Способы неинвазивного пренатального установления плоидности - RU2671980C2
Код документа: RU2671980C2
Чертежи

















Описание
Ссылка на родственные заявки
По настоящей заявке испрашивается приоритет по дате подачи предварительной заявки на выдачу патента США №61/462972, которая была подана 9 февраля 2011 г.; предварительной заявки на выдачу патента США №61/448547, которая была подана 2 марта 2011 г.; предварительной заявки на выдачу патента США №61/516996, которая была подана 12 апреля 2011 г.; заявки на выдачу патента США на изобретение с серийным №13/110685, которая была подана 18 мая 2011 г., и предварительной заявки на выдачу патента США №61/571248, которая была подана 23 июня 2011 г., и все эти заявки полностью включены в настоящий документ посредством ссылки.
Область техники, к которой относится настоящее изобретение
Настоящее раскрытие, по сути, относится к способам неинвазивного пренатального установления плоидности.
Предшествующий уровень техники настоящего изобретения
Современные способы пренатальной диагностики могут предупреждать врачей и родителей о патологиях у растущего плода. Без пренатальной диагностики один из 50 малышей рождается с серьезным физическим или умственным дефектом, а один из 30 будет страдать некоторой формой врожденного порока развития. К сожалению, стандартные способы либо обладают недостаточной точностью, либо предусматривают инвазивную процедуру, которая несет риск самопроизвольного аборта. Способы на основе содержания гормонов в крови матери или ультразвуковые измерения являются неинвазивными, однако, они также характеризуются низкой точностью. Способы, такие как амниоцентез, проба ворсинчатого хориона и забор образцов плодной крови, характеризуются высокой точностью, но являются инвазивными и влекут за собой существенный риск. Амниоцентез выполнялся при приблизительно 3% всех беременностей в США, хотя за последнее десятилетие частота его применения снизилась наполовину.
Недавно было открыто, что бесклеточная плодная ДНК и интактные плодные клетки могут попадать в материнский кровоток. Следовательно, анализ этого генетического материала может обеспечить раннюю неинвазивную пренатальную генетическую диагностику (NPD).
В норме у людей в каждой здоровой диплоидной клетке имеется два набора из 23 хромосом - по одной копии, полученной от каждого родителя. Анеуплоидия, состояние ядерной клетки, при котором клетка содержит слишком много и/или слишком мало хромосом, как полагают, отвечает за большое процентное отношение неудачных имплантаций, самопроизвольных абортов и генетических заболеваний. Выявление хромосомных аномалий может идентифицировать индивидуумов или эмбрионов с состояниями, такими как синдром Дауна, синдром Клайнфельтера и синдром Тернера, среди прочих, вдобавок к повышающимся шансам успешной беременности. Тестирование по хромосомным аномалиям является особенно важным, если мать в возрасте: подсчитано, что у матерей возрастом 35-40 лет по меньшей мере 40% эмбрионов являются аномальными, а у матерей возрастом более 40 лет аномальными являются более половины эмбрионов.
Некоторые тесты, используемые для пренатального скрининга
Низкое содержание ассоциированного с беременностью белка A в плазме (PAPP-A), измеренной в материнской сыворотке крови во время первого триместра, может быть связано с хромосомными аномалиями, в том числе с трисомиями хромосом 13, 18 и 21. Кроме того, низкое содержание PAPP-A в первом триместре может предсказывать неблагоприятный исход беременности, в том числе низкую массу плода для данного гестационного возраста (SGA) или рождение мертвого плода. В первом триместре беременные женщины часто подвергаются анализу сыворотки крови, что обычно предусматривает тестирование женщин на содержание в крови гормонов PAPP-A и бета-хорионического гонадотропина человека (beta-hCG). В некоторых случаях женщины также проходят ультразвуковое исследование на выявление возможных физиологических дефектов. В частности, оценивание затылочной прозрачности (NT) может указать на риск анеуплоидии у плода. Во многих областях стандартный режим пренатального скрининга предусматривает анализ сыворотки крови в первом триместре в комбинации с тестом NT.
Тройной тест, также называемый тройным скринингом, тестом Кеттеринга или тестом Бэрта, представляет собой исследование, проводимое во втором триместре беременности для классификации пациентки в зависимости от высокого риска или низкого риска хромосомных аномалий (и дефектов нервной трубки). Вместо него иногда используется термин «мультимаркерный скрининговый тест». Термин «тройной тест» может охватывать термины «двойной тест», «учетверенный тест», «четырехкомпонентный тест» и «пятикомпонентный тест».
Тройной тест измеряет содержание в сыворотке крови альфа-фетопотеина (AFP), неконъюгированного эстриола (UE3), бета-хорионического гонадотропина человека (beta-hCG), инвазивного трофобластного антигена (ITA) и/или ингибина. Положительный тест означает наличие высокого риска хромосомных аномалий (и дефектов нервной трубки), и такие пациентки затем направляются на более чувствительные и специфичные процедуры для проведения окончательной диагностики, чаще всего инвазивных процедур, подобных амниоцентезу. Тройной тест может быть использован для скрининга ряда состояний, в том числе трисомии 21 (синдрома Дауна). Тройным и учетверенным тестами проверяется, кроме синдрома Дауна, плодная трисомия 18, также известная как синдром Эдвардса, открытые дефекты нервной трубки, а также может выявляться повышенный риск синдрома Тернера, триплоидности, мозаицизма трисомии хромосомы 16, смерти плода, синдрома Смита-Лемли-Омитца и недостаточности стероидной сульфатазы.
Краткое раскрытие настоящего изобретения
В настоящем документе раскрываются способы определения статуса плоидности хромосомы у вынашиваемого плода. Согласно проиллюстрированным в настоящем документе аспектам согласно варианту осуществления способ определения статуса плоидности хромосомы у вынашиваемого плода предусматривает получение первого образца ДНК, который содержит материнскую ДНК от матери плода и плодной ДНК от плода, подготовку первого образца путем выделения ДНК с получением подготовленного образца, измерение ДНК в подготовленном образце во множестве полиморфных локусов в хромосоме, вычисление на компьютере числа аллелей во множестве полиморфных локусов из измерений ДНК, выполненных в подготовленном образце, создание на компьютере множества гипотез плоидности, каждая из которых относится к разному возможному состоянию плоидности хромосомы, построение на компьютере модели совместного распределения для ожидаемых чисел аллелей во множестве полиморфных локусов в хромосоме для каждой гипотезы плоидности, определение на компьютере относительной вероятности каждой из гипотез плоидности с использованием модели совместного распределения и числа аллелей, измеренных в подготовленном образце, и установления состояния плоидности плода путем отбора состояния плоидности, соответствующего гипотезе с наибольшей вероятностью.
Согласно некоторым вариантам осуществления ДНК в первом образце происходит от материнской плазмы. Согласно некоторым вариантам осуществления подготовка первого образца дополнительно предусматривает амплификацию ДНК. Согласно некоторым вариантам осуществления подготовка первого образца дополнительно предусматривает предпочтительное приумножение ДНК в первом образце множеством полиморфных локусов.
Согласно некоторым вариантам осуществления предпочтительное приумножение ДНК в первом образце множеством полиморфных локусов предусматривает получение множества предварительно циркуляризованных зондов, при этом каждый зонд нацелен на один из полиморфных локусов, а 3'- и 5'-концы зондов сконструированы для гибридизации с областью ДНК, которая отделена от полиморфного сайта локуса небольшим количеством оснований, где небольшое количество составляет 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21-25, 26-30, 31-60 или их комбинацию, гибридизацию предварительно циркуляризованных зондов с ДНК из первого образца, заполнение гэпа между концами гибридизированных зондов с использованием ДНК-полимеразы, циркуляризацию предварительно циркуляризованного зонда и амплификацию циркуляризованного зонда.
Согласно некоторым вариантам осуществления предпочтительное приумножение ДНК во множестве полиморфных локусов предусматривает получение множества опосредованных лигированием зондов ПЦР, где каждый зонд ПЦР нацелен на один из полиморфных локусов, и где расположенные выше и ниже зонды ПЦР сконструированы для гибридизации с областью ДНК, на одной цепи ДНК, которая отделена от полиморфного сайта локуса небольшим количеством оснований, при этом небольшое количество составляет 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21-25, 26-30, 31-60 или их комбинацию, гибридизацию опосредованных лигированием зондов ПЦР с ДНК из первого образца, заполнение гэпа между концами опосредованных лигированием зондами ПЦР с использованием ДНК-полимеразы, дотирование опосредованных лигированием зондов ПЦР и амплификацию лигированных опосредованных лигированием зондов ПЦР.
Согласно некоторым вариантам осуществления предпочтительное приумножение ДНК во множестве полиморфных локусов предусматривает получение множества зондов гибридного захвата, которые нацелены на полиморфные локусы, гибридизацию зондов гибридного захвата с ДНК в первом образце и физическое удаление некоторой или всей из негибридизированной ДНК из первого образца ДНК.
Согласно некоторым вариантам осуществления зонды гибридного захвата сконструированы для гибридизации с областью, которая является фланкирующей, но не перекрывающей полиморфный сайт. Согласно некоторым вариантам осуществления зонды гибридного захвата сконструированы для гибридизации с областью, которая является фланкирующей, но не перекрывающей полиморфный сайт, и при этом длина фланкирующего зонда захвата может быть выбрана из группы, состоящей из менее приблизительно 120 оснований, менее приблизительно 110 оснований, менее приблизительно 100 оснований, менее приблизительно 90 оснований, менее приблизительно 80 оснований, менее приблизительно 70 оснований, менее приблизительно 60 оснований, менее приблизительно 50 оснований, менее приблизительно 40 оснований, менее приблизительно 30 оснований и менее приблизительно 25 оснований. Согласно некоторым вариантам осуществления зонды гибридного захвата сконструированы для гибридизации с областью, которая перекрывает полиморфный сайт, и при этом множество зондов гибридного захвата содержит по меньшей мере два зонда гибридного захвата для каждого полиморфного локуса, и каждый зонд гибридного захвата сконструирован комплементарным к другому аллелю в этом полиморфном локусе.
Согласно некоторым вариантам осуществления предпочтительное приумножение ДНК во множестве полиморфных локусов предусматривает получение множества внутренних прямых праймеров, при котором каждый праймер нацелен на один из полиморфных локусов, и при котором 3'-конец внутренних прямых праймеров сконструирован для гибридизации с областью ДНК, расположенной выше от полиморфного сайта и отделенной от полиморфного сайта небольшим количеством оснований, где небольшое количество выбрано из группы, состоящей из 1, 2, 3, 4, 5, 6-10, 11-15, 16-20, 21-25, 26-30 или 31-60 пар оснований, необязательно получение множества внутренних обратных праймеров, при котором каждый праймер нацелен на один из полиморфных локусов, и где 3'-конец внутренних обратных праймеров сконструирован для гибридизации с областью ДНК, расположенной выше от полиморфного сайта и отделенной от полиморфного сайта небольшим количеством оснований, где небольшое количество выбрано из группы, состоящей из 1, 2, 3, 4, 5, 6-10, 11-15, 16-20, 21-25, 26-30 или 31-60 пар оснований, гибридизацию внутренних праймеров с ДНК и амплификацию ДНК с использованием полимеразной цепной реакции для образования ампликонов.
Согласно некоторым вариантам осуществления способ также предусматривает получение множества внешних прямых праймеров, при котором каждый праймер нацелен на один из полиморфных локусов, и при котором внешние прямые праймеры сконструированы для гибридизации с областью ДНК, расположенной выше от внутреннего прямого праймера, необязательно получение множества внешних обратных праймеров, при котором каждый праймер нацелен на один из полиморфных локусов, и где внешние обратные праймеры сконструированы для гибридизации с областью ДНК, расположенной непосредственно после внутреннего обратного праймера, гибридизацию первых праймеров с ДНК и амплификацию ДНК с использованием полимеразной цепной реакции.
Согласно некоторым вариантам осуществления способ также предусматривает получение множества внешних обратных праймеров, где каждый праймер нацелен на один из полиморфных локусов, и где внешние обратные праймеры сконструированы для гибридизации с областью ДНК, расположенной непосредственно после внутреннего обратного праймера, необязательно получение множества внешних прямых праймеров, где каждом праймер нацелен на один из полиморфных локусов, и при котором внешние прямые праймеры сконструированы для гибридизации с областью ДНК, расположенной выше от внутреннего прямого праймера, гибридизацию первых праймеров с ДНК и амплификацию ДНК с использованием полимеразной цепной реакции.
Согласно некоторым вариантам осуществления подготовка первого образца дополнительно предусматривает добавление универсальных адаптеров к ДНК в первом образце и амплификацию ДНК в первом образце с использованием полимеразной цепной реакции. Согласно некоторым вариантам осуществления по меньшей мере фракция ампликонов, которые являются амплифицированными, содержат менее 100 пар оснований, менее 90 пар оснований, менее 80 пар оснований, менее 70 пар оснований, менее 65 пар оснований, менее 60 пар оснований, менее 55 пар оснований, менее 50 пар оснований или менее 45 пар оснований, составляет 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% или 99%.
Согласно некоторым вариантам осуществления амплификация ДНК выполняется в одном или нескольких отдельных объемах реакционной смеси, и при этом каждый отдельный объем реакционной смеси содержит более 100 различных пар прямых и обратных праймеров, более 200 различных пар прямых и обратных праймеров, более 500 различных пар прямых и обратных праймеров, более 1000 различных пар прямых и обратных праймеров, более 2000 различных пар прямых и обратных праймеров, более 5000 различных пар прямых и обратных праймеров, более 10000 различных пар прямых и обратных праймеров, более 20000 различных пар прямых и обратных праймеров, более 50000 различных пар прямых и обратных праймеров или более 100000 различных пар прямых и обратных праймеров.
Согласно некоторым вариантам осуществления подготовка первого образца дополнительно предусматривает разделение первого образца на множество частей, и при этом ДНК в каждой части предпочтительно приумножается в подмножестве множества полиморфных локусов. Согласно некоторым вариантам осуществления внутренние праймеры выбирают путем идентификации пар праймеров, способных образовывать нежелательные дуплексы праймеров, и удаления из множества праймеров по меньшей мере одной пары праймеров, идентифицированной как способной образовывать нежелательные дуплексы праймеров. Согласно некоторым вариантам осуществления внутренние праймеры содержат область, которую конструируют для гибридизации либо выше, либо ниже от целевого полиморфного локуса, и необязательно содержит универсальную праймирующую последовательность, сконструированную с обеспечением ПЦР-амплификации. Согласно некоторым вариантам осуществления по меньшей мере некоторые из праймеров дополнительно содержат случайную область, которая отличается в каждой отдельной молекуле праймера. Согласно некоторым вариантам осуществления по меньшей мере некоторые из праймеров дополнительно содержат молекулярный штрих-код.
Согласно некоторым вариантам осуществления способ также предусматривает получение генотипических данных одного или обоих родителей плода. Согласно некоторым вариантам осуществления получение генотипических данных одного или обоих родителей плода предусматривает подготовку ДНК от родителей, при этом подготовка предусматривает предпочтительное приумножение ДНК во множестве полиморфных локусов с получением подготовленной родительской ДНК, необязательно амплификацию подготовленной родительской ДНК и измерение родительской ДНК в подготовленном образце во множестве полиморфных локусов.
Согласно некоторым вариантам осуществления построение модели совместного распределения для ожидаемых вероятностей числа аллелей множества полиморфных локусов в хромосоме осуществляется с использованием полученных генетических данных одного или обоих родителей. Согласно некоторым вариантам осуществления первый образец был выделен из материнской плазмы, и при этом получение генотипических данных от матери осуществляется путем оценивания материнских генотипических данных из измерений ДНК, выполненных в подготовленном образце.
Согласно некоторым вариантам осуществления предпочтительное приумножение приводит к средней степени систематической ошибки числа аллелей между подготовленным образцом и первым образцом с фактором, выбранным из группы, состоящей из фактора не более чем 2, фактора не более чем 1,5, фактора не более чем 1,2, фактора не более чем 1,1, фактора не более чем 1,05, фактора не более чем 1,02, фактора не более чем 1,01, фактора не более чем 1,005, фактора не более чем 1,002, фактора не более чем 1,001 и фактора не более чем 1,0001. Согласно некоторым вариантам осуществления множеством полиморфных локусов являются SNP. Согласно некоторым вариантам осуществления измерение ДНК в подготовленном образце осуществляется путем секвенирования.
Согласно некоторым вариантам осуществления раскрывается диагностический бокс для помощи в определении статуса плоидности хромосомы у вынашиваемого плода, при этом с помощью диагностического бокса можно выполнять этапы подготовки и измерения способа по пункту 1.
Согласно некоторым вариантам осуществления подсчеты числа аллелей являются вероятностными, а не бинарными. Согласно некоторым вариантам осуществления измерения ДНК в подготовленном образце во множестве полиморфных локусов также используются для определения того, унаследовал ли плод один или множество связанных с заболеванием гаплотипов.
Согласно некоторым вариантам осуществления построение модели совместного распределения для вероятностей числа аллелей осуществляют с использованием данных о вероятности хромосом с кроссинговером в различных локализациях в хромосоме для моделирования зависимости между полиморфными аллелями в хромосоме. Согласно некоторым вариантам осуществления построение модели совместного распределения для числа аллелей и этап определения относительной вероятности каждого предположения выполняют с использованием способа, для которого не нужно применять эталонную хромосому.
Согласно некоторым вариантам осуществления при определении относительной вероятности каждой гипотезы применяют оцениваемую фракцию плодной ДНК в подготовленном образце. Согласно некоторым вариантам осуществления измерения ДНК из подготовленного образца, используемого в вычислении вероятностей числа аллелей и определении относительной вероятности каждой гипотезы, предусматривают первичные генетические данные. Согласно некоторым вариантам осуществления отбор состояния плоидности, соответствующий гипотезе с наибольшей вероятностью, выполняют с использованием максимально правдоподобных оценок или максимальных апостериорных оценок.
Согласно некоторым вариантам осуществления установление состояния плоидности плода также предусматривает объединение относительных вероятностей каждой из гипотез плоидности, определенной с использованием модели совместного распределения и вероятностей числа аллелей, с относительными вероятностями каждой из гипотез плоидности, которые рассчитываются с использованием статистических методик из группы, состоящей из анализа подсчета считываний, сравнения степеней гетерозиготности, статистика которых доступна только при использовании родительской генетической информации, вероятности нормализованных сигналов генотипа для определенных родительских контекстов, статистика которых рассчитывается с использованием оцениваемой фракции плода первого образца или подготовленного образца, а также их комбинаций.
Согласно некоторым вариантам осуществления оценивание достоверности рассчитывается для установленного состояния плоидности. Согласно некоторым вариантам осуществления способ также предусматривает осуществление клинического действия на основании установленного состояния плоидности плода, в котором клиническое действие выбирается из прерывания беременности или сохранения беременности.
Согласно некоторым вариантам осуществления способ может быть выполнен для плодов на 4-5 неделях гестации; 5-6 неделях беременности; 6-7 неделях беременности; 7-8 неделях беременности; 8-9 неделях беременности; 9-10 неделях беременности; 10-12 неделях беременности; 12-14 неделях беременности; 14-20 неделях беременности; 20-40 неделях беременности; в первом триместре; во втором триместре; в третьем триместре или их комбинациях.
Согласно некоторым вариантам осуществления отчет, показывающий определенный статус плоидности хромосомы у вынашиваемого плода, генерируется с использованием способа. Согласно некоторым вариантам осуществления раскрывается набор для определения статуса плоидности целевой хромосомы у вынашиваемого плода, разработанный для использования в способе по пункту 9, где набор содержит множество внутренних прямых праймеров и необязательно множество внутренних обратных праймеров, при этом каждый из праймеров конструируют для гибридизации с областью ДНК, расположенной непосредственно выше и/или ниже от одного из полиморфных сайтов в целевой хромосоме и необязательно дополнительных хромосомах, в которых область гибридизации отделена от полиморфного сайта небольшим количеством оснований, где небольшое количество выбрано из группы, состоящей из 1, 2, 3, 4, 5, 6-10, 11-15, 16-20, 21-25, 26-30, 31-60 и их комбинаций.
Согласно некоторым вариантам осуществления раскрывается способ определения присутствия или отсутствия анеуплоидии плода в образце материнской ткани, содержащем плодную и материнскую геномную ДНК, предусматривающий (a) получение смеси плодной и материнской геномной ДНК из указанного образца материнской ткани, (b) проведение массивно-параллельного секвенирования ДНК фрагментов ДНК, случайно выбранных из смеси плодной и материнской геномной ДНК этапа a), для определения последовательности указанных фрагментов ДНК, (c) идентификацию хромосом, которым принадлежат полученные на этапе b) последовательности, (d) использование данных этапа c) для определения количества по меньшей мере одной первой хромосомы в указанной смеси материнской и плодной геномной ДНК, при этом предполагается, что указанная по меньшей мере одна первая хромосома является эуплоидной у плода, (e) использование данных этапа c) для определения количества второй хромосомы в указанной смеси материнской и плодной геномной ДНК, при котором предполагается, что указанная вторая хромосома является анеуплоидной у плода, (f) вычисление фракции плодной ДНК в смеси плодной и материнской ДНК, (g) вычисление ожидаемого распределения количества второй целевой хромосомы, если вторая целевая хромосома является эуплоидной, с использованием количества, полученного на этапе d), (h) вычисление ожидаемого распределения количества второй целевой хромосомы, если вторая целевая хромосома является анеуплоидной, с использованием первого количества, полученного на этапе d), и рассчитанной фракции плодной ДНК в смеси плодной и материнской ДНК на этапе f), и (i) использование максимального правдоподобия или максимального апостериорного подхода для определения того, является ли количество второй хромосомы, определенное на этапе e), с большей вероятностью частью распределения, рассчитанного на этапе g), или распределения, рассчитанного на этапе h); что тем самым указывает на присутствие или отсутствие анеуплоидии у плода.
Краткое описание графических материалов
Раскрытые в настоящем документе варианты осуществления далее будут поясняться со ссылкой на приложенные графические материалы, в которых одинаковые структуры обозначаются одинаковыми позициями на нескольких видах. Представленные графические материалы необязательно выполнены в масштабе, вместо этого акцент сделан на иллюстрацию принципов раскрытых в настоящем документе вариантов осуществления.
На фиг.1 графически представлен способ прямой мультиплексной мини-ПЦР.
На фиг.2 графически представлен способ полувложенной мини-ПЦР.
На фиг.3 графически представлен способ полной вложенной мини-ПЦР.
На фиг.4 графически представлен способ гемивложенной мини-ПЦР.
На фиг.5 графически представлен способ тройной гемивложенной мини-ПЦР.
На фиг.6 графически представлен способ односторонней вложенной мини-ПЦР.
На фиг.7 графически представлен способ односторонней мини-ПЦР.
На фиг.8 графически представлен способ обратной полувложенной мини-ПЦР.
На фиг.9 представлены некоторые возможные технологические процессы для полувложенных способов.
На фиг.10 графически представлены петлевые адаптеры лигирования.
На фиг.11 графически представлены внутренние меченые праймеры.
На фиг.12 представлен пример некоторых праймеров с внутренними метками. 1) Последовательность адаптера секвенирования располагается внутри последовательности праймера и фланкируется целевой специфичной последовательностью на обеих сторонах. 10 оснований являются специфичными по отношению к мишени на 3'-конце каждого праймера. Праймеры успешно тестировали с помощью ПЦР в реальном времени. При секвенировании это снижало число праймерных оснований, которые подлежали секвенированию. 2) Последовательность адаптера секвенирования располагается внутри последовательности праймера и фланкируется целевой специфичной последовательностью на обеих сторонах. Внутренняя метка образуется в «шпилечной» структуре 10 комплементарными основаниями на любом конце. Это приводит специфичные по отношению к мишени концы в непосредственную близость и препятствует неспецифичному связыванию с внутренней меткой. 10 оснований являются специфичными по отношению к мишени на 3'-конце каждого праймера. Праймеры успешно тестировали с помощью ПЦР в реальном времени.
На фиг.13 графически представлен способ с использованием праймеров с областью связывания адаптера лигирования.
На фиг.14 представлены точности моделированных признаков плоидности для способа подсчета двумя различными методиками анализа.
На фиг.15 представлено отношение двух аллелей для множества SNP в линии клеток в эксперименте 4.
На фиг.16 представлено отношение двух аллелей для множества SNP в линии клеток в эксперименте 4, отсортированное по хромосоме.
На фиг.17 представлено отношение двух аллелей для множества SNP в четырех образцах плазмы беременных женщин, отсортированное по хромосоме.
На фиг.18 представлена фракция данных, которые могут быть объяснены биномиальным расхождением, до коррекции данных и после нее.
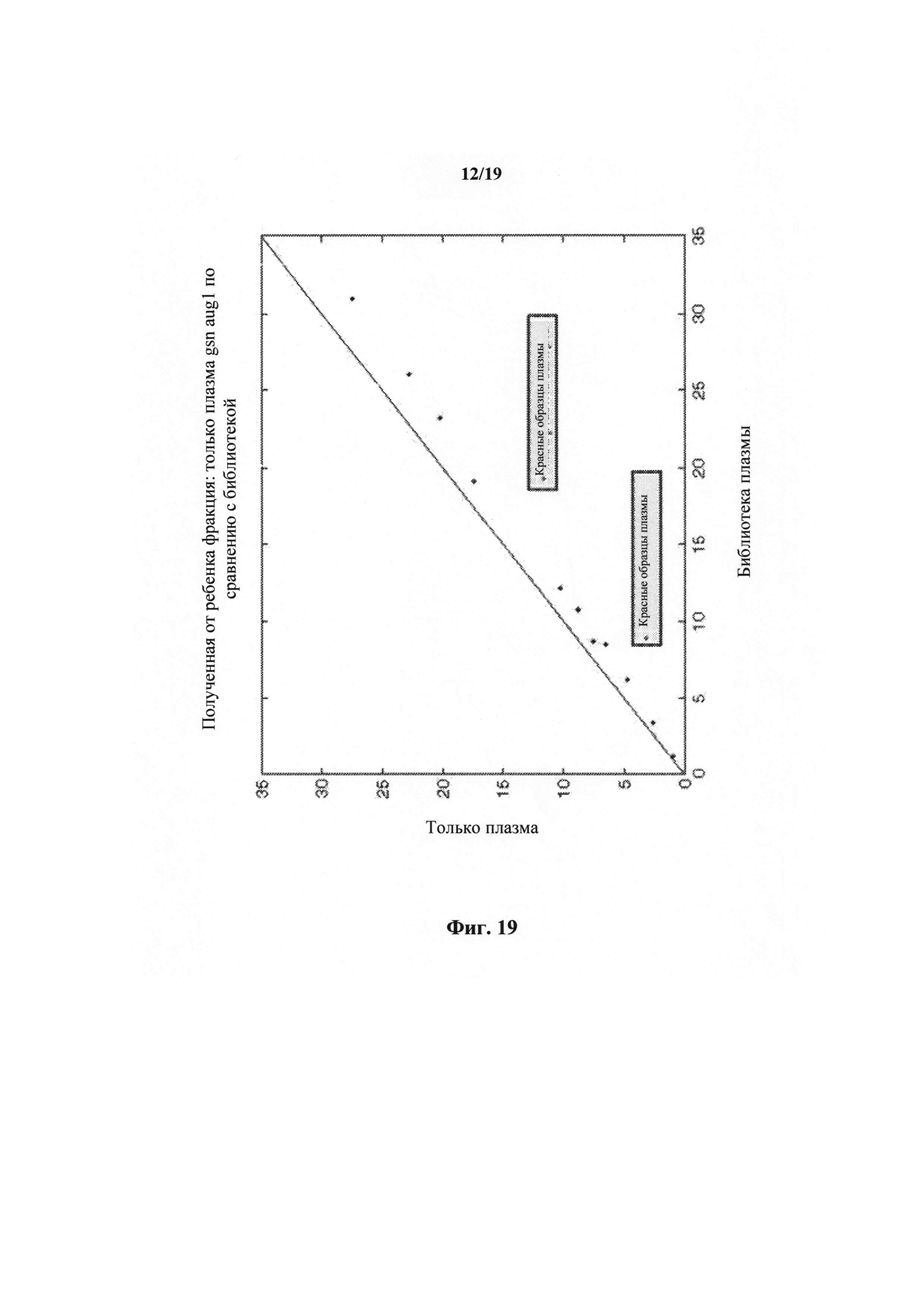
На фиг.19 представлен график, показывающий относительное приумножение плодной ДНК в образцах после короткого протокола приготовления библиотеки.
На фиг.20 представлен график глубины считывания, сравнивающий способы прямой ПЦР и полувложенной ПЦР.
На фиг.21 представлено сравнение глубины считывания для прямой ПЦР трех геномных образцов.
На фиг.22 представлено сравнение глубины считывания для полувложенной мини-ПЦР трех геномных образцов.
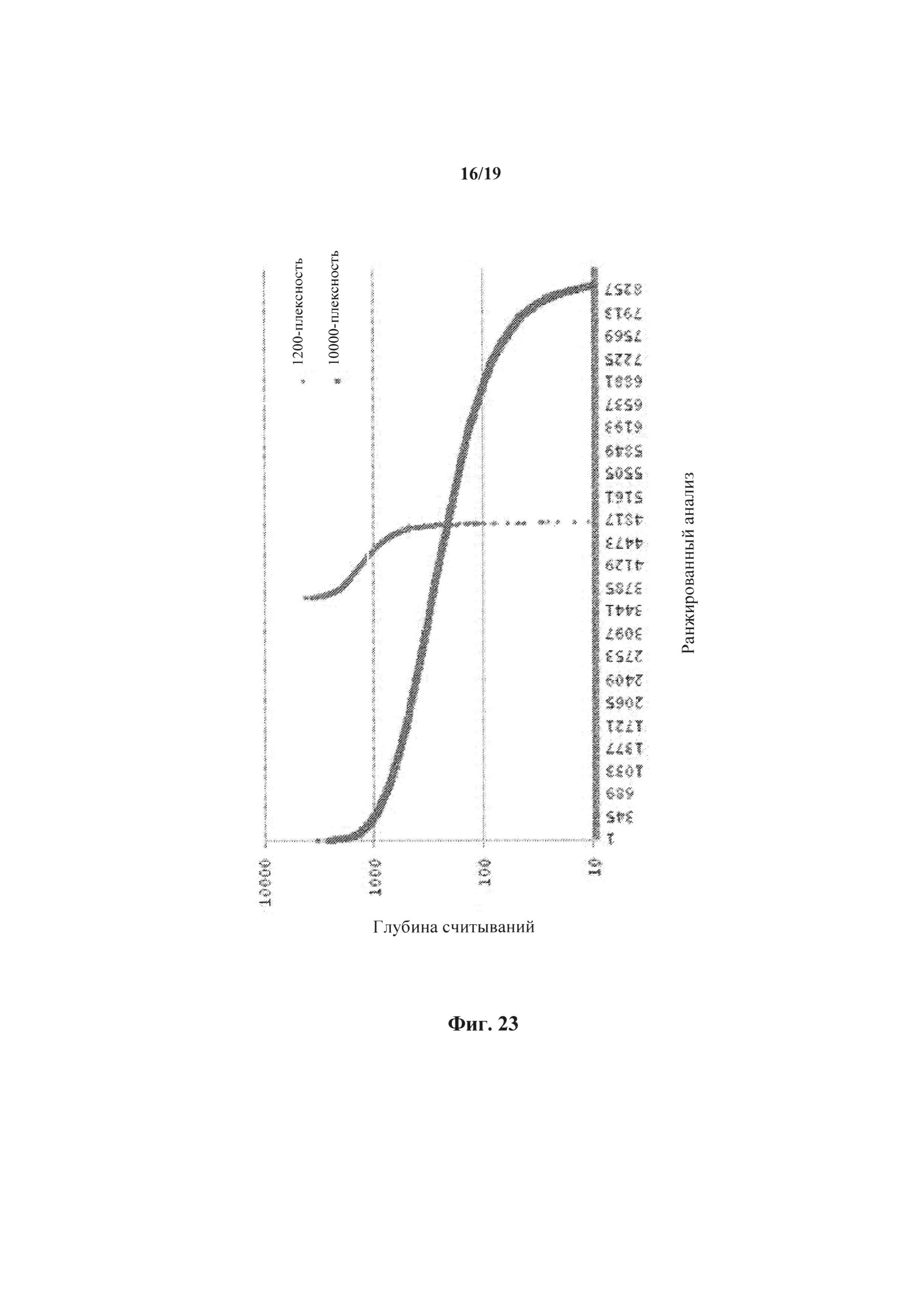
На фиг.23 представлено сравнение глубины считывания для 1200-плексной и 9600-плексной реакций.
На фиг.24 представлены отношения подсчета считываний для шести клеток по трем хромосомам. Для каждого SNP нормализовали DOR SNP по среднему в трех XY-3 клетках, затем усредняли на хромосому, затем отношение для каждой хромосомы сравнивали с хромосомой 1 образца. Использовали все SNP с DOR>200 в 46XY_BC25 (100 для X).
На фиг.25 представлены аллельные отношения для двух реакций по трем клеткам и выполнение третьей реакции в 1 нг геномной ДНК по трем хромосомам.
На фиг.26 представлены аллельные отношения для двух реакций по единичной клетке по трем хромосомам.
Несмотря на то, что вышеописанные графические материалы поясняют раскрытые в настоящем документе варианты осуществления, также предполагаются другие варианты осуществления, отмеченные в обсуждении. В настоящем раскрытии пояснительные варианты осуществления представлены с целью иллюстрации, а не для ограничения. Специалистами в данной области может быть разработан ряд других модификаций и вариантов осуществления, которые охватываются объемом и идеей принципов раскрытых в настоящем документе вариантов осуществления.
Подробное раскрытие настоящего изобретения
Согласно варианту осуществления настоящее раскрытие относится к ex vivo способам определения статуса плоидности хромосомы у вынашиваемого плода по генотипическим данным, измеренным в смешанном образце ДНК (т.е. ДНК от матери плода и ДНК от плода), и необязательно по генотипическим данным, измеренным в образце генетического материала матери, а также возможно отца, при которых определение осуществляется с использованием модели совместного распределения для создания набора ожидаемых аллельных распределений для различных возможных плодных состояний плоидности с учетом родительских генотипических данных, сравнения ожидаемых аллельных распределений с фактическими аллельными распределениями, измеренными в смешанном образце, и выбора того состояния плоидности, чей паттерн ожидаемого аллельного распределения наиболее близко совпадает с паттерном наблюдаемого аллельного распределения. Согласно варианту осуществления смешанный образец получают из крови матери или материнской сыворотки крови или плазмы. Согласно варианту осуществления смешанный образец ДНК может быть предпочтительно приумножен множеством полиморфных локусов. Согласно варианту осуществления предпочтительное приумножение осуществляется путем, при котором минимизируется систематическая ошибка подсчета числа аллелей. Согласно варианту осуществления настоящее раскрытие относится к составу ДНК, который был предпочтительно приумножен множеством локусов так, что систематическая ошибка подсчета числа аллелей является низкой. Согласно варианту осуществления аллельное распределение(ия) измеряется(ются) секвенированием ДНК в смешанном образце. Согласно варианту осуществления модель совместного распределения предполагает, что аллели будут распределяться биномиальным образом. Согласно варианту осуществления набор ожидаемых совместных распределений аллелей создается для генетически связанных локусов с учетом частот существующих рекомбинаций из различных источников, например, с использованием данных Международного консорциума HapMap.
Согласно варианту осуществления настоящее раскрытие относится к способам неинвазивной пренатальной диагностики (NPD), в частности, к определению статуса анеуплоидии плода с помощью исследования аллельных измерений во множестве полиморфных локусов в генотипических данных, измеренных в смесях ДНК, при котором некоторые аллельные измерения указывают на анеуплоидию плода, тогда как другие аллельные измерения указывают на эуплоидию плода. Согласно варианту осуществления генотипического данные измеряются путем секвенирования смеси ДНК, которая походит из материнской плазмы. Согласно варианту осуществления образец ДНК может быть предпочтительно приумножен молекулами ДНК, которые соответствуют множеству локусов, чьи распределения аллелей подлежат вычислению. Согласно варианту осуществления измеряются образец ДНК, содержащий только или почти только генетический материал матери, а возможно также и образец ДНК, содержащий только или почти только генетический материал отца. Согласно варианту осуществления генетические измерения одного или обоих родителей вместе с оцениваемой плодной фракцией используются для создания множества ожидаемых распределений аллелей, соответствующих различным возможным лежащим в основе генетического статуса плода; ожидаемые распределения аллелей могут называться гипотезой. Согласно варианту осуществления материнские генетические данные не определяются с помощью измерения генетического материала, который по природе исключительно или почти исключительно является материнским, скорее они оцениваются по генетическим измерениям, выполненным в материнской плазме, которая содержит смесь материнской и плодной ДНК. Согласно некоторым вариантам осуществления гипотеза может предусматривать плоидность плода по одной или нескольким хромосомам, какие сегменты каких хромосом у плода наследовались от кого из родителей, а также их комбинации. Согласно некоторым вариантам осуществления состояние плоидности плода определяется сравнением наблюдаемых аллельных измерений с различными гипотезами, при этом по меньшей мере некоторые из гипотез соответствуют различным состояниям плоидности, и отбором состояния плоидности, соответствующего гипотезе, которая, вероятнее всего, является истинной, с учетом наблюдаемых аллельных измерений. Согласно варианту осуществления этот способ предусматривает использование данных измерений аллелей по некоторым или всем измеренным SNP, независимо от того, являются ли локусы гомозиготными или гетерозиготными, и, поэтому, не предусматривает использование аллелей в локусах, которые являются только гетерозиготными. Этот способ неприемлем в ситуациях, при которых генетические данные относятся только к одному полиморфному локусу. Этот способ особенно выгоден, если генетические данные содержат данные по более десяти полиморфным локусам для целевой хромосомы или более двадцати полиморфным локусам. Этот способ особенно выгоден, если генетические данные содержат данные по более 50 полиморфным локусам для целевой хромосомы, более 100 полиморфным локусам или более 200 полиморфным локусам для целевой хромосомы. Согласно некоторым вариантам осуществления генетические данные могут содержать данные по более 500 полиморфным локусам для целевой хромосомы, более 1000 полиморфным локусам, более 2000 полиморфным локусам или более 5000 полиморфным локусам для целевой хромосомы.
Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает методику селективных приумножений, которые сохраняют относительные частоты аллелей, присутствующие в оригинальном образце ДНК в каждом полиморфном локусе из набора полиморфных локусов. Согласно некоторым вариантам осуществления методика амплификации и/или селективного приумножения может предусматривать ПЦР, такую как опосредованная лигированием ПЦР, захват фрагмента путем гибридизации, молекулярные инверсионные зонды или другие зонды циркуляризации. Согласно некоторым вариантам осуществления способы амплификации или селективного приумножения могут предусматривать использование зондов, если при корректной гибридизации с целевой последовательностью 3'-конец или 5-конец нуклеотидного зонда отделяется от полиморфного сайта аллеля небольшим числом нуклеотидов. Такое отделение снижает предпочтительную амплификацию одного аллеля, что называется систематической ошибкой подсчета числа аллелей. В этом заключается улучшение по сравнению со способами, которые предусматривают использование зондов, если 3'-конец или 5-конец корректно гибридизированного зонда находится непосредственно рядом с полиморфным сайтом аллеля или очень близко к нему. Согласно варианту осуществления зонды, в которых область гибридизации может содержать или заведомо содержит полиморфный сайт, исключаются. Полиморфные сайты в сайте гибридизации могут вызывать неравномерную гибридизацию или ингибировать гибридизацию в целом в некоторых аллелях, что приводит к предпочтительной амплификации определенных аллелей. Такие варианты осуществления являются улучшениями по сравнению с другими способами, которые предусматривают целевую амплификацию и/или селективное приумножение, заключающимися в том, они надежнее сохраняют оригинальные частоты аллелей образца в каждом полиморфном локусе, является ли образец чистым геномным образцом от одного индивидуума или смесью от нескольких индивидуумов.
Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает высокоэффективную высокомультиплексную целевую ПЦР для амплификации ДНК с последующим высокопроизводительным секвенированием для определения частот аллелей в каждом целевом локусе. Возможность мультиплексирования более приблизительно 50 или 100 праймеров ПЦР в одной реакции таким путем, что большая часть полученных в результате считываний последовательности картируется с целевыми локусами, является новой и неочевидной. Эта методика, обеспечивающая выполнение высокомультиплексной целевой ПЦР высокоэффективным способом, предусматривает конструирование праймеров, которые вряд ли гибридизируются друг с другом. Зонды ПЦР, как правило, называемые праймерами, отбираются путем создания термодинамической модели потенциально неблагоприятных взаимодействий между по меньшей мере 500, по меньшей мере 1000, по меньшей мере 5000, по меньшей мере 10000, по меньшей мере 20000, по меньшей мере 50000 или по меньшей мере 100000 потенциальными парами праймеров или непредусмотренных взаимодействий между праймерами и образцом ДНК, а затем с использованием модели для устранения конструкций, которые несовместимы с другими конструкциями в пуле. Другая методика, обеспечивающая выполнение высокомультиплексной целевой ПЦР высокоэффективным способом, заключается в использовании частичного или полного вложенного подхода в целевой ПЦР. Использование одного или комбинации этих подходов обеспечивает мультиплексирование по меньшей мере 300, по меньшей мере 800, по меньшей мере 1200, по меньшей мере 4000 или по меньшей мере 10000 праймеров в одном пуле с получением в результате амплифицированной ДНК, содержащей большую часть молекул ДНК, которая после секвенирования будет картироваться с целевыми локусами. Использованием одного или комбинации этих подходов обеспечивает мультиплексирование большого числа праймеров в одном пуле с получением в результате амплифицированной ДНК, содержащей более 50%, более 80%, более 90%, более 95%, более 98% или более 99% молекул ДНК, которые картируются с целевыми локусами.
Согласно варианту осуществления раскрытый в настоящем документе способ позволяет количественно измерить число независимых наблюдений каждого аллеля в полиморфном локусе. В этом заключается отличие от большинства способов, таких как микроматрицы или качественная ПЦР, которые обеспечивают информацию об отношении двух аллелей, но не определяют количество независимых наблюдений каждого аллеля. В способах, которые обеспечивают количественную информацию относительно числа независимых наблюдений, в вычислениях плоидности используется только отношение, тогда как количественной информация сама по себе не используется. Для иллюстрации важности сохранения информации о числе независимых наблюдений рассматривается модельный локус с двумя аллелями A и B. В первом эксперименте наблюдаются двадцать аллелей A и двадцать аллелей B, во втором эксперименте наблюдаются 200 аллелей A и 200 аллелей B. В обоих экспериментах отношение (A/(A+B)) равняется 0,5, однако, второй эксперимент предоставляет больше информации об определении частоты аллеля A или B, чем первый. Некоторые известные в уровне техники способы предусматривают усреднение или суммирование аллельных отношений (канальных отношений) (т.е. xi/yi) по индивидуальному аллелю и анализы этого отношения, либо путем сравнения его с эталонной хромосомой, либо с использованием принципа относительно ожидаемого поведения этого отношения в конкретных ситуациях. В таких известных в уровне техники способах не предусматривается взвешивание аллелей, а предполагается, что можно обеспечить приблизительно одинаковое количество продукта ПЦР для каждого аллеля, и что все аллели будут вести себя одинаково. Такой способ обладает рядом недостатков, и что более важно, исключает применение ряда улучшений, описанных в настоящем раскрытии.
Согласно варианту осуществления раскрытый в настоящем документе способ четко моделирует распределения частоты аллелей, ожидаемые при дисомии, а также множество распределений частоты аллелей, которые могут ожидаться в случаях трисомии, возникающей в результате нерасхождения в ходе мейоза I, нерасхождения в ходе мейоза II и/или нерасхождения в ходе раннего митоза в развитии плода. Чтобы понять важность этого, можно представить случай отсутствия кроссинговеров: нерасхождение в ходе мейоза I дает в результате трисомию, при которой два разных гомолога были унаследованы от одного родителя; наоборот, нерасхождение в ходе мейоза II или в ходе раннего митоза в развитии плода дает в результате две копии одного и того же гомолога от одного родителя. Каждый сценарий приведет в результате к различным ожидаемым частотам аллелей в каждом полиморфном локусе, а также во всех совместно рассматриваемых локусах из-за генетического сцепления. Кроссинговеры, которые приводят к обмену генетическим материалом между гомологами, делают паттерн наследования более сложным; согласно варианту осуществления способ в соответствии с настоящим изобретением предусматривает для этого использование информации степени рекомбинации вдобавок к физическому расстоянию между локусами. Согласно варианту осуществления для обеспечения улучшенного распознавания нерасхождения при мейозе I и нерасхождения при мейозе II или при митозе способ в соответствии с настоящим изобретением предусматривает включение в модель повышения вероятности кроссинговера по мере увеличения расстояния от центромеры. Нерасхождение при мейозе II и при митозе может отличаться тем, что митотическое нерасхождение, как правило, дает в результате идентичные или почти идентичные копии одного гомолога, в то время как два гомолога, присутствующие после события нерасхождения при мейозе II, часто отличаются из-за одного или нескольких кроссинговеров в ходе гаметогенеза.
Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ предусматривает сравнение наблюдаемых аллельных измерений с теоретической гипотезой, соответствующей возможной генетической анеуплоидии плода, и не предусматривает этап количественного определения отношения аллелей в гетерозиготном локусе. Если число локусов ниже приблизительно 20, то определение плоидности, выполненное с использованием способа, предусматривает количественное определение отношения аллелей в гетерозиготном локусе, а определение плоидности, выполненное с использованием способа, предусматривающего сравнение наблюдаемых аллельных измерений с теоретической гипотезой распределения аллелей, соответствующей возможным генетическим статусам плода, может дать подобный результат. Однако, если число локусов превышает 50, эти два способа могут дать сильно различающиеся результаты; если число локусов превышает 400, превышает 1000 или превышает 2000, эти два способа могут дать еще более сильно различающиеся результаты. Причиной таких различий является то, что способ, предусматривающий количественное определение отношения аллелей в гетерозиготном локусе без измерения интенсивности каждого аллеля независимо и объединения или усреднения отношений, исключает применение методик, предусматривающих использование модели совместного распределения, выполнение анализа сцепления, использование модели биномиального распределения и/или других улучшенных статистических методик, в то время как при использовании способа, предусматривающего сравнение наблюдаемых аллельных измерений с теоретической гипотезой распределения аллелей, соответствующей возможным генетическим статусам плода, могут применяться те методики, которые могут существенно повысить точность определения.
Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает определение того, свидетельствует ли распределение наблюдаемых аллельных измерений об эуплоидии или анеуплоидии плода, с использованием модели совместного распределения. Применение модели совместного распределения является значительным улучшением и отличием от способов, которые определяют степени гетерозиготности путем обработки полиморфных локусов независимо, заключающемся в том, что осуществленные в результате определения характеризуются значительно более высокой точностью. Без привязки к какой-либо конкретной теории полагают, что причина более высокой точности заключается в том, что модель совместного распределения учитывает сцепление между SNP и вероятность кроссинговеров, которые произошли в ходе мейоза, дающего начало гаметам, сформировавшим эмбрион, который превратился в плод. Целью использования концепции сцепления при создании ожидаемого распределения аллельных измерений для одной или нескольких гипотез является обеспечение создания ожидаемых распределений аллельных измерений, которые соответствуют действительности гораздо лучше, чем без использования сцепления. Например, представьте, что имеется два SNP-1 и 2, расположенные рядом друг с другом, и мать характеризуется A по SNP 1 и A по SNP 2 в гомологе один, а также B по SNP 1 и B по SNP 2 в гомологе два. Если отец характеризуется A по обоим SNP в обоих гомологах, и B измеряется для плодного SNP 1, это показывает, что гомолог два был наследован плодом, и, поэтому, существует намного более высокая вероятность того, что B присутствует у плода в SNP 2. Модель, учитывающая сцепление, будет предсказывать это, в то время как модель, неучитывающая сцепление, не будет это делать. В качестве альтернативы, если мать представляла собой AB в SNP 1 и AB около SNP 2, то могут быть использованы две гипотезы, соответствующие материнской трисомии в этой локализаци, - одна, предусматривающая погрешность совпадения копий (нерасхождение в мейозе II или митозе на ранней фазе развития плода), а другая, предусматривающая погрешность несовпадения копий (нерасхождение в мейозе I). В случае погрешности совпадения копий при трисомии, если плод наследовал AA от матери в SNP 1, то плод с гораздо большей вероятностью наследовал либо AA, либо BB от матери в SNP 2, а не AB. В случае погрешности несовпадения копий плод будет наследовать AB от матери в обоих SNP. Гипотеза распределения аллелей, полученная способом установления плоидности, учитывающим сцепление, сможет дать такие прогнозы, и, поэтому, соответствует фактическим аллельным измерениям в значительно более высокой степени, чем при способе установления плоидности без учета сцепления. Следует отметить, что подход с учетом сцепления не возможен при использовании способа, который заключается в вычислении аллельных отношений и объединении этих аллельных отношений.
Считается, что одной из причин того, что определения плоидности с применением способа, предусматривающего сравнение наблюдаемых аллельных измерение с теоретической гипотезой, соответствующей возможным генетическим статусам плода, обладают более высокой точностью, заключается в том, что при секвенировании, используемом для измерения аллелей, этот способ может собрать больше информации по данным от аллелей, если общее число считываний ниже, чем при других способах; например, способ, который заключается в вычислении и объединении аллельных отношений, будет давать непропорционально измеренный стохастический шум. Например, представьте ситуацию с измерением аллелей с использованием секвенирования и с набором локусов, в котором только пять считываний последовательности выявлялись в каждом локусе. Согласно варианту осуществления для каждого из аллелей данные можно сравнивать с гипотетическим распределением аллелей и взвешивать согласно числу считываний последовательности; поэтому данные этих измерений соответствующим образом взвешены и включены в общее определение. В этом заключается отличие от способа, который предусматривает количественное определение отношения аллелей в гетерозиготном локусе, поскольку этот способ может рассчитать только отношения 0%, 20%, 40%, 60%, 80% или 100% как возможные аллельные отношения; ни одно из них не может быть близким к ожидаемым аллельным отношениям. В последнем случае вычисленные аллельные отношения должны быть отброшены из-за недостаточных считываний, иначе будут характеризоваться непропорциональным взвешиванием и введением стохастического шума в определение, что снизит точность определения. Согласно варианту осуществления измерения отдельных аллелей могут быть обработаны как независимые измерения, при этом взаимосвязь между измерениями, выполненными в аллелях одного и того же локуса, не отличается от взаимосвязи между измерениями, выполненными в аллелях различных локусов.
Согласно варианту осуществления раскрытый в настоящем документе способ (названный способом RC) предусматривает определение того, указывает ли распределение наблюдаемых аллельных измерений на эуплоидию или анеуплоидию плода, без сравнения каких-либо метрик с наблюдаемыми аллельными измерениями в эталонной хромосоме, которая, как ожидается, является дисомной. Это является значительным улучшением по сравнению со способами, такими как способы с использованием секвенирования методом «дробовика», которые выявляют анеуплоидию путем оценивания пропорции случайно секвенированных фрагментов из сомнительных хромосом относительно одной или нескольких предполагаемых дисомных эталонных хромосом. Способ RC дает некорректные результаты, если предполагаемая дисомная эталонная хромосома не является фактически дисомной. Это может происходить в случаях, если анеуплоидия является более существенной, чем трисомия одной хромосомы, или если плод является триплоидным, а все аутосомы являются трисомными. В случае триплоидного (69, XXX) плода женского пола дисомных хромосом фактически совсем не существует. Описанный в настоящем документе способ не требует эталонной хромосомы и может корректно идентифицировать трисомные хромосомы у триплоидного плода женского пола. Модель совместного распределения может быть использована для каждой хромосомы, гипотезы, фракции ребенка и уровня шума без данных эталонной хромосомы, общего оценивания фракции ребенка или постоянной эталонной гипотезы.
Согласно варианту осуществления раскрытый в настоящем документе способ демонстрирует, как наблюдение распределений аллелей в полиморфных локусах может быть использовано для определения состояния плоидности плода с большей точностью, чем в известных в уровне техники способах. Согласно варианту осуществления в способе применяется целевое секвенирование для получения смешанного материнского-плодного генотипов и необязательно генотипов матери и/или отца во множестве SNP с установлением сначала различных ожидаемого распределений частоты аллелей при различных гипотезах, а затем с наблюдением количественной информации об аллелях, полученной в материнской-плодной смеси, и оцениванием, какая гипотеза лучше соответствует данным, при этом генетический статус, соответствующий гипотезе с лучшим соответствием данным, называется корректным генетическим статусом. Согласно варианту осуществления в раскрытом в настоящем документе способе также применяется степень соответствия для получения достоверности того, что установленный генетический статус является корректным генетическим статусом. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает использование алгоритмов, которые анализируют распределение аллелей, найденное для локусов, которые характеризуются различными родительскими контекстами, и сравнение наблюдаемых распределений аллелей с ожидаемым распределением аллелей для различных состояний плоидности для различных родительских контекстов (различных родительских генотипических паттернов). В этом заключается улучшение и отличие от способов, в которых не применяются способы с возможностью оценки числа независимых случаев каждого аллеля в каждом локусе в смешанном материнском-плодном образце. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает определение того, свидетельствует ли распределение наблюдаемых аллельных измерений об эуплоидии или анеуплоидии плода, с использованием наблюдаемых аллельных распределений, измеренных в локусах, по которым мать гетерозиготна. В этом заключается улучшение и отличие от способов, в которых не применяются наблюдаемые аллельные распределения в локусах, по которым мать является гетерозиготной, поскольку в случаях, при которых ДНК предпочтительно не приумножается или предпочтительно приумножается локусами, которые не являются, как известно, высоко информативными для этого конкретного целевого индивидуума, это позволяет применять приблизительно в два раза больше данных генетических измерений в наборе данных последовательности в определении плоидности, что дает более точное определение.
Согласно варианту осуществления в раскрытом в настоящем документе способе применяется модель совместного распределения, которая предполагает, что аллельные частоты в каждом локусе являются по природе полиномиальными (и, таким образом, биномиальными, если SNP являются биаллельными). Согласно некоторым вариантам осуществления в модели совместного распределения применяются бета-биномиальные распределения. Если использование методики измерения, такой как секвенирование, обеспечивает количественную меру для каждого аллеля, присутствующего в каждом локусе, биномиальная модель может быть использована для каждого локуса и степени лежащих в основе частот аллелей, а также достоверности, с которой частота может быть установлена. С известными в уровне технике способами, которые генерируют признаки плоидности из аллельных отношений, или способами, в которых не учитывается количественная информация аллелей, определенность наблюдаемого отношения не может быть установлена. Улучшение и отличие способа в соответствии с настоящим изобретением по сравнению со способами, в которых рассчитываются аллельные отношения и объединяются эти отношения, заключаются в получении признака плоидности, поскольку любой способ, в котором предусматривается вычисление аллельного отношения в конкретном локусе, а затем объединение этих отношений, необязательно предполагает, что измеренные интенсивности или подсчеты, которые указывают на количество ДНК от какого-либо данного аллеля или локуса, будут распределяться по Гауссу. Раскрытый в настоящем документе способ не предусматривает вычисление аллельных отношений. Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ может предусматривать включение в модель числа наблюдений каждого аллеля во множестве локусов. Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ может предусматривать вычисление ожидаемых распределений самих по себе, что обеспечивает применение модели совместного биномиального распределения, которая может быть более точной, чем какая-либо модель, которая предполагает распределение по Гауссу измерений аллелей. Вероятность того, что модель биномиального распределения значительно более точная, чем распределение по Гауссу, увеличивается с увеличением числа локусов. Например, если исследуется менее 20 локусов, вероятность того, что модель биномиального распределения значительно лучше, низкая. Однако, если используется более 100, или особенно более 400, или особенно более 1000, или особенно более 2000 локусов, то модель биномиального распределения будет характеризоваться очень высокой вероятностью того, что она значительно более точная, чем модель распределения по Гауссу, что, тем самым, приводит к более точному определению плоидности. Вероятность того, что модель биномиального распределения значительно более точная, чем распределение по Гауссу, также повышается с повышением числа наблюдений в каждом локусе. Например, если наблюдаются менее 10 отдельных последовательностей в каждом локусе, вероятность того, что модель биномиального распределения значительно лучше, низкая. Однако, если для каждого локуса используется более 50 считываний последовательности, или особенно более 100 считываний последовательности, или особенно более 200 считываний последовательности, или особенно более 300 считываний последовательности, модель биномиального распределения будет характеризоваться очень высокой вероятностью того, что она значительно более точная, чем модель распределения по Гауссу, что, тем самым, приводит к более точному определению плоидности.
Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает секвенирование для измерения числа случаев каждого аллеля в каждом локусе в образце ДНК. Каждое считывание при секвенировании может быть картировано со специфичным локусом и обработано как бинарное считывание последовательности; в качестве альтернативы, вероятность идентичности считывания и/или картирования может быть включена как часть считывания последовательности, что дает в результате вероятностное считывание последовательности, то есть вероятное целое или дробное число считываний последовательности, которые картируются с данными локусами. С использованием бинарных подсчетов или вероятности подсчетов можно применять биномиальное распределение для каждого набора измерений, что обеспечивает расчет интервала достоверности по всему числу подсчетов. Такая возможность применения биномиального распределения позволяет рассчитать более точные оценки плоидности и более точные интервалы достоверности. В этом заключается улучшение и отличие по сравнению со способами, которые предусматривают интенсивности для измерения количества присутствующего аллеля, например, способами, которые предусматривают микроматрицы, или способами, которыми осуществляются измерения с использованием флуоресцентных устройств считывания для измерения интенсивности флуоресцентно меченной ДНК в электрофорезных полосках.
Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает аспекты представленного набора данных для определения параметров для оцениваемого распределения частоты аллелей, для которого собраны данные. В этом заключается улучшение по сравнению со способами, при которых используется обучающий набор данных или предварительные наборы данных для набора параметров присутствующих ожидаемых распределений частоты аллелей или возможных ожидаемых аллельных отношений. Это потому, что существуют различные наборы условий, включенных в коллекцию и в измерение каждого генетического образца, и, таким образом, способ, предусматривающий данные из моментального набора данных для определения параметров для модели совместного распределения, которая подлежит использованию в определении плоидности для этого образца, будет обладать тенденцией к большей точности.
Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает определение того, указывает ли распределение наблюдаемых аллельных измерений на эуплоидию или анеуплоидию плода, с использованием методики максимального правдоподобия. В применении методики максимального правдоподобия заключается существенное улучшение и отличие по сравнению со способами, которые предусматривают методику отклонения простой гипотезы, заключается в том, что результирующие определения будут выполнены со значительно более высокой точностью. Одной из причин является то, что методики отклонения простой гипотезы устанавливают пороги отсечения на основе только одного распределения измерений, а не двух, а это означает, что пороги, как правило, не являются оптимальными. Другой причиной является то, что методика максимального правдоподобия обеспечивает оптимизацию порога отсечения для каждого отдельного образца вместо определения порога отсечения, подлежащего использованию для всех образцов независимо от конкретных характеристик каждого отдельного образца. Следующая причина заключается в применении методики максимального правдоподобия, позволяющей вычислить достоверность для каждого признака плоидности. Возможность получения расчета достоверности для каждого признака позволяет специалисту-практику узнать, какие признаки являются точными, а какие с большей вероятностью являются ошибочными. Согласно некоторым вариантам осуществления широкий ряд способов может быть объединен с методикой оценки максимального правдоподобия для усиления точности признаков плоидности. Согласно варианту осуществления методика максимального правдоподобия может быть использована в комбинации со способом, описанным в патенте США №7888017. Согласно варианту осуществления методика максимального правдоподобия может быть использована в комбинации со способом использования целевой ПЦР-амплификации для амплификации ДНК в смешанном образце с последующим секвенированием и анализом с использованием способа подсчета считываний, такого как использованный TANDEM DIAGNOSTICS, представленный на Международном конгрессе генетики человека 2011 в Монреале в октябре 2011 г. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает оценивание плодной фракции ДНК в смешанном образце и использование этой оценки для расчета и признака плоидности и достоверности признака плоидности. Следует отметить, что в этом заключается и различие, и отличие от способов, которые предусматривают оцениваемую плодную фракцию в качестве скрининга достаточной плодной фракции, с последующим получением признака плоидности с использованием методики отклонения простой гипотезы, которая не учитывает плодную фракцию, а также не позволяет рассчитать достоверность для признака.
Согласно варианту осуществления раскрытый в настоящем документе способ учитывает тенденцию данных к искажению и содержанию погрешностей путем добавления вероятности для каждого измерения. Применение методик максимального правдоподобия для выбора корректной гипотезы из набора гипотез, которые были получены с использованием данных измерения с добавленными вероятностными оценками, делает более вероятным то, что некорректные измерения будут игнорироваться, а корректные измерения будут использоваться для вычислений, что даст признак плоидности. Точнее, этот способ систематически снижает влияние некорректно измеренных данных на определение плоидности. В этом заключается улучшение по сравнению со способами, при которых все данные оцениваются в равной степени корректно, или со способами, при которых далекие данные без достаточных оснований исключаются из вычислений, дающих признак плоидности. Существующие способы с использованием измерений канальных отношений заявляют о распространении способа на несколько SNP путем усреднения канальных отношений отдельного SNP. Отсутствия взвешивания отдельных SNP путем ожидаемого расхождения измерений на основе качества SNP и наблюдаемой глубины считывания снижает точность полученной в результате статистики, что приводит к существенному снижению точности признака плоидности, особенно в спорных случаях.
Согласно варианту осуществления раскрытый в настоящем документе способ не предусматривает информации о том, какие SNP или другие полиморфные локусы у плода являются гетерозиготными. Этот способ позволяет получить признак плоидности в тех случаях, если недоступна информация о родительских генотипах. В этом заключается улучшение по сравнению со способами, для которых заранее должно быть известно о том, какие SNP являются гетерозиготными, для того, чтобы приемлемым образом выбрать целевые локусы, или для интерпретации генетических измерений, выполненных в смешанном плодном/материнском образце ДНК.
Описанные в настоящем документе способы особенно полезны при использовании с образцами, в которых доступно небольшое количество ДНК, или в которых процент плодной ДНК низкий. Это связано с соответственно более высокой степенью исключения аллелей, что происходит, если доступно только небольшое количество ДНК, и/или с соответственно более высокой степенью исключения аллелей плода, если процент плодной ДНК в смешанном образце плодной и материнской ДНК низкий. Высокая степень исключения аллелей, означающая, что большое процентное отношение аллелей не было измерено для целевого индивидуума, приводит к низкой точности вычислений плодных фракций и к низкой точности определений плоидности. Поскольку раскрытые в настоящем документе способы могут предусматривать применение модели совместного распределения, которая учитывает сцепление в паттернах наследования между SNP, могут быть выполнены значительно более точные определения плоидности. Описанные в настоящем документе способы обеспечивают выполнение точного определения плоидности, если процент молекул ДНК, которые являются плодными, в смеси составляет менее 40%, менее 30%, менее 20%, менее 10%, менее 8% и даже менее 6%.
Согласно варианту осуществления можно определить состояние плоидности индивидуума на основе измерений, если ДНК этого индивидуума смешивается с ДНК родственного индивидуума. Согласно варианту осуществления смесь ДНК представляет собой свободно плавающую ДНК, обнаруженную в материнской плазме, которая может содержать ДНК от матери с известным кариотипом и известным генотипом, и которая может быть смешана с ДНК плода с неизвестным кариотипом и неизвестным генотипом. Можно применять известную генотипическую информацию от одного или от обоих родителей для предсказания множества потенциальных генетических статусов ДНК в смешанном образце для различных состояний плоидности, различных хромосомных вкладов от каждого родителя плоду, и необязательно различных фракций плодной ДНК в смеси. Каждый потенциальный состав может быть назван гипотезой. Затем может быть определено состояние плоидности плода путем просмотра фактических измерений и определения того, какие из потенциальных составов являются наиболее возможными с учетом наблюдаемых данных.
Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ может быть использован в ситуациях, при которых присутствует очень небольшое количество ДНК, таких как оплодотворение in vitro, или в экспертных ситуациях, при которых доступны одна или небольшое количество клеток (как правило, менее десяти клеток, менее двадцати клеток, менее 40 клеток). В таких вариантах осуществления раскрытый в настоящем документе способ служит для получения признаков плоидности из небольшого количества ДНК, которая не загрязнена другой ДНК, но если установление плоидность сильно затруднено из-за небольшого количества ДНК. Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ может быть использован в ситуациях, при которых целевая ДНК загрязнена ДНК другого индивидуума, например, в крови матери в контексте пренатальной диагностики, при определении отцовства или с продуктами анализа оплодотворения. Некоторые другие ситуации, при которых эти способы будут особенно полезны, предусматривают тестирование злокачественных заболеваний, при котором имеется всего лишь одна или небольшое количество клеток среди большого количества нормальных клеток. Генетические измерения, используемые как часть этих способов, могут быть выполнены в любом образце, содержащем ДНК или РНК, например, без ограничения кровь, плазма, жидкости организма, моча, волос, слезы, слюна, ткань, кожа, ногти, бластомеры, эмбрионы, амниотическая жидкость, образцы хориальных ворсин, кал, желчь, лимфа, выделяемая шейкой матки слизь, сперма или другие клетки или материалы, содержащие нуклеиновые кислоты. Согласно варианту осуществления раскрытый в настоящем документе способ может быть выполнен со способами выявления нуклеиновых кислот, такими как секвенирование, микроматрицы, количественная ПЦР, цифровая ПЦР или другие способы, используемые для измерения нуклеиновых кислот. Если по какой-либо причине оно было выявлено как желаемое, то будут рассчитаны отношения вероятности числа аллелей в локусе, и аллельные отношения могут быть использованы для определения состояния плоидности в комбинации с некоторыми из описанных в настоящем документе способов, при условии, что способы являются совместимыми. Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ предусматривает вычисление на компьютере аллельных отношений во множестве полиморфных локусов по измерениям ДНК, выполненным на обработанных образцах. Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ предусматривает вычисление на компьютере аллельных отношений во множестве полиморфных локусов по измерениям ДНК, выполненным на обработанных образцах, вместе с какой-либо комбинацией других описанных в настоящем раскрытии улучшений.
Дальнейшее обсуждение этих положений может быть найдено в других разделах настоящего документа.
Неинвазивная пренатальная диагностика (NPD)
Способ неинвазивной пренатальной диагностики предусматривает ряд этапов. Некоторые из этапов могут предусматривать (1) получение генетического материала от плода; (2) приумножение генетического материала плода, который может находиться в смешанном образце ex vivo; (3) амплификацию генетического материала ex vivo; (4) предпочтительно приумножение специфичных локусов в генетическом материале ex vivo; (5) измерение генетического материала ex vivo и (6) анализ генотипических данных на компьютере и ex vivo. Способы осуществления этих шести и других соответствующих этапов описаны в настоящем документе. По меньшей мере некоторые из этапов способа непосредственно не применяются на организме. Согласно варианту осуществления настоящее раскрытие относится к способам лечения и диагностики, применяемым к ткани и другим биологическим материалам, выделенным и отделенным от организма. По меньшей мере некоторые из этапов способа осуществляются на компьютере.
Некоторые варианты осуществления настоящего раскрытия позволяют практикующему врачу определить генетический статус вынашиваемого матерью плода неинвазивным способом так, что здоровье ребенка не подвергается риску при заборе генетического материала плода, и нет необходимости подвергать мать инвазивной процедуре. Более того, в определенных аспектах настоящее раскрытие обеспечивает определение генетического статуса плода с высокой точностью, значительно большей точностью, чем, например, неинвазивные тесты на основе аналитического образца материнской сыворотки крови, такие как тройной тест, который широко используется в медицинском обслуживании беременных.
Высокая точность раскрытых в настоящем документе способов является результатом описанного в настоящем документе подхода на основе информатики к анализу генотипических данных. Современные технологические достижения обеспечили возможность измерения больших количеств генетической информации в генетическом образце с использованием таких способов, как высокопроизводительное секвенирование и матрицы генотипирования. Раскрытые в настоящем документе способы позволяют практикующему врачу в большей степени использовать преимущества больших количеств данных и осуществлять более точную диагностику генетического статуса плода. Подробности ряда вариантов осуществления приводятся ниже. Различные варианты осуществления могут предусматривать различные комбинации вышеупомянутых этапов. Различные комбинации разных вариантов осуществления разных этапов могут быть использованы взаимозаменяемо.
Согласно варианту осуществления у беременной матери берется образец крови, и свободно плавающая ДНК в плазме крови матери, которая содержит смесь и ДНК материнского происхождения, и ДНК плодного происхождения, выделяется и используется для определения статуса плоидности плода. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает предпочтительное приумножение таких последовательностей ДНК в смеси ДНК, которая соответствует полиморфным аллелям таким образом, что аллельные отношения и/или аллельные распределения остаются главным образом постоянными при приумножении Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает целевую основанную на ПЦР амплификацию такую, что очень высокое процентное отношение полученных в результате молекул соответствует целевым локусам. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает секвенирование смеси ДНК, которая содержит и ДНК материнского происхождения, и ДНК плодного происхождения. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает использование измеренных аллельных распределений для определения состояния плоидности плода, который вынашивается матерью. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает сообщение определенного состояния плоидности практикующему врачу. Согласно варианту осуществления раскрытый в настоящем документе способ предусматривает осуществление клинического действия, например, выполнение сопутствующего инвазивного теста, такого как проба ворсинчатого хориона или амниоцентез, для подготовки к рождению трисомного индивидуума или к добровольному прерыванию беременности трисомным плодом.
Настоящая заявка ссылается на заявку на выдачу патента США на изобретение с серийным №11/603406, поданную 28 ноября 2006 г. (публикацию патентного документа США №20070184467); заявку на выдачу патента США на изобретение с серийным №12/076348, поданную 17 марта 2008 г. (публикацию патентного документа США №20080243398); PCT заявку с серийным № PCT/US 09/52730, поданную 4 августа 2009 г. (PCT публикацию № WO/2010/017214); PCT заявку с серийным № PCT/US 10/050824, поданную 30 сентября 2010 г. (PCT публикацию № WO/2011/041485), и заявку на выдачу патента США на изобретение с серийным №13/110685, поданную 18 мая 2011 г. Некоторая терминология, используемая в настоящей поданной заявке, может иметь свои предпосылки в этих ссылках. Некоторые из описанных в настоящем документе концепций могут быть более понятны в свете концепций указанных ссылок.
Скрининг крови матери, содержащей свободно плавающую плодную ДНК
Описанные в настоящем документе способы могут быть использованы для обеспечения определения генотипа ребенка, плода или другого целевого индивидуума, если генетический материал цели обнаруживается в присутствии количества другого генетического материала. Согласно некоторым вариантам осуществления генотип может относиться к состоянию плоидности одной или нескольких хромосом, он может относиться к одному или нескольким связанным с заболеванием аллелям или к некоторой их комбинации. В настоящем раскрытии обсуждение фокусируется на определении генетического статуса плода, если плодная ДНК обнаруживается в крови матери, но этот пример не означает ограничение возможных контекстов, в которых этот способ может быть применен. Кроме того, способ может применяться в случаях, если количество целевой ДНК находится в любой пропорции с нецелевой ДНК; например, целевая ДНК может составлять от 0,000001 до 99,999999% имеющейся ДНК. Кроме того, нецелевая ДНК не обязательно должна быть от одного индивидуума или даже от родственного индивидуума, поскольку генетические данные от некоторых или всех соответствующих нецелевых индивидуумов известны. Согласно варианту осуществления раскрытый в настоящем документе способ может быть использован для определения генотипических данных плода из крови матери, которая содержит плодную ДНК. Это также может быть использовано в случае, если в матке беременной женщины находится несколько плодов, или если другая загрязняющая ДНК может присутствовать в образце, например, от других уже рожденных братьев или сестер.
Эта методика может обеспечить использование явления плодных кровяных клеток, получивших доступ в кровообращение матери через ворсины плаценты. Как правило, только очень небольшое количество плодных клеток попадает в кровообращение матери таким путем (недостаточное для обеспечения положительного теста Клейхауэра-Бетке на плодное-материнское кровотечение). Плодные клетки могут быть отсортированы и проанализированы с помощью ряда методик поиска конкретных последовательностей ДНК, но без рисков, которые несут инвазивные процедуры. Эта методика также может обеспечить использование явления свободно плавающей плодной ДНК, получившей доступ в кровообращение матери путем высвобождения ДНК после апоптоза плацентарной ткани, если рассматриваемая плацентарная ткань содержит ДНК того же генотипа, что и плод. Было показано, что свободно плавающая обнаруженная в материнской плазме ДНК содержит плодную ДНК в пропорциях более 30-40% плодной ДНК.
Согласно варианту осуществления кровь может быть получена от беременной женщины. Исследование показало, что кровь матери может содержать небольшое количество свободно плавающей ДНК плодного происхождения, в добавок к свободно плавающей ДНК материнского происхождения. Кроме того, также могут наблюдаться ядросодержащие плодные кровяные клетки, содержащие ДНК плодного происхождения, в добавок к многочисленным клеткам крови материнского происхождения, которые, как правило, не содержат ядерную ДНК. Имеется много известных из уровня техники способов выделения плодной ДНК или создания фракций, приумноженных плодной ДНК. Например, было показано, что с помощью хроматографии создаются определенные фракции, которые приумножены плодной ДНК.
Как только образец крови, плазмы или другой жидкости матери, содержащий количество плодной ДНК, либо клеточной, либо свободно плавающей, или приумноженный в его пропорции к материнской ДНК, или в его оригинальном отношении, получен, относительно неинвазивным путем, можно определить генотип ДНК, найденной в указанном образце. Согласно некоторым вариантам осуществления кровь может быть получена с использованием иглы для забора крови из вены, например, из подкожной медиальной вены руки. Описанный в настоящем документе способ может быть использован для определения генотипических данных плода. Например, он может быть использован для определения состояния плоидности в одной или нескольких хромосомах, он может быть использован для определения идентичности одного или нескольких SNP, включая вставки, делеции и транслокализации. Он может быть использован для определения одного или нескольких гаплотипов, в том числе родительского происхождения из одного или нескольких генотипических признаков.
Следует отметить, что этот способ будет работать с любыми нуклеиновыми кислотами, которые могут быть использованы для любых способов генотипирования и/или секвенирования, таких как платформа INFINIUM ARRAY от ILLUMINA, GENECHIP от AFFYMETRIX, GENOME ANALYZER от ILLUMINA или SOLID SYSTEM от LIFE TECHNOLGIES. Он предусматривает экстрагирование свободно плавающей ДНК из плазмы или ее амплификации (например, полногеномную амплификацию, ПЦР); геномной ДНК из других типов клеток (например, лимфоцитов человека из цельной крови) или ее амплификации. Для получения ДНК также подходит любой способ экстракции или очистки, который дает геномную ДНК, приемлемую для одной из этих платформ. Этот способ будет работать также хорошо с образцами РНК. Согласно варианту осуществления хранение образцов могут осуществляться с минимальным разрушением (например, замораживание ниже точки замерзания при приблизительно -20°C или при более низкой температуре).
PARENTAL SUPPORT
Некоторые варианты осуществления могут быть использованы в комбинации с методом PARENTAL SUPPORT™ (PS), варианты осуществления которого описаны в заявке на выдачу патента США №11/603406 (публикации патентного документа США №20070184467), заявке на выдачу патента США №12/076348 (публикации патентного документа США №20080243398), заявке на выдачу патента США №13/110685, PCT заявке № PCT/US 09/52730 (PCT публикации № WO/2010/017214), PCT заявке № PCT/US 10/050824 (PCT публикации № WO/2011/041485), которые включены в настоящий документ во всей своей полноте посредством ссылки. PARENTAL SUPPORT™ является основанным на информатике подходом, который может быть использован для анализа генетических данных. Согласно некоторым вариантам осуществления раскрытые в настоящем документе способы могут рассматриваться как часть метода PARENTAL SUPPORT™. Согласно некоторым вариантам осуществления метод PARENTAL SUPPORT™ представляет собой совокупность методов, которые могут быть использованы для определения генетических данных целевого индивидуума с высокой точностью по одной клетке или небольшому количеству клеток от этого индивидуума или по смеси ДНК, содержащей ДНК от целевого индивидуума и ДНК от одного или множества других индивидуумов, особенно для определения связанных с заболеванием аллелей, других представляющих интерес аллелей, состояния плоидности одной или нескольких хромосом у целевого индивидуума, и/или степени родства другого индивидуума с целевым индивидуумом. PARENTAL SUPPORT™ может относиться к любому из этих способов. PARENTAL SUPPORT™ является примером основанного на информатике способа.
Метод PARENTAL SUPPORT™ позволяет использовать известные родительские генетические данные, т.е. генетические данные гаплотипа и/или диплоидности матери и/или отца, наряду с информацией о механизме мейоза и неполным измерением целевой ДНК, и, возможно, одного или нескольких родственных индивидуумов, вместе с популяционными частотами кроссинговера, для восстановления in silico генотипа на множестве аллелей и/или и/или состояния плоидности эмбриона, или любой целевой клетки(клеток) и целевой ДНК с локализацией ключевых локусов с высокой степенью достоверности. Метод PARENTAL SUPPORT™ может восстанавливать не только однонуклеотидные полиморфизмы (SNP), которые были плохо измерены, но также вставки и делеции, и SNP или целые области ДНК, которые совсем не измерялись. Более того, метод PARENTAL SUPPORT™ может измерять множественные связанные с заболеванием локусы, а также тестировать анеуплоидию в единичной клетке. Согласно некоторым вариантам осуществления метод PARENTAL SUPPORT™ может быть использован для характеристики одной или нескольких клеток из эмбриона, биопсированного в ходе цикла IVF, для определения генетического состояния одной или нескольких клеток.
Метод PARENTAL SUPPORT™ позволяет очистить искаженные генетические данные. Это может быть выполнено путем заключения корректных генных аллелей в целевом геноме (эмбрионе) с использованием генотипа родственных индивидуумов (родителей) в качестве эталона. PARENTAL SUPPORT™ может быть особенно релевантным, если доступна только небольшое количество генетического материала (например, PGD), и если прямые измерения генотипов существенно искажены из-за ограниченных количеств генетического материала. PARENTAL SUPPORT™ может быть особенно релевантным, если доступна только небольшая фракция генетического материала от целевого индивидуума (например, NPD), и если прямые измерения генотипов искажены из-за сигнала загрязняющей ДНК от другого индивидуума. С помощью метода PARENTAL SUPPORT™ можно восстановить высокоточные упорядоченные последовательности диплоидных аллелей в эмбрионе вместе с числом копий сегментов хромосом, даже в том случае, если обычные измерения неупорядоченного диплоида могут быть охарактеризованы высокими степенями исключений аллелей, ложных считываний, переменных ошибок амплификации и других погрешностей. Для метода могут использоваться и базовая генетическая модель, и базовая модель погрешности измерения. Генетическая модель может определять и вероятности аллелей на каждом SNP, и вероятности кроссинговера между SNP. Вероятности аллелей могут быть моделированы на каждом SNP на основе данных, полученных от родителей и модели вероятностей кроссинговера между SNP на основе данных полученных из базы данных HapMap, разработанной Международным проектом HapMap. С учетом надлежащей базовой генетической модели и модели погрешности измерения может быть использована оценка апостериорного максимума (MAP) с модификациями для вычислительной эффективности, чтобы корректно оценить упорядоченные значения аллелей на каждом SNP в эмбрионе.
Вышеописанные методики в некоторых случаях позволяют определить генотип индивидуума с учетом весьма небольшого количества ДНК от этого индивидуума. Это может быть ДНК от одной или небольшого количества клеток, или это может быть ДНК от небольшого количества плодной ДНК, обнаруженной в крови матери.
Определения
«Однонуклеотидный полиморфизм (SNP)» относится к отдельному нуклеотиду, который может отличаться в геномах двух членов одного и того же вида. Использование термина не должно подразумевать какое-либо ограничение частоты, с которой встречается каждый вариант.
«Последовательность» относится к последовательности ДНК или генетической последовательности. Она может относиться к первичной физической структуре молекулы или цепи ДНК у индивидуума. Она может относиться к последовательности нуклеотидов, обнаруженных в этой молекуле ДНК, или к цепи, комплементарной к молекуле ДНК. Она может относиться к информации, содержащейся в молекуле ДНК, как она представлена in silico.
«Локус» относится к конкретной представляющей интерес области на ДНК индивидуума, которая может относиться к SNP, сайту возможной вставки или делении или сайту некоторой другой соответствующей генетической вариации. Связанные с заболеванием SNP также могут относиться к связанным с заболеванием локусам.
«Полиморфный аллель», также «полиморфный локус», относится к аллелю или локусу, по которому генотип варьирует у индивидуумов данного вида. Некоторые примеры полиморфных аллелей включают в себя однонуклеотидные полиморфизмы, короткие тандемные повторы, делеции, дупликации и инверсии.
«Полиморфный сайт» относится к специфичным нуклеотидам, обнаруженным в полиморфной области, которая варьирует у индивидуумов.
«Аллель» относится к генам, которые занимают конкретный локус.
«Генетические данные», также «генотипические данные», относится к данным, описывающим аспекты генома одного или нескольких индивидуумов. Они могут относиться к одному или нескольким локусам, частичным или полным последовательностям, частичным или полным хромосомам или полному геному. Они могут относиться к идентичности одного или нескольких нуклеотидов; они могут относиться к набору последовательных нуклеотидов или нуклеотидов из различных локализаций в геноме или к их комбинации. Генотипического данные рассматриваются, как правило, in silico, однако, также можно рассматривать физические нуклеотиды в последовательности как химически кодированные генетические данные. Генотипические данные могут быть указаны «в» индивидууме(ах), «для» индивидуума(ам), «на» индивидууме(ах), «от» индивидуума(ов) или «по» индивидууму(ам). Генотипические данные могут относиться к выходным измерениям из платформы генотипирования, по которой выполняются эти измерения в генетическом материале.
«Генетический материал», также «генетический образец», относится к физическому материалу, такому как ткань или кровь, включающему ДНК или РНК, от одного или нескольких индивидуумов.
«Искаженные генетические данные» относятся к генетическим данным с чем-либо из следующего: исключения аллелей, недостоверные измерения пар оснований, некорректные измерения пар оснований, отсутствующие измерения пар оснований, недостоверные измерения вставок или делеций, недостоверные измерения чисел копий хромосомных сегментов, ложные сигналы, отсутствующие измерения, другие погрешности или их комбинации.
«Достоверность» относится к статистическому правдоподобию того, что названный SNP, аллель, набор аллелей, признак плоидности или определенное число копий хромосомных сегментов корректно представляет реальный генетический статус индивидуума.
«Установление плоидности», также «установление числа копий хромосомы» или «установление числа копий» (CNC), может относиться к действию по определению количества и/или хромосомной идентичности одной или нескольких хромосом, присутствующих в клетке.
«Анеуплоидия» относится к состоянию, при котором в клетке присутствует неправильное число хромосом. В случае соматической клетки человека она может относиться к случаю, при котором клетка не содержит 22 пары аутосомных хромосом и одну пару половых хромосом. В случае гаметы человека, она может относиться к явлению, когда клетка не содержит одну из каждой из 23 хромосом. В случае одного типа хромосом она может относиться к случаю, когда присутствует более или менее двух гомологичных, но неидентичных, копий хромосом, или когда присутствуют две копии хромосом, которые происходят от одного и того же родителя.
«Состояние плоидности относится к количеству и/или хромосомной идентичности одного или нескольких типов хромосом в клетке.
«Хромосома» может относиться к одной копии хромосомы, т.е. к одной молекуле ДНК, которых 46 в нормальной соматической клетке; примером является хромосома 18 материнского происхождения. Хромосома также может относиться к типу хромосом, которых 23 в нормальной соматической клетке человека; примером является хромосома 18.
«Хромосомная идентичность» может относиться к референтному числу хромосом, т.е. к типу хромосом. В норме у людей имеется 22 типа пронумерованных типов аутосомных хромосом и два типа половых хромосом. Она также может относиться к хромосоме родительского происхождения. Она также может относиться к конкретной хромосоме, унаследованной от родителя. Она также может относиться к другим признакам идентификации хромосомы.
«Статус генетического материала» или просто «генетический статус» может относиться к идентичности набора SNP в ДНК, к фазированным гаплотипам генетического материала или к последовательности ДНК, в том числе к вставкам, делециям, повторам и мутациям. Он также может относиться к состоянию плоидности одной или нескольких хромосом, хромосомных сегментов или наборов хромосомных сегментов.
«Аллельные данные» относится к набору генотипических данных, касающихся набора одного или нескольких аллелей. Они могут относиться к фазированным, гаплотипическим данным. Они могут относиться к идентичностям SNP, а также могут относиться к данным последовательностей ДНК, в том числе вставок, делеций, повторов и мутаций. Они могут предусматривать родительское происхождение каждого аллеля.
«Аллельное состояние» относится к фактическому состоянию генов в наборе одного или нескольких аллелей. Оно может относиться к фактическому состоянию генов, описанных аллельными данными.
«Аллельное отношение» или «отношение аллелей» относится к отношению между количеством каждого аллеля в локусе, которое имеется в образце или у индивидуума. Если образец измеряется с помощью секвенирования, аллельное отношение может означать отношение считываний последовательности, которые картируются с каждым аллелем в локусе. Если образец измеряется с помощью способа измерения интенсивности, аллельное отношение может означать отношение количеств каждого аллеля, присутствующего в локусе, подсчитанных способом измерения.
«Подсчет числа аллелей» или «число аллелей» относится к числу последовательностей, которые картируются с конкретным локусом, и, если этот локус является полиморфным, это относится к числу последовательностей, которые картируются с каждым из аллелей. Если каждый аллель подсчитывается бинарным образом, то числом аллелей будет целое число. Если аллели подсчитываются в вероятностном смысле, то число аллелей может быть дробным числом.
«Вероятность числа аллелей» относится к числу последовательностей, которые возможно картируются с конкретным локусом или набором аллелей в полиморфном локусе, комбинированным с вероятностью картирования. Следует отметить, что подсчеты числа аллелей являются эквивалентными вероятностям числа аллелей, при этом вероятность картирования для каждой подсчитанной последовательности является бинарной (нулевой или единичной). Согласно некоторым вариантам осуществления вероятности числа аллелей могут быть бинарными. Согласно некоторым вариантам осуществления вероятности числа аллелей могут быть установлены равными измерениям ДНК.
«Аллельное распределение» или «распределение числа аллелей» относится к относительному количеству каждого аллеля, присутствующего в каждом локусе из набора локусов. Аллельное распределение может относиться к индивидууму, к образцу или к набору измерений, выполненных в образце. В контексте секвенирования аллельное распределение относится к числу или вероятному числу считываний, которые картируются с конкретным аллелем для каждого аллеля в наборе полиморфных локусов. Измерения аллелей могут быть обработаны в вероятностном смысле, т.е. правдоподобие того, что данный аллель присутствует в данном считывании последовательности, представляет собой фракцию от 0 до 1, или они могут быть обработаны бинарным способом, т.е. любое данное считывание принимается за нулевую или единичную копии конкретного аллеля.
«Паттерн аллельного распределения» относится к набору различных распределений аллелей для различных родительских контекстов. Определенные паттерны распределения аллелей могут указывать на определенные состояния плоидности.
«Систематическая ошибка подсчета числа аллелей» относится к степени, с которой измеренное отношение аллелей в гетерозиготном локусе отличается от отношения, которое наблюдалось в оригинальном образце ДНК. Степень систематической ошибки подсчета числа аллелей в конкретном локусе равняется наблюдаемому измеренному аллельному отношению в этом локусе, деленному на отношение аллелей в оригинальном образце ДНК в этом локусе. Систематическая ошибка подсчета числа аллелей может быть определена как превышающая единицу, так, что если расчет степени систематической ошибки подсчета числа аллелей возвращает значение x, которое менее 1, то степень систематической ошибки подсчета числа аллелей может быть пересчитана как 1/x. Систематическая ошибка подсчета числа аллелей возможна из-за стандартной ошибки амплификации, стандартной ошибки очистки или какого-либо другого явления, которое неодинаково влияет на различные аллели.
«Праймер», также «зонд ПЦР», относится к отдельной молекуле ДНК (олигомеру ДНК) или коллекции молекул ДНК (олигомеров ДНК), в которой молекулы ДНК идентичны или почти идентичны, и при этом праймер содержит область, которая конструируется для гибридизации с целевым полиморфным локусом, и может содержать праймирующую последовательность, сконструированную для обеспечения ПЦР-амплификации. Праймер также может содержать молекулярный штрихкод. Праймер может содержать случайную область, которая отличается у каждой отдельной молекулы.
«Зонд гибридного захвата» относится к любой последовательности нуклеиновой кислоты, возможно модифицированной, которая получена различными способами, такими как ПЦР или прямой синтез, и предназначена быть комплементарной одной цепи конкретной целевой последовательности ДНК в образце. Экзогенные зонды гибридного захвата могут быть добавлены в подготовленный образец и гибридизированы посредством процесса денатурации и повторного отжига с образованием двойных спиралей экзогенных-эндогенных фрагментов. Затем эти двойные спирали можно физически отделить от образца различными средствами.
«Считывание последовательности» относится к представлению данных последовательности нуклеотидных оснований, которые были измерены с использованием способа клонального секвенирования. С помощью клонального секвенирования можно получать данные последовательности, представляющие отдельную молекулу ДНК или клоны, или кластеры одной оригинальной молекулы ДНК. Считывание последовательности также может быть связано с оценкой качества в каждом положении основания последовательности, показывающей вероятность того, что нуклеотид был установлен правильно.
«Картирование считывания последовательности» представляет собой процесс определения локализации считывания последовательности из источника в геномной последовательности конкретного организма. Локализация источника считываний последовательности основывается на подобии последовательности нуклеотидов считывания и геномной последовательности.
«Ошибка спаренных копий», также «анеуплоидия спаривания хромосом» (MCA), относится к состоянию анеуплоидии, при котором одна клетка содержит две идентичных или почти идентичных хромосомы. Этот тип анеуплоидии может возникать в ходе формирования гамет в мейозе и может быть назван ошибкой мейотического нерасхождения. Этот тип ошибки может возникать в митозе. Трисомия спаривания может относиться к случаю, при котором три копии данной хромосомы присутствуют у индивидуума, и две из копий являются идентичными.
«Ошибка неспаренных копий», также «анеуплоидия уникальной хромосомы» (UCA), относится к состоянию анеуплоидии, при котором одна клетка содержит две хромосомы, которые походят от одного и того же родителя и которые могут быть гомологичными, но не являются идентичными. Этот тип анеуплоидии может возникать в мейозе, и может быть назван мейотической ошибкой. Трисомия неспаривания может относиться к случаю, при котором три копии данной хромосомы присутствуют у индивидуума, и две из копий походят от одного и того же родителя и являются гомологичными, но не являются идентичными. Следует отметить, что трисомия неспаривания может относиться к случаю, при котором присутствуют две гомологичных хромосомы от одного родителя, и при котором некоторые сегменты хромосом являются идентичными, тогда как другие сегменты являются только гомологичными.
«Гомологичные хромосомы» относятся к копиям хромосом, которые содержат один и тот же набор генов, которые в норме спариваются в ходе мейоза.
«Идентичные хромосомы» относятся к копиям хромосом, которые содержат один и тот же набор генов, и для каждого гена в них содержится один и тот же набор аллелей, которые являются идентичными или почти идентичными.
«Выпадение аллеля (ADO)» относится к ситуации, при которой по меньшей мере одно из пары оснований в наборе пар оснований из гомологичных хромосом в данном аллеле не выявляется.
«Выпадение локуса (LDO)» относится к ситуации, при которой оба из пары оснований в наборе пар оснований из гомологичных хромосом в данном аллеле не выявляются.
«Гомозиготный» относится к содержащему подобные аллели в соответствующих хромосомных локусах.
«Гетерозиготный» относится к содержащему несходные аллели в соответствующих хромосомных локусах.
«Степень гетерозиготности» относится к степени индивидуумов в популяции, имеющих гетерозиготные аллели в данном локусе. Степень гетерозиготности также может относиться к ожидаемому или измеренному отношению аллелей в данном локусе у индивидуума или в образце ДНК.
«Высокоинформативный однонуклеотидный полиморфизм (HISNP)» относится к SNP, при этом плод имеет аллель, которая не присутствует в генотипе матери.
«Хромосомная область» относится к сегменту хромосомы или к полной хромосоме.
«Сегмент хромосомы» относится к участку хромосомы, размер которого может варьировать от одной пары оснований до всей хромосомы.
«Хромосома» относится либо к полной хромосоме, либо к сегменту или участку хромосомы.
«Копии» относятся к числу копий хромосомного сегмента. Они могут относиться к идентичным копиям или к неидентичным, гомологичным копиям хромосомного сегмента, при этом различные копии хромосомного сегмента содержат в основном подобный набор локусов, и один или несколько аллелей являются разными. Следует отметить, что в некоторых случаях анеуплоидии, таких как ошибка копий M2, возможно наличие некоторых копий данного хромосомного сегмента, которые являются идентичными, а также некоторых копий одного и того же хромосомного сегмента, которые не являются идентичными.
«Гаплотип» относится к комбинации аллелей в нескольких локусах, которые, как правило, наследованы вместе в одной и той же хромосоме. Гаплотип может относиться либо к всего лишь двум локусам, либо ко всей хромосоме в зависимости от количества событий рекомбинации, произошедших между данным набором локусов. Гаплотип также может относиться к набору однонуклеотидных полиморфизмов (SNP) на одной хроматиде, которые статистически связаны.
«Гаплотипические данные», также «фазированные данные» или «упрорядоченные генетические данные», относится к данным из одной хромосомы в диплоидном или полиплоидном геноме, т.е. либо к сегрегированной материнской, либо к отцовской копии хромосомы в диплоидном геноме.
«Фазирование» относится к действию по определению гаплотипических генетических данных из имеющихся неупорядоченных диплоидных (или полиплоидных) генетических данных индивидуума. Оно может относиться к действию по определению, какой из двух генов в аллеле, для набора аллелей, обнаруженного в одной хромосоме, ассоциируется с каждой из двух гомологичных хромосом у индивидуума.
«Фазированные данные» относятся к генетическим данным с определением одного или нескольких гаплотипов.
«Гипотеза» относится к возможному состоянию плоидности в данном наборе хромосом или к набору возможных аллельных состояний в данном наборе локусов. Набор вероятностей может содержать один или несколько элементов.
«Гипотеза числа копия», также «гипотеза состояния плоидности», относится к гипотезе, касающейся числа копий хромосомы у индивидуума. Она также может относиться к гипотезе, касающейся идентичности каждой из хромосом, в том числе родителя происхождения каждой хромосомы, а также того, какие из двух хромосом родителей присутствуют у индивидуума. Она также может относиться к гипотезе, касающейся того, какие хромосомы или хромосомные сегменты, если имеются, от родственного индивидуума генетически соответствуют данной хромосоме от индивидуума.
«Целевой индивидуум» относится к индивидууму, чей генетический статус подлежит определению. Согласно некоторым вариантам осуществления доступно только ограниченное количество ДНК от целевого индивидуума. Согласно некоторым вариантам осуществления целевым индивидуумом является плод. Согласно некоторым вариантам осуществления может быть более одного целевого индивидуума. Согласно некоторым вариантам осуществления каждый плод, появившийся от пары родителей, может считаться целевым индивидуумом. Согласно некоторым вариантам осуществления генетического данные, подлежащие определению, представляют собой один или набор аллельных признаков. Согласно некоторым вариантам осуществления генетического данные, подлежащие определению, представляют собой признак плоидности.
«Родственный индивидуум» относится к любому индивидууму, который является генетически родственным целевому индивидууму и, таким образом, обладает общими гаплотипическими блоками с целевым индивидуумом. В одном контексте родственным индивидуумом может быть генетический родитель целевого индивидуума или какой-либо генетический материал от родителя, такой как сперма, полярное тельце, эмбрион, плод или ребенок. Он также может относиться к сиблингу, родителю или к дедушке или бабушке.
«Сиблинг» относится к какому-либо индивидууму, чьи генетические родители являются теми же самыми, что и у рассматриваемого индивидуума. Согласно некоторым вариантам осуществления он может относиться к рожденному ребенку, эмбриону или плоду, или одной или нескольким клеткам, происходящим от рожденного ребенка, эмбриона или плода. Сиблинг также может относиться к гаплоидному индивидууму, который происходит от одного из родителей, например, к сперме, полярному тельцу или какому-либо другому набору гаплотипического генетического материала. Индивидуум может считаться сиблингом без связи с другими явлениями.
«Плодный» относится к «относящемуся к плоду» или к «области плаценты, которая генетически подобна плоду». У беременной женщины некоторая часть плаценты генетически подобна плоду, и свободно плавающая плодная ДНК, обнаруженная в крови матери, может происходить из части плаценты, генотип которой совпадает с таковым плода. Следует отметить, что генетическая информация в половине из хромосом у плода наследуется от матери плода. Согласно некоторым вариантам осуществления ДНК от этих унаследованных от матери хромосом, которые походят от плодной клетки, считается имеющей «плодное происхождение», а не «материнское происхождение».
«ДНК плодного происхождения» относится к ДНК, которая была первоначально частью клетки, генотип которой главным образом был эквивалентен таковому плода.
«ДНК материнского происхождения» относится к ДНК, которая была первоначально частью клетки, генотип которой был главным образом эквивалентен таковому матери.
«Ребенок» может относиться к эмбриону, бластомеру или плоду. Следует отметить, что в раскрытых в настоящем документе вариантах осуществления описанные концепции в равной степени применяются к индивидуумам, которые представляют собой рожденного ребенка, плод, эмбрион или набор их клеток. Применение термина «ребенок» может просто означать, что названный ребенком индивидуум является генетическим потомком родителей.
«Родитель» относится к генетическим матери или отцу индивидуума. У индивидуума, как правило, имеется два родителя, мать и отец, хотя это может быть необязательно в случае, таком как генетический или хромосомный химеризм. Родитель может рассматриваться как индивидуум.
«Родительский контекст» относится к генетическому статусу данного SNP в каждой из двух соответствующих хромосом для одного или обоих из двух родителей цели.
«Развиваться по желанию», также «нормально развиваться» относится к жизнеспособному эмбриону, имплантированному в матку и приводящему к беременности, и/или к беременности, продолжающейся и приводящей к рождению живого ребенка, и/или к родившемуся ребенку без хромосомных аномалий, и/или к родившемуся ребенку без других нежелательных генетических состояний, таких как связанные с заболеванием гены. Термин «развиваться по желанию» предназначен охватывать все, что могут желать родители или специалисты в области здравоохранения. В некоторых случаях «развиваться по желанию» может относиться к нежизнеспособному или жизнеспособному эмбриону, который применяется для медицинского исследования или для других целей.
«Введение в матку» относится к процессу переноса эмбриона в полость матки в контексте in vitro оплодотворения.
«Материнская плазма» относится к порции плазмы крови женщины, являющейся беременной.
«Клиническое решение» относится к какому-либо решению по принятию или непринятию действия, результат которого влияет на здоровье или выживаемость индивидуума. В контексте пренатальной диагностики клиническое решение может относиться к решению о прерывании или о продолжении беременности. Клиническое решение также может относиться к решению о проведении дополнительного тестирования, к принятию действий по минимизации нежелательного фенотипа или к принятию действий по подготовке к рождению ребенка с аномалиями.
«Диагностический бокс» относится к одному или к комбинации устройств, разработанных для выполнения одного или множество аспектов раскрытых в настоящем документе способов. Согласно варианту осуществления диагностический бокс может быть размещен в пункте наблюдения за пациентом. Согласно варианту осуществления с помощью диагностического бокса может выполняться целевая амплификация с последующим секвенированием. Согласно варианту осуществления диагностический бокс может функционировать самостоятельно или может управляться специалистом.
«Основанный на информатике способ» относится к способу, который в значительной мере опирается на статистику для осмысления большого количества данных. В контексте пренатальной диагностики он относится к способу, разработанному для определения состояния плоидности по одной или нескольких хромосомах или аллельного состояния в одном или нескольких аллелях с помощью статистического заключения о наиболее возможном состоянии, а не с помощью непосредственного физического измерения состояния, при большом количестве генетических данных, например, из молекулярной матрицы или секвенирования. Согласно варианту осуществления настоящего раскрытия основанная на информатике методика может быть методикой, раскрытой в настоящем изобретении. Согласно варианту осуществления настоящего раскрытия это может быть PARENTAL SUPPORT™.
«Первичные генетические данные» относятся к сигналам аналогичной интенсивности, которые производятся платформой генотипирования. В контексте матриц SNP первичные генетические данные относится к сигналам интенсивности перед осуществлением установления какого-либо генотипа. В контексте секвенирования первичные генетического данные относятся к аналогичным измерениям, аналогичным хроматограмме, которые выходят из секвенатора до определения идентичности какой-либо пары оснований и до картирования последовательности с геномом.
«Вторичные генетические данные» относятся к обработанным генетическим данным, которые производятся платформой генотипирования. В контексте матриц SNP вторичные генетические данные относятся к аллельным признакам, полученным программным обеспечением, ассоциированным с устройством считывания матрицы SNP, в котором программное обеспечение осуществляет получение признака того, присутствует или не присутствует данная аллель в образце. В контексте секвенирования вторичные генетические данные относятся к идентичности пары оснований последовательностей, которые были определены, и возможно также последовательностей, которые были картированы с геномом.
«Предпочтительное приумножение» ДНК, которая соответствует локусу, или предпочтительное приумножение ДНК в локусе относится к любому способу, который дает процентное отношение молекул ДНК в постприумноженной смеси ДНК, которая соответствует локусам, более высокое, чем процентное отношение молекул ДНК в доприумноженной смеси ДНК, которая соответствует локусам. Способ может предусматривать селективную амплификацию молекул ДНК, которые соответствуют локусам. Способ может предусматривать удаление молекул ДНК, которые не соответствуют локусам. Способ может предусматривать комбинацию способов. Степень приумножения определяется как процентное отношение молекул ДНК в постприумноженной смеси, которая соответствует локусу, поделенное на процентное отношение молекул ДНК в доприумноженной смеси, которая соответствует локусу. Предпочтительное приумножение может быть выполнено во множестве локусов. Согласно некоторым вариантам осуществления настоящего раскрытия степень приумножения составляет более 20. Согласно некоторым вариантам осуществления настоящего раскрытия степень приумножения составляет более 200. Согласно некоторым вариантам осуществления настоящего раскрытия степень приумножения составляет более 2000. Если предпочтительное приумножение выполняется во множестве локусов, степень приумножения может относиться к средней степени приумножения всех локусов в наборе локусов.
«Амплификация» относится к способу, который увеличивает число копий молекулы ДНК.
«Селективная амплификация» может относиться к способу, который увеличивает число молекулярных копий конкретной молекулы ДНК или молекул ДНК, которые соответствуют конкретной области ДНК. Она также может относиться к способу, который увеличивает число копий конкретной целевой молекулы ДНК или целевой области ДНК в большей степени, чем увеличивает нецелевые молекулы или области ДНК. Селективная амплификация может быть способом предпочтительного приумножения.
«Универсальная праймирующая последовательность» относится к последовательности ДНК, которая может быть добавлена к популяции целевых молекул ДНК, например, путем лигирования, ПЦР или опосредованной лигированием ПЦР. При добавлении к популяции целевых молекул праймеры, специфичные к универсальным праймирующим последовательностям, могут быть использованы для амплификации целевой популяции с использованием одной пары амплификационных праймеров. Универсальные праймирующие последовательности, как правило, не являются родственными целевым последовательностям.
«Универсальные адаптеры», или «адаптеры лигирования», или «метки библиотеки» представляют собой молекулы ДНК, содержащие универсальную праймирующую последовательность, которая может быть ковалентно связана с 5'-концом и 3'-концом популяции целевых двухцепочечных молекул ДНК. Добавление адаптеров обеспечивает универсальные праймирующие последовательности на 5'-конце и 3'-конце целевой популяции, по которой может осуществляться ПЦР-амплификация, амплификация всех молекул из целевой популяции, с использованием одной пары амплификационных праймеров.
«Нацеливание» относится к способу, используемому для селективной амплификации или иного предпочтительного приумножения тех молекул ДНК, которые соответствуют набору локусов, в смеси ДНК.
«Модель совместного распределения» относится к модели, которая определяет вероятность событий, определенных в виде нескольких случайных переменных, с учетом множества случайных переменных, определенных в одном и том же пространстве вероятностей, в котором вероятности переменной являются связанными. Согласно некоторым вариантам осуществления может быть использован вырожденный случай, при котором вероятности переменных не являются связанными.
Гипотеза
В контексте настоящего раскрытия гипотеза относится к возможному генетическому статусу. Она может относиться к возможному состоянию плоидности. Она может относиться к возможному аллельному состоянию. Набор гипотез может относиться к набору возможных генетических статусов, набору возможных аллельных состояний, набору возможных состояний плоидности или их комбинациям. Согласно некоторым вариантам осуществления набор гипотез может быть разработан так, что одна гипотеза из набора будет соответствовать действительному генетическому статусу любого данного индивидуума. Согласно некоторым вариантам осуществления набор гипотез может быть разработан так, что каждый возможный генетический статус может быть описан по меньшей мере одной гипотезой из набора. Согласно некоторым вариантам осуществления настоящего раскрытия один аспект способа заключается в определении того, какая из гипотез соответствует действительному генетическому статусу рассматриваемого индивидуума.
Согласно другому варианту осуществления настоящего раскрытия один этап предусматривает создание гипотезы. Согласно некоторым вариантам осуществления это может быть гипотеза числа копий. Согласно некоторым вариантам осуществления может предусматриваться гипотеза, касающаяся того, какие сегменты хромосомы от каждого из родственных индивидуумов генетически соответствуют каким сегментам, если соответствие имеется, от других родственных индивидуумов. Создание гипотезы может относиться к действию установления границ переменных так, что весь набор исследуемых возможных генетических статусов охватывается этими переменными.
«Гипотеза числа копий», также называемая «гипотезой плоидности» или «гипотезой состояния плоидности», может относиться к гипотезе, касающейся возможного состояния плоидности для копии данной хромосомы, типа хромосомы или участка хромосомы целевого индивидуума. Она также может относиться к состоянию плоидности более одного типа хромосом индивидуума. Набор гипотез числа копий может относиться к набору гипотез, в котором каждая гипотеза соответствует различному возможному состоянию плоидности у индивидуума. Набор гипотез может касаться набора возможных состояний плоидности, набора вкладов возможных родительских гаплотипов, набора возможных процентных отношений плодной ДНК в смешанном образце или их комбинаций.
Нормальный индивидуум содержит по одной из каждого типа хромосом от каждого родителя. Однако вследствие погрешностей мейоза и митоза индивидуум может иметь 0, 1, 2 или более хромосом данного типа от каждого родителя. На практике случаи наличия более двух данных хромосом от родителя встречаются редко. В настоящем раскрытии некоторые варианты осуществления рассматривают только возможные гипотезы, при которых от родителя получено 0, 1 или 2 копии данной хромосомы; тривиальным продолжением этого является рассмотрение ситуации, при которой от родителя получено больше или меньше возможных копий. Согласно некоторым вариантам осуществления для данной хромосомы имеется девять возможных гипотез: три возможные гипотезы касаются 0, 1 или 2 хромосом материнского происхождения, помноженные на три возможные гипотезы, касающиеся 0, 1 или 2 хромосом отцовского происхождения. Пусть (m, f) относится к гипотезе, при которой m представляет собой число копий данной хромосомы, унаследованной от матери, а f представляет собой число копий данной хромосомы, унаследованной от отца. Следовательно, девятью гипотезами являются (0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1) и (2, 2). Они также могут быть записаны как H00, H01, H02, H10, H12, H20, H21 и H22. Различные гипотезы соответствуют различным состояниям плоидности. Например, (1, 1) относится к нормальной дисомной хромосоме; (2, 1) относится к материнской трисомии, а (0, 1) относится к отцовской моносомии. Согласно некоторым вариантам осуществления случай, при котором две хромосомы унаследованы от одного родителя, и одна хромосома унаследована от другого родителя, может быть далее дифференцирован на два случая: когда две хромосомы идентичны (ошибка спаренных копий), и когда две хромосомы гомологичны, но не идентичны (ошибка неспаренных копий). В этих вариантах осуществления имеется шестнадцать возможных гипотез. Следует понимать, что можно использовать другие наборы гипотез и различное число гипотез.
Согласно некоторым вариантам осуществления настоящего раскрытия гипотеза плоидности относится к гипотезе, касающейся того, какая хромосома от других родственных индивидуумов соответствует хромосоме, обнаруженной в геноме целевого индивидуума. Согласно некоторым вариантам осуществления ключом к методу является факт, что можно предполагать, что родственные индивидуумы обладают общими блоками гаплотипа, и с использованием измеренных генетических данных родственных индивидуумов вместе со информацией о том, какие блоки гаплотипа имеют соответствие между целевым индивидуумом и родственным индивидуумом, можно сделать заключение о корректности генетических данных для целевого индивидуума с большей достоверностью, чем при использовании только генетических измерений целевого индивидуума. В этой связи, согласно некоторым вариантам осуществления гипотеза плоидности может касаться не только числа хромосом, но и того, какие хромосомы у родственных индивидуумов идентичны или почти идентичны с одной или несколькими хромосомами целевого индивидуума.
После того, как набор гипотез определен, когда алгоритмы оперируют с входными генетическими данными, они могут вывести определенную статистическую вероятность для каждой из рассматриваемых гипотез. Вероятности различных гипотез могут быть определены путем математических расчетов для каждой из различных гипотез, значение того, что вероятности равны, как установлено с помощью одной или нескольких экспертных методик, алгоритмов и/или способов, описанных в других разделах в настоящем раскрытии, с использованием соответствующих генетических данных в качестве входных данных.
После того как вероятности различных гипотез оценены, как определено с помощью нескольких методик, их можно комбинировать. Это может означать для каждой гипотезы умножение вероятностей, определенных каждой из методик. Продукт вероятностей гипотез можно нормализовать. Следует отметить, что одна гипотеза плоидности относится к одному возможному состоянию плоидности для хромосомы.
Процесс «комбинирования вероятностей», также называемый «комбинированием гипотез» или «комбинированием результатов экспертных методик», является концепцией, с которой должны быть знакомы специалисты в области линейной алгебры. Один из возможных способов комбинирования вероятностей заключается в следующем: когда экспертная методика используется для оценки набора гипотез для данного набора генетических данных, конечный продукт способа - это набор вероятностей, которые взаимно-однозначно ассоциированы с каждой гипотезой в наборе гипотез. Когда набор вероятностей, которые были определены с помощью первой экспертной методики, каждая из которых ассоциирована с одной из гипотез набора, комбинируется с набором вероятностей, которые были определены с помощью второй экспертной методики, каждая из которых ассоциирована с тем же самым набором гипотез, затем два набора вероятностей перемножаются. Это означает, что для каждой гипотезы набора две вероятности, которые ассоциированы с этой гипотезой, как определено двумя экспертными методиками, перемножаются, и соответствующий продукт является конечной вероятностью. Этот процесс может быть расширен на любое число экспертных методик. Если используется только одна экспертная методика, то конечные вероятности являются такими же, как и входные вероятности. Если используется более двух экспертных методик, то соответствующие вероятности можно перемножить в то же самое время. Продукты могут быть нормализованы, так что вероятности гипотез набора должны составлять в сумме 100%.
Согласно некоторым вариантам осуществления, если комбинированные вероятности для данной гипотезы больше, чем комбинированные вероятности для любых других гипотез, можно считать, что эта гипотеза определена как наиболее вероятная. Согласно некоторым вариантам осуществления гипотеза может быть определена как наиболее вероятная, и состояние плоидности или другой генетический статус может быть установлен, если нормализованная вероятность выше пороговой. Согласно варианту осуществления это может означать, что число и идентичность хромосом, которые ассоциированы с этой гипотезой, могут быть установлены в качестве состояния плоидности. Согласно варианту осуществления это может означать, что идентичность аллелей, которые ассоциированы с этой гипотезой, может быть установлена в качестве аллельного состояния. Согласно некоторым вариантам осуществления порог может составлять от приблизительно 50% до приблизительно 80%. Согласно некоторым вариантам осуществления порог может составлять от приблизительно 80% до приблизительно 90%. Согласно некоторым вариантам осуществления порог может составлять от приблизительно 90% до приблизительно 95%. Согласно некоторым вариантам осуществления порог может составлять от приблизительно 95% до приблизительно 99%. Согласно некоторым вариантам осуществления порог может составлять от приблизительно 99% до приблизительно 99,9%. Согласно некоторым вариантам осуществления порог может составлять более приблизительно 99,9%.
Родительские контексты
Родительский контекст относится к генетическому статусу данного аллеля в каждой из двух соответствующих хромосом для одного из двух или обоих родителей цели. Следует отметить, что согласно варианту осуществления родительский контекст не означает аллельное состояние цели, скорее он относится к аллельному состоянию родителей. Родительский контекст для данного SNP может состоять из четырех пар оснований, двух отцовских и двух материнских; они могут быть одинаковыми или отличаться друг от друга. Он, как правило, записывается как «m1m2|f1f2», при этом m1 и m2 представляют генетический статус данного SNP в двух материнских хромосомах, а f1 и f2 представляют генетический статус данного SNP в двух отцовских хромосомах. Согласно некоторым вариантам осуществления родительский контекст может быть записан как «f1f2|m1m2». Следует отметить, что индексы «1» и «2» относятся к генотипу в данном аллеле первой и второй хромосом; также следует отметить, что выбор, какая хромосома отмечается «1», а какая отмечается «2», может быть произвольным.
Следует отметить, что в настоящем раскрытии A и B часто используются для группового представления идентичностей пар оснований; A или B могут одинаково хорошо представлять C (цитозин), G (гуанин), A (аденин) или T (тимин). Например, если на данном основанном на SNP аллеле генотип матери представлял собой T в этом SNP в одной хромосоме и G в этом SNP в гомологичной хромосоме, и генотип отца в этом аллеле представляет собой G в этом SNP в обеих гомологичных хромосомах, можно сказать, что аллель целевого индивидуума характеризуется родительским контекстом AB|BB; также можно сказать, что аллель характеризуется родительским контекстом AB|AA. Следует отметить, что теоретически любой из четырех возможных нуклеотидов может встречаться в данном аллеле, и таким образом возможно, например, чтобы мать имела генотип AT, а отец имел генотип GC в данном аллеле. Однако, эмпирические данные показывают, что в большинстве случаев только две из четырех возможных пар оснований наблюдаются в данном аллеле. Возможно, например, при использовании отдельных тандемных повторов наличие более двух родительских, более четырех и даже более десяти контекстов. В настоящем раскрытии обсуждение предполагает, что только две возможных пары оснований будут наблюдаться в данном аллеле, хотя раскрытые в настоящем документе варианты осуществления могут быть модифицированы с учетом тех случаев, когда эта гипотеза не принимается.
«Родительский контекст» может относиться к набору или подгруппе целевых SNP, которые характеризуются одинаковым родительским контекстом. Например, если было измерено 1000 аллелей в данной хромосоме целевого индивидуума, то контекст AA|BB может относиться набору всех аллелей в группе из 1000 аллелей, при этом генотип матери целевого индивидуума был гомозиготным, и генотип целевого индивидуума был гомозиготным, но материнский генотип и отцовский генотип являются несходными в этом локусе. Если родительские данные не являются фазированными, и, таким образом, AB=BA, то существует восемь возможных родительских контекстов: AA|AA, AA|AB, AA|BB, AB|AA, AB|AB, AB|BB, BB|AA, BB|AB и BB|BB. Если родительские данные являются фазированными, и, таким образом, AB≠BA, то существует шестнадцать различных возможных родительских контекстов: AA|AA, AA|AB, AA|BA, AA|BB, AB|AA, AB|AB, AB|BA, AB|BB, BA|AA, BA|AB, BA|BA, BA|BB, BB|AA, BB|AB, BB|BA и BB|BB. Каждый аллель SNP в хромосоме, за исключением некоторых SNP в половых хромосомах, характеризуется одним из этих родительских контекстов. Набор SNP, в котором родительский контекст для одного родителя является гетерозиготным, может называться гетерозиготным контекстом.
Применение родительских контекстов в NPD
Неинвазивная пренатальная диагностика является важной методикой, которая может быть использована для определения генетического статуса плода по полученному неинвазивным способом генетическому материалу, например, взятому из крови беременной матери. Кровь может быть разделена, и выделена плазма, а затем выделена ДНК плазмы. Отбор по размеру может быть использован для выделения ДНК приемлемой длины. ДНК может быть предпочтительно приумножена набором локусов. Затем эта ДНК может быть измерена рядом средств, таких как гибридизация для матрицы генотипирования и измерение флуоресценции или секвенирование на высокопроизводительном секвенаторе.
Если секвенирование используется для установления плоидности плода в контексте неинвазивной пренатальной диагностики, имеется ряд способов для применения данных последовательности. Наиболее общим подходом может быть применение данных последовательности для простого подсчета числа считываний, которые картируются с данной хромосомой. Например, представьте, что пытаетесь определить состояние плоидности хромосомы 21 у плода. Далее представьте, что ДНК в образце состоит из 10% ДНК плодного происхождения и 90% ДНК материнского происхождения. В этом случае следует найти среднее число считываний в хромосоме, которая, как предполагается, является дисомной, например, хромосома 3, и сравнить его с числом считываний в хромосоме 21, при этом считывания приводятся в соответствие с числом пар оснований в этой хромосоме, которые являются частью уникальной последовательности. Если плод был эуплоидным, можно ожидать, что количество ДНК на единицу генома будет приблизительно равным во всех локализациях (с учетом стохастических вариаций). С другой стороны, если плод был трисомным по хромосоме 21, то можно ожидать, что будет немного больше ДНК на генетическую единицу из хромосомы 21, чем из других локализаций в геноме. В частности, можно ожидать, что будет на приблизительно 5% больше ДНК из хромосомы 21 в смеси. Если для измерения ДНК используется секвенирование, можно ожидать на приблизительно 5% больше однозначно картирующихся считываний из хромосомы 21 на уникальный сегмент, чем из других хромосом. Можно применять наблюдение количества ДНК из конкретной хромосомы, которое выше определенного порога, при приведении в соответствие с числом последовательностей, однозначно картирующихся с этой хромосомой, как основу для диагностики анеуплоидии. Другой способ, который может быть использован для выявления анеуплоидии, подобен вышеописанному за исключением того, что могут быть учтены родительские контексты.
При рассмотрении аллелей для нацеливаний можно учитывать вероятность того, что некоторые родительские контексты, вероятно, будут более информативными, чем другие. Например, AA|BB и симметричный контекст BB|AA являются наиболее информативными контекстами, поскольку известно, что плод несет аллель, отличный от материнского. Из соображений симметрии контексты и AA|BB, и BB|AA могут упоминаться как AA|BB. Другим набором информативных родительских контекстов является AA|AB и BB|AB, поскольку в этих случаях имеется 50% вероятности того, что плод несет аллель, который отсутствует у матери. Из соображений симметрии контексты и AA|AB, и BB|AB могут упоминаться как AA|AB. Третьим набором информативных родительских контекстов является AB|AA и AB|BB, поскольку в этих случаях плод несет известный родительский аллель, и этот аллель также присутствует в материнской геноме. Из соображений симметрии контексты и AB|AA, и AB|BB могут упоминаться как AB|AA. Четвертым родительским контекстом является AB|AB, при котором аллельное состояние плода неизвестно, и все, что известно об аллельном состоянии - это то, что мать имеет те же аллели. Пятым родительским контекстом является AA|AA, при котором мать и отец гетерозиготны.
Различные выполнения раскрытых в настоящем документе вариантов осуществления
В настоящем документе раскрывается способ определения состояния плоидности целевого индивидуума. Целевым индивидуумом может быть бластомер, эмбрион или плод. Согласно некоторым вариантам осуществления настоящего раскрытия способ определения состояния плоидности одной или нескольких хромосом у целевого индивидуума может предусматривать какой-либо из описанных в настоящем документе этапов и их комбинации.
Согласно некоторым вариантам осуществления источником генетического материала для использования в определении генетического статуса плода могут быть плодные клетки, такие как ядросодержащие плодные красные кровяные клетки, выделенные из крови матери. Способ может предусматривать получение образца крови от беременной матери. Способ может предусматривать выделение плодных красных кровяных клеток с использованием визуальных методик, основанных на идее, что определенная комбинация цветов уникально связана с ядросодержащей красной кровяной клеткой, и подобная комбинация цветов не связана с любой другой присутствующей в крови матери клеткой. Комбинация цветов, связанных с ядросодержащими красными кровяными клетками, может содержать красный цвет гемоглобина вокруг ядра, причем цвет можно сделать более четким с помощью окрашивания, и цвет ядерного материала, который можно окрасить, например, голубым. Путем выделения клеток из крови матери и распределения их по предметному стеклу, а затем идентификации тех точек, в которых виден и красный (от гемоглобина), и голубой (от ядерного материала) можно идентифицировать локализацию ядросодержащих красных кровяных клеток. Затем можно экстрагировать такие ядросодержащие красные кровяные клетки с использованием микроманипулятора, использовать методики генотипирования и/или секвенирования для измерения аспектов генотипа генетического материала в этих клетках.
Согласно варианту осуществления можно окрасить ядросодержащую красную кровяную клетку красителем, который флуоресцирует только в присутствии плодного гемоглобина, а не материнского гемоглобина, и таким образом устранить неясность, происходит ли ядросодержащая красная кровяная клетка от матери или от плода. Некоторые варианты осуществления настоящего раскрытия могут предусматривать окрашивание или иную маркировку ядерного материала. Некоторые варианты осуществления настоящего раскрытия могут предусматривать специфичную маркировку плодного ядерного материал с использованием специфичных к плодным клеткам антител.
Существует множество других путей выделения плодных клеток из крови матери или плодной ДНК из крови матери или приумножения образцов плодного генетического материал в присутствии материнского генетического материала. Некоторые из этих способов приведены в настоящем документе, но это не должно расценивается как исчерпывающий перечень. Для удобства в настоящем документе приведены некоторые приемлемые методики: использование флуоресцентно или иным образом меченых антител, эксклюзионная хроматография, магнитные или меченые иным образом аффинные метки, эпигенетические различия, такие как различное метилирование между материнскими и плодными клетками в определенных аллелях, центрифугирование в градиенте плотности с последующим истощением CD45/14 и CD71-положительным отбором из CD45/14-отрицательных клеток, одинарные или двойные градиенты Перколла с различными осмоляльностями или специфичный по отношению к галактозе пектиновый метод.
Согласно варианту осуществления настоящего раскрытия целевым индивидуумом является плод, и различные генотипические измерения выполняются во множестве образцов ДНК от плода. Согласно некоторым вариантам осуществления настоящего раскрытия образцы плодной ДНК являются выделенными из плодных клеток, при этом плодные клетки могут быть смешаны с материнскими клетками. Согласно некоторым вариантам осуществления настоящего раскрытия образцы плодной ДНК походят от свободно плавающей плодной ДНК, при этом плодная ДНК может быть смешана со свободно плавающей материнской ДНК. Согласно некоторым вариантам осуществления образцы плодной ДНК могут быть получены из материнской плазмы или крови матери, которая содержит смесь материнской ДНК и плодной ДНК. Согласно некоторым вариантам осуществления плодная ДНК может быть смешана с материнской ДНК в отношении материнской к плодной, варьирующем от 99,9:0,1% до 99:1%; от 99:1% до 90:10%; от 90:10% до 80:20%; от 80:20% до 70:30%; от 70:30% до 50:50%; от 50:50% до 10:90% или от 10:90% до 1:99%; от 1:99% до 0,1:99,9%.
Согласно некоторым вариантам осуществления генетический образец может быть получен, выделен и/или очищен. Согласно некоторым вариантам осуществления образец может быть центрифугирован для разделения разных слоев. Согласно некоторым вариантам осуществления получение ДНК может предусматривать амплификацию, отделение, очистку хроматографией, очистку электрофорезом, фильтрацию, разделение жидкостей, выделение, осаждение, предпочтительное приумножение, предпочтительную амплификацию, целевую амплификацию или любую из ряда других методик, либо известных в уровне техники, либо описанных в настоящем документе.
Согласно некоторым вариантам осуществления способ настоящего раскрытия может предусматривать амплификацию ДНК. Амплификация ДНК, процесс, который трансформирует небольшое количество генетического материала в большее количество генетического материала, который содержит подобный набор генетических данных, может быть выполнена с помощью широкого ряда способов, в том числе без ограничения с помощью полимеразной цепной реакции (ПЦР). Одним способом амплификации ДНК является полногеномная амплификация (WGA). Существует ряд доступных для WGA способов: опосредованная дотированием ПЦР (LM-PCR), ПЦР с вырожденными олигонуклеотидными праймерами (DOP-PCR) и амплификация с множественным вытеснением цепи (MDA). При LM-PCR короткие последовательности ДНК, названные адаптерами, лигируются по тупым концам ДНК. Эти адаптеры содержат универсальные амплификационные последовательности, которые используются для амплификации ДНК с помощью ПЦР. При DOP-PCR случайные праймеры, которые также содержат универсальные амплификационные последовательности, используются в первом раунде отжига и ПЦР. Затем второй раунд ПЦР используется для амплификации последовательностей с универсальными праймерными последовательностями. При MDA используется полимераза phi-29, которая является высоко процессивным и неспецифичным ферментом, который реплицирует ДНК и используется для анализа единичных клеток. Полногеномная амплификация единичных клеток успешно использовалась в ряде примений в течение многих лет. Существуют другие способы амплификации ДНК из образца ДНК. Амплификация ДНК преобразует изначальный образец ДНК в образец ДНК, которая подобна в ряде последовательностей, но содержится в гораздо больших количествах. В некоторых случаях амплификация может быть не нужна.
Согласно некоторым вариантам осуществления ДНК может быть амплифицирована с использованием универсальной амплификации, такой как WGA или MDA. Согласно некоторым вариантам осуществления ДНК может быть амплифицирована с помощью целевой амплификации, например, с использованием целевой ПЦР, или зондов циркуляризации. Согласно некоторым вариантам осуществления ДНК может быть предпочтительно приумножена с использованием способа целевой амплификации или способа, который дает полное или частичное отделение желательной ДНК от нежелательной, такого как захват путем гибридизационных подходов. Согласно некоторым вариантам осуществления ДНК может быть амплифицирована с использованием комбинации способа универсальной амплификации и способа предпочтительного приумножения. Более полное описание некоторых из этих способов можно найти в других разделах настоящего документа.
Генетические данные целевого индивидуума и/или родственного индивидуума могут быть преобразованы из молекулярного состояния в электронное состояние путем измерения приемлемого генетического материала с использованием инструментов и/или методик из группы, включающей в себя без ограничения микроматрицы генотипирования и высокопроизводительное секвенирование. Некоторые способы высокопроизводительного секвенирования предусматривают секвенирование ДНК по методу Сэнгера, пиросеквенирование, платформу SOLEXA от ILLUMINA, GENOME ANALYZER от ILLUMINA или платформу секвенирования 454 от APPLIED BIOSYSTEM, платформу TRUE SINGLE MOLECULE SEQUENCING от HELICOS, метод секвенирования с использованием электронного микроскопа от HALCYON MOLECULAR или любой другой способ секвенирования. Все эти способы физически преобразуют генетические данные, хранящиеся в образце ДНК, в набор генетических данных, которые, как правило, хранятся до обработки в запоминающем устройстве.
Генетические данные соответствующего индивидуума могут быть измерены путем анализа веществ, выбранных из группы, включающей без ограничения массу диплоидной ткани индивидуума, одну или несколько диплоидных клеток от индивидуума, одну или несколько гаплоидных клеток от индивидуума, одного или нескольких бластомеров от целевого индивидуума, внеклеточный генетический материал, обнаруженный у индивидуума, внеклеточный генетический материал от индивидуума, обнаруженный в крови матери, клетки от индивидуума, обнаруженные в крови матери, один или несколько эмбрионов, образованных из гаметы(гамет) от родственного индивидуума, один или несколько бластомеров, взятых от такого эмбриона, внеклеточный генетический материал, обнаруженный у родственного индивидуума, генетический материал, который, как известно, походит от родственного индивидуума, и их комбинации.
Согласно некоторым вариантам осуществления набор по меньшей мере из одной гипотезы состояния плоидности может быть создан для каждого из представляющих интерес типов хромосом целевого индивидуума. Каждая из гипотез состояния плоидности может относиться к одному возможному состоянию плоидности хромосомы или хромосомного сегмента целевого индивидуума. Набор гипотез может содержать некоторые или все из возможных состояний плоидности, которыми, как ожидается, может характеризоваться хромосома целевого индивидуума. Некоторые из возможных состояний плоидности могут предусматривать нуллисомию, моносомию, дисомию, однородительскую дисомию, эуплоидию, трисомию, трисомию спаривания, трисомию неспаривания, материнскую трисомию, отцовскую трисомию, тетрасомию, сбалансированную (2:2) тетрасомию, несбалансированную (3:1) тетрасомию, пентасомию, гексасомию, другую анеуплоидию и их комбинации. Любое из этих состояний анеуплоидии может быть смешанной или частичной анеуплоидией, такой как несбалансированные транслокализации, сбалансированные транслокализации, Робертсоновские транслокации, рекомбинации, делеции, вставки, кроссинговеры и их комбинации.
Согласно некоторым вариантам осуществления информация об определенном состоянии плоидности может быть использована для принятия клинического решения. Эта информация, которая, как правило, хранится как физическое размещение материала в запоминающем устройстве, затем может быть преобразована в отчет. Затем согласно отчету могут быть приняты соответствующие меры. Например, клиническим решением может быть решение о прекращении беременности; в качестве альтернативы, клиническим решением может быть решение о продолжении беременности. Согласно некоторым вариантам осуществления клиническое решение может предусматривать вмешательство, предназначенное для снижения тяжести фенотипического проявления генетического нарушения, или решение об осуществлении соответствующих этапов подготовки к особенным потребностям ребенка.
Согласно варианту осуществления настоящего раскрытия любой из описанных в настоящем документе способов может быть модифицирован для обеспечения нескольких целей одного и того же целевого индивидуума, например, несколько заборов крови от одной и той же беременной матери. Это может улучшить точность модели, поскольку несколько генетических измерений могут обеспечить больше данных, с которыми может быть установлен целевой генотип. Согласно варианту осуществления один набор целевых генетических данных служил в качестве сообщаемых первичных данных, а другой служил в качестве данных для двойной проверки первичных целевых генетических данных. Согласно варианту осуществления несколько наборов генетических данных, каждый из которых измерен в генетическом материале, взятом от целевого индивидуума, рассматриваются параллельно, и, таким образом, оба набора целевых генетических данных служат для обеспечения определения. Согласно варианту осуществления один набор целевых генетических данных служил в качестве сообщаемых первичных данных, а другой служил в качестве данных для двойной проверки первичных целевых генетических данных. Согласно варианту осуществления несколько наборов генетических данных, каждый из которых измерен в генетическом материале, взятом от целевого индивидуума, рассматриваются параллельно, и, таким образом, оба набора целевых генетических данных служат для обеспечения определения того, какая часть родительских генетических данных, измеренных с высокой точностью, содержит геном плода.
Согласно варианту осуществления способ может быть использован для установления отцовства. Например, данную основанную на SNP генотипическую информацию от матери и от мужчины, который может быть или может не быть генетическим отцом, и измеренную генотипическую информацию из смешанного образца можно определить, если генотипическая информация мужчины действительно представляет, что он фактический генетический отец вынашиваемого плода. Простой способ осуществления этого заключается в простом рассматривании контекстов, в которых мать представляет AA, а возможный отец представляет AB или BB. В этих случаях можно ожидать увидеть половину вклада отца (AA|AB) или весь (AA|BB) в момент времени, соответственно. С учетом ожидаемого ADO просто определять, находятся или не находятся наблюдаемые плодные SNP в соответствии с таковыми возможного отца.
Одним вариантом осуществления настоящего раскрытия может быть следующее: беременная женщина хочет знать, не поражен ли ее плод синдромом Дауна, и/или не будет ли он страдать муковисцидозом, и она не желает рожать ребенка, пораженного каким-либо из этих состояний. Врач берет ее кровь, окрашивает гемоглобин одним маркером так, что он становится отчетливо красным, и окрашивает ядерный материал другим маркером так, что он становится отчетливо синим. Известно, что материнские красные кровяные клетки, как правило, являются безъядерными, тогда как высокая пропорция плодных клеток содержит ядро, врач может визуально выделить ряд ядросодержащих красных кровяных клеток путем идентификации тех клеток, в которых проявляется и красный, и синий цвета. Доктор захватывает эти клетки с предметного стекла микроманипулятором и посылает их в лабораторию, в которой амлифицируются и генотипируются десять клеток индивидуума. Путем использования генетических измерений методом PARENTAL SUPPORT™ можно определить, что шесть из десяти клеток являются клетками крови матери, и четыре из десяти клеток являются плодными клетками. Если ребенок уже родился от беременной матери, PARENTAL SUPPORT™ также может быть использован для определения того, что плодные клетки отличаются от клеток рожденного ребенка путем получения достоверных аллельных признаков в плодных клетках и демонстрации того, что они не похожи на таковые рожденного ребенка. Следует отметить, что концепция этого способа подобна варианту осуществления определения отцовства в соответствии с настоящим раскрытием. Генетические данные, измеренные в плодных клетках могут быть очень плохого качества, в том числе многочисленные выпадения аллелей, из-за сложности генотипирования единичных клеток. Практикующий врач может использовать измеренную плодную ДНК вместе с достоверными измерениями ДНК родителей, чтобы вывести аспекты генома плода с высокой точностью с использованием PARENTAL SUPPORT™, тем самым превращая генетические данные, содержащиеся в генетическом материале от плода, в предсказанный генетический статус плода, хранящийся на компьютере. Практикующий врач может определить и состояние плоидности плода, и присутствие или отсутствие ряда представляющих интерес связанных с заболеванием генов. Если оказывается, что плод является эуплоидным и не несет муковисцидоза, мать принимает решение о продолжении беременности.
Согласно варианту осуществления настоящего раскрытия беременная мать хотела бы определить, поражен ли ее плод какими-либо аномалиями целых хромосом. Она идет к своему врачу и сдает образец своей крови, а также она и ее муж сдают образцы своих ДНК из буккальных мазков. Сотрудник лаборатории генотипирует родительскую ДНК с использованием протокола MDA для амплификации родительской ДНК и матриц INFINIUM от ILLUMINA для измерения генетических данных родителей на большом числе SNP. Затем сотрудник лаборатории осаждает кровь центрифугированием, отбирает плазму и выделяет образец свободно плавающей ДНК с использованием эксклюзионной хроматографии. В качестве альтернативы, сотрудник лаборатории использует одно или несколько флуоресцентных антител, таких как антитело, которое является специфичным по отношению к гемоглобину плода, для выделения ядросодержащей плодной красной кровяной клетки. Затем сотрудник лаборатории берет выделенный или приумноженный плодный генетический материал и амплифицирует его с использованием библиотеки из соответствующим образом сконструированных 70-мерных олигонуклеотидов так, что два конца каждого олигонуклеотида соответствуют фланкирующим последовательностям по обеим сторонам целевого аллеля. После добавления полимеразы, лигазы и приемлемых реагентов олигонуклеотиды подвергаются заполняющей гэпы циркуляризации, захватывающей желаемый аллель. Добавляется экзонуклеаза, инактивируется нагреванием, и продукты используются непосредственно в качестве шаблона для ПЦР-амплификации. Продукты ПЦР секвенируются на GENOME ANALYZER от ILLUMINA. Считывания последовательности используются в качестве входных данных для метода PARENTAL SUPPORT™, с помощью которого затем предсказывается состояние плоидности плода.
Согласно другому варианту осуществления мать, являющаяся беременной и находящаяся в преклонном материнском возрасте, хочет знать, не страдает ли вынашиваемый плод синдромом Дауна, синдромом Тернера, синдромом Прадера-Вилли или некоторыми другими аномалиями целых хромосом. Акушер берет кровь матери и отца. Кровь отсылается в лабораторию, где лаборант центрифугирует материнский образец с выделением плазмы и лейкоцитарной пленки. ДНК в лейкоцитарной пленке и в родительском образце крови трансформируется путем амплификации, а генетические данные, закодированные в амплифицированном генетическом материале далее трансформируются из хранящихся в молекуле генетических данных в хранящиеся в электронном виде генетические данные путем прогона генетического материала на высокопроизводительном секвенаторе для измерения родительских генотипов. Образец плазмы предпочтительно приумножается набором локусов с использованием метода 5000-плексной гемивложенной целевой ПЦР. Смесь фрагментов ДНК готовится в виде библиотеки ДНК, приемлемой для секвенирования. Затем ДНК секвенируется с использованием способа высокопроизводительного секвенирования, например, GENOME ANALYZER GAIIx от ILLUMINA. Секвенирование преобразует информацию, которая закодирована молекулярно в ДНК, в информацию, которая закодирована в электронном виде в аппаратных средствах компьютера. Для определения плоидности плода может быть использована основанная на информатике методика, которая предусматривает раскрытые в настоящем документе варианты осуществления, такие как PARENTAL SUPPORT™. Она может предусматривать вычисление на компьютере вероятностей числа аллелей во множестве полиморфных локусов из измерений ДНК, выполненных в подготовленном образце; создание на компьютере множества гипотез плоидности, касающихся различных возможных состояний плоидности хромосомы; построение на компьютере модели совместного распределения для ожидаемых подсчетов числа аллелей во множестве полиморфных локусов в хромосоме для каждой гипотезы плоидности; определение на компьютере относительной вероятности каждой из гипотез плоидности с использованием модели совместного распределения и подсчетов числа аллелей, измеренных в подготовленном образце; а также установление состояния плоидности плода путем отбора состояния плоидности, соответствующего гипотезе с наибольшей вероятностью. Определено, что плод страдает синдромом Дауна. Отчет распечатывается или отсылается в электронном виде акушеру беременной женщины, который передает диагноз женщине. Женщина, ее муж и врач садятся и обсуждают отчет. Пара решает прекратить беременность на основе информации о том, что плод поражен трисомным состоянием.
Согласно варианту осуществления компания может принять решение о предложении технологии диагностирования, разработанной для выявления анеуплоидии у вынашиваемого плода по взятой у матери крови. Эта разработка может предусматривать визит матери к ее акушеру, который может взять ее кровь. Акушер также может взять генетический образец отца плода. Практикующий врач может выделить плазму из крови матери и очистить ДНК от плазмы. Практикующий врач также может выделить слой лейкоцитарной пленки из крови матери и получить ДНК из лейкоцитарной пленки. Практикующий врач также может получить ДНК из генетического образца отца. Практикующий врач может использовать описанные в настоящем раскрытии методики молекулярной биологии для добавления универсальных меток амплификации к ДНК в ДНК, полученной из образца плазмы. Практикующий врач может амплифицировать универсально меченную ДНК. Практикующий врач может предпочтительно приумножить ДНК с помощью ряда методик, предусматривающих захват путем гибридизации и целевую ПЦР. Целевая ПЦР может предусматривать вложение, гемивложение или полувложение или любой другой подход для получения эффективного приумножения полученной из плазмы ДНК. Целевая ПЦР может быть массивно мультиплексной, например, с 10000 праймерами в одной реакции, в которой праймеры нацеливаются на SNP в хромосомах 13, 18, 21, X и тех, локусы которых являются общими и для X, и для Y, а также необязательно в других хромосомах. Селективные приумножение и/или амплификация могут предусматривать мечение каждой отдельной молекулы различными метками, молекулярными штрихкодами, метками для амплификации и/или метками для секвенирования. Затем практикующий врач может секвенировать образец плазмы, а также возможно подготовленную материнскую и/или отцовскую ДНК. Молекулярно-биологические этапы могут быть выполнены либо полностью, либо частично с помощью диагностического бокса. Данные последовательности могут быть загружены в отдельный компьютер или в другой тип вычислительной платформы, такой как находящаяся в «облаке». Вычислительная платформа может осуществить подсчеты числа аллелей в целевых полиморфных локусах по измерениям, выполненным с помощью секвенатора. Вычислительная платформа может создать множество гипотез плоидности, касающихся нуллисомии, моносомии, дисомии, трисомии спаривания и трисомии неспаривания, для каждой из хромосом 13, 18, 21, X и Y. Вычислительная платформа может построить модель совместного распределения для ожидаемых подсчетов числа аллелей в целевых локусах в хромосоме для каждой гипотезы плоидности в каждой из пяти хромосом, подлежащих исследованию. Вычислительная платформа может определить вероятность истинности для каждой гипотезы плоидности с использованием модели совместного распределения и подсчета числа аллелей, измеренных в предпочтительно приумноженной ДНК, полученной из образца плазмы. Вычислительная платформа может определить состояние плоидности плода для каждой из хромосом 13, 18, 21, X и Y путем отбора состояния плоидности, соответствующего релевантной гипотезе с наибольшей вероятностью. Отчет может быть сгенерирован с содержанием установленных состояний плоидности, и его можно послать акушеру в электронном виде, отображенном на устройстве вывода, или распечатанная твердая копия отчет может быть доставлена акушеру. Акушер может информировать пациентку и необязательно отца плода, и они могут решать, какие клинические варианты доступны им, а какие являются наиболее желательными.
Согласно другому варианту осуществления беременная женщина, далее называемая «матерью», может решить узнать, имеет или не имеет ее плод(ы) какие-либо генетические аномалии или другие состояния. Она может захотеть убедиться в том, что не имеется каких-либо аномалий развития, перед решением о продолжении беременности. Она может пойти к своему акушеру, который может взять образец ее крови. Он также может взять генетический образец, такой как буккальный мазок с ее щеки. Он также может взять генетический образец отца плода, такой как буккальный мазок, образец спермы или образец крови. Он может послать образцы практикующему врачу. Практикующий врач может приумножить фракцию свободно плавающей плодной ДНК в образце крови матери. Практикующий врач может приумножить фракцию безъядерных плодных клеток крови в образце крови матери. Практикующий врач может применять различные аспекты описанных в настоящем документе способов для определения генетических данных плода. Генетические данные могут предусматривать состояние плоидности плода и/или идентичность одного или нескольких связанных с заболеванием аллелей у плода. Отчет может быть сгенерирован с суммированием результатов пренатальной диагностики. Отчет может быть передан или отправлен почтой врачу, который может сообщить матери генетический статус плода. Мать может решить прекратить беременность на основе того факта, что плод характеризуется одной или несколькими хромосомными или генетическими аномалиями или нежелательными состояниями. Она также может принять решение о продолжении беременности на основе того факта, что плод не характеризуется какими-либо хромосомными или генетическими аномалиями развития или какими-либо представляющими интерес генетическими состояниями.
Другой пример может предусматривать беременную женщину, которая была искусственно оплодотворена спермой донора и является беременной. Она желает минимизировать риск того, что плод, который она носит, имеет генетическое заболевание. Она сдает кровь из вены, и описанные в настоящем раскрытии методики используются для выделения трех ядросодержащих плодных красных кровяных клеток, а также собирается образец ткани матери и генетического отца. Генетический материал плода, а также матери и отца амплифицируется приемлемым образом и генотипируется с использованием INFINIUM BEADARRAY от ILLUMINA, и с помощью описанных в настоящем документе способов родительский и плодный генотип очищается и фазируется с высокой точностью, а также получаются признаки плоидности для плода. Плод оказывается эуплоидным, и фенотипические предрасположенности прогнозируются по реконструированному плодному генотипу, отчет генерируется и отсылается врачу матери, чтобы они могли решить, какие клинические решения могут быть наилучшими.
Согласно варианту осуществления необработанный генетический материал матери и отца преобразуется путем амплификации в количество ДНК, которая подобна по последовательности, но представлена в большем количестве. Затем путем способа генотипирования генотипические данные, которые закодированы нуклеиновыми кислотами, преобразуются в генетические измерения, которые могут храниться в физическом и/или электронном виде в запоминающем устройстве, таком как описанные выше. Соответствующие алгоритмы, которые составляют алгоритм PARENTAL SUPPORT™, соответствующие части которого подробно обсуждаются в настоящем документе, переносятся в компьютерную программу с использованием языка программирования. Затем путем выполнения компьютерной программы в аппаратных средствах компьютера вместо физически закодированных битов и байтов, расположенных в паттерне, который представляет необработанные данные измерения, они преобразуются в паттерн, который представляет высоко достоверное определение отцовства плода. Подробности этого преобразования будут зависеть от самих данных, а также от компьютерного языка и системы аппаратных средств, используемых для выполнения описанного в настоящем документе способа. Затем данные, которые физически сконфигурированы для представления высококачественного определения плоидности плода, преобразуются в отчет, который может быть отослан практикующему медику. Такое преобразование может быть выполнено с использованием принтера или компьютерного дисплея. Отчет может быть печатной копией на бумаге или другой приемлемой среде или, кроме того, может быть электронным. В случае электронного отчета он может быть преобразован, может храниться физически в запоминающем устройстве с размещением в компьютере, доступном практикующему медику; он также может быть показан на экране так, что его можно считывать. В случае экранного устройства отображения данные могут быть преобразованы в считываемый формат путем физического преобразования пикселей на устройстве отображения. Преобразование может быть выполнено путем физической активизации электронов на фосфоресцентном экране, путем изменения электрического заряда, что физически изменяет прозрачность определенного набора пикселей на экране, который может располагаться перед подложкой, которая испускает или поглощает протоны. Такое преобразование может быть выполнено путем изменения наномасштабной ориентации молекул в жидком кристалле, например, от неметической до холестерической или смектической фазы, в определенном наборе пикселей. Такое преобразование может быть выполнено с помощью вызывающих электрический ток фотонов, испускаемых из определенного набора пикселей из множества светоизлучающих диодов, расположенных в значимом паттерне. Такое преобразование может быть выполнено любым другим способом, используемым для отображения информации, таким как компьютерный экран или любое другое устройство вывода, или путем передачи информации. Затем практикующий медик может действовать согласно отчету так, что данные в отчете превращаются в действие. Действие может предусматривать продолжение или прекращение беременности, в этом случае вынашиваемый плод с генной аномалией превращается в неживой плод. Перечисленные в настоящем документе преобразования могут быть сгруппированы так, что, например, можно преобразовать генетический материал беременной матери и отца посредством ряда описанных в настоящем раскрытии этапов в медицинское решение, заключающееся в абортировании плода с генетическими аномалиями или заключающееся в продолжение беременности. В качестве альтернативы, можно преобразовать набор генотипических измерений в отчет, который поможет врачу лечить его беременную пациентку.
Согласно варианту осуществления настоящего раскрытия описанный в настоящем документе способ может быть использован для определения состояния плоидности плода, даже если мать суррогатная, т.е. женщина, являющаяся беременной, но не являющаяся биологической матерью плода, которого она вынашивает. Согласно варианту осуществления настоящего раскрытия описанный в настоящем документе способ может быть использован для определения состояния плоидности плода только с использованием образца крови матери и без необходимости генетического образца отца.
Некоторые математические расчеты раскрытых в настоящем документе вариантов осуществления обеспечивают гипотезу, касающуюся ограниченного числа состояний анеуплоидии. В некоторых случаях, например, только ноль, одна или две хромосомы, как ожидается, походят от каждого родителя. Согласно некоторым вариантам осуществления настоящего раскрытия математические выводы могут быть расширены с учетом других форм анеуплоидии, таких как квадросомия, при которой три хромосомы походят от одного родителя, пентасомия, гексасомия и т.д., без изменения основных концепций настоящего изобретения. В то же время, можно сосредоточиться на меньшем количестве состояний плоидности, например, только на трисомии и дисомии. Следует отметить, что определения плоидности, которые указывают на отличное от целого число хромосом, могут указывать на мозаицизм в образце генетического материала.
Согласно некоторым вариантам осуществления генетические аномалии принадлежат типу анеуплоидии, такие как синдром Дауна (или трисомия 21), синдром Эдвардса (трисомия 18), синдром Патау (трисомия 13), синдром Тернера (45X), синдром Клайнфелтера (мужщина с 2 хромосомами X), синдром Прадера-Вилли и синдром ДиДжорджи (UPD 15). Врожденные нарушения, такие как перечисленные в предыдущем предложении, обычно являются нежелательными, и информация о том, что плод поражен одной или несколькими фенотипическими аномалиями, может составить основу решения о прекращении беременности, о принятии необходимых мер предосторожности для подготовки к рождению ребенка со специальными потребностями или о принятии определенного терапевтического подхода, чтобы уменьшить тяжесть хромосомной аномалии.
Согласно некоторым вариантам осуществления описанные в настоящем документе способы могут быть использованы в очень раннем внутриутробном возрасте, например, всего лишь четыре недели, всего лишь пять недель, всего лишь шесть недель, всего лишь семь недель, всего лишь восемь недель, всего лишь девять недель, всего лишь десять недель, всего лишь одиннадцать недель и всего лишь двенадцать недель.
Следует отметить, что было продемонстрировано, что ДНК, происходящая от злокачественной опухоли, которая имеется у больного, может быть обнаружена в крови больного. Таким образом, может быть выполнен генетический диагноз по измерению смешанной ДНК, обнаруженной в крови матери, генетический диагноз также хорошо можно выполнить по измерениям смешанной ДНК, обнаруженной в крови больного. Генетические диагнозы могут предусматривать состояния анеуплоидии или генные мутации. Любые притязания в настоящем раскрытии, которые осуществляют определение состояния плоидности или генетический статус плода по измерениям, выполненным в крови матери, могут также хорошо осуществлять определение состояния плоидности или генетический статус злокачественной опухоли по измерениям в крови больного.
Согласно некоторым вариантам осуществления способ настоящего раскрытия позволяет определить статус плоидности злокачественной опухоли, при этом способ предусматривает получение смешанного образца, который содержит генетический материал больного и генетический материал злокачественной опухоли; измерение ДНК в смешанном образце; вычисление фракции ДНК, которая имеет происхождение от злокачественной опухоли, в смешанном образце и определение статуса плоидности злокачественной опухоли с использованием измерений, выполненных в смешанном образце и рассчитанной фракции. Согласно некоторым вариантам осуществления способ может дополнительно предусматривать введение противоракового терапевтического средства на основе определения состояния плоидности злокачественной опухоли. Согласно некоторым вариантам осуществления способ может дополнительно предусматривать введение противоракового терапевтического средства на основе определения состояния плоидности злокачественной опухоли, при котором противораковое терапевтическое средство берется из группы, содержащей фармацевтическое средство, биологическое терапевтическое средство, терапевтическое средство на основе антитела и их комбинацию.
Согласно некоторым вариантам осуществления раскрытый в настоящем документе способ используется в контексте предимплантационной генетической диагностики (PGD) для отбора эмбриона при оплодотворении in vitro, при этом целевым индивидуумом является эмбрион, и родительские генотипические данные могут быть использованы для осуществления определений плоидности эмбриона по данным секвенирования по биопсии одной или двух клеток от трехдневного эмбриона или по биопсии трофектодермы от пятидневного или шестидневного эмбриона. При установлении PGD измеряется только ДНК ребенка, и тестируется только небольшое количество клеток, как правило, от одной до пяти, примерно десять, двадцать или пятьдесят. Общее число исходных копий аллелей A и B (в SNP) затем тривиально определяется по генотипу ребенка и числу клеток. При NPD число исходных копий очень высокое, и, поэтому, аллельное отношение после ПЦР, как ожидается, будет точно отражать исходное отношение. Однако небольшое количество исходных копий при PGD означает, что загрязнение и недостаточная эффективность ПЦР нетривиально влияет на аллельное отношение после ПЦР. Этот эффект может быть более важным, чем глубина считывания в прогнозировании расхождения в аллельном отношении, измеренном после секвенирования. Распределение измеренного аллельного отношения с учетом известного генотипа ребенка может быть создано моделированием методом Монте-Карло процесса ПЦР на основе эффективности зонда ПЦР и вероятности загрязнения. С учетом распределения аллельных отношений для каждого возможного генотипа ребенка могут быть рассчитаны вероятности различных гипотез, как описано для NIPD.
Любой из вариантов осуществления, раскрытых в данном документе, можно реализовать в цифровой электронной схеме, интегральной схеме, специально сконструированных ASIC (специализированных интегральных микросхемах), компьютерном аппаратном средстве, аппаратно реализованном программном обеспечении, программном обеспечении или в их сочетаниях. Аппарат в соответствии с раскрытыми в данном документе вариантами осуществления можно реализовать в продукте-компьютерной программе, материально осуществляемой в машиночитаемом устройстве для хранения данных для выполнения программируемым процессором; и этапы способа в соответствии с раскрытыми в данном документе вариантами осуществления могут быть осуществлены программируемым процессором, выполняющим программу из инструкций с осуществлением функций в соответствии с раскрытыми в данном документе вариантами осуществления, обрабатывая вводимые данные и генерируя выводимые данные. Раскрытые в данном документе варианты осуществления могут быть реализованы преимущественно в одной или нескольких компьютерных программах, которые являются выполнимыми и/или интерпретируемыми на программируемой системе, включающей по меньшей мере один программируемый процессор, который может быть специализированным или многоцелевым, соединенный для получения данных и инструкций от и для передачи данных и инструкций к системе хранения данных, по меньшей мере одно устройство ввода данных и по меньшей мере одно устройство вывода данных. Каждая компьютерная программа может быть реализована на высокоуровневом процедурном или объектно-ориентированном языке программирования или на языке ассемблера или машинном языке, если это необходимо; и в любом случае язык может быть транслируемым и интерпретируемым языком. Компьютерную программу можно использовать в любом виде, в том числе в виде независимой программы или в виде модуля, компонента, стандартной подпрограммы или другой секции, подходящих для применения в вычислительной среде. Компьютерную программу можно использовать для выполнения или интерпретации на одном компьютере или на многих компьютерах в одном центре или распределять по многим центрами взаимосвязанными с помощью коммуникационной сети.
Считываемая компьютером среда хранения данных, как используется в данном документе, относится к физическому или материальному хранению (в противоположность сигналам) и включает без ограничения не сохраняющие информацию при отключении питания и сохраняющие информацию при отключении питания, съемные и несъемные носители, реализуемые в любом способе и технологии для материального хранения информации, такой как считываемые компьютером инструкции, структуры данных, модули программы или другие данные. Считываемая компьютером среда хранения данных включает RAM (запоминающее устройство с произвольным доступом), ROM (постоянное запоминающее устройство), EPROM (перепрограммируемое постоянное запоминающее устройство), EEPROM (электрически стираемое программируемое постоянное запоминающее устройство), флэш-память или постоянные запоминающие устройства, созданные по другой технологии, CD-ROM (постоянное запоминающее устройство на основе компакт-диска), DVD (цифровой многофункциональный диск) или другое оптическое устройство хранения данных, компакт-кассеты, магнитную ленту, запоминающее устройство на магнитном диске или другие магнитные запоминающие устройства, но не ограничивается ими, или любые другие материальные или физические среды которые можно применять для материального хранения необходимой информации, или данных, или инструкций и к которым может иметь доступ компьютер или процессор.
Любой из способов, описанных в данном документе, может включать вывод данных в физическом формате, как например, на экране компьютера или на бумажной распечатке. В пояснениях к любому из вариантов осуществления в других местах в данном документе следует понимать, что описанные способы можно сочетать с выводом данных, на которые может производиться воздействие, в формате, на который может воздействовать врач. Помимо этого, описанные способы можно объединить с фактическим выполнением клинического решения, которое приведет в результате к клиническому лечению, или к выполнению клинического решения не предпринимать каких-либо действий. Некоторые варианты осуществления, описанные в данном документе в отношении определения генетических данных, касающихся целевого индивида, могут быть объединены с решением о выборе одного или нескольких эмбрионов для переноса в условиях IVF (экстракорпоральное оплодотворение), необязательно в сочетании с процессом переноса эмбриона в матку будущей матери. Некоторые из вариантов осуществления, описанных в данном документе в отношении определения генетических данных, касающихся целевого индивида, могут быть объединены с уведомлением о возможной хромосомной аномалии или ее отсутствии, причем медицинский работник необязательно может объединить их с решением о необходимости проведения аборта или об отсутствии необходимости проведения аборта в отношении плода в случае пренатальной диагностики. Некоторые из вариантов осуществления, описанные в данном документе, можно объединить с выводом данных, на которые может быть произведено воздействие, и выполнением клинического решения, которое приведет в результате к клиническому лечению, или выполнением клинического решения не предпринимать каких-либо действий.
Целевое приумножение и секвенирование
Применение методики приумножения образца ДНК в наборе целевых локусов с последующим секвенированием как части способа неинвазивного пренатального установления аллелей или установления плоидности может обеспечивать ряд неожиданных преимуществ. Согласно некоторым вариантам осуществления настоящего раскрытия способ предусматривает измерение генетических данных для применения с основанным на информатике способом, таким как PARENTAL SUPPORT™ (PS). Конечным итогом некоторых вариантов осуществления является получение генетических данных эмбриона или плода. Имеется много способов, которые могут быть использованы для измерения генетических данных индивидуума и/или родственных индивидуумов как часть осуществляемых способов. В настоящем документе согласно варианту осуществления раскрывается способ приумножения концентрации набора целевых аллелей, при этом способ предусматривает один или несколько из следующих этапов: целевая амплификация генетического материала, добавление специфичных по отношению к локусам олигонуклеотидных зондов, лигирование определенных цепочек ДНК, выделение наборов желаемой ДНК, удаление нежелаемых компонентов реакции, выявление определенных последовательностей ДНК путем гибридизации и выявление последовательности из одной или множества цепочек ДНК способами секвенирования ДНК. В некоторых случаях цепочки ДНК могут относиться к целевому генетическому материалу, в некоторых случаях они могут относиться к праймерам, в некоторых случаях они могут относиться к синтезированным последовательностям или к их комбинациям. Эти этапы могут быть выполнены в различном порядке. С учетом высоковариабельной природы молекулярной биологии, как правило, не является очевидным, какие способы и какие комбинации этапов будут работать плохо, хорошо или наилучшим образом в различных ситуациях.
Например, этап универсальной амплификации ДНК до целевой амплификации может обеспечить несколько преимуществ, таких как устранение риска затруднения и снижение систематической ошибки подсчета числа аллелей. ДНК может быть смешана с олигонуклеотидным зондом, который может гибридизироваться с двумя соседними областями целевой последовательности, по одному с каждой стороны. После гибридизации концы зонда могут быть соединены путем добавления полимеразы, средства для лигирования, и каких-либо необходимых реагентов для обеспечения циркуляризации зонда. После циркуляризации может быть добавлена экзонуклеаза для расщепления нециркуляризованного генетического материала с последующим выявлением циркуляризованного зонда. ДНК может быть смешана с праймерами ПЦР, которые могут гибридизоваться с двумя соседними областями целевой последовательности, по одному с каждой стороны. После гибридизации концы зонда могут быть соединены путем добавления полимеразы, средства для лигирования, и каких-либо необходимых реагентов для выполнения ПЦР-амплификации. Амплифицированная или неамплифицированная ДНК может быть целью для зондов гибридного захвата, которые нацелены на набор локусов; после гибридизации зонд может быть локализован и отделен от смеси для обеспечения смеси ДНК, которая приумножается целевыми последовательностями.
Согласно некоторым вариантам осуществления этот способ может быть использован для генотипирования единичной клетки, небольшого количества клеток, от двух до пяти клеток, от шести до десяти клеток, от десяти до двадцати клеток, от двадцати до пятидесяти клеток, от пятидесяти до ста клеток, от ста до тысячи клеток или небольшого количества внеклеточной ДНК, например, от одного до десяти пикограмм, от десяти до ста пикограмм, от ста пикограмм до одного нанограмма, от одного до десяти нанограмм, от десяти до ста нанограмм или от ста нанограмм до одного микрограмма.
Применение способа для нацеливания на определенные локусы с последующим секвенированием как части способа установления аллелей или установления плоидности может обеспечить ряд неожиданных преимуществ. Некоторые способы, с помощью которых можно нацелиться на ДНК или предпочтительно приумножить, предусматривают использование зондов циркуляризации, связанных инвертированных зондов (LIP, MIP), способов захвата путем гибридизации, таких как SURESELECT, и стратегии целевой ПЦР или опосредованной лигированием ПЦР-амплификации.
Согласно некоторым вариантам осуществления способ настоящего раскрытия предусматривает измерение генетических данных для применения с основанным на информатике способом, таким как PARENTAL SUPPORT™ (PS). PARENTAL SUPPORT™ является основанным на информатике подходом для манипулирования генетическими данными, аспекты которого описываются в настоящем документе. Конечным итогом некоторых из вариантов осуществления является получение генетических данных эмбриона или плода с последующим клиническим решением на основе полученных данных. Алгоритмы метода PS учитывают измеренные генетические данные целевого индивидуума, часто эмбриона или плода, и измеренные генетические данные родственных индивидуумов и обеспечивают повышенную точность определения генетического статуса целевого индивидуума. Согласно варианту осуществления измеренные генетические данные используются в контексте осуществления определений плоидности при пренатальной генетической диагностике. Согласно варианту осуществления измеренные генетические данные используются в контексте осуществлений определения плоидности или аллельных признаков в эмбрионах при оплодотворении in vitro. Существует много способов, которые могут быть использованы для измерения генетических данных индивидуума и/или родственных индивидуумов в вышеупомянутых контекстах. Различные способы предусматривают ряд этапов, которые часто предусматривают амплификацию генетического материала, добавление олигонуклеотидных зондов, лигирование определенных цепочек ДНК, выделение наборов желаемой ДНК, удаление нежелаемых компонентов реакции, выявление определенных последовательностей ДНК путем гибридизации, выявление последовательности из одной или множества цепочек ДНК способами секвенирования ДНК. В некоторых случаях цепочки ДНК могут относиться к целевому генетическому материалу, в некоторых случаях они могут относиться к праймерам, в некоторых случаях они могут относиться к синтезированным последовательностям или их комбинациям. Эти этапы могут быть выполнены в различном порядке. С учетом высоковариабельной природы молекулярной биологии, как правило, не является очевидным, какие способы и какие комбинации этапов будут работать плохо, хорошо или наилучшим образом в различных ситуациях.
Следует отметить, что теоретически возможно нацеливание на любое число локусов в геноме, например, от одного локуса до значительно более одного миллиона локусов. Если образец ДНК подвергается нацеливанию, а затем секвенированию, то процентное отношение аллелей, которые считываются секвенатором, будет приумножено в отношении их природного относительного содержания в образце. Степень приумножения может составлять от одного процента (или даже меньше) до большего в десять раз, в сто раз, в тысячу раз или даже во много миллионов раз. В человеческом геноме существует около 3 миллиардов пар оснований и нуклеотидов, содержащихся в приблизительно 75 миллионах полиморфных локусов. Чем на большее число локусов происходит нацеливание, тем меньшая степень приумножения возможна. Чем на меньшее число локусов происходит нацеливание, тем большая степень приумножения возможна, и большая глубина считывания может быть достигнута на этих локусах для данного числа считываний последовательности.
Согласно варианту осуществления настоящего раскрытия нацеливание или предпочтительное приумножение может быть полностью сфокусировано на SNP. Согласно варианту осуществления нацеливание или предпочтительное приумножение может быть сфокусировано на любом полиморфном сайте. Ряд коммерческих продуктов для нацеливания доступен для приумножения экзонов. Удивительно то, что нацеливание исключительно на SNP или исключительно на полиморфные локусы особенно выгодно при использовании способа NPD, который заключается в распределениях аллелей. Также опубликованы способы NPD с использованием секвенирования, например, в патенте США №7888017, предусматривающие анализ подсчета считываний, при котором подсчет считываний фокусируется на подсчете числа считываний, которые картируются с данной хромосомой, при этом анализируемые считывания последовательности не направлены на области генома, которые являются полиморфными. Такие типы технологии, которые не направлены на полиморфные аллели, не будут столь же полезными, как при нацеливании или предпочтительном приумножении набора аллелей.
Согласно варианту осуществления настоящего раскрытия можно применять способ нацеливания, который направлен на SNP для приумножения генетического образца в полиморфных областях генома. Согласно варианту осуществления можно фокусироваться на небольшом количестве SNP, например, от 1 до 100 SNP, или на большем количестве, например, от 100 до 1000, от 1000 до 10000, от 10000 до 100000 или более 100000 SNP. Согласно варианту осуществления можно фокусироваться на одной или небольшом количестве хромосом, которые сопоставляются с рождениями живых трисомиков, например, на хромосомах 13, 18, 21, X и Y, или некоторой их комбинации. Согласно варианту осуществления можно приумножить целевые SNP в небольшое число раз, например, от 1,01 раза до 100 раз, или в большее число раз, например, от 100 раз до 1000000 раз или даже более чем в 1000000 раз. Согласно варианту осуществления настоящего раскрытия можно использовать способ нацеливания для создания образца ДНК, который предпочтительно приумножается полиморфными областями генома. Согласно варианту осуществления можно применять этот способ для создания смеси ДНК с какой-либо из этих характеристик, при этом смесь ДНК содержит материнскую ДНК, а также свободно плавающую плодную ДНК. Согласно варианту осуществления можно применять этот способ для создания смеси ДНК, которая характеризуется какой-либо комбинацией этих факторов. Например, описанный в настоящем документе способ может быть использован для получения смеси ДНК, которая содержит материнскую ДНК и плодную ДНК и которая предпочтительно приумножается ДНК, соответствующей 200 SNP, все из которых расположены в любой из хромосом 18 или 21 и которые приумножены в среднем в 1000 раз. В другом примере можно применять этот способ для создания смеси ДНК, которая предпочтительно приумножается 10000 SNP, все из которых или почти все расположены в хромосомах 13, 18, 21, X и Y, и среднее приумножение локусами составляет более 500 раз. Любые описанные в настоящем документе способы нацеливания могут быть использованы для создания смесей ДНК, которые предпочтительно приумножаются определенными локусами.
Согласно некоторым вариантам осуществления способ настоящего раскрытия дополнительно предусматривает измерение ДНК в смешанной фракции с использованием высокопроизводительного секвенатора ДНК, в котором ДНК в смешанной фракции содержит непропорциональное число последовательностей от одной или нескольких хромосом, при этом одна или нескольких хромосом выбраны из группы, содержащей хромосому 13, хромосому 18, хромосому 21, хромосому X, хромосому Y и их комбинации.
В настоящем документе описаны три способа - мультиплексная ПЦР, целевой захват путем гибридизации и связанные инвертированные зонды (LIP), которые могут быть использованы для получения и анализа измерений по достаточному числу полиморфных локусов в образце материнской плазмы в целях выявления анеуплоидии плода; это не означает исключение других способов селективного приумножения целевых локусов. Одинаково успешно могут быть применены другие способы без изменения сути способа. В каждом случае анализируемый полиморфизм может предусматривать однонуклеотидные полиморфизмы (SNP), небольшие вставки или STR. Предпочтительный способ предусматривает использование SNP. Каждый подход дает данные частоты аллелей; данные частоты аллелей для каждого целевого локуса и/или совместные распределения частот аллелей для этих локусов могут быть анализированы для определения плоидности плода. Каждый подход характеризуется своими собственными принципами из-за ограниченного исходного материала и того факта, что материнская плазма состоит из смеси материнской и плодной ДНК. Этот способ может быть скомбинирован с другими подходами для обеспечения более точного определения. Согласно варианту осуществления этот способ может быть скомбинирован с подходом подсчета последовательностей, таким как описанный в патенте США №7888017. Описанные подходы также могут быть использованы для неинвазивного выявления отцовства плода по образцам материнской плазмы. Кроме того, каждый подход может применяться на других смесях ДНК или чистых образцах ДНК для выявления присутствия или отсутствия анеуплоидных хромосом, для генотипирования большого числа SNP в расщепленных образцах ДНК, для выявления сегментных вариаций числа копий (CNV), для выявления других представляющих интерес генотипических состояний или некоторой их комбинации.
Точное измерение аллельных распределений в образце
Современные подходы секвенирования можно использовать для оценки распределения аллелей в образце. Один такой способ предусматривает случайный выбор последовательностей из пула ДНК, называемый секвенированием методом «дробовика». Доля конкретного аллеля в данных секвенирования, как правило, очень низкая и может быть определена простой статистикой. Геном человека содержит приблизительно 3 миллиарда пар оснований. Итак, если при используемом методе секвенирования считывается 100 пар оснований, конкретный аллель будет измерен приблизительно один раз на каждые 30 миллионов считываний последовательностей.
Согласно варианту осуществления способ настоящего раскрытия используется для определения присутствия или отсутствия двух или более различных гаплотипов, которые содержат одинаковый набор локусов в образце ДНК по измеренным аллельным распределениям локусов этой хромосомы. Различные гаплотипы могут представлять две различные гомологичные хромосомы одного индивидуума, три различные гомологичные хромосомы трисомного индивидуума, три различные гомологичные гаплотипа от матери и плода, при этом один из гаплотипов одинаковый у матери и плода, три или четыре гаплотипа от матери и плода, при этом один или два гаплотипа одинаковы у матери и плода, или другие комбинации. Аллели, которые являются полиморфными между гаплотипами, имеют тенденцию быть более информативными, однако, любые аллели, по которым мать и отец не являются гомозиготными, дадут полезную информацию посредством измеренного аллельного распределения помимо информации, доступной из простого анализа числа считываний.
Секвенирование методом «дробовика» такого образца, однако, чрезвычайно неэффективно, поскольку оно дает много последовательностей из областей, которые неполиморфны между различными гаплотипами в образце, или из хромосом, которые не являются предметом исследования, и, следовательно, не дает информации о пропорции целевых гаплотипов. В настоящем документе описаны способы, которые специфично нацелены на сегменты ДНК в образце, которые, скорее всего, являются полиморфными в геноме, и/или предназначены для предпочтительного приумножения такими сегментами, что повышает выход информации об аллелях, полученной методом секвенирования. Следует отметить, что измеренные аллельные распределения в приумноженном образце правильно представляют действительные количества аллелей, имеющихся у целевого индивидуума, критичным является то, что не происходит предпочтительного приумножения одним аллелем по сравнению с другими аллелями в данных локусах целевого сегмента, или оно происходит в малой степени. Современные известные в уровне техники способы нацеливания на полиморфные аллели разработаны с гарантией выявления по меньшей мере некоторых из присутствующих аллелей. Однако эти способы не предназначены для целей измерения распределения полиморфных аллелей, присутствующих в оригинальной смеси, без стандартной ошибки расчета аллельных распределений. Неочевидно, что любой конкретный способ целевого приумножения сможет дать приумноженный образец, в котором измеренные аллельные распределения будут точно представлять аллельные распределения, характерные для оригинального неамплифицированного образца, лучше, чем любой другой способ. Хотя теоретически можно ожидать, что многие методы приумножения могут достичь этой цели, рядовому специалисту в данной области будет понятно, что существует большая доля стохастической или детерминистической стандартной ошибки в современных методах амплификации, нацеливания и других методах предпочтительного приумножения. Один вариант осуществления описанного в настоящем документе способа позволяет амплифицировать множество аллелей, обнаруженных в смеси ДНК, которые соответствуют данному локусу в геноме, или предпочтительно приумножать образец ими таким образом, что степень приумножения каждым из аллелей практически одинакова. Другими словами, этот способ позволяет увеличить относительные количества аллелей, присутствующих в смеси как целое, при сохранении в сущности таких же отношений между аллелями, которые соответствуют каждому локусу, как и в оригинальной смеси ДНК. Известные в уровне техники способы предпочтительного приумножения локусами могут привести к систематическим ошибкам подсчета числа аллелей более 1%, более 2%, более 5% и даже более 10%. Такое предпочтительное приумножение может быть обусловлено стандартной ошибкой захвата, когда используется захват методом гибридизации, или стандартной ошибкой амплификации, которая может быть невелика в каждом цикле, но может значительно усугубиться в течение 20, 30 или 40 циклов. Для целей настоящего раскрытия сохранение отношения по сути на том же уровне означает, что отношение аллелей в оригинальной смеси, поделенное на отношение аллелей, полученное в конечной смеси, составляет от 0,95 до 1,05, от 0,98 до 1,02, от 0,99 до 1,01, от 0,995 до 1,005, от 0,998 до 1,002, от 0,999 до 1,001 или от 0,9999 до 1,0001. Следует отметить, что расчет аллельных отношений, представленный в настоящем документе, не может быть использован для определения состояния плоидности целевого индивидуума, и может служить только метрикой для использования при измерении систематической ошибки подсчета аллелей.
Согласно варианту осуществления после того, как смесь была предпочтительно приумножена набором целевых локусов, она может быть секвенирована с использованием любого из предыдущих, современных методов секвенирования или инструментов секвенирования следующего поколения, которые секвенируют клонированный образец (образец, сгенерированный из единичной молекулы; примеры включают в себя GAIIx от ILLUMINA, HISEQ от ILLUMINA, SOLiD 5500XL от LIFE TECHNOLOGIES). Отношения могут быть оценены посредством секвенирования специфичных аллелей в пределах целевой области. Эти считывания последовательностей можно проанализировать, подсчитать по типу аллелей и соответственно определить отношения различных аллелей. Для вариаций длиной в одно или несколько оснований выявление аллелей будет проводиться секвенированием, и важно, чтобы считывание последовательности перекрыло исследуемый аллель для оценки аллельного состава захваченной молекулы. Общее число захваченных молекул, анализируемых для генотипа, может быть увеличено посредством увеличения длины считывания последовательности. Полное секвенирование всех молекул гарантирует сбор максимального количества данных, доступных в приумноженном пуле. Однако в настоящее время секвенирование является дорогим, и способ, которым можно измерить аллельные распределения с использованием меньшего числа считываний последовательностей, представлял бы большую ценность. Кроме того, существуют технические ограничения максимальной возможной длины считывания, а также ограничения точности по мере увеличения длины считывания. Наиболее полезные аллели будут длиной в одно или несколько оснований, но теоретически может быть использован любой аллель короче длины считывания последовательности. Хотя вариации аллелей встречаются во всех типах, примеры, представленные в настоящем документе, фокусируются на SNP или вариантах, состоящих из нескольких соседних пар оснований. Большие варианты, такие как варианты числа копий сегмента, можно выявить по объединениям этих меньших вариаций во многих случаях, поскольку целые коллекции SNP, внутренних для данного сегменты, дуплицируются. Варианты крупнее нескольких оснований, такие как STR, требуют отдельного рассмотрения, и некоторые подходы нацеливания работают, в то время как другие - нет.
Существуют многочисленные подходы нацеливания, которые могут быть использованы для специфичного выделения и приумножения одним или множеством положений варианта в геноме. Как правило, они основываются на преимуществах инвариантной последовательности, фланкирующей вариантную последовательность. В уровне техники известно нацеливание в контексте секвенирования, при котором субстратом является материнская плазма (см., например, Liao et al., Clin. Chem. 2011; 57(1): pp.92-101). Однако во всех известных в уровне техники подходах используются нацеливающиеся зонды, целями которых являются экзоны, и не фокусируются на нацеливании на полиморфные области генома. Согласно варианту осуществления способ в соответствии с настоящим раскрытием предусматривает использование нацеливающихся зондов, которые фокусируются исключительно или почти исключительно на полиморфных областях. Согласно варианту осуществления способ настоящего раскрытия предусматривает использование нацеливающихся зондов, которые фокусируются исключительно или почти исключительно на SNP. Согласно некоторым вариантам осуществления настоящего раскрытия целевые полиморфные сайты состоят из по меньшей мере 10% SNP, по меньшей мере 20% SNP, по меньшей мере 30% SNP, по меньшей мере 40% SNP, по меньшей мере 50% SNP, по меньшей мере 60% SNP, по меньшей мере 70% SNP, по меньшей мере 80% SNP, по меньшей мере 90% SNP, по меньшей мере 95% SNP, по меньшей мере 98% SNP, по меньшей мере 99% SNP, по меньшей мере 99,9% SNP или исключительно SNP.
Согласно варианту осуществления способ настоящего раскрытия может быть использован для выявления генотипов (состава оснований ДНК в специфичных локусах) и относительных пропорций этих генотипов в смеси молекул ДНК, которые могут происходить от одного или нескольких генетически различных индивидуумов. Согласно варианту осуществления способ настоящего раскрытия может быть использован для выявления генотипов набора полиморфных локусов и относительных отношений количеств различных аллелей, присутствующих в этих локусах. Согласно варианту осуществления полиморфные локусы могут состоять полностью из SNP. Согласно варианту осуществления полиморфные локусы могут содержать SNP, единичные тандемные повторы и других полиморфизмы. Согласно варианту осуществления способ настоящего раскрытия может быть использован для определения относительных распределений аллелей набора полиморфных локусов в смеси ДНК, при этом смесь ДНК содержит ДНК от матери и ДНК от плода. Согласно варианту осуществления совокупные аллельные распределения могут быть установлены в смеси ДНК, выделенной из крови беременной женщины. Согласно варианту осуществления распределения аллелей в наборе локусов могут быть использованы для определения состояния плоидности одной или нескольких хромосом вынашиваемого плода.
Согласно варианту осуществления смесь молекул ДНК может быть получена из ДНК, экстрагированной из множества клеток одного индивидуума. Согласно варианту осуществления оригинальная коллекция клеток, из которых выделяется ДНК, может содержать смесь диплоидных или гаплоидных клеток одинакового или различных генотипов, если индивидуум является мозаиком (гаметическим или соматическим). Согласно варианту осуществления смесь молекул ДНК может быть получена из ДНК, экстрагированной из единичных клеток. Согласно варианту осуществления смесь молекул ДНК может быть получена из ДНК, экстрагированной из смеси двух или более клеток одного и того же индивидуума или различных индивидуумов. Согласно варианту осуществления смесь молекул ДНК может быть получена из ДНК, выделенной из биологического материала, который уже высвобожден из клеток, такого как плазма крови, которая, как известно, содержит бесклеточную ДНК. Согласно варианту осуществления этот биологический материал может быть смесью ДНК одного или нескольких индивидуумов, как в случае беременности, когда в смеси, как было показано, присутствует плодная ДНК. Согласно варианту осуществления биологический материал может происходить из смеси клеток, которые были обнаружены в крови матери, при этом некоторые из клеток имеют плодное происхождение. Согласно варианту осуществления биологическим материалом могут быть клетки из крови беременной женщины, которые были приумножены плодными клетками.
Зонды циркуляризации
Некоторые варианты осуществления настоящего раскрытия предусматривают использование «Linked Inverted Probes» (LIP), которые ранее были описаны в литературе. LIP - это общий термин, относящийся к технологиям, которые предусматривают создание кольцевых молекул ДНК, при которых зонды сконструированы с тем, чтобы гибридизироваться с целевой областью ДНК на одной из сторон целевого аллеля так, что добавление приемлемых полимераз и/или лигаз, буферов и других реагентов, а также приемлемые условия дополнят комплементарную инвертированную область ДНК между концами целевого аллеля с созданием кольцевой петли ДНК, в которой будет содержаться информация, обнаруженная в целевом аллеле. LIP также могут быть названы предварительно циркуляризованными зондами, зондами предварительной циркуляризации или зондами циркуляризации. Зондом LIP может быть линейная молекула ДНК длиной от 50 до 500 нуклеотидов, а согласно варианту осуществления длиной от 70 до 100 нуклеотидов; согласно некоторым вариантам осуществления она может быть длиннее или короче, чем описанные в настоящем документе. Другие варианты осуществления настоящего раскрытия включают различные воплощения технологии LIP, такие как зонды «висячие замки» и молекулярные инверсионные зонды (MIP).
Один способ нацеливания на специфичных локализаций для секвенирования заключается в синтезе зондов, в которых 3'- и 5'-концы зондов отжигаются до целевой ДНК в локализациях, примыкающих к одной из сторон целевой области, инвертированным образом так, что добавление ДНК-полимеразы и ДНК-лигазы приводит к удлинению от 3'-конца присоединением оснований к одноцепочечному зонду, которые комплементарны целевой молекуле (заполнение гэпов), с последующим лигированием нового 3'-конца с 5'-концом оригинального зонда, что приводит к формированию кольцевой молекулы ДНК, которая может быть впоследствии отделена от сопутствующей ДНК. Концы зонда сконструированы для фланкирования представляющей интерес целевой области. Один аспект этого подхода обычно называется MIPS и используется в сочетании с матричными технологиями для определения природы заполняемой последовательности. Одним из недостатков использования MIP в контексте измерения отношения аллелей является то, что этапы гибридизации, циркуляризации и амплификации осуществляются с разными скоростями для различных аллелей в одних и тех же локусах. Это приводит к тому, что измеренные отношения аллелей не являются типичными по отношению к фактическим отношениям аллелей в оригинальной смеси.
Согласно варианту осуществления зонды циркуляризации сконструированы так, что область зонда, которая сконструирована для гибридизации в 3'-5'-направлении от целевого полиморфного локуса, и область зонда, которая сконструирована для гибридизации в 5'-3'-направлении от целевого полиморфного локуса, ковалентно связываются посредством остова, не являющегося нуклеиновой кислотой. Этим остовом может быть любая биосовместимая молекула или комбинация биосовместимых молекул. Некоторыми примерами возможных биосовместимых молекул являются поли(этиленгликоль), поликарбонаты, полиуретаны, полиэтилены, полипропилены, сульфоновые полимеры, кремнийорганическое соединение, целлюлоза, фторполимеры, акриловые соединения, стирольные блок-сополимеры и другие блок-сополимеры.
Согласно варианту осуществления настоящего раскрытия этот подход был модифицирован с целью облегчения секвенирования как средства исследования заполняемой последовательности. С целью сохранения оригинальных пропорций аллелей оригинального образца необходимо принять во внимание по меньшей мере одно ключевое соображение. Вариабельные положения между различными аллелями в области заполнения гэпов не должны быть расположены слишком близко к связывающим сайтам зонда, поскольку ДНК-полимераза может сделать стандартную ошибку инициации, что приведет к перепаду в содержании вариантов. Другое соображение заключается в том, что в связывающих сайтах зонда могут присутствовать дополнительные вариации, которые сопоставимы с вариантами в области заполнения гэпов, что может привести к неравной амплификации различных аллелей. Согласно варианту осуществления настоящего раскрытия 3'-концы и 5'-концы предварительно циркуляризованного зонда сконструированы так, чтобы гибридизироваться с основаниями в одном или нескольких положениях на расстоянии от вариантных положений (полиморфных сайтов) целевого аллеля. Числом оснований между полиморфным сайтом (SNP или иным) и основанием, с которым 3'-конец и/или 5'-конец предварительно циркуляризованного зонда должен гибридизироваться, может быть одно основание, может быть два основания, может быть три основания, может быть четыре основания, может быть пять оснований, может быть шесть оснований, может быть от семи до десяти оснований, может быть от одиннадцати до пятнадцати оснований или может быть от шестнадцати до двадцати оснований, от двадцати до тридцати оснований или от тридцати до шестидесяти оснований. Для гибридизации на различном расстоянии по числу оснований от полиморфного сайта могут быть сконструированы прямые и обратные праймеры. При современных технологиях синтеза ДНК зонды циркуляризации могут быть произведены в больших количествах, что дает возможность получения и потенциального сбора большого числа зондов, позволяющих одновременно исследовать многие локусы. Сообщалось о работе более чем с 300000 зондами. Двумя статьями, в которых обсуждается метод, предусматривающий зонды циркуляризации и который может быть использован для измерения геномных данных целевого индивидуума, являются Porreca et al., Nature Methods, 2007 4(11), pp.931-936; и Turner et al., Nature Methods, 2009, 6(5), pp.315-316. Методы, описанные в данных статьях, могут быть использованы в комбинации с другими описанными в настоящем документе способами. Некоторые этапы метода из этих двух статей могут быть использованы в комбинации с другими этапами других описанных в настоящем документе способов.
Согласно некоторым вариантам осуществления раскрытых в настоящем документе способов генетический материал целевого индивидуума необязательно амплифицируется с последующей гибридизацией предварительно циркуляризованных зондов, выполнением заполнения гэпов для заполнения основаниями промежутка между двумя концами гибридизируемых зандов, лигированием двух концов с формированием циркуляризованного зонда и амплификации циркуляризованного зонда с использованием, например, амплификации по типу катящегося кольца. После того, как генетическая информация желаемого целевого аллеля захвачена приемлемо сконструированными олигонуклеотидными зондами циркуляризации, такими как в системе LIP, генетическую последовательность циркуляризованных зондов можно измерить для получения данных о желаемой последовательности. Согласно варианту осуществления приемлемо сконструированные олигонуклеотидные зонды могут быть циркуляризованы непосредственно в неамплифицированный генетический материал целевого индивидуума и амплифицированы впоследствии. Следует отметить, что ряд процедур амплификации может быть использован для амплификации оригинального генетического материала или циркуляризованных LIP, в том числе амплификация по типу катящегося кольца, MDA или другие протоколы амплификации. Для измерения генетической информации целевого генома могут быть использованы различные способы, например, использование высокопроизводительного секвенирования, секвенирования по Сэнгеру, других способов секвенирования, захвата гибридизацией, захвата циркуляризацией, мультиплексной ПЦР, других способов гибридизации и их комбинаций.
После того, как генетический материал индивидуума измерен с использованием одного из вышеупомянутых способов или их комбинации, для определения состояние плоидности одной или нескольких хромосом индивидуума и/или генетического статус одного аллеля или набора аллелей, в частности, аллелей, коррелирующих с представляющим интерес заболеванием или генетическим статусом, может быть использован способ, основанный на информатике, такой как PARENTAL SUPPORT™ наряду с приемлемыми генетическими измерениями. Следует отметить, что сообщалось о применении LIP для мультиплексного захвата генетических последовательностей с последующим генотипированием с секвенированием. Однако данные секвенирования, полученные в результате основанной на LIP стратегии амплификации генетического материала, найденного в единичной клетке, небольшом количестве клеток или во внеклеточной ДНК, не использовались в целях определения состояния плоидности целевого индивидуума.
Применение основанного на информатике способа для определения состояния плоидности индивидуума по генетическим данным, измеренным посредством матриц гибридизации, таких как матрица INFINIUM от ILLUMINA, или генного чипа AFFYMETRIX, было описано в документах, процитированных в других разделах настоящего документа. Однако описанный в настоящем документе способ демонстрирует улучшения по сравнению с ранее описанными в литературе способами. Например, основанный на LIP подход с последующим высокопроизводительным секвенированием вопреки ожиданиям обеспечивает лучшие данные генотипирования, благодаря подходу, характеризующемуся лучшей способностью к мультиплексированию, лучшей специфичностью захвата, лучшей однородностью и низкой систематической ошибкой подсчета числа аллелей. Усиленное мультиплексирование позволяет сделать целями больше аллелей, что обеспечивает более точные результаты. Лучшая однородность позволяет измерить большее число целевых аллелей, что обеспечивает более точные результаты. Более низкие частоты систематической ошибки подсчета числа аллелей приводит к более низким частотам неправильных определений, что обеспечивает более точные результаты. Более точные результаты обеспечивают улучшение клинических исходов и лучшее медицинское обслуживание.
Важно отметить, что LIP могут быть использованы в качестве способа нацеливания на специфичные локусы в образце ДНК для генотипирования способами, отличными от секвенирования. Например, LIP могут быть использованы для нацеливания на ДНК для генотипирования с использованием матриц SNP или других основанных на ДНК или РНК микроматриц.
Опосредованная лигированием ПЦР
Опосредованная лигированием ПЦР представляет собой ПЦР, используемую для предпочтительного приумножения образца ДНК посредством амплификации одного или множества локусов в смеси ДНК, при этом способ предусматривает получение набора пар праймеров, в котором каждый праймер в паре содержит целевую специфичную последовательность и нецелевую последовательность, при этом целевая специфичная последовательность сконструирована для отжига с целевой областью, одна в 3'-5'-направлении и одна в 5'-3'-направлении от полиморфного сайта, и которая может быть отделена от полиморфного сайта 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11-20, 21-30, 31-40, 41-50, 51-100, или более 100 основаниями; полимеризацию ДНК от 3'-конца в 3'-5'-направлении праймера для заполнения одноцепочечной области между ним и 5'-концом в 5'-3'-направлении праймера нуклеотидами, комплементарными целевой молекуле; лигирование последнего полимеризованного основания в 3'-5'-направлении праймера с примыкающим с основанием на 5'-конце в 5'-3'-направлении праймера; и амплификацию только полимеризованных и дотированных молекул с использованием нецелевых последовательностей, содержащихся на 5'-конце в 3'-5'-направлении праймера и 3'-конце в 5'-3'-направлении праймера. Пары праймеров для распознавания разных целей могут быть смешаны в одной и той же реакции. Нецелевые последовательности служат в качестве универсальных последовательностей так, что все пары праймеров, которые были успешно полимеризованы и лигированы, могли быть амплифицированы с помощью одной пары амплификационных праймеров.
Захват гибридизацией
Предпочтительное приумножение специфичного набора последовательностей в целевом геноме может быть выполнено посредством ряда способов. В других разделах настоящего документа приводится описание того, как LIP могут быть использованы для нацеливания на специфичный набор последовательностей, но во всех этих применениях могут быть использованы другие способы нацеливания и/или предпочтительного приумножения с результатами в равной степени хорошими. Одним примером другого способа нацеливания является захват гибридизацией. Некоторые примеры коммерческих методик захвата гибридизацией включают в себя SURE SELECT от AGILENT и TRUSEQ от ILLUMINA. При захвате гибридизацией набору олигонуклеотидов, комплементарных или в основном комплементарных желаемым целевым последовательностям, дают возможность гибридизироваться со смесью ДНК, а затем физически отделяют от смеси. После того, как желаемые последовательности гибридизировались с олигонуклеотидами нацеливания, эффект физического удаления олигонуклеотидов нацеливания также заключается в удалении целевых последовательностей. После удаления гибридизированных олигонуклеотидов их можно нагреть до температуры, превышающей их точку плавления, и они могут быть амплифицированы. Некоторые способы физического удаления олигонуклеотидов нацеливания заключаются в ковалентном связывании олигонуклеотидов нацеливания с твердой подложкой, например, с магнитной гранулой или чипом. Другой способ физического удаления олигонуклеотидов нацеливания заключается в ковалентном связывании их с молекулярным фрагментом с высокой аффинностью к другому молекулярному компоненту. Примером такой молекулярной пары является биотин и стрептавидин, такие как используемые в SURE SELECT. Таким образом, целевые последовательности могут быть ковалентно прикреплены к молекуле биотина, и после гибридизации можно использовать твердую подложку со стрептавидином, прикрепленном так, чтобы тянуть вниз биотинилированные олигонуклеотиды, с которыми гибридизированы целевые последовательности.
Гибридный захват предусматривает зонды гибридизации, которые комплементарны представляющим интерес целевым участкам в целевых молекулах. Зонды гибридного захвата были изначально разработаны для нацеливания и приумножения больших фракций генома с относительной однородностью между целями. При таком применении было важно, чтобы все цели были амплифицированы с достаточной однородностью для того, чтобы все области можно было выявить секвенированием, однако, сохранению пропорций аллелей оригинального образца внимания не уделялось. После захвата аллели, присутствующие в образце, можно было определить прямым секвенированием захваченных молекул. Эти данные секвенирования можно было проанализировать и количественно оценить по типу аллелей. Однако при использовании этой современной технологии измеренное распределение аллелей в захваченных последовательностях, как правило, не отражает оригинальные распределения аллелей.
Согласно варианту осуществления выявление аллелей осуществляется посредством секвенирования. Для того, чтобы установить идентичность аллели в полиморфном сайте, важно, чтобы считывание при секвенировании охватывали рассматриваемый аллель, чтобы оценить аллельный состав захваченной молекулы. Поскольку длина молекул захвата при секвенировании часто варьирует, невозможно гарантировать перекрытие вариантных положений, если не секвенируется вся молекула. Однако соображения, качающиеся затрат, а также технические ограничения относительно максимальной возможной длины и точности считываний при секвенировании делают секвенирование всей молекулы нецелесообразным. Согласно варианту осуществления длина считывания может быть увеличена от приблизительно 30 до приблизительно 50 или приблизительно 70 оснований, что может значительно повысить число считываний, которые перекрывают положения варианта в целевых последовательностях.
Другой способ повышения числа считываний, которые запрашивают представляющее интерес положение, заключается в уменьшении длины зонда в такой степени, чтобы это не привело в стандартной ошибке в основных приумноженных аллелях. Длина синтезированного зонда должна быть достаточно большой для того, чтобы два зонда, сконструированные для гибридизации с двумя различными аллелями, обнаруженными в одном локусе, гибридизировались практически с равной аффинностью с различными аллелями в оригинальном образце. В настоящее время способы, известные в уровне техники, описывают зонды, которые, как правило, длиннее 120 оснований. В текущем варианте осуществления, если аллель представляет собой одно или несколько оснований, то зонды захвата могут быть менее приблизительно 110 оснований, менее приблизительно 100 оснований, менее приблизительно 90 оснований, менее приблизительно 80 оснований, менее приблизительно 70 оснований, менее приблизительно 60 оснований, менее приблизительно 50 оснований, менее приблизительно 40 оснований, менее приблизительно 30 оснований и менее приблизительно 25 оснований, и этого достаточно для обеспечения равного приумножения всеми аллелями. Когда смесь ДНК, которая должна быть приумножена с использованием методики гибридного захвата, представляет собой смесь, содержащую свободно плавающую ДНК, выделенную из крови, например, крови матери, средняя длина ДНК достаточно мала, как правило, менее 200 оснований. Использование более коротких зондов повысит шанс того, что зонды гибридного захвата захватят желаемые фрагменты ДНК. Более длинные вариации могут потребовать более длинных зондов. Согласно варианту осуществления представляющие интерес вариации состоят из одного (SNP) или нескольких оснований. Согласно варианту осуществления целевые области в геноме могут быть предпочтительно приумножены с использованием зондов гибридного захвата, при этом длина зондов гибридного захвата менее 90 оснований, и может быть менее 80 оснований, менее 70 оснований, менее 60 оснований, менее 50 оснований, менее 40 оснований, менее 30 оснований или менее 25 оснований. Согласно варианту осуществления с целью повышения шанса секвенирования желаемого аллеля длина зонда, который конструируется для гибридизации с областями, фланкирующими локализацию полиморфного аллеля, может быть уменьшена от приблизительно 90 оснований до приблизительно 80 оснований или до приблизительно 70 оснований, или до приблизительно 60 оснований, или до приблизительно 50 оснований, или до приблизительно 40 оснований, или до приблизительно 30 оснований, или до приблизительно 25 оснований.
Существует минимальное перекрытие между синтезированным зондом и целевой молекулой для того, чтобы осуществить захват. Такой синтезированный зонд можно сделать по возможности коротким, но все же длиннее, чем минимальное необходимое перекрытие. Эффект использования более короткого зонда для нацеливания на полиморфную область заключается в том, что будет больше молекул, перекрывающих область целевого аллеля. Состояние фрагментации оригинальных молекул ДНК также влияет на число считываний, которые будут перекрывать целевые аллели. Некоторые образцы ДНК, такие как образцы плазмы, уже фрагментированы вследствие биологических процессов, протекающих in vivo. Однако образцы с более длинными фрагментами получают преимущество при фрагментировании перед секвенированием препарата библиотеки и приумножением. Если и зонды, и фрагменты короткие (~60-80 пар оснований), максимальная специфичность может быть достигнута только для относительно небольшого количества считываний последовательности, поскольку не удается перекрыть представляющую интерес критическую область.
Согласно варианту осуществления условия гибридизации могут быть настроены для максимальной однородности захвата различных аллелей, присутствующих в оригинальном образце. Согласно варианту осуществления температуры гибридизации снижаются для сведения к минимуму различий в стандартной ошибке гибридизации между аллелями. В способах, известных в уровне техники, избегают использования более низких температур для гибридизации, потому что снижение температуры увеличивает вероятность гибридизации зондов с непредусмотренными целями. Однако, если целью является сохранение отношений аллелей с максимальной точностью, подход с использованием более низких температур гибридизации обеспечивает оптимально точные отношения аллелей, несмотря на тот факт, что на современном уровне техники рекомендуется воздерживаться от такого подхода. Температура гибридизации также может быть повышена для достижения большего перекрытия между целью и синтезированным зондом так, что захватываются только цели с существенным перекрытием целевой области. Согласно некоторым вариантам осуществления настоящего раскрытия температура гибридизации снижается от нормальной температуры гибридизации до приблизительно 40°C, до приблизительно 45°C, до приблизительно 50°C, до приблизительно 55°C, до приблизительно 60°C, до приблизительно 65 или до приблизительно 70°C.
Согласно варианту осуществления зонды гибридного захвата могут быть сконструированы так, что область зонда захвата с ДНК, которая комплементарна ДНК, обнаруженной в областях, фланкирующих полиморфный аллель, не примыкает непосредственно к полиморфному сайту. Вместо этого зонд захвата может быть сконструирован так, что область зонда захвата, сконструированная для гибридизации с ДНК, фланкирующей полиморфный сайт цели, отделена от части зонда захвата, которая будет контактировать с полиморфным сайтом посредством вандерваальсовских взаимодействий, небольшим расстоянием, эквивалентным по длине одному основанию или небольшому числу оснований. Согласно варианту осуществления зонд гибридного захвата конструируется для гибридизации с областью, фланкирующей полиморфный аллель, но не пересекающей его; такой зонд может быть назван фланкирующим зондом захвата. Длина фланкирующего зонда захвата может быть менее приблизительно 120 оснований, менее приблизительно 110 оснований, менее приблизительно 100 оснований, менее приблизительно 90 оснований, и может быть менее приблизительно 80 оснований, менее приблизительно 70 оснований, менее приблизительно 60 оснований, менее приблизительно 50 оснований, менее приблизительно 40 оснований, менее приблизительно 30 оснований или менее приблизительно 25 оснований. Область генома, которая является целью фланкирующего зонда захвата может быть отделена от полиморфного локуса 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11-20 или более 20 парами оснований.
Описано скрининговое тестирование заболеваний, основанное на целевом захвате, с использованием захвата целевых последовательностей. Захват заказанных целевых последовательностей подобен таковым предлагаемым в настоящее время компаниями AGILENT (SURE SELECT), ROCHE-NIMBLEGEN или ILLUMINA. Зонды захвата могут быть сконструированы на заказ с целью обеспечения захвата различных типов мутаций. Для точковых мутаций будет достаточно одного или нескольких зондов, перекрывающих точковую мутацию, для захвата и секвенирования мутации.
Для небольших инсерций или делеций одного или нескольких зондов, перекрывающих мутацию, может быть достаточно для захвата и секвенирования фрагментов, содержащих мутацию. Гибридизация может быть менее эффективной между зондами, ограничивающими эффективность захвата, сконструированными, как правило, для эталонной последовательности генома. Для обеспечения захвата фрагментов, содержащих мутацию, следует конструировать два зонда, один из которых соответствует нормальному аллелю, а второй - мутантному аллелю. Более длинный зонд может усиливать гибридизацию. Множественные перекрывающиеся зонды могут усиливать захват. Наконец, помещение зонда в непосредственной близости от мутации, но без ее перекрывания, может дать относительно сходную эффективность захвата нормального и мутантного аллелей.
Для простых тандемных повторов (STR) маловероятно, чтобы зонд, перекрывающий эти высоко вариабельные сайты, хорошо захватывал фрагмент. Для усиления захвата зонд можно поместить в непосредственной близости от вариабельного сайта, но без его перекрывания. Фрагмент можно впоследствии секвенировать как нормальный для определения длины и состава STR.
Для крупных делеций может сработать серия перекрывающихся зондов, обычный подход, применяемый в настоящее время в системах захвата экзома. Однако при этом подходе может быть затруднительно определение того, гетерозиготен ли индивидуум или нет. Нацеливание на SNP и их оценка в пределах захваченной области потенциально могут определить утрату гетерозиготности в рамках данной области, что будет свидетельствовать о том, что индивидуум является носителем. Согласно варианту осуществления можно поместить неперекрывающиеся или единичные зонды в пределах потенциально делегированной области и использовать число захваченных фрагментов как меру гетерозиготности. В случае если индивидуум несет крупную делецию, предполагается, что половина числа фрагментов будет доступна для захвата по сравнению с неделетированным (диплоидным) эталонным локусом. Следовательно, число считываний, полученных из делегированных областей, должно составлять приблизительно половину числа считываний, полученных из нормального диплоидного локуса. Суммируя и усредняя глубину считывания секвенирования от нескольких единичных зондов в пределах потенциально делегированной области, можно усилить сигнал и улучшить достоверность диагноза. Эти два подхода, нацеливание на SNP для идентификации утраты гетерозиготности и использование нескольких единичных зондов с целью получения количественной меры числа основных фрагментов из этого локуса, также могут быть использованы в комбинации. Любая из этих стратегий или они обе могут применяться в комбинации с другими стратегиями для достижения лучшего результата.
Если во время тестирования cfDNA плода мужского пола, что доказывается присутствием фрагментов Y-хромосомы, захваченных и секвенированных в одном и том же тесте, выявляется X-сцепленная доминантная мутация, если мать и отец не поражены, или доминантная мутация, если мать не поражена, это будет указывать на повышенный риск для плода. Выявление двух мутантных рецессивных аллелей одного и того же гена у плода от здоровой матери означает, что плод унаследовал один мутантный аллель от отца, а второй мутантный аллель, вероятно, от матери. Во всех случаях может быть показано тестирование при последующем наблюдении с помощью амниоцентеза или взятия пробы хориальных ворсин.
Основанный на принципе целевого захвата скрининг заболеваний можно комбинировать с основанным на принципе целевого захвата неинвазивным пренатальным диагностическим тестом на анеуплоидию.
Существует ряд подходов для снижения вариабельности глубины считывания (DOR), например, можно повысить концентрации праймеров, использовать более длинные зонды для целевой амплификации или провести больше циклов STA (например, больше 25, больше 30, больше 35 или даже больше 40).
Целевая ПЦР
Согласно некоторым вариантам осуществления ПЦР может быть использована для нацеливания на специфичные локализации в геноме. В образцах плазмы оригинальная ДНК высоко фрагментирована (как правило, менее 500 пар оснований, со средней длиной менее 200 пар оснований). При ПЦР для осуществления амплификации как прямые, так и обратные праймеры должны отжигаться с одним и тем же фрагментом. Следовательно, если фрагменты короткие, в ходе анализов ПЦР также должны амплифицироваться относительно короткие области. Подобно MIPS, если полиморфные положения находятся слишком близко к сайту связывания полимеразы, это может привести к стандартным ошибкам амплификации из различных аллелей. В настоящее время праймеры ПЦР, целями которых являются полиморфные области, например, такие, которые содержат SNP, как правило, конструируются так, что 3'-конец праймера будет гибридизироваться с основанием, непосредственно примыкающим к полиморфному основанию или основаниям. Согласно варианту осуществления настоящего раскрытия 3'-концы как прямых, так и обратных праймеров ПЦР сконструированы так, чтобы гибридизироваться с основаниями, которые расположены на расстоянии одного или нескольких положений от вариантных положений (полиморфных сайтов) целевого аллеля. Число оснований между полиморфным сайтом (SNP или иным сайтом) и основанием, с которым должен гибридизироваться 3'-конец праймера, может составлять одно основание, может составлять два основания, может составлять три основания, может составлять четыре основания, может составлять пять оснований, может составлять шесть оснований, может составлять от семи до десяти оснований, может составлять от одиннадцати до пятнадцати оснований или может составлять от шестнадцати до двадцати оснований. Прямые и обратные праймеры могут быть сконструированы для гибридизации на различном расстоянии по числу оснований от полиморфного сайта.
Анализ ПЦР может проводиться в больших количествах, однако, взаимодействия между различными анализами ПЦР затрудняет их мультиплексирование при их количестве, превышающем приблизительно сто анализов. Для повышения уровня мультиплексирования могут быть использованы различные комплексные молекулярные подходы, но их применение может быть ограничено числом меньшим 100, вероятно 200, или возможно 500 анализов на реакцию. Образцы с большими количествами ДНК можно разделить на несколько субреакций, а затем повторно объединить перед секвенированием. Для образцов, в которых либо весь образец, либо субпопуляция молекул ДНК ограничивается, расщепление образца будет вносить статистический шум. Согласно варианту осуществления небольшое или ограниченное количество ДНК может относиться к количеству ниже 10 пг, от 10 до 100 пг, от 100 пг до 1 нг, от 1 до 10 нг или от 10 до 100 нг. Следует отметить, что хотя данный способ особенно применим при небольших количествах ДНК, при которых другие способы, предусматривающие расщепление образца на множество пулов, могут вызвать значительные проблемы, связанные с возникновением стохастического шума, он все же обеспечивает преимущество минимизации стандартной ошибки при применении на образцах с любым количеством ДНК. В таких ситуациях можно использовать этап универсальной преамплификации для увеличения количества всего образца. В идеале такой этап преамплификации не должен значимо изменять распределения аллелей.
Согласно варианту осуществления способ в соответствии с настоящим раскрытием может образовывать продукты ПЦР, которые являются специфичными для большого числа целевых локусов, в частности для от 1000 до 5000 локусов, от 5000 до 10000 локусов или более 10000 локусов, для генотипирования секвенированием или другими способами генотипирования, из ограниченных образцов, таких как единичные клетки или ДНК из жидкостей организма. В настоящее время выполнение мультиплексной ПЦР для более 5-10 целей представляет основную проблему, и ему часто препятствуют побочные продукты праймеров, такие как димеры праймеров, и другие артефакты. При выявлении целевых последовательностей с использованием микроматриц с зондами гибридизации димеры праймеров и другие артефакты можно проигнорировать, поскольку они не выявляются. Однако при использовании секвенирования в качестве способа выявления подавляющее большинство считываний секвенирования будет считывать в образце такие артефакты, а не желаемые целевые последовательности. Описанные в уровне техники методы, используемые для мультиплексирования более 50 или 100 реакций в одной реакции с последующим секвенированием, как правило, дадут более 20%, а часто более 50%, во многих случаях более 80%, а в некоторых случаях более 90% считываний нецелевых последовательностей.
В целом, для выполнения целевого секвенирования множества (n) целей в образце (более 50, более 100, более 500 или более 1000) можно разделить образец на ряд параллельных реакций, в которых будет амплифицироваться одна индивидуальная цель. Это можно выполнять в многолуночных планшетах для ПЦР или на коммерчески доступных платформах, таких как FLUIDIGM ACCESS ARRAY (48 реакций на образец в микрожидкостных чипах) или методом капельной ПЦР по технологии RAIN DANCE TECHNOLOGY (от сотен до нескольких тысяч целей). К сожалению, такие методы расщепления и объединения являются проблематичными для образцов с ограниченным количеством ДНК, поскольку часто отсутствует достаточное количество копий генома для обеспечения того, чтобы в каждую лунку попала одна копия каждой области генома. Это представляет особенно серьезную проблему, если целями являются полиморфные локусы, и нужны относительные пропорции аллелей в полиморфных локусах, поскольку стохастический шум, возникающий в результате расщепления и объединения, будет являться причиной очень низкой точности измерений пропорций аллелей, присутствующих в оригинальном образце ДНК. В настоящем документе описывается способ для эффективной и производительной амплификации во множестве реакций ПЦР, который применим для случаев, если доступно только ограниченное количество ДНК. Согласно варианту осуществления метод может применяться для анализа единичных клеток, жидкостей организма, смесей ДНК, таких как свободно плавающая ДНК, обнаруживаемая в материнской плазме, биоптатов, образцов, взятых из окружающей среды и/или экспертных образцов.
Согласно варианту осуществления целевое секвенирование может предусматривать один, несколько или все из следующих этапов. a) Создание и амплификация библиотеки с адаптерными последовательностями на обоих концах фрагментов ДНК. b) Разделение на несколько реакций после амплификации библиотеки. c) Создание и необязательная амплификация библиотеки с адаптерными последовательностями на обоих концах фрагментов ДНК. d) Выполнение от 1000- до 10000-плексной амплификации выбранных целей с использованием одного специфичного по отношению к цели «прямого» праймера на цель и одного праймера специфичного по отношению к маркеру. e) Выполнение второй амплификации этого продукта с использованием «обратных» праймеров специфичных по отношению к цели и одного (или нескольких) праймеров, специфичных по отношению к универсальному маркеру, который был введен как часть прямых специфичных по отношению к цели праймеров, в первом раунде. f) Выполнение 1000-плексной преамплификации выбранных целей в течение ограниченного числа циклов. g) Разделение продукта на множество аликвот и амплификация субпулов целей в индивидуальных реакциях (например, от 50 до 500-плексной, хотя могут быть использованы все, вплоть до одноплексной). h) Объединение продуктов реакций в параллельных субпулах. i) Во время этих амплификации праймеры могут нести совместимые с секвенированием маркеры (частичные или полной длины) так, что продукты могут быть секвенированы.
Высоко мультиплексная ПЦР
В настоящем документе раскрываются способы, обеспечивающие целевую амплификацию от свыше ста до десятков тысяч целевых последовательностей (например, локусов SNP) из геномной ДНК, полученной из плазмы. Амплифицированный образец может быть относительно свободен от продуктов димеров праймеров и характеризоваться низкой статистической ошибкой подсчета числа аллелей в целевых локусах. Если во время или после амплификации к продуктам добавить совместимые с секвенированием адаптеры, анализ таких продуктов можно выполнять посредством секвенирования.
Проведение высоко мультиплексной ПЦР-амплификации с использованием известных в уровне техники способов приводит к образованию продуктов димеров праймеров в избытке по отношению к желаемым продуктам амплификации и не приемлемых для секвенирования. Это можно снизить эмпирически путем элиминирования праймеров, которые формируют такие продукты, или путем выполнения in silico отбора праймеров. Однако, чем больше число анализов, тем более значительной становится проблема.
Одним из решений является расщепление 5000-плексной реакции на несколько амплификации с более низкой плексностью, например, сто 50-плексных или пятьдесят 100-плексных реакций, или использование подходов микрофлюидики, или даже расщепление образца на индивидуальные реакции ПЦР. Однако если количество ДНК в образце ограничено, например, в образцах плазмы беременных при неинвазивной пренатальной диагностике, разделения образца на множественные реакции следует избегать, поскольку оно вызовет затруднения.
Описанные в настоящем документе способы предназначены для того, чтобы сначала амплифицировать всю ДНК из образца плазмы, а затем разделить образец на множество мультиплексных реакций приумножения целей с более умеренным количеством целевых последовательностей на реакцию. Согласно варианту осуществления способ в соответствии с настоящим раскрытием может быть использован для предпочтительного приумножения смеси ДНК во множестве локусов, при этом способ предусматривает один или несколько следующих этапов: получения и амплификации библиотеки из смеси ДНК, при этом молекулы в библиотеке содержат адаптерные последовательности, дотированные с обоих концов фрагментов ДНК, разделения амплифицированной библиотеки на множество реакций, выполнения первого раунда мультиплексной амплификации выбранных целей с использованием одного специфичного по отношению к цели «прямого» праймера на цель и одного или нескольких специфичных по отношению к адаптеру универсальных «обратных» праймеров. Согласно варианту осуществления способ в соответствии с настоящим раскрытием дополнительно предусматривает выполнение второй амплификации с использованием специфичных к целям «обратных» праймеров и один или несколько специфичных по отношению к маркеру универсальных праймеров, который был введен как часть специфичных к целям прямых праймеров в первом раунде. Согласно варианту осуществления способ может предусматривать подход полностью вложенной, гемивложенной, полувложенной, односторонней полностью вложенной, односторонней гемивложенной или односторонней полувложенной ПЦР. Согласно варианту осуществления способ в соответствии с настоящим раскрытием используется для предпочтительного приумножения смеси ДНК множеством локусов, при этом способ предусматривает выполнение мультиплексной преамплификации выбранных целей в течение ограниченного числа циклов, разделение продукта на множественные аликвоты, амплификацию субпулов целей в индивидуальных реакциях и объединение продуктов реакций параллельных субпулов. Следует отметить, что такой подход может быть использован для проведения целевой амплификации таким образом, что он обеспечит низкие уровни систематической ошибки подсчета числа аллелей для 50-500 локусов, для 500-5000 локусов, для 5000-50000 локусов или даже для 50000-500000 локусов. Согласно варианту осуществления праймеры несут совместимые с секвенированием маркеры частичной или полной длины.
Технологический процесс может предусматривать (1) экстракцию ДНК из плазмы, (2) подготовку библиотеки фрагментов с универсальными адаптерами на обоих концах фрагментов, (3) амплификацию библиотеки с использованием универсальных праймеров, специфичных по отношению к адаптерам, (4) разделение амплифицированной «библиотеки» образца на множественные аликвоты, (5) проведение мультиплексных (например, приблизительно 100-плексной, 1000- или 10000-плексной с одним специфичным по отношению к цели праймером на цель и специфичным по отношению к маркеру праймером) амплификации аликвот, (6) объединение аликвот одного образца, (7) определение штрихкодов образца, (8) смешивание образцов и регулирование концентрации (9) секвенирование образца. Технологический процесс может предусматривать множественные подэтапы, которые предусматривают один из перечисленных этапов (например, этап (2) подготовки библиотеки может включать в себя три ферментативных этапа (формирования тупых концов, наращивания dA и адаптерного лигирования) и три этапа очистки). Этапы технологического процесса можно комбинировать, разделять или выполнять в различном порядке (например, определение штрихкодов и объединение образцов).
Важно отметить, что амплификацию библиотеки можно выполнять таким образом, что она будет смещена в сторону более эффективной амплификации коротких фрагментов. Благодаря этому возможна предпочтительная амплификация более коротких последовательностей, например, мононуклеосомных фрагментов ДНК, таких как внеклеточная плодная ДНК (плацентарного происхождения), выявляемая в кровотоке беременных женщин. Следует отметить, что при анализах ПЦР используются маркеры, например, маркеры секвенирования (обычно процессированная форма из 15-25 оснований). После мультиплексирования ПЦР-мультиплексы образца объединяются, а затем завершается маркирование (в том числе штрихкодирование) с помощью маркер-специфичной ПЦР (также может выполняться с помощью лигирования). Также в ту же самую реакционную смесь мультиплексирования могут быть добавлены маркеры полного секвенирования. В первых циклах цели могут быть амплифицированы специфичными к целям праймерами, впоследствии начинают работать специфичные по отношению к маркерам праймеры, которые завершают SQ-адаптерную последовательность. Праймеры ПЦР могут не иметь маркеров. Маркеры секвенирования могут быть добавлены к продуктам амплификации путем лигирования.
Согласно варианту осуществления высоко мультиплексная ПЦР с последующей оценкой амплифицированного материала путем секвенирования клонов может быть использована для выявления анеуплоидии плода. В то время как традиционные мультиплексные ПЦР оценивают до пятидесяти локусов одновременно, описанный в настоящем документе подход может быть использован одновременной оценки более 50 локусов одновременно, более 100 локусов одновременно, более 500 локусов одновременно, более 1000 локусов одновременно, более 5000 локусов одновременно, более 10000 локусов одновременно, более 50000 локусов одновременно и более 100000 локусов одновременно. Эксперименты показали, что до 10000 и больше различных локусов могут быть проанализированы одновременно в одной реакции с достаточно хорошей эффективностью и специфичностью для проведения неинвазивной пренатальной диагностики анеуплоидии и/или определения числа копий признаков с высокой точностью. Анализы можно комбинировать в одной реакции со всем образцом cfDNA, выделенной из материнской плазмы, с e фракцией или с процессированными производными cfDNA образца. cfDNA или ее производные также можно разделить на множественные параллельные мультиплексные реакции. Оптимальное расщепление образца и мультиплексирование устанавливается путем изменения одних показателей производительности процесса за счет других. Вследствие ограниченного количества материала расщепление образца на множественные фракции может внести шумовой сигнал, увеличить время обработки и повысить вероятность погрешности. Напротив, более высокое мультиплексирование может привести к большим количествам побочных продуктов амплификации и большим диспропорциям в амплификации, оба явления могут снижать показатели производительности теста.
Двумя ключевыми взаимосвязанными соображениями при применении описанных в настоящем документе способов являются ограниченное количество оригинальной плазмы и число оригинальных молекул в материале, из которого поучают частоту аллелей или другие измерения. Если число оригинальных молекул падает ниже определенного уровня, случайный шумовой сигнал становится значимым и может повлиять на точность теста. Как правило, данные удовлетворительного качества для осуществления неинвазивной пренатальной диагностики анеуплоидии могут быть получены, если измерения выполняются на образце, содержащем эквивалент 500-1000 оригинальных молекул на целевой локус. Существует ряд способов увеличения количества отдельных измерений, например, увеличение объема образца. Каждая манипуляция, проводимая с образцом, также потенциально приводит к потере материала. Важно характеризовать потери, понесенные в результате различных манипуляций, и избегать их или при необходимости повышать выход определенных манипуляций во избежание потерь, которые могут ухудшить производительность теста.
Согласно варианту осуществления можно снизить потенциальные потери на последовательных этапах посредством амплификации всей cfDNA образца или фракции оригинальной cfDNA. Доступны различные способы для амплификации всего генетического материала в образце с увеличением количества материала, доступного для процедур в 5'-3'-направлении. Согласно варианту осуществления при опосредованной дотированием ПЦР (LM-PCR) фрагменты ДНК амплифицируются путем ПЦР после дотирования или одного отдельного адаптера, или двух отдельных адаптеров, или множества отдельных адаптеров. Согласно варианту осуществления при амплификации с множественным замещением цепей (MDA) полимераза phi-29 используется для амплификации всей ДНК в изотермических условиях. В DOP-PCR и вариациях для амплификации ДНК из оригинального материала используется случайный прайминг. Каждый способ имеет определенные характеристики, такие как однородность амплификации по всем представленным областям генома, эффективность захвата и амплификации оригинальной ДНК, а также производительность амплификации как функция длины фрагмента.
Согласно варианту осуществления LM-PCR может быть использована с единичным гетеродуплексным адаптером, имеющим тирозин на 3'-конце. Гетеродуплексный адаптер дает возможность использовать единичную молекулу адаптера, которая может быть превращена в две различные последовательности на 5'-конце и 3'-конце оригинального фрагмента ДНК во время первого раунда ПЦР. Согласно варианту осуществления можно фракционировать амплифицированную библиотеку по размерам или продуктам, таким как AMPURE, TASS, или другими аналогичными способами. Перед лигированием образец ДНК может быть снабжен тупыми концами с последующим добавлением единичного аденозинового основания на 3'-конце. Перед лигированием ДНК может быть расщеплена с использованием фермента рестрикции или каким-либо другим способом расщепления. Во время лигирования 3'-концевой аденозин фрагментов образца и комплементарный 3'-концевой тирозин выступают над адаптером и могут повысить эффективность лигирования. Этап удлинения ПЦР-амплификации может быть ограничен во времени с целью уменьшения амплификации фрагментов, длиннее приблизительно 200 пар оснований, приблизительно 300 пар оснований, приблизительно 400 пар оснований, приблизительно 500 пар оснований или приблизительно 1000 пар оснований. Поскольку более длинные фрагменты ДНК, выявляемые в материнской плазме, практически полностью являются материнскими, это может привести к приумножению плодной ДНК на 10-50% и улучшению производительности теста. Ряд реакций проводился с использованием условий, указанных в коммерчески доступных наборах; в результате успешное лигирование достигалось менее чем для 10% молекул ДНК образца. После серии оптимизаций условий реакции лигирование было улучшено до приблизительно 70%.
Мини-ПЦР
Схема традиционного анализа ПЦР приводит к значительным потерям отдельных плодных молекул, однако, потери могут быть существенно уменьшены разработкой очень коротких анализов ПЦР, называемых анализами мини-ПЦР. Плодная cfDNA в материнской сыворотке высоко фрагментирована, и размеры фрагментов распределяются приблизительно по закону распределения вероятностей Гаусса со средней длиной 160 пар оснований, стандартным отклонением 15 пар оснований, минимальным размером приблизительно 100 пар оснований и максимальным размером приблизительно 220 пар оснований. Распределение стартовых и концевых положений фрагмента относительно целевых полиморфизмов, не являясь обязательно случайным, значительно варьирует между отдельными целями и между всеми целями вместе, и полиморфный сайт одного конкретного целевого локуса может занимать любое положение от старта до конца в различных фрагментах, происходящих от это локуса. Следует отметить, что термин мини-ПЦР может в равной степени относиться к обычной ПЦР без дополнительных оговорок или ограничений.
Во время ПЦР будет происходить амплификация только тех матричных фрагментов ДНК, которые содержат сайты как прямых, так и обратных праймеров. Поскольку фрагменты плодной cfDNA короткие, правдоподобие того, что сайты обоих праймеров присутствуют, означает правдоподобие существования плодного фрагмента длиной L, содержащего сайты как прямых, так и обратных праймеров, и равняется отношению длины ампликона к длине фрагмента. При идеальных условиях в анализе, в котором ампликон составляет 45, 50, 55, 60, 65 или 70 пар оснований, будет успешно амплифицироваться 72%, 69%, 66%, 63%, 59% или 56%, соответственно, доступных фрагментов-матриц молекул. Длина ампликона - это расстояние между 5'-концами прямых и обратных праймирующих сайтов. Ампликон с меньшей длиной по сравнению с теми, которые, как правило, известны в уровне техники, может дать более эффективные измерения желаемых полиморфных локусов, требуя считывания только коротких последовательностей. Согласно варианту осуществления существенная фракция ампликонов должна составлять менее 100 пар оснований, менее 90 пар оснований, менее 80 пар оснований, менее 70 пар оснований, менее 65 пар оснований, менее 60 пар оснований, менее 55 пар оснований, менее 50 пар оснований или менее 45 пар оснований.
Следует отметить, что в способах, известных в уровне техники, коротких анализов, таких как описанные в настоящем документе, обычно избегают, потому что они не являются необходимыми и накладывают значительные ограничения на конструирование праймеров, ограничивая длину праймера, характеристики отжига и расстояние между прямым и обратным праймерами.
Также следует отметить, что существует вероятность ошибочной амплификации, если 3'-конец любого из праймеров находится приблизительно на расстоянии 1-6 оснований от полиморфного сайта. Такая разница в одном основании в сайте начального связывания полимеразы может привести к предпочтительной амплификации одного аллеля, что может изменить наблюдаемые частоты аллелей и ухудшить производительность. Все эти ограничения делают идентификацию праймеров, которые будут успешно амплифицировать конкретный локус, и, следовательно, конструирование больших наборов праймеров, которые были бы совместимы в одной мультиплексной реакции, очень проблематичным. Согласно варианту осуществления 3'-конец внутренних прямых и обратных праймеров конструируется для гибридизации с областью ДНК в 3'-5'-направлении от полиморфного сайта и отделяется от полиморфного сайта небольшим числом оснований. В идеале, число оснований может составлять от 6 до 10 оснований, но может в равной степени составлять от 4 до 15 оснований, от трех до 20 оснований, от двух до 30 оснований или от 1 до 60 оснований, с достижением по сути одинакового результата.
Мультиплексная ПЦР может предусматривать один раунд ПЦР, в котором амплифицируются все цели, или может предусматривать один раунд ПЦР с последующим одним или несколькими раундами вложенной ПЦР или некоторым вариантом вложенной ПЦР. Вложенная ПЦР состоит из последовательного раунда или раундов ПЦР-амплификации с использованием одного или нескольких новых праймеров, которые внутренне связываются с помощью по меньшей мере одной пары оснований с праймерами, использованными в предыдущем раунде. Вложенная ПЦР снижает число побочной амплификации целей посредством амплификации в последовательных реакциях только тех продуктов предыдущего раунда, которые имеют корректную внутреннюю последовательность. Снижение побочной амплификации целей повышает количество полезных измерений, которые могут быть получены, особенно при секвенировании. Вложенная ПЦР, как правило, означает конструирование праймеров, полностью внутренних по отношению к связывающим сайтам предыдущих праймеров, с увеличением в обязательном порядке минимального размера сегмента ДНК, необходимого для амплификации. Для образцов, таких как cfDNA из материнской плазмы, в которых ДНК высоко фрагментирована, больший размер анализируемых фрагментов снижает число отдельных молекул cfDNA, из которых можно получить измерение. Согласно варианту осуществления с целью компенсации этого эффекта можно использовать частично вложенный подход, при котором один или оба праймера второго раунда перекрывают сайты связывания праймеров первого раунда, несколько увеличивая внутреннее количество оснований для достижения дополнительной специфичности и при этом минимально увеличивая общий размер анализируемых фрагментов.
Согласно варианту осуществления мультиплексный пул ПЦР анализируемых фрагментов сконструирован для амплификации потенциально гетерозиготных SNP или других полиморфных или неполиморфных локусов в одной или нескольких хромосомах, и эти анализируемые фрагменты используются в одной реакции для амплификации ДНК. Количество анализируемых фрагментов в ПЦР может составлять от 50 до 200 анализируемых фрагментов ПЦР, от 200 до 1000 анализируемых фрагментов ПЦР, от 1000 до 5000 анализируемых фрагментов ПЦР или от 5000 до 20000 анализируемых фрагментов ПЦР (50-200-плексная, 200-1000-плексная, 1000-5000-плексная, 5000-20000-плексная, более чем 20000-плексная, соответственно). Согласно варианту осуществления мультиплексный пул из приблизительно 10000 анализируемых фрагментов ПЦР (10000-плексной) конструируется для амплификации потенциально гетерозиготных SNP локусов в хромосомах X, Y, 13, 18 и 21 и 1 или 2, и эти анализируемые фрагменты используются в одной реакции для амплификации cfDNA, полученной из материала образца плазмы, образцов ворсинок хориона, образцов амниоцентеза, единичных клеток или небольшого количества клеток, других жидкостей или тканей организма, злокачественных опухолей или другого генетического материала. Частоты SNP в каждом локусе могут быть определены секвенированием клонов или некоторыми другими способами секвенирования ампликонов. Статистической анализ распределения частот аллелей или отношений всех проанализированных фрагментов может быть использован для определения, содержит ли образец трисомию по одной или нескольким хромосомам, включенным в тест. Согласно другому варианту осуществления образцы оригинальной cfDNA расщепляются на два образца, и выполняются параллельные 5000-плексные анализы. Согласно другому варианту осуществления образцы оригинальной cfDNA расщепляются на n образцов, и выполняются параллельные (~10000/n)-плексные анализы, где n составляет от 2 до 12, или от 12 до 24, или от 24 до 48, или от 48 до 96. Данные собираются и анализируются таким же образом, как описано выше. Следует отметить, что этот способ в равной степени применим для выявления транслокаций, делеций, дупликаций и других хромосомных аномалий.
Согласно варианту осуществления к 3'-концу или 5'-концу любого из праймеров могут добавляться хвосты, не имеющие гомологии с целевым геномом. Эти хвосты облегчают последующие манипуляции, процедуры или измерения. Согласно варианту осуществления хвостовая последовательность может быть одинаковой для прямых и обратных специфичных по отношению к цели праймеров. Согласно варианту осуществления различные хвосты могут использоваться для прямых и обратных специфичных по отношению к цели праймеров. Согласно варианту осуществления множество различных хвостов может быть использовано различных локусов или наборов локусов. Некоторые хвосты могут быть общими для всех локусов или субнаборов локусов. Например, использование прямых и обратных хвостов, соответствующих прямым и обратным последовательностям, требуемым любой из применяемых в настоящее время платформ секвенирования, может дать возможность прямого секвенирования после амплификации. Согласно варианту осуществления хвосты могут быть использованы в качестве обычных сайтов прайминга для всех амплифицируемых целей, которые могут быть использованы для добавления других полезных последовательностей. Согласно некоторым вариантам осуществления внутренние праймеры могут содержать область, которая конструируется для гибридизации или в 3'-5'-направлении, или в 5'-3'-направлении от целевого полиморфного локуса. Согласно некоторым вариантам осуществления праймеры могут содержать молекулярный штрихкод. Согласно некоторым вариантам осуществления праймер может содержать универсальную праймирующую последовательность, сконструированную для обеспечения ПЦР-амплификации.
Согласно варианту осуществления создается пул анализируемых фрагментов для 10000-плексной ПЦР, таким образом, что прямые и обратные праймеры имеют хвосты, соответствующие прямым и обратным последовательностям, необходимым для инструмента высокопроизводительного секвенирования, такого как HISEQ, GAIIX или MYSEQ, доступных от ILLUMINA. Кроме того, включенный в хвосты секвенирования 5'-конец представляет собой дополнительную последовательность, которая может быть использована в качестве праймирующего сайта в последующей ПЦР для добавления последовательностей нуклеотидов штрихкода к ампликонам, что обеспечивает возможность мультиплексного секвенирования множества образцов на одной дорожке инструмента высокопроизводительного секвенирования.
Согласно варианту осуществления создается пул анализируемых фрагментов для 10000-плексной ПЦР таким образом, что обратные праймеры имеют хвосты, соответствующие обратным последовательностям, необходимым для инструмента высокопроизводительного секвенирования. После амплификации в первом 10000-плексном анализе может быть выполнена последующая ПЦР-амплификация с использованием другого 10000-плексного пула, содержащего частично вложенные прямые праймеры (например, из 6 вложенных оснований) для всех целей и обратный праймер, соответствующий обратному хвосту секвенирования, включенный в первом раунде. Этот последующий раунд частично вложенной амплификации только с одним специфичным по отношению к цели праймером и универсальным праймером ограничивает необходимый размер анализируемого фрагмента, снижает шумовой сигнал, а также значительно уменьшает число побочных ампликонов. Хвосты секвенирования могут добавляться к присоединенным адаптерам лигирования и/или как часть зондов ПЦР так, что хвост является частью конечного ампликона.
Плодная фракция оказывает влияние на производительность теста. Существует ряд способов приумножения ДНК, обнаруженной в материнской плазме, плодной фракцией. Плодная фракция может быть увеличена уже обсуждаемым ранее способом LM-PCR, а также целевым удалением длинных материнских фрагментов. Согласно варианту осуществления перед мультиплексной ПЦР-амплификацией целевых локусов может быть проведена дополнительная мультиплексная ПЦР с целью селективного удаления длинных и в основном материнских фрагментов, соответствующих целевым локусам в последующей мультиплексной ПЦР. Конструируются дополнительные праймеры для отжига сайта, расположенного на большем расстоянии от полиморфизма, чем ожидается во фрагментах внеклеточной плодной ДНК. Такие праймеры могут быть использованы в одном цикле мультиплексной ПЦР до мультиплексной ПЦР целевых полиморфных локусов. Эти дистальные праймеры метятся молекулой или частью молекулы, которая может обеспечить селективное распознавание меченых кусочков ДНК. Согласно варианту осуществления эти молекулы ДНК могут быть ковалентно модифицированы молекулой биотина, которая обеспечивает удаление свежесформированной двухцепочечной ДНК, содержащей эти праймеры после одного цикла ПЦР. Двухцепочечная ДНК, сформированная во время первого раунда, скорее всего по происхождению является материнской. Удаление гибридного материала можно выполнить с использованием магнитных стрептавидиновых гранул. Существуют другие способы мечения, которые могут работать в равной степени хорошо. Согласно варианту осуществления для приумножения образца более короткими цепями ДНК, например, менее приблизительно 800 пар оснований, менее приблизительно 500 пар оснований или менее приблизительно 300 пар оснований, могут быть использованы способы отбора по размеру. После этого амплификацию коротких фрагментов можно проводить как обычно.
Описанный в настоящем раскрытии способ мини-ПЦР дает возможность высоко мультиплексной амплификации и анализа от сотен до тысяч или даже миллионов локусов в одной реакции из одного образца. В то же время выявление амплифицированной ДНК может быть мультиплексным; десятки и сотни образцов могут быть мультиплексированы на одной дорожке секвенирования с использованием ПЦР штрихкодирования. Такое мультиплексное выявление было успешно протестировано на примерах вплоть до 49-плексного, и возможна гораздо более высокая степень мультиплексирования. Фактически, это обеспечивает проведение генотипирования сотен образцов в тысячах SNP в одной серии секвенирования. Для этих образцов способ дает возможность определения генотипа и уровня гетерозиготности и одновременного определения числа копий, оба подхода могут быть использованы в целях выявления анеуплоидии. Этот способ особенно полезен при выявлении анеуплоидии вынашиваемого плода по анализу свободно плавающей ДНК, выделенной в материнской плазме. Этот способ может быть использован как часть способа установления пола плода и/или прогнозирования отцовства плода. Он может быть использован как часть способа установления дозы мутаций. Этот способ может быть использован для любого количества ДНК или РНК, и целевыми областями могут быть SNP, другие полиморфные области, неполиморфные области и их комбинации.
Согласно некоторым вариантам осуществления может быть использована опосредованная лигированием универсальная ПЦР-амплификация фрагментированной ДНК. Опосредованная лигированием универсальная ПЦР-амплификация может быть использована для амплификации ДНК плазмы, которая затем может быть поделена между множественными параллельными реакциями. Она также может быть использована для предпочтительной амплификации коротких фрагментов, то есть приумножения плодной фракцией. Согласно некоторым вариантам осуществления добавление маркеров к фрагментам посредством лигирования может дать возможность выявления более коротких фрагментов, использования порций специфичных по отношению к более коротким целевым последовательностям праймеров, и/или отжига при более высоких температурах, что снижает неспецифичные реакции.
Описанные в настоящем документе способы могут быть использованы для ряда целей, при этом имеется целевой набор ДНК, которая смешана с некоторым количеством загрязняющей ДНК. Согласно некоторым вариантам осуществления целевая ДНК и загрязняющая ДНК могут происходить от индивидуумов, связанных генетическим родством. Например, генетические аномалии плода (цели) могут быть выявлены из материнской плазмы, которая содержит плодную (целевую) ДНК, а также материнскую (загрязняющую) ДНК; аномалии включают в себя аномалии целых хромосом (например, анеуплоидию), аномалии части хромосом (например, делеции, дупликации, инверсии, транслокализации), полинуклеотидный полиморфизм (например, STR), однонуклеотидный полиморфизм и/или другие генетические аномалии или различия. Согласно некоторым вариантам осуществления целевая и загрязняющая ДНК могут происходить от одного и того же индивидуума, но при этом целевая и загрязняющая ДНК различаются одной или несколькими мутациями, например, в случае злокачественного заболевания (см., например, Н. Mamon et al. Preferential Amplification of Apoptotic DNA from Plasma: Potential for Enhancing Detection of Minor DNA Alterations in Circulating DNA. Clinical Chemistry 54:9 (2008)). Согласно некоторым вариантам осуществления ДНК может быть обнаружена в супернатанте культуры клеток (апоптических). Согласно некоторым вариантам осуществления можно индуцировать апоптоз в биологических образцах (например, крови) для последующего приготовления библиотеки, амплификации и/или секвенирования. В других разделах настоящего раскрытия представлен ряд технологических процессов и протоколов для достижения этой цели.
Согласно некоторым вариантам осуществления целевая ДНК может происходить из единичных клеток, из образцов ДНК, состоящих из менее одной копии целевого генома, из небольших количеств ДНК, из ДНК смешанного происхождения (например, из плазмы беременных: плацентарная и материнская ДНК; из плазмы и опухолей больных злокачественным заболеванием: смесь ДНК здоровых и раковых клеток, трансплантация и т.д.), из других жидкостей организма, из культур клеток, из супернатантов культур, из экспертных образцов ДНК, из древних образцов ДНК (например, насекомых в янтаре), из других образцов ДНК и их комбинаций.
Согласно некоторым вариантам осуществления может быть использован короткий ампликон. Аампликоны небольших размеров особенно подходят для фрагментированной ДНК (см., например, A. Sikora, et sl. Detection of increased amounts of cell-free fetal DNA with short PCR amplicons. Clin Chem. 2010 Jan; 56(1): 136-8).
Использование коротких ампликонов может дать некоторые существенные преимущества. Короткие ампликоны могут способствовать оптимизации эффективности амплификации. Короткие ампликоны, как правило, дают более короткие продукты, следовательно, меньше вероятность неспецифичного прайминга. Более короткие продукты могут быть более плотно сгруппированы в проточной ячейке секвенатора, поскольку кластеры будут меньше. Следует отметить, что описанные в настоящем документе способы могут в равной степени хорошо работать и с более длинными ПЦР-ампликонами. Длина ампликона при необходимости может быть увеличена, например, если секвенируются более длинные отрезки. Эксперименты с 146-плексной целевой амплификацией с анализируемыми фрагментами длиной от 100 пар оснований до 200 пар оснований на первом этапе протокола вложенной ПЦР были проведены на ДНК единичных клеток и на геномной ДНК с положительными результатами.
Согласно некоторым вариантам осуществления описанные в настоящем документе способы могут быть использованы для амплификации и/или определения SNP, числа копий, метилирования нуклеотидов, уровней мРНК, уровней экспрессии РНК других типов, других генетических и/или эпигенетических признаков. Описанные в настоящем документе способы мини-ПЦР могут быть использованы вместе с секвенированием следующего поколения; они могут быть использованы с другими способами 5'-3'-направления, такими как микроматрицы, подсчет способом цифровой ПЦР, ПЦР в реальном времени, масс-спектрометрия и т.д.
Согласно некоторым вариантам осуществления описанные в настоящем документе способы мини-ПЦР амплификации могут быть использованы как часть способа точного количественного определения минорных популяций. Он может быть использован для определения абсолютного количества с использованием пиковых калибраторов. Он может быть использован для количественного анализа мутантного/минорного аллеля посредством очень глубокого секвенирования и может выполняться по высоко мультиплексному типу. Он может быть использован для стандартного установления отцовства, родства и происхождения у человека, животных, растений или других существ. Он может быть использован для экспертного тестирования. Он может быть использован для быстрого генотипирования и анализа числа копий (CN) на материале любого типа, например, амниотической жидкости и CVS, сперме, продуктах оплодотворения (POC). Он может быть использован для анализа единичных клеток, такого как генотипирование образцов, взятых на биопсию из эмбрионов. Он может быть использован для быстрого анализа эмбрионов (в течение менее одного, одного или двух дней после биопсии) с помощью целевого секвенирования с использованием мини-ПЦР.
Согласно некоторым вариантам осуществления он может быть использован для анализа опухолей: в биоптатах опухолей часто присутствует смесь здоровых и опухолевых клеток. Целевая ПЦР дает возможность глубокого секвенирования SNP и локусов, близких к нефоновым последовательностям. Он может быть использован для определения числа копий и утраты гетерозиготности на опухолевой ДНК. Указанная опухолевая ДНК может присутствовать во многих различных жидкостях организма или тканях больных с опухолями. Он может быть использован для выявления рецидива опухолей и/или скрининга опухолей. Он может быть использован для контроля качества семян. Он может быть использован в селекции и рыбоводстве. Следует отметить, что любой из этих способов может быть в равной степени использован для нацеливания на неполиморфные локусы с целью установления плоидности.
Некоторые литературные источники, описывающие некоторые из фундаментальных способов, лежащих в основе раскрытых в настоящем документе способов, включают в себя: (1) Wang HY, Luo M, Tereshchenko IV, Frikker DM, Cui X, Li JY, Hu G, Chu Y, Azaro MA, Lin Y, Shen L, Yang Q, Kambouris ME, Gao R, Shih W, Li H. Genome Res. 2005 Feb; 15(2): 276-83. Department of Molecular Genetics, Microbiology and Immunology / The Cancer Institute of New Jersey, Robert Wood Johnson Medical School, New Brunswick, New Jersey 08903, USA; (2) High-throughput genotyping of single nucleotide polymorphisms with high sensitivity. Li H, Wang HY, Cui X, Luo M, Hu G, Greenawalt DM, Tereshchenko IV, Li JY, Chu Y, Gao R. Methods Mol Biol. 2007; 396 - PubMed PMID: 18025699; (3) A method comprising multiplexing of an average of 9 assays for sequencing is described in: Nested Patch PCR enables highly multiplexed mutation discovery in candidate genes. Varley KE, Mitra RD. Genome Res. 2008 Nov; 18(11): 1844-50; Epub 2008 Oct 10. Следует отметить, что раскрытые в настоящем документе способы дают возможность мультиплексирования более высоких порядков, чем описанные в вышеуказанных ссылках.
Конструирование праймеров
Высоко мультиплексная ПЦР может часто приводить к продуцированию очень высоких пропорций продуктов ДНК, получающихся в результате непродуктивных побочных реакций, таких как формирование димеров праймеров. Согласно варианту осуществления праймеры, которые с наибольшей вероятностью вызывают непродуктивные побочные реакции, могут быть удалены из библиотеки праймеров, результатом чего будет библиотека праймеров с большей пропорцией амплифицированной ДНК, картирующей геном. Этап удаление проблемных праймеров, т.е. тех праймеров, которые с повышенной вероятностью формируют димеры, неожиданно обеспечил возможность ПЦР с исключительно высокими уровнями мультиплексирования для последующего анализа секвенированием. В системах, таких как секвенирование, в которых производительность существенно ухудшается при наличии димеров праймеров и/или других вредных продуктов, было достигнуто мультиплексирование, превышающее в более 10, более 50 и более 100 раз мультиплексирование, описанное другими. Следует отметить, что это противопоставимо способам выявления, основанным на зондах, например, микроматрицам, TaqMan, ПЦР и т.д., при которых избыток димеров праймеров не оказывает значимого влияния на исход. Также следует отметить, что, как правило, в уровне техники предполагается, что мультиплексирование ПЦР для секвенирования ограничивается приблизительно 100 анализируемыми фрагментами в одной и той же лунке. Например, Fluidigm и Rain Dance предлагают платформы для выполнения ПЦР 48 или 1000 анализируемых фрагментов из одного образца в параллельных реакциях.
Существует ряд способов выбора праймеров для библиотеки, при которых количество некартирующих димеров праймеров или других вредных продуктов праймеров сводится к минимуму. Эмпирические данные указывают на то, что за большое количество побочных реакций с участием некартирующих димеров праймеров ответственно небольшое количество «плохих» праймеров. Удаление этих «плохих» праймеров может повысить процент считываний последовательностей, которые картируются с целевыми локусами. Одним из способов идентификации «плохих» праймеров является просмотр данных секвенирования ДНК, амплифицированной в ходе целевой амплификации; димеры праймеров, наблюдающиеся с наибольшей частотой, могут быть удалены с получением библиотеки праймеров, которая со значительно меньшей вероятностью вызовет образование побочных продуктов ДНК, которые не картируются с геномом. Существуют также общедоступные программы, которые могут рассчитать энергию связывания различных комбинаций праймеров, и удаление праймеров с самой высокой энергией связывания также даст библиотеку праймеров, которая со значительно меньшей вероятностью вызовет образование побочных продуктов ДНК, которые не картируются с геномом.
Мультиплексирование больших количеств праймеров налагает значительные ограничения на анализируемые фрагменты, которые могут быть включены в исследование. Анализируемые фрагменты, которые взаимодействуют случайным образом, приводят к образованию побочных продуктов амплификации. Ограничения размера для мини-ПЦР могут привести к дальнейшим ограничениям. Согласно варианту осуществления можно начать с очень большого числа потенциальных SNP-целей (от приблизительно 500 до более 1 миллиона) и попытаться сконструировать праймеры для амплификации каждого SNP. Если праймеры могут быть сконструированы, можно попытаться идентифицировать пары праймеров, которые с большой вероятностью будут способствовать формированию побочных продуктов, путем оценки правдоподобия формирования побочных дуплексов праймеров между всеми возможными парами праймеров с использованием опубликованных термодинамических параметров образования дуплексов ДНК. Взаимодействия праймеров можно ранжировать по функции оценивания, связанной с взаимодействием, и праймеры с худшими индексами взаимодействия элиминируются, пока не будет достигнуто желаемое число праймеров. В случаях, если SNP, гетерозиготные с большой вероятностью, наиболее полезны, возможно также ранжирование перечня анализируемых фрагментов и отбор наиболее гетерозиготных совместимых анализируемых фрагментов. Эксперименты подтвердили, что праймеры с высокими индексами взаимодействия с наибольшей вероятностью будут формировать димеры праймеров. При высоком уровне мультиплексирования невозможно элиминировать все побочные взаимодействия, однако важно удалить праймеры или пары праймеров с наиболее высокими индексами взаимодействия in silico, поскольку они могут доминировать во всей реакции, в значительной степени ограничивая амплификацию от намеченных целей. Такая процедура выполнялась авторами для создания мультиплексных наборов праймеров, включающих до 10000 праймеров. Улучшение, достигнутое благодаря этой процедуре, является значительным и дает возможность амплификации более 80%, более 90%, более 95%, более 98% и даже более 99% целевых продуктов, как было установлено путем секвенирования всех продуктов ПЦР, по сравнению с 10% после реакции, из которой худшие праймеры не были удалены. При комбинации с описанным ранее частичным полувложенным подходом более 90% и даже более 95% ампликонов могут быть картированы с целевыми последовательностями.
Следует отметить, что существуют другие способы выявления, какие зонды ПЦР вероятно будут формировать димеры. Согласно варианту осуществления анализа пула ДНК, которая была амплифицирована с использованием неоптимизированного набора праймеров, может быть достаточно для выявления проблематичных праймеров. Например, анализ может быть выполнен с использованием секвенирования, и те праймеры, чьи димеры присутствуют в наибольших количествах, считаются теми праймерами, которые с большой вероятностью будут формировать димеры и которые подлежат удалению.
Этот способ имеет ряд потенциальных применений, например, для генотипирования SNP, выявления степени гетерозиготности, измерения числа копий и других применений целевого секвенирования. Согласно варианту осуществления этот способ конструирования праймеров может быть использован в комбинации со способом мини-ПЦР, описанным в других разделах настоящего документа. Согласно некоторым вариантам осуществления этот способ конструирования праймеров может быть использован как часть массивного способа мультиплексной ПЦР.
Использование маркеров в праймерах может снизить амплификацию и секвенирование продуктов димеров праймеров. Маркированные праймеры могут быть использованы для укорачивания необходимой специфичной по отношению к цели последовательности до менее 20, менее 15, менее 12 и даже менее 10 пар оснований. При конструировании стандартных праймеров может случайно оказаться так, что целевая последовательность фрагментируется внутри сайта связывания праймера, или она может быть заложена в конструкцию праймера. Преимущества этого способа включают в себя повышение числа анализируемых фрагментов, которые могут быть сконструированы для ампликона определенной максимальной длины, и сокращение «неинформативного» секвенирования последовательностей праймеров. Он также может быть использован в комбинации с внутренним маркированием (см. другие разделы настоящего документа).
Согласно варианту осуществления относительное количество непродуктивных продуктов мультиплексной целевой ПЦР-амплификации может быть снижено путем повышения температуры отжига. В случаях амплификации библиотек с одинаковым маркером в специфичных по отношению к целям праймерах температуру отжига можно повысить по сравнению с температурой для геномной ДНК, поскольку маркеры будут способствовать связыванию праймеров. Согласно некоторым вариантам осуществления авторами использовались значительно более низкие концентрации праймеров, чем те, что указывались ранее, наряду с более длительным временем отжига, чем то, что упоминается в где-либо еще. Согласно некоторым вариантам осуществления время отжига может составлять больше 10 минут, больше 20 минут, больше 30 минут, больше 60 минут, больше 120 минут, больше 240 минут, больше 480 минут и даже больше 960 минут. Согласно варианту осуществления используется более длительное время отжига, чем в предыдущих сообщениях, что позволяет снизить концентрации праймеров. Согласно некоторым вариантам осуществления концентрация праймеров снижается до 50 нМ, 20 нМ, 10 нМ, 5 нМ, 1 нМ и менее 1 мкМ. Удивительно, результатом этого является полноценная производительность высоко мультиплексных реакций, например, 1000-плексных реакций, 2000-плексных реакций, 5000-плексных реакций, 10000-плексных реакций, 20000-плексных реакций, 50000-плексных реакций и даже 100000-плексных реакций. Согласно варианту осуществления при амплификации используются один, два, три, четыре или пять циклов, проводимых с длительным временем отжига с последующим циклами ПЦР с обычным временем отжига при использовании маркированных праймеров.
Отбор целевых локализаций можно начать с конструирования пула пар кандидатных праймеров и создания термодинамической модели потенциально неблагоприятных взаимодействий между парами праймеров, а затем использовать модель для элиминации конструкций, которые несовместимы с другими конструкциями в пуле.
Варианты целевой ПЦР-вложение
Существует много технологических процессов проведения ПЦР; описаны некоторые технологические процессы, типичные для раскрытых в настоящем документе способов. Указанные в настоящем документе этапы не означают исключения других возможных этапов и не подразумевают, что какой-либо из этапов, описанных в настоящем документе необходим для того, чтобы способ работал соответствующим образом. В литературе известен широкий ряд вариаций параметров или другие модификации, и они могут быть выполнены без затрагивания сущности настоящего изобретения. Один особенно обобщенный технологический процесс приведен ниже с последующим рядом возможных вариантов. Варианты, как правило, относятся к возможным вторичным реакциям ПЦР, например, к различным типам вложения, которые могут быть выполнены (этап 3). Важно отметить, что варианты могут быть выполнены в другое время или в другом порядке, чем то, как это описано в настоящем документе.
1. ДНК в образце может содержать адаптеры лигирования, часто упоминаемые как маркеры библиотеки или маркеры-адаптеры лигирования (LT), добавляемые в тех случаях, если адаптеры лигирования содержат универсальную праймирующую последовательность с последующей универсальной амплификацией. Согласно варианту осуществления это может быть выполнено с использованием стандартного протокола, разработанного для создания библиотек секвенирования после фрагментации. Согласно варианту осуществления образец ДНК может быть снабжен тупыми концами, и затем A может быть добавлен к 3'-концу. Y-адаптер с выступающим T может быть добавлен и лигирован. Согласно некоторым вариантам осуществления могут быть использованы другие липкие концы, отличные от выступающих A или Т. Согласно некоторым вариантам осуществления другие адаптеры могут быть добавлены, например, петлевые адаптеры лигирования. Согласно некоторым вариантам осуществления адаптеры могут содержать маркер, сконструированный для ПЦР-амплификации.
2. Специфичная амплификация целей (STA). Преамплификация сотен, тысяч, десятков тысяч и даже сотен тысяч целей может быть мультиплексирована в одной реакции. STA, как правило, проводится в ходе 10-30 циклов, хотя она может проводиться в ходе 5-40 циклов, в ходе 2-50 циклов и даже в ходе 1-100 циклов. Праймеры могут быть снабжены хвостами, например, для упрощения технологического процесса или для избегания секвенирования больших пропорций димеров. Следует отметить, что, как правило, димеры обоих праймеров, несущих одинаковый маркер не будут эффективно амплифицироваться или секвенироваться. Согласно некоторым вариантам осуществления может быть проведено от 1 до 10 циклов ПЦР; согласно некоторым вариантам осуществления может быть проведено от 10 до 20 циклов ПЦР; согласно некоторым вариантам осуществления может быть проведено от 20 до 30 циклов ПЦР; согласно некоторым вариантам осуществления может быть проведено от 30 до 40 циклов ПЦР; согласно некоторым вариантам осуществления может быть проведено более 40 циклов ПЦР. Амплификацией может быть линейной амплификацией. Число циклов ПЦР может быть оптимизировано для получения оптимального профиля глубины считывания (DOR). Различные профили DOR могут быть целесообразны для различных целей. Согласно некоторым вариантам осуществления целесообразно более равномерное распределение считываний между всеми анализируемыми фрагментами; если DOR слишком мала для некоторых анализируемых фрагментов, стохастический шум может быть слишком высок для того, чтобы данные были полезными, в то время как, если глубина считывания слишком высокая, пограничная полезность каждого дополнительного считывания относительно мала.
Хвосты праймеров могут улучшить выявление фрагментированной ДНК из универсально маркированных библиотек. Если маркер библиотеки и хвосты праймеров содержат гомологичную последовательность, гибридизация может быть улучшена (например, снижена температура плавления (TM)), а праймеры можно удлинить, если только часть целевой последовательности праймера находится во фрагменте ДНК образца. Согласно некоторым вариантам осуществления могут быть использованы 13 или больше пар оснований, специфичных по отношению к цели. Согласно некоторым вариантам осуществления могут быть использованы от 10 до 12 пар оснований, специфичных по отношению к цели. Согласно некоторым вариантам осуществления могут быть использованы от 8 до 9 пар оснований, специфичных по отношению к цели. Согласно некоторым вариантам осуществления могут быть использованы от 6 до 7 пар оснований, специфичных по отношению к цели. Согласно некоторым вариантам осуществления STA может быть выполнена на преамплифицированной ДНК, например. MDA, RCA, другие виды полногеномных амплификации или опосредованная адаптерами универсальная ПЦР. Согласно некоторым вариантам осуществления STA может быть выполнена на образцах и популяциях, приумноженных определенными последовательностями или истощенных по определенным последовательностям, например, путем отбора по размеру, целевого захвата, направленного разрушения.
3. Согласно некоторым вариантам осуществления возможно выполнение вторичных мультиплексных ПЦР или реакций удлинения праймеров для повышения специфичности и снижения количества нежелательных продуктов. Например, полное вложение, полувложение, гемивложение и/или разделение на меньшие пулы анализируемых фрагментов для параллельных реакций являются методиками, которые могут быть использованы для повышения специфичности. Эксперименты показали, что расщепление образца на три 400-плексные реакции приводит к образованию продукта ДНК с большей специфичностью, чем одна 1200-плексная реакция с такими же праймерами. Аналогично, эксперименты показали, что расщепление образца на четыре 2400-плексные реакции приводит к образованию продукта ДНК с большей специфичностью, чем одна 9600-плексная реакция с такими же праймерами. Согласно варианту осуществления возможно использование специфичных по отношению к целям и специфичных по отношению к маркерам праймеров одинаковой и противоположной направленностей.
4. Согласно некоторым вариантам осуществления можно амплифицировать образец ДНК (разведенный, очищенный или иным путем обработанный), полученный реакцией STA с использованием специфичных по отношению к маркеру праймеров и «универсальной амплификацией», т.е. амплифицировать многие или все преамплифицированные и маркированные цели. Праймеры могут содержать дополнительные функциональные последовательности, например, штрихкоды или полную адаптерную последовательность, необходимую для секвенирования на платформе высокопроизводительного секвенирования.
Эти способы могут быть использованы для анализа любого образца ДНК и особенно полезны, если образец ДНК особенно мал, или если это образец ДНК, в котором ДНК происходит от более одного индивидуума, например, в случае материнской плазмы. Эти способы могут быть использованы на образцах ДНК, таких как ДНК единичных клеток или небольшого количества клеток, геномная ДНК, ДНК плазмы, амплифицированные библиотеки плазмы, амплифицированные библиотеки апоптического супернатанта, или на других образцах смешанной ДНК. Согласно варианту осуществления эти способы могут быть использованы в случае, если у одного индивидуума присутствуют клетки различной генетической структуры, такие как раковые клетки или клетки трансплантатов.
Варианты протокола (варианты и/или добавления к описанному выше технологическому процессу)
Прямая мультиплексная мини-ПЦР. Специфичная целевая амплификация (STA) множества целевых последовательностей с маркированными праймерами показана на фиг.1. 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК с адаптерами лигирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК, которая была универсально амплифицирована гибридизованными праймерами ПЦР. 104 обозначает конечный продукт ПЦР. Согласно некоторым вариантам осуществления STA может быть выполнена на более 100, более 200, более 500, более 1000, более 2000, более 5000, более 10000, более 20000, более 50000, более 100000 или более 200000 целях. В последующей реакции специфичные по отношению к маркеру праймеры амплифицируют все целевые последовательности и удлиняют маркеры для включения всех необходимых последовательностей для секвенирования, включая индексы образца. Согласно варианту осуществления праймеры могут быть немаркированы, или только определенные праймеры могут быть маркированы. Адаптеры секвенирования могут быть добавлены посредством общепринятого лигирования адаптеров. Согласно варианту осуществления начальные праймеры могут нести маркеры.
Согласно варианту осуществления праймеры конструируются так, что длина амплифицированной ДНК является неожиданно короткой. В уровне техники было показано, что рядовые специалисты в данной области, как правило, конструируют ампликоны 100 + пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной менее 80 пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной менее 70 пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной менее 60 пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной менее 50 пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной менее 45 пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной менее 40 пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной менее 35 пар оснований. Согласно варианту осуществления ампликоны могут быть сконструированы длиной от 40 до 65 пар оснований.
Эксперимент был проведен согласно данному протоколу с использованием 1200-плексной амплификации. Были использованы как геномная ДНК, так и плазма беременной женщины; приблизительно 70% считываний последовательностей картировались с целевыми последовательностями. Подробности представлены в других разделах настоящего документа. Секвенирование продуктов 1042-плексной амплификации без дизайна и отбора анализируемых фрагментов приводило к тому, что >99% последовательностей являлись продуктами димеров праймеров.
Последовательная ПЦР. После STA1 множественные аликвоты продукта могут быть амплифицированы параллельно с пулами пониженной комплексности и теми же самыми праймерами. Первая амплификация может дать достаточно материала для расщепления. Этот способ особенно хорош для небольших образцов, например, таких, которые составляют приблизительно 6-100 пг, от приблизительно 100 пг до 1 нг, от приблизительно 1 нг до 10 нг или от приблизительно 10 нг до 100 нг. Протокол 1200-плексной амплификации был разделен на три 400-плексные. Картирование считываний последовательностей возросло от приблизительно 60-70% при 1200-плексной амплификации, выполненной монокомпонентно, до более 95%.
Полу вложенная мини-ПЦР (см. фиг.2). После STA 1 вторая STA проводится с мультиплексным набором внутренних вложенных прямых праймеров (103B, 105b) и одним (или несколькими) специфичным по отношению к маркеру обратным праймером (103A). 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК с адаптерами лигирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК, которая была универсально амплифицирована с прямым праймером B и гибридизированным обратным праймером A. 104 обозначает продукт ПЦР из 103. 105 обозначает продукт из 104 с гибридизированным вложенным прямым праймером В и обратного маркера A, который уже является частью молекулы из ПЦР, проведенной между 103 и 104. 106 обозначает конечный продукт ПЦР. При таком технологическом процессе обычно более 95% последовательностей картируются с намеченными целями. Вложенный праймер может перекрываться с последовательностью внешнего прямого праймера, но вводит дополнительные основания на 3'-конце. Согласно некоторым вариантам осуществления на 3'-конце можно использовать от одного до 20 дополнительных оснований. Эксперименты показали, что использование 9 или более дополнительных 3'-концевых оснований в 1200-плексном дизайне работает хорошо.
Полностью вложенная мини-ПЦР (см. фиг.3). После этапа 1 STA можно провести вторую мультиплексную ПЦР (или параллельные мультиплексные ПЦР пониженной комплексности) с двумя вложенными праймерами, несущими маркеры (A, a, B, b). 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК с адаптерами лигирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК, которая была универсально амплифицирована с прямым праймером B и гибридизированным обратным праймером A. 104 обозначает продукт ПЦР из 103. 105 обозначает продукт из 104 с вложенным прямым праймером b и гибридизированным вложенным обратным праймером a. 106 обозначает конечный продукт ПЦР. Согласно некоторым вариантам осуществления можно использовать два полных набора праймеров. Эксперименты с использованием протокола полностью вложенной мини-ПЦР были использованы для проведения 146-плексной амплификации на единичных клетках и трех клетках без этапа 102 добавления универсальных адаптеров лигирования и амплификации.
Гемивложенная мини-ПЦР (см. фиг.4). Можно использовать целевую ДНК, которая имеет адаптеры на концах фрагментов. STA выполняется с применением мультиплексного набора прямых праймеров (B) и одного (или нескольких) специфичного по отношению к маркеру обратного праймера (A). Вторая STA может быть выполнена с использованием универсального специфичного по отношению к маркеру прямого праймера и специфичного по отношению к целями обратного праймера. 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК с адаптерами лигирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК, которая была универсально амплифицирована с гибридизированным обратным праймером A. 104 обозначает продукт ПЦР из 103, который был амплифицирован с использованием обратного праймера A и праймера LT - маркера адаптера лигирования. 105 обозначает продукт из 104 с гибридизированным прямым праймером B. 106 обозначает конечный продукт ПЦР. При данном технологическом процессе специфичные по отношению к целям прямой и обратный праймеры используются в отдельных реакциях, что снижает, таким образом, комплексность реакции и предотвращает формирование димеров прямого и обратного праймеров. Следует отметить, что в данном примере праймеры A и B могут рассматриваться как первые праймеры, а праймеры «a» и «b» могут рассматриваться как внутренние праймеры. Этот способ представляет собой большое усовершенствование прямой ПЦР, поскольку он также хорош, как прямая ПЦР, но позволяет избежать образования димеров праймеров. После первого раунда гемивложенного протокола, как правило, наблюдается ~99% нецелевой ДНК, однако, после второго раунда, как правило, происходит большое улучшение.
Тройная гемивложенная мини-ПЦР (см. фиг.5). Можно использовать целевую ДНК, которая имеет адаптер на концах фрагментов. STA проводится с применением мультиплексного набора прямых праймеров (B) и одного или нескольких специфичных по отношению к маркеру обратных праймеров (A) и (a). Вторая STA может быть проведена с использованием универсального специфичного по отношению к маркеру прямого праймера и специфичного по отношению к целям обратного праймеров. 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК адаптерами дотирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК, которая была универсально амплифицирована с гибридизированным обратным праймером A. 104 обозначает продукт ПЦР из 103, который был амплифицирован с использованием обратного праймера A и праймера LT - маркера адаптера лигирования. 105 обозначает продукт из 104 с гибридизированным прямым праймером B. 106 обозначает продукт ПЦР из 105, который был амплифицирован с использованием обратного праймера A и прямого праймера B. 107 обозначает продукт из 106 с гибридизированным обратным праймером «a». 108 обозначает конечный продукт ПЦР. Следует отметить, что в данном примере праймеры «a» и B могут рассматриваться как внутренние праймеры, и A может рассматриваться как первый праймер. Необязательно и A, и B могут рассматриваться как первые праймеры, а «a» может рассматриваться как внутренний праймер. Обозначения обратного и прямого праймеров может поменяться местами. При данном технологическом процессе специфичные по отношению к целям прямой и обратный праймеры используются в отдельных реакциях, что снижает, таким образом, комплексность реакции и предотвращает формирование димеров прямого и обратного праймеров. Этот способ представляет собой большое усовершенствование прямой ПЦР, поскольку он также хорош, как прямая ПЦР, но позволяет избежать образования димеров праймеров. После первого раунда гемивложенного протокола, как правило, наблюдается ~99% нецелевой ДНК, однако, после второго раунда, как правило, происходит большое улучшение.
Односторонняя вложенная мини-ПЦР (см. фиг.6). Можно использовать целевую ДНК, которая имеет адаптер на концах фрагментов. STA также может быть проведена с мультиплексным набором вложенных прямых праймеров и с использованием маркера адаптера лигирования в качестве обратного праймера. Затем можно провести вторую STA с использованием набора вложенных прямых праймеров и универсального обратного праймера. 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК с адаптерами лигирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК, которая была универсальной амплифицирована с гибридизированным прямым праймером A. 104 обозначает продукт ПЦР из 103, который был амплифицирован с использованием прямого праймера A и обратного праймера LT - маркера адаптера лигирования. 105 обозначает продукт из 104 с гибридизированным вложенным прямым праймером a. 106 обозначает конечный продукт ПЦР. Этот способ выявляет более короткие целевые последовательности, чем стандартная ПЦР с использованием перекрывающихся праймеров в первой и второй STA. Способ, как правило, выполняется на образце ДНК, который уже был подвергнут описанному выше этапу 1 STA - добавлению универсальных маркеров и амплификации; два вложенных праймера находятся исключительно на одной стороне, на другой стороне используется маркер библиотеки. Способ выполнялся на библиотеках апоптических супернатантов и плазме беременных женщин. При данном технологическом процессе приблизительно 60% последовательностей картируются с намеченными целями. Следует отметить, что считывания, которые содержали последовательность обратного адаптера, не картировались, так что предполагается, что это количество будет выше, если считывания, содержащие последовательность обратного адаптера, будут картироваться.
Односторонняя мини-ПЦР. Можно использовать целевую ДНК, которая имеет адаптер на концах фрагментов (см. фиг.7). STA может быть проведена с мультиплексным набором прямых праймеров и одним (или несколькими) специфичным по отношению к маркеру обратным праймером. 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК с адаптерами лигирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК с гибридизированными прямыми праймерами A. 104 обозначает продукт ПЦР из 103, который был амплифицирован с использованием прямого праймера A и обратного праймера LT - маркера адаптера дотирования, и который является конечным продуктом ПЦР. Этот способ может выявить более короткие целевые последовательности, чем стандартная ПЦР. Однако он может быть относительно неспецифичным, поскольку используется только один специфичный по отношению к цели праймер. Данный протокол эффективен в качестве половины односторонней вложенной мини-ПЦР.
Обратная полу вложенная мини-ПЦР. Можно использовать целевую ДНК, которая имеет адаптер на концах фрагментов (см. фиг.8). STA может быть выполнена с мультиплексным набором прямых праймеров и одним (или несколькими) специфичным по отношению к маркеру обратным праймером. 101 обозначает двухцепочечную ДНК с исследуемым полиморфным локусом в X. 102 обозначает двухцепочечную ДНК с адаптерами лигирования, добавленными для универсальной амплификации. 103 обозначает одноцепочечную ДНК с гибридизированным обратным праймером B. 104 обозначает продукт ПЦР из 103, который был амплифицирован с использованием обратного праймера B и прямого праймера LT - маркера адаптера лигирования. 105 обозначает продукт ПЦР из 104 с гибридизированным прямым праймером A и внутренним обратным праймером «b». 106 обозначает продукт ПЦР, который был амплифицирован из 105 с использованием прямого праймера A и обратного праймера «b» и который является конечным продуктом ПЦР. Данный способ может выявить более короткие целевые последовательности, чем стандартная ПЦР.
Может также существовать больше вариантов, которые просто являются повторами или комбинациями вышеописанных способов, таких как двойная вложенная ПЦР, в которой используются три набора праймеров. Другой вариант - это полуторосторонняя вложенная мини-ПЦР, в которой STA также может быть выполнена с мультиплексным набором вложенных прямых праймеров и одного (или нескольких) специфичных по отношению к маркеру обратного праймера.
Следует отметить, что во всех этих вариантах идентичность прямого праймера и обратного праймера может быть взаимно изменена. Следует отметить, что согласно некоторым вариантам осуществления вложенный вариант может быть в равной степени хорошо проведен без начального приготовления библиотеки, предусматривающего добавление маркеров адаптера, и этапа универсальной амплификации. Следует отметить, что согласно некоторым вариантам осуществления могут быть предусмотрены дополнительные раунды ПЦР с дополнительными прямыми и/или обратными праймерами и этапами амплификации; эти дополнительные этапы могут быть особенно полезны, если желательно повысить процент молекул ДНК, соответствующих целевым локусам.
Вложенные технологические процессы
Существует много способов выполнения амплификации с различной степенью вложения и с различной степенью мультиплексирования. На фиг.9 представлена схема технологических операций с некоторыми возможными технологическими процессами. Следует отметить, что использование 10000-плексной ПЦР приведено только в качестве примера; такие схемы технологических операций будут работать в равной степени хорошо для других степеней мультиплексирования.
Петлевые адаптеры лигирования
При добавлении универсальных маркированных адаптеров, например, с целью получения библиотеки для секвенирования, существует ряд способов лигирования адаптеров. Один способ заключается в том, чтобы снабдить ДНК образца тупыми концами, присоединить A-хвост и лигировать адаптеры, которые имеют выступающий T-конец. Существует ряд других способов лигировать адаптеры. Существует также ряд адаптеров, которые могут быть лигированы. Например, Y-адаптер может быть использован, когда адаптер состоит из двух цепочек ДНК, в которых одна цепочка имеет двухцепочечную область и область, обозначенную областью прямого праймера, и в которых другая цепочка, обозначена двухцепочечной областью, которая комплементарна двухцепочечной области первой цепочки, и областью с обратным праймером. Двухцепочечные области при отжиге могут содержать выступающий T-конец для целей лигирования с двухцепочечной ДНК с выступающим A-концом.
Согласно варианту осуществления адаптер может быть петлей ДНК, в которой концевые области комплементарны, и в которой петлевая область содержит маркированную область прямого праймера (LFT), маркированную область обратного праймера (LRT) и сайт расщепления между ними (см. фиг.10). 101 относится к двухцепочечной целевой ДНК с тупыми концами. 102 относится к целевой ДНК с A-хвостом. 103 относится к петлевому адаптеру лигирования с выступающим T-концом «T» и сайтом расщепления «Z». 104 относится к целевой ДНК с добавленными петлевыми адаптерами лигирования. 105 относится к целевой ДНК с добавленными адаптерами лигирования, расщепленными в сайте расщепления. LFT относится к прямому маркеру адаптера лигирования, а LRT относится к обратному маркеру адаптера лигирования. Комплементарная область может заканчиваться на выступающем T-конце или на других структурах, которые могут использоваться для лигирования с целевой ДНК. Сайт расщепления может быть серией урацилов для расщепления UNG или последовательностью, которая может быть распознана и расщеплена ферментом рестрикции или другим способом расщепления, или просто базовой амплификацией. Такие адаптеры могут быть использованы для приготовления любых библиотек, например, для секвенирования. Эти адаптеры могут быть использованы в комбинации с любыми другими описанными в настоящем документе способами, например, со способами амплификации мини-ПЦР.
Внутренне маркированные праймеры
При использовании секвенирования для определения аллеля, присутствующего в данном полиморфном локусе, считывание последовательности, как правило, начинается в 3'-5'-направлении от связывающего сайта праймера (a), а затем продолжается до полиморфного сайта (X). Маркеры, как правило, скомпонованы, как показано на фиг.11 слева. 101 относится к одноцепочечной целевой ДНК с исследуемым полиморфным локусом в «X» и праймером «a» с добавленным маркером «b». Чтобы избежать неспецифичной гибридизации, связывающий сайт праймера (область целевой ДНК, комплементарная «a»), как правило, состоит из 18-30 пар оснований. Последовательность маркера «b» составляет, как правило, приблизительно 20 пар оснований; теоретически они могут быть длиннее приблизительно 15 пар оснований, хотя многие пользуются последовательностями праймеров, которые продаются компаниями, выпускающими платформы секвенирования. Расстояние «d» между «a» и «X» может составлять по меньшей мере 2 пары оснований с тем, чтобы избежать систематической ошибки подсчета числа аллелей. При выполнении мультиплексной ПЦР-амплификации с использованием раскрытых в настоящем документе способов или других способов, когда необходим тщательный дизайн праймеров для того, чтобы избежать избыточного взаимодействия между праймерами, окно допустимых расстояний «d» между «a» и «X» может достаточно сильно варьировать: от 2 пар оснований до 10 пар оснований, от 2 пар оснований до 20 пар оснований, от 2 пар оснований до 30 пар оснований или даже от 2 пар оснований до более 30 пар оснований. Следовательно, при использовании конфигурации праймеров, показанной на фиг.11 слева, считывание последовательностей должно составлять минимум 40 пар оснований для получения считываний, достаточно длинных для измерения полиморфного локуса, и в зависимости от длин «a» и «d» может потребоваться увеличение считываний последовательностей до 60 или 75 пар оснований. Как правило, чем длиннее считывания последовательностей, тем выше стоимость и больше время секвенирования данного числа считываний, следовательно, минимизация необходимой длины считывания может сберечь как время, так и деньги. Кроме того, поскольку в среднем основания, которые считываются в начале считывания более точные, чем основания, которые считываются позже, уменьшение необходимой длины считывания последовательности может также увеличить точность измерений полиморфной области.
Согласно варианту осуществления, называемом внутреннее маркированные праймеры, связывающий сайт праймера (a) расщепляется на множество сегментов (a', a'', a''' …), а маркер последовательности (b) локализован в сегменте ДНК, который находится посредине между двумя связывающими сайтами праймера, как показано на фиг.11, 103. Такая конфигурация позволяет секвенатору выполнять более короткие считывания последовательностей. Согласно варианту осуществления a'+a'' должно составлять по меньшей мере приблизительно 18 пар оснований и может составлять 30, 40, 50, 60, 80, 100 или более 100 пар оснований. Согласно варианту осуществления a'' должен составлять по меньшей мере приблизительно 6 пар оснований и согласно варианту осуществления он составляет от приблизительно 8 до 16 пар оснований. При равноценности всех прочих факторов использование внутренне маркированных праймеров может сократить необходимую длину считывания последовательностей по меньшей мере на 6 пар оснований, не менее чем на 8 пар оснований, 10 пар оснований, 12 пар оснований, 15 пар оснований и даже 20 или 30 пар оснований. Это может дать существенное преимущество в стоимости, времени и точности. Пример внутренне маркированных праймеров представлен на фиг.12.
Праймеры с областью, связывающей адаптеры лигирования
Одна из проблем с фрагментированной ДНК состоит в том, что поскольку фрагменты короткие, вероятность того, что полиморфизм расположен близко к концу цепи ДНК, выше, чем для длинной цепи (например, 101, фиг.10). Поскольку захват ПЦР полиморфизма требует, чтобы связывающий сайт праймера имел приемлемую длину по обе стороны от полиморфизма, значительное число цепей ДНК с целевым полиморфизмом будет пропущено вследствие недостаточного перекрытия между праймером и целевым связывающим сайтом. Согласно варианту осуществления целевая ДНК 101 может содержать присоединенные адаптеры лигирования 102, а целевой праймер 103 может содержать область (cr), комплементарную маркеру адаптера лигирования (lt), присоединенному в 3'-5'-направлении от предназначенной области связывания (a) (см. фиг.13); таким образом, в случаях, если связывающая область (область 101, которая комплементарна а) короче 18 пар оснований, как правило, требуемых для гибридизации, область (cr) в праймере, которая комплементарна маркеру библиотеки, способна увеличить энергию связывания до точки, при которой ПЦР может продолжаться. Следует отметить, что любая специфичность, которая утрачивается из-за более короткой связывающей области, может быть достигнута для других праймеров ПЦР с надлежаще длинными целевыми связывающими областями. Следует отметить, что этот вариант осуществления может быть использован в комбинации с прямой ПЦР или любыми другими описанными в настоящем документе способами, такими как вложенная ПЦР, полувложенная ПЦР, гемивложенная ПЦР, односторонняя вложенная или полу-, или гемивложенная ПЦР, или другими протоколами ПЦР.
При использовании данных секвенирования для определения плоидности в комбинации с аналитическим способом, который предусматривает сравнение наблюдаемых данных аллелей с ожидаемыми аллельными распределениями для различных гипотез, каждое дополнительное считывание с аллелей с низкой глубиной считывания даст больше информации, чем считывание с аллеля с большой глубиной считывания. Следовательно, в идеале, нужно добиваться однородной глубины считывания (DOR), при которой каждый локус будет иметь сходные количества репрезентативных считываний последовательности. Следовательно, желательно минимизировать дисперсию DOR. Согласно варианту осуществления можно понизить коэффициент дисперсии DOR (который может быть определен как стандартное отклонение DOR / среднее значение DOR) путем увеличения времени отжига. Согласно некоторым вариантам осуществления время отжига может составлять более 2 минут, более 4 минут, более 10 минут, более 30 минут и более одного часа или даже еще больше. Поскольку отжиг представляет собой равновесный процесс, не существует предела для улучшения дисперсии DOR путем увеличения времени отжига. Согласно варианту осуществления повышение концентрация праймеров может снизить дисперсию DOR.
Диагностический бокс
Согласно варианту осуществления настоящее раскрытие предусматривает диагностический бокс, выполненный с возможностью частичного или осуществления видов способов, описанных в настоящем раскрытии. Согласно варианту осуществления диагностический бокс может быть размещен в кабинете врача, в лаборатории больницы или в любом приемлемом месте, разумно близком к пункту наблюдения за пациентом. С помощью бокса виды способа могут быть полностью автоматизированы, или в боксе может потребоваться выполнение одного или ряда этапов вручную лаборантом. Согласно варианту осуществления бокс может предоставлять возможность анализировать генотипические данные, измеренные на материнской плазме. Согласно варианту осуществления бокс может быть связан со средствами передачи измеренных диагностическим боксом генотипических данных во внешний вычислительный центр, который затем может анализировать генотипические данные и, возможно, также создавать отчет. В диагностическом боксе может содержаться роботизированный модуль, который способен перемещать водные или жидкие образцы из одного контейнера в другой. В нем может содержаться ряд реагентов, как твердых, так и жидких. В нем может содержаться высокопроизводительный секвенатор. В нем может содержаться компьютер.
Набор праймеров
Согласно некоторым вариантам осуществления набор может быть составлен с содержанием множества праймеров, сконструированных для реализации описанных в настоящем раскрытии способов. Праймеры могут быть внешними прямыми и обратными праймерами, внутренними прямыми и обратными праймерами, как раскрыто в настоящем документе, они могут быть праймерами, которые были сконструированы с низкой связывающей аффинностью по отношению к другим праймерам в наборе, как раскрыто в разделе по конструированию праймеров, они могут быть зондами гибридного захвата или предварительно циркуляризованными зондами, как описано в соответствующих разделах, или некоторой комбинацией таковых. Согласно варианту осуществления набор может быть составлен для определения статуса плоидности целевой хромосомы у вынашиваемого плода, разработанный для использования в раскрытых в настоящем документе способах набор содержит множество внутренних прямых праймеров и необязательно множество внутренних обратных праймеров, а также необязательно внешние прямые праймеры и внешние обратные праймеры, при этом каждый из праймеров конструируется для гибридизации с областью ДНК непосредственно в 3'-5'-направлении и/или в 5'-3'-направлении от одного из полиморфных сайтов целевой хромосомы и необязательно дополнительных хромосом. Согласно варианту осуществления набор праймеров может быть использован в комбинации с описанным в другом разделе настоящего документа диагностическим боксом.
Состав ДНК
При выполнении анализа, основанного на методах информатики, данных секвенирования, измеренных в смеси плодной и материнской крови для выявления геномной информации, принадлежащей плоду, например, состояния плоидности плода, может быть эффективно измерение аллельных распределений в наборе аллелей. К сожалению, во многих случаях, таких как попытка определения состояния плоидности плода по смеси ДНК, обнаруженной в образце плазмы крови матери, количество доступной ДНК недостаточно для непосредственного измерения аллельных распределений в смеси с хорошей точностью воспроизведения. В этих случаях амплификация смеси ДНК предоставит достаточное количество молекул ДНК, при котором намеченные аллельные распределения могут быть измерены с хорошей точностью воспроизведения. Однако современные способы амплификации, как правило, используемые для амплификации ДНК для секвенирования, очень часто дают стандартную ошибку подсчета, означающую, что они не амплифицируют оба аллеля полиморфного локуса в одинаковых количествах. Амплификация со стандартной ошибкой может привести к тому, что аллельные распределения будут существенно отличаться от аллельных распределений в оригинальной смеси. Для большинства целей нет необходимости в высокоточных измерениях относительных количеств аллелей, присутствующих в полиморфных локусах. Напротив, согласно варианту осуществления настоящего раскрытия являются эффективными амплификация или способы приумножения, которые специфично приумножают полиморфными аллелями и сохраняют аллельные отношения.
в настоящем документе описан ряд способов, которые могут быть использованы для предпочтительного приумножения образца ДНК по множеству локусов таким образом, что систематическая ошибка подсчета числа аллелей будет сведена к минимуму. В некоторых примерах используются зонды циркуляризации для нацеливания на множество локусов, при этом 3'-концы и 5'-концы предварительно циркуляризованных зондов сконструированы для гибридизации с основаниями, которые расположены на расстоянии одного или нескольких положений от полиморфных сайтов целевого аллеля. Другой пример заключается в использовании зондов ПЦР, в которых 3'-конец зонда ПЦР конструируется для гибридизации с основаниями, которые расположены на расстоянии одного или нескольких положений от полиморфных сайтов целевого аллеля. Другой пример заключается в использовании подхода расщепления и объединения для создания смесей ДНК, в которых предпочтительно приумноженные локусы приумножены с низкой систематической ошибкой подсчета числа аллелей без недостатков прямого мультиплексирования. Другой пример заключается в использовании подхода гибридного захвата, при котором зонды захвата сконструированы так, что область зонда захвата, которая конструируется для гибридизации с ДНК, фланкирующей полиморфный сайт цели, отделяется от полиморфного сайта одним или небольшим количеством оснований.
В случае, когда измеренные аллельные распределения в наборе полиморфных локусов используется для определения состояния плоидности индивидуума, желательно сохранить относительные количества аллелей в образце ДНК в процессе его подготовки для генетических измерений. Такое приготовление может предусматривать амплификацию WGA, целевую амплификацию, методики селективного приумножения, методики гибридного захвата, зонды циркуляризации или другие способы, предназначенные для амплификации количества ДНК и/или селективного увеличения числа молекул ДНК, которые соответствуют определенным аллелям.
Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается набор ДНК-зондов, сконструированных для нацеливания на локусы, которые имеют максимальные частоты минорных аллелей. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается набор зондов, которые сконструированы для нацеливания на области, где локусы характеризуются максимальным правдоподобием того, что плод имеет высокоинформативный SNP в этих локусах. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается набор зондов, которые сконструированы для нацеливания на локусы, при этом зонды оптимизированы для данной подгруппы популяции. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается набор зондов, которые сконструированы для нацеливания на локусы, при этом зонды оптимизированы для данной смеси подгрупп популяции. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается набор зондов, которые сконструированы для нацеливания на локусы, при этом зонды оптимизированы для данной пары родителей, происходящих из различных подгрупп популяции, которые характеризуются различными профилями частот минорных аллелей. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается циркуляризованная цепь ДНК, которая содержит по меньшей мере одну пару оснований, которая отжигается с фрагментом ДНК плодного происхождения. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается циркуляризованная цепь ДНК, которая содержит по меньшей мере одну пару оснований, которая отжигается с фрагментом ДНК плацентарного происхождения. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается циркуляризованная цепь ДНК, которая циркуляризована, в то время как по меньшей мере некоторые из нуклеотидов отжигаются с ДНК плодного происхождения. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается циркуляризованная цепь ДНК, которая циркуляризована, в то время как по меньшей мере некоторые из нуклеотидов отжигаются с ДНК плацентарного происхождения. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается набор зондов, в котором некоторые из зондов нацелены на единичные тандемные повторы, и некоторые из зондов нацелены на единичные нуклеотидные полиморфизмы. Согласно некоторым вариантам осуществления локусы отбираются в целях неинвазивной пренатальной диагностики. Согласно некоторым вариантам осуществления зонды используются в целях неинвазивной пренатальной диагностики. Согласно некоторым вариантам осуществления на локусы нацеливаются с использованием способа, который может предусматривать зонды циркуляризации, MIP, захват зондами гибридизации, зонды на матрице SNP или их комбинации. Согласно некоторым вариантам осуществления зонды используются в качестве зондов циркуляризации, MIP, захвата зондами гибридизации, зондов на матрицу SNP или их комбинаций. Согласно некоторым вариантам осуществления локусы секвенируются в целях неинвазивной пренатальной диагностики.
В случае, когда относительная информативность последовательности выше при комбинировании с соответствующими родительскими контекстами, доведение до максимума числа считываний последовательностей, которые содержат SNP с известным родительским контекстом, может дать максимальную информативность набора считываний последовательностей в смешанном образце. Согласно варианту осуществления число считываний последовательностей, которые содержат SNP с известными родительскими контекстами, может быть увеличено использованием количественной ПЦР для предпочтительной амплификации специфичных последовательностей. Согласно варианту осуществления число считываний последовательностей, которые содержат SNP с известными родительскими контекстами, может быть увеличено с использованием зондов циркуляризации (например, MIP) для предпочтительной амплификации специфичных последовательностей. Согласно варианту осуществления число считываний последовательностей, которые содержат SNP с известными родительскими контекстами, может быть увеличено методом захвата гибридизацией (например, SURESELECT) для предпочтительной амплификации специфичных последовательностей. Различные способы могут быть использованы для увеличения числа считываний последовательностей, которые содержат SNP с известными родительскими контекстами. Согласно варианту осуществления нацеливание может быть выполнено лигированием удлинения, лигированием без удлинения, захватом гибридизацией или ПЦР.
В образце фрагментированной геномной ДНК фракция последовательностей ДНК уникально картируется с индивидуальными хромосомами; другие последовательности ДНК могут быть обнаружены в различных хромосомах. Следует отметить, что ДНК, обнаруживаемая в плазме, как материнской, так и плодной по происхождению, как правило, фрагментирована, часто длиной до 500 пар оснований. В типичном геномном образце приблизительно 3,3% картируемых последовательностей будут картироваться с хромосомой 13; 2,2% картируемых последовательностей будут картироваться с хромосомой 18; 1,35% картируемых последовательностей будут картироваться с хромосомой 21; 4,5% картируемых последовательностей будут картироваться с хромосомой X у женщин; 2,25% картируемых последовательностей будут картироваться с хромосомой X (у мужчин); и 0,73% картируемых последовательностей будут картироваться с хромосомой Y (у мужчин). Эти хромосомы у плода, по всей вероятности, анеуплоидны. Также, среди коротких последовательностей приблизительно 1 из 20 последовательностей будет содержать SNP при использовании SNP, содержащихся в dbSNP. С учетом того, что многие SNP еще не открыты, эта пропорция может быть намного выше.
Согласно варианту осуществления настоящего раскрытия способы нацеливания могут быть использованы для увеличения фракции ДНК в образце ДНК, которая картируется с данной хромосомой, так, что эта фракция значительно превосходит приведенные выше процентные отношения, которые типичны для геномных образцов. Согласно варианту осуществления настоящего раскрытия способы нацеливания могут быть использованы для увеличения фракции ДНК в образце ДНК так, что процентное отношение последовательностей, которые содержат SNP, значительно больше тех, что могут быть обнаружены в типичных для геномных образцов. Согласно варианту осуществления настоящего раскрытия способы нацеливания могут быть использованы для нацеливания на ДНК хромосомы или набора SNP в смеси материнской и плодной ДНК в целях пренатальной диагностики.
Следует отметить, что сообщалось о способе (патент США №7888017) определения анеуплоидии плода путем подсчета числа считываний, которые картируются с подозрительной хромосомой, и сравнения их с числом считываний, которые картируются с эталонной хромосомой, и использования предположения о том, что избыточное количество считываний в подозрительной хромосоме соответствует триплоидности плода по этой хромосоме. В этих способах пренатальной диагностики не используется нацеливание какого-либо вида, и не описывается использование нацеливания для пренатальной диагностики.
Путем использования подходов нацеливания при секвенировании смешанного образца можно достичь определенного уровня точности с меньшим числом считываний последовательностей. Точность может относиться к чувствительности, она может относиться к специфичности или она может относиться к их комбинациям. Желаемый уровень точности может составлять от 90% до 95%; он может составлять от 95% до 98%; он может составлять от 98% до 99%; он может составлять от 99% до 99,5%; он может составлять от 99,5% до 99,9%; он может составлять от 99,9% до 99,99%; он может составлять от 99,99% до 99,999%, он может составлять от 99,999% до 100%. Уровни точности выше 95% могут считаться высокой точностью.
В уровне техники уже известен ряд опубликованных способов, которые демонстрируют, как можно определить состояние плоидности плода по смешанному образцу материнской и плодной ДНК, например, G.J. W. Liao et al. Clinical Chemistry 2011; 57(1) pp.92-101. Эти способы фокусируются на тысячах локализаций в каждой хромосоме. Число локализаций в хромосоме, которые могут служить целями, хотя и дает высокую точность определения плоидности плода, для данного числа считываний последовательностей из смешанного образца ДНК является неожиданно низким. Согласно варианту осуществления настоящего раскрытия точное определение плоидности может быть выполнено с помощью целевого секвенирования с использованием любого способа нацеливания, например, количественной ПЦР, опосредованной лигандом ПЦР, других методов ПЦР, захвата гибридизацией или зондами циркуляризации, при котором число локусов в хромосоме, необходимых для нацеливания, может составлять от 5000 до 2000 локусов; оно может составлять от 2000 до 1000 локусов; оно может составлять от 1000 до 500 локусов; оно может составлять от 500 до 300 локусов; оно может составлять от 300 до 200 локусов; оно может составлять от 200 до 150 локусов; оно может составлять от 150 до 100 локусов; оно может составлять от 100 до 50 локусов; оно может составлять от 50 до 20 локусов; оно может составлять от 20 до 10 локусов. Оптимально оно может составлять от 100 до 500 локусов. Высокий уровень точности может быть достигнут путем нацеливания на небольшое количество локусов и выполнения неожиданно небольшого числа считываний последовательностей. Число считываний может составлять от 100 миллионов до 50 миллионов считываний; число считываний может составлять от 50 миллионов до 20 миллионов считываний; число считываний может составлять от 20 миллионов до 10 миллионов считываний; число считываний может составлять от 10 миллионов до 5 миллионов считываний; число считываний может составлять от 5 миллионов до 2 миллионов считываний; число считываний может составлять от 2 миллионов до 1 миллиона; число считываний может составлять от 1 миллиона до 500000; число считываний может составлять от 500000 до 200000; число считываний может составлять от 200000 до 100000; число считываний может составлять от 100000 до 50000; число считываний может составлять от 50000 до 20000; число считываний может составлять от 20000 до 10000; число считываний может быть меньше 10000. Меньшее число считываний требуется для больших количеств вводимой ДНК.
Согласно некоторым вариантам осуществления предусматривается состав, содержащий смесь ДНК плодного происхождения и ДНК материнского происхождения, в котором процент последовательностей, уникально картирующихся с хромосомой 13 составляет более 4%, более 5%, более 6%, более 7%, более 8%, более 9%, более 10%, более 12%, более 15%, более 20%, более 25% или более 30%. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается состав, содержащий смесь ДНК плодного происхождения и ДНК материнского происхождения, в котором процент последовательностей, уникально картирующихся с хромосомой 18 составляет более 3%, более 4%, более 5%, более 6%, более 7%, более 8%, более 9%, более 10%, более 12%, более 15%, более 20%, более 25% или более 30%. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается состав, содержащий смесь ДНК плодного происхождения и ДНК материнского происхождения, в котором процент последовательностей, уникально картирующихся с хромосомой 21 составляет более 2%, более 3%, более 4%, более 5%, более 6%, более 7%, более 8%, более 9%, более 10%, более 12%, более 15%, более 20%, более 25% или более 30%. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается состав, содержащий смесь ДНК плодного происхождения и ДНК материнского происхождения, в котором процент последовательностей, уникально картирующихся с хромосомой X составляет более 6%, более 7%, более 8%, более 9%, более 10%, более 12%, более 15%, более 20%, более 25% или более 30%. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается состав, содержащий смесь ДНК плодного происхождения и ДНК материнского происхождения, в котором процент последовательностей, уникально картирующихся с хромосомой Y составляет более 1%, более 2%, более 3%, более 4%, более 5%, более 6%, более 7%, более 8%, более 9%, более 10%, более 12%, более 15%, более 20%, более 25% или более 30%.
Согласно некоторым вариантам осуществления описывается состав, содержащий ДНК плодного происхождения и ДНК материнского происхождения, в котором процент последовательностей, уникально картирующихся с хромосомой и содержащих по меньшей мере один однонуклеотидный полиморфизм, составляет более 0,2%, более 0,3%, более 0,4%, более 0,5%, более 0,6%, более 0,7%, более 0,8%, более 0,9%, более 1%, более 1,2%, более 1,4%, более 1,6%, более 1,8%, более 2%, более 2.5%, более 3%, более 4%, более 5%, более 6%, более 7%, более 8%, более 9%, более 10%, более 12%, более 15% или более 20%, и в котором хромосома выбрана из группы хромосом 13, 18, 21, X или Y. Согласно некоторым вариантам осуществления настоящего раскрытия предусматривается состав, содержащий ДНК плодного происхождения и ДНК материнского происхождения, в котором процент последовательностей, уникально картирующихся с хромосомой и содержащих по меньшей мере один однонуклеотидный полиморфизм из набора однонуклеотидных полиморфизмов, составляет более 0,15%, более 0,2%, более 0,3%, более 0,4%, более 0,5%, более 0,6%, более 0,7%, более 0,8%, более 0,9%, более 1%, более 1,2%, более 1,4%, более 1,6%, более 1,8%, более 2%, более 2,5%, более 3%, более 4%, более 5%, более 6%, более 7%, более 8%, более 9%, более 10%, более 12%, более 15% или более 20%, в котором хромосома выбрана из набора хромосом 13, 18, 21, X и Y, и в котором число однонуклеотидных полиморфизмов в наборе однонуклеотидных полиморфизмов составляет от 1 до 10, от 10 до 20, от 20 до 50, от 50 до 100, от 100 до 200, от 200 до 500, от 500 до 1000, от 1000 до 2000, от 2000 до 5000, от 5000 до 10000, от 10000 до 20000, от 20000 до 50000 и от 50000 до 100000.
Теоретически каждый цикл амплификации удваивает количество присутствующей ДНК; однако в реальности степень амплификации несколько ниже, чем два. Теоретически амплификация, в том числе целевая амплификация, приведет к стандартной ошибке свободной амплификации смеси ДНК; в реальности, однако, различные аллели имеют тенденцию амплифицироваться с различной степенью. При амплификации ДНК степень систематической ошибки подсчета числа аллелей, как правило, возрастает с числом этапов амплификации. Согласно некоторым вариантам осуществления описанные в настоящем документе способы предусматривают амплификацию ДНК с низким уровнем систематической ошибки подсчета числа аллелей. Поскольку систематическая ошибка подсчета числа аллелей усугубляется с каждым дополнительным циклом, путем вычислений корня n-ой степени общей стандартной ошибки, где n представляет собой основание логарифма 2 степени приумножения, можно определить систематическую ошибку подсчета числа аллелей на цикл. Согласно некоторым вариантам осуществления предусматривается состав, содержащий вторую смесь ДНК, в котором вторая смесь ДНК была предпочтительно приумножена множеством полиморфных локусов из первой смеси ДНК, в котором степень приумножения составляет по меньшей мере 10, по меньшей мере 100, по меньшей мере 1000, по меньшей мере 10000, по меньшей мере 100000 или по меньшей мере 1000000, и в котором отношение аллелей во второй смеси ДНК в каждом локусе отличается от отношения аллелей в данном локусе в первой смеси ДНК фактором, составляющим в среднем менее 1000%, 500%, 200%, 100%, 50%, 20%, 10%, 5%, 2%, 1%, 0,5%, 0,2%, 0,1%, 0,05%, 0,02% или 0,01%. Согласно некоторым вариантам осуществления предусматривается состав, содержащий вторую смесь ДНК, в котором вторая смесь ДНК была предпочтительно приумножена множеством полиморфных локусов из первой смеси ДНК, в котором систематическая ошибка подсчета числа аллелей на цикл для множества полиморфных локусов составляет в среднем менее 10%, 5%, 2%, 1%, 0,5%, 0,2%, 0,1%, 0,05% или 0,02%. Согласно некоторым вариантам осуществления множество полиморфных локусов содержит по меньшей мере 10 локусов, по меньшей мере 20 локусов, по меньшей мере 50 локусов, по меньшей мере 100 локусов, по меньшей мере 200 локусов, по меньшей мере 500 локусов, по меньшей мере 1000 локусов, по меньшей мере 2000 локусов, по меньшей мере 5000 локусов, по меньшей мере 10000 локусов, по меньшей мере 20000 локусов или по меньшей мере 50000 локусов.
Оценки, полученные с использованием способа максимального правдоподобия
Большинство известных в уровне техники способов определения присутствия или отсутствия биологического явления или медицинского состояния включают применение теста отклонения одной гипотезы, при котором измеряют показатель, с которым коррелирует состояние, и если показатель находиться по одну сторону от заданного порогового значения, то состояние присутствует, тогда как если показатель попадает по другую сторону от порогового значения - состояние отсутствует. Тест отклонения одной гипотезы учитывает только распределение, соответствующее нулевой гипотезе, при выборе между нулевой и альтернативной гипотезами. Без учета распределения, соответствующего альтернативной гипотезе, специалист не может оценить правдоподобие каждой гипотезы, принимая во внимание данные наблюдений, и вследствие этого не может рассчитать достоверность при прогнозировании. Следовательно, с тестом отклонения одной гипотезы специалист получит ответ ʺдаʺ или ʺнетʺ без знания достоверности, связанной с конкретным случаем.
Согласно некоторым вариантам осуществления способ, раскрытый в данном документе, способен выявить присутствие или отсутствие фенотипа или генотипа, например, хромосомной аномалии, медицинского состояния с использованием способа максимального правдоподобия. Он является существенным улучшением по сравнению со способами, в которых используется методика с отклонением одной гипотезы, поскольку пороговое значение для выяснения отсутствия или присутствия состояния можно корректировать подходящим образом для каждого случая. Это особенно уместно для диагностических методик, целью которых является определение наличия или отсутствия анеуплоидии у вынашиваемого плода, исходя из генетических данных, доступных от смеси ДНК плода и матери, присутствующей в свободноплавающей ДНК, обнаруживаемой в плазме крови матери. Дело в том, что поскольку доля ДНК плода в полученной из плазмы крови фракции меняется, оптимальное пороговое значение для выявления анеуплоидии в противоположность эуплоидии изменяется. Поскольку доля ДНК плода падает, распределение данных, которое связано анеуплоидией, становится все более подобным распределению данных, которое связанно с эуплоидией.
Способ оценки максимального правдоподобия использует распределения, связанные с каждой гипотезой, для оценки правдоподобия данных с учетом условий для каждой гипотезы. Эти обусловленные вероятности можно затем преобразовать в прогноз и достоверность гипотезы. Подобным образом, в способе оценки с использованием апостериорного максимума применяются те же самые обусловленные вероятности, что и при оценке максимального правдоподобия, но он также включает априорные распределения в популяции при выборе наилучшей гипотезы и определении достоверности.
Исходя из вышеизложенного, использование методики оценки максимального правдоподобия (MLE) или тесно связанной методики с использованием апостериорного максимума (MAP) дает два преимущества, во-первых, она повышает вероятность верного прогнозирования, и она также позволяет рассчитать достоверность для каждого прогноза. Согласно варианту осуществления выбор результата статуса плоидности, соответствующий гипотезе с наибольшей вероятностью, выполняют с использованием оценок, полученных с помощью способа максимального правдоподобия, или оценок, полученных с использованием апостериорного максимума. Согласно варианту осуществления раскрыт способ определения статуса плоидности вынашиваемого плода, который включает использование любого способа, известного в настоящее время в уровне техники, в котором используется методика отклонения единственной гипотезы, и переформулирование его так, чтобы в нем использовались методики MLE или MAP. Некоторые примеры способов, которые можно существенно улучшить с помощью применения этих методик, можно найти в патенте США №8008018, патенте США №7888017 или патенте США №7332277.
Согласно варианту осуществления описан способ определения наличия или отсутствия анеуплоидии у плода по образцу плазмы крови матери, содержащем геномную ДНК матери и плода, причем способ включает: получение образца плазмы крови матери; измерение фрагментов ДНК, обнаруживаемых в образце плазмы крови, с использованием секвенатора с высокой пропускной способностью; нанесение последовательностей на карту хромосомы и определение количества ридов последовательности, которые нанесены на карту каждой хромосомы; расчет доли ДНК плода в образце плазмы крови; расчет ожидаемого распределения количества целевой хромосомы, которое, как ожидается, будет присутствовать, если вторая целевая хромосома является эуплоидной, и одного или множества ожидаемых распределений, которые будут ожидаться, если таковая хромосома является анеуплоидной, с использованием доли ДНК плода и количества ридов последовательности, которые нанесены на карту одной или нескольких эталонных хромосом, которые, как ожидается, являются эуплоидными; и применение MLE или MAP для определения того, какое из распределений наиболее вероятно будет верным, таким образом указывая на наличие или отсутствие анеуплоидии у плода. Согласно варианту осуществления измерение ДНК из плазмы крови может включать проведение массивно-параллельного секвенирования методом дробовика. Согласно варианту осуществления измерение ДНК из образца плазмы крови может включать секвенирование ДНК, которая была преимущественно обогащена, например посредством направленной амплификации, по множеству полиморфных или неполиморфных локусов. Множество локусов можно определить для нацеливания на одну или небольшое количество предполагаемых анеуплоидных хромосом и одну или небольшое количество эталонных хромосом. Цель преимущественного обогащения заключается в повышении количества ридов последовательности, которая является источником информации при определении плоидности.
Способы прогнозирования плоидности на основе информатики
В данном документе описан способ определения статуса плоидности плода с учетом данных секвенирования. Согласно некоторым вариантам осуществления эти данные секвенирования получают на секвенаторе с высокой пропускной способностью. Согласно некоторым вариантам осуществления данные секвенирования можно получить с использованием ДНК, которая происходит из свободноплавающей ДНК, выделенной из крови матери, где свободноплавающая ДНК содержит некоторое количество ДНК материнского происхождения и некоторое количество ДНК фетального/плацентарного происхождения. В этом разделе будет описан один вариант осуществления настоящего раскрытия, в котором определяют статус плоидности плода, исходя из предположения, что доля ДНК плода в смеси, которая подвергается анализу, неизвестна и будет оценена на основе данных. Также будет описан вариант осуществления, в котором долю ДНК плода (ʺдолю фетальной ДНКʺ) или процент ДНК плода в смеси можно измерить с помощью другого способа, и, как предполагается, она известна при определении статуса плоидности плода. Согласно некоторым вариантам осуществления долю ДНК плода можно рассчитать с использованием только данных генотипирования, полученных с помощью измерений, выполненных на отдельном образце крови матери, который представляет собой смесь ДНК плода и матери. Согласно некоторым вариантам осуществления долю можно также рассчитать с использованием установленного с помощью измерений или иным образом известного генотипа матери и/или установленного с помощью измерений или иным образом известного генотипа отца. Согласно другому варианту осуществления статус плоидности плода можно определить исключительно на основе рассчитанной доли ДНК плода для исследуемой хромосомы в сравнении с рассчитанной долей ДНК плода для эталонной хромосомы, предполагаемой дисомной.
В предпочтительном варианте осуществления в качестве примера предположим, что в отношении конкретной хромосомы мы наблюдаем и анализируем N SNP, для которых мы имеем:
- набор данных NR, полученных с помощью измерений при секвенировании свободноплавающей ДНК, S=(s1, …, sNR). Поскольку в данном способе используются данные, полученные с помощью измерений SNP, все данные секвенирования, которые соответствуют неполиморфным локусам, можно не принимать во внимание. В упрощенном варианте, где мы имеем импульсы счета (A, B) при каждом SNP, где A и B соответствуют двум аллелям, присутствующим в данном локусе, S можно записать в виде S=((a1, b1), …, (aN, bN)), где ai представляет собой одиночный импульс счета для A при SNP i, bi представляет собой одиночный импульс счета для B при SNP i, и
- Данные родителей включают
- генотипы, полученные с использованием микроматрицы для выявления SNP или другой платформы для генотипирования на основе плотности аллеля: мать M=(m1, …, mN), отец F=(f1, …, fN), где mi, fi∈(AA, AB, BB).
- И/ИЛИ данные секвенирования, полученные с помощью измерений: NRM полученные с помощью измерений SM=(sm1, …, smnrm) данные для матери, NRF полученные с помощью измерений SF=(sf1, …, sfnrf) данные для отца. Подобно вышеизложенному упрощению, если мы имеем количество импульсов счета (А, В) при каждом SNP, SM=((am1, bm1), …, (amN, bmN)), SF=((af1, bf1), …, (afN, bfN))
В совокупности, данные для ребенка от матери и отца обозначены как D=(M, F, SM, SF, S). Следует заметить, что данные родителей являются желательными и повышают точность алгоритма, но НЕ являются необходимыми, особенно данные для отца. Это означает, что даже в отсутствие данных для матери и/или отца возможно получение очень точного результата в отношении количества копий.
Возможно получение наилучшей оценки количества копий

.
Подобным образом, правдоподобие апостериорной гипотезы с учетом данных можно записать в виде:
.
Где priorprob(H) представляет собой априорную вероятность, заданную для каждой гипотезы H на основе построения модели и первоначальных сведений.
Также возможно использование априорных данных для получения оценки апостериорного максимума:
Согласно варианту осуществления гипотезами о количестве копий, которые могут рассматриваться, являются:
- моносомия:
- материнская по H10 (одна копия от матери),
- отцовская по H01 (одна копия от отца);
- дисомия: по H11 (по одной копии от матери и отца);
- простая трисомия, случаи кроссинговера не рассматриваются:
- материнская: H21_совпадающая (две идентичные копии от матери, одна копия от отца), H21_несовпадающая (ОБЕ копии от матери, одна копия от отца),
- отцовская: H12_совпадающая (одна копия от матери, две идентичные копии от отца), H12_несовпадающая (одна копия от матери, обе копии от отца);
- сложная трисомия с учетом случаев кроссинговера (с использованием модели совместного распределения):
- материнская по H21 (две копии от матери, одна от отца),
- отцовская по H12 (одна копия от матери, две копии от отца)
В других вариантах осуществления могут рассматриваться другие статусы плоидности, такие как нуллисомия (H00), однородительская дисомия (H20 и H02) и тетрасомия (H04, H13, H22, H31 и H40).
При отсутствии случаев кроссинговера, каждая трисомия, явился ли ее первопричиной митоз, мейоз I или мейоз II, будет одной из совпадающих или несовпадающих трисомий. Вследствие случаев кроссинговера истинная трисомия обычно является сочетанием двух вышеуказанных. Вначале описан способ получения значений правдоподобия гипотезы для гипотез простой трисомий. Затем описан способ получения значений правдоподобия гипотезы для гипотез сложной трисомий, сочетающий значения правдоподобия для отдельных SNP (однонуклеотидный полиморфизм) со случаями кроссинговера.
LIK(D|H) для гипотезы простой трисомий
Согласно варианту осуществления LIK(D|H) для гипотез простой трисомий можно определить следующим образом. Для гипотез простой трисомий H LIK(H), логарифм значения правдоподобия гипотезы H для целой хромосомы, можно рассчитать в виде суммы логарифмов значений правдоподобия для отдельных SNP, предполагая известную или выведенную долю ДНК ребенка cf. Согласно варианту осуществления можно вывести cf, исходя из данных.
.
Эта гипотеза не предполагает какой-либо связи между SNP и, исходя из вышеизложенного, не использует модель совместного распределения.
Согласно некоторым вариантам осуществления логарифм значения правдоподобия можно определить в расчете на один SNP. При конкретном SNP i, предполагая гипотезу плоидности плода H и процент ДНК плода cf, логарифм значения правдоподобия для наблюдаемых данных D определен как:
где m представляет собой возможные истинные генотипы матери, f представляет собой возможные истинные генотипы отца, где m,f∈{AA, AB, BB}, и с представляет собой возможные генотипы ребенка с учетом гипотезы H. В частности, для моносомии с ∈{A,B}, для дисомии с ∈{AA, AB, BB}, для трисомии с ∈{AAA, AAB, ABB, BBB}.
Априорная частота генотипа: p(m|i) представляет собой общую априорную вероятность генотипа матери m при SNP i, исходя из конкретной частоты в популяции для SNP I, обозначаемой pAi. В частности,
p(AA|pAi)=(pAi)2,
p(AB|pAi)=2(pAi)*(1-pAi),
Вероятность для генотипа отца, p(f|i), можно определить аналогичным образом.
Вероятность для истинного генотипа ребенка: p(c|m, f, H) представляет собой вероятность получения истинного генотипа ребенка =c с учетом генотипов родителей m, f и предположения гипотезы H, которую можно легко рассчитать. Например, для совпадающей по H11, H21 и несовпадающей по H21 p(c|m, f, H) указаны ниже.
Правдоподобие данных: P(D|m, f, c, H, i, cf) представляет собой вероятность для исходных данных D при SNP i с учетом истинного генотипа матери m, истинного генотипа отца f, истинного генотипа ребенка c, гипотезы H и доли ДНК ребенка cf. Ее можно разбить на вероятность для данных матери, отца и ребенка следующим образом:
Правдоподобие для данных в отношении SNP матери, полученных с использованием микроматриц: вероятность полученных с использованием микроматриц данных n для SNP в генотипе матери при SNP i при сравнении с истинным генотипом m, предполагая, что данные в отношении SNP в генотипах, полученные с помощью микроматриц, являются верными, представляет собой просто
Правдоподобие для данных от матери, полученных с использованием секвенирования: вероятность данных от матери, полученных с использованием секвенирования, для SNP i в случае количества импульсов счета Si=(ami, bmi) без включенных дополнительного шума или ошибки представляет собой вероятность, выраженную биномиальной функцией, определенной как P(SM|m, i)=PX|m(ami), где X|m~Binom(pm(A), ami+bmi), причем

Правдоподобие данных от отца: подобное уравнение применяется для правдоподобия данных от отца.
Следует заметить, что является возможным определение генотипа ребенка без данных от родителей, особенно данных от отца. Например, если данные для генотипа отца F недоступны, специалист в данной области техники может просто использовать P(F|f, i)=1. Если данные секвенирования SF от отца недоступны, специалист в данной области техники может просто использовать P(SF|f, i)=1.
Согласно некоторым вариантам осуществления способ включает создание модели совместного распределения ожидаемых количеств импульсов счета для аллелей во множестве полиморфных локусов на хромосоме для каждой гипотезы плоидности; один способ достижения такого результата приведен в данном описании. Правдоподобие данных для несвязанной ДНК плода: P(S|m, с, H, cf, i) представляет собой вероятность для данных секвенирования несвязанной ДНК плода при SNP i с учетом истинного генотипа матери m, истинного генотипа ребенка c, гипотезы о количестве копий ДНК ребенка H и предполагаемой доле ДНК ребенка cf. В действительности, она представляет собой вероятность для данных секвенирования S при SNP i с учетом истинной вероятности содержания A при SNP i μ(m, c, cf, H)
P(S|m, c, Н, cf, i)=P(S|μ(m, c, cf, H), i)
Для количеств импульсов счета, где Si=(ai, bi) без дополнительного шума или ошибки во включенных данных,
P(S|μ(m, c, cf, Н), i)=Px(ai)
где X~Binom(p(A), ai+bi) при p(A)= μ(m, c, cf, H). В более сложном случае, где точное выравнивание и количества импульсов счета для (A, B) при SNP неизвестны, P(S|μ(m, c, cf, H), i) представляет собой сочетание интегрированных биномиальных функций.
Истинная вероятность содержания A: μ(m, c, cf, H), истинная вероятность содержания A при SNP i в данной смеси ДНК матери/ребенка при предположении, что истинный генотип матери = m, истинный генотип ребенка = c, и суммарная доля ДНК ребенка = cf, определяется как
где #A(g) = количество A в генотипе g, nm=2 представляет сомию матери, и nc представляет собой плоидность ребенка при гипотезе H (1 для моносомии, 2 для дисомии, 3 для трисомии).
Использование модели совместного распределения: LIK(D|H) для гипотезы сложной трисомии
Согласно некоторым вариантам осуществления способ включает создание модели совместного распределения ожидаемых количеств импульсов счета для аллелей во множестве полиморфных локусов в хромосоме для каждой гипотезы плоидности; один способ для достижения такого результата описан в данном описании. Во многих случаях трисомия обычно не является исключительно совпадающей или несовпадающей вследствие случаев кроссинговера, так что в данном разделе получены результаты для гипотез сложной трисомии по H21 (материнской трисомии) и по H12 (отцовской трисомии), которая сочетает совпадающую и несовпадающую трисомию, учитывая возможные случаи кроссинговера.
В случае трисомии при отсутствии случаев кроссинговера, трисомия может быть просто совпадающей или несовпадающей трисомией. При совпадающей трисомии ребенок наследует две копии сегмента идентичной хромосомы от родителя. При несовпадающей трисомии ребенок наследует одну копию сегмента каждой гомологичной хромосомы от родителя. Вследствие кроссинговера некоторые сегменты хромосомы могут иметь совпадающую трисомию, а другие части могут иметь несовпадающую трисомию. В данном разделе написано о том, как создать модель совместного распределения степеней гетерозиготности для набора аллелей; то есть ожидаемых количеств импульсов счета для аллелей в ряде локусов при одной или нескольких гипотезах.
Предположим, что при SNP i LIK(D|Hm, i) представляет собой аппроксимацию гипотезы совпадающей трисомии Hm, и LIK(D|Hu, i) представляет собой аппроксимацию гипотезы несовпадающей трисомии Hu, и pc(i) = вероятность кроссинговера между SNP i-1 и i. Специалист в данной области техники может затем рассчитать полное значение правдоподобия в виде:
,
где LIK(D|E, 1:N) представляет собой правдоподобие по окончанию при гипотезе E для SNP 1:N. E = гипотеза для последнего SNP, E∈(Hm, Hu). Рекурсивно, специалист в данной области техники может рассчитать:
где ~E представляет собой гипотезу, отличную от E (не E), где рассматриваемыми гипотезами являются Hm и Hu. В частности, специалист в данной области техники может рассчитать значение правдоподобия 1:i SNP, исходя из значений правдоподобия от 1 до (i-1) SNP либо при той же гипотезе и отсутствии кроссинговера, либо при противоположной гипотезе и кроссинговере, умноженных на значения правдоподобия SNP i
Для SNP 1, i=1, LIK(D|E, 1:1)=LIK(D|E, 1).
Для SNP 2, i=2,
и так далее для i=3:N.
Согласно некоторым вариантам осуществления можно определить долю ДНК ребенка. Доля ДНК ребенка может относиться к соотношению последовательностей, которые происходят из ребенка, в смеси ДНК. Применительно к неинвазивной пренатальной диагностики доля ДНК ребенка может относиться к соотношению последовательностей в плазме крови матери, которые происходят из плода или части плаценты с генотипом плода. Она может относиться к доле ДНК ребенка в образце ДНК, который был получен из плазмы крови матери и может быть обогащен ДНК плода. Одна из целей определения доли ДНК ребенка в образце ДНК заключается в использовании в алгоритме, который может давать прогнозы в отношении плоидности плода, исходя из вышеизложенного, доля ДНК ребенка может относиться к какому-либо образцу ДНК, анализируемому с помощью секвенирования с целью неинвазивной пренатальной диагностики.
Некоторые из алгоритмов, представленных в данном раскрытии, которые являются частью способа неинвазивной пренатальной диагностики анеуплоидии, предполагают известную долю ДНК ребенка, которая не всегда присутствует. Согласно варианту осуществления можно найти наиболее вероятную долю ДНК ребенка путем максимального увеличения значения правдоподобия для дисомии в выбранных хромосомах при наличии или в отсутствие данных от родителей.
В частности, предположим, что LIK(D|H11, cf, chr) = логарифм значения правдоподобия, которое описано выше, для гипотезы дисомии и для доли ДНК ребенка cf в хромосоме chr. Для выбранных хромосом в Cset (набор хромосом) (обычно 1:16), предполагаемых эуплоидными, суммарное значение правдоподобия представляет собой:

Наиболее вероятное значение доли ДНК ребенка

.
Возможно использование любого набора хромосом. Также возможно получение значения доли ДНК ребенка, не предполагая эуплоидию в эталонных хромосомах. С использованием этого способа возможно определение доли ДНК ребенка для любой из следующих ситуаций: (1) специалист в данной области техники имеет полученные с использованием микроматриц данные от родителей и данные, полученные с использованием секвенирования методом ʺдробовикаʺ, для плазмы крови матери; (2) специалист в данной области техники имеет полученные с использованием микроматриц данные от родителей и данные, полученные с использованием направленного секвенирования, для плазмы крови матери; (3) специалист в данной области техники имеет полученные с использованием направленного секвенирования данные для обоих родителей и для плазмы крови матери; (4) специалист в данной области техники имеет данные, полученные с использованием направленного секвенирования, как для матери, так и для фракции плазмы крови матери; (5) специалист в данной области техники имеет данные, полученные с использованием направленного секвенирования, для фракции плазмы крови матери; (6) другие комбинации результатов, полученных с помощью измерения доли родительской ДНК и доли ДНК ребенка.
Согласно некоторым вариантам осуществления способ на основе информатики может учитывать выпадения данных; это может привести в результате к определению плоидности с большей точностью. В других местах в данном документе предполагалось, что вероятность получения A является непосредственной функцией истинного генотипа матери, истинного генотипа ребенка, доли ДНК ребенка в смеси и количества копий ДНК ребенка. Также возможно, что аллели матери или ребенка могут выпасть, например, вместо измерения характерного для ребенка истинного AB в смеси возможен случай, при котором измеряют только последовательности, нанесенные на область карты, соответствующую аллелю A. Специалист в данной области техники может обозначить частоту выпадения аллеля у родителей с данными, полученными с использованием анализа генома Illumina, dpg, частоту выпадения аллеля у родителей с данными, полученными с использованием секвенирования, dps, и частоту выпадения аллеля у ребенка с данными, полученными с использованием секвенирования, dcs. Согласно некоторым вариантам осуществления предполагается, что частота выпадения аллеля у матери равна нулю, и частоты выпадения аллея у ребенка являются относительно низкими; в этом случае выпадения не оказывают значительного отрицательного воздействия на результаты. Согласно некоторым вариантам осуществления возможность выпадений аллеля может быть значительно большей, что приведет к значительному воздействию на предварительный прогноз плоидности. Для такого случая, выпадения аллелей учли в алгоритме, описанном в данном документе:
Выпадения полученных с использованием микроматриц данных для SNP у родителей: для данных анализа генома матери M предположим, что генотип после выпадения представляет собой md, тогда
,
где являются такими же, как указано ранее, а P(md|m) представляет собой правдоподобие генотипа md после возможного выпадения с учетом истинного генотипа m, определенного ниже, для частоты выпадения d.
Подобное уравнение применяется к полученным с использованием микроматриц данным для SNP у отца.
Выпадения данных, полученных с использованием секвенирования, у родителей: для данных матери, полученных с использованием секвенирования, SM
,
где P(md|m) определен так же, как и в предыдущем разделе, и вероятность , исходя из биномиального распределения, определена так же, как и ранее в разделе о правдоподобии данных для отца. Подобное уравнение применяется к полученным с использованием секвенирования данным от родителей.
Выпадения данных секвенирования свободноплавающей ДНК:
,
где P(S|μ(md, cd, cf, H), i) является таким, как определено в разделе о правдоподобии данных для свободноплавающей ДНК.
Согласно варианту осуществления p(md|m) представляет собой вероятность наблюдаемого генотипа матери md с учетом истинного генотипа матери m, предполагая частоту выпадения dps, и p(cd|c) представляет собой вероятность наблюдаемого генотипа ребенка cd с учетом истинного генотипа ребенка c, предполагая частоту выпадения dcs. Если nAT = количество аллелей A в истинном генотипе c, nAD = количество аллелей A в наблюдаемом генотипе cd, где nAT≥nAD, и подобным образом, nBT = количество аллелей B в истинном генотипе c, nBD = количество аллелей B в наблюдаемом генотипе cd, где nBT≥nBD, и d = частота выпадения, тогда
.
Согласно варианту осуществления способ на основе информатики может учитывать случайную и систематическую ошибку. В идеальных условиях не существует систематической ошибки в выборке или случайного шума (дополнительно к вариации в биномиальном распределении) в количестве импульсов счета, полученных при секвенировании, в расчете на один SNP. В частности, при SNP i для генотипа матери m, истинном генотипе ребенка с и доле ДНК ребенка cf, и X = количество аллеля A в наборе ридов (A+B) при SNP i, X действует подобно X~Binomial(p, A+B), где р=μ(m, c, cf, H) = истинная вероятность содержания аллеля A.
Согласно варианту осуществления способ на основе информатики может учитывать случайную ошибку. Так как она часто имеет место, предположим, что в измерениях присутствует ошибка, так что вероятность получения A при этом SNP равна q, которая немного отличается от p, которая определена выше. То, насколько сильно p отличается от q, зависит от точности процесса измерения и ряда других факторов и может быть количественно определено с помощью стандартных отклонений q от p. Согласно варианту осуществления можно моделировать q как характеризующееся бета-распределением с параметрами α, β, зависящими от среднего значения данного распределения с центром в p и определенного установленного стандартного отклонения s. В частности, это дает X|q~Bin(q, D1i), где q~Beta(α, β). Если мы допустим, что E(q)=p, V(q)=s2, то параметры α, β можно получить в виде α=pN, β=(1-p)N, где .
Это выражение является определением бета-биномиального распределения, где оно представляет собой выборку из биномиального распределения с переменным параметром q, где q следует бета-распределению со средним значением p. Таким образом, в ситуации с отсутствием ошибки при SNP i вероятность для данных секвенирования для родителей (SM), предполагая истинный генотип матери (m), с учетом данных секвенирования для матери в виде количества импульсов счета для аллеля A при SNP i (ami) и данных секвенирования для матери в виде количества импульсов счета для аллеля B при SNP i (bmi) можно рассчитать как:
P(SM|m, i)=PX|m(ami), где X|m~Binom(pm(A), ami+bmi)
Теперь, включая случайную ошибку со стандартным отклонением s, оно приобретает вид:
X|m~BetaBinom(pm(A), ami+bmi, s)
В случае отсутствия ошибки вероятность для данных, полученных с использованием секвенирования ДНК плазмы крови матери, (S), предполагая истинный генотип матери (m), истинный генотип ребенка (c), долю ДНК ребенка (cf), предполагая гипотезу для статуса плоидности ребенка H, с учетом данных количества импульсов счета для аллеля A, полученных с использованием секвенирования свободноплавающей ДНК, при SNP i (ai) и данных количества импульсов счета для аллеля B, полученных с использованием секвенирования свободноплавающей ДНК, при SNP i (bi) можно рассчитать как
P(S|m, c, cf, H, i)=Px(ai),
где X~Binom(p(A), ai+bi) при р(A)= μ(m, c, cf, H).
Согласно варианту осуществления включающем случайную ошибку со стандартным отклонением s это выражение приобретает вид X~BetaBinom(p(A), ai+bi, s), где величину дополнительной вариации определяют с помощью параметра отклонения s или, эквивалентно, N. Чем меньше значение s (или чем больше значение N), тем ближе данное распределение к нормальному биномиальному распределению. Можно оценить величину ошибки, то есть оценить вышеуказанное значение N, исходя из однозначных контекстов AA|AA, BB|BB, AA|BB, BB|AA, и использовать оцененное в расчете вероятности выше. В зависимости от характера изменения данных N можно сделать постоянной, не зависящей от ʺглубиныʺ рида ai+bi или функцией ai+bi, делающей ошибку меньшей при больших значениях ʺглубиныʺ рида.
Согласно варианту осуществления способ на основе информатики может учитывать систематическую ошибку из расчета на SNP. Вследствие появления артефактов в процессе секвенирования некоторые SNP могут характеризоваться систематически более низкими или более высокими значениями количества импульсов счета вне зависимости от истинной величины содержания аллеля A. Предположим, что SNP i систематически прибавляет ошибку на wi процент количества импульсов счета для аллеля A. Согласно некоторым вариантам осуществления эту ошибку можно оценить, исходя из набора данных режима обучения, полученных при таких же условиях, и прибавить к оценке данных секвенирования для родителей в виде:
P(SM|m, i)=PX|m(ami), где X|m~BetaBinom(pm(A)+wi, ami+bmi, s),
и с оценкой вероятности данных секвенирования свободноплавающей ДНК в виде:
P(S|m, c, cf, Н, i)=Px(ai), где X~BetaBinom(p(A)+wi, ai+bi, s),
Согласно некоторым вариантам осуществления способ можно записать так, чтобы специально учитывать дополнительный шум, различное качество образцов, различное качество SNP и случайные ошибки выборки. Пример такой записи приведен в данном документе. Данный способ, как было показано, является особенно полезным применительно к данным, полученным с использованием протокола для массивно мультиплексной мини-ПЦР, и его использовали в экспериментах 7-13. Способ включает несколько этапов, каждый из которых учитывает отдельный вид шума и/или ошибки в конечной модели:
(1) предположим, что первый образец, который содержит смесь ДНК матери и плода, содержит исходное количество молекул ДНК с размером = N0, обычно в диапазоне 1000-40000, где p = истинный % от эталонных значений;
(2) при амплификации с использованием универсальных адаптеров для лигирования предположим, что N1 молекул включены в образец; обычно N1~N0/2 молекул, и учитывается случайная ошибка выборки. Амплифицированный образец может содержать количество молекул N2, где N2>>N1. Пусть X1 представляет количество локусов сравнения (в расчете на SNP) без включенных в образец молекул N1 при вариации в p1=X1/N1, что учитывает случайную ошибку выборки в остальной части протокола. Эта ошибка выборки учитывается в модели путем использования бета-биномиального (BB) распределения вместо использования модели простого биномиального распределения. Параметр N для бета-биномиального распределения может быть оценен позже в расчете на образец, исходя из данных режима обучения после поправки на выброс и ошибку при амплификации для SNP с 0 (3) Этап амплификации будет увеличивать любую аллельную ошибку, при этом ошибка при амплификации вводится вследствие неравномерной амплификации. Предположим, что один аллель в локусе амплифицируется f раз, а другой аллель в данном локусе амплифицируется g раз, где f=geb и где b=0 указывает на отсутствие ошибки. Параметр ошибки, b, имеет среднее значение, равное 0, и указывает на то, насколько больше или меньше амплифицируется аллель A в сравнении с аллелем B при конкретном SNP. Параметр b может отличаться от SNP к SNP. Параметр ошибки b можно оценить в расчете на SNP, например, исходя из данных режима обучения. (4) Этап секвенирования включает секвенирование образца амлифицированных молекул. На этом этапе может иметь место выброс, где выброс представляет собой ситуацию, когда SNP прочитывается неверно. Выброс может происходить из-за ряда проблем, и может приводить в результате к прочтению SNP не как верного аллеля A, а как другого аллеля B, находящегося в данном локусе, или как аллеля C или D, которые, как правило, не находятся в данном локусе. Предположим, что при секвенировании получают с помощью измерения данные секвенирования для ряда молекул ДНК из амплифицированного образца с размером N3, где N3 Различные протоколы могут включать сходные этапы с вариациями в этапах, на которых используются методы молекулярной биологии, приводящими в результате к различным количествам в случайной выборке, различным уровням амплификации и разной ошибке при выбросе. Следующая модель может одинаково хорошо применяться к каждому из этих случаев. Модель для количества ДНК в образце из расчета на SNP имеет вид: Х3~Beta-Binomial (L(F(p, b), pr, pg), N*H(p, b)), где p = представляет собой истинное количество эталонной ДНК, b = ошибка на SNP, и, как описано выше, pg представляет собой вероятность верного прочтения, pr представляет собой вероятность того, что рид прочтен неверно, но по стечению обстоятельств все же похож на правильный аллель, в случае неправильного рида, как описано выше, и: F(p, b)=peb/(peb+(1-p)), Н(р, b)=(ebp+(1-р))2/eb, L(p, pr, pg)=p*pg+pr*(1-pg). Согласно некоторым вариантам осуществления в способе используется бета-биномиальное распределение вместо простого биномиального распределения; что учитывает случайную ошибку выборки. Параметр N бета-биномиального распределения оценивают в расчете на образец при необходимости. Использование коррекции ошибки F(p, b), H(p, b), вместо просто p, учитывает ошибку при амплификации. Параметр b ошибки оценивают в расчете на SNP, исходя из данных режима обучения, полученных заблаговременно. Согласно некоторым вариантам осуществления в способе используется коррекция выброса L(p, pr, pg) вместо просто p; она учитывает ошибку при выбросе, то есть изменение SNP и качества образца. Согласно некоторым вариантам осуществления параметры pg, pr, po оценивают в расчете на SNP, исходя из данных режима обучения, полученных заблаговременно. Согласно некоторым вариантам осуществления параметры pg, pr, po можно обновлять при обработке текущего образца без остановки процесса с тем, чтобы учесть изменяющееся качество образца. Модель, описанная в данном документе, является достаточно общей и может учитывать как различающееся качество образцов, так и различное качество SNP. Разные образцы и SNP обрабатывают по-разному, что подтверждается, например, тем фактом, что согласно некоторым вариантам осуществления используют бета-биномиальные распределения, у которых среднее значение и дисперсия являются функцией исходного количества ДНК, а также качества образца и SNP. Базовое моделирование Рассмотрим один SNP, где ожидаемое соотношение аллелей, присутствующих в плазме крови, представляет собой r (исходя из генотипов матери и плода). Ожидаемое соотношение аллелей определено как ожидаемая доля аллелей A в объединенной ДНК матери и плода. Для генотипа матери gm и генотипа ребенка gc ожидаемое соотношение аллелей задается уравнением 1 при предположении, что генотипы представлены в той же мере как и соотношения аллелей. Результат наблюдений при SNP состоит из количества нанесенных на карту ридов, соответствующих присутствию каждого аллеля, na и nb, которое равно ʺглубинеʺ рида d. Предположим, что пороговые значения уже были применены к вероятностям нанесения на карту и оценкам phred, так что результаты нанесения на карту и данные наблюдения для аллелей можно рассматривать как верные. Оценка phred представляет собой численную меру, которая связана с вероятностью того, что конкретные полученные с помощью измерений данные для конкретного основания являются ошибочными. Согласно варианту осуществления, где данные для основания были получены с помощью измерений при секвенировании, оценку phred можно рассчитать, исходя из соотношения интенсивности свечения красителя, соответствующей прогнозируемому основанию, к интенсивности свечения красителя для других оснований. Простейшей моделью для правдоподобия результатов наблюдения является биномиальное распределение, которое предполагает, что каждый из d ридов независимо взят из большого пула, который характеризуется соотношением аллелей r. Уравнение 2 описывает данную модель. Биномиальную модель можно уточнить рядом способов. Если генотипы матери и плода представляют собой либо все A, либо все B, ожидаемое соотношение аллелей в ДНК в плазме крови будет 0 или 1, и вероятность, выражаемая биномиальной функцией, не будет четко определенной. На практике иногда наблюдают неожиданные аллели. Согласно варианту осуществления является возможным использование скорректированного соотношения аллелей для того, чтобы добиться небольшого количества неожиданных аллелей. Согласно варианту осуществления является возможным использование данных режима обучения для моделирования частоты проявления неожиданных аллелей при каждом SNP и использование этой модели для коррекции ожидаемого соотношения аллелей. Если ожидаемое соотношение аллелей не представляет собой 0 или 1, наблюдаемое соотношение аллелей может не сходиться со значительной ʺглубинойʺ рида при ожидаемом соотношении аллелей вследствие ошибки при амплификации или другого явления. Соотношение аллелей можно затем моделировать в виде бета-распределения с центром в точке, соответствующей ожидаемому соотношению аллелей, приводя к бета-биномиальному распределению для Р(na, nb|r), которое характеризуется более высокой дисперсией, чем биномиальное. Базовая модель для ответа при одном SNP будет определяться как F(a, b, gc, gm, f) (3), или вероятность наблюдения na=a и nb=b с учетом генотипов матери и плода, которая также зависит от доли ДНК плода через уравнение 1. Функциональной формой F может быть биномиальное распределение, бета-биномиальное распределение или подобные функции, которые обсуждались выше. Согласно варианту осуществления долю ДНК ребенка можно определить следующим образом. Оценку максимального правдоподобия для доли ДНК плода f при пренатальном тесте можно получить без использования информации от родителей. Это может быть уместно в тех случаях, когда генетические данные для родителей являются недоступными, например, когда зарегистрированный отец на самом деле не является генетическим отцом плода. Долю ДНК плода оценивают, исходя из набора SNP, где генотип матери представлен 0 или 1, что приводит в результате к набору только из двух возможных генотипов плода. Определим S0 как набор SNP с генотипом матери 0 и S1 как набор SNP с генотипом матери 1. Возможные генотипы плода при S0 представлены О и 0,5, давая в результате набор возможных соотношений аллелей R0(f)={0, f/2}. Подобным образом, R1(f)={1-f/2, 1}. Данный способ можно обычным образом расширить с включением SNP, где материнский генотип представлен 0,5, но эти SNP будут давать меньше информации вследствие большего набора возможных соотношений аллелей. Определим Na0 и Nb0 как векторы, образованные nas и nbs для SNP s в S0, и, подобным образом, Na1 и Nb1 - для S1. Оценка максимального правдоподобия для f определяется уравнением 4. При предположении, что количества импульсов счета для аллелей при каждом SNP являются независимыми с учетом условий для соотношения аллелей в ДНК плазмы крови при SNP, вероятности можно выразить в виде произведений для SNP в каждом наборе (5).

Зависимость от f укладывается в наборы возможных соотношений аллелей R0(f) и R1(f). Вероятность для SNP P(nas, nbs|f) можно приблизительно выразить, предполагая генотип с максимальным правдоподобием с учетом условий для f. При достаточно высокой доле ДНК плода и ʺглубинеʺ рида выбор генотипа с максимальным правдоподобием будет иметь высокую достоверность. Например, при доле ДНК плода 10 процентов и ʺглубинеʺ рида 1000 рассмотрим SNP, где мать имеет генотип ноль. Ожидаемые соотношения аллелей равны 0 и 5 процентов, они будут легко различаться при достаточно большой ʺглубинеʺ рида. Замена оцениваемого генотипа ребенка в уравнении 5 приводит в результате к законченному уравнению (6) для оценки доли ДНК плода.
Доля ДНК плода должна находиться в диапазоне [0, 1] и, таким образом, можно легко осуществить оптимизацию с помощью одномерного поиска с заданными ограничениями.
При наличии малой ʺглубиныʺ рида или высокого уровня шума может быть предпочтительным не предполагать генотип с максимальным правдоподобием, что может привести к завышенным значениям достоверности. Другим способом может быть суммирование по возможным генотипам при каждом SNP, приводящее в результате к следующему выражению (7) для P(na, nb|f) при SNP в S0. Априорную вероятность P(r) можно предположить равномерной для R0(f), или она может зависеть от частот в популяции. Продолжение на группу S1 является ординарным.

Согласно некоторым вариантам осуществления значения вероятности могут быть получены следующим образом. Достоверность можно рассчитать, исходя из данных правдоподобия двух гипотез Ht и Hf. Правдоподобие каждой гипотезы получают, исходя из модели ответа, оцененной доли ДНК плода, генотипов матери, частоты аллеля в популяции и количества импульсов счета, соответствующих аллелю, при анализе плазмы крови.
Определим следующие обозначения:
Gm, Gcистинные генотипы матери и ребенка
Gaf, Gtfистинные генотипы предполагаемого отца и истинного отца
G(gc, gm, gtf)=P(Gc=gc|Gm=gm, Gtf=gtf) вероятности наследования
P(g)=P(Gtf=g) частота в популяции для генотипа g при конкретном SNP
При предположении, что данные наблюдения при каждом SNP являются независимыми с учетом условий для соотношения аллелей в плазме крови, значение правдоподобия для гипотезы отцовства представляет собой произведение значений правдоподобия при SNP. В следующих уравнениях получают значение правдоподобия для одного SNP. Уравнение 8 представляет собой общее выражение для правдоподобия любой гипотезы h, которая будет затем разбита на конкретные случаи Ht и Hf.
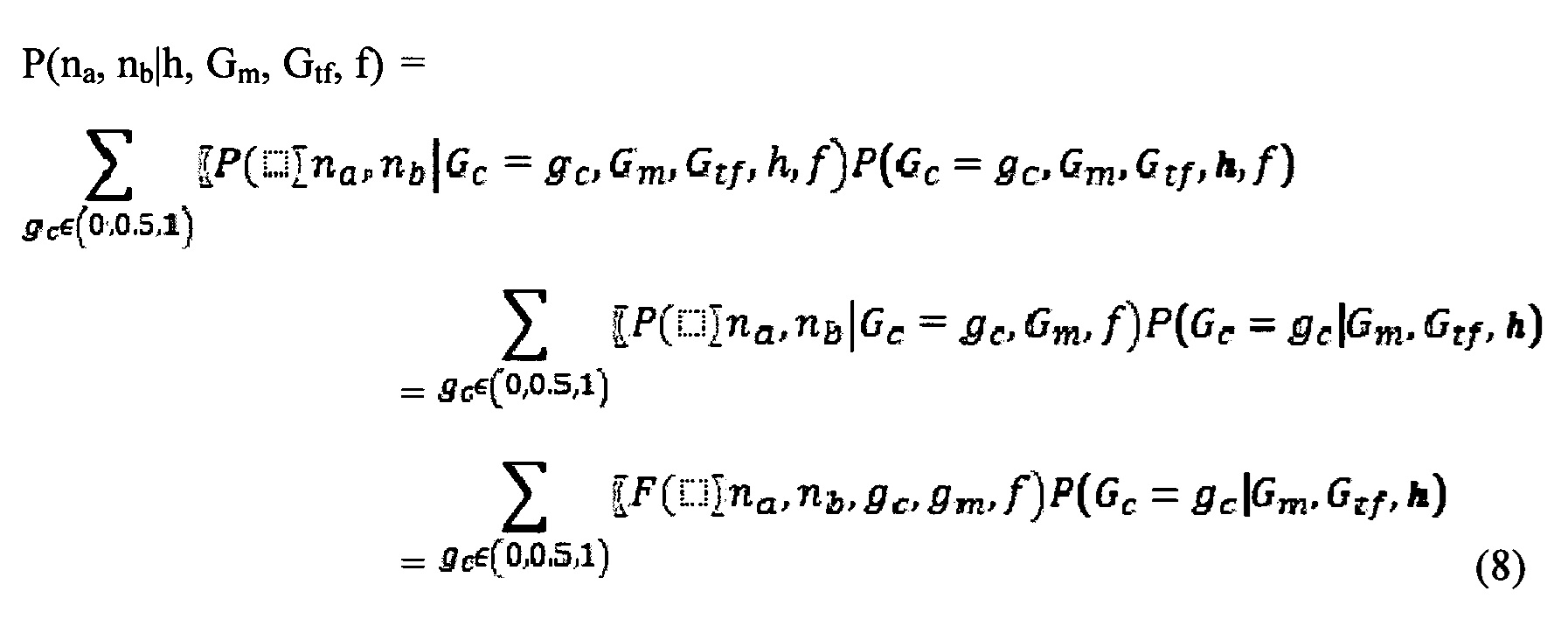
В случае Ht предполагаемый отец является истинным отцом, и генотипы плода наследуются из генотипов матери и генотипов предполагаемого отца в соответствии с уравнением 9.


В случае Hf предполагаемый отец не является истинным отцом. Наилучшая оценка для истинных генотипов отца задается частотами в популяции для каждого SNP. Следовательно, значения вероятности для генотипов ребенка определяют по известным генотипам матери и частотам в популяции, как в уравнении 10.

Достоверность Cp для верного отцовства рассчитывают из произведения по SNP двух значений правдоподобия с использованием правила Байеса (11).
Модель максимального правдоподобия с использованием доли ДНК плода в процентах
Определение статуса плоидности плода путем измерения свободноплавающей ДНК, содержащейся в сыворотке крови матери, или путем измерения генотипического материала в любом смешанном образце, является неординарной задачей. Существует ряд способов, например, проведение анализа количества импульсов счета для ридов, где основанием для предположения является то, что если плод является трисомиком по конкретной хромосоме, то общее количество ДНК от этой хромосомы, обнаруживаемой в крови матери, будет повышенным по сравнению с эталонной хромосомой. Одном способом выявления трисомии у таких плодов является нормализация количества ДНК, ожидаемого для каждой хромосомы, например, в соответствии с количеством SNP в анализируемом наборе, которые соответствуют заданной хромосоме, или в соответствии с количеством однозначно нанесенных на карту частей хромосомы. Когда данные, полученные с помощью измерений, нормализованы, любые хромосомы, для которых измеренное количество ДНК превышает определенное пороговое значение, определяются как трисомические. Этот подход описан у Fan, et al. PNAS, 2008; 105(42); pp.16266-16271, а также у Chiu et al. BMJ 2011; 342:c7401. В статье Chiu et al. нормализацию выполняли путем расчета оценки Z следующим образом:
оценка Z для процентного содержания хромосомы 21 в условиях теста = ((процентное содержание хромосомы 21 в условиях теста) - (среднее значение процентного содержания хромосомы 21 в сравниваемых контролях)) / (стандартное отклонение для процентного содержания хромосомы 21 в сравниваемых контролях).
В этих способах статус плоидности плода определяют с использованием способа отклонения одной гипотезы. Однако они подвержены некоторым значительным недостаткам. Поскольку эти способы определения плоидности плода являются инвариантными по процентному содержанию ДНК плода в образце, в них используют одно отсекающее значение; результатом чего является неоптимальность показателей точности определения, и те случаи, где процентное содержание ДНК плода в смеси является относительно низким, имеют наихудшие показатели точности.
Согласно варианту осуществления способ согласно настоящему раскрытию используют для определения статуса плоидности плода, при этом способ включает учет доли ДНК плода в образце. Согласно другому варианту осуществления настоящего раскрытия способ включает использование оценок максимального правдоподобия. Согласно варианту осуществления способ согласно настоящему раскрытию включает расчет процента ДНК, которая является фетальной или плацентарной по происхождению, в образце. Согласно варианту осуществления пороговое значение для прогнозирования анеуплоидии адаптивно корректируют, исходя из рассчитанного процента ДНК плода. Согласно некоторым вариантам осуществления способ оценки процентного содержания ДНК фетального происхождения в смеси ДНК включает получение смешанного образца, который содержит генетический материал от матери и генетический материал от плода, получение генетического образца от отца плода, измерение ДНК в смешанном образце, измерение ДНК в образце от отца и расчет процентного содержания ДНК фетального происхождения в смешанном образце с использованием результатов, полученных с помощью измерений ДНК в смешанном образце и в образце от отца.
Согласно варианту осуществления настоящего раскрытия можно измерить долю ДНК плода или процентное содержание ДНК плода в смеси. Согласно некоторым вариантам осуществления долю можно рассчитать с использованием данных, полученных с помощью измерения при генотипировании на образце плазмы крови матери самом по себе, который представляет собой смесь ДНК плода и матери. Согласно некоторым вариантам осуществления долю можно также рассчитать с использованием установленного с помощью измерений или иным образом известного генотипа матери и/или установленного с помощью измерений или иным образом известного генотипа отца. Согласно некоторым вариантам осуществления процент ДНК плода можно рассчитать с использованием данных, полученных с помощью измерений, выполненных на смеси ДНК матери и плода, вместе с данными контекстов родителей. Согласно варианту осуществления долю ДНК плода можно рассчитать с использованием частот в популяции для коррекции модели в отношении вероятности при измерениях конкретного аллеля.
Согласно варианту осуществления настоящего раскрытия достоверность можно рассчитать с точностью определения статуса плоидности плода. Согласно варианту осуществления достоверность гипотезы наибольшего правдоподобия (Hmajor) можно рассчитать как (1-Hmajor)/Σ (для всех H). Можно определить достоверность гипотезы, если распределения для всех гипотез являются известными. Возможно определение распределения для всех гипотез, если известна информация о генотипах родителей. Возможен расчет достоверности определения плоидности, если известно ожидаемое распределение данных для эуплоидного плода и ожидаемое распределение данных для анеуплоидного плода. Возможен расчет этих ожидаемых распределений, если известны данные для генотипов родителей. Согласно варианту осуществления специалист в данной области техники может использовать сведения о распределении статистического критерия при гипотезе, утверждающей нормальность плода, и при гипотезе, утверждающей наличие аномалии, как для определения достоверности прогноза, так и для уточнения порогового значения с получением более достоверного прогноза. Это является особенно полезным, когда количество и/или процент ДНК плода в смеси являются низкими. Это поможет избежать ситуации, когда плод, который фактически является анеуплоидным, считают эуплоидным, поскольку статистический критерий, такой как статистический критерий Z не превышает порогового значения, которое установлено, исходя из порогового значения, оптимизированного для случая, где присутствует более высокий процент ДНК плода.
Согласно варианту осуществления способ, раскрытый в данном документе, можно применять для определения анеуплоидии у плода путем определения количества копий целевых хромосом матери и ребенка в смеси генетического материала матери и плода. Способ может включать в себя получение ткани матери, содержащей генетический материал как матери, так и плода; согласно некоторым вариантам осуществления этой тканью матери может быть плазма крови матери или ткань, выделенная из крови матери. Данный способ может также включать в себя получение смеси генетического материала матери и плода из указанной ткани матери путем обработки вышеупомянутой ткани матери. Данный способ может включать в себя распределение полученного генетического материала на множество образцов для реакции, чтобы в произвольном порядке обеспечить отдельные образцы для реакции, которые содержат целевую последовательность из целевой хромосомы, и отдельные образцы для реакции, которые не содержат целевую последовательность из целевой хромосомы, например для проведения на образце секвенирования с высокой пропускной способностью. Данный способ включает в себя анализ целевых последовательностей в генетическом материале, присутствующем или отсутствующем в указанных отдельных образцах для реакции, с получением первого ряда двоичных результатов, представляющих наличие или отсутствие предположительно эуплоидной хромосомы плода в образцах для реакции, и второго ряда двоичных результатов, представляющих наличие или отсутствие возможно анеуплоидной хромосомы плода в образцах для реакции. Любой из ряда двоичных результатов можно рассчитать, например, с помощью методики на основе информатики, которая подсчитывает количество ридов при секвенировании, которые наносятся на карту конкретной хромосомы, конкретной области хромосомы, конкретного локуса или набора локусов. Данный способ может включать нормализацию ряда двоичных событий, исходя из длины хромосомы, длины области хромосомы или количества локусов в наборе. Данный способ может включать в себя расчет ожидаемого распределения в ряду двоичных результатов для предположительно эуплоидной хромосомы плода в образцах для реакции с использованием первого ряда. Данный способ может включать в себя расчет ожидаемого распределения в ряду двоичных результатов для предположительно анеуплоидной хромосомы плода в образцах для реакции с использованием первого ряда и оцененной доли ДНК плода, обнаруживаемой в смеси, например, путем умножения ожидаемого распределения количества импульсов счета для ридов из ряда двоичных результатов для предположительно эуплоидной хромосомы плода на (1+n/2), где n представляет собой оцененную долю ДНК плода. Согласно некоторым вариантам осуществления риды при секвенировании можно рассматривать как вероятностные результаты нанесения на карту, а не двоичные результаты; данный способ будет давать на выходе большую точность, но требует больших вычислительных мощностей. Долю ДНК плода можно оценить с помощью множества способов, некоторые из которых описаны в других местах в данном раскрытии. Данный способ может включать использование метода максимального правдоподобия для определения соответствия второго ряда ситуации, когда возможно анеуплоидная хромосома плода является эуплоидной или является анеуплоидной. Данный способ включает прогнозирование того, является ли статус плоидности плода статусом плоидности, который соответствует гипотезе с максимальным правдоподобием, являющейся верной с учетом данных, полученных с помощью измерений.
Следует заметить, что модель максимального правдоподобия можно использовать для повышения точности любого способа, с помощью которого определяют статус плоидности плода. Подобным образом, достоверность можно рассчитать для любого способа, с помощью которого определяют статус плоидности плода. Использование модели максимального правдоподобия будет приводить к улучшению точности способа, где определение плоидности выполняют с использованием методики с отклонением одной гипотезы. Модель максимального правдоподобия можно использовать для любого способа, где распределение значений правдоподобия можно рассчитать как для случая, соответствующего норме, так и для случая, соответствующего аномалии. Использование модели максимального правдоподобия подразумевает возможность расчета достоверности для прогноза плоидности.
Дальнейшее обсуждение способа
Согласно варианту осуществления в способе, раскрытом в данном документе, используют количественную меру числа независимых наблюдений для каждого аллеля в полиморфном локусе, причем он не включает расчет соотношения аллелей. Он отличается от способов, таких как некоторые способы на основе использования микроматриц, с помощью которых получают информацию о соотношении двух аллелей в локусе, но не определяют количественно число независимых наблюдений того или другого аллеля. Некоторые способы, известные в уровне техники, могут обеспечить количественную информацию в отношении числа независимых наблюдений, но в расчетах, приводящих к определению плоидности, используются только соотношения аллелей и не используется количественная информация. Чтобы проиллюстрировать важность сохранения информации о числе независимых наблюдений, рассмотрим примерный локус с двумя аллелями, A и B. В первом эксперименте наблюдают двадцать аллелей A и двадцать аллелей B, во втором эксперименте наблюдают 200 аллелей A аллели и 200 аллелей B. В обоих экспериментах соотношение (A/(A+B)) является равным 0,5, однако второй эксперимент предоставляет больше информации о достоверности частоты аллеля A или B, нежели первый. В данном способе вместо использования соотношений аллелей используются количественные данные для более точного моделирования наиболее вероятных частот аллеля в каждом полиморфном локусе.
Согласно варианту осуществления в данных способах создают генетическую модель для объединения данных измерений от многих полиморфных локусов для того, чтобы лучше отличать трисомию от дисомии, а также для того, чтобы определить тип трисомии. Кроме того, в данном способе учитывается информация о генетическом сцеплении для повышения точности способа. Это отличается от некоторых способов, известных в уровне техники, где соотношения аллелей усредняют по всем полиморфным локусам в хромосоме. В способе, раскрытом в данном документе, подробно моделируют распределения частоты аллеля, ожидаемые при дисомии, также как и при трисомии, возникающей в результате нерасхождения в ходе мейоза I, нерасхождения в ходе мейоза II и нерасхождения в ходе митоза на ранних стадиях развития плода. Для иллюстрации того, почему это столь важно, укажем, что если отсутствуют случаи кроссинговера, то нерасхождение в ходе мейоза I будет приводить в результате к трисомии, при которой два различных гомолога были унаследованы от одного родителя; нерасхождение в ходе мейоза II или в ходе митоза на ранних стадиях развития плода будет приводить в результате к двум копиям одного и того же гомолога от одного родителя. Каждый сценарий приводит в результате к различным ожидаемым частотам аллелей в каждом полиморфном локусе, а также во всех физически сцепленных локусах (то есть локусах в той же хромосоме), рассматриваемых совместно. Случаи кроссинговера, которые приводят в результате к обмену генетического материала между гомологами, делают характер наследования более сложным, однако данный способ компенсирует это путем использования информации о генетическом сцеплении, то есть информации о скорости рекомбинации и физическом расстоянии между локусами. Для лучшего установления различий между нерасхождением при мейозе I и нерасхождением при мейозе II или митозе данный способ учитывает в модели возрастающую вероятность кроссинговера с возрастанием расстояния от центромеры. Нерасхождение при мейозе II и митозе можно отличить на основании того факта, что нерасхождение при митозе, как правило, приводит в результате к идентичным или почти идентичным копиям одного гомолога, тогда как два гомолога, присутствующие после события нерасхождения при мейозе II, часто отличаются вследствие одного или нескольких случаев кроссинговера в ходе гаметогенеза.
Согласно варианту осуществления в способе согласно настоящему раскрытию можно не определять гаплотипы родителей, если предполагается дисомия. Согласно варианту осуществления в случае трисомии данный способ может включать определение гаплотипов одного или обоих родителей, используя тот факт, что в плазме крови содержаться две копии от одного родителя, и информацию относительно фазы родителя можно определить, отметив, какие две копии были унаследованы от изучаемого родителя. В частности, ребенок может унаследовать любые две из одинаковых копий родительской хромосомы (совпадающая трисомия) или обе копии родительской хромосомы (несовпадающая трисомия). Для каждого SNP специалист в данной области техники может рассчитать правдоподобие совпадающей трисомии и несовпадающей трисомии. В способе прогнозирования плоидности, в котором не используется модель сцепления, учитывающая случаи кроссинговера, будут рассчитывать общее правдоподобие трисомии как простое средневзвешенное значение для совпадающей и несовпадающей трисомии по всем хромосомам. Однако из-за биологических механизмов, которые приводят в результате к ошибке, заключающейся в нерасхождении хромосом, и случаев кроссинговера трисомия в хромосоме может меняться с совпадающей на несовпадающую (и наоборот) только в случаях, если имеет место кроссинговер. Данный способ вероятностно учитывает правдоподобие для кроссинговера, что дает в результате прогнозы плоидности с большей точностью, чем у способов, которые не учитывают этого.
Согласно варианту осуществления эталонную хромосому используют для определения доли ДНК ребенка и величины уровня шума или распределения вероятности. Согласно варианту осуществления долю ДНК ребенка, уровень шума и/или распределение вероятности определяют с использованием только генетической информации, доступной для хромосомы, статус плоидности которой определяют. Данный способ работает без эталонной хромосомы, также как и без установления конкретного значения доли ДНК ребенка или уровня шума. Это является существенным улучшением и отличием от способов, известных в уровне техники, где генетические данные для эталонной хромосомы являются необходимыми для того, чтобы точно установить значение доли ДНК ребенка и поведение хромосом.
Согласно варианту осуществления, где эталонная хромосома не является необходимой для определения доли ДНК плода, определение гипотезы выполняют следующим образом:
.
С алгоритмом с эталонной хромосомой специалист в данной области техники, как правило, предполагает, что по эталонной хромосоме присутствует дисомия, и затем специалист в данной области техники может либо (a) установить наиболее вероятное значение доли ДНК ребенка и произвольный уровень шума N, исходя из данного предположения и данных для эталонной хромосомы:
,
а затем сократить
LIK(D|H)=LIK(D|H, cfr)
либо (b) оценить распределение доли ДНК ребенка и уровня шума, исходя из данного предположения и данных для эталонной хромосомы. В частности, специалист в данной области техники не будет устанавливать лишь одно значение для cfr и N, а задаст вероятность p(cfr, N) для более широкого диапазона возможных значений cfr, N:
p(cfr, N)~LIK(D(ref. chrom)|H11, cfr, N)*priorprob(cfr, N),
где priorprob(cfr, N) представляет собой априорную вероятность для конкретного значения доли ДНК ребенка и уровня шума, определенного из ранее известных сведений и экспериментов. Если это необходимо, просто одинаковое по диапазону cfr, N. Специалист в данной области техники может затем записать:
Оба вышеприведенных способа дают хорошие результаты.
Следует заметить, что в некоторых случаях использование эталонной хромосомы не является желательным, возможным или целесообразным. В таком случае можно получить наилучший прогноз плоидности для каждой хромосомы отдельно. В частности:
p(cfr, N|H) может быть определена, как указано выше, для каждой хромосомы отдельно, предполагая гипотезу H, а не только для эталонной хромосомы, предполагая дисомию. Возможно использование данного способа с сохранением установленных параметров как шума, так доли ДНК ребенка, с установкой любого из параметров или с сохранением обоих параметров в вероятностной форме для каждой хромосомы и каждой гипотезы.
Измерения ДНК имеют тенденцию к присутствию шума и/или ошибок, особенно измерения, где количество ДНК является небольшим или где ДНК присутствует в смеси с загрязняющей ДНК. Этот шум приводит в результате к менее точным данным о генотипе и менее точным прогнозам плоидности. Согласно некоторым вариантам осуществления базовое моделирование или какой-либо другой способ моделирования шума можно использовать для противодействия неблагоприятным воздействиям шума на определение плоидности. В данном способе используется совместная модель для обоих каналов, которая учитывает случайный шум, обусловленный количеством поступающей ДНК, качеством ДНК и/или качеством протокола.
Это отличается от некоторых способов, известных в уровне техники, где определение плоидности выполняют с использованием соотношения плотностей аллеля в локусе. Этот способ заранее исключает точное моделирование шума при SNP. В частности, ошибки при измерениях, как правило, не зависят специфически от измеряемого в канале соотношения плотности, что сокращает модель до использования одномерной информации. Точное моделирование шума, качества в канале и взаимодействия каналов требует двумерной совместной модели, которая не может быть создана с использованием соотношений аллелей.
В частности, перевод информации от двух каналов в соотношение r, где f(x, y) представляет собой r=x/y, не является подходящим для точного моделирования шума и ошибки для канала. Шум при конкретном SNP не является функцией соотношения, то есть шум (x, y)≠f(x, y), а на самом деле является совместной функцией обоих каналов. Например, в биномиальной модели шум для измеряемого соотношения характеризуется дисперсией r(1-r)/(x+y), которая не является функцией исключительно r. В такой модели, куда включены любая ошибка или шум в канале, предположим, что при SNP i наблюдаемое в канале X значение представляет собой x=aiX+bi, где X представляет собой истинное значение для канала, bi представляет дополнительную ошибку в канале и случайный шум. Подобным образом, предположим, что y=ciY+di. Наблюдаемое соотношение r=x/y не может точно предсказать истинное соотношение X/Y или смоделировать оставшийся шум, поскольку (aiX+bi)/(ciY+di) не является функцией X/Y.
Способ, раскрытый в данном документе, описывает эффективный метод моделирования шума и ошибки с использованием совместных биномиальных распределений для всех каналов измерения по отдельности. Соответствующие уравнения можно найти в других местах в данном документе в разделах, в которых идет речь о систематической ошибке на SNP, показателях P(good) и P(ref|bad), P(mut|bad), которые эффективно корректируют характер изменения SNP. Согласно варианту осуществления в способе согласно настоящему раскрытию используется бета-биномиальное распределение, которое избегает ограничивающего способа, полагающегося только на соотношения аллелей, а вместо этого моделирует характер изменения, исходя из количества импульсов счета по обоим каналам.
Согласно варианту осуществления с помощью способа, раскрытого в данном документе, можно прогнозировать плоидность вынашиваемого плода, исходя из генетических данных, получаемых из плазмы крови матери с использованием всех доступных измерений. Согласно варианту осуществления с помощью способа, раскрытого в данном документе, можно прогнозировать плоидность вынашиваемого плода, исходя из генетических данных, получаемых из плазмы крови матери с использованием измерений только от одной подгруппы контекстов родителей. В некоторых способах, известных в уровне техники, используют только полученные с помощью измерения генетические данные, где контекст родителей представляет собой один из контекстов AA|BB, то есть, где оба родителя являются гомозиготными по данному локусу, но имеют разные аллели. Одной из проблем этого способа является то, что малая доля присутствующих полиморфных локусов происходит из контекста AA|BB, как правило, менее 10%. Согласно варианту осуществления способа, раскрытого в данном документе, в способе не используются генетические данные, полученные с помощью измерений на плазме крови матери, выполненных по локусам, где контекст родителей представляет собой AA|BB. Согласно варианту осуществления в данном способе используются полученные с помощью измерений на плазме крови данные только для таких полиморфных локусов, где контекст родителей представляет собой AA|AB, AB|AA и AB|AB.
Некоторые способы, известные в уровне техники, включают усреднение соотношений аллелей от SNP в контексте AA|BB, где представлены генотипы обоих родителей, и, как заявлено, определяют прогнозы в отношении плоидности, исходя из среднего соотношения аллелей при этих SNP. Этот способ страдает от существенной неточности вследствие различного характера изменения SNP. Следует заметить, что в этом способе предполагают, что известны генотипы обоих родителей. В отличие от этого, согласно некоторым вариантам осуществления в данном способе используется модель совместного распределения для каналов, которая не предполагает наличие данных одного из двух родителей и не предполагает одинакового характера изменения SNP. Согласно некоторым вариантам осуществления в данном способе учитываются, различный характер изменения/вес SNP. Согласно некоторым вариантам осуществления данный способ не требует знания генотипов одного или обоих родителей. Пример того, как в данном способе можно достичь этого, следует ниже.
Согласно некоторым вариантам осуществления логарифм значения правдоподобия гипотезы можно определить из расчета на SNP. При конкретном SNP i, предполагая гипотезу плоидности плода H и процент ДНК плода cf, логарифм значения правдоподобия для полученных данных D определяется как:
где m представляют собой возможные истинные генотипы матери, f представляют собой возможные истинные генотипы отца, где m, f∈{AA, AB, BB}, и где с представляют собой возможные истинные генотипы ребенка с учетом гипотезы H. В частности, для моносомии с {A, B}, для дисомии с∈{AA, AB, BB}, для трисомии с∈{AAA, AAB, ABB, BBB}. Следует заметить, что включение данных о генотипе родителей, как правило, приводит в результате к более точным определениям плоидности, однако данные о генотипе родителей не являются необходимыми для того, чтобы данный способ работал хорошо.
Некоторые способы, известные в уровне техники, включают усреднение соотношений аллелей от SNP, когда мать является гомозиготной, но отличающийся аллель обнаруживают с помощью измерений на плазме крови (контексты либо AA|AB, либо AA|BB) и, как заявлено, определяют прогнозы в отношении плоидности, исходя из среднего соотношения аллелей при этих SNP. Этот способ предназначен для случаев, когда генотип отца является недоступным. Следует заметить, что вопросы вызывает то, с какой точностью специалист в данной области техники может утверждать, что плазма крови является гетерозиготной по конкретному SNP без наличия гомозиготного и противоположного контекста BB отца: для случаев с низким значением доли ДНК ребенка то, что выглядит как присутствие аллеля B, может быть лишь присутствием шума; кроме того, то, что выглядит как отсутствие аллеля B, может быть просто выпадением аллеля при проведении измерений ДНК плода. Даже в том случае, когда специалист в данной области техники действительно может определить гетерозиготность плазмы, этот способ не будет способен установить различия между родительскими трисомиями. В частности, для SNP, где мать представлена AA, и где некоторое количество B измерено в плазме крови, если отец представлен GG, то полученный в результате генотип ребенка представляет собой AGG, давая в результате среднюю долю A 33% (при доле ДНК ребенка = 100%). Но в случае, когда отец представлен AG, полученный в результате генотип ребенка может представлять собой AGG при совпадающей трисомии, составляя долю A 33%, или AAG при несовпадающей трисомии, доводя среднюю долю A до 66%. С учетом того, что многие трисомии имеют место в хромосомах с кроссинговером, хромосома, в целом, может иметь эти значения в любых пределах между отсутствием несовпадающей трисомии и трисомиями, все из которых являются несовпадающими, это значение может варьировать в любых пределах между 33-66%. При явной дисомии доля должна составлять около 50%. Без использования модели сцепления или модели точной ошибки для среднего значения этот способ будет пропускать много случаев отцовской трисомии. В отличие от этого способ, раскрытый в данном документе, назначает вероятности генотипа отца для каждого отцовского генотипа-кандидата, исходя из доступной информации о генотипе и частоты в популяции, и не требует точного знания генотипов отца. Кроме того, способ, раскрытый в данном документе, способен выявить трисомию даже при отсутствии или наличии данных о генотипе родителей и может компенсировать путем идентификации точек возможного кроссинговера, исходя из совпадающей и несовпадающей трисомии с использованием модели сцепления.
В некоторых способах, известных в уровне техники, заявлен способ усреднения соотношений аллелей для SNP, где не известен ни генотип отца, ни генотип матери, и определения прогнозов в отношении плоидности, исходя из среднего соотношения при этих SNP. Однако способ достижения этих результатов не раскрыт.Способ, раскрытый в данном документе, дает возможность сделать точные прогнозы в отношении плоидности в таких условиях, а внедрение в практику раскрыто в других местах в данном документе, используя способ получения совместной вероятности с максимальным правдоподобием, и необязательно использует модели шума и ошибки при SNP, а также модель сцепления.
Некоторые способы, известные в уровне техники, включают усреднение соотношений аллелей и, как заявлено, определяют прогнозы в отношении плоидности, исходя из среднего соотношения аллелей для одного или нескольких SNP. Однако такие способы не используют концепцию сцепления. Способы, раскрытые в данном документе, не подвержены этим недостаткам.
Использование длины последовательности в качестве априорного показателя для определения происхождения ДНК
Сообщалось, что распределение длины последовательностей для ДНК матери и плода отличается, при этом ДНК плода обычно короче. Согласно варианту осуществления настоящего раскрытия можно использовать полученные ранее данные в форме экспериментальных данных и построить априорное распределение для ожидаемой длины ДНК как матери (P(X|матери), так и плода (P(X|плода)). С учетом новой неидентифицированной последовательности ДНК с длиной x, можно задать вероятность того, что данная последовательность ДНК является либо ДНК матери, либо ДНК плода, исходя из априорного значения правдоподобия x с учетом того, что последовательность принадлежит либо матери, либо ребенку. В частности, если P(x|матери)>P(x|плода), то последовательность ДНК можно классифицировать как принадлежащую матери, причем P(x|матери)=P(x|матери)/[(P(x|матери)+P(x|плода)], и если p(x|матери) Переменная ʺглубинаʺ рида для сведения к минимуму затрат на секвенирование Во многих клинических испытаниях, касающихся диагностики, например у Chiu et al. BMJ 2011; 342: c7401, устанавливают протокол с рядом параметров и затем тот же протокол выполняют с теми же параметрами в отношении каждого из пациентов, принимающих участие в испытании. В случае определения статуса плоидности у вынашиваемого матерью плода с использованием секвенирования для проведения измерений на генетическом материале подходящим параметром будет количество ридов. Количество ридов может относиться к количеству фактических ридов, количеству предполагаемых ридов, неполным дорожкам, полным дорожкам или полным проточным ячейкам в секвенаторе. В этих исследованиях количество ридов, как правило, устанавливают на уровне, который будет гарантировать, что для всех или почти всех образцов будет достигнут желаемый уровень точности. В настоящее время секвенирование является дорогостоящей технологией со стоимостью приблизительно 200 долларов на 5 нанесенных на карту миллионов ридов, и хотя цена резко снижается, любой способ, который позволит проводить диагностику на основе секвенирования с подобным уровнем точности, но при меньшем количестве ридов, обязательно сэкономит значительную сумму денег. Точность определения плоидности, как правило, зависит от ряда факторов, включая количество ридов и долю ДНК плода в смеси. Точность, как правило, является более высокой, когда доля ДНК плода в смеси выше. В то же время, точность, как правило, выше, если количество ридов больше. Можно получить два случая для ситуации, когда статус плоидности определяют со сравнимыми значениями точности, где в первом случае присутствует более низкая доля ДНК плода в смеси, чем во втором, и большее количество ридов получено при секвенировании в первом случае, чем во втором. Можно использовать оцененную долю ДНК плода в смеси в качестве ориентира при определении количества ридов, необходимого для достижения заданного уровня точности. Согласно варианту осуществления настоящего раскрытия можно провести анализ набора образцов, в котором разные образцы в наборе секвенируют с различными значениями ʺглубиныʺ ридов, где количество ридов, проанализированных в каждом из образцов, выбирают с тем, чтобы достичь заданного уровня точности с учетом рассчитанной доли ДНК плода в каждой смеси. Согласно варианту осуществления настоящего раскрытия это может включать в себя проведение измерения смешанного образца для определения доли ДНК плода в смеси; эту оценку доли ДНК плода можно выполнить с использованием секвенирования, ее можно выполнить с использованием технологии TaqMan, ее можно выполнить с использованием qPCR (количественной ПЦР), ее можно выполнить с использованием микроматриц для выявления SNP, ее можно выполнить с использованием любого способа, с помощью которого можно установить различия между различными аллелями в заданных локусах. Необходимость оценки доли ДНК плода можно исключить путем включения гипотез, которые распространяются на все или выбранный набор значений доли ДНК плода в наборе гипотез, которые рассматривают при сравнении с фактическими данными, полученными с помощью измерений. После определения доли ДНК плода в смеси можно определить количество прочитанных последовательностей для каждого образца. Согласно варианту осуществления настоящего раскрытия 100 беременных женщин посещают своих соответствующих ОВ (врачей-гинекологов), и их крови забирают в пробирки для забора крови со средством, препятствующим лизису, и/или чем-нибудь, инактивирующим ДНКазу. Каждая из них берет домой набор для отца их вынашиваемого плода, который сдает образец слюны. Оба набора генетических материалов для всех 100 пар отсылают обратно в лабораторию, где кровь матери осаждают центрифугированием и выделяют лейкоцитарную пленку, а также плазму крови. Плазма крови содержит смесь ДНК матери, а также происходящую из плаценты ДНК. Лейкоцитарную пленку матери и кровь отца генотипируют с использованием микроматриц для выявления SNP, и на ДНК в образах плазмы крови матери нацеливают гибридизационные зонды SURESELECT. Расщепленную ДНК с зондами используют для создания 100 меченных библиотек, по одной на каждый из материнских образцов, где каждый образец является помеченным разной меткой. Часть от каждой библиотеки забирают, каждую из этих частей смешивают вместе и добавляют в две дорожки секвенатора ДНК ILLUMINA HISEQ в мультиплексном режиме, где каждая дорожка дает в результате примерно 50 миллионов нанесенных на карту ридов, дает в результате примерно 100 нанесенных на карту ридов на 100 объединенных смесей или примерно 1 миллион ридов на образец. Риды последовательностей использовали для определения доли ДНК плода в каждой смеси. 50 из образцов имели более 15% ДНК плода в смеси, и 1 миллиона ридов было достаточно для определения статуса плоидности у плодов с достоверностью 99,9%. Из числа оставшихся смесей 25 содержали от 10% до 15% ДНК плода; часть каждой из полученных соответствующих библиотек из этих смесей объединяли и прогоняли по одной дорожке на HISEQ, генерируя дополнительные 2 миллиона ридов для каждого образца. Два набора данных секвенирования для каждой из смесей с 10-15% ДНК плода складывали, и получали в результате 3 миллиона ридов на образец, чего было достаточно для определения статуса плоидности у этих плодов с достоверностью 99,9%. Из числа оставшихся смесей 13 содержали от 6% до 10% ДНК плода; часть каждой из полученных соответствующих библиотек из этих смесей объединяли и прогоняли по одной дорожке на HISEQ, генерируя дополнительные 4 миллиона ридов для каждого образца. Два набора данных секвенирования для каждой из смесей с 6-10% ДНК плода складывали, и получали в сумме 5 миллионов ридов на смесь, чего было достаточно для определения статуса плоидности у этих плодов с достоверностью 99,9%. Из числа оставшихся смесей 8 содержали от 4% до 6% ДНК плода; часть каждой из полученных соответствующих библиотек из этих смесей объединяли и прогоняли по одной дорожке на HISEQ, генерируя дополнительные 6 миллионов ридов для каждого образца. Два набора данных секвенирования для каждой из смесей с 4-6% ДНК плода складывали, и получали в сумме 7 миллионов ридов на смесь, чего было достаточно для определения статуса плоидности у этих плодов с достоверностью 99,9%. Из оставшихся четырех смесей все содержали от 2% до 4% ДНК плода; часть каждой из полученных соответствующих библиотек из этих смесей объединяли и прогоняли по одной дорожке на HISEQ, генерируя дополнительные 12 миллионов ридов для каждого образца. Два набора данных секвенирования для каждой из смесей с 2-4% ДНК плода складывали, и получали в сумме 13 миллионов ридов на смесь, чего было достаточно для определения статуса плоидности у этих плодов с достоверностью 99,9%. Данный способ требует шести дорожек для секвенирования на аппарате HISEQ для достижения точности 99,9% на 100 образцах. Если бы то же количество прогонов требовалось для каждого образца, чтобы гарантировать, что каждое определение плоидности выполнялось с точностью 99,9%, это заняло бы 25 дорожек для секвенирования, и если бы частота отсутствия прогноза или частота ошибки 4% была допустимой, ее можно было бы достичь с 14 дорожками для секвенирования. Использование необработанных данных генотипирования Существует ряд способов, с помощью которых можно осуществлять NPD (неинвазивную пренатальную генетическую диагностику) с использованием генетической информации плода, полученной с помощью измерений на ДНК плода, находящейся в крови матери. Некоторые из этих способов включают проведение измерений ДНК плода с использованием микроматриц для выявления SNP, некоторые способы включают ненаправленное секвенирование и некоторые способы включают направленное секвенирование. Направленное секвенирование может быть направлено на SNP, оно может быть направлено на STR (короткие концевые повторы), оно может быть направлено на другие полиморфные локусы, оно может быть направлено на неполиморфные локусы или на их сочетание. Некоторые из этих способов могут включать использование коммерческого или проприетарного идентификатора аллеля, который указывает идентификационную информацию об аллелях, исходя из данных интенсивности, которые поступают от сенсоров в аппарате, выполняющем измерение. Например, система ILLUMINA INFINIUM или система для микроматричного анализа AFFYMETRIX GENECHIP включает бусины или микрочипы с присоединенными последовательностями ДНК, которые могут гибридизоваться с комплементарными сегментами ДНК; при гибридизации происходит изменение флуоресцентных свойств сенсорной молекулы, которое можно выявить. Также существуют способы секвенирования, например геномный секвенатор ILLUMINA SOLEXA GENOME SEQUENCER или геномный секвенатор ABI SOLID GENOME SEQUENCER, в которых секвенируют генетическую последовательность фрагментов ДНК; при продлении нити ДНК, комплементарной секвенируемой нити, идентификационную информацию для продолжаемого нуклеотида, как правило, детектируют через флуоресцентную или радиоизотопную метку, прикрепленную к комплементарному нуклеотиду. Во всех этих способах данные о генотипе или данные секвенирования, как правило, определяют на основе флуоресцентных или других сигналов или их отсутствия. Эти системы, как правило, объединены с пакетами низкоуровневого программного обеспечения, которое делает прогнозы для конкретного аллеля (вторичные генетические данные), исходя из аналоговых выводимых данных флуоресцентного или другого устройства для детектирования (первичные генетические данные). Например, в случае заданного аллеля на микроматрице для выявления SNP программное обеспечение будет делать прогноз, например того, что определенный SNP присутствует или не присутствует, если интенсивность флуоресценции является результатом измерения выше или ниже определенного порогового значения. Подобным образом, выводимые данные секвенатора представляют собой хроматограмму, которая показывает уровень флуоресценции, выявленный для каждого из красителей, и программное обеспечение будет делать прогноз того, что определенная пара оснований представляет собой A или T или C или G. Секвенаторы с высокой пропускной способностью, как правило, выполняют серию таких измерений, называемых ридом, который представляет наиболее вероятную структуру последовательности ДНК, которая подвергается секвенированию. Непосредственный аналог выводимых данных хроматограммы определен в данном описании как первичные генетические данные, и количество пар оснований/сигналов при SNP, производимые программным обеспечением рассматривают в данном описании как вторичные генетические данные. Согласно варианту осуществления первичные данные относятся к необработанным данным интенсивности, которые представляют собой выводимые данные от платформы для генотипирования без обработки, где платформа для генотипирования может относиться к микроматрице для выявления SNP или к платформе для секвенирования. Вторичные генетические данные относятся к обработанным генетическим данным, где был выполнен прогноз аллеля, или к данным секвенирования, которые были заданы в виде пар оснований, и/или ридам от секвенирования, которые были нанесены на карту генома. Многие высокоуровневые приложения используют эти прогнозы для аллея, прогнозы для SNP и риды для последовательности, то есть вторичные генетические данные, которые производит программное обеспечение для генотипирования. Например, DNA NEXUS, ELAND или MAQ будут брать риды от секвенирования и наносить их на карту генома. Например, применительно к неинвазивной пренатальной диагностике сложное средство на основе информатики, такое как PARENTAL SUPPORT™, может максимально использовать большое количество прогнозов для SNP для определения генотипа индивида. Также, применительно к преимплантационной генетической диагностике можно взять набор ридов для последовательности, которые нанесены на карту генома, и взяв нормализованное количество импульсов счета для ридов, которые можно нанести на карту каждой хромосомы или части хромосомы, можно определить статус плоидности индивида. Применительно к неинвазивной пренатальной диагностике можно взять набор ридов для последовательности, которые были измерены в присутствующей в плазме крови матери ДНК, и нанести их на карту генома. Специалист может взять нормализованное количество импульсов счета для ридов, которые можно нанести на карту каждой хромосомы или части хромосомы, и использовать эти данные для определения статуса плоидности у индивида. Например, можно сделать вывод, что те хромосомы, которые характеризуются непропорционально большим количеством ридов, являются трисомными у плода вынашиваемого матерью, у которой брали кровь. Однако в действительности исходные выводимые данные от измерительных приборов представляют собой аналоговый сигнал. Когда определенная пара оснований прогнозируется программным обеспечением, которое связано с программным обеспечением для секвенирования, например программное обеспечение может указывать пару оснований T, тогда как в действительности указание представляет собой прогноз, который, как предполагает программное обеспечение, является наиболее вероятным. В некоторых случаях, однако, прогноз может иметь низкую достоверность, например, аналоговый сигнал может указывать, что конкретная пара оснований с вероятностью только 90% представляет собой T, а с вероятностью 10% представляет собой A. В другом примере прогнозирующее генотип программное обеспечение, которое связано с ридером микроматриц для выявления SNP, может прогнозировать, что определенный аллель представляет собой G. Однако в действительности лежащий в основе аналоговый сигнал может указывать на существование только 70% вероятности того, что аллель представляет собой G, и 30% вероятности того, что аллель представляет собой T. В этих случаях, если высокоуровневые приложения используют прогнозы для генотипа и прогнозы для секвенирования, выполняемые низкоуровневым программным обеспечением, они теряют некоторое количество информации. То есть, первичные генетические данные, которые измерены непосредственно с помощью платформы для генотипирования, могут быть ʺгрязнееʺ, чем вторичные генетические данные, которые определены с помощью прикладных пакетов программного обеспечения, но они содержат больше информации. При нанесении вторичных генетических данных для последовательностей на карту генома многие риды выбрасывают, поскольку некоторые основания не прочитываются с достаточной ясностью и/или нанесение на карту не является однозначным. Когда используют первичные генетические данные для ридов последовательностей, все или многие из этих ридов, которые могли быть выброшены при первоначальном преобразовании во вторичные генетические данные для рида последовательности, могут быть использованы с помощью обработки ридов вероятностным методом. Согласно варианту осуществления настоящего раскрытия высокоуровневое программное обеспечение не использует прогнозы для аллеля, прогнозы для SNP или риды последовательности, которые выполняются низкоуровневым программным обеспечением. Вместо этого высокоуровневое программное обеспечение основывает свои расчеты на аналоговых сигналах, непосредственно измеряемых платформой для генотипирования. Согласно варианту осуществления настоящего раскрытия способ на основе информатики, такой как PARENTAL SUPPORT™, модифицируют с тем, чтобы его способность реконструировать генетические данные эмбриона / плода / ребенка давала возможность непосредственного использования первичных генетических данных, которые измеряются платформой для генотипирования. Согласно варианту осуществления настоящего раскрытия с помощью способа на основе информатики, такого как PARENTAL SUPPORT™, можно выполнить прогнозы для аллелей и/или прогнозы для количества копий хромосомы с использованием первичных генетических данных и без использования вторичных генетических данных. Согласно варианту осуществления настоящего раскрытия все генетические прогнозы, прогнозы для SNP, риды последовательности, результаты нанесения последовательности на карту обрабатывают вероятностным методом при использовании необработанных данных интенсивности, которые измерены непосредственно платформой для генотипирования, а не путем превращения первичных генетических данных во вторичные генетические прогнозы. Согласно варианту осуществления данные, полученные с помощью измерений ДНК из подготовленного образца, используемые при расчете вероятности количества импульсов счета для аллеля и определении относительной вероятности каждой гипотезы, содержат первичные генетические данные. Согласно некоторым вариантам осуществления способ может повышать точность генетических данных целевого индивида, при это учитывая генетические данные по меньшей мере одного родственного индивида, способ включает получение первичных генетических данных, специфических для генома целевого индивида, и генетических данных, специфических для генома (геномов) родственного индивида (индивидов), создание набора из одной или нескольких гипотез, касающихся, возможно, того, какие сегменты каких хромосом от родственного индивида (индивидов) соответствуют таким сегментам в геноме целевого индивида, определение вероятности каждой из гипотез с учетом первичных генетических данных целевого индивида и генетических данных родственного индивида (индивидов) и использование вероятностей, связанных с каждой гипотезой, для определения наиболее вероятного состояния имеющегося генетического материала от целевого индивида. Согласно некоторым вариантам осуществления с помощью способа можно определить количество копий сегмента хромосомы в геноме целевого индивида, при этом способ включает создание набора гипотез количества копий о том, какое количество копий сегмента хромосомы присутствует в геноме целевого индивида, включение первичных генетических данных от целевого индивида и генетической информации от одного или нескольких родственных индивидов в набор данных, оценка характеристик полученного платформой ответного сигнала, связанного с набором данных, где ответный сигнал, полученный платформой, может изменяться от одного эксперимента к другому, вычисление обусловленных вероятностей гипотезы каждого количества копий с учетом набора данных и характеристик ответного сигнала, полученного платформой, и определение числа копий сегмента хромосомы, исходя из наиболее вероятной гипотезы количества копий. Согласно варианту осуществления с помощью способа согласно настоящему раскрытию можно определить статус плоидности для по меньшей мере одной хромосомы у целевого индивида, при этом способ включает получение первичных генетических данных от целевого индивида и от одного или нескольких родственных индивидов, создание набора из по меньшей мере одной гипотезы статуса плоидности для каждой из хромосом целевого индивида, использование одной или нескольких экспертных методик для определения статистической вероятности каждой гипотезы статуса плоидности в наборе для каждой используемой экспертной методики с учетом полученных генетических данных, объединение статистических вероятностей для каждой гипотезы статуса плоидности, которые определены с помощью одной или нескольких экспертных методик, и определение статуса плоидности для каждой из хромосом у целевого индивида, исходя из объединенных статистических вероятностей для каждой гипотезы статуса плоидности. Согласно варианту осуществления с помощью способа согласно настоящему раскрытию можно определить аллельный статус в наборе аллелей у целевого индивида, и у одного или обоих родителей целевого индивида, и необязательно у одного или нескольких родственных индивидов, при этом способ включает получение первичных генетических данных от целевого индивида, и от одного или обоих родителей, и от любых родственных индивидов, создание набора из по меньшей мере одной гипотезы в отношении аллеля для целевого индивида, и для одного или обоих родителей, и необязательно для одного или нескольких родственных индивидов, где гипотезы описывают возможные аллельные статусы в наборе аллелей, определение статистической вероятности для каждой гипотезы в отношении аллеля в наборе гипотез с учетом полученных генетических данных и определение аллельного статуса для каждого из аллелей в наборе аллелей для целевого индивида, и для одного или обоих родителей, и необязательно для одного или нескольких родственных индивидов, исходя из статистических вероятностей каждой из гипотез в отношении аллеля. Согласно некоторым вариантам осуществления генетические данные от смешанного образца могут включать данные секвенирования, где данные секвенирования могут не быть однозначно нанесенными на карту генома человека. Согласно некоторым вариантам осуществления генетические данные от смешанного образца могут содержать данные секвенирования, где данные секвенирования нанесены на карту, соответствующую множеству мест нахождения в геноме, где каждый возможный результат нанесения на карту связан с вероятностью того, что данное нанесение на карту является верным. Согласно некоторым вариантам осуществления не предполагается, что риды последовательности связаны с конкретным положением в геноме. Согласно некоторым вариантам осуществления риды последовательности связаны с множеством положений в геноме и связанной вероятностью принадлежности к этому положению. Сочетание способов пренатальной диагностики Существует много способов, которые можно использовать для пренатальной диагностики или пренатального скрининга в отношении анеуплоидии или других генетических дефектов. В других местах в данном документе и в заявке США на полезную модель с серийным номером 11/603406, поданной 28 ноября 2006 года; заявке США на полезную модель с серийным номером 12/076348, поданной 17 марта 2008 года, и PCT заявке на полезную модель с серийным номером PCT/S09/52730 описан один такой способ, в котором генетические данные родственных индивидов используются для повышения точности, с которой определяют или оценивают генетические данные целевого индивида, такого как плод. Другие способы, применяемые для пренатальной диагностики, включают измерение уровней определенных гормонов в крови матери, где концентрация этих гормонов коррелирует с различными генетическими аномалиями. Пример подобных анализов называется тройным тестом, при котором в крови матери измеряют уровни нескольких (зачастую двух, трех, четырех или пяти) различных гормонов. В случае, когда применяют несколько способов для определения правдоподобия заданного конечного результата, где ни один из способов не является исчерпывающим сам по себе, можно сочетать информацию, получаемую с помощью этих способов, чтобы получить прогноз более точный, чем от любого из способов по-отдельности. При тройном тесте объединение информации, получаемой для трех различных гормонов, может дать в результате прогноз генетических аномалий, который является более точным, чем тот, который можно сделать по уровням отдельных гормонов. В данном документе раскрыт способ получения более точных прогнозов в отношении генетического статуса плода, в частности, возможности генетических аномалий у плода, который включает объединение прогнозов генетических аномалий у плода, где эти прогнозы выполняют с использованием ряда способов. ʺБолее точныйʺ способ может относиться к способу диагностики аномалии, который характеризуется более низким относительным числом ложноотрицательных результатов при заданном относительном числе ложноположительных результатов. В предпочтительном варианте осуществления согласно настоящему раскрытию один или несколько из прогнозов получают на основе генетических данных, известных для плода, где генетические сведения были получены с использованием способа PARENTAL SUPPORT™, то есть с использованием генетических данных от родственных плоду индивидов для определения генетических данных плода с большей точностью. Согласно некоторым вариантам осуществления генетические данные могут включать статус плоидности плода. Согласно некоторым вариантам осуществления генетические данные могут касаться набора прогнозов для аллелей в геноме плода. Согласно некоторым вариантам осуществления некоторые из прогнозов могли быть получены с использованием тройного теста. Согласно некоторым вариантам осуществления некоторые из прогнозов могли быть получены с использованием измерений уровней других гормонов в крови матери. Согласно некоторым вариантам осуществления прогнозы, полученные с помощью рассмотренных способов диагностики, можно объединить с прогнозами, полученными с помощью рассмотренных способов скрининга. Согласно некоторым вариантам осуществления способ включает измерение уровней альфа-фетопротеина (AFP) в крови матери. Согласно некоторым вариантам осуществления способ включает измерение уровней неконъюгированного эстриола (UE3) в крови матери. Согласно некоторым вариантам осуществления способ включает измерение уровней бета-хоринического гонадотропина человека (beta-hCG) в крови матери. Согласно некоторым вариантам осуществления способ включает измерение уровней инвазивного трофобластического антигена (ITA) в крови матери. Согласно некоторым вариантам осуществления способ включает измерение уровней ингибина в крови матери. Согласно некоторым вариантам осуществления способ включает измерение уровней ассоциированного с беременностью плазменного протеина A (PAPP-A) в крови матери. Согласно некоторым вариантам осуществления способ включает измерение уровней других гормонов или сывороточных маркеров в крови матери. Согласно некоторым вариантам осуществления некоторые из прогнозов могли быть получены с использованием других способов. Согласно некоторым вариантам осуществления некоторые из прогнозов могли быть получены с использованием полностью интегрированного теста, такого как объединяющий ультразвуковое исследование и анализ крови примерно на 12 неделе беременности и второго анализа примерно на 16 неделе. Согласно некоторым вариантам осуществления способ включает измерение прозрачности шейной складки (NT) у плода. Согласно некоторым вариантам осуществления способ включает использование измеренных уровней вышеупомянутых гормонов для получения прогнозов. Согласно некоторым вариантам осуществления способ включает сочетание вышеупомянутых способов. Существует много способов объединения прогнозов, например, специалист в данной области техники может преобразовать результаты измерений гормонов в кратное медианы (MoM) и затем в отношения правдоподобия (LR). Подобным образом, другие измеряемые показатели можно трансформировать в LR с использованием смешанной модели распределений показателя NT. LR для показателей NT и биохимических маркеров можно умножить на риск, связанный с возрастом и вынашиванием, для получения значений риска для различных состояний, таких как трисомия по 21 хромосоме. Частоты обнаружения (DR) и частоты ложноположительных результатов (FPR) можно рассчитать, взяв соотношения рисков выше заданного порогового значения риска. Согласно варианту осуществления способ прогнозирования статуса плоидности включает объединение относительных вероятностей каждой из определяемых гипотез плоидности с использованием модели совместного распределения и вероятностей количества импульсов счета для аллеля с относительными вероятностями каждой из гипотез плоидности, которые рассчитывают с использованием статистических методик, взятых из других способов, которые определяют оценку риска трисомии у плода, включающих, но не ограничивающихся следующим: анализ количества импульсов счета для ридов, сравнение степеней гетерозиготности, статистические методы, которые доступны только при использовании генетической информации от родителей, вероятность нормализованных сигналов для генотипа в определенных родительских контекстах, статистические показатели, которые рассчитывают с использованием оцененной доли ДНК плода в первом образце или подготовленном образце, и их сочетания. Другой способ может включать ситуацию с измеряемыми уровнями четырех гормонов, где распределение вероятности для этих гормонов является известным: p(x1, x2, x3, x4|e) для случая эуплоидии и p(x1, x2, x3, x4|a) для случая анеуплоидии. Затем специалист в данной области техники может получить распределение вероятности для показателей, полученных с помощью измерения ДНК, g(y|e) и g(y|a) для случаев эуплоидии и анеуплоидии, соответственно. Предполагая, что они являются независимыми с учетом предположения об эуплоидии/анеуплоидии, специалист в данной области техники может объединить их в виде p(x1, x2, х3, x4|a)g(y|a) и p(x1, x2, х3, x4|e)g(y|e) и затем умножить каждую из них на априорные p(a) и p(e) с учетом возраста матери. Специалист в данной области техники может затем выбрать значение, которое является самым высоким. Согласно варианту осуществления можно вызвать центральную предельную теорему, чтобы предположить, что распределение в g(y|a или e) является гауссовым, и измерить среднее значение и стандартное отклонение, учитывая множество образцов. Согласно другому варианту осуществления специалист в данной области техники может предположить, что они не являются независимыми с учетом результата, и собрать достаточно образцов для оценки совместного распределения p(x1, x2, x3, x4|a или e). Согласно варианту осуществления статус плоидности у целевого индивида определяют как статус плоидности, который связан с гипотезой, чья вероятность является наибольшей. В некоторых случаях одна гипотеза будет иметь нормализованную объединенную вероятность более 90%. Каждая гипотеза является связанной с одним или набором статусов плоидности, и статус плоидности, связанный с гипотезой, чья нормализованная объединенная вероятность является большей, чем 90% или какая-либо другая величина порогового значения, как например, 50%, 80%, 95%, 98%, 99%, или 99,9%, может быть выбран в качестве порогового значения, необходимого для объявления гипотезы определенным статусом плоидности. ДНК от детей от предыдущих беременностей в крови матери Одна из трудностей для неинвазивной пренатальной диагностики заключается в том, чтобы отличить клетки плода от наблюдаемой в настоящее время беременности от клеток плода от предыдущих беременностей. Некоторые полагают, что генетический материал от предыдущих беременностей будет исчезать через некоторое время, но неоспоримые доказательства этого не были предоставлены. Согласно варианту осуществления настоящего раскрытия можно определить происходящую от отца ДНК плода, присутствующую в крови матери, (то есть ДНК, которую плод унаследовал от отца) с использованием способа PARENTAL SUPPORT™ (PS) и сведений о геноме отца. В этом способе может использоваться фазированная генетическая информация от отца. Можно фазировать генотип отца, исходя из информации для генотипирования в нефазированной форме с использованием генетических данных от деда (таких как генетические данные, полученные с помощью измерений на сперме от деда), или генетических данных от других рожденных детей, или образца из выкидыша. Специалист в данной области техники может также фазировать генетическую информацию в нефазированной форме посредством фазирования на основе карт гаплотипов HapMap или гаплотипирования клеток отца. Успешное гаплотипирование было продемонстрировано при задержке клеток на фазе митоза, когда хромосомы представляют собой тугие пучки, и использовании микрогидродинамических методов для помещения отдельных хромосом в отдельные лунки. Согласно другому варианту осуществления можно использовать фазированные данные гаплотипирования от отца для выявления присутствия более чем одного гомолога от отца, подразумевая, что в крови присутствует генетический материал от более чем одного ребенка. Сосредоточив внимание на хромосомах, которые, как ожидается, являются эуплоидными у плода, специалист может исключить возможность того, что плод имеет трисомию. Определение также возможно, если ДНК плода не происходит от нынешнего отца, в этом случае специалист может использовать другие способы, такие как тройной тест, для прогноза генетических аномалий. Существует много других источников генетического материала плода, доступных посредством способов, отличающихся от забора крови. В случае, когда генетический материал плода доступен в крови матери, существуют две основных его категории: (1) цельные клетки плода, например ядерные красные кровяные клетки плода или эритробласты, и (2) свободноплавающая ДНК плода. В случае цельных клеток плода, существуют некоторые доказательства того, что клетки плода могут сохраняться в крови матери в течение длительного периода времени, так что является возможным выделение из беременной женщины клетки, которая содержит ДНК от ребенка или плода от предыдущей беременности. Также существует доказательство того, что свободноплавающая ДНК плода удаляется из системы в течение нескольких недель. Одна сложность заключается в том, как определить принадлежность индивида, чей генетический материал содержится в клетке, а именно, чтобы убедиться в том, что генетический материал, на котором проводят измерения, не происходит из плода от предыдущей беременности. Согласно варианту осуществления настоящего раскрытия сведения о генетическом материале матери можно использовать, чтобы убедиться в том, что генетический материал, о котором идет речь, не является генетическим материалом матери. Существует ряд способов достижения такого результата, включая способы на основе информатики, такие как PARENTAL SUPPORT™, описанные в данном документе или в любом из патентов, на которые ссылается данный документ. Согласно варианту осуществления настоящего раскрытия кровь, забранную у беременной матери, можно разделить на фракцию, содержащую свободноплавающую ДНК плода, и фракцию, содержащую ядерные красные кровяные клетки. Свободноплавающую ДНК можно необязательно обогатить и получить от ДНК с помощью измерений информацию о генотипе. Исходя из информации о генотипе, полученной с помощью измерений свободноплавающей ДНК, сведения о генотипе матери можно использовать для определения характеристик генотипа плода. Эти характеристики могут относиться к статусу плоидности и/или идентификационным данным для набора аллелей. Затем, отдельные ядерные красные кровяные клетки можно генотипировать с использованием способов, описанных в других местах в данном документе и других патентах, на которые ссылается данный документ, особенно упомянутых в первом разделе данного документа. Сведения о геноме матери позволят специалисту в данной области техники определить, является ли любая заданная отдельная кровяная клетка генетически материнской или нет. И характеристики генотипа плода, которые были определены, как описано выше, позволят специалисту в данной области техники определить, если отдельная кровяная клетка является генетически происходящей от плода, который вынашивается в настоящее время. В сущности, аспект настоящего раскрытия позволяет специалисту в данной области техники использовать генетические сведения от матери и, возможно, генетическую информацию от других родственных индивидов, таких как отец, вместе с генетической информацией, полученной с помощью измерений свободноплавающей ДНК, обнаруживаемой в крови матери, для определения того, является ли выделенная ядерная клетка, обнаруживаемая в крови матери, (a) генетически материнской, (b) генетически происходящей из плода, вынашиваемого в настоящее время, или (c) генетически происходящей из плода от предыдущей беременности. Пренатальное определение анеуплоидии половых хромосом В известных в уровне техники способах специалисты в попытках определить пол вынашиваемого плода по крови матери, использовали тот факт, что в плазме матери присутствует плодная свободно плавающая ДНК (fffDNA). Если выявляются Y-специфичные локусы в материнской плазме, это означает, что вынашиваемый плод мужского пола. Однако при использовании известных в уровне техники способов отсутствие выявленных Y-специфичных локусов в плазме не всегда гарантирует то, что вынашиваемый плод женского пола, поскольку в некоторых случаях количество fffDNA слишком мало для того, чтобы можно было гарантировать, что Y-специфичные локусы будут выявлены в случае плода мужского пола. В настоящем документе представлен новый способ, который не требует измерения Y-специфичных нуклеиновых кислот, т.е. ДНК из локусов исключительно отцовского происхождения. В раскрытом ранее методе PARENTAL SUPPORT для определения состояния плоидности вынашиваемого плода используются данные частоты кроссинговера, родительские генотипические данные и методики информатики. Пол плода - это просто состояние плоидности половых хромосом плода. Ребенок женского пола имеет генотип XX, а мужского пола - XY. Описанный в настоящем документе способ также дает возможность определить состояние плоидности плода. Следует отметить, что определение пола является фактически синонимом определения плоидности половых хромосом; в случае определения пола часто формулируется предположение, что ребенок эуплоидный, следовательно, возможных гипотез становится меньше. Раскрытый в настоящем документе способ предусматривает изучение локусов, которые являются общими и для X, и для Y хромосом, для создания базового уровня по показателю ожидаемого количества присутствующей плодной ДНК для плода. Затем области, специфичные только для X-хромосомы, могут быть изучены для определения того, является ли плод женского или мужского пола. В случае мужского пола ожидается увидеть меньше плодной ДНК из локусов, специфичных для X-хромосомы, чем из локусов, специфичных и для X-, и для Y-хромосом. Напротив, если плоды женского пола, ожидается, что количество ДНК для каждой из этих групп будет одинаковым. Исследуемая ДНК может быть измерена любой методикой, которая количественно определяет количество ДНК, присутствующей в образце, например, количественная ПЦР, матрицы SNP, матрицы генотипирования или секвенирование. Для ДНК, которая принадлежит исключительно одному индивидууму, ожидается увидеть следующее:
В случае, если ДНК плода смешана с ДНК матери, и фракция плодной ДНК в смеси представляет собой F, и если фракция материнской ДНК в смеси представляет собой M, так что F+M=100%, ожидается увидеть следующее:
В случае, если F и M известны, можно вычислить ожидаемые отношения и наблюдаемые данные можно сравнить с ожидаемыми данными. В случае, если Мир неизвестны, порог может быть выбран на основании накопленных данных. В обоих случаях измеренное количество ДНК в локусах, специфичных и для X, и для Y, может быть использовано в качестве базового уровня, и тест на определение пола плода может быть основан на количестве ДНК, наблюдаемом в локусах, специфичных только для X-хромосомы. Если это количество меньше базового уровня приблизительно на ½ F, или на величину, которая ставит его ниже заранее определенного порога, устанавливается, что плод мужского пола, и если это количество приблизительно равно базовому уровню, или если оно не ниже на величину, которая ставит его ниже заранее определенного порога, устанавливается, что плод женского пола.
Согласно другому варианту осуществления можно рассматривать только те локусы, которые являются общими и для X-, и для Y-хромосом, часто называемых Z-хромосомой. Поднабор локусов в Z-хромосоме всегда обозначается A для X-хромосомы и B для Y-хромосомы. Если выясняется, что SNP из Z-хромосомы имеют B-генотип, то считается, что плод мужского пола; если выясняется, что SNP из Z-хромосомы имеют только A-генотип, то считается, что плод женского пола. Согласно другому варианту осуществления можно рассматривать локусы, которые обнаруживаются только в X-хромосоме. Контексты, такие как AA|B являются особенно информативными, поскольку присутствие B указывает на то, что плод получил X-хромосому от отца. Контексты, такие как AB|B также информативны, поскольку ожидается увидеть, что B присутствует в количестве в 2 раза меньшем, как это часто бывает в случае, если плод женского пола, по сравнению с плодом мужского пола. Согласно другому варианту осуществления можно рассматривать SNP в Z-хромосоме, при этом в X- и Y-хромосомах присутствуют как аллель A, так и аллель B, и при этом известно, какие SNP происходят из отцовской Y-хромосомы, A какие из отцовской X-хромосомы.
Согласно варианту осуществления можно амплифицировать однонуклеотидные положения, которые, как известно, варьируют между гомологичными нерекомбинирующимися областями (HNR), общими для Y- и X-хромосом. Последовательность в пределах такой области HNR в основном идентична между X- и Y-хромосомами. Внутри этой идентичной области имеются однонуклеотидные положения, которые, будучи инвариантыми среди X-хромосом и среди Y хромосом в популяции, различны у X- и Y-хромосом. Каждый анализ ПЦР может амплифицировать последовательность из локусов, присутствующих и в X-, и в Y-хромосомах. В каждой амплифицированной последовательности будет одно основание, которое может быть выявлено с использованием секвенирования или некоторых других способов.
Согласно варианту осуществления пол плода можно установить по плодной свободно плавающей ДНК, обнаруживаемой в материнской плазме, способ предусматривает некоторые или все следующие этапы: 1) конструирование праймеров ПЦР (или обычной или мини-ПЦР с мультиплексированием при желании), амплифицирующих варианты X/Y однонуклеотидных положений в области HNR, 2) получение материнской плазмы, 3) ПЦР, амплификация целей из материнской плазмы с использованием матриц ПЦР для HNR X/Y, 4) секвенирование ампликонов, 5) проверка данных секвенировния на предмет присутствия Y-аллеля в одной или нескольких амплифицированных последовательностях. Присутствие одного или нескольких таких аллелей будет свидетельствовать о том, что плод мужского пола. Отсутствие всех Y-аллелей во всех ампликонах указывает на то, что плод женского пола.
Согласно варианту осуществления можно использовать целевое секвенирование для измерения ДНК в материнской плазме и/или родительских генотипов. Согласно варианту осуществления можно игнорировать все последовательности, которые явно происходят из родительских источников ДНК. Например, в контексте AA|AB можно подсчитать число A-последовательностей и проигнорировать все B-последовательности. Чтобы определить степень гетерозиготности для вышеупомянутого алгоритма, можно сравнить число наблюдаемых A-последовательностей с ожидаемым числом общих последовательностей для данного зонда. Существует много способов, с помощью которых можно рассчитать ожидаемое число последовательностей для каждого зонда на образец. Согласно варианту осуществления можно использовать накопленные данные для определения фракции всех считываний последовательностей, принадлежащей каждому специфичному зонду, а затем использовать эту эмпирическую фракцию в комбинации с общим числом считываний последовательностей для оценки числа последовательностей по каждому зонду. Другой подход может заключаться в нацеливании на некоторые известные гомозиготные аллели и в последующем использовании накопленных данных для того, чтобы соотнести число считываний по каждому зонду с числом считываний известных гомозиготных аллелей. Для каждого образца затем можно измерить число считываний гомозиготных аллелей, а затем использовать это измерение вместе с эмпирически выведенными взаимосвязями для оценки числа считываний последовательностей по каждому зонду.
Согласно некоторым вариантам осуществления можно определить пол плода путем объединения прогнозов, выполненных несколькими способами. Согласно некоторым вариантам осуществления несколько способов выбраны из описанных в настоящем раскрытии способов. Согласно некоторым вариантам осуществления по меньшей мере один из нескольких способов выбран из описанных в настоящем раскрытии способов.
Согласно некоторым вариантам осуществления описанный в настоящем документе способ может быть использован для определения состояния плоидности вынашиваемого плода. Согласно варианту осуществления в способе выяснения плоидности используются локусы, специфичные для X-хромосомы или общие и для X-, и для Y-хромосом, но не используются какие-либо Y-специфичные локусы. Согласно варианту осуществления в способе выяснения плоидности используется один или несколько из следующего: локусы, специфичные для X-хромосомы, локусы, общие и для X-, и для Y-хромосом, и локусы, специфичных для Y-хромосомы. Согласно варианту осуществления, если отношения половых хромосом подобны, например, 45, X (синдром Тернера), 46, XX (нормальная женщина) и 47, XXX (трисомия X), установление различий может быть выполнено путем сравнения аллельных распределений с ожидаемыми аллельными распределениями в соответствии с различными гипотезами. Согласно другому варианту осуществления это может быть выполнено путем сравнения относительного числа считываний последовательностей для половых хромосом с одной или множеством эталонных хромосом, которые предположительно эуплоидны. Также следует отметить, что эти способы могут быть расширены для включения случаев анеуплоидии.
Скрининг. моногенных заболеваний
Согласно варианту осуществления способ определения состояния плоидности плода может быть расширен для обеспечения возможности одновременного тестирования на моногенные заболевания. Диагностика моногенных заболеваний предусматривает те же целевые подходы, которые используются для тестирования на анеуплоидию, и требует дополнительных специфичных целей. Согласно варианту осуществления диагностика моногенного NPD осуществляется посредством анализа сцепления. Во многих случаях прямое тестирование образца cfDNA не надежно, поскольку присутствие материнской ДНК делает практически невозможным определение наследования плодом мутации матери. Выявление уникального аллеля отца менее проблематично, но оно полностью информативно только, если заболевание является доминантным признаком, и отец является носителем, что ограничивает практическую ценность этого подхода. Согласно варианту осуществления способ предусматривает ПЦР или связанные с ней подходы амплификации.
Согласно некоторым вариантам осуществления способ предусматривает фазирование аномального аллеля с окружающими очень тесно сцепленными SNP у родителей с использованием информации о родственниках первой степени родства. Затем может быть проведен PARENTAL SUPPORT на данных целевого секвенирования, полученных по этим SNP, с целью определения того, какие гомологи, нормальные или аномальные, плод унаследовал от обоих родителей. При условии, что SNP достаточно сцеплены, наследование генотипа плодом может быть установлено с большой надежностью. Согласно некоторым вариантам осуществления способ предусматривает (a) добавление набора локусов SNP для плотного фланкирования определенного набора распространенных заболеваний с мультиплексным пулом в соответствии с настоящим изобретением для тестирования на анеуплоидию; (b) надежное фазирование аллелей из этих добавленных SNP с нормальными и аномальными аллелями на основе генетических данных о разных родственниках и (c) реконструкцию диплотипа плода или набора фазированных аллелей SNP в унаследованных материнских и отцовских гомологах в области, окружающей локус заболевания, с целью установления генотипа плода. Согласно некоторым вариантам осуществления к набору полиморфных локусов, используемых для тестирования на анеуплоидию, добавляются дополнительные зонды, которые тесно сцеплены со связанным с заболеванием локусом.
Реконструкция диплотипа плода затруднительна, потому что образец представляет собой смесь материнской и плодной ДНК. Согласно некоторым вариантам осуществления способ предусматривает относительную информацию для фазирования SNP и аллелей заболевания, затем учитывает физическое расстояние SNP и данные о рекомбинации, исходя из правдоподобия рекомбинации специфичных локализаций, и данные, наблюдаемые по генетическим измерениям материнской плазмы, для получения наиболее вероятного генотипа плода.
Согласно варианту осуществления число дополнительных зондов на связанный с заболеванием локус включается в набор целевых полиморфных локусов; число дополнительных зондов на связанный с заболеванием локус может составлять от 4 до 10, от 11 до 20, от 21 до 40, от 41 до 60, от 61 до 80 или их комбинации.
Определение числа молекул ДНК в образце
В настоящем документе описывается способ определения числа молекул ДНК в образце путем образования уникально идентифицируемой молекулы для каждой из оригинальных молекул ДНК в образце во время первого раунда амплификации ДНК. В настоящем документе описывается процедура для осуществления вышеупомянутой цели с последующим секвенированием единичной молекулы или клональным секвенированием.
Этот подход предусматривает нацеливание на один или несколько специфичных локусов и генерирование маркированной копии оригинальных молекул таким образом, что большинство или все маркированные молекулы из каждого целевого локуса будут нести уникальный маркер, и их можно будет различать при секвенировании этого штрихкода с использованием клонального секвенирования или секвенирования единичных молекул. Уникальный штрихкод каждой из последовательностей представляет уникальную молекулу в оригинальном образце. Одновременно данные секвенирования используются для выяснения локуса, из которого происходит молекула. С использованием этой информации можно определить число уникальных молекул в оригинальном образце для каждого локуса.
Этот способ может быть использован в любых применениях, для которых требуется количественная оценка числа молекул в оригинальном образце. Более того, число уникальных молекул одной или нескольких целей может быть соотнесено с числом уникальных молекул одной или нескольких других целей для определения относительного числа копий, аллельного распределения или аллельного отношения. В качестве альтернативы, число копий, установленное для различных целей, может быть смоделировано по распределению, чтобы идентифицировать наиболее вероятное число копий оригинальных целей. Применения предусматривают без ограничения выявление инсерций и делеций, таких как обнаруженные у носителей мышечной дистрофии Дюшенна; количественное определение делеций или дупликаций сегментов хромосом, таких как наблюдаемые при вариантах числа копий; число копий хромосом в образцах рожденных индивидуумов; число копий хромосомы в образцах нерожденных индивидуумов, таких как эмбрионы или плоды.
Возможно комбинирование способа с одновременной оценкой вариаций, содержащихся в целевой последовательности. Он может быть использован для определения числа молекул, представляющих каждый аллель в оригинальном образце. Этот способ определения числа копий можно комбинировать с оценкой SNP или других вариаций последовательностей для определения числа копий хромосом рожденных и нерожденных индивидуумов; различения и количественного определения копий локусов, которые содержат вариации коротких последовательностей, но в которых ПЦР может амплифицировать множество целевых областей, таких как у носителя делеции атрофии остистой мышцы; определения числа копий различных источников молекул из образцов, содержащих смеси материала различных индивидуумов, например, при определении анеуплоидии плода по свободно плавающей ДНК, полученной из материнской плазмы.
Согласно варианту осуществления способ, касающийся единичного целевого локуса, может предусматривать один или несколько следующих этапов. (1) Конструирование стандартной пары олигомеров для ПЦР-амплификации специфичного локуса. (2) Добавление во время синтеза последовательности определенных оснований с минимальной комплементарностью к целевому локусу или геному с 5'-конца одного из специфичных по отношению к цели олигомеров или без таковой. Эта последовательность, называемая хвостом, является известной последовательностью, она предназначена для последующей амплификации, и за ней следует последовательность из случайных нуклеотидов. Эти случайные нуклеотиды составляют случайную область. Случайная область содержит случайно образованную последовательность нуклеиновых кислот, которые в вероятностном смысле отличаются у молекулы каждого зонда. Следовательно, после синтеза пул олигомеров с хвостами будет состоять из коллекции олигомеров, начинающихся с известной последовательности с последующей неизвестной последовательностью, которая отличается у молекул, после которой следует специфичная по отношению к цели последовательность. (3) Проведение одного раунда амплификации (денатурации, отжига, удлинения) с использованием только олигомеров, снабженных хвостами. (4) Добавление в реакционную смесь экзонуклеазы, которая эффективно останавливает ПЦР, и инкубация реакционной смеси при соответствующей температуре для удаления прямых одноцепочечных олигонуклеотидов, которые не отжигаются с матрицей и удлиняются с образованием двухцепочечных продуктов. (5) Инкубация реакционной смеси при высокой температуре для денатурации экзонуклеазы и элиминации ее активности. (6) Добавление к реакционной смеси нового олигонуклеотида, который комплементарен хвосту олигомера, использованного в первой реакции вместе с другими специфичными по отношению к цели олигомерами для ПЦР-амплификации продукта, образованного в первом раунде ПЦР. (7) Продолжение амплификации для образования достаточного количества продукта для клонального секвенирования в 5'-3'-направлении. (8) Измерение амплифицированного продукта ПЦР несколькими способами, например, клональным секвенированием, до получения достаточного для охвата последовательности числа оснований.
Согласно варианту осуществления способ настоящего раскрытия предусматривает нацеливание на множественные локусы параллельно или иным образом. Праймеры для различных целевых локусов могут быть образованы независимо и смешаны для создания мультиплексных пулов ПЦР. Согласно варианту осуществления оригинальные образцы можно разделить на субпулы, и в каждом субпуле целями могут быть различные локусы до рекомбинирования и секвенирования. Согласно варианту осуществления могут быть проведены этап маркирования и ряд циклов амплификация до разделения пула для обеспечения эффективного нацеливания на все цели перед расщеплением и для улучшения последующей амплификации путем продолжения амплификации с использованием меньших наборов праймеров в разделенных субпулах.
Одним примером применения, при котором эта технология будет особенно полезна, является неинвазивная пренатальная диагностика анеуплоидии, при этом отношение аллелей в данном локусе или распределение аллелей в ряде локусов может быть использовано для определения числа копий хромосомы, присутствующих у плода. В этом контексте желательно амплифицировать ДНК, присутствующую в изначальном образце, сохраняя при этом относительные количества различных аллелей. При некоторых обстоятельствах, особенно в случаях, если имеется очень небольшое количество ДНК, например, меньше чем 5000 копий генома, меньше чем 1000 копий генома, меньше чем 500 копий генома и меньше чем 100 копий генома, можно столкнуться с явлением, называемым «бутылочное горлышко». Это наблюдается, если в изначальном образце имеется небольшое количество копий любого данного аллеля, и стандартные ошибки амплификации могут привести к тому, что в амплифицированном пуле ДНК отношения этих аллелей значительно отличаются от отношений, характерных для изначальной смеси ДНК. Применяя уникальный или почти уникальный набор штрихкодов для каждой цепочки ДНК перед стандартной ПЦР-амплификацией, можно исключить n-1 копий ДНК из набора n идентичных молекул секвенированной ДНК, ведущей происхождение от одной и той же оригинальной молекулы.
Например, представьте себе гетерозиготный SNP в геноме индивидуума и смесь ДНК индивидуума, в которой десять молекул каждого аллеля присутствуют в оригинальном образце ДНК. После амплификации может быть 100000 молекул ДНК, соответствующей этому локусу. Вследствие стохастических процессов отношение ДНК может составлять от 1:2 до 2:1, однако, поскольку каждая оригинальная молекула была маркирована уникальным маркером, можно будет установить, что ДНК в амплифицированном пуле происходит точно от 10 молекул ДНК каждого аллеля. Этот способ, следовательно, даст возможность более точного измерения относительных количеств каждого аллеля, чем способ, при котором не используется этот подход. Для способов, при которых желательно минимизировать систематическую ошибку подсчета числа аллелей при установлении относительных количеств, данный способ обеспечит получение более точных данных.
Сопоставление секвенированного фрагмента с целевым локусом может быть достигнуто с помощью ряда способов. Согласно варианту осуществления для охвата штрихкода молекулы и достаточного числа уникальных оснований, соответствующих целевой последовательности, из целевого фрагмента получают последовательность достаточной длины для обеспечения однозначной идентификации целевого локуса. Согласно другому варианту осуществления праймер молекулярного штрихкодирования, который содержит случайно образованный молекулярный штрихкод, может также содержать специфичный по отношению к локусу штрихкод (штрихкод локуса), который идентифицирует цель, с которой он должен быть ассоциирован. Этот штрихкод локуса будет идентичен среди всех праймеров молекулярного штрихкодирования для каждой индивидуальной цели и, следовательно, для всех получающихся в результате ампликонов, но различен для всех других целей. Согласно варианту осуществления описанный в настоящем документе способ маркирования может комбинироваться с протоколом одностороннего вложения.
Согласно варианту осуществления конструирование и получение праймеров молекулярного штрихкодирования может быть на практике сведено к следующему: праймеры молекулярного штрихкодирования могут состоять из последовательности, которая не комплементарна целевой последовательности с последующей случайной областью молекулярного штрихкода, за которой следует специфичная по отношению к цели последовательность. Последовательность молекулярного штрихкода на 5'-конце может быть использована для последующей ПЦР-амплификации и может содержать последовательности, полезные для превращения ампликона в библиотеку для секвенирования. Случайная последовательность молекулярного штрихкода может быть образована несколькими способами. Предпочтительным способом является синтез маркирующего молекулу праймера таким образом, чтобы во время синтеза области шртихкода в реакцию включались все четыре основания. Все или различные комбинации оснований могут быть определены с использованием кодов неопределенности IUPAC DNA. Таким образом, синтезированная коллекция молекул будет содержать случайную смесь последовательностей в области молекулярного штрихкода. Длина области штрихкода будет определять, сколько праймеров будут содержать уникальные штрихкоды. Число уникальных последовательностей связано с длиной области штрихкода как NL, где N представляет собой число оснований, как правило, 4, a L представляет собой длину штрихкода. Штрихкод из пяти оснований может дать до 1024 уникальных последовательностей; штрихкод из восьми оснований может дать до 65536 уникальных штрихкодов. Согласно варианту осуществления ДНК может быть измерена способом секвенирования, при котором данные последовательности представляют последовательность единичной молекулы. Могут быть предусмотрены способы, в которых единичные молекулы секвенируются непосредственно, или способы, в которых единичные молекулы амплифицируются с образованием клонов, выявляемых с помощью инструмента секвенирования, но все же представляют единичные молекулы, что называется в настоящем документе клональным секвенированием.
Некоторые варианты осуществления
Согласно некоторым вариантам осуществления раскрывается способ генерирования отчета, раскрывающего установленный статус плоидности хромосомы вынашиваемого плода, предусматривающий: получение первого образца, который содержит ДНК матери плода и ДНК плода; получение генотипических данных одного или обоих родителей плода; подготовку первого образца путем выделения ДНК с тем, чтобы получить подготовленный образец; измерение ДНК в подготовленном образце во множестве полиморфных локусов; вычисление на компьютере числа аллелей или вероятностей подсчета числа аллелей во множестве полиморфных локусов по измерениям ДНК, выполненным в подготовленном образце; создание на компьютере множества гипотез плоидности, касающихся ожидаемых вероятностей числа аллелей во множестве полиморфных локусов в хромосоме для различных возможных состояний плоидности хромосомы; построение на компьютере модели совместного распределения вероятности числа аллелей каждого полиморфного локуса в хромосоме для каждой гипотезы плоидности с использованием генотипических данных одного или обоих родителей плода; определение на компьютере относительной вероятности каждой гипотезы плоидности с использованием модели совместного распределения и вероятностей числа аллелей, вычисленных для подготовленного образца; установление состояния плоидности плода путем отбора состояния плоидности, соответствующего гипотезе с наибольшей вероятностью и генерирование отчета, раскрывающего установленный статус плоидности.
Согласно некоторым вариантам осуществления используется способ определения состояния плоидности множества вынашиваемых плодов у множества соответствующих матерей, дополнительно предусматривающий определение процента ДНК плодного происхождения в каждом из подготовленных образцов; при котором этап измерения ДНК в подготовленном образце осуществляется посредством секвенирования ряда молекул ДНК в каждом подготовленном образце, и при котором секвенируется больше молекул ДНК из подготовленных образцов, которые содержат меньшую фракцию плодной ДНК, чем из тех подготовленных образцов, которые содержат большую фракцию плодной ДНК.
Согласно некоторым вариантам осуществления используется способ определения состояния плоидности множества вынашиваемых плодов у множества соответствующих матерей, при котором измерение ДНК в подготовленном образце осуществляется для каждого из плодов путем секвенирования первой фракции подготовленного образца ДНК для получения первого набора измерений, дополнительно предусматривающий: осуществление первого определения относительной вероятности для каждой из гипотез плоидности для каждого плода с учетом первого набора измерений ДНК; повторное секвенирование второй фракции подготовленного образца от тех плодов, для которых первое определение относительной вероятности для каждой гипотезы плоидности показывает, что гипотеза плоидности, соответствующая анеуплоидному плоду, характеризуется значимой, но не доказательной вероятностью, для получения второго набора измерений; осуществление второго определения относительной вероятности для гипотез плоидности плодов с использованием второго набора измерений и необязательно также первого набора измерений и установление состояний плоидности плодов, вторые образцы которых были повторно секвенированы, путем отбора состояния плоидности, соответствующего гипотезе с наибольшей вероятностью, установленной при втором определении относительной вероятности.
Согласно некоторым вариантам осуществления раскрывается состав материала, этот материал содержит: образец, предпочтительно приумноженной ДНК, при этом образец предпочтительно приумноженной ДНК был предпочтительно приумножен множеством полиморфных локусов из первого образца ДНК, при этом первый образец ДНК состоял из смеси материнской ДНК и плодной ДНК, полученной из материнской плазмы, в котором степень приумножения представляет собой по меньшей мере фактор 2, и при этом систематическая ошибка подсчета числа аллелей между первым образцом и предпочтительно приумноженным образцом, в среднем выбрана из группы, состоящей из менее 2%, менее 1%, менее 0,5%, менее 0,2%, менее 0,1%, менее 0,05%, менее 0,02% и менее 0,01%. Согласно некоторым вариантам осуществления раскрывается способ создания образца такой предпочтительно приумноженной ДНК.
В некотором варианте осуществления раскрывается способ определения присутствия или отсутствия анеуплоидии плода в образце материнской ткани, содержащей плодную и материнскую геномную ДНК, предусматривающий: (a) получение смеси плодной и материнской геномной ДНК из указанного образца материнской ткани; (b) селективное приумножение смеси плодной и материнской ДНК множеством полиморфных аллелей; (c) распределение селективно приумноженных фрагментов из смеси плодной и материнской геномной ДНК из этапа (a) для обеспечения реакции в образцах, содержащих единичную молекулу геномной ДНК, или амплификации продуктов единичной молекулы геномной ДНК; (d) проведение массивного параллельного секвенирования ДНК селективно приумноженных фрагментов геномной ДНК в реакционных образцах этапа (c) для определения последовательности указанных селективно приумноженных фрагментов; (e) идентификацию хромосом, к которым принадлежат полученные на этапе (d) последовательности; (f) анализ данных этапа (d) для определения i) числа фрагментов геномной ДНК из этапа (d), принадлежащие по меньшей мере одной первой целевой хромосоме, которая предположительно является диплоидной как у матери, так и у плода, и ii) числа фрагментов геномной ДНК из этапа (d), которые принадлежат второй целевой хромосоме, при этом предполагается, что указанная вторая хромосома у плода анеуплоидна; (g) вычисление ожидаемого распределения числа фрагментов геномной ДНК из этапа (d) для второй целевой хромосомы, если вторая целевая хромосома эуплоидна, с использованием числа, установленного на этапе (f) в части i); (h) вычисление ожидаемого распределения числа фрагментов геномной ДНК из этапа (d) для второй целевой хромосомы, если вторая целевая хромосома анеуплоидна, с использованием первого числа, установленного на этапе f) в части i), и оцененной фракции плодной ДНК, обнаруженной в смеси на этапе (b); и (i) использование максимального правдоподобия или максимального апостериорного подхода для определения, является ли число фрагментов геномной ДНК, установленное на этапе f) в части ii), с большей вероятностью частью распределения, рассчитанного на этапе g), или распределения, рассчитанного на этапе h); благодаря чему устанавливается присутствие или отсутствие анеуплоидии плода.
Экспериментальный раздел
Раскрытые в настоящем документе варианты осуществления иллюстрируются в следующих примерах, которые изложены с целью разъяснения раскрытия и не должны рассматриваться как какое-либо ограничение объема раскрытия, определенного формулой изобретения, которая следует далее. Следующие примеры приведены, чтобы обеспечить специалистам в данной области полное раскрытие и описание с использованием описанных вариантов осуществления, и не предназначены для ограничения объема раскрытия, а также не должны означать, что нижеприведенные эксперименты являются всеми или единственными выполняемыми экспериментами. Были предприняты усилия по обеспечению точности в отношении используемых показателей (например, количеств, температуры и т.д.), но должны быть учтены некоторые экспериментальные погрешности и отклонения. Если не указано иное, части являются объемными частями, а температура выражается в градусах Цельсия. Следует понимать, что вариации в описанных способах могут быть выполнены без изменения фундаментальных аспектов, которые должны иллюстрировать эксперименты.
Эксперимент 1
Целью являлась демонстрация того, что байесовский алгоритм оценивания максимального правдоподобия (MLE), в котором используются генотипы родителей для расчета плодной фракции, улучшает точность неинвазивной пренатальной диагностики трисомии по сравнению с опубликованными способами.
Данные моделирования секвенирования для материнской cfDNA создавали путем сбора считываний, полученных при трисомии-21 и из соответствующих линий материнских клеток. Частоты корректной дисомии и признаков трисомии определяли на основании 500 моделирований в различных плодных фракциях согласно опубликованному способу (Chiu et al. BMJ 2011; 342: c7401) и в соответствии с основанным на MLE алгоритмом в соответствии с настоящим изобретением. Проверяли моделирования, получив 5 миллионов показаний методом «дробовика» от четырех беременных матерей и соответствующих отцов, собранных согласно протоколу, одобренному IRB. Генотипы родителей получали на матрице 290К SNP (см. фиг.14).
При моделировании основанный на MLE подход позволял достигнуть 99,0%-ной точности для плодных фракций с низким содержанием, таким как 9%, и зарегистрированных уровней достоверности, которые достаточно соответствовали общей точности. Проверяли эти результаты с использованием четырех реальных образцов, в которых получали все корректные признаки с рассчитанной достоверностью, превосходящей 99%. Напротив, применение опубликованного Chiu et al. алгоритма потребовало 18% плодной фракции для достижения 99,0% точности, а при 9% плодной ДНК была достигнута только 87,8% точность.
Определение плодной фракции из родительских генотипов с применением основанного на MLE подхода позволяло достичь большей точности, чем с опубликованными алгоритмами, на плодных фракциях, ожидаемых во время 1-го и раннего 2-го триместров. Более того, с помощью раскрытого в настоящем документе способа получали метрику достоверности, которая являлась ключевой в определении надежности результата, особенно при низком содержании плодных фракций, при котором определять плоидность особенно сложно. В опубликованных методах используются способы с меньшим порогом точности для установления плоидности, основанные на больших наборах подготовительных данных по дисомии, подход, который предопределяет частоту ложных положительных результатов. Кроме того, без метрики достоверности опубликованные методы не исключают риска получения ложных отрицательных результатов, когда для различения признака недостаточно плодной cfDNA. Согласно некоторым вариантам осуществления рассчитывается оценка достоверности для установленного состояния плоидности.
Эксперимент 2
Целью являлось улучшение неинвазивного определения плодной трисомии 18, 21 и X, в частности, в образцах, содержащих небольшое количество плодной фракции с использованием подхода целевого секвенирования в комбинации с генотипами родителей и данными HapMap по байесовскому алгоритму оценивания максимального правдоподобия (MLE).
Материнские образцы от четырех эуплоидных и двух положительных по трисомии беременностей и соответствующие образцы от отцов получали согласно протоколу, одобренному IRB, от пациентов с известным кариотипом плода. Материнскую cfDNA экстрагировали из плазмы и получали приблизительно 10 миллионов считываний последовательностей после предпочтительного приумножения ДНК целевыми специфичными SNP. Образцы родителей секвенировали аналогичным образом для получения генотипов.
Описанный алгоритм правильно выявлял дисомию хромосом 18 и 21 во всех эуплоидных образцах и нормальные хромосомы в анеуплоидных образцах. Признаки трисомии 18 и 21 были правильными, так же как и число копий X-хромосомы в плодах мужского и женского пола. Достоверность, полученная при применении этого алгоритма, превышала 98% во всех случаях.
Описанным способом точно регистрировали плоидность всех протестированных хромосом в шести образцах, включая образцы, содержащие менее 12% плодной ДНК, что соответствует примерно 30% в образцах 1-го и раннего 2-го триместров. Ключевое различие между данным алгоритмом MLE и опубликованными методами заключается в том, что он максимально использует родительские генотипы и данные HapMap для улучшения точности и генерирования метрики достоверности. При низком содержании плодных фракций все способы становятся менее точными; важно корректно идентифицировать образцы в условиях недостатка плодной cfDNA для надежного распознавания признака. В других методах использовали специфичные по отношению к Y-хромосоме зонды для оценки плодной фракции плодов мужского пола, но сопутствующее генотипирование родителей давало возможность оценки плодной фракция для плодов обоих полов. Другое ограничение, присущее опубликованным методов с использованием нецелевого секвенирования методом «дробовика», состоит в том, что точность определения плоидности варьирует у хромосом вследствие различий в таких факторах, как приумноженность GC. Подход непосредственного целевого секвенирования по большей части не зависит от таких вариаций хромосомного масштаба и дает более устойчивую характеристику у хромосом.
Эксперимент 3
Целью являлось определение выявляемости трисомии с высокой достоверностью у триплоидного плода с использованием новых методов информатики для анализа локусов SNP в свободно плавающей плодной ДНК из материнской плазмы.
После патологических показаний ультразвукового исследования у беременной пациентки брали 20 мл крови. После центрифугирования из лейкоцитарной пленки экстрагировали материнскую ДНК (DNEASY, QIAGEN); бесклеточную ДНК экстрагировали из плазмы (QIAAMP QIAGEN). Целевое секвенирование применяли на локусах SNP в хромосомах 2, 21 и X в обоих образцах ДНК. Байесовским оцениванием максимального правдоподобия выбирали наиболее вероятную гипотезу из набора всех возможных состояний плоидности. Способом определяли фракцию плодной ДНК, состояние плоидности и явную достоверность определения плоидности. Предположения относительно плоидности эталонной хромосомы не формулировали. В диагностике использовали тестовую статистику, которая не зависит от количества считываний последовательностей, что является последним словом в уровне техники.
Способ в соответствии с настоящим изобретением позволял точно диагностировать трисомию по хромосомам 2 и 21. Оцененная фракция ребенка составляла 11,9% [CI 11,7-12,1]. Обнаруживали, что плод имеет одну материнскую и две отцовские копии хромосом 2 и 21 с эффективной достоверностью 1 (вероятность погрешности <10-30). Это достигали при 92600 и 258100 считываниях на хромосомах 2 и 21, соответственно.
Это первая демонстрация неинвазивной пренатальной диагностики трисомии хромосом по крови матери при триплоидности плода, что подтверждали исследованием кариотипа в метафазе. Существующие способы неинвазивной диагностики не определили бы анеуплоидию в этом образце. Современные способы основаны на избытке считываний последовательностей на трисомной хромосоме по сравнению со считываниями на дисомных эталонных хромосомах; однако триплоидный плод не имеет дисомного эталона. Более того, существующие способы не достигли бы определения плоидности с аналогично высокой достоверностью на данной фракции плодной ДНК и при данном количестве считываний последовательностей. Не вызывает затруднения расширение данного подхода на все 24 хромосомы.
Эксперимент 4
Следующий протокол использовали для 800-плексной амплификации ДНК, выделенной из материнской плазмы при эуплоидной беременности, а также геномной ДНК из линии триплоидных по хромосоме 21 клеток с использованием стандартной ПЦР (т.е. вложение не использовалось). Приготовление библиотеки и амплификация предусматривали однопробирочное образование тупых концов с последующим присоединением A-хвоста. Адаптерное лигирование проводили с использованием набора для лигирования, входящего в комплект набора SURESELECT от AGILENT, и ПЦР осуществляли в течение 7 циклов. Затем выполняли 15 циклов STA (95°C в течение 30 секунд; 72°C в течение 1 минуты; 60°C в течение 4 минут; 65°C в течение 1 минуты; 72°C в течение 30 секунд) с использованием 800 пар различных праймеров, целями которых являлись SNP в хромосомах 2, 21 и X. Реакция проводили при концентрации праймеров 12,5 нМ. Затем ДНК секвенировали на секвенсоре IIGAX от ILLUMINA. Выход секвенатора составлял 1,9 миллиона считываний, из которых 92% картировалось с геномом; из картирующихся с геномом показаний более 99% картировалось с одной из областей, являющихся целями для целевых праймеров. Числа были по сути одинаковые для ДНК плазмы и геномной ДНК. На фиг.15 показано отношение двух аллелей для ~780 SNP, которые выявляли секвенатором в геномной ДНК, взятой из линии клеток с известной трисомией по хромосоме 21. Следует отметить, что отношения аллелей в настоящем документе представлены в виде графиков для облегчения восприятия, потому что распределение аллелей нельзя напрямую визуально считывать. Кружочки означают SNP в дисомных хромосомах, а звездочки означают SNP в трисомной хромосоме. На фиг.16 по-другому представлены те же данные, что и на фиг X, на которой по оси Y отложено относительные число A и B, измеренное для каждого SNP, а на оси X - номер SNP, при этом SNP сгруппированы по хромосоме. На фиг.16 SNP от 1 до 312 обнаруживали в хромосоме 2, SNP от 313 до 605 обнаруживали в хромосоме 21, которая является трисомной, и SNP от 606 до 800 обнаруживали в X-хромосоме. Данные по хромосомам 2 и X показывают, что это дисомные хромосомы, поскольку относительные количества последовательностей группируются по трем кластерам: AA вверху графика, BB внизу графика, и AB в середине графика. Данные по хромосоме 21, которая является трисомной, показывают наличие четырех кластеров: AAA наверху графика, AAB около линии 0,65 (2/3), ABB около линии 0,35 (1/3), и BBB внизу графика.
На фиг.17 представлены данные того же 800-плексного протокола, но измеренные на ДНК, которую амплифицировали из четырех образцов плазмы, взятых у беременных женщин. Для этих четырех образцов предполагали увидеть семь кластеров точек: (1) вдоль верхней части графика расположены те локусы, по которым и мать, и плод являются AA, (2) несколько ниже верхней части графика находятся локусы, по которым мать является AA, а плод является AB, (3) несколько выше линии 0,5 расположены локусы, по которым мать является AB, а плод является AA, (4) вдоль линии 0,5 находятся локусы, по которым и мать, и плод являются AB, (5) несколько ниже линии 0,5 находятся локусы, по которым мать является AB, а плод является BB, (6) несколько выше нижней части графика расположены локусы, по которым мать является BB, а плод является AB, (7) по нижней части графика находятся локусы, по которым и мать, и плод являются BB. Чем меньше плодная фракция, тем меньше расхождения между кластерами (1) и (2), между кластерами (3), (4) и (5), а также между кластерами (6) и (7). Расхождение ожидается, если половина фракции ДНК имеет плодное происхождение. Например, если ДНК на 20% плодная и на 80% материнская, прогнозировали, что кластеры от (1) до (7) центрированы на 1,0, 0,9, 0,6, 0,5, 0,4, 0,1 и 0,0, соответственно; см., например, фиг.17, POOL1_BC5_ref_rate. Если ДНК на 8% плодная, а на 92% материнская, прогнозировали, что кластеры от (1) до (7) центрированы на 1,00, 0,96, 0,54, 0,50, 0,46, 0,04 и 0,00, соответственно; см., например, фиг.17, POOL1_BC2_ref_rate. Если плодную ДНК не выявляли, то не предполагали увидеть кластеры (2), (3), (5) или (6); в качестве альтернативы, можно сказать, что расхождение нулевое, и, следовательно, кластеры (1) и (2) находятся на верхней части друг друга, как и (3), (4) и (5), а также (6) и (7); см., например, фиг.17, POOL1_BC7_ref_rate. Следует отметить, что плодная фракция для фиг.17, POOL1_BC1_ref_rate, составляла приблизительно 25%.
Эксперимент 5
Большинство способов амплификации ДНК и измерений дает некоторую систематическую ошибку подсчета числа аллелей, при которой два аллеля, которые, как правило, обнаруживали в локусе, выявлялись с интенсивностями или в количествах, не соответствующих действительным количествам аллелей в образце ДНК. Например, у одного индивидуума в гетерозиготном локусе ожидали увидеть отношение 1:1 двух аллелей, что является теоретическим отношением, ожидаемым для гетерозиготного локуса; однако, вследствие систематической ошибки подсчета числа аллелей, наблюдали 55:45 или даже 60:40. Также следует отметить, что в контексте секвенирования, если глубина считывания низкая, то простой стохастический шум может привести к значительной систематической ошибки подсчета числа аллелей. Согласно варианту осуществления можно смоделировать поведение каждого SNP таким образом, что если постоянно наблюдается стандартная ошибка для конкретных аллелей, эту стандартную ошибку можно скорректировать. На фиг.18 представлена часть данных, которую можно объяснить дисперсией биномиального распределения, до и после внесения поправки на стандартную ошибку. На фиг.18, звездочками обозначена стандартная ошибка подсчета числа аллелей, наблюдаемая на необработанных данных секвенирования для 800-плексного эксперимента; кружечками обозначена стандартная ошибка подсчета числа аллелей после коррекции. Следует отметить, что в отсутствии стандартной ошибки подсчета числа аллелей предполагали, что данные будут располагаться вдоль линии x=y. Аналогичный набор данных получали при амплификации ДНК с использованием 150-плексной целевой амплификации; после коррекции стандартной ошибки полученные данные располагались очень близко к линии 1:1.
Эксперимент 6
Универсальная амплификация ДНК с использованием дотированных адаптеров с праймерами, специфичными по отношению к маркерам адаптеров, при которой время отжига праймеров и удлинения ограничено несколькими минутами, обладает эффектом приумножения более короткими цепями ДНК. Большинство протоколов библиотек, предназначенных для создания приемлемых для секвенирования библиотек ДНК, предусматривают такой этап, и примеры протоколов опубликованы и хорошо известны специалистам в данной области. Согласно некоторым вариантам осуществления настоящего изобретения адаптеры с универсальным маркером лигировали с ДНК плазмы и амплифицировали с использованием праймеров, специфичных по отношению к маркеру адаптеров. Согласно некоторым вариантам осуществления универсальным маркером может быть тот же маркер, который использовали для секвенирования, он может быть универсальным маркером только для ПЦР-амплификации, или он может представлять собой набор маркеров. Поскольку плодная ДНК, как правило, короткая по природе, в то время как материнская ДНК может быть как короткой, так и длинной по природе, этот способ позволяет приумножить пропорцию плодной ДНК в смеси. Свободно плавающая ДНК, которая, как считали, походила из апоптических клеток, и которая содержала и плодную, и материнскую ДНК, являлась короткой - в основном короче 200 пар оснований. Клеточная ДНК, высвобождаемая при лизисе клеток, обычном явлении после флеботомии, как правило, почти полностью была материнской, а также достаточно длинной - в основном длиннее 500 пар оснований. Следовательно, образцы крови, которые стояли дольше нескольких минут, содержали смесь короткой (плодной + материнской) и более длинной (материнской) ДНК. Проведение универсальной амплификации с относительно коротким временем удлинения в образце материнской плазмы с последующей целевой амплификацией имеет тенденцию к увеличению относительной пропорции плодной ДНК по сравнению с ДНК плазмы, которую амплифицировали только с использованием целевой амплификации. Это можно видеть на фиг.19, на которой представлен измеренный процент плодной ДНК, если входящей являлась ДНК плазмы (вертикальная ось), по сравнению с измеренным процентом плодной ДНК, если входящей являлась ДНК плазмы из библиотеки, приготовленной в соответствии с протоколом приготовления библиотек GAIIx от ILLUMINA. Все точки располагаются ниже линии, что указывает на то, что этап приготовления библиотеки приумножает ДНК фракцией плодного происхождения. Два образца плазмы, которые были красными, что свидетельствует о гемолизе, и, следовательно, в которых должно было содержаться повышенное количество длинной материнской ДНК, высвободившейся в результате лизиса клеток, показали особенно значительное приумножение плодной фракцией, если целевой амплификации предшествовало приготовление библиотеки. Раскрытый в настоящем документе способ особенно полезен в случаях гемолиза или в некоторой другой ситуации, когда происходит лизис клеток, содержащих относительно длинные цепи загрязняющей ДНК, которая смешанный образец короткой ДНК загрязняет длинной ДНК. Как правило, относительно короткое время отжига и удлинения составляет от 30 секунд до 2 минут, хотя оно могут быть сокращено до 5 или 10 секунд или меньше, или продлено до 5 или 10 минут.
Эксперимент 7
Следующий протокол использовали для проведения 1200-плексной амплификации ДНК, выделенной из материнской плазмы при эуплоидной беременности, а также геномной ДНК из линии триплоидных по хромосоме 21 клеток с использованием протокола прямой ПЦР и полувложенного подхода. Приготовление библиотеки и амплификация предусматривали однопробирочное образование тупых концов с последующим присоединением A-хвостов. Адаптерное лигирование проводили с использованием модификации набора для лигирования, входящего в комплект набора SURESELECT от AGILENT, а ПЦР проводили в течение 7 циклов. В пуле целевых праймеров содержалось 550 анализируемых фрагментов для SNP хромосомы 21 и 325 анализируемых фрагментов для SNP каждой из хромосом 1 и X. Оба протокола предусматривали 15 циклов STA (95°C в течение 30 секунд; 72°C в течение 1 минуты; 60°C в течение 4 минут; 65°C в течение 30 секунд; 72°C в течение 30 секунд) при концентрации праймеров 16 нМ. Протокол полувложенной ПЦР предусматривал вторую амплификацию из 15 циклов STA (95°C в течение 30 секунд; 72°C в течение 1 минуты; 60°C в течение 4 минут; 65°C в течение 30 секунд; 72°C в течение 30 секунд) с использованием концентрации внутреннего прямого маркера 29 нМ и концентрации обратного маркера 1 мкМ или 0,1 мкМ. Затем ДНК секвенировали на секвеннаторе IIGAX от ILLUMINA. При протоколе прямой ПЦР 73% считываний картировались с геномом; при протоколе полувложенной ПЦР 97,2% считываний последовательностей картировались с геномом. Следовательно, полувложенный протокол позволял получить на приблизительна 30% больше информации, предположительно в основном благодаря элиминации праймеров, которые с высокой вероятностью образовывали димеры праймеров.
Вариабельность глубины считывания имеет тенденцию к повышению при использовании полувложенного протокола в сравнении с использованием протоколом прямой ПЦР (см. фиг.20), при этом ромбики обозначают глубину считывания для локусов, исследованных по полувложенному протоколу, а квадратики обозначают глубину считывания для локусов, исследованных без вложения. SNP распределены по глубине считывания, обозначенной ромбиками, так что все ромбики укладываются на кривую, в то время как квадратики распределяются свободно; расположение SNP является произвольным, и скорее высота точки обозначает глубину считывания, а не ее локализация слева направо.
Согласно некоторым вариантам осуществления описанные в настоящем документе способы могут достигать отличных вариаций глубины считывания (DOR). Например, в одном варианте этого эксперимента (фиг.21) с использованием 1200-плексной прямой ПЦР-амплификации геномной ДНК из 1200 анализируемых фрагментов: 1186 анализируемых фрагментов характеризовались DOR более 10; средняя глубина считывания составляла 400; 1063 анализируемых фрагмента (88,6%) характеризовались глубиной считывания от 200 до 800 и идеальным окном, в котором число считываний для каждого аллеля достаточно высоко для получения значимых данных, и в то же время число считываний для каждого аллеля не настолько высоко, чтобы пограничное использование этих считываний было особенно малым. Только 12 аллелей характеризовались более высокой глубиной считывания с самым высоким значением при 1035 считываниях. Стандартное отклонение DOR составляло 290, среднее значение DOR составляло 453, коэффициент дисперсии DOR составлял 64%, всего получали 950000 считываний, и 63,1% считываний картировалось с геномом. В другом эксперименте (фиг.22) с использованием 1200-плексного полувложенного протокола DOR была выше. Стандартное отклонение DOR составляло 583, среднее значение DOR составляло 630, коэффициент дисперсии DOR составлял 93%, всего получали 870000 считываний, и 96,3% считываний картировалось с геномом. Следует отметить, что в обоих случаях SNP располагаются по глубине считывания для матери так, что кривая представляет материнскую глубину считывания. Разграничение между ребенком и отцом не является значимым; имеется только тенденция, что оно может быть значимым в целях объяснения.
Эксперимент 8
В эксперименте использовали протокол полувложенной 1200-плексной ПЦР для амплификации ДНК из одной клетки и из трех клеток. Этот эксперимент подходит для пренатального тестирования на анеуплоидию с использованием плодных клеток, выделенных из крови матери, или для преимплантационной генетической диагностики с использованием бластомеров из биоптата или образцов трофэктодермы. Имелось 3 репликата из 1 и 3 клеток от 2 индивидуумов (46 XY и 47 XX+21) для каждого условия. Анализировали хромосомы 1, 21 и X. Использовали три различных способа лизиса: ARCTURUS, MPERv2 и щелочной лизис. Секвенирование проводили с мультиплексированием 48 образцов на одной дорожке секвенирования. Алгоритм повторял корректные признаки плоидности для каждой из трех хромосом и для каждого репликата.
Эксперимент 9
В одном эксперименте четыре образца материнской плазмы готовили и амплифицировали с использованием полувложенного 9600-плексного протокола. Образцы готовили следующим образом: до 40 мл крови матери центрифугировали с целью выделения лейкоцитарной пленки и плазмы. Геномную ДНК матери получали из лейкоцитарной пленки, а отцовскую ДНК получали из образца крови или образца слюны. Бесклеточную ДНК из материнской плазмы выделяли с использованием набора CIRCULATING NUCLEIC ACID от QIAGEN и элюировали в 45 мкл буфера TE в соответствии с инструкциями производителя. Универсальные адаптеры дотирования присоединяли к концу каждой молекулы в количестве 35 мкл очищенной ДНК плазмы, и библиотеки амплифицировали в течение 7 циклов с использованием праймеров, специфичных по отношению к адаптерам. Библиотеки очищали с помощью гранул AGENCOURT AMPURE и элюировали в 50 мкл воды.
Амплифицировали 3 мкл ДНК в течение 15 циклов STA (95°C в течение 10 минут для начальной активации полимеразы, затем 15 циклов при 95°C в течение 30 секунд; 72°C в течение 10 секунд; 65°C в течение 1 минуты; 60°C в течение 8 минут; 65°C в течение 3 минут и 72°C в течение 30 секунд; и финальное удлинение при 72°C в течение 2 минут) с использованием концентрации 9600 специфичных по отношению к целям маркированных обратных праймеров 14,5 нМ и концентрации одного специфичного к адаптеру библиотеки прямого праймера 500 нМ.
Протокол полувложенной ПЦР предусматривал вторую амплификацию разведенного продукта первых STA в течение 15 циклов STA (95°C в течение 10 минут для начальной активации полимеразы, затем 15 циклов при 95°C в течение 30 секунд; 65°C в течение 1 минуты; 60°C в течение 5 минут; 65°C в течение 5 минут и 72°C в течение 30 секунд; и финальное удлинение при 72°C в течение 2 минут) с использованием концентрации обратного маркера 1000 нМ и концентрации 16,6 нМ каждого из 9600 специфичных по отношению к целям прямых праймеров.
Затем аликвоту продуктов STA амплифицировали стандартной ПЦР в течение 10 циклов с 1 мкМ специфичных по отношению к маркеру прямых праймеров и обратных праймеров со штрихкодом для получения библиотек секвенирования со штрихкодом. Аликвоту из каждой библиотеки смешивали с библиотеками различных штрихкодов и очищали с использованием спин-колонки.
Таким образом, 9600 праймеров использовали в однолуночных реакциях; праймеры были предназначены для нацеливания на SNP в хромосомах 1, 2, 13, 18, 21, X и Y. Затем ампликоны секвенировали с использованием секвенатора GAIIX от ILLUMINA. Секвенатором генерировали приблизительно 3,9 миллиона считываний на образец, из них 3,7 миллиона считываний картировались с геномом (94%), и из них 2,9 миллиона считываний (74%) картировались с целевым SNP со средней глубиной считывания 344 и медианой глубины считывания 255. Плодная фракция в четырех образцах составляла 9,9%, 18,9%, 16,3% и 21,2%.
Значимые образцы материнской и отцовской геномной ДНК амплифицировали с использованием полувложенного 9600-плексного протокола и секвенировали. Полувложенный протокол отличается тем, что в нем используются 9600 внешних прямых праймеров и маркированных обратных праймеров при концентрации 7,3 нМ в первой STA. Условия термоциклирования и состав второй STA и штрихкодирующей ПЦР были такими же, как и в полувложенном протоколе.
Данные секвенирования анализировали с использованием раскрытых в настоящем документе методов информатики и определяли состояние плоидности для шести хромосом плода, чья ДНК присутствовала в 4 образцах материнской плазмы. Плоидность всех 28 хромосом в наборе определяли правильно с достоверностью выше 99,2% за исключением одной хромосомы, плоидность которой определяли правильно, но с достоверностью 83%.
На фиг.23 показана глубина считывания при 9600-плексном полувложенном подходе вместе с глубиной считывания при 1200-плексном полувложенном подходе, описанном в эксперименте 7, хотя число SNP с глубиной считывания более 100, более 200 и более 400 было значительно выше, чем при 1200-плексном протоколе. Число считываний при 90-м процентиле может быть разделено на число считываний при 10-м процентиле для получения безразмерной метрики, которая служит показателем однородности глубины считывания; чем меньше число, тем более однородна (уже) глубина считывания. Среднее отношение 90-го процентиля к 10-ому процентилю составляло 11,5 для способа, использованного в эксперименте 9, и 5,6 - для способа, использованного в эксперименте 7. Более узкая глубина считывания для протокола данной плексности лучше для эффективности секвенирования, поскольку требуется меньше считываний последовательностей для того, чтобы гарантировать, что определенное процентное отношение считываний находится выше порога числа считываний.
Эксперимент 10
В одном эксперименте четыре образца материнской плазмы готовили и амплифицировали с использованием полувложенного 9600-плексного протокола. Подробности эксперимента 10 были очень похожи на эксперимент 9, в том числе идентичность четырех образцов, за исключением вложенного протокола. Признаки плоидности для всех 28 хромосом набора определяли правильно с достоверностями выше 99,7%. 7,6 миллиона (97%) считываний картировались с геномом, а 6,3 миллиона (80%) считываний картировались с целевым SNP. Средняя глубина считывания составляла 751, а медиана глубины считывания составляла 396.
Эксперимент 11
В одном эксперименте три образца материнской плазмы разделяли на пять равных порций, и каждую порцию амплифицировали с использованием 2400 мультиплексных праймеров (четыре порции) или 1200 мультиплексных праймеров (одна порция) по полувложенному протоколу с использованием в целом 10800 праймеров. После амплификации порции объединяли для секвенирования. Подробности эксперимента 11 были очень похожи на эксперимент 9, за исключением протокола вложения и подхода расщепления и объединения. Плоидность для всех 21 хромосомы набора устанавливали правильно с достоверностями выше 99,7%, за исключением одного пропущенного признака, для которого достоверность составляла 83%. 3,4 миллиона считываний картировались с целевым SNP, средняя глубина считывания составляла 404, и медиана глубины считывания составляла 258.
Эксперимент 12
В одном эксперименте четыре образца материнской плазмы разделяли на четыре равные порции, и каждую порцию амплифицировали с использованием 2400 мультиплексных праймеров и амплифицировали с использованием полувложенного протокола; всего использовали 9600 праймеров. После амплификации порции объединяли для секвенирования. Подробности эксперимента 12 были очень похожи на эксперимент 9, за исключением протокола вложения и подхода расщепления и объединения. Признаки плоидность для всех 28 хромосом набора устанавливали правильно достоверностями выше 97%, за исключением одного пропущенного признака, для которого достоверность составляла 78%. 4,5 миллиона считываний картировались с целевым SNP, средняя глубина считывания составляла 535, а медиана глубины считывания составляла 412.
Эксперимент 13
В одном эксперименте четыре образца материнской плазмы приготовили и амплифицировали с использованием 9600-плексного трижды полувложенного протокола и всего использовали 9600 праймеров. Подробности эксперимента 12 были очень похожи на эксперимент 9, за исключением протокола вложения, который предусматривал три раунда амплификации; три раунда предусматривали 15, 10 и 15 циклов STA, соответственно. Признаки плоидности для 27 из 28 хромосом набора устанавливали правильно с достоверностями выше 99,9%, за исключением одной хромосомы, плоидность которой устанавливали правильно с достоверностью 94,6% и одного пропущенного признака, для которого достоверность составляла 80,8%. 3,5 миллиона считываний картировались с целевыми SNP, средняя глубина считывания составляла 414, а медиана глубины считывания составляла 249.
Эксперимент 14
В одном эксперименте 45 наборов клеток амплифицировали с использованием 1200-плексного полувложенного протокола, секвенировали и для трех хромосом определяли плоидность. Следует отметить, что этот эксперимент был предназначен для моделирования условий выполнения преимплантационной генетической диагностики на одноклеточных биоптатах, полученных от 3-дневных эмбрионов, или биоптатах трофэктодермы, полученных от 5-дневных эмбрионов. Помещали 15 индивидуальных единичных клеток и 30 агрегатов из трех клеток в 45 индивидуальных реакционных пробирок для проведения обшей сложностью 45 реакций, при этом в каждой реакции участвовали клетки только одной клеточной линии, но в разных реакциях участвовали клетки различных клеточных линий. Клетки готовили в 5 мкл отмывочного буфера, лизировали добавлением 5 мкл лизирующего буфера ARCTURUS PICOPURE (от APPLIED BIOSYSTEMS) и инкубировали при 56°C в течение 20 минут и при 95°C в течение 10 минут.
ДНК единичных/трех клеток амплифицировали в течение 25 циклов STA (95°C в течение 10 минут для начальной активации полимеразы, затем 25 циклов при 95°C в течение 30 секунд; 72°C в течение 10 секунд; 65°C в течение 1 минуты; 60°C в течение 8 минут; 65°C в течение 3 минут и 72°C в течение 30 секунд; и финальное удлинение при 72°C в течение 2 минут) с использованием концентрации 1200 специфичных по отношению к целям прямых и маркированных обратных праймеров 50 нМ.
Полувложенный протокол ПЦР предусматривал три параллельные вторые амплификации разведенного продукта первых STA в течение 20 циклов STA (95°C в течение 10 минут для начальной активации полимеразы, затем 15 циклов при 95°C в течение 30 секунд; 65°C в течение 1 минуты; 60°C в течение 5 минут; 65°C в течение 5 минут и 72°C в течение 30 секунд; и финальное удлинение при 72°C в течение в течение 2 минут) с использованием концентрации обратных специфичных по отношению к маркеру праймеров 1000 нМ и концентрации 60 нМ для каждого из 400 специфичных по отношению к целям «вложенных» прямых праймеров. Таким образом, в трех параллельных 400-плексных реакциях амплифицировали всего 1200 целей, амплифицированных в первой STA.
Затем аликвоту продуктов STA амплифицировали методом стандартной ПЦР в течение 15 циклов с 1 мкМ специфичных по отношению к маркеру прямых праймеров и обратных праймеров со штрихкодом для получения библиотек со штрихкодом для секвенирования. Аликвоту каждой библиотеки смешивали с библиотеками различных штрихкодов и очищали с использованием спин-колонки.
Таким образом, использовали 1200 праймеров в реакциях с участием единичных клеток; праймеры конструировали для нацеливания на SNP хромосом 1, 21 и X. Затем ампликоны секвенировали с использованием секвенатора GAIIX от ILLUMINA. С помощью секвенатора генерировали приблизительно 3,9 миллиона считываний на образец, при этом от 500000 до 800000 миллионов считываний картировались с геномом (от 74% до 94% от всех считываний на образец).
Значимые образцы материнской и отцовской геномной ДНК из клеточных линий анализировали с использованием того же полувложенного 1200-плексного пула анализируемых фрагметов по аналогичному протоколу с меньшим количеством циклов и 1200-плексной второй STA и секвенировали.
Данные секвенирования анализировали с использованием раскрытых в настоящем документе методов информатики и для образцов определяли состояние плоидности по трем хромосомам.
На фиг.24 представлены нормализованные отношения глубины считывания (вертикальная ось) для шести образцов по трем хромосомам (1 = хромосома 1; 2 = хромосома 21; 3 = хромосома X). Отношения выравнивали по числу считываний, картирующихся с данной хромосомой, нормализовали и делили на усредненное по трем лункам число считываний, картирующихся с данной хромосомой, при этом в каждой лунке находилось три клетки 46XY. Предполагали, что три набора точек замера, соответствующих клеткам 46XY, имели отношения 1:1. Предполагали, что три набора точек замера, соответствующих клеткам 47XX+21, имели отношения 1:1 для хромосомы 1, 1,5:1 для хромосомы 21 и 2:1 для X-хромосомы.
На фиг.25 представлены аллельные отношения в графическом виде для трех хромосом (1, 21, X) по трем реакциям. Область внизу слева показывает реакцию на трех клетках 46XY. Область слева - это аллельные отношения для хромосомы 1, средняя область - это аллельные отношения для хромосомы 21, и правая область - это аллельные отношения для X-хромосомы. Для клеток 46XY для хромосомы 1 ожидали наблюдать отношения 1, 0,5 и 0, соответствующие генотипам SNP AA, AB и BB. Для клеток 46XY для хромосомы 21 ожидали наблюдать отношения 1, 0,5 и 0, соответствующие генотипам SNP AA, AB и BB. Для клеток 46XY для X-хромосомы ожидали наблюдать отношения 1 и 0, соответствующие генотипам SNP A и B. Область внизу справа показывает реакцию на трех клетках 47XX+21. Аллельные отношения сегрегированы по хромосомам, как в нижней левой части графика. Для клеток 47XX+21 для хромосомы 1 ожидали наблюдать отношения 1, 0,5 и 0, соответствующие генотипам SNP AA, AB и BB. Для клеток 47X+21 для хромосомы 21 ожидали наблюдать отношения 1, 0,67, 0,33 и 0, соответствующие генотипам SNP AAA, AAB, ABB и BBB. Для клеток 47XX+21 для X-хромосомы ожидали наблюдать отношения 1, 0,5 и 0, соответствующие генотипам SNP AA, AB, и BB. График вверху справа строили на основании данных реакции с 1 нг геномной ДНК из клеточной линии 47XX+21. На фиг.26 представлены те же графики, что и на фиг.25, но для реакций, проведенных только на одной клетке. Слева график для реакции с клеткой 47XX+21, а справа график для реакции с клеткой 46XX.
Из графиков, показанных на фиг.25 и фиг.26, видно, что имеется два кластера точек для хромосом, в которых ожидается видеть отношения 1 и 0; три кластера точек для хромосом, в которых ожидается видеть отношения 1, 0,5 и 0, а также четырех кластеров точек для хромосом, в которых ожидается видеть отношения 1, 0,67, 0,33 и 0. С помощью алгоритма PARENTAL SUPPORT стало возможным получение корректных признаков по всем трем хромосомам для всех 45 реакций.
Все патенты, заявки на выдачу патентов и опубликованные ссылки, цитированные в настоящем документе, тем самым включены посредством ссылки во всей своей полноте. Несмотря на то, что способы настоящего раскрытия описаны со специфичными вариантами его осуществления, будет понятно, что возможна дополнительная модификация. Более того, настоящая заявка призвана охватывать любые вариации, применения или переработки способов в соответствии с настоящим раскрытием, в том числе такие отступления от настоящего раскрытия, которые известны или являются обычной практикой в области, к которой принадлежат способы в соответствии с настоящим раскрытием, и которые попадают в объем приложенной формулы изобретения.
Реферат
Предложенная группа изобретений относится к области медицины. Предложены способы определения статуса плоидности хромосомы или сегмента хромосомы у вынашиваемого плода. Проводят мультиплексную амплификацию по меньшей мере 1000 полиморфных локусов на хромосоме или сегменте хромосомы из образца, который содержит свободноплавающую материнскую ДНК от матери плода и свободноплавающую плодную ДНК с использованием множества праймеров в одной реакции для получения смеси амплифицированной плодной и материнской геномной ДНК по меньшей мере 1000 полиморфных локусов. Предложенная группа изобретений обеспечивает эффективные неинвазивные способы пренатального установления плоидности. 2 н. и 30 з.п. ф-лы, 26 ил., 4 табл., 14 пр.
Комментарии