Способ и устройство для векторного квантования с надежным предсказанием параметров линейного предсказания в кодировании речи с переменной битовой скоростью - RU2326450C2
Код документа: RU2326450C2
Чертежи
Описание
Область техники, к которой относится изобретение
Настоящее изобретение относится к усовершенствованному способу цифрового кодирования звукового сигнала, в частности речевого сигнала и т.д., с точки зрения передачи и синтезирования указанного звукового сигнала. Более конкретно, настоящее изобретение имеет отношение к способу и устройству для векторного квантования параметров линейного предсказания в кодировании, основанном на линейном предсказании, с переменной битовой скоростью (скоростью передачи битов).
УРОВЕНЬ ТЕХНИКИ
Кодирование речи и квантование параметров линейного предсказания (ЛП, LP).
Системы цифровой речевой связи, например, системы радиосвязи, используют речевые кодеры для увеличения пропускной способности при поддержании высокого качества речи. Речевой кодер осуществляет преобразование речевого сигнала в цифровой поток битов, который передается через канал связи или сохраняется на носителе информации. Речевой сигнал оцифровывается, то есть дискретизируется и квантуется, обычно, 16-битами на выборку. Назначение речевого кодера состоит в представлении указанных цифровых выборок меньшим количеством битов при поддержании хорошего субъективного качества речи. Речевой декодер или синтезатор функционирует на переданном или сохраненном потоке битов и преобразует его обратно в звуковой сигнал.
Способы цифрового кодирования речи, основанные на анализе линейного предсказания, были очень удачны для кодирования речи с низкой битовой скоростью. В частности, одним из наилучших известных способов для достижения хорошего компромисса между субъективным качеством и битовой скоростью являетсякодирование с кодовым линейным предсказанием (CELP). Указанный способ кодирования является базовым для нескольких стандартов кодирования речи в приложениях проводной связи и радиосвязи. В CELP-кодировании дискретизированный речевой сигнал обрабатывается в последовательных блоках из N выборок, обычно называемых кадрами, где N является предварительно определенным числом, обычно соответствующим 10-30 мс. Каждый кадр вычисляется, кодируется, и передается фильтр A(z) линейного предсказания (LP). Обычно вычисление LP-фильтра A(z) требует просмотра вперед, включающего сегмент речи в 5-15 мс из последующего кадра. Кадр из N выборок делится на меньшие блоки, называемые подкадрами. Обычно количество подкадров составляет три или четыре, что приводит к подкадрам в 4-10 мс. В каждом подкадре сигнал возбуждения обычно получается из двух составляющих, прошлого возбуждения и нового возбуждения, устанавливаемого по кодовой книге. Составляющая, формируемая из прошлого возбуждения, часто определяется как возбуждение основным тоном или по адаптивной кодовой книге. Параметры, характеризующие сигнал возбуждения, кодируются и передаются в декодер, где воссозданный сигнал возбуждения используется в качестве входных данных синтезирующего LP-фильтра.
Синтезирующий LP-фильтр задается следующим образом:
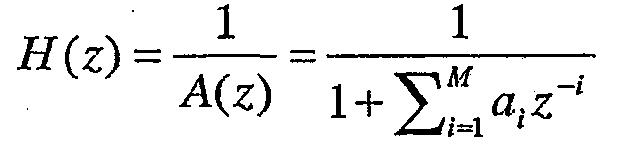
где ai являются коэффициентами линейного предсказания, а М является порядком LP-анализа. Синтезирующий LP-фильтр моделирует огибающую спектра речевого сигнала. В декодере при фильтровании декодируемого возбуждения через синтезирующий LP-фильтр воссоздается речевой сигнал.
Набор коэффициентов линейного предсказания ai вычисляется так, чтобы минимизировалась ошибка предсказания
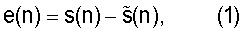
где s(n) является входным сигналом в момент времени n, а
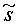
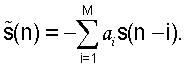
Соответственно, ошибка предсказания задана следующим образом:
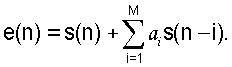
Это соответствует в области z-преобразования:
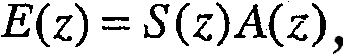
где A(z) является LP-фильтром порядка М, заданным следующим образом:
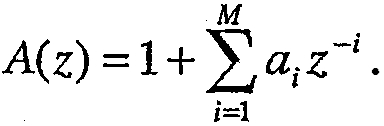
Обычно коэффициенты линейного предсказания ai вычисляются посредством минимизации среднеквадратичной ошибки предсказания по блоку L выборок, L является целым числом, обычно не меньшим N (L обычно соответствует 20-30 мс). Специалистам в данной области техники известны иные способы вычисления коэффициентов линейного предсказания. Возможный вариант такого вычисления приведен в [Рекомендации ITU-T G.722.2 "Wideband coding of speech at round 16 kbit/s using adaptive multi-rate wideband (AMR-WB)", Женева, 2002].
Коэффициенты линейного предсказания ai не могут непосредственно квантоваться для передачи в декодер. Причина этого состоит в том, что малые ошибки квантования на коэффициентах линейного предсказания могут создавать большие спектральные ошибки в функции преобразования LP-фильтра и могут даже привести к неустойчивости фильтра. Следовательно, до квантования к коэффициентам линейного предсказания ai применяется преобразование. Преобразование выдает то, что называется представлением коэффициентов линейного предсказания ai. Следовательно, после приема квантованных преобразованных коэффициентов линейного предсказания ai, декодер может применить обратное преобразование для получения квантованных коэффициентов линейного предсказания. Одним широко используемым представлением для коэффициентов линейного предсказания ai являются частоты спектральных линий(ЧСЛ, LSF), также известные как пары спектральных линий (ПСЛ, LSP). Подробности вычисления частот спектральных линий могут быть найдены в [Рекомендации ITU-T G.729 "Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear prediction (CS-ACELP)", Женева, март 1996].
Подобным представлением являются частоты спектрального иммитанса(ЧСИ, ISF), которые использовались в стандарте кодирования AMR-WB [Рекомендации ITU-T G.722.2 "Wideband coding of speech at around 16 kbit/s using Adaptive Multi-Rate Wideband (AMR-WB)", Женева, 2002]. Возможны и использовались также другие представления. Без потери общности в последующем описании будет рассмотрен конкретный случай представления ISF.
Так полученные параметры LP (частоты LSF, ISF и т.д.) квантуются с использованием или скалярного квантования (СК, SQ) или векторного квантования (ВК, VQ). В скалярном квантовании параметры LP квантуются по отдельности и обычно требуется 3 или 4 бита на параметр. В векторном квантовании параметры LP группируются в вектор и квантуются как объект. Хранится кодовая книга, или таблица, содержащая набор квантованных векторов. Квантователь ищет кодовую книгу для элемента кодовой книги, который наиболее близок к входному вектору в соответствии с определенным показателем расстояния. Индекс выбранного квантованного вектора передается в декодер. Векторное квантование дает более высокую эффективность, чем скалярное квантование, но за счет повышенных требований на память и сложности.
Обычно для уменьшения сложности и требований на память VQ используется структурированное векторное квантование. В VQ с разделением вектор параметров LP разделяется по меньшей мере на два субвектора, которые квантуются по отдельности. В многоэтапном VQ квантованный вектор является суммой элементов из отдельных кодовых книг. VQ с разделением и многоэтапное VQ приводят к понижению сложности и уменьшению памяти при поддержании высокой эффективности квантования. Кроме того, интересующий подход должен объединять многоэтапное VQ и VQ с разделением для дополнительного понижения сложности и требования на память. Согласно [Рекомендации ITU-T G.729 "Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear prediction (CS-ACELP)", Женева, март 1996], квантование вектора параметров LP осуществляется на двух этапах, где вектор второго этапа разделяется на два субвектора.
Параметры LP проявляют сильную корреляцию между последовательными кадрами, и это обычно используется при применении квантования с предсказанием для повышения эффективности. В векторном квантовании с предсказанием на основе информации из прошлых кадров вычисляется предсказанный вектор параметров LP. Затем предсказанный вектор удаляется из входного вектора, и осуществляется векторное квантование ошибки предсказания. Обычно используются два вида предсказания: (АР, AR) предсказание авторегрессией и предсказание скользящим средним значением (СС, MA). В AR предсказании предсказанный вектор вычисляется как комбинация квантованных векторов из прошлых кадров. В MA предсказании предсказанный вектор вычисляется как комбинация векторов ошибки предсказания из прошлых кадров. AR предсказание выдает лучшую эффективность. Однако AR предсказание не является надежным в условиях потери кадров, с которыми сталкиваются в системах радиосвязи и системах связи, основанных на пакетах. В случае потерянных кадров ошибка распространяется на последующие кадры, так как предсказание основывается на предыдущих разрушенных кадрах.
Кодирование с переменной битовой скоростью (ПБС, VBR)
В некоторых системах связи, например системах радиосвязи, использующих технологию множественного доступа с кодовым разделением каналов (МДКР, CDMA), использование кодирования речи с переменной битовой скоростью (VBR), управляемого источником, существенно повышает пропускную способность системы. В кодировании VBR, управляемом источником, кодер может функционировать при нескольких битовых скоростях, и используется блок выбора скорости для определения битовой скорости, используемой при кодировании каждого кадра речи, на основе характеристики кадра речи, например вокализованный, невокализованный, переходной, фоновый шум и т.д. Задача состоит в получении наилучшего качества речи при заданной средней битовой скорости, также определенной, как средняя скорость передачи данных (СПД, ADR). Кодер также может действовать в соответствии с различными режимами функционирования посредством настройки блока выбора скорости для получения различных ADR для различных режимов, где с увеличением ADR повышается эффективность кодера. Это обеспечивает кодер механизмом компромисса между качеством речи и пропускной способностью системы. В системах CDMA, например CDMA-one и CDMA2000, обычно используется 4 битовых скорости, определяемых как полноскоростная (ПС, FR), полускоростная (ПуС, HR), четвертьскоростная (ЧС, QR) и 1/8-скоростная (ER). В этой системе CDMA поддерживаются два набора скоростей и определяются, как Набор скоростей I и Набор скоростей II. В Наборе скоростей II кодер с переменной битовой скоростью с механизмом выбора скорости функционирует при битовых скоростях, управляемых источником, в 13,3 (FR); 6,2 (HF); 2,7 (QR) и 1,0 (ER) кбит/с, соответствующих большим битовым скоростям в 14,4; 7,2; 3,6 и 1,8 кбит/с (с некоторыми битами, добавленными для обнаружения ошибок).
Широкополосный кодек, известный как адаптивный многоскоростной широкополосный (AMR-WB) речевой кодек, недавно был выбран ITU-T (Международным телекоммуникационным союзом - Сектором стандартизации коммуникаций) для отдельной широкополосной речевой телефонной связи и услуг, и 3GPP (Проектом Партнерства третьего Поколения) для GSM (глобальной системы мобильной связи (ГСМС)) и W-CDMA (широкополосных множественного доступа с кодовым разделением каналов) систем радиосвязи третьего поколения. Кодек AMR-WB включает в себя девять битовых скоростей в диапазоне от 6,6 до 23,85 кбит/с. Разработка для системы CDMA2000 кодека VBR, управляемого источником, основанного на AMR-WB, имеет преимущество обеспечения возможности взаимодействия между CDMA2000 и другими системами, использующими кодек AMR-WB. Битовая скорость AMR-WB в 12,65 кбит/с является наиболее близкой скоростью, которая может соответствовать полноскоростной 13,3 кбит/с Набора Скоростей II CDMA2000, скорость в 12,65 кбит/с может использоваться как общая скорость между широкополосным VBR кодеком CDMA2000 и кодеком AMR-WB, которая обеспечивает возможность взаимодействия без транскодирования, которое ухудшает качество речи. Должна быть добавлена половинная скорость в 6,2 кбит/с для обеспечения возможности эффективного функционирования в структуре Набора II скоростей. Полученный в результате кодек может функционировать в некоторых режимах, определенных для CDMA2000, и включает в себя режим, обеспечивающий возможность взаимодействия с системами, использующими кодек AMR-WB.
Обычно полускоростное кодирование выбирается в кадрах, где входной речевой сигнал является стационарным. При менее частом обновлении параметров кодирования или при использовании меньшего количества битов для кодирования некоторых из этих параметров кодирования достигается экономия битов по сравнению с полноскоростным кодированием. Более конкретно, в стационарных вокализованных сегментах информация основного тона кодируется только один раз на кадр, и меньшее количество битов используется для представления фиксированных параметров кодовой книги и коэффициентов линейного предсказания.
Так как VQ с предсказанием с MA-предсказанием обычно применяется для кодирования коэффициентов линейного предсказания, то может наблюдаться излишнее повышение шума квантования в указанных коэффициентах линейного предсказания. MA-предсказание, в противоположность AR-предсказанию, используется для повышения надежности в отношении потерь кадров; однако, в стационарных кадрах коэффициенты линейного предсказания развиваются так медленно, что использование AR-предсказания в этом конкретном случае меньше влияет на распространение ошибки в случае потерянных кадров. При наблюдении можно заметить, что в случае отсутствия кадров, большинство декодеров применяет процедуру скрытия, которая по существу экстраполирует коэффициенты линейного предсказания последнего кадра. Если отсутствующий кадр является стационарным вокализованным кадром, то указанная экстраполяция создает значения, точно подобные переданным в действительности, но не принятым, параметрам LP. Соответственно, воссозданный вектор параметров LP является близким к тому, который должен был быть декодирован, если бы кадр не был потерян. Следовательно, в этом конкретном случае использование AR-предсказания в процедуре квантования коэффициентов линейного предсказания не может влиять слишком неблагоприятно на распространение ошибки квантования.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Согласно настоящему изобретению, предложен способ квантования параметров линейного предсказания в кодировании звукового сигнала с переменной битовой скоростью, включающий в себя прием входного вектора параметров линейного предсказания, классификацию кадра звукового сигнала, соответствующего входному вектору параметров линейного предсказания, вычисление вектора предсказания, удаление вычисленного вектора предсказания из входного вектора параметров линейного предсказания для создания вектора ошибки предсказания, масштабирование вектора ошибки предсказания и квантование масштабированного вектора ошибки предсказания. Вычисление вектора предсказания включает выбор одной из множества схем предсказания в отношении классификации кадра звукового сигнала и вычисление вектора предсказания в соответствии с выбранной схемой предсказания. Масштабирование вектора ошибки предсказания включает выбор по меньшей мере одной из множества схем масштабирования в отношении выбранной схемы предсказания, и масштабирование вектора ошибки предсказания в соответствии с выбранной схемой масштабирования.
Также, согласно настоящему изобретению, предложено устройство для квантования параметров линейного предсказания в кодировании звукового сигнала с переменной битовой скоростью, содержащее средство приема входного вектора параметров линейного предсказания, средство классификации кадра звукового сигнала, соответствующего входному вектору параметров линейного предсказания, средство вычисления вектора предсказания, средство удаления вычисленного вектора предсказания из входного вектора параметров линейного предсказания для создания вектора ошибки предсказания, средство масштабирования вектора ошибки предсказания и средство квантования масштабированного вектора ошибки предсказания. Средство вычисления вектора предсказания содержит средство выбора одной из множества схем предсказания в отношении классификации кадра звукового сигнала, и средство вычисления вектора предсказания в соответствии с выбранной схемой предсказания. Также средство масштабирования вектора ошибки предсказания содержит средство выбора по меньшей мере одной из множества схем масштабирования в отношении выбранной схемы предсказания и средство масштабирования вектора ошибки предсказания в соответствии с выбранной схемой масштабирования.
Настоящее изобретение также относится к устройству для квантования параметров линейного предсказания в кодировании звукового сигнала с переменной битовой скоростью, содержащему вход для приема входного вектора параметров линейного предсказания, классификатор кадра звукового сигнала, соответствующего входному вектору параметров линейного предсказания, вычислитель вектора предсказания, вычитатель для удаления вычисленного вектора предсказания из входного вектора параметров линейного предсказания для создания вектора ошибки предсказания, блок масштабирования, снабжаемый вектором ошибки предсказания, этот блок масштабирует вектор ошибки предсказания, и квантователь масштабированного вектора ошибки предсказания. Вычислитель вектора предсказания содержит селектор одной из множества схем предсказания в отношении классификации кадра звукового сигнала для вычисления вектора предсказания в соответствии с выбранной схемой предсказания. Блок масштабирования содержит селектор по меньшей мере одной из множества схем масштабирования в отношении выбранной схемы предсказания для масштабирования вектора ошибки предсказания в соответствии с выбранной схемой масштабирования.
Настоящее изобретение, дополнительно, относится к способу обратного квантования параметров линейного предсказания в декодировании звукового сигнала с переменной битовой скоростью, включающему в себя прием по меньшей мере одного индекса квантования, прием информации относительно классификации кадра звукового сигнала, соответствующего упомянутому по меньшей мере одному индексу квантования, восстановление вектора ошибки предсказания посредством применения по меньшей мере одного индекса по меньшей мере к одной таблице квантования, воссоздание вектора предсказания и создание вектора параметров линейного предсказания в зависимости от восстановленного вектора ошибки предсказания и воссозданного вектора предсказания. Воссоздание вектора предсказания включает обработку восстановленного вектора ошибки предсказания посредством одной из множества схем предсказания в зависимости от информации классификации кадра.
Настоящее изобретение еще дополнительно относится к устройству для обратного квантования параметров линейного предсказания в декодировании звукового сигнала с переменной битовой скоростью, содержащему средство приема по меньшей мере одного индекса квантования, средство приема информации относительно классификации кадра звукового сигнала, соответствующего по меньшей мере одному индексу квантования, средство восстановления вектора ошибки предсказания посредством применения по меньшей мере одного индекса по меньшей мере к одной таблице квантования, средство воссоздания вектора предсказания и средство создания вектора параметров линейного предсказания в зависимости от восстановленного вектора ошибки предсказания и воссозданного вектора предсказания. Средство воссоздания вектора предсказания содержит средство обработки восстановленного вектора ошибки предсказания посредством множества схем предсказания в зависимости от информации классификации кадра.
В соответствии с последним аспектом настоящего изобретения, предложено устройство для обратного квантования параметров линейного предсказания в декодировании звукового сигнала с переменной битовой скоростью, содержащее средство приема по меньшей мере одного индекса квантования, средство приема информации относительно классификации кадра звукового сигнала, соответствующего по меньшей мере одному индексу квантования, по меньшей мере одну таблицу квантования, снабжаемую упомянутым по меньшей мере одним индексом квантования для восстановления вектора ошибки предсказания, блок воссоздания вектора предсказания и формирователь вектора параметров линейного предсказания в зависимости от восстановленного вектора ошибки предсказания и воссозданного вектора предсказания. Блок воссоздания вектора предсказания содержит по меньшей мере один предсказатель, снабжаемый восстановленным вектором ошибки предсказания для обработки восстановленного вектора ошибки предсказания посредством одной из множества схем предсказания в зависимости от информации классификации кадра.
Изложенные и другие задачи, преимущества и признаки настоящего изобретения станут более ясны после прочтения, согласно приложенным чертежам, не предназначенного для ограничения последующего описания его иллюстративных вариантов осуществления, приведенных исключительно в виде возможного варианта.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
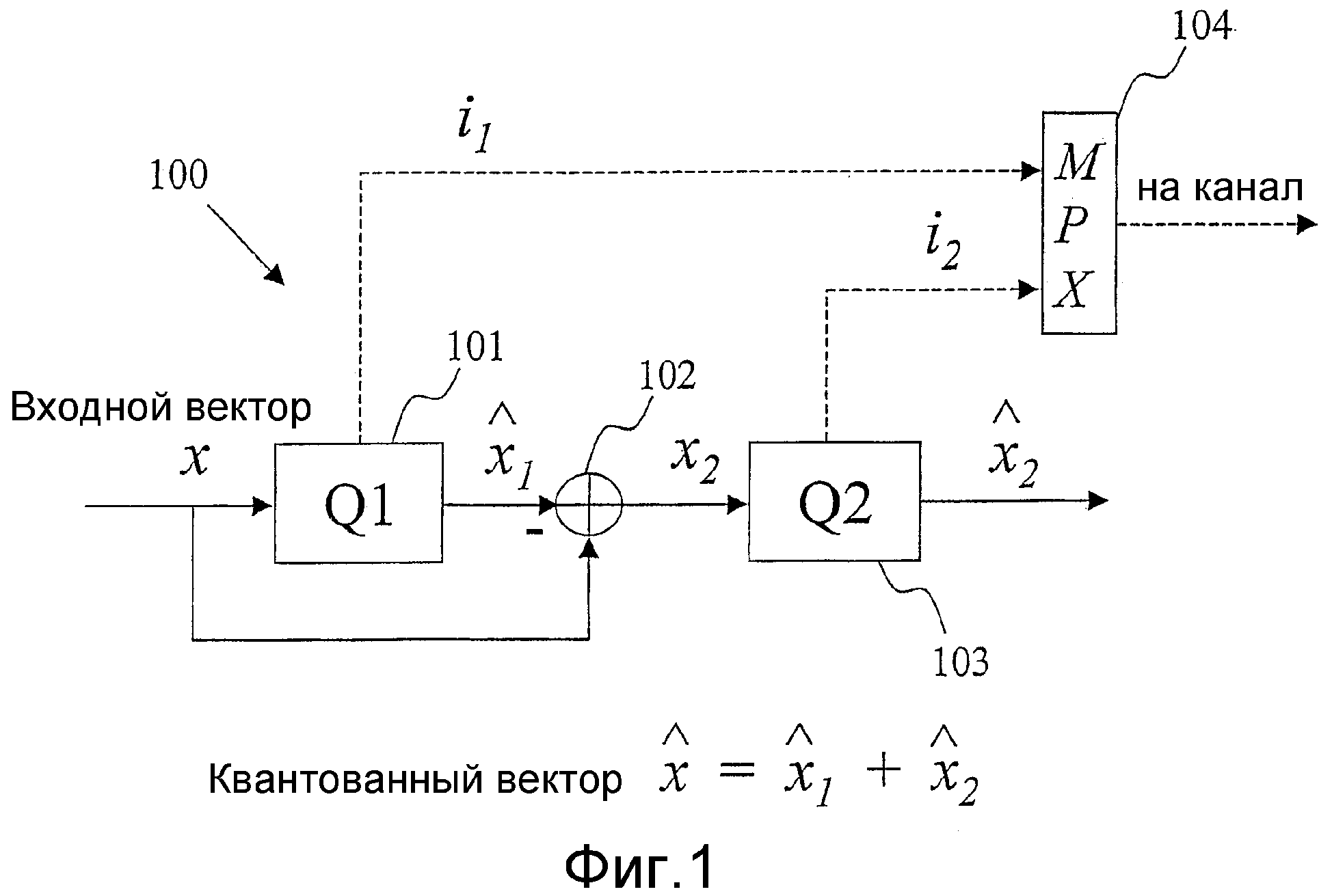
Фиг.1 - блок-схема, иллюстрирующая возможный вариант, не предназначенный для ограничения, многоэтапного векторного квантователя.
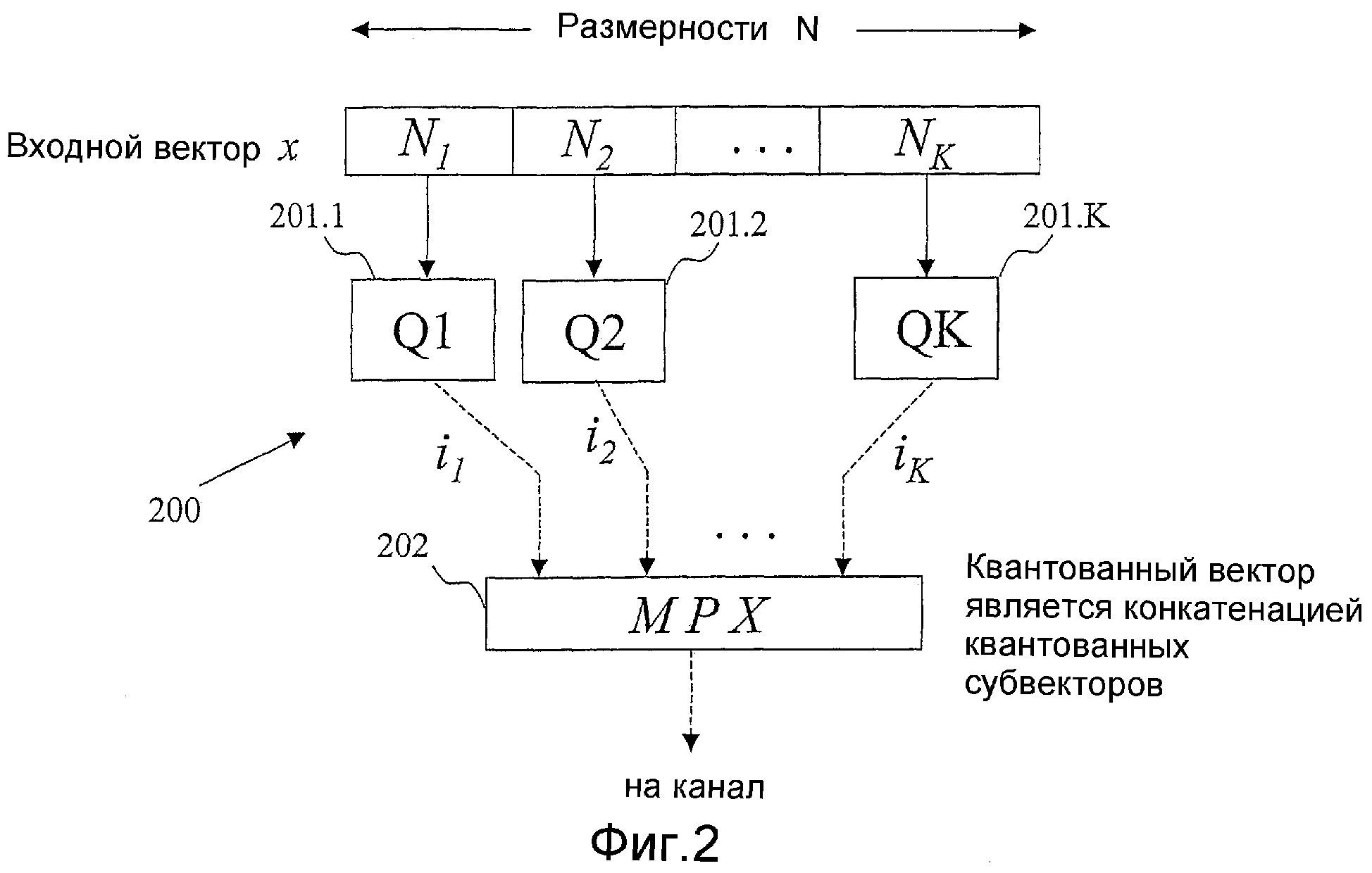
Фиг.2 - блок-схема, иллюстрирующая возможный вариант, не предназначенный для ограничения, векторного квантователя с разделением вектора.
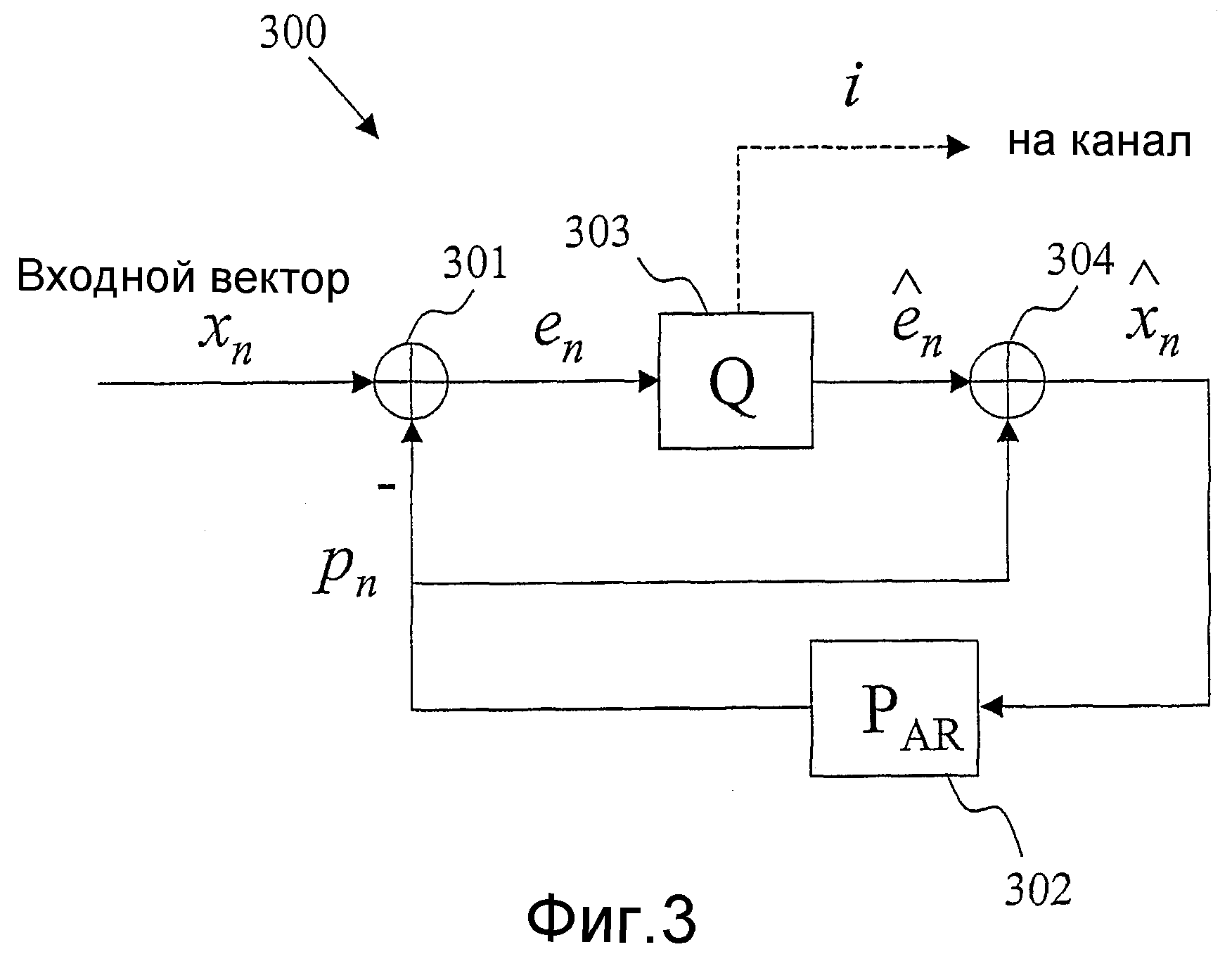
Фиг.3 - блок-схема, иллюстрирующая возможный вариант, не предназначенный для ограничения, векторного квантователя с предсказанием, использующего (AR) предсказание авторегрессией.
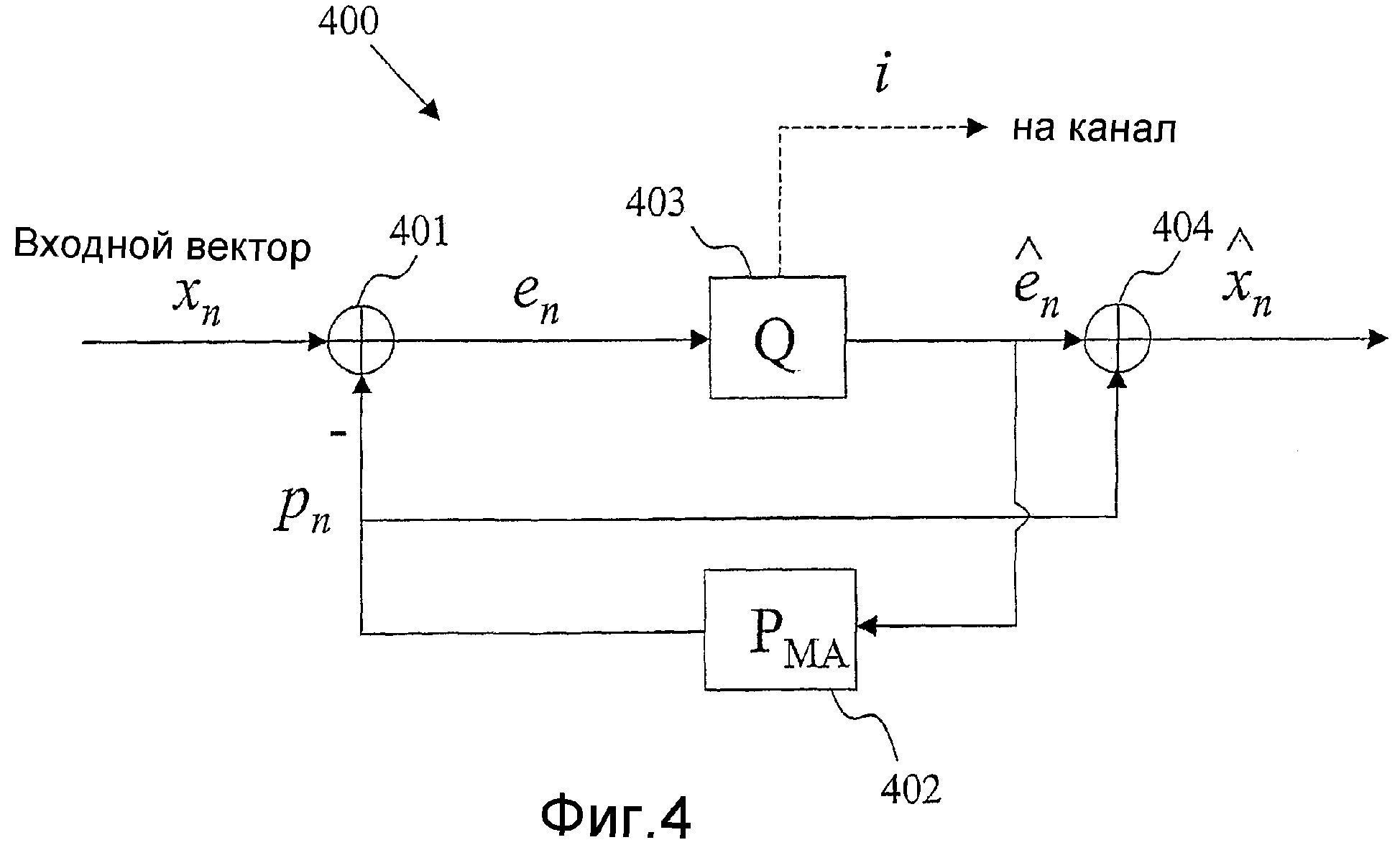
Фиг.4 - блок-схема, иллюстрирующая возможный вариант, не предназначенный для ограничения, векторного квантователя с предсказанием, использующего (MA) предсказание скользящим средним значением.
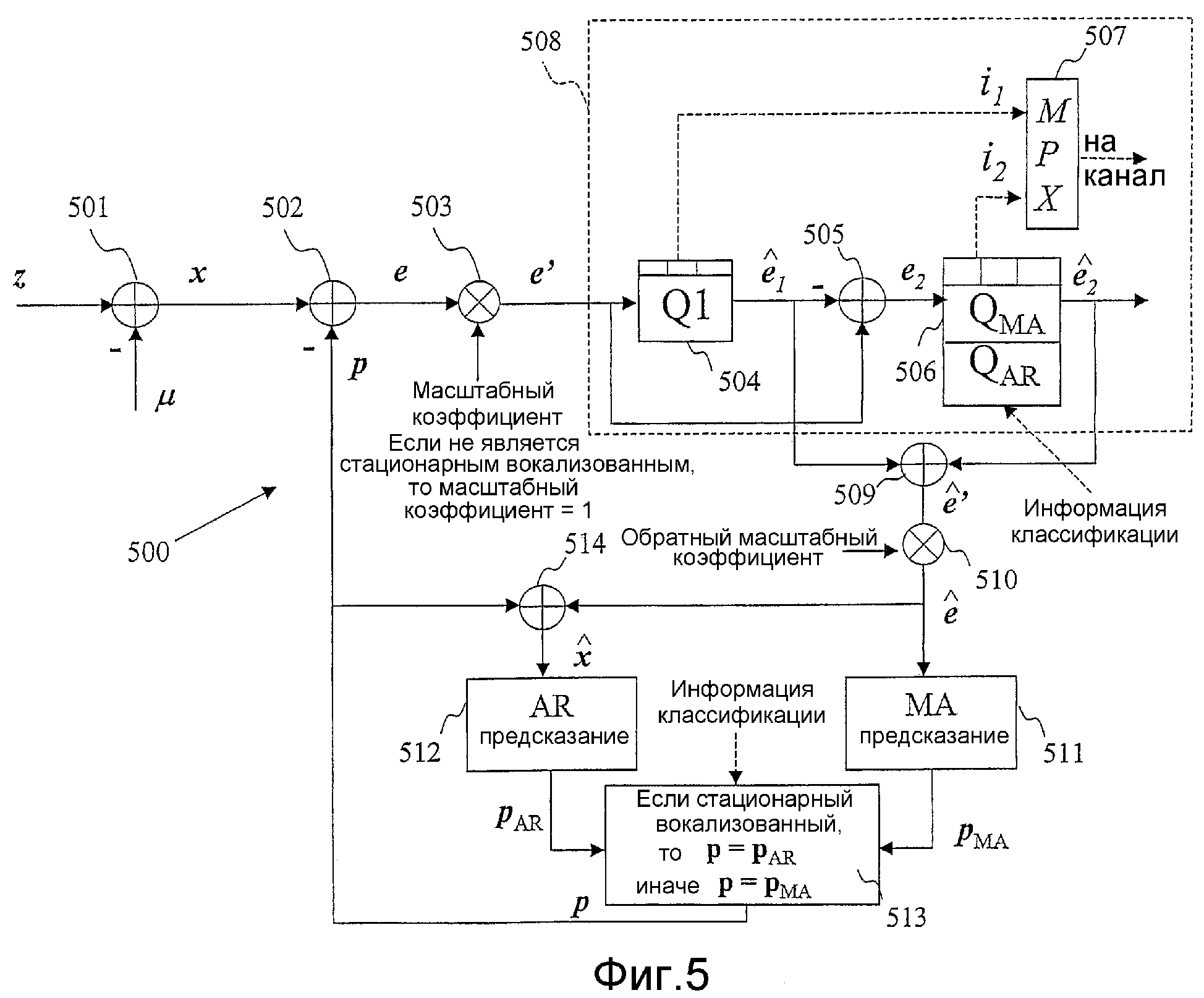
Фиг.5 - блок-схема возможного варианта переключаемого векторного квантователя с предсказанием в кодере, согласно иллюстративному варианту осуществления настоящего изобретения, не предназначенному для ограничения.
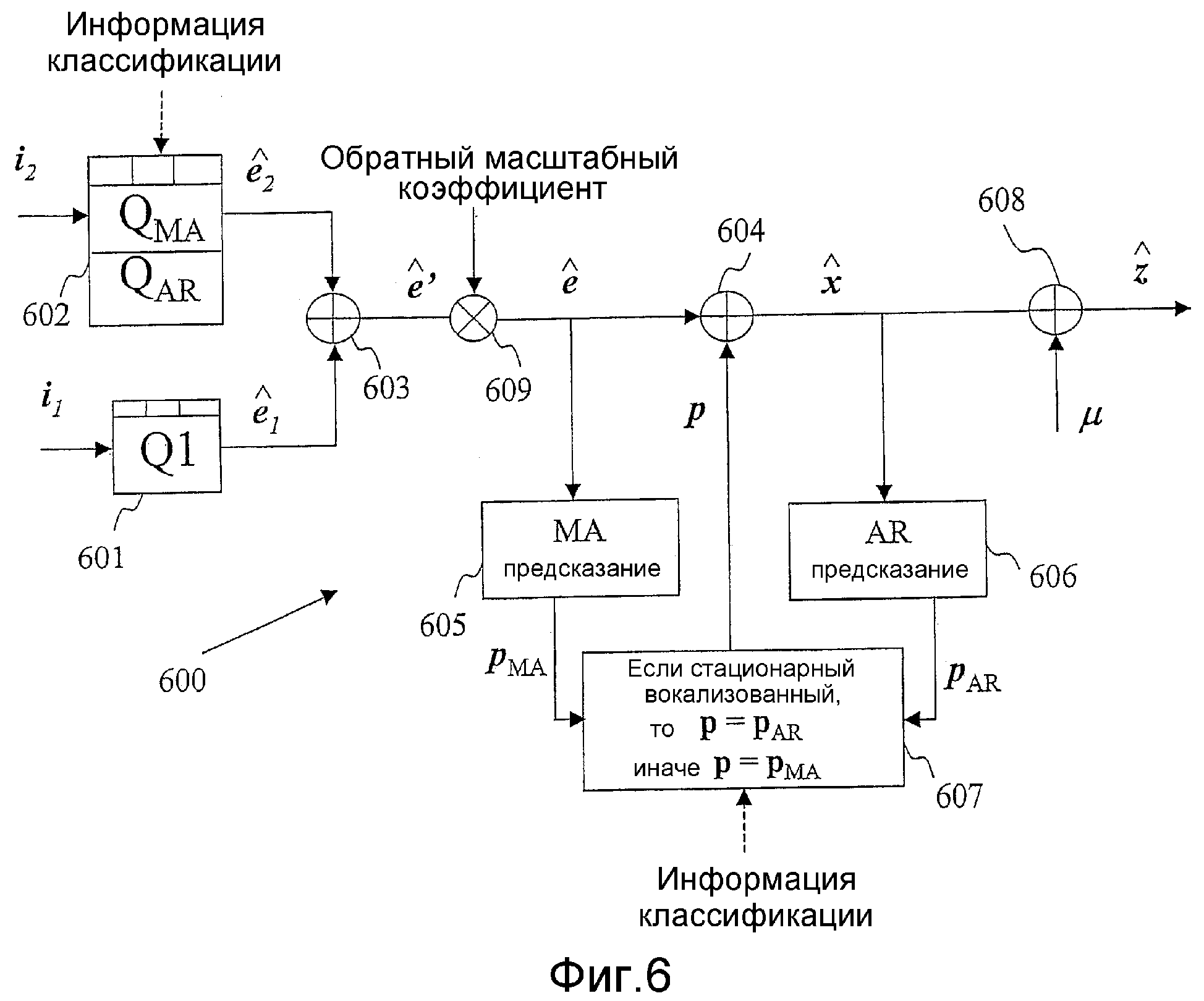
Фиг.6 - блок-схема возможного варианта переключаемого векторного квантователя с предсказанием в декодере, согласно иллюстративному варианту осуществления настоящего изобретения, не предназначенному для ограничения.
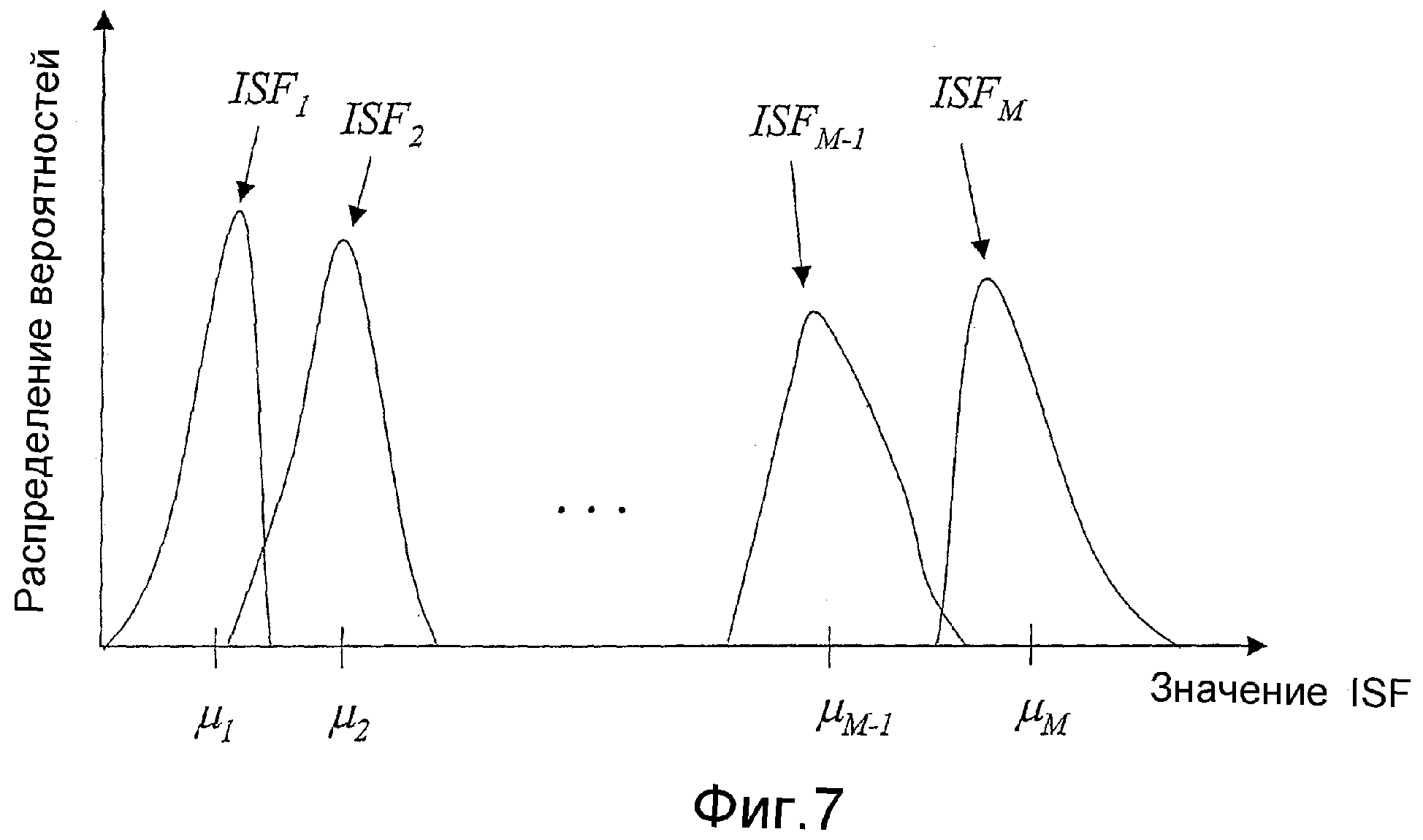
Фиг.7 - иллюстративный возможный вариант, не предназначенный для ограничения, распределения ISF по частоте, в котором каждое распределение является функцией вероятности обнаружения ISF в данной позиции в векторе ISF.
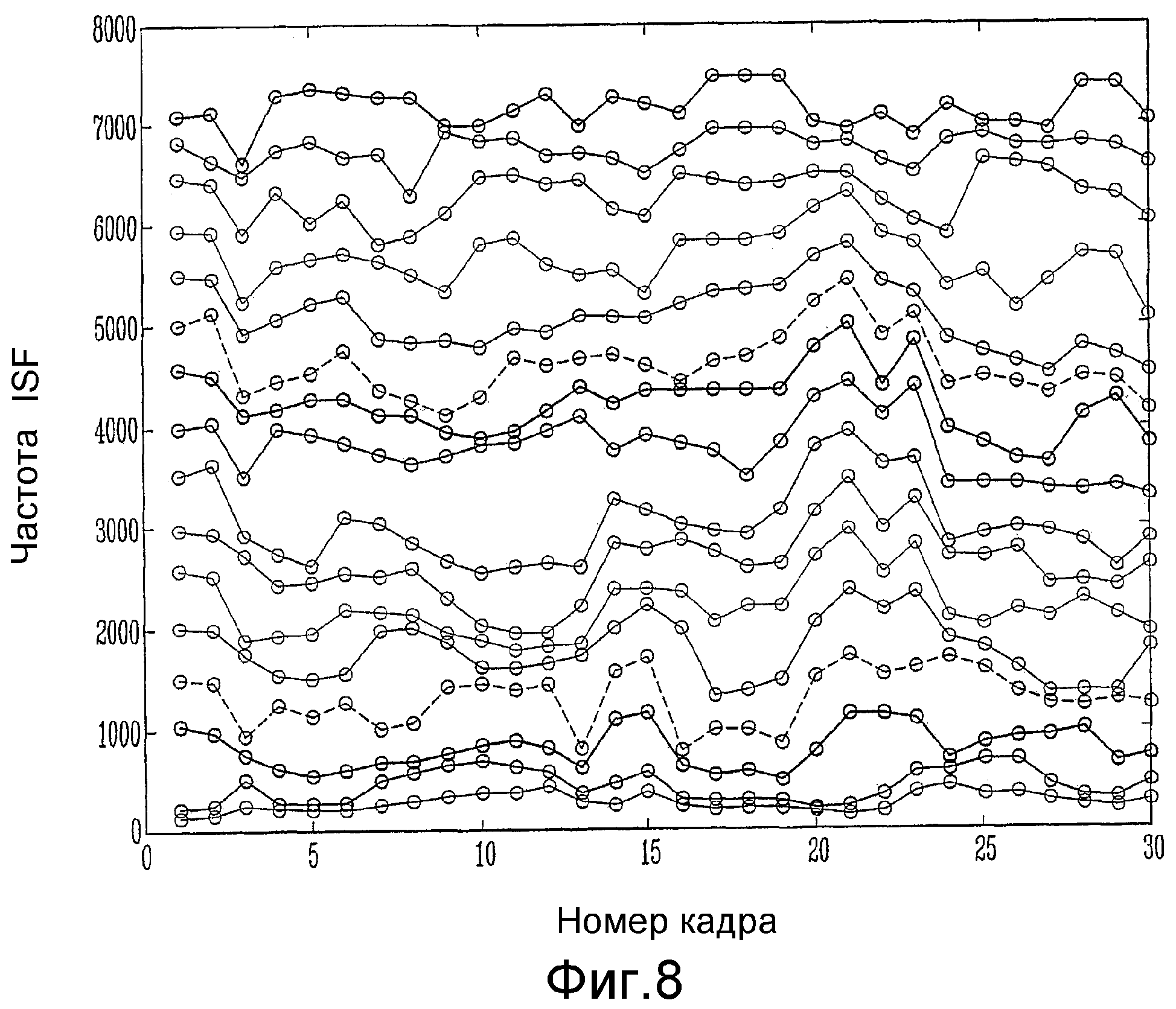
Фиг.8 - график, изображающий стандартный возможный вариант развития параметров ISF по последовательным кадрам речи.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Хотя в последующем описании иллюстративные варианты осуществления настоящего изобретения будут описаны в отношении применения к речевому сигналу, должно учитываться, что настоящее изобретение также может быть применено к другим видам звуковых сигналов.
Наиболее современные способы кодирования речи основаны на анализе линейного предсказания, например, кодирование CELP. Параметры LP вычисляются и квантуются в кадрах в 10-30 мс. В настоящем иллюстративном варианте осуществления используются кадры в 20 мс и предполагается порядок анализа LP, равный 16. Возможный вариант вычисления параметров LP в системе кодирования речи можно обнаружить при обращении к [Рекомендации ITU-T G.722.2 "Wideband coding of speech at around 16 kbit/s using Adaptive Multi-Rate Wideband (AMR-WB)", Женева, 2002]. В указанном иллюстративном возможном варианте предварительно обработанный речевой сигнал обрабатывается методом окна, и вычисляются автокорреляции речи, обработанной методом окна. Затем используется рекурсия Левинсона-Дюрбина (Levinson-Durbin) для вычисления коэффициентов линейного предсказания ai, i = 1,..., М из автокорреляций R(k), k=0,...,М, где М является порядком предсказания.
Коэффициенты линейного предсказания ai не могут непосредственно квантоваться для передачи в декодер. Причина состоит в том, что малые ошибки квантования на коэффициентах линейного предсказания могут создавать большие спектральные ошибки в функции преобразования LP-фильтра, и даже могут привести к неустойчивости фильтра. Следовательно, до квантования к коэффициентам линейного предсказания ai применяется преобразование. Преобразование выдает то, что называется представлением коэффициентов линейного предсказания ai. Следовательно, после приема квантованных преобразованных коэффициентов линейного предсказания ai, декодер может применить обратное преобразование для получения квантованных коэффициентов линейного предсказания. Одним широко используемым представлением для коэффициентов линейного предсказания ai являются частоты спектральных линий (LSF), также известные как пары спектральных линий (LSP). Подробности вычисления частот LSF могут быть найдены в [Рекомендации ITU-T G.729 "Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear prediction (CS-ACELP)", Женева, март 1996]. Частоты LSF состоят из полюсов полиномов
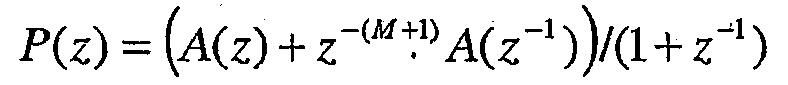
и
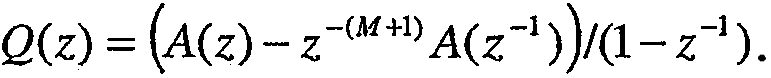
Для четных значений М, каждый полином имеет M/2 сопряженных корня на единичной окружности (e±jωi). Соответственно, полиномы могут быть записаны как
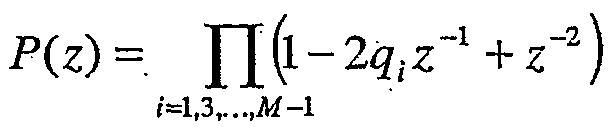
и
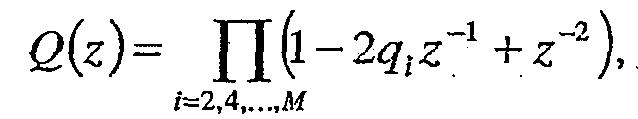
где qi=cos(ωi) с ωi, являющимися частотами спектральных линий (LSF), удовлетворяющими свойству упорядочения 0 < ω1 < ω2 < ... < ωM < π. В этом конкретном возможном варианте частоты LSF составляют параметры LP (линейного предсказания).
Подобным представлением являются пары спектрального иммитанса (ISP) или частоты спектрального иммитанса (ISF), которые использовались в стандарте кодирования AMR-WB. Подробности вычисления частот ISF могут быть найдены при обращении к [Рекомендации ITU-T G.722.2 "Wideband coding of speech at round 16 kbit/s using adaptive multi-rate wideband (AMR-WB)", Женева, 2002]. Также возможны и использовались другие представления. Без потери общности в последующем описании будет рассматриваться случай представления ISF как иллюстративный возможный вариант, не предназначенный для ограничения.
Для LP-фильтра M-го порядка, где М является четным, пары ISP определяются как корни полиномов:
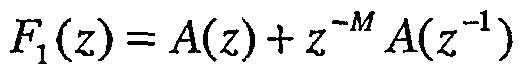
и
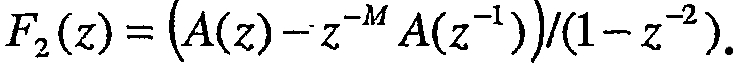
Полиномы F1(z) и F2(z) имеют M/2 и M/2-1 сопряженных корня на единичной окружности (e±jwi), соответственно. Следовательно, полиномы могут быть записаны как
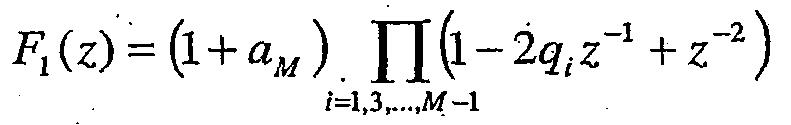
и
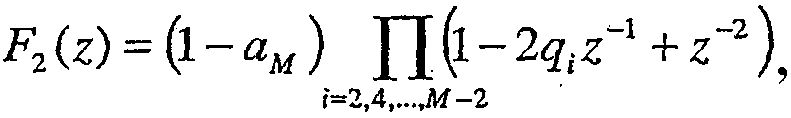
где qi=cos(ωi) с ωi, являющимися частотами спектрального иммитанса (ISF), и aM является последним коэффициентом линейного предсказания. Частоты ISF удовлетворяют свойству упорядочения 0 < ω1 < ω2 < ... < ωM < π. В этом конкретном возможном варианте частоты LSF составляют параметры LP (линейного предсказания). Соответственно, частоты ISF состоят из M-1 частот дополнительно к последним коэффициентам линейного предсказания. В представленном иллюстративном варианте осуществления частоты ISF отображаются в частоты в диапазоне от 0 до fS/2, где fS является частотой дискретизации, с использованием следующего отношения:
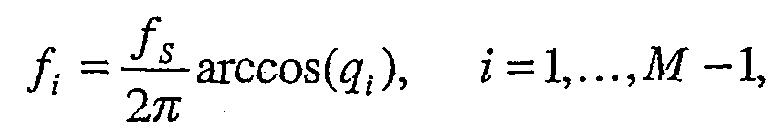
и
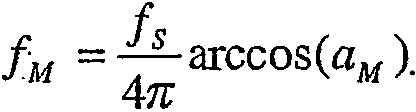
Частоты LSF и ISF (параметры LP) широко использовались благодаря некоторым свойствам, которые делают их применимыми для квантования. Среди этих свойств имеются хорошо определенный динамический диапазон, их гладкое развитие, приводящее к сильным корреляциям внутри кадра и между кадрами, и наличие свойства упорядочения, которое обеспечивает устойчивость квантуемого LP-фильтра.
В этом документе, термин "параметр LP" используется для определения любого представления коэффициентов LP, например, LSF, ISF, LSF с удаленным средним значением или ISF с удаленным средним значением.
Теперь для понимания используемых подходов квантования будут описаны основные свойства частот ISF (параметров LP (линейного предсказания)). На фиг.7 изображен типичный возможный вариант функции распределения вероятностей (ФРВ, PDF) коэффициентов ISF. Каждая кривая представляет PDF отдельного коэффициента ISF. На горизонтальной оси показано среднее значение каждого распределения (μk). Например, кривая для ISF1 указывает все значения с вероятностью их возникновения, которые может принимать первый коэффициент ISF в кадре. Кривая для ISF2 указывает все значения с вероятностью их возникновения, которые может принимать второй коэффициент ISF в кадре, и так далее. Функция PDF обычно получается применением гистограммы к значениям, принимаемым данным коэффициентом, как наблюдается по нескольким последовательным кадрам. Видно, что каждый коэффициент ISF занимает ограниченный интервал по всем возможным значениям ISF. Это действительно уменьшает пространство, которое должен охватывать квантователь и повышает эффективность битовой скорости. Также важно отметить что, хотя функции PDF коэффициентов ISF могут перекрываться, коэффициенты ISF в заданном кадре всегда упорядочены (ISFk+1 - ISFk > 0, где k является позицией коэффициента ISF внутри вектора коэффициентов ISF).
При длительностях кадра от 10 до 30 мс, обычных в речевом кодере, коэффициенты ISF проявляют корреляцию между кадрами. Фиг.8 иллюстрирует развитие коэффициентов ISF по кадрам в речевом сигнале. Фиг.8 был получена при выполнении анализа LP более чем по 30 последовательным кадрам в 20 мс в речевом сегменте, содержащем вокализованные и невокализованные кадры. Коэффициенты LP (16 на кадр) были преобразованы в коэффициенты ISF. На фиг.8 изображено, что линии никогда не пересекают друг друга, что означает, что частоты ISF всегда упорядочены. Фиг.8 также отражает, что коэффициенты ISF обычно развиваются медленно по сравнению с частотой кадров. Это на практике означает, что квантование с предсказанием может применяться для уменьшения ошибки квантования.
Фиг.3 иллюстрирует возможный вариант векторного квантователя 300 с предсказанием, использующего (AR) предсказание авторегрессией. Как изображено на фиг.3, сначала получается вектор ошибки предсказания en посредством вычитания (Процессор 301) вектора предсказания pn из входного вектора параметров LP, который должен квантоваться, xn. Символ n здесь относится к индексу кадра во времени. Вектор предсказания pn вычисляется предсказателем P (Процессор 302) с использованием прошлых квантованных векторов параметров LP,
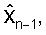
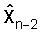
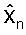
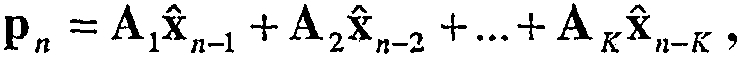
где Ak являются матрицами предсказания размерностью MxM, а K является порядком предсказателя. В простом виде предсказателя P (Процессор 302) используется предсказание первого порядка:
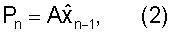
где A является матрицей предсказания размерности MxM, где М является размерностью вектора параметров LP xn. Простым видом матрицы предсказания является диагональная матрица с диагональными элементами α1, α2,..., αM, где αi являются коэффициентами предсказания для отдельных параметров LP. Если для всех параметров LP используется идентичный коэффициент α, то уравнение 2 сокращается до
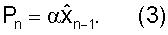
Если используется простой вид предсказания Уравнения (3), то на фиг.3 квантованный вектор параметров LP
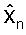
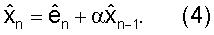
Рекурсивный вид Уравнения (4) подразумевает, что при использовании квантователя 300 с AR предсказанием вида, изображенного на фиг.3, ошибки канала распространятся по нескольким кадрам. Это может быть более заметно, если Уравнение (4) записано в следующем математически эквивалентном виде
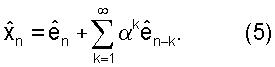
Из этого вида ясно видно, что в принципе каждый прошлый декодированный вектор ошибки предсказания кn-k вносит вклад в значение квантованного вектора параметров LP
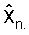
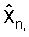
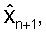
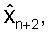
Чтобы смягчить указанную проблему распространения, вместо AR предсказания может использоваться (MA) предсказание скользящим средним значением. В MA предсказании бесконечная последовательность Уравнения (5) обрезается до конечного количества членов. Идея состоит в аппроксимации авторегрессионного вида предсказателя P в Уравнении (4) посредством использования малого количества членов в Уравнении (5). Следует отметить, что для лучшей аппроксимации предсказателя P Уравнения (4) могут быть изменены веса в суммировании.
Возможный вариант, не предназначенный для ограничения, векторного квантователя 400 с MA предсказанием изображен на фиг.4, при этом процессоры 401, 402, 403 и 404 соответствуют процессорам 301, 302, 303 и 304, соответственно. Общий вид предсказателя P (Процессор 402) является следующим:
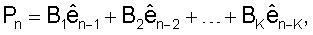
где Bk являются матрицами предсказания с размерностью MxM, а K является порядком предсказателя. Следует отметить, что в MA предсказании ошибки передачи распространяются только на следующие K кадров.
В простом виде предсказателя P (Процессор 402) используется предсказание первого порядка:
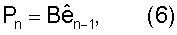
где B является матрицей предсказания с размерностью MxM, где М является размерностью вектора параметров LP. Простым видом матрицы предсказания является диагональная матрица с диагональными элементами β1, β2, ..., βM, где βi являются коэффициентами предсказания для отдельных параметров LP. Если для всех параметров LP используется идентичный коэффициент β, то Уравнение (6) сокращается до
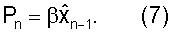
Если используется простой вид предсказания Уравнения (7), то на фиг.4 квантованный вектор параметров LP
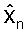
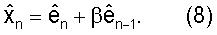
В иллюстративном возможном варианте векторного квантователя 400 с предсказанием, использующего MA предсказание, как изображено на фиг.4, память предсказателя (в Процессоре 402) сформирована прошлыми декодированными векторами ошибки предсказания кn-1, кn-2 и т.д. Следовательно, максимальным количеством кадров, по которым может распространяться ошибка канала, является порядок предсказателя P (Процессор 402). В иллюстративном возможном варианте предсказателя Уравнения (8) используется предсказание 1-го порядка, так что ошибка MA предсказания может распространяться только на один кадр.
Хотя MA предсказание является более надежным, чем AR предсказание в отношении ошибок передачи, оно не достигает идентичного выигрыша в предсказании для заданного порядка предсказания. Следовательно, ошибка предсказания имеет больший динамический диапазон, и может требовать большего количества битов, чем при квантовании с AR предсказанием, для достижения идентичного выигрыша в кодировании. Соответственно, компромисс состоит в надежности в отношении ошибок канала против выигрыша в кодировании при заданной битовой скорости.
В кодировании с переменной битовой скоростью (VBR), управляемым источником, кодер функционирует при нескольких битовых скоростях, и блок выбора скорости используется для определения битовой скорости, используемого для кодирования каждого кадра речи, на основе характеристики кадра речи, например вокализованный, невокализованный, переходной, фоновый шум. Характеристика кадра речи, например вокализованный, невокализованный, переходной, фоновый шум и т.д., может быть определена так же, как для VBR CDMA. Задача состоит в достижении наилучшего качества речи при заданной средней битовой скорости, также определенной, как средняя скорость передачи данных (ADR). В качестве иллюстративного возможного варианта, в системах CDMA, например CDMA-one и CDMA2000, обычно используется 4 битовых скорости, определяемых как полноскоростная (ПС, FR), полускоростная (ПС, HR), четвертьскоростная (ЧС, QR) и 1/8-скоростная (ER). В этой системе CDMA поддерживаются два набора скоростей и определяются, как Набор скоростей I и Набор скоростей II. В Наборе скоростей II кодер с переменной битовой скоростью с механизмом выбора скорости функционирует при битовой скорости, управляемой источником, в 13,3 (FR); 6,2 (HF); 2,7 (QR) и 1,0 (ER) кбит/с.
В кодировании VBR используется механизм классификации и выбора скорости для классификации кадра речи в соответствии с его характеристикой (вокализованный, невокализованный, переходный, шум и т.д.) и выбора битовой скорости, необходимой для кодирования кадра в соответствии с классификацией и требуемой средней скоростью передачи данных (ADR). Обычно в кадрах, где входной речевой сигнал является стационарным, выбирается полускоростное кодирование. Экономия битов по сравнению с полноскоростным (кодированием)достигается посредством менее частого обновления параметров кодера или использования меньшего количества битов для кодирования некоторых параметров. Дополнительно, указанные кадры проявляют сильную корреляцию, что может использоваться для уменьшения битовой скорости. Более конкретно, в стационарных вокализованных сегментах информация основного тона кодируется только один раз в кадре, и меньшее количество битов используются для фиксированной кодовой книги и коэффициентов LP. В невокализованных кадрах не требуется предсказание основного тона, и возбуждение может быть смоделировано малыми кодовыми книгами в HR или случайным шумом в QR.
Так как обычно для кодирования параметров LP применяется VQ с предсказанием с MA предсказанием, это приводит к излишнему увеличению шума квантования. MA предсказание, в противоположность AR предсказанию, используется для повышения надежности в отношении потери кадра; однако, в стационарных кадрах параметры LP развиваются медленно, так что использование AR предсказания в этом случае должно оказывать меньшее влияние на распространение ошибки в случае потерянных кадров. При наблюдении обнаружено, что в случае отсутствия кадров большинство декодеров применяет процедуру скрытия, которая по существу экстраполирует параметры LP последнего кадра. Если отсутствующий кадр является стационарным вокализованным кадром, то при такой экстраполяции создаются значения, весьма подобные переданным в действительности, но не принятым параметрам LP. Соответственно, воссозданный вектор параметров LP является очень близким к тому, который должен был быть декодирован, если бы кадр не был потерян. В этом конкретном случае использование AR предсказания в процедуре квантования LP коэффициентов не может влиять слишком неблагоприятно на распространение ошибки квантования.
Соответственно, согласно иллюстративному варианту осуществления настоящего изобретения, не предназначенному для ограничения, раскрыт способ VQ с предсказанием для параметров LP, при котором предсказатель переключается между MA и AR предсказанием в соответствии с характеристикой обрабатываемого кадра речи. Более конкретно, в переходных и нестационарных кадрах используется MA предсказание, в то время как в стационарных кадрах используется AR предсказание. Кроме того, так как AR предсказание приводит к вектору ошибки предсказания en с меньшим динамическим диапазоном, чем MA предсказание, то использовать идентичные таблицы квантования для обоих видов предсказания не эффективно. Для преодоления этой проблемы вектор ошибки предсказания после AR предсказания масштабируется соответствующим образом, чтобы он мог квантоваться с использованием таблиц квантования, идентичных таблицам квантования в случае MA предсказания. Когда для квантования вектора ошибки предсказания используется многоэтапное VQ, первый этап может использоваться для обоих видов предсказания после соответственного масштабирования вектора ошибки AR предсказания. Так как на втором этапе достаточно использовать VQ с разделением, которое не требует памяти большой емкости, таблицы квантования этого второго этапа могут быть подготовлены и разработаны отдельно для обоих видов предсказания. Безусловно, вместо разработки таблиц квантования первого этапа для MA предсказания и масштабирования вектора ошибки AR предсказания, также допустимо обратное, то есть первый этап может быть разработан для AR предсказания, и до квантования масштабируется вектор ошибки MA предсказания.
Соответственно, согласно иллюстративному варианту осуществления настоящего изобретения, не предназначенному для ограничения, также раскрыт способ векторного квантования с предсказанием для квантования параметров LP в речевом кодеке с переменной битовой скоростью, при котором предсказатель P переключается между MA и AR предсказанием в соответствии с информацией классификации, относящейся к характеристике обрабатываемого кадра речи, и при котором вектор ошибки предсказания масштабируется соответствующим образом, так что для обоих видов предсказания могут использоваться идентичные таблицы квантования первого этапа в многоэтапном VQ ошибки предсказания.
Возможный вариант 1
На фиг.1 изображен возможный вариант, не предназначенный для ограничения, двухэтапного векторного квантователя 100. Сначала входной вектор x квантуется квантователем Q1 (Процессор 101) для создания квантованного вектора
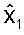
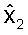
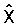
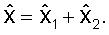
На фиг.2 изображен иллюстративный возможный вариант векторного квантователя 200 с разделением. Входной вектор x размерности М разделяется на K субвекторов с размерностями N1, N2, ..., NK и квантуется векторными квантователями Q1, Q2, ..., QK, соответственно (Процессоры 201.1, 201.2 ... 201.K). Создаются квантованные субвекторы
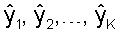
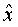
Эффективный подход для векторного квантования должен объединять многоэтапное VQ и VQ с разделением, что приводит к хорошему компромиссу между качеством и сложностью. В первом иллюстративном возможном варианте может использоваться двухэтапное VQ, при котором вектор ошибки второго этапа к2 разделяется на несколько субвекторов и квантуется квантователями второго этапа Q21, Q22, ..., Q2K, соответственно. Во втором иллюстративном возможном варианте входной вектор может быть разделен на два субвектора, затем каждый субвектор квантуется двухэтапным VQ с использованием дополнительного разделения на втором этапе, как в первом иллюстративном возможном варианте.
Фиг.5 - схематическая блочная диаграмма, иллюстрирующая возможный вариант, не предназначенный для ограничения, переключаемого векторного квантователя 500 с предсказанием, согласно настоящему изобретению. Во-первых, вектор среднего значения параметров LP μ удаляется из входного вектора параметров LP z для создания вектора параметров LP с удаленным средним значением x (Процессор 501). Как указано в приведенном описании, векторами параметров LP могут быть векторы параметров LSF, параметров ISF, или любое другое релевантное представление параметров LP. Удаление вектора среднего значения параметров LP μ из входного вектора параметров LP z является необязательным, но приводит к повышенной эффективности предсказания. Если Процессор 501 блокирован, то вектор параметров LP с удаленным средним значением x будет идентичен входному вектору параметров LP z. Здесь следует отметить, что для упрощения индекс кадра n, используемый на фиг.3 и 4, здесь был опущен. Затем вычисляется вектор предсказания p и удаляется из вектора параметров LP с удаленным средним значением x для создания вектора ошибки предсказания e (Процессор 502). Затем на основе информации относительно классификации кадра, если кадр, соответствующий входному вектору параметров LP z, является стационарным вокализованным кадром, то используется AR предсказание, и вектор ошибки e масштабируется с некоторым коэффициентом (Процессор 503) для получения масштабированного вектора ошибки предсказания e'. Если кадр не является стационарным вокализованным кадром, то используется MA предсказание, и масштабный коэффициент (Процессор 503) равен 1. Вновь, классификация кадра, например вокализованный, невокализованный, переходный, фоновый шум и т.д., может быть определена, например, так же, как для VBR CDMA. Масштабный коэффициент, обычно, больше 1 и приводит к повышению выше среднего уровнядинамического диапазона вектора ошибки предсказания, чтобы он мог квантоваться квантователем, разработанным для MA предсказания. Значение масштабного коэффициента зависит от коэффициентов, используемых для MA и AR предсказания. Обычные значения, не предназначенные для ограничения: коэффициент MA предсказания β=0,33, коэффициент AR предсказания α=0,65, и масштабный коэффициент =1,25. Если квантователь разработан для AR предсказания, то будет выполнена обратная операция: будет масштабироваться вектор ошибки предсказания для MA предсказания, и масштабный коэффициент будет меньше 1.
Затем масштабированный вектор ошибки предсказания e' векторно квантуется (Процессор 508) для создания квантованного масштабированного вектора ошибки предсказания к'. В возможном варианте, изображенном на фиг.5, процессор 508 состоит из двухэтапного векторного квантователя, где используется VQ с разделением на обоих этапах, и при этом таблицы векторного квантования первого этапа идентичны для MA и AR предсказания. Двухэтапный векторный квантователь 508 состоит из процессоров 504, 505, 506, 507 и 509. В квантователе первого этапа Q1 масштабированный вектор ошибки предсказания e' квантуется для создания квантованного вектора ошибки предсказания первого этапа к1 (Процессор 504). Этот вектор к1 удаляется из масштабированного вектора ошибки предсказания e' (Процессор 505) для создания вектора ошибки предсказания второго этапа e2. Затем этот вектор ошибки предсказания второго этапа e2 квантуется (Процессор 506) векторным квантователем QMA второго этапа или векторным квантователем QAR второго этапа для создания квантованного вектора ошибки предсказания второго этапа к2. Выбор между векторными квантователями QMA и QAR второго этапа зависит от информации классификации кадра (например, как указано выше, AR, если кадр является стационарным вокализованным кадром, и MA, если кадр не является стационарным вокализованным кадром). Квантованный масштабированный вектор ошибки предсказания к' воссоздается (Процессор 509) посредством суммирования квантованных векторов ошибки предсказания, к1 и к2 из двух этапов: к'=к1+к2. В заключение, к квантованному масштабированному вектору ошибки предсказания к' применяется операция, обратная масштабированию процессора 503 (Процессор 510) для создания квантованного вектора ошибки предсказания к. В представленном иллюстративном возможном варианте размерность вектора равна 16, и на обоих этапах используется VQ с разделением. Индексы квантования i1 и i2 из квантователя Q1 и квантователя QMA или QAR мультиплексируются и передаются через канал связи (Процессор 507).
Вектор предсказания p вычисляется в MA предсказателе (Процессор 511) или в AR предсказателе (Процессор 512) в зависимости от информации классификации кадра (например, как указано выше, AR, если кадр является стационарным вокализованным, и MA, если кадр не является стационарным вокализованным). Если кадр является стационарным вокализованным, то вектор предсказания равен выходным данным AR предсказателя 512. Иначе вектор предсказания равен выходным данным MA предсказателя 511. Как поясняется здесь выше, MA предсказатель 511 функционирует на квантованных векторах ошибки предсказания из предыдущих кадров, в то время как AR предсказатель 512 функционирует на квантованных входных векторах LP параметров из предыдущих кадров. Квантованный входной вектор параметров LP (с удаленным средним значением) создается посредством суммирования квантованного вектора ошибки предсказания к с вектором предсказания p (Процессор 514):
Фиг.6 является схематической блочной диаграммой, изображающей иллюстративный вариант осуществления переключаемого векторного квантователя 600 с предсказанием в декодере, согласно настоящему изобретению. На стороне декодера принятые наборы индексов квантования i1 и i2 используются таблицами квантования (Процессоры 601 и 602) для создания квантованных векторов ошибки предсказания первого этапа и второго этапа к1 и к2. Следует отметить, что квантование второго этапа (Процессор 602) состоит из двух наборов таблиц для MA и AR предсказания, как описано выше в отношении стороны кодера фиг.5. Затем в Процессоре 603 воссоздается масштабированный вектор ошибки предсказания посредством суммирования векторов ошибки предсказания, квантованных на двух этапах: к' = к1 + к2. В Процессоре 609 применяется обратное масштабирование для создания квантованного вектора ошибки предсказания к. Следует отметить, что обратное масштабирование является функцией информации классификации принятого кадра и является обратным масштабированию, выполняемому процессором 503 фиг.5. Затем в Процессоре 604 воссоздается квантованный входной вектор параметров LP с удаленным средним значением
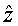
Безусловно, несмотря на тот факт, что в некотором кадре используются только выходные данные MA предсказателя или AR предсказателя, блоки памяти обоих предсказателей должны обновляться каждый кадр с учетом того, что в следующем кадре может использоваться MA или AR предсказание. Это верно и для стороны декодера и для стороны кодера.
Для оптимизации выигрыша в кодировании некоторые векторы первого этапа, предназначенные для MA предсказания, могут быть заменены новыми векторами, предназначенными для AR предсказания. В иллюстративном варианте осуществления, не предназначенном для ограничения, размер кодовой книги первого этапа равен 256, и имеет содержимое, идентичное содержимому в стандарте AMR-WB на 12,65 кбит/с, и при использовании AR предсказания в кодовой книге первого этапа заменяются 28 векторов. Соответственно, расширенная кодовая книга первого этапа формируется следующим образом: сначала 28 векторов первого этапа, наименее используемых при применении AR предсказания, но пригодных для использования для MA предсказания, помещаются в начале таблицы, затем в таблицу добавляются оставшиеся 256-28=228 векторов первого этапа, пригодных для использования и для AR и для MA предсказания, и в завершение в конце таблицы помещаются 28 новых векторов, пригодных для использования для AR предсказания. Соответственно, длина таблицы составляет 256+28=284 вектора. При использовании MA предсказания на первом этапе используются первые 256 векторов таблицы; при использовании AR предсказания используются последние 256 векторов таблицы. Для обеспечения возможности взаимодействия с стандартом AMR-WB используется таблица, которая содержит соответствие между позицией вектора первого этапа в указанной новой кодовой книге и его исходной позицией в кодовой книге первого этапа для AMR-WB.
Подводя итог, описанные выше иллюстративные варианты осуществления настоящего изобретения, не предназначенные для ограничения, описанные согласно фиг.5 и 6, имеют следующие признаки:
- Переключаемое AR/MA предсказание используется в зависимости от режима кодирования кодера с переменной битовой скоростью, зависящим непосредственно от характеристики текущего кадра речи.
- По существу, применяется ли AR или MA предсказание, используется один квантователь первого этапа, что приводит к экономии памяти. В иллюстративном варианте осуществления, не предназначенном для ограничения, используется предсказание LP 16-го порядка, и параметры LP представляются в области значений ISF. Кодовая книга первого этапа является идентичной используемой в режиме 12,65 кбит/с кодера AMR-WB, где кодовая книга была разработана с использованием MA предсказания (вектор параметров LP с размерностью 16 разделяется на 2 для получения двух субвекторов с размерностью 7 и 9, и на первом этапе квантования используются две кодовые книги с 256 элементами).
- В стационарном режиме вместо MA предсказания используется AR предсказание, в частности, в полускоростном вокализованном режиме; иначе используется MA предсказание.
- В случае AR предсказания первый этап квантователя идентичен случаю MA предсказания. Однако второй этап может быть соответственно разработан и подготовлен для AR предсказания.
- Для учета указанного переключения в режиме предсказателя, блоки памяти MA и AR предсказателей обновляются каждый кадр с учетом того, что для следующего кадра могут использоваться оба, MA или AR, предсказания.
- Дополнительно, для оптимизации выигрыша в кодировании, некоторые векторы первого этапа, разработанные для MA предсказания, могут быть заменены новыми векторами, разработанными для AR предсказания. Согласно этому иллюстративному варианту осуществления, не предназначенному для ограничения, при использовании AR предсказания в кодовой книге первого этапа заменяется 28 векторов.
- Соответственно, расширенная кодовая книга первого этапа может быть сформирована следующим образом: сначала 28 векторов первого этапа, наименее используемых при применении AR предсказания, помещается в начале таблицы, затем в таблицу добавляются оставшиеся 256-28=228 векторов первого этапа, и в завершение в конце таблицы помещаются 28 новых векторов. Соответственно, длина таблицы составляет 256+28=284 векторов. При использовании MA предсказания на первом этапе используются первые 256 векторов таблицы; при использовании AR предсказания используются последние 256 векторов таблицы.
- Для обеспечения возможности взаимодействия с стандартом AMR-WB используется таблица, которая содержит соответствие между позицией вектора первого этапа в указанной новой кодовой книге и исходной позицией в кодовой книге первого этапа AMR-WB.
- Так как при использовании на стационарных сигналах AR предсказание достигает более низкой энергии ошибки предсказания, чем MA предсказание, к ошибке предсказания применяется масштабный коэффициент. В иллюстративном варианте осуществления, не предназначенном для ограничения, при использовании MA предсказания масштабный коэффициент равен 1, и при использовании AR предсказания 1/0,8. Это увеличивает ошибку AR предсказания в динамическом эквиваленте ошибки MA предсказания. Следовательно, на первой стадии для MA и AR предсказания может использоваться один квантователь.
Хотя в приведенном выше описании настоящее изобретение было описано в отношении его иллюстративных вариантов осуществления, не предназначенных для ограничения, не удаляясь от сущности и не выходя из объема настоящего изобретения указанные варианты осуществления могут быть при необходимости изменены в пределах объема приложенной формулы изобретения.
Реферат
Изобретение относится к способу и устройству для квантования параметров линейного предсказания в кодировании звукового сигнала с переменной битовой скоростью, при котором принимают входной вектор параметров линейного предсказания, классифицируют кадр звукового сигнала, соответствующий входному вектору параметров линейного предсказания, вычисляют вектор предсказания, вычисленный вектор предсказания удаляют из входного вектора параметров линейного предсказания для создания вектора ошибки предсказания, и вектор ошибки предсказания квантуют. Вычисление вектора предсказания включает в себя выбор одной из множества схем предсказания в отношении классификации кадра звукового сигнала и обработку вектора ошибки предсказания посредством выбранной схемы предсказания. Изобретение относится к способу и устройству для обратного квантования параметров линейного предсказания в декодировании звукового сигнала с переменной битовой скоростью, при котором принимают, по меньшей мере, один индекс квантования и информацию классификации кадра звукового сигнала, соответствующую индексу квантования, восстанавливают вектор ошибки предсказания посредством применения индекса по меньшей мере к одной таблице квантования, воссоздают вектор предсказания, и создают вектор параметров линейного предсказания в зависимости от восстановленного вектора ошибки предсказания и воссозданного вектора предсказания. Воссоздание вектора предсказания включает в себя обработку восстановленного вектора ошибки предсказания посредством одной из множества схем предсказания в зависимости от информации классификации кадра. Технический результат - уменьшение ошибок квантования. 6 н. и 51 з.п ф-лы, 8 ил.
Формула
Документы, цитированные в отчёте о поиске
Речевой кодер с линейным предсказанием и использованием анализа через синтез
Комментарии