Способ последующей обработки с высокой разрешающей способностью для речевого декодера - RU2199157C2
Код документа: RU2199157C2
Чертежи
Описание
Изобретение относится к способу последующей обработки для речевого декодера с целью получения высокой разрешающей способности по частоте. Такой речевой декодер предпочтительно используют в радиоприемнике для системы радиосвязи с подвижными объектами.
УРОВЕНЬ ТЕХНИКИ
При кодировании речи и звука обычно применяют способы последующей обработки в декодере для того, чтобы повысить
воспринимаемое (органолептическое) качество декодированной речи.
Способы последующей обработки, например традиционная адаптивная последующая фильтрация (постфильтрация), предназначены для обеспечения улучшений восприятия путем выделения предыскажений формантных и гармонических структур и для некоторой коррекции предыскажений формантных впадин.
В данном изобретении предлагается новый способ последующей обработки, который включает этап анализа с высокой разрешающей способностью в декодере. Этот новый способ является более общим с точки зрения уменьшения шума и улучшений речи для широкого диапазона сигналов, включая речь и музыку.
До сих пор не найдено техническое решение применительно к схеме последующей обработки для речевых или аудиодекодеров, при которой используется анализ принимаемых параметров, и спектра принимаемого сигнала для оценки более точного уровня шума кодирования в сочетании с высокоизбирательной (негармонической) частотной фильтрацией, корректирующей предысажения.
Хорошо известны формантные постфильтры (последующие фильтры) в кодерах, основанных на принципе линейного кодирования с предсказанием (ЛКП-кодерах), в которых такой фильтр выполняет свои функции, исходя из принимаемых параметров ЛКП. Он не использует точную структуру спектра и обеспечивает очень ограниченную разрешающую способность по частоте.
Хорошо известны различные типы постфильтров с линейным предсказанием и преобразованием (ЛПП-постфильтров). Такие фильтры могут лишь влиять на общую гармоническую структуру декодированного сигнала, а также, хотя и могут обеспечить высокую разрешающую способность по частоте, не влияют на негармонический локализованный шум кодирования или на искажения. Кроме того, эти фильтры приспособлены конкретно к речевым сигналам.
Известно также, что анализ декодированной речи на стороне приемника можно использовать для оценки параметров, например, в постфильтре основного тона. Так поступают, например, при линейном декодировании с кодовозбуждаемым линейным предсказанием (ЛД-КВЛП). Однако это лишь постфильтр гармонического основного тона, в котором "анализ" имеет целью только поиск гармоник основного тона. Общий анализ мест возникновения проблем действительного шума кодирования и искажений не проводится.
Были также предложены относительно избирательные по частоте "постфильтры" в смысле удаления частотных областей, не кодируемых кодером, работающим на очень низкой скорости передачи данных в битах [1].
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Во многих речевых кодерах, например основанных на принципе ЛКП, для анализа с последующим синтезом (ЛКПАПС-кодерах),
осуществляется использование критерия ошибки при поиске параметров, который имеет очень ограниченную чувствительность по частоте. Кроме того, критерий согласования сигналов во многих таких кодерах
будет ограничивать работоспособность для областей низкой энергии, например спектральных впадин, т.е. управление распределением шума в таких частотных зонах гораздо менее точное.
Когда в кодере используют взвешивание спектрального шума, происходит формирование общего спектра ошибки, т.е. шума кодирования, хотя этот процесс и ограничен разрешающей способностью по частоте фильтра со взвешиванием. Тем не менее, по-прежнему могут оставаться спектральные области, как правило в спектральных впадинах или других областях низкой энергии, с относительно высоким шумом или звуковыми искажениями, которые ограничивают воспринимаемое качество. При данной скорости передачи данных в битах, структуре кодера и входном сигнале, кодер может достигать лишь определенного уровня шума. Относительно слабая избирательность по частоте в кодере и при последующей обработке, а также ограничивающая скорость передачи данных в битах могут не влиять на зоны, в которых возникают проблемы качества, при всех типах сигналов.
Традиционный, имеющий увеличенную ширину полосы формантный ЛКП-постфильтр низкого порядка (обычно - порядка десятых), обладает относительно низкой избирательностью по частоте и не может влиять на локализованный шум или искажения.
Постфильтры гармонического основного тона могут обеспечивать высокое разрешение по частоте, но могут осуществлять только гармоническую фильтрацию, т.е. нелокализованную негармоническую фильтрацию.
Речевые и музыкальные сигналы, к примеру, имеют коренным образом отличающиеся структуры, так что нужно применять разные стратегии последующей обработки. Этого нельзя достичь, если при последующей обработке не анализируют принимаемый сигнал и не используют селективные фильтры с высокой разрешающей способностью. В настоящее время это не делается.
Задача данного изобретения состоит в том, чтобы получить способ последующей обработки с высокой разрешающей способностью по частоте для декодированного сигнала из устройства декодирования речи или звука, по меньшей мере, уменьшающий нежелательное влияние негармонических составляющих и иного шума кодирования в спектре декодированных частот.
Декодированный сигнал анализируют для нахождения вероятных частотных зон с шумом кодирования. Анализ с высокой разрешающей способностью осуществляют в спектре декодированного речевого сигнала и на основе знаний о свойствах алгоритма кодирования речи, а также о параметрах из речевого декодера. Результатом анализа является стратегия фильтрации в зависимости от частотных зон, в которых сигнал подвергается коррекции предыскажений для уменьшения шума кодирования и повышения общего воспринимаемого качества кодированной речи.
При осуществлении способа, соответствующего изобретению, применяют преобразование, которое дает описание спектра с высоким разрешением по частоте. Это можно реализовать, используя преобразование Фурье или любое другое преобразование со строгой корреляцией с содержанием спектра. Продолжительность преобразования может быть синхронизирована с длиной кадра декодера (например, для минимизации задержки), но должна обеспечивать достаточно высокую разрешающую способность по частоте.
После преобразования осуществляют анализ содержимого спектра и атрибутов декодера для того, чтобы идентифицировать проблемные зоны, в которых способ кодирования обусловил внесение шума звуковой частоты или искажений. При анализе также используют модель восприятия слуха человека. Информация из декодера и знания об алгоритме кодирования помогают оценить величину шума кодирования и его распределение.
Информацию, полученную на этапе анализа, и модель восприятия используют для синтеза фильтра в два
этапа:
определяют частотные зоны, подлежащие коррекции предыскажений;
определяют степень фильтрации в каждой зоне.
Это дает фильтр-кандидат, который потом можно усовершенствовать в зависимости от динамических свойств. Например, характеристика фильтра может быть неудовлетворительной, так как он создает искажения при использовании после предварительных фильтров. Кроме того, можно учитывать динамические свойства декодированного сигнала, ограничивая степень изменения фильтрации по сравнению с тем, насколько изменяется декодированный сигнал.
Описанная выше стратегия синтеза фильтра обеспечивает очень избирательную по частоте постфильтрацию (последующую фильтрацию), которая сосредоточена в адаптивно подавляемых проблемных зонах. Она отличается от применяемой в настоящее время постфильтрации общего назначения, которая всегда применяется без конкретного анализа. Более того, этот способ обеспечивает различную фильтрацию для различных типов сигналов, например - речи и музыки.
Фильтрацию декодированного сигнала нужно осуществлять с высокой разрешающей способностью по частоте. Фильтр можно реализовать, например, в частотной области, а на его выходе можно осуществить обратное преобразование. Однако можно использовать любую альтернативную реализацию процесса фильтрации.
При альтернативной реализации предложенного решения, предусматривающей малую задержку, фильтрацию можно осуществлять, используя лишь результат анализа и синтеза фильтра, полученный в предыдущих кадрах. Тогда можно сделать задержку, вносимую этой реализацией решения, очень малой.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Способ, соответствующий данному изобретению, будет подробно описан со
ссылками на прилагаемые чертежи, где
фиг. 1 изображает блок-схему различных функциональных блоков для осуществления способа в соответствии с одним конкретным вариантом данного изобретения,
фиг. 2 изображает блок-схему другого конкретного варианта осуществления способа в соответствии с данным изобретением,
фиг. 3 изображает более подробную блок-схему анализа и синтеза
фильтра, показанного на фиг.1 и 2,
фиг. 4 изображает график, который иллюстрирует спектр частот декодированного сигнала и принципы последующей обработки в соответствии с данным
изобретением.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ КОНКРЕТНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Нижеследующее описание иллюстрирует рабочую реализацию вышеописанного изобретения. Оно предназначено
для использования в кодере с кодовозбуждаемым линейным предсказанием (КВЛП-кодере). Такие кодеры обычно генерируют шум в зонах низкой энергии спектра и, в частности, во впадинах между пиками, которые
имеют комплексную негармоническую связь, как, например, в музыке. Нижеследующие положения и фиг.3 иллюстрируют подробную реализацию.
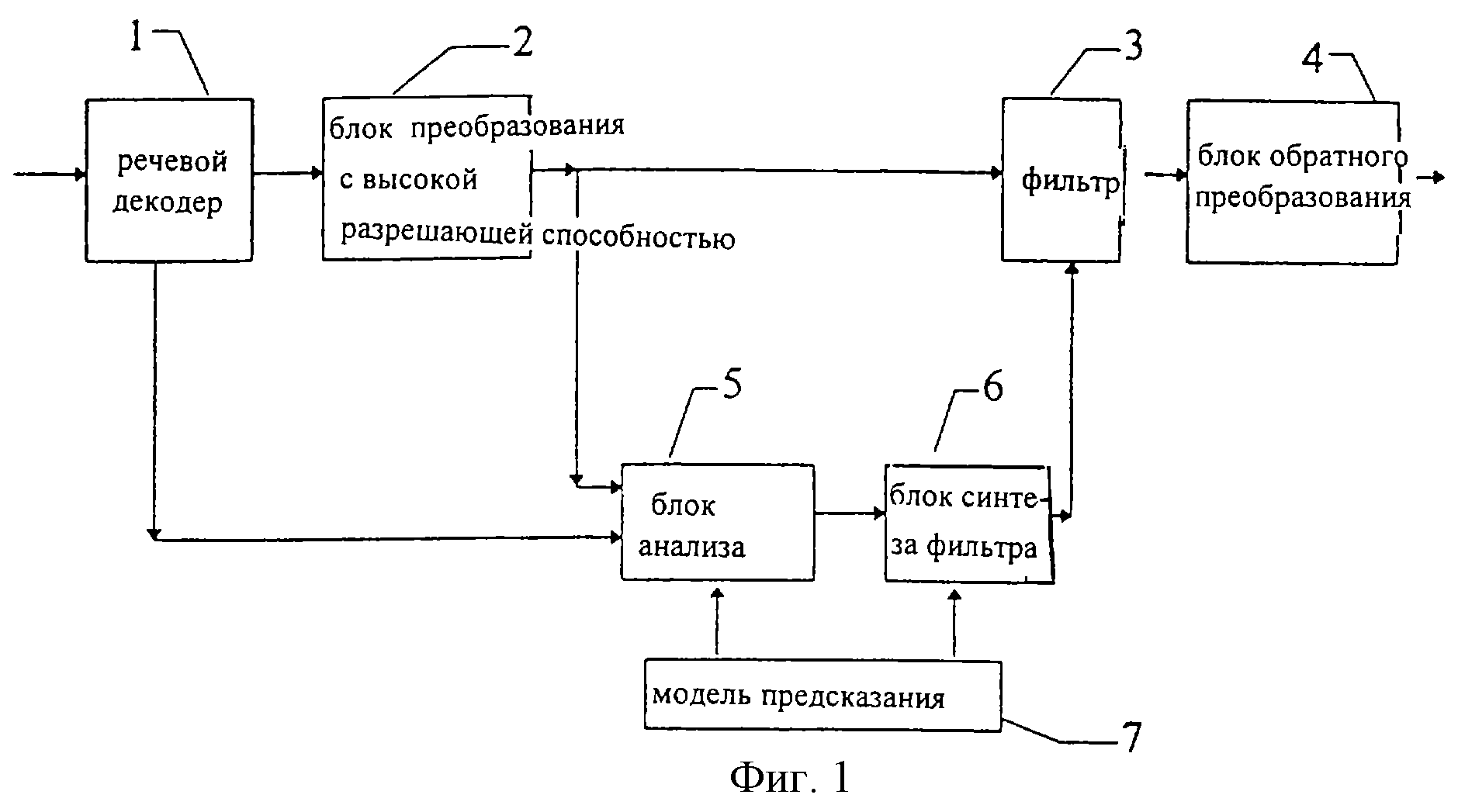
На фиг.1 изображена блок-схема различных функций, выполняемых данным изобретением. Речевой декодер 1, например, в радиоприемнике системы телефонной связи с подвижными объектами декодирует входящий демодулированный радиосигнал, в котором параметры для декодера 1 переданы через радиосреду.
На выходе декодера получают декодированный речевой сигнал. Спектр частот декодированного сигнала имеет определенные характеристики, зависящие от передачи и характеристик декодирования речевого декодера 1.
Декодированный сигнал во временной области преобразуют путем быстрого преобразования Фурье, БПФ, осуществляемого блоком 2, в результате чего получают спектр частот декодированного сигнала. Этот спектр частот вместе с частотными характеристиками речевого декодера анализируют с помощью блока 5, а результат анализа подают в блок 6 синтеза фильтра. Этот блок 6 синтеза фильтра выдает информационный сигнал в постфильтр 3. Этот фильтр осуществляет постфильтрацию спектра частот речевого сигнала для того, чтобы исключить или, по меньшей мере, уменьшить влияние составляющих шума в спектре декодированного речевого сигнала. Сигнал спектра из фильтра 3, не содержащий возмущающие частотные составляющие, или, по меньшей мере, содержащий значительно уменьшенные возмущающие составляющие, подают в блок 4, где осуществляется преобразование, обратное тому, которое осуществляется в блоке 2.
Анализ и синтез фильтра можно дополнить моделью восприятия 7, которая влияет на фильтрацию (блок 3) спектра декодированного речевого сигнала так, как требуется. Эта модель не является существенной частью данного способа и поэтому в дальнейшем не описывается.
Вообще говоря, содержание спектра декодированного сигнала анализируют следующим образом, чтобы получить меры, которые используются для идентификации областей, подлежащих коррекции предыскажений.
Оценивают огибающую спектра амплитуд, чтобы выделить общую форму спектра из точной структуры с высокой разрешающей способностью. Эту огибающую можно оценивать с помощью процесса выбора пиков, используя скользящее окно достаточной ширины.
Во избежание пульсации, можно провести сглаживание спектра амплитуд.
Получаемые два вектора используют для идентификации достаточно узких спектральных впадин определенной глубины. Это дает зоны-кандидаты, в которых можно применять фильтрацию.
Можно также анализировать спектр с помощью модели восприятия для того, чтобы получить порог маскировки шума.
Для того чтобы получить вероятное распределение и уровень шума или искажений, внесенных конкретным кодером при эксплуатации, анализируют атрибуты из декодера. Эти атрибуты зависят от алгоритма кодирования, но могут включать в себя, например, форму спектра, формирование шума, фильтрацию со взвешиванием оцененной ошибки, коэффициенты усиления предсказания, например при ЛКП и ЛПП, распределение битов, и т.д. Эти атрибуты характеризуют поведение алгоритма кодирования и рабочую характеристику при кодировании конкретного сигнала, о котором идет речь.
Вся информация о полученном кодированном сигнале или ее части выдается (выдаются) в результате анализа 5 и используется (используются) для синтеза 6 фильтра.
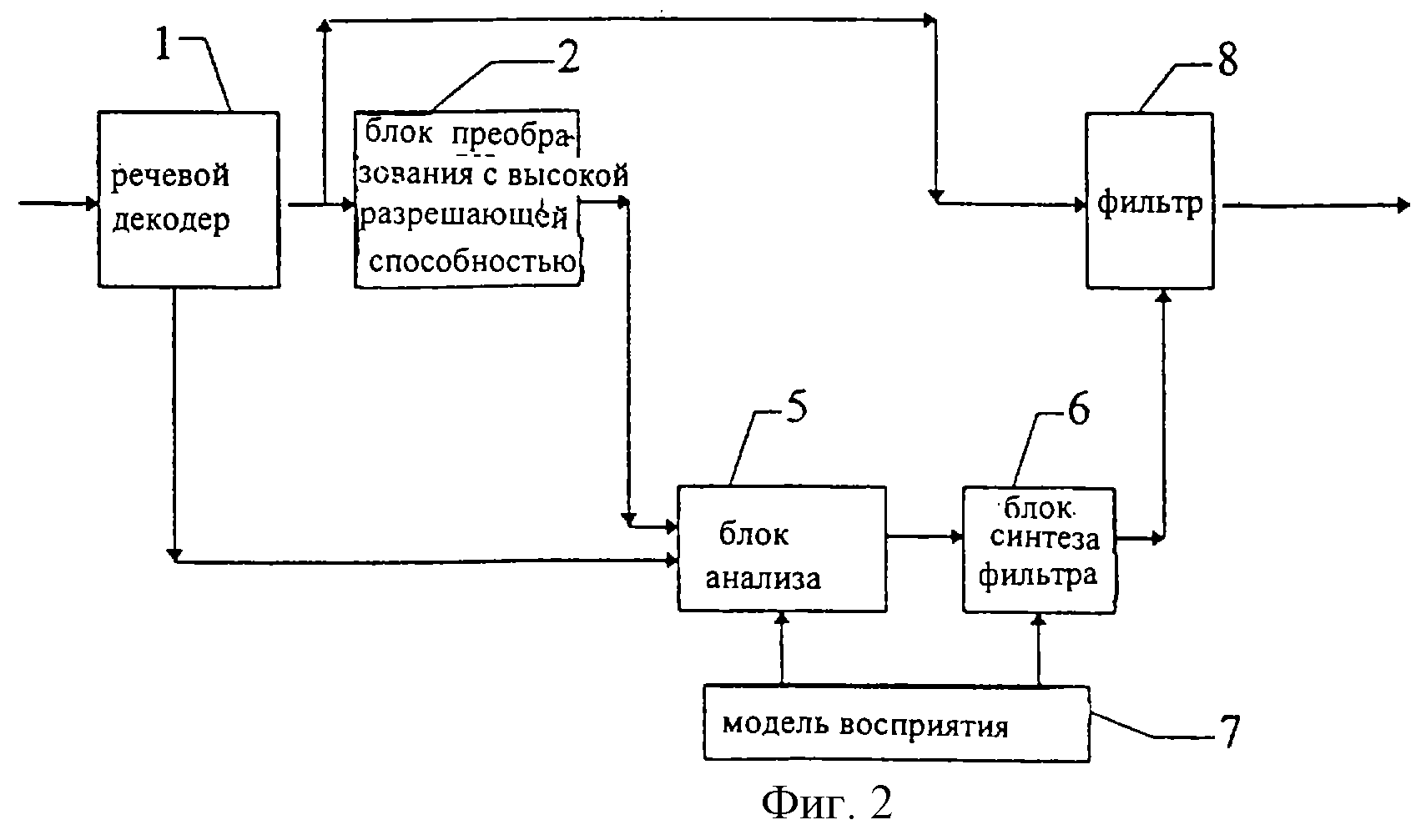
На фиг.2 изображен другой конкретный вариант осуществления способа последующей обработки. Отличие от фиг. 1 заключается в том, что анализ 5 и синтез 6 фильтра осуществляют в частотной области, тогда как постфильтрацию 8 декодированного речевого сигнала осуществляют во временной области. Выход блока 6 синтеза фильтра выдает информационный/управляющий сигнал, но теперь в фильтр 8 во временной области, а не в указанный выше фильтр 3 в частотной области.
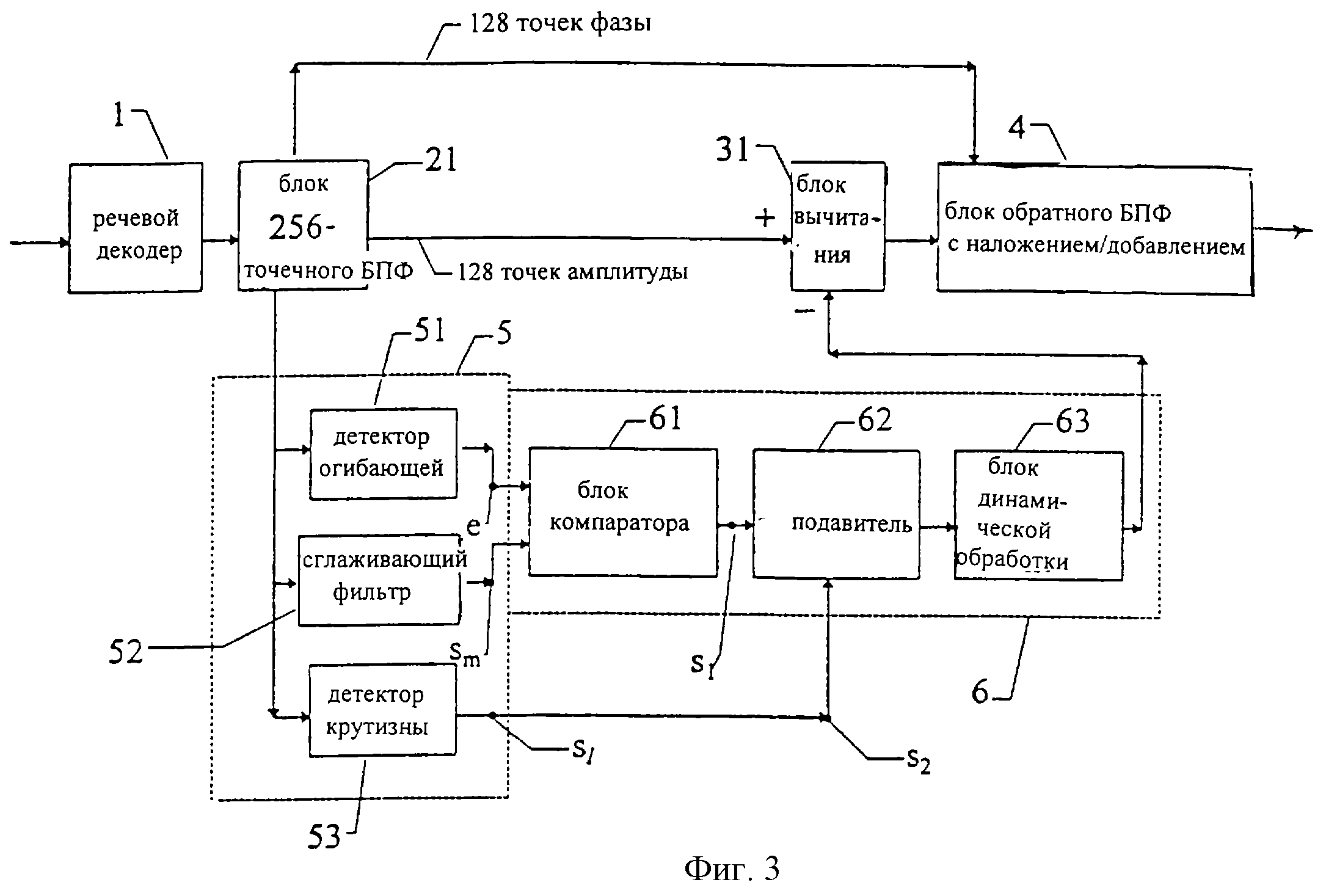
Фиг. 3 изображает более подробную блок-схему, чем фиг.1 и 2, для иллюстрации предлагаемого способа.
Выход речевого декодера, например в радиоприемнике, соединяют с функциональным блоком 21, осуществляющим быстрое 256-точечное преобразование Фурье (БПФ). Затем через каждые 128 выборок осуществляют 256-точечное БПФ с использованием окна Хеннинга (Hanning). Таким образом, через каждые 128 выборок обрабатывается новый блок. Наряду с спектром фаз (который не обрабатывается), вычисляют логарифмическую амплитуду БПФ.
Анализ (блок 5) заключается в следующем.
Оценивают огибающую спектра логарифмических амплитуд путем вычисления каждой частотной точки как максимума спектра логарифмических амплитуд в пределах скользящего окна длиной 200 Гц в каждом направлении. Осуществляют выбор пиков на результирующем векторе путем нахождения частотных точек, в которых спектр логарифмических амплитуд равен вектору максимальных значений. Осуществляют линейную интерполяцию между пиками для получения вектора огибающей.
Осуществляют сглаживание спектра логарифмических амплитуд, принимая максимум в пределах скользящего окна длиной 75 Гц в каждом направлении.
Оценивают крутизну спектра.
Синтез фильтра (блок 6) заключается в том, что определяют зоны, где сглаженная кривая логарифмического спектра ниже, чем кривая огибающей логарифмических амплитуд, на величину, превышающую некоторое конкретное значение. Эти зоны подавляют, если они соответствуют более чем одной последовательной частотной точке. Далее, если впадина глубже, чем определенное высокое значение, подавление расширяют с тем, чтобы распространить его на всю зону между пиками. Степень спектрального подавления в логарифмической области в каждой частотной точке, где оно осуществляется, определяют по крутизне таким образом, что зоны низкой энергии получают большее подавление. Используемая формула является линейной в логарифмической области, с отсутствием подавления на протяжении, по меньшей мере, 1 кГц у нижнего конца подавления (т. е. при малой крутизне первый 1 кГц не подавляют, а при большой крутизне поступают по-другому). Так делают из-за характера КВЛП-кодера, который склонен генерировать больший шум в случае частотных зон низкой энергии.
Квадрат расстояния спектра логарифмических амплитуд между текущим и предыдущим спектром вычисляют с одной и той же мерой для векторов подавления. Если отношение значений для вектора подавления и самого спектра превышает определенное значение (т. е. подавление претерпевает относительно значительное изменение по сравнению со спектром сигнала), то вектор подавления сглаживают путем простой замены его средним для текущего и предыдущего подавления.
Операцию фильтрации (блок 31) осуществляют путем простого вычитания степени подавления, определенной в предыдущей точке из спектра логарифмических амплитуд декодированного сигнала.
Осуществляют обратное преобразование (блок 4) путем восстановления сначала преобразования Фурье, исходя из спектра логарифмических амплитуд, полученного в результате фильтрации, и спектра фаз, полученного непосредственно из преобразования. Отметим, что, во избежание искажений из-за разрывов между кадрами анализа, выполняют процедуру наложения и добавления.
Блок анализа 5, показанный на фиг.1, состоит в этом конкретном варианте осуществления из детектора 51 огибающей, сглаживающего фильтра 52 и детектора 53 крутизны.
Из детектора огибающей получают сигнал огибающей
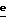
Блок 6 синтеза фильтра состоит в этом конкретном варианте осуществления из блока 61 компаратора, блока 62, формирующего значение подавления, и блока 63 динамической обработки.
Оба сигнала е и Sm из блока анализа 5 объединяют в блоке 61 компаратора. Разность между сигналами е и Sm сравнивают с фиксированным порогом Тh в блоке 61 компаратора, чтобы определить нежелательную формантную впадину и связанный с ней интервал частот. Получается сигнал S1, который содержит информацию о них.
Блоком 62, формирующим значение подавления, управляет сигнал S2, полученный из блока 53 крутизны в блоке анализа 5. Сигнал S2 указывает крутизну и в зависимости от того, больше или меньше значение крутизны, осуществляется подавление в спектре частот, определяемом сигналом S1.
Блок 63 динамической обработки осуществляет адаптацию подавления от одного кадра к другому, так что внезапное увеличение подавления, указываемое в выходном сигнале из блока 62, формирующего значение подавления, не происходит.
Фильтр 3, показанный на фиг. 1, в конкретном варианте осуществления, соответствующем фиг. 3, является фильтром 31 (соответствующим фильтру 3 на фиг. 1), который осуществляет спектральное вычитание. Значение сигнала, полученное из блока 63 динамической обработки, является значением подавления и затем вычитается из характеристики спектра частот, полученной из блока 21 БПФ в пределах интервалов частот, определяемых сигналом S1, как указано выше. Результатом будет то, что впадины в спектре частот из речевого декодера 1 уменьшаются до требуемого значения перед окончательным обратным преобразованием в блоке 4.
В зависимости от крутизны S1 характеристики спектра частот получают различные средние значения амплитуд спектра. Крутизна дает высокие значения амплитуд в начале спектра частот, где речевой декодер 1 является "сильным", т. е. способен декодировать правильно, независимо от возможных составляющих шума в спектре. При более высоких частотах, когда крутизна обуславливает меньшие значения амплитуд характеристики спектра, важнее осуществлять хорошее подавление впадин в такой характеристике.
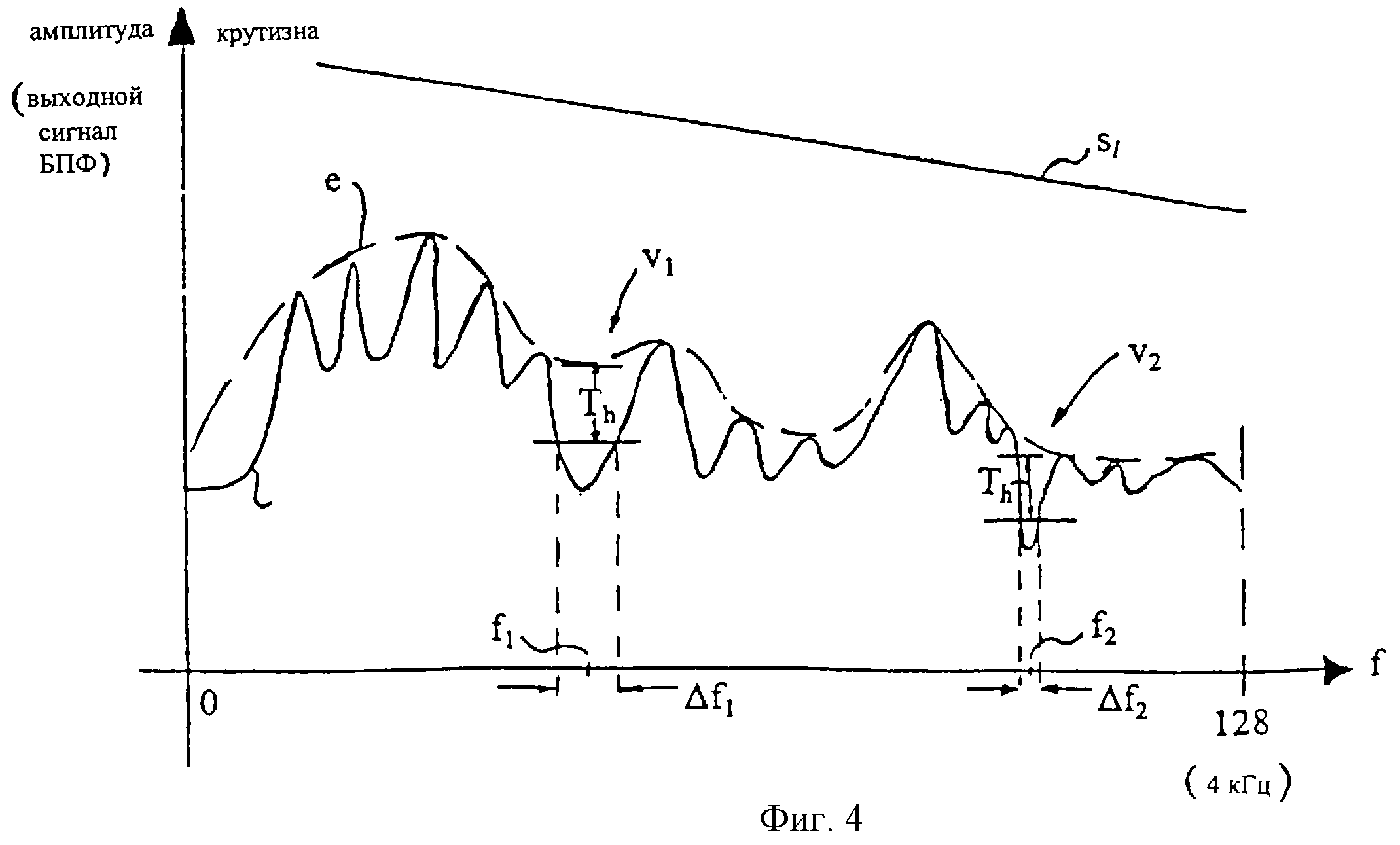
Для иллюстрации этого предназначен график частот, показанный на фиг.4. Сглаженный спектр Sm частот и его огибающая е сравниваются, как упоминалось выше, а их разность сравнивается с фиксированным порогом Тh. В данном примере это дает, по меньшей мере, две различные частотные зоны f1 и f2 около частот f1 и f2 соответственно, для которых впадины V1 и V2 считаются возмущающими, например, вследствие негармонических составляющих/возмущающего шума, который речевой декодер не может обрабатывать. На фиг. 4 проиллюстрированы только эти две частотные зоны, хотя несколько других таких зон есть как в нижней, так и в верхней части спектра частот.
Сигнал S1 из компаратора несет информацию о том, какие частотные зоны f1, f2, ...подлежат подавлению, а сигнал S2 из детектора крутизны несет информацию о том, насколько большое подавление следует применить. Как упоминалось выше, если обнаруженная частотная зона находится в начале спектра, как например f1, подавление может быть малым, тогда как для зоны f2, которая находится в верхней полосе, подавление должно быть больше.
Блок 63 динамической обработки адаптирует подавление от одного речевого блока к другому. Предпочтительно, входящий речевой блок (128 точек) обрабатывают с наложением, так что когда половина речевого блока обработана в блоках 5 и 6, начинается обработка нового последующего речевого блока в блоке анализа 5.
Таким образом, блок 63 динамической обработки выдает сигнал, который представляет значения коррекции, вычитаемые из характеристики спектра, которая создается в блоке вычитания 31, соответствующем фильтру 3 на фиг.1. Улучшенный спектр частот речевого сигнала после этого подвергается обратному преобразованию Фурье в блоке 4, как описывалось выше в связи с накладываемыми речевыми блоками.
Этот способ можно также применять к сигналу внутри речевого или аудио-декодера. Такой сигнал затем будет обработан с помощью этого способа, а потом дополнительно использован декодером для получения декодированного речевого или аудиосигнала. Примером этого является сигнал возбуждения в ЛКП-декодере, который можно обрабатывать с помощью предлагаемого сигнала перед восстановлением декодированной речи с помощью синтезирующего фильтра с линейным предсказанием.
Тем фактом, что способ обеспечивает коррекцию предыскажений частотных зон в декодированном сигнале, можно воспользоваться при кодировании, так что попытки кодирования можно переадресовывать из зон, подвергнутых коррекции предыскажений. Например, для того, чтобы осуществить это, фильтр со взвешиванием ошибки ЛКПАПС-кодера можно модифицировать для уменьшения взвешивания ошибки в зонах, подвергнутых коррекции предысажений. Таким образом, способ можно использовать вместе с модифицированным кодером, в котором учитывается последующая обработка, вносимая этим способом.
Достоинства изобретения
Возможность подавлять шум кодирования и искажения в локализованных частотных зонах с
высокой разрешающей способностью. Это, в частности, полезно для сложных сигналов, например музыки. Способ значительно повышает качество звука для сложных сигналов при одновременном повышении качества
чистой речи, хотя и в более ограниченной степени.
Литература
1. Д. Сен и У.Х.Холмс, "ОУВПКССЧЛП - Ощутимо улучшенное, возбуждаемое посредством кодового словаря случайных чисел
линейное предсказание", в сборнике "Труды ИИЭР (Института инженеров по электротехнике и радиоэлектронике). Кодирование речи в технических целях", община Адель, Квебек, Канада (D.Sen and W.H.Holmes,
"PERCELP - Perceptually Enhanced Random Codebook Excited Linear Prediction", in Proc. IEEE Workshop Speech Coding. Ste. Adele, Que., Canada), c. 101-102, 1993.
Реферат
Изобретение относится к речевым декодерам, применяемым в радиоприемниках систем радиосвязи с подвижными объектами. Техническим результатом является уменьшение нежелательного влияния негармонических составляющих и иного шума кодирования в спектре декодированных частот. Для этого способ включает следующие этапы: преобразуют декодированный сигнал во временной области в сигнал в частотной области посредством преобразования с высокой разрешающей способностью по частоте (быстрого преобразования Фурье, БПФ); анализируют распределение энергии указанного сигнала в частотной области по всей его частотной зоне для нахождения возмущающих частотных составляющих и назначения приоритета таким частотным составляющим, которые находятся в верхней части спектра частот; находят степень подавления для указанных возмущающих частотных составляющих на основании указанного назначения приоритета; управляют последующей фильтрацией (постфильтрацией) указанного преобразования в зависимости от указанного нахождения и осуществляют обратное преобразование преобразования, подвергнутого постфильтрации, для получения подвергнутого постфильтрации декодированного речевого сигнала во временной области. 2 с. и 8 з.п. ф-лы, 4 ил.
Комментарии