Разрешение анафоры на основе технологии глубинного анализа - RU2601166C2
Код документа: RU2601166C2
Чертежи




















Описание
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0001] Изобретение относится к системам и методам создания технологий, систем и продуктов для автоматической обработки текстовой информации (=Natural Language Processing - NLP), извлечения информации из текстов на естественных языках. Важнейшими элементами таких технологий, включая методы и создаваемые на их основе приложения, являются системы анализа текстов на естественном языке, языковые описания, системы извлечения информации и онтологии как модели предметных областей. Благодаря интернету, становятся доступными большие объемы информации, представленной в электронном виде. Эта информация, как правило, неструктурированна, поэтому актуальной задачей является задача автоматического извлечения и структурирования доступной информации, включая все многообразие объектов, сущностей реального мира и связей между ними, формализация и отождествление сущностей и установление связей между ними для последующего использования при построении формальных моделей предметных областей в различных приложениях.
УРОВЕНЬ ТЕХНИКИ
[0002] Объем неструктурированной информации, представленной в электронном виде, в настоящее время неуклонно растет. Эта информация может содержать текст и другие данные (например, числа, даты и пр.). В частности, большой объем неструктурированной информации становится легко доступным благодаря сети Интернет. В то же время, не существует универсальных способов обработки и структурирования информации, извлечения фактов и знаний, позволяющих делать это эффективно и в приемлемое время без участия человека. Интерпретацию этой информации усложняют неоднозначность, свойственная естественному языку, и вариативность способов выражения. Отличительной особенностью любого естественного языка является возможность выразить одну и ту же мысль, описать один и тот же факт, событие множеством различных способов, требующих нетривиального подхода к синтаксическому анализу и наличия исчерпывающих языковых описаний. Поэтому остается актуальной задача построения таких языковых описаний и способов их использования, чтобы существовала возможность обработки всего многообразия языковых явлений, включая анафорические и кореферентные связи, сопоставление и отождествление одних и тех же сущностей, фактов, событий, действий и т.п.
[0003] Настоящее изобретение создает предпосылки для создания программной системы, решающей такие задачи, как извлечение информации из текстов на естественном языке, поиск информации в коллекциях документов, мониторинг информации и др. Настоящее изобретение представляет частичное продолжение технологий, описанных в ряде US Patent Applications. В частности, рассматриваемые семантические описания и методы анализа подробно изложены в US Patent Application 13/288,953, filed November 3, 2011, which is a continuation-in-part of U.S. patent application Ser. No. 11/548,214 that was filed on 10 Oct. 2006, now US Patent 8,078,450.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0004] Изобретение относится к способам и системам обработки естественного языка, с целью последующего использования в системах информационного поиска, в системах машинного перевода, для классификации текстов и других приложениях, связанных с информацией на естественном языке. Основной особенностью настоящего изобретения является то, что для извлечения информации используются результаты полного семантико-синтаксического анализа входного текста.
[0005] Способ настоящего изобретения включает использование применимой к любому естественному языку технологии глубинного анализа текста на основе универсальной семантической иерархии и конкретно-языковых описаний естественного языка. Метод включает следующие этапы. Имеющиеся тексты подвергаются полному синтаксическому и семантическому разбору. Строятся семантические структуры, содержащие семантические классы и глубинные отношения. На полученных семантических структурах устанавливаются недревесные связи, отражающие сложные языковые явления, такие как анафора, кореференция и др. Это, в частности, позволяет отождествлять объекты, представленные в тексте различным образом, и опционально извлекать дополнительную информацию об объектах поиска. Установление недревесных связей происходит в результате применения всех возможных для данного текста моделей, установления всех потенциально возможных недревесных связей с последующей фильтрацией и выбором наилучших вариантов.
[0006] В одной из реализаций, способ построения семантико-синтаксических структур предложений естественного языка в различных задачах обработки естественного языка включает: генерацию процессором, по меньшей мере, одного синтаксического дерева для каждого предложения, включающего множество синтаксических узлов и множество древесных синтаксических связей; генерацию процессором, по меньшей мере, одной семантической структуры, соответствующей по меньшей мере одному синтаксическому дереву, где по крайней мере одна семантическая структура включает множество семантических узлов, соответствующих множеству синтаксических узлов, и множество семантических связей соответствует множеству древесных связей; если по крайней мере одно синтаксическое дерево содержит по меньшей мере два различных синтаксических узла соответствующих одной и той же сущности, то установление связи между семантическими узлами, соответствующими этим синтаксическим узлам посредством по крайней мере одной недревесной связи; и выполнение последующей обработки текста процессором с использованием построенной семантической структуры.
[0007] Другой вариант реализации относится к системе. Такая система включает одно или несколько вычислительных средств, одно или несколько запоминающих устройств, в которых хранятся команды. В этом варианте реализации пример системы включает: модуль синтаксического анализа, сконфигурированный для того, чтобы генерировать по меньшей мере по одному синтаксическому дереву для каждого предложения, включающему множество синтаксических узлов и множество древесных синтаксических связей; модуль семантического анализа, сконфигурированный для того, чтобы: генерировать, по меньшей мере, одну семантическую структуру, соответствующую, по меньшей мере, одному синтаксическому дереву, где по крайней мере одна семантическая структура включает множество семантических узлов, соответствующих множеству синтаксических узлов и множество семантических связей соответствует множеству древесных связей; если, по крайней мере, одно синтаксическое дерево содержит, по меньшей мере, два различных синтаксических узла соответствующих одной и той же сущности, то установить связи между семантическими узлами, соответствующими этим синтаксическим узлам посредством, по крайней мере, одной недревесной связи; и модуль последующей обработки текста процессором с использованием построенной семантической структуры.
[0008] Еще один вариант реализации относится к машиночитаемому носителю данных, содержащему машинные команды, при выполнении которых вычислительным устройством это вычислительное устройство выполняет следующие операции: полный синтаксический и семантический разбор имеющихся корпусов текстов, построение семантических структур, содержащих семантические классы и глубинные отношения, для предложений из текстов, образующих эти корпуса.
[0009] В этом еще одном варианте реализации компьютерный программный продукт, записанный на машиночитаемый носитель, программный продукт, включающий выполняемые компьютером инструкции для генерации синтактико-семантических структур предложений естественного языка при автоматической обработке текстов, включает инструкции для генерирования посредством процессора по меньшей мере по одному синтаксическому дереву для каждого предложения, включающему множество синтаксических узлов и множество древесных синтаксических связей; инструкции для выполнения семантического анализа, чтобы сгенерировать, по меньшей мере, одну семантическую структуру, соответствующую по меньшей мере одному синтаксическому дереву, где по крайней мере одна семантическая структура включает множество семантических узлов, соответствующих множеству синтаксических узлов, и множество семантических связей соответствует множеству древесных; если, по крайней мере, одно синтаксическое дерево содержит по меньшей мере два различных синтаксических узла соответствующих одной и той же сущности, то установить связи между семантическими узлами, соответствующими этим синтаксическим узлам посредством по крайней мере одной недревесной связи; и модуль последующей обработки текста процессором с использованием построенной семантической структуры.
[0010] В некоторых вариантах, связывание семантических узлов, по меньшей мере, одной недревесной связью включает генерацию множества возможных вариантов недревесных связей между синтаксическими узлами; вычисление оценки для каждой потенциально возможной недревесной связи и выбор недревесных связей с наивысшей оценкой. В некоторых вариантах, вычисление оценки для каждой потенциально возможной связи использует метрику схожести для объектов семантической иерархии, соответствующих семантическим узлам семантических структур. В некоторых вариантах, по меньшей мере два синтаксических узла принадлежат по меньшей мере двум разным синтаксическим деревьям. В некоторых случаях, по меньшей мере, два синтаксических узла включают узел-контроллер и узел-местоимение, управляемый контроллером, при этом установление того, что узел-контроллер и узел-местоимение соответствуют одной сущности, включает применение правил разрешения анафорических связей.
[0011] Технический результат от внедрения изобретения состоит в повышении точности представления и извлечения информации в системах автоматической обработки текстов, представленных предложениями на естественном языке, что достигается за счет построения более точного формального представления предложения на естественном языке, учитывающего анафорические и кореферентные связи, сопоставления и отождествления одних и тех же сущностей, фактов, событий, действий и т.д.
[0012] Вышеприведенное упрощенное описание примеров реализации предназначено только для понимания основных идей настоящего изобретения. Это краткое описание не является полноценным обзором всех предусмотренных аспектов и не предназначено для того, чтобы ни определить ключевые или критические элементы всех аспектов, ни определить охват каких-либо или всех аспектов настоящего раскрытия. Его единственная цель состоит в том, чтобы представить один или более аспектов в упрощенной форме как вступление к более подробному описанию последующего раскрытия. В дополнение к выше упомянутому, один или более аспектов настоящего раскрытия включают особенности, описанные и особенно подчеркнутые в формуле изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0013] Детали различных вариантов реализации изложены в прилагаемых чертежах и приведенном ниже описании. Другие особенности, аспекты и преимущества настоящего изобретения станут очевидными из описания, чертежей и формулы изобретения, в которых:
[0014] Фиг. 1 иллюстрирует способ настоящего изобретения;
[0015] Фиг. 2 представляет собой блок-схему способа получения множества синтаксических деревьев из документов и из других источников в соответствии с одним или несколькими вариантами реализации изобретения;
[0016] Фиг. 2А содержит пример лексико-морфологической структуры предложения в соответствии с одним или несколькими вариантами реализации;
[0017] Фиг. 2В представляет собой схему, иллюстрирующую используемые языковые описания, согласно одной из возможных реализаций изобретения;
[0018] Фиг. 3 содержит схему, иллюстрирующую морфологические описания в соответствии с одним или несколькими вариантами осуществления;
[0019] Фиг. 4 содержит схему, иллюстрирующую синтаксические описания в соответствии с одним или несколькими вариантами осуществления;
[0020] Фиг. 5 содержит схему, иллюстрирующую семантические описания в соответствии с одним или несколькими вариантами осуществления;
[0021] Фиг. 6 содержит схему, иллюстрирующую лексические описания в соответствии с одним или несколькими вариантами осуществления;
[0022] Фиг. 7 иллюстрирует последовательность структур данных, которые строятся в процессе анализа в соответствии с одним или несколькими вариантами осуществления;
[0023] На Фиг. 8 приведен схематичный пример графа обобщенных составляющих для ранее упомянутого предложения «This boy is smart, he′ll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) в соответствии с одним или несколькими вариантами осуществления;
[0024] Фиг. 9 содержит пример синтаксической структуры английского предложения «This boy is smart, he′ll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) в соответствии с одним или несколькими вариантами осуществления;
[0025] Фиг. 10 иллюстрирует семантическую структуру английского предложения «This boy is smart, he′ll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) в соответствии с одним или несколькими вариантами осуществления;
[0026] На Фиг. 11 иллюстрирует синтаксическое дерево предложения без недревесных связей согласно одной из возможных реализаций изобретения.
[0027] Фиг. 11А иллюстрирует синтаксическую структуру предложения с установленными недревесными связями согласно одной из возможных реализаций изобретения.
[0028] На Фиг. 12 иллюстрирует синтаксическое дерево предложения без недревесных связей согласно одной из возможных реализаций изобретения.
[0029] Фиг. 12А иллюстрирует синтаксическую структуру предложения с установленными недревесными связями согласно одной из возможных реализаций изобретения.
[0030] Фиг. 12В иллюстрирует синтаксическую структуру предложения с установленными недревесными связями согласно одной из возможных реализаций изобретения.
[0031] Фиг. 13 иллюстрирует пример установления недревесных связей на множестве предложений.
[0032] Фиг. 13А иллюстрирует фрагмент семантической иерархии.
[0033] Фиг. 13В иллюстрирует другой фрагмент семантической иерархии.
[0034] Фиг. 13С иллюстрирует еще один фрагмент семантической иерархии.
[0035] На Фиг. 14 указаны вычислительные средства для создания компьютерной системы согласно одной из возможных реализаций изобретения.
[0036] Нижеследующее детальное описание изобретения содержит ссылки на соответствующие чертежи. Одни и те же обозначения на чертежах указывают на одни и те же компоненты, если не указано иное. Примеры реализации, представленные данным описанием, иллюстрациями и формулой изобретения, не являются единственно возможными. Примеры реализации могут быть использованы или модифицированы иными способами, не описанными ниже, без уменьшения их охвата или их сущности. Различные варианты реализации, представленные в спецификации и проиллюстрированные с помощью чертежей, могут быть расположены, заменены и сгруппированы в широком наборе различных конфигураций, которые подробно рассмотрены в настоящей спецификации.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0037] Примеры реализации описаны здесь в контексте системы и метода для разрешения анафоры, основанных на лингвистических технологиях. Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, приведенными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется только в объеме приложенной формулы.
[0038] Описанные способ и система основаны на универсальном подходе к анализу текста, который включает технологию, использующую описания языка в универсальных, не зависящих от конкретного языка терминах (ядро), и лексическое наполнение, которое включает лексику конкретного языка и языковые модели словообразования и словоизменения, а также синтаксические модели словоупотребления и согласования в этом языке.
[0039] Это универсальное независимое от конкретного языка ядро, называемое семантической иерархией, содержит исчерпывающий набор знаний о мире и способов выражения этих знаний в естественных языках. Это знание может быть представлено в виде иерархического описания имеющихся в мире сущностей, их свойств, возможных атрибутов, их взаимоотношений и способов выражения таких знаний в конкретном языке. Семантическое описание такого типа является полезным для создания технологий автоматической обработки естественного языка, особенно приложений, которые способны «понимать смысл», выраженный на естественном языке; они необходимы для создания приложений и решения многочисленных задач по обработке естественного языка, таких как машинный перевод, семантическое индексирование и семантический поиск, включая многоязычный семантический поиск, извлечение фактов, анализ тональности, поиск похожих документов, классификация документов, обобщение, анализ больших объемов данных, электронное обнаружение, морфологический и лексический анализатор и другие приложения.
[0040] В частности, раскрываемые системы и способы дают возможность создавать системы обработки естественного языка, извлекать информацию из текстов, хранить и обрабатывать единицы текста (слова, предложения и тексты) и производить такие же операции с лексическими и семантическими значениями слов, предложений, текстов и других единиц информации.
[0041] Настоящее изобретение представляет собой способ и систему обработки языковых явлений, порождающих недревесные связи в предложениях. Предложения подвергаются глубинному семантико-синтаксическому анализу. Строится по крайней мере по одному семантико-синтаксическому дереву на одно предложение входного текста. В процессе анализа в этих деревьях могут появляться недревесные связи, которые возникают, если в соответствующем предложении есть такие языковые явления, как эллипсис, анафора, кореференция и др. Получающиеся структуры называются семантическими структурами или семантико-синтаксическими деревьями. Эти структуры порождаются парсером, выполняющим анализ текста в соответствии со способом, описанным в Патенте США №8,078,450. Каждое дерево, лежащее в основе семантической структуры, проективно, узлы соответствуют словам входного текста, но допускаются и нулевые узлы (не имеющие поверхностного выражения). Узлам сопоставлены универсальные сущности - узлы семантической иерархии, называемые семантическими классами, дуги размечены глубинными позициями.
[0042] Поясним проблему установления недревесных связей на примерах. Рассмотрим предложение "Мальчик дал девочке свое яблоко". В этом предложении существует очевидная связь между словами "мальчик" и "свое", указывающая на то, что мальчик дал именно свое яблоко, а не любое другое, например, лежащее на тарелке или сорванное с дерева. Эта связь может и должна быть установлена, однако для этого требуются некоторые нетривиальные действия. Для этого в синтаксической модели должно содержаться соответствующее описание и в анализируемом предложении должна быть идентифицирована семантическая роль (Possessor - владелец), которую играет слово, в данном случае притяжательное местоимение, в предложении. Однако, такого рода недревесные связи бывают разных типов и определение семантической роли и, соответственно, выбор глубинной позиции не всегда является однозначным. В предложении "Мальчик знает своего врага", лексема "свой " выполняет другую семантическую роль - Object. Если возможны разные варианты установления недревесных связей, разные варианты выбора семантических ролей, то рассматриваются все возможные случаи, каждый вариант оценивается и выбирается наиболее релевантный.
[0043] Рассматриваются следующие типы анафорических связей.
[0044] Местоименная (pronominal) анафора
[0045] Местоименной анафорой называется явление, выражаемое в тексте местоимениям: он, она, оно, они, я, мы, ты, вы, себя, свой, друг друга, таковой и некоторые другие.
[0046] Относительная анафора
[0047] Другой тип анафоры, который подлежит анализу и разрешению, встречается в предложениях, содержащих именную группу и относительное местоимение, например, "Мальчик, который пришел ".
[0048] Кореференция - это попытка ассоциировать два или более различных имени (названия) или именных группы, которые отсылают к одной и той же сущности. Задача усложняется, если именные группы не имеют текстового пересечения, как например, Обама и Президент США (относительно простым случаем является Обама и Барак Обама). Эта задача кореллирует с проблемой распознавания именованных сущностей и извлечением фактов из текстов.
[0049] Фиг. 1 иллюстрирует последовательность действий, совершаемых системой в соответствии с методом настоящего изобретения. На вход системы 100 подается текст 110, в общем случае, текстовый корпус, каждое предложение которого на предварительном этапе в результате синтаксического анализа 120 преобразуется в синтаксическое дерево. Этот этап является довольно сложным в реализации, поэтому требует отдельных пояснений, которые будут сделаны при описании Фиг. 2. На следующем этапе 130 в синтаксических деревьях генерируются недревесные связи. Недревесные связи генерируются на основе моделей недревесного синтаксиса, эти модель являются частью синтаксических описаний языка, которые будут подробно проиллюстрированы при описании Фиг. 4. Обычно вариантов установления этих связей может быть достаточно много, поэтому на этапе 140 все сгенерированные варианты оцениваются и ранжируются (150), затем из множества исключающих друг друга вариантов выбираются варианты с наилучшей оценкой и на этапе 160 происходит оценка и ранжирование (160) синтаксических структур с выбранными недревесными связями, после чего осуществляется переход (170) к семантической структуре 180. Дополнительно, в завершение процесса на этапе 170 может происходить извлечение сущностей и их отождествление. Ниже перечисленные этапы процесса описываются в деталях.
[0050] На Фиг. 2 показана блок-схема синтаксического анализа, целью которого является построение синтаксических деревьев (120), которые в дальнейшем могут преобразовываться в универсальное представление обрабатываемой информации в виде множества семантических деревьев. Под обрабатываемой информацией понимаются тексты документов, данных, текстовых корпусов, изображений, а также получаемые от серверов электронной почты, из социальных сетей, распознанной речи, видео и других источников. Если документ является изображением, имеет формат pdf, формат tif или другой нетекстовый формат, то предварительно применяется OCR (оптическое распознавание символов) или другой способ преобразования документа в текстовый формат. На этих этапах могут использоваться любые известные коммерческие системы, например, программа FineReader. В случае обработки речевых или аудио файлов добавляется другой предварительный этап - распознавание речи.
[0051] На этапе 214, для каждого предложения 212 текста, выполняется лексико-морфологический анализ, т.е. идентифицируются морфологические значения слов предложения. Другими словами, предложение разбивается на лексические элементы, после чего определяются их потенциальные леммы (начальные или основные формы), а также соответствующие варианты грамматических значений. Обычно для каждого элемента идентифицируется множество вариантов вследствие омонимии и совпадения словоформ различных грамматических значений. Схематический пример результата этапа 214 для предложения «This boy is smart, he′ll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) приведен на Фиг. 2А.
[0052] Затем на лексико-морфологической структуре проводится синтаксический анализ. Синтаксический анализ - двухэтапный. Он включает грубый синтаксический анализ 215, включающий активацию синтаксических моделей одного или нескольких потенциальных лексических значений рассматриваемого слова и установление всех потенциальных поверхностных связей в предложении, что выражается в построении структуры данных, называемой графом обобщенных составляющих. Затем из графа обобщенных составляющих на этапе точного синтаксического анализа 216 формируется по меньшей мере одна структура данных - синтаксическое дерево, которое представляет собой синтаксическую структуру предложения. Этот процесс подробно описан в U.S. Patent Application Ser. №11/548,214, поданной 10 октября 2006 г., теперь это US Patent 8,078,450, который включен в настоящий документ посредством ссылки. В общем случае формируется несколько таких структур, что связано, прежде всего, с наличием различных вариантов для лексического выбора. Каждый вариант синтаксической структуры имеет свою собственную оценку, структуры упорядочены от наиболее вероятной к менее вероятной.
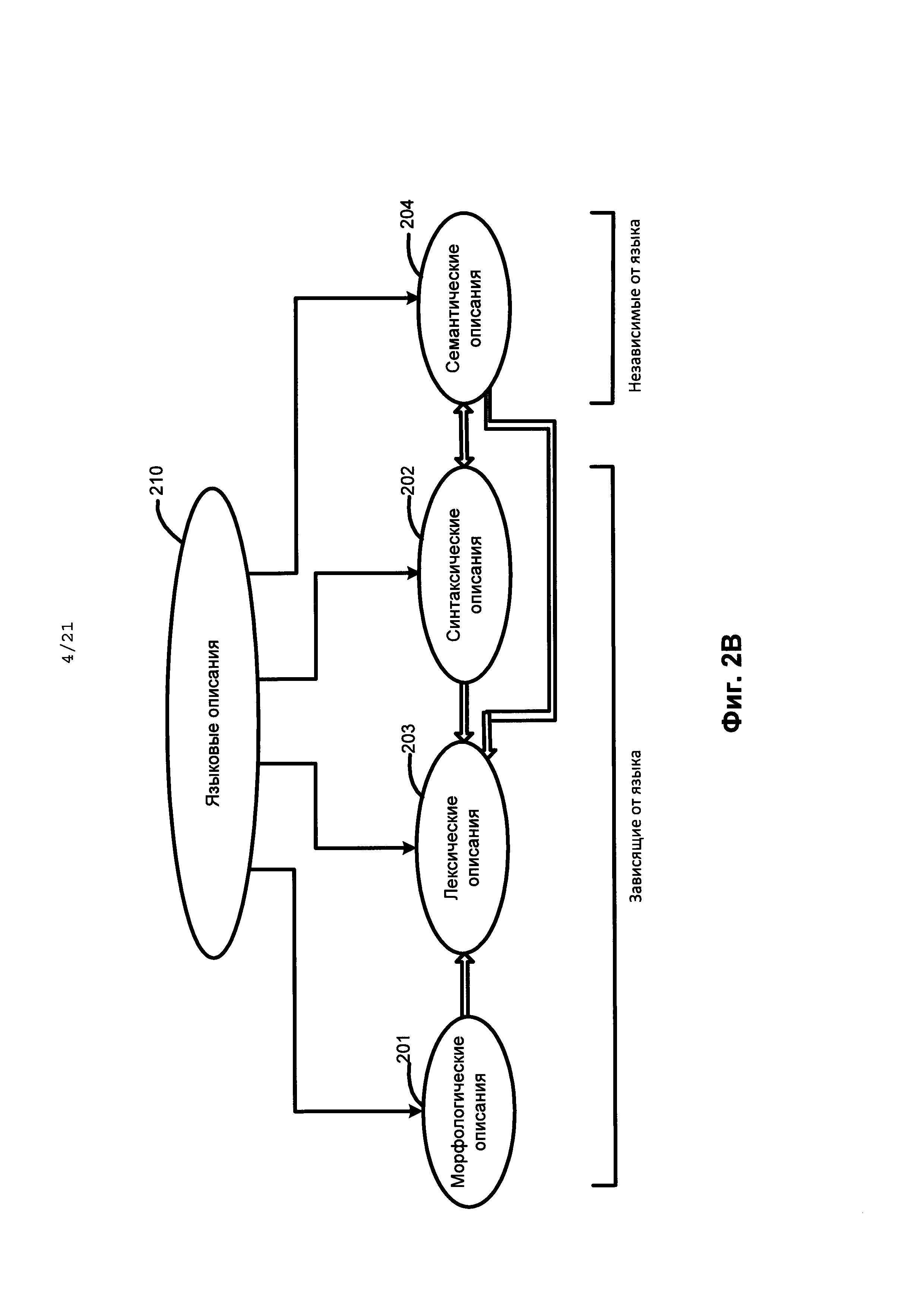
[0053] На всех этапах описываемого метода настоящего изобретения широко используется большой спектр лингвистических описаний. Ниже подробно описывается набор упомянутых лингвистических описаний и отдельные этапы метода настоящего изобретения. Фиг. 2В представляет собой схему, иллюстрирующую языковые описания (210) согласно одному из вариантов реализаций изобретения.
[0054] Языковые описания (210) включают морфологические описания (201), синтаксические описания (202), лексические описания (203) и семантические описания (204). Среди них морфологические описания (201), лексические описания (203) и синтаксические описания (202) создаются для каждого конкретного языка по определенным шаблонам. Семантические описания (204)универсальны, они используются для описания независимых от языка семантических признаков различных языков и для построения независимых от языка семантических структур. Языковые описания (210) связаны между собой и, рассматриваемые во взаимосвязи, они представляют собой модель исходного языка.
[0055] Так, всякое лексическое значение в лексических описаниях (203) также может иметь одну или несколько поверхностных моделей в синтаксических описаниях (202) для данного лексического значения. Всякой поверхностной модели в синтаксических описаниях (202) соответствует некоторая глубинная модель в семантических описаниях (204).
[0056] На Фиг. 3 приведены примеры морфологических описаний. Компоненты морфологических описаний (201) включают: описания словоизменения (310), грамматическую систему (320) и описания словообразования (330) и т.д. Грамматическая система (320) представляет собой набор грамматических категорий, таких, например, как «часть речи», «падеж», «пол», «число», «лицо», «возвратность», «время», «вид» и т.д., а каждая категория - набор значений, в дальнейшем называемых «граммемами», в том числе, например, прилагательное, существительное, глагол и т.д.; именительный, винительный, родительный падеж и т.д.; женский, мужской, нейтральный род и т.д. и т.д.
[0057] Описание словоизменения (310) показывает, как основная форма слова может меняться в зависимости от падежа, пола, числа, времени, и т.п., и в широком смысле оно включает в себя или описывает все возможные формы этого слова. Словообразование (330) определяет, какие новые слова могут быть созданы с участием этого слова (сложных слов, композитов). Граммемы могут использоваться для построения описания словоизменения (310) и описания словообразования (330).
[0058] При установлении синтаксических отношений между элементами исходного предложения используются модели составляющих. Составляющая представляет собой группу соседних слов в предложении, ведущих себя как единое целое. Ядром составляющей является слово, составляющая также может включать дочерние составляющие на более низких уровнях. Дочерняя составляющая является зависимой составляющей, она может быть прикреплена к другой составляющей (родительской) для построения синтаксической структуры.
[0059] На Фиг. 4 показаны синтаксические описания. Синтаксические описания (202) могут включать в том числе: поверхностные модели (410), описания поверхностных позиций (420), референциальные описания и описания структурного контроля (430), описания управления и согласования (440), описание недревесного синтаксиса (450) и правила анализа (460). Синтаксические описания 202 используются для построения возможных синтаксических структур исходного предложения на данном исходном языке с учетом свободного линейного порядка слов, недревесных синтаксических явлений (например, координации, эллипсиса и т.д.), референциальных отношений и других соображений.
[0060] Поверхностные модели (410) представлены в виде совокупностей из одной или нескольких синтаксических форм («синтформ» 412) для описания возможных синтаксических структур предложений, включенных в синтаксические описания (202). В целом, любое лексическое значение в языке связано с поверхностными (синтаксическими) моделями (410), которые представляют составляющие, возможные в том случае, когда это лексическое значение играет роль «ядра», а всякая поверхностная модель включает набор поверхностных позиций дочерних элементов, описание линейного порядка, диатез и т.д.
[0061] В модели составляющих используется множество поверхностных позиций (415) дочерних составляющих и описаний их линейного порядка (416), она описывает грамматические значения (414) возможных заполнителей этих поверхностных позиций (415). Диатезы (417) представляют соответствия между поверхностными позициями (415) и глубинными позициями (514) (как показано на Фиг. 5). Коммуникативные описания (480) описывают коммуникативный порядок в предложении.
[0062] Описание линейного порядка (416) задается в виде выражений линейного порядка для того, чтобы выразить последовательность, в которой различные поверхностные позиции (415) могут встречаться в предложении. Выражения линейного порядка могут включать имена переменных, имена поверхностных позиций, круглые скобки, граммемы, оценки, оператор «or» (или) и т.д. Например, описание линейного порядка для простого предложения «Boys play football» (Мальчики играют в футбол.) можно представить в виде «Subject Core Object Direct» (Подлежащее - Ядро - Прямое дополнение), где «Subject» (Подлежащее), «Core» (Ядро) и «Object Direct» (Прямое дополнение) представляют собой имена поверхностных позиций (415), соответствующих порядку слов.
[0063] Коммуникативные описания (480) описывают порядок слов в синтаксической форме (412) с точки зрения коммуникативных актов, представленных в виде коммуникативных выражений порядка, которые похожи на выражения линейного порядка. Описание управления и согласования (440) содержит правила и ограничения на грамматические значения прикрепленных составляющих, которые используются во время синтаксического анализа.
[0064] Недревесные синтаксические описания (450) создаются для обработки различных языковых явлений, таких как эллипсис и согласование, они используются при трансформациях синтаксических структур, которые создаются на различных этапах анализа в различных вариантах реализации изобретения. Недревесные синтаксические описания (450) включают, в том числе, описание эллипсиса (452), описание сочинения (454), а также описание референциального и структурного контроля (430).
[0065] Правила анализа (460) используются на этапе семантического анализа и описывают свойства конкретного языка. Правила анализа (460) могут включать в том числе: правила вычисления семантем (462) и правила нормализации (464). Правила нормализации (464) используются в качестве правил трансформации для описания трансформаций семантических структур, которые могут отличаться в разных языках.
[0066] На Фиг. 5 приведена схема, иллюстрирующая пример семантических описаний. Компоненты семантических описаний (204) не зависят от языка, и включают в том числе: семантическую иерархию (510), описания глубинных позиций (520), систему семантем (530) и прагматические описания (540).
[0067] Ядром семантических описаний является семантическая иерархия (510), которая состоит из семантических понятий (семантических сущностей), называемых семантическими классами, расположенных в иерархической структуре в отношениях "родитель-потомок". Дочерний семантический класс наследует большинство свойств своего прямого родителя и всех семантических классов - предков. Например, семантический класс SUBSTANCE (Вещество) является дочерним семантическим классом класса ENTITY (Сущность) и материнским семантическим классом для классов GAS (Газ), LIQUID (Жидкость), METAL (Металл), WOOD_MATERIAL (Древесина) и т.д.
[0068] Каждый семантический класс в семантической иерархии (510) сопровождается глубинной моделью (512). Глубинная модель (512) семантического класса представляет собой набор глубинных позиций (514), которые отражают семантические роли дочерних составляющих в различных предложениях с объектами семантического класса в качестве ядра родительской составляющей, а также возможные семантические классы в качестве заполнителей глубинных позиций. Глубинные позиции (514) выражают семантические отношения, в том числе, например, «агенс», «адресат», «инструмент», «количество» и т.д. Дочерний семантический класс наследует и уточняет глубинную модель (512) своего родительского семантического класса.
[0069] Описания глубинных позиций (520) используются для описания общих свойств глубинных позиций (514), они отражают семантические роли дочерних составляющих в глубинных моделях (512). Описания глубинных позиций (520) также содержат грамматические и семантические ограничения заполнителей глубинных позиций (514). Свойства и ограничения глубинных позиций (514) и их возможных заполнителей очень похожи, часто они идентичны в разных языках. Таким образом, глубинные позиции (514) являются не зависимыми от языка.
[0070] Система семантем (530) представляет собой набор семантических категорий и семантем, которые представляют значения семантических категорий. В качестве примера семантическую категорию «DegreeOfComparison» (Степень сравнения) можно использовать для описания степени сравнения прилагательных, ее семантемами могут быть, например, «Positive» (Положительная), «ComparativeHigherDegree» (Сравнительная степень), «SuperlativeHighestDegree» (Превосходная степень) и др. В качестве другого примера семантическую категорию «RelationToReferencePoint» (Отношение к точке сравнения) можно использовать для описания порядка до референциальной точки или после нее; ее семантемами могут быть «Previous» (Предыдущая), «Subsequent» (Последующая), соответственно, причем этот порядок может быть пространственным или временным в широком смысле этих анализируемых слов. В еще одном примере можно использовать семантическую категорию «EvaluationObjective» (Оценка) для описания объективной оценки, такой как «Bad» (Плохой), «Good» (Хороший) и т.д.
[0071] Система семантем (530) включает независимые от языка семантические атрибуты, которые выражают не только семантические характеристики, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы можно использовать для выражения атомарного значения, которое находит регулярное грамматическое и (или) лексическое выражение в языке. По назначению и использованию систему семантем (530) можно разделить на различные виды, которые включают, в том числе: грамматические семантемы (532), лексические семантемы (534) и классифицирующие грамматические (дифференцирующие) семантемы (536).
[0072] Грамматические семантемы (532) используются для описания грамматических свойств составляющих при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы (534) описывают конкретные свойства объектов (например, "being flat" (быть плоским) или "being liquid" (являться жидкостью)), они используются в описаниях глубинных позиций (520) как ограничение заполнителей глубинных позиций (например, для глаголов «face (with)» (облицовывать) и «flood» (заливать), соответственно). Классифицирующие грамматические (дифференцирующие) семантемы (536) выражают дифференциальные свойства объектов внутри одного семантического класса; например, в семантическом классе HAIRDRESSER (Парикмахер) семантема «RelatedToMen» (Относится к мужчинам) присваивается лексическому значению «barber», в отличие от других лексических значений, которые также относятся к этому классу, например, «hairdresser», «hairstylist» и т.д.
[0073] Именно использование универсальных, независимых от языка семантических признаков, выражаемых элементами семантических описаний - семантическими классами, глубинными позициями, семантемами и т.д. в правилах извлечения информации составляет существенное отличие настоящего изобретения от других известных способов.
[0074] Прагматическое описание (540) позволяет системе назначить соответствующие тему, стиль или жанр текстам и объектам семантической иерархии (510). Например: «Экономическая политика», «Внешняя политика», «Юриспруденция», «Законодательство», «Торговля», «Финансы» и т.д. Прагматические свойства также могут выражаться семантемами. Например, прагматичный контекст может приниматься во внимание при семантическом анализе.
[0075] На Фиг. 6 приведена схема, иллюстрирующая лексические описания. Лексические описания (203) представляют множество лексических значений (612) конкретного языка для каждого компонента предложения. Для каждого лексического значения (612) можно установить связь (602) с его независимым от языка семантическим родителем для того, чтобы указать положение того или иного заданного лексического значения в семантической иерархии (510).
[0076] Каждое лексическое значение (612) имеет свою поверхностную модель (410), которая связана с соответствующей глубинной моделью (512) посредством диатез (417). Каждое лексическое значение (612) лексического описания языка наследует семантический класс от своего родителя и уточняет свою глубинную модель (512).
[0077] Каждая поверхностная модель (410) лексического значения включает одну или несколько синтаксических форм (412). Каждая синтаксическая форма (412) поверхностной модели (410) может включать одну или несколько поверхностных позиций (415) со своими описаниями линейного порядка (416), одно или несколько грамматических значений (414), выраженных в виде набора грамматических характеристик (граммем), одно или нескольких семантических ограничений на заполнители поверхностных позиций и одну или несколько диатез (417). Семантические ограничения на заполнитель поверхностной позиции представляют собой набор семантических классов, объекты которых могут заполнить эту поверхностную позицию.
[0078] Вернемся к Фиг. 2, на которой показаны основные этапы процесса семантико-синтаксического анализа. Дополнительно, на Фиг. 7 приведена последовательность структур данных, которые порождаются в процесс анализа.
[0079] Предварительно исходное предложение 212 на исходном языке подвергается лексико-морфологическому анализу 214 для построения лексико-морфологической структуры (722) исходного предложения. Лексико-морфологическая структура (722) представляет собой набор всех возможных пар «лексическое значение - грамматическое значение» для каждого лексического элемента (слова) в предложении. Пример такой структуры приведен на Фиг. 2В.
[0080] Затем проводится первый этап синтаксического анализа (на лексико-морфологической структуре) - грубый синтаксический анализ (215) для построения графа обобщенных составляющих (732). В процессе грубого синтаксического анализа (215) к каждому элементу лексико-морфологической структуры (722) применяются все возможные синтаксические модели возможных лексических значений, они проверяются для того, чтобы найти все потенциальные синтаксические связи в этом предложении, которые отражаются в графе обобщенных составляющих (732).
[0081] Граф обобщенных составляющих (732) представляет собой ациклический граф, узлами котором являются обобщенные (это означает, что они хранят все варианты) составляющие, а ветви - это поверхностные (синтаксические) позиции, выражающие различные типы отношений между обобщенными лексическими значениями. Все потенциально возможные поверхностные синтаксические модели проверяются для каждого элемента лексико-морфологической структуры предложения в качестве потенциального ядра составляющих. Затем строятся все возможные составляющие и обобщаются в графе обобщенных составляющих (732). Соответственно, рассматриваются все возможные синтаксические модели и синтаксические структуры исходного предложения (212), и в результате на основе набора обобщенных составляющих строится граф обобщенных составляющих (732). Граф обобщенных составляющих (732) на уровне поверхностной модели отражает все потенциальные связи между словами исходного предложения (212). Поскольку количество вариаций синтаксического разбора в общем случае может оказаться большим, граф обобщенных составляющих (732) является избыточным, он имеет большое число вариаций как в отношении выбора лексического значения для вершины, так и в отношении выбора поверхностных позиций для ветвей графа.
[0082] Граф обобщенных составляющих (732) изначально строится в виде дерева, начиная с листьев в сторону корня (снизу вверх) путем добавления дочерних компонентов к родительским составляющим, они заполняют поверхностные позиции (415) родительских составляющих для того, чтобы охватить все лексические единицы исходного предложения (712).
[0083] Как правило, корень дерева, который является главной вершиной графа (732), представляет собой предикат. В ходе этого процесса дерево обычно становится графом, поскольку составляющие более низкого уровня могут включаться в несколько составляющих более высокого уровня. Несколько составляющих, построенных для одних и тех же элементов лексико-морфологической структуры, в дальнейшем могут быть обобщены для получения обобщенных составляющих. Составляющие обобщаются на основе лексических значений или грамматических значений (414), например, основанных на частях речи и отношениях между ними. На Фиг. 8 приведен схематический пример графа обобщенных составляющих для ранее упоминавшегося предложения: «This boy is smart, he′ll succeed in life» (Этот мальчик умный, он добьется успеха в жизни).
[0084] Точный синтаксический анализ (216, Фиг. 2) выполняется для выделения синтаксического дерева (742) из графа обобщенных составляющих (732). Вычленяется одно или несколько синтаксических деревьев (218, Фиг. 2), и для каждого из них вычисляется общая оценка на основе использования множества априорных и вычисляемых оценок. Синтаксические деревья ранжируются от дерева с наилучшей оценкой к наименее вероятным деревьям. В одной из возможных реализаций может быть выбрано некоторое пороговое значение оценки для исключения "плохих" деревьев, которые в дальнейшем рассматриваться не будут. Таким образом, на данном этапе имеется, в общем случае, некоторое множество синтаксических деревьев. Генерация, вычисление оценок и обработка синтаксических деревьев может производиться независимо, в том числе и параллельно на разных вычислительных устройствах в компьютерной системе, в том числе с использованием системы client-server и т.п. На Фиг. 9 показан пример одного из синтаксических деревьев для ранее упоминавшегося предложения: «This boy is smart, he′ll succeed in life» (Этот мальчик умный, он добьется успеха в жизни).
[0085] Синтаксические деревья формируются в процессе выдвижения и проверки гипотез о возможной синтаксической структуре предложения, в этом процессе гипотезы о структуре частей предложения формируются в рамках гипотезы о структуре всего предложения.
[0086] Теперь вернемся к Фиг. 1. На этапе 130 в процессе перехода от выбранного синтаксического дерева к синтаксической структуре (746) генерируются недревесные связи. В общем случае, для каждого синтаксического дерева имеется некоторое множество вариантов установления недревесных связей, потому на этапе 130 (Фиг. 1) для каждого (одного или более) синтаксического дерева могут быть сгенерировано множество вариантов установления недревесных связей. На этапе 140 вычисляются оценки вариантов недревесных связей для одного или более синтаксических деревьев, фактически рассматривается множество синтаксических структур 744, которые являются "кандидатами" для получения наилучшей синтаксической структуры 746. На этапе 150 происходит ранжирование вариантов недревесных связей для каждого (одного или более) из синтаксических деревьев. Для каждой синтаксической структуры вычисляется оценка с учетом установленных недревесных связей, и синтаксические структуры, полученные на основе одного или более синтаксических деревьев, ранжируются (160) в соответствие с полученной оценкой. Выбирается структура с наилучшей оценкой. Таким образом, результатом точного анализа (216, Фиг. 2) является синтаксическая структура (746), которая рассматривается как лучшая синтаксическая структура анализируемого предложения. Фактически, в результате выбора лучшей синтаксической структуры (746) одновременно производится лексический выбор, т.е. определение лексических значений элементов предложения. Для иллюстрации недревесных связей рассмотрим несколько примеров.
[0087] Далее, на этапе 170 (Фиг. 1) производится переход к независимой от языка семантической структуре, которая отражает смысл предложения в универсальных, не зависимых от языка терминах. Независимая от языка семантическая структура предложения представляется в виде ациклического графа (дерева, дополненного недревесными связями), причем слова на конкретном языке в нем представлены узлами, размеченными универсальными (независимыми от языка) семантическими сущностями - семантическими классами семантической иерархии (510), а дуги соответствуют семантическим (глубинным) отношениям. Этот переход осуществляется с помощью применения правил анализа (460), в результате чего семантические классы сопровождаются наборами атрибутов (атрибуты выражают лексические, синтаксические и семантические свойства конкретных слов исходного предложения).
[0088] На Фиг. 9А показана синтаксическая структура с установленными недревесными связями для ранее упоминавшегося предложения: «This boy is smart, he′ll succeed in life» (Этот мальчик умный, он добьется успеха в жизни). Связь 901 демонстрирует сочинение, 902 - местоименную анафору, а 903 - некоторая вспомогательная связь, позволяющая собирать статистику и реализовать согласование в тех языках, где оно требуется. На Фиг. 10 показана соответствующая семантическая структура.
[0089] Остановимся подробнее на этапе 130 (Фиг. 1), в частности, на правилах, позволяющих устанавливать недревесные связи на В зависимости от типа анафорической связи применяются те или иные правила анализа.
[0090] Например, в результате синтаксического анализа предложения "Мальчик дал девочке свое яблоко" получается синтаксическое дерево, изображенное на Фиг. 11. Однако, в этом предложении существует смысловая, но не выраженная в синтаксическом дереве, связь между словами "мальчик" и "свое", указывающая на то, что мальчик дал именно свое яблоко, а не чье-то еще или просто любое другое, например, лежащее на тарелке или сорванное с дерева. Эта связь может и должна быть установлена, как показано на Фиг. 11А и быть выражена при помощи пунктирной стрелки 1110, однако для этого требуются некоторые нетривиальные действия. Кроме того, притяжательное местоимение, выраженное вершиной "свое" заменяется вершиной "мальчик"(1120), которая является недревесным контроллером и выполняет семантическую роль Possessor (владелец). Для того, чтобы связь 1110 была установлена, в синтаксической модели должно содержаться описание такой недревесной связи. Описание такой недревесной связи может связано с описанием лексического значения, лексемы, местоимения, либо с описанием поверхностной позиции, может также находиться среди описаний референциального контроля (456, Фиг. 4) etc.
[0091] Однако, определение контроллера и, соответственно, выбор глубинной позиции контроллера не всегда является однозначным. На Фиг. 12 и Фиг. 12А представлен результат разбора другого предложения "Мальчик любит этот дом, он его строил", без недревесных связей и с установленными недревесными связями - соответственно. Здесь также происходит замена вершины "он" на контроллер "мальчик", а "его" на "дом".
[0092] В зависимости от типа анафорической связи применяются те или иные правила анализа. Правила разрешения местоименной анафоры применяются, если в тексте встречаются определенного рода (certain) местоимения: он, она, оно, они, я, мы, ты, вы, себя, свой, друг друга, таковой и некоторые другие. Каждое такое правило содержит, по крайней мере, следующие компоненты:
[0093] список местоимений, которые инициируют это правило;
[0094] описание возможного пути, преимущественно, посредством поверхностных позиций, от возможного контроллера к местоимению (контроллером называется объект, который заменен в тексте местоимением);
[0095] описание допустимых свойств контроллера;
[0096] правило согласования контроллера и местоимения;
[0097] направление связи (находится контроллер слева или справа от местоимения);
[0098] вес связи.
[0099] Например, в примере, представленном на Фиг. 11 (Мальчик дал девочке свое яблоко) подходящее правило выбирает вершину с поверхностной позицией $Subject ("мальчик" - 1102) в качестве контроллера, поскольку в соответствующем правиле описан возможный путь от элемента с поверхностной позицией $Subject, но не описан как возможный путь от $Obiect_Dative (1104). Описание возможных свойств контроллера может заключаться, например, в недопустимости некоторых слов и словосочетаний в качестве контроллера. Вершина 1120 - результат замены в "свое " на "мальчик " в процессе установления анафорической связи 1110.
[00100] В предложениях "Мальчик любит девочку. Она красивая."" анафора разрешается однозначно, поскольку правило согласования предполагает согласование местоимения и контроллера в роде и числе.
[00101] Рассмотрим предложение "Мальчик любит этот дом - он его строил." Первоначально в результате анализа получается синтаксическое дерево без недревесных связей, представлено на Фиг. 12. Затем, как только система находит в этом фрагменте текста местоимения (он, его), срабатывают правила разрешения анафоры и продуцируются следующие связи:
[00102] link 1: Proform "он"; ProformParent "строить"; ProformSlot Object_Direct; Controller "дом"
[00103] link 2: Proform "он"; ProformParent "строить"; ProformSlot Object_Direct; Controller "мальчик"
[00104] link 3: Proform "он"; ProformParent "строить"; ProformSlot Subject; Controller "мальчик"
[00105] link 4: Proform "он"; ProformParent "строить"; ProformSlot Subject; Controller "дом"
[00106] На этапе 130 инициируются все возможные недревесные связи, однако, всякое местоимение может иметь только один контроллер. Система пытается применить все возможные варианты замены местоимения соответствующим контроллером и выбрать семантические роли (глубинные позиции) для них. Это порождает целое множество возможных синтаксических структур (с замененными местоимениями). Каждая из этих структур получает некоторую интегральную оценку (rating) в зависимости от семантической и синтаксической совместимости с другими элементами предложения. Структуры ранжируются и выбирается структура с наилучшей оценкой как результат анализа. Пример наилучшей структуры с недревесными связями представлен на Фиг. 12А.
[00107] На Фиг. 12А местоимение "он" заменено его контроллером "мальчик"в семантической роли Agent, а соответствующая анафорическая связь показана пунктирной стрелкой 1201. В свою очередь, местоимение "его"- заменяется контроллером "дом" в семантической роли Object_CreationDestruction, а соответствующая анафорическая связь показана пунктирной стрелкой 1202.
[00108] Относительная анафора встречается в предложениях, содержащих именную группу и относительное местоимение, например, Мальчик, который пришел.
[00109] Связи такого типа описываются такими же правилами, как для местоименной анафоры, за исключением того, что если для некоторого относительного местоимения контроллер не найден, вся такая структура отбрасывается. Относительные местоимения в семантической структуре также заменяется своими контроллерами в соответствующих семантических ролях, что также направлено на то, чтоб выбрать лучшего кандидата среди возможных, основываясь на семантической совместимости. Диапазон возможных кандидатов в случае относительного местоимения, как правило, несколько уже, т.к. контроллер относительного местоимения должен непосредственно управлять (govern) соответствующим релятивным клозом (clause), однако, и здесь возможны неоднозначности. Например, Мальчику понравилась игрушка девочки, которая пришла. Для разрешения этой неоднозначности система должна осознавать, что девочка с большей вероятностью может прийти, чем игрушка. Эта информация может быть получена только с учетом семантической совместимости.
[00110] Семантическая структура данного предложения показана на Фиг. 12В, где узел которая заменен на девочка в семантической роли Agent. Структура, где игрушка заполняет позицию предиката прийти, также рассматривается как потенциально возможная, но отвергается из-за низкой оценки.
[00111] Анафора является одним из примеров более сложной задачи - кореференции. Кореференция - это попытка связать несколько разных отсылок в тексте к одному реальному объекту. Задача усложняется, если именные группы не имеют текстового пересечения, как например, Обама и Президент США (относительно простым случаем является Обама и Барак Обама). Эта задача кореллирует с проблемой распознавания именованных сущностей и извлечением фактов из текстов.
[00112] В распознавании именованных сущностей обычно используют коллекции персон, локаций и организаций. Один из эвристических подходов состоит в том, что, если именованная сущность, т.е. имя собственное употребляется вместе (рядом) с именем несобственным, то, по крайней мере, на протяжении данного текста их можно отождествить полностью и даже иногда частично. Например, если в некотором тексте встречается Президент США Барак Обама, то можно предположить, что Президент США = Барак Обама и Президент США = Обама. Наиболее простой подход в распознавании имен персон состоит в использовании списков имен и идентификации капитализации первой буквы слова. Однако списки могут быть не полны, капитализация не является надежным способом, существует множество омонимичных имен (например, Bob, Virginia, Слава), а также имя собственное может относиться к именованию сущности, отличной от персоны. Например, пароход "Иван Федорович Крузенштерн ", ресторан "Пушкин " и т.п. Наконец, ссылка на персону может быть выражена несобственным именем или именной группой общего вида, например, мальчик, мужчина, космонавт, глава государства, state senator.
[00113] В общем случае, имя собственное может отсутствовать в словаре. В этом случае семантико-синтаксический анализ помогает установить эту ссылку на семантико-синтаксической структуре. Если некоторая вершина в дереве в результате анализа оказывается помеченной UNKOWN_BEING (т.е. для нее не определился семантический класс), то система анализирует родительскую вершину в дереве, т.е. ту вершину, которая управляет данной и потомком которой является UNKOWN BEING. Пример такого дерева для предложения "Язашел к капитану Харгуду" приведен на Фиг. 12С. Если эта родительская вершина оказывается названием профессии, звания, титула и т.п., частицей, указывающей на дворянское происхождение (vori) или леди, мистер, мисс, мадам, сеньор и т.п., то с большой вероятностью управляемая ею вершина является фамилией или именем персоны.
[00114] Другие маркеры персон могут включать, например, указание года рождения (Гельмгольц, 1989 г. р.), места рождения, организации (как места работы), скобочные конструкции с иностранными словами (Кхиеу Порн (Khieu Porn) стал жертвой своих земляков), локации, страны (Вик Уайлд (Россия) - 1 место), а также наличие некоторых специфичных глаголов (жениться, свататься и т.п.). Наличие в ближнем контексте - им может быть то же самое или соседнее (близко расположенное) предложение, других слов, указывающих на "персону", например, "спортсмен", "премьер-министр", "космонавт", "актриса", "девушка" и т.п., а также указательных местоимений, таких как "этот", "this" и т.п. позволяет строить и проверять гипотезы относительно отождествления из с другими именами и именными группами. В английском языке, например, наличие определенного артикля при существительном позволяет почти однозначно связать сущность с ее предшествующим упоминанием. Существуют соответствующие приемы для извлечения локаций, локаций, названий организаций и т.д.
[00115] Задача усложняется, если имеется несколько вариантов для отождествления сущностей. Однако, использование описанной выше технологии семантико-синтаксического анализа дает важные преимущества при разрешении кореференции. Суть подхода в данном случае сводится к двум этапам - 1) идентификации и 2) фильтрации. В ходе первого этапа выделяются пары для идентификации, на втором сопоставляются атрибуты элементов пар с тем, чтобы выявить совпадающие или наиболее близкие.
[00116] Возможность анализировать полученную в результате работы парсера синтаксическую структуру предложения и выявленные значения параметров (атрибуты) единиц этого предложения, такие как род, число и т.д. позволяют, например, различать сущности в предложениях.
[00117] Дополнительно к использованию правил, основанных на синтаксических моделях, могут учитываться семантические ограничения (restrictions). Например, если некоторый узел синтактико-семантической структуры с подчиненным узлом, представляющим "персону" в качестве объекта имеет именное дополнение? (nominal complement), система установит специальную дополнительную связь (link) от объекта к этому дополнению. Тогда, если та же самая лексема встречается где-либо в тексте в качестве дополнения, вторая "персона" будет идентифицирована и соотнесена (merged) с первой посредством этой специальной связи (two person objects will merge due to that special link). Например, имеется задача отождествления сущностей Бьорндален = биатлонист = спортсмен в следующем примере:
[00118] Бьорндален - великий биатлонист. Спортсмен показал высший класс на олимпиаде в Сочи. Биатлониста такого уровня нельзя списывать со счетов и после 40 лет.
[00119] Иллюстративный пример установления референциальных связей на множестве синтаксических деревьев, представляющих данные предложения, приведен на Фиг. 13. В первую очередь правила извлечения (extraction rules) идентифицируют три сущности: "Бьорндален", "биатлонист" и второй "биатлонист". Два упоминания "биатлонист" объединяются в одну сущность (связь 1301) на основании принадлежности к одному семантическому классу и после того, как синтаксическая структура первого предложения указывает на отождествление первого вхождения "биатлонист" с фамилией Бьорндален (связь 1302).
[00120] Чтобы восстановить всю цепочку кореференции, следует также связать "биатлонист/Бьорндален" с "спортсмен"(связи 1304 и 1305).
[00121] В одной из возможных реализаций для фильтрации пар, могут использоваться грамматические атрибуты (род, число, одушевленность и т.п.), а также используется метрика семантической близости в вышеупомянутой семантической иерархии. В этом случае можно оценить "расстояние" между лексическими значениями. На Фиг. 13А приведен фрагмент семантической иерархии с лексическими значениями "биатлонист" и "спортсмен". Они находятся в одной "ветке" дерева семантической иерархии и "биатлонист" находится в выделенном семантическом классе BIATHLETE, который в свою очередь является прямым потомком семантического класса SPORTSMAN, а "спортсмен" непосредственно включен в этот же класс SPORTSMAN. Т.е. "биатлонист" и "спортсмен" расположены "близко" в семантической иерархии, они имеют общего "предка" - семантический класс SPORTSMAN, более того, "спортсмен" является репрезентативным его представителем и в этом смысле гиперонимом по отношению к "биатлонист". Неформально говоря, для того, чтоб попасть из "биатлонист" в "спортсмен", в семантической иерархии нужно сделать всего несколько шагов. Метрика может учитывать принадлежность одному семантическому классу, наличие близко расположенного общего предка - семантического класса, репрезентативность, наличие/отсутствие некоторых семантем и т.п.
[00122] Кроме того, признаком, указывающим на возможную референциальную связь, является наличие указательного местоимения "этот", "тот", (также "эта", "это", "эти" и т.д.). Например, (лошадь - эта кляча; призрак - тот самый обозлившийся на него дух; аппарат - это устройство). В английском языке - определенный артикль "the", а также "this", "these", "that".
[00123] Подход легко распространяется на задачу установления референциальных связей не только при анализе и извлечении именованных сущностей (named entities), но и произвольные объекты реального мира.
[00124] Пример: Я помню замечательный эпизод, когда она похвасталась нам каким-то дорогим одеколоном, который она приобрела для молодого супруга. Мы попросили понюхать этот парфюм.
[00125] Фрагмент семантической иерархии изображен на Фиг. 13В Семантический класс "одеколон" (EAU-DE-COLOGNE) является прямым потомком класса "парфюм" (PRFUMES, который также включает "парфюмерия"), что позволяет объединить эти два объекта. Указательное местоимение "который" заменяется его контроллером "одеколон", а также включается в цепочку кореференции.
[00126] Другой пример: Скоро ужасную клячу, словно сбежавшую с живодерни увидали и другие зрители. Люди смеялись, удивлялись, спрашивали, негодовали. Как могла попасть сюда эта лошадь?
[00127] В семантической иерархии, фрагмент которой представлен на Фиг. 13С "лошадь" и "кляча" расположены в одном семантическом классе HORSE, при этом "кляча" является стилистически окрашенным синонимом для "лошадь". Правило установления референциальной связи, основанное на наличии указательного местоимения и близости в семантической иерархии, применимо и в этом случае.
[00128] Таким образом, в описываемом подходе могут не использоваться предопределенные списки сущностей, данный подход использует универсальную меру схожести, основанную на иерархическом представлении множества объектов реального мира и вычислении меры их "близости" в данном графовом представлении. В качестве такого иерархического представления может быть использована упомянутая выше семантическая иерархия (510, Фиг. 5).
[00129] Аналогично установлению анафорических недревесных связей, задача установления референциальных связей в пределах нескольких предложений также решается в два этапа. На первом этапе выделяются все возможные "кандидаты" - пары потенциально отождествляемых объектов, на втором этапе эти пары оцениваются и ранжируются в соответствии с выбранной мерой "близости".
[00130] На Фиг. 14 показан иллюстративный пример вычислительных средств для реализации описанных в настоящем документе методов и систем в соответствии с одним из вариантов осуществления настоящего изобретения. Как показано на Фиг. 14, пример оборудования (1400) включает по меньшей мере один процессор (1402), соединенный с запоминающим устройством (1404). Процессор (1402) может представлять собой один или несколько процессоров (например, микропроцессоров), а память (1404) может представлять собой устройства оперативной памяти (RAM), содержащие основное запоминающее устройство оборудования (1400), а также любые дополнительные уровни памяти (например, кэш-память, энергонезависимые или резервные запоминающие устройства, такие как программируемые запоминающие устройства или флэш-накопители), постоянные запоминающие устройства и т.д. Кроме того, память (1404) может включать запоминающее устройство, физически расположенное в другом месте оборудования (1400), например любую кэш-память в процессоре (1402), а также любое запоминающее устройство, используемое в качестве виртуальной памяти, например, память, хранящуюся в запоминающем устройстве большой емкости (1410).
[00131] Оборудование (1400) может иметь несколько входов и выходов для обмена информацией с другими устройствами. В качестве интерфейса пользователя или оператора оборудование (1400) может включать одно или несколько устройств ввода пользователя (1406) (например, клавиатуру, мышь, устройство обработки изображений, сканер и микрофон), а также одно или несколько устройств вывода (1208) (например, панель жидкокристаллического дисплея (LCD) и устройство воспроизведения звука (динамик)). Для реализации настоящего изобретения оборудование (1400) может включать в себя как минимум одно устройство с экраном.
[00132] Для дополнительного хранения данных оборудование (1400) может также включать одно или несколько устройств большой емкости (1410), например, накопитель на гибком диске или на другом съемном диске, накопитель на жестком диске, запоминающее устройство с прямым доступом (ЗУПД), оптический привод (например, привод оптических дисков (формата CD), привод с цифровым универсальным диском (формата DVD)), а также другие устройства. Кроме того, оборудование (1400) может включать интерфейс с одним или несколькими сетями (1412) (например, с локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и (или) Интернет и т.д.) для обмена информацией с другими компьютерами, подключенными к этим сетям. Следует иметь в виду, что оборудование (1400) обычно включает соответствующие аналоговые и (или) цифровые интерфейсы между процессором (1402) и каждым из компонентов (1404), (1406), (1408) и (1412), что хорошо известно специалистам в данной области.
[00133] Оборудование (1400) работает под управлением операционной системы (1414), на нем выполняются различные компьютерные программные приложения, компоненты, программы, объекты, модули и т.д. для реализации описанных выше способов. Кроме того, различные приложения, компоненты, программы, объекты и т.д., которые совместно обозначены на Фиг. 14 как прикладное программное обеспечение (1416), также могут выполняться в одном или нескольких процессорах в другом компьютере, подключенном к оборудованию (1400) через сеть (1412), например, в распределенной вычислительной среде, в результате чего обработка, необходимая для реализации функций компьютерной программы, может быть распределена по нескольким компьютерам в сети.
[00134] В целом, стандартные программы, выполняемые для реализации вариантов осуществления настоящего изобретения, могут быть реализованы как часть операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности команд, которые называются «программа для компьютера». Обычно программа для компьютера содержит один набор команд или несколько наборов команд, записанных в различные моменты времени в различных запоминающих устройствах и системах хранения в компьютере; после считывания и выполнения одним или несколькими процессорами в компьютере эти команды приводят к тому, что компьютер выполняет операции, необходимые для выполнения элементов, связанных с различными аспектами настоящего изобретения. Кроме того, несмотря на то, что это изобретение описано в контексте полностью работоспособных компьютеров и компьютерных систем, специалистам в данной области техники будет понятно, что различные варианты осуществления этого изобретения могут распространяться в виде программного продукта в различных формах, и что это изобретение в равной степени применимо для фактического распространения независимо от используемого конкретного типа машиночитаемых носителей. Примеры машиночитаемых носителей включают в том числе: записываемые носители, такие как энергонезависимые и энергозависимые устройства памяти, гибкие диски и другие съемные диски, накопители на жестких дисках, оптические диски (например, постоянные запоминающие устройства на компакт-диске (формата CD-ROM), накопители на цифровом универсальном диске (формата DVD), флэш-память и т.д.) и т.д.. Другой тип распространения можно реализовать в виде загрузки из сети Интернет.
[00135] Детали реализации представлены в данном описании исключительно для разъяснения. Для специалистов в данной области совершенно очевидно, что данные детали есть не более, чем примеры реализации изобретения. Структуры и устройства показаны только в виде блок-диаграмм во избежание неоднозначности интерпретаций.
[00136] Некоторые варианты реализации описаны и показаны на прилагаемых чертежах, однако следует понимать, что они являются лишь примерами, которыми не ограничивается область изобретения, и настоящее изобретение не ограничивается приведенными и описанными конструкциями и механизмами, поскольку специалисты в данной области техники после изучения данного описания могут предложить и другие модификации. В подобных быстрорастущих областях технологии сложно предвидеть дальнейшие достижения, и раскрытые варианты осуществления могут быть легко изменены или переделаны в тех или иных аспектах благодаря технологическим достижениям без отступления при этом от принципов настоящего раскрытия.
[00137] Несмотря на то, что данное описание содержит множество конкретных подробностей реализации, они не должны толковаться как ограничивающие объем любых изобретений или содержания возможных патентных заявок, а скорее как описание особенностей, характерных для конкретных вариантов реализаций конкретных изобретений. Некоторые функции, описанные в данном описании в контексте отдельных вариантов реализаций, также могут быть реализованы совместно в одном варианте осуществления. И наоборот, различные особенности, которые описаны в контексте одного варианта осуществления, также могут быть реализованы в нескольких вариантах осуществления отдельно или в виде любой подходящей комбинации.
[00138] Аналогичным образом, изображение операций на чертежах в определенном порядке не следует понимать как требование того, что такие операции необходимо производить в конкретной указанной последовательности, или что все показанные действия должны быть выполнены для достижения желаемого результата. При определенных обстоятельствах может оказаться предпочтительной многозадачная и параллельная обработка. Более того, разделение различных компонентов системы в описанных выше вариантах осуществления не следует понимать как необходимость такого разделения во всех вариантах осуществления; следует понимать, что описанные компоненты и программные системы могут быть интегрированы в единый программный продукт или совмещены в нескольких программных продуктов.
[00139] Таким образом, в настоящем описании были описаны конкретные варианты осуществления объекта изобретения. Другие варианты осуществления включены в объем приведенной ниже формулы изобретения. В некоторых случаях действия, изложенные в формуле изобретения, могут выполняться в другом порядке, при этом по-прежнему будут достигаться желаемые результаты. Кроме того, показанные на прилагаемых чертежах процессы не обязательно требуют указанного определенного порядка или последовательности действий для достижения желаемых результатов. В некоторых вариантах осуществления можно использовать многозадачность или параллельную обработку.
Реферат
Изобретение относится к системам и методам создания технологий, систем и продуктов для автоматической обработки текстовой информации и извлечения информации из текстов на естественных языках. Техническим результатом является повышение точности представления и извлечения информации в системах автоматической обработки текстов. В способе для создания синтактико-семантических структур предложений естественного языка в системах автоматической обработки текстов генерируют синтаксическое дерево для каждого предложения естественного языка, включающего множество синтаксических узлов и множество древесных синтаксических связей. Генерируют семантическую структуру, соответствующую синтаксическому дереву и включающую множество семантических узлов, соответствующих множеству синтаксических узлов, и множество древесных семантических связей, соответствующих множеству древесных синтаксических связей. Причем если синтаксическое дерево включает два различных синтаксических узла, соответствующих одной сущности, то соединяют семантические узлы, соответствующие этим синтаксическим узлам, недревесной связью. 3 н. и 15 з.п. ф-лы, 24 ил.
Формула
генерацию, посредством процессора вычислительного устройства, по крайней мере одного синтаксического дерева для каждого предложения естественного языка, включающего множество синтаксических узлов и множество древесных синтаксических связей;
генерацию, посредством процессора вычислительного устройства, по крайней мере одной семантической структуры, соответствующей по крайней мере одному синтаксическому дереву,
где по крайней мере одна семантическая структура включает множество семантических узлов, соответствующих множеству синтаксических узлов, и множество древесных семантических связей, соответствующих множеству древесных синтаксических связей;
если по крайней мере одно синтаксическое дерево включает по крайней мере два различных синтаксических узла, соответствующих одной сущности, то соединение семантических узлов, соответствующих этим синтаксическим узлам, по меньшей мере одной недревесной связью; и
выполнение, посредством процессора вычислительного устройства, дальнейшей обработки текста с использованием полученной семантической структуры.
генерацию множества возможных недревесных связей между синтаксическими узлами;
вычисление оценки для каждой возможной недревесной связи; и
выбор возможных недревесных связей с наивысшей оценкой.
где по крайней мере два различных синтаксических узла включают узел-контроллер и местоименный узел, управляемый узлом-контроллером;
где определение того, что узел-контроллер и местоименный узел соответствуют одной сущности, включает применение правила разрешения анафоры для местоименного узла;
где определение того, что узел-контроллер и местоименный узел соответствуют одной сущности, включает по меньшей мере одно из следующих действий:
определение, является ли путь в синтаксическом дереве между узлом-контроллером и местоименным узлом возможным в соответствии с данным правилом;
определение, является ли по крайней мере одно из свойств узла-контроллера допустимым в соответствии с данным правилом;
определение, являются ли узел-контроллер и местоименный узел грамматически согласованными в соответствии с данным правилом;
определение, является ли направление связи между узлом-контроллером и местоименным узлом возможным в соответствии с данным правилом;
определение, являются ли семантический узел, соответствующий узлу-контроллеру, и семантический узел, соответствующий местоименному узлу, семантически совместимыми;
определение, является ли значение оценки недревесной связи между семантическим узлом, соответствующим узлу-контроллеру, и семантическим узлом, соответствующим местоимению, выше некоторого порогового значения.
генерацию для по крайней мере одного синтаксического дерева различных наборов недревесных связей между по меньшей мере некоторыми синтаксическими узлами из множества синтаксических узлов;
вычисление оценки для каждого набора недревесных связей; и
определение, что синтаксические узлы, связываемые посредством недревесных связей с наивысшей оценкой, соответствуют одной сущности.
модуль синтаксического анализа, сконфигурированный для того, чтобы сгенерировать по крайней мере одно синтаксическое дерево для каждого предложения естественного языка, включающее множество синтаксических узлов и множество древесных синтаксических связей;
модуль семантического анализа, сконфигурированный для того, чтобы:
сгенерировать по крайней мере одну семантическую структуру, соответствующую по крайней мере одному синтаксическому дереву,
где по крайней мере одна семантическая структура включает множество семантических узлов, соответствующих множеству синтаксических узлов, и множество древесных семантических связей, соответствующих множеству древесных синтаксических связей;
определить, если по крайней мере одно синтаксическое дерево включает по крайней мере два различных синтаксических узла, соответствующих одной сущности, то обеспечить связывание семантических узлов, соответствующих этим синтаксическим узлам, по меньшей мере одной недревесной связью; и
модуль обработки текста для дальнейшей обработки текста с использованием полученной семантической структуры.
генерацию множества возможных недревесных связей между синтаксическими узлами;
вычисление оценки для каждой возможной недревесной связи; и
выбор возможных недревесных связей с наивысшей оценкой.
где по крайней мере два различных синтаксических узла включают узел-контроллер и местоименный узел, управляемый узлом-контроллером;
где определение того, что узел-контроллер и местоименный узел соответствуют одной сущности, включает применение правила разрешения анафоры для местоименного узла;
где определение того, что узел-контроллер и местоименный узел соответствуют одной сущности, включает по меньшей мере одно из следующих действий:
определение, является ли путь в синтаксическом дереве между узлом-контроллером и местоименным узлом возможным в соответствии с данным правилом;
определение, является ли по крайней мере одно из свойств узла-контроллера допустимым в соответствии с данным правилом;
определение, являются ли узел-контроллер и местоименный узел грамматически согласованными в соответствии с данным правилом;
определение, является ли направление связи между узлом-контроллером и местоименным узлом возможным в соответствии с данным правилом;
определение, являются ли семантический узел, соответствующий узлу-контроллеру, и семантический узел, соответствующий местоименному узлу, семантически совместимыми;
определение, является ли значение оценки недревесной связи между семантическим узлом, соответствующим узлу-контроллеру, и семантическим узлом, соответствующим местоимению, выше некоторого порогового значения.
генерацию для по крайней мере одного синтаксического дерева различных наборов недревесных связей между по меньшей мере некоторыми синтаксическими узлами из множества синтаксических узлов;
вычисление оценки для каждого набора недревесных связей; и
определение, что синтаксические узлы, связываемые посредством недревесных связей с наивысшей оценкой, соответствуют одной сущности.
генерации, посредством процессора вычислительного устройства, по крайней мере одного синтаксического дерева для каждого предложения естественного языка, включающего множество синтаксических узлов и множество древесных синтаксических связей;
генерации, посредством процессора вычислительного устройства, по крайней мере одной семантической структуры, соответствующей по крайней мере одному синтаксическому дереву,
где по крайней мере одна семантическая структура включает множество семантических узлов, соответствующих множеству синтаксических узлов, и множество древесных семантических связей, соответствующих множеству древесных синтаксических связей;
если по крайней мере одно синтаксическое дерево включает по крайней мере два различных синтаксических узла, соответствующих одной сущности, то включающий инструкции для соединения семантических узлов, соответствующих этим синтаксическим узлам, по меньшей мере одной недревесной связью; и
выполнения, посредством процессора вычислительного устройства, дальнейшей обработки текста с использованием полученной семантической структуры.
генерацию множества возможных недревесных связей между синтаксическими узлами;
вычисление оценки для каждой возможной недревесной связи; и
выбор возможных недревесных связей с наивысшей оценкой.
где по крайней мере два различных синтаксических узла, соответствующих одной сущности, принадлежат по крайней мере двум различным синтаксическим деревьям.
где по крайней мере два различных синтаксических узла включают узел-контроллер и местоименный узел, управляемый узлом-контроллером;
где определение того, что узел-контроллер и местоименный узел соответствуют одной сущности, включает применение правила разрешения анафоры для местоименного узла;
где определение того, что узел-контроллер и местоименный узел соответствуют одной сущности, включает по меньшей мере одно из следующих действий:
определение, является ли путь в синтаксическом дереве между узлом-контроллером и местоименным узлом возможным в соответствии с данным правилом;
определение, является ли по крайней мере одно из свойств узла-контроллера допустимым в соответствии с данным правилом;
определение, являются ли узел-контроллер и местоименный узел грамматически согласованными в соответствии с данным правилом;
определение, является ли направление связи между узлом-контроллером и местоименным узлом возможным в соответствии с данным правилом;
определение, являются ли семантический узел, соответствующий узлу-контроллеру, и семантический узел, соответствующий местоименному узлу, семантически совместимыми;
определение, является ли значение оценки недревесной связи между семантическим узлом, соответствующим узлу-контроллеру, и семантическим узлом, соответствующим местоимению, выше некоторого порогового значения.
генерацию для по крайней мере одного синтаксического дерева различных наборов недревесных связей между по меньшей мере некоторыми синтаксическими узлами из множества синтаксических узлов;
вычисление оценки для каждого набора недревесных связей; и
определение, что синтаксические узлы, связываемые посредством недревесных связей с наивысшей оценкой, соответствуют одной сущности.
Комментарии