Способы и относящиеся к ним системы построения моделей и прогнозирования операционных результатов операции бурения - RU2600497C2
Код документа: RU2600497C2
Чертежи
Описание
ПРЕДПОСЫЛКИ
[0001] В контексте бурения углеводородной скважины, значительное количество данных может быть собрано одновременно с бурением, например, данные измерения во время бурения (MWD), данные каротажа во время бурения (LWD), и данные от массива датчиков в и вокруг буровой установки. Эти данные могут быть использованы в краткосрочной перспективе, чтобы принимать решения относительно бурения конкретного ствола скважины (например, регулирование направления бурения, решение о смене бурового долота). Однако данные относительно бурения конкретного ствола скважины не могут быть просмотрены еще раз после того, как ствол скважины пробурен, и даже если эти данные просмотрены и/или проанализированы на более позднюю дату, связь данных с операционными результатами других стволов скважин, пробуренных раньше по времени или позже во времени, трудно вывести.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0002] Для подробного описания примерных вариантов осуществления ссылки будут делаться на приложенные чертежи, на которых:
[0003] Фиг. 1 показывает в форме блок-схемы высокоуровневую диаграмму потока рабочего процесса в соответствии с по меньшей мере некоторыми вариантами осуществления;
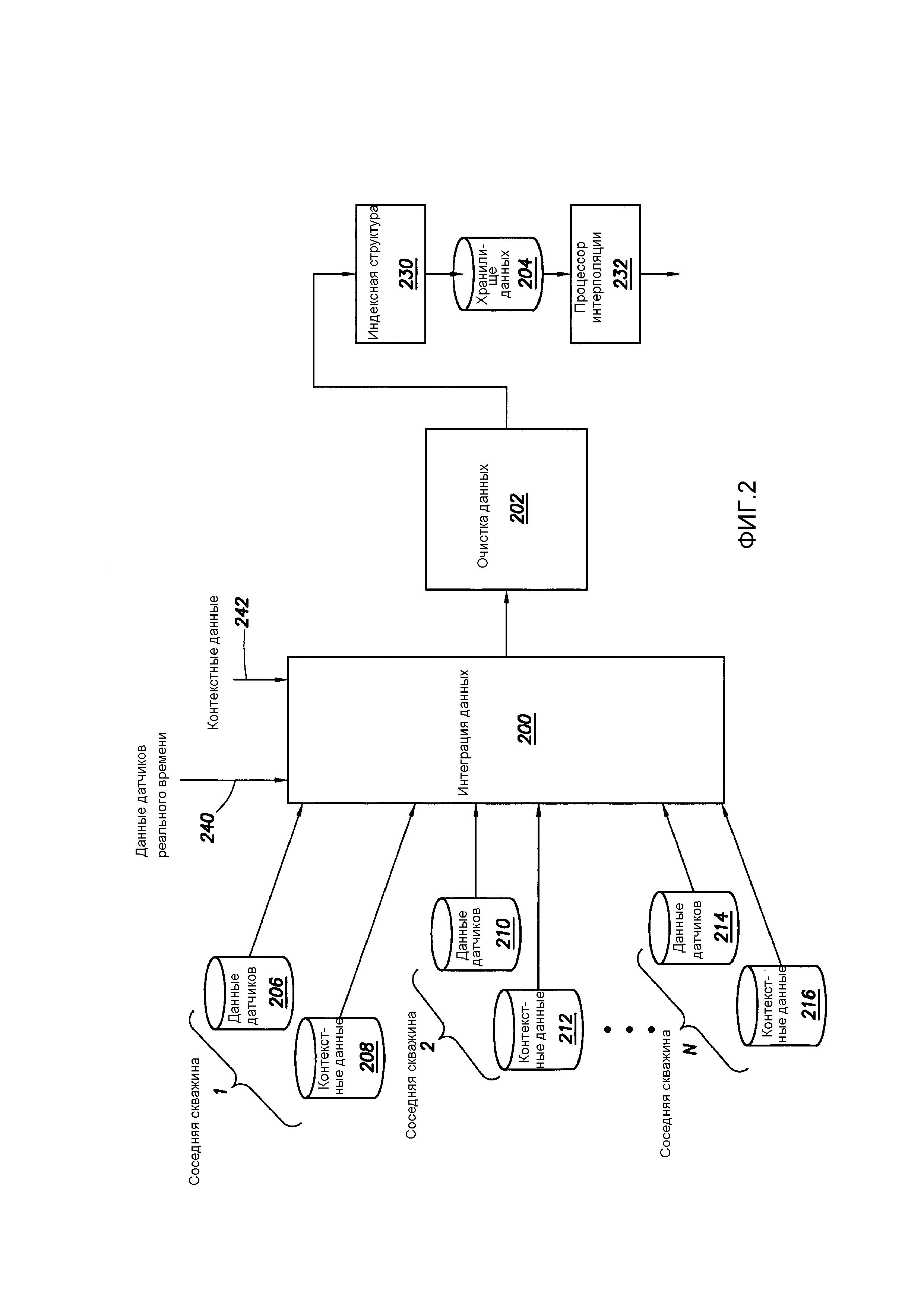
[0004] Фиг. 2 показывает визуальное изображение примерного рабочего процесса в соответствии с по меньшей мере некоторыми вариантами осуществления;
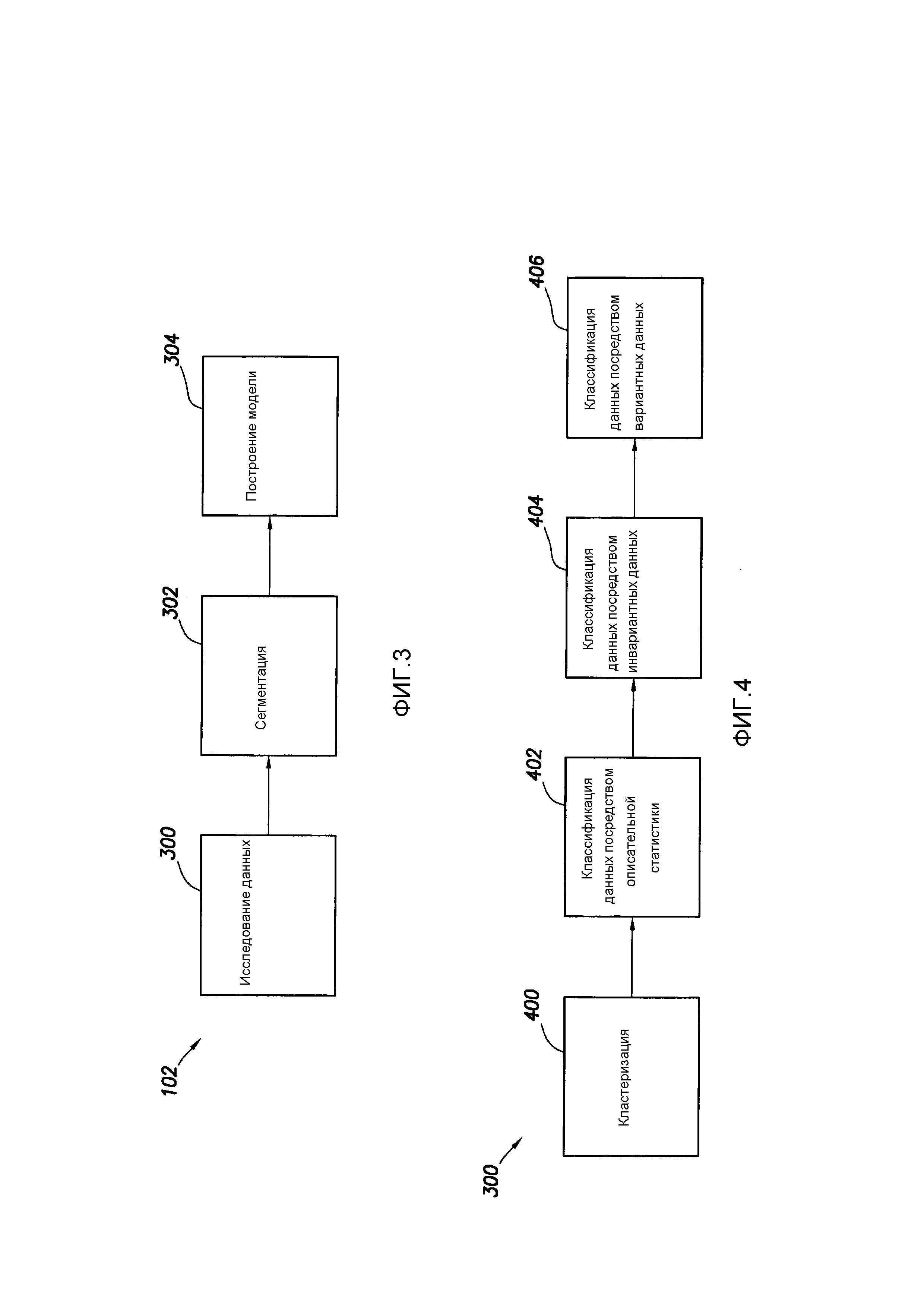
[0005] Фиг. 3 показывает в форме блок-схемы примерный рабочий процесс в соответствии с по меньшей мере некоторыми вариантами осуществления;
[0006] Фиг. 4 показывает в форме блок-схемы примерный рабочий процесс в соответствии с по меньшей мере некоторыми вариантами осуществления;
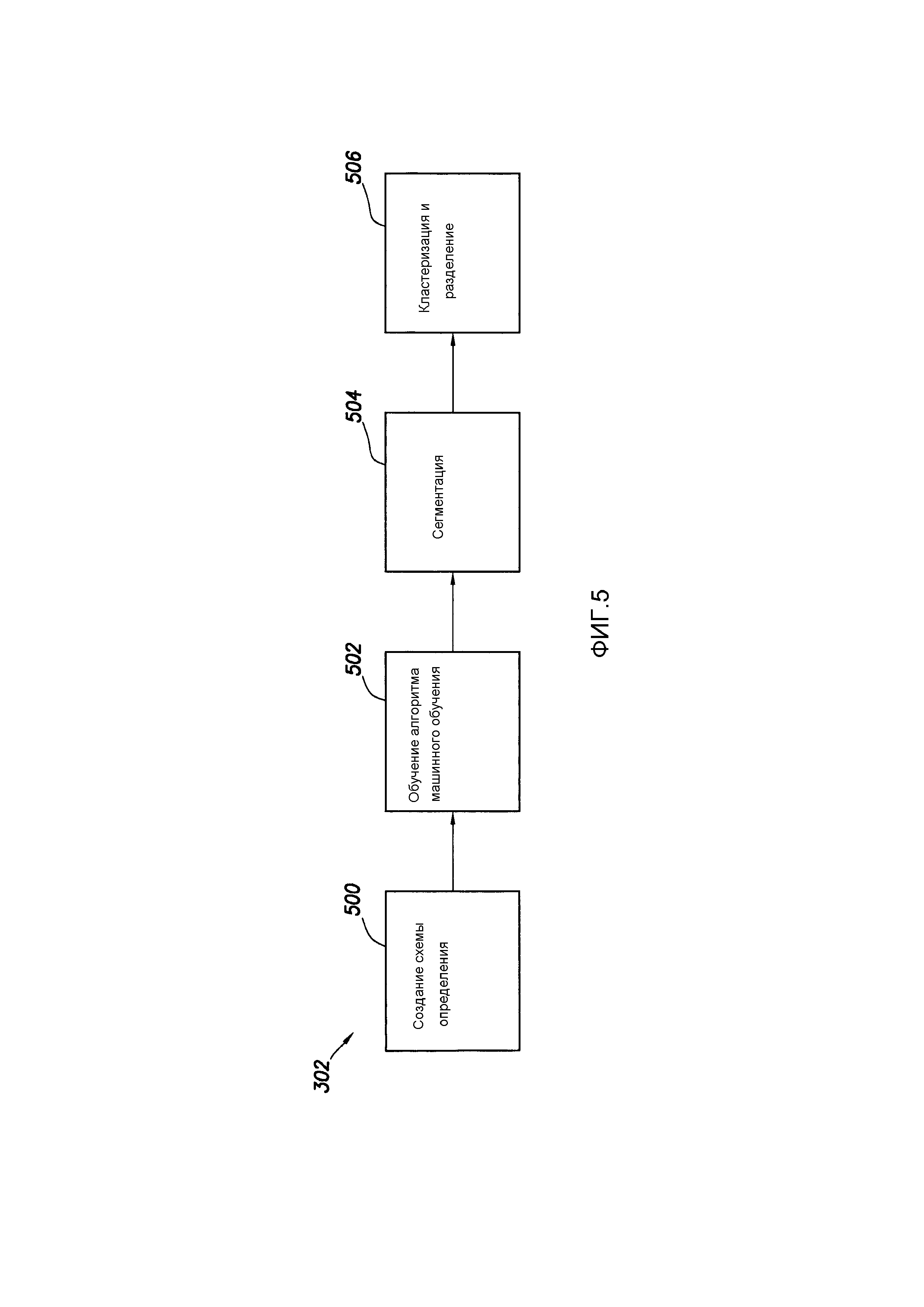
[0007] Фиг. 5 показывает в форме блок-схемы примерный рабочий процесс в соответствии с по меньшей мере в некоторыми вариантами осуществления;
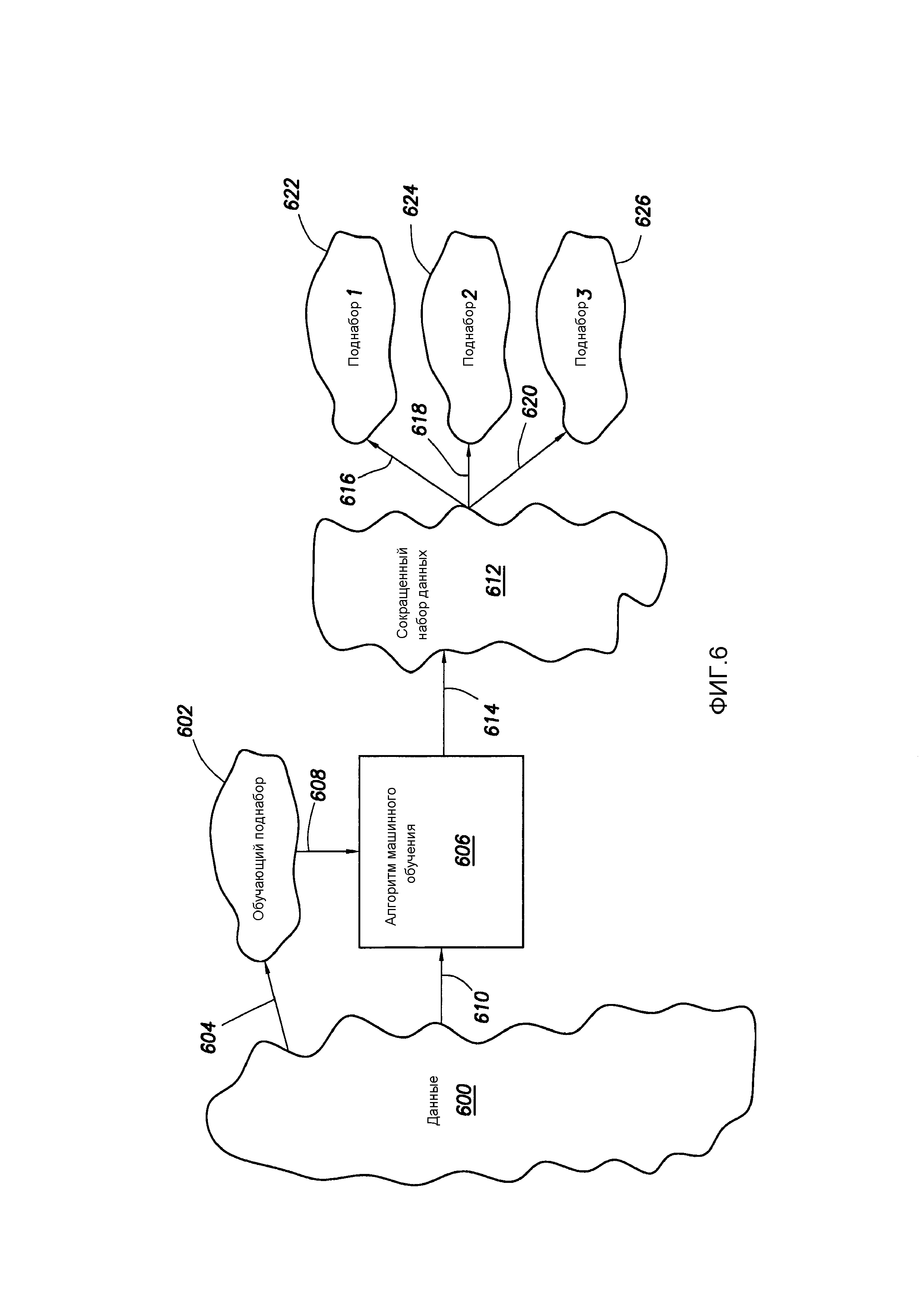
[0008] Фиг. 6 показывает примерный рабочий процесс в соответствии с по меньшей мере некоторыми вариантами осуществления;
[0009] Фиг. 7 показывает в форме блок-схемы примерный рабочий процесс в соответствии с по меньшей мере некоторыми вариантами осуществления;
[0010] Фиг. 8 показывает примерную операцию бурения в соответствии с по меньшей мере некоторыми вариантами осуществления;
[0011] Фиг. 9 показывает в форме блок-схемы логическую операцию прогнозирующих сегментов в соответствии с по меньшей мере некоторыми вариантами осуществления;
[0012] Фиг. 10 показывает в форме блок-схемы логическую операцию прогнозирующих сегментов в соответствии с по меньшей мере некоторыми вариантами осуществления;
[0013] Фиг. 11 показывает в форме блок-схемы компьютерную систему в соответствии с по меньшей мере некоторыми вариантами осуществления; и
[0014] Фиг. 12 показывает блок-схему последовательности операций в соответствии с по меньшей мере некоторыми вариантами осуществления.
ОБОЗНАЧЕНИЯ И ТЕРМИНОЛОГИЯ
[0015] Некоторые термины используются во всем нижеследующем описании и формуле изобретения для обозначения отдельных компонентов системы. Как будет понятно специалисту в данной области техники, различные компании могут ссылаться на компоненты под разными наименованиями. Настоящий документ не имеет намерения проводить различие между компонентами, которые отличаются по названию, но не по функции. В последующем обсуждении и в формуле изобретения термины "включающий" и "содержащий" используются в открытом смысле, и, таким образом, должны интерпретироваться, чтобы означать "в том числе, но не ограничиваясь указанным…".
[0018] Кроме того, термин "связывают" или "связывает" предназначен для обозначения либо опосредованного, либо непосредственного соединения. Таким образом, если первое устройство связано с вторым устройством, это соединение может быть осуществлено через прямое соединение или через косвенное соединение через другие устройства и соединения.
[0017] "Данные датчиков" означают данные, созданные физическими датчиками или на основе физических датчиков, ассоциированных с операцией бурения, где данные изменяются в зависимости от времени или изменяются в зависимости от глубины бурения. Примерами данных датчиков, созданных непосредственно физическими датчиками, являются: температура в скважине, измеряемая во время бурения; давление бурового раствора в забое скважины, измеряемое в процессе бурения; данные каротажа в процессе бурения; и данные измерения в процессе бурения. Примеры данных датчиков, созданных на основе (например, непосредственно выведенных из или вычисленных посредством детерминированного вычисления) физических датчиков, включают в себя скорость проходки (ROP) во время операции бурения и объем потерь бурового раствора как функцию времени/глубины.
[0018] "Контекстные данные" означают данные, относящиеся к аспектам операции бурения, которые не измеряются физическими датчиками, ассоциированными с операцией бурения. Примерами контекстных данных являются: многолетний опыт буровой бригады; тип используемого бурового долота; тип бурового раствора; суточная стоимость промыслового оборудования; физические характеристики подземного пласта.
[0019] "Соседняя (периферийная, подсасывающая) скважина” должно означать скважину, пробуренную в прошлом или пробуриваемую одновременно с проектной или фактической скважиной, представляющей интерес.
[0020] "Проектный ствол скважины" должно означать ствол скважины или части ствола скважины, который еще должен быть пробурен.
[0021] "В реальном времени" по отношению к данным должно означать данные, которые были измерены или созданы в течение последнего часа.
[0022] "Алгоритм машинного обучения" должно означать компьютерную программу, которая выполняет задачу, чтобы после обучения компьютерной программы выполнять задачу с помощью набора обучающих данных. Алгоритмы машинного обучения могут включать в себя искусственные нейронные сети, векторные машины поддержки, алгоритмы обучения дерева решений и Байесовы сети.
[0023] "Очистка данных" должно означать удаление данных из набора данных, так что данные, оставшиеся в наборе данных, имеют улучшенную метрику качества.
[0024] "Параметры бурения" должно означать управляемую переменную операции бурения. Например, параметры бурения могут содержать: нагрузку на долото, давление бурового раствора, направление бурения, вращательную скорость бурильной колонны и вращательную скорость бурового долота, вращаемого забойным двигателем.
[0025] "Операционный результат" должно означать неуправляемую переменную или параметр операции бурения, фактическое или прогнозируемое значение или состояние которого изменяется, в некоторых случаях от изменений фактического(их) или прогнозируемого(ых) параметра(ов) бурения. Например, скорость проходки бурения через пласт является операционным результатом, потеря бурового раствора является операционным результатом, как и предсказание события прихвата труб.
[0026] "Многомерная структура данных" должно означать логическую конструкцию данных, построенных или сохраненных в многомерном пространстве в памяти с компьютерным доступом. "Многомерная структура данных" не должно трактоваться как требующее создания физической структуры.
ОРГАНИЗАЦИОННАЯ СВОДКА
[0027] Настоящее описание организовано в виде множества разделов и подразделов. Следующий обзор разделов и подразделов призван помочь читателю в понимании организационной структуры документа.
[0028] ОБЗОР
[0029] Хранение аналитических данных (сбор и хранение данных)
[0030] - Типы данных и исторические недостатки
[0031] - Создание хранилища данных
[0032] - Система интеграции данных
[0033] - Система очистки данных
[0034] - Хранилище данных
[0035] - Аспекты реального времени
[0036] - Хранение аналитических данных
[0037] Аналитика данных и построение модели
[0038] - Исследование данных
[0039] - Кластеризация
[0040] - Классификация данных посредством описательной статистики
[0041] - Классификация данных посредством инвариантных данных
[0042] - Классификация данных посредством вариантных данных
[0043] - Сегментация
[0044] - Создание схемы определения
[0045] - Обучение алгоритма машинного обучения
[0046] - Построение модели
[0047] - Обучение
[0048] - Тестирование
[0049] - Проверка и оценка
[0050] Прогнозная аналитика
[0051] - Примерная операционная среда
[0052] - Операционные методы
[0053] Соображения реализации
ПОДРОБНОЕ ОПИСАНИЕ
[0054] Следующее обсуждение направлено на различные варианты осуществления изобретения. Хотя один или более из этих вариантов осуществления могут быть предпочтительными, раскрытые варианты осуществления не должны толковаться или иным образом использоваться как ограничивающие объем раскрытия, включая формулу изобретения. Кроме того, специалисту в данной области техники должно быть понятно, что последующее описание имеет широкое применение, и обсуждение любого варианта осуществления означает только пример этого варианта осуществления, а не предназначается, чтобы подразумевать, что объем раскрытия, включая формулу изобретения, ограничен этим вариантом осуществления.
[0055] ОБЗОР
[0056] Различные варианты осуществления направлены на способы и соответствующие системы прогнозирования, либо перед бурением, либо одновременно с бурением, операционных (эксплуатационных) результатов операции бурения. Более конкретно, примеры способов и систем направлены на сбор и анализ больших объемов разнородных данных, генерируемых в отношении соседних скважин (например, данных датчиков, контекстных данных), выявление корреляции в данных, относящихся к операционным результатам в операции бурения, создание одной или более моделей на основе корреляций и прогнозирование операционных результатов (в том числе будущих событий), связанных с операцией бурения, на основе одного или более параметров.
[0057] Фиг. 1 показывает в форме блок-схемы высокоуровневую диаграмму рабочих процессов в соответствии с различными вариантами осуществления. Каждый из примерных рабочих процессов на фиг.1 представляет реализуемые компьютером методы, приводящие к созданию структур данных и/или программных средств, которые затем используются в следующем рабочем процессе. В частности, первый аспект содержит рабочий процесс 100 хранения аналитических данных. Рабочий процесс 100 хранения аналитических данных собирает данные датчиков и контекстные данные в соседних скважинах и помещает данные в хранилище данных, так что к данным (как датчиков, так и контекстным) может предоставляться доступ посредством универсального интерфейса прикладного программирования. Второй аспект включает в себя рабочий процесс 102 аналитики данных и построения модели. Примерный рабочий процесс 102 анализирует данные, полученные из хранилища данных рабочего процесса 100 хранения аналитических данных, чтобы выявлять корреляции среди прогнозных данных операционных результатов в процессе бурения. После того, как корреляции определены, сокращенный набор данных создается в рабочем процессе 102, содержащие данные, для которых были определены корреляции, и из сокращенного набора данных создаются одна или более прогнозирующих моделей. Прогнозирующие модели, созданные в рабочем процессе 102, затем применяются в рабочем процессе 104 прогнозирующей аналитики для прогнозирования одного или более операционных результатов (например, будущих значений операционного результата, будущих событий).
[0058] В некоторых случаях примерные рабочие процессы на фиг. 1 используются в качестве инструмента планирования. То есть, примерные рабочие процессы используются для планирования и прогнозирования параметров бурения для достижения прогнозируемых операционных результатов относительно ствола скважины, которая еще должна быть пробурена. Однако в других примерных системах рабочие процессы по фиг. 1 используются итерационно во время бурения ствола скважины. Таким образом, в примерных системах прогнозируемые операционные результаты используются в смысле замкнутого контура (как показано линией 106) вместе с данными датчиков реального времени и контекстными данными (как показано линией 108), чтобы уточнить модели (и, как обсуждается ниже, в некоторых случаях, чтобы выбрать из моделей-кандидатов) в процессе бурения ствола скважины. Каждый рабочий процесс будет обсуждаться, в свою очередь, начиная с рабочего процесса 100 хранения аналитических данных.
[0059] Хранение аналитических данных (сбор и хранение данных)
[0060] - Типы данных и исторические недостатки
[0061] Существуют несколько типов данных, ассоциированных с операцией бурения ствола скважины. В частности, буровая установка может быть ассоциирована с массивом датчиков, измеряющих параметры бурения, такие как давление бурового раствора на поверхности, скорость потока (расход) бурового раствора и скорость вращения бурильной колонны. Примерные отмеченные датчики создают поток данных, которое в большинстве случаев индексирован по времени (например, давление как функция времени, обороты в минуту (RPM) как функция времени). Кроме того, забойная компоновка бурильной колонны может содержать MWD и/или LWD инструменты, которые измеряют скважинные параметры бурения во время бурения. Пример скважинных параметров бурения может содержать скважинное давление бурения, нагрузку на буровое долото, скважинную температуру, наклон забойной компоновки, скорость вращения ротора турбобура и параметры пласта, измеренные LWD инструментами (например, сопротивление, пористость). Скважинные параметры бурения могут быть проиндексированы по времени или подобному времени параметру (например, глубине, которая может быть прослежена назад по времени, если необходимо, посредством коррелирования с моментом, когда скважинный датчик прошел упомянутую глубину). Различные типы данных, описанные в этом абзаце, будет упоминаться как данные датчиков. В большинстве случаев, данные датчиков являются данными большого объема, высокой частоты - это означает, что поток данных является почти непрерывным в течение времени, когда данные создаются, и включает в себя значительное количество информации.
[0062] Другим типом данных, представляющих интерес для настоящего описания, являются данные, ассоциированные с контекстом операции бурения. Примеры контекста могут содержать идентификатор оператора буровой (т.е. название компании), идентификатор буровой бригады, совокупный многолетний опыт буровой бригады, количество членов буровой бригады, тип используемого бурового раствора, тип использованного или используемого бурового долота, суточную стоимость промыслового оборудования (например, суточную стоимость буровой установки) и минералогию отдельной подземной формации. Различные данные, описанные в этом абзаце, будет упоминаться как контекстные данные. Следует отметить, что хотя примеры контекстных данных могут включать в себя данные с временной зависимостью (например, кумулятивный многолетний опыт буровой бригады), скорость, с которой изменяются контекстные данные как функция времени (например, дни, месяцы, годы), значительно медленнее, чем у данных датчиков (например, отсчеты давления, взятые и записанные 100 раз в секунду).
[0063] Примерные типы данных традиционно хранятся в различных и отдельных структурах данных. Например, MWD и LWD данные могут быть сохранены в документах расширяемого языка разметки (XML) и, более конкретно, как документы стандартного языка разметки переноса информации стороны скважины (WITSML), организованные и/или индексированные по времени/глубине. В отличие от этого, контекстные данные могут быть сохранены неиндексированным по времени способом, например, в реляционной базе данных (например, реляционной базе данных Модели данных инжиниринга (EDM™)). В других случаях, исторические данные (независимо от типа данных) относительно ствола скважины могут быть сохранены в формате хранения двоичного объекта большого размера (BLOB), которые не могут быть легко запрошены для извлечения соответствующей информации.
[0064] В известном уровне техники анализ исторических данных, охватывающих различные типы данных, затруднителен, если ни по какой другой причине, чем несходные данные, методы хранения данных делают сбор данных трудным и/или требующим значительных затрат времени. По этой причине, хотя различные нефтяные и газовые компании могут иметь и хранить значительные объемы исторических данных датчиков и контекстных данных, когда ствол скважины завершен, данные после этого не используются ни в прогнозировании операционных результатов проектируемых будущих стволов скважин, которые должны быть пробурены, ни во время бурения стволов скважин, бурение которых начинается после завершения соседних скважин.
[0065] - СОЗДАНИЕ ХРАНИЛИЩА ДАННЫХ
[0066] Фиг. 2 показывает визуальное изображение соотношения между различными типами данных и объединение в хранилище данных. В частности, фиг. 2 показывает данные датчиков и контекстные данные, ассоциированные с соседними скважинами. Различные типы данных, ассоциированные с соседними скважинами, предоставляются в систему 200 интеграции данных, которая, как следует из названия, объединяет исторические данные (как датчиков, так и контекстные) от различных соседних скважин. Система 200 интеграции данных более подробно обсуждается ниже. Собранные данные могут быть поданы в систему 202 очистки данных, которая выполняет различные функции выравнивания, сглаживания и интерполяции (также дополнительно обсуждены ниже). Продукт примерной системы по фиг. 2 представляет собой хранилище 204 данных, в котором хранятся различные типы данных из различных соседних скважин, и из которого данные доступны для последующих рабочих процессов (например, аналитики данных и построения модели и прогнозирующей аналитики). Сбор различных типов данных в “единое” хранилище данных обеспечивает не только возможность запрашивать по всей совокупности данных, хранящихся в хранилище данных, но и сокращает временные рамки для доступа, обеспечивающие принятие решений на основе данных в хранилище данных во временных рамках по шкале минут или часов (а не недель или месяцев). Настоящее описание сначала обращается к более подробному описанию системы 200 интеграции данных.
[0067] - СИСТЕМА ИНТЕГРАЦИИ ДАННЫХ
[0068] Все еще со ссылкой на фиг. 2, система 200 интеграции данных логически связана, по меньшей мере на начальном этапе, с данными датчиков и контекстными данными из множества соседних скважин. Как показано, система 200 интеграции данных связывается с данными 206 датчиков и контекстными данными 208 для "соседней скважины 1", связывается с данными 210 датчиков и контекстными данными 212 для "соседней скважины 2" и связывается с данными 214 датчиков и контекстными данными 216 для "соседней скважины N". Фиг. 2, таким образом, иллюстрирует, что данные интегрированы по множеству соседних скважин, а не ограничиваются только тремя соседними скважинами. В некоторых случаях, соседние скважины находятся в непосредственной близости от проектируемого или фактического ствола скважины, представляющего интерес. Например, соседние скважины могут быть всеми скважинами в области, которые были пробурены через и/или в тот же подземный углеводородный продуктивный слой. В других случаях, соседние скважины могут быть скважинами в целом регионе, даже охватывающем несколько целевых пластов. Кроме того, соседние скважины могут быть всеми скважинами, ранее пробуренными конкретным оператором, в некоторых случаях в любой точке мира.
[0069] В большинстве случаев данные 208, 210 и 214 датчиков каждой соседней скважины либо индексируются по времени, либо индексируются по глубине, которая является время-подобным параметром. Однако соседние скважины, скорее всего, пробурены в разные календарные дни (то есть, в разные моменты времени). Кроме того, даже если соседние скважины могут быть пробурены через и/или в те же подземные углеводородные пласты, высота поверхности каждого ствола скважины может быть различной, и, кроме того абсолютная глубина углеводородного продуктивного пласта может отличаться для каждой соседней скважины ввиду того, что углеводородные продуктивные пласты могут пролегать в иных, чем полностью горизонтальные, ориентациях. Таким образом, для того, чтобы более легко анализировать данные по соседним скважинам, система 200 интеграции данных может выполнять различные процедуры выравнивания, такие как выравнивание временных баз (например, время начала операций бурения) и выравнивание или компенсация различий высоты поверхности и/или подземного пласта (например, выравнивание к высоте опорного базиса).
[0070] В некоторых примерных системах, плотность данных из данных датчиков может быть больше, чем необходимо для прогнозирования одного или нескольких операционных результатов. Например, некоторые данные датчиков могут включать в себя сотни выборок в секунду, однако плотность данных в сотни выборок в секунду может не требоваться для прогнозирования операционных результатов, таких как ROP, эффективность бригады бурения или потеря бурового раствора. Таким образом, в некоторых примерных системах система 200 интеграции данных может выполнять функцию понижающей дискретизации данных, посредством которой число выборок данных снижается. В примерном случае набора данных датчиков, имеющих сотни выборок в секунду, система 200 интеграции данных может снизить частоту дискретизации до одной выборки в секунду. Любой подходящий способ может быть использован для понижающей дискретизации данных, такой как выбор усредненного значения, выбор среднего значения или случайный выбор. Следует отметить, что понижающая дискретизация не обязательно выполняется в любой ситуации, так как операционный результат, подлежащий прогнозированию, может потребовать более высоких частот дискретизации для точности.
[0071] С другой стороны, в некоторых случаях данные датчиков могут быть прерывистыми по периоду выборки или глубине. Например, степень естественного искривления ствола скважины может быть определена по отношению к конкретным съемочным точкам (т.е. глубинам) в стволе скважины, но не всем глубинам. Система 200 интеграции данных может, таким образом, распространить некоторые локализованные данные на другие глубины, используя любой подходящий механизм, такой как прямая линейная интерполяция различных алгоритмов подгонки кривой.
[0072] Помимо данных датчиков и проблем с выравниванием, система 200 интеграции данных также выполняет свертку контекстных данных 208, 212 и 216 от соседних скважин. В некоторых случаях, контекстные данные не имеют фактической временной зависимости (например, минералогия), но могут быть отнесены к временной зависимости с "периодом времени", охватываемым данными датчиков. В примере минералогии, временная зависимость может быть отнесена к периодам времени, когда соседняя скважина была пробурена через пласт с приписываемой минералогией. Другие контекстные данные имеют временную зависимость (например, используемое буровое долото), но такая временная зависимость является медленно меняющейся по сравнению с данными датчиков. Здесь снова, система 200 интеграции данных может приписывать временную зависимость по мере необходимости. В примере используемого бурового долота, временная зависимость может быть приписана к периодам времени (и/или глубинам), когда использовалось конкретное буровое долото. Другие контекстные данные могут не иметь временной зависимости или иметь временную зависимость, которая изменяется настолько медленно, что временная зависимость может рассматриваться как постоянная в течение промежутка времени сбора данных датчиков (например, количество лет опыта буровой бригады). Здесь снова, система 200 интеграции данных может применить зависимость времени/глубины, как необходимо для "выравнивания". В примере с количеством лет опыта буровой бригады, временная зависимость может устанавливаться системой 200 интеграции данных как постоянная по промежутку времени сбора данных датчиков.
[0073] - СИСТЕМА ОЧИСТКИ ДАННЫХ
[0074] В некоторых примерных системах данные, представленные в хранилище данных, очищаются перед использованием для дальнейших рабочих процессов, отмеченных на фиг. 1. На фиг. 2 система 202 очистки данных показана как логически находящаяся между системой 200 интеграции данных и фактическим хранилищем 204 данных. Следовательно, в некоторых случаях аспекты очистки данных выполняются перед вводом данных в хранилище данных. Однако в других вариантах осуществления данные могут быть помещены в хранилище 204 данных, а затем проанализированы и очищены, как желательно.
[0075] В некоторых примерных системах, система 202 очистки данных 202 выполняет множество типов анализа данных как часть очистки, в том числе удаление данных, когда это необходимо, и настройку значений, когда это необходимо. Примерные методы, используемые системой очистки данных, могут включать в себя идентификацию и удаление недействительных данных, детерминированные методы для идентификации аномалий данных и вероятностные методы для идентификации аномалий данных. Каждый из них будет обсуждаться по очереди.
[0076] Одним способом очистки является удаление недействительных данных. Примеры недействительных данных, которые могут быть удалены, содержат текстовые строки в полях значений, значения в полях текстовых строк, пустые поля, где ожидались значения, заполнители записей, такие как "TBD" и "NA", и тому подобное. Иначе говоря, примерный аспект "недействительных данных" очистки данных может выполнять проверку на наличие недействительных данных, принимая во внимание ожидаемый тип данных, подвергаемых анализу, и любые такие идентифицированные недействительные данные могут быть удалены.
[0077] В дополнение или вместо аспектов удаления данных очистки данных, обсужденной выше, примерная система 202 очистки данных может применять детерминированные методы для идентификации аномалий данных, не идентифицированных в анализе недействительных данных. Например, даже в группе значений данных датчиков, где каждый член данных в группе не является недействительным, части данных могут, тем не менее, представлять "плохие" данные. Рассмотрим, в качестве примера, упрощенную группу значений насыщенности газа для непрерывного пласта как функцию глубины (90%, 91%, 90%, 20%, 90%, 89%). Каждое из значений в примерной группе может попасть в пределы ожидаемого диапазона значений насыщения газом для пласта; однако, маловероятно, что насыщение газом пласта по непрерывным глубинам резко упадет до 20%, когда в примыкающих глубинах насыщение газом измеряется как 90%.
[0078] Таким образом, в соответствии с по меньшей мере некоторыми примерными системами, данные очищаются путем детерминированных статистических методов (например, анализ стандартного отклонения, анализ хи-квадратичного распределения). Для примерной группы значений, указанных выше, анализ стандартного отклонения группы по каждому отдельному элементу выявил бы 20% значение как множество стандартных отклонений ниже среднего или усредненного (даже с учетом 20% значения в вычислении значения стандартного отклонения). Для каждого элемента данных, найденного подозрительным при статистических вычислениях, система очистки данных может удалить элемент данных и/или заменить элемент данных.
[0079] Кроме того, система 202 очистки данных может применять детерминированные фильтры для данных, чтобы идентифицировать выпадающие из диапазона значения для любого конкретного контекста. Рассмотрим, в качестве примера, элемент данных, индексированный по глубине 90000 футов в скважине, где общая длина ствола скважины 2000 футов. В этой примерной ситуации примерный элемент данных находится вне логической границы общей длины ствола скважины, и, таким образом, примерный элемент данных может быть удален. В качестве другого примера рассмотрим значения вне диапазона, такие как отрицательная нагрузка на буровое долото (WOB) или отрицательная ROP в процессе бурения. Опять же, эти значения вне ограничений могут быть удалены. Иначе говоря, система 202 очистки данных может применять полученные данные к детерминированным (то есть, вопросам с ответом да/нет) испытаниям (например, испытание на минимальное/максимальное значение, испытания граничных значений в соответствии с требованиями) как часть методов очистки данных.
[0080] Кроме того, в дополнение или вместо детерминированных тестов, примерная система 202 очистки данных может применять вероятностные методы (например, в методах интеллектуального анализа данных эти данные могут анализироваться на наличие аномалий на основе шаблона), чтобы идентифицировать аномалии данных, не идентифицированные в детерминированном анализе. Например, крутящий момент, число оборотов в минуту и амперная нагрузка верхнего приводного двигателя являются тремя параметрами бурения, которые имеют очень высокие корреляции. Если два параметра следуют тем же трендам (трендам, которые могут быть сложными, связывающими смесь общего полу-линейного увеличения, синусоидальных колебаний и полу-случайных выбросов), а третий параметр временами не следует им, то моменты, когда последний не согласуется, могут быть отброшены. Должно быть принято во внимание, что методы интеллектуального анализа данных и алгоритмы очистки, так же, как понижающая дискретизация, всегда должны выполняться в контексте желательного результата. Например, в предыдущем примере, если результат заключается в использовании чистого сигнала, который моделирует скважинное вращение, такая очистка может быть уместной. С другой стороны, такое отсутствие корреляции, как правило, указывает на неисправные датчики, и, следовательно, такая очистка может не выполняться, если желаемым результатом было предсказать неисправность датчика. В некоторых случаях, вероятностный анализ может быть выполнен с помощью алгоритма машинного обучения (например, векторной машины поддержки (SVM)). В частности, шаблоны, указывающие на аномалии данных, могут быть предопределенными или могут быть определены на основе анализа поднабора полных данных. Несмотря на это, данные (или баланс данных) могут быть проанализированы с помощью SVM, чтобы идентифицировать (или дополнительно идентифицировать) шаблоны, указывающие аномалии. В некоторых примерных системах, данные, идентифицированные с использованием вероятностных методов, удаляются. В других случаях, данные, идентифицированные с использованием вероятностных методов, будут скорректированы. В еще других случаях данные, идентифицированные с использованием вероятностных методов, остаются неизменными, а значение, указывающее на качество данных, может быть соответствующим образом скорректировано на основе идентифицированных аномалий.
[0081] - ХРАНИЛИЩЕ ДАННЫХ
[0082] Снова со ссылкой на фиг. 2, хранилище 204 данных может принимать любую подходящую форму. Что касается данных датчиков, в соответствии с различными вариантами осуществления, хранилище данных реализует схему хранения, которая позволяет осуществлять достаточно быстрый доступ к данным датчиков, которые будут использоваться для других последующих аспектов, обсуждаемых дополнительно ниже. В частности, данные датчиков могут быть сохранены в многоколонном формате (например, HBase на Hadoop распределенной файловой системы) с индексацией по времени. Однако один только индекс времени может оказаться недостаточным для обеспечения подходящего времени доступа в условиях большого объема данных, и, таким образом, примерные варианты осуществления также включают в себя индексную структуру 230 "поверх” многоколонных данных хранилища 204 данных, так что начальное индексирование может находиться в индексной структуре 230 в качестве грубого искателя местоположения, с последующей точной индексацией в данных многоколонного формата. Таким образом, посредством интерфейса прикладного программирования (API) вставки, индексированные данные временных рядов могут быть быстро вставлены в базу данных временных рядов и путем извлечения информации API могут быть считаны и использованы для других аспектов, рассмотренных ниже более подробно.
[0083] В некоторых случаях отсутствующие данные от различных соседних скважин создаются любым подходящим способом с помощью системы 200 интеграции данных. Однако в других случаях с отсутствующими данными обращаются другими способами. Например, на фиг. 2 хранилище 204 данных ассоциировано с серверным процессором 232 интерполяции. В частности, в дополнение или вместо системы 200 интеграции данных, выполняющей интерполяцию для замены отсутствующих данных, процессор 232 интерполяции может обеспечивать функцию интерполяции для любых запрошенных данных, которые в противном случае отсутствуют в хранилище 204 данных. В случае исторических данных соседних скважин, количество времени, необходимое для выполнения функции интерполяции недостающих данных, может не представлять важности. То есть, для целей прогнозирования операционных результатов для ствола скважины, которая еще должна быть пробурена, количество времени, необходимое для интерполяции данных в рамках системы 200 интеграции данных, может не представлять важности. Однако для прогнозирования операционных результатов в реальном времени с бурением и создания данных датчиков в реальном времени, система может отказаться от интерполяции для пропущенных данных, если и пока данные не будут запрошены из структуры данных, и в этом случае процессор 232 интерполяции может выполнять задачу в реальном времени с запросом.
[0084] В то время как фиг. 2 показывает хранилище 204 данных в виде единого "объекта", следует понимать, что хранилище 204 данных может охватывать множество накопителей на дисках, множество массивов накопителей на дисках и/или множество компьютерных систем. В некоторых случаях, хранилище данных может быть реализованы на "облаке", и, таким образом, количество компьютерных систем, а также их соответствующие местоположения могут не быть известны и/или могут изменяться с загрузкой. В примерных системах единый унифицированной API используется для размещения данных в хранилище данных и считывания данных из хранилища данных, и API не обязательно ограничивается, чтобы работать с одним физическим местоположением для хранилищ 204 данных.
[0085] - АСПЕКТЫ РЕАЛЬНОГО ВРЕМЕНИ
[0086] Все еще со ссылкой на фиг. 2, различные варианты осуществления, обсуждаемые в данный момент, в основном ссылались на сбор данных датчиков относительно соседних скважин и контекстных данных относительно соседних скважин, а также размещение данных в хранилище данных для использования для дальнейшего анализа. Однако в других случаях части данных датчиков могут быть данными датчиков в реальном времени, и контекстные данные ассоциированы с данными датчиков в реальном времени. Таким образом, те же методы, используемые в отношении соседних скважин, для сбора несходных типов данных и вставки данных в хранилище данных (включая аспекты очистки данных) могут быть реализованы в примерной системе в реальном времени с бурением ствола скважины, представляющего интерес. В частности, фиг. 2 показывает данные датчиков реального времени и ассоциированные контекстные данные для представляющего интерес ствола скважины, подаваемые в систему 200 интеграции данных, посредством стрелок 240 и 242, соответственно. В большинстве случаев, интеграция данных, выполняемая по отношению к соседним скважинам, будет завершена к тому времени, когда применяются данные датчиков реального времени, так что только данные датчиков реального времени и связанные с ними контекстные данные рассматриваются системой 200 интеграции данных. Однако в случае скважин, пробуриваемых одновременно, данные соседних скважин также могут быть данными "реального времени". Иначе говоря, работающая система может содержать данные соседних скважин, также создаваемые в "реальном времени", но для простоты описания в настоящем описании будет считаться, что данные соседних скважин все являются историческими данными.
[0087] - ХРАНЕНИЕ АНАЛИТИЧЕСКИХ ДАННЫХ
[0088] Конечным результатом рабочего процесса хранения 100 аналитических данных является хранилище данных с данными из множества соседних скважин, и в случае операций в реальном времени хранилище данных может быть постоянно растущим в размерах, начиная первоначально с данных соседних скважин и увеличиваясь со вставкой данных датчиков реального времени и связанных контекстных данных. Концептуально, хранилище данных создает одну или более многомерных структур данных, причем время/глубина является одной "размерностью", но любые из релевантных контекстных данных также могут быть "размерностями" в многомерной структуре данных. В некоторых случаях каждая соседняя скважина имеет отдельную многомерную структуру данных, но в других случаях соседние скважины могут быть объединены, чтобы создавать многомерные структуры данных, которые логически охватывают многие соседние скважины.
[0089] Индексная структура 230, которая находится "поверх” хранилища данных, уменьшает время доступ для вставки, так что данные в хранилище данных являются доступными рациональным образом для прогнозов в реальном времени для пробуриваемого ствола скважины, представляющего интерес. Далее настоящее описание обращается к рабочему процессу 102 аналитики данных и построения модели.
[0090] АНАЛИТИКА ДАННЫХ И ПОСТРОЕНИЕ МОДЕЛИ
[0091] Фиг. 3 показывает в форме блок-схемы примерный рабочий процесс, который может быть выполнен как часть рабочего процесса 102 аналитики данных и построения модели. В частности, фиг. 3 показывает рабочий процесс 300 исследования данных с результатами рабочего процесса 300 исследования данных, применяемыми к рабочему процессу 302 сегментации, и, наконец, результаты рабочего процесса 302 сегментации применяются к рабочему процессу 304 построения модели. Каждый рабочий процесс будет обсуждаться по очереди.
[0092] - ИССЛЕДОВАНИЕ ДАННЫХ
[0093] Хранилище 204 данных, обсужденное выше, содержит одну или более многомерных структур данных. В структурах данных существуют различные корреляции между данными датчиков, контекстными данными и операционным результатом в операции бурения, подлежащей прогнозированию (например, ROP, потеря бурового раствора). Во многих случаях корреляция между данными датчиков и контекстными данными, с одной стороны, и, с другой стороны, операционным результатом, подлежащим моделированию и прогнозированию, будет известна заранее. Например, вероятно, известно заранее, что ROP сильно коррелирована с типом пробуриваемого пласта. Тем не менее, в соответствии с примерными вариантами осуществления, идентифицируется по меньшей мере одна корреляция между частями данных датчиков и частями контекстных данных в многомерной структуре данных, где корреляция прогнозируется для операционного результата, и где корреляция не выбирается заранее до идентификации.
[0094] Фиг. 4 показывает в форме блок-схемы высокоуровневую диаграмму примерных рабочих процессов, являющихся частью рабочего процесса 300 исследования данных. В частности, рабочий процесс 300 исследования данных может содержать рабочий процесс 400 кластеризации, рабочий процесс 402 классификации данных посредством описательной статистики, рабочий процесс 404 классификации данных посредством инвариантных данных, рабочий процесс 406 классификации данных посредством вариантных данных. Каждый из них будет обсуждаться по очереди.
[0095] - КЛАСТЕРИЗАЦИЯ
[0096] Хранилище данных содержит многомерную структуру данных, которая связывает "факты" (например, данные датчиков) с “размерностями” (например, временем, контекстными данными). Любое количество размерностей возможно, и в некоторых случаях многомерная структура данных может рассматриваться как реализованная по звездообразной схеме. В рабочем процессе 400 кластеризации, кластеризация осуществляется на многомерной(ых) структуре(ах) данных. Иначе говоря, "факты" (например, выбранные данные датчиков) и “размерности” (например, выбранные контекстные данные) применяются к алгоритму кластеризации. Однако, в отличие от соответствующей уровню техники кластеризации, где предварительно выбирается мера "расстояния", которая определяет кластер среди кластерных точек данных (например, предварительно выбранное евклидово расстояние для местоположений стволов скважин), в соответствии с примерными вариантами осуществления алгоритм кластеризации выполняется без ограничения кластеризации какой-либо конкретной мерой расстояния. Другими словами, данные применяются к одному или более алгоритмам кластеризации, и данные сами выявляют, что оказывается наиболее релевантной функцией “расстояния” (то есть, корреляцией) для данных.
[0097] Рассмотрим возможные меры "расстояния", которые могут быть ассоциированы с ROP, в качестве операционного результата, представляющего интерес, “размерности” в форме контекстных данных, ассоциированных с бригадами, которые работают на буровой установке. Например, для одного набора данных общее число лет опыта для бригады может обеспечить лучшую корреляцию с ROP, чем другие возможные меры "расстояние" (например, средний возраст, количество дней на море, количество членов в бригаде). Для другого набора данных, корреляции могут быть сильнее в некоторой другой размерности, такой как число членов бригады. Целью этих примеров является подчеркнуть, что в соответствии с по меньшей мере некоторыми вариантами кластеризация выполняется без предвзятых понятий, чем должны быть меры "расстояния". В первом примере, общее число лет опыта оказалось лучшей мерой "расстояния" (то есть, показало лучшую корреляцию), а во втором примере число членов бригады оказалось лучшей мерой "расстояния" (показало лучшую корреляцию).
[0098] В качестве еще одного примера вне контекста буровой бригады, рассмотрим слои ствола скважины (например, идентификатор слоя подземного пласта), как это относится к ROP. Слои ствола скважины могут быть определены с точки зрения расстояния ниже поверхности (истинная вертикальная глубина), но во многих случаях слой, представляющий интерес, не является горизонтально расположенным по отношению к поверхности, и, таким образом, когда выполняется кластеризация, истинная вертикальная глубина может показать низкую корреляцию, но контекстные данные в виде типа слоя могут показать высокую корреляцию. Таким образом, мерой "расстояния" в данном примере может быть тип слоя (или переходы слоев).
[0099] Хотя будут лучшие и худшие меры "расстояния" в кластерных данных, следующим шагом в иллюстративном способе может быть выбор наилучших мер "расстояния". В некоторых случаях, выбор может включать в себя отображение кластеров так, что или компьютерный интеллект, и/или человеческий интеллект может быть применен для выбора наилучшей меры "расстояния". Например, может быть создано топографическое представление, на котором каждый кластер отображается таким образом, что человеческий глаз может различить кластеры (например, изменение цвета, тепловые карты, штриховки). В других случаях, компьютерная программа может отображать кластеры в “слоях” на основании результатов кластеризации или, возможно, в трехмерной проекции.
[0100] После того, как одна или несколько корреляций, связанных с операционными результатами, определены, последующие шаги в иллюстративной процедуре рабочего процесса 300 исследования данных являются последовательностью рабочих процессов классификации данных (например, рабочих процессов 402, 404 и 408). Высокоуровневым обзором дальнейших рабочих процессов (как группы) является то, что рабочие процессы являются методом создания параметров, на основе кластеризации, причем этим параметры в дальнейшем используются для создания сокращенных данных. То есть, анализ может начинаться с терабайта данных или более, и дальнейшие рабочие процессы по фиг. 4 могут быть использованы для идентификации (но еще не создания) меньшего поднабора данных, который представляет найденные корреляции.
[0101] - КЛАССИФИКАЦИЯ ДАННЫХ ПОСРЕДСТВОМ ОПИСАТЕЛЬНОЙ СТАТИСТИКИ
[0102] Первый примерный рабочий процесс классификации данных является рабочим процессом 402 классификации данных посредством описательной статистики. То есть, разрабатывается серия описательной статистики о релевантных данных, идентифицированных кластеризацией. Рассмотрим, в качестве примера, что если анализ показывает, что 90% от релевантных данных попадает в узкую полосу значений, репрезентативная выборка данных может быть взята (в последующих рабочих процессах) из узкой полосы значений. В качестве еще одного примера, рассмотрим, что если при анализе идентифицировано некоторое число пиков в данных, репрезентативная выборка данных может быть взята (в последующих рабочих процессах) на основе местоположения пиков. В еще одном примере, рассмотрим, что при анализе идентифицировано "расстояние" между средними значениями в каждой гистограмме, репрезентативная выборка данных может быть взята (в последующих рабочих процессах) на основе расстояния между средними значениями. В последнем примере, рассмотрим, что если анализ показывает определенный перекос в данных (например, неравномерное распределение по разбитым на интервалы данным), репрезентативная выборка данных может быть взята (в последующих рабочих процессах) с учетом перекоса.
[0103] Описательная статистика, указанная в предыдущем абзаце, является только примерами. В каждой конкретной ситуации, никакая, некоторая или вся описательная статистика может быть использована в качестве предшественника к рабочему процессу 302 сегментации, дополнительно обсужденному ниже.
[0104] - КЛАССИФИКАЦИЯ ДАННЫХ ПОСРЕДСТВОМ ИНВАРИАНТНЫХ ДАННЫХ
[0105] Вторым примерным рабочим процессом классификации данных является рабочий процесс 404 классификации данных посредством инвариантных данных. То есть, анализ выполняется по отношению к данным и одной или более размерностям, представляющим интерес, таким как классификация на основе временных бинов (интервалов) различных размеров, отношений глубин или любой другой размерности или группы размерностей, идентифицированных в кластеризации. Опять же, данные не обязательно извлекаются на этой стадии, но различные процессы используются для выявления данных для последующего извлечения и использования в различных моделях.
[0106] - КЛАССИФИКАЦИЯ ДАННЫХ ПОСРЕДСТВОМ ВАРИАНТНЫХ ДАННЫХ
[0107] Третьим примерным рабочим процессом классификации данных является рабочий процесс 406 классификации данных посредством вариантных данных. В принципе, этот рабочий процесс может идентифицировать шаблоны, которые не соответствуют общим трендам, и сохранять шаблоны, идентифицированные как новые указания. То есть, классификация данных может быть основана на вероятностных методах для идентификации аномалий данных. Анализ этого логического раздела может быть охарактеризован как согласование шаблонов данных, чтобы идентифицировать шаблоны. В качестве еще одного примера, различные варианты осуществления могут включать классификацию, основанную на обработке естественного языка данных из свободно плавающего текста (например, временная сводка, 24-часовая сводка). В качестве еще одного примера, различные варианты осуществления изобретения могут включать в себя классификацию данных на основе аномалий, обнаруженных при согласовании шаблонов.
[0108] Подводя итоги, прежде чем продолжать, рабочий процесс 300 исследования данных, подробно показанный на фиг. 4, идентифицирует корреляции в данных с операционным результатом, представляющим интерес. Набор данных, идентифицированный на основе корреляций, затем классифицируется посредством одного или более методов классификации данных как предшественник сегментации, обсуждаемой далее.
[0109] - СЕГМЕНТАЦИЯ
[0110] Кратко ссылаясь на фиг. 3, следующий этап в иллюстративном рабочем процессе является рабочим процессом 302 сегментации (как часть большего рабочего процесса 102 аналитики данных и построения модели на фиг. 1). Фиг. 5 показывает в форме блок-схемы набор рабочих процессов, которые могут быть реализованы как часть большего рабочего процесса 302 сегментации. В частности, сегментация может включать в себя рабочий процесс 500 схемы определения, рабочий процесс 502 обучения алгоритма машинного обучения, рабочий процесс 504 сегментации, основанной на алгоритме машинного обучения, и, наконец, рабочий процесс 506 кластеризации и разделения. Каждый из них будет обсуждаться по очереди.
[0111] - СОЗДАНИЕ СХЕМЫ ОПРЕДЕЛЕНИЯ
[0112] Первым примерным рабочим процессом является создание схемы определения 500. В частности, схема определения определяет, на концептуальном уровне, данные из общего хранилища данных, которые были идентифицированные как коррелированные с операционным результатом операции бурения, подлежащим прогнозированию. В примерных системах схема определения создается на основе классификаций данных, ассоциированных с рабочими процессами 300 исследования данных, и, более конкретно, рабочими процессами классификации данных (то есть 402, 404 и 408), выполняемыми после рабочего процесса 400 кластеризации.
[0113] Из классификации посредством описательной статистики, классификации посредством инвариантных данных и/или классификации посредством вариантных данных создается набор определений, который "определяет", какие данные в большом количестве данных в хранилище данных релевантны для операционного результата операции бурения, подлежащего прогнозированию.
[0114] - ОБУЧЕНИЕ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ
[0115] В соответствии с примерными системами, сегментация общего набора данных, сохраненного в хранилище 204 данных, чтобы прийти к сокращенному набору данных выполняется, по меньшей мере частично, с помощью алгоритма машинного обучения. В случае сегментации для получения сокращенного набора данных, нейронные сети и/или векторные машины состояний могут быть особенно подходящими для выполнения сегментации, но и другие алгоритмы машинного обучения могут быть использованы в дополнение или вместо нейронных сетей и/или векторных машин состояний. Фиг. 6 показывает концептуальное представление рабочих процессов, выполняемых в связи с рабочим процессом 302 сегментации, и последующие абзацы одновременно ссылаются на фиг. 5 и 6.
[0116] Независимо от типа алгоритма машинного обучения, подлежащего использованию, алгоритм машинного обучения должен быть обучен. Таким образом, используя схему определения, созданную в рабочем процессе 500, данные в хранилище данных анализируется, и извлекается обучающий поднабор. То есть, данные в общих данных 600 анализируются по схеме определения, и создается малый обучающий поднабор 602 данных, как показано стрелкой 604. С использованием обучающего поднабора 602 алгоритм 606 машинного обучения обучается, как показано стрелкой 608. То есть, алгоритм машинного обучения снабжается малым обучающим поднабором 602 данных и обучается с его помощью.
[0117] После того, как алгоритм машинного обучения обучен, иллюстративный рабочий процесс переходит к фактическому рабочему процессу 504 сегментации. То есть, данные 600 в общем наборе данных применяются и/или предоставляются в обученный алгоритм 606 машинного обучения, как показано стрелкой 610. Алгоритм 606 машинного обучения извлекает релевантные данные из общих данных 600 и, таким образом, создает сокращенный набор данных 612, извлечение показано стрелкой 614. Как будет описано ниже, сокращенный набор данных используется для создания и обучения различных моделей, которые затем используются для прогнозирования операционных результатов операции бурения.
[0118] Снова со ссылкой одновременно на фиг. 5 и 6, следующим этапом в иллюстративном наборе рабочих процессов является рабочий процесс 506 кластеризации и разделения. В частности, из сокращенного набора данных 612 создаются три репрезентативных поднабора данных, как показано стрелками 616, 618 и 620 и соответствующими поднаборами 622, 624, 626. Разделение сокращенного набора данных на три поднабора 622, 624 и 626 может первоначально содержать применение сокращенного набора данных к одному или более алгоритмам кластеризации. Кластеризация, выполняемая по отношению к сокращенному набору данных, отличается от предыдущей кластеризации тем, что предыдущая кластеризация была направлена на то, чтобы помочь определить атрибуты или размерности, представляющие интерес, в общей популяции данных. Кластеризация в сокращенном наборе данных, напротив, является предшественником к созданию меньших поднаборов данных 622, 624 и 626, причем эти поднаборы данных будут использованы в обучении, тестирования и проверке моделей (обсуждается более подробно ниже). В некоторых случаях метрики расстояния для кластеризации могут быть определены самими данными, а в других случаях функции расстояния обеспечиваются внешним образом. В других случаях, могут быть использованы комбинации алгоритмически выбранных функций расстояния и заданных вручную функций расстояния.
[0119] Кластеризация данных в сокращенном наборе данных будет выявлять два или более центроида ("центр" точек данных, связанных в кластере). Для того чтобы выбрать данные для создания поднаборов данных, множество градаций на основе функции расстояния определяются из каждого центроида. Градация, таким образом, определяет области "близости" к каждому центроиду. В соответствии с по меньшей мере некоторыми вариантами осуществления, выбор поднаборов данных, таким образом, может включать в себя выборки точек данных в каждой градации, ассоциированной с центроидом. Например, для создания первого поднабора данных 622, компьютерная система может программным образом выбрать предопределенный процент (например, 33%) точек данных в "ближайший" градации, предопределенный процент (например, 33%) точек данных во второй градации и так далее. Авторы настоящего изобретения обнаружили, что наборы выборок являются более равномерными при использовании вышеуказанного способа выбора, чем при использовании других способов взятия выборок, например, случайных выборок в кластере.
[0120] Прежде чем продолжить, следует отметить, что в других вариантах осуществления может быть создано множество сокращенных наборов данных. То есть, рабочий процесс 300 исследования данных может быть использован для идентификации релевантных данных для множества операционных результатов в буровой операции. В некоторых случаях каждый операционный результат, подлежащий прогнозированию, может иметь отдельный созданный сокращенный набор данных. В других случаях, может иметься единственный операционный результат, подлежащий прогнозированию, но для того, чтобы иметь несколько моделей (которые могут быть использованы в различных временных рамках и/или различных диапазонах глубин), может быть создано множество сокращенных наборов данных. Следует также отметить, что сокращенный набор данных не обязательно связан только с одной моделью, которая должна быть создана - созданный сокращенный набор данных (и, более конкретно, созданные поднаборы) может быть использован для обучения и тестирования различных моделей.
[0121] - ПОСТРОЕНИЕ МОДЕЛИ
[0122] Фиг. 7 показывает в форме блок-схемы, различные примерные этапы при выполнении рабочего процесса 304 построения модели. Созданные модели (далее модели-кандидаты) могут принимать различные формы. Например, модели-кандидаты могут содержать: нейронные сети (в том числе несколько нейронных сетей с различным числом узлов), векторные машины поддержки, математические модели, основанные на правилах модели и статистические модели. По отношению к одной или более моделям-кандидатам, которые должны быть созданы, примерный рабочий процесс включает в себя рабочий процесс 700 обучения, рабочий процесс 702 тестирования и рабочий процесс 704 проверки и оценки. Каждый из них будет обсуждаться по очереди.
[0123] - ОБУЧЕНИЕ
[0124] При общей цели создания одной или более моделей-кандидатов, которые будут использоваться для прогнозирования операционного результата операции бурения, первым этапом может быть создание модели(ей)-кандидата(ов) на основе поднабора 622 данных (далее обучающий поднабор). В случае математических и статистических моделей, модели могут быть созданы с помощью обучающего поднабора. В других случаях, базовая форма модели уже может быть известна, например, нейронная сеть или векторная машина состояний. Таким образом, вместо "создания" модели-кандидата как таковой, обучающий поднабор может быть использован применительно к модели-кандидату для обучения модели-кандидата. Независимо от точной формы, одна или более "обученных" моделей-кандидатов создаются с помощью обучающего поднабора.
[0125] Модели-кандидаты, даже обученные модели-кандидаты, не обязательно всегда являются "хорошими" моделями. В самом деле, несколько моделей-кандидатов одного и того же базового типа (например, нейронные сети с разным числом входных, выходных и/или "скрытых" узлов) могут по-разному прогнозировать тот же самый операционный результат, когда обучаются на одном и том же обучающем поднаборе. Таким образом, в соответствии с различными примерными вариантами осуществления, следующий иллюстративный рабочий процесс является проверкой 702 одной или более моделей-кандидатов.
[0128] - ТЕСТИРОВАНИЕ
[0127] Используя поднабор данных 624 (далее тестирующий поднабор), каждая модель-кандидат, созданная и обученная с использованием обучающего поднабора, тестируется с использованием тестирующего поднабора. В то время как данные в тестирующем поднаборе "отличаются" от обучающего поднабора, методы взятия выборок, используемые для создания обучающего поднабора и тестирующего поднабора, должны обеспечить, что соотношения операционного результата в процессе бурения и данных в каждом поднаборе примерно одни и те же. Таким образом, одна или более моделей-кандидатов "выполняются" с использованием поднабора тестирования, и прогнозные результаты собираются.
[0128] - ПРОВЕРКА И ОЦЕНКА
[0129] В случаях, когда несколько моделей-кандидатов создаются и тестируются с использованием тех же соответствующих обучающих и тестирующих поднаборов, прогнозы моделей-кандидатов могут сравниваться и сопоставляться друг с другом, и из анализа могут быть выведены уровни достоверности каждой модели-кандидата (по меньшей мере среди моделей-кандидатов). Однако в соответствии с другими вариантами осуществления, прогнозирующие выходы моделей-кандидатов (то есть, прогнозные операционные результаты) также могут тестироваться на третьем поднаборе 826 (далее поднаборе проверки). Различные метрики ошибок генерируются для каждой модели-кандидата на основе поднабора проверки, такие как среднеквадратичные ошибки (RMSE), средняя абсолютная ошибка в процентах (MAPE) и другие пользовательские метрики.
[0130] Кроме того, метрики ошибок для каждой модели- кандидата могут учитывать качество базовых данных, используемых для создания и тестирования модели. Например, рассмотрим ситуацию, когда множество рабочих процессов сегментации осуществляется на основе различных схем определения. Множество рабочих процессов сегментации могут привести к различным (хотя концептуально перекрывающимся) сокращенным наборам данных, и различные наборы моделей-кандидатов могут быть созданы на основе каждого сокращенного набора данных. Однако метрика качества данных в каждом сокращенном наборе данных может не быть одинаковой. Метрика качества может быть ниже для сокращенных наборов данных, где значительные данные отсутствуют, и выше для сокращенных наборов данных, где присутствует больше релевантных данных. Кроме того, статистический анализ каждого сокращенного набора данных может выявить более высокие или более низкие доверительные интервалы для данных в сокращенном наборе данных.
[0131] Таким образом, метрики ошибок, созданные для каждой модели-кандидата, могут включать в себя вклады не только из анализа по отношению к поднабору проверки, но и также вклады, основанные на метриках качества сокращенного набора данных, из которого была построена и тестирована модель-кандидат.
[0132] Рассмотрим, в качестве примера, множество моделей-кандидатов, созданных на основе сокращенного набора данных, созданного с целью прогнозирования ROP. То есть, данные датчиков и контекстные данные от множества соседних скважин, в том числе фактическая ROP, экспериментально полученная во множестве соседних скважин, могут быть проанализированы, и определены корреляции. Сегментация может, таким образом, создать сокращенный набор данных, и сокращенный набор данных может быть затем разделен на поднаборы обучения, тестирования и проверки. Одна или более моделей-кандидатов могут обучаться и тестироваться, и прогнозы ROP моделей-кандидатов могут сравниваться с "актуальной" ROP поднабора проверки. Различные метрики ошибок могут быть определены для сравнения прогнозной и фактической ROP и настроены на основе метрик качества сокращенного набора данных. В некоторых случаях, одна или более моделей могут быть отброшены на основе метрик ошибок. В других случаях, однако, модели-кандидаты могут быть ранжированы для будущего использования.
[0133] ПРОГНОЗНАЯ АНАЛИТИКА
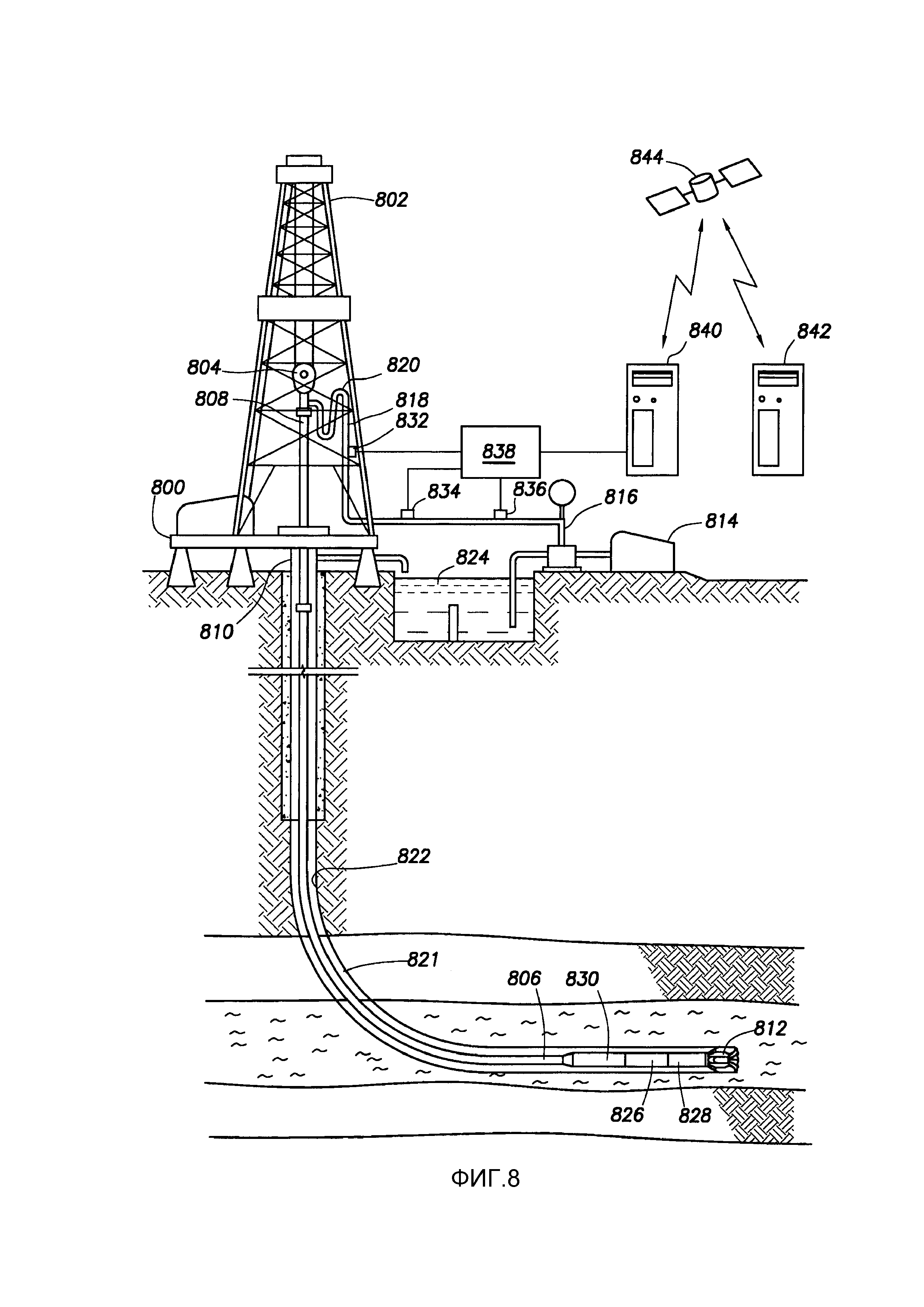
[0134] Вновь со ссылкой на фиг. 1, следующим этапом в примерных способах и системах является рабочий процесс 104 прогнозной аналитики. Прогнозную аналитику можно рассматривать как имеющую две формы - прогнозирование операционных результатов перед операцией бурения (т.е. на этапах проектирования ствола скважины) и прогнозирование операционных результатов во время операции бурения. Аспекты прогнозирования операционных результатов перед операцией бурения по существу описаны выше. Для того чтобы обеспечить контекст для прогнозирования операционных результатов во время операции бурения, ссылка делается на примерную буровую систему по фиг. 8.
[0135] - ПРИМЕРНАЯ ОПЕРАЦИОННАЯ СРЕДА
[0136] Фиг. 8 показывает операцию бурения в соответствии с по меньшей мере некоторыми вариантами осуществления. В частности, фиг. 8 изображает буровую платформу 800, оснащенную буровой вышкой 802, которая поддерживает подъемник 804. Бурение в соответствии с некоторыми вариантами осуществления выполняется колонной бурильных труб, соединенных вместе с помощью "замковых" соединений так, чтобы образовать бурильную колонну 806. Подъемник 804 подвешивает верхний привод 808, который используется для вращения бурильной колонны 806, по мере того как подъемник спускает бурильную колонну через устье скважины 810. С нижним концом бурильной колонны 806 соединено буровое долото 812. Буровое долото 812 вращается, и бурение выполняется путем вращения бурильной колонны 806, с использованием скважинного гидравлического забойного двигателя (не показан) рядом с буровым долотом 812, который вращает буровое долото, или обоими способами. Буровой раствор закачивается буровым насосом 814 через нагнетательный трубопровод 816, буровой стояк 818, S-образное колено 820, верхний привод 808 и вниз по бурильной колонне 806 при высоких давлениях и объемах, чтобы выйти через сопла или форсунки в буровое долото 812. Затем буровой раствор проходит вверх по стволу скважины через кольцевое пространство 821, образованное между внешней стороной бурильной колонны 806 и стенкой 822 скважины, через противовыбросовый превентор (не показан) и в приемную емкость 824 для бурового раствора на поверхности. На поверхности буровой раствор очищается и затем снова нагнетается буровым насосом 814. Буровой раствор используется, чтобы охлаждать буровое долото 812, переносить буровой шлам из нижней части ствола скважины на поверхность и балансировать гидростатическое давление в скальных породах.
[0137] В соответствии с различными вариантами осуществления, бурильная колонна 806 может содержать различные инструменты, которые создают данные датчиков, такие как LWD инструмент 826 и MWD инструмент 828. Различие между LWD и MWD несколько расплывчато в промышленности, но для целей этого описания и формулы изобретения, LWD инструменты измеряют свойства окружающего пласта (например, пористость, проницаемость) и MWD инструменты измеряют свойства, ассоциированные со стволом скважины (например, наклон и направление). Инструменты 826 и 828 могут быть соединены с модулем 830 телеметрии, который передает данные на поверхность. В некоторых вариантах осуществления модуль 830 телеметрии посылает данные датчиков на поверхность электромагнитным способом. В других случаях модуль 830 телеметрии посылает данные датчиков на поверхность посредством электрических или оптических проводников, погруженных в трубы, которые составляют бурильную колонну 806. В других случаях модуль 830 телеметрии модулирует сопротивление потоку буровой жидкости в бурильной колонне, чтобы генерировать импульсы давления, которые распространяются со скоростью звука в буровом растворе на поверхность, и где данные датчиков закодированы в импульсах давления.
[0138] Еще со ссылкой на фиг. 8, в иллюстративном случае данных датчиков, закодированных в импульсах давления, которые распространяются к поверхности, один или несколько преобразователей, таких как преобразователи 832, 834 и/или 836, преобразуют сигнал давления в электрические сигналы для устройства 838 оцифровки сигнала (например, аналого-цифрового преобразователя). Дополнительные наземные датчики, создающие данные датчиков (например, приборы измерения RPM, приборы измерения бурового давления, приборы измерения уровня приемной емкости для бурового раствора) могут также присутствовать, но не показаны, чтобы не усложнять чертеж. Устройство 838 оцифровки выдает в цифровой форме измерения множества датчиков на компьютер 840 или в устройство обработки данных в некоторой другой форме. Компьютер 840 работает в соответствии с программным обеспечением (которое может быть сохранено на машиночитаемом носителе), чтобы обрабатывать и декодировать принятые сигналы и чтобы выполнять прогнозирование операционных результатов на основе моделей, созданных, как описано выше.
[0139] В соответствии с по меньшей мере некоторыми вариантами осуществления по меньшей мере часть данных датчиков из операции бурения применяется (компьютерной системой 840) к одной или более моделям, и выполняются прогнозирования операционных результатов. Прогнозы могут помогать бурильщику при внесении изменений и/или поправок в параметры бурения, таких как изменения направления или изменения, чтобы лучше контролировать операционный результат (например, изменения нагрузки на буровое долото для управления ROP). В других примерных вариантах осуществления компьютер 840 на поверхности может собирать данные датчиков и затем пересылать данные датчиков на другую компьютерную систему 842, такую как компьютерная система в домашнем офисе провайдера услуг нефтяного промысла, путем удаленного подключения. Используя данные датчиков, компьютерная система 842 может исполнять модели для предсказания операционного результата в операции бурения, а также предоставлять прогнозируемый операционный результат бурильщику через компьютерную систему 840. Передача данных между компьютерной системой 840 и компьютерной системой 842 может иметь любую подходящую форму, например, через Интернет, через локальную или глобальную сеть или, как показано, по спутниковому каналу связи 844.
[0140] Далее настоящее описание обращается к примерным операционным методам, в которых могут быть использованы различные модели, созданные выше.
[0141] - ОПЕРАЦИОННЫЕ МЕТОДЫ
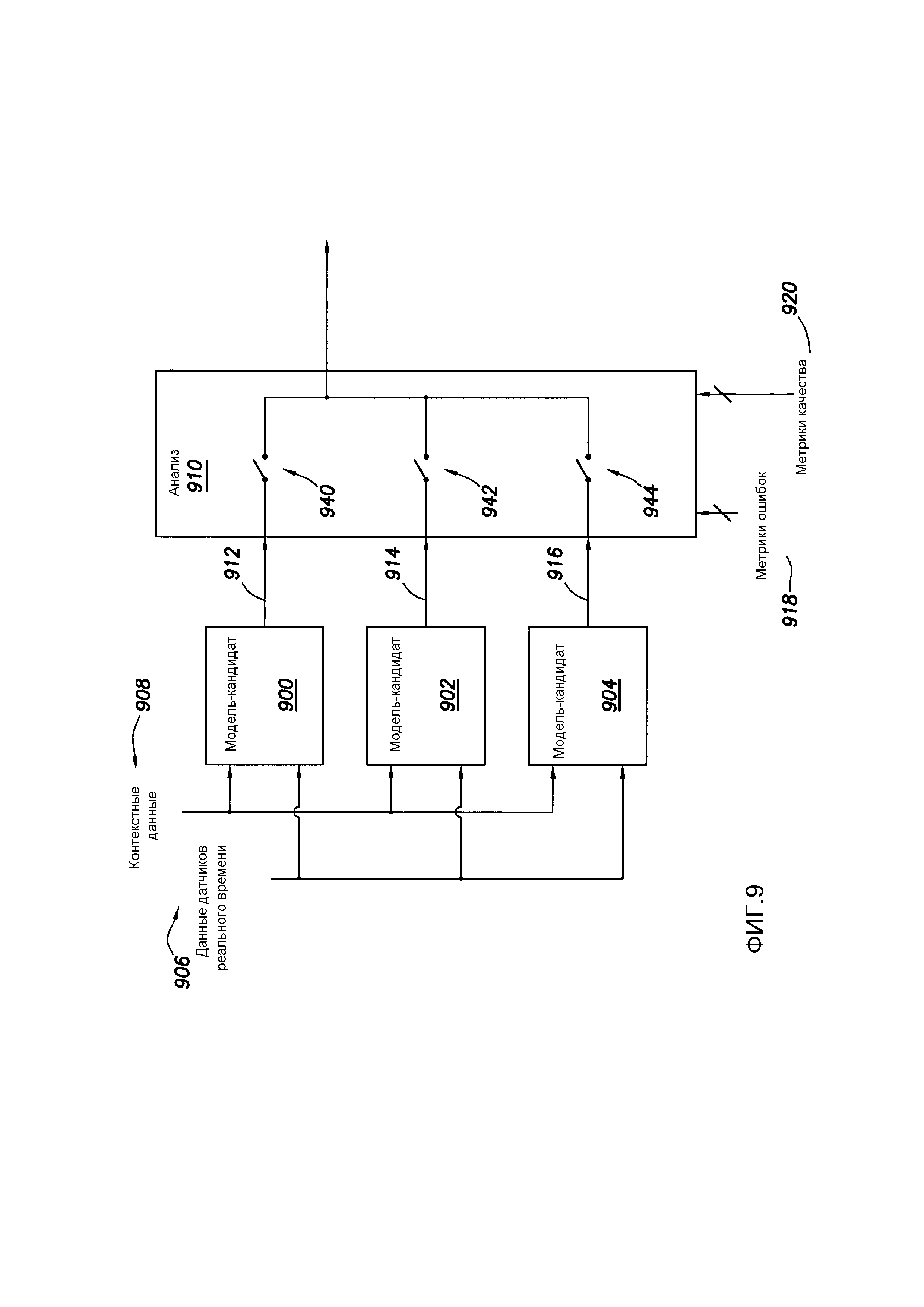
[0142] Фиг. 9 показывает в форме блок-схемы примерную систему использования моделей, созданных в соответствии с рабочими процессами, рассмотренными выше. Более конкретно, фиг. 9 показывает примерный метод с точки зрения различных моделей в прогнозных аспектах в процессе бурения. В частности, фиг. 9 показывает три модели-кандидата 900, 902 и 904, хотя могут быть использованы две или более моделей-кандидатов. Эти модели-кандидаты могут быть созданы в соответствии с рабочим процессом 102 анализа данных и формирования модели, описанным выше. В некоторых случаях, каждая модель-кандидат основана на том же сокращенном наборе данных, однако в других случаях каждая модель-кандидат может быть создана на основе различных сокращенных наборов данных. Независимо от конкретной ситуации, касающейся создания моделей-кандидатов, каждая модель-кандидат коммуникативно связана с данными датчиков 906 реального времени и связанными контекстными данными 908. Во время бурения, каждая модель-кандидат производит прогнозируемый операционный результат, причем этот операционный результат коммуникативно связан с процессором 910 анализа, как показано стрелками 912, 914 и 918, соответственно. Кроме того, процессор 910 анализа может иметь доступ к другим данным, которые полезны при оценке выхода каждой модели-кандидата, таким как метрики 918 ошибок и метрики 920 качества в отношении каждой модели-кандидата, как описано выше.
[0143] С использованием прогнозных выходов и, возможно, дополнительных метрик, процессор анализа в примерных вариантах осуществления выбирает одну из моделей-кандидатов в качестве активной модели для прогнозирования операционных результатов. Другими словами, в этих примерных системах процессор 910 анализа выполняет анализ и действует как мультиплексор, чтобы выбрать одну модель-кандидат в качестве активной модели, и передает прогноз процессора 910 анализа для предоставления бурильщику. Например, если выбрана модель-кандидат 900, логический переключатель 940 может быть замкнут, в то время как логические переключатели 942 и 944 могут быть разомкнуты. Следует понимать, что не требуется обязательно физический переключатель, соответствующий переключателям 940, 942 и 944, так как эти функции реализуются в программном обеспечении либо посредством локальной компьютерной системы 840, удаленной компьютерной системы 842, либо комбинации компьютерных систем.
[0144] В некоторых случаях модель-кандидат выбирается и активируется в качестве активной модели для всей продолжительности процесса бурения. Однако в других примерных вариантах осуществления выбранная модель-кандидат может изменяться по времени/глубине пробуриваемого ствола скважины. Например, модель-кандидат 900 может быть более эффективной в прогнозировании операционных результатов в течение определенного времени в процессе бурения (например, при бурении вертикальной части), и в течение такого времени процессор анализа может выбрать модель-кандидат 900 в качестве активной модели. Однако модель-кандидат 902 может быть более эффективной в прогнозировании операционного результата в течение других времен процесса бурения (например, в течение периодов времени, когда траектория скважины меняется), и в течение таких периодов времени процессор анализа может выбрать модель-кандидат 902 в качестве активной модели. Кроме того, модель-кандидат 904 может быть более эффективной в прогнозировании операционного результата в течение третьих периодов времени процесса бурения (например, в течение периодов времени, когда траектория бурения по существу горизонтальна), и в течение таких периодов времени процессор анализа может выбрать модель-кандидат 904 в качестве активной модели.
[0145] В еще одних случаях, модели-кандидаты могут быть эквивалентны с точки зрения сокращенного набора данных, используемого для обучения, тестирования и проверки, и могут все прогнозировать тот же самый операционный результат в процессе бурения. Однако процессор 910 анализа может поддерживать одну модель (например, модель-кандидат 900) как активную модель до тех пор, пока одна или более ошибок и/или метрик качества, созданных в реальном времени с бурением, показывают, что ошибка увеличивается и/или качество прогнозирования снижается. Одновременно с моделью-кандидатом 900, являющейся активной моделью, другая модель (например, модель-кандидат 902) может быть принята оф-лайн (то есть, не прогнозирует операционный результат), и вместо этого оф-лайн модель может быть помещена в обучающий режим с использованием данных датчиков реального времени, связанных контекстных данных и фактического операционного результата ожидаемой операции бурения. В момент времени, когда ошибки и/или метрики качества указывают, что примерная модель-кандидат 900 превысила предопределенное пороговое значение, модель-кандидат 902 может быть активирована в качестве активной модели, а бывшая активная модель может быть помещена обратно в рабочий процесс для дальнейшего обучения на основе данных датчиков и связанных контекстных данных, применимых к пробуриваемому стволу скважины.
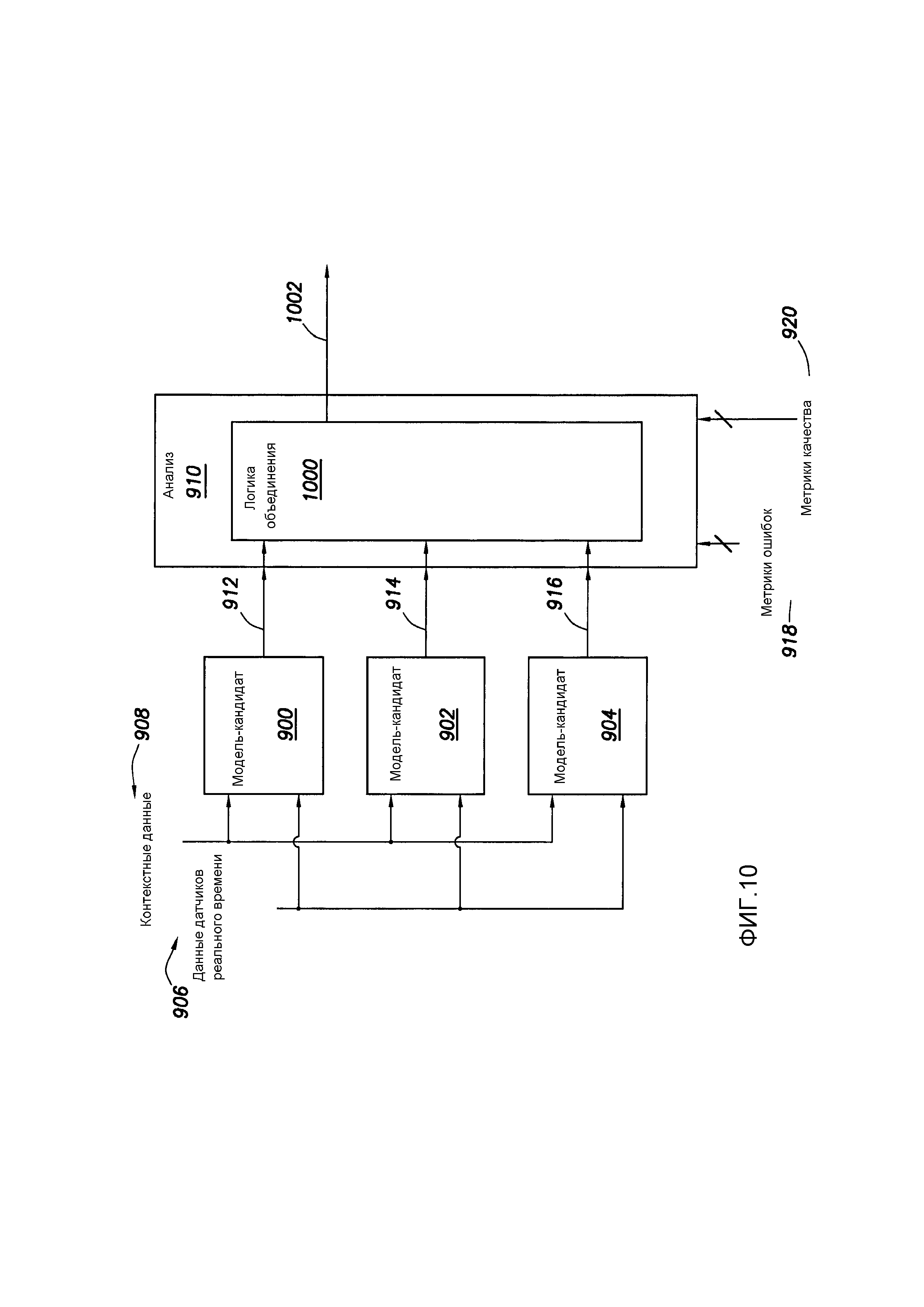
[0146] Фиг. 10 показывает в форме блок-схемы альтернативную примерную систему использования моделей, созданных в соответствии с рабочими процессами, рассмотренными выше. Более конкретно, фиг. 10 показывает альтернативные примерные методы в отношении различных моделей в прогнозных аспектах в процессе бурения. В частности, фиг. 10 показывает функциональную установку, эквивалентную фиг. 9, в плане коммуникативной связи моделей-кандидатов, данных датчиков реального времени и различных метрик ошибок. Как и в некоторых операционных методах, обсужденных со ссылкой на фиг. 9, на фиг.10 во время бурения каждая модель-кандидат вырабатывает прогнозируемый операционный результат. В отличие от фиг. 9, где прогнозный операционный результат выбирается взаимно исключающим образом из моделей-кандидатов, фиг. 10 иллюстрирует операционную философию, где прогнозируемый операционный результат создается путем объединения прогнозирующих выходов каждой модели-кандидата.
[0147] В частности, в процессоре 910 анализа примерной системы может быть программным образом реализована логика 1000 объединения. Логика 950 объединения объединяет прогнозные операционные результаты каждой модели-кандидата 900, 902 и 904 для получения одного прогнозного операционного результата 1002. В случае прогнозных операционных результатов в форме действительных чисел, логика 950 объединения объединяет их любым подходящим способом, таким как усреднение, статически взвешенное усреднение на основе метрик ошибок/качества (т.е., по всему диапазону времени/глубины, представляющему интерес) и/или динамически взвешенное усреднение, которое принимает во внимание изменения в метриках ошибок/качества для каждой модели- кандидата в зависимости от времени/глубины.
[0148] В ситуациях, когда прогнозируемый операционный результат является будущим булевым событием (например, будущее событие прихвата труб), прогнозы моделей-кандидатов также могут быть объединены статически или динамически взвешенным образом для получения булева прогноза.
[0149] Следует отметить, что операционные методы, рассмотренные в связи с фиг. 9 и 10, являются сами по себе не взаимоисключающими. В некоторых случаях группы моделей-кандидатов (например, каждая соответствующая группа моделей-кандидатов, созданных на основе соответствующих и различных сокращенных наборов данных) могут иметь соответствующие выходы, объединенные способом, как описано со ссылкой на фиг. 10, но процессор анализа может осуществить выбор в режиме мультиплексора среди выходов, созданных соответствующей логикой 1000 объединения.
[0150] Конечным результатом является прогнозный операционный результат, предоставляемый бурильщику, причем бурильщик может затем вносить изменения в параметр бурения на основе прогноза(ов).
[0151] СООБРАЖЕНИЯ РЕАЛИЗАЦИИ
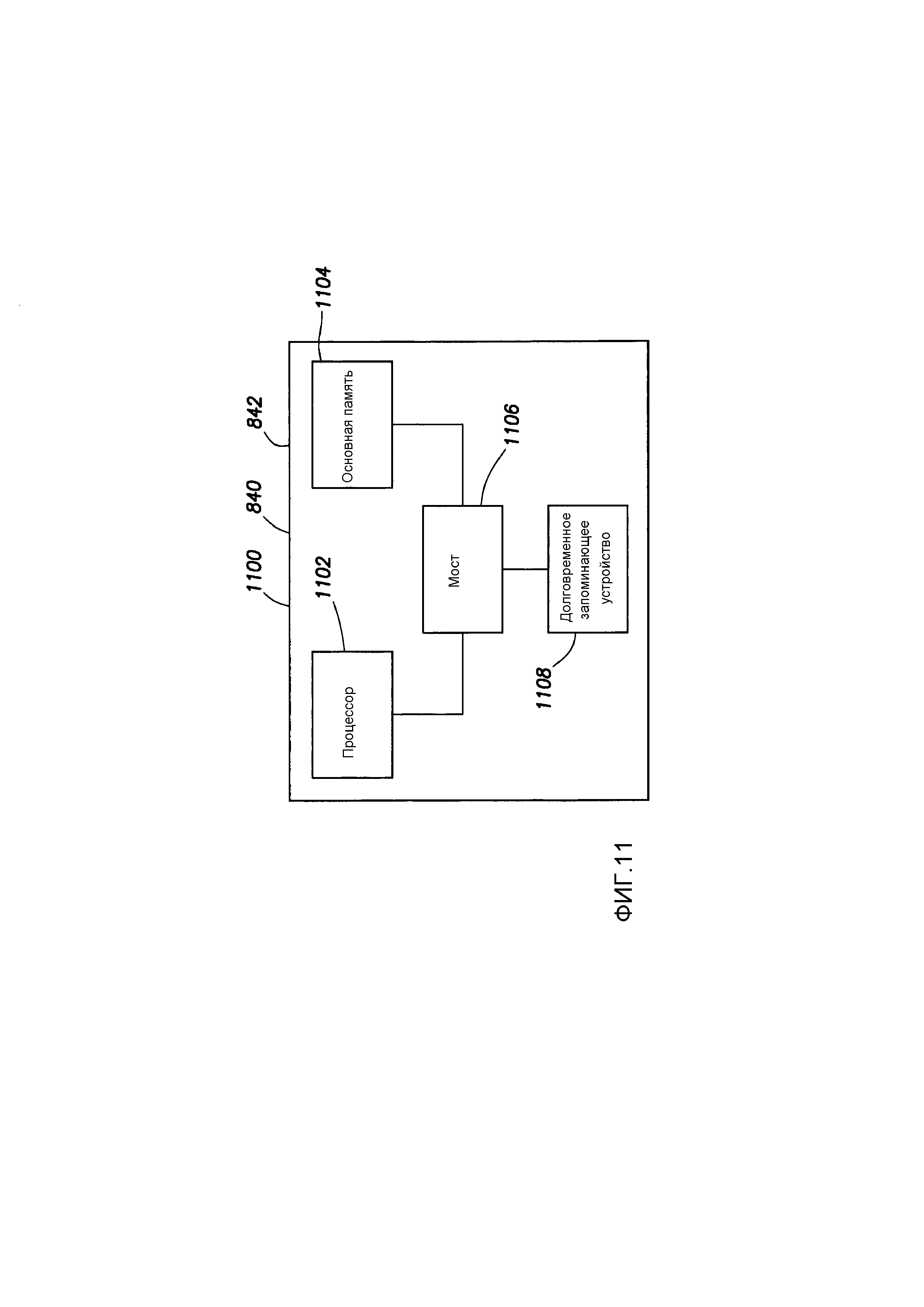
[0152] Фиг. 1 показывает компьютерную систему 1100, которая является иллюстративной компьютерной системой, на которой могут быть практически реализованы любые из различных вариантов осуществления или их части. Компьютерная система 1100 может иллюстрировать, например, компьютерную систему 840 или 842. В частности, компьютерная система 1100 включает в себя процессор 1102, и процессор связан с основной памятью 1104 посредством мостового устройства 1106. Кроме того, процессор 1102 может связываться с долговременным запоминающим устройством 1108 (например, накопителем на жестком диске, твердотельным диском, модулем памяти, оптическим диском) посредством мостового устройства 1106. Программы, исполняемые процессором 1102, могут быть сохранены на запоминающем устройстве 1108, и обеспечивается доступ к ним в случае необходимости с помощью процессора 1102. Программы, сохраненные на запоминающем устройстве 1108, могут включать в себя программы для реализации различных вариантов осуществления согласно настоящему описанию, таких как показанные на фиг. 1. В некоторых случаях программы копируются из запоминающего устройства 108 в основную память 1104, и программы исполняются из основной памяти 1104. Таким образом, основная память 1104 и запоминающее устройство 1108 должны рассматриваться как считываемые компьютером носители информации.
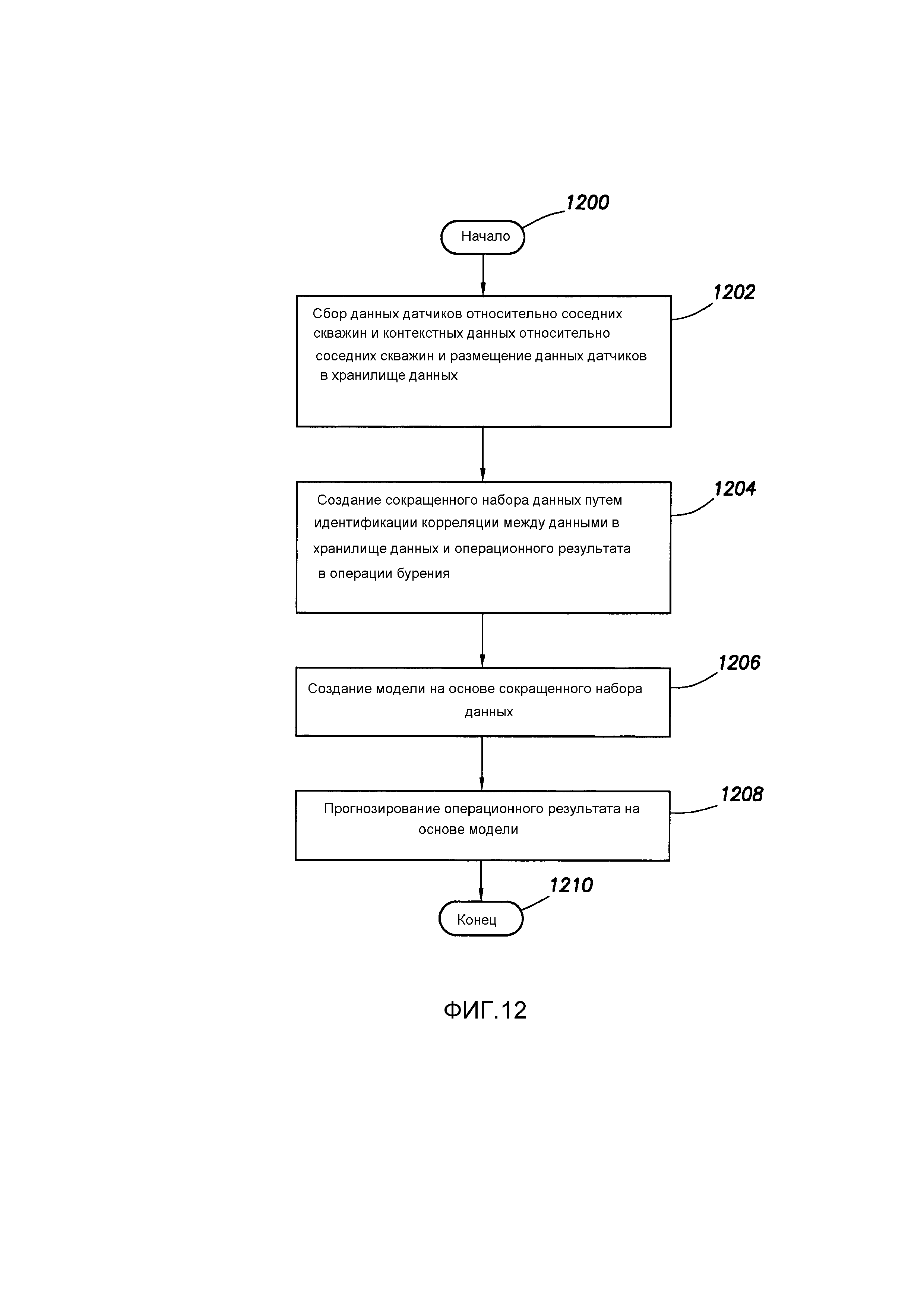
[0153] Фиг. 12 показывает способ (часть из которого может выполняться как программа) в соответствии с по меньшей мере некоторыми вариантами осуществления. В частности, способ начинается (блок 1200) и включает в себя: сбор данных датчиков относительно соседних скважин и контекстных данных относительно соседних скважин, а также размещение данных датчиков и контекстных данных в хранилище данных (блок 1202); создание сокращенного набора данных путем идентификации корреляции между данными в хранилище данных и операционным результатом в процессе бурения (блок 1204); создание модели, основанной на сокращенном наборе данных (блок 1206); и прогнозирование операционного результата на основе модели (блок 1208). В некоторых случаях примерный способ может быть немедленно перезапущен.
[0154] Следует отметить, что хотя теоретически можно выполнять некоторые или все из вычислений, кластеризации, анализа данных и/или моделирования человеком с использованием только карандаша и бумаги, временные измерения для ориентированной на человека эффективности таких задач может находиться в диапазоне от человеко-лет до человеко-десятилетий, если не больше. Таким образом, настоящий абзац должен служить в качестве поддержки для любого ограничения пунктов формулы, существующих сейчас или добавленных позже, устанавливая, что период времени, чтобы выполнить любую задачу, описанную здесь, меньше, чем время, необходимое для выполнения этой задачи вручную, меньше, чем половина времени, чтобы выполнить задачу вручную, и меньше, чем одна четверть времени, чтобы выполнить задачу вручную, где "вручную" относится к выполнению работ с использованием исключительно карандаша и бумаги.
[0155] Из описания, представленного здесь, специалист в данной области техники легко сможет объединить методы, описанные выше, в виде программного обеспечения с соответствующими аппаратными средствами компьютера общего назначения или специального назначения, чтобы создать компьютерную систему и/или компьютерные субкомпоненты, воплощающие изобретение, чтобы создать компьютерную систему и/или компьютерные субкомпоненты для осуществления способа по настоящему изобретению, и/или чтобы создать не-временные (нетранзиторные) считываемые компьютером носители (то есть, не несущую волну) для хранения программного обеспечения для реализации аспектов способа согласно изобретению.
[0158] Приведенное выше обсуждение предназначено для иллюстрации принципов и различных вариантов осуществления настоящего изобретения. Многочисленные вариации и модификации станут очевидными специалистам в данной области техники на основе изучения приведенного выше описания. Предполагается, что следующие пункты формулы изобретения должны интерпретироваться так, чтобы охватывать все такие варианты и модификации.
[0157] По меньшей мере некоторые из иллюстративных вариантов являются способами, включающими в себя: сбор данных датчиков относительно соседних скважин и контекстных данных относительно соседних скважин, и размещение данных датчиков и контекстных данных в хранилище данных; создание сокращенного набора данных путем определения корреляции между данными в хранилище данных и операционным результатом в операции бурения; создание модели, основанной на сокращенном наборе данных; и прогнозирование операционного результата на основе модели.
[0158] Прогнозирование в способе может дополнительно содержать прогнозирование операционного результата до операции бурения.
[0159] Изменение способа может дополнительно включать в себя изменение запланированных параметров бурения на основе прогнозирования операционного результата.
[0160] Способ может дополнительно содержать: способ, в котором сбор дополнительно содержит сбор в реальном времени данных датчиков и контекстных данных, относительно ствола скважины при бурении ствола скважины; и способ, в котором прогнозирование дополнительно содержит прогнозирование будущих значений операционного результата во время операции бурения ствола скважины.
[0161] Способ может дополнительно содержать изменение параметра бурения в ответ на будущие значения операционного результата.
[0162] Создание сокращенного набора данных в способе может дополнительно содержать: считывание многомерной структуры данных из по меньшей мере части хранилища данных; идентификацию корреляции между частями данных датчиков и частями контекстных данных в многомерной структуре данных, корреляции, прогнозирующей операционный результат, и корреляции, не выбранной перед идентификацией; и сегментацию многомерной структуры данных для получения сокращенного набора данных.
[0163] Сегментация в способе может дополнительно содержать сегментацию посредством алгоритма машинного обучения.
[0164] Сегментация посредством алгоритма машинного обучения может дополнительно содержать создание обучающего набора данных на основе корреляции и обучение алгоритма машинного обучения с использованием обучающего набора данных.
[0165] Способ может дополнительно содержать выполнение очистки данных на сокращенном наборе данных.
[0166] Способ может содержать: способ, в котором создание модели дополнительно содержит создание первой модели-кандидата и второй модели-кандидата; и в котором прогнозирование операционных параметров дополнительно содержит: прогнозирование операционного результата с использованием первой модели- кандидата, создавая при этом первый прогноз; прогнозирование операционного результата с использованием второй модели- кандидата, создавая при этом второй прогноз; и выбор между первым прогнозом и вторым прогнозом на основе индикации ошибки каждого прогноза.
[0167] Прогнозирование в способе может дополнительно содержать прогнозирование по меньшей мере одного события из группы, состоящей из: события прихвата труб и избыточного отклонения направления бурения.
[0168] Другими иллюстративными вариантами осуществления являются компьютерные системы, содержащие: процессор; память, связанную с процессором; и устройство отображения, связанное с процессором. Память хранит программу, которая при выполнении процессором, побуждает процессор: собирать данные датчиков относительно соседних скважин и контекстные данные относительно соседних скважин, и размещать данные датчиков и контекстные данные в хранилище данных; создавать сокращенный набор данных путем идентификации корреляции между данными в хранилище данных и операционным результатом в операции бурения; создавать по меньшей мере одну модель на основе сокращенного набора данных; и предсказывать операционный результат на основе по меньшей мере одной модели.
[0169] В компьютерной системе, когда процессор прогнозирует, программа побуждает процессор прогнозировать операционный результат перед операцией бурения.
[0170] В компьютерной системе, программа дополнительно побуждает процессор выполнять по меньшей мере одно выбранное из группы, состоящей из: изменения запланированного параметра бурения на основе прогнозирования операционного результата; и изменения параметра бурения во время бурения, причем изменение основано на прогнозировании операционного результата.
[0171] В компьютерной системе: когда процессор выполняет сбор данных, программа дополнительно побуждает процессор собирать в реальном времени данные датчиков и контекстные данные относительно ствола скважины при бурении ствола скважины; и, когда процессор прогнозирует, программа дополнительно побуждает процессор прогнозировать будущие значения операционного результата во время операции бурения ствола скважины.
[0172] В компьютерной системе программа дополнительно побуждает процессор изменять параметр бурения в ответ на будущие значения операционного результата.
[0173] В вычислительной системе, когда процессор создает сокращенные данные, программа побуждает процессор: считывать многомерную структуру данных из по меньшей мере части хранилища данных; идентифицировать корреляцию между частями данных датчиков и частями контекстных данных в многомерной структуре данных, корреляцию, прогнозирующую операционный результат, и корреляцию, не выбранную перед идентификацией; и сегментировать многомерную структуру данных для получения сокращенного набора данных.
[0174] В компьютерной системе программа дополнительно побуждает процессор выполнять очистку данных на сокращенном наборе данных.
[0175] В компьютерной системе, когда процессор прогнозирует, программа побуждает процессор прогнозировать будущее появление по меньшей мере одного события из группы, состоящей из: события прихвата труб и избыточного отклонения направления бурения.
Реферат
Изобретение относится к области геофизики и может быть использовано для прогнозирования операционных результатов операции бурения. По меньшей мере некоторыми из иллюстративных вариантов осуществления являются способы, включающие в себя сбор данных датчиков относительно соседних скважин и контекстных данных относительно соседних скважин и размещение данных датчиков и контекстных данных в хранилище данных, создание сокращенного набора данных посредством идентификации корреляции между данными в хранилище данных и операционным результатом в операции бурения, создание модели на основе сокращенного набора данных и прогнозирование операционного результата на основе модели. При этом контекстные данные относятся к аспектам бурения, которые не измеряются физическими датчиками, ассоциированными с операцией бурения. Технический результат - повышение достоверности прогнозирования операционных результатов операции бурения. 3 н. и 24 з.п. ф-лы, 12 ил.
Формула
сбор данных датчиков относительно соседних скважин и контекстных данных относительно соседних скважин и размещение данных датчиков и контекстных данных в хранилище данных; причем контекстные данные относятся к аспектам операции бурения, которые не измеряются физическими датчиками, ассоциированными с операцией бурения;
создание сокращенного набора данных путем идентификации корреляции между данными в хранилище данных и операционным результатом в операции бурения;
создание модели на основе сокращенного набора данных; и
прогнозирование операционного результата на основе модели.
причем сбор дополнительно включает в себя сбор в реальном времени данных датчиков и контекстных данных относительно ствола скважины во время операции бурения ствола скважины; и
причем прогнозирование дополнительно содержит прогнозирование будущих значений операционного результата во время операции бурения ствола скважины.
считывание многомерной структуры данных из по меньшей мере части хранилища данных;
идентификацию корреляции между частями данных датчиков и частями контекстных данных в многомерной структуре данных, корреляции, прогнозирующей операционный результат, и корреляции, не выбранной перед идентификацией; и
сегментацию многомерной структуры данных для получения сокращенного набора данных.
создание обучающего набора данных на основе корреляции; и
обучение алгоритма машинного обучения с использованием обучающего набора данных.
причем создание модели, дополнительно содержит создание первой модели-кандидата модель и второй модели-кандидата;
причем прогнозирование операционного параметра дополнительно содержит:
прогнозирование операционного результата с использованием первой модели-кандидата, тем самым создавая первый прогноз;
прогнозирование операционного результата с использованием второй модели-кандидата, тем самым создавая второй прогноз; и
выбор между первым прогнозом и вторым прогнозом на основе индикации ошибки каждого прогноза.
процессор;
память, связанную с процессором;
устройство отображения, связанное с процессором;
причем память хранит программу, которая, при выполнении процессором, побуждает процессор:
собирать данные датчиков относительно соседних скважин и контекстные данные относительно соседних скважин и размещать данные датчиков и контекстные данные в хранилище данных; причем контекстные данные относятся к аспектам операции бурения, которые не измеряются физическими датчиками, ассоциированными с операцией бурения;
создавать сокращенный набор данных посредством идентификации корреляции между данными в хранилище данных и операционным результатом в операции бурения;
создавать по меньшей мере одну модель на основе сокращенного набора данных; и
прогнозировать операционный результат на основе по меньшей мере одной модели.
причем, когда процессор выполняет сбор данных, программа дополнительно побуждает процессор собирать в реальном времени данные датчиков и контекстные данные относительно ствола скважины во время операции бурения ствола скважины; и
причем, когда процессор прогнозирует, программа дополнительно побуждает процессор прогнозировать будущие значения операционного результата во время операции бурения ствола скважины.
считывать многомерную структуру данных из по меньшей мере части хранилища данных;
идентифицировать корреляцию между частями данных датчиков и части контекстных данных в многомерной структуре данных, корреляцию, прогнозирующую операционный результат, и корреляцию, не выбранную перед идентификацией; и
сегментировать многомерную структуру данных для получения сокращенного набора данных.
собирать данные датчиков относительно соседних скважин и контекстные данные относительно соседних скважин и помещать данные датчиков и контекстные данные в хранилище данных; причем контекстные данные относятся к аспектам операции бурения, которые не измеряются физическими датчиками, ассоциированными с операцией бурения,
создавать сокращенный набор данных путем идентификации корреляции между данными в хранилище данных и операционным результатом в операции бурения;
создавать по меньшей мере одну модель на основе сокращенного набора данных; и
прогнозировать операционный результат на основе по меньшей мере одной модели.
когда процессор выполняет сбор данных, программа дополнительно побуждает процессор собирать в реальном времени данные датчиков и контекстные данные относительно ствола скважины при бурении ствола скважины; и
когда процессор прогнозирует, программа дополнительно побуждает процессор прогнозировать будущие значения операционного результата во время операции бурения ствола скважины.
считывать многомерную структуру данных из по меньшей мере части хранилища данных;
идентифицировать корреляцию между частями данных датчиков и частями контекстных данных в многомерной структуре данных, корреляцию, прогнозирующую операционный результат, и корреляцию, не выбранную перед идентификацией; и
сегментировать многомерную структуру данных для получения сокращенного набора данных.
Комментарии