного кодирования является обеспечение средней длины кода по каждому символу, которая максимально близка к энтропии.
Мультиплексор 405 принимает аудиоданные, сжатые с высокой эффективностью, и дополнительную информацию из блока 404 энтропийного кодирования и, далее, передает поток аудиоданных в декодер принимающей стороны.
Фиг.5 представляет собой структурную схему устройства аудиокодирования, в котором используется психоакустическая модель, согласно еще одному варианту осуществления настоящего изобретения.
Ссылаясь на Фиг.5, устройство аудиокодирования, в котором используется психоакустическая модель, согласно еще одному варианту осуществления настоящего изобретения включает в себя блок 501 фильтров (блок фильтров анализа), блок 502 психоакустической модели, блок 503 квантования и назначения битов, блок 504 энтропийного кодирования и мультиплексор 505. В частности, блок 502 психоакустической модели включает в себя блок 502a генерации коэффициента и блок 502b определения опорной величины ограничения шума.
Чтобы удалить статистическую избыточность аудиосигнала, блок 501 фильтра преобразует аудиосигнал в выборку поддиапазона. Блок 501 фильтров преобразует аудиосигнал в сигнал оси частоты путем выполнения Модифицированного Дискретного Косинусного Преобразования (Modified Discrete Cosine Transform, MDCT), чтобы кодировать введенный аудиосигнал, который представляет собой сигнал оси времени.
Блок 502 психоакустической модели определяет размер допустимого максимального шума квантования по каждой частоте, необходимого для процесса назначения битов, путем выполнения анализа перцепционной характеристики введенного аудиосигнала. Обычно процесс квантования выполняется в ходе кодирования аудиосигнала, чтобы преобразовать аналоговый сигнал в цифровой сигнал. В этом процессе квантования образуется ошибка, генерируемая из-за округления непрерывной величины, и величина этой ошибки называется шумом квантования. Этот шум квантования варьирует согласно назначению битов. Чтобы представить шум квантования в числовом виде используется Отношение Сигнала к Шуму Квантования (Signal to Quantization Noise Ratio, SQNR). Это отношение выражается как 20×N log 2=6,02×N (дБ). В этом случае N указывает количество битов, назначаемых каждой выборке. Максимально допустимый шум квантования по каждой частоте может быть схематически представлен как опорная величина ограничения шума. Следовательно, если величина назначения битов повышается, то шум квантования сокращается и увеличивается вероятность того, что шум квантования будет сокращен ниже опорной величины ограничения шума.
Блок 502 психоакустической модели включает в себя блок 502a генерации коэффициента, сконфигурированный так, чтобы генерировать коэффициент линейного предсказания путем выполнения анализа линейного предсказания и чтобы генерировать коэффициент предсказания ограничения путем применения веса к коэффициенту линейного предсказания, и блок 502b определения опорной величины ограничения шума, который использует этот сгенерированный коэффициент предсказания ограничения. Опорная величина ограничения шума генерируется с использованием коэффициента предсказания ограничения путем перцепционного кодирования с весовыми коэффициентами для назначения веса коэффициенту линейного предсказания, выведенному посредством кодирования с линейным предсказанием.
Блок 503 квантования квантует результирующий объект, сгенерированный путем "кодирования с потерями", для удаления размера шума квантования, лежащего ниже опорной величины ограничения шума, определенной блоком 501 психоакустической модели в аудиосигнале, преобразованном в сигнал частотной оси посредством блока 501 фильтров. Блок 503 квантования также назначает биты квантованному сигналу. Процесс назначения битов оптимизируется таким образом, что шум квантования, генерируемый из-за процесса квантования, становится меньше размера максимально допустимого шума согласно новой установленной опорной величине ограничения шума в заданной битовой скорости. В частности, биты квантования спектра MDCT назначаются таким образом, чтобы обеспечить возможность маскирования шума квантования сигналом на основании опорной величины ограничения шума в каждом кадре. Например, преобразованный по частоте аудиосигнал разделяется на множество сигналов поддиапазона. Представляется возможность квантовать каждый из сигналов поддиапазона, используя коэффициент предсказания ограничения на основании опорной величины ограничения шума, соответствующей каждому из сигналов поддиапазона.
Блок 504 энтропийного кодирования максимизирует коэффициент сжатия аудиосигнала путем назначения кода аудиосигналу, который был квантован и которому были назначены биты блоком 403 квантования согласно используемой частоте. В частности, эффективность сжатия максимизируется путем назначения кода таким образом, чтобы средняя длина кода была максимально близка к энтропии. То есть размер данных оптимизируется таким образом, чтобы представлять каждый символ или последовательные символы как код соответствующей длины согласно частоте статистического появления символов данных. Средний размер информации, обозначаемый термином "энтропия", определяется согласно вероятности появления символа данных. Целью энтропийного кодирования является обеспечение средней длины кода по каждому символу, которая максимально близка к энтропии. При выполнении энтропийного кодирования блок 504 энтропийного кодирования не ограничивается конкретным способом, и возможно применение кодирования Хаффмана, арифметического кодирования, LZW-кодирования и т.п.
Мультиплексор 505 принимает аудиоданные, сжатые с высокой эффективностью, и дополнительную информацию из блока 404 энтропийного кодирования и, далее, передает поток аудиоданных в декодер принимающей стороны.
Между тем, аудиоданные, закодированные по способу аудиокодирования настоящего изобретения, могут быть декодированы в декодере следующим образом.
Во-первых, принимается аудиосигнал, квантованный посредством демультиплексора декодера. Аудиосигнал восстанавливается из квантованного аудиосигнала. В этом случае, квантованный аудиосигнал генерируется с использованием опорной величины ограничения шума для преобразованного по частоте аудиосигнала. Опорная величина ограничения шума может быть определена с использованием коэффициента предсказания ограничения, который генерируется путем применения веса к коэффициенту линейного предсказания аудиосигнала.
Фиг.6 представляет собой диаграмму вариаций модифицированной по шуму опорной величины посредством блока психоакустической модели согласно еще одному варианту осуществления настоящего изобретения.
Ссылаясь на Фиг.6, горизонтальная ось представляет частоту, а вертикальная ось представляет мощность сигнала (дБ). Сплошная линия ○,1 обозначает спектр входного аудиосигнала. Пунктирная линия ○,2 обозначает энергию входного аудиосигнала. Сплошная линия ○,3 обозначает предыдущую опорную величину ограничения шума. Пунктирная линия ○,4 обозначает новую опорную величину ограничения шума, сгенерированную посредством коэффициента линейного предсказания, вычисленного с помощью анализа линейного предсказания, и коэффициента предсказания ограничения, сгенерированного путем применения заданного веса к коэффициенту линейного предсказания.
Верхняя точка формы волны называется формантой, а нижняя точка называется впадиной. Например, на Фиг.6 точка A становится формантой, а точка B становится впадиной. В случае кодирования речи, на основании того факта, что слуховые характеристики человека чувствительны к шуму квантования в области впадины частотного спектра, при кодировании аудиосигнала в области впадины назначается относительно большее количество битов, чтобы устранить шум квантования в области впадины. А в области форманты назначается относительно меньшее количество битов путем приращения опорной величины ограничения шума в области форманты.
Следовательно, сохраняется коэффициент сжатия и может быть обеспечено лучшее качество звука. В частности, опорная величина ограничения шума в точке A устанавливается выше, чем для предыдущей точки, и величина кривой маскирования в точке B устанавливается ниже соответствующей точки. Следовательно, обеспечивается возможность повысить эффективность кодирования сигнала речи. То есть на этапе квантования преобразованного по частоте сигнала вес применяется для увеличения шума квантования аудиосигнала, соответствующего области форманты на частотном спектре для коэффициента линейного предсказания, и для уменьшения шума квантования аудиосигнала, соответствующего области впадины.
Так, блок 502a генерации коэффициента с Фиг.5 может найти передаточную функцию с коэффициентами линейного предсказания путем анализа линейного предсказания. Частотный спектр этой передаточной функции заключается в огибающую для входного сигнала. Эта передаточная функция называется коэффициентом линейного предсказания, который демонстрирует форму, схожую с опорной величиной ограничения шума Психоакустической Модели (Psychoacoustic Model, PAM), используемой для процесса аудиокодирования в данной области техники. Используя эту особенность, выводится передаточная функция, найденная блоком 502a генерации коэффициента, то есть коэффициент линейного предсказания. Путем регулирования опорной величины ограничения шума, найденной экспериментальным путем на основании выведенного коэффициента линейного предсказания, обеспечивается возможность более эффективно ослаблять шум квантования согласно сокращению битовой скорости. Также обеспечивается возможность сокращения объема вычислительных операций. Более того, блок 502a генерации коэффициента генерирует коэффициент предсказания ограничения путем реализации взвешивающего фильтра, который применяет подходящий весовой коэффициент к коэффициентам линейного предсказания. Следовательно, обеспечивается возможность регулирования весов в области форманты и впадины на спектре простым способом, используя коэффициент предсказания ограничения.
Если эта схема применяется к процессу аудиокодирования, то большее количество битов назначается области впадины спектра, в которой влияние шума квантования чувствительно с точки зрения слухового аспекта, путем сокращения опорной величины ограничения шума, и путем повышения опорной величины ограничения шума сокращается количество битов, назначаемых области форманты, имеющей относительно меньшее влияние из-за ошибки. Следовательно, обеспечивается возможность улучшения производительности кодирования с точки зрения слухового восприятия. Таким образом, эффективность кодирования может быть дополнительно повышена путем адаптивного регулирования весовых коэффициентов для регулирования перцепционного взвешивания согласно таким характеристикам входного сигнала, как плоскость спектра, вместо того, чтобы применять идентичные весовые коэффициенты. Следовательно, при улучшении опорной величины ограничения шума с использованием линейного предсказания и веса обеспечивается преимущество, заключающееся в том, что опорная величина ограничения шума может быть выведена путем применения перцепционного взвешивания к психоакустической модели без анализа огибающей по спектру.
Фиг.7 представляет собой схему последовательности операций способа генерации модифицированной по шуму опорной величины посредством блока психоакустической модели согласно еще одному варианту осуществления настоящего изобретения.
Ссылаясь на Фиг.7, если аудиосигнал вводится в блок 502 психоакустической модели, то блок 502a генерации коэффициента генерирует передаточную функцию с коэффициентами линейного предсказания, используя кодирование с линейным предсказанием [S200]. Частотный спектр этой передаточной функции заключается в огибающую для входного сигнала. Эта передаточная функция называется коэффициентом линейного предсказания и имеет форму, которая схожа с опорной величиной ограничения шума Психоакустической Модели (Psychoacoustic Model, PAM), используемой для процесса аудиокодирования в данной области техники. Блок 502a генерации коэффициента принимает ввод аудиосигнала и, далее, определяет весовой коэффициент, подходящий для коэффициентов линейного предсказания [S210]. Далее, блок 502b определения опорной величины ограничения шума генерирует огибающие, скорректированные путем применения весового коэффициента, определенного на этапе S210, к формирующей огибающей передаточной функции, сформированной посредством весовых коэффициентов, найденных на этапе S200 [S220]. Блок 502b определения опорной величины ограничения шума вычисляет импульсную характеристику огибающей, сгенерированной на этапе S220 [S230]. В этом случае, импульсная характеристика выполняет роль фильтрации. Блок 502b определения опорной величины ограничения шума преобразует сигнал временной оси в сигнал частотной оси путем выполнения FFT на огибающей, отфильтрованной на этапе S230 [S240]. Блок 502b определения опорной величины определяет уровень маскирования, чтобы установить опорную величину ограничения шума к огибающей, преобразованной в сигнал частотной оси [S250]. В заключение, блок 502b определения опорной величины ограничения шума разделяет Отношение Сигнала к Маске (Signal to Mask Ratio, SMR) по каждому поддиапазону [S260].
С помощью вышеописанного процесса взвешивающий фильтр реализуется путем применения весового коэффициента к психоакустическим коэффициентам. По сравнению с опорной величиной ограничения шума существующего уровня техники величина области форманты опорной величины ограничения шума увеличивается, а величина области впадины уменьшается. Следовательно, предоставляется возможность назначать относительно большее количество битов области впадины.
Между тем, предоставляется возможность улучшить эффективность кодирования посредством Искаженного Кодирования с Линейным Предсказанием (Warped Linear Predictive Coding, WLPC) вместо кодирования с линейным предсказанием на этапе S200. В частности, искаженное кодирование с линейным предсказанием выполняется, чтобы сократить скорость данных в аудиокодере с высокой эффективностью путем сжатия сигнала посредством главной схемы аудиокодирования, по которой психоакустическая модель настоящего изобретения применяется к низкочастотному диапазону, а к остальным высокочастотным коэффициентам применяется расширение полосы пропускания или Репликация Спектрального Диапазона (Spectral Band Replication, SBR), используя информацию низкой частоты. В случае этого высокочастотного кодера, психоакустическая модель, основанная на опорной величине ограничения шума, необходима только для полосы до определенной низкой частоты. В случае использования искаженного кодирования с линейным предсказанием, может быть обеспечена возможность повышения эффективности моделирования огибающей путем увеличения частотного разрешения конкретного частотного диапазона.
Кодер аудиосигнала, показанный на Фиг.4 или 5, может работать в устройстве, которое снабжено как кодером сигнала музыки, так и кодером сигнала речи. В случае, когда музыкальная характеристика доминирует в конкретном кадре или сегменте сигнала, подвергнутом понижающему микшированию, кодер аудиосигнала кодирует этот сигнал согласно схеме кодирования музыки. В этом случае, кодер сигнала музыки может соответствовать кодеру Модифицированного Дискретного Косинусного Преобразования (Modified Discrete Cosine Transform, MDCT).
В случае, когда речевая характеристика доминирует в конкретном кадре или сегменте сигнала, подвергнутого понижающему микшированию, кодер аудиосигнала кодирует этот сигнал согласно схеме кодирования речи. Между тем, обеспечивается возможность улучшения схемы кодирования с линейным предсказанием, используемой для кодера сигнала речи, путем ее преобразования в схему, предложенную настоящим изобретением. В случае, когда гармонический сигнал имеет высокую избыточность по временной оси, он может быть моделирован посредством линейного предсказания для предсказания текущего сигнала на основании старого сигнала. В этом случае обеспечивается возможность повысить эффективность кодирования, если применяется схема кодирования с линейным предсказанием. Между тем, кодер сигнала речи может соответствовать кодеру временной области.
Фиг.8 представляет собой структурную схему устройства аудиодекодирования согласно одному варианту осуществления настоящего изобретения.
Ссылаясь на Фиг.8, устройство декодирования способно реконструировать сигнал из введенного битового потока путем выполнения процесса, который инвертирован относительно процесса кодирования, выполняемого устройством кодирования, которое описано со ссылкой на Фиг.1. В частности, устройство декодирования может включать в себя демультиплексор 210, блок 220 определения декодера, блок 230 декодирования и блок 240 синтеза. Блок 230 декодирования может включать в себя множество блоков 231, 232 и 233 декодирования, чтобы выполнять декодирование по разным схемам. Эти блоки декодирования действуют под управлением блока 220 определения декодера. Более конкретно, блок 230 декодирования может включать в себя блок 231 декодирования с линейным предсказанием, блок 232 психоакустического декодирования и блок 233 декодирования смешанного сигнала. Более того, блок 233 декодирования смешанного сигнала может включать в себя блок 234 извлечения информации, блок 235 частотного преобразования и блок 236 линейного предсказания.
Демультиплексор 210 извлекает множество кодированных сигналов и дополнительную информацию из введенного битового потока. В этом случае, дополнительная информация извлекается, чтобы реконструировать сигналы. Демультиплексор 210 извлекает дополнительную информацию, которая включена в состав битового потока, например информацию первого типа и информацию второго типа, и, далее, направляет извлеченную дополнительную информацию в блок 220 определения декодера.
Блок 220 определения декодера определяет одну из схем декодирования в блоках 231, 232 и 233 декодирования из принятой информации первого типа и принятой информации второго типа (если она присутствует). Хотя блок 220 определения декодера может определять схему декодирования, используя дополнительную информацию, извлеченную из битового потока, если в битовом потоке дополнительной информации нет, то блок 220 определения декодера может определить схему по независимому способу определения. Этот способ определения может быть выполнен таким образом, чтобы использовать особенности вышеупомянутого блока классификации сигнала (см. 100 на Фиг.1).
Декодер 231 линейного предсказания в блоке 230 декодирования может декодировать тип сигнала речи. Психоакустический декодер 233 декодирует тип сигнала музыки. Декодер 233 смешанного сигнала декодирует смешанный тип аудиосигнала. В частности, декодер 233 смешанного сигнала включает в себя блок 234 извлечения информации, который извлекает из аудиосигнала спектральные данные и коэффициент линейного предсказания, блок 235 частотного преобразования, который генерирует остаточный сигнал для линейного предсказания путем обратного преобразования спектральных данных, и блок 236 линейного предсказания, который генерирует выходной сигнал путем применения кодирования с линейным предсказанием к коэффициенту линейного предсказания и остаточному сигналу.
Декодированные сигналы восстанавливаются в исходный аудиосигнал путем их синтеза в блоке 240 синтеза.
В следующем разделе приведено подробное описание способа декодирования согласно настоящему изобретению со ссылкой на схему последовательности операций с Фиг.11.
Во-первых, демультиплексор 210 извлекает из введенного битового потока информацию первого типа и информацию второго типа (если это необходимо). Блок 220 определения декодера определяет тип кодирования принятого аудиосигнала, используя информацию первого типа из извлеченной информации [S1000]. Если принят сигнал музыки, то используется блок 232 психоакустического декодирования в блоке 230 декодирования. Схема кодирования, примененная по каждому кадру или подкадру, определяется согласно информации первого типа. Далее, выполняется декодирование путем применения подходящей схемы кодирования [S1100].
Если определяется, что тип кодирования принятого аудиосигнала не является типом кодирования сигнала музыки, то блок 220 определения декодера определяет, является ли тип кодирования принятого аудиосигнала типом кодирования сигнала речи или типом кодирования смешанного сигнала, используя информацию второго типа [S1200].
Если информация второго типа указывает тип кодирования сигнала речи, то схема кодирования, примененная по каждому кадру или подкадру, определяется путем использования информации идентификации кодирования, извлеченной из битового потока посредством блока 231 декодирования линейного предсказания в блоке 230 декодирования. Далее, выполняется декодирование путем применения подходящей схемы кодирования [S1300].
Если информация второго типа указывает тип кодирования смешанного сигнала, то схема кодирования, примененная по каждому кадру или подкадру, определяется путем использования информации идентификации кодирования, извлеченной из битового потока посредством блока 233 декодирования смешанного сигнала в блоке 230 декодирования. Далее, выполняется декодирование путем применения подходящей схемы кодирования [S1400].
Кроме того, в качестве постобработки процесса декодирования аудиосигнала с использованием блока 231 декодирования линейного предсказания, блока 232 психоакустического декодирования и блока 233 декодирования смешанного сигнала блок декодирования расширения полосы пропускания может выполнить процесс расширения частотного диапазона (не показан). Процесс расширения частотного диапазона выполняется таким образом, что блок декодирования расширения полосы пропускания генерирует спектральные данные другого диапазона (например, высокочастотного диапазона) из части спектральных данных или всех спектральных данных путем декодирования информации расширения полосы пропускания, входящей в состав битового потока аудиосигнала. Таким образом, единицы с одинаковыми характеристиками могут быть сгруппированы в блок при расширении частотного диапазона. Это соответствует способу генерации области огибающей путем группирования временных слотов (или выборок) с общей огибающей (или характеристикой огибающей).
Фиг.9 представляет собой схему конфигурации изделия, реализованного посредством устройства аудиодекодирования, согласно одному варианту осуществления настоящего изобретения. Фиг.10 представляет собой схему одного примера взаимосвязей между изделиями, реализованными посредством устройства аудиодекодирования, согласно одному варианту осуществления настоящего изобретения.
Ссылаясь на Фиг.9, блок 910 проводной/беспроводной связи принимает битовый поток через систему проводной/беспроводной связи. В частности, блок 910 проводной/беспроводной связи может включать в себя, по меньшей мере, один блок 910A проводной связи, блок 910B инфракрасной (ИК) связи, блок 910C Bluetooth и блок 910D связи беспроводной локальной сети.
Блок 920 аутентификации пользователя принимает ввод информации пользователя и выполняет аутентификацию пользователя. Блок 920 аутентификации пользователя может включать в себя, по меньшей мере, один блок из группы, в которую входят блок 920A распознавания отпечатков пальцев, блок 920B распознавания радужной оболочки глаза, блок 920C распознавания лица и блок 920D распознавания речи. Блок 920 аутентификации пользователя может выполнять аутентификацию пользователя путем ввода информации отпечатка пальца/радужной оболочки глаза/контура лица/речи в соответствующий блок 920A/920B/920C/920D распознавания, преобразуя введенную информацию в информацию пользователя и, далее, определяя, совпадает ли эта информация с предварительно зарегистрированными данными пользователя.
Блок 930 ввода представляет собой устройство ввода для обеспечения возможности пользователю вводить разные типы команд. Блок 930 ввода может включать в себя, по меньшей мере, один блок из группы, в которую входят блок 930A клавиатуры, сенсорный блок 930B и блок 930C дистанционного контроллера. Блок 940 декодирования сигнала может включать в себя устройство 945 аудиодекодирования, которое может представлять собой устройство аудиодекодирования, описанное со ссылкой на Фиг.8. Устройство 945 аудиодекодирования определяет, по меньшей мере, одну из различных схем и выполняет декодирование, используя, по меньшей мере, один блок из группы, в которую входят блок декодирования линейного предсказания, блок психоакустического декодирования и блок декодирования смешанного сигнала. Блок 940 декодирования сигнала выводит выходной сигнал путем декодирования, используя блок декодирования, который соответствует характеристике сигнала.
Блок 950 управления принимает входные сигналы из устройств ввода и управляет всеми процессами блока 940 декодирования сигнала и блока 960 вывода. Блок 960 вывода представляет собой элемент для вывода выходного сигнала, сгенерированного блоком 940 декодирования сигнала или т.п. Блок 960 вывода может включать в себя блок 960A громкоговорителя и блок 960B отображения. Если выходной сигнал является аудиосигналом, то он выводится на громкоговоритель. Если выходной сигнал является видеосигналом, то он выводится на дисплей.
Фиг.10 представляет собой иллюстрацию взаимосвязей между терминалом и сервером, которые соответствуют продуктам, показанным на Фиг.9. Ссылаясь на Фиг.10(A), первый терминал 1001 и второй терминал 1002 могут осуществлять двунаправленную связь друг с другом через блок проводной/беспроводной связи, чтобы обмениваться данными и/или битовыми потоками. Ссылаясь на Фиг.10(B), сервер 1003 и первый терминал 1001 могут выполнять проводную/беспроводную связь.
Способ обработки аудиосигнала согласно настоящему изобретению может быть реализован в программе, которая будет выполняться на компьютере и храниться на машиночитаемом носителе. Мультимедийные данные, имеющие структуру согласно настоящему изобретению, могут храниться на машиночитаемом носителе. Машиночитаемые носители включают в себя все типы устройств записи, на которых хранятся данные, считываемые компьютерной системой. Машиночитаемые носители включают в себя, например, ОЗУ, ПЗУ, диски CD-ROM, магнитные ленты, дискеты, оптические устройства хранения и т.п., причем они также включают в себя реализации типа несущей волны (например, передачу через сеть Интернет). Более того, битовый поток, генерируемый посредством настоящего способа кодирования, сохраняется в машиночитаемом носителе записи или может быть передан через сеть проводной/беспроводной связи.
Соответственно, настоящее изобретение предоставляет следующие эффекты или преимущества.
Настоящее изобретение сортирует аудиосигналы на разные типы и предоставляет схему аудиокодирования, подходящую для характеристик этих отсортированных аудиосигналов, в результате чего обеспечивается более эффективное сжатие и реконструкция аудиосигнала.
Наряду с тем, что настоящее изобретение было описано и проиллюстрировано со ссылкой на его предпочтительные варианты осуществления, специалистам в данной области техники будет очевидно, что в рамках объема и сущности настоящего изобретения возможны различные модификации и вариации. Соответственно, настоящее изобретение имеет целью охватить все подобные модификации и вариации, которые входят в объем прилагаемой формулы изобретения и ее эквивалентов.
Реферат
Изобретение относится к устройству и способу обработки аудиосигнала для эффективного кодирования и декодирования различных типов аудиосигналов. Техническим результатом является повышение эффективности кодирования/декодирования аудиосигналов разных видов. Указанный результат достигаетя тем, что в способе обработки аудиосигнала идентифицируют, является ли тип кодирования аудиосигнала типом кодирования сигнала музыки, используя информацию первого типа. Если нет, то идентифицируют, является ли тип кодирования аудиосигнала типом кодирования сигнала речи или типом кодирования смешанного сигнала, используя информацию второго типа. Если типом кодирования аудиосигнала является тип кодирования смешанного сигнала, то извлекают из аудиосигнала спектральные данные и коэффициент линейного предсказания, генерируют остаточный сигнал для линейного предсказания путем выполнения обратного частотного преобразования упомянутых спектральных данных и реконструируют аудиосигнал путем выполнения кодирования с линейным предсказанием по коэффициенту линейного предсказания и упомянутому остаточному сигналу. Если типом кодирования аудиосигнала является тип кодирования сигнала музыки, то используют только информацию первого типа, и если типом кодирования аудиосигнала является тип кодирования сигнала речи или тип кодирования смешанного сигнала, то используют как информацию первого типа, так и информацию второго типа. 4 н. и 11 з.п. ф-лы, 14 ил.
Формула
идентифицируют, является ли тип кодирования аудиосигнала типом кодирования сигнала музыки, используя информацию первого типа;
если типом кодирования аудиосигнала не является тип кодирования сигнала музыки, то идентифицируют, является ли тип кодирования аудиосигнала типом кодирования сигнала речи или типом кодирования смешанного сигнала, используя информацию второго типа;
если типом кодирования аудиосигнала является тип кодирования смешанного сигнала, то извлекают из аудиосигнала спектральные данные и коэффициент линейного предсказания;
генерируют остаточный сигнал для линейного предсказания путем выполнения обратного частотного преобразования упомянутых спектральных данных; и
реконструируют аудиосигнал путем выполнения кодирования с линейным предсказанием по коэффициенту линейного предсказания и упомянутому остаточному сигналу,
причем если типом кодирования аудиосигнала является тип кодирования сигнала музыки, то используют только информацию первого типа, и
причем если типом кодирования аудиосигнала является тип кодирования сигнала речи или тип кодирования смешанного сигнала, то используют как информацию первого типа, так и информацию второго типа.
если типом кодирования аудиосигнала является тип кодирования смешанного сигнала, то реконструируют сигнал высокочастотного диапазона, используя сигнал низкочастотного диапазона реконструированного аудиосигнала; и
генерируют множество каналов путем повышающего микширования реконструированного аудиосигнала.
извлекают моду коэффициента линейного предсказания; и
извлекают коэффициент линейного предсказания, имеющий переменный битовый размер, соответствующий извлеченной моде коэффициента линейного предсказания.
демультиплексор, который извлекает из битового потока информацию первого типа и информацию второго типа;
блок определения декодера, который идентифицирует, является ли типом кодирования аудиосигнала тип кодирования сигнала музыки, используя информацию первого типа, причем декодер идентифицирует, является ли тип кодирования аудиосигнала типом кодирования сигнала речи или типом кодирования смешанного сигнала, если тип кодирования аудиосигнала не является типом кодирования сигнала музыки, причем декодер затем определяет схему декодирования;
блок извлечения информации, который извлекает из аудиосигнала спектральные данные и коэффициент линейного предсказания, если типом кодирования аудиосигнала является тип кодирования смешанного сигнала;
блок частотного преобразования, который генерирует остаточный сигнал для линейного предсказания путем выполнения обратного частотного преобразования упомянутых спектральных данных; и
блок линейного предсказания, который реконструирует аудиосигнал путем выполнения кодирования с линейным предсказанием по коэффициенту линейного предсказания и упомянутому остаточному сигналу,
причем, если типом кодирования аудиосигнала является тип кодирования сигнала музыки, то используется только информация первого типа,
причем, если типом кодирования аудиосигнала является тип кодирования сигнала речи или тип кодирования смешанного сигнала, то используется как информация первого типа, так и информация второго типа.
блок декодирования расширения полосы пропускания, который реконструирует сигнал высокочастотного диапазона, используя сигнал низкочастотного диапазона реконструированного аудиосигнала, если типом кодирования аудиосигнала является тип кодирования смешанного сигнала; и
блок декодирования расширения канала, который генерирует множество каналов путем повышающего микширования реконструированного аудиосигнала.
определяют тип кодирования аудиосигнала;
если аудиосигнал является сигналом музыки, то генерируют информацию первого типа, которая указывает, что аудиосигнал кодируется в тип кодирования сигнала музыки;
если аудиосигнал не является сигналом музыки, то генерируют информацию второго типа, которая указывает, что аудиосигнал кодируется либо в тип кодирования сигнала речи, либо в тип кодирования смешанного сигнала;
если типом кодирования аудиосигнала является тип кодирования смешанного сигнала, то генерируют коэффициент линейного предсказания путем выполнения кодирования с линейным предсказанием в отношении этого аудиосигнала;
генерируют остаточный сигнал для кодирования с линейным предсказанием;
генерируют спектральный коэффициент путем частотного преобразования остаточного сигнала; и
генерируют битовой поток аудио, который включает в себя информацию первого типа, информацию второго типа, коэффициент линейного предсказания и остаточный сигнал,
причем, если типом кодирования аудиосигнала является тип кодирования сигнала музыки, то генерируется только информация первого типа,
причем, если типом кодирования аудиосигнала является тип кодирования сигнала речи или тип кодирования смешанного сигнала, то генерируется как информация первого типа, так и информация второго типа.
блок классификации сигнала, который определяет тип кодирования аудиосигнала, причем блок классификации сигнала генерирует информацию первого типа, указывающую, что аудиосигнал кодируется в тип кодирования сигнала музыки, если аудиосигнал является сигналом музыки, причем блок классификации сигнала генерирует информацию второго типа, указывающую, что аудиосигнал кодируется либо в тип кодирования сигнала речи, либо в тип кодирования смешанного сигнала, если аудиосигнал не является сигналом музыки;
блок моделирования линейного предсказания, который генерирует коэффициент линейного предсказания путем выполнения кодирования с линейным предсказанием в отношении этого аудиосигнала, если типом кодирования аудиосигнала является тип кодирования смешанного сигнала;
блок извлечения остаточного сигнала, который генерирует остаточный сигнал для кодирования с линейным предсказанием; и
блок частотного преобразования, который генерирует спектральный коэффициент путем частотного преобразования остаточного сигнала,
причем, если типом кодирования аудиосигнала является тип кодирования сигнала музыки, то генерируется только информация первого типа,
причем, если типом кодирования аудиосигнала является тип кодирования сигнала речи или тип кодирования смешанного сигнала, то генерируется как информация первого типа, так и информация второго типа.
блок генерации коэффициента, который генерирует коэффициент линейного предсказания, используя кодирование с линейным предсказанием, если типом кодирования аудиосигнала является кодирование сигнала музыки, и причем блок генерации коэффициента назначает вес коэффициенту линейного предсказания; и
блок определения опорной величины, который генерирует опорную величину ограничения шума, используя упомянутый коэффициент линейного предсказания с назначенным весом.
Комментарии