Измерение остроты зрения человека - RU2730977C1
Код документа: RU2730977C1
Чертежи





Описание
Область техники, к которой относится изобретение
Настоящее изобретение относится в целом к клиническим измерениям остроты зрения. В частности, и без ограничения, настоящее изобретение направлено на способ, систему и устройство для улучшения измерения остроты зрения человека.
Предпосылки создания изобретения
Острота зрения является наиболее важной офтальмологической величиной, которая описывает воспринимаемую разрешающую способность человеческого глаза. Ее измерение основано на распознавании символов (букв, цифр или знаков любого типа). Однако распознавание зависит не только от оптических свойств глаза, но также и от когнитивных и моторных способностей. Из-за данной сложности, показатель остроты зрения зависит от психического состояния, усталости и факторов окружающей среды. В клинической практике стандартные измерения проводятся с использованием таблиц для исследования остроты зрения, или оптометрических таблиц. Задача человека – верно распознать символы, размер которых уменьшается от строки к строке. Согласно методу оценки по принципу «назначения строк», показатель остроты зрения соответствует строке, на которой более чем 50-60% символов распознаются верно (см. 1. Duane T. (2006). Duane's Clinical Ophthalmology, Lippincott Williams & Wilkins, CD-ROM Edition. http: //www.oculist.net/downaton502/prof/ebook/duanes/index.html), и 2. (International Council of Ophthalmology, Visual Functions Committee (1988). Visual Acuity Measurement Standard, ICO 1984, Italian Journal of Ophthalmology, II/I 1988, pp 1/ 15.)
Его показатель в виде десятичной дроби отображается как V и определяется как

где 5α представляет собой угол видимости наименьшего видимого символа, исчисляемый в минутах дуги.
На результаты измерений оказывают сильное влияние многие параметры окружающей среды, такие как стиль/контрастность/цвет букв (символов), количество букв в строке, освещение таблицы и комнаты, расстояния, на котором проводится исследование и т.д. Не существует международного стандарта для установки параметров, однако существуют различные стандартные системы. Например, таблица ETDRS (Лечение диабетической ретинопатии на ранней стадии) применяется во многих клинических исследованиях и считается стандартом США (Duane, 2006; International Council of Ophthalmology (ICO), 1984). Данная таблица имеет особую структуру, согласно которой отображаются 5 букв на каждой строке, причем расстояние между буквами и между строками соответствует размеру букв. Она реализуется с помощью так называемых знаков SLOAN, которые были разработаны специально для измерений остроты зрения, чтобы обеспечить приблизительно одинаковую удобочитаемость знаков. Другие системы примерно одинаковы в большинстве стран, но в некоторых случаях сильно отличаются.
Размер букв на современных оптометрических таблицах уменьшается примерно в 1/1,26 раза от строки к строке (т. е. 0,1 на шкале logMAR), что ограничивает точность изменений для быстрого цикла исследования. В отличие от стандартных клинических исследований, клинические научные исследования требуют более высокой точности и лучшей воспроизводимости. Для этого существует несколько способов оценки, основанных на записи ответов на показ отдельных букв, а не целых строк («однобуквенная» оценка). В соответствии с наиболее распространенной практикой, значение logMAR последней строки, видимой для субъекта, увеличивается на 0,02 за каждую ошибочно названную букву, поскольку в строке, как правило, присутствует 5 букв (0,02 = 0,1/5) (Kaiser, P. K. (2009)). (Prospective Evaluation of Visual Acuity Assessment: a Comparison of Snellen Versus ETDRS Charts in Clinical Practice (an AOS Thesis), Transactions of the American Ophthalmological Society, 107:31 1-324). Хотя это, безусловно, помогает уточнить записанную оценку, полученный результат тяжело поддается интерпретации, поскольку он не соответствует обычному 60%-ному порогу вероятности для оценки назначения строк, представленной выше.
При стандартной однобуквенной оценке исследователь регистрирует то, верно ли человек распознал отображаемые буквы или нет. В этом случае проверяется сам факт распознавания или, если точнее, вероятность распознавания (P), благодаря чему ответы представлены в двоичном виде, нулями и единицами, соответствующими неверным/верным ответам. Однако в действительности ситуация более сложна: при неверном ответе нет уверенности в том, что человек в принципе не видит конкретную букву. Другими словами, перепутывание похожих букв, таких как «P» и «F», подразумевает под собой лучший показатель зрения, в отличие от неверного распознавания совершенно разных букв, таких как «B» и «A».
Документ США 2016089018 также относится к измерению остроты зрения, в котором предусмотрены система и способ измерения остроты зрения. Система содержит компьютер или проектор, приспособленные для проецирования сгенерированного компьютером изображения оптотипа на поверхность, например, дисплейный экран компьютера или экран на стене, при этом она также содержит блок управления. Компьютер или проектор приспособлены для проецирования оптотипов с постоянно меняющимся размером в виде непрерывного набора изображений. Исследование проводится путем изменения размера оптотипа в обоих направлениях, чтобы компенсировать время реакции пациента (человека). Например, начиная с большого оптотипа, размер постепенно понижается до тех пор, пока пациент не укажет, что он больше не может прочитать оптотип. Затем исследование продолжается, начиная с маленького оптотипа и постепенно увеличивая его размер, пока пациент не укажет, что он может прочитать оптотип. Проблема, связанная с данным уровнем техники, заключается в том, что здесь также не учитываются сходства различных символов.
Нами была поставлена задача улучшить измерение остроты зрения при помощи настоящего изобретения.
Краткое описание изобретения
В настоящем изобретении предлагается способ, система и вычислительное устройство, которые решают вышеупомянутые проблемы, а также другие проблемы, которые станут очевидными при понимании следующего описания.
Соответственно, одним из аспектов настоящего изобретения является предоставление способа измерения остроты зрения человека. В указанном способе наборы символов разного размера отображают для человека на дисплейном устройстве. На устройстве ввода получают ответы человека. Ответы указывают вид символов. В вычислительном устройстве: a) регистрируют значения в соответствии с ответами, относящимися к предварительно вычисленным значениям сходства символов, b) вычисляют значение коэффициента распознавания (RR) для каждого размера символа и c) определяют измеренную остроту зрения исходя из значений RR.
В другом аспекте настоящее изобретение направлено на систему, содержащую дисплейное устройство, устройство ввода и вычислительное устройство. Дисплейное устройство выполнено с возможностью отображения человеку наборов символов разного размера. Устройство ввода выполнено с возможностью получения ответов человека, указывающих вид символов, а вычислительное устройство выполнено с возможностью: a) регистрации значений в соответствии с ответами, относящимися к предварительно вычисленным значениям сходства символов, b) вычисления значения коэффициента распознавания (RR) для каждого размера символа и c) определения измеренной остроты зрения исходя из значений RR.
В еще одном аспекте настоящее изобретение относится к вычислительному устройству. Вычислительное устройство содержит процессор и память. Память содержит команды, выполняемые указанным процессором, благодаря чему указанное вычислительное устройство выполнено с возможностью: a) регистрации значений в соответствии с ответами, относящимися к предварительно вычисленным значениям сходства символов, b) вычисления значения коэффициента распознавания (RR) для каждого размера символа, c) определения измеренной остроты зрения исходя из значений RR.
Настоящее изобретение также относится к компьютерной программе, содержащей команды, которые при выполнении по меньшей мере одним процессором вычислительного устройства вынуждают вычислительное устройство выполнять этапы способа, описанные выше.
Настоящее изобретение также относится к носителю, содержащему компьютерную программу, причем носителем является одно из электронного сигнала, оптического сигнала, радиосигнала или машиночитаемого носителя данных.
В одном из предпочтительных вариантов осуществления для количественного определения сходства между символами (например, буквами) вводится количество «корреляций оптотипов» (OC), которое является предварительно вычисленным значением для каждой пары символов. Предварительное вычисление означает, что данные значения вычисляются до ответов человека. OC может быть основано на видоизмененных соответствующим образом корреляционных значениях Пирсона, рассчитанных по символам, и описывает особенности данных символов на математической основе корреляции. Возможные значения OC охватывают интервал между -1 и +1, где большие значения отображают лучший показатель сходства. В частности, +1 отображает идеальное совпадение, 0 – случайный выбор, а -1 означает, что два символа прямо противоположны друг другу. Во время измерения остроты зрения предварительно вычисленные значения OC записываются для каждого символа одинакового размера в соответствии с ответами человека. Показатели зрения человека количественно измеряются посредством значения «коэффициента распознавания» (RR), которое представляет собой среднюю величину значений OC, которые человек продемонстрировал для набора символов одинакового размера.
Наиболее важным преимуществом настоящего изобретения является то, что оно снижает неопределенность измерений остроты зрения.
Краткое описание графических материалов
Для более полного понимания настоящего изобретения делается ссылка на следующее подробное описание совместно с прилагаемыми графическими материалами, на которых:
фиг. 1 представляет собой пример корреляции двух символов;
фиг. 2 представляет собой пример числовых значений корреляции оптотипов для первых пяти букв английского алфавита;
на фиг. 3 показан пример взаимосвязи между коэффициентом распознавания (RR) и обратным углом видимости (ν);
на фиг. 4 представлено комбинированное изображение примера способа, системы и вычислительного устройства для измерения остроты зрения;
фиг. 5 представляет собой пример способа измерения;
фиг 6 представляет собой пример вычислительного устройства.
Подробное описание вариантов осуществления
Количественное определение сходств между символами может быть выполнено на основании вычисления корреляции. Данный показатель называется «корреляцией оптотипов» (OC). Термин «оптотип» обозначает символы, знаки и числа согласно уровню техники. OC не должна зависеть от того, насколько точно человек видит символы; вместо этого она должна сравнивать символы в их первоначальном виде, чтобы избежать появления специфичных для человека артефактов. Кроме того, на значение OC также не может влиять размер символа, т.к. в его определении должна учитываться только форма символа. Для этого предварительное вычисление OC проводится на неискаженных черно-белых изображениях символов с высоким разрешением, например, на изображениях заглавных букв английского алфавита, где сами изображения представлены в виде двумерных матриц. Математическая функция, разработанная специально для сравнения изображений, называется корреляцией Пирсона, которая характеризует сходство двух изображений по одному скалярному числу


В приведенном выше уравнении





В качестве примера см. фиг. 1, где буквы «L» и «I» находятся в позиции максимальной корреляции. Области 11, 12, 13, 14 относятся к букве «I», а области 13, 15 относятся к букве «L». Чтобы распределение корреляционных значений для случайных ответов человека стало согласованным со стандартным обозначением неверных ответов посредством нулей, ожидаемое значение корреляций видоизменяется до нуля в случае неверного распознавания. Именно таким образом получают OC:

где

Численные значения OC первых пяти букв английского алфавита, в случае применения знаков SLOAN, изображены на фиг. 2. Матрица OC для всех 26 букв английского алфавита является симметричной, а это значит, что операция схожести является коммутативной для своих переменных. Для одинаковых букв, расположенных на главной диагонали матрицы, значения равны единице. Более того, для более похожих букв, таких как «B» и «E», корреляция оптотипов становится больше (0,79), чем для менее похожих букв, таких как «A» и «B» (-0,21). Из вышеприведенного уравнения следует, что в случае маленьких букв (когда человек вообще не видит букв) средняя корреляция оптотипов, полученная при данном размере букв, равна вероятности распознавания. Если во время исследования применяются все двадцать шесть букв английского алфавита, значение вероятности распознавания равняется P = 1/26 ≈ 0,04. Результаты составляют хорошее соответствие с данным теоретическим ожиданием: среднее значение всей матрицы OC с единичными значениями составляет 0,04. В то же время, в случае больших букв, когда человек видит каждую деталь знаков, ожидаемое значение как корреляции оптотипов, так и вероятности распознавания составляет 1.
Согласно приведенному выше описанию, среднее значение OC прямо сопоставимо с вероятностью распознавания (P), однако оно предоставляет больше информации о зрении. Исходя из этого предлагается новый показатель для количественного определения остроты зрения при заданном размере символа, который называют коэффициентом распознавания (RR):
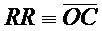
который представляет собой средние значения OC при данном размере символа. Следует отметить, что показатель RR в промежуточной области, в которой человек видит некоторое размытие от символов, всегда несколько выше, чем вероятность распознавания (P). На фиг. 3 представлены результаты RR стандартного измерения для ясного понимания взаимосвязи между RR и обратным углом видимости (ν)

Острота зрения (V) может быть точно определена для данного человека по супергауссовой кривой, соответствующей его/ее зарегистрированным значениям RR: измеренная острота зрения соответствует конкретному размеру символа (νo), при котором RR равно (или падает ниже) данного порога (RR0). Это может быть математически выражено следующим образом:

На фиг. 4 представлена комбинированная схема, демонстрирующая пример способа, системы и вычислительного устройства для измерения остроты зрения. На дисплейном устройстве (41) человеку отображают (S411) наборы символов разного размера. Символами могут быть знаки, буквы или оптотипы разного размера.
Устройство 42 ввода получает S421 ответы человека, указывающие вид символов. Ответами могут быть голосовая или тактильная реакции относительно вида символов, введенных в устройство 42 ввода, поэтому устройство 42 ввода может представлять собой, например, микрофон с модулем 421 распознавания голоса для приема устного ответа от человека, или же модуль 422 распознавания тактильной реакции, такой как клавиатура, которые предназначены для получения ответов человека, указывающих вид символов, и отправки информации, содержащейся в ответе, на вычислительное устройство 43. Разделение дисплейного устройства 41, устройства 42 ввода и вычислительного устройства 43 основано на выполняемой ими функции, а не на физических объектах, в которых они реализованы. Например, дисплейное устройство 41, устройство 42 ввода и вычислительное устройство 43 могут быть реализованы в одном ноутбуке, имеющем клавиатуру, монитор, встроенный в вычислительное устройство ноутбука или подключенный к нему, и процессор с памятью, выполненный с возможностью управления монитором для генерации изображений символов. В другой реализации дисплейное устройство 41 может представлять собой экран на стене, отображающий изображения символов, проецируемых проектором. Проектор также может находиться под управлением ноутбука, однако он также может находиться под управлением другого объекта.
В вычислительном устройстве 43 регистрируют S431 значения в соответствии с ответами, относящимися к предварительно вычисленным значениям сходства символов. На этом этапе значение «1» регистрируется, если ответ человека является верным, т.е. вид символа, отображаемого на дисплейном устройстве 41, соответствует ответу. С другой стороны, когда ответ человека неверный, регистрируется предварительно вычисленное значение. Данное предварительно вычисленное соответствует значению, вычисленному для схожести пары символов, как изображено на фиг. 2. В предпочтительном варианте осуществления сходство может быть предварительно вычислено в качестве корреляции оптотипов (OC). Например, отображаемым символом была буква «C» и человек ответил «C». В данном случае, зарегистрированным значением является «1». Если отображаемым символом была буква «C», но человек ответил «D», то зарегистрированное значение составляет «0,46», т. е. оно представляет собой значение в поле столбца «C» и ряда «D». Следующим этапом является вычисление S432 значения коэффициента распознавания (RR) для каждого размера символа. RR может быть вычислен в качестве среднего из зарегистрированных значений для каждого размера символа.
В следующем этапе измеренную остроту зрения определяют S433 исходя из значений RR. Определение может включать в себя этапы вычисления функции, подходящей для значений RR для каждого размера символа, и определения остроты зрения, относящейся к порогу RR (RR0).
Чтобы продемонстрировать применимость способа измерения остроты зрения согласно настоящему изобретению и предоставить данные для процесса калибровки RR0, была реализована специальная измерительная установка, в которой условия окружающей среды находились под жестким контролем. Символы были представлены человеку один за другим на экране компьютера (LCD-монитор), реализующего функцию дисплейного устройства. Расстояние исследования было выбрано достаточно большим, чтобы обеспечить измерения без аккомодации. Глубина поля зрения человеческого глаза составляет 1/4 диоптрии, а это означает, что расстояние исследования должно быть более 4 метров. Был использован LCD-монитор с плоскостным переключением и шагом пикселей, равным 0,265 миллиметров. Чтобы символы отображались в достаточно высоком разрешении, расстояние исследования было установлено на 9,5 метра. Это относительно большое расстояние обеспечивает более частую выборку по шкале остроты зрения (ΔlogMAR ≈ 0,05), чем та, которая достигается при клинических измерениях, что еще больше снижает погрешность результатов. Для измерения использовался каждый размер символа (всего 14), для которых толщина штриха символов представляла собой целое число, кратное шагу пикселей. Поскольку зрачок человека в мезоскопических условиях шире, чем в фотопических условиях, измерения были проведены в затемненной комнате с освещенностью приблизительно 10 люкс (т.е. средняя яркость равна 3,2 кд/м2). В данных условиях окружающей среды рефракционные аномалии (хроматические отклонения и монохроматические отклонения более высокого порядка) оказывают более существенное влияние на остроту зрения. Яркость монитора составляла 90 кд/м2-с, что соответствует стандарту ICO (минимум 80 кд/м2). Пример данного способа изображен на фиг. 5.
Наиболее важными параметрами ввода S51 программы являются размеры символов, которые должны отображаться, и количество исследуемых символов соответствующего размера. Одним из основных преимуществ основанной на базе ПК системы является то, что можно выполнять индивидуальные измерения, т. е. возможен подбор параметров исследования, подходящих исследуемому в настоящий момент человеку. Кроме того, для исследования людей с широким диапазоном остроты зрения достаточно лишь одного расстояния исследования, что обеспечивает простоту реализации, а также точные и надежные результаты. Во время измерения алгоритм работает с размерами S52 символов и типами S54 символов, а также меняет порядок S53 символов каждого размера. Таким образом, человек не может выучить последовательность символов наизусть. Алгоритм выводит S55 символы на монитор и ожидает ответа. После получения ответа отображенная идентифицированная пара символов сохраняется для дальнейшего анализа. Следующий проверочный символ всегда отображается только после полученного S57 ответа. Символы отображаются на постоянном белом фоне, один за другим, так что скученность символов не влияет на измерение. Способ отображения «по одному за раз» позволяет исследовать все символы, например, все двадцать шесть заглавных букв английского алфавита при каждом размере буквы, вместо пяти символов, напечатанных в строке на таблице для исследования остроты зрения согласно уровню техники. Из-за увеличенного количества исследованных символов данная система предоставляет больше информации в отличие от клинических измерений, что статистически понижает погрешности результатов. Кроме того, тот факт, что, например, все двадцать шесть букв английского алфавита исследуются при каждом размере букв, гарантирует то, что человеку придется выполнять точно такие же задачи при каждом размере букв, что обеспечивает надежную оценку остроты зрения. Для четырнадцати буквенных размеров (охватывающих нормальные и увеличенные диапазоны остроты зрения по оптометрическим таблицам, т. е. от 0,2 до -0,4 значения logMAR) и двадцати шести оптотипов подряд измерение занимает приблизительно полчаса.
Во время измерений, как и в случае с клиническими измерениями, человек смотрел на монитор одним глазом, в то время как другой был прикрыт прозрачным матовым щитком. Другими словами, острота зрения определяется отдельно для двух глаз. Поскольку размер зрачка оказывает существенное влияние на остроту зрения, диаметр зрачка непрерывно контролировался S56 во время измерения остроты зрения посредством цифровой камеры. Ответы были зарегистрированы S58 с корреляцией оптотипов, и коэффициент распознавания был вычислен S59. Остроту зрения определяют S60 на основании RR.
На фиг. 6 проиллюстрирован пример вычислительного устройства 43. Вычислительной устройство 43 получает информацию от устройства 42 ввода для вычисления остроты зрения человека. В данном варианте осуществления вычислительное устройство 43 содержит процессор 431 и запоминающее устройство 432. Указанное запоминающее устройство 432 содержит команды, выполняемые указанным процессором 431, посредством чего указанное вычислительное устройство 43 выполнено с возможностью регистрации S431 значений в соответствии с ответами, относящимися к предварительно вычисленным значениям схожести символов, вычисления S432 значения коэффициента распознавания RR для каждого размера символа и определения S433 измеренной остроты зрения исходя из значений RR. Вычислительное устройство 43 также выполнено с возможностью вычисления S432 RR как средней величины из зарегистрированных значений для каждого размера символа и определения S433 измеренной остроты зрения исходя из значений RR. Определение S433 может включать этапы вычисления функции, подходящей для значений RR каждого размера символа, и определения остроты зрения, относящейся к порогу RR, RR0.
Вычислительное устройство 43 управляется компьютерной программой, содержащей команды, которые при выполнении по меньшей мере одним процессором 431 вынуждают вычислительное устройство 43 выполнять этапы регистрации S431 значений в соответствии с ответами, относящимися к предварительно вычисленным значениям схожести символов, вычисления S432 значения RR для каждого размера символа и определения S433 измеренной остроты зрения исходя из значений RR.
Вычислительное устройство 43 содержит запоминающее устройство 432, содержащее по меньшей мере регистрирующую часть 4321, вычислительную часть 4322 и определительную часть 4323, предназначенные для выполнения этапов регистрации S431 значений в соответствии с ответами, относящимися к предварительно вычисленным значениям схожести символов, вычисления S432 значения RR для каждого размера символа и определения S433 измеренной остроты зрения исходя из значений RR.
Хотя предпочтительные варианты осуществления настоящего изобретения были проиллюстрированы на прилагаемых графических материалах и описаны в вышеприведенном подробном описании, следует понимать, что настоящее изобретение не ограничивается раскрытыми вариантами осуществления, а также выполнено с возможностью проведения многочисленных перестановок, модификаций и замен для измерения остроты зрения без отступления от сущности настоящего изобретения, как это реализовано и определено в нижеследующей формуле изобретения.
Реферат
Группа изобретений относится к медицине. В клинических измерениях остроты зрения предусмотрены способ, система и устройство для измерения остроты зрения человека. В соответствии с реализацией система содержит дисплейное устройство, устройство ввода и вычислительное устройство. Дисплейное устройство выполнено с возможностью отображения человеку наборов символов разного размера. Устройство ввода выполнено с возможностью получения ответов человека, указывающих вид символов, а вычислительное устройство выполнено с возможностью: a) регистрации значений в соответствии с ответами, относящимися к предварительно вычисленным значениям сходства символов, b) вычисления значений коэффициента распознавания (RR) для каждого размера символа и c) определения измеренной остроты зрения исходя из значений коэффициента распознавания. Применение данной группы изобретений позволит улучшить измерение остроты зрения. 4 н. и 10 з.п. ф-лы, 6 ил.
Формула


Комментарии