Документ текстовой обработки, хранящийся в едином файле xml, которым могут манипулировать приложения, понимающие язык xml - RU2358311C2
Код документа: RU2358311C2
Чертежи



Описание
Уровень техники
За последние годы широкое распространение получили языки разметки. Один из типов языка разметки, называемый «расширяемый язык разметки» (XML), является универсальным языком, который обеспечивает возможности идентификации, обмена и обработки данных различных типов. Например, язык XML используют для создания документов, которые могут найти применение во множестве различных прикладных программ. Элементы файла XML имеют ассоциированные пространство имен и схему.
В языке XML пространство имен является уникальным идентификатором для совокупности имен, используемых в документах XML в виде типов элементов и имен атрибутов. Имя пространства имен обычно используют для уникальной идентификации каждого класса документов XML. Уникальные пространства имен отличаются элементами разметки, которые поступают от разных источников, но случается, имеют одинаковое имя.
Схемы XML предоставляют способ описания и оценки достоверности данных в среде XML. Схема устанавливает: какие элементы и атрибуты используются для описания содержимого (контента) в документе XML; где разрешен каждый элемент; какие типы текстового содержимого разрешены в нем и какие элементы могут появляться в каких (других) элементах. Использование этих схем гарантирует непротиворечивость структуры документа. Схемы могут создаваться пользователем, причем они обычно поддерживаются соответствующим языком разметки, таким как язык XML. Используя редактор XML, пользователь может обрабатывать файл XML и формировать документы XML, подсоединяемые к схеме, которую создал пользователь. Документы XML можно создавать для подсоединения к одной или нескольким схемам.
Обычно внешние приложения «не понимают» документы, полученные в результате текстовой обработки (далее «документы текстовой обработки»), если эти приложения не знакомы с конкретной структурой документа. Из-за этого приложениям очень трудно манипулировать документами текстовой обработки, не имея всесторонней информации о данном приложении. Таким образом, необходимо иметь способ для легкого манипулирования, создания и отображения документов, связанных с текстовым процессором.
Сущность изобретения
Целью настоящего изобретения является создание документа текстовой обработки в собственном формате файла XML, который может восприниматься приложением, понимающим язык XML, либо предоставление возможности другому приложению или услуге создать в XML документ с широкими возможностями, с тем, чтобы приложение текстовой обработки могло его открыть, как если бы это был один из его собственных документов.
Согласно одному аспекту изобретения текстовый процессор имеет собственный формат файла XML. Правильно сформированный файл XML полностью представляет документ текстового процессора и полностью поддерживает расширенное форматирование текстового процессора. Соответственно одной из целей указанного собственного представления XML является недопущение потерь признаков при хранении документов текстового процессора в XML в соответствии с заданным файлом XSD.
Согласно другому аспекту изобретения имеется опубликованный файл XSD, который определяет все правила дополнительно к формату файла XML текстового процессора. Схема описывает структуру XML текстового процессора. Файл схемы отражает внутреннюю программу текстового процессора, позволяя еще ее легко использовать. Таким образом, схема позволяет услугам и приложениям третьей стороны создавать документы XML, которые будут понятны приложению текстовой обработки.
Согласно еще одному аспекту изобретения в файлах, связанных с XML, предлагаются подсказки, обеспечивающие приложениям, которые понимают язык XML, сокращенной клавиатурной командой (комбинацией клавиш) для осмысления некоторых признаков, предоставляемых текстовым процессором. Используя эти подсказки, приложения, для того чтобы воссоздать некоторый признак, не обязаны знать все конкретные детали внутренней обработки, выполненной текстовым процессором.
Согласно следующему аспекту изобретения документ, полученный в результате текстовой обработки, запоминается в едином файле XML. Приложение может полностью воссоздать документ из указанного единого файла XML. Сюда относятся все изображения и другие двоичные данные, которые могут присутствовать в документе. Изобретение обеспечивает способ представления всех данных документа в едином файле XML.
Согласно еще одному аспекту изобретения манипулирование документами текстовой обработки можно осуществлять на вычислительных устройствах, которые сами не содержат текстовый процессор.
Краткое описание чертежей
Фиг. 1 - типовое вычислительное устройство, которое можно использовать в одном типовом варианте настоящего изобретения;
Фиг.2 - блок-схема, иллюстрирующая типовую среду для практической реализации настоящего изобретения
Фиг. 3 - типовой файл WPML;
Фиг.4 - типовой документ текстового процессора XML, показанный в виде дерева;
Фиг. 5 - блок-схема типовой структуры документа XML текстового процессора; и
Фиг. 6 - блок-схема процесса, раскрывающая документ текстового процессора согласно аспектам настоящего изобретения.
Подробное описание предпочтительных вариантов осуществления изобретения
Следующие термины, употребляемые во всем описании и формуле изобретения, имеют указанный ниже смысл, если из контекста недвусмысленно не следует иное.
Термины «язык разметки» или «ML» относятся к языку для специальных кодов в документе, которые определяют, каким образом приложение должно интерпретировать части документа. В файле текстового процессора язык разметки определяет, как должен форматироваться и размещаться текст, тогда как в документе HTML язык ML способствует определению структурной функции текста (например, заголовок, параграф и т.д.).
Термины «язык разметки текстового процессора» или «WPML» относятся к элементам языка разметки, которые связаны с приложением текстового процессора и схемой (логической структурой данных), связанной с этим приложением текстового процессора. Данный тип ML или схему также часто называют «собственной» схемой или разметкой текстового процессора.
Термин «элемент» относится к базовой единице документа ML. Элемент может содержать атрибуты, другие элементы, текст и другие компоновочные блоки для документа ML.
Термин «тег» относится к команде, вставляемой в документ, которая очерчивает элементы в документе ML. Каждый элемент может иметь не более двух тегов: начальный тег и конечный тег. Возможен пустой элемент (без контента); в этом случае допускается иметь один тег.
Контент (содержимое) между тегами рассматривают как «порожденные объекты» (или потомки) элемента. Таким образом, другие элементы, встроенные в контент элемента, называют «порожденными элементами» или «порожденными узлами» данного элемента. Текст, встроенный непосредственно в контент элемента, рассматривают как «порожденные текстовые узлы» элемента. Порожденные элементы и текст в элементе образуют вместе «контент» элемента.
Термин «атрибут» относится к дополнительному свойству с установленным конкретным значением, связанному с элементом. Элементы могут иметь произвольное количество связанных с ними устанавливаемых значений атрибутов, в том числе не иметь таких элементов. Атрибуты используют для связывания дополнительной информации с элементом, который не будет содержать дополнительные элементы, либо будет обрабатываться как текстовый узел.
Пример рабочей среды
Обратимся к фиг.1, где одна типовая система для реализации изобретения включает в себя вычислительное устройство, такое как вычислительное устройство 100. В базовой конфигурации вычислительное устройство 100 обычно включает в себя по меньшей мере один блок обработки 102 и системную память 104. В зависимости от конкретной конфигурации и типа вычислительного устройства системная память 104 может быть энергозависимой (такой как ОЗУ), энергонезависимой (такой как ПЗУ, флэш-память и т.д.), либо представлять собой некоторую их комбинацию. Системная память 104 обычно включает в себя операционную систему 105, одно или несколько приложений 106, а также может включать в себя программные данные 107. В одном варианте приложение 106 может содержать приложение текстового процессора 120, которое дополнительно включает в себя редактор ML 122. Эта базовая конфигурация показана на фиг.1 с использованием компонентов, очерченных пунктирной линией 108.
Вычислительное устройство 100 может иметь дополнительные признаки или функциональные возможности. Например, вычислительное устройство 100 может также включать в себя дополнительные запоминающие устройства для данных (съемные и/или несъемные) такие как, например, магнитные диски, оптические диски или ленту. Такое дополнительное запоминающее устройство показано на фиг. 1 в виде съемного запоминающего устройства 9 и несъемного запоминающего устройства 110. Компьютерная запоминающая среда может включать в себя энергозависимую и энергонезависимую, съемную и несъемную среду, реализованную любым способом или по любой технологии для запоминания информации, такой как машинно-считываемые команды, структуры данных, программные модули или другие данные. Системная память 104, съемная память 109 и несъемная память 110 являются примерами компьютерной запоминающей среды. Компьютерная запоминающая среда включает в себя, но не только: ОЗУ, ПЗУ, ЭСППЗУ (электрически стираемое программируемое ПЗУ), флэш-память, либо другие технологии памяти, ПЗУ на компакт-дисках (CD-ROM), цифровые многофункциональные диски (DVD) либо другое оптическое запоминающее устройство, магнитные кассеты, магнитную ленту, память на магнитных дисках или другие магнитные запоминающие устройства либо любой другой носитель, который можно использовать для запоминания необходимой информации и который может быть доступен вычислительному устройству 100. Любая указанная компьютерная запоминающая среда может являться частью устройства 100. Вычислительное устройство 100 может также иметь устройство (устройства) ввода 112, такое как клавиатура, мышь, перо, устройство ввода речи, сенсорное устройство ввода и т.д. Сюда также могут быть включены устройство (устройства) вывода 114, такие как дисплей, динамики, принтер и т.д. Эти устройства хорошо известны специалистам в данной области техники, и обсуждать их далее нет необходимости.
Вычислительное устройство 100 может также содержать соединения для связи 116, которые позволяют устройству осуществлять связь с другими вычислительными устройствами 118, к примеру, через сеть. Соединение для связи 116 является одним из примеров среды связи. Среда связи обычно может быть воплощена с помощью машинно-считываемых команд, структур данных, программных модулей или других данных в модулированном сигнале данных, таком как несущий сигнал или другой механизм транспортировки, причем среда связи включает любую среду для доставки информации. Термин «модулированный сигнал данных» означает сигнал, который имеет одну или несколько характеристик, устанавливаемых или изменяемых таким образом, чтобы кодировать информацию в сигнале. Например, но не только среда связи включает проводную среду, такую как проводная сеть или прямое проводное соединение, и беспроводную среду, такую как акустическая, радиочастотная, инфракрасная или другая беспроводная среда. Используемый здесь термин «машинно-считываемая среда» включает как запоминающую среду, так и среду связи.
Структура файла текстового процессора
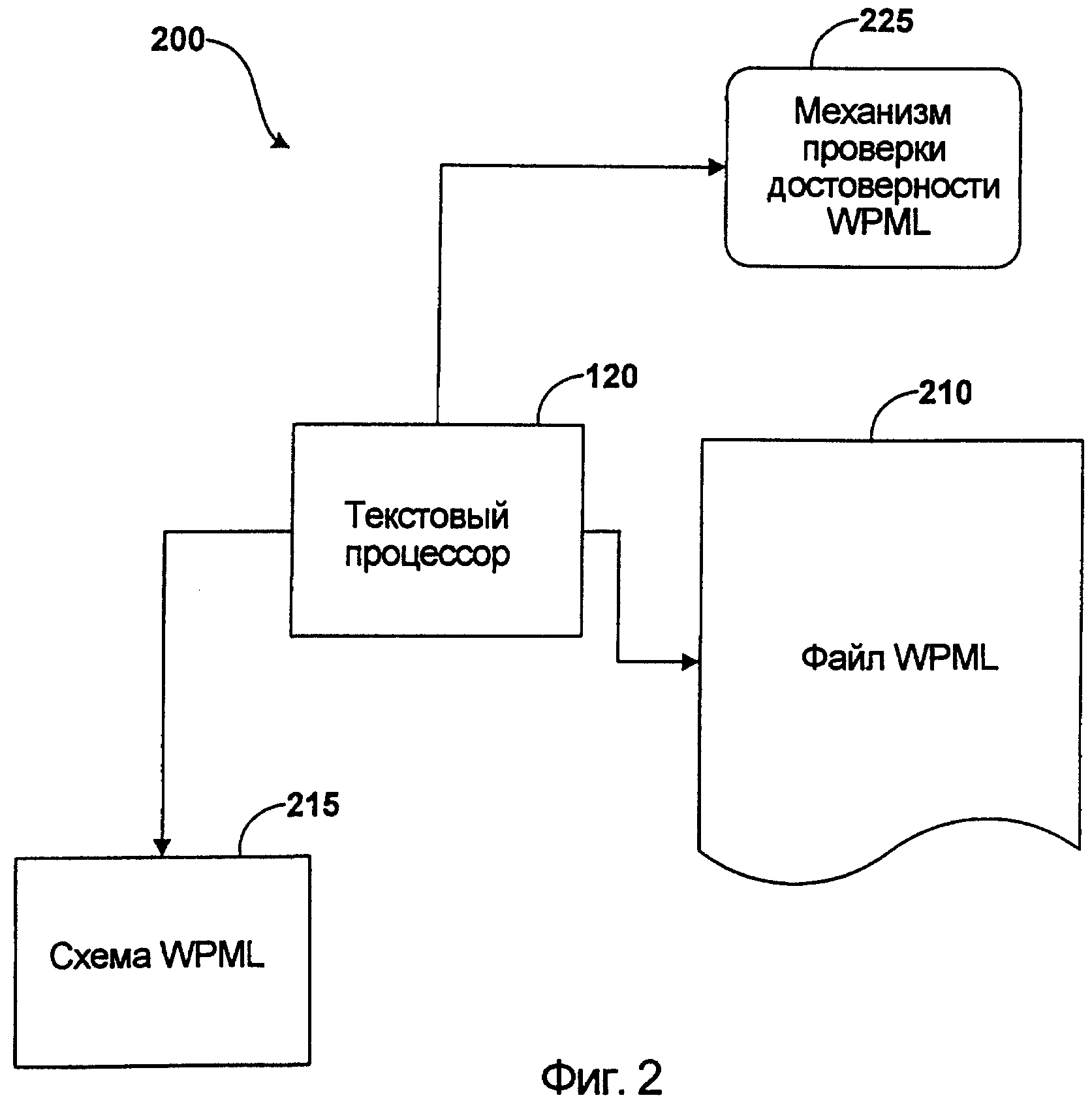
На фиг. 2 представлена блок-схема, иллюстрирующая типовую среду для практической реализации изобретения. Типовая среда, показанная на фиг. 2 представляет собой среду 200 текстового процессора, которая включает в себя текстовый процессор 120, файл 210 WPML, схему 215 WPML и механизм 225 проверки достоверности WPML.
В одном варианте текстовый процессор 120 имеет свои собственное пространство или пространства имен и схему (логическую структуру данных) или набор схем, который задается для использования с документами, связанными с текстовым процессором 120. Набор тегов и атрибутов, определенных схемой (логической структурой данных) для текстового процессора 120, задает формат документа до такой степени, что его называют собственным «родным» языком разметки - языком разметки текстового процессора (WPML). Язык WPML поддерживается текстовым процессором 120 и может придерживаться правил других языков разметки, такого как XML, в то же время создавая для себя собственные дополнительные правила. Язык WPML обеспечивает язык разметки, который включает расширенную информацию отображения, которую пользователь может запросить без необходимости тратить время на создание схемы, соответствующей отображаемой информации.
Текстовый процессор 120 выполняет внутреннюю проверку файла 210 WPML. При проверке элементы WPML анализируются на предмет того, соответствуют ли они схеме 215 WPML. Как было описано ранее, схема устанавливает: какие теги и атрибуты используются для описания контента (содержимого) в документе ML; где разрешен каждый тег; и какие теги могут появляться внутри других тегов, что гарантирует одинаковую структуру документации. Соответственно файл WPML 210 будет достоверным, когда он построен, как это определено в произвольно выбранной схеме 215 WPML.
Механизм 225 проверки достоверности WPML действует аналогично другим имеющимся механизмам проверки достоверности для документов ML. Механизм 225 проверки достоверности WPML оценивает WPML, который имеет формат механизма 225 проверки достоверности WPML. Например, элементы XML направляют в механизм проверки достоверности XML. В одном варианте для проверки достоверности значительного количества форматов ML с текстовым процессором 120 может быть связано значительное количество механизмов проверки достоверности.
На фиг. 3 показан пример файла WPML согласно настоящему изобретению. Файл WPML 300 включает в себя элементы WPML. Элемент в языке разметки обычно включает открывающий тег (указываемый в виде “<” и “>”), некоторый контент и закрывающий тег (указываемый как “”). В этом примере теги, связанные с языком WPML, включают в себя “w:” в теге (например, 302). Префикс “w:” используют в качестве краткого обозначения для пространства имен, связанного с данным элементом.
Чтобы полностью воссоздать документ из указанного единого файла XML, имеется достаточно элементов WPML для приложения, которое понимает язык XML. Можно также добавить теги-подсказки, которые обеспечивают приложение информацией, помогающей ему понять контент файла. Для более полного описания языка WPML, используемого согласно одному варианту изобретения, следует обратиться к материалу, изложенному ниже. Далее более подробно обсуждается пример файла WPML.
Текст, содержащийся в документе, следует за тегом “Т”, что облегчает приложению выделение текстового контента из документа текстовой обработки, созданного согласно аспектам изобретения. При условии что приведенный пример относится к достоверному файлу, файл 210 WPML создает документ, содержащий тело и два параграфа, которые включают в себя текст «Работа» в первом параграфе и «123 Главная часть» во втором параграфе. На фиг. 4 показан документ текстового процессора в виде дерева согласно аспектам изобретения. Первые поля в документе XML относятся к информации и свойствам документа.
Например, может запоминаться статистическая информация по документу. Эта информация может включать, но не только: название, тему, автора, менеджера, компанию, категорию, ключевые слова. Информация может также относиться к статистическим данным по документу, таким как дата создания, дата модификации, дата последнего доступа, дата последней распечатки, количество страниц, слов, строк, символов и т.п. Могут также запоминаться характеристики клиента.
Согласно одному варианту изобретения все шрифты задаются заранее. Информация о шрифтах включает в себя информацию для поддержки шрифтов.
Аналогичным образом задают стили, таблицы, нумерацию и т.п. Поля стилей включают в себя форматирование на различных уровнях списка, тип списка либо любую другую информацию, необходимую для списка. Параграфы, содержащиеся в документе XML, могут указывать на стили списка, которые могут быть установлены по умолчанию.
Стиль символов содержит информацию, относящуюся к тексту в документе текстовой обработки. Например, стиль символов может включать в себя свойства, относящиеся к стилю, размеру, цвету шрифта, стилю подчеркивания, текстовым эффектам, масштабированию, расстоянию между символами, кернингу и т.п. Можно включить любое свойство символов, определенное текстовым процессором. Текст документа текстовой обработки («прогон документа») указывает на стили, определяющие, как должен отображаться текст. Также может быть обеспечена подсказка, помогающая приложению отобразить текст.
Стиль параграфа обычно включает свойства символов, а также свойства параграфа. Свойства параграфа могут включать в себя значение выравнивание для параграфа, уровень контура, отступ, интервал перед и после параграфа, интервал между строками, свойства разбиения на страницы и тому подобное. Раздел параграфа может включать такую информацию как название стиля параграфа, информацию о списке и тому подобное.
Стили таблицы содержат большой объем информации, относящийся к структуре таблицы. Сюда относится такая информация, как разбиение, и тому подобное. Свойства таблиц включают в себя такую информацию, как границы, ширина и элементы сетки. Элементы сетки таблицы используют для определения ширины клетки.
Текстовый узел содержит действительный контент документа. В этом узле хранится весь текст для документа после текстовой обработки. Это очень облегчает доступ к контенту документа. Все другие элементы могут быть проигнорированы, если текст - это все, что необходимо.
Свойства раздела содержат такую информацию как макет страницы, информацию о нижнем колонтитуле и заголовке и другую информацию, касающуюся раздела документа текстового процессора.
Прогон текста ссылается на название стиля символа, а также допустимые свойства.
В параграфе имеются изображения и объекты. В параграфе содержаться даже «плавающие» объекты. Плавающие объекты сопровождаются появлением символа анкера (привязки). Согласно одному варианту изобретения изображения запоминаются в виде двоичных кодов. Пример изображения, запомненного в виде двоичных кодов, можно найти в примере файла текстового редактора, приведенном ниже.
В документе текстового процессора также может храниться информация о шаблоне, относящаяся к текстовому процессору. Согласно одному варианту изобретения информация о шаблоне хранится в документе текстового процессора в двоичных кодах.
Элемент метки параграфа представляет метку параграфа. Поскольку сама метка параграфа может иметь применяемое к ней форматирование, необходимо вывести элемент для представления метки параграфа, которой можно придать свойства символов.
Как можно видеть из примера макета файла, приложение может использовать ровно столько информации, сколько ему потребуется. Если приложение хочет воссоздать или создать документ, точно так как это затем сделает текстовый процессор, то в документе для этого имеется вполне достаточно информации. С другой стороны, если приложение захочет воссоздать контент в минимальном формате, то оно сможет сделать и это.
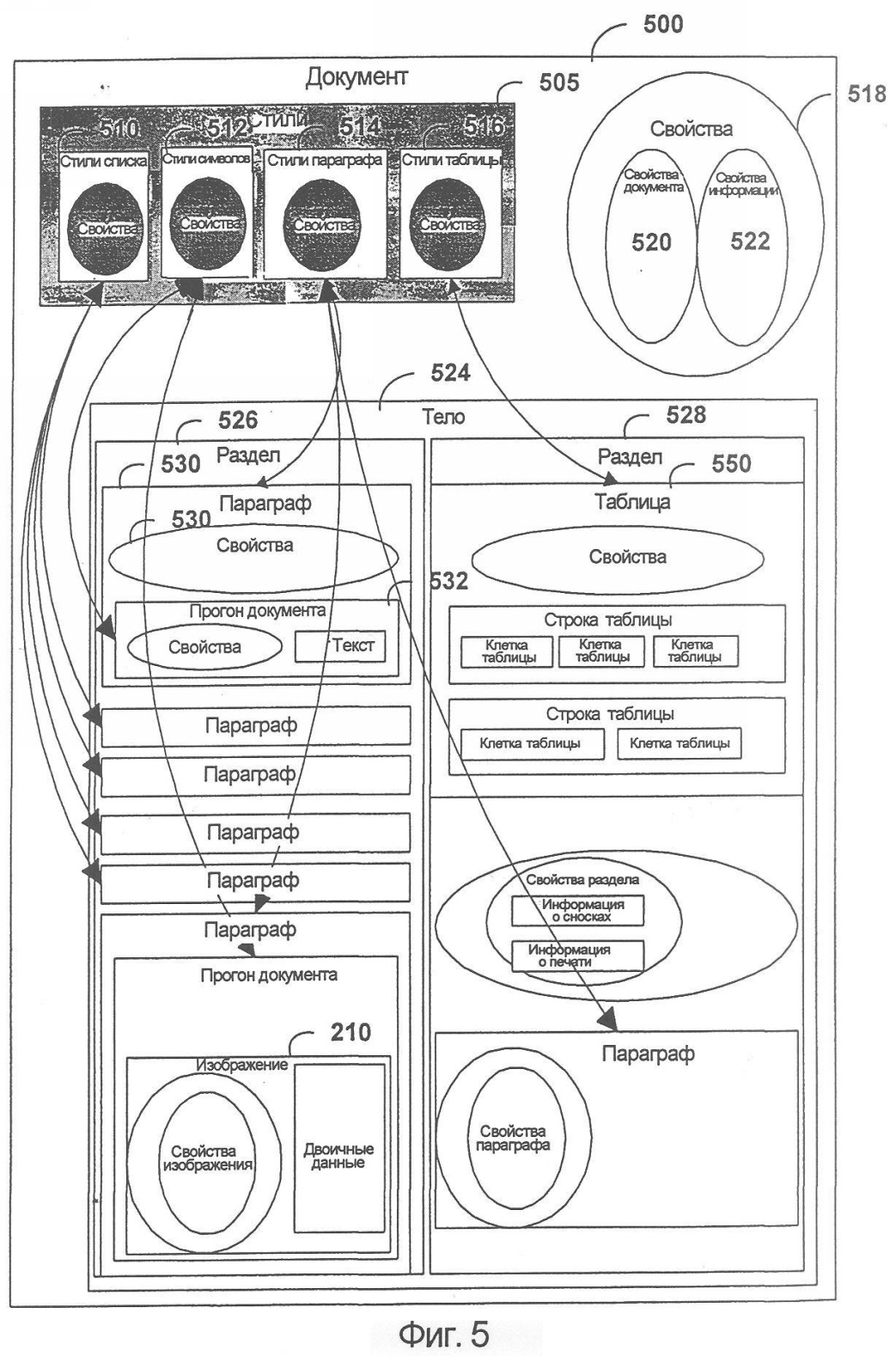
На фиг. 5 показана блок-схема документа согласно аспектам настоящего изобретения. Стили 505 включают в себя стили списка 510, стили символов 512, стили параграфа 520 и информационные свойства 522. Свойства 518 включают в себя свойства документа 520 и информационные свойства 522. Тело 524 включает в себя типовой раздел 526 и типовой раздел 528. Раздел 526 включает в себя параграф 530, который содержит информацию о конкретных свойствах 530 и прогон текста 532. Как видно из фигуры, прогоны текста могут включать в себя свойства и текст либо, как вариант, изображение или объект.
Типовой раздел 528 включает в себя таблицу 550, которая содержит свойства, относящиеся к таблице, и определение строк таблицы и клеток, содержащихся в таблице. Разделы могут также включать в себя информацию, касающуюся сносок, информацию о печати и т.п.
Различные части документа могут ссылаться на стили (505) для определения того, как должен отображаться документ. Например, как показано на фигуре, некоторые параграфы могут ссылаться к стилям 414 списка или стилям 516 параграфа. Прогоны текста ссылаются к стилям 412 символов, а таблицы могут ссылаться к стилям таблицы.
Документ текстового процессора включает в себя всю информацию в документе, которая позволяет приложению его воссоздать.
В документ также может быть включена другая информация, которая не нужна программе обработки текстов. Согласно одному варианту изобретения включается элемент с «подсказками», который позволяет внешним программам легко понять, что представляет собой конкретный элемент, либо каким образом его можно воссоздать. Например, в списке может находится определенный формат числа, который используеться внешней программой для воссоздания документа без знания конкретных деталей данного стиля.
На фиг. 6 показан процесс 600 для интерпретации документа текстового процессора согласно аспектам изобретения. После прохождения стартового блока процесс переходит к этапу 610, где происходит анализ документа текстового процессора. Анализ может включать просмотр всего документа либо только его определенных частей. Например, одно приложение может анализировать только текст документа, другое приложение может анализировать как текст, так и изображения, принимая во внимание, что для другого документа может потребоваться весь разнообразный контент в данном документе.
При переходе к этапу 615 документ интерпретируется в соответствии с опубликованным файлом XSD (файл определения логической структуры XML). XSD определяет, как интерпретировать документ XML, созданный текстовым процессором.
В блоке 620 принятия решения определяется, следует ли отображать документ. Когда документ должен быть отображен, процесс переходит к этапу 625, где документ отображается. Документ может быть отображен пользователю для редактирования или для каких-то других целей. Когда документ не отображается, процесс переходит к этап у 630 принятия решения.
В блоке принятия решения 630 определяется, требуется ли модификация документа. Документ может быть модифицирован пользователем либо самим приложением без взаимодействия с пользователем. Документ может быть модифицирован по многим причинам. Например, можно добавить дополнительный текст либо удалить какой-то текст, часть документа можно отформатировать по-другому, можно добавить изображение и т.п. Когда документ необходимо модифицировать, процесс переходит к этапу 635, где документ модифицируется (смотри фиг. 7 и связанное с ней обсуждение). Документ модифицируется в соответствии с XSD, который определяет всю информацию, необходимую для создания документа текстового процессора. Типовой файл XSD описан ниже.
В качестве дополнительной иллюстрации типового документа текстового процессора далее приведен документ текстового процессора, созданный согласно аспектам настоящего изобретения. Согласно одному варианту изобретения документ текстового процессора запоминается в виде единого документа XML.































Документ текстового процессора, созданный согласно аспектам изобретения, обладает расширенными возможностями. Если это необходимо, приложение, которое понимает язык XML, может создать и/или модифицировать документ текстового процессора. Приложение, если надо, может также проигнорировать многие элементы в документе. Например, приложению может понадобиться только текст, содержащийся в документе. Согласно данному конкретному примеру приложение должно будет лишь выделить элементы, идентифицированные тегом
Для того чтобы приложение воспринимало документы, созданные текстовым процессором, предусмотрен файл XSD. Ниже приведен пример файла XSD, который можно использовать для интерпретации и/или создания документов текстовой обработки с расширенными возможностями в XML.































































Как обсуждалось выше, в ассоциированных файлах XML могут быть предусмотрены подсказки, обеспечивающие приложения, которые понимают язык XML, сокращенной клавиатурной командой для осмысления некоторых признаков, обеспечиваемых текстовым процессором. Используя эти подсказки, приложения, для того чтобы воссоздать некоторый признак, не должны знать все конкретные детали внутренней обработки, выполненной текстовым процессором. Ниже в качестве примера представлена схема подсказок согласно аспектам изобретения.



Вышеприведенное описание, примеры и данные дают полное описание процесса создания и использования состава изобретения. Поскольку многие варианты изобретения можно выполнить, оставаясь в рамках существа и объема изобретения, изобретение определяется прилагаемой формулой изобретения.
Реферат
Изобретение относится к текстовым процессорам. Техническим результатом является расширение функциональных возможностей документа текстового процессора, заключающихся в том, что приложение может создавать и/или модифицировать этот документ. Текстовый процессор включает в себя собственный формат файла XML. Правильно сформатированный файл XML полностью представляет документ текстового процессора и полностью поддерживает 100-процентное расширенное форматирование текстового процессора. При сохранении документов в виде XML их признаки не теряются. Опубликованный файл XSD определяет все правила вслед за форматом файла XML текстового процессора. В файлах, связанных с XML, могут быть предусмотрены подсказки, обеспечивающие приложения, которые понимают язык XML, сокращенной комбинацией нажатых клавиш клавиатуры осмысления некоторых из признаков, предоставляемых текстовым процессором. Документ текстового процессора сохраняется в едином файле XML. Вдобавок возможно манипулирование документами текстовой обработки на вычислительных устройствах, которые сами не содержат текстовый процессор. 4 н. и 26 з.п. ф-лы, 6 ил.
Формула
создают посредством текстового процессора единый файл WPML (на языке разметки документа текстового процессора), причем упомянутый WPML-файл содержит текстовый документ и все команды, необходимые различным внешним приложениям для обработки упомянутого документа;
проверяют правильность, посредством одного из множества механизмов проверки достоверности, созданного файла на его соответствие XSD (определению схемы XML),
интерпретируют текстовый документ по меньшей мере одним внешним приложением, понимающим язык XML, в соответствии с XSD, и
выполняют посредством упомянутого по меньшей мере одного внешнего приложения действия над упомянутым документом требуемым для этого внешнего приложения образом.
проверку правильности модифицированного текстового документа на его соответствие файлу XSD, и
запись модифицированного документа в единый файл WPML после проверки правильности.
первую компоненту для создания посредством текстового процессора единого файл WPML (на языке разметки документа текстового процессора), причем упомянутый WPML-файл содержит текстовый документ и все команды, необходимые различным внешним приложениям для взаимодействия с упомянутым документом,
вторую компоненту для обеспечения интерпретации текстового документа по меньшей мере одним из множества внешних приложений с использованием XSD (определения схемы XML) и выполнения упомянутым одним из множества внешних приложений действий над упомянутым документом; и
третью компоненту для выполнения, посредством одного из множества механизмов проверки достоверности, проверки достоверности документа текстового процессора на его соответствие формату WPML-файла, и если упомянутые действия включают в себя модификацию текста в документе -записи документа в единый WPML-файл после упомянутой проверки.
единый WPML-файл, причем упомянутый файл WPML содержит текстовый документ на языке разметки и все команды, необходимые различным внешним приложениям для взаимодействия с упомянутым документом;
определение схемы XML, которое определяет правила и структуру документа,
текстовый процессор, выполненный с возможностью: создания упомянутого файла WPML в соответствии с упомянутым XSD,
множество механизмов проверки достоверности для проверки достоверности WPML-файла, причем каждый механизм проверки достоверности проверяет созданные документы на их соответствие XSD, a также проверяет текстовые документы WPML-файла после их интерпретации по меньшей мере одним внешним приложением, понимающим XML, с использованием XSD и выполнения упомянутым внешним приложением действий над этими текстовыми документами,
причем текстовый процессор выполнен с возможностью записи модифицированного упомянутым внешним приложением текстового документа в упомянутый единый WPML-файл после выполнения проверки правильности.
первую компоненту для создания посредством текстового процессора единого файла WPML (на языке разметки документа текстового процессора), причем WPML-файл содержит текстовый документ и все команды, необходимые внешним приложениям, понимающим XML, для взаимодействия с упомянутым документом,
при этом упомянутый документ является XML-документом и содержит элемент свойств; элемент стилей; элемент тела, где элемент тела содержит:
элемент параграфа,
элемент прогона текста, включающий в себя текст, который представляет собой текстовый контент документа текстового процессора, причем текст для каждого элемента прогона текста сохранен между тегом начала текста и тегом конца текста, которые не включают в себя каких-либо промежуточных тегов, и при этом тег начала текста и тег конца текста не включают в себя форматирование текста; и
элемент таблицы;
вторую компоненту, которая использует файл XSD (определение схемы XML), определяющий правила и структуру WPML-документа в дополнение к формату XML, для обеспечения интерпретации документа текстового процессора по меньшей мере одним внешним приложением из множества внешних приложений и выполнения внешним приложением действий над упомянутым документом; и
третью компоненту для выполнения проверки достоверности документа текстового процессора на его соответствие формату WPML-файла, и записи XML-документа в упомянутый единый WPML-файл после упомянутой проверки правильности, если упомянутые действия включают в себя модификацию текста в документе.
Документы, цитированные в отчёте о поиске
Компьютерная система и способ подготовки текста на исходном языке и перевода на иностранные языки
Комментарии