Устройство для перевода фраз из нескольких слов с первого языка на второй - RU2070734C1
Код документа: RU2070734C1
Описание
Настоящее изобретение относится к системе для перевода фраз с первого языка на второй, в частности, но не исключительно к такой системе, которая вырабатывает речевой выход на втором языке из речевого входа на первом языке.
Уже много лет идет поиск машины, которая смогла бы быстро и автоматически осуществлять перевод, в частности устный, с одного языка на другой. Однако даже несмотря на огромные успехи в вычислительной технике, распознавания и синтезации речи за последние годы, такие машины остаются предметом фантастики и мечты.
В области автоматического перевода текста были выполнены интенсивные исследовательские работы с применением вычислительных систем. Помимо очень ограниченных применений (например, перевод прогнозов погоды), не существует систем, способных автоматически осуществлять точные переводы и, следовательно, заменять людей-переводчиков. Проблемы перевода речи усугубляются ошибками в распознавании речи, дополнительной информации, содержащейся в интонации, ударении и т.п. а также неточности самой речи.
К сожалению, существующие пакеты автоматического перевода текстов так или иначе неэффективны и не отвечают требованиям, предъявляемым к системам речевого перевода. Большая часть таких пакетов была разработана в помощь профессиональным переводчикам и результат работы таких пакетов должен быть отредактирован, прежде чем он примет приемлемый вид на том языке, на который осуществлялся перевод. Большинство таких пакетов является диалоговыми или интерактивными и работают в медленном режиме пакетной обработки и ни один из них не способен работать в реальном масштабе времени с речевым переводом. Кроме того, пакеты программ, использующиеся для перевода, неподвижны, поскольку идиомы и другие исключения из правил вполне могут вызвать ошибку на выходе: пользователь не имеет гарантии, что полученный текст переведен правильно. Существующие системы, кроме того, весьма интенсивно используют центральный процессор, что делает их дорогими в эксплуатации и, следовательно, неподходящими для недорогих применений.
Согласно настоящему изобретению предлагается устройство автоматического перевода, в котором устранены указанные недостатки.
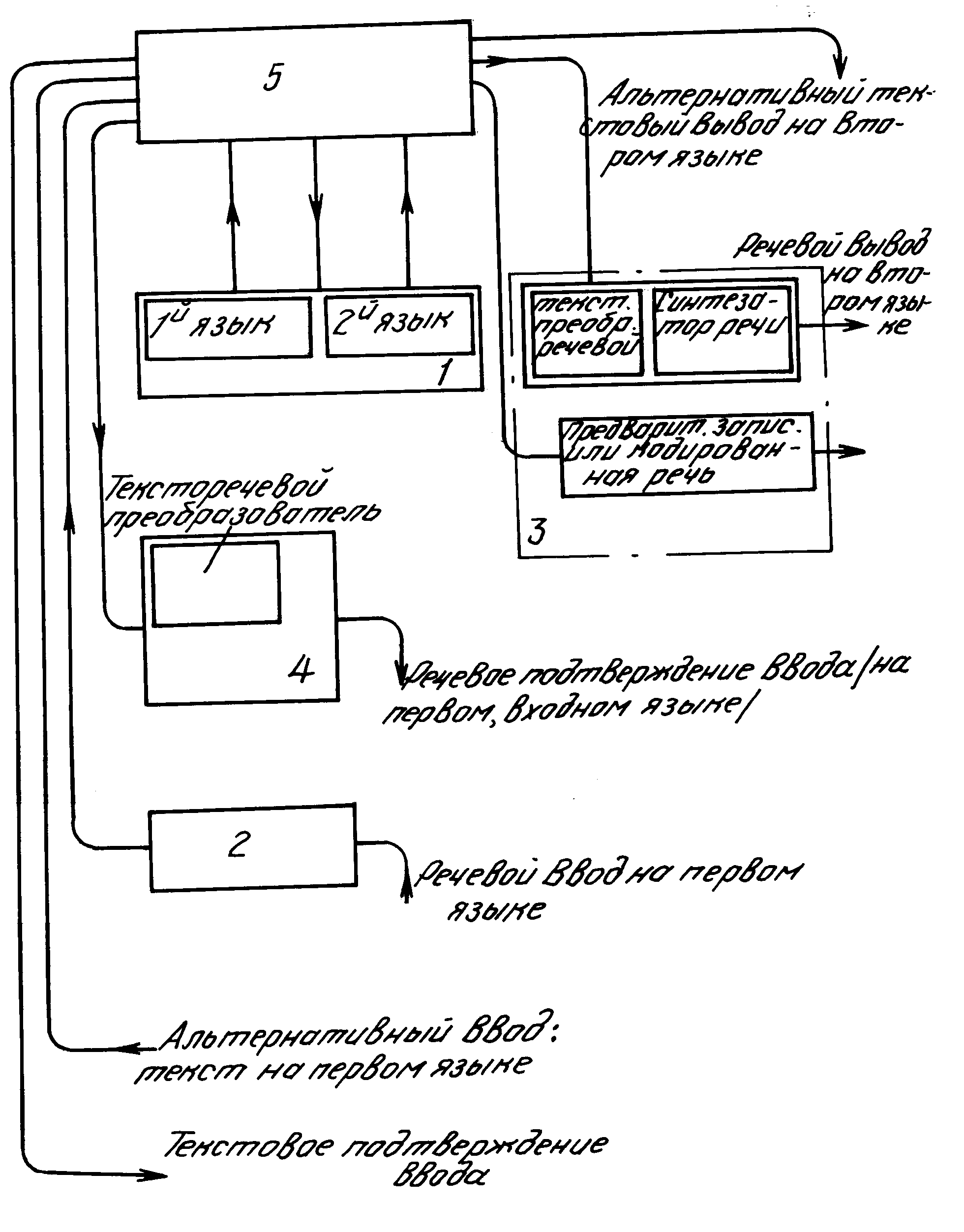
Согласно настоящему изобретению предлагается устройство для перевода фраз с первого языка на второй язык (см. чертеж), содержащее средство запоминания данных 1, в котором содержится набор фраз на втором языке, входное средство 2 для приема фразы на первом языке, выходное средство 3 для вывода на втором языке одной из фраз из указанного набора фраз на втором языке, средство 4 распознавания речи для определения, какая из фраз указанного набора соответствует входной фразе; обрабатывающее средство 5, срабатывающее под воздействием указанного характеризующего средства для управления средством вывода и для обеспечения вывода той же фразы из набора, которая соответствует входной фразе.
Такое устройство обеспечивает очень быстрый перевод. Затрачиваемое время равно времени на идентификацию (характеризацию выходной фразы и на поиск "ответа" на втором языке.
Устройство может быть реализовано так, чтобы давать пользователю, осуществляющему ввод, подтверждение, что он-она распознаны/поняты системой правильно, что особенно важно в системах перевода устной речи.
Когда пользователь получил подтверждение, что его сообщение охарактеризовано правильно, точность перевода обеспечивается, поскольку хранимый набор фраз состоит только из ранее выполненных точных переводов.
Устройство также обеспечивает быстрый перевод на несколько вторых языков; по существу необходимо добавить лишь дополнительные запоминающие устройства, содержащие наборы фраз на каждом из дополнительных вторых языков.
На чертеже, приведена блок-схема принципиальных компонентов устройства по настоящему изобретению.
Изобретение базируется на нашем признании того, что имеется возможность охарактеризовать и уловить семантическое содержание большого числа отдельных фраз с помощью гораздо меньшего числа ключевых слов. Посредством соответствующего отбора ключевых слов можно использовать уже имеющиеся коммерчески доступные устройства распознавания речи, которые способны распознавать значительно меньшее количество слов, чем содержалось бы в достаточно большом наборе фраз, для характеризации и дифференциации большого набора фраз.
Работа устройства автоматизированного перевода в целом опирается на способность таких ключевых слов проводить правильное различие между фразами. Чем больше степень разделения фраз достигается при работе, тем выше толерантность устройства к ошибкам распознавания и к различным несоответствиям, вводимым самим говорящим.
Отбор ключевых слов.
Соответствующая процедура поиска такова:
1. Разместить каждое из К слов в N фразах в соответствии с частотой появления слова во фразах.
2. Отобрать М наиболее часто встречающихся слов в качестве исходного списка ключевых слов, где М число слов словаря средства распознавания речи.
Затем определяется наличие или отсутствие каждого ключевого слова в каждой фразе. Считается число фраз (Е), не определенных ключевыми словами.
4. Пусть i=I.
5. Ключевое слово временно исключается из списка и подсчитывается новая величина Е(Е').
6. Временно исключенному ключевому слову присваивается величина Е-Е', это будет показатель ухудшения работы после обновления ключевого слова и, следовательно, его вклад в общую эффективность системы. Фактически этот показатель используется для того, чтобы каждое ключевое слово вносило свой вклад в сепарацию максимально возможного числа пар фраз, но без дублирования функций других ключевых слов.
7. Временно исключенные ключевые слова восстанавливаются и процесс повторяется для каждого из М ключевых слов.
8. Слово с наименьшим показателем исключается из текущего списка ключевых слов.
9. Для замены исключенного слова используется (М+i)-е наиболее часто встречающееся слово, после чего вычисляется новое значение Е.
10. Если новое значение Е показывает улучшение работы по сравнению с предыдущим значением Е, то коэффициент i увеличивается на единицу и процесс повторяется с шага 5 до тех пор, пока M+i>K, в таком случае процесс завершается.
В противном случае (M+i)-е слово отбрасывается, коэффициент увеличивается на единицу и процесс повторяется с шага 9 до тех пор, пока M+i>K, в таком случае слово, отброшенное в шаге 8, заменяется и процесс завершается.
Окончательный перечень ключевых слов содержит оптимальный набор из М отдельных ключевых слов для идентификации фраз.
Разделению фраз может способствовать дальнейшая итерация, начинающаяся с М наилучших слов, полученных предыдущей итерацией. Для определения последовательности слов-кандидатов можно использовать и другие эвристические методы, помимо частотной сортировки, особенно, если имеется априорная лингвистическая информация. Кроме того, имеется вероятность того, что слова, находящиеся в нижней части частотного списка, не будут играть заметной роли в разделении фраз, поэтому поиск в нижней половине или в нижних двух третях частотного списка может оказаться излишним.
Иногда случается, что большинство фраз различны и значение Е становится очень близким к нулю на довольно ранних этапах поиска. В этих случаях можно рассчитать Е на том основании, что фразы считаются различными только тогда, если различаются более, чем одно ключевое слово. Это приведет к тому, что большинство фраз будут разделены по более, чем минимальному числу ключевых слов, и в некоторой степени обеспечит защиту от ошибок при распознавании речи.
При поиске становится ясным, что несколько классов фраз невозможно разделить, если не расширить словарь ключевых слов. Эти "грозди" или группы фраз имеют тенденцию отличаться друг от друга только одним словом или цепочкой подчиненных слов (например, даты в деловом письме) и представляют собой кандидаты, которые были получены автоматически для подготовки субсловарей ключевых слов (см.ниже).
Очевидно, что распознавание отдельных ключевых слов не принимает в расчет порядок слов и дополнительный смысл, который может в них содержаться. Наличие или отсутствие пар (или других множественных групп) ключевых слов с различным разделением между ними может, следовательно, также быть полезным для повышения эффективности набора одиночных ключевых слов. При распознавании речи это дает то преимущество, что эффективность может быть без расширения словаря распознавания. Если устройство используется для работы с текстами, дополнительные преимущества могут быть получены за счет генерации ключевых слов, чтобы они включали знаки препинания, части слов и комбинации слов и частей слов, например "ать*кровать"(где "*" может быть любым словом) будет присутствовать во фразах "убирать свою кровать" и "продавать эту кровать".
Применение пар ключевых слов повышает ценность отдельных слов-компонентов, если удается разрешить другие противоречия. Поиск пар слов, которые не обязательно смежные, но разделены различным количеством других слов, вновь начинается с частотной сортировки. Пары слов с обеими компонентами в М ключевых словах составляются из отсортированного списка, если они разрешают остающиеся противоречия фразы. Окончательный список единичных ключевых слов и пар ключевых слов оценивается, как и выше, и вычисляется общая оценка противоречия фразы Е.
Теперь начинается поиск
наилучшим образом работающих пар, где одно или оба входящих в пару ключевых слов не входит в текущий список ключевых слов. Кандидаты в следующую пару слов берутся сверху частотно отсортированного
списка и присоединяются к нижней части списка ключевых слов. Отдельные слова пары, которые еще не присутствуют в списке, также присоединяются, и равное количество наименее эффективных отдельных
ключевых слов стирается. Это может привести к стиранию других пар, если входящее в них слово больше не присутствует в списке. Вычисляется новое значение E (E'). Если обнаруживается улучшение и
E' Следует отметить, что некоторые ключевые слова большую роль играют при участии в
нескольких группах слов, чем по отдельности. Этот метод распространяется и на формирование больших групп ключевых слов (содержащих более 2 слов), однако по мере снижения частоты
влияние на разрешения противоречий фраз заметно только в очень большом наборе фраз. Количество вычислений, осуществляемых для поиска ключевых слов, возрастает с ростом числа ключевых
слов и числа фpаз. Их можно уменьшить, во-первых, осуществляя алгоритм на подмножестве фраз, которые противоречивы или близки к тому, чтобы быть противоречивы, ключевые слова и их оценочные
коэффициенты, полученные таким образом, обеспечивают более эффективную сортировку "кандидатов" в ключевые слова для основного алгоритма, который будет работать с более полным набором фраз. При распознавании речи применение некоторых слов, которые не входят в набор ключевых слов, может привести к многочисленным случаям ложного распознавания ключевого слова, например появление
слова "я" может привести к распознаванию его как ключевого слова "для". Однако, если группы противоречивых слов рассматриваются как синонимичные до того, как начинается поиск ключевых слов, при
последующей идентификации фраз фактическая сепарация фраз не будет затронута этой проблемой. Более того, поскольку частота возникновения синонимов будет выше, если они взяты вместе, по сравнению с
отдельными словами, обычно с их обнаружением будет связываться больший объем информации, содержащейся во фразе. Применение ключевых слов можно распространять и на части ключевых слов,
т.е. на фонемы, которые также встречаются с большей частотой и которые несут большую информацию о различии фраз, чем целые слова. Более того, идентификация определенных частей слов в непрерывной речи
часто не столь трудна, как идентификация полных слов, и поэтому предпочтительна в системах перевода, в которых на вход поступает устная речь. В настоящем описании термин "ключевое слово" для кратности
используется для обозначения как целых ключевых слов, так и частей ключевых слов. Фразы различных классов отличаются друг от друга только подчиненными фразами и придаточными
предложениями, которые могут содержать детали, такие как даты, время, цены позиции, наименования или другие группы слов. Может случиться так, что словарь средства распознавания речи будет достаточным,
чтобы отнести фразу к конкретному классу или группе фраз, но в нем будут отсутствовать ключевые слова, позволяющие разделить эти подчиненные структуры. Более того, весьма возможно, что
общий словарь, необходимый для разделения классов фраз и подчиненных структур, будет содержать много слов, которые будут путаться друг с другом. Преимуществом способа по настоящему изобретению
является то, что исходное высказывание (или какая-либо трансформация исходного высказывания) можно ввести в буфер и процесс распознавания можно повторять после того, как будет определен класс фразы.
Таким образом, средство распознавания не должно подменять общий словарь с его многими потенциальными ошибками, связанными с путаницей в словах. Эта задача возлагается на пользователя. Следует отметить,
что скорость второго процесса распознавания не ограничена скоростью исходного высказывания, и в принципе это второе распознавание может проводиться быстрее, чем в "реальном времени", и, следовательно,
не будет вносить заметных задержек. Итерацию распознавания можно осуществлять столько раз, сколько это необходимо для идентификации требуемой фразы и ее подчиненных структур. Таким образом,
оказывается возможным "вкладывать" процесс распознавания, фразу, характеризуемую несколькими раздельными шагами, при этом на каждом шаге привлекаются различные словари ключевых слов.
Многие, если не все, подчиненные цепочки слов в исходном языке будут зависимы от контактов. Это происходит потому, что позиции цепочных слов определяются в этом качестве только, если есть несколько
альтернатив, снижающих для них тесную контекстуальную зависимость. Помимо контекстуальной важности предполагается, что имеются зависимости между словами, которые находятся внутри и вне потенциальной
подчиненной цепочки, и, следовательно, должна быть цель для ключевых слов, заключающаяся в разделении фразы в целом без использования слов внутри цепочки. Это иллюстрируется во фразах, содержащих
меняющиеся даты, где редко меняются слова, за исключением самих дат (дальнейшие исследования должны продемонстрировать справедливость или несправедливость предположения о том, что такая независимость
от контекста в целом инвариантна между языками и может использоваться для бесконечного расширения перевода фраз). Этот конкретный аспект настоящего изобретения имеет также существенные
преимущества при применении в переводе текста, где стоимость вычислительного процесса при поиске в больших словарях может быть резко снижена за счет использования такой иерархии меньших словарей и
разговорников. Некоторые подчиненные фразы не требуют перевода, и часто в таких случаях в целом будет невозможно распознавать автоматически слова в таких фразах. Самый общий случай такой ситуации
возникает в высказываниях, которые содержат отсылки к таким меткам, как имена собственные: "Позовите к телефону г-на Смита, пожалуйста". Как и раньше, устройство может определить класс фразы вместе с
положением слов в буфете, которые соответствуют отсылке к метке. Обработка таких слов, отсылающих к метке во время перевода, представляют собой просто передачу исходного акустического сигнала в
соответствующем месте высказывания на объектном языке. Ясно, что желательно, чтобы синтезированный голос на объектном языке соответствовал голосу говорящего, а для речевых синтезаторов, работающих на
основе входного текста, необходимо, чтобы были заданы определенные параметры речи, чтобы можно было достичь максимально возможного соответствия голоса (молодой, старый, мужской, женский и т.п.). Для того, чтобы пользователь был уверен, что на объектном языке будет выдана правильная фраза, устройство указывает, какая фраза на входном языке будет повторяться. Для обеспечения этой
функции устройство имеет средство 1, в котором содержится полный набор фраз на входном языке. Предпочтительно, в устройстве фразы хранятся в виде текста в коде AS CII, например,
поскольку это снижает потребность в объеме памяти очень существенно по сравнению с обычной сжатой или несжатой речью. Если требуется голосовой вывод, текст выбирается из памяти и передается на
тексто-речевой преобразователь и синтезатор речи. При использовании кода AS CII требуется один байт на знак, поэтому в памяти объемном 0,5 М можно разместить около 10000 фраз. Таким образом,
устройство обеспечивающее перевод около 10000 фраз, требует памяти около 1 мегабайта, что легко осуществимо на жестком диске. Применение двух симметрично сконструированных устройств обеспечивает
осуществление двусторонней связи. Здесь преимущество заключается в том, что каждое устройство распознает и синтезирует слова на языке оператора этого устройства. Связь со вторым устройством
осуществляется по протоколу, который определяет фразы и содержание подчиненных фраз. Протокол независим от языка и, следовательно, позволяет передавать сообщения без необходимости идентификации
объектный язык. Кроме того, это позволяет людям, говорящим на нескольких языках, получать одновременно переводы с выхода единственного устройства. Пример. Демонстрационная система,
подключенная к телефонной сети, эксплуатировалась для демонстрации эффективности подхода типа "разговорник". В демонстрационной системе использовались устройства распознавания речи "Вотан", синтезатор
речи "Инфовокс" и ЭВМ ИБМ РС ХТ. Анализатор речи "Вотан" может распознавать до 64 непрерывно произносимых слов по телефонной сети. Если четыре слова "да", "нет", "конец" и "ввод"
использовать для управления системой, можно в качестве ключевых выбрать до 60 слов. Слова, управляющие системой, не должны появляться во входных фразах, поэтому предпочтительно по возможности
использовать кнопки управления, а не голосовые команды. Память фраз содержит 400 английских фраз и их французские эквиваленты. В английских фpазах содержится около 1100 различных слов.
Такое количество фраз обычно содержится в типичном разговорнике для деловых людей. После того, как была выполнена программа отбора ключевых слов, описанная выше, было выбрано 60 слов, которые успешно
разделяют все фразы. Из 400 фраз только 33 разделяются по одному слову, при этом эти 32 фразы находятся в 16 парах. Демонстрационная система при распознавании ключевого слова находит
соответствующую фразу, устно подтверждает ее и выдает через синтезатор речи ее французский эквивалент. Важно отметить, что тексто-речевой синтезатор не обязателен для настоящего
изобретения. Весьма желательно, например, синтезировать речь на объективном языке из предварительно записанных или кодированных слов и фраз. Здесь преимуществом является то, что такая речь может быть
записана пользователем и акустически может соответствовать любой введенной речи, что устраняет необходимость в тексто-речевом синтезаторе. Этот подход, кроме того, устраняет необходимость в
тексто-речевом синтезаторе на языках важнейших стран, где такая технология вряд ли получит аппаратную реализацию в ближайшее время, например, для языков Хинди и арабского. Помимо
устного перевода, настоящее устройство применимо и к системам письменного перевода, письменно-устного или устно-письменного перевода. Особенно полезным оно будет в области автоматизации конторских
работ, где легко можно реализовать управляемую голосом машину, автоматически выдающую текст на иностранном языке. По существу в такой машине будут использовать анализатор речи, вышеописанную программу
и систему управления, но выдавать текст на втором языке будет на принтер или телекс или другое устройство связи. Нетрудно ввести стандартные фразы рутинной деловой корреспонденции на разных языках.
Реферат
Изобретение относится к системе для перевода фраз с первого языка на второй язык, в частности, но не исключительно, к такой системе, которая вырабатывает речевой выход на втором языке из речевого входа на первом языке. Устройство содержит средство запоминания данных 1, входное средство 2, выходное средство 3, средство 4 распознавания речи, обрабатывающее средство 5. 10 з.п. ф-лы, 1 ил.
Комментарии