Способ распознавания символа на банкноте и сопроцессор для вычислительной системы устройства для обработки банкнот - RU2707320C1
Код документа: RU2707320C1
Чертежи





Описание
Группа изобретений относится к способу распознавания символов на банкнотах и сопроцессору вычислительной системы устройства обработки банкнот, позволяющему реализовать данный способ.
Банкнота представляет собой ценный документ, каждый экземпляр которого помечен уникальной строкой символов, которую принято называть серийным номером. Серийный номер, несмотря на свое название, может содержать не только цифры, но также и буквы в произвольной комбинации. В современной технологии обработки банкнот необходимо вести учет движения индивидуальных экземпляров банкнот по цепочкам денежного оборота. Для этого необходимо оборудование, которое может распознавать символы в серийном номере для их последующего использования в системах учета движения.
Кроме учета движения, распознавание серийного номера позволяет проверить подлинность банкноты. С этой целью, распознанный серийный номер на банкноте сравнивают с базой данных известных серийных номеров фальшивых банкнот. Кроме того, для банкнот, в которых строка символов серийного номера напечатана на банкноте дважды, распознают в отдельности каждую из этих строк, затем сравнивают полученные результаты между собой, и при различии в распознанных символах, признают банкноту подозрительной. За счет такого сравнения двух строк серийного номера удается выявить неплатежеспособные банкноты, составленные из частей различных подлинных банкнот.
Машинное распознавание символов известно с конца 1960-х годов и к настоящему моменту представляет собой зрелую область техники, в которой, в разнообразных комбинациях применяется множество различных способов распознавания, описанных как в научной, так и в патентной литературе (группы МПК G06K 9/46, G06K 9/48, G06K 9/50, G06K 9/52, G06K 9/62 и другие).
Распознавание символов применяется для получения текста, содержащегося в документе, в виде цифровой последовательности кодов символов. Как правило, на документе, подлежащем распознаванию, сначала выделяют отдельные знакоместа, а затем, по раздельности, распознают символы в знакоместах. Под знакоместом понимают участок документа или его изображения, имеющий форму параллелограмма или прямоугольника, который содержит одиночный символ. Положение знакоместа может быть заранее известно, либо же его определяют на основе характерных признаков. Например, если фон имеет белый цвет и символ имеет черный цвет, то границы знакоместа целиком попадают на белые пиксели, а во внутренней части знакоместа имеются черные пиксели.
Главной областью применения машинного распознавания символов является перевод в цифровую форму печатных изданий, а также документов, используемых в деловом и административном обороте. Это определило основные цели и технические достижения при совершенствовании распознавания символов.
Шрифтом в полиграфии принято называть набор символов определенного размера и рисунка. Графический рисунок символов, составляющих один шрифт, объединен художественным стилистическим единством. Шрифты могут отличаться друг от друга как рисунком, так и размером символов. Понятие шрифта необходимо отличать от близкого понятия гарнитуры шрифта, которая представляет собой набор символов, имеющих стилистическое единство начертания. Рисунок для одного и того же вида символа, например, для определенной буквы либо цифры, в различных шрифтах может отличаться множеством особенностей, таких как: наклон символа; соотношение ширины и высоты символа; толщина линий; постоянство либо изменение толщины линий; характер и расположение изгибов линий; наличие засечек на концах линий, и многие другие. В полиграфической практике применяются сотни различных гарнитур шрифтов, обладающих большим разнообразием рисунков.
Документы и печатные издания для распознавания обычно напечатаны заранее неизвестным шрифтом, либо множеством разных шрифтов. Поэтому, в современном уровне техники основное внимание уделено способам распознавания, работоспособность которых не зависит от рисунка и размера символа шрифта. Такие способы обладают высокой вычислительной сложностью, однако, к ним не предъявляются жесткие требования по быстродействию. Как правило, время распознавания в пределах нескольких секунд на страницу считается вполне допустимым. Кроме того, для реализации алгоритмов, применяемых в этих способах, обычно применяются высокопроизводительные процессоры рабочих станций или серверов с архитектурой IBM PC. Использование высокопроизводительных процессоров компенсирует повышенные вычислительные затраты на распознавание символа, независимое от шрифта.
Еще одной особенностью большинства современных способов распознавания является высокое качество цифрового изображения распознаваемого документа. Для его получения применяются сканеры достаточно высокого разрешения, от 300 точек на дюйм и выше. К быстродействию сканирования не предъявляются очень высокие требования, поэтому, скорости взаимного перемещения документа и элементов сканера оказываются небольшими. За счет этого в цифровом изображении практически отсутствуют динамические геометрические искажения сканирования. Далее, за исключением небольшого числа особых видов документов (исторические документы, древняя литература), распознаваемые документы имеют высокое качество печати. Как правило, они напечатаны черным цветом на белом фоне, а загрязнения бумаги и повреждения красочного слоя практически отсутствуют. При сканировании таких документов получается контрастное и целостное изображение каждого символа.
Как правило, к точности распознавания отдельных символов на обычных документах и печатных изданиях не предъявляются очень высокие требования. Это связано с тем, что для коррекции ошибок в распознавании отдельных символов применяются алгоритмы, опирающиеся на набор слов и грамматические правила того языка, на котором выполнен документ. Ошибка в одном символе в слове исправляется, исходя из правильного написания слова и грамматического контекста всего предложения. Когда ошибки в документе совершенно недопустимы, результат автоматического распознавания дополнительно проверяет человек.
Распознавание серийных номеров банкнот представляет собой совершенно иную задачу. Рисунок и размер символов шрифта серийного номера всегда известны. Качество сканирования банкнот в машинах для обработки наличности значительно уступает качеству сканирования обычных документов, поскольку банкнота перемещается в машине на высокой скорости (до 10 километров в час), а на получение цифрового изображения, как правило, отводится менее 100 миллисекунд. Это приводит к невысокому разрешению сканирования, не более 200 точек на дюйм, а также к большим динамическим геометрическим искажениям из-за проскальзывания банкнот в банкнотопроводном тракте.
Далее, банкноты постоянно находятся в обращении, что приводит к постепенному истиранию красочного слоя, покрыванию пятнами и общему загрязнению бумаги. В результате, контрастность и целостность изображения символа на банкнотах могут очень ощутимо снижаться. Ситуация также осложняется тем, что серийный номер далеко не всегда печатается на белом участке банкноты. Во многих случаях, он наносится на ранее запечатанную область, поэтому, даже на новых банкнотах, фон символа уже содержит дополнительное изображение, мешающее распознаванию.
За счет высокой скорости перемещения банкноты в машине, высокие требования предъявляются и к быстродействию распознавания серийного номера. Обычно, допустимым является время распознавания строки серийного номера в пределах нескольких миллисекунд. Это время примерно сопоставимо с временем распознавания слова той же длины в современных способах распознавания обычных документов, выполняемых на высокопроизводительных процессорах. Однако, применение высокопроизводительных процессоров в большинстве машин для обработки банкнот невозможно по экономическим причинам. Те же виды процессоров, которые экономически оправданы для применения в машинах для обработки банкнот, имеют в 10 и более раз низкую производительность, чем производительность процессора рабочей станции с архитектурой IBM PC.
Вероятность ошибки в распознавании серийного номера банкноты должна быть весьма низкой. Более точно, совершенно недопустимо распознавание изображения одного символа как другого. Однако, более допустимым является вывод о нераспознанности такого символа. Это связано с особенностью обработки банкнот: банкнота с нераспознанным символом может быть далее отбракована для повторной обработки, в то время как неверно распознанный символ приведет не к отбраковке, но к скрытой ошибке в финансовом учете движения банкнот. Нужно отметить, что при распознавании обычных документов, когда возникает сомнение в распознавании конкретного символа, обычно стараются найти для него наиболее вероятный вариант значения, и лишь в крайнем случае помечают символ как нераспознанный. Так как серийный номер не является словом какого-либо языка и не входит в предложение, отсутствует возможность исправить ошибку распознавания символа на основе контекста и грамматики языка.
Таким образом, отличие распознавания серийных номеров банкнот от распознавания обычных документов в чем-то облегчает, но в большинстве аспектов усложняет задачу. Задача распознавания серийных номеров облегчается из-за того, что заранее известны рисунок и размер символов шрифта. Однако, она усложняется из-за низкого качества изображения символа, высоких требований по безошибочности и быстродействию распознавания, низкого уровня вычислительной мощности процессора, которая доступна для реализации способа, а также невозможности контекстной и грамматической коррекции ошибок. На современном уровне техники, поиск оптимального решения этой задачи пока не завершен. Для ее решения применяются технические приемы, отличающиеся от используемых в распознавании обычных документов.
Известна задача распознавания регистрационного номера автомобиля по его фотографии. Такая задача возникает при учете потока автомобилей в ходе регулирования дорожного движения. Распознавание регистрационного номера автомобиля имеет определенное сходство с распознаванием серийного номера банкноты. В обеих этих задачах распознается строка символов, не являющаяся словом языка, и к точности распознавания предъявляются высокие требования.
Также, в обеих задачах символы имеют известный рисунок и размер символов шрифта. Различия между задачами заключаются в требованиях быстродействия и в качестве изображения символа. Практическое быстродействие распознавания регистрационного номера при нынешнем уровне техники составляет одну секунду или несколько секунд, то есть более чем на два порядка хуже, чем требуется при распознавании серийных номеров банкнот. Изображение регистрационного номера автомобиля, используемое для распознавания, имеет существенно худшее качество, чем изображение серийного номера банкноты. Так как фотографирование автомобиля может производиться с разных расстояний и под разными ракурсами, то изображение регистрационного номера всегда имеет искажения масштаба и перспективные искажения, которые требуют обязательной коррекции перед распознаванием. На разборчивость символов влияют состояние атмосферы, загрязнение и повреждение таблички с номером и неточная фокусировка камеры, а также неравномерность внешнего освещения. Из-за этого, попытки сегментации изображения символа в регистрационном номере, то есть выделения пикселей, относящихся к символу, часто приводят к полной потере формы символа, даже при использовании современных алгоритмов бинаризации. Как следствие, дальнейшее распознавание оказывается невозможным. Для сравнения, сегментация символов серийного номера банкноты может привести к появлению незначительных разрывов контура символа или небольших шумовых ложных кластеров пикселей, не относящихся, на самом деле, к символу. Однако, эти нарушения не препятствуют распознаванию сегментированного символа.
По указанной причине, в распознавании регистрационных номеров используются, главным образом, те методы, которые не требуют предварительного сегментирования. К ним относится вычисление двумерной корреляции с шаблонами всех символов в шрифте, метод гистограммы градиентов, а также сверточные нейронные сети. Эти методы хорошо известны специалистам в области распознавания изображений. Не вдаваясь в подробное техническое описание, отметим, что все они обладают высокой способностью к распознаванию сильно зашумленных изображений символов, но отличаются очень большими вычислительными затратами. Кроме того, возникает проблема предварительного обучения алгоритма распознавания на образцах. Для обучения распознаванию определенного символа шрифта требуется обработать множество образцов изображений этого символа, полученных в несколько отличающихся условиях. Это приводит к большим затратам времени и труда на подготовку и ввод образцов.
Наилучшие результаты, среди остальных методов, при относительно небольших вычислительных затратах дают сверточные нейронные сети. Однако, они требуют обучения на очень большом количестве образцов, измеряемом сотнями тысяч. Корреляционные методы требуют наименьшего обучения, но отличаются самыми большими вычислительными затратами. Метод гистограммы градиентов дает достаточно высокое быстродействие и требует среднего количества образцов для обучения, но неточно работают при загрязнении или при резких перепадах в освещении регистрационного номера. Некоторое увеличение быстродействия всех трех перечисленных методов, в последнее время, стало достигаться за счет использования мощных специализированных сопроцессоров, ориентированных на ускорение и параллельное выполнение типовых операций распознавания.
При распознавании серийных номеров банкнот наибольшую применимость находит метод гистограммы градиентов с классификацией при помощи машины опорных векторов. Такой выбор связан с тем, что качество изображения серийного номера на банкноте, в целом, выше, чем качество изображения регистрационных номеров автомобиля. Подобный метод, например, используется в способе распознавания серийного номера банкноты, описанном в международной заявке WO 2017016240, опубл. 02.02.2017, МПК G07D 7/20. После извлечения признаков, для классификации применяется классификатор на основе машины опорных векторов, предварительно обученный по методу последовательной минимальной оптимизации (SMO). Некоторые символы, сходные по рисунку, такие как «В» и «8», при применении машины опорных векторов могут определяться с ошибкой. Для более точного различения этих символов, дополнительно проводится проверка при помощи корреляционного сравнения определенной зоны символа с шаблоном. Расположение зоны выбирается таким образом, чтобы в ней находилась та часть символа, которая в наибольшей степени отличает его от других похожих на него символов.
Метод гистограммы градиентов, хотя и является относительно быстродействующим по сравнению с корреляционными методами, все же требует достаточно высокой вычислительной мощности процессора или же применения специализированного сопроцессора. Для построения локальной гистограммы градиентов требуется 8 операций сравнения на каждый пиксель изображения, к чему далее прибавляются массивные матричные вычисления. В результате, распознавание серийных номеров оказывается затруднительным реализовать в простом оборудовании, предназначенном для массового применения. Изучая уровень техники, авторы заявленного изобретения пришли к выводу, что для широкого применения распознавания символа серийного номера банкнот критически важно обеспечить высокое быстродействие с использованием процессоров небольшой вычислительной мощности, при достижении устойчивости к искажениям изображения, характерным для обработки банкнот. Эта задача требует применения иных способов распознавания, менее затратных с точки зрения вычислительной сложности.
В уровне техники известны способы, в которых повышение быстродействия достигается за счет упрощения вычисления признаков, которые далее используются для классификации. Один из таких способов описан в заявке CN 108320374, опубл. 24.07.2018, МПК G06K 9/62. В нем для характеризации банкноты применяется так называемый перцептивный хэш (perceptual hash, хэш зрительного восприятия). Перцептивный хэш - это двоичное число, обычно 64-битное, которое вычисляется для определенного изображения. Его можно использовать для сравнения двух изображений. Чем более сходными являются изображения, тем меньшим оказывается количество двоичных разрядов, в которых отличаются перцептивные хэши этих изображений. Количество отличающихся двоичных разрядов известно как расстояние Хэмминга. В упомянутой заявке, в ходе обучения находят перцептивные хэши для всех возможных видов символа. Для символа, подлежащего распознаванию, вычисляют перцептивный хэш и определяют расстояния Хэмминга от него до перцептивных хэшей всех возможных символов, полученных в ходе обучения. Этот набор расстояний используют как вектор признаков, подаваемый на предварительно обученный классификатор на основе машины опорных векторов. Преимуществом такого распознавания можно считать быстроту выполнения, так как в нем используется самый быстрый из известных алгоритмов перцептивного хэширования, так называемый усредняющий хэш (average hash). Классификация усилена за счет того, что классификатор принимает решение не только по степени схожести изображения с наиболее вероятным видом символа, но и по степени отличия от других видов символов. Учет степени отличия от других видов символов улучшает классификацию символов тем сильнее, чем больше различий между разными видами символов. Недостатки этого способа являются продолжениями его достоинств. Перцептивное хэширование, в особенности, работающее по усредняющему алгоритму, подчеркивает крупные элементы изображения и игнорирует малые. Поэтому, хэши сходных символов, таких, как цифры «8», «9» и «6», имеют очень малые различия, особенно, если шрифт имеет тонкое начертание, а зазоры между концом штриха и окружностью в цифрах «9» и «6» сделаны очень узкими. Из-за этого трудно различить такие символы, используя перцептивный хэш. Примером шрифта с тонким начертанием и малыми зазорами является шрифт серийного номера на российских рублях, выпущенных до 2017 года. Кроме того, учет степени различия с другими символами не позволяет улучшить классификацию сходных символов, так как расстояния Хэмминга от каждого из сходных символов до другого, сильно отличающегося символа оказывается почти одинаковыми. Поэтому, применимость данного способа ограничена шрифтами, специально оптимизированными под машинное распознавание.
Нужно отметить, что общим недостатком способов, использующих машину опорных векторов для классификации, является частая выдача неправильного вида символа при ошибке распознавания. Как уже указывалось выше, по финансовым причинам, для серийного номера банкноты более правильно сообщить о невозможности распознавания символа, чем сообщить вид символа, который не соответствует действительности. Известен патент США US 4,180,800, опубл. 25.12.1979, МПК G06K 9/50, в котором описано устройство распознавания символов, основанное на построчном анализе цифрового изображения знакоместа. Оно отличается исключительной простотой формирования признаков. Строки знакоместа последовательно, одна за другой, анализируются, и содержимое каждой из них классифицируется по небольшому количеству возможных вариантов кодов, иначе называемых строчными признаками. Так, код С0 обозначает пустую строку, С1 - узкую метку в строке слева, С3 - узкую метку справа, С6 - широкую метку по центру и т.д. Тогда, стилизованная цифра «2», состоящая из отрезков, ориентированных друг к другу под прямым углом, при движении по строкам сверху вниз будет кодироваться как С0 (пустая строка сверху) С6 С6 (верхний горизонтальный штрих) С3 С3 С3 С3 (правый вертикальный штрих) С6 С6 (средний горизонтальный штрих) С1 С1 С1 С1 (левый вертикальный штрих) С6 С6 (нижний горизонтальный штрих) С0 (пустая строка снизу).
В ходе анализа строк, коды последовательно подаются на конечный автомат, так что каждый код вызывает переход из одного состояния автомата в другое в соответствии с предварительно заданным графом. Работа автомата начинается с начального состояния и к моменту прохода по всем строкам знакоместа автомат переходит в одно из состояний, соответствующих возможному распознанному символу. Такое устройство хорошо приспособлено к распознаванию цифр, напечатанных специальным шрифтом, где каждая цифра имеет фиксированный размер и состоит из отрезков, ориентированных друг к другу под прямым углом. Подобные шрифты успешно используются для пометки и автоматической сортировки почтовых отправлений, начиная с 1970-х годов. Реализация устройства в виде логических схем кодера строк и конечного автомата обеспечивает высокое быстродействие. Некоторое усложнение графа переходов конечного автомата позволяет устройству успешно распознавать символы, имеющие умеренный наклон из-за неверной ориентации сканера по отношению к документу.
Это устройство имеет два главных недостатка. Во-первых, оно адаптировано только к одному виду шрифта, который сильно отличается от традиционных типографских шрифтов. Адаптация к другому шрифту возможна только с заменой графа переходов, и новый шрифт также должен состоять только из отрезков, ориентированных под прямым углом.
Во-вторых, устройство не обладает устойчивостью к дефектам изображения символа. Истирание части красочного слоя или пятно грязи вызывает неверную последовательность кодов, которая не позволяет конечному автомату прийти в нужное состояние, соответствующее реальному символу.
Благодаря указанным недостаткам, область применения устройства ограничивается высококачественными документами, выполненными специально адаптированным шрифтом.
Патент US 4,180,800 был выбран в качестве прототипа заявленного изобретения. Технический результат состоит в расширении возможности применения способа к распознаванию символов шрифта, обладающего практически любыми особенностями рисунка.
Этот технический результат достигается за счет того, что в способе распознавания символа на банкноте, относящегося к известному шрифту,
сканируют банкноту с получением цифрового изображения, состоящего из пикселей, для которого определяют принадлежность к определенному классу, на основании указанного класса определяют место расположения символа, подлежащего распознаванию,
совмещают знакоместо заранее заданной формы и размера с изображением символа, подлежащего распознаванию, так чтобы пиксели, относящиеся к символу, находились в пределах границ знакоместа,
при этом проводят бинаризацию для выделения пикселей, относящихся к символу, причем,
для знакоместа заранее определен набор проверочных прямых линий, пересекающих это знакоместо,
и на каждой из проверочных прямых линий задана одномерная система координат,
так что положение каждой проверочной прямой линии и начало системы координат на ней установлено заранее заданным образом относительно границ знакоместа,
затем, на каждой проверочной прямой отмечают пиксели, по которым проходит эта прямая, указывая их различным образом для пикселей символа и для пробельных пикселей,
и сопоставляют каждой проверочной прямой набор числовых характеристик, включающий в себя
длину интервала, охватывающего все указанные пиксели символа,
количество интервалов указанных пикселей символа, в которых указанные пиксели символа расположены подряд друг за другом,
координату центра тяжести указанных пикселей символа, выраженную в системе координат для данной проверочной прямой,
и суммарное число всех указанных пикселей символа,
после чего выполняют классификацию символа, подлежащего распознаванию, с использованием ранее полученных наборов числовых характеристик в качестве признаков.
На знакоместе символа заранее определяют набор проверочных прямых. По пересечению этих прямых с изображением будут выбираться пиксели для последующей классификации символа. В общем случае, прямые могут быть ориентированы любым образом: вдоль строк изображения, вдоль его столбцов, или же под произвольным углом. В основе использования набора проверочных прямых для классификации лежит особенность символа как набора графических элементов. Символы алфавитов, созданных человеком, имеют только два уровня интенсивности. Один уровень, обычно черный, соответствует самому символу, а другой уровень, обычно белый, соответствует пробелу. Термины «черный» и «белый» используются здесь с определенной условностью, поскольку банкноты имеют многокрасочную печать, а сканирование идет с использованием определенных длин волн подсветки. Черным мы называем уровень, соответствующий оптически контрастной краске с высоким поглощением излучения подсветки, а белым называется уровень, соответствующий бумаге или красочному слою с низким поглощением излучения подсветки.
Символ состоит из линий, которые имеют постоянную либо слабо изменяющуюся толщину. В результате, пересечение проверочной прямой с линиями символа представляется набором черных отрезков, где каждый отрезок соответствует отдельной линии, а длина отрезка определяется толщиной линии и углом пересечения с проверочной прямой. Набор проверочных прямых позволяет, таким образом, характеризовать изображение символа не как двумерный массив пикселей, а как множество отрезков, возникающих на пересечении линий символа с проверочными прямыми. Таким образом, описанная здесь характеризация дает возможность анализировать структуру неизвестного символа, как набора линий. Эта возможность важна для быстрого и достоверного распознавания, поскольку конкретный вид символа, к которому требуется отнести распознаваемое изображение символа, определяется именно количеством и взаиморасположением составляющих его линий.
В прототипе используются проверочные прямые, ориентированные вдоль строк изображения. Результат пересечения проверочной прямой с линиями символа анализируется по грубым признакам наличия отрезка и оценки его длины как короткого, либо длинного. В результате обработки пересечения проверочной прямой с изображением символа, в прототипе находят код, относящийся к небольшому множеству возможных кодов. Заявленный способ, в отличие от прототипа, не ограничен распознаванием символов, состоящих из ортогональных штрихов.
В заявленном способе, в отличие от прототипа, вместо кода формируется набор из четырех числовых характеристик. Эти характеристики дают значительно более широкие возможности для описания особенностей формы и расположения линий символа, даже если рисунок символа отличается высокой сложностью. С другой стороны, через допустимые отклонения числовых характеристик, при классификации можно учесть влияние различных факторов, искажающих изображение и мешающих достоверному распознаванию символа. К таким факторам относятся геометрические погрешности сканирования, выражающиеся в смещении элементов цифрового изображения, а также отклонения толщины линий от номинала, возникающие как из-за погрешностей в печатном процессе, так и из-за износа банкнот и градационных погрешностей сканирования.
На исходном знакоместе выделяют пиксели, относящиеся к символу, а остальные пиксели знакоместа относят к пробельным. Эта операция известна в обработке цифровых изображений под названием бинаризации. Известно множество алгоритмов бинаризации, из которых наибольшее распространение получил алгоритм Отсу, обеспечивающий высокое качество отделение символа от фона при хорошем быстродействии. Заявленный метод не накладывает ограничений на применяемый алгоритм бинаризации. В результате, получается бинаризованное изображение, имеющее только два уровня интенсивности пикселей, один из которых соответствует символу, а другой пробелу. На каждой проверочной прямой отмечают пиксели, по которым проходит эта прямая, с указанием их типа: как пиксели символа, либо как пробельные пиксели. Если прямая проходит по строке или по столбцу изображения, для этого достаточно составить линейный массив, в котором каждое значение соответствует значению пикселя соответствующей строки либо соответствующего столбца бинаризованного изображения. Для наклонной прямой необходимо составить линейный массив, копируя в него значения пикселей бинаризованного изображения, взятые по определенному пути их обхода, который является аппроксимацией наклонной прямой. Такой путь обхода может быть составлен с использованием широкоизвестного алгоритма Берзенхема, применяемого в компьютерной графике для рисования прямых.
Рассмотрим числовые характеристики более подробно. Длину интервала на проверочной прямой, охватывающего все пиксели символа, мы будем в этом описании называть шириной и обозначать W. Ширина измеряется в пикселах и показывает полную протяженность участка, на котором проверочная прямая пересекает линии символа. Для различных изображений одного и того же символа, относящегося к известному шрифту, ширина на определенной проверочной прямой является стабильной характеристикой, которая изменяется в небольшой степени по причине геометрических погрешностей сканирования и погрешностей толщины линии.
Количество интервалов пикселей символа, в которых пиксели символа расположены друг за другом, мы будем называть числом штрихов и обозначать Р. Число штрихов обозначает, сколько линий символа пересекла проверочная прямая. Для различных изображений одного и того же символа, число штрихов на определенной проверочной прямой практически не изменяется, за исключением тех случаев, когда проверочная прямая проходит вблизи мест слияния или пересечения линий либо же касается линии. В этих особых случаях, значение Р может изменяться от малейших случайных факторов и не является показательным, поэтому, его рекомендуется не учитывать для анализа. Координата центра тяжести пикселей символа, выраженная в пикселях в системе координат проверочной прямой, будет далее называться центром и обозначаться С. Центр показывает месторасположение на проверочной прямой того участка, на котором эта прямая пересекает линии символа. Центр С на проверочной прямой слабо изменяется при геометрических погрешностях сканирования, и почти не зависит от погрешностей толщины линии. Однако, это единственная из четырех числовых характеристик, которая отсчитывается от начала системы координат проверочной прямой, положение которой установлено некоторым заданным образом относительно границ знакоместа. Поэтому, для стабильного вычисления С нужно обеспечить установку положения начала системы координат по отношению к границам знакоместа с учетом расположения изображения символа в знакоместе. Как будет показано в дальнейшем, для такой установки положения лучше всего использовать ось тяжести либо центр тяжести всего изображения знакоместа.
Суммарное число всех пикселей символа, отмеченных на проверочной прямой, мы будем называть весом и обозначать WT. Для различных изображений одного и того же символа, вес мало зависит от геометрических погрешностей сканирования, и почти полностью определяется погрешностями толщины линии.
Вычисление всех четырех числовых характеристик в соответствии с приведенным описанием их значения является достаточно очевидным для специалиста. Перед их вычислением, проводимым для определенной проверочной прямой, нужно положить Р, W, С и WT равными нулю. Двигаясь по проверочной прямой от края знакоместа в определенном направлении, необходимо анализировать значение каждого отмеченного пикселя, и каждый раз принимать решение о возможном увеличении Р, W, WT в соответствии со значением пикселя. Для вычисления центра С необходимо подсчитать сумму координат для всех пикселей на прямой, относящихся к символу, и разделить ее на вес WT. Это соответствует общеизвестному методу подсчета центра тяжести. Сумма координат для всех пикселей на прямой, относящихся к символу, является промежуточной цифровой характеристикой, которую мы далее будем обозначать SC.
Вычисление числовых характеристик проверочной строки является быстрой операцией, которая не требует множества сравнений и матричных действий, характерных, например, для широко известного метода гистограммы градиентов. Более того, так как вычисление числовых характеристик для разных проверочных прямых не взаимосвязано, то оно легко поддается распараллеливанию. Распараллеливание позволяет многократно ускорить работу при использовании многоядерного центрального процессора в вычислительной системе машины для обработки банкнот. В целом, заявленный способ обеспечивает быстродействие не хуже прототипа. Дополнительное ускорение работы может быть реализовано за счет вычисления числовых характеристик в аппаратном обеспечении при помощи несложного сопроцессора. Такой сопроцессор может быть реализован в структуре микросхемы программируемой логики (FPGA).
Выбор четырех числовых характеристик Р, W, С и WT для кодирования результата пересечения изображения символа с проверочной прямой обоснован тем, что такое кодирование можно рассматривать как разновидность локального частотного анализа. Частотный анализ, например, преобразование Фурье, и локальный анализ, такой, как вейвлетное преобразование, зарекомендовали себя в обработке изображений как надежные методы обнаружения структурных особенностей изображения, что важно для распознавания символа. Кодирование при помощи четырех числовых характеристик имеет значительное сходство с методом оконного преобразования Фурье, хорошо известного в цифровой обработке сигналов и являющегося комбинацией частотного и локального анализа. Укажем здесь на соответствие параметров оконного преобразования Фурье и числовых характеристик. Ширина W примерно соответствует ширине прямоугольного окна оконного преобразования. Центр С соответствует положению центра окна. Значение числа штрихов Р задает количество периодов синусной компоненты, укладывающееся в окно. А именно, значение (2Р-1) примерно равно числу полупериодов синусной компоненты в пределах ширины окна. Так, при Р=1 в окне укладывается половина периода синусоиды и формирует единственный пик, соответствующий единственному отрезку на проверочной прямой, полученному в результате пересечения с единственной линией символа. При Р=2 в окне укладывается полтора периода, которые формируют два пика, соответствующих паре отрезков на проверочной прямой и пересечению с двумя линиями символа. При Р=3 в окне укладывается два с половиной периода, которые формируют три пика, соответствующих трем отрезкам на проверочной прямой и пересечению с тремя линиями символа.
Удобство использования локального частотного преобразования состоит в том, чтобы закодировать результат пересечения проверочной прямой с изображением символа в виде одной, доминирующей компоненты, которая определяется шириной окна, положением центра окна, и частотой периодической функции в этом окне. В терминах числовых характеристик, это соответствует набору из W, С и Р, соответственно. Такая кодировка является приближенной, поскольку она отбрасывает остаточные компоненты преобразования, и оставляет только доминирующую. При обратном преобразовании этой доминирующей компоненты к значениям пикселей на проверочной прямой, можно приблизительно восстановить исходное распределение черных и белых пикселей. Так как пиксели на проверочной прямой могут принимать только два возможных значения, то для отображения доминирующей компоненты, представленной с помощью синусоиды, на значения пикселей, нужно применить бинаризацию.
Однако, только лишь доминирующей синусной компоненты оказывается недостаточно для правильного восстановления исходной доли черных пикселей в пределах ширины W. Для передачи этой доли нужно дополнительно кодировать постоянную составляющую, которая поднимает или опускает синусоиду относительно нулевого уровня. Вес WT нелинейным образом задает уровень постоянной составляющей. Если принять порог бинаризации равным О, то при отсутствующей постоянной составляющей и Р>1 ширина черных и белых отрезков на проверочной прямой оказываются равными, то есть WT=W/2. При изменении постоянной составляющей доля черных пикселей будет уменьшаться и увеличиваться, вместе с весом WT.
Набор числовых характеристик вычисляется, как было описано выше, однократным проходом по пикселям на прямой без применения технологий Фурье-преобразования. Такая кодировка оказывается несколько менее точной, чем полный расчет доминирующего компонента Фурье-преобразования, но выполняется очень быстро. Более детально, связь между оконным Фурье-преобразованием и набором числовых характеристик будет описана далее.
В результате обработки изображения неизвестного символа в знакоместе это изображение преобразуется в массив, где каждой проверочной прямой соответствует четыре числовых характеристики Р, W, С и WT. Высокая эффективность кодирования при помощи такого набора была показана в экспериментах, проведенных авторами. В качестве проверочных прямых были выбраны все строки знакоместа. После кодирования изображения реального символа, проводилось обратное восстановление изображения на основе полученного массива числовых характеристик. Для этого, интервал пикселей в каждой строке, имеющий центр С и ширину W, заполнялся числом Р черных отрезков одинаковой длины WT/P пикселей, равномерно расположенных с одинаковым шагом W/P. Полученное восстановленное изображение, кроме редких исключений, сохраняло стилистические особенности рисунка и полную узнаваемость символа, хотя и имело определенные визуальные отличия от оригинала. То есть, кодирование при помощи набора числовых характеристик Р, W, С и WT, хотя и теряет несущественную часть графической информации, в целом сохраняет данные, необходимые для успешного распознавания символа. Числовые характеристики успешно передают особенности рисунка символа, такие как толщина линий, их наклон, изменение толщины линии вдоль ее длины, расположение точек пересечения и стыковки линий, и тому подобное.
В отличие от прототипа, в заявленном способе проверочные прямые не ограничены единственным направлением и могут быть расположены таким образом, чтобы их пересечение с линиями символа в наибольшей степени охватывало различные графические элементы, характерные для рисунка символов определенного шрифта. За счет того, что проверочные прямые имеют много пересечений с различными графическими элементами, характерными для символа, может быть повышено количество полезной информации о расположении линий.
Числовые характеристики, найденные для проверочных прямых, являются входными признаками для работы классификатора, который принимает решение о том, к какому виду относится распознаваемый символ. В уровне техники известно множество классификаторов, таких, как нейронные сети, статистические классификаторы, каскады слабых классификаторов и многие другие. Построение и обучение классификатора освещено в научной литературе и хорошо известно специалистам. Для достоверной классификации необходимо, чтобы признаки достаточно полно передавали особенности классифицируемых объектов. Массив числовых характеристик, как было указано выше, обладает высокой полнотой представления изображения символа.
Особенностями заявленного способа являются высокая эффективность кодирования формы символа, а также возможность использования требуемого количества и произвольной ориентации проверочных прямых для учета особенностей даже самых сложных рисунков символов. Эти особенности позволяют использовать заявленный способ для распознавания шрифта, имеющего практически неограниченные особенности рисунка символов, а не только для простого шрифта с ортогонально направленными штрихами. Это расширяет возможности применения способа к различным шрифтам с практически произвольными особенностями рисунка символов и обеспечивает технический результат.
В предпочтительной реализации способа, дополнительно обеспечивается надежность распознавания на банкнотах, имеющих загрязнения и повреждения красочного слоя, при сохранении высокого быстродействия. Этот результат достигается за счет того, что, при классификации,
для каждого из возможных видов символа выполняют последовательную проверку набора критериев принадлежности к этому виду,
где наборы критериев заданы предварительно, и, по меньшей мере, часть критериев в каждом наборе установлена на основе числовых характеристик проверочных прямых,
при обнаружении выполнения всех критериев в наборе, соответствующем какому-либо возможному виду символа, прерывают дальнейшую проверку и заключают, что символ, подлежащий распознаванию, относится к этому виду,
если же, после сопоставления с наборами критериев для всех возможных видов символов, не найдено соответствие ни одному из возможных видов символа, заключают, что символ не распознан,
при этом для каждого из критериев, установленных на основе характеристик проверочных прямых, предварительно задаются
требования критерия к характеристикам проверочной прямой, содержащие допуск для значения по меньшей мере одной числовой характеристики,
и набор проверочных прямых для проверки критерия,
причем такой критерий считается выполненным, если количество проверочных прямых в наборе, соответствующих требованиям этого критерия, находится внутри заранее заданного интервала.
Решение о том, к какому виду относится неизвестный символ, принимается на основе последовательной проверки набора критериев, где каждому набору критериев соответствует отдельный вид символа. Критерий проверяет соответствие определенному правилу набора числовых характеристик, найденных для тех или иных проверочных прямых. Если обнаруживается, что выполнены все критерии в наборе для определенного вида символа, то заключают, что неизвестный символ относится к этому определенному виду.
Такое построение набора критериев позволяет индивидуально подбирать критерии в зависимости от рисунка определенного вида символов. За счет этого повышается быстродействие и качество распознавания. А именно, из всего набора проверочных прямых могут быть выбраны только те прямые, которые в наибольшей степени характеризуют особенности рисунка. Это увеличивает быстродействие, так как не проверяются прямые, которые не обладают высокой информативностью в отношении особенностей рисунка определенного символа. Далее, в критериях можно исключить использование прямых, проходящих вблизи мест слияния и пересечения линий, а также касания линии символа и проверочной прямой. Характеристики для этих прямых могут быть нестабильны и в случае их проверки качество распознавания может только ухудшиться.
Если же, по ходу проверки набора критериев для определенного символа, обнаруживается несоответствие какому-либо критерию, то дальнейшая проверка этого набора сразу же прекращается, и начинается проверка следующего набора, соответствующего другому виду символа. Этот подход мы будем называть ранним завершением. Раннее завершение позволяет не выполнять проверки, предусмотренные для какого-либо вида символа, как только становится ясно, что неизвестный символ не относится к этому виду. Раннее завершение, как показывает опыт, позволяет во много раз сократить общее число проверяемых критериев, и соответствующим образом увеличить быстродействие. Проверка подавляющего большинства критериев завершается почти сразу же после своего начала. Этим заявленный способ отличается от известных методов, основанных на сверточных нейронных сетях и на машинах опорных векторов, где для вынесения заключения нужно выполнить неснижаемый большой объем вычислений.
Все перечисленные особенности заявленного способа обеспечивают ему высокое быстродействие.
В критерии может быть задана проверка на множестве из более чем одной проверочной прямой, причем, для выполнения критерия может быть допустимым соответствие требованиям критерия не для всех прямых этого множества. Это позволяет выполнить критерий даже в случае локального повреждения изображения, попадающего на одну из проверочных прямых. Таким повреждением может быть пятно или местная потертость красочного слоя. Для поврежденной прямой, условие соответствия для набора числовых характеристик не будет выполнено. Однако, для остальных проверочных прямых такое условие будет выполняться, что позволит считать критерий, в целом, выполненным. То есть, заявленный способ обеспечивает устойчивость к локальным повреждениям изображения. Отметим, что в прототипе локальное повреждение изображения и соответствующий ему неверный код почти всегда приводит к неверному переходу автомата состояния и, как следствие, к ошибке распознавания символа.
В критерии устанавливаются требования к числовым характеристикам проверочной прямой, которые предусматривают определенный допуск для, по крайней мере, одной из характеристик. Такие допуски позволяют учесть естественные геометрические погрешности сканирования и погрешности толщины линий, которые возникают при печати, обращении и обработке банкнот. На изображении символа того типа, к которому относится критерий, результат проверки критерия будет положительным, несмотря на геометрические погрешности сканирования и погрешности толщины линии. То есть, заявленный способ позволяет в необходимой степени затрубить критерии распознавания, чтобы избежать ложно негативных результатов на нормальных банкнотах.
Таким образом, заявленное изобретение, при сохранении высокого быстродействия, обеспечивает устойчивость к дефектам и искажениям изображения символа, которые характерны для серийных номеров на банкнотах.
Дополнительным преимуществом предпочтительной реализации заявленного способа является то, что в случае ошибки он, как правило, выдает заключение о нераспознанности символа. Это связано с тем, что последовательность принятия решения основана на проверке наборов логических критериев, где для заключения о распознавании какого-либо вида символа необходим положительный результат каждого из критериев в соответствующем ему наборе. Поэтому, если наборы критериев составлены достаточно полными для подтверждения соответствующего им вида символа, то естественным результатом при ошибке распознавания является отрицательный результат проверки каждого из наборов критериев, что вызывает итоговое заключение о нераспознанности символа. Выдача неправильного заключения о распознавании символа как относящегося к какому-то виду может иметь место только при недостаточно полном наборе критериев для этого вида. Очевидным решением для исключения возможности неправильного заключения будет добавление дополнительных критериев в набор для ужесточения принятия решения. В этом заявленный способ отличается от классификаторов, основанных на разделяющих поверхностях, таких, как машина опорных векторов. Для подобных классификаторов возможность управлять ужесточением принятия решения сильно ограничена.
Для буквенных символов европейских алфавитов, а также для большинства неевропейских цифровых систем, характерна вертикальная вытянутость символов и преимущественно вертикальная направленность линий. Для этих символов наиболее выгодно располагать проверочные прямые вдоль строк изображения знакоместа, поскольку этим обеспечивается пересечение одной проверочной прямой многих линий символа и, как следствие, более высокая информативность числовых характеристик этой прямой.
Небольшие дефекты изображения, такие как мелкие пятна загрязнения и небольшие потертости красочного слоя, без дополнительной обработки приводят к получению ошибочных числовых характеристик. Чтобы избежать этой ошибки, следует, по определенным правилам, фильтровать пиксели, отмеченные на проверочной прямой. Наиболее простым видом коррекции является замена коротких черных отрезков на белые и коротких белых отрезков на черные. Короткий черный отрезок обычно возникает из-за мелких пятен загрязнения, и его замена на белый уничтожает влияние пятна. Аналогичным образом, короткий белый отрезок возникает из-за небольшой потертости красочного стоя, не повреждающей линию символа на ее полную ширину. Замена этого отрезка на черный восстанавливает целостность линии. Предельное ограничение длины отрезков, подлежащих замене, выбирают достаточно малым, чтобы это не приводило к существенному искажению неповрежденного символа.
Фильтрацию удобнее всего производить непосредственно в процессе нахождения числовых характеристик. В качестве альтернативного способа фильтрации, можно, в ходе подсчета Р, С и WT, игнорировать короткие черные и короткие белые отрезки, с получением таких же результатов, как при описанной выше замене значения пикселей.
Для того, чтобы подтвердить принадлежность символа к определенному виду, требования к характеристикам проверочной прямой задают в виде допустимых интервалов для каждой из характеристик, причем, для выполнения требований, значения всех характеристик должны находиться в допустимых для них интервалах. Ширина допустимых интервалов должна задаваться в соответствии с геометрическими погрешностями и погрешностями толщины линии, характерными для определенного типа банкнот и определенного устройства обработки банкнот, на котором проводится сканирование.
Иногда, два разных вида символа оказываются очень похожими, и при проверке набора критериев соответствия одному виду нужно исключить принадлежность символа к другому виду. Для этого требования к характеристикам проверочной прямой задают в виде недопустимых интервалов для каждой из характеристик, причем, для выполнения требований, значение хотя бы одной характеристики должно находиться вне недопустимого для нее интервала.
Проверка попадания числовых характеристик в допустимые интервалы является очень быстрой операцией, которая, для процессоров общего назначения, требует не более 8 последовательных сравнений для контроля каждой строки. Имеются возможности для еще большего увеличения быстродействия такой проверки. Указанные последовательные сравнения могут выполняться параллельно, если архитектура процессора обеспечивает такую возможность. В процессорах с возможностью расширения набора команд, возможно создать специальную команду проверки, которая проверяет все четыре числовые характеристики одновременно за один такт.
В случае возможности существенного перекоса банкноты при сканировании, изображение символа также может оказаться перекошенным, что ухудшает достоверность его распознавания. Для борьбы с этим явлением следует, еще до совмещения изображения символа со знакоместом, компенсировать перекос путем поворота изображения символа на угол перекоса в направлении, противоположном направлению перекоса. Поворот изображения можно использовать и в том случае, когда символ расположен на банкноте под известным углом к ее стороне. Альтернативой повороту изображения может быть поворот самого знакоместа на угол перекоса при совмещении знакоместа с изображением символа. Этот подход, как правило, оказывается более затратным в вычислительном смысле из-за наклонной ориентации проверочных прямых по отношению к строкам изображения.
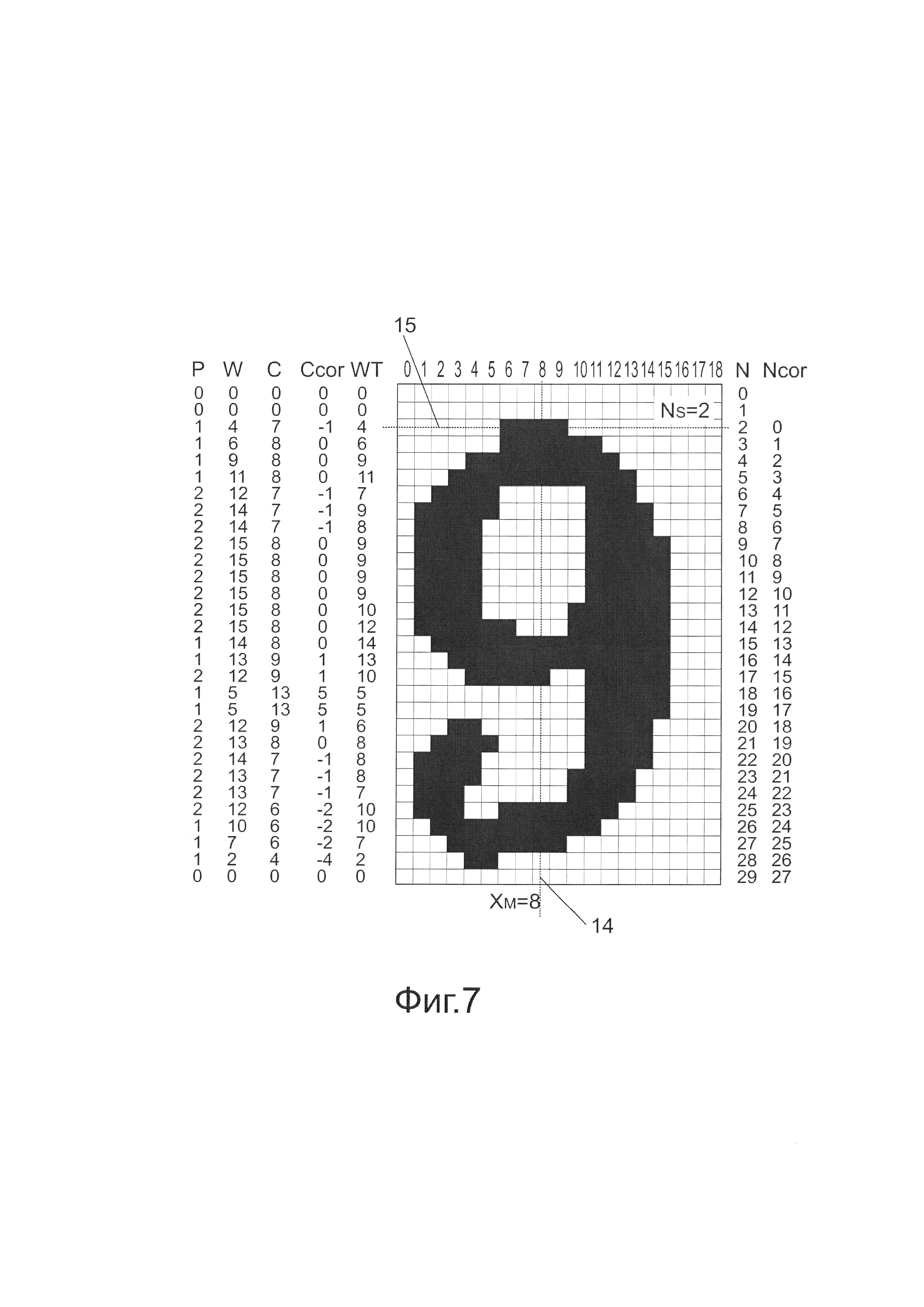
Положение каждой проверочной прямой линии и начало системы координат на ней устанавливают относительно границ знакоместа заранее заданным образом. Однако, графические элементы символа могут располагаться относительно границ знакоместа со значительной случайной погрешностью, поскольку совмещение изображения символа со знакоместом является достаточно грубой операцией и только обеспечивает нахождение символа внутри знакоместа. Указанная случайная погрешность приводит к увеличенному случайному разбросу числовых характеристик и ухудшает достоверность распознавания. Для детального отражения информации об изображении символа, в некоторых реализациях способа, проверочные прямые имеют взаимно-однозначное соответствие со строками изображения знакоместа. Проверочные прямые нумеруют и используют номер прямой для ее идентификации при проверке критериев.
Для устранения указанного случайного разброса, дополнительно выполняют коррекцию номера проверочной прямой и положения начала ее системы координат на основе ранее полученных наборов числовых характеристик. Изменение положения начала системы координат проверочной прямой, в свою очередь, приводит к изменению значения числовой характеристики центра С без изменения трех остальных характеристик, поскольку только числовая характеристика центра С отсчитывается от начала системы координат.
Описанная коррекция позволяет привязать проверочные прямые, используемые в критериях, и связанные с ними числовые характеристики к действительному положению символа внутри знакоместа. Подобная привязка, в свою очередь, помогает улучшить достоверность распознавания одного и того же символа на различных изображениях, поскольку каждый критерий применяется к проверке именно той части символа, для которой он предназначен, а числовые характеристики проверочных прямых не зависят от смещения изображения символа по отношению к границам знакоместа.
Как показывает опыт, определенные графические элементы различных изображений одного и того же символа имеют практически одни и те же координаты в строчном и столбцевом направлениях, измеряемые относительно центра тяжести изображения. Поэтому, положение центра тяжести либо оси тяжести изображения внутри знакоместа может быть успешно использовано для проведения привязки. В частности, высокую стабильность привязки дает установка начала системы координат на проверочных прямых относительно оси тяжести изображения символа. Когда символы вытянуты в столбцевом направлении и проверочные прямые направлены вдоль строк изображения, то наиболее предпочтительна коррекция в соответствии с положением оси тяжести изображения в пределах знакоместа, направленной в столбцевом направлении, такая, что координата на проверочной прямой в результате проведения коррекции отсчитывается от точки ее пересечения с указанной осью. Аналогичным образом, коррекцию номеров проверочных прямых можно проводить таким образом, чтобы расстояние от проверочной прямой с определенным номером до центра тяжести изображения, в результате проведения коррекции, соответствовало бы заранее заданной закономерности. Например, проверочные прямые, в результате проведения коррекции, можно нумеровать при помощи целого значения расстояния от проверочной прямой до центра тяжести изображения знакоместа.
Для символов европейских алфавитов, верхняя кромка изображения, как правило, устойчиво задается такими графическими элементами, как конец линии, горизонтальная линия или же верхняя точка дугообразной линии. Поэтому, высокая стабильность привязки в столбцевом направлении может быть получена при установке номеров проверочных линий в соответствии с расстоянием до верхней стороны охватывающего прямоугольника изображения, которая соответствует его верхней кромке. Такая коррекция номеров проверочных линий успешно сочетается с коррекцией положения начала системы координат на проверочной прямой в соответствии с положением оси тяжести изображения в пределах знакоместа, направленной в столбцевом направлении.
Чтобы провести коррекцию в случае взаимно-однозначного соответствия между строками изображения и проверочными прямыми, следует использовать не само изображение, а наборы числовых характеристик, полученные для каждой строки этого изображения. Это позволяет сократить объем вычислений, так как ранее вычисленные числовые характеристики уже несут в себе информацию, которая обеспечивает простое вычисление положения осей тяжести и центра тяжести, а также верхней стороны охватывающего прямоугольника символа. Будем полагать, что проверочные прямые соответствуют строкам и пронумерованы числом N от самой верхней до самой нижней, начиная с нулевого значения. Номер строки является ее вертикальной координатой. Горизонтальные координаты отсчитываются от левого края знакоместа. Тогда, горизонтальное положение оси тяжести изображения, направленной в столбцевом направлении, в соответствии с общепринятым определением оси тяжести, можно получить из характеристик С и WT как

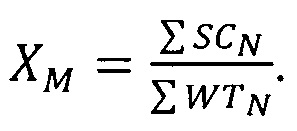
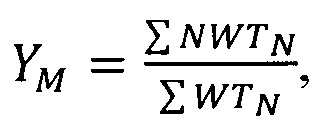
Если PN=0, то строка изображения N не содержит пикселей, относящихся к символу. Поэтому строка, соответствующая верхней кромке изображения, то есть верхней стороне охватывающего прямоугольника, имеет самый малый номер NS, при котором
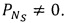
В символах восточноазиатских слоговых алфавитов, таких как корейский или японский, как правило, отсутствует выделенное направление линий. Для распознавания таких символов предпочтительно часть проверочных прямых ориентировать вдоль строк знакоместа, а другую их часть ориентировать вдоль столбцов. Это обеспечит получение информации о линиях символа, имеющих различные направления.
Для повышения точности различения разных видов символов со схожим рисунком, в набор критериев могут быть добавлены критерии, не основанные на проверке числовых характеристик. Одним из таких критериев может быть проверка сходства заранее сохраненного эталонного изображения с областью в знакоместе, размер и расположение которой заданы заранее. В качестве меры сходства могут применяться различные известные методы сравнения изображений. Это может быть вычисление попиксельного манхеттенского расстояния между шаблоном и областью на изображении символа, корреляционное сопоставление, тот или иной вид нейронной сети, и другие, известные специалистам в области распознавания изображений. Критерий считается выполненным, если значение показателя сходства оказывается лучше некоторого, заранее заданного порогового значения.
Проверка сходства требует значительно больше времени, чем проверка попадания числовых характеристик в заданные интервалы. Поскольку критерий проверки сходства является только частью набора критериев, то в силу раннего завершения он будет проверяться далеко не всегда. С точки зрения повышения быстродействия проверку этого критерия желательно проводить после проверки всех критериев в наборе, которые основаны на числовых характеристиках. Тогда, время будет затрачено на проверку только при почти полной уверенности в принадлежности символа к определенному виду.
Аналогичным образом, в набор критериев может быть введен контроль наличия заранее заданного структурного элемента в знакоместе. Например, может проводиться проверка того, является ли определенная пробельная часть в символе островом, полуостровом или проливом. Такие виды проверки, основанные на контроле связности областей, широко применяются в других способах распознавания символов. Однако, так как проверка связности является достаточно медленной операцией, то ее также следует выполнять после проверки всех критериев в наборе, которые основаны на числовых характеристиках.
Как уже указывалось, вычисление числовых характеристик проверочной прямой хорошо подходит для аппаратной реализации в виде специального сопроцессора, что позволяет значительно увеличить быстродействие распознавания символа с сохранением всех преимуществ от применения заявленного способа. Это достигается тем, что в вычислительной системе устройства для обработки банкнот применяется сопроцессор, содержащий
входной порт для получения значений пикселей, соответствующих знакоместу, где указанное значение определяет либо пиксель символа, либо пиксель пробела,
решающую логическую схему, выполненную с возможностью обеспечить нахождение набора числовых характеристик для каждой проверочной прямой знакоместа, включающего в себя
длину интервала, охватывающего все пиксели символа, расположенные на проверочной прямой,
количество интервалов пикселей символа, в которых пиксели символа расположены на проверочной прямой друг за другом,
сумму координат пикселей символа, расположенных на проверочной прямой, выраженных в одномерной системе координат проверочной прямой,
и суммарное число всех пикселей символа, расположенных на проверочной прямой,
и выходной порт для выдачи наборов числовых характеристик, соответствующих строкам знакоместа.
Вычислительная система устройства для обработки банкнот содержит центральный процессор, память и интерфейсы связи. Сопроцессор подключается к вычислительной системе и берет на себя нагрузку по формированию наборов числовых характеристик для проверочных прямых, которые заданы для знакоместа. Остальные шаги заявленного способа выполняются центральным процессором вычислительной системы.
Отметим, что вместо числовой характеристики центра С в сопроцессоре формируется сумма SC координат пикселей символа, расположенных на проверочной прямой, выраженных в одномерной системе координат проверочной прямой. Из этой суммы величина С непосредственно получается при делении на WT. Деление, по завершении обработки проверочной прямой, может производиться либо в центральном процессоре, либо в сопроцессоре. Возможность вынести деление из сопроцессора связана с тем, что быстродействующие схемы деления сложны по структуре, а деление может быстрее выполняться в центральном процессоре в связи с более высокой тактовой частотой его ядра.
Решающая логическая схема, специально разработанная для одновременного формирования всех четырех числовых характеристик, может обрабатывать по одному пикселю за такт без дополнительных накладных расходов на манипуляцию с данными. Это превосходит быстродействие центрального процессора общего назначения, в котором, для обработки одного пикселя нужно выполнить несколько команд в связи с необходимостью дополнительной внутренней пересылки данных между элементами процессора.
Входной порт может быть выполнен любым способом, обеспечивающим нужное быстродействие. Например, он может быть подключен к передающему порту межпроцессорной связи, или к контроллеру прямого доступа к памяти, либо же работать как мастер на шине с самостоятельной генерацией адресной последовательности. Если необходима подача пикселей, расположенных на наклонной прямой, то соответствующая выборка значений из памяти может быть реализована за счет сложных режимов генерации адреса при прямом доступе к памяти. А именно, речь идет о двумерной генерации адресов либо о прямом доступе по связанному списку адресов.
Выходной порт может использовать те же механизмы передачи данных, что и входной порт. Так как объем передаваемых данных выходного порта обычно меньше, чем объем входных данных, для выходного порта может быть разумным чтение результатов за счет обращения центрального процессора к регистрам сопроцессора.
В связи с независимостью обработки пикселей, соответствующих отдельным проверочным прямым, решающая логическая схема может быть выполнена с возможностью одновременной обработки пикселей, находящихся на нескольких проверочных прямых. Это достигается размножением сегмента решающей схемы, обрабатывающего данные одной прямой, на несколько экземпляров. Производительность самой решающей схемы растет пропорционально количеству таких экземпляров. Предельно достижимое быстродействие, чаще всего, ограничивается уже не быстродействием логической схемы, а скоростью подачи данных во входной порт и скоростью откачки данных из выходного порта.
Логическая схема для обработки пикселей, находящихся на одной проверочной прямой, может содержать конечный автомат, в котором обеспечена последовательная подача на вход значений пикселей, находящихся на проверочной прямой. Подаваемое входное значение определяет переход между состояниями автомата, а граф переходов обеспечивает формирование числовых характеристик проверочной прямой во внутренних регистрах автомата. Конечный автомат обрабатывает по одному пикселю за такт.
Однако, логическая схема для обработки пикселей, находящихся на проверочной прямой, может выполняться и в виде комбинационной схемы, поскольку значения числовых характеристик определяются исключительно значениями пикселей. При такой реализации схема обрабатывает все пиксели на проверочной прямой за один такт, что дает многократное ускорение по сравнению с реализацией в виде конечного автомата.
Фильтрация пикселей на проверочной прямой может быть реализована в решающей логической схеме аналогично тому, как фильтрация ранее была описана в отношении заявленного способа. Очень часто повреждения цифрового изображения проявляются в соседних пикселах на смежных проверочных прямых. Данную особенность можно использовать для более точного выявления дефектов. С этой целью, фильтрация может анализировать соотношения значений соседних пикселей, находящихся на смежных проверочных прямых.
Заявленный способ предназначен, прежде всего, для распознавания серийных номеров на банкнотах. Однако, он может успешно использоваться для распознавания другой текстовой информации, выполненной заранее известным шрифтом, например, указания номинала, версии банкноты и года ее эмиссии. Также, он может применяться для обработки надписей в неденежных документах, выполненных заранее известным шрифтом.
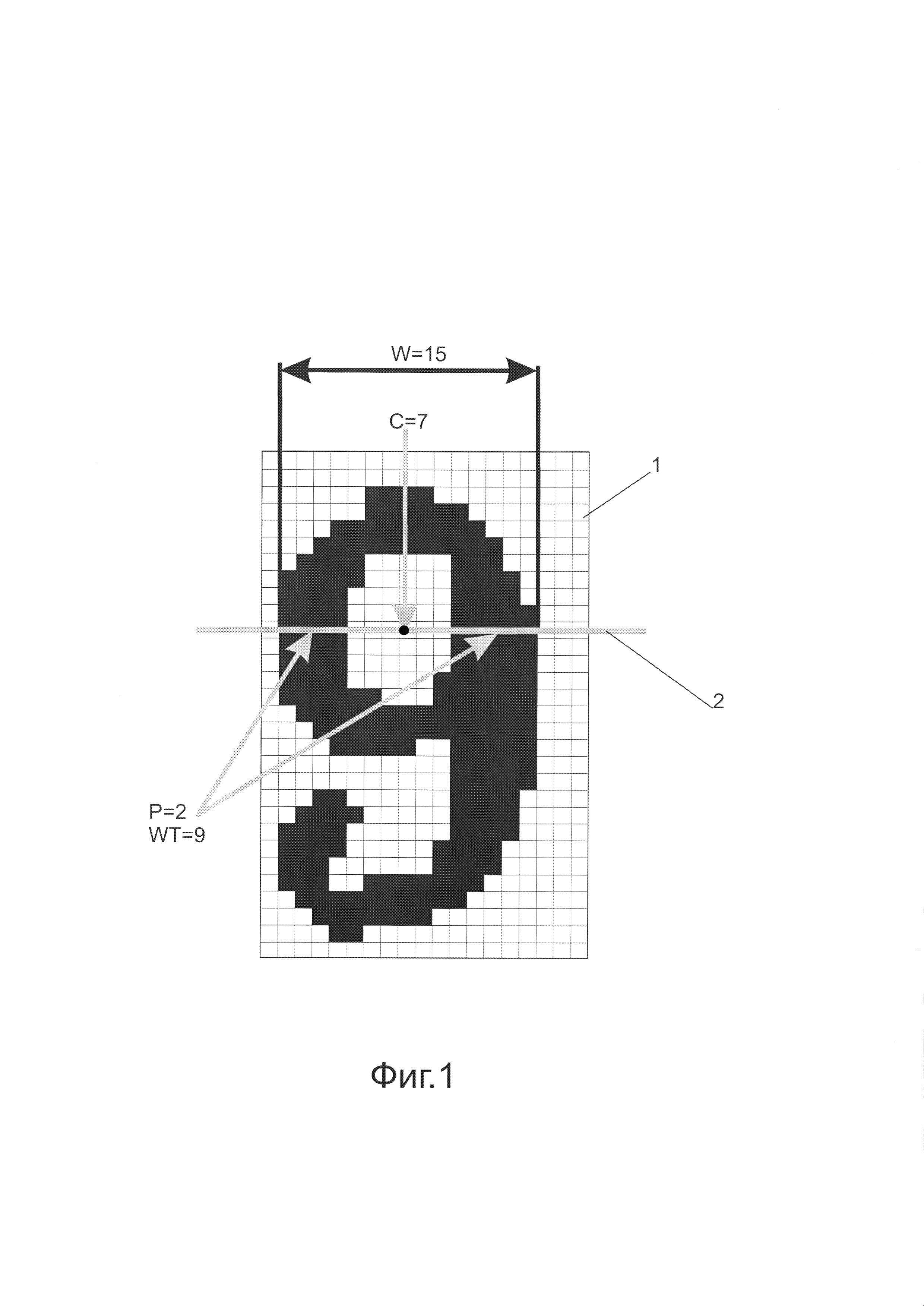
На Фиг. 1 показан принцип нахождения числовых характеристик, соответствующих проверочной прямой.
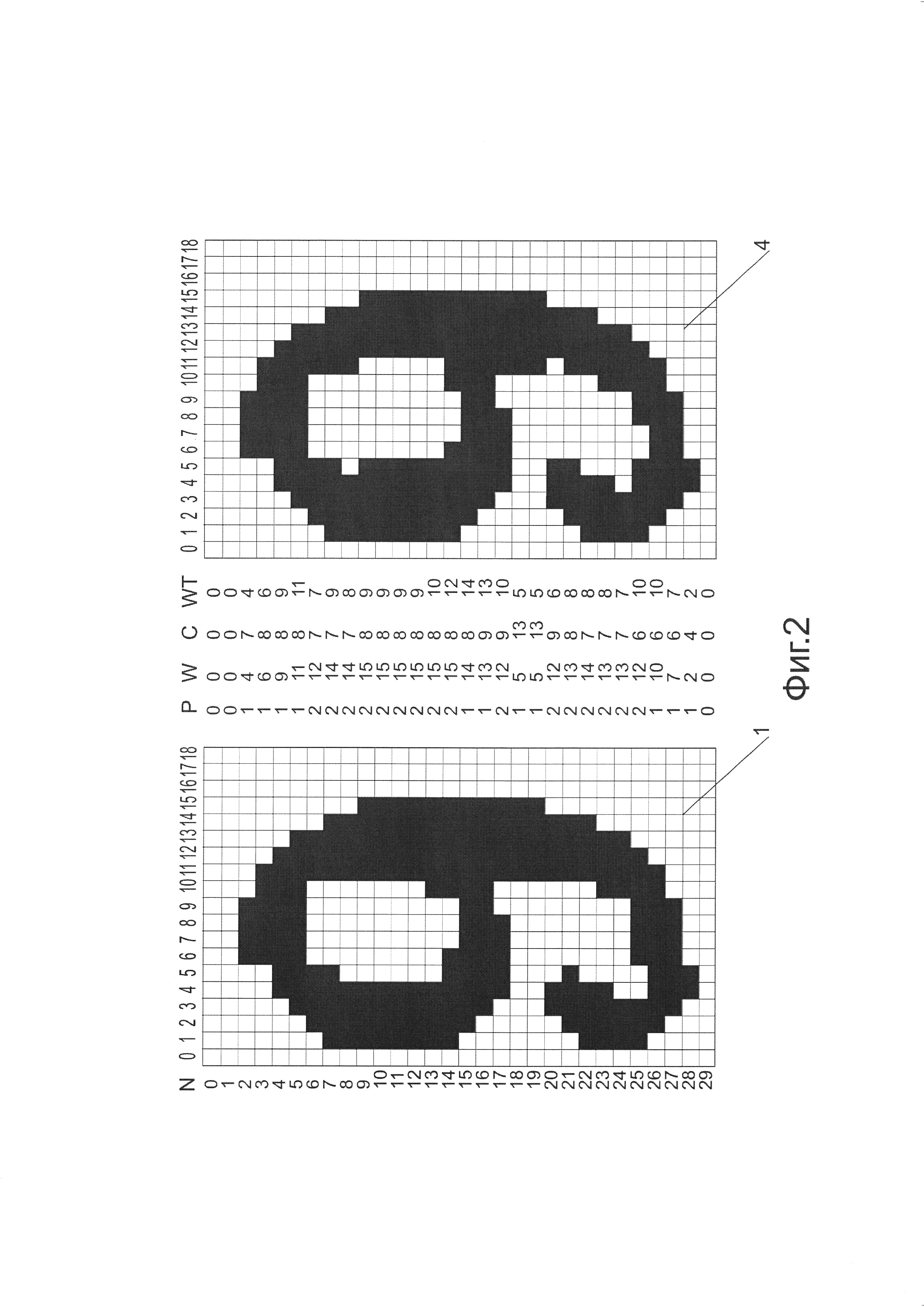
Фиг. 2 иллюстрирует массив числовых характеристик, кодирующих строки символа, и возможность обратного преобразования от массива числовых характеристик к изображению символа.
На Фиг. 3 показана взаимосвязь между оконным преобразованием Фурье и числовыми характеристиками.
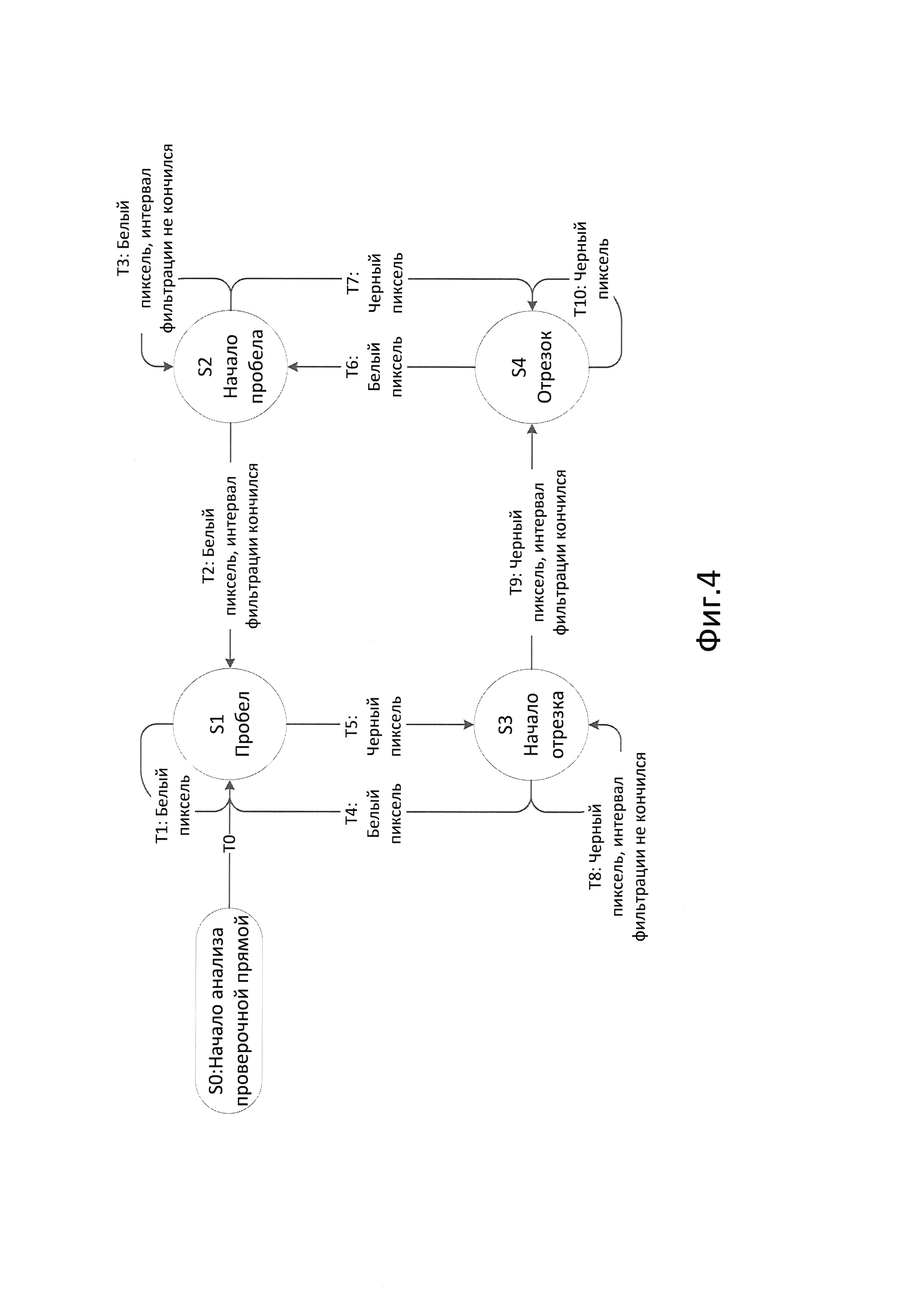
На Фиг. 4 представлен граф переходов конечного автомата, реализующего вычисление числовых характеристик с фильтрацией дефектных пикселей. На Фиг. 5 показано изображение символа с дефектными пикселями.
На Фиг. 6 изображена структурная схема реализации сопроцессора для вычисления числовых характеристик.
На Фиг. 7 показана коррекция привязки координат изображения символа.
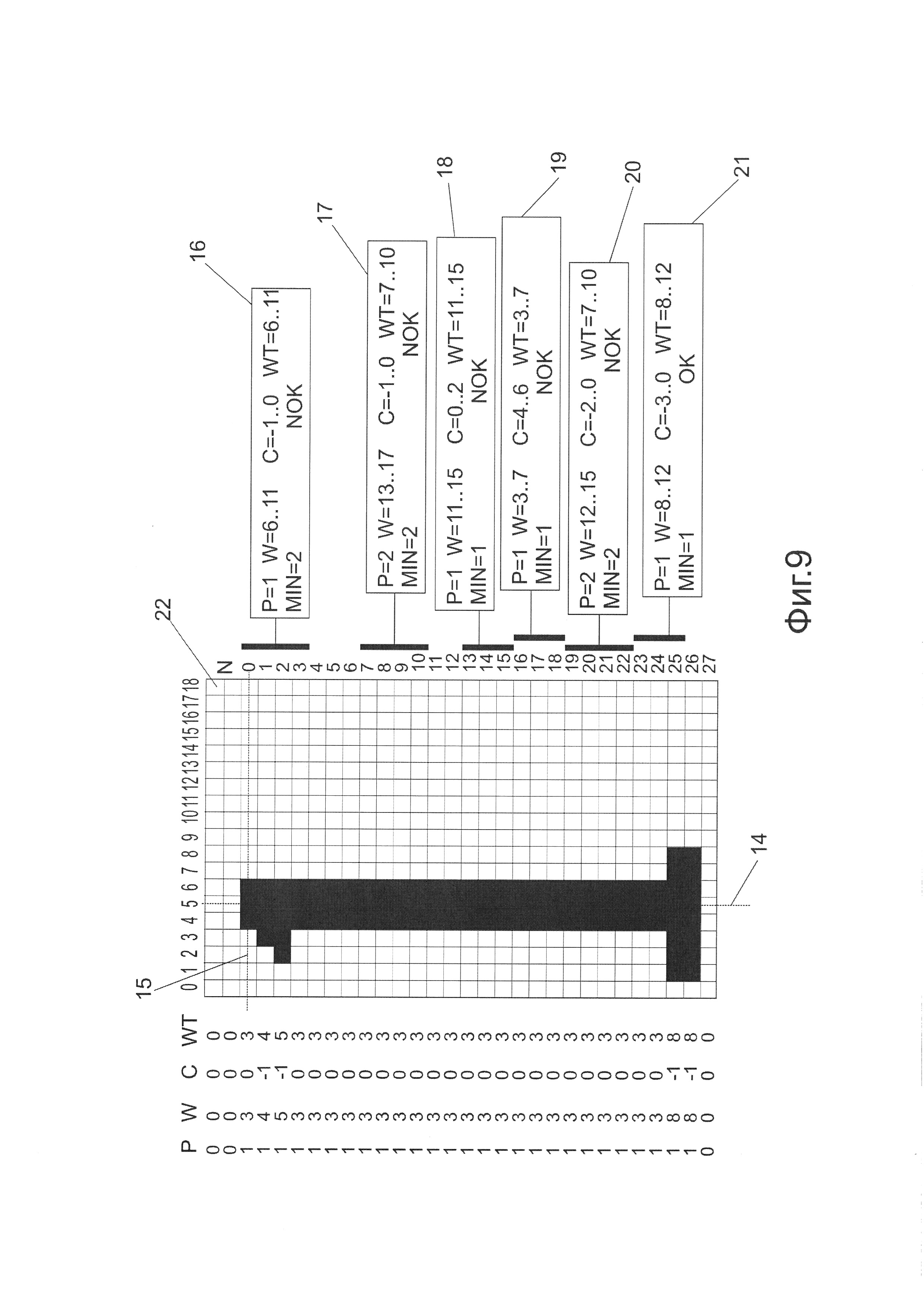
На Фиг. 8 и Фиг. 9 показан набор критериев и результаты проверки критериев для изображений различных символов.
На Фиг. 10 показана пошаговая последовательность распознавания символа.
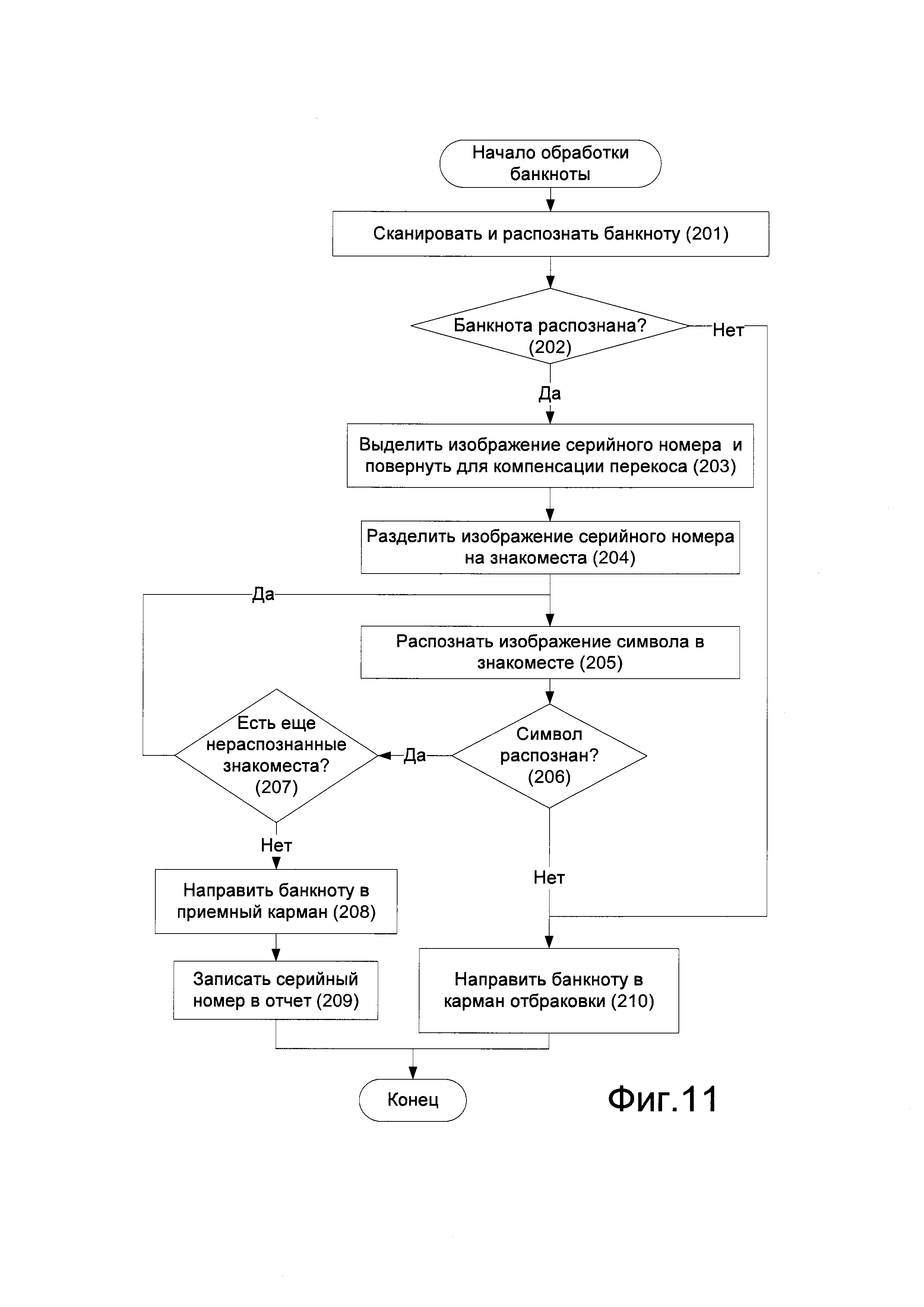
На Фиг. 11 изображена пошаговая последовательность обработки банкноты в машине для обработки банкнот.
Пример реализации заявленного способа описывает его выполнение при помощи счетно-сортировальной машины, содержащей: банкиотопроводный механизм, обеспечивающий перемещение банкнот из подающего кармана в приемные карманы; систему датчиков, позволяющую сканировать цифровое изображение банкноты по мере ее движения в банкнотопроводном механизме; и встроенную вычислительную систему. Вычислительная система, в свою очередь, содержит центральный процессор, память, пользовательский интерфейс, а также периферические устройства и электрические схемы для подключения датчиков и приводов банкнотопроводного механизма.
При движении в банкнотопроводном механизме, банкноту сканируют в проходящем красном и проходящем инфракрасном излучении, а также с обеих сторон в отраженном белом излучении. При этом, получают цифровые изображения низкого разрешения (25 линий на дюйм). Для отраженного белого излучения, дополнительно к названным, получают цифровые изображения высокого разрешения (200 линий на дюйм). При сканировании банкноты измеряют угол и направление ее перекоса. Далее, производят поворот цифровых изображений низкого разрешения на тот же угол, но в противоположную сторону, для компенсации перекоса изображения.
Цифровые изображения низкого разрешения используют для определения валюты, номинала и ориентации банкноты, а также для проверки ее подлинности. Для этого применяют способ, описанный в патенте RU 2438182, опубл. 27.12.2011, МПК G07D 7/00. Сначала, осуществляют предварительную классификацию на основе размера цифрового изображения банкноты. Таким образом, определяют множество возможных классов, к которым может относиться банкнота. Далее, выполняется детальная проверка принадлежности банкноты к выбранным возможным классам. Цифровые изображения банкноты последовательно проверяются на соответствие отдельным наборам, состоящим из множества критериев, где каждый набор соответствует определенному классу. В критериях проверяется, попадает ли в заданный интервал значений отношение средних интенсивностей цифровых изображений в заданных зонах банкноты. Проверка набора критериев прекращается, как только обнаруживается невыполнение хотя бы одного из составляющих его критериев. Если все критерии в наборе оказываются выполненными, то проверку банкноты прекращают и делают вывод о ее принадлежности к тому классу, которому соответствует этот набор. Если же ни в одном наборе критериев не удалось выполнить все критерии, то считают банкноту нераспознанной.
Место расположения серийного номера для каждой разновидности банкноты четко определено банком-эмитентом. Как только становится известной валюта, номинал и ориентация банкноты, можно сделать вывод о месте расположения серийного номера банкноты в цифровом изображении высокого разрешения. По завершении распознавания банкноты, из цифрового изображения высокого разрешения вырезают участок, содержащий изображение серийного номера. Вместе с вырезанием, цифровое изображение серийного номера дополнительно поворачивают на известный угол перекоса с целью компенсации перекоса, возникшего в ходе сканирования.
Затем, цифровое изображение серийного номера разбивают на прямоугольные знакоместа, где каждое знакоместо соответствует отдельному символу. Для определенности, здесь описывается разбиение серийного номера, строка которого ориентирована в горизонтальном направлении. Область расположения каждого символа определяют по проекции цифрового изображения серийного номера на горизонтальную ось. В местах расположения символов, более темных, чем окружающий их фон, проекция имеет минимальные значения, а максимальные значения проекции соответствуют промежуткам между символами. Таким образом, находят вертикальные границы между зонами расположения символов на серийном номере. Далее, для каждой такой зоны в отдельности определяют проекцию на вертикальную ось, и по этой проекции находят вертикальные границы символа. На основе найденных границ, знакоместо совмещают с изображением символа таким образом, чтобы символ целиком располагался внутри знакоместа. Если строка серийного номера ориентирована вертикально, то разбиение выполняют аналогичным образом, но с взаимной заменой вертикального и горизонтального направления для всех действий. Разделение строк на символы при помощи проекции широко применяется в распознавании документов и хорошо известно специалистам в этой области техники.
Далее, проводят бинаризацию изображения знакоместа. Для нахождения порога бинаризации используют хорошо известный метод Отсу. Тем пикселам, которые относятся к символам, присваивают значение 0, а пробельным пикселам присваивают значение 255. Пример полученного в результате этого изображения 1 знакоместа приведен на Фиг. 1. После бинаризации получают массив числовых характеристик для проверочных прямых, которые в описываемой реализации совпадают со строками изображения. Между строками изображения знакоместа и проверочными прямыми существует взаимно-однозначное соответствие: каждой строке изображения знакоместа соответствует проверочная прямая, и каждой проверочной прямой соответствует строка изображения знакоместа. Поэтому, в дальнейшем описании мы не будем делать существенной разницы между строками изображения знакоместа и проверочными прямыми.
Покажем получение числовых характеристик на примере одной проверочной прямой. Прямая 2, проходящая вдоль строки изображения, пересекает символ таким образом, что интервал W, охватывающий все пиксели символа на этой прямой, равен 16. При этом, количество Р интервалов пикселей, в которых пиксели символа расположены друг за другом, равно 2. Общее количество WT пикселей символа на прямой, равно 9. Центр тяжести С пикселей символа на прямой равен 7, причем, отсчет координат центра тяжести ведется от левого края знакоместа.
Массив полученных числовых характеристик для каждой строки изображения 1 показан на Фиг. 2. Колонка значений N указывает номер каждой строки, отсчитываемый от самой верхней строки знакоместа. На том же рисунке показано изображение знакоместа 4, восстановленное на основе массива числовых характеристик. Для этого, интервал пикселей в каждой строке, имеющий центр С и ширину W, заполнялся числом Р черных отрезков одинаковой длины WT/P пикселей, равномерно расположенных с одинаковым шагом W/P. Из-за округления до целого значения, длина отрезков в восстановленной строке может различаться на один пиксель. Можно увидеть, что символ сохранил форму и полную узнаваемость, несмотря на небольшие отличия от исходного цифрового изображения 1. Это говорит о том, что кодирование изображения символа при помощи четырех числовых характеристик Р, W, С и WT обладает хорошей полнотой, а потери информации при кодировании несущественны для цели распознавания символа.
Заметим, что при единственном отрезке пикселей символа на прямой, то есть когда Р=1, значения W и WT всегда совпадают.
Как уже говорилось, кодирование строки при помощи числовых характеристик Р, W, С и WT очень близко к кодированию строки с применением оконного преобразования Фурье. Связь между этими способами кодирования показана на Фиг. 3 на примере приведения базисной функции оконного преобразования Фурье к набору числовых характеристик Р, W, С и WT. Прямоугольное окно 5 шириной Т=20 пикселей определяет оконную функцию преобразования. Для простоты объяснения будем считать, что левый край окна соответствует координате 0 на проверочной прямой. Вне окна, базисная функция имеет нулевой уровень, показанный положением прямой 6. Внутри окна, базисная функция

Проведем квантование и бинаризацию базисной функции таким образом, чтобы при ее отрицательном значении пиксели получали черный цвет, а для значений больше либо равных нулю пикселям назначался белый цвет. Размер пикселя нами принят равным 1. При бинаризации функций 8, 7, 9 получаются строки 10, 11, 12 пикселей, соответственно. На рисунке приведены значения характеристик Р, W, С и WT для каждой из полученных строк. Как видно из этих значений, числовые характеристики определяются параметрами базисной функции. Значение ширины W примерно равно размеру окна Т. Количество штрихов связано с количеством периодов внутри окна:
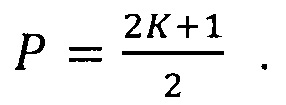
Таким образом, с определенной степенью приближения, можно сказать, что кодирование строки через числовые характеристики эквивалентно кодированию при помощи наиболее значимой базисной функции оконного преобразования Фурье. То есть, кодирование при помощи Р, W, С и WT является, на самом деле, вариантом локального частотного анализа, при котором определяется доминантная пространственная частота, интервал ее локализации, и уровень постоянной составляющей. В отличие от реального оконного преобразования Фурье, вычисление числовых характеристик происходит очень быстро, что дает существенное преимущество по быстродействию для всего способа распознавания символа.
Вычисление числовых характеристик для каждой строки цифрового изображения производится при помощи конечного автомата, граф переходов которого изображен на Фиг. 4. В приводимом примере, конечный автомат реализован программным образом, однако, как будет показано далее, он также может быть выполнен в виде аппаратного сопроцессора.
Конечный автомат имеет начальное состояние S0, и четыре рабочих состояния S1-S4. После включения, автомат сразу же переходит в состояние S1 (Пробел). Автомат анализирует значения пикселей, один за другим последовательно выбираемые из строки цифрового изображения. Переход из одного рабочего состояния в другое осуществляется при выборке каждого пикселя, в зависимости от его значения.
Автомат имеет внутренние переменные для ширины W, числа штрихов Р, веса WT и суммы координат черных пикселей SC. По ходу обработки строки, эти переменные накапливают соответствующие значения числовых характеристик. Из величины SC центр С вычисляется по формуле C=SC/WT в самом конце обработки строки. Начальные значения этих переменных равны нулю. Также, в автомате есть внутренние переменные для проведения фильтрации дефектных пикселей. Переменная FC представляет собой счетчик пикселей фильтруемого интервала. Она имеет начальное значение 2 и равна предельно допустимой длине фильтруемого интервала минус 1. Переменная FA накапливает сумму координат пикселей, входящих в фильтруемый интервал. Она имеет нулевое начальное значение.
С момента начала анализа строки, приход каждого пикселя увеличивает на 1 значение внутренней переменной PC, в которой хранится координата очередного пикселя. Переменная PC имеет начальное значение, равное 0. То же самое выполняется и для промежуточной переменной WC, которая служит для подсчета числовой характеристики ширины.
В начале анализа строки автомат находится в состоянии S1 (Пробел). Это состояние соответствует устойчивому состоянию обнаруженного пробела в строке. Пробел может иметь длину несколько пикселей. Если в этом состоянии выбирается белый пиксель (переход Т1), то считается, что длина пробела увеличилась на один пиксель, и автомат остается в состоянии S1.
Если же выбирается черный пиксель (переход Т5), то автомат переходит в состояние S3 (Начало отрезка). Это состояние соответствует процессу фильтрации, при котором еще не понятно, является ли черный пиксель началом черного отрезка на пересечении с линией символа, или шумовым пикселем, возникшим из-за черного дефекта изображения. При входе в S3 переменная FC сбрасываются к начальному значению, а в FA координата текущего пикселя. Если очередной выбранный пиксель оказывается белым, то считается, что закончился черный дефект изображения, и по переходу Т4 автомат возвращается в состояние S1. Если очередной пиксель черный, и предельное значение фильтруемого интервала еще не достигнуто, то автомат остается в состоянии S3 (переход Т8). По каждому переходу Т8 счетчик FC увеличивается на единицу, а к накопительной переменной FA прибавляется значение координаты пришедшего пикселя. Если же предельное значение достигнуто, то по приходу черного пикселя (переход Т9) считается, что дефекта изображения не было, и автомат переходит в состояние S4 (Отрезок).
В момент перехода Т9, происходит увеличение переменной Р на 1, что соответствует обнаружению нового черного отрезка. Если это первый обнаруженный черный отрезок (то есть Р=1), то значение счетчика FC записывается в промежуточный счетчик ширины WC. Дополнительно, значение FC по этому переходу всегда прибавляется к WT. Значение накопительной переменной FA и координата текущего пикселя прибавляются к SC. Все эти действия позволяют правильно учесть в числовых характеристиках те пиксели, которые анализировались в состоянии S3 и оказались принадлежащими черному отрезку. Переход Т4 в состояние S1 игнорирует накопленные значения FC и FA, поскольку интервал фильтрации, пройденный в состоянии S3, относится к пробелу.
В состоянии S4 (Отрезок) приход каждого черного пикселя не изменяет состояния (переход Т10), поскольку черный отрезок продолжается. По этому переходу, переменная WT увеличивается на 1, переменная SC увеличивается на значение координаты текущего пикселя, а в переменную ширины W записывается значение временного счетчика ширины WC, уменьшенное на 1. При появлении белого пикселя автомат выполняет переход Т6 в состояние S2 (Начало пробела).
В состоянии S2 производится фильтрация с обнаружением шумовых белых пикселей. При входе в S3 переменная FC сбрасываются к начальному значению, а в FA заносится координата текущего пикселя. При приходе белого пикселя, если предельное значение интервала фильтрации пока не достигнуто (переход Т3), то автомат остается в состоянии S2. По каждому переходу Т3 счетчик FC увеличивается на единицу, а к накопительной переменной FA прибавляется значение координаты этого пикселя. Если пришел белый пиксель и предельное значение достигнуто (переход Т2), то автомат переходит в состояние S1 (Пробел). Этим подтверждается завершение черного отрезка без белых дефектных пикселей. Если же пришел черный пиксель, это говорит о том, что предыдущий белый пиксель был дефектным, поэтому, автомат возвращается (переход Т7) в состояние S4.
В момент перехода Т7, значение FC всегда прибавляется к WT. Значение накопительной переменной FA и координата текущего пикселя прибавляются к SC. Все эти действия позволяют правильно учесть в числовых характеристиках те пиксели, которые анализировались в состоянии S2 и оказались принадлежащими черному отрезку. Переход Т2 в состояние S1 (Пробел) игнорирует накопленные значения FC и FA, поскольку интервал фильтрации, пройденный в состоянии S2, относится к пробелу.
Когда на вход автомата был подан последний пиксель в строке, анализ строки прекращают, и накопленные значения Р, W, C=SC/WT и WT сохраняют в массиве числовых характеристик. При Р=0 значения остальных числовых характеристик W, С и WT не имеют смысла, и им присваивают нулевые значения.
Покажем на примере анализ строки с номером N=11 на изображении знакоместа 13, как показано на Фиг. 5. Строка N=11 имеет дефекты в пикселях с номерами р7 и p13. Предел интервала фильтрации установлен в значение 2, чему соответствует только один допустимый дефектный пиксель.
Анализ начинается в состоянии S1 (Пробел) с белого пикселя р0. Приход следующего черного пикселя p1 переводит автомат по переходу Т5 в состояние S3 (Начало отрезка). Накопительные переменные получают значения FC=2 (начальное) и FA=1 (координата этого пикселя). Следующий пиксель р2 тоже является черным, при этом, предельная длина интервала фильтрации 2 уже достигнута. Происходит переход Т9 в состояние S4 (Отрезок). Значение Р увеличивается на 1, то есть, Р=1. По этому переходу, так как он произошел первый раз, в промежуточный счетчик ширины WC записывается значение FC: WC=2. Также, к WT прибавляется FC, так что, WT=2. Значение SC получается как сумма координаты текущего пикселя 3 и FA, то есть, SC=3. При подаче последующих черных пикселей р3 и р4 состояние S4 сохраняется, и происходит переход Т8. В результате, получается WC=4, WT=4 и SC=T0.
Белый пиксель р5 запускает переход Т6 автомата в состояние S2 (начало пробела), и в переменную ширины W записывается значение временного счетчика ширины WC: W=WC-1=4. Интервал фильтрации начинается сначала, поэтому, устанавливается FC=2 (начальное) и FA=5 (координата этого пикселя). Следующий пиксел р6 тоже оказывается белым, и фиксируется предельная длина интервала фильтрации с переходом Т2 в состояние S1 (Пробел). Однако, следующий пиксел р7 оказывается черным, и автомат (Т5) переходит в состояние S3 (Начало отрезка). Дальнейший пиксель р8 является белым, поэтому автомат по переходу Т4 вновь возвращается к состоянию S1 (Пробел). Таким образом, была проверена фильтрация дефектного пикселя р7. Дальнейшие белые пиксели р9 и р10 не изменяют состояния автомата и обрабатываются по переходу Т1.
Пиксель р11 оказывается черным, что переводит автомат в состояние S3 (Начало отрезка). Устанавливается FC=2 (начальное) и FA=11 (координата этого пикселя). На черном пикселе р12 фиксируется завершение фильтрового интервала. Происходит переход Т9 в состояние S4, при этом получается P=1+1=2, WT=4+2=6, SC=10+11+12=33. Черный пиксель р13 не меняет состояния при переходе Т10, и изменяет следующие переменные: WT=6+1=7, SC=33+13=46.
Дефектный пиксель р14 является белым, он переводит автомат в состояние S2 (Начало пробела) с установкой FC=2 (начальное) и FA=14 (координата этого пикселя). Следующий черный пиксель р15 вызывает переход Т7 в состояние S4 (Отрезок), по которому происходят следующие действия: WT=7+FC=2, SC=46+FA+15=75. Таким образом, происходит фильтрация дефектного белого пиксела.
Белый пиксель р16 запускает переход Т6 автомата в состояние S2 (Начало пробела), и в переменную ширины W записывается значение временного счетчика ширины WC: W=WC-1=15. Пиксель р17, по превышению предельного интервала фильтрации, переводит автомат в состояние S1 (Пробел). Следующий белый пиксел р18 выполняет переход Т1 без изменения состояния автомата. На этом, анализ строки прекращается, и фиксируются накопленные к этому моменту числовые характеристики строки N=1: Р=2, W=15, WT=9 и C=SC/WT=75/9=8. Сравнивая это с изображением знакоместа 1 без дефектов на Фиг. 2, можно убедиться, что наличие дефектных пикселей не повлияло на полученные числовые характеристики этой строки.
Альтернативная реализация вычисления числовых характеристик строки предполагает применение аппаратного сопроцессора, подключаемого к центральному процессору вычислительной системы. Структурная схема сопроцессора показана на Фиг. 6. Сопроцессор реализует бинаризацию пикселей и конечный автомат, описанный нами выше, для строк знакоместа длиной до 32 пикселей. Он содержит регистр номера состояния 25 и связанное с ним по входу и выходу микропрограммное запоминающее устройство 26. Для хранения накапливаемых значений числовых характеристик W, WT, SC и Р предусмотрены регистры 27-30. Их содержимое может быть считано центральным процессором через выходной порт в виде шинного формирователя 31, подключенного к 32-разрядной шине данных центрального процессора. Временный счетчик ширины WC реализован в регистре 38. Счетчик пикселей фильтруемого интервала FC размещен в регистре 37, а накопитель суммы координат фильтруемого интервала FA представлен регистром 44. Счетчик пикселей строки PC находится в регистре 35.
Входной порт 32 предназначен для подключения к шине данных центрального процессора, где импульс WR формируется при записи в определенный адрес памяти. Сигнал Reset формируется центральным процессором перед обработкой очередной строки для сброса всех элементов сопроцессора к начальным значениям. Шина Pixel предназначена для передачи на нее байтового значения пикселя. Для передачи пикселей используется прямой доступ к памяти, при котором из памяти вычислительной системы последовательно считываются байтовые значения пикселей, и записываются по адресу входного порта 32 сопроцессора, с генерацией импульса WR.
Все элементы сопроцессора, кроме шинного формирователя 31, выполнены с синхронной связью, где сигнал WR используется в качестве тактового сигнала. При записи значения очередного пикселя в порт 32 это значение сравнивается компаратором 33 с уровнем бинаризации ТН, хранимым в регистре 34. Уровень бинаризации ТН вычисляется центральным процессором по гистограмме изображения серийного номера с использованием метода Отсу, и загружается в регистр 34. Выходная линия компаратора 33 представляет собой бинаризованное значение символа (0 или 1). Она подключается ко входу микропрограммного ПЗУ 26.
Центральный процессор, перед началом работы, также загружает в регистр 43 значение предела длины отрезка фильтрации FL. Значение FL сравнивается компаратором 42 со значением FC, хранимым в регистре 37, для определения необходимости перехода из состояния S3 (Начало отрезка) в S4 (Отрезок), а также из состояния S2 (Начало пробела) в S1 (Пробел). Выход компаратора 42 подключен ко входу микропрограммного ПЗУ 26.
ПЗУ 26 и регистр номера состояния 25 образуют устройство микропрограммного управления сопроцессора. Согласно графу переходов автомата, показанному на Фиг. 4, переходы между состояниями определяются номером состояния, значением входного пикселя и тем, достигнута ли предельная длина фильтруемого отрезка. Соответственно, микропрограммное ПЗУ 26 формирует сигналы сброса, записи и инкремента для регистров сопроцессора, в соответствии с номером состояния в регистре 25, уровнем входного пиксела и с сигналом достижения предельной длины фильтруемого отрезка, которые подаются ему на вход. Номер следующего состояния подается с выхода ПЗУ 26 на вход регистра номера состояния 25. Переход конечного автомата происходит по перепаду сигнала WR, который тактирует перезапись регистра номера состояния 25. Регистры и другие элементы схемы сопроцессора выполнены и соединены таким образом, чтобы каждый из возможных переходов автомата выполнялся синхронно за один такт сигнала WR.
Значение количества штрихов Р в регистре 30 инкрементируется в соответствии с описанной логикой работы автомата по сигналу от ПЗУ 26. Значение FC счетчика 37 пикселей фильтруемого интервала используется для записи в счетчик 38 ширины WC и для прибавления к регистру 28 веса WT при помощи сумматора 39. Из счетчика 38 ширины WC значение переписывается в регистр 27 ширины W с аппаратно реализованным вычитанием единицы.
Счетчик 35 номера пикселя PC, накопитель 44 суммы координат фильтруемого интервала FA и регистр 29 суммы координат SC связаны между собой через сумматоры 36, 40 и 41 для реализации накопления и передачи суммы координат в соответствии с описанием работы конечного автомата, приведенным выше. Сумматор 36 реализует прибавление координаты текущего пиксела к накопителю 44 суммы координат фильтруемого интервала FA. Сумматоры 40 и 41 образуют трехвходовую схему суммирования и обеспечивают прибавление координаты текущего пиксела PC и суммы координат фильтруемого интервала FA к сумме координат SC.
После завершения передачи всех пикселей строки в порт 32 регистры 27-30 содержат готовые значения числовых характеристик W (5 бит), WT (5 бит), SC (9 бит) и Р (3 бита). Разрядность регистров соответствует указанной ранее максимальной длине строки 32 пикселя. Все четыре полученные характеристики упаковываются шинным формирователем выходного порта 31 в одно 32-разрядное слово. Центральный процессор обращается к заданному адресу выходного порта 31 с генерацией импульса сигнала RD и, таким образом, считывает его содержимое. После считывания, если значение Р не равно 0, центральный процессор самостоятельно выполняет деление SC на WT для получения числовой характеристики центра строки С.
Обработка одного пикселя в описанной схеме сопроцессора занимает один такт передачи по каналу прямого доступа к памяти. Заметим, что сопроцессор в том же такте выполняет бинаризацию пиксела. Та же самая обработка пикселя при программной реализации автомата с помощью центрального процессора требует несколько десятков тактов частоты ядра процессора. Для современных процессоров цифровой обработки сигналов частота ядра в 5-10 раз превосходит тактовую частоту прямого доступа к памяти. Несмотря на это, сопроцессор, все равно, дает выигрыш в производительности в несколько раз по сравнению с программной реализацией.
Сопроцессор удобнее всего реализовать в виде отдельного логического блока в структуре микросхемы программируемой логики (FPGA), которая уже имеется в вычислительной системе большинства счетно-сортировальных машин. Особое преимущество может быть достигнуто в том случае, когда в вычислительной системе центральный процессор и FPGA объединены в единую микросхему. В таких микросхемах можно обеспечить более высокую частоту передачи данных во входной порт сопроцессора, чем при размещении FPGA в виде отдельной микросхемы.
Для повышения производительности сопроцессора можно подавать входные данные не через байтовую 8-разрядную шину, как показано на Фиг. 6, а через шину большей разрядности, например, 32-разрядную. Это даст ускорение работы сопроцессора примерно в четыре раза. Для обработки 32-разрядных слов возможны два варианта. По первому из них, организуют разделение 32-разрядного слова на четыре байта, соответствующие четырем последовательным пикселям строки. Для их обработки вводят тактовый генератор, который формирует 4 тактовых импульса на каждую запись 32-разрядного слова, и эти тактовые импульсы используются для синхронизации автомата вместо сигнала WR. Также, вводят схему ускоренного сдвига 32-разрядного слова, которая обеспечивает сдвиг его содержимого на 8 разрядов и выдачу очередного байта на компаратор 33 с каждым тактовым импульсом. Основным ограничением для этого варианта может оказаться слишком высокая тактовая частота, при которой будет затруднительно реализовать сопроцессор в FPGA.
По второму варианту, используют 32-разрядное слово, отдельные байты которого соответствуют пикселям четырех строк. Эти четверки пикселей обрабатывают параллельно при помощи четырех одинаковых и независимо работающих автоматов, аналогичных изображенному на Фиг. 6. В таком случае, тактовая частота сопроцессора будет соответствовать частоте циклов прямого доступа к памяти. Сложность в реализации этого варианта связана с тем, что при хранении изображений в памяти каждое слово обычно содержит 4 последовательных пикселя строки. Для одновременной подачи на 4 конечных автомата, необходимо упаковывать пиксели четырех разных строк в одно 32-разрядное слово. Это может быть выполнено, например, с помощью контроллера прямого доступа к памяти, имеющего режим двумерной адресации данных и режим упаковки байтов в слова. Либо же, эта упаковка может быть выполнена во входном порте сопроцессора при помощи специального буфера емкостью четыре строки. Такой буфер должен обеспечивать запись четырех последовательных пикселей одной строки в каждом слове, и последовательное чтение в виде четырех пикселей каждой из строк в одном слове. Подобных буферов должно быть два: в то время, как из первого буфера пиксели четырех строк выдаются на вход конечных автоматов, во второй буфер записываются пиксели следующих четырех строк. Когда все пиксели из первого буфера выданы, а второй буфер заполнен новыми строками, буфера меняют местами путем перекоммутации их входов и их выходов, и продолжают работу.
Чтобы уменьшить нагрузку на центральный процессор, выходной порт сопроцессора может быть подключен к каналу прямого доступа к памяти для выгрузки результатов обработки строки из шинного формирователя 31 в память системы. Выгрузка результатов должна сбрасывать регистры сопроцессора к начальным значениям. Дополнительно, в сопроцессор нужно ввести схему обнаружения конца строки по содержимому счетчика 35 пикселей PC, которая, после получения последнего пикселя строки, будет выставлять запрос на прямой доступ к памяти для выгрузки результатов. Подача данных во входной порт может вестись непрерывно, строка за строкой. Такое изменение сопроцессора позволит обрабатывать все изображение знакоместа без участия центрального процессора в переключении с одной строки на другую. Числовые характеристики изображения будут автоматически накапливаться в массиве в памяти.
В описываемой реализации, привязка проверочных прямых к границам знакоместа проводится с учетом содержания изображения в знакоместе. Это позволяет точно привязать проверочные прямые к графическим элементам изображения символа, чтобы компенсировать случайные смещения знакоместа относительно символа при их совмещении. Кроме того, привязка с учетом содержания изображения оказывается полезной для устранения ошибок квантования положения графических элементов символа, возникающих при сканировании и при повороте изображения.
В описываемой реализации привязка в строчном направлении выполняется к оси тяжести изображения, которая идет перпендикулярно строкам. Пересечение оси тяжести со строкой считается точкой начала одномерной системы координат этой строки. Привязка в столбцевом направлении производится к верхней кромке охватывающего прямоугольника символа, то есть, к самой верхней строке, которая содержит пиксели, относящиеся к символу. Нумерацию проверочных прямых, которые соответствуют строкам изображения, корректируют таким образом, что нумерация начинается и идет вниз от этой строки.
Анализ содержания изображения для обеспечения привязки можно выполнять в виде отдельной операции, еще до нахождения числовых характеристик. Однако, значительно менее затратным в вычислительном отношении является иной путь, выбранный в описываемой реализации и проиллюстрированный на Фиг. 7. Набор числовых характеристик, включая промежуточную величину SC, вычисляют для каждой строки изображения знакоместа, и далее используют эти наборы числовых характеристик для выполнения привязки. Находят горизонтальную координату оси тяжести 14 изображения

При использовании аппаратного сопроцессора, суммы ΣSCN и ΣWTN могут вычисляться внутри него вместе с вычислением числовых характеристик строк. Для вычисления каждой такой суммы дополнительно потребуется один накопительный регистр и один сумматор. Сброс регистров нужно производить перед началом обработки знакоместа, а не перед началом обработки строки, как делается для других регистров сопроцессора. Суммирование должно производиться каждый раз по завершении обработки строки.
Далее, выполняют коррекцию номера каждой строки: NCORR=N-NS. За счет этого, строка с нулевым скорректированным номером оказывается привязана к верхней кромке 15 охватывающего прямоугольника изображения символа в знакоместе. Новый, скорректированный номер строки далее будет использоваться для идентификации проверочной прямой. Строки с отрицательными скорректированными номерами являются пустыми и далее не рассматриваются.
Для каждой строки вычисляют новое, скорректированное значение центра тяжести этой строки CCORR=С-ХМ. Таким образом, система координат на каждой проверочной прямой оказывается привязанной к оси 14 тяжести изображения, направленной в вертикальном направлении.
При совмещении знакоместа с изображением символа требуется только лишь обеспечить расположение всех пикселей, относящихся к символу, внутри знакоместа. Поэтому, графические элементы символа могут позиционироваться по отношению к границам знакоместа с определенной случайной ошибкой, размах которой примерно равен разности размера знакоместа и размера символа. После выполнения привязки с коррекцией номера строки и начала координат на самой строке, наборы числовых характеристик для строк, составляющих изображение символа, становятся независимыми от этой случайной ошибки. Вне зависимости от того, каким оказалось расположение изображения символа относительно границ знакоместа, наборы числовых характеристик, которые соответствуют проверочным прямым, в описываемой реализации будут примерно одинаковыми для одного и того же вида символа. За счет этого, описанный способ привязки значительно улучшает достоверность распознавания символа.
Проверка того, что изображение символа в знакоместе относится к определенному виду символов, производится при помощи набора критериев. Для каждого возможного вида символов имеется свой набор критериев. На Фиг. 8 показан символ «9» и набор из шести критериев 16-21, которые соответствуют этому виду. Каждый критерий описывается набором допустимых интервалов для числовых характеристик Р, W, С и WT. Здесь и далее мы рассматриваем уже скорректированные значения центра тяжести строки С и номера строки N. Число штрихов Р является наиболее важным для проверки, поэтому интервал допустимых значений для его проверки состоит из одного числа.
Для каждого критерия задан набор строк, на которых нужно проверить соответствие числовых характеристик допустимым интервалам. Так, в критерии 16 проверяются строки с номерами 0-3. Для каждой строки, проверяют, что Р=1, что W лежит в интервале от 6 до 11, что С лежит в интервале от -1 до 0, и что WT лежит в интервале от 6 до 11. Если хотя бы одна из числовых характеристик не попадает в допустимый интервал, то считают, что для этой строки критерий не выполнен. На всем наборе строк, который задан в критерии, должно быть не менее MIN строк, для которых критерий выполнен. Так, для критерия 16 должно быть не менее двух таких строк. В реальности их три: это строки 1, 2 и 3. Чтобы уменьшить затраты времени на проверку критерия, как только обнаружено выполнение критерия для MIN строк, то проверку критерия завершают. Например, при проверке критерия 16 проверяют строки 0, 1 и 2. Поскольку две из этих строк, с номерами 1 и 2, уже соответствуют критерию, то обнаруживают достижение MIN=2, и завершают проверку критерия сообщением об успехе, не проверяя строку 3.
В прямоугольнике, которым изображен критерий, обозначают успешную проверку критерия при помощи OK и неуспешную его проверку при помощи NOK. Как видно на Фиг. 8, все критерии в наборе помечены OK, то есть, завершились успехом. Если в наборе критериев проверка всех критериев завершилась успехом, то делают вывод об успешной проверке всего набора и о принадлежности изображения символа в знакоместе к тому виду, которому соответствует критерий.
Критерии в наборе проверяются в определенном порядке. Как только обнаруживается, что очередной проверяемый критерий завершился неуспехом, проверку данного набора критериев тут же завершают и делают вывод о неуспешной проверке всего набора. Неуспех проверки набора критериев, соответствующего определенному виду символа, говорит о том, что изображение символа в знакоместе не относится к этому виду.
На Фиг. 9 показана проверка того же набора критериев 16-21, соответствующего символу «9», для изображения 22 символа «1». Как видно по значениям числовых характеристик строк и допустимым интервалам критериев, только критерий 21 оказывается успешно выполненным, а критерии 16-20 не выполняются. Так как критерии проверяются в порядке 16-17-18-19-20-21, то уже после неуспешного результата проверки критерия 16 проверка набора критериев прекращается с выводом о неуспехе проверки. То есть, происходит раннее завершение проверки набора критериев. Если упрощенно считать, что проверка критериев занимает примерно одинаковое время, то раннее завершение произошло по истечении примерно 17% времени, необходимого для полной проверки всех критериев в наборе.
Для того, чтобы распознать изображение символа в знакоместе, то есть, найти тот вид символа, к которому это изображение относится, проводят последовательную проверку наборов критериев, соответствующих всем возможным видам символа. Например, если в определенной позиции серийного номера банкноты знакоместо может содержать только цифру, то проверяют десять наборов критериев, соответствующих цифрам от «0» до «9». Как только происходит успешная проверка какого-либо набора критериев, то завершают распознавание символа в знакоместе и делают заключение о том, что этот символ относится к тому виду, для которого проверка набора критериев завершилась успехом. Если же, после проверки наборов критериев для всех возможных видов символа, ни одна из этих проверок не завершилась успехом, то делают вывод о том, что символ не распознан.
Порядок проверки критериев в наборе выбирают таким образом, чтобы первыми проверялись те критерии, которые более всего отличают символ данного вида от других видов. Это позволяет как можно раньше завершить проверку набора критериев для определенного вида, если символ в изображении знакоместа не относится к этому виду. Такое раннее завершение существенно ускоряет классификацию изображения в знакоместе, поскольку наборы большинства критериев для разных видов проверяются не полностью, а лишь на небольшую часть.
Критерии, входящие в каждый из наборов, могут быть составлены человеком-оператором вручную, либо же при помощи машинного обучения, на основе анализа множества изображений одного и того же вида символа. Для составления критериев вручную удобным является графическое представление изображение символа на экране компьютера, где, как на Фиг. 8, отображаются номера строк и числовые характеристики каждой строки. Оператору необходимо выбрать интервалы строк, характерные для определенного вида символа, на которых проявляется отличие графических элементов этого вида символов от других возможных видов символов. Для каждого из этих интервалов нужно составить отдельный критерий, который проверяет соответствующий графический элемент. Например, критерии 16, 18 и 21 на Фиг. 8 проверяют горизонтальные штрихи, критерии 17 и 20 проверяют вертикальные штрихи, а критерий 19 контролирует размыкание линии. Как показывает опыт, в большинстве случаев достаточным оказывается от 5 до 10 интервалов и соответствующих им критериев.
Выбор значения MIN позволяет сделать критерий, в определенной степени, нечувствительным к искажению строк изображения. Например, требования критерия 16 на Фиг. 8 для символа «9» обычно выполняются для трех строк 1-3, а значение MIN в критерии задано равным двум. Такое, несколько уменьшенное значение MIN, позволяет успешно распознать изображение символа, в котором одна из строк 1-3 повреждена из-за пятна, потертости красочного слоя или дефекта сканирования.
Таким образом, заявленный способ предусматривает два механизма обеспечения устойчивого распознавания при повреждениях цифрового изображения. Фильтрация отрезков дефектных пикселей при получении числовых характеристик строки позволяет уменьшить негативное влияние небольших дефектов, не приводящих к разрыву линии. Соответствующий выбор значения MIN позволяет уменьшить негативное влияние более существенных дефектов, приводящих к разрыву одной линии либо слиянию нескольких линий.
Применение допустимых интервалов в критериях 16-21 позволяет учесть нестабильность числовых характеристик, получаемых на различных изображениях одного и того же символа. Толщина линии символа может меняться как на реальной банкноте из-за нестабильности печатного процесса либо износа банкноты в обращении, так и на сканированном изображении из-за изменения фокусировки сканирующего датчика и из-за погрешности процесса бинаризации. Толщина линии символа в небольшой степени влияет на ширину W, и в значительной степени оказывает влияние на вес WT. Геометрические погрешности сканирования, то есть, погрешности взаимного расположения графических элементов, возникают при сканировании из-за округления координаты до целого числа пикселей и из-за проскальзывания банкноты в тракте, а также из-за округлений положения пикселя при выполнении поворота изображения для компенсации перекоса. Геометрические погрешности влияют, главным образом, на ширину W, и в меньшей степени, на центр С. Они почти не влияют на WT. Допустимые интервалы в критериях должны выбираться таким образом, чтобы естественные отклонения толщины линии символов и геометрические погрешности сканирования не приводили к неуспешной проверке критерия. Тогда, использование допустимых интервалов обеспечивает устойчивое распознавание, несмотря на естественные геометрические погрешности сканирования и отклонения толщины линии, характерные для конкретного класса банкнот и для применяемого оборудования для обработки банкнот.
Для дополнительного различения сходных символов могут использоваться критерии с логической инверсией результата. То есть, если найдено количество MIN или более строк, для которых числовые характеристики попадают в заданные интервалы, то критерий считается невыполненным. И, напротив, если таких строк найдено меньше, чем MIN, то критерий считается успешно выполненным. Критерий с инверсией результата позволяет проверить отсутствие определенного графического элемента в символе.
Критерии, основанные на числовых характеристиках строк, подобные критериям 16-21, проверяются очень быстро. Для проверки такого критерия для одной строки, в описываемой реализации, нужно выполнить 7 независимых сравнений и объединить их результат логической операцией. При использовании центрального процессора с очень длинным словом команды (VLIW), либо суперскалярного центрального процессора, некоторые из этих сравнений могут выполняться параллельно. Если же имеется возможность добавления специальной команды в состав команд центрального процессора, то проверка критерия может сразу выполняться единственной специальной командой. Для этого, интервалы критерия, а также числовые характеристики нужно упаковать в слова процессора. Для наиболее практичного горизонтального размера знакоместа, не превышающего 32 пикселей, можно выделить для хранения числовых характеристик строки 3 бита на число штрихов (Р), по 5 битов на ширину и вес (W и WT) и 4 бита на центр (С), что суммарно составляет 17 бит. Тогда, для кодирования пределов, потребуется 3 бита на число штрихов (Р), по 10 битов на интервалы ширины и веса (W и WT) и 8 битов на интервал центра (С), что суммарно укладывается в 31 бит. Таким образом, специальная команда проверки критерия может использовать 32-разрядное слово для числовых характеристик строки и 32-разрядное слово для пределов критерия. За счет этого, такая команда в 32-разрядном процессоре с современной архитектурой RISC может выполняться за один такт ядра.
В реализации заявленного способа могут быть добавлены другие виды критериев, не опирающиеся на значения числовых характеристик. Могут использоваться любые критерии, которые оценивают изображение знакоместа на предмет сходства с определенным видом символа и выдают бинарный результат оценки в виде успеха либо неуспеха. Такие критерии могут потребоваться для различения весьма схожих символов. Например, может применяться проверка сходства заранее сохраненного эталонного изображения с областью в знакоместе, размер и расположение которой заданы заранее. Для нее нужно вычислить коэффициент корреляции между эталоном и изображением знакоместа для нескольких положений эталона как в точке его расчетного размещения на изображении знакоместа, так и вблизи нее. Если, в результате, коэффициент корреляции хотя бы в одном из положений превысит заданное пороговое значение, то критерий завершается успехом. Если же, ни в одном из положений, пороговое значение не будет превышено, то критерий завершается неуспехом.
Такой корреляционный критерий позволяет обнаружить разницу между весьма сходными символами, например, «D» и «0». Однако, как и любой корреляционный метод, он является очень затратным в вычислительном смысле. Поэтому, корреляционный критерий желательно проверять в конце набора критериев, так чтобы проверка корреляционных критериев производилась только один или два раза за время распознавания символа, а в большинстве наборов корреляционный критерий вообще бы не проверялся из-за раннего завершения. Таким образом, регулярно применяемое раннее завершение проверки набора критериев, является отличительной особенностью заявленного способа и позволяет обеспечить высокое быстродействие, в том числе, при использовании вычислительно затратных критериев, не основанных на числовых характеристиках проверочной прямой.
В качестве другого критерия может применяться проверка связности пробельных элементов, позволяющая определить наличие структурного элемента в символе. Например, символ «8» содержит два изолированных пробельных элемента, которые обычно называют островами. Остров со всех сторон окружен пикселями, относящимися к символу, и не связан с другими пробельными областями. Символ «9» содержит один остров и один полуостров, где под полуостровом понимается неизолированный пробельный элемент, соединенный перемычкой с другой пробельной областью. Символ «3» содержит два полуострова. Проверка связанности позволяет различить между собой несколько символов, похожих по рисунку и отличающихся только структурными элементами, таких, как «8», «3», «6» и «9».
Для критериев, не основанных на числовых характеристиках проверочных прямых, используется точно такая же коррекция номеров строк и положения начала системы координат на строке, какая была описана ранее и проиллюстрирована на Фиг. 7.
На Фиг. 10 показана общая последовательность реализации распознавания изображения символа. На шаге 101 проводится бинаризация изображения в знакоместе. На шаге 102 находят наборы числовых характеристик для всех строк знакоместа. Затем, на шаге 103 обеспечивают привязку номеров строк и начала координат на каждой строке к границам знакоместа, опираясь на числовые характеристики изображения, вычисленные на предыдущем шаге. Далее, на шаге 104 выбирают вид символа для проверки принадлежности к этому виду. На шаге 105 последовательно проверяют выполнение всех критериев из того набора критериев, который соответствует проверяемому виду. Если проверка всех критериев в наборе завершилась успехом (шаг 107), то сообщают, что изображение символа принадлежит к проверяемому виду, и завершают распознавание символа. Если же при проверке всех критериев обнаруживается критерий, проверка которого завершилась неуспехом, то дальнейшую проверку набора критериев прекращают и дополнительно проверяют (шаг 106), есть ли еще непроверенные виды символов. В случае, когда такие виды символов есть, возвращаются к шагу 104, выбирают следующий вид символа для проверки и опять проводят проверку набора критериев (шаг 105).
Если же на шаге 106 выясняется, что больше не осталось видов символов для проверки, то сообщают (шаг 108), что символ не распознан, и завершают распознавание.
Описанная последовательность шагов 101-108 может выполняться как целиком на центральном процессоре вычислительной системы, так и при совместной работе центрального процессора и описанного здесь сопроцессора. Сопроцессор берет на себя часть шага бинаризации (101) и почти весь шаг получения числовых характеристик (102).
Последовательность обработки банкноты с применением заявленного способа в счетно-сортировальной машине показана на Фиг. 11. Машина обеспечивает транспортировку банкнот из подающего кармана, при этом проводится сканирование и распознавание (шаг 201). Если банкнота не распознана, то принимается решение (шаг 210) направить банкноту в карман отбраковки. Это решение реализуется при помощи электромеханического перенаправляющего узла, размещенного в банкнотопроводном тракте счетно-сортировальной машины.
Если же банкнота распознана, то выделяют цифровое изображение серийного номера и поворачивают его для компенсации перекоса (шаг 203). Далее, разделяют цифровое изображение серийного номера на знакоместа и совмещают знакоместа с изображениями символов серийного номера (шаг 204). Изображения символов в знакоместах распознают последовательно. Вначале, распознают один символ (шаг 205), используя для этого последовательность шагов 101-108, описанную выше. Если символ не распознан (шаг 206), то принимают решение о направлении банкноты в карман отбраковки (шаг 210). Если же символ распознан, то запоминают соответствующий ему код символа в кодировке Unicode в массиве-строке серийного номера, и проверяют, имеются ли еще нераспознанные знакоместа (шаг 207). Если такие знакоместа имеются, то возвращаются к шагу 205 и распознают следующее знакоместо.
Когда на шаге 207 обнаруживается, что все знакоместа уже распознаны, то направляют банкноту в приемный карман (шаг 208) и записывают серийный номер из массива-строки в электронный отчет о сортировке (шаг 209). Описанную обработку (шаги 201-210) повторяют для всех банкнот, находящихся в подающем кармане счетно-сортировальной машины. После этого, распознанные банкноты с успешно распознанным серийным номером оказываются в приемном кармане машины, а в электронном отчете находится список серийных номеров этих банкнот. Банкноты, которые были не распознаны, либо же в серийном номере которых были распознаны не все символы, оказываются в кармане отбраковки. Электронный отчет, содержащий список серийных номеров, может далее использоваться для отслеживания движения банкнот в обороте.
Возможно множество других вариантов использования информации, полученной в результате распознавания символов серийного номера. Эти варианты хорошо известны специалистам в области автоматизированной обработки банкнот. Заявленный способ относится лишь к распознаванию отдельного символа, и не касается последующей обработки распознанного серийного номера.
Реферат
Группа изобретений относится к способу распознавания символов на банкнотах и сопроцессору вычислительной системы устройства обработки банкнот, позволяющему реализовать данный способ. В способе распознавания символа сканируют банкноту с получением цифрового изображения, состоящего из пикселей, для которого определяют принадлежность к определенному классу, на основании указанного класса определяют место расположения символа, подлежащего распознаванию, совмещают знакоместо заранее заданной формы и размера с изображением символа, при этом проводят бинаризацию для выделения пикселей, относящихся к символу. Сопроцессор для вычислительной системы устройства для обработки банкнот содержит входной порт для получения значений пикселей, соответствующих знакоместу, где указанное значение определяет либо пиксель символа, либо пиксель пробела, решающую логическую схему, выполненную с возможностью обеспечить нахождение набора числовых характеристик для каждой проверочной прямой знакоместа и выходной порт для выдачи наборов числовых характеристик, соответствующих строкам знакоместа. Технический результат состоит в расширении возможности применения способа к распознаванию символов шрифта практически любого начертания. 2 н. и 18 з.п. ф-лы, 11 ил.
Формула
Документы, цитированные в отчёте о поиске
Способ обработки банкнот (варианты)
Комментарии