Оптимизированная для потоков многопроцессорная архитектура - RU2427895C2
Код документа: RU2427895C2
Чертежи



Описание
ПЕРЕКРЕСТНАЯ ССЫЛКА К СООТНЕСЕННЫМ ЗАЯВКАМ
Данная заявка испрашивает приоритет предварительной патентной заявки США № 60/764 955, поданной 3 февраля 2006. Все содержимое данной временной заявки представлено для справки.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ И СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Скорость компьютера можно увеличивать, используя два общих подхода: с помощью увеличения скорости выполнения команд или с помощью выполнения большего количества команд параллельно. Поскольку скорость выполнения команд приближается к пределам подвижности электронов в кремнии, параллелизм становится лучшей альтернативой для увеличения скорости компьютера.
Предыдущие попытки параллелизма включают в себя:
1. Совмещение выборки следующей команды с выполнением текущей команды.
2. Конвейерная обработка команд. Конвейер команд разбивает каждую команду на максимально возможное количество частей и затем пытается отобразить последовательные команды на параллельные исполнительные устройства. Теоретическое максимальное улучшение редко достигается из-за неэффективности многошаговых команд, неспособности многих программ обеспечить достаточное количество последовательных команд для сохранения параллельных исполнительных устройств заполненными и больших потерь времени, требуемых, когда встречается конструкция перехода, цикла или выбора, когда требуется вторичное заполнение исполнительных устройств.
3. Одна команда - множество данных, или SIMD. Этот тип методики можно найти в наборе команд Intel SSE, который воплощен в Intel Pentium 3 и других процессорах. В данной методике одна команда выполняется с множеством наборов данных. Эта методика удобна только для специальных приложений, таких как визуализация видеографики.
4. Гиперкуб. Эта методика использует большие двумерные массивы, а иногда трехмерные массивы процессоров и локальной памяти. Связи и взаимные соединения, необходимые для поддержания этих массивов процессоров по существу ограничивают их очень специализированными приложениями.
Конвейер является устройством, исполняющим команды, состоящим из множества последовательных ступеней, которые последовательно выполняют этапы исполнения команды, такие как выборка, декодирование, выполнение, сохранение и т.д. Несколько конвейеров можно размещать параллельно, так что команды программы подают на каждый конвейер одна за другой до тех пор, пока все конвейеры не будут исполнять команду. Затем заполнение командами повторяют с исходного конвейера. Когда N конвейеров заполнены командами и их исполнением, эффект производительности теоретически является таким же, как увеличение в N раз скорости выполнения для одного исполнительного устройства.
Успешная конвейерная обработка зависит от следующего:
1. Должна существовать возможность определения исполнения команды как нескольких последовательных состояний.
2. Каждая команда должна иметь одинаковое количество состояний.
3. Количество состояний в команде определяет максимальное количество параллельных исполнительных устройств.
Так как при конвейерной обработке можно достигать увеличения производительности, основываясь на количестве параллельных конвейеров, и так как количество параллельных конвейеров определяется количеством состояний в команде, конвейеры стимулируют использование сложных команд со многими состояниями.
Компьютеры с большим количеством конвейеров очень редко достигают производительности, приближающейся к теоретическому улучшению производительности, ожидаемому от исполнительных устройств с параллельными конвейерами. Некоторые из причин такого отсутствия улучшения при использовании конвейеров включают в себя:
1. Программы не состоят только из последовательных команд. Различные исследования показывают, что изменения потока выполнения происходят через каждые 8-10 команд. Любой переход, который изменяет процесс выполнения программы, вызывает сбой конвейера. Попытки минимизировать сбои конвейера имеют тенденцию быть сложными и неполными в их уменьшении.
2. То, что все команды вынуждены иметь одинаковое количество состояний, часто приводит к тому, что конвейеры выполнения удовлетворяют требованиям команды с наименьшим общим знаменателем (т.е. самой медленной и самой сложной). Из-за конвейера все команды принудительно имеют то же самое количество состояний, независимо от того, нужны они в них или нет. Например, логические операции (такие, как «И» или «ИЛИ») выполняют упорядочивание величин быстрее, чем команда ADD, но часто обеим распределяют одно и то же количество времени для выполнения.
3. Конвейеры стимулируют использование сложных команд со многими состояниями. Команды, в которых могут потребоваться два состояния, обычно растягивают, чтобы заполнить 20 состояний, потому что это - глубина конвейера. (Intel Pentium 4 использует конвейер с 20 состояниями).
4. Время, требуемое для каждого конвейерного состояния, должно учитывать задержки распространения через логическую схему и соответствующие транзисторы, в дополнение к отклонениям или допускам разработки для конкретного состояния.
5. Арбитраж для доступа к конвейерному регистру и другим ресурсам часто уменьшает производительность из-за задержек распространения в транзисторах в арбитражной логике.
6. Существует верхний предел количества состояний, на которые может быть разбита команда, до того, как дополнительное состояние фактически замедляет выполнение, а не ускоряет его. Некоторые исследования предполагают, что конвейерная архитектура в последнем поколении процессоров Альфа Корпорации Цифрового Оборудования превысила эту точку и фактически имеет более низкую производительность, чем предыдущая версия процессора с более коротким конвейером.
Разбиение конвейеров
Одной из перспектив реорганизации конструкции ЦП является разработка исполнительных устройств с конвейерной обработкой, которые затем разбивают на множество (N) упрощенных процессоров. (Регистры и некоторые другие логические схемы, возможно, необходимо дублировать при такой конструкции.) Каждый из N упрощенных процессоров будет иметь следующие преимущества перед обсуждаемой выше конвейерной архитектурой:
1. Нет остановок конвейерной обработки. Не требуется предсказания переходов.
2. Команды могут использовать такое количество времени, сколько им необходимо, а не все распределяемое одинаковое время выполнения, как для самой медленной команды.
3. Команды можно упрощать с помощью уменьшения количества необходимых состояний выполнения, таким образом уменьшая потери в конвейере.
4. Каждое состояние, удаленное из конвейера, может устранять задержки распространения и удалять допуски разработки, необходимые для данного состояния.
5. Арбитраж регистров можно устранять.
Кроме того, у системы с N упрощенными процессорами могут быть следующие преимущества перед центральным процессором с конвейерной обработкой:
1. Устранен предел максимального конвейерного параллелизма.
2. В отличие от процессора с конвейерной обработкой информации многочисленные автономные процессоры можно выборочно выключать для уменьшения потребляемой мощности, если их не используют.
Другие проблемы при существующем подходе к параллелизму
Многие реализации параллелизма не выдерживают ограничений закона Амдала (Amdahl). Ускорение через параллелизм ограничено служебной информацией из-за не преобразуемых в последовательную форму частей задачи. В основном, когда степень параллелизма увеличивается, связи, необходимые для его поддержания, уничтожают прибыль из-за параллелизма.
«Стоп-сигнал», расположенный на «красной линии»
Другой неэффективностью существующих процессоров является неспособность масштабирования вычислительной мощности для удовлетворения требований немедленного вычисления. Большинство компьютеров проводит большую часть своего времени, ожидая, когда что-нибудь произойдет. Они ждут ввода-вывода, следующей команды, доступа к памяти или иногда взаимодействия с пользователем. Это ожидание является неэффективной тратой вычислительной мощности. Кроме того, компьютерное время, потраченное на ожидание, часто приводит к увеличению потребления мощности и генерации тепла.
Исключениями из правила ожидания являются такие применения, как контроллеры двигателей, процессоры обработки сигналов и маршрутизаторы межсетевого экрана. Эти применения являются превосходными кандидатами на ускорение параллелизма из-за предопределенной природы наборов задач и наборов решений. Задача, которая требует результата N независимых умножений, может быть решена быстрее с использованием N блоков умножения.
Субъективно оцениваемой производительностью универсального компьютера является на самом деле его пиковая производительность. Самое близкое, что универсальный компьютер может получить для полного использования, является выполнение видеоигры с быстрым обновлением изображения, компиляция большого исходного файла или выполнение поиска в базе данных. В оптимальном случае визуализацию видеоизображения разлагают на специальные аппаратные средства построения теней, преобразования и визуализации. Одним из способов организации программирования таких специальных аппаратных средств является использование «потоков».
Потоки являются независимыми программами, которые являются самодостаточными и редко обмениваются данными с другими потоками. Обычным использованием потоков является сбор данных от медленной деятельности в реальном времени и выдача собранных результатов. Поток можно также использовать для обработки изменений на дисплее. Поток может переходить через тысячи или миллионы состояний прежде, чем потребовать дополнительного взаимодействия с другим потоком. Независимые потоки представляют возможность увеличения производительности через параллелизм.
Многие компиляторы программного обеспечения поддерживают генерацию и управление потоками в целях организации процесса разработки программного обеспечения. Одно и то же разложение поддерживает параллельную обработку множества ЦП через методику параллелизма на уровне потоков, воплощенную в оптимизированном для потоков микропроцессоре (TOMI) предпочтительного варианта осуществления.
Параллелизм на уровне потоков
Разбиение на потоки является хорошо понятной методикой для организации программы на одном центральном процессоре. Параллелизм на уровне потоков может обеспечивать ускорение работы программы через использование процессора TOMI.
Одним из существенных преимуществ процессора TOMI над другими параллельными подходами является то, что процессор TOMI требует минимальных изменений в текущей методике создания программного обеспечения. Не требуется разрабатывать новые алгоритмы. Многие существующие программы, возможно, придется перекомпилировать, но по существу не переписывать.
Эффективную компьютерную архитектуру TOMI необходимо создавать на основе большого количества упрощенных процессоров. Различная архитектура может использоваться для различных видов вычислительных задач.
Основные компьютерные операции
Для универсального компьютера самыми обычными операциями в порядке снижения частоты являются: загрузка и сохранение; определение последовательности; математические и логические операции.
Загрузка и сохранение (LOAD и STORE)
Параметрами команд LOAD и STORE являются источник и адресат. Мощностью команд LOAD и STORE является диапазон источника и адресата (например, 4 гигабайта является более мощным диапазоном чем 256 байтов). Местоположение относительно текущего источника и адресата важно для многих наборов данных. Наиболее часто используют плюс 1, минус 1. Большие смещения от текущего источника и адресата используют значительно реже.
На выполнение команд LOAD и STORE может также влиять иерархия памяти. Команда LOAD с запоминающего устройства может быть самой медленной операцией, которую может выполнять центральный процессор.
Определение последовательности
Переходы и циклы являются основными командами определения последовательности. Изменения последовательности команд, которые основаны на проверке, являются способом, которым компьютеры принимают решения.
Математические и логические операции
Математические и логические операции являются наименее используемыми из этих трех видов операций. Логические операции являются самыми быстрыми операциями, которые ЦП может выполнять, и они могут требовать всего одной задержки логического элемента. Математические операции более сложны, так как старшие биты зависят от результатов операций с младшими битами. 32-разрядная команда ADD («сложение») может потребовать по меньшей мере 32 задержки логического элемента, даже с предсказанием переноса. Команда MULTIPLY («умножение») с использованием методики сдвига и сложения может потребовать время, равное выполнению 32 операций ADD.
Компромисс относительно размера команды
Совершенный набор команд состоит из кодов операций, которые являются достаточно большими для выбора бесконечного количества возможных источников, адресатов, операций и следующих команд. К сожалению коды операции совершенного набора команд являются бесконечно широкими, и полоса пропускания для команды поэтому будет нулевой.
Разработка компьютера для команд с большой полосой пропускания включает создание набора команд с кодами операции, способными эффективно определять самые обычные источники, адресаты, операции и следующие команды с помощью наименьшего количества битов кода операции.
Широкие коды операции приводят к высоким требованиям полосы пропускания шины команд, и результирующая архитектура будет быстро ограничена узким местом фон Неймана (Von Neumann), причем производительность компьютера ограничена скоростью, с которой он выбирает команды из памяти.
Если шина памяти имеет ширину 64 бита, то можно выбирать одну 64-битовую команду, две 32-битовые команды, четыре 16-битовые команды или восемь 8-битовых команд в каждом цикле обращения к памяти. 32-битовая команда должна быть в два раза эффективней 16-битовой команды, так как она обрезает полосу пропускания команды наполовину.
Главная цель разработки набора команд состоит в уменьшении избыточности команд. В общем случае оптимизированный эффективный набор команд использует местоположение и команд, и данных. Самая простая оптимизация команд давно сделана. Для большинства компьютерных программ наиболее вероятной следующей командой является последовательно следующая команда в памяти. Поэтому вместо того чтобы каждая команда имела поле следующей команды, большинство команд предполагает, что следующей командой является текущая команда + 1. Можно создавать архитектуру с нулем битов для источника и нулем битов для адресата.
Архитектура стека
Компьютеры с архитектурой стека также называют архитектурой с нулевым операндом. Архитектура стека выполняет все операции, основываясь на содержимом стека магазинного типа. Операция с двумя операндами требует, чтобы оба операнда присутствовали в стеке. При выполнении операции оба операнда считывают из стека, выполняют операцию и результат записывают назад в стек. У компьютеров с архитектурой стека могут быть очень короткие коды операции, так как подразумевается, что источник и адресат находятся в стеке.
Большинство программ требует содержимого глобальных регистров, которые не всегда могут быть доступны в стеке при необходимости. Попытки минимизации таких случаев включают в себя индексирование стека, что позволяет обращаться к другим операндам, чем те, которые находятся на вершине стека. Индексация стека требует или дополнительных битов кода операции, что приводит к увеличению размера команд, или дополнительных операций для размещения значения индекса стека в сам стек. Иногда определяют один или большее количество дополнительных стеков. Лучшим, но не оптимальным, решением является комбинация архитектур стека/регистра.
Работа архитектуры стека также часто избыточна в том, что игнорирует очевидную оптимизацию. Например, каждая операция POP (считывания из стека) и PUSH (записи в стек) потенциально может вызвать затрачивающую время операцию обращения к памяти, поскольку стеком манипулируют в памяти. Кроме того, операция стека может использовать операнд, который может потребоваться немедленно для следующей операции, таким образом требуя дублирования операнда с потенциальной возможностью еще одной операции обращения к памяти. Рассматривают, например, операцию умножения всех элементов одномерного массива на 15.
В архитектуре стека ее воплощают с помощью:
1. PUSH начальный адрес массива
2. DUPLICATE адрес (таким образом имеют адрес для сохранения результата в массиве)
3. DUPLICATE адрес (таким образом имеют адрес для считывания из массива)
4. PUSH INDIRECT (записывают содержимое местоположения массива, на которое указывает вершина стека)
5. PUSH 15
6. MULTIPLY (15 раз содержимое массива, которые считывают в строке 3)
7. SWAP (получают адрес массива на вершине стека для следующей команды)
8. POP INDIRECT (считывают результат умножения и сохраняют его назад в массив)
9. INCREMENT (указывают на следующий элемент массива)
10. Переходят на этап 2 до тех пор, пока массив не будет обработан.
Счетчик цикла в строке 9 требует дополнительного параметра. В некоторых архитектурах этот параметр сохраняют в другом стеке.
В гипотетической архитектуре регистра/сумматора данный пример воплощают с помощью:
1. STORE POINTER начальный адрес массива
2. READ POINTER (считывают содержимое по указанному адресу в сумматор)
3. MULTIPLY 15
4. STORE POINTER (сохраняют результат по указанному адресу)
5. INCREMENT POINTER
6. Переходят к строке 2, пока массив не будет обработан.
Можно сравнить девять этапов для архитектуры стека с пятью этапами для архитектуры регистра для приведенного выше примера. Кроме того, у операции стека существует по меньшей мере 3 возможных дополнительных обращения к памяти из-за операции стека. Управление циклами гипотетической архитектурой регистра/сумматора можно легко обрабатывать в регистре.
Стеки удобны для оценки выражений и используются также в большинстве компиляторов. Стеки также удобны для вложенных операций, таких как вызов функции. Большинство компиляторов языка Си воплощают вызов функции с помощью стека. Однако, без дополнения универсальной памятью, архитектура стека требует большого количества дополнительных перемещений и обработки данных. В целях оптимизации операций со стеком команды PUSH и POP также необходимо отделять от математических и логических операций. Но как можно заметить по приведенному выше примеру, стеки, в частности, неэффективны, когда повторно загружают и сохраняют данные, так как адреса массива используются командами PUSH INDIRECT и POP INDIRECT.
В одном из аспектов изобретение содержит систему, содержащую: (a) множество параллельных процессоров в одной микросхеме; и (b) компьютерную память, расположенную в данной микросхеме и доступную каждому из процессоров; причем каждый из процессоров предназначен для обработки минимального набора команд, и причем каждый из процессоров содержит локальную кэш-память, выделенную для каждого из по меньшей мере трех определенных регистров в процессоре.
В различных вариантах осуществления: (1) размер каждой локальной кэш-памяти равен одной строке оперативной памяти в микросхеме; (2) по меньшей мере три определенных (конкретных) регистра со связанной кэш-памятью включают в себя регистр команды, регистр-источник и регистр-адресат; (3) минимальный набор команд состоит из семи команд; (4) каждый из процессоров предназначен для обработки одного потока; (5) сумматор является операндом для каждой команды, кроме команды приращения; (6) адресатом для каждой команды всегда является регистр операнда; (7) три регистра автоинкрементные и три регистра автодекрементные; (8) каждая команда требует только одного тактового цикла для завершения; (9) набор команд не содержит команд BRANCH и JUMP; (10) каждая команда имеет длину самое большее 8 битов; и (11) один главный процессор отвечает за управление каждым из параллельных процессоров.
В другом аспекте изобретение содержит систему, содержащую: (a) множество параллельных процессоров в одной микросхеме; и (b) компьютерную память, расположенную в данной микросхеме и доступную каждому из процессоров, причем каждый из процессоров предназначен для обработки набора команд, оптимизированного для параллельной обработки на уровне потоков.
В различных вариантах осуществления: (1) каждый из процессоров предназначен для обработки минимального набора команд; (2) каждый из процессоров содержит локальную кэш-память, выделенную для каждого из по меньшей мере трех определенных регистров в процессоре; (3) размер каждой локальной кэш-памяти равен одной строке оперативной памяти в микросхеме; (4) по меньшей мере три определенных регистра включают в себя регистр команды, регистр-источник и регистр-адресат; (5) минимальный набор команд состоит из семи команд; (6) каждый из процессоров предназначен для обработки одного потока; и (7) один главный процессор отвечает за управление каждым из параллельных процессоров.
В другом аспекте изобретение содержит способ параллельной обработки на уровне потоков, используя множество параллельных процессоров, главный процессор и компьютерную память на одной микросхеме, причем каждый из множества процессоров предназначен для обработки минимального набора команд и обработки одного потока, содержащий этапы: (a) распределяют локальную кэш-память каждому из трех определенных регистров в каждом из множества процессоров; (b) распределяют один из множества процессоров для обработки одного потока; (c) обрабатывают каждый распределенный поток с помощью процессоров; (d) обрабатывают результаты каждого потока, обработанного с помощью данных процессоров; и (e) выполняют освобождение одного из множества процессоров после того, как поток обработан.
В различных вариантах осуществления: (1) минимальный набор команд состоит из семи команд; (2) команда в минимальном наборе команд имеет длину самое большее 8 битов; и (3) каждую команду в минимальном наборе команд обрабатывают в одном тактовом цикле.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 показывает примерную архитектуру TOMI одного из вариантов осуществления.
Фиг. 2 показывает примерный набор команд.
Фиг. 2A показывает операцию перехода вперед.
Фиг. 3 показывает фактические адреса при различных способах адресации.
Фиг. 4 показывает, как легко создают маршруты обработки данных из 4-32 битов.
Фиг. 5 показывает примерную локальную кэш-память.
Фиг. 6 показывает примерные состояния управления кэш-памятью.
Фиг. 7 показывает один из вариантов осуществления дополнительных функциональных возможностей обработки, организованных для использования преимуществ широкой шины системной ОП.
Фиг. 8 показывает примерную карту памяти.
Фиг. 9 показывает примерную таблицу доступности процессов.
Фиг. 10 показывает три компонента распределения процессоров.
Фиг. 11 показывает примерное разбиение.
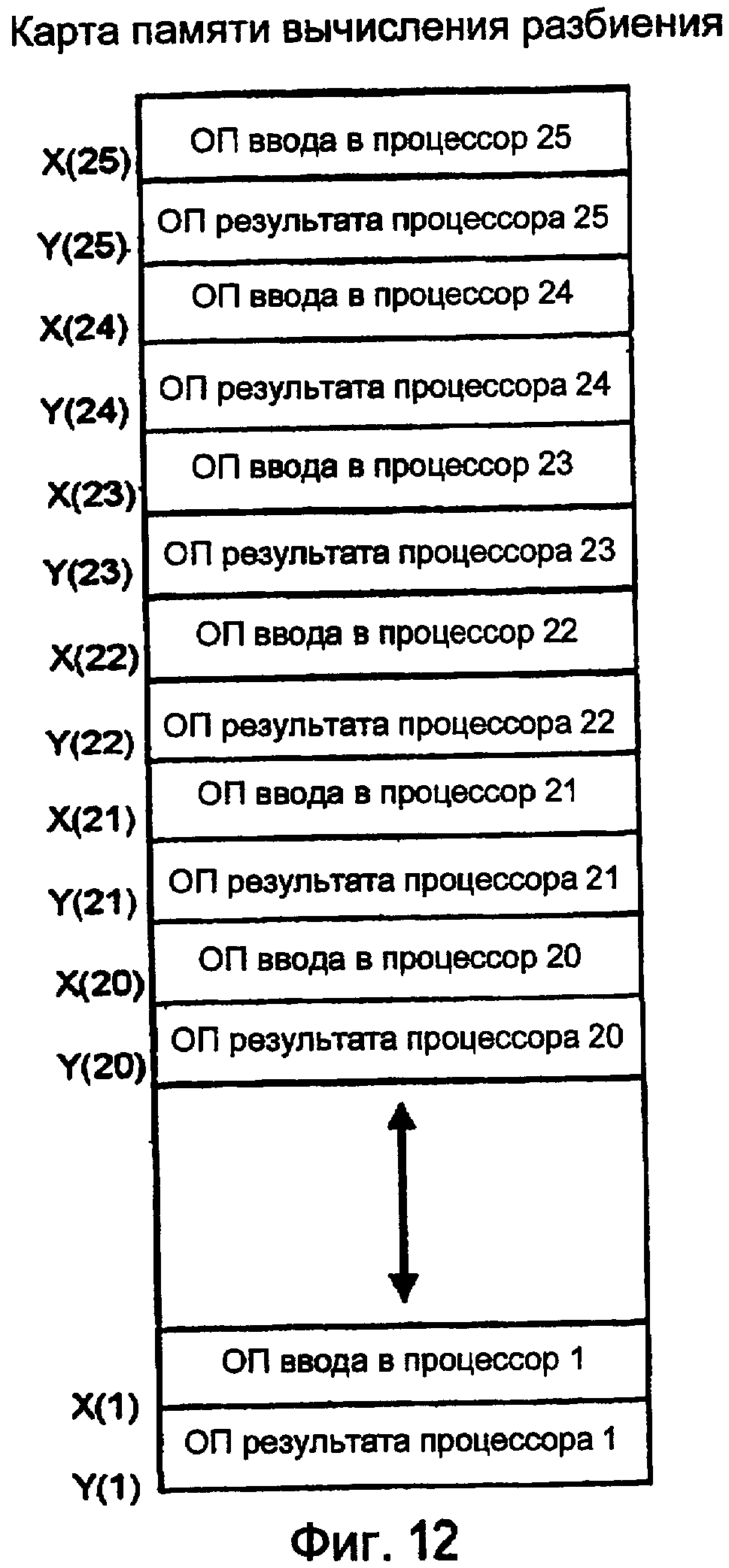
Фиг. 12 показывает примерную системную ОП.
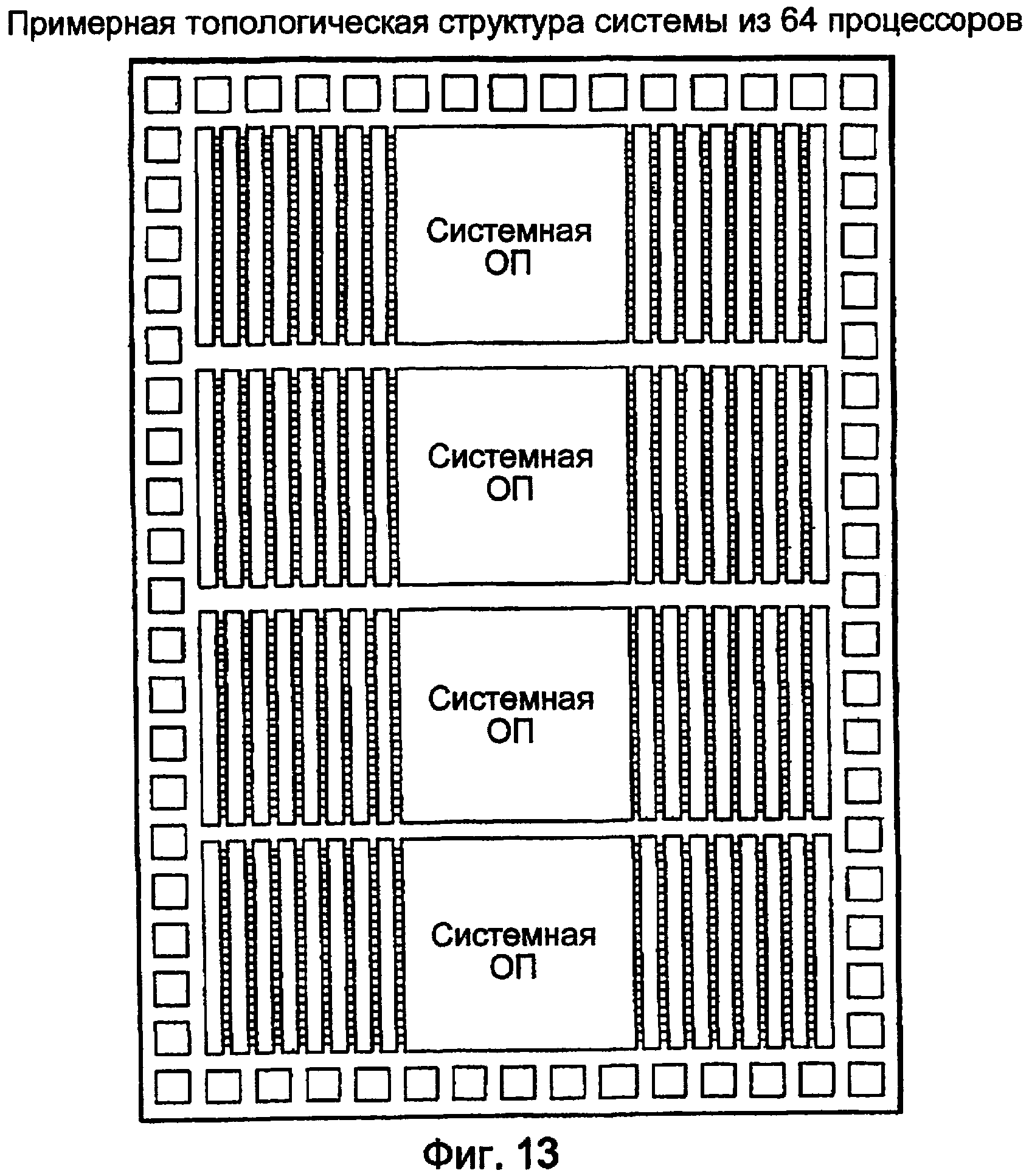
Фиг. 13 показывает примерную общую топологическую структуру для монолитного массива из 64 процессоров.
ПОДРОБНОЕ ОПИСАНИЕ ОПРЕДЕЛЕННЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Архитектура TOMI по меньшей мере одного из вариантов осуществления настоящего изобретения предпочтительно использует минимальное количество логических схем для предоставления возможности работать в качестве универсального компьютера. Самым обычным операциям уделяют первостепенное значение (дают заданный приоритет). Большинство операций являются очевидными, стандартными и доступными для оптимизации с помощью компилятора.
В одном из вариантов осуществления архитектура TOMI является разновидностью архитектуры сумматора, регистра и стека, как показано на фиг. 1. В данном варианте осуществления:
1. Как в архитектуре сумматора, сумматор всегда является одним из операндов, за исключением команды приращения.
2. Как в архитектуре с регистрами, адресат всегда является одним из регистров операндов.
3. Сумматор и счетчик программы находятся также в пространстве регистра, и поэтому с ними можно выполнять операции.
4. Три специальных регистра являются автоинкрементными и автодекрементными и удобны для создания стеков и потоков ввода/вывода.
5. Все операции требуют одного тактового цикла (и двух состояний: высокий уровень синхроимпульса, низкий уровень синхроимпульса).
6. Все команды имеют длину 8 битов, что упрощает и ускоряет декодирование команд.
7. Не существует команд BRANCH или JUMP.
8. Существует только семь команд, что предоставляет возможность выбора 3 бит оператора из 8-битовой команды, как показано на фиг. 2.
Некоторые из преимуществ предпочтительного варианта осуществления включают в себя:
1. Все операции работают на максимальной скорости, которую позволяют логические схемы, а не ограничены одинаковым размером, который требует конвейер. Логические операции являются самыми быстрыми. Математические операции являются следующими самыми быстрыми. Операции, требующие доступа к памяти, являются самыми медленными.
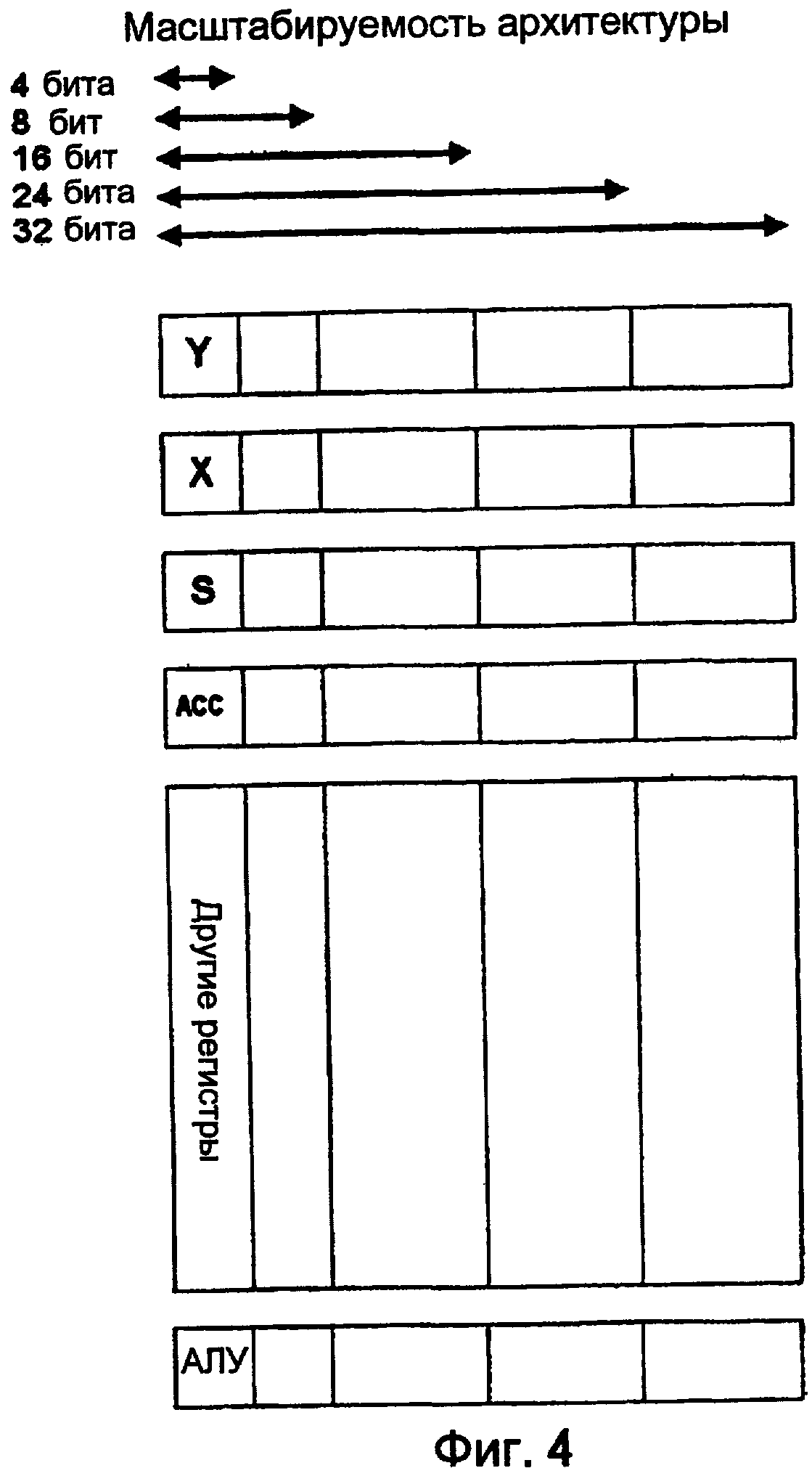
2. Архитектуру масштабируют к любой ширине данных, ограничиваясь только количеством выводов корпуса, временем переноса в сумматоре и возможностью использования.
3. Архитектура имеет почти минимальные функциональные возможности, необходимые для выполнения всех операций универсального компьютера.
4. Архитектура является очень прозрачной, очень регулярной, и большинство операций доступно для оптимизирующего компилятора.
Архитектуру проектируют так, чтобы было достаточно просто дублировать много раз одну монолитную микросхему. В одном из вариантов осуществления внедряют множество копий центрального процессора, объединенных с памятью. 32-разрядный центральный процессор можно воплощать меньше чем в 1500 вентилях, причем большинство вентилей определяет регистры. Почти 1000 центральных процессоров TOMI предпочтительного варианта осуществления можно осуществлять, используя то же самое количество транзисторов, как в одном Intel Pentium 4.
Набор команд
Эти семь команд в наборе команд показаны на фиг. 2 наряду с их поэлементными отображениями. Каждая команда предпочтительно состоит из одного 8-битового слова.
Способы адресации
Фиг. 3 показывает фактические адреса при различных способах адресации.
Способы адресации:
Непосредственная
С помощью регистра
Косвенная с помощью регистра
Косвенная с помощью автоинкрементного регистра
Косвенная с помощью автодекрементного регистра
Особые случаи
Регистр 0 и регистр 1, оба относятся к счетчику программ (PC). Все операции с регистром 0 (PC) в качестве операнда являются условными в зависимости от бита переноса сумматора (C), равного 1. Если C=1, то старое значение PC заносится в сумматор (ACC). Все операции с регистром 1 (PC) в качестве операнда являются безусловными.
Отсутствие перехода
Операции Branch и Jump обычно являются проблемой для проектировщиков центрального процессора, потому что они требуют многих битов драгоценного пространства кода операции. Выполняющую переход функцию можно создавать, загружая необходимый адрес перехода в ACC, используя LOADACC, xx и затем используя команду STOREACC, PC для выполнения перехода. Переход можно делать условным в зависимости от состояния C с помощью сохранения в регистр 0.
Пропуск
Пропуск можно создавать, выполняя INC, PC. Выполнение потребует два цикла, один для завершения текущего цикла приращения PC и один для команды INC. Пропуск можно делать условным в зависимости от состояния C с помощью увеличения регистра 0.
Относительный переход
Относительный переход можно создавать, загружая необходимое смещение в ACC и затем выполняя команду ADD, PC. Относительный переход можно делать условным в зависимости от состояния C с помощью добавления в регистр 0.
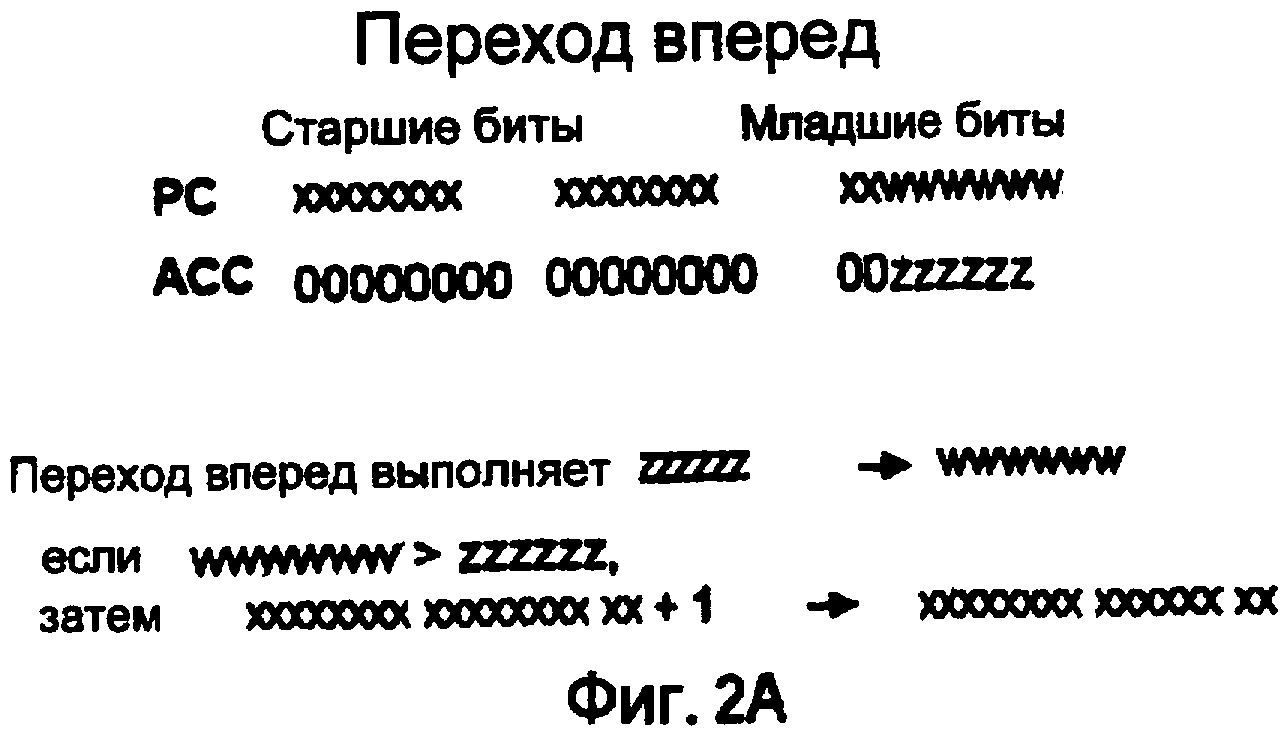
Переходы вперед
Переходы вперед более удобны, чем переходы назад, поскольку местоположения переходов назад, необходимые для циклов, легко фиксировать с помощью сохранения PC, когда этапы программы проходят через вершину цикла в первый раз.
Более эффективный переход вперед, чем относительный переход, можно создавать, загружая наименьшие биты оконечной точки перехода в ACC и затем сохраняя в PC. Так как к PC можно обращаться и условно и безусловно в зависимости от использования регистра 0 или регистра 1, переход вперед может также быть условным или безусловным с помощью выбора регистра PC (регистра 0 или регистра 1) в качестве операнда-адресата.
Например:
LOADI, #1C
STOREACC, PC
Если старшие биты ACC равны нулю, то только младшие 6 битов перемещают в регистр PC. Старшие биты регистра остаются неизменными, если младшие 6 битов текущего регистра PC меньше значения ACC, которое будет загружено. Если младшие 6 битов текущего регистра PC больше значения ACC, которое должно быть загружено, то текущий регистр PC увеличивают, начиная с 7-го бита.
Это фактически позволяет выполнять переходы до 31 команды вперед. При возможности необходимо использовать этот способ перехода вперед, потому что он не только требует 2 команды по сравнению с 3 командами для относительного перехода, но он не требует прохода через сумматор, что является одной из самых медленных операций. Фиг. 2A показывает операцию перехода вперед.
Циклы
Верхний адрес цикла можно сохранять, используя LOADACC, PC. Результирующий указатель на вершину конструкции выполнения цикла можно затем сохранять в регистре или помещать в один из автоиндексируемых регистров. В нижней части цикла указатель можно извлекать с помощью LOADACC, EA и восстанавливать в PC, используя STOREACC, PC, таким образом вызывая назад цикл. Цикл можно сделать условным в зависимости от состояния C с помощью сохранения в регистр 0, таким образом вызывая условный обратный цикл.
Самомодифицирующийся код
Возможно написать самомодифицирующийся код, используя STOREACC, PC. Команда может быть создана или выбрана в ACC и затем сохранена в PC, где она выполняется как следующая команда. Эта методика может использоваться для создания конструкции CASE.
Предположим, что массив таблицы переходов в памяти состоит из N адресов, и базовым адресом является JUMPTABLE. Для удобства JUMPTABLE может находиться в младших адресах памяти, таким образом его адрес можно создавать с помощью LOADI или LOADI с последующим одним или более сдвигов вправо, ADD, ACC.
Предположим, что индекс для таблицы переходов находится в ACC, и базовый адрес таблицы переходов находится в универсальном регистре под названием JUMPTABLE:
ADD, JUMPTABLE Добавляют индекс к базовому адресу таблицы переходов
LOADACC, (JUMPTABLE) Загружают индексированный адрес
STOREACC, PC Выполняют переход
Если младшая память, начиная с 0000, распределена системным вызовом, то каждый системный вызов можно выполнять следующим образом, где SPECIAL_FUNCTION - название непосредственного операнда 0-63:
LOADI, SPECIAL_FUNCTION Загружают номер системного вызова
LOADACC, (ACC) Загружают адрес системного вызова
STOREACC, PC Переходят к функции
Сдвиг вправо
Базовая архитектура не предполагает операцию сдвига вправо. Если такая операция требуется, то решение предпочтительного варианта осуществления состоит в определении одного из универсальных регистров в качестве «регистра сдвига вправо». STOREACC, RIGHTSHIFT сохраняет ACC, сдвинутый вправо на одну позицию, в «регистр сдвига вправо», где его значение можно считывать с помощью LOADACC, RIGHTSHIFT.
Масштабируемость архитектуры
Архитектура TOMI предпочтительно использует 8-битовые команды, но ширина данных не должна быть ограничена. Фиг. 4 показывает, как легко создавать маршруты передачи данных любой ширины из 4-32 битов. Создание обработки данных большей ширины требует только увеличения ширины набора регистров, внутренних маршрутов передачи данных и арифметико-логического устройства до требуемого размера. Верхняя граница маршрута передачи данных ограничена только задержкой распространения переноса сумматора и запланированным количеством транзисторов.
Предпочтительную архитектуру TOMI осуществляют как конфигурацию с памятью фон Неймана для простоты, но реализация архитектуры Гарварда (с отдельными шинами данных и команд) также возможна.
Обычные математические операции
Математические операции с дополнительным двоичным кодом можно выполнять несколькими способами. Универсальный регистр можно предварительно конфигурировать, как все «1», и назвать ALLONES. Операнд, как предполагается, будет находиться в регистре под названием OPERAND:
LOADACC, ALLONES
XOR, OPERAND
INC, OPERAND Дополнительный двоичный код остается в OPERAND
Обычные конструкции компилятора
Большинство компьютерных программ генерируют с помощью компилятора. Поэтому удобная архитектура вычислительной системы должна иметь большой опыт по части обычных конструкций компилятора.
Компилятор языка Си обычно поддерживает стек для передачи параметров для вызова функции. Регистры S, X или Y можно использовать в качестве указателя вершины стека. При вызове функции помещают параметры в один из автоиндексируемых регистров, действующих как стек, используя, например: STOREACC, (X)+. После ввода функции параметры будут считываться из стека в универсальные регистры для использования.
Относительная адресация стека
Существуют моменты времени, когда для вызова функции передают больше элементов, чем может обычным образом поместиться в универсальных регистрах. Для последующего примера предполагают, что операция записи в стек уменьшает значение стека. Если S используется в качестве регистра стека, то для считывания N-ного элемента относительно вершины стека:
LOADI, N
STOREACC, X
LOADACC, S
ADD, X
LOADACC, (X)
Индексирование в массиве
При функции ввода информации в массив базовый адрес массива расположен в универсальном регистре под названием ARRAY. Для считывания N-ного элемента в массиве:
LOADI, N
STOREACC, X
LOADACC, ARRAY
ADD, X
LOADACC, (X)
Индексирование в массиве элементов из N слов
Иногда массив распределен для элементов, имеющих ширину N слов. Базовый адрес массива расположен в универсальном регистре под названием ARRAY. Для обращения к первому слову N-го элемента в массиве шириной 5 слов:
LOADI, N
STOREACC, X Сохраняют во временном регистре
ADD, ACC Умножают на 2
ADD, ACC Снова умножают на 2 = 4
ADD, X Плюс 1 = 5
LOADACC, ARRAY
ADD, X плюс базовый адрес массива
LOADACC, (X)
Локальное кэширование TOMI
Кэш-память имеет меньший размер и более быстрый доступ, чем оперативная память. Уменьшенное время доступа и локальность программ и данных, к которым получают доступ, позволяют операциям кэш-памяти увеличивать производительность предпочтительного процессора TOMI для многих операций. С другой точки зрения кэш-память увеличивает производительность параллельной обработки, увеличивая независимость процессора TOMI от оперативной памяти. Относительная производительность кэш-памяти по сравнению с оперативной памятью и количество циклов, которое процессор TOMI может выполнять до того, как потребуется другая загрузка или сохранение из/в оперативной памяти в/из кэш-памяти, определяют увеличение производительности из-за параллелизма процессора TOMI.
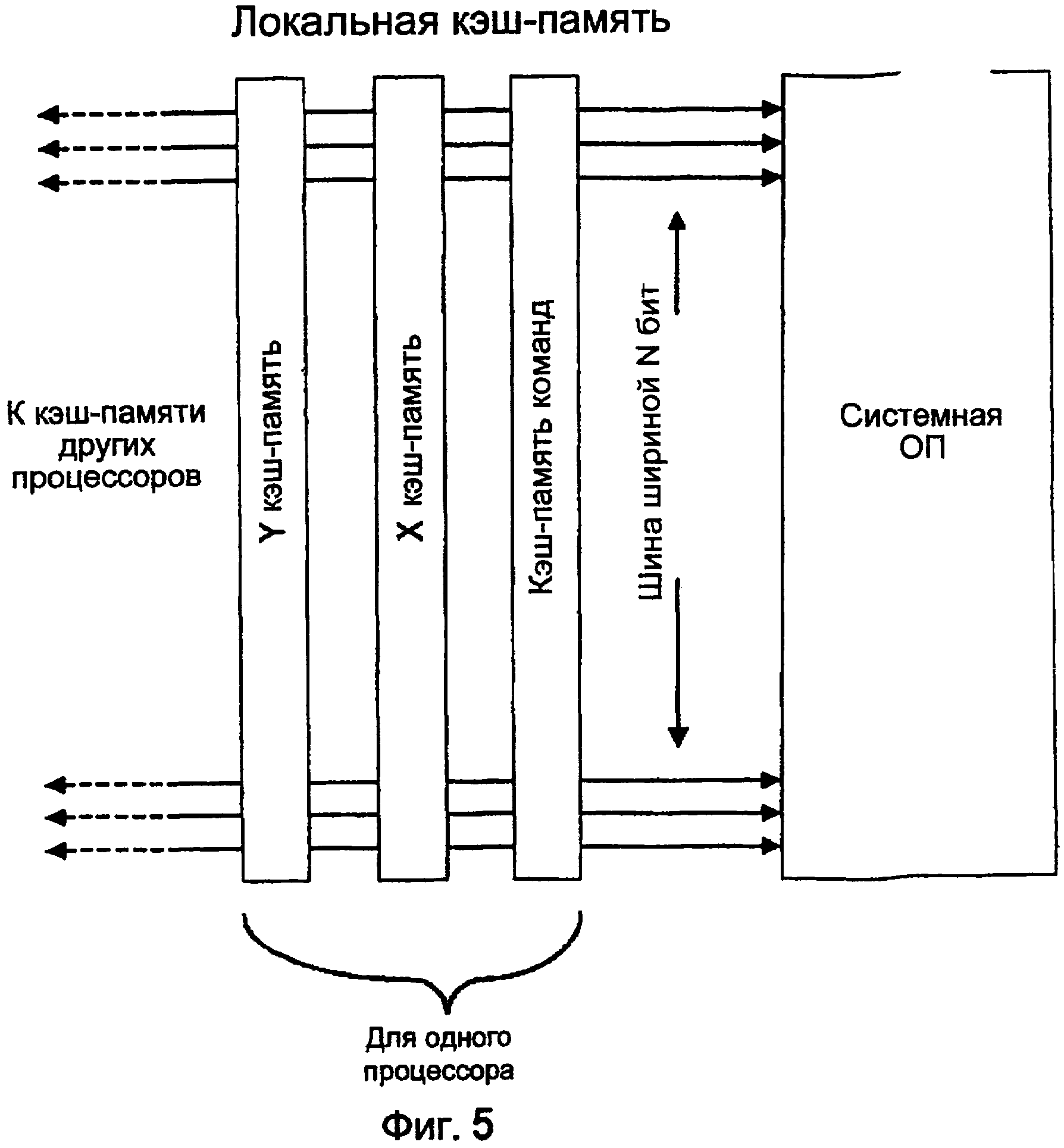
Локальная кэш-память TOMI увеличивает производительность из-за параллелизма процессора TOMI. У каждого процессора TOMI предпочтительно существуют три связанных с ним локальных кэш-памяти, как показано на фиг. 5:
команды - связана с PC,
источника - связана с регистром X,
адресата - связана с регистром Y.
Оптимальная размерность этой кэш-памяти зависит от применения. В обычном варианте осуществления может потребоваться 1024 байтов для каждой кэш-памяти. Другими словами, 1024 команды и 256 32-разрядных слов источника и адресата. По меньшей мере два коэффициента определяют оптимальный размер кэш-памяти. Первый - это количество состояний, которые процессор TOMI может циклически повторять до того, как потребуется другая операция загрузки или сохранения кэш-памяти. Второй - стоимость операции загрузки или сохранения кэш-памяти из оперативной памяти относительно количества циклов выполнения процессора TOMI, возможных во время операции оперативной памяти.
Внедрение процессоров TOMI в ОП
В одном из вариантов осуществления широкая шина соединяет большую внедренную память с кэш-памятью, таким образом операция загрузки или сохранения в кэш-память могут происходить быстро. С процессорами TOMI, внедренными в оперативную память, загрузка или сохранение всей кэш-памяти состоят из одного цикла памяти для столбца оперативной памяти. В одном из вариантов осуществления внедренная память отвечает на запросы 63 процессоров TOMI, таким образом время ответа загрузки или сохранения кэш-памяти для одного процессора TOMI может увеличиваться, пока завершается загрузка или сохранение кэш-памяти другого процессора TOMI.
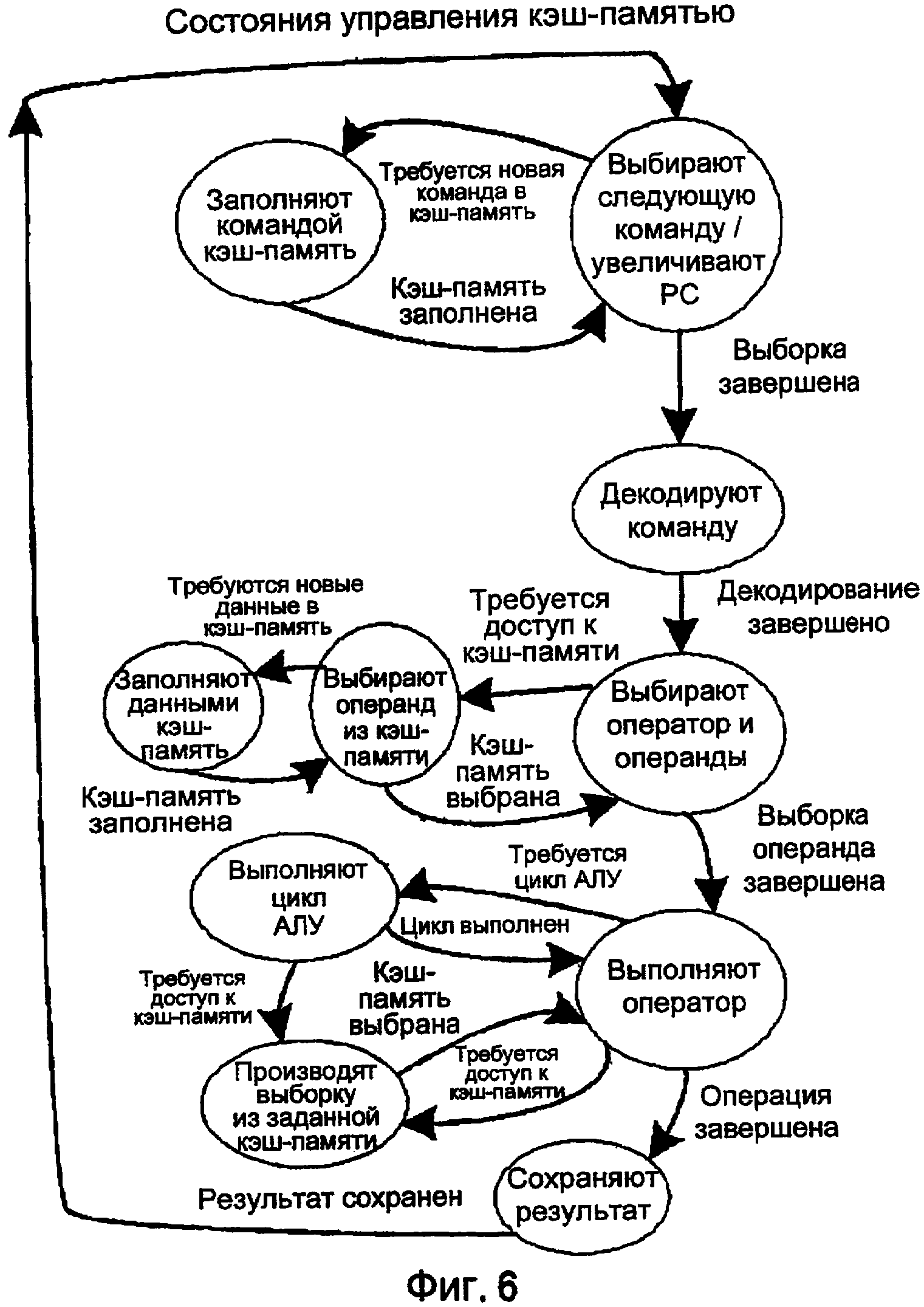
Кэш-память можно сохранять и загружать, основываясь на изменениях соответствующих регистров X, Y, PC, которые адресуют память, как показано на фиг. 6. Например, полная ширина регистра PC может составлять 24 бита. Если кэш-память PC составляет 1024 байта, младшие 10 битов PC определяют доступ в пределах кэш-памяти PC. Когда PC записывают таким образом, что существуют изменения в старших 14 битах, требуется цикл загрузки кэш-памяти. Центральный процессор TOMI, связанный с этой кэш-памятью PC, прекращает выполнение до тех пор, пока цикл загрузки кэш-памяти не закончен, и указанную команду можно выбрать из кэш-памяти PC.
Двойная буферизация кэш-памяти
Вторичную кэш-память можно загружать в ожидании требования загрузки кэш-памяти. Две кэш-памяти идентичны, и их поочередно выбирают, основываясь на содержимом старших 14 битов PC. В приведенном выше примере, когда старшие 14 битов PC изменяются, чтобы соответствовать тем данным, которые ранее кэшированы во вторичной кэш-памяти, вторичную кэш-память выбирают в качестве первичной кэш-памяти. Прежняя первичная кэш-память теперь становится вторичной кэш-памятью. Так как большинство компьютерных программ линейно увеличивается в памяти, в одном из вариантов осуществления изобретения во вторичную кэш-память всегда извлекают содержимое кэш-памяти из оперативной памяти, к которой обращаются с помощью старших 14 битов текущего PC плюс 1.
Добавление вторичной кэш-памяти уменьшает время, в течение которого процессор TOMI должен ждать данных памяти, которые должны быть выбраны из оперативной памяти, когда перемещаются за пределы текущей кэш-памяти. Добавление вторичной кэш-памяти почти удваивает сложность процессора TOMI. Для оптимальной системы это удвоение сложности необходимо компенсировать соответствующим удвоением производительности процессора TOMI. Иначе, два более простых процессора TOMI без вторичной кэш-памяти можно воплощать с помощью одного и того же количества транзисторов.
Высокоскоростное умножение, операции с плавающей запятой, дополнительные функциональные возможности
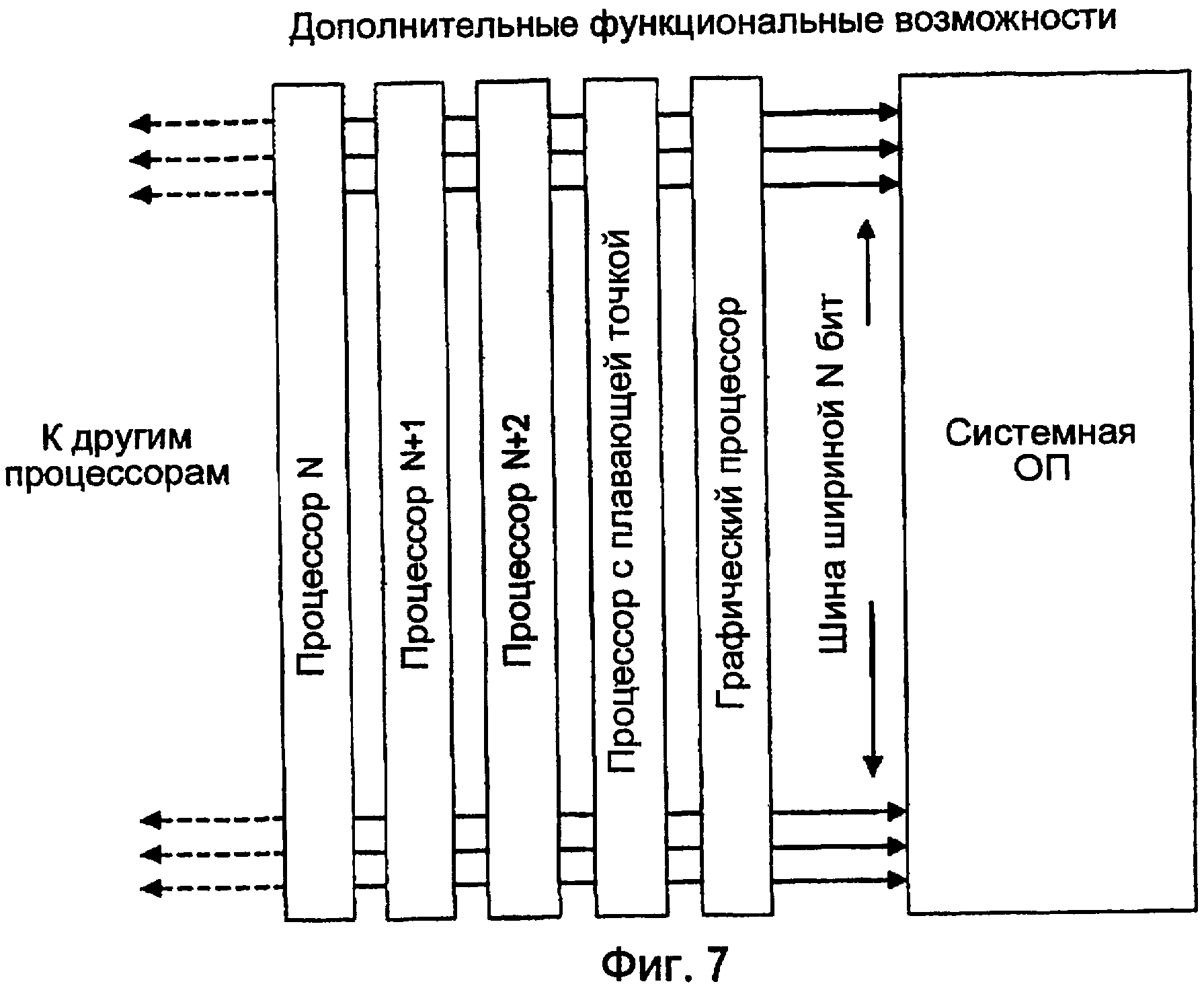
Целочисленное умножение и все операции с плавающей запятой требуют выполнения множества циклов, даже с помощью специальных аппаратных средств. Таким образом, они должны быть организованы в других процессорах, и их не должен включать в себя основной процессор TOMI. Операции процессора цифровой обработки сигналов (ПЦОС) часто используют блоки умножения с большим конвейером, который выдает результат каждый цикл даже при том, что полное умножение может потребовать множества циклов. Для приложений обработки сигналов, которые повторяют один и тот же алгоритм много раз, такая архитектура блока умножения оптимальна, и его можно внедрять как периферийный процессор в процессор TOMI, но это может увеличивать сложность и уменьшать полную производительность, если его внедрять непосредственно в процессор TOMI. Фиг. 7 показывает один из примеров дополнительных функциональных возможностей обработки, организованных для использования преимуществ широкой шины системной ОП.
Стратегия прерываний TOMI
Прерывание является событием, внешним к нормальной последовательности операций процессора, которое заставляет процессор немедленно изменять свою последовательность операции.
Примерами прерываний могут быть завершение операции внешним устройством или возникновение условия ошибки в некоторых аппаратных средствах. Традиционные процессоры переходят к большей длине для быстрой остановки нормальной последовательности операций, сохранения состояния текущей операции, начала выполнения некоторой специальной операции для обработки независимо от того, какое событие вызвало прерывание, и когда специальная операция закончена, для восстановления предыдущего состояния и продолжения последовательности операций. Главным показателем качества обработки прерываний является время ответа.
Прерывания создают несколько проблем традиционным процессорам. Они делают время выполнения неопределенным. Они тратят впустую циклы процессора на сохранение и затем восстановление состояния. Они усложняют конструкцию процессора и могут вводить задержки, которые замедляют каждую операцию процессора.
Немедленный ответ на прерывание не нужен для большинства процессоров, с исключениями, которыми являются обработка ошибок и те процессоры, которые непосредственно взаимодействуют с деятельностью в реальном мире.
В одном из вариантов осуществления многопроцессорной системы TOMI только один процессор обладает возможностью первичного прерывания. Все другие процессоры работают непрерывно, пока они не завершат некоторую назначенную работу и сами остановятся или пока их не остановит координирующий процессор.
Ввод-вывод (в/в)
В одном из вариантов осуществления конфигурации процессора TOMI один процессор отвечает за все взаимодействие с внешним миром.
Управление прямым доступом к памяти (DMA)
В одном из вариантов осуществления немедленный ответ на внешнее воздействие в системе с процессором TOMI происходит через контроллер DMA. Контроллер DMA, когда его запрашивает внешнее устройство, перемещает данные от внешнего устройства на внутреннюю шину данных для записи в системную ОП. Тот же самый контроллер также перемещает данные из системной ОП на внешнее устройство, когда требуется. Запрос DMA имеет самый высокий приоритет для доступа к внутренней шине.
Организация массива процессоров TOMI
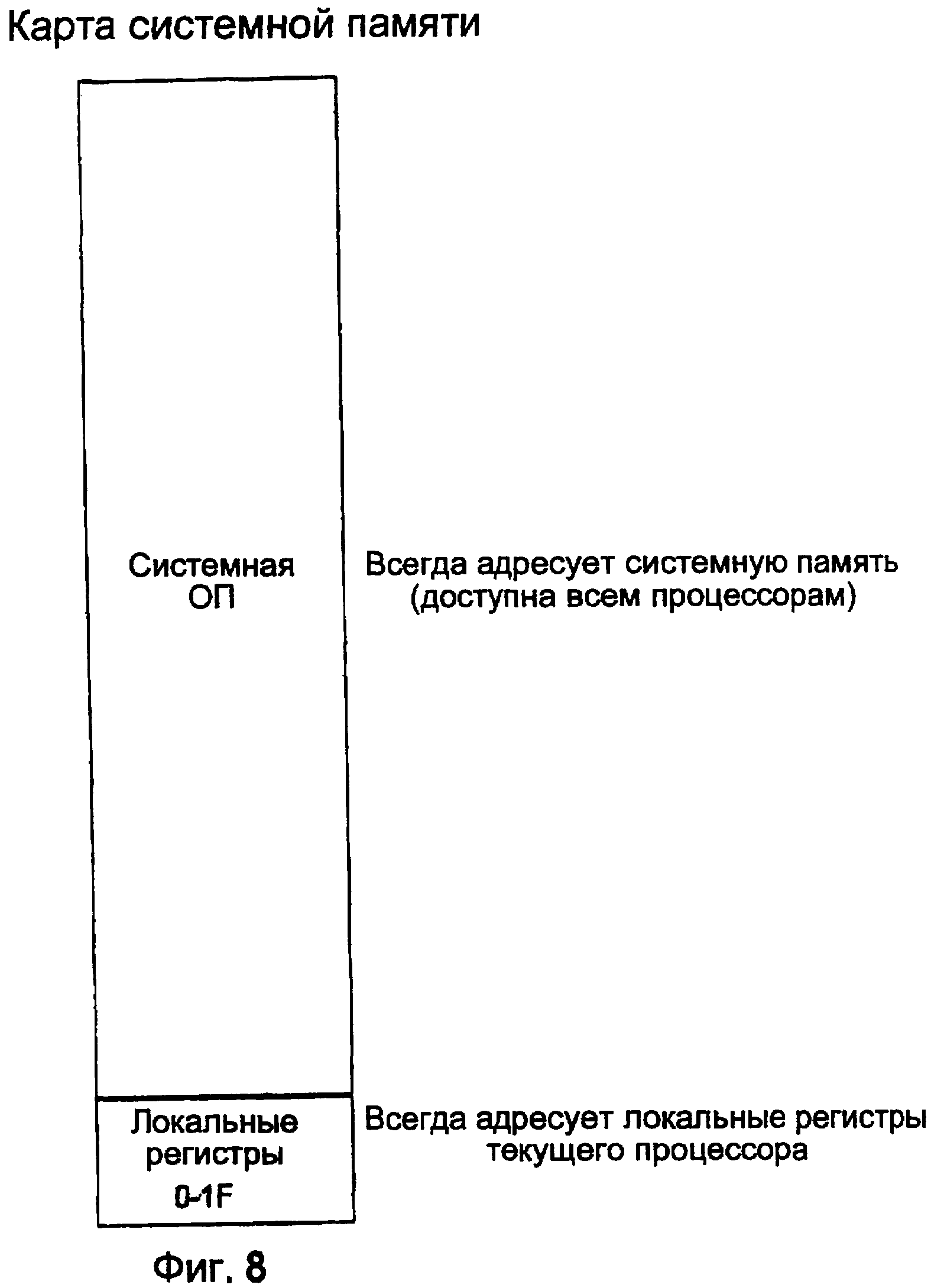
Процессор TOMI предпочтительных вариантов осуществления изобретения проектируют так, чтобы его можно было скопировать большое количество раз и объединить с дополнительными функциональными возможностями обработки, очень широкой внутренней шиной и системной памятью на монолитной микросхеме. Примерная карта памяти для такой системы показана на фиг. 8.
Карта распределения памяти для каждого процессора выделяет первые 32 ячейки (1F в шестнадцатеричном виде) локальным регистрам для этого процессора (см. фиг. 3). К остальной части памяти могут обращаться все процессоры через их регистры кэш-памяти (см. фиг. 6). Адресуемость системной оперативной памяти ограничена только шириной трех регистров, связанных с локальной кэш-памятью; PC, X и Y. Если регистры имеют ширину 24 бита, то полная адресуемость составляет 4 мегабайта, но не существует верхнего предела.
В одном из вариантов осуществления 64 процессора TOMI реализованы как единое целое с памятью. Один главный процессор отвечает за управление другими 63. Когда один из подчиненных процессоров простаивает, его не синхронизируют, так что он потребляет немного или совсем не потребляет мощности и генерирует небольшое количество или совсем не генерирует тепло. При инициализации работает только главный процессор. Главный процессор начинает выбирать и выполнять команды перед моментом времени, когда поток должен быть начат. Каждый поток предварительно компилируют и загружают в память. Для запуска потока главный процессор распределяет данный поток одному из ЦП TOMI.
Доступность процессора
Координацию доступности процессоров TOMI для выполнения работы предпочтительно осуществляют с помощью таблицы доступности процессоров, показанной на фиг. 9. Координирующий (главный) процессор предпочтительно может выполнять следующие функции:
1. Записывает параметры вызова для подчиненного процессора в его стек, которые включают в себя адрес выполнения для потока, память-источник и память-адресат, но не ограничены ими.
2. Запускает подчиненный процессор.
3. Отвечает на событие завершения потока подчиненного процессора или с помощью опроса, или с помощью ответа на прерывание.
Запрос процессора
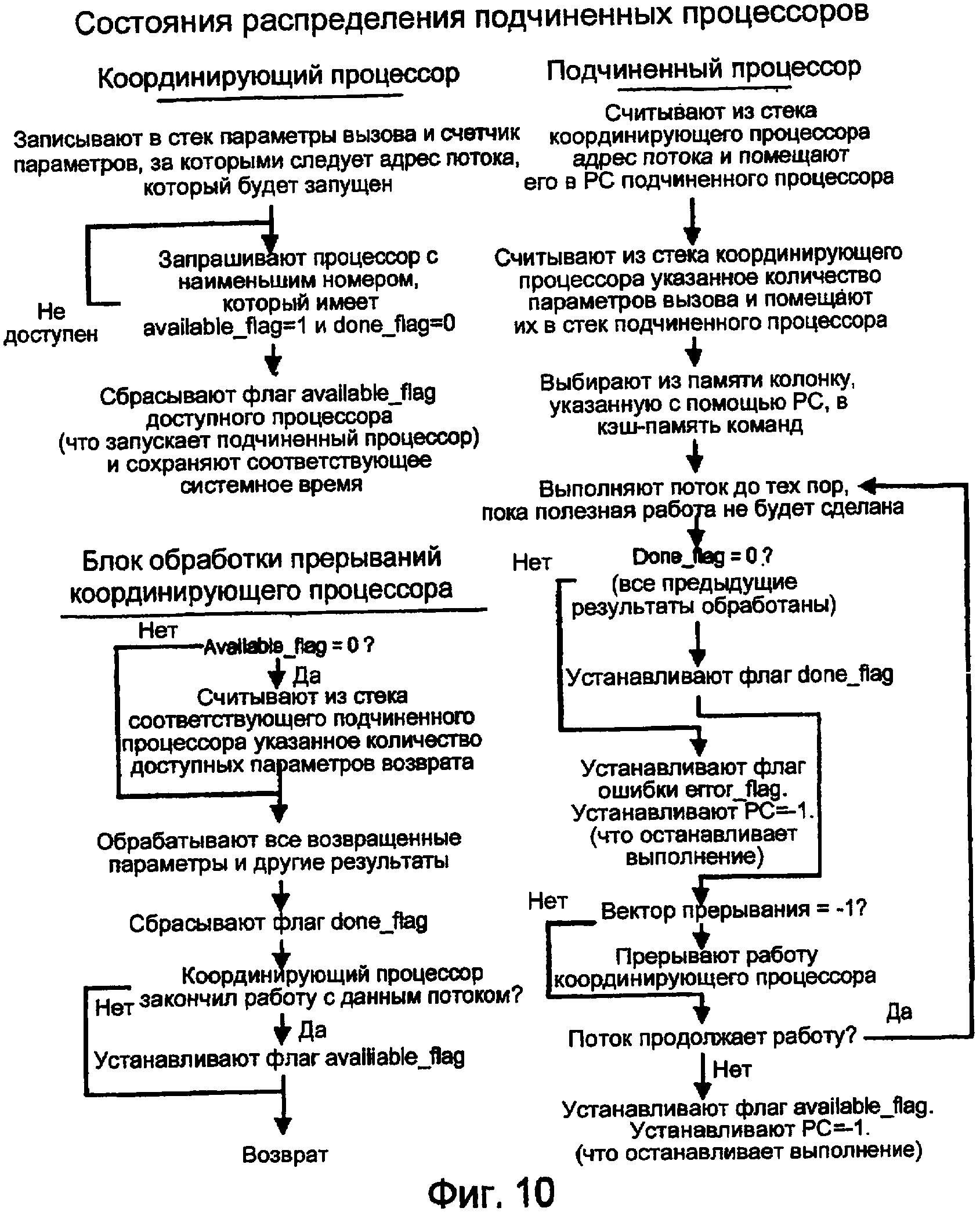
Координирующий процессор может запрашивать процессор из таблицы доступности. Возвращают номер самого младшего процессора с флагом available_flag, установленным в «0». Координирующий процессор может затем устанавливать флаг available_flag, связанный с доступным процессором, в «1», таким образом запуская подчиненный процессор. Если ни один процессор не доступен, то запрос возвращает ошибку. Альтернативно, процессоры можно распределять с помощью координирующего процессора, основываясь на уровне приоритета, связанном с запрашиваемой работой, которую будут выполнять. Методики распределения ресурсов, основанные на приоритетных схемах, известны из предшествующего уровня техники. Фиг. 10 показывает три предпочтительных компонента распределения процессоров; операции инициирования координирующего процессора, операции подчиненного процессора и результирующую обработку координирующего процессора через ответ на прерывание.
Поэтапный запуск подчиненного процессора
1. Координирующий процессор записывает параметры потока для работы в свой собственный стек. Параметры могут включить в себя: начальный адрес потока, память-источник для потока, память-адресат для потока и последнее значение parameter_count.
2. Координирующий процессор запрашивает доступный процессор.
3. Логическая схема распределения процессоров возвращает или номер самого младшего по номеру подчиненного процессора, у которого и установлен связанный с ним флаг available_flag, и сброшен связанный с ним флаг done_flag, или ошибку.
4. Если возвращают ошибку, то координирующий процессор может или повторять запрос до тех пор, пока подчиненный процессор не станет доступным, или выполнять некоторую специальную операцию для обработки ошибок.
5. Если возвращают номер доступного процессора, то координирующий процессор очищает флаг available_flag для указанного процессора. Эта операция помещает количество параметров стека parameter_count в стек выбранного подчиненного процессора. Флаг done_flag сбрасывают в ноль.
6. Подчиненный процессор извлекает верхний элемент стека и перемещает его в счетчик программы подчиненного процессора.
7. Подчиненный процессор затем выбирает столбец памяти, указанный счетчиком программы, в кэш-память команды.
8. Подчиненный процессор начинает выполнять команды с начала кэш-памяти команды. Первые команды могут извлекать из стека параметры вызова.
9. Подчиненный процессор выполняет поток из кэш-памяти команды. Когда поток завершается, он проверяет состояние связанного с ним флага done_flag. Если флаг done_flag установлен, то он ждет, пока флаг done_flag не будет сброшен, указывая, что координирующий процессор обработал все предыдущие результаты.
10. Если вектор прерывания, связанный с подчиненным процессором, установлен в -1, то никаких прерываний не будет создано с помощью установки флага done_flag. Координирующий процессор может поэтому опрашивать, установлен или нет флаг done_flag.
Когда координирующий процессор обнаруживает, что флаг done_flag установлен, он может обрабатывать результаты подчиненного процессора и, возможно, переназначать подчиненный процессор для выполнения новой работы. Когда результаты подчиненного процессора обработаны, связанный координирующий процессор сбрасывает соответствующий флаг done_flag.
Если вектор прерывания, связанный с подчиненным процессором, не равен -1, то установка соответствующего флага done_flag заставит координирующий процессор прерваться и начать выполнять средство обработки прерываний по адресу вектора прерывания.
Если соответствующий флаг available_flag также установлен, то координирующий процессор может также считывать параметры возврата, записанные в стек подчиненного процессора.
Средство обработки прерываний обрабатывает результаты подчиненного процессора и может переназначать подчиненный процессор для выполнения новой работы. Когда результаты подчиненного процессора обработаны, средство обработки прерываний, выполняющееся на координирующем процессоре, сбрасывает соответствующий флаг done_flag.
11. Если флаг done_flag сброшен, то подчиненный процессор устанавливает соответствующий флаг done_flag и сохраняет новое значение start_time. Подчиненный процессор может продолжать выполнять работу или может возвращаться в доступное состояние. Для возвращения в доступное состояние подчиненный процессор может поместить параметры возврата в свой стек, сопровождаемые счетчиком стека, и установить свой флаг available_flag.
Блокировка памяти
Процессоры TOMI считывают и записывают в системную память через их кэш-память. Полностью кэшируемый столбец считывают или записывают одновременно. Любой процессор может считывать любую часть системной памяти. Отдельный процессор может блокировать столбец памяти для своей исключительной записи. Этот механизм блокировки помогает избегать конфликтов между процессорами при записи в память.
Предложенные применения
Параллелизм эффективно ускоряет приложения, которые можно разложить на независимые обрабатываемые части работы для отдельных процессоров. Одним из применений, в котором можно хорошо выполнять разложение, является обработка изображений для автоматизированной системы технического зрения. Алгоритмы обработки изображений включают в себя корреляцию, выравнивание, идентификацию краев и другие операции. Многие из них выполняют с помощью матричной обработки. Очень часто данные алгоритмы хорошо выполняют разложение, как показано на фиг. 11.
На фиг. 11 примерное изображение показывает 24 процессора, причем процессор назначают для управления данными изображения для прямоугольного подмножества всего изображения.
Фиг. 12 показывает, как системную ОП TOMI можно распределять в одном из вариантов осуществления. Один блок системной ОП содержит пиксели ввода изображения, и другой блок содержит обработанные результаты.
При работе координирующий процессор распределяет канал DMA для передачи пикселей изображения из внешнего источника на внутреннюю системную ОП каждый фиксированный промежуток времени. Обычная скорость ввода изображений может быть равна 60 изображений в секунду.
Координирующий процессор затем включает подчиненный процессор 1 с помощью размещения адреса изображения, которое будет использоваться регистром X, адреса обработанного изображения, которое будет использоваться регистром Y, счетчика параметров в 2 и адреса алгоритма обработки изображений. Координирующий процессор последовательно и таким же образом включает процессоры 2-25. Процессоры продолжают работать независимо и параллельно до тех пор, пока алгоритм обработки изображения не будет закончен.
Когда алгоритм закончен, каждый процессор устанавливает соответствующий ему флаг done_flag в таблице доступности процессора. Результаты обрабатываются координирующим процессором, который опрашивает о завершении или отвечает на прерывание о событии «завершено».
Фиг. 13 показывает примерную общую топологическую структуру для монолитного массива из 64 процессоров.
Следует признать, что настоящее изобретение описано только для примера и в отношении сопроводительных чертежей и что усовершенствования и модификации могут быть сделаны к изобретению, не отступая от его формы или объема.
Реферат
Изобретение относится к многопроцессорным архитектурам. Техническим результатом изобретения является ускорение работы программы с использованием оптимизированного для потоков микропроцессора. В одном из аспектов изобретение содержит систему, содержащую: (а) множество параллельных процессоров в одной микросхеме; и (b) компьютерную память, расположенную в данной микросхеме и доступную каждому из процессоров; причем каждый из процессоров предназначен для обработки минимального набора команд, состоящего из семи команд, и причем каждый из процессоров содержит локальные кэш-памяти, предназначенные для каждого из по меньшей мере трех определенных регистров в процессоре. В другом аспекте изобретение содержит систему, содержащую: (а) множество параллельных процессоров в одной микросхеме; и (b) компьютерную память, расположенную в данной микросхеме и доступную каждому из процессоров, причем каждый из процессоров предназначен для обработки набора команд, оптимизированного для параллельной обработки на уровне потоков. 3 н. и 17 з.п. ф-лы, 14 ил.
Формула
множество параллельных процессоров в одной микросхеме для обработки потоков и
компьютерную память, расположенную в указанной микросхеме и доступную каждому из указанных процессоров, причем каждый из указанных процессоров предназначен для обработки минимального набора команд, состоящего из семи команд, и причем каждый из указанных процессоров содержит локальные кэш-памяти, выделенные каждому из по меньшей мере трех конкретных регистров в указанном процессоре.
множество параллельных процессоров в одной микросхеме и
компьютерную память, расположенную в указанной микросхеме и
доступную каждому из указанных процессоров,
причем каждый из указанных процессоров предназначен для обработки набора команд, оптимизированного для параллельной обработки на уровне потоков,
при этом упомянутый набор команд является минимальным набором команд, содержащим семь команд.
(a) распределяют локальные кэш-памяти каждому из трех конкретных регистров в каждом из указанного множества процессоров;
(b) распределяют один из множества процессоров для обработки одного потока;
(c) обрабатывают каждый распределенный поток с помощью указанных процессоров;
(d) обрабатывают результаты каждого потока, обработанного указанными процессорами; и
(e) освобождают один из указанного множества процессоров после обработки потока.
Документы, цитированные в отчёте о поиске
Параллельная процессорная система
Комментарии