Обнаружение языковой неоднозначности в тексте - RU2643438C2
Код документа: RU2643438C2
Чертежи


















Описание
УРОВЕНЬ ТЕХНИКИ
[0001] Зачастую при составлении документации, в частности на двух и более языках, приходится сталкиваться с фразами, имеющими неоднозначность в толковании. В результате этого данные фразы могут быть неверно интерпретированы. Чтобы избежать неоднозначности в настоящее время проверка составленных документов зачастую полностью осуществляется вручную. Помимо этого существуют множество статей и руководств, которые содержат правила и рекомендации о том, как правильно писать и составлять документы, в том числе юридические документы и правовые акты, чтобы избежать неоднозначности в их толковании. Неверное толкование документации может иметь негативные последствия. Данные статьи и руководства обычно содержат формализованный набор правил, которым должен следовать специалист. Одним из лучших способов проверки на наличие неоднозначности в документе является независимая проверка документа несколькими людьми. Однако, в силу ряда причин, даже такая проверка может быть выполнена формально, халатно или непрофессионально. В частности, человек, проверяющий документ, может не обладать достаточными филологическими знаниями для того, чтобы выявить неоднозначные фразы и предложения. Задача окажется еще более трудоемкой для человека, не являющегося носителем языка, поскольку обнаружение неоднозначности требует глубокого знания лексики, синтаксических и морфологических правил, исключений и т.д. В то время как привлечение высококвалифицированных профессионалов - носителей языка, имеющих филологическое образование, может быть довольно затратным мероприятием, которое не всегда может быть доступно для компании или частного лица.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0002] В настоящем описании представлены системы, машиночитаемые носители и способы выявления языковой неоднозначности в тексте. Иллюстрируемый способ включает в себя анализ предложений из первого текста (с использованием одного или нескольких процессоров) с целью: определения синтаксических связей между обобщенными составляющими предложения; построения графа обобщенных составляющих предложения на основе синтаксических связей и лексико-морфологической структуры предложения; анализа графа с целью выявления множества синтаксических структур предложения; присвоения оценки всем синтаксическим структурам, где оценка отображает вероятность того, что данная синтаксическая структура является верной гипотезой, описывающей, полную синтаксическую структуру предложения. Далее способ включает определение семантических структур, соответствующих синтаксическим структурам, и выбор первой семантической структуры из семантических структур и второй семантической структуры из семантических структур, где первая и вторая семантические структуры имеют соответствующие синтаксические структуры, каждая из которых имеет оценки не ниже порогового значения, и где, первая семантическая структура отлична от второй семантической структуры. Далее способ дополнительно включает в себя обнаружение семантической неоднозначности предложения на основе анализа различий между двумя семантическими структурами.
[0003] Приведена иллюстративная система, которая включает в себя анализ предложений из первого текста, с использованием одного или нескольких процессоров, с целью: определения синтаксических связей между обобщенными составляющими предложения; построения графа обобщенных составляющих предложения на основе синтаксических связей и лексико-морфологической структуры предложения; анализа графа с целью выявления множества синтаксических структур предложения; присвоения оценки всем синтаксическим структурам где оценка отображает вероятность того, что синтаксическая структура является правильной гипотезой, описывающей полную синтаксическую структуру предложения. Один или более процессоров дополнительно выполнены с возможностью определения семантических структур, соответствующих синтаксическим структурам, и выбор первой семантической структуры из семантических структур и второй семантической структуры из семантических структур, где первая и вторая семантические структуры имеют соответствующие синтаксические структуры, каждая из которых имеет оценки не ниже порогового значения, и где, первая семантическая структура отлична от второй семантической структуры. Затем один или более процессоров дополнительно выполнены с возможностью обнаружения семантической неоднозначности предложения на основе анализа различий между первой и второй семантическими структурами.
[0004] На приведенном в описании энергонезависимом машиночитаемом носителе информации хранятся команды для анализа предложений из первого текста, с использованием одного или нескольких процессоров, с целью: определения синтаксических связей между обобщенными составляющими предложения; построения графа обобщенных составляющих предложения на основе синтаксических связей и лексико-морфологической структуры предложения; анализа графа с целью выявления множества синтаксических структур предложения; присвоения оценки всем синтаксическим структурам, где оценка отображает вероятность того, что синтаксическая структура является правильной гипотезой, описывающей полную синтаксическую структуру предложения. Далее применяются команды для определения семантических структур, соответствующих синтаксическим структурам, и выбора первой семантической структуры из семантических структур и второй семантической структуры из семантических структур, где первая и вторая семантические структуры имеют соответствующие синтаксические структуры, каждая из которых имеет оценки не ниже порогового значения, и где, первая семантическая структура отлична от второй семантической структуры. Затем используются команды по обнаружению семантической неоднозначности предложения на основе анализа различий между первой и второй семантическими структурами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0005] Вышеуказанные и другие особенности настоящего раскрытия изобретения станут более очевидными из последующего описания и прилагаемой формулы изобретения, рассматриваемых совместно с прилагаемыми чертежами. Представленные иллюстрации показывают лишь несколько вариантов осуществления в соответствии с раскрытием изобретения и, следовательно, не должны рассматриваться как ограничивающие его область. Изобретение будет раскрыто с дополнительной конкретизацией и подробностями посредством прилагаемых чертежей.
[0006] Фиг. 1 иллюстрирует последовательность шагов выполнения глубинного анализа в соответствие с примером осуществления в описании.
[0007] Фиг. 2 иллюстрирует последовательность структур, строящихся в процессе анализа предложения в соответствие с примером осуществления в описании.
[0008] Фиг. 2А иллюстрирует пример лексико-морфологической структуры для предложения на английском языке "The child is smart, he’ll do well in life", в соответствии с примером осуществления в описании.
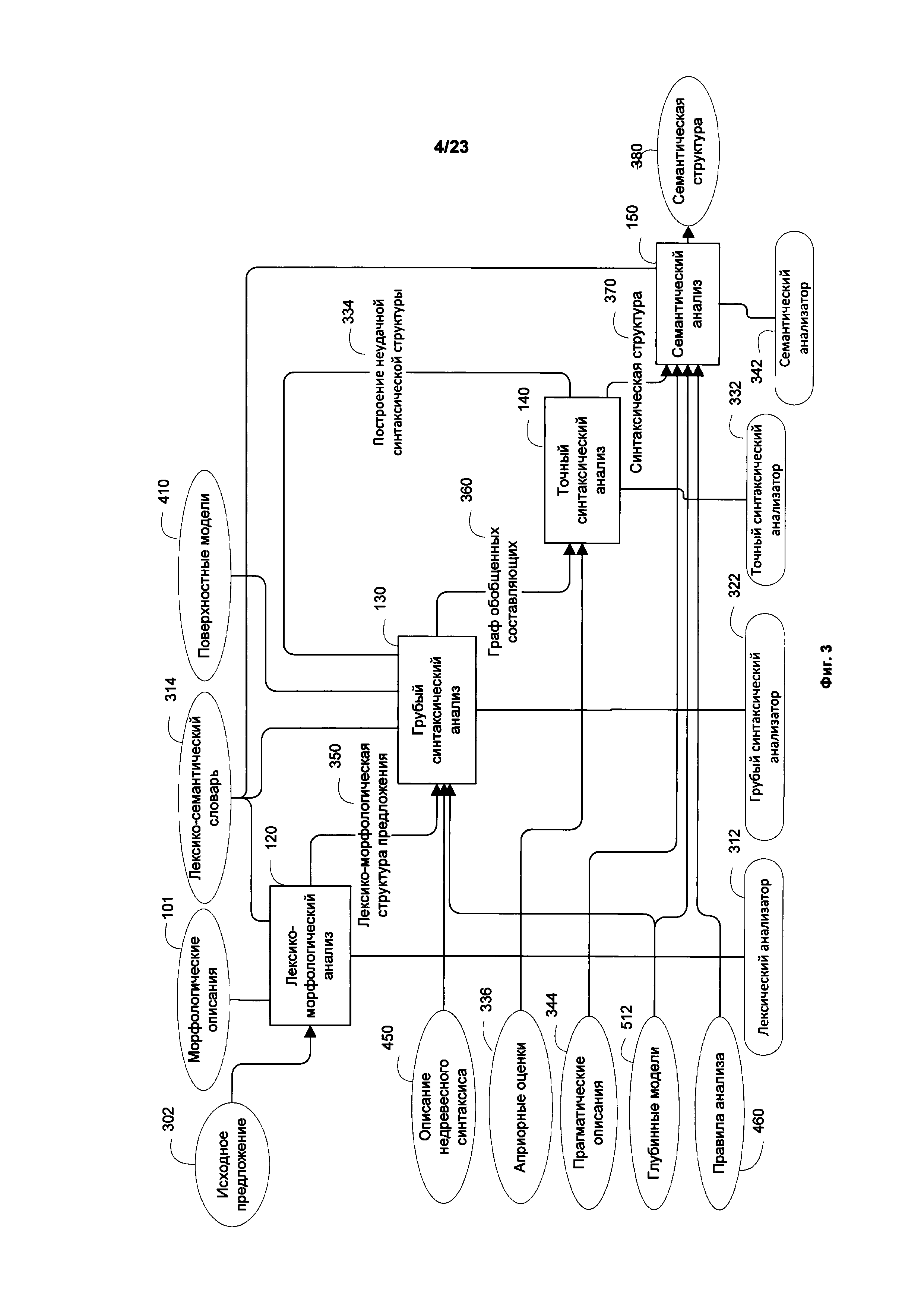
[0009] Фиг. 3 иллюстрирует блок-схему в соответствии с примером осуществления в описании.
[0010] Фиг. 4 иллюстрирует пример блок-схемы семантических описаний в соответствии с примером осуществления в описании.
[0011] Фиг. 5 иллюстрирует блок-схему грубого синтаксического анализа в соответствии с примером осуществления в описании.
[0012] Фиг. 6 иллюстрирует пример графа обобщенных составляющих для предложения "This child is smart, he’ll do well in life", в соответствии с примером осуществления в описании.
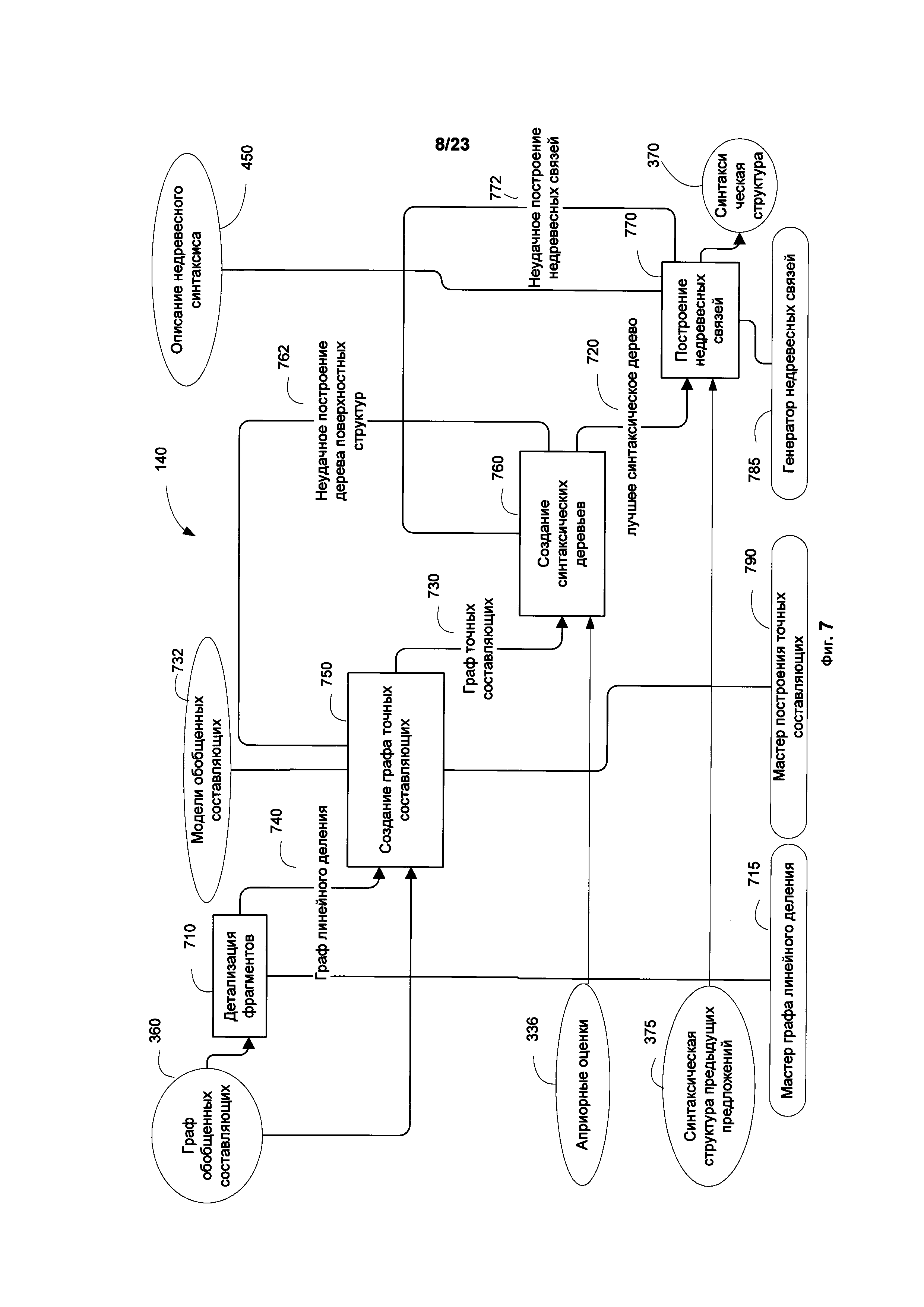
[0013] Фиг. 7 иллюстрирует блок-схему точного синтаксического анализа в соответствии с примером осуществления в описании.
[0014] Фиг. 8 иллюстрирует блок-схему синтаксического дерева в соответствии с примером осуществления в описании.
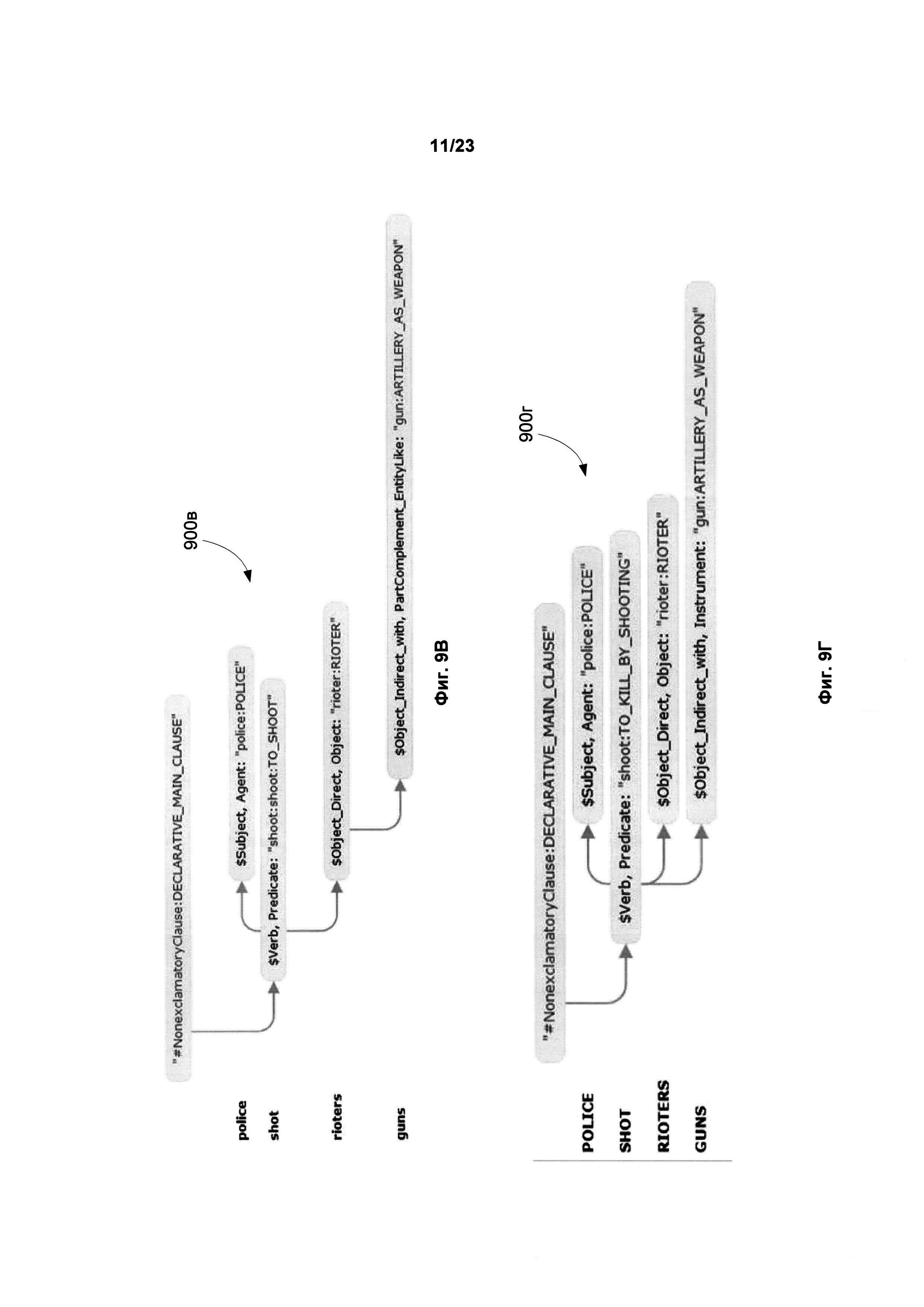
[0015] Фиг. 9А, 9Б, 9В и 9Г иллюстрирует примеры синтаксических и семантических структур для предложения "The police shot rioters with guns" в соответствии с примером осуществления в описании.
[0016] Фиг. 10 иллюстрирует блок-схему языкового описания в соответствии с примером осуществления в описании.
[0017] Фиг. 11 иллюстрирует блок-схему морфологического описания в соответствии с примером осуществления в описании.
[0018] Фиг. 12 иллюстрируетблок-схему семантического описания в соответствии с примером осуществления в описании.
[0019] Фиг. 13 иллюстрируетблок-схему лексического описания, в соответствии с примером осуществления в описании.
[0020] Фиг. 14 иллюстрирует блок-схему последовательности шагов анализа документа на наличие в нем предложений, имеющих несколько толкований в соответствии с примером осуществления в описании.
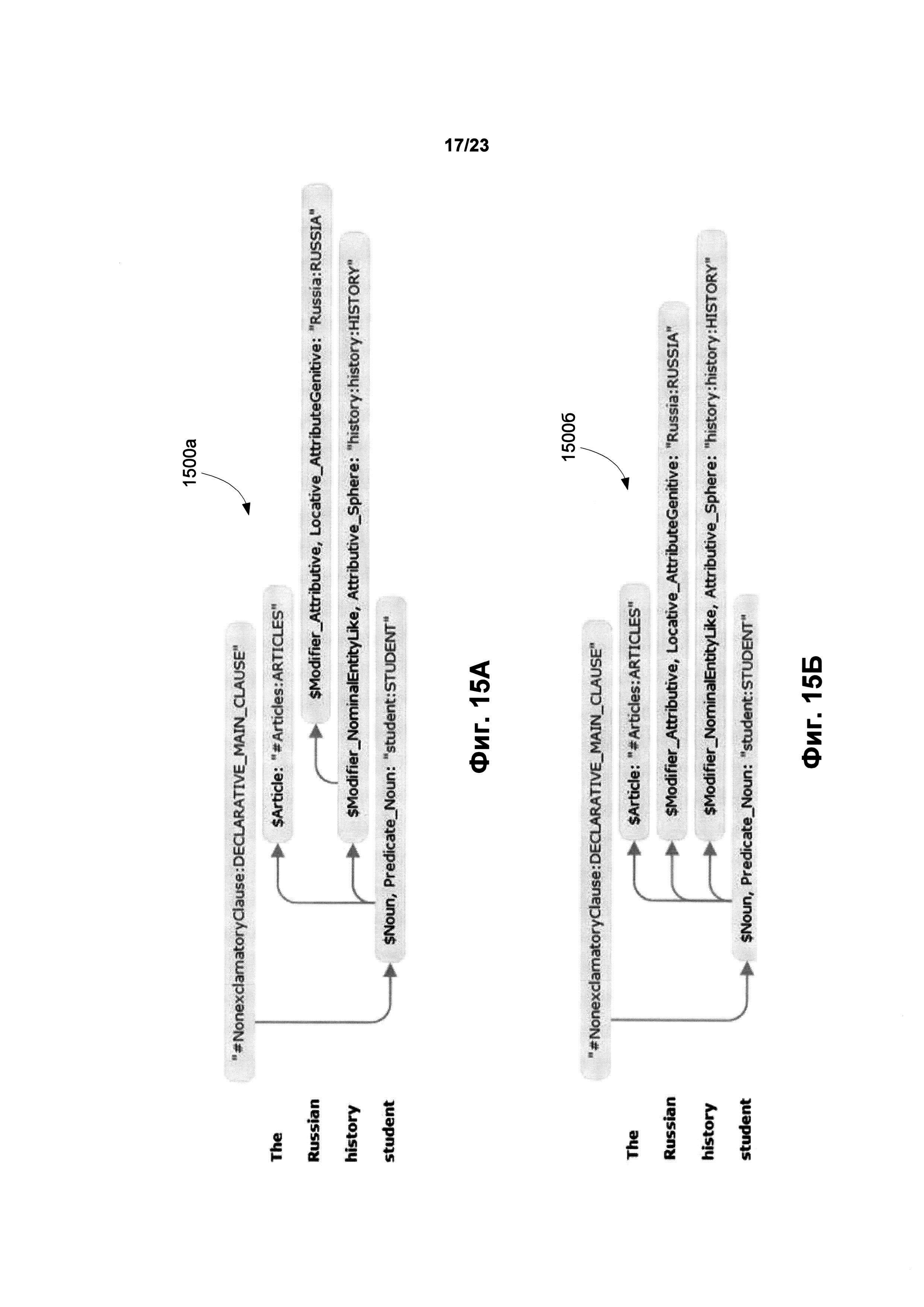
[0021] Фиг. 15А, 15Б, 15В и 15Г иллюстрируют примеры (схемы)синтаксического дерева, полученного в результате точного синтаксического анализа английского словосочетания "The Russian history student" в соответствии с примером осуществления в описании.
[0022] Фиг. 16 иллюстрирует блок-схему для синтеза перевода с использованием универсальной семантической в соответствии с примером осуществления в описании.
[0023] Фиг. 17 иллюстрирует блок-схему последовательности шагов анализа параллельных документов на наличие в них предложений, имеющих несколько толкований в соответствии с примером осуществления в описании.
[0024] Фиг. 18А и 18Б иллюстрируют примеры семантических деревьев, полученных в результате анализа предложения на английском "Chickens are ready for dinner" и предложения на русском "Куры готовы поесть" в соответствии с примером осуществления в описании.
[0025] Фиг. 19 иллюстрирует пример семантического дерева для предложения на русском языке "ПОЧВУ НУЖНО ПОКРЫТЬ УДОБРЕНИЕМ, ПРЕЖДЕ ЧЕМ ОНА ЗАМЕРЗНЕТ" в соответствии с примером осуществления в описании.
[0026] Фиг. 20 иллюстрирует схему аппаратного обеспечения в соответствии с примером осуществления в описании.
[0027] В представленном ниже подробном описании даются ссылки на сопровождающие чертежи. Одинаковые символы на чертежах соответствуют одинаковым компонентам, если не указано иное. Примеры применения, приведенные в подробном описании, чертежах и формулах, не являются единственными возможными. Изобретение может быть применено или изменено другими, не описанными ниже способами, без нарушения области или его сущности. Различные варианты, приведенные в описании изобретения и проиллюстрированные чертежами, могут быть расположены, заменены и сгруппированы в широком выборе различных конфигураций, которые подробно рассмотрены в настоящем описании.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0028] Применение различных описанных способов реализации, связанных с определением смысла предложений в тексте, в том числе, на основе использования семантической иерархии.
[0029] Настоящее изобретение включает в себя системы, машиночитаемые носители и способы обнаружения неоднозначности предложений в тексте. Согласно представленному в настоящем описании способу, пользователь может получить результаты автоматической проверки, Например, результаты данной проверки могут быть представлены в виде визуальных и иных сигналов, указывающих на неоднозначные предложения, для которых построено несколько семантических структур. Пользователь имеет возможность взглянуть на обнаруженную неоднозначность и различные способы интерпретации предложения, имеющего неоднозначность. Помимо этого пользователь может детально рассмотреть семантические структуры, построенные для предложения, содержащего неоднозначность, и вручную проверить результаты работы системы согласно представленному описанию.
[0030] Например, по причине наличия неоднозначности в тексте может возникнуть такая ситуация, что условия в уже подписанном юридическом соглашении могут толковаться участниками соглашения по-разному. Система анализа естественных языков, входящая в настоящее изобретение, может автоматически находить и выделять в документе неоднозначные фразы или утверждения, которые могут трактоваться двумя или более возможными способами. Таким образом, изобретение позволяет устранить риски, связанные с человеческим фактором, которые могут возникнуть при ручной проверке соглашений юристами обеих сторон. Более того, данная система может быть использована в машинном переводе (пользователю могут быть представлены несколько вариантов перевода для предложений, имеющих различные толкования) или для проверки правильности результатов машинного перевода. Более того, данное изобретение также может быть использовано для проверки параллельных текстов (корпусов текстов) на точность их выравнивания. Такая функция особенно полезна при проверке ручного выравнивания параллельных текстов из внешних источников, переводческих баз данных и пр.
[0031] Настоящее изобретение предназначено для выявления и анализа семантической неоднозначности в текстах (корпусе текстов). В основе изобретения лежит принцип синтаксического анализа на базе исчерпывающих лингвистических описаний, описанных в патенте США 8078450. Так как подобный анализ основан на использовании независимых от языка смысловых единиц, данное изобретение также не зависит от языка и позволяет работать с одним или несколькими естественными языками.
[0032] В патенте США 8078450 описан способ, включающий глубинный синтаксический и семантический анализ текстов на естественном языке, основанный на исчерпывающих лингвистических описаниях. Данная технология может быть использована для выявления смысловой неоднозначности текста. Способ использует широкий спектр лингвистических описаний и семантических механизмов, как универсальных, так и относящихся к конкретному языку, что позволяет отразить многообразие реального языка, не прибегая к упрощениям и искусственным ограничениям, а также без угрозы неуправляемого роста сложности. Кроме того, указанные способы анализа основаны на принципах целостного и целенаправленного распознавания. Это означает, что гипотезы о структуре части предложения верифицируются в рамках проверки гипотезы о структуре всего предложения, что позволяет избежать анализа множества аномалий и вариаций.
[0033] Глубинный анализ включает в себя лексико-морфологический, синтаксический и семантический анализ предложений в текстовом корпусе, в результате которых строятся независимые от языка семантические структуры, в которых каждому слову текста сопоставляется соответствующий семантический класс. Фиг. 1 иллюстрирует общую схему способа глубинного анализа. Текст (105) подвергается исчерпывающему семантико-синтаксическому анализу (106) с использованием лингвистических описаний исходного языка и универсальных семантических описаний, что позволяет анализировать не только поверхностную синтаксическую структуру, но и глубинную семантическую структуру, выражающую смысл высказывания, содержащегося в каждом предложении, а также связи между предложениями или фрагментами текста. Лингвистические описания могут включать лексические (101), морфологические (102), синтаксические (103) и семантические описания (104). Анализ (106) представляет собой синтаксический анализ, реализованный в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа) с использованием лингвистических моделей и информации различных уровней для вычисления вероятностей и генерации множества синтаксических структур. Фиг. 2 иллюстрирует последовательность структур, строящихся в процессе анализа предложения. Фиг. 2 и Фиг. 2А описаны более подробно ниже.
[0034] Грубый синтаксический анализ
[0035] Фиг. 3 иллюстрирует блок-схему этапа, обозначенного под номером 106 на Фиг. 1. На этом этапе применяется грубый синтаксический анализатор (322) для выявления всех потенциально возможных синтаксических связей в предложении. В результате создается граф обобщенных составляющих (360) на основе проведенного анализатором (312) лексико-морфологического анализа (120) лексико-морфологической структуры (350) с использованием поверхностных моделей (410), глубинных моделей (512) и лексико-семантического словаря (314). Граф обобщенных составляющих (360) - это ациклический граф, вершины которого представляют собой обобщенные (включающие все возможные варианты) лексические значения слов предложения, а дуги - поверхностные (синтаксические) позиции, выражающие разные типы отношений между соединяемыми лексическими значениями. Для каждого элемента лексико-морфологической структуры предложения, который может представлять собой ядро составляющих, применяются все возможные поверхностные синтаксические модели. Далее все возможные составляющие включаются в граф обобщенных составляющих (232). В результате анализа всех возможных синтаксических описаний и структур для исходного предложения (302) на основе множества обобщенных составляющих строится граф обобщенных составляющих (360). Граф обобщенных составляющих (360) отражает все потенциальные связи между словами исходного предложения (302) с помощью поверхностной модели. Поскольку число вариантов синтаксического разбора может быть велико, граф обобщенных составляющих (360) избыточен, т.е. может содержать множество вариантов - как для выбора лексического значения (вершины), так и для поверхностных позиций (дуги графа).
[0036] Для каждой пары "лексическое значение-грамматическое значение" инициализируется ее поверхностная модель и прикрепляются другие составляющие в поверхностных позициях (415) синтформы (412) ее поверхностной модели (410) к правым и левым соседним составляющим. Синтаксические описания проиллюстрированы на Фиг. 4. Если подходящая синтаксическая форма найдена в поверхностной модели соответствующего лексического значения (410), выбранное лексическое значение может служить ядром новой составляющей.
[0037] Согласно примеру осуществлении, граф обобщенных составляющих (360) вначале строится в виде дерева (другие структуры также могут быть использованы) или другой структуры, начиная от листьев к корням (снизу вверх). Построение дополнительных составляющих может происходить путем снизу вверх путем прикрепления дочерних составляющих к родительским составляющим посредством заполнения поверхностных позиций (415) родительских составляющих для того, чтобы охватить все начальные лексические единицы исходного предложения (302).
[0038] Согласно примеру осуществления в описании, корень дерева является главной частью, представляющей специальную составляющую, соответствующую различным типам максимальных единиц текстового анализа (завершенным предложениям, нумерации, заглавиям, и т.д.). Ядром главной части является обычно предикат (сказуемое). Фактически, дерево превращается в граф, поскольку составляющие более низких уровней (листья) могут быть включены в различные составляющие верхнего уровня (корни).
[0039] Некоторые составляющие, построенные для одних и тех же составляющих лексико-морфологической структуры, могут быть впоследствии обобщены для создания обобщенных составляющих. Составляющие обобщаются на основе лексических (1312, Фиг. 13) и грамматических значений (414), например, на основе частей речи и их связей. Поскольку в предложении существует множество различных синтаксических связей, и одно и то же слово может быть включено в несколько составляющих, составляющие обобщаются при помощи границ (связей). В результате грубого синтаксического анализа (130) строится граф обобщенных составляющих (360), который описывает все предложение целиком.
[0040] Фиг. 5 иллюстрирует процесс грубого синтаксического анализа (130) в соответствии с одной или несколькими реализациями изобретения. Грубый синтаксический анализ (130) обычно включает предварительный сбор составляющих (510), построение обобщенных составляющих (520), фильтрацию (170), построение моделей обобщенных составляющих (540), обработку согласований (550), восстановление эллипсисов (560) и т.д.
[0041] Согласно примеру осуществления в описании, предварительный сбор составляющих (510) на этапе грубого синтаксического анализа (130) выполняется на основе лексико-морфологической структуры (350) анализируемого предложения, включая определенные группы слов, слова в скобках, кавычках, и т.д. Только одно слово в группе (ядро составляющей) может присоединять составляющую или быть присоединенным к составляющей за пределами группы. Предварительный сбор (510) выполняется в начале грубого синтаксического анализа (130) перед построением обобщенных составляющих (520) и моделей обобщенных составляющих (530) для того, чтобы охватить все связи во всем предложении. В процессе грубого синтаксического анализа (130) обрабатывается огромное число составляющих, которые могут быть построены, а также синтаксических связей между ними. Некоторые из поверхностных моделей (410) выбираются, чтобы отсортировать в процессе фильтрации (570) до и после построения составляющих для того, чтобы значительно уменьшить число составляющих, которые необходимо проанализировать. Поэтому на начальном этапе грубого синтаксического анализа (130) используются наиболее подходящие поверхностные модели и синтформы, подобранные на основе априорных оценок. К грубым априорным оценкам относятся оценки лексических значений, оценки заполнителей, оценки семантических описаний и пр. Фильтрация (570) на этапе грубого синтаксического анализа (130) представляет собой фильтрацию множества синтаксических форм (412), которая выполняется до и во время построения обобщенных составляющих (520). Синтформы (412) и поверхностные позиции (415) фильтруются заранее, а составляющие - после того, как они уже построены. Процесс фильтрации (570) позволяет существенно уменьшить число рассматриваемых вариантов разбора. Следует учесть, что исключение маловероятных вариантов значений, поверхностных моделей и синтформ из последующего анализа может привести к потере маловероятного, но, тем не менее, возможного смысла.
[0042] Когда все возможные составляющие построены, выполняется процедура обобщения для построения обобщенных составляющих (520). Все возможные омонимы и значения для элементов исходного предложения, которые могут быть представлены одной и той же частью речи, собираются и обобщаются. Все возможные составляющие, построенные таким образом, группируются в обобщенные составляющие (522).
[0043] Согласно примеру осуществления, обобщенная составляющая (522) описывает все составляющие со всеми возможными связями в исходном предложении, которое имеет словарные формы в качестве основных составляющих, и различные лексические значения этой формы слова.. Далее выполняется построение моделей обобщенных составляющих (530) и строится множество моделей (532) обобщенных составляющих, имеющих обобщенные модели всех обобщенных лексем. Модели обобщенных составляющих лексем содержат обобщенную глубинную и обобщенную поверхностную модель. Обобщенная глубинная модель лексем включает список всех глубинных позиций, которые имеют одинаковое лексическое значение для каждой лексемы, а также описания всех требований для заполнителей глубинных позиций. Обобщенная поверхностная модель содержит информацию о синтформах (412), в которых может содержаться лексема, поверхностных позициях (415), диатезах (417) (связях поверхностных (415) и глубинных позиций (1214)), а также описание линейного порядка (416).
[0044] Диатеза (417) строится на этапе грубого синтаксического анализа (130). Каждая диатеза представляет собой соответствие между обобщенными поверхностными и обобщенными глубинными моделями. Список всех возможных семантических классов для всех диатез лексемы (417) рассчитывается для каждой поверхностной позиции (415).
[0045] На Фиг. 5 показано, как информация из синфторм (412) синтаксического (102) и семантического описания (104) используется для построения моделей обобщенных составляющих (532). Например, зависимые составляющие могут прикрепляться к лексическим значениям (1312). В данном случае грубый синтаксический анализ (130) необходим для того, чтобы установить, может ли возможная составляющая или зависимая составляющая стать заполнителем соответствующей глубинной позиции семантического описания (104) для основной составляющей. Такой сравнительный анализ позволяет отсечь на ранней стадии неверные синтаксические связи.
[0046] Далее выполняется построение графа обобщенных составляющих (540). Граф обобщенных составляющих (360) описывает все возможные синтаксические структуры предложения путем сбора и связи обобщенных составляющих (522) друг с другом.
[0047] Фиг. 6 демонстрирует пример графа обобщенных составляющих (600) для предложения "This child is smart, he’ll do well in life". Составляющие представлены в виде прямоугольников. Ядром каждой из составляющих является лексема. Морфологическая парадигма ядра составляющей (как правило, это часть речи) выражена граммемами частей речи. На схеме парадигма расположена под лексемами и обозначена угловыми скобками. Морфологические парадигмы (части описания слова) могут изменяться. Морфологическое описание содержит всю информацию о словоизменении одной или нескольких частей речи. Например, слово "do" может быть одной из двух частей речи: глаголом (
Помимо этого слово "well" на графе также представлено двумя составляющими. Поскольку в исходном предложении использовано сокращение "he’ll", в графе представлены два возможных значения: "will" и "shall". Задача точного синтаксического анализа состоит в выборе из всех возможных составляющих лишь тех, которые будут образовывать синтаксическую структуру исходного предложения.
[0048] Связи в графе (600) представляют собой заполненные поверхностные позиции ядра составляющей. Название позиции показано на стрелке графа. Составляющая сформирована ядром лексемы, которая может иметь исходящие именованные стрелки, которые обозначают поверхностные позиции (415) заполненные дочерними составляющими совместно с дочерними составляющими как таковыми. Входящая стрелка обозначает прикрепление этой составляющей к поверхностной позиции другой составляющей. Граф (600) имеет множество стрелок (дуг) все возможные связи, которые могут быть установлены между составляющими предложения. Среди них существуют связи, которые будут в дальнейшем отвергнуты. Значение упомянутых ранее грубых способов оценкис Сохраняется для каждой стрелки, обозначающей заполненную глубинную позицию. Как правило, только поверхностные позиции и связи с высоким значением рейтинговых оценок в первую очередь будут выбраны на следующем этапе синтаксического анализа.
[0049] Возможно, что несколько ветвей могут соединять одни и те же пары составляющих. Это означает, что для этой пары составляющих существует несколько подходящих поверхностных моделей, и несколько поверхностных позиций родительских составляющих могут быть независимо заполнены этими дочерними составляющими. Например, три поверхностных позиции - Idiomatic_Adverbial (610), Modifier Adverbial (620) и AdjunctTime (630) родительской составляющей "do
[0050] На Фиг. 5 показано, как обработка согласований (550) также выполняется на графе обобщенных составляющих (360). Согласование - это явление языка, которое представлено в предложениях с числительными и (или) соединительными союзами, такими как [и], [или], [но], и т.д. Простой пример предложения с координацией - "John, Mary and Bill come home". В этом случае только одна из дочерних составляющих прикрепляется к поверхностной позиции родительской составляющей на этапе построения графа обобщенных составляющих (540). Если составляющая, которая может быть родительской, имеет поверхностную позицию, заполненную для согласованной составляющей, для всех согласованных составляющих делается попытка прикрепления дочерних составляющих к родительской, независимо от наличия связи между согласованными составляющими. На этапе обработки согласования (550) определяется линейный порядок, а также возможность множественного заполнения поверхностных позиций. Если возможно, создается и прикрепляется предварительная форма, которая относится к общей дочерней составляющей. На Фиг. 5 показано, как обработчик сгласования (582) или другие алгоритмы могут быть адаптированы для выполнения обработки согласования (550) с использованием описаний (454) при построении графа обобщенных составляющих (540). Алгоритм диспетчера (590) может быть настроен для построения моделей обобщенных составляющих (540).
[0051] Построение графа обобщенных составляющих (540) может быть невозможным без восстановления эллипсиса (560). Эллипсис - это явление языка, выраженное в отсутствии основной составляющей. Процесс восстановление эллипсиса (560) также необходим для восстановления пропущенных составляющих. В английском языке примером эллиптического предложения может быть "The President signed the agreement and the secretary [signed] the protocol". Согласование (550) и восстановление эллипсиса (560) выполняются на этапе каждого цикла программы-диспетчера (590) по окончании построения графа обобщенных составляющих (540), после чего построение может быть продолжено (этот шаг обозначен стрелкой 542). В случае необходимости восстановления эллипсиса (560) и результатов (130) грубого синтаксического анализа (например, несвязанных составляющих), все остальные составляющие обрабатываться не будут. Алгоритм обработки эллипсиса (580) может быть адаптирован для восстановления эллипсиса (560).
[0052] Точный синтаксический анализ
[0053] Точный синтаксический анализ (140) выполняется в целях построения синтаксического дерева исходного предложения, которое представляет собой дерево лучшей синтаксической структуры. Дерево описывает лучшую синтаксическую структуру (370) исходного предложения, выявленную на основе анализа совокупности оценок. Может быть построено множество синтаксических деревьев. В качестве лучшего дерева будет принята наиболее вероятная синтаксическая структура предложения (370). Семантический анализ (150) проводится семантическим анализатором (342) на основе лучшей синтаксической структуры (370). На его основе генерируется семантическая структура исходного предложения (380). Фиг. 3 показывает, что точный синтаксический анализатор (332) или его аналоги предназначены для выполнения точного синтаксического анализа (140) и создания наилучшей синтаксической структуры (370) на основе вычисления оценок с использованием априорных оценок (336) из графа обобщенных составляющих (360). Априорные оценки (336) включают в себя оценки лексических значений (таких как частота или вероятность), оценки синтаксических конструкций (идиомы, словосочетания и т.д.) для каждого элемента в предложении, а также оценки степени согласованности выбранной синтаксической конструкции и семантического описания глубинных позиций (1220). Помимо априорных оценок могут использоваться статистические оценки, полученные в результате обучения анализатора на больших текстовых корпусах. Вычисляются интегральные оценки и сохраняются системой.
[0054] На следующем этапе выдвигаются гипотезы об общей синтаксической структуре предложения. Каждая гипотеза представлена в виде дерева, которое в свою очередь является подграфом графа обобщенных составляющих (360), охватывающего все предложение целиком. После этого вышеуказанные оценки рассчитываются для каждого синтаксического дерева. В ходе выполнения точного синтаксического анализа (140) гипотезы о синтаксической структуре предложения проверяются путем расчета различных типов оценок. Эти оценки высчитываются как степень согласованности заполнителя глубинных позиций составляющей к их грамматическим и семантическим описаниям, таким как грамматические ограничения в синтформах (например, грамматические значения (414)) и семантические ограничения на заполнение глубинных позиций (1214) в глубинной модели (1212). Также используются степени свободы лексических значений (1312) прагматических описаний (344). Они представляет собой абсолютные и (или) условные вероятностные оценки синтаксических конструкций (поверхностных моделей (410)) и степень сочетаемости их лексических значений с остальными составляющими.
[0055] Оценки для каждого вида гипотез могут быть рассчитаны на основе грубых априорных оценок, полученных в результате грубого синтаксического анализа (130). Например, грубая оценка рассчитывается для каждой обобщенной составляющей в графе обобщенных составляющих (360), в результате чего могут быть получены рейтинговые оценки. Для различных оценок могут быть построены синтаксические деревья. Рассчитанные рейтинговые оценки используются при создании гипотез о полной синтаксической структуре предложения. Для этого выбирается гипотеза с наибольшей оценкой. Рейтинг рассчитывается в ходе выполнения точного синтаксического анализа до тех пор, пока не будет получен удовлетворительный результат (построено лучшее синтаксическое дерево с наибольшей оценкой).
[0056] Далее генерируются и выдвигаются гипотезы, которые отражают наиболее вероятную синтаксическую структуру всего предложения. Гипотезы, полученные на основе анализа синтаксической структуры (370), могут иметь более высокий или более низкий рейтинг. Анализ выполняется до тех пор, пока не будет получен удовлетворительный результат или не будет построено лучшее синтаксическое дерево с наибольшей оценкой.
[0057] Лучшее синтаксическое дерево выбирается в качестве гипотезы о синтаксической структуре с наибольшей оценкой, которая отражена в графе (360) обобщенных составляющих. Это синтаксическое дерево считается наилучшей (наиболее вероятной) гипотезой о синтаксической структуре исходного предложения (302). Затем в предложении строятся недревесные связи. После этого синтаксическое дерево трансформируется в граф с наилучшей синтаксической структурой (370), иллюстрирующий наилучшую гипотезу о синтаксической структуре исходного предложения. Если в лучшей синтаксической структуре недревесные связи не могут быть восстановлены, анализ повторяется с использованием следующей в рейтинге структуры.
[0058] Если точный синтаксический анализ выполнен неуспешно или наиболее вероятная гипотеза не может быть найдена после точного синтаксического анализа, происходит возврат (334) от построения неудачной синтаксической структуры на этапе точного синтаксического анализа (140) к этапу проведения грубого синтаксического анализа (130). Причем в процессе повторного анализа рассматриваются все синтформы (а не только лучшие). Если ни одно лучшее синтаксическое дерево не найдено или система не смогла восстановить недревесные связи во всех выбранных "наилучших структурах", проводится дополнительный грубый синтаксический анализ (130), который учитывает "плохие" синтформы, которые не были проанализированы ранее.
[0059] Фиг. 7 подробно иллюстрирует точный синтаксический анализ (140), который выполняется для выбора множества наилучших синтаксических структур (370), в соответствии с рассматриваемыми способами осуществления изобретения. Точный синтаксический анализ (140) проводится от структур более высокого к структурам более низкого уровня ("сверху-вниз"). Например, анализ может вестись от вершины в возможном узле графа обобщенных составляющих (360) к дочерним составляющим более низкого уровня.
[0060] Точный синтаксический анализ (140) может включать различные этапы: первоначальный этап, этап создания графа точных составляющих (750), этап создания синтаксических деревьев и дифференциального выбора наилучшей синтаксической структуры (760), этап восстановления недревесных связей (770), получение лучшей синтаксической структуры и т.д. На этапе предварительного анализа граф обобщенных составляющих (360) анализируется с целью подготовки данных для точного синтаксического анализа (140).
[0061] В процессе точного синтаксического анализа (140) строятся точные составляющие. Обобщенные составляющие (522) используются для построения графа точных составляющих (730), на основе которого затем создаются деревья точных составляющих. Для каждой обобщенной составляющей индексируются и маркируются все возможные связи и их дочерние составляющие.
[0062] Генерация синтаксических деревьев (760) выполняется с целью получения наилучшего синтаксического дерева (720). На этапе восстановления недревесных связей 770 используются правила установления недревесных связей и информация о синтаксической структуре предыдущих предложений (375) для анализа синтаксических деревьев (720) и выбора наилучшей синтаксической структуры (370). Каждая дочерняя обобщенная составляющая может быть включена в одну или несколько родительских составляющих в одном или нескольких фрагментах. Точные составляющие являются узлами графа (730), на основе которых строятся деревья точных составляющих. Если в лучшей синтаксической структуре недревесные связи не могут быть восстановлены (772), анализ повторяется с использованием следующей в рейтинге структуры (этап 706).
[0063] Граф точных составляющих (730) является промежуточным представлением между графом обобщенных составляющих (360) и синтаксическими деревьями. В отличие от синтаксического дерева, граф точных составляющих (730) может иметь несколько альтернативных заполнителей для каждой поверхностной позиции. Точные составляющие выстраиваются в виде графа таким образом, что каждая составляющая может быть включена сразу в несколько родительских составляющих для того, чтобы оптимизировать дальнейший анализ для выбора синтаксического дерева. В результате формируется компактная структура промежуточного графа, достаточно удобная для подсчета структурного рейтинга.
[0064] В ходе рекурсивного этапа создания графа точных составляющих (750), точные составляющие строятся на графе линейного деления (740) с помощью левых и правых связей ядра составляющих. На этапе (750) могут быть проанализированы разные модели обобщенных составляющих (732). Мастер точных составляющих (790) или другие алгоритмы могут быть адаптированы с целью построении графа точных составляющих (750). Для каждой составляющей в графе линейного деления (740) строится путь, определяется множество синтформ, а для каждой из синтформ проверяется и оценивается линейный порядок. В результате для каждой синтформы создается точная составляющая, а построение точных дочерних составляющих запускается рекурсивно.
[0065] По окончании этапа 750 строится граф точных составляющих, охватывающий все предложение. Если этап создания графа точных составляющих 750 завершился неудачно (730) (т.е. не все предложение было покрыто), инициируется процедура с попыткой покрыть предложение с синтаксически отдельными фрагментами (согласно описанному в этапе детализации фрагментов 710). За детализацию фрагментов отвечает графа линейного деления (715) или иной алгоритм.
[0066] На Фиг. 7 показано, что если граф точных составляющих (730), охватывающий все предложение, был построен успешно, одно или более синтаксических деревьев могут быть построены на этапе создания 760 в ходе точного синтаксического анализа 140. На этапе генерации синтаксических деревьев (760) создается одно или несколько деревьев с определенной синтаксической структурой. Так как поверхностная структура фиксирована в заданной составляющей, могут быть сделаны поправки в оценках структурного рейтинга, включая наложенные штрафные синтформы, которые могут быть сложными или не соответствовать стилю, или рейтингу контактного линейного порядка, и т.д..
[0067] Граф точных составляющих (730) включает несколько альтернатив, соответствующих различным фрагментациям предложения и (или) различным наборам поверхностных позиций. Таким образом, граф представляет собой множество возможных деревьев (синтаксических и пр.), поскольку каждая позиция может быть занята несколькими альтернативными заполнителями. Заполнители с наилучшим рейтингом используются в качестве точных составляющих (дерева) с наилучшим рейтингом. Таким образом, точные составляющие представляют собой недвусмысленные (однозначное) синтаксическое дерево с наилучшим рейтингом. На этапе 760 производится поиск альтернатив для построения деревьев с фиксированной синтаксической структурой. Недревесные связи в дереве, созданном на этом этапе, пока еще не установлены - они будут созданы на этапе 770 генератором недревесных связей (785). Результатом данного шага является получение множества синтаксических деревьев (720) с наиболее высокими оценками.
[0068] Синтаксические деревья строятся на основе графа точных составляющих, в порядке убывания их структурных рейтинговых оценок. Лексические рейтинги на данном этапе не могут быть использованы в полной мере, так как их глубинная семантическая структура к этому моменту еще не определена. В отличие от исходных точных составляющих, каждое синтаксическое дерево на выходе имеет фиксированную синтаксическую структуру, и каждая точная составляющая в ней имеет своего собственного заполнителя для каждой поверхностной позиции.
[0069] На этапе 760 лучшее синтаксическое дерево (720) может быть сгенерировано рекурсивно и трансверсально, на основе графа точных составляющих (730). Лучшие синтаксические поддеревья строятся для лучших дочерних точных составляющих; синтаксическая структура строится на основе заданной точной составляющей, а дочерние поддеревья присоединяются к сформированной синтаксической структуре. Лучшее синтаксическое дерево (720) может быть построено, например, путем выбора поверхностной позиции с наилучшей оценкой среди остальных поверхностных позиций данной составляющей, или путем создания копии дочерней составляющей, чье поддерево обладает наилучшим качеством. Это процедура применяется рекурсивно к дочерней точной составляющей.
[0070] На основе каждой точной составляющей может быть сгенерировано множество наилучших синтаксических деревьев с определенной рейтинговой оценкой. Эта рейтинговая оценка может быть рассчитана заранее и задана в точных составляющих. После того как лучшие деревья сгенерированы, новая составляющая создается на основе предыдущей точной составляющей. Эта новая составляющая, в свою очередь, генерирует синтаксические деревья со вторым по порядку рейтингом. Таким образом, на основе точной составляющей может быть получено и построено наилучшее синтаксическое дерево. Например, для каждой точной составляющей на этапе 760 могут быть сформированы два вида рейтинга - рейтинг качества лучшего синтаксического дерева, которое может быть построено на основе этой точной составляющей, и рейтинг качества второго наилучшего дерева. Затем рейтинг синтаксического дерева может быть рассчитан на основе текущей точной составляющей.
[0071] Рейтинг синтаксического дерева вычисляется на основе следующих значений: структурный рейтинг составляющей, максимальный рейтинг для набора лексических значений; статистика максимальной глубины дочерних позиций и рейтинг дочерних составляющих. После того, как точная составляющая проанализирована для подсчета рейтинга синтаксического дерева, который может быть создан на ее основе, дочерние составляющие с наилучшими рейтингами анализируются в поверхностной позиции. Вычисление рейтинга для второго по рейтингу синтаксического дерева отличается только тем, что для одной из дочерних позиций выбирается его вторая по качеству составляющая. Синтаксическое дерево с минимальным отличием в рейтинге относительно лучшего синтаксического дерева должно выбираться на этапе 760.
[0072] На этапе 760 также может быть построено синтаксическое дерево с полностью определенной синтаксической структурой. В такой синтаксической структуре полностью определены синтаксические формы и дочерние составляющие, которые заполняют поверхностные позиции. Синтаксическое дерево (720), созданное на основе наилучшей (наиболее вероятной) гипотезы о синтаксической структуре исходного предложения, считается лучшим деревом. В случае, если синтаксических деревьев с удовлетворяющим рейтингом нет, или точный синтаксический анализ не успешен, система возвращается (762) от создания синтаксических деревьев (720) к построению графа обобщенных составляющих (750).
[0073] Фиг. 8 схематично иллюстрирует синтаксическое дерево, согласно примеру осуществления. На Фиг. 8 составляющие показаны в форме прямоугольников (напр., 810, 820, 822, 824, 830 и 832), а стрелками обозначаются заполненные поверхностные позиции. Ядро составляющей представляет собой слово с его морфологическим значением (M-value) и семантическим классом (Semantic Class). Дочерние составляющие соединяются стрелками, в которых обозначены заполненные поверхностные позиции. Каждая составляющая имеет также синтаксическое значение (S-value), выраженное в форме граммем синтаксических категорий. Граммемами характеризуются синтаксические формы, выбранные для составляющей в ходе выполнения точного синтаксического анализа (140).
[0074] На Фиг. 1 показан этап построения независимой от языка семантической структуры (107), передающей смысл исходного предложения. Этот этап может включать также восстановление референциальных связей между предложениями. Одним из примеров референциальной связи является анафора - языковая конструкция, которая может быть интерпретирована лишь с учетом другого, как правило, предшествующего, фрагмента текста.
[0075] Фиг. 2 иллюстрирует блок-схему способа анализа предложения, согласно описываемому способу реализации изобретения. На Фиг. 1 и Фиг. 2 показано, как лексико-морфологическая структура (222) определяется на этапе анализа (106) исходного предложения (105). Фиг. 2А иллюстрирует пример лексико-морфологической структуры для предложения на английском языке "The child is smart, he’ll do well in life". Лексико-морфологическая структура здесь представляет собой структуру данных, хранящую множество возможных вариантов пар "лексическое/грамматическое значение" для каждой лексической единицы (слова) в предложении. Каждому из слов могут быть присущи несколько значений, а, следовательно, несколько вариантов лексико-грамматических пар. Например, "11" (2207) может означать "shall" (2112) и "will" (2114). Поэтому на схеме указаны оба этих варианта. Слово "shall" может образовывать следующие виды лексико-грамматических пар:
[0076] Как было упомянуто выше, грубый синтаксический анализ применяется к исходному предложению и включает, в частности, генерацию всех потенциально возможных лексических значений слов, образующих предложение или словосочетание, всех потенциально возможных отношений между ними и всех потенциально возможных составляющих. Применяются все вероятные поверхностные синтаксические модели для каждого элемента лексико-морфологической структуры. Затем строятся и обобщаются все возможные составляющие так, чтобы были представлены все возможные варианты синтаксического разбора предложения. В результате формируется граф обобщенных составляющих (232) для последующего точного синтаксического анализа. Граф обобщенных составляющих (232) включает в себя все потенциально возможные связи в предложении. За грубым синтаксическим анализом следует точный синтаксический анализ на графе обобщенных составляющих, в результате которого из него "извлекаются" множество синтаксических деревьев (242), описывающих структуру исходного предложения. Построение синтаксического дерева (242) включает в себя лексический выбор для вершин графа и выбор отношений между ними. Из графа может быть выбрано множество априорных и статистических оценок лексических вариантов и отношений. Априорные и статистические оценки могут быть использованы как для анализа отдельных частей графа, так и для всего дерева. На данном этапе также проверяются и строятся недревесные связи. Далее из полученного множества синтаксических (или семантических) деревьев выбираются только деревья с высокой интегральной оценкой и непохожей синтаксической (или семантической структурой). Например, на основе лучших синтаксических структур могут быть созданы лучшие/наиболее вероятные синтаксические структуры (246) и универсальная, независимая от языка, семантическая структура (252). Ниже описан один из возможных способов оценки сходства/различия структур.
[0077] В описанном способе реализации изобретения сходство между i-ой и j-ой семантическими структурами может быть измерено, как

[0078] В описанном способе реализации изобретения различие между i-ой и j-ой семантическими структурами может быть измерено, как
[0079]

[0080] Вектор переменных (x1i, …, xni) используется для i-ой семантической структуры, а вектор переменных (x1j, …, xnj) - для j-й семантической структуры. Координаты векторов представляют собой значения параметров, используемых для описания данной семантической структуры. Например, могут быть использованы такие переменные как SemClassi,.deepSlotsi, non - treeLinks, α, β, γ и т.д., где SemClass - семантические классы семантической структуры; deepSlots - глубинные позиции, присвоенные составляющим в семантической структуре; non - treeLinks - недревесные связи, восстановленные в семантической структуре; α, β, γ - значения весов, присваиваемые для перемененных в данном уравнении. Для описываемого примера осуществления для предложения может быть рассчитана функция, определяющая меру близости (или расстояние) ρ(Cki, Clj) между семантическими классом Ck в i-й и классом Clj в j-й семантических структурах, где C(Structurei)=(C-1i, …, Cki, …, Cni) является набором семантических классов для i-й семантической структуры, a (C(Structurej)=C1j, …, Clj, …, Cmj.) - набором семантических классов для j-й семантической структуры. Число семантических классов n в j-й семантической структуре может не быть равным числу семантических классов m в j-й семантической структуре.
[0081] Например, сходство между структурами Structurei и Structurej может быть посчитано с помощью следующей формулы:

[0082] где |C(Structurei)| - мощность множества Structurei (т.е. число классов в i-ой структуре), |С(Structurei)| - мощность множества Structurej (т.е. число классов в j-ой структуре), а в качестве g выступает математическая функция. Вышеприведенная формула может использоваться для измерения сходства как между семантическими, так и между синтаксическими структурами.
[0083] Помимо этого, разность между структурами может быть посчитана по формуле:

[0084] Фиг. 9А и 9Б иллюстрируют примеры синтаксических структур (деревьев) 900а и 900б, полученных в результате точного синтаксического анализа английского предложения "THE POLICE SHOT THE RIOTERS WITH GUNS". В результате проведенного анализа были выделены две наиболее вероятные синтаксические структуры. Структуры 900а и 900б содержат такие данные об определенной синтаксической информации, как лексические значения, части речи, синтаксические роли, грамматические значения, синтаксические отношения (позиции), синтаксические модели, типы недревесных связей и т.д. В виду того, что исходное предложение содержит неоднозначность (существительное "gun" может зависеть либо от существительного "rioters" либо от глагола "shot"), синтаксические структуры 900а 900б различаются как структурой, так и своими поверхностными/глубинными позициями. Например, существует различие в подчиненности слова "gun". Характер подчиненности проиллюстрирован на схеме стрелками 901 и 903. Содержание глубинных позиций 902 и 904 для лексического значения "gun: ARTILLERY_AS_WEAPON" также различается. В глубинной позиции 903 это "PartComplement_EntityLike", а в позиции 904 - "Instrument". В других примерах возможны различия, обусловленные выбором лексических значений и семантических классов, которые проявляют себя особенно заметно в случаях омонимии и омографии.
[0085] Подход двухэтапного анализа базируется на принципе целостного и целенаправленного распознавания. Это означает, что гипотезы о структуре части предложения верифицируются через существующие лингвистические модели в рамках целого предложения. При таком подходе отпадает необходимость в анализе множество тупиковых вариантов разбора. В большинстве случаях такой подход позволяет существенно снизить нагрузку на вычислительные ресурсы, необходимые для анализа предложения.
[0086] Фиг. 9В и 9Г иллюстрируют схему семантических структур 900в и 900г, полученной в результате анализа предложения "THE POLICE SHOT THE RIOTERS WITH GUNS". Эта структура не зависит от языка исходного предложения и содержит всю информацию для установления передаваемого смысла. Структуры данных 900в и 900г содержат информацию о семантических классах, семантемах (не показаны на рисунке), семантических отношениях (глубинных позициях), недревесных связях и другие данные, достаточные для восстановления смысла исходного предложения на любом языке.
[0087] Независимая от языка семантическая структура предложения представляет собой ациклический граф (дерево, дополненное недревесными связями), где каждое слово определенного языка заменено универсальными (независимыми от языка) семантическими сущностями, называемыми также семантическими классами. Организация семантических классов в семантическую иерархию имеет практический смысл для данного осуществления изобретения. Семантическая иерархия организована в форме иерархии семантических классов, где каждый "дочерний" семантический класс и его "потомки" наследуют значительную часть свойств родительского и всех предшествующих семантических классов ("предков"). Например, семантический класс SUBSTANCE (вещество) является дочерним классом достаточно широкого класса ENTITY (сущность), и в то же время он является "родителем" для семантических классов GAS (газ), LIQUID (жидкость), METAL (металл), WOOD_MATERIAL (дерево как материал), и т.д. Каждый семантический класс в семантической иерархии привязан к глубинной семантической модели. Глубинная модель представляет собой множество глубинных позиций (напр., типов семантических отношений в предложениях). Глубинные позиции отражают семантические роли дочерних составляющих (структурных единиц предложения) в различных предложениях с объектами определенного семантического класса в качестве ядра родительской составляющей, а также возможные семантические классы для заполнения позиций. Эти глубинные позиции выражают семантические отношения между составляющими, такими как "agent" (агент), "addressee" (адресат), "instrument" (инструмент), "quantity" (количество) и т.д. Дочерний класс наследует и подстраивает глубинную модель родительского класса.
[0088] Семантическая иерархия устроена таким образом, что более общие понятия находятся на верхних уровнях иерархии. Например, в отношении документов могут применяться следующие семантические классы: PRINTED_MATTER (печатное издание), SCIENTIFIC_AND_LITERARY_WORK (научные труды и литература), TEXT_AS_PART_OF_CREATIVE_WORK (творческие тексты). Эти классы могут быть потомками класса TEXT_OBJECTS_AND_DOCUMENTS (текстовые объекты и документы). Класс PRINTED_MATTER (печатное издание) в свою очередь является родительским для семантического класса EDITION_AS_TEXT (издание как текст), содержащего классы PERIODICAL (периодические издания) и NONPERIODICAL (непериодические издания), где PERIODICAL (периодические издания) - родительский класс для классов ISSUE (выпуск), MAGAZINE (журнал), NEWSPAPER (газета) и т.д. Подход к делению на классы может отличаться. Отметим, что в основе описываемого изобретения лежат понятия, не зависящие от конкретного языка.
[0089] Фиг. 10 представляет собой схему, иллюстрирующую взаимосвязь языковых описаний (1010), согласно описываемой реализации изобретения. Лингвистические описания (1010) - это лексические (101), морфологические (102), синтаксические (103) и семантические описания (104). Все лингвистические описания (1010) объединены в общее понятие. На Фиг. 11 представлена схема, подробно иллюстрирующая морфологические описания (102). На Фиг. 4 подробно проиллюстрированы синтаксические описания (103). На Фиг. 13 представлена схема, подробно иллюстрирующая лексические описания (101). На Фиг. 12 представлена схема, подробно иллюстрирующая семантические описания (104).
[0090] Семантическая иерархия может быть создана единовременно, а затем заполнена для каждого определенного языка. Семантический класс в каждом отдельном языке включает лексические значения с соответствующими моделями. Семантические описания (104) не зависят от языка. Семантические описания (104) могут содержать описания глубинных составляющих, а также содержать семантическую иерархию, описания глубинных позиций, систему семантем и прагматических описаний.
[0091] В описываемом варианте осуществления морфологические (101), лексические (103), синтаксические (102) и семантические описания (104) связаны между собой, как показано на Фиг. 10. Лексическое значение может иметь несколько поверхностных (синтаксических) моделей, обусловленных семантемами и прагматическими характеристиками. Синтаксические описания (102) и семантические описания (104) также связаны между собой. Например, диатеза синтаксических описаний (102) может рассматриваться как "интерфейс" между зависимыми от языка поверхностными моделями и независимыми от языка глубинными моделями семантического описания (104).
[0092] Фиг.4 дает пример синтаксического описания (102). В состав синтаксического описания (102) могут включаться поверхностные модели (410), синтаксические формы (412), поверхностные позиции (415), описания линейного порядка (416), диатезы (417), грамматические значения (414), описания управления и согласования (440), коммуникативные описания (480), правила анализа (460), правила вычисления семантем (462), правила нормализации (464), описания поверхностных позиций (420), описания недревесного синтаксиса (450), описания эллипсиса (452), описания сочинения (454) и описания референциального и структурного управления (456). Синтаксические описания (102) используются для построения возможных синтаксических структур предложения на исходном языке, с учетом порядка слов, недревесного синтаксиса (согласования, эллипсис и пр.), референциального управления и прочих явлений.
[0093] Фиг. 11 дает пример морфологического описания (101), согласно примеру осуществления изобретения. Составляющими морфологических описаний (101) могут быть описания словоизменений (1110), грамматических систем (1120) и словообразований (1130). В описываемом осуществлении грамматическая система (1120) включает в себя такие грамматические категории, как "Часть речи", "Падеж", "Род", "Число", "Лицо", "Возвратность", "Время", "Вид", а также их значения. Подобные категории называются граммемами.
[0094] Фиг. 12 дает пример семантического описания (104), согласно примеру осуществления изобретения. В то время как поверхностные позиции (420) отражают синтаксические отношения и способы их реализации в конкретном языке, глубинные позиции (1214) - семантические роли дочерних (зависимых) составляющих в глубинных моделях (1212) семантической иерархии (1210). Следовательно, описания поверхностных позиций (и поверхностных моделей в целом) будут уникальны для каждого конкретного языка. Описания глубинных моделей (1220) содержат грамматические и семантические ограничения для заполнителей глубинных позиций. Свойства и ограничения глубинных позиций (1214), а также их заполнители в глубинных моделях (1212), зачастую похожи и даже идентичны для различных языков.
[0095] Система семантем (1230) представляет собой множество семантических категорий. Семантемы могут отражать лексические (1234) и грамматические (1232) категории или атрибуты, а также дифференциальные свойства и стилистические, прагматические и коммуникативные характеристики. Например, семантическая категория "DegreeOfComparison" (степень сравнения) может быть использована для описания степеней сравнения, выраженных разными формами прилагательных, например, "easy", "easier" and "easiest". Поэтому категории могут быть присущи такие семантемы, как "Positive", "ComparativeHigherDegree" и "SuperlativeHighestDegree". Лексические семантемы (1234) описывают специфические свойства объектов, такие как "быть плоским" (being flat) или "быть жидким" (being liquid), которые выступают в роли ограничений для заполнителей глубинных позиций. Классификация грамматических (дифференциальных) семантем (1236) используется для выражения дифференциальных свойств внутри одного семантического класса. Прагматические описания (1240) служат для того, чтобы в процессе анализа текста фиксировать его тему, стиль или жанр, а также присваивать соответствующие характеристики объектам семантической иерархии. Прагматические описания (1240) могут служить, например, для описания таких тем, как экономическая политика, внешняя политика, правосудие, законодательство, торговля, финансы и т.п.
[0096] Фиг. 13 дает схему, иллюстрирующую лексические описания (103), согласно описываемой реализации изобретения. Лексические описания (103) включают в себя лексико-семантический словарь (1304), состоящий из ряда лексических значений (1312), образующих вместе со своими семантическими классами семантическую иерархию, где каждое лексическое значение (1312) связано с независимой от языка семантической категорией (или "местом" в семантической иерархии - 1302), глубинной моделью (1212), поверхностной моделью (410), а также грамматическим (1308) и семантическим значением (1310). Лексическое значение может объединять различные дериваты (например, слова, выражения, фразы), выражающие смысл с помощью различных частей речи, форм слова, однокоренных слов и пр. В свою очередь, семантический класс объединяет лексические значения близких по смыслу слов и выражений на разных языках.
[0097] В процессе анализа текста системе приходится решать задачу выявления неоднозначности в тексте.
[0098] Под неоднозначностью понимается выявление нескольких различных высоковероятных структур на одном из этапов глубинного анализа текста. Под высоковероятной понимается структура, обладающая высокой интегральной оценкой. Помимо этого могут быть использованы любые другие критерии определения высоковероятной структуры.
[0099] Пошаговая реализация алгоритма глубинного анализа, основанного на использовании семантической иерархии (СИ), представлена в настоящем описании. Тип неоднозначности определяется на этапе ее обнаружения. Например, под синтаксической неоднозначностью может пониматься возникновение нескольких вероятных синтаксических структур на этапе синтаксического анализа. Аналогичным образом, под семантической неоднозначностью может пониматься возникновение нескольких вероятных семантических структур на этапе семантического анализа.
[00100] За вероятную принимается та структура, которая обладает высокой интегральной оценкой, полученной на основе множество априорных и статистических оценок. Априорные и статистические оценки могут быть использованы как для анализа отдельных частей графа на разных этапах, так и для всего дерева. В описываемой реализации изобретения на этапе синтаксического анализа строится множество структур (например, синтаксических деревьев). Из множества синтаксических структур выбираются лучшие.
[00101] Может случиться так, что дерево, имеющее меньшую интегральную оценку, также может корректно отражать структуру анализируемого предложения. Тем не менее, оно может быть исключено из дальнейшего анализа как менее вероятное, ввиду различных способов вычисления статистических оценок, может обладать меньшей интегральной оценкой или иных причин. Такая возможность учитывается в рамках представленного способа выявления неоднозначности в текстах на естественном языке. Поэтому на различных этапах глубинного анализа текста извлекаются отличающиеся структуры, обладающие высокими интегральными оценками.
[00102] Например, на этапе построения синтаксических и семантических структур для каждой соответствующей структуры в тексте вычисляются интегральные оценки. Выявление нескольких различных синтаксических (семантических) структур с наибольшей интегральной оценкой будет означать синтаксическую (семантическую) неоднозначность текста. Значение Δ, отражающее допустимую разницу между интегральными оценками структур, может быть установлено заранее, и на основании него можно различать отдельные структуры. Условно этот правило может быть записано в виде неравенства:

[00103] Si - интегральная оценка i-й семантической структуры, Sj - интегральная оценка j-й семантической структуры, Δ - некоторое заранее установленное (или подобранное) значение, в пределах которого могут отличаться оценки семантических структур, чтобы считаться наиболее вероятными и быть отобранными из исходного множества структур.
[00104] Помимо числового значения, отображающего оценку структуры (синтаксической или семантической), могут быть введены другие правила, согласно которым определяется, насколько должны быть различны семантические структуры, чтобы считаться разными. Предложение, в котором есть неоднозначность, может быть визуально выделено в тексте.
[00105] Согласно описываемому варианту осуществления изобретения, неоднозначность может быть обнаружена на основе анализа содержимого документа. Допустим, что документ представляет собой юридический или иной правовой акт, составленный на естественном языке. Однако текст в документе может не ограничиваться одним единственным языком, документ может включать блоки текста на различных языках. В результате глубинного анализа всех предложений в тексте документа система визуально отображает пользователю слова, словосочетания, предложения или абзацы, в которых зафиксирована неоднозначность. Выявление неоднозначности поможет пользователю предотвратить ошибки, которые могут возникнуть, например, при переводе документа на иностранный язык по причине неверного толкованием исходного текста.
[00106] Кроме того, данное изобретение может быть использовано при машинном переводе текста. Подробное описание различных способов машинного перевода дано в следующих патентных заявках США: 12/187 131 - "СПОСОБ ПЕРЕВОДА ДОКУМЕНТОВ С ОДНОГО ЯЗЫКА НА ДРУГОЙ С ПОМОЩЬЮ БАЗЫ ПЕРЕВОДОВ, ТЕРМИНОЛОГИЧЕСКОГО СЛОВАРЯ, ПЕРЕВОДНОГО СЛОВАРЯ И СИСТЕМЫ МАШИННОГО ПЕРЕВОДА; 13/477021 - СПОСОБ И СИСТЕМА ПЕРЕВОДА ПРЕДЛОЖЕНИЙ С ОДНОГО ЯЗЫКА НА ДРУГОЙ" (12/187 131 A METHOD FOR TRANSLATING DOCUMENTS FROM ONE LANGUAGE INTO ANOTHER USING A DATABASE OF TRANSLATIONS, A TERMINOLOGY DICTIONARY, A TRANSLATION DICTIONARY, AND A MACHINE TRANSLATION SYSTEM; 13/477021 - METHOD AND SYSTEM FOR TRANSLATING SENTENCES BETWEEN LANGUAGES).
[00107] Большинство систем машинного перевода предлагает один возможный вариант перевода предложения или фразы, предоставляя возможность просматривать или изменять лишь переводы отдельных слов. В описываемом варианте осуществления изобретения пользователю предоставляется доступ к альтернативным вариантам перевода целого предложения (если его толкование неоднозначно). При этом альтернативные варианты перевода могут отражать совершенно разные смыслы предложения и иметь разные семантические и синтаксические структуры. Такая возможность особенно полезна для пользователей, не являющихся носителями языка.
[00108] Таким образом, на этапе синтеза перевода на основе построенных семантических структур формируется несколько вариантов перевода, каждый из которых доступен пользователю в качестве альтернативы. Фиг. 16 показывает блок-схему, иллюстрирующую алгоритм синтеза перевода на основе построенных семантических структур.
[00109] Фиг. 14 иллюстрирует блок-схему, согласно примеру реализации изобретения. Система получает на входе документ или текст (1410), в котором предполагается найти предложения или словосочетания, содержащие неоднозначность. Понятие "текст" распространяется на любые документы, содержащие знаки, в том числе иероглифические. В случае, если текст представлен в нередактируемом формате, документ может быть предварительно распознан при помощи технологии оптического или интеллектуального распознавания.
[00110] Затем проводится глубинный анализ текста (1420), включающий лексико-морфологический, синтаксический и семантический анализ. Подробное описание процесса глубинного анализа предложения представлено выше. Также подробное описание системы глубинного анализа приведено в патенте США 8078450 - "СПОСОБ И СИСТЕМА АНАЛИЗА РАЗЛИЧНЫХ ЯЗЫКОВ И ПОСТРОЕНИЕ НЕЗАВИСИМЫХ ОТ ЯЗЫКА СЕМАНТИЧЕСКИХ СТРУКТУР" (METHOD AND SYSTEM FOR ANALYZING VARIOUS LANGUAGES AND CONSTRUCTING LANGUAGE-INDEPENDENT SEMANTIC STRUCTURES).
[00111] В процессе выполнения глубинного анализа 1420 проводится грубый, а затем точный синтаксический анализ, формируются графы обобщенных составляющих, на основе которых строятся синтаксические и семантические деревья. Синтаксические деревья с наибольшими интегральными оценками считаются наилучшими, или другими словами, наиболее вероятными. Некоторые деревья, полученные в результате глубинного структурного анализа, по своей оценке могут лишь незначительно отличаться от наиболее вероятных деревьев, но, тем не менее, иметь другую структуру, другие зависимости, недревесные связи и пр. Такие дополнительные структуры могут отображать дополнительный (скрытый, менее частотный) смысл предложения. Поэтому они учитываются и обрабатываются в дальнейшем анализе.
[00112] Например, в тексте может быть проанализирована синтаксическая неоднозначность. Синтаксическая неоднозначность может быть выявлена на этапе синтаксического анализа 1420. Иными словами, на этапе синтаксического анализа могут быть построены синтаксические деревья с разной структурой, но высокими интегральными оценками, отличающимися на некоторое значение Δ.
[00113] На этапе семантического анализа (1430) на основе лучших синтаксических структур строятся независимые от языка семантические структуры, передающие смысл исходного предложения. Если на этапе построения синтаксических структур выявлено несколько наиболее вероятных деревьев, то строится несколько семантических структур. Свидетельством семантической неоднозначности в тексте будем считать наличие нескольких вероятных семантических структур.
[00114] На этапе 1440 проводится дальнейший анализ семантических структур. Например, может быть рассчитана степень сходства или различия между семантическими структурами (в соответствие с формулами описанными выше). Выявление нескольких различных структур с высокими интегральными оценками в параллельных предложениях в параллельных текстах (когда различаются структуры аналогичных по расположению в тексте предложений (1450)) служит индикатором того, что в предложении существует неоднозначность (1460).
[00115] Пример синтаксической неоднозначности представлен в следующем словосочетании: "THE RUSSIAN HISTORY STUDENT", которое может трактоваться как "СТУДЕНТ, ИЗУЧАЮЩИЙ РУССКУЮ ИСТОРИЮ" или "РУССКИЙ СТУДЕНТ, ИЗУЧАЮЩИЙ ИСТОРИЮ". Фиг. 15А и Фиг. 15Б иллюстрируют примеры синтаксических деревьев 1500а и 15006, отражающих синтаксические связи в английском словосочетании. На Фиг. 15А прилагательное "Russian", относящееся к Лексическому объекту "Russia: RUSSIA" с глубинной позицией "Locative_AttributeGenitive" зависит от существительного "history", в то время как само существительное "history" зависит от существительного "student". Согласно второму толкованию, синтаксическое дерево которого проиллюстрировано на Фиг. 15Б, прилагательное "Russian" и существительное "history" относятся к существительному "student". Оба синтаксических дерева обладают высокими интегральными оценками, но различной структурой. Это свидетельствует о том, что исходное предложение содержит синтаксическую неоднозначность. Поскольку синтаксические структуры различны, будут отличаться и семантические структуры, построенные для каждого синтаксического дерева в отдельности. Семантические структуры 1500в и 1500г показаны на Фиг. 15В и Фиг. 15Г. По результатам синтеза перевода на основе семантических структур (блок-схема на Фиг. 14), перевод фразы на русский язык согласно первой синтаксической структуре будет звучать как “СТУДЕНТ, ИЗУЧАЮЩИЙ РУССКУЮ ИСТОРИЮ”, а на немецкий - “EIN STUDENT, DER DIE RUSSISCHE GESCHICHTE LERNT”. Согласно второй синтаксической структуре перевод на русский будет будет звучать как "РУССКИЙ СТУДЕНТ, ИЗУЧАЮЩИЙ ИСТОРИЮ", а на немецкий - “EIΝ RUSSISCHER STUDENT, DER DIE GESCHICHTE LERNT”.
[00116] Другим примером синтаксической неоднозначности является словосочетание “temporary and part-time employees”. На основе первой, наиболее вероятной семантической структуры перевод может звучать, как “временно нанятые сотрудники” и “сотрудники, нанятые на неполный рабочий день" (employees who are temporary or employees who are part-time). На основе второй семантической структуры перевод звучит как “сотрудники, которые наняты временно на неполный рабочий день” (employees, each of whom is both temporary and part-time). В данном примере может быть пропущено существительное «employee», к которому может относиться прилагательное (один из однородных членов) «temporary». Подобный вид сочинительной связи в словосочетании может являться субъектом эллиптической связи.
[00117] Фиг. 16 иллюстрирует блок-схему синтеза перевода. Согласно блок-схеме перевод осуществляется на основе семантических структур (1600). Далее на этапе 1610 происходит построение поверхностных структур на основе синтаксических (102), лексических (103) и семантических (104) описаний. После формирования семантических структур проводится морфологический анализ (1620) на основе морфологических (101) и лексических описаний (103). В итоге пользователю выдается результат перевода на шаге 1630.
[00118] Вернемся к примеру предложения, содержащего синтаксическую неоднозначность: "THE POLICE SHOT THE RIOTERS WITH GUNS". Фиг. 9A и Фиг. 9Б иллюстрируют два синтаксических дерева с наибольшими интегральными оценками. На Фиг. 9А показано, что существительное "gun" лексического класса (ЛК) "ARTILLERY_AS_WEAPON" зависит от существительного "rioters" лексического класса "RIOTERS". На Фиг. 9А эта зависимость отражена стрелкой 901. Фиг. 9Б показывает второе синтаксическое дерево, согласно которому существительное "gun" ЛК класса "ARTILLERY_AS_WEAPON" зависит от глагола "shoot" ЛК "TO_KILL_BY_SHOOTING". На Фиг. 9Б эта зависимость отражена стрелкой 903. На основе синтаксических деревьев строятся соответствующие им семантические структуры, необходимые на этапе синтеза перевода. Они также будут различаться и, соответственно, передавать разный смысл исходного предложения. На Фиг. 16 показано, как на этапе синтеза перевода на русский язык образуются альтернативные варианты перевода. Первый вариант перевода, основанный на первой семантической структуре, будет звучать как "ПОЛИЦИЯ ЗАСТРЕЛИЛА ТЕРРОРИСТОВ С ОРУЖИЕМ". Согласно второй семантической структуре перевод будет иным: "ПОЛИЦИЯ ЗАСТРЕЛИЛА ТЕРРОРИСТОВ ИЗ ОРУЖИЯ". Данный пример показывает, что семантические структуры неодинаковы для различных синтаксических структур, следовательно, будут отличаться и варианты перевода, которые синтезируются на их основе. На основе анализа можно сделать вывод, что в исходном предложении - "THE POLICE SHOT THE RIOTERS WITH GUNS" - заключена неоднозначность, которая может быть выявлена с помощью описываемого изобретения.
[00119] Существует множество примеров синтаксической неоднозначности. Другим примером может служить следующее предложение: "THE YOUNG MEN AND WOMEN LEFT THE ROOM". Данное словосочетание может трактоваться как "THE (YOUNG MEN) AND WOMEN" или "THE YOUNG (MEN AND WOMEN)". В зависимости от того, к какому существительному относится прилагательное "young", будут отличаться семантические структуры, следовательно, будут различными варианты перевода на целевой язык. Данное словосочетание также может являться субъектом нереференциальных связей, в частности, эллипсиса. Словосочетания, содержащие союзы "or" или "and", и другие неоднозначности подобного рода, особенно часто встречаются в юридических актах и правовых документах, Выявление и разрешение неоднозначности в таких документах особенно актуально.
[00120] Приведем примеры неоднозначности, которые могут быть выявлены с помощью описываемого способа реализации изобретения. "НЕ GAVE HER CAT FOOD". На основе семантических структур этого примера могут быть сформированы следующие варианты перевода на русский язык: "ОН ДАЛ ЕЙ КОШАЧЬЕЙ ЕДЫ" и "ОН ДАЛ ЕЕ КОШКЕ ЕДЫ". Предложение "НЕ SAW JANE COMING ТО THE BANK" имеет четыре варианта семантических структур с одинаково высокой интегральной оценкой: "ОН УВИДЕЛ ДЖЕЙН ИДУЩЕЙ В БАНК"; "ОН УВИДЕЛ ДЖЕЙН ИДУЩЕЙ К БЕРЕГУ"; "ИДЯ В БАНК, ОН УВИДЕЛ ДЖЕЙН"; "ИДЯ К БЕРЕГУ, ОН УВИДЕЛ ДЖЕЙН".
[00121] В альтернативных осуществлениях данного изобретения на вход могут подаваться параллельные тексты на различных языках, включая переводы одного и того же исходного документа. Например, такими документами могут быть юридические акты, соглашения и лицензии на различных языках. Может возникнуть ситуация, когда предложение или фраза в тексте будут истолкованы по-разному, в результате чего исходный документ и его переводы на иностранные языки будут нести различные смыслы.
[00122] В другом примере осуществления система может получать на входе корпусы параллельных текстов и память переводов (из внешних источников). В связи с этим прежде, чем использовать корпуса для анализа, например, для обучения, необходимо проверить качество корпуса, а именно, прежде всего, необходимо проверить корректность выравнивания, т.е. проверить насколько предложения одного языка соответствуют по смыслу соответствующим согласно выравниванию предложениям другого языка.
[00123] Фиг. 17 показывает блок-схему альтернативного способа применения, в которой на вход поступают параллельные корпуса текстов, или параллельные документы (1710), т.е. переводы одного исходного документа на различные языки, которые требуются проанализировать с целью выявления неоднозначности. В данном случае это могут быть уже выровненные параллельные тексты или тексты, не подвергавшиеся выравниванию.
[00124] На этапе 1720 проводится установление соответствий между предложениями и абзацами в параллельных текстах. С этой целью может быть использован один из существующих алгоритмов выравнивания. Например, один из возможных способов выравнивания текстов описан в патентной заявке США 12/708 337 - "СПОСОБЫ И СИСТЕМЫ ДЛЯ ВЫРАВНИВАНИЯ КОРПУСОВ ПАРАЛЛЕЛЬНЫХ ТЕКСТОВ" ("METHODS AND SYSTEMS FOR ALIGNMENT OF PARALLEL TEXT CORPORA").
[00125] После выравнивания каждый из параллельных документов обрабатывается системой независимо (1730). Для каждого из параллельных документов проводится глубинный анализ, включающий лексико-морфологический, синтаксический и семантический анализ всех предложений в документе, согласно алгоритму, описанному выше.
[00126] На выходе строятся синтаксические структуры, на основе которых далее формируются независимые от языка семантические структуры (1740) для каждого предложения во всех параллельных текстах (в т.ч. в текстах на разных языках). Помимо этого на этапе семантического анализа устанавливаются референциальные связи. Одним из примеров референциальных связей может быть анафора. Разрешение анафоры - одна из наиболее трудоемких задач машинного перевода. Однако даже при ручном переводе текста некоторые анафорические связи могут быть прослежены неверно, в результате чего может исказиться смысл предложения. Благодаря описываемому способу можно проследить анафорические связи как в исходном, так и в переведенном тексте. Отличие связей в параллельных текстах будет свидетельствовать о том, что предложение содержит неоднозначность, которая при переводе была интерпретирована неверно.
[00127] Таким образом, после проведения лексико-морфологического, синтаксического и семантического анализа, для каждого предложения в каждом из текстов на разных языках выстраиваются независимые от языка семантические структуры, отражающие исходный смысл. На этапе 1750 (Фиг. 17) выполняется сравнение семантических структур для соответствующих согласно результатам выравнивания предложений: устанавливается взаимосвязь между семантической структурой предложения в тексте на языке А с соответствующим предложением в тексте на языке Б и т.д.
[00128] Различие семантических структур (1760) будет означать неоднозначность исходного предложения. Наличие неоднозначности может быть визуализировано (1770) с помощью одного из известных способов. Рекомендуется использовать способ построения недостающих дополнительных семантических структур, выявленных в процессе анализа. Также на основе полученных семантических структур может быть выполнен перевод.
[00129] На Фиг. 18А и 18Б проиллюстрирована неоднозначность в толковании на примере предложения на английском языке: "Chickens are ready for dinner". Допустим, что в параллельном документе был сформирован следующий перевод данного предложения на русский язык - "Куры готовы поесть". Согласно описанному способу выявления неоднозначности, данное предложение будет тщательно проанализировано: проведен глубинный анализ, построены синтаксические и семантические структуры для каждого предложения. Таким образом, полученная семантическая структура (1800а) английского предложения "Chickens are ready for dinner", представленная на Фиг. 18А. В данной семантической структуре существительное "chickens" относится к лексическому классу "CHICKEN_MEAT" с глубинной позицией "Experiencer_Metaphoric". Семантическая структура (1800b) русского предложения "Куры готовы пообедать" показана на Фиг. 18Б. В данной семантической структуре существительное "куры" относится к лексическому классу "HEN_ROOSTER" с глубинной позицией "Experiencer". В результате проведения параллельного анализа текстов выявлены различающиеся семантические структуры. Различные семантические структуры параллельных предложений свидетельствуют о том, что в исходном предложении существует неоднозначность в толковании.
[00130] Рассмотрим другой пример неоднозначности в предложении "THE SOIL SHALL BE COVERED BY FERTILIZER BEFORE IT FREEZES". Пусть имеются три предложения на трех различных языках. Первое - исходное предложение на английском языке, содержащее неоднозначность. Два других предложения - переводы на русский и немецкий языки. Если неоднозначность в исходном английском предложении не была зафиксирована в процессе перевода (человеком или системой машинного перевода), на выходе будут получены отличающиеся по смыслу предложения. Неоднозначность в исходном английском предложении заключается в том, что местоимение "it" может относиться как к существительному "soil", так и к существительному "fertilizer". По этой причине переводы на целевые языки, русский или немецкий, будет отличаться по смыслу, в зависимости от того, к какому слову будет отнесено местоимение "it". Предложения такого рода могут быть поняты по-разному разными переводчиками, вследствие чего переводы будут отличаться. В подобных случаях они будут визуализированы, как предложения, содержащие неоднозначность. Например, если при переводе местоимение "it" было отнесено к существительному "soil", перевод на русский язык (по алгоритму, представленному на Фиг. 16) будет следующим: "В ПОЧВУ НУЖНО ВНЕСТИ УДОБРЕНИЕ, ПРЕЖДЕ ЧЕМ ОНА ЗАМЕРЗНЕТ". Но местоимение "it" может быть также отнесено к существительному "fertilizer". В этом случае в переводе на немецкий язык будет получено: "DER BODEN SOLLTE MIT DUNGEMITTEL ABGEDECKT WERDEN, BEVOR ES FRIERT". Согласно описываемому изобретению, для каждого предложения в русском и немецком вариантах перевода документа строятся семантические структуры, которые отображают различные зависимости, представленные в виде недревесных связей. Пример семантической структуры для русского варианта перевода (1900) изображен на Фиг.19. Структура отображает зависимость местоимения "она" (1901) от существительного "почва" лексической категории "EARTH_AS_SUBSTANCE" (1902) в виде недревесной связи (1903). В то же время, семантическая структура перевода на немецкий язык отображает зависимость местоимения "Es" от существительного "Düngemittel". Поэтому приведенный пример демонстрирует, что исходное предложение на английском языке содержит неоднозначность, представленную в виде референциальной связи - анафоры. Данный вид неоднозначности порожден несимметричностью в разных языках. Например, в английском языке для местоимения "it", обозначающего неодушевленные предметы, в русском языке существуют местоимения "он", "она", "оно". Предложение сложно правильно перевести вне контекста и при неоднозначной зависимости этого местоимения от антецедента. Описанная система помогает обнаружить подобного рода неоднозначности в тексте и указать на них пользователю. Неоднозначность, причиной которой стала неверная пунктуация в предложении, может быть выявлена на этапе синтаксического анализа. Лексическая неоднозначность, заключающаяся в существовании у слова нескольких лексических значений, также может быть выявлена на этапе проведения лексического анализа текста.
[00131] На Фиг. 20 приведена схема аппаратного обеспечения (2000), которая может быть использована для внедрения настоящего изобретения. Аппаратное средство (2000) должно включать в себя, по крайней мере, один процессор (2002) соединенный с памятью (2004). Слово "процессор" на схеме (2002) может обозначать один или несколько процессоров с одним или несколькими вычислительными ядрами, вычислительное устройство или любой иной имеющийся на рынке ЦП. Цифрами 2004 обозначается устройство оперативной памяти (RAM), являющееся основным хранилищем (2000), а также дополнительные уровни памяти - кэш, энергонезависимая, резервная память (например, программируемая или флэш-память), ПЗУ и т.д. Кроме того, обозначение памяти (2004) может подразумевать также и хранилище, расположенное в другой части системы (например, кэш процессора (2002) или иное хранилище, используемое в качестве виртуальной памяти, такое как внутреннее или внешнее ПЗУ (2010).
[00132] Аппаратное средство (2000), как правило, располагает некоторым количеством входов и выходов для передачи и получения информации извне. В качестве пользовательского или операторского интерфейса аппаратного средства (2000) может применяться одно или несколько устройств пользовательского ввода (2006), таких как клавиатура, мышь, формирователь изображений и пр., а также одно или несколько устройств вывода (жидкокристаллический дисплей или иное (2008)) и устройства воспроизведения звука (динамик).
[00133] Для получения дополнительного объема для хранения данных используются накопители данных (2010), такие как дискеты или иные съемные диски, жесткие диски, ЗУ прямого доступа (DASD), оптические приводы (компакт-диски и пр.), DVD-приводы, магнитные ленточные накопители и пр. Аппаратное средство (2000) может также включать в себя интерфейс сетевого подключения (2012) - LAN, WAN, Wi-Fi, Интернет и пр. - для связи с другими компьютерами, находящимися в сети. В частности, можно использовать локальную сеть (LAN) или беспроводную сеть Wi-Fi, не подключенную ко всемирной сети Интернет. Необходимо учесть, что аппаратное средство (2000) также включает в себя различные аналоговые и цифровые интерфейсы соединения процессора (2002) и других компонентов системы (2004, 2006, 2008, 2010 и 2012).
[00134] Аппаратное средство (2000) работает под управлением Операционной Системы (ОС) (2014), которая запускает различные приложения, компоненты, программы, объекты, модули, и пр. с целью осуществления описанного здесь процесса. В состав прикладного ПО должно быть включено приложение по выявлению семантической неоднозначности языка.
Также могут быть включены клиентский словарь, приложение для автоматизированного перевода и прочие установленные приложения для отображения тестового и графического содержимого (текстовый процессор и пр). Помимо этого приложения, компоненты, программы и иные объекты, собирательно обозначенные числом 2016 на Фиг. 20, могут также запускаться на процессорах других компьютеров, соединенных с аппаратным обеспечением (2000) по сети (2012). В частности, задачи и функции компьютерной программы могут распределяться между компьютерами в распределенной вычислительной среде.
[00135] Все рутинные операции по применению осуществлений могут выполняться операционной системой или отдельными приложениями, компонентами, программами, объектами, модулями или последовательными инструкциями, обобщенно именуемыми "компьютерными программами". Обычно компьютерные программы представляют собой ряд инструкций, выполняемых в разное время разными устройствами памяти и хранения данных на компьютере. После прочтения и выполнения инструкций процессоры выполняют операции необходимые для запуска элементов описанного осуществления. Несколько вариантов осуществлений было описано в контексте полностью функционирующих компьютеров и компьютерных систем. Специалисты отрасли по достоинству оценят возможности распространения некоторых модификаций в форме различных программных продуктов на любых типах информационных носителей. Примерами таких носителей являются как энергозависимые, так и энергонезависимые устройства памяти, такие как дискеты и другие съемные диски, жесткие диски, оптические диски (напр., CD-ROM, DVD, флэш-диски) и многое другое. Также программный пакет может быть загружен через Интернет.
[00136] В вышеизложенном описании множество конкретных деталей изложено исключительно для пояснения. Специалистам в данной области техники очевидно, что эти конкретные детали являются лишь примерами. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание неоднозначности толкований.
[00137] Приводимые в данном описании ссылки на «один вариант осуществления/ реализации» или «вариант осуществления/реализации» означают, что конкретный признак, структура или характеристика, описанные для варианта реализации, являются компонентом по меньшей мере одного варианта реализации. Использование фразы «в одном варианте реализации» в различных фрагментах описания не означает, что описания относятся к одному и тому же варианту реализации либо что эти описания относятся к различным или альтернативным, взаимно исключающим вариантам реализации. Кроме того, различные описания характеристик могут относиться к некоторым вариантам реализации, но не относиться к другим вариантам реализации. Различные описания требований могут относиться к некоторым вариантам реализации и не относиться к другим вариантам реализации.
[00138] Некоторые образцы вариантов реализации были описаны и показаны на прилагаемых иллюстрациях. Однако необходимо понимать, что такие варианты реализации являются просто примерами, но не ограничениями описываемых вариантов реализации, и что эти варианты реализации не ограничиваются конкретными показанными и описанными конструкциями и устройствами, поскольку специалисты в данной области техники на основе приведенных материалов могут создать собственные варианты реализации. В области технологии, к которой относится настоящее изобретение, быстрое развитие и дальнейшие достижения сложно прогнозировать, поэтому описываемые варианты реализации могут быть с легкостью изменены в устройстве и деталях благодаря развитию технологии, с соблюдением при этом принципов настоящего описываемого изобретения.
Реферат
Изобретение относится к обработке текста на естественном языке, в частности к определению смысла предложений в тексте. Техническим результатом является обеспечение возможности автоматически находить и выделять в документе неоднозначные фразы или утверждения, которые могут трактоваться несколькими возможными способами. В способе обнаружения языковой неоднозначности предложение анализируется с целью определения синтаксических связей между его обобщенными составляющими. На основе синтаксических связей и лексико-морфологической структуры предложения строится граф обобщенных составляющих, который анализируется для выявления множества синтаксических структур предложения. Всем синтаксическим структурам присваивается оценка вероятности того, что структура является верной гипотезой о полной синтаксической структуре. Строятся семантические структуры, соответствующие синтаксическим структурам. Выбираются первая и вторая семантические структуры, каждая из которых имеет оценки не ниже порогового значения, причем первая семантическая структура отлична от второй семантической структуры. На основе анализа различий между двумя семантическими структурами устанавливается семантическая неоднозначность в предложении. 3 н. и 17 з.п. ф-лы, 28 ил.
Комментарии