Быстрое векторное вычисление деления без ветвления - RU2531862C2
Код документа: RU2531862C2
Чертежи


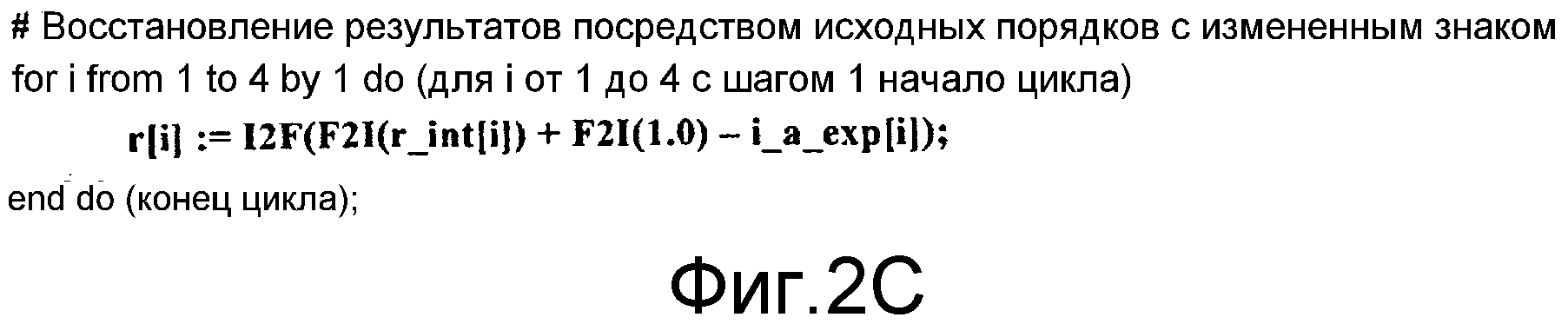
Описание
Область техники, к которой относится изобретение
Настоящее изобретение, в общем, относится к области вычислений. В частности, один вариант осуществления настоящего изобретения, в общем, относится к методикам быстрого векторного вычисления деления без ветвления.
Уровень техники
По сравнению с другими простыми арифметическими операциями аппаратные осуществления операций деления были довольно медленными, к примеру, ввиду большего времени запаздывания. Некоторое ускорение могло быть достигнуто в векторных случаях ввиду существования различных типов параллелизма в современных архитектурах, например, посредством параллелизма SIMD (один поток команд, множество потоков данных), суперскалярности и выполнения с изменением очередности. К примеру, обратное приближение с дополнительным методом уточняющих итераций Ньютона-Рафсона (рассматриваемый по ссылке http://en.wikipedia.org/wiki/Newton%E2%80%93Raphson_method), как правило, хорошо действует для случая с одинарной точностью (SP), в некоторых осуществлениях обеспечивая ускорение вплоть до двукратного относительно аппаратной операции деления. Однако этот подход теряет большую часть своих преимуществ в случаях с удвоенной точностью (DP) по причине отсутствия обратных операций удвоенной точности в существующих SSE-архитектурах. Как следствие, может потребоваться выполнение дополнительных преобразований из DP в SP и из SP в DP вместе с манипуляциями над полем порядка в числах с плавающей точкой. Кроме того, вышеописанные приближения SP и DP, в общем, требуют специальной обработки знаменателя с бесконечным (INF) или нулевым значением, что уменьшает параллелизм и уменьшает потенциальное увеличение производительности.
Краткое описание чертежей
Подробное описание обеспечивается со ссылками на сопроводительные чертежи. На чертежах левая цифра (левые цифры) ссылочной позиции указывает на чертеж, на котором эта ссылочная позиция впервые появляется. Использование одних и тех же ссылочных позиций на разных чертежах указывает на схожесть или идентичность элементов.
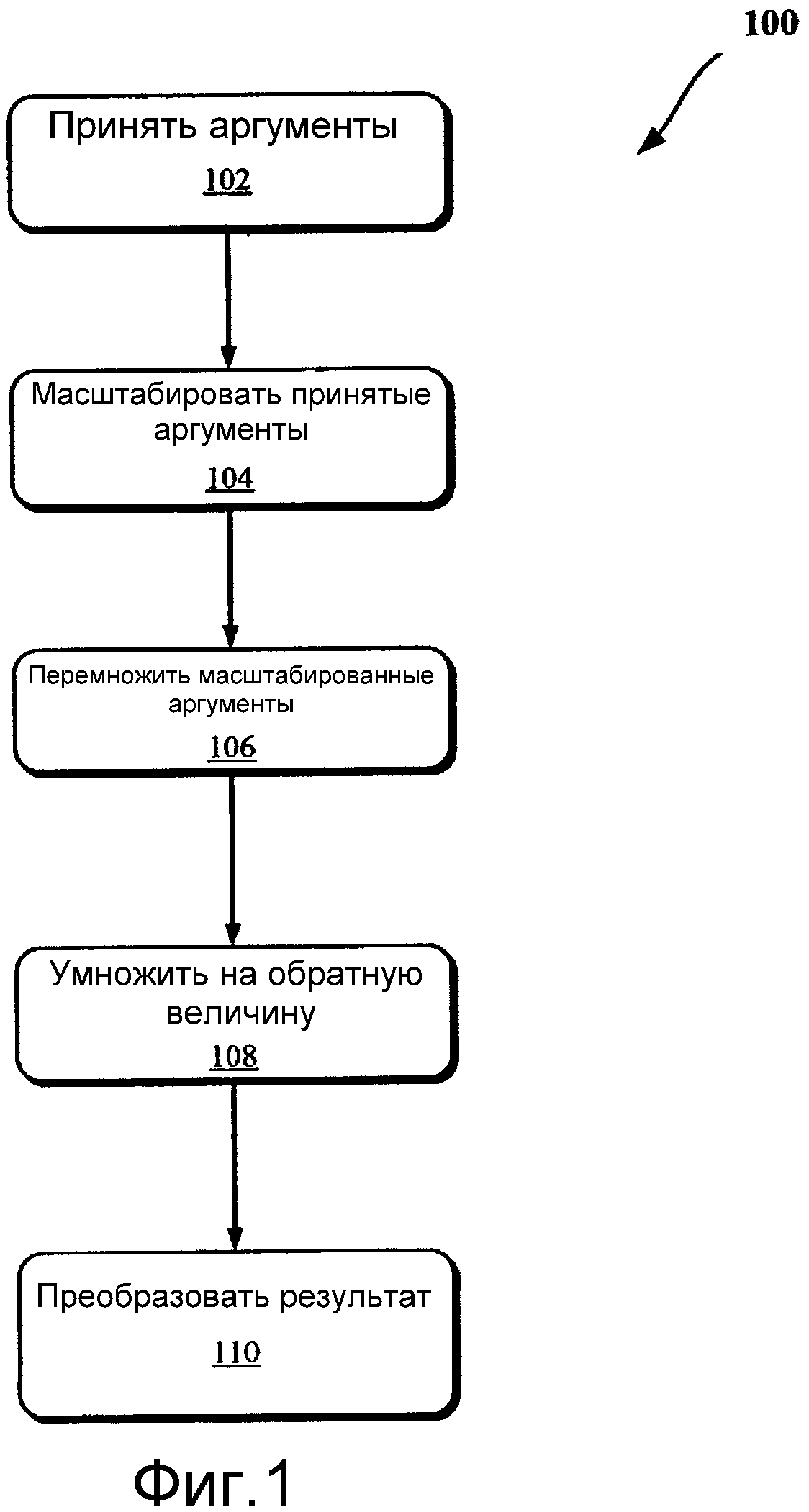
Фиг.1 изображает блок-схему способа согласно одному варианту осуществления настоящего изобретения.
Фиг.2A-2C изображают сегменты псевдокода, которые могут использоваться в некоторых вариантах осуществления.
Фиг.3 изображает структурную схему быстрого векторного деления согласно одному варианту осуществления.
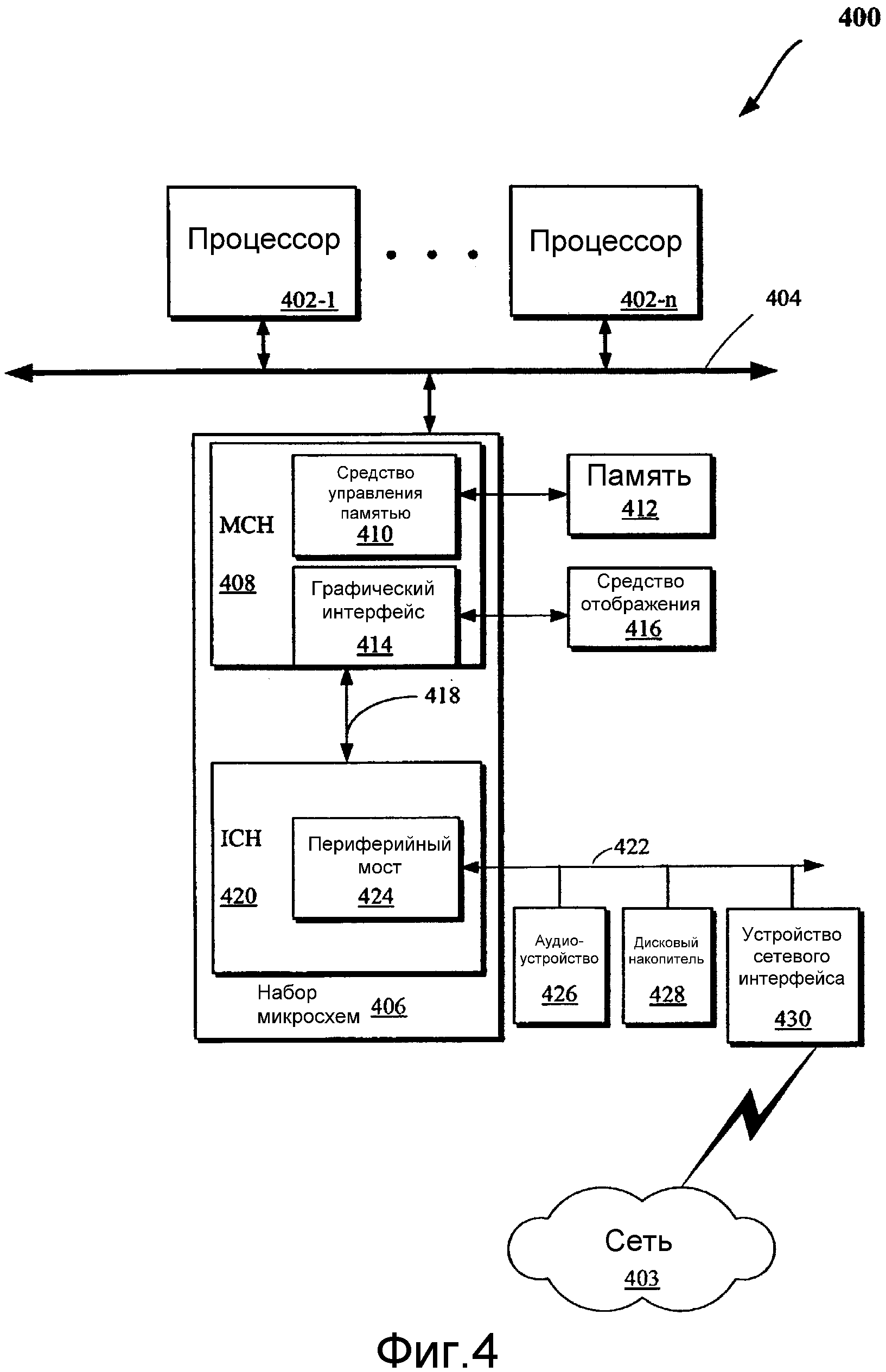
Фиг.4 и 5 изображают структурные схемы вариантов осуществления вычислительных систем, которые могут быть задействованы для осуществления некоторых вариантов осуществления, рассматриваемых здесь.
Подробное описание
В последующем описании множество характерных подробностей изложено с целью обеспечить полное понимание различных вариантов осуществления. Однако различные варианты осуществления настоящего изобретения могут применяться без этих характерных подробностей. В других случаях широко известные способы, процедуры, компоненты и цепи не были описаны подробно, чтобы не нарушать ясность отдельных вариантов осуществления настоящего изобретения. Кроме того, различные аспекты вариантов осуществления настоящего изобретения могут выполняться с использованием различных средств, таких как интегральные полупроводниковые цепи ("аппаратные средства"), считываемые компьютером инструкции, образующие одну или несколько программ ("программные средства"), или некая комбинация аппаратных средств и программных средств. В целях этого раскрытия упоминание "логического узла" будет означать аппаратные средства, программные средства (включая, к примеру, микрокод, который управляет работой процессора) или некую их комбинацию.
Упоминание в техническом описании "одного варианта осуществления" или "какого-либо варианта осуществления" означает, что некоторый признак, структура или характеристика, описанная в связи с этим вариантом осуществления, может включаться по меньшей мере в одно осуществление. Все различные появления словосочетания "в одном варианте осуществления" в различных местах технического описания могут относиться, а могут и не относиться к одному и тому же варианту осуществления.
Также в описании и в формуле изобретения могут использоваться термины "объединенные" и "соединенные" вместе с их производными формами. В некоторых вариантах осуществления настоящего изобретения термин "соединенные" может использоваться для указания на то, что два или более элементов находятся в непосредственном физическом или электрическом контакте друг с другом. Термин "объединенные" может означать, что два или более элементов находятся в непосредственном физическом или электрическом контакте. Однако термин "объединенные" может также означать, что два или более элементов могут не находиться в непосредственном контакте друг с другом, но все равно могут осуществлять совместную работу или взаимодействие друг с другом.
Некоторые из вариантов осуществления, рассматриваемые здесь, могут обеспечивать улучшенную производительность для векторных вычислений деления/обращения удвоенной точности, например, не требуя ветвей или специальных действий, которые прежде были необходимы. Векторные вычисления деления могут выполняться на вычислительных платформах SIMD. В общем, SIMD является методикой, задействуемой для достижения параллелизма уровней данных. В частности, множество данных может обрабатываться в множестве соответствующих полос векторного SIMD-процессора (такого как процессоры 402 и 502/504 с фиг.4 и 5 соответственно) в соответствии с единственной инструкцией.
В некоторых осуществлениях только одна операция деления выполняется для нескольких обращений. Принимая последующее в качестве примера (предложено И.И. Заварзиным, В.Ф. Курякиным, В.В. Луневым, Д.М. Обувалиным, В.Г. Рыжих в работе "Оптимизация вычислений векторных функций". ВАНТ. сер. Математическое моделирование физических процессов. 1997. Т.4 (русскоязычный журнал)):
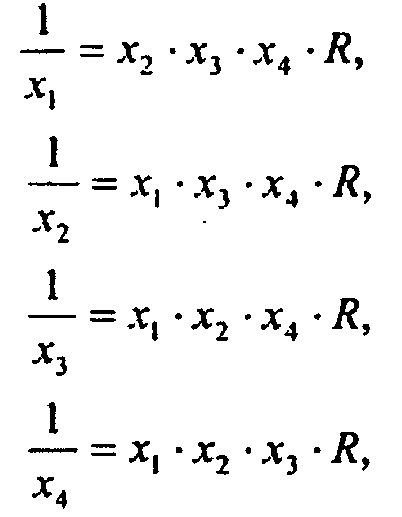
где
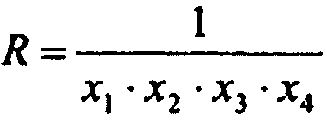
Обращение каждого аргумента может быть вычислено с использованием трех дополнительных умножений посредством R и трех остальных аргументов, что в общем случае быстрее, чем четыре деления аппаратными средствами, которые требуют долгого времени запаздывания и высокого значения пропускной способности. А именно, для общего случая N значений оценкой следующей максимальной возможной выгоды производительности (gain) для этой методики (D, M - значения пропускной способности для Деления и Умножения соответственно) может быть:
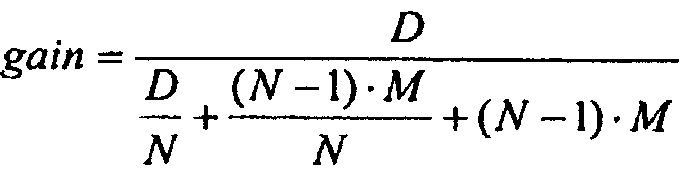
Недостаток этого подхода состоит в высокой вероятности возникновения переполнения или исчезновения значащих разрядов для произведения x1∙x2∙x3∙x4 по причине различности порядков аргументов, что может привести к ошибочным выходным данным для всего набора из четырех аргументов. К примеру, если x1=0,0, но x2≠0,0, x3≠0,0, x4≠0,0, то R=INF, и три результата из четырех будут ошибочными: 1/x2=1/x3=1/x4=INF.
Для разрешения этой проблемы должна быть гарантия, что сумма всех входных порядков не вызовет переполнения или исчезновения значащих разрядов. Это довольно сильно сужает рабочий интервал и требует сравнения аргументов с возможными ветвями для особых случаев, которые не смогут быть обработаны должным образом в стержневой ветви. В одном варианте осуществления вышеупомянутые проблемы могут быть разрешены путем масштабирования и восстановления аргумента.
В частности, фиг.1 изображает блок-схему способа 100 в соответствии с одним вариантом осуществления. На операции 102 принимается один или несколько аргументов (например, x1, x2 и т.д.). Аргументы могут быть представлены в виде x=(-1)sbn∙f, где обозначения определяются следующим образом:
s={0, 1} - знак для "s" в (-1)s,
b - база (например, для двоичного случая b=2),
n - порядок (Emax ≤n≤Emin), где Emax и Emin соответственно означают минимальный и максимальный порядок для соответствующего типа данных согласно ANSI/IEEE Std 754-2008.
f=20+f1∙2-1+f2∙2-2+...+fp∙2-p=1.f1f2...fpB - мантисса (1≤f<2).
Обращение может определяться следующим образом: 1/x=1/(-1)s2n∙f=(-1)s2-n∙1/f.
Предположим, что (x1, x2, x3, x4) являются входными аргументами, где xi=(-1)si2ni∙fi для i=. Они масштабируются на операции 104 по так: zi=1,0∙fi=20∙fi. Масштабированные аргументы перемножаются на операции 106 (например, M=z1z2z3z4), и результат перемножения обращается на операции 108 (например, R=1/M). К примеру, каждое 1/zi для i= вычисляется следующим образом:
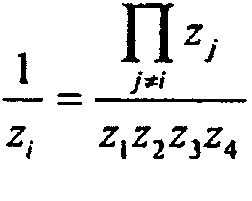
На операции 110 результат восстанавливают так: 1/xi=(-1)si∙∙1/zi, где , в одном варианте осуществления, путем "вставки" входного порядка с измененным знаком и исходного знака в 1/zi.
Такой подход обеспечивает достаточную точность и обрабатывает особые значения по стандарту Института инженеров по электротехнике и радиоэлектронике (IEEE) в рамках той же стержневой ветви. Поскольку zi∈[1, 2), никаких результатов с переполнением или исчезновением значащих разрядов не может произойти во время вычислений, например, произведение любых двух значений zi∙zj∈[1, 4), любых трех значений zi∙zj∙zk∈[1, 8), всех четырех аргументов z1∙z2∙z3∙z4∈[1, 16), и 1/zi∈(0,5, 1], и т.д.
Кроме того, каждое умножение может быть выполнено путем округления до рабочей точности с погрешностью не более 0,5 ulp (Единица в последней позиции или Единица наименьшей точности; см., например, http://en.wikipedia.org/wiki/Ulp; также см., например, "Об определении ulp(x)" Жана-Мишеля Мюллера, INRIA Technical Report 5504), то есть погрешность вычисления z1∙z2∙z3∙z4 не будет превышать 3∙0,5=1,5 ulp.
В одном варианте осуществления, чтобы найти , другие три умножения могут использоваться с дополнительным 3∙0,5=1,5 ulp и одно обращение, которое в этом случае не порождает погрешности. Таким образом, погрешность результата 1/zi будет меньше или равна (3+3)*0,5=3,0 ulp. Конечное восстановление 1/xi=(-1)si∙2mi∙1/zi не добавляет дополнительных погрешностей ввиду IEEE-представления чисел с плавающей точкой. Получаемое в результате 3,0 ulp не выходит за рамки требований для значения малой точности по умолчанию векторных математических библиотек ICL (Intel Compiler), SVML (Short Vector Math Library), MKL (Math Kernel Library) и IPP (Intel Performance Primitives) - до 4 ulp, что соответствует двум неточным разрядам мантиссы, чего достаточно для подавляющего большинства приложений.
Кроме того, несмотря даже на то, что здесь рассматривается случай с набором из четырех значений, эти методики могут применяться к наборам любого размера.
Фиг.2A-2C изображают псевдокоды для выполнения быстрого векторного вычисления деления без ветвления согласно некоторым вариантам осуществления. Конкретнее, фиг.2A изображает аргументы, результаты, приведения и другие определения. Фиг.2B изображает псевдокод для масштабирования аргументов и сохранения исходных значений порядков вместе с перемножением масштабированных аргументов, например, как рассматривалось со ссылками на фиг.1. Фиг.2C изображает псевдокод для результата восстановления. В некоторых вариантах осуществления для полного деления r[i] могут быть умножены на числители.
Фиг.3 изображает структурную схему быстрого векторного деления согласно одному варианту осуществления. Как изображено, обработка порядковой и мантиссовой частей числа (302) с плавающей точкой выполняется раздельно (304). Хотя на изображенном примере число (обозначенное как "arg") указано в изображенном диапазоне, другие диапазоны могут использоваться в зависимости от осуществления, процессора, ширины канала данных и т.д. Кроме того, для получения обращения аргумента обращение порядка (306) и обращение мантиссы (308) могут определяться раздельно и затем конечный результат определяется на основе их произведения. В одном варианте осуществления обращение порядка может выполняться на основе замены знака (310 и 312), как рассматривалось со ссылками на фиг.1-2C. В некоторых вариантах осуществления это может быть выполнено посредством целочисленных операций и без каких-либо потерь в точности. Для обращения мантиссы (314 и 316) она может быть представлена в виде числа с плавающей точкой с нулевым порядком. Наконец, конечный результат определяется (318) на основе перемножения обращенных мантиссы и порядка (что считается точным результатом, поскольку по меньшей мере один из множителей имеет нулевую дробную часть).
Фиг.4 изображает структурную схему одного варианта осуществления вычислительной системы 400. В различных вариантах осуществления один или несколько компонентов системы 400 могут обеспечиваться в различных электронных устройствах с возможностью выполнения одной или нескольких операций, рассматриваемых здесь со ссылками на некоторые варианты осуществления настоящего изобретения. К примеру, один или несколько компонентов системы 400 могут использоваться для выполнения операций, рассматриваемых со ссылками на фиг.1-3, например, путем генерирования значений, соответствующих делению/обращению, с улучшенной производительностью посредством использования SIMD и т.д. в соответствии с операциями, рассматриваемыми здесь. Также различные устройства хранения данных, рассматриваемые здесь (например, со ссылками на фиг.4 и/или 5), могут использоваться для хранения данных, результатов операций и т.д. В одном варианте осуществления данные, ассоциированные с операцией по способу 300 с фиг.3, могут быть сохранены в запоминающем устройстве (запоминающих устройствах) (таком как память 412 или один или несколько кэшей (например, L1-кэши в одном варианте осуществления), представленных в процессорах 402 с фиг.4 или 502/604 с фиг.5). Эти процессоры могут затем применять операции, рассматриваемые здесь, для быстрого деления/обращения (такие как одна или несколько из операций с фиг.1-3). Соответственно, в некоторых вариантах осуществления процессоры 402 с фиг.4 или 502/604 с фиг.5 могут являться векторными процессорами с возможностью поддерживать SIMD-операции.
Кроме того, вычислительная система 400 может включать в себя один или несколько центральных процессоров (CPU) 402 или процессоров, которые связываются посредством внутрисхемной сети (или шины) 404. Процессоры 402 могут включать в себя универсальный процессор, сетевой процессор (который обрабатывает данные, передаваемые по компьютерной сети 403) или процессоры других типов (включая процессор компьютера с сокращенным набором инструкций (RISC) или компьютер со сложным набором инструкций (CISC)). Кроме того, процессоры 402 могут иметь конструкцию с единственным ядром или с множеством ядер. Процессоры 402 с многоядерной конструкцией могут включать в себя процессорные ядра различных типов на одном кристалле интегральной цепи (IC). Также процессоры 402 с многоядерной конструкцией могут быть осуществлены в виде симметричных или асимметричных мультипроцессоров. Дополнительно, процессоры 402 могут задействовать SIMD-архитектуру. Кроме того, операции, рассматриваемые со ссылками на фиг.1-3, могут выполняться одним или несколькими компонентами системы 400.
Набор 406 микросхем может также связываться через внутрисхемную сеть 404. Набор 406 микросхем может включать в себя концентратор 408 управления памятью (MCH). MCH 408 может включать в себя средство 410 управления памятью, которое связывается с памятью 412. Память 412 может хранить данные, включая последовательности инструкций, которые выполняет CPU 402 или любое другое устройство, включаемое в вычислительную систему 400. В одном варианте осуществления настоящего изобретения память 412 может включать в себя одно или несколько энергозависимых запоминающих устройств (или устройств памяти), таких как оперативное запоминающее устройство (RAM), динамическое RAM (DRAM), синхронное DRAM (SDRAM), статическое RAM (SRAM) или запоминающие устройства других типов. Также могут быть задействованы энергонезависимые запоминающие устройства, такие как жесткий диск. Дополнительные устройства могут связываться посредством внутрисхемной сети 404, такие как множество CPU и/или множество устройств системной памяти.
MCH 408 может также включать в себя графический интерфейс 414, который связывается со средством 416 отображения. Средство 416 отображения может использоваться для отображения пользователю результатов операций, ассоциированных с быстрым делением/обращением, рассматриваемых здесь. В одном варианте осуществления настоящего изобретения графический интерфейс 414 может связываться со средством 416 отображения посредством ускоренного графического порта (AGP). В одном варианте осуществления настоящего изобретения средство 416 отображения может быть плоскопанельным дисплеем, который связывается с графическим интерфейсом 414 через, к примеру, преобразователь сигнала, который переводит цифровое представление изображения, сохраненное в запоминающем устройстве, таком как видеопамять или системная память, в отображаемые сигналы, которые расшифровываются и отображаются средством 416 отображения. Отображаемые сигналы, производимые интерфейсом 414, могут проходить через различные управляющие устройства перед расшифровкой и последующим отображением на средстве 416 отображения.
Концентраторный интерфейс 418 может позволять MCH 408 и концентратору 420 управления вводом-выводом (ICH) взаимосвязываться. ICH 420 может обеспечивать интерфейс с устройствами ввода-вывода, которые связываются с вычислительной системой 400. ICH 420 может связываться с шиной 422 через периферийный мост (или управляющее средство) 424, такой как мост соединения периферийных компонентов (PCI), управляющее средство универсальной последовательной шины (USB) и периферийные мосты или управляющие средства других типов. Мост 424 может обеспечить канал данных между CPU 402 и периферийными устройствами. Могут быть задействованы топологии других типов. Также множество шин может связываться с ICH 420, например, через множество мостов или управляющих средств. Кроме того, другие периферийные устройства в связи с ICH 420 могут включать в себя в различных вариантах осуществления настоящего изобретения встроенные электронные средства управления диском (IDE) или жесткий(ие) диск(и) интерфейса малых компьютерных систем (SCSI), USB-порт(ы), клавиатуру, мышь, порт(ы) параллельного ввода данных, порт(ы) последовательного ввода данных, гибкий(ие) дисковый(ые) накопитель(и), поддержку цифрового вывода (например, интерфейсом цифрового вывода (DVI)) или другие устройства.
Шина 422 может связываться с аудиоустройством 426, одним или несколькими дисковыми накопителями 428 и устройством 430 сетевого интерфейса, которые могут состоять в связи с компьютерной сетью 403. В одном варианте осуществления устройство 430 может являться NIC с возможностью беспроводной связи. Другие устройства могут связываться через шину 422. Также различные компоненты (такие как устройство 430 сетевого интерфейса) могут связываться с MCH 408 в некоторых вариантах осуществления настоящего изобретения. В дополнение, процессор 402 и MCH 408 могут объединяться для образования единой цепи. Кроме того, графический интерфейс 414 может включаться в MCH 408 в других вариантах осуществления настоящего изобретения.
Кроме того, вычислительная система 400 может включать в себя энергозависимую и/или энергонезависимую память (или запоминающее устройство). К примеру, энергонезависимая память может включать в себя одно или несколько из следующих устройств: постоянное запоминающее устройство (ROM), программируемое ROM (PROM), стираемое PROM (EPROM), электрически стираемое EPROM (EEPROM), дисковый накопитель (например, 428), гибкий диск, ROM на компакт-диске (CD-ROM), универсальный цифровой диск (DVD), флэш-память, магнитооптический диск или энергонезависимые машиночитаемые носители других типов с возможностью сохранения электронных данных (например, включающих инструкции). В одном варианте осуществления компоненты системы 400 могут быть организованы в двухточечную (PtP) конфигурацию, такую как рассматриваемая со ссылками на фиг.5. К примеру, процессоры, память и/или устройства ввода-вывода могут быть взаимосвязаны некоторым количеством двухточечных интерфейсов.
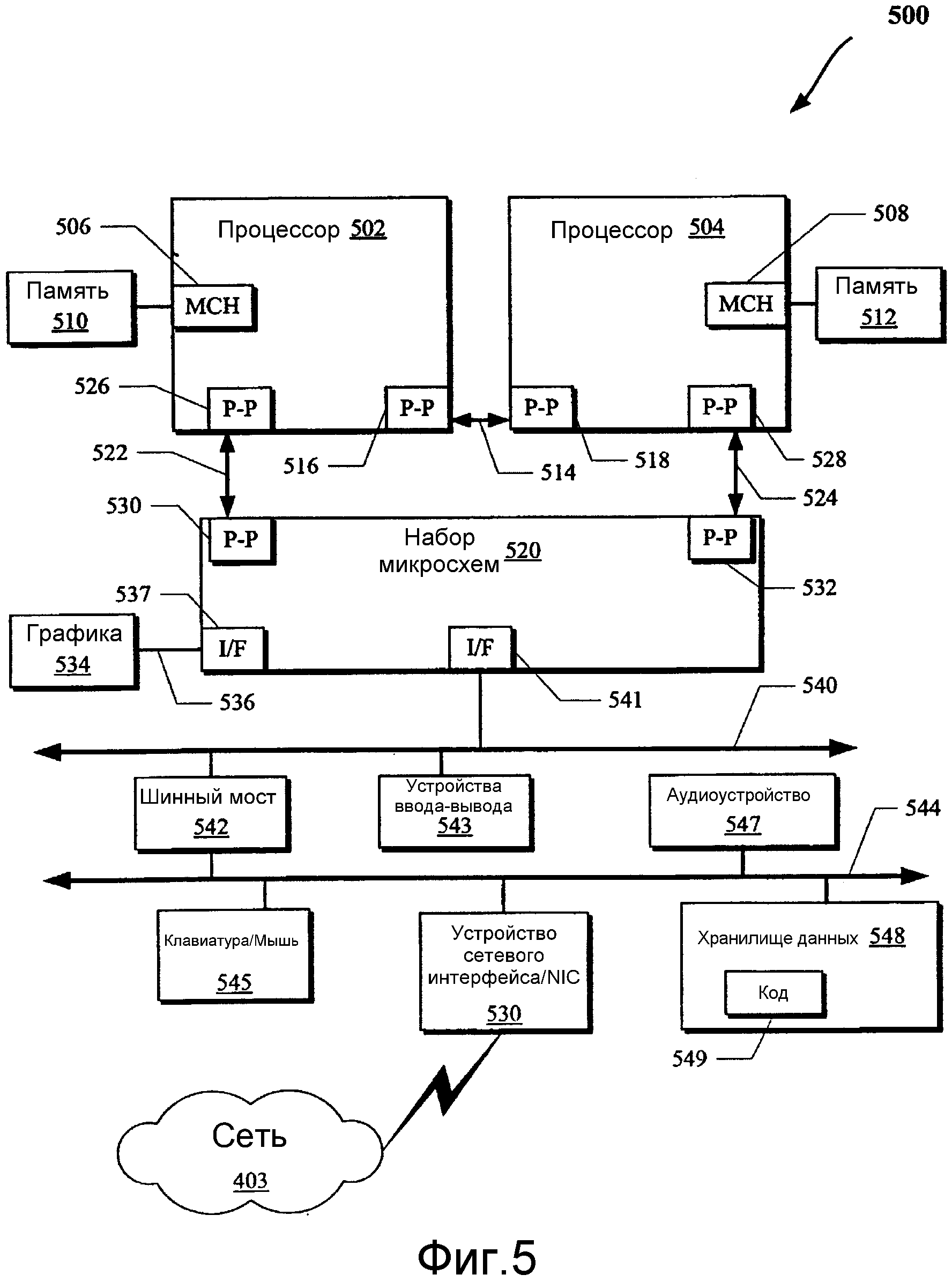
Конкретнее, фиг.5 изображает вычислительную систему 500, которая организована в двухточечную (PtP) конфигурацию, согласно одному варианту осуществления настоящего изобретения. В частности, фиг.5 изображает систему, где процессоры, память и устройства ввода-вывода взаимосвязаны некоторым количеством двухточечных интерфейсов. Операции, рассматриваемые со ссылками на фиг.1-4, могут выполняться одним или несколькими компонентами системы 500.
Как изображено на фиг.5, система 500 может включать в себя несколько процессоров, из которых в целях ясности изображены только два процессора 502 и 504. Каждый из процессоров 502 и 504 может включать в себя концентратор 506 и 508 управления локальной памятью (MCH) для объединения с устройствами 510 и 512 памяти. Устройства 510 и/или 512 памяти могут хранить различные данные, такие как рассмотренные со ссылками на память 412 с фиг.4.
Процессоры 502 и 504 могут быть любыми подходящими процессорами, такими как рассмотренные со ссылками на процессоры 402 с фиг.4. Процессоры 502 и 504 могут осуществлять обмен данными посредством двухточечного (PtP) интерфейса 514 с использованием цепей 516 и 518 PtP интерфейса соответственно. Каждый из процессоров 502 и 504 может осуществлять обмен данных с набором микросхем 520 через отдельные PtP интерфейсы 522 и 524 с использованием цепей 526, 528, 530 и 532 двухточечного интерфейса. Набор микросхем 520 может также осуществлять обмен данными с графической цепью 534 высокой производительности посредством графического интерфейса 536 высокой производительности с использованием цепи 537 PtP интерфейса.
По меньшей мере один вариант осуществления настоящего изобретения может обеспечиваться путем задействования процессоров 502 и 504. К примеру, процессоры 502 и/или 504 могут выполнять одну или несколько из операций с фиг.1-4. Другие варианты осуществления настоящего изобретения, однако, могут существовать в других цепях, логических блоках или устройствах внутри системы 500 с фиг.5. Кроме того, другие варианты осуществления настоящего изобретения могут быть распределены по нескольким цепям, логическим блокам или устройствам, изображенным на фиг.5.
Набор микросхем 520 может объединяться с шиной 540 посредством цепи 541 PtP интерфейса. Шина 540 может иметь одно или несколько устройств, объединенных с ней, таких как шинный мост 542 и устройства 543 ввода-вывода. Через шину 544 шинный мост 543 может объединяться с другими устройствами, такими как клавиатура/мышь 545, устройство 530 сетевого интерфейса, рассматриваемое со ссылками на фиг.5 (такое как модемы, сетевые интерфейсные карты (NIC) или подобные, которые могут объединяться с компьютерной сетью 403), устройство ввода-вывода аудио и/или устройство 548 хранения данных. Устройство 548 хранения данных может хранить код 549, который может быть выполнен процессорами 502 и/или 504.
В различных вариантах осуществления настоящего изобретения операции, рассмотренные здесь, например, со ссылками на фиг.1-5, могут осуществляться в виде аппаратных средств (например, набора логических цепей), программных средств (включая, к примеру, микрокод, который управляет работой процессора, такого как процессоры, рассмотренные со ссылками на фиг.4-5), программно-аппаратных средств или комбинаций перечисленного, которые могут обеспечиваться в виде компьютерного программного продукта, например, включающего в себя материальный машиночитаемый или считываемый компьютером носитель с сохраненными на нем инструкциями (или процедурами программных средств), используемыми для программирования компьютера (например, процессора или другого логического средства вычислительного устройства) для выполнения операции, рассматриваемой здесь. Машиночитаемый носитель может включать в себя запоминающее устройство, такое как рассмотренные здесь.
Дополнительно, такие материальные считываемые компьютером носители могут быть загружены в качестве компьютерного программного продукта, причем программа может быть передана от удаленного компьютера (например, сервера) запрашивающему компьютеру (например, клиенту) в виде сигналов данных, осуществленных в материальной среде распространения, по линии связи (например, шине, модему или сетевому соединению).
Таким образом, хотя варианты осуществления настоящего изобретения были описаны в контексте структурных признаков и/или методологических действий, следует понимать, что заявляемое изобретение не может быть ограничено описанными здесь характерными признаками или действиями. Наоборот, характерные признаки и действия раскрываются лишь как формы осуществления заявляемого изобретения.
Реферат
Изобретение относится к средствам векторных вычислений деления/обращения удвоенной точности на вычислительных платформах с одним потоком команд и множеством потоков данных (SIMD). Технический результат заключается в увеличении производительности векторных вычислений. Множество SIMD-полос предназначены для обработки одного элемента из множества данных, сохраненных в памяти, в соответствии с SIMD-инструкцией. Масштабируют множество аргументов для генерирования множества соответствующих масштабированных аргументов. Перемножают множество масштабированных аргументов для генерирования первого значения. Масштабируют порядковую часть и мантиссовую часть первого значения из множества значений данных для соответственного генерирования второго значения и третьего значения. Обращают второе значение и третье значение для соответственного генерирования четвертого значения и пятого значения. Перемножают четвертое значение и пятое значение для генерирования обратной версии первого значения. 3 н. и 14 з.п. ф-лы, 7 ил.
Формула
масштабируют множество аргументов для генерирования множества соответствующих масштабированных аргументов;
перемножают множество масштабированных аргументов для генерирования первого значения;
масштабируют порядковую часть и мантиссовую часть первого значения из множества значений данных для соответственного генерирования второго значения и третьего значения;
обращают второе значение и третье значение для соответственного генерирования четвертого значения и пятого значения; и
перемножают четвертое значение и пятое значение для генерирования обратной версии первого значения.
память для хранения множества значений данных, соответствующих инструкции SIMD (один поток команд, множество потоков данных); и
процессор, имеющий множество SIMD-полос, причем каждая из множества SIMD-полос предназначена для обработки одного элемента из множества данных, сохраненных в памяти, в соответствии с SIMD-инструкцией, причем процессор предназначен для того, чтобы:
масштабировать порядковую часть и мантиссовую часть первого значения из множества значений данных для соответственного генерирования второго значения и третьего значения;
обращать второе значение и третье значение для соответственного генерирования четвертого значения и пятого значения; и
перемножать четвертое значение и пятое значение для генерирования обратной версии первого значения, причем второе значение должно быть обращено путем изменения знака порядковой части первого значения.
масштабировать множество аргументов для генерирования множества соответствующих масштабированных аргументов;
перемножать множество масштабированных аргументов для генерирования первого значения;
масштабировать порядковую часть и мантиссовую часть первого значения из множества значений данных для соответственного генерирования второго значения и третьего значения;
обращать второе значение и третье значение для соответственного генерирования четвертого значения и пятого значения; и
перемножать четвертое значение и пятое значение для генерирования обратной версии первого значения.
Комментарии