Способ многосенсорного улучшения речи на мобильном ручном устройстве и мобильное ручное устройство - RU2376722C2
Код документа: RU2376722C2
Чертежи
















Описание
Область техники
Настоящее изобретение относится к снижению шума. В частности, настоящее изобретение относится к удалению шума из сигналов речи, принятых мобильными ручными устройствами.
Предшествующий уровень техники
Мобильные ручные устройства, такие как портативные телефоны и персональные цифровые помощники, которые обеспечивают телефонные функции или принимают входной речевой сигнал, часто используются в среде с неблагоприятными шумовыми условиями, например на многолюдных улицах, ресторанах, аэропортах и автомобилях. Сильный фоновый шум в такой окружающей среде может сделать неразборчивой речь пользователя и затруднить понимание того, что человек говорит.
Хотя были разработаны системы фильтрования шума, которые были попыткой удалить шум на основании модели шума, эти системы не способны удалить весь шум. В частности, многие из этих систем столкнулись с трудностями удаления шума, который возникает в качестве фона, когда говорят другие люди. Одной из причин этого является то, что для этих систем чрезвычайно трудно, если не невозможно, определить, что сигнал речи, принятый микрофоном, поступил от какого-то другого человека, отличного от человека, использующего мобильное устройство.
Для головных телефонов с наушниками, которые находятся на голове пользователя, охватывая голову или ухо пользователя, были разработаны системы, которые обеспечивает более надежное фильтрование шума, полагаясь на дополнительные типы датчиков в головном телефоне. В одном из примеров датчик, использующий костную проводимость, помещен с одной стороны головного телефона и прижат для обеспечения контакта с кожей, охватывая череп, ухо или нижнюю челюсть пользователя вследствие упругости головного телефона. Датчик, использующий костную проводимость, обнаруживает колебания в черепе, ухе или нижней челюсти, которые создаются, когда пользователь говорит. Используя сигнал от датчика, использующего костную проводимость, эта система способна лучше определить, когда говорит пользователь, и в результате лучше способна фильтровать шум в сигнале речи.
Хотя такие системы работают хорошо для головных телефонов, когда контакт между датчиком, использующий костную проводимость, и пользователем поддерживается в соответствии с механической конструкцией головных телефонов, эти системы не могут использоваться непосредственно в ручных мобильных устройствах, потому что для пользователей трудно удерживать датчик, использующий костную проводимость, в надлежащем положении, и эти системы не учитывают, что датчик, использующий костную проводимость, не может удерживаться в надлежащем положении.
Сущность изобретения
Предлагается мобильное устройство, которое включает в себя цифровой вход, которым можно управлять пальцами или большим пальцем пользователя, микрофон с воздушной проводимостью и альтернативный датчик, который обеспечивает сигнал альтернативного датчика, указывающий наличие речи. В некоторых вариантах осуществления мобильное устройство также включает в себя датчик приближения, который обеспечивает сигнал приближения, указывающий на расстояние от мобильного устройства до объекта. В некоторых вариантах осуществления используются сигнал от микрофона с воздушной проводимостью, сигнал альтернативного датчика и сигнал приближения для формирования оценки значения чистой речи. В других вариантах осуществления звук формируется через громкоговоритель в мобильном устройстве на основании величины шума в этом значении чистой речи. В других вариантах осуществления звук, сформированный через громкоговоритель, основан на сигнале датчика приближения.
Краткое описание чертежей
Фиг.1 иллюстрирует вид в перспективе одного варианта осуществления настоящего изобретения.
Фиг.2 иллюстрирует телефон на фиг.1 в положении с левой стороны головы пользователя.
Фиг.3 иллюстрирует телефон на фиг.1 в положении на правой стороне головы пользователя.
Фиг.4 иллюстрирует блок-схему микрофона, использующего костную проводимость.
Фиг.5 иллюстрирует вид в перспективе для альтернативного варианта осуществления настоящего изобретения.
Фиг.6 иллюстрирует поперечное сечение альтернативного микрофона, использующего костную проводимость, согласно варианту осуществления настоящего изобретения.
Фиг.7 иллюстрирует блок-схему мобильного устройства согласно варианту осуществления настоящего изобретения.
Фиг.8 является блок-схемой обычной системы обработки речи согласно настоящему изобретению.
Фиг.9 изображает блок-схему системы для обучения параметров снижения шума согласно варианту осуществления настоящего изобретения.
Фиг.10 изображает последовательность операций для обучения параметров снижения шума, используя систему согласно фиг.9.
Фиг.11 иллюстрирует блок-схему системы для идентификации оценки чистого сигнала речи из зашумленного тестового сигнала речи согласно варианту осуществления настоящего изобретения.
Фиг.12 иллюстрирует последовательность операций способа для идентификации оценки чистого сигнала речи с использованием системы согласно фиг.11.
Фиг.13 иллюстрирует блок-схему альтернативной системы для идентификации оценки чистого сигнала речи.
Фиг.14 иллюстрирует блок-схему второй альтернативной системы для идентификации оценки чистого сигнала речи.
Фиг.15 иллюстрирует последовательность операций способа для идентификации оценки чистого сигнала речи с использованием системы согласно фиг.14.
Фиг.16 иллюстрирует перспективный вид дополнительного варианта осуществления мобильного устройства согласно настоящему изобретению.
Подробное описание примерных вариантов осуществления
Варианты осуществления настоящего изобретения предлагают ручные мобильные устройства, которые содержат и микрофон с воздушной проводимостью и альтернативный датчик, которые могут использоваться в детектировании речи и фильтровании шума. Фиг.1 иллюстрирует примерный вариант осуществления, в котором ручное мобильное устройство является мобильным телефоном 100. Мобильный телефон 100 включает в себя клавиатуру 102, дисплей 104, средство 106 управления курсором, микрофон 108 с воздушной проводимостью, громкоговоритель 110, два микрофона 112 и 114, использующих костную проводимость и необязательно - датчик 116 приближения.
Сенсорная панель 102 позволяет пользователю вводить числа и буквы в мобильный телефон. В других вариантах осуществления сенсорная панель 102 объединена с дисплеем 104 в форме сенсорного экрана. Средство 106 управления курсором позволяет пользователю подсвечивать и выбирать информацию 104 на дисплее и просматривать изображения и страницы, которые являются по размеру большими, чем дисплей 104.
Как показано на фиг.2 и 3, когда мобильный телефон 100 помещен в стандартное положение для преобразования посредством телефона, громкоговоритель 110 размещается около левого уха пользователя 200 или правого уха 300, и микрофон 108 с воздушной проводимостью размещается около рта 202 пользователя. Когда телефон размещается около левого уха пользователя, как на фиг.2, микрофон 114, использующий костную проводимость, контактирует с черепом или ухом пользователя и формирует сигнал альтернативного датчика, который может использоваться для удаления шума из сигнала речи, принятого микрофоном 108 с воздушной проводимостью. Когда телефон размещен около правого уха пользователя, как на фиг.3, микрофон 112, использующий костную проводимость, контактирует с черепом или ухом пользователя и формирует сигнал альтернативного датчика, который может использоваться для удаления шума из сигнала речи.
Необязательный датчик 116 приближения указывает как близко к пользователю находится телефон. Как дополнительно описано ниже, эта информация используется для взвешивания вклада микрофонов, использующих костную проводимость, в формирование значения чистой речи. Обычно, если датчик приближения обнаруживает, что телефон находится рядом с пользователем, сигналам микрофона, использующего костную проводимость, придается больший вес, чем если телефон находится на некотором расстоянии от пользователя. Это регулирование отражает тот факт, что сигнал микрофона, использующего костную проводимость, является более показательным для разговора пользователя, когда он находится в контакте с пользователем. Когда он удален от пользователя, он более восприимчив к фоновому шуму. Датчик приближения используется в вариантах осуществления настоящего изобретения, так как пользователи не всегда держат телефон прижатым к голове.
Фиг.4 иллюстрирует один вариант осуществления датчика 400, использующего костную проводимость, согласно настоящему изобретению. В датчике 400 мягкий эластомерный мостик (дужка) 402 приклеен к диафрагме 404 обычного микрофона 406 с воздушной проводимостью. Этот мягкий мостик 402 проводит колебания от контакта 408 с кожей пользователя непосредственно к диафрагме 404 микрофона 406. Движение диафрагмы 404 преобразуется в электрический сигнал преобразователем 410 в микрофоне 406.
Фиг.5 иллюстрирует альтернативный вариант осуществления портативного телефона 500 ручного мобильного устройства согласно настоящему изобретению. Мобильный телефон 500 включает в себя клавиатуру 502, дисплей 504, средство 506 управления курсором, микрофон 508 с воздушной проводимостью, громкоговоритель 510 и комбинацию микрофона, использующего костную проводимость, и датчика 512 приближения.
Как показано в поперечном сечении на фиг.6, комбинация микрофона, использующего костную проводимость, и датчика 512 приближения состоит из мягкой, заполненной средой (жидкостью или эластомером) подкладки 600, которая имеет внешнюю поверхность 602, предназначенную для контакта с пользователем, когда пользователь размещает телефон напротив своего уха. Подкладка 600 образует кольцо вокруг отверстия, которое обеспечивает проход для звука от громкоговорителя 510, который расположен в отверстии или непосредственно ниже отверстия в телефоне 500. Подкладка 600 не ограничена этой формой, и может использоваться любая форма для подкладки. Обычно, однако, предпочтительно, если подкладка 600 включает в себя части слева и справа от громкоговорителя 510 так, чтобы по меньшей мере одна часть подкладки 600 находилась в контакте с пользователем, независимо от того напротив какого уха пользователь размещает телефон. Части подкладки могут быть внешне непрерывными или могут быть внешне отдельными, но в телефоне связаны друг с другом жидкой средой.
Электронный преобразователь 604 давления гидравлически связан с жидкостью или эластомером в подкладке 600 и преобразовывает давление жидкости в подкладке 600 в электрический сигнал в проводнике 606. Примеры электронного преобразователя 604 давления включают в себя преобразователи на основе MEMS (микроэлектромеханических преобразователей). Обычно преобразователь 604 давления должен иметь высокочастотный отклик.
Электрический сигнал в проводнике 606 включает в себя два компонента, постоянную составляющую (DC) и переменную составляющую (AC). Постоянная составляющая обеспечивает сигнал датчика приближения, так как статическое давление в пределах подкладки 600 будет выше, когда телефон прижат к уху пользователя, чем то, когда телефон находится на некотором расстоянии от уха пользователя. Переменная составляющая электрического сигнала обеспечивает сигнал микрофона, использующего костную проводимость, так как колебания в костях черепа, челюсти или уха пользователя создают флуктуации давления в подкладке 600, которые преобразуются в переменный электрический сигнал преобразователем 604 давления. Согласно варианту осуществления для электрического сигнала используется фильтр, чтобы обеспечить прохождение постоянной составляющей сигнала и переменной составляющей выше минимальной частоты.
Хотя выше описаны два примера датчиков, использующих костную проводимость, другие формы датчиков, использующих костную проводимость, также входят в объем настоящего изобретения.
Фиг.7 иллюстрирует блок-схему мобильного устройства 700 согласно варианту осуществления настоящего изобретения. Мобильное устройство 700 включает в себя микропроцессор 702, память 704, интерфейс 706 ввода/вывода и интерфейс 708 связи для обмена информацией с удаленными компьютерами, сетями связи или другими мобильными устройствами. В одном варианте осуществления вышеупомянутые компоненты соединяются для связи друг с другом по соответствующей шине 710.
Память 704 может быть осуществлена в виде энергонезависимой электронной памяти, например памяти с произвольным доступом (ОЗУ) с модулем дублирования батареи (не показан), так что информация, сохраненная в памяти 704 не теряется, когда обычное питание не подается на мобильное устройство 700. Альтернативно, вся или части памяти 704 могут быть энергозависимой или энергонезависимой сменной памятью. Часть памяти 704 предпочтительно выполнена как адресуемая память для выполнения программы, в то время как другая часть памяти 704 предпочтительно используется для хранения, например, эмуляции хранения на накопителе на магнитных дисках.
Память 704 содержит операционную систему 712, прикладные программы 714, а также хранилище 716 объектов. Во время работы операционная система 712 предпочтительно выполняется процессором 702 из памяти 704. Операционная система 712 в одном предпочтительном варианте осуществления является операционной системой WINDOWS® CE, коммерчески доступной от корпорации Microsoft. Операционная система 712 предпочтительно предназначена для мобильных устройств и реализует характеристики базы данных, которые могут использоваться приложениями 714 с помощью набора открытых (доступных) интерфейсов прикладных программ и методов. Объекты в хранилище 716 объектов поддерживаются приложениями 714 и операционной системой 712, по меньшей мере частично в ответ на запросы к доступным интерфейсам прикладных программ и методам.
Интерфейс 708 связи представляет многочисленные устройства и технологии, которые позволяют мобильному устройству 700 посылать и принимать информацию. В вариантах осуществления портативного телефона интерфейс 708 связи представляет собой интерфейс сети сотового телефона, который взаимодействует с сетью сотовых телефонов, чтобы позволить выполнять и принимать вызовы. Другие устройства, возможно представленные интерфейсом 708 связи, включают в себя проводные и беспроводные модемы, приемники спутниковой связи и тюнеры радиовещания разнообразного вида. Мобильное устройство 700 может также быть непосредственно связано с компьютером для обмена с ним информацией. В таких случаях интерфейс 708 связи может быть инфракрасным приемопередатчиком или соединением с последовательной или параллельной передачей данных, все из которых способны к потоковой передаче информации.
Выполняемые компьютером инструкции, которые выполняются процессором 702, чтобы осуществить настоящее изобретение, могут быть сохранены в памяти 704 или приняты через интерфейс 708 связи. Эти инструкции хранятся в компьютере на считываемом носителе, который, без ограничения может включать в себя среду хранения компьютера и среду передачи данных.
Среда хранения компьютера включают в себя и энергозависимые и энергонезависимые, сменные и несменные носители, осуществленные любым способом или технологией для хранения информации, такой как считываемые компьютером инструкции, структуры данных, программные модули или другие данные. Компьютерная среда хранения включает в себя, но не ограничивается ими, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или память по другой технологии, CD-ROM, цифровые универсальные диски (DVD) или другую оптическую память на дисках, магнитные кассеты, магнитную ленту, память на магнитном диске или другие магнитные устройства хранения, или любую другую среду, которая может использоваться для хранения требуемой информации и к которой можно обращаться.
Среда передачи данных обычно заключает в себе считываемые компьютером команды, структуры данных, программные модули или другие данные в модулируемом сигнале данных, таком как сигнал несущей или другой транспортный механизм, и включают в себя любые информационные средства доставки информации. Термин "модулированный сигнал данных" означает сигнал, который имеет одну или более из его характеристик установленной или измененной таким образом, чтобы кодировать информацию в сигнале. Посредством примера, а не ограничения, среда передачи данных включает в себя проводную среду, например проводную сеть, или непосредственное проводное соединение, и беспроводную среду, например среду передачи акустических, РЧ, инфракрасных лучей и других беспроводных средств передачи информации. Комбинации любых вышеупомянутых средств также должны быть включены в понятие считываемых компьютером носителей.
Интерфейс 706 ввода/вывода данных предоставляет интерфейсы к набору устройств ввода/вывода, включая громкоговоритель 730, цифровой вход 732 (такой как одна или набор кнопок, сенсорный экран, трекбол, мышь, ролик или комбинацию этих компонентов, которые могут управляться большим пальцем пользователя или другим пальцем), дисплей 734, микрофон 736 с воздушной проводимостью, альтернативный датчик 738, альтернативный датчик 740 и датчик 742 приближения. Согласно варианту осуществления альтернативными датчиками 738 и 740 являются микрофоны, использующие костную проводимость. Устройства, перечисленные выше, приведены посредством примера и не обязательно должны все присутствовать на мобильном устройстве 700. Далее, по меньшей мере в одном варианте осуществления альтернативный датчик и датчик приближения объединены в единый датчик, который обеспечивает сигнал датчика приближения и сигнал альтернативного датчика. Эти сигналы могут быть выданы на отдельные проводящие линии или могут быть компонентами сигнала на однопроводной линии. Кроме того, другие устройства ввода/вывода могут быть использованы или применены вместе с мобильным устройством 700 в настоящем изобретении.
Фиг.8 обеспечивает основную блок-схему системы обработки речевых сигналов согласно вариантам осуществления настоящего изобретения. На фиг.8 диктор 800 формирует сигнал 802 речи, который обнаруживается микрофоном 804 с воздушной проводимостью и одним или обоими из альтернативного датчика 806 и альтернативного датчика 807. Одним из примеров альтернативного датчика является датчик, использующий костную проводимость, который расположен непосредственно на или рядом с лицевой или черепной костью пользователя (например, челюстной кости) или на ухе пользователя, и который воспринимает колебания уха, черепа или челюсти, которые соответствуют речи, сформированной пользователем. Другим примером альтернативного датчика является инфракрасный датчик, который направлен на и обнаруживает движение рта пользователя. Следует заметить, что в некоторых вариантах осуществления будет присутствовать только один альтернативный датчик. Микрофон 804 с воздушной проводимостью является типом микрофона, который обычно используется, чтобы преобразовать звуковые радиоволны в электрические сигналы.
Микрофон 804 с воздушной проводимостью также принимает шум 808, сформированный одним или более шумовых источников 810. В зависимости от типа альтернативного датчика и уровня шума шум 808 может также быть обнаружен альтернативными датчиками 806 и 807. Однако согласно вариантам осуществления настоящего изобретения альтернативные датчики 806 и 807 обычно менее чувствительны к фоновому шуму, чем микрофон 804 с воздушной проводимостью. Таким образом, сигналы альтернативных датчиков 812 и 813, сформированные альтернативными датчиками 806 и 807, соответственно, обычно включают в себя меньшее количество шума, чем сигнал 814 микрофона с воздушной проводимостью, сформированный микрофоном 804 с воздушной проводимостью.
Если имеются два альтернативных датчика, например два датчика, использующих костную проводимость, сигналы датчиков 812 и 813 можно произвольно выдавать на блок 815 сравнения/выбора. Блок 815 сравнения/выбора сравнивает уровень двух сигналов и выбирает более сильный сигнал в качестве своего выходного сигнала 817. Более слабый сигнал не передается для дальнейшей обработки. Для вариантов осуществления портативного телефона, такого как портативный телефон на фиг.1-3, блок 815 сравнения/выбора будет обычно выбирать сигнал, сформированный датчиком, использующим костную проводимость, который находится в контакте с кожей пользователя. Таким образом, на фиг.2 может быть выбран сигнал от датчика 114, использующего костную проводимость, и на фиг.3 будет выбран сигнал от датчика 112, использующего костную проводимость.
Сигнал 817 альтернативного датчика и сигнал 814 микрофона с воздушной проводимостью выдается к блоку 816 оценки чистого сигнала, который оценивает чистый сигнал 818 речи посредством процесса, описанного ниже более подробно. Необязательно, блок 816 оценки чистого сигнала также принимает сигнал 830 приближения от датчика 832 приближения, который используется в оценке чистого сигнала 818. Как отмечено выше, датчик приближения может быть объединен с альтернативным сигналом датчика в некоторых вариантах осуществления. Чистый сигнал 818 оценки выдается к блоку 820 обработки речи. Чистый сигнал 818 речи может быть или фильтрованным сигналом во временной области или характеристическим вектором области. Если чистый сигнал 818 оценки является сигналом во временной области, блок 820 обработки речи может быть приемником, передатчиком сотового телефона, системой кодирования речи или системой распознавания речи. Если чистый сигнал 818 речи является характеристическим вектором области, блок 820 обработки речи будет обычно системой распознавания речи.
Блок 816 оценки чистого сигнала также формирует оценку 819 шума, которая показывает оцененный шум, который присутствует в чистом сигнале 818 речи. Оценка 819 шума выдается на генератор 821 побочного тона, который формирует тональный сигнал через громкоговорители мобильного устройства на основании оценки 819 шума. В частности, генератор 821 побочного тона увеличивает уровень громкости побочного тона, когда оценка 819 шума увеличивается.
Сигнал побочного тона обеспечивает обратную связь пользователю, которая указывает, держит ли пользователь мобильное устройство в наилучшем положении, чтобы воспользоваться преимуществом альтернативного датчика. Например, если пользователь не прижимает датчик, использующий костную проводимость, к своей голове, блок оценки чистого сигнала принимает слабый сигнал альтернативного датчика и формирует зашумленный чистый сигнал 818 из-за слабого сигнала альтернативного датчика. Это приводит к более громкому побочному тону. Когда пользователь приводит датчик, использующий костную проводимость, в контакт со своей головой, сигнал альтернативного датчика улучшается, таким образом уменьшая шум в чистом сигнале 818 и уменьшая громкость сигнала побочного тона. Таким образом, пользователь может быстро понять, как держать телефон, чтобы сильнее уменьшить шум в чистом сигнале, на основании обратной связи в сигнале побочного тона.
В альтернативных вариантах осуществления сигнал побочного тона формируется на основании сигнала 830 датчика приближения от датчика 832 приближения. Когда датчик приближения указывает, что телефон контактирует или находится слишком близко к голове пользователя, громкость побочного тона будет низка. Когда датчик приближения указывает, что телефон находится далеко от головы пользователя, сигнал побочного тона будет громче.
Настоящее изобретение использует несколько способов и систем для оценки чистой речи, используя сигнал 814 микрофона с воздушной проводимостью, сигнал 817 альтернативного датчика, и необязательно сигнал 830 датчика приближения. Одна система использует стереоданные обучения, чтобы обучить векторы коррекции для сигнала альтернативного датчика. Когда эти векторы коррекции позднее добавляют к тестовому вектору альтернативного датчика, они обеспечивают оценку вектора чистого сигнала. Один из дополнительных вариантов развития этой системы заключается сначала в отслеживании изменяющихся во времени искажений и затем включении этой информации в вычисление векторов коррекции и в оценку чистой речи.
Вторая система обеспечивает интерполяцию между оценкой чистого сигнала, сформированной векторами коррекции, и оценкой, сформированной вычитанием оценки текущего шума в тестовом сигнале воздушной проводимости из сигнала воздушной проводимости. Третья система использует сигнал альтернативного датчика, чтобы оценить основной тон сигнала речи, и затем использует оцененный основной тон, чтобы идентифицировать оценку для чистого сигнала речи. Каждая из этих систем описана отдельно ниже.
Обучение векторов стереокоррекции
Фиг.9 и 10 иллюстрируют блок-схему и последовательность операций для обучения векторов стереокоррекции для двух вариантов осуществления настоящего изобретения, которые полагаются на векторы коррекции для того, чтобы сформировать оценку чистой речи.
Способ идентификации векторов коррекции начинается на этапе 1000 на фиг.10, где "чистый" сигнал микрофона с воздушной проводимостью преобразуют в последовательность характеристических векторов. Для этого диктор 900 на фиг.9 говорит в микрофон 910 с воздушной проводимостью, который преобразует звуковые волны в электрические сигналы. Электрические сигналы затем дискретизируются аналого-цифровым преобразователем 914 для формирования последовательности цифровых значений, которые группируют во фреймы значений конструктором 916 фреймов. В одном варианте осуществления аналого-цифровой преобразователь 914 дискретизирует аналоговый сигнал с частотой 16 кГц и 16 битов на отсчет, таким образом создавая 32 килобайта данных речи в секунду, и конструктор 916 фреймов создает новый фрейм каждые 10 миллисекунд, который включает в себя 25-миллисекундную цену данных.
Каждый фрейм данных, выдаваемый конструктором 916 фреймов, преобразуется в характеристический вектор блоком 918 извлечения характеристик. Согласно варианту осуществления блок 918 извлечения характеристик формирует кепстральные характеристики. Примеры таких характеристик включают в себя полученные кодированием методом линейного предсказания (LPC) кепстры, и коэффициенты кепстра (коэффициенты косинусного преобразования Фурье) Mel-частоты (частоты чистого тона). Примеры других возможных модулей извлечения характеристик, которые могут использоваться в настоящем изобретении, включают в себя модули для выполнения кодирования методом линейного предсказания (LPC), перцептивное линейное предсказание (PLP) и извлечение характеристик на основе модели слышимости. Следует заметить, что изобретение не ограничено этими модулями извлечения характеристик, и в контексте настоящего изобретения могут использоваться другие модули.
На этапе 1002 на фиг.10 сигнал альтернативного датчика преобразуют в характеристические векторы. Хотя преобразование на этапе 1002 показано как выполняющееся после преобразования на этапе 1000, любая часть преобразования может быть выполнена прежде, в течение или после этапа 1000 согласно настоящему изобретению. Преобразование на этапе 1002 выполняют с помощью процесса, подобному описанному выше для этапа 1000.
В варианте осуществления на фиг.9 этот процесс начинается, когда альтернативные датчики 902 и 903 обнаруживают физическое событие, связанное с формированием речи диктором 900, например вибрацию кости или движение лица. Поскольку альтернативный датчик 902 и 903 отделены на мобильном устройстве, они не будут обнаруживать одни и те же значения в связи с формированием речи. Альтернативные датчики 902 и 903 преобразуют физическое событие в аналоговые электрические сигналы. Эти электрические сигналы подаются к блоку 904 сравнения/выбора, который выделяет более сильный из двух сигналов и выдает более сильный сигнал в качестве своего выходного сигнала. Следует заметить, что в некоторых вариантах осуществления используется только один альтернативный датчик. В таких случаях блок 904 сравнения/выбора отсутствует.
Выбранный аналоговый сигнал дискретизируется аналого-цифровым преобразователем 905. Характеристики дискретизации для аналого-цифрового преобразователя 905 являются теми же, что описаны выше для аналого-цифрового преобразователя 914. Отсчеты, выданные аналого-цифровым преобразователем 905, собираются в фреймы конструктором 906 фреймов, который действует способом, подобным конструктору 916 фреймов. Фреймы отсчетов затем преобразуют в характеристические векторы блоком 908 извлечения характеристик, который использует тот же способ извлечения характеристик, что и блок 918 извлечения характеристик.
Характеристические векторы для сигнала альтернативного датчика и сигнала воздушной проводимости подают к блоку 920 обучения снижения шума на фиг.9. На этапе 1004 на фиг.10 блок 920 обучения снижения шума группирует характеристические векторы для сигнала альтернативного датчика в смешанные компоненты. Эта группировка может быть сделана посредством группировки подобных характеристических векторов вместе, используя способы обучения по максимальной вероятности, или группируя характеристические векторы, которые вместе представляют временную секцию сигнала речи. Специалисту в области техники понятно, что могут использоваться другие способы для группировки характеристических векторов, и что два способа, перечисленных выше, представлены только в качестве примеров.
Блок 920 обучения снижения шума затем определяет вектор коррекции, rs, для каждого компонента смеси, s, на этапе 1008 на фиг.10. Согласно варианту осуществления вектор коррекции для каждого компонента смеси определяют, используя критерий максимальной вероятности. Согласно этому способу вектор коррекции рассчитывают следующим образом:

где xt является значением вектора воздушной проводимости для фрейма t, и bt является значением вектора альтернативного датчика для фрейма t. В уравнении 1:

где p(s) - просто один из ряда компонентов смеси, и p(bt|s) моделируется как распределение Гаусса:

со средним μb и дисперсией Гb, полученной с использованием алгоритма максимизации ожидания (EM), где каждая итерация состоит из следующих шагов:



Уравнение (4) является E-шагом в EM-алгоритме, который использует предварительно оцененные параметры. Уравнение (5) и уравнение (6) являются М-этапом, который обновляет параметры, используя результаты E-этапа.
E- и М-этапы алгоритма повторяют до тех пор пока не будут определены устойчивые значения для параметров модели. Эти параметры затем используются, чтобы оценить уравнение 1 для формирования векторов коррекции. Векторы коррекции и параметры модели затем сохраняют в памяти 922 параметров снижения шума.
После того как вектор коррекции определен для каждого компонента смеси, на этапе 1008 процесс обучения системы снижения шума согласно настоящему изобретению завершается. Как только вектор коррекции определен для каждой смеси, векторы могут использоваться в способе снижения шума согласно настоящему изобретению. Два отдельных способа снижения шума, которые используют векторы коррекции, описаны ниже.
Снижение шума, используя вектор коррекции и оценку шума
Система и способ, который уменьшает шум в зашумленном сигнале речи, на основании векторов коррекции и оценке шума, иллюстрируются на блок-схеме на фиг.11 и блок-схеме последовательности операций на фиг.12, соответственно.
На этапе 1200 звуковой тестовый сигнал, обнаруженный микрофоном 1104 с воздушной проводимостью, преобразуют в характеристические векторы. Звуковой тестовый сигнал, принятый микрофоном 1104, включает в себя речь от диктора 1100 и аддитивный шум от одного или более шумовых источников 1102. Звуковой тестовый сигнал, обнаруженный микрофоном 1104, преобразуют в электрический сигнал, который подается к аналогово-цифровому преобразователю 1106.
Аналого-цифровой преобразователь 1106 преобразует аналоговый сигнал от микрофона 1104 в последовательность цифровых значений. В нескольких вариантах осуществления аналого-цифровой преобразователь 1106 дискретизирует аналоговый сигнал с частотой 16 кГц и 16 битов на отсчет, таким образом формируя 32 килобайта данных речи в секунду. Эти цифровые значения подаются на конструктор 1108 фреймов, который в одном варианте осуществления группирует значения в 25 миллисекундные фреймы, которые начинаются через 10 миллисекунд друг от друга.
Фреймы данных, созданные конструктором 1108 фреймов, подаются на блок 1110 извлечения характеристик, который извлекает характеристику из каждого фрейма. Согласно варианту осуществления этот блок извлечения характеристик отличается от блоков 908 и 918 извлечения характеристик, которые использовались, чтобы обучить векторы коррекции. В частности, в данном варианте осуществления блок 1110 извлечения характеристик формирует значения энергетического спектра вместо кепстральных значений. Извлеченные характеристики подаются на блок 1122 оценки чистого сигнала, блок 1126 обнаружения речи и блок 1124 обучения модели шума.
На этапе 1202 физическое событие, например вибрация кости или движение лица, связанные с формированием речи диктором 1100, преобразуют в характеристический вектор. Хотя показан как отдельный этап на фиг.12, специалисту понятно, что части этого этапа могут быть выполнены в одно и то же время, что и этап 1200. В течение этапа 1202 физическое событие обнаруживается одним или обоими альтернативными датчиками 1112 и 1114. Альтернативные датчики 1112 и 1114 формируют аналоговые электрические сигналы на основании физического события. Аналоговые сигналы подаются на блок 1115 сравнения и выбора, который выбирает сигнал большей амплитуды в качестве своего выходного сигнала. Следует заметить, что в некоторых вариантах осуществления обеспечивается только один альтернативный датчик. В таких вариантах осуществления в блоке 1115 сравнения и выбора нет необходимости.
Выбранный аналоговый сигнал преобразуют в цифровой сигнал аналого-цифровым преобразователем 1116, и получившиеся цифровые отсчеты группируют в фреймы конструктором 1118 фреймов. Согласно варианту осуществления аналого-цифровой преобразователь 1116 и конструктор 1118 фреймов работает аналогично аналого-цифровому преобразователю 1106 и конструктору 1108 фреймов.
Фреймы цифровых значений подаются к блоку 1120 извлечения характеристик, который использует тот же самый способ извлечения характеристик, который использовался для обучения векторов коррекции. Как упомянуто выше, примеры таких модулей извлечения характеристики включают в себя модули для выполнения кодирования с линейным прогнозированием (LPC), кепстры, полученные на основе LPC, перцептивное линейное предсказание (PLP), извлечение характеристики на основе модели слышимости, и извлечение характеристик на основе кепстральных коэффициентов Mel-частоты (MFCC). Во многих вариантах осуществления, однако, используются способы извлечения характеристики, которые формируют кепстральные характеристики.
Модуль извлечения характеристики формирует поток характеристических векторов, каждый из которых связан с отдельным фреймом сигнала речи. Этот поток характеристических векторов подается на блок 1122 оценки чистого сигнала.
Фреймы значений из конструктора 1118 фреймов также подаются на блок 1121 извлечения характеристик, который в одном варианте осуществления извлекает энергию каждого фрейма. Значение энергии для каждого фрейма подается на блок 1126 обнаружения речи.
На этапе 1204 блок 1126 обнаружения речи использует характеристику энергии сигнала альтернативного датчика, чтобы определить, когда вероятно присутствует речь. Эту информацию пропускают к блоку 1124 обучения модели шума, который пытается моделировать шум в течение периодов, когда не имеется никакой речи на этапе 1206.
Согласно варианту осуществления блок 1126 обнаружения речи сначала отыскивает последовательность значений энергии фреймов, чтобы найти пик энергии. Затем он отыскивает точку минимума после пика. Энергия этой точки минимума называется разделителем энергии, d. Чтобы определить, содержит ли фрейм речь, это отношение, k, энергии фреймов, e, по разделителю энергии, d, затем определяют следующим образом: k=e/d. Доверительное значение речи, q, для фрейма затем определяется как:

где α определяет переход между двумя состояниями и в одном варианте осуществления установлена равным 2. Наконец, среднее доверительное значение из его 5 соседних фреймов (включая его самого) используется в качестве окончательного доверительного значения для этого фрейма.
Согласно варианту осуществления используется установленное пороговое значение, чтобы определить, присутствует ли речь, так что если доверительное значение превышает порог, фрейм рассматривается как содержащий речь, а если доверительное значение не превышает порог, фрейм рассматривается как не содержащий речь. Согласно варианту осуществления используется пороговое значение 0,1.
Для каждого не-речевого фрейма, обнаруженного блоком 1126 обнаружения речи, блок 1124 обучения модели шума обновляет модель 1125 шума на этапе 1206. Согласно варианту осуществления моделью 1125 шума является Гауссова модель, которая имеет среднее значение μn и дисперсию
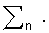
Векторы коррекции и параметры модели в памяти 922 параметров и модель 1125 шума подаются на блок 1122 оценки чистого сигнала с характеристическими векторами, b, для альтернативного датчика и характеристических векторов, Sy, для сигнала шума микрофона с воздушной проводимостью. На этапе 1208 блок 1122 оценки чистого сигнала оценивает начальное значение для чистого сигнала речи на основании характеристического вектора альтернативного датчика, векторов коррекции и параметров модели для альтернативного датчика. В частности, оценка альтернативного датчика чистого сигнала вычисляется следующим образом:

где

На этапе 1210 начальная оценка чистой речи альтернативного датчика очищается посредством объединения ее с оценкой чистой речи, которая сформирована из вектора шума микрофона с воздушной проводимостью и модели шума. Это приводит к очищенной оценке 1128 чистой речи. Чтобы объединить кепстральное значение начальной оценки чистого сигнала с характеристическим вектором энергетического спектра шума микрофона с воздушной проводимостью, кепстральное значение преобразуют к области энергетического спектра, используя:

где C-1 является обратным дискретным косинусным преобразованием, и

Как только начальная оценка чистого сигнала от альтернативного датчика переведена в область энергетического спектра, она может быть объединена с вектором шума микрофона с воздушной проводимостью и моделью шума следующим образом:

где









В упрощенном варианте осуществления уравнение 10 может быть переписано в следующем виде:

где α(f) - функция и времени и диапазона частот. Например, если альтернативный датчик имеет ширину полосы до 3 кГц, α(f) выбирается равной 0 для диапазона частот ниже 3 кГц. В основном, начальная оценка чистого сигнала от альтернативного датчика является доверительной для низкочастотных диапазонов.
Для диапазонов высоких частот начальная оценка чистого сигнала от альтернативного датчика не рассматривается как надежная. Интуитивно, когда шум мал для диапазона частот в текущем фрейме, большое значение α(f) выбирают так, чтобы больше информации было принято от микрофона с воздушной проводимостью для этого диапазона частот. Иначе, больше информации от альтернативного датчика используется при выборе малого α(f). В одном варианте осуществления используется энергия начальной оценки чистого сигнала от альтернативного датчика, чтобы определить уровень шума для каждого диапазона частот. Пусть E(f) обозначают энергию для диапазона f частот. Пусть М=maxfЕ(f). α(f) как функция от f определяется следующим образом:

где линейная интерполяция используется для перехода от 3К к 4К для обеспечения гладкости α(f).
Согласно варианту осуществления близость мобильного устройства к голове пользователя включается в определение α(f). Конкретно, если датчик 832 приближения формирует значение D максимального расстояния и значение d текущего расстояния, уравнение 13 может быть изменено следующим образом:

где β имеет значение между нулем и единицей и выбирается на основании того, какой фактор - энергия или близость, как полагают, обеспечивает лучшую индикацию того, обеспечит ли модель шума для микрофона с воздушной проводимостью или вектор коррекции для альтернативного датчика лучшую оценку чистого сигнала.
Если β установлена равной нулю, α(f) более не является частотно-зависимой и просто становится равной:

Очищенная оценка чистого сигнала в области энергетического спектра может использоваться для построения фильтра Винера (Wiener), чтобы отфильтровать зашумленный сигнал микрофона с воздушной проводимостью. В частности, фильтр Винера, H, устанавливают так что:

Этот фильтр может затем применяться к зашумленному сигналу микрофона с воздушной проводимостью во временной области, чтобы сформировать с уменьшенным шумом или чистый сигнал во временной области. С уменьшенным шумом сигнал можно выдавать приемнику (слушателю) или подавать на устройство распознавания речи.
Следует заметить, что уравнение 12 обеспечивает очищенную оценку чистого сигнала, которая является взвешенной суммой двух факторов, один из которых - оценка чистого сигнала от альтернативного датчика. Эта взвешенная сумма может быть расширена, чтобы включить в себя дополнительные коэффициенты для дополнительных альтернативных датчиков. Таким образом, могут использоваться более одного альтернативного датчика, чтобы сформировать независимые оценки чистого сигнала. Эти множественные оценки могут затем быть объединены, используя уравнение 12.
В одном варианте осуществления также оценивают шум очищенной оценки чистого сигнала. Согласно варианту осуществления этот шум обрабатывают как нулевое Гауссово среднее значение с ковариацией, которая определяется следующим образом:

где
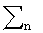


больше, если альтернативный датчик не имеет хорошего контакта с поверхностью кожи. Насколько контакт является хорошим, может быть измерено или посредством использования дополнительного датчика приближения или анализом альтернативного датчика. Для последнего, учитывая, что альтернативный датчик формирует малый высокочастотный отклик (больший чем 4 кГц), если он находится в хорошем контакте, измеряют качество контакта с помощью отношения низкочастотной энергии (меньше чем 3 кГц) к высокочастотной энергии. Чем выше отношение, тем лучше имеется контакт.
В некоторых вариантах осуществления используется шум в оценке чистого сигнала, чтобы сформировать сигнал побочного тона, как описано выше со ссылкой на фиг.6. Когда увеличивается шум в очищенной оценке чистого сигнала, громкость побочного тона увеличивается, чтобы поощрить пользователя разместить альтернативный датчик в лучшее положение так, чтобы процесс усиления улучшился. Например, сигнал побочного тона поощряет пользователей прижимать датчик, использующий костную проводимость, к своей голове так, чтобы процесс усиления был улучшен.
Снижение шума, используя вектор коррекции без оценки шума
Фиг.13 иллюстрирует блок-схему альтернативной системы для оценки значения чистой речи согласно настоящему изобретению. Система по фиг.13 подобна системе фиг.11 за исключением того, что оценка значения чистой речи сформирована без использования микрофона с воздушной проводимостью или модели шума.
На фиг.13, физическое событие, связанное с диктором 1300, формирующим речь, преобразуют в характеристический вектор альтернативным датчиком 1302, аналого-цифровым преобразователем 1304, конструктором 1306 фреймов и блоком 1308 извлечения характеристик способом, подобным описанному выше для альтернативного датчика 1114, аналого-цифрового преобразователя 1116, конструктора 1117 фреймов и блока 1118 извлечения характеристик на фиг.11. Следует заметить, что хотя только один альтернативный датчик показан на фиг.13, дополнительные альтернативные датчики могут использоваться как на фиг.11 с дополнительным блоком сравнения и выбора, как описано выше для фиг.11.
Характеристические векторы из блока 1308 извлечения характеристики и параметров 922 снижения шума подаются на блок 1310 оценки чистого сигнала, который определяет оценку значения 1312 чистого сигнала,
Оценка чистого сигнала,

Этот фильтр может затем применяться к зашумленному сигналу микрофона с воздушной проводимостью во временной области, чтобы сформировать с уменьшенным шумом или чистый сигнал. С уменьшенным шумом сигнал можно выдавать слушателю (приемнику) или подавать на устройство распознавания речи.
Альтернативно, оценка чистого сигнала в кепстральной области,

Снижение шума, используя отслеживание основного тона
Альтернативный способ для формирования оценок чистого сигнала речи показывается на блок-схеме на фиг.14 и блок-схеме последовательности операций на фиг.15. В частности, вариант осуществления на фиг.14 и 15 определяет оценку чистой речи, идентифицируя основной тон сигнала речи, используя альтернативный датчик и затем используя основной тон для декомпозиции зашумленного сигнала микрофона с воздушной проводимостью на гармоническую составляющую и случайную составляющую. Таким образом, сигнал шума представляют следующим образом:

где y - сигнал шума, yh - гармоническая составляющая и yr - случайная составляющая. Взвешенную сумму гармонической составляющей и случайной составляющей используют, чтобы сформировать характеристический вектор с уменьшенным шумом, представляющий сигнал речи с уменьшенным шумом.
Согласно варианту осуществления гармоническая составляющая моделируется как сумма синусоид связанных гармоник так что:

где yh является фундаментальной или основной частотой, и K - общее количество гармоник в сигнале.
Таким образом, чтобы идентифицировать гармоническую составляющую, должна быть определена оценка частоты основного тона и параметры амплитуды
{a1a2…akb1b2…bk}.
На этапе 1500 зашумленный сигнал речи собирают и преобразуют в цифровые отсчеты. Для этого микрофон 1404 с воздушной проводимостью преобразует звуковые волны от диктора 1400 и одного или более источников аддитивного шума 1402 в электрические сигналы. Электрические сигналы затем дискретизируют аналого-цифровым преобразователем 1406, чтобы сформировать последовательность цифровых значений. В одном варианте осуществления аналого-цифровой преобразователь 1406 дискретизирует аналоговый сигнал с частотой 16 кГц и 16 битов на отсчет, таким образом создавая 32 килобайта данных речи в секунду. На этапе 1502 цифровые отсчеты группируют в фреймы конструктором 1408 фреймов. Согласно варианту осуществления конструктор 1408 фреймов создает новый фрейм каждые 10 миллисекунд, который включает в себя 25 миллисекунд значимых данных.
На этапе 1504 физическое событие, связанное с формированием речи, обнаруживается альтернативным датчиком 1444. В этом варианте осуществления альтернативный датчик, который способен обнаружить гармонические составляющие, например датчик, использующий костную проводимость, является лучшим для использования в качестве альтернативного датчика 1444. Следует заметить, что хотя этап 1504 показан как отдельный от этапа 1500, специалисту ясно, что эти этапы могут быть выполнены в одно и то же время. Кроме того, хотя только один альтернативный датчик показан на фиг.14, могут использоваться дополнительные альтернативные датчики, как на фиг.11, с добавлением блока сравнения и выбора, как описано выше для фиг.11.
Аналоговый сигнал, сформированный альтернативным датчиком 1444, преобразуют в цифровые отсчеты аналого-цифровым преобразователем 1446. Цифровые отсчеты затем группируют в фреймы конструктором 1448 фреймов на этапе 1506.
На этапе 1508 фреймы сигнала альтернативного датчика используются блоком 1450 отслеживания основного тона, чтобы идентифицировать основной тон или основную частоту речи.
Оценка для частоты основного тона может быть определена, используя любое количество доступных систем отслеживания основного тона. Во многих из этих систем используются основные тона-кандидаты, чтобы идентифицировать возможное разнесение между центрами сегментов сигнала альтернативного датчика. Для каждого основного тона-кандидата определяют корреляцию между последовательными сегментами речи. Вообще, основной тон-кандидат, который обеспечивает наилучшую корреляцию, будет основной частотой фрейма. В некоторых системах используется дополнительная информация, чтобы очистить выбор основного тона, например энергия сигнала и/или ожидаемый канал основного тона.
Имея оценку основного тона от блока 1450 отслеживания основного тона, вектор сигнала воздушной проводимости может быть разложен на гармоническую составляющую и случайную составляющую на этапе 1510. Для этого уравнение 19 переписывают следующим образом:

где y - вектор из N отсчетов зашумленного сигнала речи, А - матрица размером N×2K, заданная следующим образом:
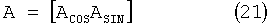
с элементами

и b есть вектор размером 2K×1, заданный следующим образом:
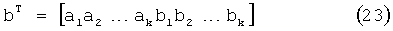
Затем, решением по методу наименьших квадратов к коэффициентам амплитуды является:

Используя


Оценка случайной составляющей затем вычисляется следующим образом:

Таким образом, используя уравнения 20-26, приведенные выше, блок 1410 разложения на гармоники способен сформировать вектор отсчетов 1412 гармонической составляющей, yh, и вектор отсчетов 1414 случайной составляющей, yr.
После того как отсчеты фрейма были разложены на гармонические и случайные отсчеты, параметр масштабирования, или вес, определяют для гармонической составляющей на этапе 1512. Этот параметр масштабирования используется как часть вычисления сигнала речи с уменьшенным шумом, как описано далее ниже. Согласно варианту осуществления параметр масштабирования рассчитывают следующим образом:

где αh является параметром масштабирования, yh(i) - i-ый отсчет в векторе отсчетов yh гармонической составляющей, и y(i) является i-ым отсчетом зашумленного сигнала речи для этого фрейма. В уравнении 27 числителем является сумма энергии каждого отсчета гармонической составляющей, а знаменателем - сумма энергии каждого отсчета зашумленного сигнала речи. Таким образом, параметр масштабирования есть отношение энергии гармоник фрейма к полной энергии фрейма.
В альтернативных вариантах осуществления параметр масштабирования устанавливают, используя блок вероятностного обнаружения голос - не голос. Такие блоки выдают вероятность, что конкретный фрейм речи является голосовым, вместо не голосового, означая, что голосовые связки резонируют в течение фрейма. Вероятность, что фрейм взят из голосовой области речи, может использоваться непосредственно как параметр масштабирования.
После того, как параметр масштабирования определен или пока он определяется, Mel-спектр (спектр чистого тона) для вектора отсчетов гармонической составляющей и вектора случайных составляющих отсчетов определяют на этапе 1514. Это включает в себя прохождение каждого вектора отсчетов через дискретное преобразование Фурье (DFT) 1418, чтобы сформировать вектор значений 1422 частот гармонической составляющей, и вектор значений 1420 частот случайной составляющей. Спектр энергии, представленный векторами значений частот затем сглаживают блоком 1424 взвешивания Mel (чистого тона), используя ряд функций взвешивания треугольником, применяемых вдоль шкалы Mel. Это приводит Mel-спектральному вектору 1428 гармонической составляющей, Yh, и Mel-спектральному вектору 1426 случайной составляющей, Yr.
На этапе 1516 Mel-спектры для гармонической составляющей и случайной составляющей объединяют как взвешенную сумму, чтобы сформировать оценку Mel-спектра с уменьшенным шумом. Этот этап выполняют блоком 1430 вычисления взвешенной суммы, используя коэффициент масштабирования, определенный выше, в следующем уравнении:

где

После вычисления Mel-спектра с уменьшенным шумом на этапе 1516 определяют логарифм 1432 для Mel-спектра и затем подают на дискретное косинусное преобразование 1434 на этапе 1518. Это дает характеристический вектор 1436 кепстральных коэффициентов Mel-частоты (MFCC), который представляет сигнал речи с уменьшенным шумом.
Отдельный характеристический вектор MFCC с уменьшенным шумом формируется для каждого фрейма зашумленного сигнала. Эти характеристические векторы могут использоваться для любой требуемой цели, включая усиление речи и распознание речи. Для усиления речи характеристические векторы MFCC могут быть преобразованы в область энергетического спектра и могут использоваться с зашумленным сигналом воздушной проводимости, чтобы сформировать фильтр Винера.
Хотя настоящее изобретение было описано выше со ссылками на использование конкретных датчиков, использующих костную проводимость, в качестве альтернативных датчиков могут использоваться другие альтернативные датчики. Например, на фиг.16 мобильное устройство согласно настоящему изобретению использует инфракрасный датчик 1600, который обычно направлен на лицо пользователя, особенно на область рта, и формирует сигнал, указывающий на изменения в движении лица пользователя, что соответствует речи. Сигнал, сформированный инфракрасным датчиком 1600, может использоваться как сигнал альтернативного датчика в способах, описанных выше.
Хотя настоящее изобретение было описано в отношении конкретных вариантов осуществления, специалистам очевидно, что могут быть сделаны изменения в форме и деталях без отрыва от объема и контекста изобретения.
Реферат
Изобретение относится к удалению шума из сигналов речи, принятых мобильными ручными устройствами. Мобильное ручное устройство с многосенсорным улучшением речи содержит микрофон с воздушной проводимостью, который преобразует акустические волны в электрический сигнал микрофона, указывающий фрейм речи, по меньшей мере один альтернативный датчик, использующий костную проводимость и выдающий электрический сигнал альтернативного датчика, указывающий упомянутый фрейм речи, и процессор, который использует сигнал микрофона и сигнал альтернативного датчика, чтобы оценить значение чистой речи для фрейма речи. Мобильное ручное устройство может также содержать датчик приближения, отдельный от микрофона с воздушной проводимостью, который указывает расстояние от мобильного устройства до объекта, и блок оценки чистого сигнала, который использует сигнал микрофона, сигнал упомянутого альтернативного датчика и сигнал приближения для удаления шума из сигнала микрофона и получения, таким образом, усиленного сигнала чистой речи. Удаляется шум из сигналов речи, принятых мобильными ручными устройствами и формируется звук с учетом величины шума для обеспечения чистой речи. 3 н. и 26 з.п. ф-лы, 16 ил.
Формула
микрофон с воздушной проводимостью, который преобразует акустические волны в электрический сигнал микрофона, указывающий фрейм речи;
по меньшей мере, один альтернативный датчик, использующий костную проводимость и выдающий электрический сигнал альтернативного датчика, указывающий упомянутый фрейм речи; и
процессор, который использует сигнал микрофона и сигнал альтернативного датчика, чтобы оценить значение чистой речи для фрейма речи.
микрофон с воздушной проводимостью, который преобразует акустические волны в электрический сигнал микрофона;
альтернативный датчик, использующий костную проводимость, который выдает электрический сигнал альтернативного датчика, указывающего речь;
датчик приближения, отдельный от микрофона с воздушной проводимостью, который выдает электрический сигнал приближения, отдельный от сигнала микрофона с воздушной проводимостью, который указывает расстояние от мобильного устройства до объекта, и
блок оценки чистого сигнала, который использует сигнал микрофона, сигнал альтернативного датчика, использующего костную проводимость, и сигнал приближения для удаления шума из сигнала микрофона и получения, таким образом, усиленного сигнала чистой речи.
использование оценки шума для формирования звука через громкоговоритель в мобильном устройстве.
Документы, цитированные в отчёте о поиске
Система адаптивной фильтрации аудиосигналов для улучшения разборчивости речи при наличии шума
Комментарии