Адаптивная система фильтрации ненужных сообщений - RU2327205C2
Код документа: RU2327205C2
Чертежи


Описание
Перекрестные ссылки на связанные заявки
Настоящая заявка относится к следующим патентам и патентным заявкам, которые включены в настоящее описание во всей своей полноте: патент США 6161130 на «Способ, использующий вероятностный классификатор для обнаружения ненужных сообщений электронной почты путем автоматического обновления обучения и повторного обучения классификатора на основе обновления обучающего множества»; патентная заявка США № 09/448408 (номер дела поверенного 124243.01) на «Средство обучения системы классификации, использующей обратный перенос с максимальным запасом с вероятностным выходом», поданная 23 ноября 1999, и патентная заявка США № 10/278591 (номер дела поверенного 1150749.1) на «Способ и систему для идентификации ненужной электронной почты», поданная 23 октября 2002.
Область техники
Настоящее изобретение относится к системам и способам для идентификации нежелательной информации (например, ненужных сообщений электронной почты), более конкретно к адаптивному фильтру, который облегчает такую идентификацию.
Предшествующий уровень техники
С появлением глобальных коммуникационных сетей, таких как Интернет, появились коммерческие возможности для достижения огромного числа потенциальных потребителей. Электронная передача сообщений, в частности электронная почта, все более широко применяется в качестве средства распространения нежелательных рекламных сообщений и продвижений (также обозначаемых как «спам») среди сетевых пользователей.
По оценкам компании Radicati Group. Inc., специализирующейся на консалтинге и исследованиях рынка, в августе 2002 каждый день посылалось 2 миллиарда ненужных сообщений электронной почты, и ожидается, что это число будет утраиваться каждые два года. Для индивидуальных лиц и организаций (например, предприятий, правительственных агентств и т.д.) такие нежелательные сообщения все в большей степени причиняют беспокойство и зачастую являются оскорбительными. Как таковая, ненужная («макулатурная») электронная почта близка к тому, чтобы стать главной угрозой для заслуживающей доверия компьютерной среды.
Ключевым методом, используемым для пресечения ненужной электронной почты (спама), является использование систем/методов фильтрации. Один испытанный метод фильтрации основан на машинном методе обучения, при котором машинные обучающие фильтры присваивают входящему сообщению вероятность того, что сообщение является спамом. В этом методе в типовом случае извлекаются признаки из двух классов типовых сообщений (например, ненужные сообщения (спам) и полезные сообщения (не-спам)), и обучающий фильтр применяется для вероятностного различения этих двух классов. Поскольку многие признаки сообщения связаны с содержанием (например, слова, фразы в теме и/или в теле сообщения), такие типы фильтров обычно упоминаются как «фильтры, основанные на содержании».
Некоторые фильтры ненужной почты/спама являются адаптивными, важность чего заключается в том, что многоязычным пользователям и пользователям, которые говорят на редких языках, требуется фильтр, который может адаптироваться к их специфическим потребностям. Кроме того, не все пользователи имеют единое мнение в вопросе, что является ненужной почтой/спамом, а что нет. Соответственно, путем использования фильтра, который может неявно обучаться (например, путем наблюдения поведения пользователя), соответствующий фильтр может быть подстроен динамически для удовлетворения конкретных потребностей пользователя по идентификации сообщений.
Один подход к адаптации фильтрации состоит в запрашивании пользователя о маркировке сообщений как ненужных (спам) и как полезных (не-спам). К сожалению, такие методы обучения с интенсивными ручными операциями нежелательны для многих пользователей вследствие сложности, связанной с таким обучением, не говоря уже о затратах времени, требуемых для надлежащего осуществления такого обучения. Другой метод обучения адаптивного фильтра состоит в использовании неявных обучающих подсказок. Например, если пользователь отвечает на сообщение или посылает сообщение, то метод предполагает, что это сообщение не является спамом. Однако использование только таких подсказок для сообщений вводит статистические смещения в процесс обучения, давая в результате фильтры соответственно более низкой точности.
Еще один подход состоит в использовании всей пользовательской электронной почты для обучения, где первоначальные метки присваиваются существующим фильтром, и пользователь иногда переопределяет эти назначения явно выраженными подсказками (например, метод «пользовательской коррекции»), например, путем выбора опций, таких как «удалить как спам» и «не спам», и/или неявно выраженными подсказками. Хотя такой метод более эффективен, чем методы, описанные выше, он все равно обладает недостатками по сравнению с тем, что обеспечивает заявленное изобретение, как представлено в формуле изобретения.
Сущность изобретения
Ниже представлена упрощенная сущность изобретения для пояснения некоторых аспектов изобретения. Это краткое описание сущности изобретения не является исчерпывающей характеристикой изобретения. Оно не предназначено для идентификации ключевых и принципиально важных элементов изобретения или для определения объема изобретения. Его единственной целью является представление некоторых концепций изобретения в упрощенной форме в качестве введения в более детальное описание, как представлено далее.
Настоящее изобретение предусматривает систему и способ, которые обеспечивают использование имеющегося фильтра (например, начального фильтра или нового фильтра), наилучшим образом приспособленного для идентификации ненужных сообщений/спама. Изобретение использует начальный фильтр, который обеспечивает фильтрацию сообщений и имеет связанную с ним частоту ложных позитивных тревог (например, почта, не являющаяся спамом, некорректно классифицируется как спам) и частоту ложных негативных тревог (например, спам некорректно классифицируется как почта, не являющаяся спамом). Новый фильтр также используется для фильтрации сообщений - новый фильтр оценивается соответственно частоте ложных позитивных тревог и частоте ложных негативных тревог, связанных с начальным фильтром. Данные, используемые для определения частот ложных позитивных тревог и ложных негативных тревог начального фильтра, используются для определения новых частот ложных позитивных тревог и ложных негативных тревог нового фильтра, как функции порога.
Новый фильтр используется вместо начального фильтра, если для нового фильтра существует пороговое значение такое, что новые частоты ложных позитивных тревог и ложных негативных тревог нового фильтра совместно рассматриваются как лучшие, чем частоты ложных позитивных тревог и ложных негативных тревог начального фильтра. Новая частота ложных позитивных тревог и новая частота ложных негативных тревог определяются соответственно сообщениям, которые маркированы пользователем как спам и не-спам (например, с использованием процесса пользовательской коррекции). Процесс пользовательской коррекции включает в себя переопределение начальной классификации сообщения, при этом начальная классификация сообщения выполняется автоматически начальным фильтром, когда пользователь принимает сообщение. Порог может представлять собой одно пороговое значение или выбирается из множества генерированных пороговых значений. Если используется множество значений, то выбранное пороговое значение может быть определено путем выбора, например, среднего порогового значения в диапазоне приемлемых пороговых значений (например, пороговое значение с минимальной частотой ложных позитивных тревог или пороговое значение, которое максимизирует ожидаемую пользователем полезность на основе Р*-функции полезности). Альтернативно, пороговое значение может быть выбрано, только если частоты ложных позитивных тревог и ложных негативных тревог нового фильтра, по меньшей мере, такого же качества, что и соответствующие параметры начального фильтра при данном выбранном пороге, и одна лучше. Дополнительно, критерии выбора могут быть обеспечены таким образом, что новый фильтр выбирается, только если частоты для нового фильтра лучше, чем частота для начального фильтра не только при выбранном пороге, но и при других близких порогах.
Другой аспект изобретения предусматривает графический пользовательский интерфейс, который облегчает фильтрацию данных. Этот интерфейс обеспечивает интерфейс фильтрации, который осуществляет информационный обмен с системой конфигурации в связи с конфигурированием фильтра. Интерфейс обеспечивает множество выбираемых пользователем уровней фильтра, включая, по меньшей мере, один устанавливаемый по умолчанию, улучшенный и исключительный. Интерфейс обеспечивает различные инструментальные средства, которые облегчают выполнение вышеупомянутых системы и способа, соответствующих изобретению.
Для достижения вышеуказанных и связанных с ними целей далее описаны некоторые иллюстративные аспекты изобретения во взаимосвязи с последующим описанием и приложенными чертежами. Эти аспекты иллюстрируют некоторые из различных путей, которыми могут быть использованы принципы изобретения, причем настоящее изобретение предназначено для охвата всех таких аспектов и их эквивалентов. Другие преимущества и новые признаки изобретения поясняются в последующем детальном описании изобретения, иллюстрируемом чертежами.
Краткое описание чертежей
Фиг.1 - обобщенная блок-схема системы фильтрации в соответствии с настоящим изобретением.
Фиг.2 - график компромиссных требований по отношению к частоте перехвата.
Фиг.3 - блок-схема способа, соответствующего настоящему изобретению.
Фиг.4а и 4в - примеры пользовательских интерфейсов для конфигурирования адаптивной системы фильтрации ненужной электронной почты в соответствии с настоящим изобретением.
Фиг.5 - обобщенная блок-схема архитектуры обработки, использующей настоящее изобретение.
Фиг.6 - система с одним или более клиентскими компьютерами, которая облегчает многопользовательские входы в систему и фильтрацию входящих сообщений согласно способам, соответствующим настоящему изобретению.
Фиг.7 - система, в которой первоначальная фильтрация выполняется на сервере сообщений, а вторичная фильтрация выполняется на одном или более клиентах, в соответствии с настоящим изобретением.
Фиг.8 - блок-схема адаптивной системы фильтрации для полномасштабной реализации.
Фиг.9 - блок-схема компьютера, предназначенного для выполнения раскрытой архитектуры.
Детальное описание изобретения
Настоящее изобретение описывается далее со ссылками на чертежи, на которых одинаковыми ссылочными позициями обозначены сходные элементы на всех чертежах. В последующем изобретении, в целях объяснения, различные конкретные детали изложены для того, чтобы обеспечить более глубокое понимание сущности изобретения. Однако очевидно, что изобретение может быть реализовано без использования этих конкретных деталей. В других случаях хорошо известные структуры и устройства показаны на блок-схеме, чтобы облегчить описание настоящего изобретения.
Термины «компонент» и «система», как они использованы в настоящем описании, предназначены для ссылок на компьютерные объекты, в том числе аппаратные средства, комбинацию аппаратных средств и программного обеспечения, на программное обеспечение или исполняемое программное обеспечение. Например, компонент может представлять собой, без ограничения указанным, процесс, исполняемый на процессоре, процессор, объект, выполняемый модуль, поток выполнения, программу и/или компьютер. В качестве иллюстрации, как приложение, исполняемое на сервере, так и сервер могут являться компонентом. Один или более компонентов могут находиться в процессе и/или потоке выполнения, и компонент может быть локализован на компьютере или распределен между двумя и более компьютерами.
Настоящее изобретение может воплощать в себе различные схемы и/или методы вывода в связи с фильтрацией нежелательных сообщений. Термин «вывод», как он использован в настоящем описании, относится в целом к процессу обоснования или выводу умозаключения относительно состояний системы, среды и/или пользователя из набора наблюдений, реализованных посредством событий и/или данных. Вывод может использоваться для идентификации конкретного контекста или действия или может генерировать, например, распределение вероятности по состояниям. Вывод может быть вероятностным, то есть представлять собой вычисление распределения вероятностей по состояниям, представляющим интерес, на основе учета данных и событий. Вывод может также ссылаться на методы, используемые для образования событий более высоких уровней из набора событий и/или данных. Такой вывод приводит в результате к созданию новых событий или действий из набора наблюдаемых событий и/или сохраненных данных событий, независимо от того, коррелированны или нет события в ближайшей временной окрестности, и происходят ли события и данные из одного или нескольких источников событий или данных.
Также понятно, что хотя термин «сообщение» повсеместно используется в описании, этот термин не ограничен сообщениями электронной почты как таковыми, но может быть соответственно адаптирован для включения электронных сообщений иной формы, которые могут распространяться по соответствующей коммуникационной архитектуре. Например, приложения конференций, которые облегчают конференцию между двумя или более пользователями (например, программы интерактивного диалога и программы мгновенной отсылки сообщений), также могут использовать выгоды от фильтрации, раскрытые в настоящем изобретении, поскольку нежелательный текст может электронными средствами вкрапляться в нормальные сообщения интерактивного диалога, когда пользователи обмениваются сообщениями, и/или вводиться как начальное сообщение, завершающее сообщение или использовать все из указанного выше. В этом конкретном приложении фильтр может быть конфигурирован для автоматической фильтрации конкретного содержания сообщения (текста и изображений), чтобы перехватить и маркировать как спам нежелательное содержание (например, передачу рекламы, продвижение товаров или объявления).
На фиг.1 представлена блок-схема системы 100 обнаружения ненужных сообщений, соответствующая настоящему изобретению. Система 100 принимает входящий поток сообщений 102, который может фильтроваться для облегчения обнаружения ненужных сообщений и их устранения. Сообщения 102 принимаются в компонент 104 управления фильтром, который может маршрутизировать сообщения 102 между первым фильтром 106 (например, начальным фильтром) и вторым фильтром 108 (например, новым фильтром), в зависимости от критериев фильтрации, определенных в соответствии с адаптивным аспектом настоящего изобретения. Соответственно, если первый фильтр 106 определен как достаточно эффективный в обнаружении ненужных сообщений, второй фильтр 108 не используется и управление 104 фильтром будет продолжать маршрутизировать сообщения 102 на первый фильтр 106. Однако если второй фильтр 108 определен как, по меньшей мере, настолько же эффективный, как и первый фильтр 106, то управление 104 фильтром может принять решение маршрутизировать сообщения 102 на второй фильтр 108. Критерии, используемые для принятия такого решения, описаны более подробно ниже. При начальном использовании система 100 фильтрации может быть конфигурирована на установку предварительно заданного по умолчанию фильтра, так что сообщения 102 будут маршрутизироваться на первый фильтр 106 для фильтрации (например, как в типовом случае, когда первый фильтр 106 представляет собой явным образом обученный фильтр, поставленный вместе с конкретным продуктом).
На основе установок первого фильтра 106 сообщение, принятое в первый фильтр 106, будет запрашиваться на предмет ненужной информации, связанной с ненужными данными. Ненужная информация может включать в себя, без ограничения указанным, следующее: информацию отправителя (от отправителя, который известен как посылающий спам), такую как IP-адрес источника, имя отправителя, адрес электронной почты отправителя, доменное имя отправителя, неразборчивые буквенно-числовые строки в полях идентификатора; термины и фразы текста сообщения, обычно используемые в ненужной электронной почте, такие как "loan" (ссуда), "sex" (пол), "rate" (ставка), "limited offer" (ограниченное предложение), "buy now" (купить сейчас) и т.д.; особенности текста сообщения, такие как размер шрифта, цвет шрифта, использование специальных символов; и встроенные ссылки на всплывающие рекламные объявления. Нежелательные данные могут быть определены на основе, по меньшей мере частично, предварительно заданных, а также динамически определяемых критериев спама. Сообщение также запрашивается на предмет «хороших» данных, таких как слова, подобные "weather" (погода), "team" (команда), которые в типовом случае не появляются в ненужной почте или в почте от отправителя или IP-отправителя, который известен как посылающий только нужную почту. Понятно, что если продукт поставлялся без начального фильтра, без каких-либо установленных критериев фильтрации, то все сообщения проходят без маркировки сначала через фильтр 106 в почтовый ящик 112 пользователя для входящих сообщений (также обозначенный как выход первого фильтра). Понятно, что почтовый ящик 112 может просто представлять собой хранилище данных, расположенное в различных местоположениях (например, сервер, блок массовой памяти, клиентский компьютер, распределенная сеть и т.д.). Кроме того, понятно, что первый фильтр 106 и/или второй фильтр 108 могут использоваться множеством пользователей/компонентов, и что почтовый ящик 112 для входящих сообщений может быть подразделен для хранения сообщений отдельно для соответствующих пользователей/компонентов. Кроме того, система 100 может использовать множество вторичных фильтров 108, так что наиболее подходящий один из вторичных фильтров используется в связи с конкретной задачей. Такие аспекты настоящего изобретения описаны более детально ниже.
Когда пользователь просматривает сообщения почтового ящика, некоторые сообщения могут быть определены как ненужные, а другие нет. Это основано, отчасти, на явной маркировке ненужной почты или почты, не являющейся ненужной (спам, не-спам), пользователем, например, путем нажатия кнопки и на неявной маркировке сообщений посредством действий пользователя, связанных с конкретным сообщением. Сообщение может неявно определяться как не являющееся спамом на основе, например, следующих действий пользователя или процессов сообщения: сообщение прочитано и оставлено в почтовом ящике для входящей почты; сообщение прочитано и переслано; сообщение прочитано и помещено в какую-либо папку, но не в «корзину для мусора»; на сообщение отвечено; или пользователь открывает и редактирует сообщение. Другие пользовательские действия также могут быть определены как связанные с сообщениями, не являющимися спамом. Сообщение может неявно определяться как ненужное, например, на основе того, что сообщение не прочитано за неделю или сообщение удалено без прочтения. Таким образом, система 100 контролирует эти пользовательские действия (или процессы сообщения) посредством компонента 114 пользовательской коррекции. Эти пользовательские действия или процессы сообщений могут быть предварительно конфигурированы в компоненте 14 пользовательской коррекции, так что когда пользователь первоначально просматривает и выполняет действия над сообщениями, система 100 может начать формирование данных частоты ложных позитивных тревог и частоты ложных негативных тревог для первого фильтра 106. По существу, любое пользовательское действие (или процесс сообщения), предварительно не конфигурированное в блоке 114 пользовательской коррекции, будет автоматически позволять «неизвестному» сообщению проходить на выход 112 фильтра немаркированным до тех пор, пока система 100 не адаптируется для рассмотрения сообщений таких типов. Понятно, что термин «пользователь», как он использован в настоящем описании, предназначен для включения в него лица, группы лиц, компонента, а также комбинации, включающей в себя лицо (лица) и компонент(ы).
Когда сообщение в пользовательском почтовом ящике 112 для входящей почты принято как немаркированное сообщение, но в действительности является ненужным сообщением, система 100 обрабатывает это как значение ложных негативных данных. Компонент 114 пользовательской коррекции затем вводит эту ложную негативную информацию назад в компонент 104 управления фильтром в качестве значения данных, используемого для определения эффективности первого фильтра 106. С другой стороны, если первый фильтр маркирует сообщение как ненужное сообщение электронной почты, если оно в действительности не является ненужным сообщением, то система 100 обрабатывает это как значение ложных позитивных данных. Компонент 114 пользовательской коррекции затем вводит эту ложную позитивную информацию назад в компонент 104 управления фильтром в качестве значения данных, используемого для определения эффективности первого фильтра 106. Таким образом, когда пользователь корректирует сообщения, принимаемые в почтовом ящике 112 входящих сообщений, ложные негативные и ложные позитивные данные вырабатываются для первого фильтра 106.
Система 100 определяет, имеется ли порог для второго фильтра 108, такой, что частоты ложных позитивных тревог и ложных негативных тревог ниже (например, в пределах приемлемой вероятности), чем соответствующие значения для первого фильтра 106. Если это так, то система 100 выбирает один из приемлемых порогов. Система также может выбрать второй фильтр, когда частота ложных позитивных порог одинакового качества, а частота ложных негативных тревог лучше, или когда частота ложных негативных тревог одинакового качества, а частота ложных позитивных тревог лучше. Таким образом, настоящее изобретение обеспечивает определение того, имеется ли порог (и каким должен быть этот порог) для второго фильтра 108, который гарантирует, с приемлемой вероятностью, что второй фильтр обеспечивает одинаковую или лучшую полезность по отношению к обнаружению ненужных сообщений, независимо от конкретной функции полезности пользователя и от того, безошибочно ли пользователь скорректировал ошибки первого фильтра 106.
Система 100 обучает новый (или второй) фильтр 108 на основе потребности в новом обучении ввиду пользовательской проверки ложных позитивных и ложных негативных идентификаций. Более конкретно, система 100 использует данные, маркированные метками «спам» и «не-спам», определенными способом пользовательской коррекции. С использованием этих данных частота ложных позитивных тревог (например, не являющиеся ненужными сообщения ошибочно маркированы как ненужные) и частота ложных отрицательных тревог (например, ненужные сообщения ошибочно маркированы как не являющиеся ненужными) определяются для первого (то есть существующего или начального) фильтра 106. Те же самые данные используются для обучения нового (то есть второго) фильтра 108, то есть эти данные используются в связи с определением частот ложных позитивных и ложных негативных тревог в функции порога. Поскольку данные оценки являются теми же самыми, что и использованные для обучения второго фильтра, предпочтительно используется метод перекрестной проверки, известный специалистам в данной области техники, как более подробно пояснено ниже. Если второй набор данных определяется как того же качества, что и первый набор данных, то запускается второй фильтр 108. Компонент 104 управления затем маршрутизирует все входящие сообщения на второй фильтр 108 до тех пор, пока в процессе сравнения не будет определено, что фильтрация должна быть переведена назад к первому фильтру 106, который теперь имеет лучшие результаты фильтрации.
Один конкретный аспект изобретения основывается на двух предпосылках. Первая предпосылка состоит в том, что первая проверка (например, пользовательская коррекция) не содержит ошибок (например, пользователь не удаляет как ненужное то сообщение, которое не является ненужным). При этой предпосылке метки данных, хотя и всегда корректные, являются «по меньшей мере, настолько же корректными», что и метки, присвоенные первым фильтром 106. Таким образом, если второй фильтр 108 не менее полезен, чем существующий фильтр, согласно таким меткам, то истинная ожидаемая полезность второго фильтра 108 может быть не хуже, чем у первого фильтра 106. Вторая предпосылка состоит в том, что желательными являются более низкие частоты ложных позитивных тревог и ложных негативных тревог. В соответствии с этой предпосылкой, если обе частоты ошибок второго фильтра 108 не больше, чем соответствующие характеристики у первого фильтра 106, то второй фильтр 108, по меньшей мере, того же качества, что и первый фильтр 106, в отношении обнаружения ненужных сообщений, независимо от конкретной пользовательской функции полезности.
Одна причина того, что второй фильтр 108 может не всегда быть настолько же эффективным, что и первый фильтр, состоит в том, что второй фильтр основан на меньшем количестве данных, чем первый фильтр 106. Первый фильтр 106 может быть «начальным» фильтром, имеющим начальные данные, которые генерируются из данных других пользователей. По существу, большинство, если не все адаптивные фильтры поставляются с начальным фильтром, так что пользователю обеспечивается конфигурация фильтра, которая должна идентифицировать типовые ненужные сообщения электронной почты, не требуя от пользователя конфигурировать фильтр, что представляет хорошие возможности работы с новой моделью компьютера для неопытного пользователя. Другая причина состоит в том, что второй фильтр 108 может не всегда быть настолько эффективным, как первый фильтр 106. Это зависит от двух факторов: фильтры не являются идеальными, и они могут быть некалиброванными. Оба эти фактора обсуждаются ниже, и затем рассматривается вопрос определения того, является ли второй фильтр 108 лучшим.
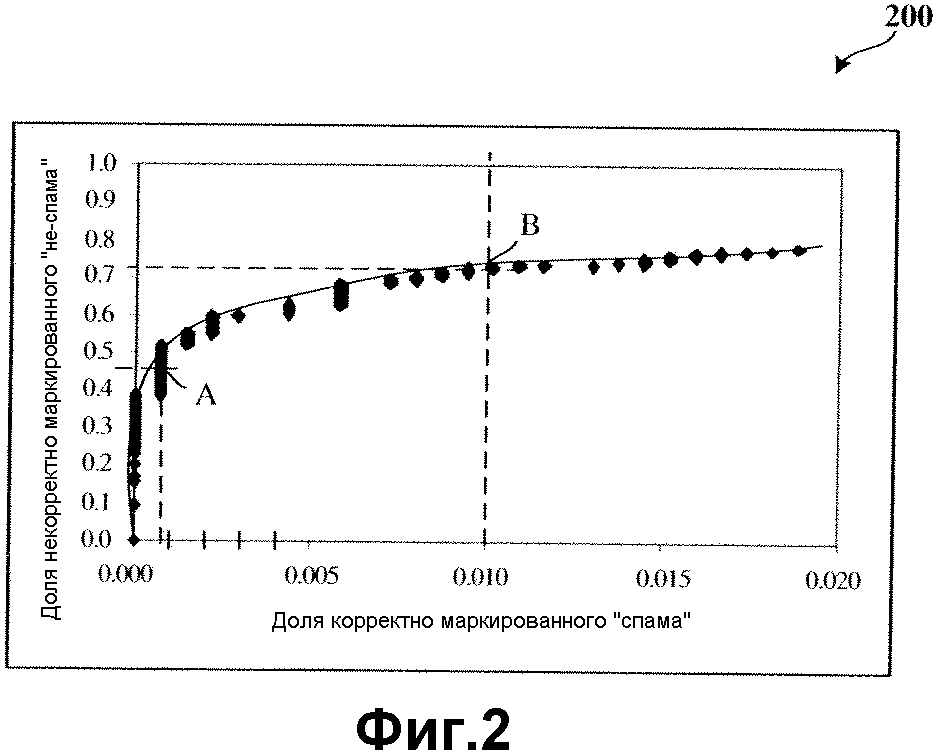
На фиг.2 показан график, отражающий компромисс между эффективностью и вероятностью правильного определения (процент спама, маркированного корректным образом, определяемый как единица минус частота ложных негативных тревог) и частотой ложных позитивных тревог (процент ненужных сообщений, маркированных как не являющиеся ненужными). Как показано на чертеже, специалисту в данной области техники должно быть понятно, что ни один фильтр не является идеальным. Таким образом, существуют компромиссы между идентификацией и обнаружением большего количества ненужных сообщений и случайной неверной маркировкой сообщений, не являющихся ненужными, как ненужных сообщений. Этот компромисс эффективности (также определяемый здесь как вероятность точного определения) изображен на графике в виде характеристики, известной как кривая «приемник-оператор» (ROC) 200. Каждая точка кривой соответствует некоторому компромиссу. Пользователь выбирает «рабочую точку» для фильтра путем настройки порога вероятности или порог вероятности может быть предварительно установлен. Если вероятность р того, что сообщение представляет собой ненужное сообщение (как считается фильтром), превышает этот порог, то сообщение маркируется как ненужное сообщение. Таким образом, если пользователь принимает решение работать в режиме, где вероятность точного определения высока (то есть число ложных позитивных определений низка по сравнению с числом корректно маркированных сообщений), то рабочая точка на кривой 200 ближе к началу координат. Например, если пользователь выбирает рабочую точку А на ROC-кривой 200, то частота ложных позитивных тревог примерно равна 0.0007, а соответствующее значение по координате у для числа корректно маркированных сообщений примерно равно 0.45. Пользователь будет иметь округленную частоту точности фильтра 0.45/0.0007=643, то есть одно ложное позитивное сообщение примерно на каждые 643 сообщения, которые маркированы корректным образом. С другой стороны, если рабочая точка соответствует точке В, то более низкая частота точного определения вычисляется как примерно равная 0.72/0.01=72, что означает, что будет иметь место одно ложное позитивное сообщение примерно на каждые 72 сообщения, которые маркированы корректным образом.
Различные пользователи будут принимать такие компромиссные решения различным образом, по отношению к их индивидуальному уникальному набору предпочтений, т.е. на языке теории принятия решений различные пользователи имеют различные функции полезности для фильтрации ненужных сообщений. Например, один класс пользователей может быть индифферентным к некорректному маркированию не являющегося ненужным сообщения и к ошибке в обнаружении N ненужных сообщений. Для пользователей этого класса оптимальный порог (р*) вероятности для определения ненужного сообщения может быть определен посредством следующего сообщения:
p*=N/(N+D)
где N - число сообщений, и N может изменяться для разных пользователей класса.
Таким образом, пользователи в этом классе определяются как имеющие «функцию полезности р*». При этом, если пользователь имеет функцию полезности р*, и если второй фильтр откалиброван, то оптимальный порог может быть выбран автоматически, а именно порог должен устанавливаться на р*. Другому классу пользователей может быть желательным, чтобы не более Х% его сообщений электронной почты, не являющихся ненужными, маркировались как ненужные. Для этих пользователей оптимальный порог зависит от распределения вероятностей, которое второй фильтр 108 присваивает сообщениям.
Второе замечание состоит в том, что фильтры могут иметь возможность калибровки, а могут и не иметь ее. Калиброванный фильтр имеет свойство, заключающееся в том, что когда он определяет с вероятностью р, что множество сообщений электронной почты являются ненужными, то р из этих сообщений будут ненужными. Многие методы машинного обучения генерируют калиброванные фильтры, при условии, что пользователь скрупулезно корректирует ошибки существующих фильтров. Если пользователь корректирует ошибки только для части времени (например, менее 80%), то фильтры, вероятно, будут некалиброванными, то есть эти фильтры будут калиброванными по отношению к некорректным меткам, но некалиброванными по отношению к истинным меткам. Настоящее изобретение обеспечивает средство для определения, имеется ли порог (и каким должен быть такой порог) для второго фильтра 108, который гарантирует (с некоторой вероятностью), что второй фильтр 108 обеспечивает равную или лучшую полезность для пользователя, чем первый фильтр 106, независимо от пользовательской функции полезности и от того, насколько скрупулезно пользователь скорректировал ошибки существующего фильтра 106.
На фиг.3 показана блок-схема способа, соответствующего одному из аспектов изобретения. Для простоты объяснения способ показан и описан как последовательность действий, однако понятно, что настоящее изобретение не ограничено этим порядком действий, так как некоторые действия, в соответствии с настоящим изобретением, могут осуществляться в других порядках и/или одновременно с другими действиями, относительно того, что показано на чертежах и описано. Например, специалистам в данной области техники должно быть понятно, что способ может быть представлен как последовательность взаимосвязанных состояний или событий, например как на диаграмме состояний. Кроме того, не все показанные действия могут потребоваться для реализации способа, соответствующего изобретению.
Основной подход требует двух предпосылок. Первая предпосылка состоит в том, что пользовательские коррекции не содержат ошибок (например, ошибкой было бы, если пользователь удаляет как ненужное то сообщение, которое не является ненужным). При этой предпосылке метки данных, хотя и всегда корректные, являются «по меньшей мере, настолько же корректными», что и метки, присвоенные первым/начальным фильтром. Таким образом, если второй фильтр не менее полезен, чем первый фильтр, согласно таким меткам, то истинная ожидаемая полезность второго фильтра не хуже, чем у первого фильтра. Вторая предпосылка состоит в том, что все пользователи предпочитают более низкие частоты ложных позитивных тревог и ложных негативных тревог. В соответствии с этой предпосылкой, если обе частоты ошибок второго фильтра не выше, чем соответствующие характеристики у первого фильтра, то второй фильтр не хуже, чем первый фильтр, независимо от конкретной пользовательской функции полезности.
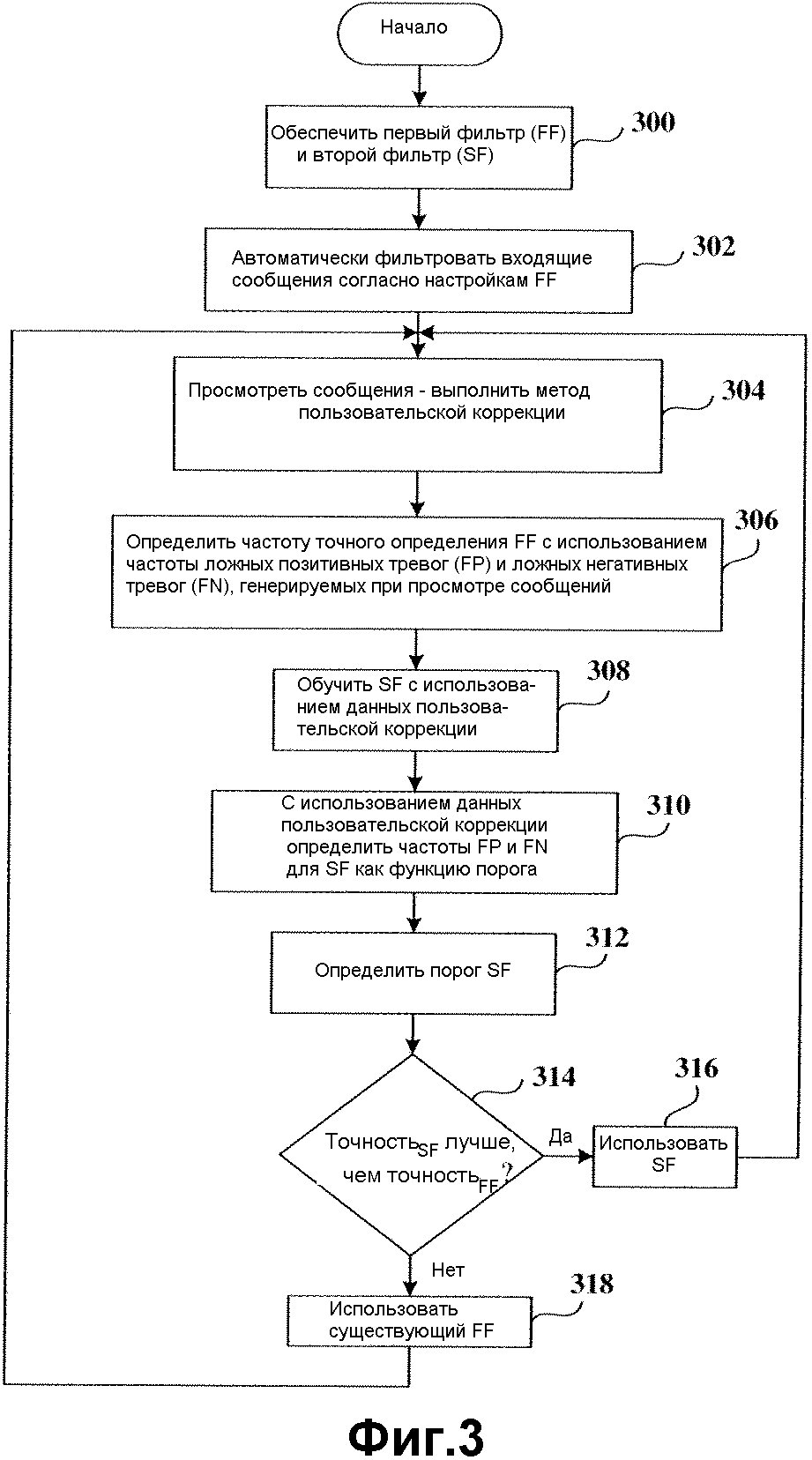
На этапе 300 первый и второй фильтр обеспечиваются средством взаимодействия (например, для изменения установок и общего управления настройкой и конфигурацией фильтров). На этапе 302 первый фильтр конфигурируется для автоматической фильтрации входящих сообщений в соответствии с одной или более настройками фильтра. Настройки могут включать в себя настройки, установленные по умолчанию, обеспеченные изготовителем. При приеме отфильтрованных сообщений (например, в папку «входящие») на этапе 304 сообщения просматриваются, и осуществляется определение (например, методом пользовательской коррекции), не были ли сообщения, не являющиеся ненужными, ошибочно маркированы как ненужные (например, ложные позитивные определения), и какие ненужные сообщения не были маркированы как ненужные (например, ложные негативные определения). На этапе 304 функция пользовательской коррекции может быть выполнена путем маркировки сообщений с ложным негативным определением как ненужная электронная почта, либо в явной форме, либо неявно, и удаления меток сообщений с ложным позитивным определением как не являющихся ненужными. Такая функция пользовательской коррекции обеспечивает вероятность точного определения для первого фильтра путем определения его данных частоты ложных позитивных тревог и ложных негативных тревог. На этапе 308 второй фильтр обучается в соответствии со скорректированными пользователем данными первого фильтра 106. Те же данные затем используются для определения вторых частот ложных позитивных тревог и ложных негативных тревог второго фильтра как функции порога, как указано на этапе 310. На этапе 312 определяется пороговое значение. Определение осуществляется относительно того, существует ли порог для второго фильтра, такой, что связанные частоты ложной позитивной и ложной негативной тревог ниже, чем эти частоты первого фильтра (с некоторой приемлемой вероятностью). То есть определяется, как показано на этапе 314, является ли частота точности второго фильтра (ТочностьВФ) лучше, чем частота точности первого фильтра (ТочностьПФ). Если да, то соответствующий порог выбирается и второй фильтр используется для фильтрации входящего сообщения, как показано на этапе 316. Если нет, то процесс переходит к этапу 318, где первый фильтр выполнят фильтрацию входящих сообщений. Процесс динамически циклируется путем выполнения вышеописанных действий, по мере необходимости.
Процесс анализа точности может происходить каждый раз, когда реализуется функция пользовательской коррекции, так что второй фильтр может использоваться или переводиться в неактивное состояние в любой момент на основе определения порога. Поскольку данные оценки первого фильтра являются теми же самыми, что и использованные для обучения второго фильтра, то используется процесс перекрестной проверки. А именно, данные сегментируются на k наборов (k - целое) для каждого процесса пользовательской коррекции, и для каждого набора данных второй фильтр обучается с использованием данных в других k-1 наборах. Эффективность (или точность) второго фильтра затем оценивается для выбранного набора из k-1 наборов. Другой возможностью является ожидание, пока N1 и N2 сообщений с метками «спам» и «не-спам», соответственно, не будут накоплены (например, N1=N2=1000), и затем повторение исполнения каждый раз, когда будут накоплены N3 и N4 дополнительных сообщений с метками «спам» и «не-спам» (например, N3=N4=100). Другой альтернативой является планирование такого процесса на основе календарного времени.
Если имеется более одного порогового значения, делающего второй фильтр (фильтры) не хуже, чем первый фильтр, то существует несколько альтернатив для выбора порога для использования. Одной альтернативой является выбор порога, который максимизирует ожидаемую полезность пользователя в предположении, что пользователь имеет функцию полезности р*. Другой альтернативой является выбор порога с самой низкой частотой ложных позитивных тревог. Еще одной альтернативой является выбор среднего значения в диапазоне выбираемых пороговых значений.
С учетом неопределенности в измеряемых частотах ошибок, пусть k1 и k2 обозначают число ошибок неправильной маркировки как «не-спам» (или как «спам») для первого и второго фильтров соответственно. Простой статистический анализ показывает, что если
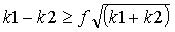
то можно ожидать, что примерно на ˜х% можно быть уверенным, что частота ошибок второго фильтра не хуже, чем у первого фильтра (например, если f=2, x=97.5; если f=0; x=50). С учетом консервативной оценки, если любое из k1и k2 равно нулю, то в члене квадратного корня должно быть использовано значение 1. Заметим, что x является консервативным значением, когда х близко к 100, тогда с более высокой определенностью второй фильтр (фильтры) будет лучше, чем первый фильтр перед использованием второго фильтра (фильтров). Это вычисление определенности (или неопределенности) включает в себя предположение, что ошибки между первым и вторым фильтром (фильтрами) являются независимыми. Один из подходов в устранении этого предположения состоит в оценке числа ошибок в целом, то есть числа ошибок, которые должны иметь место в предположении независимости. Если найдено на kбольше ошибок, чем это число, то надо заменить k1и k2в вышеприведенных вычислениях на (k1-k)и (k2-k). Кроме того, по мере того как число сообщений в обучающих данных увеличивается, то становится все более вероятным, что второй фильтр (фильтры) будет более точным (при любом пороге), чем первый фильтр. Оценка неопределенности, приведенная выше, игнорирует такое «априорное знание». Специалистам в данной области техники, знакомым с байесовской вероятностью и статистикой, должно быть понятно, что имеются принципиальные методы для включения этого априорного знания в оценки неопределенности.
В одном аспекте базового подхода представим, что ненужное сообщение маркируется первым фильтром как «не-спам». Кроме того, предположим, что пользователь не корректирует эту ошибку и, таким образом, система по умолчанию определяет это сообщение как «не-спам». Второй фильтр, имеющий более точные обучающие данные, может маркировать это сообщение как «спам». Следовательно, частота ложных позитивных тревог для первого фильтра будет недооцененной, в то время как частота ложных позитивных тревог для второго фильтра будет переоцененной. Этот эффект усиливается вследствие того обстоятельства, что большинство фильтров ненужной электронной почты работают с порогом, при котором многие ненужные сообщения маркируются как «не-спам», чтобы поддерживать низкой вероятность ложных позитивных тревог.
Имеются различные подходы, которые могут использоваться с учетом данного аспекта базового подхода. Первый подход состоит в том, что предполагается, что пользователю соответствует функция полезности р* при, например, N=20, и второй фильтр (фильтры) запускается всякий раз, когда может быть найден порог, который делает второй фильтр не худшим, чем первый фильтр. В данном случае второй фильтр может быть запущен, даже если, например, частота ложных позитивных тревог второго фильтра больше, чем соответствующая характеристика первого фильтра. То есть, при данном подходе, второй фильтр с большей вероятностью будет активизирован.
Второй подход состоит в ограничении тестового множества, чтобы сообщения, маркированные как «не-спам», на самом деле были известны как «не-спам» с высокой степенью определенности. Например, тестовое множество включает в себя только сообщения, которые были маркированы пользователем, выбирающим кнопку «не-спам», то есть сообщения, которые были прочитаны и не удалены, сообщения, которые были отосланы, и сообщения, на которые пользователь ответил.
Третий подход состоит в том, что система может использовать вероятности, генерированные калиброванным фильтром (например, первым фильтром) для генерации лучшей оценки частоты ложных позитивных тревог для второго фильтра. А именно, вместо простого подсчета числа сообщений и с меткой «не-спам» в данных, и с меткой «спам» из первого фильтра система может суммировать вероятность (в соответствии с калиброванным фильтром), что каждое такое сообщение является нормальным («не-спамом»). Эта сумма будет меньше, чем отсчет, и будет лучшей оценкой отсчета, если пользователь скрупулезно корректировал все сообщения.
В относительно более простом четвертом подходе контролируется ожидаемое число раз коррекции пользователем символов с использованием кнопок «не-спам» и «спам». В данном случае ожидания принимаются в отношении фильтра, который известен как калиброванный (например, первый/начальный фильтр). Если действительное число коррекций падает ниже ожидаемого числа (в абсолютном числе или в процентах), то система не обучает второй фильтр.
На практике пользовательский интерфейс может обеспечить множество порогов, из которых пользователь может выбрать один. В этой ситуации новый фильтр активизируется, только если он лучше, чем начальный фильтр, с использованием порога, выбранного пользователем. Кроме того, желательно, чтобы новый фильтр был лучше, чем начальный фильтр при других настройках порога, особенно при настройках вблизи текущего выбора, сделанного пользователем. Следующий алгоритм представляет собой один такой способ облегчения подобного подхода. Вводится параметр, определенный, например, как полупериод скользящего окна (SHL), который выражается действительным числом, например, 0.25. Для каждого порогового значения определяется, является ли новый фильтр таким же по качеству или лучше, чем первый фильтр. Тогда используется текущее выбранное пороговое значение. Однако осуществляется переключение, если новый фильтр лучше, чем первый/начальный фильтр, при текущей настройке порога, и значение суммарного веса (w), который описан ниже, больше или равно нулю. Первоначально суммарный вес = 0. Для каждой нетекущей настройки порога:
\\Присвоить вес на основе его расстояния от текущей настройки
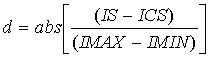
d = расстояние;
IS = индекс настройки;
ICS = индекс текущей настройки;
IMAX = индекс максимальной настройки;
IMIN = индекс минимальной настройки.
W=.5(d/SHL)
Если новый фильтр лучше, чем эта настройка, то нужно добавить ее вес к суммарному весу; в противном случае вычесть ее вес из суммарного веса.
Отметим, что этот алгоритм только определяет, является ли новый фильтр лучшим при каждой настройке порога. Он не учитывает то, насколько лучше или хуже новый фильтр по сравнению с первым/начальным фильтром. Алгоритм может быть модифицирован, чтобы принимать во внимание степень улучшения или ухудшения с использованием функций новой или старой частоты ложных негативных тревог, частоты ложных позитивных тревог, числа ложных негативных определений и/или числа ложных позитивных определений.
На фиг.4а показан приведенный для примера пользовательский интерфейс 400, который может быть представлен пользователю в качестве базовой конфигурации раскрытой здесь адаптивной системы фильтрации ненужных сообщений и пользовательского почтового ящика. Интерфейс 400 включает в себя страницу (или окно) 401 ненужной электронной почты со строкой 402 меню, которая включает в себя, без ограничения указанным, следующие заголовки выпадающего меню: файл, правка, вид, выписка, помощь и настройки. Окно 401 также включает в себя строку 404 связи, которая способствует перемещению вперед и назад и позволяет пользователю переходить на другие страницы, к другим инструментальным средствам и функциям интерфейса 400, включая «домой», «предпочтения», «поиск», «почта и к тому же», «курьер», «развлечения», «финансы», «покупка товаров», «люди и диалоги», «обучение» и «фото». Строка 406 меню облегчает выбор окон одной или более конфигураций для окна 401 конфигурации ненужной электронной почты. Как показано, подокно 408 «настройки» позволяет пользователю выбрать ряд опций базовых конфигураций для фильтрации ненужной электронной почты. Первая опция 410 позволяет пользователю запустить фильтрацию ненужной электронной почты. Пользователь может также выбрать различные уровни защиты электронной почты. Например, вторая опция 412 позволяет пользователю выбрать установленную по умолчанию настройку фильтра, которая позволяет фиксировать только наиболее очевидную ненужную почту. Третья опция 414 позволяет пользователю выбрать более совершенную фильтрацию, так что больше ненужных сообщений электронной почты фиксируется и отбрасывается. Четвертая опция 416 позволяет пользователю выбрать только прием электронной почты от достоверных сторон, например от сторон, перечисленных в адресной книге пользователя и в надежном списке. Область 418 связанных настроек обеспечивает средство для просмотра перечисленных областей, включая фильтр ненужной электронной почты, надежный список, список адресатов, список блокирования отправителей.
На фиг.4b показано окно 420 пользовательского почтового ящика пользовательского интерфейса 400, которое представляет характеристики пользовательского почтового ящика. Окно 420 почтового ящика включает в себя строку 402 меню, которая включает в себя, без ограничения указанным, следующие заголовки выпадающего меню: файл, правка, вид, выписка, помощь и настройки. Окно 420 почтового ящика также включает в себя строку 404 связи, которая способствует перемещению вперед и назад и позволяет пользователю переходить на другие страницы, к другим инструментальным средствам и функциям интерфейса 400, включая «домой», «предпочтения», «поиск», «почта и к тому же», «курьер», «развлечения», «финансы», «покупка товаров», «люди и диалоги», «обучение» и «фото». Окно 420 также содержит панель 422 инструментальных средств управления электронной почтой, которая включает в себя следующее: выбор «написать сообщение» для обеспечения пользователю возможности создать новое сообщение; опцию «удалить» для удаления сообщения; опцию «спам» для маркировки сообщения как «спам»; опцию «ответить» для ответа на сообщение; опцию «положить в папку» для перемещения сообщения в другую папку; и пиктограмму «отправить» для отправки сообщения.
Окно 420 также содержит подокно 424 выбора папок, которое обеспечивает пользователю опцию для выбора отображения содержания папок «входящие сообщения», «корзина» и «ненужная почта». Пользователи могут, таким образом, получать доступ к различным папкам, включая «сохраненные сообщения», «исходящие сообщения», «отправленные сообщения», «корзина, «черновики», «демонстрационная программа» и «старая ненужная почта». Число сообщений в папках «ненужная почта» и «старая ненужная почта» также указано рядом с соответствующим наименованием папки. В подокне 426 списка сообщений представлен список принятых сообщений, в соответствии с выбором папки в подокне 424 выбора папок. В подокне 428 предварительного просмотра сообщений часть содержания выбранного сообщения представляется пользователю для предварительного просмотра. Окно 420 может быть видоизменено для включения информации пользовательских предпочтений, которая представлена в подокне пользовательских предпочтений (не показано). Подокно предпочтений может быть включено в часть на правой стороне показанного окна 420, как показано на фиг.4а. Сюда включается, без ограничения указанным, информация о погоде, биржевая информация, предпочтительные ссылки на web-сайты и т.д.
Представленный для примера интерфейс 400 не ограничен тем, что показано, но может включать в себя другие традиционные графику, изображения, текст инструкций, опции меню и т.д., которые могут быть реализованы в целях помощи пользователю при осуществлении выбора фильтра и перемещения по другим страницам интерфейса и которые могут не требоваться для конфигурирования фильтра электронной почты.
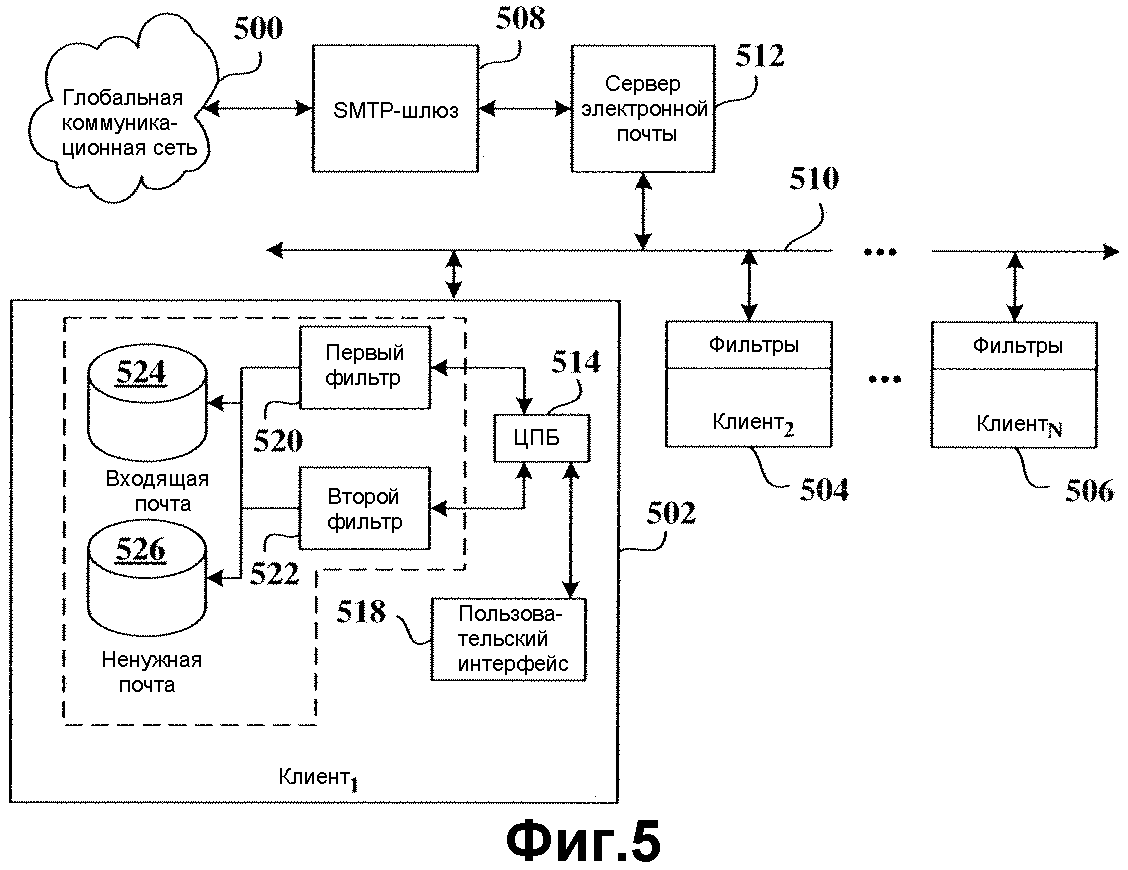
На фиг.5 представлена обобщенная блок-схема архитектуры, которая использует раскрытую технику фильтрации. Сеть 500 обеспечивает информационный обмен посредством электронной почты с одним или более клиентами 502, 504 и 506 (также обозначенными как Клиент1, Клиент2,..., КлиентN). Сеть 500 может представлять собой глобальную коммуникационную сеть (GCN), такую как Интернет, сеть широкого охвата (WAN), локальную сеть (LAN) или любую другую сетевую архитектуру. В этой конкретной реализации шлюзовой сервер протокола SMTP (Простой протокол электронной почты) 508 взаимодействует с сетью 500 для обеспечения услуг протокола SMTP для сети LAN 510. Сервер 512 электронной почты, оперативно размещенный в сети LAN 510, взаимодействует со шлюзом 508 для управления и обработки входящей и исходящей электронной почты клиентов 502, 504 и 506, которые также размещены в сети LAN 510, чтобы получить доступ, по меньшей мере, к услугам электронной почты, предусмотренной в ней.
Клиент 502 содержит центральный процессорный блок (ЦПБ) 514, который управляет клиентскими процессами, причем понятно, что ЦПБ 514 может содержать множество процессоров. ЦПБ 514 выполняет инструкции в связи с обеспечением одной или более функций фильтрации, описанных выше. Эти инструкции включают в себя, без ограничения указанным, кодированные инструкции, которые исполняют, по меньшей мере, описанный выше базовый метод фильтрации, по меньшей мере любой или все из методов, которые могут быть использованы в комбинации с ним, с учетом неуспеха пользователя в осуществлении пользовательских коррекций, неоднозначности определения, в определении порога, вычислениях частоты точного определения с использованием данных частот ложных позитивных тревог и ложных негативных тревог и осуществляемого пользователем интерактивного выбора. Пользовательский интерфейс 518 предназначен для облегчения информационного обмена с ЦПБ 514 и клиентской операционной системой, чтобы пользователь мог взаимодействовать с ними для конфигурирования настроек фильтра и доступа к электронной почте.
Клиент 502 также содержит, по меньшей мере, первый фильтр 520 (аналогичный первому фильтру 106) и второй фильтр 522 (аналогичный второму фильтру 108), работающие в соответствии с описаниями фильтров, представленными выше. Клиент 502 также имеет местоположение (или папку) 524 для хранения входящей электронной почты для приема отфильтрованной электронной почты от, по меньшей мере, одного из упомянутых первого фильтра 520 и второго фильтра 522, т.е. сообщений, которые предполагаются маркированной надлежащим образом электронной почтой. Второе местоположение (или папка) 526 для хранения электронной почты может быть предусмотрено для помещения ненужной электронной почты, которую пользователь определяет как ненужную электронную почту и выбирает вариант ее сохранения, хотя это также может быть папкой корзины. Как указано выше, папка 524 входящей электронной почты может включать в себя электронную почту, которая была отфильтрована либо первым фильтром 520, либо вторым фильтром 522, в зависимости от того, использовался ли второй фильтр 522 помимо первого фильтра 520, для обеспечения одинаковой или лучшей фильтрации входящей электронной почты.
После того как пользователь принял электронную почту от сервера 512 электронной почты, пользователь будет внимательно просматривать почту в папке 524 входящей электронной почты, чтобы прочитать и определить действительный статус отфильтрованных сообщений электронной почты в папке входящей электронной почты. Если ненужная почта прошла через первый фильтр 520, пользователь будет затем выполнять в явной или неявной форме функцию пользовательской коррекции, которая указывает системе, что сообщение действительно было ненужным сообщением электронной почты. Первый и второй фильтры (520 и 522) затем обучаются на основе этих данных пользовательской коррекции. Если второй фильтр 522 определяется как имеющий лучшую частоту точного определения, чем первый фильтр 520, то он будет использоваться вместо первого фильтра 520, чтобы обеспечить фильтрацию того же качества или лучше. Как показано выше, если второй фильтр 522 имеет по существу такую же частоту точного определения, что и для первого фильтра 520, он может использоваться или не использоваться. Обучение фильтра может быть выбрано пользователем для осуществления в соответствии с рядом предварительно заданных критериев, как показано выше.
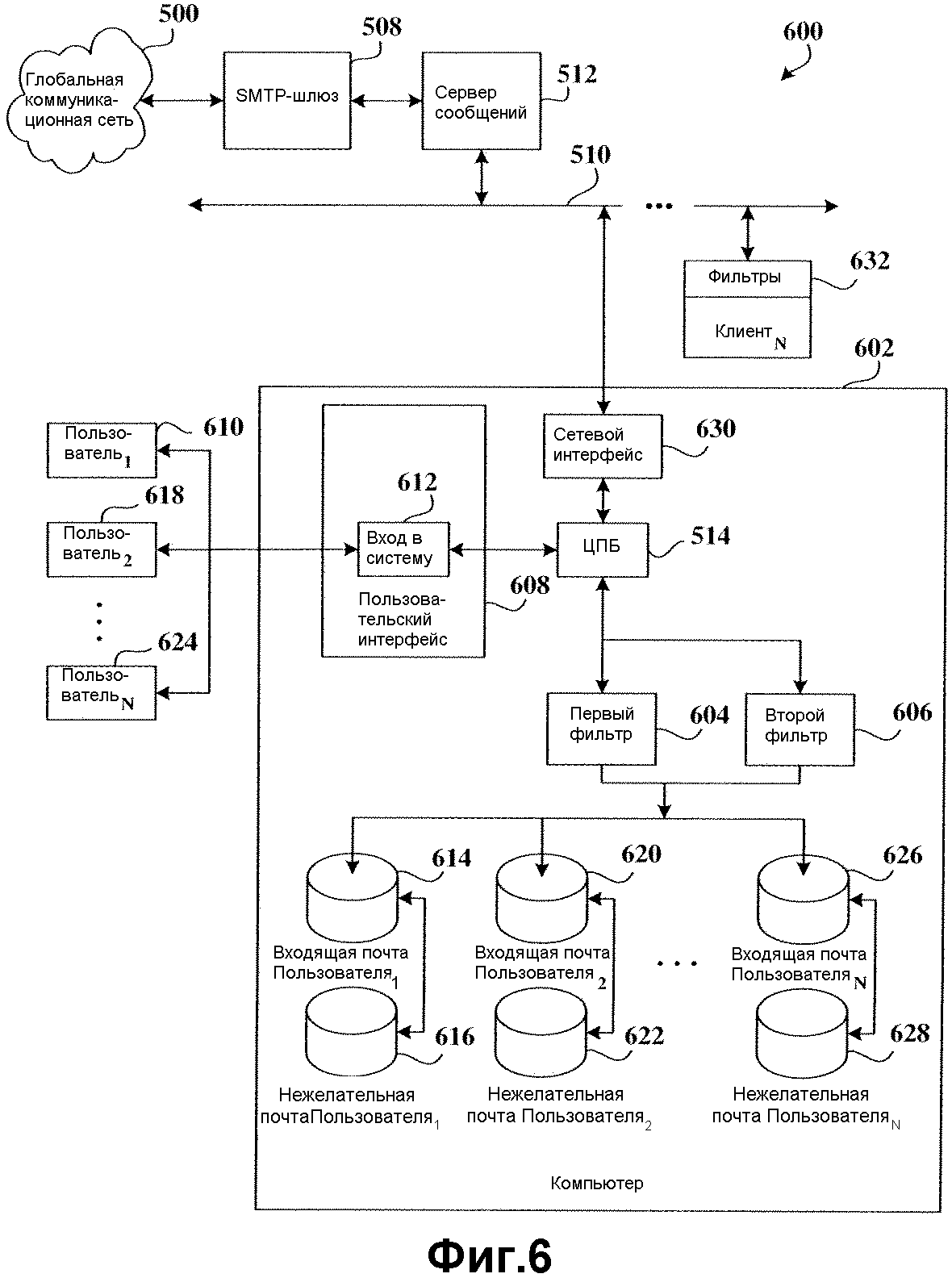
На фиг.6 показана система 600, имеющая один или более клиентских компьютеров 602, которые обеспечивают многопользовательский вход в систему и фильтруют входящие сообщения в соответствии с методами фильтрации согласно настоящему изобретению. Клиент 602 содержит функцию множественного входа в систему, так что первый фильтр 604 и второй фильтр 606 соответственно обеспечивают фильтрацию сообщений для каждого индивидуального пользователя, который входит в систему на компьютере 602. Таким образом, обеспечен пользовательский интерфейс 608, который представляет экран регистрации в качестве части процесса начальной загрузки операционной системы компьютера или, если необходимо, для ввода ассоциированного пользовательского профиля, прежде чем пользователь сможет получить доступ к своим входящим сообщениям. Таким образом, когда первый пользователь 610 (также обозначенный как Пользователь1) выбирает опцию доступа к сообщениям, первый пользователь 610 входит в систему на клиентском компьютере 602 посредством экрана 612 регистрации пользовательского интерфейса 608 путем ввода информации доступа, в типовом случае в форме имени пользователя и пароля пользователя. ЦПБ 514 обрабатывает информацию доступа для разрешения доступа первому пользователю посредством приложения передачи сообщений (например, клиента электронной почты) только для местоположения 614 входящей почты первого пользователя (также определяемого как папка входящей электронной почты Пользователя1) и местоположения 616 ненужных сообщений первого пользователя (также определяемого как ненужные сообщения Пользователя1).
Когда ЦПБ 514 принимает информацию доступа входа в систему пользователя, ЦПБ 514 оценивает информацию предпочтений фильтрации первого пользователя для использования первого фильтра 604 и второго фильтра 606, чтобы затем фильтровать входящие сообщения, которые могут быть загружены в клиентский компьютер 602. Информация предпочтений фильтрации всех пользователей (Пользователя1, Пользователя2,..., ПользователяN), предусмотренная для ввода в компьютер, может быть сохранена локально в таблице предпочтений фильтрации. К информации предпочтений фильтрации может обращаться ЦПБ 514, когда первый пользователь регистрируется на компьютере 602 или определяет соответствующий профиль первого пользователя. Таким образом данные частоты ложных негативных тревог и ложных позитивных тревог первого пользователя 610 для первого и второго фильтров (604 и 606) обрабатываются для использования либо первого фильтра 604, либо второго фильтра 606 для фильтрации сообщений, которые должны загружаться. Как указано выше, в соответствии с изобретением, данные частоты ложных негативных тревог и ложных позитивных тревог получают из, по меньшей мере, процесса пользовательской коррекции. После того как первый пользователь 610 загрузил сообщения, данные частоты ложных негативных тревог и ложных позитивных тревог могут обновляться в соответствии с ошибочно маркированными сообщениями. В некоторый момент времени, прежде чем другой пользователь зарегистрируется в компьютере 602, упомянутые обновленные данные частоты для первого пользователя сохраняются в таблице предпочтений фильтрации для будущих ссылок.
Когда второй пользователь 608 входит в систему, данные частоты ложных негативных тревог и ложных позитивных тревог могут изменяться в соответствии с предпочтениями фильтрации, связанными с этим. После того как второй пользователь введет свою информацию регистрации, ЦПБ 514 обращается к информации предпочтений фильтрации второго пользователя и соответственно вводит первый фильтр 604 или второй фильтр 606. Операционная система компьютера, во взаимосвязи с приложением передачи сообщений компьютера, ограничивает услуги передачи сообщений для второго пользователя 618 доступом только к папке 620 входящей электронной почты второго пользователя (также определяемой как папка входящей электронной почты Пользователя2) и местоположению 622 ненужных сообщений второго пользователя (также определяемого как ненужные сообщения Пользователя2). Данные частоты ложных негативных тревог и ложных позитивных тревог второго пользователя 618 для первого и второго фильтров (604 и 606) обрабатываются для использования либо первого фильтра 604, либо второго фильтра 606 для фильтрации сообщений второго пользователя 618, которые должны загружаться. Как указано выше, в соответствии с изобретением, данные частоты ложных негативных тревог и ложных позитивных тревог получают из, по меньшей мере, процесса пользовательской коррекции. После того как второй пользователь 618 загрузил сообщения, данные частоты ложных негативных тревог и ложных позитивных тревог могут обновляться в соответствии с ошибочно маркированными сообщениями.
Операции для N-ного пользователя 624, обозначенного как ПользовательN, обеспечиваются аналогично тому, как это осуществляется для первого и второго пользователей (610 и 618). Как и для всех других пользователей, N-ный пользователь 624 ограничен только пользовательской информацией, связанной с N-ным пользователем 624, и получает доступ только к папке 626 входящей электронной почты ПользователяN и местоположению 622 ненужных сообщений ПользователяN и ни к каким другим папкам входящей электронной почты (614 и 620) и местоположениям ненужной электронной почты (616 и 622) при использовании приложения передачи сообщений.
Компьютер 602 соответственно конфигурирован для осуществления связи с другими клиентами в локальной сети 510 и для доступа к сетевым услугам, размещенным в ней, с использованием сетевого интерфейса 630 клиента. Таким образом, обеспечен сервер 512 сообщений для приема сообщений от шлюза 508 протокола SMTP для управления и обработки входящих и исходящих сообщений клиентов (602 и 632 (также обозначенного как КлиентN)) и любые другие проводные или беспроводные устройства, обеспечивающие передачу сообщений через локальную сеть 510 к серверу 512 сообщений. Клиенты (602 и 632) устанавливаются в оперативное соединение с локальной сетью 510 для доступа, по меньшей мере, к услугам передачи сообщений, предусмотренным в ней. Шлюз 508 протокола SMTP взаимодействует с сетью GCN 500 для обеспечения SMTP-совместимых услуг передачи сообщений между сетевыми устройствами сети GCN 500 и объектами передачи сообщений в локальной сети 510.
Понятно, что усреднение данных частоты, как описано выше, может быть использовано для определения наилучшей усредненной настройки для использования фильтров (604 и 606). Аналогичным образом, наилучшие данные частоты пользователей, которым разрешен вход в систему на компьютере 602, также могут быть использованы для конфигурирования фильтров для всех пользователей, которые зарегистрировались на нем.
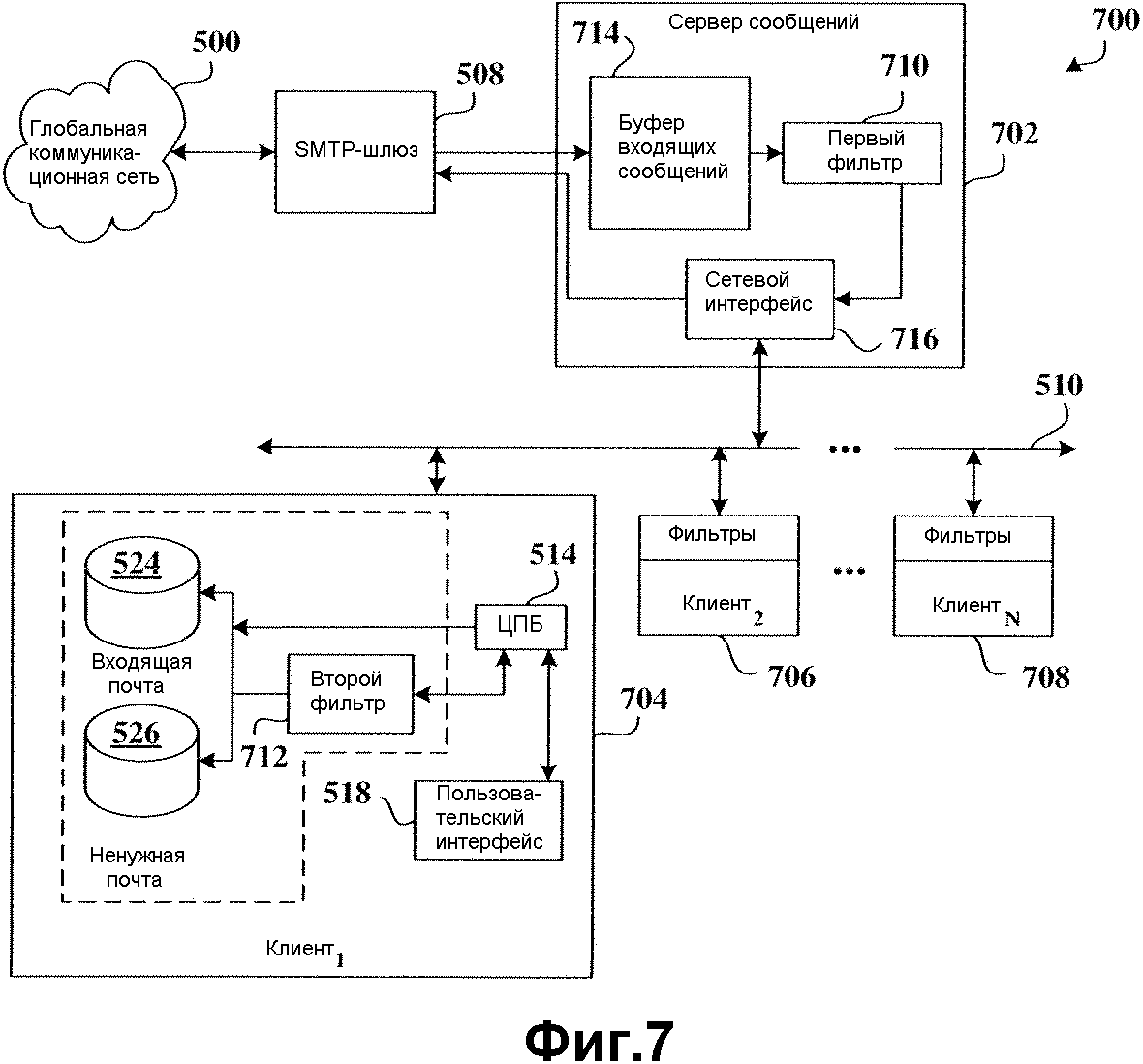
На фиг.7 показана система 700, где первоначальная фильтрация выполняется на сервере 702 сообщений, а вторичная фильтрация выполняется на одном или более клиентах. Сеть GCN 500 предусмотрена для облегчения передачи сообщений (например, электронной почты) на один или более клиентов (704, 706 и 708) (также обозначаемых как Клиент1, Клиент2,...,КлиентN)или от этих клиентов. Шлюзовой SMPT-сервер 508 взаимодействует с сетью GCN 500 для обеспечения SMPT-совместимых услуг передачи сообщений между сетевыми устройствами сети GCN 500 и объектами, передающими сообщения, в локальной сети 510.
Сервер 702 сообщений оперативно расположен в локальной сети 510 и взаимодействует со шлюзом 508 для управления и обработки входящих и исходящих сообщений клиентов 704, 706 и 708 и любых других беспроводных устройств, функционирующих для передачи сообщений по локальной сети 510 к серверу 702 сообщений. Клиенты (704, 706 и 708) (например, проводные и беспроводные устройства) расположены с возможностью оперативной связи с локальной сетью 510 для доступа, по меньшей мере, к услугам передачи сообщений, обеспеченным в ней.
В соответствии с одним из аспектов настоящего изобретения, сервер 702 сообщений выполняет первоначальную фильтрацию путем использования первого фильтра 710 (аналогичного первому фильтру 106), а клиент выполняет вторичную фильтрацию с использованием второго фильтра 712 (аналогичного второму фильтру 108). Таким образом, входящие сообщения принимаются от шлюза 508 в буфер 714 входящих сообщений сервера 702 сообщений для временного хранения, когда первый фильтр 710 обрабатывает сообщения для определения того, являются ли они спамом или не-спамом. Буфер 714 может представлять собой простую архитектуру FIFO, так что все сообщения обрабатываются по принципу «первым прибыл, первым обслужен». Однако понятно, что сервер 702 сообщений может фильтровать процесс буферизованных сообщений в соответствии с маркированным приоритетом. Таким образом, буфер 714 соответствующим образом конфигурируется для обеспечения приоритизации сообщений, так что сообщения, маркированные отправителем как имеющие более высокий приоритет, направляются буфером 714 для фильтрации раньше других сообщений, которые маркированы как менее приоритетные. Маркировка приоритета может основываться на других критериях, не связанных с меткой приоритета отправителя, включая, без ограничения указанным, размер сообщения, дату сообщения, наличие у сообщения присоединенного файла, размера присоединенного файла, продолжительности времени нахождения сообщения в буфере 714 и т.д.
Для генерации данных частот ложных позитивных и ложных негативных тревог первого фильтра 710 администратор может брать выборки выходных данных для определения того, сколько нормальных сообщений были неверно маркированы как спам, и сколько ненужных сообщений были неверно маркированы как корректные сообщения. Как показано выше, в соответствии с одним аспектом настоящего изобретения, эти данные частоты первого фильтра 710 затем используются в качестве базы для определения новых данных частот ложных позитивных и ложных негативных тревог второго фильтра 712.
В любом случае, когда первый фильтр 710 отфильтровал сообщение, оно маршрутизируется от сервера 702 через сетевой интерфейс 716 сервера по сети 610 к соответствующему клиенту (например, первому клиенту 704) на основе адреса IP-адреса клиента-получателя. Первый клиент 704 содержит ЦПБ 514, который управляет всеми клиентскими процессами. ЦПБ 514 осуществляет информационный обмен с сервером 702 сообщений для получения данных частот ложных позитивных и ложных негативных тревог первого фильтра 710 и выполняет сравнение с данными частот ложных позитивных и ложных негативных тревог второго фильтра 712 для определения, когда следует использовать второй фильтр. Если результаты сравнения таковы, что данные частот второго фильтра хуже, чем данные частот первого фильтра 710, то используется второй фильтр 712 и ЦПБ 514 осуществляет информационный обмен с сервером 702 сообщений, чтобы обеспечить прохождение сообщений, предназначенный для первого клиента 704, через сервер 702 нефильтрованными.
Если пользователь первого клиента 704 просматривает принятые сообщения и выполняет пользовательскую корректировку, то новые данные частот ложных позитивных и ложных негативных тревог второго фильтра 712 обновляются. Если новые данные частот становятся хуже, чем первые данные частот, то первый фильтр 710 будет повторно использован для обеспечения фильтрации для первого клиента 704. ЦПБ 514 продолжает осуществлять сравнения данных частот для определения того, когда переключить фильтрацию между первым и вторым фильтрами (710 и 712) для данного конкретного клиента 704.
ЦПБ 514 выполняет алгоритм, действующий в соответствии с командами, для обеспечения любой из одной или более описанных функций фильтрации. Алгоритм включает, без ограничения указанным, кодированные команды для выполнения, по меньшей мере, базовой методологии фильтрации, описанной выше, по меньшей мере, одного или всех методов, которые могут быть использованы в комбинации с ним, для учета неуспеха операций пользователя по осуществлению пользовательских коррекций, определения неоднозначности, определения порога, вычислений частоты точного определения с использованием данных частот ложных позитивных и ложных негативных тревог и интерактивных операций выбора пользователя. Пользовательский интерфейс 518 предусмотрен для облегчения взаимодействия с ЦПБ 514 и клиентской операционной системой, так что пользователь может осуществлять взаимодействие для конфигурирования настроек фильтра и доступа к сообщениям.
Клиент 502 также включает в себя, по меньшей мере, один второй фильтр 712, действующий в соответствии с описаниями фильтра, приведенными выше. Клиент 502 также содержит местоположение (или папку) 524 для хранения входящей почты для приема отфильтрованных сообщений от, по меньшей мере, одного первого фильтра 710 и второго фильтра 712, причем сообщения предполагаются надлежащим образом маркированными сообщениями. Второе местоположение (или папка) 526 для хранения сообщений может быть предусмотрено для помещения ненужной почты, которую пользователь определил как спам и выбрал вариант такого ее сохранения, хотя это также может быть папка для «мусора» (корзина). Как показано выше, папка 524 входящей почты может включать в себя сообщения, которые были отфильтрованы либо первым фильтром 710, либо вторым фильтром 712, в зависимости от того, был ли второй фильтр использован взамен первого фильтра 710 для обеспечения такой же или лучшей фильтрации входящих сообщений.
Как показано выше, как только пользователь загрузил сообщения из сервера 702 сообщений, пользователь будет затем тщательно посматривать сообщения в папке 524 входящей почты для прочтения и определения действительного статуса отфильтрованных сообщений входящей почты. Если нежелательное сообщение прошло через первый фильтр 710, то пользователь будет выполнять функцию явной или неявной пользовательской коррекции, которая указывает системе, что сообщение в действительности было ненужным сообщением. Первый и второй фильтры (710 и 712) затем обучаются на основе этих данных пользовательской коррекции. Если второй фильтр 712 определен как имеющий лучшую частоту точного определения, чем первый фильтр 710, то он будет использован вместо первого фильтра 710 для обеспечения одинаковой или лучшей фильтрации. А если второй фильтр 712 имеет по существу одинаковую частоту точного определения с первым фильтром 710, то он может использоваться, а может и не использоваться. Ввод обучения фильтра может выбираться пользователем в соответствии с рядом предварительно заданных критериев, как отмечено выше.
Понятно, что поскольку другие клиенты (706 и 708) используют сервер 702 сообщений для фильтрации сообщений, эти новые данные частоты соответствующих клиентов (706 и 708) будут влиять на операцию фильтрации первого фильтра 710. Таким образом, соответствующие клиенты (706 и 708) также осуществляют информационный обмен с сервером сообщений 702 для запуска или блокирования первого фильтра 710 в соответствии с конкретными новыми данными частот вторых фильтров этих клиентов (706 и 708). Сервер 702 сообщений может содержать таблицу предпочтений фильтрации, содержащую клиентские предпочтения, связанные с требованиями фильтрации соответствующих клиентов. Таким образом, каждое буферизованное сообщение опрашивается на предмет IP-адреса получателя и обрабатывается в соответствии с предпочтениями фильтрации, связанными с данным адресом получателя, сохраненным в таблице фильтрации. Таким образом, хотя для переданного ненужного сообщения, предназначенного для первого клиента 704, может потребоваться обработка вторым фильтром 712 первого клиента 704, согласно результатам сравнения данных частот первого клиента 704, для того же самого ненужного сообщения, также предназначенного для второго клиента 706, может потребоваться обработка первым фильтром 710 сервера 702 сообщений, согласно результатам сравнения данных частот, полученным с его помощью.
Кроме того, понятно, что индивидуальные новые данные частот индивидуальных клиентов (704, 706 и 708) могут приниматься и обрабатываться одновременно сервером 702 для определения среднего их значения. Это среднее значение может затем использоваться для определения того, следует ли переключить использование первого фильтра 710 или второго фильтра 712 клиентов, индивидуально или группой. Альтернативно, наилучшие новые данные частот клиентов (704, 706 и 708) могут определяться сервером 702 и использоваться для переключения между первым фильтром и клиентскими фильтрами 712, индивидуально или группой.
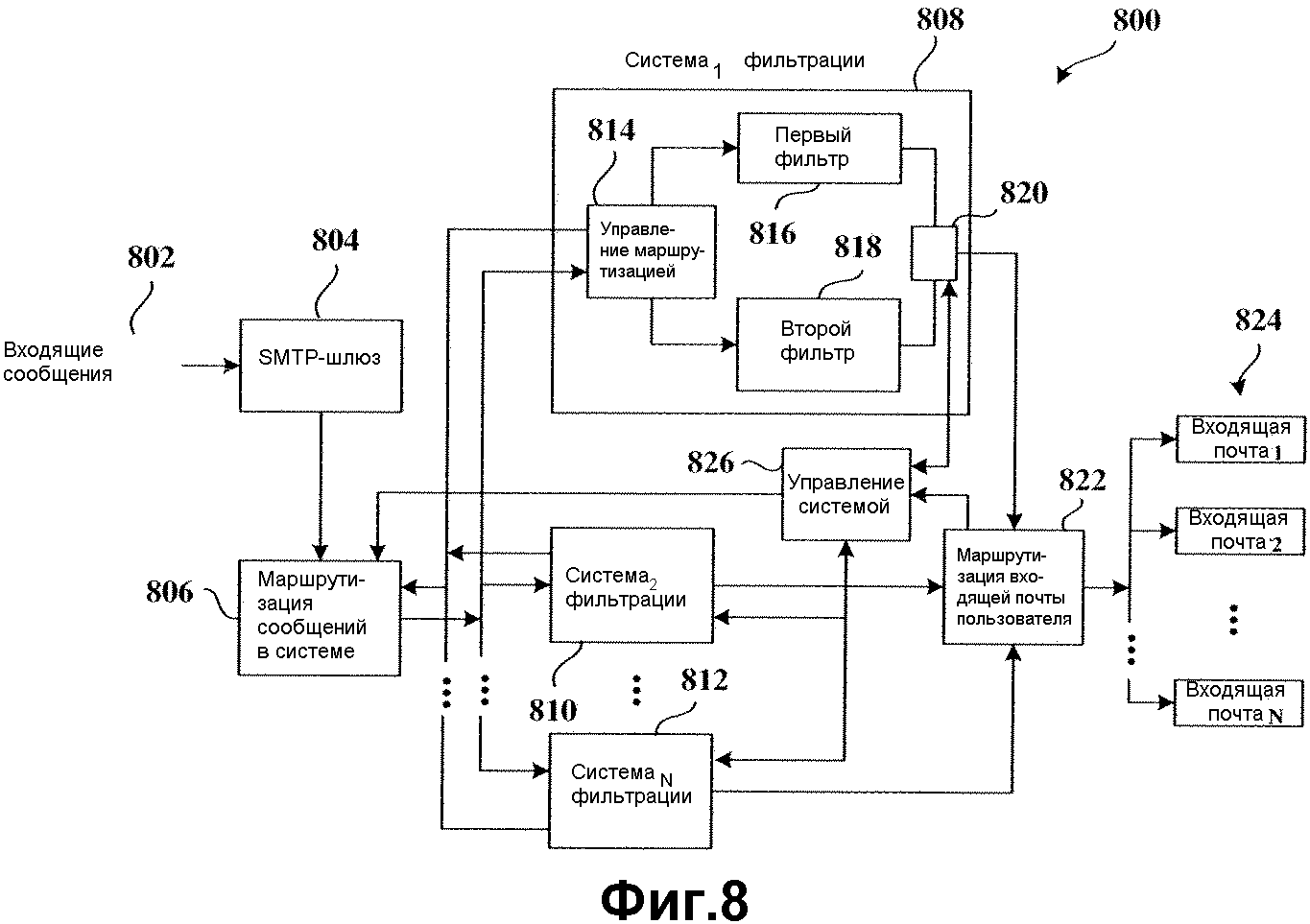
На фиг.8 показан альтернативный вариант осуществления крупномасштабной системы 800 фильтрации, использующей аспекты фильтрации согласно настоящему изобретению. В более надежных реализациях, где фильтрация сообщений выполняется в массовом масштабе системными почтовыми системами, например провайдером Интернет-сервиса, множество систем фильтрации могут использоваться для обработки большого количества входящих сообщений. Большое число входящих сообщений 802 принимаются и адресуются в места назначения различных пользователей. Сообщения 802 входят в систему провайдера, например, через SMTP-шлюз и затем передаются в системный компонент 806 маршрутизации сообщений для маршрутизации к различным системам 808, 810 и 812 фильтрации (также обозначенные как Система1 Фильтрации, Система2 Фильтрации, ..., СистемаN Фильтрации).
Каждая система 808, 810 и 812 фильтрации содержит компонент управления маршрутизацией, первый фильтр, второй фильтр и выходной буфер. Таким образом, система 808 фильтрации содержит компонент 814 управления маршрутизацией для маршрутизации сообщений между первым фильтром 816 системы и вторым фильтром 818 системы. Выходы первого и второго фильтров (816 и 818) соединены с выходным буфером 820 для временного хранения сообщений перед тем, как сообщения будут переданы в компонент 822 маршрутизации пользовательской входящей почты. Компонент 822 маршрутизации пользовательской входящей почты опрашивает каждое сообщение, принятое из выходного буфера 820 системы 808 фильтрации, на предмет адреса пользователя-получателя и маршрутизирует сообщение в соответствующий пользовательский почтовый ящик для входящей почты из множества пользовательских почтовых ящиков 824 (также определяемых как Входящая Почта1, Входящая Почта2,..., Входящая ПочтаN).
Системный компонент 806 маршрутизации сообщений содержит функцию выравнивания нагрузки для маршрутизации сообщений между системами (808, 810 и 812) фильтрации в соответствии с располагаемой шириной полосы систем (808, 810 и 812) фильтрации для обеспечения обработки сообщений. Таким образом, если очередь входящих сообщений (не показана, но является частью компонента 814 маршрутизации) первой системы 808 фильтрации образовала «пробку» и не может удовлетворить необходимую пропускную способность для системы 800, то информация статуса этой очереди подается назад в системный компонент 806 маршрутизации из компонента 814 управления маршрутизацией, так что входящие сообщения 802 затем маршрутизируются на другие системы фильтрации (810 и 912) до тех пор, пока очередь входящей почты системы 814 не сможет принимать последующие сообщения. Каждая из остальных систем фильтрации (810 и 812) содержит эту функцию обратной связи очереди, так что системный компонент 806 маршрутизации может обрабатывать нагрузку сообщений между всеми имеющимися системами фильтрации, включая Систему1 Фильтрации, Систему2 Фильтрации, ..., СистемуN Фильтрации.
Функция адаптивного фильтра первой системы 808 фильтрации описана ниже более детально. В этой конкретной реализации системы системный администратор имеет задачу по определению того, что составляет ненужную почту для системы 800 за счет обеспечения обратной связи относительно точности определения фильтров для обеспечения маркированных/немаркированных сообщений. То есть администратор выполняет пользовательскую коррекцию, чтобы генерировать информацию FN и FP для каждой из соответствующих систем (808, 810 и 812). Ввиду большого количества входящих сообщений это может быть выполнено в соответствии с методом статистической выборки, который обеспечивает математически высокую степень вероятности, что взятая выборка отражает точность фильтрации, выполненной соответствующей системой (808, 810 и 812) фильтрации при определении того, что является ненужным сообщением, а что не является им.
В поддержку этого администратор будет брать выборку сообщений с буфера 820 через компонент 826 управления системой и проверять точность маркировки сообщений по выборке. Компонент 826 управления системой может представлять собой аппаратную и/или программную систему обработки, которая соединена с системами фильтрации (808, 810 и 812) для контроля и управления ими. Любые сообщения, маркированные некорректным образом, будут использоваться для установления данных частот ложных негативных и ложных позитивных тревог для первого фильтра 816. Эти данные частот FN/FP используются затем во втором фильтре 818. Если данные частот для первого фильтра 816 снижаются ниже порогового значения, то может быть активизирован второй фильтр 818 для обеспечения фильтрации, по меньшей мере, того же качества, что и первый фильтр 816. Когда администратор вновь выполняет взятие выборок из буфера 820, если данные частот FN/FP второго фильтра 818 хуже, чем соответствующие данные первого фильтра 816, то компонент 814 управления маршрутизацией будет обрабатывать эти данные частот FN/FP второго фильтра 818 и определять, что маршрутизация сообщений должна быть переключена обратно на первый фильтр 816.
Компонент 826 управления системой взаимодействует с системным компонентом 806 маршрутизации сообщений для осуществления информационного обмена с ним и обеспечения управления посредством администратора. Компонент 826 управления системой также взаимодействует с выходным буфером других систем, таких как Система2 Фильтрации, ..., СистемаN Фильтрации, для обеспечения функции взятия выборок для этих систем. Администратор также может получить доступ к компоненту 822 маршрутизации входящей почты пользователя через компонент 826 управления системой, чтобы контролировать его операции.
Точность фильтра, как описано выше со ссылкой на фиг.1, может быть повышена до точности множества систем фильтрации. Данные частот FN/FP первой системы 808 могут затем использоваться для обучения фильтров всей системы 800. Аналогичным образом, управление нагрузкой может выполняться в соответствии с данными частот FN/FP конкретной системы. То есть, если данные частот FN/FP первой системы 808 хуже, чем данные частот FN/FP второй системы, то больше сообщений может быть маршрутизировано ко второй системе 810, чем к первой системе 808.
Понятно, что системы фильтрации (808, 810 и 812) могут представлять собой отдельные алгоритмы фильтрации, каждый из которых исполняется на специализированных компьютерах или на комбинации компьютеров. Альтернативно, если существуют возможности аппаратной реализации, алгоритмы могут исполняться вместе на одном компьютере, так что вся фильтрация выполняется на одной надежной машине.
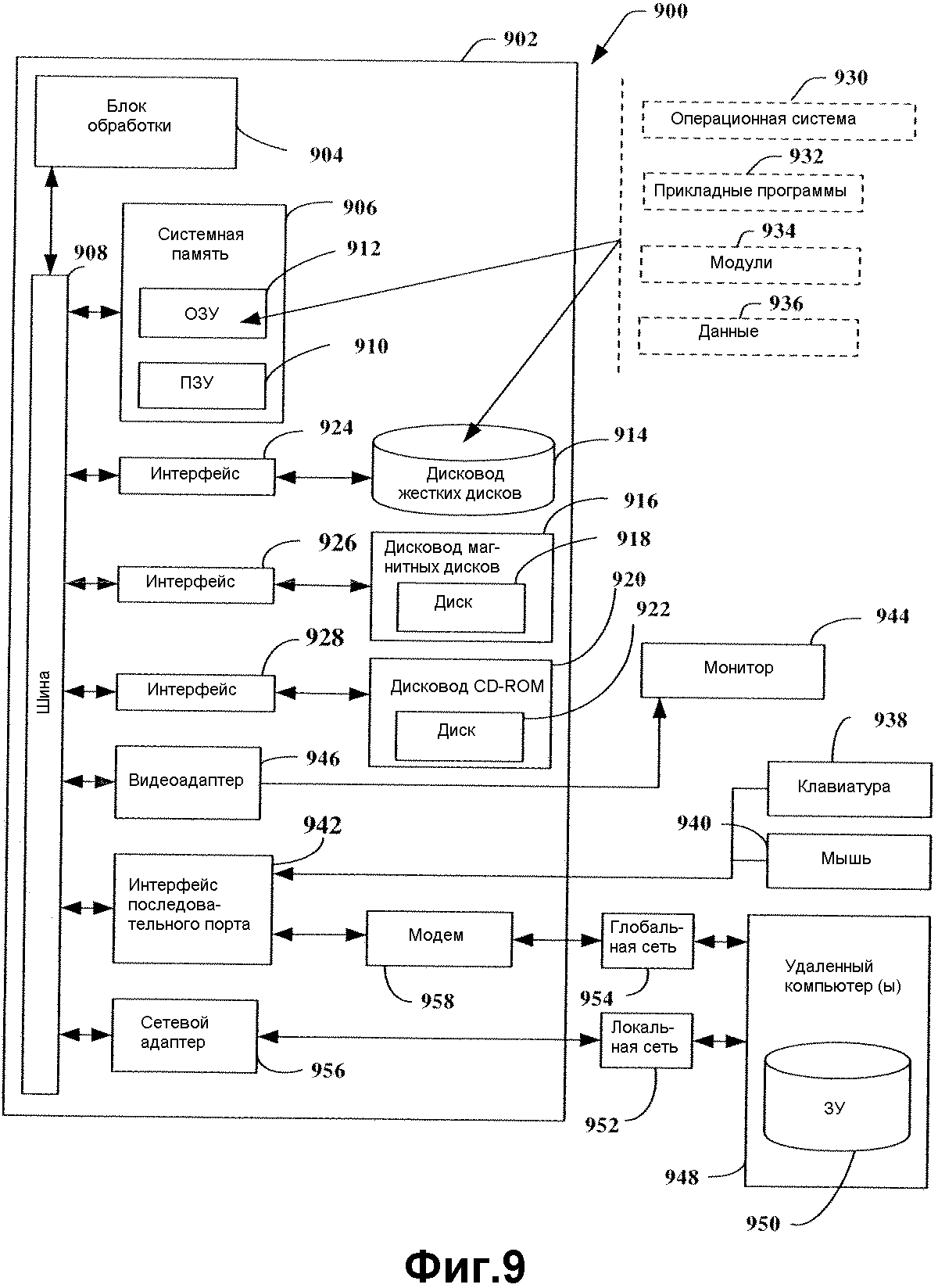
На фиг.9 показана блок-схема компьютера, который может использоваться для реализации описанной архитектуры. Для обеспечения дополнительного контекста для различных аспектов настоящего изобретения фиг.9 и последующее описание предназначены для обеспечения краткого обобщенного описания подходящей компьютерной среды 900, в которой могут быть реализованы различные аспекты настоящего изобретения. Хотя изобретение описано выше в общем аспекте исполняемых компьютером команд, которые могут исполняться на одном или более компьютерах, специалисту должно быть понятно, что изобретение также может быть реализовано в комбинации с другими программными модулями и/или как комбинация аппаратных средств и программного обеспечения. В общем случае программные модули включают в себя стандартные программы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют некоторые абстрактные типы данных. Кроме того, изобретение может быть реализовано с использованием других конфигураций компьютерных систем, включая однопроцессорные или мультипроцессорные компьютерные системы, миникомпьютеры, большие компьютеры (мэйнфреймы), персональные компьютеры, портативные вычислительные устройства, микропроцессорные системы или программируемые приборы бытовой электроники и т.п., каждое из которых может быть оперативно связано с одним или более соответствующих устройств. Проиллюстрированные аспекты изобретения также могут быть реализованы в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, которые связаны коммуникационной сетью. В распределенной вычислительной среде программные модули могут размещаться как в локальных, так и удаленных устройствах памяти.
Как показано на фиг.9, приведенная для примера среда 900 для реализации различных аспектов изобретения включает в себя компьютер 902, содержащий блок 904 обработки, системную память 906 и системную шину 908, которая связывает различные системные компоненты, включая системную память 906, с блоком 904 обработки. Блок 904 обработки может быть любым из различных коммерчески доступных процессоров. Сдвоенные микропроцессоры и другие мультипроцессорные архитектуры также могут использоваться в качестве блока 904 обработки.
Системная шина 908 может быть любой из различных типов шинных структур, включая шину памяти или контроллер памяти, шину периферийных устройств, локальную шину, использующую любую из разнообразных шинных архитектур. Системная память включает в себя постоянную память (ROM, ПЗУ) 910 и оперативную память (RAM, ОЗУ) 912. Базовая система ввода/вывода (BIOS), содержащая базовые подпрограммы, которые способствуют переносу информации между элементами в персональном компьютере 902, например, при запуске, в типовом случае сохранена в ПЗУ 910.
Компьютер 902 также содержит дисковод 914 жестких дисков, дисковод 916 магнитных дисков для считывания со съемного магнитного диска 918 и записи на него и дисковод 920 оптических дисков для считывания диска 922 CD-ROM или для считывания и записи на иные оптические носители записи. Дисковод 914 жестких дисков, дисковод 916 магнитных дисков и дисковод 920 оптических дисков могут быть соединены с системной шиной 908 посредством интерфейса 924 дисковода жестких дисков, интерфейса 926 магнитных дисков и интерфейса 928 оптических дисков, соответственно. Дисководы и связанные с ними машиночитаемые носители обеспечивают энергонезависимое хранение машиночитаемых команд, структур данных, программных модулей и других данных. Для компьютера 902 дисководы и носители обеспечивают хранение программных данных в соответствующем цифровом формате. Хотя при описании машиночитаемых носителей даются ссылки на жесткий диск, съемный магнитный диск и CD, специалистам в данной области техники должно быть понятно, что в приведенной для примера операционной среде могут использоваться другие типы машиночитаемых носителей записи для хранения данных, такие как накопители с архивированием, кассеты на магнитных лентах, карты флэш-памяти, цифровые видеодиски, картриджи и т.п, и что любые такие носители могут содержать исполняемые компьютером команды для выполнения способов, соответствующих изобретению.
Ряд программных модулей может быть сохранен на накопителях и ОЗУ 912, включая операционную систему 930, одну или более прикладных программ 932, другие программные модули 934 и программные данные 936. Настоящее изобретение может быть реализовано с различными коммерчески доступными операционными системами или комбинациями операционных систем.
Пользователь может вводить команды и информацию в компьютер 902 посредством клавиатуры 938 и координатно-указательного устройства, например мыши 940. Другие устройства ввода (не показаны) могут включать в себя микрофон, ИК пульт дистанционного управления, джойстик, игровую панель, спутниковую параболическую антенну, сканер и т.п. Эти и другие устройства ввода часто соединяются с блоком 904 обработки через интерфейс 942 последовательного порта, связанный с системной шиной 908, но могут быть соединены и посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB), ИК интерфейс и т.д. Монитор 944 или иное устройство отображения также соединено с системной шиной 908 через интерфейс, например, такой как видеоадаптер 946. Помимо монитора 944, компьютер обычно включает в себя другие периферийные устройства вывода (не показаны), такие как громкоговорители и принтеры.
Компьютер 902 может работать в сетевой среде с использованием логических соединений с одним или более удаленными компьютерами, такими как удаленный компьютер(ы) 948. Удаленный компьютер 948 может представлять собой рабочую станцию, серверный компьютер, маршрутизатор, персональный компьютер, портативный компьютер, микропроцессорное электронное развлекательное устройство, одноранговое устройство или другой обычный сетевой узел и в типовом случае включает в себя многие или все из элементов, описанных выше применительно к персональному компьютеру 902, хотя для наглядности показано только устройство 950 памяти. Логические соединения, показанные на фиг.1, включают в себя локальную сеть (LAN) 952 и глобальную сеть (сеть широкого охвата - WAN) 954. Такие сетевые среды являются общеизвестными в офисах, компьютерных сетях предприятий, интранетах и в Интернет.
При использовании в сетевой среде локальной сети (LAN) компьютер 902 соединяется с локальной сетью 952 через сетевой интерфейс или адаптер 956. При использовании в сетевой среде глобальной сети (WAN) компьютер 902 в типовом случае включает в себя модем 958 или соединен с коммуникационным сервером в локальной сети LAN, или имеет иное средство для установления связи посредством глобальной сети WAN 954, такой как Интернет. Модем 958, который может быть внутренним или внешним, соединен с системной шиной 908 через интерфейс 942 последовательного порта. В сетевой среде программные модули, описанные для компьютера 902 или его частей, могут быть сохранены в удаленном устройстве 950 памяти. Следует иметь в виду, что показанные сетевые соединения приведены для примера, и что могут быть использованы и другие средства установления канала связи между компьютерами.
В соответствии с одним аспектом изобретения, архитектура фильтрации адаптируется к степени фильтрации, требуемой для конкретного пользователя системы, на которой используется фильтрация. Однако понятно, что этот «адаптивный» аспект может быть распространен от локальной среды пользователя системы на процесс изготовления поставщика системы, где степень фильтрации для конкретного класса пользователей может быть выбрана для реализации в системах, выпускаемых на производстве для продажи. Например, если покупатель принимает решение, что первая партия приобретаемых систем должна быть предназначена для пользователей, которым не потребуется доступ ни к какой ненужной почте, то настройки, устанавливаемые по умолчанию в заводских условиях для данной партии систем, должны быть высокими, в то время как вторая партия систем для второго класса пользователей может быть конфигурирована для более низких настроек, чтобы обеспечить просмотр всей ненужной почты. В любом сценарии адаптивный характер настоящего изобретения может быть реализован локальным образом, чтобы обеспечить возможность индивидуальным пользователям любого класса настроить степень фильтрации, или блокирован для предотвращения какого-либо изменения настроек, установленных по умолчанию. Также понятно, что сетевой администратор, который пользуется сопоставимыми правами доступа для конфигурирования одного или более систем, имеющих конфигурацию с использованием раскрытой архитектуры фильтрации, может также реализовать локальным образом такие конфигурации классов.
Выше были приведены примеры настоящего изобретения. Разумеется, невозможно описать каждую мыслимую комбинацию компонентов или методов в целях описания настоящего изобретения, однако специалисту в данной области техники должно быть понятно, что многие другие комбинации и перестановки настоящего изобретения являются возможными. Соответственно, настоящее изобретение предполагает охват всех таких изменений, модификаций и вариаций, которые соответствуют сущности и объему формулы изобретения. Кроме того, в той степени, в которой термин «включает в себя» используется в детальном описании и в формуле изобретения, такой термин предполагает «включение» тем же способом, что и в случае термина «содержащий», так как «содержащий» интерпретируется при использовании в качестве переходного термина в пунктах формулы изобретения.
Реферат
Изобретение относится к системам и способам для идентификации нежелательной информации. Система фильтрации данных содержит первый (начальный) фильтр, имеющий связанную с ним частоту позитивных ложных тревог и частоту негативных ложных тревог, и второй (новый) фильтр, который также используется для фильтрации сообщений, причем второй фильтр оценивается соответственно частоте позитивных ложных тревог и частоте негативных ложных тревог, связанных с первым фильтром. Данные, используемые для определения частот позитивных ложных тревог и негативных ложных тревог первого фильтра, используются для определения новых частот позитивных ложных тревог и негативных ложных тревог второго фильтра, в функции порога. Второй фильтр используется вместо первого фильтра, если для второго фильтра существует порог такой, что новые частоты позитивных ложных тревог и негативных ложных тревог второго фильтра совместно рассматриваются как лучшие, чем частоты позитивных ложных тревог и негативных ложных тревог первого фильтра. Технический результат - повышение эффективности за счет облегчения идентификации ненужной информации. 11 н. и 52 з.п. ф-лы, 10 ил.
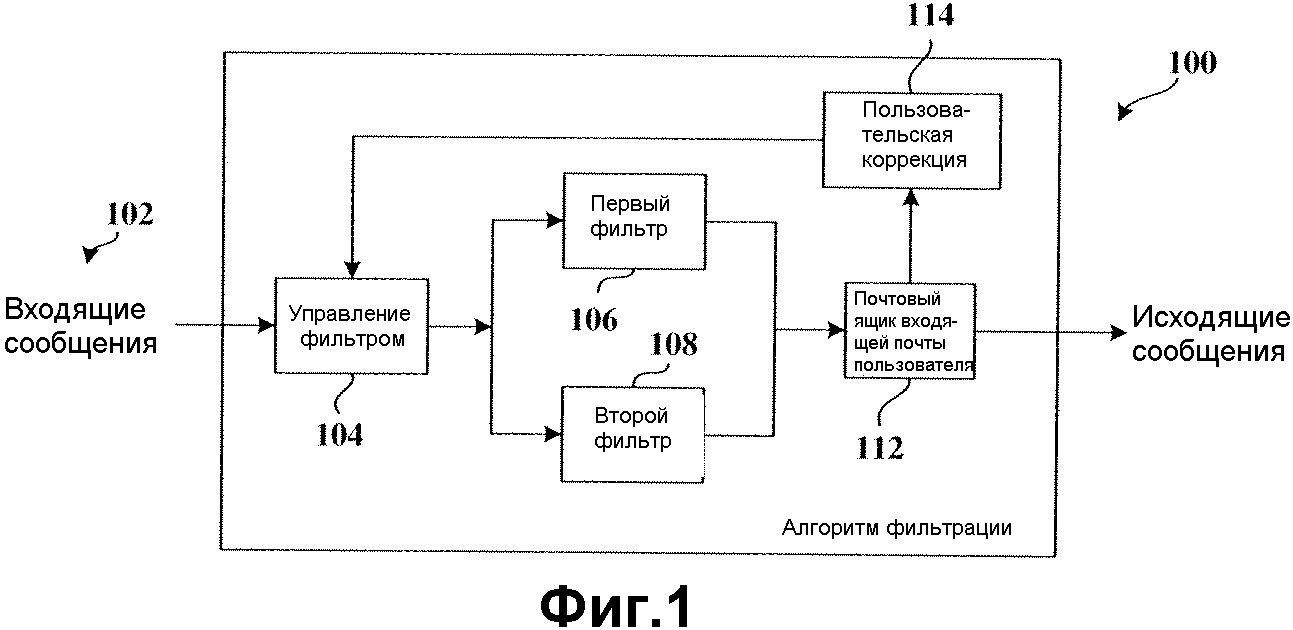
Формула
Документы, цитированные в отчёте о поиске
Усовершенствованный способ и устройство для динамического смещения между пакетами маршрутизации и коммутации в сети передачи данных
Комментарии