Устройство и способ кластерного хранения - RU2663358C2
Код документа: RU2663358C2
Чертежи
Описание
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее изобретение относится к области компьютерных технологий и, в частности, к устройству и способу кластерного хранения.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0002] В базе данных, данные, как правило, хранятся посредством использования таблицы, и существует три типа общих структур хранения таблицы, которыми являются таблица-куча (Heap Table), индексно-организованная таблица (Index Organization Table, IOT), и таблица-кластер (Cluster Table).
[0003] В предшествующем уровне техники, когда таблица-куча используется для хранения данных в запоминающем носителе информации, из-за того, что каждая строка данных непоследовательно сохраняется в соответствии с естественной последовательностью, в которой вставляются данные, оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных. Кроме того, после того, как таблица-куча используется для хранения данных в запоминающем носителе информации, если требуется запросить данные таблицы-кучи применительно к фрагменту данных, требуется выполнять сравнение построчно с первой строки таблицы-кучи до тех пор, пока не будет найден фрагмент данных.
[0004] Тем не менее, когда таблица-куча используется для хранения данных в запоминающем носителе информации, данные хранятся непоследовательно, и когда осуществляется запрос данных в таблице-куче, требуется выполнять сравнение построчно с первой строки таблицы-кучи; вследствие этого, несмотря на то, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных, коэффициент сжатия данных и эффективность запроса данных являются относительно низкими.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] Варианты осуществления настоящего изобретения предоставляют устройство и способ кластерного хранения, так что может быть улучшена эффективность запроса данных и эффективность сжатия данных в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
[0006] Следующие технические решения используются в вариантах осуществления настоящего изобретения.
[0007] В соответствии с первым аспектом, вариант осуществления настоящего изобретения предоставляет способ кластерного хранения, при этом способ применяется в системе базы данных и включает в себя этапы, на которых:
кэшируют первые данные, которые должны быть сохранены, построчно в локальную память в системе базы данных;
определяют первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память;
сортируют вторые данные в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных; и
сохраняют сортированные вторые данные в кластерной форме в запоминающем носителе информации в системе базы данных.
[0008] В первом возможном варианте реализации первого аспекта, предварительно установленное условие используется, чтобы представлять отношение между объемом данных вторых данных, которые были кэшированы в локальную память, и объемом данных, разрешенным для хранения в локальной памяти.
[0009] Со ссылкой на первый аспект или первый возможный вариант реализации первого аспекта, во втором возможном варианте реализации, предварительно установленное условие состоит в том, что количество строк вторых данных больше или равно первой предварительно установленной пороговой величине; и
этап, на котором сортируют вторые данные в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, в частности включает в себя этап, на котором:
если количество строк вторых данных больше или равно первой предварительно установленной пороговой величине, сортируют вторые данные в соответствии с первым столбцом сортировки.
[0010] Со ссылкой на первый аспект или первый возможный вариант реализации первого аспекта, в третьем возможном варианте реализации, предварительно установленное условие состоит в том, что размер, который занимается вторыми данными, локальной памяти больше или равен второй предварительно установленной пороговой величине; и
этап, на котором сортируют вторые данные в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, в частности включает в себя этап, на котором:
если размер, который занимается вторыми данными, локальной памяти больше или равен второй предварительно установленной пороговой величине, сортируют вторые данные в соответствии с первым столбцом сортировки.
[0011] Со ссылкой на первый аспект или любой вариант реализации с первого возможного варианта реализации по третий возможный вариант реализации первого аспекта, в четвертом возможном варианте реализации, этап, на котором сортируют вторые данные в соответствии с первым столбцом сортировки, в частности включает в себя этап, на котором:
сортируют вторые данные в соответствии с числовым значением первого столбца сортировки или хэш-значением числового значения первого столбца сортировки.
[0012] Со ссылкой на первый аспект или любой вариант реализации с первого возможного варианта реализации по четвертый возможный вариант реализации первого аспекта, в пятом возможном варианте реализации, этап, на котором сохраняют сортированные вторые данные в кластерной форме в запоминающем носителе информации в системе базы данных, в частности включает в себя этап, на котором:
сохраняют сортированные вторые данные в кластерной форме в незанятом физическом блоке в запоминающем носителе информации, где незанятый физический блок является физическим блоком за исключением физического блока, занимаемого третьими данными, а третьи данные являются данными, которые были сохранены в кластерной форме в запоминающем носителе информации перед вторыми данными, в первых данных.
[0013] Со ссылкой на первый аспект или любой вариант реализации с первого возможного варианта реализации по пятый возможный вариант реализации первого аспекта, в шестом возможном варианте реализации, первый столбец сортировки включает в себя, по меньшей мере, одно из следующего: физический столбец и выражение.
[0014] Со ссылкой на первый аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации первого аспекта, в седьмом возможном варианте реализации, после того, как все первые данные сохранены в запоминающем носителе информации, способ дополнительно включает в себя этапы, на которых:
определяют столбец запроса; и
если столбец запроса является первым в первом столбце сортировки, выполняют операцию запроса над первыми данными в соответствии с первым в первом столбце сортировки.
[0015] Со ссылкой на седьмой возможный вариант реализации первого аспекта, в восьмом возможном варианте реализации, после этапа, на котором определяют столбец запроса, и перед этапом, на котором выполняют операцию запроса над первыми данными в соответствии с первым в первом столбце сортировки, способ дополнительно включает в себя этап, на котором:
считывают первые данные, хранящиеся в запоминающем носителе информации, в локальную память; где
этап, на котором выполняют операцию запроса над первыми данными в соответствии с первым в первом столбце сортировки, в частности включает в себя этап, на котором:
выполняют, в локальной памяти в форме двоичного поиска, операцию запроса по каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки.
[0016] Со ссылкой на первый аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации первого аспекта, в девятом возможном варианте реализации, после того, как все первые данные сохранены в запоминающем носителе информации, способ дополнительно включает в себя этапы, на которых:
определяют второй столбец сортировки; и
если второй столбец сортировки является первым в первом столбце сортировки, выполняют операцию сортировки над первыми данными в соответствии с первым в первом столбце сортировки.
[0017] Со ссылкой на девятый возможный вариант реализации первого аспекта, в десятом возможном варианте реализации, после этапа, на котором определяют второй столбец сортировки, и перед этапом, на котором выполняют операцию сортировки над первыми данными в соответствии с первым в первом столбце сортировки, способ дополнительно включает в себя этап, на котором:
считывают первые данные, хранящиеся в запоминающем носителе информации, в локальную память; где
этап, на которой выполняют операцию сортировки над первыми данными в соответствии с первым в первом столбце сортировки, в частности включает в себя этап, на котором:
выполняют, в локальной памяти, сортировку слиянием над первыми данными в соответствии с первым в первом столбце сортировки.
[0018] Со ссылкой на первый аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации первого аспекта, в одиннадцатом возможном варианте реализации, после того, как все первые данные сохранены в запоминающем носителе информации, способ дополнительно включает в себя этапы, на которых:
определяют столбец агрегации; и
если столбец агрегации является первым в первом столбце сортировки, выполняют операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки, где операция агрегации является операцией поиска по первым данным максимального значения или минимального значения.
[0019] Со ссылкой на одиннадцатый возможный вариант реализации первого аспекта, в двенадцатом возможном варианте реализации, после этапа, на котором определяют столбец агрегации, и перед этапом, на котором выполняют операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки, способ дополнительно включает в себя этап, на котором:
считывают первые данные, хранящиеся в запоминающем носителе информации, в локальную память; где
этап, на котором выполняют операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки, в частности включает в себя этапы, на которых:
определяют, в локальной памяти, максимальное значение или минимальное значение в каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки; и
последовательно сравнивают максимальное значение или минимальное значение в каждой странице данных с тем, чтобы определить максимальное значение или минимальное значение в первых данных.
[0020] В тринадцатом возможном варианте реализации первого аспекта, перед этапом, на котором кэширую первые данные, которые должны быть сохранены, построчно в локальную память в системе базы данных, способ дополнительно включает в себя этап, на котором:
создают таблицу в запоминающем носителе информации, где таблица используется, чтобы загружать первые данные; где
этап, на котором сохраняют сортированные вторые данные в кластерной форме в запоминающем носителе информации в системе базы данных, в частности включает в себя этап, на котором:
вставляют сортированные вторые данные построчно в таблицу с тем, чтобы сохранить сортированные вторые данные в кластерной форме в запоминающем носителе информации.
[0021] В соответствии со вторым аспектом, вариант осуществления настоящего изобретения предоставляет устройство кластерного хранения, где устройство применяется в системе базы данных, и включает в себя:
блок кэширования, выполненный с возможностью кэширования первых данных, которые должны быть сохранены, построчно в локальную память в системе базы данных;
блок определения, выполненный с возможностью определения первого столбца сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память;
операционный блок, выполненный с возможностью, если вторые данные, которые были кэшированы в локальную память посредством блока кэширования, удовлетворяют предварительно установленному условию, сортировки вторых данных в соответствии с первым столбцом сортировки, определенным посредством блока определения, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных; и
блок хранения, выполненный с возможностью сохранения, в кластерной форме в запоминающем носителе информации в системе базы данных, вторых данных, сортированных посредством операционного блока.
[0022] В первом возможном варианте реализации второго аспекта, предварительно установленное условие используется, чтобы представлять отношение между объемом данных вторых данных, которые были кэшированы в локальную память, и объемом данных, разрешенным для хранения в локальной памяти.
[0023] Со ссылкой на второй аспект или первый возможный вариант реализации второго аспекта, во втором возможном варианте реализации, предварительно установленное условие состоит в том, что количество строк вторых данных больше или равно первой предварительно установленной пороговой величине; и
операционный блок в частности выполнен с возможностью, если количество строк вторых данных больше или равно первой предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0024] Со ссылкой на второй аспект или первый возможный вариант реализации второго аспекта, в третьем возможном варианте реализации, предварительно установленное условие состоит в том, что размер, который занимается вторыми данными, локальной памяти больше или равен второй предварительно установленной пороговой величине; и
операционный блок в частности выполнен с возможностью, если размер, который занимается вторыми данными, локальной памяти больше или равен второй предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0025] Со ссылкой на второй аспект или любой вариант реализации с первого возможного варианта реализации по третий возможный вариант реализации второго аспекта, в четвертом возможном варианте реализации, операционный блок в частности выполнен с возможностью сортировки вторых данных в соответствии с числовым значением первого столбца сортировки или хэш-значением числового значения первого столбца сортировки, который определяется посредством блока определения.
[0026] Со ссылкой на второй аспект или любой вариант реализации с первого возможного варианта реализации по четвертый возможный вариант реализации второго аспекта, в пятом возможном варианте реализации, блок хранения в частности выполнен с возможностью сохранения, в кластерной форме в незанятом физическом блоке в запоминающем носителе информации, вторых данных, сортированных посредством операционного блока, где незанятый физический блок является физическим блоком за исключением физического блока, занимаемого третьими данными, а третьи данные являются данными, которые были сохранены в кластерной форме в запоминающем носителе информации перед вторыми данными, в первых данных.
[0027] Со ссылкой на второй аспект или любой вариант реализации с первого возможного варианта реализации по пятый возможный вариант реализации второго аспекта, в шестом возможном варианте реализации, первый столбец сортировки, определенный посредством блока определения, включает в себя, по меньшей мере, одно из следующего: физический столбец и выражение.
[0028] Со ссылкой на второй аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации второго аспекта, в седьмом возможном варианте реализации, блок определения дополнительно выполнен с возможностью, после того, как блок хранения сохраняет все первые данные в запоминающем носителе информации, определения столбца запроса; и
операционный блок дополнительно выполнен с возможностью, если столбец запроса, определенный посредством блока определения, является первым в первом столбце сортировки, выполнения операции запроса над первыми данными в соответствии с первым в первом столбце сортировки.
[0029] Со ссылкой на седьмой возможный вариант реализации второго аспекта, в восьмом возможном варианте реализации, блок кэширования дополнительно выполнен с возможностью, после того, как блок определения определяет столбец запроса, и перед тем, как операционный блок выполняет операцию запроса над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации, в локальную память; и
операционный блок в частности выполнен с возможностью выполнения, в локальной памяти в форме двоичного поиска в соответствии с первым в первом столбце сортировки, операции запроса по каждой странице данных из одной или более страниц данных первых данных, кэшированных посредством блока кэширования.
[0030] Со ссылкой на второй аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации второго аспекта, в девятом возможном варианте реализации, блок определения дополнительно выполнен с возможностью, после того, как блок хранения сохраняет все первые данные в запоминающем носителе информации, определения второго столбца сортировки; и
операционный блок дополнительно выполнен с возможностью, если второй столбец сортировки, определенный посредством блока определения, является первым в первом столбце сортировки, выполнения операции сортировки над первыми данными в соответствии с первым в первом столбце сортировки.
[0031] Со ссылкой на девятый возможный вариант реализации второго аспекта, в десятом возможном варианте реализации, блок кэширования дополнительно выполнен с возможностью, после того, как блок определения определяет второй столбец сортировки и перед тем, как операционный блок выполняет операцию сортировки над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации, в локальную память; и
операционный блок в частности выполнен с возможностью выполнения, в локальной памяти в соответствии с первым в первом столбце сортировки, сортировки слиянием над первыми данными, кэшированным посредством блока кэширования.
[0032] Со ссылкой на второй аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации второго аспекта, в одиннадцатом возможном варианте реализации, блок определения дополнительно выполнен с возможностью, после того, как блок хранения сохраняет все первые данные в запоминающем носителе информации, определения столбца агрегации; и
операционный блок дополнительно выполнен с возможностью, если столбец агрегации, определенный посредством блока определения, является первым в первом столбце сортировки, выполнения операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, где операция агрегации является операцией поиска по первым данным максимального значения или минимального значения.
[0033] Со ссылкой на одиннадцатый возможный вариант реализации второго аспекта, в двенадцатом возможном варианте реализации, блок кэширования дополнительно выполнен с возможностью, после того, как блок определения определяет столбец агрегации, и перед тем как операционный блок выполняет операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации, в локальную память; и
операционный блок в частности выполнен с возможностью определения, в локальной памяти в соответствии с первым в первом столбце сортировки, максимального значения или минимального значения в каждой странице данных из одной или более страниц данных первых данных, кэшированных посредством блока кэширования, и последовательного сравнения максимального значения или минимального значения в каждой странице данных с тем, чтобы определить максимальное значение или минимальное значение в первых данных.
[0034] В тринадцатом возможном варианте реализации второго аспекта, устройство кластерного хранения дополнительно включает в себя блок создания, где
блок создания выполнен с возможность, перед тем, как блок кэширования кэширует первые данные, которые должны быть сохранены, построчно в локальную память в системе базы данных, создания таблицы в запоминающем носителе информации, где таблица используется, чтобы загружать первые данные; и
операционный блок в частности выполнен с возможностью вставки сортированных вторых данных построчно в таблицу, созданную посредством блока создания, с тем, чтобы сохранить сортированные вторые данные в кластерной форме в запоминающем носителе информации.
[0035] В соответствии с третьим аспектом, вариант осуществления настоящего изобретения предоставляет систему базы данных, включающую в себя:
запоминающий носитель информации нижнего слоя;
память, связанную с запоминающим носителем информации нижнего слоя, и выполненную с возможностью работы в качестве кэша запоминающего носителя информации нижнего слоя, где один или более блоки данных в запоминающем носителе информации нижнего слоя соотнесены с целевым блоком данных в кэше; и
процессор, связанный с памятью, где процессор исполняет инструкцию в памяти, выполненный с возможностью:
кэширования первых данных, которые должны быть сохранены, построчно в память; определения первого столбца сортировки; сортировки вторых данных в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в память, удовлетворяют предварительно установленному условию; и сохранения сортированных вторых данных в кластерной форме в запоминающем носителе информации нижнего слоя, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в память, а вторые данные являются данными, которые были кэшированы в память, в первых данных.
[0036] В первом возможном варианте реализации третьего аспекта, предварительно установленное условие используется, чтобы представлять отношение между объемом данных вторых данных, которые были кэшированы в память, и объемом данных, разрешенным для хранения в памяти.
[0037] Со ссылкой на третий аспект или первый возможный вариант реализации третьего аспекта, во втором возможном варианте реализации, предварительно установленное условие состоит в том, что количество строк вторых данных больше или равно первой предварительно установленной пороговой величине; и
процессор в частности выполнен с возможностью, если количество строк вторых данных больше или равно первой предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0038] Со ссылкой на третий аспект или первый возможный вариант реализации третьего аспекта, в третьем возможном варианте реализации, предварительно установленное условие состоит в том, что размер, который занимается вторыми данными, памяти больше или равен второй предварительно установленной пороговой величине; и
процессор в частности выполнен с возможностью, если размер, который занимается вторыми данными, памяти больше или равен второй предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0039] Со ссылкой на третий аспект или любой вариант реализации с первого возможного варианта реализации по третий возможный вариант реализации третьего аспекта, в четвертом возможном варианте реализации, процессор в частности выполнен с возможностью сортировки вторых данных в соответствии с числовым значением первого столбца сортировки или хэш-значением числового значения первого столбца сортировки.
[0040] Со ссылкой на третий аспект или любой вариант реализации с первого возможного варианта реализации по четвертый возможный вариант реализации третьего аспекта, в пятом возможном варианте реализации, процессор в частности выполнен с возможностью сохранения вторых данных в кластерной форме в незанятом физическом блоке в запоминающем носителе информации нижнего слоя, где незанятый физический блок является физическим блоком за исключением физического блока, занимаемого третьими данными, а третьи данные являются данными, которые были сохранены в кластерной форме в запоминающем носителе информации нижнего слоя перед вторыми данными, в первых данных.
[0041] Со ссылкой на третий аспект или любой вариант реализации с первого возможного варианта реализации по пятый возможный вариант реализации третьего аспекта, в шестом возможном варианте реализации, первый столбец сортировки, определенный посредством процессора, включает в себя, по меньшей мере, одно из следующего: физический столбец и выражение.
[0042] Со ссылкой на третий аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации третьего аспекта, в седьмом возможном варианте реализации, процессор дополнительно выполнен с возможностью: после того, как все первые данные сохраняются в запоминающем носителе информации нижнего слоя, определения столбца запроса; и если столбец запроса является первым в первом столбце сортировки, выполнения операции запроса над первыми данными в соответствии с первым в первом столбце сортировки.
[0043] Со ссылкой на седьмой возможный вариант реализации третьего аспекта, в восьмом возможном варианте реализации, процессор дополнительно выполнен с возможностью: после определения столбца запроса и перед выполнением операции запроса над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации нижнего слоя, в память; и выполнения, в памяти в форме двоичного поиска, операции запроса по каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки.
[0044] Со ссылкой на третий аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации третьего аспекта, в девятом возможном варианте реализации, процессор дополнительно выполнен с возможностью: после того, как все первые данные сохраняются в запоминающем носителе информации нижнего слоя, определения второго столбца сортировки; и если второй столбец сортировки является первым в первом столбце сортировки, выполнения операции сортировки над первыми данными в соответствии с первым в первом столбце сортировки.
[0045] Со ссылкой на девятый возможный вариант реализации третьего аспекта, в десятом возможном варианте реализации, процессор дополнительно выполнен с возможностью: после определения второго столбца сортировки и перед выполнением операции сортировки над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации нижнего слоя, в память; и выполнения, в памяти, сортировки слиянием над первыми данными в соответствии с первым в первом столбце сортировки.
[0046] Со ссылкой на третий аспект или любой вариант реализации с первого возможного варианта реализации по шестой возможный вариант реализации третьего аспекта, в одиннадцатом возможном варианте реализации, процессор дополнительно выполнен с возможностью: после того, как все первые данные сохраняются в запоминающем носителе информации нижнего слоя, определения столбца агрегации; и если столбец агрегации является первым в первом столбце сортировки, выполнения операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, где операция агрегации является операцией поиска по первым данным максимального значения или минимального значения.
[0047] Со ссылкой на одиннадцатый возможный вариант реализации третьего аспекта, в двенадцатом возможном варианте реализации, процессор дополнительно выполнен с возможностью: после определения столбца агрегации и перед выполнением операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации нижнего слоя, в память; и определения, в памяти, максимального значения или минимального значения в каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки; и последовательного сравнения максимального значения или минимального значения в каждой странице данных с тем, чтобы определить максимальное значение или минимальное значение в первых данных.
[0048] В тринадцатом возможном варианте реализации третьего аспекта, процессор дополнительно выполнен с возможность: перед тем, как первые данные, которые должны быть сохранены, кэшируются построчно в память, создания таблицы в запоминающем носителе информации нижнего слоя; и вставки сортированных вторых данных построчно в таблицу с тем, чтобы сохранить сортированные вторые данные в кластерной форме в запоминающем носителе информации нижнего слоя, где таблица используется, чтобы загружать первые данные.
[0049] В соответствии с устройством и способом кластерного хранения, предоставленными в вариантах осуществления настоящего изобретения, первые данные, которые должны быть сохранены, кэшируются построчно в локальную память в системе базы данных; определяется первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память; вторые данные сортируются в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных; и сортированные вторые данные сохраняются в кластерной форме в запоминающем носителе информации в системе базы данных. Посредством использования данного решения, в процессе кэширования первых данных, которые должны быть сохранены, построчно в локальную память, когда объем данных вторых данных, которые были кэшированы в локальную память, превышает объем данных, разрешенный для хранения в локальной памяти, начинается сортировка вторых данных в соответствии с определенным первым столбцом сортировки, и сортированные вторые данные сохраняются в запоминающем носителе информации в системе базы данных. Поскольку данные, которые должны быть сохранены, могут сортироваться и сохраняться по частям, с тем чтобы совершить загрузку данных, можно гарантировать то, что данные в запоминающем носителе информации в системе базы данных являются частично последовательными, так что можно гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0050] Чтобы описать технические решения в вариантах осуществления настоящего изобретения или в предшествующем уровне техники более четко, нижеследующее кратко представляет таблицы и сопроводительные чертежи, требуемые для описания вариантов осуществления и предшествующего уровня техники. Очевидно, что таблицы и сопроводительные чертежи в нижеследующем описании показывают лишь некоторые варианты осуществления настоящего изобретения, т.е., таблицы и сопроводительные чертежи, предоставленные в настоящем изобретении, включают, но не ограничиваются, таблицы и сопроводительные чертежи в нижеследующем описании.
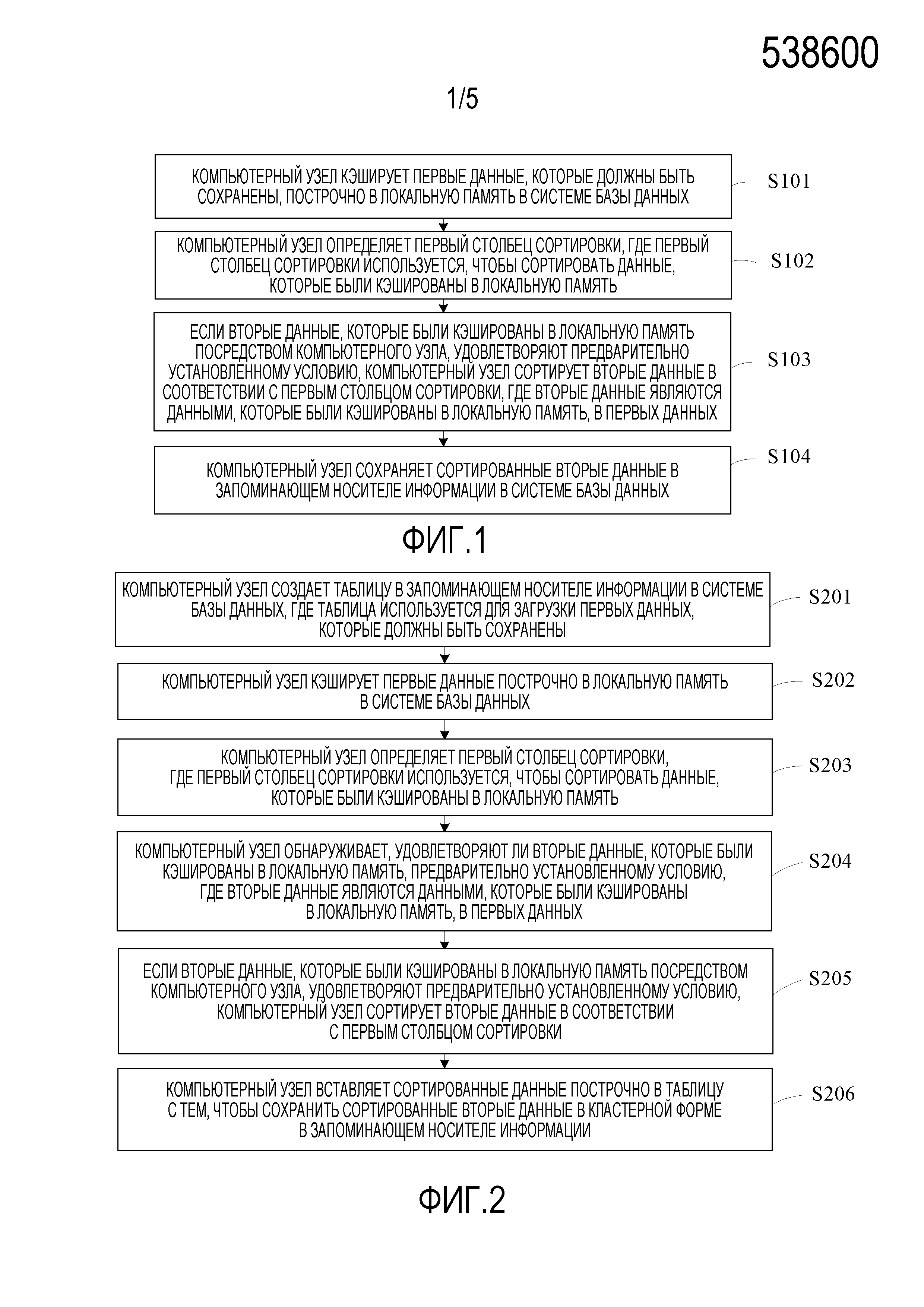
[0051] Фиг. 1 является первой блок-схемой последовательности операций способа кластерного хранения в соответствии с вариантом осуществления, настоящего изобретения;
[0052] Фиг. 2 является второй блок-схемой последовательности операций способа кластерного хранения в соответствии с вариантом осуществления, настоящего изобретения;
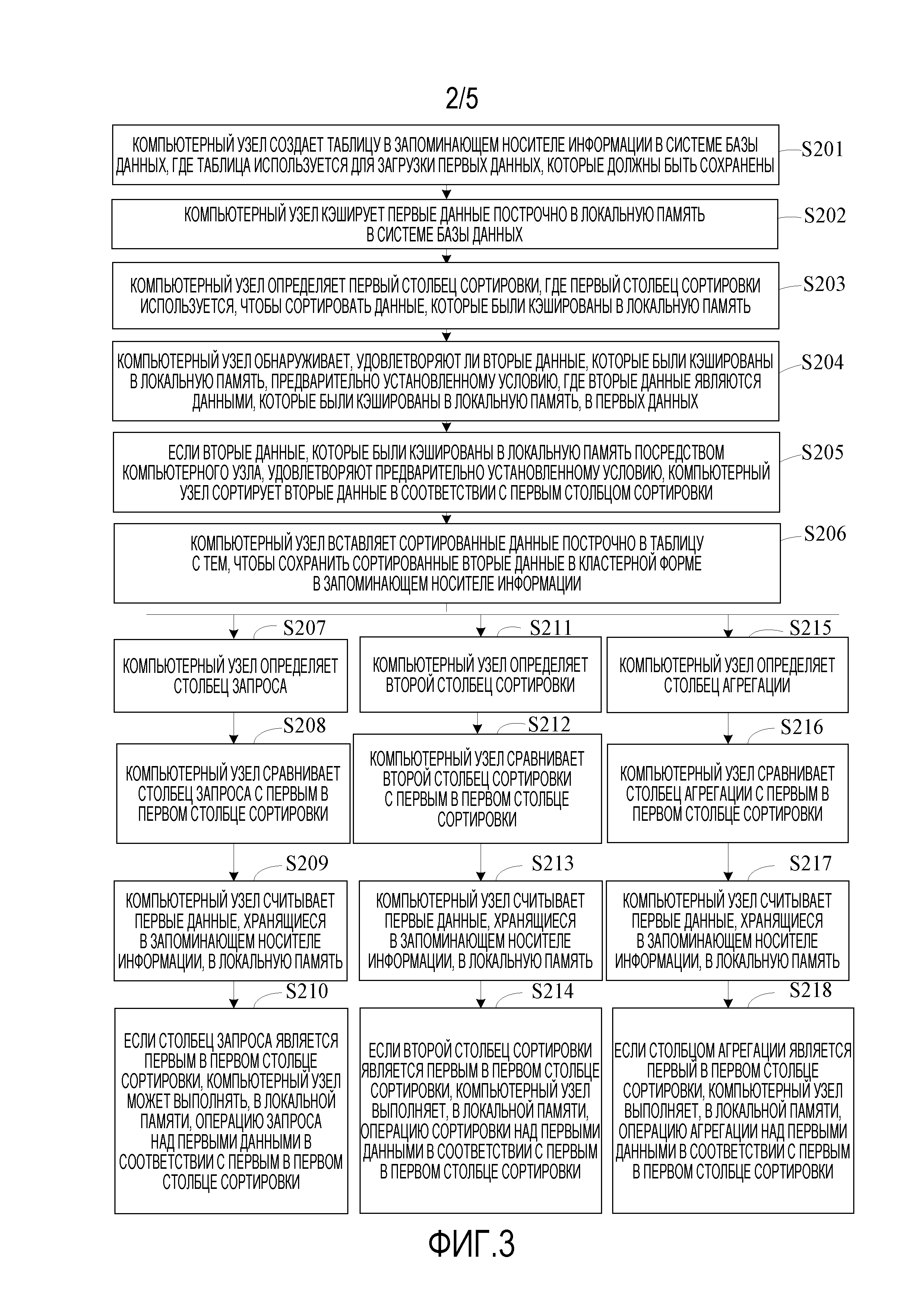
[0053] Фиг. 3 является третьей блок-схемой последовательности операций способа кластерного хранения в соответствии с вариантом осуществления, настоящего изобретения;
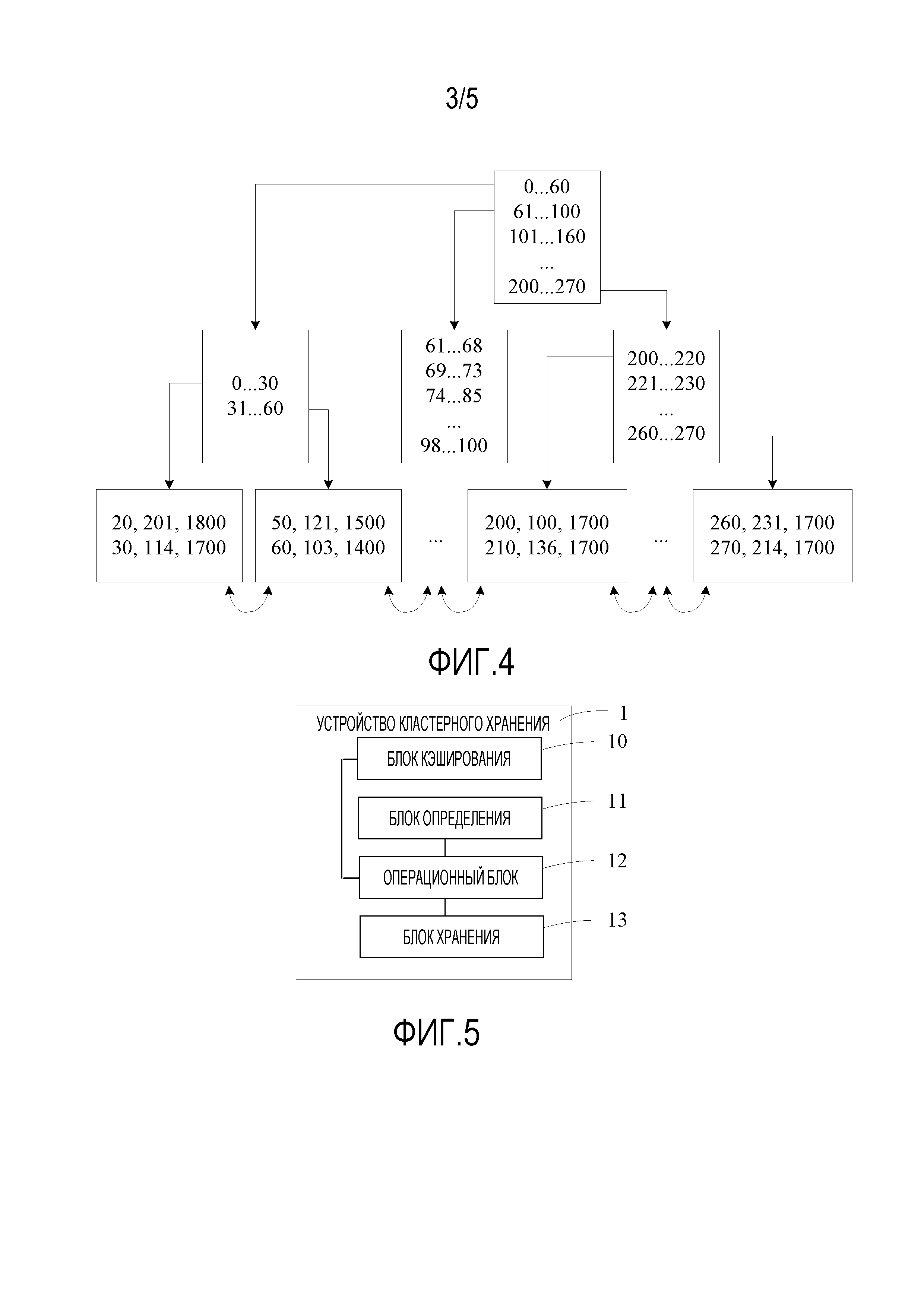
[0054] Фиг. 4 является принципиальной структурной схемой индексно-организованной таблицы в соответствии с вариантом осуществления настоящего изобретения;
[0055] Фиг. 5 является первой принципиальной структурной схемой устройства кластерного хранения в соответствии с вариантом осуществления настоящего изобретения;
[0056] Фиг. 6 является второй принципиальной структурной схемой устройства кластерного хранения в соответствии с вариантом осуществления настоящего изобретения;
[0057] Фиг. 7 является принципиальной структурной схемой системы базы данных в соответствии с вариантом осуществления настоящего изобретения;
[0058] Фиг. 8 является первой принципиальной схемой для хранения данных в кластерной форме в соответствии с вариантом осуществления настоящего изобретения; и
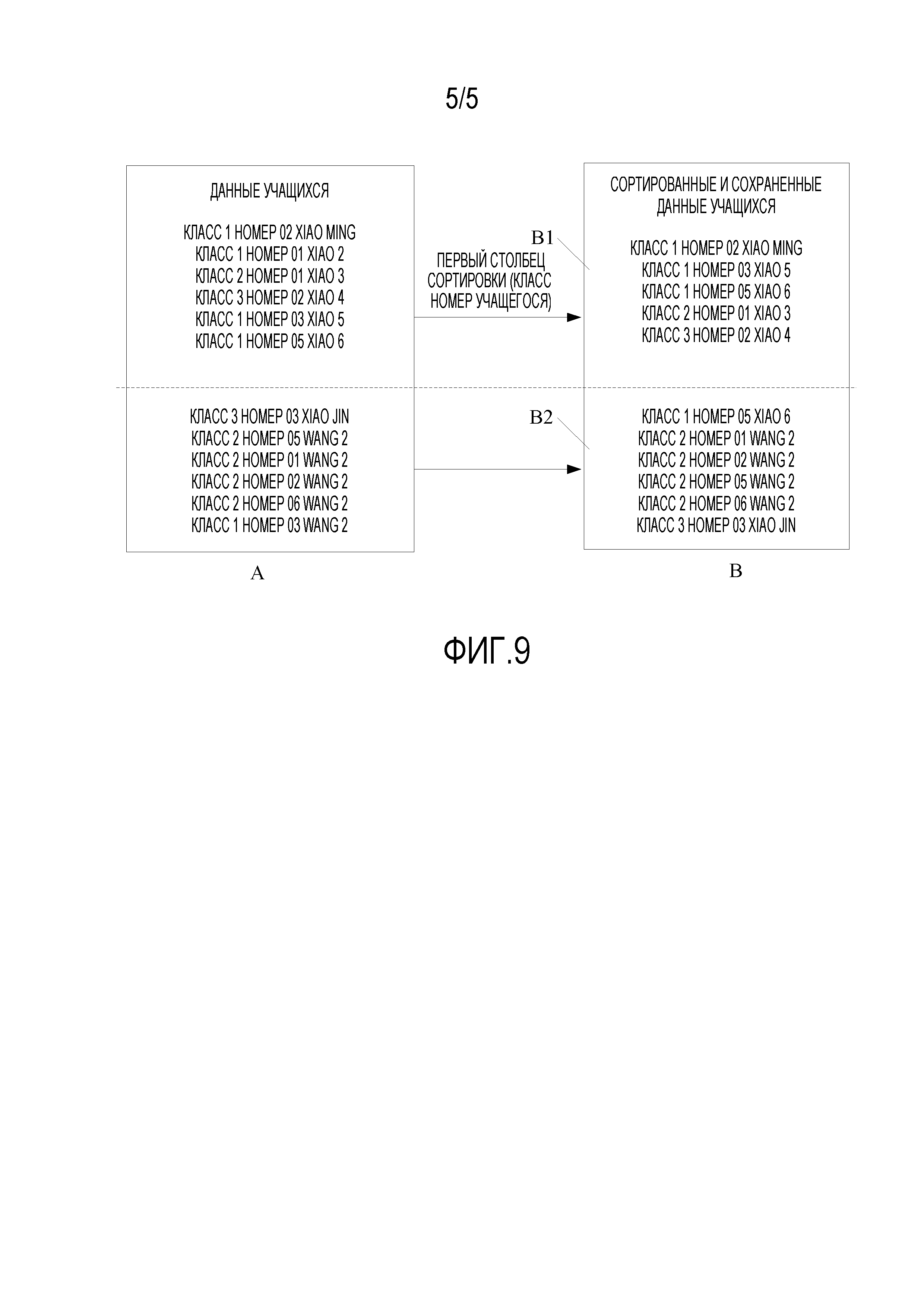
[0059] Фиг. 9 является второй принципиальной схемой для хранения данных в кластерной форме в соответствии с вариантом осуществления настоящего изобретения.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0060] В способе кластерного хранения, предоставленном в настоящем изобретении, в соответствии с идеей кластерного хранения, когда данные сохраняются в запоминающем носителе информации в системе базы данных, гарантируется, только то, что данные, сохраняемые каждый раз в запоминающем носителе информации, являются последовательными (данные являются частично последовательными) не полагая, что все данные, сохраненные в запоминающем носителе информации, являются последовательными (данные являются глобально последовательными). Вследствие этого, в сравнении со случаем, при котором таблица-куча используется для хранения данных в запоминающем носителе информации в форме непоследовательного хранения в предшествующем уровне техники, посредством использования способа кластерного хранения, предоставленного в настоящем изобретении, из-за того, что один и тот же тип данных в запоминающем носителе информации, сохраняется после того, как частично сортируется, можно гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных. В частности, посредством использования способа кластерного хранения, предоставленного в вариантах осуществления настоящего изобретения, в одном аспекте, из-за того, что один и тот же тип данных в запоминающем носителе информации в системе базы данных сохраняется после того, как частично сортируется, то после того, как данные сохраняются, эффективность запроса данных и эффективность сжатия данных являются относительно высокими; в одном аспекте, в процессе сохранения данных, когда данные загружаются, из-за того, что данные загружаются по частям, можно гарантировать то, что оказывается незначительное влияние на эффективность загрузки; и в другом аспекте, когда требуется обновление данных в запоминающем носителе информации то, так как часть данных, в которой располагаются данные, которые должны быть обновлены, в запоминающем носителе информации, может быть непосредственно обновлена (если обновление является добавлением, добавленные данные могут быть непосредственно и последовательно сохранены в запоминающем носителе информации), и не требуется обновления для всех данных в запоминающем носителе информации, можно гарантировать то, что оказывается незначительное влияние на эффективность обновления данных. Т.е., посредством использования способа кластерного хранения, предоставленного в настоящем изобретении, можно гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
[0061] Кроме того, в соответствии со способом кластерного хранения, предоставленным в настоящем изобретении, в процессе сохранения данных, требуется лишь сортировка данных в локальной памяти, и не требуется сортировка в запоминающем носителе информации, и скорость обработки данных в локальной памяти много выше, чем скорость обработки данных в запоминающем носителе информации; вследствие этого, когда способ кластерного хранения, предоставленный в настоящем изобретении, используется для обновления данных, может быть сэкономлено время и ресурсы системы.
[0062] Нижеследующее четко описывает устройство и способ кластерного хранения, предоставленные в вариантах осуществления настоящего изобретения, со ссылкой на таблицы и сопроводительные чертежи в вариантах осуществления настоящего изобретения. Очевидно, что описываемые варианты осуществления являются лишь некоторыми, а не всеми из вариантов осуществления настоящего изобретения. Устройство и способ кластерного хранения, предоставленные в вариантах осуществления настоящего изобретения, могут быть применены в системе базы данных, где система базы данных может включать в себя объект аппаратного обеспечения и среду базы данных устройства кластерного хранения, и объект аппаратного обеспечения устройства кластерного хранения может быть компьютерным узлом (или именуемый вычислительным узлом), или может быть другим устройством, которое может реализовывать решение кластерного хранения, предоставленное в вариантах осуществления настоящего изобретения, т.е., способ кластерного хранения, предоставленный в вариантах осуществления настоящего изобретения, может быть исполнен посредством компьютерного узла или другого устройства. Нижеследующее использует компьютерный узел в качестве примера для описания устройства и способа кластерного хранения, предоставленных в вариантах осуществления настоящего изобретения.
Вариант 1 Осуществления
[0063] Вариант осуществления настоящего изобретения предоставляет способ кластерного хранения, где способ применяется в системе базы данных. Как показано на Фиг. 1, способ может включать в себя следующие этапы:
[0064] S101. Компьютерный узел кэширует первые данные, которые должны быть сохранены, построчно в локальную память в системе базы данных.
[0065] Если данные хранятся в виде текста на жестком диске, т.е., первые данные, которые должны быть сохранены, требуется сохранить на запоминающем носителе информации в системе базы данных, то чтобы способствовать последующему доступу к первым данных, в процессе сохранения первых данных, компьютерному узлу требуется сортировать сначала первые данные, и затем сохранять сортированные первые данные в запоминающем носителе данных. В процессе, в котором компьютерный узел сохраняет первые данные в запоминающем носителе информации, компьютерному узлу сначала требуется считать первые данные с жесткого диска в локальную память в системе базы данных. В частности, компьютерный узел может кэшировать первые данные построчно с жесткого диска в локальную память.
[0066] S102. Компьютерный узел определяет первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память.
[0067] В процессе, в котором компьютерный узел кэширует первые данные построчно в локальную память, компьютерный узел может определять первый столбец сортировки, где первый столбец сортировки может быть предварительно установленным и первый столбец сортировки может быть использован, чтобы сортировать данные, которые были кэшированы в локальную память.
[0068] Необязательно, в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, при сортировке первых данных, компьютерный узел может сортировать первые данные в соответствии с числовым значением первого столбца сортировки или хэш-значением числового значения первого столбца сортировки.
[0069] Специалист в соответствующей области техники может понимать, что запоминающий носитель информации в системе базы данных, предоставленный в данном варианте осуществления настоящего изобретения, может быть диском, где диск может включать в себя жесткий диск и гибкий диск. Обычно используемым диском является, как правило, съемный диск, где съемный диск может быть классифицирован на два типа: Одним типом является USB флэш-накопитель (Универсальная Последовательная Шина, флэш-накопитель универсальной последовательной шины) или флэш-диск, основанный на чипе для хранения; а другим типом является съемный жесткий диск, основанный на жестком диске, где съемный диск является съемным жестким диском во многих случаях, и съемный жесткий диск классифицируется на съемный жесткий диск компьютера класса ноутбук и съемный жесткий диск настольного компьютера в соответствии с разными жесткими дисками. Съемный жесткий диск, как правило, соединен с компьютером посредством USB интерфейса, т.е., в качестве запоминающего носителя информации, съемный жесткий диск может хранить данные, которые передаются между съемным жестким диском и компьютером посредством USB интерфейса.
[0070] В частности, первый столбец сортировки может именоваться первичным ключом, или может именоваться частичным ключом кластера (частичный ключ кластера).
[0071] Следует отметить, что первый столбец сортировки является основой для сортировки, когда пользователь предписывает компьютерному узлу создать таблицу, первых данных, в соответствии со столбцом сортировки, указанным посредством атрибута первых данных, т.е., компьютерный узел может раздельно сортировать, в соответствии с первым столбцом сортировки, каждую часть данных, которая была кэширована в локальную память, в первых данных, которые должны быть сохранены, так, что каждая часть данных в первых данных располагается раздельно и последовательно, чтобы гарантировать то, что первые данные являются частично последовательными.
[0072] Кроме того, при предписании создать таблицу, пользователь может указывать структуру хранения таблицы посредством использования оператора, где первый столбец сортировки указывается в структуре хранения таблицы. Например, пользователь может использовать оператор следующим образом:
Создать таблицу t(c1 int, c2 int, частичный ключ кластера (c1, c2+1), чтобы указывать структуру хранения таблицы t, где структура хранения таблицы t включает в себя первый столбец сортировки, т.е., частичный ключ кластера.
[0073] Таблица формируется посредством группы записей данных. Таблица является группой связанных данных, которые располагаются в соответствии со строкой; и каждая таблица включает в себя информацию одного и того же типа. Таблица является фактически двумерной таблицей. Например, результаты теста всех учащихся в классе могут быть сохранены в таблице, где каждая строка в таблице соответствует одному учащемуся, и каждая строка включает в себя всю информацию касательно соответствующего учащегося, например, может включать в себя следующее об учащемся: номер учащегося, имя и результат по каждому курсу.
[0074] Структура хранения таблицы является полем, типом, первичным ключом, внешним ключом, индексом, и подобным определенной таблицы, т.е., эти базовые атрибуты составляют структуру хранения таблицы. После того, как определяется структура хранения таблицы, данные разных типов могут быть непосредственно вставлены в соответствии со структурой хранения таблицы.
[0075] База данных является хранилищем для хранения данных, база данных формируется посредством одной таблицы или группы таблиц, и данные в базе данных организуются в единице таблицы. Каждая база данных хранится на диске в форме файла, т.е., каждая база данных соответствует одному физическому файлу. Разные базы данных соответствуют физическому файлу по разному. Например, база данных может включать в себя таблицу или может включать в себя несколько таблиц.
[0076] Кроме того, в соответствии со способом кластерного хранения, предоставленным в данном варианте осуществления настоящего изобретения, так как компьютерный узел совершает сортировку в отношении первых данных в локальной памяти в системе базы данных и подчиняется ограничениям по размеру и возможностям обработки данных локальной памяти, компьютерный узел может сортировать первые данные только по частям. Компьютерный узел затем последовательно сохраняет, в запоминающем носителе информации в системе базы данных, данные, которые сортированы по частям, и таким образом, можно гарантировать то, что первые данные, хранящиеся в запоминающем носителе информации являются частично последовательными.
[0077] S103. Если вторые данные, которые были кэшированы в локальную память посредством компьютерного узла, удовлетворяют предварительно установленному условию, компьютерный узел сортирует вторые данные в соответствии с первым столбцом сортировки, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных.
[0078] В процессе, в котором компьютерный узел кэширует первые данные, из-за того, что локальная память в системе базы данных имеет ограниченный размер и ограниченные возможности обработки данных, первые данные не могут быть все кэшированы в локальную память за раз, т.е., компьютерный узел может раздельно кэшировать первые данные по частям в локальную память, так что компьютерный узел может последовательно обрабатывать, по частям, данные, которые раздельно кэшируются в локальной памяти. В частности, компьютерный узел может собирать статистику, в режиме реального времени, по ситуации вторых данных, которые были кэшированы в локальную память. Когда компьютерный узел обнаруживает, что вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, компьютерный узел может начинать сортировать вторые данные в соответствии с первым столбцом сортировки, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных.
[0079] Кроме того, вышеупомянутое предварительно установленное условие может быть использовано, чтобы представлять отношение между объемом данных вторых данных, которые были кэшированы в локальную память, и объемом данных, разрешенным для хранения в локальной памяти.
[0080] S104. Компьютерный узел сохраняет сортированные вторые данные в запоминающем носителе информации в системе базы данных.
[0081] В базе данных, чтобы улучшить скорость запроса атрибута или группы атрибутов, кортеж, который обладает одним и тем же значением в атрибуте или группе атрибутов (именуемый кодом кластера), может быть централизовано сохранен в последовательных физических блоках. Данный способ хранения именуется кластерным. Сохранение данных в кластерной форме может значительно улучшить эффективность при выполнении запроса в соответствии с кодом кластера.
[0082] После того, как компьютерный узел сортирует вторые данные, компьютерный узел может сохранять сортированные вторые данные в кластерной форме в запоминающем носителе информации в системе базы данных с тем, чтобы совершать процесс загрузки вторых данных.
[0083] Следует отметить, что компьютерный узел может неоднократно выполнять вышеупомянутые этапы с S101 по S104 до тех пор, пока все первые данные, которые должны быть сохранены, не сохраняются в запоминающем носителе информации в системе базы данных.
[0084] Может быть понятно, что компьютерный узел может последовательно и раздельно сортировать, в соответствии с предварительно установленным первым столбцом сортировки, каждую часть данных, которые были кэшированы в локальную память, в первых данных, и сохранять, в запоминающий носитель информации, каждую часть данных, которая получается после того, как сортируется, каждый раз так, что можно гарантировать то, что первые данные, сохраненные в запоминающем носителе информации, являются частично последовательными, т.е., каждая часть данных в первых данных, сохраненных в запоминающем носителе информации, является последовательно расположенной.
[0085] В качестве примера, если пользователю требуется сохранить первые данные, т.е., информацию касательно 500 учащихся на отделении танца в колледже в запоминающем носителе информации в системе базы данных для обеспечения последующего доступа, пользователю сначала требуется ввести информацию касательно 500 учащихся в компьютерный узел и сохранить информацию на жестком диске компьютерного узла в форме текста. В процессе, в котором компьютерный узел сохраняет информацию касательно 500 учащихся в запоминающем носителе информации в системе базы данных в соответствии с инструкцией пользователя, компьютерный узел может считывать информацию касательно 500 учащихся из текста на жестком диске в локальную память в форме считывания информации касательно каждого учащегося построчно в соответствии с каждым учащимся.
[0086] Предполагается, что информация касательно каждого учащегося включает в себя атрибуты, такие как класс, имя, номер учащегося, возраст, специализация, и информацию о семье. В соответствии со способом кластерного хранения, предоставленным в данном варианте осуществления настоящего изобретения, информация касательно 500 учащихся может составлять одну таблицу. Как показано в Таблице 1, каждая строка (т.е., информация касательно каждого учащегося) в Таблице 1 является кортежем, и каждый столбец (информация элемента касательно всех учащихся) является атрибутом.
Таблица 1
[0087] Следует отметить, что при вводе информации касательно 500 учащихся, пользователь может не вводить информацию в соответствии с конкретной последовательностью, и, вследствие этого, информация касательно 500 учащихся, хранящаяся в виде текста на жестком диске, не расположена последовательно. Для обеспечения последующего повторного использования информации касательно 500 учащихся, например, чтобы выполнять операции, такие как запрос и сортировка, над информацией касательно 500 учащихся, информация касательно 500 учащихся должна быть сохранена в запоминающем носителе информации в системе базы данных для обеспечения долгосрочного использования и устранения повторяющихся операций. В частности, когда данные должны быть сохранены в запоминающем носителе информации в системе базы данных, для хранения главным образом может быть использована соответствующая структура хранения таблицы. В сравнении со структурой хранения таблицы, предоставленной в предшествующем уровне техники, структура хранения таблицы (структура хранения у таблицы, созданной компьютерным узлом в данном варианте осуществления настоящего изобретения), предоставляемая в данном варианте осуществления настоящего изобретения, т.е., структура хранения таблицы, показанная в Таблице 1, может гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
[0088] Из вышеприведенной Таблицы 1 можно понять, что: в данном примере, первым столбцом сортировки, указанным пользователем, т.е., частичным ключом кластера (первичным ключом), может быть класс и номер учащегося. Это потому, что каждый учащийся может быть определен только когда определяются два атрибута, т.е., как класс, так и номер учащегося, т.е., каждого учащегося можно отличить от другого учащегося только когда определены как класс, так и номер учащегося.
[0089] Посредством использования способа кластерного хранения, предоставленного в данном варианте осуществления настоящего изобретения, первые данные, которые должны быть сохранены, могут быть сохранены в запоминающем носителе информации в системе базы данных после сортировки по частям, и это может гарантировать то, что каждая часть данных, хранящаяся в запоминающем носителе информации является последовательно расположенной. Таким образом, из-за того, что данные, которые должны быть сохранены, могут сортироваться и сохраняться по частям с тем, чтобы совершить загрузку данных, можно гарантировать то, что данные хранятся в запоминающем носителе информации частично последовательно так, что может быть гарантировано то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
[0090] В соответствии со способом кластерного хранения, предоставленным в данном варианте осуществления настоящего изобретения, первые данные, которые должны быть сохранены, кэшируются построчно в локальную память в системе базы данных; определяется первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память; вторые данные сортируются в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, где вторые данные являются данными, которые были кэшированы в локальной памяти, в первых данных; и сортированные вторые данные сохраняются в кластерной форме в запоминающем носителе информации в системе базы данных. Посредством использования данного решения, в процессе кэширования первых данных, которые должны быть сохранены, построчно в локальной памяти, когда объем вторых данных, которые были кэшированы в локальную память, превышает объем данных, разрешенный для хранения в локальной памяти, начинается сортировка вторых данных в соответствии с определенным первым столбцом сортировки, и сортированные вторые данные сохраняются в запоминающем носителе информации в системе базы данных. Из-за того, что данные, которые должны быть сохранены, могут сортироваться и сохраняться по частям с тем, чтобы совершить загрузку данных, можно гарантировать то, что данные в запоминающем носителе информации в системе базы данных частично последовательные так, что может быть гарантировано то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
Вариант 2 Осуществления
[0091] Вариант осуществления настоящего изобретения предоставляет способ кластерного хранения, где способ применяется в системе базы данных. Как показано на Фиг. 2, способ может включать в себя следующие этапы:
[0092] S201. Компьютерный узел создает таблицу в запоминающем носителе информации в системе базы данных, где таблица используется для загрузки первых данных, которые должны быть сохранены.
[0093] Если данные хранятся в виде текста на жестком диске, т.е., первые данные, которые должны быть сохранены, в отношении которых требуется сохранение в запоминающем носителе информации в системе базы данных, компьютерный узел может сначала создавать таблицу в запоминающем носителе информации, где таблица может быть использована, чтобы загружать первые данные.
[0094] Специалист в соответствующей области техники может понимать, что запоминающим носителем информации в системе базы данных, предоставленным в данном варианте осуществления настоящего изобретения, может быть диск, где диск может включать в себя жесткий диск и гибкий диск. Обычно используемым диском является, как правило, съемный диск, где съемный диск может быть классифицирован на два типа: Одним типом является USB флэш-накопитель или флэш-диск, основанный на чипе для хранения; а другим типом является съемный жесткий диск, основанный на жестком диске, где съемный диск является съемным жестким диском во многих случаях, и съемный жесткий диск классифицируется на съемный жесткий диск компьютера класса ноутбук и съемный жесткий диск настольного компьютера в соответствии с разными жесткими дисками. Съемный жесткий диск, как правило, соединен с компьютером посредством USB интерфейса, т.е., в качестве запоминающего носителя информации, съемный жесткий диск может хранить данные, которые передаются между съемным жестки диском и компьютером посредством USB интерфейса.
[0095] S202. Компьютерный узел кэширует первые данные построчно в локальную память в системе базы данных.
[0096] В способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, для обеспечения последующего доступа к первым данным, в процессе сохранения первых данных, компьютерному узлу требуется сначала сортировать первые данные и затем сохранять сортированные первые данные в запоминающем носителе информации в системе базы данных. В процессе, в котором компьютерный узел сохраняет первые данные в запоминающем носителе информации, компьютерному узлу сначала требуется считать первые данные с жесткого диска в локальную память в системе базы данных. В частности, компьютерный узел может кэшировать первые данные построчно с жесткого диска в локальную память.
[0097] S203. Компьютерный узел определяет первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память.
[0100] В процессе, в котором компьютерный узел кэширует первые данные построчно в локальную память, компьютерный узел может определять первый столбец сортировки, где первый столбец сортировки может быть использован, чтобы сортировать данные, которые были кэшированы в локальную память.
[0101] В частности, первый столбец сортировки может именоваться первичным ключом, или может именоваться частичным ключом кластера.
[0102] Следует отметить, что первый столбец сортировки является основой для сортировки, когда пользователь предписывает компьютерному узлу создать таблицу, первых данных, в соответствии со столбцом сортировки, указанным посредством атрибута первых данных, т.е., компьютерный узел может раздельно сортировать, в соответствии с первым столбцом сортировки, каждую часть данных, которая была кэширована в локальную память, в первых данных, которые должны быть сохранены, так, что каждая часть данных в первых данных располагается раздельно и последовательно, чтобы гарантировать то, что первые данные являются частично последовательными.
[0103] Кроме того, при предписании создать таблицу, пользователь может указывать структуру хранения таблицы посредством использования оператора, где первый столбец сортировки указывается в структуре хранения таблицы. Например, пользователь может использовать оператор следующим образом:
Создать таблицу t(c1 int, c2 int, частичный ключ кластера (c1, c2+1), чтобы указывать структуру хранения таблицы t, где структура хранения таблицы t включает в себя первый столбец сортировки, т.е., частичный ключ кластера.
[0104] Таблица формируется посредством группы записей данных. Таблица является группой связанных данных, которые располагаются в соответствии со строкой; и каждая таблица включает в себя информацию одного и того же типа. Таблица является фактически двумерной таблицей. Например, результаты теста всех учащихся в классе могут быть сохранены в таблице, где каждая строка в таблице соответствует одному учащемуся, и каждая строка включает в себя всю информацию касательно соответствующего учащегося, например, может включать в себя следующее об учащемся: номер учащегося, имя и результат по каждому курсу.
[0105] Структура хранения таблицы является полем, типом, первичным ключом, внешним ключом, индексом, и подобным определенной таблицы, т.е., эти базовые атрибуты составляют структуру хранения таблицы. После того, как определяется структура хранения таблицы, данные разных типов могут быть непосредственно вставлены в соответствии со структурой хранения таблицы.
[0106] База данных является хранилищем для хранения данных, база данных формируется посредством одной таблицы или группы таблиц, и данные в базе данных организуются в единице таблицы. Каждая база данных хранится на диске в форме файла, т.е., каждая база данных соответствует одному физическому файлу. Разные базы данных соответствуют физическому файлу по разному. Например, применительно к базам данных в форматах dBASE, FoxPro, и Paradox, таблица является отдельным файлом базы данных, а применительно к базам данных в форматах Microsoft Access и Btrieve, файл базы данных может включать в себя несколько таблиц.
[0107] Кроме того, в соответствии со способом кластерного хранения, предоставленным в данном варианте осуществления настоящего изобретения, так как компьютерный узел совершает сортировку в отношении первых данных в локальной памяти в системе базы данных и подчиняется ограничениям по размеру и возможностям обработки данных локальной памяти, компьютерный узел может сортировать первые данные только по частям. Компьютерный узел затем последовательно сохраняет, в запоминающем носителе информации в системе базы данных, данные, которые сортированы по частям, и таким образом, можно гарантировать то, что первые данные, хранящиеся в запоминающем носителе информации являются частично последовательными.
[0108] Необязательно, вышеупомянутый первый столбец сортировки может включать в себя, по меньшей мере, одно из следующего: физический столбец и выражение. В частности, первый столбец сортировки может быть физическим столбцом, может быть выражением, может быть физическим столбцом и выражением, или может быть любым другим форматом, который удовлетворяет требованию сортировки, которое не ограничивается в настоящем изобретении.
[0109] В качестве примера, вышеупомянутый оператор для указания первого столбца сортировки используется в качестве примера. В операторе, первым столбцом сортировки является «c1, c2+1», где «c1» является физическим столбцом, а «c2+1» является выражением.
[0110] Кроме того, как показано в Таблице 2, если данные в таблице являются первыми данными, которые должны быть сохранены, первый столбец сортировки может быть столбцом элемента и столбцом порядкового номера, или столбом числового значения, где столбец элемента и столбец порядкового номера, или столбец числового значения могут именоваться физическим столбцом; или первый столбец сортировки может быть абсолютным значением столбца числового значения, где абсолютное значение столбца числового значения может именоваться выражением. Может быть понятно, что компьютерный узел может сортировать первые данные, показанные в Таблице 2, в соответствии с вышеупомянутым первым столбцом сортировки, который указывается пользователем в соответствии с требованием пользователя.
[0111] В частности, если первый столбец сортировки является столбцом элемента и столбцом порядкового номера, результат, который получается после того, как компьютерный узел сортирует данные в Таблице 2 в соответствии со значениями первого столбца сортировки в возрастающем порядке (сортировка выполняется для столбца элемента в алфавитном порядке, и сортировка выполняется для столбца порядкового номера в числовом порядке), показан в Таблице 3; если первым столбцом сортировки является столбец числового значения, результат, который получается после того, как компьютерный узел сортирует данные в Таблице 2 в соответствии со значениями первого столбца сортировки в возрастающем порядке, показан в Таблице 4; и если первым столбцом сортировки является абсолютное значение столбца числового значения, результат, который получается после того, как компьютерный узел сортирует данные в Таблице 2 в соответствии со значениями первого столбца сортировки в возрастающем порядке, показан в Таблице 5.
Таблица 2
Таблица 3
Таблица 4
Таблица 5
[0112] Из вышеприведенных Таблицы 3, Таблицы 4, и Таблицы 5 может быть видно, что, применительно к разному первому столбцу сортировки, результат сортировки является разным; и применительно к одному и тому же первому столбцу сортировки, результат сортировки, выполняемый в соответствии с выражением первого столбца сортировки также отличается от результата сортировки, выполняемого непосредственно в соответствии с первым столбцом сортировки. В частности, сортировка может быть выполнена в соответствии с фактическим требованием пользователя, которое не ограничивается в настоящем изобретении.
[0113] Необязательно, количество первых столбцов сортировки может соответствовать, по меньшей мере, одному, т.е., может присутствовать, по меньшей мере, одна основа для сортировки первых данных. Когда количество первых столбцов сортировки соответствует, по меньшей мере, двум, по меньшей мере, два первых столбца сортировки могут включать в себя первичный первый столбец сортировки и, по меньшей мере, один вторичный первый столбец сортировки, так что компьютерный узел может сначала сортировать каждую часть данных в первых данных в соответствии с первичным первым столбцом сортировки, а затем раздельно сортировать каждую часть данных в первых данных в соответствии с, по меньшей мере, одним вторичным первым столбцом сортировки.
[0114] В качестве примера, то, что вышеупомянутый первый столбец сортировки является «c1,c2+1», используется в качестве примера, где «c1» является первичным первым столбцом сортировки, а «c2+1» является вторичным первым столбцом сортировки.
[0115] Кроме того, как показано в Таблице 2, если первый столбец сортировки является столбцом элемента и столбцом порядкового номера, то столбец элемента может быть установлен в качестве первичного первого столбца сортировки, а столбец порядкового номера может быть установлен в качестве вторичного первого столбца сортировки; или столбец порядкового номера может быть установлен в качестве первичного первого столбца сортировки, а столбец элемента может быть установлен в качестве вторичного первого столбца сортировки. Конкретная форма установки может адаптивно регулироваться в соответствии с фактическим требованием, что не ограничивается в настоящем изобретении.
[0116] S204. Компьютерный узел обнаруживает, удовлетворяют ли вторые данные, которые были кэшированы в локальную память, предварительно установленному условию, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных.
[0117] В процессе, в котором компьютерный узел кэширует первые данные в локальную память, компьютерный узел может обнаруживать, удовлетворяют ли вторые данные, которые были кэшированы в локальную память, предварительно установленному условию, где вторые данные могут быть данными, которые были кэшированы в локальную память, в первых данных.
[0118] Предварительно установленное условие может быть использовано, чтобы представлять отношение между объемом данных вторых данных, которые были кэшированы в локальную память, и объемом данных, разрешенным для хранения в локальной памяти. Предварительно установленное условие может состоять в том, что количество строк вторых данных больше или равно первой предварительно установленной пороговой величине, может состоять в том, что размер, занимаемый вторыми данными, локальной памяти больше или равен второй предварительно установленной пороговой величине, или может состоять в любом другом предварительно установленном условии, которое удовлетворяет требованию исполнения, что не ограничивается в настоящем изобретении.
[0119] В частности, компьютерный узел может обнаруживать, является ли количество строк вторых данных, которые были кэшированы в локальную память, больше или равно первой предварительно установленной пороговой величине; или компьютерный узел может обнаруживать, является ли размер, который занимается вторыми данными, которые были кэшированы в локальную память, локальной памяти больше или равен второй предварительно установленной пороговой величине.
[0120] Следует отметить, что значения первой предварительно установленной пороговой величины и второй предварительно установленной пороговой величины могут быть установлены в соответствии с размером памяти, который фактически используется компьютерным узлом, и возможностями обработки данных памяти, что не ограничивается в настоящем изобретении.
[0121] S205. Если вторые данные, которые были кэшированы в локальную память посредством компьютерного узла, удовлетворяют предварительно установленному условию, компьютерный узел сортирует вторые данные в соответствии с первым столбцом сортировки.
[0122] В процессе, в котором компьютерный узел кэширует первые данные, так как локальная память в системе базы данных имеет ограниченный размер и ограниченные возможности обработки данных, первые данные не могут быть все кэшированы в локальную память за раз, т.е., компьютерный узел может раздельно кэшировать первые данные по частям в локальную память, так что компьютерный узел может последовательно обрабатывать, по частям, данные, которые раздельно кэшируются в локальную память. В частности, компьютерный узел может собирать статистику, в режиме реального времени, по ситуации вторых данных, которые были кэшированы в локальную память. Когда компьютерный узел обнаруживает, что вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, компьютерный узел может начинать сортировать вторые данные в соответствии с первым столбцом сортировки.
[0123] Например, если первая предварительно установленная пороговая величина составляет 10000 строк, когда количество строк вторых данных, которые были кэшированы в локальную память, больше или равно 10000 строк, компьютерный узел может начинать сортировать вторые данные в соответствии с первым столбцом сортировки; и соответственно, если вторая предварительно установленная пороговая величина составляет 6 гигабайт, когда размер, который занимается вторыми данными, которые были кэшированы в локальную память, локальной памяти больше или равен 6 гигабайтам, компьютерный узел может начинать сортировать вторые данные в соответствии с первым столбцом сортировки.
[0124] Кроме того, размер, который занимается вторыми данными, которые были кэшированы в локальной памяти, локальной памяти также может быть представлен посредством процента. Например, если емкость локальной памяти составляет 8 гигабайт, и второй предварительно установленной пороговой величиной может быть 90% (процентов) от 8 гигабайт, когда размер, который занимается вторыми данными, которые были кэшированы в локальную память, локальной памяти больше 90% от 8 гигабайт, компьютерный узел может начинать сортировать вторые данные в соответствии с первым столбцом сортировки.
[0125] Кроме того, в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, при сортировке первых данных, компьютерный узел может сортировать вторые данные в соответствии с числовым значением первого столбца сортировки или хэш-значением числового значения первого столбца сортировки.
[0126] Двоичное значение произвольной длины может быть соотнесено с меньшим двоичным значением фиксированной длины в соответствии с алгоритмом хэширования, и меньшее двоичное значение фиксированной длины именуется хэш-значением двоичного значения. Хэш-значение является сегментом чрезвычайно компактной формы представления числового значения с уникальными данными. Например, если должно быть вычислено хэш-значение сегмента данных, при условии, что любой знак в сегменте данных меняется перед вычислением, два хэш-значения, которые получаются посредством вычисления до и после изменения, также являются разными.
[0127] Соответственно, хэш-значение числового значения первого столбца сортировки может быть получено посредством соотнесения двоичного значения числового значения первого столбца сортировки с меньшим двоичным значением фиксированной длины в соответствии с алгоритмом хэширования.
[0128] S206. Компьютерный узел вставляет сортированные данные построчно в таблицу с тем, чтобы сохранить сортированные вторые данные в кластерной форме в запоминающем носителе информации.
[0129] В базе данных, чтобы улучшить скорость запроса атрибута или группы атрибутов, кортеж, который обладает одним и тем же значением в атрибуте или группе атрибутов (именуемый кодом кластера), может быть централизовано сохранен в последовательных физических блоках. Данный способ хранения именуется кластерным. Сохранение данных в кластерной форме может значительно улучшить эффективность при выполнении запроса в соответствии с кодом кластера.
[0130] После того, как компьютерный узел сортирует вторые данные, компьютерный узел может вставлять сортированные вторые данные построчно в таблицу, созданную посредством компьютерного узла, с тем, чтобы сохранить сортированные вторые данные в кластерной форме в запоминающем носителе информации в системе базы данных, с тем чтобы совершить процесс загрузки вторых данных.
[0131] В частности, компьютерный узел может сохранять сортированные вторые данные в кластерной форме в незанятом физическом блоке в запоминающем носителе информации в системе базы данных, где незанятый физический блок является физическим блоком за исключением физического блока, занимаемого третьими данными, а третьи данные являются данными, которые были сохранены в кластерной форме в запоминающем носителе информации перед вторыми данными, в первых данных.
[0132] В частности, компьютерный узел может сохранять сортированные вторые данные в кластерной форме в последовательных незанятых физических блоках в запоминающем носителе информации, или может сохранять сортированные вторые данные в кластерной форме в непоследовательных незанятых физических блоках в запоминающем носителе информации (например, часть данных во вторых данных сохраняется в кластерной форме в некоторых последовательных незанятых физических блоках, а другая часть данных во вторых данных сохраняется в кластерной форме в некоторых других последовательных незанятых физических блоках, где некоторые последовательные незанятые физические блоки и некоторые другие последовательные незанятые физические блоки не являются последовательными физическими блоками), и конкретная форма хранения не ограничивается в настоящем изобретении. Т.е., неважно, какая из вышеупомянутых форм хранения используется в настоящем изобретении, можно гарантировать то, что данные хранятся в запоминающем носителе информации частично последовательно.
[0133] Следует отметить, что компьютерный узел может неоднократно выполнять вышеупомянутые этапы с S202 по S206 до тех пор, пока все первые данные, которые должны быть сохранены, не сохраняются в запоминающем носителе информации в системе базы данных.
[0134] Может быть понятно, что компьютерный узел может последовательно сортировать каждую часть данных, которые были кэшированы в локальную память, в первых данных, и сохранять, в запоминающий носитель информации, каждую часть данных, которая получается после того, как сортируется, каждый раз так, что можно гарантировать то, что первые данные, сохраненные в запоминающем носителе информации, являются частично последовательными, т.е., каждая часть данных в первых данных, сохраненных в запоминающем носителе информации, является последовательно расположенной.
[0135] В качестве примера, если пользователю требуется сохранить первые данные, т.е., информацию касательно 500 учащихся на отделении танца в колледже в запоминающем носителе информации в системе базы данных для обеспечения последующего доступа, пользователю сначала требуется ввести информацию касательно 500 учащихся в компьютерный узел и сохранить информацию на жестком диске компьютерного узла в форме текста. В процессе, в котором компьютерный узел сохраняет информацию касательно 500 учащихся в запоминающем носителе информации в системе базы данных в соответствии с инструкцией пользователя, компьютерный узел может считывать информацию касательно 500 учащихся из текста на жестком диске в локальную память в системе базы данных. В частности, компьютерный узел может последовательно считывать информацию касательно 500 учащихся в локальную память в форме считывания информации касательно каждого учащегося построчно в соответствии с каждым учащимся.
[0136] Предполагается, что информация касательно каждого учащегося включает в себя атрибуты, такие как класс, имя, номер учащегося, возраст, специализация, и информацию о семье. В соответствии со способом кластерного хранения, предоставленным в данном варианте осуществления настоящего изобретения, информация касательно 500 учащихся может составлять одну таблицу. Как показано в Таблице 1, каждая строка (т.е., информация касательно каждого учащегося) в Таблице 1 является кортежем, и каждый столбец (информация элемента касательно всех учащихся) является атрибутом.
[0137] Следует отметить, что при вводе информации касательно 500 учащихся, пользователь может не вводить информацию в соответствии с конкретной последовательностью, и, вследствие этого, информация касательно 500 учащихся, хранящаяся в виде текста на жестком диске, не расположена последовательно. Для обеспечения последующего повторного использования информации касательно 500 учащихся, например, чтобы выполнять операции, такие как запрос и сортировка, над информацией касательно 500 учащихся, информация касательно 500 учащихся должна быть сохранена в запоминающем носителе информации в системе базы данных для обеспечения долгосрочного использования и устранения повторяющихся операций. В частности, когда данные должны быть сохранены в запоминающем носителе информации в системе базы данных, для хранения главным образом может быть использована соответствующая структура хранения таблицы. В сравнении со структурой хранения таблицы предоставленной в предшествующем уровне техники, структура хранения таблицы (структура хранения у таблицы, созданной компьютерным узлом в данном варианте осуществления настоящего изобретения), предоставляемая в данном варианте осуществления настоящего изобретения, т.е., структура хранения таблицы, показанная в Таблице 1, может гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
[0138] Из вышеприведенной Таблицы 1 можно понять, что: в данном примере, первым столбцом сортировки, указанным пользователем, т.е., частичным ключом кластера (первичным ключом), может быть класс и номер учащегося. Это потому, что каждый учащийся может быть определен только когда определяются два атрибута, т.е., как класс, так и номер учащегося, т.е., каждого учащегося можно отличить от другого учащегося только когда определены как класс, так и номер учащегося.
[0139] Кроме того, как показано на Фиг. 3, после того, как компьютерный узел сохраняет все первые данные в запоминающем носителе информации, пользователь может выполнять, в соответствии с требованием пользователя, соответствующую операцию, такую как запрос, сортировка, или агрегация над первыми данными, сохраненным в запоминающем носителе информации. В частности, способ кластерного хранения, предоставленный в данном варианте осуществления настоящего изобретения, может дополнительно включать в себя следующие этапы:
[0140] S207. Компьютерный узел определяет столбец запроса.
[0141] После того, как компьютерный узел сохраняет все первые данные в запоминающем носителе информации, если пользователю требуется выполнить операцию запроса над первыми данными, пользователю требуется указать соответствующий столбец запроса, т.е., компьютерный узел может определять столбец запроса, указанный пользователем, где столбец запроса может быть использован как основа для выполнения операции запроса над первыми данными.
[0142] S208. Компьютерный узел сравнивает столбец запроса с первым в первом столбце сортировки.
[0143] После того, как компьютерный узел определяет столбец запроса, компьютерный узел может сравнивать столбец запроса с первым в первом столбце сортировки с тем, чтобы определить, является ли столбец запроса первым в первом столбце запроса.
[0144] S209. Компьютерный узел считывает первые данные, хранящиеся в запоминающем носителе информации, в локальную память.
[0145] После того, как компьютерный узел определяет столбец запроса и перед тем, как выполняется операция запроса над первыми данными в соответствии со столбцом запроса, компьютерному узлу требуется считать первые данные, хранящиеся в запоминающем носителе информации, в локальную память с тем, чтобы совершить, в локальной памяти, операцию запроса над данными.
[0146] После того, как выполняется этап S207, последовательность исполнения этапов S208 и S209 не ограничивается в настоящем изобретении, т.е., в настоящем изобретении, сначала может быть выполнен этап S208, а затем выполняется этап S209; сначала может быть выполнен этап S209, а затем выполняется этап S208; или этапы S208 и S209 могут быть выполнены в одно и тоже время.
[0147] S210. Если столбец запроса является первым в первом столбце сортировки, компьютерный узел может выполнять, в локальной памяти, операцию запроса над первыми данными в соответствии с первым в первом столбце сортировки.
[0148] Если столбец запроса является первым в первом столбце сортировки, компьютерный узел может выполнять, в локальной памяти, операцию запроса над первыми данными в соответствии с первым в первом столбце сортировки.
[0149] Может быть понятно, что если количество первых столбцов сортировки соответствует одному, первый в первом столбце сортировки является первым столбцом сортировки; а если количество первых столбцов сортировки соответствует двум или более, чем два, первый в первых столбцах сортировки является первичным первым столбцом сортировки в первых столбцах сортировки.
[0150] В частности, в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, так как компьютерный узел может хранить, в кластерной форме в запоминающем носителе информации, данные, которые получаются после того, как первые данные сортируются по частям, можно гарантировать то, что первые данные являются частично и последовательно расположенными в запоминающем носителе информации. Вследствие этого, когда требуется выполнение операции запроса над первыми данными в соответствии с первым в первом столбце сортировки, компьютерный узел может считывать первые данные, хранящиеся в запоминающем носителе информации, в локальную память, и непосредственно выполнять операцию запроса, в локальной памяти в форме двоичного поиска, по каждой странице данных из одной или более страниц данных первых данных.
[0151] Двоичный поиск также именуется дихотомическим поиском, и преимущества двоичного поиска являются следующими: небольшое количество раз сравнения, высокая скорость поиска, и высокая средняя эффективность; а недостатки двоичного поиска являются следующими: таблица, по который должен быть осуществлен поиск, должна быть упорядоченной таблицей, и относительно сложно вставить данные и удалить данные. Вследствие этого, форма двоичного поиска применима к упорядоченной таблице, которая не меняется часто, но по которой часто осуществляется поиск. В качестве примера, предполагается, что элементы в таблице расположены в соответствии с первым столбцом сортировки в возрастающем порядке, ключевое слово, записанное в средней позиции таблицы сравнивается с ключевым словом поиска, и если ключевое слово, записанное в средней позиции таблицы, равно ключевому слову поиска, поиск является успешным; в противном случае, ключевое слово, записанное в средней позиции, используется, чтобы разделить таблицу на две подтаблицы, т.е., предыдущую подтаблицу и последующую подтаблицу, и если ключевое слово, записанное в средней позиции таблицы, больше, чем ключевое слово поиска, осуществляется дальнейший поиск по предыдущей подтаблице, и в противном случае, осуществляется дальнейший поиск по последующей подтаблице. Вышеупомянутый процесс повторяется до тех пор, пока не находятся данные, которые удовлетворяют условию запроса, и в данном случае, поиск успешный; или вышеупомянутый процесс повторяется до тех пор, пока не определяется, что подтаблицы не существует, и в данном случае поиск не успешный.
[0152] Следует отметить, что так как первые данные являются частично и последовательно расположенными в запоминающем носителе информации, первые данные, которые считываются компьютерным узлом из запоминающего носителя информации в локальную память, также являются частично и последовательно расположенными. Если первые данные должны быть запрошены в соответствии с первым в первом столбце сортировки, компьютерный узел может быстро найти, в первых данных в локальной памяти, посредством выполнения вышеупомянутых этапов с S207 по S210, данные, которые удовлетворяют условию запроса, тем самым сокращая количество раз обзора данных и сравнения данных, и улучшая эффективность запроса данных.
[0153] Кроме того, в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, как показано на Фиг. 4, индекс, соответствующий первым данным, также может быть использован, чтобы запрашивать данные. Индекс, соответствующий первым данным, может быть создан в процессе сохранения первых данных в запоминающем носителе информации, или индекс, соответствующий первым данным, может быть создан после того, как первые данные сохраняются в запоминающем носителе информации, что не ограничивается в настоящем изобретении.
[0154] Может быть понятно, что индекс, соответствующий первым данным, может быть использован, чтобы указывать конкретное местоположение хранения первых данных в запоминающем носителе информации. Например, индекс, соответствующий первым данным, может быть использован, чтобы указывать физический блок, страницу данных и строку данных, в которых первые данные в частности хранятся в запоминающем носителе информации.
[0155] В частности, после того, как первые данные сохраняются в запоминающем носителе информации посредством использования способа кластерного хранения, предоставленного в данном варианте осуществления настоящего изобретения, так как первые данные являются частично и последовательно сохраненными, строка данных, по которой должен быть осуществлен поиск, может быть непосредственно найдена в запоминающем носителе информации в соответствии со столбцом запроса и созданным индексом, который соответствует первым данным. Вследствие этого, в сравнении со случаем, в котором данные непоследовательно сохраняются в предшествующем уровне техники, значительно сокращается количество раз запроса данных и улучшается эффективность запроса данных.
[0156] В частности, так как способ для поиска данных в соответствии с индексом, соответствующим первым данным, является сходным со способом для поиска данных в соответствии с индексом в предшествующем уровне техники, подробности здесь вновь не описываются.
[0157] S211. Компьютерный узел определяет второй столбец сортировки.
[0158] После того, как компьютерный узел сохраняет все первые данные в запоминающем носителе информации, если пользователю требуется сортировать первые данные, пользователю требуется указать соответствующий столбец сортировки, т.е., компьютерный узел может определять второй столбец сортировки, указанный пользователем, где второй столбец сортировки может быть использован как основа для выполнения операции сортировки над первыми данными.
[0159] S212. Компьютерный узел сравнивает второй столбец сортировки с первым в первом столбце сортировки.
[0160] После того, как компьютерный узел определяет второй столбец сортировки, компьютерный узел может сравнивать второй столбец сортировки с первым в первом столбце сортировки с тем, чтобы определить, является ли второй столбец сортировки первым в первом столбце сортировки.
[0161] S213. Компьютерный узел считывает первые данные, хранящиеся в запоминающем носителе информации, в локальную память.
[0162] После того, как компьютерный узел определяет второй столбец сортировки и перед тем, как операция сортировки выполняется над первыми данными в соответствии со вторым столбцом сортировки, компьютерному узлу требуется считать первые данные, хранящиеся в запоминающем носителе информации, в локальную память с тем, чтобы совершить, в локальной памяти, операцию сортировки над данными.
[0163] После того, как выполняется этап S211, последовательность исполнения этапов S212 и S213 не ограничивается в настоящем изобретении, т.е., в настоящем изобретении, сначала может быть выполнен этап S212, а затем выполняется этап S213; сначала может быть выполнен этап S213, а затем выполняется этап S212; или этапы S212 и S213 могут быть выполнены в одно и тоже время.
[0164] S214. Если второй столбец сортировки является первым в первом столбце сортировки, компьютерный узел выполняет, в локальной памяти, операцию сортировки над первыми данными в соответствии с первым в первом столбце сортировки.
[0165] Если второй столбец сортировки является первым в первом столбце сортировки, компьютерный узел может выполнять, в локальной памяти, операцию сортировки над первыми данными в соответствии с первым в первом столбце сортировки.
[0166] В частности, в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, так как компьютерный узел может хранить, в кластерной форме в запоминающем носителе информации, данные, которые получены после того, как первые данные сортируются по частям, можно гарантировать то, что первые данные являются частично и последовательно расположенными в запоминающем носителе информации. Вследствие этого, когда требуется выполнение операции сортировки над первыми данными в соответствии с первым в первом столбце сортировки, компьютерный узел может считывать первые данные, хранящиеся в запоминающем носителе информации, в локальную память, и непосредственно сортировать, в локальной памяти, каждую часть данных в первых данных, т.е., компьютерный узел может выполнять сортировку слиянием над первыми данными.
[0167] Сортировка слиянием (Merge) является способом сортировки для объединения двух (или более чем двух) упорядоченных последовательностей в новую упорядоченную последовательность. Сортировка слиянием является эффективным алгоритмом сортировки, который основан на операции слияния. Сортировка слиянием, предоставленная в данном варианте осуществления настоящего изобретения, может происходить следующим образом: Компьютерный узел объединяет несколько упорядоченных подпоследовательностей, которые хранятся в кластерной форме в запоминающем носителе информации, в цельную упорядоченную последовательность.
[0168] Следует отметить, что так как первые данные являются частично и последовательно расположенными в запоминающем носителе информации, первые данные, которые считываются компьютерным узлом из запоминающего носителя информации в локальную память, также являются частично и последовательно расположенными. Если требуется, чтобы первые данные были сортированы в соответствии с первым в первом столбце сортировки, компьютерный узел может быстро сортировать первые данные, в локальной памяти, посредством выполнения вышеупомянутых этапов с S211 по S214 так, что может быть улучшена эффективность при сортировке данных.
[0169] S215. Компьютерный узел определяет столбец агрегации.
[0170] После того, как компьютерный узел сохраняет все первые данные в запоминающем носителе информации, если пользователю требуется выполнить операцию агрегации над первыми данными, пользователю требуется указать соответствующий столбец агрегации, т.е., компьютерный узел может определять столбец агрегации, указанный пользователем, где столбец агрегации может быть использован как основа для выполнения операции агрегации над первыми данными.
[0171] Следует отметить, что в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, операция агрегации является операцией поиска по первым данным максимального значения или минимального значения.
[0172] S216. Компьютерный узел сравнивает столбец агрегации с первым в первом столбце сортировки.
[0173] После того, как компьютерный узел определяет столбец сортировки, компьютерный узел может сравнивать столбец агрегации с первым в первом столбце сортировки с тем, чтобы определять, является ли столбец агрегации первым в первом столбце сортировки.
[0174] S217. Компьютерный узел считывает первые данные, хранящиеся в запоминающем носителе информации, в локальную память.
[0175] После того, как компьютерный узел определяет столбец агрегации и перед тем, как операция агрегации выполняется над первыми данными в соответствии со столбцом агрегации, компьютерному узлу требуется считать первые данные, хранящиеся в запоминающем носителе информации, в локальную память с тем, чтобы совершить, в локальной памяти, операцию агрегации над данными.
[0176] После того, как выполняется этап S215, последовательность исполнения этапов S216 и S217 не ограничивается в настоящем изобретении, т.е. в настоящем изобретении, сначала может быть выполнен этап S216, а затем выполняется этап S217; сначала может быть выполнен этап S217, а затем выполняется этап S216; или этапы S216 и S217 могут быть выполнены в одно и тоже время.
[0177] S218. Если столбцом агрегации является первый в первом столбце сортировки, компьютерный узел может выполнять, в локальной памяти, операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки.
[0178] Если столбец агрегации является первым в первом столбце сортировки, компьютерный узел может выполнять, в локальной памяти, операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки.
[0179] Кроме того, способ, в котором компьютерный узел выполняет операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки, может в частности включать в себя:
[0180] (1) Компьютерный узел может определять, в локальной памяти, максимальное значение или минимальное значение в каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки.
[0181] (2) Компьютерный узел может последовательно сравнивать максимальное значение или минимальное значение в каждой странице данных с тем, чтобы определять максимальное значение или минимальное значение в первых данных.
[0182] Кроме того, в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, так как компьютерный узел может хранить, в кластерной форме в запоминающем носителе информации, данные, которые получаются после того, первые данные сортируются по частям, первые данные являются частично и последовательно расположенными в запоминающем носителе информации. Вследствие этого, когда требуется выполнение операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, компьютерный узел может считывать первые данные, хранящиеся в запоминающем носителе информации, в локальную память; и посредством использования вышеупомянутого способа, компьютерный узел сначала определяет, в локальной памяти, максимальное значение или минимальное значение в каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки, а затем компьютерный узел последовательно сравнивает максимальное значение или минимальное значение в каждой странице данных с тем, чтобы определить максимальное значение или минимальное значение в первых данных.
[0183] Следует отметить, что так как первые данные являются частично и последовательно расположенными в запоминающем носителе информации, первые данные, которые считываются компьютерным узлом из запоминающего носителя информации в локальную память также являются частично и последовательно расположенными. Если требуется выполнение операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, компьютерный узел может быстро совершать, в локальной памяти посредством выполнения вышеупомянутых этапов с S215 по S218, операцию агрегации над первыми данными, т.е., компьютерный узел может быстро определять максимальное значение или минимальное значение в первых данных, тем самым улучшая эффективность в агрегации данных.
[0184] Кроме того, в способе кластерного хранения, предоставленном в данном варианте осуществления настоящего изобретения, как показано на Фиг. 4, операция агрегации также может быть выполнена над данными посредством использования индекса, соответствующего первым данным. Индекс, соответствующий первым данным может быть создан в процессе сохранения первых данных в запоминающем носителе информации, или индекс, соответствующий первым данным, может быть создан после того, как первые данные сохраняются в запоминающем носителе информации, что не ограничивается в настоящем изобретении.
[0185] Может быть понятно, что индекс, соответствующий первым данным, может быть использован, чтобы указывать конкретное местоположение хранения первых данных в запоминающем носителе информации. Например, индекс, соответствующий первым данным, может быть использован, чтобы указывать физический блок, страницу данных и строку данных, в которых первые данные в частности хранятся в запоминающем носителе информации.
[0186] В частности, после того, как первые данные сохраняются в запоминающем носителе информации посредством использования способа кластерного хранения, предоставленного в данном варианте осуществления настоящего изобретения, так как первые данные являются частично и последовательно сохраненными, максимальное значение или минимальное значение в каждой странице данных из одной или более страниц данных, может быть непосредственно найдено в запоминающем носителе информации в соответствии со столбцом агрегации и созданным индексом, который соответствует первым данным. Вследствие этого, в сравнении со случаем, в котором данные непоследовательно сохраняются в предшествующем уровне техники, значительно сокращается количество раз выполнения операции агрегации над данными и улучшается эффективность агрегации данных.
[0187] В частности, так как способ для выполнения операции агрегации над данными в соответствии с индексом, соответствующим первым данным, является сходным с тем, что в предшествующем уровне техники, подробности здесь вновь не описываются.
[0188] Может быть понятно, что последовательности исполнения этапов с S207 по S210, с S211 по S214, и с S215 по S218 не ограничиваются в настоящем изобретении, т.е., после того, как первые данные все сохраняются в запоминающем носителе информации, этапы, которые требуется выполнить, могут быть выбраны в соответствии с фактическим требованием операции. Например, в примерах, соответствующих вышеупомянутым операциям, таким как запрос, сортировка и агрегация над первыми данными, если требуется выполнение операции запроса над первыми данными, компьютерный узел может выполнять этапы с S207 по S210; если требуется выполнение операции сортировки над первыми данными, компьютерный узел может выполнять этапы с S211 по S214; и если требуется выполнение операции агрегации над первыми данными, компьютерный узел может выполнять этапы с S215 по S218.
[0189] Кроме того, вышеупомянутые перечисленные разнообразные операции, выполняемые над первыми данными, являются лишь примерными, и после того, как первые данные сохраняются посредством использования способа кластерного хранения, предоставленного в данном варианте осуществления настоящего изобретения, соответствующая операция может быть дополнительно выполнена над первыми данными в соответствии с другим соответствующим требованием, что не ограничивается в настоящем изобретении.
[0190] В качестве примера, как показано в Таблице 6, Таблица 6 показывает фактические данные теста между последовательным хранением, предоставленным в предшествующем уровне техники, и частично последовательным кластерном хранении предоставленном в данном варианте осуществления настоящего изобретения, когда TPCH (стандарт вычислительного теста бизнес-аналитики), применяется для тестирования данных. TPCH реализуется Комитетом по Вопросам Обработки Транзакций и ее Производительности (Transaction Processing Performance Council, TPC), и TPCH может моделировать работу базы данных в системе поддержки принятия решения, чтобы тестировать время ответа на сложный запрос в системе базы данных.
Таблица 6
[0191] Из Таблицы 6 может быть видно, что, время для тестирования данных посредством применения TPCH, когда способ последовательного хранения, предоставленный в предшествующем уровне техники, используется, чтобы хранить данные, является много длиннее, чем время для тестирования данных посредством применения TPCH, когда способ кластерного хранения, предоставленный в данном варианте осуществления настоящего изобретения, используется, чтобы хранить данные. Т.е., посредством использования способа кластерного хранения, предоставленного в данном варианте осуществления настоящего изобретения, чтобы хранить данные, время для тестирования данных посредством применения TPCH может быть сокращено, тем самым улучшая эффективность тестирования у тестирования данных посредством применения TPCH.
[0192] Кроме того, как показано в Таблице 6, в операции запроса данных посредством применения TPCH, в сравнении с последовательным хранением, предоставленным в предшествующем уровне техники, в частичном последовательном кластерном хранении, предоставленном в данном варианте осуществления настоящего изобретения, эффективность запроса у запроса данных посредством применения TPCH заметно улучшается. В частности, показатели улучшения эффективности запроса трех запросов Q6, Q12, и Q15 находятся выше 300%.
[0193] Следует отметить, что способ кластерного хранения, предоставленный в данном варианте осуществления настоящего изобретения, может быть применен в сценарии одной таблицы в системе базы данных, или может быть применен в сценарии, в котором несколько таблиц в системе базы данных служат в качестве объединений (объединение). В частности, способ кластерного хранения, предоставленный в данном варианте осуществления настоящего изобретения, может быть применен в соответствии с фактическим требованием использования, что не ограничивается в настоящем изобретении.
[0194] Посредством использования способа кластерного хранения, предоставленного в данном варианте осуществления настоящего изобретения, первые данные, которые должны быть сохранены, могут быть сохранены в запоминающем носителе информации в системе базы данных после того, как сортируются по частям, и это может гарантировать то, что каждая часть данных, сохраненная в запоминающем носителе информации, является последовательно расположенной. Таким образом, так как данные, которые должны быть сохранены, могут сортироваться и сохраняться по частям с тем, чтобы совершить загрузку данных, можно гарантировать то, что данные, сохраненные в запоминающем носителе информации, являются частично последовательными, так что можно гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
[0195] В соответствии со способом кластерного хранения, предоставленным в данном варианте осуществления настоящего изобретения, первые данные, которые должны быть сохранены, кэшируются построчно в локальную память в системе базы данных; определяется первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память; вторые данные сортируются в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных; и сортированные вторые данные сохраняются в кластерной форме в запоминающем носителе информации в системе базы данных. Посредством использования данного решения, в процессе кэширования первых данных, которые должны быть сохранены, построчно в локальную память, когда объем данных вторых данных, которые были кэшированы в локальную память, превышает объем данных разрешенный для хранения в локальной памяти, начинается сортировка вторых данных в соответствии с определенным первым столбцом сортировки, и сортированные вторые данные сохраняются в запоминающем носителе информации в системе базы данных. Так как данные, которые должны быть сохранены, могут сортироваться и сохраняться по частям с тем, чтобы совершить загрузку данных, можно гарантировать то, что данные в запоминающем носителе информации в системе базы данных являются частично последовательными, так что можно гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
Вариант 3 Осуществления
[0196] Как показано на Фиг. 5, вариант осуществления настоящего изобретения предоставляет устройство 1 кластерного хранения, где устройство применяется в системе базы данных. Устройство 1 кластерного хранения может включать в себя:
блок 10 кэширования, выполненный с возможностью кэширования первых данных, которые должны быть сохранены, построчно в локальную память в системе базы данных;
блок 11 определения, выполненный с возможностью определения первого столбца сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память;
операционный блок 12, выполненный с возможностью, если вторые данные, которые были кэшированы в локальную память посредством блока 10 кэширования, удовлетворяют предварительно установленному условию, сортировки вторых данных в соответствии с первым столбцом сортировки, определенным посредством блока 11 определения, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных; и
блок 13 хранения, выполненный с возможностью сохранения, в кластерной форме в запоминающем носителе информации в системе базы данных, вторых данных, сортированных посредством операционного блока 12.
[0197] Необязательно, предварительно установленное условие используется, чтобы представлять отношение между объемом данных вторых данных, которые были кэшированы в локальную память, и объемом данных, разрешенным для хранения в локальной памяти.
[0198] Необязательно, предварительно установленное условие состоит в том, что количество строк вторых данных больше или равно первой предварительно установленной пороговой величине; и
операционный блок 12 в частности выполнен с возможностью, если количество строк вторых данных, которые были кэшированы посредством блока 10 кэширования в локальную память, больше или равно первой предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0199] Необязательно, предварительно установленное условие состоит в том, что размер, который занимается вторыми данными, локальной памяти больше или равен второй предварительно установленной пороговой величине; и
операционный блок 12 в частности выполнен с возможностью: если размер, который занимается вторыми данными, которые были кэшированы посредством блока 10 кэширования в локальную память, локальной памяти больше или равен второй предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0200] Необязательно, операционный блок 12 в частности выполнен с возможностью сортировки вторых данных в соответствии с числовым значением первого столбца сортировки или хэш-значением числового значения первого столбца сортировки, который определяется посредством блока 11 определения.
[0201] Необязательно, блок 13 хранения в частности выполнен с возможностью сохранения, в кластерной форме в незанятом физическом блоке в запоминающем носителе информации, вторых данных, сортированных посредством операционного блока 12, где незанятый физический блок является физическим блоком за исключением физического блока, занимаемого третьими данными, а третьи данные являются данными, которые были сохранены в кластерной форме в запоминающем носителе информации перед вторыми данными, в первых данных.
[0202] Необязательно, первый столбец сортировки, определенный посредством блока 11 определения, включает в себя, по меньшей мере, одно из следующего: физический столбец и выражение.
[0203] Необязательно, блок 11 определения дополнительно выполнен с возможностью, после того, как блок 13 хранения сохраняет все первые данные в запоминающем носителе информации, определения столбца запроса; и операционный блок 12 дополнительно выполнен с возможностью, если столбец запроса, определенный посредством блока 11 определения, является первым в первом столбце сортировки, выполнения операции запроса над первыми данными в соответствии с первым в первом столбце сортировки.
[0204] Кроме того, блок 10 кэширования дополнительно выполнен с возможностью, после того, как блок 11 определения определяет столбец запроса, и перед тем, как операционный блок 12 выполняет операцию запроса над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации, в локальную память; и
операционный блок 12 в частности выполнен с возможностью выполнения, в локальной памяти в форме двоичного поиска в соответствии с первым в первом столбце сортировки, операции запроса по каждой странице данных из одной или более страниц данных первых данных, кэшированных посредством блока 10 кэширования.
[0205] Необязательно, блок 11 определения дополнительно выполнен с возможностью, после того, как блок 13 хранения сохраняет все первые данные в запоминающем носителе информации, определения второго столбца сортировки; и операционный блок 12 дополнительно выполнен с возможностью, если второй столбец сортировки, определенный посредством блока 11 определения, является первым в первом столбце сортировки, выполнения операции сортировки над первыми данными в соответствии с первым в первом столбце сортировки.
[0206] Кроме того, блок 10 кэширования дополнительно выполнен с возможностью, после того, как блок 11 определения определяет второй столбец сортировки и перед тем, как операционный блок 12 выполняет операцию сортировки над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации, в локальную память; и
операционный блок 12 в частности выполнен с возможностью выполнения, в локальной памяти в соответствии с первым в первом столбце сортировки, сортировки слиянием над первыми данными, кэшированным посредством блока 10 кэширования.
[0207] Необязательно, блок 11 определения дополнительно выполнен с возможностью, после того, как блок 13 хранения сохраняет все первые данные в запоминающем носителе информации, определения столбца агрегации; и операционный блок 12 дополнительно выполнен с возможностью: если столбец агрегации, определенный посредством блока 11 определения, является первым в первом столбце сортировки, выполнения операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, где операция агрегации является операцией поиска по первым данным максимального значения или минимального значения.
[0208] Кроме того, блок 10 кэширования дополнительно выполнен с возможностью, после того, как блок 11 определения определяет столбец агрегации, и перед тем как операционный блок 12 выполняет операцию агрегации над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе информации, в локальную память; и
операционный блок 12 в частности выполнен с возможностью определения, в локальной памяти в соответствии с первым в первом столбце сортировки, максимального значения или минимального значения в каждой странице данных из одной или более страниц данных первых данных, кэшированных посредством блока 10 кэширования, и последовательного сравнения максимального значения или минимального значения в каждой странице данных с тем, чтобы определить максимальное значение или минимальное значение в первых данных.
[0209] Кроме того, как показано на Фиг. 6, устройство 1 кластерного хранения, предоставленное в данном варианте осуществления настоящего изобретения, дополнительно включает в себя блок 14 создания, где
блок 14 создания выполнен с возможность, перед тем, как блок 10 кэширования кэширует первые данные, которые должны быть сохранены, построчно в локальную память в системе базы данных, создания таблицы в запоминающем носителе информации, где таблица используется, чтобы загружать первые данные; и
операционный блок 12 в частности выполнен с возможностью вставки сортированных вторых данных построчно в таблицу, созданную блоком 14 создания, с тем, чтобы сохранить сортированные вторые данные в кластерной форме в запоминающем носителе информации.
[0210] Необязательно, количество первых столбцов сортировки, определенное посредством блока 11 определения, соответствует, по меньшей мере, одному, где когда количество первых столбцов сортировки соответствует, по меньшей мере, двум, по меньшей мере, два первых столбца сортировки включают в себя первичный первый столбец сортировки и, по меньшей мере, один вторичный первый столбец сортировки.
[0211] В соответствии с устройством кластерного хранения, предоставленным в данном варианте осуществления настоящего изобретения, устройство кластерного хранения кэширует первые данные, которые должны быть сохранены, построчно в локальную память в системе базы данных, и определяет первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память; если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, устройство кластерного хранения сортирует вторые данные в соответствии с первым столбцом сортировки, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных; и устройство кластерного хранения сохраняет сортированные вторые данные в кластерной форме в запоминающем носителе информации в системе базы данных. Посредством использования данного решения, в процессе, в котором устройство кластерного хранения кэширует первые данные, которые должны быть сохранены, построчно в локальную память, когда объем данных вторых данных, которые были кэшированы в локальную память, превышает объем данных разрешенный для хранения в локальной памяти, устройство кластерного хранения начинает сортировать вторые данные в соответствии с определенным первым столбцом сортировки, и сохраняет сортированные вторые данные в запоминающем носителе информации в системе базы данных. Так как данные, которые должны быть сохранены, могут сортироваться и сохраняться по частям с тем, чтобы совершить загрузку данных, можно гарантировать то, что данные в запоминающем носителе информации в системе базы данных являются частично последовательными, так что можно гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
Вариант 4 Осуществления
[0212] Как показано на Фиг. 7, вариант осуществления настоящего изобретения предоставляет систему базы данных, где система базы данных может включать в себя объект аппаратного обеспечения и среду программного обеспечения. Объект аппаратного обеспечения может быть компьютерным узлом, а среда программного обеспечения может быть средой базы данных, где компьютерный узел может включать в себя процессор 20, и среда базы данных может включать в себя запоминающий носитель 21 информации нижнего слоя и память 22, где
запоминающий носитель 21 информации нижнего слоя выполнен с возможностью хранения первых данных, которые должны быть сохранены;
память 22 связана с запоминающим носителем 21 информации нижнего слоя, и используется в качестве кэша запоминающего носителя 21 информации нижнего слоя, и должно быть понятно, что один или более блоки данных в запоминающем носителе 21 информации нижнего слоя соотнесены с целевым блоком данных в кэше; и
процессор 20, связан с памятью 22, и процессор 20 исполняет инструкцию в памяти 22 с тем, чтобы:
кэшировать первые данные, которые должны быть сохранены, построчно в память 22; определять первый столбец сортировки; сортировать вторые данные в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в память 22, удовлетворяют предварительно установленному условию; и сохранять сортированные вторые данные в кластерной форме в запоминающем носителе 21 информации нижнего слоя, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в память 22, а вторые данные являются данными, которые были кэшированы в память 22, в первых данных.
[0213] Необязательно, предварительно установленное условие используется, чтобы представлять отношение между объемом данных вторых данных, которые были кэшированы в память 22, и объемом данных, разрешенным для хранения в памяти 22.
[0214] Необязательно, предварительно установленное условие состоит в том, что количество строк вторых данных больше или равно первой предварительно установленной пороговой величине; и
процессор 20 в частности выполнен с возможностью, если количество строк вторых данных, которые были кэшированы в память 22, больше или равно первой предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0215] Необязательно, предварительно установленное условие состоит в том, что размер, который занимается вторыми данными, памяти 22 больше или равен второй предварительно установленной пороговой величине; и
процессор 20 в частности выполнен с возможностью, если размер, который занимается вторыми данными, которые были кэшированы в память 22, памяти 22 больше или равен второй предварительно установленной пороговой величине, сортировки вторых данных в соответствии с первым столбцом сортировки.
[0216] Необязательно, процессор 20 в частности выполнен с возможностью сортировки вторых данных в соответствии с числовым значением первого столбца сортировки или хэш-значением числового значения первого столбца сортировки.
[0217] Необязательно, процессор 20 в частности выполнен с возможностью сохранения вторых данных, в кластерной форме в незанятом физическом блоке в запоминающем носителе 21 информации нижнего слоя, где незанятый физический блок является физическим блоком за исключением физического блока, занимаемого третьими данными, а третьи данные являются данными, которые были сохранены в кластерной форме в запоминающем носителе 21 информации нижнего слоя перед вторыми данными, в первых данных.
[0218] Необязательно, первый столбец сортировки, определенный посредством процессора 20, включает в себя, по меньшей мере, одно из следующего: физический столбец и выражение.
[0219] Необязательно, процессор 20 дополнительно выполнен с возможностью: после того, как все первые данные сохраняются в запоминающем носителе 21 информации нижнего слоя, определения столбца запроса; определения, является ли столбец запроса первым в первом столбце сортировки; и если определяется, что столбец запроса является первым в первом столбце сортировки, выполнения операции запроса над первыми данными в соответствии с первым в первом столбце сортировки, и вывода результата запроса.
[0220] Кроме того, процессор 20 дополнительно выполнен с возможностью, после определения столбца запроса и перед выполнением операции запроса над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе 21 информации нижнего слоя, в память 22; и
процессор 20 в частности выполнен с возможностью выполнения, в памяти 22 в форме двоичного поиска, операции запроса по каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки, и вывода результата запроса.
[0221] Необязательно, процессор 20 дополнительно выполнен с возможностью: после того, как все первые данные сохраняются в запоминающем носителе 21 информации нижнего слоя, определения второго столбца сортировки; определения, является ли второй столбец сортировки первый в первом столбце сортировки; и если определяется, что второй столбец сортировки является первым в первом столбце сортировки, выполнения операции сортировки над первыми данными в соответствии с первым в первом столбце сортировки, и вывода сортированных первых данных.
[0222] Кроме того, процессор 20 дополнительно выполнен с возможностью, после определения второго столбца сортировки и перед выполнением операции сортировки над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе 21 информации нижнего слоя, в память 22; и
процессор 20 в частности выполнен с возможностью: выполнения, в памяти 22, сортировки слиянием над первыми данными в соответствии с первым в первом столбце сортировки, и вывода сортированных первых данных.
[0223] Необязательно, процессор 20 дополнительно выполнен с возможностью: после того, как все первые данные сохраняются в запоминающем носителе 21 информации нижнего слоя, определения столбца агрегации; определения, является ли столбец агрегации первым в первом столбце сортировки; и если определяется, что столбец агрегации является первым в первом столбце сортировки, выполнения операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, и вывода результата выполнения операции агрегации, где операция агрегации является операцией поиска по первым данным максимального значения или минимального значения.
[0224] Кроме того, процессор 20 дополнительно выполнен с возможностью, после определения столбца агрегации и перед выполнением операции агрегации над первыми данными в соответствии с первым в первом столбце сортировки, считывания первых данных, хранящихся в запоминающем носителе 21 информации нижнего слоя, в память 22; и
процессор 20 в частности выполнен с возможностью определения, в памяти 22, максимального значения или минимального значения в каждой странице данных из одной или более страниц данных первых данных в соответствии с первым в первом столбце сортировки; и последовательного сравнения максимального значения или минимального значения в каждой странице данных с тем, чтобы определить максимальное значение или минимальное значение в первых данных; и вывода максимального значения или минимального значения.
[0225] Кроме того, процессор 20 дополнительно выполнен с возможность, перед тем, как первые данные, которые должны быть сохранены, кэшируются построчно в память 22, создания таблицы в запоминающем носителе 21 информации нижнего слоя, где таблица используется, чтобы загружать первые данные; и
процессор 20 в частности выполнен с возможностью вставки сортированных вторых данных построчно в таблицу с тем, чтобы сохранить сортированные вторые данные в кластерной форме в запоминающем носителе 21 информации нижнего слоя.
[0226] Необязательно, количество первых столбцов сортировки, определенное посредством процессора 20, соответствует, по меньшей мере, одному, где когда количество первых столбцов сортировки соответствует, по меньшей мере, двум, по меньшей мере, два первых столбца сортировки включают в себя первичный первый столбец сортировки и, по меньшей мере, один вторичный первый столбец сортировки.
[0227] В данном варианте осуществления настоящего изобретения, компьютерный узел может быть компьютером или любым другим устройством, которое может хранить данные в кластерной форме, что не ограничивается в настоящем изобретении. Т.е., как аппаратура, так и устройство, которое может реализовать способ кластерного хранения, предоставленный в варианте осуществления настоящего изобретения, должны лежать в рамках объема правовой защиты настоящего изобретения.
[0228] В соответствии с системой базы данных, предоставленной в данном варианте осуществления настоящего изобретения, компьютерный узел в системе базы данных кэширует первые данные, которые должны быть сохранены, построчно в память в системе базы данных, и определяет первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в память; если вторые данные, которые были кэшированы в память, удовлетворяют предварительно установленному условию, компьютерный узел сортирует вторые данные в соответствии с первым столбцом сортировки, где вторые данные являются данными, которые были кэшированы в память, в первых данных; и компьютерный узел сохраняет сортированные вторые данные в кластерной форме в запоминающем носителе информации нижнего слоя в системе базы данных. Посредством использования данного решения, в процессе, в котором компьютерный узел кэширует первые данные, которые должны быть сохранены, построчно в память, когда объем данных вторых данных, которые были кэшированы в локальную память, превышает объем данных разрешенный для хранения в памяти, компьютерный узел начинает сортировать вторые данные в соответствии с определенным первым столбцом сортировки, и сохраняет сортированные вторые данные в запоминающем носителе информации нижнего слоя. Так как данные, которые должны быть сохранены, могут сортироваться и сохраняться по частям с тем, чтобы совершить загрузку данных, можно гарантировать то, что данные в запоминающем носителе информации нижнего слоя в системе базы данных являются частично последовательными, так что можно гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
Вариант 5 Осуществления
[0229] Чтобы понять способ кластерного хранения, предоставленный в варианте осуществления настоящего изобретения более четко, нижеследующее использует конкретный пример, чтобы дополнительно описать способ кластерного хранения, предоставленный в варианте осуществления настоящего изобретения. Как показано на Фиг. 8, предполагается, что первые данные, которые должны быть сохранены, составляют 9,000,000 строк данных учащихся, и в частности, каждая строка данных указывает информацию, которая относится к каждому учащемуся, такую как класс, номер учащегося, и имя, которые показаны на Фиг. 9.
[0230] Следует отметить, что, как показано на Фиг. 9, вид A указывает несортированные данные, а вид B указывает данные, которые получаются после сортировки и сохранения посредством использования способа кластерного хранения, предоставленного в варианте осуществления настоящего изобретения.
[0231] В системе базы данных, процесс сортировки первых данных в кластерной форме посредством использования способа кластерного хранения, предоставленного в варианте осуществления настоящего изобретения, в частности является следующим:
[0232] (1) Компьютерный узел кэширует данные учащихся, которые должны быть сохранены, построчно в локальную память в системе базы данных.
[0233] (2) Компьютерный узел определяет, что первым столбцом сортировки является класс и номер учащегося, где первый столбец сортировки используется, чтобы сортировать данные учащихся, которые были кэшированы в локальную память, и столбец сортировки указывается пользователем в соответствии с фактическим требованием.
[0234] (3) Если данные учащихся, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, предоставленному в данном варианте осуществления настоящего изобретения, компьютерный узел сортирует, в соответствии с классом и номером учащегося у учащегося, данные учащихся, которые были кэшированы в локальную память.
[0235] (4) Компьютерный узел сохраняет, в кластерной форме в запоминающем носителе информации в системе базы данных, сортированные данные учащихся в локальной памяти.
[0236] (5) Компьютерный узел циклически выполняет этапы с (1) по (4) до тех пор, пока не будут отсортированы и сохранены по частям в запоминающем носителе информации все данные учащихся, которые должны быть сохранены.
[0237] В качестве примера, на виде A на Фиг. 9, присутствует 12 строк данных учащихся, которые должны быть сохранены, и 12 строк данных учащихся сохранены не последовательно. Когда способ кластерного хранения, предоставленный в варианте осуществления настоящего изобретения, используется чтобы сохранить данные учащихся, компьютерный узел может кэшировать, начиная с первой строки данных учащихся, данные учащихся построчно в локальную память в системе базы данных. Предполагается, что только 6 строк данных учащихся могут быть кэшированы в локальную память каждый раз, и когда компьютерный узел кэшировал 6 строк данных учащихся в локальную память, компьютерный узел может сортировать 6 строк данных учащихся, и сохранять сортированные 6 строк данных учащихся в кластерной форме в запоминающем носителе информации в системе базы данных, как показано на виде B1 на Фиг. 9. После того, как компьютерный узел совершает сохранение 6 строк данных учащихся, компьютерный узел может продолжить кэшировать другие 6 строк данных учащихся построчно в локальную память, сортировать другие 6 строк данных учащихся после того, как совершается кэширование, и сохранять сортированные другие 6 строк данных учащихся в кластерной форме в запоминающем носителе информации, как показано на виде B2 на Фиг. 9. В данном случае, компьютерный узел сохраняет все 12 строк, которые должны быть сохранены, данных учащихся в кластерной форме в запоминающем носителе информации, и 12 строк данных учащихся являются частично и последовательно сохраненными в запоминающем носителе информации, как показано на виде B на Фиг. 9.
[0238] Кроме того, при кэшировании данных учащихся, компьютерный узел может кэшировать данные учащихся в соответствии с размером локальной памяти. В частности, если размер некоторых строк данных учащихся, кэшированных посредством компьютерного узла за раз, относительно большой, количество строк данных учащихся, кэшированное посредством компьютерного узла в этот раз относительно небольшое; и наоборот, если размер некоторых строк данных учащихся, кэшированных посредством компьютерного узла за раз относительно небольшой, количество строк данных учащегося, кэшированное посредством компьютерного узла в этот раз относительно большое. В частности, размер данных учащихся, кэшированных посредством компьютерного узла, может быть определен в соответствии с фактической ситуацией, что не ограничивается в настоящем изобретении.
[0239] В способе кластерного хранения, предоставленном в варианте осуществления настоящего изобретения, компьютерный узел может кэшировать данные, которые должны быть сохранены, построчно в соответствии с возможностью обработки локальной памяти в системе базы данных, и когда часть данных, кэшированных в локальной памяти, находится за пределами возможности обработки локальной памяти, компьютерный узел может начинать сортировать часть данных в соответствии с определенным столбцом сортировки, указанным пользователем, и сохранять сортированную часть данных в запоминающем носителе информации в системе базы данных. Так как компьютерный узел может сортировать данные, которые должны быть сохранены, по частям и сохранять сортированные данные с тем, чтобы совершить загрузку данных, это может гарантировать то, что данные в запоминающем носителе информации являются частично последовательными, так что это может гарантировать то, что эффективность запроса данных и эффективность сжатия данных улучшаются в предположении того, что оказывается незначительное влияние на эффективность загрузки данных и эффективность обновления данных.
[0240] Специалисту в соответствующей области техники может быть четко понятно, что в целях обеспечения удобства и краткости описания, деление вышеупомянутых функциональных модулей используется в качестве примера для иллюстрации. В фактическом приложении, вышеупомянутые функции могут быть распределены другим функциональным модулям и реализованы в соответствии с требованием, т.е., внутренняя структура устройства делится на разные функциональные модули, чтобы реализовать все или некоторые из функций, описанных выше. В отношении подробного рабочего процесса вышеупомянутой системы, устройства, и блока, можно обратиться к соответствующему процессу в вышеупомянутых вариантах осуществления способа, и подробности здесь вновь не описываются.
[0241] В нескольких вариантах осуществления, предоставленных в настоящей заявке, следует понимать, что раскрытая система, устройство, и способ могут быть реализованы другими путями. Например, описанный вариант осуществления устройства является лишь примерным. Например, деление на модули или блоки является лишь логическим функциональным делением и может быть другим делением в фактической реализации. Например, несколько блоков или компонентов могут быть объединены или интегрированы в другую систему, или некоторые признаки могут быть проигнорированы или не выполняться. В дополнение, отображенные или рассмотренные взаимные связывания или непосредственные связывания или соединения связи могут быть реализованы посредством некоторых интерфейсов. Непрямые связывания или соединения связи между устройствами или блоками могут быть реализованы в электронной, механической, или других формах.
[0242] Блоки, описанные в качестве раздельных частей могут быть или могут не быть физически разделены, а части, отображенные в качестве блоков, могут быть или могут не быть физическими блоками, могут быть расположены в одной позиции, или могут быть распределены по нескольким сетевым блокам. Некоторые или все из блоков могут быть выбраны в соответствии с фактическими потребностями для достижения целей решений вариантов осуществления.
[0243] В дополнение, функциональные блоки в вариантах осуществления настоящего изобретения могут быть интегрированы в один блок обработки, или каждый из блоков может существовать отдельно физически, или два или более блока интегрируются в один блок. Интегрированный блок может быть реализован в форме аппаратного обеспечения, или может быть реализован в форме функционального блока программного обеспечения.
[0244] Когда интегрированный блок реализуется в форме функционального блока программного обеспечения или продается или используется в качестве независимого продукта, интегрированный блок может быть сохранен на компьютерно-читаемом запоминающем носителе информации. На основании такого понимания, технические решения настоящего изобретения, по существу, или часть, которая вносит свой вклад в предшествующий уровень техники, или все или некоторые из технических решений могут быть реализованы в форме продукта программного обеспечения. Продукт программного обеспечения хранится на запоминающем носителе информации и включает в себя несколько инструкций для предписания компьютерному устройству (которое может быть персональным компьютером, сервером, или сетевым устройством) или процессору (процессор) выполнения всех или некоторых из этапов способов, описанных в вариантах осуществления настоящего изобретения. Вышеупомянутый запоминающий носитель информации включает в себя: любой носитель информации, который может хранить код программы, такой как USB флэш-накопитель, съемный жесткий диск, постоянная память (ROM, Постоянная Память), память с произвольным доступом (RAM, Память с Произвольным Доступом), магнитный диск, или оптический диск.
[0245] Вышеупомянутые описания являются лишь конкретными вариантами реализации настоящего изобретения, и не предназначены для того, чтобы ограничивать объем правовой защиты настоящего изобретения. Любая вариация или замена легко понятная специалисту в соответствующей области техники в рамках технического объема, раскрытого в настоящем изобретении, должна лежать в рамках объема правовой защиты настоящего изобретения. Вследствие этого, объем правовой защиты настоящего изобретения должен подчиняться объему правовой защиты формулы изобретения.
Реферат
Изобретение относится к средствам кластерного хранения. Технический результат заключается в снижении влияния загрузки и обновления данных на запросы и сжатие данных. В способе сохраняют первые данные, которые должны быть сохранены, построчно в локальную память в системе базы данных; определяют первый столбец сортировки, где первый столбец сортировки используется, чтобы сортировать данные, которые были кэшированы в локальную память; сортируют вторые данные в соответствии с первым столбцом сортировки, если вторые данные, которые были кэшированы в локальную память, удовлетворяют предварительно установленному условию, где вторые данные являются данными, которые были кэшированы в локальную память, в первых данных; и сохраняют сортированные вторые данные в кластерной форме в запоминающем носителе информации в системе базы данных. 2 н. и 28 з.п. ф-лы. 9 ил., 6 табл.
Комментарии