Процессор, выполненный с возможностью транзакций, и схема регистрации для отчета об операциях транзакций - RU2625524C2
Код документа: RU2625524C2
Чертежи





Описание
Область техники, к которой относится изобретение
Настоящее изобретение относится к области компьютерных наук, в частности к процессору, выполненному с возможностью осуществления транзакций и схеме отчетности об операциях транзакций.
Уровень техники
Многоядерные процессоры и/или многопоточные конвейеры выполнения команд в процессорных ядрах побудили разработчиков программного обеспечения (ПО) разработать многопоточные программные продукты (в отличие от однопоточных программных продуктов). Многопоточное ПО естественно сложнее из-за параллельного выполнения различных процессов. В то же время многопоточное ПО к тому же трудно поддается отладке из-за аспекта "недетерминизма" в способе его выполнения. В частности, многопоточный программный продукт может выполняться различно в двух отличающихся временах прогона, даже если программа начинается с одинакового состояния ввода.
По этой причине осуществляется "протоколирование" с целью регистрации некоторых критических моментов в ходе выполнения многопоточных программных продуктов. В настоящее время процессоры оснащаются схемами регистрации данных, отслеживающими выполнение ПО процессором и регистрирующими некоторые критические события, на выявление которых настроены схемы регистрации данных. Если ПО дает сбой, то проводится анализ журнала записей с целью изучения хода выполнения программы, приведшего к сбою.
Краткое описание чертежей
Настоящее изобретение описывается с использованием примеров, не носящих ограничительного характера, со ссылкой на прилагаемые к описанию чертежи, на которых одинаковые элементы обозначены одинаковыми ссылочными позициями и на которых показано:
на Фиг. 1 - процессор предыдущего уровня техники,
на Фиг. 2 - усовершенствованный процессор,
на Фиг. 3А - первый способ, который может осуществляться упомянутым процессором,
на Фиг. 3Б - второй способ, который может осуществляться упомянутым процессором,
на Фиг. 3В - третий способ, который может осуществляться упомянутым процессором,
на Фиг. 3Г - четвертый способ, который может осуществляться упомянутым процессором,
на Фиг. 4 - структура пакета данных,
на Фиг. 5 - вычислительная система.
Осуществление изобретения
На Фиг. 1 показан процессор предыдущего уровня техники, выполненный на полупроводниковом кристалле и имеющий схему 101_1-101_N регистрации данных для отслеживания конкретных аспектов многопоточного программного потока и регистрации вне процессора 100 таких аспектов, так что ход выполнения программы может быть позже проанализирован и понят. В одном из вариантов осуществления изобретения каждая реализация схемы 101_1-101_N регистрации данных предназначена для просмотра каждого потока своего локального процессорного ядра, имеющего вид "фрагментов" потока, прерываемых некоторыми специально отыскиваемыми событиями. Благодаря сохранению последовательности фрагментов каждого потока в ячейке памяти, такой как системная память 103, может быть тщательно проанализировано многопоточное выполнение более крупной многопоточной программы, которая возможно выполняет потоки на всех ядрах 105_1-105_N.
Каждой реализации схемы регистрации данных приписывается конкретная область системной памяти 103, в которой хранятся ее соответствующие фрагменты. Каждому аппаратному потоку, выполняемому конкретным ядром, приписывается соответствующее пространство в области системной памяти, выделенной для схемы регистрации данных. В данном случае, как известно из уровня техники, один конвейер выполнения команды может параллельно выполнять несколько аппаратных потоков (к примеру, 8 аппаратных потоков). Более того, каждое процессорное ядро может содержать более одного конвейера выполнения команд (к примеру, на Фиг. 1 показано, что каждое ядро имеет два конвейера 106 выполнения команд).
Под аппаратными потоками понимаются потоки, активно выполняемые конвейером выполнения команд. Конвейеры выполнения команд, как правило, предназначены для параллельного выполнения максимального/ограниченного количества аппаратных потоков, где максимум/предел определяется аппаратной конструкцией конвейера. Под программным потоком понимается одиночный поток команд программного кода. Количество программных потоков, поддерживаемых процессором, может существенно превышать количество аппаратных потоков. Программный поток признается также в качестве аппаратного потока, если состояние/контекстная информация потока подключается к конвейеру выполнения команд. Программный поток теряет свой статус аппаратного потока, если его состояние/контекст отключается от конвейера выполнения команд. В одном из вариантов осуществления изобретения имеется одна реализация схемы регистрации данных на каждый аппаратный поток (для простоты на Фиг. 1 показана только одна схема регистрации на ядро).
В одном из вариантов осуществления изобретения реализация схемы регистрации данных (к примеру, схема 101_1) предназначена для прерывания фрагмента потока при наступлении любого из нижеперечисленных событий: 1) состояния гонки за память; 2) перехода потока из активного режима в спящий режим; 3) неисправности буфера быстрого преобразования адреса; 4) перехода потока за пределы уровня привилегий, на который он был рассчитан (к примеру, переходы потока с уровня привилегий "пользователя" на уровень привилегий "ядра" в ответ на прерывание или нештатную ситуацию); 5) попытки потока получить доступ к некэшируемой области памяти. Здесь каждое из вышеописанных событий приводит к недетерминированному способу выполнения многопоточных программ.
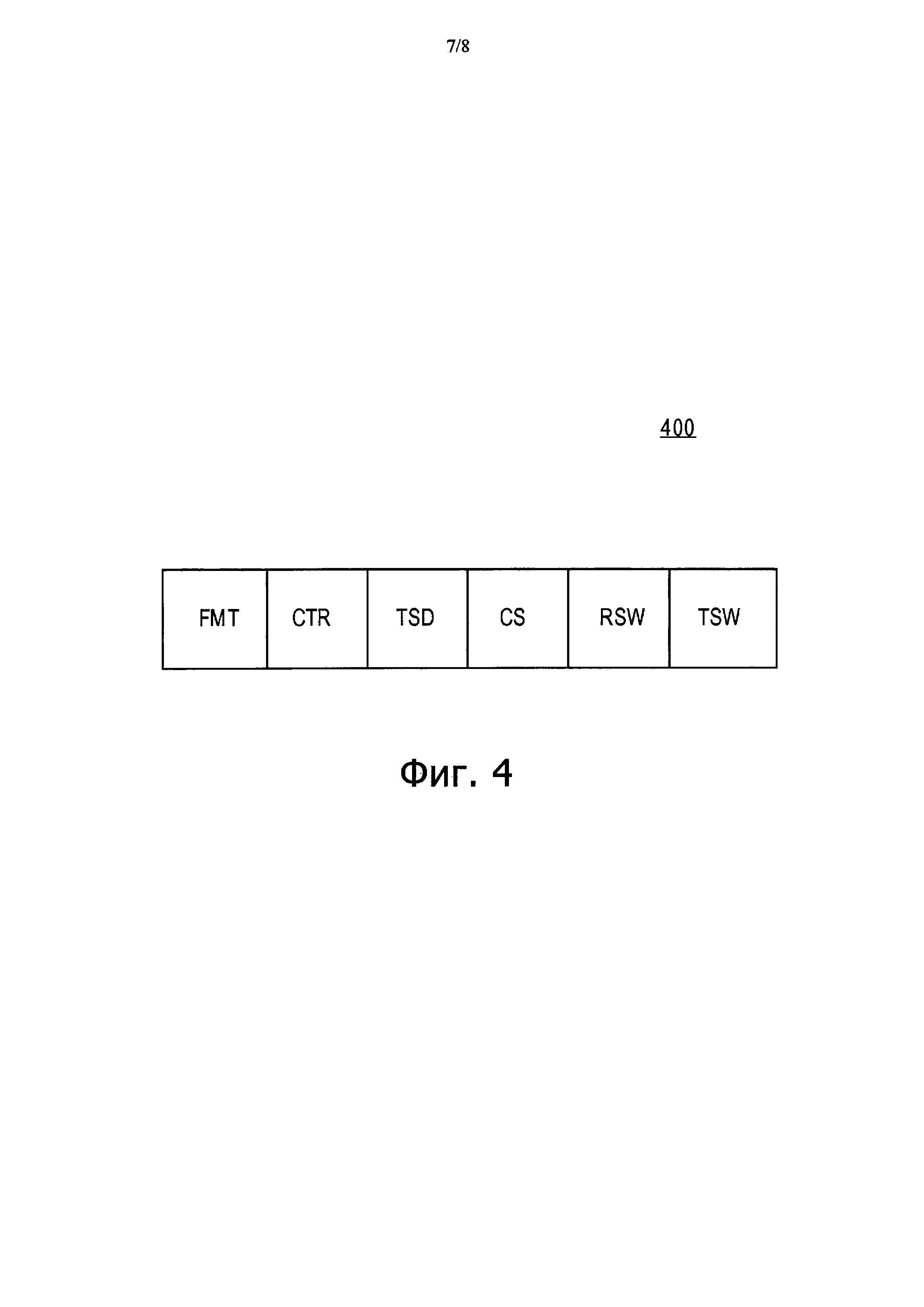
На Фиг. 1 также показана структура 120 пакета данных предыдущего уровня техники для фрагмента конкретного потока. Как видно из структуры 120, пакет содержит: 1) идентификатор формата пакета (FMT); 2) причину прерывания фрагмента (CTR); 3) дифференциальную временную метку (время между данным пакетом и предыдущим пакетом фрагмента) (TSD); 4) количество команд, которые были выполнены фрагментом между прерыванием предыдущего фрагмента потока и прерыванием текущего фрагмента (CS); 5) количество незавершенных записей фрагмента (т.е. количество отмененных, но все еще в целом видимых (зафиксированных) операций сохранения (RSW); 6) количество невыполненных операций обмена с памятью наиболее старой еще невыполненной макрокоманды (NTB). В одном из вариантов осуществления изобретения идентификатор ядра и идентификатор потока добавляются программным уровнем, который может определять и тот и другой идентификаторы, исходя из того, где фрагмент хранится в системной памяти 103.
Здесь каждая реализация схемы 101_1-101_N регистрации связана с "захватчиками" 104_1-104_N в их соответствующих процессорных ядрах 105_1-105_N процессора (к примеру, вблизи конвейеров 106_1-106_N выполнения команд, выполняющих соответствующие потоки команд различных программных потоков), которые предназначены для обнаружения отыскиваемых событий прерывания фрагментов. Во время выполнения конкретного потока различные захватчики обнаруживают события прерывания фрагментов для потока и информируют о событии схему 101 регистрации данных. В ответ схема 101 регистрации данных формирует пакет в соответствии со структурой 120 и инициирует запись пакета во внешнюю память 103.
Один из таких захватчиков в каждом ядре связан со схемой 107_1-107_N обнаружения гонки за память. Как видно из Фиг. 1, у каждого процессорного ядра, непосредственно связанного с кэш-памятью L1 108_1-108_N ядра, имеется одна схема обнаружения гонки за память. Каждая схема 107_1-107_N обнаружения гонки за память предназначена для обнаружения гонки за связанную с ней кэш-память L1.
Гонка за память происходит, если два различных программных процесса (к примеру, два различных потока) пытаются получить доступ к одной и той же ячейке памяти. Здесь каждая последовательность команд запоминает все доступы к памяти (адреса) текущего фрагмента. Фрагмент прерывается и создается новый фрагмент, если обнаружен конфликт обращений к одному из адресов, хранящихся в текущем фрагменте (независимо от того, как долго длился доступ в прошлом).
В частности, всего гонка может возникать, если два различных потока в одном и том же ядре пытаются получить доступ к одной и той же ячейке памяти или если два различных потока в двух различных ядрах пытаются получить доступ к одной и той же ячейке памяти. В последнем случае первое ядро будет подглядывать в кэш-память L1 второго ядра. Здесь для транспортировки таких подглядываний используется сеть 109 с внутрисхемной коммутацией.
Каждая схема 107_1-107_N обнаружения гонки за память отслеживает недавние операции считывания и недавние операции записи (называемые "наборами считывания" и "наборами записи") и сравнивает их с приходящими запросами считывания и приходящими запросами записи. Схема обнаружения гонки за память обнаруживает условие гонки за память каждый раз, когда она обнаруживает операции "считывания после записи" (RAW), "записи после записи" (WAW) или "записи после считывания" (WAR), адресованные к одной и той же ячейке памяти. В различных вариантах осуществления изобретения идентичность конфликтного адреса может дополнительно включаться во фрагмент (в зависимости от того, какие фрагменты желательны, более длинные или более короткие), который записывается для гонки за память.
На Фиг. 2 показан улучшенный процессор по сравнению с известным из уровня техники процессором, изображенным на Фиг. 1. Здесь улучшенный процессор с Фиг. 2 в одном из вариантов осуществления изобретения предполагает все функциональности, описанные выше в отношении процессора с Фиг. 1, плюс дополнительные улучшения, которые описываются ниже.
Как видно из Фиг. 2, отдельные ядра 205_1-205_N процессора включают в себя дополнительную функциональность выполнения "транзакций". Выполнение транзакций соответствует выполнению спекулятивного кода гораздо дальше границ традиционного спекулятивного выполнения. Традиционное спекулятивное выполнение, такое как прогнозирование ветвления, позволяет конвейеру выполнения команды выполнять программу в соответствии с программной ветвью до получения подтверждения, что выбранное направление представляет собой правильный ход выполнения программы. Здесь результаты выполненных команд содержатся (к примеру, в буфере переупорядочения) внутри конвейера, а не записываются вне архитектурной структуры (регистров) процессора. Как таковые, результаты спекулятивного выполненных команд в целом не видны. Если выбранное направление некорректно, конвейер выключается из работы, и процесс выполнения программы перезапускается с некорректно выбранной ветви. Если прогнозирование корректно, то результаты выполнения команд фиксируются в архитектурной структуре вне конвейера для общего просмотра другими процессами. В целом, однако, объем сохраняемых изменений данных ограничен по размеру, и, следовательно, объем спекулятивно выполненного кода ограничен.
В противоположность этому процессорные ядра, поддерживающие транзакции, позволяют спекулятивное выполнение, даже не учитывая рассмотренный выше тип спекулятивного выполнения (хотя ядра, показанные на Фиг. 2, могут быть также спроектированы с включением функциональности предсказания ветвления). В случае транзакций процессы способны действовать так, "как если бы" они блокировали совместно используемые элементы данных. В основном подходе процесс (к примеру, программный поток) запрашивает блокировку всей базы данных (к примеру, всей совместно используемой памяти, такой как кэш-память протокола управления логическими связями и/или системной памяти 203 или ее области, где хранятся данные процесса). Процесс реализует некую логику и после выполнения логики определяет, что необходимо изменить один или несколько информационных элементов. Затем процесс "фиксирует" информационные элементы в базе данных и разблокирует базу данных, тем самым открывая доступ другим процессам к информационным элементам.
В одном из вариантов осуществления изобретения конвейеры 206_1-206_N процессора имеют улучшенные функциональные узлы для поддержки команд (к примеру, XACQUIRE и XRELEASE), которые позволяют программному потоку считать, что он заблокировал базу данных, как это описано выше. Т.е. выполненная команда XACQUIRE извещает о начале спекулятивного выполнения транзакции и блокировке базы данных. Выполнение команды XRELEASE извещает об окончании спекулятивного выполнения транзакции и разблокировании базы данных. Важно отметить, что в одном из вариантов осуществления изобретения базовое аппаратное обеспечение процессора 200 действует таким образом, чтобы позволить программному потоку полагать, что он заблокировал базу данных, когда на самом деле технически он не заблокировал всю базу данных, а скорее побудил находящееся в процессоре аппаратное средство 221 обнаружения конфликтов отслеживать и принудительно заставлять конкурирующие потоки обращаться к одному и тому же информационному элементу последовательно.
Здесь должно быть понятным, что разрешение первому программному потоку блокировать всю базу данных может наносить вред производительности, если имеется другой параллельный поток, который хотел бы использовать ту же базу данных. У второго потока иного выбора, как ждать пока первый поток зафиксирует свои данные в базе данных и разблокирует базу данных. На практике текущая блокировка всей базы данных будет заставлять конкурирующие потоки использовать одну и ту же базу данных скорее последовательно, чем параллельно.
Сама по себе команда XACQUIRE приводит к "включению" имеющегося в процессоре аппаратного средства 221 обнаружения конфликтов, что подразумевает поведение базы данных (к примеру, системной памяти или ее конкретной части), "как если бы она была заблокирована". Это означает, что аппаратное средство 221 обнаружения конфликтов будет разрешать другому процессу доступ к базе данных до тех пор, пока доступ не начнет конкурировать с доступами процесса, который выполнил команду XACQUIRE и полагает, что он заблокировал базу данных (здесь под конкурирующим доступом следует понимать доступ к той же ячейке памяти). Если обнаружены конкурирующие доступы, поток "прерывается", что приводит к сбросу на диск состояния транзакции, и возвращению программы к команде XACQUIRE для осуществления повторной попытки проведения транзакции. Здесь аппаратное средство 221 обнаружения конфликтов обнаруживает, когда другой процесс попытался получить доступ к тому же адресу ячейки памяти, что и транзакция, которая выполнила команду XACQUIRE и выполняет машинную программу в спекулятивной области.
В другом варианте осуществления изобретения процессор поддерживает также дополнительные команды, что позволяет использовать более продвинутую транзакционную семантику (к примеру, XBEGIN, XEND и XABORT). Команды XBEGIN и END, как правило, действуют так же, как XACQUIRE и XRELEASE соответственно. Здесь команда XBEGIN извещает о начале спекулятивного выполнения (включает схему 221 обнаружения конфликтов), а команда XEND извещает об окончании спекулятивного выполнения (отключает схему 221 обнаружения конфликтов). Функционирование команд осуществляется, как описано выше, за исключением того, что прекращение транзакции передает код ошибки в пространство регистра 222 управления (к примеру, в автоматический электронный коммутатор пространства модельно-зависимого регистра процессора, реализованный с помощью одной или нескольких схем регистра (ЕАХ регистр)) ядра, которое выполняло прерванный поток, обеспечивая больше подробностей о прерывании (к примеру, прерывание было вызвано командой ABORT (ПРЕРЫВАНИЕ), транзакция может достичь цели при повторной попытке, прерывание было вызвано конфликтом, переполнение внутреннего буфера, обнаружена отладка по точке останова, прерывание произошло во время осуществления встроенной транзакции).
Информация, оставленная в пространстве 222 регистра, может быть использована для направления процесса выполнения программы после прерывания по иному пути, чем путь автоматического повторения транзакции. Дополнительно процессор может поддерживать команду (к примеру, XABORT), которая однозначно прерывает транзакцию. Команда XABORT дает разработчику программы возможность определять другие условия прерывания транзакции, чем те, что однозначно встроены в аппаратные средства процессора. В случае XABORT, ЕАХ регистр будет содержать информацию, предоставленную командой XABORT (к примеру, информацию, описывающую событие, вызвавшее прерывание).
Процессоры, поддерживающие транзакции, увеличивают сложность отладки многопоточного программного кода. Сам по себе улучшенный процессор 200, показанный на Фиг. 2, включает в себя дополнительные усовершенствования схемы 201 регистрации данных, которая служат цели идентификации наличия транзакций и ограничения размеров основанных на них фрагментов. Более конкретно, на Фиг. 2 видны дополнительные захватчики 230 в ядре, которые предназначены для: 1) обнаружения выполнения команды, которая является признаком начала выполнения спекулятивного кода транзакции (к примеру, XACQUIRE или XBEGIN) и извещения о событии схемы 201 регистрации данных, и 2) обнаружения выполнения команды, которая является признаком окончания выполнения спекулятивного кода транзакции (к примеру, XRELEASE или XEND) и извещения о событии схемы 201 регистрации данных. В ответ на любое из этих событий схема регистрации 201 данных прерывает фрагмент, формирует пакет, описывающий прерывание фрагмента, и регистрирует упомянутый пакет в системной памяти 203 (к примеру, с помощью контроллера 209 памяти).
Кроме того, новые захватчики 230 докладывают о наличии прерванной транзакции. В ответ схема 201 регистрации данных прерывает фрагмент, формирует пакет данных, который описывает прерывание фрагмента и производит перезапись упомянутого пакета в системную память 203. В частности, при таком подходе обнаружение прерывания для целей регистрации обходит схему 221 обнаружения конфликтов в процессорных ядрах 205, которая на самом деле обнаруживает конфликты для прерывания транзакций скорее, чем схема 207 обнаружения гонки за память. Отношение между схемой 221 обнаружения конфликтов и схемой 207 обнаружения гонки за память более подробно рассматривается ниже. В одном из вариантов осуществления изобретения, где процессор включает в себя пространство 222 регистра (к примеру, вышеупомянутое пространство ЕАХ регистра), которое содержит дополнительную информацию, описывающую прерывание, дополнительные захватчики 230 дополнительно предназначены для доклада информации, содержащейся в пространстве 222 регистра, в схему 201 регистрации данных. В процессорах, которые поддерживают команду, однозначно прерывающую транзакцию (к примеру, XABORT), также формируется и направляется пакет данных о прерывания транзакции (к примеру, с содержанием ЕАХ регистра, если оно имеется).
На Фиг. 3А показан первый способ, реализуемый изображенным на Фиг. 2 процессором. Как видно из Фиг. 3А, выполняется 301 команда, которая означает начало выполнения спекулятивно выполняемого кода транзакции. В одном из вариантов осуществления изобретения команда не считается "выполненной", пока она не завершена. В ответ на выполнение команды сигнал отправляется 302 в схему регистрации. В ответ на сигнал схема регистрации формирует 303 пакет данных о прерывании фрагмента, который указывает, что фрагмент прерван из-за того, что началась транзакция. Пакет данных о прерывания фрагмента регистрируется 304 вне процессора (к примеру, записывается во внешнюю системную память).
На Фиг. 3В показан второй способ, реализуемый изображенным на Фиг. 2 процессором. Как видно из Фиг. 3В, выполняется 311 команда, которая означает завершение выполнения спекулятивно выполняемого кода транзакции (к примеру, после того, как транзакция успешно зафиксировала изменения своих данных). В одном из вариантов осуществления изобретения команда не считается "выполненной", пока она не завершена. В ответ на выполнение команды сигнал отправляется 302 в схему регистрации данных. В ответ на выполнение команды в схему регистрации данных направляется 312 сигнал. В ответ на сигнал схема регистрации данных формирует 303 пакет данных о прерывании фрагмента, который указывает, что фрагмент прерван ввиду окончания транзакции. Пакет данных о прерывании фрагмента регистрируется 314 вне процессора (к примеру, записывается во внешнюю системную память).
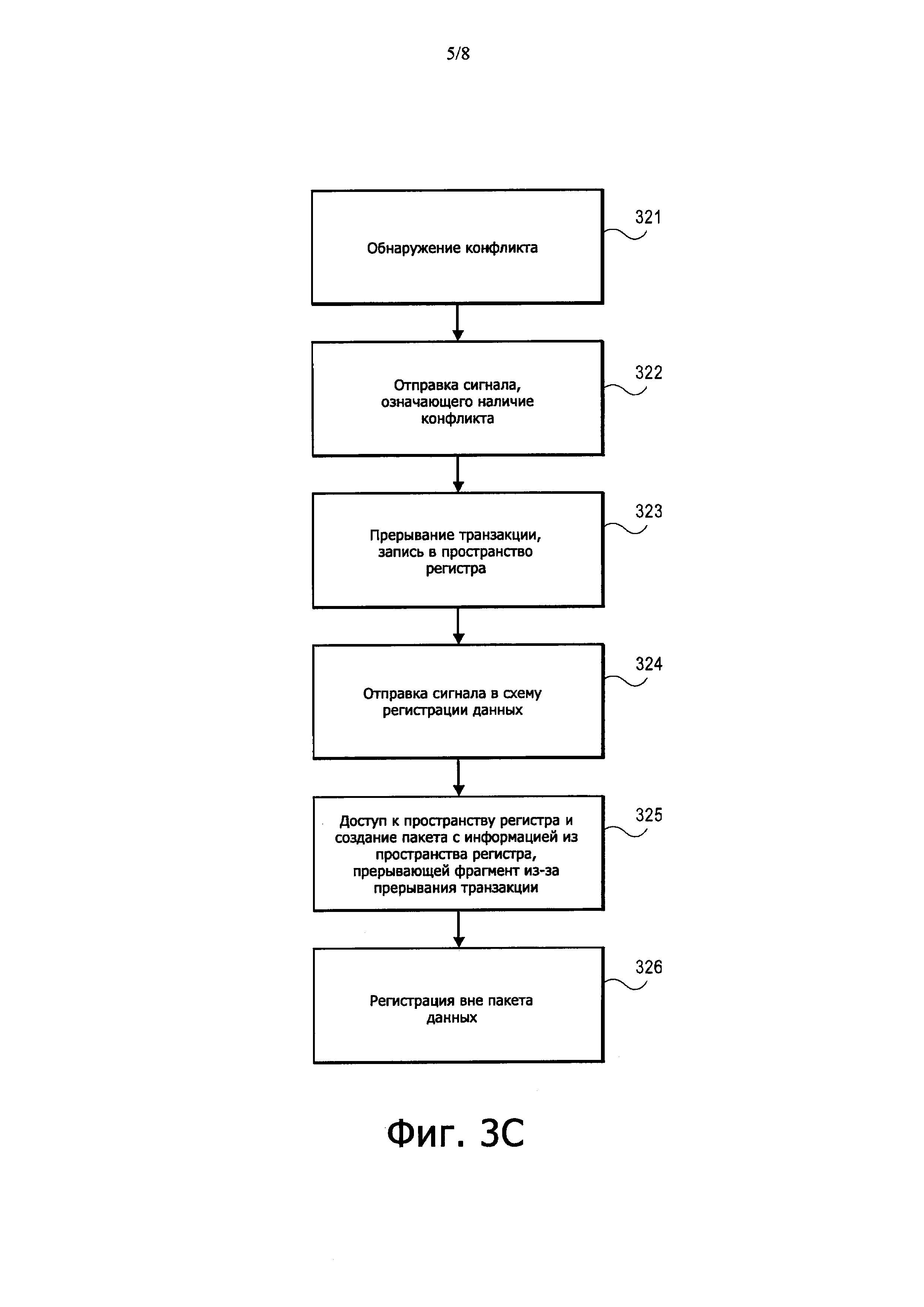
На Фиг. 3С показан третий способ, реализуемый изображенным на Фиг. 2 процессором. Как видно из Фиг. 3С, аппаратное средство (к примеру, схема 221 обнаружения конфликтов) обнаруживает 321, что другой поток пытается получить доступ к ячейке памяти, к которой получила доступ транзакция. Отправляется 322 сигнал, означающий наличие конфликта (к примеру, со схемы 222 обнаружения конфликтов в конвейер процессорного ядра, выполняющего транзакцию). В ответ на это сигнал транзакция прерывается 323, и информация записывается в пространство регистра управления. В ответ на сигнал, отправленный в схему регистрации данных, схема регистрации данных получает доступ к пространству регистра и формирует 325 пакет данных, указывающий, что фрагмент прерван ввиду прерывания транзакции, и включающий в себя информацию из регистра. Пакет данных о прерывании фрагмента регистрируется 326 вне процессора (к примеру, записывается во внешнюю системную память).
На Фиг. 3D показан четвертый способ, реализуемый изображенным на Фиг. 2 процессором. Как видно из Фиг. 3D, выполняется 331 команда, которая однозначно прерывает транзакцию и записывает информацию в регистр управления. В ответ на прерывание транзакции сигнал отправляется 332 в схему регистрации данных. В ответ на сигнал, отправленный в схему регистрации данных, схема регистрации данных получает доступ к регистру и формирует 333 пакет данных о прерывании фрагмента, который указывает, что фрагмент прерван ввиду прерывания транзакции, и содержит информацию из регистра. Пакет данных о прерывании фрагмента регистрируется 334 вне процессора (к примеру, записывается во внешнюю системную память).
На Фиг. 4 показан вариант выполнения структуры 400 пакета, который записывается вне процессора изображенной на Фиг. 2 схемой 201 регистрации данных при регистрации относящихся к транзакции пакетов данных о прерывании фрагмента. Как видно из Фиг. 4, структура пакета по большому счету та же, что и изображенная на Фиг. 1 структура 120 пакета предыдущего уровня техники. Здесь, однако, в отличие от структуры 120 пакета предыдущего уровня техники поле CTR причины прекращения фрагмента может содержать информацию, указывающую любое из дополнительных событий: 1) начало транзакции; 2) конец транзакции; 3) прерывание транзакции. В еще одном варианте осуществления изобретения поле CTR может дополнительно указывать, поддерживает ли процессор команду однозначного прерывания (к примеру, XABORT).
Кроме того, дополнительным улучшением показанной на Фиг. 1 структуры пакета является то, что количество невыполненных операций обмена с памятью наиболее старой еще не выполненной макрокоманды (обозначенной сокращением NTB в пакете 120 на Фиг. 1) заменено на данные о "состоянии транзакции" (TSW), предоставляющие дополнительную информацию, описывающую причину прерывания фрагментов транзакций.
В одном из вариантов осуществления изобретения состояние транзакции (TSW) содержит содержимое регистра управления (к примеру, ЕАХ регистра) в случае прерывания транзакции или содержимое не показанного на чертеже регистра "встроенного счетчика транзакций" в случае начала или конца транзакции. В случае прерывания транзакции в одном из вариантов осуществления изобретения содержимое регистра управления ЕАХ указывает: 1) является ли прерывание следствием команды XABORT; 2) можно ли добиться успеха при повторной попытке провести транзакцию; 3) является ли прерывание следствием конфликта; 4) является ли прерывание следствием переполнения; 5) является ли прерывание следствием отладки точки прерывания; 6) является ли прерванная транзакция встроенной. Для встроенных транзакций процессор предназначен для поддержки цепочки транзакций в пределах транзакции (к примеру, первая транзакция запускает вторую транзакцию и т.д.). Показание встроенного счетчика транзакций в пределах зарезервированного пространства регистра обычно отслеживает, какой внутренней транзакции (если таковая имеется) соответствует текущая транзакция.
В одном из вариантов осуществления изобретения может задействоваться схема 207 обнаружения гонки за память (часть изображенной на Фиг. 1 технологии регистрации предыдущего уровня техники), хотя также задействуются специальные захватчики 230 для обнаружения прерывания транзакции и регистрации. Этого можно добиться путем создания показанного на Фиг. 2 процессора 200, имеющего режим работы, позволяющий иметь как новые транзакционные захватчики 230, так и захватчики гонки за память, которые могут задействоваться и быть активными в одно и то же время. Это позволяет, к примеру, записывать все конфликты, которые потенциально могут произойти в рамках транзакции (к примеру, ввиду того, что захватчики гонки за память побуждают схему 201 регистрации выводить отчет о любых обнаруженных конфликтах во время выполнения транзакции (в частности, условие гонки за память и конфликт являются аналогичными событиями)). Такая дополнительная информация может быть, в частности, полезной в варианте осуществления изобретения, когда информация регистра управления (к примеру, вышеупомянутого ЕАХ регистра), предоставляемая соразмерно прерыванию, не указывает конкретный адрес ячейки памяти, где наблюдается конфликт, вызвавший прерывание транзакции (в других альтернативных вариантах осуществления изобретения схема 221 обнаружения конфликтов может быть модифицирована, чтобы сообщать эту информацию для ввода в соответствующее пространство регистра).
Также информация о состоянии транзакции (TSW) из пакета о прерывании фрагмента может включать в себя относящуюся к прерыванию информацию о том, обнаружила ли схема 207 обнаружения гонки за память какие-либо конфликты. Если нет, то это позволяет предположить, что схема 221 обнаружения конфликтов, прервавшая транзакцию, подвергается в настоящий момент "ложноположительному" конфликту. В одном из вариантов осуществления изобретения ложные результаты возможны в схеме 221 обнаружения конфликтов ввиду того, что кэш-память (подобная кэш-памяти L1) использует кэширующие схемы для определения, где должна быть сохранена кэшированная позиция данных и, как правило, множество различных адресов памяти может кэшироваться в одну и ту же ячейку памяти. В еще одном варианте осуществления изобретения схема 207 обнаружения гонки за память также способна генерировать ложные результаты по аналогичным причинам, хотя кэширование и хранение адресов ячеек памяти могут отличаться в схеме обнаружения гонки за память (к примеру, для поддержания наборов считывания и записи используется фильтр Блума, и адреса ячеек памяти кэшируются в специальном фильтре Блума), чем в схемах кэширования, где постоянно находится схема 221 обнаружения конфликтов транзакции. По существу, в случае, если схема обнаружения гонки за память извещает о каких-либо конфликтах, на них нельзя полностью полагаться при обнаружении транзакционных прерываний.
В еще одном варианте осуществления изобретения содержащаяся в пакете CTR информация о причине прерывания относящегося к транзакции фрагмента извещает, была ли прервана транзакция из-за запоздалого запроса блокирования (LLA). Запоздалый запрос блокирования является особым условием, позволяющим транзакции зафиксировать свои данные, даже если транзакция не завершена. Обычно LLA накладывается, если необходимо "сделать паузу" в транзакции, к примеру, в ответ на нештатную команду или небезопасную команду, так что состояние транзакции может быть сохранено вне процессора. После внешнего сохранения состояния транзакции возобновляется ее нормальное выполнение. В этом случае захватчики внутри процессорных ядер также докладывают о возникновении любого LLA события в схему 201 регистрации, которая выводит в качестве отчета часть данных прерывания события, относящегося к LLA, и прерывание транзакции.
Схема 201 регистрации данных может быть реализована различными путями. С одной стороны, схема 201 регистрации данных может быть реализована в виде полностью специализированной заказной логической схемой. С другой стороны, схема 201 регистрации данных может быть реализована в виде микроконтроллера или другой схемы выполнения программного кода, которая выполняет программный код (к примеру, встроенную программу) для осуществления своих функций. Также возможны промежуточные комбинации.
В силу того, что любой вышеописанный логический процесс может быть осуществлен с помощью контроллера, микроконтроллера или аналогичного им компонента, такие процессы могут осуществляться с помощью программных кодов, таких как выполняемые машиной команды, которые побуждают выполняющую эти команды машину осуществлять некоторые функции.
Считается, что упомянутые в вышеприведенном описании процессы могут также быть описаны программным кодом исходного уровня на различных объектно-ориентированных и необъектно-ориентированных языках программирования. Для хранения программного кода может использоваться готовое промышленное изделие. Готовое промышленное изделие для хранения программного кода может быть реализовано, но не ограничивается этим, в виде одного или нескольких устройств памяти (к примеру, одного или нескольких устройств флэш-памяти, оперативного запоминающего устройства (статического, динамического и т.д.)), оптических дисков, постоянного запоминающего устройства на компакт дисках (CD-ROM), постоянного запоминающего устройства на цифровых универсальных дисках (DVD ROM), стираемого программируемого постоянного запоминающего устройства (EPROM), электронно-стираемого программируемого постоянного запоминающего устройства (EEPROM), магнитных или оптических плат или других видов машиночитаемых носителей, пригодных для хранения электронных команд. Программный код может быть также загружен с удаленного компьютера (к примеру, с сервера) в требуемый компьютер (к примеру, в клиентский компьютер) с помощью сигналов данных, передаваемых по среде распространения (к примеру, по линии связи (например, по сетевому соединению)).
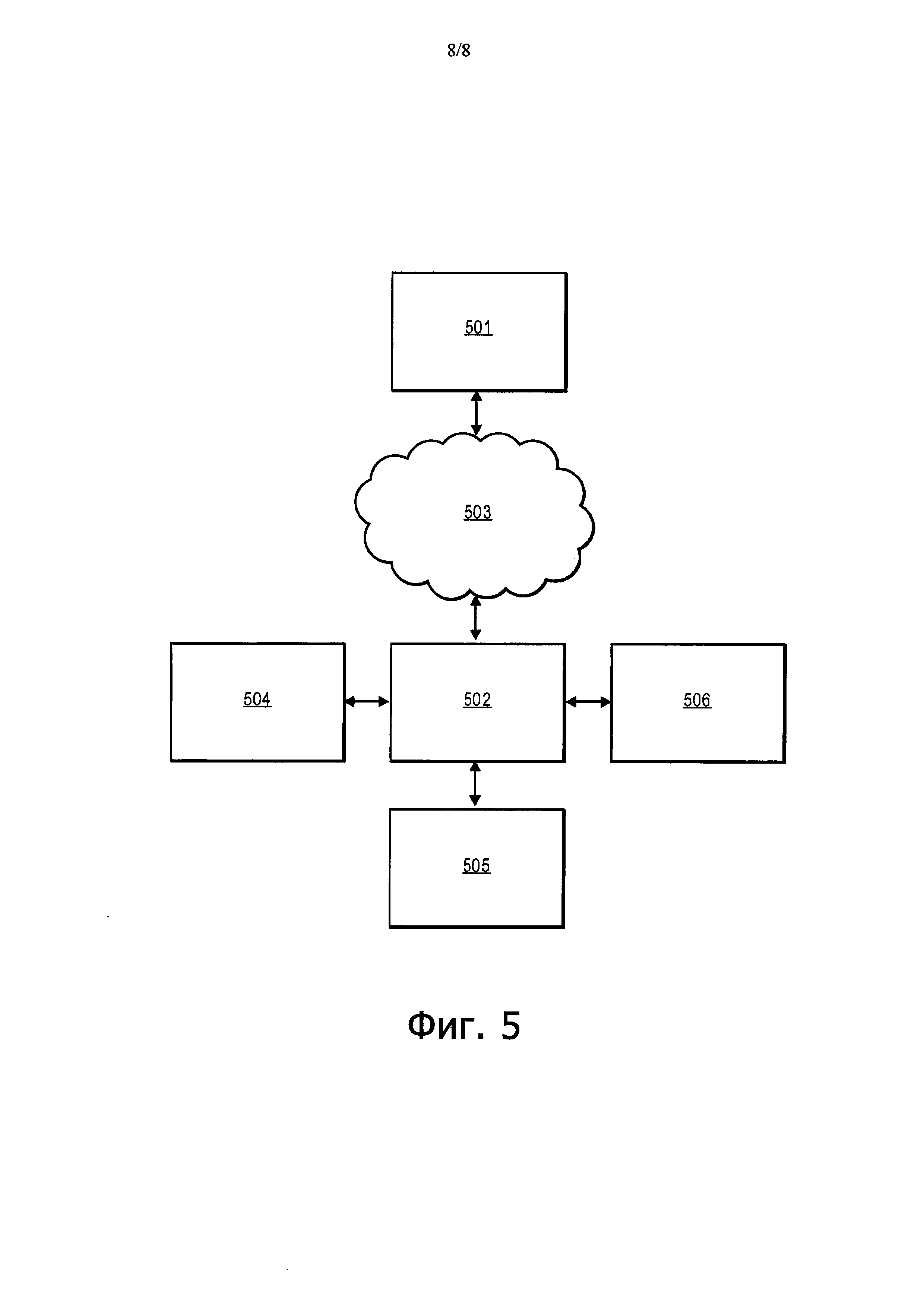
На Фиг. 5 показан вариант выполнения вычислительной системы (к примеру, компьютера). Компьютер включает в себя один или несколько процессоров 501, таких как изображенный на Фиг. 2 процессор 200, или по меньшей мере один или несколько процессоров, имеющих описанную выше относящуюся к транзакционной функциональности схему регистрации данных. В случае нескольких процессоров 501 они взаимодействуют друг с другом и с контроллером 502 памяти посредством сети 503 межсоединений. Графический процессор 504 может соединяться с сетью 503 межсоединений или непосредственно с контроллером 502 памяти. Аналогично, концентратор 505 ввода-вывода может соединяться с сетью 503 межсоединений или непосредственно с контроллером 502 памяти. Контроллер памяти соединяется с системной памятью 506.
Выше по тексту описан процессор, включающий в себя: схему обнаружения конфликтов доступа к памяти для идентификации относящегося к выполняемой транзакции конфликта, по потоку, который полагает, что он заблокировал информацию в памяти; схему регистрации данных для формирования и регистрации вне процессора пакета данных, если схема обнаружения конфликта доступа к памяти идентифицирует конфликт, который вызывает прерывание транзакции. В одном из вариантов осуществления изобретения процессор включает в себя пространство регистра для хранения информации, относящейся к прерыванию транзакции. В одном из вариантов осуществления изобретения пакет данных содержит информацию из упомянутого пространства регистра. В еще одном варианте осуществления изобретения упомянутая информация указывает, что транзакция была прервана из-за того, что схема обнаружения конфликтов доступа к памяти выявила конфликт. В еще одном варианте осуществления изобретения процессор содержит схему обнаружения гонки за память для обнаружения гонки за память, схему регистрации данных для формирования и регистрации вне процессора пакета данных, если схема обнаружения гонки за память обнаружит гонку за память. В еще одном варианте осуществления изобретения процессор служит для выдачи разрешения схеме регистрации данных параллельно быстро реагировать как на схему обнаружения конфликтов доступа к памяти, так и на схему обнаружения гонки за память. В еще одном варианте осуществления изобретения процессор поддерживает команду, которая однозначно прерывает транзакцию, схему регистрации данных для регистрации вне процессора второго пакета данных, если команда выполнена. В еще одном варианте осуществления изобретения процессор поддерживает команду, которая означает начало транзакции, схему регистрации данных для регистрации вне процессора второго пакета данных, если команда выполнена. В еще одном варианте осуществления изобретения процессор поддерживает команду, которая означает конец успешно выполненной транзакции, схему регистрации данных для регистрации вне процессора второго пакета данных, если команда выполнена.
Описан способ, предусматривающий: выполнение команды, которая обозначает начало транзакции, причем команда является частью потока, который полагает, что он заблокировал информацию в памяти; формирование и регистрацию вне процессора пакета сообщений о регистрации в ответ на выполнение команды; и формирование и отправку второго пакета сообщений о регистрации в ответ на закончившуюся транзакцию. В одном из вариантов осуществления изобретения транзакция успешно закончилась, и формирование и регистрация вне процессора второго пакета данных быстро реагируют на выполнение второй команды, которая обозначает успешное завершение транзакции. В еще одном варианте осуществления изобретения транзакция прервана, и формирование и регистрация вне процессора второго пакета данных быстро реагируют на выполнение второй команды, которая однозначно прерывает транзакцию. В еще одном варианте осуществления изобретения транзакция прерывается из-за обнаружения конфликта доступа к памяти. В еще одном варианте осуществления изобретения способ дополнительно предусматривает обнаружение гонки за память во время выполнения транзакции. В еще одном варианте осуществления изобретения способ дополнительно предусматривает формирование и регистрацию вне процессора третьего пакета сообщений о регистрации в ответ на обнаружение гонки за память.
Описана вычислительная система, включающая в себя: а) процессор, содержащий: схему обнаружения конфликтов доступа к памяти для идентификации конфликта, относящегося к выполняемой транзакции, по потоку, который полагает, что он заблокировал информацию в памяти; схему регистрации данных для формирования и регистрации вне процессора пакета данных, если схема обнаружения конфликтов доступа к памяти идентифицирует конфликт, который вызвал прерывание транзакции; и б) контроллер памяти, связанный с памятью. В одном из вариантов осуществления изобретения процессор поддерживает команду, которая однозначно прерывает транзакцию, схему регистрации данных, которая регистрирует вне процессора второй пакет данных, если команда выполнена. В еще одном варианте осуществления изобретения процессор поддерживает команду, которая означает начало транзакции, схему регистрации данных для регистрации вне процессора второго пакета данных, если команда выполнена. В еще одном варианте осуществления изобретения процессор поддерживает команду, которая означает конец успешно выполненной транзакции, схему регистрации данных для регистрации вне процессора второго пакета данных, если команда выполнена. В еще одном варианте осуществления изобретения процессор включает в себя пространство регистра для хранения информации, относящейся к прерыванию транзакции, и пакет содержит информацию из упомянутого пространства регистра.
В вышеприведенной спецификации изобретение описано со ссылкой на конкретные типичные варианты его осуществления. Однако очевидно, что могут быть выполнены различные модификации таких вариантов и осуществлены изменения, не выходящие за рамки существа и объема настоящего изобретения, определенные в формуле изобретения. Спецификацию и чертежи следует, соответственно, рассматривать скорее в иллюстративном, чем в ограничительном смысле.
Реферат
Изобретение относится к многоядерным процессорам с многопоточными конвейерами выполнения команд. Технический результат заключается в обеспечении выполнения операций с памятью в режиме транзакций с определением условий прерывания транзакции. Указанный результат достигается за счет применения процессора, содержащего: схему обнаружения конфликтов доступа к памяти для идентификации конфликта, относящегося к выполняемой, в потоке, транзакции; схему регистрации для формирования и вывода в качестве отчета пакета данных, при идентификации, упомянутой схемой обнаружения конфликтов доступа к памяти, конфликта, вызывающего прерывание упомянутой транзакции, при этом пакет данных содержит содержимое, описывающее причину указанного прерывания транзакции, а структура пакета данных содержит поле для указания одного из начала транзакции, конца транзакции и указанного прерывания, причем указанное содержимое выводится в качестве отчета на указанную схему регистрации в ответ на прерывание. 2 н. и 13 з.п. ф-лы, 8 ил.
Комментарии