Способ и устройство для анализа семантической информации - RU2704531C1
Код документа: RU2704531C1
Чертежи




Описание
Перекрестные ссылки на связанные заявки
[0001] Настоящая заявка ссылается на приоритет заявки на патент КНР
№201610338834.2, зарегистрированной в Государственном ведомстве по интеллектуальной собственности КНР (SIPO) 19 августа 2016 года, содержимое которой полностью включено в настоящий документ путем ссылки.
Область техники
[0002] Настоящее изобретение относится к области компьютерных технологий, а именно, к области Интернет-технологий, в частности, к способу и устройству для семантического анализа.
Предпосылки создания изобретения
[0003] В последние годы одним из важнейших и наиболее быстро развивающихся направлений в научной области и области знаний об искусственном интеллекте стали технологии обработки естественного языка, что привело к расширению теоретических исследований и позволило применять полученные знания для конструирования интеллектуальных роботов. Все больше веб-сайтов, связанных с Интернет-торговлей или предоставлением услуг, где требуются услуги консультантов, применяют подобные технологии для замены традиционного «ручного сервиса».
[0004] Сегодня применение технологий роботов с искусственным интеллектом в Интернет-продуктах сравнительно ограничено, например, следующими областями: консультирование по банковским услугам, вопросы и ответы, связанные с предпродажным и послепродажным сервисом в области Интернет-торговли. В подобных сервисах способ анализа семантической информации, выполняемого роботами, как правило, включает: во-первых, организацию знаний о сервисе вручную, классификацию знаний о сервисе, назначение вопросов и ответов, и затем «обучение» робота под «руководством» человека, и наконец, замена человека роботом для предоставления сервиса.
[0005] Однако, если у сервиса имеются множество точек обслуживания, описанный выше способ анализа пользовательской семантики роботами позволяет выявить лишь общий смысл пользовательского ввода, при этом точность анализа семантической информации невысока.
Сущность изобретения
[0006] Цель настоящего изобретения - предложить улучшенные способ и устройство для анализа семантической информации, которые бы позволили решить технические задачи, упомянутые в разделе «Предпосылки создания изобретения».
[0007] В первом аспекте настоящего изобретения предложен способ анализа семантической информации. Способ включает: прием семантической информации, введенной пользователем; анализ семантической информации, чтобы получить первичный текстовый признак для соответствующего сервиса; вычисление степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе; использование лингвистических данных, которым принадлежит признак лингвистических данных, наиболее сходный с упомянутым первичным текстовым признаком, в качестве первичного распознанного текста; извлечение признака из первичного распознанного текста, чтобы получить вторичный текстовый признак; получение признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса, и области сервиса, которой принадлежит полученный признак сервиса; получение весового значения, связанного с полученным признаком сервиса в базе данных весов признаков сервиса; использование области сервиса, которой принадлежит признак сервиса с наибольшим весовым значением, в качестве области сервиса, которой принадлежит упомянутый первичный распознанный текст; и анализ первичного распознанного текста в области сервиса, которой принадлежит первичный распознанный текст, чтобы получить вторичный распознанный текст.
[0008] Во втором аспекте настоящего изобретения предложено устройство для анализа семантической информации. Устройство включает: блок приема семантической информации, сконфигурированный для приема семантической информации, введенной пользователем; блок первичного анализа, сконфигурированный для анализа семантической информации, чтобы получить первичный текстовый признак для соответствующего сервиса; блок вычисления степени сходства, сконфигурированный для вычисления степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе; блок определения лингвистических данных, сконфигурированный для использования лингвистических данных, которым принадлежит признак лингвистических данных, наиболее сходный с упомянутым первичным текстовым признаком, в качестве первичного распознанного текста; блок извлечения признака, сконфигурированный для извлечения признака из первичного распознанного текста, чтобы получить вторичный текстовый признак; блок получения признака, сконфигурированный для получения признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса, и области сервиса, которой принадлежит полученный признак сервиса; блок получения веса, сконфигурированный для получения весового значения, связанного с полученным признаком сервиса в базе данных весов признаков сервиса; блок определения области, сконфигурированный для использования области сервиса, которой принадлежит признак сервиса с наибольшим весовым значением, в качестве области сервиса, которой принадлежит упомянутый первичный распознанный текст; и блок вторичного анализа, сконфигурированный для анализа первичного распознанного текста в области сервиса, которой принадлежит первичный распознанный текст, чтобы получить вторичный распознанный текст.
[0009] Путем извлечения текстового признака для сервиса, который соответствует семантической информации, введенной пользователем, чтобы получить первичный текстовый признак, и затем - вычисления степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе, использования лингвистических данных, которым принадлежит признак лингвистических данных, наиболее сходный с первичным текстовым признаком, в качестве первичного распознанного текста, извлечения признака первичного распознанного текста, с получением вторичного текстового признака, получения признака сервиса, который соответствует вторичному текстовому признаку в базе денных признаков сервиса, и области сервиса, которой принадлежит полученный признак сервиса, получения весового значения, связанного с полученным признаком сервиса в базе данных весов признаков сервиса, использования области сервиса, которой принадлежит признак сервиса с наибольшим значением веса, в качестве области сервиса, которой принадлежит первичный распознанный текст, и получения в результате этого вторичного распознанного текста, способ и устройство для анализа семантической информации, предложенные в настоящем изобретении, позволяют повысить точность результатов анализа семантической информации.
Краткое описание чертежей
[0010] Множество дополнительных элементов, целей и преимуществ настоящего изобретения могут стать очевидными при прочтении подробного описания неограничивающих вариантов осуществления настоящего изобретения, выполненного со ссылками на следующие приложенные чертежи:
[0011] фиг. 1 представляет собой блок-схему примера системной архитектуры, в которой может применяться настоящее изобретение;
[0012] фиг. 2 представляет собой блок-схему алгоритма для одного из вариантов осуществления способа анализа семантической информации в соответствии с настоящим изобретением;
[0013] фиг. 3 представляет эскизную собой блок-схему алгоритма для одного из сценариев применения способа анализа семантической информации в соответствии с настоящим изобретением;
[0014] фиг. 4 представляет собой структурную блок-схему одного из вариантов осуществления устройства для анализа семантической информации в соответствии с настоящим изобретением; и
[0015] фиг. 5 представляет собой эскизную структурную блок-схему компьютерной системы, приспособленной для реализации терминального устройства или сервера в вариантах осуществления настоящего изобретения.
Подробное описание вариантов осуществления изобретения
[0016] Ниже, в комбинации с приложенными чертежами, настоящее изобретение будет описано более подробно. Нужно понимать, что конкретные варианты осуществления настоящего изобретения в данном документе используются исключительно для описания настоящего изобретения, но не для его ограничения. При этом следует отметить, что для простоты описания на приложенных чертежах показаны только те элементы, которые имеют непосредственное отношение к настоящему изобретению.
[0017] Нужно также понимать, что варианты осуществления настоящего изобретения и различные их элементы могут комбинироваться друг с другом, если не возникает противоречий. Ниже настоящее изобретение будет рассмотрено более подробно, на примере приложенных чертежей, и в сочетании с различными вариантами его осуществления.
[0018] На фиг. 1 показан пример системной архитектуры 100, в которой может применяться способ анализа семантической информации или устройство для анализа семантической информации в соответствии с вариантами осуществления настоящего изобретения.
[0019] В соответствии с иллюстрацией фиг. 1 системная архитектура 100 может включать терминальные устройства 101, 102 и 103, сетью 104, и сервера 105 и 106. Сеть 104 служит в качестве среды передачи, обеспечивающей линию связи между терминальными устройствами 101, 102 и 103, и серверами 105 и 106. Сеть 104 может включать множество различных типов соединений, например, проводные или беспроводные линии передачи, или оптоволокно.
[0020] Пользователь 110 может использовать терминальные устройства 101, 102 и 103 для взаимодействия с серверами 105 и 106 по сети 104, с целью передачи, приема сообщений и т.п.На терминальных устройствах 101, 102 и 103 могут быть установлены различные клиентские приложения для связи, например, приложение браузера веб-страниц, приложения для покупок, приложения для поиска, инструменты мгновенных сообщений, клиенты электронной почты, а также программное обеспечение социальных платформ.
[0021] Терминальные устройства 101, 102 и 103 могут быть различными электронными устройствами, имеющими экраны и поддерживающими ввод семантической информации пользователем, включая, без ограничения перечисленным, смартфоны, планшетные компьютеры, устройства для чтения электронных книг, МР3-проигрыватели (Moving Picture Experts Group Audio Layer III, аудиослой для стандарта группы экспертов по движущемуся изображению, 3-я версия), МР4-проигрыватели (Moving Picture Experts Group Audio Layer IV, аудиослой для стандарта группы экспертов по движущемуся изображению, 4-я версия), портативные компьютеры и настольные компьютеры.
[0022] Серверы 105 и 106 могут быть серверами, предоставляющими различные сервисы, например, бекенд-серверы, анализирующие семантическую информацию, которую пользователь вводит при помощи терминальных устройств 101, 102 и 103, и предоставляющие ответную информацию. Бекенд-сервер может выполнять такую обработку данных, как анализ данных, например, семантической информации, введенной пользователем, и возвращать результат обработки (к примеру, ответ) в терминальные устройства.
[0023] Следует отметить, что способ анализа семантической информации в соответствии с различными вариантами осуществления настоящего изобретения исполняют, в основном, при помощи серверов 105 и 106. Соответственно, устройство для анализа семантической информации устанавливают, главным образом, на серверы 105 и 106.
[0024] Нужно понимать, что конкретное количество терминальных устройств, сетей и серверов на фиг. 1 приведено исключительно для примера. В зависимости от фактических требований может присутствовать любое количество терминальных устройств, сетей и серверов.
[0025] Обратимся к фиг. 2, где проиллюстрирован алгоритм 200 для одного из вариантов осуществления способа анализа семантической информации в соответствии с настоящим изобретением. Способ анализа семантической информации включает описанные ниже шаги.
[0026] Шаг 201 включает прием семантической информации, введенной пользователем.
[0027] В данном варианте осуществления настоящего изобретения электронное устройство (например, сервер, показанный на фиг. 1), на котором выполняют способ анализа семантической информации, может принимать семантическую информацию от терминала, при помощи которого пользователь совершает ввод, по проводному или беспроводному соединению. Следует отметить, что беспроводное соединение может включать, без ограничения перечисленным, соединение 3G/4G, соединение WiFi, соединение Bluetooth, соединение WiMAX, соединение Zigbee, соединение со сверхширокой полосой пропускания (ultra wideband, UWB) и другие беспроводные соединения, уже существующие или которые могут быть разработаны в будущем.
[0028] Обычно пользователи просматривают веб-страницы при помощи установленных в терминале приложений, например, приложения веб-браузера, приложения для покупок, приложения для поиска или приложения мгновенного обмена сообщениями. В таком случае для ввода семантической информации пользователь может применять один или более из следующих типов информации: голосовая информация, текстовая информация и информация о движениях губ. В данном варианте осуществления настоящего изобретения анализа семантическая информация может включать информацию в текстовом формате, формате изображения, или другую семантическую информацию, которая может иметь разработанный в будущем формат.
[0029] Шаг 202 включает анализ семантической информации, чтобы получить первичный текстовый признак для соответствующего сервиса.
[0030] В данном варианте осуществления настоящего изобретения, на основе семантической информации, принятой на шаге 201, может быть выполнен анализ семантической информации с получением первичного текстового признака для соответствующего сервиса. В данном примере, если семантическая информация является текстовой информацией, могут непосредственно быть извлечены признаки текстовой информации, и из этих извлеченных признаков может быть отобран первичный текстовый признак для соответствующего сервиса; если семантическая информация является голосовой информацией или информацией о движении губ, голосовая информация и/или информация о движении губ сначала должна быть проанализирована с получением соответствующей текстовой информации, и затем для этой текстовой информации выполняют извлечение признаков, после чего из извлеченных признаков отбирают первичный текстовый признак для соответствующего сервиса.
[0031] В данном примере для извлечения признаков текстовой информации может применяться статистический метод извлечения признаков, используемый в существующих технологиях или в технологиях, которые могут быть предложены в будущем. К примеру, для извлечения признаков из текстовой информации может применяться мера "частота слова - обратная частота документов", метод частоты слова, метод частоты документов и другие методы. Подобные статистические методы извлечения признаков позволяют оценить каждый из признаков в наборе признаков при помощи построения оценочной функции, и получения значения для каждого признака, благодаря чему каждое слово получает оценочное значение, которое также называют весовым значением. Все признаки затем упорядочивают по весовым значением, и заранее заданное количество оптимальных признаков извлекают в качестве подмножества признаков, являющихся результатом извлечения.
[0032] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения анализ семантической информации с получением первичного текстового признака для соответствующего сервиса может включать: сначала получение текстовой информации из упомянутой семантической информации; затем выполнение очистки и понижения размерности текстовой информации; затем выполнение семантического и синтаксического анализа над очищенной текстовой информацией с пониженной размерностью, чтобы получить признак текстовой информации, и наконец, - извлечение признака для соответствующего сервиса из этого признака текстовой информации, чтобы получить первичный текстовый признак.
[0033] В данном случае под выполнением очистки текстовой информации понимают последнюю процедуру поиска и исправления поддающихся идентификации ошибок в массивах данных, включая проверки целостности данных, обработку некорректных и недостающих значений. Задача очистки данных заключается в отфильтровывании данных, которые не подходят под требования. Данные, не подходящие под требования, в основном относятся к трем типам: неполные данные, ошибочные данные и дублирующие данные. К примеру, очистка может включать преобразование символов китайского и английского алфавита в текстовой информации, преобразование символов традиционного и упрощенного китайского алфавита, а также очистку дублирующих данных, конфликтующих данных, незначащих символов и т.п. Под незначащими символами здесь понимаются признаки, которые не влияют на классификацию, например, «здравствуйте", «извините» и бранные слова. Понижение размерности текстовой информации означает отображение выборочных точек из исходного пространства в пространство меньшей размерности при помощи линейного или нелинейного преобразования, в результате чего получают компактное и маломерное представление исходного набора данных. К примеру, для понижения размерности текстовой информации могут применяться следующие методы: метод отношения пропущенных значений, метод отфильтровывания данных с высокой корреляцией, метод главных компонент и т.п.
[0034] В данном случае выполнение семантического и синтаксического анализа над очищенной текстовой информацией с пониженной размерностью позволяет получать признаки текстовой информации, маркирующие различные размерности. Под синтаксическим анализом здесь понимается анализ различных грамматических соотношений между словами, а также словами в синтаксической структуре: подлежащее-сказуемое, сказуемое-дополнение, сказуемое - прямое дополнение, придаточное предложение, союзное предложение и т.п. Под семантическими взаимоотношениями здесь понимается соотношения между реальными объектами, представленными при помощи лингвистических компонентов в семантической информации. Под семантическим отношением понимают отношение между действиями и агентами, действиями и принимающей стороной действий, действиями и местами, вещами и вещами, и т.п. При семантическом и синтаксическом анализе может применяться заранее заданная модель сегментации на слова. Данные для «обучения» модели сегментации могут быть накопленными данными из истории вопросов и ответов, содержащие знания о сервисе, или данные, добавленные вручную.
[0035] В данном документе под извлечением признака для соответствующего сервиса из признака текстовой информации понимают отбрасывание некоторой части слов текстового признака, не относящихся к признакам сервиса, и увеличение весов для остальной части слов текстового признака, на основе упомянутого признака текстовой информации.
[0036] Шаг 203 вычисление степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе.
[0037] В данном варианте осуществления настоящего изобретения под корпусом понимают набор текстов, промаркированных заранее, или текст, полученный преобразованием головой информации, который может использоваться для анализа языка и для описания языка. Корпус при этом может рассматривать как конечный набор машиночитаемых текстов, представляющих язык, или вариант языка, наиболее полно. За счет вычисления степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе могут быть определены лингвистические данные, к которым принадлежит признак лингвистических данных, наиболее сходный с первичным текстовым признаком, т.е. первичный распознанный текст.
[0038] Шаг 204 включает использование лингвистических данных, которым принадлежит признак лингвистических данных, наиболее сходный с упомянутым первичным текстовым признаком, в качестве первичного распознанного текста.
[0039] В данном варианте осуществления настоящего изобретения, на основе степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе, вычисленной на шаге 203, могут быть выбраны лингвистические данные, к которым принадлежит признак лингвистических данных, наиболее сходный с первичным текстовым признаком, и эти выбранные лингвистические данные используют в качестве первичного распознанного текста.
[0040] Шаг 205 включает извлечение признака из первичного распознанного текста, в результате чего получают вторичный текстовый признак.
[0041] В данном варианте осуществления настоящего изобретения, на основе первичного распознанного текста, полученного на шаге 204, может быть извлечен признак первичного распознанного текста, и этот извлеченный признак первичного распознанного текста используют в качестве вторичного текстового признака.
[0042] В данном примере способ извлечения признака первичного распознанного текста может быть таким же, как описанный выше способ извлечения текстового признака, или может отличаться, при этом для извлечения признака из первичного распознанного текста могут использоваться статистические методы извлечения признаков, применяемые в существующих или созданных в будущем технологиях. К примеру, для извлечения признака из первичного распознанного текста применяться мера «частота слова - обратная частота документов», метод частоты слова, метод частоты в документах и другие методы. Подобные статистические методы извлечения признаков позволяют оценить каждый из признаков в наборе признаков при помощи построения оценочной функции, и получения значения для каждого признака, благодаря чему каждое слово получает оценочное значение, которое также называют весовым значением. Все признаки затем упорядочивают по весовым значением, и заранее заданное количество оптимальных признаков извлекают в качестве подмножества признаков, являющихся результатом извлечения.
[0043] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения извлечение признака первичного распознанного текста для получения вторичного текстового признака включает: сначала, получение первичного распознанного текста; затем выполнение очистки и понижение размерности над первичным распознанным текстом; и выполнение семантического и синтаксического анализа над очищенным первичным распознанным текстом пониженной размерности, в результате чего получают вторичный текстовый признак.
[0044] В данном случае очистка и понижение размерности представляют собой аналогичный описанному выше способу очистки и понижения размерности текстовой информации, и соответственно, его подробное описание повторно приведено не будет.
[0045] Шаг 206 включает получение признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса, и области сервиса, которой принадлежит полученный признак сервиса.
[0046] В данном варианте осуществления настоящего изобретения база данных признаков сервиса содержит признаки сервиса, заранее извлеченные из вопросов пользователей, а также области сервиса, которым эти признаки принадлежат. На основе вторичного текстового признака, полученного на шаге 205, в безе данных признаков сервиса может быть получен признак сервиса, соответствующий вторичному текстовому признаку, после чего получают область сервиса, которой принадлежит этот признак сервиса. Нужно понимать, что для каждой области сервиса в базе данных признаков сервиса может присутствовать один или более признаков сервиса, которые соответствуют одному вторичному текстовому признаку.
[0047] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения, для получения упрощенного признака сервиса, после выявления совпадения вторичного текстового признака и признаков в базе данных признаков сервиса, для полученного признака сервиса может выполняться разрешение анафоры, то есть, получение признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса может включать: сначала, получение признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса; затем выполнение разрешения анафоры для признака сервиса, соответствующего вторичному текстовому признаку, в результате чего получают анафоро-разрешенный признак сервиса; и наконец, назначение анафоро-разрешенного признака сервиса в качестве полученного признака сервиса.
[0048] В данном примере правила разрешения анафоры могут включать описанные ниже случаи.
[0049] В первом случае признаки сервиса включают местоимения, такие как: "this" («это»), "this one" («этот»), "the present" («текущий»), "the present one" («настоящий»), и эти местоимения заменяют существительные, герундии, и местоимения разрешают; во втором случае слова сервиса являются существительными или герундиями, при этом перед словами сервиса имеются прилагательные и герундии, в этом случае выполняют разрешение для прилагательных и герундия; в третьем случае словами, относящимися к сервису, являются существительные или герундий, при этом имеются глаголы, перед или после слов сервиса, и в этом случае выполняют разрешение для предшествующих глаголов; в четвертом случае, словами, относящимися к сервису, являются глаголы, при этом предложение содержит только одно существительное и один глагол, и в этом случае разрешение выполняют для других частей речи, например, в результате разрешения для "whether a system/n adapts/v (service word) well" («хорошо ли адаптируется (глагол, слово сервиса) система (существительное))» получают "system adapts" («система адаптируется»); в пятом случае, словами сервиса являются существительные, и при этом имеется только одно существительное в предложении, например, в результате разрешения для "what is this size/n (слово сервиса)" («Какой это размер (существительное, слово сервиса)») получают "size" («размер»); и в шестом случае словами сервиса являются прилагательные, при этом, если перед и после слова сервиса имеются другие слова сервиса, сравнивают их веса, и сохраняют слова сервиса с большим весом.
[0050] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения способ анализа семантической информации дополнительно включает: получение и определение признака сервиса в базе данных признаков сервиса, и области сервиса, которой принадлежит этот признак сервиса, при помощи следующих шагов: получение образца информации сервиса, в отмеченной области сервиса; выполнение сегментации на слова для этого образца на основе статистики и машинного обучения, и определение части речи для сегментированных слов; и определение признака сервиса в базе данных признаков сервиса, а также области сервиса, которой принадлежит признак сервиса, в соответствии с частотой встречаемости и частью речи для упомянутых сегментированных слов; К примеру, в модели, где областью сервиса является размер, тексты могут быть следующими: "what/a is/v goods/n's/uj size/n" (какой размер у товара) и "what/a is/v goods/n's/uj thickness/n" (какая толщина у товара), где n - существительное, nj - структурная вспомогательная морфема, v - глагол, а - прилагательное, и тогда признаками сервиса являются "size" (размер) и "thickness" (толщина). Затем анализируют связь между этими словами сервиса, то есть, {thickness}∈{size}, и следовательно, областью сервиса, к которой относятся эти признаки сервиса, является размер.
[0051] Шаг 207 включает получение весового значения, связанного с полученным признаком сервиса в базе данных весов признаков сервиса.
[0052] В данном варианте осуществления настоящего изобретения, если на шаге 206 получают один признак сервиса, то вес, соответствующий этому признаку сервиса может быть получен из базы данных весов для признаков сервиса, а если на шаге 206 получают множество признаков сервиса, то из базы данных весов для признаков сервиса могут быть получены соответствующие веса для каждого признака сервиса.
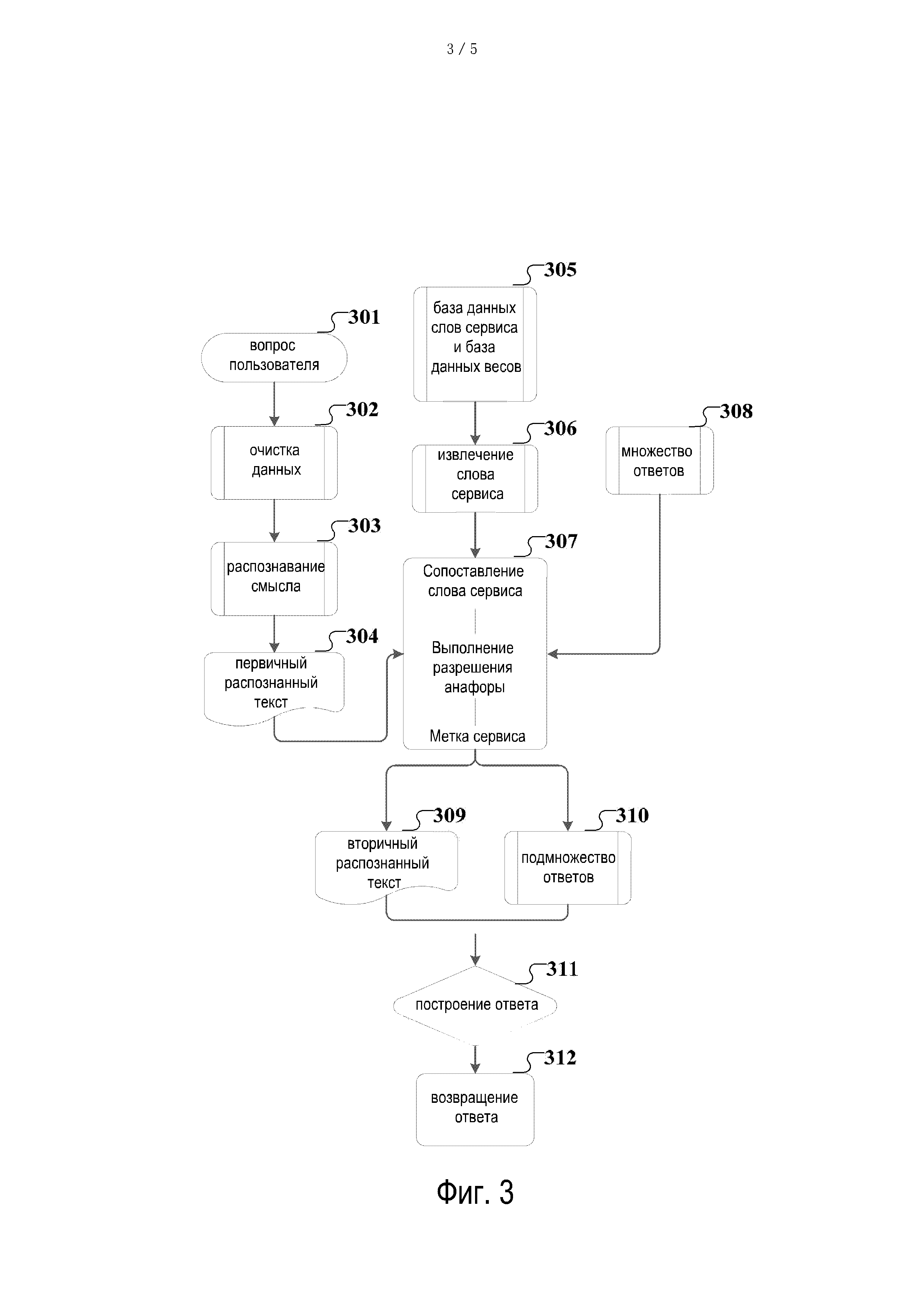
[0053] В данном примере база данных весов включает веса, заданные заранее на основе признака сервиса и области сервиса, к которой этот признак сервиса принадлежит. При назначении весов, как правило, считается что больший вес получают те признаки сервиса, которые позволяют выразить суть. При назначении весов признакам сервиса, могут в полной мере учитываться такие факторы, как частота встречаемости слова, часть речи, длина слова, расположение и синонимия. К примеру, слова с близким или идентичным значением могут трактоваться как одно слова, и их частоты могут складываться; существительное или комбинированное слово, содержащее существительное, может получать больший вес; и слово, содержащее 4 или более слов, может также получать больший вес.
[0054] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения способ анализа семантической информации дополнительно включает: назначение веса для признака сервиса в базе данных весов признаков сервиса в соответствии с гранулярностью признаков сервиса и заранее заданным отношением соответствия между гранулярностью и весом.
[0055] Под гранулярностью здесь понимается точность и полнота признака сервиса. К примеру, в соответствии с критерием разделения признака сервиса, веса в базе данных весов признаков сервиса могут быть разделены на три уровня: детализованные данные, среднее обобщение и высокое обобщение. Следует отметить один из возможных принципов определения гранулярности данных: чем выше степень уточнения, тем меньше гранулярность; чем ниже степень уточнения, тем выше гранулярность.
[0056] После определения гранулярности признака сервиса вес этого признака сервиса в базе данных весов признаков сервиса может быть назначен в соответствии с заранее заданным отношением соответствия между гранулярностью и весом.
[0057] Шаг 208 включает использование области сервиса, которой принадлежит признак сервиса с наибольшим весовым значением, в качестве области сервиса, которой принадлежит упомянутый первичный распознанный текст.
[0058] В данном варианте осуществления настоящего изобретения, если вес признака сервиса, полученный на шаге 207, является одиночным весом, то область сервиса, которой принадлежит этот признак сервиса, используют в качестве области сервиса, к которой принадлежит первичный распознанный текст; и если на шаге 207 получены множество весов для признаков сервиса, то это множество весов упорядочивают по убыванию, и область сервиса, к которой принадлежит признак сервиса, соответствующий первому весу, выбирают в качестве области сервиса, к которой принадлежит первичный распознанный текст, что позволяет более точно определить область, к которой принадлежит сообщение пользователя.
[0059] Шаг 209 включает анализ первичного распознанного текста в области сервиса, которой принадлежит первичный распознанный текст, в результате чего получают вторичный распознанный текст.
[0060] В данном варианте осуществления настоящего изобретения, исходя из области сервиса, к которой принадлежит первичный распознанный текст, полученной на шаге 208, над первичным распознанным текстом выполняют сегментацию на слова на основе статистики, и затем сегментированное слово сравнивают с признаком в области сервиса, к которой принадлежит первичный распознанный текст, в результате чего получают вторичный распознанный текст в области сервиса, к которой принадлежит первичный распознанный текст.
[0061] В некоторых из альтернативных реализаций данного варианта осуществления настоящего изобретения после получения вторичного распознанного текста может быть также получен ответ на вторичный распознанный текст, на основе вторичного распознанного текста: сначала определяют подмножество ответов, соответствующее данной области сервиса, во множестве ответов в соответствии с областью сервиса, которой принадлежит первичный распознанный текст, затем запрашивают вопрос, соответствующий вторичному распознанному тексту, в упомянутом подмножестве ответов, и затем получают ответ, соответствующий этому вопросу, и используют этот ответ в качестве ответа, соответствующего вторичному распознанному тексту, то есть, способ анализа семантической информации также включает: запрос ответа, соответствующего вторичному распознанному тексту, во множестве ответов, соответствующем области сервиса, к которому принадлежит первичный распознанный текст; и отображение ответа, соответствующего вторичному распознанному тексту.
[0062] Нужно понимать, что набор ответов здесь может включать, в общем случае, заранее заданные вопросы и ответы (question and answer, Q&A) с пометкой области, Q&A, включающие вопрос и ответ, соответствующий этом вопросу, при этом Q&A могут быть взяты из частых вопросов на официальном веб-сайте и соответствующих им ответов, могут быть взяты из Q&A, выбранных из записей чатов службы поддержки клиентов, которые велись вручную, или могут быть Q&A, записанными вручную в соответствии с вопросами.
[0063] Рассмотрим фиг. 3, которая представляет собой эскизную блок-схему алгоритма для одного из сценариев применения способа анализа семантической информации в соответствии с данным вариантом осуществления настоящего изобретения.
[0064] В соответствии с иллюстрацией фиг. 3, способ анализа семантической информации включает описанные ниже шаги.
[0065] Шаг 301 включает прием вопроса пользователя, затем переходят к шагу 302.
[0066] Шаг 302 включает очистку данных и понижение размерности текстовой информации из принятого вопроса пользователя, и затем переходят к шагу 303.
[0067] Шаг 303 включает распознавание смысла очищенной текстовой информации пониженной размерности, что включает: выполнение семантического и синтаксического анализа очищенной текстовой информации пониженной размерности, в результате чего получают признак текстовой информации, и извлечение признака соответствующего сервиса из текстовой информации, в результате чего получают первичный текстовый признак, и затем - вычисление степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе, и использование лингвистических данных, к которым принадлежит признак лингвистических данных, наиболее сходный с первичным текстовым признаком, качестве результата распознавания смысла, после чего переходят к шагу 307.
[0068] Шаг 304 включает использование результата распознавания смысла в качестве первичного распознанного текста.
[0069] Шаг 305 включает офлайн-вычисление базы данных признаков сервиса, включающей признаки сервиса и области сервиса, а также базу данных весов для признаков сервиса, включающую признаки сервиса и веса.
[0070] Шаг 306 включает извлечение признаков сервиса и весов для признаков сервиса из базы данных признаков сервиса.
[0071] Шаг 307 включает выполнение сегментации на слова на основе статистики для первичного распознанного текста и затем сопоставление каждого сегментированного слова с извлеченным признаком сервиса, и при выявлении соответствия, запись позиции сегментированного слова, а также поиск и определение, согласуется ли сегментированное слова с частями речи для предшествующего и последующего сегментированных слов, или является ли оно разрешимым, например, такими частями речи могут быть местоимения, прилагательные или герундий, и если это так, то слияние слов от упомянутой позиции слова до конца поиска в одну фразу, разрешение этой фразы в ключевое слово сервиса и прикрепление соответствующего веса; и затем, когда разрешение выполнено до конца текста, слияние разрешенного текста заново, назначение области сервиса, к которой принадлежит признак сервиса с наибольшим весом, в качестве области сервиса, к которой принадлежит первичный распознанный текст, и пометка области сервиса для объединенного текста, и затем переход к шагам 309 и 310.
[0072] Шаг 308 включает предварительное определение множества ответов, при этом множество ответов включает вопросы и ответы (Q&A) с пометкой области.
[0073] Шаг 309 включает повторный анализ первичного распознанного текста в области сервиса, о которой сделана пометка для объединенного текста, в результате чего получают вторичный распознанный текст, и затем переходят к шагу 311.
[0074] Шаг 310 включает извлечение подмножества ответов, соответствующего области сервиса, которой помечен объединенный текст, из множества ответов, определенного на шаге 308, и затем переходят к шагу 311.
[0075] Шаг 311 включает запрос признаков ответа, соответствующих признаку вторичного распознанного текста, из подмножества ответов, и сборку признаков ответа в ответ, и затем переходят к шагу 312.
[0076] Шаг 312 включает возврат построенного ответа.
[0077] В одном из сценариев применения, соответствующем рассмотренной выше блок-схеме алгоритма на фиг. 3, сначала от пользователя принимают ввод: "Hello, can this red pomegranate wash-free sleep mask improve a dark yellow skin type?" («Здравствуйте, будет ли эта ночная несмываемая маска «красный гранат» полезна для темно-желтого типа кожи»). При помощи очистки данных, понижения размерности и сопоставления с корпусом, такой ввод превращается в первичный распознанный текст "This red pomegranate wash-free sleep mask can improve a dark yellow skin type?" («Эта несмываемая ночная маска «красный гранат» будет полезна для темно-желтого типа кожи»). Затем выполняют сегментацию на слова и обнаруживают соответствующие слова сервиса, которыми являются: "mask {w=0.48}" (маска), "dark yellow {w=0.80}" (темно-желтый) и "skin type {w=0.6}" (тип кожи). В данном случае red (красный) является прилагательным, которое модифицирует pomegranate (гранат), их, соответственно, объединяют в "red pomegranate", перед которым находится местоимение "this", в результате чего "this red pomegranate" разрешают как "red pomegranate". Слово сервиса mask (маска) имеет глаголы (wash-free, sleep) и существительное (red pomegranate) перед ним, и эти слова разрешают в "mask" (маска). Прилагательное "dark yellow" (темно-желтый) модифицирует "skin type" (тип кожи). Поскольку областью сервиса, к которой принадлежит первичный распознанный текст, является «эффективность продукции», и вес "dark yellow" больше, чем вес "skin type", "dark yellow skin type" разрешается в "dark yellow', и окончательным проанализированным предложением будет "mask {w=0.48} may improve dark yellow {w=0.80}" («маска будет полезна темно-желтому»). Затем в соответствии с "mask {w=0.48} may improve dark yellow {w=0.80}" запрашивают соответствующий ответ в области "эффективность продукции" и возвращают построенный ответ.
[0078] Способ, предложенный в рассмотренном выше варианте осуществления настоящего изобретения, позволяет повысить точность результатов анализа семантической информации за счет определения области сервиса, к которой принадлежит первичный распознанный текст, и анализа первичного распознанного текста в выделенной области сервиса с получение вторичного распознанного текста.
[0079] Далее, на примере фиг. 4 рассмотрен вариант осуществления устройства для анализа семантической информации, которое является реализацией способа, проиллюстрированного на предыдущих чертежах. Данный вариант осуществления устройства соответствует варианту осуществления способа, показанного на фиг. 2, при этом предложенное устройство может применяться, в частности, в различных электронных устройствах.
[0080] В соответствии с иллюстрацией фиг. 4, устройство 400 для анализа семантической информации, предложенное в данном варианте осуществления настоящего изобретения, включает: блок 410 приема семантической информации, блок 420 первичного анализа, блок 430 вычисления степени сходства, блок 440 определения лингвистических данных, блок 450 извлечения признака, блок 460 получения признака, блок 470 получения веса, блок 480 определения области и блок 490 вторичного анализа.
[0081] В данном варианте осуществления настоящего изобретения блок 410 приема семантической информации сконфигурирован для приема семантической информации, введенной пользователем. Блок 420 первичного анализа сконфигурирован для анализа семантической информации, в результате чего получают первичный текстовый признак для соответствующего сервиса. Блок 430 вычисления степени сходства сконфигурирован для вычисления степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе. Блок 440 определения лингвистических данных сконфигурирован для использования лингвистических данных, которым принадлежит признак лингвистических данных, наиболее сходный с упомянутым первичным текстовым признаком, в качестве первичного распознанного текста. Блок 450 извлечения признака сконфигурирован для извлечения признака из первичного распознанного текста, в результате чего получают вторичный текстовый признак. Блок 460 получения признака сконфигурирован для получения признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса, и области сервиса, которой принадлежит полученный признак сервиса. Блок 470 получения веса сконфигурирован для получения весового значения, связанного с полученным признаком сервиса в базе данных весов признаков сервиса. Блок 480 определения области сконфигурирован для использования области сервиса, которой принадлежит признак сервиса с наибольшим весовым значением, в качестве области сервиса, которой принадлежит упомянутый первичный распознанный текст. Блок 490 вторичного анализа сконфигурирован для анализа первичного распознанного текста в области сервиса, которой принадлежит первичный распознанный текст, в результате чего получают вторичный распознанный текст.
[0082] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения устройство для анализа семантической может дополнительно включать (не показано на чертежах): блок запроса ответа, сконфигурированный для запроса ответа, соответствующего вторичному распознанному тексту, в множестве ответов, соответствующем области сервиса, к которому принадлежит первичный распознанный текст; и блок отображения ответа, сконфигурированный для отображения ответа, соответствующего вторичному распознанному тексту.
[0083] В некоторых из альтернативных реализаций данного варианта осуществления настоящего изобретения блок первичного анализа может быть дополнительно сконфигурирован: для получения текстовой информации из упомянутой семантической информации; для выполнения очистки и понижения размерности текстовой информации; для выполнения семантического и синтаксического анализа над очищенной текстовой информацией с пониженной размерностью, в результате чего получают признак текстовой информации, и для извлечения признака для соответствующего сервиса из этого признака текстовой информации, в результате чего получают первичный текстовый признак; и/или блок извлечения признака дополнительно сконфигурирован: для получения первичного распознанного текста; для выполнения очистки и понижения размерности над первичным распознанным текстом; и для выполнения семантического и синтаксического анализа над очищенным первичным распознанным текстом пониженной размерности, в результате чего получают вторичный текстовый признак.
[0084] В некоторых из альтернативных реализаций данного варианта осуществления настоящего изобретения блок получения признака может быть дополнительно сконфигурирован: для получения признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса; для выполнения разрешение анафоры для признака сервиса, соответствующего вторичному текстовому признаку, в результате чего получают анафоро-разрешенный признак сервиса; и для назначения анафоро-разрешенного признака сервиса в качестве полученного признака сервиса.
[0085] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения устройство для анализа семантической может дополнительно включать (не показано на чертежах): блок получения образца, сконфигурированный для получения образца информации сервиса, в отмеченной области сервиса; блок определения части речи, сконфигурированный для выполнения сегментации на слова для этого образца на основе статистики и машинного обучения, и для определения частей речи для сегментированных слов; и блок определения признака, сконфигурированный для определения признака сервиса в базе данных признаков сервиса, а также области сервиса, которой принадлежит признак сервиса, в соответствии с частотой встречаемости и частями речи для упомянутых сегментированных слов.
[0086] В некоторых альтернативных реализациях данного варианта осуществления настоящего изобретения устройство для анализа семантической может дополнительно включать (не показано на чертежах): блок назначения веса, сконфигурированный для назначения веса для признака сервиса в базе данных весов признаков сервиса в соответствии с гранулярностью признаков сервиса и заранее заданным отношением соответствия между гранулярностью и весом.
[0087] Специалисты в данной области техники должны понимать, что описанное выше устройство 400 для анализа семантической информации может также включать другие, общеизвестные структуры, например, процессоры и память. Чтобы излишне не усложнять описание вариантов осуществления настоящего изобретения, подобные общеизвестные структуры на фиг. 4 не показаны.
[0088] Нужно понимать, что блоки, описанные в составе устройства 400, соответствуют различным шагам способа, описанного на примере фиг. 2. Таким образом, операции и элементы, описанные выше для способа анализа семантической информации, равно применимы и к устройству 400, а также к блокам в его составе, и следовательно, их подробное описание не будет приведено повторно. Для реализации решений, предложенных в вариантах осуществления настоящего изобретения, соответствующие блоки в устройстве 400 могут взаимодействовать с блоками в терминальном устройстве и/или сервере.
[0089] В рассмотренных выше вариантах осуществления настоящего изобретения выражения «первичный текстовый признак» и «вторичный текстовый признак» указывают лишь на то, что исходные данные полученных текстовых признаков не являются идентичными, и что сами полученные текстовые признаки не являются идентичными, при этом способы получения текстовых признаков могут быть как одинаковыми, так и различными. Специалисты в данной области техники должны понимать, что слова «первичный» и «вторичный» не накладывают никаких ограничений на текстовые признаки.
[0090] В рассмотренных выше вариантах осуществления настоящего изобретения выражения «первичный распознанный текст» и «вторичный распознанный текст» указывают лишь на то, что исходные данные анализа не являются идентичными, что способы анализа не идентичны и что результирующие распознанные тексты не идентичны. Специалисты в данной области техники должны понимать, что слова «первичный» и «вторичный» не накладывают никаких ограничений на распознанные тексты.
[0091] Обратимся к фиг. 5, которая представляет собой эскизную структурную блок-схему компьютерной системы 500, приспособленной для реализации терминального устройства или сервера в вариантах осуществления настоящего изобретения.
[0092] В соответствии с иллюстрацией фиг. 5, компьютерная система включает центральный процессорный блок (central processing unit, CPU) 501, который может исполнять различные подходящие действия и процедуры в соответствии с программой, хранимой в памяти типа «только для чтения» (read-only memory, ROM), или программой, загружаемой в память с произвольным доступом (random access memory, RAM) из подсистемы 508 хранения. В RAM-памяти 503 также хранят различные программы и данные, необходимые для работы системы 500. CPU 501, ROM 502 и RAM 503 соединены друг с другом при помощи шины 504. К шине 504 подключен также интерфейс 505 ввода-вывода (input/output, I/O).
[0093] К интерфейсу 505 ввода-вывода подключены следующие компоненты: подсистема 506 ввода, включающая клавиатуру, мышь и т.п.; подсистема 507 вывода, включающая катодно-лучевую трубку (cathode ray tube (CRT), жидкокристаллическое дисплейное устройство (liquid crystal display, LCD), громкоговоритель и т.п.; подсистема 508 хранения, включающая жесткий диск или аналогичное устройство; и подсистема 509 связи, включающая сетевую интерфейсную карду, например, LAN-карту, и модем. Подсистема 509 связи выполняет процедуры связи по сети, например, Интернет. К интерфейсу 505 ввода-вывода может быть также подключен привод В привод 510 может устанавливаться съемный носитель 511, например, магнитный диск, оптический диск, магнитооптический диск или полупроводниковая память, в результате чего, при необходимости, обеспечивается извлечение компьютерной программы со съемного носителя 511 и установка ее в подсистему 508 хранения.
[0094] В частности, в соответствии с вариантами осуществления настоящего изобретения, процедура, описанная выше на примере блок-схемы алгоритма, может быть реализована в виде компьютерной программы. К примеру, один из вариантов осуществления настоящего изобретения может включать компьютерный программный продукт, который включает компьютерную программу, материально воплощенную на машиночитаемом носителе. Компьютерная программа включает программные коды для исполнения способа, проиллюстрированного на блок-схеме алгоритма. В таком варианте осуществления настоящего изобретения компьютерная программа может загружаться и устанавливаться из сети через подсистему 509 связи, и/или может быть установленной на съемном носителе 511. Компьютерная программа, при ее исполнении центральным процессорным блоком (CPU) 501 реализует описанную выше функциональность, определенную способами, предложенными в настоящем изобретении.
[0095] Блок-схемы и блок-схемы алгоритмов на приложенных чертежах иллюстрируют архитектуры, функции и операции, которые могут быть реализованы в соответствии с системами, способами и компьютерными программными продуктами из различных вариантов осуществления настоящего изобретения. В этой связи каждый из блоков на блок-схемах или блок-схемах алгоритмов может быть представлением модуля, программного сегмента или фрагмента кода, при этом упомянутые модуль, программный сегмент или фрагмент кода включают одну или более исполняемых инструкции для реализации заданных логических функций. Следует отметить, что в некоторых альтернативных реализациях, функции, обозначенные блоками, могут выполняться в последовательности, отличающейся от проиллюстрированной на чертежах. К примеру, любые два блока, изображенные как последовательные, могут исполняться по существу параллельно, или в некоторых случаях могут иметь обратную последовательность, в зависимости от исполняемой функции. Следует также отметить, что все блоки на блок-схемах и/или блок-схемах алгоритмов, а также комбинации из этих блоков, могут быть реализованы с использованием специализированной аппаратной системы, исполняющей заданные функции или операции, или с использованием комбинации из специализированного аппаратного обеспечения и компьютерных инструкций.
[0096] Блоки, задействованные в вариантах осуществления настоящего изобретения, могут быть реализованы при помощи программного обеспечения или аппаратного обеспечения. Описанные блоки могут быть при этом реализованы процессором, например, в соответствии со следующим описанием: процессор, включающий блок приема семантической информации, блок первичного анализа, блок вычисления степени сходства, блок определения лингвистических данных, блок извлечения признака, блок получения признака, блок получения веса, блок определения области и блок вторичного анализа, при этом наименования этих блоков сами по себе не всегда накладывают ограничения на эти блоки. К примеру, блок приема семантической информации может быть также описан как «блок для приема семантической информации, введенной пользователем».
[0097] В еще одном из аспектов настоящего изобретения предложен энергонезависимый компьютерный носитель. Энергонезависимый компьютерный носитель может быть энергонезависимым компьютерным носителем, входящим в состав устройства из описанных выше вариантов осуществления настоящего изобретения, или автономным энергонезависимым носителем, не входящим в состав устройства. На энергонезависимом компьютерном носителе хранят одну или более программ. Эти одна или более программ при исполнении устройством обеспечивают выполнение этим устройством следующего: прием семантической информации, введенной пользователем; анализ семантической информации, в результате чего получают первичный текстовый признак для соответствующего сервиса; вычисление степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе; использование лингвистических данных, которым принадлежит признак лингвистических данных, наиболее сходный с упомянутым первичным текстовым признаком, в качестве первичного распознанного текста; извлечение признака из первичного распознанного текста, в результате чего получают вторичный текстовый признак; получение признака сервиса, соответствующего вторичному текстовому признаку в базе данных признаков сервиса, и области сервиса, которой принадлежит полученный признак сервиса; получение весового значения, связанного с полученным признаком сервиса в базе данных весов признаков сервиса; использование области сервиса, которой принадлежит признак сервиса с наибольшим весовым значением, в качестве области сервиса, которой принадлежит упомянутый первичный распознанный текст; и анализ первичного распознанного текста в области сервиса, которой принадлежит первичный распознанный текст, в результате чего получают вторичный распознанный текст.
[0098] Приведенное выше описание лишь представляет собой лишь разъяснение предпочтительных вариантов осуществления настоящего изобретения и применяемых технических принципов. Специалисты в данной области техники должны понимать, что объем настоящего изобретения не ограничен техническими решениями конкретных комбинаций из рассмотренных выше технических элементов. В объем настоящего изобретения входят также другие технические решения, образованные любыми комбинациями из рассмотренных выше технических элементов, или эквивалентных им элементов, соответствующих замыслу настоящего изобретения. Неограничивающим примером подобного может служить замена рассмотренных выше элементов на элементы со сходными функциями, рассмотренными в настоящем изобретении.
Реферат
Изобретение относится к области компьютерных технологий для анализа семантической информации. Технический результат заключается в повышении точности результатов анализа семантической информации. Технический результат достигается за счёт анализа семантической информации для получения первичного текстового признака соответствующего сервиса; вычисления степени сходства между первичным текстовым признаком и признаком лингвистических данных в корпусе; использования лингвистических данных, которым принадлежит признак лингвистических данных, наиболее сходный с упомянутым первичным текстовым признаком, в качестве первичного распознанного текста; извлечения признака из первичного распознанного текста для получения вторичного текстового признака; получения признака сервиса, соответствующего вторичному текстовому признаку, и области сервиса, которой принадлежит полученный признак сервиса; получения весового значения, связанного с полученным признаком сервиса; анализа первичного распознанного текста в области сервиса, которой принадлежит первичный распознанный текст, с получением вторичного распознанного текста; устройства для анализа семантической информации. 3 н. и 10 з.п. ф-лы, 5 ил.
Комментарии