Способ распределенного хранения данных с подтвержденной целостностью - RU2758943C1
Код документа: RU2758943C1
Чертежи



Описание
Область техники, к которой относится изобретение
Предлагаемое изобретение относится к области радио- и электросвязи, а именно к области способов и систем распределенного хранения информации.
Уровень техники
а) Описание аналогов
Известны способы хранения данных, обеспечение целостности (защита от утраты) в которых осуществляется за счет средств резервного копирования данных с использованием программно-аппаратной или программной реализации, например, технологии RAID (Redundant Array of Independent Disks) [Патент США №7392458 публ. 24.06.2008; Патент США №7437658 публ. 14.10.2008; Патент США №7600176 публ. 06.10.2009; Заявка на патент США №20090132851 публ. 21.05.2009; Заявка на патент США №20100229033 публ. 09.09.2010; Заявка на патент США №201101145677 публ. 16.06.2011; Заявка на патент США №20110167294 публ. 07.07.2011].
Недостатками данных способов являются:
- достаточно сложная процедура восстановления утраченных данных;
- распределение данных между узлами хранения (дисками), которые реализованы как единый конструктивный блок (RAID-массив).
Известен способ [Патент РФ №2502124 С1 публ. 20.12.2013] распределенного хранения данных, обеспечение целостности в котором основывается на методах резервирования, когда на базе нескольких узлов хранения (жестких дисков, флэш-накопителей и т.п.) строится запоминающее устройство (хранилище), устойчивое к утрате данных даже при выходе из строя некоторого количества носителей, образующих запоминающее устройство (хранилище).
Недостатками данного способа являются:
- фиксированный уровень восстанавливаемых данных при единовременном возникновении отказов и сбоев;
- отсутствие механизмов обеспечения безопасности (конфиденциальности) хранимой информации.
Известны способы комплексной защиты информации, используемые как в системах хранения, выполненных в едином конструктивном исполнении, так и в распределенных информационных системах [Заявка на патент США №20050081048 А1 публ. 14.04.2005; Заявка на патент США №8209551 В2 публ. 26.06.2012], для которых требования безопасности информации: конфиденциальность, целостность и доступность - обеспечиваются последовательным применением средств криптографического преобразования данных и технологий их резервного копирования.
Недостатками данных способов являются:
- характерная для многих режимов работы средств криптографической защиты информации конструктивная (алгоритмическая) способность к размножению ошибок, когда один или более ошибочных бит в блоке шифртекста оказывает(ют) влияние при расшифровании последующих блоков данных;
- высокий уровень избыточности хранимой информации.
б) Описание ближайшего аналога (прототипа)
Наиболее близким по своей технической сущности к заявленному техническому решению и принятым за прототип является способ и система, описанные в [Патент РФ №2680350 С2 публ. 10.07.2018].
В рассматриваемом способе-прототипе обеспечение целостности информации в системе распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации осуществляется следующим образом.
Система распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации состоит из k блоков обработки данных с соответствующими узлами хранения данных, включая файлы, подлежащие хранению. Блок управления отслеживает доступность узлов хранения данных, их местоположение, объемы допустимой памяти узлов хранения данных с блоком восстановления данных. Взаимодействие в системе распределенного хранения восстанавливаемых данных осуществляется посредством локальной или беспроводной сети. Физическая утрата (потеря) любого узла хранения данных (деградация системы распределенного хранения восстанавливаемых данных) или его неспособность к соединению с сетью в условиях преднамеренных (имитирующих) действий злоумышленника приведет к частичной потере или полной утрате информации. При этом распределенное по узлам хранения данных множество информационных данных с вычисленными избыточными данными позволяет выполнить блоком восстановления данных полное восстановление утраченных файлов данных даже при отказе одного или более узлов хранения данных. Недоступный узел хранения данных может быть заменен другим узлом хранения данных, при этом доступные узлы хранения данных совместно с введенным новым узлом хранения данных формируют множество информационных и избыточных данных для введенного узла хранения данных и осуществляют их повторное распределение (реконфигурация системы). При этом совокупность распределенных узлов хранения данных рассматривается как единая система запоминающих устройств, предусматривающая введение избыточности в сохраняемую информацию.
Схема, поясняющая сущность работы способа-прототипа, представлена на фигуре 1.
Недостатком известного способа является отсутствие механизмов восстановления целостности информации при навязывании (имитации) злоумышленником ложной информации.
Раскрытие изобретения
а) Технический результат, на достижение которого направлено изобретение
Целью заявляемого технического решения является обеспечение информационной устойчивости системы распределенного хранения информации к преднамеренным имитирующим воздействиям злоумышленника.
б) Совокупность существенных признаков
Поставленная цель достигается тем, что в известном способе распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации, заключающемся в том, что каждый из доступных блоков обработки данных с соответствующими узлами хранения данных содержит множество данных, сформированных из файлов, соответствующих блокам обработки данных с узлами хранения данных, при этом множество данных предварительно подвергается процедуре блочного шифрования с нелинейными биективными преобразованиями, а сформированное множество блоков криптограмм блоков обработки данных с узлами хранения данных распределяется между доступными узлами хранения данных, в которых посредством методов многозначного помехоустойчивого кодирования формируется соответствующее множество избыточных данных, далее поступившие от других блоков обработки данных с узлами хранения данных блоки криптограмм удаляются с целью сокращения общей избыточности, при этом сформированное множество избыточных данных с блоками криптограмм блока обработки данных с узлом хранения данных, осуществлявшего их формирование, используется для восстановления утерянных файлов данных, при этом блок восстановления данных получает информацию от блока управления в отношении того, какие блоки обработки данных с соответствующими узлами хранения данных в настоящий момент доступны и, соответственно, имеют множество информационных и избыточных данных файла, затем блок восстановления данных получает множество информационных и избыточных данных от указанных блоков обработки данных с узлами хранения данных, блок восстановления данных выполняет полное восстановление утраченных файлов данных, данные, восстановленные блоком восстановления данных, совместно с данными доступных блоков обработки данных с соответствующими узлами хранения данных передаются на вновь введенный блоком управления блок обработки данных с узлом хранения данных для формирования блоков избыточных данных, в представленном же способе совокупность узлов хранения системы распределенного хранения данных разбивается на множество локальных подгрупп, в рамках каждой подгруппы на узлах хранения устанавливаются весовые коэффициенты (например, в зависимости от первоочередности решаемой задачи или важности сохраняемых данных), на основании которых в подгруппах определяются «ведущие» узлы хранения (например, по минимальному значению веса), осуществляющие взаимодействие между подгруппами. Новым является то, что в каждом узле хранения данных локальной подгруппы от файла данных ƒ формируются блоки шифртекста и избыточные блоки данных подвергающиеся процедуре блочного шифрования с нелинейными биективными преобразованиями, что путем рекурсивного сдваивания информационного и избыточного блоков шифртекста на узле хранения формируется промежуточный блок данных, который поступает «ведущему» узлу хранения. Новым является то, что с другого узла хранения локальной подгруппы, сформированный промежуточный блок данных поступает «ведущему» узлу хранения и обобщается путем рекурсивного свдваивания с поступившим промежуточным блоком данных. Новым является то, что данные «ведущего» узла хранения подвергаются процедуре блочного шифрования с нелинейными биективными преобразованиями, сформированный блок шифртекста совместно с поступившими обобщенными блоками данных узлов хранения данных локальной подгруппы, а также с блоками шифртекста поступивших от других «ведущих» узлов хранения, используя методы многозначного помехоустойчивого кодирования, формируют последовательность из r≥1 избыточных блоков данных, которые подвергаются процедуре блочного шифрования с нелинейными биективными преобразованиями, при этом блоки шифртекста других «ведущих» узлов хранения удаляются. Новым является то, что сформированная совокупность блоков шифртекста и избыточных блоков шифртекста «локальных» подгрупп и «ведущих» узлов хранения используется для исправления искажений, возникающих в условиях преднамеренных воздействий злоумышленника (в результате преднамеренного несанкционированного изменения данных) и восстановления утраченных данных (обеспечение целостности) на различных уровнях обработки информации.
в) Причинно-следственная связь между признаками и техническим результатом
Благодаря новой совокупности существенных признаков в способе реализована возможность:
- выполнить имитоустойчивое перекодирование структуры хранимых данных, посредством чего реализовать процедуру обнаружения преднамеренных (имитирующих) воздействий злоумышленника;
- обеспечить подтвержденную целостность в рамках всей системы за счет восстановления информации, подвергнутой преднамеренным (имитирущим) воздействиям злоумышленника;
- обеспечить подтвержденную целостность в рамках всей системы за счет восстановления утерянной информации при физической утрате некоторой заранее установленной предельной численности узлов хранения данных;
- осуществлять реконфигурацию системы, равномерно перераспределяя хранимую информацию с соответствующими избыточными данными по узлам хранения данных при переполнении предельно допустимого объема памяти узла хранения данных или его физической утрате.
Доказательства соответствия заявленного изобретения условиям патентноспособности «новизна» и «изобретательский уровень»
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующие совокупности признаков, тождественных всем признакам заявленного технического технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентноспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта показали, что они не следуют явными из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обуславливающих тот же технический результат, который достигнут в заявленном способе. Следовательно, заявленное изобретение соответствует уровню патентноспособности «изобретательский уровень».
Краткое описание чертежей
Заявленный способ поясняется чертежами, на которых показано:
- фиг. 1 - изображена схема, поясняющая сущность работы способа-прототипа;
- фиг. 2 изображена схема организации взаимодействия (соединения) двухуровневого «модуля» РСХИ;
- фиг. 3 изображена схема структурных компонент блока хранения данных и порядок их взаимодействия;
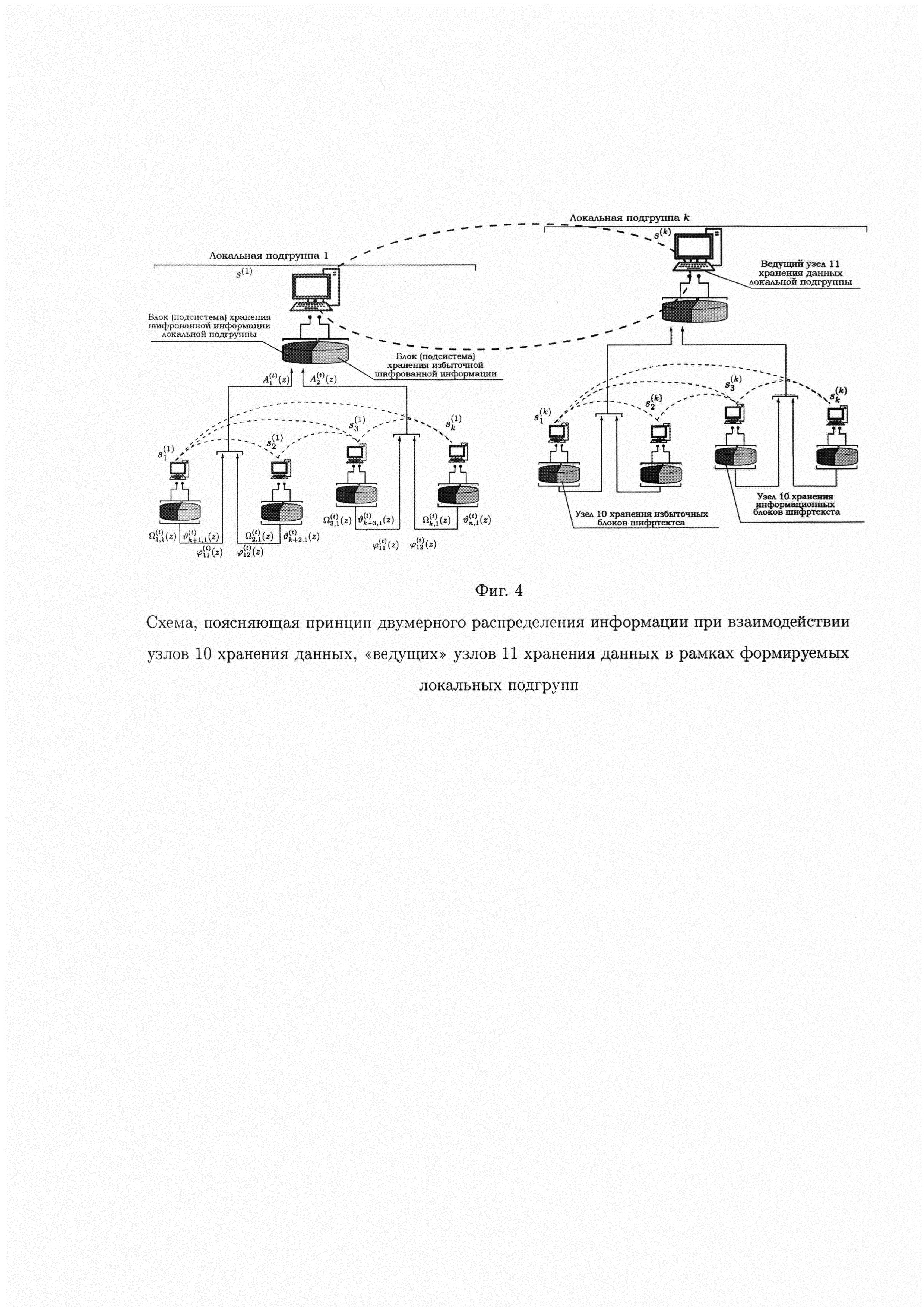
- фиг. 4 изображена схема, поясняющая принцип двумерного распределения информации при взаимодействии узлов 10 хранения данных, «ведущих» узлов 11 хранения данных в рамках формируемых локальных подгрупп.
Осуществление изобретения
Структура распределенной системы хранения информации (РСХИ) в рамках рассматриваемого способа соответствует признакам многоуровневых систем. Из теории многоуровневых систем известно [Месарович М.Д, Мако Д., Катахара И. Теория иерархических многоуровневых систем. М.: Мир, 1973. 344 с.], что простейшей системой такого типа, в которой проявляются все наиболее существенные свойства многоуровневых систем, является двухуровневая иерархическая система. При этом более сложные системы могут быть построены из двухуровневых систем как из модулей. Поэтому рассмотрим только двухуровневый «модуль» РСХИ, который состоит из «ведущего» узла 11 хранения данных, локальной подгруппы узлов 10 хранения данных (ведомых), причем число последних желательно должно быть четным, сети 12, обеспечивающей взаимодействие узлов 10 хранения данных между собой и с «ведущим» узлом 11 хранения данных. Схема организации взаимодействия (соединения) двухуровневого «модуля» РСХИ представлена на фигуре 2.
Состав и структура «ведущего» и ведомых узлов хранения данных являются идентичными и включают: блок 10(11).1 ввода данных, блок 10(11).2 приема данных, подсистему 10(11).3 управления, подсистему 10(11).4 криптокодовой защиты информации, блок 10(11).5 передачи данных, блок 10(11).6 хранения данных. Схема структурных компонент блока хранения данных и порядок их взаимодействия, представлена на фигуре 3.
В момент времени t в условиях деструктивных (имитирующих) воздействий злоумышленника структура указанного двухуровневого «модуля» РСХИ включает: локальные подгруппы



Физическая утрата (потеря) любого узла 10 хранения данных локальной подгруппы (деградация РСХИ), неспособность к соединению с сетью 12, обусловленная преднамеренными (имитирующими) действиями злоумышленника, приведет к частичной потере или полной утрате информации. При этом распределенное по узлам 10 хранения данных множество информационных данных с вычисленными избыточными данными позволяет «ведущим» узлам 11 хранения выполнить полное восстановление утраченных файлов данных даже при отказе одного или более узлов 10 хранения данных локальных подгрупп.
Недоступный узел 10 хранения данных локальной подгруппы может быть заменен другим узлом 10 хранения данных, введенным «ведущим» узлом 11 хранения данных. При этом доступные узлы 10 хранения данных, а также «ведущие» узлы 11 хранения данных совместно с введенным новым узлом 10 хранения данных выполняют процедуру формирования множества информационных и избыточных данных и повторного распределения сформированной информации, выполняется реконфигурация системы. При этом совокупность распределенных узлов 10 хранения данных локальных подгрупп с «ведущими» узлами 11 хранения данных рассматривается как единая система запоминающих устройств, предусматривающая введение избыточности в сохраняемую информацию. Сформированные узлами 10 хранения данных локальных подгрупп избыточные блоки данных образуют уровень локальной избыточности, в тоже время «ведущие» узлы 11 хранения данных формируют уровень глобальной избыточности.
В одном варианте исполнения способ распределенного хранения данных с подтвержденной целостностью может быть реализован с использованием модулярных полиномиальных кодов (МПК).
Математический аппарат МПК основывается на фундаментальных положениях Китайской теоремы об остатках для многочленов [Mandelbaum D.M. On Efficient Burst Correcting Residue Polynomial Codes // Information and control. 1970. 16. p. 319-330). Пусть






где
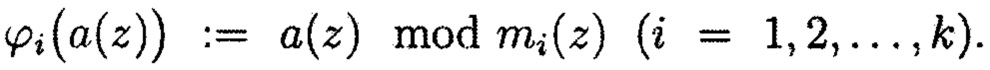

где




тогда получим расширенный МПК - множество вида:

где





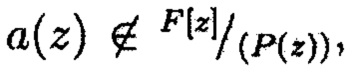




где ς - кодовое пространство. Минимальное кодовое расстояние dmin связано с корректирующими способностями расширенного МПК. Так как два кодовых слова отличаются по крайней мере в dmin вычетах, то невозможно изменить одно кодовое слово на другое путем замены dmin - 1 или меньшего количества вычетов. Таким образом, расширенный МПК может гарантированно обнаружить любые

ошибочных вычетов. Если b наибольшее целое число, меньшее или равное

то для b или меньшего числа ошибочных вычетов результирующее кодовое слово остается ближе к исходному, что позволяет расширенному МПК гарантированно исправлять b ошибочных вычетов.
С целью обеспечения необходимого уровня конфиденциальности информации сформированный набор данных W(z) (файл ƒ) узла 10 хранения данных локальной подгруппы поступает в блок 10.1 ввода данных, где разбивается на блоки фиксированной длины




где кe,i - итерационные ключи зашифрования.
Длина блока данных определяется используемым алгоритмом шифрования, например, ГОСТ 34.12-2015 с блоками 64, 128 бит соответственно.
Подсистема 10.3 управления узла 10 хранения данных на основании связности сети 12 в момент времени t осуществляет распределение блоков шифртекста, выработанных


Полученную совокупность информационных блоков шифртекста Ωi(z) (i=1, 2, …, k)
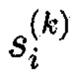

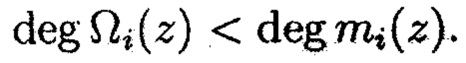
Далее в подсистеме 10.4 криптокодовой защиты информации


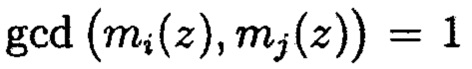


где

Общий вид уравнений преобразований процесса расширения системы оснований криптокодовых конструкций может быть представлен в виде:
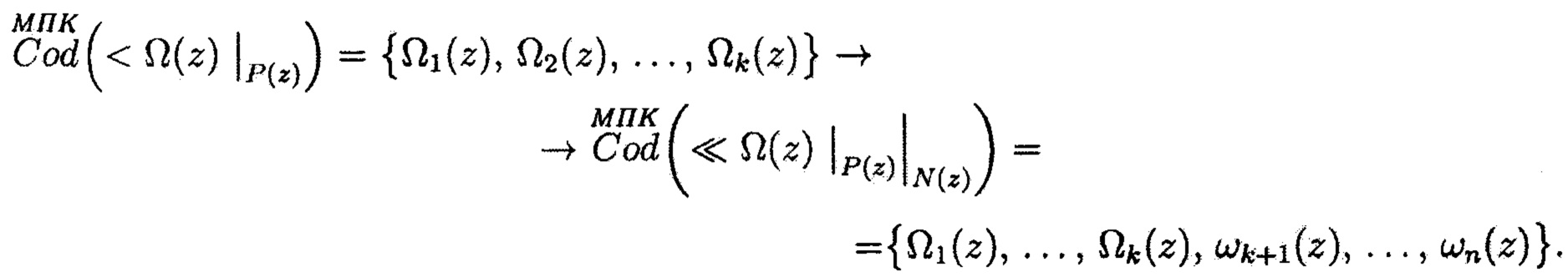
Здесь избыточные блоки данных криптокодовых конструкций
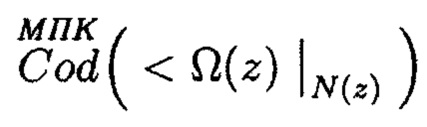
формируются по правилу

где i=k+1, k+2, …, n.
С целью исключения подмены (изменения) информации сформированные избыточные полиномиальные вычеты



где

Полученная совокупность информационных и избыточных блоков шифртекства образует криптокодовые конструкции, обладающие свойствами расширенного МПК:

После формирования подсистемой 10.4 криптокодовой защиты информации



Подсистема 11.3 управления «ведущего» узла 11 хранения локальной подгруппы s(k) отслеживает доступность узлов 10 хранения данных локальной подгруппы, их местоположение, предельные объемы допустимой памяти, и позволяет рассматривать совокупность узлов 10 хранения данных локальной подгруппы как единый узел хранения данных, а его содержимое представить в виде информационной матрицы:

С учетом вычисленных избыточных блоков шифртекста

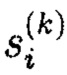
Тогда целостность информации локальной подгруппы определяется системой функций от переменных ci,j(z) (информационных и избыточных блоков шифртекста) расширенной матрицы А:

Для нахождения значения полиномов ai(z) через значения координат функций ƒi воспользуемся выражением (1), предварительно выполнив процедуру обратного преобразования избыточных блоков шифртекста
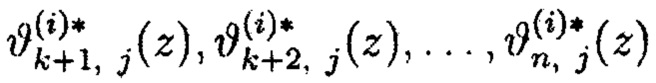



где

Элементы криптокодового слова
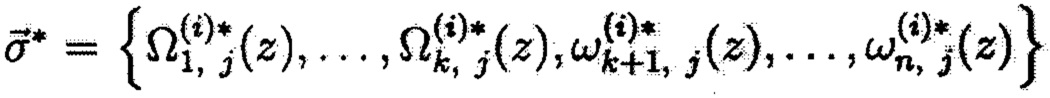


В случае физической утраты некоторой предельной численности узлов 10 хранения данных локальной подгруппы и, соответственно, узлов 10 хранения данных из их совокупности, расширенная матрицы А примет вид (таблица 2). Рассмотренная процедура иллюстрирует процесс обеспечения целостности данных в рамках одной локальной подгруппы посредством формирования локальной избыточности. Следующий этап способа предполагает формирование защиты на «межуровневом» (групповом) взаимодействии (введение «глобальной» избыточности),

т.е. имитоустойчивом перекодировании структуры хранимых данных, формируемых на уровне «ведущих» узлов хранения данных. По сути имитоустойчивое перекодирование структуры хранимых данных на уровне «ведущих» узлов 11 хранения данных путем взаимно однозначных преобразований позволяет использовать сформированные избыточные данные для восстановления утраченных (имитируемых злоумышленником) данных на локальных уровнях, когда кратность искажений превышает корректирующую способность криптокодовых конструкций, формируемых в рамках i-ой локальной подгруппы.
Для реализации процедуры имитоустойчивого перекодирования структуры хранимых данных выполним операцию рекурсивного сдваивания сформированных информационных блоков шифртекста и выработанных избыточных блоков шифртекста (данных) узлов 10 хранения локальной подгруппы. При этом ввиду однотипности вычислительных операций на узлах 10 хранения данных локальных подгрупп ограничимся рассмотрением операции рекурсивного сдваивания сформированных информационных блоков шифртекста


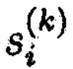

На первом шаге в


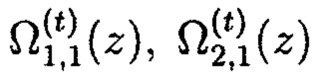


для


для


где




Полученные промежуточные блоки



В подсистеме 11.4 криптокодовой защиты информации «ведущего» узла 11 хранения данных выполняются очередные шаги процедуры рекурсивного сдваивания принятых промежуточных блоков данных в соответствии с выражением:

где

Полученные в подсистеме 11.4 криптокодовой защиты информации блоки данных

С учетом заранее введенной избыточности в сохраняемую информацию физическая утрата некоторых узлов 10 хранения данных или непригодность хранимой на них информации, обусловленная преднамеренными (имитирующими) воздействиями злоумышленника, не приводит к полной или частичной потере информации.
Подсистема управления «ведущего» узла 11 хранения данных сообщает какие узлы 10 хранения данных локальной подгруппы в настоящий момент доступны и, соответственно, имеют множество информационных и избыточных данных файла. Затем «ведущий» узел 10 хранения данных может непосредственно получить множество информационных и избыточных данных от указанных узлов 10 хранения данных.
При этом процедура обратного преобразования рекурсивно сдвоенных данных осуществляется в соответствии с выражениями:
для


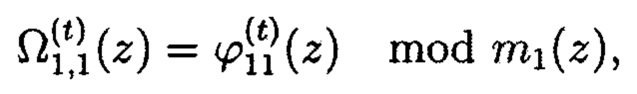

для




«Ведущий» узел 11 хранения данных выполняет процедуру обнаружения искаженных (имитируемых) злоумышленником данных, где их количество обусловлено выражением (4). Восстановление потерянной или искаженной информации осуществляется с учетом (5) путем вычисления наименьших вычетов или любым другим известным методом декодирования избыточных МПК:

где символы «**» указывают на вероятностный характер восстановления.
Восстановленные данные «ведущим» узлом 11 хранения данных, совместно с данными доступных узлов 10 хранения данных локальной подгруппы передаются на вновь введенный «ведущим» узлом 11 хранения данных узел 10 хранения данных для формирования блоков избыточных данных.
Достоинством данного решения является возможность формирования системы распределенного хранения информации на узлах 11 хранения данных с взаимосвязью данных локальных подгрупп между собой через выработанную «локальную» избыточную информацию на уровне локальной подгруппы узлов 10 хранения данных и уровне «ведущих» узлов 11 хранения данных по средством формирования «глобальной» избыточности. При таком способе взаимодействия и имитоустойчивом перекодировании структуры хранимых данных допускается возможность физической утраты подавляющего большинства узлов 10 хранения данных локальных подгрупп. Необходимо отметить, что роль «ведущего» узла 11 хранения данных может при прочих равных условиях быть возложена на любой узел 10 хранения данных из локальной подгруппы.
Реферат
Изобретение относится к вычислительной технике для распределенного хранения информации. Технический результат заключается в повышении информационной устойчивости системы распределенного хранения информации (РСХИ) к преднамеренным имитирующим воздействиям злоумышленника. Технический результат достигается тем, что совокупность узлов хранения РСХИ разбивается на множество локальных подгрупп, в которых определяются «ведущие» узлы хранения (например, в зависимости от первоочередности решаемой задачи или важности сохраняемых данных на узлах хранения), осуществляющие взаимодействие между подгруппами. Физическая утрата (потеря) любого узла хранения данных локальной подгруппы (деградация РСХИ), неспособность к соединению с сетью, обусловленная преднамеренными (имитирующими) действиями злоумышленника, приведет к частичной потере или полной утрате информации. При этом распределенное по узлам хранения данных множество информационных данных с вычисленными избыточными данными, объединенных в единый блок данных посредством применения операции рекурсивного сдваивания позволяет «ведущим» узлам хранения выполнить полное восстановление утраченных файлов данных даже при отказе одного или более узлов хранения данных локальных подгрупп. 4 ил.
Формула
Документы, цитированные в отчёте о поиске
Способ восстановления записей в запоминающем устройстве и система для его осуществления
Комментарии