Способ управления автоматизированной системой правовых консультаций - RU2718978C1
Код документа: RU2718978C1
Чертежи
Описание
ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к вычислительной технике и, в частности, к автоматизированным экспертным системам и может быть использовано в качестве автоматизированной системы ответов на вопросы правового характера, например, при выявлении возможностей предъявления претензий, установления фактов правонарушений, а также по вопросам совершения действий, не противоречащих закону в условиях сложных бытовых ситуаций.
УРОВЕНЬ ТЕХНИКИ
Известные системы используют обратную связь для формирования решающих методов, по результатам реакции конечных пользователей. При этом ошибки методов устраняются, как правило, по мере расширения базы данных вопросов и ответов, и по мере сбора ответов оценок правильности принятых экспертным решений по результатам анкетирования пользователей. Недостаток известных систем заключается в том, что при применении к вопросам юридической практики, системы не обеспечивают принятие верных решений или формирование верных ответов по причинам объективного и субъективного характера.
Одной из объективных причин является тот факт, что для части правовых коллизий не существует правильных ответов и решение по вопросу формируется субъективным образом, например, судьей, исходя из субъективного понятия о справедливости. Субъективной причиной может являться взаимодействие пользователя экспертной системы и департамента, принимающего решение по объекту интереса. Например, сведения, предоставленные ненадлежащим образом и за пределами установленного срока, могут быть не приняты к рассмотрению, что может привести к негативному отзыву пользователя экспертной системы по всему вопросу, несмотря на то, что недостаток рекомендации заключался в отсутствии указания на важность соблюдения формы сроков предоставления надлежащих документов. Кроме того, в процессе правоприменения могут меняться толкования нормативных документов.
Из уровня техники известна справочная правовая система хранения и поиска данных (см. RU 2223537, 10.02.2004), содержащая блок выбора вида поиска, формирователь запроса, один выход которого связан с блоком проведения поиска, вход-выход которого соединен через соответствующие шины с базами данных системы, блоком отображения и контроллером, предназначенным для управления поиском данных, отличающаяся тем, что в систему введены блок выбора условий поиска, вход которого связан с выходом блока выбора вида поиска, первый выход связан со входом формирователя запроса, второй выход соединен со входом формирователя атрибутов фильтра, первый вход-выход которого связан со вторым входом-выходом формирователя запроса, второй вход-выход - с блоком памяти атрибутов фильтра, первый вход-выход формирователя запроса соединен с блоком памяти запросов.
К недостаткам такого решения можно отнести, по крайней мере, отсутствие возможности формирования ответов на поставленный пользователем вопрос и обеспечения высокой адекватности ответов, заключающейся в понимании вопроса, поставленного пользователем и формировании ответа, соответствующего поставленному вопросу.
Из уровня техники известна система сбора правовой информации и ее анализа для выявления проблемных вопросов и недостатков нормативного правового регулирования (см. RU115095, 20.04.2012), содержащая базы данных, блок ввода документов в указанные базы, центральный сервер и компьютеризированные средства пользователей, отличающаяся тем, что базы данных сформированы в блок, который включает в себя по крайней мере базу «Правовые акты», базу «Юридические консультации», базу «Судебная практика», базу «Диссертации и исследования», базу «Обзоры, статьи публикации», базу «Зарубежное законодательство», базу «Региональное законодательство», базу «Законодательство государства», содержащие подбор документов, относящихся к тематикам перечисленных баз и имеющих идентификационные признаки для их обнаружения и представления на мониторе в электронном формате, блок ввода указанных документов в базу данных, выполненный с функцией перевода документа на бумажном или машиночитаемом носителе в электронный формат с присвоением идентификационных признаков и распределения по указанным базам данных, блок загрузки документов из блока баз данных, отобранных по общему критерию совпадения идентификационных признаков, который связан с центральным сервером, выполненным с возможностью соединения с компьютеризированными средствами пользователей для отображения на экранах их мониторов загруженных документов и который выполнен с функцией предоставления поискового аппарата для формирования запроса в связанном с центральным сервером блоке обработке запросов, блок регистрации пользователей, выполненный с функцией сохранения данных о пользователях с их кодами доступа к блоку с базами данных и объемом прав по этому доступу, который связан с центральным сервером и с блоком обработки запросов для выделения санкционированного канала доступа для пользователя после его идентификации при соединении с центральным сервером, блоком сбора предложений, направляемых в режиме свободного доступа с компьютеризированных средств пользователей, выполненным с функцией регистрации предложения и идентификации отправителя и передачи этого предложения в блок группирования предложений по тематической сущности или предметному назначению и передачи сгруппированных пакетов этих предложений в блок аналитической обработки для сопоставления отраженных в предложениях вопросов с правовыми нормами их регулирования и с документами из блока баз данных для формирования вывода.
К недостаткам такого решения можно отнести, по крайней мере, отсутствие возможности формирования ответов на поставленный пользователем вопрос и обеспечения высокой адекватности ответов, заключающейся в понимании вопроса, поставленного пользователем и формировании ответа, соответствующего поставленному вопросу.
Также, из уровня техники известны способ и система (см. US 20100063925 A1, 11.03.2010) для оказания определенных видов юридических услуг лицензированными и практикующими юристами клиентам и потенциальным клиентам юридической фирмы, причем система, реализующая такой способ, содержит первое вычислительное устройство для передачи первого набора запрашиваемой клиентом информации; второе вычислительное устройство для передачи набора консультативной информации юридического характера, причем второе устройство удалено от первого устройства; промежуточный сервер, сконфигурированный для удаленной работы с упомянутым первым устройством и вторым устройством; а также, по крайней мере, одну базу данных, связанную с указанным промежуточным сервером, причем база данных способна хранить информацию, запрашиваемую клиентом и информации юридических консультаций, причем способ включает ввод ответа юристом на вопрос клиента; хранение такого ответа в базе данных и интерфейс для получения указанного ответа клиентом с использованием программного обеспечения, установленного на вычислительном устройстве пользователя.
Недостатками такого решения являются, по крайней мере, низкую вероятность формирования правильного ответа на поставленный пользователем вопрос, высокое влияние экспертов, в том числе, неквалифицированных экспертов, на результаты работы системы, а также, низкую адекватность ответов, заключающуюся в понимании вопроса, поставленного пользователем и формировании ответа, соответствующего поставленному вопросу.
Таким образом, в уровне техники существует потребность в автоматизированной экспертной системе, относящейся к решению правовых вопросов с максимальной вероятностью принятия верных решений и выдаче рекомендаций с максимальной полнотой, достаточной, достаточной для того, чтобы пользователь либо решил далее вопрос самостоятельно, либо оценил сложность решения вопроса и доверил его решение квалифицированному специалисту. Также, в уровне техники существует потребность в способе управления автоматизированной системой правовых консультаций.
СУЩНОСТЬ
Предложенное изобретение решает поставленную задачу, а также обеспечивает достижение технического результата, заключающегося в повышении вероятности формирования правильного ответа на поставленный пользователем вопрос, актуализации правоприменительной практики, снижения влияния неквалифицированных экспертов на результаты работы системы, а также адекватности ответов. Здесь под адекватностью понимается верное понимание вопроса, поставленного пользователем и формирование ответа, соответствующего поставленному вопросу.
Согласно одному из вариантов реализации, предлагается способ управления автоматизированной системой правовых консультаций, содержащей базу данных знаний, которая содержит совокупность норм и правил действующих правовых документов, модуль предобработки и классификации вопросов, выполненный формирующим векторное представление сущности вопросов и модуль формирования ответов из базы данных знаний в лексическое представление, соответствующее лексическому построению вопроса, при этом формируют базу данных произвольных вопросов, выбирают вопросы одной области права, для которой определяют количество направлений ответов в виде категорий вопросов, векторизуют тексты вопросов в бинарные вектора вопросов посредством представления уникальных слов в виде таблицы, содержащей уникальные слова с указанием наличия или отсутствия уникальных слов в тексте каждого из вопросов, причем совокупность значений таблицы формирует вектор, классифицируют вопросы по категориям по признаку близости векторов посредством группировки вопросов с использованием норм и правил действующих правовых документов, хранящихся в базе данных знаний, и кластерного анализа, в процессе которого формируют кластеры, количество которых равно сформированным экспертами группам для каждой отрасли права, количество которых вместе с векторами вопросов и словарем уникальных слов и словосочетаний, обрабатывается с использованием кластерного анализа, так что формируют классы для отраслей права и при поступлении в систему вопроса пользователя производят лексический парсинг вопроса пользователя с определением лексической структуры вопроса пользователя, определяют на основании сформированных классов для отраслей права содержащееся в базе данных знаний положение нормативно-правового акта, релевантного вопросу пользователя по векторам нормативно-правовых актов, формируют лексическую структуру ответа пользователю, соответствующую лексической структуре вопроса пользователя и положению нормативно-правового акта, релевантного ответу пользователя и предоставляют пользователю лексическую структуру ответа в виде текстового сообщения.
В одном из частных вариантов реализации преобразуют вопросы пользователей в формат, пригодный для автоматизированного анализа, посредством автоматизированной обработки вопросов с формированием векторного представления для каждого вопроса.
В одном из частных вариантов реализации определяют соответствие группировки вопросов по признаку близости векторов и группировки вопросов по направлениям ответов и при несоответствии группировки вопросов по признаку близости векторов и группировки вопросов по направлениям ответов изменяют параметры преобразования вопросов пользователей в формат, пригодный для автоматизированного анализа, и при соответствии группировки вопросов по признаку близости векторов и группировки вопросов по направлениям ответов используют параметры преобразования вопросов пользователей в формат, пригодный для автоматизированного анализа, для преобразования вопросов пользователей в формат, пригодный для автоматизированного анализа, и положений нормативно-правовых актов с формированием векторов нормативно-правовых актов.
В одном из частных вариантов реализации преобразованные вопросы пользователей в формат, пригодный для автоматизированного анализа, представлены в виде аргументов запросов и описаний ответов, представленных в виде значений функций.
В одном из частных вариантов реализации группируют вопросы по признаку близости векторов и группируют вопросы по направлениям ответов.
В одном из частных вариантов реализации при обработке текстов вопросов: удаляют из текста вопросов нерелевантные символы, включающие, по крайней мере, знаки препинания, элементы HTML разметки; выполняют токенизацию текстов, разделяя предложения на отдельные символы, являющимися токенами; выполняют конкатенацию слов с предлогами и частицами для сохранения эмоциональной окраски текстов; удаляют нерелевантные слова, не несущие смысловой нагрузки, в том числе местоимения и вопросительные слова и слова, встречающиеся более чем в 80% вопросов; выполняют лемматизацию токенов, осуществляя сведение токенов к словарной форме; выполняют стемминг посредством нахождения основы слова для заданного исходного слова, если словарная форма не найдена.
В одном из частных вариантов реализации словарь уникальных слов состоит из словарных форм, полученных в процессе лемматизации токенов и/или стемминга.
В одном из частных вариантов реализации для каждой из фраз определяют наличие в фразе вопроса уникальных слов и словосочетаний и формируют табличную строку, в которой количество ячеек соответствует количеству слов и словосочетаний словаря, так что каждая из ячеек соответствует одному из словарных слов и словосочетаний, а значение, занесенное в ячейку соответствует наличию или отсутствию соответствующего слова или словосочетания в фразе, соответствующего позиции или номеру ячейки, где совокупность значений, занесенных в ячейки таблицы является вектором и используется для анализа соответствующей фразы.
В одном из частных вариантов реализации при кластеризации используется алгоритм k-средних, осуществляющий сортировку размеченных специалистами вопросов по кластерам, где каждый из вопросов относится к одному кластеру, расположенному на наименьшем расстоянии от вектора вопроса.
В одном из частных вариантов реализации лексический парсинг осуществляют с использованием, по крайней мере, одного семантического парсера, причем парсеры осуществляют поиск в вопросах цепочек символов, заранее заданных в словарях, где цепочками символов являются слова или словосочетания, объединённые общим свойством в исходном тексте вопроса пользователя, так что создают классы юридических проблем, которые идентифицируются алгоритмом и имеют общее законодательное обоснование, определяющее принадлежность вопроса к кластеру.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
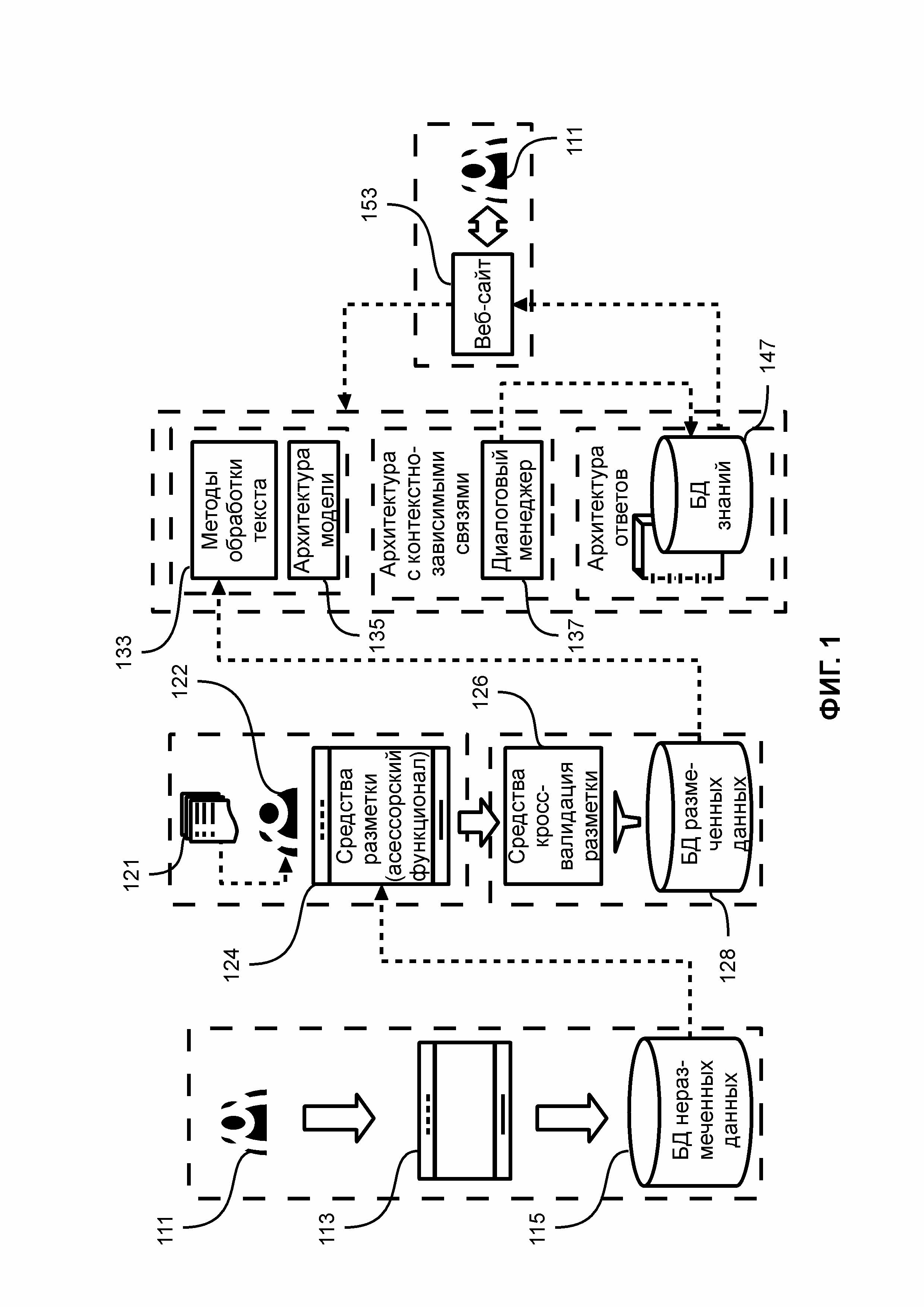
ФИГ. 1 иллюстрирует диаграмму настройки и работы предложенной системы, реализующей предложенный способ;
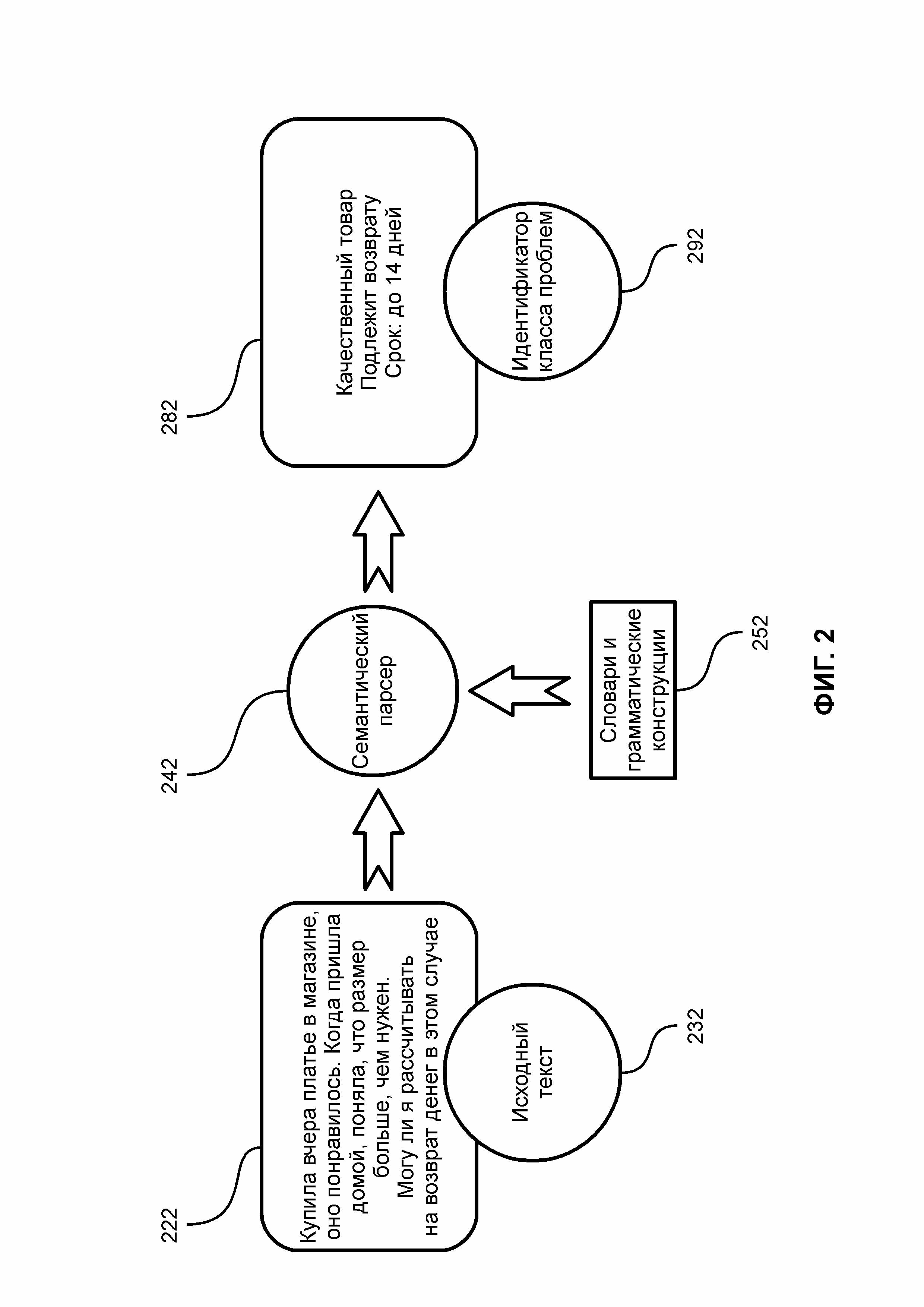
ФИГ. 2 иллюстрирует схему работы семантического парсера;
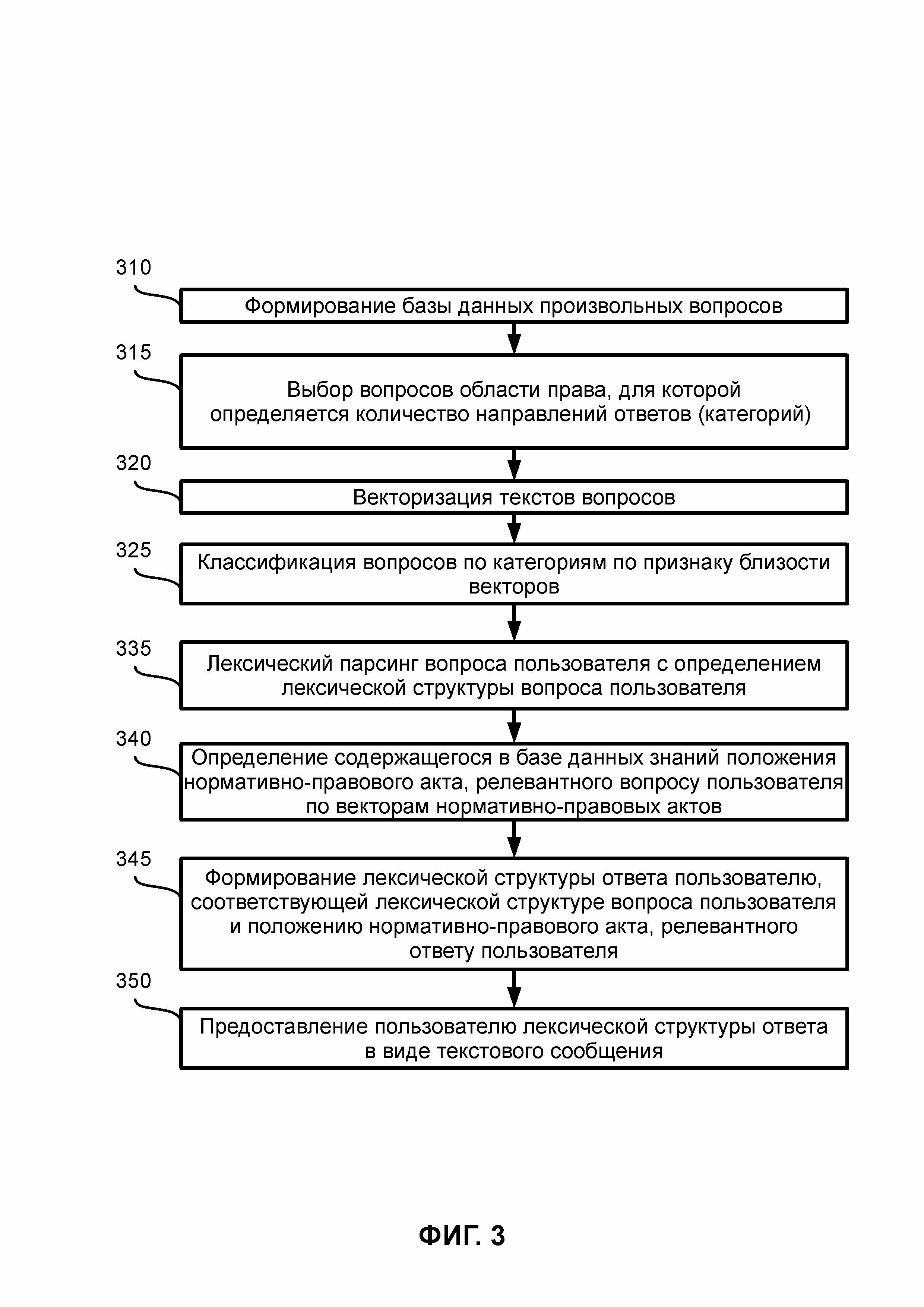
ФИГ. 3 иллюстрирует примерный вариант осуществления настоящего изобретения;
ФИГ. 4 иллюстрирует упрощенный пример аппаратной реализации предложенного изобретения;
ФИГ. 5 иллюстрирует пример вычислительной системы, пригодный для реализации элементов предложенного изобретения.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Для решения поставленной задачи и достижения технического результата, предлагается способ, реализуемый правовой экспертной системой, диаграмма настройки и работы которой показана на ФИГ. 1.
В процессе управления системой осуществляется формирование базы данных размеченных данных (базы данных произвольных вопросов) 128 с использованием данных из базы данных неразмеченной информации (данных) 115, как описано в рамках настоящего изобретения.
База данных неразмеченной информации 115 содержит вопросы пользователей и рекомендации консультантов, сформулированные в соответствии с поставленными вопросами, где вопросы и рекомендации представлены в терминах естественного языка. В качестве базы данных неразмеченной информации 115 может быть использована база данных, созданная, в частности, подготовленная, по результатам общения пользователей 111 с консультантами - физическими лицами. Далее база данных неразмеченной информации 115 также может пополняться диалогами с системой, в частности, вопросами пользователей (222, ФИГ. 2), содержащими исходный текст (232, ФИГ. 2), и сформированными системой, в частности, модулем формирования ответов, ответами (282, ФИГ. 2).
База данных размеченных данных 128 формируется модулем предобработки и классификации вопросов из вопросов пользователей (преобразованных в формат, пригодный для автоматизированного анализа), в частности представленных в виде аргументов запросов и описаний ответов, представленных в виде значений функций.
Система, показанная на ФИГ. 1 также содержит базу данных знаний 147, которая содержит совокупность норм и правил действующих правовых документов, представленных в виде аргументов описаний ответов.
Также правовая экспертная система содержит:
- средства разметки вопросов пользователей 124, представленных на естественном языке, с обеспечением выделения из вопросов пользователей раздельных тематик вопросов и группировке тематик по нескольким независимым группам по признаку сходства. Средства разметки вопросов пользователей 124 реализованы в асессорском блоке, реализующем асессорский функционал;
- реализующие алгоритмы кроссвалидации средства валидации разметки 126, выполненные с возможностью выбора, для каждой раздельной тематики вопроса, наиболее вероятную группу для каждой из предложенных;
- средства группировки размеченных данных, использующиеся (и, в частном случае, являющиеся его частью), по крайней мере, модулем предобработки и классификации вопросов, выполняющие классификацию по тематикам вопросов по формальным признакам сходства, где для конкретного вопроса пользователя используется конкретный ответ на вопрос;
- диалоговый менеджер (диалоговый блок, средства (автоматизированного) диалога с пользователем) 137, выполненный принимающим вопрос пользователя 111 на естественном языке, осуществляющим семантический анализ текста вопроса, с учетом тематики определенной ранее, и формирующим ответ на вопрос пользователя, при этом конечный ответ системы (с использованием модуля формирования ответов) основан на уточнениях пользователя, полученных в процессе взаимодействия с диалоговым менеджером 137. Вопросы системы формируются, первоначально, в формате, обеспечивающем предельную лаконичность ответа, а затем, в формате, понятном пользователю по итогам предыдущего уточнения, причем тематика является наименованием отдельной группы вопросов, например, «Раздел имущества супругов». Также, диалоговый менеджер 137 может осуществлять преобразование вопросов (в том числе частей вопросов, например, фраз) в формат, пригодный для автоматизированного анализа средствами описываемой системы, а также осуществлять выделение тематики вопроса из преобразованного вопроса,
Модуль предобработки и классификации вопросов использует (в частном случае, содержит) средство разметки вопросов пользователей 124 и средство (кросс-)валидации разметки 126.
В дополнительных вариантах реализации изобретения для формирования ответа требуются уточнения, представление в описании ситуации, соответствующей вопросу и используется дополнительная система уточнений, формирующая вопросы пользователю. Вопросы формируются, первоначально, в формате, обеспечивающем предельную лаконичность ответа, а затем, в формате, понятном пользователю по итогам предыдущего ответа.
В другом дополнительном варианте использования изобретения,
- для систематизации используется дублирование сортировки понятий, для чего используется система человеческой проверки параллельно с машиной систематизацией.
- для каждого из систематизаторов устанавливается параметр качества, в частном случае, путем голосования, а результаты группировки принимаются с учетом вероятности правильного ответа,
- группировка производится как прямым, так и косвенным путём, где для группировки прямым путем экспертом формулируется правильный ответ, а для косвенной оценки, определяется качество предложенного ответа, соответствующего одной из тематик. В частном случае для каждого эксперта определяется вероятность качества оценки путем сопоставления его ответов с ответами других экспертов и с результатами работы экспертной системы. Качество оценки определенного эксперта определяется с учетом влияющих факторов, например, времени суток или тематики.
После первоначальной разметки вопросов экспертами, производится обучение автоматизированной системы.
Для обучения автоматизированной системы модулем предобработки и классификации вопросов производится преобразование тематик (или фраз), содержащихся в вопросах пользователей, в формализованный вид, в частности, используются векторизованные тексты вопросов пользователей, причем модулем предобработки и классификации вопросов осуществляется векторизация текстов вопросов. Под формализованным видом понимается представление тематик, изложенных в вопросах в виде векторов, то есть, строк определенной длины. Дополнительным параметром тематики может являться описание лексического построения вопроса. Описание лексического построения вопроса используется для автоматизированной формулировки ответа на вопрос с учетом грамматических особенностей вопроса, предметной области и объекта обсуждения. Например, для вопроса: «в какой срок подлежит возврату «мужская обувь» ненадлежащего качества?», ответ будет содержать термин, в частности, словосочетание, «мужская обувь». Для вопроса с термином, в частности, словом, «ботинки», ответ будет содержать термин, в частности, слово, «ботинки».
В процессе управления системой осуществляется выбор вопросов одной области права, для которой определяется количество направлений ответов (категорий). Для тематик вопросов производится (предварительная) группировка данных, которая далее используется для формирования автоматизированной системы принятия решений. Исходный выбор тематик определяется областью права, к которой принадлежат вопросы, например, «авторское право» или «защита прав потребителей. Группировка проводится с учетом возможности возникновения ошибок, вызванных, например, возможностью неоднозначного толкования вопроса, либо невнимательностью специалиста, осуществляющего сортировку.
Дополнительно, при группировке специалистам предъявляются возможные ответы на вопросы, относящиеся к фразе или тематике для оценки релевантности ответа поставленному вопросу или фразе из вопроса.
При этом, ответы также указывают на группу к которой принадлежит вопрос, например, верный ответ, заведомо принадлежащий к определённой группе ответа указывает на группу, к которой принадлежит вопрос, неверный ответ указывает на то, что вопрос не принадлежит к группе ответа.
Разметка базы данных неразмеченных данных 115 осуществляется исполнителями, в частности, специалистами (асессорами, например, юристами-асессорами) 122 с использованием средств разметки вопросов пользователей 124 и раскрытой выше (и далее в описании) методики, что позволяет, по крайней мере, ускорить разметку данных для решения задач автоматизации дальнейшего процесса консультирования пользователей.
Методика реализована в асессорском блоке, обеспечивающим формирование базы данных заданий для специалистов и требований к выполнению заданий, включающих инструкции (121). Для сформированных заданий, обеспечивается предъявление заданий асессорам, а также сбор результатов выполнения заданий и обработку результатов.
Для осуществления разметки данных, в частности, для упрощения разметки данных:
- создается дерево категорий (где категориями являются, например: ГК, 4 часть ГК, патенты, патенты на полезную модель, гражданское право, защита прав потребителей, возврат товара, замена товара и т.д). Так, например, категорией может являться «Семейное право», а подкатегориями «Раздел имущества супругов», «Заключение брака», «Определение места жительства ребенка», «Перемещение ребенка», «Опека»;
- исполнители (асессоры) с использованием средств разметки вопросов пользователей 124, т.е. в частном случае, исполнители подключаются к асессорскому функционалу, в частности, используются средства разметки 124;
- формируются задания для разметки, в частности, загружаются файлы с данными, выбираются правила разметки (из существующих), назначаются исполнители для конкретных заданий. Правилами разметки является список возможных для разметки категорий, причем для каждой категории разрабатывается инструкция, в которой указываются все условия (правила) отнесения вопроса именно к этой категории, а также список исключений из этих правил. Так, например, данные в задании могут быть размечены по следующим категориям: “Некачественный товар”, “Некачественный технически-сложный товар”, “Навязанная услуга”, “Отказ от услуги” и т.д. Для категории “Некачественный товар” создается инструкция, которая содержит условия отнесения вопроса к этой категории, например: некачественный товар - это товар из части 1 статьи 18 Закон РФ "О защите прав потребителей" за исключением технически сложного товара; если пользователь (клиент) спрашивает, в какой срок ему вернут деньги при отказе от некачественного товара; если клиент спрашивает что делать, если некачественный товар долго ремонтируется и т.д. Количество условий варьируется в зависимости от категории и сложности вопросов в данной категории.
- определяются другие условия для выполнения задания: например, сколько раз каждый объект показывается разным исполнителям для разметки.
Далее, через личный кабинет (исполнителя), с использованием логинов и паролей, исполнители получают доступ к заданиям, исполнителям демонстрируются объекты для разметки, исполнители размечают данные, например, путем указания категорий из дерева категорий.
Размеченные данные сохраняются в базе данных размеченных данных 128, в частности, локальной базе данных , например, реализованной с использованием MySQL, где указываются метки категорий, указанных асессорами, а также информация, которая позволяет учитывать индивидуальный уровень эффективности асессоров (с использованием алгоритма кросс-валидации разметки асессоров-юристов, который позволяет автоматически рассчитывать вероятности каждого ответа асессора и отсекать ошибочные ответы, как описано в рамках настоящего изобретения), влияющий на результаты разметки. Так, метками категорий могут являться наименования категорий, идентификаторы категорий и т.д., которые сохраняются в базу данных размеченных вопросов 128.
В следующем этапе осуществляется кросс-валидация разметки разных асессоров средствами кросс-валидации разметки 126.
При реализации способа, для каждого действия определяется вероятность правильного решения, а неверные ответы, выявленные с применение предложенного способа, а также ответы, которые отличаются от заведомо верных ответов, исключаются из последующего рассмотрения, но учитываются при определении вероятности получения неверного ответа от соответствующего специалиста.
Следует также отметить, что для разметки используются предварительно выбранные вопросы пользователей из базы данных заданных вопросов сервисов юридических консультаций 113, т.е. в базу данных 115 сохраняется информация, содержащаяся в вопросах пользователей, задаваемых (и сохраняемых) на различных ресурсах, в системах обмена (текстовыми, мгновенными и т.д.) сообщениями и т.д. Так, например, для осуществления разметки может быть выбрана часть вопросов из общего количества заданных пользователями вопросов, например, из 3000000 заданных вопросов, для разметки может быть выбрано 2000000 вопросов, каждый из которых может иметь отношение к нескольким отраслям права.
Далее часть выбранных для разметки вопросов, например, 300000 вопросов, размечаются специалистами 122 с использованием средств разметки вопросов пользователя 124, другие вопросы могут быть размечены в автоматизированном режиме с использованием преобразования вопросов в формат, пригодный для автоматизированного анализа, и формированием векторов для каждой тематики вопроса.
Разметка данных, в частности, классификация вопросов по категориям, в том числе по признаку близости векторов, в том числе на основании заданных правил, включает совместное использование экспертной группировки вопросов и результатов методов кластерного анализа. Для осуществления классификации вопросов по категориям осуществляется обучение системы классифицировать вопросы по (выделенным) категориям Так, может осуществляться обучение алгоритмов классифицировать вопросы по выделенным категориям. Так, слова, встречающиеся в схожих контекстах, стремятся иметь близкий смысл, например, согласно гипотезе распределения в лингвистике. Слово может быть представлено в виде вектора, элементы которого соответствуют числу вхождений в некоторый контекст. Близость векторов определяет семантическое сходство. Экспертная группировка вопросов осуществляется на основе анализа системой репрезентативной выборки из базы данных неразмеченной информации 115. Упомянутая репрезентативная выборка является выборкой конечного объёма, обладающей всеми свойствами исходной популяции, значимыми с точки зрения задач исследования.
Специалисты (юристы-эксперты) 122 группируют вопросы исходя из законодательной базы и юридических случаев (кейсов), возникающих у пользователей. Далее, с использованием алгоритма кластеризации, использующего метод кластеризации k-means (метод k-средних), формируются содержащие тексты вопросов кластеры (машинные кластеры), количество которых было заранее определено исходя из экспертной группировки. Таким образом, по результатам разметки вопросов и тематик вопросов асессорами, задается число совокупностей или кластеров, к которым относятся размеченные вопросы. В самом простом случае, для (первой) отрасли права, например, для «защиты прав потребителей», число таких кластеров равно 44, что является одним из параметров, передаваемых в алгоритм кластеризации (алгоритм k-means), так что для каждой статьи (для каждой нормы соответствующей отрасли права) формируется соответствующий кластер. Кроме этого, за основу принимается соответствие размеченных вопросов одному из кластеров. Далее упомянутый параметр передается в алгоритм k-means в качестве параметра k, являющимся числом кластеров. Использование количества кластеров равного количеству норм соответствующей отрасли права наиболее удобный вариант, поскольку изменения законодательства, в большинстве случаев приводят к уточнениям в формируемых ответах и не требуют повторной кластеризации вопросов.
Выборка для выделения машинных кластеров используется та же репрезентативная выборка из базы данных неразмеченной информации 115, что и при экспертной группировке.
Осуществляется предобработка выборки, в частности, при обработке (в том числе при нормализации) текста для проведения кластеризации (в том числе, автоматизированной кластеризации), в процессе которой используются технологии обработки естественного языка (от англ. - Natural Language Processing, NLP), включающие операции, указанные ниже:
1. Очистка вопросов от нерелевантных символов, например, знаков препинания, html-элементы (элементы HTML разметки) и пр., в частности, осуществляется удаление нерелевантных символов;
2. Токенизация текстов - разделение предложений на отдельные символы (токены);
3. Конкатенация слов с определенными предлогами и частицами для сохранения верного значения (наличие/отсутствие), а также для сохранения эмоциональной окраски текстов. Так, например, при обработке текста "Мы НЕ согласны с результатами экспертизы", если не произвести конкатенацию частицы "НЕ" со словом "согласны", при удалении нерелевантных слов получится следующий текст "Мы согласны с результатами экспертизы", который имеет смысл, противоположный изначальному тексту;
4. Удаление нерелевантных слов, которые не несут смысловой нагрузки, в частности, которые могут встречаться в любом контексте - местоимений, вопросительных слов и тех, которые встречались более чем в 80% вопросов (в частности, наблюдений) из анализируемой выборки;
5. Лемматизация токенов - сведение токенов к (базовой) словарной форме, а там, где словарная форма не найдена, проводится стемминг, т.е. нахождение основы слова для заданного исходного слова.
В частном случае реализации для каждой из тематик (то есть, для составных фраз вопросов, имеющих различное смысловое содержание) вопросов пользователей средствами системы производится (раздельная) нормализация, то есть преобразование (фразы) в формат, пригодный для автоматизированного анализа.
В частном случае реализации используются технологии обработки естественного языка, реализующие анализ фраз, обеспечивающий понимание принадлежности фразы к определённой тематике, а также выделение из фраз ключевых элементов, обеспечивающих последующий синтез фраз ответов, в части генерации грамотного текста.
Тексты вопросов преобразуются в бинарные вектора, т.е. векторизуются, с использованием словаря уникальных терминов (словарь уникальных слов и словосочетаний), в частности, выбирается представление данных - векторизация текстов вопросов в бинарные вектора (вектора вопросов, вектора наблюдений). Словарь уникальных терминов строится путем выбора, в частности, формирования терминов, из базы данных размеченных данных 128 (исходной базы данных). Вектора вопросов передаются в алгоритм кластеризации (k-means), по результатам работы которого формируется список машинных кластеров. Таким образом, формируется словарь уникальных терминов, состоящий из словарных форм, использованных на этапе лемматизации токенов, а также словарных форм, полученных в результате стемминга. Для каждой из фраз определяется наличие в фразе уникальных терминов и формируется табличная строка, в которой количество ячеек соответствует количеству словарных терминов, каждая из ячеек соответствует одному из терминов из словаря, а значение, занесенное в ячейку, соответствует наличию или отсутствию соответствующего термина в фразе, соответствующего позиции или номеру ячейки. Совокупность значений, занесенных в ячейки таблицы, называется вектором и используется для анализа соответствующей фразы. Таким образом, для нормализованных векторов, с использованием алгоритма к-средних размеченные вопросы сортируются по кластерам, где каждый из вопросов относится к одному кластеру, расположенному на наименьшем расстоянии от вектора вопроса. На первом шаге алгоритма к-средних (k-means) данные произвольно разбиваются на кластеры, и для каждого из кластеров вычисляется центр масс в соответствии со значениями векторов данных, входящих в кластер. На последующих шагах, для каждого вектора находится ближайший центр масс, происходит перераспределение векторов по кластерам, последующие шаги процесса происходят итеративно до тех пор, пока последующий шаг не дает перераспределения векторов, по отношению к предыдущему.
Центры масс или кластеры в дальнейшем используются для определения принадлежности неразмеченных вопросов к соответствующей тематике.
При обычном исходном несовпадении машинных и экспертных кластеров около 40%, формируются новые группы для несовпадающих кластеров на основе построенных семантических парсеров, причем парсеры (242, ФИГ. 2) осуществляют поиск определенных цепочек символов, заранее заданных в словарях (252, ФИГ. 2). Цепочки символов - это слова или словосочетания, объединённые общим свойством в исходном тексте вопроса пользователя 111, задающего вопрос, например, на веб-сайте 153. Например, общим свойством группы вопросов может являться “некачественные технически-сложные товары”. С использованием идентификатора класса проблем (292, ФИГ. 2) многослойной нейронной сети могут быть созданы такие классы юридических проблем, которые, с одной стороны, может с высоким качеством идентифицировать упомянутый алгоритм, с другой стороны, имеют общее законодательное обоснование, в частности, определяющее принадлежность к кластеру. В частном случае, таких классов в отрасли защиты прав потребителей получено 33.
Для формирования автоматизированной системы ответов на вопросы или юридических консультаций проводится обучение системы, а именно, при обучении системы проверяется актуальность нормативных актов. Так, например, сравниваются нормативные акты, содержащиеся в базе знаний 147 с нормативными актами, содержащимися в эталонной (регулярно обновляющейся) актуальной базе данных (например, базе данных, содержащейся на удаленном сервере, в сети Интернет и т.д.) и по результатам сравнения обновляются данные в базе данных 147. Для обучения системы используется многослойная нейронная сеть, архитектура которой разработана с учетом специфики обрабатываемых данных. Также в процессе разработки архитектуры сети использовались методы Монте-Карло и проводились многочисленные эксперименты Монте-Карло, которые позволяют выбрать наилучшие параметры сети для обучения.
В дальнейшем алгоритмы нормализации, применяющие нейронные сети, используются для нормализации тематик других отраслей права, что позволяет существенно экономить время и ресурсы на подготовку системы к использованию, правильность формирования векторов для других отраслей права проверяется специалистами 122 в ускоренном режиме, преимущественно путем определения области соответствующего кластера.
На завершающем этапе машинного обучения обучается модель, которая в дальнейшем позволяет предсказывать категорию вопроса задаваемого пользователем.
При обработке текста для проведения кластеризации, также используются операции NLP:
- очистка вопросов от нерелевантных символов, например, знаков препинания, html-элементов и пр.;
- токенизация текстов - разделение предложений на отдельные символы (токены);
- конкатенация слов с определенными предлогами и частицами для сохранения эмоциональной окраски текстов;
- удаление нерелевантных слов, которые не несут смысловой нагрузки - местоимения, вопросительные слова и те, которые встречались более, чем в 80% наблюдений из анализируемой выборки;
- лемматизация токенов - сведение их к словарной форме, а там, где словарная форма не найдена проводится стемминг.
В частном случае, методом градиентного бустинга формируются решающие деревья, которые определяют формат ответа на вопрос в соответствии с векторами тематик, а содержание ответов определяется в соответствии с кластером, к которому относится тематика. Помимо прочего учитываются стилистические особенности вопроса.
Тексты вопросов преобразуются в бинарные вектора (векторизуются). Преобразование в вектора производится с использованием словаря уникальных терминов, извлеченных из выборки вопросов из исходной базы данных. Вектора вопросов передаются в алгоритм k-means, результатом работы которого является группировка вопросов по кластерам.
Как было сказано выше, по тематике защиты прав потребителей предложенной методикой было сформировано 33 класса из 44 кластеров.
При осуществлении разметки вопросов специалистами 122 для каждого специалиста определено входное качество работы, которое выражается в доле правильно размеченных вопросов.
В Таблице 1 приведен примерный вариант разметки вопросов специалистами.
Таблица 1.
Так, например, для Вопроса 1 три специалиста разметили Вопрос 1. Вероятность правильного ответа для Вопроса 1 рассчитывается по следующей формуле:
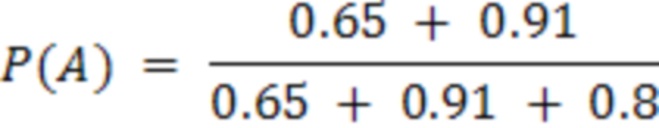
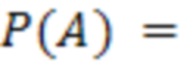
Таким образом, наиболее вероятным вариантом ответа в Вопрос 1 является А с вероятностью 66%. Такой подход позволяет выявлять ошибки специалистов и, в частности, сократить стоимость разметки на 20%, при этом качество разметки выросло на 40%, что повышает качестве работы алгоритмов классификации.
Значение входного качества работы каждого специалиста меняется с каждым размеченным вопросом, т.е. может увеличиваться или уменьшаться, в зависимости от того, отметил специалист наиболее вероятный ответ или нет.
Данный этап позволяет сформировать базу данных размеченных данных 128 с метками классов проблем по нескольким отраслям права.
Важным этапом является предобработка текстовых данных с использованием описанных в настоящем изобретении методов обработки текста 133, которые включают лемматизацию, стемминг, удаление стоп-слов, приведение текста к нижнему регистру, токенизацию, и архитектуры модели 135, которая включает многослойную нейронную сеть. Помимо очистки текста от шума и векторизации, в предложенном решении используются другие оригинальные способы обработки текста.
Модуль предобработки и классификации вопросов осуществляет приведение текста к представлению, которое понятно алгоритмам машинного обучения. На вход алгоритмы принимают тензоры разных рангов с числовыми значениями, так что осуществляется преобразование текста в формат векторов с числовыми значениями, где каждое отдельное значение - это индекс некоторого слова из словаря.
В частном случае, модуль предобработки и классификации вопросов, или, по крайней мере, одна его часть, в частности, часть, осуществляющая обработку исходного текста, реализован как класс языка программирования, внутри которого методы класса преобразуют исходный текст в числовые векторы. Методы класса используют алгоритмы NLP - токенизация, лемматизация, стемминг, как более подробно описано выше. Так, исходный текст вопроса (232), преобразованный в вектор чисел модулем предобработки и классификации вопросов, поступает на первый уровень обученной модели, которая определяет относится ли поступивший вопрос целевой отрасли права. Это бинарная модель, которая возвращает два исхода - «0» или «1». Если модель возвращает 1, то вопрос передается следующей модели, которая идентифицирует юридическую проблему, т.е. осуществляется многоклассовая классификация.
Результатом работы модели многоклассовой классификации является упорядоченный по убыванию вероятности список меток классов. Первый элемент этого списка является наиболее вероятным по расчетам модели. В процессе обучения модели осуществляется отслеживание мест, в которых она ошибается - какие категории юридических проблем ей бывает сложно правильно дифференцировать. Чтобы избежать таких ошибок используется алгоритм, который идентифицирует пары похожих для модели категорий и в этом случае позволяет уточнять у клиента, с чем именно связана его проблема. После уточнения клиента робот, реализованный программными средствами и являющийся частью диалогового менеджера 137, выбирает окончательную метку класса, которая используется для выбора тематики и формирования ответа. Такой подход, в частности, позволяет поднять точность работы модели на 15%.
При реализации системы используется диалоговый менеджер 137, где робот общаясь с клиентом и задавая контекстно-зависимые вопросы, с использованием реализованной архитектурой системы с контекстно-зависимыми связями, на выходе формирует подготовленный под конкретного пользователя (кастомизированный) ответ для пользователя. Диалоговый менеджер 137 имеет архитектуру с контекстно-зависимыми связями и моделями семантической обработки (семантического разбора) текста, причем диалоговый менеджер 137 является частью модуля формирования ответов из базы данных знаний в лексическое представление, соответствующее лексическому построению вопроса. В частном случае, упомянутый робот является приложением, способным взаимодействовать с модулями системы, в том числе имитируя действия человека, например, взаимодействовать с интерфейсами системы и с данными баз данных и выполнять определенные операции в соответствии с заданными алгоритмами обработки данных.
Определенная моделью на втором уровне метка класса передается в качестве параметра в диалоговый менеджер 137. Подключается соответствующий классу диалоговый модуль диалогового менеджера 137. Диалоговый менеджер 137 реализует древовидную структуру, по которой осуществляется (проходит) диалог робота и пользователя. Вопрос на каждом последующем шаге зависит от ответа пользователя на предыдущий вопрос. Семантический анализатор извлекает из текста вопроса клиента необходимые сущности и использует их в качестве ответа, по крайней мере, на часть вопросов модулем формирования ответов. За счёт этого сокращается время взаимодействия клиента с роботом и увеличивается скорость ответа на вопрос примерно на 30%.
Ответы упомянутого робота, предъявляемые пользователям модулем формирования ответов, формируются системой динамически - после диалога с клиентом (пользователем) модуль формирования ответов обращается к данным базы знаний 147, которая обновляется и соответствует реальному законодательству. Так, при изменениях в законах база знаний 147 обновляется и, следовательно, изменяются ответы робота, т.е. модуль формирования ответов формирует ответы с учетом обновленной (и обработанной) информации, содержащейся в базе данных знаний 147.
На ФИГ. 3 показан примерный вариант осуществления настоящего изобретения.
В шаге 310 осуществляется формирование базы данных размеченных данных (базы данных произвольных вопросов) 128 с использованием данных из базы данных неразмеченной информации (данных) 115, как описано в рамках настоящего изобретения. База данных неразмеченной информации 115 содержит вопросы пользователей и рекомендации консультантов в терминах естественного языка. Данные в базу данных произвольных вопросов могут добавляться из существующих баз данных, в которых сохранены вопросы пользователей, задаваемых на различных интернет-ресурсах, в различных приложениях (приложениях для компьютера, смартфона и т.д.) и т.д., а также сохранены ответы специалистов (консультантов) на такие вопросы пользователей. Также, в базу данных размеченных данных 128 могут добавляться после обработки системой вопросы пользователей, задаваемых пользователями с использованием диалогового менеджера 137, на которые формирует ответы описываемая система с использованием модуля формирования ответов.
Формирование базы данных размеченных данных 128, в том числе, разметка базы данных неразмеченных данных 115, осуществляется средствами системы и специалистами с использованием модуля предобработки вопросов, использующего, по крайней мере, средства разметки вопросов пользователей 124.
В шаге 315 осуществляется выбор вопросов одной области права, для которой определяют количество направлений ответов (категорий), как описано в рамках настоящего изобретения, причем специалистам предъявляются возможные ответы на вопросы, относящиеся к фразе или тематике, для оценки релевантности ответа поставленному вопросу или фразе из вопроса, причем ответы также указывают на группу, к которой принадлежит вопрос.
Специалисты с использованием предоставляемых системой средств обработки данных, а также средства системы, выделяют из вопросов пользователей раздельные тематики вопросов и осуществляют группировку тематик по нескольким независимым группам по признаку сходства, причем для тематик вопросов производится сортировка данных для исключения ошибок, совершаемых специалистами. Средства разметки вопросов пользователей 124 осуществляют и позволяют осуществлять специалистам выделять из вопросов пользователей раздельные тематики вопросов и группировать тематики по нескольким независимым группам по признаку сходства.
Средства (кросс-)валидации разметки 126 позволяют осуществлять выбор для каждой раздельной тематики вопроса наиболее вероятную группу для каждой из предложенных.
В шаге 320 осуществляется векторизация текстов вопросов пользователей, как описано в рамках настоящего изобретения.
Модуль классификации вопросов осуществляет преобразование тематик, содержащихся в вопросах пользователей, в формализованный вид, в частности, осуществляет векторизацию текстов вопросов пользователей. Тексты вопросов пользователей преобразуются в бинарные вектора с использованием словаря уникальных слов и словосочетаний (терминов). Так, векторизация текстов (вопросов пользователей) осуществляется посредством представления уникальных слов и словосочетаний в виде таблицы, содержащей уникальные термины (слова и словосочетания) с указанием наличия или отсутствия уникальных слов и словосочетаний в тексте каждого из вопросов, причем совокупность значений таблицы формирует вектор. Для каждой из фраз определяют наличие в фразе вопроса уникальных терминов и формируют табличную строку, в которой количество ячеек соответствует количеству терминов словаря, так что каждая из ячеек соответствует одному из словарных терминов, а значение, занесенное в ячейку соответствует наличию или отсутствию соответствующего термина в фразе, соответствующего позиции или номеру ячейки, где совокупность значений, занесенных в ячейки таблицы является вектором и используется для анализа соответствующей фразы, в том числе для классификации вопросов, как описано в рамках настоящего изобретения.
При обработке текстов вопросов, в частном случае, как при формировании базы данных произвольных вопросов, так и при обработке задаваемых пользователями вопросов в процессе диалога пользователя с диалоговым менеджером посредством вычислительного устройства, осуществляется удаление из текста вопросов, нерелевантных символов, включающие, по крайней мере, знаки препинания, элементы HTML разметки и т.д. Также осуществляется токенизация текстов с разделением частей текста, например, предложений на отдельные части, в частности, символы, являющимися токенами, а также осуществляется конкатенацию слов с предлогами и частицами для сохранения эмоциональной окраски текстов. Также, осуществляется удаление нерелевантных слов, не несущих смысловой нагрузки, в том числе местоимения и вопросительные слова и слова, как описано в рамках настоящего изобретения. Также, осуществляется лемматизация токенов, т.е. сведение токенов к словарной форме и осуществляется стемминг посредством нахождения основы слова для заданного исходного слова, если словарная форма не найдена.
В шаге 325 осуществляется классификация вопросов по категориям по признаку близости векторов на основании заданных правил. Средства группировки размеченных данных, в частности, являющиеся частью модуля классификации вопросов, осуществляют и позволяют осуществлять специалистам классификацию по тематикам вопросов по формальным признакам сходства. Так, по крайней мере, классификация осуществляется посредством группировки вопросов с использованием норм и правил действующих правовых документов из базы данных знаний, и кластерного анализа, в процессе которого формируют кластеры, количество которых равно сформированным экспертами группам для каждой отрасли права, количество которых вместе с векторами вопросов и словарем уникальных слов, обрабатывается с использованием кластерного анализа, так что формируют классы для отраслей права. При кластеризации системой используется алгоритм k-средних, осуществляющий сортировку размеченных специалистами вопросов по кластерам, где каждый из вопросов относится к одному кластеру, расположенному на наименьшем расстоянии от вектора вопроса.
Также, в частности в промежуточном шаге, осуществляется преобразование вопросов в формат, пригодный для автоматизированного анализа, при поступлении в систему вопроса пользователя. При упомянутой обработке вопросов (текстов вопросов пользователей) удаляют из текста вопросов нерелевантные символы, выполняют токенизацию текстов, выполняют конкатенацию слов с предлогами и частицами для сохранения эмоциональной окраски текстов, удаляют нерелевантные слова, не несущие смысловой нагрузки, выполняют лемматизацию токенов или стемминг. В частном случае реализации для каждой из тематик, то есть, для составных частей (например, фраз, словосочетаний и т.д. вопросов, имеющих различное смысловое содержание) вопросов пользователей может осуществляться преобразование фразы в формат, пригодный для автоматизированной обработки данных, в том числе анализа. В частном случае, преобразование вопросов в формат, пригодный для автоматизированного анализа, осуществляется посредством автоматизированной обработки вопросов с формированием векторного представления для каждого вопроса.
В шаге 335 осуществляется лексический парсинг вопроса пользователя с определением лексической структуры вопроса пользователя. Лексический парсинг осуществляют с использованием, по крайней мере, одного семантического парсера, причем парсеры осуществляют поиск в вопросах цепочек символов, заранее заданных в словарях, где цепочками символов являются слова или словосочетания, объединённые общим свойством в исходном тексте вопроса пользователя, так что создают классы юридических проблем, которые идентифицируются алгоритмом и имеют общее законодательное обоснование, определяющее принадлежность вопроса к кластеру.
В шаге 340 осуществляется определение содержащегося в базе данных знаний положения нормативно-правового акта, релевантного вопросу пользователя по векторам нормативно-правовых актов. Так, например, может осуществляться сравнение положений нормативно-правовых актов из базы данных знаний и вопроса пользователя, в частности, осуществляется сравнение (заранее) векторизованных положений нормативно-правовых актов и векторизованных вопросов пользователей. Также может осуществляться группировка вопросов по признаку близости векторов и группировка вопросов по направлениям ответов.
В шаге 345 осуществляется формирование лексической структуры ответа пользователю, соответствующей лексической структуре вопроса пользователя и положению нормативно-правового акта, релевантного ответу пользователя, причем системой обрабатываются и учитываются грамматические особенности вопроса, предметная область и объект обсуждения, в частности, вопроса.
Диалоговый менеджер 137 с использованием автоматизированных средств общения с пользователем, в частности, программного робота, ведет диалог в текстовом формате с пользователем, задавая контекстно-зависимые вопросы, с использованием реализованной архитектурой системы с контекстно-зависимыми связями, и формирует подготовленный под вопрос пользователя ответ. Ответы формируются системой динамически, в частности, в том числе в процессе диалога с пользователем (клиентом) модуль формирования ответов запрашивает необходимую для обработки вопроса пользователя и для формирования ответа информацию, по крайней мере, из обновляемой базы знаний (базы данных) 147, а также из базы данных размеченных данных 128, информация в которой корректируется автоматически системой и специалистами, в том числе на основе вопросов пользователей и ответов системы.
В шаге 350 осуществляется предъявление пользователю лексической структуры ответа в виде сообщения, например, текстового. Такое сообщение может быть предъявлено (задавшему вопрос) пользователю на веб-сайте, в приложении и т.д., отображаемом на экране вычислительного устройства.
Также, в частном случае, в процессе обработки вопросов пользователя, в том числе при формировании ответа на вопрос пользователя, осуществляется определение соответствия группировки вопросов по признаку близости векторов и группировки вопросов по направлениям ответов и при несоответствии группировки вопросов по признаку близости векторов и группировки вопросов по направлениям ответов осуществляется изменение параметров преобразования вопросов пользователей в формат, пригодный для автоматизированного анализа, и при соответствии группировки вопросов по признаку близости векторов и группировки вопросов по направлениям ответов используются параметры преобразования вопросов пользователей в формат, пригодный для автоматизированного анализа, для преобразования вопросов пользователей в формат, пригодный для автоматизированного анализа, и положений нормативно-правовых актов с формированием векторов нормативно-правовых актов.
На ФИГ. 4 показан упрощенный пример аппаратной реализации предложенного изобретения. Компьютерная сеть может представлять собой географически распределенную совокупность узлов, соединенных линиями связи и сегментами для передачи данных между конечными узлами, такими как персональные компьютеры, рабочие станции, или периферийные устройства, такие как принтеры или сканеры. Доступно множество типов сетей, от локальных сетей (LAN) до глобальных сетей (WAN). Как показано на ФИГ. 4, примерная компьютерная сеть 900 может содержать множество сетевых устройств, таких как маршрутизаторы, коммутаторы, компьютеры и тому подобное, связанных между собой линиями связи. Например, множество сетевых устройств может соединять одно или несколько пользовательских устройств 910 (или «клиентских устройств» 910), которые могут использоваться пользователем, таких как компьютеры, смартфоны, планшеты и т.д. Каналы связи, соединяющие различные сетевые устройства, могут быть проводными линиями или общими средами (например, беспроводными линиями), где определенные устройства могут поддерживать связь с другими устройствами на основе расстояния, уровня сигнала, текущего рабочего состояния, местоположения и т.п. Каналы связи могут соединять различные сетевые устройства в любой возможной конфигурации. Один или несколько серверов 920 (например, хост-серверы, веб-серверы, базы данных и т.д.) Могут поддерживать связь с сетью 900 и, таким образом, с множеством клиентских устройств 910. Специалистам в данной области техники будет понятно, что в компьютерной сети может использоваться любое количество и расположение узлов, устройств, линий связи и т. д., а иллюстрация, показанная на ФИГ. 4 является упрощенным примером аппаратной реализации системы.
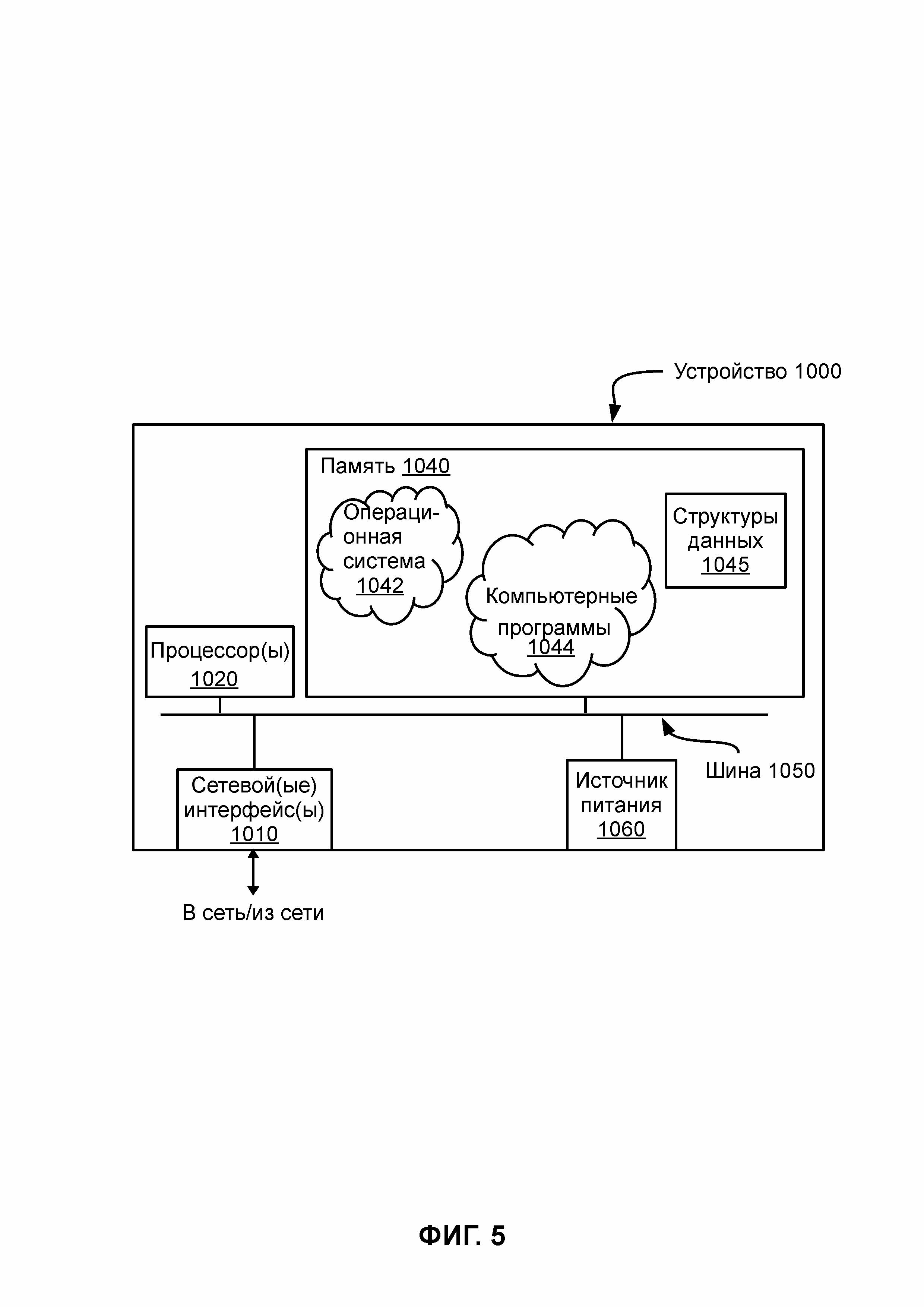
На ФИГ. 5 показан пример вычислительной системы, пригодный для реализации элементов предложенного изобретения. Как показано на ФИГ. 5, вычислительная система содержит вычислительное устройство 1000, которое может использоваться в качестве устройства пользователя или сервера, в памяти 1040 которого хранятся операционная система 1042, компьютерные программы 1044 и структуры данных 1045. Память 1040 устройства 1000 связана шиной 1050 с источником питания 1060, по крайней мере, одним процессором 1020 и, по крайней мере, одним сетевым интерфейсом 1010, осуществляющим передачу данных в сеть 900 (ФИГ. 4) и из сети 900 (ФИГ. 4).
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
Реферат
Изобретение относится к вычислительной технике. Техническим результатом является повышение вероятности формирования правильного ответа на вопрос пользователя, снижение влияния неквалифицированных экспертов на результаты работы системы. Способ управления автоматизированной системой правовых консультаций заключается в том, что формируют базу данных произвольных вопросов, выбирают вопросы одной области права, для которой определяют количество направлений ответов в виде категорий вопросов, векторизуют тексты вопросов в бинарные вектора вопросов, классифицируют вопросы по категориям по признаку близости векторов, так что формируют классы для отраслей права, и при поступлении в систему вопроса пользователя производят лексический парсинг вопроса пользователя с определением лексической структуры вопроса пользователя, определяют на основании сформированных классов для отраслей права содержащееся в базе данных знаний положение нормативно-правового акта, релевантного вопросу пользователя по векторам нормативно-правовых актов, формируют лексическую структуру ответа пользователю, соответствующую лексической структуре вопроса пользователя и положению нормативно-правового акта, релевантного ответу пользователя, и предоставляют пользователю лексическую структуру ответа в виде текстового сообщения. 9 з.п. ф-лы, 5 ил., 1 табл.