Сульфонилмочевина-реактивные репрессорные белки - RU2532854C2
Код документа: RU2532854C2
Чертежи







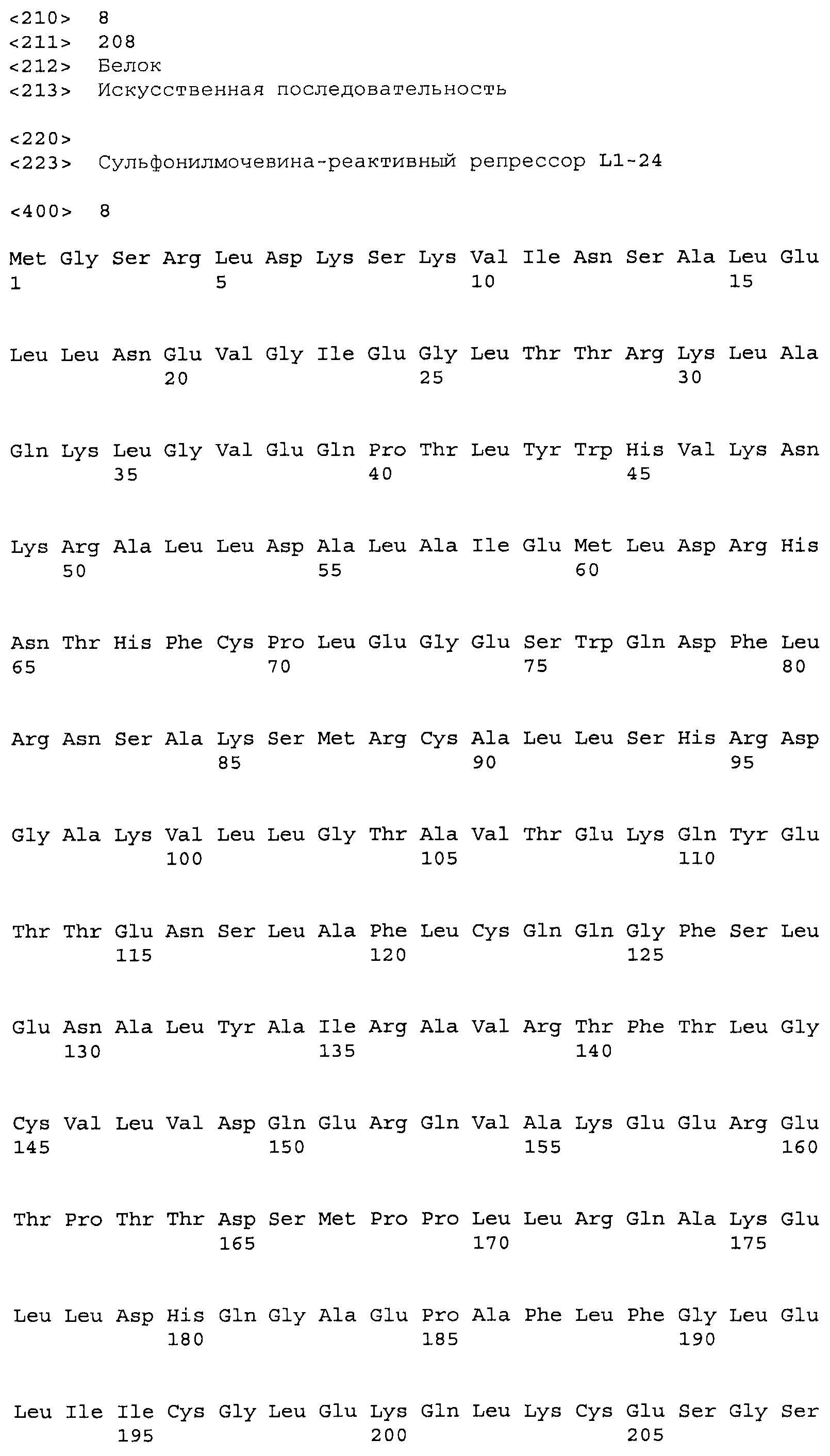


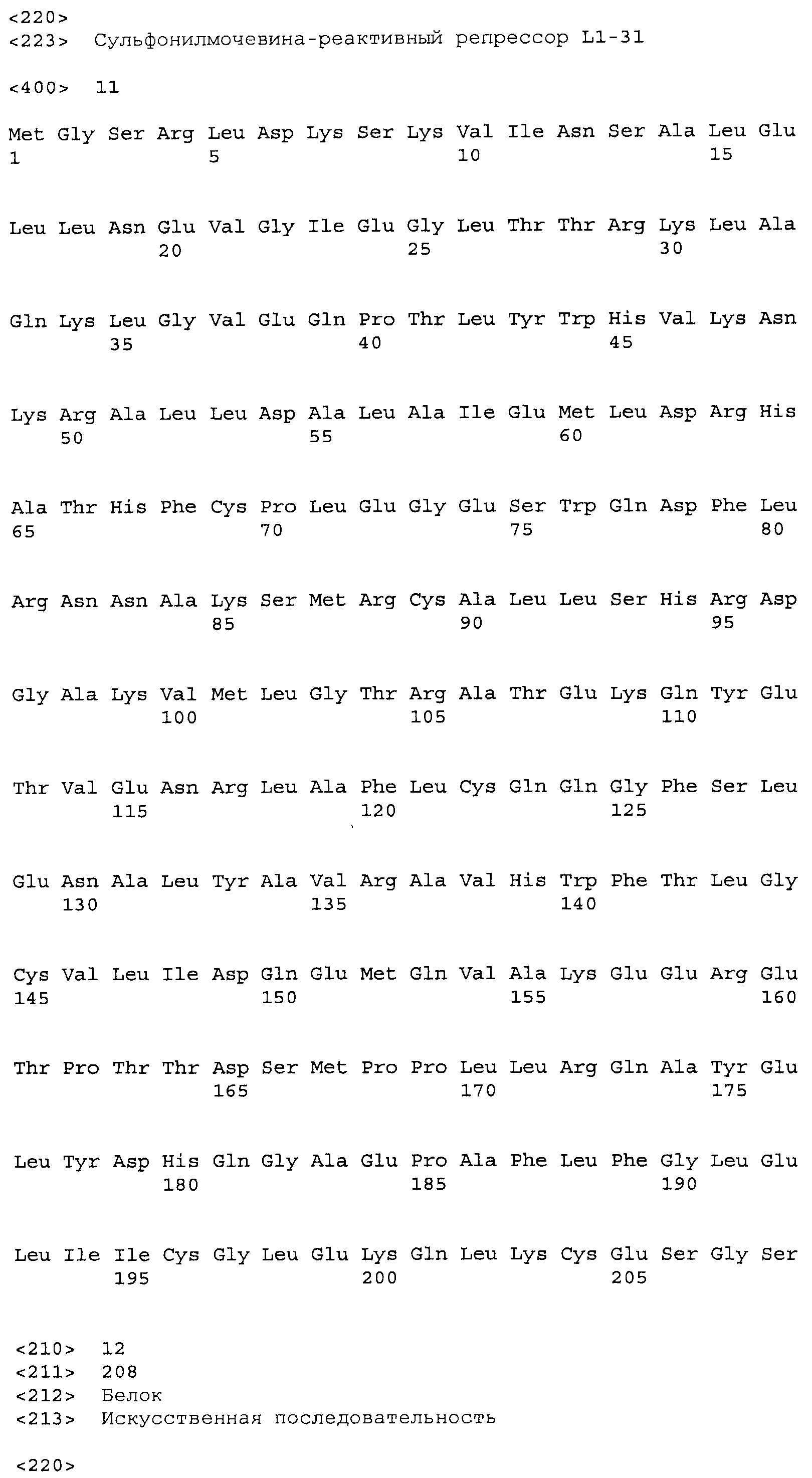


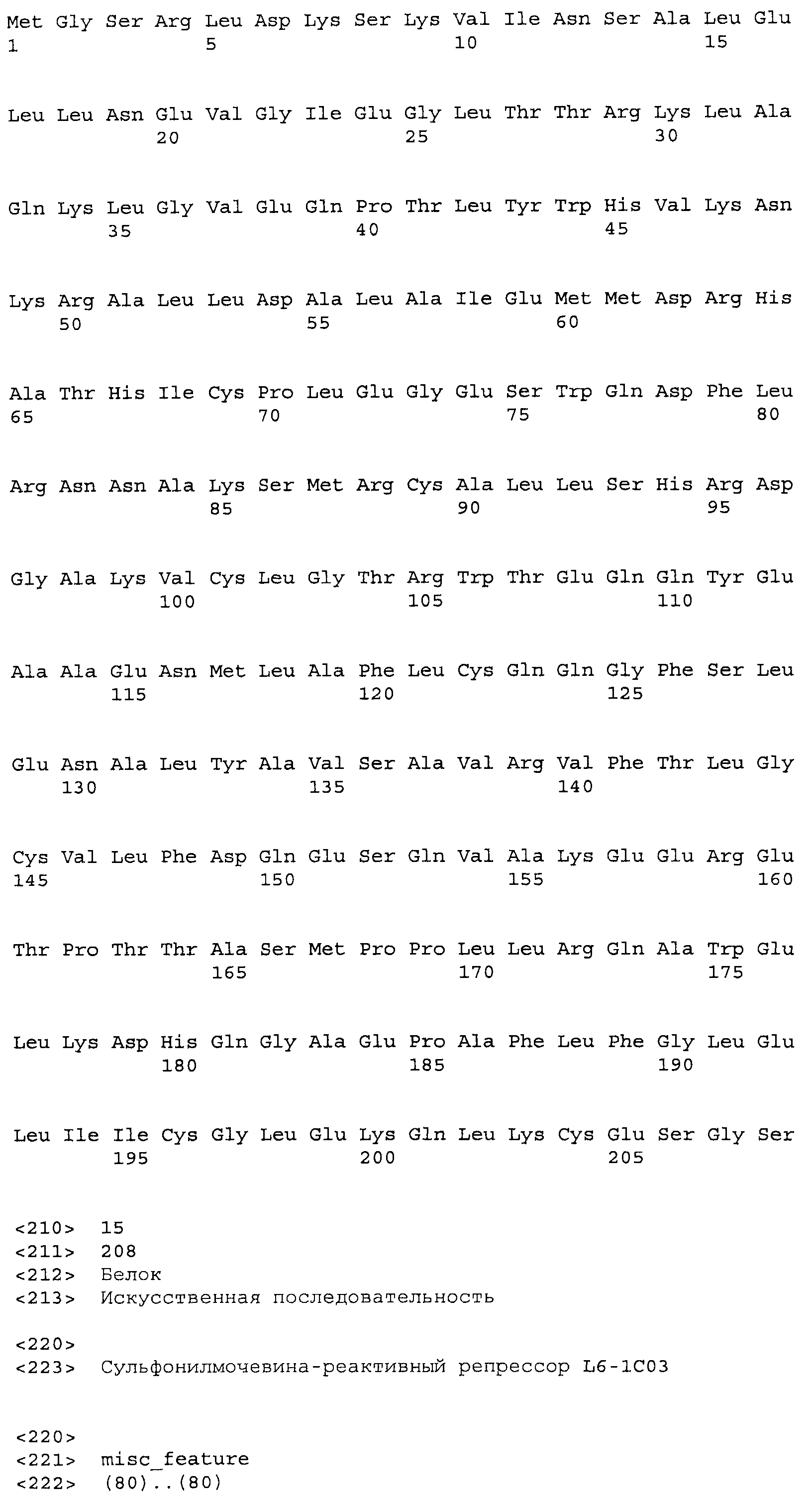

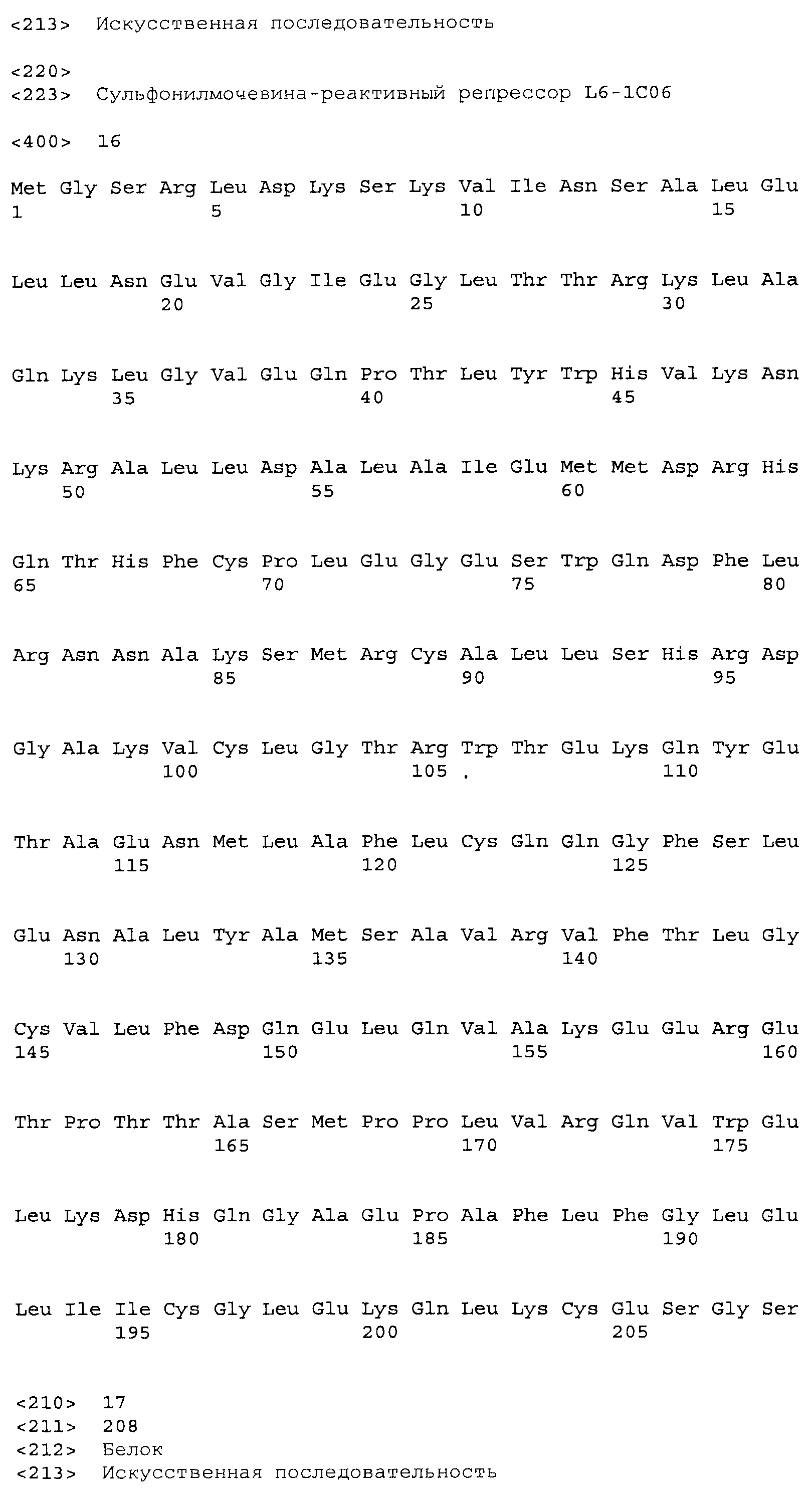

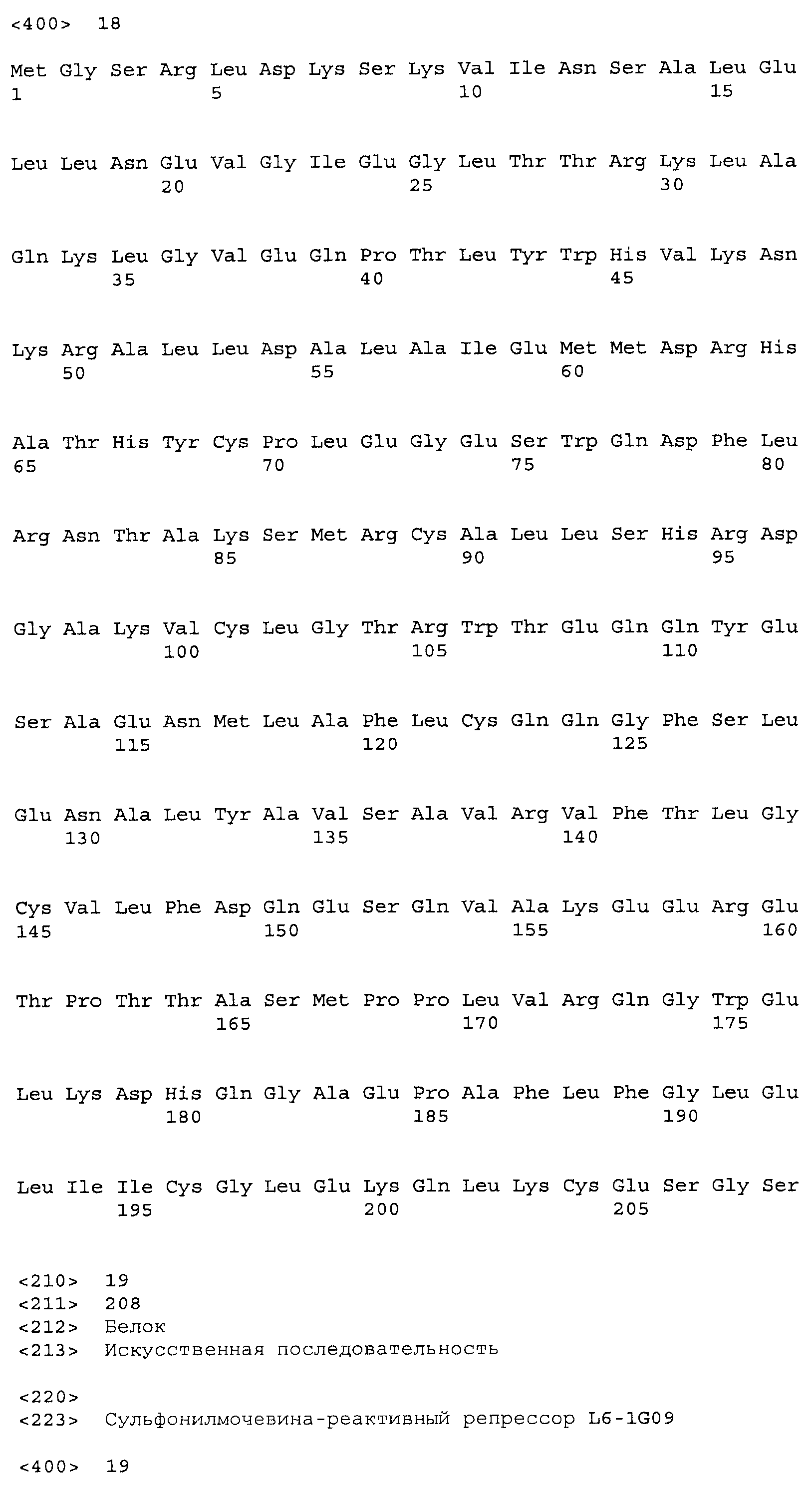


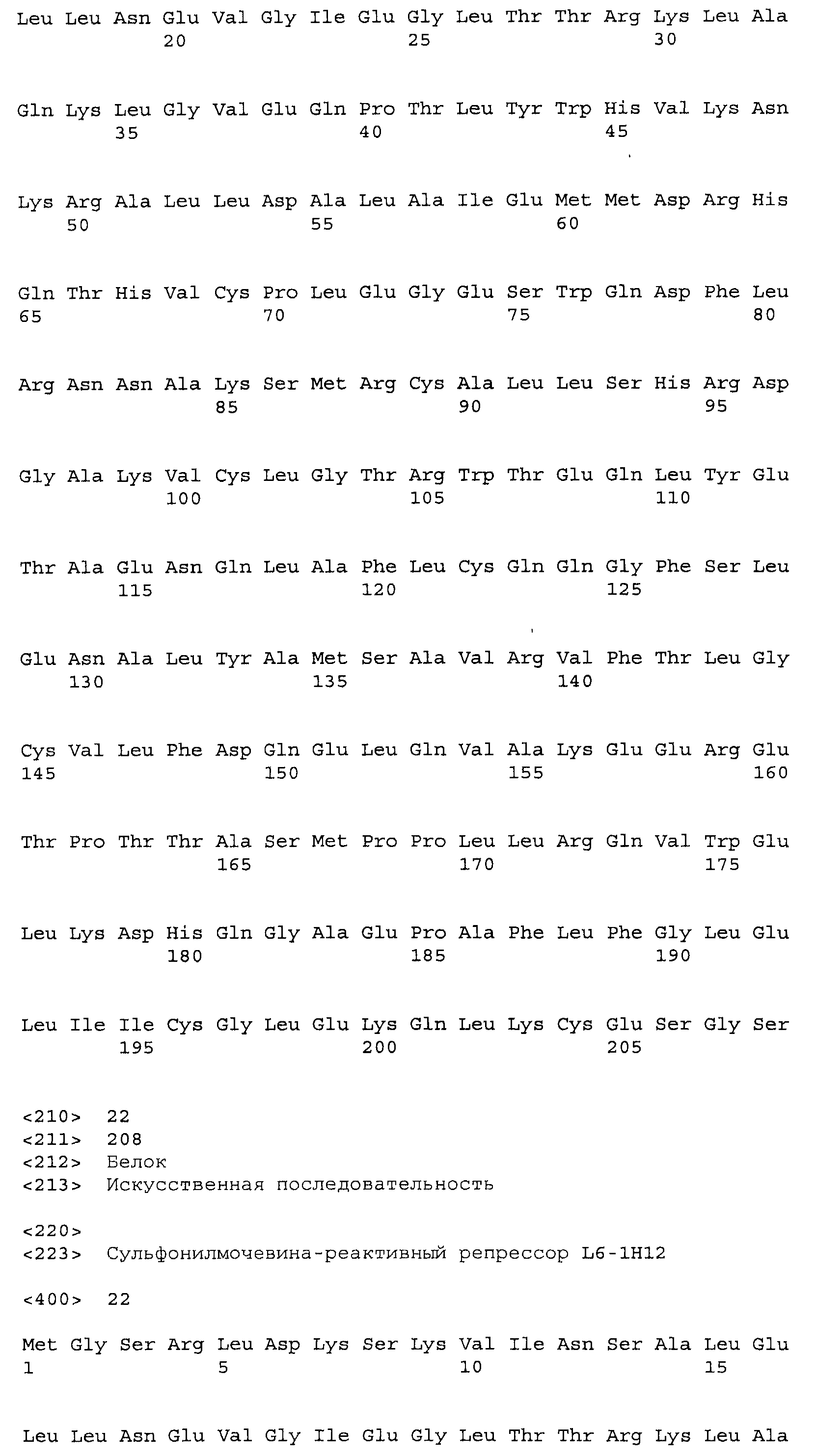














































































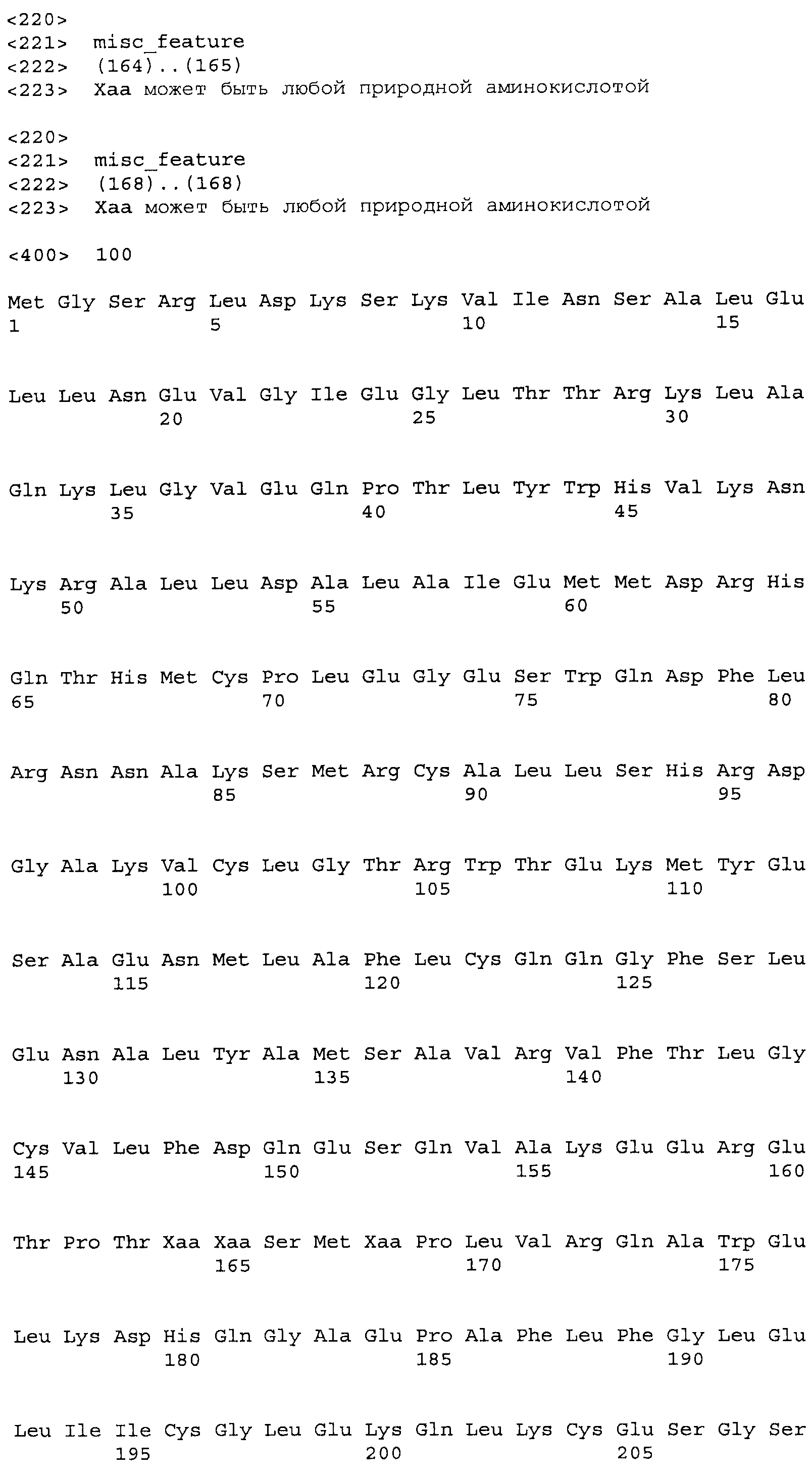







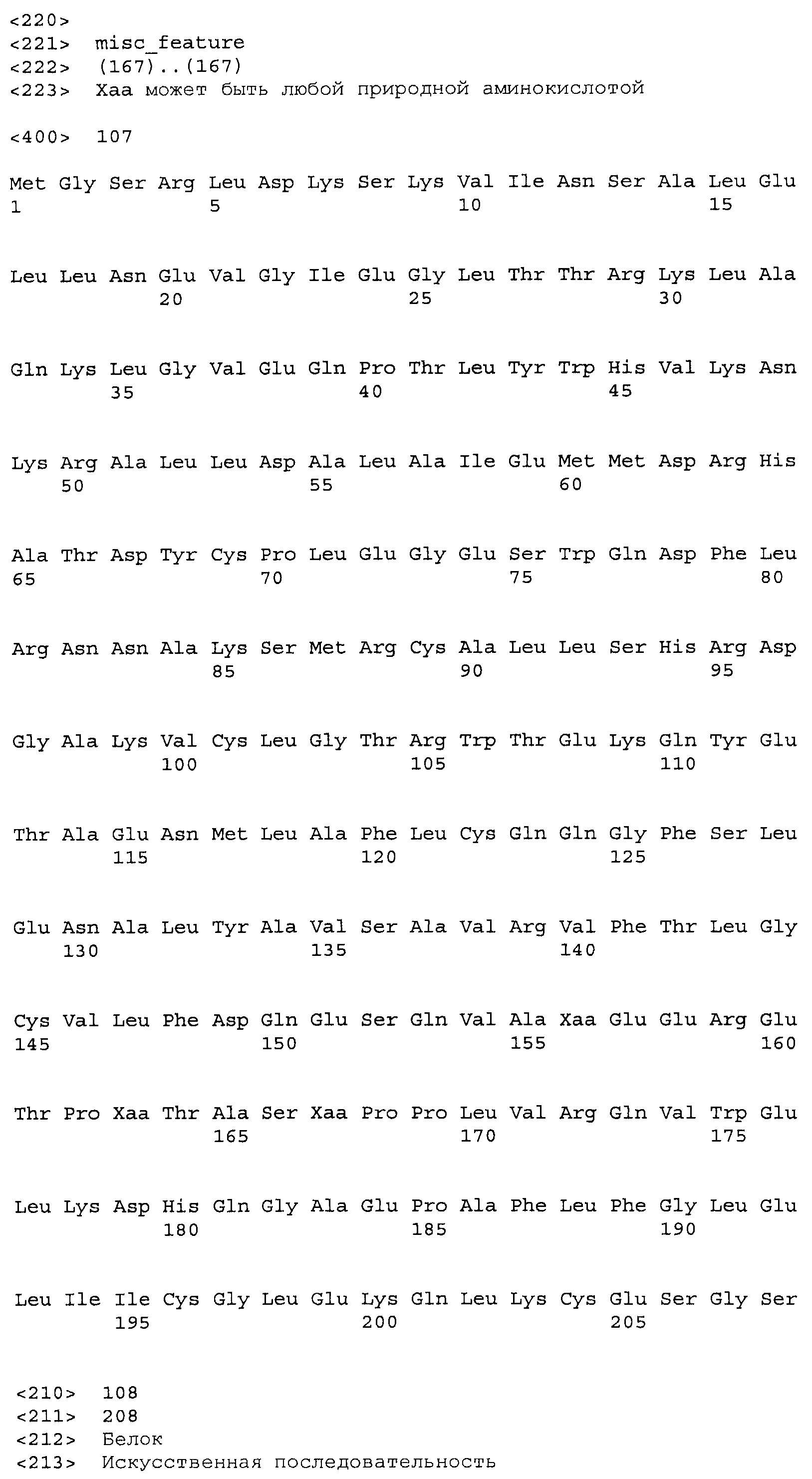





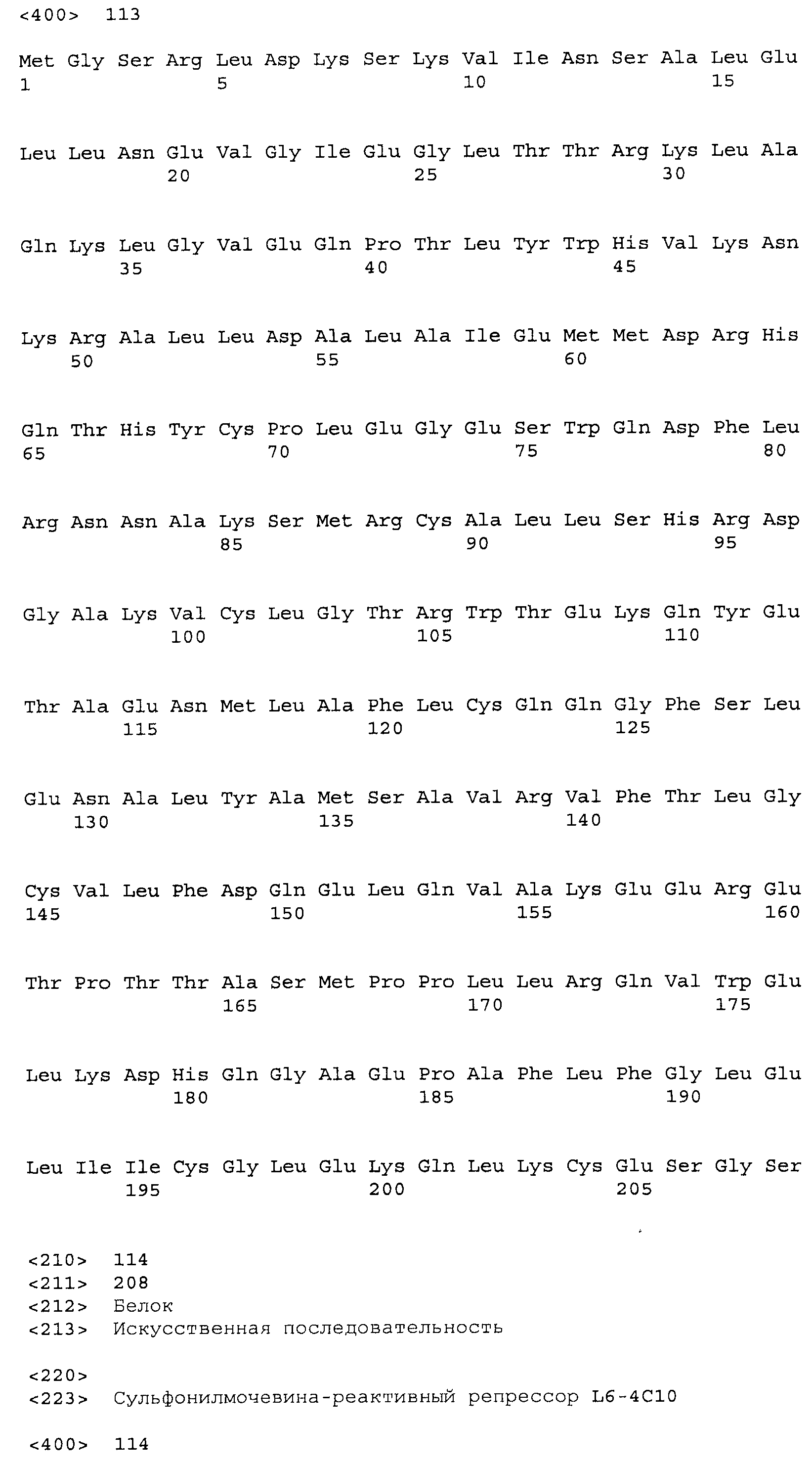
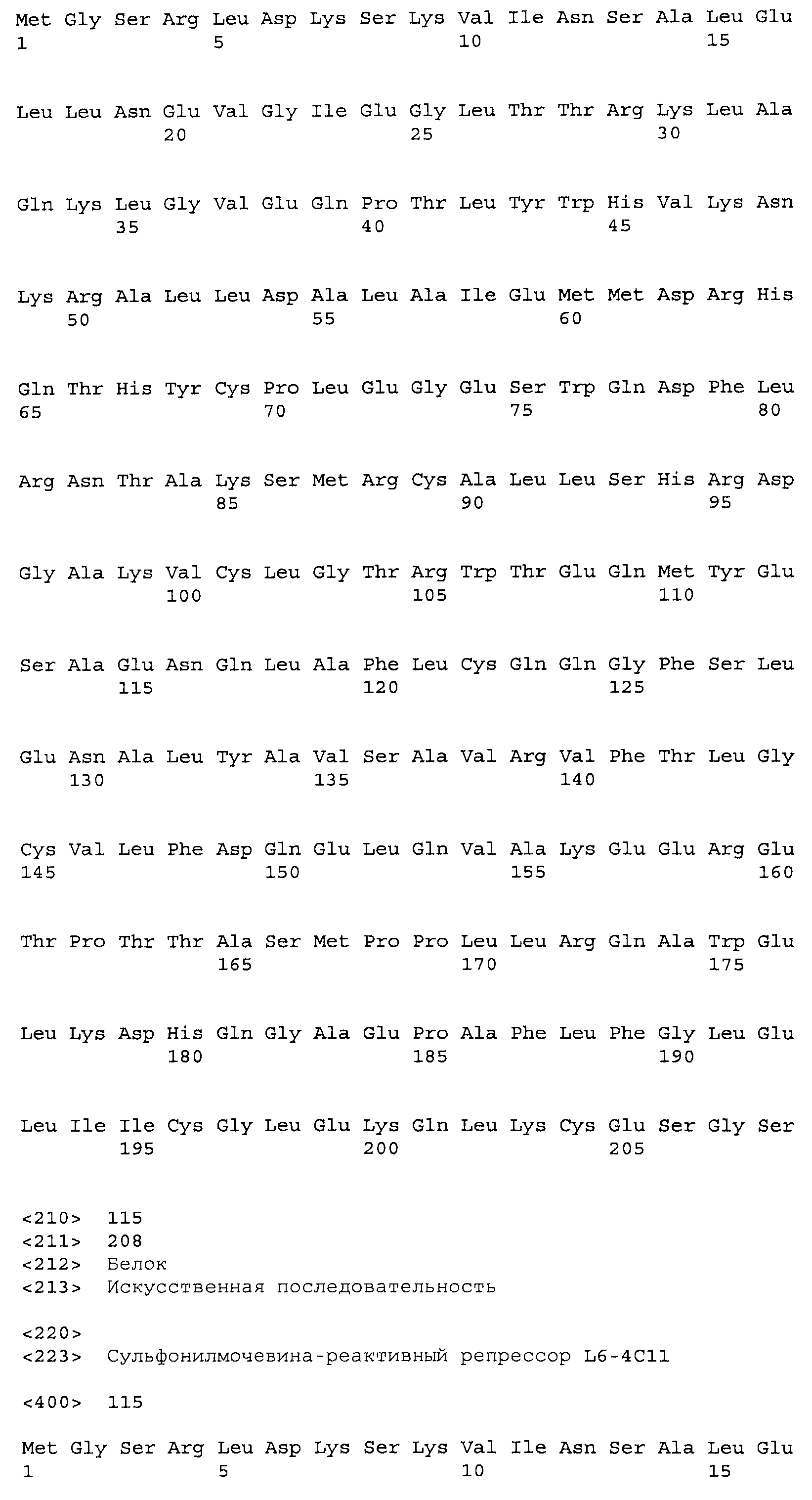












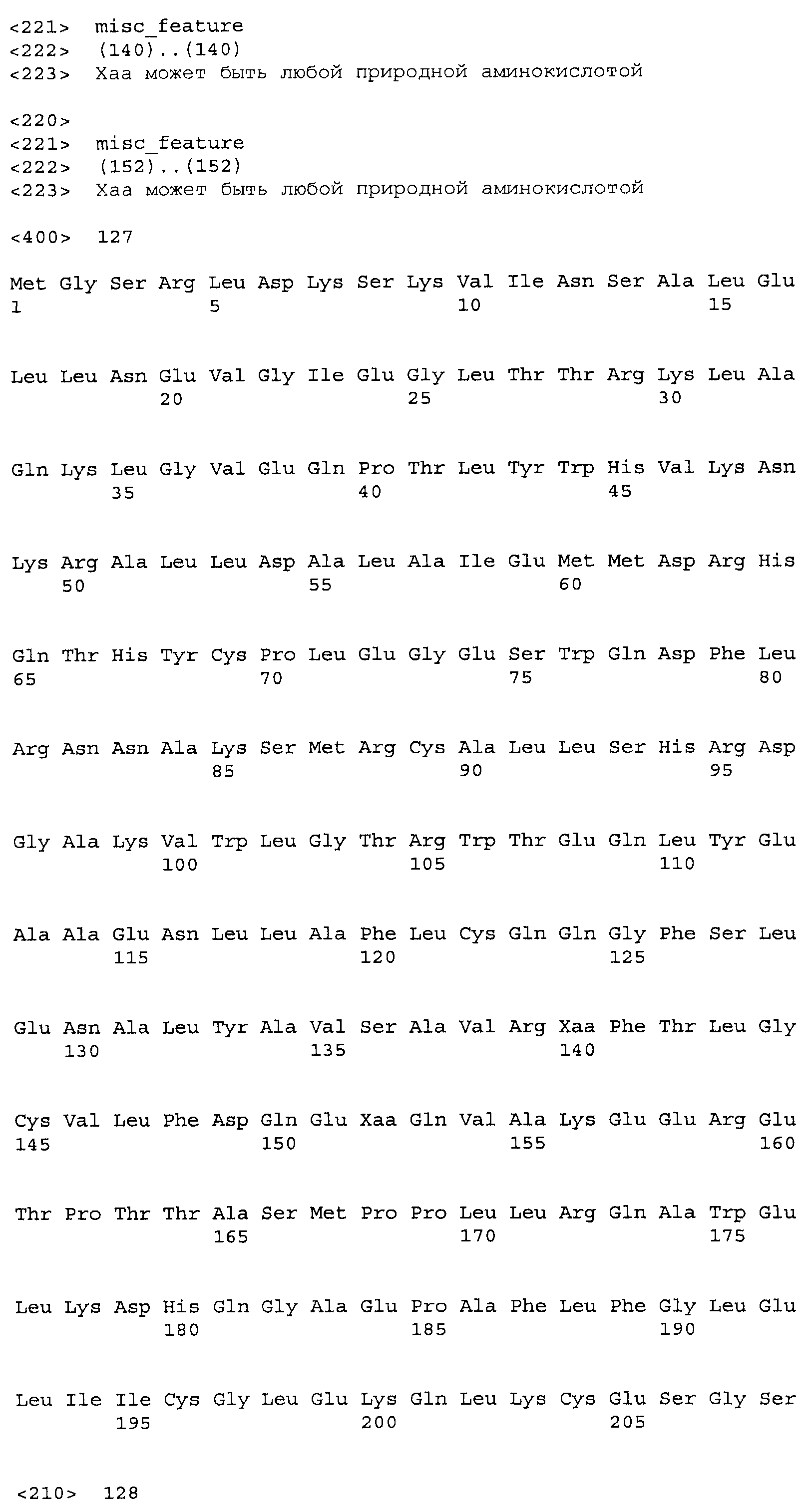


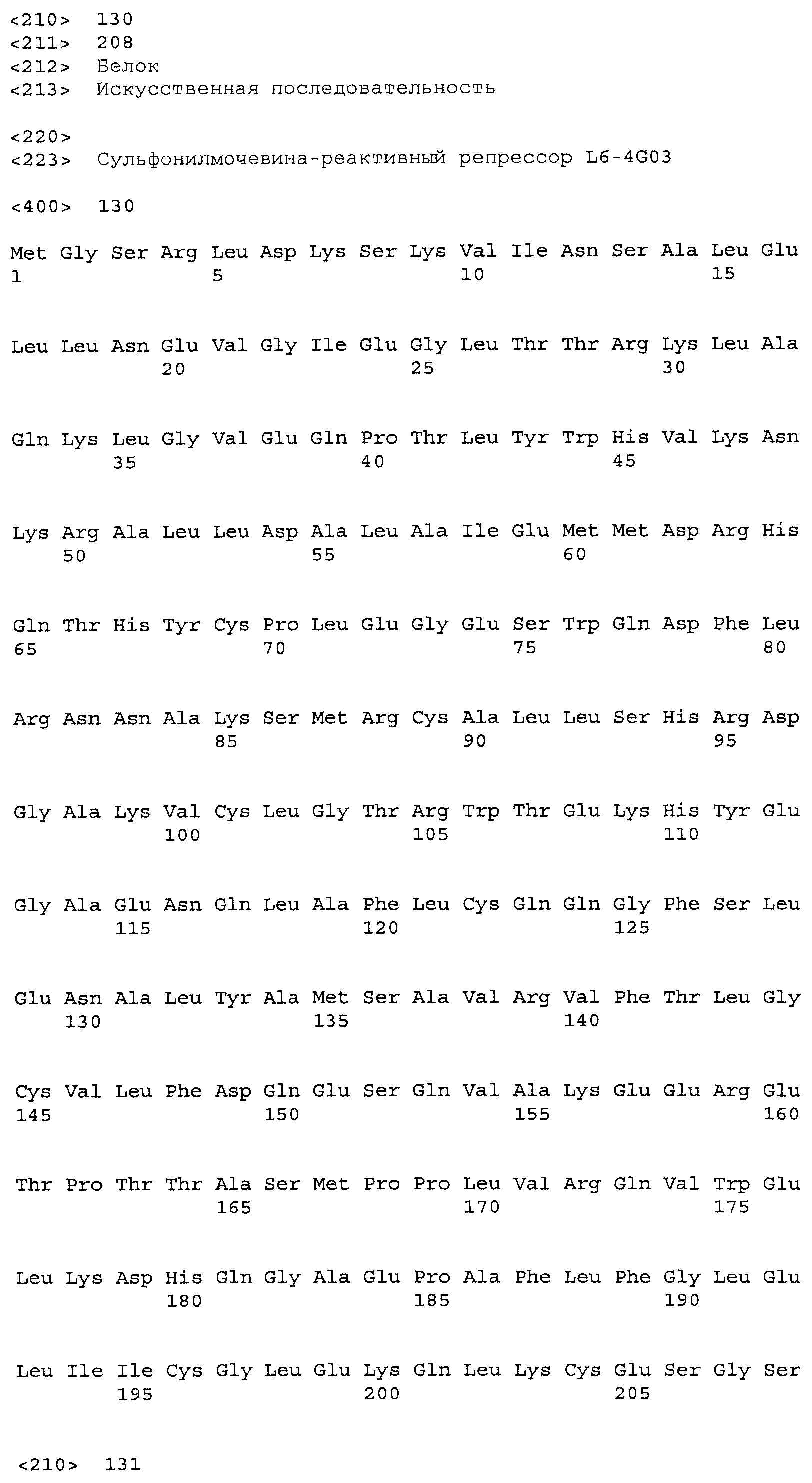


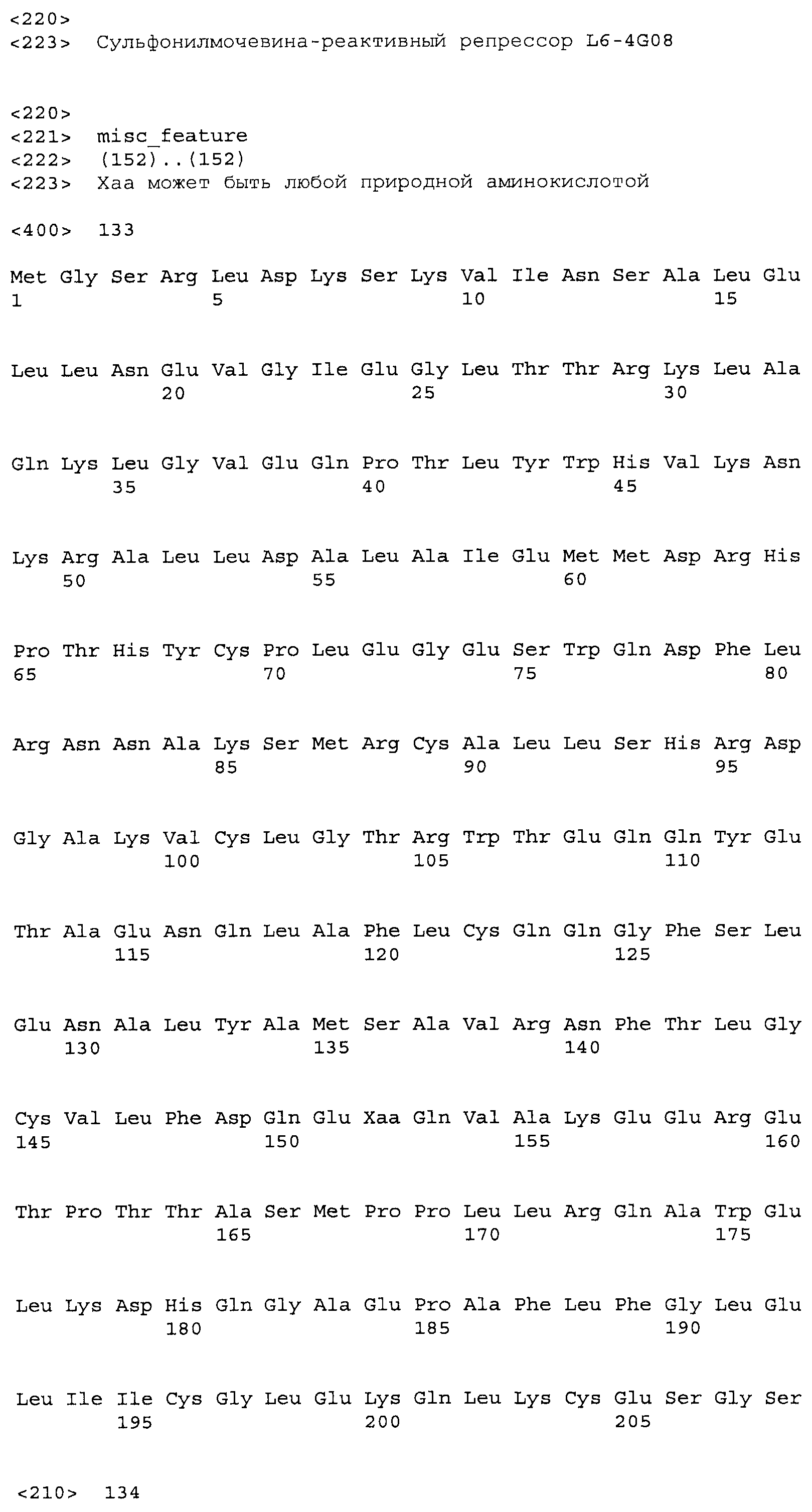






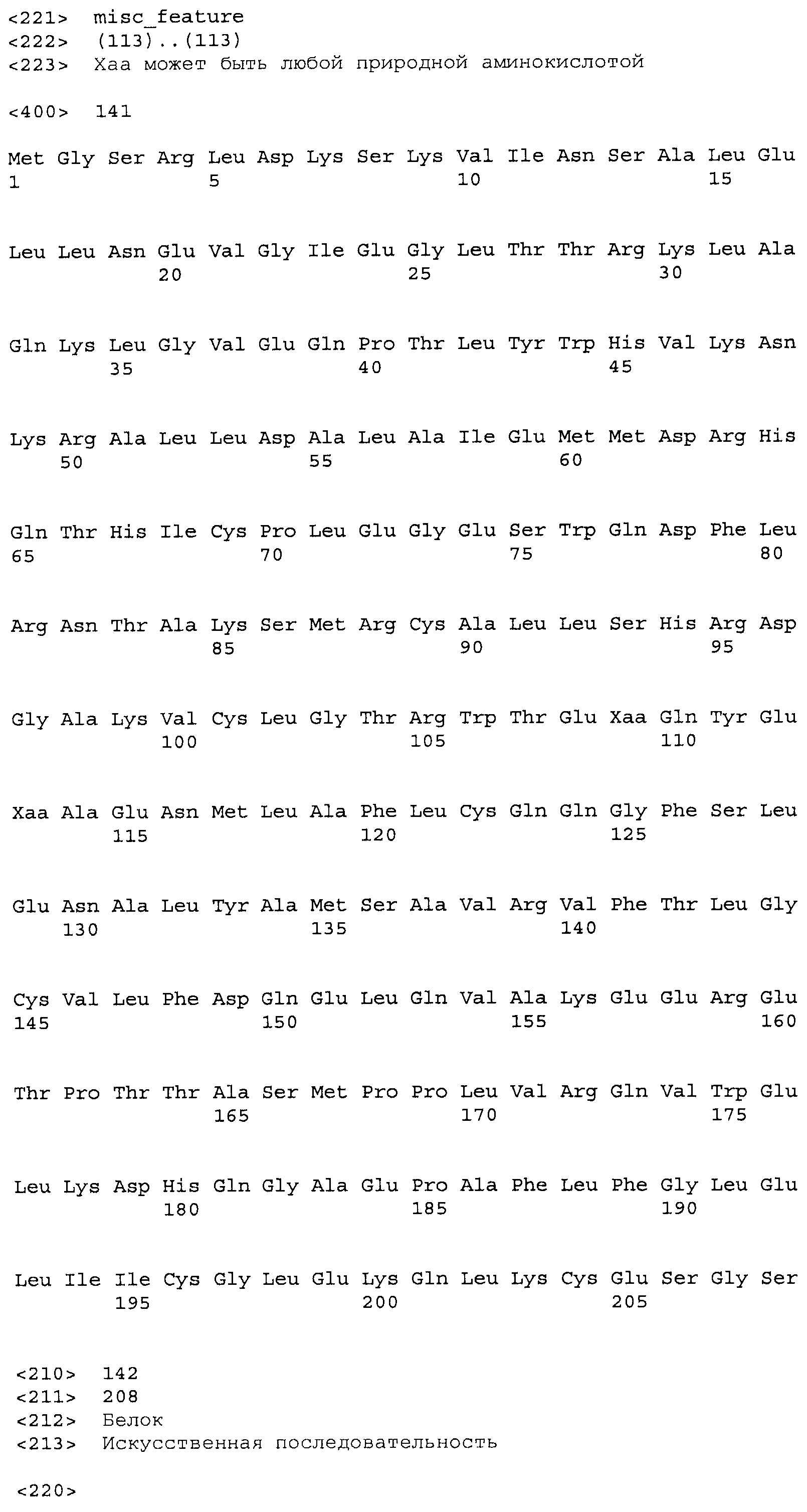











































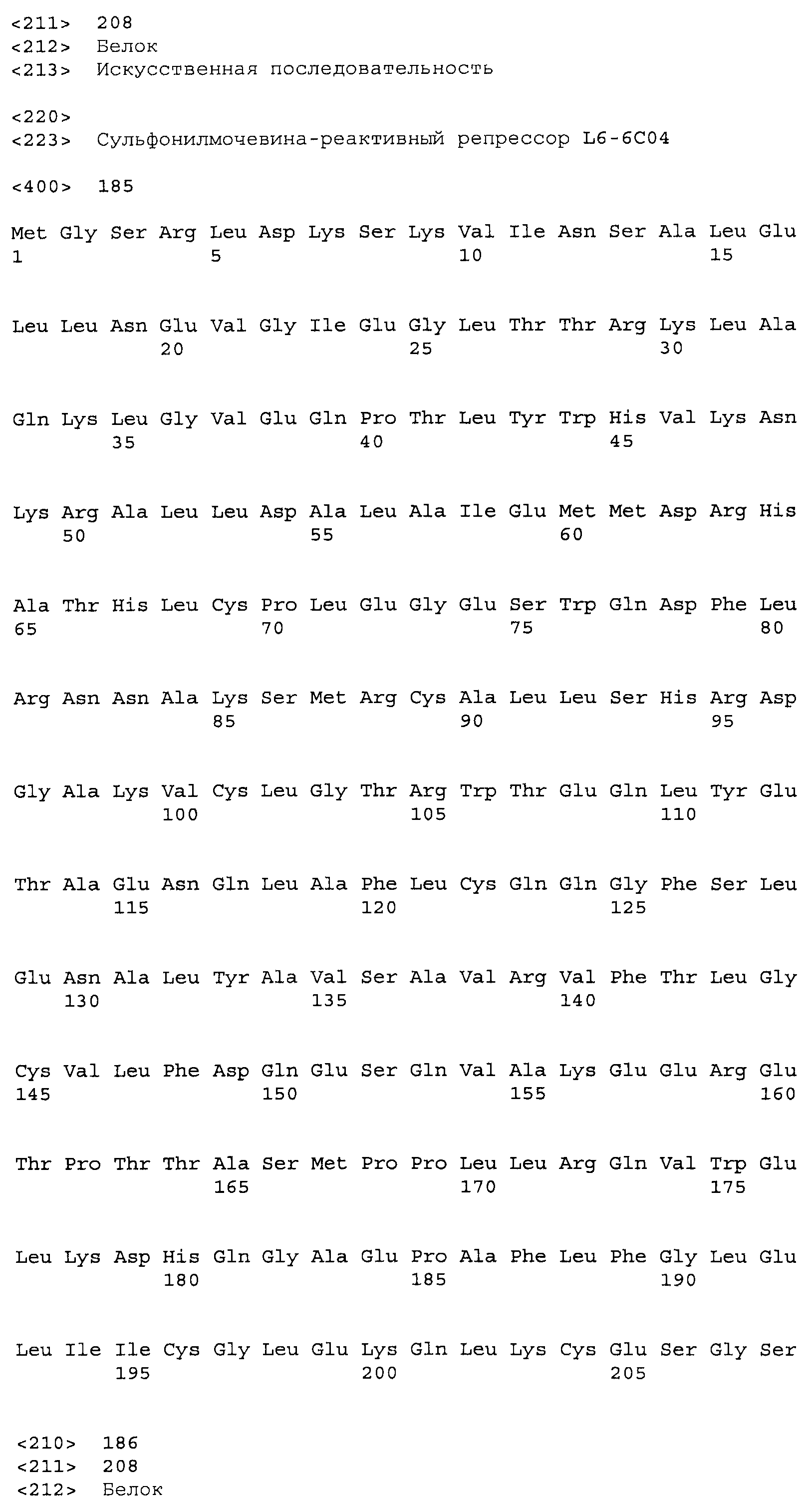
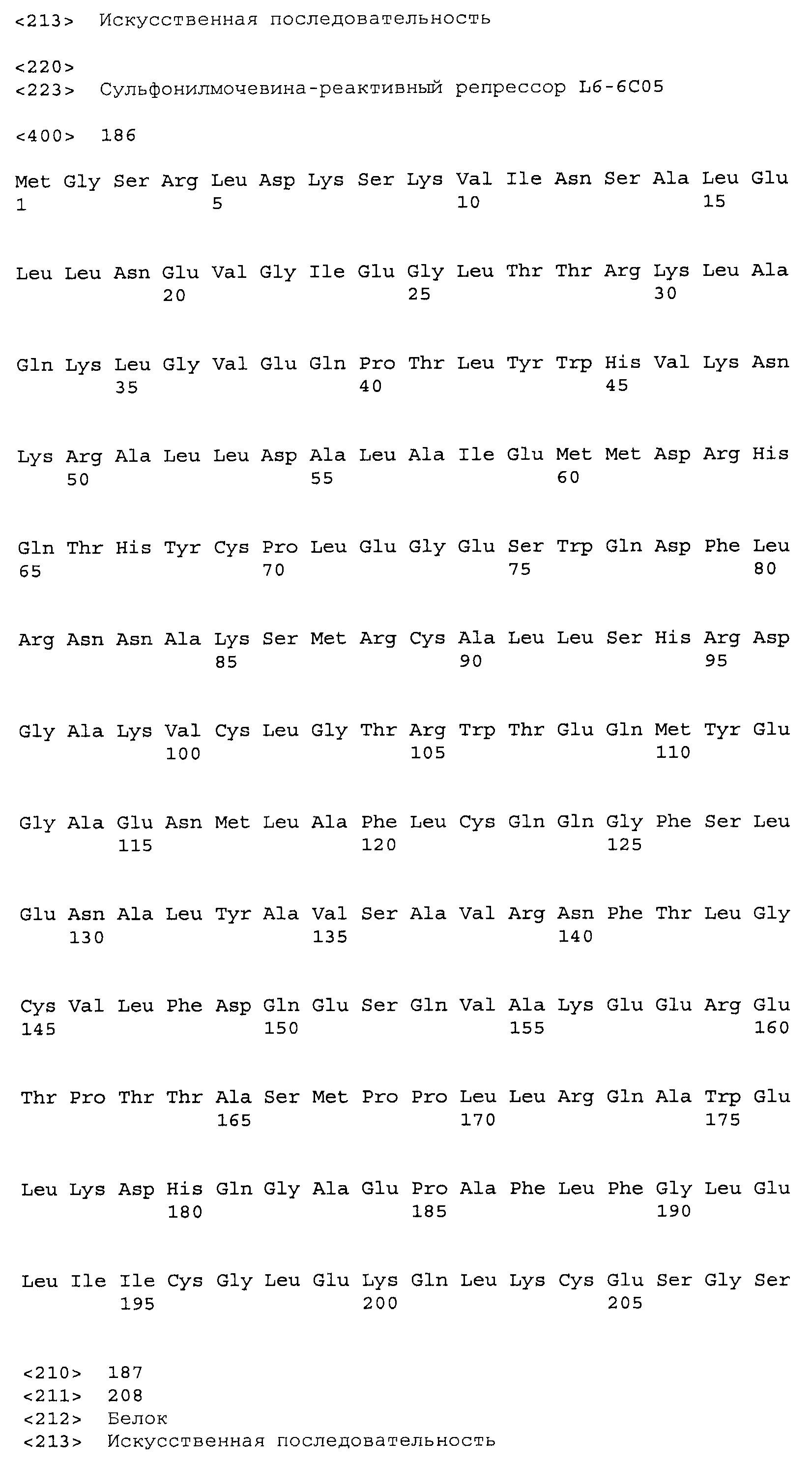





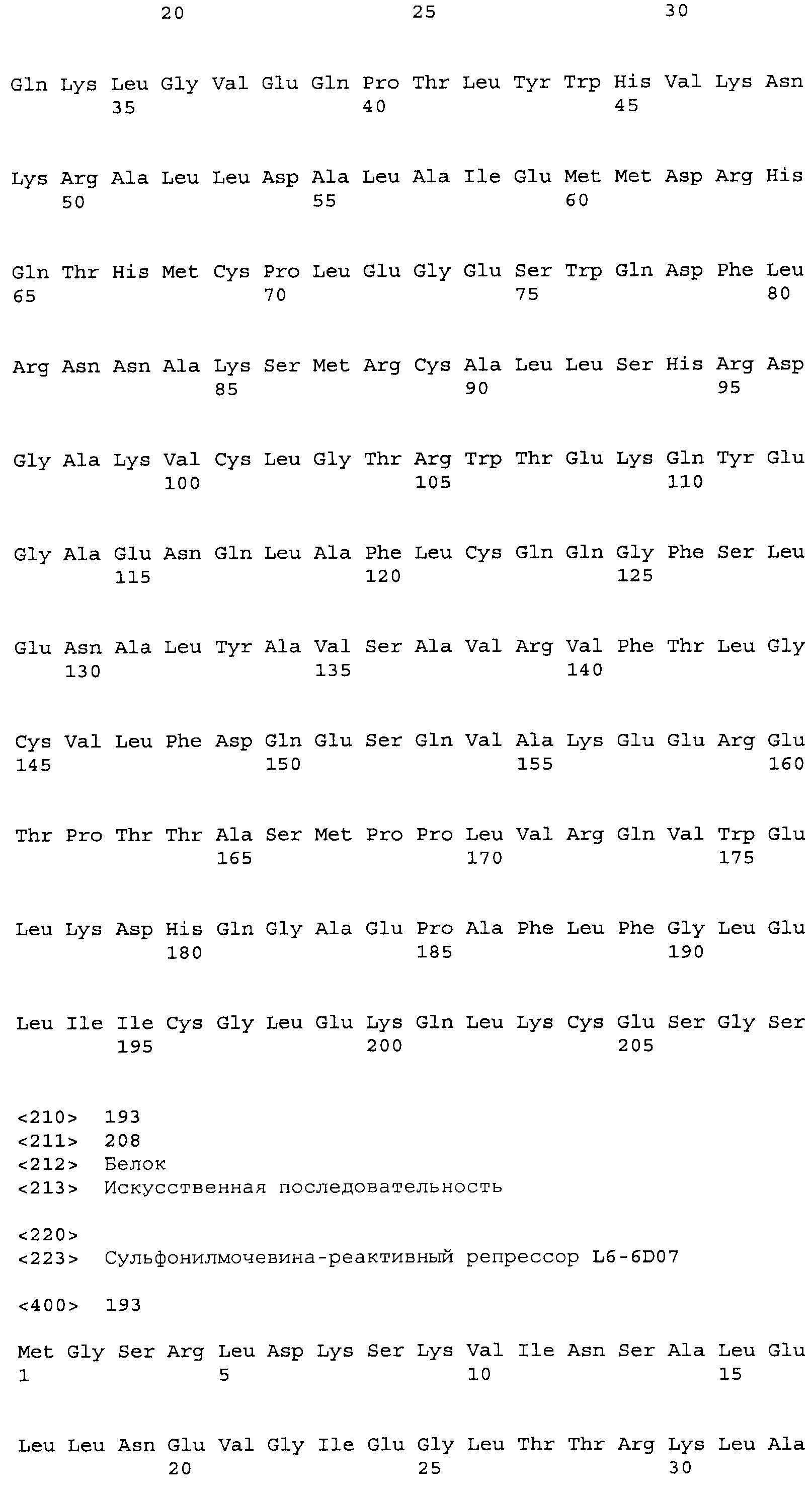





















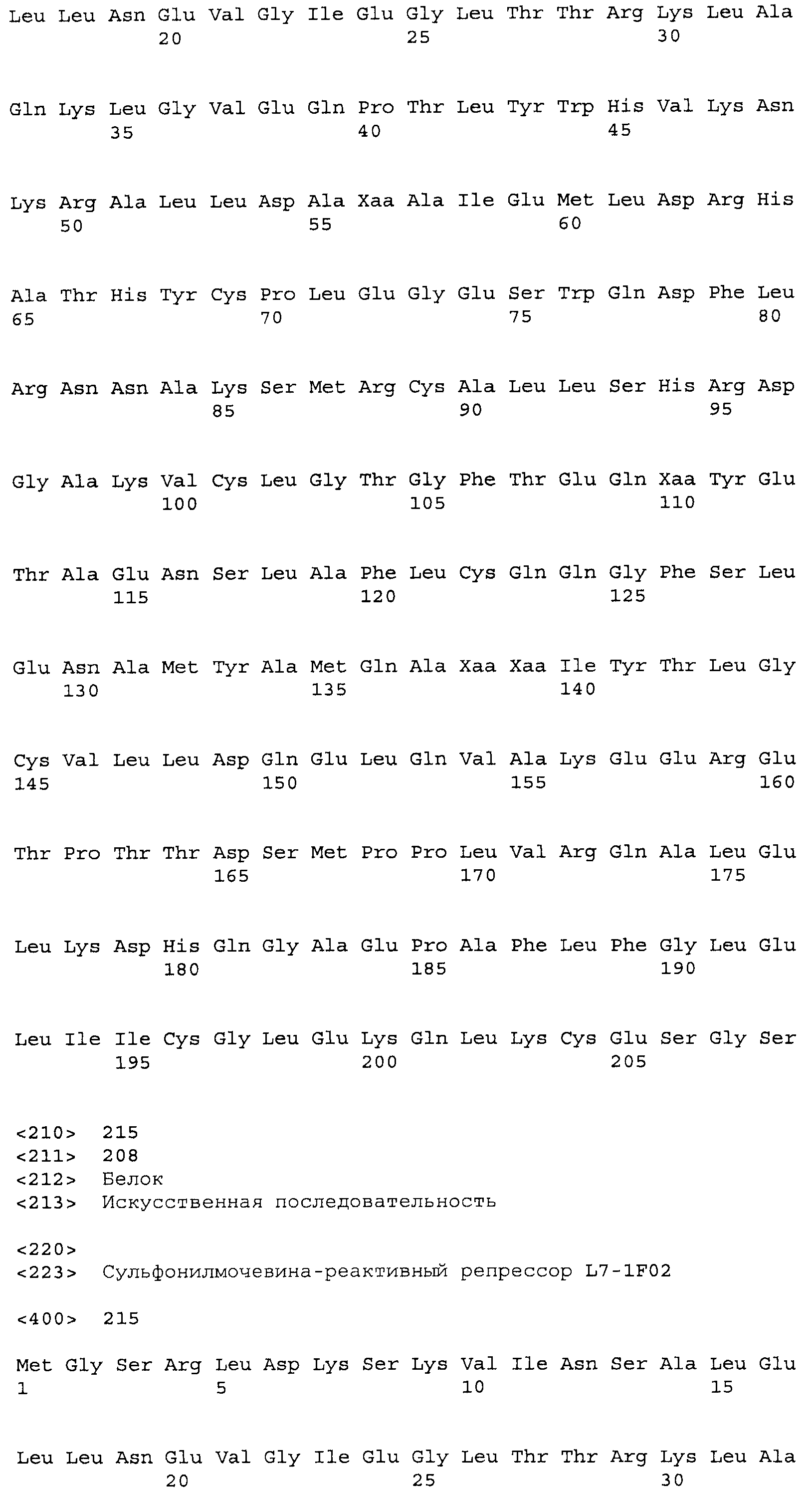













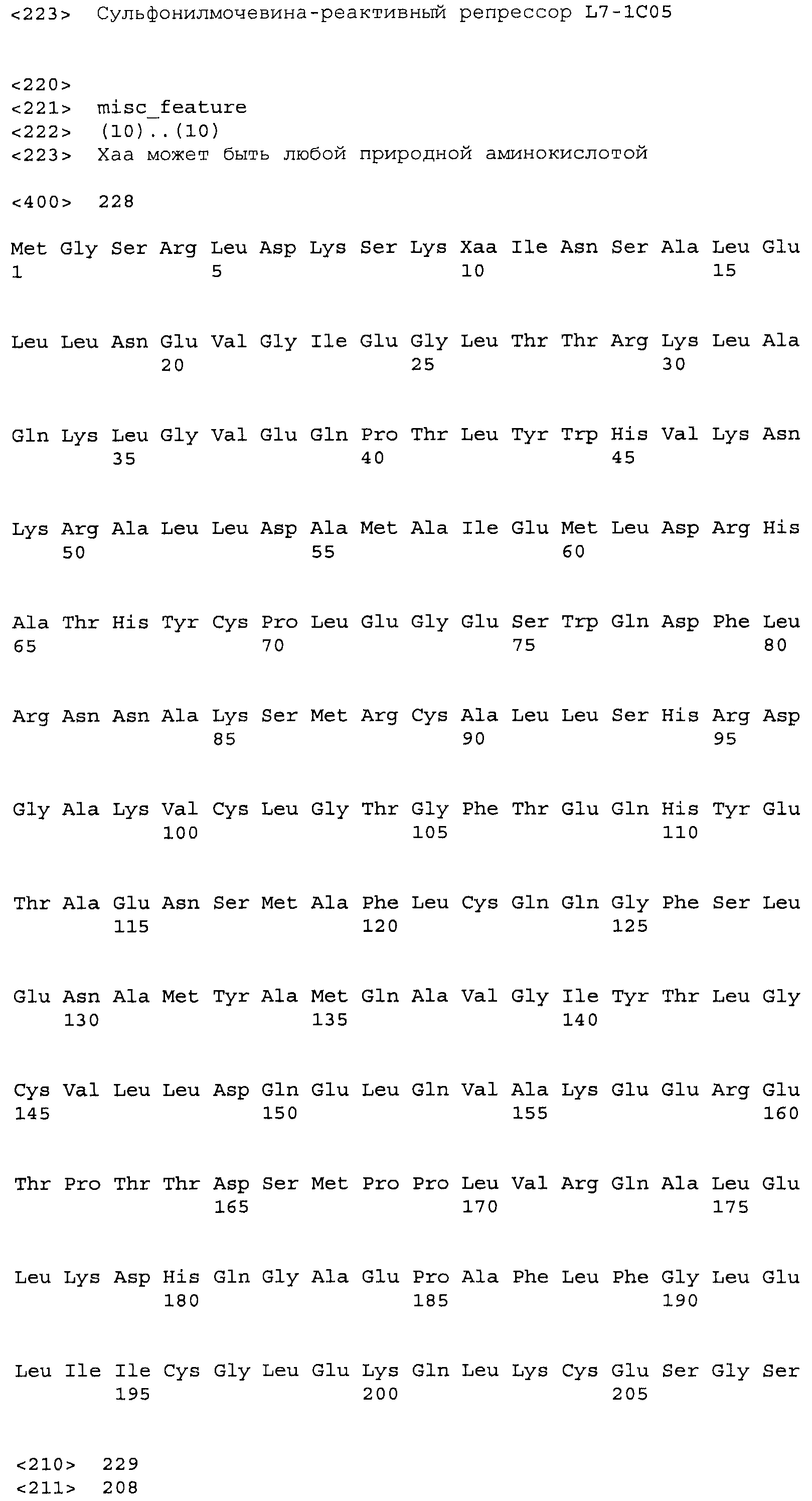


















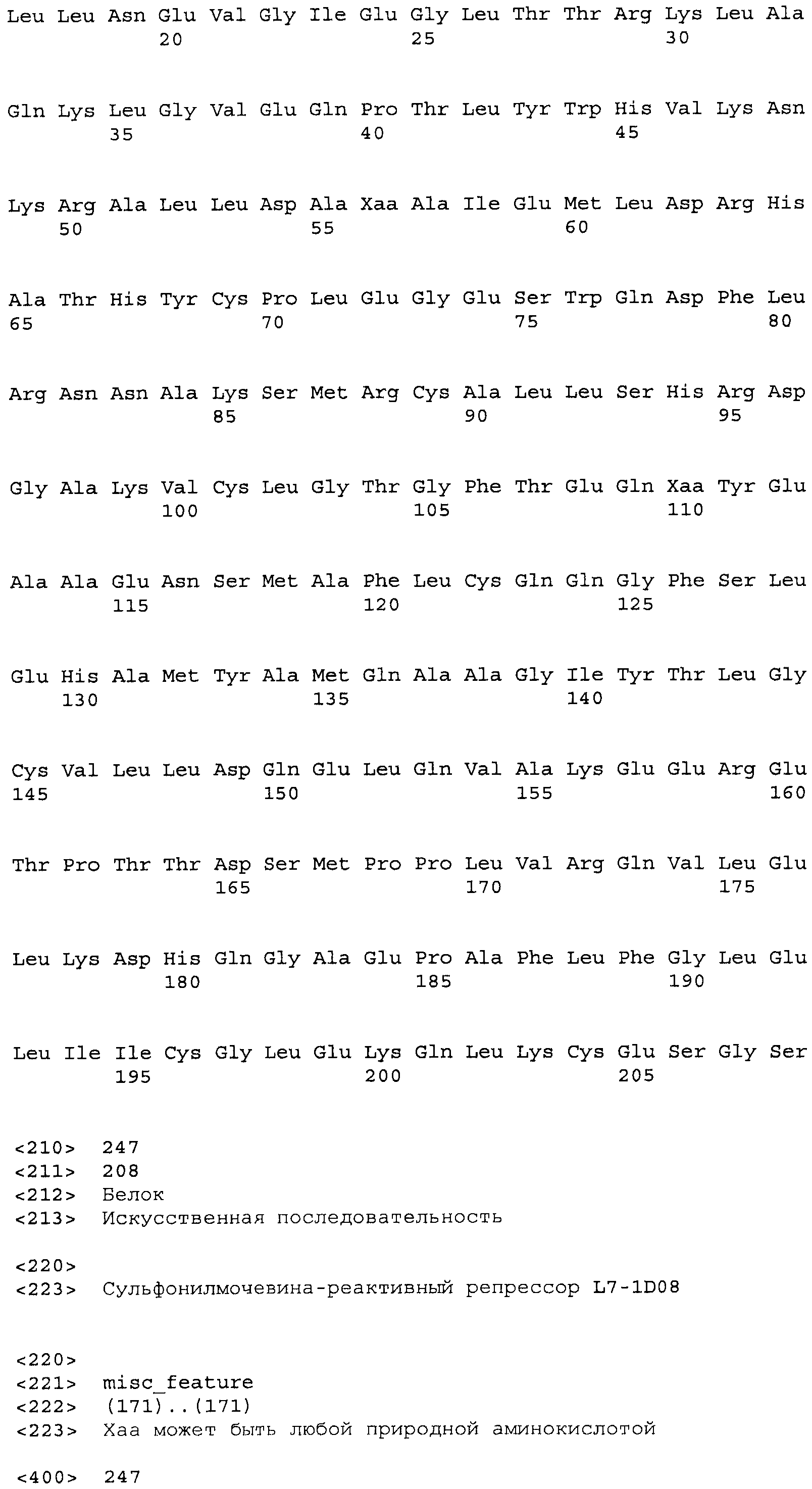




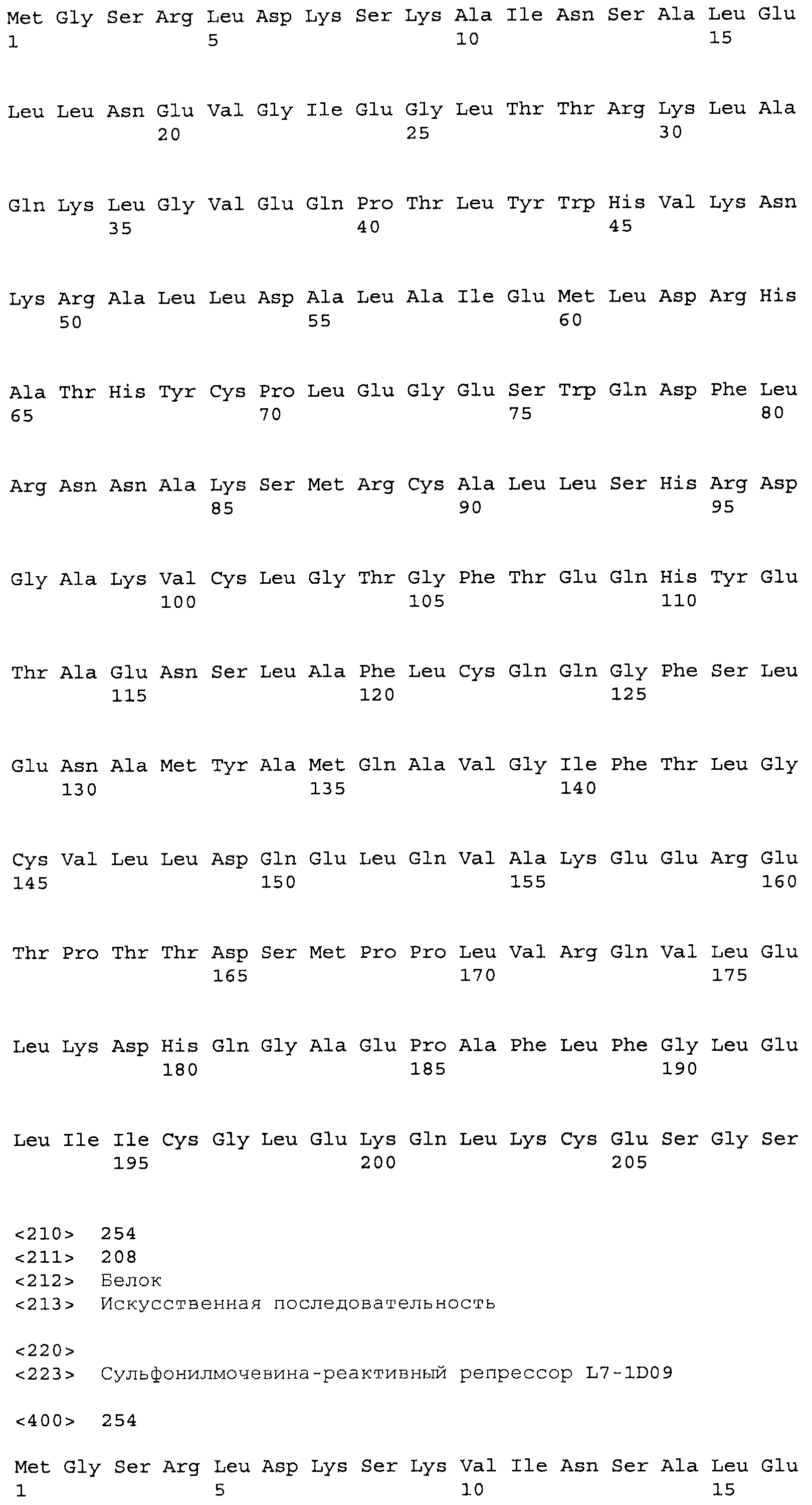


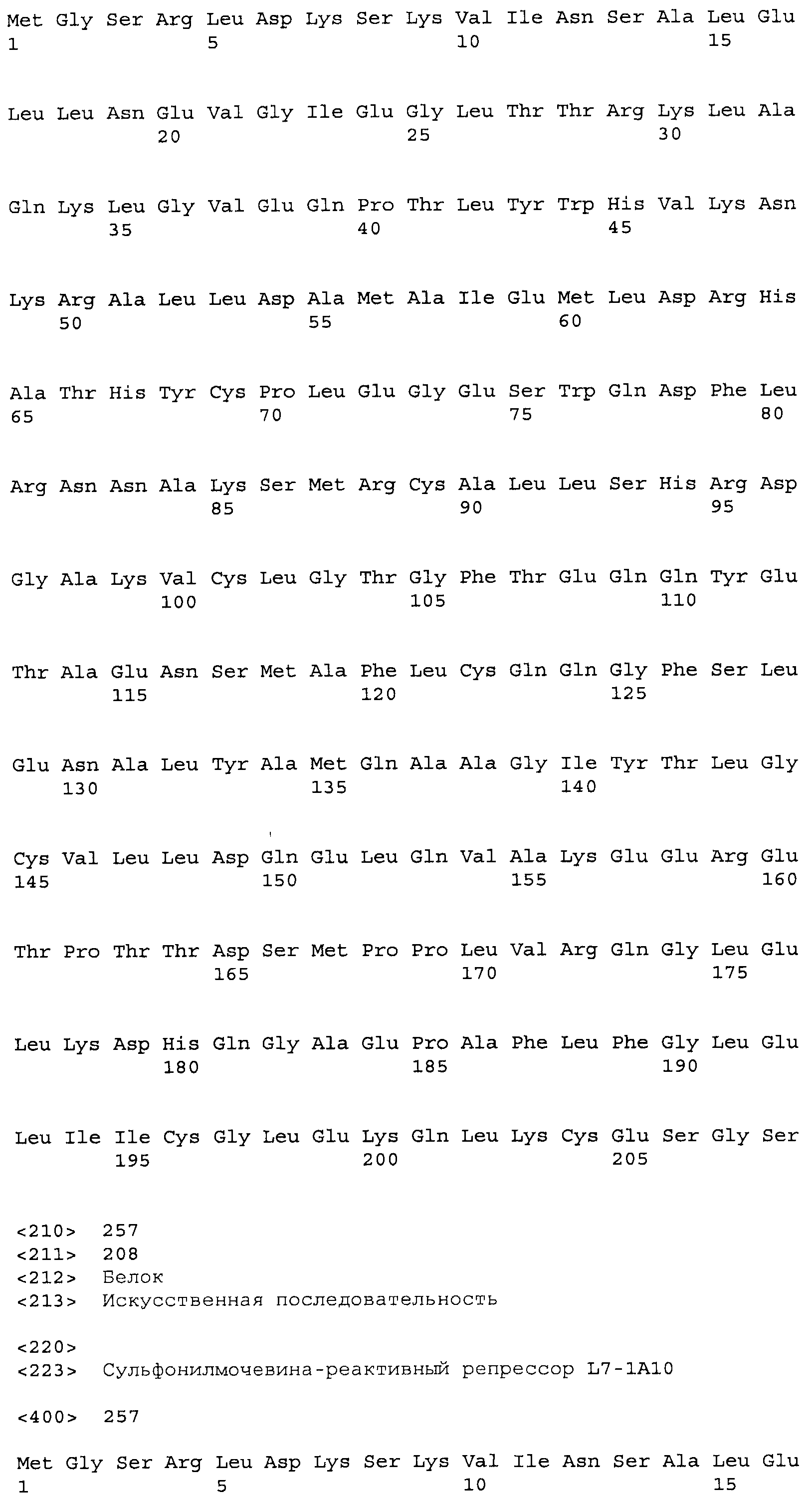



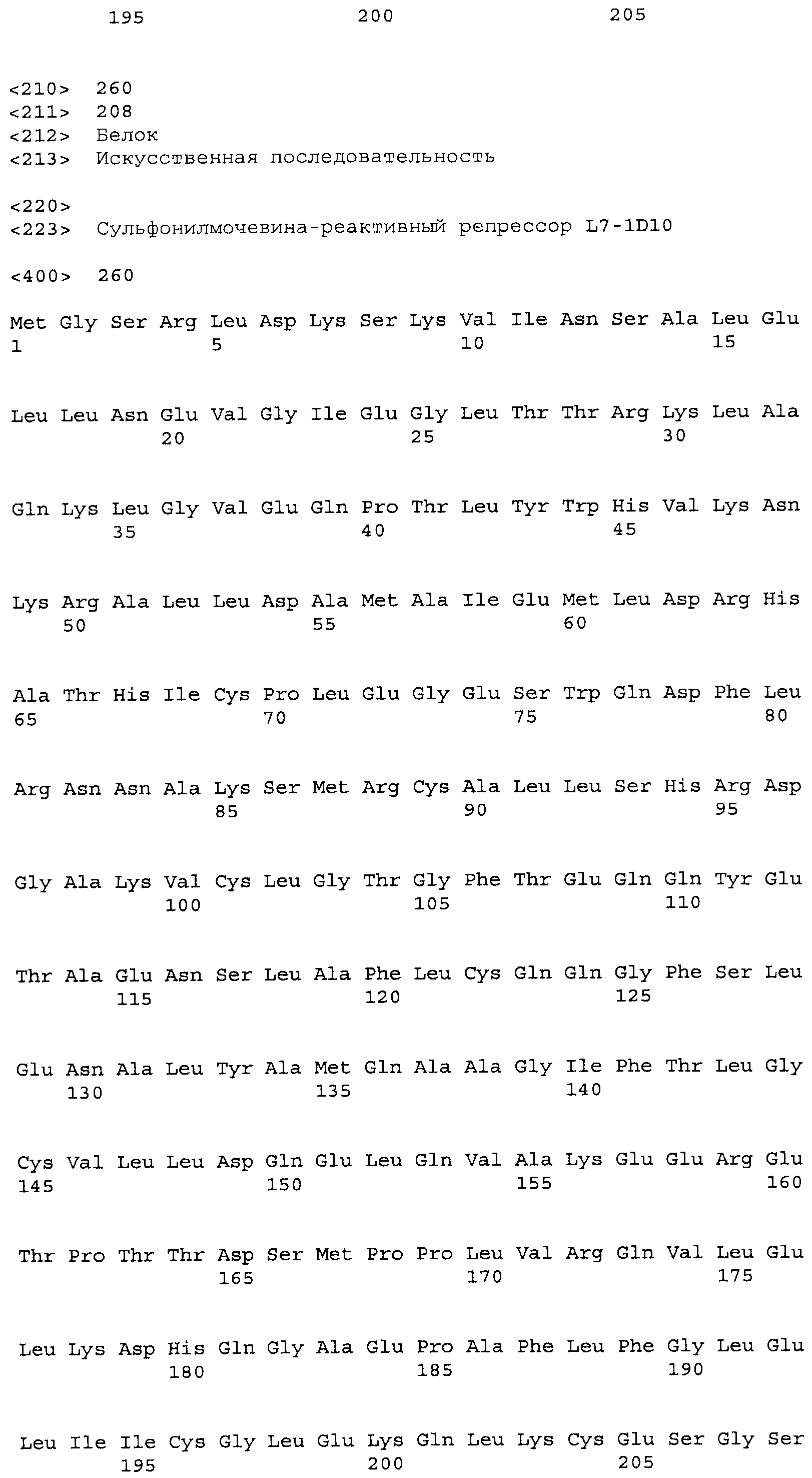






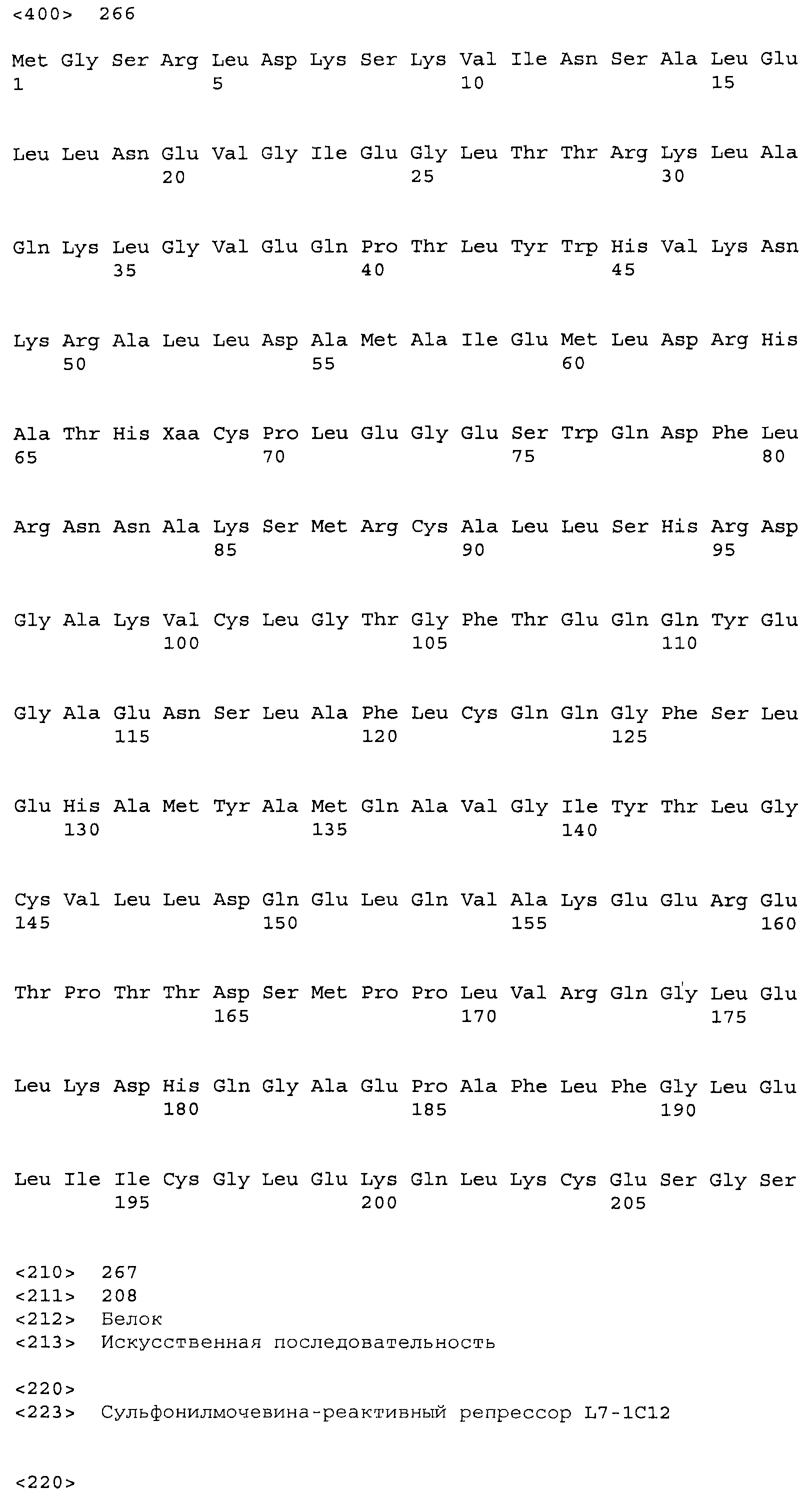




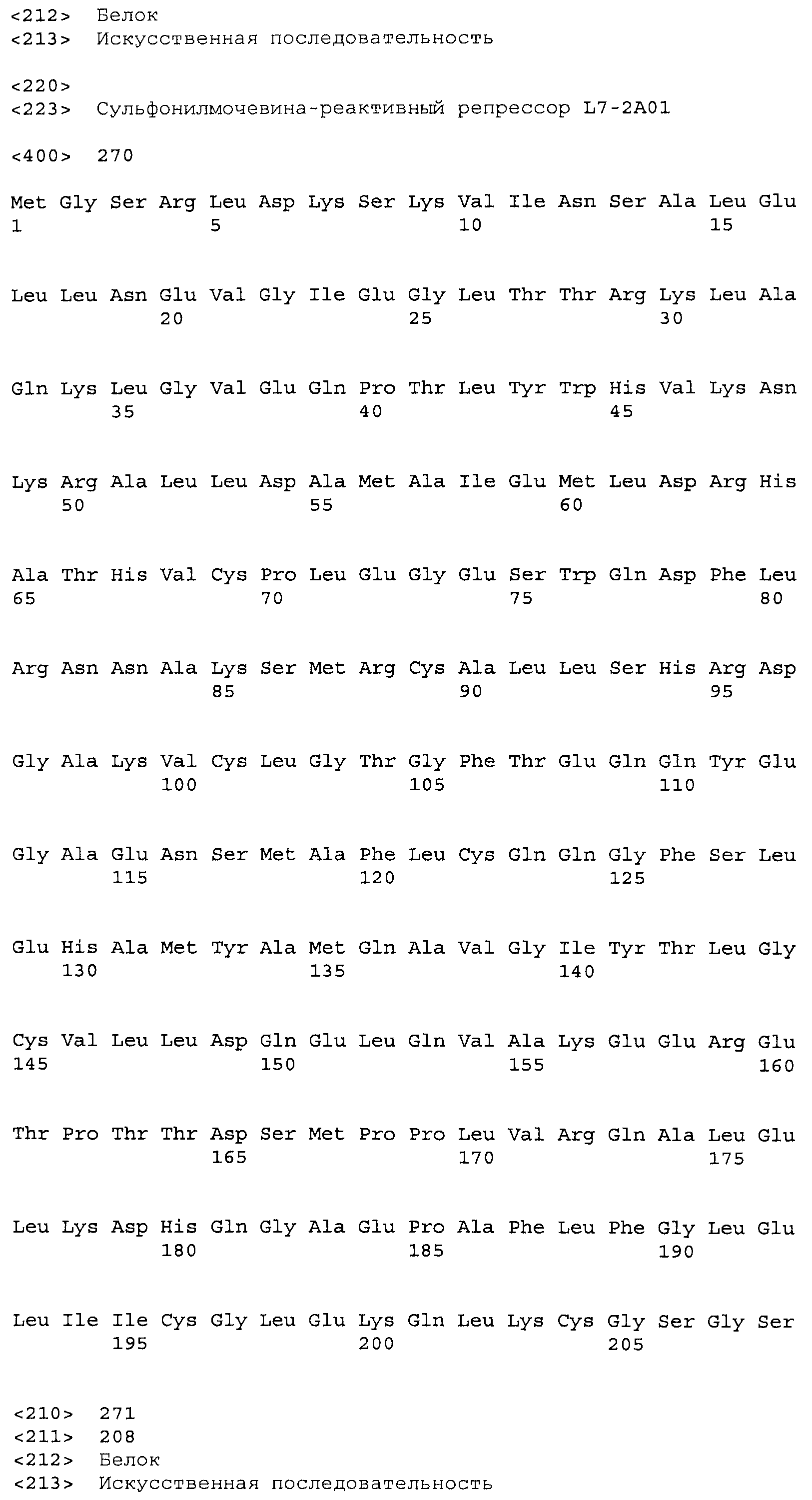



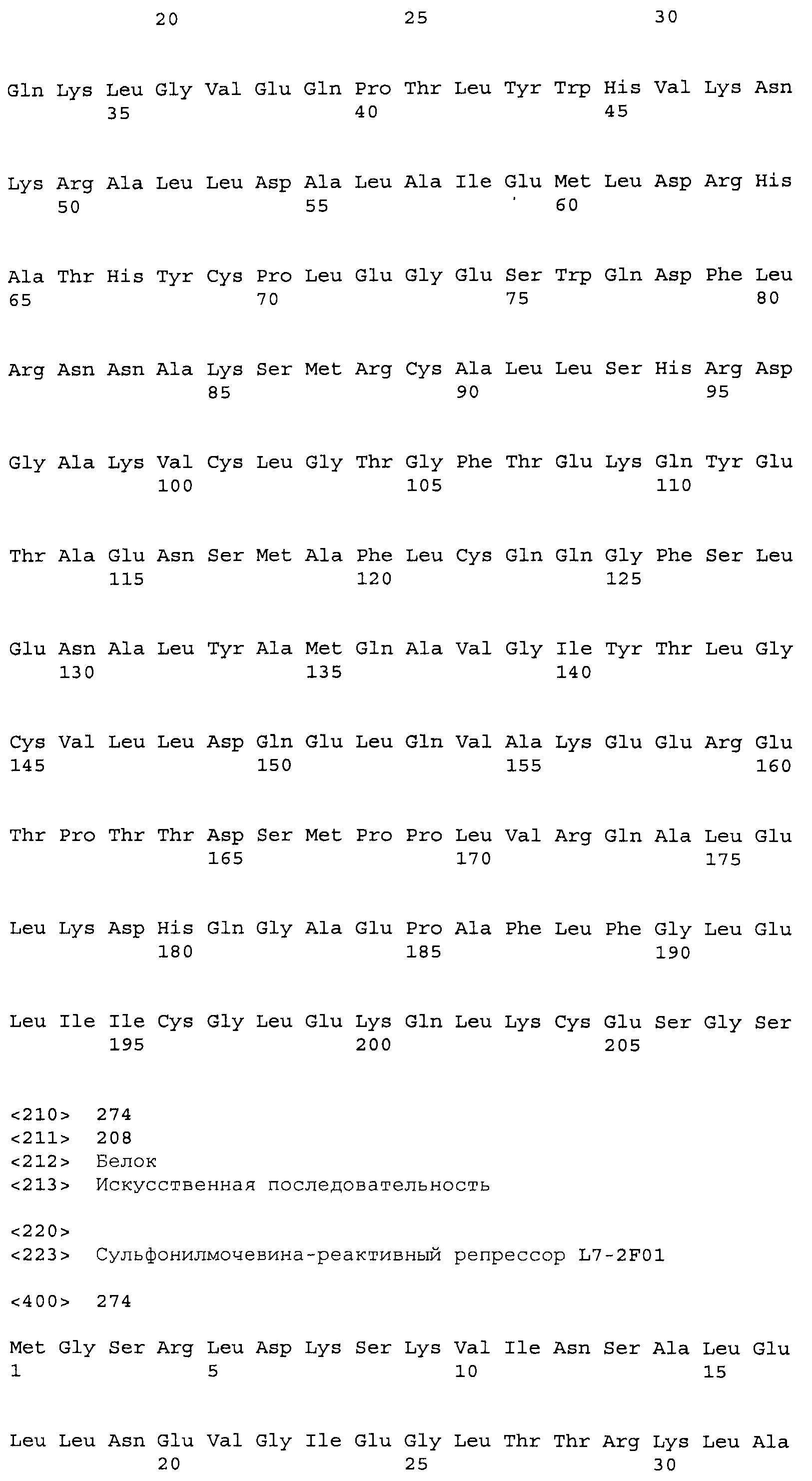

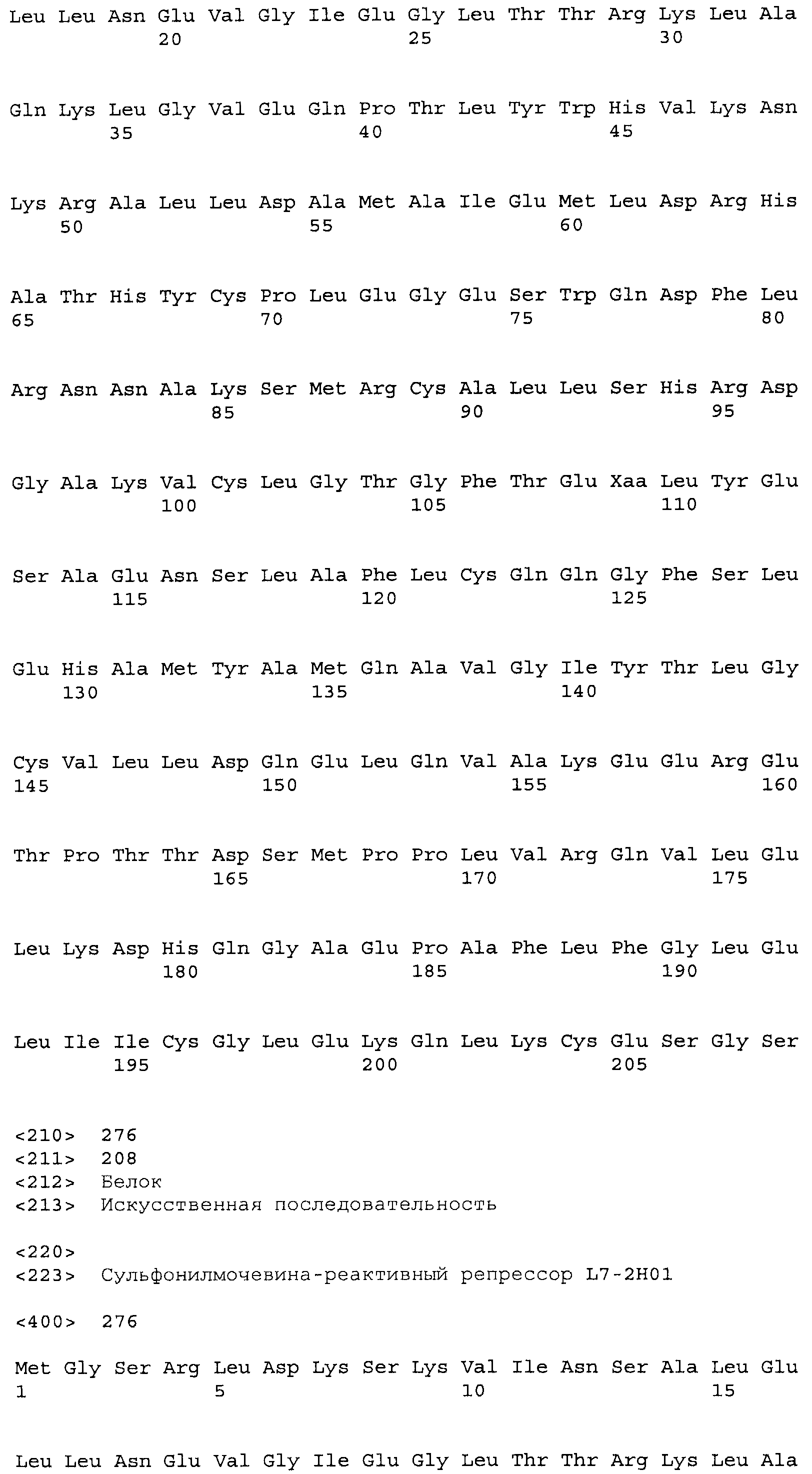



















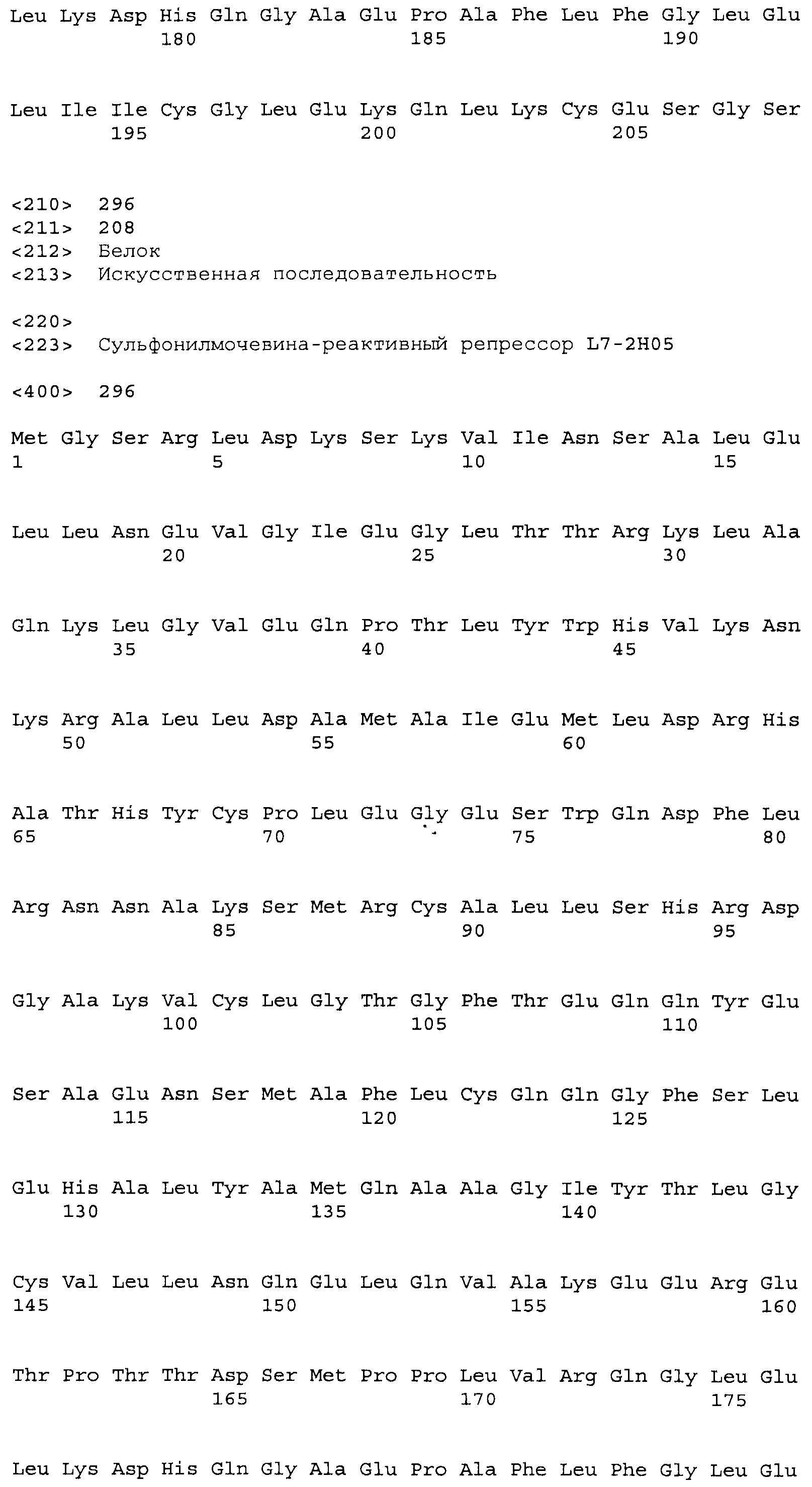

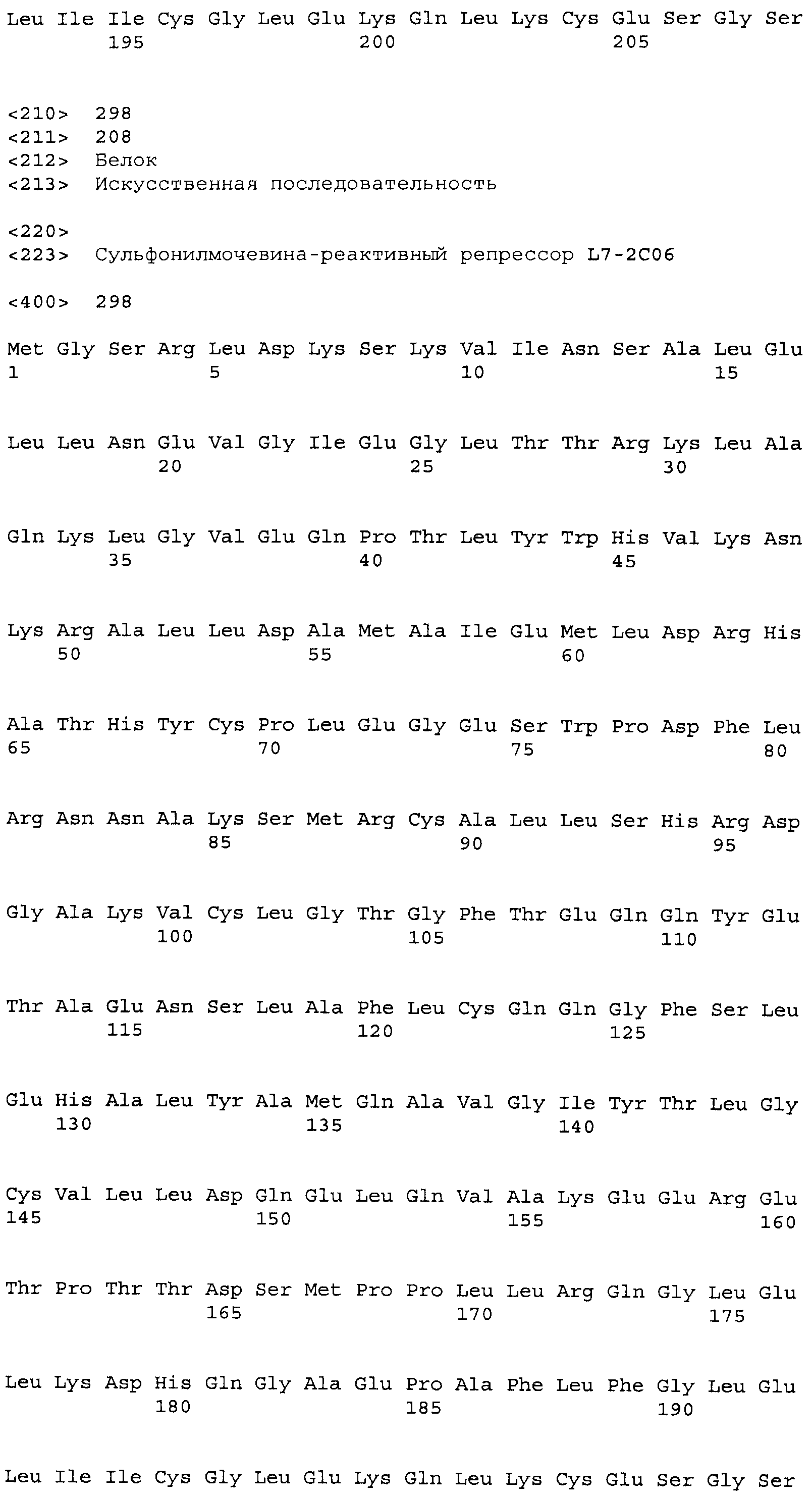
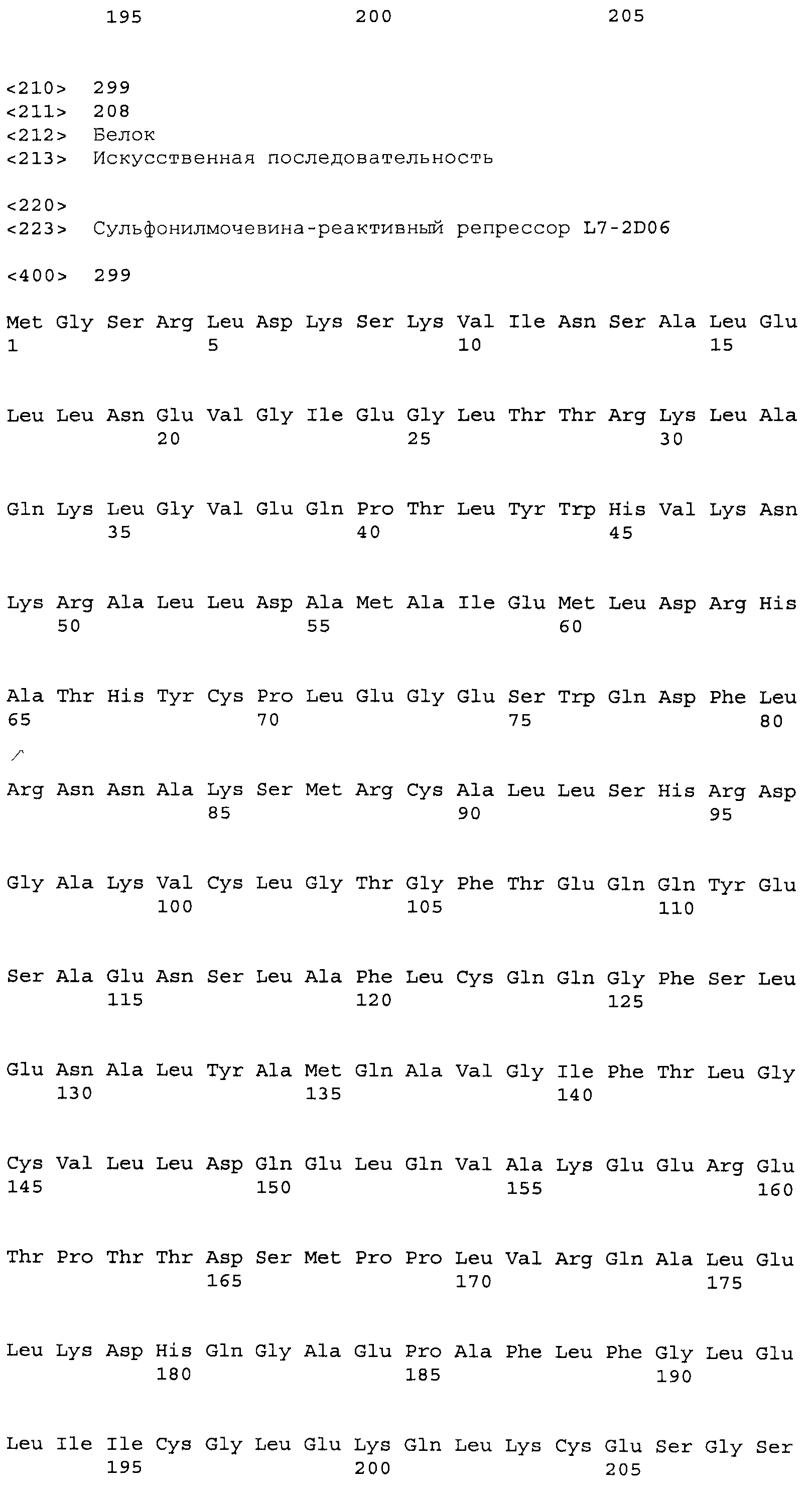





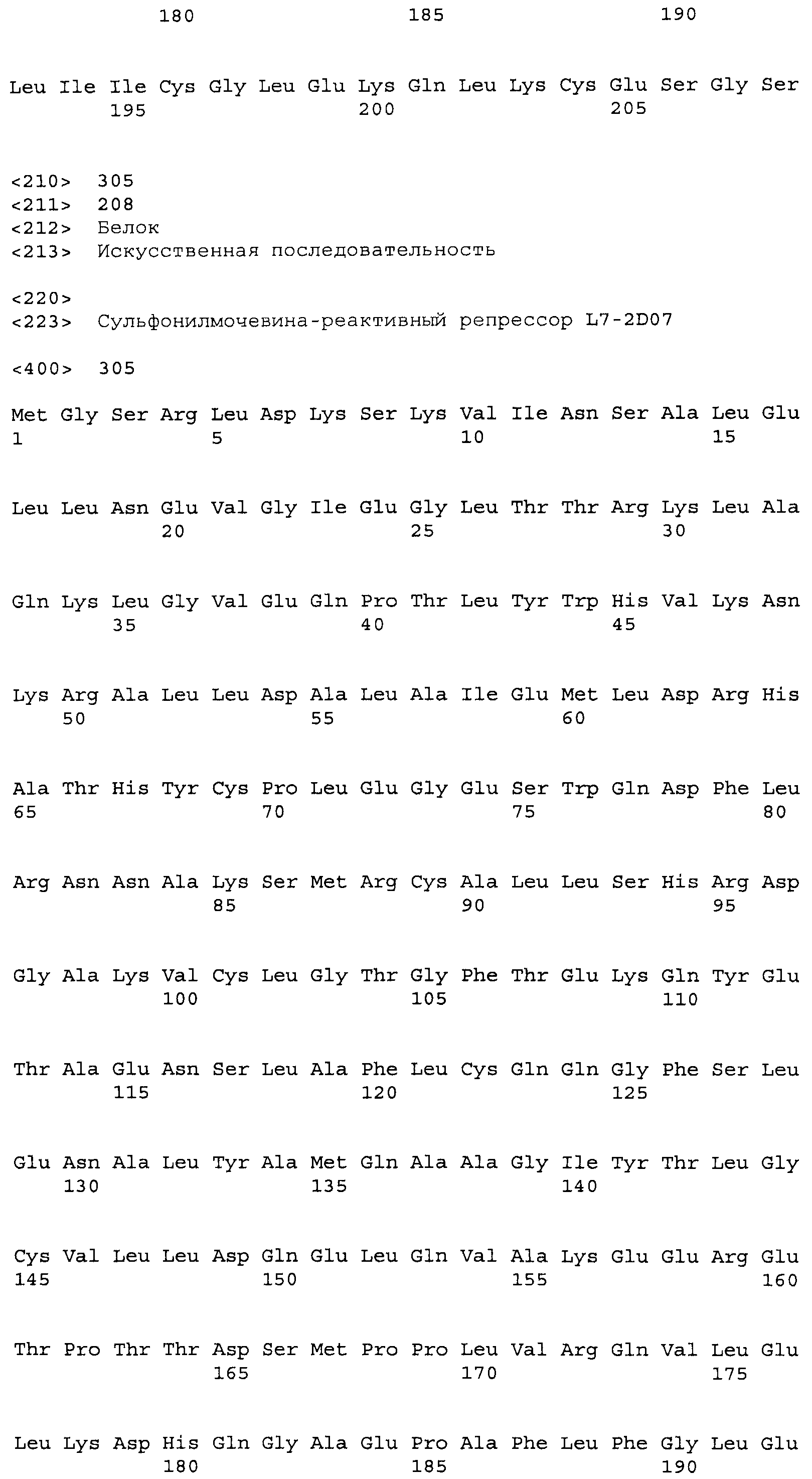
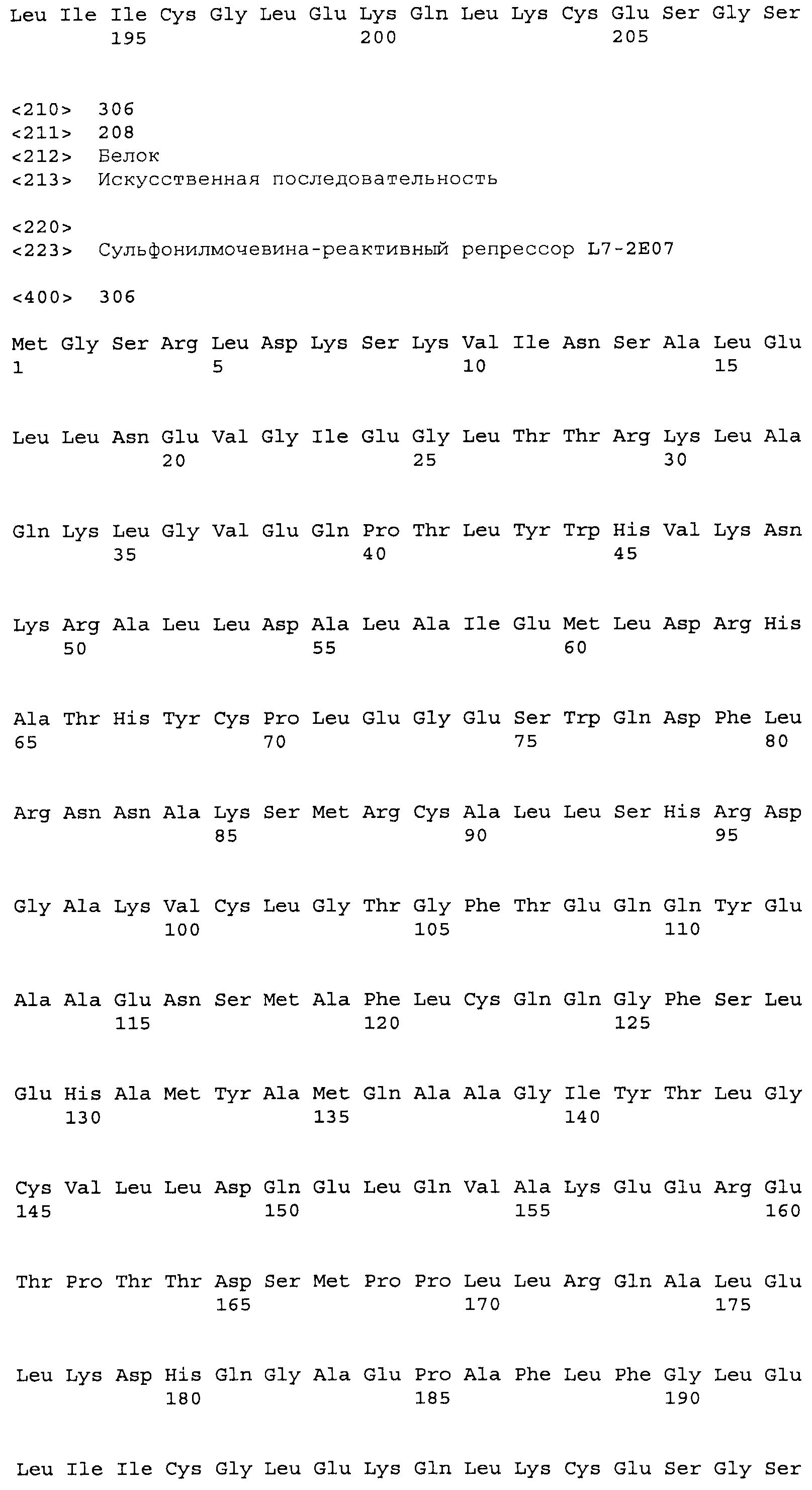








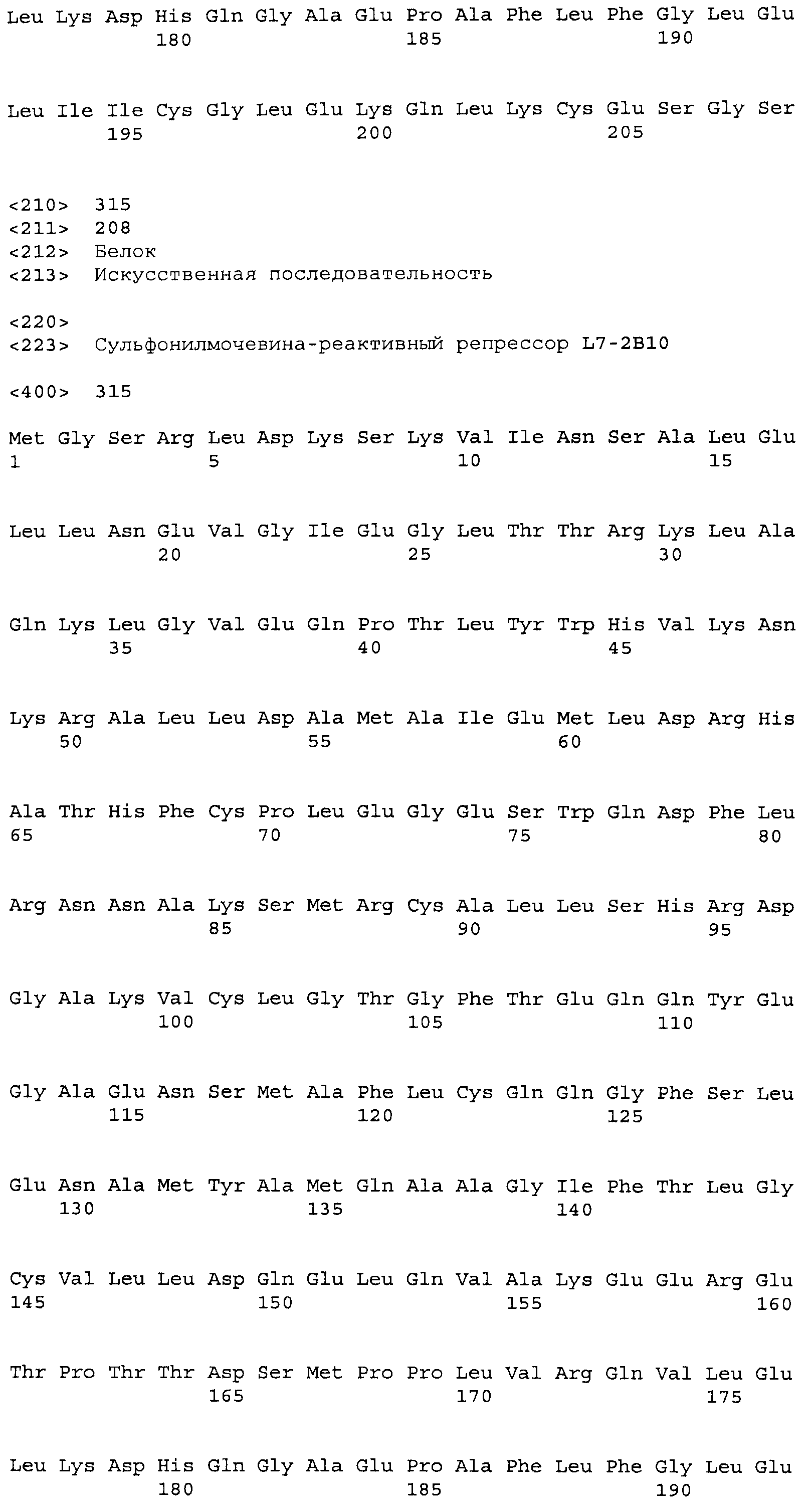














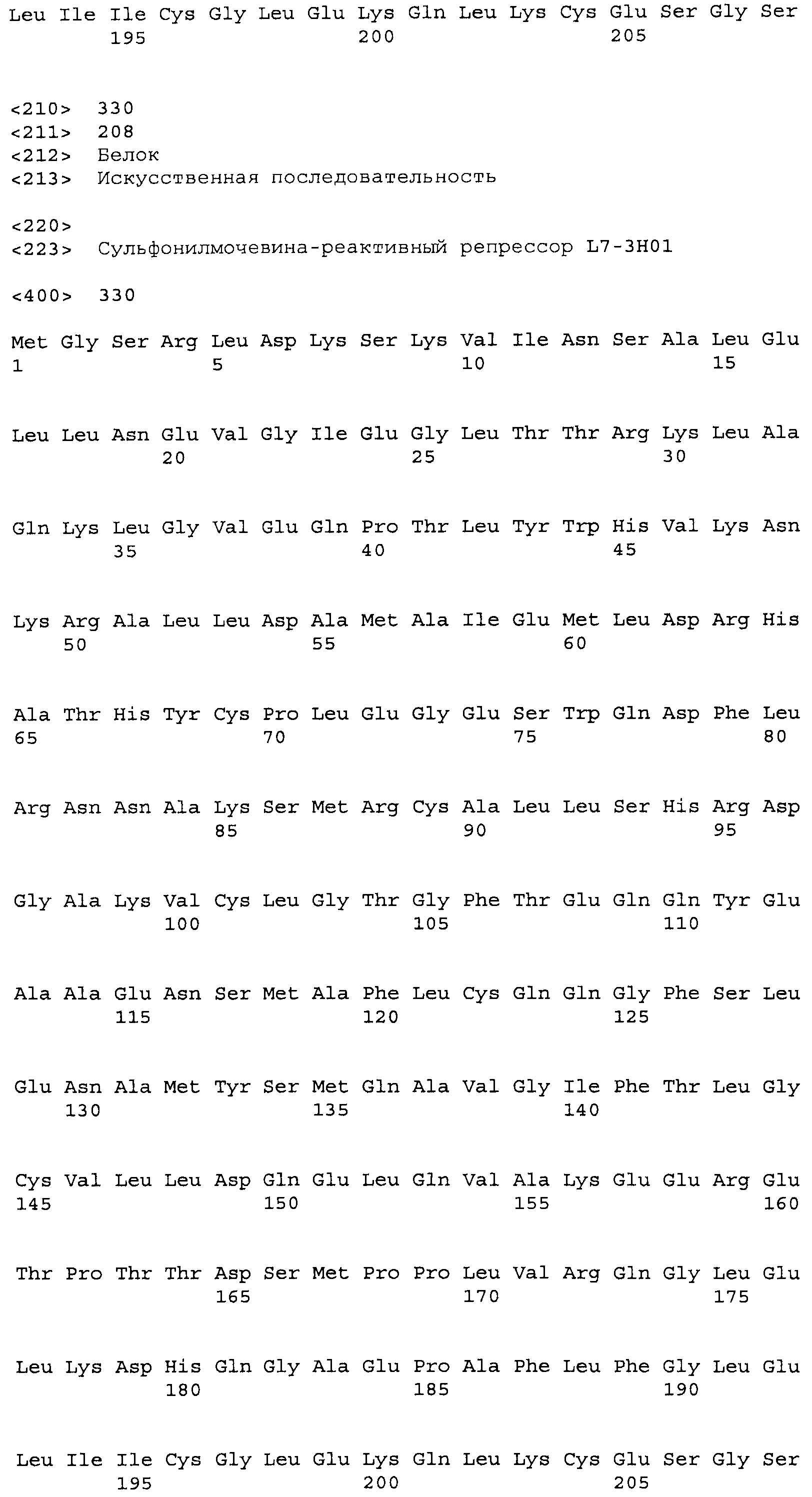



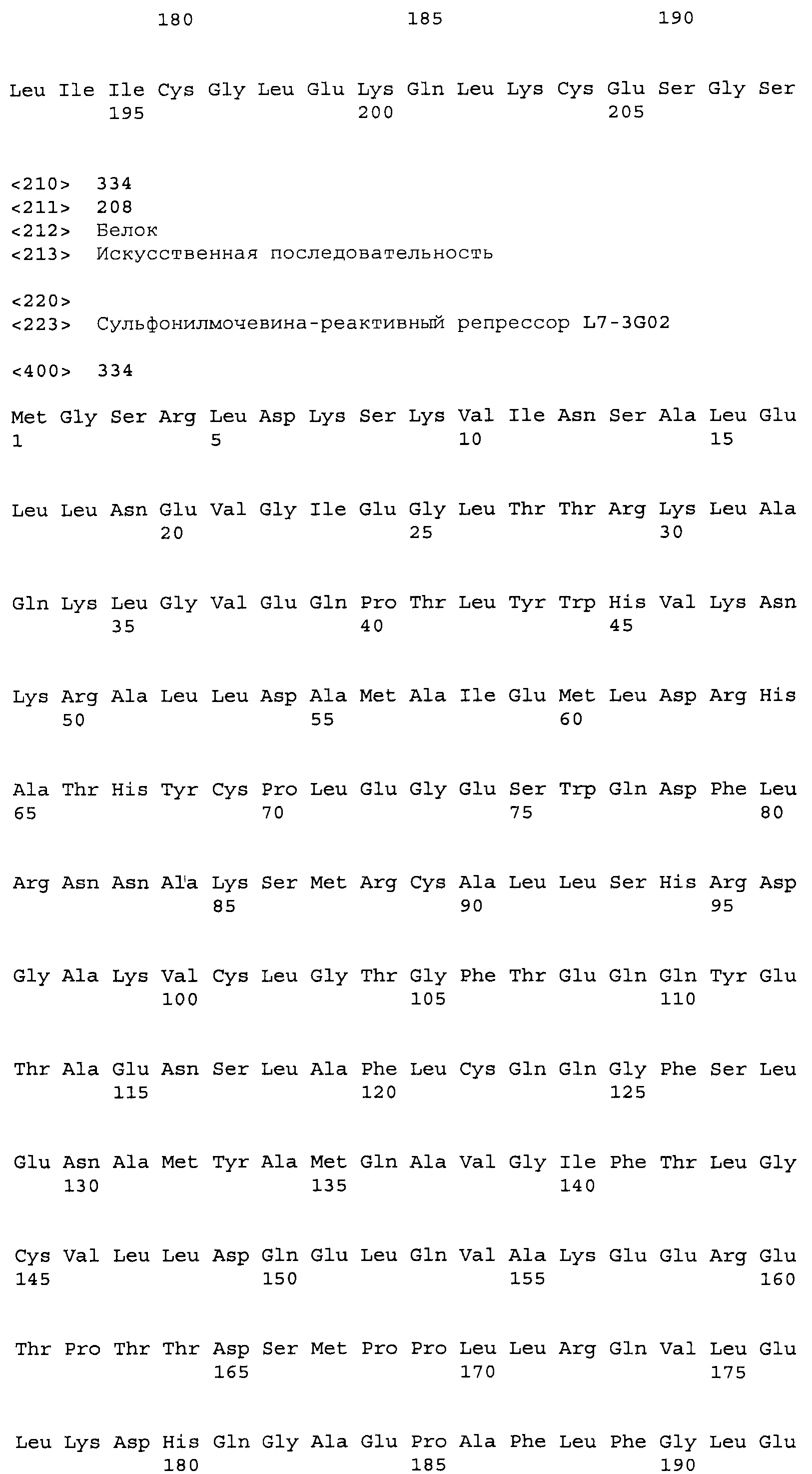








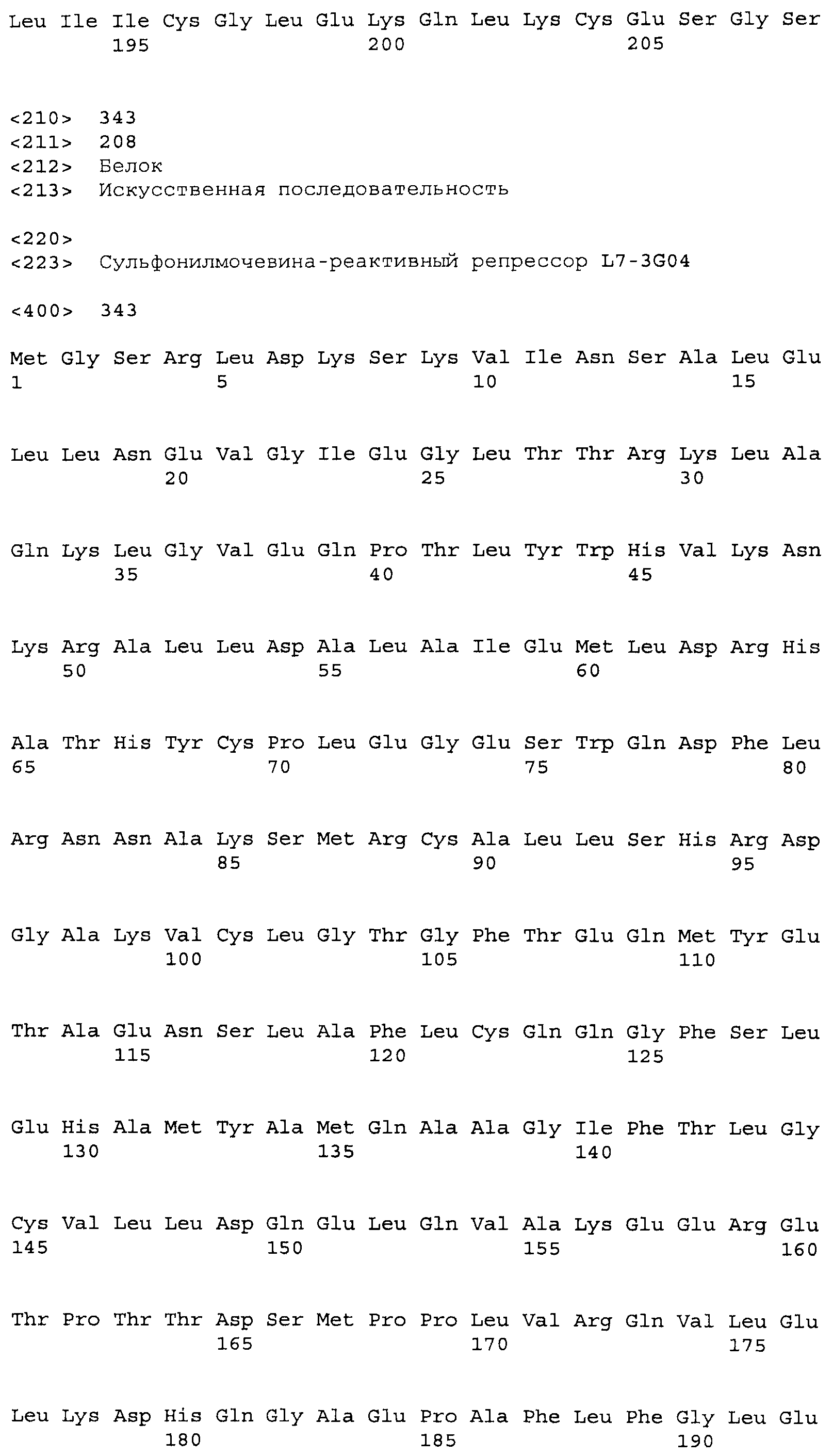


















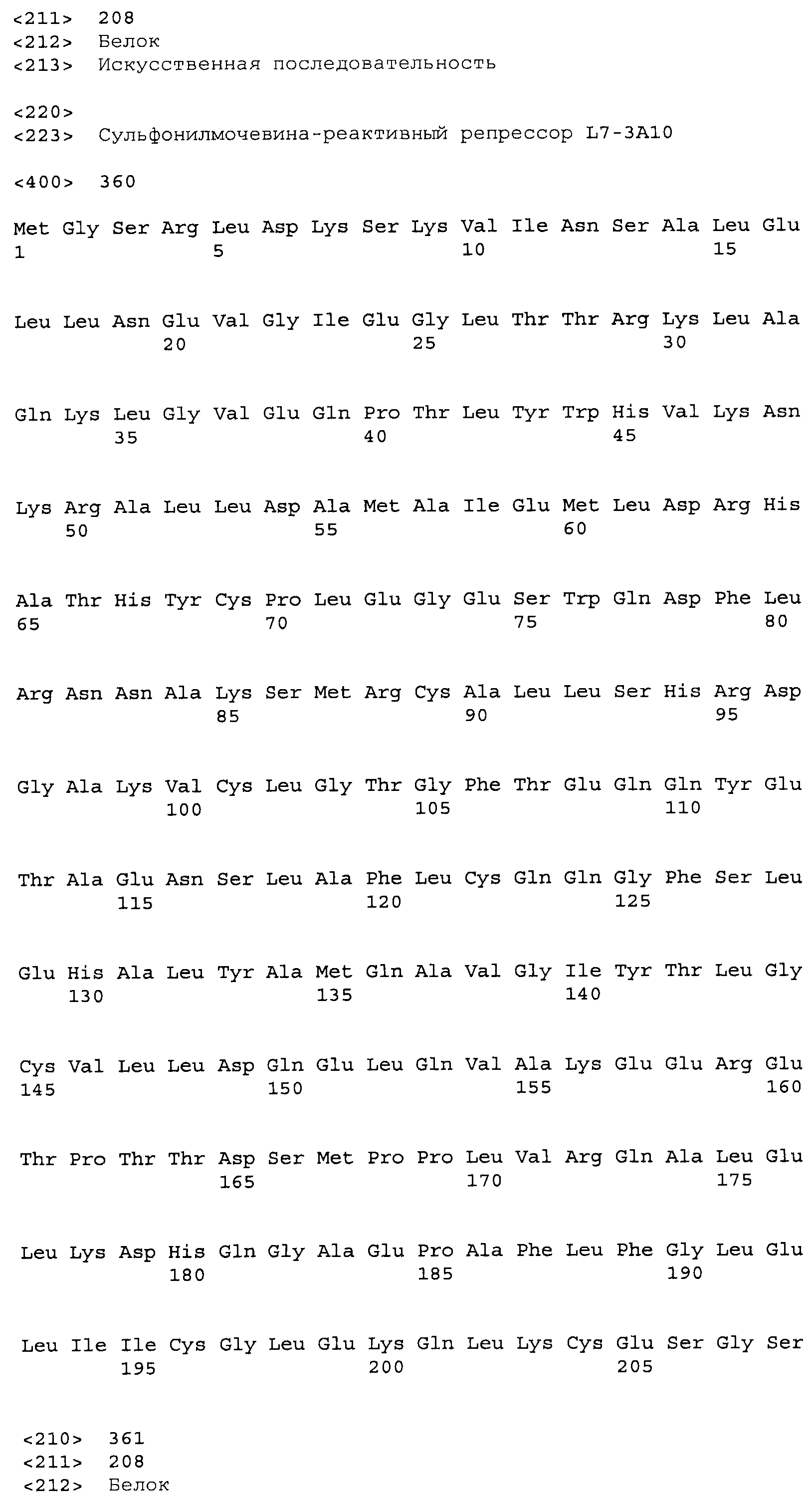
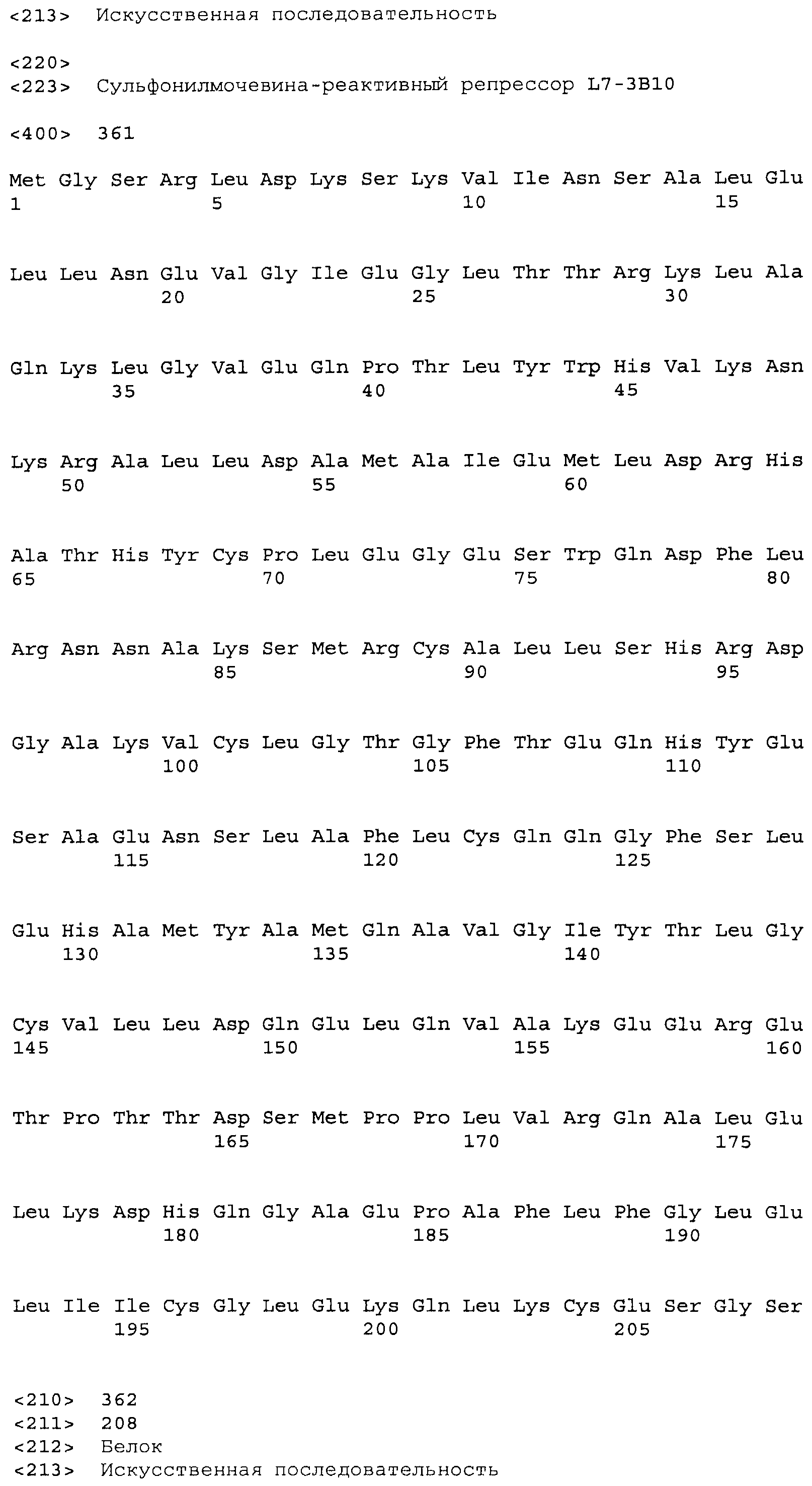
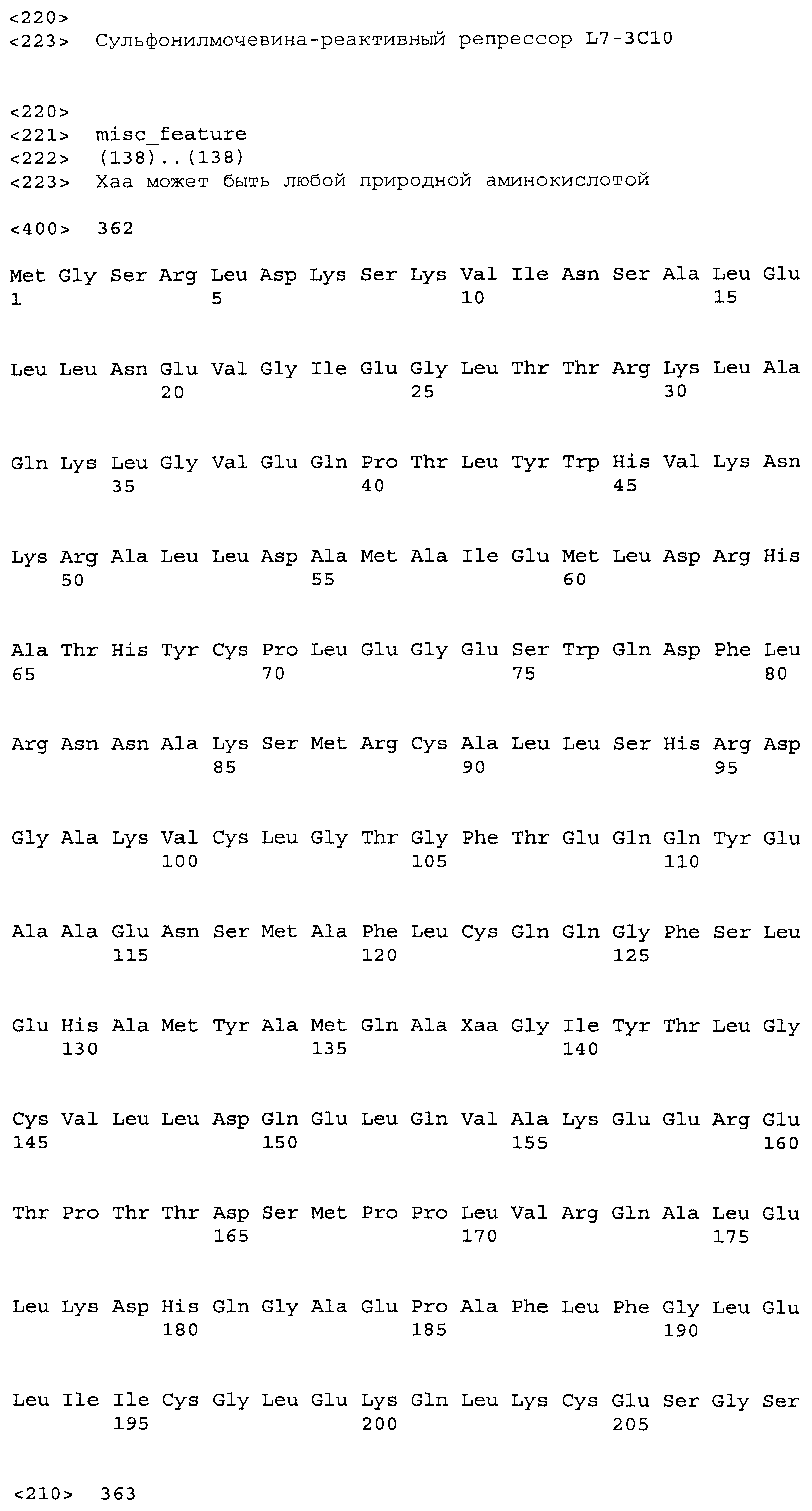

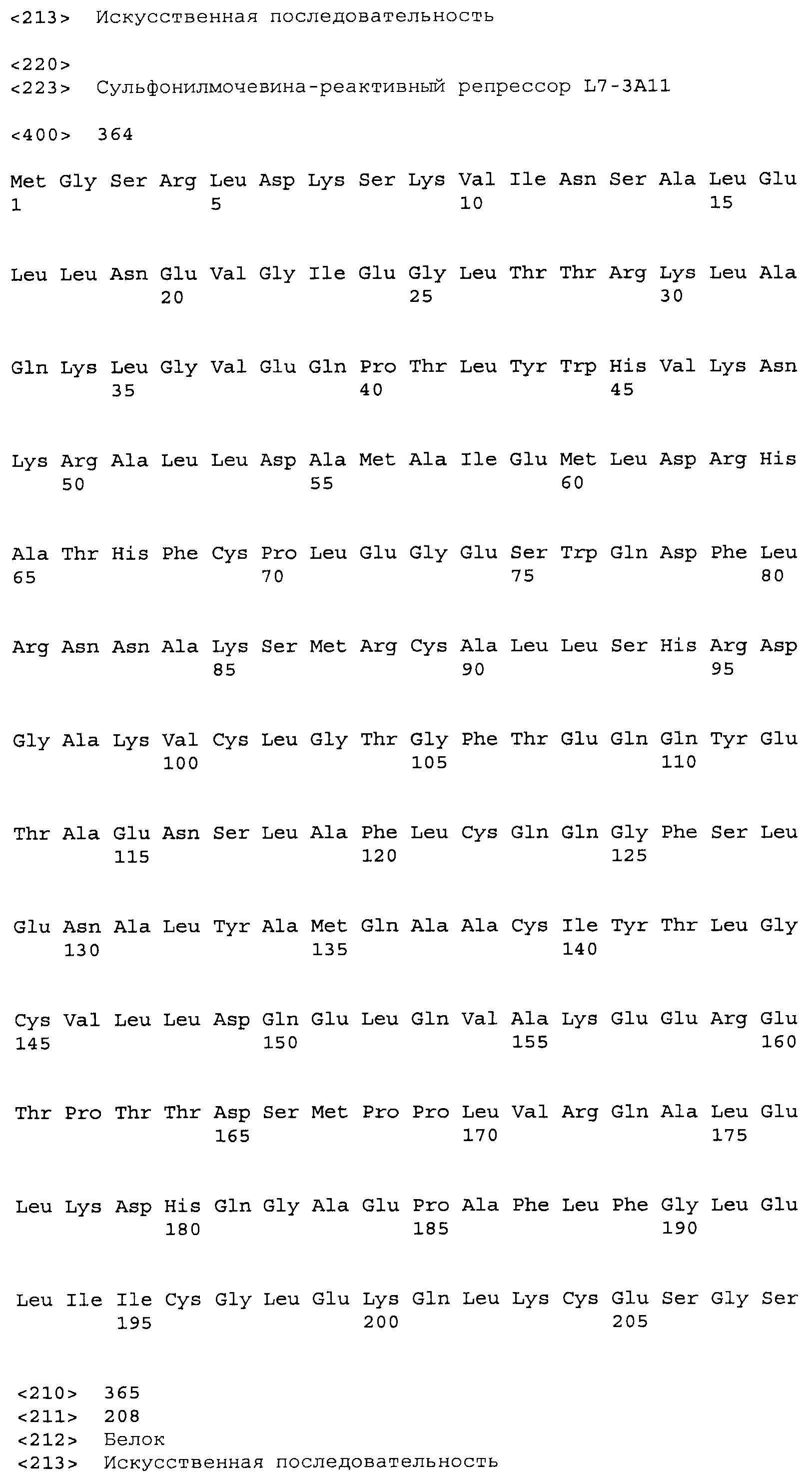





















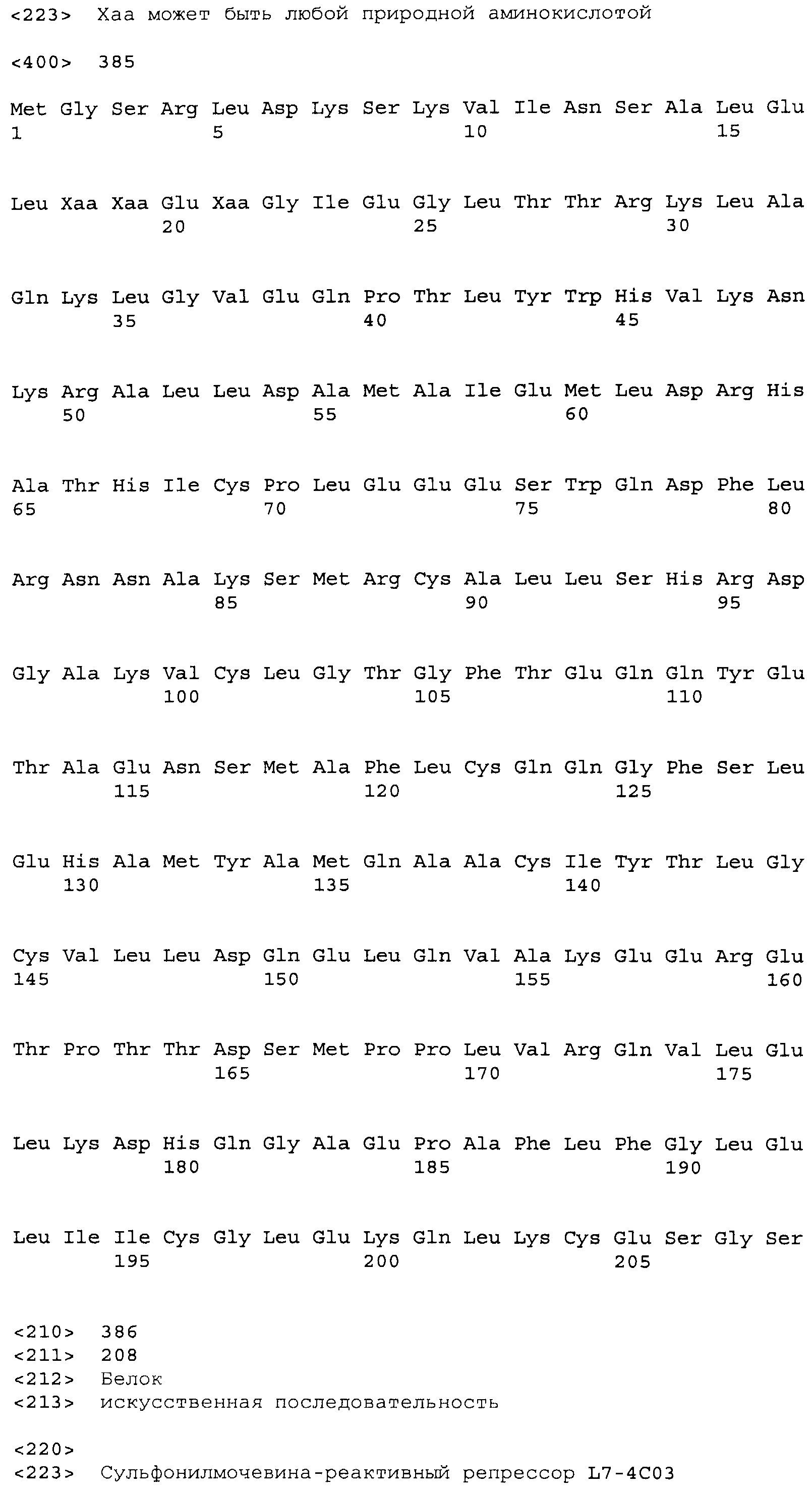
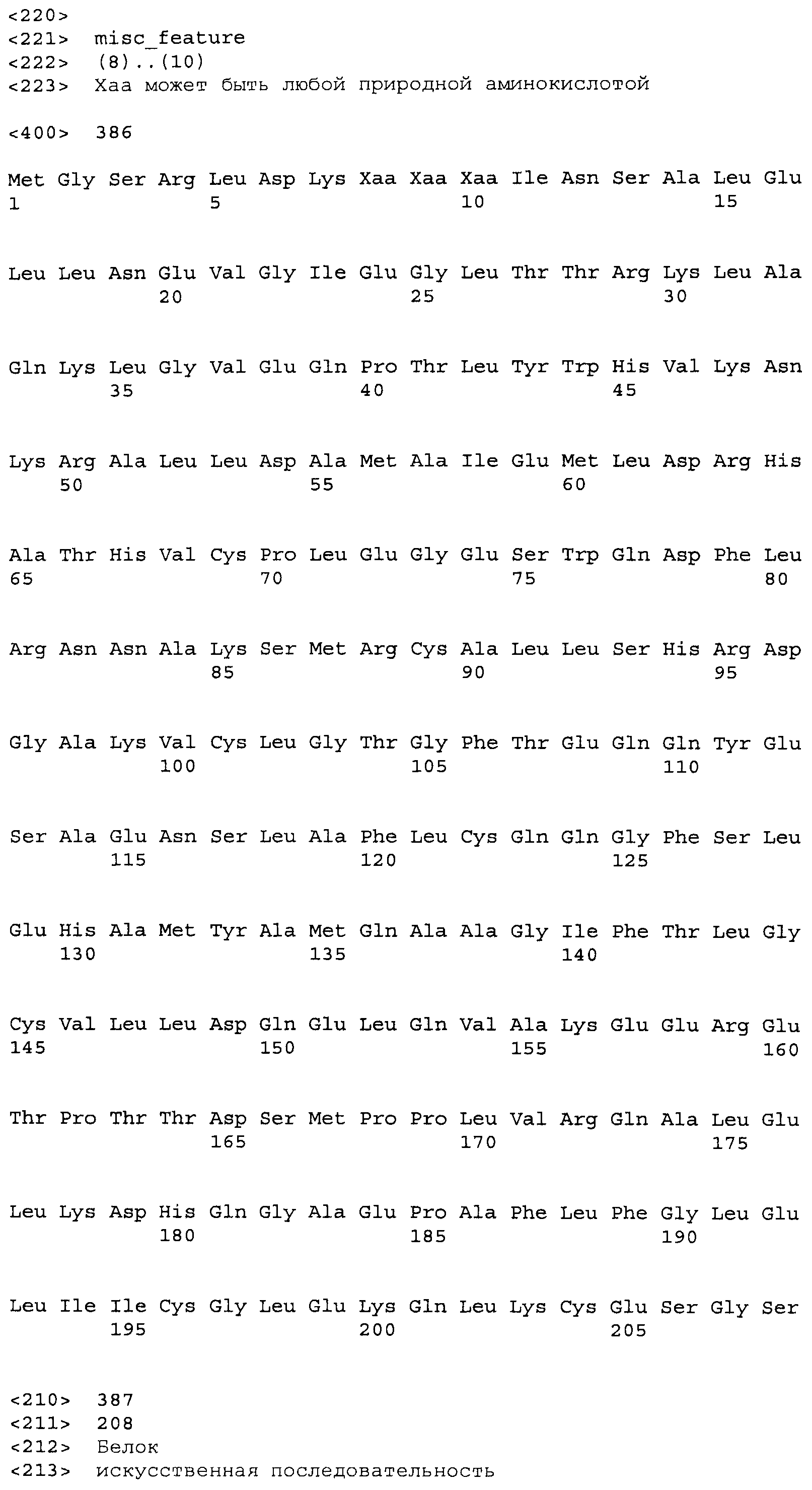
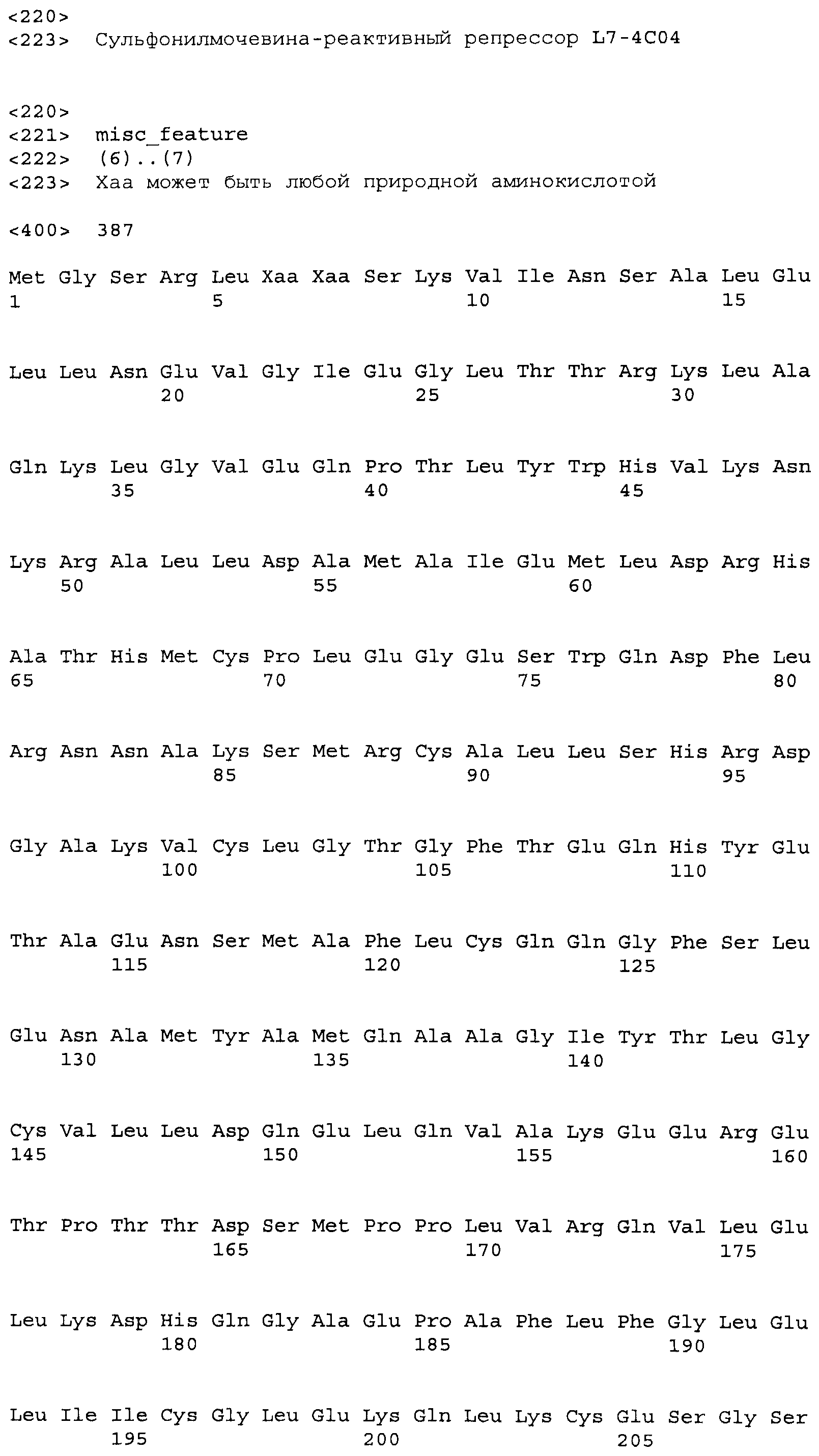








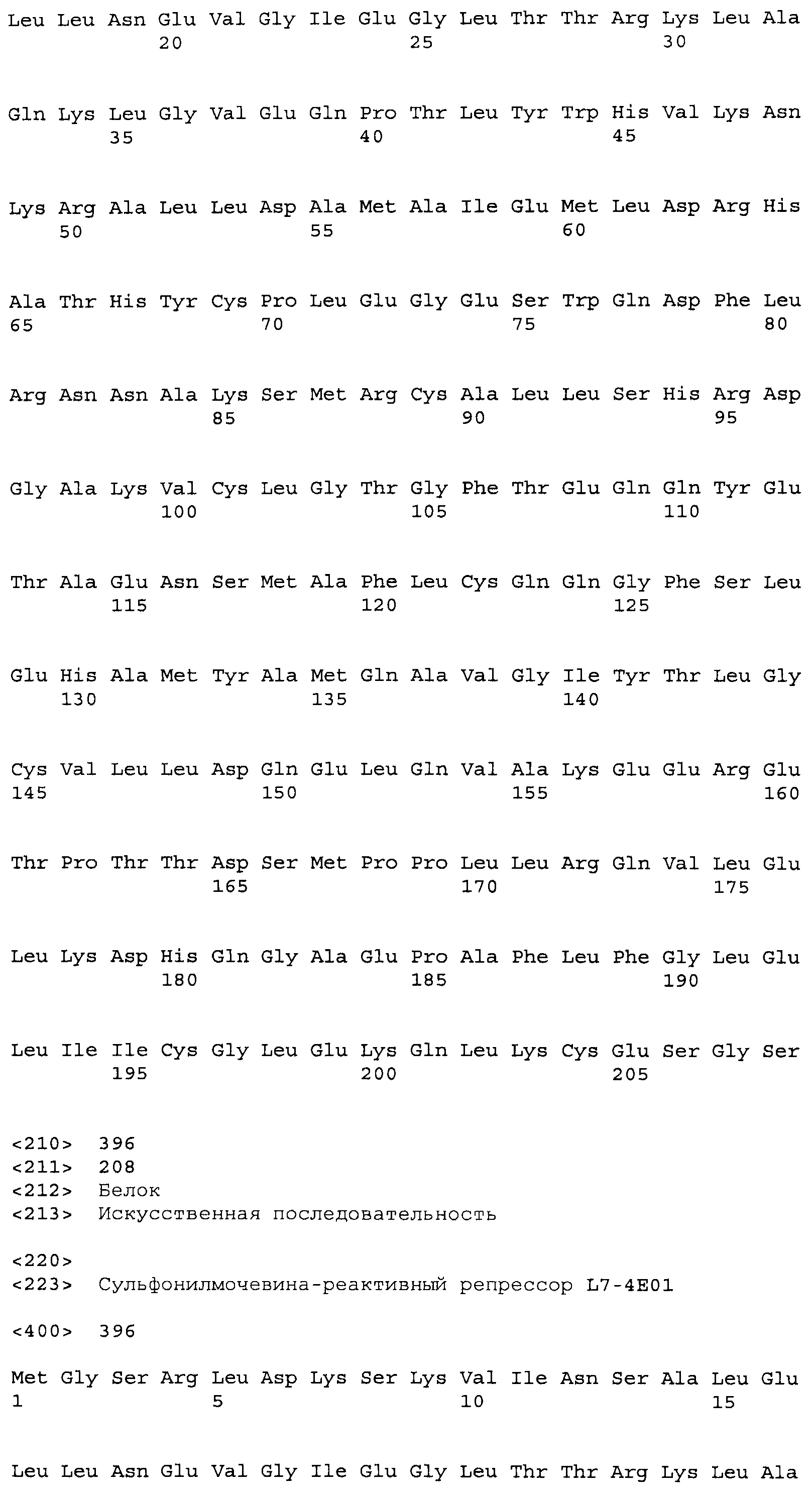


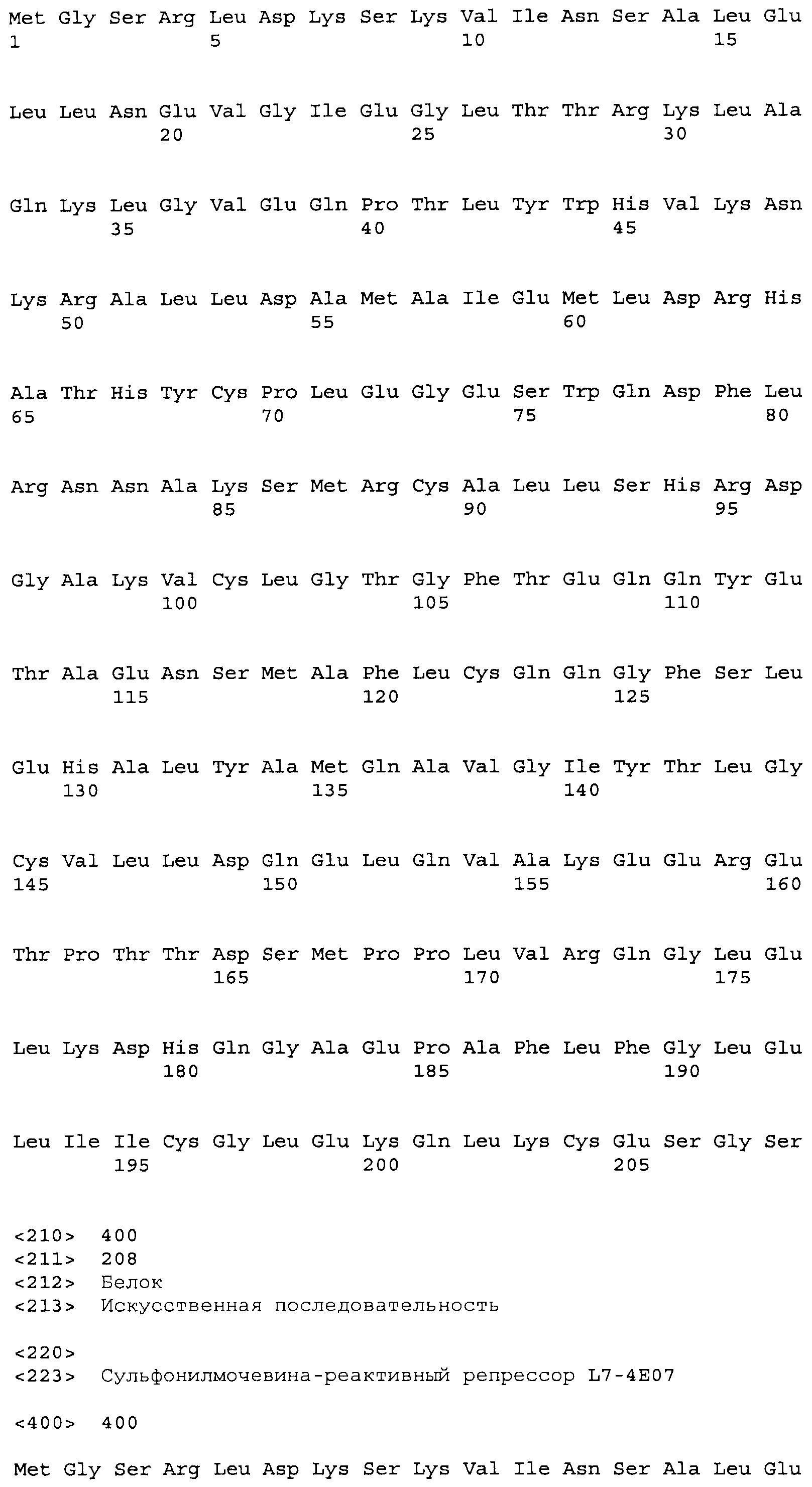
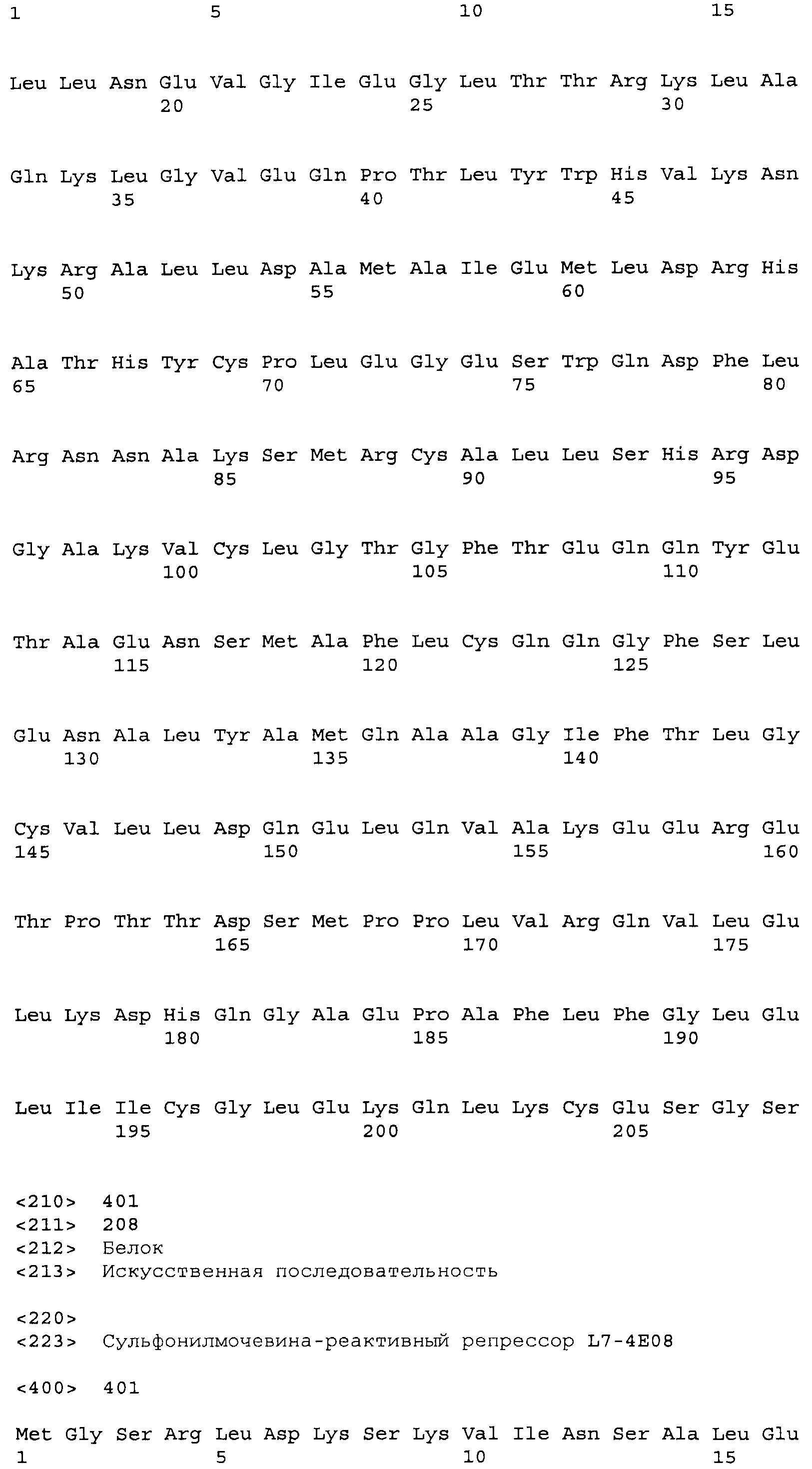







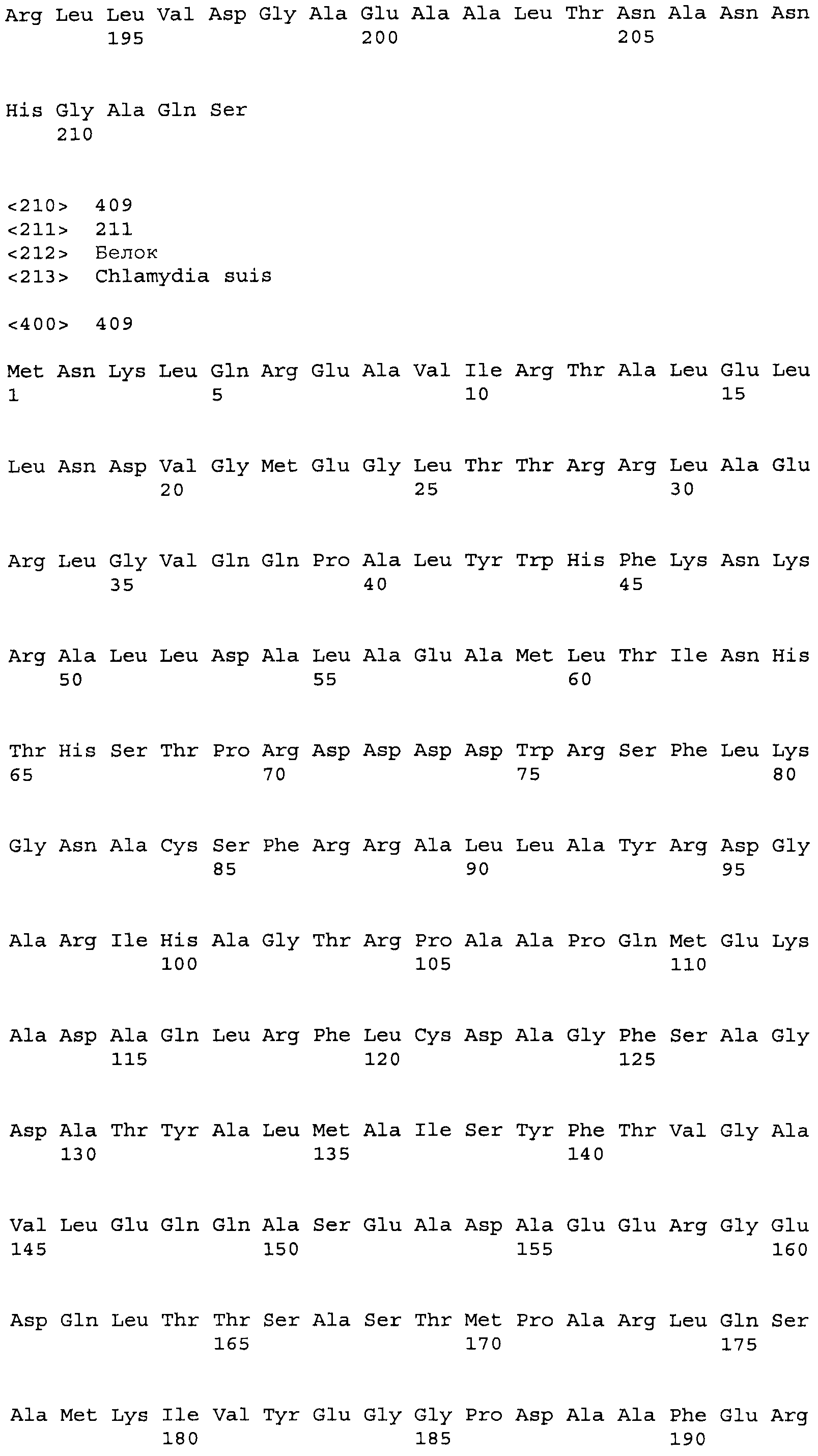

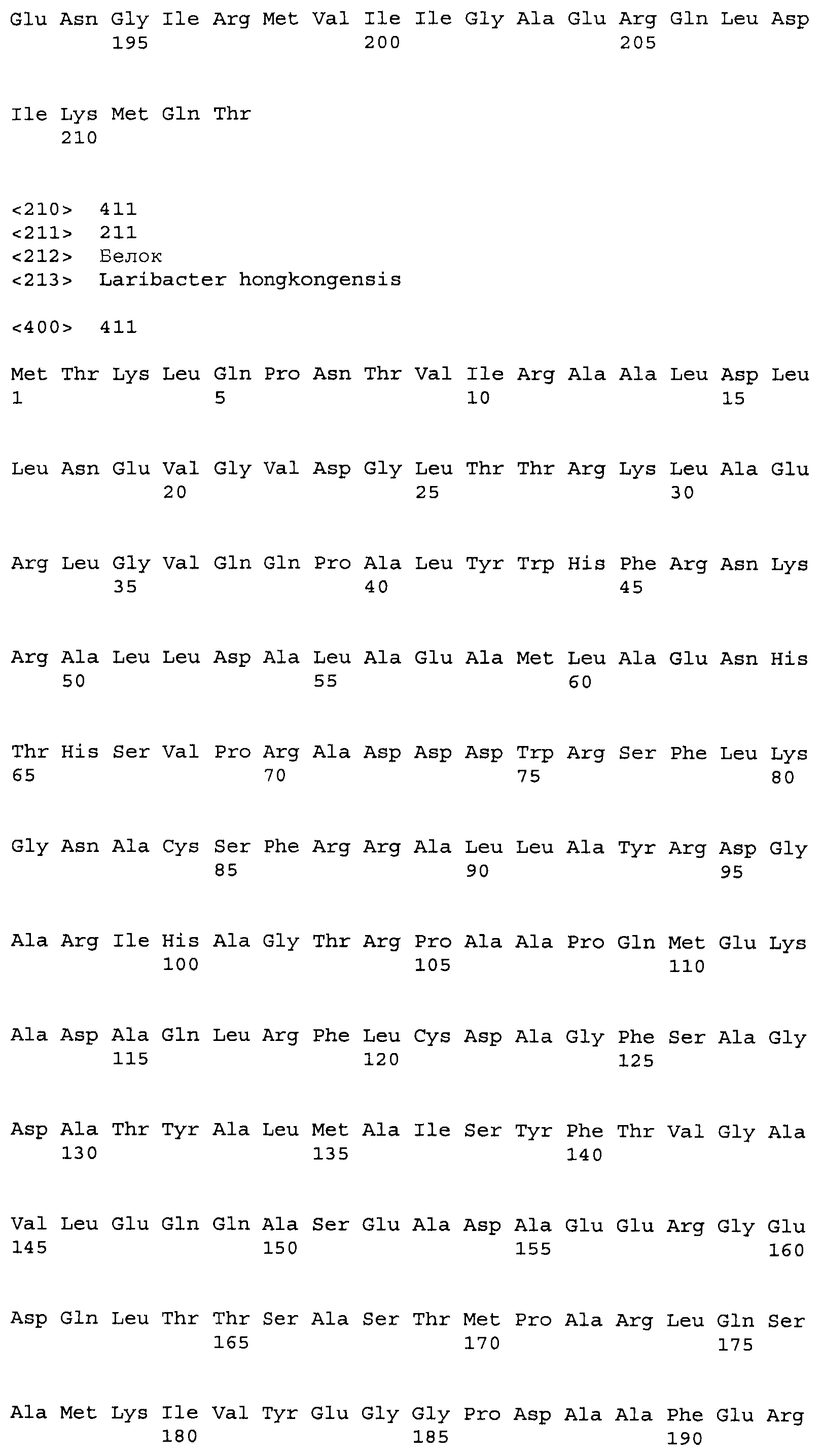
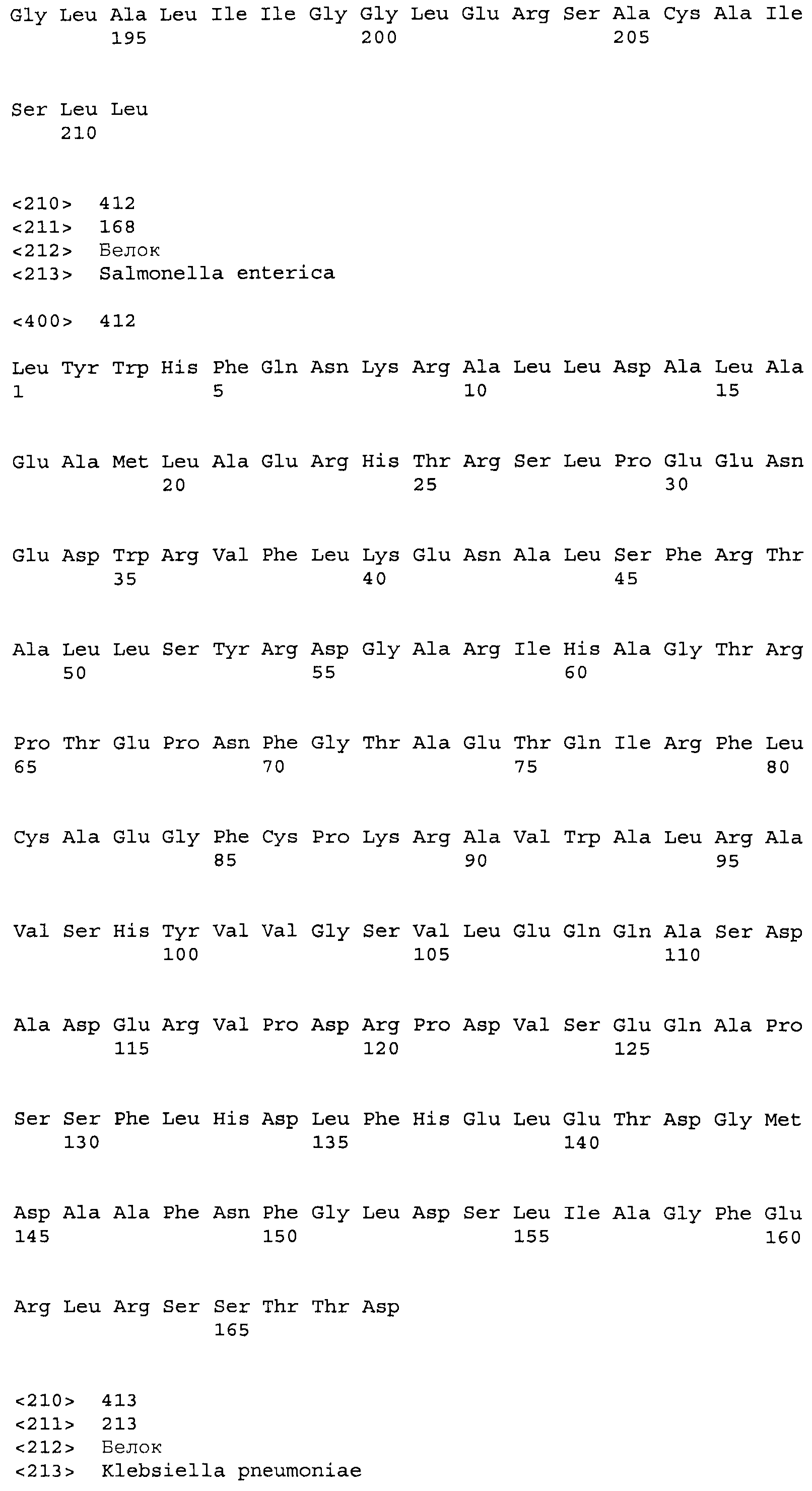
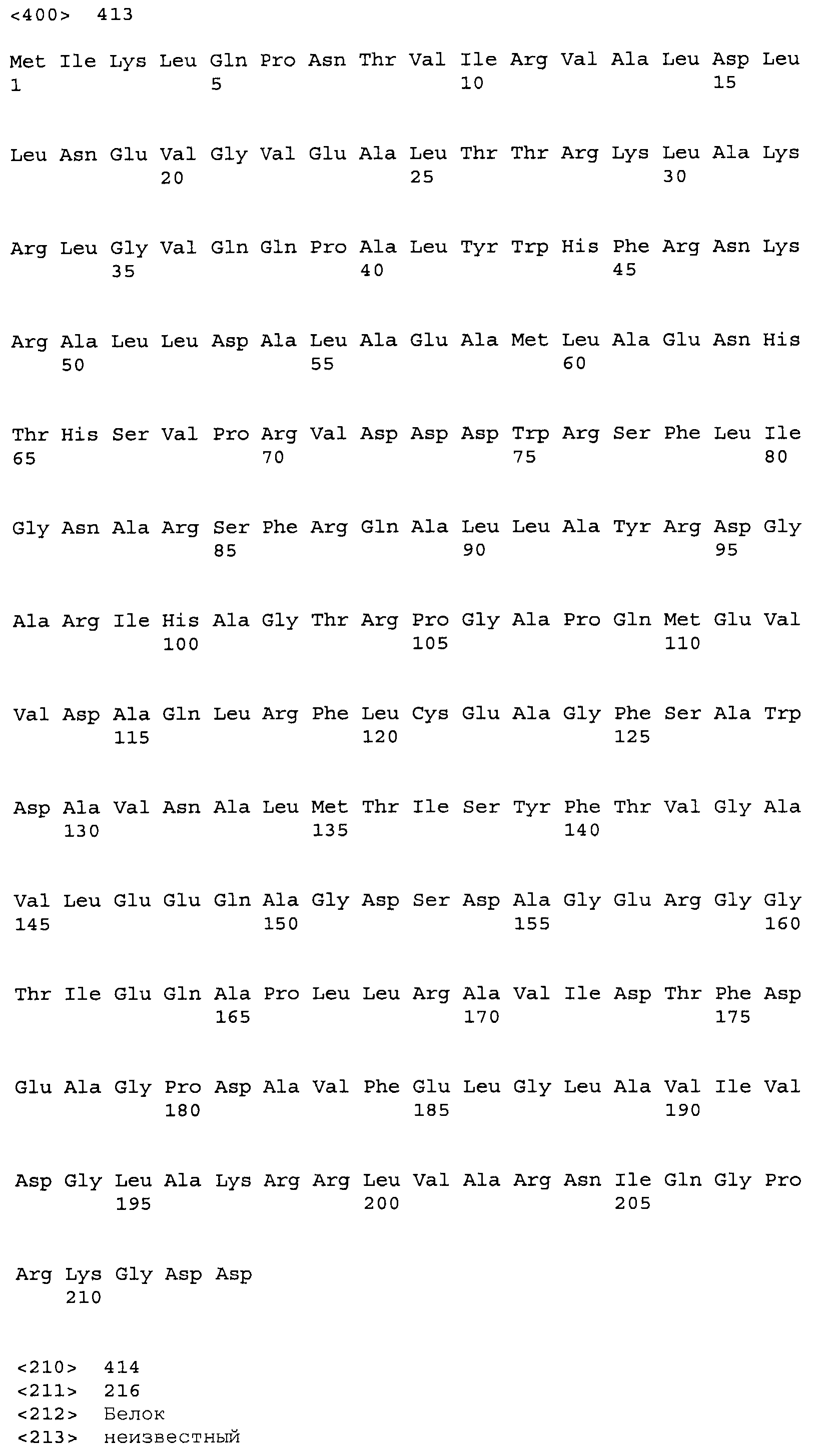

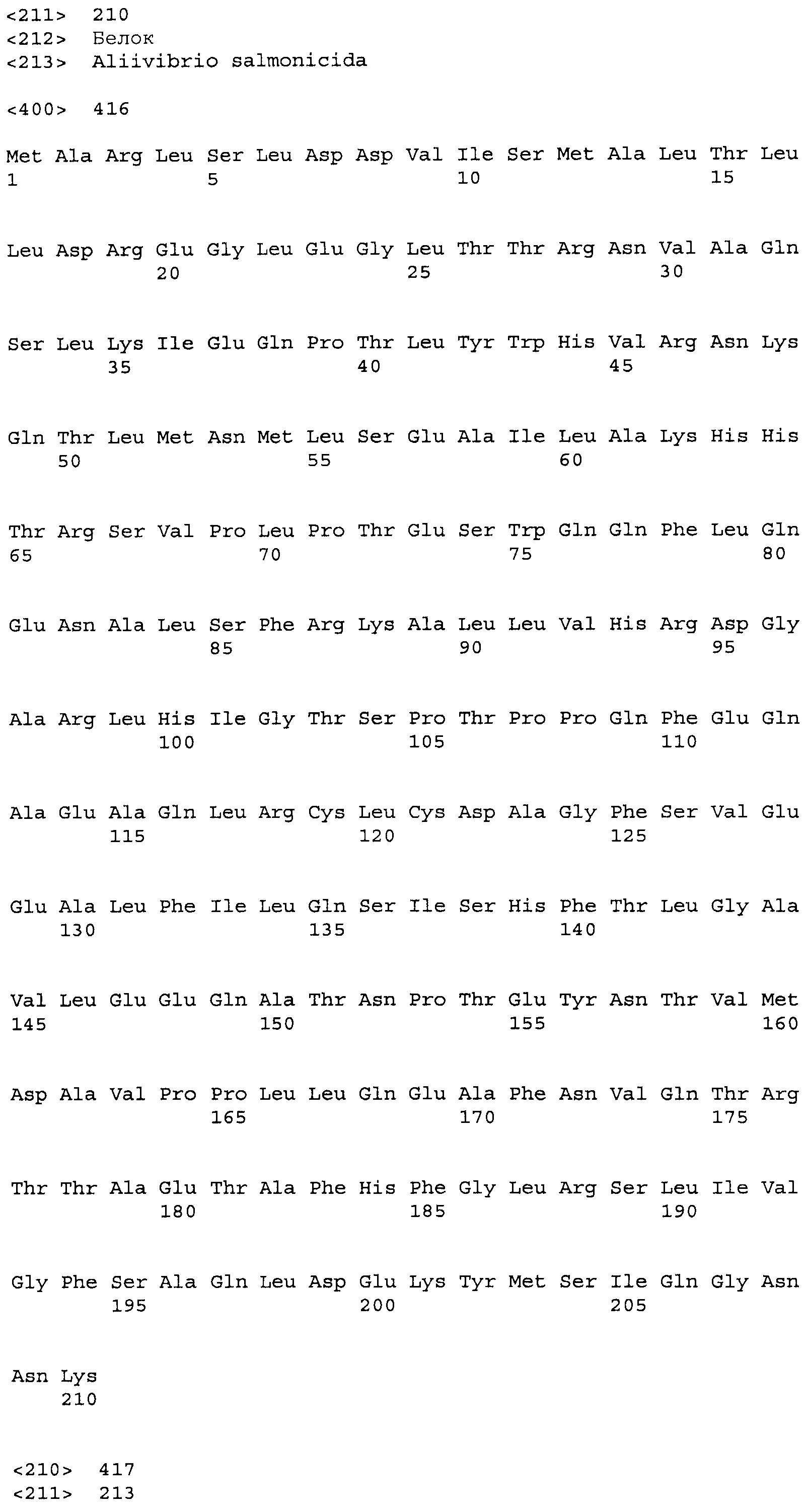

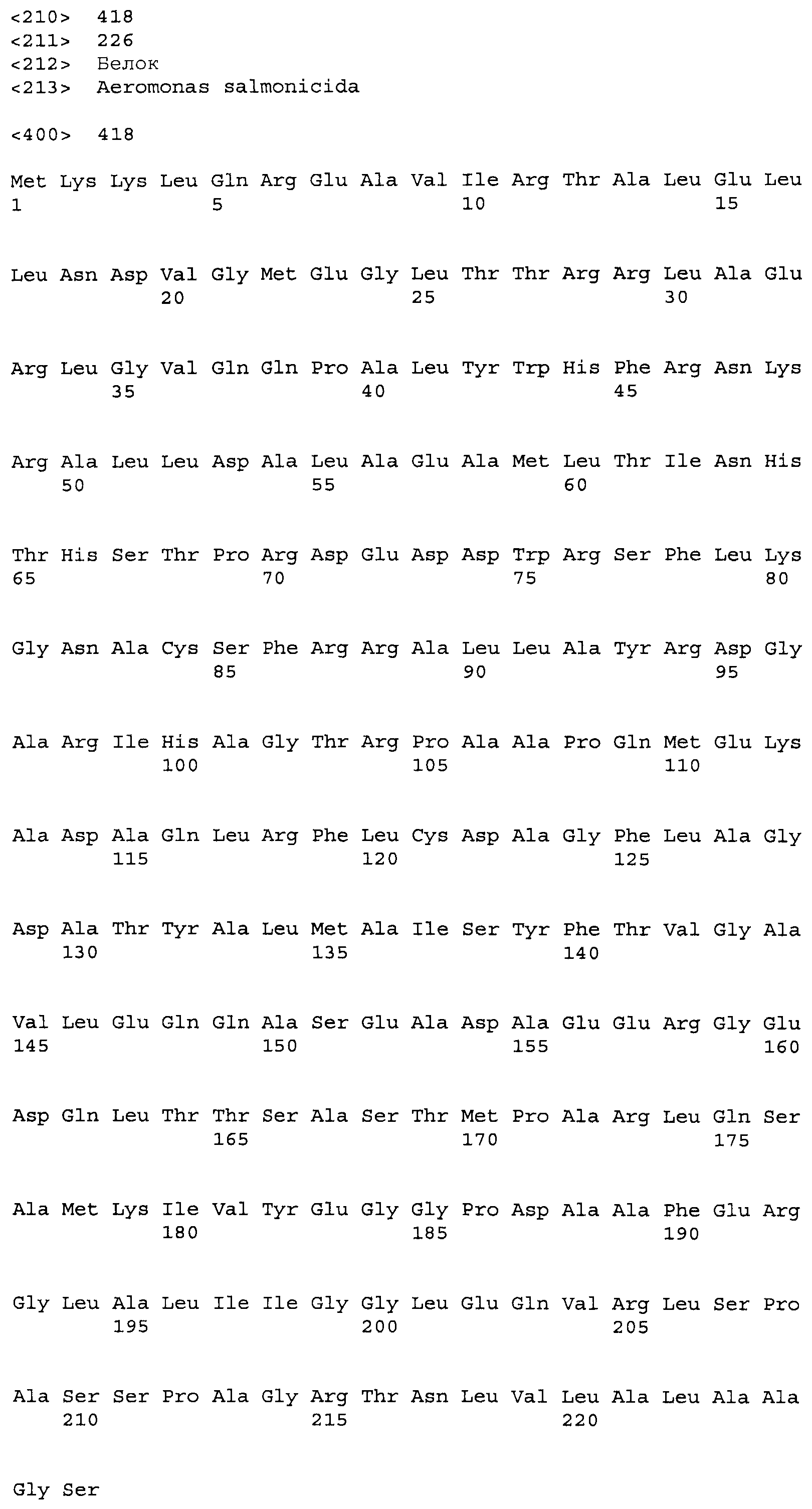


























































































































































































































































































































Описание
Область техники, к которой относится изобретение
Изобретение относится к области молекулярной биологии, более конкретно к регуляции экспрессии генов.
Уровень техники
Тетрациклиновая оперонная система, включающая репрессорные и операторные элементы, первоначально была выделена из бактерий. Оперонная система строго регулируется присутствием тетрациклина, и самостоятельно регулирует уровень экспрессии генов tetA и tetR. Продукт tetA удаляет тетрациклин из клетки. Продукт tetR представляет собой репрессорный белок, который связывается с операторными элементами с Kd приблизительно 10 пМ в отсутствие тетрациклина, блокируя, таким образом, экспрессию tetA и tetR.
Данная система была модифицирована с целью регуляции экспрессии других целевых полинуклеотидов и/или применения в других организмах, главным образом, для применения в животных системах. Системы на основе Tet оперона находили ограниченное применение в растениях по меньшей мере частично из-за проблем с индукторами, которые обычно являются антибиотическими соединениями и чувствительны к свету.
Существует потребность в регуляции экспрессии целевых последовательностей в организмах, предложены композиции и способы для строгой регуляции экспрессии под действием соединений сульфонилмочевины.
Сущность изобретения
Предложены композиции и способы, относящиеся к применению сульфонилмочевина-реактивных репрессоров. Композиции включают полипептиды, которые специфично связываются с оператором, где специфичное связывание регулируется соединением сульфонилмочевины. Композиции также включают полинуклеотиды, кодирующие полипептиды, а также конструкции, векторы, прокариотические и эукариотические клетки и эукариотические организмы, включая растения и семена, включающие полинуклеотид и/или полученные с применением способов. Также предложены способы введения сульфонилмочевина-реактивных репрессоров в клетку или организм и регуляции экспрессии целевого полинуклеотида в клетке или организме, включая клетку растения или растение.
Краткое описание фигур
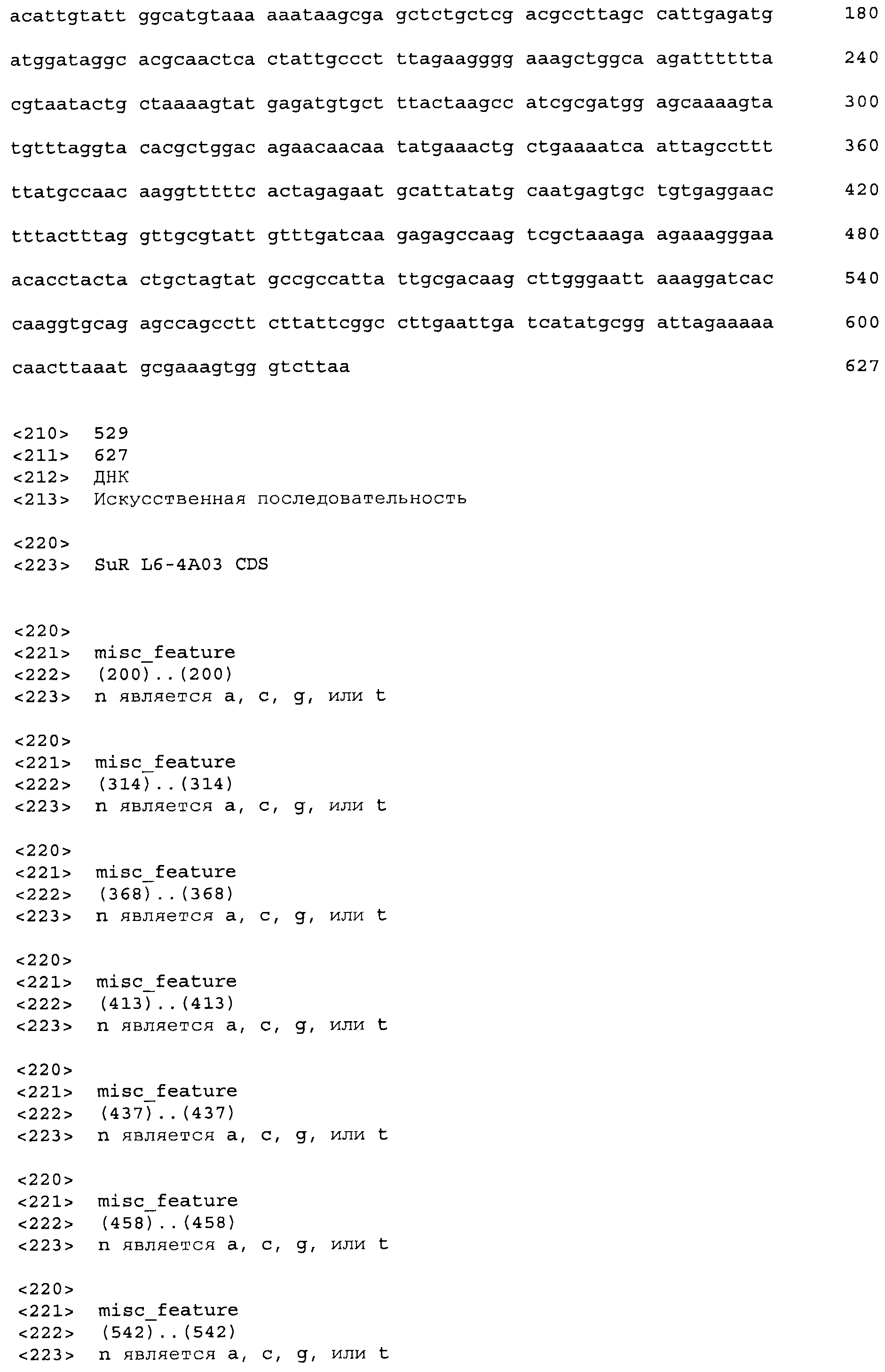
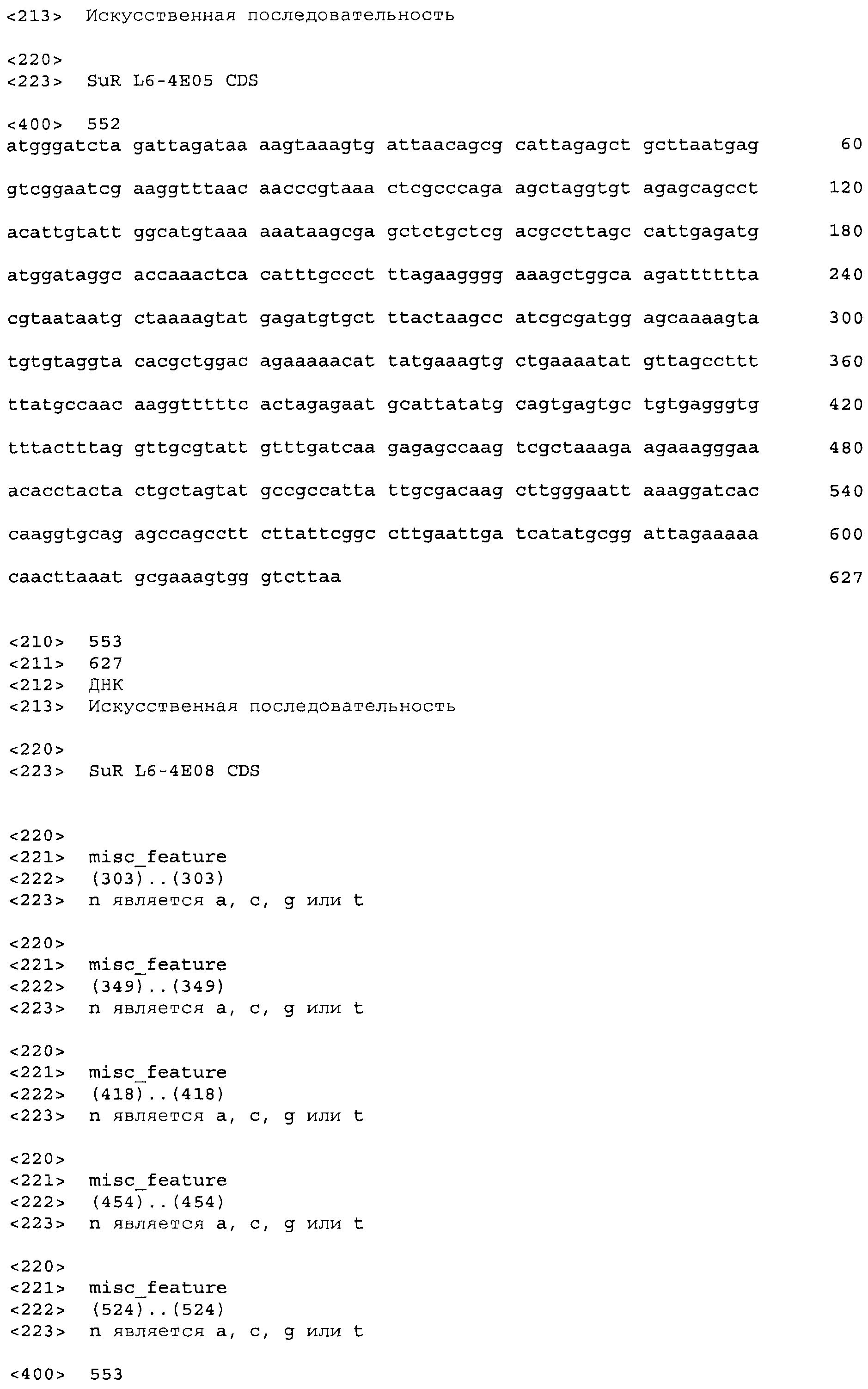
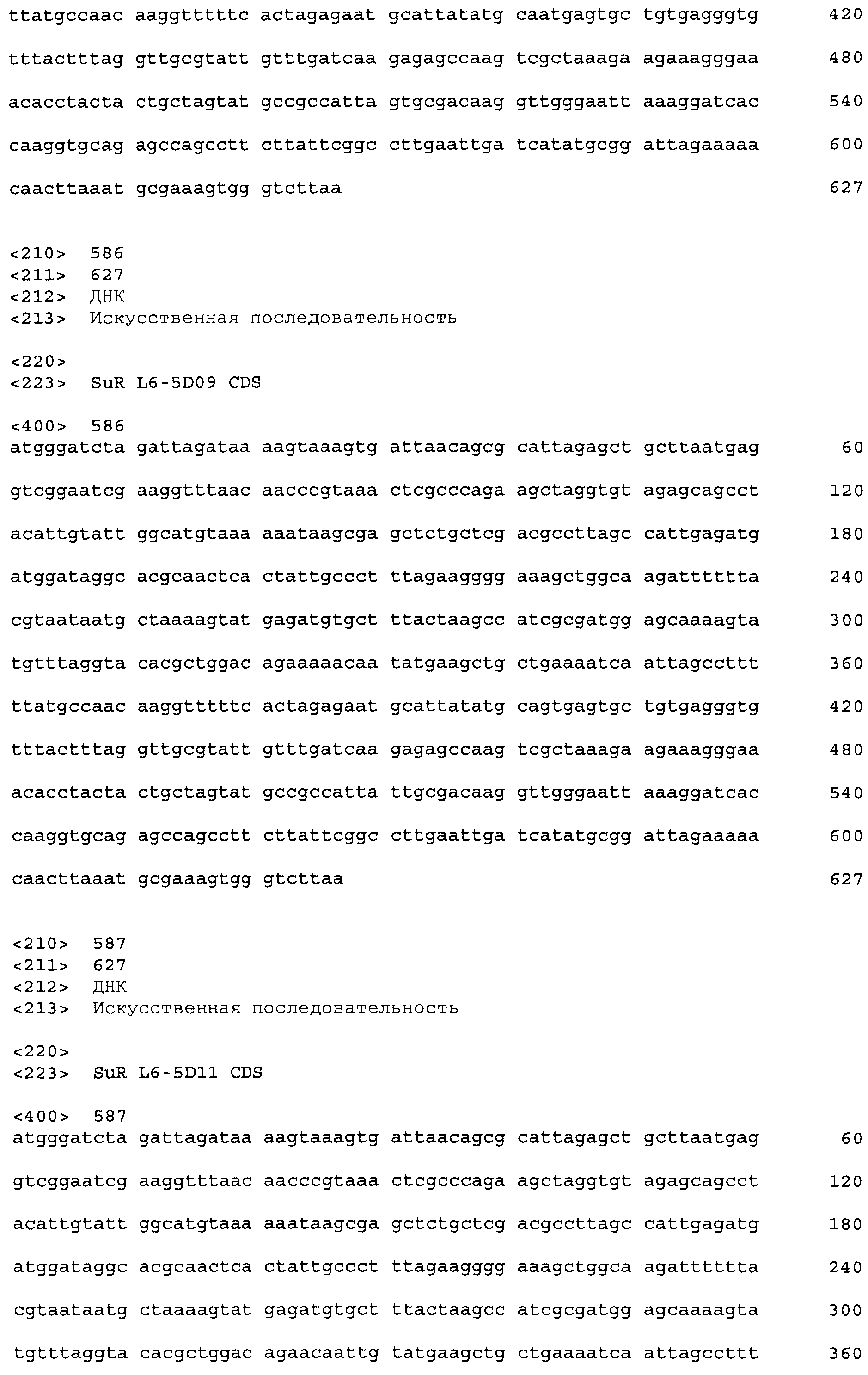
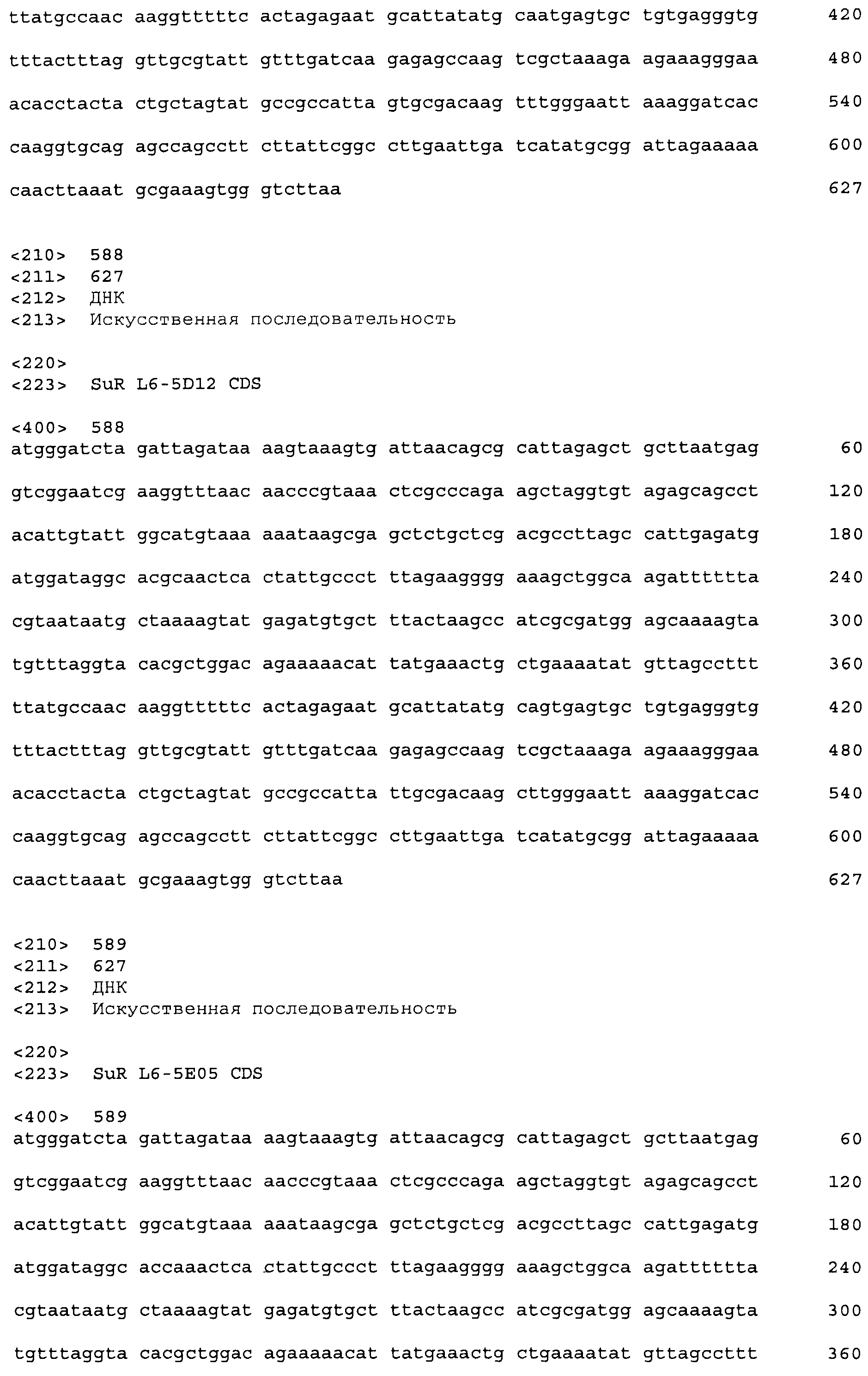
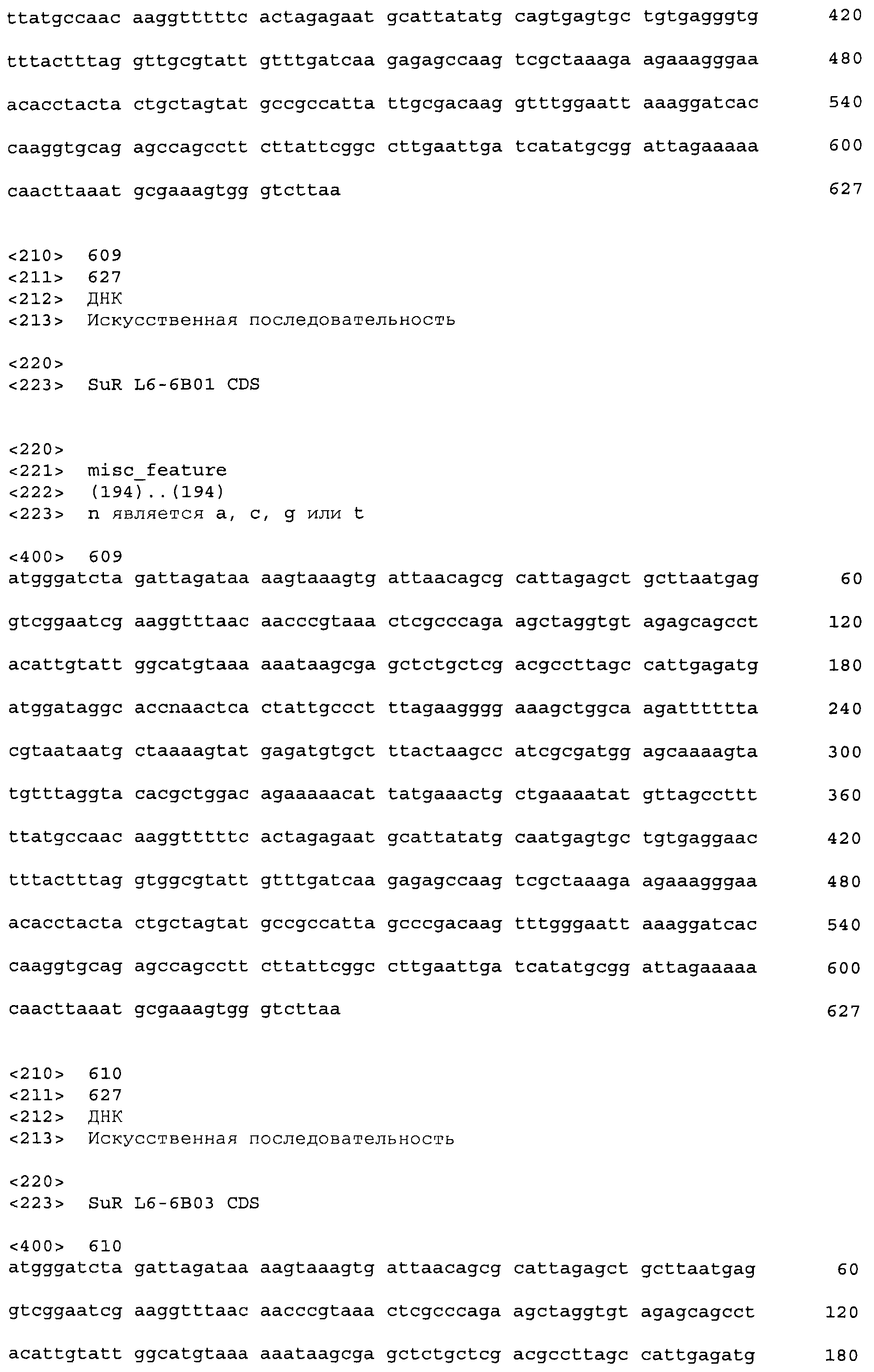
Фигура 1. Связывание тетрациклин-Mg++ и соединения сульфонилмочевины Harmony® (тифенсульфурон-метил; Ts) в связывающем кармане TetR класса D на основании кристаллической структуры 1 DU7 из Protein Databank (PDB).
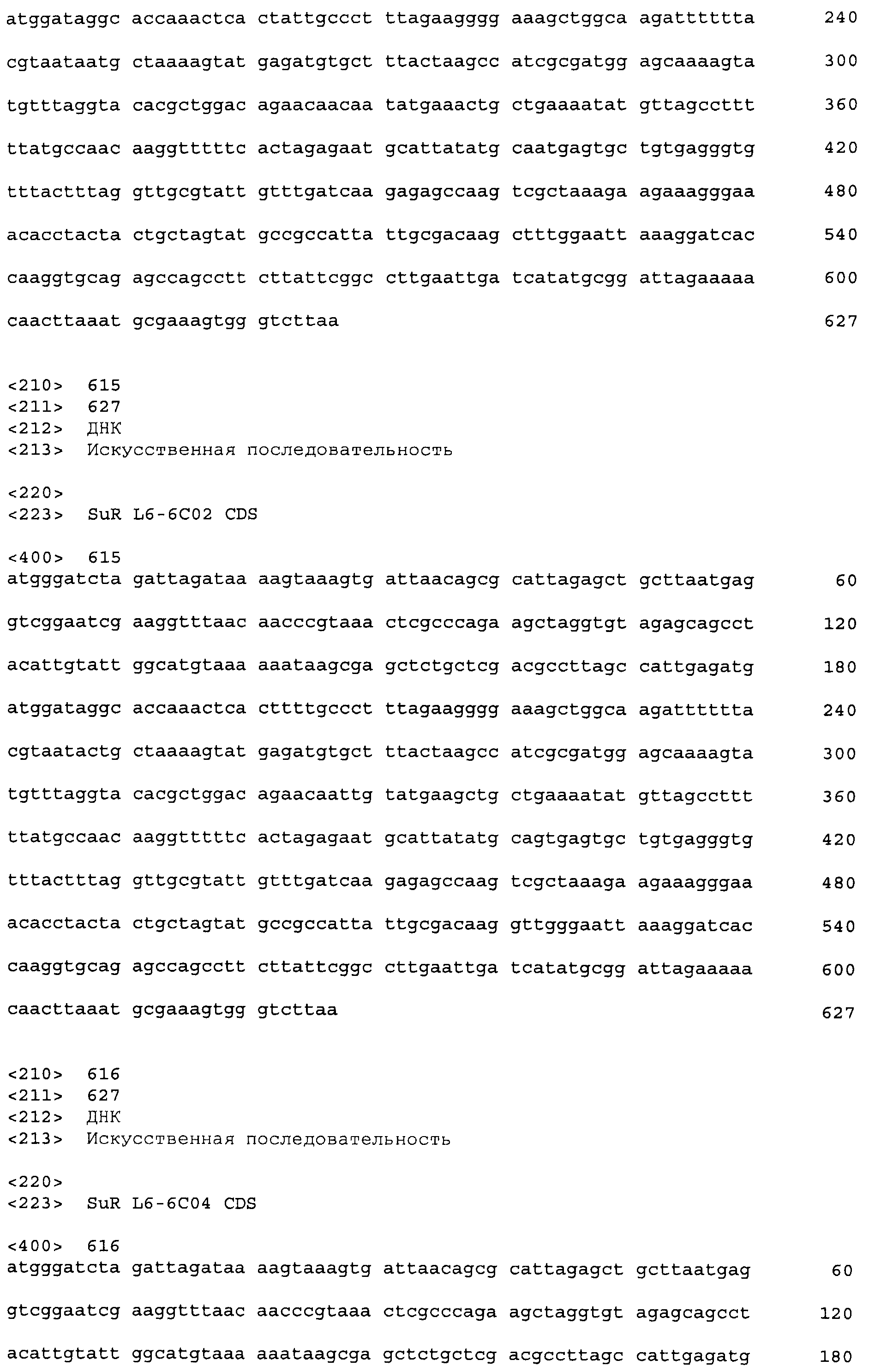
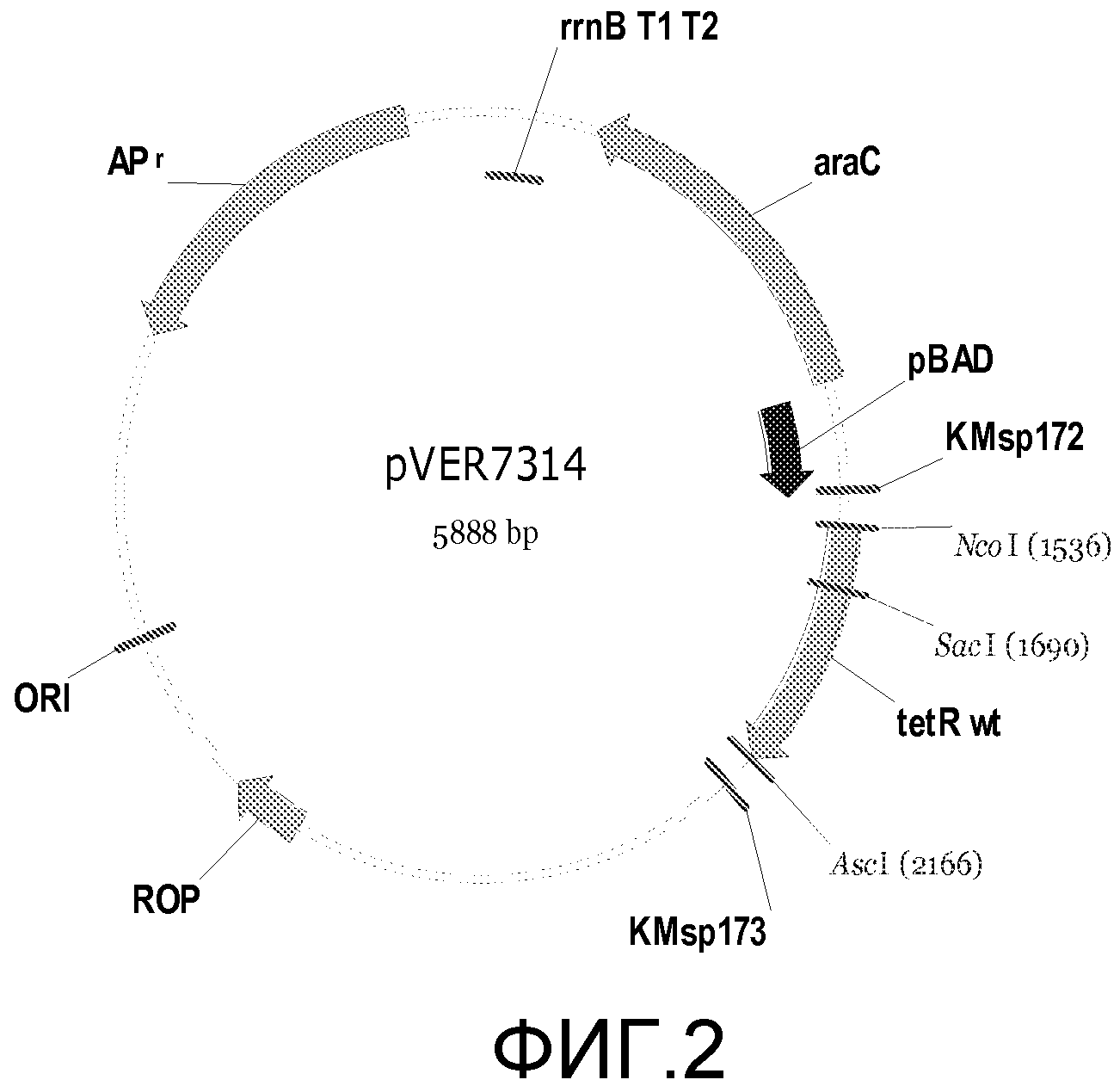
Фигура 2. Схема примерного вектора экспрессии tetR на основе E. coli, pVER7314. Репликон основан на репликоне из pBR322. Кодирующая последовательность лиганд-связывающего домена TetR (LBD) фланкирована сайтами SacI и AscI. KMsp172 и KMsp173 представляют собой участки связывания праймеров, используемых для секвенирования ДНК встроенных генов tetR. rrnB T1 T2 является сильным терминатором транскрипции, ингибирующим круговую транскрипцию и нерегулируемую экспрессию tetR.
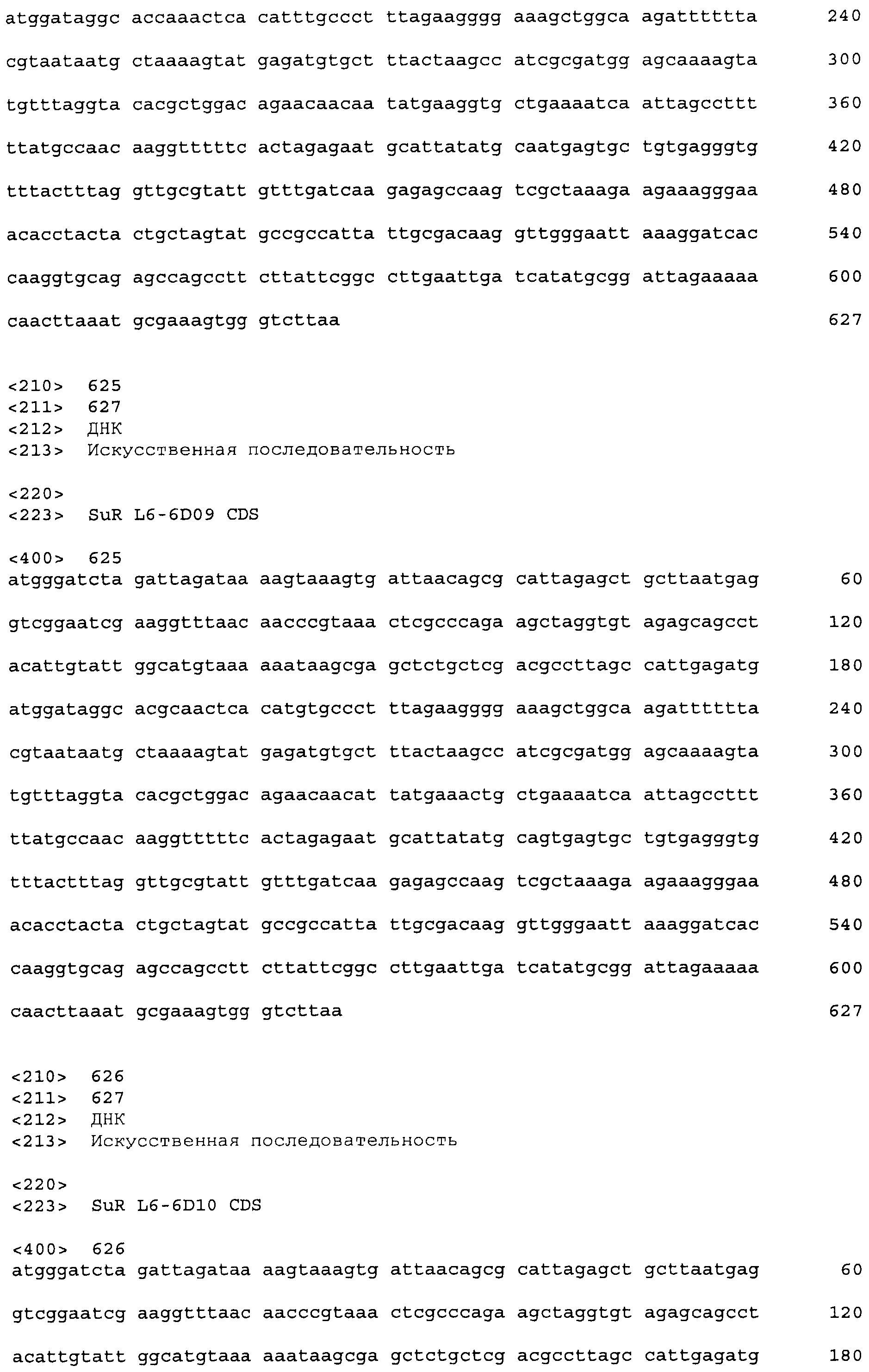
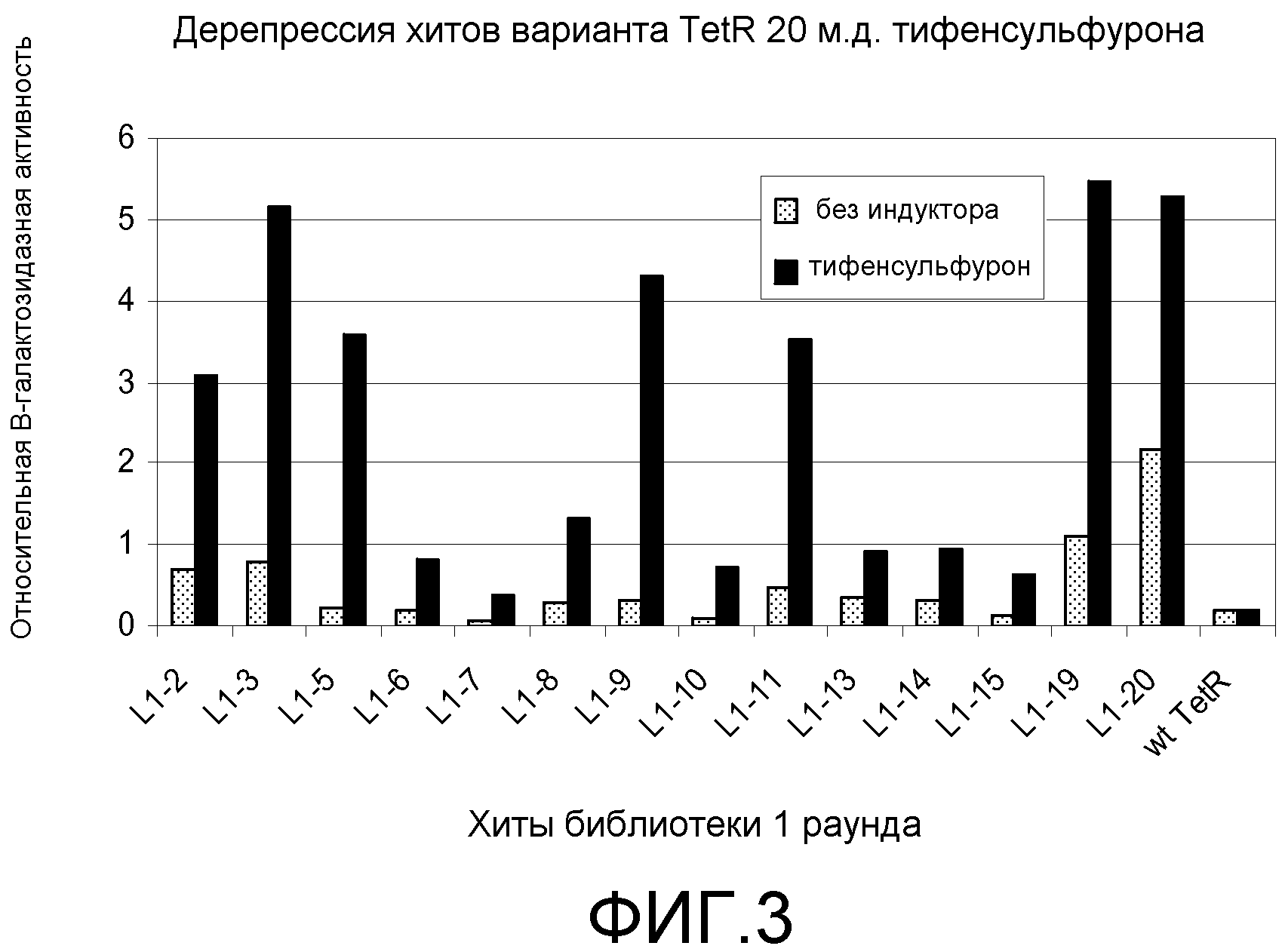
Фигура 3. Ответ хитов в библиотеке 1 при обработке 20 мкг/мл тифенсульфурон-метила (Ts). Клетки E. coli KM3, несущие предполагаемые хиты tetR L1-1 - L1-20, или tetR дикого типа, сеяли на чашки со средой для анализа M9 +/-20 мкг/мл Ts с последующим инкубированием при 30°C до появления синих/белых колоний. В указанный момент делали снимок колоний и определяли относительную β-галактозидазную активность по степени синего цвета колонии.
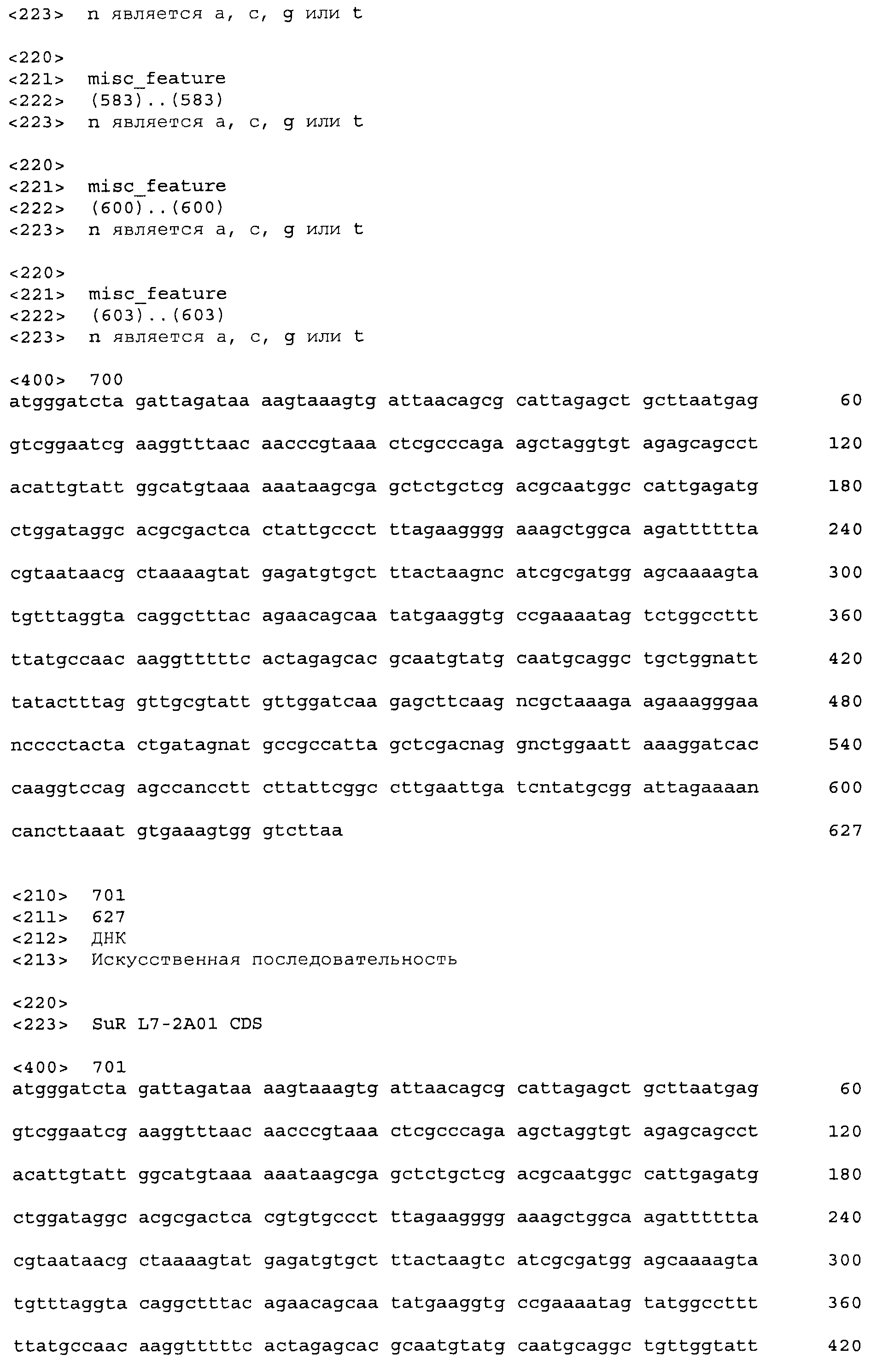
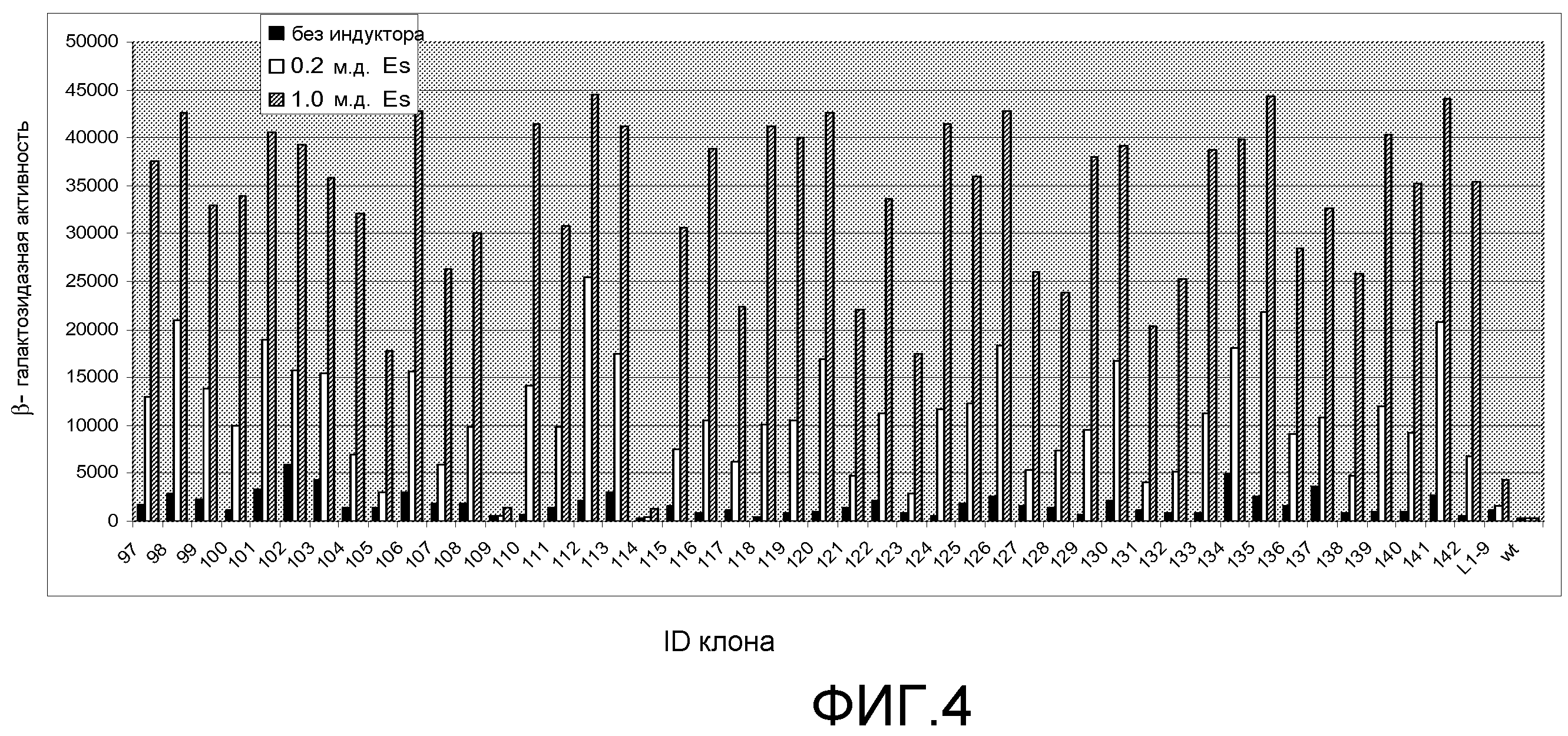
Фигура 4. Относительная β-галактозидазная активность 45 предполагаемых хитов библиотеки L4 при 0, 0,2 и 1,0 м.д. этаметсульфурона (Es). Индуцированную активность измеряли при использовании 5 мкл смеси перфорированных цельных клеток, а фоновую активность измеряли при использовании 25 мкл смеси перфорированных цельных клеток, чтобы регистрируемую активность можно было измерять в одной временной рамке для всех обработок. Фоновые значения активности умножали на 10 для приведения их в соответствие с диапазоном графика. Правая сторона графика содержит контрольные образцы - TetR дикого типа и хит 1-го раунда L1-9.
Фигура 5. Индукция β-галактозидазы этаметсульфуроном в хитах L7. Лучшие варианты из библиотеки L7 перегруппировывали и тестировали в формате культуры в 96-луночном планшете для сравнения относительной индукции при использовании 0,02 мкг/мл и 0,2 мкг/мл индуктора (Es), и для сравнения фоновой активности в отсутствие индуктора. Индуцированную активность оценивали при использовании 5 мкл смеси перфорированных клеток, тогда как 25 мкл клеток использовали для определения фоновой активности. Это позволило измерить все измеряемые активности в одной временной рамке для всех обработок. Фоновые значения активности умножали на десять для приведения их в соответствие с диапазоном графика. В правой части графика показаны контрольные образцы: хиты 2-го раунда L4-89 и L4-120, а также TetR(B) дикого типа с этаметсульфуроном, а также TetR дикого типа с 0,4 мкM atc в качестве родственного индуктора для сравнения (столбик с диагональной штриховкой). Код лунки указан наклонным текстом, согласно коду при перегруппировке в анализе, тогда как исходный код клона указан ниже горизонтальным текстом.
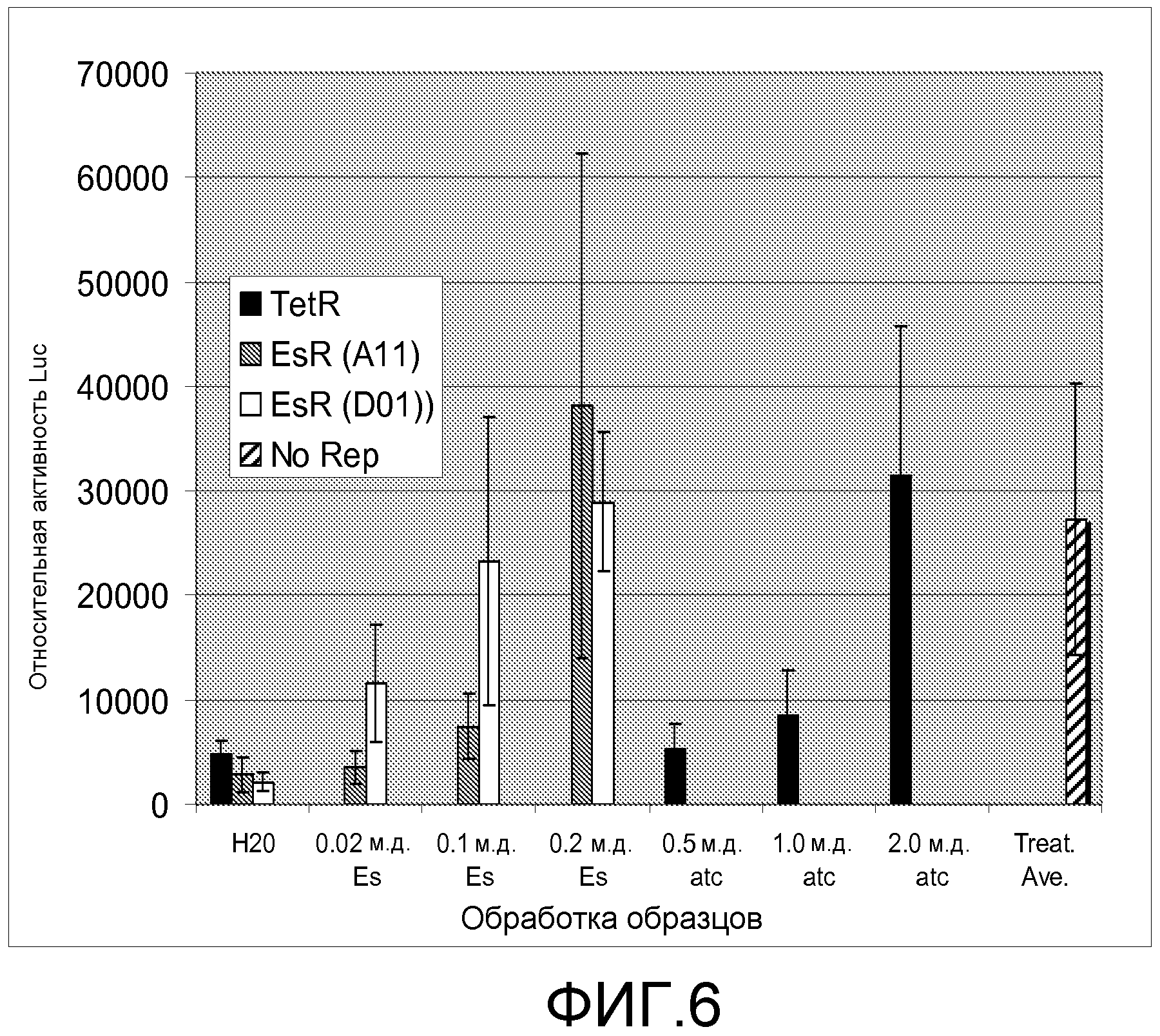
Фигура 6. Эффект дозы этаметсульфурона двух вариантов EsR, определенных транзиентной экспрессией в листьях Nicotiana benthamiana. Черные столбики обозначают TetR дикого типа, серые столбики обозначают хит EsR A11, и белые столбики обозначают хит EsR D01. Заштрихованный столбик обозначают контроль без репрессора, который указывает максимальный уровень репортерной экспрессии в анализе.
Фигура 7. Связывание ДНК с tetOp в отсутствие или в присутствии лиганда. Пять пмоль TetO или контрольной ДНК смешивали с указанными количествами репрессорного белка и индуктора в сложном буфере, содержащем 20 мМ Трис-HCl (pH 8,0) и 10 мМ ЭДТА.
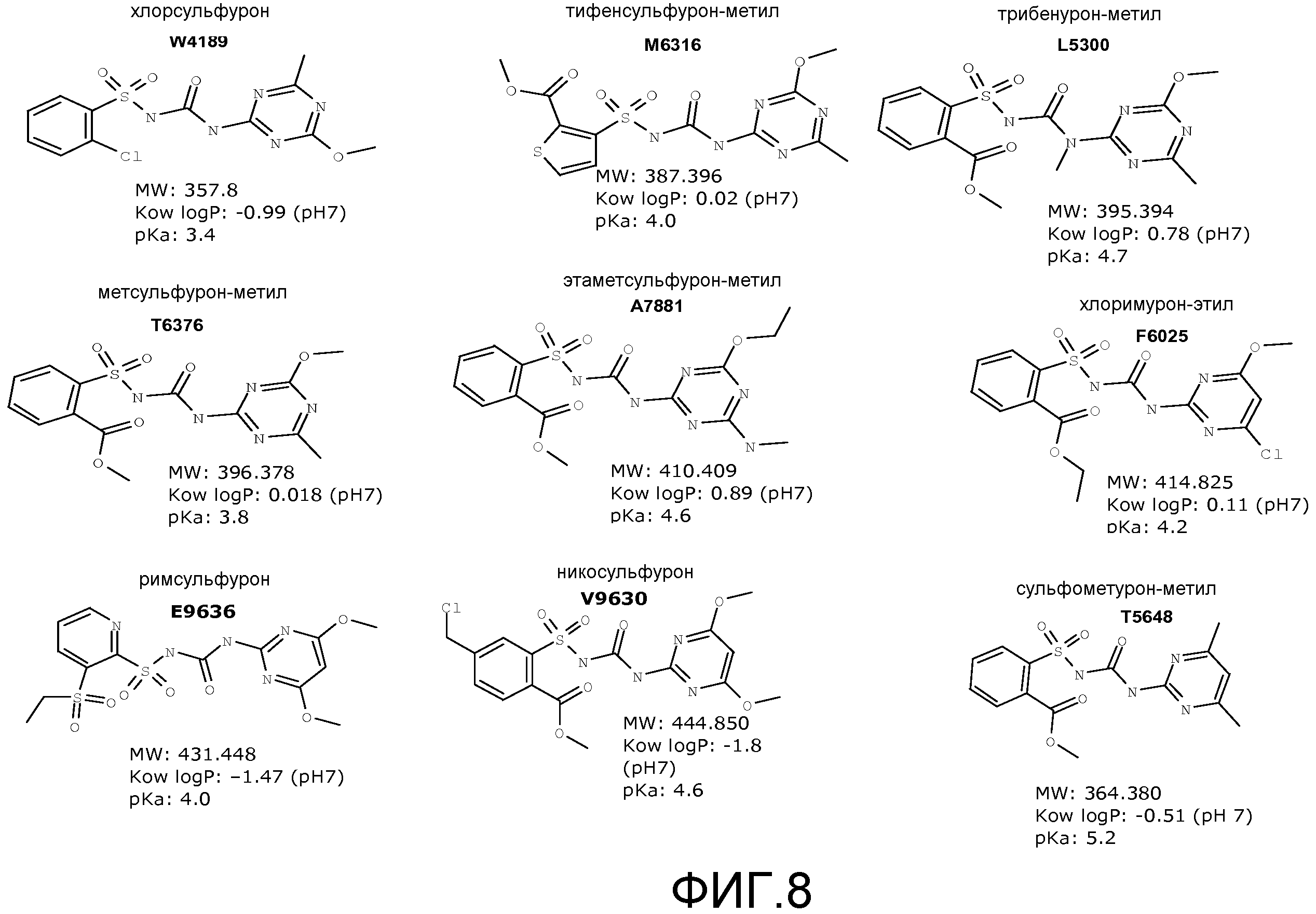
Фигура 8. Структуры примерных зарегистрированных соединений сульфонилмочевины.
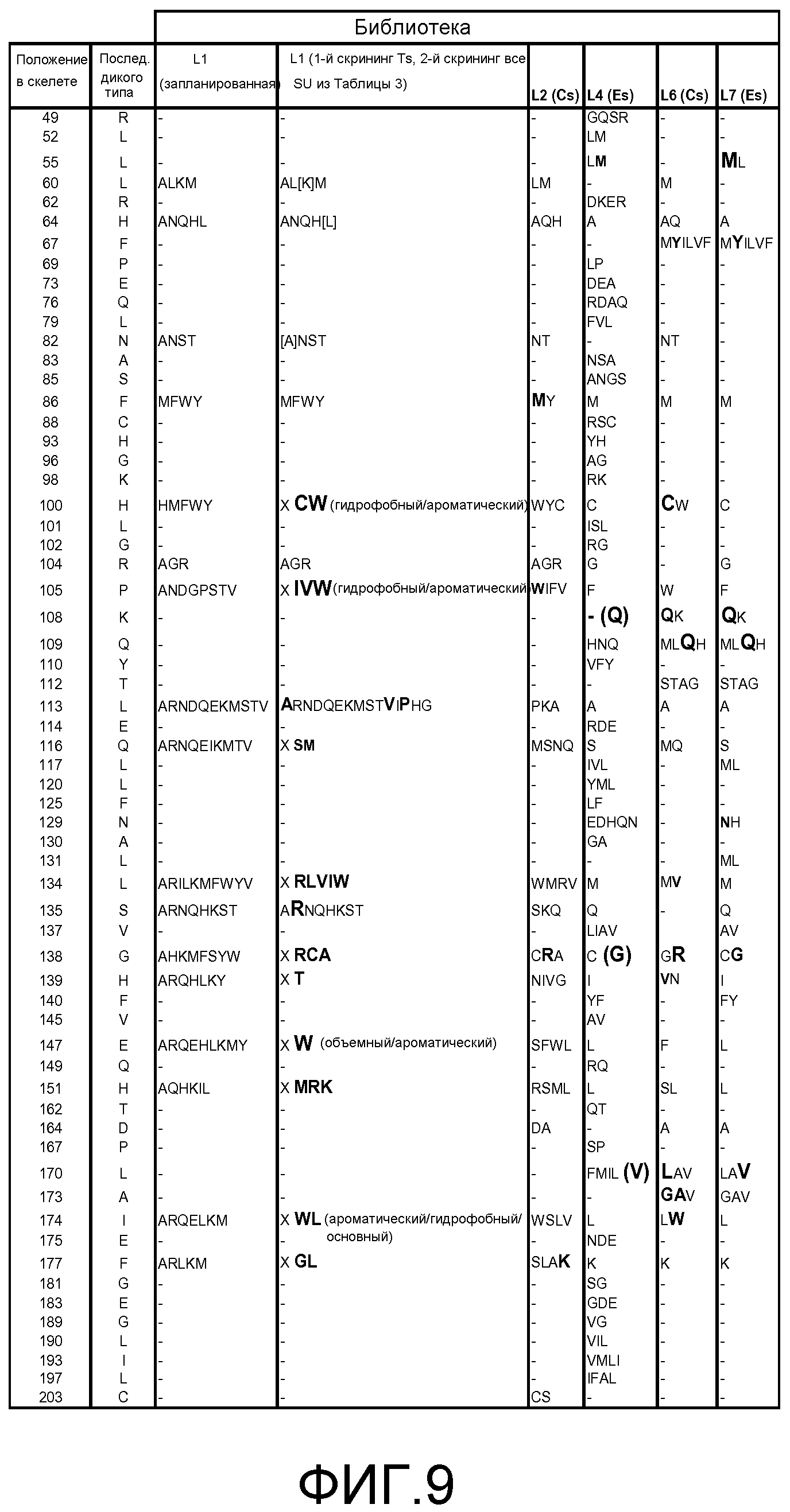
Фигура 9. Обобщение разнообразия источников, дизайна библиотек, а также разнообразия хитов и смещения популяции для нескольких поколений сульфонилмочевина-репрессорных шаффлинг-библиотек. Черта ("-") указывает отсутствие аминокислотного разнообразия, введенного в данном положении в библиотеке. X указывает, что олиги библиотеки были созданы для введения полного аминокислотного разнообразия (любая из 20 аминокислот) в данном положении в библиотеке. Остатки, выделенные жирным шрифтом, указывают замещение в ходе селекции, при этом больший размер шрифта соответствует большей степени замещения в отобранной популяции. Остатки в круглых скобках указывают отобранные мутации. Пул филогенетического разнообразия получен из широкого семейства 34 последовательностей репрессора тетрациклина.
Фигура 10. Депрессия флуоресцентного репортера под действием сульфонилмочевины в каллусе кукурузы (A) или растениях (B).
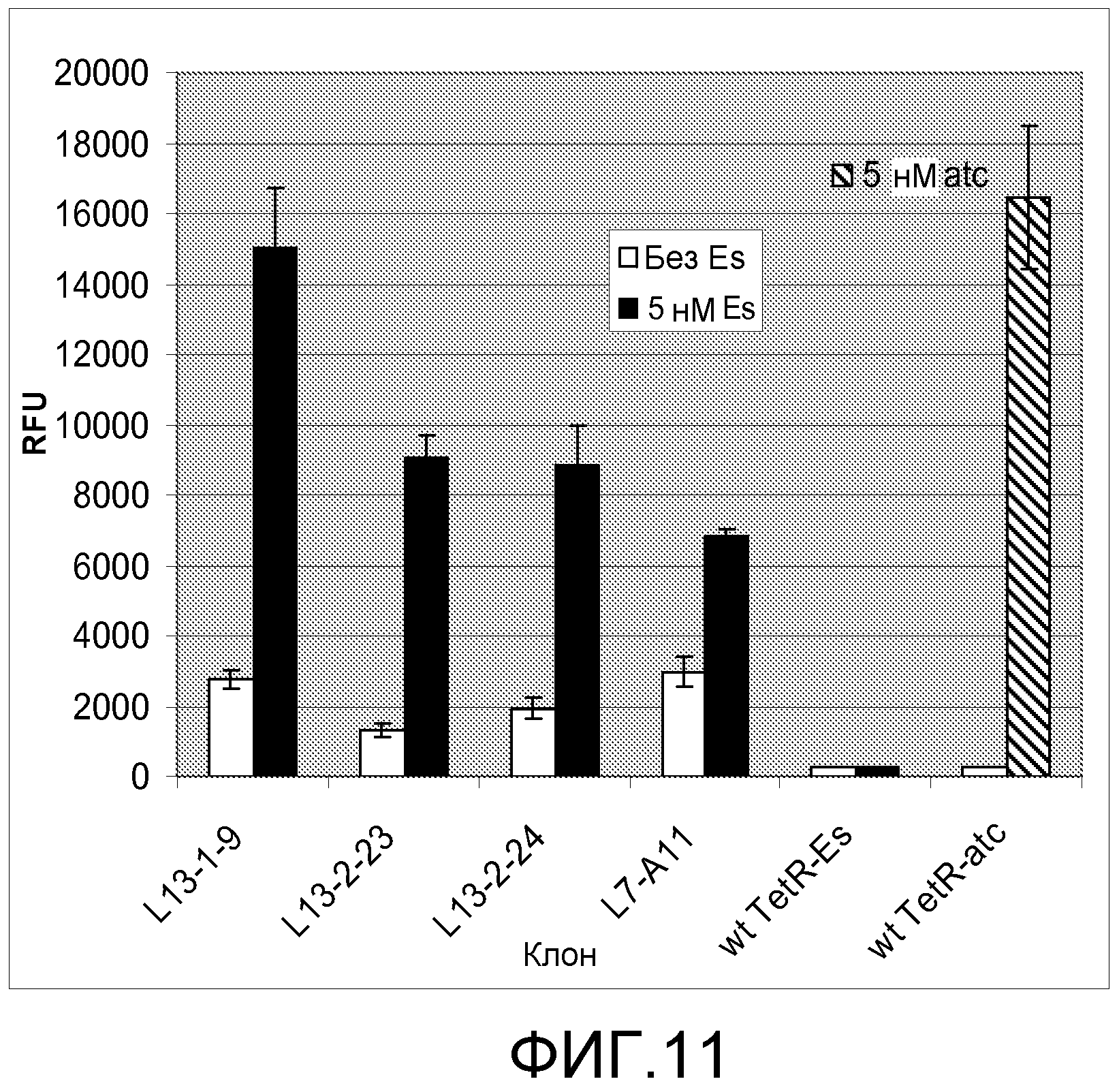
Фигура 11. Индукция β-галактозидазы этаметсульфуроном в примерных вариантах L13.
Подробное описание
Химически регулируемые инструменты экспрессии оказались ценными при изучении функции и регуляции генов во многих биологических системах. Данные системы позволяют тестировать эффект экспрессии любого целевого гена в культуральной системе или цельном организме, когда трансген нельзя специфически регулировать или непрерывно экспрессировать вследствие негативных последствий. Указанные системы по существу обеспечивают возможность проведения "пульс" или "пульс-чейз" тестирования экспрессии генов. Система экспрессии, опосредованной химическим выключателем, позволяет исследовать геномные, протеомные и/или метаболические ответы непосредственно после активации целевого гена. Подобные типы тестов невозможно провести с использованием конститутивных, экспериментальных или тканеспецифических систем экспрессии. Технологии химических выключателей также могут обеспечивать средство для генной терапии.
Системы химических выключателей могут применяться коммерчески, например, в сельскохозяйственной биотехнологии. В сельскохозяйственных целях предпочтительно обеспечить возможность контроля экспрессии и/или генетического потока трансгенов в окружающей среде, например, генов устойчивости к гербицидам, особенно в тех случаях, когда существуют дикие родственные формы целевых культур. Кроме того, наличие семейства жизнеспособных механизмов химического выключения позволило бы управлять арсеналом признаков из одной трансгенной культуры, например, одна продуктивная линия могла бы использоваться для предоставления выбранных признаков по желанию заказчика через определенную химическую активацию. Кроме того, получение гибридных семян можно было бы упростить с применением химического контроля в работе с гибридами.
Система выключателя генов на основе Tet-репрессора (TetR), широко используемая в животных системах, находила ограниченное применение в растительных генетических системах частично из-за сложностей, связанных с активаторными лигандами. TetR был модифицирован, чтобы узнавать коммерческие производные сульфонилмочевины вместо производных тетрациклина, с сохранением способности специфично связываться с последовательностями тетрациклинового оператора. Это было достигнуто путем модификации лиганд-связывающего домена Tet-репрессора с применением рационального моделирования белка и ДНК-шаффлинга ("перетасовки") для получения возможности узнавать коммерческие производные сульфонилмочевины. Первичная перетасовка TetR и скрининг с использованием чувствительного in vivo β-галактозидазного теста привели к специфичному узнаванию гербицида Harmony® (тифенсульфурон-метила) при концентрации 20 м.д. в ростовой среде и потере узнавания тетрациклина. После тестирования с другими соединениями сульфонилмочевины, многие из хитов, реактивных по отношению к Harmony®, также отвечали на другие соединения SU. В некоторых случаях, хиты обладали еще более высокой реактивностью в отношении родственных гербицидов хлорсульфурона и этаметсульфурона (2 м.д.). Последующие раунды шаффлинга и скрининга производных TetR приводили к вариантам TetR, которые сильно реагировали с 0,2 м.д. хлорсульфурона и 0,02 м.д. этаметсульфурона, согласно измерению с использованием in vivo анализов индукции в E. coli. Наиболее активные SuR варианты, чувствительные к этаметсульфурону (EsR), демонстрировали способность к индукции, почти равную соответствующей способности к индукции TetR класса B дикого типа ангидротетрациклином (atc) при использовании подобных концентраций индуктора. Указанные молекулы SuR не обладают активностью в отношении тетрациклинов, при этом TetR(B) дикого типа (SEQ ID NO: 2) не обладает активностью в отношении сульфонилмочевин.
Предложены композиции и способы, касающиеся применения сульфонилмочевина-реактивных репрессоров. Сульфонилмочевина-реактивные репрессоры (SuR) включают любой репрессорный полипептид, связывание которого с операторной последовательностью регулируется лигандом, который включает соединение сульфонилмочевины. В некоторых примерах репрессор специфично связывается с оператором в отсутствие лиганда, соединения сульфонилмочевины. В некоторых примерах репрессор специфично связывается с оператором в присутствии лиганда, соединения сульфонилмочевины. Репрессоры, которые связываются с оператором в присутствии лиганда, иногда называются обратными репрессорами. В некоторых примерах композиции включают SuR полипептиды, которые специфично связываются с тетрациклиновым оператором, где специфичное связывание регулируется соединением сульфонилмочевины. В некоторых примерах композиции включают выделенный сульфонилмочевина-репрессорный (SuR) полипептид, включающий, по меньшей мере, одну аминокислотную замену в лиганд-связывающем домене тетрациклинового репрессорного белка дикого типа, где полипептид SuR или его мультимер специфично связываются с полинуклеотидом, включающим операторную последовательность, где связывание репрессора-оператора регулируется отсутствием или присутствием соединения сульфонилмочевины. В некоторых примерах композиции включают выделенные сульфонилмочевинные репрессоры, включающие лиганд-связывающий домен, включающий, по меньшей мере, одну аминокислотную замену в лиганд-связывающем домене репрессорного тетрациклинового белка дикого типа, слитом с гетерологичным операторным ДНК-связывающим доменом, который специфично связывается с полинуклеотидом, включающим операторную последовательность или ее производную, где связывание репрессора-оператора регулируется отсутствием или присутствием соединения сульфонилмочевины. Может использоваться любой операторный ДНК-связывающий домен, включая, помимо прочего, операторный ДНК-связывающий домен из репрессоров, включающих tet, lac, trp, phd, arg, LexA, phiCh1 репрессор, лямбда C1 и Cro репрессоры, репрессор фага X, MetJ, phir1t rro, phi434 C1 и Cro репрессоры, RafR, gal, ebg, uxuR, exuR, ROS, SinR, PurR, FruR, P22 C2, TetC, AcrR, Betl, Bm3R1, EnvR, QacR, MtrR, TcmR, Ttk, YbiH, YhgD и mu Ner, или ДНК-связывающие домены в семействе Interpro, включая, помимо прочего, IPR001647, IPR010982 и IPR011991.
В некоторых примерах композиции включают выделенные сульфонилмочевина-репрессорные (SuR) полипептиды, включающие, по меньшей мере, одну аминокислотную замену в репрессорном тетрациклиновом белке дикого типа, где полипептид SuR или его мультимер специфично связываются с полинуклеотидом, включающим последовательность тетрациклинового оператора, где связывание репрессора-оператора регулируется отсутствием или присутствием соединения сульфонилмочевины.
Репрессоры дикого типа включают тетрациклиновые репрессоры класса A, B, C, D, E, G, H, J и Z. Пример класса TetR(A) присутствует в транспозоне 1721 Tn и депонирован под номером GenBank X61307, перекрестная ссылка gi48198, с соответствующим кодируемым белком под номером CAA43639, перекрестная ссылка gi48195, и под номером UniProt Q56321. Пример класса TetR(B) присутствует в транспозоне Tn10 и депонирован под номером GenBank X00694, перекрестная ссылка gi43052, с соответствующим кодируемым белком под номером CAA25291, перекрестная ссылка gi43052, и под номером UniProt P04483. Пример класса TetR(C) присутствует в плазмиде pSC101 и депонирован под номером GenBank M36272, перекрестная ссылка gi150945, с соответствующим кодируемым белком под номером AAA25677, перекрестная ссылка gi150946. Пример класса TetR(D) присутствует в Salmonella ordonez и депонирован под номером GenBank X65876, перекрестная ссылка gi49073, с соответствующим кодируемым белком под номером CAA46707, перекрестная ссылка gi49075, и под номером UniProt P0ACT5 и P09164. Пример класса TetR(E) был выделен из транспозона Tn10 E. coli и депонирован под номером GenBank M34933, перекрестная ссылка gi155019, с соответствующим кодируемым белком под номером AAA98409, перекрестная ссылка gi155020. Пример класса TetR(G) был выделен из Vibrio anguillarium и депонирован под номером GenBank S52438, перекрестная ссылка gi262928, с соответствующим кодируемым белком под номером AAB24797, перекрестная ссылка gi262929. Пример класса TetR(H) присутствует в плазмиде pMV111, выделенной из Pasteurella multocida и депонированной под номером GenBank U00792, перекрестная ссылка gi392871, с соответствующим кодируемым белком под номером AAC43249, перекрестная ссылка gi392872. Пример класса TetR(J) был выделен из Proteus mirabilis и депонирован под номером GenBank AF038993, перекрестная ссылка gi4104704, с соответствующим кодируемым белком под номером AAD12754, перекрестная ссылка gi4104706. Пример класса TetR(Z) был найден в плазмиде pAGI, выделенной из Corynebacterium glutamicum, и депонирован номером GenBank AF121000, перекрестная ссылка gi4583389, с соответствующим кодируемым белком под номером AAD25064, перекрестная ссылка gi4583390. В некоторых примерах тетрациклиновый репрессор дикого типа является тетрациклиновым репрессорным белком класса B. В некоторых примерах тетрациклиновый репрессор дикого типа является тетрациклиновым репрессорным белком класса D.
В некоторых примерах сульфонилмочевина-репрессорные (SuR) полипептиды включают аминокислотную замену в лиганд-связывающем домене тетрациклинового репрессорного белка дикого типа. В TetR белках дикого типа классов B и D аминокислотные остатки 6-52 представляют собой ДНК-связывающий домен. Остальная часть белка участвует в связывании лиганда и последующей аллостерической модификации. Что касается TetR класса B, остатки 53-207 представляют собой лиганд-связывающий домен, тогда как в TetR класса D остатки 53-218 составляют лиганд-связывающий домен. В некоторых примерах SuR полипептиды включают аминокислотную замену в лиганд-связывающем домене белка TetR(B) дикого типа. В некоторых примерах SuR полипептиды включают аминокислотную замену в лиганд-связывающем домене белка TetR(B) дикого типа SEQ ID NO: 1.
В некоторых примерах выделенные SuR полипептиды включают аминокислоту или любую комбинацию аминокислот, соответствующую эквивалентным аминокислотным положениям, выбранным из разнообразия аминокислот, показанных на Фигуре 9, где положение аминокислотного остатка, показанного на Фигуре 9, соответствует аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полипептиды включают лиганд-связывающий домен, включающий, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, показанных на Фигуре 9, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полипептиды включают, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, показанных на Фигуре 9, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенный полипептид SuR включает лиганд-связывающий домен, включающий аминокислотную замену в положении остатка, выбранном из группы, состоящей из положения 55, 60, 64, 67, 82, 86, 100, 104, 105, 108, 113, 116, 134, 135, 138, 139, 147, 151, 170, 173, 174, 177 и любой их комбинации, где положение аминокислотного остатка и замена соответствуют эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенный полипептид SuR дополнительно включает аминокислотную замену в положении остатка, выбранном из группы, состоящей из 109, 112, 117, 131, 137, 140, 164 и любой их комбинации. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO: 1.
В некоторых примерах выделенные SuR полипептиды включают лиганд-связывающий домен, включающий, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из группы, состоящей из:
(a) M или L в положении аминокислотного остатка 55;
(b) A, L или M в положении аминокислотного остатка 60;
(c) A, N, Q, L или H в положении аминокислотного остатка 64;
(d) M, I, L, V, F или Y в положении аминокислотного остатка 67;
(e) N, S или T в положении аминокислотного остатка 82;
(f) F, M, W или Y в положении аминокислотного остатка 86;
(g) C, V, L, M, F, W или Y в положении аминокислотного остатка 100;
(h) R, A или G в положении аминокислотного остатка 104
(i) A, I, V, F или W в положении аминокислотного остатка 105;
(j) Q или K в положении аминокислотного остатка 108;
(k) A, M, H, K, T, P или V в положении аминокислотного остатка 113;
(l) I, L, M, V, R, S, N, P или Q в положении аминокислотного остатка 116;
(m) I, L, V, M, R, S или W в положении аминокислотного остатка 134;
(n) R, S, N, Q, K или А в положении аминокислотного остатка 135;
(o) A, C, G, H, I, V, R или T в положении аминокислотного остатка 138;
(p) A, G, I, V, M, W, N, R или T в положении аминокислотного остатка 139;
(q) I, L, V, F, W, T, S или R в положении аминокислотного остатка 147;
(r) M, L, W, Y, K, R или S в положении аминокислотного остатка 151;
(s) I, L, V или А в положении аминокислотного остатка 170;
(t) A, G или V в положении аминокислотного остатка 173;
(u) L, V, W, Y, H, R, K или S в положении аминокислотного остатка 174; и,
(v) A, G, I, L, Y, K, Q или S в положении аминокислотного остатка 177,
где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полипептиды включают, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из аминокислотных остатков, перечисленных в (a)-(v) выше, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенные SuR полипептиды, выбранные из-за своей повышенной активности по отношению к хлорсульфурону, включают лиганд-связывающий домен, включающий, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из группы, состоящей из:
(a) M в положении аминокислотного остатка 60;
(b) A или Q в положении аминокислотного остатка 64;
(c) M, F, Y, I, V или L в положении аминокислотного остатка 67;
(d) N или T в положении аминокислотного остатка 82;
(e) M в положении аминокислотного остатка 86;
(f) C или W в положении аминокислотного остатка 100;
(g) W в положении аминокислотного остатка 105;
(h) Q или K в положении аминокислотного остатка 108;
(i) M, Q, L или H в положении аминокислотного остатка 109;
(j) G, A, S или T в положении аминокислотного остатка 112;
(k) A в положении аминокислотного остатка 113;
(l) M или Q в положении аминокислотного остатка 116;
(m) M или V в положении аминокислотного остатка 134;
(n) G или R в положении аминокислотного остатка 138;
(o) N или V в положении аминокислотного остатка 139;
(p) F в положении аминокислотного остатка 147;
(q) S или L в положении аминокислотного остатка 151;
(r) A в положении аминокислотного остатка 164;
(s) A, L или V в положении аминокислотного остатка 170;
(t) A, G или V в положении аминокислотного остатка 173;
(u) L или W в положении аминокислотного остатка 174; и
(v) K в положении аминокислотного остатка 177,
где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полипептиды включают, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из аминокислотных остатков, перечисленных в (a)-(v) выше, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO: 1.
В некоторых примерах выделенные SuR полипептиды, выбранные из-за своей повышенной активности по отношению к этаметсульфурону, включают лиганд-связывающий домен, включающий, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из группы, состоящей из:
(a) M или L в положении аминокислотного остатка 55;
(b) A в положении аминокислотного остатка 64;
(c) M, Y, F, I, L или V в положении аминокислотного остатка 67;
(d) M в положении аминокислотного остатка 86;
(e) C в положении аминокислотного остатка 100;
(f) G в положении аминокислотного остатка 104;
(g) F в положении аминокислотного остатка 105;
(h) Q или K в положении аминокислотного остатка 108;
(i) Q, M, L или H в положении аминокислотного остатка 109;
(j) S, T, G или А в положении аминокислотного остатка 112;
(k) A в положении аминокислотного остатка 113;
(l) S в положении аминокислотного остатка 116;
(m) M или L в положении аминокислотного остатка 117;
(n) M или L в положении аминокислотного остатка 131;
(o) M в положении аминокислотного остатка 134;
(p) Q в положении аминокислотного остатка 135;
(q) A или V в положении аминокислотного остатка 137;
(r) C или G в положении аминокислотного остатка 138;
(s) I в положении аминокислотного остатка 139;
(t) F или Y в положении аминокислотного остатка 140;
(u) L в положении аминокислотного остатка 147;
(v) L в положении аминокислотного остатка 151;
(w) A в положении аминокислотного остатка 164;
(x) V, A или L в положении аминокислотного остатка 170;
(y) G, A или V в положении аминокислотного остатка 173
(z) L в положении аминокислотного остатка 174; и
(aa) N или K в положении аминокислотного остатка 177,
где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полипептиды включают, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из аминокислотных остатков, перечисленных в (a)-(aa) выше, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислоты нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенный SuR полипептид обладает, по меньшей мере, приблизительно 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичностью последовательности с лиганд-связывающим доменом TetR(B) дикого типа, представленным в качестве примера аминокислотными остатками 53-207 из SEQ ID NO:1, где идентичность последовательности определена по полной длине лиганд-связывающего домена с применением метода глобального выравнивания. В некоторых примерах в методе глобального выравнивания используется алгоритм GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight (вес открытия пропуска) 8 и Length Weight (вес продления пропуска) 2, а также матрицы замен BLOSUM62.
В некоторых примерах выделенный SuR полипептид обладает, по меньшей мере, приблизительно 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности с TetR(B) дикого типа, представленным в качестве примера SEQ ID NO:1, где идентичность последовательности определена по полной длине полипептида при использовании метода глобального выравнивания. В некоторых примерах в методе глобального выравнивания используется алгоритм GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62.
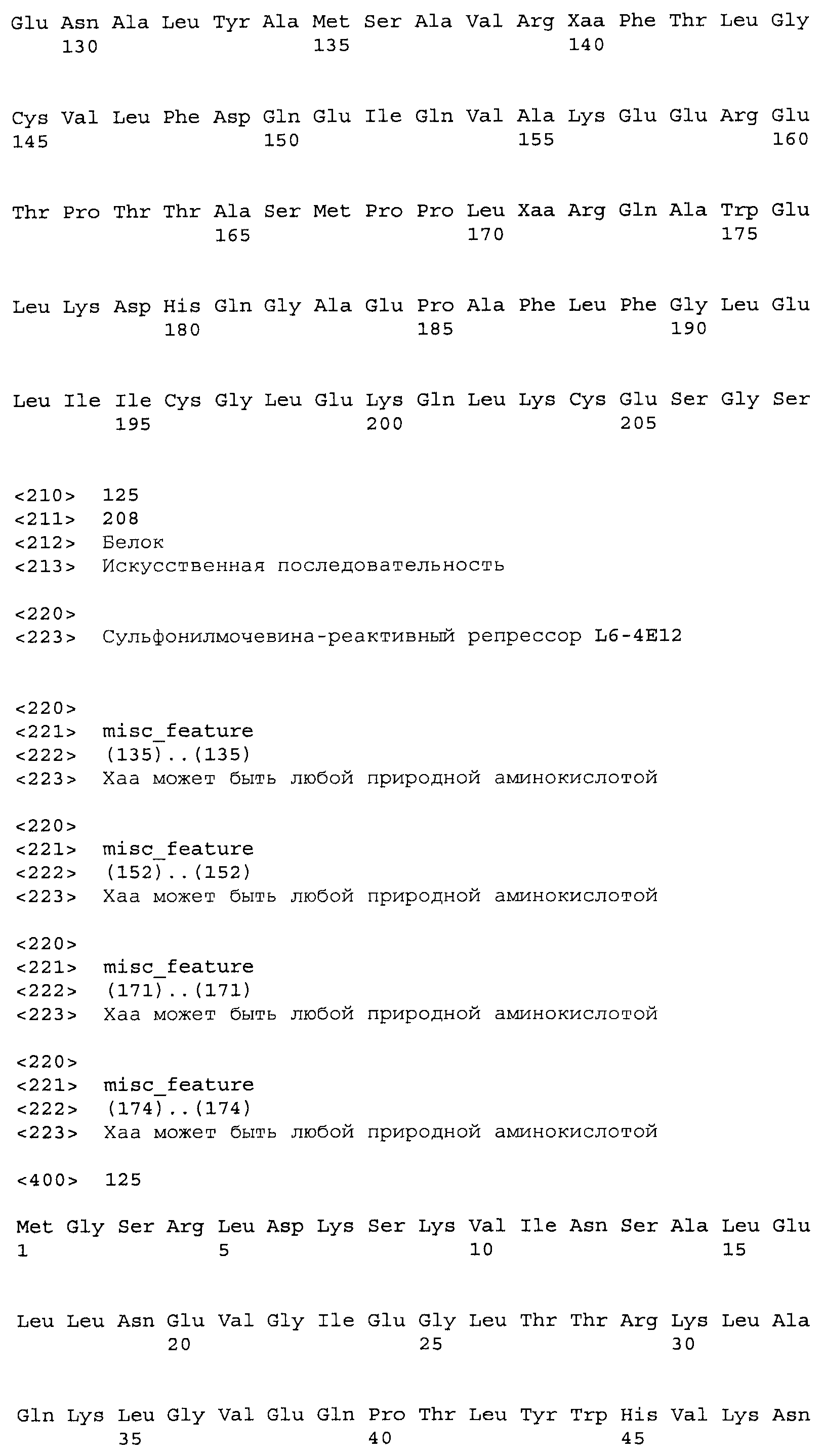
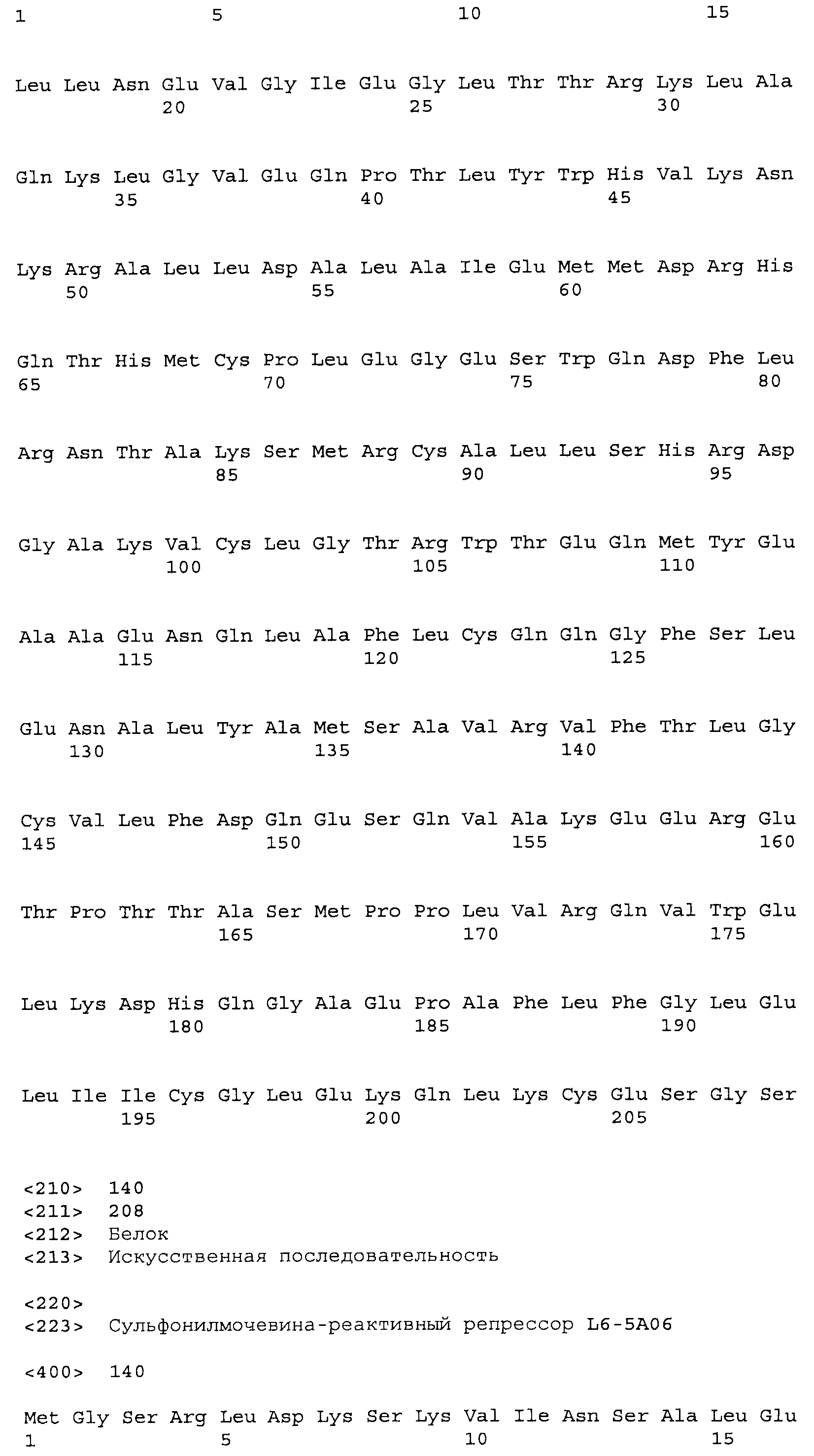
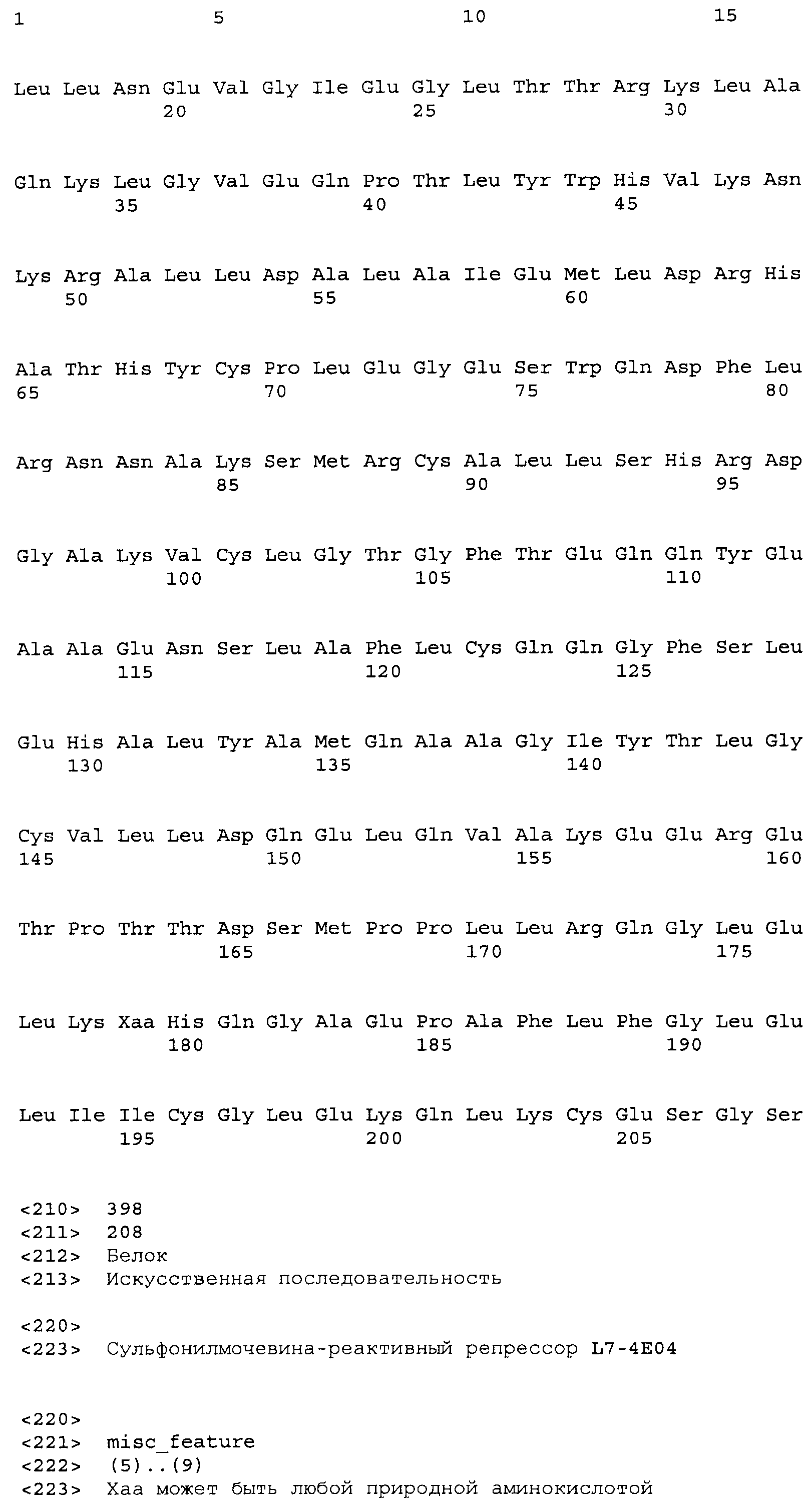
Композиции включают выделенные SuR полипептиды, обладающие, по меньшей мере, приблизительно 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичностью последовательности с лиганд-связывающим доменом SuR полипептида, выбранного из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243, где идентичность последовательности определена по полной длине лиганд-связывающего домена при использовании метода глобального выравнивания. В некоторых примерах в методе глобального выравнивания используется алгоритм GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62.
В некоторых примерах выделенный SuR полипептид обладает, по меньшей мере, приблизительно 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичностью последовательности с SuR полипептидом, выбранным из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243, где идентичность последовательности определена по полной длине полипептида при использовании метода глобального выравнивания. В некоторых примерах в методе глобального выравнивания используется алгоритм GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO: 220), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением числа битов BLAST, по меньшей мере, 374, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена с помощью выравнивания BLAST при использовании матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением процента идентичности последовательности, по меньшей мере, 88% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определяется с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO: 220), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением значения величины E (e-value) BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением числа битов BLAST, по меньшей мере, 387, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена с применением выравнивания BLAST при использовании матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением процента идентичности последовательности, по меньшей мере, 92% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах идентичность процента определена с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением числа битов BLAST, по меньшей мере, 393, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением значения подобия BLAST, по меньшей мере, 1006, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением значения E BLAST, по меньшей мере, e-112, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид отобран из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4) с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением числа битов BLAST, по меньшей мере, 388, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением процента идентичности последовательности, по меньшей мере, 93% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах идентичность процента определена с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 11 10, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения подобия BLAST, по меньшей мере, 996, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения E BLAST, по меньшей мере, e-111, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO: 6), с получением процента идентичности последовательности, по меньшей мере, 93% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением значения E BLAST, по меньшей мере, e-111, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением процента идентичности последовательности, по меньшей мере, 93% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением числа битов BLAST, по меньшей мере, 381, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения подобия BLAST, по меньшей мере, 978, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения E BLAST, по меньшей мере, e-108, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением процента идентичности последовательности, по меньшей мере, 90% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11, и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением числа битов BLAST, по меньшей мере, 368, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением значения подобия BLAST, по меньшей мере, 945, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением значения E BLAST, по меньшей мере, e-105, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84 (B12) (SEQ ID NO:1230), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84 (B12) (SEQ ID NO:1230), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84 (B12) (SEQ ID NO:1230), с получением процента идентичности последовательности, по меньшей мере, 86% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84 (B12) (SEQ ID NO:1230), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84 (B12) (SEQ ID NO:1230), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением числа битов BLAST, по меньшей мере, 320, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением процента идентичности последовательности, по меньшей мере, 86% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения подобия BLAST, по меньшей мере, 819, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах SuR полипептиды включают аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения E BLAST, по меньшей мере, e-90, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243.
В некоторых примерах выделенные SuR полипептиды включают лиганд-связывающий домен из полипептида, выбранного из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные SuR полипептиды включают аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенный SuR полипептид выбран из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243, а соединение сульфонилмочевины выбрано из группы, состоящей из хлорсульфурона, этаметсульфурона, метсульфурона, сульфометурона, трибенурона, хлоримурона, никосульфурона, римсульфурона и тифенсульфурона.
В некоторых примерах выделенные SuR полипептиды имеют константу равновесного связывания в отношении соединения сульфонилмочевины больше 0,1 нМ и меньше 10 мкМ. В некоторых примерах выделенный SuR полипептид имеет константу равновесного связывания в отношении соединения сульфонилмочевины по меньшей мере 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ, но меньше 10 мкМ. В некоторых примерах выделенный SuR полипептид имеет константу равновесного связывания в отношении соединения сульфонилмочевины, по меньшей мере, 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, но меньше чем 1 мкМ. В некоторых примерах выделенный SuR полипептид имеет константу равновесного связывания в отношении соединения сульфонилмочевины, больше 0 нМ, но меньше чем 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ или 10 мкМ. В некоторых примерах соединением сульфонилмочевины является хлорсульфурон, этаметсульфурон, метсульфурон, сульфометурон, трибенурон, хлоримурон, никосульфурон, римсульфурон и/или тифенсульфурон.
В некоторых примерах выделенные SuR полипептиды имеют константу равновесного связывания в отношении последовательности оператора больше 0,1 нМ и меньше 10 мкМ. В некоторых примерах выделенный SuR полипептид имеет константу равновесного связывания в отношении последовательности оператора по меньшей мере 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ, но меньше 10 мкМ. В некоторых примерах выделенный SuR полипептид имеет константу равновесного связывания в отношении последовательности оператора, по меньшей мере, 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, но меньше 1 мкМ. В некоторых примерах выделенный SuR полипептид имеет константу равновесного связывания в отношении последовательности оператора больше 0 нМ, но меньше 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ или 10 мкМ. В некоторых примерах последовательность оператора является последовательностью Tet оператора. В некоторых примерах последовательность Tet оператора является последовательностью TetR(A) оператора, последовательностью TetR(B) оператора, последовательностью TetR(D) оператора, последовательностью TetR(E) оператора, последовательностью TetR(H) оператора или их функциональной производной.
Выделенные SuR полипептиды специфично связываются с соединением сульфонилмочевины. Молекулы сульфонилмочевины включают сульфонилмочевинную группу (-S(O)2NHC(O)NH(R)-). В сульфонилмочевинных гербицидах сульфонильный конец сульфонилмочевинной группы связан, напрямую или через атом кислорода или необязательно замещенную амино или метиленовую группу, с типично замещенной циклической или нециклической группой. На противоположном конце сульфонилмочевинного мостика аминогруппа, которая может иметь заместитель, такой как метил (R является CH3), вместо водорода, связана с гетероциклической группой, обычно симметричным пиримидиновым или триазиновым кольцом, имеющим один или два заместителя, таких как метил, этил, трифторметил, метокси, этокси, метиламино, диметиламино, этиламино и галогены. Сульфонилмочевинные гербициды могут находиться в форме свободной кислоты или соли. В форме свободной кислоты сульфонамидный атом азота на мостике не депротонирован (то есть, -S(O)2NHC(O)NH(R)-), тогда как в форме соли сульфонамидный атом азота на мостике депротонирован (то есть, -S(O)2NC(O)NH(R)-) и присутствует катион, обычно щелочного металла или щелочноземельного металла, обычно катион натрия или калия. Соединения сульфонилмочевины включают, например, классы соединений, такие как соединения пиримидинилсульфонилмочевины, соединения триазинилсульфонилмочевины, соединения тиадиазолилмочевины и фармацевтические средства, такие как противодиабетические средства, а также их соли и другие производные. Примеры соединений пиримидинилсульфонилмочевины включают амидосульфурон, азимсульфурон, бенсульфурон, бенсульфурон-метил, хлоримурон, хлоримурон-этил, циклосульфамурон, этоксисульфурон, флазасульфурон, флуцетосульфурон, флупирсульфурон, флупирсульфурон-метил, форамсульфурон, галосульфурон, галосульфурон-метил, имазосульфурон, мезосульфурон, мезосульфурон-метил, никосульфурон, ортосульфамурон, оксасульфурон, примисульфурон, примисульфурон-метил, пиразосульфурон, пиразосульфурон-этил, римсульфурон, сульфометурон, сульфометурон-метил, сульфосульфурон, трифлоксисульфурон, а также их соли и производные. Примеры соединений триазинилсульфонилмочевины включают хлорсульфурон, циносульфурон, этаметсульфурон, этаметсульфурон-метил, иодосульфурон, иодосульфурон-метил, метсульфурон, метсульфурон-метил, просульфурон, тифенсульфурон, тифенсульфурон-метил, триасульфурон, трибенурон, трибенурон-метил, трифлусульфурон, трифлусульфурон-метил, тритосульфурон, а также их соли и производные. Примеры соединений тиадиазолилмочевины включают бутиурон, этидимурон, тебутиурон, тиазафлурон, тидиазурон, а также их соли и производные. Примеры противодиабетических средств включают ацетогексамид, хлорпропамид, толбутамид, толазамид, глипизид, гликлазид, глибенкламид (глибурид), гликвидон, глимепирид, а также их соли и производные. В некоторых примерах выделенные SuR полипептиды специфично связываются с более чем одним соединением сульфонилмочевины. В некоторых примерах соединение сульфонилмочевины выбрано из группы, состоящей из хлорсульфурона, этаметсульфурон-метила, метсульфурон-метила, тифенсульфурон-метила, сульфометурон-метила, трибенурон-метила, хлоримурон-этила, никосульфурона и римсульфурона.
Композиции также включают выделенные полинуклеотиды, кодирующие SuR полипептиды, которые специфично связываются с тетрациклиновым оператором, где специфичное связывание регулируется соединением сульфонилмочевины. В некоторых примерах выделенные полинуклеотиды кодируют сульфонилмочевина-репрессорные (SuR) полипептиды, включающие аминокислотную замену в лиганд-связывающем домене тетрациклинового репрессорного белка дикого типа. В TetR белках класса B и D дикого типа аминокислотные остатки 6-52 представляют собой ДНК-связывающий домен. Остальная часть белка участвует в связывании лиганда и последующей аллостерической модификации. Что касается TetR класса B, остатки 53-207 представляют собой лиганд-связывающий домен, тогда как в TetR класса D остатки 53-218 составляют лиганд-связывающий домен. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную замену в лиганд-связывающем домене белка TetR(B) дикого типа. В некоторых примерах полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную замену в лиганд-связывающем домене белка TetR(B) дикого типа SEQ ID NO:1.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислоту или любую комбинацию аминокислот, выбранных из разнообразия аминокислот, показанного на Фигуре 9, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа, представленного в качестве примера в SEQ ID NO:1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие лиганд-связывающий домен, включающий, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, показанных на Фигуре 9, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, показанных на Фигуре 9, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие лиганд-связывающий домен, включающий аминокислотную замену в положении остатка, выбранном из группы, состоящей из положения 55, 60, 64, 67, 82, 86, 100, 104, 105, 108, 113, 1 16, 134, 135, 138, 139, 147, 151, 170, 173, 174, 177 и любой их комбинации, где положение аминокислотного остатка и замена соответствуют эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, дополнительно включающие аминокислотную замену в положении остатка, выбранном из группы, состоящей из 109, 112, 117, 131, 137, 140, 164 и любой их комбинации. В некоторых примерах последовательность полипептида TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, в которых лиганд-связывающий домен включает, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из группы, состоящей из:
(a) M или L в положении аминокислотного остатка 55;
(b) A, L или M в положении аминокислотного остатка 60;
(c) A, N, Q, L или H в положении аминокислотного остатка 64;
(d) M, I, L, V, F или Y в положении аминокислотного остатка 67;
(e) N, S или T в положении аминокислотного остатка 82;
(f) F, M, W или Y в положении аминокислотного остатка 86;
(g) C, V, L, M, F, W или Y в положении аминокислотного остатка 100;
(h) R, A или G в положении аминокислотного остатка 104
(i) A, I, V, F или W в положении аминокислотного остатка 105;
(j) Q или K в положении аминокислотного остатка 108;
(k) A, M, H, K, T, P или V в положении аминокислотного остатка 113;
(l) I, L, M, V, R, S, N, P или Q в положении аминокислотного остатка 116;
(m) I, L, V, M, R, S или W в положении аминокислотного остатка 134;
(n) R, S, N, Q, K или А в положении аминокислотного остатка 135;
(o) A, C, G, H, I, V, R или T в положении аминокислотного остатка 138;
(p) A, G, I, V, M, W, N, R или T в положении аминокислотного остатка 139;
(q) I, L, V, F, W, T, S или R в положении аминокислотного остатка 147;
(r) M, L, W, Y, K, R или S в положении аминокислотного остатка 151;
(s) I, L, V или А в положении аминокислотного остатка 170;
(t) A, G или V в положении аминокислотного остатка 173;
(u) L, V, W, Y, H, R, K или S в положении аминокислотного остатка 174; и,
(v) A, G, I, L, Y, K, Q или S в положении аминокислотного остатка 177,
где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полинуклеотиды кодируют SuR полипептиды, включающие, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из аминокислотных остатков, перечисленных в (a)-(v) выше, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, которые выбраны из-за своей повышенной активности в отношении хлорсульфурона и имеют лиганд-связывающий домен, включающий, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из группы, состоящей из:
(a) M в положении аминокислотного остатка 60;
(b) A или Q в положении аминокислотного остатка 64;
(c) M, F, Y, I, V или L в положении аминокислотного остатка 67;
(d) N или T в положении аминокислотного остатка 82;
(e) M в положении аминокислотного остатка 86;
(f) C или W в положении аминокислотного остатка 100;
(g) W в положении аминокислотного остатка 105;
(h) Q или K в положении аминокислотного остатка 108;
(i) M, Q, L или H в положении аминокислотного остатка 109;
(j) G, A, S или T в положении аминокислотного остатка 112;
(k) A в положении аминокислотного остатка 113;
(l) M или Q в положении аминокислотного остатка 116;
(m) M или V в положении аминокислотного остатка 134;
(n) G или R в положении аминокислотного остатка 138;
(o) N или V в положении аминокислотного остатка 139;
(p) F в положении аминокислотного остатка 147;
(q) S или L в положении аминокислотного остатка 151;
(r) A в положении аминокислотного остатка 164;
(s) A, L или V в положении аминокислотного остатка 170;
(t) A, G или V в положении аминокислотного остатка 173;
(u) L или W в положении аминокислотного остатка 174; и;
(v) K в положении аминокислотного остатка 177,
где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полинуклеотиды кодируют SuR полипептиды, включающие по меньшей мере 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из аминокислотных остатков, перечисленных в (a)-(v) выше, где положения аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, которые выбраны из-за своей повышенной активности в отношении этаметсульфурона и имеют лиганд-связывающий домен, включающий, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из группы, состоящей из:
(a) M или L в положении аминокислотного остатка 55;
(b) A в положении аминокислотного остатка 64;
(c) M, Y, F, I, L или V в положении аминокислотного остатка 67;
(d) M в положении аминокислотного остатка 86;
(e) C в положении аминокислотного остатка 100;
(f) G в положении аминокислотного остатка 104;
(g) F в положении аминокислотного остатка 105;
(h) Q или K в положении аминокислотного остатка 108;
(i) Q, M, L или H в положении аминокислотного остатка 109;
(j) S, T, G или А в положении аминокислотного остатка 112;
(k) A в положении аминокислотного остатка 113;
(l) S в положении аминокислотного остатка 116;
(m) M или L в положении аминокислотного остатка 117;
(n) M или L в положении аминокислотного остатка 131;
(o) M в положении аминокислотного остатка 134;
(p) Q в положении аминокислотного остатка 135;
(q) A или V в положении аминокислотного остатка 137;
(r) C или G в положении аминокислотного остатка 138;
(s) I в положении аминокислотного остатка 139;
(t) F или Y в положении аминокислотного остатка 140;
(u) L в положении аминокислотного остатка 147;
(v) L в положении аминокислотного остатка 151;
(w) A в положении аминокислотного остатка 164;
(x) V, A или L в положении аминокислотного остатка 170;
(y) G, A или V в положении аминокислотного остатка 173;
(z) L в положении аминокислотного остатка 174; и
(aa) N или K в положении аминокислотного остатка 177,
где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах выделенные SuR полинуклеотиды кодируют SuR полипептиды, включающие, по меньшей мере, 10%, 20%, 30%, 40%, 50%, 55%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% аминокислотных остатков, выбранных из аминокислотных остатков, перечисленных в (a)-(aa) выше, где положение аминокислотного остатка соответствует эквивалентному положению при использовании аминокислотной нумерации TetR(B) дикого типа. В некоторых примерах TetR(B) дикого типа соответствует SEQ ID NO:1.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, обладающие, по меньшей мере, приблизительно 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности с лиганд-связывающим доменом, показанным аминокислотными остатками 53-207 в SEQ ID NO:1, где идентичность последовательности определена по полной длине лиганд-связывающего домена с применением метода глобального выравнивания. В некоторых примерах методом глобального выравнивания является GAP, в котором параметры по умолчанию используются для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, обладающие, по меньшей мере, приблизительно 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности с SEQ ID NO:1, где идентичность последовательности определена по полной длине полипептида с применением метода глобального выравнивания. В некоторых примерах методом глобального выравнивания является GAP, в котором параметры по умолчанию используются для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62.
В некоторых примерах выделенные полинуклеотиды включают последовательности нуклеиновой кислоты, которые селективно гибридизуются при жестких условиях гибридизации с полинуклеотидом, кодирующим SuR полипептид. Полинуклеотиды, которые селективно гибридизуются, являются полинуклеотидами, которые связываются с целевой последовательностью на уровне, по меньшей мере, в 2 раза превышающим фон по сравнению с гибридизацией с нецелевой последовательностью. Жесткие условия зависят от последовательности и условий. Характерные жесткие условия являются такими условиями, при которых концентрация соли составляет приблизительно 0,01-1,0 M при pH 7,0-8,3 и температуре 30°C для коротких зондов (например, 10-50 нуклеотидов) или приблизительно 60°C для длинных зондов (например, больше 50 нуклеотидов). Строгие условия могут включать формамид или другие дестабилизирующие агенты. Примерные условия умеренной жесткости включают гибридизацию в 40-45% формамиде, 1 M NaCl, 1% SDS при 37°C и промывку в 0,5× - 1× SSC при 55-60°C. Примерные условия высокой жесткости включают гибридизацию в 50% формамиде, 1 M NaCl, 1% SDS при 37°C и промывку в 0,1×SSC при 60-65°C.
На специфичность влияют условия постгибридизационной промывки, обычно посредством ионной силы и температуры. Для ДНК-ДНК гибридов Tm может быть приближенно выражена уравнением Meinkoth и Wahl, (1984) Anal. Biochem. 138:267-284: Tm = 81,5°C + 16,6 (log M) + 0,41 (%GC) - 0,61 (% формамида) - 500/L; где M является молярностью одновалентных катионов, %GC является процентным содержанием гуанозиновых и цитозиновых нуклеотидов в ДНК, % формамида является процентным содержанием формамида в гибридизационном растворе, и L является длиной гибрида в парах оснований. Подробное руководство по гибридизации нуклеиновых кислот можно найти в Tijssen, Laboratory Techniques in Biochemistry and Molecular Biology-Hybridization with Nucleic Acid Probes, Part I, Chapter 2, "Overview of principles of hybridization and the strategy of nucleic acid probe assays", Elsevier, New York (1993); и Current Protocols in Molecular Biology, Chapter 2, Ausubel, et al., Eds., Greene Publishing and Wiley-lnterscience, New York (1995). В некоторых примерах, выделенные полинуклеотиды, кодирующие SuR полипептиды, специфично гибридизуются с полинуклеотидом SEQ ID NO:434-832, 1214-1221, 1234-1239 или 1244-1247 при умеренно жестких условиях или при очень жестких условиях.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO: 220), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением числа битов BLAST, по меньшей мере, 374, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением процента идентичности последовательности, по меньшей мере, 88% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO: 220), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 600, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-1A04 (SEQ ID NO:220), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением числа битов BLAST, по меньшей мере, 387, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением процента идентичности последовательности, по меньшей мере, 92% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 600, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-22 (SEQ ID NO:7), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO:434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением числа битов BLAST, по меньшей мере, 393, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением значения подобия BLAST, по меньшей мере, 1006, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-29 (SEQ ID NO:10), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-02 (SEQ ID NO:3), с получением значения E BLAST, по меньшей мере, e-112, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO:434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением числа битов BLAST, по меньшей мере, 388, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением процента идентичности последовательности, по меньшей мере, 93% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11, и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения подобия BLAST, по меньшей мере, 996, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11, и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-07 (SEQ ID NO:4), с получением значения E BLAST, по меньшей мере, e-111, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO:434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением процента идентичности последовательности, по меньшей мере, 93% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-20 (SEQ ID NO:6), с получением значения E BLAST, по меньшей мере, e-111, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO:3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением процента идентичности последовательности, по меньшей мере, 93% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L1-44 (SEQ ID NO:13), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением числа битов BLAST, по меньшей мере, 381, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения подобия BLAST, по меньшей мере, 978, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3A09 (SEQ ID NO:1228), с получением значения E BLAST, по меньшей мере, e-108, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO:434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением процента идентичности последовательности, по меньшей мере, 90% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L6-3H02 (SEQ ID NO:94), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO: 1229), с получением числа битов BLAST, по меньшей мере, 368, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO: 1229), с получением значения подобия BLAST, по меньшей мере, 945, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO:1229), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L7-4E03 (SEQ ID NO: 1229), с получением значения E BLAST, по меньшей мере, e-105, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO:434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84(B12) (SEQ ID NO: 1230), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84(B12) (SEQ ID NO: 1230), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84(B12) (SEQ ID NO: 1230), с получением процента идентичности последовательности, по меньшей мере, 86% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84(B12) (SEQ ID NO: 1230) с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L10-84(B12) (SEQ ID NO: 1230), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO: 1231), с получением числа битов BLAST, по меньшей мере, 200, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700 или 750, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением числа битов BLAST, по меньшей мере, 320, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением процента идентичности последовательности, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением процента идентичности последовательности, по меньшей мере, 86% идентичности последовательности, где идентичность последовательности определена при выравнивании BLAST с использованием матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. В некоторых примерах процент идентичности последовательности определен с применением метода глобального выравнивания при использовании алгоритма GAP с параметрами по умолчанию для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения подобия BLAST, по меньшей мере, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 750, 800, 850, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000, 1010, 1020, 1030, 1040, 1050, 1060, 1070, 1080, 1090, 1100, 1110, 1120, 1130, 1140, 1150, 1160, 1170, 1180, 1190 или 1200, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения подобия BLAST, по меньшей мере, 819, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения E BLAST, по меньшей мере, e-60, e-70, e-75, e-80, e-85, e-90, e-95, e-100, e-105, e-106, e-107, e-108, e-109, e-110, e-111, e-112, e-113, e-114, e-115, e-116, e-117, e-118, e-119, e-120 или e-125, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, которая может быть оптимально выровнена с последовательностью полипептида L13-46 (SEQ ID NO:1231), с получением значения E BLAST, по меньшей мере, e-90, где в BLAST выравнивании используется матрица BLOSUM62, штраф за внесение пропуска 11 и штраф за удлинение пропуска 1. В некоторых примерах выделенный полинуклеотид кодирует полипептид, выбранный из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептид, включающий лиганд-связывающий домен из полипептида, выбранного из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах выделенные полинуклеотиды кодируют SuR полипептиды, включающие аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах кодируемый SuR полипептид выбран из группы, состоящей из SEQ ID NO: 3-401, 1206-1213, 1228-1233 или 1240-1243, а соединение сульфонилмочевины выбрано из группы, состоящей из хлорсульфурона, этаметсульфурон-метила, метсульфурон-метила, сульфометурон-метила и тифенсульфурон-метила. В некоторых примерах выделенные полинуклеотиды включают полинуклеотидную последовательность SEQ ID NO: 434-832, 1214-1221, 1234-1239 или 1244-1247, или соответствующий комплементарный полинуклеотид.
В некоторых примерах выделенный полинуклеотид SuR кодирует SuR полипептид, имеющий константу равновесного связывания в отношении соединения сульфонилмочевины больше 0,1 нМ и меньше 10 мкМ. В некоторых примерах кодируемый SuR полипептид имеет константу равновесного связывания в отношении соединения сульфонилмочевины, по меньшей мере, 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ, но меньше 10 мкМ. В некоторых примерах кодируемый SuR полипептид имеет константу равновесного связывания в отношении соединения сульфонилмочевины, по меньшей мере, 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, но меньше 1 мкМ. В некоторых примерах кодируемый SuR полипептид имеет константу равновесного связывания в отношении соединения сульфонилмочевины, больше 0 нМ, но меньше 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ или 10 мкМ. В некоторых примерах соединением сульфонилмочевины является соединение хлорсульфурона, этаметсульфурона, метсульфурона, сульфометурона и/или тифенсульфурона.
В некоторых примерах выделенный полинуклеотид SuR кодирует SuR полипептид, имеющий константу равновесного связывания в отношении последовательности оператора больше 0,1 нМ и меньше 10 мкМ. В некоторых примерах кодируемый SuR полипептид имеет константу равновесного связывания в отношении последовательности оператора, по меньшей мере, 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ, но меньше 10 мкМ. В некоторых примерах кодируемый SuR полипептид имеет константу равновесного связывания в отношении последовательности оператора, по меньшей мере, 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, но меньше 1 мкМ. В некоторых примерах кодируемый SuR полипептид имеет константу равновесного связывания в отношении последовательности оператора больше 0 нМ, но меньше 0,1 нМ, 0,5 нМ, 1 нМ, 10 нМ, 50 нМ, 100 нМ, 250 нМ, 500 нМ, 750 нМ, 1 мкМ, 5 мкМ, 7 мкМ или 10 мкМ. В некоторых примерах последовательность оператора является последовательностью Tet оператора. В некоторых примерах последовательность оператора Tet является последовательностью TetR(A) оператора, последовательностью TetR(B) оператора, последовательностью TetR(D) оператора, последовательностью TetR(E) оператора, последовательностью TetR(H) оператора или их функциональной производной.
В некоторых примерах выделенные полинуклеотиды, кодирующие SuR полипептиды, включают профили кодонного состава, соответствующие предпочтительным кодонам для конкретных клеток-хозяев или органелл клеток-хозяев. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в прокариотах. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в бактериях. В некоторых примерах бактериями являются E. coli или Agrobacterium. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в пластидах. В некоторых примерах выделенные полинуклеотиды включают кодоны предпочтительные в эукариотах. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в ядре. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в растениях. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в однодольных растениях. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в кукурузе, рисе, сорго, ячмене, пшенице, ржи, просо, газонной траве и/или овсе. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в двудольных растениях. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в сое, подсолнечнике, сафлоре, Brassica, люцерне, Arabidopsis, табаке и/или хлопке. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в дрожжах. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в млекопитающих. В некоторых примерах выделенные полинуклеотиды включают кодоны, предпочтительные в насекомых.
Композиции также включают выделенные полинуклеотиды, полностью комплементарные полинуклеотиду, кодирующему SuR полипептид, кассеты экспрессии, репликоны, векторы, T-ДНК, библиотеки ДНК, клетки-хозяева, ткани и/или организмы, включающие полинуклеотиды, кодирующие SuR полипептиды, и/или комплементарные полинуклеотиды, или их производные. В некоторых примерах предложена библиотека ДНК, включающая популяцию полинуклеотидов, которые кодируют популяцию вариантов полипептида SuR. В некоторых примерах полинуклеотид стабильно включен в геном хозяйской клетки, ткани и/или организма. В некоторых примерах клетка-хозяин является прокариотом, включающим штаммы E. coli и Agrobacterium. В некоторых примерах хозяином является эукариот, включающий, например, дрожжи, насекомых, растения и млекопитающих.
Также предложены способы применения композиций. В одном из примеров предложены способы регуляции транскрипции целевого полинуклеотида в клетке-хозяине, включающие: предоставление клетки, включающей целевой полинуклеотид, функционально связанный с промотором, включающим, по меньшей мере, одну последовательность тетрациклинового оператора; предоставление SuR полипептида и предоставление соединения сульфонилмочевины с регуляцией, таким образом, транскрипции целевого полинуклеотида. Может использоваться любая клетка-хозяин, включающая, например, прокариотические клетки, такие как клетки бактерий, и эукариотические клетки, включающие клетки дрожжей, растений, насекомых и млекопитающих. В некоторых примерах получение SuR полипептида включает контакт клетки с кассетой экспрессии, включающей функциональный в клетке промотор, который функционально связан с полинуклеотидом, кодирующим SuR полипептид.
Также предложены способы получения и селекции разнообразных библиотек с целью получения дополнительных SuR полинуклеотидов, включая полинуклеотиды, кодирующие SuR полипептиды с улучшенными и/или усовершенствованными свойствами, например, измененными константами связывания в отношении соединений сульфонилмочевины и/или целевой ДНК последовательности оператора и/или повышенной стабильностью, которые основаны на селекции полинуклеотидного элемента библиотеки на предмет новых или улучшенных функций. В некоторых примерах предложена, по меньшей мере, одна библиотека или популяция олигонуклеотидов, созданных с целью введения модификации и/или разнообразия последовательности в полипептид лиганд-связывающего домена TetR дикого типа или модифицированного TetR. В некоторых примерах библиотека или популяция созданы с целью введения модификации и/или разнообразия в полипептид TetR дикого типа или модифицированный TetR полипептид. В некоторых примерах в библиотеку или популяцию вводят, по меньшей мере, одну модификацию, как в качестве примера показано на Фигуре 9. В некоторых примерах библиотека или популяция включают, по меньшей мере, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 или больше различных олигонуклеотидов. В некоторых примерах библиотека или популяция включают олигонуклеотиды, выбранные из олигонуклеотидов, показанных, по меньшей мере, в одной из Таблиц 2, 9, 12, 13, 15, 17, 19 или их комбинаций. В некоторых примерах библиотека или популяция включают один или более олигонуклеотидов, выбранных из группы, состоящей из SEQ ID NO: 833-882, 885-986, 987-059, 1060-1083, 1084-1124, 1125-1154, 1159-1205.
В некоторых примерах соединением сульфонилмочевины является этаметсульфурон. В некоторых примерах этаметсульфурон предоставляют в концентрации приблизительно 0,001, 0,002, 0,003, 0,004, 0,005, 0,006, 0,007, 0,008, 0,009, 0,01, 0,02, 0,03, 0,04, 0,05, 0,06, 0,07, 0,08, 0,09, 0,10, 0,15, 0,2, 0,25, 0,3, 0,35, 0,4, 0,45, 0,5, 0,55, 0,6, 0,65, 0,7, 0,75, 0,8, 0,85, 0,9, 0,95, 1,0, 1,5, 2,0, 2,5, 3,0, 3,5, 4,0, 4,5, 5,0, 5,5, 6,0, 6,5, 7,0, 7,5, 8,0, 8,5, 9,0, 9,5, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 100, 200 или 500 мкг/мл. В некоторых примерах SuR полипептид имеет лиганд-связывающий домен, обладающий, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности с SuR полипептидом SEQ ID NO: 205-401, 1206-1213 или 1228-1233, где идентичность последовательности определена по полной длине полипептида с применением метода глобального выравнивания. В некоторых примерах методом глобального выравнивания является GAP, в котором параметры по умолчанию используются для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах полипептид имеет лиганд-связывающий домен из полипептида SuR, выбранного из группы, состоящей из SEQ ID NO: 205-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO: 205-401, 1206-1213, 1228-1233 или 1240-1243. В некоторых примерах полипептид кодируется полинуклеотидом SEQ ID NO: 636-832, 1214-1221, 1234-1239 или 1244-1247.
В некоторых примерах соединением сульфонилмочевины является хлорсульфурон. В некоторых примерах хлорсульфурон предоставляют в концентрации приблизительно 0,01, 0,02, 0,03, 0,04, 0,05, 0,06, 0,07, 0,08, 0,09, 0,10, 0,15, 0,2, 0,25, 0,3, 0,35, 0,4, 0,45, 0,5, 0,55, 0,6, 0,65, 0,7, 0,75, 0,8, 0,85, 0,9, 0,95, 1,0, 1,5, 2,0, 2,5, 3,0, 3,5, 4,0, 4,5, 5,0, 5,5, 6,0, 6,5, 7,0, 7,5, 8,0, 8,5, 9,0, 9,5, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 100, 200 или 500 мкг/мл. В некоторых примерах SuR полипептид имеет лиганд-связывающий домен, обладающий, по меньшей мере, 50%, 60%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичности последовательности с SuR полипептидом SEQ ID NO:14-204, где идентичность последовательности определена по полной длине полипептида с применением метода глобального выравнивания. В некоторых примерах методом глобального выравнивания является GAP, в котором параметры по умолчанию используются для % идентичности и % подобия аминокислотной последовательности, с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62. В некоторых примерах полипептид имеет лиганд-связывающий домен из полипептида SuR, выбранного из группы, состоящей из SEQ ID NO:14-204. В некоторых примерах полипептид выбран из группы, состоящей из SEQ ID NO:14-204. В некоторых примерах полипептид кодируется полинуклеотидом SEQ ID NO:445-635.
Возможность фиксировать стоимость на различных рынках семян будет требовать развития технологии для контроля распространения генно-инженерных признаков. Одним из вариантов является система деактивации/активации признака с применением химически регулируемого выключателя гена. До настоящего времени подобной системы не существовало, в значительной степени из-за нехватки подходящих химических соединений, например, на основе сельскохозяйственной и/или фармацевтической химической продукции, которые могут применяться в качестве лиганда в технологии чувствительных генных выключателей.
Для создания лиганда генного выключателя на основе сельскохозяйственного химиката, TetR модифицировали с использованием белкового моделирования, ДНК-шаффлинга и высокочувствительного метода скрининга, с получением репрессора, который специфично узнает соединения сульфонилмочевины. Что касается сельскохозяйственных применений, соединения сульфонилмочевины способны к транспорту по флоэме и являются коммерчески доступными, обеспечивая, таким образом, хороший базис для их применения в качестве химических лигандов-выключателей. После трех раундов моделирования и ДНК-шаффлинга были получены репрессоры, которые узнают SU химию почти так же, как TetR дикого типа узнает когнатные индукторы, и к тому же являются полностью специфичными в отношении производных сульфонилмочевины. Указанные полипептиды включают действительные сульфонилмочевинные репрессоры (SuR), которых оценивали в растениях с применением недавно разработанной системы транзиентного анализа, чтобы продемонстрировать функциональные возможности системы SuR выключателя. Хотя пример был приведен в сельскохозяйственном контексте, указанные способы и композиции могут применяться в целом ряде других условий и организмов.
Как правило, наиболее предпочтительной является такая система химического выключателя, в которой применяемый химикат быстро проникает и воспринимается всеми типами клеток в организме, но не нарушает эндогенных регуляторных сетей. Другие важные аспекты имеют отношение к свойствам сенсорного компонента, например, жесткости регуляции и ответа в отсутствие или присутствии индуктора. Обычно предпочтительна система выключателя, имеющая строгую регуляцию "выключенного" состояния в отсутствие индуктора, и с быстрым и интенсивным ответом в присутствии индуктора.
Способность обратимо включать и выключать гены имеет большую ценность для исследований экспрессии и функции генов, особенно для тех генов, продукты которых токсичны для клетки. Хорошо изученный механизм регуляции в прокариотах включает связывание репрессорных белков с операторной ДНК для предотвращения инициации транскрипции (Wray and Reznikoff, (1983) J. Bacteriol. 156:1 188-1191), и репрессор-регулируемые системы были разработаны для регуляции экспрессии, как в животных (Wirtz and Clayton, (1995) Science 268:1179-1183; Deuschle et al., (1995) Mol. Cell Biol. 15:1097-1914; Furth et al., (1994) Proc. Natl. Acad. Sci. USA 91:9032-9306; Gossen and Bujard, (1992) Proc. Natl. Acad. Sci. USA 89:5547-5551 и Gossen et al., (1995) Science 268:1766-1769), так и в растениях (Wilde et al., (1992) EMBO J. 11:1251-1259; Gatz et al., (1992) Plant J. 2:397-404; Roder et al., (1994) Mol. Gen. Genet. 243-32-38 и Ulmasov et al., (1997) Plant Mol. Biol. 35:417-424).
Две главных системы на основе репрессоров успешно применялись для регуляции экспрессии генов растений: система на основе lac оператора-репрессора (Ulmasov et al., (1997) Plant Mol. Biol. 35:417-424; Wilde et al., (1992) EMBO J. 11:1251-1259) и система на основе tet оператора-репрессора (Wilde et al., (1992) EMBO J. 11:1251-1259; Gatz et al., (1992) Plant J. 2:397-404; Roder et al., (1994) Mol. Gen. Genet. 243:32-38; Ulmasov et al., (1997) Plant Mol. Biol. 35-417-424). Обе системы являются системами, основанными на репрессоре/операторе, ключевые элементы которых получены из соответствующего прокариотического оперона, а именно, лактозного оперона E. coli в случае lac и транспозона Tn10 тетрациклинового оперона в случае tet. Как правило, данные системы регулируют активность промотора с помощью операторных последовательностей, расположенных вблизи сайта начала транскрипции гена, при этом экспрессия гена в опероне ингибируется при связывании белка-репрессора с узнаваемой им операторной последовательностью. Однако, в присутствии индуцирующего агента связывание репрессора с оператором ингибируется, что вызывает активацию промотора и активирует экспрессию гена. Стандартным индуцирующим агентом в lac системе является изопропил-B-D-тиогалактопиранозид (IPTG), тогда как тетрациклин и/или доксициклин обычно используются в качестве индуцирующих агентов в tet системе.
Экспрессия Tn10-оперона регулируется связыванием tet-репрессора с его операторными последовательностями (Beck et al., (1982) J. Bacteriol. 150:633-642; Wray and Reznikoff, (1983) J. Bacteriol. 156:1188-1191). Высокая специфичность тетрациклинового репрессора к tet-оператору, высокая эффективность индукции тетрациклином и его производными, низкая токсичность индуктора, а также способность тетрациклина легко проникать в большинство клеток являются предпосылками к применению tet-системы в регуляции соматических генов в эукариотических клетках животных (Wirtz and Clayton, (1995) Science 268:1179-1183; Gossen et al., (1995) Science 268:1766-1769), человека (Deuschle et al., (1995) Mol. Cell Biol. 15:1907-1914; Furth et al., (1994) Proc. Natl. Acad. Sci. USA 91 :9302-9306; Gossen and Bujard, (1992) Proc. Natl. Acad. Sci. USA 89:5547-5551; Gossen et al., (1995) Science 268:1766-1769), и культурах клеток растений (Wilde et al., (1992) EMBO J. 11:1251-1259; Gatz et al., (1992) Plant J. 2:397-404; Roder et al., (1994) Mol. Gen. Genet. 243:32-28; Ulmasov et al., (1997) Plant Mol. Biol. 35:417-424).
Было создано множество вариантов систем на основе тетрациклинового оператора/репрессора. Например, одна система, основанная на превращении tet-репрессора в активатор, была создана путем слияния репрессора с доменом трансактивации транскрипции, например, VP16 из вируса простого герпеса и tet-репрессора (tTA, Gossen and Bujard, (1992) Proc. Natl. Acad. Sci. USA 89:5547-5551). В данной системе минимальный промотор активируется в отсутствие тетрациклина при связывании tTA с последовательностями tet-оператора, а тетрациклин инактивирует трансактиватор и ингибирует транскрипцию. Данную систему применяли в растениях (Weinmann et al., (1994) Plant J. 5:559-569), сердце крысы (Fishman et al., (1994), J. Clin. Invest. 93:1864-1868) и в мышах (Furth et al., (1994) Proc. Natl. Acad. Sci. USA 91:9302-9306). Впрочем, наблюдались признаки того, что химерный tTA слитый белок был токсичен для клеток в уровнях, требуемых для эффективной регуляции генов (Bohl et al., (1996) Nat. Med. 3:299-305).
Известны промоторы, модифицированные с целью регуляции тетрациклином и его аналогами (Matzke et al., (2003) Plant Mol. Biol. Rep. 21:9-19; Padidam, (2003) Curr. Op. Plant Biol. 6:169-177; Gatz and Quail, (1988) Proc. Natl. Acad. Sci. USA 85:1394-1397; Ulmasov et al., (1997) Plant Mol. Biol. 35:417-424; Weinmann et al., (1994) Plant J. 5:559-569). Одна или несколько последовательностей tet-оператора могут быть добавлены к промотору с получением тетрациклин-индуцируемого промотора. В некоторых примерах перед последовательностью минимального промотора было введено до 7 tet-операторов, и TetR::VP16 слитый домен активации применяли в трансактивации экспрессии только в отсутствие индуктора (Weinmann et al., (1994) Plant J. 5:559-569; Love et al., (2000) Plant J. 21:579-588). Была создана хорошо отработанная тетрациклин-регулируемая система экспрессии для растений с использованием 35S промотора CaMV (Gatz et al., (1992) Plant J. 2:397-404), включающая три tet-оператора около TATA-бокса (3XOpT 35). 3XOpT 35S промотор в целом функционировал в табаке и картофеле, однако также сообщалось о токсичности и плохом фенотипе растений в томатах и Arabidopsis (Gatz (1997) Ann. Rev. Plant Physiol. Plant Mol. Biol. 48:89-108; Corlett et al., (1996) Plant Cell Environ. 19:447-454). Другой фактор состоит в том, что тетрациклиновые соединения быстро разрушаются на свету, что ограничивает их применение при тестировании в лабораторных условиях.
TetR подвергали ДНК-шаффлингу с целью изменения его специфичности к индуктору с тетрациклина на 4-де(диметиламино)-6-дезокси-6-деметил-тетрациклин (cmt3), сходное, но не вызывающее индукции соединение (Scholz et al., (2003) J. Mol. Biol. 329:217-227), которое не содержит химических боковых групп в положениях 4 и 6, и поэтому имеет меньший размер, чем тетрациклин. Специфичность TetR была изменена путем сужения лиганд-связывающего кармана, стерически блокируя, таким образом, природный тетрациклиновый лиганд. Исходный полипептид представлял собой химерный TetR(BD), состоящий из аминокислот 1-50 из TetR(B) и остатков 51-208 из TetR(D). Несколько раундов эволюции и селекции использовали для изменения специфичности TetR с тетрациклина на cmt3. Не являющийся индуктором cmt3 обладал небольшой исходной активностью, которую затем повысили до уровня тетрациклина с получением активности, повышенной в несколько тысяч раз, при этом тетрациклин почти не обладал индуцирующей активностью в отношении мутантных репрессоров. Хотя возможность изменения специфичности TetR на cmt3 лиганд представляет большой интерес, следует учитывать, что cmt3 весьма схож с природным лигандом тетрациклином. Из данных экспериментов вовсе не очевидно, что TetR может применяться в качестве основы для получения специфичности к совершенно другому классу химических лигандов.
Для получения новой системы химического выключения, TetR систему подвергли изменению, чтобы она смогла распознавать химические соединения, пригодные для применения в сельском хозяйстве. Процесс модернизации начинали с выбора зарегистрированного агрохимического соединения, обладающего превосходными свойствами абсорбции и распределения в растениях, а также имеющего размер и форму, приемлемые для моделирования в лиганд-связывающем кармане TetR дикого типа. Выбранное соединение, тифенсульфурон-метил (Harmony®) является одним из представителей семейства коммерческих гербицидов сульфонилмочевинного типа, ингибирующих ключевой растительный фермент в биосинтезе разветвленных аминокислот, ацетолактатсинтазу (ALS). Тифенсульфурон (Ts) и подобные гербициды структурно несопоставимы с тетрациклином, поэтому было маловероятно, что они будут обладать какой-либо изначальной активностью в отношении TetR. ДНК-шаффлинг является мощной технологией и может повышать аффинность к субстратам или число оборотов субстратов в несколько тысяч раз, однако пока что не позволяла создавать исходную активность de novo. Чтобы заполнить данный пробел в пути эволюции, предположили, что стратегия компьютерного моделирования позволит сузить поиск подходящего разнообразия аминокислот для перетасовки. Недавно разработанная технология моделирования использовалась для изменения специфичности периплазматических связывающих белков E. coli, которые обычно связываются с сахарами, чтобы они реагировали и инициировали сигнализацию с наборами совершенно других соединений, таких как серотонина, L-лактат и тринитротолуол (Looger et al., (2003) Nature 423:185-190). При использовании белкового дизайна вместе с ДНК-шаффлингом и системой высокочувствительного скрининга были идентифицированы варианты белка TetR, которые отвечают на тифенсульфурон (Ts) и другие родственные SU соединения. После нескольких раундов ДНК-шаффлинга были получены варианты TetR, обладающие функцией выключателя гена с SU лигандами (SuR), аналогично функции TetR с тетрациклиновыми индукторами.
Любой способ рационального белкового дизайна может использоваться отдельно или в комбинации. Например, филогенетическое разнообразие в пределах семейства последовательностей белка может использоваться для идентификации положений в первичной структуре, содержащих аминокислотные замены, и определения типов произошедших замен, а также их влияния на функцию. Семейства консервативных доменов также могут быть выровнены и исследованы аналогичным образом с целью идентификации положений в первичной структуре, содержащих аминокислотные замены, и определения типов произошедших замен, а также их влияния на функцию. Вторичная структура (структуры) и функциональные области могут быть оценены, при этом могут применяться различные модели, используемые для предсказания допустимости или влияния аминокислотных замен на структуру и функции. Моделирование с использованием третичной структуры и/или четвертичной структуры и лиганда, связывания субстрата и/или кофактора обеспечивает дополнительное понимание эффектов аминокислотных замен и/или дополнительных лигандов, взаимодействий субстратов и/или кофакторов с полипептидом.
Для изучения филогенетического разнообразия тетрациклиновых репрессоров использовали обширное семейство тетрациклиновых белков-репрессоров, а также близкородственных тетрациклиновых репрессоров. Тридцать четыре белка были идентифицированы и выровнены с целью исследования разнообразия аминокислот в различных положениях в семействе репрессоров (SEQ ID NO: 1 и 402-433). Обширное семейство тетрациклиновых репрессоров включало мутант TetR(D), структура которого была определена путем кристаллизации PDB_1A6I (Orth et al., (1998) J. Mol. Biol. 279:439-447), и общедоступные последовательности под номерами A26948, AAA98409, AAD12754, AAD25094, AAD25537, AAP93923, AAR96033, AAW66496, AAW83818, ABO14708, ABS19067, CAA24908, CAC80726, CAC81917, EAY62734, NP_387455, NP_387462, NP_511232, NP_824556, P51560, YP_001220607, YP_001370475, YP_368094, YP_620166, YP_772551, ZP_00132379, ZP_01558383 и ZP_01567051. Близкородственные тетрациклиновые репрессоры включали TetR(A) P03038, TetR(B) P04483, TetR(D) P0ACT4, TetR(E) P21337 и TetR(H) P51561. Выравнивания указанных последовательностей использовали при поиске разнообразия в полных последовательностях, а также разнообразия в ДНК и лиганд-связывающих доменах (см., Пример 1H, SEQ ID NO: 1 и 402-433).
Модульная архитектура белков-репрессоров и сходство спираль-петля-спиральных ДНК-связывающих доменов позволяет создать SuR полипептиды, обладающие измененной ДНК-связывающей специфичностью. Например, ДНК-связывающая специфичность может быть изменена путем слияния SuR лиганд-связывающего домена с дополнительным ДНК-связывающим доменом. Например, ДНК-связывающий домен из TetR класса D может быть слит с SuR лиганд-связывающим доменом, с получением SuR полипептидов, которые специфично связываются с полинуклеотидами, включающими тетрациклиновый оператор класса D. В некоторых примерах может использоваться вариант ДНК-связывающего домена или его производная. Например, может использоваться ДНК-связывающий домен из варианта TetR, который специфично узнает оператор tetO-4C или оператор tetO-6C (Helbl и Hillen, (1998) J. Mol. Biol. 276:313-318; Helbl et al., (1998) J. Mol. Biol. 276:319-324). Четырехспиральные пучки, сформированные спиралями α8 и α10 в обеих субъединицах, можно заменить, чтобы обеспечить специфичность димеризации при направлении на два различных операторспецифичных варианта репрессора в одной клетке, чтобы предотвратить гетеродимеризацию (например, Rossi et al., (1998) Nat. Genet. 20:389-393; Berens and Hillen, (2003) Eur. J. Biochem. 270:3109-3121). В другом примере ДНК-связывающий домен из репрессора LexA была слит с GAL4, где указанный гибридный белок унавал операторы LexA и в E. coli, и в дрожжах (Brent and Ptashne, (1985) Cell 43:729-736). В другом примере все предполагаемые ДНК-связывающие или ДНК-распознающие R-группы репрессора 434 были заменены соответствующими положениями репрессора P22. Оператор-связывающая специфичность гибридного репрессора 434R[α3(P22R)] была протестирована in vivo и in vitro, при этом каждый тест показал, что данная направленная модификация 434 изменяла ДНК-связывающую специфичность с оператора 434 на оператор P22 (Wharton and Ptashne, (1985) Nature 316:601-605). Данную работу продолжили, создав гетеродимер 434R дикого типа и 434R[α3(P22R)], который после этого специфично узнавал последовательность химерного оператора P22/434 (HolMs et al., (1988) Proc. Natl. Acad. Sci. USA 85:5834-5838). В другом примере N-концевая часть белка AraC была слита с ДНК-связывающим доменом репрессора LexA. Полученная в результате химера AraC:LexA димеризовалась, связывала оператор LexA и репрессировала экспрессию слитого гена оператора LexA:β-галактозидазы арабиноза-чувствительным путем (Bustos and Schleif, (1993) Proc. Natl. Acad. Sci. USA 90:5638-5642).
Выделенные полинуклеотиды, кодирующие SuR полипептиды, могут также применяться в качестве субстратов для процедур создания разнообразия, включая мутацию, рекомбинацию и реакции рекурсивной рекомбинации, с получением дополнительных вариантов SuR полинуклеотида и/или полипептида с требуемыми свойствами. Кроме того, SuR полинуклеотиды могут применяться для процедур создания разнообразия, с получением вариантов полинуклеотида и/или полипептида, обладающих измененными свойствами по сравнению с исходным материалом, например, способных связываться с другим лигандом-индуктором. Процесс создания разнообразия производит к изменениям последовательности, включая одиночные нуклеотидные замены, множественные нуклеотидные замены, а также вставку или делецию участков последовательности нуклеиновой кислоты. Процедуры создания разнообразия могут применяться отдельно и/или в комбинации, с получением одного или нескольких SuR вариантов, или набора вариантов, а также вариантов кодируемых белков. Отдельно и вместе, данные процедуры обеспечивают надежные, широко применимые способы получения модифицированных полинуклеотидов и полипептидов, а также наборов полинуклеотидов и полипептидов, включая библиотеки. Указанные варианты и наборы вариантов могут применяться для создания или быстрой эволюции полинуклеотидов, белков, метаболических путей, клеток и/или организмов с новыми и/или улучшенными свойствами. Получаемые варианты полинуклеотида и/или полипептида могут быть подвергнуты селекции или скринингу на предмет измененных особенностей и/или свойств, включая измененное связывание лиганда, замедление ДНК связывания и/или количественное определение связывающих свойств.
Любой способ может применяться для обеспечения разнообразия последовательности в библиотеке. Доступны многие процедуры создания разнообразия, включая мультигенную перетасовку и способы создания модифицированных последовательностей нуклеиновых кислот, включая например, Soong et al., (2000) Nat. Genet. 25:436-39; Stemmer et al., (1999) Tumor Targeting 4:1-4; Ness et al., (1999) Nature Biotech. 17:893-896; Chang et al., (1999) Nature Biotech. 17:793-797; Minshull and Stemmer, (1999) Curr. Op. Chem. Biol. 3:284-290; Christians et al., (1999) Nature Biotech. 17:259-264; Crameri et al., (1998) Nature 391:288-291; Crameri et al., (1997) Nature Biotech 15:436-438; Zhang et al., (1997) Proc. Natl. Acad. Sci. USA 94:4504-4509; Patten et al., (1997) Curr. Op. Biotech. 8:724-733; Crameri et al., (1996) Nature Med. 2:100-103; Crameri et al., (1996) Nature Biotech. 14:315-319; Gates et al., (1996) J. Mol. Biol. 255:373- 386; Stemmer, (1996) "Sexual PCR and Assembly PCR", в The Encyclopedia of Molecular Biology (VCH Publishers, New York) pp. 447-457; Crameri and Stemmer, (1995) BioTechniques 18:194-195; Stemmer et al., (1995) Gene 164:49-53; Stemmer, (1995) Science 270:1510; Stemmer, (1995) Bio/Technology 13:549-553; Stemmer, (1994) Nature 370:389-391, а также Stemmer (1994) Proc. Natl. Acad. Sci. USA 91:10747-10751. Мутационные способы создания разнообразия включают, например, сайт-направленный мутагенез (Ling et al., (1997) Anal. Biochem. 254:157-178; Dale et al., (1996) Methods Mol. Biol. 57:369-374; Smith, (1985) Ann. Rev. Genet. 19:423-462; Botstein and Shortle, (1985) Science 229:1193-1201; Carter, (1986) Biochem J. 237:1-7, а также Kunkel, (1987) "The efficiency of oligonucleotide directed mutagenesis", в Nucleic Acids and Molecular Biology (Eckstein and Lilley, eds., Springer Verlag, Berlin). Методы мутагенеза с применением урацил-содержащих матриц включают Kunkel, (1985) Proc. Natl. Acad. Sci. USA 82:488-492; Kunkel et al., (1987) Methods Enzymol. 154:367-382; и Bass et al., (1988) Science 242:240-245. Методы олигонуклеотид-направленного мутагенеза включают Zoller and Smith, (1983) Methods Enzymol. 100:468-500; Zoller and Smith, (1982) Nucl. Acids Res. 10:6487-6500, а также Zoller and Smith, (1987) Methods Enzymol. 154:329-350. Методы мутагенеза с фосфоротиоат-модифицированной ДНК включают Taylor et al., (1985) Nucl. Acids Res. 13:8749-8764; Taylor et al., (1985) Nucl. Acids Res. 13:8765-8787; Nakamaye и Eckstein, (1986) Nucl. Acids Res. 14:9679-9698; Sayers et al., (1988) Nucl. Acids Res. 16:791-802, а также Sayers et al., (1988) Nucl. Acids Res. 16:803-814. Методы мутагенеза с использованием двунитевой ДНК с однонитевыми разрывами включают (Kramer et al., (1984) Nucl. Acids Res. 12:9441-9456; Kramer and Fritz, (1987) Methods Enzymol. 154:350-367; Kramer et al., (1988) Nucl. Acids Res. 16:7207; а также Fritz et al., (1988) Nucl. Acids Res. 16:6987-6999. Дополнительные подходящие способы создания разнообразия включают исправление точкового ошибочного спаривания (Kramer et al., (1984) Cell 38:879-887); мутагенез с использованием репарационно-дефицитных хозяйских штаммов (Carter et al., (1985) Nucl. Acids Res. 13:4431-4443; а также Carter, (1987) Methods Enzymol. 154:382-403); делеционный мутагенез (Eghtedarzadeh and Henikoff, (1986) Nucl. Acids Res. 14:5115); рестрикцию-селекцию и рестрикцию-очистку (Wells et al., (1986) Phil. Trans. R. Soc. Lond. A 317:415-423); мутагенез с помощью синтеза полного гена (Nambiar et al., (1984) Science 223:1299-1301; Sakamar and Khorana, (1988) Nucl. Acids Res. 14:6361-6372; Wells et al., (1985) Gene 34:315-323, а также Grundstrom et al., (1985) Nucl. Acids Res. 13:3305-3316); восстановление двунитевых разрывов (Mandecki, (1986) Proc. Natl. Acad. Sci. USA 83:7177-7181; а также Arnold, (1993) Curr. Op. Biotech. 4:450-455). Нуклеиновые кислоты могут быть рекомбинированы in vitro с помощью любого метода или комбинации методов, включая, например, расщепление ДНКазой нуклеиновых кислот, подвергаемых рекомбинации, с последующим лигированием и/или ПЦР-сборкой нуклеиновых кислот. Например, может использоваться мутагенез методом половой ПЦР (ДНК-шаффлинг), в котором фрагментация молекулы ДНК сопровождается рекомбинацией in vitro, на основе подобия последовательности, между молекулами ДНК с различными, но схожими ДНК последовательностями, с последующей фиксацией кроссинговера при удлинении в полимеразной цепной реакции. Аналогичным образом нуклеиновые кислоты могут быть рекурсивно рекомбинированы in vivo, например, когда рекомбинациям между нуклеиновыми кислотами позволяют проходить в клетках. Такие форматы необязательно обеспечивают прямую рекомбинацию между целевыми нуклеиновыми кислотами или обеспечивают рекомбинацию между конструкциями, векторами, вирусами и/или плазмидами, включающими целевые нуклеиновые кислоты. Также могут использоваться методы рекомбинации полного генома, в которых полные геномы клеток или других организмов рекомбинируют, необязательно включая введение в смеси геномной рекомбинации требуемых компонентов библиотек. Указанные методы имеют множество применений, включая такие, в которых идентичность целевого гена не известна. Любой из перечисленных способов может применяться отдельно или в комбинации, с получением полинуклеотидов, кодирующих SuR полипептиды. Любой из способов создания разнообразия может применяться многократно, с использованием одного или более циклов мутации/рекомбинации или других методов создания разнообразия, необязательно сопровождаемых одним или более методами селекции, с получением дополнительных рекомбинантных нуклеиновых кислот.
Для удобства и высокой производительности обычно желательно проводить скрининг/селекцию на наличие нужных модифицированных нуклеиновых кислот в микроорганизме, таком как бактерии, такие как E. coli, или в одноклеточном эукариоте, таком как дрожжи, включая S. cerevisiae, S. pombe, P. pastoris, или одноклеточных, таких как Chlamydomonas, или в модельных клеточных системах, таких как SF9, Hela, CHO, BMS, BY2, или в других системах клеточных культур. В некоторых случаях может быть предпочтителен скрининг в клетках растения или растениях, включая клетку растения или системы эксплантных культур, или модельные растительные системы, такие как Arabidopsis или табак. В некоторых примерах производительность повышают посредством скрининга пулов клеток-хозяев, экспрессирующих различные модифицированные нуклеиновые кислоты, либо отдельно, либо как часть слитой генной конструкции. Любые пулы, в которых обнаруживается существенная активность, могут быть разложены на отдельные клоны с целью идентификации клонов, экспрессирующих целевую активность.
Предложены рекомбинантные конструкции, включающие одну или несколько последовательностей нуклеиновых кислот, кодирующих SuR полипептид. Конструкции включают вектор, такой как плазмиду, космиду, фаг, вирус, искусственную бактериальную хромосому (BAC), искусственную дрожжевую хромосому (YAC) и т.п., в которую был встроен полинуклеотид, кодирующий SuR полипептид. В некоторых примерах конструкция дополнительно включает регуляторные последовательности, включающие, например, промотор, функционально связанный с последовательностью. Подходящие векторы известны и включают хромосомные, нехромосомные и синтетические ДНК последовательности, такие как производные SV40; бактериальные плазмиды; репликоны; ДНК фага; бакуловирус; дрожжевые плазмиды; векторы, полученные из комбинаций плазмид и фаговой ДНК, ДНК вируса, например, осповакцины, аденовируса, вируса оспы птиц, вируса ложного бешенства, аденовируса, адено-ассоциированных вирусов, ретровирусов, геминивирусов, ВТМ, ХВК, других вирусов растений, Ti плазмиды, Ri плазмиды и многие другие.
Векторы необязательно могут содержать один или несколько селективных маркерных генов, которые придают фенотипический признак для селекции трансформированных клеток-хозяев. Обычно селективный маркерный ген кодирует устойчивость к гербициду или антибиотику. Подходящие гены включают гены, которые кодируют устойчивость к антибиотику спектиномицину или стрептомицину (например, ген aadA), ген стрептомицин-фосфотрансферазы (SPT) в случае устойчивости к стрептомицину, ген неомицин-фосфотрансферазы (NPTII или NPTIII) в случае устойчивости к канамицину или генетицину, ген гигромицин-фосфотрансферазы (HPT) в случае устойчивости к гигромицину. Дополнительные селективные маркерные гены включают дигидрофолатредуктазу или устойчивость к неомицину для культуры эукариотических клеток, а также устойчивость к ампициллину или тетрациклину. Гены, кодирующие устойчивость к гербицидам, включают такие гены, которые ингибируют действие глутаминсинтазы, такие как фосфинотрицин или basta (например, ген bar), EPSPS, GOX или GAT, которые обеспечивают устойчивость к глифосату, мутантную ALS (ацетолактатсинтазу), которая обеспечивает устойчивость к гербицидам сульфонилмочевинного типа, или любые другие известные гены.
Доступен ряд векторов экспрессии для бактериальных систем. Такие векторы включают, помимо прочих, многофункциональные клонирующие и экспрессионные векторы E. coli, такие как BLUESCRIPT (Stratagene); векторы plN (В Van Heeke and Schuster, (1989) J. Biol. Chem. 264:5503-5509); векторы pET (Novagen, Madison Wis.) и т.п. Аналогично, в S. cerevisiae множество векторов, содержащих конститутивные или индуцируемые промоторы, такие как промоторы альфа-фактора, алкогольоксидазы и PGH, могут использоваться для продукции полипептидов. Относительно обзора, см. Ausubel and Grant et al., (1987) Meth. Enzymol. 153:516-544. Различные системы экспрессии могут применяться в клетках-хозяевах млекопитающих, включая вирусные системы, например, системы на основе аденовируса и вируса саркомы Рауса (RSV). Может использоваться любое количество коммерческих или общедоступных систем экспрессии или их производных.
На растительных клетках экспрессию можно вести с кассеты экспрессии, интегрированной в хромосому растения или органеллу, или в цитоплазме с эписомной или вирусной нуклеиновой кислоты. Было описано множество растительных регуляторных последовательностей, включая последовательности, которые направляют экспрессию в тканеспецифической манере, например, TobRB7, пататин B33, промотры гена GRP, промотор rbcS-3A и т.п. В альтернативе высокий уровень экспрессии может быть достигнут при транзиентной экспрессии экзогенных последовательностей растительного вирусного вектора, например, ВТМ, ВМК, геминивируса, включая ВКП и т.п.
Характерные векторы, используемые для экспрессии нуклеиновых кислот в высших растениях, известны и включают векторы, полученные из опухолеиндуцирующей (Ti) плазмиды Agrobacterium tumefaciens, описанной Rogers et al., (1987) Meth. Enzymol. 153:253-277. Примеры векторов A. tumefaciens включают плазмиды pKYLX6 и pKYLX7 (Schardl et al., (1987) Gene 61:1-11 и Berger et al., (1989) Proc. Natl. Acad. Sci. USA 86:8402-8406), а также плазмиду pB101.2, доступную от Clontech Laboratories, Inc. (Palo Alto, CA). В качестве векторов может применяться ряд известных вирусов растений, включая вирус мозаики цветной капусты (CaMV), геминивирусы, вирус мозаики костра и вирус табачной мозаики.
SuR может применяться для регуляции экспрессии целевого полинуклеотида. Целевой полинуклеотид может быть любой целевой последовательностью, включая, помимо прочего, последовательности, кодирующие полипептид, кодирующие мРНК, кодирующие РНКи предшественника, кодирующие активный РНКи агент, миРНК, антисмысловой полинуклеотид, рибозим, слитый белок, реплицирующийся вектор, скринируемый маркер и т.п. Экспрессия целевого полинуклеотида может применяться для индукции экспрессии кодирующей РНК и/или полипептида или, наоборот, для подавления экспрессии кодируемой РНК, целевой последовательности РНК и/или полипептида. В определенных примерах полинуклеотидная последовательность может быть полинуклеотидом, кодирующим растительный гормон, защитный растительный белок, белок транспорта питательных веществ, белок биотической ассоциации, целевой входной признак, целевой выходной признак, ген устойчивости к стрессу, ген устойчивости к гербициду, ген устойчивости к заболеванию/патогену, мужскую стерильность, ген, связанный с развитием, регуляторный ген, ген репарации ДНК, ген регуляции транскрипции, или любой другой целевой полинуклеотид и/или полипептид.
Множество промоторов может применяться в композициях и способах. Например, полинуклеотид, кодирующий SuR полипептид, может быть функционально связан с конститутивным, тканеспецифическим, индуцируемым, регулируемым в процессе развития, временно и/или пространственно регулируемым, или другими промоторами, включая промоторы растительных вирусов или других патогенов, которые функционируют в растительной клетке. Различные промоторы, применяемые в растениях, рассмотрены в обзоре Potenza et al., (2004) In vitro Cell. Dev. Biol. Plant 40:1-22.
Может быть получен любой полинуклеотид, включая целевые полинуклеотиды, полинуклеотиды, кодирующие SuR, регуляторные области, интроны, промоторы и промоторы, включающие TetOp последовательности, и последовательность нуклеотида может быть определена с помощью любого стандартного метода. Полинуклеотиды могут быть химически синтезированы полностью или собраны из химически синтезированных олигонуклеотидов (Kutmeier et al., (1994) BioTechniques 17:242). Сборка из олигонуклеотидов обычно включает синтез перекрывающихся олигонуклеотидов, отжиг и лигирование указанных олигонуклеотидов, с последующей ПЦР-амплификацией лигированного продукта. В альтернативе полинуклеотид может быть выделен или получен из подходящего источника, включая подходящую библиотеку кДНК, полученную из ткани или клеток, геномной библиотеки, или непосредственно выделенную из хозяина посредством ПЦР-амплификации с использованием специфичных праймеров к 3' и 5' концам последовательности или путем клонирования с использованием нуклеотидного зонда, специфичного к целевому полинуклеотиду. Затем амплифицированные молекулы нуклеиновой кислоты, полученные с помощью ПЦР, могут быть клонированы в реплицирующиеся клонирующие векторы с использованием стандартных методов. Полинуклеотид может быть подвергнут дополнительным манипуляциям с использованием любых стандартных методов, включая методы генной инженерии, конструирование векторов, мутагенез и ПЦР (см., например, Sambrook et al., (1990) Molecular Cloning, A Laboratory Manual, 2d Ed., Cold Spring Harbor Laboratory, Cold Spring Harbor, NY; Ausubel et al., Eds. (1998) Current Protocols in Molecular Biology, John Wiley and Sons, NY).
Может использоваться любой метод введения последовательности в клетку или организм, при условии, что полинуклеотид или полипептид получает доступ внутрь, по меньшей мере, одной клетки. Методы введения последовательностей в растения известны и включают, помимо прочего, стабильную трансформацию, транзиентную трансформацию, вирусно-опосредованные методы и половое размножение. Стабильно включенный указывает, что введенный полинуклеотид интегрирован в геном и может быть унаследован потомством. Транзиентная трансформация указывает, что введенная последовательность не интегрирована в геном так, что она может наследоваться потомством хозяйского организма. Любые способы могут применяться для объединения SuR и целевого полинуклеотида, функционально связанного с промотором, включающим TetOp, включая, например, стабильную трансформацию, транзиентную доставку, слияние клеток, половое скрещивание или любую комбинацию перечисленного.
Методики трансформации, а также методики для введения полипептидов или полинуклеотидных последовательностей в растения могут варьировать в зависимости от типа растительной клетки или растения, намеченного для трансформации. Подходящие методы введения полипептидов и полинуклеотидов в клетки растения включают микроинъекцию (Crossway et al., (1986) Biotechniques 4:320-334, и патент США 6300543), электропорацию (Riggs et al., (1986) Proc. Natl. Acad. Sci. USA 83:5602-5606), агробактериальную трансформацию (патенты США 5563055 и 5981840), прямой перенос генов (Paszkowski et al., (1984) EMBO J. 3:2717-2722), баллистическое ускорение частиц (патенты США 4945050, 5879918, 5886244 и 5932782; Тома et al., (1995) в Plant Cell, Tissue and Organ Culture: Fundamental Methods, ed. Gamborg and Phillips (Springer-Verlag, Berlin); McCabe et al., (1988) Biotechnology 6:923-926). Также см., Weissinger et al., (1988) Ann. Rev. Genet. 22:421-477; Sanford et al., (1987) Particulate Science and Technology 5:27-37; Christou et al., (1988) Plant Physiol. 87:671-674; Finer and McMullen, (1991) In Vitro Cell Dev. Biol. 27P:175-182 (соя); Singh et al., (1998) Theor. Appl. Genet. 96:319-324; Datta et al., (1990) Biotechnology 8:736-740; Klein et al., (1988) Proc. Natl. Acad. Sci. USA 85:4305-4309; Klein et al., (1988) Biotechnology 6:559-563; патенты США 5240855, 5322783 и 5324646; Klein et al., (1988) Plant Physiol 91:440-444; Fromm et al., (1990) Biotechnology 8:833-839; Hooykaas-Van Slogteren et al., (1984) Nature 311:763-764; патент США 5736369; Bytebier et al., (1987) Proc. Natl. Acad. Sci. USA 84:5345-5349; De Wet et al., (1985) в The Experimental Manipulation of Ovule Tissues, под ред. Chapman et al., (Longman, New York), стр. 197-209; Kaeppler et al., (1990) Plant Cell Rep. 9:415-418; Kaeppler et al., (1992) Theor. Appl. Genet. 84:560-566; D'Halluin et al., (1992) Plant Cell 4:1495-1505; Li et al., (1993) Plant Cell Rep. 12:250-255; Christou and Ford, (1995) Ann. Bot. 75:407-413, а также Osjoda et al., (1996) Nat. Biotechnol. 14:745-750. В альтернативе полинуклеотиды могут быть введены в растения при контакте растений с вирусом или вирусными нуклеиновыми кислотами. Способы введения полинуклеотидов в растения посредством молекулы вирусной ДНК или РНК известны, см., например, патенты США 5889191, 5889190, 5866785, 5589367, 5316931, а также Porta et al., (1996) Mol. Biotech. 5:209-221.
Термин растение включает клетки растения, протопласты растения, культуры тканей растительных клеток, из которых растение может быть регенерировано, каллус растения, клубни растения и клетки растения, которые являются интактными в растениях, или части растений, такие как зародыши, пыльца, семяпочки, семена, листья, цветы, ветви, плоды, косточки, колосья, початки, оболочки, стебли, корни, корневые кончики, пыльники и т.п. Также включено потомство, варианты и мутанты регенерированных растений.
В некоторых примерах SuR может быть введен в пластиду, либо с помощью трансформации пластиды, либо путем направленного транспорта SuR транскрипта или полипептида в пластиду. Может использоваться любой метод трансформации, ядра или пластиды, в зависимости от целевого продукта и/или применения. Трансформация пластиды обеспечивает преимущества, включающие высокую экспрессию трансгена, регуляцию экспрессии трансгена, способность экспрессировать полицистронные транскрипты, сайт-специфическую интеграцию посредством гомологичной рекомбинации, отсутствие сайленсинга трансгена и позиционных эффектов, регуляцию передачи трансгена через партеногенетическое наследование пластидного гена и секвестрацию экспрессированных полипептидов в органелле, что может устранять возможные неблагоприятные воздействия на цитоплазматические компоненты (например, см. обзоры, включающие Heifetz, (2000) Biochimie 82:655-666; Daniell et al., (2002) Trends Plant. Sci. 7:84-91; Maliga, (2002) Curr. Op. Plant Biol. 5:164-172; Maliga, (2004) Ann. Rev. Plant Biol. 55-289-313; Daniell et al., (2005) Trends Biotechnol. 23:238-245, и Verma and Daniell, (2007) Plant Physiol. 145:1129-1143).
Способы и композиции пластидной трансформации хорошо известны, например, способы трансформации включают (Boynton et al., (1988) Science 240:1534-1538; Svab et al., (1990) Proc. Natl. Acad. Sci. USA 87:8526-8530; Svab et al., (1990) Plant Mol. Biol. 14:197-205; Svab et al., (1993) Proc. Natl. Acad. Sci. USA 90:913-917; Golds et al., (1993) Bio/Technology 11:95-97; O'Neill et al., (1993) Plant J. 3:729-738; Koop et al., (1996) Planta 199:193-201; Kofer ef al., (1998) In vitro Plant 34:303-309; Knoblauch et al., (1999) Nat. Biotechnol. 17:906-909); а также векторы, элементы и селекцию для пластидной трансформации (Newman et al., (1990) Genetics 126:875-888; Goldschmidt-Clermont, (1991) Nucl. Acids Res. 19:4083-4089; Carrer et al., (1993) Mol. Gen. Genet. 241:49-56; Svab et al., (1993) Proc. Natl. Acad. Sci. USA 90:913-917; Verma and Daniell, (2007) Plant Physiol. 145:1129-1143).
Способы и композиции для регуляции экспрессии генов в пластидах хорошо известны и включают McBride et al., (1994) Proc. Natl. Acad. Sci. USA 91:7301-7305; Lossl et al., (2005) Plant Cell Physiol. 46:1462-1471; Heifetz, (2000) Biochemie 82:655-666; Surzycki et al., (2007) Proc. Natl. Acad. Sci. USA 104:17548-17553; патенты США 5576198 и 5925806; WO 2005/0544478), а также способы и композиции для импорта полинуклеотидов и/или полипептидов в пластиду, включая трансляционное слияние в транзитный пептид (например, Comai et al., (1988) J. Biol. Chem. 263:15104-15109).
SuR полинуклеотиды и полипептиды обеспечивают средство регуляции экспрессии пластидного гена посредством химического индуктора, который с легкостью проникает в клетку. Например, при помощи системы T7 экспрессии для хлоропластов (McBride et al., (1994) Proc. Natl. Acad. Sci. USA 91:7301-7305) SuR мог применяться для регуляции ядерной экспрессии T7-полимеразы. В альтернативе, SuR-регулируемый промотор мог быть интегрирован в пластидный геном и функционально связан с целевым полинуклеотидом (полинуклеотидами), при этом SuR экспрессировался и импортировался из ядерного генома или интегрировался в пластиду. Во всех случаях, применение соединения сульфонилмочевины служит для эффективной регуляции целевого полинуклеотида (полинуклеотидов).
Любой тип клетки и/или организма, прокариотического или эукариотического, может применяться в способах и композициях SuR. Например, любая бактериальная клеточная система может быть трансформирована композициями. Например, способы трансформации E. coli, Agrobacterium и другой бактериальной клетки, получение плазмид и использование фагов подробно описаны, например, в Current Protocols in Molecular Biology (Ausubel, et al., (eds.) (1994), совместное предприятие между Greene Publishing Associates, Inc. и John Wiley & Sons, Inc.).
SuR системы могут применяться с любой эукариотической клеточной линией, включая дрожжи, одноклеточные, водоросли, клетки насекомых, птиц или клетки млекопитающих. Например, доступны многие коммерческие и/или общедоступные штаммы S. cerevisiae, как и плазмиды, применяемые для трансформации указанных клеток. Например, штаммы могут быть получены из Американской коллекции типовых культур (ATCC, Manassas, VA) и включают фонд Центра генетических культур дрожжей, который вошел в ATCC в 1998 году. Другие линии дрожжей, таких как S. pombe и P. pastoris, и т.п., также являются доступными. Например, методы трансформации дрожжей, получения плазмид и т.п. подробно описаны, например, в Current Protocols in Molecular Biology (Ausubel et al., (eds.) (1994) совместное предприятие между Greene Publishing Associates, Inc. и John Wiley and Sons, Inc., в частности см. Главу 13). Методы трансформации дрожжей включают трансформацию сферопластов, электропорацию, а также литийацетатный метод. Универсальный, высокоэффективный метод трансформации дрожжей с использованием ацетата лития, ПЭГ 3500 и ДНК-носителя описан в Gietz and Woods, (2002) Methods Enzymol. 350:87-96,.
SuR могут применяться в клетках млекопитающих, таких как CHO, HeLa, BALB/c, фибробласты, эмбриональные стволовые клетки мыши и т.п. Многие коммерчески доступные линии компетентных клеток и плазмиды известны и с легкостью могут быть получены, например, из ATCC (Manassas, VA). Выделенные полинуклеотиды для трансформации и трансформации клеток млекопитающих могут быть приготовлены любым методом, известным в уровне техники. Например, методы трансформации клеток млекопитающих и других эукариотических клеток, получения плазмид и использования вирусов подробно описаны, например, в Current Protocols in Molecular Biology (Ausubel et al., (eds.) (1994) совместное предприятие между Greene Publishing Associates, Inc. и John Wiley and Sons, Inc., в частности см. Главу 9). Например, доступно много методов, таких как трансфекция с фосфатом кальция, электропорация, трансфекция с DEAE-декстраном, липосомно-опосредованная трансфекция, микроинъекция, а также вирусные методы.
Любые виды растений могут применяться в способах и композициях SuR, включая, помимо прочего, однодольные и двудольные. Примеры растений включают, помимо прочего, кукурузу (Zea mays), Brassica spp. (например, B. napus, B. rapa, B. juncea), клещевину, пальму, люцерну (Medicago sativa), рис (Oryza sativa), рожь (Secale cereale), сорго (Sorghumbicolor, Sorghumvulgare), просо (например, просо африканское (Pennisetum glaucum), просо обыкновенное (Panicum miliaceum), просо итальянское (Setaria italica), просо пальчатое (Eleusine coracana)), подсолнечник (Helianthus annuus), сафлор (Carthamus tinctorius), пшеницу (Triticum aestivum), сою (Glycine max), табак (Nicotiana tabacum), картофель (Solanum tuberosum), арахис (Arachis hypogaea), хлопок (Gossypium barbadense, Gossypium hirsutum), батат (Ipomoea batatus), маниоку (Manihot esculenta), кофе (Coffea spp.), кокос (Cocos nucifera), ананас (Ananas comosus), цитрусовые растения (Citrus spp.), какао (Theobroma cacao), чай (Camellia sinensis), банан (Musa spp.), авокадо (Persea americana), инжир (Ficus casica), гуаву (Psidium guajava), манго (Mangifera indica), оливу европейскую (Olea europaea), папайю (Carica papaya), кешью (Anacardium occidentale), макадамию (Macadamia integrifolia), миндаль (Prunus amygdalus), сахарную свеклу (Beta vulgaris), сахарный тростник (Saccharum spp.), Arabidopsis thaliana, овес (Avena spp.), ячмень (Hordeum spp.), бобовые растения, такие как гуаровые бобы, плоды рожкового дерева, пажитник, турецкие бобы, коровий горох, фасоль золотистая, конские бобы, чечевица и нут, овощи, декоративные растения, травы и хвойные. Овощи включают томаты (Lycopersicon esculentum), латук (например, Lactuca sativa), зеленые бобы (Phaseolus vulgaris), лимскую фасоль (Phaseolus limensis), горох (Pisium spp., Lathyrus spp.), а также виды Cucumis, такие как огурец (C. sativus), канталупа (C. cantalupensis) и мускусная дыня (C. melo). Декоративные растения включают азалию (Rhododendron spp.), гортензию (Macrophylla hydrangea), гибискус (Hibiscus rosasanensis), розу (Rosa spp.), тюльпаны (Tulipa spp.), нарциссы (Narcissus spp.), петунии (Petunia hybrida), гвоздику (Dianthus caryophyllus), пуансеттию (Euphorbia pulcherrima), а также хризантему. Хвойные включают сосны, например, сосну ладанную (Pinus taeda), сосну Эллиота (Pinus elliotii), сосну желтую (Pinus ponderosa), сосну скрученную широкохвойную (Pinus contorta) и сосну лучистую (Pinus radiata), дугласию (Pseudotsuga menziesii); тсугу канадскую (Tsuga canadensis), ель ситхинскую (Picea glauca), секвойю вечнозеленую (Sequoia sempervirens), истинные ели, такие как пихта приятная (Abies amabilis) и пихта бальзамическая (Abies balsamea), а также кедры, такие как туя гигантская (Thuja plicata) и кипарисовик нутканский (Chamaecyparis nootkatensis).
Клетки и/или ткань растения, которые были трансформированы, могут быть выращены в растения с использованием стандартных методов (см., например, McCormick et al., (1986) Plant Cell Rep. 5:81-84). Затем полученные растения могут быть выращены и самоопылены, подвергнуты беккроссу и/или ауткроссу, с последующей идентификацией полученного потомства, обладающего нужными свойствами. Два или больше поколения могут быть выращены, чтобы гарантировать стабильное сохранение и наследование свойства, с последующим сбором семян. Предложено полученное таким способом трансформированное/трансгенное семя, содержащее ДНК-конструкцию, включающую целевой полинуклеотид и/или модифицированный полинуклеотид, кодирующий SuR, стабильно включенную в геном семени. Растение и/или семя, стабильно включающее ДНК-конструкцию, может быть дополнительно охарактеризовано на предмет экспрессии, агрономию и число копий.
Идентичность последовательности может использоваться для сравнения первичной структуры двух полинуклеотидов или последовательностей полипептидов, описания первичной структуры первой последовательности в сравнении со второй последовательностью, и/или описания отношений последовательности, таких как варианты и гомологи. Идентичность последовательности измеряет остатки в двух последовательностях, которые являются одинаковыми при выравнивании с максимальным соответствием. Отношения последовательности могут быть проанализированы с применением компьютерных алгоритмов. Отношения последовательности между двумя или более полинуклеотидами или двумя или более полипептидами могут быть определены путем вычисления наилучшего выравнивания последовательностей и оценки совпадений и пропусков в выравнивании, что приводит к определению процента идентичности последовательности и процента подобия последовательности. Отношения полинуклеотидов могут быть также описаны на основании сравнения полипептидов, которые кодируют каждый из полинуклеотидов. Известно множество программ и алгоритмов для сравнения и анализа последовательностей. Если не указано иное, значения идентичности/подобия последовательности, приводимые в настоящей заявке, относятся к значению, полученному с применением GAP Version 10 (GCG, Accelrys, San Diego, CA) при использовании следующих параметров: % идентичности и % подобия для нуклеотидной последовательности с использованием GAP Weight 50 и Length Weight 3, а также матрицы замен nwsgapdna.cmp; % идентичности и % подобия для аминокислотной последовательности с использованием GAP Weight 8 и Length Weight 2, а также матрицы замен BLOSUM62 (Henikoff and Henikoff, (1992) Proc. Natl. Acad. Sci. USA 89:10915-10919). В GAP для поиска выравнивания двух полных последовательностей с максимальным числом совпадений и минимальным числом пропусков используется алгоритм Нидлмана и Вунша (Needleman and Wunsch, (1970) J. Mol. Biol. 48:443-453).
В альтернативе полинуклеотиды и/или полипептиды могут быть оценены с использованием других программных средств оценки последовательностей. Например, полинуклеотиды и/или полипептиды могут быть оценены с использованием средства выравнивания BLAST. Локальные пропуски выравнивания состоят просто из пары сегментов последовательностей, один от которых подвергают сравнению. Модификация алгоритмов Смита-Ватермана или Селлерса находит все пары сегментов, балл которых не может быть повышен путем продления или укорачивания, называемых парами сегментов с максимальным сходством (HSP). Результаты выравниваний BLAST включают статистические оценки, показывающие вероятность, с которой показатель BLAST можно ожидать со случайной вероятностью. Исходная оценка S вычисляется из числа пропусков и замен, связанных с каждой выровненной последовательностью, где более высокие показатели подобия указывают на более высокую достоверность выравнивания. Показатели замен даются таблицей соответствия (см. PAM, BLOSUM). Показатели пропусков обычно вычисляются как сумма G, штрафа за введение пропуска, и L, штрафа за удлинение пропуска. Для пропуска длиной n, стоимость пропуска будет соответствовать G+Ln. Выбор стоимостей пропусков, G и L, является эмпирическим, однако, как правило, выбирают высокое значения для G (10-15) и низкое значение для L (1-2). Число битов, S', получают из исходной оценки S выравнивания, в котором учитывались статистические показатели используемой системы оценки. Число битов нормализуют относительно системы оценки, поэтому они могут использоваться для сравнения оценок выравнивания из различных поисков. Значение E (E-value), или ожидаемое значение, описывает вероятность, с которой последовательность с подобным показателем присутствует в базе данных случайно. Данное значение является предсказанием числа различных выравниваний с показателем, превышающим или равным S, которое, как ожидают, будет получено при поиске в базе данных случайно. Чем меньше значение E, тем более достоверным является выравнивание. Например, выравнивание, имеющее значение E e-117, означает, что последовательность с подобным показателем с малой вероятностью будет найдена просто случайно. Кроме того, ожидаемый показатель для выравнивания случайной пары аминокислот должен быть отрицательным, иначе длинные выравнивания имели бы высокий показатель независимо от сходства выровненных сегментов. Дополнительно, в алгоритме BLAST используется соответствующая матрица замен, для нуклеотида или аминокислоты, и для выравниваний с пропусками используются штрафы за внесение и продление пропуска. Например, выравнивание BLAST и сравнение полипептидных последовательностей обычно выполняют при использовании матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1. Если не указано иное, показатели, полученные при анализах BLAST, получены при использовании матрицы BLOSUM62, штрафа за внесение пропуска 11 и штрафа за удлинение пропуска 1.
База данных белковых последовательностей UniProt является информационным архивом функциональных и структурных данных белков и обеспечивает стабильную, исчерпывающую, полностью классифицированную, подробно и точно аннотируемую базу знаний о белковых последовательностях, с обширными перекрестными ссылками и интерфейсами запросов, свободно доступными для научного сообщества. Сайт UniProt оборудован программным средством, UniRef, которое предоставляет кластер белков, обладающих 50%, 90% или 100% идентичностью последовательности с последовательностью целевого белка из базы данных. Например, на запрос с использованием TetR(B) (ссылка UniProt - P04483) выводится кластер из 18 белков, обладающих 90%-ой идентичностью последовательности с P04483:
Указанные белковые последовательности могут использоваться как источники разнообразия последовательностей для белкового дизайна и/или направленной эволюции лиганд-связывающего домена. Кроме того, указанные белковые последовательности могут использоваться как источники оператор-связывающих доменов для химерных репрессорных белков, или для дизайна и/или эволюции оператор-связывающего домена.
Свойства, домены, мотивы и функция тетрациклиновых репрессоров известны, как и стандартные методики, и анализы для оценки любого производного репрессора, включающего одну или более аминокислотных замен. Структура белка TetR класса D включает 10 альфа-спиралей с соединяющимися петлями и витками. 3 N-концевые спирали формируют ДНК-связывающий HTH домен, расположенный в обратной ориентации относительно HTH мотивов в других ДНК-связывающих белках. Ядро белка, сформированного спиралями 5-10, включает домен интерфейса димеризации, и для каждого мономера включает связывающий карман для лиганда/эффектора и двухвалентного катионного кофактора (Kisker et al., (1995) J. Mol. Biol. 247:260-180; Orth et al., (2000) Nat. Struct. Biol. 7:215-219). Любая аминокислотная замена может включать неконсервативную или консервативную аминокислотную замену. Консервативные замены обычно относятся к замене одной аминокислоты другой аминокислотой, обладающей аналогичными химическими и/или структурными свойствами (см., например, Dayhoff et al., (1978) Atlas of Protein Sequence and Structure, Natl. Biomed. Res. Found., Washington, DC). Различное объединение аминокислот в группы по сходству было разработано в зависимости от оцениваемого свойства, например, кислотности в сравнении с основностью, полярности в сравнении с неполярностью, амфифильностью и т.п., и используется при оценке возможного эффекта любой замены или комбинации замен.
Многочисленные варианты TetR были идентифицированы и/или получены и тщательно изучены. В контексте тетрациклиновой репрессорной системы, эффекты различных мутаций, модификаций и/или их комбинаций использовались для тщательного описания и/или изменения таких свойств тетрациклиновых репрессоров, как связывание кофактора, константы связывания лиганда, кинетика и константы диссоциации, ограничения оператор-связывающих последовательностей, кооперативность, константы связывания, кинетика и константы диссоциации и активности слитого белка и свойства. Варианты включают варианты TetR с обратным фенотипом связывания операторной последовательности в присутствии тетрациклина или его аналога, варианты с измененными свойствами связывания оператора, варианты с измененной специфичностью операторной последовательности, и варианты с измененной лиганд-специфичностью, а также слитые белки. См., например, Isackson and Bertrand, (1985) Proc. Natl. Acad. Sci. USA 82:6226-6230; Smith and Bertrand, (1988) J. Mol. Biol. 203:949-959; Altschmied et al., (1988) EMBO J. 7:4011-4017; Wissmann et al., (1991) EMBO J 10:4145-4152; Baumeister et al., (1992) J. Mol. Biol. 226:1257-1270; Baumeister et al., (1992) Proteins 14:168-177; Gossen and Bujard (1992) Proc. Natl. Acad. Sci. USA 89:5547-5551; Wasylewski et al., (1996) J. Protein Chem. 15:45-58; Berens et al., (1997) J. Biol. Chem. 272:6936-6942; Baron et al., (1997) Nucl. Acids Res. 25:2723-2729; Helbl and Hillen, (1998) J. Mol. Biol. 276:313-318; Urlinger et al., (2000) Proc. Natl. Acad. Sci. USA 97:7963-7968; Kamionka et al., (2004) Nucl. Acids Res. 32:842-847; Bertram et al., (2004) J. Mol. Microbiol. Biotechnol. 8:104-110; Scholz et al., (2003) J. Mol. Biol. 329: 217-227; а также патентную публикацию US 2003/0186281.
Известны трехмерные структуры тетрациклиновых репрессоров и вариантов тетрациклиновых репрессоров, связанных с лигандом и/или кофактором (кофакторами), а также соединенных с операторной последовательностью (см., например, Kisker et al., (1995) J. Mol. Biol. 247:260-280; Orth et al., (1998) J. Mol. Biol. 279:439-447; Orth et al., (1999) Biochemistry 38:191-198; Orth et al., (2000) Nat. Struct. Biol. 7:215-219; Luckner et al., (2007) J. Mol. Biol. 368:780-790), которые обеспечивают чрезвычайно хорошо описанную структуру (структуры), идентификацию доменов и индивидуальных аминокислот, ассоциируемых с различными функциями и связывающими свойствами, а также теоретическую модель (модели) потенциальных эффектов любой аминокислотной замены (замен) и возможные структурные основы для фенотипа (фенотипов) известных мутантов тетрациклинового репрессора. Один из примеров процента идентичности последовательности, наблюдаемого среди представителей семейства тетрациклиновых репрессоров, представлен ниже.
ПРИМЕРЫ
ПРИМЕР 1: Эволюция TetR для узнавания производных сульфонилмочевины
A. Компьютерное моделирование
3-D кристаллические структуры тетрациклинового репрессора класса D (выделенного из E. coli; TET-связанный димер, 1DU7 (Orth et al., (2000) Nat. Struct. Biol. 7:215-219); и ДНК-связанного димера, 1QPI (Orth et al., (2000) Nat. Struct. Biol. 7:215-219)), использовали в качестве основы дизайна для компьютерного замещения молекулы тетрациклина (TET) молекулой тифенсульфурон-метила (Ts, Harmony®) в лиганд-связывающем кармане. TET и производные сульфонилмочевины (SU) обычно имеют сходный размер и содержат структуры на основе ароматических колец с донорами и акцепторами водородных связей, что потенциально позволяет связывать SU модифицированному TetR. Впрочем, между семейством тетрациклина и семейством молекул SU существуют заметные различия. TET является внутренне жестким и довольно плоским, с одной плоскостью сильного водородного связывания, содержащей гидроксильные и кетогруппы, logP ~ -0,3. Сульфонилмочевины (SU) являются намного более гибкими и ароматическими, с центральной группой сульфонилмочевины, которая обычно соединяет замещенный бензол, пиридин или тиофен (как в случае Harmony®) на одной стороне, и замещенный пиримидин, или 1,3,5-триазин на другой стороне. Хотя Harmony® имеет другие функциональные группы, его logP подобен (~0,02 при pH 7) logP tet. Наилучшее расположение молекулы Harmony® в связывающем кармане TetR получили в молекулярном моделировании in silico (Фигура 1). На основе данной модели семнадцать положений аминокислотных остатков (60, 64, 82, 86, 100, 104, 105, 113, 116, 134, 135, 138 и 139 из мономера A и положения 147, 151, 174 и 177 из мономера B, при использовании нумерации TetR(B)) были определены как находящиеся в достаточной близости к молекуле связанного Harmony® для расположения в связывающей поверхности. Компьютерную оптимизацию боковых цепей использовали для дизайна наборов аминокислот в каждом из указанных 17 положений, рассматриваемых как наиболее соответствующих связыванию SU. В результате получили библиотеку с (4, 5, 4, 4, 5, 3, 8, 11, 10, 10, 8, 8, 7, 9, 6, 7 и 5) аминокислотами в указанных 17 положениях, при полном размере полученной библиотеки 4×1013. Выбор аминокислот в положениях библиотеки был продиктован стерическими и физико-химическими факторами в целях точного соответствия лиганду, входящему в лиганд-связывающий карман.
В качестве исходной молекулы для получения шаффлинг-производных выбирали TetR класса B дикого типа из Tn 10 (SEQ ID NO:2). Он немного отличался от последовательности, использованной в компьютерном дизайне (P0ACT4, класс D, для которого доступна кристаллическая структура 1DU7 с высоким разрешением), но это лишь немного повлияло на связывание лиганда. Сравнение TetR(D) (SEQ ID NO:401) и TetR(B) (SEQ ID NO:2) показано ниже, при этом положения, участвующие в узнавании и связывании tet, выделены полужирным шрифтом:

Исходный полинуклеотид, используемый для экспрессии TetR, был синтезирован коммерчески, при этом были введены сайты рестрикции для удобства при создании библиотеки и последующих манипуляциях (DNA2.0, Menlo Park, California, USA). Введенные сайты рестрикции включали сайт NcoI на 5' конце, сайт SacI, 5'-фланкирующий лиганд-связывающий домен (LBD), и сайт AscI после стоп-кодона. Это позволяет конструировать библиотеку в пределах ДНК-сегмента ~ 480 п.н., содержащего лиганд-связывающую область, чтобы избежать случайных мутаций в других областях, таких как ДНК-связывающий домен. Синтетический ген был функционально связан с 5'-фланкирующим арабиноза-индуцируемым промотором, PBAD, с использованием NcoI/AscI для создания вектора экспрессии TetR pVER7314 (Фиг. 2). Введение сайта NcoI на 5'-конце кодирующей области привело к вставке глицина после N-концевого метионина в аминокислотном положении 1 (SEQ ID NO: 2). Данную последовательность использовали в качестве контрольного TetR дикого типа во всех исследованиях, если не указано иное, при этом наблюдаемая активность была эквивалентна TetR без вставки серина (SEQ ID NO: 1). Впрочем, во всех ссылках на аминокислотные положения и изменения, введенные при дизайне и наблюдаемые, используется аминокислотная нумерация TetR(B) дикого типа (207 ак) например, SEQ ID NO:1.
B. Дизайн библиотеки
Вследствие большого количества предполагаемых замен во многих положениях, находящихся в непосредственной близости друг с другом, компьютерную библиотеку (Таблица 1, Расчетная библиотека) было сложно кодировать небольшим количеством вырожденных кодонов. Это особенно заметно в участках последовательности, таких как аминокислоты 134, 135, 138 и 139, которые можно было рационально кодировать одним праймером. По этой причине библиотека последовательностей, полученная и протестированная в лаборатории, содержала предполагаемый набор аминокислот в 6 из 17 положений, немного увеличенный в 1 из 17 положений, и полностью вырожденный (кодон NNK) в 10 из 17 положений (Таблица 1). Это привело к намного более высокому теоретическому разнообразию последовательности, в общей сложности 3×1019 последовательностей.
Сконструированная библиотека, названная 'L1', кодировалась в общей сложности пятьюдесятью олигонуклеотидами (Таблица 2), а не тысячами, которые потребовались бы для полного определения разработанной намеченной библиотеки. Таблица 2 также включает два ПЦР праймера для амплификации.

Сборку олигов 'L1' проводили с помощью удлинения перекрывающихся фрагментов (Ness et al., (2002) Nat. Biotech. 20:1251-1255), с получением ПЦР-фрагмента, фланкированного сайтами рестрикции SacI/AscI. Условия сборки всех фрагментов библиотеки были следующими: олигонуклеотиды, представляющие библиотеку, нормализовали до концентрации 10 мкМ, а затем смешивали равные объемы, получив 10 мкМ пул. ПЦР-амплификацию фрагментов библиотеки выполняли в шести идентичных реакциях объемом 25 мкл, содержащих: 1 мкМ пула олигов библиотеки; 0,5 мкМ каждого праймера спасения: L1:5' и L1:3', и по 200 мкМ дНТФ в реакции с полимеразой Herculase II (Stratagene, La Jolla, CA, USA). Условия ПЦР были следующими: 98°C в течение 1 минуты (начальная денатурация), затем 25 циклов с денатурацией при 95°C в течение 20 секунд, отжигом в течение 45 секунд при 45°C - 55°C (градиент), затем элонгация матрицы в течение 30 секунд при 72°C. Реакцию завершала достройка при 72°C в течение 5 минут. TetR(B) дикого типа вырезали из вектора экспрессии PBAD-tetR pVER7314 с использованием SacI/AscI. Основной фрагмент pVER7314 обрабатывали кишечной фосфатазой теленка и очищали, затем встраивали полный пул фрагментов библиотеки (~500 п.н.), расщепленный рестриктазами SacI/AscI, с получением плазмидной библиотеки L1. Приблизительно 50 случайных клонов из библиотеки L1 секвенировали и собирали информацию в целях проверки качества. Результаты показали, что в наборе разнообразия были представлены почти все намеченные аминокислоты (данные не показаны). Секвенирование показало, что 17% последовательностей содержали стоп-кодоны. Это меньше, чем расчетные 27% (например, в 10 положениях 1/32 кодонов является стоп-кодоном, 1-(31/32)10 ~ 27%). Кроме того, анализ последовательности показал, что в 13% клонов произошел сдвиг рамки из-за ошибок в процессе удлинения перекрывающихся фрагментов. Таким образом, приблизительно 30% от полной библиотеки состояло из клонов, кодирующих усеченные полипептиды.
C. Схема скрининга
Для проверки библиотеки на наличие редких клонов, реагирующих на тифенсульфурон-метил (Ts), разработали генетический скрининг на основе чувствительной E. coli. Данный скрининг являлся модификацией известной системы анализа (Wissmann et al., (1991) Genetics 128:225-232). Скрининг состоял из двух частей: предварительного скрининга репрессора и последующего скрининга с индукцией. Для этого получили штамм E. coli, обладающий обеими функциональностями. Для предварительного скрининга репрессора разработали генетический каскад, в котором ген npfIII, кодирующий устойчивость к канамицину, находится под контролем lac-промотора. Lac-промотор репрессируется Lac-репрессором, кодируемым lacI, экспрессию которого в свою очередь регулирует tet-промотор (PtetR). Tet-промотор репрессируется TetR, который блокирует продукцию LacI и, таким образом, окончательно обеспечивает экспрессию устойчивости к канамицину.
Поскольку tet-регулон имеет бивалентные промоторы, один промотор для tetR и другой промотор для tetA, такой же штамм сконструировали с геном lacZE. coli, кодирующим репортерный фермент β-галактозидазу, под контролем tetA-промотора (PtetA). Затем двойной регулон, кодирующий lacI и lacZ, фланкировали сильными терминаторами транскрипции: терминатор РНК рибосомного оперона rrnB T1-T2 E. coli (Ghosh et al., (1991) J. Mol. Biol. 222:59-66) и терминатор rpoC C-субъединицы РНК-полимеразы E. coli, при этом ложные транскрипты, прочитываемые в направлении любого tet-промотора, не будут препятствовать экспрессии какого-либо другого транскрипта. В присутствии функционального TetR, штамм демонстрирует lac- фенотип, при этом колонии могут быть легко оценены на предмет индукции с помощью нового химического метода с использованием X-gal, где индукция приводит к окрашиванию колоний в синий цвет. Кроме того, индукция с использованием X-gal в жидких культурах может быть измерена количественно при использовании β-галактозидазного анализа с колориметрическими или флуориметрическими субстратами.
Дальнейшая обработка хозяйского штамма заключалась в нокауте локуса tolC при введении репортера Plac-nptIII. Это было выполнено с целью получения лучшего проникновения соединений SU в клетку E. coli (Robert LaRossa - DuPont: личное сообщение). Сильный терминатор транскрипции T22 из фага P22 S. typhimurium, поместили перед lac-промотором, чтобы предотвратить нерегулируемую подтекающую экспрессию зависимого маркера устойчивости к канамицину. Названием сконструированного конечного штамма является E. coli KM3.
Популяцию "перетасованных" tetR LBD клонировали в вектор pVER7314 на основе Apr/ColE1, после PBAD промотора. Такую конструкцию создали для того, чтобы обеспечить возможность тонкой регуляции экспрессии TetR путем изменения концентраций арабинозы в ростовой среде (Guzman et al., (1995) J. Bacteriol. 177:4121-4130). Несмотря на то, что белок TetR находился под контролем PBAD промотора, он экспрессировался на достаточном уровне без добавки арабинозы, чтобы позволяло проводить селекцию по устойчивости к канамицину в штамме KM3. Впрочем, экспрессию можно повысить путем добавления арабинозы, например, если требуется изменить жесткость анализа.
D. Скрининг библиотеки
После сборки олигов L1 и встраивания в вектор pVER7314, полученной библиотекой трансформировали штамм E. coli KM3 и сеяли на чашки с LB, содержащей 50 мкг/мл карбенициллина для отбора плазмид библиотеки, и 60 мкг/мл канамицина для отбора популяции с активным репрессором в отсутствие целевого лиганда ("апо-репрессоры"). Анализ ДНК последовательности отобранной популяции показал, что данный этап сильно обогатил несколько положений библиотеки, указывая на то, что некоторые комбинации аминокислот в лиганд-связывающем домене привели к конформации, совместимой с ДНК связыванием N-концевой областью. Кроме того, данный этап исключил клоны с преждевременными стоп-кодонами и/или мутациями со сдвигом рамки. Затем указанные апорепрессорные последовательности скринировали на наличие изменений репрессорной активности в присутствии Harmony® (Ts). Это выполняли посредством получения реплик предварительно отобранной Kmr популяции из жидких культур в 384-луночном формате на M9-агаре, содержащий 0,1% глицерина в качестве источника углерода, 0,04% казаминовых кислот (для предотвращения истощения аминокислот с разветвленной цепью, вызванного применением сульфонилмочевины), 50 мкг/мл карбенициллина для поддержания плазмиды, 0,004% X-gal для обнаружения β-галактозидазной активности, и +/-SU индуктор Ts в концентрации 20 мкг/мл. Начальные хиты идентифицировали из популяции, содержавшей почти 20000 колоний, которые скринировали на наличие ответа к Ts после инкубирования при 30°C в течение 2 дней. Четырнадцать предполагаемых идентифицированных 'хитов' затем повторно тестировали в таких же условиях, но уже в 96-луночном формате (Фигура 3).
Анализ ДНК последовательности показал, что клоны L1-3 и L1-19 были идентичны и что наиболее сильно реагировавшие хиты (L-2, -3(19), -5, -9, -11 и -20) имели существенное обогащение в нескольких положениях библиотеки, что указывало на участие во взаимодействии с лигандом, прямое или опосредованное. Затем ту же библиотеку подвергали повторному скринингу, чтобы идентифицировать другие 10 хитов, в результате чего общее количество клонов довели до 23.
Все 23 предполагаемых хита затем скринировали в анализе того же формата в планшетах, с панелью из девяти производных сульфонилмочевины (SU), зарегистрированные для коммерческого применения (Таблица 3), в котором 11 хитов, как установили, существенно реагировали на другие лиганды SU (Таблица 4). Для этого эксперимента клоны E. coli, кодирующие хиты L1 или TetR дикого типа (SEQ ID NO:2), рядами переносили в 96-луночный формат и перепечатывали на среды для анализа M9 с X-gal, с или без тестируемых соединений SU в концентрации 20 мкг/мл. После 48-часового роста при 30°C чашки сканировали в цифровом формате и преобразовывали интенсивность цвета колонии в относительные значения β-галактозидазной активности. Использовали следующие индукторы: тифенсульфурон (Ts), метсульфурон (Ms), сульфометурон (Sm), этаметсульфурон (Es), трибенурон (Tb), хлоримурон (Ci), никосульфурон (Ns), римсульфурон (Rs), хлорсульфурон (Cs) при концентрации 20 м.д., а также ангидротетрациклин (atc) в качестве положительного контроля при 0,4 мкМ для индукции TetR дикого типа. Неожиданно, некоторые соединения сульфонилмочевины, особенно хлоримурон, этаметсульфурон и хлорсульфурон, оказались более мощными активаторами, чем исходный лиганд Harmony®.
Аминокислотные замены в указанных одиннадцати лучших хитах приведены в Таблице 5. Последовательности сравнивали с TetR (B) дикого типа, и показаны только те положения, которые имеют различия, при использовании нумерации согласно TetR(B) (например, SEQ ID NO:1). Черта в выравнивании указывает отсутствие изменений по сравнению с лиганд-связывающим доменом TetR д/т.
Начальный скрининг библиотеки 1 также выявил элементы библиотеки, обладающие обратной репрессорной активностью (SEQ ID NO:1206-1213), где полипептид был связан с оператором в присутствии SU лиганда. Указанные хиты демонстрировали экспрессию β-галактозидазы без SU лиганда, которая существенно снизилась после добавления лиганда, например тифенсульфурона. Затем указанные хиты скринировали в анализе такого же формата в планшетах, как описано выше, с панелью из девяти соединений сульфонилмочевины (SU), зарегистрированных для коммерческого применения (Таблица 3), где 8 хитов, как установили, существенно реагировали на другие лиганды SU (Таблица 6).
Аминокислотные замены в указанных восьми обратных репрессорных хитах (SEQ ID NO: 1206-1213, кодированных в соответствии с SEQ ID NO: 1214-1221) приведены в Таблице 7. Последовательности сравнивали с TetR (B) дикого типа, при этом показаны только те положения, которые имеют различия, при использовании нумерации согласно TetR(B) (например, SEQ ID NO: 1). Черта в выравнивании указывает отсутствие изменения по сравнению с лиганд-связывающим доменом TetR д/т.
E. Корреляция результатов первого раунда шаффлинга со структурной моделью
Существенное обогащение произошло в большинстве положений библиотеки, где обогащение включает замещение конкретных желательных аминокислот и замещение конкретных нежелательных аминокислот. Первичный скрининг включал две стадии с целью идентификации репрессорной и дерепрессорной функции. Обогащение наблюдали в обеих стадиях скрининга. В первой стадии положения были обогащены при селекции "апорепрессоров", то есть, белков, которые подавляют транскрипцию гена в отсутствие лиганда. Во второй стадии положения были обогащены при селекции "активаторов", то есть, белков, которые активируют транскрипцию гена в присутствии лиганда. Положения могут быть обогащены либо в соответствии с одним из критериев селекции, в соответствии с обоими критериями, либо ни с одним. Результаты первого раунда скрининга репрессорной активности представлены ниже:
Обогащение на активаторном уровне согласовывалось с компьютерной моделью SU связывания: стерически выбранные положения (например, 60, 86, 104, 105, 113, 138, 139) были расположены наиболее близко к моделируемому лиганду, электростатически выбранные положения (например, 135, 147, 151, 177) были расположены вблизи моделируемой сульфонильной группы, и ароматически выбранные положения (например, 100, 105, 147, 174) моделировали для формирования ароматических стекинг-взаимодействий с плоскими кольцевыми структурами в тифенсульфуроне. Обогащение на апорепрессорном уровне согласовывалось с теоретическим механизмом связывания ДНК: обогащенные положения моделировали для обеспечения возможности модуляции ассоциации репрессорного белка с операторной ДНК последовательностью.
В случае скрининга с индукцией SU, обогащение свидетельствовалось наличием обоих избыточно представленных аминокислот, которых моделировали для формирования благоприятных взаимодействий с лигандом (например, метионин (M) и валин (V) в положении 116 моделировали для обеспечения хорошей упаковки относительно триазинового кольца молекулы SU) и недостаточно представленных аминокислот, которых моделировали с получением неблагоприятных взаимодействий с лигандом (например, в положении 86 моделировали триптофан (W), так как он слишком большой для того, чтобы лиганд мог входить в связывающий карман). В случае апорепрессора обогащение приняло форму как избыточно представленных аминокислот, которые моделировали с целью получения функциональной конформации репрессора, способной связываться с операторными ДНК последовательностями в отсутствие лиганда (например, аланин (А) в положении 113, который поддерживает структурную целостность данной α-спирали), так и недостаточно представленных аминокислот, которые моделировали с целью нарушения активной репрессорной конформации в отсутствие лиганда (например, глицин и пролин (P) в положении 113, которые уменьшают структурную целостность данной α-спирали).
Результаты различных раундов скрининга и селекции могут обеспечивать измененное обогащение в некоторых положениях, как результат взаимодействий с другими выбранными аминокислотами, или с малой молекулой. Обогащенные последовательности демонстрируют только то, что боковые цепи могут благоприятствовать активным индукторам без исключения каких-либо аминокислот. Таким образом, выбранные хиты, вероятно, представят только подгруппу возможных активных последовательностей. Целый ряд возможных механизмов связывания лигандов и белковых взаимодействий может допускаться для одной и той же молекулы SU, и, таким образом, обогащение нескольких типов боковых цепей в определенном положении может образовать множества популяций активных белков. Компьютерное моделирование обогащенных последовательностей является ценным, поскольку оно позволяет установить приоритеты в разнообразии аминокислот в раундах скрининга и селекции.
В целом, приведенные результаты обогащения подтверждают общую компьютерную модель и облегчают последующий дизайн. Несколько положений, которые были сконструированы в виде полностью вырожденных кодонов (все 20 аминокислот), дали результаты первого раунда скрининга, согласующиеся с предложенной компьютерной моделью. Например, компьютерное моделирование предполагало, что ароматические боковые цепи W, Y и F в положении 100 будут способствовать связыванию SU. Библиотеку первого раунда скринировали с вырожденным кодоном в указанном положении, и при этом аминокислоты W, Y и F были значительно обогащены. Созданные библиотеки позволяют сузить разнообразие последовательности в положениях библиотеки, с акцентом на уменьшение разнообразия в спаренных положениях, благодаря чему можно избежать полностью вырожденных кодонов. Кроме того, больше положений можно задействовать для введения разнообразия, чтобы достичь большего покрытия более высококачественной, более специализированной библиотеки последовательностей. Это позволяет сконструировать библиотеки с достаточно небольшим числом элементов для скрининга, с хорошим охватом, и при этом с достаточным разнообразием, чтобы обнаружить последовательности с детектируемой активностью. Затем такие последовательности могут быть улучшены путем введения большего разнообразия в положениях библиотеки, со скринингом или селекцией, позволяющими выбрать оптимальные клоны, независимые от прогнозов на основе моделей. Таким образом, комбинация компьютерного моделирования и направленной эволюции позволяет получать сконструированные последовательности, которые вряд ли можно обнаружить с помощью одной методики в отдельности.
F. Второй круг шаффлинга
Исходную библиотеку создавали к тифенсульфурону, однако поскольку индуцирующая активность была обнаружена также с другими соединениями SU, обладающими потенциально лучшей стабильностью в почве и в растениях, чем исходный лиганд, процесс эволюции перенаправили на указанные альтернативные лиганды. Особенный интерес представляли гербициды метсульфурон, сульфометурон, этаметсульфурон и хлорсульфурон. Для этой цели родительские клоны L1-9, -22, -29 и -44 выбрали для дальнейшего шаффлинга. Клон L1-9 обладал высокой активностью в отношении и этаметсульфурона, и хлорсульфурона; клон L1-22 обладал высокой активностью в отношении сульфометурона; клон L1-29 обладал умеренной активностью в отношении метсульфурона; и клон L1-44 обладал умеренной активностью в отношении метсульфурона, этаметсульфурона и хлорсульфурона (Таблица 4). Ни один клон, обнаруженный в начальном скрининге, не обладал исключительной активностью в отношении метсульфурона. Указанные четыре клона также выбрали из-за их относительно высокой репрессорной активности, с низкой фоновой β-gal активностью без индуктора. Высокая репрессорная активность важна для получения системы, которая одновременно является очень чувствительной к присутствию индуктора, и строго выключенной в отсутствие индуктора.
На основе данных последовательности родительских клонов L1-9, -22, -29 и -44, были разработаны, сконструированы и скринированы две библиотеки второго раунда. Первая библиотека, L2, состояла из 'семейства' перетасовки, в котором аминокислотное разнообразие между выбранными родительскими клонами варьировали с использованием синтетических собранных олигонуклеотидов, чтобы выявить клоны с улучшенной реактивностью в отношении любого из четырех новых целевых лигандов. Краткое описание используемого разнообразия и полученных в результате хитов последовательностей для библиотеки L2 приведено в Таблице 8.

Олигонуклеотиды, используемые для конструирования библиотеки, показаны в Таблице 9. L2 олигонуклеотиды были собраны, клонированы и скринированы согласно методике, описанной для библиотеки L1, за исключением того, что каждый лиганд тестировали в концентрации 2 м.д. для повышения жесткости анализа, что соответствует 10-кратному уменьшению концентрации в скрининге библиотеки 1-го раунда.




G. Результаты скрининга для библиотеки L2
Почти 8000 колоний, полученных в результате предварительного репрессорного скрининга, подвергали активационному скринингу на среде M9, содержащей потенциальные индукторы этаметсульфурон, сульфометурон, метсульфурон или хлорсульфурон в концентрации 2 м.д. Чашки анализировали через 48 часов инкубирования при 30°C. Двенадцать предполагаемых хитов с указанных чашек переносили рядами в 96-луночный формат и повторно тестировали в таком же наборе сред (Таблица 10). Только клон L2-14 имел сильный индукторный ответ и строгую регуляцию к любому из индукторов в указанной, более низкой дозе 2 м.д., при которой он имел сильный ответ на Cs с низким фоновым уровнем без индуктора. Клон L2-18 имел умеренный ответ на данный лиганд и фоновый уровень. Клон L2-9 также хорошо реагировал на Cs, но имел более высокую фоновую активность без индуктора. Ни один из изолятов не показал существенного ответа на метсульфурон. Неожиданное наблюдение состояло в том, что родительский клон L1-9 обладал чувствительностью к 2 м.д. Es. Анализ последовательности хитов клонов из библиотеки 2 (Таблица 6) показал, что F86M, G138R и F177K были предпочтительными заменами в реактивных хитах. Это было особенно заметно в положении 138, в котором значительно чаще представлен A в популяции, не подвергнутой селекции, и все же пять клонов содержат в данном положении R, тогда как только один содержит аланин. R105W также может быть важной, но в случайной популяции последовательностей W105 уже замещено на C или Y.
H. Сборка библиотеки второго раунда L4
Другую библиотеку второго раунда, L4, создавали из синтетических олигонуклеотидов с использованием клона L1-9 в качестве матрицы, при этом вводили новое аминокислотное разнообразие в последовательность, основанную на филогенетическом сравнении 34 TetR и родственных молекул. Множественное выравнивание последовательности SEQ ID NO: 1 и SEQ ID NO: 402-433, выполненное с использованием GCG SeqWeb PILEUP (Accelrys, San Diego, CA) с параметрами по умолчанию GAP Weight = 8, gap length weight = 2, и матрицы BLOSUM62, показано ниже:


Аминокислотные положения с относительно консервативными аминокислотными заменами между представителями семейства рассматривали в целях выбора разнообразия. Кроме того, положения выбирали для изменения на основании интервала, чтобы ограничить число изменений в паре перекрывающихся олигонуклеотидов. Краткое описание библиотеки приведено в Таблице 11. Цель данной библиотеки состояла в поиске хитов, улучшенных по показателю реактивности либо к этаметсульфурону, либо к хлорсульфурону.

Сборку синтетических олигонуклеотидов библиотеки L4 выполняли так же, как и в случае предыдущих библиотек, за исключением того, что использовали два набора олигонуклеотидных пулов. Вначале множество олигонуклеотидов, образующих разнообразие на участке отжига одного олигонуклеотида, объединяли в пулы ("Группа" в Таблице 12). Затем равный объем каждой группы олигов объединяли в пулы, чтобы образовать новое разнообразие L4. Аналогично, олигонуклеотиды, представляющие каркасную последовательность L1-9, объединяли в пулы (Таблица 13). Реакцию сборки L4 проводили посредством встраивания пула олигонуклеотидного разнообразия в каркасный пул L1-9 в соотношении приблизительно 1:3.
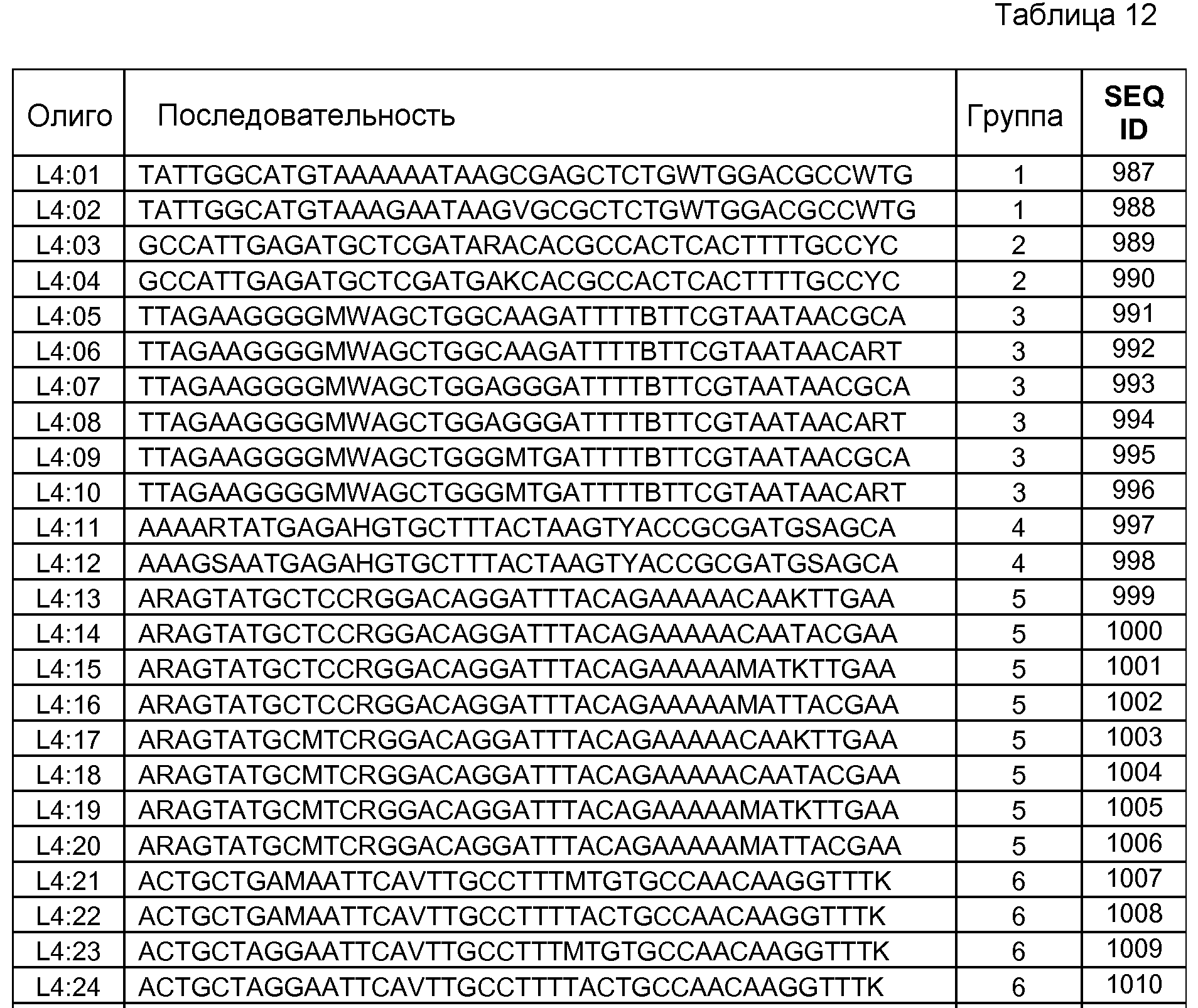

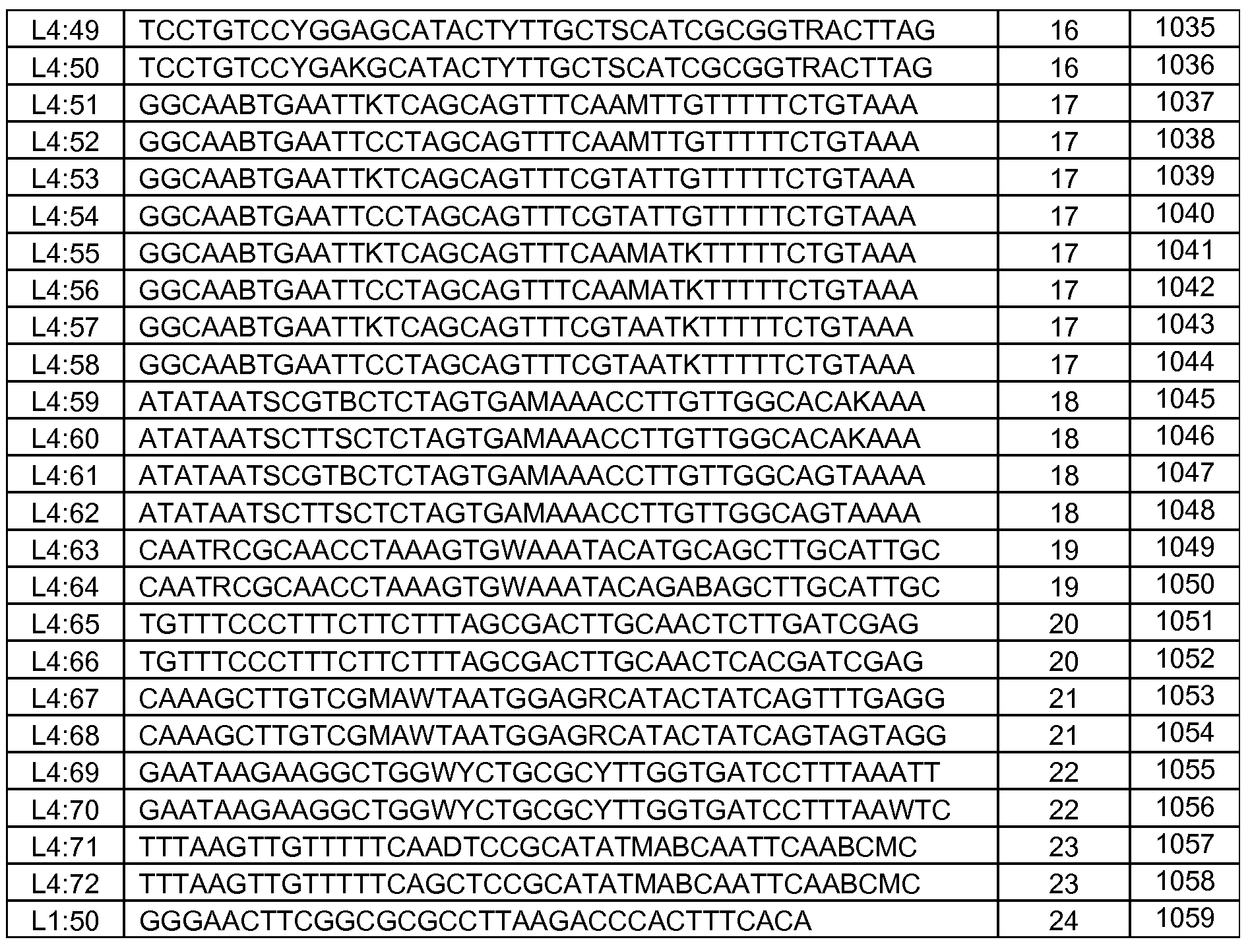


Продукты реакции сборки клонировали в каркас pVER7314 и трансформировали в тестовый штамм E. coli KM3. Для выполнения анализа разнообразия библиотеки, препараты ДНК из 96 колоний, выращенных только на LB+Cs (не представляющих изменения репрессорной позитивной селекции), подвергали анализу последовательности. Полученные данные показали, что приблизительно 30% полученных клонов представляли собой неизменный каркас L1-9, а оставшиеся клоны содержали приблизительно одно-два намеченных изменения на клон. Дополнительные ненамеченные изменения остатков были выявлены в мутированной популяции либо вследствие ошибок ПЦР, либо вследствие низкого качества олигонуклеотидов, включенных в реакции сборки.
I. Скрининг библиотеки L4
Приблизительно 20000 клонов, полученных в результате предварительного репрессорного скрининга, тестировали на активацию при концентрациях 0, 0,2 и 1 мкг/мл этаметсульфурона с использованием аналитических чашек M9. Неожиданно, более 100 хитов были обнаружены при обработке 0,2 мкг/мл этаметсульфурона. Указанные предполагаемые хиты переносили рядами в 96-луночный формат и повторно тестировали посредством индукции β-галактозидазы 0, 0,2 и 1 м.д. этаметсульфурона при использовании системы анализа на основе жидкой культуры. На Фигуре 4 показана относительная β-галактозидазная активность 45 примерных предполагаемых хитов клонов 97-142 библиотеки L4 при концентрациях этаметсульфурона 0, 0,2 и 1 м.д. Культуры, выращенные в 96-луночном формате, переносили в новую LB с индуктором при указанной концентрации и выращивали в течение ночи, а затем обрабатывали для анализа фермента. Для обнаружения индуцированной активности использовали 5 мкл смеси перфорированных клеток. Для обнаружения фоновой активности использовали 25 мкл клеток, при этом детектируемая активность могла быть измерена в той же временной рамке для всех обработок. Значения фоновой активности умножали на десять для приведения в диапазон графика. Числа под каждым образцом относятся к номеру клона в библиотеке. Последняя часть графика содержит контроли хита 1-го раунда L1-9, а также TetR дикого типа.
Последовательности ДНК для всех хитов 142 предполагаемых клонов определяли и выравнивали транслированные полипептиды. После присвоения каждому полипептиду в выравнивании относительного ответа этаметсульфурона, идентифицировали профили включения аминокислот в измененных или мутированных остатках, связанных с высокой или низкой активностью ответа и высокой или низкой неиндуцированной активностью. Наиболее значимые данные, полученные из указанного анализа, были следующими: C138G или мутации L170V были предпочтительны в лучших клонах L4-59, -89, -110, -116, -118, -120, -124, -129, -133, -139, -140 и -142; и K108Q был включен в клоны с наибольшей активностью при минимальной дозе 0,2 м.д., однако указанные клоны показали некоторую подтекающую фоновую активность (например, L4-98, -106, -113, -126, -130 и -141). Результаты клона L4-18, содержащего K108Q, показали другую возможную интересную мутацию L55M. Указанный клон индуцировался с высоким уровнем при 0,2 м.д. Es, но не показывал связанную высокую фоновую активность, как правило наблюдаемую у K108Q-содержащих клонов. Мутация L55M, возможно, повышала репрессорную активность. Представляет интерес то, что ни одно из указанных изменений кроме L55M не являлось запланированным разнообразием - все они были получены в результате ошибочного включения нуклеотидов в ходе сборки библиотеки, при этом немногие из этих изменений были представлены в популяции клонов, не подвергнутых селекции.
J. Конструкция и скрининг библиотеки третьего раунда
Библиотека L6: шаффлинг с повышенным ответом к хлорсульфурону
Так как клоны L2-14 и L2-18 обладали наилучшим профилем активности в отношении хлорсульфурона из библиотеки L2, их аминокислотное разнообразие использовали в качестве основы для следующего раунда шаффлинга. В дополнение к разнообразию, обеспечиваемому указанными базовыми последовательностями, были включены дополнительные изменения остатков, предполагаемые с целью улучшения упаковки хлорсульфурона на основании прогноза с использованием 3D модели. Новые намеченные аминокислотные положения были следующими: 67, 109, 112 и 173 (см. Таблицу 14). Было показано, что замена Gln (Q) в положении 108 и Val (V) в положении 170, вероятно, являются важными изменениями в библиотеке L4 для получения улучшенной реактивности SU, и поэтому в данном случае также были подвергнуты изменению. Краткое описание выбранного разнообразия представлено в Таблице 14. Олигонуклеотиды, разработанные и используемые для получения библиотеки 6, показаны в Таблице 15.
Библиотеку L6 собирали, выделяли, лигировали в pVER7314, трансформировали в E. coli KM3 и сеяли на LB с карбенициллином/канамицином, и только с карбенициллином в контрольной среде, как ранее. Затем колонии с чашек библиотек переносили в 42 384-луночных микротитровальных планшета (~16000 клонов), содержащих по 60 мкл среды LB с карбенициллином (Cb) в лунке. После выращивания в течение ночи при 37°C культуры перепечатывали на аналитические чашки M9, не содержащие индуктора, с 0,2 м.д. и 2.0 м.д. хлорсульфурона в качестве тестируемого индуктора. После инкубирования при 30°C в течение ~48 ч, предполагаемые хиты, отвечающие на обработку хлорсульфуроном, что определяли по синему окрашиванию колонии, переносили рядами в шесть 96-луночных микротитровальных планшета и использовали для перепечатывания новый набор аналитических чашек M9, чтобы подтвердить вышеуказанные результаты. Для более детального анализа относительной индукции хлорсульфурона делали цифровые фотоснимки чашек в различные моменты инкубирования при 30°C и измеряли интенсивность цвета колоний, используя бесплатно распространяемую программу для анализа цифровых изображений ImageJ (Rasband, US National Institutes of Health, Bethesda, MD, USA, rsb.info.nih.gov/ij/, 1997-2007). Применение полученных результатов позволило ранжировать клоны в мультиплексном формате по фоновой активности (без индуктора), активации с применением низкого или высокого уровня индуктора (синий цвет с индуктором) и относительной активации (активации, деленной на фон). Исследования с активацией при использовании в качестве индуктора 0,2 мкг/мл хлорсульфурона для основного набора клонов показали приблизительно 3-кратное усиление активации, с одновременным получением более низких уровней неиндуцированной экспрессии (Таблица 12). В дополнение к этому анализу, получили данные ДНК последовательности для большинства клонов (490 клонов), и выравнивали полученные полипептиды друг с другом, а также сравнивали их соответствующие данные по активности. В результате данного анализа получили отношения последовательности-активности (Таблица 12). Остатки, замещенные для повышения активности, обозначены более крупным полужирным шрифтом. Вкратце, C в положении 100 и Q в положениях 108 и 109 убедительно коррелировали с активацией, тогда как R в положении 138, L в положении 170 и A или G в положении 173 были наиболее предпочтительны в клонах с самой низкой фоновой активностью. Хотя некоторые положения были сильно замещены, то есть, их более часто наблюдали в выбранной популяции, полноту введенного разнообразия наблюдали в полной популяции хитов. Данная информация может быть полезной при создании последующих библиотек, направленных на улучшение реактивности по отношению к хлорсульфурону.
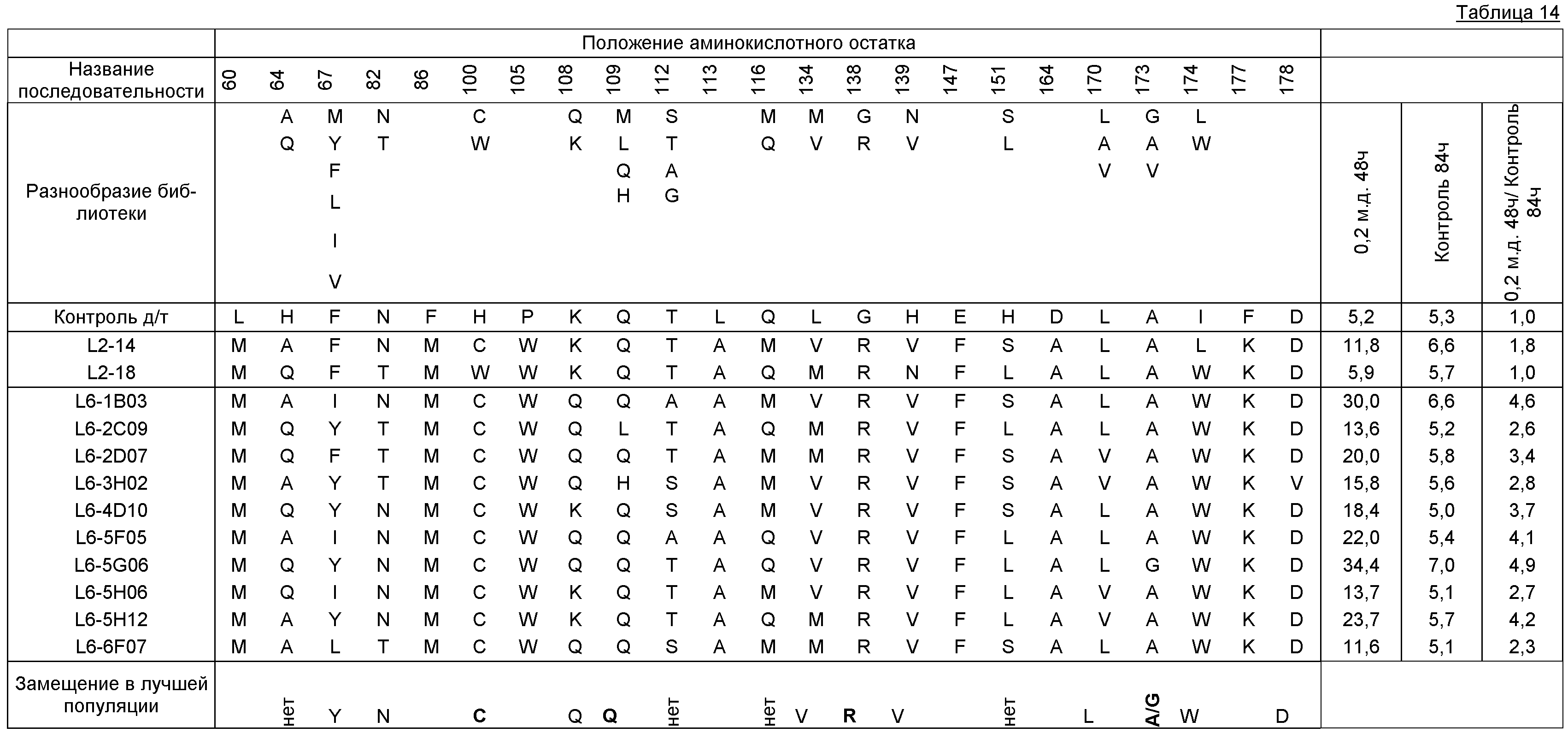


K. Библиотека L7: Шаффлинг с целью усиления ответа к этаметсульфурону
Выбор родителей для представления разнообразия аминокислотных остатков в библиотеке L7 был основан на результатах анализа библиотеки L4, а именно, включении мутаций K108Q, C138G и L170V. Также выбрали клоны для введения других изменений, которые появлялись с намного более низкой частотой в L4, но, возможно, вносили вклад в активность. Указанными остатками являлись L55M, N129H, V137A и F140Y. В дополнение к разнообразию семейства другие модификации остатков в аминокислотных положениях 67, 109, 112, 117, 131 и 173, вводили на основе структурного моделирования. Данная информация приведена в Таблице 14, в которой представлено краткое описание разнообразия L7. Также в Таблице 16 показано выравнивание последовательности лучших 10 хитов L7, ограниченное различиями между хитами и TetR д/т. Активность определяли с использованием анализа цвета колоний на снимках (программа ImageJ) аналитических чашек M9, содержащих 0, 0,02 или 0,2 м.д. этаметсульфурона. В нижней части Таблицы 16 представлено краткое описание анализа отношения последовательности-активности для полного набора данных, полученных более чем от 300 клонов, сильно замещенные положения показаны более крупным полужирным шрифтом. Несмотря на то, что некоторые положения были сильно замещены, то есть, их более часто наблюдали в выбранной популяции, например, M в положении 55, полноту введенного разнообразия наблюдали в полной популяции хитов.
Библиотеку L7 сконструировали также, как и Библиотеку L1, используя набор олигонуклеотидов, показанных ниже в Таблице 17.
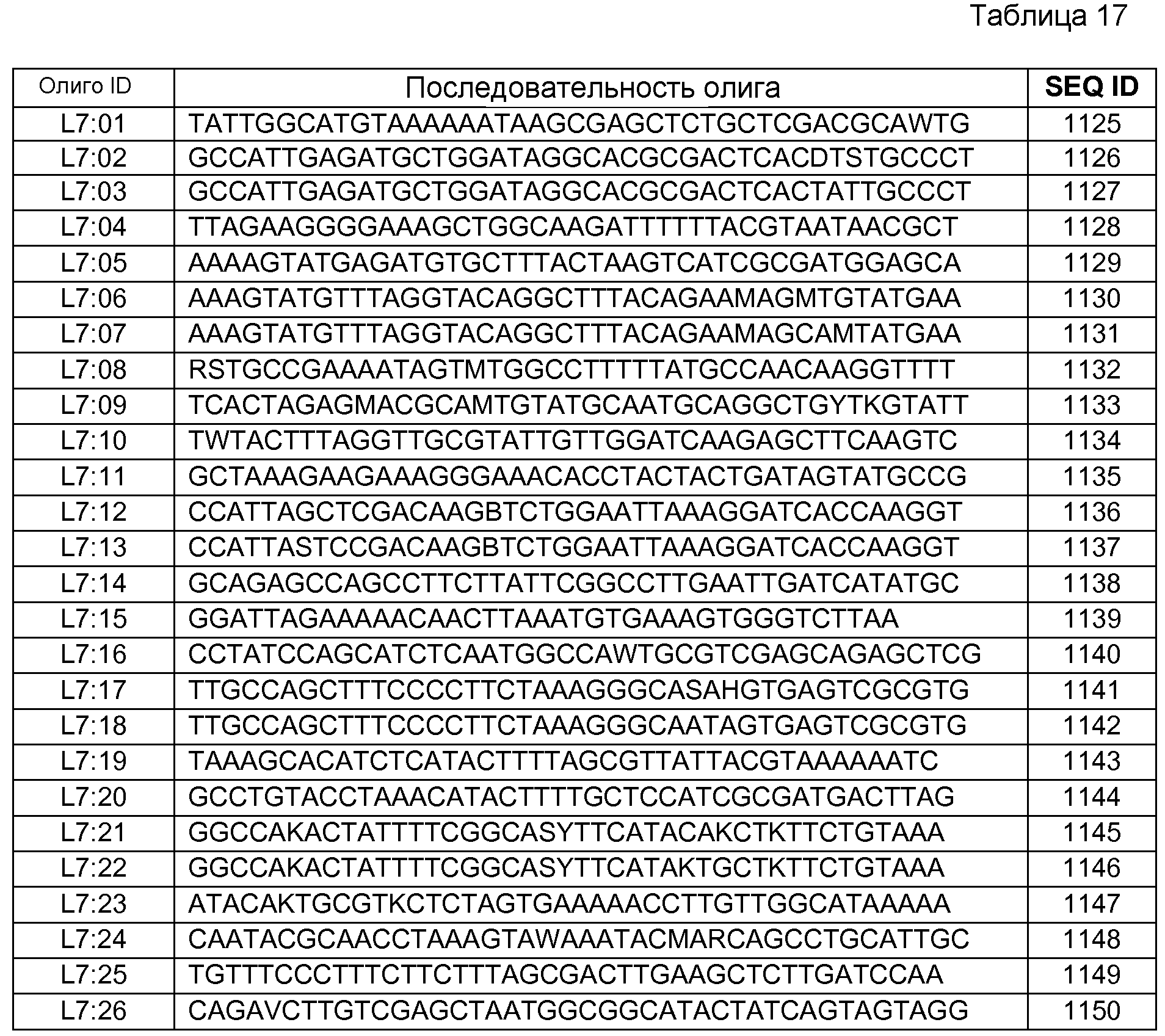

После трансформации библиотеки в E. coli KM3 и посева на LB+Cb+Km, полученные колонии переносили в пятьдесят два 384-луночных микротитровальных планшета (~20000 колоний) и впоследствии использовали для получения реплики на аналитической среде M9, содержащей 0 мкг/мл, 0,02 мкг/мл или 0,2 мкг/мл этаметсульфурона. После инкубирования при 30°C в течение 48 часов чашки изучали и идентифицировали 326 хитов, отвечающих на 0,02 мкг/мл индуктора, которые переносили рядами в 96-луночный формат. После инкубирования при 30°C в течение 15, 24, 48 и 120 часов делали цифровые снимки планшетов и преобразовывали относительную окраску колоний в числовые данные. Параллельно проводили анализ ДНК последовательности, и два набора данных объединяли для вычисления отношений последовательности-активности. Данные последовательности лучших десяти клонов, а также полученные отношения последовательности-активности показаны в Таблице 16. Результаты исследования отношений последовательности-активности выявили предпочтения, влияющие и на активацию, и на фоновые активности предполагаемых этаметсульфурон-репрессоров (EsR). Например, один из существенных результатов, полученных при анализе данной библиотеки, состоял в том, что модификация L55M сильно уменьшала фоновую активность и, таким образом, повышала уровни относительной активации. Как можно видеть из библиотек L4 и L6, K108Q и д/т Q109 были предпочтительны для активации. Также наблюдалась высокая степень замещения L170V, связанного с активацией. Это отличается от замещения L170A или L170G, наблюдаемого в библиотеке L6, поскольку такие модификации сильно коррелировали с понижением фоновой активности в библиотеке L6. Наконец, оказывающей менее существенное влияние на активацию, но, тем не менее, предпочтительной заменой является F67Y.
L. Индукционные свойства лучших хитов L7 в жидких культурах
На основе характеристик перегруппированных хитов провели вторую перегруппировку и протестировали клоны на β-галактозидазную активность в жидкой культуре вместе с контрольными TetR д/т, после чего отобрали хиты 2-го раунда, чтобы дополнительно проанализировать их характеристики и эффективность шаффлинга. Лучшие хиты из библиотеки L7 перегруппировывали и тестировали в культурах в 96-луночном формате с относительной индукцией 0,02 и 0,2 мкг/мл индуктора или фоновой активностью без индуктора (Фигура 5). Культуры выращивали в течение ночи и затем переносили в новую среду, содержащую соответствующие добавки. Через шесть часов инкубирования клетки обрабатывали для ферментативного анализа. Для анализа индуцированной активности использовали 5 мкл смеси перфорированных клеток, для фоновой активности использовали 25 мкл клеток, при этом детектируемая активность могла быть измерена в той же временной рамке для всех обработок. Значения фоновой активности умножали на десять, чтобы привести их в соответствие с диапазоном графика. Числа под каждым образцом относятся к ID конечной перегруппированной лунки (вертикальный шрифт) и ID исходной перегруппированной лунки (горизонтальный шрифт). В последней части графика содержится контроль. Показаны хиты 2-го раунда L4-89 и L4-120, а также TetR д/т. Конечный образец показывает контроль, включающий TetR д/т с 0,4 мкМ atc в качестве родственного индуктора для сравнения. Результаты показывают, что от десяти до пятнадцати лучших хитов обладали индуцированной активностью, приближающейся к активности TetR д/т, индуцируемого 0,4 мкМ atc. Кроме того, многие из хитов обладали почти такой же низкой фоновой активностью, как и TetR дикого типа. Некоторые из лучших хитов имеют отношения индукции с 0,2 м.д. индуктора (0,5 мкМ), приближающиеся к 70-80% отношения TetR д/т (~1200-кратное). Интересно, что хиты, наиболее активные при низкой концентрации индуктора 0,02 м.д. (50 нМ), также обладали более высокой фоновой активностью, что указывает на то, что они менее строго связаны с tet-оператором и более легко освобождаются при транзиентном связывании индуктора.
Сравнение активности индукции между хитами 2-го и 3-го раундов было поразительным, показав более чем 200-кратное улучшение. С учетом такого улучшения, всего один дополнительный раунд шаффлинга и скрининга может привести к сульфонилмочевина-репрессорам (SuR), которые являются почти такими же чувствительными к этаметсульфурону, каким является TetR дикого типа к тетрациклину.
Выводы
На Фигуре 9 представлен совокупный итог введенного разнообразия и наблюдаемых аминокислот в активных SuR, полученных в результате скрининг-анализа. Несмотря на то, что, что некоторые положения были сильно замещены, то есть, более часто наблюдались в выбранной популяции, как обозначено более крупным полужирным шрифтом, полнота введенного разнообразия наблюдалась в полных популяциях хитов.
M. Новое разнообразие посредством in vitro мутагенеза
Остатки A64, M86, C100, G104, F105, Q108, A113, S116, M134, Q135, I139, Y140, L147, L151, V170, L174 и K177 хита 3 раунда L7-A11 мутировали с заменой всеми возможными 20 аминокислотами, с получением набора из 340 клонов. Каждый из клонов перепечатывали на аналитическую среду M9, содержащую 0, 5, 20 и 200 млрд.д. этаметсульфурона. Для оценки относительной активности каждого из мутантов, чашки, содержащие лиганд, фотографировали через 18 часов инкубирования при 37°C. Для определения подтекания репрессорных клонов, чашку, не содержащую добавки лиганда, фотографировали после инкубирования в течение 24 ч при 37°C, сопровождавшегося 48 ч инкубированием при 25°C. Количественные измерения проводили путем сканирования цифровых фотографий каждой колонии с определением интенсивности синего цвета при использовании программы ImageJ.
Указанные данные показали, что выбранные замены в положениях L60, A64, N82, M86, A113, S116, M134, L174 и K177 демонстрировали увеличение чувствительности к этаметсульфурону по сравнению с родительским клоном L7-А11.
N. Пятый раунд шаффлинга
Выполняли шаффлинг, разработанный для повышения чувствительности к этаметсульфурону. Библиотеку L13 (Таблица 18) разработали для включения нового разнообразия, полученного в ходе эксперимента in vitro мутагенеза в Примере 1M, которое оказывало положительное или нейтральное воздействие на активность. Кроме того, библиотека также включала разнообразие в выбранных остатках цистеина в каркасе, как указано ниже (Таблица 18). Теоретический размер библиотеки составлял 124000 членов.
Библиотеку собирали из синтетических олигонуклеотидов, перечисленных в Таблице 19, используя методику, предварительно описанную в данном примере.
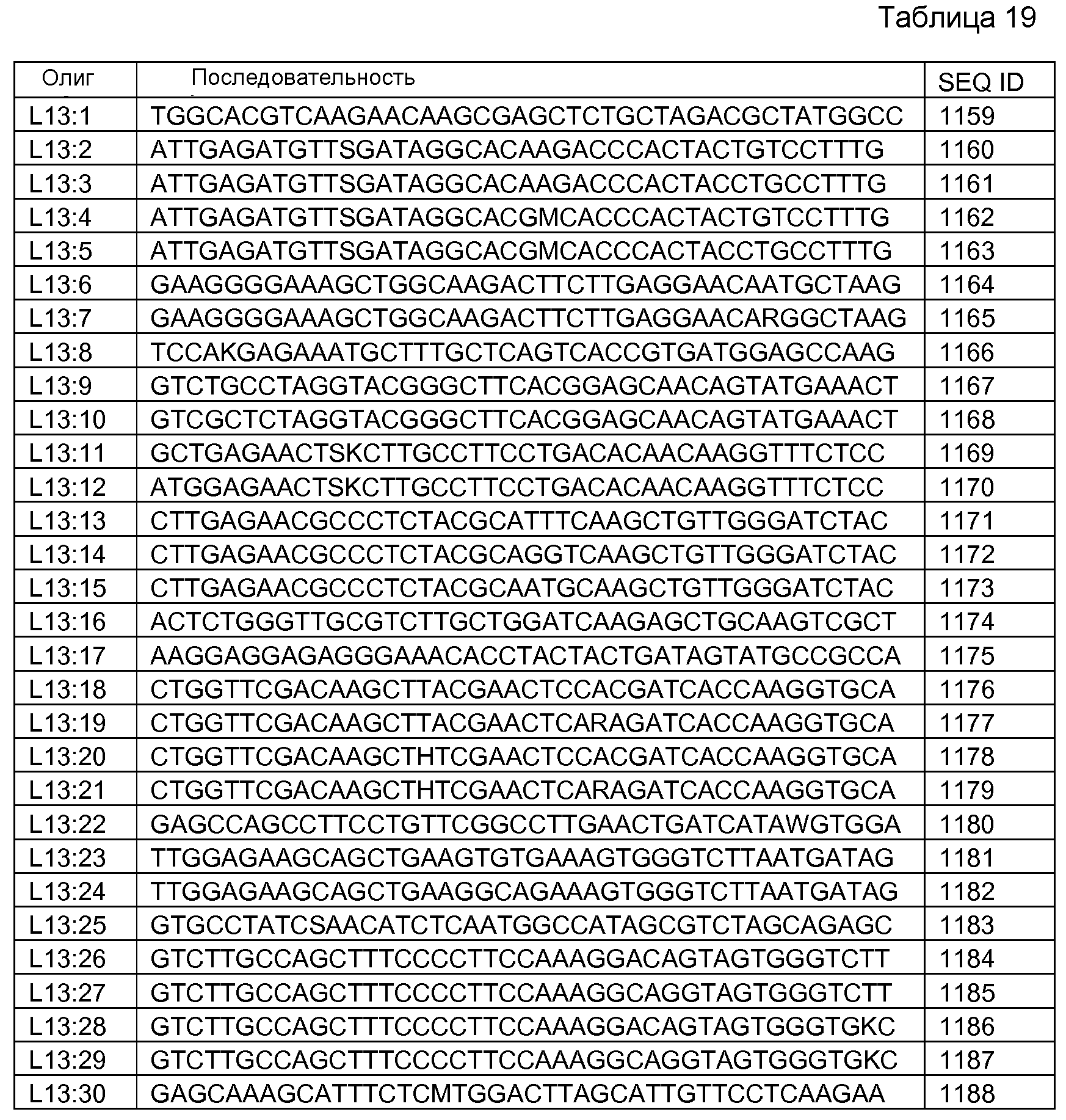
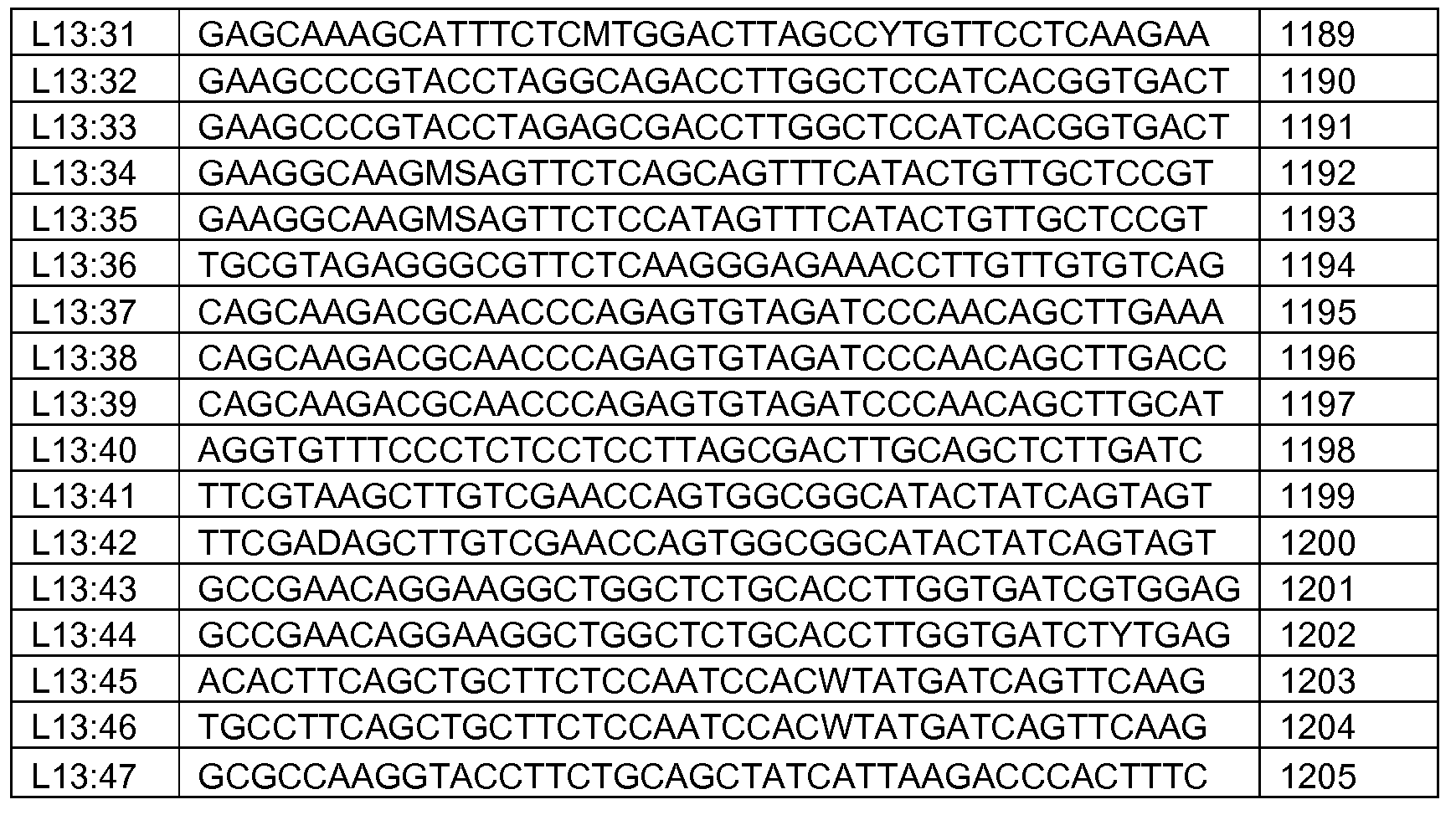
Затем собранную библиотеку клонировали в pVER7571. Указанный вектор аналогичен вектору pVER7314, за исключением наличия мутированного сайта связывания рибосомы с целью уменьшения количества репрессора, продуцируемого в клетке. Подобная модификация позволяет произвести более строгую оценку репрессорной активности в стандартном синем/белом генетическом анализе колоний, а также в количественном β-галактозидазном цельноклеточном анализе на основе жидкой культуры. После посева библиотеки, приблизительно 5000 клонов перегруппировывали и перепечатывали на аналитические чашки M9 без добавки, или с 2 млрд.д. этаметсульфурона плюс 0,002% арабинозы. Колонии, наиболее сильно реагирующие на этаметсульфурон и остающиеся при этом белыми без индуктора, отбирали в качестве хитов. Один из хитов, L13-23, как находили, был в ~3 раза улучшен по сравнению с родителем 3 раунда L7-А11, и обладал лучшей репрессорной активностью в рамках данного сравнения (Фигура 11). Изменения последовательности хита 5 раунда по сравнению с родительской молекулой L7-А11 и TetR д/т показаны в Таблице 20.
ПРИМЕР 2: РАЗРАБОТКА АНАЛИЗА НА РАСТЕНИЯХ
A. Анализ инфильтрации в листья Nicotiana benthamiana
Требовалось создать систему транзиентного анализа на растениях, которая позволяет быстро подтверждать функциональность кандидатных SU-реактивных репрессоров в растениях перед анализом на трансгенных растениях. Ввиду этого, разработали анализ инфильтрации в листья, основанный на Agrobacterium, для измерения репрессорной и дерепрессорной активности. Применяемая стратегия состоит в инфильтрации листьев смесью репортерного и эффекторного (репрессорного) штамма Agrobacterium, в результате чего активность репортера уменьшается на ~90% в присутствии эффектора и затем дерепрессируется после обработки индуктором.
Два этаметсульфуроновых репрессора, EsR A11 и EsR D01, отбирали для тестирования, вместе с контролем TetR дикого типа, эффекта дозы этаметсульфурона на транзиентную экспрессию в листьях Nicotiana benthamiana (Фигура 6). Для этой цели, три тестовых штамма получали посредством трансформации Agrobacterium tumefaciens EHA105 тремя различными векторами на основе T-ДНК. Сконструировали штаммы Agrobacterium, несущие бинарные векторы с 35S::tetO-Renilla люциферазным репортером и dPCSV-tetR или -SuR эффекторными вариантами. В дополнение к указанным тестовым культурам, к аналитической смеси добавляли существующий штамм Agrobacterium, несущий T-ДНК dMMV-GFP, для контроля развития агробактериальной инфекции с целью взятия проб.
Для тестирования системы на активацию химического выключателя, смеси тестовых культур Agrobacterium, содержащих 10% репортера 35S:tetO-ReLuc Agro, 10% dMMV-GFP Agro и 80% dPCSV-tetR д/т Agro инфильтрировали в листья N. benthamiana и совместно культивировали в течение 36 часов в климатической камере. В данный период инфильтрированные листья срезали и помещали стебельки в воду (отрицательный контроль) или индуктор в тестовых концентрациях, указанных на Фигуре 6, и оставляли для совместного культивирования еще на 36 часов. Зараженные области листьев оценивали на наличие активности люциферазы Renilla и сравнивали обработки индуктором. Результаты продемонстрировали существенную репрессию активности репортера (~90%) без обработки индуктора (водный контроль) для всех протестированных репрессоров и существенную, но неполную индукцию репрессора EsR D01 при концентрации индуктора не выше 0,02 м.д. Es. Оба EsR полностью индуцировались при 0,2 м.д. Es, тогда как TetR полностью индуцировался только при 2,0 м.д. ангидротетрациклина (atc) (Фигура 6).
B. Разработка высокопроизводительного анализа на растениях с использованием культуры клеток N. tabacum BY-2
В дополнение к анализу на листьях было желательно располагать таким анализом на растениях, который бы позволял выполнять высокопроизводительный скрининг библиотек SuR на предмет оптимальных функциональностей растений. Разработали систему, подобную анализу на листьях, но с использованием культуры клеток табака BY-2 в 96-луночном формате. Культуры клеток BY-2 трансформировали конструкцией dMMV-HRA, чтобы культура могла выдерживать обработку целевыми тестируемыми соединениями сульфонилмочевины. Полученная в результате линия клеток росла и была полностью устойчива к 200 млрд.д. хлорсульфурона.
ПРИМЕР 3: АНАЛИЗ СВЯЗЫВАНИЯ ОПЕРАТОРА
Для подтверждения того, что сульфонилмочевинные лиганды связывались непосредственно с модифицированными молекулами репрессоров и вызывали дерепрессию, проводили in vitro исследование подвижности tet-оператора в геле.
Анализ изменения электрофоретической подвижности (EMSA) вариантов EsR проводили с целью контроля связывания с последовательность tet-оператора (tetO) и ответа комплекса на индукторы Es и Cs. TetO состоит из синтетического tetO-содержащего фрагмента размером 48 пн, полученного в результате гибридизации олигонуклеотида tetO1 (SEQ ID NO:1155):
5'-CCTAATTTTTGTTGACACTCTATCATTGATAGAGTTATTTTACCACTC-3'
и комплементарного олигонуклеотида tetO2 (SEQ ID NO:1156):
5'-GGATTAAAAACAACTGTGAGATAGTAACTATCTCAATAAAATGGTGAG-3'
Tet-оператор выделен полужирным.
Олигонуклеотид и его комплемент такого же размера, не содержащие палиндромной последовательности, использовались в качестве контроля (SEQ ID NO: 1157):
5'-CCTAATTTTTGTTGACTGTGTTAGTCCATAGCTGGTATTTTACCACTC-3'
и комплементарный олигонуклеотид (SEQ ID NO: 1158):
5'-GGATTAAAAACAACTGACACAATCAGGTATCGACCATAAAATGGTGAG-3'
Пять пмоль TetO или контрольной ДНК смешивали с указанными количествами (Фигура 7) этаметсульфурон-репрессорного белка (L7A11) или контроля BSA, с или без индуктора в сложном буфере, содержащем 20 мМ Трис-HCl (pH 8,0) и 10 мМ ЭДТА. Смесь инкубировали при комнатной температуре в течение 0,5 часа перед нанесением в гель. Реакционную смесь подвергали электрофорезу в 6%-ом ДНК-задерживающем геле Novex (Invitrogen, EC6365BOX) при комнатной температуре, 38 В, в 0,5×TBE буфере в течение приблизительно 2 часов. ДНК детектировали окрашиванием бромистым этидием. В качестве маркер размера ДНК использовали ДНК-маркер низкой массы (Invitrogen 10068-013).
Результаты показаны на Фигуре 7. Представленные результаты непосредственно демонстрируют, что модифицированные репрессоры связываются с ДНК оператора (дорожка 1 в сравнении с дорожками 3-5), а затем освобождаются от последовательности оператора индуктор-специфическим и дозозависимым путем. Данные также указывают предпочтение Es по сравнению с Cs при высвобождении индуктора от оператора (дорожки 9 и 10). Изменений при высвобождении от оператора atc в сравнении с отсутствием индуктора обнаружено не было (дорожки 5 и 11).
ПРИМЕР 4: КОНСТАНТЫ СВЯЗЫВАНИЯ И ДИССОЦИАЦИИ
Выбранные SU репрессоры дополнительно характеризовали по кинетике связывания оператора и лиганда, аффинности и диссоциации при использовании технологии Biacore™ SPR (Biacore, GE Healthcare, USA). Технология основана на поверхностном плазмонном резонансе (SPR), оптическом явлении, которое позволяет обнаруживать немеченые взаимодействующие молекулы в режиме реального времени. Биодатчики на основе SPR могут применяться при определении активной концентрации, скрининге, а также в анализе аффинности и кинетики.
Кинетика взаимодействия, то есть, скорость образования (ka) и диссоциации (kd) комплекса, может быть определена на основе данных сенсограммы. Если связывание происходит, когда образец проходит по подготовленной поверхности сенсора, отклик на сенсограмме возрастает. Если достигается равновесие, наблюдается постоянный сигнал. Замена образца буфером вызывает диссоциацию связанных молекул и уменьшение отклика. Программа оценки Biacore генерирует значения ka и kd, приводя данные в соответствие с моделями взаимодействия.
Аффинность взаимодействия определяется из уровня связывания в равновесии (регистрируемого как постоянный сигнал) в зависимости от концентрации образца. Аффинность может быть также определена из кинетических измерений. Для простого взаимодействия 1:1 равновесная константа KD является отношением кинетических констант скорости, kd/ka.
A. Характеристика связывания репрессоров с оператором
B. Характеристика связывания репрессоров и SU
ПРИМЕР 5: СЛИТЫЕ ЛИГАНД-СВЯЗЫВАЮЩИЕ ДОМЕНЫ СУЛЬФОНИЛМОЧЕВИННЫХ РЕПРЕССОРОВ
Лиганд-связывающие домены из сульфонилмочевинных репрессоров, предложенных в настоящей заявке, могут быть слиты с альтернативными ДНК-связывающими доменами в целях создания дополнительных сульфонилмочевинных репрессоров, которые селективно и специфично связываются с другими ДНК последовательностями (например, Wharton and Ptashne, (1985) Nature 316:601-605). Было опубликовано много экспериментов по обмену доменов, демонстрирующих широту и гибкость данного подхода. Как правило, используется оператор-связывающий домен или специфичные аминокислотные/операторные контактные остатки из разных репрессорных систем, но также могут использоваться другие ДНК-связывающие домены. Например, полинуклеотид, кодирующий химерный полипептид TetR(D)/SuR, состоящий из ДНК-связывающего домена из TetR(D) (например, аминокислотных остатков 1-50) и лиганд-связывающего домена из SuR остатков (например, аминокислотных остатков 51-208 из TetR(B)), может быть сконструирован с использованием любого стандартного метода молекулярной биологии или их комбинаций, включая расщепление рестриктазами и лигирование, ПЦР, синтетические олигонуклеотиды, мутагенез или рекомбинационное клонирование. Например, полинуклеотид, кодирующий SuR, включающий химеру TetR(D)/SuR, может быть сконструирован с помощью ПЦР (Landt et al., (1990) Gene 96:125-128; Schnappinger et al., (1998) EMBO J. 17:535-543) и клонирован в подходящую кассету экспрессии и вектор. Связывающие домены любого другого TetOp можно заменить с получением SuR, который специфично связывается с когнатной последовательностью tet-оператора.
Кроме того, могут использоваться связывающие домены мутантного TetOc из вариантов TetR, обладающие супрессорной активностью в отношении конститутивных операторных последовательностей (tetO-4C и tetO-6C) (см., например, Helbl and Hillen, (1998) J. Mol. Biol. 276:313-318; и Helbl et al., (1998) J. Mol. Biol. 276:319-324). Более того, полинуклеотиды, кодирующие указанные ДНК-связывающие домены, могут быть модифицированы с целью изменения их оператор-связывающих свойств. Например, полинуклеотиды могут быть подвергнуты шаффлингу с целью повышения силы или специфичности связывания с дикой или модифицированной последовательностью tet-оператора, или селекции на предмет специфичного связывания с новой операторной последовательностью.
Дополнительные варианты могут быть созданы путем слияния SuR репрессора или лиганд-связывающего домена SuR с активирующим доменом. Подобные системы были разработаны с использованием Tet-репрессоров. Например, в одной системе tet-репрессор преобразовали в активатор путем слияния репрессора с доменом трансактивации транскрипции, например, VP16 из вируса простого герпеса и tet-репрессора (tTA, Gossen and Bujard, (1992) Proc. Natl. Acad. Sci. USA 89:5547-5551). Слитый репрессор применяется в сочетании с минимальным промотором, который активируется в отсутствие тетрациклина при связывании tTA с последовательностями tet-оператора. Тетрациклин инактивирует трансактиватор и ингибирует транскрипцию.
ПРИМЕР 6: Тестирование репрессорных белков в сое
Любые методики трансформации, методики культивирования, источник сои и среды, а также методы молекулярного клонирования могут применяться в композициях и способах.
A. Трансформация и регенерация сои (Glycine max)
Трансгенные линии сои получают методом бомбардировки частицами (Klein et al., Nature 327:70-73 (1987); патент США 4945050) с применением установки BIORAD Biolistic PDS1000/He и плазмидной или фрагментированной ДНК. Следующие стоковые растворы и среды используются для трансформации и регенерации растений сои:
Стоковые растворы:
Сульфатный 100× сток: 37,0 г MgSO4·7H2O, 1,69 г MnSO4·H2O, 0,86 г ZnSO4·7H2O, 0,0025 г CuSO4·5H2O
Галогенный 100× сток: 30,0 г CaCl2·2H2O, 0,083 г KI, 0,0025 г CoCl2·6H2O
P, B, Мо 100× сток: 18,5 г KH2PO4, 0,62 г H3BO3, 0,025 г Na2MoO4·2H2O
Fe ЭДТА 100× сток: 3,724 г Na2ЭДТА, 2,784 г FeSO4·7H2O
2,4-D сток: 10 мг/мл 2,4-дихлорфеноксиуксусной кислоты
Витамины B5, 1000× сток: 100,0 г миоинозит, 1,0 г никотиновой кислоты, 1,0 г пиридоксина·HCl, 10 г тиамина·HCl.
Среды (на литр):
Твердая среда SB199: 1 соль MS пакета ((Gibco/BRL, кат. 11117-066), 1 мл 1000× стока (основной раствор) витаминов B5, 30 г сахарозы, 4 мл 2,4-D (конечная концентрация 40 мг/л), pH 7,0, 2 г Gelrite
Твердая среда SB1: 1 пакет солей MS (Gibco/BRL, кат. 11117-066), 1 мл 1000× стока витаминов B5, 31,5 г глюкозы, 2 мл 2,4-D (конечная концентрация 20 мг/л), pH 5,7, 8 г агара TC
SB196: по 10 мл каждого из вышеуказанных стоковых растворов 1-4, 1 мл стока витаминов B5, 0,463 г (NH4)2SO4, 2,83 г KNO3, 1 мл стока 2,4-D, 1 г аспарагина, 10 г сахарозы, pH 5,7
SB71-4: соли Gamborg's B5, 20 г сахарозы, 5 г агара TC, pH 5,7.
SB103: 1 пакет смеси солей Мурасиге и Скуга, 1 мл стока витаминов B5, 750 мг гексагидрата MgCl2, 60 г мальтозы, 2 г Gelrite, pH 5,7.
SB166: SB103, с добавкой 5 г/л активированного угля.
Инициирование эмбриогенной суспензионной культуры сои:
Культуры сои инициировали дважды в месяц с перерывом 5-7 дней между каждым инициированием. Стручки с незрелыми семенами из доступных растений сои через 45-55 дней после посадки собирали, извлекали из оболочек и помещали в стерилизованную камеру с фуксином. Семена сои стерилизовали путем встряхивания в течение 15 минут в 5%-ом растворе Clorox с 1 каплей мыла ivory soap (то есть, тщательно смешивали 95 мл автоклавированной дистиллированной воды плюс 5 мл Clorox и 1 капля мыла). Семена промывали с использованием 2 1-литровых бутылок стерильной дистиллированной воды и семена размером менее 3 мм помещали на индивидуальные предметные стекла. Небольшую часть семени надрезали и выдавливали семядоли из семенной оболочки. Семядоли переносили на чашки, содержащие среду SB199 (25-30 семядоль на чашку) на 2 недели, затем переносили в SB1 на 2-4 недели. Чашки оборачивали волокнистой лентой. По истечении указанного периода вторичные эмбрионы срезали и помещали в жидкую среду SB196 на 7 дней.
Условия культивирования:
Эмбриогенные суспензионные культуры сои (cv. Jack), поддерживали в 50 мл жидкой среды SB196 в ротационном шейкере при 150 об/мин, 26°C при холодном белом флуоресцентном свете с фотопериодом 16:8 ч дня/ночи и интенсивностью света 60-85 мкE/м2/с. Культуры пересевали каждые 7 дней - две недели, инокулируя приблизительно 35 мг ткани в 50 мл новой среды SB196 (предпочтительный интервал субкультивирования - каждые 7 дней). Подготовка ДНК для бомбардировки:
В процедурах бомбардировки частицами можно использовать очищенную интактную плазмидную ДНК или фрагментированную ДНК, содержащую только рекомбинантную целевую ДНК кассету (кассеты) экспрессии. Для каждых семнадцати баллистических трансформаций готовили 85 мкл суспензии, содержащей 1-90 пикограммов (пг) плазмидной ДНК на пару нуклеотидов каждой плазмидной ДНК. Обе рекомбинантных ДНК плазмид совместно осаждали на частицы золота следующим образом. ДНК в суспензии добавляли к 50 мкл 10-60 мг/мл 0,6 мкМ суспензии частиц золота, а затем объединяли с 50 мкл CaCl2 (2,5 M) и 20 мкл спермидина (0,1 M). Смесь встряхивали на вортексе 5 секунд, осаждали в микроцентрифуге 5 секунд и удаляли супернатант. Затем частицы, покрытые ДНК, однократно промывали 150 мкл 100%-ого этанола, встряхивали на вортексе и осаждали, затем ресуспендировали в 85 мкл безводного этанола. Затем пять мкл покрытых ДНК частиц золота наносили на каждый диск-носитель.
Подготовка ткани и бомбардировка ДНК:
Приблизительно 150-250 мг суспензионной культуры двухнедельного возраста помещали в пустые 60×15 мм чашки Петри и с помощью пипетки удаляли с ткани остаточную жидкость. Ткань помещали приблизительно на расстоянии 3,5 дюйма (~9 см) от задерживающего экрана и подвергали каждую чашку с тканью однократной бомбардировке. Давление разрыва мембраны устанавливали на уровне 650 psi (4,48 МПа) и вакуумировали камеру до -28 дюймов рт.ст. После бомбардировки ткань из каждой чашки разделяли на две колбы, помещали обратно в жидкую среду и культивировали, как описано выше.
Отбор трансформированных эмбрионов и регенерация растений:
После бомбардировки ткань из каждой бомбардированной чашки разделяли и помещали в две колбы с поддерживающей жидкой культуральной средой SB196 на чашку бомбардированной ткани. Через семь дней после бомбардировки жидкую среду в каждой колбе заменяли новой поддерживающей культуральной средой SB196 с добавкой 100 нг/мл селективного агента (селективная среда). Трансформированные клетки сои могут быть отобраны с использованием соединения сульфонилмочевины (SU), такого как 2-хлор-N-((6-метил-4-метокси-1,3,5-триазин-2-ил)аминокарбонил)-бензолсульфонамид (стандартные название: DPX-W4189 и хлорсульфурон). Хлорсульфурон (Cs) является активным компонентом в сульфонилмочевинном гербициде DuPont, GLEAN®. Селективную среду, содержащую SU, заменяют каждые две недели в течение 6-8 недель. После 6-8 недельного периода селекции наблюдают островки зеленой, трансформированной ткани, растущей из нетрансформированных, некротических эмбриогенных кластеров. Указанные предполагаемые трансгенные объекты выделяют и выдерживают в жидкой среде SB196 с Cs в концентрации 100 нг/мл в течение еще 2-6 недель с заменой среды каждые 1-2 недели, с получением новых, клонально размноженных, трансформированных эмбриогенных суспензионных культур. Эмбрионы находятся в общей сложности в течение приблизительно 8-12 недель в контакте с Cs. Суспензионные культуры пересевают и поддерживают в виде кластеров незрелых эмбрионов, а также регенирируют в целые растения при созревании и развитии индивидуальных соматических эмбрионов.
Соматические эмбрионы становятся пригодны для выращивания через четыре недели на среде созревания (1 неделя на SB166, затем на 3 недели на SB103). Затем их удаляют из среды созревания и сушат в пустых чашках Петри в течение семи дней. После этого высушенные эмбрионы выращивают в среде SB714, где им позволяют расти при таких же светотемпературных условиях, как описано выше. Выросшие эмбрионы переносят в грунт и выращивают до созревания с целью получения семян.
B. Конструирование и тестирование вектора
Плазмиды были созданы с использованием стандартных методик, и из полученной плазмидной ДНК выделяли фрагменты, используя эндонуклеазы рестрикции и выделение из агарозного геля согласно методике, описанной в Примере 6A. Каждый фрагмент ДНК содержал три кассеты. Кассета 1 являлась кассетой экспрессии репортера; Кассета 2 являлась кассетой экспрессии репрессора; и Кассета 3 являлась кассетой экспрессии, обеспечивающей ген HRA. Репрессоры, протестированные в Кассете 2, описаны в Таблице 21. Полинуклеотиды, включающие кодирующую область репрессора, синтезировали с целью включения кодонов, предпочтительных в растениях. Во всех случаях Кассета 1 содержала 35S промотор вируса мозаики цветной капусты с тремя tet-операторами, расположенными около TATA-бокса (Gatz et al., (1992) Plant J. 2:397-404 (3XOpT 35S)), направляющий экспрессию DsRed, за которым располагалась 3'-терминаторная область 35S вируса мозаики цветной капусты. Во всех случаях кассета три содержала промотор S-аденозилметионинсинтазы, затем HRA вариант гена ацетолактатсинтазы (ALS), затем Glycine max ALS 3'-терминатор. HRA вариант гена ALS придает устойчивость к сульфонилмочевинным гербицидам. EF1A1 представляет собой промотор фактора элонгации трансляции EF1 альфа сои, описанный в патентной публикации US20080313776.
Фрагменты ДНК использовали для трансформации сои согласно методике, описанной в Примере 6A. Растения регенерировали и с молодых листьев собирали листовые диски (~ 0,5 см). Листовые диски инкубировали в жидкой среде SB103, содержащей 0 м.д., 0,5 м.д. или 5 м.д. этаметсульфурона в течение 2-5 дней. Этаметсульфурон (код продукта PS-2183) был приобретен в Chem Service (West Chester, PA) и солюбилизирован в 10 мМ NaOH или 10 мМ NH4OH. Каждый день листовые диски исследовали под препарационным микроскопом с фильтром полосы пропускания DsRed. Присутствие DsRed оценивали визуально.
Растения, которые экспрессировали DsRed в точке времени 0, оценивали как подтекающие. Растения, которые не экспрессировали DsRed через пять дней, оценивали как отрицательные. Растения, которые экспрессировали DsRed после добавления этаметсульфурона, оценивали как индуцируемые. Результаты растений, полученных из ДНК, описанных в Таблице 21, представлены в Таблице 22.
Это показывает, что репрессорный белок отвечает на этаметсульфурон, вызывая экспрессию DsRed. Растения, полученные из первых четырех фрагментов, демонстрировали визуальное доказательство присутствия DsRed через три дня инкубирования. Растения, полученные из последних двух фрагментов, демонстрировали визуальное доказательство присутствия DsRed через два дня инкубирования. Присутствие DsRed оценивали визуально, но также подтверждали с помощью Вестерн-блот анализа при селекции трансформантов с использованием поликлонального антитела кролика (ab41336) фирмы Abeam (Cambridge, MA).
Листовые диски собирали, как описано выше, после селекции трансформантов и инкубировали в среде SB103 с 0, 5, 50, 250 и 500 млрд.д. этаметсульфурона. При всех концентрациях этаметсульфурона в листьях визуально регистрировали присутствие DsRed через три дня инкубирования. При самой низкой концентрации (5 млрд.д.) присутствие DsRed ограничивалось "ореолом" около внешнего края листового диска.
Растениям позволяли созреть, как описано в Примере 6A. Так как соя является самоопыляемым растением, семена T1, полученные из указанных растений, должны были расщепляться на 1 дикий тип: 2 гемизиготы: 1 гомозиготу, если в процессе трансформации был образован только один трансгенный локус. Посадили шестнадцать семян из пяти различных объектов и им позволили прорасти. Листовые диски собирали с молодой рассады и инкубировали в среде SB103 с 0 и 5 м.д. этаметсульфурона. Листовые диски оценивали на наличие экспрессии DsRed и 0 и 3 дней, результаты показаны в Таблице 23.
ПРИМЕР 7: Тестирование репрессорных белков в кукурузе
Для оценки SU репрессоров на растениях, RFP репортерные конструкции конструировали и трансформировали в клетки кукурузы с помощью Agrobacterium при использовании следующей конфигурации T-ДНК:
RB-35S/TripleOp/Pro::RFP-Ubi Pro::EsR-HRA кассета-PAT кассета-LB.
Используя стандартные методики молекулярной биологии и клонирования, сконструировали T-ДНК векторы, имеющие вышеуказанную конфигурацию, включающие выбранные SU репрессоры (EsRs) 3 раунда. Синтезировали полинуклеотиды, включающие кодирующую область репрессора, с целью включения кодонов, предпочтительных в растениях. Конструкции представлены ниже:
T-ДНК репортерная конструкция содержала 35S промотор, с двумя tet-операторами, фланкирующими TATA-бокс, и одним после, примыкающим к сайту инициации транскрипции (как описано Gatz et al., (1992) Plant Cell 2:397-404), направляющий экспрессию гена красного флуоресцентного белка, убиквитин-регулируемый SU репрессор (EsR), кассету экспрессии, содержащую ген HRA кукурузы, придающий устойчивость к SU, а также кассету экспрессии moPAT для селекции.
Незрелые эмбрионы трансформировали, используя стандартные методы и среды. Вкратце, незрелые эмбрионы выделяли из кукурузы и подвергали контакту с суспензией Agrobacterium для переноса T-ДНК, содержащей кассету экспрессии сульфонилмочевины, по меньшей мере, в одну клетку, по меньшей мере, одного из незрелых эмбрионов. Незрелые эмбрионы погружали в суспензию Agrobacterium для инициирования инокуляции и культивировали в течение семи дней. Затем эмбрионы переносили в культуральную среду, содержащую карбенициллин, чтобы убить остаточные агробактерии. Затем, инокулированные эмбрионы культивировали на среде, содержащей карбенициллин и биалафос (селективный агент), и собирали растущий трансформированный каллус. После этого каллус регенерировали в ростки на твердых средах перед переносом в почву, получив в результате зрелые растения. Приблизительно 10 однокопийных объектов каждой из конструкций помещали в оранжерею.
Для оценки дерепрессии каллус переносили в среду с и без этаметсульфурона и хлорсульфурона, и наблюдали флуоресценцию RFP под микроскопом (см. Фигуру 10A). Большинство объектов было дерепрессировано, при этом не наблюдалось каких-либо очевидных различий между протестированными репрессорами третьего раунда. Для оценки дерепрессии в растениях семена однокопийных растений проращивали в присутствии этаметсульфурона, после чего наблюдали и фотографировали флуоресценция (см. Фигуру 10B). В качестве положительного контроля вектор, содержащий такую же конфигурацию кассет экспрессии, как и PHP37707-10, но с UBI::TetR вместо UBI::EsR, трансформировали в незрелые эмбрионы кукурузы и тестировали на индукцию доксициклином. При выращивании в присутствии 1 мг/л доксициклина, трансгенный каллус и растения, содержащие кассету экспрессии TetR, индуцировались за аналогичный 5-6-дневный период.
В качестве примера “элемент” означает один или более элементов. Все книги, журналы, доступные публикации и гранты, указанные в описании, служат показателем уровня специалистов, квалифицированных в данной области. Все публикации и заявки на патенты в настоящей заявке включены в той же степени, как если бы каждая отдельная публикация или заявка на патент была прямо и индивидуально указана как включенная путем отсылки. Хотя вышеизложенное изобретение было описано в некоторых деталях в качестве иллюстрации и примера, в целях ясности понимания, некоторые изменения и модификации могут быть осуществлены в рамках прилагаемой формулы. Указанные примеры и описания иллюстративны и не должны рассматриваться как ограничение объема прилагаемой формулы.
Реферат
Изобретение относится к биохимии и представляет собой выделенный полипептид, содержащий сульфонилмочевина-реактивный репрессор, который специфично связывается с полинуклеотидом, содержащим операторную последовательность, где связывание регулируется соединением сульфонилмочевины и где указанный полипептид содержит аминокислотную последовательность, которая по меньшей мере на 90% идентична последовательности SEQ ID NO:1233. Изобретение также относится к полинуклеотиду, кодирующему полипептид, а также к клетке, трансформированной полинуклеотидом. Также предложен способ регуляции транскрипции целевого полинуклеотида в клетке с использованием заявленного полинуклеотида. 4 н. и 27 з.п. ф-лы, 29 табл., 7 пр., 11 ил.
Формула
(a) получение клетки-хозяина, содержащей целевой полинуклеотид, где целевой полинуклеотид функционально связан с промотором, включающим по меньшей мере одну операторную последовательность;
(b) осуществление специфичного связывания полипептида по любому из пп.1 или 2 с операторной последовательностью; и
(c) связывание соединения сульфонилмочевины с полипептидом с образованием комплекса, который изменяет свойства связывания полипептида с оператором, тем самым регулируя транскрипцию целевого полинуклеотида в клетке-хозяине.
Комментарии