Формирование псевдо-кт по мр-данным с использованием регрессионной модели на основе признаков - RU2703344C1
Код документа: RU2703344C1
Чертежи














Описание
ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННУЮ ЗАЯВКУ
[001] Настоящее изобретение относится к заявке по патентному реестру 12475.0050 00000, «Pseudo-CT Generation from MR Data Using Tissue Parameter Estimation», поданной 13 октября 2015 г., содержание которой целиком включено в настоящую заявку путем отсылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[002] Настоящее изобретение относится, в общем, к лучевой терапии или радиотерапии. В частности, изобретение относится к системам и способам для формирования псевдо-КТ (компьютерно-томографических) изображений по МР (магнитно-резонансным) данным для применения при разработке плана лучевой терапии, подлежащего использованию во время радиотерапии.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
[003] Радиотерапию применяют для лечения раковых заболеваний и других заболеваний ткани млекопитающих (например, человека и животных). Один подобный метод радиотерапии представляет собой гамма-нож, посредством которого пациента облучают большим числом гамма-лучей низкой интенсивности, которые сходятся с высокой интенсивностью и высокой точностью на мишени (например, опухоли). В другом варианте осуществления радиотерапия выполняется с использованием линейного ускорителя, с помощью которого опухоль облучают высокоэнергетическими частицами (например, электронами, протонами, ионами и т.п.). Установкой и дозой пучка излучения следует точно управлять для гарантированного получения назначенного излучения опухолью, установка пучка должна быть такой, чтобы минимизировать поражение окружающей здоровой ткани, часто называемой органом(ами) риска (OAR). Излучение именуется «назначенным» потому, что врач предписывает предварительно заданное количество излучения для опухоли и окружающих органов, аналогично рецепту на лекарственное средство.
[004] Для каждого пациента традиционно может быть создан план лучевой терапии («план лечения») с использованием метода оптимизации, основанного на клинических и дозиметрических целях и ограничениях (например, максимальной, минимальной и средней дозах излучения для опухоли и критических органов). Процесс планирования лечения может включать в себя использование трехмерного изображения пациента, чтобы идентифицировать область мишени (например, опухоль), и чтобы идентифицировать критические органы вблизи опухоли. Создание плана лечения может быть длительно выполняемым процессом, в ходе которого составитель плана стремится обеспечить соответствие с различными целями или ограничениями лечения (например, целями гистограммы доза-объем (DVH)), с учетом их индивидуальной значимости (например, весовых коэффициентов), чтобы создать план лечения, который является клинически допустимым. Данная задача может представлять собой долговременно выполняемый метод проб и ошибок, который усложняется различными органами риска (OAR), поскольку по мере того, как число OAR возрастает (например, до 13 при терапии головы и шеи), сложность метода аналогично возрастает. OAR, удаленные от опухоли, можно легко уберечь от излучения, а OAR, находящие рядом или частично совпадающие с целевой опухолью, может быть трудно уберечь от излучения.
[005] Компьютерная томография (КТ) традиционно служит основным источником данных изображений при планировании лечения для лучевой терапии. КТ-изображения обеспечивают точное представление геометрии пациента, и КТ-значения можно непосредственно преобразовывать в плотности электронов (например, единицы Хаунсфилда) для вычисления дозы излучения. Однако, применение КТ приводит к облучению пациента дополнительной дозой излучения. Кроме КТ-изображений, при лучевой терапии можно использовать изображения, полученные методом магнитно-резонансной томографии, (МРТ-изображения) благодаря тому, что контраст мягких тканей на них выше, чем на КТ-изображениях. МРТ обходится без ионизирующего излучения и может применяться для сбора функциональной информации о человеческом организме, например, метаболизме и функциях тканей.
[006] Следовательно, МРТ можно применять, чтобы дополнять КТ для более точного оконтуривания структур. Однако, МРТ-значения интенсивности не напрямую связаны с плотностями электронов и не могут непосредственно использоваться для вычисления дозы; поэтому МРТ-изображение желательно преобразовать в соответствующее производное изображение, обычно, КТ-изображение (часто называемое «псевдо-КТ-изображением»). Псевдо-КТ-изображение, подобно реальному КТ-изображению, имеет набор точек данных, которые указывают КТ-значения, которые являются непосредственно преобразуемыми в плотности электронов для вычисления дозы излучения. Таким образом, псевдо-КТ-изображение, выведенное из МР-изображения, можно использовать, чтобы облегчать вычисление дозы пациента при планировании лучевой терапии. Следовательно, желательно точно формировать псевдо-КТ-изображение по данным МР-изображения, чтобы избавлять пациентов от дополнительной лучевой нагрузки, обусловленной КТ-визуализацией. При этом, от псевдо-КТ-изображений требуется способность заменять «реальное» КТ-изображение.
[007] Обычно, для создания псевдо-КТ-изображений используют изображения из атласа. Изображение из атласа является ранее существующим изображением, которое используют в качестве эталона для облегчения того, как следует преобразовывать новое изображение, чтобы сформировать производное изображение. Например, в контексте формирования псевдо-КТ-изображения, МР-изображение из атласа и КТ-изображение из атласа можно использовать как эталоны для формирования производного КТ-изображения из нового МР-изображения. Изображения из атласа могут быть сформированы предварительно для той же области интереса того же самого пациента, который является объектом новых МР-изображений, при этом упомянутые изображения из атласа анализировались для идентификации структур интереса. Например, во многих случаях лечения или диагностики, визуализацию пациента потребуется выполнять в разные периоды времени в течение курса лечения или диагностики. Однако, данное не всегда является правильным, например, изображения из атласа не обязательно должны быть изображениями одного и того же человека.
[008] МР-изображение из атласа и КТ-изображение из атласа предпочтительно выставляют одно относительно другого методом совмещения (т.е. так, чтобы МР-изображение из атласа и КТ-изображение из атласа были «совмещены» одно с другим или являются «совмещенными»). При таком совмещении, заданную точку в МР-изображении из атласа для конкретного местоположения объекта можно отобразить в заданную точку в КТ-изображении из атласа для того же конкретного местоположения (и наоборот). Однако, возможна некоторая величина ошибки, которая может быть представлена на данном совмещении. По существу, совмещение между МР-изображением из атласа и КТ-изображением из атласа не может быть идеальным.
[009] Для замены реального КТ-изображения, псевдо-КТ-изображение должно как можно точнее приближаться к реальному КТ-изображению пациента с целью вычисления дозы при планировании лучевой терапии или для формирования рентгеновских изображений, полученных методом цифровой реконструкции, (DRR-изображений) для контроля по изображениям. Однако, между значениями интенсивности КТ-изображения (КТ-значениями) и МР-значениями интенсивности не существует простой математической зависимости. Трудность возникает потому, что МР-значения интенсивности не стандартизованы и могут значительно изменяться в зависимости от разных настроек МР-сканера или разных параметров последовательности МР-визуализации. Следовательно, существующие методы, например, назначение КТ-значений на основании сегментации тканей в МР-изображении или методы, основанные на поточечном сравнении и взвешенной комбинации, обеспечивают лишь очень приблизительное присвоение, дающее, в результате, существующие псевдо-КТ-изображения, в которых отсутствуют анатомические детали истинного КТ-изображения.
[010] Поэтому существует потребность в формировании псевдо-КТ-изображений с повышенным качеством, которые способны заменять реальные КТ-изображения в целях вычисления доз при планировании лечения, с формированием рентгеновских изображений, полученных методом цифровой реконструкции, (DRR-изображений) для контроля по изображениям и т.п.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[011] В одном аспекте настоящее изобретение предусматривает систему для формирования модели прогнозирования псевдо-КТ. Система может включать в себя базу данных, сконфигурированную с возможностью хранения данных для обучения, содержащих МР-данные и КТ-данные множества объектов для обучения. Каждый объект для обучения может иметь, по меньшей мере, одно МР-изображение и, по меньшей мере, одно КТ-изображение. Система может также включать в себя процессор, связанный с возможностью обмена информацией с базой данных для доступа к информации, хранимой в базе данных. Система может дополнительно включать в себя память, связанную с возможностью обмена информацией с процессором. Память может хранить команды, которые, при выполнении процессором, конфигурируют процессор для выполнения различных операций. Операции могут включать в себя осуществление доступа к базе данных для поиска и выборки данных для обучения, включающих в себя, по меньшей мере, одно МР-изображение и, по меньшей мере, одно КТ-изображение для каждого из множества объектов для обучения. Для каждого объекта для обучения, операции могут включать в себя выделение множества признаков из каждой точки изображения, по меньшей мере, одного МР-изображения, создание вектора признаков для каждой точки изображения, исходя из выделенных признаков, и выделение КТ-значения из каждой точки изображения, по меньшей мере, одного КТ-изображения. Операции могут также включать в себя формирование модели прогнозирования псевдо-КТ, исходя из векторов признаков и КТ-значений множества объектов для обучения.
[012] В другом аспекте настоящее изобретение предусматривает систему для формирования псевдо-КТ-изображения. Система может включать в себя процессор и память, связанную с возможностью обмена информацией с процессором. Память может хранить команды, которые, при выполнении процессором, конфигурируют процессор для выполнения различных операций. Операции могут включать в себя прием МР-изображения пациента и выделение множества признаков из каждой точки изображения МР-изображения. Операции могут также включать в себя создание вектора признаков для каждой точки изображения, исходя из выделенных признаков. Операции могут дополнительно включать в себя определение CT значения для каждой точки изображения, исходя из вектора признаков, созданного для данной точки изображения, с использованием модели прогнозирования. Дополнительно операции могут включать в себя формирование псевдо-КТ-изображения, исходя из КТ-значений, установленных для всех точек изображения.
[013] В дополнительном аспекте настоящее изобретение предусматривает систему для формирования псевдо-КТ прогностического изображения пациента. Система может включать в себя процессор и память, связанную с возможностью обмена информацией с процессором. Память может хранить команды, которые, при выполнении процессором, конфигурируют процессор для выполнения различных операций. Операции могут включать в себя прием МР-изображения пациента и выделение множества признаков из МР-изображения. Операции могут также включать в себя формирование промежуточного изображения с использованием модели прогнозирования, исходя из выделенных признаков. Операции могут дополнительно включать в себя выделение одного или более признаков из промежуточного изображения. Дополнительно операции могут включать в себя формирование псевдо-КТ-изображения пациента, исходя из множества признаков, выделенных из МР-изображения, и одного или более признаков, выделенных из промежуточного изображения.
[014] В дополнительном аспекте настоящее изобретение предусматривает систему для формирования модели прогнозирования псевдо-КТ. Система может включать в себя базу данных, сконфигурированную с возможностью хранения данных для обучения, содержащих многоканальные МР-данные и КТ-данные множества объектов для обучения. Каждый объект для обучения может иметь несколько МР-изображений и, по меньшей мере, одно КТ-изображение. Система может также включать в себя процессор, связанный с возможностью обмена информацией с базой данных для доступа к информации, хранимой в базе данных. Система может дополнительно включать в себя память, связанную с возможностью обмена информацией с процессором. Память может хранить команды, которые, при выполнении процессором, конфигурируют процессор для выполнения различных операций. Операции могут включать в себя осуществление доступа к базе данных для поиска и выборки данных для обучения, включающих в себя несколько МР-изображений и, по меньшей мере, одно КТ-изображение для каждого из множества объектов для обучения. Для каждого объекта для обучения, операции могут включать в себя определение, по меньшей мере, одной карты параметров тканей на нескольких МР-изображениях и получение КТ-значений, исходя из, по меньшей мере, одного КТ-изображения. Операции могут также включать в себя формирование модели прогнозирования псевдо-КТ, исходя из карт параметров тканей и КТ-значений множества объектов для обучения.
[015] В дополнительном аспекте настоящее изобретение предусматривает систему для формирования псевдо-КТ-изображения. Система может включать в себя процессор и память, связанную с возможностью обмена информацией с процессором. Память может хранить команды, которые, при выполнении процессором, конфигурируют процессор для выполнения различных операций. Операции могут включать в себя прием нескольких многоканальных МР-изображений пациента и преобразование нескольких многоканальных МР-изображений в, по меньшей мере, одну карту параметров тканей. Операции могут также включать в себя формирование КТ-значений посредством применения модели прогнозирования к, по меньшей мере, одной карте параметров тканей. Операции могут дополнительно включать в себя формирование псевдо-КТ-изображения, исходя из КТ-значений, сформированных с помощью модели прогнозирования.
[016] В дополнительном аспекте настоящее изобретение предусматривает компьютерно-реализуемый способ формирования модели прогнозирования псевдо-КТ. Способ может включать в себя поиск и выборку данных для обучения, включающих в себя несколько многоканальных МР-изображений и, по меньшей мере, одно КТ-изображение для каждого из множества объектов для обучения. Для каждого объекта для обучения, способ может включать в себя определение, по меньшей мере, одной карты параметров тканей, исходя из нескольких многоканальных МР-изображений, и получение КТ-значений, исходя из, по меньшей мере, одного КТ-изображения. Способ может также включать в себя формирование модели прогнозирования псевдо-КТ, исходя из карт параметров тканей и КТ-значений множества объектов для обучения.
[017] Следует понимать, что как вышеприведенное общее описание и последующее подробное описание являются всего лишь примерными и разъясняющими и не ограничивают раскрытые варианты осуществления, определяемые в формуле изобретения. Приведенные и другие признаки и преимущества настоящего изобретения будут очевидны специалистам со средним уровнем компетенции в данной области техники после рассмотрения идей, описанных в последующем описании, на чертежах и в формуле изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[018] Прилагаемые чертежи, которые включены в настоящее описание и являются его составной частью, иллюстрируют раскрываемые варианты осуществления и, совместно с описанием и формулой изобретения, служат для разъяснения раскрываемых вариантов осуществления. Данные варианты осуществления являются наглядными и не должны считаться исчерпывающими или единственными вариантами осуществления настоящих устройств, систем или способов. На чертежах, которые не обязательно вычерчены в масштабе, сходные числовые позиции могут обозначать подобные компоненты на разных видах. Сходные числовые позиции, имеющие буквенные индексы или разные буквенные индексы, могут представлять разные примеры подобных компонентов.
[019] Фиг. 1 - схема примерного процесса для построения модели прогнозирования псевдо-КТ.
[020] Фиг. 2 - схема примерного процесса для выделения признаков из каждого вокселя МР-изображения.
[021] Фиг. 3 - схема примерного процесса для применения модуля прогнозирования, показанного на фиг. 1, с целью формирования псевдо-КТ-изображения пациента.
[022] Фиг. 4A - изображение примерной радиотерапевтической системы.
[023] Фиг. 4B - изображение примерного радиотерапевтического устройства, гамма-ножа.
[024] Фиг. 4C - изображение примерного радиотерапевтического устройства, которое является линейным ускорителем.
[025] Фиг. 5 - изображение примерной системы для построения модели прогнозирования псевдо-КТ и формирования псевдо-КТ-изображений.
[026] Фиг. 6 - блок-схема последовательности операций примерного процесса для обучения и построения модели прогнозирования псевдо-КТ.
[027] Фиг. 7 - блок-схема последовательности операций примерного процесса для применения модели прогнозирования псевдо-КТ с целью формирования псевдо-КТ-изображения.
[028] Фиг. 8 - схема примерного процесса для обучения и построения многоэтапной модели прогнозирования псевдо-КТ.
[029] Фиг. 9 - схема примерного процесса для применения многоэтапной модели прогнозирования псевдо-КТ с целью формирования псевдо-КТ-изображения.
[030] Фиг. 10 - схема примерного процесса для обучения модели прогнозирования псевдо-КТ с использованием параметра ткани, оцененного по многоканальным МР-сканированиям.
[031] Фиг. 11 - блок-схема последовательности операций примерного способа построения модели прогнозирования псевдо-КТ с использованием многоканальных МР-данных.
[032] Фиг. 12 - блок-схема последовательности операций примерного способа формирования псевдо-КТ-изображения для пациента с использованием многоканальных МР-изображений.
ПОДРОБНОЕ ОПИСАНИЕ
[033] Далее приводятся подробные ссылки на раскрываемые варианты осуществления, примеры которых иллюстрируются на прилагаемых чертежах. Там, где удобно, одинаковые числовые позиции будут служить на всех чертежах для ссылки на одинаковые или сходные части.
[034] В одном варианте осуществления, для создания псевдо-КТ-изображения (называемого также синтезированным КТ-изображением или теоретически полученным КТ-изображением) из МР-изображения, предложен основанный на обучении метод, который включает в себя обучающий модуль и прогнозирующий модуль. Обучающий модуль строит модель прогнозирования (называемую также регрессионной моделью), которую можно использовать для прогнозирования КТ-значения для любого данного вокселя, исходя из признаков, выделенных из одного или более МР-изображений для выбранного местоположения. Во время обучения, МР-сканирования и КТ-сканирования собирают с множества существующих пациентов, чтобы формировать данные для обучения. Данные для обучения включают в себя пары предварительно выставленных КТ- и МР-изображений существующих пациентов. Для каждой пары изображений, соответствующие МР- и КТ-значения известны и совмещены для каждого пикселя или вокселя (называемого также точкой изображения, которая включает в себя как 2-мерный, так и 3-мерный сценарии).
[035] Модель прогнозирования можно обучать с использованием данных для обучения. В течение фазы обучения, с собранными данными для обучения можно применять регрессионные способы (например, методы статистического обучения, регрессионного анализа или машинного обучения), чтобы обучить модель. После того, как модель прогнозирования обучена, модель может быть применена прогнозирующим модулем для прогнозирования КТ-значения для каждой точки изображения в изображении пациента. Следовательно, обученную модель можно использовать для создания псевдо-КТ-изображений из МР-данных любых будущих сканирований и для того же самого или другого пациента.
[036] На фиг. 1 изображена блок-схема примерного процесса для построения модели 150 прогнозирования псевдо-КТ, соответствующей раскрываемым вариантам осуществления. Как показано, один вариант осуществления представляет собой основанный на обучении метод, который включает в себя обучающий модуль и прогнозирующий модуль. Обучающий модуль создает, в варианте осуществления, регрессионную модель (например, модель 150 псевдо-КТ), которая может быть использована прогнозирующим модулем для прогнозирования псевдо-КТ-значений, исходя из одного или более новых МР-сканирований.
[037] В одном варианте осуществления данные 110 для обучения могут быть собраны с существующих пациентов или объектов (совместно именуемых «объектами для обучения»). Объекты для обучения могут иметь как МР-сканирования, так и соответствующие КТ-сканирования, ранее снятые и доступные для использования с целью построения модели 150 прогнозирования псевдо-КТ. Данные 110 для обучения могут включать в себя данные по множеству объектов для обучения, которые имели, по меньшей мере, одно МР-сканирование и, по меньшей мере, одно КТ-сканирование (например, данные 110a - 110N объектов для обучения). Большее число объектов для обучения, взятых для предоставления данных для обучения, (например, больший набор данных) обычно допускает формирование более точной модели прогнозирования псевдо-КТ по сравнению с моделью, построенной из меньшего набора данных. Данные 110a - 110N объектов для обучения включают в себя пары предварительно выставленных МР- и КТ-изображений. МР- и КТ-изображения могут быть получены по-отдельности; следовательно, если изображения накладываются одно на другое, они обычно не согласуются. Поэтому, чтобы выставить МР- и КТ-изображения, применяют известное в технике совмещение изображений. В соответствии с некоторыми вариантами осуществления, МР-изображения, соответствующие объектам для обучения, могут создаваться таким же МР-сканером, как сканер для получения МР-сканирования(ий) нового пациента, для которого требуется псевдо-КТ-изображение. В других вариантах осуществления, МР-сканирования, соответствующие объектам для обучения могут производиться разными МР-сканерами. Кроме того, несколько МР-сканирований, соответствующих единственному объекту для обучения, могут включать в себя МР-сканирования с разными контрастными характеристиками (например, T1-взвешенное, T2-взвешенное и т.п.), чтобы обеспечить более точные результаты формирования псевдо-КТ.
[038] Модуль 111 выделения признаков изображения может служить для выделения признаков изображения из МР-изображений, связанных с данными 110 для обучения. Признаки изображения могут относиться к численным (например, значениям интенсивности, координатам местоположения признака и т.п.) или категориальным свойствам (например, типу ткани, структурной метке и т.п.) МР-вокселя. Например, «признак интенсивности» может относиться к значению интенсивности МР-вокселя. Однако, никакой единственный МР-признак не может быть достаточным для точного представления МР-вокселей с целью формирования псевдо-КТ-изображений. Например, значение интенсивности МР-вокселя, само по себе, обеспечивает неоднозначное представление для КТ-оценки. Единственное значение интенсивности является неоднозначным потому, что, помимо прочего, два МР-вокселя с одинаковым уровнем интенсивности могут принадлежать разным тканям (например, кости и воздуху), имеющим разные КТ-значения. В контексте настоящей заявки, термин «ткань» относится к классификации, а не просто предполагает специфические типы ткани; например, воздух не является тканью. Следовательно, чтобы обеспечить более четкое описание МР-вокселей, выделяется множество типов признаков для каждого МР-вокселя MR-сканирования.
[039] При использовании нескольких МР-изображений или многоканальных МР-изображений можно выделить обширный набор признаков, основанных на анализе изображения, который предоставляет больше информации и может приводить к более точному прогнозированию псевдо-КТ. Модуль 111 выделения признаков изображения можно использовать для выделения признаков из каждого изображения или каждого канала по-отдельности (например, вектора 120 МР-признаков).
[040] Полученные вектора 120 МР-признаков могут включать в себя множество наборов собранных векторов признаков изображения, каждый из которых связан с МР-сканированием(ями) объекта для обучения, (например, наборы 120a-120N векторов признаков изображения. Каждый набор 120a-120N векторов признаков изображения может включать в себя множество векторов признаков. Например, каждый столбец данного набора (например, 120a) векторов признаков может представлять вектор признаков, который включает в себя множество признаков в качестве элементов вектора. Множество признаков вектора признаков представляет разные типы признаков изображения, относящихся, например, к точке изображения (например, вокселю) МР-сканирования/изображения объекта для обучения. Число элементарных признаков в векторе признаков (например, число элементов в столбце) также относится к размерности вектора признаков. В некоторых вариантах осуществления вектора признаков могут также располагаться построчно или с использованием других подходящих форм. Выделение признаков в соответствии с раскрываемыми вариантами осуществления дополнительно подробно описано ниже со ссылкой на фиг. 2.
[041] Фиг. 2 иллюстрирует процесс выделения признаков в соответствии с раскрываемыми вариантами осуществления. Для каждого МР-вокселя МР-сканирования пациента (например, объекта a 210 МР-сканирования) можно выделить множество признаков изображения. Как показано на фиг. 2, выделенные признаки изображения могут включать в себя локальный признак 212 образа, ориентирный признак 214, контекстный признак 216 и признаки 218 различных других типов. Каждый из упомянутых признаков может представляться одним или более элементарных признаков, изображенных небольшими блоками, совместно формирующими столбец вектора признаков на фиг. 2. Признаки могут относиться к пикселю изображения (в 2-мерном сценарии), вокселю изображения (в 3-мерном сценарии), или совокупности точек изображения (например, участку изображения в 2-мерном или 3-мерном сценариях). Например, фиг. 2 показывает вектора признаков (например, столбцы), относящиеся к вокселю i, вокселю i+1, …, вокселю M. Множество векторов признаков, например, совокупность векторов признаков, относящихся к нескольким вокселям МР-изображения (например, воксели от i до M), может формировать набор 120a векторов признаков, соответствующих объекту a для обучения.
[042] Неограничивающий список возможных признаков изображения включает в себя:
Признаки интенсивности: значения интенсивности МР-изображения по нескольким шкалам, либо исходные значения интенсивности, либо после некоторой предварительной обработки, например, после поправки на смещение МР-интенсивности и/или стандартизации/нормирования МР-интенсивности;
Признаки на основе ориентиров: относительное местоположение, расстояние или другие геометрические признаки, которые вычисляются для данного вокселя относительно одной или более ориентирных точек (например, точек передней комиссуры-задней комиссуры (AC-PC) головного мозга, центра каждого глазного яблока и т.п.);
Контекстные признаки: любые другие признаки изображения, которые вычисляются в некоторых местоположениях, соседних с данной точкой;
Признаки местоположения: нормированные координаты каждого вокселя. Нормирование можно выполнять, например, посредством выставления каждого изображения относительно общей системы координат, с использованием либо линейного, либо нелинейного совмещения изображений;
Признаки участков: участок может относиться в некоторых вариантах осуществления к субобласти или поднабору изображения, окружающего воксель изображения, для которого вычисляются признаки. Например, участок может включать в себя 5×5×5 вокселей по размеру, и значения интенсивности изображения в местоположениях 125 вокселей могут соответствовать 125 элементарным признакам для точки в центре участка;
Высокоуровневые признаки можно теоретически получить из одного или более участков: признаки данных типов могут включать в себя множество дескрипторов признаков, известных в технике, например SIFT (масштабно-инвариантное преобразование признака), SURF (ускоренный поиск устойчивых признаков), GLOH (гистограмма локализации и ориентации градиентов), LBP (локальные бинарные шаблоны) или HOG (гистограмма ориентированных градиентов) и т.п. Данные признаки могут быть вычислены для каждого 2-мерного изображения среза, которое содержит рассматриваемый воксель, и, дополнительно, данные признаки можно распространить, в некотором варианте осуществления, на 3-мерное изображение;
Текстурные признаки: например, энергия, энтропия, контраст, однородность и корреляция полутоновой матрицы смежности локальных изображений, а также изображений, вычисленных фильтрацией изображений фильтром Габора, и т.п.;
Совместные признаки: например, когда к данному объекту для обучения относится множество МР-изображений (например, T1-взвешенные, T2-взвешенные и т.п.). В подобных случаях, такие признаки, как интенсивность, участок, текстура и т.п., могут быть выделены из каждого МР-сканирования независимо, для последующего объединения. Дополнительно, в местоположении каждого вокселя можно вычислять признаки, которые характеризовали корреляцию между множеством МР-сканирований, например, локальную объединенную гистограмму и/или локальную кросс-корреляцию, или ковариацию нескольких МР-каналов;
Признаки, теоретически получаемые сверткой изображений с, по меньшей мере, одним линейным или нелинейным фильтром, (например, локальной фазой, градиентами, кривизной, краевыми детекторами или детекторами углов и т.п.);
Признаки, теоретически получаемые преобразованием изображений, (например, преобразованием Фурье, преобразованием Гильберта, преобразованием Радона, дистанционным преобразованием, дискретным косинусным преобразованием, вейвлет-преобразованием и т.п.);
Ковариационные признаки области: ковариация любого из вышеперечисленных точечных признаков внутри локальной субобласти; и
Признаки, основанные на классификации, подробно описанные ниже.
[043] Как показано на фиг. 2, совокупность признаков, относящихся к вокселю МР-изображения, можно представить единственным вектором (например, вектором, соответствующим вокселю i, вокселю i+1, …, вокселю M).
[044] Как также показано на фиг. 1, после выделения признаков изображения, вектор 120 МР-признаков может иметь несколько измерений (например, каждый элементарный признак в векторе признаков можно считать измерением, как показано на фиг. 2). Однако, когда число выделенных признаков из МР-изображений увеличивается, задача создания модели прогнозирования может выполняться с большим трудом. Это обусловлено тем, что каждое изображение пациента обычно содержит миллионы вокселей, и каждый воксель может быть связан с большим числом признаков. Поэтому, если для построения модели прогнозирования используются признаки, выделенные из всех вокселей всех изображений от всего множества существующих пациентов, то вычислительные затраты на обработку такого огромного количества данных могут быть очень большими. В результате, практическое число измерений зависит от вычислительной мощности доступного компьютера в сравнении с вычислительными затратами. Дополнительно, эффективность модели прогнозирования, обусловленная обработкой выделенных признаков, может и не быть пропорциональной числу признаковых измерений. В некоторых случаях, когда число признаковых измерений увеличивается, эффективность моделей прогнозирования может снижаться, так как влияние одного признака может аннулироваться или ослабляться другим признаком, если оба признака включаются в обработку. Большое число признаков может также вызывать неприемлемые вычислительные затраты при использовании модели прогнозирования для определения псевдо-КТ-изображений, исходя из новых МР-данных. Следовательно, в варианте осуществления можно применить модуль 132 снижения размерности для формирования векторов 140 признаков с пониженной размерностью, без существенной потери отличительной информации, обеспечиваемой МР-признаками. Модуль 132 снижения размерности можно использовать для сбора большей части релевантной информации от исходного вектора признаков, при понижении исходного числа измерений. Например, некоторые измерения векторов 120 МР-признаков могут включать в себя шум или другую информацию, нерелевантную к формированию псевдо-КТ-изображений, которую можно исключить. Другие измерения могут включать в себя избыточную информацию, которую можно объединять или оптимизировать для более компактного представления отличительной информации, обеспечиваемой признаками. Например, если исходные данные согласуются с гауссовым распределением, то общую размерность исходных данных можно понизить представлением исходных данных с использованием среднего и стандартного отклонения исходных данных. Такой способ снижения размерности обуславливает преобразование исходных данных. В некоторых вариантах осуществления степень снижения размерности может изменяться в пределах от использования исходных векторов признаков (т.е. без какого-либо снижения) до любой предварительно заданной степени размерности (например, приведенного набора векторов признаков). Следовательно, в варианте осуществления модуль 132 снижения размерности может быть необязательным, и для создания модели 150 псевдо-КТ можно использовать исходные вектора признаков.
[045] Если модуль 132 снижения размерности используется, то методы снижения размерности, используемые модулем 132, могут включать в себя методы, по меньшей мере, двух типов: (1) неконтролируемое снижение размерности и (2) контролируемое снижение размерности. Обычно, контролируемое снижение размерности лучше неконтролируемого снижения размерности, как описано ниже.
[046] Неконтролируемое снижение размерности может исключать бессодержательный шум и избыточность данных и требовать только векторов 120 МР-признаков в качестве входных данных. Обычные методы неконтролируемого снижения размерности включают в себя, например, анализ главных компонент (PCA) и его нелинейную версию, ядерный анализ главных компонент (KPCA).
[047] Контролируемое снижение размерности может использовать другие представляющие интерес данные, чтобы дополнительно отфильтровывать измерения, нерелевантные к формированию псевдо-КТ-изображения. Например, для снижения размерности можно использовать КТ-значения 130. КТ-значения 130 (например, исходные КТ-значения или КТ-числа) можно получать из данных КТ-сканирования данных 110 для обучения. Контролируемое снижение размерности может использовать вектора 120 МР-признаков и КТ-значения 130 в качестве входных данных. Возможные методы контролируемого снижения размерности включают в себя, например: методы канонического анализа компонент (CCA), метрического обучения (ML), контролируемый анализ главных компонент (SPCA), локально-чувствительное хэширование (LSH), локально-чувствительный дискриминантный анализ (LSDA) и т.п. Для методов снижения размерности, которые нуждаются в соотнесении представляющих интерес данных с метками дискретных классов, к КТ- или МР-сканированиям в данных 110 для обучения можно применить сегментацию изображений, дающую, в результате классы сегментации, которые можно использовать как метки классов.
[048] КТ-значения 130 могут использоваться модулем 132 снижения размерности, чтобы определять, какие сигналы в данных 110 для обучения имеют отношение к исходным КТ-значениям. При использовании исходных КТ-значений, нерелевантные сигналы можно подавлять с сохранением релевантных сигналов. В общем, должно быть в наличии, по меньшей мере, одно КТ-изображение для каждого объекта для обучения. В некоторых вариантах осуществления могут быть в наличии несколько КТ-изображений. Большее число КТ-сканирований можно усреднять для подавления шума в изображении, что повышает эффективность модуля 132 снижения размерности. Выходными данными модуля 132 снижения размерности является вектор 140 признаков с пониженной размерностью.
[049] После того, как данные для обучения собраны и обработаны (например, методами выделения признаков изображения, снижения размерности и т.п.), можно построить модель 150 прогнозирования псевдо-КТ с использованием методов либо статистического обучения, либо машинного обучения. В одном варианте осуществления, для построения модели 150 прогнозирования псевдо-КТ можно использовать регрессионный анализ. Регрессионный анализ является статистическим процессом для оценки зависимостей между переменными. Существует несколько известных способов выполнения регрессионного анализа, например: линейная регрессия или обычная регрессия методом наименьших квадратов, наряду с другими, являются «параметрическими» в том смысле, что функция регрессии определяется как конечное число неизвестных параметров модели, которые можно оценить по данным для обучения. Для формирования псевдо-КТ-изображения, регрессионную модель (например, уравнение 1) можно задать, например, следующим образом:

где «H» означает КТ-значения, «X» означает вектор входных переменных (например, любой из векторов 120 МР-признаков или векторов 140 признаков с пониженной размерностью), и «β» означает вектор неизвестных параметров, подлежащих определению или обучению для регрессионной модели. В варианте осуществления КТ-значения могут быть значениями Хаунсфилда для КТ-сканирования.
[050] Данные 110 для обучения, которые включают в себя МР-сканирования и КТ-сканирования, предоставляют набор известных значений H (например, КТ-значений, связанных с КТ-сканированием объекта для обучения), содержащих соответствующие значения X (например, вектора признаков, выделенные из МР-сканирования того же самого объекта для обучения). При использовании упомянутых данных, параметр β модели можно вычислить с использованием методов аппроксимации данных, например, наименьших квадратов, максимального правдоподобия и т.п. После оценки β, модель может вычислять H (например, псевдо-КТ-значения) для нового набора значений X (например, вектора признаков, выделенные из нового МР-сканирования).
[051] В другом варианте осуществления, для построения модели 150 прогнозирования псевдо-КТ можно использовать машинное обучение и контролируемое обучение. Контролируемое обучение является ответвлением машинного обучения, которое выводит модель прогнозирования, если дан набор данных для обучения. Каждая выборка данных для обучения является парой, состоящей из входных данных (например, вектор результатов измерений или признаков) и требуемого выходного значения (называемого также контрольным сигналом). Алгоритм контролируемого обучения анализирует данные для обучения и вырабатывает функцию прогнозирования, которая является регрессионной функций, когда выходная переменная является численной или является непрерывной. В соответствии с раскрываемыми вариантами осуществления можно применить множество разных алгоритмов, включая, но без ограничения: регрессию kNN (по k ближайшим соседям), машины опорных векторов, нейронные сети, деревья решений, случайные леса и методы градиентного бустинга.
[052] Фиг. 3 представляет блок-схему последовательности операций примерного процесса для прогнозирующего модуля, который может использовать модель 150 псевдо-КТ в соответствии с раскрываемыми вариантами осуществления. После того, как модель 150 псевдо-КТ создана и обучена, модель 150 может быть использована прогнозирующим модулем 301 на стадии применения для формирования псевдо-КТ-изображения из нового МР-сканирования, либо для того же пациента, либо для нового пациента. Как показано на фиг. 3, процесс формирования псевдо-КТ-изображения 350 аналогичен процессу, описанному выше для фиг. 1, за тем исключением, что на стадии применения используется модель 150 прогнозирования псевдо-КТ, ранее сформированная и обученная. В ходе процесса, в прогнозирующий модуль 301 вводится новое МР-сканирование 310. В варианте осуществления прогнозирующий модуль 301 может включать в себя модуль 311 выделения признаков изображения и модель 150 прогнозирования псевдо-КТ. В данном варианте осуществления МР-сканирование 310 не имеет соответствующего КТ-сканирования. Из МР-сканирования 310 можно выделить признаки, чтобы сформировать вектора 320 МР-признаков пациента аналогично тому, как описано выше по отношению к формированию векторов 120 МР-признаков. Для снижения размерностей векторов 320 МР-признаков пациента можно включить в состав модуль 321 снижения размерности. В качестве альтернативы, вектора 320 МР-признаков пациента могут быть использованы моделью 150 прогнозирования псевдо-КТ без какого-либо снижения размерности, как показано штриховой линией 331.
[053] При этом, прогнозирующий модуль 301 использует модель 150 прогнозирования псевдо-КТ, образованную на стадии обучения, чтобы прогнозировать псевдо-КТ-значение в каждом местоположении МР-изображения 310 пациента, так как первоначально не обеспечено никакого КТ-сканирования, соответствующего новому МР-сканированию. Поскольку модель 150 прогнозирования псевдо-КТ может действовать «поточечно», например, в каждом местоположении в изображении, то псевдо-КТ-значение представляет собой значение, теоретически полученное, исходя из вектора признаков, для конкретного вокселя в конкретном местоположении в МР-сканировании 310. Поэтому модель прогнозирования 301 может формировать псевдо-КТ-значения 340. Псевдо-КТ-значения 340 представляют множество значений интенсивности для псевдо-КТ-изображения 350. Чтобы сформировать псевдо-КТ-изображение 350, псевдо-КТ-значения 340 обычно помещают в подходящие для них местоположения на сетке вокселей. В варианте осуществления модель прогнозирования 301 может прогнозировать некоторые значения (например, псевдо-КТ-значения 340) сетки вокселей, так как изображение является сеткой вокселей (например, прогнозируется не каждый воксель изображения); и затем можно применить интерполяцию, чтобы сформировать псевдо-КТ-изображение 350 для изображения точного визуального представления анатомических деталей пациента.
[054] Модель 150 прогнозирования псевдо-КТ можно обучить однократно с использованием данных 110 для обучения всех имеющихся пациентов, и затем модель 150 прогнозирования псевдо-КТ можно использовать для всех будущих новых пациентов. В качестве альтернативы, одинаковую модель 150 прогнозирования псевдо-КТ можно и не использовать для каждого пациента. Модель 150 прогнозирования псевдо-КТ можно адаптировать для конкретного пациента. Например, данные для обучения можно выбирать так, чтобы они включали в себя данные, наиболее соответствующие или свойственные новому пациенту, и модель можно построить специально для нового пациента.
[055] Фиг. 4A изображает примерную радиотерапевтическую систему 400 в соответствии с некоторыми вариантами осуществления настоящего изобретения. Радиотерапевтическая система 400 может включать в себя обучающий модуль 412, прогнозирующий модуль 414, базу данных 422 для обучения, базу данных 424 испытаний, радиотерапевтическое устройство 430 и устройство 440 получения изображений. Радиотерапевтическая система 400 может быть также подключена к системе 442 планирования лечения (TPS) и онкологической информационной системе (OIS) 444, которая может предоставлять информацию о пациенте. Дополнительно, радиотерапевтическая система 400 может включать в себя устройство отображения и пользовательский интерфейс (не показанный).
[056] Фиг. 4B изображает пример радиотерапевтического устройства 430 одного типа (например, Leksell Gamma Knife, выпускаемый компанией Elekta, AB, Stockholm, Sweden) в соответствии с некоторыми вариантами осуществления настоящего изобретения. Как показано на фиг. 4B, во время сеанса лучевой терапии на пациента 452 может быть надета координатная рамка 454, чтобы поддерживать стабильность части тела пациента (например, головы), подвергаемой хирургической операции или радиотерапии. Координатная рамка 454 и система 456 позиционирования пациента могут устанавливать пространственную систему координат, которую можно использовать во время визуализации пациента или во время лучевой хирургии. Радиотерапевтическое устройство 430 может включать в себя защитный корпус 464 для ограждения множества источников 462 излучения. Источники 462 излучения могут формировать множество пучков излучения (например, элементарных пучков) через каналы 466 пучков. Множество пучков излучения может быть сконфигурировано с возможностью фокусировки на изоцентр 458 с разных направлений. Хотя каждый отдельный пучок излучения может иметь относительно низкую интенсивность, изоцентр 458 может получать относительно высокий уровень излучения, когда несколько доз от разных пучков излучения накапливаются в изоцентре 458. В некоторых вариантах осуществления изоцентр 458 может соответствовать мишени, подлежащей операции или лечению, например, опухоли. Радиотерапевтическое устройство 430 (например, Leksell Gamma Knife, выпускаемое компанией Elekta, AB, Stockholm, Sweden) может, в варианте осуществления, использовать МР-изображения с присвоенными объемными плотностями или КТ-изображения, слитые с МР-изображениями, и может использовать псевдо-КТ-изображения, сформированные в соответствии с раскрываемыми вариантами осуществления.
[057] Фиг. 4C изображает другой пример радиотерапевтического устройства 430 (например, линейный ускоритель 470) в соответствии с некоторыми вариантами осуществления настоящего изобретения. При использовании линейного ускорителя 470, пациент 472 может быть расположен на столе 473 для пациента, чтобы получать дозу излучения, установленную планом лечения. Линейный ускоритель 470 может включать в себя головку 475 излучателя, которая формирует пучок 476 излучения. Головку 475 излучателя целиком может поворачиваться вокруг горизонтальной оси 477. Дополнительно под столом 473 для пациента может быть обеспечен плоскопанельный сцинтилляционный детектор 474, который может поворачиваться синхронно с головкой 475 излучателя вокруг изоцентра 471. Пересечение оси 477 с центром пучка 476, формируемого головкой 475 излучателя, обычно именуется изоцентром. Стол 473 для пациента может быть снабжен электроприводом, чтобы пациента 472 можно было поместить с расположением опухоли в изоцентре 471 или вблизи него. Головка 475 излучателя может поворачиваться вокруг гентри 478, чтобы снабжать пациента 472 множеством изменяющихся доз излучения в соответствии с планом лечения. В альтернативном варианте осуществления линейный ускоритель 470 может быть линейным ускорителем, объединенным с магнитно-резонансным томографом (установка «MR-LINAC»). Как линейный ускоритель 10, так и установка MR-LINAC могут, в варианте осуществления, использовать МР-изображения, КТ-изображения и могут использовать псевдо-КТ-изображения, сформированные в соответствии с раскрываемыми вариантами осуществления.
[058] Фиг. 5 является примерной системой 500 для построения модели прогнозирования псевдо-КТ и формирования псевдо-КТ-изображений в соответствии с раскрываемыми вариантами осуществления. В соответствии с некоторыми вариантами осуществления, система 500 может представлять собой одно или более из высокоэффективных компьютерных устройств, способных идентифицировать, анализировать, поддерживать, генерировать и/или обеспечивать большие количества данных в соответствии с раскрываемыми вариантами осуществления. Система 500 может быть автономной, или данная система может быть частью подсистемы, которая, в свою очередь, может быть частью более крупной системы. Например, система 500 может представлять собой распределенные высокопроизводительные серверы, которые расположены дистанционно и обмениваются информацией по сети, например, сети Internet или такой специализированной сети, как локальная сеть (LAN) или глобальной сети (WAN). В некоторых вариантах осуществления система 500 может включать в себя встроенную систему, МР-сканер и/или устройство отображения с сенсорным экраном, обменивающиеся информацией с одним или более дистанционно расположенными высокопроизводительными компьютерными устройствами.
[059] В одном варианте осуществления система 500 может включать в себя один или более из процессоров 514, одну память 510 или более и один или более из связных интерфейсов 515. Процессор 514 может быть процессорным устройством, включающим в себя одно или более из универсальных процессорных устройств, например, микропроцессор, центральный процессор (CPU), графический процессор (GPU) или что-то подобное. В частности, процессор 514 может быть микропроцессором с комплексным набором команд (CISC-микропроцессор), микропроцессором с сокращенным набором команд (RISC-микропроцессор), микропроцессором с очень длинным командным словом (VLIW-микропроцессор), процессором, реализующим другие наборы команд, или процессорами, реализующими комбинацию наборов команд. Процессор 514 может представлять собой также одно или более из специализированных процессорных устройств, например, специализированную интегральную схему (ASIC), вентильную матрицу с эксплуатационным программированием (FPGA), цифровой сигнальный процессор (DSP), систему на кристалле (SoC) или что-то подобное. Специалистам в данной области техники должно быть понятно, что в некоторых вариантах осуществления процессор 514 может быть специализированным процессором, а не универсальным процессором. Процессор 514 может включать в себя одно или более из известных процессорных устройств, например, микропроцессор из семейства Pentium™ или Xeon™, изготавливаемых компанией Intel™, семейства Turion™, изготавливаемого компанией AMD™, или любой из различных процессоров, изготавливаемых компанией Sun Microsystems. Процессор 514 может также включать в себя графические процессоры, изготавливаемые компанией Nvidia™. Раскрываемые варианты осуществления не ограничены каким-либо типом процессора(ов), иначе сконфигурированных с возможностью удовлетворения спроса на вычисления для идентификации, анализа, поддержки, генерации и/или обеспечения больших количеств данных визуализации или данных любого другого типа в соответствии с раскрываемыми вариантами осуществления.
[060] Память 510 может включать в себя одно или более из запоминающих устройств, сконфигурированных с возможностью хранения компьютерно-выполняемых команд, используемых процессором 514 для выполнения функций, связанных с раскрываемыми вариантами осуществления. Например, память 510 может хранить компьютерно-выполняемые команды для программного обеспечения 511 планирования лечения, программного обеспечения 512 операционной системы и программного обеспечения 513 обучения/прогнозирования. Процессор 514 может быть связан с возможностью обмена информацией с памятью/запоминающим устройством 510, и процессор 514 может быть сконфигурирован с возможностью выполнения компьютерно-выполняемых команд, хранящихся в памяти, чтобы выполнять одну или более из операций в соответствии с раскрываемыми вариантами осуществления. Например, процессор 514 может выполнять программное обеспечение 513 обучения/прогнозирования, чтобы реализовать функции обучающего модуля 412 и прогнозирующего модуля 414. Дополнительно, процессор 514 может выполнять программное обеспечение 511 планирования лечения (например, программное обеспечение Monaco®, выпускаемое компанией Elekta), которое может взаимодействовать с программным обеспечением 513 обучения/прогнозирования.
[061] Раскрываемые варианты осуществления не ограничены отдельными программами или компьютерами, предназначенными для выполнения специальных задач. Например, память 510 может включать в себя единственную программу, которая выполняет функции системы 500 или нескольких программ (например, программного обеспечения 511 планирование лечения и/или программного обеспечения 513 обучения/прогнозирования). Кроме того, процессор 514 может выполнять одну или более из программ, расположенных дистанционно от системы 500, например, программ, хранящихся в базе данных 520, при этом удаленные программы могут включать в себя программное обеспечение онкологической информационной системы или программное обеспечение планирования лечения. Память 510 может также хранить данные изображения или данные/информацию любого другого типа в любом формате, который система может использовать для выполнения операций в соответствии с раскрываемыми вариантами осуществления.
[062] Связной интерфейс 515 может представлять собой одно или более из устройств, выполненных с возможностью приема и/или передачи данных системой 500. Связной интерфейс 515 может включать в себя одно или более из цифровых и/или аналоговых устройств связи, которые позволяют системе 500 обмениваться информацией с другими установками и устройствами, например, дистанционно расположенными компонентами системы 500, базой данных 520 или больничной базой данных 530. Например, процессор 514 может быть соединен с возможностью обмена информацией с базой(ами) данных 520 или больничной(ыми) базой(ами) данных 530 посредством связного интерфейса 515. Например, связной интерфейс 515 может быть компьютерной сетью, например, сетью Internet, или специализированной сетью, например, LAN или WAN. В качестве альтернативы, связной интерфейс 515 может быть линией спутниковой связи или линией цифровой или аналоговой связи любой формы, которая позволяет процессору 514 посылать/принимать данные в/из любой базы(ы) данных 520, 530.
[063] База(ы) данных 520 и больничная(ые) база(ы) данных 530 могут включать в себя одно или более из запоминающих устройств, которые хранят информацию и выбираются и управляются системой 500. Например, база(ы) данных 520, больничная(ые) база(ы) данных 530 или базы данных обоих типов могут включать в себя реляционные базы данных, например, базы данных Oracle™, базы данных Sybase™ или другие, и могут включать в себя нереляционные базы данных, например, последовательные файлы Hadoop, HBase, Cassandra или другие базы данных. Базы данных или другие файлы могут включать в себя, например, исходные данные МР-сканирования или КТ-сканирования, относящиеся к объектам для обучения, вектора 120 МР-признаков, КТ-значения 130, вектора признаков 140 с пониженной размерностью, модель(ли) 150 прогнозирования псевдо-КТ, псевдо-КТ-значение(ия) 340, псевдо-КТ-изображение(ия) 350, данные в стандарте DICOM и т.п. Однако, системы и способы раскрываемых вариантов осуществления не ограничены отдельными базами данных. В одном аспекте система 500 может включать в себя базу(ы) данных 520 или больничную(ые) базу(ы) данных 530. В качестве альтернативы, база(ы) данных 520 и/или больничная(ые) база(ы) данных 530 могут располагаться удаленно от системы 500. База(ы) данных 520 и больничная(ые) база(ы) данных 530 могут включать в себя компьютерные компоненты (например, систему управления базами данных, сервер базы данных и т.п.), сконфигурированные с возможностью приема и обработки запросов данных, хранящихся в запоминающих устройствах баз(ы) данных 520 или больничной(ых) баз(ы) данных 530, и предоставления данных из баз(ы) данных 520 или больничной(ых) баз(ы) данных 530.
[064] Система 500 может обмениваться информацией с другими устройствами и компонентами системы 500 по сети (не показанной). Сеть может быть сетью любого типа (включая инфраструктуру), которая обеспечивает связь, обменивается информацией или облегчает обмен информацией и допускает передачу и прием информации между другими устройствами и/или компонентами системы 500 по сети (не показанной). В других вариантах осуществления один или более компонентов системы 500 может обмениваться информацией непосредственно по специализированной(ым) линии(ям) связи, например, по линии (в частности, проводной линии, беспроводной линии, спутниковой линии или другой линии связи) между системой 500 и базой(ами) данных 520 и больничной(ыми) базой(ами) данных 530.
[065] Конфигурация и границы функциональных строительных блоков системы 500 определены в настоящей заявке для удобства описания. Альтернативные границы можно задавать при условии, что конкретные функции и их взаимосвязи выполняются должным образом. Специалистам в соответствующей(их) области(ях) техники будут очевидны альтернативные варианты (в том числе, эквиваленты, расширения, изменения, отклонения и т.п. вариантов, описанных в настоящей заявке), исходя из идей, содержащихся в настоящей заявке. Упомянутые альтернативные варианты находятся в пределах объема и существа раскрываемых вариантов осуществления.
[066] Фиг. 6 является блок-схемой последовательности операций примерного процесса 600 для обучения и построения модели прогнозирования псевдо-КТ, в соответствии с раскрываемыми вариантами осуществления. Процесс 600 включает в себя множество этапов, некоторые из которых могут быть необязательными. На этапе 610, система 500 может выбирать данные 110 для обучения, относящиеся к множеству объектов для обучения, из, например, базы данных 520 и/или больничной базы данных 530. Данные 110 для обучения могут включать в себя, по меньшей мере, одно МР-сканирование и, по меньшей мере, одно КТ-сканирование для каждого объекта для обучения (например, показанные на фиг. 1 данные 110a - 110N по объектам для обучения). В некоторых вариантах осуществления данные 110 для обучения могут включать в себя, по меньшей мере, одно МР-сканирование и несколько КТ-сканирований для одного и того же пациента.
[067] В соответствии с некоторыми вариантами осуществления, система 500 может определять, нуждаются ли некоторые или все данные 110 для обучения в предварительной обработке перед использованием для обучения и построения модели 150 прогнозирования псевдо-КТ. На этапе 620, процессор 514 определяет, выставлены ли МР-сканирования и соответствующие КТ-сканирования для одного или более объектов для обучения в данных для обучения (например, известно(ны) ли КТ-значение(ия) из соответствующего КТ-вокселя для каждого МР-вокселя). Если МР- и КТ-изображения не выставлены, то процесс 600 следует по ветви 621 (например, «Нет»), чтобы выставить сканирования на этапе 624. При необходимости, система 600 может выставить МР-сканирование и соответствующее(ие) КТ-сканирование(ия) в соответствии со способами, известными специалистам в данной области техники. В качестве альтернативы, если МР- и КТ-изображение(ия) выставлены, процесс 600 следует по ветви 622 (например, «Да») на этап 630.
[068] При желании, на этапе 630, процессор 514 проверяет, включают ли данные 110 для обучения в себя несколько КТ-сканирований для одного и того же объекта для обучения. Если имеется несколько КТ-сканирований, то процессор 514 определяет средние КТ-значения для соответствующих КТ-вокселей по нескольким КТ-сканированиям, чтобы ослабить шум в изображении для одного и того же пациента. В ином случае, процесс 600 переходит с этапа 620 непосредственно на этап 640.
[069] На этапе 640, в рамках предварительной обработки, процессор 514 определяет, следует ли подавлять или устранять артефакты изображения из МР-сканирования, на основании, например, системных настроек, отраженных в программном обеспечении 511 планирования лечения или программном обеспечении 513 обучения/прогнозирования. Если подавление артефактов изображения желательно, то процесс 600 следует по ветви 642 («Да») на этап 644. На этапе 644, процессор 514 может применить, в рамках предварительной обработки, методов подавления артефактов изображения. Посредством предварительной обработки МР-сканирования, процессор 514 может устранять или подавлять артефакты изображения, например, неравномерности интенсивности (известные также как поле смещения МР-изображения), и шум в изображении. Кроме того, предварительная обработка может нормировать/стандартизировать значения интенсивности МР-изображений по всем разнотипным МР-сканерам (например, изготавливаемым компаниями GE, Siemens и т.п; или различным напряженностям магнитных полей, например, 0,5 Тесла, 1,5 Тесла и т.п.). Методы предварительной обработки можно также применять для устранения или подавления артефактов изображения в МР-сканировании 310 нового пациента (как показано на фиг. 3). Если подавление артефактов изображения не выполняется, то процесс 600 переходит на этап 650 для выделения признаков. В некоторых вариантах осуществления один или несколько этапов предварительной обработки (например, обведенных штриховыми линиями на фиг. 6) можно исключить.
[070] На этапе 650, из данных 110 для обучения могут быть выделены признаки. В некоторых вариантах осуществления система 500 может выделять признаки из каждого вокселя каждого МР-сканирования в данных 110 для обучения. Например, для выделения признаков можно использовать само МР-изображение, и можно использовать каждый воксель или выбранные воксели из МР-изображения. В качестве альтернативы, процессор 514 может сегментировать МР-изображение на ткани разных типов и сегментировать воксели изображения каждого МР-сканирования, исходя из типов тканей. В некоторых случаях, данный подход может быть полезен потому, что типы тканей можно использовать как дополнительный признак, например, в дополнение к другим выделенным признакам.
[071] На этапе 660, система 500 может создать вектор МР-признаков, исходя из выделенных признаков изображения для каждого вокселя МР-сканирования. Следовательно, процессором 514 может быть сформирован вектор, содержащий множество признаков для каждого вокселя МР-сканирования. Процессором 514 может быть сформировано множество векторов 120 МР-признаков для множества вокселей МР-сканирования.
[072] На этапе 670, система 500 может выделить КТ-значение из каждого вокселя каждого КТ-сканирования в данных для обучения.
[073] На этапе 680, система 500 может определить, следует ли уменьшить число измерений, относящихся к векторам 120 МР-признаков.
[074] Например, процессор 514 системы 500 может определить, что число измерений, относящихся к векторам 120 МР-признаков, приведет к большим вычислительным затратам или, возможно, создаст проблемы производительности, при обработке моделью 150 прогнозирования псевдо-КТ. В другом примере, система 500 может определить, что вектора 120 МР-признаков включают шум или дублированные данные, превышающие пороги, которые, как предполагается, снизят точность модели 150 прогнозирования псевдо-КТ. В другом варианте осуществления система 500 может определить, следует ли выполнять снижение размерности на основании факторов, влияющих на снижение эффективности и/или качество выходных данных. Поэтому, если процессор 514 определяет, что снижение размерности необходимо, то процесс 600 следует по ветви 682 (например, «Да») на этап 686, на котором процессор 514 может сократить измерения, относящиеся к векторам 120 МР-признаков. В качестве альтернативы, в некоторых вариантах осуществления система 500 может получить ввод (например, от пользователя), предписывающий не выполнять никакого снижения размерности векторов 120 МР-признаков.
[075] Если снижения размерности не требуется, то процесс 600 может проследовать непосредственно по ветви 684 на этап 690. На этапе 690, система 500 может использовать методы статистического или машинного обучения, чтобы сформировать модель 150 прогнозирования псевдо-КТ, исходя из векторов МР-признаков (например, 120) и выделенных КТ-значений. В некоторых вариантах осуществления могут использоваться вектора 140 признаков с пониженной размерностью.
[076] В соответствии с некоторыми вариантами осуществления, в качестве основы для обучения и построения модели 150 прогнозирования псевдо-КТ можно использовать поднабор данных 110 для обучения. Следовательно, система 500 может определять (например, на основании пользовательского ввода и/или системных настроек, отраженных в программном обеспечении 511 планирования лечения и/или программном обеспечении 513 обучения/прогнозирования) поднабор данных 110 для обучения, чтобы обучить и построить модель 150 прогнозирования псевдо-КТ. В другом варианте осуществления поднабор данных 110 для обучения может классифицироваться на основании конкретных областей изображения. Например, поднабор 110 данных для обучения может быть: 1) по конкретным анатомическим областям, 2) по различным классификациям тканей, или 3) по характеристикам объектов для обучения.
[077] Например, один или более признаков могут обеспечивать наилучшую интерпретацию исходной анатомической структуры для данного МР-сканирования пациента; и, следовательно, из данных 110 для обучения можно выделять только поднабор наиболее важных признаков, чтобы применить при обучении модели 150 прогнозирования псевдо-КТ. Благодаря применению наиболее важных признаков можно повысить прогнозирующую способность модели 150 прогнозирования псевдо-КТ для оценки соответствующих псевдо-КТ-значений 340 для данного МР-сканирования пациента. Поднабор признаков можно применять для формирования и обучения одной или более моделей псевдо-КТ.
[078] В варианте осуществления, при построении модели прогнозирования псевдо-КТ по конкретной анатомической области, для обучения и построения модели прогнозирования псевдо-КТ 150 можно использовать поднабор данных 110 для обучения (например, только данные 110 для обучения, относящиеся к области интереса тела). Вместо одной модели прогнозирования псевдо-КТ, процессор 514 может формировать множество моделей прогнозирования псевдо-КТ по конкретным анатомическим зонам тела (например, голове, верхней части тела, нижней части тела и т.п.). Следовательно, процессор 514 может использовать вектора 120 МР-признаков (или вектора 140 признаков с пониженной размерностью) и КТ-значения 130 для предварительно заданного анатомического местоположения интереса, чтобы сформировать модель 150 прогнозирования псевдо-КТ для упомянутого конкретного анатомического местоположения интереса, изображенного при МР-сканировании.
[079] Например, система 500 может определить, что МР-сканирование 130 пациента включает в себя МР-изображение простаты пациента. В таком случае, в соответствии с раскрываемыми вариантами осуществления, система 500 может идентифицировать модель прогнозирования псевдо-КТ, которая построена и обучена, исходя из данных 110 для обучения, с использованием одного или более МР-сканирований и КТ-сканирований простаты в качестве данных для обучения. В варианте осуществления может быть в наличии, по меньшей мере, две модели прогнозирования псевдо-КТ, при этом каждая модель может изображать, например, различные анатомические аспекты простаты. Поэтому может формироваться множество моделей прогнозирования псевдо-КТ, при этом каждая модель прогнозирования псевдо-КТ предназначена для конкретной анатомической зоны (например, модель прогнозирования псевдо-КТ для простаты, модель прогнозирования псевдо-КТ для правого легкого, модель прогнозирования псевдо-КТ для левого легкого, модель прогнозирования псевдо-КТ для головного мозга и т.п.).
[080] В другом варианте осуществления модель 150 прогнозирования псевдо-КТ может быть сформирована, исходя из признаков, основанных на классификации, например, классификации тканей. Например, система 500 может использовать модуль 111 выделения признаков изображения, чтобы сегментировать воксели изображения каждого МР-сканирования в данных 110 для обучения в зависимости от класса ткани (например, кости, жира, мышц, воды, воздуха и структурных классов, например, сердечной ткани, легочной ткани, ткани печени, ткани головного мозга и т.п.). Для каждого МР-сканирования может быть сформировано множество карт сегментации, исходя из сегментированных вокселей изображения. Признаки изображения могут быть выделены из карт сегментации. Признаки изображения, выделенные по картам сегментации, можно объединять с признаками изображения, выделенными из МР-сканирования, для каждого вокселя. Вектора МР-признаков можно определять для каждого объекта для обучения, исходя из объединенных признаков изображения. Возможно формирование модели прогнозирования псевдо-КТ, основанной на векторах объединенных МР-признаков, и выделенных КТ-значениях. Как изложено выше, термин «ткань» используется в качестве классификации, а не просто предполагает специфические типы ткани (например, воздух не является тканью).
[081] В еще одном дополнительном варианте осуществления, процесс для формирования псевдо-КТ-изображения(ий) может быть основан на использовании данных для обучения, выбранных в зависимости от характеристик объекта для обучения. Например, система 500 может идентифицировать одну или более общих характеристик в поднаборе объектов для обучения. Например, система 500 может идентифицировать возраст, пол, класс по весу и т.п., относящиеся к каждому объекту для обучения, и выбрать объекты для обучения, имеющие одну или более общих характеристик. В других примерах, система 500 может идентифицировать одну или более общих характеристик объектов для обучения, исходя из МР- и КТ-сканирования(ий) в данных 110 для обучения. Дополнительно, система 500 может идентифицировать одну или более общих характеристик пациента (например, нового пациента) подобно тому, как с поднабором объектов для обучения. Например, система 500 может идентифицировать одну или более общих характеристик пациента и сравнить характеристики пациента с характеристиками, идентифицированными для объектов для обучения, чтобы идентифицировать общие характеристики. Затем система 500 может выбрать объекты для обучения, имеющие одну или более общих характеристик, в качестве данных для обучения, чтобы обучить и построить модель 150 прогнозирования псевдо-КТ.
[082] Признаки изображения можно выделять из МР-сканирований и КТ-чисел из КТ-сканирований, связанных с характеристиками объектов для обучения. Например, система 500 может выделить признаки изображения из МР-сканирований и КТ-значений 130 из КТ-сканирований в данных 110 для обучения, относящихся к поднабору объектов для обучения, имеющих общие характеристики с новым пациентом. В таком случае, вектора МР-признаков можно определять для каждого объекта для обучения из поднабора, исходя из выделенных признаков изображения. Модель прогнозирования псевдо-КТ можно формировать, исходя из данных векторов МР-признаков и выделенных КТ-значений.
[083] Модель 150 прогнозирования псевдо-КТ можно обучать с использованием всех данных 110 для обучения и затем использовать для нового МР-сканирования нового пациента. Модель 150 прогнозирования псевдо-КТ можно также использовать для всех будущих новых пациентов. В некоторых вариантах осуществления, одну и ту же модель 150 прогнозирования псевдо-КТ, возможно, нельзя использовать для каждого пациента. Модель 150 прогнозирования псевдо-КТ можно адаптировать для конкретного пациента. Например, данные для обучения можно выбирать, исходя из объектов для обучения, которые подобны или соответствуют новому пациенту, и модель можно построить специально для нового пациента.
[084] Медицинский персонал может обнаружить, что полезно оценивать как МР-характеристики, так и КТ-характеристики области интереса в пациенте, чтобы определять оптимальное лечение или диагностику. Кроме того, модель псевдо-КТ можно использовать для теоретического получения КТ-изображения из МР-изображения, чтобы способствовать вычислению дозы пациента при планировании лучевой терапии. Это желательно для точного формирования псевдо-КТ-изображения из МР-изображения, чтобы избавлять пациентов от дополнительной лучевой нагрузки, обусловленной КТ-визуализацией. Для того, чтобы заменить реальное КТ-изображение, псевдо-КТ-изображение должно как можно точнее соответствовать реальному КТ-изображению пациента с целью вычисления дозы при планировании лучевой терапии или для формирования рентгеновских изображений, полученных методом цифровой реконструкции, (DRR-изображений) для контроля по изображениям. Однако, между значениями интенсивности КТ-изображения (КТ-значениями) и МР-значениями интенсивности не существует простой математической зависимости. Трудность возникает потому, что МР-значения интенсивности не стандартизованы и могут значительно изменяться в зависимости от разных настроек МР-сканера или разных параметров последовательности МР-визуализации.
[085] Фиг. 7 является блок-схемой последовательности операций примерного процесса 700 для применения модели прогнозирования псевдо-КТ (описанной в связи с фиг. 1 и фиг. 6) после того, как модель обучена, чтобы формировать псевдо-КТ-значения и псевдо-КТ-изображения (как описано в связи с фиг. 3), в соответствии с раскрываемыми вариантами осуществления. На этапе 710, система 500 может принять, по меньшей мере, одно МР-сканирование (например, МР-сканирование 310), относящееся к пациенту (например, новому пациенту). По меньшей мере, одно МР-сканирование может и не иметь соответствующего КТ-сканирования. МР-сканирование служит для формирования псевдо-КТ-изображения.
[086] На этапе 720, процессор 514 может определить, следует ли сегментировать воксели МР-изображения. Сегментация МР-сканирования не обязательна. Процессор 514 может принимать команды либо из программного обеспечения 511 планирования лечения (показанного на фиг. 5), либо из пользовательского интерфейса (не показанного), следует ли сегментировать МР-сканирование. Если так, то процесс 700 следует по ветви 722 (например, «Да»), чтобы сегментировать МР-сканирование. На этапе 730, воксели изображения МР-сканирования сегментируются в зависимости от, например, классификации ткани. Сегментация может выполняться в соответствии с методами сегментации, известными специалистам в данной области техники. Например, процессор 514 может использовать метод сегментации по алгоритму кластеризации методом k-средних, метод сегментации по алгоритму нечетких C-средних и т.п., чтобы создать одну или более карт сегментации.
[087] Процессор 514 может дополнительно использовать более развитые методы сегментации. Например, процессор 514 может использовать подход на основе обучения или на основе признаков, чтобы выполнять сегментацию, что может включать в себя построение классификационной модели прогнозирования, использующую, например, алгоритмы (например, локального признака образа, ориентирного признака, контекстного признака и т.п.) для прогнозирования метки ткани для каждого вокселя изображения, исходя из признаков вокселей изображения.
[088] На этапе 732, процессор 514 может формировать множество карт сегментации для каждого МР-сканирования, исходя из сегментированных вокселей изображения, чтобы создать классификационную модель прогнозирования. Например, бинарная карта сегментации костей может быть изображением со значениями, равными «1» в вокселях, помеченных как кости, и «0» во всех других вокселях. Процессор 514 может использовать карты сегментации для выделения дополнительных признаков из исходных МР-изображений. В соответствии с раскрываемыми вариантами осуществления, основанные на обучении способы, раскрытые выше, можно использовать для обучения и построения модели прогнозирования с целью формирования одной или более карт сегментации. В качестве альтернативы, если сегментации МР-сканирования не требуется, то процесс 700 следует по ветви 724 (например, «Нет»).
[089] На этапе 740, процессор 514 может выделять признаки изображения из МР-сканирования пациента. Если необязательный путь вышеописанной сегментации МР-сканирования выполнялся, то выделенные признаки изображения можно представить по ветви 722. На этапе 734, процессор 514 может объединять дополнительные признаки, выделенные с помощью карты сегментации из МР-сканирования, вместе с признаками, выделенными непосредственно из МР-изображений, чтобы формировать объединенный набор признаков для каждой точки данных (например, вокселя).
[090] Независимо от того, сегментировано ли или нет МР-сканирование, после того, как признаки изображения выделены, процессор 700 переходит (например, по ветви 744 или 736) на этап 750. На этапе 750, процессор 514 может определять вектора 120 признаков для каждого объекта для обучения по выделенным признакам изображения.
[091] На этапе 760, процессор 514 может ввести вектора 120 МР-признаков в модель 150 прогнозирования псевдо-КТ. На этапе 770, процессор 514 может применить модель 150 прогнозирования псевдо-КТ к введенным векторам 120 МР-признаков, чтобы определить КТ-числа (например, псевдо-КТ-значения 340) для каждого вокселя МР-изображения 310 пациента.
[092] На этапе 780, исходя из псевдо-КТ-значений 340, процессор 514 может сформировать псевдо-КТ-изображение 350 для пациента. Полученное псевдо-КТ-изображение 350 можно использовать для вычисления дозы при планировании лечения, с формированием DRR-изображений для контроля по изображениям и т.п.
[093] Фиг. 8 представляет схему примерного способа для дополнения данных для обучения для построения модели прогнозирования псевдо-КТ в соответствии с раскрываемыми вариантами осуществления. Способ, представленный на фиг. 8, можно также назвать методом каскадного обучения или многоэтапным методом обучения, в котором первоначально обученную модель прогнозирования используют для формирования промежуточного результата прогнозирования, который, в свою очередь, используется в составе данных для обучения, чтобы дополнительно уточнить модель прогнозирования. Метод каскадного обучения может включать в себя несколько стадий обучения. На каждой стадии модель прогнозирования обучается с использованием исходных данных (например, данных 110 для обучения), объединенных с результатом прогнозирования, произведенным моделью прогнозирования, сформированной на предварительной стадии.
[094] В одном варианте осуществления модель 150 прогнозирования псевдо-КТ может быть первоначально построена и обучена с использованием первоначального набора данных для обучения, как описано выше со ссылкой на фиг. 1. В рамках первоначального процесса обучения, из множества сканированных изображений выделяются признаки изображения, и из выделенных признаков изображения определяются вектора признаков. Дополнительно, из КТ-сканирования могут быть определены соответствующие КТ-значения. Например, в наличии должно быть, по меньшей мере, одно КТ-изображение для каждого объекта для обучения. В варианте осуществления в наличии может быть несколько КТ-изображений. Если в наличии имеется несколько КТ-изображений, то КТ-изображения можно усреднить, чтобы подавить шум в изображении. Модель псевдо-КТ может быть обучена на любой стадии процесса каскадного обучения.
[095] В другом варианте осуществления классификационная модель прогнозирования может быть обучена как первоначальная модель или любая промежуточная модель. Как описано выше, классификационную модель прогнозирования можно использовать для прогнозирования одной или более карт сегментации, из которых можно выделить признаки, основанные на классификации, и использовать на следующей стадии обучения.
[096] В примерном процессе каскадного обучения, модели прогнозирования псевдо-КТ и классификационные модели прогнозирования можно использовать в любом сочетании на нескольких стадиях, при условии, что модель прогнозирования псевдо-КТ обучается и строится на последней стадии.
[097] Как представлено на фиг. 8, первоначально построенная модель прогнозирования показана как модель № 1. Модель № 1 формируется обработкой исходных данных для обучения, например, каждого МР-сканирования, каждого КТ-сканирования или каждой пары МР- и КТ-сканирований (например, 110a, 110b), на стадии № 1 обучения. Как описано выше, модель № 1 может быть моделью прогнозирования псевдо-КТ или классификационной моделью прогнозирования. Затем модель № 1 можно использовать в процессе обучения следующей стадии. Например, модель № 1 можно использовать для формирования множества результатов прогнозирования (например, результата 1 прогнозирования, стадии 1; результата 2 прогнозирования, стадии 1, …, результата N прогнозирования, стадии 1). Например, когда модель № 1 является моделью прогнозирования псевдо-КТ, МР-сканирование объекта a для обучения можно использовать в качестве входных данных (например, как если бы объект a для обучения является новым пациентом, и МР-сканирование объекта a для обучения является новым МР-сканированием) для модели № 1, чтобы сформировать результат 1120a прогнозирования псевдо-КТ: результат 1 прогнозирования, стадии 1. В другом примере, когда модель № 1 является классификационной моделью прогнозирования, результат прогнозирования модели № 1 может быть картой сегментации. Другие результаты 1120b … 1120N прогнозирования могут быть сформированы аналогичным образом. Затем данные результаты прогнозирования можно добавить к первоначальным данным для обучения, чтобы сформировать дополненные данные 1120 для обучения. Например, посредством привязки пар МР- и КТ-сканирований (например, 110a, 110b, … 110N) с соответствующими им результатами (например, 1120a, 1120b, … 1120N) прогнозирования, сформированными из модели № 1, можно создать дополненные данные 1120 для обучения. Дополненные данные 1120 для обучения могут быть использованы обучающим модулем (например, обучающим модулем 412) на следующей стадии обучения для формирования другой модели (например, модели № 2).
[098] Таким образом может быть сформирована новая уточненная модель (например, модель № 2, модель № 3, … модель № M) на каждой стадии. Модель, разработанная на предыдущей стадии, может уточняться подачей дополненных данных для обучения (например, дополненных данных 1120, 1130 и т.п. для обучения) в обучающий модуль. Например, модель № 2 может быть создана использованием дополненных данных 1120 для обучения, включающих в себя результаты прогнозирования, сформированные моделью № 1. Для создания модели № 2, дополненные 1120 данные для обучения можно ввести в обучающий модуль (например, обучающий модуль 412) на стадии № 2 обучения. В некоторых вариантах осуществления результат прогнозирования, созданный моделью № 1, может быть изображением (например, псевдо-КТ-изображением) или картой (например, картой сегментации) для каждого объекта для обучения. Затем из результата прогнозирования (например, изображения или карты) можно выделить признаки изображения с использованием, например, модуля 111 выделения признаков изображения. Признаки изображения, которые могут быть выделены из результата прогнозирования, могут включать в себя любые признаки, описанные ранее, например, признаки интенсивности, контекстные признаки, признаки участков, локальные признаки образа, ориентирные признаки и т.п. Признаки, выделенные из результата прогнозирования, можно объединять с признаками, выделенными из исходных МР-изображений, для формирования нового, расширенного вектора признаков для каждой точки изображения. Расширенный вектор признаков можно использовать на следующей стадии обучения, чтобы обучать, например, модель № 2. Когда каждая последующая модель прогнозирования (например, модель № 2) строится и обучается с использованием результатов прогнозирования предшествующей ей модели прогнозирования (например, модели № 1), в процесс обучения может добавляться новая информация, обнаруживаемая из результатов прогнозирования, и характеристики последующей модели прогнозирования могут повышаться. Данный процесс использования дополненных данных для обучения (например, дополненных данных 1120, 1130 и т.п. для обучения) с целью обучения каждой последовательной модели (например, модели № 1, модели № 2, … и т.п.) продолжается до тех пор, пока не обучается и строится окончательная модель прогнозирования, модель № M. Если целью процесса каскадного обучения является построение модели прогнозирования псевдо-КТ, то последняя модель, модель № M, является моделью прогнозирования псевдо-КТ, а все остальные модели на промежуточных стадиях могут быть любыми моделями. Число используемых стадий может зависеть от проверки модели № M на точность прогнозирования КТ-значения. Например, приведенный итерационный процесс может прекращаться, когда разность прогнозированных значений псевдо-КТ, сформированных последней моделью и исходных КТ-значений меньше предварительно заданного порога. В другом примере, итерационный процесс может прекращаться, когда разность между результатами прогнозирования последовательными моделями прогнозирования псевдо-КТ становится меньше предварительно заданного порога.
[099] Как описано выше, метод каскадного обучения применим к обучению и построению моделей прогнозирования псевдо-КТ и/или классификационных моделей тканей. При обучении и построении классификационных моделей тканей, каждая промежуточная модель прогнозирования (например, модель № 1, модель № 2, … модель № M-1) может быть классификационной моделью ткани, которая может, например, обеспечивать карты сегментации, отражающие метки ткани вместо формирования псевдо-КТ-значений. При использовании вышеописанного многоэтапного процесса обучения, каждая классификационная модель ткани может быть построена и обучена с использованием дополненных данных, включающих в себя результаты прогнозирования предыдущей модели, чтобы снова и снова уточнять модель на каждой стадии. Дополнительно, в многоэтапном процессе можно смешивать классификацию тканей и прогнозирование псевдо-КТ. Например, на первых K стадиях, обученная модель может быть классификационной моделью ткани, и результаты прогнозирования могут быть результатами классификации ткани. После того, классификационная модель ткани обучена, результат классификации ткани можно использовать на стадии K+1, чтобы прогнозировать псевдо-КТ-значения, при этом результат классификации ткани можно использовать для выделения набора признаков вместе с другими признаками, выделенными из МР-сканирований. Можно выполнить одну дополнительную стадию (например, если M=K+1), или можно выполнять дополнительные стадии, пока не достигается число M стадий (например, если M>K+1). В конце процесса обучают и строят окончательную модель прогнозирования, модель № M, чтобы формировать псевдо-КТ-значения.
[0100] Фиг. 9 представляет схему примерного процесса для применения многоэтапных моделей с целью прогнозирования псевдо-КТ-значений, в соответствии с раскрываемыми вариантами осуществления.
[0101] Как показано на фиг. 9, процессор (например, процессор 514, показанный на фиг. 5) может получать одно или более МР-сканирований 310 пациента из устройства 440 получения изображений или из баз данных 520, 530 (показанных на фиг. 5).
[0102] После того, как МР-сканирование пациента получено, из каждого МР-вокселя МР-сканирования(ий) может быть выделено множество признаков изображения. Как описано выше для фиг. 2, выделенные признаки изображения могут включать в себя локальный признак 212 образа, ориентирный признак 214, контекстный признак 216 и признаки 218 различных других типов. Признаки могут относиться к точке изображения, вокселю изображения или образцу изображения. Как показано на фиг. 9, модуль 311 выделения признаков изображения можно использовать для выделения признаков КТ-изображения из МР-сканирования(ий). Признаки изображения могут относиться к численным (например, значениям интенсивности, координатам местоположения признака и т.п.) или категориальным свойствам (например, типу ткани, структурной метке и т.п.) МР-вокселя. Выделенные признаки изображения для каждой точки изображения могут формировать вектор признаков, как описано выше. Наборов векторов признаков (например, 320), например, для всех точек изображения МР-сканирования(ий) М, можно вводить в модель № 1 (модель, сформированную на стадии 1 обучения на фиг. 8). Другими словами, процессор 514 может применить модель № 1, сформированную на стадии 1 обучения в ходе многоэтапного процесса обучения, показанного на фиг. 8, к набору векторов признаков, выделенных из МР-сканирования 310. Модель № 1 может выдать результаты № 1 прогнозирования, обозначенные позицией 940, (например, псевдо-КТ-значения, карты сегментации и т.п., в зависимости от типа модели № 1). Затем, результаты № 1 прогнозирования, обозначенные позицией 940, и МР-сканирование(ия) могут быть объединены и еще раз обработаны модулем 311 выделения признаков изображения. Поскольку результатами № 1 прогнозирования, обозначенными позицией 940, предоставляется больше информации, то в результате второго выделения может быть получено больше признаков изображения, или признаки изображения, полученные в результате второго выделения, могут иметь более высокое качество, чем признаки выделения, полученные в результате первого выделения. Признаки изображения, полученные в результате второго выделения, могут формировать набор векторов МР-признаков, которые можно ввести в модель № 2, сформированную на стадии 2 обучения, показанную на фиг. 8, чтобы сформировать результаты № 2 прогнозирования, обозначенные позицией 950, которые можно объединить с МР-сканированием(ями) 310. Модуль 311 выделения признаков изображения может еще раз выделить набор векторов МР-признаков из объединенных результатов № 2 прогнозирования, обозначенных позицией 950, и МР-сканирования(ий) 310. Данный процесс повторяется до тех пор, пока окончательная модель прогнозирования, модель № M, не применяется для формирования псевдо-КТ-значений 340. В соответствии с некоторыми вариантами осуществления, модели прогнозирования от модели № 1 до модели № M должны применяться в таком же порядке, как порядок применения моделей, сформированных в процессе обучения. Псевдо-КТ-значения 340 можно использовать для формирования псевдо-КТ-изображения 350, отображающего точное визуальное представление анатомической геометрии пациента.
[0103] В некоторых вариантах осуществления любая из моделей прогнозирования, а именно, модель № 1, модель № 2, … модель № M-1, может быть классификационной моделью ткани. Например, классификационной моделью может быть модель № 1. Применение модели № 1 к векторам признаков, выделенных из МР-сканирования(ий) 310, может создать классификационную карту, например, карту классификации тканей. Карту классификации тканей, вместе с МР-сканированием(ями) 310, можно использовать как входные данные для модуля 311 выделения признаков изображения, чтобы формировать вектора признаков, обеспечивающие больше информации или повышенное качество, к которым можно применить модель № 2. Аналогичные этапы можно повторять, чтобы дополнительно уточнить вектора признаков. На основе многоэтапного процесса обучения (фиг. 8) можно обеспечить последовательность классификационных моделей. Например, модель № 1может быть классификационной моделью A, модель № 2 может быть классификационной моделью B и т.п. Классификационные модели A и B могут относиться к одному классу ткани, но с разными степенями точности, или могут относиться к разным классам тканей. Как описано выше, окончательная модель № M прогнозирования является моделью прогнозирования псевдо-КТ, которая дает псевдо-КТ-значения 340 в соответствии с раскрываемыми вариантами осуществления.
[0104] В некоторых вариантах осуществления модель прогнозирования можно строить и обучать с помощью данных для обучения 110 (показанных на фиг. 1), которые включают в себя многоканальные МР-сканирования и соответствующие КТ-значения. Многоканальные МР-сканирования предоставляют больше информации, чем одноканальные МР-сканирования. Больший объем информации, доступный с многоканальными МР-изображениями допускает более точное и более надежное прогнозирование КТ-значений для формирования псевдо-КТ-изображения. Например, многоканальные МР-изображения допускают преобразование из МР-значений интенсивности в значения характеристических параметров тканей.
[0105] МРТ представляет собой многофункциональный метод визуализации, который позволяет изучать различные (например, как структурные, так и функциональные) свойства человеческого тела посредством манипуляции магнитным и радиочастотным (РЧ) полями. Для стандартной структурной (или анатомической) визуализации, измеренный МР-сигнал (например, интенсивность МР-изображения) может зависеть от небольшого числа характеристических параметров ткани: протонной плотности (






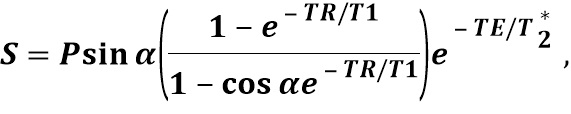
где



[0106] Чтобы прогнозировать КТ-числа по МР-изображениям, модель прогнозирования может основываться, главным образом, на характеристических параметрах (


[0107] Применение многоканальных МР-изображений позволяет оценивать упомянутые характеристические параметры ткани, так как многоканальные МР-изображения могут предоставлять множество изображений, из которых каждое изображение имеет разную настройку параметров (
[0108] В некоторых вариантах осуществления последовательность рабочих операций для реализации раскрытого способа включает в себя две стадии: стадию обучения (например, построения модели) и стадию применения (например, формирования псевдо-КТ). В некоторых вариантах осуществления вычисления стадии обучения требуется выполнять только один раз после того, как собраны данные для обучения. После того, как модель прогнозирования обучена, обученную модель можно применить на стадии применения к новым многоканальным МР-сканированиям, чтобы создать псевдо-КТ-изображение для нового пациента с помощью только многоканальных МР-сканирований. В последующем описании, фиг. 10 и 11 относятся к стадии обучения, а фиг. 12 относится к стадии прогнозирования.
[0109] Фиг. 10 изображает схему примерного процесса для обучения модели прогнозирования псевдо-КТ с использованием параметров ткани, оцененных по многоканальным МР-сканированиям. Подобно процессу, показанному на фиг. 1, можно собрать данные для обучения от множества объектов для обучения, имеющих как КТ-сканирования, так и многоканальные МР-сканирования. Например, как показано на фиг. 10, для объекта a могут быть собраны данные 1010a многоканального МР-изображения и данные 1014a КТ-изображения. Многоканальные МР-данные 1010a могут включать в себя множество МР-изображений, полученных с использованием разных установок параметров последовательности. Аналогично, для объекта b могут быть собраны данные 1010b многоканального МР-изображения и данные 1014b КТ-изображения. Данные многоканального МР-изображения и данные КТ-изображения могут быть собраны из устройства получения изображений (например, 440) или из базы данных (например, 520, 530) изображений. Процесс получения/сбора данных происходит, пока в данные для обучения не включен n-й набор данных (например, 1010n и 1014n). В одном варианте осуществления данные для обучения, показанные на фиг. 10, сходны с данными 110 для обучения, показанными на фиг. 1, за тем исключением, что данные МР-изображения на фиг. 10 являются многоканальными МР-данными, а МР-данные на фиг. 1 могут быть либо одноканальными, либо многоканальными МР-данными.
[0110] В некоторых вариантах осуществления КТ-сканирования (например, 1014a) и многоканальные МР-сканирования (например, 1010a) выставлены. Если не выставлены, то к ним можно применить процедуру автоматического или полуавтоматического совмещения, или выставления изображений, чтобы выставить упомянутые сканирования. Как описано выше, выставленная пара КТ-изображения и МР-изображения означает, что для каждого вокселя (например, указывающего пространственное местоположение в изображении) известны соответствующие значения КТ- и МР-изображений или зависимость соответствия. МР-изображения могут также дополнительно обрабатываться по некоторой процедуре для коррекции геометрических искажений.
[0111] Настоящая заявка раскрывает основанный на обучении метод построения и обучения модели прогнозирования с использованием данных для обучения. В варианте осуществления модель прогнозирования может быть регрессионной моделью, или регрессионная функция на выходе модели прогнозирования может быть непрерывной переменной (например, КТ-значением).
[0112] Чтобы построить и/или обучить модель прогнозирования, которая сможет прогнозировать интенсивности КТ-изображения (известные также как КТ-значения или КТ-числа), исходя из признаков, теоретически полученных из МР-изображений, можно применить много способов статистического или машинного обучения. Например, контролируемое обучение является ответвлением машинного обучения, которое можно использовать для определения модели прогнозирования, исходя из набора данных для обучения. Каждая выборка данных для обучения является парой, включающей в себя входные данные (например, вектор результатов измерений или признаков) и требуемое выходное значение (например, контрольного сигнала). Алгоритм контролируемого обучения может анализировать данные для обучения и вырабатывать функцию прогнозирования (например, регрессионную функцию), когда выходная переменная является численной или непрерывной, что обычно справедливо для прикладной задачи формирования псевдо-КТ-изображений. Для определения модели прогнозирования можно применять различные алгоритмы, включая, но без ограничения: машины опорных векторов, нейронные сети, деревья решений и случайные леса.
[0113] Модель прогнозирования, обученную однажды с использованием данных для обучения, можно использовать, чтобы формировать псевдо-КТ-изображения для любого нового набора многоканальных МР-сканирований того же самого или другого пациента.
[0114] Варианты осуществления по настоящей заявке могут преобразовывать МР-значения интенсивности (например,
[0115] Чтобы построить модель прогнозирования, исходя из параметров ткани, интенсивности МР-изображения требуется преобразовать в значения параметров ткани для каждого пациента. Это можно обеспечить решением уравнения МР-визуализации (например, уравнения 2) в каждой точке изображения (например, вокселе) МР-изображений пациента. Можно составить набор изображений параметров тканей (называемый также картами параметров тканей). Набор может включать в себя одну карту параметров тканей для каждого из параметров тканей. Например, набор может включать в себя карту
[0116] Как видно из фиг. 10, карты параметров тканей для каждого объекта для обучения могут быть сформированы по данным многоканального МР-изображения. Например, карты 1012a параметров тканей объекта могут включать в себя набор всех трех карт параметров тканей. В некоторых вариантах осуществления, если оценка всех трех параметров тканей по многоканальным МР-изображениям является затруднительной, то модель можно также строить с использованием только поднабора параметров тканей. После того, как получены карты параметров тканей каждого объекта для обучения, карты (например, 1012b, …, 1012n) параметров тканей можно использовать вместе с соответствующим КТ-изображением, чтобы построить и обучить модель 1050 прогнозирования псевдо-КТ с использованием обучающего модуля 1045 (например, с использованием методов статистического или машинного обучения). В некоторых вариантах осуществления для каждой точки изображения (например, вокселя), набор параметров тканей можно трактовать как признаки, содержащиеся в векторе признаков, как показано на фиг. 1. Например, если используются все три параметра тканей, то можно построить вектор [
[0117] Фиг. 11 является блок-схемой последовательности операций примерного способа 1100 построения модели прогнозирования псевдо-КТ с использованием многоканальных МР-данных. Способ 1100 может выполняться системой 500. На этапе 1110, процессор 514 может принимать данные для обучения, включающие в себя многоканальные МР-данные (например, 1010a, 1010b и т.п.) и КТ-данные (например, 1014a, 1014b и т.п.). Многоканальные МР-данные могут включать в себя многоканальные МР-изображения для одного или более пациентов. В некоторых вариантах осуществления многоканальные МР-данные могут включать в себя, по меньшей мере, два многоканальных МР-изображения для каждого пациента. Многоканальные МР-изображения одного и того же пациента могут быть получены с использованием разных параметров последовательности визуализации. КТ-данные могут включать в себя КТ-изображения для одного или более пациентов. В некоторых вариантах осуществления КТ-данные могут включать в себя, по меньшей мере, одно КТ-изображение для каждого пациента. Если в наличии имеются несколько КТ-изображений, их можно усреднить для подавления шума в изображении. Для данного пациента, КТ-изображение и многоканальные МР-изображения могут быть выставлены. В некоторых вариантах осуществления, если КТ-изображение и многоканальные МР-изображения не выставлены, то можно применить методы совмещения изображений для их выставления.
[0118] На этапе 1120, процессор 514 может определить, по меньшей мере, одну карту (например, 1012a, 1012b и т.п.) параметров тканей по МР-интенсивностям из многоканальных МР-данных. Например, по меньшей мере, одну карту параметров
[0119] В некоторых вариантах осуществления карта параметров тканей может быть создана оценкой отдельных точек изображения. Например, набор значений параметров тканей, включающих в себя несколько видов параметров (например,
[0120] На этапе 1130, процессор 514 может получить КТ-значения, соответствующие карте(ам) параметров тканей, созданной(ым) на этапе 1120. В некоторых вариантах осуществления КТ-значения могут быть КТ-значениями интенсивности КТ-изображения для того же пациента, что и карта(ы) параметров тканей. Как описано выше, поскольку КТ-изображение выставлено с МР-изображениями, то КТ-изображение также выставлено с картой(ами) параметров тканей, преобразованными из МР-изображений.
[0121] На этапе 1140, процессор 514 может сформировать модель (например, 1050) прогнозирования псевдо-КТ по КТ-значениям и карте(ам) параметров тканей. В некоторых вариантах осуществления КТ-значения и карта(ы) параметров тканей можно вводить в обучающий модуль (например, 1045), чтобы обучать модель 1050 псевдо-КТ. Для обучения модели прогнозирования, обучающим модулем 1045 могут быть применены регрессионные способы, например, методы статистического обучения или машинного обучения. Обученная модель 1050 прогнозирования может быть математической или статистической моделью, которую можно использовать, чтобы прогнозировать КТ-число, исходя из одного или более значений (например,
[0122] Фиг. 12 является блок-схемой последовательности операций примерного способа 1200 формирования псевдо-КТ-изображения для пациента с использованием многоканальных МР-изображений. Способ 1200 может быть реализован системой 500 и использован для формирования псевдо-КТ-изображений для нового пациента с использованием модели (например, 1050) прогнозирования, построенной способом 1100.
[0123] На этапе 1210, процессор 514 может принимать многоканальные МР-изображения пациента (например, нового пациента) из, например, устройства 440 получения изображений или базы данных 520, 530. Принятые многоканальные МР-изображения могут и не иметь соответствующих КТ-изображений. На этапе 1220, процессор 514 может преобразовать многоканальные МР-изображения в, по меньшей мере, одну карту параметров тканей. Например, процессор 514 может преобразовать многоканальные МР-изображения в карту(ы) параметров тканей посредством решения уравнения 2 с использованием метода аппроксимации или подобного метода. Одна или более из карт параметров тканей, например, карты для
[0124] На этапе 1230, процессор 514 может применить модель (например, 1050) прогнозирования к карте(ам) параметров тканей. Например, преобразованная(ые) карта(ы) параметров тканей можно использовать для ввода в модель прогнозирования. В некоторых вариантах осуществления модель прогнозирования может действовать поточечно, при этом модель прогнозирования прогнозирует КТ-число в каждом местоположении изображения пациента (например, псевдо-КТ-изображение), исходя из значения(ий) параметров тканей, вычисленного(ых) в данном местоположении. Можно также использовать более сложную(ые) модель(и) прогнозирования. Например, модель может учитывать соседнее(ие) значение(ия) параметров тканей для каждой точки, что может повысить надежность по отношению к шуму данных. Модель может также выполнять прогнозирование на основании комбинации значения(ий) параметров тканей и другой информации, например, местоположении точки изображения или других признаков, которые можно теоретически вывести из карт(ы) параметров тканей, например, текстуры, градиента и т.п.
[0125] На этапе 1240, псевдо-КТ-изображение для пациента может формироваться компоновкой псевдо-КТ-значений, полученных на этапе 1230.
[0126] Для обучения модели прогнозирования и использования модели с целью прогнозирования псевдо-КТ-значений, можно применить параметрические способы, линейную регрессию или обычную регрессию методом наименьших квадратов. В ходе выполнения данных параметрических способов, функция регрессии задается как конечное число неизвестных параметров модели, которые можно оценивать по входным данным. Например, регрессионная модель может быть задана в форме:

где




[0127] На стадии обучения, данные для обучения могут обеспечивать большое число наблюдений, например, набор известных значений

[0128] В некоторых вариантах осуществления, вместо или кроме использования параметров тканей в качестве входных данных для модели прогнозирования, можно также собрать другую информацию. Например, дополнительные признаки, которые можно вычислить или собрать, включают в себя, но без ограничения:
Координаты точки изображения или нормированные координаты относительно внешнего базового пространства, или одной или нескольких внутренних ориентирных точек;
Значения кривизны карт(ы) параметров тканей, вычисленные в местоположении точки измерения;
Текстурные показатели карт(ы) параметров тканей, вычисленные в местоположении точки измерения; и
Участки локальных значений параметров тканей, например, значения параметров тканей в пределах окрестности 5×5×5 точки измерения.
[0129] Разработчиком программного обеспечения могут быть составлены компьютерные программы, основанные на письменном описании и способах настоящего описания. Различные программы или программные модули могут быть созданы с использованием множества различных методов разработки программного обеспечения. Например, сегменты программы или программные модули можно разрабатывать с помощью языков Java, Python, C, C++, языка ассемблера или любых известных языков программирования. Один или более из таких сегментов или модулей программного обеспечения можно интегрировать в компьютерную систему и/или на компьютерно-читаемые носители.
[0130] Кроме того, хотя выше описаны наглядные варианты осуществления, объем изобретения включает в себя все варианты осуществления, содержащие эквивалентные элементы, модификации, исключения, комбинации (например, аспектов различных вариантов осуществления), адаптации или изменения, основанные на настоящем раскрытии. Элементы в формуле изобретения следует интерпретировать в широком смысле на основе языка, используемого в формуле изобретения, и без ограничения примерами, изложенными в настоящем описании или при рассмотрении заявки, при этом примеры следует толковать как неисключающие. Поэтому предполагается, что описание и примеры следует считать только наглядными, при этом истинный объем и сущность определяются последующей формулой изобретения и всеми ее эквивалентами.
Реферат
Изобретение относится к системам для формирования псевдо-КТ-изображения. Техническим результатом является повышение качества формирования псевдо-КТ-изображения. Система включает в себя процессор, сконфигурированный с возможностью поиска и выборки данных для обучения, включающих в себя по меньшей мере одно МР-изображение и по меньшей мере одно КТ-изображение для каждого из множества объектов для обучения. Для каждого объекта для обучения процессор может выделять множество признаков из каждой точки изображения по меньшей мере одного МР-изображения, создавать вектор признаков для каждой точки изображения по выделенным признакам и выделять КТ-значение из каждой точки изображения по меньшей мере одного КТ-изображения, выполнять обучение метода машинного обучения и формировать обученным методом машинного обучения псевдо-КТ-изображения. 3 н. и 16 з.п. ф-лы, 14 ил.
Комментарии