Способ функционирования канала беспроводной связи и система портативного терминала - RU2661791C2
Код документа: RU2661791C2
Чертежи










Описание
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
1. ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к мобильному терминалу с поддержкой функции голосового общения и способу управления голосовым общением, и более конкретно, к мобильному терминалу с поддержкой функции голосового общения и способу управления голосовым общением для вывода контента в точности в соответствии с текущим эмоциональным состоянием, возрастом и полом пользователя.
2. ОПИСАНИЕ РОДСТВЕННОЙ ОБЛАСТИ ТЕХНИКИ
Общепринятая функция голосового общения действует таким образом, что ответ на вопрос пользователя выбирается из базового набора ответов, предоставленного изготовителем терминала. Соответственно, функция голосового общения ограничивается тем, что на один и тот же вопрос отвечают одним и тем же ответом независимо от пользователя. Это означает, что когда многочисленные пользователи используют мобильный терминал с поддержкой функции голосового общения, общепринятая функция голосового общения не обеспечивает ответ, оптимизированный для каждого пользователя.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение направлено на решение по меньшей мере описанных выше проблем и недостатков и на обеспечение по меньшей мере преимуществ, описанных ниже. Соответственно, аспект настоящего изобретения обеспечивает мобильный терминал для вывода контента, отражающего текущее эмоциональное состояние, возраст и пол пользователя, и способ управления голосовым общением для него.
В соответствии с аспектом настоящего изобретения, обеспечен мобильный терминал, поддерживающий функцию голосового общения. Терминал включает в себя блок отображения, блок обработки звука и блок управления, выполненный с возможностью выбора контента, соответствующего первому критерию, ассоциированному с пользователем, в ответ на ввод от пользователя, определения схемы вывода контента на основании второго критерия, ассоциированного с пользователем, и вывода выбранного контента через блок отображения, и блок обработки звука в соответствии со схемой вывода контента.
В соответствии с другим аспектом настоящего изобретения, обеспечен способ голосового общения мобильного терминала. Способ включает в себя выбор контента, соответствующего первому критерию, ассоциированному с пользователем, в ответ на ввод от пользователя, определение схемы вывода контента на основании второго критерия, ассоциированного с пользователем, и вывод выбранного контента через блок отображения и блок обработки звука мобильного терминала в соответствии со схемой вывода контента.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Вышеупомянутые и другие аспекты, признаки и преимущества вариантов осуществления настоящего изобретения станут понятными из последующего подробного описания, рассматриваемого совместно с прилагаемыми чертежами, на которых:
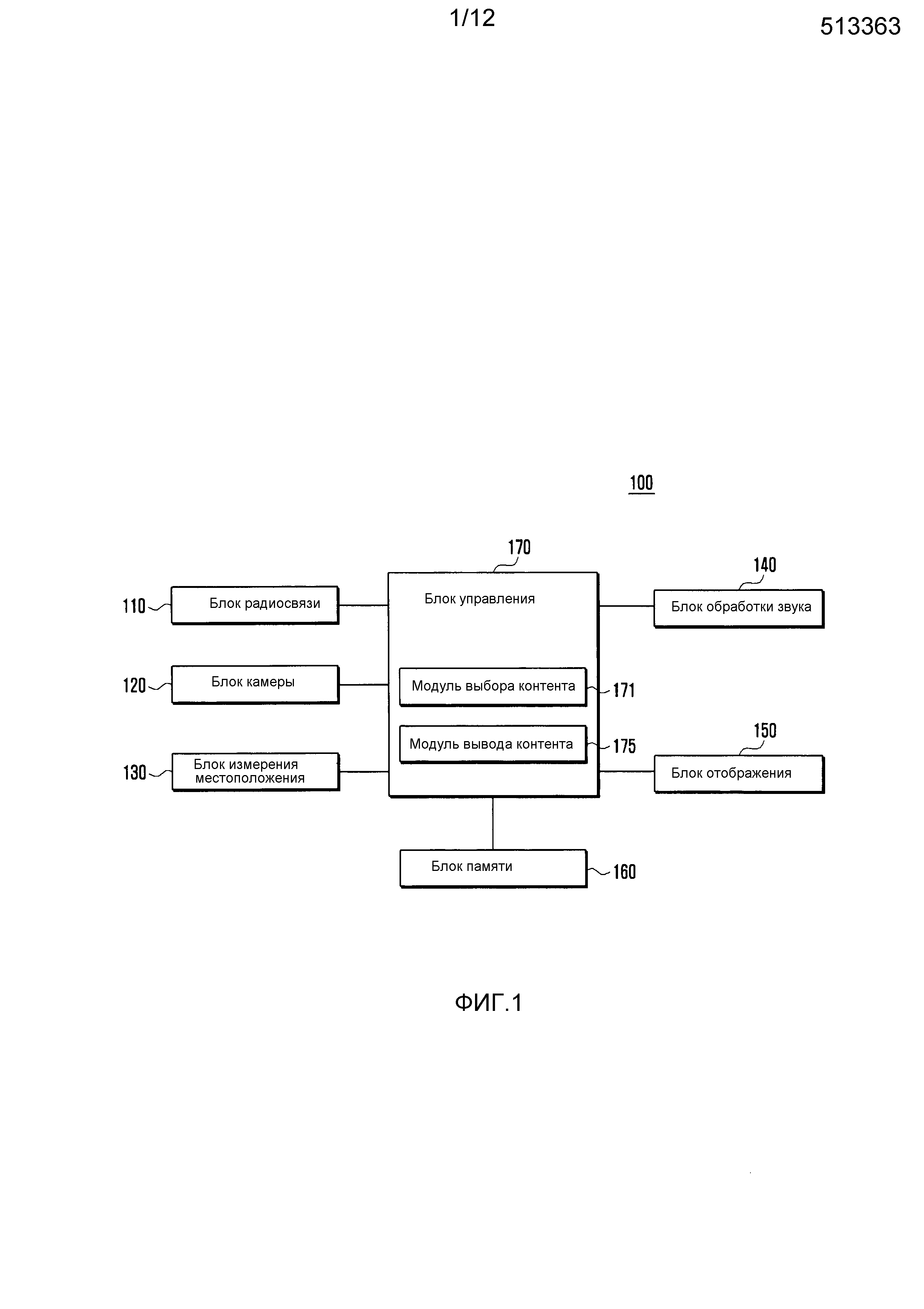
фиг. 1 представляет блок-схему, иллюстрирующую конфигурацию мобильного терминала 100 в соответствии с вариантом осуществления настоящего изобретения;
фиг. 2 представляет схему последовательности операций, иллюстрирующую способ управления функцией голосового общения в соответствии с вариантом осуществления настоящего изобретения;
фиг. 3 представляет таблицу, сопоставляющую эмоциональные состояния и элементы контента для использования в способе управления голосовым общением в соответствии с вариантом осуществления настоящего изобретения;
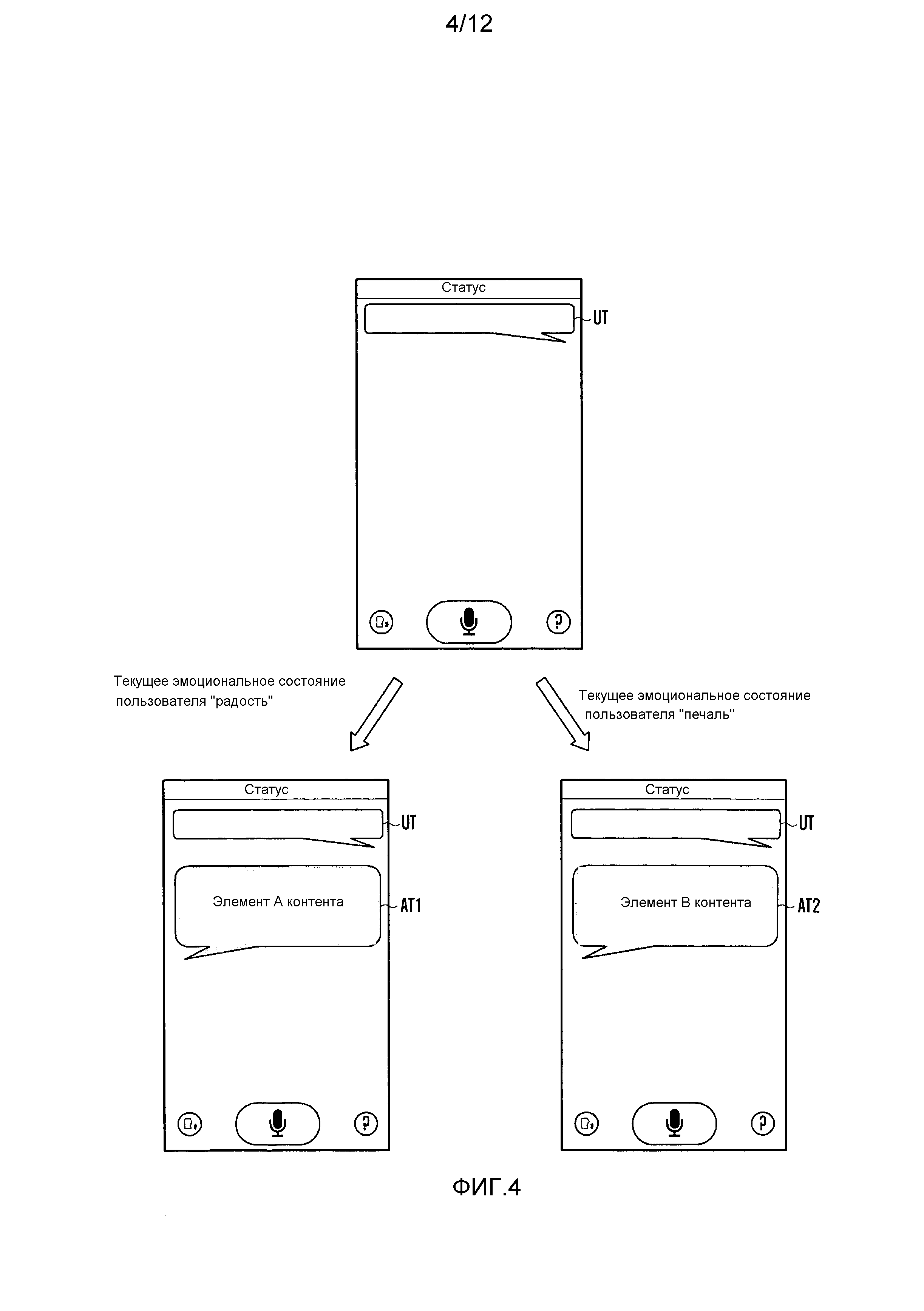
фиг. 4 и 5 представляют схемы отображений на экране, иллюстрирующие вывод контента на основании первого критерия в соответствии с вариантом осуществления настоящего изобретения;
фиг. 6 представляет схему последовательности операций, иллюстрирующую подробности первого этапа получения критерия, показанного на фиг. 2;
фиг. 7 представляет таблицу, сопоставляющую эмоциональные состояния и элементы контента для использования в способе управления голосовым общением в соответствии с вариантом осуществления настоящего изобретения;
фиг. 8 и 9 представляют схемы отображений на экране, иллюстрирующие вывод контента на основании первого критерия в соответствии с вариантом осуществления настоящего изобретения;
фиг. 10 представляет таблицу, сопоставляющую эмоциональные состояния и элементы контента для использования в способе управления голосовым общением в соответствии с вариантом осуществления настоящего изобретения;
фиг. 11 представляет схему отображений на экране, иллюстрирующую вывод контента на основании первого критерия в соответствии с вариантом осуществления настоящего изобретения; и
фиг. 12 является схематическим представлением, иллюстрирующим систему для функции голосового общения мобильного терминала в соответствии с вариантом осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ НАСТОЯЩЕГО ИЗОБРЕТЕНИЯ
Настоящее изобретение будет описано более подробно со ссылкой на прилагаемые чертежи, на которых показаны иллюстративные варианты осуществления изобретения. Однако, данное изобретение может быть воплощено во многих различных формах и не должно быть истолковано, как ограниченное вариантами осуществления, изложенными в данном документе. Скорее, эти варианты осуществления обеспечены так, чтобы описание настоящего изобретения было полным и завершенным и полностью передавало объем изобретения специалистам в данной области техники. Настоящее изобретение определяется прилагаемой формулой изобретения.
Хотя имеются порядковые номера, такие как описаны более подробно ниже со ссылкой на прилагаемые чертежи, на которых показаны иллюстративные варианты осуществления изобретения, однако данное изобретение может быть воплощено во многих различных формах и не должно быть ограничено только теми терминами, которые используются лишь для того, чтобы отличать один элемент, компонент, область, уровень или раздел от другого. Таким образом, первый элемент, компонент, область, уровень или раздел, обсуждаемые ниже, можно назвать вторым элементом, компонентом, областью, уровнем или разделом, не отступая от концепций изобретения. Описания следует понимать, как включающие в себя любые и все комбинации одного или более из ассоциированных перечисленных элементов, когда эти элементы описываются с использованием соединительного термина "и/или" и т.п.
Фиг. 1 представляет блок-схему, иллюстрирующую конфигурацию мобильного терминала 100 в соответствии с вариантом осуществления настоящего изобретения.
Как показано на фиг. 1, мобильный терминал 100 включает в себя блок 110 радиосвязи, блок 120 камеры, блок 130 измерения местоположения, блок 140 обработки звука, блок 150 отображения, блок 160 памяти и блок 170 управления.
Блок 110 радиосвязи передает/принимает радиосигналы, несущие данные. Блок 110 радиосвязи может включать в себя радиочастотный (РЧ) передатчик, выполненный с возможностью преобразования с повышением частоты и усиления передаваемых сигналов, и РЧ приемник, выполненный с возможностью усиления с низким уровнем шумов и преобразования с понижением частоты принимаемых сигналов. Блок 110 радиосвязи передает данные, принимаемые по радиоканалу, в блок 170 управления и передает по радиоканалу выходные данные от блока 170 управления.
Блок 120 камеры принимает видеосигналы. Блок 120 камеры обрабатывает видеокадры неподвижных и движущихся изображений, полученные датчиком изображения в режиме видеоконференции или в режиме съемки изображений. Блок 120 камеры может выводить обработанный видеокадр в блок 150 отображения. Видеокадр, обработанный блоком 120 камеры, может быть сохранен в блоке памяти и/или передан внешним образом посредством блока 110 радиосвязи.
Блок 120 камеры может включать в себя два или больше модулей камеры в зависимости от реализации мобильного терминала 100. Например, мобильный терминал 100 может включать в себя камеру, обращенную в том же направлении, что и экран блока 150 отображения, и другую камеру, обращенную в противоположную от экрана сторону.
Блок 130 измерения местоположения может быть снабжен модулем приема спутниковых сигналов для измерения текущего местоположения мобильного терминала 100 на основании сигналов, принимаемых от спутников. Посредством блока 110 радиосвязи, блок 130 измерения местоположения также может измерять текущее местоположение мобильного терминала 100 на основании сигналов, принимаемых от внутреннего или внешнего устройства радиосвязи внутри учреждения.
Блок 140 обработки звука может быть снабжен пакетом кодеков, включающим в себя кодек данных для обработки пакетных данных и аудиокодек для обработки звукового сигнала, такого как голос. Блок 140 обработки звука может преобразовывать цифровые звуковые сигналы в аналоговые звуковые сигналы посредством аудиокодека, чтобы выводить аналоговый сигнал через динамик (SPK), и преобразовывать ввод аналоговых сигналов через микрофон (MIC) в цифровые звуковые сигналы.
Блок 150 отображения отображает для пользователя в визуальной форме меню, вводимые данные, информацию о конфигурации функционирования и т.д. Блок 150 отображения выводит экран загрузки, экран ожидания, экран меню, экран телефонной связи и другие экраны выполнения приложения.
Блок 150 отображения может быть реализован с помощью одного из жидкокристаллического дисплея (LCD), дисплея на основе органических светодиодов (OLED), дисплея с активной матрицей OLED (AMOLED), гибкого дисплея и трехмерного (3D) дисплея.
Блок 160 памяти сохраняет программы и данные, необходимые для функционирования мобильного терминала 100, и может быть разделен на область программ и область данных. Область программ может сохранять основные программы для управления всей работой мобильного терминала 100, операционную систему (ОС) для загрузки мобильного терминала 100, приложения для воспроизведения мультимедийного контента и другие приложения для выполнения дополнительных функций, таких как голосовое общение, камера, воспроизведение звука и воспроизведение видео. Область данных может сохранять данные, сгенерированные в состоянии использования мобильного терминала 100, такие как неподвижные и движущиеся изображения, телефонная книга и аудиоданные.
Блок 170 управления управляет всеми операциями компонентов мобильного терминала 100. Блок 170 управления принимает речевой ввод пользователя через блок 140 обработки звука и управляет блоком 150 отображения для отображения на экране контента, соответствующего речи пользователя, в функции голосового общения, выполняемой в соответствии с манипулированием пользователя. Блок 170 управления также может воспроизводить контент, соответствующий речи пользователя, через блок 140 обработки звука. В данном документе, контент может включать в себя по меньшей мере одно из мультимедийного контента, такого как текст, изображение, звук, фильм и видеоклип, и информации, такой как погода, рекомендуемые местоположения и избранный контакт.
Более подробно, блок 170 управления распознает речь пользователя для получения соответствующего текста. Затем, блок 170 управления извлекает контент, соответствующий тексту, и выводит контент по меньшей мере через одно из блока 150 отображения и блока 140 обработки звука. Наконец, блок 170 управления может проверять смысл текста для извлечения соответствующего контента из числа сходного контента, хранящегося в блоке 160 памяти. Таким образом, при использовании интерактивной речевой связи, пользователю может быть предоставлена надлежащая информация через соответствующий сохраненный контент. Например, если пользователь говорит "Какая сегодня погода?", мобильный терминал 100 принимает речевой ввод пользователя через блок 140 обработки звука. Затем мобильный терминал 100 принимает контент (информацию о погоде), соответствующий тексту "Какая сегодня погода", полученному из речи пользователя, и выводит извлеченный контент по меньшей мере через одно из блока 150 отображения и блока 140 обработки звука.
В частности, в варианте осуществления настоящего изобретения, блок 170 управления может выбирать контент, подлежащий выведению через блок 150 отображения и/или блок 140 обработки звука, в зависимости от текущего эмоционального состояния, возраста и пола пользователя. Для того, чтобы выполнять это, блок 170 управления, в соответствии с вариантом осуществления настоящего изобретения, может включать в себя модуль 171 выбора контента и модуль 175 вывода контента.
Фиг. 2 представляет схему последовательности операций, иллюстрирующую способ управления функцией голосового общения в соответствии с вариантом осуществления настоящего изобретения.
Как показано на фиг. 2, если на этапе S210 выполняется функция голосового общения, на этапе S220 модуль 171 выбора контента получает первый критерий, ассоциированный с пользователем. В данном документе, первый критерий может включать в себя текущее эмоциональное состояние пользователя. Эмоциональное состояние обозначает настроение или переживаемое чувство, такое как радость, печаль, гнев, удивление и т.д.
Модуль 171 выбора контента на этапе S230 определяет, обнаружен ли речевой ввод пользователя. Если речевой ввод пользователя обнаружен через блок 140 обработки звука, модуль 171 выбора контента на этапе S240 выбирает контент, соответствующий речевому вводу пользователя, на основании первого критерия. Более подробно, модуль 171 выбора контента извлекает фразу из речи пользователя. Затем, модуль 171 выбора контента выбирает элементы контента, соответствующие этой фразе. Затем, модуль 171 выбора контента выбирает элементы контента, используя информацию об эмоциональном состоянии, предварительно определенную на основании первого критерия. В данном документе, характерная для эмоционального состояния информация о контенте может быть предварительно сконфигурирована и сохранена в блоке 160 памяти. Модуль 171 выбора контента также может извлекать элементы контента сначала на основании первого критерия, а затем выбирать один из этих элементов контента, соответствующих фразе.
В противном случае, если на этапе S230 речевой ввод пользователя не обнаружен, на этапе S250 модуль 171 выбора контента выбирает контент на основании первого критерия.
Если контент выбран, на этапе S260 модуль 175 вывода контента получает второй критерий, ассоциированный с пользователем. В данном документе, второй критерий может включать в себя по меньшей мере одно из возраста и пола пользователя. Возраст пользователя может быть точным возрастом пользователя или одной из предварительно определенных возрастных групп. Например, возраст пользователя может быть обозначен с помощью точного числа, такого как 30 или 50, или с помощью возрастной группы, такой как 20-летние, 50-летние, ребенок, взрослый и пожилой.
Более подробно, модуль вывода контента принимает изображение лица пользователя от блока 120 камеры. Модуль 175 вывода контента может получать второй критерий автоматически на основании изображения лица пользователя, основываясь на усредненной информации о лице для каждого пола или для каждой возрастной группы, хранящейся в блоке 160 памяти. Модуль 175 вывода контента также принимает речевой ввод пользователя через блок 140 обработки звука. Затем, модуль 175 вывода контента может получить второй критерий из речи пользователя, используя усредненную информацию о речи для каждой возрастной группы или для каждого пола. Модуль 175 вывода контента также может получить второй критерий на основании слов, составляющих фразу, полученную из речи пользователя. В это время, модуль 175 вывода контента может получить второй критерий, используя слова, характерные для каждого пола или для каждой возрастной группы. Например, если из речи пользователя получена фраза "I want new jim-jams (Я хочу новую пижаму)", можно судить о пользователе, как о ребенке, основываясь на слове "jim-jams" (пижама).
Модуль 175 вывода контента может получать второй критерий на основании как изображения лица, так и речи пользователя. Хотя описание относится к случаю, когда модуль 175 вывода контента получает второй критерий, основываясь на изображении лица и речи пользователя, различные варианты осуществления настоящего изобретения не ограничиваются только этим, а могут быть воплощены так, чтобы второй критерий вводил пользователь. В этом случае, второй критерий, введенный пользователем, может быть сохранен в блоке 160 памяти. Тогда модуль 175 вывода контента выполняет предварительно определенные функции, основанные на втором критерии, хранящемся в блоке 160 памяти.
Если второй критерий получен, модуль 175 вывода контента на этапе S270 определяет схему вывода контента на основании второго критерия. Таким образом, модуль 175 вывода контента определяет схему вывода контента посредством изменения слов, составляющих контент, выбранный модулем 171 выбора контента, скорости вывода выбранного контента и размера вывода выбранного контента.
Более подробно, модуль 175 вывода контента может изменять слова, составляющие выбранный контент, на слова, подходящие для второго критерия, основываясь на информации о словах для каждой возрастной группы или информации о словах для каждого пола. Например, если контент включает в себя "Pajamas store" (магазин пижам) и если пользователь принадлежит к возрастной группе "дети", модуль 175 вывода контента изменяет слово "Pajamas" (пижама) на слово "jim-jams" (пижама), подходящее для детей.
Модуль 175 вывода контента определяет скорость вывода выбранного контента на основании информации о скорости вывода для каждой возрастной группы или информации о скорости вывода для каждого пола, хранящейся в блоке 160 памяти. Например, если пользователь принадлежит к возрастной группе "дети" или "пожилые", модуль 175 вывода контента может уменьшить скорость воспроизведения речи для выбранного контента.
Модуль 175 вывода контента также определяет размер вывода выбранного контента, основываясь на информации о размере вывода для каждой возрастной группы или информации о размере вывода для каждого пола. Например, если пользователь принадлежит к возрастной группе "пожилые", модуль 175 вывода контента может увеличить объем вывода выбранного контента и размер отображения (например, размер шрифта) выбранного контента, основываясь на информации о размере вывода для каждой возрастной группы. Блок 160 памяти хранит таблицу, которая содержит сопоставление возрастной группы или пола со схемой вывода контента (скорость и размер вывода контента), и модуль 175 вывода контента определяет схему вывода выбранного контента, основываясь на данных, хранящихся в сопоставлении таблицы. Если схема вывода контента выбрана, на этапе S280 модуль 175 вывода контента выводит контент, выбранный модулем 171 выбора контента, через блок 150 отображения и блок 140 обработки звука в соответствии со схемой вывода контента.
Впоследствии, если на этапе S290 обнаружен запрос завершения функции голосового общения, блок 170 управления завершает функцию голосового общения. Если запрос завершения функции голосового общения на этапе S290 не обнаружен, блок 170 управления возвращает процедуру к этапу S220.
Как описано выше, способ управления голосовым общением согласно настоящему изобретению выбирает контент, подходящий для текущего эмоционального состояния пользователя, и определяет схему вывода контента в соответствии с возрастом и/или полом пользователя, чтобы предоставить пользователю персонализированный контент. Этот способ позволяет обеспечивать более реалистичные функциональные возможности голосового общения.
Между тем, если фраза, полученная из речевого ввода пользователя через блок 140 обработки звука, представляет собой запрос на изменение схемы вывода контента, модуль 175 вывода контента изменяет схему вывода контента в соответствии с этой фразой. Например, после того, как контент был выведен в соответствии со схемой вывода контента, определенной на основании второго критерия, если пользователь говорит фразу "Можете ли вы говорить быстрее и потише?", модуль 175 вывода контента увеличивает скорость воспроизведения речи на одну ступень и уменьшает громкость звука на одну ступень.
Модуль 175 вывода контента может сохранить измененную схему вывода контента в блоке 160 памяти. Впоследствии, модуль 175 вывода контента изменяет схему вывода контента, определенную на основании второго критерия, с использованием истории ранее сохраненных схем вывода элементов контента. Модуль 175 вывода контента может выводить выбранный контент в соответствии с измененной схемой вывода контента.
Процедура вывода контента в соответствии с вариантом осуществления изобретения описана ниже со ссылкой на фиг. 3-5.
Фиг. 3 представляет таблицу, сопоставляющую эмоциональные состояния и элементы контента для использования в способе управления голосовым общением в соответствии с вариантом осуществления настоящего изобретения. Фиг. 4 и 5 представляют схемы отображений на экране, иллюстрирующие вывод контента на основании первого критерия в соответствии с вариантом осуществления настоящего изобретения.
Как показано на фиг. 3, элементы контента предварительно сопоставляются с эмоциональными состояниями. Эмоциональное состояние "радость" сопоставляется с элементом A контента, эмоциональное состояние "печаль" - с элементом В контента, эмоциональное состояние "гнев" - с элементом C контента, а эмоциональное состояние "удивление" - с элементом D контента. Эти эмоциональные состояния и элементы контента предварительно сопоставляются и сохраняются в блоке 160 памяти.
Модуль 171 выбора контента может выбирать контент, подходящий для первого критерия (текущего эмоционального состояния пользователя), из числа элементов контента для каждого эмоционального состояния.
Как показано на фиг. 4, на основании фразы UT, полученной из речевого ввода пользователя через блок 140 обработки звука, и первого критерия (текущего эмоционального состояния пользователя), модуль 171 выбора контента выбирает контент А (AT1) для эмоционального состояния "радость" и элемент В контента (AT2) для эмоционального состояния "печаль".
Как показано на фиг. 5, модуль 171 выбора контента выбирает элемент С контента (AT1) для эмоционального состояния "гнев" и элемент D контента (AT2) для эмоционального состояния "удивление" на основании первого критерия (текущего эмоционального состояния пользователя).
Хотя фиг. 3 направлена на сопоставление одного элемента контента для каждого эмоционального состояния, настоящее изобретение этим не ограничено, а может быть воплощено так, чтобы сопоставлять множество элементов контента для каждого эмоционального состояния. В этом случае, модуль 171 выбора контента может выбирать один из множества элементов контента, соответствующих первому критерию (текущему эмоциональному состоянию пользователя), случайным образом.
Элементы контента могут быть сгруппированы для каждого эмоционального состояния. Термин "группа элементов контента" обозначает набор элементов контента, имеющих одинаковое/аналогичное свойство. Например, группа элементов контента может быть отнесена к одной из группы элементов контента фильмов жанра "боевик", группы элементов контента музыки жанра "R&B" (ритм-н-блюз) и т.д. В этом случае, модуль 171 выбора контента может выбирать один из элементов контента в группе элементов контента, удовлетворяющей первому критерию (текущему эмоциональному состоянию пользователя), случайным образом.
Фиг. 6 представляет схему последовательности операций, иллюстрирующую подробности первого этапа получения критерия, показанного на фиг. 2.
Как показано на фиг. 6, модуль 171 выбора контента на этапе S310 получает изображение лица пользователя от блока 120 камеры и на этапе S320 из этого изображения лица обнаруживает область лица. Таким образом, модуль 171 выбора контента обнаруживает область лица, имеющую глаза, нос и рот.
Затем, модуль 171 выбора контента на этапе S330 извлекает контрольные точки глаз, носа и рта, и на этапе S340 распознает выражение лица на основании этих контрольных точек. Таким образом, модуль 171 выбора контента распознает текущее выражение лица пользователя, основываясь на информации о контрольных точках для каждого выражения, хранящейся в блоке 160 памяти.
Впоследствии, модуль 171 выбора контента автоматически извлекает первый критерий, основываясь на выражении, определенном на основании предварительно определенной информации о выражении для каждого эмоционального состояния, на этапе S350. В данном документе, информация о выражении для каждого эмоционального состояния может быть предварительно сконфигурирована и храниться в блоке 160 памяти.
Хотя описание относится к случаю, когда модуль 171 выбора контента получает первый критерий, основываясь на изображении лица пользователя, настоящее изобретение этим не ограничено, а может быть воплощено так, чтобы первый критерий вводился пользователем.
Другая процедура вывода контента в соответствии с вариантом осуществления настоящего изобретения описана ниже со ссылкой на фиг. 7-9.
Фиг. 7 представляет таблицу, сопоставляющую эмоциональные состояния и элементы контента для использования в способе управления голосовым общением в соответствии с вариантом осуществления настоящего изобретения. Фиг. 8 и 9 представляют схемы отображений на экране, иллюстрирующие вывод контента на основании первого критерия в соответствии с вариантом осуществления настоящего изобретения.
Модуль 171 выбора контента может выбирать контент на основании первого критерия (текущего эмоционального состояния пользователя), используя историю прошлых воспроизведений контента пользователя. История прошлых воспроизведений контента хранится в блоке 160 памяти и обновляется всякий раз, когда контент воспроизводится в соответствии с манипулированием пользователя.
Как показано на фиг. 7, количества воспроизведений или соответствующие элементы контента хранятся в блоке 160 памяти. Элемент A1 контента воспроизводился три раза, элемент A2 контента - десять раз, элемент B1 контента - пять раз, элемент B2 контента - дважды, элемент C1 контента - восемь раз, элемент C2 контента - пятнадцать раз, элемент D1 контента - дважды, и элемент D2 контента - однажды. Элементы A1 и A2 контента сопоставляются с эмоциональным состоянием "радость", элементы B1 и B2 контента - с эмоциональным состоянием "печаль", элементы C1 и C2 контента - с эмоциональным состоянием "гнев", а элементы D1 и D2 контента - с эмоциональным состоянием "удивление" (см. фиг. 3).
Модуль 171 выбора контента может выбирать один из множества элементов контента, подходящий для первого критерия (текущего эмоционального состояния пользователя), основываясь на истории прошлых воспроизведений элементов контента.
Как показано на фиг. 8, если первый критерий (текущее эмоциональное состояние пользователя) представляет собой "радость", модуль 171 выбора контента выбирает элемент A2 контента (AT1), который воспроизводился чаще из числа элементов A1 и A2 контента, сопоставленных с первым критерием (текущим эмоциональным состоянием пользователя). Если первый критерий (текущее эмоциональное состояние пользователя) представляет собой "печаль", модуль 171 выбора контента выбирает элемент В1 контента (AT2), который воспроизводился чаще из числа элементов B1 и B2 контента, сопоставленных с первым критерием (текущим эмоциональным состоянием пользователя).
В это время, модуль 171 выбора контента может выбрать множество элементов контента, сопоставленных с первым критерием (текущим эмоциональным состоянием пользователя). Затем модуль 175 вывода контента может определить позиции вывода множества элементов контента, основываясь на истории прошлых воспроизведений элементов контента.
Как показано на фиг. 9, если первый критерий (текущее эмоциональное состояние пользователя) представляет собой "радость", модуль 171 выбора контента выбирает оба элемента A1 и A2 контента в качестве элементов контента (AT1), удовлетворяющих первому критерию (текущему эмоциональному состоянию пользователя). Затем модуль 175 вывода контента классифицирует элемент A1 контента ниже элемента A2 контента (AT1), который воспроизводился более часто. Если первый критерий (текущее эмоциональное состояние пользователя) представляет собой "печаль", модуль 171 выбора контента выбирает оба элемента B1 и B2 контента в качестве элементов контента (AT2), удовлетворяющих первому критерию (текущему эмоциональному состоянию пользователя). Затем модуль 175 вывода контента классифицирует элемент B2 контента ниже элемента В1 контента (AT2), который воспроизводился более часто.
Другая процедура вывода контента в соответствии с вариантом осуществления настоящего изобретения описана ниже со ссылкой на фиг. 10 и 11.
Фиг. 10 представляет таблицу, сопоставляющую эмоциональные состояния и элементы контента для использования в способе управления голосовым общением в соответствии с вариантом осуществления настоящего изобретения. Фиг. 11 представляет схему отображений на экране для иллюстрирования вывода контента на основании первого критерия в соответствии с вариантом осуществления настоящего изобретения.
Модуль 171 выбора контента может выбирать контент на основании первого критерия (текущего эмоционального состояния пользователя) и истории вывода контента на основании прошлых эмоциональных состояний пользователя. История вывода контента на основании прошлых эмоциональных состояний пользователя сохраняется в блоке 160 памяти и обновляется всякий раз, когда контент выводится в соответствии с эмоциональным состоянием пользователя, в то время как функция голосового общения активирована.
Как показано на фиг. 10, количество выводов элементов контента на основании прошлых эмоциональных состояний сохраняется в блоке 160 памяти. Элемент A1 контента был выведен три раза, элемент A2 контента - восемь раз, элемент В1 контента - четыре раза, элемент B2 контента - однажды, элемент C1 контента - три раза, элемент C2 контента - одиннадцать раз, элемент D1 контента - дважды, и элемент D2 контента - пять раз.
Модуль 171 выбора контента может выбирать один из множества элементов контента, сопоставленных с первым критерием (текущим эмоциональным состоянием пользователя), с использованием истории вывода контента на основании прошлых эмоциональных состояний.
Как показано на фиг. 11, если первый критерий (текущее эмоциональное состояние пользователя) представляет собой "радость", модуль 171 выбора контента в качестве контента (AT1), соответствующего первому критерию, выбирает элемент A2 контента, который выводился чаще в связи с прошлым эмоциональным состоянием пользователя, из числа элементов A1 и A2 контента. Если первый критерий (текущее эмоциональное состояние пользователя) представляет собой "печаль", модуль 171 выбора контента выбирает элемент B1 контента, который выводился чаще в связи с прошлым эмоциональным состоянием пользователя, в качестве контента (AT2), соответствующего первому критерию (текущему эмоциональному состоянию пользователя) из числа элементов B1 и B2 контента.
Модуль 171 выбора контента может выбирать все сопоставленные элементы контента для удовлетворения первому критерию (текущему эмоциональному состоянию пользователя). Затем модуль 175 вывода контента определяет позиции вывода множества элементов контента, используя историю вывода контента на основании прошлых эмоциональных состояний. Например, если первый критерий (текущее эмоциональное состояние пользователя) представляет собой "радость", модуль 171 выбора контента выбирает оба элемента A1 и A2 контента в качестве элементов контента, соответствующих первому критерию (текущему эмоциональному состоянию пользователя). Затем модуль 175 вывода контента классифицирует элемент A1 контента ниже элемента A2 контента, который воспроизводился чаще в соответствии с прошлым эмоциональным состоянием пользователя.
Ниже описывается другая процедура вывода контента в соответствии с вариантом осуществления настоящего изобретения.
Модуль 171 выбора контента может выбирать элементы контента на основании первого критерия (текущего эмоционального состояния пользователя) с использованием информации о текущем местоположении мобильного терминала 100, которая получается через блок 130 измерения местоположения. Более подробно, модуль 171 выбора контента получает множество элементов контента на основании первого критерия (текущего эмоционального состояния пользователя). Затем, модуль 171 выбора контента выбирает контент, ассоциированный с областью в пределах предварительно определенного радиуса вокруг текущего местоположения мобильного терминала, из числа полученных элементов контента. Например, если контент представляет собой информацию о рекомендуемых местах (ресторан, кафе и т.д.), модуль 171 выбора контента может выбрать контент, подходящий для текущего местоположения мобильного терминала 100, основываясь на информации о текущем местоположении мобильного терминала.
Конечно, модуль 171 выбора контента может получить множество элементов контента, ассоциированных с областью в пределах предварительно определенного радиуса вокруг текущего местоположения мобильного терминала, и затем выбрать контент, удовлетворяющий первому критерию (текущему эмоциональному состоянию пользователя), из числа полученных элементов контента.
Хотя описание было направлено на случай, в котором блок 170 управления, модуль 171 выбора контента и модуль 175 вывода контента выполнены по отдельности и отвечают за различные функции, настоящее изобретение этим не ограничено, а может быть воплощено таким образом, чтобы блок управления, модуль выбора контента и модуль вывода контента функционировали интегрированным образом.
Фиг. 12 является схематическим представлением, иллюстрирующим систему для функции голосового общения мобильного терминала в соответствии с вариантом осуществления настоящего изобретения.
Поскольку мобильный терминал 100 в данном случае идентичен мобильному терминалу, описанному выше в отношении фиг. 1, подробное описание мобильного терминала 100 в этом случае опускается. Мобильный терминал 100 в соответствии с вариантом осуществления настоящего изобретения соединен с сервером 200 через сеть 300 беспроводной связи.
В описанных выше вариантах осуществления, блок 170 управления мобильного терминала 100 выполняет операцию получения первого критерия, операцию выбора контента на основании первого критерия, операцию получения второго критерия и операцию определения схемы вывода контента.
Однако, в этом варианте осуществления, блок 170 управления мобильного терминала 100 обменивается данными с сервером посредством блока 100 радиосвязи и выполняет операцию получения первого критерия, операцию выбора контента на основании первого критерия, операцию получения второго критерия и операцию определения схемы вывода контента.
Например, блок 170 управления мобильного терминала 100 предоставляет серверу 200 ввод изображения лица пользователя через блок 120 камеры и речевой ввод пользователя через блок 140 обработки звука. Затем сервер 200 получает первый и второй критерии, основываясь на изображении лица и речи пользователя. Сервер 200 предоставляет мобильному терминалу 100 полученные первый и второй критерии.
Хотя описание было сделано в предположении о единственном пользователе, настоящее изобретение этим не ограничено, и оно также может быть применено к случаю, когда мобильный терминал 100 используется множеством пользователей. В этом случае необходимо добавить операцию для идентификации текущего пользователя мобильного терминала 100. История прошлых схем вывода контента пользователя, история прошлых воспроизведений контента пользователя и история вывода контента на основании прошлых эмоциональных состояний пользователя могут быть сохранены для каждого пользователя. Соответственно, даже когда множество пользователей используют мобильный терминал 100, можно предоставлять характерный для пользователя контент.
Как описано выше, мобильный терминал с поддержкой функции голосового общения и способ управления голосовым общением согласно настоящему изобретению способны выбирать какой-либо контент, подходящий для текущего эмоционального состояния пользователя, и определять схему вывода контента в соответствии с возрастом и полом пользователя. Соответственно, может быть предоставлен контент, адаптированный для индивидуального пользователя. Соответственно, настоящее изобретение способно реализовывать функцию реалистичного голосового общения.
Хотя выше были подробно описаны варианты осуществления изобретения, специалистам в данной области техники должно быть понятно, что множество вариаций и модификаций основной концепции изобретения, описанной в данном документе, все еще будут находиться в пределах сущности и объема изобретения, как определено в нижеследующей формуле изобретения и ее эквивалентах.
Реферат
Изобретение относится к мобильному терминалу с поддержкой функции голосового общения и способу управления голосовым общением. Технический результат заключается в расширении арсенала средств. Мобильный терминал, поддерживающий функцию голосового общения, включает блок отображения, блок обработки звука, блок управления, выполненный с возможностью выбора контента, соответствующего первому критерию, ассоциированному с пользователем, в ответ на ввод от пользователя, определения схемы вывода контента на основании второго критерия, ассоциированного с пользователем, и вывода выбранного контента через блок отображения и блок обработки звука в соответствии со схемой вывода контента, причем первый критерий основан на изображении лица пользователя. 2 н. и 28 з.п. ф-лы, 12 ил.
Комментарии