Способ кодирования речи (варианты), кодирующее и декодирующее устройство - RU2214048C2
Код документа: RU2214048C2
Чертежи























Описание
Предпосылки к созданию изобретения
Настоящее изобретение относится к кодированию и декодированию речи.
Кодирование и декодирование речи имеют множество приложений и подверглись интенсивному исследованию. Вообще говоря, при одном типе кодирования речи, называемом сжатием речи, стараются уменьшить скорость передачи данных, необходимую для передачи речевого сигнала без существенного снижения качества или внятности речи. Способы сжатия речи можно реализовать с помощью речевого кодера.
Как правило, считают, что речевой кодер включает в себя кодирующее устройство и декодирующее устройство. Кодирующее устройство выдает сжатый поток битов из цифрового представления речи, например такой, который может быть сформирован путем преобразования аналогового сигнала, выданного микрофоном, с помощью аналого-цифрового преобразователя. Декодирующее устройство преобразует сжатый поток битов в цифровое представление речи, которое пригодно для воспроизведения посредством цифроаналогового преобразователя и динамика. Во многих приложениях кодирующее устройство и декодирующее устройство физически разделены, а поток битов передается между ними с использованием канала связи.
Ключевым параметром речевого кодера является величина сжатия, которой достигает кодирующее устройство и которая измеряется скоростью передачи битов потока битов, выдаваемого кодирующим устройством. Скорость передачи битов кодирующего устройства в целом зависит от желаемого критерия верности звуковоспроизведения (т.е. качества речи) и типа используемого речевого кодера. Для работы на высоких скоростях (свыше 8 килобит в секунду), средних скоростях (3-8 килобит в секунду) и низких скоростях (менее 3 килобит в секунду) разработаны различные типы кодеров речи. В последнее время среднескоростные и низкоскоростные речевые кодеры привлекли внимание в связи с широким диапазоном приложений мобильной связи (например, в сотовой телефонии, спутниковой телефонии, наземном мобильном радио и летной телефонии). В этих приложениях обычно требуется высококачественная речь и робастность к артефактам, вызванным акустическим шумом и шумом в канале (например, ошибками в битах).
Вокодеры являются классом речевых кодеров, проявивших себя как весьма приемлемые для мобильной связи. Вокодер моделирует речь в качестве отклика системы на возбуждение на коротких интервалах времени. Примеры систем вокодеров включают в себя вокодеры с линейным предсказанием, гомоморфные вокодеры, канальные вокодеры, кодеры с синусоидальным преобразованием (КСП), вокодеры с многополосным возбуждением (МПВ) и вокодеры с усовершенствованным многополосным возбуждением (УсовМПВ). В этих вокодерах речь делится на короткие сегменты (обычно 10-40 мс), причем каждый сегмент характеризуется набором параметров модели. Эти параметры обычно представляют собой несколько основных элементов каждого речевого сегмента, например шаг сегмента, речевое состояние и спектральную огибающую. Вокодер может использовать одно из множества известных представлений для каждого из этих параметров. Например, шаг может быть представлен периодом шага, основной частотой, или задержкой долгосрочного предсказания. Аналогично речевое состояние может быть представлено одним или несколькими озвученными/неозвученными решениями, мерой речевой вероятности или отношением периодической энергии к стохастической. Спектральную огибающую часто представляют в виде отклика фильтра с передаточной характеристикой с одними полюсами, но можно также представить набором спектральных амплитуд или других спектральных замеров.
Поскольку они позволяют представлять сегмент речи с использованием лишь небольшого количества параметров, речевые кодеры на основе моделей, например вокодеры, обычно способны работать на скоростях передачи данных в диапазоне от средних до низких. Однако качество системы, основанной на модели, зависит от точности модели, лежащей в ее основе. Поэтому следует использовать модель с высокой верностью звуковоспроизведения, если эти речевые кодеры должны достигать высокого качества речи.
Одной моделью речи, которая проявила себя как обладающая способностью обеспечивать высококачественную речь и работать на скоростях передачи битов от средних до низких, является модель речи с многополосным возбуждением (МПВ), разработанная Гриффином (Griffin) и Лимом (Lim). В этой модели используется гибкая речевая структура, которая позволяет ей получать более естественно звучащую речь и которая делает ее более устойчивой к присутствию акустического фонового шума. Эти свойства привели к использованию модели речи с МПВ во множестве коммерческих приложений мобильной связи.
Речевая модель с МПВ представляет сегменты речи с помощью основной частоты, набора спектральных озвученных/неозвученных (О/НО) метрик и набора спектральных амплитуд. Главное преимущество модели с МПВ перед более традиционными моделями заключается в речевом представлении. Модель с МПВ обобщает традиционное одиночное O/НО-решение, приходящееся на сегмент, с получением набора решений, каждое из которых представляет речевое состояние в конкретной полосе частот. Эта дополнительная гибкость в речевой модели позволяет модели с МПВ лучше адаптироваться к смешанным речевым звукам типа некоторых речевых фрикативных шумов. Кроме того, эта дополнительная гибкость позволяет получить более точное представление речи, которая искажена акустическим фоновым шумом. Длительные испытания показали, что это обобщение приводит к повышенному качеству и внятности речи.
Кодирующее устройство речевого МПВ-кодера оценивает набор параметров модели для каждого речевого сегмента. Параметры МПВ-модели включают в себя основную частоту (величину, обратную периоду шага), набор О/НО-метрик или решений, которые характеризуют речевое состояние, и набор спектральных амплитуд, которые характеризуют спектральную огибающую. После оценки параметров МПВ-модели для каждого сегмента кодирующее устройство квантует параметры с получением кадра битов. Кодирующее устройство может (необязательно) защищать эти биты кодами исправления/обнаружения ошибок перед перемежением и передачей результирующего потока битов в соответствующее декодирующее устройство.
Декодирующее устройство преобразует принятый поток битов обратно в отдельные кадры. В качестве части этого преобразования декодирующее устройство может осуществлять обращенное перемежение и декодирование с управлением контроля ошибок для коррекции или обнаружения ошибок в битах. После этого декодирующее устройство использует кадры битов для восстановления параметров МПВ-модели, которую декодирующее устройство применяет для синтеза речевого сигнала, имеющего высокую степень ощутимого сходства с исходной речью. Кодирующее устройство может синтезировать отдельные озвученные и неозвученные составляющие, а затем может вводить эти озвученные и неозвученные составляющие, чтобы получить окончательный речевой сигнал.
В системах, основанных на МПВ, кодирующее устройство использует спектральную амплитуду для представления спектральной огибающей в каждой гармонике оцениваемой основной частоты. Обычно каждую гармонику помечают как озвученную или неозвученную в зависимости от того, была ли полоса частот, содержащая соответствующую гармонику, объявлена озвученной или неозвученной. Затем кодирующее устройство оценивает спектральную амплитуду для частоты каждой гармоники. Если частота гармоники была отмечена как озвученная, кодирующее устройство может использовать устройство оценки амплитуды, которое отличается от устройства оценки амплитуды, используемого в случае, когда частота гармоники была отмечена как неозвученная. В устройстве декодирования идентифицируются озвученные и неозвученные гармоники и с помощью различных процедур синтезируются отдельные озвученные и неозвученные составляющие. Неозвученную составляющую можно синтезировать с помощью способа взвешенного перекрытия и объединения для фильтрации сигнала белого шума. Фильтр настраивают на обнуление всех областей частот, отмеченных как озвученные, с одновременным согласованием в противном случае тех спектральных амплитуд, которые отмечены как неозвученные. Озвученную составляющую синтезируют с помощью блока генераторов с резонансным контуром, в котором для каждой гармоники, которая отмечена как озвученная, предназначен один генератор. Мгновенную амплитуду, частоту и фазу интерполируют для согласования соответствующих параметров в соседних сегментах.
Речевые кодеры, основанные на МПВ, включают в себя речевой УсовМПВ-кодер и речевой кодер с улучшенным многополосным возбуждением (УМПВ-кодер). Речевой УМПВ-кодер был разработан для улучшения ранее известных способов, основанных на МПВ. Он предусматривает более устойчивый способ оценки параметров возбуждения (основной частоты и О/НО решений), который дает возможность лучше отслеживать отклонения и шум, обнаруживаемые в реальной речи. Речевой УМПВ-кодер использует блок фильтров, который обычно включает в себя шестнадцать каналов и нелинейность для получения набора выходных сигналов каналов, по которым можно надежно оценивать параметры возбуждения. Выходные сигналы каналов объединяют и обрабатывают для оценки основной частоты, а затем каналы в каждой из отдельных (например - восьми) тональных полос обрабатывают для оценки О/НО-решения (или другой тональной метрики) для каждой тональной полосы.
Речевой УМПВ-кодер также может оценивать спектральные амплитуды независимо от тональных решений. Чтобы сделать это, речевой кодер рассчитывает быстрое преобразование Фурье (БПФ) для каждого субкадра речи, взвешенного с использованием финитной функции, а затем усредняет энергию по областям частот, значения которой являются кратными оцененной основной частоты. Этот подход может также включать в себя компенсацию для удаления из оцененных спектральных амплитуд артефактов, введенных сеткой выборки БПФ.
Речевой УМПФ-кодер может также включать в себя составляющую синтеза фазы, которая восстанавливает информацию о фазе, используемую при синтезе озвученной речи без подробной передачи информации о фазе из кодирующего устройства в декодирующее устройство. Можно применить синтез произвольной фазы на основе О/НО-решений, как и в случае речевого УМПВ кодера. Вместо этого декодирующее устройство может использовать сглаживающее ядро для восстановленных спектральных амплитуд, чтобы получить информацию о фазе, которая может быть явно ближе к информации о фазе исходной речи, чем информация о произвольно полученной фазе.
Отмеченные выше способы описаны, например, в книге Фланагэна (Flanagan) "Анализ, синтез и восприятие речи" (Speech Analysis, Synthesis and Perception), издательство "Шпрингер-Верлаг" (Springer-Verlag), 1972, страницы 378-386 (описывающей систему анализа и синтеза речи на основе частоты), в работе Джейанта (Jayant) и др. "Цифровое кодирование сигналов" (Digital Coding of Waveforms), издательство "Прентис-Холл" (Prentice-Hall), 1984 (описывающей кодирование речи в целом), в патенте США 4885790 (описывающем способ синусоиадальной обработки), в патенте США 5054072 (описывающем способ синусоиадального кодирования), в работе Альмейды (Almeida) и др. "Нестационарное моделирование озвученной речи" (Nonstationary Mobelling of Voiced Speech), Труды TASSP Института инженеров по электротехнике и радиоэлекронике (ИИЭЭ), том ASSP-31, 3, июнь 1983, сс. 664-677 (описывающей гармоническое моделирование и соответствующий кодер), в работе Альмейды и др. "Синтез с переменной частотой: усовершенствованная схема гармонического кодирования" (Variable-Freguency Synthesis: An Improved Harminic Coding Scheme), труды ICASSP 84 ИИ-ЭЭ, сс. 27.5.1-27.5.4 (описывающей способ полиноминального речевого синтеза), в работе Кватиери (Quatieri) и др. "Преобразования речи на основе синусоидального представления" (Speech Transformations Based on a Sinusoidal Representation), труды TASSP ИИЭЭ, том ASSP34, 6, декабрь 1986 г., страницы 1449-1986 (описывающей способ анализа и синтеза на основе синусоидального представления), в работе Мак-Аулея (McAulay) и др. "Среднескоростное кодирование на основе синусоидального представления речи" (Mid-Rate Coding Based on a Sinusoidal Representation of Speech), труды ICASSP 85, страницы 945-948, Тампа, штат Флорида, 26-29 марта 1985 г. (описывающей речевой кодер с синусоидальным преобразованием), в работе Гриффина "Вокодер с многополосным возбуждением" (Multibans Excitation Vocoder), тезисы диссертации на соискание ученой степени доктора философии, Массачусетский технологический институт, 1987 (описывающей модель речи с многополосным возбуждением (МПВ) и речевой МПВ-кодер, работающий со скоростью 8000 бит в секунду), в работе Хардвика (Hardwick) "Речевой МПВ-кодер, работающий со скоростью 4,8 килобит в секунду" (А 4.8 kbps Multi-Band Excitation Speech Coder), тезисы диссертации на соискание ученой степени магистра естественных наук, Массачусетский технологический институт, 1988 (описывающей речевой кодер с многополосным возбуждением, работающий со скоростью 4800 бит в секунду), в руководящем материале Ассоциации промышленности электросвязи (АПЭ) "Проект 25 ЭйПиСиОу. Описание вокодера" (АРСО Project 25 Vocoder Description) версия 1.3, 15 июля 1993 г., IS102BABA (описывающем речевой УсовМПВ-кодер для стандарта, соответствующего проекту 25 ЭйПиСиОу), в патенте США 5081681 (описывающем синтез произвольной фазы с УсовМПВ), в патенте США 5247579 (описывающем способ смягчения последствий ошибок в канале и способ улучшения формант для речевых кодеров на основе МПВ), в патенте США 5226084 (описывающем способ квантования и смягчения последствий ошибок для речевых кодеров на основе МПВ), и в патенте США 5517511 (описывающем способы поляризации битов и контроля ошибок методом прямого исправления (МПИ) для речевых кодеров на основе МПВ).
КРАТКОЕ ИЗЛОЖЕНИЕ
СУЩЕСТВА ИЗОБРЕТЕНИЯ
Изобретение характеризуется тем, что относится к новому речевому УМПВ-кодеру для использования в спутниковой системе связи с целью получения высококачественной речи из
потока битов, передаваемого по мобильному спутниковому каналу с низкой скоростью передачи данных. В этом речевом кодере сочетаются низкая скорость передачи данных, высокое качество речи и стойкость к
фоновому шуму и ошибкам в каналах. Это обещает улучшение состояния уровня техники с кодированием речи для мобильной спутниковой связи. Новый речевой кодер достигает высокой работоспособности за счет
нового квантователя спектральных амплитуд на основе сдвоенных субкадров, который осуществляет совместное квантование спектральных амплитуд исходя из двух последовательных субкадров. Этот квантователь
достигает верности воспроизведения, сравнимой с известными системами, при использовании меньшего количества битов для квантования параметров спектральных амплитуд. Речевые УМПВ-кодеры в целом описаны
в заявке на патент США 08/222119, поданной 4 апреля 1994 г., под названием "Оценка параметров возбуждения" (ESTIMATION OF EXCITATION PARAMETERS), в заявке на патент США 08/392188, поданной 22 февраля
1995 г., под названием "Спектральные представления для речевых кодеров с многополосным возбуждением" (SPECTRAL REPRESENTATIONS FOR MULTI-BAND EXCITATION SPEECH CODERS), и в заявке на патент США
08/392099, поданной 22 февраля 1995 г., под названием "Синтез речи с использованием информации о восстановленной фазе (SYNTHESIS OF SPEECH USING REGENERATED PHASE INFORMATION), которые приведены здесь
для сведения.
В одном аспекте изобретение в целом представляет собой способ кодирования речи в 90-миллисекундный кадр битов для передачи по каналу спутниковой связи. Речевой сигнал преобразуют в цифровую форму с получением последовательности цифровых выборок речи, эти цифровые выборки речи разделяют на последовательность субкадров, номинально появляющихся на интервалах по 22,5 миллисекунды, и оценивают набор параметров модели для каждого из субкадров. Параметры модели для субкадра включают в себя набор параметров спектральных амплитуд, которые представляют спектральную информацию для субкадра. Два последовательных субкадра из последовательности субкадров объединяют в блок и совместно квантуют параметры спектральных амплитуд субкадров внутри блока. Совместное квантование включает в себя формирование параметров предсказанных спектральных амплитуд для предшествующего блока, вычисление остаточных параметров как разности между параметрами спектральных амплитуд и параметрами предсказанных спектральных амплитуд для блока, объединение остаточных параметров из обоих субкадров внутри блока и использование векторных квантователей для квантования объединенных остаточных параметров с получением набора закодированных спектральных битов. Затем к закодированным спектральным битам из каждого блока добавляют избыточные биты управления ошибкой для защиты закодированных спектральных битов внутри блока от ошибок в битах. Затем добавленные избыточные биты управления ошибкой и закодированные спектральные биты из двух последовательных блоков объединяют в 90-миллисекундный кадр битов для передачи по каналу спутниковой связи.
Конкретные варианты осуществления изобретения могут включать в себя один или несколько следующих признаков. Объединение остаточных параметров из обоих субкадров внутри блока может включать в себя разделение остаточных параметров из каждого из субкадров на частотные блоки, осуществление линейного преобразования на остаточных параметрах внутри каждого из частотных блоков для получения набора преобразованных остаточных коэффициентов для каждого из субкадров, группирование меньшинства из преобразованных остаточных коэффициентов из всех частотных блоков в вектор PRBA и группирование остальных преобразованных остаточных коэффициентов для каждого из частотных блоков в вектор с коэффициентами более высокого порядка (КБВП) для частотного блока. Векторы PRBA для каждого субкадра можно преобразовать с получением преобразованных векторов PRBA, а векторную сумму и разность преобразованных векторов PRBA для субкадров блока можно вычислить для объединения преобразованных векторов PRBA. Аналогично векторную сумму и разность для каждого частотного блока можно вычислить для объединения двух КБВП-векторов из двух субкадров для каждого частотного блока.
Параметры спектральных амплитуд могут представлять логарифмические спектральные амплитуды, оцененные для модели речи с многополосным возбуждением (МПВ). Параметры спектральных амплитуд можно оценивать исходя из вычисленного спектра независимо от звукового состояния. Предсказанные параметры спектральных амплитуд можно сформировать путем применения коэффициента усиления меньше единицы для линейной интерполяции квантованных спектральных амплитуд из последнего субкадра в предыдущем блоке.
Избыточные биты управления ошибкой для каждого блока можно сформировать с помощью кодов блоков, включающих в себя коды Голея (Golay) и коды Хемминга. Например, эти коды могут включать в себя один [24, 12] расширенный код Голея, три [23, 12] кода Голея и два [15, 11] кода Хемминга.
Преобразованные остаточные коэффициенты можно вычислить для каждого из частотных блоков с использованием дискретного косинус-преобразования (ДКП) с последующим линейным преобразованием 2х2 на двух коэффициентах ДКП наименьшего порядка. Для этого вычисления можно использовать четыре частотных блока, и при этом длина каждого частотного блока может быть приблизительно пропорциональной количеству параметров спектральных амплитуд внутри субкадра.
Векторные квантователи могут включать в себя векторный квантователь с тройным расщеплением, использующий 8 бит, плюс 6 бит, плюс 7 бит применительно к сумме векторов PRBA, и векторный квантователь с двойным расщеплением, использующий 8 бит плюс 6 бит применительно к разности векторов PRBA. Кадр битов может включать в себя дополнительные биты, представляющие ошибку в преобразованных остаточных коэффициентах, которая вводится векторными квантователями.
В еще одном аспекте изобретение представляет собой систему кодирования речи в 90-миллисекундный кадр битов для передачи по каналу спутниковой связи. Система включает в себя преобразователь в цифровую форму, который преобразует речевой сигнал в последовательность цифровых выборок речи, генератор субкадров, который разделяет цифровые выборки речи на последовательность субкадров, которые включают каждый множество цифровых выборок речи. Блок оценки параметров модели оценивает набор параметров модели, которые включают в себя набор параметров спектральных амплитуд для каждого из субкадров. Схема объединения объединяет два последовательных субкадра из последовательности субкадров в блок. Квантователь спектральных амплитуд на основе сдвоенных кадров совместно квантует параметры из обоих субкадров внутри блока. Совместное квантование включает в себя формирование параметров предсказанных спектральных амплитуд из параметров квантованных спектральных амплитуд из предыдущего блока, вычисление остаточных параметров как разности между параметрами спектральных амплитуд и параметрами предсказанных спектральных амплитуд, объединение остаточных параметров из обоих субкадров внутри блока и использование векторных квантователей для квантования объединенных остаточных параметров в набор закодированных спектральных битов.
В еще одном аспекте изобретение в целом представляет собой декодирование речи из 90-миллисекундного кадра, который закодирован, как указано выше. Декодирование включает в себя разделение кадра битов на два блока, причем каждый блок битов представляет два субкадра речи. К каждому блоку применяется декодирование с управлением ошибок, осуществляемое с использованием избыточных битов управления ошибкой, содержащихся внутри блока, для получения битов декодированных ошибок, которые, по меньшей мере частично, защищены от ошибок в битах. Биты декодированных ошибок используются для совместного восстановления параметров спектральных амплитуд для обоих субкадров внутри блока. Совместное восстановление включает в себя использование кодовых словарей векторных квантователей для восстановления набора объединенных остаточных параметров, исходя из которых вычисляют отдельные остаточные параметры для обоих субкадров, формирование параметров предсказанных спектральных амплитуд из восстановленных параметров спектральных амплитуд из предыдущего блока и добавление отдельных остаточных параметров к параметрам предсказанных спектральных амплитуд с формированием восстановленных параметров спектральных амплитуд для каждого субкадра внутри блока. Потом синтезируют цифровые выборки речи для каждого субкадра с помощью восстановленных параметров спектральных амплитуд для субкадра.
В еще одном аспекте изобретение в целом представляет собой декодирующее устройство для декодирования речи из 90-миллисекундного кадра битов, принятых по каналу спутниковой связи. Декодирующее устройство включает в себя делитель, который делит кадр битов на два блока битов. Каждый блок битов представляет два субкадра речи. Декодирующее устройство с управлением ошибок осуществляет декодирование ошибок в каждом блоке битов с помощью избыточных битов управления ошибкой, содержащихся в блоке, для получения битов декодированных ошибок, которые, по меньшей мере частично, защищены от ошибок в битах. Блок восстановления спектральных амплитуд на основе сдвоенных кадров совместно восстанавливает параметры спектральных амплитуд для обоих субкадров внутри блока, причем совместное восстановление включает в себя использование кодовых словарей векторных квантователей для восстановления набора объединенных остаточных параметров, исходя из которых вычисляют отдельные остаточные параметры для обоих субкадров, формирование предсказанных параметров спектральных амплитуд из восстановленных параметров спектральных амплитуд из предыдущего блока и добавление отдельных остаточных параметров к предсказанным параметрам случайных амплитуд для формирования восстановленных параметров спектральных амплитуд для каждого субкадра внутри блока. Синтезатор синтезирует цифровые выборки речи для каждого субкадра, используя восстановленные параметры спектральных амплитуд для субкадра.
Другие признаки и преимущества изобретения станут очевидны из нижеследующего описания, включая чертежи, и из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 изображает
упрощенную блок-схему спутниковой системы,
фиг.2 изображает блок-схему линии связи системы, показанной на фиг.1,
фиг. 3 и 4 изображают блок-схему кодирующего устройства и
декодирующего устройства системы, показанной на фиг.1,
фиг. 5 изображает общую блок-схему составных частей кодирующего устройства, показанного на фиг.3,
фиг. 6 изображает алгоритм,
предназначенный для выполнения функций обнаружения речи и тона кодирующим устройством,
фиг.7 изображает блок-схему квантователя амплитуды на основе двойных субкадров кодирующего устройства,
показанного на фиг.5,
фиг. 8 изображает блок-схему квантователя среднего вектора квантователя амплитуды, показанного на фиг.7.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Конкретный вариант осуществления изобретения описывается в контексте нового речевого УМПВ-кодера или вокодера, предназначенного для использования в системе 30 мобильной спутниковой связи "Иридий".
"Иридий" - это глобальная система мобильной спутниковой связи, состоящая из шестидесяти шести спутников 40, находящихся на низкой околоземной орбите. "Иридий" обеспечивает речевую связь с ручными или
расположенными на транспортном средства абонентскими терминалами 45 (т.е. мобильными телефонами).
Со ссылкой на фиг.2 отмечается, что абонентский терминал на передающем конце начинает речевую связь путем преобразования в цифровую форму речи 50, принимаемой через микрофон 60, с использованием аналого-цифрового (АЦ) преобразователя 70, который производит выборки речи на частоте 8 кГц. Преобразованный в цифровую форму речевой сигнал проходит через речевое кодирующее устройство 80, где обрабатывается, как описано ниже. Затем сигнал передается по линии связи передатчиком 90. На другом конце линии связи приемник 100 принимает сигнал и передает его в декодирующее устройство 110. Декодирующее устройство преобразует сигнал в синтетический цифровой речевой сигнал. Затем цифроаналоговый (ЦА) преобразователь 120 преобразует синтетический цифровой речевой сигнал в аналоговый речевой сигнал, который преобразуется динамиком 130 в звучащую речь 140.
Линия связи использует множественный доступ с временным разделением каналов (МДВРК) с пакетной передачей и с использованием 90-миллисекундного кадра. Поддерживаются две различные скорости передачи данных для речи: режим с половинной скоростью передачи, составляющей 3467 бит в секунду (312 бит за 90-миллисекундный кадр), и режим с полной скоростью передачи, составляющей 6933 бит в секунду (624 бита за 90-миллисекундный кадр). Кодирование битов каждого кадра подразделяется на речевое кодирование и кодирование с опережающей коррекцией ошибок (ОКО) для снижения вероятности ошибок в битах, которые обычно возникают при передаче по каналу спутниковой связи.
Со ссылкой на фиг. 3 отмечается, что речевой кодер в каждом терминале включает в себя кодирующее устройство 80 и декодирующее устройство 110. Кодирующее устройство включает в себя три основных функциональных блока: 200 анализа речи. 210 квантования параметров и 220 кодирования с коррекцией ошибок. Точно так же, как показано на фиг.4, декодирующее устройство подразделяется на функциональные блоки 230 декодирования с коррекцией ошибок, 240 восстановления параметров (т.е. обратного квантования) и 250 синтеза речи.
Речевой кодер может работать на двух отличающихся скоростях передачи данных: полной скорости передачи, составляющей 4933 бит в секунду, и половинной скорости передачи, составляющей 2289 бит в секунду. Эти скорости передачи данных представляют речь или биты источника и не включают биты ОКО. Биты ОКО обуславливают величины скорости передачи данных для вокодеров, работающих на полной скорости передачи данных и половинной скорости передачи данных, составляющие 6933 бит в секунду и 3467 бит в секунду соответственно, как отмечалось выше. Система использует размер речевого кадра, составляющий 90 мс, который подразделяется на четыре 22,5-миллисекундных субкадра. Анализ и синтез речи осуществляются на основе субкадров, тогда как квантование и ОКО-кодирование осуществляются на 45-миллисекундном блоке квантования, который включает в себя два субкадра. Использование 45-миллисекундных блоков для квантования и ОКО-кодирования приводит к наличию 103 речевых бит и 53 ОКО-бит на блок в системе, работающей на половинной скорости передачи данных, и к наличию 222 речевых бит и 90 ОКО-бит на блок в системе, работающей на полной скорости передачи данных. В качестве альтернативы, количество речевых битов и ОКО-битов можно корректировать в некотором диапазоне и с оказанием лишь постепенного влияния на работоспособность. В системе, работающей на половинной скорости передачи данных, можно осуществить коррекцию речевых битов в диапазоне 80-120 бит с соответствующей коррекцией ОКО-битов в диапазоне 76-36 бит. Аналогично в системе, работающей на полной скорости передачи данных, можно корректировать речевые биты в диапазоне 180-260 бит с соответствующей коррекцией ОКО-битов в диапазоне от 132 до 52 бит. Речевые и ОКО-биты объединяют с формированием 90-миллисекундного кадра.
Кодирующее устройство 80 сначала осуществляет анализ 200 речи. Первым этапом в анализе речи является обработка с помощью блока фильтров, осуществляемая на каждом субкадре, с последующей оценкой параметров МПВ-модели для каждого субкадра. Это предусматривает деление входного сигнала на перекрывающиеся 22,5-миллисекундные субкадры с помощью окна анализа. Для каждого 22, 5-миллисекундного субкадра блок оценки параметров МПВ-субкадра оценивает набор параметров модели, которые включают в себя основную частоту (величину, обратную периоду шага), набор озвученных/неозвученных (О/НО) решений и набор спектральных амплитуд. Эти параметры формируются с помощью способов УМПВ. Речевые УМПВ-кодеры описаны в общем виде в заявке на патент США 08/222119, поданной 4 апреля 1994 г., под названием "Оценка параметров возбуждения" (EXTIMATION OF EXCITATION PARAMETERS), в заявке на патент США 08/392188, поданной 22 февраля 1995 г., под названием "Спектральные представления для речевых кодеров с многоголосным возбуждением" (SPECTRAL REPRESENTATIONS FOR MULTIBAND EXCITATION SPEECH CODERS), и в заявке на патент США 08/392099, поданной 22 февраля 1995 г., под названием "Синтез речи с использованием информации о восстановленной фазе (SYNTHESIS OF SPEECH USING REGENERATED PHASE INFORMATION), которые приведены здесь для сведения.
Кроме того, вокодер, работающий на полной скорости передачи данных, включает в себя временной интервал ИД, способствующий идентификации прибытия МДВРК-пакетов в приемнике в неправильном порядке, причем вокодер может использовать эту информацию для размещения информации в правильном порядке до декодирования. Параметры речи полностью описывают речевой сигнал и пропускаются в блок 210 квантования кодирующего устройства для дальнейшей обработки.
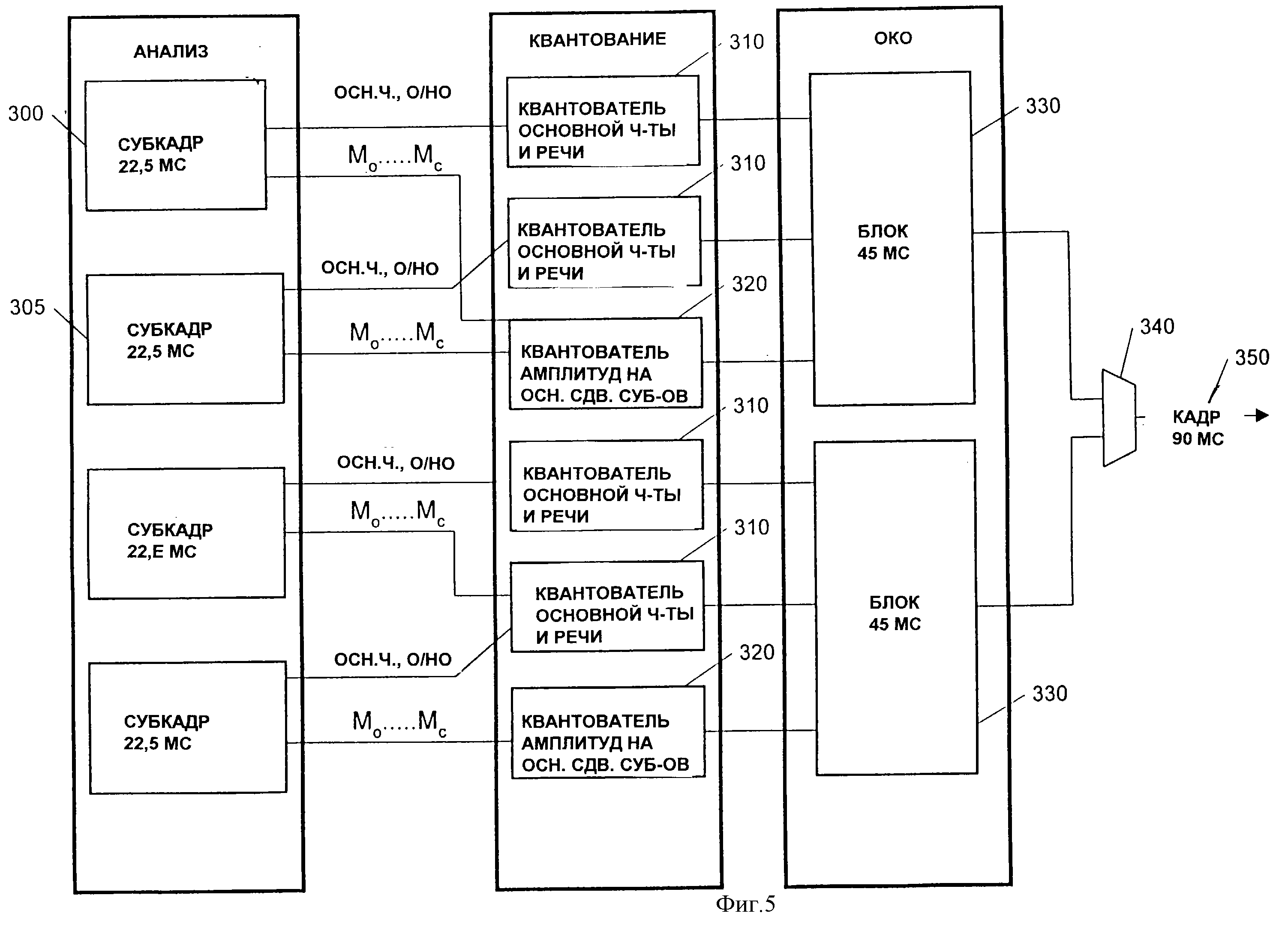
Со ссылкой на фиг.5 отмечается, что, как только параметры 300 и 305 модели субкадра оценены для двух последовательных 22, 5-миллисекундных субкадров внутри кадра, квантователь 310 основной частоты и речи кодирует основные частоты для обоих субкадров с получением последовательности битов основных частот, а затем кодирует озвученные/неозвученные (О/НО) решения (или иные речевые метрики) с получением последовательности речевых битов.
В описанном конкретном варианте осуществления десять бит используются для квантования и кодирования двух основных частот. Обычно основные частоты сводятся к основной оценке для диапазона примерно [0,008, 0,005], где 1,0 - частота Найквиста (8 кГц), и квантователь основной частоты ограничивается аналогичным диапазоном. Поскольку инверсия квантованной основной частоты для данного субкадра обычно пропорциональна L, числу спектральных амплитуд для этого субкадра (L= ширина полосы/основная частота), самые старшие биты основной частоты, как правило, чувствительны к ошибкам в битах и, следовательно, получают высокий приоритет при ОКО-кодировании.
В желаемом конкретном варианте осуществления используется восемь бит при половинной скорости передачи и шестнадцать бит при полной скорости передачи для кодирования речевой информации для обоих субкадров. Квантователь речи использует распределенные ему биты для кодирования двоичного речевого состояния (т. е. 1=озвучено, 0=не озвучено) в каждой из предпочтительных восьми речевых полос, где состояние речи определяется речевыми метриками, оцененными во время анализа речи. Эти речевые биты имеют среднюю чувствительность к ошибкам в битах и, следовательно, получают средний приоритет при ОКО-кодировании.
Биты основных частот и речевые биты объединяются в схеме объединения 330 с битами квантованных спектральных амплитуда из квантователя 320 амплитуд на основе сдвоенных субкадров, и для этого 45-миллисекундного блока осуществляется кодирование с опережающей коррекцией ошибок (ОКО). Затем в схеме объединения 340 формируется 90-миллисекундный кадр, который объединяет два последовательных 45-миллисекундных квантованных блока в один кадр 350.
Кодирующее устройство включает в себя адаптивный детектор речевой активности (ДРА), который классифицирует каждый 22,5-миллисекундный субкадр либо как речь или фоновый шум, либо как тон в соответствии с процедурой 600. Как показано на фиг.6, алгоритм ДРА использует локальную информацию для отличения речевых субкадров от фонового шума (шаг 605). Если оба субкадра внутри каждого 45-миллисекундного блока классифицированы как шум (шаг 610), то кодирующее устройство квантует фоновый шум, который присутствует в виде специального шумового блока (шаг 615). Если два 45-миллисекундных блока, составляющие 90-миллисекундный кадр, оба классифицированы как шум, то система может не выбрать передачу этого кадра в декодирующее устройство и декодирующее устройство будет использовать ранее принятые данные шума вместо пропускаемого кадра. Этот способ передачи, активизируемый речью, повышает работоспособность системы тем, что требует передачи только речевых кадров и случайных шумовых кадров.
Кодирующее устройство может также отличаться обнаружением и передачей тонов при поддержке двухтональной мультичастотной маршрутизации (ДММ) прохождения вызова (например, набора, состояния "занято" и обратного вызова) и одиночных тонов. Кодирующее устройство проверяет каждый 22, 5-миллисекундный кадр, чтобы определить, содержит ли текущий субкадр действительный тональный сигнал. Если в любом из двух субкадров 45-миллисекундного блока обнаружен тональный сигнал (шаг 620), то кодирующее устройство квантует параметры обнаруженного тонального сигнала (амплитуду и индекс) в специальном тональном блоке, как показано в таблице 1 (шаг 625), и применяет ОКО-кодирование до передачи блока в декодирующее устройство для последующего синтеза. Если тональный сигнал не обнаружен, то квантуется стандартный речевой блок, как указано ниже (шаг 630).
В табл.1 ССБ - самые старшие биты, а СМБ - самые младшие биты.
Вокодер осуществляет детектирование речевой готовности (ДРА) и детектирование тона для классификации каждого 45-миллисекундного блока либо как стандартного речевого блока, либо как специального тонального блока, либо как специального шумового блока. В случае если 45-миллисекундный блок не классифицирован как специальный тональный блок, речевая или шумовая информация (определяемая посредством ДРА) квантуется для пары субкадров, составляющих этот блок. Имеющиеся биты (156 - для половинной скорости передачи, 312 - для полной скорости передачи) распределяются по параметрам модели, и осуществляется ОКО-кодирование, как показано в таблице 2, где интервал ИД является специальным параметром, используемым приемником, работающим на полной скорости передачи, для идентификации правильного порядка кадров, которые могут прибывать в неправильном порядке. После резервирования битов для параметров возбуждения (основной частоты и речевых метрик) осуществляется ОКО-кодирование, при котором для интервала ИД имеются 85 бит для спектральных амплитуд в системе, работающей на половинной скорости передачи, и 183 бит в системе, работающей на полной скорости передачи. Чтобы поддерживать в системе, работающей на полной скорости передачи, минимальный объем дополнительной сложности, в качестве квантователя амплитуд, работающего на полной скорости передачи, используется тот же самый квантователь, что и системе, работающей на половинной скорости передачи, плюс квантователь ошибок, который использует скалярное квантование для кодирования разности между неквантованными спектральными амплитудами и квантованным выходным сигналом квантователя спектральных амплитуд, работающего на половинной скорости передачи.
Квантователь на основе сдвоенных субкадров используется для квантования спектральных амплитуд. Этот квантователь сочетает логарифмическое компандирование, спектральное предсказание, дискретные косинус-преобразования (ДКП) и векторное и скалярное квантование для достижения высокой эффективности, измеряемой верностью звуковоспроизведения в пересчете на бит, с целесообразной сложностью. Квантователь можно рассматривать как двухмерный кодер предсказывающего преобразования.
Фиг. 7 иллюстрирует квантователь амплитуд на основе сдвоенных субкадров, который принимает входные сигнала 1а и 1b из устройств оценки параметров МПВ для двух последовательных 22,5-миллисекундных субкадров. Выходной сигнал 1а представляет спектральные амплитуды для 22,5-миллисекундных субкадров с нечетными номерами и задается индексом 1. Число амплитуд для субкадра номер 1 обозначается символом L1. Входной сигнал 1b представляет спектральную амплитуду для 22, 5-миллисекундных субкадров с четными номерами и задается индексом 0. Число амплитуд для субкадра номер 0 обозначается символом L0.
Входной сигнал 1а проходит через
логарифмический компандер 2а, который выполняет операцию логарифмирования по основанию 2 на каждой из L1 амплитуд, содержащихся во входном сигнале 1а, и формирует еще один вектор с L1 элементами в следующем порядке:
y[i]=log2(х[i] для i=1, 2,..., L1,
где y[i] представляет сигнал 3а. Компандер 2b выполняет операцию логарифмирования по
основанию 2 на каждой из L0 амплитуд, содержащихся во входном сигнале 1b, и формирует еще один вектор с L0 элементами в следующем порядке:
y[i]=log2(х[i] для
i=1, 2,..., L0,
где y[i] представляет сигнал 3b.
Блоки 4а и 4b вычисления средних значений, следующие за компандерами 2а и 2b, вычисляют средние значения 5а и 5b для каждого субкадра. Среднее значение, или значение коэффициента усиления, представляет средний речевой уровень для субкадра. В пределах каждого субкадра определяются два значения коэффициента усиления 5а, 5b путем вычисления среднего значения логарифмических спектральных амплитуд и последующего суммирования смещения в зависимости от числа гармоник в пределах субкадра.
Вычисление средних значений логарифмических спектральных амплитуд 3а производится следующим образом:
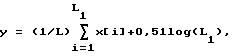
где выходной сигнал у представляет сигнал 5а среднего значения.
Вычисление 4b средних значений логарифмических спектральных амплитуд 3b производится аналогичным образом:

где выходной сигнал у представляет сигнал 5b среднего значения.
Сигналы 5а и 5b
средних значений квантуются квантователем 6, который дополнительно изображен на фиг. 8, где сигналы 5а и 5b средних значений обозначены соответственно как "среднее 1" и "среднее 2". Сначала блок
усреднения 810 усредняет сигналы средних значений. Выходной сигнал блока усреднения равен 0,5 ("среднее 1" х "среднее 2"). Затем среднее значение квантуется пятиразрядным скалярным квантователем 820 с
равномерным шагом. Выходной сигнал квантователя 820 образует первые пять битов выходного сигнала квантователя 6. Затем биты выходного сигнала квантователя обратно квантуются пятиразрядным обратным
скалярным квантователем 830 с равномерным шагом. Потом блоки вычитания 835 вычитают выходной сигнал обратного квантователя 830 из входных средних значений "среднее 1" и "среднее 2" с выдачей входных
сигналов в пятиразрядный векторный квантователь 840. Два входных сигнала составляют подлежащий квантованию двухмерный вектор (z1 и z2). Этот вектор сравнивается с каждым двухмерным вектором (состоящим
из х1(n) и х2(n) в таблице, приведенной в табл. А ("Кодовый словарь (на пять бит) векторного квантователя (ВК) для коэффициентов усиления"). Сравнение основано на квадрате расстояния, е, который
вычисляется следующим образом:
e(n)=[x1(n)-z1]2+[x2(n)-z2]2
для n=0, 1,... 31. Вектор из табл. А, который минимизирует квадрат расстояния е, выбирается для
получения последних пяти битов выходного сигнала блока 6. Пять битов из выходного сигнала векторного квантователя 840 объединяются с пятью битами из выходного сигнала пятиразрядного скалярного
квантователя 820 с равномерным шагом с помощью схемы объединения 850. Выходным сигналом схемы объединения 850 являются десять битов, составляющие выходной сигнал блока 6, который помечен как 21с и
используется в качестве входного сигнала, подаваемого на схему объединения 22, показанную на фиг.7.
Обращаясь далее к тракту основного сигнала квантователя, отмечается, что логарифмические компандированные входные сигналы 3а и 3b проходят через схемы объединения 7а и 7b, которые вычитают значения предсказания 33а и 33b из части сигнала участка обратной связи квантователя для получения сигнала D1(1), 8а, и сигнала D1(1), 8b.
После этого сигналы 8а и 8b делятся на четыре частотных блока с помощью таблицы просмотра, приведенной в табл. О. Эта таблица дает количество амплитуд, распределяемых в каждый из четырех частотных блоков на основании общего количества амплитуд для разделяемого субкадра. Поскольку количество амплитуд, содержащихся в любом субкадре, находится в диапазоне от минимума 9 до максимума 56, таблица содержит значения для этого самого диапазона. Длина каждого частотного блока регулируется таким образом, что они находятся в соотношении 0,2:0,225:0,275:0,3 друг с другом, а сумма длин равна количеству спектральных амплитуд в текущем субкадре.
Каждый частотный блок после этого проходит
дискретное косинус-преобразование (ДКП) 9а или 9b для эффективной декорреляции данных внутри каждого частотного блока. Первые два коэффициента 10а или 10b ДКП из каждого частотного блока затем
выделяются и проходят через операцию 12а или 12b поворота 2х2 для получения преобразованных коэффициентов 13а или 13b. Затем на преобразованных коэффициентах 13а или 13b осуществляется восьмиточечное
ДКП 14а или 14b для получения вектора PRBA 15а или 15b. Остальные коэффициенты 11а и 11b
ДКП для каждого частотного блока образуют набор из четырех переменных векторов с коэффициентами более
высокого порядка (КБВП) длины.
Как описано выше, после частотного разделения каждый блок обрабатывается блоками 9а или 9b дискретного косинус-преобразования. Блоки ДКП используют
количество W входных элементов разрешения и значения каждого из элементов разрешения х(0), х(1),..., x(W-l) следующим образом:

для 0≤k≤(W-1).
Значения у(0) и у(1) (обозначенные как 10а) отличаются от других выходных значений у(2) на у(W-1) (обозначено как 11а).
Затем осуществляется операция 12а и 12b поворота для преобразования двухэлементного входного вектора 10a и 10b, (х(0), х(1) в двухэлементный выходной вектор 13а и 13b, (у(0),
у(1)) с помощью следующей процедуры поворота:
у(0)=x(0)+sgrt(2)(x(1), и
у(0)=x(0)+sgrt(2)(x(1).
Затем осуществляется восьмиточечное ДКП на четырех двухэлементных
векторах, (х(0), х(1),...х(7)) из 13а или 13b в соответствии со следующим уравнением:

для 0≤k≤7.
Выходной сигнал у(к) является восьмиэлементным вектором PRBA 15а или 15b.
Сразу же после завершения предсказания и ДКП амплитуд отдельных субкадров
оба вектора PRBA квантуются. Два восьмиэлементных вектора сначала объединяются с помощью преобразования 16 суммы-разности в вектор суммы и вектор разности. В частности операцию 16 суммы/разности
осуществляют на двух восьмиэлементных векторах PRBA 15а и 15b, которые представлены величинами "х" и "у" соответственно, для получения 16-элементного вектора 17, представленного "z", следующим
образом:
z(i)=x(i)+y(i), и
z(8+i)=x(i)-y(i),
для i=0, 1,..., 7.
Эти векторы затем квантуют с помощью расщепляющего векторного квантователя 20а, в котором 8, 6 и 7 бит используются для элементов 1-2, 3-4 и 5-7 вектора суммы соответственно, а 8 и 6 бит используются для элементов 1-3 и 4-7 вектора разности соответственно. Элемент 0 каждого вектора игнорируется, поскольку он функционально эквивалентен значению коэффициента усиления, который квантуется отдельно.
Квантование векторов 17 PRBA суммы и разности осуществляется в
расщепляющем векторном квантователе PRBA 20а для получения квантованного вектора 21а. Два элемента z(l) и z(2) составляют двухмерный квантуемый вектор. Этот вектор сравнивается с каждым двухмерным
вектором (состоящим из х1(n) и х2(n)) в таблице, содержащейся в табл. В ("Кодовый словарь (на восемь бит) ВК для суммы [1, 2] PRBA"). Это сравнение основано на квадрате расстояния е, который
вычисляется следующим образом:
e(n)=[x1(n)-z(1)]2+[х2(n)-z(2)]2 для n=0, 1,..., 255.
Вектор из табл. В, который минимизирует квадрат расстояния е, выбирается для получения первых 8 бит выходного вектора 21а.
Далее два элемента z(3) и z(4) составляют двухмерный вектор, подлежащий квантованию. Этот вектор сравнивается с каждым
двухмерным вектором (состоящим из х1(n) и х2(n)) в таблице, содержащейся в табл. С ("Кодовый словарь (на шесть бит) ВК для суммы [3, 4] PRBA"). Это сравнение основано на квадрате расстояния е, который
вычисляется следующим образом:
e(n)=[x1(n)-z(3)]2+[х2(n)-z(4)]2 для n=0,1,..., 63.
Вектор из табл. С, который минимизирует квадрат расстояния е, выбирается для получения следующих 6 бит выходного вектора 21а.
Далее три элемента z(5), z(6) и z(7) составляют трехмерный вектор, подлежащий квантованию. Этот вектор сравнивается с
каждым трехмерным вектором (состоящим из x1(n), х2(n) и х3(n)) в таблице, содержащейся в табл. D ("Кодовый словарь (на семь бит) ВК для суммы [5, 7] PRBA"). Это сравнение основано на квадрате
расстояния е, который вычисляется следующим образом:
е(n)=[x1(n)-z(5)]2+[x2(n)-z(6)]2+[х3(n)-z(7)]2 для n=0, 1,..., 127.
Вектор из табл. D, который минимизирует квадрат расстояния е, выбирается для получения следующих 7 бит выходного вектора 21а.
Далее три элемента z(9), z(10) и z(11) составляют трехмерный вектор,
подлежащий квантованию. Этот вектор сравнивается с каждым трехмерным вектором (состоящим из х1(n), х2(n) и х3(n) в таблице, содержащейся в табл. Е ("Кодовый словарь (на восемь бит) ВК для разности [1,
3] PRBA"). Это сравнение основано на квадрате расстояния е, который вычисляется следующим образом:
е(n)=[xl(n)-z(9)]2+[x2(n)-z(10)]2+[х3(n)-z(11)]2 для n=0, 1,
..., 255.
Вектор из табл. Е, который минимизирует квадрат расстояния е, выбирается для получения следующих 8 бит выходного вектора 21а.
И наконец, четыре элемента z(12),
z(13), z(14) и z(15) составляют четырехмерный вектор, подлежащий квантованию. Этот вектор сравнивается с каждым четырехмерным вектором (состоящим из х1(n), х2(n), х3(n) и х4(n)) в табл. F ("Кодовый
словарь (на шесть бит) ВК для разности [4, 7] PRBA"). Это сравнение основано на квадрате расстояния е, который вычисляется следующим образом:
е(n)= [x1(n)-z(12)]2+[x2(n)-z(13)]2+[x3(n)-z{l4)]2+[х4(n)-z(15)]2 для n= 0, 1,..., 63.
Вектор из табл. F, который минимизирует квадрат расстояния е, выбирается для получения последних 6 бит выходного вектора 21а.
Вектора КБВП квантуются аналогично векторам PRBA. Сначала для каждого из четырех частотных блоков соответствующая пара векторов КБВП из двух субкадров объединяется с помощью преобразования 18 суммы-разности, которое дает вектор 19 суммы и разности для каждого частотного блока.
Операция суммы-разности осуществляется раздельно для
каждого частотного блока на векторах КБВП 11а и 11b, обозначаемых "х" и "у" соответственно, для получения вектора zm:
J=max(Bm0, Bm1)-2,
К=min(Bm0, Вm1)-2,
zm(i)=0,5[x(i)+y(i)] для 1≤i≤K,

zm(J+1)=0,5[x(i)-y(i)] для 0≤i≤K,
где Bm0 и Bm1 - длины m-гo частотного блока для соответственно субкадров ноль и единица, как указано в табл. О, a z определяется для каждого частотного блока (т.е. m равно от 0 до 3). (J+K)-элементные векторы zm суммы и разности объединяются для всех четырех частотных блоков (m равно от 0 до 3) для образования вектора 19 суммы/разности КБВП.
Благодаря изменяющемуся размеру каждого вектора КБВП векторы суммы и разности также имеют изменяющиеся и, возможно, разные длины. Это поддерживается на этапе квантования векторов путем игнорирования любых элементов, кроме первых четырех элементов каждого вектора. Остальные элементы подвергаются векторному квантованию с использованием семи бит для вектора суммы и трех бит для вектора разности. После осуществления векторного квантования исходное преобразование суммы-разности обращается на векторах суммы и разности. Поскольку этот процесс применяется ко всем четырем частотным блокам, для векторного квантования векторов КБВП, соответствующих обоим субкадрам, используются всего сорок (4•(7+3)) бит.
Квантование векторов 19 суммы и разности КБВП осуществляется раздельно на всех четырех частотных блоках с помощью расщепляющего векторного квантователя 20b КБВП. Сначала вектор zm,
представляющий m-ый частотный блок, выделяется и сравнивается с каждым вектором-кандидатом в соответствующих кодовых словарях суммы и разности, содержащихся в таблицах. Кодовый словарь
идентифицируется на основе частотного блока, которому он соответствует, и на основании того, является ли он словарем кодов суммы или разности. Таким образом, "Кодовый словарь (на семь бит) ВК суммы 0
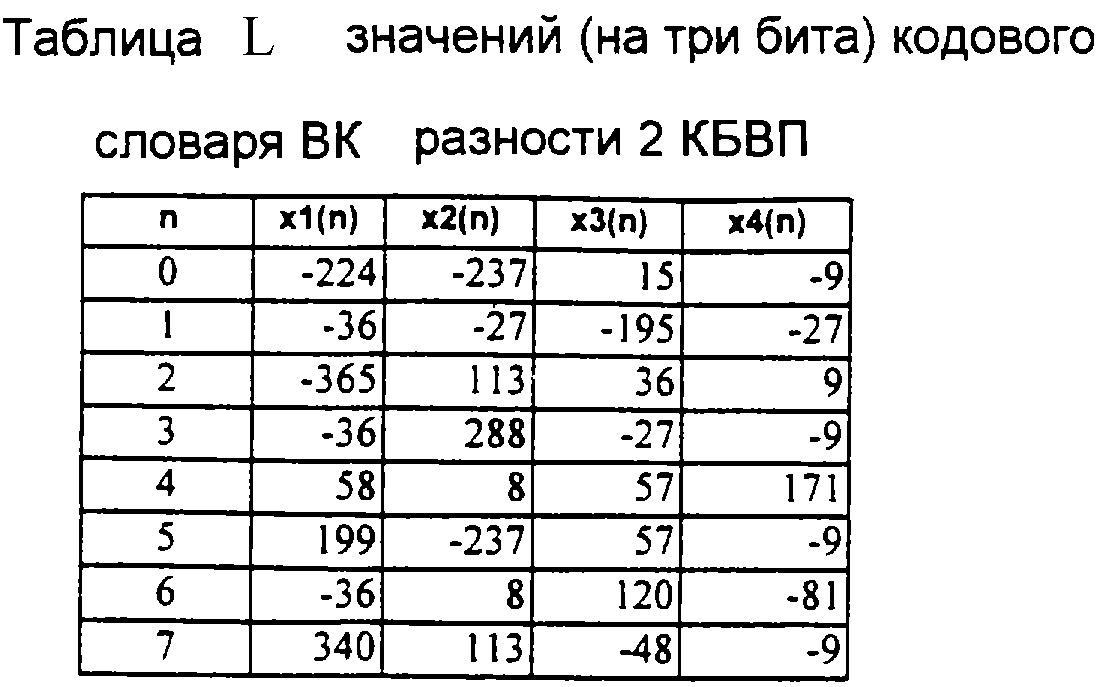
КБВП" из табл. G представляет кодовый словарь суммы для частотного блока 0. Другими кодовыми словарями являются словари из табл. Н (Кодовый словарь (на три бита) ВК разности 0 КБВП"), табл. I (Кодовый
словарь (на семь бит) ВК суммы 1 КБВП"), табл. J (Кодовый словарь (на три бита) ВК разности 1 КБВП"), табл. К (Кодовый словарь (на семь бит) ВК суммы 2 КБВП"), табл. L (Кодовый словарь (на три бита)
ВК разности 2 КБВП"), табл. М (Кодовый словарь (на семь бит) ВК суммы 2 КБВП") и табл. N (Кодовый словарь (на три бита) ВК разности 3 КБВП"). Сравнение вектора zm для каждого частотного
блока с каждым вектором-кандидатом из соответствующих кодовых словарей суммы основано на квадрате расстояния е1n для каждого вектора-кандидата суммы (состоящего из х1(n), х2(n), х3(n) и
х4(n)), который рассчитывается как

и на квадрате расстояния e2m для каждого вектора-кандидата разности (состоящего из х1(n), х2(n), х3(n) и х4(n), который рассчитывается как

где J и К вычисляются, как описано выше.
Индекс n вектора-кандидата суммы из соответствующего кодового словаря суммы, который минимизирует квадрат расстояния е1n, представляется семью битами, и индекс m вектора-кандидата разности, который минимизирует квадрат расстояния е2m, представляется тремя битами. Эти десять бит объединяются из всех четырех частотных блоков с образованием 40 выходных бит КБВП 21b.
Блок 22 мультиплексирует квантованные векторы PRBA 21а, квантованное среднее значение 21b и квантованное среднее значение 21с для получения выходных битов 23. Эти биты 23 являются окончательными выходными битами квантователя амплитуд на основе сдвоенных субкадров и также подаются на участок обратной связи квантователя.
Блок 24 обратной связи квантователя на основе сдвоенных субкадров представляет обращение функций, осуществляемых в суперблоке, обозначенном буквой Q на чертеже. Блок 24 выдает оцененные значения 25а и 25b для D1(1) и D1(0) (8a и 8b) в ответ на квантованные биты 23. Эти оценки должны быть равны D1(1) и D1(0) в отсутствие ошибки квантования в суперблоке, обозначенном буквой Q.
Блок 26 прибавляет масштабированное значение 33а предсказания, которое равно 0,8 P1(l), к оценке для D1(1) 25a с получением оценки M1(1) 27. Блок 28 осуществляет временную задержку оценки M1(1) 27 на один кадр (40 мс) для получения оценки M1(-1) 29.
Затем блок предсказания 30 интерполирует оцененные амплитуды и осуществляет их повторную выборку для получения L1 оцененных амплитуд, после чего среднее значение оцененных амплитуд вычитается из каждой из L1 оцененных амплитуд для получения выходного сигнала Р1 (1) 31а. Затем осуществляют интерполирование и повторную выборку входных оцененных амплитуд для получения L0 оцененных амплитуд, после чего среднее значение оцененных амплитуд вычитается из каждой из L0 оцененных амплитуд для получения выходного сигнала P1 (0) 31b.
Блок 32а умножает каждую амплитуду в P1 (1) 31a на 0,8 для получения выходного вектора 33а, который используется в блоке 7а объединения элементов обратной связи. Точно так же блок 32b умножает каждую амплитуду в P1 (0) 31b на 0,8 для получения выходного вектора 33b, который используется в блоке 7b объединения элементов обратной связи. Выходным для этого процесса является выходной вектор 23 квантованных амплитуд, который затем объединяется с выходным вектором двух других субкадров, как описано выше.
Сразу же после того, как кодирующее устройство осуществило квантование параметров модели для каждого 45-миллисекундного блока, квантованные биты получают приоритет, подвергаются ОКО-кодированию и перемежаются перед передачей. Квантованные биты сначала получают приоритет, чтобы их приближенная чувствительность к их порядку следования соответствовала их приближенной чувствительности к ошибкам. Экспериментальные исследования показали, что векторы суммы PRBA и КБВП обычно более чувствительны к ошибкам, чем соответствующие векторы разности. Кроме того, вектор суммы PRBA обычно более чувствителен, чем вектор суммы КБВП. Эти относительные чувствительности используются в схеме предоставления приоритета, которая в общем придает наивысший приоритет битам средней основной частоты и среднего коэффициента усиления, за которыми следуют биты суммы PRBA и биты суммы КБВП, за которыми следуют биты разности суммы PRBA и биты разности КБВП, за которыми следуют любые остальные биты.
Затем используется смесь [24, 12] расширенных кодов Голея, [23, 12] кодов Голея и [15, 11] кодов Хеминга для добавления более высоких уровней избыточности к более чувствительным битам с одновременным добавлением меньшей избыточности или вообще без такого добавления к менее чувствительным битам. Система, работающая на половинной скорости передачи, применяет один [24, 12] код Голея, за которым следуют три [23, 12] кода Голея, за которыми следуют два [15, 11] кода Хеминга, а остальные 33 бита не защищены. Система, работающая на полной скорости передачи, применяет два [24, 12] кода Голея, за которым следуют шесть [23, 12] кодов Голея, а остальные 126 бит не защищены. Это распределение было предназначено для осуществления эффективного использования ограниченного количества битов, имеющихся для ОКО. Завершающим этапом является перемежение закодированных ОКО-битов внутри каждого 45-миллисекундного блока для распространения эффекта на любые короткие посылки с ошибками. Затем перемеженные биты из двух последовательных 45-миллисекундных блоков объединяются в 90-миллисекундный кадр, который образует выходной поток битов кодирующего устройства.
Соответствующий декодер предназначен для воспроизведения высококачественной речи из закодированного потока битов после того, как он передается и принимается по каналу. Декодирующее устройство сначала делит каждый 90-миллисекундный кадр на два 45-миллисекундных блока квантования. Затем декодирующее устройство проводит обращенное перемежение для каждого блока и осуществляет декодирование с коррекцией ошибок для коррекции и/или обнаружения некоторых вероятных образований ошибок в битах. Чтобы обеспечить надлежащую работоспособность по всему мобильному спутниковому каналу, все коды коррекции ошибок обычно декодируются вплоть до реализации ими полной коррекции ошибок. Затем декодированные ОКО-биты используются декодирующим устройством для повторной сборки битов квантования для того блока, из которого восстанавливаются параметры модели, представляющие два субкадра внутри этого блока.
Декодирующее УМПВ-устройство использует восстановленные логарифмические спектральные амплитуды для синтеза набора фаз, которые используются речевым синтезатором для получения естественно звучащей речи. Использование синтезированной информации о фазе значительно уменьшает скорость передачи передаваемых данных по сравнению с системой, которая непосредственно использует эту информацию или ее эквивалент между кодирующим устройством и декодирующим устройством. Затем декодирующее устройство применяет спектральное улучшение для восстановленных спектральных амплитуд, чтобы улучшить ощутимое качество речевого сигнала. Декодирующее устройство также проверяет наличие ошибок в битах и сглаживает восстановленные параметры, если локальные оцененные условия канала показывают наличие возможных нескорректированных ошибок в битах. Улучшенные и сглаженные параметры модели (основная частота, O/НО-решения, спектральные амплитуды и синтезированные фазы) используются при синтезе речи.
Восстановленные параметры образуют входные значения для алгоритма синтеза речи декодирующим устройством, который интерполирует последовательные кадры параметров модели с получением гладких 22,5-миллисекундных сегментов речи. Алгоритм синтеза использует набор генераторов гармоник (или его БПФ-эквивалент на высоких частотах) для синтеза озвученной речи. Она добавляется к выходным значениям для алгоритма со взвешенным перекрытием и суммированием с целью синтеза неозвученной речи. Суммы образуют синтезированный речевой сигнал, который является выходным сигналом для ЦА-преобразователя и предназначен для воспроизведения с помощью динамика. Хотя этот синтезированный речевой сигнал может и не быть близким к оригиналу в повыборочной основе, слушатель испытывает те же ощущения.
Реферат
Изобретение относится к кодированию и декодированию речи. Технический результат - повышение точности воспроизведения речи. В способе осуществляют кодирование речи с получением 90-миллисекундного кадра битов для передачи по каналу спутниковой связи. Речевой сигнал преобразуют в цифровую форму с получением цифровых выборок речи, а затем делят на субкадры. Параметры модели, которые включают в себя набор параметров спектральных амплитуд, представляющих спектральную информацию для субкадра, оценивают для каждого субкадра. Два последовательных субкадра из последовательности субкадров объединяют в блок и их параметры спектральных амплитуд совместно квантуют. Совместное квантование включает в себя формирование предсказанных параметров спектральных амплитуд из квантованных параметров спектральных амплитуд из предыдущего блока, вычисление остаточных параметров как разности между параметрами спектральных амплитуд и предсказанных параметров спектральных амплитуд, объединение остаточных параметров из обоих субкадров внутри блока и использование векторных квантователей для квантования объединенных остаточных параметров в набор закодированных спектральных битов. К закодированным спектральным битам из каждого блока можно добавлять избыточные биты управления ошибкой для защиты закодированных спектральных битов внутри блока от ошибок в битах. Добавленные избыточные биты управления ошибкой и закодированные спектральные блоки из двух последовательных блоков можно объединять в 90-миллисекундный кадр битов для передачи по каналу спутниковой связи. 4 с. и 26 з.п.ф-лы, 17 табл., 8 ил.

Комментарии